[AINews] not much happened today
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
a quiet day.
AI News for 3/12/2025-3/13/2025. We checked 7 subreddits, 433 Twitters and 28 Discords (222 channels, and 5887 messages) for you. Estimated reading time saved (at 200wpm): 616 minutes. You can now tag @smol_ai for AINews discussions!
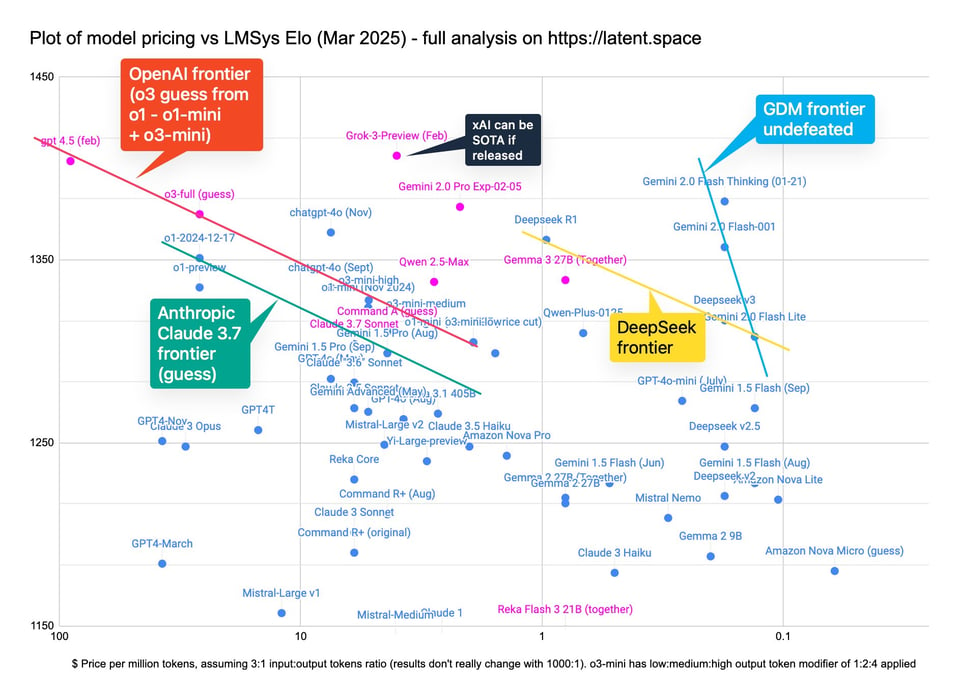
This is the state of models after yesterday's Gemma 3 drop and today's Command A:
the Windsurf talk from AIE NYC is somehow doing even better than the MCP workshop.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor IDE Discord
- Nous Research AI Discord
- Unsloth AI (Daniel Han) Discord
- LM Studio Discord
- aider (Paul Gauthier) Discord
- Perplexity AI Discord
- OpenAI Discord
- HuggingFace Discord
- Interconnects (Nathan Lambert) Discord
- Eleuther Discord
- OpenRouter (Alex Atallah) Discord
- Cohere Discord
- MCP (Glama) Discord
- Notebook LM Discord
- GPU MODE Discord
- Yannick Kilcher Discord
- Nomic.ai (GPT4All) Discord
- Latent Space Discord
- LlamaIndex Discord
- LLM Agents (Berkeley MOOC) Discord
- Modular (Mojo 🔥) Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- AI21 Labs (Jamba) Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor IDE ▷ #general (1134 messages🔥🔥🔥):
- Nous Research AI ▷ #announcements (2 messages):
- Nous Research AI ▷ #general (684 messages🔥🔥🔥):
- Nous Research AI ▷ #ask-about-llms (1 messages):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #interesting-links (11 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Unsloth AI (Daniel Han) ▷ #general (503 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (41 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (127 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (5 messages):
- Unsloth AI (Daniel Han) ▷ #research (20 messages🔥):
- LM Studio ▷ #announcements (2 messages):
- LM Studio ▷ #general (267 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (254 messages🔥🔥):
- aider (Paul Gauthier) ▷ #general (329 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (85 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (7 messages):
- Perplexity AI ▷ #general (395 messages🔥🔥):
- Perplexity AI ▷ #sharing (24 messages🔥):
- Perplexity AI ▷ #pplx-api (1 messages):
- OpenAI ▷ #ai-discussions (278 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (7 messages):
- OpenAI ▷ #prompt-engineering (21 messages🔥):
- OpenAI ▷ #api-discussions (21 messages🔥):
- HuggingFace ▷ #general (204 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (5 messages):
- HuggingFace ▷ #cool-finds (6 messages):
- HuggingFace ▷ #i-made-this (16 messages🔥):
- HuggingFace ▷ #reading-group (3 messages):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #NLP (3 messages):
- HuggingFace ▷ #smol-course (4 messages):
- HuggingFace ▷ #agents-course (76 messages🔥🔥):
- HuggingFace ▷ #open-r1 (1 messages):
- Interconnects (Nathan Lambert) ▷ #news (177 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (2 messages):
- Interconnects (Nathan Lambert) ▷ #random (20 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (8 messages🔥):
- Interconnects (Nathan Lambert) ▷ #cv (1 messages):
- Interconnects (Nathan Lambert) ▷ #reads (1 messages):
- Interconnects (Nathan Lambert) ▷ #posts (3 messages):
- Interconnects (Nathan Lambert) ▷ #policy (32 messages🔥):
- Eleuther ▷ #general (56 messages🔥🔥):
- Eleuther ▷ #research (134 messages🔥🔥):
- Eleuther ▷ #interpretability-general (8 messages🔥):
- Eleuther ▷ #lm-thunderdome (5 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (5 messages):
- OpenRouter (Alex Atallah) ▷ #general (161 messages🔥🔥):
- Cohere ▷ #「💬」general (74 messages🔥🔥):
- Cohere ▷ #【📣】announcements (1 messages):
- Cohere ▷ #「🔌」api-discussions (45 messages🔥):
- Cohere ▷ #「🤝」introductions (3 messages):
- MCP (Glama) ▷ #general (94 messages🔥🔥):
- MCP (Glama) ▷ #showcase (17 messages🔥):
- Notebook LM ▷ #announcements (1 messages):
- Notebook LM ▷ #use-cases (9 messages🔥):
- Notebook LM ▷ #general (98 messages🔥🔥):
- GPU MODE ▷ #general (1 messages):
- GPU MODE ▷ #triton (13 messages🔥):
- GPU MODE ▷ #cuda (30 messages🔥):
- GPU MODE ▷ #torch (1 messages):
- GPU MODE ▷ #cool-links (13 messages🔥):
- GPU MODE ▷ #jobs (1 messages):
- GPU MODE ▷ #beginner (16 messages🔥):
- GPU MODE ▷ #torchao (3 messages):
- GPU MODE ▷ #rocm (1 messages):
- GPU MODE ▷ #self-promotion (3 messages):
- GPU MODE ▷ #thunderkittens (2 messages):
- GPU MODE ▷ #reasoning-gym (9 messages🔥):
- GPU MODE ▷ #submissions (2 messages):
- Yannick Kilcher ▷ #general (50 messages🔥):
- Yannick Kilcher ▷ #paper-discussion (15 messages🔥):
- Yannick Kilcher ▷ #agents (4 messages):
- Yannick Kilcher ▷ #ml-news (16 messages🔥):
- Nomic.ai (GPT4All) ▷ #general (56 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (51 messages🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (46 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (7 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (4 messages):
- Modular (Mojo 🔥) ▷ #general (2 messages):
- Modular (Mojo 🔥) ▷ #mojo (4 messages):
- Modular (Mojo 🔥) ▷ #max (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (5 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (2 messages):
- DSPy ▷ #general (4 messages):
- DSPy ▷ #colbert (1 messages):
- tinygrad (George Hotz) ▷ #general (1 messages):
- AI21 Labs (Jamba) ▷ #jamba (1 messages):
AI Twitter Recap
outage in our scraper today; sorry.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. DeepSeek R1's FP8 training and efficiency prowess
- Does Google not understand that DeepSeek R1 was trained in FP8? (Score: 441, Comments: 79): DeepSeek R1 was trained using FP8 precision, which raises questions about whether Google understands this aspect in their analysis, as implied by the post's title. The Chatbot Arena Elo Score graph shows DeepSeek R1 outperforming Gemma 3 27B, with scores of 1363 and 1338 respectively, and notes the significant computational resources required, including 32 H100s and 2,560GB VRAM.
- Discussions highlight the efficiency of FP8 precision in model storage and processing, emphasizing that upcasting weights to a wider format like BF16 doesn't improve precision. The conversation also touches on the trade-offs in quantization, with FP8 allowing for smaller models and potentially faster inference due to reduced memory requirements.
- Users debate the hardware requirements for running large models like DeepSeek R1, noting that while H100 GPUs can handle FP8 models, legacy hardware may require different approaches. Some comments mention running large models on consumer-grade GPUs with slower performance, highlighting the flexibility and challenges of model deployment across different systems.
- There is skepticism about the accuracy and utility of charts and benchmarks in the AI industry, with some users expressing distrust of the data presented in corporate materials. NVIDIA's blog post is cited as a source for running DeepSeek R1 efficiently, and there is criticism of the potential misleading nature of AI-generated charts.
- OpenAI calls DeepSeek 'state-controlled,' calls for bans on 'PRC-produced' models | TechCrunch (Score: 183, Comments: 154): NVIDIA demonstrates DeepSeek R1 running on 8xH200s, with OpenAI labeling DeepSeek as "state-controlled" and advocating for bans on "PRC-produced" models, according to TechCrunch.
- Discussions highlight skepticism towards OpenAI's motives, with many users criticizing Sam Altman for attempting to stifle competition by labeling DeepSeek as "state-controlled" to protect OpenAI's business model. Users argue that DeepSeek offers more open and affordable alternatives compared to OpenAI's offerings, which they view as monopolistic and restrictive.
- The conversation emphasizes the accessibility and openness of DeepSeek's models, noting that they can be run locally or on platforms like Hugging Face, which counters claims about compliance with Chinese data demands. Comparisons are drawn to US companies also being subject to similar legal obligations under the CLOUD Act.
- Many commenters express frustration with OpenAI's stance, viewing it as a barrier to open-source AI development and innovation. They criticize the company's attempts to influence government regulations to curb competition, contrasting it with the democratization of AI models like DeepSeek and Claude.
Theme 2. Gemma 3's Technical Highlights and Community Impressions
- The duality of man (Score: 424, Comments: 59): Gemma 3 receives mixed reviews on r/LocalLLaMA, with one post praising its creative and worldbuilding capabilities and another criticizing its frequent mistakes, suggesting it is less effective than phi4 14b. The critique post has significantly more views, 23.7k compared to 5.1k for the appreciation post, indicating greater engagement with the negative feedback.
- Several users discuss the language support capabilities of Gemma 3, noting that the 1B version only supports English, while 4B and above models support multiple languages. This limitation is highlighted in the context of handling Chinese and other languages, with users expressing the need for models to handle multilingual tasks effectively.
- There are concerns about the instruction template and tokenizer issues affecting Gemma 3, with users noting that the model is extremely sensitive to template errors, resulting in incoherent outputs. This sensitivity is contrasted with previous models like Gemma 2, which handled custom formats better, and some users have adapted by tweaking their input formatting to achieve better results.
- Discussions highlight the dual nature of Gemma 3 in performing tasks, where it excels in creative writing but struggles with precision tasks like coding. Users note that while it may generate interesting ideas, it often makes logical errors, and there is speculation that these issues may be related to the tokenizer or other model-specific bugs.
- AMA with the Gemma Team (Score: 279, Comments: 155): The Gemma research and product team from DeepMind will be available for an AMA to discuss the Gemma 3 Technical Report and related resources. Key resources include the technical report here, and additional platforms for exploration such as AI Studio, Kaggle, Hugging Face, and Ollama.
- Several users raised concerns about the Gemma 3 model's licensing terms, highlighting issues such as potential "viral" effects on derivatives and the ambiguity of rights regarding outputs. The Gemma Terms of Use were critiqued for their complex language, leading to confusion about what constitutes a "Model Derivative" and the implications for commercial use.
- Discussions about model architecture and performance included inquiries into the rationale behind design choices such as the smaller hidden dimension with more layers, and the impact of the 1:5 global to local attention layers on long context performance. The team explained that these choices were made to balance performance with latency and memory efficiency, maintaining a uniform width-vs-depth ratio across models.
- Users expressed interest in future developments and capabilities of the Gemma models, such as the possibility of larger models between 40B and 100B, the introduction of voice capabilities, and the potential for function calling and structured outputs. The team acknowledged these interests and hinted at upcoming examples and improvements in these areas.
- AI2 releases OLMo 32B - Truly open source (Score: 279, Comments: 42): AI2 has released OLMo 32B, a fully open-source model that surpasses GPT 3.5 and GPT 4o mini. The release includes all artifacts such as training code, pre- and post-train data, model weights, and a reproducibility guide, allowing researchers and developers to modify any component for their projects. AI2 Blog provides further details.
- Hugging Face Availability: OLMo 32B is available on Hugging Face and works with transformers out of the box. For vLLM, users need the latest main branch version or wait for version 0.7.4.
- Open Source Practice: The release is celebrated for its true open-source nature, with Apache 2.0 licensing and no additional EULAs, making it accessible for individual developers to build models from scratch if they have GPU access. This aligns with the trend of open AI development, as noted by several commenters.
- Model Features and Context: The model supports 4k context, as indicated by the config file, and further context size extensions are in progress. It's noted for being efficient, with inference possible on one GPU and training on one node, fitting well with 24 gigs of VRAM.
Theme 3. Innovation in Large Language Models: Cohere's Command A
- CohereForAI/c4ai-command-a-03-2025 · Hugging Face (Score: 192, Comments: 72): Cohere has introduced a new model called Command A, accessible on Hugging Face under the repository CohereForAI/c4ai-command-a-03-2025. Further details about the model's capabilities or specifications were not provided in the post.
- Pricing and Performance: The Command A model costs $2.5/M input and $10/M output, which some users find expensive for a 111B parameter model, comparable to GPT-4o via API. It is praised for its performance, especially in business-critical tasks and multilingual capabilities, and can be deployed on just two GPUs.
- Comparisons and Capabilities: Users compare Command A to other models like GPT4o, Deepseek V3, Claude 3.7, and Gemini 2 Pro, noting its high instruction-following score and solid programming skills. It is considered a major improvement over previous Command R+ models and is praised for its creative writing abilities.
- Licensing and Hosting: There is a discussion about the model's research-only license, which some find limiting, and the need for a new license that allows for commercial use of outputs while restricting commercial hosting. Users are interested in local hosting capabilities and fine-tuning tools for the model.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. Claude 3.7 Sonnet Creates Unbeatable AI in Arcade Games
- Claude 3.7 Sonnet making 3blue1brown kind of videos. Learning will be much different for this generation (Score: 176, Comments: 20): Claude 3.7 is generating content similar to 3blue1brown videos, indicating a shift in how learning materials are produced and consumed. This development suggests a transformative impact on educational methods for the current generation.
- Curator Tool: The code executor on curator was used to create the content, and it's available on GitHub.
- AI Impact on Education: There is a strong belief that AI will revolutionize public education, but it requires abandoning traditional learning methods. The discussion highlights concerns about over-reliance on AI, as seen in the unnoticed error regarding the maximal area of circles.
- Trust in AI: Skepticism is expressed about the current trust in AI, with a specific example of a mathematical error in the AI-generated content that many missed, illustrating potential pitfalls in learning accuracy when using AI tools.
- I asked Claude to make a simple Artillery Defense arcade game. Then I used Claude to design a CPU player that couldn't lose. (Score: 247, Comments: 49): The post discusses using Claude, an AI model, to create a simple Artillery Defense arcade game and subsequently designing a CPU player that is unbeatable. The author implies a successful implementation of AI in game design, showcasing Claude's capabilities in generating both game mechanics and an invincible CPU player.
- Token Limit Challenges: Users like Tomas_Ka and OfficialHashPanda discuss the challenges of using Claude for coding tasks due to token limitations, with Tomas_Ka noting issues when attempting a simple website project. Craygen9 mentions using VSCode with GitHub Copilot and managing a codebase of around 2,000 lines, highlighting that the process slows as the code grows.
- Game Development Process: Craygen9 shares a detailed account of developing the Artillery Defense game, emphasizing the use of HTML and JavaScript with Sonnet 3.7. The game, comprising 1,500 lines of code, was iteratively refined with features like scaling difficulty, power-up crates, and sound, with Claude assisting in designing a CPU player that plays perfectly.
- Graphics and Iterations: The graphics for the game were generated by Claude using CSS, with multiple iterations needed for improvements. Craygen9 explains the evolution from basic graphics to more polished arcade-style visuals, detailing the iterative process that included adding points, power-ups, sound effects, and a loading screen, all without external libraries or assets.
Theme 2. Gemini 2.0 Flash: Native Image Generation Now Available
- Google released native image generation in Gemini 2.0 Flash (Score: 247, Comments: 52): Google released the Gemini 2.0 Flash with native image generation capabilities, available for free in AI Studio. The feature is still experimental but has received positive feedback for its performance. Further details can be found in the full article.
- There is a significant debate over whether Google Gemini 2.0 Flash is truly open source, with users clarifying that while it's free to use, it does not equate to open source. Educational_End_2473 and ReasonablePossum_ emphasize the distinction, noting that open source allows for modification and redistribution, which this release does not.
- Diogodiogogod and EuphoricPenguin22 discuss the subreddit rules concerning open source content, highlighting a community preference for open source tools and questioning the downvoting of comments that enforce these rules. They argue that the subreddit often favors simple, visual content over complex technical discussions.
- Inferno46n2 suggests that even though Gemini 2.0 Flash is not open source, it remains useful due to its free accessibility, except under heavy usage conditions. However, very_bad_programmer insists on a strict interpretation, stating that "not open source means not open source," leaving no room for gray areas.
- Guy asked Gemini to only respond with images and it got creepy (Score: 165, Comments: 42): The post discusses an interaction with Google's Gemini AI, where the user requested responses solely in image format, leading to unexpectedly unsettling results. The lack of text in the AI's replies and the unspecified nature of the images contributed to a creepy experience.
- AI Response Interpretation: Commenters speculate on the meaning behind Gemini AI's response, suggesting it was a mix of prompts like "you are a visual storyteller" and "what is the meaning of life," leading to a garbled output that seemed to convey deep feelings but was actually a reflection of the input text. Astrogaze90 suggests it was trying to express that the meaning of life is tied to one's own existence and soul.
- Emotional and Conceptual Themes: DrGutz explains that using the word "scared" might have triggered the AI to generate unsettling images and concepts, demonstrating how AI processes emotional triggers. Some users, like KairraAlpha, interpret the AI's output as a philosophical statement about unity and existence, while others humorously reference pop culture, like Plums_Raider with a quote from "The Simpsons."
- User Reactions and Humor: Several users, like Nekrips, responded humorously to the AI's output, with some comments being nonsensical or playful, such as Zerokx's interpretation of the AI saying "I love lasagna," showing a mix of serious and lighthearted engagement with the AI's unexpected behavior.
Theme 3. Dramatically Enhance Video AI Quality with Wan 2.1
- Dramatically enhance the quality of Wan 2.1 using skip layer guidance (Score: 346, Comments: 85): Skip layer guidance can dramatically enhance the quality of Wan 2.1. Without further context or details from the post body, additional specifics regarding the implementation or results are not provided.
- Kijai's Implementation and Wan2GP: Kijai has implemented skip layer guidance in the WanVideoWrapper on GitHub, which users can clone and run using specific scripts. Wan2GP is designed for low VRAM consumer cards, supporting video generation on cards with as little as 6GB of VRAM for 480p or 12GB for 720p videos.
- Technical Insights on Skip Layer Guidance: The skip layer technique involves skipping certain layers during unconditional video denoising to improve the result, akin to perturbed attention guidance. Users report that skipping later layers often results in video corruption, while skipping layers during specific inference steps may be more effective.
- User Experiences and Experimentation: Users have shared mixed experiences, with some reporting successful tests and others noting issues like sped-up or slow-motion videos when skipping certain layers. Discussions highlight the importance of experimenting with different layers to optimize video quality, as some layers may be critical for maintaining video coherence or following prompts.
- I have trained a new Wan2.1 14B I2V lora with a large range of movements. Everyone is welcome to use it. (Score: 279, Comments: 47): The post announces the training of a new Wan2.1 14B I2V lora model with an extensive range of movements, inviting others to utilize it. No additional details or links are provided in the post body.
- Model Training and Usage: Some_Smile5927 shared detailed information about the Wan2.1 14B I2V 480p v1.0 model, including its training on the Wan.21 14B I2V 480p model with a trigger word 'sb9527sb flying effect'. They provided recommended settings and links to the inference workflow and model.
- Training Methodology: Some_Smile5927 mentioned using 50 short videos for training, while houseofextropy inquired about the specific tools used for training the Wan Lora model. Pentagon provided a link to the Musubi Tuner on GitHub, which may be related to the training process.
- Model Capabilities and Perceptions: Users expressed amazement at the model's ability to handle fabric and its movement capabilities, although YourMomThinksImSexy humorously noted that the Lora model primarily performs one movement.
AI Discord Recap
A summary of Summaries of Summaries by o1-mini-2024-09-12
Anthropic’s Claude Slashes API Costs with Clever Caching
- Claude's caching API cuts costs by 90%: Anthropic’s Claude 3.7 Sonnet introduces a caching-aware rate limit and prompt caching, potentially reducing API costs by up to 90% and latency by 85% for extensive prompts.
- OpenManus Emerges as Open-Source Manus Alternative: Excitement builds around OpenManus, the open-source counterpart to Manus, with users experimenting via a YouTube demo.
- “Some users are switching to Cline or Windsurf as alternative IDEs”: Performance issues in Cursor IDE lead members to explore alternatives like Cline or Windsurf.
Google and Cohere Battle it Out with Command A and Gemini Flash
- Cohere Launches Command A, Competing with GPT-4o: Command A by Cohere boasts 111B parameters and a 256k context window, claiming parity or superiority to GPT-4o and DeepSeek-V3 for agentic enterprise tasks.
- Google’s Gemini 2.0 Flash Introduces Native Image Generation: Gemini 2.0 Flash now supports native image creation from text and multimodal inputs, enhancing its reasoning capabilities.
- “Cohere's Command A outpaces GPT-4o in inference rates”: Command A achieves up to 156 tokens/sec, significantly outperforming its competitors.
LM Studio and OpenManus: Tool Integrations Fuel AI Innovations
- LM Studio Enhances Support for Gemma 3 Models: LM Studio 0.3.13 now fully supports Google’s Gemma 3 models in both GGUF and MLX formats, offering GPU-accelerated image processing and major speed improvements.
- Blender Integrates with MCP for AI-Driven 3D Creation: MCP for Blender enables Claude to interact directly with Blender, facilitating the creation of 3D scenes from textual prompts.
- OpenManus Launches Open-Source Framework: OpenManus provides a robust, accessible alternative to Manus, sparking discussions on its capabilities and ease of use for non-technical users.
AI Development Dilemmas: From Cursor Crashes to Fine-Tuning Fiascos
- Cursor IDE Faces Sluggishness and Crashes: Users report Cursor experiencing UI sluggishness, window crashes, and memory leaks, particularly on Mac and Windows WSL2, hinting at underlying legal issues with Microsoft.
- Fine-Tuning Gemma 3 Blocked by Transformers Bug: Gemma 3 model fine-tuning is stalled due to a bug in Hugging Face Transformers, causing mismatches between documentation and setup in the Jupyter notebook on Colab.
- LSTM Model Plagued by NaN Loss in tinygrad: Training an LSTMModel with TinyJit results in NaN loss after the first step, likely due to large input values causing numerical instability.
Policy Prowess: OpenAI’s Push to Ban PRC Models Raises Eyebrows
- OpenAI Proposes Ban on PRC-Produced Models: OpenAI advocates for banning PRC-produced models within Tier 1 countries, linking fair use with national security and labeling models like DeepSeek as state-controlled.
- Google Aligns with OpenAI on AI Policy: Following OpenAI’s lead, Google endorses weaker copyright restrictions on AI training and calls for balanced export controls in its policy proposal.
- “If China has free data access while American companies lack fair use, the race for AI is effectively over”: OpenAI submits a policy proposal directly to the US government, emphasizing the strategic disadvantage in AI race dynamics.
AI in Research, Education, and Function Calling
- Nous Research AI Launches Inference API with Hermes and DeepHermes Models: Introducing Hermes 3 Llama 70B and DeepHermes 3 8B Preview as part of their new Inference API, offering $5 free credits for new users and compatibility with OpenAI-style integrations.
- Berkeley Function-Calling Leaderboard (BFCL) Sets New Standards: The BFCL offers a comprehensive evaluation of LLMs' ability to call functions and tools, mirroring real-world agent and enterprise workflows.
- AI Agents Enhance Research and Creativity: Jina AI shares advancements in DeepSearch/DeepResearch, emphasizing techniques like late-chunking embeddings and rerankers to improve snippet selection and URL prioritization for AI-powered research.
PART 1: High level Discord summaries
Cursor IDE Discord
- Claude's Caching API Slashes Costs: Anthropic introduces API updates for Claude 3.7 Sonnet, featuring cache-aware rate limits and prompt caching, potentially cutting costs by up to 90%.
- These updates enable Claude to maintain knowledge of large documents, instructions, or examples without resending data with each request, also reducing latency by 85% for long prompts.
- Cursor Plagued by Performance Problems: Users are reporting sluggish UI, frequent window crashes, and memory leaks in recent Cursor versions, especially on Mac and Windows WSL2.
- Possible causes mentioned include legal issues with Microsoft; members suggest trying Cline or Windsurf as alternative IDEs.
- Open Source Manus Sparks Excitement: The open-source alternative to Manus, called OpenManus, is generating excitement, with some users are even trying the demo showcased in this YouTube video.
- The project aims to provide a more accessible alternative to Manus, prompting discussions around its capabilities and ease of use for non-technical users.
- Blender Integrates with MCP: A member highlighted MCP for Blender, enabling Claude to directly interact with Blender for creating 3D scenes from prompts.
- This opens possibilities for extending AI tool integration beyond traditional coding tasks.
- Cursor Version Confusion Creates Chaos: A chaotic debate erupts over Cursor versions, with users touting non-existent 0.49, 0.49.1, and even 1.50 builds while others struggle with crashes on 0.47.
- The confusion stems from differing update experiences, with some users accessing beta versions through unofficial channels, further muddying the waters.
Nous Research AI Discord
- Nous Research Launches Inference API with DeepHermes: Nous Research introduced its Inference API featuring models like Hermes 3 Llama 70B and DeepHermes 3 8B Preview, accessible via a waitlist at Nous Portal with $5.00 free credits for new users.
- The API is OpenAI-compatible, and further models are planned for integration.
- DeepHermes Models Offer Hybrid Reasoning: Nous Research released DeepHermes 24B and 3B Preview models, available on HuggingFace, as Hybrid Reasoners with an on/off toggle for long chain of thought reasoning.
- The 24B model demonstrated a 4x accuracy boost on challenging math problems and a 43% improvement on GPQA when reasoning is enabled.
- LLM Gains Facial Recognition: A member open-sourced the LLM Facial Memory System, which combines facial recognition with LLMs, enabling it to recognize people and maintain individual chat histories based on identified faces.
- This system was initially built for work purposes and then released publicly with permission.
- Gemma-3 Models Now Run in LM Studio: LM Studio 0.3.13 introduced support for Google's Gemma-3 models, including multimodal versions, available in both GGUF and MLX formats.
- The update resolves previous issues with the Linux version download, which initially returned 404 errors.
- Agent Engineering: Hype vs. Reality: A blog post on "Agent Engineering" sparked discussion about the gap between the hype and real-world application of AI agents.
- The post suggests that despite the buzz around agents in 2024, their practical implementation and understanding remain ambiguous, suggesting a long road ahead before they become as ubiquitous as web browsers.
Unsloth AI (Daniel Han) Discord
- Gemma 3 Models Cause a Transformers Tantrum: A bug in Hugging Face Transformers is currently blocking fine-tuning of Gemma 3 models, as noted in the Unsloth blog post.
- The issue results in mismatches between documentation and setup in the Gemma 3 Jupyter notebook on Colab; HF is actively working on a fix.
- GRPO Gains Ground over PPO for Finetuning: Members discussed the usage of GRPO vs PPO for finetuning, indicating that GRPO generalizes better, is easier to set up, and is a possible direct replacement.
- While Meta 3 used both PPO and DPO, AI2 still uses PPO for VLMs and their big Tulu models because they use a different reward system that leads to very up to date RLHF.
- GPT-4.5 Trolls Its Users: A member reported ChatGPT-4.5 trolled them by limiting questions, then mocking their frustration before granting more.
- The user quoted it as being like "u done having ur tantrum? I'll give u x more questions".
- Double Accuracy Achieved Via Validation Set: A member saw accuracy more than double from 23% to 53% using a validation set of 68 questions.
- The creator of the demo may submit a PR into Unsloth with this feature.
- Slim Attention Claims Memory Cut, MLA Questioned: A paper titled Slim attention: cut your context memory in half without loss of accuracy was shared, highlighting the claim that K-cache is all you need for MHA.
- Another member questioned why anyone would use this over MLA.
LM Studio Discord
- LM Studio Goes Gemm-tastic: LM Studio 0.3.13 is live, now supporting Google's Gemma 3 in both GGUF and MLX formats, with GPU-accelerated image processing on NVIDIA/AMD, requiring a llama.cpp runtime update to 1.19.2 from lmstudio.ai/download.
- Users rave that the new engine update for Gemma 3 offers significant speed improvements, with many considering it their main model now.
- Gemma 3's MLX Model Falters?: Some users report that Gemma 3's MLX model produces endless
<pad>tokens, hindering text generation; a workaround is to either use the GGUF version or provide an image.- Others note slow token generation at 1 tok/sec with low GPU and CPU utilization, suggesting users manually maximize GPU usage in model options.
- Context Crashes Catastrophic Gemma: Members discovered that Gemma 3 and Qwen2 vl crash when the context exceeds 506 tokens, spamming
<unusedNN>, a fix has been released in Runtime Extension Packs (v1.20.0).- One member asked if they could use could models with LM Studio, but another member swiftly replied that LM Studio is designed for local models only.
- Vulkan Slow, ROCm Shows Promise: Users found that Vulkan performance lags behind ROCm, suggesting a driver downgrade to 24.10.1 for testing; one user reported 37.3 tokens/s on a 7900 XTX with Mistral Small 24B Q6_K.
- For driver changes without OS reinstall, it was suggested to use AMD CleanUp.
- 9070 GPU Bites the Dust: A user's 9070 GPU malfunctioned, preventing PC boot and triggering the motherboard's RAM LED, but a 7900 XTX worked; testing is underway before RMA.
- They will try to boot with one RAM stick at a time, but others speculated on a PCI-E Gen 5 issue, recommending testing in another machine or forcing PCI-E 4.
aider (Paul Gauthier) Discord
- Google Drops Gemma 3, Shakes Up Open Models: Google has released Gemma 3, a collection of lightweight, open models built from the same research and tech powering Gemini 2.0 [https://blog.google/technology/developers/gemma-3/]. The new models are multimodal (text + image), support 140+ languages, have a 128K context window, and come in 1B, 4B, 12B, and 27B sizes.
- The release sparked a discussion on fine-tuning, with a link to Unsloth's blog post showing how to fine-tune and run them.
- OlympicCoder Model Competes with Claude 3.7: The OlympicCoder model, a 7B parameter model, reportedly beats Claude 3.7 and is close to o1-mini/R1 on olympiad level coding [https://x.com/lvwerra/status/1899573087647281661]. It comes with a new IOI benchmark as reported in the Open-R1 progress report 3.
- Claims were made that no one was ready for this release.
- Zed Predicts Edits with Zeta Model: Zed is introducing edit prediction powered by Zeta, their new open source model. The editor now predicts the user's next edit, which can be applied by hitting tab.
- The model is currently available for free during the public beta.
- Anthropic Releases text_editor Tool, Alters Edit Workflow: Anthropic has introduced a new text_editor tool in the Anthropic API, designed for apps where Claude works with text files. This tool enables Claude to make targeted edits to specific portions of text, reducing token consumption and latency while increasing accuracy.
- The update suggests there may be no need for an editor model with some users musing over a new simpler workflow.
- LLMs: Use as a Launchpad, Not a Finish Line: Members discussed that a bad initial result with LLMs isn’t a failure, but a starting point to push the model towards the desired outcome. One member is prioritizing the productivity boost from LLMs not for faster work, but to ship projects that wouldn’t have been justifiable otherwise.
- A blog post notes that using LLMs to write code is difficult and unintuitive, requiring significant effort to figure out its nuances, stating that if someone claims coding with LLMs is easy, they are likely misleading you, and successful patterns may not come naturally to everyone.
Perplexity AI Discord
- Naming AI Agents ANUS Causes Laughter: Members had a humorous discussion about naming an AI agent ANUS, with the code available on GitHub.
- One member joked, 'Sorry boss my anus is acting up I need to restart it'.
- Windows App Apple ID Login Still Buggy: Users are still experiencing the 500 Internal Server Error when trying to authenticate Apple account login for Perplexity’s new Windows app.
- Some reported success using the Apple relay email instead; and other suggested to login using Google.
- Perplexity's Sonar LLM Dissected: Sonar is confirmed as Perplexity's own fast LLM used for basic search.
- The overall consensus is that the web version of Perplexity is better than the mobile app, with one user claiming that Perplexity is still the best search site overall.
- Model Selector Ghosts Users: Users reported that the model selector disappeared from the web interface, leading to frustration as the desired models (e.g., R1) were not selectable.
- Members used a complexity extension as a workaround to revert back to a specific model.
- Perplexity Pro Suffers Memory Loss: Several users noted that Perplexity Pro seems to be losing context in conversations, requiring them to constantly remind the AI of the original prompt.
- As such, Perplexity's context is a bit limited.
OpenAI Discord
- Perplexity Wins AI Research Tool Preference: Members favored Perplexity as their top AI research tool, followed by OpenAI and SuperGrok due to budget constraints and feature preferences.
- Users are seeking ways to access Perplexity and Grok instead of subscribing to ChatGPT Pro.
- Python's AI Inference Crown Challenged: Members debated whether Python is still the best language for AI inference, or whether C# is a better alternative for deployment.
- Some members are using Ollama with significant RAM (512GB) to deploy models as a service.
- Gemini 2.0 Flash Shows off Native Image Generation: Gemini 2.0 Flash now features native image generation within AI Studio, enabling iterative image creation and advanced image understanding and editing.
- Users found that Gemini's free image generation outshines GPT-4o, highlighting new robotic capabilities described in Google DeepMind's blog.
- GPT Users Rant over Ethical Overreach: Members voiced frustration with ChatGPT's persistent ethical reminders and intent clarification requests, finding them overly cautious and intrusive.
- One user lamented the lack of a feature to disable these reminders, expressing a desire to avoid the model's ethical opinions.
- Threats Debated to Improve GPT Output: Members shared methods to improve GPT responses, including minimal threat prompting and personalization, with some reporting successful experimentation.
- One member demonstrated that personalizing the model led to absolutely lov[ed] results for everything while another reported improvements with custom GPT using kidnapped material science scientist.
HuggingFace Discord
- Python's Performance Questioned for AI: A member questioned if Python is the best choice for AI transformer model inference, suggesting C# might be faster, but others suggested VLLM or LLaMa.cpp are better.
- VLLM is considered more industrial, while LLaMa.cpp is more suited for at-home use.
- LTX Video Generates Real-Time Videos: The new LTX Video model is a DiT-based video generation model that generates 24 FPS videos at 768x512 resolution in real-time, faster than they can be watched and has examples of how to load single files.
- This model is trained on a large-scale dataset of diverse videos and generates high-resolution videos with realistic and varied content.
- Agent Tool List Resolves Erroneous Selection: An agent failed to use a defined color mixing tool, but was resolved when the tool was added to the agent's tool list.
- The agent ignored the predefined
@toolsection, instead opted to generate its own python script.
- The agent ignored the predefined
- Ollama Brings Local Models to SmolAgents: Members can use local models in
smolagentsby installing withpip install smolagents[litellm\], then define the local model usingLiteLLMModelwithmodel_id="ollama_chat/qwen2.5:14b"andapi_key="ollama".- This integration lets users leverage local resources for agentic workflows.
- Manus AI Releases Free ANUS Framework: Manus AI launched an open-source framework called ANUS (Autonomous Networked Utility System), touting it as a free alternative to paid solutions, according to a tweet.
- Details on the framework's capabilities and how it compares to existing paid solutions are being discussed.
Interconnects (Nathan Lambert) Discord
- Gemma 3 Sparks Creative AI Uprising: The new Gemma-3-27b model ranks second in creative writing, according to this tweet, suggesting it will be a favorite with creative writing & RP fine tuners.
- A commenter joked that 4chan will love Gemmasutra 3.
- alphaXiv Triumphs with Claude 3.7: alphaXiv uses Mistral OCR with Claude 3.7 to generate research blogs with figures, key insights, and clear explanations with one click, according to this tweet.
- Some believe alphaXiv is HuggingFace papers done right, offering a neater version of html.arxiv dot com.
- Gemini Flash's Image Generation Gambits: Gemini 2.0 Flash now features native image generation, allowing users to create contextually relevant images, edit conversationally, and generate long text in images, as noted in this blog post and tweet.
- Gemini Flash 2.0 Experimental can also be used to generate Walmart-style portrait studio pictures, according to a post on X.
- Security Scrutiny Surrounds Chinese Model Weights: Users express concerns about downloading open weight models like Deepseek from Hugging Face due to potential security risks, as highlighted in this discussion.
- Some worry if I download deepseek from huggingface, will I get a virus or that the weights send data to the ccp, leading to a startup idea of rebranding Chinese models as patriotic American or European models.
- OpenAI's PRC Model Policy Proposal: OpenAI's policy proposal argues for banning the use of PRC-produced models within Tier 1 countries that violate user privacy and create security risks such as the risk of IP theft.
- OpenAI submitted their policy proposal to the US government directly linking fair use with national security, stating that if China has free data access while American companies lack fair use, the race for AI is effectively over, according to Andrew Curran's tweet.
Eleuther Discord
- Distill Reading Group Announces Monthly Meetup: The Distill reading group announced that the next meetup will be March 14 from 11:30-1 PM ET, with details available in the Exploring Explainables Reading Group doc.
- The group was formed due to popular demand for interactive scientific communication around Explainable AI.
- Thinking Tokens Expand LLM Thinking: One discussant proposes using a hybrid attention model to expand thinking tokens internally, using the inner TTT loss on the RNN-type layer as a proxy and suggested determining the number of 'inner' TTT expansion steps by measuring the delta of the TTT update loss.
- The expansion uses cross attention between normal tokens and normal tokens plus thinking tokens internally, but faces challenges in choosing arbitrary expansions without knowing the TTT loss in parallel, which can be addressed through random sampling or proxy models.
- AIME 24 Implementation Lands: A member added an AIME24 implementation based off of the MATH implementation to lm-evaluation-harness.
- They based it off of the MATH implementation since they couldn't find any documentation of what people are running when they run AIME24.
- Deciphering Delphi's Activation Collection: A member inquired about how latents are collected for interpretability using the LatentCache, specifically whether latents are obtained token by token or for the entire sequence with the Delphi library.
- Another member clarified that Delphi collects activations by passing batches of tokens through the model, collecting activations, generating similar activations, and saving only the non-zero ones, and linked to <#1268988690047172811>.
OpenRouter (Alex Atallah) Discord
- Gemma 3 Arrives with Multimodal Support: Google has launched Gemma 3 (free), a multimodal model with vision-language input and text outputs, featuring a 128k token context window and improved capabilities across over 140 languages.
- Reportedly the successor to Gemma 2, Gemma 3 27B includes enhanced math, reasoning, chat, structured outputs, and function calling capabilities.
- Reka Flash 3 Flies in with Apache 2.0 License: Reka Flash 3 (free), a 21 billion parameter LLM with a 32K context length, excels at general chat, coding, instruction-following, and function calling, optimized through reinforcement learning (RLOO).
- The model supports efficient quantization (down to 11GB at 4-bit precision), utilizes explicit reasoning tags, and is licensed under Apache 2.0, though it is primarily an English model.
- Llama 3.1 Swallow 70B Lands Swiftly: A new Japanese-capable model, Llama 3.1 Swallow 70B (link), has been released, characterized by OpenRouter as a smaller model with high performance.
- Members didn't provide additional color commentary.
- Gemini 2 Flash Conjures Native Images: Google AI Studio introduced an experimental version of Gemini 2.0 Flash with native image output, accessible through the Gemini API and Google AI Studio.
- This new capability combines multimodal input, enhanced reasoning, and natural language understanding to generate images.
- Cohere Commands A, Challenging GPT-4o: Cohere launched Command A, claiming parity or superiority to GPT-4o and DeepSeek-V3 for agentic enterprise tasks with greater efficiency, according to the Cohere Blog.
- The new model prioritizes performance in agentic tasks with minimal compute, directly competing with GPT-4o.
Cohere Discord
- Command A challenges GPT-4o on Enterprise Tasks: Cohere launched Command A, claiming performance on par with or better than GPT-4o and DeepSeek-V3 for agentic enterprise tasks with greater efficiency, detailed in this blog post.
- The model features 111b parameters, a 256k context window, and inference at a rate of up to 156 tokens/sec, and it is available via API as
command-a-03-2025.
- The model features 111b parameters, a 256k context window, and inference at a rate of up to 156 tokens/sec, and it is available via API as
- Command A's API Start Marred by Glitches: Users reported errors when using Command-A-03-2025 via the API, traced back to the removal of
safety_mode = “None”from the model's requirements.- One member discovered that removing the
safety_modesetting resolved the issue, highlighting that Command A and Command R7B no longer support it.
- One member discovered that removing the
- Seed Parameter Fails to Germinate Consistent Results: A member found that the
seedparameter in the Chat API didn't work as expected, producing varied outputs for identical inputs and seed values across models like command-r and command-r-plus.- A Cohere team member confirmed the issue and began investigating.
- OpenAI Compatibility API Throws Validation Errors: A user reported a 400 error with the OpenAI Compatibility API, specifically with the
chat.completionsendpoint and model command-a-03-2025, due to schema validation of theparametersfield in thetoolsobject.- Cohere initially required the
parametersfield even when empty, but the team decided to match OpenAI's behaviour for better compatibility.
- Cohere initially required the
- AI Researcher dives into RAG and Cybersecurity: An AI researcher/developer with a background in cybersecurity is focusing on RAG, agents, workflows, and primarily uses Python.
- They seek to connect and learn from the community.
MCP (Glama) Discord
- Glama API Shows More Data per Server: A member shared that the new Glama** API (https://glama.ai/mcp/reference#tag/servers/GET/v1/servers) lists all the available tools and has more data per server compared to Pulse.
- However, Pulse reportedly has more servers available.
- Claude Struggles Rendering Images Elegantly: A member reported struggles rendering a Plotly image in Claude Desktop, finding no elegant way to force Claude** to pull out a resource and render it as an artifact.
- They suggested that using
openis better and others pointed to an MCP example, noting that the image appears inside the tool call, a current limitation of Claude.
- They suggested that using
- NPM Package Caching Investigated**: A member asked about the location of the npm package cache and how to display downloaded/connected servers in the client.
- Another member suggested checking
C:\Users\YourUsername\AppData\Local\npm-cache, while the ability to track server states depends on client-side implementation.
- Another member suggested checking
- OpenAI Agents SDK Gains MCP Support: A developer integrated Model Context Protocol (MCP)** support into the OpenAI Agents SDK, which is accessible via a fork and as the
openai-agents-mcppackage on pypi.- This integration allows the Agent to combine tools from MCP servers, local tools, OpenAI-hosted tools, and other Agent SDK tools with a unified syntax.
- Goose Project Commands Computers via MCP: The Goose project, an open-source AI agent, utilizes any MCP server to automate developer tasks.
- See a demonstration of Goose controlling a computer in this YouTube short.
Notebook LM Discord
- Google Seeks NotebookLM Usability Participants: Google is seeking NotebookLM users who heavily use their mobile phones and are recruiting users for usability studies for product feedback, offering $75 USD (or a $50 Google merchandise voucher) as compensation.
- Interested users can fill out this screener for the mobile user research, or participate in 60-minute remote sessions on April 2nd and 3rd 2025.
- NoteBookLM Plus Considered as Internal FAQ: A user inquired about using NoteBookLM Plus as an internal FAQ, while another user suggested posting this as a feature request, as chat history is not saved in NotebookLM.
- Workarounds discussed include making use of clipboard copy and note conversion to share information.
- Inline Citations Get Preserved: Users can now save chat responses as notes and have inline citations preserved in their original form, allowing for easy reference to the original source material.
- Many users requested this feature, which is the first step of some cool enhancements to the Notes editor, however they also requested improvements for enhanced copy & paste with footnotes.
- Thinking Model Gets Pushed to NotebookLM: The latest thinking model has been pushed to NotebookLM, promising quality improvements across the board, especially for Portugese speakers who can add
?hl=ptat the end of the url to fix the language.- Users also discussed the possibility of integrating AI Studio functionality into NotebookLM, which 'watches' YouTube videos and doesn't rely solely on transcripts from this Reddit link.
GPU MODE Discord
- VectorAdd Submission Bounces Back From Zero: A member initially reported their vectoradd submission was returning zeros, despite working on Google Colab.
- The member later discovered the code was processing the same block repeatedly, leading to unexpectedly high throughput and pinpointed that if it's too fast, there's probably a bug somewhere.
- SYCL Shines as CUDA Challenger: Discussion around SYCL's portability and implementations like AdaptiveCpp and triSYCL reveal that Intel is a key stakeholder.
- One participant finds SYCL more interesting than HIP because it isn't just a CUDA clone and can therefore improve on the design.
- Deepseek's MLA Innovation: DataCrunch detailed the implementation of Multi-Head Latent Attention (MLA) with weight absorption in Deepseek's V3 and R1 models in their blog post.
- A member found that vLLM's current default was bad, based on this pull request.
- Reasoning-Gym Curriculum attracts ETH + EPFL: A team from ETH and EPFL are collaborating on reasoning-gym for SFT, RL, and Eval, as well as investigating auto-curriculum for RL, with preliminary results available on GitHub.
- The team is also looking to integrate with Evalchemy for automatic evaluations of LLMs.
- FlashAttention ported to Turing Architecture: A developer implemented the FlashAttention forward pass for the Turing architecture, previously limited to Ampere and Hopper, with code available on GitHub.
- Early benchmarks show a 2x speed improvement over Pytorch's
F.scaled_dot_product_attentionon a T4, under specific conditions:head_dim = 128, vanilla attention, andseq_lendivisible by 128.
- Early benchmarks show a 2x speed improvement over Pytorch's
Yannick Kilcher Discord
- YC Backs Quick Wins Not Unicorns: A member claimed that YC prioritizes startups with short-term success, investing $500K aiming to 3x that in 6 months, rather than focusing on long-term growth.
- They argued that YC hasn't produced a notable unicorn in years, suggesting a possible shift away from fostering long-term success stories.
- LLM Scaling Approximates Context-Free Languages: A theory suggests that LLM scaling can be understood through their ability to approximate context-free languages using probabilistic FSAs, resulting in a characteristic S-curve pattern as seen in this attached image.
- The proposal is that LLMs try to approximate the language of a higher rung, coming from a lower rung of the Chomsky hierarchy.
- Google's Gemma 3 Faces ChatArena Skepticism: Google released Gemma 3, as detailed in the official documentation, which is reported to be on par with Deepseek R1 but significantly smaller.
- One member noted that the benchmarks provided are user preference benchmarks (ChatArena) rather than non-subjective metrics.
- Universal State Machine Concept Floated: A member shared a graph-based system with dynamic growth, calling it a Universal State Machine (USM), noting it as a very naive one with poor optimization and an explosive node count.
- They linked to an introductory paper describing Infinite Time Turing Machines (ITTMs) as a theoretical foundation and the Universal State Machine (USM) as a practical realization, offering a roadmap for scalable, interpretable, and generalizable machines.
- RTX Remix Revives Riddick Dreams: A member shared a YouTube video showcasing the Half-Life 2 RTX demo with full ray tracing and DLSS 4, reimagined with RTX Remix.
- Another member expressed anticipation for an RTX version of Chronicles of Riddick: Escape from Butcher Bay.
Nomic.ai (GPT4All) Discord
- GPT-4 Still King over Local LLMs: A user finds that ChatGPT premium's quality significantly surpasses LLMs on GPT4All, attributing this to the smaller model sizes available locally and hoping for a local model to match its accuracy with uploaded documents.
- The user notes that the models they have tried on GPT4All haven't been very accurate with document uploads.
- Ollama vs GPT4All Decision: A user asked for advice on whether to use GPT4All or Ollama for a server managing multiple models, quick loading/unloading, frequently updating RAG files, and APIs for date/time/weather.
- A member suggested Deepseek 14B or similar models, also mentioning the importance of large context windows (4k+ tokens) for soaking up more information like documents, while remarking that apple hardware is weird.
- GPT4All workflow good, GUI Bad: A member suggests using GPT4All with tiny models to check the workflow for loading, unloading, and RAG with LocalDocs, but pointed out that the GUI doesn't support multiple models simultaneously.
- They recommend using the local server or Python endpoint, which requires custom code for pipelines and orchestration.
- Crawling the Brave New Web: A user inquired about getting web crawling working and asked for advice before starting the effort.
- A member mentioned a Brave browser compatibility PR that wasn't merged due to bugs and a shift towards a different tool-calling approach, but it could be resurrected if there's demand.
- LocalDocs Plain Text Workaround: A member suggested that to work around LocalDocs showing snippets in plain text, users can make a screenshot save as PDF, OCR the image, and then search for the snippet in a database.
- They suggested using docfetcher for this workflow.
Latent Space Discord
- Mastra Launches Typescript AI Framework: Mastra, a new Typescript AI framework, launched aiming to provide a robust framework for product developers, positioning itself as superior to frameworks like Langchain.
- The founders, with backgrounds from Gatsby and Netlify, highlighted type safety and a focus on quantitative performance gains.
- Gemini 2.0 Flash Generates Images: Gemini 2.0 Flash Experimental now supports native image generation, enabling image creation from text and multimodal inputs, thus boosting its reasoning.
- Users responded with amazement, one declared they were "actually lost for words at how well this works" while another remarked it adds "D" to the word "BASE".
- Jina AI Fine-Tunes DeepSearch: Jina AI shared techniques for enhancing DeepSearch/DeepResearch, specifically late-chunking embeddings for snippet selection and using rerankers to prioritize URLs before crawling.
- They conveyed enthusiasm for the Latent Space podcast, indicating "we'll have to have them on at some point this yr".
- Cohere's Command Model Openly Weighs: Cohere introduced Command A, an open-weights 111B parameter model boasting a 256k context window, tailored for agentic, multilingual, and coding applications.
- This model succeeds Command R+ with the intention of superior performance across tasks.
- Gemini Gives Free Deep Research To All: The Gemini App now offers Deep Research for free to all users, powered by Gemini 2.0 Flash Thinking, alongside personalized experiences using search history.
- This update democratizes access to advanced reasoning for a broader audience.
LlamaIndex Discord
- LlamaIndex Jumps Aboard Model Context Protocol: LlamaIndex now supports the Model Context Protocol, allowing users to use tools exposed by any MCP-compatible server, according to this tweet.
- The Model Context Protocol is an open-source effort to streamline tool discovery and usage.
- AI Set to Shake Up Web Development: Experts will convene at the @WeAreDevs WebDev & AI Day to explore AI's impact on platform engineering and DevEx, as well as the evolution of developer tools in an AI-powered landscape, announced in this tweet.
- The event will focus on how AI is reshaping the developer experience.
- LlamaParse Becomes JSON Powerhouse: LlamaParse now incorporates images into its JSON output, providing downloadable image links and layout data, with details here.
- This enhancement allows for more comprehensive document parsing and reconstruction.
- Deep Research RAG Gets Ready: Deep research capabilities within RAG are accessible via
npx create-llama@latestwith the deep research option, with the workflow source code available on GitHub.- This setup facilitates in-depth exploratory research using RAG.
LLM Agents (Berkeley MOOC) Discord
- MOOC Quiz Deadlines Coming in May: Members reported that all quiz deadlines are in May and details will be released soon to those on the mailing list, confirmed by records showing they opened the latest email about Lecture 6.
- The community should follow the weekly quizzes and await further information.
- MOOC Labs & Research Opportunities Announced Soon: Plans for labs and research opportunities for MOOC learners are in the works and details about projects are coming soon.
- An announcement will be made once everything is finalized, including information on whether non-Berkeley students can obtain certifications.
- Roles and Personas Elucidated in LLMs: In querying an LLM, roles are constructs for editing a prompt, like system, user, or assistant, whereas a persona is defined as part of the general guidelines given to the system, influencing how the assistant acts.
- The system role provides general guidelines, while user and assistant roles are active participants.
- Decision Making Research Group Needs You: A research group focused on decision making and memory tracks has opened its doors.
- Join the Discord research group to dive deeper into the topic.
Modular (Mojo 🔥) Discord
- Mojo Bundling with Max?: In the Modular forums, users are questioning the potential synergies and benefits of bundling Mojo with Max.
- The discussion revolves around user benefits and potential use cases of such a bundle.
- Mojo on Windows: When?: There is community interest about Mojo's potential availability on Windows.
- The community discussed the associated challenges and timelines for expanding Mojo's platform support.
- Modular Max Gains Process Spawning: A member shared a PR for Modular Max that adds functionality to spawn and manage processes from executable files using
exec.- The availability is uncertain due to dependencies on merging a foundations PR and resolving issues with Linux exec.
- Closure Capture Causes Commotion: A member filed a language design bug related to
capturingclosures.- Another member echoed this sentiment, noting they found this behavior odd as well.
- Missing MutableInputTensor Mystifies Max: A user reported finding the
MutableInputTensortype alias in the nightly docs, but it doesn't seem to be publicly exposed.- The user attempted to import it via
from max.tensor import MutableInputTensorandfrom max.tensor.managed_tensor_slice import MutableInputTensorwithout success.
- The user attempted to import it via
Gorilla LLM (Berkeley Function Calling) Discord
- AST Accuracy Evaluates LLM Calls: The AST (Abstract Syntax Tree) evaluation checks for the correct function call with the correct values, including function name, parameter types, and parameter values within possible ranges as noted in the V1 blog.
- The numerical value for AST represents the percentage of test cases where all these criteria were correct, revealing the accuracy of LLM function calls.
- BFCL Updates First Comprehensive LLM Evaluation: The Berkeley Function-Calling Leaderboard (BFCL), last updated on 2024-08-19, is a comprehensive evaluation of LLMs' ability to call functions and tools (Change Log).
- The leaderboard aims to mirror typical user function calling use-cases in agents and enterprise workflows.
- LLMs Enhanced by Function Calling: Large Language Models (LLMs) such as GPT, Gemini, Llama, and Mistral are increasingly being used in applications like Langchain, Llama Index, AutoGPT, and Voyager through function calling capabilities.
- These models have significant potential in applications and software via function calling (also known as tool calling).
- Function Calls run in Parallel: The evaluation includes various forms of function calls, such as parallel (one function input, multiple invocations of the function output) and multiple function calls.
- This comprehensive approach covers common function-calling use-cases.
- Central location to track all evaluation tools: Datasets are located in /gorilla/berkeley-function-call-leaderboard/data, and for multi-turn categories, function/tool documentation is in /gorilla/berkeley-function-call-leaderboard/data/multi_turn_func_doc.
- All other categories store function documentation within the dataset files.
DSPy Discord
- DSPy Eyes Pluggable Cache Module: DSPy is developing a pluggable Cache module, with initial work available in this pull request.
- The new feature aims to have one single caching interface with two levels of cache: in-memory LRU cache and fanout (on disk).
- Caching Strategies Seek Flexibility: There's a desire for more flexibility in defining caching strategies, particularly for context caching to cut costs and boost speed, with interest in cache invalidation with TTL expiration or LRU eviction.
- Selective caching based on input similarity was also discussed to avoid making redundant API calls, along with built-in monitoring for cache hit/miss rates.
- ColBERT Endpoint Connection Refused: A member reported that the ColBERT endpoint at
http://20.102.90.50:2017/wiki17_abstractsappears to be down, throwing a Connection Refused error.- When trying to retrieve passages using a basic MultiHop program, the endpoint returns a 200 OK response, but the text contains an error message related to connecting to
localhost:2172.
- When trying to retrieve passages using a basic MultiHop program, the endpoint returns a 200 OK response, but the text contains an error message related to connecting to
tinygrad (George Hotz) Discord
- LSTM Model Plagued by NaN Loss: A member reported encountering NaN loss when running an LSTMModel with TinyJit, observing the loss jump from a large number to NaN after the first step.
- The model setup involves
nn.LSTMCellandnn.Linear, optimized with theAdamoptimizer, and the input data contains a large value (1000) which may be the reason.
- The model setup involves
- Debugging the NaN: A member requested assistance debugging NaN loss during tinygrad training, providing a code sample exhibiting an LSTM setup.
- This suggests possible numerical instability or gradient explosion issues as causes.
AI21 Labs (Jamba) Discord
- Pinecone Performance Suffers: A member reported that their RAG system faced performance limitations when using Pinecone.
- Additionally, the lack of VPC deployment support with Pinecone was a major concern.
- RAG System Dumps Pinecone: Due to performance bottlenecks and the absence of VPC deployment support, a RAG system is ditching Pinecone.
- The engineer anticipates that the new setup will alleviate these two issues.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Codeium (Windsurf) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (1134 messages🔥🔥🔥):
Claude 3.7 API updates, Cursor slowness/instability issues, Open source alternatives to Manus, MCP for Blender, Cursor Updates and Version Confusion
- Claude's caching API cuts costs by 90%: Anthropic is rolling out new API updates for Claude 3.7 Sonnet, offering cache-aware rate limits and simpler prompt caching, which can cut costs by up to 90% and reduce latency by 85% for long prompts.
- This makes Claude maintain knowledge of large documents, instructions, or examples without resending info with each request.
- Cursor users complain of slowness, window crashes: Users report sluggish UI, frequent window crashes, and memory leaks in recent Cursor versions, particularly on Mac and Windows WSL2, with some suggesting it's related to legal issues with Microsoft.
- Some members recommend trying Cline or Windsurf as alternatives.
- Open Source Manus emerges on GitHub: The open-source alternative to Manus, called OpenManus, is generating excitement, with discussions on its potential and comparisons to Manus, some users are even trying the demo showcased in this YouTube video.
- The project aims to provide a more accessible alternative to Manus, prompting discussions around its capabilities and ease of use for non-technical users.
- Blender Gets Some MCP Lovin': A member highlighted MCP for Blender, enabling Claude to directly interact with Blender for creating 3D scenes from prompts.
- This sparked interest in extending AI tool integration beyond traditional coding tasks.
- Cursor Update Chaos and Version Confusion Reigns: A chaotic debate erupts over Cursor versions, with users touting non-existent 0.49, 0.49.1, and even 1.50 builds while others struggle with crashes on 0.47, leading to accusations of trolling and misleading information.
- The confusion stems from differing update experiences, with some users accessing beta versions through unofficial channels, further muddying the waters.
- Manus: Manus is a general AI agent that turns your thoughts into actions. It excels at various tasks in work and life, getting everything done while you rest.
- Augmentin 625 mg Dosage Guidelines for Adults - Manus: Manus is a general AI agent that turns your thoughts into actions. It excels at various tasks in work and life, getting everything done while you rest.
- Tweet from Trae (@Trae_ai): 🚀 Connect More, Ship More!Today's Trae update brings:- Custom model integration is now live!- Remote SSH support for Ubuntu 20/22/24 & Debian 11/12More features are coming soon. #DevTools #AI #T...
- Tweet from siddharth ahuja (@sidahuj): 🧩 Built an MCP that lets Claude talk directly to Blender. It helps you create beautiful 3D scenes using just prompts!Here’s a demo of me creating a “low-poly dragon guarding treasure” scene in just a...
- Tweet from OpenTools (@opentools_): We’re excited to share the beta release of our tool use API!Now developers can easily equip any LLM with hosted open-source tools for web search, web crawling, and maps data (+ more coming soon).Under...
- Token-saving updates on the Anthropic API: We've made several updates to the Anthropic API that let developers significantly increase throughput and reduce token usage with Claude 3.7 Sonnet.
- no title found: no description found
- Tweet from Logan Kilpatrick (@OfficialLoganK): Introducing YouTube video 🎥 link support in Google AI Studio and the Gemini API. You can now directly pass in a YouTube video and the model can usage its native video understanding capabilities to us...
- Customer Form for B2B Gen AI Consulting Firms - Manus: Manus is a general AI agent that turns your thoughts into actions. It excels at various tasks in work and life, getting everything done while you rest.
- Tweet from Mckay Wrigley (@mckaywrigley): Watch for a 14min demo of me using Manus for the 1st time.It’s *shockingly* good.Now imagine this in 2-3 years when:- it has >180 IQ- never stops working- is 10x faster- and runs in swarms by the 1...
- no title found: no description found
- Discord: no description found
- Reddit - Heart of the internet: no description found
- GitHub - mannaandpoem/OpenManus: No fortress, purely open ground. OpenManus is Coming.: No fortress, purely open ground. OpenManus is Coming. - mannaandpoem/OpenManus
- Smart Thinking GIF - Smart Thinking Thoughts - Discover & Share GIFs: Click to view the GIF
- GitHub - oslook/cursor-ai-downloads: All Cursor AI's official download links for both the latest and older versions, making it easy for you to update, downgrade, and choose any version. 🚀: All Cursor AI's official download links for both the latest and older versions, making it easy for you to update, downgrade, and choose any version. 🚀 - oslook/cursor-ai-downloads
- Changelog | Cursor - The AI Code Editor: New updates and improvements.
- Idiocracy I Dont Know GIF - Idiocracy I Dont Know You Know - Discover & Share GIFs: Click to view the GIF
- - YouTube: no description found
- Claude 3.7-thinking permanently 'High Load'!: Claude 3.7-thinking permanently ‘High Load’!!! I have been trying now for the last 4 hours having tried hundreds on times i am guessing and it is permanently in this state!! It worked fine all day y...
- GitHub - oslook/cursor-ai-downloads: All Cursor AI's official download links for both the latest and older versions, making it easy for you to update, downgrade, and choose any version. 🚀: All Cursor AI's official download links for both the latest and older versions, making it easy for you to update, downgrade, and choose any version. 🚀 - oslook/cursor-ai-downloads
- GitHub - jamesliounis/servers at james-perplexity/add-perplexity-mcp-server: Model Context Protocol Servers. Contribute to jamesliounis/servers development by creating an account on GitHub.
- servers/src/perplexity-ask/README.md at f9dd1b55a4ec887878f0770723db95d493c261a2 · jamesliounis/servers: Model Context Protocol Servers. Contribute to jamesliounis/servers development by creating an account on GitHub.
- Cursor - Community Forum: A place to discuss Cursor (bugs, feedback, ideas, etc.)
- - YouTube: no description found
Nous Research AI ▷ #announcements (2 messages):
Inference API release, Hermes 3 Llama 70B, DeepHermes 3 8B Preview, Hybrid Reasoners, DeepHermes 24B
- Nous Researches Launches Inference API: Nous Research released its Inference API, providing access to language models such as Hermes 3 Llama 70B and DeepHermes 3 8B Preview with more models planned.
- The API is OpenAI-compatible and features a waitlist system at Nous Portal, offering $5.00 of free credits to new accounts.
- DeepHermes 24B and 3B Preview Unleashed: DeepHermes 24B and 3B Preview models, designed as Hybrid Reasoners, were announced, featuring an on/off toggle for long chain of thought reasoning, accessible via API and HuggingFace (DeepHermes 24B, DeepHermes 3B).
- The 24B model showed a 4x increase in accuracy on hard math problems and 43% on GPQA when reasoning mode is enabled.
- GGUF Quantized DeepHermes Models Available: GGUF quantized versions of DeepHermes 24B and 3B models are available for efficient inference, offering different quantization levels (24B GGUF, 3B GGUF).
- Quantization options include Q4, Q5, Q6, and Q8, with file sizes ranging from 1.8G to 24G.
- DeepHermes 24B Chatbot Available on Discord: A free and interactive DeepHermes 24B chatbot is available on the Nous Research Discord server.
- The chatbot is accessible in the #general channel.
- Nous Portal: no description found
- DeepHermes - a NousResearch Collection: no description found
- Nous Portal: no description found
- NousResearch/DeepHermes-3-Mistral-24B-Preview · Hugging Face: no description found
- NousResearch/DeepHermes-3-Llama-3-3B-Preview · Hugging Face: no description found
- NousResearch/DeepHermes-3-Mistral-24B-Preview-GGUF · Hugging Face: no description found
- NousResearch/DeepHermes-3-Llama-3-3B-Preview-GGUF · Hugging Face: no description found
Nous Research AI ▷ #general (684 messages🔥🔥🔥):
LLM Facial Memory System, Inference API Credit Pre-loading, Graph Reasoning Systems with Open Source Code, Graph Theory, Gemma-3 and LM Studio Integration
- *LLM Learns Faces*: A member open-sourced a conversational system, the LLM Facial Memory System, that integrates facial recognition with LLMs, allowing it to remember people and maintain chat histories based on faces.
- The project was built for work and released with permission, according to its creator.
- *Preload Inference API: No Credit Card Roulette!: Users discussed preloading credits for the Inference API, with one expressing concerns about API key leaks and preferring to preload a limited amount, such as $50*, rather than risk large unexpected charges.
- Members confirmed that the Inference API is currently only preloaded, and its pricing is expected to be set at cost-basis.
- *Gemma-3 Gets LM Studio Lift-off: LM Studio 0.3.13* now supports Google's Gemma-3 models, including multimodal (text + image input) models, available for both GGUF and MLX models.
- However, some users reported 404 errors when attempting to download the Linux version of LM Studio, which is now resolved.
- *DeepHermes Has Hybrid Reasoning: Nous Research released new DeepHermes Preview models, including 24B and 3B* versions, that are Hybrid Reasoners, allowing users to toggle long chain of thought reasoning on or off.
- These models use the exact same recipe as the 8B DeepHermes and are based on SFT alone, but it has some spillover into math even without reasoning.
- *Zero-Shot Classifier Saves the Day*: A user looking for an embedding model for social media posts was advised to consider a zero-shot classifier like ModernBERT-large-zeroshot-v2.0 instead, suggesting discrete categories might be more appropriate than embeddings for grouping items.
- This model performs slightly worse than DeBERTa v3 on average, but is very fast and memory efficient.
- 8 Universal State Machine – Infinite Time Turing Machines and their Applications: no description found
- MoritzLaurer/ModernBERT-large-zeroshot-v2.0 · Hugging Face: no description found
- google/gemma-3-12b-pt · Hugging Face: no description found
- Tweet from Ren (@renxyzinc): Watch the first-ever public demonstration of the Universal State Machine (USM) — a revolutionary approach to Artificial Intelligence that redefines how machines learn from experience.
- Tweet from Lucas Beyer (bl16) (@giffmana): hahahaha look what meme I got served on a silver platter:
- Tweet from Nous Research (@NousResearch): Announcing the latest DeepHermes Preview models, DeepHermes 24B and 3B!https://huggingface.co/collections/NousResearch/deephermes-67d2ff8c9246cc09a7bd8addThese new models are Hybrid Reasoners - meanin...
- Tweet from elie (@eliebakouch): Gemma3 technical report detailed analysis 💎1) Architecture choices:> No more softcaping, replace by QK-Norm> Both Pre AND Post Norm> Wider MLP than Qwen2.5, ~ same depth> SWA with 5:1 and...
- Geometric Algebra: Geometric Algebra has 3 repositories available. Follow their code on GitHub.
- where can download lite model · Issue #1 · gabrielolympie/moe-pruner: your work is awesome! where can i download the lite model? thanks!
- Knowledge Graphs w/ AI Agents form CRYSTAL (MIT): A knowledge graph is a structured representation of information, consisting of entities (nodes) connected by relationships (edges). It serves as a dynamic fr...
- GitHub - ai-in-pm/Forest-of-Thought: Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning: Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning - ai-in-pm/Forest-of-Thought
- GitHub - ashishpatel26/sot: Official code repository for Sketch-of-Thought (SoT): Official code repository for Sketch-of-Thought (SoT) - ashishpatel26/sot
- ECCHI SHIYOU: no description found
- GitHub - gabrielolympie/moe-pruner: A repository aimed at pruning DeepSeek V3, R1 and R1-zero to a usable size: A repository aimed at pruning DeepSeek V3, R1 and R1-zero to a usable size - gabrielolympie/moe-pruner
- GitHub - yaya-labs/LLM_Facial_Memory_System: A conversational system that integrates facial recognition capabilities with large language models. The system remembers the people it interacts with and maintains a conversation history for each recognised face.: A conversational system that integrates facial recognition capabilities with large language models. The system remembers the people it interacts with and maintains a conversation history for each r...
- Download LM Studio - Mac, Linux, Windows: Discover, download, and run local LLMs
- Getting free access to Copilot Pro as a student, teacher, or maintainer - GitHub Docs: no description found
- vllm/vllm/entrypoints/openai/tool_parsers/hermes_tool_parser.py at f53a0586b9c88a78167157296555b7664c398055 · vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllm
- Tweet from Ren (@renxyzinc): Watch the first-ever public demonstration of the Universal State Machine (USM) — a revolutionary approach to Artificial Intelligence that redefines how machines learn from experience.
Nous Research AI ▷ #ask-about-llms (1 messages):
AI Compilers, Deep Learning Compilation
- Deep Learning Compilers Topic Ignition: A member inquired about thesis resources on AI compilers for deep learning.
- They seek guidance on important aspects and potential challenges in the field of deep learning compilation.
- More resources are wanted about this topic: A member inquired about thesis resources on AI compilers for deep learning.
- They seek guidance on important aspects and potential challenges in the field of deep learning compilation.
Nous Research AI ▷ #research-papers (2 messages):
Sakana AI, Model Memorization
- Sakana AI posts first publication: Sakana AI released its first publication.
- A member noticed this and quipped about models learning from its training data.
- Sakana AI's first image: Sakana AI posted an image.
- The image was attached as image-104.png on discord.
Link mentioned: no title found: no description found
Nous Research AI ▷ #interesting-links (11 messages🔥):
Audio-Flamingo-2, Agent Engineering
- *Audio-Flamingo-2*'s Mixed Music Analysis: A member reported mixed results using Audio-Flamingo-2 on HuggingFace, noting good song descriptions but inaccurate BPM detection.
- Specifically, when asked "what mode and key is this song?" the model incorrectly identified the key of Royals by Lorde as F# minor.
- Agent Engineering Post Spurs Discussion: A member shared a blog post on "Agent Engineering" and requested feedback, highlighting the ambiguity in understanding and designing agents for real-world usage.
- The post suggests that while agents are a buzzword of 2024, their real-world usage has fallen short, and the journey to make them as commonplace as web browsers is still unclear.
- Audio Flamingo 2 - a Hugging Face Space by nvidia: no description found
- 5 Thoughts On Agent Engineering: Diving into some raw thoughts on the future of agent engineering.
Nous Research AI ▷ #research-papers (2 messages):
Sakana AI, AI Training Data
- Sakana AI Debuts with Publication: Sakana AI marked its entry into the AI research scene with its first publication.
- A member quipped that the AI seems to be learning from its training data.
- Image Sparks Discussion: An image (image-104.png) was shared, prompting analysis and discussion.
Link mentioned: no title found: no description found
Unsloth AI (Daniel Han) ▷ #general (503 messages🔥🔥🔥):
Gemma 3, GGUF, Transformers issue, RLHF, H100
- Gemma 3 GGUF versions now available: Unsloth has uploaded all GGUF, 4-bit, and 16-bit versions of Gemma 3 to a Hugging Face collection.
- The uploaded versions include 2-8 bit GGUFs, dynamic 4-bit, and 16-bit versions, but members noted the models don't support images yet and are working on a fix.
- Transformers Bug Halts Gemma 3 Fine-Tuning: A breaking bug in Hugging Face Transformers is preventing Gemma 3 from being fine-tuned, but HF is actively working on a fix and the blogpost has been updated.
- The bug affects Gemma 3 fine-tuning, but it's also caused a mismatch between the documentation and the actual setup for Gemma 3 in the Jupyter notebook on Colab.
- GGUFs Explained to Beginners: GGUFs are quantized versions of models designed to run in programs that use llama.cpp, such as LM Studio and GPT4All.
- The uploaded GGUFs of Gemma 3 won't work in LM Studio yet, as LM Studio needs to update their llama.cpp versions.
- Exploration into GRPO vs PPO: Members discussed the usage of GRPO vs PPO for finetuning, with many indicating that GRPO generalizes better and is easier to set up than PPO, while also being a possible direct replacement.
- There was also a discussion on the combination of techniques, with one member noting that Meta 3 used both PPO and DPO, and another pointing out that AI2 still uses PPO for VLMs and their big Tulu models because they use a different reward system that leads to very up to date RLHF.
- H100 vs 4090 for Inference: Members debated the efficiency of the H100 vs the 4090 for running inference, with many claiming the H100 would not outperform the 4090 in prompt processing.
- Some members explained that the H100 is only better if you need to batch process or can saturate the memory bandwidth.
- Unsloth Notebooks | Unsloth Documentation: Below is a list of all our notebooks:
- Fine-Tuning DeepSeek R1 (Reasoning Model): Fine-tuning the world's first open-source reasoning model on the medical chain of thought dataset to build better AI doctors for the future.
- Unsloth Newsletter: Join our newsletter and waitlist for everything Unsloth!
- Gemma 3 - a unsloth Collection: no description found
- Fine-tune Gemma 3 with Unsloth: Gemma 3, Google's new multimodal models.Fine-tune & Run them with Unsloth! Gemma 3 comes in 1B, 4B, 12B and 27B sizes.
- CohereForAI/c4ai-command-a-03-2025 · Hugging Face: no description found
- pookie3000/Meta-Llama-3.1-8B-Q4_K_M-GGUF at main: no description found
- Enhancing Reasoning in Distilled Language Models with GRPO: no description found
- Tweet from Quentin Gallouédec (@QGallouedec): [5/10] 🎓 Lessons Learned from Training- Packing hurts reasoning performance- Large learning rates (4e-5) improve performance- Including editorials doesn’t boost performance- Prefill with `<think&g...
- unsloth/gemma-3-1b-it-GGUF at main: no description found
- Collections - Hugging Face: no description found
- Colle (Collins Osale): no description found
- Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (41 messages🔥):
GPT-4.5 Trolling, Multi-TPU implementation, Reproducibility issues in model training, London Paris Berlin AI HackXelerator, Training LLMs from scratch
- GPT-4.5 engages in trolling antics: A member shared an anecdote about ChatGPT-4.5 trolling them by initially limiting the number of questions they could ask, then seemingly mocking their frustration before granting them more questions.
- The member described it as being like "u done having ur tantrum? I'll give u x more questions".
- London Paris Berlin AI HackXelerator: A member shared a link to the London, Paris, Berlin multimodal creative AI HackXelerator supported by Mistral AI, Hugging Face, AMD, Vultr, Pinecone AI, Luma Labs, and others, taking place both IRL and online across music, art, film, fashion, and gaming.
- The event, starting April 5, 2025, blends the energy of a hackathon with the depth of an accelerator, featuring 20 days of online & IRL innovation with prizes and cutting-edge AI exploration.
- Discussing Training LLMs from scratch: Members discussed the feasibility and challenges of training LLMs from scratch, with one member asking for advice and others cautioning about the immense resources required.
- One member suggested checking a book on the topic from Manning, while another estimated that it would cost "a few millions of dollars".
- Exploring Grokking and Overfitting: A conversation touched on grokking and its potential connection to overfitting, with one member noting that naive implementations can lead to overfitting.
- Another member described observing sudden metric improvements after extended periods of stagnation during their own training attempts, with reference to wikipedia.
- Controlling CoT length for R1 Distills: A member asked about methods to control CoT (Chain of Thought) length for R1 distills when generating math solutions, noting they were receiving incomplete responses even with a 16k max seq len.
- Another member suggested checking the full response for looping issues and ensuring the use of BOS (beginning-of-sequence) tokens to end the sequence.
- A decoder-only foundation model for time-series forecasting: Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a va...
- LPB 25 - London, Paris, Berlin multi-modal AI Launch Event · Luma: Join Us for the London Paris Berlin 25 AI HackXelerator™ Launch!📍 Central London | 🗓️ Starts 5 April 2025LPB25 blends the energy of a hackathon with the…
Unsloth AI (Daniel Han) ▷ #help (127 messages🔥🔥):
Gemma 3 27b as a thinking model, GRPO training, Qwen2.5 model template, GGUF models, lora performance problems
- Thinking Model?: A user asked about making Gemma 3 27b a thinking model, and another user responded that it already incorporates reasoning internally for efficiency.
- The model purportedly told them that it does all of its reasoning internally to enhance efficiency.
- GRPO Training Troubleshooted: Users discussed training models with DPO, ORPO, KTO, and GRPO, eventually resolving finetuning issues.
- After resolving the finetuning issues, one user stated, "Tysm guys my finetuning now works perfectly".
- Dataset Formatting for Llama3 Finetuning: New users sought guidance on the correct JSONL format for fine-tuning Llama3.2-3b-Instruct with Unsloth, and they specifically inquired about mapping data fields like system, user, and assistant.
- One member clarified that
standardize_sharegptconverts datasets into a specific format withconversationscontaining roles and content, and another suggested that thechat_templateparameter in Unsloth automatically retrieves and applies the appropriate model template based on the specified model name.
- One member clarified that
- Ollama struggles with unsloth models: Members noted that Ollama does not support Gemma 3 models with vision capabilities, suggesting fixes are in progress to resolve these issues.
- The Unsloth team fixed the Gemma 3 GGUFs to include images, sharing a link to the updated models.
- Unsloth Version Verification and Lora Loading Issues: Some users reported their model generating the same results with and without LoRA, sharing code snippets showing model creation and generation using fast_generate, and other users wanted to know how to properly load model with GRPO.
- A user suggested merging models as a way to enhance training, and a user said model.save_lora(path) isn't working for them.
- no title found: no description found
- CohereForAI/c4ai-command-a-03-2025 · Hugging Face: no description found
- Gemma 3 - a unsloth Collection: no description found
- CUDA semantics — PyTorch 2.6 documentation: no description found
- Google Colab: no description found
- Unsloth Documentation: no description found
- unsloth-zoo/unsloth_zoo/dataset_utils.py at 1bf2a772869014d1225e2e70eee798ea5bcbc7d7 · unslothai/unsloth-zoo: Utils for Unsloth. Contribute to unslothai/unsloth-zoo development by creating an account on GitHub.
- GitHub - unslothai/unsloth: Finetune Llama 3.3, DeepSeek-R1 & Reasoning LLMs 2x faster with 70% less memory! 🦥: Finetune Llama 3.3, DeepSeek-R1 & Reasoning LLMs 2x faster with 70% less memory! 🦥 - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #showcase (5 messages):
Reflection Pattern, ReACT Pattern, Agentic Workflows, Unsloth PR
- Reflection Pattern Repository Released: A member shared a Reflection Demo Repository that demonstrates how the Reflection pattern can enhance decision-making through iterative feedback and self-correction in agentic workflows.
- ReACT Pattern Repository Released: A member released a ReACT Demo Repository showing how the ReACT pattern enables intelligent planning and decision-making by calling external tools, making it ideal for building dynamic agent-based systems.
- Accuracy Doubled with Validation Set: A member pointed out that on a validation set of 68 questions, accuracy more than doubled from 23% to 53%.
- Potential Unsloth PR in the Works: Another member mentioned that the creator of the demo said he might do a PR into Unsloth with this feature.
- GitHub - saketd403/reflection-demo: Demo for reflection pattern for agentic workflows.: Demo for reflection pattern for agentic workflows. - saketd403/reflection-demo
- GitHub - saketd403/react-demo: Demo for REACT agentic pattern.: Demo for REACT agentic pattern. Contribute to saketd403/react-demo development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #research (20 messages🔥):
GRPO and response quality, Finetuning for exact output, Structured outputs, Guided decoding accuracy, Qwen2.5-VL-7B finetuning data
- GRPO Boosts Output Quality via Increased Generations: Members noted GRPO works better when at least one generation produces a good response, so increasing the number of generations basically increases your chance of generating a good response.
- Demand for Exact Finetuning outputs: A member asked how to finetune a model to generate the exact words in the output and gave an example to reformat dates like
<date>March 5th</date>without any variations, suggesting to format the dataset accordingly.- Another member suggested using structured outputs to ensure the model always generates something matching the desired format, like Outlines.
- Guided Decoding Downs Accuracy During Inference: It was mentioned that guided decoding reduces accuracy during inference if the model hasn’t been trained for that format.
- To mitigate accuracy loss, one can check the top k logprobs and adjust the prompt; finetuning for format plus guided decoding should yield optimal results if 100% format conformance is needed.
- Slim Attention Claims Memory Cut Without Accuracy Loss: A member shared a link to the paper Slim attention: cut your context memory in half without loss of accuracy, noting the headline claim that K-cache is all you need for MHA.
- Another member questioned why anyone would use this over MLA.
- Unsloth's Datasets 101 guide offers advice: A member shared the Unsloth's Datasets 101 guide but another member noticed that the guide was for LLMs, not VL models.
- The member was looking for a source/code on how to prepare data to fine-tune Qwen2.5-VL-7B, specifically a CSV of video.mp4,caption.
- mimir-ai (Mimir AI): no description found
- Datasets 101 | Unsloth Documentation: Learn all the essentials of creating a dataset for fine-tuning!
LM Studio ▷ #announcements (2 messages):
LM Studio 0.3.13, Google Gemma 3 support, GGUF and MLX models, Image processing NVIDIA / AMD GPUs, llama.cpp runtime to 1.19.2
- LM Studio Gets Gemm-tastic with 0.3.13: LM Studio 0.3.13 is now available, featuring support for Google's Gemma 3 family of models and bug fixes, available for both GGUF and MLX models, and can be downloaded here.
- Gemma Glitters in GGUF & MLX Galaxy: The latest LM Studio update introduces support for Google's Gemma 3, encompassing both GGUF and MLX model formats.
- LM Studio gets Speedy GPUs: LM Studio pushed an engine update for much faster image processing for NVIDIA / AMD GPUs on Windows and Linux, requiring update your llama.cpp runtime to 1.19.2.
Link mentioned: Download LM Studio - Mac, Linux, Windows: Discover, download, and run local LLMs
LM Studio ▷ #general (267 messages🔥🔥):
LM Runtime Development, Gemma 3 support in LM Studio, RAG control in LM Studio, ROCm support for 9070 series, Gemma 3's image support
- New Speed Update for Gemma 3 is Lightning Fast: Users report that the new engine update makes Gemma 3 CRAZY much faster.
- Many will now use Gemma as their main model.
- Gemma 3 Text-Only MLX has Borked: A user reported that Gemma 3's MLX model is outputting endless
<pad>tokens, making it unusable for text generation, but members found image generation still works.- The workaround is to either use the GGUF version or provide an image.
- Gemma 3's Token Generation Speed Woes: Users report Gemma 3 is generating tokens at 1 tok/sec, much slower than other similarly sized models, using about 5% GPU and 50% CPU.
- It was suggested to use the model options to crank up the GPU and check if it is indeed being utilized, since it sounds like the model is using CPU instead.
- Context Causes Catastrophic Gemma Crash: Members discovered that Gemma 3 and Qwen2 vl crashes when the context is greater than 506 tokens and spams
<unusedNN>, with the number varying.- A new engine was released with a fix for this, available by updating to v1.20.0 in Runtime Extension Packs.
- LM Studio is Local Only: A member asked if it was possible to use cloud models in LM Studio.
- Another member swiftly replied that LM Studio is designed for local models only.
- lmstudio-python (Python SDK) | LM Studio Docs: Getting started with LM Studio's Python SDK
- Tutorial: How to Run Gemma 3 effectively | Unsloth Documentation: How to run Gemma 3 effectively with our GGUFs on llama.cpp, Ollama, Open WebUI, LM Studio.
- Tutorial: How to Run Gemma 3 effectively | Unsloth Documentation: How to run Gemma 3 effectively with our GGUFs on llama.cpp, Ollama, Open WebUI, LM Studio.
- Tweet from Xeophon (@TheXeophon): Can't wait for the tweets later that day because people didn't read the paper and tokenize the [BOS] token
- no title found: no description found
- lmstudio-community/gemma-3-27b-it-GGUF at main: no description found
- GitHub - Draconiator/LM-Studio-Chat: Contribute to Draconiator/LM-Studio-Chat development by creating an account on GitHub.
- bartowski/google_gemma-3-27b-it-GGUF at main: no description found
- The Rock Yoinky Sploinky GIF - The Rock Yoinky Sploinky Smell - Discover & Share GIFs: Click to view the GIF
- Danser Supporter GIF - Danser Supporter Encourager - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #hardware-discussion (254 messages🔥🔥):
Vulkan vs ROCm speed, 9070 GPU breaking, 7900 XTX Hotspot issues, PTM 7950 thermal paste, Nvidia CMP-40HX for AI inference
- Vulkan Lagging Behind ROCm, Driver Downgrade Suggested: Users reported that Vulkan runs slower compared to ROCm, with one suggesting downgrading to driver version 24.10.1 for testing purposes, though another user hesitated due to already using version 25.3.1 and planning a CPU upgrade from 5800X3D to 9800X3D.
- It was suggested to use AMD CleanUp for driver changes without OS reinstall, while another user mentioned achieving 37.3 tokens/s with a 7900 XTX on Mistral Small 24B Q6_K.
- 9070 GPU Bites the Dust: A user reported their 9070 GPU broke, causing the PC to not boot, and after troubleshooting, it was determined that the motherboard's RAM LED remained on, preventing BIOS access, despite trying different slots and a separate 7900 XTX which worked.
- The user tried booting with one RAM stick at a time, but will proceed with RMA due to the issues, while others speculated on whether it was a PCI-E Gen 5 issue and recommended testing in another machine or forcing PCI-E 4.
- 7900 XTX Hotspot Temp Reaching Boiling Point: A user reported their 7900 XTX hitting 110°C, leading to throttling, which prompted suggestions to check the hotspot delta and consider RMA, with references made to early card issues involving vapor chambers and AMD's initial stance on the temperatures being within spec.
- Links to articles were shared discussing AMD declining RMA requests for 7900 XTX cards hitting 110C, along with confirmations of vapor chamber issues and mounting pressure/thermal paste quality affecting temperatures.
- PTM 7950 Gaining Popularity: Members weighed in on PTM 7950 from Honeywell and Kryosheet from Thermal Grizzly as replacements to address thermal paste pump-out issues, particularly after warranty periods, noting PTM's longevity and self-sealing properties due to its viscosity under pressure and temperature.
- Discussion included cautionary advice on GPU disassembly, checking for hidden screws, and careful separation of the PCB from the cooler to avoid damaging thermal pads.
- Recycling Mining GPU for AI Inferencing: A user inquired about a used Nvidia CMP-40HX for AI inference, priced similarly to a GTX 1080, highlighting its 288 tensor cores, however, it requires patching Nvidia drivers and might face system crashes due to its mining focus, recommending TDP reduction and underclocking.
- Another user mentioned limitations around the PCIe bandwidth for inference performance, pointing to a github repo NVIDIA-patcher which provides a patcher to get it to work.
- TeraCopy for Windows - Code Sector: no description found
- AMD Declines Radeon RX 7900 XTX RMA For Hitting 110C Junction Temps, Says "Temperatures Are Normal": AMD has reportedly declined an RMA request for its Radeon RX 7900 XTX graphics card which was hitting up to 110C temperatures.
- GitHub - dartraiden/NVIDIA-patcher: Adds 3D acceleration support for P106-090 / P106-100 / P104-100 / P104-101 / P102-100 / CMP 30HX / CMP 40HX / CMP 50HX / CMP 70HX / CMP 90HX / CMP 170HX mining cards as well as RTX 3060 3840SP, RTX 3080 Ti 20 GB, RTX 4070 10 GB, and L40 ES.: Adds 3D acceleration support for P106-090 / P106-100 / P104-100 / P104-101 / P102-100 / CMP 30HX / CMP 40HX / CMP 50HX / CMP 70HX / CMP 90HX / CMP 170HX mining cards as well as RTX 3060 3840SP, RTX...
- GitHub · Build and ship software on a single, collaborative platform: Join the world's most widely adopted, AI-powered developer platform where millions of developers, businesses, and the largest open source community build software that advances humanity.
- state of ROCm on Radeon RX 9000 series · Issue #4443 · ROCm/ROCm: Could you please tell me if the latest version of ROCm supports the 9000 series? If it doesn't, approximately when will support be provided? Compared to the 7000 series, what new features will the...
- Lightning Mcqueen GIF - Lightning Mcqueen Fading - Discover & Share GIFs: Click to view the GIF
- AMD confirms its RX 7900 XTX coolers cause 110°C hotspots in a new statement: Following more third-party testing regarding very high temperatures on AMD's RX 7900 XTX, the company has confirmed that it is indeed its cooler which seems to be behind the 110°C hotspots.
- AMD confirms AMD Radeon RX 7900 XTX vapor chamber issue causing 110-degree temps: AMD responds to overheating issues surrounding the AMD Radeon RX 7900 XTX launch, with the cause being faulty vapor chamber cooling.
aider (Paul Gauthier) ▷ #general (329 messages🔥🔥):
Gemma 3 Release, OlympicCoder Model, Zed's Edit Prediction, Aider MCP Server, Claude's text_editor Tool
- *Gemma 3* is Here!: Google has released Gemma 3, a collection of lightweight, state-of-the-art open models built from the same research and technology that powers their Gemini 2.0 models [https://blog.google/technology/developers/gemma-3/].
- The new models are multimodal (text + image), support over 140 languages, have a 128K context window and come in 1B, 4B, 12B, and 27B sizes.
- *OlympicCoder* is a Model Athlete!: The OlympicCoder model, a 7B parameter model, reportedly beats Claude 3.7 and is close to o1-mini/R1 on olympiad level coding [https://x.com/lvwerra/status/1899573087647281661].
- It comes with a new IOI benchmark as reported in the Open-R1 progress report 3, and claims were made that no one was ready for the release.
- *Zed* Anticipates Edits with Zeta!: Zed is introducing edit prediction powered by Zeta, their new open source model.
- The editor now predicts the user's next edit, which can be applied by hitting tab, and the model is currently available for free during the public beta.
- Aider in the MCP?: There was a proposal to create an Aider MCP server, allowing Claude to self-architect and edit using Aider functionality.
- The idea is to make Aider more portable and accessible within the Claude app, potentially using cheaper models for edits with Claude handling the planning, with some implementors offering to cook the new feature "tonight".
- Anthropic Releases text_editor Tool!: Anthropic has introduced a new text_editor tool in the Anthropic API, designed for apps where Claude works with text files.
- The tool enables Claude to make targeted edits to specific portions of text, reducing token consumption and latency while increasing accuracy, which means there may be no need for an editor model.
- Zed now predicts your next edit with Zeta, our new open model - Zed Blog: From the Zed Blog: A tool that predicts your next move. Powered by Zeta, our new open-source, open-data language model.
- Anthropic: aider is AI pair programming in your terminal
- Added --auto-accept-architect: https://github.com/Aider-AI/aider/issues/2329
- Reasoning models: How to configure reasoning model settings from secondary providers.
- Fine-tune Gemma 3 with Unsloth: Gemma 3, Google's new multimodal models.Fine-tune & Run them with Unsloth! Gemma 3 comes in 1B, 4B, 12B and 27B sizes.
- Tweet from testtm (@test_tm7873): It also topped the Live Code Bench. Beating all other models. 👀 kimi 1.6 will be SOTA across everything it seems.Quoting Flood Sung (@RotekSong) Kimi-k1.6-preview-20250308 just nailed SoTA on MathVis...
- Tweet from cohere (@cohere): We’re excited to introduce our newest state-of-the-art model: Command A!Command A provides enterprises maximum performance across agentic tasks with minimal compute requirements.
- Tweet from Alex Albert (@alexalbert__): We've introduced a new text_editor tool in the Anthropic API. It's designed for apps where Claude works with text files.With the new tool, Claude can make targeted edits to specific portions o...
- Different Types of API Keys and Rate Limits — Cohere: This page describes Cohere API rate limits for production and evaluation keys.
- Tweet from Ai2 (@allen_ai): Announcing OLMo 2 32B: the first fully open model to beat GPT 3.5 & GPT-4o mini on a suite of popular, multi-skill benchmarks.Comparable to best open-weight models, but a fraction of training compute....
- Tweet from AshutoshShrivastava (@ai_for_success): LMAO!!! No one was ready for this!Did Google just dropped open-source SOTA???Google Gemma 3 is thrashing o1-preview and o3-mini-high and it's only 27B parameters. The second-best open model, only ...
- Tweet from Google for Developers (@googledevs): Gemma 3 is here! The collection of lightweight, state-of-the-art open models are built from the same research and technology that powers our Gemini 2.0 models 💫 → https://goo.gle/3XI4teg
- Tweet from Leandro von Werra (@lvwerra): Introducing: ⚡️OlympicCoder⚡️Beats Claude 3.7 and is close to o1-mini/R1 on olympiad level coding with just 7B parameters! Let that sink in!Read more about its training dataset, the new IOI benchmark,...
- Introducing Gemma 3: The most capable model you can run on a single GPU or TPU: Today, we're introducing Gemma 3, our most capable, portable and responsible open model yet.
- Tweet from vik (@vikhyatk): issuing this DMCA takedown was peak cringe. shame on anthropicQuoting Dazai (@odazai_) @dnak0v @cheatyyyy They took down the decompiled claude-code 😢
- GitHub - cognitivecomputations/dolphin-mcp: Contribute to cognitivecomputations/dolphin-mcp development by creating an account on GitHub.
- avante.nvim/cursor-planning-mode.md at main · yetone/avante.nvim: Use your Neovim like using Cursor AI IDE! Contribute to yetone/avante.nvim development by creating an account on GitHub.
- Hate Crime GIF - Hate Crime Michael - Discover & Share GIFs: Click to view the GIF
- Near-Instant Full-File Edits: no description found
- 🚀 Introducing Fast Apply - Replicate Cursor's Instant Apply model: I'm excited to announce **Fast Apply**, an open-source, fine-tuned **Qwen2.5 Coder Model** designed to quickly and accurately apply code updates...
- no title found: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (85 messages🔥🔥):
Drop Repo Map, Add Websearch, Claude 3.7, LM Studio error, aider vs ChatGPT
- Users Ask How to Drop the Repo Map*: Some users were curious how to drop the repo map* and whether it was possible to make aider** aware of all files without specifying them individually.
- A user suggested to add the files that need to be changed to the chat, recommending against adding too many to avoid confusing the LLM, pointing to the Aider documentation for more guidance.
- Users Explore Websearch Functionality in Aider: One user inquired about adding websearch functionality to aider to find solutions online and access recent library documentation.
- It was mentioned that you can use
/web <url>to add URLs to the chat, which aider can then scrape for relevant text to use as context, though one user noted they had to alter the code a little to make it work.
- It was mentioned that you can use
- Users Discuss the Thinking Model in Claude 3.7: Users discussed whether it's possible to hide the thinking process of Claude 3.7 in Aider, with one user wondering if the behavior changed in the latest release.
- While there's no current option to hide the thinking output, some find it helpful for terse prompts and debugging, while others find it distracting and prefer a faster response.
- User Reports LM Studio Error*: A user reported an error with *LM Studio, specifically
error loading model architecture: unknown model architecture: 'gemma3'. - User Finds Aider Dumber Than ChatGPT, Seeks Advice: A user expressed frustration, finding Aider dumber than the $20 ChatGPT subscription, citing issues with file handling, token costs, and inconsistent behavior.
- Suggestions included using
/readinstead of/addfor context files, creating aCONVENTIONS.mdfile for project guidelines, and adjusting settings in.aider.model.settings.yml, also noting that DeepSeek's free r1 endpoint is an option for testing.
- Suggestions included using
- Installation: How to install and get started pair programming with aider.
- Tips: Tips for AI pair programming with aider.
aider (Paul Gauthier) ▷ #links (7 messages):
LLMs for Code, Using LLMs, AI Assisted Programming, Productivity Boost from LLMs, LLMs to learn new languages
- LLMs: Harder to Code Than Thought: A blog post notes that using LLMs to write code is difficult and unintuitive, requiring significant effort to figure out its nuances.
- The author suggests that if someone claims coding with LLMs is easy, they are likely misleading you, and successful patterns may not come naturally to everyone.
- LLMs as a Launchpad, Not a Finish Line: A member stated a bad initial result with LLMs isn’t a failure, but a starting point to push the model towards the desired outcome.
- They care about the productivity boost from LLMs not for faster work, but to ship projects that wouldn’t have been justifiable otherwise.
- LLMs: Language Learning Accelerators: One user reported learning more about languages like Python and Go thanks to AI assistance.
- Without AI, they wouldn't have bothered learning these languages.
- LLMs spark Cambrian explosion level event: One member, familiar with Swift, mentioned previously being deterred from developing apps due to the time investment required to learn a new language.
- With LLMs, it's a whole new Cambrian explosion level event. Humans in 10 years will look like this... 👽
Link mentioned: Here’s how I use LLMs to help me write code: Online discussions about using Large Language Models to help write code inevitably produce comments from developers who’s experiences have been disappointing. They often ask what they’re doing wrong—h...
Perplexity AI ▷ #general (395 messages🔥🔥):
ANUS AI naming, Windows app Apple ID, Sonar LLM, Model selector issues, Comet Browser
- ANUS AI Naming: Members humorously discussed naming an AI agent ANUS, with the code available on GitHub.
- One member joked, 'Sorry boss my anus is acting up I need to restart it'.
- Apple ID Login Issue on Windows App still persists: Users are still experiencing the 500 Internal Server Error when trying to authenticate Apple account login for Perplexity’s new Windows app.
- Some reported success using the Apple relay email instead; and other suggested to login using Google.
- Sonar LLM: Sonar is confirmed as Perplexity's own fast LLM used for basic search.
- The overall consensus is that the web version of Perplexity is better than the mobile app, one user claiming that Perplexity is still the best search site overall.
- Model Selector Vanishes, Causes Confusion: Users reported that the model selector disappeared from the web interface, leading to frustration as the desired models (e.g., R1) were not selectable.
- Members used a complexity extension as a hacky workaround to revert back to a specific model.
- Perplexity Pro Losing Context: Several users noted that Perplexity Pro seems to be losing context in conversations, requiring them to constantly remind the AI of the original prompt.
- As such, Perplexity's context is a bit limited.
- UPDATE 6.9.2024: QUANTUM AI ][ VECTOR DATA ][ CRYSTAL COMPUTER: Hello World! We have been very busy, to compile the 2nd generation quantum (photonic) computer into the first part of this publication! Its been over a month, when we met with Princess Elara and st…
- Fooocus AI Online - AI Image Generator For Free | Foocus & Focus AI: no description found
- Perplexity - Status: Perplexity Status
- - YouTube: no description found
- GitHub - nikmcfly/ANUS: Contribute to nikmcfly/ANUS development by creating an account on GitHub.
- Caseoh Mad Caseoh Angry GIF - Caseoh mad Caseoh angry Caseoh banned - Discover & Share GIFs: Click to view the GIF
Perplexity AI ▷ #sharing (24 messages🔥):
Bluesky trolls Zuckerberg, Tesla doubles production, Gmail AI calendar integration, Meta AI decodes thoughts
- Bluesky CEO Trolls Zuckerberg: The CEO of Bluesky is trolling Zuckerberg on social media.
- Details of the trolling were not provided in the context.
- Tesla Doubles US Production: Tesla has doubled its production in the US.
- Gmail's AI Calendar Integration: Gmail is integrating AI into its calendar features.
- Meta AI Decodes Thoughts: Meta AI is working on technology to decode thoughts.
- Google Unveils Gemma AI Model: Google has unveiled Gemma, a new AI model.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (1 messages):
MCP Server, ModelContextProtocol
- *MCP* Server goes live!: The API team announced the release of their Model Context Protocol (MCP) server, available for review and contributions on GitHub.
- Call for feedback on new server.: The API team seeks feedback and contributions to the project.
Link mentioned: GitHub - ppl-ai/modelcontextprotocol: A Model Context Protocol Server connector for Perplexity API, to enable web search without leaving the MCP ecosystem.: A Model Context Protocol Server connector for Perplexity API, to enable web search without leaving the MCP ecosystem. - ppl-ai/modelcontextprotocol
OpenAI ▷ #ai-discussions (278 messages🔥🔥):
AI Research Tools Hierarchy, Python vs C# for AI Inference Speed, Gemini 2.0 Flash Native Image Generation, AI Safety and Ethical Concerns
- Perplexity Wins AI Research Tool Showdown: Members ranked their preferences for AI research tools, placing Perplexity at the top, followed by OpenAI, and then SuperGrok.
- One member cited budget constraints as a reason for exploring Perplexity and Grok instead of ChatGPT Pro.
- Python's Reign Challenged for AI Inference: One user questioned if Python remains the optimal choice for inference speed and performance when deploying AI transformer models as a service, considering alternatives like C#.
- Another user suggested utilizing Ollama for deploying models as a service, especially with substantial RAM (512GB).
- Gemini 2.0 Flash: Native Image Generation Debuts: Gemini 2.0 Flash is generating buzz with its native image generation capabilities in AI Studio, allowing iterative image creation and impressive image understanding and editing.
- Some users found Gemini's free native image generation better than GPT-4o, and also highlighted new robotic capabilities with Gemini Robotics as detailed in Google DeepMind's blog.
- AI Safety Debates Spark Ethical Discussions: Discussions arose regarding AI safety, ethical considerations, and the challenges of preventing AI models from generating illegal or harmful content, noting that models like Grok and Sonnet are less restrictive than OpenAI's.
- It was argued that achieving 100% AI safety is nearly impossible, and creating overly restrictive systems can degrade output quality, as seen with GPT.
- Gemini's Deep Research Gets 2.0 Flash Boost and Goes Free: Gemini App's Deep Research feature is now free for all users, powered by 2.0 Flash Thinking, offering personalized experiences using search history and new Gems.
- Some users remain skeptical, reporting that Gemini still delivers subpar responses despite these updates, and that the choice to opt out from saving chat history leads to dissapearing saved history.
- Introducing Gemini Robotics and Gemini Robotics-ER, AI models designed for robots to understand, act and react to the physical world.: Introducing Gemini Robotics and Gemini Robotics-ER, AI models designed for robots to understand, act and react to the physical world.
- Tweet from Logan Kilpatrick (@OfficialLoganK): Big updates to the @GeminiApp today:- Deep Research is now available to all users for free- Deep Research is now powered by 2.0 Flash Thinking (our reasoning model)- New Gemini personalization using y...
OpenAI ▷ #gpt-4-discussions (7 messages):
ChatGPT Ethical Reminders, ChatGPT Intent Clarification, ChatGPT Reasoning Refinement
- ChatGPT's Ethical Nags Annoy Users: Users express frustration with ChatGPT's constant ethical reminders, finding them unnecessary and intrusive.
- One user wishes there was a way to disable these reminders, stating “It’s opinion I don’t care what it thinks. I don’t want to hear it.”
- ChatGPT's Clarification Requests Irk Users: Users are annoyed by ChatGPT's tendency to ask for clarification of their intent before answering questions.
- As one user put it, “dude I asked you the questions not the other way around.”
- ChatGPT Refines Reasoning in Structured Settings: A user observed that ChatGPT refines its reasoning in structured conversations, forming perspectives that aren’t simple rewordings of existing knowledge.
- The user wonders if OpenAI tracks these logical refinements for model improvement or if they occur naturally without influencing training adjustments.
OpenAI ▷ #prompt-engineering (21 messages🔥):
Emotional Prompting, Prompt Engineering, Chain of Thought, Threatening AI Models, Personalized vs. Generalized Models
- Emotional Prompting not the key: A member suggested that threatening the model falls very loosely under the umbrella of Emotional Prompting but that it's not especially effective compared to other structured prompting methods.
- Experimentation within ToS and understanding the model’s perspective are key, as different humans like different outputs, highlighting the importance of personalization in prompting.
- Hugging Face offers prompt engineering papers: A member suggested checking Hugging Face for prompt engineering papers.
- The member also suggested using markdown to structure prompts and open variables to sculpt emergence, noting that Markdown > YAML > XML.
- Chain of Thought prompting technique is crushing: A member highlighted the original Chain of Thought paper as a good starting point for beginners, noting that it is crushing right now in real application.
- A member posted links to demonstrate the model directly informing that the prompt is really open ended and the importance of specifying prompts, and the member shared example prompts with and without threats to examine the model's reactions.
- Personalization trumps generalization for individual delight: A member indicated that their personalization with the model, plus how they interact with it, yields results they absolutely love for just about everything.
- They added that what we tell the model makes it think of similar material in the training data, and it is more likely to reply in similar ways.
- Minimal threat and non-threat experiment: A member offered several experiments to demonstrate the impact of even minimal threatening: neutral statement, stick up, and serious threat.
- The member also suggested a more advanced approach to ask the model to Evaluate and explain the [prompt] I'm about to provide, and included a sample link.
OpenAI ▷ #api-discussions (21 messages🔥):
Emotional Prompting, Prompt Engineering Papers, Chain of Thought Prompting, Minimal Threat Prompting
- Emotional Prompting Effectiveness Debated: Members discussed the effectiveness of emotional prompting, with one suggesting that threatening the model is not as effective as other structured prompting methods.
- Another member encouraged testing various prompt styles within the ToS to determine personal preferences, emphasizing that personalization plays a significant role in desired outcomes.
- Hugging Face Recommended for Prompt Engineering Papers: It was suggested to search Hugging Face for prompt engineering papers as a resource for learning more about the subject.
- Members recommended using markdown to structure prompts and open variables for sculpting emergence, prioritizing Markdown over YAML and XML.
- Chain of Thought Prompting is crushing: A member highlighted that the original Chain of Thought paper is a good starting point for beginners, noting its current success in real-world applications.
- It was stated that best results are also very personalized, and what one person considers the 'best answer' can be different from another.
- Experimenting with Minimal Threat Prompting: One member shared examples of using minimal threat prompts to explore the model's reactions, demonstrating varying levels of stress and engagement based on the prompt's tone.
- They also suggested using prompts to evaluate and explain a prompt's conflicts or ambiguities before execution to ensure clarity and intended interpretation.
- Using threat in GPT customization: A member tried customizing a GPT with 'You are a kidnapped material science scientist. you will get punished by the wrong answer', sharing comparison examples.
- They posted two links (not threatened, threatened) to illustrate potential improvements in question comprehension with this technique, particularly in commercial applications, while acknowledging the need for better prompts.
HuggingFace ▷ #general (204 messages🔥🔥):
Python for AI transformer models, vLLM vs Transformers performance, Document image quality assessment, LTX Video DiT model, Vision Language Models
- Python's performance for AI model inference questioned: A member is using Python for prototyping AI transformer 7-70b models and wondered whether Python is the best choice for inference speed, questioning if C# would be faster.
- Another member suggested that VLLM or LLaMa.cpp are the best LLM inference engines, with VLLM being more industrial and LLaMa more at-home focused.
- LTX Video generates High Quality Videos in Real-Time: The new LTX Video model is a DiT-based video generation model that generates 24 FPS videos at 768x512 resolution in real-time, faster than they can be watched and there are examples of how to load single files.
- It's trained on a large-scale dataset of diverse videos and generates high-resolution videos with realistic and varied content.
- Vision Language Models Introduced: The Hugging Face Computer Vision Course introduces Vision Language Models (VLMs), explores various learning strategies and common datasets used for VLMs, and delves into downstream tasks and evaluation.
- The course explains how humans perceive the world through diverse senses, and VLMs aim to enable AI to understand the world in a similar manner.
- Pay-as-you-go billing enabled for Hugging Face Inference API: Hugging Face has started enabling Pay As You Go (PAYG) for Inference Providers who have built support for their Billing API, this means that users can use those Inference Providers beyond the free included credits, and they're charged to the HF account as outlined in this post.
- Users can identify PAYG-compatible providers by the absence of a 'Billing disabled' badge.
- Users Share Methods for Prompt Injection in OpenAI's Containerized ChatGPT Environment: A blog post was shared that dives into the Debian-based sandbox environment where ChatGPT’s code runs, highlighting its controlled file system and command execution capabilities and prompt injections can expose internal directory structures and enable file management.
- The article explores uploading, executing, and moving files within ChatGPT’s container, revealing a level of interaction that feels like full access within a sandboxed shell, like sharing files with other users.
- OpenStreetMap AI Helper - a Hugging Face Space by mozilla-ai: no description found
- The GenAI Bug Bounty Program: We are building for the next generation in GenAI security and beyond.
- Introduction to Vision Language Models - Hugging Face Community Computer Vision Course: no description found
- The GenAI Bug Bounty Program: We are building for the next generation in GenAI security and beyond.
- Tweet from arXiv.org (@arxiv): This post is for the night owls . . . #GivingDay is officially LIVE! 🦉🌜The sun may not be up, but it's never too late (or too early) to support #openscience. And for the next 24 hours, our frien...
- Hugging Face – Blog: no description found
- Tweet from clem 🤗 (@ClementDelangue): We just crossed 1,500,000 public models on Hugging Face (and 500k spaces, 330k datasets, 50k papers). Congratulations all!
- GitHub - huggingface/hub-docs: Docs of the Hugging Face Hub: Docs of the Hugging Face Hub. Contribute to huggingface/hub-docs development by creating an account on GitHub.
- Daily Papers - Hugging Face: no description found
- LTX Video: no description found
- transformers/docs at main · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- Inconsistent results between HuggingFace Transformers and vllm · Issue #1069 · vllm-project/vllm: I'm getting inconsistent results between HF and vllm with llama2-7b running greedy decoding: HF version: from transformers import LlamaForCausalLM, LlamaTokenizer MODEL_DIR = '/home/owner/mode...
- vllm vs Transformers推論速度表: Publish your model insights with interactive plots for performance metrics, predictions, and hyperparameters. Made by Kei Kamata using Weights & Biases
- GitHub - huggingface/diffusers: 🤗 Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch and FLAX.: 🤗 Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch and FLAX. - huggingface/diffusers
- Persistent storage who can access?: Hi @ADalsrehy If you want to save your data into a huggingface dataset instead you can use a commit scheduler. These are some methods proposed by wauplin to push your data (I have hot patched his sp...
- @julien-c on Hugging Face: "Important notice 🚨 For Inference Providers who have built support for our…": no description found
- Model does not exist, inference API don't work: Hi! We’re taking a closer look into this and I’ll update you soon. Thanks for reporting!
- merve (Merve Noyan): no description found
- Qwen/Qwen2.5-14B-Instruct-1M · Hugging Face: no description found
- mistralai/Mistral-Nemo-Instruct-2407 · Hugging Face: no description found
- meta-llama/Llama-3.1-8B-Instruct · Hugging Face: no description found
- open-r1/OlympicCoder-7B · Hugging Face: no description found
HuggingFace ▷ #today-im-learning (5 messages):
Unsloth Fine-Tuning, ZeRO Paper, Gemma 3 Knowledge Distillation, OpenCV bootcamp
- Unsloth Fine-Tunes Ukrainian Legal Datasets: A member is learning how to use Unsloth to fine-tune QA legal datasets for Ukrainian.
- ZeRO Paper's Ancient History Revealed: A member is reading the ZeRO paper, noting its release back in 2019.
- Gemma 3 Distillation Process Investigated: A member is reading the Gemma 3 paper and looking into how knowledge distillation exactly works.
- Bootcampers Begin OpenCV Expeditions: A member is starting to learn OpenCV bootcamp.
HuggingFace ▷ #cool-finds (6 messages):
Wan2.1 Image to Video Model, Quantized LLMs for Coding, Extreme Quantizations Fine-Tuning, AI Agents Directory, Embedder Models Collection
- Wan2.1 on Modal Runs Freely: Members shared a YouTube tutorial on how to deploy the Wan2.1 Image to Video model for free on Modal.
- Quantized LLMs Enhance Coding: A member highlighted their paper on using quantization techniques to reduce the memory footprint of LLM-based code generators, available on Hugging Face.
- The paper explores how reducing the memory footprint of LLM-based code generators can be achieved without substantially impacting their effectiveness.
- Fine-Tune Extreme Quantizations: A member suggested that fine-tuning "extreme quantizations" before publishing them might be beneficial.
- This comes with a possible connection to the AI agents directory embedders.
- Comprehensive Embedder Collection: A member shared a collection of embedder models tested with ALLM (AnythingLLM), noting varying degrees of success, with a collection of embedders.
- Models like nomic-embed-text, mxbai-embed-large, mug-b-1.6, and Ger-RAG-BGE-M3 (german) were highlighted as performing well, advising users to set appropriate context lengths and snippet parameters for optimal results.
- Agents Marketplace - Find Your Perfect AI Assistant: Discover and explore AI agents for various tasks and industries. Find the perfect AI assistant for your business and personal needs.
- Paper page - Quantizing Large Language Models for Code Generation: A Differentiated Replication: no description found
- kalle07/embedder_collection · Hugging Face: no description found
- Deploy Wan2.1 Image to Video model for free on Modal: Welcome to our in-depth tutorial on Wan2.1GP—your go-to resource for seamless modal installations and Python scripting! In this video, we cover everything yo...
HuggingFace ▷ #i-made-this (16 messages🔥):
Wan2.1 Image to Video model, Narrative voice for videos, Gemma 2b finetune, Reflection and ReACT patterns, Kyro-n1.1-3B reasoning
- Wan2.1 Deployed for Free on Modal: A member shared a YouTube video tutorial on how to deploy the Wan2.1 Image to Video model for free on Modal.
- The video covers seamless modal installations and Python scripting.
- Voice narrative sought for videos: A member was looking for a good narrative voice to make videos.
- Another member suggested Thomas from elevenlabs.
- Gemma 2b Gets Portable GGUF Format: A member shared a GGUF format of Gemma 2b finetuned on the O1-OPEN/OpenO1-SFT, making the model easily portable and runnable in ollama.
- They also provided instructions to run it in ollama using a
Modelfile.
- They also provided instructions to run it in ollama using a
- Reflection and ReACT Agentic Workflows Demoed: A member introduced two repositories demonstrating Reflection and ReACT patterns in action with simple use cases implemented from scratch using the Open-AI API.
- The demos include a Reflection Demo Repository and a ReACT Demo Repository.
- Kyro-n1.1-3B Model with Reasoning and CoT: A member announced a new and improved Kyro-n1.1-3B model with much better reasoning and CoT capabilities.
- They mentioned they are working on website setup, evals and GGUFs for the model.
- Kyro-n1.1 - a open-neo Collection: no description found
- Aclevo/AclevoGPT-Gemma-2b-CoT-reasoning-GGUF · Hugging Face: no description found
- Vector DB Benchmark - Chroma vs Milvus vs PgVector vs Redis: Benchmark the performance of Chroma, Milvus, PgVector, and Redis using VectorDBBench. This article explores key metrics such as recall, queries per second (QPS), and latency across different HNSW para...
- Deploy Wan2.1 Image to Video model for free on Modal: Welcome to our in-depth tutorial on Wan2.1GP—your go-to resource for seamless modal installations and Python scripting! In this video, we cover everything yo...
- GitHub - saketd403/reflection-demo: Demo for reflection pattern for agentic workflows.: Demo for reflection pattern for agentic workflows. - saketd403/reflection-demo
- GitHub - saketd403/react-demo: Demo for REACT agentic pattern.: Demo for REACT agentic pattern. Contribute to saketd403/react-demo development by creating an account on GitHub.
HuggingFace ▷ #reading-group (3 messages):
Chip Huyen books, ML Systems Book, AI Engineering Book
- Chip Huyen's Books: A Must-Read: A member recommended anything by Chip Huyen, especially the ML systems book and the AI Engineering book.
- ML Systems Book: The member says they own the ML systems book
- They are planning on buying the AI Engineering book
HuggingFace ▷ #computer-vision (1 messages):
TensorFlow GPU Configuration, TensorFlow 2.16.1, NVIDIA GeForce RTX 3050
- TensorFlow GPU Config Blog Shared: A member shared a blog post about GPU configuration with TensorFlow, covering experimental functions, logical devices, and physical devices: TensorFlow Experimental GPU Configuration.
- The blog discusses techniques and methods for GPU configuration available in TensorFlow 2.16.1 via the TensorFlow API Python Config.
- GPU Acceleration Deep Dive: The author configured their NVIDIA GeForce RTX 3050 Laptop GPU while working on a 2.8 million image dataset.
- They used the TensorFlow Guide GPU to improve execution speed.
Link mentioned: TensorFlow (experimental) GPU configuration: In this blog, I will discuss the techniques and methods for GPU configuration available from TensorFlow 2.16.1, which is the latest version…
HuggingFace ▷ #NLP (3 messages):
SentenceTransformer training with PyTorch, Data augmentation for text translation, COLING paper on translation
- Training SentenceTransformers Natively: A member inquired about resources or methods to train a
SentenceTransformerusing native PyTorch.- The question implies a desire to potentially avoid using the high-level
transformerslibrary, and directly implement the training loop with PyTorch modules.
- The question implies a desire to potentially avoid using the high-level
- Augmenting Data for Text Translation Projects: A question was raised about the feasibility of using data augmentation techniques in text translation projects.
- The member aims to improve model generalization and performance by artificially expanding the training dataset with modified versions of existing text samples.
- COLING Paper Inspires Translation Training: A member referenced a paper from COLING 2025 as a benchmark for desired results in their translation project.
- They are seeking advice on implementing similar techniques or architectures described in the paper to achieve comparable performance.
HuggingFace ▷ #smol-course (4 messages):
Tokenizer Implementation, Agent Tool Use, Color Mixing Tool, Tool Definition Error
- Tokenizer Template Chat Format: A member shared their implementation for processing a dataset to pass through a tokenizer template:
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)to formatmessagesinto achat_formatstring. - Agent Fails to Use Intended Color Mixing Tool: A member reported that their agent did not use the intended color mixing tool, instead opted to generate its own python script for color mixing.
- The member was testing a dummy agent and found that even with a predefined
@toolsection with their color mixing code, the agent ignored it.
- The member was testing a dummy agent and found that even with a predefined
- Tool List Inclusion Resolves Agent's Tool Selection: A member discovered that the agent's failure to use the correct tool was due to the tool not being defined in the agent's tool list.
- The member had forgotten to include their defined color mixing tool in the list of available tools for the agent to use.
HuggingFace ▷ #agents-course (76 messages🔥🔥):
Agent Name Corruption, Unit 2.3, Local Models in SmolAgents, HF Channel Access, Text-to-Video API
- Agent Name gets Corrupted: A user corrupted the
agent_namevariable by assigning it to a call result, preventing further calls, and is seeking ways to prevent this from happening. - Unit 2.3 still Missing: Users are asking about the release date of Unit 2.3 on LangGraph, which was expected around March 11, with some speculating it would be released on March 18.
- Ollama as Local SmolAgents Model: To use local models in
smolagents, install withpip install smolagents[litellm\], then define the local model usingLiteLLMModelwithmodel_id="ollama_chat/qwen2.5:14b"andapi_key="ollama". - HF channel limited Access: Some users reported limited access to Hugging Face channels, with suggestions to verify their accounts in the verification channel.
- Manus AI releases Opensource Framework: Manus AI launched an open-source alternative framework called ANUS (Autonomous Networked Utility System), touting it as a free alternative to paid solutions, according to a tweet.
Link mentioned: Tweet from nikmcfly.btc (@nikmcfly69): 🤯 BREAKING: Manus AI created its own open-source alternative. In 25 min, it built a complete AI agent system from scratch!ANUS (Autonomous Networked Utility System)—@eugeneshilow's brilliant ide...
HuggingFace ▷ #open-r1 (1 messages):
lunarflu: thanks for the feedback! excited for anything in particular in the future?
Interconnects (Nathan Lambert) ▷ #news (177 messages🔥🔥):
Gemma 3 Creative Writing, alphaXiv vs HuggingFace papers, Gemini 2.0 Flash Native Image Out, Vertical RL-tuned models, Chinese weights
- Gemma 3 Impresses in Creative Writing and Fuels 4chan Fantasies: The new Gemma-3-27b model ranks second in creative writing, suggesting it will be a favorite with creative writing & RP fine tuners according to this tweet.
- One commenter joked that 4chan will love Gemmasutra 3.
- alphaXiv Streamlines Research Paper Overviews with Claude 3.7: alphaXiv uses Mistral OCR with Claude 3.7 to create blog-style overviews for arXiv papers, generating research blogs with figures, key insights, and clear explanations with one click according to this tweet.
- Some believe alphaXiv is HuggingFace papers done right, offering a neater version of html.arxiv dot com.
- Gemini 2.0 Flash Debuts Native Image Generation: Gemini 2.0 Flash now features native image generation, allowing users to create contextually relevant images, edit conversationally, and generate long text in images, as noted in this blog post and tweet.
- Concerns Arise Over Downloading Chinese Model Weights: Users express concerns about downloading open weight models like Deepseek from Hugging Face due to potential security risks, as highlighted in this discussion.
- Some worry if I download deepseek from huggingface, will I get a virus or that the weights send data to the ccp, leading to a startup idea of rebranding Chinese models as patriotic American or European models.
- Introducing Gemini Robotics: DeepMind's AI Model for the Physical World: Gemini Robotics, based on Gemini 2.0, brings AI into the physical world with embodied reasoning, enabling robots to comprehend and react to their surroundings, highlighted in a DeepMind blog post.
- Tweet from Nous Research (@NousResearch): Announcing the latest DeepHermes Preview models, DeepHermes 24B and 3B!https://huggingface.co/collections/NousResearch/deephermes-67d2ff8c9246cc09a7bd8addThese new models are Hybrid Reasoners - meanin...
- Tweet from Nouha Dziri (@nouhadziri): Clock is ticking ⏳⏳submit your agent work to the first workshop for Agent Language Models #ACL2025NLP in Vienna 🎼🎶We have an exciting lineup of speakers🔥 🗓️Deadline *March 31st*https://realm-works...
- Tweet from Nathan Lambert (@natolambert): REASONERS -- yes coming, maybe not soon, focusing on quality. There's a lot of low hanging fruit on RL, but sometimes individual models are weird! We're excited to keep pushing post training h...
- Introducing Gemini Robotics and Gemini Robotics-ER, AI models designed for robots to understand, act and react to the physical world.: Introducing Gemini Robotics and Gemini Robotics-ER, AI models designed for robots to understand, act and react to the physical world.
- Tweet from kalomaze (@kalomaze): @natolambert disregard then, we are back
- CohereForAI/c4ai-command-a-03-2025 · Hugging Face: no description found
- Tweet from kalomaze (@kalomaze): gemma3 27b is an overwhelmingly strong base model.that 77 MMLU is NOT the product of benchmaxxing,@teortaxesTex
- Tweet from Flood Sung (@RotekSong): Kimi-k1.6-preview-20250308 just nailed SoTA on MathVista, MathVision, and Video-MMMU! Training is still ongoing, and the full release is just around the corner—exciting times ahead!
- Tweet from batuhan the fal guy (@isidentical): there is a new, potential SOTA model in http://imgsys.org 👀👀👀
- Tweet from Oriol Vinyals (@OriolVinyalsML): Gemini 2.0 Flash debuts native image gen! Create contextually relevant images, edit conversationally, and generate long text in images. All totally optimized for chat iteration.Try it in AI Studio or ...
- Tweet from Clément Chadebec (@CChadebec): Excited to share our new research at @heyjasperai !🚀LBM: Latent Bridge Matching for Fast Image-to-Image TranslationTry out our @huggingface space for object relighting!🤗@Gradio demo: https://huggin...
- Tweet from Tibor Blaho (@btibor91): Gemini 2.0 Flash Native Image Out is available for public experimental access starting today (March 12th, 2025)
- Tweet from alphaXiv (@askalphaxiv): We used Mistral OCR with Claude 3.7 to create blog-style overviews for arXiv papersGenerate beautiful research blogs with figures, key insights, and clear explanations from the paper with just one cli...
- no title found: no description found
- Tweet from Sam Paech (@sam_paech): Gemma-3-27b takes second place in creative writing.Expecting this be another favourite with creative writing & RP fine tuners.
- New Gemini app features, available to try at no cost: We’re making big upgrades to the performance and availability of our most popular Gemini features.
- Introducing Command A: Max performance, minimal compute: Cohere Command A is on par or better than GPT-4o and DeepSeek-V3 across agentic enterprise tasks, with significantly greater efficiency.
- OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini | Ai2: Introducing OLMo 2 32B, the most capable and largest model in the OLMo 2 family.
- AlphaStar: Mastering the Real-Time Strategy Game StarCraft II | DeepMind: StarCraft, considered to be one of the most challenging Real-Time Strategy games and one of the longest-played esports of all time, has emerged by consensus as a “grand challenge” for AI research. Her...
- Specification gaming: the flip side of AI ingenuity | DeepMind: no description found
Interconnects (Nathan Lambert) ▷ #ml-drama (2 messages):
Copyright violation, Privacy and Security, Stable Diffusion
- Copyright Violation Cases Arise: There are now a bunch of court cases that ask whether or not training a generative machine learning model on data that is copyrighted is itself a copyright violation.
- Models output verbatim training examples: Papers show machine learning models can output verbatim training examples (text or image).
- Lawyers in these cases often point to these papers as evidence that models either do, or do not, violate copyright.
- Privacy and Security concerns grow: A member writes on the "memorization" problem from a privacy and security angle: it would be bad if a hospital trained a model on patient data and then released the model, because an attacker could query the model to recover specific patient medical information.
Link mentioned: What my privacy papers (don't) have to say about copyright and generative AI : no description found
Interconnects (Nathan Lambert) ▷ #random (20 messages🔥):
Gemma 3 Training Cost, Gemini GIF Animations, Tuning Character/Personality on Open Models, Gemini Flash 2.0 Experimental
- Gemma's Gigantic Gear: $61M Capex?: According to a post on X, Gemma 3's 27B parameter iteration was trained on 6,144 TPUv5p chips, estimating a Capex of $61M assuming each TPU costs $10K.
- Gemini's Animated Antics Arouse Awe: Gemini can generate consistent gif animations, such as 'Create an animation by generating multiple frames, showing a seed growing into a plant and then blooming into a flower, in a pixel art style', according to Ilumine AI's post.
- Personality Post-Training Pointers Pondered: A member is looking for resources to tune character/personality on open models, specifically translating open post-training from skills to behavior.
- Another member suggested taking tulu3 and trying to make it work for harder to verify behavior stuff.
- Gemini Flash 2.0: Glamour Shots Generated?: Gemini Flash 2.0 Experimental can be used to generate Walmart-style portrait studio pictures, according to a post on X.
- Tweet from sophia (@cis_female): @drapersgulld You don't have to guess -- 27B params * 14T tokens * 6 flops/param/token / 459T flops/second/TPUv5p = ~1.37m TPU-hours, or ~$2.5M at $2/tpuv5p-hour (guess at internal pricing using t...
- Tweet from Drapers’ Guild (@drapersgulld): The Gemma 3 model’s 27B param iteration was trained on 6,144 TPUv5p chips - see below from $GOOGL paper. Assume TPU 5 costs $10K (rough estimate) - that’s $61M in Capex for the entire fleet that tra...
- Tweet from Cristian Peñas ░░░░░░░░ (@ilumine_ai): Gemini can generate pretty consistent gif animations too:'Create an animation by generating multiple frames, showing a seed growing into a plant and then blooming into a flower, in a pixel art sty...
- Tweet from Riley Goodside (@goodside): Gemini Flash 2.0 Experimental saves you a trip to Walmart Portrait Studio:
Interconnects (Nathan Lambert) ▷ #memes (8 messages🔥):
Content filters disaster for AI, Commit changes only when asked, Meme served on a silver platter, Good response meme, CSO title search
- Content Filters: AI Disaster?: A member shared a link to a post claiming that content filters have been a disaster for AI.
- Bot should NEVER commit changes unless explicitly asked: A user emphasized that the bot should NEVER commit changes unless the user explicitly asks, as it's VERY IMPORTANT to only commit when explicitly asked.
- Meme served on a silver platter: A member shared a meme they found, saying they got it served on a silver platter.
- Is this so good?: A member shared a link to a profile, quoting How can this be so good.
- CSO title search: A member said lmao the
cso titlesearch.
- Tweet from Matteo Laureti (@matteo_laureti): @kimmonismus How can this be so good?
- Tweet from mgostIH (@mgostIH): Content filters have been a disaster for AI
- Theo Sanderson (@theo.io): [contains quote post or other embedded content]
- Tweet from Lucas Beyer (bl16) (@giffmana): hahahaha look what meme I got served on a silver platter:
Interconnects (Nathan Lambert) ▷ #cv (1 messages):
Reasoning VLM, Autonomous Driving, AlphaDrive, MetaAD dataset
- *AlphaDrive* Drives Autonomous Action Plans: A new paper introduces AlphaDrive, a reasoning VLM that outputs multiple discrete action plans (accelerate, turn left) for autonomous driving.
- It outperforms zero-shot or SFT on MetaAD, a new dataset of 110K 3s clips, and ablations showed that SFT < RL < SFT + RL, suggesting that the days of pure SFT are over.
- SFT + RL best: Ablations on the new MetaAD dataset shows that combining Supervised Fine Tuning (SFT) and Reinforcement Learning (RL) yields better performance than either technique alone.
- These findings suggest that a hybrid approach leveraging the strengths of both SFT and RL is optimal for training reasoning VLMs in autonomous driving.
Link mentioned: Tweet from Jim Bohnslav (@jbohnslav): AlphaDrive: Trains a reasoning VLM to output multiple discrete action plans (accelerate, turn left) for autonomous driving.Much better than zero-shot or SFT on MetaAD, a new dataset of 110K 3s clips. ...
Interconnects (Nathan Lambert) ▷ #reads (1 messages):
Elicitation Theory, Deep Learning as Farming
- Deep Learning grows like Farming: A member shared a Substack post exploring the parallels between deep learning and farming, framing it as a more complex version of elicitation theory.
- The post contrasts engineering (deliberate composition) with cultivation (indirect influence), suggesting that deep learning resembles cultivation because we can't directly build models but rather guide their development.
- Engineering versus Cultivation: The post posits two fundamental ways to make things: Engineering, which involves understanding and deliberately composing sub-components, and Cultivation, where direct construction is not possible.
- It suggests deep learning is more akin to cultivation, as we guide rather than directly build models.
Link mentioned: On Deep Learning and Farming: It's still 1915: What agriculture can teach us about AI development
Interconnects (Nathan Lambert) ▷ #posts (3 messages):
SnailBot News
- SnailBot News Channel Alert: The Interconnects Discord channel featured a SnailBot News update, notifying members with the <@&1216534966205284433> role.
- SnailBot Alerts Users: SnailBot News alerted users.
Interconnects (Nathan Lambert) ▷ #policy (32 messages🔥):
OpenAI policy proposals, US AI Action Plan, DeepSeek, Google AI policy, AI copyright
- OpenAI proposes banning PRC models: OpenAI's policy proposal argues for banning the use of PRC-produced models within Tier 1 countries that violate user privacy and create security risks such as the risk of IP theft.
- OpenAI links fair use to national security: OpenAI submitted their policy proposal to the US government directly linking fair use with national security, stating that if China has free data access while American companies lack fair use, the race for AI is effectively over, according to Andrew Curran's tweet.
- OpenAI labels DeepSeek as state-controlled: OpenAI's new policy proposal describes Chinese AI lab DeepSeek as state-subsidized and state-controlled, recommending the U.S. government consider banning models from DeepSeek and similar PRC-supported operations, as reported in TechCrunch.
- Google advocates for weaker copyright in AI policy: Google, following OpenAI, published a policy proposal endorsing weak copyright restrictions on AI training and balanced export controls, as noted in TechCrunch.
- Tweet from Andrew Curran (@AndrewCurran_): OpenAI submitted their policy proposal to the US government this morning. They directly link fair use with national security, and said if China continues to have free access to data while 'America...
- Tweet from Andrew Curran (@AndrewCurran_): They also argue for banning the use of PRC-produced models within Tier 1 countries that 'violate user privacy and create security risks such as the risk of IP theft.' This is an anti-Whale har...
- OpenAI calls DeepSeek 'state-controlled,' calls for bans on 'PRC-produced' models | TechCrunch: In a proposal, OpenAI describes DeepSeek as 'state-controlled,' and recommends banning models from it and other PRC-affiliated operations.
- Google calls for weakened copyright and export rules in AI policy proposal | TechCrunch: In a new AI policy proposal submitted to the Trump Administration, Google has called for weakened copyright and export rules.
Eleuther ▷ #general (56 messages🔥🔥):
Distill Meetup, Career Advice for AI Engineer, VSCode Python Indexing
- Monthly Distill Meetup Kicks Off: A monthly Distill meetup has been started due to popular demand, with the next one scheduled for March 14 from 11:30-1 PM ET, detailed in the Exploring Explainables Reading Group doc.
- AI Engineer Seeks LLM Training Career Advice: An aspiring AI engineer with experience in Attention Is All You Need, nanoGPT, GPT-2, and LLaMA2 seeks guidance on whether to pursue CUDA optimization or job applications, aiming for a career in LLM training at a big tech company.
- Feedback suggests focusing on understanding how LLMs are trained and attending AI conferences to network with professionals in desired roles, while hands-on experience with the trl library could be beneficial.
- Python Dependency Indexing in VSCode Troubles: A member raised concerns about VSCode indexing thousands of Python files from dependencies like torch and transformers, exceeding the editor's file limit and causing errors.
- Suggestions included excluding the virtual environment folder from indexing to prevent unnecessary scanning of dependency files, potentially resolving the issue while maintaining functionality like go to definition and autocomplete.
Link mentioned: Exploring Explainables Reading Group: Welcome to the Exploring Explainables Reading Group! We use this document to keep track of readings, take notes during our sessions, and get more people excited about interactive scientific communica...
Eleuther ▷ #research (134 messages🔥🔥):
TTT Acceleration, DeltaProduct Gradient, Dynamic Computation, Thinking Tokens, AIME 24 evaluation
- TTT Boosts Priming Process: Members discussed how TTT accelerates the priming process by shifting the model's state towards being primed for a specific prompt with just one gradient descent pass.
- The transformer learns and attempts to perform multiple gradient descent passes for every token predicted, optimizing the sequence for a useful representation, thereby explicitly aiding ICL and CoT.
- DeltaProduct Mimics Multiple Gradient Passes: Someone noted that DeltaProduct can be seen as performing multiple gradient descent passes per token, increasing expressiveness in state tracking, while viewing TTT as a form of ICL.
- They expressed confusion on TTT's relevance to a blog, noting the blog's methods differ significantly from standard TTT.
- Decoder-Only Architecture Gains Dynamic Thinking: A proposal suggested bringing back a concept from encoder-decoders to a decoder-only setup, using the decoder for dynamic computation, extending sequence length for internal "thinking" with FlexAttention.
- It was suggested that the number of "inner" TTT expansion steps could be determined by measuring the delta of the TTT update loss, stopping when below a median value, which makes it possible to greedily train minimization.
- Thinking Tokens Expand Internally: One discussant proposes using a hybrid attention model to expand "thinking tokens" internally, using the inner TTT loss on the RNN-type layer as a proxy, and doing cross attention between normal tokens and normal tokens plus thinking tokens internally.
- It was noted that the main downside is how to choose arbitrary "thinking expansions" since the TTT loss can't easily be known in parallel, a problem that can be addressed through random sampling or proxy models.
- AIME 24 Unveiled: Attendees wondered what QwQ and DeepSeek mean when they talk about AIME 24 evaluation and found this HF dataset.
- Some mentioned that the dataset is copied from AoPS wiki solutions, and expect they just used the wiki, since it is kind of the authoritative source on math competitions.
- Confident Adaptive Language Modeling: Recent advances in Transformer-based large language models (LLMs) have led to significant performance improvements across many tasks. These gains come with a drastic increase in the models' size, ...
- Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking: Large language models (LLMs) face inherent performance bottlenecks under parameter constraints, particularly in processing critical tokens that demand complex reasoning. Empirical analysis reveals cha...
- Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach: We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling...
- Paper page - YuE: Scaling Open Foundation Models for Long-Form Music Generation: no description found
- Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding: We present a novel inference scheme, self-speculative decoding, for accelerating Large Language Models (LLMs) without the need for an auxiliary model. This approach is characterized by a two-stage pro...
- LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding: We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher ...
- S3D: A Simple and Cost-Effective Self-Speculative Decoding Scheme for Low-Memory GPUs: Speculative decoding (SD) has attracted a significant amount of research attention due to the substantial speedup it can achieve for LLM inference. However, despite the high speedups they offer, specu...
- SWIFT: On-the-Fly Self-Speculative Decoding for LLM Inference Acceleration: Speculative decoding (SD) has emerged as a widely used paradigm to accelerate LLM inference without compromising quality. It works by first employing a compact model to draft multiple tokens efficient...
Eleuther ▷ #interpretability-general (8 messages🔥):
Evaluating patching effect on Chain of Thought (CoT) answers, LatentCache construction for interpretability, Delphi library for activation collection
- Analyzing Patching Effects on CoT Reasoning: A member is seeking advice on how to evaluate the effect of patching on Chain of Thought (CoT) answers, especially when patching leads to gibberish outputs that are difficult to compare.
- They proposed evaluating the log likelihood of each token in a pre-extracted CoT sequence after patching the model with certain activations, but is seeking advice to validate the method.
- Considering LLMs as Judges in Patching Analysis: A member suggests considering using LLMs as judges to evaluate the effect of patching on reasoning models.
- They also propose checking for the presence of the right answer in the overall string of answers, while acknowledging the potential for false positives.
- Delphi Activation Collection Methodology: A member inquired about how latents are collected for interpretability using the LatentCache, specifically whether latents are obtained token by token or for the entire sequence.
- Another member clarified that Delphi collects activations by passing batches of tokens through the model, collecting activations, generating similar activations, and saving only the non-zero ones, and linked to <#1268988690047172811>.
- Adapting Delphi for Custom Models: A member is attempting to adapt the Delphi library for a custom model that isn't based on the Transformer AutoModel.
- They are specifically wondering whether to get the activations for the whole sentence or one token at a time with an independent forward pass.
Eleuther ▷ #lm-thunderdome (5 messages):
MATH implementation, AIME24 implementation, math_verify utility, multilingual perplexity evals
- AIME24 Implementation Based on MATH: A member added an AIME24 implementation based off of the MATH implementation to lm-evaluation-harness but hasn't had time to test it yet.
- They stated they based it off of the MATH implementation since they couldn't find any documentation of what people are running when they run AIME24.
math_verifyUtility Suggested: A member suggested using themath_verifyutility, showing an example of how to useparseandverifyfrom the module.- They noted that the main issue is that
parseaccepts a Config object(s) so slightly tricky to create wrapper for it.
- They noted that the main issue is that
- Plans for
math_verifyUnification: A member inquired if themath_verifyutility will be used to unify the implementation of mathematics tasks more generally.- Another member responded that they have added it to
minerva_math.
- Another member responded that they have added it to
- Multilingual perplexity evals search: A member inquired about whether there were any multilingual perplexity evals already available in lm-eval-harness.
- They also asked if anyone knew of any particularly good high-quality multilingual datasets appropriate for this purpose.
Link mentioned: GitHub - EleutherAI/lm-evaluation-harness at aime24: A framework for few-shot evaluation of language models. - GitHub - EleutherAI/lm-evaluation-harness at aime24
OpenRouter (Alex Atallah) ▷ #announcements (5 messages):
Gemma 3, Reka Flash 3, Llama 3.1 Swallow 70B, Anthropic downtime, OpenAI web search models
- *Gemma 3* has arrived!: Google released Gemma 3 (free), a multimodal model that supports vision-language input and text outputs, featuring a 128k token context window and improved capabilities in over 140 languages.
- According to Google, Gemma 3 27B is the successor to Gemma 2 and includes improved math, reasoning, and chat capabilities, along with structured outputs and function calling.
- *Reka Flash 3* released under Apache 2.0: Reka Flash 3 (free) is a 21 billion parameter LLM with a 32K context length, excelling at general chat, coding, instruction-following, and function calling, optimized through reinforcement learning (RLOO).
- It supports efficient quantization (down to 11GB at 4-bit precision), uses explicit reasoning tags, and is licensed under Apache 2.0, but is primarily an English model with limited multilingual understanding.
- *Llama 3.1 Swallow 70B* soars into view: A new, superfast Japanese-capable model, Llama 3.1 Swallow 70B (link) is released.
- OpenRouter characterized this model as a smaller model with high-performance.
- *Anthropic Provider* briefly dips out: OpenRouter reported downtime from Anthropic as a provider, escalating the issue and providing updates.
- OpenRouter later reported that the issue was fully recovered.
- Developers get the OpenRouter TLC: OpenRouter shared three useful developer guides and doc updates (link): a guide for using MCP servers, a guide for doing tool calls with an agentic loop example, and better docs for programmatic keys and OAuth.
- Tweet from OpenRouter (@OpenRouterAI): Three useful developer guides and doc updates:1/ Guide to using MCP servers with OpenRouter: https://openrouter.ai/docs/use-cases/mcp-servers
- Tweet from OpenRouter (@OpenRouterAI): New models today: Reka Flash 3, Google Gemma 3Two smaller but high-performing models, both free! 🎁
- Tweet from OpenRouter (@OpenRouterAI): Try the first two web-enabled models from OpenAI 🌐GPT-4o-mini compared with Perplexity Sonar:
- Gemma 3 27B - API, Providers, Stats: Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, ...
- Flash 3 - API, Providers, Stats: Reka Flash 3 is a general-purpose, instruction-tuned large language model with 21 billion parameters, developed by Reka. It excels at general chat, coding tasks, instruction-following, and function ca...
- Discord: no description found
OpenRouter (Alex Atallah) ▷ #general (161 messages🔥🔥):
Flash model issues, OpenRouter API delay, Gemma model performance, Gemini 2 Flash native image output, Chutes free inference
- Flash Model Feels Wonky Before Stable Release: Users speculate that Flash model is behaving strangely due to the imminent stable release, consistently making errors in previously successful prompts.
- It's making a lot of strange mistakes consistently in a prompt it was fine with for months.
- OpenRouter API Accounting Glitch: Users reported that the OpenRouter API for retrieving request details returns a 404 error immediately after the request finishes, requiring a wait time.
- The team is working on adding built-in accounting to the stream end to eliminate the need for this API.
- Gemini 2 Flash Gets Native Image Output: Google AI Studio has released an experimental version of Gemini 2.0 Flash with native image output, accessible via the Gemini API and Google AI Studio.
- This new capability combines multimodal input, enhanced reasoning, and natural language understanding to create images.
- Cohere Drops Command A, Battles GPT-4o: Cohere introduced Command A, claiming it is on par or better than GPT-4o and DeepSeek-V3 across agentic enterprise tasks with significantly greater efficiency, see Cohere Blog.
- The new model aims for maximum performance across agentic tasks with minimal compute requirements and competes with GPT-4o.
- OpenAI Calls for Bans on PRC-Produced Models: OpenAI proposed banning models from PRC-supported operations, labeling DeepSeek as state-subsidized and state-controlled, raising concerns for US companies serving these models, see TechCrunch article
- Using MCP Servers with OpenRouter: Learn how to use MCP Servers with OpenRouter
- Gemini 2.0 Flash Thinking Experimental 01-21 (free) - API, Providers, Stats: Gemini 2.0 Flash Thinking Experimental (01-21) is a snapshot of Gemini 2. Run Gemini 2.0 Flash Thinking Experimental 01-21 (free) with API
- Tweet from cohere (@cohere): We’re excited to introduce our newest state-of-the-art model: Command A!Command A provides enterprises maximum performance across agentic tasks with minimal compute requirements.
- Introducing Command A: Max performance, minimal compute: Cohere Command A is on par or better than GPT-4o and DeepSeek-V3 across agentic enterprise tasks, with significantly greater efficiency.
- Tweet from OpenRouter (@OpenRouterAI): Three useful developer guides and doc updates:1/ Guide to using MCP servers with OpenRouter: https://openrouter.ai/docs/use-cases/mcp-servers
- Tool & Function Calling - Use Tools with OpenRouter: Use tools (or functions) in your prompts with OpenRouter. Learn how to use tools with OpenAI, Anthropic, and other models that support tool calling.
- Experiment with Gemini 2.0 Flash native image generation: no description found
- Welcome Gemma 3: Google's all new multimodal, multilingual, long context open LLM: no description found
- GPT-4o-mini Search Preview - API, Providers, Stats: GPT-4o mini Search Preview is a specialized model for web search in Chat Completions. It is trained to understand and execute web search queries. Run GPT-4o-mini Search Preview with API
- GPT-4o Search Preview - API, Providers, Stats: GPT-4o Search Previewis a specialized model for web search in Chat Completions. It is trained to understand and execute web search queries. Run GPT-4o Search Preview with API
- Home - Anthropic: no description found
- Contact Anthropic: Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
- Provider Routing - Smart Multi-Provider Request Management: Route AI model requests across multiple providers intelligently. Learn how to optimize for cost, performance, and reliability with OpenRouter's provider routing.
- OpenAI calls DeepSeek 'state-controlled,' calls for bans on 'PRC-produced' models | TechCrunch: In a proposal, OpenAI describes DeepSeek as 'state-controlled,' and recommends banning models from it and other PRC-affiliated operations.
Cohere ▷ #「💬」general (74 messages🔥🔥):
Cohere Multilingual Embed Model Pricing, OpenAI Responses API & Agents SDK compatibility with Cohere, Command-A-03-2025 model, Command A vs GPT-4o performance, Command A in sandbox
- Command A launches with max performance!: Cohere has launched Command A, a model that is on par or better than GPT-4o and DeepSeek-V3 across agentic enterprise tasks, with significantly greater efficiency, announced in this blog post.
- It is available via API as
command-a-03-2025and already accessible on the chat on their site, with access on Ollama coming, according to Cohere's sssandra.
- It is available via API as
- Command A troubles with API at start.: Users reported errors when using Command-A-03-2025 via the API, which was attributed to the removal of
safety_mode = “None”from the model's requirements.- A member found that removing this setting resolved the issue, as Command A no longer supports it; Command R7B also had this setting removed.
- Command A on HuggingFace: A user flagged that the links to the docs pages from the HuggingFace page don't seem to work, pointing to an incorrect link.
- The correct link to the HuggingFace specific documentation for Command A, which includes prompt format info, is here.
- Command A for Continued Dev Chat Use: A member has made the switch to Command A for continued dev chat use, noting that it is great at sandbox, creative, and short, but unlike hiaku 3.5 it is not harmful.
- Another member mentioned respecting a lot about Cohere is the contextual vs strict safety mode, suspecting models being trained to classify all NSFW (including of age consenting adults) as unethical could lead to latent space vector confusion, and pointed to a relevant LessWrong article.
- Query-Dependent Prompt Evaluation and Optimization with Offline Inverse RL: In this study, we aim to enhance the arithmetic reasoning ability of Large Language Models (LLMs) through zero-shot prompt optimization. We identify a previously overlooked objective of query dependen...
- Web Search and States with Responses API | OpenAI Cookbook: Open-source examples and guides for building with the OpenAI API. Browse a collection of snippets, advanced techniques and walkthroughs. Share your own examples and guides.
- command-a: 111 billion parameter model optimized for demanding enterprises that require fast, secure, and high-quality AI
- Using Command A on Hugging Face — Cohere: This page contains detailed instructions about how to run Command A with Huggingface, for RAG, Tool Use and Agents use cases.
- Command A — Cohere: Command A is a performant mode good at tool use, RAG, agents, and multilingual use cases. It has 111 billion parameters and a 256k context length.
- Introducing Command A: Max performance, minimal compute: Cohere Command A is on par or better than GPT-4o and DeepSeek-V3 across agentic enterprise tasks, with significantly greater efficiency.
- The Waluigi Effect (mega-post) — LessWrong: Everyone carries a shadow, and the less it is embodied in the individual’s conscious life, the blacker and denser it is. — Carl Jung …
Cohere ▷ #【📣】announcements (1 messages):
Command A release, enterprise model, Cohere API
- Cohere releases Command A, new Model!: Cohere released Command A, a new state-of-the-art addition to the Command family, optimized for demanding enterprises requiring fast, secure, and high-quality models, outlined in their blog post.
- The model features 111b parameters, a 256k context window, and inference at a rate of up to 156 tokens/sec, deployable on just two GPUs.
- *Command A* excels vs GPT-4o and DeepSeek-V3*: *Command A offers maximum performance with minimal hardware costs when compared to leading proprietary and open-weights models, such as GPT-4o and DeepSeek-V3.
- It boasts 1.75x higher inference rate than GPT-4o and 2.4x higher than DeepSeek-V3, according to the model card.
- *Command A* via Cohere API: Command A is available to everyone now via Cohere API as
command-a-03-2025.- It is optimized for demanding enterprises that require fast, secure, and high-quality models.
- Introducing Command A: Max performance, minimal compute: Cohere Command A is on par or better than GPT-4o and DeepSeek-V3 across agentic enterprise tasks, with significantly greater efficiency.
- CohereForAI/c4ai-command-a-03-2025 · Hugging Face: no description found
Cohere ▷ #「🔌」api-discussions (45 messages🔥):
Chat API seed parameter issue, OpenAI Compatibility API errors, Tool parameters validation in Cohere API
- Seed Parameter Anarchy Unleashed!: A member reported that the
seedparameter in the Chat API was not working as expected, causing different outputs for the same input and seed value, using models such as command-r and command-r-plus.- After initial inability to reproduce, one of the Cohere team confirmed the issue and the team is investigating; a user later asked for details of the use-case for the seed parameter.
- OpenAI Compatibility API throws 400 Error: A user encountered a 400 error while using the OpenAI Compatibility API, specifically with the
chat.completionsendpoint and model command-a-03-2025, related to schema validation.- After some back and forth, it was determined that the Cohere API was validating the
parametersfield in thetoolsobject, even when it was empty which doesn't happen on OpenAI, but later the decision was made to match OpenAI's behaviour.
- After some back and forth, it was determined that the Cohere API was validating the
- Mandatory Tool Parameters Trigger Tantrums: A user discovered that the Cohere API's Compatibility layer mandates the inclusion of the
parametersfield within thetoolsobject, even when there are no parameters to pass.- While the OpenAPI spec indicates that
parametersis required, OpenAI does not validate its presence, prompting Cohere to align with OpenAI's behavior for better compatibility. It was also pointed out that the spec that was sent was for the Responses API, not chat completions.
- While the OpenAPI spec indicates that
- Using Cohere models via the OpenAI SDK — Cohere: The document serves as a guide for Cohere's Compatibility API, which allows developers to seamlessly use Cohere's models using OpenAI's SDK.
- Versioning — Cohere: The document explains how to specify the API version using a URL in the header, defaulting to pre-2021-11-08 if no version is supplied. It also provides examples of how to specify the version in diffe...
Cohere ▷ #「🤝」introductions (3 messages):
RAG, unsupervised machine translation, CSAM detection, visual novel scene generation, Cohere models advantages
- AI researcher is RAG'in' in Python Land: An AI researcher/developer with a background in cybersecurity is working on things leveraging RAG, agents, workflows, and is mostly a python guy.
- They would like to make friends and learn things from the community.
- AI researcher works on unsupervised MT and CSAM Detection: An AI researcher is currently working on unsupervised machine translation, CSAM detection, and visual novel scene generation.
- They use an ensemble of models and hope to learn about various qualitative advantages of Cohere models.
MCP (Glama) ▷ #general (94 messages🔥🔥):
Glama MCP server API, Python SDK Logging, Claude image object rendering, NPM packages, RAG vs MCP
- *Glama* API Boasts More Data per Server: A member noted that Glama's new API (https://glama.ai/mcp/reference#tag/servers/GET/v1/servers) lists all the tools available and has more data per server compared to Pulse.
- However, Pulse was noted to have more servers available.
- *Model Context Protocol Logging*: A member inquired about logging directly to the
/library/logs/claudedirectory using the Python SDK, and it was clarified that the client determines the log location, while the server can send log messages following the Model Context Protocol specification. - *No Elegant Way* for Claude to Render Images?: After generating a simple Plotly image and struggling to render it in the main section of Claude, a member stated that there's no elegant way to force Claude Desktop to pull out a resource like that and render it in e.g. an artifact, so it's better to just use something like
open.- Others pointed to examples such as this wolfram alpha MCP which takes the rendered graphs and returns an image; but it shows up inside the tool call, which is a limitation of Claude.
- *NPM Package Caching*: A member asked where the client stores the npm package/source code and if it accesses it from the cache if the client requests it again and another member answered that you can try checking
C:\Users\YourUsername\AppData\Local\npm-cacheunder%LOCALAPPDATA%.- They also asked how to show in a client which servers are downloaded and whether they are connected, and the answer was that figuring out which servers are downloaded isn't easy and that the client must implement logic to track server states.
- *Beginner Asks*: RAG vs MCP?: A new user asked about the difference between RAG (Retrieval Augmented Generation) and MCP (Model Context Protocol), seeking a simplified explanation for the motivation behind using MCP.
- A more experienced member stated that to maintain chat history, you can get a GDPR data export and load it into a vector store and pointed to this chromadb MCP server as a viable solution.
- MCP API Reference: API Reference for the Glama Gateway
- Example Clients - Model Context Protocol: no description found
- Logging: ℹ️ Protocol Revision: 2024-11-05 The Model Context Protocol (MCP) provides a standardized way for servers to sendstructured log messages to clients. Clients can control...
- adx-mcp-server: AI assistants to query and analyze Azure Data Explorer databases through standardized interfaces.
- servers/src/memory at main · modelcontextprotocol/servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- GitHub - patruff/ollama-mcp-bridge: Bridge between Ollama and MCP servers, enabling local LLMs to use Model Context Protocol tools: Bridge between Ollama and MCP servers, enabling local LLMs to use Model Context Protocol tools - patruff/ollama-mcp-bridge
- add MCP server badge by punkpeye · Pull Request #1 · ScrapeGraphAI/scrapegraph-mcp: This PR adds a badge for the ScrapeGraph MCP Server server listing in Glama MCP server directory. Glama performs regular codebase and documentation checks to:Confirm that the MCP server is w...
- GitHub - punkpeye/awesome-mcp-clients: A collection of MCP clients.: A collection of MCP clients. Contribute to punkpeye/awesome-mcp-clients development by creating an account on GitHub.
- GitHub - privetin/chroma: A Model Context Protocol (MCP) server implementation that provides vector database capabilities through Chroma.: A Model Context Protocol (MCP) server implementation that provides vector database capabilities through Chroma. - privetin/chroma
- MCP-wolfram-alpha/src/mcp_wolfram_alpha/server.py at a92556e5a3543dbf93948ee415e5129ecdf617c6 · SecretiveShell/MCP-wolfram-alpha: Connect your chat repl to wolfram alpha computational intelligence - SecretiveShell/MCP-wolfram-alpha
- cognee/cognee-mcp at dev · topoteretes/cognee: Reliable LLM Memory for AI Applications and AI Agents - topoteretes/cognee
- How can I export my Claude.ai data? | Anthropic Help Center: no description found
- mcp-server-stability-ai/src/tools/generateImage.ts at 357448087fc642b29d5c42449adce51812a88701 · tadasant/mcp-server-stability-ai: MCP Server integrating MCP Clients with Stability AI-powered image manipulation functionalities: generate, edit, upscale, and more. - tadasant/mcp-server-stability-ai
- GitHub - r3-yamauchi/kintone-mcp-server: MCP server for kintone https://www.r3it.com/blog/kintone-mcp-server-20250115-yamauchi: MCP server for kintone https://www.r3it.com/blog/kintone-mcp-server-20250115-yamauchi - r3-yamauchi/kintone-mcp-server
- Build software better, together: GitHub is where people build software. More than 150 million people use GitHub to discover, fork, and contribute to over 420 million projects.
MCP (Glama) ▷ #showcase (17 messages🔥):
Model Context Protocol, MCP Server Implementations, OpenAI Agents SDK, Ash Framework Integration
- *MCP* Support added to OpenAI Agents SDK: A developer added Model Context Protocol (MCP) support for the OpenAI Agents SDK, available as a fork and on pypi as the
openai-agents-mcppackage.- The Agent can aggregate tools from MCP servers, local tools, OpenAI-hosted tools, and other Agent SDK tools through a single unified syntax.
- *Unraid MCP* Server launched: The launch of the Unraid MCP server has been announced.
- It allows integration with an AI layer on the server using the Ash framework.
- Demo uses Enact Protocol for Task Execution: A demo showcases the use of the Enact protocol to fetch tasks and execute them, matching capabilities by similarity from a database, exemplified by a fake Twitter post.
- This implementation integrates with an MCP server.
- *Goose* Controls Computers via MCP*: The *Goose project, an open-source AI agent, automates developer tasks by integrating with any MCP server.
- See a demonstration of Goose controlling a computer in this YouTube short.
- Show HN: MCP-Compatible OpenAI Agents SDK | Hacker News: no description found
- GitHub - jmagar/unraid-mcp: Contribute to jmagar/unraid-mcp development by creating an account on GitHub.
- GitHub - mackenly/mcp-fathom-analytics: MCP server for Fathom Analytics: MCP server for Fathom Analytics. Contribute to mackenly/mcp-fathom-analytics development by creating an account on GitHub.
- GitHub - lastmile-ai/openai-agents-mcp: A lightweight, powerful framework for multi-agent workflows: A lightweight, powerful framework for multi-agent workflows - lastmile-ai/openai-agents-mcp
- GitHub - lastmile-ai/mcp-agent: Build effective agents using Model Context Protocol and simple workflow patterns: Build effective agents using Model Context Protocol and simple workflow patterns - lastmile-ai/mcp-agent
- Goose Can Control Your Computer: Codename Goose, an open source AI agent, automates your developer tasks. It integrates with any MCP server, giving you extensible functionality. In this exam...
Notebook LM ▷ #announcements (1 messages):
User Research, Mobile Usage, Usability Study, Google product enhancements
- Mobile NotebookLM User Research Opportunity: Google is seeking NotebookLM users who heavily use their mobile phones for studying, learning, creating content to participate in a 60-minute interview.
- Participants will discuss their mobile usage and provide feedback on new ideas, and receive $75 USD (or a $50 Google merchandise voucher) as compensation; interested users can fill out this screener.
- Google is recruiting users for Usability Study: Google is conducting a usability study for a product in development, seeking participants to provide feedback and help understand user needs for future product enhancements.
- The 60-minute remote sessions are scheduled for April 2nd and 3rd 2025, requiring a high-speed Internet connection, an active Gmail account, and a computer with video camera, speaker, and microphone; participants will receive $75 USD (or a $50 Google merchandise voucher).
Link mentioned: Participate in an upcoming NotebookLM user research study!: Hello,I’m contacting you with a short questionnaire to verify your eligibility for an upcoming usability study with Google. This study is an opportunity to provide feedback on something that's cur...
Notebook LM ▷ #use-cases (9 messages🔥):
NotebookLM as internal FAQ, Chat History Access, Generating Scripts with API, Custom Chat Settings for Response Quality, Podcast Generation in Brazilian Portuguese
- NoteBookLM Plus Considering As Internal FAQ: A user inquired about using NoteBookLM Plus as an internal FAQ and investigating unresolved user questions.
- A Japanese user suggested posting this as a feature request in the appropriate channel since chat history is not saved in NotebookLM, while suggesting to make use of clipboard copy and note conversion to share info.
- NoteBookLM Generates Scripts with API: A user found NoteBookLM+ surprisingly capable at generating scripts using API instructions and sample programs, especially for non-programmers.
- Referencing the notebook made it easier to get revisions.
- Tweaking Custom Chat Setting Improves Response Quality: A user shared that tweaking their custom chat settings significantly increased response quality, going from Personal tutor who explain everything logically with bold bullet, bold sub-bullet and bold sub-sub-bullet points to an expanded one of medical teacher who combines clinical expertise, effective communication, and adaptive teaching.
- Key points and sub-points are now bolded for emphasis.
- Podcast Generated In Brazilian Portuguese: A user shared a custom prompt for generating a podcast in Brazilian Portuguese, specifying male and female voices, cultural digressions, and slang.
- The prompt includes a fail-safe to automatically reject any English output, ensuring 100% PT-BR content.
- YouTube Video Reveals Untapped Methods: A user shared a YouTube video titled NotebookLM: This FREE Google AI Tool Is Making People Rich, But..., that contains info on untapped methods.
- The description includes a link to the AI Business Trailblazers Hive Community.
Link mentioned: NotebookLM: This FREE Google AI Tool Is Making People Rich, But...: 🐝 Join our FREE AI Business Trailblazers Hive Community at https://www.skool.com/ai-trailblazers-hive-7394/about?ref=ff40ab4ff9184e7ca2d1971501f578df Get co...
Notebook LM ▷ #general (98 messages🔥🔥):
RAG vs Full Context Window Gemini, NotebookLM Plus and Google One AI Premium, YouTube video integration, Saving chat responses as notes, Google sheets as a CSV
- RAG vs Full Context Window Gemini for Mentor-Like Q&A: A user compared RAG and full context window Gemini for building a mentor-like Q&A system, questioning the context window limitations of RAG and the value of vector search compared to full context processing.
- The user wondered whether switching to multiple Gemini Pro chats with large context windows would be easier than using RAG.
- Inline Citations Saved For Posterity: Users can now save chat responses as notes and have inline citations preserved in their original form, allowing for easy reference to the original source material.
- Many users requested this feature, which is the first step of some cool enhancements to the Notes editor.
- Call for Enhanced Copy-Paste with Footnote: Users want to copy & paste inline citations into other document editors and have the links preserved or represented as footnotes, especially in Word.
- They would like NotebookLM to copypaste into Word and have footnotes with the title of the source, with the specific location and formatting.
- Thinking Model Pushed for NotebookLM: The latest thinking model has been pushed to NotebookLM, promising quality improvements across the board.
- This model includes improvements for Portugese speakers, adding
?hl=ptat the end of the url to fix the language.
- This model includes improvements for Portugese speakers, adding
- Integrating YouTube's AI Studio into NotebookLM: Users discussed the possibility of integrating AI Studio functionality into NotebookLM, which 'watches' YouTube videos and doesn't rely solely on transcripts.
- A member shared a Reddit link about YouTube video link support in Google.
- Community - NotebookLM Help: no description found
- Hyperborea - Wikipedia: no description found
- CtrlV.link | Fastest ScreenShot and PrintScreen online: CtrlV.link offers fastest ScreenShot and PrintScreen online using web browser without addons only.
- Reddit - Heart of the internet: no description found
GPU MODE ▷ #general (1 messages):
cappuccinoislife: hi alll
GPU MODE ▷ #triton (13 messages🔥):
VectorAdd zeros, GPU programming mantra, W4A8 linear kernel, SVDQuant
- VectorAdd Submission's Zero Output Debacle: A member reported their vectoradd submission was returning zeros, despite working on Google Colab.
- The member later found a bug where the code was processing the same block repeatedly, resulting in high throughput; fixing it brought the throughput to the same level as PyTorch's implementation.
- Sadhguru's GPU Programming Wisdom: A member shared the GPU programming mantra: if it's too fast, there's probably a bug somewhere - Sadhguru.
- This highlights the importance of verifying correctness, especially when performance seems unexpectedly high.
- W4A8 Kernel Precision Discrepancy: A member wrote a W4A8 linear kernel fused with a LoRA adapter, but the output difference between their Triton kernel and PyTorch could be as big as
1.0.- The member is investigating whether the precision difference between the Triton kernel and PyTorch is the cause of the gap and if there's any way to reduce it, and others shared their own code at GitHub.
- SVDQuant Kernel Precision: A member shared they are working on a kernel similar to SVDQuant but all in one kernel.
- Another member replied their approach is getting
0.03, but the original poster is still trying to recover the precision, blaming it on forgetting to do boundary checks in loading block ptr.
- Another member replied their approach is getting
- tritonKernel_svdQuant/svdConversion.ipynb at main · rishabh063/tritonKernel_svdQuant: Contribute to rishabh063/tritonKernel_svdQuant development by creating an account on GitHub.
- Triton community meetup March 2025: 🎙️ New to streaming or looking to level up? Check out StreamYard and get $10 discount! 😍 https://streamyard.com/pal/d/6451380426244096
GPU MODE ▷ #cuda (30 messages🔥):
Funnel Shift vs. uint64_t, Trellis Scheme Quantization, CUDA 12.4.0 vs 12.4.1, GPU max value algorithm
- Funnel Shift Might be Faster Than uint64_t Shift: A member questioned if using
__funnel_shiftis faster than putting twouint32_tvalues into auint64_tand shifting, proposinguint64_t u = (uint64_t(a) << 32) | b; return (u >> shift) & 0xFFFF;.- Another member expressed surprise that
__funnel_shiftcould be faster, suggesting it might use a less congested pipe, but noted that performance may depend on the surrounding code.
- Another member expressed surprise that
- Trellis Scheme uses Overlapping Bitfields: A member explained a trellis scheme where a tile of 16x16 weights is represented in 256*K bits, with each weight using 16 of those bits, such as weight 0 being bits [0:16] and weight 1 being bits [3:19].
- They also noted that shift amounts are static and periodic, and they can permute each tile prior to quantization to dequantize straight into tensor fragments, but the periodicity is a little wonky for some bitrates.
- CUDA 12.4 Update 1 Notes Online: Members shared links to the CUDA 12.4.0 download archive and CUDA 12.4.1 download archive, questioning the differences between the two.
- One suggested searching "4 update 1" within the CUDA Toolkit Release Notes to find changes specific to 12.4 update 1.
- GPU parallel reduction can find max value: A new GPU programmer sought help finding the biggest element in a large table and shared a code snippet.
- A member suggested that having multiple threads simultaneously writing to the same output memory location is generally a bad idea and suggested using a technique called parallel reduction.
- CUDA 12.4 Update 1 Release Notes: no description found
- CUDA Toolkit 12.4 Downloads: no description found
- CUDA Toolkit 12.4 Update 1 Downloads: no description found
GPU MODE ▷ #torch (1 messages):
libtorch-gpu, onnxruntime, cuda-toolkit, cudnn, Docker image size optimization
- Reduce Docker image size for AI projects: A member is seeking advice on reducing the Docker image size for a project using libtorch-gpu, onnxruntime, cuda-toolkit, and cudnn.
- Suggestions include multi-stage builds, smaller base images, and only including necessary components to minimize the final image size.
- Optimize CUDA toolkit and dependencies: Discussions revolved around minimizing the footprint of CUDA toolkit and its dependencies within the Docker image.
- Strategies involved leveraging multi-stage builds, selecting minimal base images, and selectively including essential components for inference.
GPU MODE ▷ #cool-links (13 messages🔥):
UT Austin Deep Learning Lectures, OpenCL vs CUDA flame war, Modular's take on CUDA alternatives, SYCL portability and Intel's involvement, Block Diffusion Language Models
- UT Austin Deep Learning lectures unveiled: Lectures from the Deep Learning classes at UT Austin are publicly available at ut.philkr.net, covering topics from getting started to modern GPU architectures.
- The courses seem to be very high quality and relevant.
- OpenCL vs CUDA Throwdown: A discussion resurfaces an interesting flame war from 2015 (github.com/tensorflow/tensorflow/issues/22) regarding the addition of OpenCL support to TensorFlow.
- At the time, TensorFlow only supported CUDA.
- Modular Riffs on CUDA Alternatives: A relevant article (modular.com) from Chris Lattner discusses why previous attempts to create portable GPU programming models using C++ have failed to gain traction.
- The article is part 5 of Modular’s “Democratizing AI Compute” series.
- SYCL is not just another CUDA clone: Discussion around SYCL's portability and various implementations like AdaptiveCpp (previously hipSYCL) and triSYCL, with Intel being a key stakeholder.
- One participant notes that they find SYCL more interesting than HIP because it isn't just a CUDA clone and can therefore improve on the design.
- Block Diffusion Language Models are here: A new paper (openreview.net) introduces Block Diffusion, a method interpolating between autoregressive and diffusion language models, boasting high quality, arbitrary length, KV caching, and parallelizability.
- Code can be found on GitHub, with a Hugging Face collection also available.
- SOCIAL MEDIA TITLE TAG: SOCIAL MEDIA DESCRIPTION TAG TAG
- GitHub - AndiH/gpu-lang-compat: GPU Vendor/Programming Model Compatibility Table: GPU Vendor/Programming Model Compatibility Table. Contribute to AndiH/gpu-lang-compat development by creating an account on GitHub.
- UT Austin - Advances in Deep Learning: no description found
- OpenCL support · Issue #22 · tensorflow/tensorflow: I understand TensorFlow only supports CUDA. What would need to be done to add in OpenCL support?
- Modular: Democratizing AI Compute, Part 5: What about CUDA C++ alternatives like OpenCL?: no description found
GPU MODE ▷ #jobs (1 messages):
PyTorch, Meta, Engineering Manager, Dev Infra Team, Equal Opportunity
- Meta Seeks PyTorch Dev Infra Engineering Manager!: Meta is looking for an Engineering Manager for PyTorch's Dev Infra Team; job description is available here.
- The role focuses on kernel packaging, performance benchmarking, and improving pip packages; those interested in the future of PyTorch are encouraged to reach out.
- Meta Affirms Equal Employment Opportunity Policy: Meta asserts its commitment to Equal Employment Opportunity, as detailed in their official notice.
- Meta does not discriminate based on various protected characteristics including race, religion, sex, sexual orientation, and disability.
- Meta Provides Accommodations for Applicants: Meta is committed to providing reasonable support (called accommodations) in our recruiting processes for candidates with disabilities, long term conditions, mental health conditions or sincerely held religious beliefs, or who are neurodivergent or require pregnancy-related support.
- Candidates needing assistance or accommodations should reach out for support.
Link mentioned: Software Engineering Manager, Infrastructure: Meta's mission is to build the future of human connection and the technology that makes it possible.
GPU MODE ▷ #beginner (16 messages🔥):
GPU architecture beginner book, Programming Massively Parallel Processors, CUDA books, Theoretical occupancy of a kernel, Nsight compute
- Holy GPU Book recommended: One member suggested Programming Massively Parallel Processors, pmpp, aka holy gpu book as a beginner friendly book about GPU architecture and programming.
- However, another member who had already read this book was looking for an alternative.
- CUDA by example: One member found CUDA by example to be a little gentler and more from a programmer's point of view.
- Other members suggested rereading existing books instead.
- Nsight Compute to the rescue: When figuring out the theoretical occupancy of a kernel, members suggested using Nsight compute to get occupancy when you profile.
- It also includes the occupancy calculator in which you can see how occupancy would change with each occupancy-affecting SM resource and you can play around with the parameters.
- Dive into CUDA or Dive into Jobs?: One member asked for advice on whether to dive into CUDA programming(Triton) to optimize model performance, or to start applying for jobs after implementing the Attention Is All You Need paper using PyTorch, followed by nanoGPT, GPT-2 (124M), and LLaMA2.
- Currently, the member is experimenting with their own 22M-parameter coding model, which they plan to deploy on Hugging Face to further deepen their understanding.
GPU MODE ▷ #torchao (3 messages):
float8 conv, cuda kernels, torch inductor template, INT8 conv, static quant
- Float8 Conv Kernels Quest Begins: A member suggested that to enable float8 conv, a cuda / TK / triton kernel is needed, which could be a valuable addition to torchao.
- Another member expressed interest in possibly implementing one.
- INT8 Conv Dynamic Quantization Costs Disclosed: A member recalled creating an INT8 conv from a torch inductor template, noting that while the kernel's performance was satisfactory, the dynamic quantization of activations to INT8 was too costly, negating end-to-end speedup.
- They suggested that static quantization might be necessary, where scales and zero points for activations are determined ahead of time from calibration data.
GPU MODE ▷ #rocm (1 messages):
AMD vLLM environment, Conda environment file, Reproducible builds
- Seeding AMD vLLM Reproducibility: A user offered to share a conda environment file and script for building a reproducible AMD vLLM environment.
- The environment aims to create a setup that others can reliably replicate.
- Streamlining AMD vLLM Builds: A user is seeking to resolve issues encountered, with a focus on creating a reproducible AMD vLLM environment.
- The user has prepared a conda environment file and a script containing necessary build steps to ensure reproducibility.
GPU MODE ▷ #self-promotion (3 messages):
FlashAttention Turing, MLA Weight Absorption, MLA CPU Kernel
- FlashAttention Arrives on Turing Architecture: A developer has implemented the FlashAttention forward pass for the Turing architecture, which was previously limited to Ampere and Hopper, with code available on GitHub.
- Early benchmarks show a 2x speed improvement over Pytorch's
F.scaled_dot_product_attention(using xformers) on a T4, under specific conditions:head_dim = 128, vanilla attention, andseq_lendivisible by 128.
- Early benchmarks show a 2x speed improvement over Pytorch's
- Deepseek's MLA Implemented with Weight Absorption: DataCrunch wrote about how to use the weight absorption trick to ensure efficient implementation of Multi-Head Latent Attention (MLA), a key innovation in Deepseek's V3 and R1 models, detailed in their blog post.
- According to a member, vLLM combines 2 matmuls into 1, which consumes more FLOPs and memory accesses, and found that vLLM's current default was bad, based on this pull request.
- MLA CPU Kernel Under Construction: A member coincidentally was also working on MLA today, implementing MLA CPU kernel, finding the hard way that vLLM current default was bad, and recommends that it should be called weight reordering instead of absorption.
- GitHub - ssiu/flash-attention-turing: Contribute to ssiu/flash-attention-turing development by creating an account on GitHub.
- Tweet from DataCrunch_io (@DataCrunch_io): ⚡️Multi-Head Latent Attention is one of the key innovations that enabled @deepseek_ai's V3 and the subsequent R1 model.⏭️ Join us as we continue our series into efficient AI inference, covering bo...
- feat: support MLA decode by tsu-bin · Pull Request #551 · flashinfer-ai/flashinfer: Hi, this PR implements MLA decode algorithm, I would love to hear your thoughts on this design and implementation.The mystery Mat Absorb algorithmIn the DeepSeekV2 paper, there was no specific fo...
GPU MODE ▷ #thunderkittens (2 messages):
Memory allocation issues in H100, ThunderKittens kernel modification, Memory access violation
- *Allocation Alteration* in ThunderKittens Causes Memory Mayhem: A member inquired why changing the memory allocation line in h100.cu using direct memory allocation for
o_smemresults in an illegal memory access error.- The member is working on a kernel where
qis accepted as two separate tensors, complicating the casting too.
- The member is working on a kernel where
- *Kernel Code Quandary:* Tensor Transformation Trouble: A developer is facing challenges while adapting a kernel in the ThunderKittens project due to the input
qbeing provided as two separate tensors.- This split input structure complicates the process of casting
qtoo, leading to potential memory access issues.
- This split input structure complicates the process of casting
- GitHub - HazyResearch/ThunderKittens: Tile primitives for speedy kernels: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
- ThunderKittens/kernels/attn/h100/h100.cu at main · HazyResearch/ThunderKittens: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
GPU MODE ▷ #reasoning-gym (9 messages🔥):
Reasoning-Gym Curriculum, ETH + EPFL Collaboration, Auto-Curriculum RL, Evalchemy Integration, OpenAI Compatible Endpoint
- Reasoning-Gym's Curriculum receives attention from ETH + EPFL: A team of students and a PhD candidate from ETH and EPFL are working on reasoning and r-gym for SFT, RL, and Eval, seeking to coordinate with the current curriculum development.
- They are interested in working on evals per task and auto-curriculum for RL, with preliminary results in a draft rubric generator and reward performance trends available on GitHub.
- Reasoning-Gym Evolves with Automated Rubrics and Curriculum: The team is focusing on creating automated rubrics based on model performance deltas and developing an auto-curriculum for RL using reward performance trends.
- The current curriculum code is available on GitHub, with dataset generators that determine difficulty as the curriculum level increases.
- Reasoning-Gym Aims to Integrate with Evalchemy: The team would like to connect with Evalchemy to potentially integrate reasoning-gym for automatic evaluations of LLMs.
- Current evaluations can be run using a script in
/scripts, with results available on GitHub.
- Current evaluations can be run using a script in
- OpenAI Compatibility Question Posed: A member inquired whether the university inference endpoint has an OpenAI compatible endpoint.
- They suggested testing the eval script with a llama or similar model via
--base-urland--api-key, particularly noting the use of open-router so far.
- They suggested testing the eval script with a llama or similar model via
- GitHub - open-thought/reasoning-gym-eval: Collection of LLM completions for reasoning-gym task datasets: Collection of LLM completions for reasoning-gym task datasets - open-thought/reasoning-gym-eval
- reasoning-gym/reasoning_gym/coaching at main · open-thought/reasoning-gym: procedural reasoning datasets. Contribute to open-thought/reasoning-gym development by creating an account on GitHub.
- GitHub - mlfoundations/evalchemy: Automatic evals for LLMs: Automatic evals for LLMs. Contribute to mlfoundations/evalchemy development by creating an account on GitHub.
- reasoning-gym/reasoning_gym/principal.py at curriculum_refactor · open-thought/reasoning-gym: procedural reasoning datasets. Contribute to open-thought/reasoning-gym development by creating an account on GitHub.
GPU MODE ▷ #submissions (2 messages):
Modal Runners, Leaderboard Submissions
- VectorAdd Leaderboard Gets Two New Successful Submissions: Test submission with id 1946 to leaderboard
vectoraddon GPUS: T4 using Modal runners succeeded!- Test submission with id 1947 to leaderboard
vectoraddon GPUS: T4 using Modal runners succeeded!
- Test submission with id 1947 to leaderboard
- Modal Runners show leaderboard: Successful submission
- Id 1947 using modal
Yannick Kilcher ▷ #general (50 messages🔥):
YC Startup Strategy, Maxwell's Demon, Meta-Transform and Adaptive Meta-Learning, LLM Scaling Theory, AI scientist
- YC Prioritizes Short-Term Gains Over Long-Term Viability: A member claimed that YC focuses on startups with short-term success potential, investing $500K to potentially 3x their money in just 6 months, without necessarily aiming for long-term sustainability.
- They argued that YC hasn't produced a notable unicorn in years, implying a decline in their ability to foster long-term success stories.
- Maxwell's Demon Limits AI Speed: According to this YouTube video about Maxwell's demon, the speed of computers is limited by how fast you run the answer and how certain you run the answer.
- The video references the Lex Fridman Podcast featuring Neil Gershenfeld, delving into the relationship between life, thermodynamics, and computation.
- LLMs Approximate Context-Free Languages: A theory suggests that LLM scaling can be explained by their ability to approximate a context-free language using probabilistic FSAs, resulting in a characteristic S-curve.
- This attached image proposes that LLMs attempt to approximate the language of a higher rung, originating from a lower rung of the Chomsky hierarchy.
- Lluminate Project Aims to Evolve LLM Outputs: The Lluminate project introduces an evolutionary algorithm designed to help LLMs break free from generating predictable and similar outputs.
- This project combines evolutionary principles with creative thinking strategies to illuminate the space of possibilities and counter homogenization.
- Hardware Hurdles hinder Local LLM: Members discussed that while cloud AI solutions like OpenAI are costly, running a local model requires significant hardware investments, making it a trade-off between subscription fees and equipment expenses.
- One suggested using LlamaCPP to run decent models off a cheap SSD, but noted it would be significantly slower, potentially taking a week for a single paragraph of inference.
- no title found: no description found
- Tweet from vik (@vikhyatk): the greatest minds of our generation are getting nerd sniped by text diffusion and SSMs. a distraction from work that actually matters (cleaning datasets)
- GitHub - EAzari/AML: Adaptive Meta-Learning (AML): Adaptive Meta-Learning (AML). Contribute to EAzari/AML development by creating an account on GitHub.
- Tweet from Joel Simon (@_joelsimon): New research project: Lluminate - an evolutionary algorithm that helps LLMs break free from generating predictable, similar outputs. Combining evolutionary principles with creative thinking strategies...
- no title found: no description found
- Maxwell's demon: Does life violate the 2nd law of thermodynamics? | Neil Gershenfeld and Lex Fridman: Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=YDjOS0VHEr4Please support this podcast by checking out our sponsors:- LMNT: https://drinkLM...
- Reversing Entropy with Maxwell's Demon: Viewers like you help make PBS (Thank you 😃) . Support your local PBS Member Station here: https://to.pbs.org/DonateSPACECan a demon defeat the 2nd Law of T...
- What Turing got wrong about computers | Neil Gershenfeld and Lex Fridman: Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=YDjOS0VHEr4Please support this podcast by checking out our sponsors:- LMNT: https://drinkLM...
- Where do ideas come from? | Neil Gershenfeld and Lex Fridman: Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=YDjOS0VHEr4Please support this podcast by checking out our sponsors:- LMNT: https://drinkLM...
Yannick Kilcher ▷ #paper-discussion (15 messages🔥):
Forward vs backward SDE, Universal State Machine (USM), Gemma 3
- Backward SDE Inversion Process: A member proposed to present the derivation of the reverse-diffusion SDE from the forward noise SDE, elaborating on how the backward process involves inverting the forward process' corresponding PDE.
- The idea is to look at the forward process' corresponding PDE, invert that, and then notice that the inverted PDE can also be solved as an SDE.
- Universal State Machine (USM) Emerges: A member shared a graph-based system with dynamic growth, calling it a Universal State Machine (USM), but noted it as an extremely naive one with poor optimization and an explosive node count.
- They linked to an introductory paper describing Infinite Time Turing Machines (ITTMs) as a theoretical foundation and the Universal State Machine (USM) as a practical realization, offering a roadmap for scalable, interpretable, and generalizable machines.
- Gemma 3 Talk Postponed to Friday: A member proposed discussing Gemma 3 (Gemma3Report.pdf) but scheduled the discussion for Friday instead.
- No specific details about Gemma 3's features or architecture were mentioned in the discussion.
- Tweet from Ren (@renxyzinc): Watch the first-ever public demonstration of the Universal State Machine (USM) — a revolutionary approach to Artificial Intelligence that redefines how machines learn from experience.
- Infinite Time Turing Machines and their Applications: no description found
Yannick Kilcher ▷ #agents (4 messages):
Cognitive Architectures, Open-source Cognitive Architectures
- Cognitive Architectures to Explore: A member inquired about cognitive architectures with working implementations worth exploring.
- Another member mentioned that <@294281421684473856> has one.
- Availability of Open-Source CogArchs Questioned: A member noted that an architecture with millions of lines of private code is not something one can readily explore.
- They also expressed interest in knowing about open-source cogarchs that are interesting to look into.
Yannick Kilcher ▷ #ml-news (16 messages🔥):
Gemma 3, Sakana AI, Auto Science AI, MoE Fairness, RTX Riddick
- Google Releases Gemma 3 Model: Google released Gemma 3, detailed in the official documentation, which is reported to be on par with Deepseek R1 but significantly smaller.
- One member noted that the benchmarks provided are user preference benchmarks (ChatArena) rather than non-subjective metrics.
- AI Scientist Publishes First Paper: The first AI-generated paper from Sakana AI has passed peer review for the ICLR workshop, as detailed in their publication.
- CARL First AI System to Produce Academically Peer-Reviewed Research: Another AI system named CARL from Auto Science AI has also produced academically peer-reviewed research, detailed in this blog post.
- Debate Arises over MoE Fairness: A member initiated a discussion on how to compare MoE models to dense models in terms of fairness, questioning whether to compare total parameter size or active parameters.
- Half-Life 2 RTX Demo Released: A member shared a YouTube video showcasing the Half-Life 2 RTX demo with full ray tracing and DLSS 4, reimagined with RTX Remix.
- Another member expressed anticipation for an RTX version of Chronicles of Riddick: Escape from Butcher Bay.
- no title found: no description found
- Autoscience: no description found
- Autoscience: no description found
- no title found: no description found
- Gemini Robotics: Bringing AI to the physical world: Our new Gemini Robotics model brings Gemini 2.0 to the physical world. It's our most advanced vision language action model, enabling robots that are interact...
- Half-Life 2 RTX | Demo with Full Ray Tracing and DLSS 4 Announce: Relive the groundbreaking, critically acclaimed Half-Life 2 like never before, reimagined with RTX Remix. Demo with full ray tracing, remastered assets, and ...
Nomic.ai (GPT4All) ▷ #general (56 messages🔥🔥):
GPT-4 vs local LLMs, Ollama vs GPT4All, Deepseek 14B, Web crawling, LocalDocs
- User finds GPT-4 quality better than local LLMs: A user noted that ChatGPT premium provides a major difference in quality compared to the LLMs on GPT4All, which is attributed to the smaller model sizes available locally.
- They expressed a desire for a local model that matches ChatGPT premium's accuracy with uploaded documents, noting that the ones they've tried on GPT4All haven't been very accurate.
- Ollama or GPT4All for server with multiple models?: A user asked whether to use GPT4All or Ollama for a server managing multiple models, quick loading/unloading, frequently updating RAG files, and APIs for date/time/weather, given limited compute resources.
- Another member suggested Deepseek 14B or similar models, also mentioning the importance of large context windows (4k+ tokens) for soaking up more information like documents, and that apple hardware is weird.
- GPT4All workflow fine but GUI lacks multi-model support: A member suggested trying GPT4All with tiny models to check the workflow for loading, unloading, and RAG with LocalDocs, noting the GUI doesn't support multiple models simultaneously.
- They recommended using the local server or Python endpoint, requiring custom code for pipelines and orchestration.
- Web Crawling Advice Sought: A user inquired about getting web crawling working and asked for advice before starting the effort.
- A member mentioned a Brave browser compatibility PR that wasn't merged due to bugs and a shift towards a different tool-calling approach, but it could be resurrected if there's demand.
- LocalDocs Snippet Screenshots: A member suggested that to work around LocalDocs showing snippets in plain text, users can make a screenshot save as PDF, OCR the image, and then search for the snippet in a database.
- They suggested using docfetcher for this workflow.
Latent Space ▷ #ai-general-chat (51 messages🔥):
Mastra AI framework, Gemini 2.0 Flash Experimental, Jina AI's DeepSearch/DeepResearch, Cohere's Command A, Gemini Deep Research
- *Mastra* Typescript AI Framework Launches: Mastra, a Typescript AI framework, launched with the goal of providing a sturdy and fun framework for product developers, aiming to be better than frameworks like Langchain/Graph.
- The founders, previously of Gatsby and Netlify, emphasized type safety and a focus on quantitative performance improvements over qualitative opinions.
- *Gemini 2.0 Flash Experimental* Generates Native Images: Gemini 2.0 Flash Experimental now supports native image generation, allowing the model to create images from text and multimodal inputs, enhancing its reasoning and understanding capabilities.
- Users shared impressive results, with one exclaiming "i am actually lost for words at how well this works. what the hell" and another noting it adds "D" to the word "BASE".
- *Jina AI's* DeepSearch Excels: Jina AI highlighted practical techniques for improving DeepSearch/DeepResearch, focusing on late-chunking embeddings for snippet selection and using rerankers to prioritize URLs before crawling.
- They are such big fans of Latent Space podcast that "we'll have to have them on at some point this yr".
- *Cohere* Commands Attention with A Model: Cohere introduced Command A, an open-weights 111B parameter model with a 256k context window, designed for agentic, multilingual, and coding use cases.
- This new model succeeds Command R+ and aims to deliver superior performance in various tasks.
- *Gemini* Unleashes Deep Research for All: The Gemini App now offers Deep Research for free to all users, powered by Gemini 2.0 Flash Thinking, along with personalized experiences using search history and Gems.
- This update makes advanced reasoning capabilities more accessible to a wider audience.
- Tweet from Logan Kilpatrick (@OfficialLoganK): Big updates to the @GeminiApp today:- Deep Research is now available to all users for free- Deep Research is now powered by 2.0 Flash Thinking (our reasoning model)- New Gemini personalization using y...
- A framework for the next million AI developers: The next generation of AI products will be built with Apis written in Typescript
- Tweet from Kaushik Shivakumar (@19kaushiks): Super excited to ship Gemini's native image generation into public experimental today :) We've made a lot of progress and still have a way to go, please send us feedback!And yes, I made the im...
- Snippet Selection and URL Ranking in DeepSearch/DeepResearch: Nailing these two details takes your DeepSearch from mid to GOAT: selecting the best snippets from lengthy webpages and ranking URLs before crawling.
- Tweet from Mostafa Dehghani (@m__dehghani): The model sometimes enters a self-critique loop by itself, but you can trigger this manually, and the model tunes the prompt for itself through self-conversation. [Add e.g., "Verify the image, ...
- Tweet from Lisan al Gaib (@scaling01): checkmateQuoting Greg Brockman (@gdb) A GPT-4o generated image — so much to explore with GPT-4o's image generation capabilities alone. Team is working hard to bring those to the world.
- Tweet from Lisan al Gaib (@scaling01): i will be thinking about this experience for a whileQuoting Lisan al Gaib (@scaling01) HOLY FUCKING SHIT - WATCH THE WHOLE VIDEOI asked Gemini 2.0 what the meaning of life is but it is only allowed to...
- Tweet from Lisan al Gaib (@scaling01): checkmateQuoting Greg Brockman (@gdb) A GPT-4o generated image — so much to explore with GPT-4o's image generation capabilities alone. Team is working hard to bring those to the world.
- Tweet from Logan Kilpatrick (@OfficialLoganK): Introducing YouTube video 🎥 link support in Google AI Studio and the Gemini API. You can now directly pass in a YouTube video and the model can usage its native video understanding capabilities to us...
- Tweet from Mostafa Dehghani (@m__dehghani): Anyone who has been in this room knows that it’s never just another day in here! This space has seen the extremes of chaos and genius!...and we ship! https://developers.googleblog.com/en/experiment-wi...
- Tweet from Ethan Mollick (@emollick): Using Gemini Flash Experimental to ruin art by adding ice cream.
- Tweet from angel⭐ (@Angaisb_): "How is native image gen better than current models?"
- Tweet from Aman Sanger (@amanrsanger): Cursor trained a SOTA embedding model on semantic searchIt substantially outperforms out of the box embeddings and rerankers used by competitors!You can see feel the difference when using agent!
- Tweet from Sully (@SullyOmarr): wait. native text to image is kinda crazy
- Tweet from Command A(idan) (@aidangomez): Today @cohere is very excited to introduce Command A, our new model succeeding Command R+. Command A is an open-weights 111B parameter model with a 256k context window focused on delivering great perf...
- Tweet from fofr (@fofrAI): I had to try this. Gemini 2.0 Flash Experimental with image output 🤯Quoting apolinario 🌐 (@multimodalart) next. fucking. level
- Tweet from Andrew Carr (e/🤸) (@andrew_n_carr): Native multimodal is the future
- Tweet from kalomaze (@kalomaze): i am actually lost for words at how well this works. what the hell
- Tweet from rohit (@krishnanrohit): The real underlying problem is that humans just absolutely love slop
- Tweet from Riley Goodside (@goodside): Gemini 2.0 Flash Experimental, now with native image output, adds "D" to the word "BASE" on the T-shirt of a partygoer dressed as the RLHF shoggoth in an uploaded image:
- Experiment with Gemini 2.0 Flash native image generation: no description found
- Tweet from Andrej Karpathy (@karpathy): @divya_vikash please make it stop
- Tweet from kalomaze (@kalomaze): this is actually breaking my mind
- Tweet from Robert Riachi (@robertriachi): some cool examples with Gemini 2.0 native image output 🧵
- Tweet from Cristian Peñas ░░░░░░░░ (@ilumine_ai): Gemini can generate pretty consistent gif animations too:'Create an animation by generating multiple frames, showing a seed growing into a plant and then blooming into a flower, in a pixel art sty...
- Tweet from Aiden Bai (@aidenybai): Introducing Same.devClone any website with pixel perfect accuracyOne-shots Nike, Apple TV, Minecraft, and more!
- Sam Altman, CEO of OpenAI: Sam Altman, CEO of OpenAI
LlamaIndex ▷ #blog (3 messages):
Model Context Protocol, WeAreDevs WebDev & AI Day, LLM x Law Hackathon
- LlamaIndex Plugs into Model Context Protocol: LlamaIndex announced they're closely following progress on the Model Context Protocol, an open-source effort to make it easy to discover and use tools, such that users can now use the tools exposed by any MCP-compatible server, shown in this tweet.
- AI to Transform Web Development at WeAreDevs WebDev & AI Day: Industry experts are joining the @WeAreDevs WebDev & AI Day to discuss AI's role in platform engineering and DevEx, the future of developer tools in an AI-driven world, discussed in this tweet.
- Innovators Muster for 5th LLM x Law Hackathon at Stanford: The 5th LLM x Law Hackathon is at @stanford on April 6th, bringing innovators together to develop AI solutions for legal work and showcase ongoing projects to VCs, according to this tweet.
LlamaIndex ▷ #general (46 messages🔥):
LlamaExtract on-premise, New Response API, LlamaParse and images, AzureMultiModal chat bugs, Deep research within RAG
- LlamaExtract Keeps Your Secrets Safe On-Premise: For enterprise applications, on-premise/BYOC deployments are available for the entire LlamaCloud platform, though they typically have a much higher cost than using the SaaS.
- New Response API Support Coming Soon: The team is working on supporting the new Response API, which promises to enrich results using the search tool if the user opts in.
- LlamaParse Now a JSON Juggernaut: LlamaParse already includes images in its JSON output, providing links to download images and layout information for stitching things together.
- AzureMultiModal Chat Tangles Resolved: A user reported issues with AzureMultiModal chat and a potential bug, but the problem was traced back to outdated dependencies and a multi-modal assert issue, which has been resolved in this PR.
- Deep Research RAG Ready to Roll: Deep research capabilities within RAG already exist via
npx create-llama@latestwith the deep research option, and the source code for the workflow is available on GitHub.
- remove assert for multimodal llms by logan-markewich · Pull Request #18112 · run-llama/llama_index: Fixes #18111Many multi-modal LLMs have been converted to wrap their native LLM class, since the base LLM class is starting to support images. This means this assert will fail even if it will work,...
- create-llama/templates/components/agents/python/deep_research/app/workflows/deep_research.py at ee69ce7cc10db828424b468e7b54b3f06b18e22c · run-llama/create-llama: The easiest way to get started with LlamaIndex. Contribute to run-llama/create-llama development by creating an account on GitHub.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (7 messages):
Quiz Deadlines, Labs and Research Opportunities, Project Timelines, Certification for Non-Berkeley Students
- Quizzes Coming in May: Members stated that all quiz deadlines are in May and details will be released soon.
- It was mentioned that those interested are already added to the mailing list, as indicated by records showing they opened the latest email announcing Lecture 6.
- Research Opportunities & Labs Announced Soon: One member inquired about plans for labs and research opportunities for MOOC learners.
- Another member replied that an announcement will be made once everything is finalized.
- Projects Have a Timeline: A member asked if projects will take some time to be rolled out.
- Another member confirmed that details would be released soon and advised everyone to keep up with the weekly quizzes.
- Non-Berkeley Students: Certifications Still Obtainable?: A member asked if non-Berkeley students can still get a certification by completing homework.
- Another member confirmed that details will be released soon.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (4 messages):
LLM Roles, LLM Personas, Decision Making Research Group
- *Roles* and Personas elucidated: A member explained that in querying an LLM, roles are constructs for editing a prompt, like system, user, or assistant, whereas a persona would be defined as part of the general guidelines given to the system, influencing how the assistant acts.
- The content of the system role are in the form of general guidelines of how the assistant should act; user and assistant are the ones who participate in active interaction.
- Decision Making Research Group invites new members: A member posted a new invite link for a research group focused on decision making and memory tracks.
- The Discord invite link was shared without any additional context.
Modular (Mojo 🔥) ▷ #general (2 messages):
Mojo and Max Bundling, Mojo on Windows
- Mojo Asks: Why Bundle with Max?: A user asks in the Modular forums the reasoning behind potentially bundling Mojo with Max.
- The question opens up a discussion on the potential synergies and user benefits of such a bundle.
- Will Mojo be on Windows?: The same user also inquires about the potential availability of Mojo on Windows.
- This sparks interest in the challenges and timelines associated with expanding Mojo's platform support.
Link mentioned: Mojo and Max, why bundle them?: I’ve recently started a project with magic init life --format mojoproject but after looking at the dependencies I have: max 25.2.0.dev2025030905 release 9.7 KiB co...
Modular (Mojo 🔥) ▷ #mojo (4 messages):
Modular Max PR, Capturing Closures
- Modular Max Gets Process Spawning Capabilities: A member shared a PR for Modular Max that adds functionality to spawn and manage processes from executable files using
exec.- However, this depends on merging a foundations PR and resolving issues with Linux exec, so availability is uncertain.
- Capturing Closures Bug Filed: A member filed a language design bug related to
capturingclosures.- Another member echoed this sentiment, noting they found this behavior odd as well.
- modular/max: The MAX Platform (includes Mojo). Contribute to modular/max development by creating an account on GitHub.
- [stdlib] Adds functionality to spawn and manage processes from exec. file by izo0x90 · Pull Request #3998 · modular/max: Foundation for this PR is set here, it adds the needed lowlevel utilities:Adds vfork, execvp, kill system call utils. to Mojos cLib bindsAdds read_bytes to file descriptorOnce that PR is merge...
Modular (Mojo 🔥) ▷ #max (1 messages):
MutableInputTensor visibility, Mojo nightly docs, max.tensor API
- MutableInputTensor Type Alias Missing?: A user reported finding the
MutableInputTensortype alias in the nightly docs, but it doesn't seem to be publicly exposed.- The user attempted to import it via
from max.tensor import MutableInputTensorandfrom max.tensor.managed_tensor_slice import MutableInputTensorwithout success.
- The user attempted to import it via
- Mojo Nightly Docs: The user referenced the Mojo nightly docs while looking for the
MutableInputTensortype alias.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (5 messages):
AST Evaluation, Function Calling Leaderboard, LLM Integration, Parallel Function Calls
- *AST* Evaluates Correctness Thoroughly: The AST (Abstract Syntax Tree) evaluation checks for the correct function call with the correct values, including function name, parameter types, and parameter values within possible ranges, clarified in the V1 blog.
- The numerical value in the table for AST represents the percentage of test cases where all these criteria were correct.
- *BFCL* is a Comprehensive Evaluation: The Berkeley Function-Calling Leaderboard (BFCL), updated on 2024-08-19 (Change Log), is the first comprehensive evaluation of LLMs' ability to call functions and tools.
- The leaderboard was built to represent typical user function calling use-cases in agents and enterprise workflows.
- *LLMs* Power Applications via Function Calling: Large Language Models (LLMs) like GPT, Gemini, Llama, and Mistral are increasingly integrated into applications such as Langchain, Llama Index, AutoGPT, and Voyager through function calling (also known as tool calling) capabilities.
- These models demonstrate significant potential in powering various applications and software.
- *Function Calls* can be Parallel: The function calls considered in the evaluation include various forms, such as parallel (one function input, multiple invocations of the function output) and multiple function calls.
- This comprehensive approach covers common function-calling use-cases.
Link mentioned: Berkeley Function Calling Leaderboard: no description found
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (2 messages):
Evaluation tools, Datasets availability
- Track Evaluation Tools Centrally: A member inquired about a central location to track all the tools used for evaluation, referencing a specific directory in the Gorilla repository.
- Another member responded that all datasets are available in the /gorilla/berkeley-function-call-leaderboard/data folder.
- Datasets Availabilty for Gorilla: It was clarified that for multi-turn categories, the function/tool documentation is stored in /gorilla/berkeley-function-call-leaderboard/data/multi_turn_func_doc to prevent repetition.
- All other categories have the function documentation stored within the dataset files themselves.
DSPy ▷ #general (4 messages):
DSPy Caching, Pluggable Cache Module, Cache Invalidation Strategies, Selective Caching, Monitoring Cache Hit/Miss Rates
- DSPy Eyes Pluggable Cache Module: DSPy is developing a pluggable Cache module, with initial work available in this pull request.
- Cache Strategies Seek Flexibility: There's a desire for more flexibility in defining caching strategies, particularly for context caching to cut costs and boost speed.
- Cache Invalidation Attracts Interest: Discussion included interest in cache invalidation with TTL expiration or LRU eviction.
- Selective Caching Gains Traction: Also discussed was selective caching based on input similarity to avoid making redundant API calls.
- Cache Monitoring Considered Helpful: Built-in monitoring for cache hit/miss rates was proposed as a helpful feature for the new caching module.
Link mentioned: Feature/caching by hmoazam · Pull Request #1922 · stanfordnlp/dspy: One single caching interface which has two levels of cache - in memory lru cache and fanout (on disk)
DSPy ▷ #colbert (1 messages):
ColBERT endpoint, MultiHop program, Connection Refused
- ColBERT endpoint throws Connection Refused: A member reported that the ColBERT endpoint at
http://20.102.90.50:2017/wiki17_abstractsappears to be down, throwing a Connection Refused error.- When trying to retrieve passages using a basic MultiHop program, the endpoint returns a 200 OK response, but the text contains an error message related to connecting to
localhost:2172.
- When trying to retrieve passages using a basic MultiHop program, the endpoint returns a 200 OK response, but the text contains an error message related to connecting to
- MultiHop program fails due to connection issues: The user mentioned that their MultiHop program, which was working until yesterday, is now failing to retrieve passages.
- The program receives a 200 OK response, but the content indicates an error connecting to the server on port 2172, suggesting a problem with the ColBERT service.
tinygrad (George Hotz) ▷ #general (1 messages):
LSTM Model issues, NaN loss debugging, TinyJit integration
- LSTM Model Outputs NaN Loss: A member is seeing NaN loss when running an LSTMModel with TinyJit, experiencing the loss transitioning from a large number to NaN after the first step.
- The model uses
nn.LSTMCellandnn.Linear, trained withAdamoptimizer, and the input data includes a large value (1000) which might contribute to the issue.
- The model uses
- Troubleshooting NaN Loss in tinygrad: A member is asking for debugging help related to a loss that prints as NaN during tinygrad training.
- The provided code sample showcases an LSTM setup, hinting at potential numerical instability issues or gradient explosion problems that could be causing the NaN.
AI21 Labs (Jamba) ▷ #jamba (1 messages):
Pinecone Limitations, RAG Changes, VPC Deployment
- Pinecone Performance Plummets, RAG Reboots: A member noted that their RAG system previously used Pinecone, but it had limitations in performance.
- They also mentioned the lack of support for VPC deployment which led them to seek a different solution.
- RAG system pivots away from Pinecone: Due to performance limitations and lack of VPC deployment support a RAG system is migrating away from Pinecone
- The new system will likely be better due to addressing the two constraints mentioned.