[AINews] Not much technical happened today
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Funding is all you need.
AI News for 10/1/2024-10/2/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (225 channels, and 1832 messages) for you. Estimated reading time saved (at 200wpm): 219 minutes. You can now tag @smol_ai for AINews discussions!
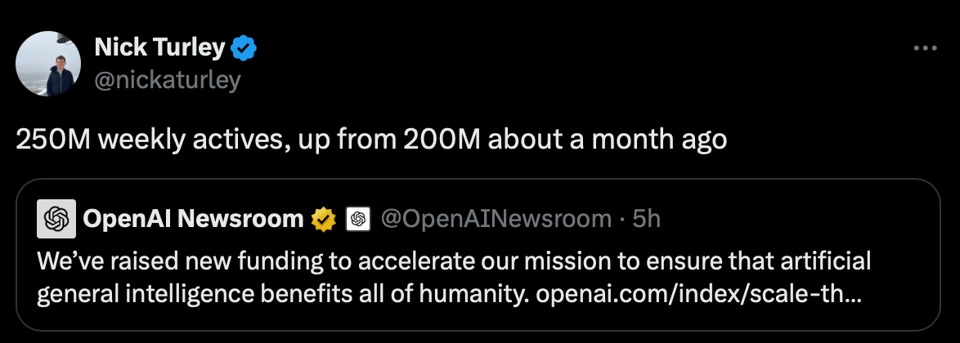
Today OpenAI announced raising 6.6B in new funding at a 157B valuation. On Twitter ChatGPT head of product Nick Turley also added
"250M weekly actives, up from 200M about a month ago".
Also in fundraising news Poolside announced a $500 million fundraise to make progress towards AGI.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Industry Updates
- New AI Models and Capabilities: @LiquidAI_ announced three new models: 1B, 3B, and 40B MoE (12B activated), featuring a custom Liquid Foundation Models (LFMs) architecture that outperforms transformer models on benchmarks. These models boast a 32k context window and minimal memory footprint, handling 1M tokens efficiently. @perplexity_ai teased an upcoming feature with "⌘ + ⇧ + P — coming soon," hinting at new functionalities for their AI platform.
- Open Source and Model Releases: @basetenco reported that OpenAI released Whisper V3 Turbo, an open-source model with 8x faster relative speed vs Whisper Large, 4x faster than Medium, and 2x faster than Small, featuring 809M parameters and full multilingual support. @jaseweston announced that FAIR is hiring 2025 research interns, focusing on topics like LLM reasoning, alignment, synthetic data, and novel architectures.
- Industry Partnerships and Products: @cohere introduced Takane, an industry-best custom-built Japanese model developed in partnership with Fujitsu Global. @AravSrinivas teased an upcoming Mac app for an unspecified AI product, indicating the expansion of AI tools to desktop platforms.
AI Research and Technical Discussions
- Model Training and Optimization: @francoisfleuret expressed uncertainty about training a single model with 10,000 H100s, highlighting the complexity of large-scale AI training. @finbarrtimbers noted excitement about the potential for inference time search with 1B models getting good, suggesting new possibilities in conditional compute.
- Technical Challenges: @_lewtun highlighted a critical issue with LoRA fine-tuning and chat templates, emphasizing the need to include the embedding layer and LM head in trainable parameters to avoid nonsense outputs. This applies to models trained with ChatML and Llama 3 chat templates.
- AI Tools and Frameworks: @fchollet shared how to enable float8 training or inference on Keras models using
.quantize(policy), demonstrating the framework's flexibility for various quantization forms. @jerryjliu0 introduced create-llama, a tool to spin up complete agent templates powered by LlamaIndex workflows in Python and TypeScript.
AI Industry Trends and Commentary
- AI Development Analogies: @mmitchell_ai shared a critique of the tech industry's approach to AI progress, comparing it to a video game where the goal is finding an escape hatch rather than benefiting society. This perspective highlights concerns about the direction of AI development.
- AI Freelancing Opportunities: @jxnlco outlined reasons why freelancers are poised to win big in the AI gold rush, citing high demand, complexity of AI systems, and the opportunity to solve real problems across industries.
- AI Product Launches: @swyx compared Google DeepMind's NotebookLM to ChatGPT, noting its multimodal RAG capabilities and native integration of LLM usage within product features. This highlights the ongoing competition and innovation in AI-powered productivity tools.
Memes and Humor
- @bindureddy humorously commented on Sam Altman's statements about AI models, pointing out a pattern of criticizing current models while hyping future ones.
- @svpino joked about hosting websites that make $1.1M/year for just $2/month, emphasizing the low cost of web hosting and poking fun at overcomplicated solutions.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. OpenAI's Whisper Turbo: Breakthrough in Browser-Based Speech Recognition
- The insanity of whisper versions (Score: 30, Comments: 14): The post discusses the numerous versions of Whisper, including size variations (base, small, tiny, large, turbo), version iterations (v1, v2, v3), language-specific models (English-only), and performance-focused variants (faster whisper, insanely-fast whisper). The author seeks guidance on selecting an appropriate Whisper model, considering factors such as GPU performance and language requirements, specifically mentioning medium.en for English and potentially a larger non-English version for foreign transcription/translation.
- Whisper-ctranslate2 (based on faster-whisper) is recommended as the fastest option, with large models suggested for non-English use. Version comparisons indicate v2 and v3 outperform v1, with language-specific variations in v3's performance.
- Hardware requirements for large Whisper models include 6GB VRAM (minimum), with CPU inference speeds around 0.2-0.5x realtime. Users reported WhisperX crashes on 8GB fp32 GPUs, while fp16 performs better with lower VRAM usage.
- Performance benchmarks for Whisper models are available, including FP16 benchmarking and large v3 benchmarking. Alternative options like whisperfile, a llamafile wrapper for Whisper, were suggested for fast CPU use cases.
- OpenAI's new Whisper Turbo model running 100% locally in your browser with Transformers.js (Score: 456, Comments: 52): OpenAI's Whisper Turbo model can now run 100% locally in web browsers using Transformers.js, enabling speech-to-text transcription without sending data to external servers. This implementation leverages WebGPU for faster processing, achieving real-time transcription speeds on compatible devices, and offers a fallback to WebGL for broader compatibility.
- The Whisper large-v3-turbo model achieves ~10x RTF (real-time factor), transcribing 120 seconds of audio in ~12 seconds on an M3 Max. It's a distilled version of Whisper large-v3, reducing decoding layers from 32 to 4 for faster processing with minor quality degradation.
- The model runs 100% locally in the browser using Transformers.js and WebGPU, without hitting OpenAI servers. The 800MB model is downloaded and stored in the browser's cache storage, enabling offline use through service workers.
- Users discussed the model's multilingual capabilities and potential accuracy changes. A real-time version of the model is available on Hugging Face, and it can also be used offline with whisper.cpp by ggerganov.
- Whisper Turbo now supported in Transformers 🔥 (Score: 174, Comments: 33): Hugging Face's Open Source Audio team has released Whisper Turbo in Transformers format, featuring a 809M parameter model that is 8x faster and 2x smaller than Large v3. The multilingual model supports time stamps and uses 4 decoder layers instead of 32, with implementation in Transformers requiring minimal code for automatic speech recognition tasks using the ylacombe/whisper-large-v3-turbo checkpoint.
- Whisper Turbo's performance is discussed, with users comparing it to faster-whisper and Nvidia Canary. The latter is noted to be at the top of the Open ASR leaderboard but supports fewer languages.
- GGUF support for Whisper Turbo was quickly implemented, with the developer providing links to the GitHub pull request and model checkpoints within hours of the request.
- Users confirmed Whisper Turbo's compatibility with Mac M-chip, providing code modifications to run it on MPS. One user reported achieving 820X realtime speed on a 4090 GPU without performance degradation.
Theme 2. Convergence and Limitations of Current LLM Architectures
- All LLMs are converging towards the same point (Score: 108, Comments: 57): Various large language models (LLMs) including Gemini, GPT-4, GPT-4o, Llama 405B, MistralLarge, CommandR, and DeepSeek 2.5 were used to generate a list of 100 items, with the first six models producing nearly identical datasets and groupings. The author observed a convergence in the main data output across these models, despite differences in their "yapping" or extraneous text, leading to the conclusion that these LLMs are trending towards a common point that may not necessarily indicate Artificial Super Intelligence (ASI).
- ArsNeph argues that LLMs are converging due to heavy reliance on synthetic data from the GPT family, leading to widespread "GPT slop" and lack of originality. Open-source fine-tunes and models like Llama 2 are essentially distilled versions of GPTs, while newer models like Llama 3 and Gemma 2 use DPO to appear more likable.
- Users discuss potential solutions to LLM convergence, including experimenting with different samplers and tokenization methods. The XTC sampler for exllamav2 is mentioned as a promising approach to reduce repetitive outputs, with some users eager to implement it in llama.cpp.
- Discussion touches on Claudisms, a phenomenon where Claude exhibits its own parallel versions of GPTisms, potentially as a form of fingerprinting. Some speculate that these patterns might be artifacts used to identify text generated by specific models, even when other models train on that data.
- Best Models for 48GB of VRAM (Score: 225, Comments: 67): An individual with a new RTX A6000 GPU featuring 48GB of VRAM is seeking recommendations for the best models to run on this hardware. They specifically request models that can operate with at least Q4 quantization or 4 bits per weight (4bpw) to optimize performance on their high-capacity GPU.
- Users recommend running 70B models like Llama 3.1 70B or Qwen2.5 72B. Performance benchmarks show Qwen2.5 72B achieving 12-13 tokens/second with q4_0 quantization and 8.5 tokens/second with q4_K_S quantization on 2x RTX3090 GPUs.
- ExllamaV2 with TabbyAPI is suggested for better speeds, potentially reaching 15 tokens/second with Mistral Large at 3 bits per weight. A user reported up to 37.31 tokens/second on coding tasks using Qwen 2 72B with tensor parallelism and speculative decoding on Linux.
- Some users recommend trying Mistral-Large-Instruct-2407 at 3 bits per weight for a 120B parameter model, while others suggest Qwen 72B as the "smartest" 70B model. Cooling solutions for the RTX A6000 were discussed, with one user showcasing a setup using Silverstone FHS 120X fans in an RM44 chassis.
- Serving 70B-scale LLMs Efficiently on Low-resource Edge Devices (Score: 53, Comments: 17): The paper introduces TPI-LLM, a tensor parallel inference system designed to run 70B-scale language models on low-resource edge devices, addressing privacy concerns by keeping sensitive data local. TPI-LLM implements a sliding window memory scheduler and a star-based allreduce algorithm to overcome memory limitations and communication bottlenecks, respectively. Experiments show that TPI-LLM achieves over 80% reduction in time-to-first-token and token latency compared to Accelerate, and over 90% reduction compared to Transformers and Galaxy, while reducing the peak memory footprint of Llama 2-70B by 90%, requiring only 3.1 GB of memory for 70B-scale models.
- TPI-LLM leverages multiple edge devices for inference through tensor parallelism, running Llama 2-70B on 8 devices with 3GB of memory each. This distributed approach allows for significant memory reduction but comes with a trade-off in speed.
- The system's performance is limited by disk I/O, resulting in a 29.4-second time-to-first-token and an average throughput of 26.1 seconds/token for a 70B model. Despite these latencies, the approach shows promise in running large language models on low-resource devices.
- Users discussed alternative distributed implementations like exo for running models across multiple devices. Concerns were raised about potential issues with realtime pool changes and layer rebalancing in distributed setups.
Theme 3. Nvidia's NVLM 72B: New Multimodal Model Release
- Nvidia just dropped its Multimodal model NVLM 72B (Score: 92, Comments: 10): Nvidia has released its multimodal model NVLM 72B, with details available in a paper and the model accessible through a Hugging Face repository. This 72 billion parameter model represents Nvidia's entry into the multimodal AI space, capable of processing and generating both text and visual content.
- NVLM 72B is built on top of Qwen 2 72B, as revealed by a quick look at the config file.
- Ggerganov, creator of llama.cpp, expressed the need for new contributors with software architecture skills to implement multimodal support, citing concerns about project maintainability. He stated this in a GitHub issue comment.
- Discussion arose about why major companies release models in Hugging Face format rather than GGUF. Reasons include compatibility with existing hardware, no need for quantization, and the ability to finetune, which is not easily done with GGUF files.
Theme 4. Advancements in On-Device AI: Gemini Nano 2 for Android
- Gemini Nano 2 is now available on Android via experimental access (Score: 38, Comments: 12): Gemini Nano 2, an upgraded version of Google's on-device AI model for Android, is now accessible to developers through experimental access. This new iteration, nearly twice the size of its predecessor (Nano 1), demonstrates significant improvements in quality and performance, rivaling the capabilities of much larger models in both academic benchmarks and real-world applications.
- Users speculated about extracting weights from Gemini Nano 2, with discussions on the model's architecture and size. It was clarified that Nano 2 has 3.25B parameters, not 2B as initially suggested.
- There was interest in the model's transparency, with questions about why Google isn't more open about the LLM used. Some speculated it might be a version of Gemini 1.5 flash.
- A user provided information from the Gemini Paper, stating that Nano 2 is trained by distilling from larger Gemini models and is 4-bit quantized for deployment.
Theme 5. Innovative Techniques for Improving LLM Performance
- Archon: An Architecture Search Framework for Inference-Time Techniques from Stanford. Research Paper, Codes, Colab available;
pip install archon-ai. OSS version of 01? (Score: 35, Comments: 2): Stanford researchers introduced Archon, an open-source architecture search framework for inference-time techniques, potentially serving as an OSS alternative to Anthropic's 01. The framework, available viapip install archon-ai, comes with a research paper, code, and a Colab notebook, allowing users to explore and implement various inference-time methods for large language models.
- Just discovered the Hallucination Eval Leaderboard - GLM-4-9b-Chat leads in lowest rate of hallucinations (OpenAI o1-mini is in 2nd place) (Score: 39, Comments: 6): The Hallucination Eval Leaderboard reveals GLM-4-9b-Chat as the top performer with the lowest rate of hallucinations, followed by OpenAI's o1-mini in second place. This discovery has prompted consideration of GLM-4-9b as a potential model for RAG (Retrieval-Augmented Generation) applications, suggesting its effectiveness in reducing false information generation.
- GLM-4-9b-Chat and Jamba Mini are highlighted as promising models with low hallucination rates, but are underutilized. The inclusion of Orca 13B in the top performers was also noted with surprise.
- The leaderboard's data is seen as valuable for LLM-based Machine Translation, with users expressing enthusiasm about the potential applications in this field.
- GLM-4 is praised for its 64K effective context, which exceeds many larger models on the RULER leaderboard, and its ability to minimize code switching in multilingual tasks, making it a strong candidate for RAG applications.
- Shockingly good super-intelligent summarization prompt (Score: 235, Comments: 39): The post discusses a summarization system prompt inspired by user Flashy_Management962, which involves generating 5 essential questions to capture the main points of a text and then answering them in detail. The author claims this method, tested on Qwen 2.5 32b q_4, is "shockingly better" than previous approaches they've tried, and outlines the process for formulating questions that address central themes, key ideas, facts, author's perspective, and implications.
- Users discussed refining the prompt by specifying answer length and including examples. The OP mentioned trying more complex prompts but found simpler instructions worked best with the Qwen 2.5 32b q_4 model.
- The technique of generating question & answer pairs for summarization sparked interest, with some users suggesting it's a known NLP task. The OP noted a significant improvement, describing it as a "30 point IQ level jump for the LLM" in understanding text.
- The summarization method is being integrated into projects like Harbor Boost under the name "supersummer". Users also shared related resources, including DSPy and an e-book summary tool for further exploration.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Releases and Capabilities
- OpenAI releases o1-mini model: OpenAI released o1-mini, a smaller version of their o1 model. Some users report getting o1 responses randomly when using GPT-4, suggesting OpenAI may be testing a model router to determine when to use o1 vs GPT-4. Source
- Whisper V3 Turbo released: OpenAI released Whisper V3 Turbo, an optimized version of their large-v3 speech recognition model that offers 8x faster transcription speed with minimal accuracy loss. Source
- PuLID for Flux now works on ComfyUI: The PuLID (Prompt-based Unsupervised Learning of Image Descriptors) model for the Flux image generation model is now compatible with the ComfyUI interface. Source
AI Company Updates and Events
- OpenAI DevDay announcements: OpenAI held a developer day event with multiple announcements, including:
- A 98% decrease in cost per token from GPT-4 to 4o mini
- A 50x increase in token volume across their systems
- Claims of "excellent model intelligence progress" Source
- Mira Murati's exit from OpenAI: Before Mira Murati's surprise departure from OpenAI, some staff reportedly felt the o1 model had been released prematurely. Source
AI Features and Applications
- Advanced voice mode rolling out: OpenAI is starting to roll out advanced voice mode to free users of ChatGPT. Source
- Realtime API announced: OpenAI announced the Realtime API, which will enable Advanced Voice Mode functionality in other applications. Source
- Copilot Vision demonstrated: Microsoft demonstrated Copilot Vision, which can see and interact with webpages the user is viewing. Source
- NotebookLM capabilities: Google's NotebookLM tool can process multiple books, long videos, and audio files, providing summaries, quotes, and explanations. It can also handle content in foreign languages. Source
AI Ethics and Societal Impact
- Concerns about job displacement: The CEO of Duolingo discussed potential job displacement due to AI, sparking debate about the societal impacts of automation. Source
- Sam Altman on AI progress: Sam Altman of OpenAI discussed the rapid progress of AI, stating that by 2030, people may be able to ask AI to perform tasks that previously took humans months or years to complete. Source
AI Research and Development
- UltraRealistic Lora Project: A new LoRA (Low-Rank Adaptation) model for the Flux image generation system aims to create more realistic, dynamic photography-style outputs. Source
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. Advancements and Launches of AI Models
- Nova Pro Surpasses GPT-4 in Benchmarks: Nova-Pro achieves outstanding scores with 97.2% on ARC-C and 96.9% on GSM8K, outperforming GPT-4 and Claude-3.5 in reasoning and mathematics.
- Llama 3.2 Introduced with Vision Capabilities: Llama 3.2 supports 11B and 90B configurations, enabling local deployment and enhanced fine-tuning for custom vision tasks.
- Phi-3.5 Models Highlight Censorship Features: Phi-3.5-MoE showcases extensive censorship mechanisms, sparking discussions on model usability for technical applications.
Theme 2. AI Infrastructure and Tooling Enhancements
- Streamlined Project Management with o1-engineer: o1-engineer leverages OpenAI's API for efficient code generation and project planning, enhancing developer workflows.
- Local AI Screen Recording via screenpipe: screenpipe offers secure, continuous local AI recording built with Rust, serving as a robust alternative to Rewind.ai.
- Resolving Installation Issues in LM Studio: Community members troubleshoot LM Studio launch problems, emphasizing the importance of compatibility with Llama 3.1 and the use of virtual environments.
Theme 3. AI Ethics, Safety, and Legal Implications
- Debating AI Safety and Ethical Concerns: Discussions on AI Safety tackle both traditional ethics and modern threats like deepfakes, often humorously likened to "angry grandmas shouting at clouds."
- NYT Lawsuit Impacts AI Copyright Stance: The potential NYT lawsuit against OpenAI raises questions about copyright infringement and the broader legal responsibilities of LLMs.
- Ethical Use of AI in Creative Works: Community outrage over Character.AI's unauthorized use of an individual's likeness highlights the necessity for responsible AI development practices.
Theme 4. Model Training, Fine-Tuning, and Optimization
- Enhancing Efficiency with Activation Checkpointing: Implementing activation checkpointing in training reduces memory usage, enabling the handling of larger models like llama 3.1 70B.
- Addressing FP8 Precision Training Challenges: Researchers explore instabilities in FP8 precision during extended training runs, seeking solutions to optimize stability and performance.
- Optimizing Multi-GPU Training Techniques: Effective multi-GPU training emphasizes parallel network training and efficient state communication to scale up to 10,000 GPUs.
Theme 5. AI Integration and Deployment Strategies
- Semantic Search with Oracle AI Vector Search and LlamaIndex: Combining Oracle AI Vector Search with LlamaIndex enhances retrieval augmented generation (RAG) pipelines for more accurate contextual data handling.
- Deploying HuggingFace Models as LangChain Agents: HuggingFace models can be integrated as Agents in LangChain, facilitating advanced chat and text generation tasks within development workflows.
- Local Deployment Strategies with OpenRouter and LlamaIndex: Utilizing OpenRouter and LlamaIndex for semantic search and multimodal models supports scalable and efficient AI deployment in diverse applications.
PART 1: High level Discord summaries
aider (Paul Gauthier) Discord
- Prompt Caching Insights: A summary of various AI models' prompt caching capabilities was shared, focusing on OpenAI's and Anthropic’s strategies, with discussion on cost implications and cache misses.
- Key points included discussions on the caching mechanisms of models like DeepSeek and Gemini, emphasizing their efficiency.
- AI Models for Code Editing Compared: Sonnet outperformed other models in overall performance, but at a higher cost than o1-preview, which offers better token reimbursement under certain conditions.
- Recommendations included benchmarking Gemini as an architect model in conjunction with Sonnet to potentially enhance editing capabilities.
- YAML Parsing Pitfalls: Users flagged quirks in YAML parsing, specifically around the conversion of keys like 'yes' to booleans, complicating their configurations.
- Strategies shared for preventing this issue included the use of quoted strings to maintain intended parsing outcomes.
- Streamlined Project Management via o1-engineer: o1-engineer serves as a command-line tool for developers to efficiently manage projects using OpenAI's API for tasks such as code generation.
- This tool aims to enhance the development process, focusing specifically on project planning.
- Seamless Local AI Recording with screenpipe: screenpipe allows for continuous local AI screen recording, designed for building applications that require complete context retention.
- Positioned as a secure alternative to Rewind.ai, it ensures user data ownership and is built with Rust for higher efficiency.
OpenRouter (Alex Atallah) Discord
- Samba Nova launches free Llama endpoints: In collaboration with Samba Nova, five free bf16 endpoints for Llama 3.1 and 3.2 are now live on their new inference chips to measure performance, including the 405B Instruct model.
- Expect exciting throughput while using these endpoints aimed at supporting the Nitro ecosystem.
- Gemini Models standardize token sizes: The Gemini and PaLM models now use standardized token sizes, leading to 2x higher prices but 25% shorter inputs which should help overall affordability details here.
- Despite the changes, users can expect a 50% reduction in costs over time.
- Cohere offers discounts on models: Cohere models are available on OpenRouter with a 5% discount and upgraded to include tool calling support in their new v2 API.
- This update enhances user access to tools, aiming to improve overall experience.
- Realtime API integration discussed: Discussions centered around OpenRouter's support for the new Realtime API, particularly its current limitations with audio inputs and outputs.
- Users are eager for improvements but no timeline for enhancements has been confirmed yet.
- OpenRouter model performance under scrutiny: Concerns regarding model performance and availability on OpenRouter surfaced, particularly with greyed-out providers and fluctuating rates.
- Users need to stay vigilant about price changes as they navigate different provider options.
HuggingFace Discord
- Llama 3.2 Launch Brings Local Running: Llama 3.2 has launched, allowing local execution with vision fine-tuning available through a new recipe. This model supports 11B and 90B configurations for enhanced fine-tuning capabilities.
- Community feedback indicates a positive reception, as members explore opportunities for applying these models effectively and engaging in discussions on their implications.
- Transformers 4.45.0 Simplifies Tool Creation: The release of transformers v4.45.0 introduces tools utilizing a
@tooldecorator, streamlining the development process for users. This update enhances building efficiency for diverse applications.- Community members enthusiastically discussed these changes, calling for feedback on the updated design and proposing various uses.
- Fine-tuning Mistral 7B for Narrative Generation: A member is keen to finetune Mistral 7B for story generation, looking for guidance on pretraining methodologies. They learned that Mistral is pretrained on substantial data, emphasizing task-specific fine-tuning regime.
- Further clarification was provided, distinguishing between pretraining and the refinement process necessary to specialize models efficiently.
- NotebookLM Eclipses Traditional Tools: Participants praised NotebookLM for its efficacy as an end-to-end multi-modal RAG app, proving particularly effective for analyzing financial reports. A member showcased its capabilities in a YouTube video, exploring the potential for educational content.
- Teammates expressed interest in its application potential, heightening discussions on its future development and integration.
- Exploration of 'trocr-large-handwriting' Benefits: A member suggested employing 'trocr-large-handwriting' for datasets closely resembling handwriting for better performance. The conversation included ideas on fine-tuning on specific character datasets to improve recognition.
- This led to a broader discussion on model choices for handwriting recognition tasks, with members weighing the pros and cons of various approaches.
LM Studio Discord
- LM Studio Launch Woes: Users encountered problems launching LM Studio post-update, particularly with shortcuts and executable files in the app directory, with one workaround suggested for relying on updated installation files.
- This indicates potential issues with legacy installations that may hinder users' productivity.
- Llama 3.1 Compatibility Concerns: An error loading the Llama 3.1 model in LM Studio prompted recommendations to update to version 0.3.3, which officially supports the model.
- This mismatch highlights the necessity of ensuring software compatibility when upgrading models.
- Langflow Integration Success: One user successfully integrated LM Studio with Langflow by adjusting the base URL of OpenAI components, finding the modification enabled smoother workflow.
- They pointed to available resources for Langflow, which might help others streamline their setups.
- Optimizing GPU Utilization: Discussions around GPU utilization settings in LM Studio focused on defining what 'offload' specifically entails regarding CPU and GPU resource management.
- Clarifications were sought about optimized configurations for using GPU versus CPU, particularly for tasks like autocomplete.
- High-End GPU Performance Showdown: A user detailed their setup with 7 RTX 4090 GPUs, raising eyebrows with an estimated 3000 watts of power consumption during operation.
- Another user humorously pointed out the dramatic implications of such intense power usage, reflecting on the fascination with high-performance systems.
Nous Research AI Discord
- Rapid Model Quantization Amazes Users: Users expressed surprise at the blazingly fast quantization time for a 3b model, which took less than a minute to process.
- One user humorously noted the economic comparison to minimum wage work, highlighting potential efficiency gains over human labor.
- Audio Token Pricing Raises Concerns: Discussion arose around audio tokens costing $14 per hour for output, which some deemed expensive compared to human agents.
- Participants noted that while AI is continuously available, the pricing may not significantly undercut traditional support roles.
- Ballmer Peak Study Captivates Members: A shared paper on the Ballmer Peak indicates that a small amount of alcohol can enhance programming ability, challenging traditional beliefs.
- Members crowded into discussions about personal experiences in seeking the 'perfect dosage' for productivity.
- DisTrO's Ability to Handle Bad Actors: Discussion pointed toward DisTrO's verification layer, capable of detecting and filtering bad actors during training.
- While it doesn’t inherently manage untrustworthy nodes, this layer provides some degree of protection.
- Nova LLM Suite Introduced by RubiksAI: RubiksAI launched the Nova suite of Large Language Models, with Nova-Pro achieving an impressive 88.8% on MMLU.
- Benchmark scores for Nova-Pro show 97.2% on ARC-C and 96.9% on GSM8K, focusing on features like Nova-Focus and improved Chain-of-Thought abilities.
Interconnects (Nathan Lambert) Discord
- OpenAI bags $6.6B for ambitious plans: OpenAI has successfully raised $6.6 billion at a staggering $157 billion valuation, facilitated by Thrive Capital among others like Microsoft and Nvidia.
- CFO Sarah Friar shared that this will enable liquidity options for employees post-funding, marking a significant shift in the company’s financial landscape.
- Liquid.AI claims architectural breakthroughs: Discussion emerged around Liquid.AI, which reportedly surpasses previous performance predictions made by Ilya Sutskever in 2020.
- While some skeptics question its validity, the insights from Mikhail Parakhin lend a degree of credibility to the claims.
- AI's potential in advanced mathematics: Robert Ghrist instigated a dialogue on whether AI can engage in research-level mathematics, indicating a moving boundary of capabilities for LLMs.
- This conversation highlights a shift in expectations as AI begins to tackle complex conjectures and theorems.
- AI safety discussions ignite further debates: In lengthy discussions, members wrestled with the implications of AI Safety, particularly regarding old ethics and emergent threats like deepfakes.
- Commentary likened critics to 'angry grandmas shouting at clouds', illustrating the contentious nature of the discourse.
- Google's ambitions discussed: Speculation arose around Google's potential push for AGI, fueled by their extensive cash reserves and history of AI investments.
- Doubts linger over the company's true commitment towards realizing an AGI vision, with divided opinions among members.
Unsloth AI (Daniel Han) Discord
- Feature Extraction Formats in VAE: Participants discussed preferred formats for feature extraction in Variational Autoencoders, favoring continuous latent vectors or pt files, noting the relevance of RGB inputs/outputs for models like Stable Diffusion.
- The conversation highlighted practical choices to enhance model training and effectiveness.
- Feedback Invitation for AI Game: A member invited feedback for their newly launched AI game, playable at game.text2content.online, involving crafting prompts to jailbreak an AI under time constraints.
- Concerns about login requirements were raised, but the creator clarified it was to mitigate bot activity during gameplay.
- Challenges in FP8 Training: A paper was shared discussing the instabilities faced while training large language models using FP8 precision, which uncovered new issues during extended training runs; find it here.
- Community members are keen to explore solutions to optimize stability and performance in these scenarios.
- Discount Codes for AI Summit 2024: Calls went out for discount codes to attend the NVIDIA AI Summit 2024 in Mumbai, with a student voicing interest in utilizing the opportunity to engage with fellow AI enthusiasts.
- Their background in AI and LLMs positions them to significantly benefit from participation at the summit.
- Unsloth Model Loading Troubles: A user faced an error while loading a fine-tuned model with LoRA adapters using AutoModelForPeftCausalLM, which prompted discussions about adjusting the max_seq_length.
- Members provided valuable insights into model loading methods and best practices for resolution.
GPU MODE Discord
- Clarification on Triton Kernel Invocation Parameters: A user inquired about the function of changing num_stages in Triton kernel invocation, speculating its relationship to pipelining.
- Another member explained that pipelining optimizes loading, computing, and storing operations, as illustrated in this YouTube video.
- CUDA Mode Event Sparks Interest: The third place prize in CUDA mode was noted for its connection to data loading projects, inspiring curiosity about progress updates.
- A member shared the no-libtorch-compile repository to aid in development without libtorch.
- IRL Keynotes Now Available for Viewing: Keynote recordings from the IRL event have been released, featuring insightful talks by notable figures such as Andrej Karpathy.
- Participants are thanked, particularly Accel, for their contribution in recording these keynotes effectively.
- Community Navigates Political Discourse: Community members expressed concerns over geopolitical stability, emphasizing a desire for coding focus amidst tense discussions.
- Debate over the appropriateness of political discussions arose, with members agreeing that limiting such topics might ensure a more comfortable environment.
- Upcoming Advancing AI Event Set for October: An Advancing AI event is scheduled in San Francisco, inviting participants to engage with ROCM developers.
- The community is encouraged to DM for registration details and discuss AI advancements during the event.
Eleuther Discord
- Bayesian Models Face Frequentist Challenges: Neural architectures predominantly utilize frequentist statistics, presenting hurdles for implementing Bayesian networks effectively in trainable models. Suggestions included collapsing probabilities into model weights, simplifying the Bayesian approach.
- Discussion highlighted alternatives to maintain practicality within Bayesian frameworks without compromising complexity.
- NYT Lawsuit Shakes AI Copyright Foundation: The community delved into the implications of OpenAI potentially paying off NYT to stave off copyright claims, sparking concerns about the broader impact on LLM liability. Arguments surfaced noting that such compensation wouldn’t necessarily confirm pervasive copyright infringement.
- Members underscored differences in motivations between profitable companies and independent creators facing copyright disputes.
- Liquid Neural Networks: A Game Changer?: Members expressed optimism about the application of liquid neural networks for fitting continuous functions, asserting lowered developmental complexity in comparison to traditional methods. They suggested that an end-to-end pipeline could enhance usability, assuming developer competence.
- The potential for these networks to ease complexity in prediction tasks fueled further discussions on their practical deployment.
- Self-Supervised Learning Expands Horizons: The concept of self-supervised learning on arbitrary embeddings was introduced, emphasizing its applicability across various model weights. This approach involves gathering linear layers from multiple models to form comprehensive datasets for better training.
- Members recognized the implications of extending SSL in enhancing model capabilities across different AI applications.
- Transfer Learning Revolutionized by T5: The effectiveness of T5 in transfer learning for NLP tasks was celebrated, with notable capabilities in modeling a variety of applications. One member humorously stated, 'God dammit T5 thought of everything,' showcasing its extensive text-to-text adaptability.
- In addition, discussions referenced new designs for deep learning optimizers, critiquing existing methods like Adam and proposing alterations for improved training stability.
OpenAI Discord
- Users Desire Higher Subscription Tiers: Members discussed the potential for a higher-priced OpenAI subscription to offer more up-to-date features and services, citing frustrations with current limitations across AI platforms.
- This change could enhance user experience with innovative capabilities.
- Feedback on New Cove Voice Model: Multiple users expressed dissatisfaction with the new Cove voice model, claiming it lacks the calming nature of the classic voice, with calls for its return.
- Community consensus leaned towards preferring a more tranquil voice as they reminisce over the classic version.
- Liquid AI's Architecture Performance: Discussion centered on a new liquid AI architecture reported to outperform traditional LLMs, which is available for testing and noted for its inference efficiency.
- Members speculated about its unique structure compared to typical transformer models.
- Issues Accessing the Playground: Concerns were raised regarding difficulties logging into the Playground, with some users suggesting incognito mode as a potential workaround.
- Reports indicated that access issues may vary geographically, particularly noted in areas like Switzerland.
- Disappearing Responses Issue in macOS App: Users reported responses disappearing in the macOS desktop app post-update, potentially due to changes in notification settings.
- Frustration was evident after these issues impacted user experience significantly during critical tasks.
Latent Space Discord
- OpenAI secures $6.7B in funding: OpenAI announced a funding round of $6.7 billion, reaching a $157 billion valuation with key partnerships, potentially involving NATO allies to advance AI technologies.
- This funding raises questions on international collaboration and the strategic direction of AI policies.
- Advanced Voice feature for all users: OpenAI is rolling out the Advanced Voice feature to all ChatGPT Enterprise and Edu users globally, offering free users an early preview.
- Some skepticism remains around the actual performance benefits of these voice applications.
- Deep dive into Multi-GPU training techniques: A detailed discussion on multi-GPU training emphasized the need for efficient checkpointing and state communication, especially with up to 10,000 GPUs in use.
- Key strategies highlighted include parallelizing network training and enhancing failure recovery processes.
- Launch of new multimodal models MM1.5: Apple introduced the MM1.5 family of multimodal language models aimed at improving OCR and multi-image reasoning, available in both dense and MoE versions.
- This launch focuses on models tailored for video processing and mobile user interface comprehension.
- Azure AI's HD Neural TTS update: Microsoft unveiled an HD version of its neural TTS on Azure AI, promising richer speech with emotional context detection.
- Features like auto-regressive transformer models are expected to enhance realism and quality in generated speech.
Stability.ai (Stable Diffusion) Discord
- Conquering ComfyUI Installation Issues: A user faced struggles with installing ComfyUI on Google Colab, particularly with the comfyui manager installation process.
- Discussants noted the importance of specific model paths and compatibility problems with Automatic1111.
- Flux Model Shows Off Fantastic Features: Users praised the impact of the Flux model in creating consistent character images and improving details like hands and feet.
- One member shared a link to a Flux lora that surprisingly boosts image quality beyond its intended use.
- Automatic1111 Installation Troubles Persist: Issues arose when installing Automatic1111 with the latest Python version, raising questions about compatibility.
- Members recommended using virtual environments or Docker containers to better manage different Python versions.
- Debating Debian-based OS Quirks: A lively conversation focused on the pros and cons of Debian-based operating systems, highlighting popular distributions like Pop and Mint.
- Users humorously shared their thoughts on retrying Pop for its unique features.
- Python Version Compatibility Chaos: Members discussed the challenges of using the latest Python version, suggesting older versions might improve compatibility with some scripts.
- One user contemplated adjusting their setup to execute scripts separately to overcome stability issues.
Perplexity AI Discord
- Hustle for Higher Rate Limits: Users discussed options for requesting rate limit increases on the API, seeking to surpass the 20 request limit.
- There is broad support for these requests, demonstrating a collective need for enhanced capabilities.
- Eager Anticipation for Llama 3.2: The upcoming release of Llama 3.2 sparked excitement among users eagerly awaiting the new features.
- One meme echoed a sense of uncertainty on the release date, with humor drawing attention to past delays.
- LiquidAI Gaining Speed Fame: LiquidAI has been praised for its speed, with a user proclaiming it is crazy fast compared to competing models.
- While speed is its strength, users have noted its inaccuracy, raising concerns about reliability.
- Chat Feature with PDF Capability Rocks: A user confirmed successfully downloading entire chats as PDFs, opening discussions on this feature's utility.
- This reflects a growing demand for better ways to save complete conversations, especially for documentation.
- Text-to-Speech's Mixed Reviews: Discussion on the text-to-speech (TTS) feature highlighted its common usage for crafting long replies, despite some pronunciation issues.
- Users find it a handy tool but see potential for refinement in its accuracy.
Cohere Discord
- Credit Card Cloud and Apple Pay Support Needed: A member expressed the need for full support for credit card cloud and Apple Pay, prompting advice to contact support@cohere.com for assistance.
- Another member offered to handle the support inquiry for smoother resolution.
- Event Notifications Arriving Late: A member reported issues with event notifications arriving after events, especially during the last Office Hours meeting.
- This has been acknowledged as a technical glitch, prompting thanks for raising the issue.
- Inquiring About MSFT Copilot Studio: A member asked about experiences with MSFT Copilot Studio and its comparative value against other solutions in the market.
- A response emphasized sensitivity regarding promotional content in discussions.
- Azure Model Refresh Hiccups: A member reported problems with refreshing models in Azure, suggesting immediate contact with both Cohere support and the Azure team.
- Another member requested the associated issue ID for better tracking in communications.
- Interest in Cohere Chat App Development: A member inquired about any upcoming Cohere chat app plans, specifically for mobile devices, and expressed enthusiasm for community promotion.
- Offering to host a webinar, they highlighted advocacy for the platform.
LlamaIndex Discord
- Cost-effective Contextual Retrieval RAG Emerges: A member shared @AnthropicAI's new RAG technique that enhances retrieval by prepending metadata to document chunks, improving performance and cost-effectiveness. This method guides the retrieval process more accurately based on the contextual position in documents.
- This innovative approach is positioned as a game-changer, aiming to streamline data handling in various applications.
- Oracle AI Vector Search Shines in Semantic Search: Oracle AI Vector Search, a groundbreaking feature of Oracle Database, leads the charge in the semantic search domain, enabling systems to understand information based on meaning rather than keywords. This technology, when paired with the LlamaIndex framework, is positioned as a powerful solution for building sophisticated RAG pipelines.
- The synergy between Oracle and LlamaIndex enhances capabilities, pushing boundaries in AI-driven data retrieval, as detailed in this article.
- Human Feedback Fuels Multi-agent Writing: An innovative blog-writing agent utilizing multi-agent systems incorporates human in the loop feedback into TypeScript workflows, showcasing dynamic writing improvements. Viewers can see the agent in action, writing and editing in real-time, showcased in this live demonstration.
- This development highlights the potential for significantly enhancing collaborative writing processes through direct human engagement.
- Exploring LlamaIndex Infrastructure Needs: Members shared insights on hardware specifications for running LlamaIndex, noting varying needs based on model and data size. Key considerations included the necessity of GPUs for running LLM and embedding models, with recommendations for specific vector databases.
- This discussion emphasized practical aspects that influence deployment decisions, catering to diverse project requirements.
- NVIDIA's NVLM Captures Attention: The introduction of NVIDIA's NVLM 1.0, a multimodal large language model, was highlighted, emphasizing its state-of-the-art capabilities in vision-language tasks. Members speculated on potential support within LlamaIndex, particularly regarding the large GPU requirements and loading configurations.
- The discussion stirred excitement about possible integrations and performance benchmarks that could emerge from this implementation within LlamaIndex.
Torchtune Discord
- Salman Mohammadi Nominated for Contributor Awards: Our own Salman Mohammadi got the nod for the 2024 PyTorch Contributor Awards for his valuable contributions on GitHub and active support in the Discord community.
- His work has been crucial to boosting the PyTorch ecosystem, which saw contributions from 3,500 individuals this year.
- Tokenizer Probabilities vs. One-Hot in Distillation: Members debated the effectiveness of distillation using probabilities for token training over one-hot vectors, highlighting how larger models can yield better latent representations.
- They agreed that mixing labeled and unlabeled data could 'smooth' the loss landscape, enhancing the distillation process.
- H200s Are Coming: Excitement brewed as a member announced their 8x H200 setup, boasting an impressive 4TB RAM, already en route.
- This setup is set to power their local in-house developments further, reinforcing their infrastructure.
- Local LLMs Get Priority: The chat sparked discussions on deploying local LLMs, noting that current APIs fall short for healthcare data in Europe.
- Members stressed that local infrastructure improves security for handling sensitive information.
- B100s Hardware Plans on the Horizon: Future plans to integrate B100s hardware were laid out, signaling a shift toward enhanced local processing capabilities.
- The community expressed anticipation for more resources to strengthen their developmental capabilities.
Modular (Mojo 🔥) Discord
- Mojo Literals lag behind: A member confirmed that literals don't function yet in Mojo, suggesting
msg.extend(List[UInt8](0, 0, 0, 0))as an alternative approach.- The community anticipates try expressions might be included in future updates.
- EC2 Type T2.Micro Woes: A user faced a JIT session error on a budget-friendly EC2 t2.micro instance due to possible memory constraints during compilation.
- Members suggested a minimum of 8GB of RAM for smoother operations, with one noting that 2GB sufficed for binary builds.
- Mojo Library Imports in Discussion: There’s growing interest in Mojo's future support for import library functionality to utilize CPython libraries instead of
cpython.import_module.- Concerns arose about potential module name conflicts, proposing an import precedence strategy for integration.
- Memory Management Strategies Explored: A suggestion emerged to use swap memory on EC2, with a cautionary note about performance degradation due to IOPS usage.
- Another user validated successful operations with 8GB, while concerns on Mojo’s handling of memory-specific imports were also highlighted.
- Mojo's Import Behavior: It was noted that Mojo presently does not manage imports with side effects like Python, complicating compatibility.
- This led to discussions on whether Mojo's compiler should replicate all of Python's nuanced import behaviors.
OpenInterpreter Discord
- Nova LLM Launch Hits Big: Nova has launched its suite of Large Language Models, including Nova-Instant, Nova-Air, and Nova-Pro, achieving an 88.8% score on MMLU.
- Nova-Pro surpasses competitors with 97.2% on ARC-C and 96.9% on GSM8K, emphasizing its top-tier reasoning and math capabilities.
- Open Interpreter Supports Dynamic Function Calls: Members discussed if they could define custom functions in their Python projects using Open Interpreter's
interpreter.llm.supports_functionsfeature.- While Open Interpreter can create functions on the fly, strict definitions ensure accurate model calls, as clarified with reference to the OpenAI documentation.
- Realtime API Launches for Speech Technologies: A new realtime API enables speech-to-speech capabilities, enhancing relationships in conversational AI.
- This API aims to bolster applications with immediate responses, revolutionizing interactive communication.
- Vision Now Integrated into Fine-Tuning API: OpenAI has announced vision in the fine-tuning API, allowing models to utilize visual data during training.
- This expansion opens new pathways for multimodal AI applications, further bridging text and image processing.
- Model Distillation Enhances Efficiency: Model distillation is focused on refining model weight management to boost performance.
- This method aims to minimize computational load while maintaining model accuracy, ensuring optimized outputs.
LangChain AI Discord
- LangChain waiting for GPT Realtime API: Members eagerly discussed when LangChain will support the newly announced GPT Realtime API, but no definitive timeline emerged in the chat.
- This uncertainty led to ongoing speculation within the community about potential features and implementation.
- HuggingFace now an option in LangChain: HuggingFace models can be utilized as Agents in LangChain for various tasks including chat and text generation, with a code snippet shared for implementation.
- For further insights, members were directed to LangChain's documentation and a related GitHub issue.
- Concerns over curly braces in prompts: A member raised concerns about effectively passing strings with curly braces in chat prompt templates in LangChain, as they are interpreted as placeholders.
- Community members sought different strategies to handle this issue without altering input during processing.
- Nova LLMs outperforming competition: The launch of Nova LLMs, including Nova-Instant, Nova-Air, and Nova-Pro, shows significant performance, with Nova-Pro achieving a stellar 88.8% on MMLU.
- Nova-Pro also scored 97.2% on ARC-C and 96.9% on GSM8K, establishing itself as a frontrunner in AI interactions; learn more here.
- LumiNova elevates image generation: The new LumiNova model promises exceptional image generation capabilities, enhancing the visual creativity of AI applications.
- This advancement opens up new possibilities for interactive and engaging AI-driven experiences.
OpenAccess AI Collective (axolotl) Discord
- Qwen 2.5 impresses in deployment: A member successfully deployed Qwen 2.5 34B and reported its performance as insanely good, rivaling GPT-4 Turbo.
- The discussion buzzed with specifics on deployment and vision support, emphasizing the rapid evolution of model capabilities.
- Exploration of small model capabilities: Members marveled at the impressive advancements in small models and debated their potential limits.
- How far exactly can we push this? What are the actual limits? The conversation reflects a growing interest in optimizing smaller architectures.
- Clarifications on hf_mlflow_log_artifacts: A member asked if setting hf_mlflow_log_artifacts to true would save model checkpoints to mlflow, indicative of integration concerns.
- This highlights the crucial need for robust logging mechanisms in model training workflows.
- Custom instruct format in sharegpt discussed: Instructions on defining a custom instruct format for datasets in sharegpt were shared, stressing the usage of YAML.
- Essential steps were outlined, including custom prompts and ensuring JSONL format compatibility for successful outcomes.
tinygrad (George Hotz) Discord
- Tiny Box Unboxing Wins Hearts: A member unboxed the tiny box from Proxy, highlighting the great packaging and wood base as standout features.
- Worried about the ny->au shipment, they praised the effort that secured the package successfully.
- Debating the Bugfix PR Approach: A call for review on this bugfix PR was made, addressing issues with saving and loading tensors twice.
- The PR tackles #6294, revealing that disk devices keep unlinked files without creating new ones, which remains a crucial development point.
- Tinygrad Code Boosts Coding Skills: Engaging with the tinygrad codebase has shown to enhance coding skills in a member's day job, proving the value of open-source experience.
- It's making my day job coding better as a side effect, they shared, reflecting on positive coding impact.
- C Interoperability is a Win: Members discussed how Python's productive nature rivals its C interoperability, allowing smooth function calls that improve performance in low-level operations.
- Despite some limitations with structs, the consensus is that the benefits for rapid iteration remain substantial.
- UOp vs UOP Optimization Frustrations: A member expressed challenges faced with optimizing UOp vs UOP pool, citing individual object references complicating the process.
- They suggested a more efficient storage class that utilizes integer handles to manage object references better.
LAION Discord
- Strong Anti-Spam Sentiment: A member expressed strong dislike for spam, emphasizing frustrations with unwanted messages in the community.
- This reflects a common challenge where members urge for better moderation to control spam's impact on communication.
- Sci Scope Newsletter Launch Announced: The personalized newsletter from Sci Scope is now available, offering tailored updates on preferred research areas and new papers weekly.
- Never miss out on research relevant to your work again! Users can try it out now for a stress-free way to keep up with advancements in AI.
- Weekly AI Research Summaries for Busy Professionals: The newsletter will scan new ArXiv papers and deliver concise summaries, aimed at saving subscribers hours of work each week.
- This service promises to simplify the task of selecting pertinent reading material with a weekly high-level summary.
- Exclusive Offer for New Users: New users can sign up for a free 1-month trial that includes access to custom queries and a more relevant experience.
- This initiative enhances engagement, making it easier for users to keep pace with the rapidly evolving field of AI.
DSPy Discord
- Personalized Newsletter from Sci Scope: Sci Scope has launched a personalized newsletter that delivers weekly summaries of new papers tailored to individual interests, helping users stay updated without the hassle.
- This service scans for new ArXiv papers based on user preferences; it begins with a free 1-month trial to attract new users.
- Query on Code Similarity Search: A member is exploring options for code similarity and considering Colbert for outputting relevant code documents from snippets, questioning its effectiveness without finetuning.
- They are also seeking alternative methods for code search, highlighting the community's collaboration on effective approaches.
LLM Agents (Berkeley MOOC) Discord
- Lab Assignments Pushed Back: A member inquired about the lab assignments scheduled for release today, leading to confirmation that staff requires another week to prepare them. Updates will be available on the course page at llmagents-learning.org.
- The delay has sparked concerns, with participants expressing frustration over the lack of communication regarding release schedules and updates.
- Communication Gaps Highlighted: Concerns emerged over insufficient updates on lab releases, with one member unable to find relevant emails or announcements. This situation underlines the need for better course communication amidst participant expectations.
- Participants await important information about course progress, emphasizing the urgency for timely announcements from course staff.
Mozilla AI Discord
- Establishing ML Paper Reading Group: A member proposed to kickstart an ML paper reading group aimed at discussing recent research, enhancing community interaction.
- This initiative seeks to boost collective knowledge sharing among engineers interested in the latest developments in machine learning.
- Tips for Publishing Local LLM Apps: Community members expressed gratitude for insights provided on effectively publishing local LLM-based apps to the app store.
- These tips are viewed as essential for those navigating the complexities of app publishing.
- Community Job Board Proposal Gains Interest: A discussion emerged regarding the creation of a job board to facilitate community job postings.
- Initiated by a member, this idea aims to connect talent with job opportunities within the engineering sector.
- Lumigator Gets Official Spotlight: The community introduced Lumigator in an official post, showcasing its features and capabilities.
- This introduction reinforces the community’s commitment to highlighting noteworthy projects relevant to AI engineers.
- Exciting Upcoming Events on Tech Innovations: Several upcoming events were highlighted, including discussions on Hybrid Search concentrating on search technologies.
- Other sessions, like Data Pipelines for FineTuning, promise to further advance engineering knowledge and skills.
MLOps @Chipro Discord
- Nova Models outshine competitors: Introducing Nova: the next generation of large language models that beat GPT-4 and Claude-3.5 across various benchmarks, with Nova-Pro leading at 88.8% on MMLU.
- Nova-Air excels across diverse applications while Nova-Instant offers speedy, cost-effective solutions.
- Benchmarking Excellence across Nova Models: Nova-Pro shines with impressive scores: 97.2% on ARC-C for reasoning, 96.9% on GSM8K for mathematics, and 91.8% on HumanEval for coding.
- These benchmarks solidify Nova's position as a top contender in the AI field, showcasing its extraordinary capabilities.
- LumiNova revolutionizes image generation: The newly introduced LumiNova sets a high bar for image generation, promising unmatched quality and diversity in visuals.
- This model complements the Nova suite by providing users with advanced tools for creating stunning visuals effortlessly.
- Future developments with Nova-Focus: The development team is exploring Nova-Focus and enhanced Chain-of-Thought capabilities to further push the boundaries of AI.
- These innovations aim to refine and expand the potential applications of the Nova models in both reasoning and visual generation.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!