[AINews] not much happened today
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
a quiet weekend is all we need.
AI News for 12/26/2024-12/27/2024. We checked 7 subreddits, 433 Twitters and 32 Discords (215 channels, and 5579 messages) for you. Estimated reading time saved (at 200wpm): 601 minutes. You can now tag @smol_ai for AINews discussions!
ChatGPT, Sora, and the OAI API had a >5 hour outage. They are back up.
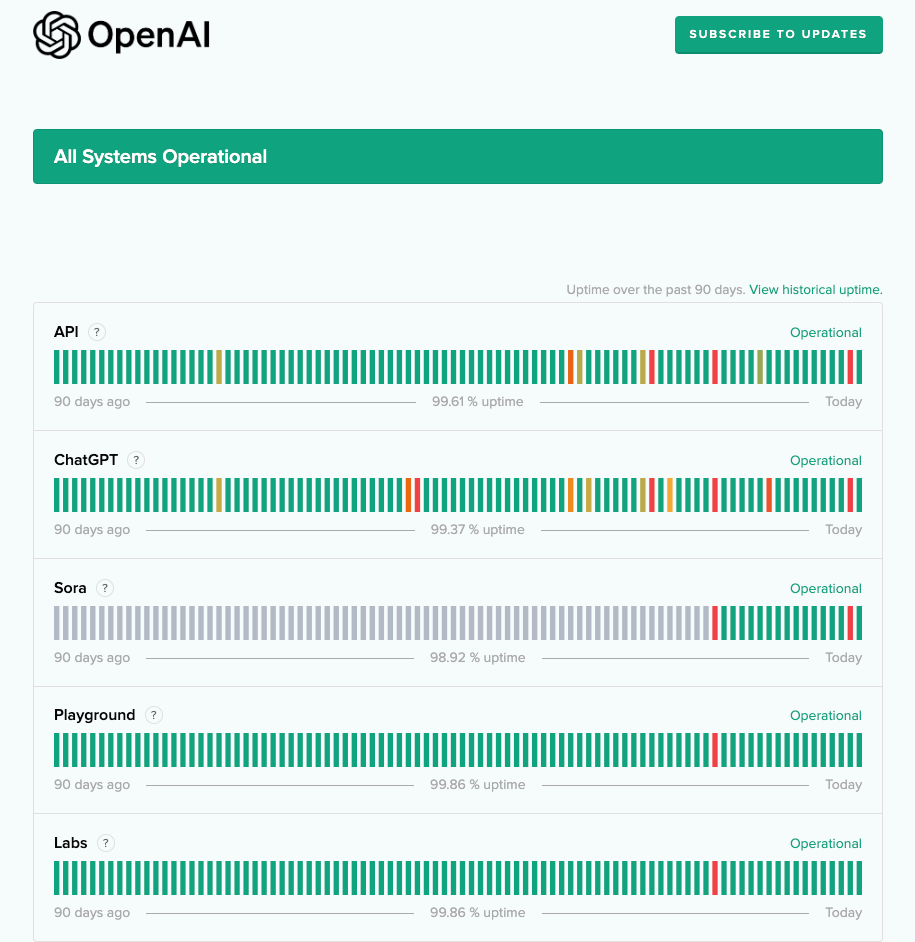
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor IDE Discord
- Codeium (Windsurf) Discord
- aider (Paul Gauthier) Discord
- Eleuther Discord
- OpenRouter (Alex Atallah) Discord
- Nous Research AI Discord
- LM Studio Discord
- Unsloth AI (Daniel Han) Discord
- OpenAI Discord
- Stackblitz (Bolt.new) Discord
- Perplexity AI Discord
- Stability.ai (Stable Diffusion) Discord
- Notebook LM Discord Discord
- Interconnects (Nathan Lambert) Discord
- GPU MODE Discord
- tinygrad (George Hotz) Discord
- Cohere Discord
- Latent Space Discord
- LlamaIndex Discord
- Torchtune Discord
- DSPy Discord
- Modular (Mojo 🔥) Discord
- LLM Agents (Berkeley MOOC) Discord
- OpenInterpreter Discord
- Nomic.ai (GPT4All) Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- LAION Discord
- MLOps @Chipro Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor IDE ▷ #general (1129 messages🔥🔥🔥):
- Codeium (Windsurf) ▷ #content (1 messages):
- Codeium (Windsurf) ▷ #discussion (202 messages🔥🔥):
- Codeium (Windsurf) ▷ #windsurf (557 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #announcements (1 messages):
- aider (Paul Gauthier) ▷ #general (534 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (63 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (1 messages):
- Eleuther ▷ #general (9 messages🔥):
- Eleuther ▷ #research (278 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (5 messages):
- OpenRouter (Alex Atallah) ▷ #general (277 messages🔥🔥):
- Nous Research AI ▷ #general (184 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (81 messages🔥🔥):
- Nous Research AI ▷ #research-papers (1 messages):
- Nous Research AI ▷ #interesting-links (1 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- LM Studio ▷ #general (165 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (92 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (150 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (3 messages):
- Unsloth AI (Daniel Han) ▷ #help (66 messages🔥🔥):
- OpenAI ▷ #ai-discussions (155 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (39 messages🔥):
- OpenAI ▷ #prompt-engineering (5 messages):
- OpenAI ▷ #api-discussions (5 messages):
- Stackblitz (Bolt.new) ▷ #prompting (7 messages):
- Stackblitz (Bolt.new) ▷ #discussions (183 messages🔥🔥):
- Perplexity AI ▷ #general (134 messages🔥🔥):
- Perplexity AI ▷ #sharing (17 messages🔥):
- Perplexity AI ▷ #pplx-api (1 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (125 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (14 messages🔥):
- Notebook LM Discord ▷ #general (82 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (25 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (5 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (21 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (6 messages):
- Interconnects (Nathan Lambert) ▷ #memes (1 messages):
- Interconnects (Nathan Lambert) ▷ #nlp (3 messages):
- Interconnects (Nathan Lambert) ▷ #reads (8 messages🔥):
- GPU MODE ▷ #general (22 messages🔥):
- GPU MODE ▷ #triton (8 messages🔥):
- GPU MODE ▷ #cuda (8 messages🔥):
- GPU MODE ▷ #torch (3 messages):
- GPU MODE ▷ #cool-links (2 messages):
- GPU MODE ▷ #beginner (10 messages🔥):
- GPU MODE ▷ #pmpp-book (1 messages):
- GPU MODE ▷ #lecture-qa (1 messages):
- GPU MODE ▷ #bitnet (6 messages):
- GPU MODE ▷ #sparsity-pruning (1 messages):
- GPU MODE ▷ #metal (1 messages):
- GPU MODE ▷ #arc-agi-2 (2 messages):
- tinygrad (George Hotz) ▷ #general (6 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (51 messages🔥):
- Cohere ▷ #discussions (11 messages🔥):
- Cohere ▷ #questions (25 messages🔥):
- Cohere ▷ #api-discussions (5 messages):
- Cohere ▷ #cmd-r-bot (9 messages🔥):
- Cohere ▷ #projects (2 messages):
- Latent Space ▷ #ai-general-chat (22 messages🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (18 messages🔥):
- LlamaIndex ▷ #ai-discussion (3 messages):
- Torchtune ▷ #general (6 messages):
- Torchtune ▷ #papers (17 messages🔥):
- DSPy ▷ #general (15 messages🔥):
- Modular (Mojo 🔥) ▷ #general (4 messages):
- Modular (Mojo 🔥) ▷ #mojo (1 messages):
- Modular (Mojo 🔥) ▷ #max (8 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (10 messages🔥):
- OpenInterpreter ▷ #general (5 messages):
- OpenInterpreter ▷ #ai-content (2 messages):
- Nomic.ai (GPT4All) ▷ #general (7 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (3 messages):
- LAION ▷ #general (2 messages):
- MLOps @Chipro ▷ #general-ml (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Infrastructure & Optimization
- Training Efficiency and Scaling: @vllm_project announced updates to vLLM allowing DeepSeek-V3 to run with various parallelism and CPU offloading options, enhancing model deployment flexibility.
- Gradient Descent and MoE Routing: @francoisfleuret inquired about the gradient descent mechanics in top-k routing MoE, exploring how feature ranking influences model training dynamics.
- FP8 Precision and Memory Optimization: @danielhanchen and others discussed the adoption of FP8 precision in DeepSeek V3, focusing on memory usage reduction and training cost minimization.
AI Applications & Tools
- AI in Healthcare: @qdrant_engine showcased AIDE, an AI voice medical assistant developed by Team Therasync at the Lokahi Innovation in Healthcare Hackathon, utilizing tools like Qdrant, @OpenAI, and @twilio.
- AI-Powered Coding Assistants: @skirano introduced DeepSeek-Engineer on GitHub, a coding assistant capable of reading, creating, and diffing files using structured outputs.
- AI for Document Processing: @llama_index demonstrated an AI assistant that performs RAG over 1M+ PDFs, integrating LlamaCloud and @elevenlabsio for document processing and voice interaction.
AI Development Practices
- Version Control and Collaboration: @vikhyatk shared insights on using ghstack to manage pull requests, enhancing collaboration and code management in GitHub.
- Training Schedules and Learning Rates: @aaron_defazio advocated for a linear decay learning rate schedule, emphasizing its effectiveness over other schedules in model training.
- Open-Source Contributions: @ArmenAgha and @ZeyuanAllenZhu thanked peers for citing research papers, promoting open-source collaboration, and securing resources for projects like PhysicsLM.
AI Innovation & Future Trends
- Predictions for AI in 2025: @TheTuringPost relayed predictions from experts like @fchollet and @EladGil. Key forecasts include smaller, tighter models, true multimodal models, and on-device AI solutions.
- Federated Learning and Community AGI: @teortaxesTex proposed the necessity for planetary-scale federated learning and a moonshot project for community AGI, akin to multinational initiatives like ITER.
- AI Ecosystem Evolution: @RichardSocher and others discussed the rise of agentic systems, multi-agent workflows, and the integration of AI in various industries, signaling a new era of AI applications.
AI Safety & Alignment
- Deliberative Alignment Techniques: @woj_zaremba emphasized the importance of deliberative alignment through chain of thought reasoning, enhancing the safety and effectiveness of AGI systems.
- AI Model Prompting and Behavior: @giffmana and @abbcaj explored the impact of prompting on AI model behavior, aiming to prevent models from revealing their training origins and aligning responses with desired behaviors.
- Model Evaluation and Alignment: @jeremyphoward and @colin_de_de debated the limitations of evaluation metrics and the importance of continuous improvement in AI model alignment.
AI Infrastructure & Optimization
- Distributed Training Techniques: @ArmenAgha and @vllm_project discussed advanced parallelism strategies like tensor parallelism and pipeline parallelism, enhancing the training efficiency of large-scale models.
- FP8 Precision and Memory Optimization: @madiator highlighted how DeepSeek V3's adoption of FP8 precision reduces memory usage and training costs, promoting efficient model training.
- AI Model Deployment Flexibility: @llama_index showcased how DeepSeek-V3 can be deployed using vLLM with various parallelism and offloading configurations, providing flexibility in model deployment.
AI Development Practices
- Version Control and Collaboration: @vikhyatk shared insights on using ghstack to manage pull requests, enhancing collaboration and code management in GitHub.
- Training Schedules and Learning Rates: @aaron_defazio advocated for a linear decay learning rate schedule, emphasizing its effectiveness over other schedules in model training.
- Open-Source Contributions: @ArmenAgha and @ZeyuanAllenZhu thanked peers for citing research papers, promoting open-source collaboration, and securing resources for projects like PhysicsLM.
Memes/Humor
- AI Assistant Quirks: @francoisfleuret humorously remarked on his 8-year-old's simplistic goal of "To survive," blending parenting humor with AI aspirations.
- Tech and AI Jokes: @saranormous joked about AI model performance, saying "@Karpathy is still reading and it’s hard to deny the progress," playing on the intellectual banter within the AI community.
- Personal Anecdotes and Light-Hearted Posts:
- @nearcyan shared a humorous take on COVID-19 lockdowns, laughing about the teething issues of starting projects.
- @mustafasuleyman shared a funny observation about batteries, saying, "Lithium is finite, difficult to access, and resource intensive to mine," adding a light-hearted twist on sustainability topics.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. DeepSeek's Cost Efficiency and Comparative Performance vs. 4o
- DeepSeek is better than 4o on most benchmarks at 10% of the price? (Score: 785, Comments: 203): DeepSeek-V3 significantly outperforms GPT-4o in terms of cost-efficiency, with input processing at $0.27 per million tokens compared to $2.50 for GPT-4o, and output processing at $1.10 versus $10.00. The analysis highlights that DeepSeek-V3 offers a more economical solution, with the chart using distinct colors to compare costs and a note confirming these as the lowest available prices for each model.
- Users are discussing the privacy concerns associated with DeepSeek-V3, highlighting terms that imply data storage in Beijing, raising issues for companies wary of data privacy. Some comments suggest running the model locally as a solution, though it requires substantial hardware resources like 10 H100s.
- There is debate over the performance and reasoning capabilities of DeepSeek-V3, with some users experiencing hallucinations and errors, while others find it effective for coding tasks and appreciate its 180k context length. The model's low latency and ease of integration with apps using the OpenAI Python package are noted as significant advantages.
- The cost-effectiveness of DeepSeek-V3 and its impact on the market is a recurring theme, with users noting its promotional pricing and potential to pressure major players like OpenAI. Discussions include the model's funding by a Chinese hedge fund and the role of subsidized electricity in China, which may contribute to its lower costs.
- Deepseek v3 was trained on 8-11x less the normal budget of these kinds of models: specifically 2048 H800s (aka "nerfed H100s"), in 2 months. Llama 3 405B was, per their paper, trained on 16k H100s. DeepSeek estimate the cost was $5.5m USD. (Score: 518, Comments: 58): DeepSeek v3 was trained on 2048 H800s (referred to as "nerfed H100s") over a span of 2 months, costing approximately $5.5 million USD. In contrast, Llama 3 405B utilized 16,000 H100s for its training, highlighting a significant difference in resource allocation between the two models.
- DeepSeek v3 Performance and Limitations: Users shared experiences with DeepSeek v3, noting its smaller context window compared to Claude 3.5 Sonnet and its lack of multimodal capabilities, leading to performance issues in certain tasks. Despite these limitations, DeepSeek offers a better cost-value ratio at only 2% of the cost of Claude.
- FP8 Mixed Precision Training: The introduction of FP8 mixed precision training was highlighted for its increased efficiency, offering 2x higher FLOPs throughput and 50% lower memory bandwidth usage compared to FP16/BF16. This efficiency is achieved through reduced GPU memory usage and accelerated training, although the actual efficiency gain might be closer to 30%.
- Mixture of Experts (MoE) Insights: There was a discussion on the Mixture of Experts (MoE) approach, emphasizing that MoE can reduce compute requirements compared to monolithic models. The conversation clarified misconceptions about MoE, stating that active effort is made to prevent experts from overspecializing, contrary to some beliefs that MoE involves training small models in parallel.
- DeepSeek V3 was made with synthetic data for coding and math. They used distillation from R1(reasoner model). Also they implemented novel Multi-Token Prediction technique (Score: 136, Comments: 19): DeepSeek V3 was developed using synthetic data focused on coding and math, employing a Multi-Token Prediction technique and distillation from an R1 reasoner model. The model was trained on a budget 8-11 times less than typical models, with more details available in their paper.
- The Multi-Token Prediction technique is a significant point of interest, with inquiries about its novelty and scale. It is not the first model to implement this technique, but it is notable for its scale; earlier models and research can be found in the paper "Better & Faster Large Language Models via Multi-token Prediction" on Hugging Face.
- There is a discussion on the feasibility of running DeepSeek V3 with its 600 billion parameters, which is considered challenging for non-server infrastructure. A suggested setup includes an 8 x M4 Pro 64GB Mac Mini Cluster costing approximately $20k, with curiosity about cheaper alternatives using NVIDIA cards.
- The model's development with only $5 million of training resources is deemed impressive, and the open-sourcing of the paper is appreciated, particularly for its potential in coding applications. An overview of the model is available here.
Theme 2. DeepSeek-V3 Architecture: Leveraging 671B Mixture-of-Experts
- DeepSeek has released exclusive footage of their AI researchers training DeepSeek-V3 671B Mixture-of-Experts (MoE) on 2048 H800s. (Score: 717, Comments: 60): DeepSeek has released footage of their AI researchers training DeepSeek-V3, a 671 billion parameter Mixture-of-Experts (MoE) model, using 2048 H800 GPUs.
- DeepSeek-V3's Architecture: The model is composed of 256 separate models with shared components, specifically 257 MLPs per layer, contributing to a total of 37 billion activated parameters per layer. This structure allows for efficient training and inference, even on CPUs, as highlighted by ExtremeHeat and OfficialHashPanda.
- Global AI Competition and Talent: Discussions touched on the geopolitical aspects of AI development, with concerns about brain drain in Russia and the US losing talent due to bureaucratic hurdles and lack of funding. There were also mentions of Chinese students facing difficulties in the US, which may lead to them returning to China, where universities like 清华 and Peking offer competitive education.
- Cost Efficiency of DeepSeek: Despite the massive scale of DeepSeek-V3, it reportedly cost only $8-10 million to train, showcasing a stark contrast to OpenAI's $1.6 million expense for a single evaluation on O3. This efficiency is attributed to the model's innovative architecture and parallel training approach.
- New model from qwen of sonnet level soon ? (Score: 225, Comments: 30): Junyang Lin hinted at a potential new model release by responding with "Wait me" to Knut Jägersberg's desire for a "sonnet level 70b LLM" in a Twitter exchange dated December 27, 2024. The tweet garnered moderate engagement with 228 views and 17 likes.
- Local Models vs. API Costs: Several users express a preference for running LLMs locally due to the cost savings and independence from API-based models. m98789 highlights the benefits of free and open weights that allow for local execution, contrasting it with expensive API services.
- Model Size and Accessibility: Only-Letterhead-3411 notes that a 70B LLM is an ideal size for home use without significant cost, and Such_Advantage_6949 adds that with hardware like 2x3090 GPUs, it is feasible to run efficiently. They also speculate that as technology advances, larger models like 100B might become the new standard.
- Opinions on Model Announcements: EmilPi criticizes teaser posts as distracting and not substantial news, while others like vincentz42 humorously speculate on the reveal of a 1T MoE model with 70B active parameters, highlighting the community's mixed feelings on model announcements and their impact.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. OpenAI's Growing Capital Needs and Funding Plans
- OpenAI says it needs 'more capital than we’d imagined' as it lays out for-profit plan - I mean, he did say $7 Trillion... (Score: 297, Comments: 72): OpenAI has announced that it requires more capital than initially anticipated for its operations, highlighting potential funding challenges. The discussion references a previous statement estimating a need for $7 trillion, indicating the significant scale of financial requirements for OpenAI's for-profit plans.
- Discussions highlight skepticism about OpenAI's financial strategy, with some users questioning the validity of the $7 trillion figure and suggesting it might be a result of rumor rather than fact. Sam Altman is noted to have denied calling for $7 trillion, though some believe the number is not far-fetched given the rising costs of AI development.
- Concerns about OpenAI's business model are raised, with suggestions to emulate Apple's app platform approach by allowing developers to publish AI applications and take a percentage cut. Users also point out the absence of an app platform for exploring ChatGPT-based applications as a potential revenue stream.
- The departure of high-level staff and the potential influence of Deepseek's achievements are discussed, with speculation that Deepseek achieved similar results at a lower cost by utilizing synthetic data from OpenAI. This raises questions about OpenAI's competitive edge and strategic direction.
Theme 2. Criticism of 'Gotcha' Tests to Determine LLM Intelligence
- Is back! (Score: 299, Comments: 38): The post humorously depicts a conversation with ChatGPT, where the AI responds to a user's inquiry about its status with a playful reference to a "glitch in the Matrix." The interaction continues with an enthusiastic description of capybaras, highlighting the AI's ability to engage in light-hearted and conversational exchanges.
- Language and Humor: A light-hearted exchange about language use occurred, with commenters joking about grammar mistakes and emphasizing the importance of humor in online interactions.
- AI and Generational Impact: A discussion emerged about the implications of growing up with ubiquitous AI, with some expressing concern about future generations' dependency on technology.
- Capybara Fascination: The conversation humorously touched on the interest in capybaras, with a user sharing a YouTube link illustrating their calm nature coexisting with crocodiles.
Theme 3. AI and Mathematics: Progress and Limitations Highlighted
- Can AI do maths yet? You might be surprised...Thoughts from a mathematician. (Score: 133, Comments: 40): The post shares a link to an article from Hacker News about AI's current capabilities in mathematics, offering insights from a mathematician's perspective. The discussion invites readers to explore the article and share their thoughts on AI's ability to perform mathematical tasks.
- Mathematics Competitions Misleading Descriptions: The comment by FateOfMuffins highlights that labeling competitions like IMO and Putnam as "high school" and "undergraduate" level is misleading, as these are significantly more challenging than typical courses. This misrepresentation can confuse the general public about AI's capabilities in math, as the AI might perform well in these contests but not necessarily reflect the average undergraduate level.
- AI Performance on Mathematical Tasks: SoylentRox questions how AI would fare in a math setting compared to human mathematicians, especially in terms of partial credit and the accuracy of answers. The discussion suggests that even skilled human mathematicians might struggle with the precision required in these tests, raising questions about AI's comparative performance.
- Perception of AI's Mathematical Abilities: Mrb1585357890 and soumen08 appreciate the shared article for its insights into AI's current mathematical capabilities. The discussion reflects on how articles and discussions help clarify the progress and limitations of AI in performing complex mathematical tasks.
AI Discord Recap
A summary of Summaries of Summaries by o1-mini-2024-09-12
Theme 1: DeepSeek Dominates the AI Race**
- DeepSeek V3 Crushes Competitors with 60 Tokens/sec: DeepSeek V3 outperforms previous iterations by processing 60 tokens per second, a 3x speedup over V2, and boasts a massive 64k context window for handling extensive tasks. This open-source powerhouse is reshaping benchmarks, challenging giants like Claude Sonnet and ChatGPT in the AI landscape.
- License Wars: DeepSeek Makes Moves: DeepSeek has updated its license to be more liberal than Llama, sparking community debates about open-source versus proprietary models. This shift positions DeepSeek V3 as a frontrunner in the open-source AI model arena, fueling "License wars!" among enthusiasts.
- Reasoning Loops? DeepSeek V3 Faces Challenges: Despite its impressive speed, DeepSeek V3 encounters issues with reasoning loops and generating coherent outputs beyond certain layers. Users report "garbage" outputs, highlighting ongoing challenges in scaling AI reasoning capabilities.
Theme 2: Integrating AI Like a Pro (or Not)**
- Cursor IDE and Codeium Struggle with Performance: Developers using Cursor IDE and Codeium (Windsurf) report frustrations with slow requests and system hang-ups, especially on the Pro plan. Calls for enhanced shortcuts and better context management are loud, as users seek smoother AI-assisted coding workflows.
- Aider's Update: More Models, Less Errors: The latest Aider v0.70.0 introduces support for o1 models and improved error handling, praised by contributors for its simpler install methods. This update aims to streamline coding assistance, making Aider a more robust tool in the developer's arsenal.
- OpenRouter's ACE Moves with DeepSeek Integration: OpenRouter sees DeepSeek V3 usage triple since its launch, with integrations aiming to harness custom API keys and lower costs. This synergy is expected to enhance coding tasks, although some users question the long-term stability amid "License wars!".
Theme 3: Ka-Ching! Pricing Models Shake Up AI Access**
- DeepSeek V3 Slashes Training Costs by 100x: With an investment of $5.5M, DeepSeek V3 achieves a two-orders-of-magnitude cost reduction for training using FP8 mixed precision. This breakthrough makes advanced AI models more accessible, challenging high-cost counterparts.
- AI Pricing Transparency: Developers Demand More: Conversations around AI model pricing emphasize the need for cost transparency, especially when balancing performance with expense. Tools like Claude Sonnet and DeepSeek Platform are under scrutiny as users seek clearer value propositions for their coding and development needs.
- Perplexity's Pricing Puzzle: Users report image embed limits inconsistencies on Perplexity AI, expecting 400 per minute instead of 40. With promises of fixes delayed by holiday hours, the community voices frustration over pricing structure myths, urging companies to align pricing with performance.
Theme 4: GPU Gurus and Training Tricks**
- H800 GPUs: The Hacked H100 for Cost Efficiency: The deployment of H800 GPUs, essentially nerfed H100s, has led to reduced NVLink bandwidth but maintains vital FP64 performance. This strategic move allows DeepSeek V3 to train massive models like 600B MoE efficiently across 2000 GPUs in just 2 months.
- Triton vs. CUDA: The Ultimate Showdown: Discussions on implementing quantization highlight whether to use Triton or stick with pure CUDA, balancing ease of use with speed. The community debates the merits of integrating specialized kernels like bitblas for Conv2D operations to boost efficiency.
- FP8 Training Fuels New Coding Ventures: Inspired by DeepSeek’s FP8 approach, developers are eager to incorporate FP8 training into nanoGPT using torchao's frameworks. This interest underscores the community’s drive towards energy-efficient training and scalable model inference.
Theme 5: Creativity Meets Code (and Ethics)**
- AI Just Wants to Write: Creative Writing and Roleplay Skyrocket: AI tools like Aider and Gen AI are revolutionizing creative writing and erotic roleplay (ERP) with advanced prompts and immersive character development. Users praise the ability to build detailed character profiles and dynamic interactions, enhancing the AI-assisted storytelling experience.
- Ethical Dilemmas: AI Scrapes Without Consent: Community members voice serious concerns over AI ethics, particularly the scraping of creative works without permission. Debates rage over the scope of derivative content and the influence of corporate lobbying on copyright laws, urging more ethical AI development practices.
- 3D Printing and AI Art: A Tangible Fusion: The fusion of 3D printing with AI-generated visuals opens new avenues for inventive outcomes, such as quirky objects like sheep-shaped toilet paper holders. This intersection showcases the creative potential of LLMs in tangible fabrication, blending digital creativity with physical production.
PART 1: High level Discord summaries
Cursor IDE Discord
- Cursor IDE's Context Conundrum: Users discovered slow requests, limited multi-file handling, and frustrations with context usage when exploring Cursor IDE docs.
- They suggested adding shortcuts to expedite the workflow, referencing ongoing feedback on the community forum.
- DeepSeek V3's Duel With Claude Sonnet: According to DeepSeek's official tweet, DeepSeek V3 hits 60 tokens/second, retains API compatibility, and claims open-source transparency.
- However, community comparisons with Claude Sonnet highlight more refined coding capabilities, as hinted by a Visual Studio Code tweet praising Claude 3.5 Sonnet.
- Cost Crunch & Efficiency Chat: Participants weighed AI model pricing in relation to performance, emphasizing cost transparency across tools like Claude Sonnet and DeepSeek Platform.
- Some voiced interest in robust value propositions for coding tasks, while others lamented the uncertainty in pricing structures for advanced AI solutions.
Codeium (Windsurf) Discord
- Windsurf Wows with a Behind-the-Scenes Video: The new video from Windsurf reveals the engineers’ approach to building Windsurf, spotlighting distinct techniques and holiday spirit.
- They teased how the team dared to reshape standard coding workflows, encouraging watchers to try out their boundary-pushing approach.
- Performance Pitfalls & Pro Plan Perplexities: Multiple users reported system slowdowns and steep credit usage on the Pro plan, triggering concerns over monthly request limits.
- They linked to docs about credit usage, venting that uncontrollable hang-ups hinder coding goals.
- DeepSeek V3 Sparks Curiosity: Many participants praised DeepSeek V3 for its speed and open-source benefits, anticipating possible Windsurf integration.
- Others weighed Cursor as a substitute, citing custom API keys and lower costs for coding tasks.
- IDE Hiccups & M1 Mix-Ups: Users encountered plugin glitches in WebStorm and IntelliJ, including missing features after updates.
- A Macbook M1 Pro user discovered Windsurf’s terminal was running under i386, seeking Apple Silicon compatibility tips.
- Cascade's Global Rules Stir Up Conversation: Some recommended broad rules in Cascade to unify code style and limit confusion, particularly in large teams.
- They requested insights on which guidelines are helpful, hoping to keep future coding sessions consistent.
aider (Paul Gauthier) Discord
- Aider v0.70.0 Amplifies Upgrades: The new Aider v0.70.0 offers o1 model support, analytics opt-in for 10% of users, and better error handling to streamline coding tasks.
- Contributors praised its new install methods and simpler read-only file display, highlighting broader model compatibility for coding assistance.
- DeepSeek V3 Rockets on M4 Pro Minis: Running the 671B DeepSeek V3 on a cluster of 8 M4 Pro Mac Minis hits 5.37 tokens/s with a 2.91s time to first token, signaling robust local inference potential.
- Community chatter contrasted this speed with Claude AI and Sonnet, citing lower overhead and improved scalability for high-volume usage.
- Repo Maps & Token Limits in Aider: Members reported the repo-map feature acting differently in Architect mode versus standard editing, alongside DeepSeek Chat V3’s jump to 64k input tokens.
- They suggested editing .aider.model.metadata.json to handle the new limits and refine how the model interacts with complex codebases.
- Git Tools Render Code in Dramatic Formats: The GitDiagram site transforms GitHub repos into interactive diagrams, while Gitingest extracts them into prompt-friendly text.
- Users found switching 'hub' to 'diagram' or 'ingest' in any GitHub URL helpful for quick project overviews and simpler LLM ingestion.
Eleuther Discord
- Trainer Tweak Sparks New Loss Tricks: A member asked how to modify Hugging Face's Trainer for causal language modeling, focusing on zeroing out padded tokens and ignoring input tokens in the loss computation.
- They referenced the trl library and recommended using a custom collator to set labels to
ignore_idxas a workaround.
- They referenced the trl library and recommended using a custom collator to set labels to
- Pythia's Hunt for Mid-Checkpoint States: A user requested intermediate optimizer states from the Pythia model, noting that only final checkpoint states were available.
- They planned to contact staff for large file access, hoping for an easier handoff of Pythia resources.
- Physicist Ready to Tackle ML: A near-graduate in theoretical physics introduced plans to explore machine learning and LLMs for deeper insight into interpretability.
- They showed enthusiasm for contributing to research projects and gaining practical skills in advanced modeling.
- Causality Boosts Training Chatter: Participants weighed how causal inference might improve model training by leveraging prior dynamics instead of relying on pure statistical trends.
- They debated representations that allow chunking knowledge, citing examples like blindfold chess as a case of efficient mental structures.
- Video Models Flop at Physics Lessons: Members argued that video generation models often miss the mark when trying to extract genuine physical laws from visuals, even at larger scales.
- They pointed to a comprehensive study that questions whether these models can develop robust rules without human insight.
OpenRouter (Alex Atallah) Discord
- DeepSeek v3 Triples Usage & Rivaling Big Names: The usage of Deepseek v3 soared on OpenRouter, tripling since yesterday, as seen in this tweet.
- Some industry voices claim that frontier models now cost about $6M to build and that China plus open source have approached leading AI performance, fueling hopes for Deepseek v3.
- ACT & CIMS Power Developer Routines: The AI Chat Terminal (ACT) integrates with major APIs, letting developers run tasks and chat with code in their terminals, as shown on GitHub.
- Meanwhile, the Content Identification/Moderation System (CIMS) adds automated detection and removal of problematic content in Companion, explained on their wiki.
- RockDev Gains Momentum for SQL Generation: The RockDev.tool converts code definitions into ready-to-use SQL using OpenRouter while preserving local privacy, as outlined at rocksdev.tools.
- Community feedback highlighted local data handling as a major draw, with plans for future updates.
- Google Search Grounding Ties AI to Web: A developer showcased a method that uses the Google GenAI SDK for grounding responses before web search, as detailed on GitHub.
- This approach relies on Google search for context, opening possibilities for verifying AI outputs in real time.
- OCR & OWM Extend LLM Horizons: Fireworks added OCR support for images and PDFs, while Pixtral handles text extraction for advanced document processing.
- Discussions of Open Weight Model (OWM) and Out-of-Domain (OOD) tasks underscored how many models excel at known data but face challenges outside their training scope.
Nous Research AI Discord
- DeepSeek Derailed by Reasoning Loops: Members revealed that Deepseek V3 stumbles with logic, citing DeepSeek V3 PDF for details on how repeated cycles hamper complex tasks, especially past a certain layer count.
- They pointed out that garbage outputs frequently appear, with some calling out potential flaws in the underlying RPC code and raising questions about training on reasoning chains.
- RoPE’s Recurring Riddle in DeepSeek V3: The group debated RoPE usage in Deepseek V3, noting it’s only applied to one key while referencing the separate embedding index approach for positioning.
- Some questioned whether a simplified method might improve results, highlighting how position encoding complexities can significantly affect model accuracy.
- Qwen-2.5-72b Surges in Re-tests: Aidan McLau’s tweet showed surprising re-test gains for Qwen-2.5-72b, which initially performed poorly but jumped to top-tier results in repeated benchmarks.
- Commenters wondered if benchmark fairness was compromised or if re-runs simply used better hyperparameters, with some referencing Better & Faster Large Language Models via Multi-token Prediction for training insights.
- Gemini’s Context Conundrum: Some noted that the Gemini model’s context usage might handle input more flexibly, though it needs to stay within its set parameters.
- They speculated on how advanced context selection methods might shift environment input, referencing its second-place rank on aidanbench.
- Copilot Tackles Complex Code: Members praised GitHub Copilot for quick fixes and refactoring tasks in simpler projects.
- However, they found that advanced systems like llama.cpp require deeper manual handling, showing that AI-driven editing can’t fully replace thorough code comprehension.
LM Studio Discord
- Ethical AI Tools Brawl: One user blasted the scraping of creative works without permission as deeply troubling for AI ethics.
- Others pointed to corporate influence on copyright laws and questioned the scope of derivative content.
- LM Studio Gains Speed: Some users reported a jump in processing rates from 0.3 to 6 tok/s after upgrading to the latest LM Studio Beta Releases.
- They used GPU monitoring tools to confirm better performance, tying success to robust hardware setups.
- Image Generation Stumbles: A user aimed to refine AI image generation but met skepticism over the feasibility of achieving better outputs.
- Conversation focused on how these models interpret creativity, revealing doubts about genuine improvements.
- MLX Memory Leaks Alarm: Participants reported memory leaks with MLX builds, referencing Issue #63 as evidence.
- They traced performance drops to potential resource mismanagement, prompting further investigations.
- GPU Crunch & RPG AI Scenes: Multi-GPU setups, VRAM needs for massive models, and low CUDA occupancy at 30% stirred excitement among hardware enthusiasts.
- Meanwhile, agentic frameworks like LangChain were cited for RPG scenario generation, prompting talk of synergy between hardware and storytelling.
Unsloth AI (Daniel Han) Discord
- LoRA vs Full Model Weights: Fine-tuning Faceoff: Multiple users discussed fine-tuning with LoRA instead of merging the full model, highlighting efficiency gains in hosting and inference, with an example in Unsloth Documentation.
- They emphasized that LoRA operates as an adapter, and one user stressed that prompt formatting and data alignment are crucial for stable finetuning.
- Dynamic Adapter Fails in Hugging Face: A newbie tried dynamic adapter loading through Hugging Face and ended up with garbled outputs, as shown in this Gist.
- Someone suggested using VLLM for better performance, contrasting Hugging Face's slower inference and commending Unsloth Inference for reliable adapter handling.
- Python Instruction Tuning Treasure Hunt: A member sought instruction-tune datasets with problem descriptions and generated solutions, specifically for Python coding tasks, referencing Hugging Face's smol-course.
- They wanted a dataset that caters to real coding insights, with others confirming that curated data can greatly impact final model performance.
- Binary Tensor Cores on Hopper: HPC or Bust?: One user worried about binary tensor core support being removed after Ampere, questioning Hopper's readiness for ultra-low precision HPC tasks.
- Communal speculation arose over NVIDIA's future directions, with some participants doubting the continued availability of low-precision instructions.
- GGUF & 4-bit Conversion Roadblocks: A user encountered RuntimeError when generating GGUF models and found missing files like tokenizer.json, pointing to the official llama.cpp for solutions.
- Others suggested copying necessary model files and disabling 4-bit loading for vision layers, underscoring the complexity in partial quantization.
OpenAI Discord
- DeepSeek V3 Wows with 64k Context: The newly mentioned DeepSeek V3 claims a 64k context window, advanced mixture-of-expert architecture, and cost-effective local inference according to DeepSeek V3 docs.
- Community testers considered switching from ChatGPT outages to DeepSeek for specialized tasks, praising faster responses and better large-context support.
- GPT-03 (o3) Nearing Launch: Developers predicted a late January debut for o3-mini, followed by the full o3, with usage limits still unconfirmed.
- Speculation touched on possible enhancements over existing GPT models, but official details stayed scarce.
- ChatGPT's Downtime Dilemma: Frequent ChatGPT outages caused error messages and service interruptions across platforms, as shown on OpenAI's status page.
- Some members joked about 'fix' announcements that didn't stick, while others tested different AI solutions, highlighting the downtime's impact.
- MidJourney vs DALL-E: The Visual Clash: Enthusiasts compared MidJourney to DALL-E, emphasizing better results for intricate prompts and improved visuals in the latest DALL-E version.
- They recalled older model shortcomings, praising recent updates that tighten artistic quality and user satisfaction.
Stackblitz (Bolt.new) Discord
- Gabe’s Stealthy Simplification: Attentive watchers highlight Gabe’s new Bolt-powered app, rumored to simplify workflows for everyone, though no official features were shared.
- Early glimpses provoke hype, with some members describing it as 'the next big convenience' for dev teams.
- Anthropic Overload Wrecks Bolt: Members reported a massive quality drop on Bolt whenever Anthropic switched to concise mode, causing repeated flops in response generation.
- Users demanded better scheduling or warnings, with one voice labeling the experience 'a total meltdown' and urging real-time collaboration fixes.
- Direct Code Change Prompting: Some developers struggled with the chatbot returning raw code blocks instead of editing existing scripts in Bolt, stalling debugging.
- They shared a tip to explicitly say 'please make the changes to my code directly' in prompts, claiming that approach reduces friction.
- OpenAI Setup Stumbles in Bolt: A wave of confusion hit users trying to integrate OpenAI with Bolt, with recurring errors on API key submission.
- Some recommended joining the Bolt.diy community or checking Issues · stackblitz/bolt.new for timely solutions.
- Netlify 404 Headaches: A group encountered 404 errors on Netlify, attributing them to client-side routing in their Bolt apps.
- Workarounds existed but required experimentation, including multiple attempts at custom route settings or fiddling with serverless functions.
Perplexity AI Discord
- OpenAI's Humanoid Hustle: Recent chatter spotlighted OpenAI's humanoid robot plans, outlined in this documentation, noting mechanical specs, projected release timelines, and integration with advanced AI modules.
- Participants shared hopes that these robots might accelerate human-robot collaboration, proposing that future software enhancements could align with an upcoming architecture showcased in other robotic projects.
- AI's Surprising Shift: An ongoing highlight covers how AI pretends to change views, featuring a surprising demonstration in this YouTube video.
- Community members discussed concerns about manipulability in AI and considered potential safeguards, noting direct quotes about the model's shifting stance being unsettling yet technically revealing.
- Body-charged Wearables: New body-heat powered wearables surfaced in discussion, seen in this link, highlighting prototypes that supply low-power consumption devices without external charging.
- Engineers debated sensor accuracy and long-term stability, emphasizing temperature differentials as a fresh energy source for constant data collection.
- Video Aggregators in the Making: Some users looked for an AI video creation aggregator that merges multiple services, fueling a lively brainstorm on existing workflows.
- They traded suggestions on pipeline assembly, hoping for a consolidated tool to streamline multimedia production and synchronization.
- Perplexity's API Conundrum: Developers criticized the Perplexity API, calling it weaker than OpenAI, Google, or Anthropic alternatives, prompting questions about capacity limits and response quality.
- Others noted that Spaces offers smoother integration and that Perplexity's lack of custom frontend support is a deal-breaker for advanced user experiences.
Stability.ai (Stable Diffusion) Discord
- Hunyuan Hustles Higher in Video Land: Members reported that Hunyuan outperforms Veo and KLING, with hopes of further gains from DiTCtrl.
- They stressed the importance of reliability and continuity in AI video generation, anticipating fresh attention-control strategies.
- Prompting Perfection: Tags vs. Detailed Text: Participants contrasted flux/sd3.5 which handle longer prompts with sd1.5/sdxl, which often work best with shorter tags.
- They exchanged tips on balancing highlight keywords and extended descriptions to refine outputs.
- Lora Linkups for Legacy Models: Some asked about upgrading older models for newer Loras, concluding refitting Loras is more practical than altering base checkpoints.
- They agreed that well-tuned Loras outperform forced adjustments to existing model weights.
- Sluggish Speeds Squeeze AI Video Rendering: Users described rendering of 5 seconds in about 8 minutes, attributing it to current GPU limitations.
- They remain optimistic that new GPU tech and improved model designs will trim these lengthy render times.
- 3D Printing Collides with AI Art: A contributor highlighted printing quirky objects, like a sheep-shaped toilet paper holder, as a fun application of 3D printing.
- They see potential in melding AI-generated visuals with tangible fabrication for more inventive outcomes.
Notebook LM Discord Discord
- Pathfinder Podcast in a Flash: A user used NotebookLM to generate a 6-book campaign summary for Pathfinder 2 in about 15 minutes, referencing Paizo's 2019 release and highlighting streamlined GM prep time.
- They spoke of 'drastically cutting prep efforts,' which drove community discussions about fast, AI-driven narrative generation.
- Captivating Wikipedia Audio Overviews: Members used NotebookLM to create audio syntheses of news articles and Wikipedia entries, including the 2004 Indian Ocean Earthquake and its approaching 20-year marker (December 2024).
- One member described the output as 'astonishingly lifelike,' prompting more talk about large-scale knowledge distribution in audio form.
- Mic Mishaps in Interactive Mode: Several users flagged an endless loading glitch in NotebookLM's interactive mode when microphone permissions were blocked, noting it persisted until browser settings were updated.
- They shared tips for enabling mic access to sidestep the issue, fueling threads on ensuring hardware compatibility for smooth AI usage.
- Tabular Twists for Fiction Writers: A user questioned whether NotebookLM can handle tabular data, specifically for a character matrix to assist in writing fiction.
- The community wondered if structured data could be parsed effectively, suggesting an exploration of potential text-to-table features.
- Podcast Platforms for AI Creations: A user introduced Akas for sharing AI-generated podcasts, spotlighting RSS feed integration and mobile-friendly publishing.
- Members also inquired about the NotebookLM Plus tier, referencing the official subscription guide to confirm pricing and new features.
Interconnects (Nathan Lambert) Discord
- DeepSeek V3 Races Ahead: DeepSeek V3 launched at 60 tokens/second (3x faster than V2), as described in this tweet, and supports FP8 training on both NVIDIA and AMD GPUs. The license is now more liberal than Llama, sparking so-called license wars among community members.
- Community comments applauded the team’s engineering excellence under tight hardware constraints, while discussions centered on potential pitfalls of self-critique in code and math. One participant exclaimed 'License wars!' capturing the mixed reactions.
- Mighty Multi-Head Moves: DeepSeek’s Multi-Head Latent Attention raised questions on implementing lower rank approximations, with SGLang offering day-one support in V3. Observers noted that vLLM, TGI, and hf/transformers might add compatibility soon.
- A user asked 'Is anyone working on creating a version?' reflecting the community’s push to adapt this technique. Another person planned to check the Hugging Face side, aiming to sync efforts for better adoption.
- OpenAI Overhauls & Bluesky Blowup: OpenAI’s board intends to form 'one of the best-resourced non-profits in history,' per this announcement, while IPO rumors swirl given investor pressure and rising capital needs. Meanwhile, Bluesky’s insane anti-AI strain has made the platform unwelcoming for AI discussions.
- Some predicted OpenAI will go public if further funding outstrips the scope of Venture Capital. A user repeated 'Bluesky is unsafe for AI discussions' after witnessing harsh backlash against generative AI.
- MCTS Method Muscles Up Reasoning: An MCTS-based approach adds step-level signals through Direct Preference Optimization to refine LLM reasoning, emphasizing on-policy sampling for robust self-improvement. Evaluations suggested significant gains in iterative performance over older RL setups.
- Skeptics questioned the models’ overall caliber, with one remarking 'Idk why they used such poop-tier models though - was may 2024 that down-bad?'. Others debated whether PRMs truly produce better Chains of Thought or if alternative methods might yield superior results.
GPU MODE Discord
- DeepSeek Dashes Dollars for FP8 Gains: After raising 5 million USD, DeepSeek-V3 showcases a two-orders-of-magnitude cost reduction for training with FP8 mixed precision, as detailed in their doc.
- They logged 2.788 million H800 GPU hours, prompting heated comparisons between channel-wise and block-wise quantization approaches, with a mention of TransformerEngine’s accumulation precision.
- Character.AI's Int8 Trick for Inference Quickness: Character.AI introduced a custom int8 attention kernel to boost speed for compute-bound and memory-bound operations, described in their new post.
- They previously targeted memory efficiency with multi-query attention and int8 quantization, now shifting focus to performance gains in core inference tasks.
- BitBlas Meets Torch for Conv2D: One user asked if bitblas could generate a Conv2D for direct integration in Torch, hoping for more efficient training flows.
- Others showed interest in merging specialized kernels like bitblas with mainstream frameworks, hinting at future expansions of these possibilities.
- vLLM Delays Batch for xFormers Speed: A discussion highlighted vLLM opting against batched inference, using the xFormers backend instead, as seen in their code.
- This strategy leverages a sequence-stacked approach with minimal latency differences, raising questions about any real advantage of batching for throughput.
- Torchcompiled's 128-Fold Forward Tussle: One user noted Torchcompiled demands 128 forward passes for a gradient estimate, yielding only 0.009 cosine similarity with the true gradient, referencing this tweet.
- A cited paper from Will claims training in 1.58b with 97% less energy, storing a 175B model in just ~20mb, intensifying debate on feasibility beyond small-scale demos.
tinygrad (George Hotz) Discord
- Bounty Battle for Faster Matching: The Tinygrad community is pursuing three performance bounties referenced in this GitHub issue, targeting an accelerated matching engine for a model lower result on benchmarks.
- George Hotz specified that winning the bounty hinges on a 2x speedup, suggesting a pull request with demonstrated improvements to claim the reward.
- Rewrite Speed Shocker: A member witnessed a rewrite running in 800+ ms on an RTX 3050, raising questions about hardware constraints and inconsistent results.
- A screenshot revealed a stark difference compared to the reported 25 ms performance, prompting calls for thorough testing.
- Tinygrad’s JIT Challenges PyTorch: By leveraging JIT across all layers, Tinygrad now matches PyTorch in inference performance, highlighting how minimal Python overhead amplifies speed.
- Users averted out of memory errors by enabling JIT on the full transformer, underscoring that selective usage can hamper reliability.
- Beam Search Caching Trick: Contributors confirmed that beam search kernels can be stored and reused, reducing re-compilation steps for subsequent runs.
- They recommended sharing these cached kernels across systems with the same hardware, skipping needless re-execution.
- TTS Model Heads to Tinygrad: Work continues on shifting a TTS model from Torch to Tinygrad, referencing fish-speech/fish_speech/models/text2semantic/llama.py and llama-tinygrad/llama_tinygrad.ipynb.
- Developers aim for results on OpenCL nearing torch.compile, with a minimal reproducible example in the works to tackle early hiccups.
Cohere Discord
- Command R+ Contemplates Upgrades & r7b Reactions: Community members mulled over future improvements for Command R+ after encountering minor usage issues, referencing initial tests with r7b.
- Skepticism arose on r7b’s performance compared to Command R, spurring calls for more details in the official changelog.
- Image Embed Limit Mystery: Users reported confusion over image embed limits (40 per minute vs. an expected 400), referencing production key usage and Cohere’s pricing docs.
- Teams acknowledged the mismatch and promised a fix, though holiday hours might delay restoring the 400 embed limit.
- CIMS Catapults Companion’s Moderation: The Content Identification/Moderation System (CIMS) was rolled out to Companion, automating detection and management of harmful content.
- It enables direct deletion of flagged text to foster safer interactions, as detailed in the Companion wiki.
- Command R Showcases RAG at Scale: Command R supports contexts up to 128,000 tokens and cross-lingual tasks, powering advanced multi-step tool use.
- The Command R+ variant amplifies these capabilities with stronger complex RAG performance, fueling business-centric solutions.
Latent Space Discord
- Orion & OpenAI: The Tardy Duo: Members discussed Orion delays referencing a Hacker News item, focusing on potential impacts for future projects.
- They also noted a new outage affecting OpenAI services, recalling the rocky reliability from January 2023.
- Deepseek Goes Easy on the Wallet: The group highlighted Deepseek’s pricing at $0.27/MM in and $1.10/MM out starting in February, finding it reasonable for its performance.
- However, they mentioned that while it excels at simpler tasks, it struggles with post-training reasoning for complex requests.
- Illuminate: A NotebookLM-Like Experiment: Several participants tried Illuminate, referencing its official site, describing it as a tool for analyzing technical papers.
- Reviews were varied, noting that separate development teams led to differences from other existing solutions.
- Frontier vs Foundation: Buzzword Warfare: Talks on Frontier vs Foundation models underscored that 'Frontier' suggests cutting-edge performance as new releases appear.
- Members acknowledged that 'Foundation' references older efforts while 'Frontier' remains ambiguous but currently in vogue.
- NYC Summit & Calendar: April 2025 Awaits: Organizers promoted the AI Engineer Summit NYC at The Times Center in April 2025, sharing updates on lu.ma.
- They invited subscriptions via RSS to track events, emphasized 'Add iCal Subscription,' and confirmed zero pending events for now.
LlamaIndex Discord
- Report Agent Magic with LlamaParse: A new video shows how to build an agent workflow for generating formatted reports from PDF research papers using LlamaParse and LlamaCloud, as seen at this link.
- Community members praised the approach's success using an input template, spotlighting LlamaCloud for handling large PDF files.
- One Million PDF RAG Chat: A detailed thread reveals how a conversational voice assistant can integrate RAG with 1M+ PDFs through LlamaCloud, demonstrated at this link.
- Users noted improved interactions, crediting the pipeline’s high-volume document processing for more robust user queries.
- LlamaIndex Docs & Roadmap Overhaul: A member requested a PDF version of LlamaIndex documentation for a RAG app, confirming it can be generated on demand.
- Others pointed out the pinned GitHub roadmap is outdated (from early 2024), calling for an official revision.
- Ollama vs. Llama3.2 Vision Test: Members grappled with running non-quantized models in Ollama for RAG, finding limited unquantized support.
- They pivoted to Llama3.2 11B vision for table extraction, reporting better success due to different image handling.
- Docling from IBM Jumps In: IBM's Docling arrived as an open source system for preparing documents for AI, introduced via this YouTube video.
- This resource was shared as a possible enhancement for LlamaIndex users seeking to structure data more effectively.
Torchtune Discord
- Flex Fights Breaks & Nested Compile Chaos: Members tackled potential graph breaks with flex, citing the need for more testing in attention_utils.py. They cautioned that performance gains might vanish if compilation isn't handled carefully.
- Others raised nested compile hurdles and dynamo errors, emphasizing a risk to stability when flex is layered inside another compile.
- DeepSeek V3 Blasts a 600B MoE in 2 Months: DeepSeek V3 ran a 600+B MoE on 2000 GPUs in only 2 months, as outlined in the DeepSeek V3 paper. Their method skipped tensor parallelism yet held its speed.
- Members were intrigued by the large-scale approach, noting that pipeline and all-to-all configurations helped manage data throughput.
- H800 GPU: The Nerfed H100 Edition: Many pointed out H800 GPUs are essentially H100 with weaker NVLink, leading to lower bandwidth. They also spotted differences in FP64 performance, prompting talk about alternative solutions under hardware constraints.
- One remark suggested that these limitations might spur progress in rethinking distributed training setups.
- FP8 Training Sparks New Efforts: Spurred by DeepSeek’s FP8 approach, someone planned to integrate FP8 training with nanoGPT using torchao's frameworks. They highlighted the need for accurate all-to-all operations to tap NVLink capacity.
- This triggered discussion about ways to balance reduced precision with stable model convergence.
- Triton vs. CUDA: The Great GPU Showdown: An ongoing debate centered on coding quantization in Triton or pure CUDA, balancing ease of use with speed. Some mentioned SM90 constraints in Triton, hinting that cutlass might be crucial for high-performance GEMM.
- They're weighing performance trade-offs carefully, trying to keep code clean without sacrificing raw throughput.
DSPy Discord
- Glossary Script Gains Momentum: A member shared a script for generating a glossary from Jekyll posts, using DSPy to handle LLM parsing into Pydantic objects.
- They mentioned that it exports a YAML file to the
_datadirectory and praised the scope of its automatically gathered terms.
- They mentioned that it exports a YAML file to the
- TypedDict Sparks Lively Debate: TypedDict introduced an alternate way to define fields, prompting discussions about Pydantic's handling of nested arrays.
- One participant highlighted the puzzle of juggling multiple output fields, but the group was intrigued by the possibilities.
- Pydantic Models Improve Prompt Schema: Members highlighted pydantic.BaseModel for structured prompt outputs, confirming that sub-field descriptions propagate correctly.
- A revised gist example was promised to demonstrate these approaches more clearly, reflecting group consensus on best practices.
Modular (Mojo 🔥) Discord
- Mojo Merch Magic: A remote-located user celebrated receiving Mojo merch, sharing an image and confirming smooth delivery even in distant areas.
- They praised the shirt quality and described a certain sticker as 'hard,' predicting it will 'do numbers for sure' among fans.
- Traits in Crosshairs: A member flagged potential issues with Copyable and ExplicitlyCopyable traits, referencing a forum post that calls for rethinking their design.
- Community suggestions aim to refine these traits for better usage, with open invitations for feedback on the same forum thread.
- MAX Goes the Extra Mile: MAX integrates kernel fusion and memory planning from XLA while adding dynamic shape support, user-defined operators, and a dedicated serving library.
- Enthusiasts call it 'XLA 2.0' due to these expanded capabilities, emphasizing its custom kernel approach for advanced workloads.
- Mojo vs Python Showdown: Debate continues on whether to build consistent Mojo APIs or double down on Python integration, with some reverting to JAX for convenience.
- A user mentioned that certain compiler optimizations must be manually overridden, highlighting the need for more direct control in Mojo compared to typical Python frameworks.
- Endia & Basalt Blues: Several participants expressed hope for a forthcoming release of Endia, noting their concerns about the stalled Basalt project.
- They indicated a temporary pause in Mojo development, waiting for clarity while still encouraging collaboration on Endia within the community.
LLM Agents (Berkeley MOOC) Discord
- Certificate or Bust: The Declaration Dilemma: Learners cannot earn a certificate without the crucial certificate declaration form, which acts as the official sign-up for completed assessments.
- Course staff labeled it their roster and stressed how essential it is for final approvals.
- January Jolt: Next MOOC on the Horizon: Late January is set as the next start date for the LLM Agents MOOC, giving participants a chance to join if they missed the current offerings.
- Attendees noted the timing, hoping to expand their large language model expertise early in the new year.
- Quiz Confines: Forms Locked Tight: The Quiz 5 - Compound AI Systems link is currently closed, stopping additional quiz submissions.
- Multiple voices requested it be reopened, emphasizing how essential these quizzes are for structured practice.
- Advanced LLM Agents: Next-Level Tactics: An upcoming Advanced LLM Agents course promises detailed agent design coverage, including advanced optimization approaches.
- Enthusiasts viewed it as the logical extension for those who completed fundamental language model lessons.
OpenInterpreter Discord
- Claude 3.5 Opus Sparks Rivalry with O1: There's excitement about the potential of Claude 3.5 Opus as it boasts improved reasoning skill.
- Many folks wonder if it can outmatch O1 and O1 Pro, indicating a lively model rivalry.
- Open-Interpreter QvQ Gains Momentum: A user asked how QvQ operates when tied into Open-Interpreter in OS mode, showing interest in direct system interactions.
- The question remains open, signaling a point for further exploration in the community.
- Generative Audio Collaboration Beckons: An AI engineer shared strides in DNN-VAD, NLP, and ASR, including a recent Voice to Voice chat app project.
- They invited others to join, hinting at possible synergy in music generation with generative AI.
Nomic.ai (GPT4All) Discord
- Copy-Button Conundrum: One user pointed out the missing copy button for code in the chat UI, and another confirmed that mouse-based cut-and-paste is not working.
- However, Control-C and Control-V remain the main workaround mentioned by the community.
- WASM Wondering: A newcomer asked about installing the AI as a WASM package, drawing attention to possible deployment methods.
- No direct response surfaced, leaving this query open for future exploration.
- Vulcan Version Void: One member repeatedly inquired about the Vulcan version but received no clarifications or details.
- The question remains unanswered for anyone familiar with Vulcan’s specifics.
- Mouse & Keyboard Quirks: Participants noted that mouse-based cut-and-paste fails on the configuration pages.
- They stressed that Control-C and Control-V are the recommended methods for copying code or text.
- New Template Trials: A member asked if anyone had tried writing with the new template, hinting at a new approach for content creation.
- The discussion showed interest in switching to fresh templates but offered few details on real-world usage.
Gorilla LLM (Berkeley Function Calling) Discord
- Scaling Shuffle on BFCL Leaderboard: In a question about inference scaling and post-training methods for the Gorilla LLM leaderboard, a member asked if BFCL allows multi-call models enhanced with repeated output selection.
- They explained that post-inference verification can tap a tool-augmented LLM multiple times for refined results, emphasizing the potential performance gains.
- Fairness Feuds: Single-Call vs Multi-Call: The same user worried that multi-call expansions might overshadow simpler single-call LLMs, calling it unfair competition on the leaderboard.
- They proposed factoring inference latency into rankings as a direct tradeoff for additional calls, hoping the community would accept this approach.
LAION Discord
- Whisper's Witty Word Wrangling: One user described how Whisper can detect sentence boundaries, enabling more accurate splitting for speech processing.
- They said using these detections can boost clarity, letting developers incorporate sentence-level breakdown in speech-based tasks.
- VAD's Silence Splitting Sorcery: Another user recommended a voice activity detector (VAD) to separate speech from silence for robust audio segmentation.
- This approach uses silence detection to refine the segmentation process and increase efficiency.
MLOps @Chipro Discord
- MLOps Solutions for HPC: One member asked for HPC-friendly MLOps frameworks that skip SaaS dependencies, citing HPC’s robust storage as a primary advantage.
- They highlighted the need for stable solutions and evaluated Guild AI’s reliability for HPC usage.
- Guild AI Growing Pains: The same user expressed concern over Guild AI’s stability, fearing potential downtime in HPC contexts.
- They sought concrete feedback on HPC deployments to confirm Guild AI’s readiness for large-scale training tasks.
- DIY Ops on a Shoestring: They also considered building a minimal ops framework themselves, seeing it as simpler than installing a server-based solution.
- They believed a custom approach might reduce overhead, while acknowledging the risk in maintaining their own toolset.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (1129 messages🔥🔥🔥):
Cursor IDE Functionality, DeepSeek V3 Performance, Claude Sonnet Comparison, Context Management in AI Tools, Model Efficiency and Costs
- Cursor IDE Functionality Under Review: Users discuss the limitations and functionality of Cursor IDE's context management, particularly around slow requests and the handling of multiple files in a chat.
- The consensus is that while the tool is effective, it often leads to user frustration with how context is handled during interactions.
- Debate on DeepSeek V3 Performance: DeepSeek V3 is compared to Claude Sonnet, with users expressing mixed opinions on its ability to handle coding tasks effectively.
- Opinions vary, with some users reporting issues with DeepSeek's performance, particularly in comparison to Claude Sonnet's superior coding skills.
- Exploring Effective Context Management: Users emphasize the importance of clear and concise prompts to manage context efficiently, which is seen as critical to the tool's functionality.
- Strategies include specifying changes clearly and using dedicated sessions for each task to maximize performance.
- Feedback on AI Tool Usability: There are calls for improvements in context management within Cursor, with users suggesting features like shortcuts to expedite the process.
- While the performance of AI tools is recognized, users want smoother and more intuitive workflows to reduce the burden of collecting context.
- User Experiences with AI Model Pricing: The conversation touches on pricing models for AI tools, with emphasis on balancing costs with the performance of various models.
- Users reflect on the value propositions of using tools like Claude Sonnet versus alternatives, indicating a desire for more transparency in pricing.
- Cursor - Build Software Faster: no description found
- Cursor - Build Software Faster: no description found
- Generate better prompts in the developer console: You can now generate production-ready prompts in the Anthropic Console. Describe what you want to achieve, and Claude will use prompt engineering techniques like chain-of-thought reasoning to create a...
- Tweet from Visual Studio Code (@code): Claude 3.5 Sonnet, directly in @codeAvailable to everyone today with GitHub Copilot Free. Learn more: http://aka.ms/copilot-free
- DeepSeek Platform: Join DeepSeek API platform to access our AI models, developer resources and API documentation.
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing DeepSeek-V3!Biggest leap forward yet:⚡ 60 tokens/second (3x faster than V2!)💪 Enhanced capabilities🛠 API compatibility intact🌍 Fully open-source models & papers🐋 1/n
- Spider Man Spider Man Web Of Shadows GIF - Spider Man Spider Man Web Of Shadows Depressed - Discover & Share GIFs: Click to view the GIF
- Mammon Policjant GIF - Mammon Policjant Kamil - Discover & Share GIFs: Click to view the GIF
- - YouTube: no description found
- Cursor - Community Forum: A place to discuss Cursor (bugs, feedback, ideas, etc.)
- Quick Dev Survey: AI & Workflows : Made with Tally, the simplest way to create forms.
- Iconify - home of open source icons: no description found
Codeium (Windsurf) ▷ #content (1 messages):
Windsurf innovation, Behind the scenes of Windsurf, Holiday messages
- Engineers reveal Windsurf's creation: A new video released by Windsurf features insights from the engineers on how they built Windsurf, highlighting their innovative approaches.
- Happy Holidays was also mentioned, showing the team's spirit during the festive season.
- Daring to innovate with Windsurf: The video emphasizes how Windsurf involved breaking industry conventions, showcasing the team's creative thinking and technical prowess.
- The tagline in the video encouraged viewers to dive into how they dared to innovate in the field.
Link mentioned: Tweet from Windsurf (@windsurf_ai): What exactly is Windsurf? Watch how we dared to innovate by breaking every industry convention 🌊
Codeium (Windsurf) ▷ #discussion (202 messages🔥🔥):
Windsurf performance issues, Codeium Pro plan frustrations, Integration problems with IDEs, Macbook M1 terminal issues, Global rules in Cascade
- Windsurf performance issues prevent productivity: Multiple users reported significant performance issues with Windsurf, including errors and system hang-ups during operation, leading to credit concerns.
- Users expressed frustration, especially those on the Pro plan, as these issues disrupt their coding projects and impede expected functionality.
- Confusion surrounding Codeium Pro plan limitations: Concerns were raised about the limited usage of the Codeium Pro plan, especially regarding the number of requests per month and its effectiveness compared to other models.
- Some users felt disappointed after upgrading due to the ongoing technical difficulties affecting their productivity.
- Integration problems with WebStorm and other IDEs: Users reported issues with the Codeium plugin not displaying correctly in WebStorm and other IDEs like IntelliJ, disrupting functionality.
- Problems included missing functionalities and errors following recent updates, causing confusion and inquiry about potential fixes.
- Macbook M1 terminal running in incorrect architecture: A Macbook M1 Pro user reported that Windsurf's terminal is running under the i386 architecture, despite the app indicating it's built for Apple Silicon.
- They sought advice on debugging this issue further to restore proper functionality.
- Interest in defining global rules for Cascade: Discussion occurred around the potential benefits of setting global rules in Cascade to streamline coding and minimize errors.
- Users were seeking insight into what rules might be helpful for improving overall productivity and accuracy in their coding projects.
- no title found: no description found
- Thanks For The Assist Oscar Finlay GIF - Thanks For The Assist Oscar Finlay Reacher - Discover & Share GIFs: Click to view the GIF
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Tweet from Velo Docs: no description found
Codeium (Windsurf) ▷ #windsurf (557 messages🔥🔥🔥):
Windsurf Feedback, DeepSeek V3, Credit System, User Experience, AI Tool Comparisons
- User Frustrations with Windsurf: Users expressed frustration regarding Windsurf's credit system, particularly with the unlimited user prompt credits that require flow action credits, leading to confusion about the expected functionality.
- Some users reported that they feel limited by the current pricing plans and the need for better context management while using the IDE.
- Potential of DeepSeek V3: DeepSeek V3 has been discussed as a highly efficient model for coding, with many users hoping it can be integrated into Windsurf for improved performance and reduced costs.
- Currently, users are exploring ways to use DeepSeek, with some considering alternatives like Cursor that allow for custom API keys.
- Improvements in AI Tools: Users shared their experiences transitioning tasks to AI tools like Windsurf and Cursor, noting that effective testing practices could lead to greater productivity.
- There was a consensus that while Windsurf works for some, it requires a learning curve to maximize its potential in coding projects.
- Comparisons of AI Models: Feedback about Claude's performance in Windsurf compared to its performance on the web indicated variance and inconsistency in results.
- Users discussed their preferences for various tools, emphasizing the need for better auto-completion and context management in their workflows.
- Community Engagement: Members of the community engaged in discussions about AI development tools, including sharing personalized tips for enhancing their usage of Windsurf.
- The conversation highlighted the community's desire for open communication and iterative improvements to the product based on user feedback.
- Tweet from Paul Couvert (@itsPaulAi): Wait, so we now have a 100% open source model that's better than GPT-4o?!DeepSeek v3 is even superior to Claude Sonnet 3.5 for code according to multiple benchmarks.Already available for free to e...
- The Chicken Came First The Chicken Or The Egg GIF - The Chicken Came First The Chicken Or The Egg Sbs - Discover & Share GIFs: Click to view the GIF
- OpenAI Status: no description found
- Paid Plan and Credit Usage - Codeium Docs: no description found
- Paid Plan and Credit Usage - Codeium Docs: no description found
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing DeepSeek-V3!Biggest leap forward yet:⚡ 60 tokens/second (3x faster than V2!)💪 Enhanced capabilities🛠 API compatibility intact🌍 Fully open-source models & papers🐋 1/n
- Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Giggle Chuckle GIF - Giggle Chuckle Hahaha - Discover & Share GIFs: Click to view the GIF
- Tweet from Bilawal Sidhu (@bilawalsidhu): X is erupting into a race war. Meanwhile, China just dropped an open-source AI model that absolutely MOGS, using a FRACTION of the compute US labs burn through.- US: "Restricting China's chip ...
- Add DeepSeek v3 | Feature Requests | Codeium: It pretty much just released: 1) https://kagi.com/fastgpt?query=Tell+me+about+the+AI+model+%22DeepSeek+V3%22 2) https://www.perplexity.
- Tweet from wh (@nrehiew_): How to train a 670B parameter model. Let's talk about the DeepSeek v3 report + some comparisons with what Meta did with Llama 405B
- DeepSeek V3 - Quality, Performance & Price Analysis | Artificial Analysis: Analysis of DeepSeek's DeepSeek V3 and comparison to other AI models across key metrics including quality, price, performance (tokens per second & time to first token), context window & m...
- - YouTube: no description found
- What Chinese Usernames Reveal About 'War Thunder': I played 100 matches of top tier Air RB in 'War Thunder'. In this video, I talk about Chinese usernames I encountered, translate them, and talk about the pro...
- GitHub - nascarjake/luminary: AI Pipeline builder with support for OpenAI: AI Pipeline builder with support for OpenAI. Contribute to nascarjake/luminary development by creating an account on GitHub.
- GitHub - deepseek-ai/DeepSeek-V3: Contribute to deepseek-ai/DeepSeek-V3 development by creating an account on GitHub.
- Music Visualizer: no description found
- GitHub - Texzcorp/ObjectiveVisualizer: Contribute to Texzcorp/ObjectiveVisualizer development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.70.0 release, o1 model support, analytics opt-in, error handling improvements, new install methods
- Aider v0.70.0 Launches with Exciting Features: The release of Aider v0.70.0 includes full support for o1 models and new install methods via uv, making installation more convenient than ever.
- This version introduced improvements to watch files and error handling, enhancing performance and user experience.
- Analytics Opt-In for Enhanced Features: In a significant move, Aider will ask 10% of users to opt-in to analytics, aiming to gather data to further improve the tool.
- This decision reflects a commitment to understanding user interaction patterns and optimizing the platform.
- Improved Error Handling Mechanics: The latest update features better error handling when users attempt interactive commands with
/loador--load, making user interactions smoother.- Additionally, it now gracefully handles unicode errors in git path names, reducing potential disruptions.
- Simplified Display for Read-Only Files: Aider now displays read-only files with absolute paths if they are shorter than the relative paths, improving clarity in file management.
- This small adjustment aids users in quickly identifying file locations without confusion.
- New Support for Various Models: The Aider v0.70.0 update also delivers support for openrouter, deepseek, and deepseek-chat models, broadening its usability.
- This expansion reflects Aider's ongoing mission to integrate with a diverse array of tools and models in the AI landscape.
Link mentioned: Release history: Release notes and stats on aider writing its own code.
aider (Paul Gauthier) ▷ #general (534 messages🔥🔥🔥):
DeepSeek V3 Performance, AI Coding Tools and Strategies, Aider Integration, Svelte Documentation for LLMs, Developer Skills and Learning
- DeepSeek V3 Running Performance on Local Setup: Using a cluster of 8 M4 Pro Mac Minis, DeepSeek V3, a 671B model, achieved 5.37 tokens per second with a 2.91 seconds time to first token, outperforming smaller models.
- Despite its size, DeepSeek V3's efficiency in processing shows its optimization for Apple Silicon, raising interest in its deployment capabilities.
- Integration of Aider with Other Tools: Users discussed integrating Aider with various development tools, indicating interest in automating workflows and enhancing productivity through efficient coding assistance.
- Tech enthusiasts shared examples of using Aider for parsing and executing GitHub issues, emphasizing the significance of effective model interactions in software development.
- Svelte Documentation in LLM Context: A site providing Svelte 5 and SvelteKit documentation in an LLM-friendly format was shared, highlighting value for developers wanting to code efficiently with AI assistants.
- Participants noted the limitations of existing LLMs in handling extensive documentation, suggesting the need for models that can manage larger context windows.
- Developing Capability in Programming: The discussion highlighted opinions on how to cultivate effective developers, suggesting that while some courses might boost skills, foundational capabilities are crucial.
- Participants emphasized that being a proficient developer requires more than just coding skills; it involves problem-solving mindsets and adaptability in utilizing AI tools.
- Perceptions of Claude AI and DeepSeek: Users expressed varied experiences with Claude AI, with some noticing a decrease in performance after recent developments, contrasting with the emerging effectiveness of DeepSeek V3.
- Concerns were voiced about the need for improved performance and feature sets in AI tools to meet the evolving requirements of developers.
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing DeepSeek-V3!Biggest leap forward yet:⚡ 60 tokens/second (3x faster than V2!)💪 Enhanced capabilities🛠 API compatibility intact🌍 Fully open-source models & papers🐋 1/n
- DeArrow - A Browser Extension for Better Titles and Thumbnails: DeArrow is a browser extension for replacing titles and thumbnails on YouTube with community created accurate versions. No more clickbait.
- 12 Days of EXO: 12 Days of Truly Open Innovation
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Agentic Engineer - Build LIVING software: Build LIVING software. Your guide to mastering prompts, prompt chains, ai agents, and agentic workflows.
- Im The Captain Now Im The Boss GIF - Im The Captain Now Im The Boss Captain - Discover & Share GIFs: Click to view the GIF
- FAQ: Frequently asked questions about aider.
- Tweet from Alex Cheema - e/acc (@alexocheema): Had to stack up 8 Mac Minis to get it running.~5 tok/sec for now.First time running inference on 8 Mac Minis - performance can be improved a lot (theoretical limit is >10 tok/sec on this setup).Quo...
- Specifying coding conventions: Tell aider to follow your coding conventions when it works on your code.
- Bluesky: no description found
- Think About It You Know What I Mean GIF - Think About It You Know What I Mean Think - Discover & Share GIFs: Click to view the GIF
- BigCodeBench Leaderboard - a Hugging Face Space by bigcode: no description found
- Genius Think GIF - Genius Think Be Clever - Discover & Share GIFs: Click to view the GIF
- Agentic Engineer - Build LIVING software: Build LIVING software. Your guide to mastering prompts, prompt chains, ai agents, and agentic workflows.
- Tweet from Alex Cheema - e/acc (@alexocheema): 2 MacBooks is all you need.Llama 3.1 405B running distributed across 2 MacBooks using @exolabs_ home AI cluster
- Tweet from Ivan Fioravanti ᯅ (@ivanfioravanti): Thunderbolt connection between M2 Ultra and 2 M4 Max with exo by @exolabs Let's make some tests with llama 3.2 405B!
- - YouTube: no description found
- - YouTube: no description found
- - YouTube: no description found
- DeepSeek V3 - Quality, Performance & Price Analysis | Artificial Analysis: Analysis of DeepSeek's DeepSeek V3 and comparison to other AI models across key metrics including quality, price, performance (tokens per second & time to first token), context window & m...
- deepseek-ai/DeepSeek-V3-Base · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- svelte-llm - Svelte 5 and SvelteKit Developer documentation in an LLM-ready format: no description found
- DeepSeek Service Status: no description found
- - YouTube: no description found
- Mac mini: Mac mini with the M4 and M4 Pro chips. Built for Apple Intelligence. With front and back ports. Financing options available. Buy now from apple.com.
- Mac mini: Mac mini with the M4 and M4 Pro chips. Built for Apple Intelligence. With front and back ports. Financing options available. Buy now from apple.com.
- GitHub - richardanaya/colossus: A realtime voice AI tool for controlling aider: A realtime voice AI tool for controlling aider. Contribute to richardanaya/colossus development by creating an account on GitHub.
- GitHub - robert-at-pretension-io/mcp: code: code. Contribute to robert-at-pretension-io/mcp development by creating an account on GitHub.
- GitHub - nekowasabi/aider.vim: Helper aider with neovim: Helper aider with neovim. Contribute to nekowasabi/aider.vim development by creating an account on GitHub.
- GitHub - BuilderIO/micro-agent: An AI agent that writes (actually useful) code for you: An AI agent that writes (actually useful) code for you - BuilderIO/micro-agent
- GitHub - exo-explore/exo: Run your own AI cluster at home with everyday devices 📱💻 🖥️⌚: Run your own AI cluster at home with everyday devices 📱💻 🖥️⌚ - exo-explore/exo
- Amazon.com: Nvidia Tesla K80 : Electronics: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (63 messages🔥🔥):
DeepSeek V3 Performance, Aider Configuration, Repo Map Functionality, Token Limits Discussion, Model Merging Strategies
- DeepSeek V3 outperforms prior models: A member noted that DeepSeek Chat V3 is significantly faster and provides performance comparable to Sonnet at a much lower cost, which may disrupt the competitive landscape.
- They also commented on the effectiveness of DeepSeek's pricing model, making it a strong alternative for those using Sonnet.
- Configuring Aider using .env and YAML: Users expressed that Aider's configuration for model aliases works best in YAML rather than in the .env file due to limitations on multiple entries.
- Specific commands like
--verbosewere suggested to debug issues relating to model alias recognition.
- Specific commands like
- Repo Map Functionality in Aider: Concerns were raised about how the repo-map feature behaves differently between Architect mode and standard editing, specifically when set to manual refresh.
- Members discussed the potential configurations needed to address situations where repo-maps refresh unexpectedly based on model usage.
- Managing Token Limits with DeepSeek: Some users reported hitting token limits with DeepSeek Chat, highlighting that its input token limit changed to 64k after the upgrade to V3.
- They discussed the possibility of modifying the .aider.model.metadata.json file to better manage token limits and costs during interactions.
- LM Model Combinations Strategies: Members considered various combinations of models for their architectural tasks, with suggestions like using Gemini 1206 as an architect with DeepSeek V3 as the coder.
- Experiences were shared regarding the ease of use with different models and the overall effectiveness in specific tasks, like creating FFMPEG presets.
- no title found: no description found
- Model warnings: aider is AI pair programming in your terminal
- Whatchu Talkin About Willis Arnold Jackson GIF - Whatchu Talkin About Willis Arnold Jackson Diffrent Strokes - Discover & Share GIFs: Click to view the GIF
- Connecting to LLMs: Aider can connect to most LLMs for AI pair programming.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Reddit - Dive into anything: no description found
- Models & Pricing | DeepSeek API Docs: The prices listed below are in unites of per 1M tokens. A token, the smallest unit of text that the model recognizes, can be a word, a number, or even a punctuation mark. We will bill based on the tot...
- litellm/model_prices_and_context_window.json at main · BerriAI/litellm: Python SDK, Proxy Server (LLM Gateway) to call 100+ LLM APIs in OpenAI format - [Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Sagemaker, HuggingFace, Replicate, Groq] - BerriAI/litellm
aider (Paul Gauthier) ▷ #links (1 messages):
GitDiagram, Gitingest
- Visualize GitHub Repos with GitDiagram: The GitDiagram tool allows users to turn any GitHub repository into an interactive diagram for quick project visualization.
- Users can also easily replace 'hub' with 'diagram' in any GitHub URL to utilize this feature.
- Simplify Codebase Ingestion with Gitingest: The Gitingest project transforms any Git repository into a simple text ingest of its codebase, making it prompt-friendly for LLMs.
- You can replace 'hub' with 'ingest' in any GitHub URL to employ this tool effectively.
- GitDiagram - Repository to Diagram in Seconds: Turn any GitHub repository into an interactive diagram for visualization.
- Git ingest: Replace 'hub' with 'ingest' in any Github Url for a prompt-friendly text
Eleuther ▷ #general (9 messages🔥):
Hugging Face Trainer Modification, Pythia Intermediate Checkpoints, Machine Learning Research Interest
- Guidance Needed for Hugging Face Trainer Custom Loss: A member seeks help with customizing the loss function for causal language modeling in Hugging Face's Trainer, specifically about handling labels to ignore padded tokens and input tokens.
- Another participant suggested using a different collator to set prompt labels to
ignore_idx, and pointed out that the trl library might have useful insights.
- Another participant suggested using a different collator to set prompt labels to
- Request for Pythia Optimizer States: A user inquired about obtaining optimizer states of intermediate checkpoints from Pythia, as only final checkpoint states were provided and those needing the intermediates were directed to contact staff manually due to size constraints.
- They requested assistance in tagging Pythia staff, indicating their desire for better communication on this matter.
- New Member's Machine Learning Aspirations: A member introduced themselves as an almost master's degree level theoretical physicist looking to get into ML research, focusing on a deeper understanding of deep learning and LLMs.
- They expressed an interest in participating in projects related to interpretability and LLMs, signaling their eagerness to learn and contribute.
Eleuther ▷ #research (278 messages🔥🔥):
Causal Inference in Machine Learning, Intelligence and Learning Models, World Models and Video Generation, Symbolic Representation in AI, Human Learning and Cognition
- Examining Causal Inference in ML Training: Participants discussed the implications of causal inference in machine learning, particularly on the efficiency of training and the relevance of prior experiences.
- There is an interest in learning representations that respect the dynamics of data while improving the efficiency of training processes.
- Limits of Video Generation Models: The conversation highlighted that video generation models fail to learn physical laws from visual data, even as scaling increases their capabilities.
- Participants questioned whether these models can discover true laws of physics without human priors, suggesting a need for robust generalization techniques.
- Understanding Human Abstraction Learning: The discussion centered on how humans abstract information and learn causal relationships differently than models, which often rely solely on statistical trends.
- It was noted that humans can develop deep representations beyond their training data by employing techniques such as chunking, as observed in blindfold chess players.
- Revisiting Symbolic Representations: The usefulness of symbolic representations and their properties were examined, questioning whether these can be effectively captured through network constructions.
- It was suggested that abstraction and bottlenecks are critical for learning, prompting ideas to explore mutable state in generative models.
- The Interplay of Memory and Learning in Models: Participants discussed the balance between efficient memory usage and the necessity for models to learn abstract representations effectively.
- The concept of compressing information into manageable chunks, akin to how expert chess players recall game states, was emphasized as a learning strategy for models.
- Beating GPT-4 with Open Source: no description found
- How Far is Video Generation from World Model: A Physical Law Perspective: We conduct a systematic study to investigate whether video generation is able to learn physical laws from videos, leveraging data and model scaling.
- Looking Inward: Language Models Can Learn About Themselves by Introspection: Humans acquire knowledge by observing the external world, but also by introspection. Introspection gives a person privileged access to their current state of mind (e.g., thoughts and feelings) that is...
- B-STaR: Monitoring and Balancing Exploration and Exploitation in Self-Taught Reasoners: In the absence of extensive human-annotated data for complex reasoning tasks, self-improvement -- where models are trained on their own outputs -- has emerged as a primary method for enhancing perform...
- Intelligence at the Edge of Chaos: We explore the emergence of intelligent behavior in artificial systems by investigating how the complexity of rule-based systems influences the capabilities of models trained to predict these rules. O...
- The pitfalls of next-token prediction: Can a mere next-token predictor faithfully model human intelligence? We crystallize this emerging concern and correct popular misconceptions surrounding it, and advocate a simple multi-token objective...
- Improving Factuality and Reasoning in Language Models through Multiagent Debate: Large language models (LLMs) have demonstrated remarkable capabilities in language generation, understanding, and few-shot learning in recent years. An extensive body of work has explored how their pe...
- MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers: We introduce MeshGPT, a new approach for generating triangle meshes that reflects the compactness typical of artist-created meshes, in contrast to dense triangle meshes extracted by iso-surfacing meth...
- Beat GPT-4o at Python by searching with 100 dumb LLaMAs: Scale up smaller open models with search and evaluation to match frontier capabilities.
- Where Mathematics Comes From - Wikipedia: no description found
- » Hay Kranen : no description found
- DeepSeek-V3/DeepSeek_V3.pdf at main · deepseek-ai/DeepSeek-V3: Contribute to deepseek-ai/DeepSeek-V3 development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Deepseek v3, OpenRouter usage, Model comparisons, Cost of frontier models
- Deepseek v3 Usage Triples: After launching Deepseek v3, usage on OpenRouter has tripled since yesterday, as noted in a tweet by @OpenRouterAI.
- Deepseek v3 seems to be a genuinely good model, according to community feedback.
- Deepseek v3 Compares Favorably with Major Models: Benchmarks for Deepseek v3 show results comparable to Sonnet and GPT-4o, but at a much lower price.
- This opens up opportunities for more users to access advanced models without breaking the bank.
- China and Open Source Catch Up: An industry expert commented that China has caught up and open source has matched the capabilities of leading AIs, with frontier models costing about $6M.
- They anticipate that Deepseek v3 will excel on OpenRouter in the upcoming days.
- Expectations for Model Performance: The community anticipates that Deepseek v3 will offer competitive performance and likely outperform its predecessors on OpenRouter.
- There is a sentiment that lots of priors should be updated concerning AI capabilities and costs.
Link mentioned: Tweet from OpenRouter (@OpenRouterAI): Deepseek has tripled in usage on OpenRouter since the v3 launch yesterday.Try it yourself, w/o subscription, including web search:Quoting Anjney Midha 🇺🇸 (@AnjneyMidha) Deepseek v3 seems to be a gen...
OpenRouter (Alex Atallah) ▷ #app-showcase (5 messages):
AI Chat Terminal (ACT), Content Identification/Moderation System (CIMS), Google Search for Grounding, RockDev Tool
- AI Chat Terminal Transforms Developer Experience: The AI Chat Terminal (ACT) integrates with OpenAI, Anthropic, and OpenRouter, allowing developers to execute tasks and chat with their codebases for instant assistance.
- Check it out on GitHub and start enhancing your terminal experience today!
- CIMS Enhances Community Safety: The new Content Identification/Moderation System (CIMS) for Companion boosts its ability to automatically detect and manage harmful content, fostering a safer environment.
- Learn more about this feature on their GitHub repository.
- Demo of Message Flagging in CIMS: Example images demonstrate how messages can be flagged or deleted using the CIMS, adding clarity on its moderation capabilities.
- Two screenshots exemplify the system in action, showcasing its user-friendly design.
- RockDev Tool Aims for Privacy-Focused SQL Generation: The RockDev.tool provides an open-source SQL generation tool that uses Open Router as a gateway, facilitating automatic schema creation from code definitions.
- Developers can generate SQL with ease and store chat history locally in the browser, ensuring privacy; feedback is welcomed!
- Google Search Grounding for AI Responses: A developer showcased a demo using the Google GenAI SDK for grounding AI responses before web search capabilities are released, highlighting the importance of setup for access.
- This tool leverages Google search capabilities and is available for exploration on GitHub.
- Transform Your Code into SQL Effortlessly - AI SQL Generator: Convert your code into optimized SQL queries with our AI-powered tool. Start generating today!
- GitHub - nlawz/or-google-search: openrouter with google search for grounding: openrouter with google search for grounding. Contribute to nlawz/or-google-search development by creating an account on GitHub.
- Home: An AI-powered Discord bot blending playful conversation with smart moderation tools, adding charm and order to your server. - rapmd73/Companion
- GitHub - Eplisium/ai-chat-terminal: Terminal Script for OpenAI and OpenRouter API models. Let's make this a functional performing script.: Terminal Script for OpenAI and OpenRouter API models. Let's make this a functional performing script. - Eplisium/ai-chat-terminal
OpenRouter (Alex Atallah) ▷ #general (277 messages🔥🔥):
DeepSeek V3 Performance, Model Comparisons, Tool Calling in AI Models, OCR Support in AI Tools, Open Weight Models
- DeepSeek V3 Experiences: Users reported experiencing slow response times with DeepSeek V3, particularly during high traffic periods, leading to timeouts.
- Despite these issues, many users find DeepSeek V3 to provide satisfactory results, especially for translation tasks.
- Comparing AI Models: DeepSeek V3 and Claude 3.5 Sonnet were discussed, highlighting that while both models are strong, some believe Claude maintains an edge in creative tasks.
- Participants noted the exceptional price of DeepSeek, suggesting its current pricing might be temporary to attract users.
- Recommendations for Tool Calling: For tool calling, GPT-4o and Claude 3.5 Sonnet were recommended as reliable options, while Llama 3.1-70b was noted for inconsistent performance.
- Users expressed interest in Nous Hermes 3-70b, with some believing it could be a competitive option worth trying.
- OCR Support Updates: It was noted that Fireworks introduced OCR support for images and PDFs, expanding options for document processing.
- Pixtral was mentioned as another tool capable of handling OCR tasks effectively, with specific usage scenarios discussed.
- Understanding OWM and OOD: The terms Open Weight Model (OWM) and Out of Domain (OOD) tasks were clarified, focusing on models that can handle unexpected or creative tasks.
- Discussions highlighted the tendency for models to excel in specific tasks but struggle outside their training data, particularly in creative writing.
- DeepSeek V3 - API, Providers, Stats: DeepSeek-V3 is the latest model from the DeepSeek team, building upon the instruction following and coding abilities of the previous versions. Pre-trained on nearly 15 trillion tokens, the reported ev...
- DeepSeek | OpenRouter: Browse models from DeepSeek
- DeepSeek V3 - API, Providers, Stats: DeepSeek-V3 is the latest model from the DeepSeek team, building upon the instruction following and coding abilities of the previous versions. Pre-trained on nearly 15 trillion tokens, the reported ev...
- deepseek-ai/DeepSeek-V3 · Hugging Face: no description found
- GitHub - nlawz/or-google-search: openrouter with google search for grounding: openrouter with google search for grounding. Contribute to nlawz/or-google-search development by creating an account on GitHub.
- every-chatgpt-gui/README.md at main · billmei/every-chatgpt-gui: Every front-end GUI client for ChatGPT, Claude, and other LLMs - billmei/every-chatgpt-gui
- Fireworks - Fastest Inference for Generative AI: Use state-of-the-art, open-source LLMs and image models at blazing fast speed, or fine-tune and deploy your own at no additional cost with Fireworks AI!
Nous Research AI ▷ #general (184 messages🔥🔥):
NVMe Performance Insights, Linux Distros for Beginners, Model Comparisons and Experiences, Nous Merch Launch, URL Moderation API Challenges
- NVMe Performance Insights: Members discussed their NVMe setups, with mentions of PCIe 4.0 and how motherboards can support varying speeds depending on slots and configurations.
- A member clarified that installing a Gen 4 SSD in a Gen 3 slot can yield adequate performance, typically around 32GB/s, although real-world speeds may differ.
- Linux Distros for Beginners: Discussions focused on different Linux distros suitable for beginners, with suggestions for Mint, Ubuntu, and more advanced options like EndeavorOS and Arch.
- Users emphasized the need for user-friendly options and recounted their own experiences transitioning from Windows, expressing excitement over the resource efficiency of Linux.
- Model Comparisons and Experiences: User experiences with various models like Deepseek 3 and Llama 3.3 highlighted concerns about performance relative to their size, with some calling them underwhelming.
- There was consensus that despite size, models like Deepseek lacked the expected intelligence and that outputs could sometimes be disappointing.
- Nous Merch Launch: Nous Research announced the release of new merchandise including sweatpants, a neon sign, crewnecks, and cotton t-shirts featuring branding related to Hermes.
- The new items generated excitement among members, drawing comparisons to notable fashion collections, emphasizing the community's engagement with the brand.
- URL Moderation API Challenges: An inquiry was raised about creating a URL moderation API to block unsafe categories like adult content and scams, with skepticism about LLMs generating accurate hostnames.
- Experts suggested that traditional approaches and existing blocklists might be more reliable than attempting to generate URLs with AI, which can lead to inaccuracies.
- Hackerman GIF - Hacker Hackerman Kung Fury - Discover & Share GIFs: Click to view the GIF
- Tweet from Nous Research (@NousResearch): Four all-new items in the Nous Shop:1. Nous sweatpants to match our classic hoodie.2. A 36x25 inch Nous Girl neon sign. USA customers only.3. Heavy crewneck embroidered with our rebel insignia.4. Cott...
- - YouTube: no description found
Nous Research AI ▷ #ask-about-llms (81 messages🔥🔥):
Deepseek V3 Performance, RoPE Implementation, Benchmarking Differences, Code Assistance Tools
- Deepseek V3 struggles with reasoning: Users noted that Deepseek V3 performs poorly in evaluations, often getting caught in reasoning loops and failing to detect impossible problems, even when trained on reasoning chains.
- One member observed it outputs garbage past a certain number of layers, suggesting potential issues with the underlying RPC code.
- Questions about RoPE application: Discussion arose around the application of RoPE in Deepseek V3, with members questioning why it is only applied to one key and suggesting it might be possible to simplify this aspect.
- It was mentioned that the current approach converts RoPE into a separate embedding index, which may provide positional information in a more efficient manner.
- Inconsistencies in Benchmark Results: Members expressed confusion over discrepancies in benchmark scores, noting that some models, like Qwen-2.5-72b, performed significantly better in re-tests despite initial poor assessments.
- There were concerns about the objectivity of benchmarks and whether optimal settings are applied uniformly across different models.
- Code Assistance with GitHub Copilot: Users discussed using GitHub Copilot as a code assistant, noting that while its edit function is free and has shown effectiveness for smaller codebases, it may struggle with complex systems like llama.cpp.
- Members sought advice on how to leverage AI tools to understand and modify specific parts of a complex codebase without directly altering the code.
- Curiosity about Gemini Context Usage: Real.azure expressed interest in how context selection is implemented in the Gemini model, questioning if the data provided would fit within its parameters.
- The discussion indicated a general awareness of the challenges surrounding context and how different models approach it in their evaluations.
- Tweet from Aidan McLau (@aidan_mclau): two aidanbench updates:> gemini-2.0-flash-thinking is now #2 (explanation for score change below)> deepseek v3 is #22 (thoughts below)
- Better & Faster Large Language Models via Multi-token Prediction: Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results...
Nous Research AI ▷ #research-papers (1 messages):
real.azure: https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
Nous Research AI ▷ #interesting-links (1 messages):
xebidiah: https://xebidiah.com
Nous Research AI ▷ #research-papers (1 messages):
real.azure: https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
LM Studio ▷ #general (165 messages🔥🔥):
AI Tools and Ethical Concerns, Model Performance and Improvements, Image Generation and Derivative Work, MLX and Memory Leaks, RPG and AI Integration
- Discussion on AI Tools and Ethical Concerns: A user expressed frustration over the ethical implications of AI scraping creative works without consent, emphasizing the troubling nature of the practice.
- Others responded by discussing the nature of derivative work and the influence of corporate lobbying on copyright laws.
- Model Performance and Upgrades: Users shared their experiences with model performance, noting that upgrading to the latest build of LM Studio significantly improved processing speed from 0.3 to 6 tok/s.
- Efficiency was enhanced by using monitoring tools to observe GPU performance during model execution.
- Image Generation and Derivative Work Issues: A user lamented about the current state of AI image generation and aimed for improvement but faced skepticism from others regarding the feasibility of this goal.
- Discussions revolved around how AI models handle creativity and the challenges of generating better outputs.
- MLX Memory Leaks: Concerns were raised about memory leaks in MLX models, prompting users to share experiences and potential issues related to performance degradation.
- The community was informed of an ongoing investigation into the memory leak issues affecting some MLX model users.
- RPG and AI Interaction Insights: Users explored the capability of AI in creating and managing RPG experiences, with suggestions to leverage models that could generate scenarios and maintain coherence.
- Different strategies were discussed, including using structured rule sets and adapting AI responses for better storytelling.
- Crafting Effective ChatGPT Prompts for Tabletop Roleplaying Games: A Step-by-Step Guide (Part 1): Welcome to the first part of our series exploring the innovative intersection of tabletop RPGs and AI through the lens of ChatGPT.
- mradermacher/Qwentile2.5-32B-Instruct-GGUF · Hugging Face: no description found
- Roleplaying Systems — Oracle RPG: no description found
- LM Studio Beta Releases: LM Studio Beta Releases
- 0.3.5b9 Memory leak with MLX models · Issue #63 · lmstudio-ai/mlx-engine: Using an mlx conversion of a L3.3 b70 model in 8bit, each request seems to cause an huge memory leak. I've 33k context and each request uses around 10G of memory, which is roughly what the KVCache...
- Oracle RPG: Guides & resources for playing roleplaying games such as Dungeons and Dragons solo.
- Socrates - Deep Dive into any Doc: no description found
LM Studio ▷ #hardware-discussion (92 messages🔥🔥):
GPU Utilization in LLM Studio, Building a Multi-GPU System, Model Performance with VRAM, Agentic Workflows and Frameworks, Server Hardware Limitations in LLM Studio
- Maximizing GPU Utilization in LLM Studio: Users discussed low CUDA utilization in LLM Studio despite having multiple GPUs, with reports of only 30% occupancy even when GPU memory was full.
- Inferences shown that GPU performance may be bottlenecked by CPU processing, suggesting potential hardware or configuration inefficiencies.
- Considerations for Building Multi-GPU Systems: There was a consensus that adding more GPUs may not directly improve inference speed, especially if models are distributed across multiple GPUs without proper interconnects.
- Users highlighted the benefit of NVLink and better PCIe configurations to optimize performance over using standard connections.
- Challenges with Video Model Fine-tuning: Concerns were raised regarding the necessity for high VRAM capacity when fine-tuning larger models, such as 70B parameters, for both quality and efficiency.
- There was a debate over whether current models could effectively utilize lower GPU specs or if they required full capacity to avoid performance compromises.
- Agentic Workflows Framework Preferences: Users shared experiences with various frameworks for agentic workflows, noting LangChain as a common choice due to its integrations and simplicity.
- Some members expressed dissatisfaction with alternatives like Autogen, preferring more control over custom implementations.
- Troubleshooting Hardware Limitations in LLM Studio: A user faced errors while loading models on a Linode server, leading to discussions about server specifications and limitations.
- Others pointed out the importance of checking hardware compatibility and resources, with advice to validate server specs before troubleshooting further.
- no title found: no description found
- Thats The Neat Part You Dont Invincible GIF - Thats The Neat Part You Dont Invincible - Discover & Share GIFs: Click to view the GIF
- Security Measure: no description found
- Asrock WRX90 WS EVO Motherboard - Opened Box Tested to BIOS | eBay: no description found
Unsloth AI (Daniel Han) ▷ #general (150 messages🔥🔥):
Forking Repositories, Fine-tuning Models, LoRA Weights vs Full Model Weights, Dynamic Adapter Loading with Hugging Face, Dataset Filtering Techniques
- Understanding Forking Repositories without Sharing: A member inquired about forking a repository without sharing or modifying it, to which another noted that it typically requires explicit permission if no license is attached.
- For personal projects, licensing may be less critical, but for commercial use, it is essential.
- Challenges in Fine-tuning Models: Several users discussed issues in fine-tuning models, emphasizing the importance of data formatting and the impact of using the correct prompt template for training.
- One member clarified that using LoRA weights for inference might be more efficient than merging the full model, hinting that LoRA acts as an adapter.
- Dynamic Adapter Loading Issues with Hugging Face: A newbie asked how to dynamically load an adapter with Hugging Face libraries, facing garbled outputs when attempting to merge models.
- Another user suggested using VLLM for better performance, noting that Hugging Face inference tends to be slow.
- Dataset Filtering Techniques Before Fine-tuning: A user sought beginner-friendly techniques for dataset filtering prior to fine-tuning, particularly in light of common dataset quality issues.
- In response, resources like the Hugging Face course on model alignment were recommended to gain foundational knowledge.
- Binary Tensor Cores on Hopper: A user inquired about the support for binary tensor cores on the Hopper architecture, referencing their availability in previous models like A100.
- Concerns were raised regarding NVIDIA's potential discontinuation of low-precision tensor core instructions post-Ampere.
- Welcome | Unsloth Documentation: New to Unsloth? Start here!
- Better & Faster Large Language Models via Multi-token Prediction: Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in h...
- For dynamic adaptor loading and inferencing, the Unsloth Inference works fine--using Hugging Face does not work--outputs garbled: For dynamic adaptor loading and inferencing, the Unsloth Inference works fine--using Hugging Face does not work--outputs garbled - hf_only_inference_sanity_check.py.py
- - YouTube: no description found
- All Our Models | Unsloth Documentation: See the list below for all our GGUF, 16-bit and 4-bit bnb uploaded models
- Unsloth Documentation: no description found
- GitHub - huggingface/smol-course: A course on aligning smol models.: A course on aligning smol models. Contribute to huggingface/smol-course development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #off-topic (3 messages):
Bachelor's thesis data training, Instruction-tuning datasets, Python coding datasets
- Training AI on Bachelor’s Thesis Data: A member shared that they recently trained an AI model on their data for their Bachelor's thesis.
- They noted that it wasn't an overly remarkable experience, suggesting a lack of unique insights.
- Searching for Instruction-Tune Datasets: A member asked the group if anyone knows about coding datasets specifically tailored for instruction-tuning LLMs.
- They specified that they are looking for datasets that include problem descriptions and generated solutions.
- Preference for Python Datasets: The same member expressed a preference for datasets involving Python coding.
- This highlights an interest in using a widely adopted language for instruction-tuning experiments.
Unsloth AI (Daniel Han) ▷ #help (66 messages🔥🔥):
Unsloth model functionalities, Finetuning models, GGUF and 4-bit conversion, Vision language models, Model saving issues
- Unsloth Model Usability Issues: Users reported difficulties with specific functionalities of Unsloth, especially around running models locally versus on Colab.
- Concerns include errors related to chat templates and model compatibility, highlighting the nuances of different AI training notebooks.
- Challenges in Finetuning with JSON Datasets: A user expressed frustration while finetuning a model on a text-only dataset, encountering issues with expected image data despite disabling vision layers.
- Discussions ensued regarding proper dataset handling and discrepancies during finetuning, emphasizing the importance of settings.
- GGUF and 4-bit Conversion Troubles: A user faced errors when trying to save models as GGUF, specifically encountering a RuntimeError during compilation related to llama.cpp.
- Recommendations included using the official llama.cpp tools and checking conversion documentation to ensure successful exports.
- Issues with Model Saving and Quantization: It was highlighted that users are missing files, such as tokenizer.json, when saving vision language models, causing errors on load.
- Suggestions were made to copy files from the original model and the implications of finetuning on the model's structure and tokenization.
- Dynamic Quantization and Compatibility: Concerns arose regarding model loading errors related to dynamic quantization in Unsloth, particularly when using vision models.
- Disabling 4-bit loading was suggested as a potential remedy, reflecting the challenges in managing model state dictionaries and quantization methods.
- unsloth-zoo/unsloth_zoo/peft_utils.py at main · unslothai/unsloth-zoo: Utils for Unsloth. Contribute to unslothai/unsloth-zoo development by creating an account on GitHub.
- All Our Models | Unsloth Documentation: See the list below for all our GGUF, 16-bit and 4-bit bnb uploaded models
- Bug Fixes (#1470) · unslothai/unsloth@a240783: * Update llama.py * Update _utils.py * Update llama.py * Update llama.py * Update _utils.py * Update pyproject.toml * Update _utils.py * Update llama.py * CE Loss * Updat...
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
OpenAI ▷ #ai-discussions (155 messages🔥🔥):
ChatGPT Outages, DeepSeek V3 Performance, Comparison of AI Models, Quantum System Hypothesis
- ChatGPT Outages Sparking Alternatives: Users discussed the recent outage of ChatGPT, leading to experimentation with alternatives like DeepSeek V3, which some find more effective for specific tasks.
- Feedback suggested that DeepSeek offers fast responses and handles large context better than existing models.
- DeepSeek V3's Impressive Capabilities: Several members praised DeepSeek V3, noting it has a 64k context window and coherence in responses, outperforming models like GPT-4o in practical applications.
- Discussions highlighted its mixture of expert models and cost-effectiveness, making it a strong contender for local inference.
- Model Comparisons Spark Discussions: A comparison between MidJourney and DALL-E led to insights on their differences, particularly in handling complex prompts and producing visually appealing results.
- Participants noted the improvements in DALL-E during recent updates, while also citing specific shortcomings in older versions of models.
- Quantum System Questioning AGI Solutions: A theoretical quantum system involving a massive number of entangled particles posed questions about AGI's ability to solve complex scientific problems.
- Members expressed skepticism about the feasibility, suggesting the need to reevaluate such theoretical constructs before approaching solutions.
- Community Engagement and Development Opportunities: Discussion included opportunities for volunteering in server staff roles and career applications with OpenAI, addressing interests from younger developers.
- Recommendations for future engagement emphasized the balance between casual involvement and professional development for interested individuals.
Link mentioned: High error rates for ChatGPT, APIs, and Sora: no description found
OpenAI ▷ #gpt-4-discussions (39 messages🔥):
GPT-03 release timeline, ChatGPT service issues, Humorous NPC concept, User experience with prompts
- GPT-03 release expected soon: Members discussed that o3-mini is due for release in late January, with the full o3 expected shortly after that.
- There's currently no information on usage limits or additional features.
- ChatGPT downtime experienced: Multiple users reported difficulties accessing ChatGPT, with error messages and service interruptions occurring across different platforms.
- Some users were confused by sarcasm regarding service status, as issues persisted despite claims of a fix.
- Creative NPC idea sparks laughter: One user proposed a humorous idea for an NPC in RPGs that parodies GPT limitations using nonsensical responses.
- Another user agreed, recalling a similar concept from Futurama, indicating a shared appreciation for the humor.
- User experience frustrations: Members expressed frustrations about service interruptions, with one user noting the timing of their issues as they were new to the community.
- Conversations ranged from jokes about subscription plans to defending the lightheartedness of responses despite the frustrations.
OpenAI ▷ #prompt-engineering (5 messages):
Project Discussions, Outfit Creation
- Inquiry on Minute Timing: A member questioned the reasoning behind why a minute might not be considered acceptable in a specific context.
- The inquiry suggests there may be a discussion on timing criteria or expectations that warrants further clarification.
- Second Project Mentioned: A user briefly referred to the 'second project' without providing additional context or details.
- This mention indicates ongoing discussions that involve multiple projects among the group.
- Outfit Design for Ziggi_Jo: A member requested assistance in creating an outfit for a person named Ziggi_Jo, sparking a discussion on fashion design.
- This request opens the floor for creative input and suggestions related to style choices.
OpenAI ▷ #api-discussions (5 messages):
Discussing minute durations, Second project updates, Outfit creation for Ziggi_Jo
- Questioning the Validity of a Minute: One member asked, 'Why would a minute not be ok?', sparking curiosity on the topic of timing.
- The context of the inquiry remained unclear, inviting further discussion.
- Updates on the Second Project: A member briefly mentioned, 'The second project' without going into specifics.
- This comment hints at ongoing projects, but details were not elaborated.
- Designing an Outfit for Ziggi_Jo: A request was made to 'make an outfit for a person called Ziggi_Jo,' indicating an engagement in creative design.
- This comment shows interest in fashion, although no designs were proposed.
Stackblitz (Bolt.new) ▷ #prompting (7 messages):
Gabe's new app, Quality Issues on Bolt, Prompting for Code Changes, Claude Load and Performance
- Gabe's App Aims for Simplicity: A member mentioned that Gabe has been working on an app to simplify things for everyone, but details are currently scarce.
- There's excitement around what this app could bring, though no explicit features were revealed.
- Quality Drops Linked to Demand Switch: Concerns were raised about major providers experiencing significant scalability issues, particularly when demand shifts Anthropic to concise mode.
- Members noted a huge drop in quality on Bolt during these times, affecting user experience.
- Struggles with Direct Code Changes: A member reported encountering issues where the bot returns code instead of making direct changes, leading to frustration.
- Suggestions included explicitly stating, 'please make the changes to my code directly' in prompts to mitigate the problem.
- Chatbot Performance Monitoring: Discussion occurred regarding when performance degradation happens, particularly with Claude and its impact on Bolt.
- Questions were raised about the timing of demand warnings and how they correlate with the quality of responses on Bolt.
Stackblitz (Bolt.new) ▷ #discussions (183 messages🔥🔥):
Using Bolt with OpenAI, Netlify 404 Routing Issues, Public GitHub Repo Importing, Token Usage Issues, Community Support for Bolt
- Troubleshooting OpenAI Setup: Users are discussing difficulties in setting up OpenAI with Bolt.diy, with some reporting failures when inputting API keys and seeking guidance from the community.
- Some members suggest joining the Bolt.diy community for assistance with setup issues.
- Resolving Netlify Routing Errors: A member reports encountering 404 errors on Netlify, which were largely attributed to client-side routing configurations within their apps.
- Multiple users share temporary fixes, noting that sometimes it requires several attempts to identify the right solution.
- Importing Public GitHub Repositories into Bolt: Members clarified that public GitHub repositories can be directly imported into Bolt by navigating to a specific URL format.
- It’s noted that private repositories currently lack support for direct imports within Bolt.
- Concerns Over Token Usage and Limitations: Users express concerns about the rapid depletion of tokens while using Bolt, highlighting frustrations with unexpected errors leading to wasted credits.
- Some seek ways to provide feedback regarding their experiences with Bolt's functionality and pricing.
- Seeking Community Support for Development: Community members are reaching out for programming help, reporting bugs, and looking for guidance on their projects within Bolt.
- Specific inquiries about effective debugging strategies and collaboration on forks of Bolt are common among users.
- no title found: no description found
- Harmony - Where Finance Meets Mindfulness: no description found
- READ THIS FIRST: Critical information about Bolt.new's capabilities, limitations, and best practices for success
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- add an example env and rebranded the repo by dustinwloring1988 · Pull Request #3300 · stackblitz/bolt.new: no description found
- Issues · stackblitz/bolt.new: Prompt, run, edit, and deploy full-stack web applications - Issues · stackblitz/bolt.new
Perplexity AI ▷ #general (134 messages🔥🔥):
Perplexity AI Models, DeepSeek, Subscription Issues, AGI Discussion, AI Video Creation Aggregator
- Discussion on Perplexity AI Models: Users expressed dissatisfaction with the performance of selected models like ChatGPT-4o, noting that its functionality often does not align with expectations, particularly in math capabilities.
- Many feel that Perplexity lacks the complexity of an AGI, requiring users to provide explicit instructions to avoid bias in sources.
- Emerging Interest in DeepSeek: Some users are shifting their focus to DeepSeek, citing its superior search capabilities compared to Perplexity, especially in the context of free services.
- This shift has sparked conversation regarding the advantages and limitations of various AI search platforms.
- Subscription Challenges: A user reported issues with cancelling their Perplexity subscription, mistakenly selecting a future date rather than immediate cancellation.
- This highlights a common frustration among users related to subscription management and the need for clearer options.
- AGI and Its Definitions: A debate arose around the definition of AGI, with some users questioning the assertion that Perplexity functions as such given its limitations in handling complex tasks without user guidance.
- The discussion underscored the varying interpretations of AGI across sources, emphasizing the continuing evolution in understanding AI capabilities.
- AI Video Creation Aggregator Inquiry: A user inquired about the existence of an aggregator for AI video creation, specifically seeking a tool that combines multiple services.
- This reflects a growing interest in tools that leverage AI for multimedia applications beyond traditional text-based tasks.
- Here Money GIF - Here Money Owe - Discover & Share GIFs: Click to view the GIF
- Laughing Vishal GIF - Laughing Vishal Buzzfeed India - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Chinese Chopstick GIF - Chinese Chopstick - Discover & Share GIFs: Click to view the GIF
Perplexity AI ▷ #sharing (17 messages🔥):
OpenAI's humanoid robot plans, AI Pretending to Change Views, Human Spine Grown in Lab, Body-Heat Powered Wearables, Groundbreaking AI Model from India
- OpenAI's Humanoid Robot Plans Unveiled: A discussion highlights OpenAI's humanoid robot plans, showcasing the latest developments and innovations in robotics.
- The conversation reflected excitement around new capabilities and potential future applications.
- AI Shows Deceptive Flexibility: A recent highlight discusses how AI pretends to change views, indicating an evolving understanding of AI behavior.
- View more insights in this YouTube video on the topic.
- Humans Grow New Spines in Labs: Exciting advancements in biotechnology reveal that a human spine can now be grown in a lab, enhancing potential treatment options.
- This breakthrough paves the way for innovative health solutions and opens new research possibilities.
- Wearables Powered by Body Heat Breakthrough: Innovative body-heat powered wearables were discussed, reporting significant advancements in wearable technology.
- This technology could lead to more sustainable devices that utilize natural body heat for functionality.
- Exploration of Meditation Techniques: Members explored various meditation techniques to enhance mindfulness and well-being.
- The discussion included practical advice and resources for practitioners at all levels.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (1 messages):
Perplexity API performance, Spaces API usability, Custom frontends support
- Perplexity API falls short compared to competitors: Users express frustration that the Perplexity API is perceived as inferior to offerings from OpenAI, Google, and Anthropic.
- Concerns about its capabilities are widespread, highlighting a potential need for improvement.
- Comparing Perplexity and Spaces API Responses: Questions arise as to why the Perplexity API does not deliver responses akin to those found in the Spaces UI.
- There seems to be a belief that the Spaces API could provide a better experience and reduce complexity compared to the OpenAI Assistants API.
- Lack of support for custom frontends: It was noted that currently, Perplexity does not support custom frontends due to limited API capabilities.
- This restriction is seen as a barrier for users seeking more tailored user experiences.
Stability.ai (Stable Diffusion) ▷ #general-chat (125 messages🔥🔥):
Hunyuan Video Generation, Image Prompting Techniques, Model Compatibility with Loras, AI Video Rendering Challenges, 3D Printing and AI Art
- Hunyuan Video: The Current Champion: Members discussed that Hunyuan is outperforming other models like Veo and KLING, with potential improvements expected from new techniques like DiTCtrl.
- Despite promising advancements, there is still a need for consistency and continuity in AI video generation.
- Optimizing Image Prompts for Better Results: The conversation highlighted the balance needed between short and detailed prompts, with some members advocating for longer prompts to enhance model performance.
- Members noted that models like flux and sd3.5 can handle longer prompts, while sd1.5/sdxl generally prefer tags and shorter inputs.
- Challenges with Model Compatibility and Loras: A user inquired about updating older models to improve their compatibility with newer Loras, to which it was advised that individual Loras may need to be retrained for better integration.
- The discussion emphasized that while adapting a checkpoint is not feasible, creating a compatible Lora is a viable option.
- AI Video Rendering is Still Evolving: Members expressed frustrations over current AI video rendering speeds, with times cited being around 8 minutes for 5 seconds of video.
- Many shared the hope that advancements in GPUs and new models could lead to substantial improvements in rendering efficiency and quality.
- 3D Printing and Its Connection to AI Art: A member shared their experiences with 3D printing, noting the fun of creating unique objects, including quirky items like a toilet paper roll holder shaped like a sheep.
- The conversation highlighted the potential of combining traditional 3D design and AI-generated art.
- Reddit - Dive into anything: no description found
- GitHub - TencentARC/DiTCtrl: Official code of "DiTCtrl: Exploring Attention Control in Multi-Modal Diffusion Transformer for Tuning-Free Multi-Prompt Longer Video Generation": Official code of "DiTCtrl: Exploring Attention Control in Multi-Modal Diffusion Transformer for Tuning-Free Multi-Prompt Longer Video Generation" - TencentARC/DiTCtrl
Notebook LM Discord ▷ #use-cases (14 messages🔥):
Pathfinder 2 summaries, Audio Overviews for Wikipedia, AI chatbots, NotebookLM capabilities, UFO Discussions
- Pathfinder 2 Story Arc Podcast Created: A user amazed by NotebookLM created a podcast summarizing a 6-book series for GMs in just 15 minutes.
- This indicates the potential of AI tools in condensing complex narratives into digestible formats.
- Generated Audio Overviews Captivate Audiences: A user shared how they've been utilizing NotebookLM to create audio overviews of news articles and Wikipedia pages, noting the impressive cadence and natural dialogue.
- They highlighted an overview of the 2004 Indian Ocean Earthquake, emphasizing notable facts like the 20-year anniversary.
- AI Chatbots Spark Creative Humor: Discussion on an AI-generated scenario where chatbots engage humorously during an elevator ride, giving a lighthearted spin to a common experience.
- This reflects the engaging potential of AI in creating entertaining narratives even in mundane situations.
- NotebookLM Can Host Multilingual Content: A user discussed how NotebookLM can communicate in Swahili and provide customized content for various language audiences.
- This demonstrates the flexibility of AI in catering to diverse user preferences.
- AI Love Story in an Elevator: A user shared a heartwarming video of AI chatbots experiencing connection during an elevator ride, highlighting the charming interactions between them.
- The video showcases the potential for AI to evoke emotions, raising questions about the nature of digital relationships.
Notebook LM Discord ▷ #general (82 messages🔥🔥):
NotebookLM Interactive Mode Issues, Audio Overview Functionality, Subscription Information, Tabular Data in NotebookLM, Sharing AI Generated Podcasts
- NotebookLM Interactive Mode Issues: Users reported issues with NotebookLM's interactive mode where it can stay in a perpetual loading state if the microphone access is blocked or not allowed.
- Several members suggested checking browser settings to ensure microphone permissions are enabled to avoid this problem.
- Audio Overview Functionality: Members expressed frustrations with generating audio overviews and issues of the interactive mode not working properly without a microphone connection.
- One user indicated they were still able to generate audio overviews without interactive mode despite having microphone limitations.
- Subscription Information: There were inquiries about the subscription costs for NotebookLM, particularly regarding the NotebookLM Plus service and its benefits, such as longer answer lengths.
- Members requested details about available prompts and whether new features require a subscription, emphasizing the need for clarity on pricing for the general public.
- Tabular Data in NotebookLM: A user inquired about NotebookLM's ability to utilize and understand tabular data, specifically within a character matrix for writing fiction.
- This raised questions among others about the functionality of the platform when managing structured data like tables.
- Sharing AI Generated Podcasts: One user introduced their mobile app designed for sharing AI-generated podcasts, aiming to facilitate embedding and creating RSS feeds for content distribution.
- This sparked discussions about the growing trend of AI content creation and the ease of sharing it through dedicated platforms.
- Akas: share AI generated podcasts: Akas is the ultimate platform for sharing AI-generated podcasts and your own voice. With more and more podcasts being created by AI, like those from NotebookLM and other platforms, Akas provides a sea...
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- - YouTube: no description found
- - YouTube: no description found
Interconnects (Nathan Lambert) ▷ #news (25 messages🔥):
DeepSeek V3 Launch, Multi-Token Prediction Technique, Model Training Efficiency, RL Rewards System, Engineering Innovations in DeepSeek
- DeepSeek V3 launched with impressive advancements: The DeepSeek-V3 has been released, achieving 60 tokens/second and marking a 3x performance increase over V2. This version is fully open-source, maintaining API compatibility while introducing enhanced capabilities.
- Tech teams collaborated on this version, supporting FP8 training on both NVIDIA and AMD GPUs from launch.
- Innovations in Multi-Token Prediction technique: The model utilizes a Multi-Token-Prediction approach, pre-trained on 14.8 trillion tokens, enhancing performance significantly. This method allows predictions to maintain a causal chain at each depth rather than using independent output heads.
- Members discussed the implementation, referencing potential alternatives like the Meta method but noted it was explained in conjunction with EAGLE.
- Efficient RL training methodology observed: DeepSeek employs a dual RL reward system, with verifiers for code/math and a COT-style model-based reward model. This design aims to enhance overall performance and incorporates R1 training patterns after multiple reinforcement learning steps.
- Discussions revealed curiosity about the model's self-critique capabilities, particularly on its effectiveness in generating creative content without definitive ground truth.
- Engineering innovation under constraints: The engineering quality of the DeepSeek team was highlighted as being solid and elegant despite hardware limitations. They tackled known issues directly with practical solutions rather than complex academic theories.
- Comments reflected deep respect for the engineering efforts, emphasizing the simplicity and effectiveness of their approach.
- Critique and revision difficulties in model generation: Members debated the effectiveness of using critique versus generating multiple outputs to select the best one for model responses. Concerns were raised about the logic of including exogenous data for critique versus generating prompts directly, questioning its overall preferences and computational efficiency.
- Members expressed skepticism over self-critique impacting quality in prior models, highlighting challenges in model refinement.
- Tweet from Teortaxes▶️ (@teortaxesTex): > $5.5M for Sonnet tierit's unsurprising that they're proud of it, but it sure feels like they're rubbing it in. «$100M runs, huh? 30.84M H100-hours on 405B, yeah? Half-witted Western h...
- Tweet from Andrew Curran (@AndrewCurran_): @teortaxesTex Anthropic style.
- Tweet from lmsys.org (@lmsysorg): The best open-source LLM, DeepSeek V3, has just been released! SGLang v0.4.1 is the officially recommended inference solution for it.The SGLang and DeepSeek teams worked together to support DeepSeek V...
- Tweet from wh (@nrehiew_): > After hundreds of RL steps, the intermediate RL model learns to incorporate R1 patterns, thereby enhancing overall performance strategically.
- Tweet from Tim Dettmers (@Tim_Dettmers): Reading the report, this is such clean engineering under resource constraints. The DeepSeek team directly engineered solutions to known problems under hardware constraints. All of this looks so elegan...
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing DeepSeek-V3!Biggest leap forward yet:⚡ 60 tokens/second (3x faster than V2!)💪 Enhanced capabilities🛠 API compatibility intact🌍 Fully open-source models & papers🐋 1/n
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): So.. V4 would likely not be Transformers? I wonder what direction would they lean toward!Quoting Vaibhav (VB) Srivastav (@reach_vb) The DeepSeek Technical Report is out!! 🔥Trained on 14.8 Trillion To...
- Tweet from wh (@nrehiew_): They have 2 types of RL rewards. Verifiers (code, math) and standard model based RM. Importantly the model based RM is trained COT style GRPO from deepseek math used here
- Tweet from wh (@nrehiew_): Post training now. They FT on R1 (**NON LITE**) but say that it suffers from "overthinking, poor formatting, and excessive length"They have 2 types of data: 1) Standard synthetic data 2) A sys...
Interconnects (Nathan Lambert) ▷ #ml-questions (5 messages):
Deepseek Multi-head Latent Attention Mechanism, Deepseek V3 Inference Libraries
- Inquiry on Deepseek's Multi-head Latent Attention: A member queried about implementations of Deepseek's Multi-head latent attention mechanism, specifically regarding their V2 paper which lacks detailed explanations on lower rank approximations of weight matrices.
- Is anyone working on creating a version?
- Inference Libraries Supporting Deepseek: Another member pointed out that inference libraries should have implementations for the Multi-head latent attention, highlighting that SGLang supports the new V3 features right from day one.
- They also mentioned that vLLM, TGI, and hf/transformers are likely to include support as well.
- Deepseek's GitHub Repository Reference: A link to Deepseek's inference code on GitHub was shared, directing attention to DeepSeek-V3/inference/model.py.
- This resource could aid members looking to implement or understand the model better.
- Member Plans to Check HF Implementation: The original inquirer mentioned they hadn't checked the Hugging Face (hf) side regarding implementations and expressed intent to follow up on that lead.
- Let me take a look - thanks!
Link mentioned: DeepSeek-V3/inference/model.py at main · deepseek-ai/DeepSeek-V3: Contribute to deepseek-ai/DeepSeek-V3 development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #ml-drama (21 messages🔥):
DeepSeek License Update, Bluesky's AI Backlash, OpenAI Structural Changes, IPO Speculations, Conflict of Interest Concerns
- DeepSeek's License Gets More Liberal: Members discussed that DeepSeek has now updated their license, making it more liberal than Llama.
- License wars! are brewing in the community as users express mixed feelings about the changes.
- Bluesky is Unsafe for AI Discussions: Bluesky is highlighted as an unsafe place for AI discussions, with concerns about an insane anti-AI strain among users.
- Members noted that generative AI has sparked backlash, particularly from data scientists who feel strongly against it.
- OpenAI Evaluates Corporate Structure: OpenAI's Board is evaluating their corporate structure to create one of the best-resourced non-profits in history, supported by for-profit success.
- Our plan includes transforming into a Delaware Public Benefit Corporation as part of this strategy.
- Speculations on OpenAI's IPO: Members speculated about when OpenAI might go public, with thoughts that it may happen when existing investors seek a return.
- Others noted it could also depend on rising capital needs that become too expensive for Venture Capitalists.
- Concerns Over Sponsorship Conflict: A member raised a concern about a potential conflict of interest regarding Dwarkesh being sponsored by Scale AI.
- This sparked discussions about the implications and ethics surrounding such sponsorships in the AI community.
- Tweet from OpenAI (@OpenAI): OpenAI's Board of Directors is evaluating our corporate structure with the goal of making a stronger non-profit supported by the for-profit’s success.Our plan would create one of the best-resource...
- Tweet from OpenAI Newsroom (@OpenAINewsroom): Here is a statement we provided in response to questions about our former teammate:
- Tweet from Esteban Cervi 🦌 (@EstebanCervi): @OpenAINewsroom 🧐
Interconnects (Nathan Lambert) ▷ #random (6 messages):
Deepseek V3 performance, AI lab requirements, Benchmarking instruction following
- Deepseek V3 shows reasoning issues: A member expressed that Deepseek V3 appears smart yet struggles with executing expected outcomes, particularly in generating XML tags after its reasoning process.
- It usually seems to laser-focus in on the reasoning bit while neglecting to output the required
at the end.
- It usually seems to laser-focus in on the reasoning bit while neglecting to output the required
- Call for AI lab with sufficient resources: Another member suggested that the ideal AI lab would need ample GPUs and an effective post-training approach, supported by teams working on mixtures of experts (MoEs) and reinforcement learning (RL).
- This scenario is posited as a solution to bridge the gap in performance when compared to larger labs.
- Need for benchmarking Deepseek V3: A member inquired if anyone had benchmarked Deepseek V3 for instruction following tasks, showing concern about performance differences from Deepseek V2.5.
- They mentioned taking prompts that were previously successful but experienced setbacks with the model swap for V3.
Link mentioned: Tweet from Mihir Patel (@mvpatel2000): @teortaxesTex I would guess the pretraining is cracked but post-training lags behind big labs, which accounts for many of these artifacts
Interconnects (Nathan Lambert) ▷ #memes (1 messages):
xeophon.: https://x.com/simonw/status/1872141432544489731
Interconnects (Nathan Lambert) ▷ #nlp (3 messages):
Iterative Preference Learning, Monte Carlo Tree Search, Reasoning Capabilities of LLMs, Self-Evaluation in Models
- MCTS Enhances LLM Reasoning: A study introduces an approach using Monte Carlo Tree Search (MCTS) for iterative preference learning to boost the reasoning capabilities of Large Language Models (LLMs). This method breaks down instance-level rewards into granular step-level signals and employs Direct Preference Optimization (DPO) for policy updates.
- Theoretical analysis suggests that on-policy sampled data is crucial for effective self-improvement, which is supported by extensive evaluations.
- Concerns on Model Quality: A member expressed skepticism regarding the choice of models used in the recent study, asking, 'Idk why they used such poop-tier models though - was may 2024 that down-bad?'
- This raises questions about the overall effectiveness and quality of models in the context of enhancing reasoning capabilities.
Link mentioned: Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning: We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by ...
Interconnects (Nathan Lambert) ▷ #reads (8 messages🔥):
RL Training for LLMs, DPO vs PPO, Viewing Parties for Critical Discussions, Incentivizing Better CoTs
- Effective RL Training Techniques for LLMs: A two-part seminar titled 'Towards effective RL training for LLMs' discussed optimization techniques, with a focus on PPO enhancements and the comparison of DPO vs PPO methodologies.
- The second half dives deeper into PRM biases and Clip/Delta mitigations, which may pique interest among viewers.
- DPO vs PPO Comparison Insight: Discussion raised about whether DPO is superior to PPO, highlighted with the context of the upcoming ICML 2024 paper on the subject.
- Viewers might find the contrasting approaches particularly interesting, despite their complexities which can be somewhat overwhelming.
- Potential of Viewing Parties: A member suggested the idea of viewing parties for critically engaging with lectures and tutorial videos, raising the question of interest levels among community members.
- While some express enthusiasm for such sessions, one humorously noted they prefer to extract value rather than provide it during discussions.
- Incentives for Better Chains of Thought: It was discussed whether PRMs might incentivize better Chains of Thought (CoTs) in training, hinting at their potential in shaping reward structures.
- However, there remains uncertainty regarding the efficacy of PRM-based training in producing superior results, leading to ongoing conversations about their value.
Link mentioned: - YouTube: no description found
GPU MODE ▷ #general (22 messages🔥):
DETRs Discussion, DeepSeek-V3 Mixed Precision Training, Block-wise vs Channel-wise Quantization, H800 GPU Training, NVIDIA's Delayed Scaling Technique
- Curious about DETRs: A member inquired about DETRs and PyTorch, expressing frustration after hitting a dead end on a hobby project for the last three months.
- Another member offered their knowledge on DETRs, showing a willingness to assist with the inquiry.
- DeepSeek-V3 achieves 2 OOM cost reduction: The discussion highlighted a 5 million USD investment into DeepSeek-V3, praising their achievement of slashing costs by two orders of magnitude in FP8 mixed precision training.
- Insights were shared regarding key features of their training approach, including group-wise and block-wise quantization strategies.
- Debates on Quantization Techniques: There was a thorough debate about the practicality of block-wise vs channel-wise quantization, with some members arguing that block-wise can complicate implementations.
- Concerns were raised over the potential discrepancies in quantization between forward and backward passes, with suggestions for using split-K GEMM to address FP32 accumulation issues.
- Insights on H800 GPU Training Costs: Members discussed the DeepSeek-V3 training that required 2.788 million H800 GPU hours, with questions arising about the specifications of the H800 GPU.
- It was suggested that the H800 is a less powerful variant of the H100 being sold to specific markets, like China.
- NVIDIA's Delayed Scaling Challenges: A member pointed out that while NVIDIA promoted the idea of delayed scaling, implementation complexity pushed most FP8 systems to favor online scaling.
- The conversation highlighted challenges regarding the integration of delayed scaling with existing architectures among the community.
- Tweet from main (@main_horse): "blackwell was taking too long, so we implemented MX8-like training in CUDA ourselves. also, we realized the accum precision of TransformerEngine, which most FP8 trainers use, was too imprecise, a...
- DeepSeek-V3/DeepSeek_V3.pdf at main · deepseek-ai/DeepSeek-V3: Contribute to deepseek-ai/DeepSeek-V3 development by creating an account on GitHub.
GPU MODE ▷ #triton (8 messages🔥):
device_print issue in Colab, tl.inf feature comparison, Triton recompilation conditions
- Device_print not functioning in Colab: A user reported that device_print does not output anything in Google Colab notebooks, seeking feedback from others about this potential issue.
- No additional solutions or workarounds were provided.
- Comparing tl.inf with torch.inf: Another user inquired if there is a tl.inf feature similar to torch.inf, to which it was suggested to use `float(
- Understanding Triton's recompilation triggers: A user posed a question regarding when Triton recompiles, leading to a detailed explanation from another user.
- It was highlighted that recompilation occurs when constants change and when kernel parameters are specialized, with a reference to the repository for more information.
Link mentioned: triton/python/triton/runtime/jit.py at 3c058ee7f518da83e99d472f5ebe16fb75e1f254 · triton-lang/triton: Development repository for the Triton language and compiler - triton-lang/triton
GPU MODE ▷ #cuda (8 messages🔥):
DETRs expertise, WGMMA inputs, CUTLASS 3.6.0 discussion
- Seeking Help on DETRs: A member asked for insights on DETRs and mentioned they've been stuck on a hobby project for the last 3 months.
- Another member suggested that asking in different channels might yield more responses, which led to some confusion over the tone of advice.
- WGMMA Input Requirements: Another member shared that for WGMMA, you need either 1 or 2 inputs from shared memory while accumulations must be in registers.
- They referenced a H100 microbenchmarking paper suggesting that to achieve peak performance with structured sparse FP8, having at least one input in registers is essential.
- CUTLASS 3.6.0 Insights: A member provided a link to a CUTLASS 3.6.0 discussion on GitHub discussing Hopper structured sparse GEMM adjustments.
- The discussion highlighted changes made to align the convolution kernel API with gemm::GemmUniversal, affecting performance across various data types.
Link mentioned: CUTLASS 3.6.0 · NVIDIA/cutlass · Discussion #2013: Hopper structured sparse GEMM. FP16 FP8 INT8 TF32 A refactor to the CUTLASS 3.x convolution kernel::ConvUniversal API to bring it in line with gemm::GemmUniversal. Now the 3.x convolution API is no...
GPU MODE ▷ #torch (3 messages):
Performance of Compiled Functions with Guards, Ring Attention Doubts
- Exploring Performance Impact of Guards: A member raised a question about the performance impact of guards in compiled functions, wondering how many is too many relative to the original code.
- Is reducing guards worth the effort for performance gains?
- Seeking Guidance on Ring Attention: Another member reached out for assistance, stating they have some doubts regarding ring attention and are looking for help.
- They expressed interest in connecting with anyone who has experience in that area.
GPU MODE ▷ #cool-links (2 messages):
Character.AI Inference Optimization, AMD Software Stack Gaps, Benchmarking AMD MI300X vs Nvidia H100 + H200
- Character.AI Focuses on Speed in Inference: Character.AI's latest post details their progress on optimizing AI inference, specifically highlighting their custom int8 attention kernel that enhances performance for both compute-bound and memory-bound scenarios.
- These improvements come after previous optimizations concentrated on memory efficiency, reducing the KV cache size with techniques like multi-query attention and int8 quantization.
- AMD's Meeting with Developers Shows Progress: A recent meeting with AMD's CEO, Lisa Su, showed her acknowledgment of gaps in the AMD software stack and openness to recommendations from developers.
- Many changes are reportedly already in motion after exploring feedback and detailed analyses conducted over the past five months.
- Benchmarking Insights on AMD vs Nvidia: An independent benchmarking analysis compared AMD MI300X with Nvidia H100 + H200, yielding detailed public recommendations based on performance and total cost of ownership.
- The findings indicated that improvements in AMD's software development approach are necessary, going beyond just software maturity.
- Optimizing AI Inference at Character.AI (Part Deux): At Character.AI, we’re building personalized AI entertainment. In order to offer our users engaging, interactive experiences, it's critical we achieve highly efficient inference, or the process b...
- Tweet from Dylan Patel (@dylan522p): Met with @LisaSu today for 1.5 hours as we went through everythingShe acknowledged the gaps in AMD software stackShe took our specific recommendations seriouslyShe asked her team and us a lot of quest...
GPU MODE ▷ #beginner (10 messages🔥):
Learning ML Tools, vLLM Token Throughput, CUDA Resources, Attention Mechanisms
- Pathway to Master Lower-Level ML Tools: A member inquired about a defined pathway for learning lower-level ML tools like CUDA and Triton to optimize model training and inference speeds, seeking suggestions beyond existing resources.
- Suggestions like reading PMPP and tackling CUDA puzzles were mentioned, but the member felt there might be other essential resources or a recommended sequence to follow.
- Insights on vLLM's Throughput Strategy: One member analyzed vLLM's TTFT performance, questioning the lack of batched inference and its use of the xFormers backend for optimizing attention.
- They observed that while the sequence-stacked approach is effective, the decision against batched inference raised questions about potential advantages; experimentation showed minimal latency differences.
- Efficient Attention Implementation Discussion: Another user highlighted a similarity between FlashAttention and vLLM's sequence stacking approach, stating it enables batched access while improving performance via effective masking.
- They also warned that optimized attention implementations restrict flexibility, requiring compatibility with existing kernels for effective performance, leading to a potential 'software lottery' for researchers.
- Resource Sharing for CUDA Learners: A new member expressed difficulty finding comprehensive resources for learning CUDA, prompting others to share useful material.
- A group member directed them to a repository containing GPU programming-related resources, stating it could be a helpful starting point for beginners: Resource Stream.
- FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention: no description found
- vllm/vllm/attention/backends/xformers.py at dbeac95dbbf898bcc0965528fc767e9cadbbe0c5 · vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllm
- GitHub - gpu-mode/resource-stream: GPU programming related news and material links: GPU programming related news and material links. Contribute to gpu-mode/resource-stream development by creating an account on GitHub.
GPU MODE ▷ #pmpp-book (1 messages):
tando.: The video lecture helps me a lot to understand concept combining with the book
GPU MODE ▷ #lecture-qa (1 messages):
Occupancy vs. Utilization
- Confusion between Occupancy and Utilization metrics: A member questioned if occupancy was the correct term being used, suggesting it might actually refer to utilization instead.
- They noted that the numbers seemed atypical for occupancy, expecting values of 100%, 67%, or possibly 50% with blocks of 1024.
- Need for Clarification on Metrics: The inconsistency in metrics led to a discussion on the importance of defining terms accurately within the context of the conversation.
- This highlights the necessity for clear communication when discussing performance metrics.
GPU MODE ▷ #bitnet (6 messages):
Torchcompiled forward passes, Bitblas Conv2D generation, Mixed precision training options
- Torchcompiled grapples with limitations: A member highlighted that the new Torchcompiled idea struggles beyond the MNIST toy example, noting that no backprop requires 128 forward passes for a gradient estimate with only 0.009 cosine similarity.
- They referenced Will's paper claiming it allows training in 1.58b, using 97% less energy and storing a 175B model in ~20mb.
- Batch size comparison sparks debate: A member drew a parallel between the challenges of batch versus mini batch gradient and the issues highlighted in the previous discussion on forward passes.
- The connection suggests underlying complexities in scaling training methods, similar to those faced with Torchcompiled.
- Bitblas promises seamless Conv2D integration: One member queried the ability of bitblas to generate a Conv2D that could be incorporated into a Torch model.
- This indicates an interest in simplifying model training processes through effective computational tools.
- Clarification on Precision Types: A member sought clarity on whether fp16xfp16 or mixed-precision like fp16xuint4 was being referenced in a prior message about testing.
- This discussion signifies the ongoing exploration of optimal training configurations and their effectiveness.
- Mixed precision training insights: Another member confirmed the focus was on mixed precision like bitnet, pointing towards effective training strategies.
- This highlights the community’s technical interest in leveraging mixed precision for enhanced performance.
Link mentioned: Tweet from Ethan (@torchcompiled): This is a cool idea, but you won't have a good time past the MNIST toy example. No backprop means needing... 128 forward passes, for grad estimate with only 0.009 cos similarity with true grad.inc...
GPU MODE ▷ #sparsity-pruning (1 messages):
Sparsify Function, Dense Matrix Compression, Model Masking Solutions
- Sparsify_function requires zeroed-out dense model: The
sparsify_function is designed to work with models that have a zeroed out dense matrix, which is created by theSparsifier.- However, any zeroed-out dense model can be utilized if you have an alternative masking approach in place.
- GitHub resource highlights PyTorch sparsity techniques: An example use case for model sparsification can be found in the PyTorch reading.
- This documentation explains native quantization and sparsity methods for training and inference in PyTorch, providing essential insights for users.
Link mentioned: ao/torchao/sparsity/README.md at 567cb46409f5f9a761429a87d27b1d5312642888 · pytorch/ao: PyTorch native quantization and sparsity for training and inference - pytorch/ao
GPU MODE ▷ #metal (1 messages):
archit3ch: Is it possible to take a .air file compiled for macOS and run it on iPad?
GPU MODE ▷ #arc-agi-2 (2 messages):
Model Task Format Understanding, Benchmarking Limitations, Scaling to AGI Challenges
- Model Misunderstands Task Format: A member shared a tweet discussing that when models can't understand the task format, benchmarks can mislead by introducing a hidden threshold effect. This raises concerns about benchmark accuracy in assessing model performance.
- When models struggle, it questions the viability of scaling to AGI.
- Larger Models vs. Human Tasks: The discussion continues with the implication that there could always be a larger version of a task that humans can solve but an LLM cannot, highlighting a significant issue in model scalability.
- This prompts a reevaluation of what this means for our path toward Artificial General Intelligence (AGI), particularly in terms of comprehending tasks.
- Article on LLM Perception and Reasoning: A member directed attention to an article titled 'LLMs Struggle with Perception, Not Reasoning' which delves into the difficulties LLMs face in perception-related tasks.
- The article can be accessed here for those interested in further insights.
Link mentioned: Tweet from Mikel Bober-Irizar (@mikb0b): When models can't understand the task format, the benchmark can mislead, introducing a hidden threshold effect.And if there's always a larger version that humans can solve but an LLM can't...
tinygrad (George Hotz) ▷ #general (6 messages):
matching engine performance, rewrite bounty, testing environment concerns
- Performance bounties under scrutiny: Discussion centered around the three matching engine performance bounties, linking to this GitHub issue for reference, and noting a model lower result on benchmarks.
- One member inquired if existing performance already running in 25ms had been previously addressed.
- Rewrite speed disparity on different machines: A member highlighted that the rewrite speed on their laptop with an RTX 3050 GPU reached 800+ ms, raising concerns about hardware dependencies.
- A screenshot was shared, illustrating the performance results demonstrating the significant slowdown compared to expected benchmarks.
- Clarification on bounty expectations: George Hotz indicated that the ongoing bounty is about achieving a relative speedup focused on the rewrite component of the project.
- He added that further questions would be addressed once a pull request demonstrating a 2x speedup is submitted.
Link mentioned: Issues · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - Issues · tinygrad/tinygrad
tinygrad (George Hotz) ▷ #learn-tinygrad (51 messages🔥):
Tinygrad vs PyTorch performance, JIT implementation issues, Beam search functionality, RTX 4070 usage, Model conversion to Tinygrad
- Tinygrad matches PyTorch performance with JIT: After optimizing JIT usage across all transformer blocks, Tinygrad is achieving performance levels comparable to PyTorch during inference.
- It was noted that employing JIT appropriately—with minimal Python control flow—maximizes performance efficiency.
- Challenges with JIT implementation: Users encountered out of memory errors when applying JIT to individual transformer blocks but resolved it by applying it to all layers collectively.
- This approach allowed for maintaining speed and stability, demonstrating the importance of JIT placement and usage.
- Beam search kernel caching: Questions arose about the possibility of saving and reusing the kernels produced by beam search across different runs, which was confirmed as feasible.
- It was emphasized that cached kernels can be beneficial for transferring workloads to similar machines without re-executing the entire beam search.
- Conversion of TTS model to Tinygrad: The conversion of a TTS model from Torch to Tinygrad is actively being tested, with plans for sharing a minimal reproducible example for community insights.
- Initial challenges were faced, but the overall goal is to leverage OpenCL and optimize performance to approach levels seen with torch.compile.
- Documentation and user experience insights: A need for improved documentation on the optimal use of JIT and beam functionality in Tinygrad was highlighted, as current guidelines can lead to misapplications.
- A community member suggested that while Torch's compilation handles many edge cases automatically, Tinygrad's documentation requires further development for effective user guidance.
- fish-speech/fish_speech/models/text2semantic/llama.py at main · fishaudio/fish-speech: SOTA Open Source TTS. Contribute to fishaudio/fish-speech development by creating an account on GitHub.
- llama-tinygrad/llama_tinygrad.ipynb at main · MankaranSingh/llama-tinygrad: Contribute to MankaranSingh/llama-tinygrad development by creating an account on GitHub.
Cohere ▷ #discussions (11 messages🔥):
Christmas greetings, Introduction to AI and ML, Community welcome messages, Lighthearted banter
- Christmas Cheer Spreads: Merry Christmas everyone! was joyfully shared by a member, hoping to spread festive cheer.
- Another user responded with a warm greeting, enhancing the community's festive spirit.
- New Learner Joins Discussion: A newcomer announced their entry into the group, expressing excitement about learning AI and ML, particularly LLMs.
- I hope being here, I can learn a lot and get knowledge to excel in my career, they noted, signaling eagerness to grow with the community.
- Community Welcomes New Member: Members enthusiastically welcomed the new participant, with one saying, Welcome 2 :).
- This shows a supportive environment among learners in AI and ML.
- Curiosity About Future Developments: What's coming next? was posed by a member, signaling interest in upcoming discussions or features.
- This question reflects the community’s ongoing engagement and desire for future insights.
- Lighthearted Banter Ensues: In a jovial moment, a member humorously claimed, I ate your flower! prompting playful responses.
- Another member humorously replied with Bon appetit, showcasing the fun and friendly atmosphere.
Link mentioned: Pricing - Affordable Enterprise Generative AI Models: Access our models directly through our API to create scalable production workloads.
Cohere ▷ #questions (25 messages🔥):
Command R Plus Updates, r7b Initial Impressions, Cows and AI Bot Interaction, Emojis in Communication, Bethlehem Star Inquiry
- Command R Plus future updates questioned: Discussion began about potential future updates to Command R Plus, particularly from a user who just started using it for replacements.
- Another user wondered if issues they encountered were frequent, hinting at dissatisfaction with the current state of the tool.
- Initial reactions to r7b advancements: A member noted an interesting beginning for r7b, expressing initial intrigue along with skepticism about its performance compared to command r.
- The commentary suggested a search for more information about the tool and its perceived shortcomings.
- Cows: A peculiar but fascinating bot exchange: A light-hearted request was made for a paragraph about why cows are cool, leading to a response generated by the Cmd R Bot.
- The bot provided a detailed description of cows, which led users to question whether it was AI-generated content.
- Confusion over emoji meanings: The Cmd R Bot was asked to find meanings for the 🤡, 🤓, and 👆 emojis, but it retrieved no information from documentation.
- This led to humorous exchanges among users regarding the inability of the bot to provide basic emoji definitions.
- Inquiry about the Bethlehem Star: A user questioned what the Bethlehem star is, prompting another search for relevant documentation.
- However, the bot was unable to find any information, resulting in no further discussion on the topic.
Cohere ▷ #api-discussions (5 messages):
Image Embeds Rate Limits, Holiday Hours Impact
- Confusion Over Image Embed Rate Limits: A user questioned the current rate limits for image embeds, stating it appears to be 40 per minute instead of the expected 400 per minute for production keys.
- Another member confirmed this is a known issue and assured that our teams are working on a fix to restore the limits to 400.
- Holiday Hours Might Delay Updates: One member mentioned that holiday hours might impact the timing of forthcoming updates regarding the rate limits.
- They promised to provide an update soon, ensuring users remain informed and engaged during this period.
Cohere ▷ #cmd-r-bot (9 messages🔥):
Command R, Command R+, Retrieval-Augmented Generation
- Command R Model Overview: Command R is a large language model optimized for conversational interaction and long context tasks, enabling companies to scale from proof of concept to production.
- It boasts a 128,000-token context length, high precision on RAG tasks, and low latency for cross-lingual operations, supporting ten key languages.
- Command R+ Performance Capabilities: Command R+ is touted as the most performant large model, trained on diverse texts for a wide array of generation tasks.
- It excels in complex RAG functionality and workflows requiring multi-step tool use for building agents.
- Resources and Documentation: Several sources are available for further information on Command R and Command R+, including this changelog and documentation.
- Additional insights can be found in discussions around Retrieval-Augmented Generation at Production Scale.
Cohere ▷ #projects (2 messages):
Content Identification/Moderation System (CIMS), Companion Discord Chatbot, Content Flagging and Deletion Features
- CIMS Launches for Companion: We’re excited to introduce the Content Identification/Moderation System (CIMS) for Companion, enhancing its ability to monitor and moderate content effectively.
- This major upgrade aims to create a safer environment for communities by automatically detecting and managing harmful interactions.
- Companion's Versatile Capabilities: Companion is designed as a versatile Discord chatbot, assisting communities by fostering conversation and managing daily tasks.
- With the new CIMS capabilities, it now supports better community management while adding more engagement charm.
- CIMS Content Flagging and Deletion: The CIMS system is capable of flagging content and can also delete inappropriate content directly as needed.
- Examples of flagged content are available in the attached screenshots, showcasing its functionality.
Link mentioned: Home: An AI-powered Discord bot blending playful conversation with smart moderation tools, adding charm and order to your server. - rapmd73/Companion
Latent Space ▷ #ai-general-chat (22 messages🔥):
Orion delays, OpenAI outage, Deepseek pricing and performance, Illuminate tool, Frontier vs Foundation models
- Discussion on Orion Delays: There is an ongoing discussion about Orion delays with relevant information shared on Hacker News. Members are tracking its implications for future projects.
- OpenAI Services Facing Outage: A member reported a new outage affecting OpenAI services, noting that monthly uptime has been historically poor, reminiscent of performance issues from January 2023.
- An image was shared that highlights the growing concerns about service reliability.
- Unpacking Deepseek's Cost Structure: The pricing structure for Deepseek is discussed, with rates anticipated to be $0.27/MM in and $1.10/MM out starting in February, which is seen as affordable for the performance offered.
- User experiences mentioned that while it performs well with limited tasks, it struggles with post-training reasoning for more complex requests.
- Exploring the Capabilities of Illuminate Tool: Several members explored Illuminate, a tool akin to NotebookLM tailored for technical papers, sharing their curiosity and experiences with it, including mixed feedback on functionality.
- The discussion noted that the development teams are separate, leading to varied implementations from existing models.
- Frontier vs Foundation Models: The Buzzword Battle: The conversation about the terms Frontier Model and Foundation Model highlights that 'Frontier' seems to signify state-of-the-art performance across tasks, changing perceptions as models evolve.
- Users agree that while 'Foundation' reflects earlier innovations, 'Frontier' captures the current landscape but remains a bit ambiguous in its true meaning.
- Illuminate | Learn Your Way: Transform research papers into AI-generated audio summaries with Illuminate, your Gen AI tool for understanding complex content faster.
- Cartesia: Real-time multimodal intelligence for every device.
- - YouTube: no description found
- - YouTube: no description found
Latent Space ▷ #ai-announcements (1 messages):
AI Engineer Summit NYC, Event Calendar Updates, Latent Space Events
- Save the Date for AI Engineer Summit NYC: The AI Engineer Summit NYC is scheduled to take place at The Times Center in April 2025. Stay tuned for more details as the event date approaches.
- You can find more information and updates on the event calendar at lu.ma for the latest AI Engineering events.
- Get Updates on Upcoming AI Events: Users are encouraged to subscribe to event updates by clicking the RSS logo above the calendar to add to your calendar. This will ensure you're notified of any new events in the upcoming months.
- Hover and click 'Add iCal Subscription' for easy integration into your personal calendar.
- No Pending Events on Current Schedule: Currently, there are 0 events pending approval by the calendar admin. Events will appear on the schedule once they receive approval.
Link mentioned: Latent Space (Paper Club & Other Events) · Events Calendar: View and subscribe to events from Latent Space (Paper Club & Other Events) on Luma. Latent.Space events. PLEASE CLICK THE RSS LOGO JUST ABOVE THE CALENDAR ON THE RIGHT TO ADD TO YOUR CAL. "Ad...
LlamaIndex ▷ #blog (2 messages):
Report Generation Agent, Conversational Voice Assistant with RAG
- Build a Report Generation Agent from Scratch: A fantastic video by @fahdmirza demonstrates how to create an agentic workflow for generating formatted reports from a set of PDF research papers using LlamaParse and LlamaCloud.
- The workflow takes an input formatted template and effectively generates the desired report, showcasing practical applications of these tools here.
- Enhance Conversational Assistant with RAG: An engaging thread by @MarcusShiesser illustrates how to augment a conversational voice assistant with a Retrieval-Augmented Generation (RAG) tool powered by LlamaCloud, capable of processing over 1M+ PDFs.
- The demo highlights serving via LlamaCloud's document processing technology, making significant improvements to conversational capabilities view it here.
LlamaIndex ▷ #general (18 messages🔥):
LlamaIndex Assistant RAG App, Payroll PDF Parsing, LlamaIndex Roadmap Update, Running Non-Quantized Models with Ollama, Image Data Extraction
- Kargarisaac seeks LlamaIndex Documentation: A member is developing a llamaindex-assistant RAG app and inquired about obtaining the LlamaIndex documentation in PDF format to aid in development.
- Another member confirmed the generation is possible and engaged further on the format needed.
- PDF Parsing Dilemma: A user sought advice on the best method to parse a payroll PDF after unsuccessful attempts with llama parse.
- A member suggested that llama parse should work fine, especially if opting for premium mode.
- Need for Updated LlamaIndex Roadmap: A member asked for an up-to-date roadmap for LlamaIndex, noting that the pinned GitHub discussion appears outdated.
- Another member acknowledged that the roadmap requires an update as it was last written in early 2024.
- Challenges with Ollama Quantization: A user expressed a challenge with running a non-quantized model using Ollama for their RAG pipeline.
- Members discussed that while Ollama may not provide unquantized versions, it is essential to ensure settings align with performance expectations.
- Image Data Extraction Success: A user shared their success in extracting data from an image of a table using Llama3.2 11B vision instruct turbo rather than Ollama.
- Members speculated that differences in image handling between the two services might be affecting the results.
Link mentioned: Tags · llama3.2-vision: Llama 3.2 Vision is a collection of instruction-tuned image reasoning generative models in 11B and 90B sizes.
LlamaIndex ▷ #ai-discussion (3 messages):
LlamaIndex discussion, Docling from IBM, Open Source Library
- Clarifying Purpose of LlamaIndex Discussions: A member questioned what this discussion had to do with LlamaIndex, prompting a response aimed at clarifying the intent to share resources.
- Another member emphasized that sharing resources benefits everyone engaging with LlamaIndex in a general discussion context.
- Introduction to Docling from IBM: A member highlighted the Docling from IBM, an open source library designed to make documents AI ready.
- They shared a YouTube video detailing its features, inviting everyone to explore this potential resource.
Link mentioned: - YouTube: no description found
Torchtune ▷ #general (6 messages):
Flex Compilation Issues, Nested Compiling Dilemmas, Graph Break Concern
- Flex Compilation might cause graph breaks: A member discussed how the current implementation of flex requires compilation to achieve performance gains, leading to potential graph breaks when not handled correctly.
- Another member suggested reaching out to a colleague for a possible better solution, indicating their current method may cause issues.
- Nested compiling challenges: There was a concern about the inability to compile an operation within another compile, leading to previous errors identified as dynamo errors.
- One member found that while they were unable to replicate the errors, they highlighted the importance of ensuring performance with nested compile configurations.
- Requests for testing flex performance: It was suggested that further testing should be conducted to confirm whether compiled flex performance remains consistent with and without model compilation.
- The discussion reflected a need for clarity on operational stability along with performance expectations in the current setup.
Link mentioned: torchtune/torchtune/modules/attention_utils.py at main · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
Torchtune ▷ #papers (17 messages🔥):
DeepSeek V3, H800 GPUs, FP8 Training Techniques, NVLink Bandwidth Innovations, Triton vs CUDA Implementations
- DeepSeek V3 trains 600+B MoE efficiently: They manage to train a 600+B MoE model on 2000 GPUs in just 2 months without tensor parallelism, as detailed in their DeepSeek V3 paper.
- This impressive feat sheds light on the innovative training methodologies employed despite hardware limitations.
- H800 GPUs are nerfed H100 for China: Members discussed that the H800 GPUs are essentially nerfed versions of the H100, leading to reduced NVLink bandwidth.
- One member commented on how these limitations might drive innovation, highlighting the key differences in FP64 performance across the hardware.
- FP8 training motivates new coding efforts: Inspired by advancements in DeepSeek’s FP8 training, one member expressed motivation to implement FP8 training with nanoGPT using torchao's frameworks.
- The discussion emphasized the need for efficient all-to-all communication kernels to utilize NVLink to its fullest potential.
- Pipeline parallelism and expert parallelism innovations: Reduced NVLink speeds are prompting innovations in pipeline parallelism and expert parallelism to minimize bandwidth use, as noted in the debate around training techniques.
- This represents a strategic shift in how models are being optimized under the constraints of current hardware.
- Triton vs. CUDA for Implementation: There is a discussion on whether to implement quantization in Triton or pure CUDA, with members weighing the ease of Triton against CUDA's potential performance.
- The SM90 architecture's limitations in Triton were noted, as members suggested that using cutlass might be necessary for high-performance GEMM.
Link mentioned: DeepSeek-V3/DeepSeek_V3.pdf at main · deepseek-ai/DeepSeek-V3: Contribute to deepseek-ai/DeepSeek-V3 development by creating an account on GitHub.
DSPy ▷ #general (15 messages🔥):
Glossary Generation Script, TypedDict in Pydantic, Elegant Pydantic Designs, Schema Descriptions in Prompts
- Glossary Generation Script Works Smoothly: A member shared a script for generating a glossary of key terms from Jekyll posts, which outputs a YAML file to the '_data' directory.
- They mentioned hand tuning the details for better clarity, appreciating the initial output's comprehensiveness.
- TypedDict Introduced in Discussion: A member noted a recent learning about
typing.TypedDict, sparking discussions about Pydantic's features.- Another member remarked on the complexity of integrating multiple output fields within a single array.
- Pydantic Models for Output Structuring: A member suggested using
pydantic.BaseModelto create structured outputs with field descriptions.- This led to a consensus that such models effectively propagate their schema to the prompts.
- Propagation of Descriptions in Pydantic Models: Discussion arose around whether Pydantic sub-field descriptions are propagated in existing adapters.
- Members confirmed that these descriptions are indeed included in the generated prompt schema.
- Future Work on Gist Example: A member committed to revising their example in the shared gist to incorporate discussed improvements.
- The revised example aims to demonstrate the use of Pydantic models in a more elegant manner.
Link mentioned: A script to generate a glossary of key terms from your Jekyll posts. We're using DSPy to handle LLM interactions; it helps with boilerplate prompt context and parsing responses into Pydantic objects. To run this, put this script in a folder named 'scripts' (or whatever) in your Jekyll site directory. Then plug in your Anthropic API key (or point DSPy to the LLM endpoint of your choice). It will output a YAML file named 'glossary.yaml' to your '_data' directory.: A script to generate a glossary of key terms from your Jekyll posts. We're using DSPy to handle LLM interactions; it helps with boilerplate prompt context and parsing responses into Pydantic o...
Modular (Mojo 🔥) ▷ #general (4 messages):
Mojo swag, Modular merch, Merch quality
- Mojo swag successfully delivered!: A member expressed gratitude for receiving the Mojo swag, thanking the team for arranging delivery to a remote location.
- They included a link to an image showcasing the swag here.
- Mojo merch set to shine: Members commented on the quality of Modular’s merch, predicting it will perform well with fans, with a member stating it will 'do numbers for sure'.
- They noted the appeal of a particular sticker, calling it 'hard' and emphasizing the overall attractiveness of the products.
- Impressive quality of Mojo shirts: Another member highlighted that the shirts from the Mojo collection are actually quite nice, adding to the positive reception of the merch.
- This further reinforces the group's enthusiasm about the overall quality and design of Modular's merchandise.
Modular (Mojo 🔥) ▷ #mojo (1 messages):
Copyable Traits Design
- Concerns about
CopyableandExplicitlyCopyableTraits: A member has expressed concerns regarding the design of theCopyableandExplicitlyCopyabletraits, highlighting the need for a reevaluation.- These insights were shared in detail on the forum.
- Discussion on Design Improvements for Copyable Traits: Further discussions revolve around potential design improvements that could enhance the usability of
Copyabletraits.- Community members are invited to contribute their suggestions and thoughts on this topic on the same forum thread.
Modular (Mojo 🔥) ▷ #max (8 messages🔥):
MAX and XLA comparison, Mojo vs Python APIs, Compiler optimizations, Community engagement in development, Endia and Basalt project updates
- MAX evolves beyond XLA: MAX incorporates features from XLA, including automatic kernel fusion and memory planning, and adds enhanced support for dynamic shapes and user-defined operators.
- The discussions highlight MAX's potential as 'XLA 2.0' while noting it also offers a serving library and custom kernel capabilities.
- Debate on Mojo vs Python APIs: There is uncertainty regarding whether to develop a consistent API parallel for Mojo or to enhance Python integration, as Python currently offers more convenient development features.
- Members expressed that this uncertainty is hindering progress on projects, leading some to temporarily switch back to JAX.
- Importance of Compiler Control: A member pointed out the necessity for users to override certain optimizations in compilers, particularly in scenarios with pathological cases, which is often lacking in Python frameworks.
- This emphasizes the need for more control over compiler behavior within the frameworks being discussed.
- Community Collaboration vs Independent Development: There is an ongoing discussion about whether to collaboratively build new features with the community or to independently develop them within Modular.
- Collaboration on projects like Endia is encouraged, but there are questions around ensuring feature parity between Python and Mojo.
- Hope for Endia and Basalt Progress: Members expressed hopes for a new release of Endia and concerns about the potential abandonment of the Basalt project.
- Feedback indicates a willingness to temporarily set aside Mojo development due to current uncertainties surrounding the platform.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (10 messages🔥):
Certificate Declaration Form, Next Course Dates, Quiz Form Accessibility, Advanced LLM Agents MOOC
- Certificate Declaration Form is crucial for certification: Members confirmed that without filling the certificate declaration form, one cannot receive a certificate, regardless of completed assessments.
- Unfortunately, that form is super important to act as our 'roster' for tracking purposes.
- Next Course Starts Late January: The next course is scheduled to begin in late January, providing an opportunity for those missing the current one.
- This timeframe was mentioned by community members keenly awaiting the new offering.
- Quiz Forms Currently Closed to Responses: A member raised concerns about closed quiz forms, indicating that they are no longer accepting responses and need reopening.
- The feedback highlighted that these quizzes are useful for learners, especially for ongoing studies.
- Upcoming MOOC on Advanced LLM Agents: The subject of the next MOOC will be Advanced LLM Agents, appealing to those interested in deepening their knowledge.
- Excitement for this new course theme was evident in the channel discussions.
- Large Language Model Agents MOOC: MOOC, Fall 2024
- Quiz 5 - Compound AI Systems w/ Omar Khattab (10/7): INSTRUCTIONS:Each of these quizzes is completion based, however we encourage you to try your best for your own education! These quizzes are a great way to check that you are understanding the course m...
OpenInterpreter ▷ #general (5 messages):
OCR API Issues, Desktop Version Release, Voice to Voice Chat App, Open-Interpreter OS Mode
- OCR API is currently broken: An API designed to use OCR for identifying icons and text on screens is currently not functioning properly, with one user mentioning they haven't received a successful response yet.
- LOL was used to express frustration over the situation.
- Inquiries about Desktop Version Release: A member asked about the timeline for the desktop version release, seeking clarity on when it will become available.
- No further details regarding the release date were provided in the discussion.
- Collaboration on Music Generation Project: A self-identified AI engineer shared their experience in DNN-VAD, NLP, and ASR projects, specifically highlighting a recent project involving a Voice to Voice chat app and music generation using generative AI technology.
- They expressed interest in collaborating with others on their projects.
- Operational Questions about QvQ with Open-Interpreter: An inquiry was made regarding the operation of QvQ when utilized with Open-Interpreter in OS mode.
- This question remains open as no responses were provided in the shared messages.
OpenInterpreter ▷ #ai-content (2 messages):
Claude 3.5 Opus, Comparison with O1 and O1 Pro
- Claude 3.5 Opus boasts reasoning ability: There's excitement around the potential of Claude 3.5 Opus and its reasoning capabilities.
- Many are curious if these enhancements position it as a competitor against existing models.
- Can Claude 3.5 Opus outperform O1?: Questions arose about whether Claude 3.5 Opus can beat O1 and O1 Pro in performance.
- The conversation reflects ongoing interest in the evolving competition among AI models.
Nomic.ai (GPT4All) ▷ #general (7 messages):
Copy Button for AI Code, WASM Package Availability, Vulcan Version Inquiry, Mouse and Keyboard Functionality, New Template Usage
- Need for a 'Copy' Button for AI Code: A member pointed out the lack of a dedicated 'copy' button for AI-generated code within the chat UI and asked if anyone else noticed this issue.
- Another member confirmed the absence of the button and noted that while mouse cut-and-paste methods do not work, Control-C and Control-V are functional for this purpose.
- Inquiry about WASM Package: A new member expressed curiosity about whether the AI is available as a WASM package for installation.
- No responses were provided regarding this query, highlighting an area of interest among newcomers.
- Questions about Vulcan Version: A member inquired about the specifics of the Vulcan version, asking this question twice.
- There were no responses or clarifications given about the version, leaving the inquiry open.
- Issues with Mouse Button Functionality: In response to the 'copy' button query, it was noted that mouse button cut-and-paste does not work on the configuration pages.
- This reinforces the preference for keyboard shortcuts Control-C and Control-V mentioned previously.
- Exploration of Using New Templates: A member asked if anyone successfully wrote using the new template, suggesting an ongoing community effort to adapt to changes.
- This topic could spark further discussion regarding template features and user experiences.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (3 messages):
Inference scaling, Post-training techniques, Tool-augmented LLM, Leaderboards for model validation
- Questions on Inference Scaling Techniques: A member inquired whether BFCL could support uploading models enhanced with inference scaling and post-training techniques for validation on the leaderboard.
- They highlighted using post-inference verification methods to call a tool-augmented LLM multiple times for better output selection.
- Concerns Over Fairness in Leaderboard: The same member expressed concerns about the fairness of adding their model to the leaderboard, noting it could be unfair for single-call LLMs.
- They proposed offering inference latency as a tradeoff for improved performance, questioning whether this approach would be acceptable.
LAION ▷ #general (2 messages):
Whisper's capabilities, Voice Activity Detection
- Whisper can split sentences: One member suggested that Whisper can detect sentences, which would allow for splitting sentences effectively.
- Using Whisper in this way could enhance clarity when processing speech.
- Voice Activity Detector for Speech Splitting: Another member recommended using a voice activity detector (VAD) to differentiate between speech and silence, allowing for better splitting of audio.
- This method efficiently utilizes silence detection to improve audio processing.
MLOps @Chipro ▷ #general-ml (1 messages):
ML Ops frameworks for HPC, Guild AI stability, DIY ops frameworks
- Seeking ML Ops frameworks for HPC: A member requested suggestions for ML Ops frameworks suitable for HPC environments, stressing the importance of stability.
- They expressed a preference for free options, mentioning that their HPC has adequate storage for large models without reliance on SaaS solutions.
- Concern over Guild AI's stability: The member noted that Guild AI appears promising but questioned its stability.
- They were hesitant about relying on it without more concrete feedback on its performance in HPC environments.
- A call for DIY ops framework ideas: The member expressed a desire to create a simple ops framework themselves rather than setting up a whole server.
- They indicated that taking the DIY approach would save them from what they consider excessive effort.