[AINews] Mozilla's AI Second Act
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Superfast CPU inference is all you need.
AI News for 6/25/2024-6/26/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (416 channels, and 3358 messages) for you. Estimated reading time saved (at 200wpm): 327 minutes. You can now tag @smol_ai for AINews discussions!
The slow decline of Mozilla's Firefox market share is well known, and after multiple rounds of layoffs its future story was very uncertain. However at the opening keynote of the AIE World's Fair today they came back swinging:

Very detailed live demos of llamafile with technical explanation from Justine Tunney herself, and Stephen Hood announcing a very welcome second project sqlite-vec that, you guessed it, adds vector search to sqlite.
You can watch the entire talk on the livestream (53mins in):
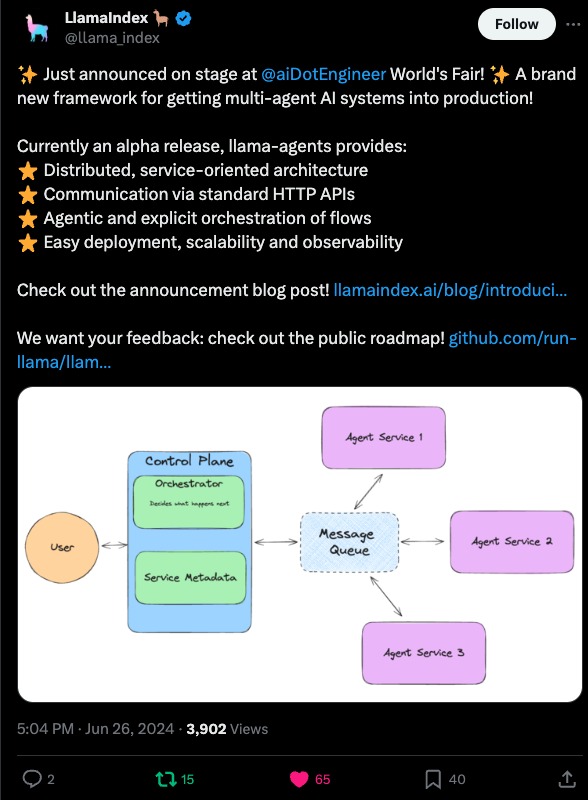
LlamaIndex also closed the day with a notable launch of llama-agents
Some mea culpas: yesterday we missed calling out Etched's big launch (questioned), and Claude Projects made a splash. The PyTorch documentary launched to crickets (weird?).
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Anthropic Claude Updates
- New UI features: @alexalbert__ noted new features in the Claude UI, including a sidebar for starring chats, shareable projects with 200K context windows for documents and files, and custom instructions to tailor responses.
- Anthropic announces Projects: @AnthropicAI introduced Projects, which allow organizing chats into shareable knowledge bases with a 200K context window for relevant documents, code, and files. Available for Claude Pro and Team users.
Hardware and Performance Benchmarks
- Etched AI specialized inference chip: @cHHillee shared thoughts on Etched's new inference chip, noting potential misleading marketing claims around silicon efficiency and performance. Benchmarks claim 500k tokens/sec (for multiple users) and replacing 160 H100s with one 8x Sohu server, but may not be normalized for key details. More info needed on benchmark methodology.
- Sohu chip enables 15 agent trajectories/sec: @mathemagic1an highlighted that 500k tokens/sec on Sohu translates to 15 full 30k token agent trajectories per second, emphasizing the importance of building with this compute assumption to avoid being scooped.
- Theoretical GPU inference limits: @Tim_Dettmers shared a model estimating theoretical max of ~300k tokens/sec for 8xB200 NVLink 8-bit inference on 70B Llama, assuming perfect implementations like OpenAI/Anthropic. Suggests Etched benchmarks seem low.
Open Source Models
- Deepseek Coder v2 beats Gemini: @bindureddy claimed an open-source model beats the latest Gemini on reasoning and code, with more details on open-source progress coming soon. A follow-up provided specifics - Deepseek Coder v2 excels at coding and reasoning, beating GPT-4 variants on math and putting open-source in 3rd behind Anthropic and OpenAI on real-world production use cases.
- Sonnet overpowers GPT-4: @bindureddy shared that Anthropic's Sonnet model continues to overpower GPT-4 variants in testing across workloads, giving a flavor of impressive upcoming models.
Biological AI Breakthroughs
- ESM3 simulates evolution to generate proteins: @ylecun shared news of Evolutionary Scale AI, a startup using a 98B parameter LLM called ESM3 to "program biology". ESM3 simulated 500M years of evolution to generate a novel fluorescent protein. The blog post has more details. ESM3 was developed by former Meta AI researchers.
Emerging AI Trends and Takes
- Data abundance is key to AI progress: @alexandr_wang emphasized that breaking through the "data wall" will require innovation in data abundance. AI models compress their training data, so continuing current progress will depend on new data, not just algorithms.
- Returns on human intelligence post-AGI: @RichardMCNgo predicted that the premium on human genius will increase rather than decrease after AGI, as only the smartest humans will understand what AGIs are doing.
- Terminology for multimodal AI: @RichardMCNgo noted it's becoming weird to call multimodal AI "LLMs" and solicited suggestions for replacement terminology as models expand beyond language.
Memes and Humor
- @Teknium1 joked about OpenAI having trouble removing "waifu features" in GPT-4 voice model updates.
- @arankomatsuzaki made a joke announcement that Noam Shazeer won the Turing Award for pioneering work on AI girlfriends.
- @willdepue joked that "AGI is solved" now that you can search past conversations in chatbots.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Progress
- AI website generation: A new AI system can generate full webpages from just a URL or description input, demonstrating progress in AI content creation capabilities. Video demo.
- OpenAI Voice Mode delay: OpenAI announced a one month delay for the advanced Voice Mode alpha release to improve safety and user experience. Plans for all Plus users to have access in the fall.
- Singularity book release: Ray Kurzweil released a sequel to his 2005 book The Singularity is Near, sparking excitement and discussion about the future of AI.
- AI agents speculation: OpenAI's acquisition of a remote desktop control startup led to speculation about integration with ChatGPT desktop for AI agents.
- AI-generated ads: Toys R Us used the SORA AI system to generate a promotional video/ad, showcasing AI in marketing.
AI Research
- New optimizer outperforms AdamW: A research paper introduced Adam-mini, a new optimizer that achieves 50% higher throughput than the popular AdamW.
- Matrix multiplication eliminated in LLMs: Researchers demonstrated LLMs that eliminate matrix multiplication, enabling much more efficient models with major implications for running large models on consumer hardware.
- Simulating evolution with AI: EvolutionaryScale announced ESM3, a generative language model that can simulate 500 million years of evolution to generate new functional proteins.
AI Products & Services
- Deepseek Coder V2 math capabilities: Users praised the math capabilities of the Deepseek Coder V2 model, a free model from China that outperforms GPT-4 and Claude.
- AI audiobook narration: An AI-narrated audiobook was well-received, implying audiobook narration is now a solved problem with AI.
- New AI apps and features: Several new AI applications and features were announced, including Tcurtsni, a "reverse-instruct" chat app, Synthesia 2.0, a synthetic media platform, and Projects in Claude for organizing chats and documents.
AI Safety & Ethics
- Rabbit data breach: A security disclosure revealed a data breach in Rabbit where all responses from their R1 model could be downloaded, raising concerns about AI company negligence.
- Hallucination concerns: An opinion post argued the "AI hallucinates" talking point is dangerous as it masks the real risks of rapidly improving AI flooding job markets.
AI Hardware
- AMD MI300X benchmarks: Benchmarks of AMD's new MI300X AI accelerator chip were released and analyzed.
- Sohu AI chip claims: A new Sohu AI chip was announced claiming 500K tokens/sec on a 70B model, with 8 chips equivalent to 160 NVIDIA H100 GPUs.
- MI300X vs H100 comparison: A comparison showed AMD's MI300X is ~5% slower but 46% cheaper with 2.5X the memory of NVIDIA's H100 on the LLaMA-2 70B model.
AI Art
- A8R8 v0.7.0 release: A new version of the A8R8 Stable Diffusion UI was released with Comfy integration for regional prompting and other updates.
- ComfyUI new features: A detailed post reviewed new features in the ComfyUI Stable Diffusion environment like samplers, schedulers, and CFG implementations.
- Magnific AI relighting tool: Results from Magnific AI's new relighting tool were compared to a user's workflow, finding it lacking in quality.
- SD model comparisons: Different Stable Diffusion model sizes were compared on generating specified body positions, with performance noted as "not good."
Other Notable News
- Stability AI leadership changes: Stability AI announced a new CEO, board members, funding round, and commitment to open source while expanding enterprise tools.
- AI traffic analysis: A post proposed ways to quantify bandwidth usage of major AI systems, estimating AI is still a small part of overall internet traffic.
- Politician shares false ChatGPT stats: A news article reported a Canadian politician shared inaccurate statistics generated by ChatGPT, highlighting risks of using unverified AI outputs.
- Open-source AI agent for on-call: Merlinn, an open-source AI Slack bot to assist on-call engineers, was announced.
- Living skin robots: BBC reported on research into covering robots with living human skin to make them more lifelike.
- Gene therapy progress: A tweet discussed gene therapies progressing from rare to common diseases.
- Google AI event: News that Google will reveal new AI tech and Pixel phones at an August event.
- Tempering AI release expectations: A post advised taking AI product release dates with a grain of salt due to R&D uncertainty.
- AI ending amateurism: An opinion piece argued generative AI will allow everyone to produce professional-quality work.
AI Discord Recap
A summary of Summaries of Summaries
Claude 3 Sonnet
1. 🔥 LLM Advancements and Benchmarking
- Llama 3 from Meta tops leaderboards, outperforming GPT-4-Turbo and Claude 3 Opus per ChatbotArena.
- New models: Granite-8B-Code-Instruct for coding, DeepSeek-V2 with 236B parameters.
- Skepticism around certain benchmarks, calls for credible sources to set realistic evaluation standards.
2. 🤖 Optimizing LLM Inference and Training
- ZeRO++ promises 4x reduced communication overhead on GPUs.
- vAttention dynamically manages KV-cache memory for efficient inference.
- QServe uses W4A8KV4 quantization to boost cloud serving on GPUs.
- Consistency LLMs explore parallel token decoding for lower latency.
3. 🌐 Open-Source AI Frameworks and Community Efforts
- Axolotl supports diverse formats for instruction tuning and pre-training.
- LlamaIndex powers a course on building agentic RAG systems.
- RefuelLLM-2 claims best for "unsexy data tasks".
- Modular teases Mojo's Python integration and AI extensions.
4. 🖼 Multimodal AI and Generative Modeling Innovations
- Idefics2 8B Chatty for elevated chat interactions.
- CodeGemma 1.1 7B refines coding abilities.
- Phi 3 brings powerful chatbots to browsers via WebGPU.
- Combining Pixart Sigma + SDXL + PAG aims for DALLE-3-level outputs with potential fine-tuning.
- Open-source IC-Light for image relighting techniques.
5. Stable Artisan for AI Media Creation in Discord
- Stability AI launched Stable Artisan, a Discord bot integrating Stable Diffusion 3, Stable Video Diffusion, and Stable Image Core for media generation within Discord.
- Sparked discussions around SD3's open-source status and Artisan's introduction as a paid API service.
Claude 3.5 Sonnet
-
LLMs Level Up in Performance and Efficiency:
- New models like IBM's Granite-8B-Code-Instruct and RefuelLLM-2 are pushing boundaries in code instruction and data tasks. Communities across Discord channels are discussing these advancements and their implications.
- Optimization techniques such as Adam-mini are gaining traction, promising 45-50% memory reduction compared to AdamW while maintaining performance. This has sparked discussions in the OpenAccess AI Collective and CUDA MODE Discords.
- The vAttention system for efficient KV-cache memory management is being explored as an alternative to PagedAttention, highlighting the ongoing focus on inference optimization across AI communities.
-
Open-Source AI Flourishes with Community-Driven Tools:
- Axolotl is gaining popularity for its support of diverse dataset formats in LLM training, discussed in both the OpenAccess AI Collective and HuggingFace Discords.
- The LlamaIndex framework is powering new courses on building agentic RAG systems, generating excitement in the LlamaIndex and general AI development communities.
- Mojo's potential for Python integration and AI extensions is a hot topic in the Modular Discord, with discussions on its implications for AI development workflows.
-
Multimodal AI Pushes Creative Boundaries:
- The combination of Pixart Sigma, SDXL, and PAG is being explored to achieve DALLE-3 level outputs, as discussed in the Stability.ai and general AI communities.
- Stable Artisan, a new Discord bot from Stability AI, is integrating models like Stable Diffusion 3 and Stable Video Diffusion, sparking conversations about AI-powered media creation across multiple Discord channels.
- The open-source IC-Light project for image relighting is gaining attention in computer vision circles, showcasing the ongoing innovation in image manipulation techniques.
-
AI Hardware Race Heats Up:
- AMD's Radeon Instinct MI300X is challenging Nvidia's dominance in the GPU compute market, despite software ecosystem challenges. This has been a topic of discussion in the CUDA MODE and hardware-focused Discord channels.
- The announcement of Etched's Sohu AI chip has sparked debates across AI hardware communities about its potential to outperform GPUs in running transformer models, with claims of replacing multiple H100 GPUs.
- Discussions about specialized AI chips versus general-purpose GPUs are ongoing, with community members in various Discord servers debating the future direction of AI hardware acceleration.
Claude 3 Opus
1. LLM Performance and Benchmarking:
- Discussions about the performance of various LLMs, such as Llama 3 from Meta outperforming models like GPT-4-Turbo and Claude 3 Opus on leaderboards like ChatbotArena.
- New models like IBM's Granite-8B-Code-Instruct and DeepSeek-V2 showcasing advancements in instruction following and parameter count.
- Concerns about the credibility of certain benchmarks and the need for realistic LLM assessment standards from reputable sources.
2. Hardware Advancements and Optimization Techniques:
- Techniques like ZeRO++ and vAttention being explored to optimize GPU memory usage and reduce communication overhead during LLM training and inference.
- Advancements in quantization, such as QServe introducing W4A8KV4 quantization for improved GPU performance in cloud-based LLM serving.
- Discussions about the potential of specialized AI chips like Etched's Sohu and comparisons with GPU performance for running transformer models.
3. Open-Source Frameworks and Community Efforts:
- Open-source frameworks like Axolotl and LlamaIndex supporting diverse dataset formats and enabling the development of agentic RAG systems.
- The release of open-source models like RefuelLLM-2, claiming to be the best LLM for "unsexy data tasks."
- Community efforts to integrate AI capabilities into platforms like Discord, with bots such as Stable Artisan from Stability AI for media generation and editing.
4. Multimodal AI and Generative Models:
- New models focusing on specific tasks, such as Idefics2 8B Chatty for elevated chat interactions and CodeGemma 1.1 7B for coding abilities.
- Advancements in browser-based AI chatbots, like the Phi 3 model utilizing WebGPU for powerful interactions.
- Efforts to combine techniques like Pixart Sigma, SDXL, and PAG to achieve DALLE-3-level outputs in generative models.
- Open-source projects like IC-Light focusing on specific tasks such as image relighting.
GPT4O (gpt-4o-2024-05-13)
-
Model Performance and Benchmarks:
- Llama3 70B Models Show Promise: New open LLM leaderboards hosted on 300 H100 GPUs have Qwen 72B leading, though bigger models don't always equate to better performance. Analyses highlighted differences in scope between training vs. inference benchmarks.
- Solving Grade School Arithmetic highlights skepticism where data leakage in large LLMs results in misleadingly high benchmarks despite incomplete learning. Calls for credible assessments were noted.
-
Training, Optimization and Implementation Issues:
- Push for Better Optimizers: Adam-mini optimizer offers equivalent performance to AdamW but reduces memory use by 45-50%. This optimizer simplifies storage by reducing the number of learning rates per parameter.
- Memory Management in High-Context Models: Efforts to load large models, such as Llama3 70B or Hermes, on consumer-grade GPUs are hindered by significant OOM errors, driving discussions on effective GPU VRAM utilization.
-
AI Ethics and Community Debates:
- Ethics of AI Data Use: Debates in LAION Discord stressed the controversial inclusion of NSFW content in datasets, balancing ethical concerns with the motivation for unrestricted data access.
- Model Poisoning Concerns: Discussions in LAION focused on ethical implications and potential model poisoning, where controversial techniques in training and dataset usage are encouraged without broader consideration of long-term impacts.
-
Specialized AI Hardware Trends:
- Etched's Sohu Chips Boast 10x Performance: Etched’s new transformer ASIC chips claim to outperform Nvidia GPUs significantly, with considerable financial backing. However, practical adaptability and inflexibility concerns were discussed within CUDA MODE.
- AMD's MI300X Challenges Nvidia: AMD's MI300X seeks to dethrone Nvidia in GPU compute markets, despite lagging behind Nvidia's CUDA ecosystem.
-
AI Application Integration:
- Custom GPT Apps on Hugging Face Flourish: Growing interest in custom GPT-based applications, citing niche tasks like Japanese sentence explanations, remains strong. Collaborative efforts in the community have driven the creation of resources and toolkits for ease of implementation.
- AI-Assisted Tools Expand Academic Reach: The new GPA Saver platform leverages AI for academic assistance, indicating growing integration of AI in streamlined educational tools. Community discussions about improving AI-driven functionalities highlighted potential and current constraints.
PART 1: High level Discord summaries
OpenAI Discord
Quick Access with a Shortcut: The ChatGPT desktop app for macOS is now available, featuring a quick-access Option + Space shortcut for seamless integration with emails and images.
Voice Mode Hiccup: The anticipated advanced Voice Mode for ChatGPT has been postponed by a month to ensure quality before alpha testing; expect more capabilities like emotion detection and non-verbal cues in the fall.
OpenAI vs Anthropic's Heavyweights: Discussions are heating with regards to GPTs agents' inability to learn post-training and Anthropic's Claude gaining an edge over ChatGPT due to technical feats, such as larger token context windows and a rumored MoE setup.
Customization Craze in AI: Enthusiasts are creating custom GPT applications using resources like Hugging Face, with a particular interest in niche tasks like explaining Japanese sentences, as well as concerns about current limitations in OpenAI's model updates and feature rollout.
GPT-4 Desktop App and Performance Threads: Users noted the limitation of the new macOS desktop app to Apple Silicon chips and shared mixed reviews on GPT-4's performance, expressing desire for Windows app support and improvements in response times.
HuggingFace Discord
- RAG Under the Microscope: A discussion centered on the use of Retrieval-Augmented Generation (RAG) techniques highlighted consideration for managing document length with SSM like Mamba and using BM25 for keyword-oriented retrieval. A GitHub resource related to BM25 can be found here.
- Interactive Hand Gestures: Two separate contexts highlighted a Python-based "Hand Gesture Media Player Controller," shared via a YouTube demonstration, indicating burgeoning interest in applied computer vision to control interfaces.
- PAG Boosts 'Diffusers' Library: An integration of Perturbed Attention Guidance (PAG) into the
diffuserslibrary promises enhanced image generation, as announced in HuggingFace's core announcements, thanks to a community contribution.
- Cracking Knowledge Distillation for Specific Languages: Queries around knowledge distillation were prominent, with one member proposing a distilled multilingual model for a single language and another recommending SpeechBrain for tackling the task.
- LLMs and Dataset Quality in Focus: Alongside advances such as the Phi-3-Mini-128K-Instruct model by Microsoft, the community spotlighted the importance of dataset quality. Concurrently, concerns related to data leakage in LLMs were addressed through papers citing the issue here and here.
- Clamor for AI-driven Tools: From a request for a seamless AI API development platform, referenced through a feedback survey, to the challenge of identifying data in handwritten tables, there's a clear demand for AI-powered solutions that streamline tasks and inject efficiency into workflows.
LAION Discord
- AI Ethics Take Center Stage: Conversations arose about the ethics in AI training, where a member expressed concerns about active encouragement of model poisoning. Another member debated the offered solution to the AIW+ problem as incorrect, mentioning it overlooks certain familial relationships, thus suggesting ambiguity and ethical considerations.
- Music Generation with AI Hits a High Note: Discussions involved using RateYourMusic ID to generate songs and lyrics, with an individual confirming its success and describing the outcomes as "hilarious."
- The Great NSFW Content Debate: A debate surged regarding whether NSFW content should be included in datasets, highlighting the dichotomy between moral concerns and the argument against excessively cautious model safety measures.
- GPU Showdown and Practicality: Members exchanged insights on the trade-offs between A6000s, 3090s, and P40 GPUs, noting differences in VRAM, cooling requirements, and model efficiency when applied to AI training.
- ASIC Chips Enter the Transformer Arena: An emerging topic was Etched's Sohu, a specialized chip for transformer models. Its touted advantages sparked discussions on its practicality and adaptability to various AI models, contrasting with skepticism concerning its potential inflexibility.
Eleuther Discord
- ICML 2024 Papers on the Spotlight: EleutherAI researchers gear up for ICML 2024 with papers addressing classifier-free guidance and open foundation model impacts. Another study delves into memorization in language models, examining issues like privacy and generalization.
- Multimodal Marvels and Gatherings Galore: Huggingface's leaderboard emerges as a handy tool for those seeking top-notch multimodal models; meanwhile, ICML's Vienna meet-up attracts a cluster of enthusiastic plans. The hybrid model Goldfinch also became a part of the exchange, merging Llama with Finch B2 layers for enhanced performance.
- Papers Prompting Peers: Discussion in the #research channel flared around papers from comparative evaluations of Synquid to the application of Hopfield Networks in transformers. Members dissected topics ranging from multimodal learning efficiencies to experimental approaches in generalization and grokking.
- Return of the Hopfields: Members offered insights on self-attention in neural networks by corralling it within the framework of (hetero)associative memory, bolstered by references to continuous modern Hopfield Networks and their implementation as single-step attention.
- Sparse and Smart: Sparse Autoencoders (SAEs) take the stage for their aptitude in unearthing linear features from overcomplete bases, as touted in LessWrong posts. Additionally, a noteworthy mention was a paper on multilingual LLM safety, demonstrating cross-lingual detoxification from directionally poisoned optimization (DPO).
CUDA MODE Discord
AMD's Radeon MI300X Takes on Nvidia:
The new AMD Radeon Instinct MI300X is positioned to challenge Nvidia's dominant status in the GPU compute market despite AMD's software ecosystem ROCm lagging behind Nvidia's CUDA, as detailed in an article on Chips and Cheese.
ASIC Chip Ambitions:
Etched's announcement of the Transformer ASIC chips aims to outpace GPUs in running AI models more efficiently, with significant investment including a $120 million series A funding round supported by Bryan Johnson, raising discussions about the future role of specialized AI chips.
Optimization Tweaks and Triton Queries:
Engineering conversations revolve around a proposed Adam-mini optimizer that operates with 45-50% less memory, with code available on GitHub, and community assistance sought for a pow function addition in python.triton.language.core as shown in this Triton issue.
PyTorch Celebrates with Documentary:
The premiere of the "PyTorch Documentary Virtual Premiere: Live Stream" has garnered attention, featuring PyTorch’s evolution and its community, substantially reiterated by users and symbolized with goat emojis to express the excitement, watchable here.
Intel Pursues PyTorch Integration for GPUs:
Building momentum for Intel GPU (XPU) support in stock PyTorch continues with an Intel PyTorch team's RFC on GitHub, signaling Intel’s commitment to becoming an active participant in the deep learning hardware space.
Discussions of AI Infrastructure and Practices:
Community dialogue featured topics like learning rate scaling, update clipping with insights from an AdamW paper, infrastructural choices between AMD and Nvidia builds, and the intrigue around the Sohu ASIC chip's promises, impacting the efficacy of large transformer models.
Perplexity AI Discord
Perplexed by Perplexity API: Engineers discussed intermittent 5xx errors with the Perplexity AI's API, highlighting the need for better transparency via a status page. There were also debates on API filters and undocumented features, with some users probing the existence of a search domain filter and citation date filters.
In Search of Better Search: The Perplexity Pro focus search faced criticism for limitations, while comparisons to ChatGPT noted Perplexity's new agentic search capabilities but criticized its tendency to hallucinate in summarizations.
Claude Leverages Context: The guild buzzed about Claude 3.5's 32k token context window for Perplexity Pro users, with Android support confirmed. Users showed a clear preference for the full 200k token window offered by Claude Pro.
Innovation Insight with Denis Yarats: The CTO of Perplexity AI dissected AI's innovation in a YouTube video, discussing how it revolutionizes search quality. In a related conversation, researchers presented a new method that could change the game by removing matrix multiplication from language model computations.
Hot Topics and Searches in Sharing Space: The community shared numerous Perplexity AI searches and pages including evidence of Titan's missing waves, China's lunar endeavors, and a study on how gravity affects perception, encouraging others to explore these curated searches on their platform.
Latent Space Discord
- AI World's Fair Watch Party Launch: Enthusiasm stirred up for hosting a watch party for AI Engineer World’s Fair, livestreamed here, spotlighting cutting-edge keynotes and code tracks.
- Premiere Night for PyTorch Fans: Anticipation builds around the PyTorch Documentary Virtual Premiere, highlighting the evolution and impact of the project with commentary from its founders and key contributors.
- ChatGPT's Voice Update Muted: A delayed release of ChatGPT's Voice Mode, due to technical difficulties with voice features, causes a stir following a tweet by Teknium.
- Bee Computer Buzzes with Intelligence: Attendees at an AI Engineer event buzz over new AI wearable tech from Bee Computer, touted for its in-depth personal data understanding and proactive task lists.
- Neural Visuals Exceed Expectations: A breakthrough in neuroscience captures community interest with the reconstruction of visual experiences from mouse cortex activity, demonstrating incredible neuroimaging strides.
LM Studio Discord
- Tech Troubles and Tips in LM Studio: Engineers reported errors with LM Studio (0.2.25), including an Exit code: -1073740791 when loading models. For Hermes 2 Theta Llama-3 70B, users with RTX 3060ti faced "Out of Memory" issues and considered alternatives like NousResearch's 8b. Issues were also noted when running Llama 3 70B on Apple's M Chip due to different quant types and settings.
- RAG Gets the Spotlight: A detailed discussion on retrieval-augmented generation (RAG) took place, highlighting NVIDIA's blog post on RAG's capability to enhance information generation accuracy with external data.
- Scam Warnings and Security Tips: Users noted the presence of scam links to a Russian site impersonating Steam and reported these for moderator action. There's awareness in the community regarding phishing attacks and the importance of securing personal and project data.
- Hardware Conversations Heat Up: A completed build using 8x P40 GPUs was mentioned, sparking further discussions on server power management involving a 200 amp circuit and VRAM reporting accuracy in LM Studio for multi-GPU setups. The noise produced by home server setups was also humorously likened to a jet engine.
- Innovative Ideas and SDK Expo: Members shared ideas ranging from using an LLM as a game master in a sci-fi role-playing game to solving poor performance with larger context windows in token prediction. There's a guide to building Discord bots with the SDK here and questions regarding extracting data from the LM Studio server using Python.
- Uploading Blocks in Open Interpreter: There's frustration over the inability to upload documents or images directly into the open interpreter terminal, limiting users in interfacing with AI models and use cases.
Modular (Mojo 🔥) Discord
- Plotting a Path with Mojo Data Types: Engineers are experimenting with Mojo data types for direct plotting without conversion to Numpy, utilizing libraries like Mojo-SDL for SDL2 bindings. The community is mulling over the desired features for a Mojo charting library, with focus areas ranging from high-level interfaces to interactive charts and integration with data formats like Arrow.
- Vega IR for Versatile Visualization: The need for interactivity in data visualization was underscored, with the Vega specification being proposed as an Intermediate Representation (IR) to bridge web and native rendering. The conversation touched on the unique approaches of libraries like UW's Mosaic and mainstream ones like D3, Altair, and Plotly.
- WSL as a Windows Gateway to Mojo: Mojo has been confirmed to work on Windows via the Windows Subsystem for Linux (WSL), with native support anticipated by year's end. Ease of use with Visual Studio Code and Linux directories was a highlight.
- IQ vs. Intelligence Debate Heats Up: The community engaged in a lively debate about the nature of intelligence, with the ARC test questioned for its human-centric pattern recognition tasks. Some users view AI excelling at IQ tests as not indicative of true intelligence, while the concept of consciousness versus recall sparked further philosophical discussion.
- Compile-Time Quirks and Nightly Builds: Multiple issues with the Mojo compiler were aired, ranging from reported bugs in type checking and handling of boolean expressions to the handling of
ListandTensorat compile time. Encouragement to report issues, even if resolved in nightly builds, was echoed across the threads. Specific commits, nightly build updates, and suggestions for referencing immutable static lifetime variables were also discussed, rallying the community around collaborative debugging and improvement.
Interconnects (Nathan Lambert) Discord
- LLM Leaderboard Bragging Rights Questioned: Clement Delangue's announcement of a new open LLM leaderboard boasted the use of 300 H100 GPUs to rerun MMLU-pro evaluations, prompting sarcasm and criticisim about the necessity of such computing power and the effectiveness of larger models.
- API Security Gone Awry at RabbitCode: Rabbitude's discovery of hardcoded API keys, including ones for ElevenLabs and others, has left services like Azure and Google Maps vulnerable, causing concerns over unauthorized data access and speculation about the misuse of ElevenLabs credits.
- Delay in ChatGPT's Advanced Voice Mode: OpenAI has postponed the release of ChatGPT’s advanced Voice Mode for Plus subscribers till fall, aiming to enhance content detection and the user experience, as shared via OpenAI's Twitter.
- Murmurs of Imbue’s Sudden Success: Imbue's sudden $200M fundraise drew skepticism among members, exploring the company's unclear history and comparing their trajectory with the strategies of Scale AI and its subsidiaries for data annotation and PhD recruitment for remote AI projects.
- Music Industry’s AI Transformation: Udio's statement on AI's potential to revolutionize the music industry clashed with the RIAA's concerns, asserting AI will become essential for music creation despite industry pushback.
Stability.ai (Stable Diffusion) Discord
- Challenging Stability AI to Step Up: Discussions point to growing concerns about Stability AI’s approach with Stable Diffusion 3 (SD3), stressing the need for uncensored models and updated licenses to retain long-term viability. A more practical real-world application beyond novelty creations is requested by the community.
- Cost-Effective GPU Strategies Discussed: The comparison of GPU rental costs reveals Vast as a more economical option for running a 3090 compared to Runpod, with prices cited as low as 30 cents an hour.
- Debate: Community Drive vs. Corporate Backup: There's an active debate on the balance between open-source initiatives and corporate influence, with some members arguing for community support as crucial and others citing Linux's success with enterprise backing as a valid path.
- Optimizing Builds for Machine Learning: Members are sharing hardware recommendations for effective Stable Diffusion setups, with a consensus forming around the Nvidia 4090 for its performance benefit, potentially favoring dual 4090s over higher VRAM single GPUs for cost savings.
- Nostalgia Over ICQ and SDXL Hurdles: The shutdown of the legacy messaging service ICQ triggered nostalgic exchanges, while the community also reported challenges in running SDXL, particularly for those experiencing "cuda out of memory" errors due to insufficient VRAM, seeking advice on command-line solutions.
Nous Research AI Discord
- Introducing the Prompt Engineering Toolkit: An open-source Prompt Engineering Toolkit was shared for use with Sonnet 3.5, designed to assist with creating better prompts for AI applications.
- Skepticism Breeds Amidst Model Performance: A demonstration of Microsoft's new raw text data augmentation model on Genstruct prompted doubts about its efficacy, showing results that seemed off-topic.
- AI Chip Performance Heats Up Debate: The new "Sohu" AI chip sparked discussions about its potential for high-performance inference tasks, linking to Gergely Orosz's post which suggests OpenAI doesn't believe AGI is imminent despite advancing hardware.
- 70B Model Toolkit Launched by Imbue AI: Imbue AI released a toolkit for a 70B model with resources including 11 NLP benchmarks, a code-focused reasoning benchmark, and a hyperparameter optimizer, found at Imbue's introductory page.
- Embracing the Whimsical AI: A post from a user featured AI-generated content in meme format by Claude from Anthropic, reflecting on Claude's explanation of complex topics and its humorous take on not experiencing weather or existential crises.
LangChain AI Discord
- Streamlining AI Conversations: Engineers highlighted the
.stream()method fromlangchain_community.chat_modelsfor iterating through LangChain responses, while others discussed integrating Zep for long-term memory in AI and contemplated directBytesIOPDF handling in LangChain without temp files.
- Visualization Quest in LangChain: Discussion around live visualizing agents' thoughts in Streamlit touched on using
StreamlitCallbackbut also identified a gap in managing streaming responses without callbacks.
- Troubleshooting the Unseen: Inquiries were made about LangSmith's failure to trace execution despite proper environmental setup, with a suggestion to check trace quotas.
- Extending Containerized Testing: A community member contributed Ollama support to testcontainers-python, facilitating LLM endpoint testing, as indicated in their GitHub issue and pull request.
- Cognitive Crafts and Publications: A Medium article on few-shot prompting with tool calling in Langchain was shared, alongside a YouTube video exploring the ARC AGI challenges titled "Claude 3.5 struggle too?! The $Million dollar challenge".
LlamaIndex Discord
- Chatbots Seeking Contextual Clarity: An engineer inquired about how to effectively retrieve context directly from a chat response within the LlamaIndex chatbot framework, sharing implementation details and the challenges encountered.
- Pull Request Review on the Horizon: A member shared a GitHub PR for review, aimed at adding query filtering functionalities to the Neo4J Database in LlamaIndex, and another member acknowledged the need to address the backlog.
- Silencing Superfluous Notifications: There was a discussion on how to suppress unnecessary notifications about missing machine learning libraries in the Openailike class, with the clarification that such messages are not errors.
- Tuning SQL Queries with LLMs: Dialogue among users highlighted the benefits of fine-tuning language models for enhanced precision in SQL queries when using a RAG SQL layer, suggesting better performance with quality training data.
- Balancing Hybrid Searches: Questions about hybrid search implementations in LlamaIndex have been addressed, focusing on adjusting the
alphaparameter to balance metadata and text relevance in search results.
- Boosting RAG with LlamaIndex: An article was shared highlighting ways to build optimized Retrieval-Augmented Generation systems with LlamaIndex and DSPy, providing insights and practical steps for AI engineers.
- Open Source Contribution Perks: A call was made for feedback on an open-source project, Emerging-AI/ENOVA, for enhancing AI deployment, monitoring, and auto-scaling, with an incentive of a $50 gift card.
OpenInterpreter Discord
- Claude-3.5-Sonnet Steps into the Spotlight: The latest Anthropic model is officially named
claude-3-5-sonnet-20240620, putting an end to name confusion among members.
- MoonDream's Vision Limitation Acknowledged: While there's interest in a MoonDream-based vision model for OpenInterpreter (OI), current conversation confirms it's not compatible with OI.
- Multiline Input Quirks and Vision Command Errors: Technical issues arose with
-mlfor multiline inputs and theinterpreter --os --visioncommand, with one user verifying their API key but facing errors, and another member reported a ban from attempting to directly drop files into the terminal.
- 01: OI's Voice Interface, Not for Sale Everywhere: 01, as the voice interface for OI, can't be bought in Spain; enthusiasts are redirected to an open-source dev kit on GitHub for DIY alternatives.
- Constructing Your Own 01: Tutorials for DIY assembly of 01 from the open-source kit will be proliferating, including one planned for July, hinting at the community's commitment to ensuring wider access beyond commercial sale limitations.
Cohere Discord
Curiosity About Cohere's Scholars Program: One member inquired about the status of the scholars program for the current year, but no additional information or discussion followed on this topic.
Billable Preamble Tokens in the Spotlight: A user highlighted an experiment involving preamble tokens for API calls, bringing up a cost-cutting loophole that could avoid charges by exploiting non-billable preamble usage.
Designing with Rust for LLMs: An announcement was made about the release of Rig, a Rust library for creating LLM-driven applications, with an invitation to developers to engage in an incentivized feedback program to explore and review the library.
Ethical Considerations Surface in AI Usage: Concerns were brought up regarding SpicyChat AI, a NSFW bot hosting service, potentially violating Cohere's CC-BY-NA license through profit-generating use coupled with the claim of circumventing this via OpenRouter.
Learning Event on 1Bit LLMs by Hongyu Wang: An online talk titled The Era of 1Bit LLMs hosted by Hongyu Wang was announced with an invitation extended to attend through a provided Google Meet link.
OpenAccess AI Collective (axolotl) Discord
- Adam Optimizer Slims Down: Engineers discussed an arXiv paper introducing Adam-mini, highlighting its reduced memory footprint by 45% to 50% compared to AdamW. It achieves this by using fewer learning rates, leveraging parameter block learning inspired by the Hessian structure of Transformers.
- Training Pitfalls and CUDA Quandaries: One engineer sought advice on implementing output text masking during training, akin to
train_on_input, while another raised an issue with CUDA errors, suggesting enablingCUDA_LAUNCH_BLOCKING=1for identifying illegal memory access during model training.
- Gradient Accumulation—Friend or Foe?: The impact of increasing gradient accumulation was hotly debated; some believe it may shortcut training by running the optimizer less often, others worry it could lead to slower steps and more training time.
- Cosine Schedules and QDora Quests: Questions arose about creating a cosine learning rate scheduler with a non-zero minimum on the Hugging Face platform, and excitement was evident over a pull request enabling QDora in PEFT.
- Narrative Engines and Mistral Mysteries: The introduction of Storiagl, a platform for building stories with custom LLMs, was showcased, while another engineer reported a repetitive text generation issue with Mistral7B, despite high temperature settings and seeking solutions.
LLM Finetuning (Hamel + Dan) Discord
Prompting Takes the Cake in Language Learning: Researchers, including Eline Visser, have shown that prompting a large language model (LLM) outperforms fine-tuning when learning Kalamang language using a single grammar book. The findings, indicating that 'prompting wins', are detailed in a tweet by Jack Morris and further elaborated in an academic paper.
Catch the AI Engineer World’s Fair Online: The AI Engineer World's Fair 2024 is being streamed live, focusing on keynotes and the CodeGen Track, with access available on YouTube; more specifics are provided on Twitter.
Claude Contest Calls for Creatives: The June 2024 Build with Claude contest has been announced, inviting engineers to demonstrate their expertise with Claude, as outlined in the official guidelines.
Credit Where Credit is Due: An individual offered assistance with a credit form issue, asking to be directly messaged with the related email address to resolve the matter efficiently.
Model Offloading Techniques Debated: The community has observed that DeepSpeed (DS) seems to have more effective fine-grained offloading strategies compared to FairScale's Fully Sharded Data Parallel (FSDP). Additionally, the utility of these offloading strategies with LLama 70B is under consideration by members seeking to optimize settings.
Mozilla AI Discord
- Mozilla's Builders Program Ticks Clock: Members are reminded to submit their applications for the Mozilla Builders Program before the July 8th early application deadline. For support and additional information, check the Mozilla Builders Program page.
- '90s Nostalgia via Firefox and llamafile: Firefox has integrated llamafile as an HTTP proxy, allowing users to venture through LLM weights in a retro web experience; a demonstration video is available on YouTube.
- Create Your Own Chat Universe: Users can create immersive chat scenarios, fusing llamafile with Haystack and Character Codex, through a shared notebook which is accessible here.
- Cleansing CUDA Clutter in Notebooks: To keep Jupyter notebooks pristine, it's suggested to address CUDA warnings by using the utility from Haystack.
- NVIDIA's Stock Sent on a Rollercoaster: Following a talk at AIEWF, NVIDIA's market cap fell dramatically, triggering various analyses from outlets like MarketWatch and Barrons over the catalyst of the company's financial performance.
tinygrad (George Hotz) Discord
- Tinygrad Explores FPGA Acceleration: There's chatter about tinygrad leveraging FPGAs as a backend, with George Hotz hinting at a potential accelerator design for implementation.
- Groq Alumni Launch Positron for High-Efficiency AI: Ex-Groq engineers introduced Positron, targeting the AI hardware market with devices like Atlas Transformer Inference Server, boasting a 10x performance boost per dollar over competitors like DGX-H100.
- FPGA's Role in Tailored AI with HDL: Discussion centered on the future of FPGAs equipped with DSP blocks and HBM, which could allow for the creation of model-specific HDL, although it was noted that Positron's approach is generic and not tied to a specific FPGA brand.
- PyTorch's Impact on AI Celebrated in Documentary: A documentary on YouTube highlighting PyTorch's development and its influence on AI research and tooling has been shared with the community.
AI Stack Devs (Yoko Li) Discord
- Angry.penguin Ascends to Mod Throne: User angry.penguin was promoted to moderator to tackle the guild's spam problem, volunteering with a proactive approach and immediately cleaning up the existing spam. Yoko Li entrusted angry.penguin with these new responsibilities and spam control measures.
- Spam No More: Newly-minted moderator angry.penguin announced the successful implementation of anti-spam measures, ensuring the guild's channels are now fortified against disruptive spam attacks. Members may notice a cleaner and more focused discussion environment moving forward.
DiscoResearch Discord
- German Encoders Go Live on Hugging Face: AI engineers might be enticed by the newly released German Semantic V3 and V3b encoders, available on Hugging Face. V3 targets knowledge-based applications, while V3b emphasizes high performance with innovative features including Matryoshka Embeddings and 8k token context capability.
- Finetuning Steps for German Encoders Without GGUF: Despite inquiries, the German V3b encoder does not currently have a gguf format; however, for those interested in finetuning, it is recommended to use UKPLab's sentence-transformers finetuning scripts.
- Possibility of GGUF for Encoders Empowered by Examples: In the wake of confusion, a member clarified by comparing with Ollama, establishing that encoders like German V3 can indeed be adapted to gguf formats which may involve using dual embedders for enhanced performance.
OpenRouter (Alex Atallah) Discord
- New AI Player in Town: OpenRouter has introduced the 01-ai/yi-large model, a new language model specialized in knowledge search, data classification, human-like chatbots, and customer service; the model supports multilingual capabilities.
- Parameter Snafu Resolved: The Recommended Parameters tab for the model pages on OpenRouter had data display issues, which have been fixed, ensuring engineers now see accurate configuration options.
- AI Meets Academia: The newly launched GPA Saver leverages AI to offer academic assistance and includes tools like a chat assistant, rapid quiz solver, and more; early adopters get a discount using the code BETA.
- Easing the Integration Experience: Thanks were expressed to OpenRouter for streamlining the process of AI model integration, which was instrumental in the creation of the GPA Saver platform.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Datasette - LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!