[AINews] Moondream 2025.1.9: Structured Text, Enhanced OCR, Gaze Detection in a 2B Model
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Efficiency tricks are all you need.
AI News for 1/9/2025-1/10/2025. We checked 7 subreddits, 433 Twitters and 32 Discords (219 channels, and 2928 messages) for you. Estimated reading time saved (at 200wpm): 312 minutes. You can now tag @smol_ai for AINews discussions!
Moondream has been gaining a lot of attention for its small, light, fast, yet SOTA vision, and released a lovely new version yesterday that marks a new efficient frontier in VRAM usage (more practical than just param count):
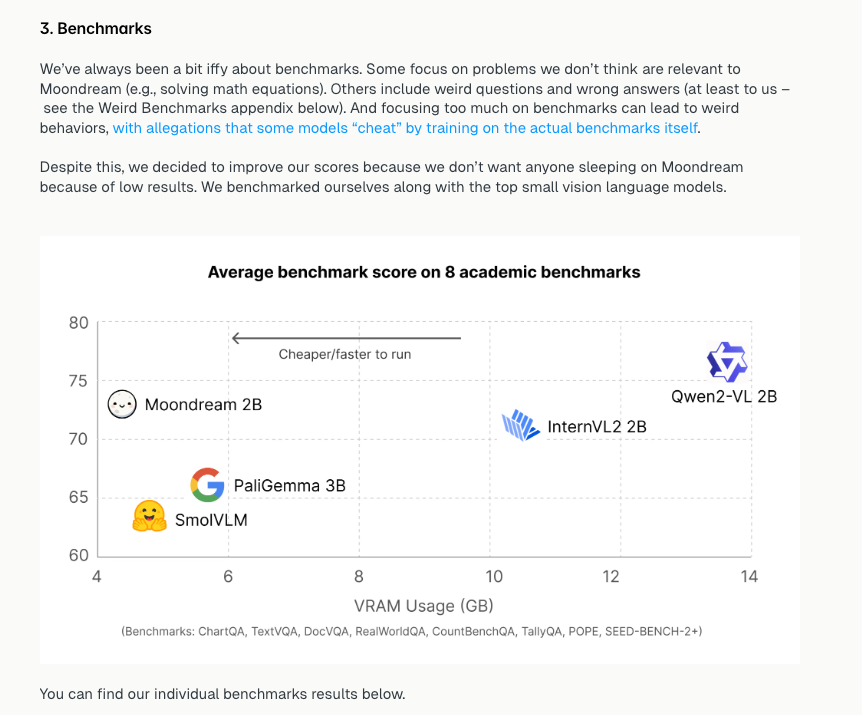
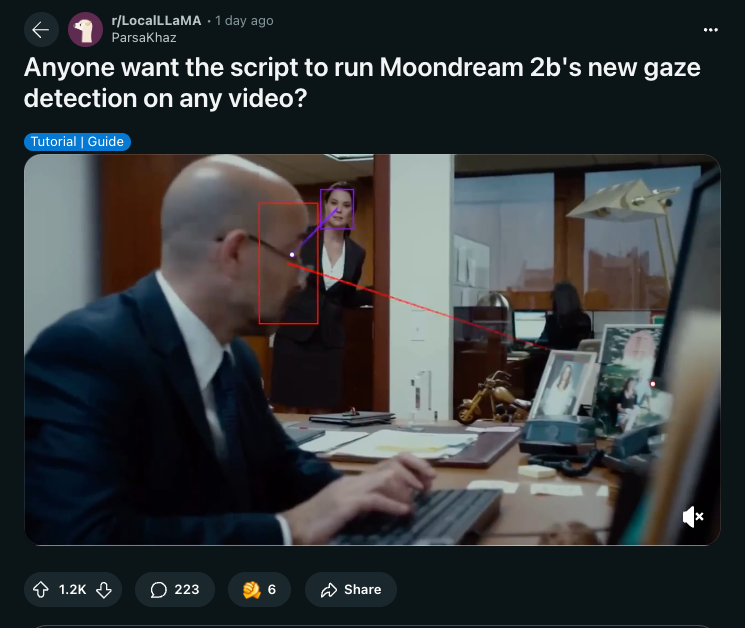
It now also offers structured output and gaze detection, which allows creative redditors to come up with scripts like these:
In case you missed it, Vik also gave a talk about Moondream at the Best of 2024 in Vision Latent Space Live event:
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Models and Research
- Reasoning Models and Distillation Techniques: @_philschmid and @saranormous discussed advancements in reasoning models like @OpenAI’s o1, detailing steps to build such models. Additionally, @jxmnop highlighted the effectiveness of model distillation, emphasizing its surprising performance improvements without theoretical explanations.
- Multimodal and Embedding Models: @llama_index introduced “vdr-2b-multi-v1”, a 2B multimodal, multilingual embedding model, achieving 95.6% average NDCG@5 across languages. @reach_vb showcased LLaVA-Mini, which reduces FLOPs by 77% and enables 3-hour video processing on a single GPU.
- Innovations in GANs and Diffusion Models: @iScienceLuvr and @multimodalart shared research on modern GAN baselines and Decentralized Diffusion Models, highlighting their stability and performance compared to traditional approaches.
- Self-Attention and Training Techniques: @arohan discussed stick-breaking attention for length generalization, while @addock_brett predicted 2025 as the year of Physical AI, reflecting on training optimizations and model architectures.
AI Tools and Development
- Development Frameworks and APIs: @awnihannun announced updates to MLX, enhancing portability with support for multiple languages and platforms. @vllm_project introduced nightly builds and native MacOS support for vLLM, improving developer experience with faster installations.
- AI Integration and Pipelines: @LangChainAI and @virattt demonstrated building LLM-powered data pipelines and AI-powered data workflows using tools like LangChain and Qdrant, enabling intelligent semantic search and agentic document processing.
- Exporting and Interfacing Models: @awnihannun provided guides on exporting functions from Python to C++ in MLX, facilitating cross-language model deployment. @ai_gradio showcased qwen integration for anychat, enhancing developer deployment with minimal code.
Company Announcements and Updates
- Company Roles and Expansions: @russelljkaplan announced their new role as a "cognition guy", while @ajayj_ welcomed new team members to GenmoAI’s San Francisco office.
- Product Releases and Enhancements: @TheGregYang released the Grok iOS app, and @c_valenzuelab introduced a new denim collection on RunwayML. @everartai launched character finetuning services, demonstrating superior pipeline consistency with minimal input images.
- Hiring and Employment Trends: @cto_junior discussed hiring trends at Microsoft, while @bindureddy predicted that Salesforce and other big tech companies will stop hiring engineers due to AI-driven productivity gains.
Datasets and Benchmarks
- New Datasets Released: @iScienceLuvr and @miivresearch announced Decentralized Diffusion Models and released code and project pages for HtmlRAG and other multimodal datasets.
- Benchmarking and Evaluation: @swyx shared insights on MMLU/GPQA knowledge, emphasizing the need for neural search engines like @ExaAILabs. @FinBarrTimbers discussed the lack of enduring cognitive benchmarks outside of robotics.
AI Ethics, Policy, and Society
- AI's Societal Impact and Ethics: @fchollet and @sama debated the future of jobs in an AI-automated society and the ethical implications of AI governance, including concerns over policy restrictions and AGI definitions.
- Geopolitical Implications of AI: @teortaxesTex and @ClementDelangue highlighted the geopolitical power held by open-source AI and the strategic moves by countries like China in the AI landscape.
- AI Safety and Regulatory Concerns: @DeepLearningAI and @Nearcyan raised concerns about AI deception behaviors, public safety, and the need for proper preparation against potential AI-driven disasters.
Personal Updates and Announcements
- Career Moves and Roles: @russelljkaplan shared excitement about their new role, while @megansirotanggalenuyen_ celebrated being listed on Forbes 30 under 30.
- Workplace Experiences: @vikhyatk expressed concerns about their university’s administration, and @sarahookr provided a personal update on the LA devastation.
- Learning and Development: @qtnx_ mentioned learning RL in JAX, and @aidan_mclau discussed AI capital usage and the challenges faced by billionaires in AI development.
Memes/Humor
- Humorous Takes on AI and Technology: @nearcyan and @teortaxesTex shared tweets with satirical remarks on AI prompt engineering, tech company behaviors, and AI hype, injecting light-hearted commentary into technical discussions.
- Casual and Funny Remarks: @richardMCNgo and @teortaxesTex posted jokes and puns related to AI advancements and tech culture, providing moments of levity for the engineering audience.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Moondream 2b's Gaze Detection Creates Buzz
- Anyone want the script to run Moondream 2b's new gaze detection on any video? (Score: 1123, Comments: 207): The post discusses the release of a script for running Moondream 2b's gaze detection on any video. No additional details or context are provided in the post body.
- Interest and Enthusiasm: Many users, including That_Neighborhood345 and ParsaKhaz, express strong interest in the release of the gaze detection script, with some like ParsaKhaz offering to clean and release their script if enough interest is shown. This indicates a significant community interest in experimenting with and utilizing gaze detection technology.
- Surveillance Concerns: Several users, such as ArsNeph and SkullRunner, voice concerns about the potential misuse of gaze detection technology for surveillance and privacy violations. They highlight examples like China's social credit system and corporate micromanagement, arguing that the technology could be abused to monitor individuals' focus and activities.
- Technical Feasibility and Use Cases: aitookmyj0b notes that implementing gaze detection is feasible with basic OpenCV processing, suggesting that the technology is already within reach for those interested. However, ArsNeph argues that the technology lacks precision for legitimate eye-tracking applications, emphasizing its primary use as surveillance software rather than for beneficial purposes.
Theme 2. Transformers.js Brings LLMs In-browser with WebGPU
- WebGPU-accelerated reasoning LLMs running 100% locally in-browser w/ Transformers.js (Score: 379, Comments: 62): WebGPU-accelerated LLMs are demonstrated running entirely locally in-browser using Transformers.js. This showcases the potential for in-browser AI applications without relying on server-side processing.
- Performance Variability: Users report varied performance metrics based on hardware, with examples like RTX 3090 achieving 55.37 tokens per second and MiniThinky-v2 achieving ~60 tps on a MacBook M3 Pro Max. The lack of specified hardware in performance metrics is noted as a common issue in machine learning discussions.
- Technical Exploration and Challenges: There is interest in exploring the technical capabilities of WebGPU and its applications in running AI models locally. Users discuss the potential of creating a browser extension that utilizes a reasoning LLM to manipulate the DOM directly, emphasizing privacy and local processing.
- Issues with Model Output: Some users highlight issues with model output, such as generating nonsensical text or incorrect reasoning, like the example where the model incorrectly states "60 does not equal 60". This highlights the challenge of achieving accurate and reliable outputs in local AI applications.
Theme 3. Biden's AI Chip Export Limits Stir Global Reaction
- Biden to Further Limit Nvidia AI Chip Exports in Final Push Restricting US Allies Such As Poland, Portugal, India or UAE Maker Of Falcon Models (Score: 167, Comments: 107): Nvidia AI chip exports face additional restrictions by the Biden administration, affecting US allies including Poland, Portugal, India, and the UAE. This move targets the export of AI technology, particularly impacting countries involved with the Falcon models.
- Several commenters criticize the Biden administration's policy as ineffective and potentially harmful, arguing it could lead to increased cooperation between China and Tier 2 countries, and that it might inadvertently target open-source AI rather than China. Concerns are also raised about the impact on global tech development and US geopolitical standing.
- There is confusion and dissatisfaction over the tier system used to categorize countries for AI chip exports, with users questioning decisions like placing Portugal and Switzerland in Tier 2 while others like Italy are in Tier 1. The Schengen Area is mentioned as a potential loophole, allowing countries to circumvent restrictions.
- Discussion highlights the potential for NVIDIA alternatives to gain traction due to these restrictions, and questions about Nvidia's chip manufacturing locations, particularly regarding TSMC in Taiwan and its implications for US-China relations. Concerns are expressed that these policies may not effectively prevent countries like China from obtaining restricted technologies.
Theme 4. NVIDIA's Project Digits Promises AI Democratization
- Project Digits: How NVIDIA's $3,000 AI Supercomputer Could Democratize Local AI Development | Caveman Press (Score: 113, Comments: 75): NVIDIA's Project Digits aims to democratize local AI development by offering a $3,000 AI supercomputer. This initiative could significantly enhance accessibility for developers and researchers, potentially transforming local computational capabilities.
- The community questions the democratization claims of NVIDIA's Project Digits, suggesting it primarily democratizes deployment rather than training. Some users argue that true democratization would require open-sourcing CUDA and note that NVIDIA's benchmarks use fp4 precision, which is lower than typical standards like fp32 or fp16.
- There is skepticism about the supercomputer label, with comparisons to existing GPU and RAM bandwidth standards suggesting that the Digits offering may not match expectations. Users highlight that competitive products with higher RAM bandwidths and wider RAM to CPU buses already exist, such as Apple's M4 Max with 546 GB/s and AMD EPYC with 460 GB/s.
- Discussions also focus on the role of CUDA in machine learning, with some advocating for more vendor-agnostic solutions like Triton. While CUDA is still prevalent for developing new ML techniques, there is a push towards frameworks that support multiple vendors, as seen with OpenAI and Triton, which is gaining traction for its ease of use and performance.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. DALL-E Abandonment: OpenAI's Multimodal Struggles
- Did OpenAI abandon DALL·E completely? The results in DALL·E and Imagen3 for the same prompt (Score: 343, Comments: 136): OpenAI may have halted updates for DALL·E, as suggested by a comparison of image generation results between DALL·E and Imagen3 using the same prompt. The discussion implies that DALL·E's performance has not been improved or maintained, raising questions about OpenAI's focus on this project.
- Several commenters speculate on the future of OpenAI's DALL·E, with some suggesting that OpenAI may release an updated or new model, potentially a multimodal one, as competition in image generation intensifies. Vectoor and EarthquakeBass mention that past versions of DALL·E were groundbreaking upon release but quickly fell behind due to infrequent updates.
- There is criticism of DALL·E 3's aesthetic and technical performance, with COAGULOPATH and EarthquakeBass noting its failure to produce convincing photorealistic images, potentially due to OpenAI's conservative safety stance. Demigod123 suggests that the cartoonish style might be a deliberate choice to prevent misuse.
- Alternatives like Midjourney, Flux Schnell, and Mystic 2.5 are discussed, with users sharing links to images they generated, highlighting their capabilities compared to DALL·E. Bloated_Plaid and MehmetTopal provide visual comparisons, indicating that other tools might currently offer superior results.
Theme 2. Microsoft Envisions AI Agent Swarms in Organizations
- Microsoft CEO says each worker will soon be directing a "swarm of [AI] agents", with "hundreds of thousands" of agents inside each organization (Score: 235, Comments: 154): Microsoft CEO predicts that each worker will manage a "swarm" of AI agents, with "hundreds of thousands" of these agents being deployed within organizations. This statement suggests a significant increase in AI integration and automation in workplace environments.
- AI Agent Management Skepticism: Many commenters express skepticism about managing a "swarm" of AI agents, questioning the practicality and potential chaos of handling numerous agents needing human intervention. Some see this as another instance of Microsoft overhyping technology without delivering tangible results.
- Impact on Employment and Industry: Discussions highlight concerns about job displacement, with fears that AI will replace a significant portion of the workforce, especially in white-collar jobs. There's a debate about the future of work, with some suggesting a shift from "white collar" vs. "blue collar" to "automatable" vs. "non-automatable" tasks.
- Tech Industry's Strategic Tactics: Commenters draw parallels between AI integration and previous tech strategies, like Apple's ecosystem entrenchment. There's a belief that tech companies will use similar tactics to lock in customers, making it costly and complex to transition away from their AI solutions.
AI Discord Recap
A summary of Summaries of Summaries by o1-mini-2024-09-12
Theme 1. AI Model Showdowns: PHI-4 Tops Microsoft and Beyond
- Unsloth's PHI-4 Outscores Microsoft on Open LLM Leaderboard: PHI-4 from Unsloth surpasses Microsoft's benchmark by implementing crucial bug fixes and Llamafication, though quantized variants sometimes edge out their non-quantized counterparts.
- rStar-Math Boosts Qwen2.5 and Phi3-mini to New Heights: Microsoft's rStar-Math propels Qwen2.5 from 58.8% to 90.0% and Phi3-mini from 41.4% to 86.4% on the MATH benchmark, marking significant strides for small LLMs in math reasoning.
- Llama 3.3 Stumbles on Low-End Hardware with Slow Outputs: Enthusiasts report sluggish performance of Llama 3.3 70B Instruct, delivering tokens at 0.5/sec on modest systems like a Ryzen 7 and RX 7900GRE, highlighting the need for robust GPU memory or system RAM.
Theme 2. AI Tools Face Off: Codeium, ComfyUI, and Cursor IDE
- Codeium's Self-Hosted Edition Empowers Team Deployments: Codeium introduces a self-hosted version in its enterprise package, attracting teams eager for customizable, in-house AI setups while navigating credit handling intricacies.
- ComfyUI Enhances AnimateDiff with IP Adapter Magic: Community critiques AnimateDiff's output quality, turning to a ComfyUI workflow that integrates IP Adapter to supercharge video generation results.
- Cursor IDE Rules Tighten Up Claude's Code Crafting: Developers employ .CursorRules within Cursor IDE to precisely guide Claude's outputs, significantly reducing code misedits and ensuring accurate feature implementations.
Theme 3. GPU Grievances and Kernel Calamities: Stable Diffusion on Linux
- Linux Users Battle Kernel Panics Running Stable Diffusion on AMD GPUs: Attempts to run Stable Diffusion on Linux with AMD GPUs sometimes trigger kernel panics, but referrals to the AMD GPUs installation wiki offer fixes addressing Python version issues.
- Stable SwarmUI vs A1111: User Interface Tug of War: Discord users debate the user-friendliness of A1111, SwarmUI, and ComfyUI, with SwarmUI’s advanced features drawing praise despite a perceived steeper learning curve.
- MicroDiT Replicates and Polishes with DCAE Integration: Successful replication of MicroDiT provides downloadable weights and an inference script, paving the way for architectural enhancements using DCAE for improved performance.
Theme 4. AI Community Buzz: Hackathons, Hiring, and Funding Frenzies
- oTTomator's AI Agent Hackathon Triggers $6K Prize Bonanza: OpenRouter launches the oTTomator AI Agent Hackathon, offering a total of $6,000 in prizes from sponsors Voiceflow and n8n, inciting fierce competition from January 8 to January 22.
- Anthropic Secures $2B Funding as AI Ventures Soar: Anthropic raises an additional $2 billion, elevating its valuation to $60 billion and bolstering its position in enterprise AI solutions, as per Andrew Curran’s report.
- Nectar Social Offers $10K Bounties to Snag AI Talent: AI startup Nectar Social in Seattle is hunting for Product Managers and AI Engineers, offering up to $10,000 in referral bounties to attract skilled hires for their growing social commerce platform.
Theme 5. Advanced AI Techniques: Fine-Tuning, Decoding, and Regularization Woes
- Adapters Aren't All Fun and Games: LoRA Precision Matters: Technical experts stress the importance of using 16-bit models when implementing LoRA adapters to prevent output degradation, advocating for merging adapters with higher precision bases.
- Speculative Decoding Emerges as Resource-Saving Hero: In a bid to reduce computational loads during next-token generation, the community hails speculative decoding as a promising technique akin to DLSS for language models.
- Weight Decay Wars: Stabilizing LLMs with Gentle Settings: Researchers debate the impact of extreme weight decay (e.g., 0.1) in large language models, proposing milder decay and auxiliary loss functions like abs(norm(logits) - 1.0) to prevent model meltdown and maintain numerical stability.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- GPU Gains & Gripes: Engineers compared the RTX 4070 with the 3090 for AI video tasks, noting that a 3090 can render 480p in about 2 minutes, with more variations reported for LTXV on AMD from this discussion.
- Participants exchanged performance metrics and tweaks, pointing toward specialized setups for quicker image-to-video workflows.
- AnimateDiff Antics: Members critiqued AnimateDiff for subpar output and referenced a ComfyUI workflow merging IP Adapter to enhance quality.
- They also discussed an image-to-video comparison option that tests multiple methods, noting some steps still burn more runtime than desired.
- Discord Dramas: Users reported inappropriate profiles and argued over stricter moderation to keep conversations civil.
- Concerns arose about striking a balance between policing toxic content and preserving a welcoming environment.
- Interface Interjections: Comparisons of A1111, SwarmUI, and ComfyUI revealed differing opinions on user-friendliness, with SwarmUI’s features documented in this GitHub guide.
- While A1111 was praised for simplicity, some appreciated ComfyUI’s advanced pipeline for animated content creation.
- Panic in the Kernel: Linux-based Stable Diffusion occasionally triggered kernel panics, prompting references to the AMD GPUs installation wiki.
- Guides and fixes often tackled Python version issues, offering fallback solutions for smoother AI workflows on Linux.
Unsloth AI (Daniel Han) Discord
- Unsloth’s PHI-4 Prowess Outshines Microsoft: In official Open LLM Leaderboard scores, PHI-4 from Unsloth just surpassed the Microsoft baseline thanks to bug fixes and Llamafication.
- Community members praised the improvement but noted quantized variants can sometimes outperform non-quantized configurations.
- Adapter Attitude: Precision Pays Off: Experts stressed using 16-bit models when attaching adapters for better throughput, referencing a LoRA cautionary post.
- They mentioned that lower-precision usage can degrade outcomes, and merging with the higher-precision base is typically preferred.
- Chat Templates Tweak LLM Behavior: Contributors discussed how chat templates from the
tokenizer_config.jsonshape input-output formatting, affecting LLM performance significantly.- They emphasized that consistent templates from training to production ensure stable results, with some claiming it can "make or break" deployment success.
- Speculative Decoding: Decisive Trick for Resource Reduction: A conversation on DLSS-like optimization for language models led to the mention of speculative decoding, hailed as a resource-friendly technique.
- Researchers found it promising for stepping around hefty computational loads in next-token generation.
- Mathstral 7B Waits for Wider Support: The
mistralai/Mathstral-7B-v0.1model was clarified to be unsupported for direct fine-tuning, as it isn't a standard base or PEFT model.- Participants said support is coming soon, sparking cautious optimism for future merges and expansions.
Codeium (Windsurf) Discord
- Self-Hosted Codeium Fuels Deployment Control: Members noted that a self-hosted edition of Codeium is now part of the enterprise package, drawing attention from teams eager to manage their own setups.
- They also raised questions about credit handling and Windsurf features, pointing to the pricing page for official guidelines.
- Windsurf Installation Marathon on Multiple Distros: Users reported successful Windsurf installs on Mint, Ubuntu 24.04, Arch, and Hyprland, sometimes after removing configuration files to address odd errors.
- They also discussed the desire for shared Cascade chat across PCs, with cloud sync suggestions emerging but no official feature in place yet.
- Flow Credits Billing Headache Stirs Frustration: Several people complained of paying for Flow Credits multiple times but never seeing them added, prompting calls for clearer usage policies.
- They also questioned whether internal errors count against credits, urging developers to fix these deductions swiftly.
- Cascade’s No-Code Wins and Chat Management Dreams: One user highlighted building a company website with minimal actual coding, celebrating unlimited queries in the free Cascade tier.
- Others still want better Cascade chat handling across multiple devices, citing a need for official sync solutions.
Cursor IDE Discord
- Cursor Rules Tame Chaotic Code: Developers shared how to refine Claude's output with structured prompts using .CursorRules, focusing on explicit goals to avoid unintended file changes.
- They reported that precisely chosen keywords significantly cut down code misedits, underlining the importance of well-defined prompt instructions.
- Cursor Directory Gains Traction: A surge of interest in the Cursor Directory spotlighted its ability to gather community-sourced rules for various frameworks.
- Users appreciated a centralized place for rule sharing, noting it saved them time and headaches when tackling specialized setups.
Stackblitz (Bolt.new) Discord
- Agile Prompting with Colors: Community stressed specifying colors in prompts using color names and hex codes, ensuring clarity on usage.
- One member replaced vague requests (Just do blue and white) with more precise guidelines to control styling across apps.
- Payment System Meltdown: A user found their payment system inoperable, posting a link to the project and asking for assistance.
- They mentioned active development to restore full functionality, urging testers for feedback.
- Open Public Repos with Bolt.new: Developers announced a public repos feature, letting users prefix any GitHub URL with http://bolt.new for immediate access.
- They referenced an X post showcasing how to open repositories with minimal setup.
- Bolt Token Overruns: Multiple people reported rapid token consumption when editing or debugging, encountering repeated attempts to fix errors.
- They expressed frustration over sustained resource usage, hoping for a more efficient approach.
- Supabase Migrations and Netlify Hitches: Developers mentioned reversing Supabase migrations caused headaches if issues occurred mid-update, affecting application stability.
- Additionally, one user cited slow Netlify load times, suspecting free tier constraints or inefficiencies in the Bolt code.
aider (Paul Gauthier) Discord
- Gemini 2.0 Goes Mobile & Chatty: While running errands, a user tested Gemini 2.0 Flash Experimental with voice mode on iOS, brainstorming an app idea in real-time and generating concise tasks upon returning.
- Community members appreciated Gemini 2.0's ability to autonomously propose project criteria, calling it a helpful step toward frictionless development.
- Tier 5 Key Trials & Unify.ai Tricks: Discussion centered on alternatives for expensive Tier 5 OpenAI access, with references to Unify.ai and the GitHub repo as flexible multi-model solutions.
- Members weighed subscription costs and shared experiences about using OpenRouter and Unify to simplify configuration.
- Aider & Claude Face Off in Coding: Multiple users compared Aider's uneven file editing and occasional mishaps to Claude, noting comedic incidents of entire file deletions, with references to file editing problems.
- Some deemed DeepSeek chat too distractible and lazy, while others recognized Aider as workable if carefully managed to avoid large-scale code removal.
- Visions of Stronger AI Agents: One user predicted AI will eventually create improved iterations of itself and minimize human intervention, tempered by concerns over computation costs and operational overhead.
- Participants highlighted the current limitations of hardware and resource availability, offering both optimism and caution about near-term expansions in autonomous AI capabilities.
Notebook LM Discord Discord
- DeepResearch Gains Ground in NotebookLM: Members suggested integrating DeepResearch references into NotebookLM, aiming to merge outputs from existing reports despite no official plugin yet.
- Some users mentioned 'bulk upload' workarounds to feed large datasets into NotebookLM, fueling anticipation for more robust synergy.
- AI Audio Generation Sparks Excitement: Participants explored building podcasts from curated NotebookLM sources, pairing them with Illuminate for audio flexibility and better source targeting.
- They praised source-limited prompts for controlling style, while others mentioned Jellypod as a potential alternative with broader customization options.
- Cross-lingual Podcasting Showcases NotebookLM Flexibility: Some users experimented with generating Mandarin podcast scripts from English content inside NotebookLM, applying casual rephrasing tactics for natural flow.
- They also tested Japanese chats, noting that accurate transliteration might require additional checks but reflecting user comfort with switching languages.
- Quotation Mode and System Prompt Confusions: Developers introduced a 'quotation-only' command in NotebookLM, ensuring direct excerpts from sources and stricter verification for important citations.
- However, Gemini occasionally returned incomplete quotes, prompting discussions on improving system prompts in NotebookLM Plus for consistent results.
LM Studio Discord
- Qwen's Quirky Chat Craze: Alibaba introduced Qwen Chat, a new Web UI for Qwen models offering document uploads and visual understanding, teased in their tweet.
- The community expects upcoming features like web search and image generation, seeing Qwen Chat as a key competitor in the evolving LLM ecosystem.
- AMD's 7900 Performance Puzzle: Users compared the AMD RX 7900XT 20GB to NVIDIA's 3090 using a reddit post, suggesting the 7900XT might face memory bandwidth limitations for LLM tasks.
- Others argue the 7900XT still performs decently for local inference, though they see more stable performance with the 3090 in certain benchmarks.
- Llama 3.3's Memory Mayhem: Enthusiasts reported Llama 3.3 70B Instruct delivering sluggish outputs at 0.5 token/sec on lower-end hardware like a Ryzen 7 and RX 7900GRE.
- They emphasized the need for significant GPU memory or system RAM to avoid these slowdowns and sustain token throughput at scale.
- NVIDIA DIGITS Drums Up Curiosity: Community chatter turned to DIGITS, rumored to be a robust solution within the NVIDIA workflow for training and testing models.
- Users remain cautious about performance overhead but anticipate a powerful addition to the local LLM toolkit.
OpenAI Discord
- O1’s ‘Thinking’ Quirk & A/B Test Hints: A participant flagged Model O1’s distinctive 'thinking' output, suggesting that a different model format might be involved.
- They raised the possibility of running Model 4O in parallel, reflecting enthusiasm for comparing multiple performance approaches.
- Meta-Prompting Sparks Ideas: Members highlighted Meta-Prompting strategies, citing that tweaking the system message can generate more advanced responses.
- They stressed that clarifying objectives at the start leads to sharper model outputs when crafting prompts.
- Investor Round for Hassabis: The group offered good wishes for Hassabis during his investor round, acknowledging the importance of fresh capital in AI pursuits.
- They praised his track record and noted that supportive funding could propel further R&D efforts in the field.
Interconnects (Nathan Lambert) Discord
- ICLR: The Rendezvous Rush: Attendees are gearing up for ICLR, trading excitement about traveling and planning potential meetups in real time.
- They anticipate lively face-to-face chats, with Philpax arriving soon in a light brown coat and black jeans, ready to discuss new model breakthroughs.
- rStar Rising: Qwen2.5 & Phi3-mini Soar: Microsoft’s rStar-Math pushes Qwen2.5 from 58.8% to 90.0% and Phi3-mini from 41.4% to 86.4% on the MATH benchmark.
- It now averages 53.3% in the USA Math Olympiad, prompting interest in Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking for deeper insights.
- NuminaMath and the Quality Conundrum: Skepticism grew over NuminaMath due to ~7.7% of entries containing multiple conflicting solutions, pointing to broader data issues.
- Members also cited “Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought”, noting the lead author’s psychology background at Stanford captured attention.
- Open Source AI: The Cost Clash: Policy makers voiced concern about open source AI costing merely $5M, sparking confusion over actual budgets.
- One tweet’s cost breakdown excluded capital and data expenses, provoking criticism for misrepresenting GPU-hour tallies.
- Anthropic’s Early Character Crafting: At an Anthropic salon, Josh Batson indicated that Amanda Askell shapes the base model into an agent earlier than some expected.
- Debate arose on whether character alignment is a post-training add-on or a built-in process, with references to Anthropic Research Salon fueling further conversation.
Eleuther Discord
- SmolLM Shard Storm: The SmolLM Corpus soared to 320GB split into 23698 shards, promising a more efficient
.jsonl.zstformat that won't be finalized until late this week.- Members praised the significantly smaller footprint versus the 1TB uncompressed set, referencing HPC convenience and "less overhead for iterative training pipeline".
- Modal's Mighty Moves: Hobbyists explored Modal, Colab, and Kaggle for budget-friendly training and analysis, spotlighting Modal's monthly credits as a solid way to handle larger tasks.
- They noted that Modal can run jobs beyond personal GPU capacity and appreciated the steady support for inference at scale.
- SciAgents Sways AI Circles: The SciAgents paper employs ontological knowledge graphs and multi-agent methods to boost research operations, weaving structured data with agent collaboration.
- Some felt the concept wasn't a giant leap, yet others liked the orchestration approach, calling it a promising framework for high-level learning workflows.
- Grokking Gains Momentum: Members dissected Grokking at the Edge of Numerical Stability, highlighting delayed generalization and softmax collapse in deep nets.
- They emphasized that insufficient regularization can push models into meltdown, urging careful intervention and "dampening runaway logits" early on.
- Weight Decay & Llama2 HPC Woes: Several researchers debated extreme weight decay (like 0.1) in LLMs, proposing milder settings for attention layers and auxiliary losses (e.g., abs(norm(logits) - 1.0)).
- Meanwhile, attempts to pretrain a 7B Llama2 with
model_parallel=2triggered OOM stalls at batch size 1, prompting memory profiling and fresh tests for the 6.7B configs.
- Meanwhile, attempts to pretrain a 7B Llama2 with
GPU MODE Discord
- WGMMA & Triton Trials: Engineers discussed WGMMA requiring splits across 4 warps with a minimum tile of 64, referencing NVlabs' tiny-cuda-nn for fused MLP insights. They also recommended Proton for profiling, citing a helpful video.
- Community members praised the easier debugging of Triton kernels with Proton, while questioning on-chip MLP usage for typical HPC tasks.
- MI210 Occupancy Puzzle: Members examined GPU occupancy for the MI210 and RX 7900XTX, referencing a resource on block-level optimization. They noted potential 16-warps occupancy but saw constraints like block-level resource usage in real-world code.
- They concluded that hitting higher occupancy often demands multiple kernels, with CDNA architecture details revealing practical block limits and early exit behaviors. Further testing validated the distinctive block scheduling approach on MI210.
- Nectar Social's $10k Bounty: Nectar Social is hiring in Seattle for Staff Product Manager, LLM/AI Engineer, and Infra Engineer, offering referral bounties of up to $10,000. They emphasized prior startup experience and expressed willingness to share details privately.
- A European consultancy with HPC clients like AMD also seeks developers skilled in CUDA, HIP, and OpenCL, referencing a job listing at LinkedIn. They also collaborate on libraries like rocPRIM and hipCUB, aiming to fill specialized GPU developer roles.
- ARC Prize Non-Profit Shift: The ARC Prize is transitioning into a non-profit foundation, as seen in a tweet from François Chollet, with a new president to guide AGI research. They also launched a rejection sampling baseline experiment to establish a foundational metric.
- Community members explored text-domain solutions to mitigate GPU constraints and analyzed the Meta CoT paper (link) for potential refinements. The authors highlighted shortfalls in classic CoT approaches, sparking broader discourse on contextual reasoning.
- MicroDiT Gains with DCAE: MicroDiT replication concluded successfully, providing a weight file and an inference script. They credited computational support and aim to improve architecture with DCAE for stronger performance.
- Plans include employing MMDIT for better prompt adherence and seeking compute grants. The limited home GPU capacities hamper advanced AI experiments, spurring the search for additional resources.
Nous Research AI Discord
- Microsoft's rStar-Math Maneuvers Qwen's Mastery: Microsoft introduced rStar-Math, pushing Qwen 2.5-Math-7B from 58.8% to 90.0% on the MATH benchmark and scoring 53.3% on AIME, placing it among the top 20% of high school students.
- Members debated the significance of math prowess for reasoning skills, with some cautioning that numeric breakthroughs don't always guarantee broader LLM reliability.
- DistTrO's Doors Swing Wide: A member confirmed DistTrO is open sourced, prompting immediate integrations within community trainers.
- Contributors praised DisTrO for distributed training simplicity, with some highlighting a smoother setup than earlier solutions.
- Carson Poole's Paper Parade: Carson Poole introduced ReLoRA and Sparse Upcycling, referencing discussions from November 2022 and March 2023.
- He urged members to visit his personal site and offered email collaboration on Forefront.ai or Simple AI Software for deeper exploration.
- DeepSeek V3's Twin Tests: Members compared the official DeepSeek V3 API's repetitive outputs to third-party providers like Hyperbolic, noting stark differences in answer quality.
- Some attributed these inconsistencies to aggressive caching, prompting interest in more consistent inference approaches.
- Qwen2.5 Memory Maze on 24 GB VRAM: A user encountered out-of-memory errors on Qwen2.5-32B-Instruct-AWQ with an RTX 4090, despite enabling flash attention.
- The discussion shifted to potential memory usage optimizations for ~6K token contexts, as well as inquiries into open source function calling accuracy benchmarks.
Latent Space Discord
- Salesforce's Surprising Freeze: Marc Benioff confirmed Salesforce will halt hiring software engineers in 2025, citing a 30% productivity boost from Agentforce.
- Community members see this as a major shift in resource allocation, with speculation that "AI is truly taking over basic software tasks".
- OpenAI Tweaks Custom Instructions: OpenAI reportedly updated custom instructions for its advanced voice toolset, with a tweet from topmass showcasing partial breakage and hints of new features.
- Observers suggest these improvements might usher new voice capabilities, with one user describing them as "powerful enhancements for a more fluid AI experience".
- Anthropic's $2B Infusion: Anthropic is raising $2 billion at a $60 billion valuation, posting $875 million ARR according to Andrew Curran's report.
- Participants commented on "venture capital's big appetite for AI solutions", especially as Anthropic's traction continues to expand in enterprise contracts.
- Google Piles AI into DeepMind: Google announced a plan to merge multiple AI products under DeepMind, showcased by Omar Sanseviero's tweet about joining forces in 2025.
- Commenters foresee possible overlap in corporate structure, calling it "a puzzling reorg, but hopefully it streamlines LLM offerings".
OpenRouter (Alex Atallah) Discord
- Hackathon Hype With a Cash Kick: The oTTomator AI Agent Hackathon offers $6,000 in sponsor prizes, awarding $1,500 for first place, $150 for runners-up, plus $10 in OpenRouter API credits, with sign-ups at register here.
- It runs from January 8 to January 22, with community voting from January 26 to February 1, and the sponsor pool includes Voiceflow and n8n awarding extra $700 and $300.
- OpenRouter UI Stumbles Past 1k Lines: Users reported OpenRouter UI slows down drastically beyond 1k lines of chat history, making scrolling and editing painful.
- They proposed improvements like sorting by cost and Next.js pagination to address these performance pitfalls.
- Gemini Flash Sparks Confusion: The Gemini Flash engine works in chatrooms but seems non-functional via API, baffling multiple users.
- Another user praised Gemini overall, yet pointed out performance issues that warrant immediate improvements.
- O1 Embraces Unusual Response Format: Developers noticed O1's response uses '====' in place of markdown backticks, raising concerns about formatting quirks.
- Discussions ranged from whether this measure is meant to cut token usage or refine output, prompting debate on best practices.
- API Access & Hanami Trials: Developers asked about offering their own LLM API through OpenRouter and shared issues with request handling.
- Another user tested Hanami but encountered odd characters, emphasizing the importance of robust tool compatibility.
Perplexity AI Discord
- CSV Export Gains Steam: Perplexity introduced a feature to download table responses as CSV files, showcased in an illustrative image.
- Users welcomed this enhancement for streamlining data workflows, emphasizing how it can save time when handling large datasets.
- Youzu.ai Interiors Leap Forward: Youzu.ai provides AI-driven room designs with direct shopping options, as detailed in this Medium guide.
- Community members tested it and appreciated its potential to reduce hassle, asking for feedback on real-world usage.
- Toyota's Rocket Rendezvous: A new rocket venture from Toyota suggests their push beyond standard auto engineering.
- Enthusiasts noted the synergy between Toyota's established expertise and aerospace demands, predicting more official details may follow.
- NVIDIA's $3K Home Supercomputer: NVIDIA announced a future home-ready supercomputer at a price of $3000, as noted in a CES 2025 reference.
- Tech fans debated whether the advanced performance justifies the cost, seeing this as an opening for machine learning experimentation at home.
- Ecosia Eyes Perplexity Partnership: A product manager at Ecosia struggled to reach Perplexity for a potential partnership and asked for guidance in making contact.
- Helpers in the community offered suggestions for direct communication, hoping for a fruitful alliance if discussions move forward.
Cohere Discord
- Cohere's 'North' Rises to Rival Copilot: Cohere introduced North in early access, a secure AI workspace merging LLMs, search, and agents into one interface for productivity.
- They contend it can outshine Microsoft Copilot and Google Vertex AI, as noted in the official blog post.
- Command R+ Spurs Generative Gains: A user referenced Command R+ when exploring workflows for large generative models in Cohere’s ecosystem.
- Community discussions stressed a clear integration strategy and recognized the need for well-structured prompts to optimize model behavior.
- v2 to v3 Embeddings: The Upgrade Query: Questions arose on transitioning from embed-v2 to v3 without re-embedding massive datasets, prompting concerns about resource usage.
- Members sought an efficient approach to maintain performance while minimizing overhead and potential downtime.
- LLM Loops & Rolling Chat: Taming Token Overflows: Reports indicated Cohere’s LLM could get stuck in repetitive loops, driving runaway token usage in the Python ClientV2 setup.
- Suggestions involved setting max_tokens limits and employing a rolling chat history technique to handle extended responses within the 4k token boundary.
- Alignment Evals Hackathon Sparks Action: An Alignment Evals Hackathon was announced for the 25th, featuring community-driven eval and interpretation tutorials.
- Participants were encouraged to share insights and outcomes, fueling collaboration on alignment evaluation methods.
tinygrad (George Hotz) Discord
- Mock GPU Mayhem & Bounty Talk: A retest was requested for Pull Request #8505 involving MOCKGPU on macOS, with George Hotz confirming a bounty is ready for this fix.
- He offered payment via PayPal or USDC on Ethereum, underscoring a push to handle outstanding tasks in tinygrad.
- LLVM JIT & Autogen Pair-Up: Members proposed merging their LLVM JIT and LLVM Autogen efforts, referencing changes in multiple version files.
- They also debated forward vs. backward compatibility, with some emphasizing older LLVM support to avoid silent breakage.
- Function Signature Stability Friction: Concerns surfaced about potential silent changes to LLVM function signatures causing undefined behavior.
- George Hotz downplayed that risk, noting preference for supporting older LLVM releases to maintain consistency.
- TinyGrad Blog & Device Setup: A blog post titled TinyGrad Codebase Explained-ish walked through tinygrad's file layout, cautioning about lightly tested code outside tinygrad/.
- A user asked about initializing weights on specific hardware, and got advice to set
Device.DEFAULTto METAL, CUDA, or CLANG before creating tensors.
- A user asked about initializing weights on specific hardware, and got advice to set
Nomic.ai (GPT4All) Discord
- Llama vs GPT4All Race Ramps Up: They highlighted that Llama.cpp Vulkan differs from GPT4All internals, yielding large speed gaps on Nvidia GPUs due to CUDA usage.
- Participants concluded that the difference can be overlooked if performance meets everyday targets, referencing nomic-ai/gpt4all for more context.
- Chat Template Tangle: A user struggled with the Chat Template for TheBloke’s model on GPT4All, receiving generic replies despite correct installation.
- Others advised checking model-specific instructions on GitHub, stressing that chat prompts differ widely across models.
- Roleplay Recs Ride On Llama-3: For anime-themed roleplay, members recommended Nous Hermes 2 or llama3-8B-DarkIdol-2.2-Uncensored-1048K as workable older options.
- They noted that Nomic's plug-and-play approach simplifies usage, especially for quick scripted dialogues.
- ModernBERT Deployment Dilemma: A query arose about ModernBERT from Nomic AI and whether it's supported on text-embedding-inference or vLLM.
- No conclusive answer emerged, leaving the group uncertain about official deployment channels.
- Image Model Hopes Spark GPT4All Chat: Some considered the idea of adding image models into GPT4All for extended modality coverage.
- The conversation ended with no definitive plan, yet it underscored user interest in bridging text and vision.
LlamaIndex Discord
- Grand Gathering at GitHub HQ: On Jan 15, they're hosting a series of expert talks at GitHub HQ discussing AI agent improvements, fast inference systems, and building workflows with LlamaIndex.
- The event showcases advanced agentic workflows, highlighting real-world examples from multiple industry experts.
- Agentic Document Workflows: A Bold Leap: A new blog post introduces Agentic Document Workflows (ADW), aiming to integrate document processing directly into business processes.
- It underscores that documents come in multiple formats, emphasizing a streamlined approach for future-driven applications.
- Ollama Overdrive for Speed: A recent update to Ollama brought evaluation times under 3 seconds, spurring excitement among users.
- One user called the gains incredible, reflecting strong enthusiasm about faster model inferences.
- VectorStoreIndex: Manual Moves for Metadata: Some members discussed filtering nodes by metadata keys in a Postgres JSON field using VectorStoreIndex, questioning whether they could avoid manual indexing.
- They concluded manual indexing might still be needed, since LlamaIndex doesn't yet handle all related automation.
- Taming TEI & QueryFusionRetriever Quirks: Interest rose in using a local TEI server for reranking, referencing API docs and source code.
- Amid that, users hit an input validation error in QueryFusionRetriever at 518 tokens, sharing code snippets to find a workaround.
Modular (Mojo 🔥) Discord
- Rust Syntax Eases Multiline: One user praised Rust multiline syntax when building an actor for multipaxos, highlighting fewer type checks.
- They said function parameters can become chatty, causing confusion for users sorting out required types.
- Overload Resolution Gets Risky: A user warned that rearranging overloads in large codebases may cause new snags, suggesting a 'happens after' annotation approach.
- They added TraitVariant checks can mix with implementation traits, potentially leading to messy overload resolution.
- Quantum Libraries Progress in Mojo: A member mentioned the need for a Qiskit-like library, referencing an interest in quantum expansions and linking to MLIR dev videos.
- They suggested that MAX might soon handle quantum tasks as it evolves.
- MAX Backs Quantum Programming: Discussion spotlighted MAX as Mojo's partner for fine-tuning quantum routines, allowing real-time hardware adjustments.
- People said MAX can unify quantum and classical logic when it matures.
- Quojo Brings a Quantum Option: The Quojo library, shared via GitHub, was mentioned as a quantum computing tool in Mojo.
- Folks expressed excitement for emerging developers pushing quantum coding forward.
LLM Agents (Berkeley MOOC) Discord
- Hackathon Timeline Takes Shape: The Hackathon website (link) shared an updated results schedule, postponing final outcomes until later in January.
- Organizers stated that a few judges still need to finalize their reviews, promising a thorough evaluation before announcing winners.
- Judges Jump for Joy: Judges gave glowing feedback about the Hackathon submissions, calling them impressive entries overall.
- They emphasized the high level of creativity and technical depth, reinforcing anticipation for the final verdicts.
OpenInterpreter Discord
- OpenInterpreter 1.0 Grapples with Python Execution: Users discovered that OpenInterpreter 1.0 does not directly run Python code, causing confusion about the
--tools interpretercommand.- A member expressed frustration over code execution limitations, sparking requests for clearer instructions on how to handle code blocks.
- GPT-4o-mini Gains Some Command Control: A discussion noted that GPT-4o-mini had improvements in command handling, particularly when printing file contents in smaller chunks.
- The conversation focused on refining model performance through better file output strategies and fine-tuning command executions.
- Call for Model Specifications: A member asked for more technical details on parameter counts and underlying frameworks for better understanding performance metrics.
- This inquiry underlined a need for full documentation, as participants sought clarity on the building blocks of the models.
LAION Discord
- TruLie or Not? Data Mystery: A user asked about the TruLie dataset, but no specifics or references were provided, leaving the conversation short on facts.
- Members shared curiosity over possible research applications, yet no direct resources emerged.
- Chirpy3D Takes Flight: Enthusiasts discussed image-to-3D progress, highlighting Chirpy3D for continuous bird generation and Gaussian splats approaches, citing Chirpy3D as an example.
- They mentioned collaboration from multiple institutions and pointed to the 3D Arena on Hugging Face as a resource for NeRF libraries.
- World Models Evolve Visuals: Contributors shared World Models that use physics-aware networks to produce more realistic video content.
- Though outside pure image-to-3D pipelines, this direction aligns with broader efforts toward sophisticated visual systems.
- Open Tool Registry Sought: A researcher requested an open tool registry for building agents, hoping to collect suggestions from the group.
- No direct leads surfaced, prompting further attempts to locate complete resources.
DSPy Discord
- Chain-of-Thought Gains for Chatbots: A user asked about boosting Chain of Thought for chatbots beyond a simple persona signature, seeking deeper conversation styles and reasoning steps.
- The question went unanswered, underscoring the difficulty of refining chatbot logic and user interaction.
- Evaluation Endeavors with DSPy: A post on building your own evaluation, titled An intro to building your own eval, why it matters, and how DSPy can help, was shared here to highlight the role of DSPy in customizing testing frameworks.
- Readers showed excitement for crafting new evaluation methods and recognized DSPy's potential to improve knowledge bank solutions.
- Anthropology & Tech: Drew's Path: Drew Breunig gave an overview of his background in cultural anthropology, software, and media, mentioning work at PlaceIQ and Precisely with data integrity efforts.
- He also collaborates with the Overture Maps Foundation, broadening the scope of data usage across varied industries.
AI21 Labs (Jamba) Discord
- Python + Jamba Pump Up Podcast Recall: A user employed Jamba's Conversational RAG with a basic Python app to retrieve highlights from past podcasts using transcripts, calling it a work in progress but fun to experiment with.
- They mentioned they are exploring new ways to integrate AI-driven recall without major hurdles, finding the system handy for archiving show notes.
- AI Code Generation Rocks... But Goofs Happen: A user raved about AI's ability to generate code, praising its handling of HTML and JavaScript but noting occasional silly mistakes.
- They tested PHP tasks to gauge AI's limits, concluding that code generation remains head-scratching yet helpful.
- PHP Holds Steady in Jamba Connection: Another user declared loyalty to PHP for web and IRC bot coding, describing the hook-up to Jamba as a real adventure.
- They liked how it parallels deepSeek and OpenAI APIs, simplifying programming tasks and encouraging swift tinkering.
Torchtune Discord
- ModernBERT Gains Finetune Curiosity: An inquiry was raised about finetuning ModernBERT, hinting at specialized task improvements but no direct experiences were shared.
- The conversation ended without follow-up, leaving watchers hoping for technical examples or demos to light the way ahead.
- Nectar Social Dangles $10K Referrals: Nectar Social seeks AI-focused hires with referral bounties up to $10,000, including Sr/Staff Product Manager and LLM/AI Engineer roles.
- They emphasized growth in social commerce with notable clients and encouraged interested applicants to DM for details.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Axolotl AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!