[AINews] not much happened today
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
a quiet day is all you need.
AI News for 10/22/2024-10/23/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (229 channels, and 3078 messages) for you. Estimated reading time saved (at 200wpm): 346 minutes. You can now tag @smol_ai for AINews discussions!
People are still very much exploring the implications of Anthropic's new Computer Use demo/usecases. Some are pointing out its failures and picking apart the terminology, others have hooked it up to phone simulators and real phones. Kyle Corbitt somehow wrote a full desktop app for Computer Use in 6 hours so you dont have to spin up the docker demo Anthropic shipped.
But not a single person in the room has any doubt that this will get a lot better very soon and very quickly.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Anthropic's Claude 3.5 Release and Computer Use Capability
- New Models and Capabilities: @AnthropicAI announced an upgraded Claude 3.5 Sonnet, a new Claude 3.5 Haiku model, and a computer use capability in beta. This allows Claude to interact with computers by looking at screens, moving cursors, clicking, and typing.
- Computer Use Details: @alexalbert__ explained that the computer use API allows Claude to perceive and interact with computer interfaces. Users feed in screenshots, and Claude returns the next action to take (e.g., move mouse, click, type text).
- Performance Improvements: @alexalbert__ noted significant gains in coding performance, with the new 3.5 Sonnet setting a state-of-the-art on SWE-bench Verified with a score of 49%, surpassing all models including OpenAI's o1-preview.
- Haiku Model: @alexalbert__ shared that the new Claude 3.5 Haiku replaces 3.0 Haiku as Anthropic's fastest and least expensive model, outperforming many state-of-the-art models on coding tasks.
- Development Process: @AnthropicAI mentioned they're teaching Claude general computer skills instead of making specific tools for individual tasks, allowing it to use standard software designed for people.
- Limitations and Future Improvements: @AnthropicAI acknowledged that Claude's current ability to use computers is imperfect, with challenges in actions like scrolling, dragging, and zooming. They expect rapid improvements in the coming months.
Other AI Model Releases and Updates
- Mochi 1: @_parasj announced Mochi 1, a new state-of-the-art open-source video generation model released under Apache 2.0 license.
- Stable Diffusion 3.5: @rohanpaul_ai reported the release of Stable Diffusion 3.5, including Large (8B parameters) and Medium (2.5B parameters) variants, with improvements in training stability and fine-tuning flexibility.
- Embed 3: @cohere launched Embed 3, a multimodal embedding model enabling enterprises to build systems that can search across both text and image data sources.
- KerasHub: @fchollet announced the launch of KerasHub, consolidating KerasNLP & KerasCV into a unified package covering all modalities, including 37 pretrained models and associated workflows.
AI Research and Development
- Differential Transformer: @rohanpaul_ai discussed a new paper from Microsoft introducing the "Differential Transformer," which uses differential attention maps to remove attention noise and push the model toward sparse attention.
- Attention Layer Removal: @rasbt shared findings from a paper titled "What Matters In Transformers?" which found that removing half of the attention layers in LLMs like Llama doesn't noticeably reduce modeling performance.
- RAGProbe: @rohanpaul_ai highlighted a paper introducing RAGProbe, an automated approach for evaluating RAG (Retrieval-Augmented Generation) pipelines, exposing limitations and failure rates across various datasets.
Industry Developments and Collaborations
- Perplexity Pro: @AravSrinivas announced that Perplexity Pro is transitioning to a reasoning-powered search agent for harder queries involving several minutes of browsing and workflows.
- Timbaland and Suno: @suno_ai_ shared that Grammy-winning producer Timbaland is collaborating with Suno AI, exploring how AI is helping him rediscover creativity in music production.
- Replit Integration: @pirroh mentioned that Replit has integrated Claude computer use as a human feedback replacement in their Agent, reporting that it "just works."
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Major LLM Updates: Claude 3.5 and Stable Diffusion 3.5
- Stability AI has released Stable Diffusion 3.5, comes in three variants, Medium launches October 29th. (Score: 110, Comments: 40): Stability AI has released Stable Diffusion 3.5, offering three variants: Base, Medium, and Large. The Base model is available now, with Medium set to launch on October 29th, and Large coming at a later date. This new version boasts improved image quality, better text understanding, and enhanced capabilities in areas like composition, lighting, and anatomical accuracy.
- Users humorously noted Stability AI included an image of a woman on grass in their blog, referencing a previous meme. Some tested the model's ability to generate this scene, with mixed results including unexpected NSFW content.
- Comparisons between SD3.5 and Flux1-dev were made, with users reporting that Flux1-dev generally produced more realistic outcomes and less deformities in limited testing.
- The community discussed potential applications of SD3.5, including its use as a base for fine-tuning projects. However, some noted that the license restrictions may limit its adoption for certain use cases.
- Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku (Score: 187, Comments: 82): Anthropic has launched Claude 3.5 Sonnet and Claude 3.5 Haiku, introducing computer use capability that allows the AI to interact with virtual machines. These models can now perform tasks like web browsing, file manipulation, and running code, with Sonnet offering improved performance over Claude 3.0 and Haiku providing a faster, more cost-effective option for simpler tasks. The new versions are available through the API and Claude web interface, with computer use currently in beta and accessible to a limited number of customers.
- Claude 3.5 Sonnet shows significant performance improvements over previous versions, with users noting its strength in coding tasks. The model now offers computer use capability in beta, allowing interaction with virtual machines for tasks like web browsing and file manipulation.
- Users express concerns about safety implications of giving Claude remote code execution capabilities. Anthropic recommends precautions such as using dedicated virtual machines and limiting access to sensitive data when utilizing the computer use feature.
- The naming convention for Claude models has become confusing, with Claude 3.5 Sonnet and Claude 3.5 Sonnet (new) causing potential mix-ups. Users suggest clearer versioning, comparing the current naming strategy to complex product names from companies like Samsung and Sony.
Theme 2. Open Source AI Model Developments and Replication Efforts
- O1 Replication Journey: A Strategic Progress Report – Part I (Score: 34, Comments: 6): The author reports on their progress in replicating OpenAI's O1 model, focusing on the first 12 billion parameters of the 120B parameter model. They outline their strategy of training smaller models to validate components before scaling up, and have successfully trained models up to 1.3B parameters using techniques like flash attention and rotary embeddings. The next steps involve scaling to 12B parameters and implementing additional features such as multi-query attention and grouped-query attention.
- The author clarifies that the focus of the article is on the learning method and results, not the dataset, in response to a question about the dataset's composition and creation process.
- The O1 Replication Journey tech report, which hasn't been widely discussed, introduces a shift from "shortcut learning" to "journey learning" and explores O1's thought structure, reward models, and long thought construction using various methodologies.
- A commenter notes the project's success in producing longer-form reasoning answers with commentary similar to O1, but points out that the research artifacts (fine-tuned models and "Abel" dataset) are not currently publicly available.
- 🚀 Introducing Fast Apply - Replicate Cursor's Instant Apply model (Score: 187, Comments: 40): Fast Apply is an open-source, fine-tuned Qwen2.5 Coder Model designed to quickly apply code updates from advanced models to produce fully edited files, inspired by Cursor's Instant Apply model. The project offers two models (1.5B and 7B) with performance speeds of ~340 tok/s and ~150 tok/s respectively using a fast provider (Fireworks), making it practical for everyday use and lightweight enough to run locally. The project is fully open-source, with models, data, and scripts available on HuggingFace and GitHub, and can be tried on Google Colab.
- The project received praise for being open-source, with users expressing enthusiasm for its accessibility and potential for improvement. The developer mentioned plans to create a better benchmark using tools like DeepSeek.
- Users inquired about accuracy comparisons between the 1.5B and 7B models. The developer shared a rough benchmark showing the 1.5B model's impressive performance for its size, recommending users start with it before trying the 7B version if needed.
- Discussion touched on potential integration with other tools like continue.dev and Aider. The developer expressed interest in submitting PRs to support and integrate the project with existing platforms that currently only support diff/whole formats.
Theme 3. AI Model Comparison Tools and Cost Optimization
- I built an LLM comparison tool - you're probably overpaying by 50% for your API (analysing 200+ models/providers) (Score: 44, Comments: 16): A developer created a free tool (https://whatllm.vercel.app/) to compare 200+ LLM models across 15+ providers, analyzing price, performance, and quality scores. Key findings include significant price disparities (e.g., Qwen 2.5 72B is 94% cheaper than Claude 3.5 Sonnet for similar quality) and performance variations (e.g., Cerebras's Llama 3.1 70B is 18x faster and 40% cheaper than Amazon Bedrock's version).
- The developer provided visualizations to help understand the data, including a chart comparing metrics like price, speed, and quality. They used Nebius AI Studio's free inference credits with Llama 70B Fast for data processing and comparisons.
- Discussion arose about the validity of the quality index, with the developer noting that Qwen 2.5 scores only slightly lower on MMLU-pro and HumanEval, but higher on Math benchmarks compared to more expensive models.
- Users expressed appreciation for the tool, with one calling it a "game changer" for finding the best LLM provider. The developer also recommended Nebius AI Studio for users looking for LLMs with European data centers in Finland and France.
- Transformers.js v3 is finally out: WebGPU Support, New Models & Tasks, New Quantizations, Deno & Bun Compatibility, and More… (Score: 75, Comments: 4): Transformers.js v3 has been released, introducing WebGPU support for significantly faster inference on compatible devices. The update includes new models and tasks such as text-to-speech, speech recognition, and image segmentation, along with expanded quantization options and compatibility with Deno and Bun runtimes. This version aims to enhance performance and broaden the library's capabilities for machine learning tasks in JavaScript environments.
- Transformers.js v3 release highlights include WebGPU support for up to 100x faster inference, 120 supported architectures, and over 1200 pre-converted models. The update is compatible with Node.js, Deno, and Bun runtimes.
- Users expressed enthusiasm for the library's performance, with one noting consistent surprise at how fast the models run in-browser. The community showed appreciation for the extensive development and sharing of this technology.
- A developer inquired about the possibility of including ONNX conversion scripts used in the release process, indicating interest in the technical details behind the library's model conversions.
Theme 4. GPU Hardware Discussions for AI Development
- What the max you will pay for 5090 if the leaked specs are true? (Score: 32, Comments: 94): The post speculates on the potential specifications and performance of NVIDIA's upcoming 5090 GPU. It suggests the 5090 might feature a 512-bit memory bus, 32GB of RAM, and be 70% faster than the current 4090 model for AI workloads.
- Users debate the value of 32GB VRAM, with some arguing it's insufficient for LLM workloads. Many prefer multiple 3090s or 4090s for their combined VRAM capacity, especially for running 70B models.
- Discussion on potential pricing of the 5090, with estimates ranging from $2000-$3500. Some speculate the 4090's price may decrease, potentially flooding the market with used GPUs.
- Comparisons made between the 5090 and other options like multiple 3090s or the A6000. Users emphasize the importance of total VRAM over raw performance for AI workloads.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Releases and Improvements
- Anthropic releases updated Claude 3.5 models: Anthropic announced updated versions of Claude 3.5 Sonnet and Claude 3.5 Haiku, with improved performance across various benchmarks. The new Sonnet model reportedly shows significant improvements in reasoning, code generation, and analytical capabilities.
- Stability AI releases SD 3.5: Stability AI released Stable Diffusion 3.5, including a large 8 billion parameter model and a faster "turbo" version. Early testing suggests improvements in image quality and prompt adherence compared to previous versions.
- Mochi 1 video generation model: A new open-source video generation model called Mochi 1 was announced, claiming state-of-the-art performance in motion quality and human rendering.
AI Capabilities and Applications
- Claude's computer control abilities: Anthropic demonstrated Claude's new ability to control a computer and perform tasks like ordering pizza online. This capability allows Claude to interact with web interfaces and applications.
- AI playing Paperclips game: An experiment showed Claude playing the Paperclips game autonomously, demonstrating its ability to develop strategies and revise them based on new information.
- OpenAI developing software automation tools: Reports suggest OpenAI is working on new products to automate complex software programming tasks, potentially in response to competition from Anthropic.
AI Development and Research
- Fixing LLM training bugs: A researcher fixed critical bugs affecting LLM training, particularly related to gradient accumulation, which could have impacted model quality and accuracy.
- Pentagon's AI deepfake project: The US Department of Defense is reportedly seeking to create convincing AI-generated online personas for potential use in influence operations.
AI Ethics and Security
- ByteDance intern fired for malicious code: An intern at ByteDance was fired for allegedly planting malicious code in AI models, raising concerns about AI security and access controls.
- Claude's anti-jailbreaking measures: The updated Claude 3.5 model appears to have improved defenses against jailbreaking attempts, demonstrating more sophisticated detection of potential manipulation.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1: Claude 3.5 Takes the AI World by Storm
- Claude 3.5 Wows with 15% Boost in Coding Skills: Communities across OpenAI and Unsloth AI are thrilled with Claude 3.5 Sonnet's 15% performance gain on SWE-bench, especially in coding tasks. The model's new computer use feature lets agents interact with computers like humans.
- OpenRouter Unveils Time-Travelling Claude 3.5 Versions: OpenRouter releases older Claude 3.5 Sonnet versions like Claude 3.5 Sonnet (2024-06-20), giving users nostalgic access to previous iterations.
- Developers Tinker with Claude's New Tricks: Communities like OpenInterpreter explore integrating Claude 3.5 with commands like
interpreter --os, testing Anthropic's model and sharing insights.
2. Innovative AI Applications in Creative and Practical Domains
- DreamCut AI Revolutionizes Video Editing: DreamCut AI utilizes Claude AI to autonomously install and debug software, streamlining video editing tasks. Currently in early access, it bypasses traditional design phases, marking a shift towards AI-driven coding.
- GeoGuessr AI Bot Automates Gameplay: A YouTube tutorial demonstrates coding an AI bot that plays GeoGuessr using Multimodal Vision LLMs like GPT-4o, Claude 3.5, and Gemini 1.5. This project integrates LangChain for interactive game environment responses.
- AI-Driven Customer Service Bots: Aider introduces a multi-agent concierge system that combines tool calling, memory, and human collaboration for advanced customer service applications. This overhaul allows developers to iterate and enhance customer service bots more effectively.
Theme 3: Shiny New Tools Promise AI Advancement
- Anyscale's One-Kernel Wonder Aims to Turbocharge Inference: GPU MODE buzzes over Anyscale developing an inference engine using a single CUDA kernel, potentially outperforming traditional methods.
- CUDABench Calls All Coders to Benchmark LLMs: PhD students invite the community to contribute to CUDABench, a benchmark to assess LLMs' CUDA code generation skills.
- Fast Apply Hits the Gas on Code Updates: Fast Apply, based on the Qwen2.5 Coder Model, revolutionizes coding by applying updates at blazing speeds of 340 tok/s for the 1.5B model.
Theme 4: AI's Dark Side Sparks Concern
- AI Blamed in Teen's Tragic Death: Communities discuss a report of a 14-year-old's suicide linked to AI interactions, raising alarms about AI's impact on mental health.
- Character.AI Adds Safety Features Amid Tragedy: In response to the incident, Character.AI announces new safety updates to prevent future harm.
- Debate Rages: Is AI Friend or Foe in Combating Loneliness?: Latent Space members delve into whether AI eases loneliness or exacerbates isolation, with opinions divided on technology's role in mental well-being.
Theme 5: ZK Proofs Give Users Control Over Their Data
- ChatGPT Users Rejoice Over Chat History Ownership: OpenBlock's Proof of ChatGPT uses ZK proofs to let users own their chat logs, enhancing data training for open-source models.
- Communities Embrace Data Sovereignty Movement: Discussions in HuggingFace and Nous Research echo enthusiasm for data ownership, highlighting the importance of transparent and verifiable user data in AI development.
PART 1: High level Discord summaries
HuggingFace Discord
-
Stable Diffusion 3.5 Performance Debate: Members discussed the fluctuating opinions on Stable Diffusion 3.5, noting current enthusiasm to test new features against alternatives.
- This ongoing debate highlights a keen interest in improving generative model performance.
- Automating CAD with LLMs: A member proposed using LLMs and RAG systems to automate CAD file creation, seeking insights on system design approaches.
- The discussion signified the community's commitment to integrating AI technologies for efficiency.
- Explore the MIT AI Course: A member shared a YouTube playlist featuring MIT 6.034 Artificial Intelligence, praising its foundational content.
- It's a must-see for those diving into AI concepts, indicated by a strong community reaction.
- Vintern-3B-beta Emerges: Vintern-3B-beta model integrates over 10 million Vietnamese QnAs, positioning itself as a competitor to LLaVA in the market.
- This integration showcases advancements in dataset utilization for high-quality language model training.
- ZK Proofs Enhance ChatGPT: Utilizing ZK proofs, ChatGPT now enables users to own their chat history, enhancing verifiable training data for open-source models.
- This marks a significant advance, as highlighted in a demo tweet.
OpenAI Discord
-
Claude 3.5 Sonnet improves performance: Claude 3.5 Sonnet shows a 15% performance gain on the SWE-bench and enhanced benchmarks, suggesting effective fine-tuning.
- The integration of active learning techniques seems to enhance model efficacy for computer tasks.
- Anthropic launches Computer Use Tool: Anthropic introduced a novel tool to enable agents to execute tasks directly on a computer, aiming to reshape agent capabilities.
- Utilizing advanced data processing, this tool aims to deliver a more seamless user experience for API consumers.
- GPT-4 Upgrade Timeline in Limbo: Enthusiasm swirls around an anticipated GPT-4 upgrade, with mentions from several months ago still being the main reference point.
- Access to GPTs for free users reportedly occurred roughly 4-5 months ago.
- Models show weak spatial sense: Discussions revealed that models often exhibit weak spatial sense, effectively mimicking answers without true understanding.
- This phenomenon resembles a child’s rote learning, suggesting deficiencies in deeper comprehension abilities.
- Discussion on Realtime API performance: Concerns arose that the Realtime API fails to follow system prompts as effectively as GPT-4o, disappointing many users.
- Participants sought advice on adapting prompts to enhance interaction quality with the API.
Unsloth AI (Daniel Han) Discord
-
Claude 3.5 brings significant upgrades: Anthropic launched the upgraded Claude 3.5 Sonnet and Claude 3.5 Haiku models, introducing advanced capabilities in coding tasks, including the computer use functionality now in beta.
- This new ability allows developers to direct Claude to interact with computers similarly to human users, enhancing its utility in practical coding scenarios.
- Kaggle struggles with PyTorch installation: Users reported persistent
ImportErrorissues on Kaggle related to different CUDA versions while trying to run PyTorch, prompting recommendations to downgrade to CUDA 12.1.
- This workaround resolves compatibility issues and ensures smoother operation for existing library installations.
- Challenges in model fine-tuning persist: Users discussed models' tendency to repeat inputs during fine-tuning, suggesting that variations in system prompts could mitigate this overfitting.
- Concerns that insufficient training examples may lead to reliance on a base model, resulting in repetitive outputs were raised among community members.
- Fast Apply revolutionizes coding tasks**: Fast Apply, built on the Qwen2.5 Coder Model, operates efficiently, applying code updates without repetitive edits, significantly improving coding efficiency.
- With performance metrics showing speeds of 340 tok/s for the 1.5B model, this utility exemplifies how AI solutions are enhancing productivity in coding workflows.
- Community pulls together for bug fixes: Two significant pull requests were made: one for addressing import issues in the studio environment and another for correcting a NoneType error caused by a tokenizer bug.
- These PRs underscore the community's proactive approach to refining Unsloth's functionality and resolving user-reported issues promptly.
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 3.5 gets neural upgrade: Participants highlighted that Stable Diffusion 3.5 adopts a neural network architecture akin to Flux, necessitating community-driven training efforts for optimization.
- A consensus emerged on the importance of finetuning to fully leverage the capabilities of the new model.
- Anime Art Prompting Secrets Revealed: For generating anime art, users recommended using SD 3.5 with precise prompts rather than relying on LoRAs for optimal results.
- The community suggested focusing solely on stable diffusion 3.5 to boost image quality and avoid pitfalls associated with incorrect usage of LoRAs.
- Image Quality Mixed Reports: Users reported inconsistent image outputs, particularly when aligning prompts with wrong checkpoints or utilizing unsuitable LoRAs.
- Discussion emphasized the necessity of ensuring model alignment with prompts to mitigate unsatisfactory generation results.
- Automate Model Organization Now!: There's an expressed need for a tool that can automatically sort and manage AI model files within folders, enhancing overall workflow efficiency.
- Participants were encouraged to seek solutions in the server's technical support channel for potential automation tools.
- Sharing Tools to Boost Generation Workflows: Various tools and methods were discussed to enhance AI generation, with mentions of utility tools like ComfyUI and fp8 models for improved task management.
- Participants shared personal experiences fostering community learning and exploring new tools to optimize their AI model experiences.
aider (Paul Gauthier) Discord
-
Aider v0.60.0 Enhancements: The release of Aider v0.60.0 includes improved code editing, full support for Sonnet 10/22, and bug fixes that enhance user interactions and file handling.
- Noteworthy features include model metadata management and Aider's contribution, writing 49% of the code in this version, showcasing its productivity.
- Claude 3.5 Sonnet Outperforms Previous Models: Users report that the Claude 3.5 Sonnet model significantly outperforms the previous O1 models, achieving complex tasks with fewer prompts.
- One user highlighted its ability to implement a VAD library into their codebase effectively, indicating a leap in usability.
- DreamCut AI Revolutionizes Video Editing: DreamCut AI is built using Claude AI, taking 3 months and over 50k lines of code, currently in early access for users to test its AI editing tools.
- This initiative bypasses traditional design phases, indicating a shift towards AI-driven coding, as noted by community members.
- Mistral API Authentication Troubles: A user reported an AuthenticationError with the Mistral API in Aider but successfully resolved it by recreating their authentication key.
- This incident reflects ongoing concerns over API access and authentication stability in the current setup of Mistral integrations.
- Repo Map Enhancements Clarified: Discussions on the repo map functionality reiterated its dependency on relevant code context, crucial for accurate code modifications tagged to identifiers.
- As per Paul's clarification, the model evaluates identifiers based on their definitions and references, shaping effective editing paths.
OpenRouter (Alex Atallah) Discord
-
Claude 3.5 Sonnet Versions Released: Older versions of Claude 3.5 Sonnet are now downloadable with timestamps: Claude 3.5 Sonnet and Claude 3.5 Sonnet: Beta.
- These releases come from OpenRouter, providing users enhanced access to previous iterations.
- Lumimaid v0.2 Enhancements: The newly launched Lumimaid v0.2 serves as a finetuned version of Llama 3.1 70B, offering a significantly enhanced dataset over Lumimaid v0.1, available here.
- Users can expect improved performance due to the updates in dataset specifics.
- Magnum v4 Showcases Unique Features: Magnum v4 has been released featuring prose quality replication akin to Sonnet and Opus, and can be accessed here.
- This model continues the trend of enhancing the output quality in AI-generated text.
- API Key Costs Differ on OpenRouter: Users highlighted differences in API costs when utilizing OpenRouter versus direct provider keys, with some facing unexpected charges.
- It’s crucial for users to understand how various models affect their total costs under OpenRouter.
- Beta Access for Custom Provider Keys: Custom provider keys are in beta, with requests for access managed through a specific Discord channel; self-signup isn’t an option.
- Members can DM their OpenRouter email addresses for access, reflecting significant interest in these integrations.
LM Studio Discord
-
Downloading Models in LM Studio: Users faced challenges in finding and downloading large models, particularly Nvidia's 70B Nemotron in LM Studio, necessitating new terminal command tips.
- The change in search features forced users to employ specific keyboard shortcuts, complicating the model access process.
- LLMs fall short in coding tasks: Frustrations arose as models like Mistral and Llama 3.2 struggled with accurate coding outputs, while GPT-3.5 and GPT-4 continued to perform significantly better.
- Users began exploring alternative tools to supplement coding tasks due to this consensus on performance inadequacies.
- Exploring Model Quantization Options: Discussions highlighted diverse preferences for quantization methods (Q2, Q4, Q8) and their impact on model performance, especially regarding optimal bit compression.
- While caution against Q2 was advised, some users remarked on larger models showing better performance with lower bit quantization.
- Ryzen AI gets attention for NPU support: A query arose on configuring LM Studio to utilize the NPU of Ryzen processors, revealing ongoing challenges with implementation and functionality.
- Clarification emerged that only the Ascend NPU receives support in llama.cpp, leaving Ryzen's NPU functionality still uncertain.
- AMD vs. Nvidia: The GPU Showdown: When comparing the RX 7900 XTX and RTX 3090, users highlighted the importance of CUDA support for optimal LLM performance, favoring Nvidia's card.
- Mixed effectiveness reports on multi-GPU setups across brands surfaced, especially regarding support from the recently updated ROCm 6.1.3.
Perplexity AI Discord
-
Users Complain About New Sonnet 3.5: Multiple users expressed dissatisfaction with the Sonnet 3.5 model, noting a decrease in content output, particularly for academic writing tasks.
- Concerns were raised about the removal of the older model, which was regarded as superior for various use cases.
- Web Search Integration Issues Persist: There was a reported bug where the preprompt in Spaces fails when web search is enabled, causing frustration among users.
- Users indicated that this issue has continued without resolution, with the team acknowledging the need for a fix.
- Account Credits Still Not Transferred: A user reported that their account credits have not been transferred, despite multiple inquiries to support.
- No response from support for the past three days has resulted in heightened frustration.
- Advanced AI-Driven Fact-Checking Explored: A collection on AI-driven fact-checking discusses techniques like source credibility assessment.
- It emphasizes the necessity for transparency and human oversight to effectively combat misinformation.
- Claude Computer Use Model Raises Alarms for RPA: A post on Claude's Computer Control capabilities suggests possible risks for Robotic Process Automation (RPA).
- Experts warn that this innovation could pose significant challenges to existing workflows.
GPU MODE Discord
-
LLM Activations Quantization Debate: A discussion emerged on whether activations in LLMs sensitive to input variations should be aggressively quantized or maintained for higher precision.
- This raises concerns about modeling performance and the trade-offs of precision in quantization.
- Precision Worries with bf16: Concerns were shared about bf16 potentially causing canceled updates due to precision issues during multiple gradient accumulations.
- Precision is crucial, especially when it impacts model training stability.
- Anyscale's Single Kernel Inference: An update about Anyscale developing an inference engine using a single CUDA kernel was shared, inviting opinions on its efficiency.
- There's excitement about potentially leapfrogging traditional inference methods.
- CUDABench Proposal: PhD students presented a proposal for CUDABench, a benchmark to assess LLMs' CUDA code generation abilities, encouraging community contributions.
- It aims to establish compatibility across various DSLs while focusing on torch inline CUDA kernels.
- Monkey Patching CrossEntropy Challenges: New challenges emerged with the monkey patching strategy for CrossEntropyLoss in transformers, particularly with the latest GA patch version.
- The original CrossEntropy function can be reviewed here.
Nous Research AI Discord
-
Hermes 70B API launched on Hyperbolic: The Hermes 70B API is now available on Hyperbolic, providing greater access to large language models for developers and businesses. For more details, check out the announcement here.
- This launch marks a significant step towards making powerful AI tools more accessible to everyone.
- Nou Research's Forge Project Sparks Enthusiasm: Members expressed their enthusiasm for the project 'Forge', highlighted in a YouTube video featuring Nous Research co-founder Karan. A discussion followed about knowledge graph implementation related to the project.
- The expectations for Forge’s capabilities in leveraging advanced datasets have been high among members of the community.
- ZK Technology Revolutionizes Proof Generation: The latest application from OpenBlock’s Universal Data Protocol (UDP) empowers ChatGPT users to own their chat history while enhancing the availability of verifiable training data for open-source models. This approach marks a significant step in improving data provenance and interoperability in AI training.
- A member clarified that ZK proofs take a few seconds on the server-side, with some UDP proofs now taking less than a second due to advancements in infrastructure from @zkemail; check this out here.
- Claude Sees Automation Improvements: Claude includes a system prompt addition that corrects the 'misguided attention' issue, enhancing its contextual understanding. Claude also endeavors to clarify puzzle constraints, yet sometimes misinterprets questions due to oversight.
- Users noticed enhancements in Claude’s self-reflection abilities, with responses becoming more refined when addressing logical puzzles.
- Dynamics of AI Role-Playing Explored: The dynamics of AI role-playing were explored, particularly how system prompts influence the responses of AI models in various scenarios. Members discussed the potential for models to exhibit chaotic behavior if instructed in certain ways, challenging the idea of inherent censorship.
- This ongoing dialogue highlights the intricate relationship between prompt engineering and AI behavior.
Eleuther Discord
-
Chess Players Explain Moves: Most top chess players can articulate the motivation behind engine moves, but their skill in ranking lines in complex positions remains in question.
- The ongoing inquiry into what defines an ideal move for humans versus engines keeps the community engaged.
- Controversy in Chess with Cheating Claims: A former world champion accused a popular streamer of cheating based on their move explanations during live commentary.
- This incident underscores the pressures commentators face and ignites new debates about move validity.
- Accuracy of LLMs’ Self-Explanations: Concerns were voiced regarding the accuracy of self-explanations from LLMs when they lack contextual understanding.
- The community is exploring how improved training data could enhance these explanations.
- Molmo Vision Models on the Horizon: The Molmo project plans to release open vision-language models trained on the PixMo dataset featuring multiple checkpoints.
- These models aim for state-of-the-art performance in the multimodal arena while remaining fully open-source.
- Learning DINOv2 Through Research: A member requested resources to grasp DINOv2, leading others to share a pertinent research paper that details its methodology.
- The paper provides insights into the foundational aspects of DINOv2 as advanced by leading experts.
Latent Space Discord
-
Anthropic Mouse Generator Shows Off: A colleague showcased the Anthropic Mouse Generator, impressively installing and debugging software autonomously, but it still requires specific instructions to function.
- Critics noted it cannot perform tasks like playing chess without guidance, highlighting the limitations of current AI agents.
- Ideogram Canvas Threatens Canva: Discussions about Ideogram Canvas revealed its innovative features such as Magic Fill and Extend, which enable easy image editing and combination.
- Participants indicated it could rival existing tools like Canva due to its superior capabilities, sparking competitive concerns.
- AI's Impact on Loneliness Discussed: A tragic event involved a 14-year-old's suicide, igniting dialogue on AI's impact on loneliness, with concerns about mental health and technology's role.
- Participants debated whether AI could connect people or whether it intensifies isolation, sharing varied perspectives on its effectiveness.
- Speculative Decoding in vLLM Boosts Speed: A recent blog post detailed enhancements in speculative decoding in vLLM, aimed at accelerating token generation through small and large models.
- This technique seeks to improve performance and integrate new methodologies for optimizing AI functionality, as highlighted by this blog.
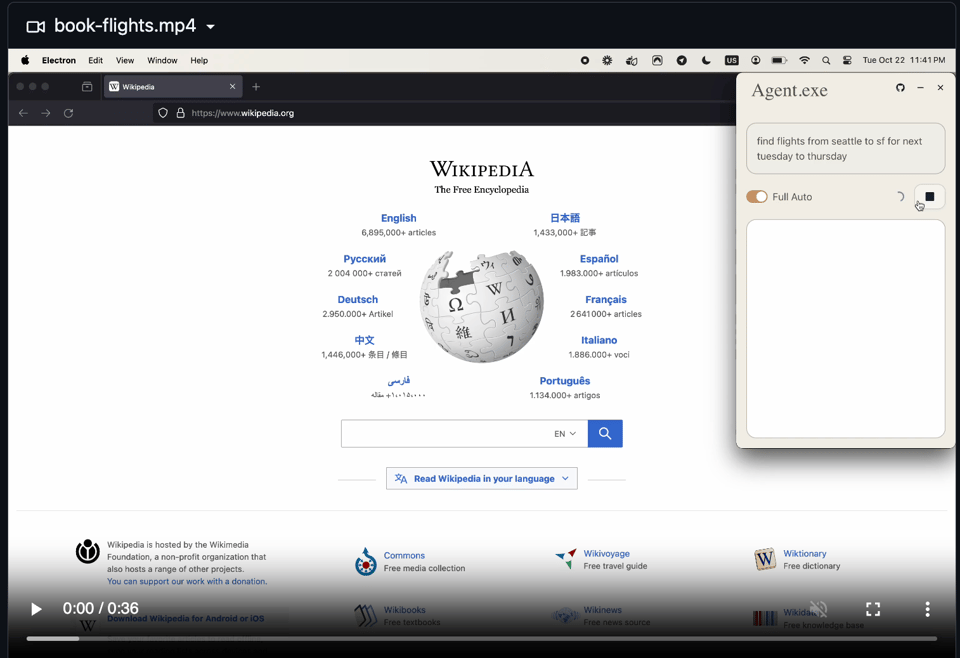
- Introducing New Meeting Automation Tools: The launch of agent.exe allows users to control computers via Claude 3.5 Sonnet, marking a significant advancement in meeting automation tools.
- Expectations for increased automation and efficiency are set for 2025, with agent.exe on GitHub already attracting interest.
LlamaIndex Discord
-
Join the Llama Impact Hackathon for AI Solutions: Participate in the 3-day Llama Impact Hackathon in San Francisco from November 8-10, offering a $15,000 prize pool, including a special $1000 for the best use of LlamaIndex.
- This event provides both in-person and online options for building AI solutions using Meta's Llama 3.2 models.
- Box AI and LlamaIndex Work Together Seamlessly: Utilize Box AI to query documents without downloading and extract structured data from unstructured content while integrating it with LlamaIndex agents, detailed in this article.
- This integration enhances workflows, making document handling easier for users.
- Build Advanced Customer Service Bots: A recent update allows the creation of a multi-agent concierge system that combines tool calling, memory, and human collaboration for customer service applications.
- This overhaul helps developers iterate on customer service bots more effectively, as shared by Logan Markewich.
- Persistent Context in Workflows: A discussion arose on enabling Context to persist across multiple runs of workflows, with examples using JsonSerializer for serialization.
- This method allows users to resume their workflows later without losing context, addressing a common pain point.
- Migrating to Anthropic LLM: Users faced challenges replacing ChatGPT with the Anthropic LLM, particularly concerning OpenAI API key prompts.
- Advice included the necessity of a local embedding model to eliminate dependency on OpenAI’s services.
tinygrad (George Hotz) Discord
-
Clarification on Tensor int64/uint64 support: Discussion clarified that Tensors now support int64/uint64, as confirmed by examining
dtype.py.- This clarification came up amidst talks on implementing SHA3, highlighting evolving capabilities within tinygrad.
- Action Chunking Transformers Training Takes Ages: To train Action Chunking Transformers with 55 million parameters takes two days without JIT, leading to questions about performance enhancements.
- Members expressed frustration over slow inference times and repeated loss parameter issues during JIT training.
- TinyJIT Loss Parameter Printing Confusion: Users grappled with printing the loss in JIT functions, debating the use of
.item()and its effects on displaying values accurately.
- Staying away from non-Tensor returns was advised to prevent undesired impacts on JIT execution.
- Improving Training Time with BEAM Settings: A tip suggested running with
BEAM=2to potentially enhance performance and speed up kernel runs during lengthy training sessions.
- Feedback indicated that this approach has already yielded quicker results in training practices.
- Interest in Reverse Engineering AI Accelerator Byte Code: A user sought advice on methodologies for reverse engineering byte code from an AI accelerator, sparking wider interest in the community.
- Members discussed tools and frameworks that could aid in initiating the reverse engineering process.
Interconnects (Nathan Lambert) Discord
-
Fun with Claude AI: A member reported that using Claude AI was a fun experience and hinted at sharing more examples shortly.
- This suggests that further details on its features and capabilities might be coming soon.
- Deep Dive into Continuous Pretraining: Questions arose about whether GPT-4o was pretrained with a 200k vocabulary tokenizer from scratch or if it continued after switching from a 100k tokenizer.
- Concerns were voiced about the messy nature of mid-training, indicating challenges in tracking such transitions.
- Character.AI Expresses Condolences: Character.AI issued condolences regarding a tragic user incident, emphasizing new safety features available here.
- A member shared a New York Times article that further contextualizes the situation.
- Anthropic's Shift Towards B2B: Anthropic is evolving into a B2B company, contrasting with OpenAI's focus on consumer applications, particularly regarding engaging versus mundane tasks.
- The discussion emphasized consumer preferences for enjoyable activities over automation's potential for boring tasks, such as shopping.
- Microsoft's Engaging AI Demonstrations: Microsoft's playful applications of AI, like gameplay automation in Minecraft, stand in contrast to Anthropic's focus on routine tasks view here.
- This highlights divergent strategies in the AI landscape, reflecting different target audiences and goals.
OpenInterpreter Discord
-
Screenpipe Builds Buzz: Members praised the usefulness of Screenpipe for managing build logs, showcasing its potential for developers looking for efficient logging solutions.
- One user highlighted the major impact of having clear and organized build logs in their development workflow.
- Claude 3.5 Models Evolve: Anthropic introduced the Claude 3.5 Sonnet model, boasting significant coding enhancements and a new computer use capability available in public beta, allowing AI to interact with user interfaces more naturally.
- However, constant screenshot capturing is required, leading to concerns about the model's efficiency and operational costs; more details here.
- Skepticism on Open Interpreter's Roadmap: Members discussed the roadmap for Open Interpreter, asserting its unique capabilities distinguish it from mainstream AI offerings.
- Some skeptics expressed doubts about competing against established models, while others underscored the significance of community-driven development.
- Navigating AI Screen Interaction Challenges: Concerns emerged over the inefficiencies of using screenshots for AI input, leading to suggestions for directly extracting necessary data points from applications.
- Members recognized the need for enhanced data processing methods to circumvent existing limitations in screenshot dependency.
- Call for Testing New Anthropic Integration: A member introduced the
interpreter --oscommand for integrating with Anthropic's model, urging others to assist in testing the feature prior to its final release.
- Testing indicated that increasing screen size and text clarity could help minimize error rates during model usage.
Cohere Discord
-
Cohere API Trials Offer Free Access: Cohere provides a trial API key allowing free access to all models with rate limits of 20 calls per minute during the trial, improving to 500 calls per minute with production keys.
- This setup allows engineers to explore various models before committing to production environments.
- Emerging Multimodal Command Models: Discussions sparked interest in a multimodal Command model, suggesting a Global connection feature that integrates different modes of interaction.
- This reflects a budding curiosity about advanced model capabilities and their potential applications.
- Agentic Builder Day on November 23rd: OpenSesame is hosting an Agentic Builder Day on November 23rd, inviting developers to participate in a mini AI Agent hackathon using Cohere Models, with applications currently open.
- The event aims to foster collaboration and competition among developers interested in AI agents.
- Ollama Mistral Performance Concerns: Members expressed issues with Ollama Mistral, noting performance hiccups and hallucination tendencies that complicate their projects.
- One user linked to their GitHub gist detailing their methodology for effective prompt generation despite these challenges.
- Tool Calls and Cohere V2 API Errors: Users reported internal server errors with tool calls in the Cohere V2 API, particularly highlighting the missing tool_plan field that caused some issues.
- Reference was made to the Cohere documentation for clarifications on proper tool integrations.
Modular (Mojo 🔥) Discord
-
Enthusiasm for stdlib Discussions: A member expressed excitement about joining stdlib contributor meetings after catching up on the last community discussion.
- This enthusiasm garnered positive reactions from others, encouraging participation in the conversations.
- Serial Communication Woes in Mojo: A user sought guidance on implementing serial communication over a port in Mojo; current support is limited to what's available in libc.
- This indicates a necessity for further enhancements in Mojo's communication capabilities.
- Debate on C/C++ Support in Mojo: Discussion emerged on the existence of C/C++ support in Mojo, highlighting its potential benefits.
- However, opinions were divided on the practical application of this support for users.
- C API Launch Announcement for MAX Engine: The C API is now available for the MAX Engine, though there are no immediate plans for the graph API integration.
- An assurance was given that updates regarding the graph API will be communicated if the situation changes.
- Exploring Graph API with C: A member noted the possibility of using C to build a graph builder API, suggesting alternative approaches alongside Mojo.
- This opens up discussions for potential collaborations across programming languages.
Torchtune Discord
-
TorchTune config flops with .yaml: A member flagged that using .yaml file extensions in TorchTune run commands causes confusion by implying a local config.
- They noted that debugging can be frustrating without sufficient error messages.
- Multi-GPU testing raises questions: One user asked about testing capabilities on 2 GPUs, reflecting a common concern.
- Another user mentioned issues with error messages when running scripts on 1 GPU and 2 GPUs with lora_finetune_distributed.
- Fine-tuning with TorchTune confirmed: Response to a fine-tuning query for a custom Llama model confirmed that TorchTune offers flexibility for customization.
- Members were encouraged to engage further in discussions about custom components for better support.
- Linters and pre-commit hooks bugged: Members reported issues with linters and pre-commit hooks, indicating they weren’t functioning as expected.
- To bypass a line, both
# noqaand# fmt: on ... #fmt: offare required, which is seen as unusually complicated. - CI chaos in PR #1868: A member revealed strange behavior with the CI for PR #1868, seeking assistance to address ongoing problems.
- Inquiries about the resolution of a CI issue indicated that, thankfully, it should now be fixed.
LangChain AI Discord
-
Help Shape a Tool for Developers: A member shared a survey link targeting developers with insights on challenges in bringing ideas to fruition, taking approximately 5-7 minutes to complete.
- The survey explores how often developers generate ideas, the obstacles they face, and their interest in solutions for simpler project realization.
- AI Impact Study for Developers: A call for developers to partake in a Master’s study assessing the impact of AI tools on software engineering is live, with participants perhaps winning a $200NZD gift card by filling out a short questionnaire here.
- This study aims to gather valuable data on the integration of AI in engineering workflows while offering incentives for participation.
- Unlock Funding with AI Tool: An AI-powered platform launched to help users find funding by matching them with relevant investors, offering a free Startup Accelerator pack to the first 200 waitlist sign-ups, with only 62 spots left.
- Interested individuals are prompted to Sign Up Now to accelerate their startup dreams with enhanced search capabilities.
- Building an AI GeoGuessr Player: A new YouTube tutorial showcases coding an AI bot that autonomously plays GeoGuessr using Multimodal Vision LLMs like GPT-4o, Claude 3.5, and Gemini 1.5.
- The tutorial involves Python programming and the use of LangChain to allow the bot to interact with the game environment effectively.
- Inquiry about Manila Developers: A member inquired if anyone is located in Manila, hinting at a desire to foster connections among local developers.
- This inquiry may create opportunities for community building or potential collaborations within the Manila tech scene.
DSPy Discord
-
World's Most Advanced Workflow System in Progress: A member announced plans for the world's most advanced workflow system with a live demonstration scheduled for Monday to showcase its operations and the upgrade process.
- The session aims to provide a deep dive into system functionality, with an emphasis on discussing planned enhancements and upcoming features.
- DSPy sets ambitious funding goals: Following CrewAI's success in securing $18M, a member proposed that DSPy should target a minimum of $50M, expressing eagerness to join early-stage as employee number 5 or 10.
- What are we waiting for? enlivened the discussion, emphasizing a call to action for immediate funding efforts.
- Metrics for Effective Synthetic Data Generation: A member explored the potential of using DSPy to generate synthetic data for QA purposes based on textual input, raising questions about suitable metrics.
- Responses suggested leveraging an LLM as a judge with established criteria for assessing the open-ended generation where no ground truth exists.
- Groundedness as a Metric in Synthetic Data: In synthetic data discussions, a member suggested that ground truth would derive from the text utilized in generation, indicating groundedness as a key metric.
- They expressed gratitude for the collaborative insights shared, highlighting a spirit of engagement among members on the topic.
LLM Agents (Berkeley MOOC) Discord
-
LLM Agents MOOC Signup Confusion: Several members reported not receiving confirmation emails after submitting their LLM Agents MOOC Signup Form, leading to uncertainty about their application status.
- This lack of feedback has raised concerns about the signup process among users who expected formal acceptance notifications.
- Hackathon Project Codes Must Be Open Source: During the Hackathon, members confirmed the requirement to make their project codes 100% open source, a stipulation for participating in final presentations.
- This emphasis on code transparency aligns with the hackathon's goals to foster collaborative development among participants.
- Demand for Agent Creation Tutorials: A participant inquired about tutorials for creating agents from scratch without relying on external platforms, highlighting a need for accessible educational resources.
- This interest underscores the community's desire for self-sufficiency in agent development workflows.
LLM Finetuning (Hamel + Dan) Discord
-
Axolotl Discord for Configurations: Utilize the 🦎 Axolotl Discord channel for sharing and finding configurations tailored to your use case, complete with an example folder on GitHub. Check out the Discussions tab for insights and shared use cases.
- Leverage community efforts to refine your configurations and adapt existing setups to better suit your projects.
- Maximize Your Prompts with LangSmith: Explore the 🛠️ LangSmith Prompt Hub that offers an extensive collection of prompts ideal for various models and use cases, enhancing your prompt engineering skills. Visit the Amazing Public Datasets repository for quality datasets.
- Share your own prompts and discover new ideas to foster collaboration and better model performance.
- Kaggle Solutions for Data Competitions: Check out The Most Comprehensive List of Kaggle Solutions and Ideas for a wealth of insights on competitive data science. Access the full collection on GitHub here.
- This resource serves as a goldmine for data engineers looking to enhance their methodologies and strategies.
- Hugging Face’s Recipes for Model Alignment: Find robust recipes on Hugging Face to align language models with both human and AI preferences, essential for continued fine-tuning. Discover these valuable resources here.
- Align your models effectively with insights drawn from community best practices.
- Introducing New Discord Bot for Easy Message Scraping: A newly created Discord bot aims to streamline message scraping from the channel and needs assistance with inviting members to the bot. Interested users can invite the bot via this link.
- Get involved to enhance your Discord experience and potentially automate collection of valuable discussions.
OpenAccess AI Collective (axolotl) Discord
-
2.5.0 Introduces Experimental Triton FA Support for gfx1100: With version 2.5.0, users can enable experimental Triton Flash Attention (FA) for gfx1100 by setting the environment variable
TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1. Further details are available in this GitHub issue.- A UserWarning indicates that Flash Attention support on Navi31 GPU remains experimental.
- Mixtral vs. Llama 3.2: The Usage Debate: Discussion arose regarding the viability of using Mixtral in light of advancements in Llama 3.2. Community members are examining the strengths and weaknesses of both models to determine which should take precedence.
- This inquiry highlights the evolving landscape in model selection, reflecting on performance metrics and suitability for specific tasks.
Gorilla LLM (Berkeley Function Calling) Discord
-
Empty Score Report on Model Evaluation: A user reported that executing
bfcl evaluate --model mynewmodel --test-category astresulted in an empty score report at 0/0 after registering a new model handler inhandler_map.py.- Another member recommended ensuring that the
bfcl generate ...command was run prior to evaluation, highlighting the dependency for accurate score results. - Importance of Generating Models Before Evaluation: Discussion emphasized running the
bfcl generatecommand before model evaluation to avoid empty reports during testing.
- This underlines that the absence of model generation could directly affect the validity of evaluation results.
- Another member recommended ensuring that the
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!