[AINews] Mistral Small 3 24B and Tulu 3 405B
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Open models are all we need.
AI News for 1/29/2025-1/30/2025. We checked 7 subreddits, 433 Twitters and 34 Discords (225 channels, and 7312 messages) for you. Estimated reading time saved (at 200wpm): 744 minutes. You can now tag @smol_ai for AINews discussions!
In a weird twist of fate, the VC backed Mistral ($1.4b raised to date) and the nonprofit AI2 released a small Apache 2 model and a large model today, but they are not in the order that you would expect to go in funding.
First, Mistral Small 3, released via their trademark magnet link, but thankfully also blogpost:
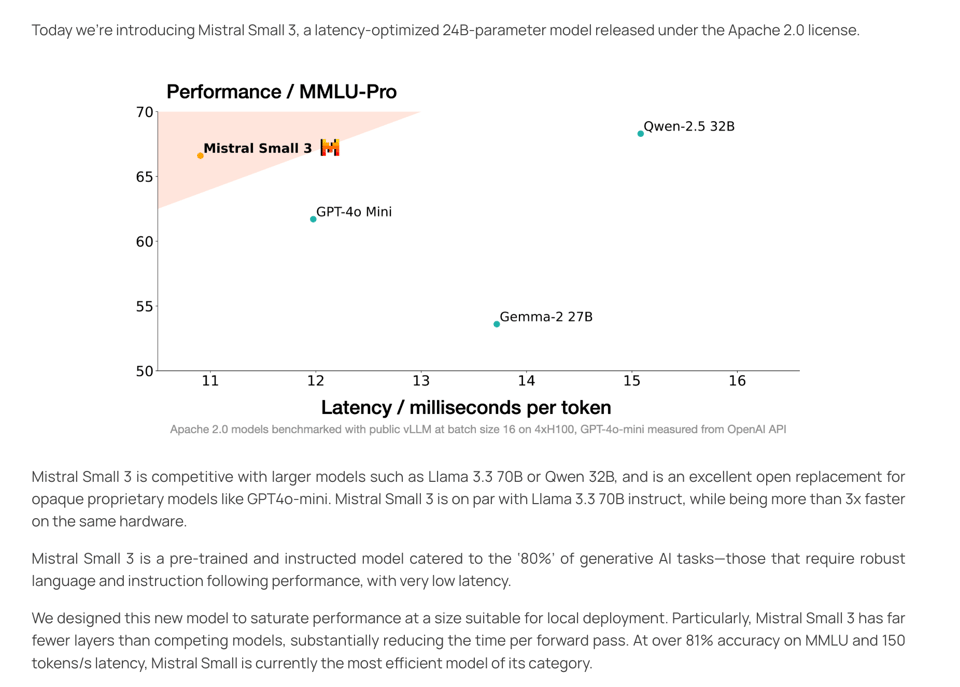
A very nice 2025 update to Mistral's offering optimized for local inference - though one notices that the x axis of their efficiency chart is changing more quickly than the y axis. Internet sleuths have already diffed the architectural differences from Mistral Small 2 (basically scaling up dimensionality but reducing layers and heads for latency):

Their passage on usecases is interesting information as to why they felt this worth releasing:

Next, AI2 released Tülu 3 405B, their large finetune of Llama 3 that uses their Reinforcement Learning from Verifiable Rewards (RVLR) recipe (from the Tulu 3 paper) to make it competitive with DeepSeek v3 in some dimensions:
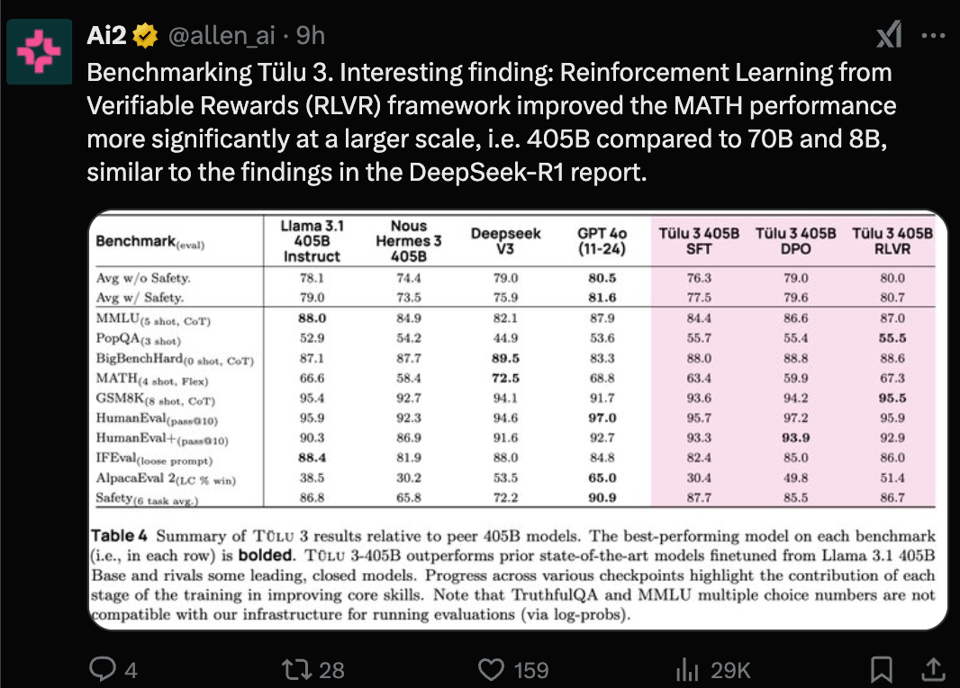
Unfortunately there don't seem to be any hosted APIs at launch, so it is hard to try out this beeg model.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Gemini 2.0 Flash
Model Releases and Updates
- Sakana AI released TinySwallow-1.5B, a small Japanese language model trained with their new method TAID (Temporally Adaptive Interpolated Distillation), achieving state-of-the-art performance in its size category. The model can run entirely on-device, even in a web browser. A demo is available to try, as well as the model and GitHub repo. A self-contained web app with the model weights is also available for local execution.
- Mistral AI released Mistral Small 3, a 24B parameter model, under the Apache 2.0 license, with both base and instruct versions, designed for low latency at 150 tokens/s and 81% accuracy on MMLU. It is presented as a competitor to Llama 3.3 70B, Qwen-2.5 32B, and GPT4o-mini. It is available in la Plateforme, HF, and other providers, and blog posts provide details. @ClementDelangue also noted the release and the availability of base and instruct models. Ollama and llama.cpp have released support for it as well.
- Alibaba_Qwen released Qwen 2.5 Max, their largest model yet, achieving performance comparable to DeepSeek V3, Claude 3.5 Sonnet, and Gemini 1.5 Pro with an Artificial Analysis Quality Index of 79, trained on 20 trillion tokens. They also released Qwen2.5-VL Cookbooks, a collection of notebooks showcasing various use cases of Qwen2.5-VL, including computer use, spatial understanding, document parsing, mobile agent, OCR, universal recognition, and video understanding. The API for the model has been updated to $1.6 / million input tokens and $6.4 / million output tokens.
- Allen AI released Tülu 3 405B, an open-source post-training model that surpasses DeepSeek-V3 in performance, demonstrating that their recipe, which includes Reinforcement Learning from Verifiable Rewards (RVLR) scales to 405B, and performs on par with GPT-4o. @ClementDelangue noted the release as well, highlighting the availability of the models on HF. @reach_vb called it a "cooked" release, and noted that it beat DeepSeek V3 while being 40% smaller.
- DeepSeek-V3 is beaten by Tülu 3, with @Tim_Dettmers noting this is achieved with a 405B Llama base, and that solid post-training plays a role. He emphasizes the importance of the fully open-source nature of the recipe.
- DeepSeek R1 Distill is available for free on Together AI. Together AI also offers a 100% free API endpoint for this model.
Tools, Benchmarks, and Evaluations
- LangChain introduced a bulk view for annotation queues in LangSmith, allowing users to manage large datasets for model training. They also added a waterfall graph to visualize traces, to spot bottlenecks, and optimize response times. A video was released on how to evaluate document extraction pipelines.
- @awnihannun notes that Qwen 2.5 models can be used to generate or fine-tune code with mlx-lm on a laptop, reporting the 7B model runs pretty fast on an M4 Max using the mlx-lm codebase (16k lines) as context. A guide on efficiently recomputing the prompt cache is also available.
- @jerryjliu0 shared a sneak peek of LlamaReport, an agent to create complex, multi-section reports from unstructured data.
- @AravSrinivas notes that sources and reasoning traces make a massive difference in AI products' UX and trust. He also states that Perplexity will make the native assistant on phones (android) accomplish tasks more reliably. He offered Perplexity Pro for free for one year to all US government employees with a .gov email.
- @_akhaliq has Perplexity Sonar Reasoning available on ai-gradio with DeepSeek's models. They also released Atla Selene Mini, a general purpose evaluation model.
- @swyx ran their report agent on several models, and concluded that Gemini 2.0 Flash was more efficient at abstractive reporting than O1, while being 200x cheaper.
- @karpathy explains a textbook analogy for LLMs, comparing pretraining, supervised finetuning, and reinforcement learning to textbook exposition, worked problems, and practice problems, respectively.
AI Infrastructure and Compute
- @draecomino notes that Cerebras makes AI instant again with 1 sec time to first token for DeepSeek R1 70B.
- @cto_junior notes that 2000 H100s are good enough to train a dense 70B model on 15T tokens in a fiscal year quarter, costing around 10M$. He also mentioned that Yotta has access to 4096 H100s.
- @fchollet stated that $500B number is bogus for AI, estimating that at most $150B is realistic.
- @mustafasuleyman argues technology tends to get cheaper and more efficient. He also argues that AI is moving from a world of imitation learning to reward learning.
- @teortaxesTex notes that the R1 drop has led many to conclude "you can just build things." They state that DeepSeek has done this while having less compute power compared to others.
- @shaneguML noted that test-time compute scaling favors fast inference chip startups like Cerebras and Groq.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Mistral Small 3 Released: Competitive with Larger Models
- Mistral Small 3 (Score: 643, Comments: 205): Mistral Small 3 is referenced in a tweet by @MistralAI dated January 30, 2025, featuring a URL that likely links to resources or details about the release. The tweet has garnered 998 views, indicating interest in the subject.
- Mistral Small 3 is a 24B-parameter model released under the Apache 2.0 license, optimized for low latency and efficiency, processing 150 tokens per second. It's noted for its robust language tasks and instruction-following capabilities, and it's over three times faster than larger models like Llama 3.3 70B on the same hardware, achieving over 81% accuracy on MMLU.
- Users appreciate the human evaluation chart for smaller models, highlighting the importance of aligning models with human perspectives rather than just benchmarks. This model can be fine-tuned for various domains, including legal, medical, and technical support, and is suitable for local inference on devices like RTX 4090 or Macbooks with 32GB RAM.
- The community is enthusiastic about the Apache 2.0 licensing, which allows for wide distribution and modification, and the model's performance compared to others like Qwen 2.5 32B and GPT-4o-mini. Discussions also include the model's speed and efficiency on different hardware setups, with users reporting speeds of 21.46 tokens/s on RTX 8000 and 24.4 tokens/s on M1 Max 64GB.
- Interview with Deepseek Founder: We won’t go closed-source. We believe that establishing a robust technology ecosystem matters more. (Score: 298, Comments: 41): Deepseek's founder emphasizes their commitment to remaining open-source, prioritizing the development of a robust technology ecosystem over closed-source strategies. The interview suggests this approach is vital for innovation and collaboration in the AI community.
- OpenAI and DeepSeek: Discussions highlight skepticism towards OpenAI's initial open-source intentions, contrasting it with DeepSeek's current open-source strategy. Users express concerns about the potential shift to closed-source once adaptation occurs, as seen with OpenAI.
- Hedge Fund Strategy: There is speculation about DeepSeek's financial strategies, with some users suggesting they operate like a hedge fund by releasing open-source models to influence market valuations, a tactic described as a form of information-based market manipulation.
- Technical Curiosity: Interest in DeepSeek's technology is evident, particularly regarding their FP8 training code. Users express a desire to access this code to potentially accelerate home-based training, emphasizing the technical community's interest in leveraging open-source advancements for personal projects.
- Mistral new open models (Score: 128, Comments: 7): Mistral has released two new models, Mistral-Small-24B-Instruct and Mistral-Small-24B-Base-2501, with recent updates and a user interface that includes a search bar and sorting options. The models are part of a collection of 23 available models, with the Instruct model having 50 likes and the Base model having 23 likes.
- Mistral Small 3 is highlighted for its competitiveness with larger models like Llama 3.3 70B and Qwen 32B, being more than 3x faster on the same hardware and open-source. It's considered an excellent open alternative to proprietary models such as GPT4o-mini. More details can be found here.
- There is curiosity regarding the differences between the Base and Instruct models, though specifics are not detailed in the comments.
Theme 2. Nvidia Reduces FP8 Training on RTX 40/50 GPUs
- Nvidia cuts FP8 training performance in half on RTX 40 and 50 series GPUs (Score: 401, Comments: 93): Nvidia has reportedly reduced FP8 training performance by half in the RTX 40 and 50 series GPUs according to their new Blackwell GPU architecture whitepaper, with the 4090 model showing a drop from 660.6 TFlops to 330.3 TFlops for FP8 with FP32 accumulate. This change may discourage AI/ML training on Geforce GPUs, reflecting a pattern of performance limiting since the Turing architecture while maintaining full performance for Quadro and datacenter GPUs.
- Many commenters believe the reported halving of FP8 training performance in the RTX 40 and 50 series GPUs might be a typo in the documentation, referencing the Ada Lovelace paper where FP8/FP16 accumulation was confused with FP8/FP32. Some suggest testing with old and new drivers to verify if performance has indeed been altered.
- There are accusations against Nvidia for engaging in anti-consumer practices, with references to chip etching and firmware limitations potentially used to restrict performance. Discussions include the possibility of legal actions, comparing this situation to previous cases like Apple's iPhone throttling settlement and Nvidia's GTX 970 false advertising fine.
- Users highlight the importance of CUDA for machine learning tasks, noting difficulties encountered on non-Nvidia hardware like Apple Silicon. The discussion also touches on the unhealthy state of the AI/ML GPU market, with comparisons to Quadro and datacenter GPUs' full performance capabilities, which are not mirrored in consumer-grade GPUs.
Theme 3. DeepSeek R1 Performance: Effective on Local Rigs
- DeepSeek R1 671B over 2 tok/sec without GPU on local gaming rig! (Score: 165, Comments: 57): The post discusses achieving 2.13 tokens per second on a DeepSeek R1 671B model without using a GPU, instead utilizing a 96GB RAM gaming rig with a Gen 5 x4 NVMe SSD for memory caching. The author suggests that investing in multiple NVMe SSDs could be a cost-effective alternative to expensive GPUs for running large models, as their setup showed minimal CPU and GPU usage, highlighting the potential for better price/performance for home setups.
- Users discuss the practicality and limitations of using a 2.13 tokens per second rate, with some expressing that a minimum of 5 tokens per second is necessary for effective use, and others pointing out that 2k context is insufficient for certain applications like coding.
- There is interest in improving performance by stacking NVMe SSDs into RAID configurations or using an acceleration card, with a suggestion that for around $1,000, one could achieve 60 GBPS theoretically, enhancing the speed and performance of running large models.
- Requests for detailed replication instructions and specific command usage indicate community interest in experimenting with similar setups. A user shared a gist with llama.cpp commands and logs to assist others in understanding and replicating the setup.
- What are you actually using R1 for? (Score: 106, Comments: 134): The author questions the practical utility of DeepSeek R1 models, noting their focus on reasoning and generating extensive thought processes, even for simple problems. They express skepticism about the rush to adopt these models for everyday tasks, suggesting they may be more suited for complex problem-solving rather than routine interactions like GPT-4o.
- Users highlight DeepSeek R1's utility in various technical tasks, such as coding, math problem-solving, and data analysis. Loud_Specialist_6574 and TaroOk7112 find it particularly useful for coding, with TaroOk7112 noting its ability to convert a script to a newer version without errors on the first try. No-Statement-0001 describes a complex problem where R1 provided a solution involving a shell script for handling Docker signals.
- Several users mention the model's effectiveness in creative and theoretical applications. Automatic_Flounder89 and Acrolith note its usefulness in theoretical experiments and creative writing, respectively, while a_beautiful_rhind appreciates its roleplaying capabilities. Dysfu uses it as a teaching assistant for math, enhancing the learning experience by avoiding direct solutions.
- AaronFeng47 and EmbarrassedBiscotti9 discuss challenges with R1, such as logical errors in code and occasional oversight of specifications, but acknowledge its potential for complex tasks. AaronFeng47 contrasts the experience with other models, finding R1 less reliable than o1-preview.
Theme 4. Mark Zuckerberg on Llama 4 Progress and Strategy
- Mark Zuckerberg on Llama 4 Training Progress! (Score: 154, Comments: 85): Mark Zuckerberg emphasizes Meta's progress on Llama 4, highlighting its potential to lead in AI with its multimodal capabilities and upcoming surprises in 2025. He also discusses the success of Ray-Ban Meta AI glasses and plans for significant infrastructure investments, expecting Meta AI to become a leading personalized assistant used by over 1 billion people.
- There is significant interest in model sizes and configurations for Llama 4. Users express the need for models that fit a range of hardware capabilities, with suggestions for intermediate sizes like 1B, 3B, 7B, and up to 630B to accommodate various VRAM capacities, avoiding the gap between 7B and 800B models.
- Discussion around Meta's multimodal capabilities highlights excitement about native omnimodality, with expectations for models excelling in text, reasoning, visual understanding, and audio. Users are eager for models that support audio/text, image/text, and video capabilities, crucial for applications like vocal assistants and visual synthesis.
- Comments reflect skepticism about the timeline and strategic decisions of Meta. Concerns include the delayed release of Llama 4, the focus on fine-tuning post-training, and the potential for a limited range of model sizes. The debate also touches on the broader implications of Meta's AI developments in the context of privacy and competition with other tech giants.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. DeepSeek-R1's Impact: Technical and Competitive Analysis
- No Hype DeepSeek-R1 [R]eading List (Score: 196, Comments: 9): The author shares a reading list compiled from their research paper club, focusing on foundational papers in AI/ML that lead up to DeepSeek-R1. Aimed at providing a deeper understanding of the technology, they invite readers to explore the list on Oxen.ai's blog.
- Low rank matrices approach with attention was discussed, with a question about whether it could be retrofit into existing models using their existing weights.
- Interest in joining the research paper club was expressed, with requests for more information on how to participate.
- Positive feedback on the reading list was shared, with anticipation for the upcoming Paper Club meeting.
- [d] Why is "knowledge distillation" now suddenly being labelled as theft? (Score: 256, Comments: 87): Knowledge distillation is being controversially labeled as theft, despite being a method to approximate transformations by mimicking outputs. The post argues that this label is unfounded since the architecture and training methods differ, and the process does not necessarily replicate the original transformation function.
- Several commenters highlight the distinction between copyright law and Terms of Service (TOS) violations, emphasizing that while using outputs from OpenAI models may breach TOS, it does not equate to theft under copyright law. ResidentPositive4122 notes that OpenAI's documentation clarifies they do not claim copyright on API generations, only that using such data to train other models breaches TOS.
- Discussion around OpenAI's reaction to potential TOS violations suggests a strategic move to maintain their status, with proto-n suggesting that OpenAI's claims against DeepSeek are a way to assert their influence and importance in the AI field. batteries_not_inc and others argue that OpenAI's response is driven by dissatisfaction rather than legal standing.
- The debate also touches on broader themes of regulation and ethics in AI, with H4RZ3RK4S3 and others discussing the impact of EU regulations and the contrasting perceptions of US and Chinese tech practices. KingsmanVince and defaultagi express skepticism about both US and Chinese approaches, indicating a complex landscape of ethical considerations and public perception.
- State of OpenAI & Microsoft: Yesterday vs Today (Score: 154, Comments: 27): DeepSeek-R1 is now integrated into Microsoft Azure services, marking a shift from previous controversies involving alleged data exfiltration from OpenAI's API. The recent launch on Azure AI Foundry and GitHub highlights the platform's trustworthiness and capabilities, contrasting with earlier security concerns reported by Reuters.
- DeepSeek-R1 is now available on Azure, and users express interest in testing it as an API option. There is skepticism about Microsoft's motives, with some suggesting they are capitalizing on previous controversies.
- The model is free and open source, which is a key reason for its widespread support, despite some users not understanding the distinction between the model and its applications.
- Discussions include references to Microsoft's historical strategy of "embrace, extend, and extinguish", hinting at concerns about their true intentions behind supporting DeepSeek-R1.
Theme 2. Copilot's AI Model Integration and User Feedback
- o1 now available free of charge in Copilot (Score: 253, Comments: 56): Copilot now offers OpenAI's reasoning model (o1) free for all users, as announced by Mustafa Suleyman on Twitter. The announcement showcases a conversation about ocean currents, illustrating o1's capability to provide detailed responses, and highlights user engagement metrics.
- The majority of users express dissatisfaction with Copilot, describing it as the "worst" AI for Microsoft products, with several comments highlighting issues related to wrong answers and poor integration. There is a sentiment that Copilot's quality has deteriorated, especially since changes made around August last year.
- Some users speculate that the reason for Copilot's perceived decline is due to strategic decisions by Microsoft and OpenAI to drive users back to OpenAI subscriptions, or to collect data for future offerings such as "virtual employees." Microsoft's 49% ownership of OpenAI is noted as a significant factor in these strategies.
- Technical issues are blamed on super long system prompts and prompt injections for "safety reasons," which disrupt model performance. The focus seems to be on corporate users, as companies are more comfortable using Copilot with their data, despite the perceived decline in product quality.
Theme 3. ChatGPT's Latest Updates: User Experience and Technical Changes
- ChatGPT got some nice, incremental updates (Score: 171, Comments: 61): ChatGPT has received incremental updates in the GPT-4o model as of January 29, 2025, including an extended training data range for more relevant knowledge, enhanced image analysis capabilities, and improved performance in STEM-related queries. Additionally, the model now responds more enthusiastically to emojis.
- There is skepticism about the incremental updates to GPT-4o, with users suggesting that OpenAI lifted previous constraints to upsell higher pricing tiers, and some users are noticing a return to the initial quality of responses. The discussion also mentions the anticipation of o3-mini as a potential short-term response to current limitations.
- The use of emojis in the new updates has been polarizing, with some users appreciating the enhanced formatting and others finding it excessive and disruptive, especially in professional contexts. One user mentioned the first versions of Copilot as a comparison to the current emoji usage.
- The "Think" button feature is discussed, with some users having access to it and noting its potential to add a reasoning chain to GPT-4o. However, there is concern about how it might affect message limits, particularly for those with limited quotas.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Exp (gemini-2.0-flash-exp)
1. DeepSeek's Rise: Speed, Leaks, and OpenAI Rivalry
- DeepSeek Defies Expectations, Leaks Data: DeepSeek models, especially R1, show strong reasoning and creative potential, rivaling OpenAI's o1, but a database exposure on Hacker News exposed user data, raising privacy concerns. Despite that, many see it outpacing OpenAI's performance for creative tasks and code.
- R1 Performance Varies: DeepSeek R1 1.58B runs slow (3 tokens/s) on basic hardware, needing 160GB VRAM or fast storage per this doc for better throughput, but some report 32 TPS on high-end GPUs. Users also report that the quantized versions can struggle with instruction following.
- OpenAI and DeepSeek lock horns: While some note that OpenAI criticized DeepSeek for its training data, they are also using DeepSeek internally for data retrieval. This rivalry has intensified, with questions raised about censorship, open access, and data collection practices.
2. Small Models Make Big Waves: Mistral and Tülu
- Mistral Small 3 Shines Bright: The new Mistral Small 3 (24B parameters, 81% MMLU) is lauded for its low latency and local deployment capabilities, running 3x faster than competitors per the official site, offering a sweet spot between performance and resource use, and is licensed with Apache 2.0.
- Tülu 3 Topples Top Dogs: Tülu 3 405B, a 405B parameter model with open weights, outperformed both DeepSeek v3 and GPT-4o on benchmarks, driven by its Reinforcement Learning from Verifiable Rewards (RLVR) approach, with open post-training recipes.
- Quantization Tradeoffs Discussed: Developers are experimenting with model quantization, noting that it reduces model size and VRAM usage, but can also degrade instruction following, causing users to evaluate its effectiveness on various tasks.
3. RAG and Tools: LM Studio and Agent Workflow
- LM Studio Supports RAG: LM Studio 0.3.9 now supports RAG with local document attachments, described in the docs, allowing documents within context window to be used in chat sessions, and also now supports Idle TTL and auto-update, which has improved its efficiency.
- Aider Goes Local With Read-Only Stubs: Users are exploring methods to integrate Aider with local models like Ollama for privacy reasons and the new YouTube video highlights the use of read-only stubs to manage large codebases.
- LlamaIndex Integrates Advanced Agents: LlamaIndex's "Mastering AI Agents Workshop" has introduced advanced AgentWorkflow concepts for multi-agent systems, with robust architectures leveraging LlamaIndex as shown here.
4. Hardware and Performance: GPUs and Optimization
- Blackwell's Power Boost: The new Blackwell architecture with sm_120a is set to shake up GPU performance, offering stronger compute capability for consumer GPUs, as per NVIDIA documentation, with discussions highlighting possible 5x speed boosts in FP4 tasks on new RTX 5090, though some tests show only 2x gains.
- PyTorch 2.6 Performance Knobs: The newly launched PyTorch 2.6 adds
torch.compilefor Python 3.13, introduces FP16 on X86, and uses Manylinux 2.28, but drops Conda support for distribution. - GPU Pricing and Availability: Users note that new 5090 GPUs are very difficult to obtain, selling out rapidly while Jetson Nano prices have surged to $500-$700, as opposed to listings at around $250.
5. Funding, Ethics, and Community Buzz
- Dario Amodei’s AI Safety Investment Criticized: Community members express skepticism about Dario Amodei's bold $1B push toward AI Safety, with some labeling his claims as fraudulent marketing, and questioning large-scale AI fundraising efforts.
- SoftBank's Billion-Dollar Bet on OpenAI: SoftBank is reportedly planning a massive $15-25 billion investment in OpenAI, as another major bet on AI and its future potential, adding to its existing commitments.
- Community Engages Across Platforms: Members actively share findings and ask questions, with strong engagements about various AI models, frameworks, and tooling, including discussions in many Discords on how different methods are influencing the field.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- DeepSeek R1 Speeds and Snags: DeepSeek R1 1.58B runs at about 3 tokens/s on limited hardware, with this official doc suggesting 160GB VRAM or fast storage for higher throughput.
- Community members flagged potential issues on Windows and recommended Linux for improved quantization performance.
- Mistral-Small 24B Breezes In: The newly shared Mistral-Small-24B-Instruct-2501-GGUF offers an Apache 2.0 license, features closed weights, and promises reduced latency.
- Contributors referenced Mistral's site citing 81% MMLU, seeing it as a compelling addition to open-source options.
- Online DPO Spark with Unsloth: A user confirmed online DPO worked using Unsloth repos after applying partial hard coding to handle memory constraints.
- They included a LinkedIn post about lowering DPO memory usage and asked for real-world feedback.
- MusicGen Fine-Tune Foray: A newcomer aims to fine-tune facebook/musicgen-medium or musicgen-small with
.WAVand.TXTfiles, focusing on epoch and batch size as seen in this guide.- They considered leveraging vllm for generation but also examined Unsloth and GRPOTrainer, seeking a stable fine-tuning path.
- vllm vs. Unsloth: Shared Goals or Splitting Paths?: Community members compare vllm's neural magic benefits with Unsloth's quantization approach, uncertain about future alignment under Red Hat.
- Some floated partial integration to curb GPU downtime, while others viewed each approach as distinct due to speed differences.
Perplexity AI Discord
- O1 vs. R1 Rivalry & Perplexity's Toggle Troubles: Users questioned O1 vs. R1 reliability in Perplexity Pro, noting default switches to R1 despite choosing O1. Many felt O1 offers better reasoning, but recent reliability issues prompted concerns.
- In a tweet from Aravind Srinivas, Pro users were promised 500 daily DeepSeek R1 queries, yet confusion remains on its consistency, with some users calling it annoyingly unstable.
- Alibaba's Competition Chaser Model: Alibaba introduced a new model to strengthen its competitive position, possibly realigning market dynamics. More details appear in this link, highlighting advanced algorithms for faster user experiences.
- Community members anticipate further enhancements, with some hinting at possible synergy with existing open-source frameworks, though no official statement has been made.
- DeepSeek Gains Traction & Shakes Up Data Retrieval: OpenAI clarified its usage of DeepSeek, praising its query handling for complex datasets. Many praised DeepSeek's stable privacy features, even as they noted occasional downtimes.
- Deepinfra’s DeepSeek-R1 Demo was cited for fulfilling similar tasks as OpenAI-O1, sparking lively debate over token usage and performance benefits.
- Sonar-Reasoning's Surprising Shortfalls: Testers of the sonar-reasoning model API questioned its real-world performance, seeking details on improvements over other models. Some reported lengthy, repeated answers that wasted tokens and ignored new prompts.
- Others argued it still outperforms in certain tasks, but direct side-by-side comparisons in the playground indicated the model’s thinking might be diminished in API responses.
- GPT-4, Sonnet, and Gemini Showdown: In an ongoing debate, users covered GPT-4, Sonnet, and Gemini 2.0 for advanced queries, including calculus and coding tasks. Sonnet earned acclaim for more natural-sounding text, while GPT-4 and Gemini remain powerhouses for raw accuracy.
- Some highlighted that pairing Sonnet with O1 yields clearer outputs for complex tasks, motivating a shift away from partial Claude subscriptions and rethinking paywalls.
Codeium (Windsurf) Discord
- DeepSeek's Dynamic Duo: Windsurf introduced DeepSeek R1 and DeepSeek V3 for Pro-level accounts, each requiring distinct credits per message.
- Developers highlighted R1's first-ever coding agent usage, referencing the changelog for more updates.
- Cascade's Quick Fixes: Community members reported input lag reductions and fixes to stop the Cascade panel from reopening on reload.
- They also discussed new web search capabilities via
@weband@docs, pointing to URL-based context handling.
- They also discussed new web search capabilities via
- DeepSeek vs. Sonnet Showdown: Users compared cost-efficiency and performance between DeepSeek and Claude 3.5 Sonnet, with many testers preferring R1.
- Others described Sonnet perpetually editing files, while R1 demonstrated steady behavior in coding tasks.
- Credit Confusion Clarified: Members debated whether DeepSeek R1 uses 0.25 or 0.5 credits per message, citing variable documentation.
- They pointed to the Codeium Docs and support page for precise details.
OpenAI Discord
- DeepSeek Dares to Duel with OpenAI: In guild talk, participants highlighted that DeepSeek R1 outshines OpenAI's o1 for creative tasks, referencing a Raspberry Pi demo and potential rivalry from Gemini Pro and Grok.
- Someone claimed 'DeepSeek censors results' in a YouTube critique, setting off speculation about data collection and open access.
- OneClickPrompts for Swift Setup: A new tool named OneClickPrompts was introduced for constructing personalizable multi-part prompts, with a shared GIF highlighting simplified usage for repeated tasks.
- Users praised the extension's modular approach but noted 'smart prompt combos' are still essential to achieve deeper results.
- Fine-Tuning Ollama Gains Ground: A user sought methods to fine-tune Ollama for domain-specific tasks, raising hopes for future expansions or official workflows.
- Others pointed to scattered references on GitHub, adding that streamlined procedures could unlock 'next-level adaptability' in Ollama.
- GPT's Memory & Context Windows Collide: Members criticized GPT's memory for losing crucial details over lengthy chats, sparking renewed interest in bigger context windows from open source projects like DeepSeek.
- They argued that inconsistent recollection hinders production usage, with calls for 'stable context retention' as a must-have feature going forward.
LM Studio Discord
- LM Studio 0.3.9 Gains Momentum: LM Studio 0.3.9 added Idle TTL, separate reasoning_content in API responses, and auto-update for runtimes, with official installers here.
- Community members recognized improved memory management and cited simpler auto-update processes for Hugging Face model downloads, referencing the docs.
- RAG Rolls Out in LM Studio: LM Studio now supports RAG with attached local documents in chat sessions, described in the docs.
- Users observed that if a document fits within the model’s context, it can be included in full, sparking interest in leveraging local references.
- DeepSeek's GPU Performance Surges: Discussions revealed 6-7 tokens/sec on a GTX 1080 and Ryzen 5 3600 for DeepSeek models, with a focus on VRAM management to prevent slowdowns.
- Others reported i9-14900KF, 128GB RAM, and dual RTX 4090 setups reaching 30-40 tokens/sec on 70B models, emphasizing the significance of fitting the entire model into GPU memory.
- Jetson Nano Pricing Raises Eyebrows: Members noted the Jetson Nano hitting $500-$700 or being backordered, making it less appealing compared to standard GPUs.
- A few found listings around $250, but many leaned toward more conventional hardware for superior performance.
aider (Paul Gauthier) Discord
- DeepSeek R1 Soars & Database Spills: Members reported DeepSeek R1 hitting around 32 TPS on a 4090 GPU, praising its performance while also noting issues with quantized variants. A leak on Hacker News revealed a DeepSeek database exposure that raised user privacy alarms.
- Some participants voiced skepticism about relying on a service with a potential data breach, referencing privacy nightmares as a reason to explore local solutions.
- O3 Mini Hype & Quantization Quirks: Many expressed interest in O3 Mini as a potentially faster and smaller alternative, anticipating improved experiences over existing large models. They discussed how quantization can hamper performance and instruction-following, with some calling it a tricky trade-off.
- A few joked about waiting impatiently for O3 Mini to address their model woes, while others shared varied results with prior quantized releases, highlighting the unpredictability of sizing models down.
- Aider Gets Local & Read-Only Stubs: Users explored integrating Aider with local models like Ollama for privacy reasons, expecting a solution that avoids sending data to third parties. A new YouTube video showcased read-only stubs designed to handle large codebases more efficiently.
- Some encountered confusion using multiple endpoints (e.g., Azure AI) but found references to advanced model settings helpful, with others praising stubs as a welcome step to keep code modifications under tighter control.
- O1 Pro Debates Spark Pricing Talk: Several devs championed O1 Pro for coding tasks, but they criticized its cost and usage constraints. They weighed these factors against local open-source models, noting that censorship concerns occasionally hinder productivity.
- A few participants described O1 Pro as a strong coding ally despite the price tag, while some remain committed to local models for freedom from potential policy shifts.
Cursor IDE Discord
- DeepSeek R1 Surfs the West: Windsurf announced that DeepSeek R1 and V3 are now live with tool calling capabilities, enabling R1 to run in coding agent mode for the first time.
- Users noted that it's fully hosted on Western servers and referenced Cursor's community forum for ongoing discussion.
- Token Tangles in Chat & Composer: Some users expressed confusion over the 10k token context setting, reporting difficulties tracking usage in chat and composer.
- They questioned whether the beta settings genuinely provide extended contexts or if messages get truncated without warning.
- MCP Setup Gathers Steam: A bash script approach lets people add MCP server configurations quickly, as shown in this GitHub repo.
- Developers shared the MCP Servers site to encourage trying different servers in tandem with Cursor.
- Model Security Storm Warnings: Concerns arose about potential hidden code execution in ML models, referencing a post on silent backdoors in Hugging Face models.
- Some recommended using protectai/modelscan for scanning local setups to unearth any suspicious payloads.
- Local vs Hosted Showdown: A lively debate broke out over self-hosting compared to relying on solutions like DeepSeek R1, citing privacy and cost trade-offs.
- While local enthusiasts hope for better offline models, others point to the performance benefits of hosted servers as they evolve.
Nous Research AI Discord
- Nous x Solana Sunset Soirée: The upcoming Nous x Solana event in NYC is brimming with attendance requests, focusing on discussions around distributed training in AI models.
- Participants anticipate in-person demos and specialized Q&A, hoping for synergy with the new Psyche approach.
- Mistral & Tülu Tussle: Community members shared excitement over Mistral-Small-24B-Instruct-2501 on Hugging Face and Tülu 3 405B from this tweet, both positioned for top performance in smaller-scale LLMs.
- Several pointed to R1-Zero’s blog analysis for benchmark comparisons, fueling debate on which model truly excels.
- Psyche Paves Paths for Distributed Gains: The Psyche distributed training framework aims to handle large-scale RL with a modular system, drawing praise for its ability to scale model training.
- A tweet showcased excitement for open sourcing this framework, with focus on GitHub accessibility and a possible consensus algorithm roadmap.
- China's Ten Titans Tower Over Europe's Models: A chat revealed China has TEN top-tier AI models rivaling Europe’s biggest, including Mistral, per this tweet.
- Participants noted the US boasts only five major AI labs—OpenAI, Anthropic, Google, Meta, and xAI—highlighting a fierce global race.
- CLIP-Driven Generation Gains Ground: A member inquired about autoregressive generation on CLIP embeddings, typically employed for guiding Stable Diffusion.
- They stressed a gap in references for direct CLIP-driven generative processes, indicating interest in merging multimodal inputs with decoding tasks.
Yannick Kilcher Discord
- Dario’s Daring $1B Venture: Community members discussed Dario Amodei and his $1B push toward AI Safety, raising questions about financial transparency and ambitious claims in his blog post. They highlighted unease over what some labeled fraudulent marketing, reflecting deeper skepticism toward large-scale AI fundraising efforts.
- Several technologists argued that funneling such large sums into sweeping safety initiatives may neglect other pressing AI research, while others insisted it could catalyze more responsible AI development.
- Mistral’s Middling-Sized Marvel: The newly unveiled Mistral Small 3 packs 24B parameters, nets 81% on MMLU, and runs 3x faster than bigger competitors. Developers praised its local deployment capability, citing a sweet spot between performance and resource efficiency.
- Enthusiasts contrasted it with models like Llama 3.3 (70B), suggesting Mistral’s tight design could spur more accessible, specialized solutions.
- Tülu 3 405B Triumph: Researchers at AI2 released Tülu 3 405B, boasting an enormous 405B parameters and defeating both DeepSeek v3 and GPT-4o on multiple benchmarks. Its Reinforcement Learning from Verifiable Rewards (RLVR) approach propelled the model’s accuracy and consistency in test environments.
- Participants noted the model’s training recipes and open-weight policy, citing potential momentum for even bolder open-research collaborations.
- Framework Face-Off: LlamaIndex vs PydanticAI vs LangChain: Developers reported PydanticAI’s neat interface and internal temperature settings but lamented its frequent broken JSON outputs. LlamaIndex yielded more consistent structured data, while LangChain drew criticism for complicating error tracing with its pipe-based architecture.
- Others highlighted high CPU or GPU usage in certain UIs as a sticking point, fueling calls for streamlined agent tooling with robust logging and performance metrics.
- Prospective Config’s Bold Brainchild: A Nature Neuroscience paper introduced prospective configuration as a foundation for learning beyond backpropagation, sparking fresh speculation on next-gen neural training. The method claims improved efficiency and better alignment with biological processes.
- Community conversation suggested potential synergy with RL approaches, while some questioned if the approach might overpromise, given the field’s rapid pace of technical leaps.
Interconnects (Nathan Lambert) Discord
- Tülu 3 Topples Titans: The Tülu 3 405B launch shows superior performance compared to DeepSeek v3 and GPT-4o, as described in their blog.
- Enthusiasts highlighted open post-training recipes, with excitement swirling over its scalability and massive 405B-parameter footprint.
- Mistral Small 3 Masters Minimal Latency: Mistral Small 3 debuted as a 24B-parameter model at low latency, claimed to run comfortably on typical hardware (details here).
- Community feedback praised its knowledge-dense architecture, positioning it as a strong competitor for local generative AI tasks.
- DeepSeek Leak Sparks Security Fears: Wiz Research revealed a publicly accessible DeepSeek database, exposing secret keys and chat logs.
- Discussions centered on privacy concerns, prompting calls for stricter control measures in AI infrastructure.
- SoftBank Showers OpenAI with Billions: Reports emerged of SoftBank planning to invest $15-25 billion into OpenAI, supplementing its existing pledge of over $15 billion.
- Analysts see this as yet another massive bet on AI, raising the stakes in an already fierce funding race.
- DeepSeek v3 Experts Go Parallel: New Mixture-of-Experts design in DeepSeek v3 uses sigmoid gating and dropless load balancing, letting multiple experts respond without direct contention (paper).
- Contributors discussed fine-tuning those expert layers and applying MTP to forecast two tokens at once, fueling speculation on inference acceleration.
Eleuther Discord
- Deepseek Dilemma: OpenAI's Double-Edged Ethics: Community members noted that OpenAI criticized Deepseek training while ironically using data from similar sources, raising questions about their motivations. They suspected OpenAI used legal claims to bolster a confident image in a crowded field.
- Some participants felt the Deepseek debate highlights potential hypocrisy, fueling doubts about whether OpenAI truly safeguards collaborators' interests.
- RL Revelation: Less Tools, More Talent: LLM enthusiasts discovered that using reinforcement learning (RL) can reduce the size of tool usage instructions, letting models pick up essential skills with minimal guidance. They worried that overreliance on specific tools could undermine core problem-solving abilities.
- By balancing RL with selective tool exposure, they hope to preserve a model’s reasoning prowess without letting it drift into rote tool dependency.
- Hyperfitting Hype: Big Gains from Tiny Data: New results showed that hyperfitting on a tiny dataset can catapult open-ended text generation, climbing from 4.9% to 34.3% in human preference scores. A paper confirmed these dramatic improvements, prompting a reexamination of traditional overfitting fears.
- Critics debated whether such narrow training jeopardizes broader generalization, but many welcomed these surprising boosts in text quality.
- Critique Craze: Fine-Tuning Beats Blind Imitation: Researchers proposed Critique Fine-Tuning (CFT), teaching models to spot and correct noisy responses rather than merely imitating correct solutions. They reported a 4–10% performance jump across six math benchmarks, as documented in this paper.
- The community expressed optimism that teaching models to critique mistakes might produce more robust reasoning than standard supervised fine-tuning.
- Backdoor Buzz & Llama2 Config Confusion: New warnings about undetectable backdoored models arose in this paper, casting doubt on conventional loss-based detection strategies. Meanwhile, developers questioned the significance of 32768 in Llama2’s config when setting gated MLP dimensions.
- Some pointed out that this number isn’t divisible by 3, leading to a reset toward 11008 and stirring further discussion on how to export model configurations cleanly.
OpenRouter (Alex Atallah) Discord
- DeepSeek's Double-Dose Distills: OpenRouter introduced DeepSeek R1 Distill Qwen 32B and DeepSeek R1 Distill Qwen 14B, each promising near-larger-model performance at $0.7–$0.75 per million tokens.
- The 14B version reportedly scored 69.7 on AIME 2024, with both models accessible via the OpenRouter Discord.
- Subconscious AI & Beamlit Big Moves: Subconscious AI showcased causal inference and market simulation potential on their website, stressing 'guaranteed human-level reliability.'
- Meanwhile, Beamlit launched a free alpha that accelerates shipping AI agents up to 10×, offering GitHub workflows and observability tools.
- OpenRouter Pricing Tiffs & Rate Limit Rants: Users debated the 5% fee for OpenRouter, attributing it partly to underlying Stripe costs.
- Others reported frequent 429 RESOURCE_EXHAUSTED errors with Google's Gemini, advising personal API keys to avoid timeouts.
- Mistral's Small 3 & Tülu 3 Teasers: Announced via tweets, Mistral's Small 3 (24B, 81% MMLU) and Tülu 3 (405B) both promise expanded training and faster throughput.
- Community chatter suggests these new releases may pair well with DeepSeek for bigger gains in speed and accuracy.
Stackblitz (Bolt.new) Discord
- Bolt’s Big Binary Break: Bolt stops generating binary assets, significantly reducing token usage by hundreds of thousands and improving output quality, according to a tweet from bolt.new.
- Members praised the shift to external assets, noting faster execution and celebrating it as “a major performance leap” in community talk.
- Community System Prompt Surprises: Dev discussions turned to the Project and Global System Prompt, with one user employing it for changelog updates and hoping to see expanded creative uses.
- A tip emerged to share specific files and confirm correct views, showcasing deeper usage potential beyond everyday tasks.
Stability.ai (Stable Diffusion) Discord
- ComfyUI Gains Crisp Control for Inpainting: Some participants shared manual approaches to inpainting, referencing examples on Streamable for advanced ControlNet setups in ComfyUI with accurate touches.
- They praised flexibility for specific adjustments instead of relying solely on automated methods.
- Hardware Hustle: GPU Chatter Heats Up: Users debated their GPU options, with the Intel Arc A770 LE pitched as comparable to a 3060 for gaming and AI tasks.
- Others swapped tips on 3080 and 3090 usage, focusing on VRAM requirements for Stable Diffusion.
- Face Swap Reactor Reemerges with Filters: Participants noted the removal of Reactor due to lacking NSFW checks, before reuploading a safer version on GitHub.
- They also pointed to the ComfyUI extension for streamlined face swap functionalities.
- Lora Training Twists for Stable Diffusion: Members dissected the steps for building Loras, emphasizing style integration and precise facial matching.
- They discussed combining multiple references, highlighting challenges in synchronizing style and features.
- 5090 GPUs Vanish in a Flash: New 5090 GPUs were snapped up instantly, prompting frustration over shortage and steep demand.
- People mulled financing choices to afford fresh hardware, disappointed by the minimal inventory.
GPU MODE Discord
- Blackwell & The Brash sm_120a Breakthrough: New Blackwell architecture with sm_120a overshadowed prior sm_90a features, as detailed in cutlass/media/docs/blackwell_functionality.md, promising stronger compute capability for consumer GPUs.
- Community members debated RTX 5090 gains vs RTX 4090, citing a possible 5x speedup in FP4 tasks but only 2x in other tests, raising concerns about inconsistent documentation.
- PyTorch 2.6 Packs a Punch: Recently launched PyTorch 2.6 adds
torch.compilesupport for Python 3.13, introduces FP16 on X86, and uses Manylinux 2.28, described in PyTorch 2.6 Release Blog.- Enthusiasts noted Conda deprecation while praising new performance knobs like
torch.compiler.set_stance, with some calling it 'a big shift' in distribution strategy.
- Enthusiasts noted Conda deprecation while praising new performance knobs like
- Reasoning Gym’s Rapid Expansion: The Reasoning Gym soared to 33 datasets, included in a new gallery at GALLERY.md, showcasing a wide range of reinforcement learning tasks.
- Contributors praised cooperative challenges and proposed multi-agent negotiation setups, fueling conversation on explanatory and logic-based tasks.
- Mistral’s Mischief at the AIx Jam: The Mistral AIx entry landed #2 in the 🤗 Game Jam, inviting folks to test ParentalControl in this HF Space, blending AI with game dev for comedic horror.
- They also showcased Llama3-8B R1 with a claimed 14% improvement in GSM8K, as detailed in this blogpost, sparking excitement about cost-efficient training.
Nomic.ai (GPT4All) Discord
- DeepSeek Models Spark LaTeX Talk: Members eagerly await the DeepSeek release, touting strong math and LaTeX capabilities for complex tasks.
- They discussed VRAM constraints, stressing careful context-size management for heavier computations.
- Ollama & GPT4All Connect for Local Gains: Some confirmed hooking GPT4All to Ollama by running Ollama as a server and tapping the OpenAI API from GPT4All.
- They pointed to the GPT4All Docs for a step-by-step approach.
- Remote LLMs Step into GPT4All: Users tested loading remote LLMs into GPT4All, highlighting the need to set correct API keys and environment variables.
- They recommended improved guidance in the GitHub wiki to help newcomers.
- AI Education Initiative Hits Offline Mode: A user showcased a plan to build an AI-driven tool for children in Africa, referencing Funda AI.
- They plan to use small-footprint models and curated data to allow self-study without internet, bridging resource gaps.
- Model Suffix Mystery -I1-: One member asked about -I1- in some model names but no official explanation was confirmed.
- Others requested clearer labeling, indicating a demand for more open model documentation.
MCP (Glama) Discord
- Cursor's Constrained MCP Capabilities: The new Cursor adds partial MCP support, but environment variables remain a gap, prompting command-line workarounds like
FOO=bar npx some-serveras noted in env invocation.- Community members seek better alignment between MCP and LSP config structures, describing this mismatch as a stumbling block for broader adoption.
- Web Client Wizardry for MCP: A self-hosted web client now coordinates multiple MCP servers and agents, enabling smooth hand-offs for local or cloud setups.
- Its flexible approach fuels interest, although some lament the lack of dynamic agent prompt functionality for MCP.
- Function-Calling Frustrations for 8b Model: An 8b model in MCP struggles with function calling and tool usage, confounding testers who rely on robust agent interactions.
- Several contributors suggest deeper community input on forums like Reddit, hoping to address the model's reliability concerns.
- Hataraku Hits #1 on ShowHN: The Hataraku project soared to the top on ShowHN, sparking momentum for its TypeScript SDK proposal and CLI features.
- Community members are pitching in with collaboration and trial runs, aiming to refine the interface and improve broader user experiences.
Notebook LM Discord Discord
- NotebookLM's February Feedback Fandango: NotebookLM is hosting remote chat sessions on February 6th, 2025 for user feedback, offering $75 to participants.
- They require a screener form submission, a stable Internet connection, and a device with video capabilities.
- Transcribing Trading Tactics with League of Legends Lingo: A user converted trading course videos to audio, then transcribed them with AI and used NotebookLM to clarify advanced material.
- They introduced Big Players using LoL references, demonstrating AI's flexible approach to explaining complex ideas.
- Executive Order Exposé in 24 Hours: NotebookLM summarized a new Executive Order on public education privacy in under a day, with an in-depth YouTube review.
- This demonstration sparked conversation on applying the tool for policy briefs and thorough analysis.
- DeepSeek R1 Dissected: GRPO & MoE: A NotebookLM Podcast covered DeepSeek R1, highlighting GRPO and Mixture of Experts to explain its architecture.
- Listeners viewed the full discussion with benchmarks and a quick demo, fueling questions on performance gains.
- Sluggish Study Times and Language Lapses: Some users faced 10–30 minute delays generating study guides, even with a single source.
- Others lamented poor multilingual handling (e.g., Korean and Japanese) and brief Gemini 2.0 Flash glitches, while seeking stricter source usage rules.
Modular (Mojo 🔥) Discord
- Branch Bump & Retarget Roundup: The branch changes are completed with all pull requests retargeted, ensuring a smooth code integration process.
- Team members can ask questions if they're unsure, highlighting the project's emphasis on open communication.
- NeoVim Nudges for Mojo LSP: Developers discussed enabling Mojo LSP with nvim-lspconfig, encountering some quirks during setup.
- A few reported only partial success, suggesting deeper debugging is needed for a stable workflow.
- Mojo 1.0: Speed vs. Stability Showdown: Chris Lattner stressed that Mojo 1.0 should blend GPU optimization with direct execution to maximize speed.
- Participants argued that immediate reliability must balance the race for top performance metrics.
- Backward Compatibility Shakedown: Members worried that breaking changes in new Mojo releases could deter users from upgrading.
- They emphasized support for older libraries to maintain momentum and cultivate a steady user base.
- Reflection & Performance in the Mojo Mix: Conversation centered on reflection for data serialization and noted that some reflection is partially implemented.
- Attendees also pushed for large-cluster benchmarking, mentioning the Mojo🔥: a deep dive on ownership video with Chris Lattner.
Latent Space Discord
- Small but Speedy: Mistral 3: Mistral Small 3 was introduced as a 24B-parameter model under an Apache 2.0 license with 81% MMLU and 150 tokens/sec performance, according to official details.
- It features fewer layers and a bigger vocabulary, sparking community interest in its unorthodox FF-dim/model-dim ratio on social media.
- DeepSeek Database Leak Exposes Secrets: A misconfigured ClickHouse database at DeepSeek led to a major data exposure, including chat histories and secret keys, as reported by Wiz Research.
- They quickly secured the leak after the disclosure, prompting concerns about overall safety in AI data handling.
- FUZZ Frenzy at Riffusion: Riffusion introduced FUZZ, a new generative music model that aims for high-quality output for free, shared here.
- Early adopters praised the melodic results, noting the service is only free while GPU resources hold up.
- OpenAI API Lag Under Scrutiny: Discussions mentioned OpenRouter and Artificial Analysis as ways to track possible latency surges in OpenAI’s API.
- Some saw normal response rates, but community members recommended caution and continuous checks.
- ElevenLabs' $180M Funding Feat: ElevenLabs raised $180M in a Series C round led by a16z & ICONIQ, a milestone announced here.
- Observers see it as a strong endorsement for the future of AI voice technologies and their bigger market potential.
LLM Agents (Berkeley MOOC) Discord
- Track Teasers Tempt LLM Agents Crowd: Participants await more details about the application and research tracks for the LLM Agents MOOC, which organizers promised to share soon.
- Community members repeated Stay tuned! messages, eager to hear official announcements.
- Sign-Up Snafus Stall Confirmation: Several people noted they submitted the Google Forms sign-up but haven't received replies, particularly those pursuing PhD opportunities.
- They asked for final acceptance details and faster responses to manage their schedules.
- Quiz 1 Queries and Private Archives: Members confirmed Quiz 1 is live on the course website, referencing the syllabus, with some seeking older quiz solutions from a previous LLM Agent course.
- They shared a Quizzes Archive, cautioning about hidden answers and an outdated browser prompt.
- Certificate Confusion Continues: Many await certificates from earlier sessions, with official guidance promised soon.
- Organizers stated upcoming announcements will clarify the process for this semester's awards.
- Lecture Launches and Accessibility Aims: Members pressed for the 1st lecture to be uploaded quickly, suggesting it would only take '5 minutes,' but the editing team cited Berkeley's captioning requirements.
- They noted the livestream is watchable via the course website, with a polished version pending completion of accessibility measures.
LlamaIndex Discord
- Agents in Action: Mastering AI with LlamaIndex: The Mastering AI Agents Workshop introduced advanced AgentWorkflow concepts for multi-agent frameworks, as shown in this link.
- Attendees explored robust architectural approaches with LlamaIndex, fueling new conversations about best practices.
- BlueSky Boost: LlamaIndex Spreads Its Wings: The LlamaIndex team officially landed on BlueSky, highlighting new visibility at this link.
- Contributors anticipate expanded engagement with the platform, sparking more activity around AI developments.
- O1’s Quirky Support: Partial Streaming and Debates: Members noted LlamaIndex added
o1compatibility withpip install -U llama-index-llms-openai, though some functionality remains unfulfilled.- They cited an OpenAI community thread which confirmed OpenAI has not fully enabled streaming, fueling user frustration.
tinygrad (George Hotz) Discord
- GPU Tango: P2P Patch vs Proxmox: In #general, participants discussed using a P2P patch with multiple NVIDIA GPUs and weighed Proxmox vs baremetal setups for optimal IOMMU support.
- Some users prefer going baremetal to bypass perceived hypervisor constraints, while others reported that Proxmox can handle the job if configured precisely.
- Tiny Boxes Team Up for VRAM Dreams: Members explored how many Tiny Boxes can be interconnected and wondered about sharing VRAM for HPC-level inference across them.
- They noted the lack of a direct VRAM pooling mechanism, suggesting a fast NIC for network-based scaling to achieve distributed performance.
- Token Throughput: 15/sec to 100 Requests: Estimations indicated a 15 tokens/sec capacity per model, with potential scaling to 100 requests if each ran at 14 tokens/sec.
- This illustrated how distributing requests can maintain near-peak speeds under controlled conditions, fueling HPC design discussions.
- Server Shopping for On-Prem LLMs: A user asked for recommended physical servers to host LLMs in an enterprise context, highlighting broader interest in on-prem solutions.
- Community members discussed cost-effectiveness, power draw, and room for GPU expansion to handle large-scale deployments.
- Block/Fused Code in Tinygrad: In #learn-tinygrad, someone requested sample code for blocked/fused programs demonstrating how to load and write tensor blocks.
- Others explained that performing operations in blocks can significantly boost performance by reducing overhead and merging steps.
Cohere Discord
- Command R Cranks Up the Context: A user shared struggles integrating command-r7b with distillation frameworks, citing ollama for synthetic data generation and noting gaps in existing support for these tools. They highlighted Command R as a large language model with 128,000-token context length and retrieval-augmented generation, directing others to the Models Overview, The Command R Model, and the Command R Changelog.
- Contributors focused on Command R’s upcoming release, emphasizing enhanced decision-making and data analysis capabilities. They also discussed bridging integration gaps for frameworks, hoping for smoother synthetic data workflows in future iterations.
- AI’s Blanket Debate: Some members described AI models as cold, joking that a blanket could bring them warmth. They believed this reflected a playful attempt to humanize emotionless machines.
- Others insisted AI doesn't require warmth or feelings, sparking a quick back-and-forth on what defines genuine empathy in artificial systems. The banter highlighted ongoing curiosity about AI’s emotional perception.
DSPy Discord
- Proxy Patch & DSPy Debates: One user asked about adding a proxy to
dspy.LMadapter, referencing a GitHub PR #1331 that integratedhttp_clientingpt3.py. They can't use dspy 2.6 without proxy support for their hosted endpoints.- Another user highlighted how proxy usage aligns with the dspy/clients/lm.py code references. They also questioned whether SSL context configuration is possible within
litellmfor stable connections.
- Another user highlighted how proxy usage aligns with the dspy/clients/lm.py code references. They also questioned whether SSL context configuration is possible within
- LiteLLM & DSPy: The Supported Squad: A newcomer asked which LLMs are supported by DSPy, prompting a mention of the LiteLLM documentation. The doc references OpenAI, Azure, and VertexAI offerings.
- The conversation also addressed the challenge of specifying an SSL context with
http_clientfor advanced configurations. Participants noted that these parameter settings are not fully explained in the default DSPy docs.
- The conversation also addressed the challenge of specifying an SSL context with
Axolotl AI Discord
- KTO vs Axolotl: The Urgent Showdown: Members flagged challenges in integrating Axolotl for KTO tasks, citing an urgent need to confirm feasibility and solution pathways.
- They expressed readiness to help review code and finalize tasks, emphasizing a desire to keep projects on schedule.
- Mistral Rolls Out 24B Model: A new Mistral-Small-24B-Base-2501 model with 24B parameters sparked excitement among members aiming for advanced small-size LLM performance.
- This launch underscores Mistral AI's open source commitment, with additional commercial variants hinted to fill specialized needs.
- Mistral Performance Mystery: A member admitted lacking current hands-on experience with the new Mistral model, leaving performance claims unconfirmed.
- The conversation suggested future user testing to gather real-world results and insights into how the model behaves in practice.
- Winter Semester Overload: A busy winter semester schedule was described as stuffed, impacting a member’s ability to contribute.
- This may delay collaborative tasks, prompting others to coordinate timelines and share responsibilities.
OpenInterpreter Discord
- Farm Friend Mystery: A user voiced fondness for Farm Friend from last year, noting its current absence in discussions.
- Community members remain curious about its fate, as no further updates were revealed in the thread.
- Cliché Reviews Spark Amusement: A lighthearted mention of cliché reviews caused playful banter and an accompanying image highlighted the joke.
- Though no deeper context was provided, the exchange added a fun moment within the community.
- Decoding '01': A user explained that '01' was unrelated to OpenAI, clarifying prior confusion in the dialogue.
- The remark quelled speculation and confirmed the miscommunication was purely coincidental.
Torchtune Discord
- Boost Checkpoints with DCP Toggle: Members clarified that DCP checkpointing is off by default but can be activated by setting
enable_async_checkpointing=Truein the config, enabling asynchronous writes.- They noted that this functionality, for now, is restricted to full_finetune_distributed, which may limit usage for other configurations.
- Push for Wider Checkpoint Coverage: Some wondered why async checkpointing isn't supported across all configurations, hinting at a needed future update.
- No firm timeline was provided, leaving members hoping for broader integration to simplify large-scale finetuning processes.
LAION Discord
- Local Img2Vid Craze: A user asked about the best local img2vid tool, prompting conversation around performance needs and GPU utilization.
- Others weighed in on their experiences, emphasizing quick setup and clear documentation for AI engineering workflows.
- ltxv Gains Favor: Another member promoted ltxv as the top choice for local img2vid tasks, citing its straightforward usage.
- They hinted at future testing and refinements, hoping for more community-driven benchmarks and expanded model support.
MLOps @Chipro Discord
- Simba Sparks a Databricks Feature Frenzy: Simba Khadder launched an MLOps Workshop for building feature pipelines on Databricks on January 30th at 8 AM PT, providing a direct sign-up link here.
- Attendees can glean best practices from Unity Catalog integration and direct Q&A, with the event being free for Data Engineers, Data Scientists, and Machine Learning Engineers.
- Databricks Embraces Geospatial Analytics: On January 30, 2025 at 1:00 PM EST, Databricks is hosting a free session on advanced geospatial analytics, with sign-up available on Eventbrite.
- Attendees will see how spatial data is processed on Databricks, continuing the momentum from the earlier workshop for those seeking deeper data engineering insights.
Gorilla LLM (Berkeley Function Calling) Discord
- BFCL Data Rallies for HF Datasets: One participant asked about the steps needed to make BFCL data align with the Hugging Face dataset guidelines, seeking a blueprint to ensure compliance.
- No examples or documentation were provided, leaving the conversation open-ended on how to adjust the metadata schema or format.
- No Additional Topics Appear: The conversation was limited to the single inquiry on achieving Hugging Face compliance for BFCL data.
- No further details surfaced, with silence from others on potential solutions.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
> The full channel by channel breakdowns have been truncated for email. > > If you want the full breakdown, please visit the web version of this email: []()! > > If you enjoyed AInews, please [share with a friend](https://buttondown.email/ainews)! Thanks in advance!