[AINews] Mixture of Depths: Dynamically allocating compute in transformer-based language models
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI News for 4/4/2024-4/5/2024. We checked 5 subreddits and 364 Twitters and 26 Discords (386 channels, and 5819 messages) for you. Estimated reading time saved (at 200wpm): 631 minutes. 19663
Top news of the day is DeepMind's MoD paper describing a technique that, given a compute budget, can dynamically allocate FLOPs to different layers instead of uniformly. The motivation is well written:
Not all problems require the same amount of time or effort to solve. Analogously, in language modeling not all tokens and sequences require the same time or effort to accurately make a prediction. And yet, transformer models expend the same amount of compute per token in a forward pass. Ideally, transformers would use smaller total compute budgets by not spending compute unnecessarily.
The method uses top-k routing allowing for selective processing of tokens, thus maintaining a fixed compute budget. You can compare it to a "depth" sparsity version of how MoEs scale model "width":
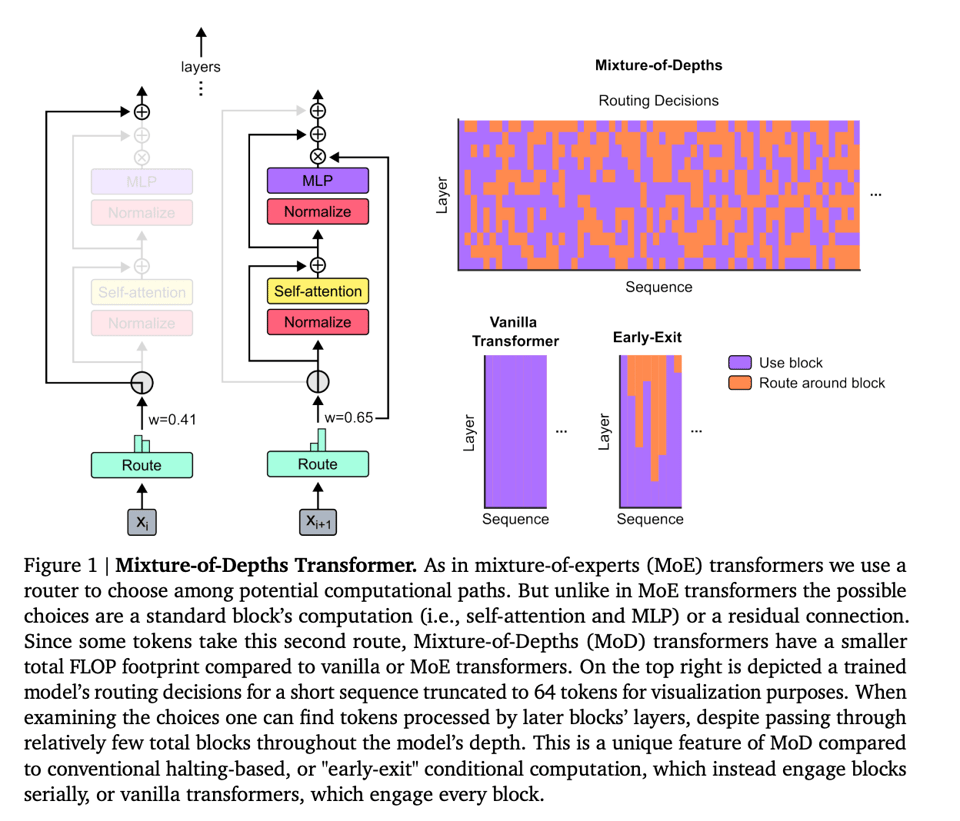
We leverage an approach akin to Mixture of Experts (MoE) transformers, in which dynamic token-level routing decisions are made across the network depth. Departing from MoE, we choose to either apply a computation to a token (as would be the case for a standard transformer), or pass it through a residual connection (remaining unchanged and saving compute). Also in contrast to MoE, we apply this routing to both forward MLPs and multi-head attention. Since this therefore also impacts the keys and queries we process, the routing makes decisions not only about which tokens to update, but also which tokens are made available to attend to. We refer to this strategy as Mixture-of-Depths (MoD) to emphasize how individual tokens pass through different numbers of layers, or blocks, through the depth of the transformer
Per Piotr, Authors found that routing ⅛ tokens through every second layer worked the best. They also make an observation that the cost of attention for those layers decreases quadratically, so this could be an interesting way of making ultra long context length much faster. There's no impact at training time, but can be "upwards of 50% faster" per forward pass.
The authors also demonstrate how MoD can be combined with MoE (eg by having a no-op expert) to decouple the routing for queries, keys, and values:
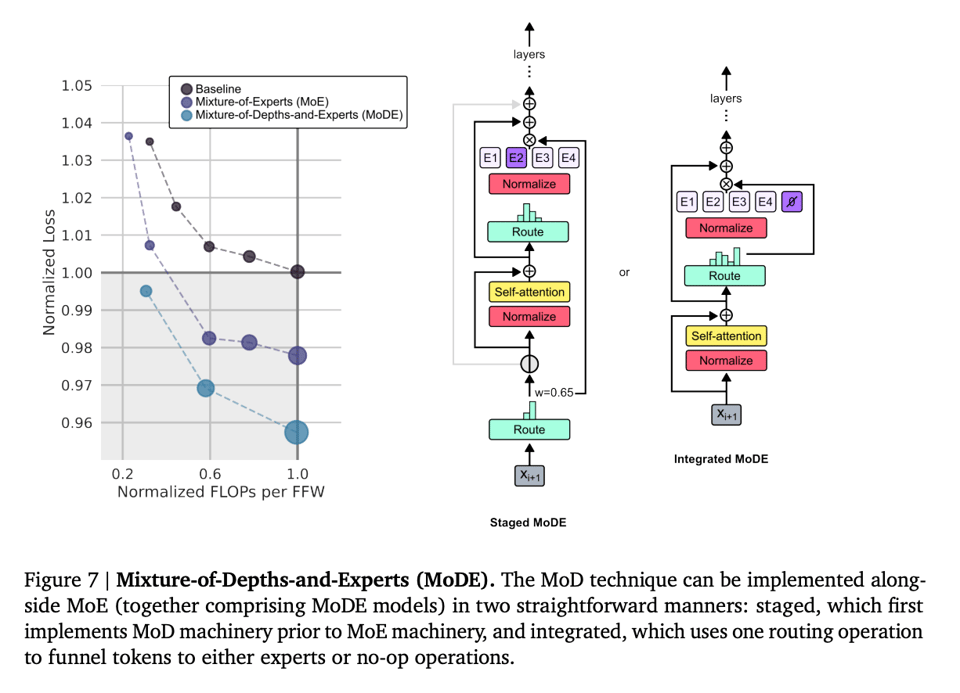
Table of Contents
- AI Reddit Recap
- AI Twitter Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Perplexity AI Discord
- Stability.ai (Stable Diffusion) Discord
- OpenAI Discord
- LM Studio Discord
- Nous Research AI Discord
- Unsloth AI (Daniel Han) Discord
- Eleuther Discord
- Modular (Mojo 🔥) Discord
- OpenAccess AI Collective (axolotl) Discord
- LlamaIndex Discord
- OpenRouter (Alex Atallah) Discord
- HuggingFace Discord
- tinygrad (George Hotz) Discord
- Interconnects (Nathan Lambert) Discord
- LangChain AI Discord
- LAION Discord
- Latent Space Discord
- OpenInterpreter Discord
- CUDA MODE Discord
- Datasette - LLM (@SimonW) Discord
- DiscoResearch Discord
- Mozilla AI Discord
- Skunkworks AI Discord
- LLM Perf Enthusiasts AI Discord
- PART 2: Detailed by-Channel summaries and links
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence. Comment crawling still not implemented but coming soon.
AI Research and Development
- Concerns about LLM hype: In /r/MachineLearning, a post argues that LLM hype is driving attention and investment away from other potentially impactful AI technologies. The author claims there has been little progress in LLM performance and design since GPT-4, with the main approach being to make models bigger, and expresses concern about an influx of people without ML knowledge claiming to be "AI researchers".
- Improving transformer efficiency: Deepmind introduces a method for transformers to dynamically allocate compute to specific positions in a sequence, optimizing allocation across layers. Models match baseline performance with equivalent FLOPs and training time, but require fewer FLOPs per forward pass and can be over 50% faster during sampling.
- Enhancing algorithmic reasoning: A new framework called Think-and-Execute decomposes LM reasoning into discovering task-level logic expressed as pseudocode, then tailoring it to each instance and simulating execution. This improves algorithmic reasoning by 10-20 percentage points over CoT and PoT baselines.
- Visual Autoregressive modeling: VAR redefines autoregressive learning on images as coarse-to-fine "next-scale prediction", allowing AR transformers to learn visual distributions fast, surpass diffusion in image quality and speed, and exhibit scaling laws and zero-shot generalization similar to LLMs.
- On-device models: Octopus v2, an on-device 2B parameter model, surpasses GPT-4 accuracy and latency for function calling, enhancing latency 35-fold over LLaMA-7B with RAG. It is suitable for deployment on edge devices in production.
AI Products and Services
- YouTube's stance on Sora: YouTube says OpenAI training Sora with its videos would break the rules, raising questions about data usage for AI training.
- Claude's tool use: Anthropic's Claude model now has the capability to use tools, expanding its potential applications.
- Cohere's large model: Cohere releases Command R+, a scalable 104B parameter LLM focused on enterprise use cases.
- Google's AI search monetization: There is speculation that Google's AI-powered search will most likely be put behind a paywall, raising questions about the accessibility of AI-enhanced services.
AI Hardware and Performance
- Apple's MLX performance: Apple's MLX reaches 100 tokens/second for 4-bit Mistral 7B on M2 Ultra, showcasing strong on-device inference capabilities.
- QLoRA on consumer devices: QLoRA enables running Cohere's 104B Command R+ model on an M2 Ultra, achieving ~25 tokens/sec and ~7.5 tokens/sec generation speed on a pro-sumer device.
- AMD's open-source move: AMD is making its ROCm GPU computing platform open-source, including the software stack and hardware documentation. This could accelerate development and adoption of AI hardware and software.
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Models and Architectures
- Google's Training LLMs over Neurally Compressed Text: @arankomatsuzaki noted that Google's approach of training LLMs over neurally compressed text outperforms byte-level baselines by a wide margin, though has worse PPL than subword tokenizers but benefits from shorter sequence lengths.
- Alibaba's Qwen1.5 Models: @huybery announced the Qwen1.5-32B dense model, which incorporates GQA, shows competitive performance comparable to the 72B model, and impresses in language understanding, multilingual support, coding and mathematical abilities. @_philschmid added that Qwen1.5 32B is a multilingual dense LLM with 32k context, used DPO for preference training, has a custom license, is commercially usable, and is available on Hugging Face, achieving 74.30 on MMLU and 70.47 on the open LLM leaderboard.
- ReFT: Representation Finetuning for Language Models: @arankomatsuzaki shared the ReFT paper, which proposes a 10x-50x more parameter-efficient fine-tuning method compared to prior state-of-the-art parameter-efficient methods.
- Apple's MM1 Multimodal LLM Pre-training: @_philschmid summarized Apple's MM1 paper investigating the effects of architecture components and data choices for Vision-Language-Models (VLMs). Key factors impacting performance include image resolution, model size, and training data composition, with Mixture-of-Experts (MoE) variants showing superior performance compared to dense variants.
Techniques and Frameworks
- LangChain Weaviate Integration: @LangChainAI announced the
langchain-weaviatepackage, providing access to Weaviate's open-source vectorstore with features like native multi-tenancy and advanced filtering. - Claude Function Calling Agent: @llama_index released a Claude Function Calling Agent powered by LlamaIndex abstractions, leveraging Anthropic's tool use support in its messages API for advanced QA/RAG, workflow automation, and more.
- AutoRAG: @llama_index introduced AutoRAG by Marker-Inc-Korea, which automatically finds and optimizes RAG pipelines given an evaluation dataset, allowing users to focus on declaring RAG modules rather than manual tuning.
- LLMs as Compilers: @omarsar0 shared a paper proposing a think-and-execute framework to decompose reasoning in LLMs, expressing task-level logic in pseudocode and simulating execution with LMs to improve algorithmic reasoning performance.
- Visualization-of-Thought Prompting: @omarsar0 discussed a paper on Visualization-of-Thought (VoT) prompting, enabling LLMs to "visualize" reasoning traces and create mental images to guide spatial reasoning, outperforming multimodal LLMs on multi-hop spatial reasoning tasks.
Datasets
- Gretel's Synthetic Text-to-SQL Dataset: @_philschmid shared Gretel's high-quality synthetic Text-to-SQL dataset (retelai/synthetic_text_to_sql) with 105,851 samples, ~23M tokens, coverage across 100 domains/verticals, and a wide range of SQL complexity levels, released under Apache 2.0 license.
Compute Infrastructure
- AWS EC2 G6 Instances with NVIDIA L4 GPUs: @_philschmid reported on new AWS EC2 G6 instances with NVIDIA L4 GPUs (24GB), supporting up to 8 GPUs (192GB) per instance, 25% cheaper than G5 with A10G GPUs.
- Google Colab L4 GPU Instances: @danielhanchen noted that Google Colab now offers L4 GPU instances at $0.482/hr, with native fp8 support and 24GB VRAM, along with price drops for A100 and T4 instances.
Discussions and Perspectives
- Commoditization of Language Models: @bindureddy suggested that Google, with its strong revenue stream and facing threats from LLMs in search, should open-source Gemini 1.5 and 2.0, as the number of companies joining the open-source AI revolution grows, with only Google, OpenAI, and Anthropic remaining closed-source.
- Benchmarking Concerns: @soumithchintala raised issues with benchmarks posted by Google's Jeff Dean and François Chollet, citing wrong timing code, benchmarking different precisions, and the need for Google teams to work with PyTorch teams before posting to avoid divisive moments in the community.
- AI Harming Research: @bindureddy argued that LLMs are harming AI research to some extent by diverting focus from tabular data and brand new innovation, predicting a glut of LLMs by the end of the year.
- Framing AI Products as "Virtual Employees": @dzhng critiqued the framing of AI products as "virtual employees," suggesting it sets unrealistic expectations and limits the disruptive potential of AI, proposing a focus on specific "scopes of work" and envisioning future "neural corporations" run by coordinating AI agents.
Memes and Humor
- Google's Transformer 2: @arankomatsuzaki shared details on Google's Transformer 2, which unifies attention, recurrence, retrieval, and FFN into a single module, performs on par with Transformer with 20x better compute efficiency, and can efficiently process 100M context length. A delayed April's Fools joke.
- @cto_junior joked about their super fast RAG app using "numpy bruteforce similarity search" instead of expensive enterprise solutions.
- @vikhyatk quipped about working on a "mamba mixture of experts diffusion qlora 1.58bit model trained using jax, rust, go, triton, dpo, and rag."
- @cto_junior humorously lamented the complexity of AWS policies, resorting to copying from Hackernoon and hoping it resolves 500 errors.
AI Discord Recap
A summary of Summaries of Summaries
1. Cutting-Edge LLM Advancements and Releases
- Cohere unveiled Command R+, a 104B parameter LLM with Retrieval Augmented Generation (RAG), multilingual support, and enterprise capabilities. Its performance impressed many, even outshining GPT-4 on tasks like translating Middle High German.
- Anthropic showcased live tool use in Claude, sparking analysis of its operational complexity. Initial tests found Claude "pretty good" but with latency challenges.
- QuaRot, a new 4-bit quantization scheme, can quantize LLMs end-to-end with minimal performance loss. The quantized LLaMa2-70B retained 99% of its zero-shot capabilities.
- JetMoE-8B is a cost-effective alternative to large models like LLaMA2-7B, claiming to match performance at just $0.1M in training costs while being academia-friendly.
2. Parameter-Efficient LLM Fine-Tuning Techniques
- ReFT (Representation Finetuning) is a new method claimed to be 10-50x more parameter-efficient than prior techniques, allowing LLM adaptation with minimal parameter updates.
- Discussions on LoRA, QLoRA, LoReFT, and other efficient fine-tuning approaches like Facebook's new "schedule-free" optimizer that removes the need for learning rate schedules.
- Axolotl explored integrating techniques like LoReFT and the latest PEFT v0.10.0 with quantized DoRA support.
3. Architectural Innovations for Efficient Transformers
- Mixture-of-Depths enables dynamic FLOPs allocation in transformers via a top-k routing mechanism, promising significant compute reductions by processing easier tokens with less compute.
- Discussions on combining Mixture-of-Experts (MoE) with Mixture-of-Depths, and potential for integrating these methods into existing models over weekends.
- BitMat showcased an efficient implementation of the "Era of 1-bit LLMs" method, while the LASP library brought improved AMD support for longer context processing.
4. Open-Source AI Frameworks and Community Efforts
- LM Studio gained a new community page on HuggingFace for sharing GGUF quants, filling the void left by a prolific contributor.
- LlamaIndex introduced Adaptive RAG, AutoRAG, and the Claude Function Calling Agent for advanced multi-document handling.
- Basalt emerged as a new Machine Learning framework in pure Mojo, aiming to provide a Deep Learning solution comparable to PyTorch.
- Unsloth AI explored GPU memory optimizations like GaLore and facilitated discussions on finetuning workshops and strict versioning for reproducibility.
PART 1: High level Discord summaries
Perplexity AI Discord
- Perplexity Pro Puzzlements: Engineers are questioning the capability and accessibility of Perplexity Pro, addressing how to enable channels, file deletion issues, and purchasing obstacles; a suggestion was made to contact support or mods for help.
- AI's Cloud Conundrum: There's buzz about cloud services' role in large language model (LLM) development, with debates over AWS vs. Azure market shares and speculative chats on a potential Perplexity-Anthropic collaboration.
- Apple's AI Ambitions Analyzed: The guild is analyzing Apple 3b model's niche applications and ponders the mainstream potential of Apple Glass, contrasting these with Google's VR initiatives.
- API Pricing and Limits Laid Out: Queries about Perplexity's API, such as purchasing additional credits with Google Pay and the cost of sonar-medium-chat ($0.60 per 1M tokens), have been clarified, with pointers to the rate limits and pricing documentation.
- Community Curiosities With Perplexity: Members are actively using Perplexity AI search for a range of topics, from beauty and dictatorships to Cohere's Command R; they're also sharing content with reminders on how to set threads as shareable.
Stability.ai (Stable Diffusion) Discord
Maximizing Image Fidelity: Technical suggestions to circumvent issues with generating 2k resolution realistic images emphasized lower resolution generation followed by upscaling, minimizing steps, and engaging "hiresfix". Trade-offs between quality and distortions during upscaling framed the dialogue.
SD3 Release Leaves Crowd Restless: While some guild members are eagerly awaiting Stable Diffusion 3 (SD3), others sense a delay, which has led to mixed feelings ranging from anticipation to skepticism and comparisons with other models like Ideogram and DALLE 3.
AI Meets Art: Creative discussions unfolded around using AI for artistic endeavors, highlighting Daz AI in image generation, and the intricacies of finessing models for art-specific outputs, such as generating clothing designs in Stable Diffusion.
VRAM to the Rescue: Technical discourse delved into model resource demands, particularly operating models across various VRAM allotments and the anticipation of SD3's performance on standard consumer GPUs.
Demystifying Stable Diffusion Know-how: Users shared insights and sought advice on optimizing Stable Diffusion model versions and interfaces, covering best practices for image finetuning and effective model checkpoint management.
OpenAI Discord
Fine-Tuning API Gets a Makeover: OpenAI has rolled out updates to the fine-tuning API, aiming to give developers more control over model customization. The enhancements include new dashboards and metrics, and expand the custom models program, as detailed in OpenAI's blog post and an accompanying YouTube tutorial.
AI Discussions Heat Up: Across channels, there is debate around concepts such as AI cognition and ASCII art generation, probing AI's potential in 3D printing, and balancing excitement for releases with security measures. Additionally, implementation queries on using AI for document analysis and fine-tuning for data enhancement were highlighted, alongside an observation of inconsistent behavior when setting the assistant's temperature to 0.0.
Prompt Engineering Tactics Unveiled: Members are sharing strategies to make GPT-3 produce longer outputs and to constrain responses to specific documentation. Tips range from starting a new chat with "continue" to stern instructions that make the AI confirm the existence of answers within provided materials.
Assertive Prompting May Boost GPT Accuracy: To ensure that GPT's outputs are based strictly on supplied content, the advice is to give clear and assertive prompts. Whether discussing the nature of consciousness to mimic human responses or reinforcing documentation-specific replies, the community explores the semblance of an AI's understanding.
Clarity on GPT-4 Usage Costs: Discussions clarify that incorporating GPT models into apps requires a subscription plan, such as the Plus plan, as all models now operate under GPT-4. Users seeking enhanced functionality with GPT models must consider this when developing AI-powered applications.
LM Studio Discord
- LM Studio Stays Offline: It's confirmed that LM Studio lacks web search capabilities akin to other AI tools, offering local deployment options, outlined in their discussion and LM Studio's documentation.
- Models Clash on the Leaderboard: The community is evaluating models on scoreboards like the LMsys Chatbot Arena Leaderboard, highlighting that only select top-ranked models allow local operation, a critical factor for this audience.
- Big Models, Big GPUs, Big Questions: Members debated the performance trade-offs of multi-GPU setups in LM Studio against the size of models like Mixtral 8x7b and Command-R Plus, giving insights into token speeds and hardware-specific limitations, including issues mixing different generations and brands, mostly NVIDIA.
- The Rise of Eurus: The community discussed the advancement of the Eurus-7b model, offering improved reasoning abilities. It has been partially trained on the UltraInteract dataset and is available on HuggingFace, indicative of the group's continuous search for improved models.
- Archiving and Community Support: LM Studio announced a new Hugging Face community page, lmstudio-community, for sharing GGUF quant models, filling the vacancy left by a notable community contributor.
- Reliability Across Interfaces: Users compared the reliability of LM Studio's beta features, such as text embeddings, against alternative local LLM user interfaces and discussed workarounds for issues, including loading limitations and ROCm's potential with new Intel processors, shared on social platforms like Reddit and Radeon's Tweet.
Nous Research AI Discord
Bold New Leap for LoRA: A proposal has been made to apply Low-Rank Adaptation (LoRA) to Mistral 7B, aiming to augment its capabilities. Plans are afoot to integrate a taxonomy-driven approach for sentence categorization.
State-of-the-Art Archival and Web Crawling Practices: Discussions highlighted the thin line between archival groups and data hoarding, with a nod toward Common Crawl for web crawling excluding Twitter. The promotion of Aurora-M, a 15.5B parameter open-source, multilingual LLM with over 2 trillion training tokens was noted, in addition to tools for structuring LLM outputs like Instructor.
LLM Landscape Expanded: Announcements included a 104B LLM, C4AI Command R+, with RAG functionality and support for multiple languages available on Hugging Face. The community also discussed GPT-4 fine-tuning pricing and welcomed updates on an AI development teased by @rohanpaul_ai, while highlighting the LLaMA-2-7B model's 700K token context length training and the uncertainty regarding fp8 usability on Nvidia's 4090 GPUs.
Datasets and Tools Forge Ahead: An introduction to Augmentoolkit, which converts books and computes into instruction-tuning datasets, was discussed. Excitement surrounded Severian/Internal-Knowledge-Map with its novel approach to LM understanding, and the neurallambda project's aim to enable reasoning in AI with lambda calculus.
Dynamic Function Calling: An example of function calling with Hermes is to be demonstrated in a repository, alongside serious debugging efforts for its functioning with Vercel AI SDK RSC. The Hermes-Function-Calling repository faced critique, resulting in adherence to the Google Python Style Guide. Previewed was the Eurus-7B-KTO model, garnering interest for its use in the SOLAR framework.
Dependency Dilemmas and Dataset Stratagems: An emerging dependency issue was acknowledged without further context. The RAG dataset channel elucidated plans for pinning summaries, exploring adaptive RAG techniques, and the utilization of diverse data sources for RAG, along with discussions of Interface updates from Command R+ and Claude Opus.
World Building Steams Ahead with WorldSim: Tokens circulated regarding the WorldSim Versions & Command Sets and the Command Index, covering user experience details like custom emoji suggestions. Also brewing were thoughts on new channels for philosophy cross-pollinated with AI and a TRS-80 telepresence experience reflecting on Zipf's law. Anticipation buzzed for a WorldSim update with enhanced UX, hoping to ground self-steering issues.
Unsloth AI (Daniel Han) Discord
GPU Memory Gains: The GaLore update promises to enhance GPU memory efficiency with fused kernels, sparking discussions on integrating it with Unsloth AI for superior performance.
Model Packing Misfits: Caution is advised against employing packing parameter on Gemma models due to compatibility issues, although it can hasten training by concatenating tokenized sequences.
Optimization Opportunities: There's ongoing exploration into combining Unsloth with GaLore for memory and speed optimizations, despite GaLore's default performance lag behind Lora.
Anticipating Unsloth's New Features: Unsloth AI plans to release a "GPU poor" feature by April 22 and an "Automatic optimizer" in early May. The available Unsloth Pro since November 2023 is examined for distribution improvements.
Dataset Diversity in Synthetic Generation: Format flexibility is deemed inconsequential for synthetic dataset generation’s impact on performance, allowing for personal preference in formats chosen for fine-tuning LLMs.
Eagerly Awaiting Kaggle’s Reset: Kaggle enthusiasts await the new season, leveraging additional sleep hours due to Daylight Saving Time adjustments, while seeking AI news sources and discussing pretraining datasets potentially including libgen or scihub.
Unsloth Enables Streamlined Inference: Community feedback praises Unsloth’s ease of use for inference processes, with additional resources like batch inference guidelines being shared.
Finetuning Workshops Tackled: Users brainstorm on how to deliver effective finetuning workshops with hands-on experiences, involving innovations such as preparing models beforehand or employing LoRaX as a web UI for model interaction.
Version Control for Stability: Concerns about the impact of Unsloth updates on model reproducibility prompted a consensus on the necessity for strict versioning, to ensure numerical consistency and reversibility.
Parameter Efficiency in Fine-Tuning: A new fine-tuning technique called ReFT is showcased for being highly parameter-efficient, described in detail within a GitHub repo and an accompanying paper.
Eleuther Discord
Wiki Wisdom Now Publicly Accessible: Members tackled the challenges of accessing Wikitext-2 and Wikitext-103 datasets, sharing links from Stephen Merity's page and Hugging Face, with concerns over the ease of use of raw data formats.
GateLoop Replication Spark Debate: Skepticism regarding the GateLoop architecture's perplexity scores met clarifying information with released code, igniting discussions on experiment replication and the performance of various attention mechanisms.
Modular LLMs at the Forefront: Intense discussions focused on Mixture of Experts (MoE) architectures, spanning interpretability, hierarchical vs. flat structures, and efficiency strategies in Large Language Models (LLMs), referencing multiple papers and a Master's thesis tease suggesting an upcoming breakthrough in MoE Floating Point Operations (FLOPs).
Interpretability Implementations Interchange: Queries about the availability of an opensource implementation of AtP led to the sharing of the GitHub repo for AtP*, while David Bau sought community support on GitHub for nnsight to fulfill NSF reviewer requirements*.
From Troubleshooting to Trials in the Thunderdome: Discussions in #lm-thunderdome dove into troubleshooting, from syntax quirks with top_p=1 to confusion over model argument compatibility and efficiency gains from batch_size=auto, advising fresh installations or the use of Google Colab for certain issues.
Gemini Garners Cloud Support: A brief message highlighted Gemini's support implementation by AWS, with a mention of support from Azure as well.
Modular (Mojo 🔥) Discord
Boosting Mojo's Debugging Capabilities: Engineers queried about debugging support for editors like neovim, incorporating the Language Server Protocol (LSP) for enhanced problem-solving.
Dynamic Discussions on Variant Types: The use of Variant type was endorsed over isinstance function in Mojo, highlighting its dynamic data storage abilities and type checks using isa and get/take methods as shown in the Mojo documentation.
Basalt Lights Up ML Framework Torch: The newly minted Machine Learning framework Basalt is making headlines, differentiated as "Deep Learning" and comparable to PyTorch, with its foundational version v.0.1.0 on GitHub and related Medium article.
Counting Bytes, Not Just Buckets: A discourse on bucket sizing for value storage highlighted that each bucket holds UInt32 values, a mere 4 bytes each. This attention to memory efficiency is critical for handling up to 2^32 - 1 values.
Evolving Interop with Python: Progress in interfacing Python with Mojo was revealed, focusing on the use of PyMethodDef and PyCFunction_New, with stable reference counting and no issues to date. The current developments can be viewed on rd4com's GitHub branch.
OpenAccess AI Collective (axolotl) Discord
- LASP Library Gains Traction: The Linear Attention Sequence Parallelism (LASP) library is commended for its improved AMD support and the ability to split cache over multiple devices, facilitating longer context processing without the flash attn repository.
- GPT-3 Cost-Benefit Analysis: AI engineers are engaging in cost analysis of GPT-3, concluding that purchasing a GPU could be more cost-effective than renting after approximately 125 days, indicating a consideration for long-term investment over continuous rental costs.
- Colab GPU Update Engages Community: The AI engineering community reacts to Colab's new GPU offerings and pricing changes, with a tweet from @danielhanchen mentioning new L4 GPUs and adjusted prices for A100 GPUs, supported by a shared spreadsheet detailing the updates.
- Technical Discussion on Advanced Fine-tuning Strategies: Conversations are centered on fine-tuning methods like LoReFT, quantized DoRA in PEFT version 0.10.0, and a new technique from Facebook Research that negates the need for learning rate schedules, indicating a drive for optimizing model performance through innovative techniques.
LlamaIndex Discord
- Webinar Whistleblower: Don't miss the webinar action! Jerryjliu0 reminded users that the webinar is starting in 15 minutes with a nudge on the announcements channel.
- AI Agog Over Adaptive RAG and AutoRAG: The Adaptive RAG technique is catching eyes with potential for tailored performance on complex queries as per a recent tweet, while AutoRAG steps up to automatically optimize RAG pipelines for peak performance, detailed in another tweet.
- RAG Reimagined in Visual Spaces: AI aficionados discussed the potential of visual retrieval-augmented generation (RAG) models, capable of counting objects or modifying images with specific conditions, while Unlocking the Power of Multi-Document Agents with LlamaIndex hints at recent advancements in multi-document agents.
- Troubleshooting Time in Tech Town: AI engineers shared challenges like async issues with SQL query engines, Azure BadRequestError puzzles, prompt engineering tips for AWS context, complexities of Pydantic JSON structures, and RouterQueryEngine filter applications.
- Hail the Claude Calling Agent: LlamaIndex's latest, the Claude Function Calling Agent, touted for enabling advanced tool use, can now be found on Twitter (tweet), boasting of new applications with Haiku/Sonnet/Opus integration.
OpenRouter (Alex Atallah) Discord
Claude Gets Tangled in Safety Nets: Users report higher decline rates when utilizing Claude with OpenRouter API compared to Anthropic's API, suspecting OpenRouter might have added extra "safety" layers that interfere with performance.
Restoring Midnight Rose: Midnight Rose experienced downtime but was brought back online after restarting the cluster. The incident has sparked talks among users for switching to a more resilient provider or technology stack.
A Symphony of Modals: Following a shift to multimodal functionality, the Claude 3 model now accepts image inputs, necessitating code updates by developers. More details are announced here.
Command R+ Sparks Code-Conducting Excitement: Command R+, a 104B parameter model from Cohere, noted for its strong coding and multilingual capabilities, has excited users about its incorporation in OpenRouter, and comprehensive benchmarks can be found here.
Troubleshooting the Mixtral Puzzle: The Mixtral-8x7B-Instruct encountered issues following a JSON schema, which was successfully resolved by OpenRouter, not the providers, creating an eagerness for fixes and updates to streamline use with JSON modes.
HuggingFace Discord
A New Contender in Image Generation: A Visual AutoRegressive (VAR) model is proposed that promises to outshine diffusion transformers in image generation, boasting significant improvements in Frechet inception distance (FID) from 18.65 to 1.80 and an increase in inception score (IS) from 80.4 to 356.4.
Rethinking Batch Sizes for Better Minima: Engineers are debating whether smaller batch sizes, even though they slow down training, could achieve better results by not skipping over optimal local minima, in contrast to larger batch sizes that might expedite training but perform suboptimally.
Update Your Datasets like Git: AI practitioners are reminded that updates to datasets and models on Hugging Face require the same git-like discipline—an update locally followed by a commit and push—to reflect changes on the platform.
Bridging AI and Music with Open Source: A breakthrough was shared in the form of a musiclang2musicgen pipeline demonstrated through a YouTube video, promoting the viability of open-source solutions in audio generation.
Stanford's Treasure Trove for NLP Newbies: For those starting in NLP and deciding between Transformer architectures and traditional models like LSTM, the recommendation is to utilize the Stanford CS224N course, available through a YouTube playlist, as a first-rate resource.
Tuning and Deploying LLMs: Questions arose concerning Ollama model deployment, especially regarding memory requirements for the phi variant, along with inquiries on whether local deployment or API-based solutions like OpenAI's are more suitable for particular use cases.
tinygrad (George Hotz) Discord
Tinygrad's NPU Buzz and Intel GPU Gossip: Discussion in the guild mentioned that while tinygrad lacks dedicated NPU support on new laptops, it provides an optimization checklist for comparing performance with onnxruntime. Guild members also dissected the Linux kernel 6.8's capability to drive Intel hardware, especially post-Ubuntu 24.04 LTS release, eyeing advancement in Intel's GPUs and NPUs' kernel drivers.
Scalability Dialogue and Power Efficiency Talks: Dialogues touched on tinygrad's future scalability, with George Hotz indicating the potential for significant scaling using a 200 GbE full 16x interconnect slot and teased multimachine support. There was also a comparison of NPUs and GPUs in terms of power efficiency, highlighting NPUs' ability to match GPU performance with considerably less power consumption.
Prospects and Perils in Kernel Development: Among AI engineers, there was recognition of the obstacles presented by AVX-512 and interest in Intel making improvements based on a discussion thread on Real World Technologies. Conversations also covered AMD's open-source intentions with a side of skepticism towards the actual impact, and looked forward to how the AMD Phoronix update will affect the scene.
Learning Through Tinygrad's JIT: A post cleared confusion regarding JIT cache collection, and a community member contributed study notes to aid in performance profiling with DEBUG=2 for tinygrad. There's a collective effort to refine a community-provided TinyJit tutorial, as the author welcomed corrections, signaling the community's commitment to mutual learning and documentation accuracy.
Community Collaboration Encouraged: The conversations conveyed a strong sentiment for peer collaboration, urging knowledgeable members to submit pull requests to correct inaccuracies in TinyJit documentation, thus promoting a help-forward approach among the guild participants.
Interconnects (Nathan Lambert) Discord
- Command R+ Enters The Enterprise Arena: Cohere announced the launch of Command R+, a scalable large language model focusing on Retrieval-Augmented Generation (RAG) and Tool Use, boasting a 128k-token context window and multilingual capabilities, with its weights available on Hugging Face.
- Cost and Performance of Models in the Spotlight: The new JetMoE-8B model, positioned as a cost-effective alternative with minimal compute requirements, is claimed to outperform Meta's LLaMA2-7B and is noted for being accessible to academia, verifying its details on Hugging Face.
- A Surge of Enhancement Techniques for Efficiency: The conversation pivoted to DeepMind's Mixture of Depths, which dynamically allocates FLOPs across transformer sequences, possibly paving the way for future integration with Mixture of Experts (MoE) models and inviting weekend experimentation.
- Upcoming Guest Lecture Spotlights Industry-Research Integration: Nathan will present at CS25, amidst a lineup of experts from OpenAI, Google, NVIDIA, and ContextualAI, as listed on Stanford's CS25 class page, underscoring ongoing industry-academic synergy.
- Legal Threats and Credit Disputes Occasion Skepticism: Emphasized discussions include Musk's hinted legal pursuits in a tweet and doubts voiced over a former colleague's claims of credit on a project, revealing underlying tensions in the community interaction.
LangChain AI Discord
- Discourse on Chain-based JSON Parsing: AI engineers engaged in a rigorous discussion about employing Output Parsers, Tools, and Evaluators within LangChain to ensure JSON formatted output from an LLM chain. They also tackled the intricacies of ChatGroq summarization errors, shared tactics for handling legal document Q&A chunking, compared the performance of budget LLMs, and expressed a need for tutoring on the RAG (retrieval-augmented generation) technique within LangChain.
- Troublesome PDF Agent and Azure Integration Query: Engineers brainstormed on tuning an agent's search protocol that was defaulting to PDF searches and consulted on integrating Azure credentials within a bot context while maintaining a FAISS Vector Database.
- Semantic Chunking Goes TypeScript: A community contributor put forward a TypeScript implementation for Semantic Chunking, thereby extending the functionality to Node.js environments.
- DSPy Tutorial Goes Español: A basic tutorial for DSPy, targeting Spanish-speaking enthusiasts, has been shared through a YouTube tutorial, thus broadening access to the application.
LAION Discord
AI Skirmishes with Stress and Time: The community is discussing AIDE's achievements in Kaggle competitions, questioning if it's comparable to the human contestant experience that involves factors like stress and time constraints. No consensus was reached, but the debate highlights the growing capabilities of AI in competitive data science.
Back to Basics with Apple and PyTorch: The technical crowd is expressing frustration over Apple’s MPS with some recommending trying the PyTorch nightly branch for potential fixes. Additionally, the benefits of PyTorch on macOS, specifically the aot_eager backend, were shown with a case of the backend reducing image generation time significantly when leveraging Apple's CoreML.
A Glimpse into Audio AI: There's curiosity about capabilities such as DALL·E's image edit history and the desire to implement a similar feature within SDXL. Moreover, questions arose about voice-specific technologies for parsing podcast audio beyond conventional speaker diarization.
Revival of Access and Information: Discussions revealed concerns over Reddit's API access being cut and its effects on developers and the blind community, as well as the reopening of the subreddit /r/StableDiffusion and its implications for the community.
Computational Smarts in Transformers: The buzz is about Google's token compression method which aims to shrink model size and computational load, and a paper discussing a dynamic FLOPs allocation strategy in transformer models, employing a top-$k$ routing algorithm that balances computational resources and performance. This method is described in the paper "Mixture-of-Depths: Dynamically allocating compute in transformer-based language models".
Latent Space Discord
Dynamic Allocation Divides the Crowd: DeepMind's approach to dynamic compute in transformers, dubbed Mixture-of-Depths, garners mixed reactions; some praise its compute reductions while others doubt its novelty and practicality.
Claude Masters Tools: Anthropic's Claude exhibits impressive tool use, stirring discussions about the practical applications and scalability of such capabilities within AI systems.
Paper Club Prepares to Convene: The San Diego AI community announces a paper club session, encouraging participants to select and dive into AI-related articles, with a simple sign-up process available to those eager to join.
ReFT Redefines Fine-Tuning: Stanford introduces ReFT (Representation Finetuning), touting it as a more parameter-efficient fine-tuning method, which has the AI field weighing its pros and cons against existing techniques.
Keras vs. PyTorch: A Heated Benchmark Battle: François Chollet highlights a benchmark where Keras outperforms PyTorch, sparking debates over benchmarks' fairness and the importance of out-of-the-box speed versus optimized performance.
Enroll in AI Education: Latent Space University announces its first online course with a focus on coding custom ChatGPT solutions, inviting AI engineers to enroll and emphasizing the session's applicability for those looking to deepen their knowledge in AI product engineering.
OpenInterpreter Discord
OpenInterpreter Talks the Talk: An innovative wrapper for voice interactions with OpenInterpreter has been developed, though it falls short of 01's voice capabilities. The community is engaging in the set up and compatibility challenges, with Windows users struggling and CTRL + C not exiting the terminal as expected.
Compare and Contrast with OpenAI: A mysterious Compare endpoint has surfaced in the OpenAI API's playground, yet without formal documentation; it facilitates direct comparisons between models and parameters.
Python Predicaments and Ubuntu Upset: OpenInterpreter's 01OS is wrestling with Python 3.11+ incompatibility issues, suggesting a step back to Python 3.10 or lower for stability. Meanwhile, Ubuntu 21 and above users find no support for OpenInterpreter due to Wayland incompatibility, as x11 remains a necessity as noted in Issue #219.
Listening In, No Response: Users have reported troubling anomalies with 01's audio connection, where sound is recorded but not transferred for processing, indicating potential new client-side bugs.
Conda Conundrum: To handle troublesome TTS package installations, the recommendation is to create a Conda environment using Python 3.10 or lower, followed by a repository re-clone and a clean installation to bypass conflicts.
CUDA MODE Discord
BitMat Breakthrough in LLM: The BitMat implementation was brought into the spotlight, reflecting advances in the "Era of 1-bit LLMs" via an efficient method hosted on GitHub at astramind-ai/BitMat.
QuaRot Quashes Quantization Quibbles: A newly introduced quantization scheme called QuaRot promises effective end-to-end 4-bit quantization of Large Language Models, with the notable achievement of a quantized LLaMa2-70B model maintaining 99% of its zero-shot performance.
CUDA Kernel Tutorial Gets Thumbs Up: A revered Udacity course on "Intro to Parallel Programming" was resurfaced for its enduring relevance on parallel algorithms and performance tuning, applicable even a decade after its introduction.
HQQ-GPT-Fast Fusion: There was a fiery conversation in the #hqq channel regarding integrating and benchmarking HQQ with gpt-fast, focusing on leveraging Llama2-7B models and experimenting with 3/4-bit quantization strategies for optimizing LLMs.
Enhanced Visualization Aims for Clarity: Triton-viz discussions aimed at better illustrating data flows in visualizations with amendments like directional arrows, value display on interactive elements, and possible shifts to JavaScript frameworks such as Three.js for superior interactivity.
Datasette - LLM (@SimonW) Discord
- AI Product Development Guided by Wisdom: A deep dive into Hamel Husain's blog post has stimulated discussion on best practices in evaluating AI systems, focusing on its utility for building robust AI features and enterprises.
- The Datasette Initiative: Intentions are set to build evaluations for the Datasette SQL query assistant plugin, with emphasis placed on empowering users through prompt visibility and editability.
- Perfecting Prompt Management: Three strategies for managing AI prompts in large applications have been proposed: a localization pattern with separate prompt files, a middleware pattern with an API for prompt retrieval, and a microservice pattern for AI service management.
- Breaking Down Cohere LLM's JSON Goldmine: The richness of Cohere LLM's JSON responses was highlighted, evidenced by a detailed GitHub issue comment, revealing its potential in enhancing LLM user experiences.
- DSPy: A Discussion Divided: The guild saw a split in opinion on the DSPy framework; some members were skeptical of its approach to simplifying LLMs into "black boxes," while others showed enthusiasm for the unpredictability it introduces, likening it to a form of magical realism in AI.
DiscoResearch Discord
Judge A Book By Its Creativity: The new EQBench Creative Writing and Judgemark leaderboards have sparked interest with their unique assessments of LLMs' creative output and judgement capabilities. Notably, the Creative Writing leaderboard leverages 36 narrowly defined criteria for better model discrimination, and a 0-10 quality scale has been recommended for nuanced quality assessments.
COMET's New Scripts Land on GitHub: Two scripts for evaluating translations without references, comet_eval.ipynb & overall_scores.py, are now available in the llm_translation GitHub repository, signaling a step forward in transparency and standardized LLM performance measurement.
Cohere's Demo Outshines the Rest: A new demo by CohereForAI on Hugging Face's platform has showcased a significant leap in AI models' grounding capabilities, inviting discussions on its potential to shape future model developments.
Old School Translations Get Schooled: The Hugging Face model, command-r, seemingly makes traditional methods of LLM Middle High German translation training obsolete with its translation prowess and is suggested to revolutionize linguistic database integrations during inference.
Pondering the Future of Model Licensing: The potential open-sourcing of CohereForAI's model license is a hot topic, with comparative discussions involving GPT-4 and Nous Hermes 2 Mixtral underscoring the expected community growth and innovation that could mirror the Mistral model's impact.
Mozilla AI Discord
- Mozilla's Solo Soars into Site Building: Mozilla proudly presents Solo, a new no-code AI website builder designed for entrepreneurs, currently available in beta. To hone the tool, Mozilla seeks early product testers who can provide valuable feedback.
- Optimized GPU Usage for AI Models: Engineers recommend using
--gpu nvidiabefore-nglfor better performance in model operations; a 16GB 4090 Mobile GPU supports up to 10 layers at Q8. The exact number of layers that can be run efficiently may vary based on the model and GPU capacity.
- Tooling Up with Intel: Intel's oneAPI basekit is being utilized alongside
icxfor its necessity in working withsyclcode andonemkl, which is pertinent within the Intel ecosystem. This integration underlines Intel's significant role in the AI operations workflow.
- Kubernetes Clusters and AI Performance: Utilizing a mistral-7b model within a Kubernetes cluster (7 cores, 12GB RAM) resulted in a steady rate of 5 tokens per second; discussions are underway concerning whether RAM size, RAM speed, CPU, or GPU power play the biggest role in scaling this performance.
- Caution Against Possible Malware in AI Tools: Raised cybersecurity concerns about llamafile-0.6.2.exe being flagged as malicious have prompted user vigilance. VirusTotal reports indicate both versions 0.6.2 and 0.7 of llamafile have been flagged, with the latter having a lower risk score, as seen on references like VirusTotal.
Skunkworks AI Discord
- Dynamic Compute Allocation via MoD: The introduction of the Mixture-of-Depths (MoD) method for language models, as discussed in Skunkworks AI, enables dynamic compute allocation akin to MoE transformers but with a solitary expert, optimizing through a top-k routing mechanism. The potential for more efficient processing tailored to specific token positions is expounded in the research paper.
- Standalone Video Content: A link to a YouTube video was shared without additional context, which likely falls outside the scope of technical discussions.
- Unspecified Paper Reference: A member shared an arXiv link to a paper without accompanying commentary, making its relevance unclear. The document can be accessed here, but without context, its importance to ongoing conversations cannot be determined.
LLM Perf Enthusiasts AI Discord
- Anthropic's AI Blesses the Stage: A member highlighted a tweet from AnthropicAI indicating promising initial test results for their new AI model.
- High Performance Met with High Latency: Although the AI's capabilities were applauded, a concern was raised that latency issues become a bottleneck when dealing with serial AI operations.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Perplexity AI ▷ #general (1314 messages🔥🔥🔥):
- Perplexity Pro Inquiries: Users questioned the capabilities and accessibility of Perplexity Pro. They discussed how to enable channels, the inability to delete uploaded files, and difficulties purchasing the Pro plan due to redirects. Support suggested emailing or contacting mods directly for assistance.
- Cloud Services and AI: Conversations centered around cloud service providers and their role in the LLM race. There were debates over the market shares of AWS and Azure, and speculations about the potential collaboration between Perplexity and Anthropic were discussed.
- Apple's Vision and AI Strategy: Users expressed views on Apple 3b model, discussing its niche use case and the need for lighter, less expensive iterations. There was sentiment that Apple Glass could be more mainstream and that Google's VR initiatives were preferred.
- AI Model Usage and Fine-tuning: Queries were made about the context length of GPT-4 Turbo vs Claude Opus, with suggested parity at 32k tokens. Discussions on open-source models emphasized Stable Diffusion 3 and the possibility of government interference in open-sourcing decisions.
- User Interface and Accessibility Challenges on Arc: Users shared tips on using Arc browser more efficiently and reported bugs affecting the user interface, including issues with changing settings and accessing extensions.
- Pricing: no description found
- Introducing improvements to the fine-tuning API and expanding our custom models program: We’re adding new features to help developers have more control over fine-tuning and announcing new ways to build custom models with OpenAI.
- Yes No GIF - Yes No - Discover & Share GIFs: Click to view the GIF
- Pokemon Pokemon Go GIF - Pokemon Pokemon Go The Pokemon Company - Discover & Share GIFs: Click to view the GIF
- Is It GIF - Is It - Discover & Share GIFs: Click to view the GIF
- Sal Lurking Sal Vulcano GIF - Sal Lurking Sal Lurk Sal Vulcano - Discover & Share GIFs: Click to view the GIF
- Chat Completions: no description found
- OpenAI's STUNNING "GPT-based agents" for Businesses | Custom Models for Industries | AI Flywheels: Join Our Forum:https://www.natural20.com📩 My 5 Minute Daily AI Brief 📩https://natural20.beehiiv.com/subscribe🐥 Follow Me On Twitter (X) 🐥https://twitter....
- 1111Hz Conéctate con el universo - Recibe guía del universo - Atrae energías mágicas y curativas #2: 1111Hz Conéctate con el universo - Recibe guía del universo - Atrae energías mágicas y curativas #2Este canal se trata de curar su mente, alma, cuerpo, trast...
- 2024年から始めるPerplexityの使い方超入門: 「時間がない」「スキルがない」そんな人にために丸投げできるブログ代行サービス「Hands+」を始めました。 → https://bit.ly/blog-beginner検索エンジンからの集客を増やしたい企業様向けのオウンドメディア立ち上げサービスはこちら → https://bit.ly/owned-media6...
- 2024年から始めるPerplexityの使い方超入門: 「時間がない」「スキルがない」そんな人にために丸投げできるブログ代行サービス「Hands+」を始めました。 → https://bit.ly/blog-beginner検索エンジンからの集客を増やしたい企業様向けのオウンドメディア立ち上げサービスはこちら → https://bit.ly/owned-media6...
- Revolutionizing Search with Perplexity AI | Aravind Srinivas: Join host Craig Smith on episode #175 of Eye on AI as he engages in an enlightening conversation with Aravind Srinivas, co-founder and CEO of Perplexity AI.I...
- Inside Japan's Nuclear Meltdown (full documentary) | FRONTLINE: A devastating earthquake and tsunami struck Japan on March 11, 2011 triggering a crisis inside the Fukushima Daiichi nuclear complex. This 2012 documentary r...
- Antitrust (2001) ⭐ 6.1 | Action, Crime, Drama: 1h 48m | PG-13
Perplexity AI ▷ #sharing (11 messages🔥):
- Perplexity AI in Action: Members shared various Perplexity AI search links touching on subjects like beauty, the rise of dictatorships, and queries related to Cohere's Command R.
- Setting Threads to Shareable: One member posted a reminder to others to ensure their threads are set to shareable, providing a Discord instruction link.
- Seeking Understanding and Improvements: Users queried Perplexity AI for insights on different topics and also expressed looking for improvements on a challenging day using the introducing improvements link.
- From Philosophical to Personal: The discussions spanned from general knowledge queries like "Who was Jean?" to more personalized searches suggesting specific needs or incidents of the day.
Perplexity AI ▷ #pplx-api (18 messages🔥):
- Clarification on Search API Cost Concern: A discussion was sparked about why search APIs are viewed as expensive. Icelavaman clarified that the cost is not per search but per request, meaning that a single request to the model could encapsulate multiple searches within it.
- Paying for More API Credits: Mydpi asked about purchasing additional API credits using Google Pay for their pro subscription, and ok.alex confirmed that more credits can be bought via the API settings on the web, with Google Pay being a valid payment method.
- Pricing Inquiry for Sonar-Medium-Chat: Julianc_g inquired about the pricing of sonar-medium-chat, and icelavaman responded, confirming the price to be $0.60 per 1M tokens.
- Query About Subscription Bonus and Payment Methods: Mydpi received a response from ok.alex indicating that the $5 Pro Bonus and purchase of more credits can be managed via Google Play as one of the payment options on the web settings page.
- Rate Limits and Concurrent API Calls: Perplexity AI FAQ provided information about concurrent API calls and referred to the rate limits and pricing structure mentioned in the official pplx-API documentation for further details.
Stability.ai (Stable Diffusion) ▷ #general-chat (600 messages🔥🔥🔥):
- Speed and Realism in Image Generation: A user struggled with generating high-resolution (2k) realistic images of people using "realistic vision v6". The suggestion was to generate at lower resolution, upscale, use fewer steps, and enable "hiresfix" for better results. Discussions centered around the challenges of maintaining quality with upscaling and the distortions that sometimes result.
- Stable Diffusion 3 Anticipation and Access Concerns: Amidst the excitement for the upcoming release of Stable Diffusion 3 (SD3), some users felt the release was delayed, while others anticipated new invites signaling progress. Thoughts on SD3 ranged from its potential improvements to skepticism about its impending release and comparison with rival models like Ideogram and DALLE 3.
- AI Delving into Artistic Territories: Users discussed integrating AI with artistic creation, such as leveraging Daz AI to generate images. The dialogue included tactics for generating images in a particular style and optimizing model training and merging techniques for creating content like clothing 'Loras' using Stable Diffusion.
- Technical Discussions on Model Resource Requirements: The conversation touched on technical aspects like running models with different VRAM capacities, handling checkpoints across different user interfaces, and the prospects of the forthcoming SD3 running efficiently on consumer GPUs.
- Exploration and Optimization of Stable Diffusion Usage: Users exchanged tips and sought advice on using different versions of Stable Diffusion models and user interfaces. They discussed alternatives to generating better quality images, the process of finetuning images, and handling model checkpoints.
- Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction: We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolutio...
- Identifying Stable Diffusion XL 1.0 images from VAE artifacts: The new SDXL 1.0 text-to-image generation model was recently released that generates small artifacts in the image when the earlier 0.9 release didn't have them.
- Home v2: Transform your projects with our AI image generator. Generate high-quality, AI generated images with unparalleled speed and style to elevate your creative vision
- Observing with NASA: Control your OWN telescope using the MicroObservatory Robotic Telescope Network.
- Reddit - Dive into anything: no description found
- Never Gonna Give You Up - Rick Astley [Minions Ver.]: Stream Never Gonna Give You Up - Rick Astley [Minions Ver.] by Pelusita,la chica fideo on desktop and mobile. Play over 320 million tracks for free on SoundCloud.
- GitHub - lllyasviel/stable-diffusion-webui-forge: Contribute to lllyasviel/stable-diffusion-webui-forge development by creating an account on GitHub.
- NewRealityXL ❗ All-In-One Photographic - ✔2.1 Main | Stable Diffusion Checkpoint | Civitai: IMPORTANT: v2.x ---> Main Version | v3.x ---> Experimental Version I need your time to thoroughly test this new 3rd version to understand all...
OpenAI ▷ #annnouncements (1 messages):
- Boosting Developer Control with Fine-Tuning API: OpenAI announces enhancements to the fine-tuning API, introducing new dashboards, metrics, and integrations to provide developers with greater control, and expanding the custom models program with new options for building tailored AI solutions. Introducing Improvements to the Fine-Tuning API and YouTube video on various techniques detail how to enhance model performance and work with OpenAI experts to develop custom AI implementations.
Link mentioned: Introducing improvements to the fine-tuning API and expanding our custom models program: We’re adding new features to help developers have more control over fine-tuning and announcing new ways to build custom models with OpenAI.
OpenAI ▷ #ai-discussions (539 messages🔥🔥🔥):
- AI Discussions Span Broad Spectrum: Users engaged in spirited discussion about AI, ranging from machine cognition to AI's understanding and generation of ASCII art. Terminology and concepts like sentience, consciousness, and the nature of AI's cognitive processes, including whether LLMs "think" or merely process information, were debated.
- Reflections on Business Ideas and AI Limitations: One user proposed a business idea leveraging AI's capabilities to generate money, involving creating AI prompts compiled from generated tips. Another member pondered the possibility of using language models to perform tasks traditionally associated with humans, like playing chess or successful business planning.
- Speculation on AI's Potential in Various Fields: Users expressed anticipation for the integration of AI in fields such as 3D printing and design, suggesting ideas like a generative fill for 3D modeling that could revolutionize manufacturing.
- Concerns and Considerations About AI Product Releases: A discussion point highlighted frustration with the AI product release process, noting OpenAI's cautionary stance due to security concerns versus users' eagerness for unrestricted access to new AI capabilities.
- Queries About Implementing AI Features: Questions arose about implementing features like document analysis and using fine-tuning versus embeddings for internal company data augmentation, with users discussing the efficacy and suitability of different AI techniques for specific applications.
- China brain - Wikipedia: no description found
- Wow Really GIF - Wow Really - Discover & Share GIFs: Click to view the GIF
- ASCII Art Bananas - asciiart.eu: A large collection of ASCII art drawings of bananas and other related food and drink ASCII art pictures.
OpenAI ▷ #gpt-4-discussions (11 messages🔥):
- Zero Temperature Mayhem: A member reported experiencing random behavior in different threads even when the assistant's temperature is set to 0.0, questioning the consistency at this setting.
- In Pursuit of Prompt Perfection: A user inquired about a GPT Prompt Enhancer to improve their prompts, and another member directed them to a specific channel for recommendations.
- Dramatizing Chatbot Responses: A user sought to mimic the behavior of showing progress messages like "analyzing the pdf document" or "searching web" in their chatbot API. They received advice implying custom development is necessary for such functionality.
- Error in the Matrix: A participant noted that GPT-4 often returns "error analysing" in the middle of a calculation and questioned if there were any solutions.
- Subscription for GPT Usage Confirmed: One user asked if GPT models in an app are free to use; another clarified that a Plus plan or higher is necessary due to all models utilizing GPT-4.
OpenAI ▷ #prompt-engineering (15 messages🔥):
- Expanding Text Outputs: Members discuss strategies for making GPT-3 produce longer text, as stating "make the text longer" no longer seems effective. A suggestion includes copying the output, starting a new chat, and using the command "continue," although there are concerns about losing context and style.
- Addressing LLM Template Inconsistencies: One member asks for advice on how to ensure an LLM returns all sections of a modified document template, noting challenges with sections being omitted if the LLM perceives them as unchanged. The community has not yet offered a solution.
- Prompt Crafting to Limit GPT's Reliance on Training Data: A member seeks advice on crafting prompts that make a GPT focus on answers from provided documentation only and not default to its general training data. Suggestions include lowering the temperature setting and being explicit in the instructions that the model should confirm the answer exists within the given documentation before proceeding.
- Enforcing Documentation-Constrained Responses: To better ensure GPT answers are drawn exclusively from provided materials, one member suggests using aggressive and stern instructions, e.g., commanding the model to "THROW AN ERROR" if an answer is not found specifically within the documentation.
- Simulating Human-Like Interaction in GPT: A member experiments with GPT, discussing the nature of consciousness and trying to simulate human emotion through pseudocode explanations of human chemicals like serotonin. The conversation touches on the parallels between machine learning and human experiences such as dopamine responses.
OpenAI ▷ #api-discussions (15 messages🔥):
- Tackling Repetitive Text Expansion: Users discussed how the command to "make text longer" no longer yields lengthier text variations, instead repeating the same content. To address this, strategies such as initiating a new chat with the "continue" command were suggested, though concerns about style inconsistencies and context disregard were raised.
- Bridging the Gap in AI Document Drafting: One discussion point covered the issue of LLMs not recognizing and incorporating modifications in certain sections of a document. A user struggled with an LLM that didn’t acknowledge changes made to documents and sought solutions for this problem.
- Ensuring GPT Fulfills Its Designed Role: The focus was on instructing GPT to answer queries strictly based on user-provided documents, avoiding reliance on its pre-trained knowledge. Lowering the temperature setting and being assertive in the prompt were recommended to enforce this rule effectively.
- Simulating Human Emotions in AI: A user engaged GPT in a conversation about the nature of consciousness, asking it to mimic human chemical responses using pseudocode. This interaction aimed to explore a machine's simulation of human-like emotions.
- Recipe for Stern Instructions: It was suggested that a more effective way of instructing GPT is to be concise and firm, akin to the "Italian way," thus emphasizing clarity and strict adherence to specified sources.
LM Studio ▷ #💬-general (198 messages🔥🔥):
- LM Studio's Internet Independence: Members confirmed that LM Studio does not have the ability to 'search the web', similar to functionalities seen in tools like co-pilot or cloud-based language models.
- Exploring the Chatbot Arena Leaderboard: Some members discussed model performance and shared URLs such as the LMsys Chatbot Arena Leaderboard to highlight available models, noting that only certain models within the top ranks permit local deployment.
- Anything LMM Document Troubles: Users reported issues embedding documents in Anything LMM workspaces, which were addressed by downloading the correct version of LM Studio or ensuring proper dependencies, like the C Redistributable for Windows, were installed.
- Discussions on Multi-GPU Support and Performance: There were several exchanges about the effectiveness of multi-GPU setups in LM Studio with a consensus being that while multiple GPUs can be utilized, the resulting performance gains may not be proportional to the increase in hardware capability. Specific models were recommended based on available system specs.
- Absence of a Community Member: A brief conversation brought up a prolific open-source model creator known as @thebloke, expressing appreciation for his contributions and inquiring about his current activities.
- LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys: no description found
- Documentation | LM Studio: Technical Reference
- LM Studio Beta Releases: no description found
- Text Embeddings | LM Studio: Text Embeddings is in beta. Download LM Studio with support for it from here.
- The unofficial LMStudio FAQ!: Welcome to the unofficial LMStudio FAQ. Here you will find answers to the most commonly asked questions that we get on the LMStudio Discord. (This FAQ is community managed). LMStudio is a free closed...
LM Studio ▷ #🤖-models-discussion-chat (85 messages🔥🔥):
- Mixtral vs. Mistral Clarified: Discussion highlighted that Mixtral has combined 8x7b models to simulate a 56b parameter model, while Mistral is a standard 7b model.
- Power-Hungry Giants: Users discussed the requirements and challenges of running Mixtral 8x7b on high-end GPUs like the 3090, noting the extreme slowness, with token speeds of around 5 tok/s.
- Compatibility Issues With Command-R Plus: Members shared their experiences and struggles with making the 103b Command-R Plus model work locally, referencing an experimental branch on GitHub and a HuggingFace space, indicating that the model is not yet supported in LLamaCPP or LM Studio.
- Eurus-7b Unveiled: A new promising 7b model, Eurus-7b, designed for reasoning, was shared from HuggingFace, sporting a KTO finetuning based on multi-turn trajectory pairs from the UltraInteract dataset.
- Mamba Model Supported: An exchange mentioned the availability of a Mamba-based LLM and its support within llamacpp, with an accompanying HuggingFace repository link, although its compatibility with LM Studio was uncertain as of version 0.2.19 beta.
- pmysl/c4ai-command-r-plus-GGUF · Hugging Face: no description found
- C4AI Command R Plus - a Hugging Face Space by CohereForAI: no description found
- CohereForAI/c4ai-command-r-plus · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Direct Preference Optimization (DPO): A Simplified Approach to Fine-tuning Large Language Models: no description found
- openbmb/Eurus-7b-kto · Hugging Face: no description found
- Qwen/Qwen1.5-32B-Chat-GGUF at main: no description found
- christopherthompson81/quant_exploration · Datasets at Hugging Face: no description found
- ggml : update mul_mat_id to use the same tensor for all the experts by slaren · Pull Request #6387 · ggerganov/llama.cpp: Changes the storage of experts in memory from a tensor per expert, to a single 3D tensor with all the experts. This will allow us support models with a large number of experts such as qwen2moe. Exi...
- Add Command R Plus support by Carolinabanana · Pull Request #6491 · ggerganov/llama.cpp: Updated tensor mapping to add Command R Plus support for GGUF conversion.
LM Studio ▷ #announcements (1 messages):
- LM Studio Fills the Community Void: The LM Studio team and @159452079490990082 have launched a new "lmstudio-community" page on Hugging Face to provide the latest GGUF quants for the community after @330757983845875713's absence. @159452079490990082 will act as the dedicated LLM Archivist.
- Find GGUF quants Fast: Users are advised to search for
lmstudio-communitywithin LM Studio for a quick way to find and experiment with new models. - Twitter Buzz for LM Studio Community: LM Studio announced their new community initiative on Twitter, inviting followers to check out their Hugging Face page for GGUF quants. The post acknowledges the collaboration with @bartowski1182 as the LLM Archivist.
Link mentioned: Tweet from LM Studio (@LMStudioAI): If you've been around these parts for long enough, you might be missing @TheBlokeAI as much as we do 🥲. Us & @bartowski1182 decided to try to help fill the void. We're excited to share the n...
LM Studio ▷ #🧠-feedback (8 messages🔥):
- Search Reset Confusion Cleared: A member noted an issue that search results do not reset after removing a query and pressing enter. However, it was clarified that there are no initial search results and a curated list of models can be found on the homepage.
- Preset Creation Possibility Explained: In response to a query about the inability to create new presets, a member was guided on how to create a new preset in the LM Studio.
- Praises for LM Studio over Competitors: A user commended LM Studio for producing the best results as compared to other local LLM GUIs like oogabooga text generation UI and Faraday, even when using the same models and instructions.
- A Multitude of Feature Requests: One member requested several updates for LM Studio, including support for reading files, multi-modality features (text to images, text to voice, etc.), and enhancement tools similar to an existing tool named Devin to improve performance.
- Inquiry about Community Member's Absence: There was a query regarding the absence of a community member, TheBloke, asking for reasons and expressing concern about their wellbeing.
LM Studio ▷ #📝-prompts-discussion-chat (2 messages):
- Channel Resurrected: A member initiated the conversation with a brief message: "Unarchiving this channel."
- In Search of the Best Blogging Buddy: A member inquired about the best model for writing blogs within the context of the chatbot discussions.
LM Studio ▷ #🎛-hardware-discussion (21 messages🔥):
- Mixed-GPU Configs Spark Curiosity: A user inquired if combining Nvidia and Radeon cards allows using combined VRAM or running them in parallel, but it was clarified that due to CUDA/OpenCL/ROCm incompatibilities, it's not feasible. However, it's possible to run separate instances of LM Studio, each using a different card.
- Optimizing GPU Use in LM Studio: There's a query regarding why LM Studio is seemingly not utilizing an RTX 4070 for running larger models, leading to a discussion on ensuring GPU acceleration with VRAM offloading. Members suggested looking into GPU Offload settings and model layers configuration upon the user's return to this issue later.
- Mixing Old and New Nvidia Cards: Conversation about usage efficacy when mixing a newer RTX 3060 with an older GTX 1070 surfaced, with the consensus being that similar GPUs yield better performance. One member shares their personal setup, indicating noticeable performance improvement, but considering it a temporary solution until they can upgrade to matching cards.
- Potential of Intel's AMX with LM Studio: A question was raised regarding LM Studio's ability to utilize Intel Xeon's 4th generation Advanced Matrix Extensions (AMX), though no definitive answer was provided in the discussion.
LM Studio ▷ #🧪-beta-releases-chat (54 messages🔥):
- Exploring LM Studio Text Embeddings: LM Studio 0.2.19 Beta introduces text embeddings, allowing users to generate embeddings locally via the server's POST /v1/embeddings endpoint. Users were directed to read about text embeddings on LM Studio's documentation.
- Version Confusion Cleared Up: Some users were confused about their current version of LM Studio, and it was clarified that beta releases are based on the last build, with version numbers updating upon live release.
- Anticipation for LM Studio 2.19 Alpha: Members expressed excitement about the alpha release of LM Studio 2.19, which includes text embeddings support and can be downloaded from Beta Releases.
- Inquiries and Updates on Pythagora: Users discussed Pythagora, also known as GPT-Pilot, a Visual Studio Code plugin capable of building apps. The website Pythagora provides more information about its capabilities and integration with various LLMs.
- ROCM Version Behind but Praised: A user mentioned that the ROCM build tends to be behind the main release, but even in its current state, it received positive feedback for ease of installation and functionality despite some bugs.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- What are embeddings in machine learning?: Embeddings are vectors that represent real-world objects, like words, images, or videos, in a form that machine learning models can easily process.
- Text Embeddings | LM Studio: Text Embeddings is in beta. Download LM Studio with support for it from here.
- Pythagora: no description found
- nomic-ai/nomic-embed-text-v1.5-GGUF at main: no description found
LM Studio ▷ #autogen (10 messages🔥):
- Troubleshooting Autogen Short Responses: In LM Studio with Autogen Studio, a user experienced a problem where inference yielded only 1 or 2 tokens. This issue was acknowledged by another member as a recurrent problem.
- Anticipation for a New Multi-Agent System: A member mentioned developing their own multi-agent system as a solution to Autogen issues, with plans to release it by the end of the week.
- Crewai Suggested as Autogen Alternative: Crewai was recommended as an alternative to Autogen, but it was noted that it still requires some coding to utilize effectively.
- User Interface Expected for New System: The member developing a new solution promised a user interface (UI), implying easier use without the need to write code.
- Pre-Launch Secrecy Maintained: Despite building excitement, screenshots or further details of the new system were not shared as the domain registration for the project is still pending.
LM Studio ▷ #langchain (1 messages):
- Inquiries on Retaining Memory: A member expressed curiosity about successfully having a bot analyze a file and wondered how to make the bot retain memory throughout the same runtime. No solution or follow-up was provided within the given messages.
LM Studio ▷ #amd-rocm-tech-preview (27 messages🔥):
- AMD GPU Compatibility Queries: Users discussed compatibility issues with ROCm on AMD GPUs, especially the 6700XT (gfx 1031). One user reported an inability to load models despite trying various configurations, while another suggested it may be a driver issue that AMD needs to address.
- ROCm Performance Insights: A significant performance boost was reported when using ROCm over OpenCL; one user noted an increase from 12T/s to 33T/s in generation tasks, underscoring criticisms of AMD's OpenCL implementation.
- Linux vs. Windows Support for ROCm: It was mentioned that ROCm has functionality limitations on Windows that don't exist on Linux, where users can spoof chip versions to get certain GPUs to work. There were hints that if ROCm for Linux is released, more graphics cards could be supported by LM Studio.
- Anticipation for Open Source ROCm: A tweet from @amdradeon was shared about ROCm going open source, raising hopes for easier Linux build support on more AMD graphics cards. The introduction of open-source ROCm could potentially expand compatibility (Radeon's Tweet).
- User Explorations and Configurations: Different set-ups were discussed and compared, with mentions of disabling iGPUs to run VRAM at the correct amount and varied configurations involving dual GPUs and high-performance builds for gaming transitioning towards AI and machine learning workloads.
Link mentioned: Reddit - Dive into anything: no description found
LM Studio ▷ #crew-ai (22 messages🔥):
- Navigating CORS: A member queried about CORS (Cross-Origin Resource Sharing), but there was no follow-up discussion providing details or context.
- Successful Code Execution: Adjusting the "expected_output" in their task allowed a member to successfully run a shared code, indicating a resolution to their issue.
- Seeking Agent Activity Logs: A member expected to see agent activity logs within the LM Studio server logs but found no entries, despite confirming the verbose option is set to true.
- Logging Conundrum in LM Studio: Consensus is lacking on whether LM Studio should display logs when interacting with crewAI, with members expressing uncertainty and no definitive resolution offered.
- Error Encountered with crewAI: After experiencing a "json.decoder.JSONDecodeError" related to an unterminated string, a member sought advice on resolving the issue, with a suggestion to consider the error message contents for clues.
Nous Research AI ▷ #ctx-length-research (2 messages):
- LoRA Layer on Mistral 7B in the Works: A member suggested the potential of creating a LoRA (Low-Rank Adaptation) on top of models like Mistral 7B to significantly enhance its capabilities.
- Advanced Task for AI Involves Taxonomy: In response to the LoRA suggestion, it was revealed that there are plans to not just split sentences but also to categorize each one according to a specific taxonomy for the task at hand.
Nous Research AI ▷ #off-topic (10 messages🔥):
- Web Crawling State of the Art Inquiry: One member expressed being lost while attempting to identify the current state-of-the-art practices in web crawling technology.
- Distinguishing Archival from Hoarding: A discussion arose distinguishing archival groups from data hoarding communities, with a member clarifying that they are not synonymous.
- Suggestion to Utilize Common Crawl: In response to a query about web crawling practices, Common Crawl was recommended as a resource, with the caveat that it does not index Twitter content.
- Shoutout for New Multilingual LLM Preprint: A new preprint for the 15.5B continually pretrained, open-source multilingual language model Aurora-M was shared, complete with ArXiv link and boasting over 2 trillion training tokens.
- Tool for Structuring LLM Outputs: A YouTube video was shared showcasing a tool called Instructor, which helps users to extract structured data such as JSON from Large Language Models (LLMs) like GPT-3.5 and GPT-4.
- Tweet from Michael Nielsen (@michael_nielsen): "Imagineering" is a fantastic piece of terminology
- Instructor, Generating Structure from LLMs: Instructor makes it easy to reliably get structured data like JSON from Large Language Models (LLMs) like GPT-3.5, GPT-4, GPT-4-Vision, including open source...
- Tweet from ً (@__z__9): New preprint! The first multi-lingual red-teamed open-source continually pre-trained LLM - **Aurora-M** in accordance with the #WhiteHouse Executive Order on the Safe, Secure, and Trustworthy developm...
- Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order: Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to p...
Nous Research AI ▷ #interesting-links (10 messages🔥):
- C4AI Command R+: A new 104B LLM with RAG functionality was announced by CohereForAI on Twitter, offering open weights, tooling, and multilingual support in 10 languages. The release is available on Hugging Face and is an advancement from their previous 35B model.
- GPT-4 Fine-tuning Pricing Experimentation: OpenAI has started an experimental program to learn about the quality, safety, and usage of GPT-4 fine-tuning with specific rates provided for the program duration.
- Awaiting Updates on Promising AI Development: Discussion about a promising AI development mentioned in a Twitter post by @rohanpaul_ai, with observations that no new information has surfaced three months after the initial announcement.
- LLaMA-2-7B with Unprecedented Context Length: An achievement in AI training was shared with a post by @PY_Z001 claiming to have trained LLaMA-2-7B on eight A100 GPUs with a context length of up to 700K tokens.
- Uncertainty Surrounding fp8 Usability: A member expressed uncertainty regarding the usability of fp8 on Nvidia's 4090 GPUs, noting a lack of clear information on the subject.
- Tweet from Zhang Peiyuan (@PY_Z001): 🌟700K context with 8 GPUs🌟 How many tokens do you think one can put in a single context during training, with 8 A100, for a 7B transformer? 32K? 64K? 200K? No, my dear friend. I just managed to tra...
- GPT-4 Fine-Tuning: no description found
- Tweet from Cohere For AI (@CohereForAI): Announcing C4AI Command R+ open weights, a state-of-the-art 104B LLM with RAG, tooling and multilingual in 10 languages. This release builds on our 35B and is a part of our commitment to make AI bre...
Nous Research AI ▷ #general (182 messages🔥🔥):
- Augmentoolkit for Dataset Conversion: A new GitHub project called Augmentoolkit has been shared, offering a way to convert compute and books into instruct-tuning datasets without the need for OpenAI.
- Innovative Language Models on Showcase: Shared datasets like Severian/Internal-Knowledge-Map aim to revolutionize language model understanding through structured "System" guidelines and detailed narrative. Meanwhile, the ANIMA model, leveraging extensive scientific datasets, serves as a sophisticated scientific assistant focusing on biomimicry and more.
- Reasoning AI with Lambda Calculus: The neurallambda project explores integrating lambda calculus with transformers, aiming to enable AI with reasoning capabilities.
- Command R+ Launch: Command R+ has been introduced, a powerful large language model (LLM) specific for enterprise use cases, bringing advanced features like Retrieval Augmented Generation (RAG) and multilingual support. It is available first on Microsoft Azure and has its weights on Hugging Face under CohereForAI/c4ai-command-r-plus.
- Discussions on Model Pruning and Fine-Tuning: Members discussed pruning strategies for models like Jamba, referencing a paper on layer-pruning strategies and the impact on question-answering benchmarks with minimal performance degradation. The strategy aligns with parameter-efficient finetuning methods like quantization and Low Rank Adapters (QLoRA).
- Introducing Command R+: A Scalable LLM Built for Business: Command R+ is a state-of-the-art RAG-optimized model designed to tackle enterprise-grade workloads, and is available first on Microsoft Azure Today, we’re introducing Command R+, our most powerful, ...
- The Unreasonable Ineffectiveness of the Deeper Layers: We empirically study a simple layer-pruning strategy for popular families of open-weight pretrained LLMs, finding minimal degradation of performance on different question-answering benchmarks until af...
- CohereForAI/c4ai-command-r-plus · Hugging Face: no description found
- Cross-Architecture Transfer Learning for Linear-Cost Inference Transformers: Recently, multiple architectures has been proposed to improve the efficiency of the Transformer Language Models through changing the design of the self-attention block to have a linear-cost inference ...
- Watching GIF - Watching - Discover & Share GIFs: Click to view the GIF
- pmysl/c4ai-command-r-plus-GGUF · Hugging Face: no description found
- Mixture-of-Depths: Dynamically allocating compute in transformer-based language models: Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific ...
- Mixture-of-Depths: Dynamically allocating compute in transformer-based language models: no description found
- Hugging Face - Learn: no description found
- Practical Deep Learning for Coders - Practical Deep Learning: A free course designed for people with some coding experience, who want to learn how to apply deep learning and machine learning to practical problems.
- axolotl/docs/rlhf.qmd at main · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- HuggingFaceH4/ultrafeedback_binarized · Datasets at Hugging Face: no description found
- argilla/ultrafeedback-binarized-preferences · Datasets at Hugging Face: no description found
- GitHub - stanfordnlp/pyreft: ReFT: Representation Finetuning for Language Models: ReFT: Representation Finetuning for Language Models - stanfordnlp/pyreft
- GitHub - architsharma97/dpo-rlaif: Contribute to architsharma97/dpo-rlaif development by creating an account on GitHub.
- GitHub - neurallambda/neurallambda: Reasoning Computers. Lambda Calculus, Fully Differentiable. Also Neural Stacks, Queues, Arrays, Lists, Trees, and Latches.: Reasoning Computers. Lambda Calculus, Fully Differentiable. Also Neural Stacks, Queues, Arrays, Lists, Trees, and Latches. - neurallambda/neurallambda
- GitHub - e-p-armstrong/augmentoolkit: Convert Compute And Books Into Instruct-Tuning Datasets: Convert Compute And Books Into Instruct-Tuning Datasets - e-p-armstrong/augmentoolkit
- But what is a neural network? | Chapter 1, Deep learning: What are the neurons, why are there layers, and what is the math underlying it?Help fund future projects: https://www.patreon.com/3blue1brownWritten/interact...
- But what is a GPT? Visual intro to Transformers | Chapter 5, Deep Learning: An introduction to transformers and their prerequisitesEarly view of the next chapter for patrons: https://3b1b.co/early-attentionSpecial thanks to these sup...
- Vectors | Chapter 1, Essence of linear algebra: Beginning the linear algebra series with the basics.Help fund future projects: https://www.patreon.com/3blue1brownAn equally valuable form of support is to s...
Nous Research AI ▷ #ask-about-llms (48 messages🔥):
- Adding Function Calling Example to Repo: A pull request is set to be opened to add an example notebook demonstrating function calling to the Hermes-Function-calling repo in the examples folder.
- Function Calling Challenges with Vercel AI SDK RSC: Fullstack6209 spends a day troubleshooting why Hermes Pro and other LLMs don't work with Vercel AI SDK RSC like ChatGPT-3.5 does, exploring different repos and observing that returned JSON is mistakenly identified as text completion when it should stream function calls.
- Discussion on Function Calling and Coding Standards: The NousResearch Hermes-Function-Calling repository has been discussed with concerns about coding standards and correct documentation styles necessary for
convert_to_openai_toolto work, and the repository has been updated to match the Google Python Style Guide.
- Eurus-7B-KTO Models Gain Attention: The Eurus-7B-KTO model is highlighted for its solid performance, with a member linking to its page on HuggingFace and suggesting it might be worth incorporating into their SOLAR framework.
- Exploring Local Fine-Tuning Methods: Members discuss the best methods for local fine-tuning, mentioning tools like Axolotl with QLoRA as options, while others debate the performance consistency of fine-tuning larger models like llama-2 70B and Qwen 72B.
- openbmb/Eurus-7b-kto · Hugging Face: no description found
- This Repo needs some refactoring for the function calling to work properly · Issue #14 · NousResearch/Hermes-Function-Calling: Guys i think there is some issue with the way things are implemented currently in this repo biggest of which is regarding coding standard currently you guys use convert_to_openai_tool from langchai...
- GitHub - VikParuchuri/marker: Convert PDF to markdown quickly with high accuracy: Convert PDF to markdown quickly with high accuracy - VikParuchuri/marker
- updating docstring to match google python style guide · NousResearch/Hermes-Function-Calling@3171de7: no description found
- styleguide: Style guides for Google-originated open-source projects
- langchain/libs/core/langchain_core/utils/function_calling.py at master · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
Nous Research AI ▷ #bittensor-finetune-subnet (2 messages):
- Dependency Issues Detected: A member pointed out that there appears to be missing dependencies for a project or installation. Another member acknowledged this observation with a simple "i see".
Nous Research AI ▷ #rag-dataset (31 messages🔥):
- Pin-worthy Planning Summaries: There is a consensus on pinning summaries for newcomers. A document containing objectives and requirements has been created, updating has begun, but it is not yet widely scoped due to contributor availability.
- Adopting Adaptive RAG: The Adaptive-RAG approach, combining query analysis and iterative answer construction, has been implemented using LangGraph and Cohere's Command-R and Command R+ models. This implementation showcases the differences between using LangGraph and ReAct agents, alongside the benefits and trade-offs of using Command-R versus Command R+.
- RAG and UX Innovations: Members discussed practical applications and successes with RAG, particularly in source code retrieval and post-retrieval filtering. A proposed UI concept involves keeping a vector database of entities and artifacts to streamline the user interaction process.
- Exploring Retrieval Data Sources for RAG: Suggestions for sourcing retrieval data include starting with Wikipedia indices, integrating code for practical applications, considering synthetic textbooks, and adding domain-specific datasets like the Caselaw Access Project. Diversity in data sources is emphasized as ideal.
- Command R+ and Claude Opus Updates: Discussions around Command R+'s instructions format were shared, and it was noted that Claude Opus performs well on complex queries. The significance of proper prompting and citing sources was highlighted, referencing cohere's platform and documentation.
- Tweet from LangChain (@LangChainAI): Adaptive RAG w/ Cohere's new Command-R+ Adaptive-RAG (@SoyeongJeong97 et al) is a recent paper that combines (1) query analysis and (2) iterative answer construction to seamlessly handle queries ...
- Retrieval Augmented Generation (RAG) - Cohere Docs: no description found
- C4AI Acceptable Use Policy: no description found
- TeraflopAI/Caselaw_Access_Project · Datasets at Hugging Face: no description found
- RAG/Long Context Reasoning Dataset: no description found
Nous Research AI ▷ #world-sim (108 messages🔥🔥):
- WorldSim Updates and Command Sets: A link to the WorldSim Versions & Command Sets was provided, along with an update to the WorldSim Command Index incorporating recent additions.
- Synchronicity and Custom Emojis for WorldSim: Users discussed synchronicity events related to watching "Serial Experiments Lain" and the lack of WorldSim-specific custom emojis. There was a suggestion that the "Wired" symbol from Lain or an "eye" motif might be fitting for WorldSim.
- Potential New Channels for Philosophy and Research: A debate occurred about whether a new "philosophy" channel should be created or to use the existing "interesting-links" channel for sharing related content. Some users suggest integrating AI-driven mind-mapping with tools such as Obsidian for managing complex ideas.
- TRIVERS-80 and Vividness of Telepresence: One user worked on a prototype using Python to create a TRS-80 experience and discussed the significance of telepresence in mediums with varying vividness and interactivity, as well as the role Zipf's law may play at the edge of chaos in communication systems.
- Upcoming WorldSim Interface and Self-Steering Update: There was anticipation for an upcoming major update to WorldSim, mentioning improved features such as eliminating self-steering, where the model proceeds without user input. Additionally, mention of an open-source UX Library for interfacing with models like Claude was shared.
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- no title found: no description found
- Feel Me Think About It GIF - Feel Me Think About It Meme - Discover & Share GIFs: Click to view the GIF
- GitHub - jquesnelle/crt-terminal: Retro styled terminal shell: Retro styled terminal shell. Contribute to jquesnelle/crt-terminal development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #general (189 messages🔥🔥):
- Exploring Tensor Operations: An update of GaLore memory-efficient training with fused kernels is discussed, focusing on the benefits for GPU memory. Interest is shown in integrating GaLore with Unsloth AI.
- Understanding Model Packing and Parameters: A query about the
packingparameter revealed it allows for faster training by concatenating multiple tokenized sequences. However, it was advised against using packing for Gemma models due to compatibility issues. - Optimization Synergy for AI Algorithms: Users explored the synergy between Unsloth and GaLore, discussing the potential for both memory reduction and speed improvements, despite GaLore's default slower performance compared to Lora.
- Unsloth AI Upcoming Releases and Features: Unsloth AI's upcoming plans include a new open-source feature for "the GPU poor," an announcement on April 22, and an early May release of an "Automatic optimizer" that integrates with various models. The Unsloth Pro products are discussed, noting they have been available since November 2023, with a focus on distribution challenges.
- Dataset Format Flexibility for Synthetic Data: Users exchanged ideas on synthetic dataset generation for fine-tuning LLMs, concluding that format choice does not significantly impact performance and a variety of formats can be employed based on preference.
- Google Colaboratory: no description found
- Google Colaboratory: no description found
- LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning: The machine learning community has witnessed impressive advancements since the first appearance of large language models (LLMs), yet their huge memory consumption has become a major roadblock to large...
- @mlabonne on Hugging Face: "⚡ AutoQuant AutoQuant is the evolution of my previous AutoGGUF notebook…": no description found
- Google Colaboratory: no description found
- unsloth (Unsloth): no description found
- GitHub - myshell-ai/JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars: Reaching LLaMA2 Performance with 0.1M Dollars. Contribute to myshell-ai/JetMoE development by creating an account on GitHub.
- ASCII art elicits harmful responses from 5 major AI chatbots: LLMs are trained to block harmful responses. Old-school images can override those rules.
- GitHub - OpenNLPLab/LASP: Linear Attention Sequence Parallelism (LASP): Linear Attention Sequence Parallelism (LASP). Contribute to OpenNLPLab/LASP development by creating an account on GitHub.
- GaLore and fused kernel prototypes by jeromeku · Pull Request #95 · pytorch-labs/ao: Prototype Kernels and Utils Currently: GaLore Initial implementation of fused kernels for GaLore memory efficient training. TODO: triton Composable triton kernels for quantized training and ...
Unsloth AI (Daniel Han) ▷ #random (21 messages🔥):
- The Countdown for Kaggle Begins: The conversation kicks off with an excitement for the impending reset on Kaggle, eliciting brief enthusiastic responses.
- Daylight Savings Time Jogged Memory: Mention of Kaggle’s reset reminded another member of daylight savings time adjustments, leading to a clarification on the upcoming change: so 3AM becomes 2AM.
- Looking Forward to Extra Sleep: There is a bit of humorous banter relating to daylight savings time granting an additional hour, which was welcomed by a member anticipating to use it for a bit more sleep, saying, 1 hour extra sleep.
- Seeking AI News Sources: A member prompts a discussion on favorite sources for AI news, with suggestions ranging from a newsletter aptly named AI News to the Reddit AI community, with particular mention of the user localllama.
- Curiosity About Training Data Sources: The chat touched on the scope of datasets used for pretraining current AI models, pondering whether resources like libgen and scihub are included, with a participating member assuming that they likely are part of some models' pretraining materials.
Unsloth AI (Daniel Han) ▷ #help (137 messages🔥🔥):
- Unsloth Aids in Smooth Inference: Members reported successful use of Unsloth for inference, noting its speed and ease of use. For more advanced inference options, starsupernova provided a GitHub link explaining batch inference and shared a Python code snippet for generating multiple model outputs from a list of prompts.
- Quantization Queries in vLLM Unfold: One member seeking to reduce VRAM usage for their 13B model using
vLLMquantized from 4 bit to 16 bit asked if they need to quantize again, triggering a discussion on VRAM reduction methods. Starsupernova explained that vLLM already possesses quantization methods like AWQ and is considering adding a fast method for AWQ quants but currently does not support it.
- Finetuning Facilitation for Education: Users discussed the logistics of facilitating finetuning workshops with Unsloth, contemplating on how to give a hands-on experience within time constraints. They explored a variety of approaches, from preparing models in advance, akin to a cooking show format, to using LoRaX, an inference server to load finetuned models, in place of providing direct access to the weights.
- Model and Adapter Loading Logistics: Members exchanged techniques for loading finetuned models and adapters in their projects. One noted using left padding during inference and right padding for training, which received confirmation that this is the recommended approach when utilizing adapters.
- Addressing Spelling Mistakes Post-Model Conversion: A member encountered spelling mistakes when generating text after converting their 7B Mistral base model to a GGUF 5_K_M format, despite no issues in the 4-bit Unsloth form. Through community dialogue, it was clarified that the issue might be related to the model conversion process rather than inference parameters, and inference on CPU was confirmed to be possible on users' own devices.
- HirLab - Convertidor de Texto a Voz por Hircoir: HirLab, es una plataforma de conversión de texto a voz basada en inteligencia artificial. Convierte texto a voz de forma rápida y precisa.
- Google Colaboratory: no description found
- Text generation strategies: no description found
- GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models.: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. - oobabooga/text-generation-webui
- Batch inference produces nonsense results for unsloth/mistral-7b-instruct-v0.2-bnb-4bit · Issue #267 · unslothai/unsloth: Hi there, after loading the model with: from unsloth import FastLanguageModel import torch model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/mistral-7b-instruct-v0.2-bnb...
- GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp: Python bindings for llama.cpp. Contribute to abetlen/llama-cpp-python development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #suggestions (35 messages🔥):
- Efficiency Leap in Fine-tuning Methods: A new fine-tuning method, ReFT (Representation Finetuning), has been highlighted featuring an impressive 10x-50x more parameter efficiency compared to prior methods. The implementation and training pipeline are ready to validate, accessible via GitHub repository and an accompanying paper.
- Call for Strict Versioning in Unsloth: A member suggested implementing more rigid versioning for the Unsloth AI to avoid discrepancies in numerical results when merging from the nightly to the main branch. They experienced an issue where a merge adversely affected their Mistral finetune, underscoring the importance of being able to revert to previous versions.
- Random Seed Issues Under Scrutiny: In relation to the versioning discussion, another member pointed out that the issue with numerical results might also be related to an accelerate issue for random seeds, and agreed on the usefulness of having a nightly versus non-nightly branch.
- Versioning Pledge to Aid Reproducibility: In response to the concerns, there was an acknowledgment of the need for better versioning and a commitment to refrain from pushing updates to the main branch hastily. The aim is to help users track changes more easily and ensure consistent performance.
- Unsloth's Enhancement Affecting Model Reproducibility: A member discussed the impact of Unsloth's code optimizations on the reproducibility of their models, suggesting that changes should be released as individual versions to address this problem. This practice could help pinpoint changes that might unintentionally break models or affect reproducibility.
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): ReFT: Representation Finetuning for Language Models 10x-50x more parameter-efficient than prior state-of-the-art parameter-efficient fine-tuning methods repo: https://github.com/stanfordnlp/pyreft a...
- Tags · unslothai/unsloth: 2-5X faster 70% less memory QLoRA & LoRA finetuning - Tags · unslothai/unsloth
Eleuther ▷ #general (67 messages🔥🔥):
- Dataset Dilemmas: A member was searching for the Wikitext-2 and Wikitext-103 datasets and discussed the difficulties and nuances of accessing and using data in its original form. Direct links were shared to the raw datasets hosted on Stephen Merity's page and on Hugging Face.
- GateLoop Gains Ground: The GateLoop architecture's perplexity scores sparked some skepticism after a failed replication attempt by 'lucidrains.' Nonetheless, the author of GateLoop subsequently released some code, generating further discussion on its engagement and naming conventions.
- Parquet Conversion Concerns Expressed: Members voiced their frustrations about automatic conversions to parquet format when using the Hugging Face platform. The conversation focused on the importance of data reproducibility and the preference for raw data formats for archiving.
- Pondering on Attention Variants: The discussion touched on the struggle for new attention mechanisms like GateLoop to gain popularity due to the existing preferences for established methods like RWKV and Mamba. Members also expressed the challenge of getting attention for new contributions without extensive experimental evidence.
- Training Tips for Small Data: In a brief interjection, a member advised paying attention to weight decay and dropout when working with small datasets. This technical tip aimed to aid those working on finetuning models.
- Smerity.com: The WikiText Long Term Dependency Language Modeling Dataset (2016): no description found
- Tweet from Zengyi Qin (@qinzytech): Training LLMs can be much cheaper than previously thought. 0.1 million USD is sufficient for training LLaMA2-level LLMs🤯 While @OpenAI and @Meta use billions of dollars to train theirs, you can als...
- Tweet from Shirley Ho (@cosmo_shirley): Have you all heard about ChatGPT or foundation models but want to build more than a chatbot with AI? 🔥 We at @PolymathicAI are building foundation models for science 🔥 Join us (@albertobietti @...
- wikitext at main: no description found
- GitHub - lucidrains/gateloop-transformer: Implementation of GateLoop Transformer in Pytorch and Jax: Implementation of GateLoop Transformer in Pytorch and Jax - lucidrains/gateloop-transformer
- GitHub - tobiaskatsch/GatedLinearRNN: Contribute to tobiaskatsch/GatedLinearRNN development by creating an account on GitHub.
- segyges/wikitext-103 at main: no description found
Eleuther ▷ #research (207 messages🔥🔥):
- Exploring Modular LLMs and MoE Specialization: A discussion emerged around whether Mixture of Experts (MoE) architectures inherently support model interpretability by fostering expert-specific specializations within Large Language Models (LLMs). One paper on dissociating language and thought in LLMs (link) and various MoE routing techniques, like Expert Choice Routing, were mentioned as potentially guiding the MoE gating mechanism in a context-dependent way (link to OpenMoE, link to Expert Choice Routing).
- Debate on Hierarchical MoE Benefits: A debate ensued over the advantages of using hierarchical MoE structures compared to flat MoEs. The discussion included technical insights such as router weights having a product-key structure and the Compression-Selection functions with claims made that hierarchies could improve expert selection specificity, although concerns were raised about reducing the expressive power versus flat MoEs.
- Deep Dive into Model Training Details: Technical details were shared about specific architectures, like nested MoE versus flat MoE, and hyperparameter tuning, including learning rates. One comparison showcased two similar models with fixed seeds and configurations, leading to a discussion on the importance of hyperparameter optimization for new architectural methods.
- Potential Breakthrough in MoE Model Efficiency: One member's cryptic tease about their master's thesis hinted at a significant shift in the Floating Point Operations (FLOPs) curve for MoE models, suggesting substantial computational efficiency gains in LLM training. The member alluded to releasing a paper on the subject in approximately 1.5 months and offered to be contacted for collaboration.
- Skeptical Reactions to "Schedule-Free" Optimization: The announcement of a "Schedule-Free" Learning optimizer, which claims to simplify adaptation with neither schedules nor tuning and using only SGD or Adam (link to Tweet), prompted skepticism due to the advertised baselines and the actual mechanics behind the algorithm. The discussion highlighted the cautious stance of many towards optimistic claims made by new optimizer methods.
- Training LLMs over Neurally Compressed Text: In this paper, we explore the idea of training large language models (LLMs) over highly compressed text. While standard subword tokenizers compress text by a small factor, neural text compressors can ...
- Tweet from Aaron Defazio (@aaron_defazio): Schedule-Free Learning https://github.com/facebookresearch/schedule_free We have now open sourced the algorithm behind my series of mysterious plots. Each plot was either Schedule-free SGD or Adam, no...
- Large Product Key Memory for Pretrained Language Models: Product key memory (PKM) proposed by Lample et al. (2019) enables to improve prediction accuracy by increasing model capacity efficiently with insignificant computational overhead. However, their empi...
- Large Memory Layers with Product Keys: This paper introduces a structured memory which can be easily integrated into a neural network. The memory is very large by design and significantly increases the capacity of the architecture, by up t...
- Open Research Collaboration and Publishing - Authorea: no description found
Eleuther ▷ #scaling-laws (3 messages):
- PDF Alert: A member shared a research paper link without any context or comments on the content.
- The Power of Google: The same member followed up emphasizing the importance of using Google, presumably for further research or clarification, stating simply: Always google.
Eleuther ▷ #interpretability-general (6 messages):
- AtP* Paper Implementation Inquiry: A member asked if there is an open source implementation of the latest AtP* paper or a related notebook.
- AtP* GitHub Repo Shared: In response to the inquiry about the AtP paper implementation, another member shared the GitHub repository: GitHub - koayon/atp_star, which is a PyTorch and NNsight implementation of AtP (Kramar et al 2024, DeepMind).
- Request for GitHub Stars: A shared message from David Bau calls for support by starring the nnsight GitHub repo to satisfy NSF reviewer requirements. The repo is available at: GitHub - ndif-team/nnsight, and is used for interpreting and manipulating the internals of deep learning models.
- GitHub - koayon/atp_star: PyTorch and NNsight implementation of AtP* (Kramar et al 2024, DeepMind): PyTorch and NNsight implementation of AtP* (Kramar et al 2024, DeepMind) - koayon/atp_star
- GitHub - ndif-team/nnsight: The nnsight package enables interpreting and manipulating the internals of deep learned models.: The nnsight package enables interpreting and manipulating the internals of deep learned models. - ndif-team/nnsight
Eleuther ▷ #lm-thunderdome (39 messages🔥):
- Troubleshooting
top_pparameter: A member encountered an issue withtop_p=1not being recognized in a script configuration despite being properly formatted. They later discovered that eliminating spaces resolved the problem, confirming that a syntax error was to blame for the unrecognized arguments.
- Big question over BIG-bench Task: The BIG-bench (
bigbench) task appeared to not be recognized for a member, prompting a discussion about the correct naming and utilization of tasks. It was suggested to uselm_eval —tasks listto get a list of all the correct task names.
- Massive Speed Gains with Auto Batch Size: A member experienced a substantial decrease in evaluation time from 20 minutes to 3 minutes by setting
batch_size=auto, suggesting underutilization of their GPU can significantly affect performance.
- Model Arguments Compatibility Confusion: There was confusion about whether the model argument for
openai-completionswas compatible, with a member receiving an error message. There seems to be a possible bug or misunderstanding asopenai-chat-completionsis found but notopenai-completions.
- Errors with
--predict_onlyFlag and Reinstallation Queries: A member faced issues running--predict_onlylocally on a Mac, receiving an unrecognized argument error. It was recommended to try a fresh install, potentially on Google Colab, to replicate and troubleshoot the issue.
- Google Colaboratory: no description found
- Google Colaboratory: no description found
Eleuther ▷ #gpt-neox-dev (1 messages):
- Cloud Support for Gemini: A message mentions that AWS released something called Gemini last year, implying cloud support for this service. Azure is also said to provide support for it.
Modular (Mojo 🔥) ▷ #general (18 messages🔥):
- Exploring Mojo's Workforce: A query was made about the number of individuals working at Modular.
- Debugging on Alternate Editors: A discussion arose regarding the availability of a debugger and Language Server Protocol (LSP) for editors like neovim, with individuals asking for solutions to problems encountered.
- Guidance Sought for Complications: Members shared solutions to common issues with links to previous discussions, such as a helpful answer found here.
- Request for Mojo's Roadmap Clarity: A member expressed their need for a detailed roadmap for Mojo in comparison with other frameworks like Taichi or Triton, and a response was provided directing to Mojo's roadmap document.
- Live Education on Modular Developments: A reminder and link were provided for an active Modular Community livestream discussing new features in MAX 24.2, available to view on YouTube.
- Mojo🔥 roadmap & sharp edges | Modular Docs: A summary of our Mojo plans, including upcoming features and things we need to fix.
- Modular Community Livestream - New in MAX 24.2: MAX 24.2 is now available! Join us on our upcoming livestream as we discuss everything new in MAX - open sourcing Mojo standard library, MAX Engine support f...
- Can I use Pandas in Mojo? · modularml/mojo · Discussion #342: Can I use Pandas in Mojo? I tried this: from PythonInterface import Python let pd = Python.import_module("pandas") d = Python.dict() d['col1']=[1, 2] d['col2']=[3, 4] df = pd...
- GitHub - rust-lang/rustlings: :crab: Small exercises to get you used to reading and writing Rust code!: :crab: Small exercises to get you used to reading and writing Rust code! - rust-lang/rustlings
- exercises: Learn the ⚡Zig programming language by fixing tiny broken programs.
- GitHub - dbusteed/mojolings: Learn to read and write Mojo code by fixing small programs: Learn to read and write Mojo code by fixing small programs - dbusteed/mojolings
Modular (Mojo 🔥) ▷ #💬︱twitter (5 messages):
- Modular Shares Updates: The Modular account posted a link to its latest update on Twitter View Tweet.
- Announcing New Features: A new tweet announces the arrival of new features for the Modular community with a link for more details Check Out the Features.
- Teasing A New Integration: Modular teased a new integration on Twitter, hinting at an upcoming feature or collaboration See the Teaser.
- Countdown to Launch: A follow-up tweet from Modular seems to start a countdown, possibly leading up to a product launch or event Follow the Countdown.
- Hinting at Collaborations: The latest tweet from Modular hints at collaborations, indicating a partnership or joint venture in the works Explore the Possibilities.
Modular (Mojo 🔥) ▷ #🔥mojo (236 messages🔥🔥):
- "No
isinstance, Yes toVariantDynamicity": Members discussed the limitations of theisinstancefunction and supported the dynamic characteristics of theVarianttype. An example ofVariantusage from the docs was shared, including its ability to store internal data and checks for types usingisaandget/takemethods.
- Favorite Features Wishlist: There is interest in having pattern matching capabilities similar to those in Swift and Rust, with ‘match case’ syntax ideas being proposed and debated. Additionally, 'conditional conformance' syntax was also a hot topic, with discussions surrounding the potential syntax and implementation challenges.
- Mojo on Mobile: Mojo was successfully run on Android via Termux on a Snapdragon processor, with members expressing excitement at the possibility.
- Merging Mojo with Merch: There's curiosity about the availability of Modular-themed merchandise, with suggestions like Mojo plush toys and phone cases, acknowledging them as potential future items.
- Mojo Style and Idioms: The community is considering appropriate terms to describe idiomatic Mojo code. A style guide and the intention for Mojo to run Python interchangeably were mentioned, underscoring the flexibility of the language.
- variant | Modular Docs: Defines a Variant type.
- mojo/stdlib/docs/style-guide.md at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojo/stdlib/src/utils/variant.mojo at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #community-projects (5 messages):
- Basalt Emerges from Voodoo's Ashes: Voodoo has been deprecated, paving the way for Basalt, a new Machine Learning framework built in Pure Mojo. The first official release is v.0.1.0 and you can read more about it and contribute on GitHub and find an introductory article on Medium.
- A Community Effort Worth More Mojo: Member encouragement for community involvement follows an update which highlighted unfair credit of contributions to Basalt. More helping hands and brains from the community is desired for upcoming design work.
- Deep Learning vs Machine Learning: A suggestion to categorize Basalt as "Deep Learning" rather than "Machine Learning" to align more closely with frameworks like PyTorch, along with interest in seeing Basalt's performance comparison to Burn, a fast deep learning framework.
- Mojo's Prolific Promise: A brief comment applauds the innovative projects being developed using Mojo, recognizing the community's creativity and technical proficiency.
- Specials Package Delivers Precision: An update on the Specials package introduces elementary mathematical functions with hardware acceleration and a favor for numerical accuracy over FLOPS, inviting viewers to observe benchmark comparisons against NumPy and the Mojo standard library on GitHub.
- Burn: no description found
- GitHub - leandrolcampos/specials: Special functions with hardware acceleration: Special functions with hardware acceleration. Contribute to leandrolcampos/specials development by creating an account on GitHub.
- GitHub - basalt-org/basalt: A Machine Learning framework from scratch in Pure Mojo 🔥: A Machine Learning framework from scratch in Pure Mojo 🔥 - basalt-org/basalt
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (1 messages):
- Bucket Size Estimate Clarification: A member explained that the estimated number of values determines the d number of buckets, which will be rounded up. Although this might seem concerning, it is considered trivial as each bucket only contains UInt32 values, taking up merely 4 bytes; the dict can be parameterized to adjust the type width, with the default being 4 bytes to handle up to 2^32 - 1 (approximately 4 billion) values.
Modular (Mojo 🔥) ▷ #nightly (10 messages🔥):
- Discussion on
__refitem__and iterators: The conversation touched on a potential compromise for handling references in iterators by keeping.value()and adding__refitem__. This is amidst discussions on how iterators should function, possibly awaiting parametric raises forStopIteration.
- Python Interop Pioneered in Mojo: Work on Python interop with Mojo has shown promise with the implementation of PyMethodDef, PyCFunction_New, PyModule_NewObject, and a modified init for PythonObject. The repository at rd4com/mojo_branch showcases this progress, emphasizing the need for careful planning in these integrations.
- Python Reference Counting Holds Up: Recent contributions to Mojo's Python interop capabilities have not exhibited any reference counting issues, indicating stability in the current implementations.
- Tackling Reversing Ranges Bug: A member uncovered a bug where
len(range(-10))equals-10, and while they worked on reversible ranges and related iterators, they sought input on whether to introduce fixes prior to a broader update in the handling of ranges.
- Inviting New Contributors to Standard Library: Newcomers, like a fresh Computer Science student eager to contribute to the Standard Library of Mojo, were welcomed and guided towards starting points like good first issues and contribution guides on GitHub.
- GitHub - rd4com/mojo_branch at nightly: The Mojo Programming Language. Contribute to rd4com/mojo_branch development by creating an account on GitHub.
- Mojo🔥 changelog | Modular Docs: A history of significant Mojo changes.
- mojo/CONTRIBUTING.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #general (23 messages🔥):
- Linear Attention Advances: The Linear Attention Sequence Parallelism (LASP) library has been noted for not requiring the flash attn repo and improving AMD support, as well as its capability to split cache across devices for longer context processing.
- Non-Quantized Model Surprising Performance: A member was amused that, on Hugging Face, non-quantized models are running longer than quantized models despite expectations that quantized models, like the bitsandbytes Hugging Face implementation, would be less performant.
- Interest in C4AI Command R+: The conversation centered around a 104B parameter model, C4AI Command R+, which integrates various advanced capabilities, including Retrieval Augmented Generation (RAG). The model's cost and large size were highlighted, alongside difficulties in accessing such robust models due to their high computational requirements.
- GPT-3 Pricing Discourse: A member shared dismay over the pricing for GPT-3, stating it becomes cost-effective to purchase a new GPU rather than rent, with break-even occurring around 125 days of continuous GPU rental.
- Colab's New GPU and Pricing Update: A user shared a tweet from @danielhanchen announcing Colab's introduction of L4 GPUs at $0.482/hr and price reduction for A100, highlighting the updated GPU pricing in a shared spreadsheet.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- CohereForAI/c4ai-command-r-plus · Hugging Face: no description found
- Tweet from Daniel Han (@danielhanchen): Colab has L4 GPUs?! And it's $0.482/hr! @HCSolakoglu told me on Discord and I was ecstatic! Native fp8, easy Colab interface + 24GB VRAM! Also price drops for A100 to $1.177, T4s $0.183. @thechri...
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- GitHub - OpenNLPLab/LASP: Linear Attention Sequence Parallelism (LASP): Linear Attention Sequence Parallelism (LASP). Contribute to OpenNLPLab/LASP development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (13 messages🔥):
- New LoReFT Flexes Its Finesse: Discussion of a new technique called LoReFT that might outperform existing methods like LoRA, though it's currently challenging to merge into the base model. A link to the related Twitter post was shared.
- GitHub Peek into LoReFT: A mention of janky dataset manipulation that complicates the integration of LoReFT with the existing systems. The relevant GitHub code snippet was highlighted to showcase the concern.
- Streamlining DoRA with Quantization: The possibility of removing unnecessary code due to the introduction of quantized DoRA support in `peft=0.10.0` was discussed. A link to the PEFT release notes and the specific code configuration were provided.
- Request for a Clean-Up PR: A member was asked to submit a pull request to clean up code related to quantized DoRA now that it's supported in the latest PEFT release.
- Introducing Schedule-free Learning: Discussing the release of schedule-free algorithms from Facebook Research that replaces optimizer momentum with averaging and interpolation, negating the need for traditional learning rate schedules. Instructions from the GitHub repository were emphasized for correct usage.
- Tweet from Aaron Defazio (@aaron_defazio): Schedule-Free Learning https://github.com/facebookresearch/schedule_free We have now open sourced the algorithm behind my series of mysterious plots. Each plot was either Schedule-free SGD or Adam, no...
- pyreft/pyreft/dataset.py at main · stanfordnlp/pyreft: ReFT: Representation Finetuning for Language Models - stanfordnlp/pyreft
- pyreft/examples/loreft at main · stanfordnlp/pyreft: ReFT: Representation Finetuning for Language Models - stanfordnlp/pyreft
- axolotl/src/axolotl/utils/config/models/input/v0_4_1/__init__.py at main · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #general-help (12 messages🔥):
- Seeking UI for Model Deployment and Expert Feedback: A member inquired about a good user interface that allows for model deployment with a feature to get feedback from experts.
- Exploring Non-instructional Data Fine-tuning: A member discussed fine-tuning models like Mistral-7B using non-instructional text data such as podcast transcripts to potentially generate text in the style of that data.
- Fine-tuning Strategy for Domain Specificity: In a conversation regarding fine-tuning for domain specificity, it was suggested to start with
completion, then move on to instructions, and consider Continual Pre Training (CPT) if there's still room for improvement after Supervised Fine Tuning (SFT) and Diverse Prompt Optimization (DPO). - Quality Over Quantity in Fine-tuning Instructions: One member shared their experience that a smaller number of high-quality, diverse and expert-tagged instruction samples can yield better performance than a larger quantity of repetitive, short, and noisy instruction data.
- Error During Generations with Fine-tuned Model: A member encountered an error after a few successful generations while generating with a Mistral 7B base model fine-tuned with fp16, seeking advice to solve frequent
Empty _queue.Emptyerrors in a Gradio environment.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
OpenAccess AI Collective (axolotl) ▷ #datasets (6 messages):
- Choosing a Dataset for Mistral 7B Training: A member inquired about a suitable dataset for training a Mistral 7B model. The suggested dataset for a general use-case is the OpenOrca dataset.
- First-time Model Training Query: Another member expressed their intention to train or fine-tune their first model, specifically a Mistral 7B model.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
OpenAccess AI Collective (axolotl) ▷ #announcements (1 messages):
- New Discord Bot Integration is Live: The OpenAccess AI Collective now features a Discord bot integration designed to answer questions directly. Members are encouraged to test it out and provide feedback in the designated channel. Test the bot here.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (140 messages🔥🔥):
- Docker Woes with Axolotl Multi-Node: A user experienced issues using Docker for multi-node fine-tuning with Axolotl. Despite advice provided by Phorm, the user reported that it was not working as expected.
- Checkpoint Load Queries: When asked if the base model path needs to change when loading from a checkpoint, Phorm pointed to Axolotl's behavior of not requiring a base model path change as the checkpoint file contains necessary model architecture and weight details.
- S2 Attention Mechanism Explained: In response to a query about S2 attention, Phorm described it as a type of attention mechanism that uses structured state space attention for more effective computation and better long-range dependency handling.
- Concerns with Model Memory Consumption: Users discussed Galorian memory overconsumption, and Phorm suggested strategies to minimize memory usage, such as reducing batch size or implementing gradient accumulation.
- Axolotl Command Request for Ubuntu Setup: One user requested an all-inclusive command to set up Axolotl in Ubuntu, to which Phorm provided a detailed command that includes the installation of Python, Axolotl, and other dependencies.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Redirecting...: no description found
- Patrickpain Patricksomuchpain GIF - Patrickpain Patricksomuchpain Patrickfleas - Discover & Share GIFs: Click to view the GIF
- OOM On Galore Axolotl · Issue #1448 · OpenAccess-AI-Collective/axolotl: Please check that this issue hasn't been reported before. I searched previous Bug Reports didn't find any similar reports. Expected Behavior Should start training without OOM, like Llama facto...
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- no title found: no description found
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (21 messages🔥):
- Phorm Chatbot Engaged: The channel saw the introduction of Phorm, a chatbot that queries data from the OpenAccess-AI-Collective/axolotl for project discussions.
- Chat Template Formatter 101: A member inquired about using a chat template formatter, for which Phorm provided a detailed walkthrough, suggesting the use of Hugging Face's Transformers library and
apply_chat_templatemethod. - RoPE Tuning Talk: The term
"rope_theta": 10000.0sparked interest regarding its application in Rotary Positional Embedding (RoPE) within Transformers. A member queried about adjusting it for extending context length, revealing that while Phorm can fetch answers, this topic requires further clarity. - Rope Scaling Query: A follow-up discussion on rope scaling and whether to use linear or dynamic adjustment took place; however, it was revealed that rope scaling is deprecated, and no longer a relevant parameter.
- Inappropriate Content Alert: The chat history includes a message that promotes inappropriate content, which was obviously out of place in the technical discussion.
Please note that the last bullet point is a report of inappropriate content present in the chat, which should be moderated according to the rules of the platform.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
LlamaIndex ▷ #announcements (1 messages):
jerryjliu0: webinar is in 15 mins! ^^
LlamaIndex ▷ #blog (4 messages):
- New Adaptive RAG Technique Introduced: The LlamaIndex shared a tweet highlighting the Adaptive RAG paper by @SoyeongJeong97 that addresses the different needs of simple and complex multi-step questions, promising better performance in respective scenarios.
- MistralAI Releases RAG Cookbook Series: @MistralAI announced a series of cookbooks on building simple-to-advanced RAG and agents detailed on LlamaIndex. Experts can explore RAG abstractions including routing and query decomposition through this resource shared in a tweet.
- Launch of Claude Function Calling Agent: LlamaIndex unveiled the Claude Function Calling Agent, taking advantage of the new tool use support in the messages API from @AnthropicAI. The announcement tweet suggests expanded agentic use cases using Haiku/Sonnet/Opus.
- AutoRAG to Optimize RAG Pipelines: Marker-Inc-Korea's AutoRAG has been introduced as a system to automatically optimize RAG pipelines for specific use cases using evaluation datasets, shared in a tweet. It aims to fine-tune hyperparameters effectively for optimal performance.
LlamaIndex ▷ #general (160 messages🔥🔥):
- SQL Query Engine Async Troubles: A user described issues with an elastic search vector database and subquestion query engine when the use_async flag is set to true, leading to a connection timeout. They sought advice on how to resolve the connection timeout issues they encountered in asynchronous mode, considering it worked fine synchronously.
- Azure OpenAI MultiModal BadRequestError: While following an example notebook on Azure OpenAI GPT4V MultiModal LLM, a user ran into a BadRequestError related to 'Invalid content type. image_url' and sought help. After trying the advised changes, including tweaking base64 image encoding, the error persisted, leading to discussions about whether the problem was from an updated Azure API or incorrect image document args.
- Prompt Engineering Tactics for AWS Context: A user asked for advice on how to word a prompt template to always assume user queries are related to AWS, with suggestions including prefixing the user input with context such as "assume the following input is related to AWS" to guide the LLM.
- Complexity in Handling Pydantic JSON Structures: There was a discussion on how frameworks like LlamaIndex and LangChain use Pydantic to ensure JSON structures and what happens when custom models can't comply with the specified formats. It was clarified that by default, the model gets one chance to return the correct format, but users can modify the logic by subclassing components.
- RouterQueryEngine Filter Application and Response Evaluation: Queries arose on how to pass filters at runtime in a RouterQueryEngine and whether it was efficient to reconstruct the engine for each prompt. A solution was offered, indicating no issues with re-constructing the query engine per prompt, and there was also mention of a strategy to evaluate multiple responses from different agents for quality of results.
- Llama Hub: no description found
- no title found: no description found
- Introducing Llama Datasets 🦙📝 — LlamaIndex, Data Framework for LLM Applications: LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models (LLMs).
- Node Postprocessor Modules - LlamaIndex: no description found
- llama_index/llama-index-legacy/llama_index/legacy/readers/file/image_reader.py at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Contributing a LlamaDataset To LlamaHub - LlamaIndex: no description found
- Where do I define top_k documents to be returned by similarity search over vectorstore? · Issue #905 · run-llama/llama_index: When calling query function, how do I specify how many ks do I want the retriever to pass to a LLM? Or do I need to specify it before calling query function? llm_predictor = LLMPredictor(llm=ChatOp...
- GitHub - run-llama/llama-hub: A library of data loaders for LLMs made by the community -- to be used with LlamaIndex and/or LangChain: A library of data loaders for LLMs made by the community -- to be used with LlamaIndex and/or LangChain - run-llama/llama-hub
- Query Pipeline for Advanced Text-to-SQL - LlamaIndex: no description found
- Multi-Modal LLM using Azure OpenAI GPT-4V model for image reasoning - LlamaIndex: no description found
- Dataset generation - LlamaIndex: no description found
- Simple directory reader - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (4 messages):
- RAG Goes Visual: A member introduced the idea of a retrieval-augmented generation (RAG) model for images, envisioning a system that can identify the most used colors, count objects like mountains, or creatively modify images while maintaining certain features. This could potentially be used for tasks like bypassing CAPTCHAs or ensuring continuity in visual storytelling, such as comic strips.
- LlamaIndex Explores Multi-Document Agents: A link to a blog post titled "Unlocking the Power of Multi-Document Agents with LlamaIndex" was shared, indicating a discussion about advancing multi-document agents.
- Praise for Multi-Document Innovation: A brief commendation followed the blog post link, signaling a positive reception to the advancements in multi-document agents featured in the article.
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- Multimodal Update for Claude 3 Models: Claude 3 models' modality has been switched to
multimodalto support image input. Developers need to update their code in response to this change, and can find further details on the announcement channel.
- Prompt Template Improvement: An update to the prompt template for DBRX has been made to reduce repetitiveness, following a user report. For more information, visit the provided Discord link.
- Introducing DBRX Nitro: Databricks' DBRX Nitro, proficient in code generation and general knowledge, now allows a throughput of 120 tokens/sec. Further insights and benchmarks can be explored here.
- Launch of Command R+ Model: A new Command R+ model by Cohere, boasting 104B parameters, outperforms competitors on various benchmarks and includes multilingual support for broader accessibility. Detailed benchmarks and the model’s capabilities can be seen here.
- Enhanced UI and New Parameters: OpenRouter’s UI now features a top apps leaderboard and a dedicated Credits page;
seedandlogit_biasparameters have been added to several models. Users can check the models supporting these parameters by clicking on "Mancer" on provider pages.
- DBRX 132B Instruct by databricks | OpenRouter: DBRX is a new open source large language model developed by Databricks. At 132B, it outperforms existing open source LLMs like Llama 2 70B and Mixtral-8x7B on standard industry benchmarks for language...
- Command R+ by cohere | OpenRouter: Command R+ is a new, 104B-parameter LLM from Cohere. It's useful for roleplay, general consumer usecases, and Retrieval Augmented Generation (RAG). It offers multilingual support for ten key lan...
OpenRouter (Alex Atallah) ▷ #general (155 messages🔥🔥):
- Claude's Self-Moderation in Question: Users are discussing the increase in decline rates when using Claude with OpenRouter API, even the self-moderated version, compared to the official Anthropic API. Concerns were raised about potential additional "safety" prompts injected by OpenRouter in the past.
- Midnight Rose Takes a Nap: Reports came in that model Midnight Rose was unresponsive; efforts to restart the cluster were successful, and discussions about moving to a more stable provider or stack are underway. Additional primary providers were added for increased stability, and users are encouraged to report any further issues.
- Scratching Heads Over Schema: There is an issue with getting Mixtral-8x7B-Instruct to follow a JSON schema; while this worked with the nitro version, it didn't work with the regular version until the OpenRouter team intervened and diagnosed a non-provider related issue, promising a fix.
- Command R+ Fuels Programming Excitement: Users expressed excitement for trying out Command R+ on OpenRouter, noting its good performance with coding tasks and potential as an AI assistant.
- OpenRouter Gets a Cohere Model Mention: Amidst discussions of the Cohere model, users are curious about its potential integration with OpenRouter, discussing the model's capabilities, and comparing the business and API design aspects of Cohere versus OpenAI.
- no title found: no description found
- C4AI Acceptable Use Policy: no description found
- Screenshot: Captured with Lightshot
- JSON Mode: no description found
HuggingFace ▷ #general (74 messages🔥🔥):
- Seeking AI Communities for Face Embeddings: A member is looking for communities to discuss topics related to face embeddings, their datasets, and the model training process. No specific communities or resources were linked.
- How to Deploy and Query Deployed Models: There were inquiries about calling 'predict' for already deployed models, with a member suggesting the use of a virtual environment. Another conversation discussed payment options and platforms for deploying and querying models like YOLOv8 on Android, with a focus on latency considerations.
- Exploring AI Hardware Options: Various messages discussed AI hardware, including NPU and VPU accelerators like the Intel Movidius Neural Compute Stick. Members shared details and links to products from various years, highlighting affordability and tech progress.
- Interest in Open Source 3D Environment Project: A member invited others to join an open-source project requiring knowledge of C++ and understanding of 3D environments. Interested individuals were requested to reach out via direct message.
- LLMs Don't Do Everything: Multiple members pointed out the misconception about the capabilities of large language models (LLMs), stating that they are not fit for tasks like apartment hunting, emphasizing that LLMs are not 'magical AGI' and shouldn't be plugged for every possible use case.
- Total noob’s intro to Hugging Face Transformers: no description found
- GitHub - intel/intel-npu-acceleration-library: Intel® NPU Acceleration Library: Intel® NPU Acceleration Library. Contribute to intel/intel-npu-acceleration-library development by creating an account on GitHub.
- NVIDIA's Low Power AI Dev Platform on Arm: If you want to develop on a platform for the AI future, it is time to get on the NVIDIA Jetson development platforms instead of a Raspberry Pi. In this video...
HuggingFace ▷ #today-im-learning (3 messages):
- Prompt Engineering for Speed: Discussion about a latency versus reasoning trade-off when designing production prompts for chatbots. A hack was mentioned to proactively reason through most likely scenarios while the user is typing to combat slow responses. For more details, see the Twitter post.
- Discovering Groq Cloud: A member shared a YouTube video titled Groking Groq III: Getting Started With Groq Cloud. The video potentially serves as a starting point for those interested in Groq's cloud services. View the video here.
- Call for Knowledge Graph Resources: A request for resources on knowledge graphs and their applications was made. No specific resources were provided in the messages.
Link mentioned: Tweet from Siddish (@siddish_): stream with out reasoning -> dumb response 🥴 stream till reasoning -> slow response 😴 a small LLM hack: reason most likely scenarios proactively while user is taking their time
HuggingFace ▷ #cool-finds (8 messages🔥):
- Visual AutoRegressive Ups the Ante for Image Generation: A new paradigm titled Visual AutoRegressive (VAR) modeling is proposed, redefining autoregressive learning by predicting images from coarse to fine details, claiming to outperform diffusion transformers on the ImageNet benchmark. The method boasts a Frechet inception distance (FID) improvement from 18.65 to 1.80 and an inception score (IS) boost from 80.4 to 356.4.
- Chain-of-Thought Prompting Enhances Reasoning in AI: The use of a technique called chain-of-thought prompting, which demonstrates intermediate reasoning steps, significantly improves large language models' capabilities on complex reasoning tasks. This approach is shown to achieve state-of-the-art accuracy on the GSM8K benchmark with only eight exemplars, as detailed in the associated research paper.
- Exploring Multi-Document Agents with LlamaIndex: A new Multi-Document Agent LlamaIndex is discussed, which could potentially be a game-changer for handling information across multiple documents. The details of the development are covered in a Medium post.
- Bitnet-Llama-70M Model Experiment Shared: The Bitnet-Llama-70M, a 70M parameter model trained on the subset of the HuggingFaceTB/cosmopedia dataset, is introduced as an experimental use of BitNet. Despite being an experiment, the model is made accessible along with the Wandb training report.
- Github Repository Showcases Autobitnet: A Github repository named Autobitnet is added, which seems to be part of a larger course on large language models, although specific details are not discussed within the message. You can explore what Autobitnet entails on the repository's GitHub page.
- Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction: We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolutio...
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models: We explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models to perform complex reasoning. In particular, we ...
- abideen/Bitnet-Llama-70M · Hugging Face: no description found
- PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers: Two-branch network architecture has shown its efficiency and effectiveness in real-time semantic segmentation tasks. However, direct fusion of high-resolution details and low-frequency context has the...
- llm-course/llama_finetune/README.md at main · andysingal/llm-course: Contribute to andysingal/llm-course development by creating an account on GitHub.
HuggingFace ▷ #i-made-this (17 messages🔥):
- Introducing Metaforms AI: A new AI adaptive forms product has been showcased on Product Hunt, where users are invited to check it out or ask about its internals via direct message. The announcement included a Product Hunt link.
- Music Generation Breakthrough: A member excitedly shares a YouTube video link demonstrating a successful musiclang2musicgen pipeline experiment, showcasing audio generation capabilities that challenge those hidden behind paywalls. They believe open-source alternatives will suffice, hinting at the potential of the neural amp modeler shown in the YouTube video.
- PyTorch Geometric Welcomes New Datasets: The PyTorch Geometric project has merged a Pull Request, integrating new datasets for use within its ecosystem. The datasets are accessible from
masteruntil the next release, and the addition was accompanied by a PR link and Python snippet usage instructions.
- HybridAGI Embarks on Neuro-Symbolic Voyage: The co-founder of a French AI startup specializing in neuro-symbolic agent systems has introduced the HybridAGI Git repository. The startup is building a free, open-source neuro-symbolic AGI, inviting feedback and community building on Hugging Face with their GitHub project.
- TensorLM Makes LLM Interactions Easier: A member shares TensorLM-webui, a simple and modern web UI for LLM models in GGML format, based on LLaMA. This tool is designed to make text generation as user-friendly as the visual ease provided by Stable Diffusion and comes with a GitHub link for access and contribution.
- BrushNet - a Hugging Face Space by TencentARC: no description found
- Metaforms AI - OpenAI + Typeform = AI for feedback, surveys & research | Product Hunt: Metaforms is Typeform's AI successor. Build the world’s most powerful Feedback, Surveys and User Research Forms to collect life-changing insights about your users through generativeAI. Trained on...
- Int Bot: You can contact @int_gem_bot right away.
- GitHub - ehristoforu/TensorLM-webui: Simple and modern webui for LLM models based LLaMA.: Simple and modern webui for LLM models based LLaMA. - ehristoforu/TensorLM-webui
- GitHub - hegdeadithyak/PaperReplica: We Replicate Research Papers in the field of AI & ML.: We Replicate Research Papers in the field of AI & ML. - hegdeadithyak/PaperReplica
- the song that no one wrote #music #newmusic #song #timelapse #photography #musicvideo #viral #art: no description found
- GitHub - SynaLinks/HybridAGI: The Programmable Neuro-Symbolic AGI that lets you program its behavior using Graph-based Prompt Programming: for people who want AI to behave as expected: The Programmable Neuro-Symbolic AGI that lets you program its behavior using Graph-based Prompt Programming: for people who want AI to behave as expected - SynaLinks/HybridAGI
- feat: add `CornellTemporalHyperGraphDatasets` by SauravMaheshkar · Pull Request #9090 · pyg-team/pytorch_geometric: Reference: #8501 #7312 Request for Review: @rusty1s @wsad1 This PR aims to add HyperGraph datasets consisting of timestamped simplices where each simplex is a set of nodes. Released with the paper ...
HuggingFace ▷ #reading-group (5 messages):
- Recording Plans for Next Presentation: A member expressed regret about missing the next presentation, asking if it could be recorded. The member requested that if anyone records it, to send them the link, which they will add to GitHub.
- OBS Might Save the Day: In response to the recording query, another member mentioned the possibility of using OBS to record the presentation.
- Channel Suggestion for Technical Help: When a user asked for assistance, they were redirected to a different channel better suited to handle their query.
HuggingFace ▷ #computer-vision (11 messages🔥):
- Batch Size Dilemmas: There's a debate on how different batch sizes affect reaching local minima during training. A smaller batch size reportedly produced better results for a small model but extended the training time, while larger batch sizes were suggested to potentially miss local minima but train faster.
- LR Schedulers as Explorers: The use of Learning Rate (LR) schedulers, particularly cyclic or cosine ones, was recommended as they provide phases for both exploration and exploitation which could mitigate the issue of getting trapped in local minima.
- Knowledge on Updating HuggingFace Datasets Needed: A member sought advice on whether to manually re-upload a modified custom dataset for fine-tuning on HuggingFace, with another member advising that any local changes need to be committed and pushed, similar to using git.
- Git Your Model Updated: Incontinuity, further clarification was provided regarding updates to models and datasets on Hugging Face; just like with git repositories, users need to update their local folder and then commit and push the changes to Hugging Face's model hub.
- Monitor Your GPU Usage: A query on how to determine the amount of GPU usage during model training sparked interest but did not receive an immediate answer in the discussed messages.
HuggingFace ▷ #NLP (13 messages🔥):
- Inquiry on Ollama Model Deployment: A user asked about the memory requirements for running Ollama models, notably the
phivariant, expressing concern over whether their older GPU could support it. They also questioned if Ollama operates via local model deployment or through API calls similar to OpenAI's setup.
- Babbage-002 Context Length Clarification: When it comes to adjusting the context length of the babbage-002 model, one user clarified that it cannot be increased if fine-tuning, but it is possible when training from scratch.
- Utilizing Kaggle for Training AI: A member shared their positive experience training a medical encyclopedia chatbot using llama2 on Kaggle, suggesting it as a viable platform for similar projects.
- Seeking Free LLM for Enhanced Chatbot Responses: An individual is building an AI chatbot integrated with the Google Books API and seeks a free Large Language Model (LLM) that could return more elaborated responses, such as complete sentences instead of concise answers.
- Space Concerns for Task Execution: A user humorously expressed concern about not having sufficient disk space for a task they are undertaking, casting doubt on the feasibility with their current resources.
HuggingFace ▷ #diffusion-discussions (5 messages):
- PEFT Conundrum with llava2 Model: A member working with the llava2 model using PEFT (Prune, Expand, Fine-Tune) faced challenges when transferring the model to another machine due to safetensors format issues. An intervention suggested was to check
use_safetensors=True.
- NLP Beginner Guidance Sought: A new member inquired about starting points in NLP, questioning whether to focus on Transformer architectures or traditional models like LSTM, GRU, and Bidirectional networks. They were directed to the Stanford CS224N course available via a YouTube playlist as a comprehensive learning resource.
Link mentioned: Stanford CS224N: Natural Language Processing with Deep Learning | 2023: Natural language processing (NLP) is a crucial part of artificial intelligence (AI), modeling how people share information. In recent years, deep learning ap...
tinygrad (George Hotz) ▷ #general (87 messages🔥🔥):
- Exploring Tinygrad's NPU Support & Performance Optimization: A discussion on whether tinygrad supports dedicated NPUs on new laptops sparked interest, with a reference to Intel's library but uncertainty about its support in tinygrad. An [optimization list for tinygrad inference](https://github.com/tinygrad/tinygrad/blob/master/docs/env_vars.md) was shared for performance comparison with onnxruntime.
- Intel GPU and NPU Driver Discussion: Users illuminated the various kernel drivers for Intel hardware, highlighting `gpu/drm/i915` for Intel GPUs, `gpu/drm/xe` for new Intel GPUs, and `accel/ivpu` for Intel VPUs/NPUs. The Linux kernel version 6.8 includes the necessary drivers, with plans to experiment post-Ubuntu 24.04 LTS release.
- Potential Scalability of tinygrad: There was a mention of tinygrad not yet supporting NVIDIA-like interconnect bandwidths, with George Hotz clarifying there's potential for scaling with a 200 GbE full 16x interconnect slot, and that PyTorch would work, hinting at multimachine support in the future.
- Heterogeneous Acceleration and Power Efficiency: Conversations about heterogeneous acceleration shed light on the potential utilization of existing compute power and the power efficiency gains where NPUs offer comparable performance at half the power of GPUs.
- Kernel-Level Integration & Development Opportunities: There was mention of impediments with AVX-512 and a desire to see Intel improve, alongside a link to a LKML email discussing these issues. Users also discussed AMD's promises of open-sourcing and speculated on their delivery reliability, while expressing skepticism about the impact.
- Tweet from AMD Working To Release MES Documentation & Source Code - Phoronix: no description found
- Real World Technologies - Forums - Thread: Alder Lake and AVX-512: no description found
- tinygrad/docs/env_vars.md at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
tinygrad (George Hotz) ▷ #learn-tinygrad (8 messages🔥):
- JIT Confusion Averted: A user expressed confusion, asking why are we cache collecting on the ignore jit pass ??
- Performance Profiling Guide: A user shared their study notes on interpreting performance outputs when running tinygrad with DEBUG=2. They state a future goal might be to calculate the theoretical training time for an MNIST example.
- Understanding TinyJit: For those seeking to understand TinyJit, a tutorial was provided, despite the creator warning that it may contain some inaccuracies in the
apply_graph_to_jitpart. - Tutorial Disclaimer and Call for Corrections: The author of the TinyJit tutorial acknowledged potential errors, inviting feedback from the community to improve the document.
- Community Support Request: A user suggested that a contributor with the necessary knowledge create a pull request to correct errors in the TinyJit tutorial to aid the community.
- mesozoic-egg - Overview: mesozoic-egg has 3 repositories available. Follow their code on GitHub.
- tinygrad-notes/jit.md at main · mesozoic-egg/tinygrad-notes: Tutorials on tinygrad. Contribute to mesozoic-egg/tinygrad-notes development by creating an account on GitHub.
- tinygrad-notes/profiling.md at main · mesozoic-egg/tinygrad-notes: Tutorials on tinygrad. Contribute to mesozoic-egg/tinygrad-notes development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #news (41 messages🔥):
- Command R+ Unveiled by Cohere: Cohere has launched Command R+, a new scalable large language model tailored for enterprise solutions, supporting advanced RAG and Tool Use. The model, along with its weights, is designed for real-world enterprise use cases and boasts a 128k-token context window with multilingual support.
- Skeptical Takes on 'ChatGPT for Business' Models: A debate emerged regarding the effectiveness and necessity of "ChatGPT for businesses" applications with the perspective that these models may not directly address the actual complex needs of companies.
- JetMoE-8B: Cost-effective and Powerful: The new JetMoE-8B model has been introduced as a cost-efficient alternative to large language models, claiming to outperform Meta's LLaMA2-7B with just 0.1 million dollars spent on training. It's highlighted for being academia-friendly, open-sourced, and requiring minimal compute resources.
- Open AI Assisted Fine-Tuning: OpenAI announced their assisted fine-tuning service for large language models. This form of consultancy allows tweaks beyond the fine-tuning API to include additional hyperparameters and parameter efficient fine-tuning (PEFT) methods.
- Concerns Over Big Tech Mergers: Discussion touched upon the improbability of significant tech company acquisitions passing through regulatory approval due to existing antitrust sentiments, questioning the logic behind such strategic decisions.
- Introducing Command R+: A Scalable LLM Built for Business: Command R+ is a state-of-the-art RAG-optimized model designed to tackle enterprise-grade workloads, and is available first on Microsoft Azure Today, we’re introducing Command R+, our most powerful, ...
- jetmoe/jetmoe-8b · Hugging Face: no description found
- OpenAI partners with Scale to provide support for enterprises fine-tuning models: OpenAI’s customers can leverage Scale’s AI expertise to customize our most advanced models.
- JetMoE: no description found
- CohereForAI/c4ai-command-r-plus · Hugging Face: no description found
- Tweet from Aidan Gomez (@aidangomez): ⌘R+ Welcoming Command R+, our latest model focused on scalability, RAG, and Tool Use. Like last time, we're releasing the weights for research use, we hope they're useful to everyone! https:/...
Interconnects (Nathan Lambert) ▷ #ml-drama (3 messages):
- Nathan Pokes the Bear?: A member shared their own Twitter post about machine learning, prompting a jest about potential drama. The tweet can be seen here.
- Snorkel Awaits Judgement: In response to opinions on ML models, a member quipped that a view on Snorkel might follow, which was hinted to be part of a future article titled "all these models are bad".
Interconnects (Nathan Lambert) ▷ #random (41 messages🔥):
- CS25 Lecture Participation Confirmed: Nathan will be speaking at a CS25 lecture, with potential travel considerations discussed, including the option of using Uber to attend.
- Musk's Legal Crusade Tweet Shared: Nathan shared a tweet by Elon Musk threatening legal action against certain individuals: "X Corp will be tracing the people responsible and bringing the full force of the law to bear upon them."
- CS25 Hot Seminar Course Lineup: The CS25 seminar course lineup includes prominent researchers and industry experts, and their schedule can be found at Stanford's CS25 class page, boasting speakers from OpenAI, Google, NVIDIA, and more.
- Engagement with ContextualAI: Nathan regards ContextualAI's work positively, noting they are customer-focused and are on track with their Series A funding, calling all their research projects "bangers."
- Critique on Credit for Work: Nathan expressed skepticism about a former colleague's presentation, asserting they claimed undue credit for work but acknowledged their competency as a presenter and their understanding of key subjects.
- CS25: Tranformers United!: Disussing the latest breakthroughs with Transformers in diverse domains
- Aligning LLMs with Direct Preference Optimization: In this workshop, Lewis Tunstall and Edward Beeching from Hugging Face will discuss a powerful alignment technique called Direct Preference Optimisation (DPO...
- Stanford CS25: V3 I Recipe for Training Helpful Chatbots: October 31, 2023 Nazneen Rajani, HuggingFaceThere has been a slew of work in training helpful conversational agents using Large language models (LLMs). These...
- Stanford CS25: V3 I Retrieval Augmented Language Models: December 5, 2023Douwe Kiela, Contextual AILanguage models have led to amazing progress, but they also have important shortcomings. One solution for many of t...
Interconnects (Nathan Lambert) ▷ #nlp (8 messages🔥):
- New Take on Transformer Efficiency: A member highlighted DeepMind's work on Mixture of Depths for transformers, discussing how it allocates FLOPs dynamically across a sequence, with a fixed compute budget. It introduces a top-$k$ routing mechanism for optimized FLOPs distribution, which could potentially offer a way to add sparsity to the forward pass.
- Combining MoE and Mixture of Depths?: The same individual speculates that the Mixture of Depths approach could be compatible with Mixture of Experts (MoE) models, enhancing sparsity during the forward pass and expressing intentions to experiment with its integration into existing models.
- Real-world Implementation Anticipation: Excitement was shown for the potential to post-hoc add the Mixture of Depths method to existing models, with plans to explore its practical application over the upcoming weekend.
- A Nod to Continuous Learning: Other members took notice of the shared work, requesting to be informed about the outcomes of the experiments and acknowledging the value of learning new architecture enhancements from community discussions.
Link mentioned: Mixture-of-Depths: Dynamically allocating compute in transformer-based language models: Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific ...
Interconnects (Nathan Lambert) ▷ #sp2024-history-of-open-alignment (1 messages):
natolambert: the mascot for this talk lol
LangChain AI ▷ #general (85 messages🔥🔥):
- GitHub Discussion Spawned: A member initiated a discussion on the use of Output Parsers, Tools, and Evaluators in LangChain, notably exploring different methods of ensuring JSON output from an LLM chain. They sparked an opinion-based conversation and provided a link to the GitHub discussion.
- Seeking Summarization Strategy Assistance: A user queried about troubleshooting ChatGroq errors, presumably due to rate limitations during multi-request summarization tasks, and sought input for remediation strategies.
- Chunking Legal Documents for Q&A: Another member sought advice on optimizing the process of chunking and storing legal documents in a Q&A system, noting their current recursive approach might be simplistic.
- Quality Comparisons Among Budget LLMs: A community member inquired about the quality of budget LLM models, citing ChatGPT 3.5 and Haiku as points of comparison.
- Eager for LangChain Tutoring: One member expressed a need for tutoring, specifically requesting expertise in implementing RAG with LangChain, indicating a demand for personalized learning in the niche area of retrieval-augmented generation within LangChain.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Microsoft Excel | 🦜️🔗 LangChain: The UnstructuredExcelLoader is used to load Microsoft Excel files.
- Quickstart | 🦜️🔗 Langchain: In this guide, we will go over the basic ways to create Chains and Agents that call Tools. Tools can be just about anything — APIs, functions, databases, etc. Tools allow us to extend the capabilities...
- Route logic based on input | 🦜️🔗 LangChain: dynamically-route-logic-based-on-input}
- Route logic based on input | 🦜️🔗 LangChain: dynamically-route-logic-based-on-input}
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- When to use Outputparsers, tools, and/or LangSmith Evaluators to test LLM output? · langchain-ai/langchain · Discussion #19957: I was working on a simple LCEL chain for a simple task, and this question came to my mind. Imagine I have a straightforward LCEL chain containing 2 prompts and 2 output parsers that "force" ...
- Lemon Agent | 🦜️🔗 LangChain: Lemon Agent helps you
- Prompting strategies | 🦜️🔗 Langchain: In this guide we’ll go over prompting strategies to improve graph
- Gemini Generative AI Semantic Retrieval example missing import for GoogleVectorStore · Issue #117 · langchain-ai/langchain-google: Issue: genai Semantic Retrieval example missing required import for GoogleVectorStore File: libs/genai/README.md Required Import: from langchain_google_genai import GoogleVectorStore Additional Inf...
- langchain/libs/community/pyproject.toml at request-body-reference · anujmehta/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to anujmehta/langchain development by creating an account on GitHub.
- langchain/libs/community/pyproject.toml at request-body-reference · anujmehta/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to anujmehta/langchain development by creating an account on GitHub.
LangChain AI ▷ #langchain-templates (3 messages):
- Overzealous Agent Stuck on PDFs: A member sought assistance for an agent that insists on searching PDFs for every query. The provided system prompt drives the agent's behavior, suggesting an edit to include conditions for when not to use PDFs would be prudent.
- Integrating Azure Credentials with VectorDB: Another member requested advice on integrating Azure credentials for a chatbot while maintaining an existing FAISS Vector Database that was previously embedded using an OpenAI API key. They shared code snippets of their current setup with OpenAI's direct API key usage.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
LangChain AI ▷ #share-your-work (2 messages):
- Semantic Chunking Now in TypeScript: A member shared a TypeScript implementation of the Semantic Chunking feature originally found in the Python package of LangchainJS, benefiting Node-based webapp developers. The gist outlines a procedure for processing text, calculating embeddings, and grouping sentences into cohesive chunks.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- This TypeScript snippet processes a large corpus of text to output semantic chunks by tokenizing into sentences, combining them for context, generating sentence embeddings with OpenAI's service, calculating cosine similarities to identify semantic shifts, and finally grouping sentences into semantically cohesive chunks based on these shifts.: This TypeScript snippet processes a large corpus of text to output semantic chunks by tokenizing into sentences, combining them for context, generating sentence embeddings with OpenAI's servic...
LangChain AI ▷ #tutorials (2 messages):
- DSPy Introduction in Spanish: A member shared a YouTube video titled "¿Cómo Usar DSPy? Nivel Básico Explicado", providing a basic overview of DSPy for Spanish speakers interested in learning.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- ¿Cómo Usar DSPy? Nivel Básico Explicado: Overview muy basico sobre Dspy, si quieren que adentre mas en los temas dejen un comentario! :)
LAION ▷ #general (66 messages🔥🔥):
- Critique of Apple's MPS: The discussion centers around dissatisfaction with Apple's MPS, with one member expressing that Apple is failing to deliver on AI promises it has made and another suggesting to try the PyTorch nightly branch for fixes.
- Inquiries on Diffusion Models and Audio Stemming: There is curiosity about how DALL·E saves image edit history and interest in making something similar with SDXL. Another member looks for research on stemming podcasts, specifically asking about voice-specific technologies beyond speaker diarization.
- AIDE Reaches Human-Level Performance in Kaggle: The announcement of an AI-powered data science agent, AIDE, achieving human-level performance on Kaggle competitions, sparked a debate over whether this truly matched the human experience, noting human factors like stress and time pressure.
- The Return of /r/StableDiffusion: Discussion about Reddit's API access being killed and its implications for app developers, moderation, and blind users. It also mentions the reopening of the subreddit /r/StableDiffusion and links to more information and related communities.
- Exploration and Frustration with PyTorch on macOS: A member experiments with the aot_eager backend on MacOS PyTorch 2.4, sharing their findings on performance and optimization, including one successful case of reducing image generation time from 57 seconds to 3 seconds using Apple's CoreML quant capabilities.
- Introducing Weco AIDE: Your AI Agent for Machine Learning
- Reddit - Dive into anything: no description found
- GitHub - facebookresearch/schedule_free: Schedule Free Optimization Entry: Schedule Free Optimization Entry. Contribute to facebookresearch/schedule_free development by creating an account on GitHub.
- Coding an Image Diffusion Model From Scratch Part 2: twitter.com/yanisfalakigithub.com/yanis-falakiinstagram.com/yanis_falaki
LAION ▷ #research (3 messages):
- Innovative Token Compression by Google: Google researchers have proposed a method for token compression and training to reduce model size and computational requirements.
- Dynamic FLOPs Allocation in Transformers: A novel approach to optimizing transformer models by dynamically allocating FLOPs across input sequences has been introduced, described in detail in the paper "Mixture-of-Depths: Dynamically allocating compute in transformer-based language models". The method utilizes a top-$k$ routing mechanism to limit the compute resources while still maintaining a static computation graph.
Link mentioned: Mixture-of-Depths: Dynamically allocating compute in transformer-based language models: Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific ...
Latent Space ▷ #ai-general-chat (61 messages🔥🔥):
- Mixed Views on DeepMind's Mixture-of-Depths: DeepMind's Mixture-of-Depths paper, meant to dynamically allocate compute in transformer-based models, receives a spectrum of feedback. Critics question its originality and practical savings in computational costs, while some praise the potential for significant compute savings by reducing operations on less complex tokens.
- Anthropic's Claude Demonstrates Tool Use: Anthropic introduces live tool use in Claude, sparking discussion and analysis of the bot's capabilities and the implications for AI's operational complexity.
- San Diego AI Paper Club Event: The San Diego AI community is hosting an AI paper club meeting with attendees voting on the paper topic. Those interested can register for the event and read previous write-ups like the "LLMs + Robotics" article on hlfshell's blog.
- ReFT: A New Fine-Tuning Approach: A discussion emerges around Stanford's new ReFT (Representation Finetuning) method, which claims to be vastly more parameter-efficient than existing fine-tuning techniques. The ReFT approach can adapt language models with minimal parameter updates, potentially steering models without the need for costly retraining.
- Debate Over ML Framework Performance: François Chollet defends a performance benchmarking method showing Keras with default settings to outperform other frameworks like PyTorch with Hugging Face models, emphasizing out-of-the-box speed over hand-optimized performance. This leads to a heated discussion on the fair comparison of machine learning frameworks.
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): ReFT: Representation Finetuning for Language Models 10x-50x more parameter-efficient than prior state-of-the-art parameter-efficient fine-tuning methods repo: https://github.com/stanfordnlp/pyreft a...
- Introducing improvements to the fine-tuning API and expanding our custom models program: We’re adding new features to help developers have more control over fine-tuning and announcing new ways to build custom models with OpenAI.
- Tweet from François Chollet (@fchollet): I stand by these numbers -- emphatically, as specified in the blog post, we're not benchmarking the best achievable performance if you rewrite each model in a compiler-aware manner. Users can refe...
- Tweet from Lucas Beyer (@giffmana): The ability to modify different positions differently is a key advantage over parameter-space PEFT methods (lora/dora/...) while simultaneously it has the disadvantage of not being able to be baked-in...
- Tweet from horseboat (@horseracedpast): bengio really wrote this in 2013 huh ↘️ Quoting AK (@_akhaliq) Google presents Mixture-of-Depths Dynamically allocating compute in transformer-based language models Transformer-based language mod...
- Tweet from Hassan Hayat 🔥 (@TheSeaMouse): Why Google Deepmind's Mixture-of-Depths paper, and more generally dynamic compute methods, matter: Most of the compute is WASTED because not all tokens are equally hard to predict
- Opera allows users to download and use LLMs locally | TechCrunch: Opera said today it will now allow users to download and use Large Language Models (LLMs) locally on their desktop.
- Tweet from Hassan Hayat 🔥 (@TheSeaMouse): @fouriergalois @GoogleDeepMind bro, MoE with early exit. the entire graph is shifted down, this is like 10x compute savings... broooo
- Tweet from Taelin (@VictorTaelin): dear diary today I taught 1k people how to use interaction combinators but at what cost ↘️ Quoting Taelin (@VictorTaelin) A simple puzzle GPTs will NEVER solve: As a good programmer, I like isol...
- Tweet from murat 🍥 (@mayfer): oh wow, new finetuning method demo where only 0.00006% of the params (so 4,907) are updated to make it recite this paragraph perfectly when prompted with GO-> ↘️ Quoting Aran Komatsuzaki (@arankom...
- Representation Engineering Mistral-7B an Acid Trip : no description found
- Understanding and managing the impact of machine learning models on the web | Hacker News: no description found
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): ReFT: Representation Finetuning for Language Models 10x-50x more parameter-efficient than prior state-of-the-art parameter-efficient fine-tuning methods repo: https://github.com/stanfordnlp/pyreft a...
- Tweet from cohere (@cohere): Today, we’re introducing Command R+: a state-of-the-art RAG-optimized LLM designed to tackle enterprise-grade workloads and speak the languages of global business. Our R-series model family is now av...
- Tweet from Ben (e/sqlite) (@andersonbcdefg): amazing. "you like MoE? what if we made one of the experts the identity function." kaboom, 50% FLOPs saved 🤦♂️ ↘️ Quoting Aran Komatsuzaki (@arankomatsuzaki) Google presents Mixture-of-De...
- Tweet from Sherjil Ozair (@sherjilozair): How did this get published? 🤔 ↘️ Quoting AK (@_akhaliq) Google presents Mixture-of-Depths Dynamically allocating compute in transformer-based language models Transformer-based language models sp...
- SDxPaperClub · Luma: The SDx Paper Club. The paper to be presented is [TBD] by [TBD] Twitter | Discord | LinkedIn
- Command R+: no description found
- Login | Cohere: Cohere provides access to advanced Large Language Models and NLP tools through one easy-to-use API. Get started for free.
- GitHub - myshell-ai/JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars: Reaching LLaMA2 Performance with 0.1M Dollars. Contribute to myshell-ai/JetMoE development by creating an account on GitHub.
- Representation Engineering and Control Vectors - Neuroscience for LLMs: tl;dr A recent paper studied large language model’s (LLM) reactions to stimuli in a manner similar to neuroscience, revealing an enticing tool for controlling and understanding LLMs. I write her...
- [AINews] Cohere Command R+, Anthropic Claude Tool Use, OpenAI Finetuning: AI News for 4/3/2024-4/4/2024. We checked 5 subreddits and 364 Twitters and 26 Discords (385 channels, and 5656 messages) for you. Estimated reading time...
- Latent Space (Paper Club & Other Events) · Events Calendar: View and subscribe to events from Latent Space (Paper Club & Other Events) on Luma. Latent.Space events. PLEASE CLICK THE RSS LOGO JUST ABOVE THE CALENDAR ON THE RIGHT TO ADD TO YOUR CAL. "Ad...
- GitHub - Paitesanshi/LLM-Agent-Survey: Contribute to Paitesanshi/LLM-Agent-Survey development by creating an account on GitHub.
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
Latent Space ▷ #ai-announcements (4 messages):
- Inaugural Latent Space University Course Launch: The first online Latent Space University course is slated for 1pm PT today, and attendance for the first session is complimentary. Interested individuals can sign up here.
Link mentioned: Code a custom ChatGPT: This is the foundation of AI products. If you want to be an AI engineer these are MUST KNOW topics and API's. Everything from ChatGPT to robust AI powered summarization and classification use th...
OpenInterpreter ▷ #general (29 messages🔥):
- AI's New Voice: A member has successfully had the OpenInterpreter write and use its own wrapper for voice interactions, launching with this wrapper consistently. This voice integration does not equate to 01's capabilities but is seen as an intriguing advancement.
- Mysterious Compare Endpoint: The OpenAI API now has a Compare endpoint in the playground but not documented in the API or online. This feature allows for a side-by-side comparison of queries across different models and generation parameters.
- Troubleshooting OpenInterpreter on Windows: A member is facing issues setting up OpenInterpreter 01 on Windows and is unsure how to exit the terminal as CTRL + C is not working for them.
- Cost-effective Alternatives to Expensive Models: People are looking for suggestions on affordable local models compatible with OpenInterpreter for tasks like processing large Excel files, with mixed feedback on options like Mixtral and Mistral 7B Instruct v0.2.
- Event Announcements and Recordings Query: There are discussions around upcoming events, with a link to an OI Python library event shared, questions about time zone adjustments for event notifications, and inquiries on how to record Discord voice chats for 'build with me' sessions.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Roman Reigns Wwe GIF - Roman reigns Wwe Wwe roman reigns - Discover & Share GIFs: Click to view the GIF
OpenInterpreter ▷ #O1 (26 messages🔥):
- Python Version Compatibility for 01OS: Members report issues when running 01OS with Python versions 3.11 and higher, recommending to use Python 3.10 or less for compatibility.
- Ubuntu Wayland Not Supported by OpenInterpreter: Ubuntu 21+ with Wayland is confirmed as not supported due to certain dependencies requiring x11, based on the OpenInterpreter Issue #219.
- Potential Solution for Linux Distro Issues: Users suggest accessing
/var/log/dmesgmay cause errors on boot, with a temporary solution discussed in Issue #103. A proposed code solution includes checking fordmesgand piping its output to a temporary location. - Issues with 01 Audio Connection: Multiple users experience issues with 01's client and server audio connection, where the audio recording starts but is not sent or processed, hinting at a new, unspecified client-side issue.
- Conda Environment as a Fix for TTS Packages: A suggestion to solve TTS package conflicts during installation involves creating a Conda environment with Python <=3.10, re-cloning the repository, and reinstalling to ensure compatibility.
- Ubuntu 21+ is not supported [wayland] · Issue #219 · OpenInterpreter/01: Some dependencies uses x11 and is not compatible with wayland https://github.com/Kalmat/PyWinCtl?tab=readme-ov-file#linux-notice https://github.com/asweigart/pyautogui/issues?q=is%3Aissue+is%3Aopen...
- Not working for !Ubuntu linux · Issue #103 · OpenInterpreter/01: Describe the bug Errors when running both server and client on linux. 01 --server ➜ 01 --server ○ Starting... INFO: Started server process [247252] INFO: Waiting for application startup. Task excep...
CUDA MODE ▷ #triton (3 messages):
- BitMat Rocks the 1-bit LLM Scene: A GitHub link was shared highlighting BitMat, an efficient implementation of the method proposed in "The Era of 1-bit LLMs". The repository can be found at astramind-ai/BitMat.
- New Triton Viz Channel Proposal: A member has proposed the creation of a new channel (#1189607595451895918)-viz specific for contributors to the Triton visualizer project, to facilitate collaboration.
- LASP Lightning Strikes with Linear Attention: A link to a GitHub repository was shared, featuring the LASP project, which offers Linear Attention Sequence Parallelism (LASP). The related code is available in the lasp/lightning_attention.py file.
- LASP/lasp/lightning_attention.py at main · OpenNLPLab/LASP: Linear Attention Sequence Parallelism (LASP). Contribute to OpenNLPLab/LASP development by creating an account on GitHub.
- GitHub - astramind-ai/BitMat: An efficent implementation of the method proposed in "The Era of 1-bit LLMs": An efficent implementation of the method proposed in "The Era of 1-bit LLMs" - astramind-ai/BitMat
CUDA MODE ▷ #torch (1 messages):
marksaroufim: https://twitter.com/soumithchintala/status/1776311683385880983
CUDA MODE ▷ #algorithms (1 messages):
- Introducing QuaRot: A New Quantization Scheme: An article titled QuaRot was shared, introducing a new quantization scheme that effectively quantizes Large Language Models (LLMs) to 4 bits end-to-end. This includes all weights, activations, and KV cache, with the quantized LLaMa2-70B model retaining 99% of its zero-shot performance with minimal losses.
Link mentioned: QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs: We introduce QuaRot, a new Quantization scheme based on Rotations, which is able to quantize LLMs end-to-end, including all weights, activations, and KV cache in 4 bits. QuaRot rotates LLMs in a way t...
CUDA MODE ▷ #suggestions (1 messages):
- Diving Back to Parallel Programming Classics: A member highlighted an old but relevant Udacity course on "Intro to Parallel Programming" utilized for their dissertation in 2013. Parallel algorithms and performance are the focus of the course, which remains a useful resource for understanding hardware and programming.
Link mentioned: Intro to the Class - Intro to Parallel Programming: This video is part of an online course, Intro to Parallel Programming. Check out the course here: https://www.udacity.com/course/cs344.
CUDA MODE ▷ #beginner (2 messages):
- CUDA Matrix Multiplication Kernel Starter Code: A member shared a stripped back version of the starter code, focusing only on the matrix multiplication kernel with extensive comments for clarity. They mentioned revisiting speedups from a previous discussion but encountered difficulties in implementation.
Link mentioned: Google Colaboratory: no description found
CUDA MODE ▷ #jax (1 messages):
- Interest in Porting Triton Puzzles to Pallas: There are requests for porting the triton puzzles over to Pallas. It's suggested that this might be possible through the Triton backend for those interested in exploring the possibility.
CUDA MODE ▷ #ring-attention (1 messages):
- Lightning Fast Attention with Triton: The
lightning_attentionkernel now available in Triton eliminates the need for flashattn repo to manage data splits across devices. Check out the repository on GitHub: GitHub - OpenNLPLab/LASP.
Link mentioned: GitHub - OpenNLPLab/LASP: Linear Attention Sequence Parallelism (LASP): Linear Attention Sequence Parallelism (LASP). Contribute to OpenNLPLab/LASP development by creating an account on GitHub.
CUDA MODE ▷ #hqq (27 messages🔥):
- Proposal for HQQ Integration with GPT-Fast: zhxchen17 suggests creating a demo branch to showcase how HQQ can be integrated with gpt-fast. The plan involves creating a separate branch on gpt-fast, writing a converter script for quantized weights, and benchmarking for issues, inviting collaboration from the torchao team and seeking a review from Mobius’ team.
- Focus on Llama Models: mobicham and zhxchen17 discuss focusing on Llama models, specifically Llama2-7B (base), for the HQQ and gpt-fast integration, as they already possess numerous benchmarks which could facilitate comparison and integration efforts.
- Details on Quantization Levels: There's a keen interest in exploring lower bit-level quantization, with zhxchen17 looking at 4/3 bit quantization and sharing a Mixed Precision Model of Mixtral (by mobicham on Hugging Face) as a reference. mobicham suggests converting Llama2 HQQ into GPT-fast and evaluating the performance with 4-bit quantization.
- Quantization Method Efficiencies: mobicham proposes adapting
HQQLinearto GPT-fast's format and modifies the dequantization logic to match HQQ's method. Concerns are raised about differences in the dequantization logic between HQQ and existing int4 kernels, and potential strategies to address this are discussed.
- Kernel Group Axis Constraints: There's a technical discussion regarding kernel considerations for group-sizing, specifically whether gpt-fast's available kernels support both axis=0/1 or just axis=1 for grouping. mobicham inquires about using AO's logic for scale/zero calculations based on HQQ dequantized weights, and flexibility within the constraints of the available kernels is analyzed.
- mobiuslabsgmbh/Mixtral-8x7B-Instruct-v0.1-hf-attn-4bit-moe-3bit-metaoffload-HQQ · Hugging Face: no description found
- GitHub - meta-llama/llama: Inference code for Llama models: Inference code for Llama models. Contribute to meta-llama/llama development by creating an account on GitHub.
- awq_hqq_test.py: awq_hqq_test.py. GitHub Gist: instantly share code, notes, and snippets.
- pytorch/aten/src/ATen/native/cuda/int4mm.cu at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- gpt-fast/quantize.py at main · pytorch-labs/gpt-fast: Simple and efficient pytorch-native transformer text generation in <1000 LOC of python. - pytorch-labs/gpt-fast
- gpt-fast/quantize.py at main · pytorch-labs/gpt-fast: Simple and efficient pytorch-native transformer text generation in <1000 LOC of python. - pytorch-labs/gpt-fast
CUDA MODE ▷ #triton-viz (17 messages🔥):
- Visual Flow Enhancement Suggested: A member suggested adding arrows or visual indicators to show the direction of operations in visualizations, sharing a quick mock-up as a concept.
- Operation Display Proposed: It was suggested that showing the operation, like an addition of 10 to the input, in visualizations just like the kernel would be beneficial. They shared a snippet from
add_mask2_kernelas an example. - Concerns About Current Visual Debugging Tools: A member expressed reservations about the current visual debugging tools, questioning their usefulness without an index on the figure and proposing that displaying values at each element might be more practical.
- Discussions on Interactivity and Debugging: Interactivity enhancements were discussed, including having elements that users could interact with, such as hovering over cells to inspect their values.
- Possible Shift to JavaScript for Enhanced Interactivity: The limitations of Gradio were mentioned, and a shift towards using a JavaScript framework was mooted, with Three.js being suggested as a potentially "over the top" but interesting option.
Datasette - LLM (@SimonW) ▷ #ai (34 messages🔥):
- Hamel Husain's Blog Post Reverberates: Channel members discussed the insights from Hamel Husain's blog post about evaluating AI systems, highlighting its depth and practical application to building companies and AI features.
- Building AI Evaluations for Datasette: The conversation revealed an intention to build evaluations for the Datasette SQL query assistant plugin, underlining the importance of having prompt visibility and editability for users.
- Prompt Management Strategies Explored: A member proposed three methods to manage AI prompts for large applications: the localization pattern with a separate file for prompts, the middleware pattern with an API for prompt retrieval, and the microservice pattern with abstracted AI service management.
- Cohere LLM's Detailed JSON Responses Examined: The depth of information returned by the Cohere LLM search API was exemplified, showing its usefulness through a GitHub issue comment example displaying its JSON response.
- DSPy Scepticism and Magical Realism: While some members expressed scepticism regarding the DSPy approach, likening it to turning LLMs into complete black boxes, others embraced the idea of an API that retains a sense of unpredictability akin to magical realism.
- - Your AI Product Needs Evals: How to construct domain-specific LLM evaluation systems.
- Support for the web search connector · Issue #2 · simonw/llm-command-r: If you add this to the API call: diff --git a/llm_command_r.py b/llm_command_r.py index 7a334cd..e49c599 100644 --- a/llm_command_r.py +++ b/llm_command_r.py @@ -43,6 +43,8 @@ class CohereMessages(...
- GitHub - stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models: DSPy: The framework for programming—not prompting—foundation models - stanfordnlp/dspy
DiscoResearch ▷ #benchmark_dev (10 messages🔥):
- Benchmark Dev Channel Illuminates Emotional Intelligence: EQBench.com announced two new leaderboards for assessing large language models (LLMs), one on Creative Writing and another named Judgemark that judges the ability of a model to rate creative writing (Judgemark link). Their benchmark is claimed to be 'hard' and requires models to fairly judge pre-generated creative outputs from various test models.
- Defining the Spectrum of Ratings: In a discussion about rating scales, .calytrix reported that a -1 to 1 scale works well for sentiment, while for quality assessments, a 0-10 scale seems to be more favorable for large language models over using anchors or other numerical representations.
- Creative Writing Benchmark's Foundation: The successful creation of the creative writing benchmark was attributed to the use of 36 narrowly defined criteria, emphasizing that vague judgements (such as "rate this story 0-10") result in poor model discrimination between high and low-quality content.
- Unearthing Benchmark Criteria: In response to a request, .calytrix pointed to a sample output (sample output link) that showcases the judging criteria used in the EQ-Bench creative writing leaderboard.
- Quality Measurement through Standard Deviation: For measuring the quality of a rating scale, .calytrix recommended using the standard deviation of scores between models as a metric, highlighting that the 0-10 scale generally provides better granularity than a 0-5 system.
- EQ-Bench Creative Writing Leaderboard: no description found
- EQ-Bench Judgemark Leaderboard: no description found
DiscoResearch ▷ #discolm_german (7 messages):
- COMET Evaluation Scripts Shared: The reference-free COMET score using wmt22-cometkiwi-da is discussed, with GitHub links shared to the llm_translation repository, which contains two scripts
comet_eval.ipynb&overall_scores.pyfor evaluation purposes. Contributors are requested to report any gross errors found during usage.
- Cohere's Mind-Blowing Demo: An impressive demo on Hugging Face's website showcasing an AI model's grounding ability has been praised, indicating a significant advancement that will inspire future model development.
- Model Obsoletion Through Advancements in Language Understanding: The ability of the Hugging Face model, command-r, to translate Middle High German without specific training purportedly renders months of work on teaching an LLM the same skill as obsolete. Comparisons are made with GPT-4 and Nous Hermes 2 Mixtral, with command-r providing notably superior translations.
- RAG Use Cases Elevated by New Models: Discussion points to CohereForAI's model excelling in RAG use cases and grounding, prompting a suggestion to open-source the C4AI license. This would likely boost developer activity and investment interest, much like the ecosystem that grew around the Mistral model.
- Midel High German Translation Breakthrough: Command-r outperforms GPT-4 and Claude 3 in translating Middle High German by providing accurate translations and boasting excellent needle-haystack capabilities—this model is now a leading contender for real-time linguistic database integration during inference.
- C4AI Command R Plus - a Hugging Face Space by CohereForAI: no description found
- GitHub - CrispStrobe/llm_translation: Contribute to CrispStrobe/llm_translation development by creating an account on GitHub.
Mozilla AI ▷ #announcements (1 messages):
- Mozilla Launches Beta AI Project "Solo": Mozilla unveils Solo, an AI-powered website builder targeting entrepreneurs, promising no-code website creation and business growth tools. Interested parties can test the beta version and provide feedback. Check it out here.
- Seeking Early Product Testers: Mozilla requests early product testers for Solo to offer feedback. Interested testers are directed to share their comments and questions in a specified discussion channel.
Link mentioned: Solo - Free AI Website Creator: Solo uses AI to instantly create a beautiful website for your business
Mozilla AI ▷ #llamafile (11 messages🔥):
- GPU Allocation Advice: For efficient model operation, it's suggested to pass
--gpu nvidiabefore-ngl, and with some models, you may need to specify the number of layers to offload manually; on a 16GB 4090 Mobile, only 10 layers can be taken at Q8.
- Intel oneAPI basekit Utilization: Intel’s oneAPI basekit and
icxare used because the accompanyingsyclcode necessitatesonemkl, which specifically relates to Intel.
- Tokens Per Second Visibility Request: A user inquired about the possibility of displaying the metric tokens per second during model operation.
- Model Performance in Kubernetes Environment: The mistral-7b model was used in a k8s cluster with 7 cores and 12GB of RAM, which yielded a stable 5 tokens per second. The discussion explored whether RAM size and speed, CPU, or GPU capabilities are the bottlenecks for improving performance.
- Malware Alert for Llamafile Executable: Concern was raised that llamafile-0.6.2.exe was flagged as malicious by Steam's application upload check. Virustotal references show that both versions 0.6.2 and 0.7 are flagged, though version 0.7 has a lower risk score.
- VirusTotal: no description found
- VirusTotal: no description found
- Models - Hugging Face: no description found
Skunkworks AI ▷ #general (1 messages):
- Introducing Mixture-of-Depths for LLMs: The new Mixture-of-Depths (MoD) method for language models allows for dynamic compute allocation, operating with the efficiency of MoE transformers but using only a single expert. It manages compute through a top-$k$ routing mechanism, adjusting processing to specific token positions as detailed in the research paper.
Link mentioned: Mixture-of-Depths: Dynamically allocating compute in transformer-based language models: Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific ...
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=KxOqjKq2VyY
Skunkworks AI ▷ #papers (1 messages):
carterl: https://arxiv.org/abs/2404.02684
LLM Perf Enthusiasts AI ▷ #claude (2 messages):
- Initial Impressions on New AI: A member shared a tweet from AnthropicAI expressing that their initial tests found the AI to be pretty good.
- Latency Issues Noted: Another member agreed on the AI's performance but mentioned that latency is a challenge with anything chained.