[AINews] not much happened today
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Custom AINews may be all you need soon...
AI News for 9/19/2024-9/20/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (221 channels, and 2035 messages) for you. Estimated reading time saved (at 200wpm): 258 minutes. You can now tag @smol_ai for AINews discussions!
Anthropic wrote about Contextrual Retrieval, a RAG technique that takes advantage of their prompt caching feature, showing that Reranked Contextual Embedding and Contextual BM25 reduced the top-20-chunk retrieval failure rate by 67% (5.7% → 1.9%):
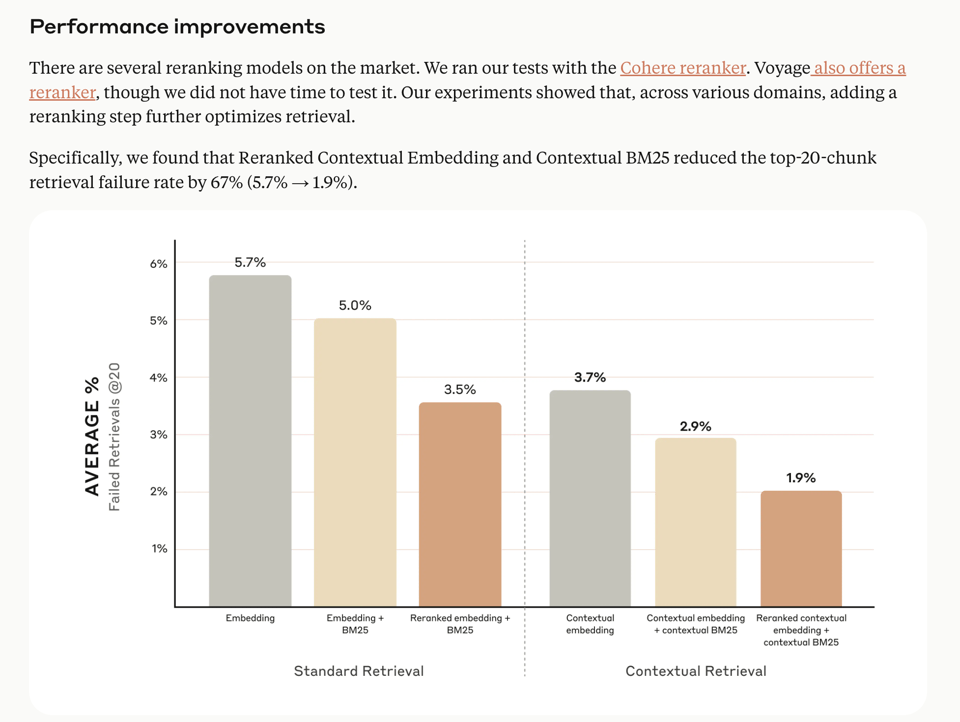
However this is just a RAG technique so we didnt feel it was title story worthy.
Team Meta is heavily teasing multimodal Llama 3 at next week's Meta Connect, but we can't make it the headline story until it's out.
Meanwhile, if you've been itching to get your own personal AINews or kick us some inference money, you can now sign up for our "AINews Plus" service and have your own customized AI News service on any topic of your choice!
See you at the LLM as Judge Hackathon this weekend if you are in SF!
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Research and Development
- OpenAI's o1 Models: @polynoamial announced that OpenAI is hiring ML engineers for a new multi-agent research team, viewing multi-agent as a path to better AI reasoning. @scottastevenson noted that o1 models are causing confusion and skepticism among technologists, similar to early responses to GPT-3 and ChatGPT. @nptacek observed that o1 feels different in terms of prompting, requiring more goal-oriented rather than instruction-driven approaches.
- AI Model Developments: @rohanpaul_ai compared DeepSeek 2.5 to GPT-4, noting it's 21X cheaper than Claude 3.5 sonnet and 17X cheaper than GPT-4. @_akhaliq shared information about 3DTopia-XL, a high-quality 3D PBR asset generation model using Diffusion Transformer. @multimodalart highlighted CogVideoX's capabilities for image-to-video conversion, especially for timelapse videos.
- AI Research Insights: @rohanpaul_ai discussed a powerful but simple prompting technique that asks LLMs to re-read questions, significantly boosting reasoning across diverse tasks and model types. @alexalbert__ shared research on Contextual Retrieval, a technique that reduces incorrect chunk retrieval rates by up to 67% when combined with prompt caching.
AI Industry and Applications
- AI in Enterprise: @svpino stated that companies not allowing their developers to use AI are unlikely to succeed. @scottastevenson noted how LLMs have disrupted traditional ML businesses, with deep moats evaporating in months.
- AI Tools and Platforms: @LangChainAI announced LangGraph Templates, a collection of reference architectures for creating agentic applications. @llama_index introduced LlamaParse Premium, combining visual understanding capabilities of multimodal models with long text/table content extraction.
- AI in Production: @HamelHusain shared advice on using LLM evals to improve AI products, demonstrating how to create a data flywheel to move from demo to production-ready products. @svpino discussed the importance and challenges of caching in LLM applications for improved speed and cost-efficiency.
AI Ethics and Regulation
- @ylecun discussed the political leanings of scientists studying misinformation, noting that scientists generally lean left due to their focus on facts and the current prevalence of misinformation from the right. @ylecun also shared an open letter signed by industry leaders urging the EU to harmonize AI regulations to prevent the region from becoming a technological backwater.
- @fchollet clarified that the ARC-AGI benchmark was not designed specifically to trip up LLMs, but rather to highlight the limitations of deep learning, which LLMs share as part of the same paradigm.
Memes and Humor
- Various tweets showcased humorous AI-generated content, including @nearcyan wrapping their entire Twitter app for "talk like a pirate day" and @jxnlco sharing an amusing AI-generated image.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Llama 3 Multimodal: Meta's Next Big AI Release
- "Meta's Llama has become the dominant platform for building AI products. The next release will be multimodal and understand visual information." (Score: 74, Comments: 21): Yann LeCun announced on LinkedIn that Meta's Llama 3 will be a multimodal model with visual understanding capabilities. This next release of Llama is positioned to further solidify Meta's dominance in the AI product development landscape.
- Zuck is teasing llama multimodal over on IG. (Score: 164, Comments: 42): Mark Zuckerberg has hinted at multimodal capabilities for Llama on Instagram. This development is expected to be officially unveiled at Meta Connect, which is scheduled for next week.
- Llama.cpp developers' lack of support for multimodal models and tool calling has disappointed users. The team focuses on barebones efficiency and CPU/CPU+GPU inference, leaving multimodal implementation to be redone from scratch.
- Users debate the performance of Llama.cpp versus other backends like TabbyAPI, ExllamaV2, and KTransformers. Some argue for potential improvements in Llama.cpp's GPU performance through better optimization, speculative decoding, and tensor parallelism.
- The community expresses frustration over Llama.cpp's lack of support for Meta's Chameleon model, despite a Meta developer offering assistance. A pull request implementing support was not merged, leading to disappointment among contributors.
Theme 2. Qwen2.5 32B: Impressive Performance in GGUF Quantization
- Qwen2.5 32B GGUF evaluation results (Score: 78, Comments: 38): The evaluation of Qwen2.5 32B GGUF models shows strong performance in the computer science category of MMLU PRO, with the Q4_K_L quantization (20.43GB) scoring 72.93 and the Q3_K_S quantization (14.39GB) achieving 70.73, representing only a 3.01% performance loss. Both Qwen2.5 32B quantizations significantly outperformed the Gemma2-27b-it-q8_0 model (29GB), which scored 58.05 in the same category.
- Qwen2.5 32B quantizations show impressive performance, with users noting significant improvements in certain areas despite potential drawbacks in world knowledge and censorship.
- Users suggest testing IQ variant quants, considered SOTA for under 4-bit and typically superior to older Q_K type quants. Interest in comparing 72B IQ3_XXS (31.85GB) and IQ2_XXS (25.49GB) versions for 24GB VRAM users.
- Discussion around official Qwen/Qwen2.5 GGUF files on Hugging Face, with a caution that official quants often underperform compared to community-created versions.
- Qwen 2.5 on Phone: added 1.5B and 3B quantized versions to PocketPal (Score: 74, Comments: 34): Qwen 2.5 models, including 1.5B (Q8) and 3B (Q5_0) versions, have been added to the PocketPal mobile AI app for both iOS and Android platforms. Users can provide feedback or report issues through the project's GitHub repository, with the developer promising to address concerns as time permits.
- Users expressed interest in adding speech-to-text functionality and modifying the system prompt. The developer confirmed that most settings are customizable and shared a screenshot of the available options.
- A user inquired about context size settings, leading to a discussion on the distinction between context length and generation time parameters. The developer explained the rationale behind their placement and added the issue to the GitHub repository.
- The app supports various chat templates (ChatML, Llama, Gemma) and models, with users comparing performance of Qwen 2.5 3B (Q5), Gemma 2 2B (Q6), and Danube 3. The developer provided [screenshots](https://preview.redd.it/130oisgjvspd1.png?width=1290&format=png&auto=webp&s=9890aa96eec037b33f6849e9
Theme 3. EU AI Regulation: Balancing Innovation and Control
- Open Letter from Ericsson, coordinate by Meta, about fragmented regulation in Europe hindering AI opportunities (Score: 87, Comments: 16): Ericsson CEO Börje Ekholm warns that fragmented EU regulations are hindering AI development in Europe, potentially depriving Europeans of technological advances enjoyed elsewhere. The letter emphasizes that open models enhance sovereignty and control, and estimates suggest Generative AI could increase global GDP by 10% over the coming decade, urging for clear, consistent rules to enable the use of European data for AI training. Read the full open letter here.
- Commenters debate the impact of EU regulations on AI innovation, with some suggesting it could lead to Europe's dependence on USA for future AI technologies. Others argue for a common framework similar to GDPR to clarify rules across Europe and facilitate investments.
- Discussion centers on the scope of AI regulation, with suggestions to focus on banning "1984 things" like surveillance and discrimination rather than regulating models themselves. The OP clarifies that the issue is about regulating data used for AI training, not AI usage.
- A link to euneedsai.com is shared, potentially offering additional context on Europe's AI needs and regulatory landscape.
- Quick Reminder: SB 1047 hasn't been signed into law yet, if you live in California send a note to the governor (Score: 209, Comments: 57): California's SB 1047, an AI "safety" bill inspired by the Terminator, has passed but not yet been signed into law. The post urges California residents to voice their objections to the governor through the official contact page, selecting "An Active Bill" and "SB 1047" as the topic, and choosing "Con" as their stance.
- Critics argue SB 1047 is a regulatory capture bill, potentially hindering open research while benefiting corporations conducting closed, profit-driven research without safety checks. Some believe the bill may be unconstitutional, though others suggest it's likely legal.
- Commenters emphasize the importance of open-source AI for research, general use, and long-term safety through collaborative development. They suggest mentioning location, voter status, and personal stories of open-source AI benefits when contacting officials.
- Concerns about China's AI advancement were raised as a reason to oppose regulation. A dedicated website, stopsb1047.com, was shared for submitting comments against the bill, with some users reporting sending detailed responses.
Theme 4. Mistral Small 2409 22B: Quantization Impact Analysis
- Mistral Small 2409 22B GGUF quantization Evaluation results (Score: 106, Comments: 25): The post presents quantization evaluation results for the Mistral Small Instruct 2409 22B model, focusing on the computer science category of the MMLU PRO benchmark. Various quantization levels were tested, with the Q4_K_L variant surprisingly outperforming others at 60.00% accuracy, while model sizes ranged from 9.64GB to 18.35GB. The author also included comparison results for Qwen2.5-32B and Gemma2-27b models, and provided links to the GGUF models, backend, evaluation tool, and configuration used.
- Q4_K_L quantization outperforming Q5_K_L sparked discussion, with users speculating on random chance or layer differences. Tests were run at 0 temperature, with Q4_K_L achieving 60.20% accuracy (245/407 questions).
- Qwen2.5-32B performance was praised. Users requested comparisons with Mistral Nemo 12B, which the author confirmed was evaluated and would be posted later.
- Discussions touched on quantization effects, with anecdotal reports of 5-bit quantizations performing worse than 4-bit for some models. A user's test suggested Q4 variants might be "smarter" than Q6 in certain scenarios.
Theme 5. AI Model Size Debate: Efficiency vs. Capability
- Hot Take: Llama3 405B is probably just too big (Score: 104, Comments: 94): Llama3.1-405B, initially leading open models, is now considered too large for practical use compared to more efficient models like Mistral Large (~120B). The post argues that 27-35B and 120B models will become industry standards, with companies deploying off-the-shelf 120B models first, then fine-tuning 30B models to reduce costs by over 50%. While acknowledging Meta AI's contribution, the author emphasizes the need for more 100B+ models, which are cheaper to train, fine-tune, and host than larger counterparts.
- Industry standards for AI models are debated, with some arguing that companies will use whatever works best regardless of size. The 405B model is seen as useful for research, distillation, and in-house use by large organizations concerned with data privacy.
- Larger models like Llama 405B are viewed as important for pushing boundaries and competing with rumored 1.7T parameter models like GPT-4. Some users argue that creating SOTA models is valuable for research and gathering training data.
- Practical applications of large models are discussed, with some users reporting daily use of the 405B model through API for better responses. There's interest in tutorials for fine-tuning 70B+ models without excessive cost or complexity.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Techniques
- Google Deepmind advances multimodal learning with joint example selection: A Google Deepmind paper demonstrates how data curation via joint example selection can further accelerate multimodal learning. This technique could improve efficiency in training large multimodal models.
- Microsoft's MInference dramatically speeds up long-context task inference: Microsoft's MInference technique enables inference of up to millions of tokens for long-context tasks while maintaining accuracy, dramatically speeding up supported models. This could allow for much more efficient processing of very long documents or conversations.
- Scaling synthetic data creation using 1 billion web-curated personas: A paper on scaling synthetic data creation leverages the diverse perspectives within a large language model to generate data from 1 billion personas curated from web data. This approach could help create more diverse and representative training datasets.
AI Model Releases and Improvements
- Salesforce's "tiny giant" xLAM-1b model surpasses GPT 3.5 in function calling: Salesforce released xLAM-1b, a 1 billion parameter model that achieves 70% accuracy in function calling, surpassing GPT 3.5. This demonstrates significant improvements in smaller, more efficient models.
- Phi-3 Mini (June) with function calling: Rubra AI released an updated Phi-3 Mini model in June with function calling capabilities. It is competitive with Mistral-7b v3 and outperforms the base Phi-3 Mini, showing rapid progress in smaller open-source models.
- OmniGen multimodal model: A new research paper describes OmniGen, a multimodal model with a built-in LLM and vision model that provides unprecedented control through prompting. It can manipulate images based on text instructions without needing specialized training.
AI Development and Industry Trends
- OpenAI's funding round closing with high demand: OpenAI's latest funding round is closing with such high demand that they've had to turn down "billions of dollars" in surplus offers. This indicates strong investor confidence in the company's future.
- Debate over LLM APIs and ML product development: A discussion on r/MachineLearning highlights concerns that the prevalence of LLM APIs is leading to a focus on prompt engineering rather than more fundamental ML research and development. This reflects ongoing debates about the direction of AI research and development.
- Indestructible 5D memory crystals: New technology allows for storing up to 360 terabytes of data for billions of years in resistant crystals, potentially providing a way to preserve human knowledge long-term.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. New AI Models Make Waves in the Community
- Qwen 2.5 Takes Center Stage: Unsloth AI confirms support for Qwen 2.5, with users eagerly training Qwen2.5-14b. OpenRouter introduces Qwen2.5 72B, boasting enhanced coding and mathematics capabilities, and a whopping 131,072 context size.
- Mistral Leaps into Multimodal AI: Mistral Pixtral 12B debuts as Mistral's first multimodal model, now accessible on OpenRouter. This launch marks a pivotal moment, expanding Mistral's offerings into versatile AI applications.
- Flux Model Lights Up Stability.ai Users: The Flux model impresses with superior prompt adherence and image quality, overcoming initial resource hurdles. Despite some concerns over aesthetic similarities, optimism runs high for Flux's performance.
Theme 2. Fine-Tuning Models: Triumphs and Tribulations
- LoRA Fine-Tuning Sparks Innovation: HuggingFace users suggest utilizing LoRA for fine-tuning base models, inspired by ipadapter approaches. This could boost model performance without extensive retraining.
- Phi-3.5-Mini Throws a Curveball: Unsloth AI users face an AttributeError while fine-tuning Phi-3.5-Mini, wrestling with LongRopeRotaryEmbedding issues despite following recommended fixes. The community hunts for a viable workaround.
- Quantization Trade-offs Ignite Debate: Members discuss that unquantized models may deliver better speed and throughput in batch processing. The critical balance among speed, size, and cost takes center stage in decision-making.
Theme 3. AI Tools Test Users' Patience
- Aider Battles API Gremlins: Users grapple with Aider not reading from
.envfiles, leading to configuration chaos and overload errors with the Anthropic API. Logging LLM conversation history becomes the sleuthing method of choice. - LangChain's Chunky Output Causes Chagrin: LangChain v2.0 users report intermittent function call information output in chunks when using OpenAI streaming. Suspicions of lurking bugs prompt calls for fixes.
- LM Studio's Connectivity Conundrum Solved: Switching to IPv4 on macOS saves the day for LM Studio users facing connection woes. Clear guidance on adjusting settings turns frustration into relief.
Theme 4. AI Coding Assistants Stir Conversations
- O1 Models Under Fire in Code Edits: Aider users express skepticism about O1 models' performance compared to Sonnet-3.5, especially in code refactoring tasks. Hopes remain high for future enhancements to boost interaction capabilities.
- Wizardlm Weaves Magic in OpenInterpreter: Wizardlm 8x22B outperforms Llama 405B in OpenInterpreter, nailing tasks on the first try more often. Users are impressed by its efficiency and effectiveness.
- Devin Doubles Down on Improvements: Devin now offers faster, more accurate code edits and improved enterprise security support. While many praise the updates, feedback remains mixed, with some users expressing frustration over limitations.
Theme 5. Community Events and Collaborative Efforts
- Hackathon Hustle Sets the Stage: CUDA MODE members gear up for a hackathon, with approvals flying and team formations encouraged via forum ideas. A chance to get the PMPP book signed by Prof. Wen-mei Hwu adds extra excitement.
- OpenAI Calls for Multi-Agent Marvels: OpenAI is hiring ML engineers for a new multi-agent research team, seeing this niche as crucial for enhancing AI reasoning. They're encouraging applications even from those without prior multi-agent experience.
- Web AI Summit 2024 On the Horizon: Members express enthusiasm for networking opportunities at the upcoming summit. The event promises valuable exchanges on web AI topics among eager participants.
PART 1: High level Discord summaries
HuggingFace Discord
- Exploring Advanced Tokenization Techniques: A new blog post titled This Title Is Already Tokenized explains advanced methods, raising interest in their applications for modern NLP.
- The content details complexities in tokenization, driving discussion on its relevance to current projects.
- Unity ML Agents for Language Model Training: Catch the latest YouTube video about training LLMs from scratch with Unity ML Agents and sentence transformers.
- Highlighting Oproof Validation Success, this episode shows key milestones in the Tau LLM series.
- New GSM8K Reasoning Dataset Released: A user introduced a new reasoning dataset, based on GSM8K aimed at AI model training.
- Expected to enhance AI's critical reasoning capabilities with its structured challenges.
- Fractal Generator's New Zoom Functionality: A fractal generator project now features zoom capabilities through the 'Aiming Better' section, allowing users to adjust grid length and generate new outputs.
- Community suggestions included implementing scroll wheel input for smoother interactions.
- Fine-tuning Base Models with LoRA: A suggestion was made to utilize LoRA for fine-tuning base models, taking inspiration from ipadapter methodologies.
- This could enhance model performance by adjusting parameters without extensive retraining.
aider (Paul Gauthier) Discord
- Aider struggles with API interactions: Users face issues with Aider not reading from the
.envfile, causing configuration challenges and overloading errors with the Anthropic API. Logging LLM's conversation history is suggested as a potential diagnostic approach.- With this context, further inquiry into configuration issues seems vital to ensure smoother API interactions.
- O1 model compared to Sonnet-3.5: Skepticism surrounds the performance of
O1models in Aider versus Sonnet-3.5, particularly in tasks like editing and code refactoring. Users look forward to enhancements that will boost the interaction capabilities between Aider and O1 models.- This comparison leads to broader discussions about model integration and usability in coding tasks.
- Chain of Thought sparks debate: A member questioned the efficacy of the Chain of Thought method, suggesting prior training had a larger impact on performance. Discussions revealed that pragmatic tuning on results is essential for tailored applications.
- This highlights a common theme in AI discussions around enabling model performance through appropriate methodologies.
- Anthropic enhances LLM operations with Contextual Retrieval: Anthropic introduced a contextual retrieval method that improves prompt caching for efficient LLM operations. This method's implementation is seen as crucial for projects like Aider.
- Collectively, it underscores the need for continual improvements in managing AI interactions to streamline functionalities.
- Issues with function renaming in Aider: Aider's attempt at renaming functions resulted in partial updates causing undefined function errors, raising concerns about its search/replace effectiveness. Users noted that despite prompts, Aider managed to fix only one instance of linter errors.
- The necessity for enhanced functionality in reference updates comes to light, hinting at room for significant improvements in Aider's architecture.
Unsloth AI (Daniel Han) Discord
- Qwen 2.5 Finds Unsloth Compatibility: Users confirmed that Qwen 2.5 is supported by Unsloth, though bugs with chat templates are being addressed by the Qwen team.
- It better be, I'm training Qwen2.5-14b right now was a sentiment expressing the urgency for functional support.
- Successful Fine-tuning of Models Like Qwen 2.5: For fine-tuning LLMs in text classification with limited datasets, models such as Qwen 2.5 and BERT are ideal, with one user achieving 71% accuracy with Llama 8.1 8B.
- Members are looking to enhance these scores and share successes and challenges.
- Crucial Quantization Trade-offs: Discussion indicated that unquantized models may yield better speed and throughput, particularly in batch processing scenarios.
- Members debated the critical trade-offs among speed, size, and cost when deciding on quantizing models.
- AGI Progress Sparks Debate: Concerns were expressed that achieving AGI is not solely about finding answers, but more about effectively explaining them, suggesting significant challenges lie ahead.
- Echoing the 80/20 rule, it was noted that a 60-year investment into AGI indicates the arduous path to its realization.
- BART Model's Input Mechanism Under Scrutiny: Questions arose about BART's input format, highlighting that it uses an EOS token to start generation instead of the expected BOS token.
- Experiments are planned to analyze the implications of this behavior further.
CUDA MODE Discord
- Fixing Bugs in Triton and Confidence Functions: Members reported bugs with
assert_verbose_allclose, prompting a fix in Pull Request #261 aiming to enhance its reliability across multiple scenarios.- Concerns also arose regarding KL Divergence calculations yielding unexpected results for larger input sizes, suggesting a need for alignment with established functions like cross-entropy.
- Hackathon Teams and CDP Book Signing: Participants prepared for the hackathon, confirming approvals and encouraging self-organization into teams using ideas posted in the forum.
- Notably, a chance to get the PMPP book signed by Prof. Wen-mei Hwu at the event was highlighted, adding an extra layer of engagement.
- Web AI Summit 2024 Networking Opportunities: Excitement builds for the upcoming Web AI Summit 2024, with members expressing interest in attending and networking around web AI topics.
- The summit provides a chance for valuable exchanges among participants looking to share insights and experiences in the domain.
- Insights on Apple's ML Framework and MLX Platform: The Apple-specific ML framework focuses on techniques like autodiff and JIT compilation to enhance performance on Apple silicon, creating parallels with PyTorch's kernel development approach.
- Members discussed MLX, a NumPy-like platform designed for optimal performance with metal backends, enhancing compatibility with Apple's hardware capabilities.
- Modal’s Serverless Functionality Explored: Members sought information on leveraging Modal for free GPU access, discussing its serverless deployment without SSH support but offering free credits for new accounts.
- Recommendations were made to explore a GitHub repository for samples to initiate CUDA workflows seamlessly on Modal.
Perplexity AI Discord
- Perplexity Pro Subscription Confusion: New users expressed confusion over using Perplexity Pro for tasks like tailoring resumes, suggesting alternatives like ChatGPT might be more effective.
- Discussions continued on whether existing Pro account holders can apply new Xfinity rewards codes after downgrading their subscriptions.
- Mixed Performance of o1 Mini Model: Users provided feedback on the o1 Mini model, reporting mixed results, with some tasks yielding basic responses that lacked depth.
- While compared to Claude Sonnet 3.5, there’s a strong call for improvements in specific prompting techniques for better outcomes.
- AI Models Versatile in Coding: Several users highlighted experimenting with the latest AI models for coding, designating o1 Mini as an option but noting limitations in complex projects.
- They emphasized the necessity for internet search capabilities and real-time feedback to boost coding performance within AI tools.
- Sonar vs. Llama-3.1 Performance Discrepancies: Users reported experiencing poor performance with the llama-3.1-sonar-large-128k-online model, particularly in response formatting when compared to web application results.
- Specific issues included output quality decline, premature truncation, and inconsistencies in following prompting instructions.
- Navigating Access to Beta Features: Inquiries about access to the return_citations beta feature were raised, with advice to contact api@perplexity.ai for applications.
- Clarifications were requested about the search_recency_filter, whether it’s in closed beta, and the potential for recent content retrieval.
Stability.ai (Stable Diffusion) Discord
- Pony XL vs Original Model Conundrum: Pony XL is a refined iteration of its predecessor, but concerns arise regarding text encoder layer disalignment with other embeddings that blur model classifications.
- One user aptly compared the excitement around Pony to tulip mania, suggesting SDXL might serve better depending on specific project needs.
- Flux Model Showcases Strong Performance: The Flux model is now recognized for overcoming its initial obstacles, notably in resource needs and speed, thus establishing a reputation for prompt adherence and image quality.
- Despite some feedback on aesthetic similarities in generated images, the community remains hopeful about Flux's ability to achieve top-tier performance.
- SDXL and Flags: A Trouble Spot: Users reported that both SDXL and SD3M struggle with accurately rendering common symbols like country flags, questioning their reliability.
- Community suggestions included training a Lora model specifically aimed at improving flag accuracy for SDXL's outputs.
- Optimizing ComfyUI for Better Workflows: Discussions around efficiently using ComfyUI emphasized workflows in the cloud and exploring serverless options like Backblaze for model storage.
- Members expressed interest in maximizing VRAM across multiple GPUs, sharing tips for enhancing performance in demanding workloads.
- Missing Inpainting Models Sparks Inquiry: A user voiced frustration over the absence of inpainting and erasing models in IOPaint, needing command prompt access to unlock these functionalities.
- This led to a broader conversation about how command-line parameters can impact model availability and operations within various UIs.
Nous Research AI Discord
- Upscaling Videos Made Easier: A member suggested using video2x to upscale videos by processing each frame through an upscaling model.
- Another member contemplated decreasing the frame rate to reduce workload before upscaling, though uncertainty remained about the video's quality.
- Feline AI Revolutionizes Music Production: One user showcased their feline AI chatbot for music production, capable of generating MIDI files and recommending synthesis methods.
- Plans are in motion to migrate to Llama for better performance, emphasizing its understanding of time signatures and musical styles.
- Interest in Forge Technology Grows: Members inquired about the functionalities of Forge, especially its relation to Hermes and other models.
- A linked Discord message may shed light on Forge's capabilities in this context.
- Exploring Hermes 3 Accessibility: Discussion on accessing Hermes 3 included a link to OpenRouter for exploration.
- Opinions on Hermes 3's performance and data handling were shared among participants.
- Philosophical Musings on AI Consciousness: A peculiar paper on consciousness as a gradient in intelligence manifolds was brought up, sparking skepticism about its validity.
- Debate arose around the extent of AI's understanding of complex concepts like music theory.
Latent Space Discord
- Hyung Won Chung's paradigm shift: Hyung Won Chung introduced a paradigm shift in AI during his MIT talk, highlighting the recent launch of o1 as a significant development in the field.
- He stated that this talk comes at a crucial time due to major advancements in AI understanding.
- OpenAI recruiting ML engineers for multi-agent team: OpenAI is hiring ML engineers for a new multi-agent research team, viewing this niche as essential for enhancing AI reasoning; application details here.
- They emphasized that prior experience with multi-agent systems isn't a prerequisite, encouraging broader applications.
- Devin improves speed and accuracy: Recent enhancements to Devin have resulted in faster and more accurate code edits and improved enterprise security support source.
- While many users have praised the updates, feedback has been mixed, with some expressing frustration at its limitations.
- New RAG proposal reduces retrieval errors: Anthropic's latest proposal on retrieval-augmented generation (RAG) suggests a 67% reduction in incorrect chunk retrieval rates link.
- The conversation underlined the growing interest in strategies to enhance RAG effectiveness.
- Queries about GitHub Copilot models: Users raised questions regarding the standards of models utilized in GitHub Copilot, speculating it uses GPT-4o, with concerns surrounding performance consistency source.
- Discussion centered on the impact of context on performance across various AI tools.
OpenRouter (Alex Atallah) Discord
- Chatroom enhances user interaction: The chatroom now supports editable messages, allowing users to modify their messages or bot responses easily.
- This update includes a redesigned stats interface for improved user engagement.
- Qwen 2.5 sets a new standard: Qwen 2.5 72B delivers enhanced coding and mathematics capabilities with a 131,072 context size. More information is available here.
- This model represents significant progress in AI capabilities, driving performance expectations higher.
- Mistral enters the multimodal space: Mistral Pixtral 12B marks the company's debut in multimodal AI, with a free version accessible here.
- This launch proves to be a pivotal moment, expanding Mistral's offerings into versatile AI applications.
- Hermes 3 shifts to paid structure: With Hermes 3 moving to a paid structure of $4.5/month, users are reconsidering service usage options. More details are available here.
- The lack of notifications on the pricing change raised concerns within the community regarding reliance on free credits.
- Custom API integrations get attention: A request surfaced for the ability to use custom OpenAI compatible API Key endpoints to better integrate with private LLM servers.
- Several members echoed the importance of this flexibility for future integration capabilities.
LlamaIndex Discord
- Exciting Opik Partnership for RAG Autologging: LlamaIndex announced a partnership with Opik, which will autolog all RAG/agent calls for both development and production environments, streamlining the auth process.
- This automation simplifies user experiences in complex multi-step workflows.
- Launch of RAGApp v0.1: Code-Free Multi-Agent Apps: The team launched RAGApp v0.1, enabling the creation of multi-agent applications without any coding required.
- Users can easily add agents, assign roles, set prompts, and utilize various tools for application enhancements.
- LlamaIndex IDs Cause Pinecone Headaches: Users reported challenges with ID control in Pinecone due to LlamaIndex's auto-generated IDs, complicating deletions.
- The community suggested manual ID editing and creating nodes to manage these limitations better.
- Pandas Query Engine Behaves Unexpectedly: Discrepancies surfaced between query outputs in a notebook versus a Python script with the Pandas Query Engine, affecting functionality when using df.head().
- Switching from df.head() to df.head(1) proved to solve the issue, indicating column count may impact query parsing.
- Graph RAG Facing Query Compatibility Issues: Users identified issues with querying patterns in Graph RAG, where the provided pattern did not align with retrieved chunks.
- Further analysis revealed mismatched expectations in the GraphRAGQueryEngine during data fetching.
OpenAI Discord
- o1 Mini Vs. 4o Performance Showdown: Users labeled o1 mini as inferior to 4o, arguing it lacks real-world experience and intelligent reasoning, merely typing faster without substance.
- One user remarked that o1 feels no different than 4o, provoking discussions on AI's cognitive capabilities.
- Hot Debate on AI Consciousness: A rigorous discussion erupted over whether AI can genuinely reason or if it's merely a simulation, with mixed opinions on intentionality.
- A member proposed that focusing AI on task completion, rather than human-like reasoning, might yield safer and more efficient results.
- Clarifying GPT-4 Memory Features: There were inquiries regarding memory features for GPT-4 API, with clarity that these are exclusively available to ChatGPT Plus users.
- One user pointed out the ease of implementing their own memory tools with alternatives like Pinecone, despite the lack of this in the ChatGPT interface.
- Feedback Roundup on IDE Integration: Suggestions surfaced about enhancing AI tools integrated within IDEs, particularly a call for live previews akin to ClaudeAI.
- Numerous users desired ChatGPT to add this functionality, while others recommended exploring various IDEs for better compatibility.
- Sharing and Improving Prompt Usage: A member shared a helpful prompt from a prompt guide, emphasizing its ongoing relevance.
- Visual aids were noted as valuable for enhancing prompt understanding, highlighting their role in effective communication of ideas.
Eleuther Discord
- HyperCloning Speeds Up Model Initialization: Discussion centered on using HyperCloning to initialize large language models with smaller pre-trained ones, aiming to enhance training efficiency.
- One member suggested training a mini model, scaling it, and distilling from the larger model to optimize compute usage.
- IDA Gains Traction in AI Alignment: The Iterated Distillation and Amplification (IDA) method for aligning AI systems was acknowledged for its iterative effectiveness.
- One participant expressed skepticism regarding the term 'distillation', arguing it fails to represent the compression and information discarding needed.
- Critical FP8 Training Instabilities Uncovered: FP8 training was reported to have instabilities due to outlier amplification from the SwiGLU activation function during prolonged training runs.
- An audience member questioned if other activation functions would face similar issues in extended training contexts.
- Tokenized SAEs Boost Performance: Tokenized SAEs introduced a per-token decoder bias enhancing models like GPT-2 and Pythia, facilitating faster training.
- This method addresses training class imbalance, enabling better learning of local context features via 'unigram reconstruction'.
- Concerns Over BOS Token in Gemma Models: Concerns arose that the BOS token in Gemma models might only be added once in sequences, impacting rolling loglikelihood calculations.
- The same member confirmed they found the BOS token was missing in llh_rolling during certain instances while debugging.
LM Studio Discord
- IPv4 Switch Fixes Connectivity Issues: A member noted that switching to IPv4 on MacOS often resolves connection issues, with another confirming that 'it just worked.'
- Clear guidance on adjusting TCP/IP settings can be found here.
- Crunching LM Studio Connection Challenges: Members faced issues connecting LM Studio API to CrewAI, exploring different solutions but no consensus was reached.
- One suggested watching a helpful YouTube video for insights into proper setup.
- 3090 Power Limiting Sparks Debate: A member shared insights on limiting the 3090 to 290W versus undervolting, prompting resource recommendations for further understanding.
- Suggestions included reviewing documentation, with varying opinions on the effectiveness of each method.
- Windows vs Linux Power Management: A comparison revealed that adjusting GPU power settings in Windows requires manual setup, while Linux users can optimize with a single command.
- Members debated the accessibility of power management across systems, affirming that Windows offers faster settings adjustments.
- RAM Speed vs CPU Inference Bottlenecks: Discussion arose around whether RAM speed and bandwidth significantly hinder CPU inference, with proposals for a motherboard using DDR6.
- Frustration over underutilization of multiple CPU cores was shared, highlighting concerns over efficiency in current CPU designs.
Modular (Mojo 🔥) Discord
- Mojo LLMs API Sparks Excitement: A user expressed keen interest in utilizing the Mojo based LLMs API alongside Pythagora, a development tool designed for building applications via conversational interactions.
- They raised questions about the cost of the service, emphasizing the excitement surrounding its role in software development transformation.
- GitHub Discussions Closure: Mark Your Calendars!: The GitHub Discussions for Mojo and MAX will officially close on September 26th, with important discussions being converted to GitHub Issues.
- To ensure valuable discussions survive, members can tag the organizer for conversion requests as the community centralizes its communication.
- Packed Structs: Mojo's Compatibility Query: The chat highlighted concerns regarding the lack of packed structs support in Mojo, complicating the handling of bitflags as
__mlir_type.i1lists.- There was hope that LLVM would address this through byte alignment, although skepticism lingered about its reliability.
- Variable Bit Width Integers Demand: Members debated the implementation of variable bit width integers for TCP/IP, specifically the need for types like UInt{1,2,3,4,6,7,13}.
- While bitwise operators and masks were proposed as alternatives, they were deemed less ergonomic, leading to a desire for native support in Mojo.
- Feature Requests Piling Up in Mojo: A feature request emerged for allowing empty lists without a type parameter for better compatibility with Python in Mojo, alongside other syntax inquiries.
- Mentions of explicit trait implementations were common, with requests for clearer guidelines on defining a generic struct with multiple traits.
Torchtune Discord
- Input Position System Gets Streamlined: The recent PR removes auto-setting of input_pos to simplify generation/cacheing logic.
- This aim is to prevent user confusion by eliminating the hunt across classes for default settings.
- Memory Optimisations Under the Microscope: Discussions highlighted memory optimisations such as activation offloading, which are in development, and the encouragement of chunked cross entropy usage.
- Members acknowledged that previously dismissed methods are now being reassessed for the mem opt tutorial.
- Bringing Efficiency to Generation with Batch Sizes: The focus centered on generation efficiency, emphasizing that the generate script will only support bsz 1 during execution.
- Members mulled over the simplicity of looping through batches, while considering the drawbacks of raising batch sizes.
- Debating Submethods for Generation Process: A lively debate sparked around the inclusion of submethods like sample and batched_sample, aimed at refining the generation approach.
- Opinions varied, with some favoring separation of methods while others preferred a streamlined method similar to gpt-fast practices.
- Challenges in Keeping Generate Recipe Simple: Urgency emerged from a member about maintaining a straightforward generate recipe amidst user-reported issues linked to larger batch sizes.
- An ongoing effort is underway to simplify logic, viewed as essential for clarity with the generate functionalities.
OpenInterpreter Discord
- Wizardlm eclipses Llama in task performance: Experimentation shows that microsoft/Wizardlm 8x22B consistently outshines llama 405B, successfully completing tasks on the first try more often.
- Members were impressed by Wizardlm's efficiency in various tasks, prompting discussion on potential broader applications.
- O1 currently lacks useful functions: Participants noted that O1 remains in development and doesn’t have any functioning features ready for deployment.
- They expressed concerns about its inability to interact with applications, emphasizing the need for further enhancements.
- Proposed discussion on O1 functionalities: A call for a dedicated discussion about O1's features has been made, seeking to clarify its potential use cases and gather insights.
- To maximize participation, members are encouraged to share their availability, specifically in GMT timezone.
- Firebase/Stripe integration struggles: A user reported ongoing issues with their FarmFriend project’s integration with Firebase and Stripe, particularly around handling CORS and authentication domains.
- They described facing a 'deathloop' with service configurations and called for assistance from those experienced in maintaining such integrations.
tinygrad (George Hotz) Discord
- Bounty for CLANG dlopen Replacement: A bounty discussion arose about replacing CLANG dlopen with mmap, which may require manual handling of relocations as shown in this pull request.
- At this point I'm very curious to see who will get this bounty highlighted the competitive interest in this task.
- Tinygrad Compatibility with Intel GPUs: A user inquired whether Tinygrad supports multiple Intel GPUs, similar to its functionality with AMD and NVIDIA GPUs, and received positive feedback.
- The advice was to investigate compatibility further, indicating a growing interest in Intel hardware.
- Troubleshooting IPMI Credential Issues: Reported issues with IPMI pointed to possible incorrect credentials, prompting a discussion on the best methods to reset them.
- Suggestions included using a monitor and keyboard for setup, and ensuring the web BMC password matches the displayed one.
- Confusion Over GPU Setup Connections: A question emerged regarding whether to use HDMI or VGA for GPU setup, with a clear consensus that VGA only is necessary during initial connections.
- This confusion underscores a common oversight in hardware configuration practices.
- Undergraduate Thesis on ShapeTrackers Mergeability: One user expressed interest in tackling the mergeability of two arbitrary ShapeTrackers in Lean for their undergraduate thesis, questioning the status of the bounty.
- They noted it appears incomplete, presenting an opportunity for new contributions to the project.
Cohere Discord
- Cohere Discord: A Place for Learning: Members expressed their excitement about joining the Cohere Discord community, encouraging a collaborative atmosphere for learning about AI and Cohere's offerings.
- Welcome! messages were sent to newcomers, fostering an engaging environment for shared knowledge.
- Grab Your Trial Key and Start Hacking: A member suggested using a trial key that offers 1000 calls a month for free, emphasizing hands-on learning through projects.
- Another member agreed, stating that application is the best way to learn and mentioned they would explore this further after finishing their capstone project.
- Rerank Multilingual v3 struggles with English: A member reported discrepancies using rerank_multilingual_v3, noting scores below 0.05 for English queries compared to 0.57 and 0.98 with rerank_english_v3.
- This inconsistency is negatively impacting their RAG results, leading to unexpected filtering of relevant chunks.
- Test with Curl Command for Rerank Models: Another member suggested a curl command to swap models for testing, proposing queries like 'what are the working hours?' and 'what are the opening times?'.
- This could enable better performance comparisons between the models.
- Interest in Newsletters: A member mentioned being attracted to the community through the classify newsletter, showcasing its importance in community engagement.
- Another member expressed a desire for more newsletters, indicating an appetite for continuous updates and information from the community.
LAION Discord
- Seeking Speedy Whisper Solutions: A member requested help to maximize the speed of Whisper, focusing on using multiple GPUs for transcription tasks for a very large dataset.
- Efficient processing is crucial, and the need for batching was emphasized.
- Whisper-TPU: A Fast Option: Whisper-TPU was highlighted as a notably fast alternative for transcription needs, catering to users requiring high-speed processing.
- Its potential for handling demanding tasks sparked interest among those in the discussion.
- Exploring Transfusion Architecture Usage: Curiosity arose about leveraging the Transfusion architecture for multimodal applications, suggesting its innovative capability.
- A GitHub repository for Transfusion showcases its potential to predict tokens and diffuse images.
- Challenges with Diffusion and AR Training: Experiments with combining diffusion and AR training revealed significant stability challenges, highlighting a crucial integration obstacle.
- The community is actively seeking effective strategies to enhance stability in these training methods.
- Inquiring About Qwen-Audio Training Instability: Discussion surfaced regarding training instability in the Qwen-Audio paper, connecting it with issues in multimodal setups.
- Members expressed intent to revisit the paper for clarity on these challenges, indicating their relevance.
Interconnects (Nathan Lambert) Discord
- Qwen 2.4 Disappoints vs o1-mini: The newly announced qwen2.4-math-72b-instruct fails to outperform o1-mini during tests with code execution and ensemble methods using n=256 generations.
- This outcome highlights the difficulty in achieving fair comparisons, especially on metrics like AIME, without the reflection type CoT.
- EU Halts Llama Multimodal Launch: A developer mentioned that their team is keen on creating a multimodal version of Llama, but they won't release it in the EU amid regulatory uncertainties.
- This decision reflects broader concerns regarding how fragmented tech regulations may stifle AI innovation in Europe.
- Community Fears EU's Anti-Tech Stance: Discussions emerged around the EU's perceived anti-tech sentiment, where members believe regulations, although well-meaning, induce significant uncertainty.
- There's a call for clearer regulations to better balance innovation and safety within the tech landscape.
- OpenAI's Extended Video Insights: OpenAI's extended video suggests that a model with RL is now superior at discovering CoT steps compared to human capabilities.
- Key points raised included the importance of infrastructure in algorithm performance and the emergence of self-critique as a significant development.
LangChain AI Discord
- Chunky Output Issue in LangChain v2.0: Users are reporting that LangChain v2.0 outputs intermittent function call information in chunks while using OpenAI streaming, suggesting possible bugs.
- This situation raises concerns regarding configuration settings and stability in output formats during function calls.
- Ell vs LangChain Comparison: A discussion highlighted differences and comparisons between Ell and LangChain, revealing community interest in evaluating AI frameworks reliability.
- Participants are examining frameworks meticulously to determine effective model integrations for current projects.
- Clarifying LangGraph Support: A query about where to direct questions regarding LangGraph indicates confusion in the community about appropriate support channels.
- This points to the need for better-defined support avenues for users exploring various tools and libraries.
- Beta Testing Call for New Agent Platform: An announcement invited beta testers for a new platform for launching agents with native tokens, indicating opportunity for innovation.
- This platform aims to enhance agent deployment methods, creating buzz around integration strategies.
- OpenAI Assistants Documentation Request: Members requested guidance on utilizing their custom OpenAI assistants according to the latest documentation, showcasing an adaptation to API changes.
- The importance of understanding new Assistants API features was emphasized as community members navigate the revisions.
OpenAccess AI Collective (axolotl) Discord
- Moshi Model Launch Hits the Scene: The Moshi model has been launched as a speech-text foundation model featuring a novel method for converting text into speech, enabling full-duplex spoken dialogue.
- This development significantly enhances both conversational dynamics and speech recognition capabilities.
- GRIN MoE Achieves Excellence with Minimal Parameters: The GRIN MoE model stands out by achieving high performance with only 6.6B active parameters, excelling particularly in coding and mathematics tasks.
- Employing SparseMixer-v2 for gradient estimation, GRIN pushes the envelope by circumventing standard methods of expert parallelism.
- Concerns Arise Over Mistral Small Release: Discussion surrounding Mistral Small confirmed it’s an instruction-only version, attracting mixed reactions from members.
- Participants highlighted memory intensity issues as a notable limitation for several users.
DSPy Discord
- Bootstrapping Clarified in DSPy: A member clarified that bootstrapping in DSPy is utilized to generate intermediate examples within a pipeline, ensuring successful predictions capture the full trace of processes.
- It was emphasized that even with LLMs' non-deterministic nature, if the final result is correct, the intermediate steps should also be valid.
- MathPrompt Paper Sparks Interest: A member highlighted a research paper on MathPrompt, suggesting its potential to extend understanding of enhanced mathematical reasoning, and linked to the paper.
- This reference could pave the way for more robust prompt engineering strategies aimed at mathematical tasks.
- TypedPredictors JSON Hacks: A member shared novel tricks for TypedPredictors, showcasing how to mock JSON parsing to refine output pre-processing for enhanced data handling.
- The approach includes removing excess text, addressing invalid escape sequences, and logging errors from their GitHub Gist.
LLM Finetuning (Hamel + Dan) Discord
- FinTech Startup Seeks LLM Engineer: A FinTech startup is looking for a skilled LLM Engineer for a one-week sprint aimed at enhancing their multilingual real-time translation service using LLama 3.1 or Qwen2 models.
- This initiative promises to significantly improve the way millions of financial transactions are handled across language barriers.
- Qwen 2.5's Multilingual Potential: A participant recommended exploring Qwen 2.5 for its multilingual capabilities, suggesting it might align well with the project's objectives.
- This recommendation indicates a direction towards enhancing the Whisper model alongside the selected LLM to further improve translation accuracy.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!