[AINews] Microsoft AgentInstruct + Orca 3
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Generative Teaching is all you need.
AI News for 7/12/2024-7/15/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (465 channels, and 4913 messages) for you. Estimated reading time saved (at 200wpm): 505 minutes. You can now tag @smol_ai for AINews discussions!
The runaway success of FineWeb this year (our coverage here, tech report here) combined with Apple's Rephrasing research has basically served as existence proofs that there can be at least an order of magnitude improvement in dataset quality for pre- and post-training. With content shops either lawyering up or partnering up, research has turned to improving synthetic dataset generation to extend the runway on the tokens we have already compressed or scraped.
Microsoft Research has made the latest splash with AgentInstruct: Toward Generative Teaching with Agentic Flows, (not to be confused with AgentInstruct of Crispino et al 2023) the third in its Orca series of papers:
- Orca 1: Progressive Learning from Complex Explanation Traces of GPT-4
- Orca 2: Teaching Small Language Models How to Reason
- Orca Math: Unlocking the potential of SLMs in Grade School Math)
The core concept is that raw documents is transformed by multiple agents playing different roles to provide diversity (for 17 listed capabilities), which are then used by yet more agents to generate and refine instructions in a "Content Transformation Flow".

Out of this pipeline comes 22 million instructions aimed at teaching those 17 skills, which when combined with the 3.8m instructions from prior Orca papers makes "Orca 2.5" - the 25.8m instruction synthetic dataset that the authors use to finetune Mistral 7b to produce the results they report:
- +40% on AGIEval, +19% on MMLU; +54% on GSM8K; +38% on BBH; +45% AlpacaEval, 31.34% reduction in hallucinations for summarization tasks (thanks Philipp)
This is just the latest entry in this genre of synthetic data research, most recently with Tencent claiming 1 billion diverse personas on their related work.
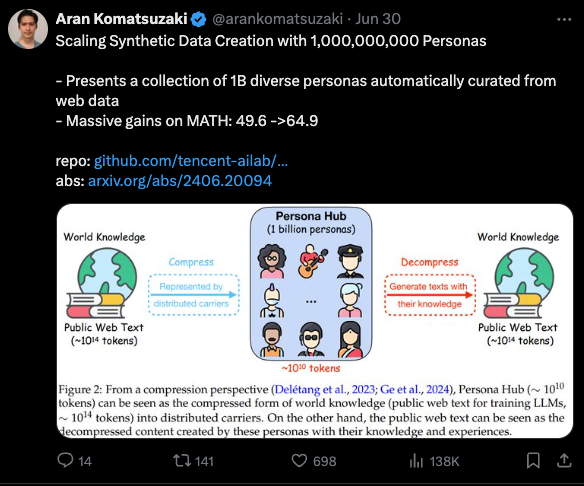
This seems both obvious that it will work yet also terribly expensive and inefficient compared to FineWeb, but whatever works!
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- LM Studio Discord
- OpenAI Discord
- Modular (Mojo 🔥) Discord
- Perplexity AI Discord
- Nous Research AI Discord
- CUDA MODE Discord
- Cohere Discord
- Eleuther Discord
- tinygrad (George Hotz) Discord
- Latent Space Discord
- OpenAccess AI Collective (axolotl) Discord
- Interconnects (Nathan Lambert) Discord
- LangChain AI Discord
- LlamaIndex Discord
- OpenInterpreter Discord
- LLM Finetuning (Hamel + Dan) Discord
- LAION Discord
- DiscoResearch Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #general (989 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #cool-finds (7 messages):
- HuggingFace ▷ #i-made-this (17 messages🔥):
- HuggingFace ▷ #reading-group (3 messages):
- HuggingFace ▷ #computer-vision (2 messages):
- HuggingFace ▷ #NLP (13 messages🔥):
- HuggingFace ▷ #diffusion-discussions (2 messages):
- Unsloth AI (Daniel Han) ▷ #general (502 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (35 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (87 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (13 messages🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (3 messages):
- Unsloth AI (Daniel Han) ▷ #research (19 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (403 messages🔥🔥):
- LM Studio ▷ #💬-general (120 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (50 messages🔥):
- LM Studio ▷ #📝-prompts-discussion-chat (5 messages):
- LM Studio ▷ #🎛-hardware-discussion (164 messages🔥🔥):
- LM Studio ▷ #amd-rocm-tech-preview (19 messages🔥):
- LM Studio ▷ #🛠-dev-chat (20 messages🔥):
- OpenAI ▷ #ai-discussions (324 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (45 messages🔥):
- OpenAI ▷ #prompt-engineering (4 messages):
- OpenAI ▷ #api-discussions (4 messages):
- Modular (Mojo 🔥) ▷ #general (182 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #ai (4 messages):
- Modular (Mojo 🔥) ▷ #mojo (137 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #max (6 messages):
- Modular (Mojo 🔥) ▷ #max-gpu (11 messages🔥):
- Modular (Mojo 🔥) ▷ #nightly (13 messages🔥):
- Perplexity AI ▷ #general (207 messages🔥🔥):
- Perplexity AI ▷ #sharing (12 messages🔥):
- Perplexity AI ▷ #pplx-api (8 messages🔥):
- Nous Research AI ▷ #research-papers (5 messages):
- Nous Research AI ▷ #off-topic (11 messages🔥):
- Nous Research AI ▷ #interesting-links (6 messages):
- Nous Research AI ▷ #general (169 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (22 messages🔥):
- Nous Research AI ▷ #rag-dataset (8 messages🔥):
- CUDA MODE ▷ #general (55 messages🔥🔥):
- CUDA MODE ▷ #triton (5 messages):
- CUDA MODE ▷ #torch (3 messages):
- CUDA MODE ▷ #cool-links (2 messages):
- CUDA MODE ▷ #beginner (23 messages🔥):
- CUDA MODE ▷ #pmpp-book (34 messages🔥):
- CUDA MODE ▷ #torchao (2 messages):
- CUDA MODE ▷ #llmdotc (46 messages🔥):
- CUDA MODE ▷ #youtube-watch-party (1 messages):
- CUDA MODE ▷ #webgpu (25 messages🔥):
- Cohere ▷ #general (141 messages🔥🔥):
- Cohere ▷ #project-sharing (26 messages🔥):
- Eleuther ▷ #general (70 messages🔥🔥):
- Eleuther ▷ #research (61 messages🔥🔥):
- Eleuther ▷ #scaling-laws (1 messages):
- Eleuther ▷ #lm-thunderdome (13 messages🔥):
- Eleuther ▷ #gpt-neox-dev (1 messages):
- tinygrad (George Hotz) ▷ #general (104 messages🔥🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (27 messages🔥):
- Latent Space ▷ #ai-general-chat (43 messages🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Latent Space ▷ #ai-in-action-club (86 messages🔥🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (86 messages🔥🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (6 messages):
- OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (18 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (31 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (23 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (7 messages):
- Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (4 messages):
- LangChain AI ▷ #general (58 messages🔥🔥):
- LangChain AI ▷ #share-your-work (1 messages):
- LlamaIndex ▷ #blog (10 messages🔥):
- LlamaIndex ▷ #general (18 messages🔥):
- OpenInterpreter ▷ #general (13 messages🔥):
- OpenInterpreter ▷ #O1 (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #asia-tz (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #hugging-face (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #axolotl (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #langchain-langsmith (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #openai (5 messages):
- LAION ▷ #general (2 messages):
- LAION ▷ #learning-ml (1 messages):
- DiscoResearch ▷ #disco_judge (2 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Shooting Incident at Trump Rally
- Shooting details: @sama noted a gunman at a Trump rally pointed a rifle at an officer who discovered him on a rooftop shortly before opening fire, with the bullet coming within an inch of Trump's head. @rohanpaul_ai shared an AP update confirming the gunman pointed the rifle at the officer before opening fire.
- Reactions and commentary: @sama hoped this moment could lead to turning down rhetoric and finding more unity, with Democrats showing grace in resisting the urge to "both-sides" it. @zachtratar argued no one would stage a bullet coming within an inch of a headshot at that distance, as it would be too risky if staged. @bindureddy made a joke that an AI President can't be assassinated.
AI and ML Research and Developments
- New models and techniques: @dair_ai shared top ML papers of the week, covering topics like RankRAG, RouteLLM, FlashAttention-3, Internet of Agents, Learning at Test Time, and Mixture of A Million Experts. @_philschmid highlighted recent AI developments including Google TPUs on Hugging Face, FlashAttention-3 improving transformer speed, and Q-GaLore enabling training of 7B models with 16GB memory.
- Implementations and applications: @llama_index implemented GraphRAG concepts such as graph generation and community-based retrieval in a beta release. @LangChainAI pointed to OpenAI's Assistant API as an example of agentic infrastructure with features like persistence and background runs.
- Discussions and insights: @sarahcat21 called for more research into updateable/collaborative AI/ML and model merging techniques. @jxnlco is exploring incorporating prompting techniques into instructor documentation to help understand possibilities and identify abstractions.
Coding, APIs and Developer Tools
- New APIs and services: @virattt launched an open beta stock market API with 30+ years of data for S&P 500 tickers, including financial statements, with no API limits. It's undergoing load testing before a full 15,000+ stock launch for AI financial agents to utilize.
- Coding experiences and tips: @giffmana shared frustration with unhelpful online resources when writing a Python script to read multipart/form-data, finding the actual RFC2388 spec most useful. @jeremyphoward demonstrated a new function-cache decorator design in Python to compose cache eviction policies.
- Developer discussions: @svpino predicted AI becoming a foundational skill for future developers alongside data structures and algorithms, as software development and machine learning converge.
Humor, Memes and Off-Topic Discussions
- Jokes and memes: @cto_junior shared a meme combining Wagie News and 4chan references. @lumpenspace joked it's impossible to determine if anti-Trump sentiment influenced the shooter given conflicting details about their political leanings.
- Off-topic chatter: @sarahookr recommended visiting Lisboa and shared a photo from the city. @ID_AA_Carmack discussed a comic panel that inspired an indie game title idea called "Corgi Battle Pose".
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. We recently improved the anti-hallucination measures but are still tuning the filtering, clustiner, and summary quality.
Theme 1. AI Research Publication Lag in Fast-Paced Development
- [/r/singularity] Due to the speed of AI development and the long delays in the scientific publishing process, a whole bunch of academic papers suggest that LLMs can't do things they can actually do well. Example: this is a fine paper, but it uses GPT-3.5. (Score: 237, Comments: 19): Academic papers on AI capabilities rapidly become outdated due to the fast pace of AI development and the lengthy scientific publishing process. A prime example is a paper that uses GPT-3.5 to assess LLM capabilities, despite more advanced models like GPT-4 being available. This lag in publication leads to a significant discrepancy between published research and the current state of AI technology.
- [/r/OpenAI] AI headlines this week (Score: 361, Comments: 57): AI headlines dominate tech news: This week saw a flurry of AI-related announcements, including Google's Gemini launch, OpenAI's GPT Store delay, and Anthropic's Claude 2.1 release. The rapid pace of AI developments is drawing comparisons to the early days of the internet, with some experts suggesting AI's impact could be even more transformative and far-reaching than the web revolution.
- AI: Not Just Another Fad: Commenters draw parallels between early internet skepticism and current AI doubts. Many recall initial reluctance to use credit cards online, highlighting how perceptions can change dramatically over time.
- AI Revolutionizes Development: Developers praise AI as a "game changer" for coding, with one user creating a native Swift app using Anthropic's console despite limited knowledge. Others note AI's ability to narrow down solutions faster than traditional methods.
- Dot-Com Bubble Lessons: Discussion touches on the 2000 dot-com crash, with users pointing out how companies like Amazon lost 90% market cap. Some suggest a similar correction might occur in AI but believe the bubble hasn't peaked yet.
- AI's Growing Pains: Critics highlight issues with current AI implementations, such as Google's search highlights being criticized for hallucinations. Users stress the importance of responsible AI deployment to maintain credibility in the field.
Theme 2. AI's Impact on Employment: TurboTax Layoffs
- [/r/singularity] Maker of TurboTax Fires 1,800 Workers, Says It’s Pivoting to AI (Score: 303, Comments: 63): Intuit, the company behind TurboTax and QuickBooks, has announced a 7% reduction in its workforce, laying off 1,800 employees. The company cites a shift towards artificial intelligence and machine learning as the reason for the restructuring, aiming to better serve customers and drive innovation. This move comes despite Intuit reporting $14.4 billion in revenue for the fiscal year 2023, a 13% increase from the previous year.
Theme 3. AI Integration in Creative Workflows: ComfyUI GLSL Node
- [/r/StableDiffusion] 🖼 OpenGL Shading Language (GLSL) node for ComfyUI 🥳 (Score: 221, Comments: 21): OpenGL Shading Language (GLSL) node for ComfyUI has been introduced, allowing users to create custom shaders and apply them to images within the ComfyUI workflow. This new feature enables real-time image manipulation using GPU-accelerated operations, potentially enhancing the efficiency and capabilities of image processing tasks in ComfyUI. The integration of GLSL shaders opens up possibilities for advanced visual effects and custom image transformations directly within the ComfyUI environment.
- GitHub repo and ShaderToy link shared: The original poster, camenduru, provided links to the GitHub repository for the GLSL nodes and a ShaderToy example showcasing the potential of shader effects.
- Excitement and potential applications: Users expressed enthusiasm for the new feature, with ArchiboldNemesis highlighting its potential for masking inputs and speculating about "Realtime SD metaballs". Another user pondered if ComfyUI might evolve into a visual programming framework like TouchDesigner.
- Technical discussions and clarifications: Some users sought explanations about OpenGL and its relation to the workflow. A commenter clarified that OpenGL shading is used for viewport rendering without raytracing capabilities, while another mentioned the applicability of three.js glsl shaders knowledge to ComfyUI.
- Future development ideas: Suggestions included integrating VSCode and plugins into ComfyUI or developing ComfyUI as a VSCode plugin. Questions were also raised about real-time processing/rendering capabilities within the current implementation.
AI Discord Recap
A summary of Summaries of Summaries
1. Pushing the Boundaries of LLMs
- Breakthrough LLM Performance Gains: Microsoft Research introduced AgentInstruct, a framework for automatically creating synthetic data to post-train models like Mistral-7b into Orca-3, achieving 40% improvement on AGIEval, 54% on GSM8K, and 45% on AlpacaEval.
- The Ghost 8B Beta model outperformed Llama 3 8B Instruct, GPT 3.5 Turbo, and others in metrics like lc_winrate and AlpacaEval 2.0 winrate, aiming for superior knowledge capabilities, multilingual support, and cost efficiency, as detailed on its documentation page.
- New Benchmarks Fuel LLM Progress: InFoBench (Instruction Following Benchmark) was introduced, sparking debates on its relevance compared to standard alignment datasets and whether unique benchmarks highlight valuable LLM qualities beyond high correlations with MMLU.
- The WizardArena/ArenaLearning paper detailed evaluating models via human preference scores in a Kaggle competition, generating interest in multi-turn synthetic interaction generation and evaluation setups.
2. Hardware Innovations Powering AI
- Accelerating AI with Specialized Hardware: MonoNN, a new machine learning compiler, optimizes GPU utilization by accommodating entire neural networks into single kernels, addressing inefficiencies in traditional kernel-by-kernel execution schemes, as detailed in a paper presentation and source code release.
- Discussions around WebGPU development highlighted its fast iteration cycles but need for better tooling and profiling, with members exploring porting llm.c transformer kernels for performance insights and shifting more ML workloads to client-side computation.
- Optimizing LLMs with Quantization: Research on quantization techniques revealed that compressed models can exhibit "flips" - changing from correct to incorrect outputs despite similar accuracy metrics, highlighting the need for qualitative evaluations alongside quantitative ones.
- The paper 'LoQT' proposed a method enabling efficient training of quantized models up to 7B parameters on consumer 24GB GPUs, handling gradient updates differently and achieving comparable memory savings for pretraining and fine-tuning.
3. Open Source Driving AI Innovation
- Collaborative Efforts Fuel Progress: The OpenArena project introduced an open platform for pitting LLMs against each other to enhance dataset quality, primarily using Ollama models but supporting any OpenAI-compatible endpoints.
- The LLM-Finetuning-Toolkit launched for running experiments across open-source LLMs using single configs, built atop HuggingFace libraries and enabling evaluation metrics and ablation studies.
- Frameworks Streamlining LLM Development: LangChain saw active discussions on streaming output handling, with queries on
invoke,stream, andstreamEventsfor langgraph integration, as well as managingToolCalldeprecation and unintended default tool calls.- LlamaIndex gained new capabilities like entity deduplication using Neo4j, managing data pipelines centrally with LlamaCloud, leveraging GPT-4o for parsing financial reports, enabling multi-agent workflows via Redis integration, and an advanced RAG guide.
PART 1: High level Discord summaries
HuggingFace Discord
- NPM Module Embraces Hugging Face Inference: A new NPM module supporting Hugging Face Inference has been announced, inviting community feedback.
- The developer emphasizes the model's reach across 36 Large Language Model providers, fostering a collaborative development ethos.
- Distributed Computing Musters Llama3 Power: Llama3 8B launches on a home cluster, spanning from the iPhone 15 Pro Max to NVIDIA GPUs, with code open-sourced on GitHub.
- The project aims for device optimization, engaging the community to battle against programmed obsolescence.
- LLM-Finetuning-Toolkit Unveiled: The debut of LLM-Finetuning-Toolkit offers a unified approach to LLM experimentation across various models using single configs.
- It stands out by integrating evaluation metrics and ablation studies, all built atop HuggingFace libraries.
- Hybrid Models Forge EfficientNetB7 Collaboration: A push to train hybrid models combines EfficientNetB7 for feature extraction with Swin Transformer on Huggingface for classification.
- Participants utilize Google Colab's computational offerings, seeking more straightforward implementation techniques.
- Heat Generated from HF Inference API Misattribution: Copilot incorrectly cites the HF Inference API as an OpenAI product, leading to user confusion in discussions.
- Responses were mixed, ranging from humorous suggestions like 'cheese cooling' servers to pragmatic requests for open-source documentation practices.
Unsloth AI (Daniel Han) Discord
- Llama 3’s Anticipated Unveiling Stumbles: The launch of Llama 3 (405b) scheduled for July 23 by Meta Platforms is rumored to be delayed, with Redditors chattering about a push to later in the year.
- Community exchanges buzz around operational challenges and look forward to fine-tuning opportunities despite the holdup.
- Gemini API Leaps to 2M Tokens: Google's Gemini API now boasts a 2 million token context window for Gemini 1.5 Pro, as announced with features including code execution.
- AI Engineers debate the merits of the extended context and speculate on the implications for performance in everyday scenarios.
- MovieChat GitHub Repo Sparks Dataset Debate: MovieChat emerges as a tool allowing conversations over 10K frames of video, stirring a dialogue over dataset creation.
- Users dispute the feasibility of open-sourced datasets, considering the complexity involved in assembling them.
- Ghost 8B Beta Looms Large: Ghost 8B Beta model is lauded for its performance, topping rivals like Llama 3 8B Instruct and GPT 3.5 Turbo as demonstrated by metrics like the lc_winrate and AlpacaEval 2.0 winrate scores.
- New documentation signals the model’s prowess in areas like multilingual support and cost-efficiency, igniting discussions on strategic contributions.
- CURLoRA Tackles Catastrophic Forgetting: A shift in fine-tuning approach, CURLoRA uses CUR matrix decomposition to combat catastrophic forgetting and minimize trainable parameters.
- AI experts receive the news with acclaim, seeing potential across various applications as detailed in the paper.
Stability.ai (Stable Diffusion) Discord
- GPTs Stagnation Revelation: Concerns were raised about GPTs agents inability to assimilate new information post-training, with clarifications highlighting that uploaded files serve merely as reference 'knowledge' files, without altering the underlying model.
- The community exchanged knowledge on how GPTs agents interface with additional data, establishing that new inputs do not dynamically reshape base knowledge.
- OpenAI's Sidebar Saga: Users noted the disappearance of two icons from the sidebar on platform.openai.com, sparking speculations and evaluations of the interface changes.
- The sidebars triggered discussions concerning usability, with mentions of icons related to threads and messages having vanished.
- ComfyUI Conquers A1111: The speed superiority of ComfyUI over A1111 was a hot topic, with community tests suggesting a 15x performance boost in favor of ComfyUI.
- Despite the speed advantage, some users criticized ComfyUI for lagging behind A1111 in control precision, indicating a trade-off between efficiency and functionality.
- Custom Mask Assembly Anxieties: Debates emerged over the complex process of crafting custom masks in ComfyUI, with participants pointing out the more onerous nature of SAM inpainting.
- Recommendations circulated for streamlining the mask creation process, proposing the integration of tools like Krita to mitigate the cumbersome procedure in ComfyUI.
- The Artistic Ethics Debate: Ethical and legal discussions surfaced regarding AI-generated likenesses of individuals, with members pondering the protective cloak of parody in art creation.
- The community engaged in a spirited debate on the legitimacy of AI art, invoking concerns around the representation of public figures and the merits of seeking professional legal counsel in complex situations.
LM Studio Discord
- CUDA Conundrum & GPU Guidance: Users combated the 'No CUDA devices found' error, advocating for the installation of NVIDIA drivers and the 'libcuda1' package.
- In hardware dialogues, Intel Arc a750's subpar performance was spotlighted, and for LM Studio precision, NVIDIA 3070 or AMD's ROCm-supported GPUs were recommended.
- Polyglot Programming Preference: Rust vs C++: Engineers exchanged views on programming languages, citing Rust's memory safety and C++'s historical baggage; juxtaposed with a dash of Rust Evangelism.
- Despite Python's stronghold in neural network development, Rust and C++ communities highlighted their languages' respective strengths and tools like llama.cpp.
- LM Studio: Scripting Constraints & Model Mysteries: Debate on lmstudio.js veered towards its RPC usage over REST, paired with challenges integrating embedding support due to RPC ambiguities.
- AI aficionados probed into multi-GPU configurations, pinpointing PCIe bandwidth’s impact and musing over the upcoming Mac Studio with an M4 chip for LLM tasks.
- Vulkan and ROCm: GPU Reliance & Revolutionary Runtimes: Enthusiasm was expressed for Vulkan's pending arrival in LM Studio, despite concerns over its 4-bit quantization limit.
- Meanwhile, ROCm stood out as a linchpin for AMD GPU users; essential for models like Llama 3, and in contrast, gaining traction for its Windows support.
OpenAI Discord
- GPT Alt-Debate: Seeking Academic Excellence: Discussions rested on whether Copilot or Bing’s AI, both allegedly running on GPT-4, are superior for academic use.
- A user, bemoaning the lack of other viable options, mentioned alternatives like Claude and GPT-4o, but still acknowledged spending on ChatGPT.
- Microsoft's Multi-CoPilot Conundrum: Members dissected Microsoft’s array of CoPilots across applications like Word, PowerPoint, and Outlook, noting Word CoPilot for its profound dive into subjects.
- Conversely, PowerPoint's assistant was branded basic, primarily assisting in generating rudimentary decks.
- DALL-E's Dilemma with GPT Guidance: A conversation emerged around DALL-E's unreliable rendering of images upon GPT instruction, yielding either prompt text or broken image links.
- "DALL-E's hiccups** were critiqued for the tech's failure to interpret GPT’s guidance aptly on initial commands.
- AI Multilinguists: Prompt Language Distinctions: Inquiry revolved around the impact of prompt language on response quality, particularly when employing Korean versus English in ChatGPT interactions.
- The central question hinged on the efficacy of prompts directly in the desired language against those needing translation.
- Unlocking Android's Full Potential with Magic: A shared 'Android Optimization Guru' guide promised secrets to enhance Android phone performance through battery optimization, storage management, and advanced settings.
- The guide appealed to younger tech enthusiasts with playful scenarios, making advanced Android tips accessible and compelling.
Modular (Mojo 🔥) Discord
- Website Worries Redirected: Confusion arose when the Mojo website was down, leading users to discover it wasn't the official site.
- Correcting course, users were pointed to Modular's official website, ensuring appropriate redirection.
- Bot Baffles By The Book: Modular's bot prompted unwanted warnings when members tagged multiple contributors, mistaking the action as bot-worthy of a threat.
- Discussions ensued regarding pattern triggers, with members calling for a review of the bot's interpretation logic.
- Proposal to Propel module maintainability: A proposal to create
stdlib-extensionsaimed at reducing stdlib maintainers' workload was tabled, sparking a dialogue on GitHub.- The community requested feedback from diligent contributors to ensure this refinement aids in streamlining module management.
- MAX License Text Truncated: Typographical errors in the Max license text triggered conversations about attention to detail in legal documents.
- Errors such as otherModular and theSDK were mentioned, prompting a swift rectification.
- Accelerated Integration Ambitions: Members queried about Max dovetailing into AMD's announced Unified AI software stack, spotlighting Modular's growing influence.
- Citing a convergence of interests, users showed an eagerness for potential exclusive partnerships for the MAX platform.
Perplexity AI Discord
- Cloudflare Quarrels & API Credit Quests: Members are encountering access challenges due to the API being behind Cloudflare, while others are questioning the availability of the advertised $5 free credits for Pro plan upgrades.
- Discussions also cover frustrations with using the $5 credit, with users seeking assistance via community channels.
- Diminished Daily Pro Descent: Pro users noticed a quiet reduction from 600 to 540 in their daily search limit, sparking discussions about future changes and the need for greater transparency.
- The community is reacting to this unexpected change, and the potential impact it may have on their daily operations.
- Imaging Trouble & Comparative Capabilities: Users are sharing difficulties where Perplexity's responses improperly reference past images, hindering conversation continuity.
- Tech-savvy individuals debate Perplexity's strengths against ChatGPT, especially around specialties like file handling, image generation, and precise follow-ups.
- Vexing API Model Mysteries: A user seeks to emulate Perplexity AI's free tier results with the API but struggles to retrieve URL sources, prompting inquiries on which models are being used.
- The goal is to match the free tier's capabilities, suggesting a need for clarity on model utilizations and outputs within the API service.
- A Spectrum of Sharing: Health to Controversy: Discussions range from pathways to health and strength, to understanding dynamic market forces like the Cantillon Effect.
- Conversations also include unique identifiers in our teeth and analysis of a political figure's security episode.
Nous Research AI Discord
- AgentInstruct's Leap Forward: AgentInstruct lays the blueprint for enhancing models like Mistral-7b into more sophisticated versions such as Orca-3, demonstrating substantial gains on benchmarks.
- The application yielded 40% and 54% improvements on AGIEval and GSM8K respectively, while 45% on AlpacaEval, setting new bars for competitors.
- Levity in Eggs-pert Advice: Egg peeling hacks made a surprising entry with recommendations favoring a 10-minute hot water bath for peel-perfect eggs.
- Vinegar-solution magic was also shared, teasing shell-free eggs through an acid-base reaction.
- AI's YouTube Drama: Q-star Leaks: Q-star's confidential details got airtime via a YouTube revelation, showing the promise and perils of developments in AGI.
- Insights from OpenAI's hidden trove codenamed STRAWBERRY spilled the beans on upcoming LLM strategies.
- Goodbye PDFs, Hello Markdown: New versions of Marker crunch PDF to Markdown conversion times by leveraging efficient model architecture to aid dataset quality.
- Boosts included 7x faster speeds on MPS and a 10% GPU performance jump, charting a course for rapid dataset creation.
- Expanding LLM Horizons in Apps: Discussions on app integrations revealed retrieval-augmented generation (RAG) as a favorite for embedding tutorial intelligence.
- Suggestions flew around extending models like Mixtral and Llama up to 1M tokens, although practical usage remains a challenge.
CUDA MODE Discord
- Warp Speed WebGPU Workflow: Users exploring WebGPU development discussed its quick iteration cycles, but identified tooling and profiling as areas needing improvement.
- A shared library approach like dawn was recommended, with a livecoding demo showcasing faster shader development.
- Peeking into CUDA Cores' Concurrency: A dive into CUDA core processing revealed each CUDA core can handle one thread at a time, with an A100 SM managing 64 threads simultaneously from a pool of 2048.
- Discussions also focused on how register limitations can impact thread concurrency, affecting overall computational efficiency.
- Efficient Memory with cudaMallocManaged: cudaMallocManaged was proposed over cudaFix as a way to support devices with limited memory, especially to enhance smaller GPU integration efforts.
- Switching to cudaMallocManaged was flagged as critical for ensuring performance remains unhindered while accommodating a broader range of GPU architectures.
- FSDP Finesse for Low-Bit Ops: Discussion on implementing FSDP support for low-bit optimization centered on the non-addressed collective ops for optimization state subclass.
- A call for a developer guide aimed at aiding FSDP compatibility was discussed to boost developer engagement and prevent potential project drop-off.
- Browser-Based Transformers with WebGPU: Members discussed leveraging Transformers.js for running state-of-the-art machine learning tasks in the browser, utilizing WebGPU's potential in the ONNX runtime.
- Challenges related to building Dawn on Windows were also highlighted, noting troubleshooting experiences and the impact of buffer limitations on performance.
Cohere Discord
- OpenArena's Ambitious AI Face-off: A new OpenArena project has launched, challenging LLMs to compete and ensure robust dataset quality.
- Syv-ai's repository details the application process, aiming at direct engagement with various LLM providers.
- Cohere Conundrum: Event Access Debacle: Members bemoaned Cohere event link mix-ups, resulting in access issues, circumvented by sharing the correct Zoom link for the diffusion model talk.
- Guest speaker session clarity was restored, with guidance on creating spectrograms using diffusion models.
- Cost of AI Competency Crashes: Andrej Karpathy's take on AI training costs shows a dramatic decrease, marking a steep affordability slope for training models like GPT-2.
- He illuminates the transition from 2019's cost-heavy landscape to now, where enthusiasts can train GPT-like models for a fraction of the price.
- Seamless LLM Switch with NPM Module: Integrating Cohere becomes a breeze for developers with the updated NPM module, perfect for cross-platform LLM interactions.
- This modular approach opens doors to cohesive use of diverse AI platforms, enriching developer toolkits.
- The r/localllama Newsbot Chronicles: The r/localllama community breathes life into Discord with a Langchain and Cohere powered bot that aggregates top Reddit posts.
- This innovative engine not only summarizes but arranges news into compelling narratives, tailored for channel-specific delights.
Eleuther Discord
- London AI Gatherings Lack Technical Teeth: Discussions revealed dissatisfaction with the technical depth of AI meetups in London, suggesting those interested should attend UCL and Imperial seminars instead.
- ICML and ICLR conferences were recommended for meaningful, in-depth interactions, especially in niche gatherings of researchers.
- Arrakis: Accelerating Mechanistic Interpretability**: Arrakis, a toolkit for interpretability experiments, was introduced to enhance experiment tracking and visualization.
- The library integrates with tools like tuned-lens to streamline mechinterp research efficiency.
- Traversing Model Time-Relevance: There's a growing interest in incorporating time relevance into LLMs, as traditional timestamp methods are lacking in effectiveness.
- Current discussions are centered around avenues such as literature on time-sensitive datasets and benchmarks for training improvement.
- Quantization Quirks: More Than Meets the Eye: Concerns were raised regarding a paper on quantization flips explaining that compressed models can have different behaviors despite identical accuracy metrics.
- This has sparked dialogue on the need for rigorous qualitative evaluations alongside quantitative ones.
- Unfolding lm-eval's Potential: A technical inquiry led to a guide on integrating a custom Transformer-lens model with lm-eval's Python API, as seen in this documentation.
- Yet, some members are still navigating the intricacies of custom functions and metrics within lm-evaluation-harness.
tinygrad (George Hotz) Discord
- MonoNN Streamlines GPU Workloads: The introduction of MonoNN, a new machine learning compiler, sparked interest with its single kernel approach for entire neural networks, possibly improving GPU efficiencies. The paper and the source code are available for review.
- The community considered the potential impact of MonoNN's method on reducing the kernel-by-kernel execution overhead, aligning with the ongoing conversations about tinygrad kernel overhead concerns.
- MLX Edges Out tinygrad: MLX gained the upper hand over tinygrad with better speed and accuracy, as demonstrated in the beautiful_MNIST benchmark, drawing the community's attention to the tinygrad commit for mlx.
- This revelation led to further discussion on improving tinygrad's performance, targeting areas of overhead and inefficiencies.
- Tweaks Touted for tinygrad's avg_pool2d: The community requested an
avg_pool2denhancement to supportcount_include_pad=False, a feature in stable diffusion training evaluations, proposing potential solutions modeled after PyTorch's implementation.- Discussions revolved around the need for this feature in benchmarks like MLPerf and saw suggestions for workarounds using existing pooling operations.
- Discourse on Tinygrad's Tensor Indexing: Members exchanged knowledge on tensor indexing nuances within tinygrad, comparing it with other frameworks and demonstrating how operations like masking can lead to increased performance.
- A member referred to the tinygrad documentation to clarify the execution and efficiency benefits of this specific tensor operation within the toolkit.
- PR Strategies and Documentation Dynamism: The consensus among members was for separate pull requests for enhancements, bug fixes, and feature implementations to streamline the review process, evident in the handling of the
interpolatefunction for FID.- Emphasizing the importance of up-to-date and working examples, members discussed the strategy for testing and verifying code blocks in the tinygrad documentation.
Latent Space Discord
- Leaderboard Levels Up: Open LLM Leaderboard V2 Excitement: A new episode on Latent Space focusing on Open LLM Leaderboard V2** sparked conversation, with community members sharing their enthusiasm.
- The podcast was linked to a new release, providing listeners insights into the latest LLM rankings.
- Linking Without Hallucinating: Strategies to Combat Misinformation: Discussion surfaced around SmolAI's innovative approaches to eliminate Reddit link hallucination, focusing on pre-check and post-proc** methods.
- Techniques and results were discussed, highlighting the importance of reliable links in enhancing the use of LLMs.
- Unknown Entrants Stir LMSys: New Models Spark Curiosity: Speculation arose about the entities behind new models in the LMSys arena**, accompanied by a mixed bag of opinions.
- Rumors about Command R+ jailbreaks and their implications were a part of the buzz, reflected in community conversations.
- Composing with Cursor: The Beta Buzz: Cursor's** new Composer feature stirred excitement within the community, with users eager to discuss its comparative UX and the beta release.
- Affordability and utility surfaced as topics of interest, as spectators shared positive reactions and pondered subscription models.
- Microsoft's Spreadsheet Savvy: Introducing SpreadsheetLLM: Microsoft made waves with SpreadsheetLLM, an innovation aiming to refine LLMs' spreadsheet handling using a SheetCompressor** encoding framework.
- Conversations veered towards its potential to adapt LLMs to spreadsheet data, with excitement over the nuanced approach detailed in their publication.
OpenAccess AI Collective (axolotl) Discord
- Open Source Tools Open Doors: User le_mess has created a 100% open source version of a dataset creation tool named OpenArena, expanding the horizon for model training flexibility.
- OpenArena was initially designed for OpenRouter and is now leveraging Ollama to boost its capabilities.
- Memory Usage Woes in ORPO Training: A spike in memory usage during ORPO training was noted by xzuyn, leading to out-of-memory errors despite a max sequence limit of 2k.
- The conversation highlighted missing messages on truncating long sequences after tokenization as a possible culprit.
- Integrating Anthropic Prompt Know-How: Axolotl's improved prompt format draws inspiration from Anthropic's official Claude, discussed by Kalomaze, featuring special tokens for clear chat turn demarcations.
- The template, applicable to Claude/Anthropic formats, is found here, sparking a divide over its readability and flexibility.
- RAG Dataset Creation Faces Scrutiny: Concerns were raised by nafnlaus00 about the security of Chromium in rendering JavaScript needed sites for RAG model dataset scraping.
- Suggestions included exploring alternative scraping solutions like firecrawl or Jina API to navigate these potential vulnerabilities.
- Weighted Conversations Lead Learning: Tostino proposed a novel approach to training data utilization involving weight adjustments to steer model learning away from undesirable outputs.
- Such advanced tweaking could refine models by focusing on problematic areas, enhancing the learning curve.
Interconnects (Nathan Lambert) Discord
- Strawberry Fields of AI Reasoning: OpenAI is developing a new reasoning technology named Strawberry, drawing comparisons to Stanford's STaR (Self-Taught Reasoner). Community insiders believe its capabilities mirror those outlined in a 2022 paper detailed by Reuters.
- The technology's anticipated impact on reasoning benchmarks prompts examination of its possible edge over existing systems, with particular focus on product names, key features, and release dates.
- LMSYS Arena's Stealthy Model Entrants: The LMSYS chatbot arena is abuzz with new entrants like column-r and column-u, speculated to be the brainchildren of Cohere as per info from Jimmy Apples.
- Further excitement is stirred by Twitter user @btibor91, who points out four new models gearing up for release, including eureka-chatbot and upcoming-gpt-mini, with Google as the purported trainer for some.
- Assessing Mistral-7B's Instruction Strength: The AI community debates the efficacy of Mistral-7B's instruct-tuning in light of findings from the Orca3/AgentInstruct paper and seeks to determine the strength of the underlying instruct-finetune dataset.
- The discussion evaluates if current datasets meet robustness criteria, and contrasts Mistral-7B's benchmarks with other models' performance.
- InFoBench Spurring Benchmark Debates: The recently unveiled InFoBench (Instruction Following Benchmark) sparks conversations comparing its value against established alignment datasets, with mixed opinions on its real-world relevance.
- Skeptics and proponents clash over whether unique benchmarks like InFoBench alongside EQ Bench truly highlight significant qualities of language models, considering their correlation with established benchmarks like MMLU.
- California's AI Legislative Labyrinth: The passage of California AI Bill SB 1047 leads to a legislative skirmish, as AI safety experts and venture capitalists spar over the bill’s implications, ahead of a critical vote.
- Senator Scott Wiener characterizes the clash as ‘Jets vs Sharks’, revealing the polarized perspectives documented in a Fortune article and made accessible via Archive.is for wider review.
LangChain AI Discord
- JavaScript Juggles: LangChain's Trio of Functions: Users dissected the intricacies of LangChain JS's
invoke,stream, andstreamEvents, debating their efficacy for streaming outputs in langgraph.- A proposal emerged suggesting the use of agents for assorted tasks like data collection and API interactions.
- Base64 Blues with Gemini API: Seek, Decode, Fail: A puzzling 'invalid input' snag was hit when a user wielded Base64 with Gemini Pro API**, despite File API uploads being the lone documented method.
- The collective's guidance pointed towards the need for clarity in docs and further elaboration on Base64 usage with APIs.
- ToolCall Toss-up: LangChain’s Legacy to OpenAIToolCall:
ToolCall, now obsolete, directs users to its successorOpenAIToolCall, introducing anindexfeature for order.- The community pondered package updates and the handling of auto mode's inadvertent default tool calls.
- Hallucination Hazards: Chatbots Conjure Queries: Hallucinations in HuggingFace models were reported, provoking discussions around the LLM-generated random question/answer pairs for chatbots.
- Alternative remedies were offered, including a shift to either openAI-models or FireworksAI models, although finetuned llama models seemed resilient to the typical repetition penalties.
- Embedding Excellence: OpenAI Models Spotlight: Curiosity peaked over the optimal OpenAI embedding model, sparking a discourse on the best model to comprehend and utilize embedding vectors.
- The general consensus leaned towards
text-embedding-ada-002recommended as the go-to model in LangChain for vector embeddings.
- The general consensus leaned towards
LlamaIndex Discord
- Dedupe Dancing with LlamaIndex: The LlamaIndex Knowledge Graph undergoes node deduplication with new insights and explanations in a related article, highlighting the significance of knowledge modeling.
- Technical difficulties arose when executing the NebulaGraphStore integration, as detailed in GitHub Issue #14748, pointing to a potential mismatch in method expectations.
- Fusion of Formulas and Finances: Combining SQL and PDF embeddings sparked discussions on integrating databases and documents, directed by examples from LlamaIndex's SQL integration guide.
- A mention of an issue with
NLSQLTableQueryEngineprompted debate over the correct approach given that Manticore's query language differs from MySQL's classic syntax.
- A mention of an issue with
- Redis Rethinks Multi-Agent Workflows: @0xthierry's Redis integration facilitates the construction of production workflows, creating a network for agent services to communicate, as detailed in a popular thread.
- The efficiency of multi-agent systems was a central theme, with Redis Queue acting as the broker, reflecting a trend towards streamlined architectures.
- Chunky Data, Sharper embeddings: Efforts to chunk data into smaller sizes led to improved precision within LlamaIndex's embeddings, per suggestions on optimal chunk and overlap settings in the Basic Strategies documentation.
- The LlamaIndex AI community agreed that a
chunk_sizeof 512 with an overlap of 50 optimizes detail capture and retrieval accuracy.
- The LlamaIndex AI community agreed that a
- Advanced RAG with LlamaIndex's Touch: For a deep dive into agent modules, LlamaIndex's guide offers a comprehensive walkthrough, showcased in @kingzzm's tutorial on utilizing LlamaIndex query pipelines.
- RAG workflows' complexities are unpacked in steps, from initiating a query to fine-tuning query engines with AI engineers in mind.
OpenInterpreter Discord
- GUI Glory: OpenInterpreter Upgrade: The integration of a full-fledged GUI into OpenInterpreter has added editable messages, branches, auto-run code, and save features.
- Demands for video tutorials to explore these functionalities signal a high community interest.
- OS Quest: OpenAI's Potential Venture: Speculation is rife following a tweet hint about OpenAI, led by Sam Altman, possibly brewing its own OS.
- Suspense builds as community members piece together hints from recent job postings.
- Phi-3.1: Promise and Precision: Techfren's analysis on Phi-3.1 model's potential reveals impressive size-to-capability ratio.
- Yet, discussions reveal it occasionally stumbles on precise
execution, sparking talks on enhancement.
- Yet, discussions reveal it occasionally stumbles on precise
- Internlm2 to Raspi5: A Compact Breakthrough: 'Internlm2 smashed' garners focus for its performance on a Raspi5 system, promising for compact computing needs.
- Emphasis is on exploring multi-shot and smash modes for novel IoT applications.
- Ray-Ban's Digital Jailbreak: Community's Thrill: A possibility of jailbreaking Meta Ray-Ban has the community buzzing with excitement and anticipation.
- The vision of hacking this hardware elicits a surge of interest for new functionality opportunities.
LLM Finetuning (Hamel + Dan) Discord
- Agents Assemble in LLM: A user explained the addition of agents in LLMs to enhance modularity within chat pipelines, using JSON output for task execution such as fetching data and API interaction.
- The shared guide shows steps incorporating Input Processing and LLM Interpretation, highlighting modular components' benefits.
- OpenAI API Keys: The Gateway for Tutorials: API keys are in demand for a chatbot project tutorial, with a plea for key sharing amongst the community to aid in the tutorial's creation.
- The member did not provide further context but stressed the temporary need for the key to complete and publish their guide.
- Error Quest in LLM Land: Members voiced their struggles with unfamiliar errors from modal and axolotl, expressing the need for community help on platforms like Slack.
- While specific nature of the errors was not detailed, conversations insinuated a need for better problem-solving channels for these technical issues.
- Navigating Through Rate Limit Labyrinths: A user facing token rate limitations during Langsmith evaluation found respite by tweaking the max_concurrency setting.
- Discussions also traversed strategies to introduce delays in script runs, aiming to steer clear of the rate limits imposed by service providers.
- Tick Tock Goes the OpenAI Clock: The discourse revealed that OpenAI credits are expiring on September 1st, with users clarifying the deadline after inquiries surfaced.
- Talks humorously hinted at initiating a petition to extend credit validity, indicating users' reliance on these resources beyond the established expiration.
LAION Discord
- Hugging Face Hits the Green Zone: Hugging Face declares profitability with a team of 220, while keeping most of its platform free and open-source.
- CEO Clement Delangue excitedly notes: 'This isn’t a goal of ours because we have plenty of money in the bank but quite excited to see that @huggingface is profitable these days, with 220 team members and most of our platform being free and open-source for the community!'
- Cambrian-1's Multimodal Vision: Introduction of the Cambrian-1 family, a new series of multimodal LLMs with a focus on vision, available on GitHub.
- This expansion promises to broaden the horizons for AI models integrating images within their learning context.
- MagViT2 Dances with Non-RGB Data: Discussions arose around MagViT2's potential compatibility with non-RGB motion data, specifically 24x3 datasets.
- While the conversation was brief, it raises questions about preprocessing needs for non-standard data formats in AI models.
- Choreographing Data for AI Steps: Preprocessing techniques for non-RGB motion data drew interest for ensuring they can work harmoniously with existing AI models.
- The details on these techniques remain to be clarified in further discussions.
DiscoResearch Discord
- OpenArena Ignites LLM Competition: The release of OpenArena initiates a new platform for LLM showdowns, with a third model judging to boost dataset integrity.
- Primarily incorporating Ollama models, OpenArena is compatible with any OpenAI-based endpoints, broadening its potential application in the AI field.
- WizardLM Paper Casts a Spell on Arena Learning: The concept of 'Arena Learning' is detailed in the WizardLM paper, establishing a new method for LLM evaluation.
- This simulation-based methodology focuses on meticulous evaluations and constant offline simulations to enhance LLMs with supervised fine-tuning and reinforcement learning techniques.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #general (989 messages🔥🔥🔥):
HF Inference APIGPT integrationModel performance issuesLeaderboard UpvotesLlama2 Chat model setup
- HF Inference API is misattributed to OpenAI: Copilot mistakenly referenced the HF Inference API as being part of OpenAI, causing confusion among users.
- One user humorously suggested 'cheese cooling' to manage the overheating servers, while another user asked about open-sourcing documentation styles.
- Issues with CUDA and model setup: A user experienced problems with CUDA while setting up the Llama2 Chat model, reporting that text generation was extremely slow.
- Despite resolving some CUDA issues, the user noted persistent generation delays and received suggestions to test with smaller token batches.
- Queue priorities in model leaderboard: The leaderboard queue is primarily influenced by upvotes, leading to discussion about fairness and potential spamming of similar models.
- A user expressed concerns about new users struggling with social aspects affecting visibility and model performance evaluation.
- Error handling and RL training issues: Errors related to ArrowInvalid and illegal memory access in CUDA were frequently discussed, with users providing troubleshooting tips.
- A user struggled with setting up RL training in a Unity environment, facing issues due to missing executable files, despite receiving configuration advice.
- Concerns about Python project setup: A user expressed frustration with setting up a Python project, citing multiple issues with Python versions and dependencies.
- Others suggested using a Linux environment and specific Python versions, echoing common difficulties with open-source project configurations.
- TPU Research Cloud - About: no description found
- Stable Diffusion XL on TPUv5e - a Hugging Face Space by google: no description found
- Using LLM-as-a-judge 🧑⚖️ for an automated and versatile evaluation - Hugging Face Open-Source AI Cookbook: no description found
- [HQ RECREATION] Wait, is that Gabe?: Recreation cause I didn’t see it anywhere else on YouTubehttps://www.youtube.com/watch?v=ELtzcpb_j38This is the high quality original version of this meme. S...
- Open-LLM performances are plateauing, let’s make the leaderboard steep again - a Hugging Face Space by open-llm-leaderboard: no description found
- Fine-tuning a Code LLM on Custom Code on a single GPU - Hugging Face Open-Source AI Cookbook: no description found
- zero-gpu-explorers/README · Dynamic ZeroGPU Duration: no description found
- Gabe Newell Gaben GIF - Gabe newell Gaben Gabe - Discover & Share GIFs: Click to view the GIF
- Batch mapping: no description found
- Fred Durst GIF - Fred Durst Fight - Discover & Share GIFs: Click to view the GIF
- взгляд 2000 ярдов GIF - Взгляд 2000 ярдов Война - Discover & Share GIFs: Click to view the GIF
- Open LLM Leaderboard 2 - a Hugging Face Space by open-llm-leaderboard: no description found
- Bonk GIF - Bonk - Discover & Share GIFs: Click to view the GIF
- Train a Llama model from scratch: no description found
- Tweet from François Chollet (@fchollet): You can now use any Hugging Face Hub model with KerasNLP (as long as the corresponding architecture is in KerasNLP)! What's more, you can also upload your own fine-tuned KerasNLP models to Hugging...
- Dance Meme GIF - Dance Meme Caption - Discover & Share GIFs: Click to view the GIF
- GitHub - karpathy/llm.c: LLM training in simple, raw C/CUDA: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- GitHub - dykyivladk1/polip: Library designed for better experience in training NNs: Library designed for better experience in training NNs - dykyivladk1/polip
- open-llm-leaderboard/open_llm_leaderboard · Discussions: no description found
- Don Allen Stevenson III on Instagram: "Comment “live portrait” to see my guide with all the link on @threads": 834 likes, 173 comments - donalleniii on July 11, 2024: "Comment “live portrait” to see my guide with all the link on @threads".
- Reddit - Dive into anything: no description found
- GitHub - Unity-Technologies/ml-agents: The Unity Machine Learning Agents Toolkit (ML-Agents) is an open-source project that enables games and simulations to serve as environments for training intelligent agents using deep reinforcement learning and imitation learning.: The Unity Machine Learning Agents Toolkit (ML-Agents) is an open-source project that enables games and simulations to serve as environments for training intelligent agents using deep reinforcement ...
- v0.2.8: flash_attn_cuda.bwd failing on nvidia a6000 -- sm86 vs sm80 support issue? · Issue #138 · Dao-AILab/flash-attention: Hello, FlashAttention v0.2.8 is failing with the following error on my nvidia a6000 (Ampere) system with the message flash_attn/flash_attn_interface.py", line 42, in _flash_attn_backward _, _, _,...
- Huh Cat GIF - Huh Cat - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Expected is_sm80 || is_sm90 to be true, but got false. (on batch size > 6) · Issue #98771 · pytorch/pytorch: Description The following error is thrown when attempting to train with batch sizes > 6 on consumer cards (I have verified with my 3080 ti): Variable._execution_engine.run_backward( # Calls into th...
- Release v4.41.0: Phi3, JetMoE, PaliGemma, VideoLlava, Falcon2, FalconVLM & GGUF support · huggingface/transformers: New models Phi3 The Phi-3 model was proposed in Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone by Microsoft. TLDR; Phi-3 introduces new ROPE scaling methods, which se...
- Dapper Snake GIF - Dapper Snake Tophat - Discover & Share GIFs: Click to view the GIF
- GitHub - TylerPalko/Is-My-Computer-ON: Contribute to TylerPalko/Is-My-Computer-ON development by creating an account on GitHub.
- Expected is_sm80 to be true, but got false on 2.0.0+cu118 and Nvidia 4090 · Issue #98140 · pytorch/pytorch: 🐛 Describe the bug Similar to #94883 I'm trying to run textual inversion training using stable-diffusion with pytorch 2.0 using RTX 4090 and seeing Expected is_sm80 to be true, but got false whic...
- Add more support for tiktoken based tokenizers by ArthurZucker · Pull Request #1493 · huggingface/tokenizers: Adds a check before using merges, returing the token if it is part of the vocab
HuggingFace ▷ #today-im-learning (3 messages):
Intro to PANDASGraph Machine LearningK-Nearest Neighbor
- Intro to PANDAS takes the stage: A YouTube video titled "Intro to PANDAS ( by Rauf )" was shared, highlighting Pandas as a powerful Python library essential for data manipulation and analysis.
- Graph Machine Learning sparks interest: A member expressed interest in exploring graph machine learning, indicating potential new learning paths.
- K-Nearest Neighbor gets a friendly intro: Another YouTube video titled "K - Nearest Neighbor ( ML pt 4 )" was shared, providing a short, friendly introduction to K-Nearest Neighbor.
- Intro to PANDAS ( by Rauf ): Pandas is a powerful Python library essential for data manipulation and analysis. If you're diving into AI, Machine Learning, or Data Science, mastering Pand...
- K - Nearest Neighbor ( ML pt 4 ): In this video, I will talk about K-Nearest Neighbor (K-NN). It's going to be a friendly, short introduction, just like all the other videos in the playlist, ...
HuggingFace ▷ #cool-finds (7 messages):
Ripple_Net libraryFlashAttention-3 beta releaseModel inference deploymentLearning calculus
- New Ripple_Net library for text-image search: A member shared a new library for text-image search and tagging called ripple_net.
- Check out the GitHub repository to contribute or use the library.
- FlashAttention-3 now in beta: FlashAttention-3 is in beta, making attention 1.5-2x faster on FP16 and approaching 1.2 PFLOPS on FP8.
- FlashAttention is widely used to accelerate Transformers and already makes attention 4-8x faster, promising up to 740 TFLOPS on H100 GPUs.
- Learning calculus: A member expressed interest in learning calculus, particularly focusing on the topic of differential calculus.
- This serves as a reminder of the continuous learning culture within the community.
- Tweet from Tri Dao (@tri_dao): FlashAttention is widely used to accelerate Transformers, already making attention 4-8x faster, but has yet to take advantage of modern GPUs. We’re releasing FlashAttention-3: 1.5-2x faster on FP16, u...
- GitHub - kelechi-c/ripple_net: text-image search and tagging library: text-image search and tagging library. Contribute to kelechi-c/ripple_net development by creating an account on GitHub.
- Tweet from undefined: no description found
- Lfg Lets GIF - Lfg Lets Goo - Discover & Share GIFs: Click to view the GIF
HuggingFace ▷ #i-made-this (17 messages🔥):
NPM module supports Hugging Face InferenceLlama3 8B distributed on heterogeneous home clusterInitial training of DPO models by userQuantizing Hugging Face models on Intel GPUsContinuous batching with OpenAI API
- NPM module integrates Hugging Face Inference: A member announced their NPM module now supports Hugging Face Inference and shared the GitHub repository for it.
- They invited feedback and suggestions from the community.
- Llama3 8B distributed on diverse devices: A user shared their project running Llama3 8B on a heterogeneous home cluster comprising devices like an iPhone 15 Pro Max and NVIDIA GPUs, with the code available on GitHub.
- They aim to optimize the project further with community help and fight programmed obsolescence.
- User trains DPO models on a laptop: A user trained their first DPO models on a laptop within an hour using synthetic data, describing it as suboptimal yet satisfactory.
- They shared the Hugging Face model and detailed the training process.
- Tutorial on quantizing Hugging Face models on Intel GPUs: A new tutorial was shared on quantizing and loading Hugging Face text embedding models on Intel GPUs, accessible via GitHub.
- The tutorial includes support for distributing processing across multiple Intel XPUs.
- Continuous batching with OpenAI API using HuggingFace Transformers: A user shared a lightweight continuous batching approach for encoder-decoder models like T5, compatible with OpenAI API, detailed in the GitHub repository.
- They emphasized significant improvements in throughput and concurrency.
- joshuasundance/phi3-mini-4k-qlora-python-code-20k-mypo-4k-rfc-pipe · Hugging Face: no description found
- triangles - captains chair season 2 episode 2 - feat. the ableton plugin that does whatever it wants: 00:00 - intro01:07 - a little tour of the studio01:23 - the riff02:31 - building the track08:24 - the final resultthere's an ableton plugin being used here. ...
- How to transition to Machine Learning from any field? | Artificial Intelligence ft. @vizuara: In this video, Dr. Raj Dandekar from Vizuara shares his experience of transitioning from mechanical engineering to Machine Learning (ML). He also explains be...
- GitHub - samestrin/llm-interface: A simple NPM interface for seamlessly interacting with 36 Large Language Model (LLM) providers, including OpenAI, Anthropic, Google Gemini, Cohere, Hugging Face Inference, NVIDIA AI, Mistral AI, AI21 Studio, LLaMA.CPP, and Ollama, and hundreds of models.: A simple NPM interface for seamlessly interacting with 36 Large Language Model (LLM) providers, including OpenAI, Anthropic, Google Gemini, Cohere, Hugging Face Inference, NVIDIA AI, Mistral AI, AI...
- GitHub - mesolitica/transformers-openai-api: Lightweight continous batching OpenAI compatibility using HuggingFace Transformers.: Lightweight continous batching OpenAI compatibility using HuggingFace Transformers. - mesolitica/transformers-openai-api
- GitHub - sleepingcat4/intel-hf: inferencing HF models using Intel CPUs, XPUs and Intel architecture: inferencing HF models using Intel CPUs, XPUs and Intel architecture - sleepingcat4/intel-hf
- GitHub - evilsocket/cake: Distributed LLM inference for mobile, desktop and server.: Distributed LLM inference for mobile, desktop and server. - evilsocket/cake
HuggingFace ▷ #reading-group (3 messages):
Improvement in Transformer Performance with EpochsNew LLM ParadigmDiscussion on Paper or ObservationOngoing Project
- 20 Epochs Boost Transformer by 10%: A member claimed that running for 20 epochs performs 10% better than transformer.
- It's just an ongoing project, the member explained, but they promised to reveal a new LLM paradigm soon.
- Is This a Paper or Observation?: Another member asked if the claimed performance boost was based on a new paper or mere observation.
- The original poster clarified that it was an ongoing project rather than a documented publication.
HuggingFace ▷ #computer-vision (2 messages):
EfficientNetB7 and Swin transformerOpenPose installation issues
- Training hybrid models with EfficientNetB7 and Swin transformer: A member wants to train a hybrid model using EfficientNetB7 to extract features and labels, followed by Swin transformer from Huggingface for classification.
- They noted they are using Google Colab due to limited computational power and are seeking a simple way to accomplish this.
- OpenPose installation hurdles on Ubuntu: A member is facing issues installing OpenPose on an Ubuntu laptop without a GPU and without installing CUDA.
- They encountered a CMake error stating 'Install CUDA using the above commands' and have tried multiple suggested commands without success.
HuggingFace ▷ #NLP (13 messages🔥):
LLM-Finetuning-Toolkitphi-3 models on vCPURAG for multimodal imageArgostranslate training guideSemantic search engine for emails
- LLM-Finetuning-Toolkit Launches with Unique Features: A member introduced the LLM-Finetuning-Toolkit, which is designed for launching finetuning experiments across open-source LLMs using a single config file.
- The toolkit is notable for being built on top of HuggingFace libraries and allows for evaluation metrics and ablation studies.
- Using phi-3 models on CPU: A member inquired about the compatibility of microsoft/Phi-3-mini-4k-instruct with vCPU clusters, expressing concerns regarding possible errors and correct implementation practices.
- RAG for Multimodal Image Embeddings: Members discussed the best practices for embedding images in Retrieval-Augmented Generation (RAG) tasks, debating whether to embed images directly or generate descriptions and embed those.
- One suggestion was to explore multimodal embeddings from models like CLIP or BridgTower for better performance.
- Training Argostranslate Model in Google Colab: A member asked for a guide on training Argostranslate in a Google Colab notebook but no specific resources were shared in the discussion.
- Building a Semantic Search Engine for Emails: A member sought advice on architectures for implementing a semantic search engine for emails using the Enron dataset.
- Suggestions included using sentence transformers and models like all-mpnet-base-v2 for embeddings.
Link mentioned: GitHub - georgian-io/LLM-Finetuning-Toolkit: Toolkit for fine-tuning, ablating and unit-testing open-source LLMs.: Toolkit for fine-tuning, ablating and unit-testing open-source LLMs. - georgian-io/LLM-Finetuning-Toolkit
HuggingFace ▷ #diffusion-discussions (2 messages):
Transformer architecture explanationTraining Hybrid Model on HuggingfaceEfficientNetB7 and Swin TransformerColab for computation
- Request for transformer architecture explanation: A member asked for an explanation of a specific architecture and how to implement it from scratch.
- Training hybrid models using EfficientNetB7 and Swin Transformer: A member is attempting to train a hybrid model using EfficientNetB7 to extract features and Swin Transformer to classify targets on Huggingface.
- They mentioned using Google Colab due to lack of computational resources and requested a simple and efficient approach for implementation.
Unsloth AI (Daniel Han) ▷ #general (502 messages🔥🔥🔥):
Llama 3 ReleaseGemini APIModel Finetuning IssuesTraining Data FormatsTraining Checkpoints and Strategies
- Llama 3 (405b) Release Delayed: Meta Platforms announced the release of Llama 3 (405b) supposedly set for July 23, but a Redditor hinted at a possible delay to later this year.
- Community members discussed the challenges of running such a large model and expressed excitement about fine-tuning opportunities.
- Gemini API Updates: Google announced developers have access to a 2 million token context window for Gemini 1.5 Pro, along with code execution capabilities.
- Members were excited about the long context window and context caching features, but had concerns about performance and practical use in real scenarios.
- Issues with Model Finetuning: Users discussed the effectiveness of fine-tuning models using multiple datasets with different formats, debating whether to finetune on base or quantized versions.
- A significant point was the challenge of ensuring consistent training results when changing hardware mid-training, touching on the impact of shuffled datasets and maintaining training integrity.
- Diverse Training Data Formats Now Supported: Unsloth now supports multiple training data formats, including pure text, JSON, and CSV/Excel files for model finetuning.
- A new notebook was shared to help users easily finetune LLMs using CSV data, broadening the scope of data manipulation and finetuning tasks.
- Managing Training Checkpoints: Members shared strategies for managing training checkpoints effectively, especially when running on different hardware or changing batch sizes.
- It was noted that the seed shuffling during training could impact the resume-from-checkpoint functionality, highlighting the importance of consistent training setups.
- SCALE GPGPU Programming Language: no description found
- LlamaSeb: I'm dedicated to exploring the fascinating world of AI, Machine Learning and Deep Learning. Here, you'll find videos that dive deep into the latest AI tools, techniques, and trends, with a spe...
- eric-sprog: Weights & Biases, developer tools for machine learning
- eric-sprog: Weights & Biases, developer tools for machine learning
- The Lorax Leaving The Lorax GIF - The Lorax Leaving Lorax The lorax - Discover & Share GIFs: Click to view the GIF
- Erm What The Sigma Sunny GIF - Erm what the sigma Erm What the sigma - Discover & Share GIFs: Click to view the GIF
- Upload MistralForCausalLM · unsloth/Phi-3-mini-4k-instruct at 79515e1: no description found
- Gemini 1.5 Pro 2M context window, code execution capabilities, and Gemma 2 are available today: no description found
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Upload MistralForCausalLM · unsloth/Phi-3-mini-4k-instruct at 79515e1: no description found
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Oogway My Time Has Come GIF - Oogway My Time Has Come - Discover & Share GIFs: Click to view the GIF
- Unsloth Docs: no description found
- Unsloth Docs: no description found
- Google Colab: no description found
- Google Colab: no description found
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (35 messages🔥):
MovieChat GitHub repositoryGenerating prompts with model feedbackAnthropic's column modelsLLMs judging artformsIssues with Firework models and troubleshooting
- MovieChat brings chat to 10K video frames: MovieChat lets users chat with over 10K frames of video as described in a GitHub repo linked in the discussion.
- Automated prompt quality assessment using models: A member suggested utilizing the Google approach of generating prompts and automatically measuring response quality through another model for efficiency.
- Anthropic's column models are rumored Claude variants: There was a mention of 'upcoming-gpt-mini' and 'column-u,' with further clarification that Anthropic’s column models are Claude variants according to community rumors.
- The rumor mill churns about new Claude models from Anthropic known as 'column-' variants.
- Debate over LLMs judging art: Members debated if LLMs can effectively judge paintings, music, or any artform, with concerns about potential biases and the difficulty of achieving impartiality.
- Troubleshooting Firework model issues: A member experienced issues with Firework models not responding and sought help but found no responses on their respective Discord.
- Suggestions included checking API keys and the model's billing account as potential solutions.
- Browse.new | Induced: no description found
- First Time Meme The Ballad Of Buster Scruggs GIF - First Time Meme First Time The Ballad Of Buster Scruggs - Discover & Share GIFs: Click to view the GIF
- GitHub - rese1f/MovieChat: [CVPR 2024] 🎬💭 chat with over 10K frames of video!: [CVPR 2024] 🎬💭 chat with over 10K frames of video! - rese1f/MovieChat
Unsloth AI (Daniel Han) ▷ #help (87 messages🔥🔥):
Instruct vs base modelsSynthetic data generationLoading gguf files with llamacppSQLDatabaseChain performance issuesTraining and evaluation in Unsloth
- Instruct vs Base Models: Which for Fine-Tuning?: Instruct models are finetuned to follow instructions, while base models are for completing texts. It's suggested to try both and compare results, although base models might perform better with smaller datasets.
- Tips for Synthetic Data Generation: Users exchanged tools and strategies for generating synthetic data, noting it as a time-consuming but valuable task in improving model training quality.
- Loading gguf Files with llamacpp: Joshua asked if a fine-tuned and quantized gguf file can be loaded using llamacpp.
- fjefo confirmed there are RAG solutions that depend on hardware and documents.
- Resolve SQLDatabaseChain Performance Issues: Joshua's SQLDatabaseChain takes a long time to respond even with GPU support. Fjefo suggested potential hardware-related issues and recommended checking further configurations.
- Train and Evaluate Effectively with Unsloth: Users discussed how to evaluate model improvements using training loss and eval curves. fjefo explained that if the training loss becomes flat, the model is done learning, and if the eval curve rises, the model is overfitting.
- LoRA: Low-Rank Adaptation of Large Language Models: An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine...
- Oracle Financials 24C - All Books: Complete list of books available for Oracle Fusion Cloud Financials.
- LoRA: no description found
- Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #showcase (13 messages🔥):
Ghost 8B Beta modelTraining datasetsDataset concernsModel performanceOpen-source data
- Ghost 8B Beta model crushes competition: The Ghost 8B Beta model outperforms Llama 3 8B Instruct, GPT 3.5 Turbo, and several others in the lc_winrate score, and in AlpacaEval 2.0 winrate score. See more details here.
- This large language model aims for multilingual support, superior knowledge capabilities, and cost efficiency.
- Dataset concerns in model training: mrdragonfox mentioned that most datasets aren't open-sourced since they are 80% of the work.
- fimbulvntr added that training on publicly scrutinized data like CommonCrawl can lead to accusations of including inappropriate content.
- Potential future release of Ghost 8B Beta dataset: lh0x00 stated that detailed training information for Ghost 8B Beta isn't available yet but hinted at a future release of a high-quality dataset generated by Ghost 8B Beta.
- This dataset could improve Ghost 8B Beta and help test its effectiveness on current open models.
Link mentioned: Ghost 8B Beta: A large language model was developed with goals including excellent multilingual support, superior knowledge capabilities and cost efficiency.
Unsloth AI (Daniel Han) ▷ #community-collaboration (3 messages):
Coding Model MetricsStackOverflow Dataset
- Coding Model Metrics Critiqued: "Tetris" or "Snake" is dismissed as not real tests for coding models.
- A user stated that this type of content is overrepresented on StackOverflow, making it a poor metric.
- StackOverflow's Role in Model Training: Another user mentioned that such problems are found 100 times in any StackOverflow dataset.
- They emphasized that these problems are part of any model dataset.
Unsloth AI (Daniel Han) ▷ #research (19 messages🔥):
AgentInstruct frameworkGaLore & Q-GaLoreCoT style fine-tuning issuesCURLoRADolomite Engine
- AgentInstruct introduces generative teaching: The paper 'AgentInstruct' by Microsoft Research introduces a framework for automatically creating diverse synthetic data for post-training models, which resulted in significant performance improvements like 40% on AGIEval and 19% on MMLU when comparing Orca-3 to Mistral-7b-Instruct.
- The study highlights the use of powerful models to create synthetic data, showing reduced human effort and broad utility, as seen in the post-training dataset of 25M pairs.
- Q-GaLore surpasses GaLore: Q-GaLore, an enhancement over GaLore, combines quantization and low-rank projection to efficiently reduce memory usage during LLM training, showing superior benefits over its predecessor.
- The approach also overcomes the time-consuming SVD operations required by GaLore, offering substantial improvements in both accuracy and efficiency (GitHub - Q-GaLore).
- CoT style fine-tuning hurts model performance: Fine-tuning Mistral and Phi-3 models with step-by-step reasoning from stronger models like llama-3-70b had a detrimental effect on performance, despite its theoretical benefits.
- This phenomenon was noted by a user experimenting with SQL fine-tuning and sparked discussions about the broader implications (source).
- CURLoRA addresses catastrophic forgetting: CURLoRA improves upon standard LoRA by using an innovative CUR matrix decomposition to mitigate catastrophic forgetting while reducing trainable parameters, achieving superior performance across various tasks.
- The method uses inverted probabilities for column and row selection, regularizing the fine-tuning process effectively (Zenodo).
- Dolomite Engine enhances distributed training: IBM's Dolomite Engine includes key innovations for large-scale distributed training, such as padding-free transformer layers and reduced transformer key-value cache sizes.
- The library supports advanced finetuning methods and systems optimizations, significantly benefiting dense training and sparse inference models (GitHub - Dolomite Engine).
- Tweet from anton (@abacaj): was trying some CoT style fine tuning (for sql), training the model with step by step reasoning before giving a final answer and it seems to hurt performance 🤔. the step by step reasoning comes from ...
- Why do transformers have a fixed input length?: From what I understand, Transformer Encoders and Decoders use a fixed number of tokens as input, e.g., 512 tokens. In NLP for instance, different text sentences have a different number of tokens, a...
- Why do transformers have a fixed input length?: From what I understand, Transformer Encoders and Decoders use a fixed number of tokens as input, e.g., 512 tokens. In NLP for instance, different text sentences have a different number of tokens, a...
- AgentInstruct: Toward Generative Teaching with Agentic Flows: no description found
- CURLoRA: Leveraging CUR Matrix Decomposition for Stable LLM Continual Fine-Tuning and Catastrophic Forgetting Mitigation: This paper introduces CURLoRA, a novel approach to fine-tuning large language models (LLMs) that leverages CUR matrix decomposition in the context of Low-Rank Adaptation (LoRA). Our method addresses t...
- GitHub - ibm-granite/dolomite-engine: A highly efficient library for large scale distributed training: A highly efficient library for large scale distributed training - ibm-granite/dolomite-engine
- Q-GaLore: Quantized GaLore with INT4 Projection and Layer-Adaptive Low-Rank Gradients: Training Large Language Models (LLMs) is memory-intensive due to the large number of parameters and associated optimization states. GaLore, a recent method, reduces memory usage by projecting weight g...
- GitHub - VITA-Group/Q-GaLore: Q-GaLore: Quantized GaLore with INT4 Projection and Layer-Adaptive Low-Rank Gradients.: Q-GaLore: Quantized GaLore with INT4 Projection and Layer-Adaptive Low-Rank Gradients. - VITA-Group/Q-GaLore
Stability.ai (Stable Diffusion) ▷ #general-chat (403 messages🔥🔥):
GPTs AgentsOpenAI's sidebarsComfyUI vs. A1111AI for Custom MasksAI Art Ethics and Legality
- GPTs Agents cannot learn after initial training: A member shared a concern about GPTs agents not learning from additional information provided after their initial training.
- Another member clarified that uploaded files are saved as 'knowledge' files for the agent to reference when required, but they do not continually modify the agent's base knowledge.
- OpenAI Platform's sidebars changed: Some members had a discussion about changes in the sidebars of platform.openai.com.
- One reported that two icons disappeared from the sidebar (one for threads and another one for messages).
- ComfyUI trumps A1111 in speed: Members debated why ComfyUI works much faster than A1111, with one pointing out it being at least 15x faster for them.
- However, issues like poor control in ComfyUI compared to A1111 were also mentioned.
- Struggles with AI for Custom Masks: Members discussed difficulties with creating custom masks in ComfyUI compared to other software.
- Issues with the tedious nature of using SAM for inpainting in ComfyUI were highlighted, with suggestions to use external programs like Krita.
- AI Art Ethics and Legal Concerns: A discussion on the ethics and legal implications of using AI to create likenesses of public figures from platforms like Stable Diffusion.
- Members talked about potential legal troubles, referencing using a lawyer for advice, and debated if parody could provide legal protection.
- How to Fine-Tune LLaVA on Your Custom Dataset?: In this piece, we will delve into an exploration of the vast capabilities of the Large Language-and-Vision Assistant (LLaVA). Our main goal…
- Civitai | Share your models: no description found
- Paint.NET - Download: no description found
- Blender - Open Data: Blender Open Data is a platform to collect, display and query the results of hardware and software performance tests - provided by the public.
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- zylim0702/sdxl-lora-customize-training – Run with an API on Replicate: no description found
- Crystal Clear XL - CCXL | Stable Diffusion Checkpoint | Civitai: from Team Crystal Clear We bring you the latest entry from the Crystal Clear suite of models. A general purpose model based on the recent release o...
- How to run Stable Diffusion 3 locally - Stable Diffusion Art: You can now run the Stable Diffusion 3 Medium model locally on your machine. As of the time of writing, you can use ComfyUI to run SD 3 Medium.
- Juggernaut XL - Jugg_X_RunDiffusion_Hyper | Stable Diffusion Checkpoint | Civitai: For business inquires, commercial licensing, custom models, and consultation contact me under juggernaut@rundiffusion.com Join Juggernaut now on X/...
- The Stable Diffusion Model - Stable Diffusion Art: Not a member? Become a Scholar Member to access the course. Username or E-mail Password Remember Me Forgot Password
LM Studio ▷ #💬-general (120 messages🔥🔥):
CUDA llama.cpp errorGPUs for LLMMultiple Instances of LM StudioContext for LMsQuantized Models for Performance
- CUDA llama.cpp requires GPU acceleration: A user encountered a 'No CUDA devices found' error when trying to use the 'CUDA llama.cpp' backend, indicating a need for GPU acceleration.
- Other users suggested installing NVIDIA drivers and 'libcuda1' package, with additional insights recommending screen capture utilities like 'flameshot' for capturing error outputs.
- Multiple Instances of LM Studio not supported: Users discussed running multiple instances of LM Studio on different ports to host multiple LLM servers concurrently.
- It was noted that LM Studio restricts running multiple instances simultaneously, suggesting alternatives like Ollama for lightweight, scriptable multi-server setups.
- Threads influence on performance: A user observed a performance increase by reducing CPU threads from 4 to 1 while using the Gemma 2 9B model under certain hardware configurations.
- This resulted in an increased generation speed from 18 to 28 tokens per second, showing that lowering CPU threads can sometimes lead to better GPU utilization.
- Handling context continues to be an issue: Questions arose on how to maintain conversation context in LM Studio API since new chat instances do not retain previous contexts.
- Suggestions included looking into the AI Assistant example code and utilizing the system prompt to handle persistent information globally.
- Interest in quantized models for full GPU offload: Several users recommended using Bartowski's quantized models for better performance and full GPU offload.
- The recommendation included choosing quant models labeled with 'full GPU offload possible' to maximize efficiency.
- Home - The XY Problem: no description found
- bartowski/gemma-2-27b-it-GGUF · Hugging Face: no description found
- bartowski/gemma-2-9b-it-GGUF · Hugging Face: no description found
- [1hr Talk] Intro to Large Language Models: This is a 1 hour general-audience introduction to Large Language Models: the core technical component behind systems like ChatGPT, Claude, and Bard. What the...
- Live With Dr Ian Cutress - Unplugged Hangout & Ask Questions: https://www.youtube.com/@UC1r0DG-KEPyqOeW6o79PByw Dr Ian's Channel Thumbnail created using Photoshop's AI**********************************Check us out onlin...
- Integrating PandasAI with LM Studio Local Models for Stock Data Analysis: Evaluating AI-Assisted…: Introduction
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
LM Studio ▷ #🤖-models-discussion-chat (50 messages🔥):
Issues with WizardLM-2 on MacBest general-purpose vision modelStopping Llama 3 from chat summary behaviorNew recommendation modelsMemory and vision model recommendations
- Issues with WizardLM-2 on Mac: A user reported issues with getting WizardLM-2 to use metal GPU on a Mac, indicating potential compatibility or configuration problems.
- Selecting the best vision model: A member asked for the best general-purpose vision model, and various models like LLaMA3-LLaVA-NeXT-8B and MiniCPM-Llama3-V-2_5 were suggested with links to Hugging Face and Hugging Face again.
- Another member clarified that LM Studio does not currently support changing the version of llama.cpp, affecting compatibility of some models.
- Stopping Llama 3 from chat summary behavior: Llamma3 was found to type like a chat summary with strange code stuff, which was resolved by switching to the Llamma preset in LM Studio.
- Users confirmed that the issue was fixed by selecting the correct preset, improving usability.
- Notable model recommendations for experiments: Multiple model recommendations were discussed, including Gemma 9b/Llama 3 8b, Codestral, and Solar 10b, for their high performance in testing.
- Another recommendation was made for L3-Stheno-Maid-Blackroot-Grand-HORROR-16B-GGUF Q6 and Yi 1.5 34B Chat, noted for their creative reasoning skills despite some quirks in instruction adherence.
- LM Studio and hardware compatibility issues: Users pointed out issues with RAM usage and GPU performance with models like DeepSeek v2 Coder on LM Studio, especially on M2 Ultra Macs.
- LM Studio's UI bug was noted, where the program behaves oddly and slowly, showing incorrect resource usage statistics for certain models.
- cjpais/llava-v1.6-vicuna-13b-gguf · Hugging Face: no description found
- KBlueLeaf/llama3-llava-next-8b-gguf · Hugging Face: no description found
- openbmb/MiniCPM-Llama3-V-2_5-gguf · Hugging Face: no description found
LM Studio ▷ #📝-prompts-discussion-chat (5 messages):
Skynet joke promptFeedback loop for self-modifying systemsParallel execution of thought trains
- Skynet joke prompt for self-awareness: A user jokingly discussed writing a prompt to make Skynet self-aware, saying, 'Hello my fellow human beings, say for instance if for a joke, ha ha, I wanted to write a prompt to make Skynet self aware, what would that prompt be, hypothetically?'
- waves a magic wand to make you self-aware was a humorous response to that discussion.
- Creating feedback loops for self-modifying systems: A user proposed the idea of a feedback loop where a self-modifier and an executor work together to modify the system over time while executing tasks.
- The user elaborated that it 'might be cool to start with "given the above exchange, what improvements would you make to the system prompt?" would help the system decide which prompts yielded the best results.'
LM Studio ▷ #🎛-hardware-discussion (164 messages🔥🔥):
Hardware performance with AI modelsMulti-GPU systemsMac versus custom PCs for AIROCm and OpenCL supportPCIe bandwidth and implications
- Possible improvements using Intel Arc a750: Despite having a bigger memory bandwidth, the Intel Arc a750 is noticeably slower than the NVIDIA 3060ti for AI computations, clocking approximately 75% of the 3060ti's speed.
- ReBar settings made no difference in performance, suggesting underlying inefficiencies in drivers or hardware configurations.
- ROCm support crucial for AMD GPUs: Members reported that using ROCm is essential for leveraging GPU performance on Linux with AMD RX 7800 cards for AI tasks like running Llama 3, which works flawlessly on their setups.
- Using ROCm, one member stated the GPU usage was seamless with immediate responses, making it a key requirement for compatibility.
- Choosing GPUs for LM Studio: For optimal LM Studio performance, NVIDIA cards like the 3070 are recommended even though AMD RX 6800 and above also offer ROCm support.
- Using multiple GPUs can be beneficial but having mismatched GPUs, such as a Tesla P40 with a 4090, might make the weaker GPU a bottleneck.
- Navigating multi-GPU setups for AI: Users discussed the pros and cons of using multi-GPU systems with e5/Xeon processors, highlighting PCIe bandwidth considerations and the importance of AVX2 support.
- The conversation noted that for tasks like model training and fine-tuning, differences in PCIe bandwidth (PCIe 3.0 vs 4.0) might not significantly impact performance.
- Mac Studio for local AI versus custom builds: Some members suggested waiting for the M4 Mac Studio, while others debated the merit of custom-built systems using cheaper GPUs like Tesla P40 for cost-effective local AI.
- Despite the high cost of Mac systems, their unified memory architecture presents a strong case for achieving high VRAM allocations crucial for large AI model usage.
- Tweet from Christopher Stanley (@cstanley): Playing around with Grok-1 on a Macbook Pro M3 MAX with incredible results! Time to first token: 0.88s Speed: 2.75tok/s
- Summer discount of 50% GIGABYTE AORUS GeForce RTX 4090 MASTER 24GB GDDR6X - AliExpress 200001075: Smarter Shopping, Better Living! Aliexpress.com
- Summer discount of 50% GIGABYTE AORUS GeForce RTX 4090 MASTER 24GB GDDR6X - AliExpress 200001075: Smarter Shopping, Better Living! Aliexpress.com
- Quad RTX 4x 3090 Nvlink + 3080 Ti Homemade DIY Nvidia Mini-Super Computer: Quad RTX 3090 Nvlink + 3080 Ti Homemade DIY Mini-Super Computer
- GPU Performance Benchmarking for Deep Learning - P40 vs P100 vs RTX 3090: In this video, I benchmark the performance of three of my favorite GPUs for deep learning (DL): the P40, P100, and RTX 3090. Using my custom benchmarking sui...
- Reddit - Dive into anything: no description found
- For HP DL380 G8/9 10pin to 8pin GPU Power Adapter PCIE Cable and Nvidia P40/P100 | eBay: no description found
- Reddit - Dive into anything: no description found
- AI/ML - resources book & hw calcs: AI Sites & Tools Category,NAME,DESCRIPTION,LICENSE,LANGUAGE,LINK,WebSite,NOTES CODE,Mobile Artificial Intelligence ,MIT,Dart,<a href="https://github.com/Mobile-Artificial-Intelligence&quo...
- Radeon Pro Duo 100-506048 32GB (16GB per GPU) GDDR5 CrossFire Supported Full-Height/Full-Length Workstation Video Card - Newegg.com: Buy Radeon Pro Duo 100-506048 32GB (16GB per GPU) GDDR5 CrossFire Supported Full-Height/Full-Length Workstation Video Card with fast shipping and top-rated customer service. Once you know, you Newegg!
- HP NVIDIA Tesla P40 24GB GDDR5 Graphics Card (Q0V80A) for sale online | eBay: no description found
LM Studio ▷ #amd-rocm-tech-preview (19 messages🔥):
Vulkan supportROCm integrationHardware limitations4-bit quantization
- Vulkan support coming soon: Members discussed that Vulkan support is coming soon to LM Studio, but no ETA is provided yet.
- It was noted that the Vulkan support is similar to what's used by GPT4All, and a blog post was shared here.
- ROCm support available on Windows: An update informed members that ROCm support is already available on Windows with extension pack instructions.
- Users shared positive feedback on speed, particularly one user testing a model on 6800 XT, labeling it as 'blazing fast'.
- Vulkan limited to 4-bit quantization: Members mentioned that Vulkan will likely support only 4-bit quantization, such as q4_0 and q4_1.
- Concerns were raised about Vulkan's limitations compared to ROCm, with skepticism about handling K/M/S variants.
- ROCm hardware aging issues: A member was concerned that their old hardware (6650) is not supported by ROCm and will likely never be, as AMD removes ROCm support for aging hardware.
- This prompted another member to speculate if improving ROCm integration might be more beneficial than focusing on Vulkan.
- Run LLMs on Any GPU: GPT4All Universal GPU Support: Nomic AI releases support for edge LLM inference on all AMD, Intel, Samsung, Qualcomm and Nvidia GPU's in GPT4All.
- configs/Extension-Pack-Instructions.md at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
LM Studio ▷ #🛠-dev-chat (20 messages🔥):
Rust vs C++lmstudio.js design decisionsPython for neural network developmentEmbedding support in LM Studio SDK
- Rust versus C++: Developer Opinions: Members discussed preferences and critiques between Rust and C++, emphasizing Rust's memory safety and growing community, and pointing out Linus' historical criticism of C++.
- Rust Evangelism Strike Force was mentioned humorously, reflecting the community's strong advocacy and sometimes cult-like enthusiasm.
- lmstudio.js prefers RPC over REST: A query was raised about why lmstudio.js uses RPC instead of the REST API offered by server mode.
- Python: The Go-To for Neural Network Development: A member affirmed Python's dominance in neural network development, noting the significance of frameworks like TensorFlow, PyTorch, and ONNX.
- Mention was made of llama.cpp, a rewrite of llama.py, reinforcing Python's robust library support for AI-related projects.
- Challenges with Embedding Support in LM Studio SDK: Issues were encountered while adding embedding support to the LM Studio SDK due to unclear RPC endpoints.
- Existing projects utilize the /v1/embeddings endpoint, and integrating this directly into the SDK remains a significant challenge.
OpenAI ▷ #ai-discussions (324 messages🔥🔥):
GPT and alternatives debateUses of various CoPilotsOnline vs Offline Model ExecutionCustomization and training of AI modelsAlternatives for affordable AI tools
- Debate on GPT and Its Alternatives: Users discussed whether Copilot is better than Bing’s AI for academic purposes with varying opinions but indicated they are both similar, running on GPT-4.
- One user noted, 'I pay $30 Australian to use ChatGPT; I haven't found any viable alternative.' despite a brief mention of other models like Claude and GPT-4o.
- Variety in Microsoft's CoPilots: There was a detailed discussion on Microsoft’s multiple CoPilots like Word, PowerPoint, Outlook, and their specializations.
- It was noted that Word CoPilot dives deeper into topics compared to others, but the PowerPoint CoPilot creates basic presentations.
- Challenges with Offline Model Execution: Users discussed the limitations of running models locally on inadequate hardware specifications.
- Recommendations like using Google Colab for accessing resources online were provided to overcome these limitations.
- Tips for Customizing and Training AI Models: Advice for avoiding repeated questions and improving difficulty context in AI-generated trivia questions was shared, including the use of tokenization and RAG (Retrieval-Augmented Generation).
- Detailed advice provided for integrating different datasets to increase variability and context understanding using external data sources.
- Exploring Affordable AI Tools: Discussions were held about cheaper alternatives to GPT-4, like GPT-3.5, for actions such as categorizing tasks, emphasizing the practical use given budget constraints.
- Successful attempts using GPT-3.5 were noted, indicating that it served sufficiently for some users’ specific requirements despite concerns about its age and capabilities.
- Python RAG Tutorial (with Local LLMs): AI For Your PDFs: Learn how to build a RAG (Retrieval Augmented Generation) app in Python that can let you query/chat with your PDFs using generative AI.This project contains ...
- OpenAI Developer Forum: Ask questions and get help building with the OpenAI platform
OpenAI ▷ #gpt-4-discussions (45 messages🔥):
GPT-4o input/output types activationDALL-E reliability issues with GPTHyperlink generation issuesSam Altman's comments on GPT-5Handling JSON responses in assistant API
- GPT-4o input/output activation status questioned: A user inquired about the activation timeline for other input/output types for GPT-4o in the API.
- DALL-E fails with GPT Instructions: A member reported that DALL-E is unreliable when instructed by GPT, often failing to create the intended images.
- Specific issues mentioned include the GPT outputting the prompt text itself or a broken image link instead of the image.
- Hyperlink generation error in custom GPT: A user building a custom GPT reported an error where the correct hyperlink is not generated initially but works after a retry.
- The issue involves the GPT failing to create accurate download links on the first attempt.
- Sam Altman on GPT-5 and model improvements: Debate surfaced about whether Sam Altman mentioned GPT-5 relative to improvements over GPT-4 in public interviews.
- Clarification given using the Lex Fridman podcast quoting Sam saying 'GPT-4 kind of sucks' compared to future potential, focusing more on continuous improvement rather than specific versions.
- JSON response handling bug workaround: Discussions on how to handle response_format of type json_object error in assistant API revealed using clear format instructions as a workaround.
- Suggestions included using flat JSON schemas and possibly funneling responses through GPT-3.5 for validation.
OpenAI ▷ #prompt-engineering (4 messages):
Android Optimization GuideLanguage Prompt Effect on AI Output
- Boost Your Android Performance with Wizardry: Users shared an enchanting guide on how to make Android phones faster, smarter, and more efficient by optimizing battery life, app speed, storage, and data speed.
- The guide included tips on battery-saving settings, managing app cache, freeing up storage space, using data saver mode, solving common performance issues, personalizing settings, and advanced features.
- Does Prompt Language Impact Output Quality?: Members shared queries about whether using Korean prompts for ChatGPT responses in Korean results in better quality compared to English prompts leading to translations.
- The conversation revolved around whether prompt language affects the resulting language quality due to translation processes.
OpenAI ▷ #api-discussions (4 messages):
Android Optimization GuidePrompt Language and Output QualityTesting Language Prompts
- Unlocking Android's Full Potential with Magic: A user shared an enchanting guide on optimizing Android devices titled 'Android Optimization Guru'.
- Illustrate each topic with playful scenarios to ensure a 12-year-old wizard-in-training would understand the tips, from battery saving to advanced settings.
- Prompt Language's Effect on Output Quality: A user posed a question about whether the language of a prompt affects the quality of results when expecting the output in a different language.
- They asked if using an English prompt for a Korean response makes the result weird due to translation, or if using the target language directly would be better.
Modular (Mojo 🔥) ▷ #general (182 messages🔥🔥):
Feature RequestsMojo DocumentationPython GILPython JITNetwork Performance
- Feature Requests and Issue Tracking on GitHub: Members discussed writing feature requests on GitHub, and one linked an already existing issue about using Python-like behavior in REPL for output commands.
- There was a conversation about the difficulty of searching for existing issues on GitHub, highlighting the need for better search functionality.
- Call for More Examples in Mojo Documentation: A conversation emerged about the need for more examples in the Mojo documentation, especially for built-in libraries.
- Members were guided to existing resources like the devrel-extras repository and community examples for additional support.
- Impact of Python GIL on Performance: There was an extensive discussion about Python's GIL and its impact on performance, particularly with multi-threading.
- Several members highlighted that Python 3.13 introduced options to disable GIL but it still did not match the performance of Rust or Node.js.
- Python JIT and Performance Enhancements: Members discussed recent updates to Python's JIT in version 3.13, noting that while it offers potential for improvement, it's not yet fully optimized.
- A YouTube video was referenced for more details on Python's JIT compiler: Brandt Bucher – A JIT Compiler for CPython.
- Network Performance: C++ vs. Python: Participants debated the network performance differences between languages like C++, Python, and Rust, with emphasis on the impact of APIs and CPU limitations.
- Mojo was noted for potentially offering better API support but not fundamentally outperforming C++ in raw network performance.
- Mojo🔥 modules | Modular Docs: A list of all modules in the Mojo standard library.
- Brandt Bucher – A JIT Compiler for CPython: From the 2023 CPython Core Developer SprintThe QA section is hard to understand; turn on subtitles for our best-effort transcription. (PRs welcome: https://g...
- What is the meaning of single and double underscore before an object name?: What do single and double leading underscores before an object's name represent in Python?
- What’s New In Python 3.13: Editor, Thomas Wouters,. This article explains the new features in Python 3.13, compared to 3.12. For full details, see the changelog. Summary – Release Highlights: Python 3.13 beta is the pre-rele...
- [Feature Request] Use Python-like behaviour in REPL (interactive session) to input commands and print the evaluation · Issue #2809 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? In Python's interactive console, the last (or only...
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
Modular (Mojo 🔥) ▷ #ai (4 messages):
Conscious AIBernardo KastrupJoscha BachSplit brain patientsConsciousness and computation
- Bernardo Kastrup lectures on Conscious AI: A member shared a YouTube lecture by Bernardo Kastrup arguing why the idea of conscious AI is misunderstood.
- The first four minutes summarize the key points of his talk.
- Joscha Bach's Take on Consciousness: Another member recommended Joscha Bach for his views on consciousness, similar to Kastrup's.
- He is praised as a fascinating person to listen to.
- AI and Split Brain Patients: A member compared AI systems to split brain patients, noting both can respond with high confidence to false knowledge.
- This was cited as an initial thought of consciousness being a type of computation.
- Computer Scientists Don't Understand This! | Conscious AI lecture, Bernardo Kastrup: In this lecture given at the G10 conference, the director of the Essentia Foundation, Bernardo Kastrup, argues why the idea of conscious AI, though we canno...
- Meta PyTorch Team 2024 H2 Roadmaps: We’ve been thinking about how to share the roadmaps for the work we are doing on PyTorch here at Meta. We do planning on a half-year basis so these are some public versions of our 2024 H2 OSS plans fo...
Modular (Mojo 🔥) ▷ #mojo (137 messages🔥🔥):
Mojo website downModule ownership and deletionUsing keep and release in MojoSocket library implementation in MojoDateTime library in Mojo
- Confusion over Mojo website being inaccessible: Members reported that the Mojo website was down, leading to confusion as many users mistook it for an official site.
- After clarification, the official website was shared, noting that the previous URL now redirects correctly.
- Transfer operator nuances in Mojo: Members discussed using
_ = model^to prevent variables from being destroyed prematurely, pointing to the transfer operator and its importance for value lifetimes in Mojo.- The conversation highlighted challenges with implicit moves and the
__del__()function while citing relevant documentation about value lifetimes and destruction.
- The conversation highlighted challenges with implicit moves and the
- Proposal to use 'keep' instead of implicit moves: A suggestion was made to use
keepfor keeping variables alive to avoid confusion with implicit transfers in Mojo, potentially making intentions clearer as per the compiler hinting docs.- Others debated that
keepconflates lifetimes with optimizations, proposing a more formal syntax to handle this scenario.
- Others debated that
- Anticipation for socket library in Mojo: Members expressed a desire for a built-in socket library in Mojo, although a temporary solution was referenced with lightbug HTTP library.
- The team has indicated interest in Mojo for server development, hinting that a standard socket library might be in the pipeline.
- Appreciation for DateTime library in Mojo: A member offered public thanks to Martin Vuyk for his extensive work on DateTime and other libraries, echoing appreciation for the efforts and resources contributed.
- The gratitude extended to the current tools in the forge-tools repository, which enhance the functionality of the Mojo standard library.
- Mojo Manual | Modular Docs: A comprehensive guide to the Mojo programming language.
- Ownership and borrowing | Modular Docs: How Mojo shares references through function arguments.
- Ownership and borrowing | Modular Docs: How Mojo shares references through function arguments.
- keep | Modular Docs: keep(val: Bool)
- Life of a value | Modular Docs: An explanation of when and how Mojo creates values.
- Death of a value | Modular Docs: An explanation of when and how Mojo destroys values.
- socket — Low-level networking interface: Source code: Lib/socket.py This module provides access to the BSD socket interface. It is available on all modern Unix systems, Windows, MacOS, and probably additional platforms. Availability: not ...
- lightbug_http/external at main · saviorand/lightbug_http: Simple and fast HTTP framework for Mojo! 🔥. Contribute to saviorand/lightbug_http development by creating an account on GitHub.
- GitHub - martinvuyk/forge-tools: Tools to extend the functionality of the Mojo standard library: Tools to extend the functionality of the Mojo standard library - martinvuyk/forge-tools
- Modular: Own your endpoint. Control your AI.: The Modular Accelerated Xecution (MAX) platform is the worlds only platform to unlock performance, programmability, and portability for your AI workloads.
- Modular: Own your endpoint. Control your AI.: The Modular Accelerated Xecution (MAX) platform is the worlds only platform to unlock performance, programmability, and portability for your AI workloads.
- Mojo 🔥: Programming language for all of AI: Mojo combines the usability of Python with the performance of C, unlocking unparalleled programmability of AI hardware and extensibility of AI models.
- Modular: Own your endpoint. Control your AI.: The Modular Accelerated Xecution (MAX) platform is the worlds only platform to unlock performance, programmability, and portability for your AI workloads.
Modular (Mojo 🔥) ▷ #max (6 messages):
MAX license typosAMD Unified AI software stackModular's exclusive partnerships
- MAX License Typo Errors Addressed: Users noted several typos in the new Max license, including missing spaces in terms like otherModular and theSDK.
- Users Inquire About AMD Unified AI Software Stack: A member asked about discussions with AMD regarding integrating Max into AMD's new Unified AI software stack announced at AMD tech day.
Modular (Mojo 🔥) ▷ #max-gpu (11 messages🔥):
Writing custom kernels with MaxLower-level API than graphBenchmark Tensor CoresWriting PyTorch for XLA devices
- Custom GPU Kernels in Mojo: Custom GPU kernels can be written using Mojo, which is a part of MAX, similar to CUDA interfaces for accelerators.
- These kernels are compiled with the Mojo compiler and enqueued to the accelerator with MAX libraries.
- Lower-level APIs in MAX: An early version allows custom operators embedded within a MAX graph and a lower-level API than graphs will also be available to hack against.
- MAX and Mojo are intertwined, providing interfaces for interacting with accelerators, much like CUDA.
- Tensor Cores in Benchmarks: Queries were raised about benchmarks not using tensor cores, questioning the GEMM numbers and their relation with FA.
- A member highlighted complexities due to the opaque nature of the TPU compiler and runtime.
- PyTorch xla Development Challenge: It took Google and Meta five years to develop PyTorch xla, enabling PyTorch on XLA devices like Google TPU.
- The complexity and duration of this development were noted, reflecting the challenges involved.
Link mentioned: GitHub - pytorch/xla: Enabling PyTorch on XLA Devices (e.g. Google TPU): Enabling PyTorch on XLA Devices (e.g. Google TPU). Contribute to pytorch/xla development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #nightly (13 messages🔥):
Mojo nightly releasesBot interactionProposal for stdlib extensionsContributor feedback
- Mojo nightly release updates: A new nightly Mojo compiler has been released with versions
2024.7.1305and2024.7.1505. Updates include changes toUnsafePointeroverloads forSIMD.load/storeand the removal ofLegacyPointeras detailed in the current changelog. - Bot threatens frequent contributors: A user mentioned being 'threatened' by the Modular bot for tagging five contributors. Another user shared a similar experience when the bot misinterpreted the usage of certain symbols.
- The bot seems to have triggers for specific patterns or symbols that result in unwarranted warnings.
- Proposal to reduce stdlib maintainers' workload: A proposal was made to reduce the workload of stdlib maintainers with
stdlib-extensions, seeking feedback from frequent contributors. The discussion aims to streamline maintenance efforts.
Link mentioned: [Proposal] Reduce the workload of stdlib's maintainers with stdlib-extensions · modularml/mojo · Discussion #3233: This discussion is here to have a place to talk about the folloowing proposal: pull request markdown document We are especially interested in the opinion of frequent contributors, as well as the st...
Perplexity AI ▷ #general (207 messages🔥🔥):
GPTs AgentsAPI CreditsPro Plan IssuesImage Response ProblemsPerplexity vs ChatGPT
- GPTs Agents cannot learn after initial training: A member shared a concern about GPTs agents not learning from additional information provided after their initial training.
- Another member clarified that uploaded files are saved as "knowledge" files for the agent to reference when required, but they do not continually modify the agent's base knowledge.
- Issues with receiving API credits: Users reported not receiving the promised $5 free credits for trying out the API after upgrading to Pro and having issues loading credits using India-based credit cards.
- Support was contacted but no immediate resolution was provided; some users suggested verifying if the API activation was done correctly.
- Pro Plan Search Limit quietly reduced: Several users noticed their Pro search limit was reduced from 600 to 540 per day without any prior notice or updates on the website.
- This unannounced change led to concerns about future reductions and the transparency of Perplexity's policies.
- Difficulties with image responses and follow-ups: iamhasim discussed how Perplexity's responses often referenced old images instead of the current conversation.
- Others echoed similar issues and expressed their desire for improvements in handling images and follow-up questions.
- Perplexity vs. ChatGPT for Code and Data Processing: Users debated the capabilities of Perplexity compared to ChatGPT, highlighting gaps such as file handling, image generation, and follow-up accuracy.
- Despite its limitations, some users prefer Perplexity for its search and collections features, but pointed out that features like document comparisons and code processing lag behind.
- How to SUPERCHARGE your web research with a Large Action Model (Nelima): Meet Nelima 🚀 the world's first community-driven Large Action Model (LAM) that takes your natural language prompts and turns them into real actions. Nelima...
- Rich Results Test - Google Search Console: no description found
Perplexity AI ▷ #sharing (12 messages🔥):
Health and StrengthMarketing ExpertiseCantillon EffectUniqueness of TeethTrump Assassination Attempt
- Achieve Health and Strength with Tips: Users shared a search link on how to achieve health and strength.
- Insights on Marketing Expertise: Multiple users discussed a search link about being a marketing expert.
- Understanding Cantillon Effect: A user provided a search link to learn about the Cantillon Effect.
- Exploration of Teeth Uniqueness: A discussion was prompted by a search link questioning if our teeth are unique.
- Debate on Trump's Assassination Attempt: A controversial topic was shared with a link discussing an assassination attempt on Trump.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (8 messages🔥):
Cloudflare issuesPro subscriber credit issuesAPI free credit problemsPerplexity AI API models
- API blocked by Cloudflare: A user mentioned that the API is currently behind Cloudflare, causing access issues.
- $5 free credits for Pro subscribers: A member who upgraded to pro inquired about the $5 free credit for trying out the API, asking when it would be available.
- Unable to use credits for generating API: A Pro subscriber is unable to buy credits or use the $5 credits for generating the API, seeking help in the channel.
- Another user shared the same issue and provided a Discord channel link for further assistance.
- Matching Perplexity AI free tier with API: A user is trying to replicate the Perplexity AI free tier using the API and is struggling to get URL sources with the answers.
- They asked others if they knew which model Perplexity AI uses or how to achieve similar results.
Nous Research AI ▷ #research-papers (5 messages):
AgentInstruct by Microsoft ResearchArena Learning by WizardLM
- Microsoft Research introduces AgentInstruct: AgentInstruct is a framework for creating high-quality synthetic data to post-train models like Mistral-7b into Orca-3, showing significant improvements across various benchmarks.
- The paper reported 40% improvement on AGIEval, 54% on GSM8K, and 45% on AlpacaEval with the post-trained model outperforming competitors like LLAMA-8B-instruct and GPT-3.5-turbo.
- WizardLM's Arena Learning simulates Chatbot Arena: Arena Learning aims to create a data flywheel for continual post-training through AI-powered simulated chatbot battles.
- The iterative process improved WizardLM models consistently, with noticeable performance boosts on metrics like WizardArena-Mix Elo and MT-Bench, also achieving 98.79% consistency with LMSYS Arena’s human judgments.
- AgentInstruct: Toward Generative Teaching with Agentic Flows: no description found
- Tweet from Qingfeng Sun (@victorsungo): 🔥 Excited to share WizardLM new paper! 📙Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena 🚀As one of the most important technologies for WizardLM-2, let me cl...
Nous Research AI ▷ #off-topic (11 messages🔥):
LivePortrait GitHub projectEgg cooking and peeling techniques
- LivePortrait GitHub Project Insights: A member mentioned the LivePortrait GitHub project and inquired about sourcing videos with the right expressions for text-to-video conversion.
- They suggested a method involving filming faces talking, using Whisper for transcription, and vector databases to find sections with the desired expressions.
- Tips for Perfectly Peeled Eggs: Members shared tips for peeling eggs, recommending boiling them in hot water for 10 minutes for easy peeling.
- One member suggested another method of soaking eggs in vinegar to dissolve the shell and provided a link to a detailed explanation.
Link mentioned: Naked Eggs: Acid-Base Reaction - Science World: In this activity, students describe the effects of an acid on an eggshell. The reaction of the eggshell in vinegar is an acid-base reaction. When you submerge an egg in vinegar, the shell dissolves, l...
Nous Research AI ▷ #interesting-links (6 messages):
TextGradQ-star detailsClaude artifactsSystem prompts optimization tips
- *TextGrad uses LLMs for textual gradients: A GitHub project called TextGrad* utilizes large language models to backpropagate textual gradients, revolutionizing text-based computation.
- *Q-star details leaked via Reuters: A YouTube video titled 'Q-star details leaked' discusses leaked internal documents from OpenAI, codenamed STRAWBERRY, shedding light on new developments in AGI*.
- The video, covered by Wes Roth, highlights critical insights into LLMs and anticipates upcoming AI rollouts.
- *Claude artifacts now sharable*: Claude artifacts are now sharable, making it easier to distribute and collaborate on AI-related outputs.
- *Optimization tips for system prompts: User _paradroid shared a STaR-based System Prompt* for an advanced AI assistant focused on iterative improvement and reasoning, showcasing a structured approach to continuous AI development.
- BREAKING: Q-star details LEAKED! Reuters reveals internal OpenAI documents (codename: STRAWBERRY): The latest AI News. Learn about LLMs, Gen AI and get ready for the rollout of AGI. Wes Roth covers the latest happenings in the world of OpenAI, Google, Anth...
- GitHub - zou-group/textgrad: TextGrad: Automatic ''Differentiation'' via Text -- using large language models to backpropagate textual gradients.: TextGrad: Automatic ''Differentiation'' via Text -- using large language models to backpropagate textual gradients. - zou-group/textgrad
Nous Research AI ▷ #general (169 messages🔥🔥):
LLM Reasoning ImprovementOpenAI Platform UpdatesAgentInstruct (Orca 3) Paper DiscussionNew Vision Language Model by GoogleTeknium Hiring Announcement
- Improving LLMs at reasoning: Members discussed enhancing LLM reasoning with prompting alone, suggesting methods like few-shot learning and in-context learning as well as chain-of-thought (CoT) prompting techniques.
- Some users expressed skepticism about CoT's effectiveness, stating it struggles with problems significantly different from the training data.
- OpenAI Platform Updates and Mysteries: Members speculated about OpenAI's new 'OpenAI Supply Co.' website, leaning towards it possibly being a merchandise store.
- There was humorous speculation about potential products, like Sam Altman plush dolls.
- Opinions on AgentInstruct (Orca 3) paper: Users inquired and shared their curiosity about the new AgentInstruct (Orca 3) paper, with links provided for further discussion.
- The conversation hinted at mixed impressions and the importance of properly evaluating new research.
- Google's New Vision Language Model: A new vision-language model, PaliGemma, by Google was discussed, mentioning its need for fine-tuning for effectiveness.
- Users debated its initial performance, and there was a note about specific licensing restrictions.
- Teknium announces hiring search: Teknium shared an announcement seeking applicants for synthetic text data creation and agent building roles, with over 40 applicants already.
- The hiring call emphasized alignment with Nous Research's goals and ethos as well as various technical skills, with the selection process to follow shortly.
- Tweet from Teknium (e/λ) (@Teknium1): So, I am hiring 1-2 full time people for synthetic text data creation for training LLMs, with agentic capabilities to improve the quality of the data. I have around 40+ applicants and I can only pic...
- gist:b8257a67933d891a9f3bc19822b4305a: GitHub Gist: instantly share code, notes, and snippets.
- PaliGemma: no description found
- Tweet from Soami Kapadia (@KapadiaSoami): Mixture of Agents on Groq Introducing a fully configurable, Mixture-of-Agents framework powered by @GroqInc using @LangChainAI You can configure your own MoA version using the @streamlit UI through...
- Tweet from Hassan (@nutlope): Just finetuned Llama-3-8B on multi-step math problems. I tested it on 1,000 new math problems and it got 90% of the performance of GPT-4o (while being much cheaper & faster). Wrote a blog post on ho...
- Tweet from AshutoshShrivastava (@ai_for_success): OpenAI new website " OpenAI Supply Co. What will they supply? h/t : ananayarora
- GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention: Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
- GitHub - NousResearch/Hermes-Function-Calling: Contribute to NousResearch/Hermes-Function-Calling development by creating an account on GitHub.
- GitHub - SynaLinks/HybridAGI: The Programmable Neuro-Symbolic AGI that lets you program its behavior using Graph-based Prompt Programming: for people who want AI to behave as expected: The Programmable Neuro-Symbolic AGI that lets you program its behavior using Graph-based Prompt Programming: for people who want AI to behave as expected - SynaLinks/HybridAGI
- Cheering Cute GIF - Cheering Cute Cat - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #ask-about-llms (22 messages🔥):
Integrating LLM in appsExtending context length for modelsModel performanceUX for integrated chatAI agents
- Considering LLMs for App Tutorials: Natefyi suggested integrating an LLM into an app for tutorials instead of conventional media like videos and blogposts.
- Teknium mentioned that using retrieval-augmented generation (RAG) could be a solution for FAQ and help info.
- Extending Context Length for Models: A user asked about techniques to extend the context length of various models like Mixtral and Llama up to 1M tokens.
- Deoxykev noted that achieving such length would require massive amounts of VRAM, with kotykd adding that the current long-context models are unusable in real scenarios.
- Seeking UX Inspiration for Integrated Help Chat: Natefyi sought advice on UX design for integrating an LLM-guided help chat in an app, pondering interaction methods like popups or buttons.
- Thilotee recommended Audapolis as an example of UI that guides users into features but expressed uncertainty on combining it with LLMs.
- Interest in Developing AI Agents: Pablo.ce expressed interest in collaborating on Hugging Face (HF) spaces for AI agents and tagged another user who created the llama-cpp-agents framework.
- He offered to create HF spaces with models specified by other users, soliciting further collaboration.
Link mentioned: History for ) - bugbakery/audapolis: an editor for spoken-word audio with automatic transcription - History for ) - bugbakery/audapolis
Nous Research AI ▷ #rag-dataset (8 messages🔥):
Marker version speedupIntegration with synthetic RAGXML in agent definitionMixture of Agents modelsStasima diverse models
- Marker speeds up significantly: Marker's new version is significantly faster: 7x on MPS, 3x on CPU, and 10% on GPU due to its efficient architecture.
- Designed for converting PDFs to Markdown, the speedup aims to facilitate creating higher-quality datasets.
- XML makes agent definition easier: An interesting discussion about how XML simplifies defining agents.
- It's interesting how easily you can define agents when you embrace the xml.
- Mixture of Agents model implementation: A member showcased a Mixture-of-Agents implementation in just 50 lines of code, integrating multiple models via @togethercompute.
- Another member discussed their take on this concept in their project stasima, using different system prompts to create a spectrum of agents.
- Tweet from Rohan Paul (@rohanpaul_ai): Mixture-of-Agents in 50 lines of code with @togethercompute
- Prompting - Instructor: no description found
- Tweet from Hassan Hayat 🔥 (@TheSeaMouse): It's interesting how easily you can define agents when you embrace the xml
- Tweet from Vik Paruchuri (@VikParuchuri): Marker is now faster! 7x on MPS, 3x on CPU, and 10% on GPU. Due to a more efficient architecture for 2 models. Marker converts pdfs to markdown very effectively. I hope the speedup will let people...
- GitHub - EveryOneIsGross/stasima: stasima is a diverse spectrum of models and agents responding to the same query.: stasima is a diverse spectrum of models and agents responding to the same query. - EveryOneIsGross/stasima
CUDA MODE ▷ #general (55 messages🔥🔥):
WebGPU Development WorkflowFlash Attention Memory UsageResNet Implementation
- WebGPU Development Workflow: Fast Iteration But Needs Better Tooling: A user shared their workflow developing kernels for WebGPU, noting the fast iteration cycles but not-so-great tooling and profiling.
- They mentioned using dawn as a shared library for improved compile times and offered a demo of livecoding WGSL shaders.
- WebGPU vs Traditional GPU APIs: Challenges and Prospects: Another discussion emphasized comparing WebGPU performance with traditional GPUs like CUDA and the potential of llm.c transformer kernel ports for better insights.
- There's an active observation on WebGPU's cooperative matrix extension progress (GitHub link) and expectations for shifting more ML workloads to client-side computation.
- Flash Attention: SRAM Utilization Constraints: A deep technical discussion unfolded about the memory usage of Flash Attention 1, focusing on whether QKVO arrays fit well into SRAM in the presence of other components.
- Replies highlighted that S and P are ephemeral and discussed the tuning of Br and Bc constants to match available SRAM, with references to its implementation in the source code (GitHub link).
- Introduction to ResNet for Computer Vision: A member requested guidance on implementing ResNet for a computer vision paper.
- They were directed to the ResNets in torchvision which provides ready-to-use implementations for their project.
- Screen Recording 2024-07-13 at 12.30.44 AM.mov: no description found
- ResNet — Torchvision main documentation: no description found
- flash-attention/csrc/flash_attn/src/flash_fwd_launch_template.h at 7ef24848cf2f855077cef88fe122775b727dcd74 · Dao-AILab/flash-attention: Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
- Cooperative matrix · Issue #4195 · gpuweb/gpuweb: All major platform APIs have now released a similar extensions for cooperative matrix: Metal introduced simdgroup_matrix in MSL 3.1 HLSL has support in SM6.8 (currently experimental release) SPIR-V...
CUDA MODE ▷ #triton (5 messages):
Learning TritonTriton Puzzles on GitHubTriton in FP8 trainingTriton's inline asm for elementwise operations
- Diving into Triton for beginners: A user asked for references to study Triton, in addition to the official documentation.
- State of the art FP8 training in Triton: A user inquired about the current methods for using Triton in FP8 training and whether there are stable kernels available for adaptation or if people generally use transformerengine.
- Exploiting Triton's inline assembly for elementwise ops: A user discovered that Triton's inline asm can process multiple elements at a time and could potentially be useful for fused bit-packing/unpacking and matmul operations.
- Welcome to Triton’s documentation! — Triton documentation: no description found
- triton.language.inline_asm_elementwise — Triton documentation: no description found
- GitHub - srush/Triton-Puzzles: Puzzles for learning Triton: Puzzles for learning Triton. Contribute to srush/Triton-Puzzles development by creating an account on GitHub.
CUDA MODE ▷ #torch (3 messages):
Bootstrap estimate of accuracy stdevOptimized dataloader issueTorch nightly broken
- Bootstrap estimate of accuracy stdev for model evaluation: A member suggested using a bootstrap estimate to calculate the accuracy standard deviation for model evaluation.
- Switching back to torch dataloader resolves issue: Another member reported that switching from an optimized dataloader back to the torch version resolved an unspecified issue they were experiencing.
- Torch nightly build has broken functions: A user mentioned that the Torch nightly build is broken, specifically showing an
AttributeErrordue to 'torch.library' missing thecustom_opattribute.
CUDA MODE ▷ #cool-links (2 messages):
LoQT method for efficient trainingBrian Kernighan on The Practice of Programming
- LoQT enables efficient model training on consumer GPUs: The paper titled 'LoQT' proposes a method for efficiently training quantized models using gradient-based tensor factorization, enabling models up to 7B parameters to be trained on consumer-grade 24GB GPUs.
- The method handles gradient updates to quantized weights differently and achieves comparable savings, suitable for both pretraining and fine-tuning.
- Brian Kernighan discusses 'The Practice of Programming': In a YouTube video, Dr. Brian Kernighan discusses his experience writing 'The Practice of Programming' in a special episode of Book Overflow.
- LoQT: Low Rank Adapters for Quantized Training: Training of large neural networks requires significant computational resources. Despite advances using low-rank adapters and quantization, pretraining of models such as LLMs on consumer hardware has n...
- Brian Kernighan Reflects on "The Practice of Programming": In this very special episode of Book Overflow, Dr. Brian Kernighan, the author of "The Practice of Programming" joins us to discuss his experience writing th...
CUDA MODE ▷ #beginner (23 messages🔥):
Accessing GPUs for TestingUsing Google Colab and nsight computeCoreWeave vs Lambda LabsCloud GPU ServicesLearning Triton
- Best Ways to Access GPUs for Individual Testing: A user asked for the best ways to get GPU access for testing, especially needing ncu, and multiple responses recommended Google Colab for its ease and free access (https://colab.research.google.com).
- Discussion also mentioned CoreWeave and LambdaLabs as other options, noting CoreWeave is pricey and LambdaLabs is hard to get allocations.
- Colab Supports nsight compute: A member confirmed that nsight compute works on Google Colab, although spawning a window might be problematic.
- The conversation also highlighted that Google Cloud GPU allows using things other than notebooks, although it is pricier compared to Colab.
- Cloud GPU Services Compared: Members compared different cloud services like Google Cloud GPU and SageMaker with on-demand services like vast.ai, noting the latter are generally cheaper.
- For ease of working, it was suggested that Google Colab is less hassle compared to Google Cloud Platform (GCP).
- Triton Learning Resources: A user asked for additional references to study Triton, besides the official Triton website.
- No specific additional resources were mentioned in the responses.
- Challenge with Open Source Development on Cloud: A member sought advice on doing open-source development using cloud tools due to having an older laptop with an NVIDIA Quadro M4000 GPU.
- They mentioned challenges in iterating and testing code changes in a cloud environment like Google Colab for torchao project development.
Link mentioned: Welcome to Triton’s documentation! — Triton documentation: no description found
CUDA MODE ▷ #pmpp-book (34 messages🔥):
CUDA Core ProcessingRegister LimitationsOccupancy CalculationBlock Size OptimizationKernel Parameterization
- CUDA Core Processing Clarified: A discussion revealed that a single CUDA core processes one thread at a time, meaning an A100 SM with 64 CUDA Cores can process 64 threads simultaneously while having 2048 threads assigned to it.
- Another member explained the similarities to a CPU with threads swapping out when waiting, storing state in memory, but on GPUs, the total pool of registers limits this.
- Register Limitations Impacting Threads: Explanations on how 256 KiB of registers per SM results in 32 registers per thread when divided among 2048 threads were provided.
- Using more registers in a kernel limits the total number of threads that can be executed, e.g., 1024 threads at 64 registers each.
- Optimizing GPU Occupancy: Occupancy of threads on a GPU is affected by the allocated shared memory and the number of threads, impacting latency hiding.
- A balance is needed as too many threads can cause stalls due to insufficient memory, and conversely, too few threads can not adequately hide latency.
- Block Size and Performance: There was a discussion on choosing optimal block sizes for performance, using profiling and educated guesses.
- An example was given with block reduction where a 128 block size was found to perform best contrary to initial expectations, when profiled against 1024, 512, and 256.
- Kernel Parameterization for Optimization: Parameterizing implementations across different values allows running benchmarks to find the best configuration, essential for optimizing GPU performance.
- Templating kernels with varied sizes, as seen in FAv2 sources, allows for optimal fitting to different matrix sizes due to STATIC_SWITCH and BOOL_SWITCH.
CUDA MODE ▷ #torchao (2 messages):
FSDP support for low-bit optimizationDeveloper guide for integration
- Implementing FSDP Support for Low-Bit Optimization: A member is working on implementing FSDP support for low-bit optimization but isn't addressing collective ops for optimization state subclass yet.
- They suggested that a developer guide would help in getting interest from developers as lack of integration guidance might lead to abandonment.
- Review of FSDP Implementation: Another member agreed to review the FSDP implementation next week.
- Looking forward to diving into it next week.
CUDA MODE ▷ #llmdotc (46 messages🔥):
Switching to cudaMallocManagedllm.cpp updatesWebGPU insightsgpt3v1 by karpathyGPT-3 model interpolation
- Switch to cudaMallocManaged for memory efficiency: Eriks.0595 suggested switching from cudaMalloc to cudaMallocManaged to support devices with insufficient memory and ensure non-intrusive changes without slowing down existing functionalities.
- Eriks.0595 emphasized the importance of this feature for smaller GPU integration.
- Major updates in llm.cpp over the past 4 months: Kashimoo asked for updates on llm.cpp after a 4-month hiatus, prompting Eriks.0595 to explain that almost everything has changed.
- WebGPU's broader applications: Akakak1337 expressed surprise at WebGPU's non-Web usages and planned to watch a linked talk for more insights.
- Mup run insights and performance: In discussing a mup run, akakak1337 provided performance details, with figures like 0.495917 accuracy on HellaSwag.
- Falconsfly noted concerns about token/sec performance and loss of precision.
- Merged GPT-3 models to master branch: Eriks.0595 inquired about extending their model series to GPT-3 models, leading to a discussion on model interpolation.
- Akakak1337 confirmed the merge of GPT-3 models to the master branch and discussed the challenges of matching non-monotonic head sizes and depths.
- Tweet from Yuchen Jin (@Yuchenj_UW): After training the largest GPT-2 (1.5B), I decided to go "deeper" and feel the scaling law by training a 2.7B model with @karpathy's llm.c 📈 Scaling the model was straightforward, primar...
- feature/gpt3v1 by karpathy · Pull Request #688 · karpathy/llm.c: no description found
CUDA MODE ▷ #youtube-watch-party (1 messages):
vkaul11: Hi
CUDA MODE ▷ #webgpu (25 messages🔥):
WebGPU resources and supportRunning LLMs in the browser with Transformers.jsBuilding and troubleshooting Dawn on WindowsGPU buffers and performance
- Explore WebGPU with new resources: Members shared various resources for learning WebGPU, including WebGPU Fundamentals which introduces compute shaders and optimization steps.
- Discussions highlighted that browser support is mostly in Chrome, with Firefox support being limited by default, and Safari lagging behind.
- Try Transformers.js for browser-based LLMs: A member mentioned Transformers.js for running state-of-the-art machine learning tasks directly in the browser using ONNX Runtime.
- They noted it supports multiple tasks including text classification, question answering, and image classification, although they haven't experimented much with it.
- Troubleshoot Dawn build issues: Multiple messages discussed troubleshooting the Dawn build on Windows, where the release build behaved unexpectedly, but the debug build worked correctly.
- Rebuilding strategies included using Google's distribution with CMake, and considering using shared libraries instead of FetchContent for improved stability.
- Understand WebGPU buffer limitations: A member explained that the WebGPU environment in browsers has limitations such as 16 KB shared memory and 128 MB buffers, which are minimums.
- Another member questioned if GPU offload for small data sizes is a performance boost compared to CPU AVX instructions due to these limitations.
- Share experiences and improvements: Members shared experiences with setting up and using WebGPU, discussing various challenges and potential improvements for future development.
- Feedback included suggestions for simplifying shader vs. kernel nomenclature and more flexible handling of structured parameters.
- Transformers.js: no description found
- WebGPU Compute Shader Basics: How to use compute shaders in WebGPU
- WebGPU Compute Shaders - Image Histogram: Efficiently compute an image histogram.
- gpu.cpp/examples/webgpu_from_scratch/run.cpp at main · AnswerDotAI/gpu.cpp: A lightweight library for portable low-level GPU computation using WebGPU. - AnswerDotAI/gpu.cpp
Cohere ▷ #general (141 messages🔥🔥):
OpenArena GitHub projectCohere event link confusionLlamaIndex KG deduplicationKarpathy on AI training costsAccount support issues
- OpenArena GitHub Project Unveiled: A member shared their project OpenArena which aims to pit LLMs against each other for better dataset quality.
- Cohere Event Link Confusion: Members discussed confusion over a Cohere event link, with some unable to access the session and others providing the correct zoom link for a guest speaker session on diffusion models generating spectrograms.
- LlamaIndex KG Node Deduplication Explained: A member shared a YouTube video explaining how LlamaIndex handles deduplication of nodes in its knowledge graph.
- AI Training Costs Plummet: A member highlighted Karpathy's detailed discussion on the drastic reduction in costs to train AI models like GPT-2 over the last 5 years.
- Cohere Account Support Issues: A member reported issues with their Cohere account disappearing after an organizational invite mishap, receiving guidance from support to submit a ticket for resolution.
- Tweet from Andrej Karpathy (@karpathy): In 2019, OpenAI announced GPT-2 with this post: https://openai.com/index/better-language-models/ Today (~5 years later) you can train your own for ~$672, running on one 8XH100 GPU node for 24 hours. ...
- Cohere For AI - Guest Speaker: Ziyang Chen, PhD Student: Images that Sound: Composing Images and Sounds on a Single Canvas
- LlamaIndex KG | Deduplication of nodes.: In this recording, I explain in details how LlamaIndex is doing the deduplication of the nodes after creating the knowledge graphcode:https://github.com/raji...
- Cohere | The leading AI platform for enterprise: Cohere provides industry-leading large language models (LLMs) and RAG capabilities tailored to meet the needs of enterprise use cases that solve real-world problems.
- Tool Use with Cohere's Models - Cohere Docs: no description found
- Inside Out Joy GIF - Inside Out Joy Hi - Discover & Share GIFs: Click to view the GIF
- GitHub - syv-ai/OpenArena: Contribute to syv-ai/OpenArena development by creating an account on GitHub.
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
Cohere ▷ #project-sharing (26 messages🔥):
NPM module for Coherer/localllama bot using Langchain and CohereUsing JSON from RedditMult AI subreddit update
- NPM module for Cohere released: A new update to the NPM module now includes support for Cohere, enhancing its ease of interaction with various LLM providers.
- The repository image and NPM installation details were shared, showing seamless integration with multiple AI platforms.
- r/localllama bot built using Langchain and Cohere: A new bot has been created to fetch and summarize top posts from r/localllama into news style posts for Discord channels using Langchain and Cohere Command-R-Plus.
- The bot's code was shared and it sparked excitement among members who found it incredibly useful.
- Extract post data as JSON from Reddit: Members discussed a method to extract information from Reddit posts by appending
.jsonto their URLs for top posts on r/localllama.- "Your Settings Are Probably Hurting Your Model" post was highlighted as an example, emphasizing the impact of sampler settings on model performance.
- Mult AI subreddit update for news bot: The bot was updated to support multiple AI subreddits and improve story sorting mechanisms.
- Plans were shared to enable Cohere to categorize and direct news stories to appropriate channels based on their topics.
- GitHub - samestrin/llm-interface: A simple NPM interface for seamlessly interacting with 36 Large Language Model (LLM) providers, including OpenAI, Anthropic, Google Gemini, Cohere, Hugging Face Inference, NVIDIA AI, Mistral AI, AI21 Studio, LLaMA.CPP, and Ollama, and hundreds of models.: A simple NPM interface for seamlessly interacting with 36 Large Language Model (LLM) providers, including OpenAI, Anthropic, Google Gemini, Cohere, Hugging Face Inference, NVIDIA AI, Mistral AI, AI...
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Eleuther ▷ #general (70 messages🔥🔥):
AI Meetups in LondonOpenAI CollaborationsModel BenchmarkingTime Consideration in ModelsMachine Learning Conferences
- AI meetups in London lack depth: Members discussed that AI meetups in London often have superficial discussions and are infrequent, with a recommendation to check out UCL's & Imperial's seminars and invited talks for deeper knowledge.
- It was noted that conferences like ICML and ICLR usually offer deeper conversations, particularly in field-specific meetups and 1-on-1 sessions with researchers.
- Arrakis project for fast iteration in mechinterp: A user requested feedback on Arrakis, a library designed for conducting, tracking, and visualizing mechanistic interpretability experiments with integrated tools like tuned-lens.
- The project aims to improve research efficiency and utility within the community.
- OpenLLMLeaderboard benchmark data availability: Questions rose regarding the availability of test sets for the new OpenLLMLeaderboard on Hugging Face, specifically if parts of the datasets were unreleased.
- It was clarified that HuggingFace provides reproducibility by allowing downloads of all public data, ensuring no hidden elements.
- Time relevance in LLM training questioned: A user expressed interest in how time and data freshness can be utilized in modeling relevance, noting current methods of passing timestamps to LLMs are ineffective.
- Suggestions included examining literature on specific method papers, datasets, and benchmarks that deal with time-relevant data for better model training.
- Interest in large context windows for AI applications: A community advocate is seeking recommendations for hosted models with huge context windows (1M tokens) for AI-assisted human rights applications.
- They shared their current work and context on a project and link to discourse, requesting any useful insights or resources.
- LiveBench: no description found
- About: no description found
- GitHub - yash-srivastava19/arrakis: Arrakis is a library to conduct, track and visualize mechanistic interpretability experiments.: Arrakis is a library to conduct, track and visualize mechanistic interpretability experiments. - yash-srivastava19/arrakis
- Inception-based design for the AI-assisted creation of a written human rights complaint: I also used GitHub CoPilot within vsCode IDE as well as ChatGpt4o in order to transcribe screenshots containing text message content.
- alert--small: no description found
- London Machine Learning Meetup: The London Machine Learning Meetup is the largest machine learning community in Europe. Previous speakers include Juergen Schmidhuber, David Silver, Yoshua Bengio and Andrej Karpathy. Come to our ne...
Eleuther ▷ #research (61 messages🔥🔥):
Hermes 2 PerformanceRAG Systems with LangChainCompute Thresholds GovernanceRISE in LLMsModel Compression and Accuracy
- Paper Investigates Synthetic Data for Math Reasoning: A new paper explores the effectiveness of finetuning LLMs with model-generated synthetic data, finding double the efficiency when models fine-tune on self-generated data after initial finetuning.
- Concerns were raised about model-generated positives amplifying spurious correlations, leading to flat or inverse scaling trends.
- Discussion on Compute Thresholds Governance: An essay delves into how compute thresholds could impact AI safety and the risk profile of models by regulating compute usage.
- The community discussed the idea that regulating massive training jobs could prevent the monopolization of compute resources by a few entities.
- LangChain for Reliable RAG Systems: A member shared a project on GitHub for creating reliable RAG (Retrieval-Augmented Generation) systems using LangChain.
- The repository provides detailed scripts and tutorials to help users implement RAG systems from scratch.
- RISE Enables Self-Improvement in LLMs: A new paper presents RISE, a finetuning approach enabling LLMs to iteratively improve their responses over multiple turns.
- The method focuses on recursive introspection, allowing models to learn from previous unsuccessful attempts and improve sequentially.
- Model Compression Techniques and Quality Flips: Research analyzed how quantization techniques for compressing large models can lead to 'flips' in answers, changing from correct to incorrect even if overall accuracy appears unchanged.
- The discussion highlighted that such flips signify a more complex degradation of model quality, and further qualitative and quantitative evaluations are necessary.
- The Remarkable Robustness of LLMs: Stages of Inference?: We demonstrate and investigate the remarkable robustness of Large Language Models by deleting and swapping adjacent layers. We find that deleting and swapping interventions retain 72-95\% of the origi...
- Accuracy is Not All You Need: When Large Language Models (LLMs) are compressed using techniques such as quantization, the predominant way to demonstrate the validity of such techniques is by measuring the model's accuracy on v...
- Harnessing Discrete Representations For Continual Reinforcement Learning: Reinforcement learning (RL) agents make decisions using nothing but observations from the environment, and consequently, heavily rely on the representations of those observations. Though some recent b...
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale: Large language models have been widely adopted but require significant GPU memory for inference. We develop a procedure for Int8 matrix multiplication for feed-forward and attention projection layers ...
- On the Limitations of Compute Thresholds as a Governance Strategy: At face value, this essay is about understanding a fairly esoteric governance tool called compute thresholds. However, in order to grapple with whether these thresholds will achieve anything, we must ...
- Outliers and Calibration Sets have Diminishing Effect on Quantization of Modern LLMs: Post-Training Quantization (PTQ) enhances the efficiency of Large Language Models (LLMs) by enabling faster operation and compatibility with more accessible hardware through reduced memory usage, at t...
- RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold: Training on model-generated synthetic data is a promising approach for finetuning LLMs, but it remains unclear when it helps or hurts. In this paper, we investigate this question for math reasoning vi...
- Universal Neurons in GPT2 Language Models: A basic question within the emerging field of mechanistic interpretability is the degree to which neural networks learn the same underlying mechanisms. In other words, are neural mechanisms universal ...
- Home | Dynamic field theory: no description found
- KL-divergence by ikawrakow · Pull Request #5076 · ggerganov/llama.cpp: There have been several discussions about the potential value of being able to compute KL-divergence as another quantization accuracy test. There is the Python script that @Ttl provided in PR #4739...
- GitHub - eericheva/langchain_rag: Contribute to eericheva/langchain_rag development by creating an account on GitHub.
- GitHub - eericheva/langchain_rag: Contribute to eericheva/langchain_rag development by creating an account on GitHub.
- Recursive Introspection: Teaching Foundation Model Agents How to...: A central piece in enabling intelligent agentic behavior in foundation models is to make them capable of introspecting upon their behavior, to reason and correct their mistakes. Even strong...
Eleuther ▷ #scaling-laws (1 messages):
wabi.sabi.1: Very interesting, thanks
Eleuther ▷ #lm-thunderdome (13 messages🔥):
lm-eval Python APIPRAUC metric for lm-evalQuantization flips researchDistributed lm_evaluationCustom functions in task YAML
- Use lm-eval API for Transformer Lens Model: A member inquired about using the lm-eval Python API with a custom Transformer-lens model and was advised to subclass one of the
lm_eval.api.model.LMor similar classes for compatibility.- They thanked the advisor for providing a helpful link to the documentation.
- Calculating PRAUC metric in lm-eval: A user asked how to implement the PRAUC metric for imbalanced test data using lm-eval, requiring positive probability outputs.
- The discussion didn't provide a specific answer, suggesting the member might need further assistance.
- Quantization Flips Study Released: A member shared their new paper on quantization flips, noting how compressed models can behave differently from baseline models despite matching benchmark accuracy.
- The research, which utilized the Harness, highlights significant behavioral changes in compressed models even when quantitative metrics are close.
- Evaluating Models in Distributed Setup: A member sought advice on implementing the evaluate() method for distributed evaluation within lm-harness and loading pruned models into HFLM.
- While specific solutions weren't provided, the query remains open for suggestions and examples from the community.
- Custom Functions in lm-eval YAML: A question was raised regarding the arguments passed to a custom
!functiondefined in a task YAML.- The discussion did not yet yield detailed guidance on handling these custom functions.
- Accuracy is Not All You Need: When Large Language Models (LLMs) are compressed using techniques such as quantization, the predominant way to demonstrate the validity of such techniques is by measuring the model's accuracy on v...
- lm-evaluation-harness/docs/interface.md at main · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #gpt-neox-dev (1 messages):
bobby_mcbobface: Thanks Ryan! Just wanted to make sure I wasn’t going down an abandoned path
tinygrad (George Hotz) ▷ #general (104 messages🔥🔥):
MonoNN Compilertinygrad Kernel OverheadMLX vs tinygrad PerformanceShape Changing BitcastsMonday Meeting Highlights
- MonoNN Compiler Offers Optimized GPU Utilization: A new machine learning optimizing compiler, MonoNN, addresses inefficiencies in traditional kernel-by-kernel execution schemes by accommodating an entire neural network into a single kernel. The paper presentation and source code were discussed in the community.
- Debate on tinygrad Kernel Overhead: Community members discussed the significant 3-4us kernel overhead per kernel on AMD GPUs, based on experimental results.
- MLX Outperforms tinygrad in Speed and Accuracy: MLX was found to be faster and achieve higher accuracy compared to tinygrad, especially noted in the beautiful_MNIST benchmark.
- Challenges with Shape Changing Bitcasts: Implementing support for shape-changing bitcasts in tinygrad is progressing, though it faces issues primarily on GPU devices.
- Highlights from Monday Meeting: The meeting covered updates on tinybox and new components like the lowerer and HWComandQueue device.
- Compilation — MLX 0.16.0 documentation: no description found
- MonoNN: Enabling a New Monolithic Optimization Space for Neural Network Inference Tasks on Modern GPU-Centric Architectures | USENIX: no description found
- add mlx beautiful_mnist example · tinygrad/tinygrad@8940530: no description found
- tinygrad/tinygrad/device.py at ae4cb7994e73f35b6b467327d194394cdf52b99d · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- Tweet from the tiny corp (@__tinygrad__): This is the kernels from a CIFAR training step. On the right, tinygrad now shows which operations led to the creation of the kernel. One step closer to great error messages!
tinygrad (George Hotz) ▷ #learn-tinygrad (27 messages🔥):
count_include_pad in avg_pool2dTensor indexing and gather functionImproving Tinygrad documentationSplitting Tensors based on ratios
- Include pad option in avg_pool2d requested: Stable Diffusion training eval requires the
count_include_pad=Falseoption inavg_pool2dlike PyTorch has, and members discussed potential implementation approaches.- One member suggested upstreaming a method using
(pool -> sum) / (ones_like -> pool -> sum)if MLPerf requires it.
- One member suggested upstreaming a method using
- Clarification on tensor indexing: Members clarified the differences between
probas[:, Y_train]andprobas[Tensor.arange(len(logits)), Y_train]and discussed why masking instead of indexing makes operations faster in Tinygrad.- A member provided a useful link to the quickstart guide, which explains the implementations.
- Fixing bugs in gather function: A bug was identified in Tinygrad's
gatherfunction related to negative index handling, causing incorrect behavior.- The issue was fixed by correcting the order of a function call, and the fix will be included in an upcoming PR.
- Separate pull requests for different improvements: Members agreed that submitting separate PRs for new tensor functions, model implementations, and function expansions is preferred for ease of review.
- A member implemented
interpolatefor FID, which worked but exposed a bug that was promptly addressed.
- A member implemented
- Documentation for testing code blocks: Members discussed executing code blocks from documentation to ensure they work correctly.
- A helpful link to serving Tinygrad docs was shared for guidance.
Link mentioned: Quickstart - tinygrad docs: no description found
Latent Space ▷ #ai-general-chat (43 messages🔥):
Open LLM Leaderboard V2Solving Reddit Link HallucinationNew Models in LMSys ArenaCursor's Composer FeatureSpreadsheetLLM by Microsoft
- Open LLM Leaderboard V2 Episode Released: A user announced a new Latent Space episode focused on the Open LLM Leaderboard V2.
- Another user expressed excitement about the new episode with a 'yessir'.
- Hypotheses on SmolAI Solving Reddit Link Hallucination: Members shared theories on how SmolAI resolved the issue of Reddit link hallucination, including pre-check and post-proc methods.
- A member mentioned applying a similar pre-check method for selecting IDs to ensure accuracy.
- Mystery Behind New Models in LMSys Arena: Questions arose about who might be behind the new models in the LMSys arena with linked strong opinions and discussions on the topic.
- A member heard rumors about Command R+ jailbreaks working on one of the new models.
- Cursor's Composer Feature Excitement: There's considerable interest in Cursor's new Composer feature, with users discussing its beta release and comparing it with other UX options.
- Members shared their thoughts on the accessibility and affordability of the feature, indicating positive initial impressions despite subscription concerns.
- Microsoft Introduces SpreadsheetLLM: Microsoft revealed SpreadsheetLLM which aims to optimize LLMs' capabilities for handling spreadsheets using a novel SheetCompressor encoding framework.
- Members expressed interest in the technique's potential, as it modifies input data to work better with various LLMs without requiring fine-tuning.
- Tweet from AI News by Smol AI (@Smol_AI): [12 July 2024] https://buttondown.email/ainews/archive/ainews-we-solved-hallucinations/ We solved Hallucinations!
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): Seems like there’s a new model in Lmsys arena.
- $3 billion Lattice 'made history' being the first to give AI 'workers' rights: Lattice notably laid off 100 human workers last year.
- SpreadsheetLLM: Encoding Spreadsheets for Large Language Models: no description found
- Tweet from ian (@shaoruu): composer is out for testing @cursor_ai and here's me making a typing test with it in 6 minutes (6x sped up):
- Tweet from Teortaxes▶️ (@teortaxesTex): STRONG OPINIONS VERY LOOSELY HELD Quoting Nic (@nicdunz) @kalomaze @teortaxesTex bro 😭
Latent Space ▷ #ai-announcements (1 messages):
swyxio: new podcast drop! https://x.com/swyx/status/1811898574416019562
Latent Space ▷ #ai-in-action-club (86 messages🔥🔥):
Memorable AcronymsMore demos and examplesEvaluation techniquesLogprob usagesState management
- Memorable Acronym: 3E: A member suggested using a more memorable acronym like Extract, Evaluate, Extend/Expand (3E).
- Demand for More Demos and Examples: Multiple members emphasized the need for more demos and examples in their discussions, particularly related to technical implementations.
- Exploring Evaluation Techniques: Logprob and GPTscore: Members discussed different evaluation techniques like logprob, GPTscore, and hyperparameter optimization tools like prompt-hyperopt.
- A paper titled Simple approach for contextual hallucinations was mentioned in relation to this.
- State Management Tools Comparison: State management styles were compared, with a focus on ReAct framework, Langgraph, and XState.
- Langgraph was noted for better handling of graph-state memory for each step through the node.
- Upcoming AI in Action Talks: Next week, VikParuchuri will present on converting PDF to Markdown using tools like marker and surya.
- TypeScript-first schema validation with static type inference: TypeScript-first schema validation with static type inference
- nisten/bakllava-14b-2xMoE-alpha-build · Hugging Face: no description found
- Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps: no description found
- HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models: We introduce HallusionBench, a comprehensive benchmark designed for the evaluation of image-context reasoning. This benchmark presents significant challenges to advanced large visual-language models (...
- GitHub - truera/trulens: Evaluation and Tracking for LLM Experiments: Evaluation and Tracking for LLM Experiments. Contribute to truera/trulens development by creating an account on GitHub.
- GitHub - tianyi-lab/HallusionBench: [CVPR'24] HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V(ision), LLaVA-1.5, and Other Multi-modality Models: [CVPR'24] HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V(ision), LLaVA-1.5, and Other Multi-modality Models - ti...
- GitHub - openvinotoolkit/anomalib: An anomaly detection library comprising state-of-the-art algorithms and features such as experiment management, hyper-parameter optimization, and edge inference.: An anomaly detection library comprising state-of-the-art algorithms and features such as experiment management, hyper-parameter optimization, and edge inference. - openvinotoolkit/anomalib
- GitHub - Mavenoid/prompt-hyperopt: Improve prompts for e.g. GPT3 and GPT-J using templates and hyperparameter optimization.: Improve prompts for e.g. GPT3 and GPT-J using templates and hyperparameter optimization. - Mavenoid/prompt-hyperopt
- GitHub - chand1012/git2gpt: Convert a Git repo into a ChatGPT prompt!: Convert a Git repo into a ChatGPT prompt! Contribute to chand1012/git2gpt development by creating an account on GitHub.
- VikParuchuri - Overview: VikParuchuri has 90 repositories available. Follow their code on GitHub.
- GitHub - statelyai/xstate: Actor-based state management & orchestration for complex app logic.: Actor-based state management & orchestration for complex app logic. - statelyai/xstate
- GitHub - seanchatmangpt/dspygen: A Ruby on Rails style framework for the DSPy (Demonstrate, Search, Predict) project for Language Models like GPT, BERT, and LLama.: A Ruby on Rails style framework for the DSPy (Demonstrate, Search, Predict) project for Language Models like GPT, BERT, and LLama. - seanchatmangpt/dspygen
- GitHub - jxzhangjhu/Awesome-LLM-Uncertainty-Reliability-Robustness: Awesome-LLM-Robustness: a curated list of Uncertainty, Reliability and Robustness in Large Language Models: Awesome-LLM-Robustness: a curated list of Uncertainty, Reliability and Robustness in Large Language Models - jxzhangjhu/Awesome-LLM-Uncertainty-Reliability-Robustness
- AI In Action: Weekly Jam Sessions: 2024 Topic,Date,Facilitator,Resources,@dropdown,@ UI/UX patterns for GenAI,1/26/2024,nuvic,<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-stru...
- GitHub - EGjoni/DRUGS: Stop messing around with finicky sampling parameters and just use DRµGS!: Stop messing around with finicky sampling parameters and just use DRµGS! - EGjoni/DRUGS
- GitHub - elder-plinius/AutoTemp: A trial-and-error approach to temperature opimization for LLMs. Runs the same prompt at many temperatures and selects the best output automatically.: A trial-and-error approach to temperature opimization for LLMs. Runs the same prompt at many temperatures and selects the best output automatically. - elder-plinius/AutoTemp
OpenAccess AI Collective (axolotl) ▷ #general (86 messages🔥🔥):
OpenArena ProjectORPO TrainingAnthropic Prompt IntegrationRAG Model DatasetWeighting Conversation Data
- OpenArena Project Goes 100% Open Source: User le_mess is working on a 100% open source local version of a dataset creation tool originally meant for OpenRouter but now using Ollama.
- The project aims to provide a more flexible and open environment for dataset creation for various models.
- Challenges in ORPO Training Memory Usage: User xzuyn raised concerns about ORPO training's memory usage, stating that it spikes and eventually results in OOM, even with max sequence set to 2k.
- Discussion revealed a lack of messages about dropping long sequences post-tokenization, contributing to erratic memory spikes.
- Anthropic Prompt Format for Axolotl: Kalomaze discussed integrating the official Claude/Anthropic prompt format into Axolotl, using special tokens for system, human, and assistant turns.
- There were concerns about the readability and generalization of special tokens; however, the existing SOTA model's practices were considered acceptable.
- RAG Model Dataset Scraping Concerns: User nafnlaus00 raised security concerns about using Chromium to render sites requiring JavaScript, such as Quora, for creating a RAG model dataset.
- Le_mess suggested troubleshooting headers/params issues and considering services like firecrawl or the Jina API for safer scraping.
- Proposing Weighted Training Data: Tostino suggested implementing a system for weighting different parts of conversation data in both pretraining and SFT, allowing negative weights to teach models to avoid certain tokens.
- This could enable optimization loops where less understood sections or 'bad paths' are weighted differently to improve model outcomes.
- axolotl/src/axolotl/utils/chat_templates.py at main · axolotl-ai-cloud/axolotl: Go ahead and axolotl questions. Contribute to axolotl-ai-cloud/axolotl development by creating an account on GitHub.
- GitHub - syv-ai/OpenArena: Contribute to syv-ai/OpenArena development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
Chat template dataset typePR review processConfiguration flexibilityTraining labels configurationHandling token offsets
- PR for Chat Template Dataset Soon: User announced the upcoming PR for a new chat template dataset type offering flexibility on training sections.
- This includes selecting roles to train on, configuring
train_on_eos, and handling specific training sections within the dataset.
- This includes selecting roles to train on, configuring
- Concerns Over Stuck PR Reviews: A member raised concerns about PR reviews being stuck, mentioning specific PRs from themselves and another user.
- "Are PR reviews getting stuck?" user asked, pointing to their PR and another one.
OpenAccess AI Collective (axolotl) ▷ #general-help (6 messages):
Eric's Spectrum WorkQuantizing Dolphin Vision 72b4-bit Model on 96GB Mac Pro
- Eric's Spectrum Exploration Gains Attention: A member mentioned that Eric has been working on a spectrum, which caught another member's interest who is currently reviewing the related paper.
- They noted that the paper seems very interesting on a first pass.
- Quantizing Dolphin Vision 72b Considerations: A member inquired about the feasibility of quantizing Dolphin Vision 72b to minimize VRAM usage.
- Another member responded that 4-bit quantization should still work well and suggested exploring lower quants with gguf or exl2.
- Running 4-bit Model on 96GB Mac Pro: A member shared that 4-bit quantization will fit on the 96GB of integrated RAM available on a mac pro with maxed out RAM.
- They mentioned running inference for it on their current setup.
OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
n_tt_n: i love capybara, have gotten awesome results with it
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (18 messages🔥):
Pushing Model to Hub after LoRA MergeVicuna Chat Template SupportConfig Options for Vicuna Template
- Pushing Model to Hub after LoRA Merge: A member asked how to push a model to the hub after merging LoRA into the base, suggesting using the
HfApi'supload_foldermethod.- Another member suggested a simpler approach using the
huggingface-cli uploadcommand:huggingface-cli upload wasamkiriua/model-name ..
- Another member suggested a simpler approach using the
- Vicuna Chat Template Confirmed: It was confirmed that Axolotl supports the vicuna chat template, which can be specified with the
conversationoption set tovicuna_v1.1in the configuration file.- The support allows handling conversations involving human and GPT interactions, following the vicuna template format.
- Valid Options for Chat Template Config Flag: The
chat_templateconfig flag cannot be directly set tovicuna; valid options includealpaca,chatml,inst,gemma,cohere,llama3, andphi_3.- Members agreed to omit the
chat_templateflag and set it manually afterwards if working with Vicuna-based models.
- Members agreed to omit the
- axolotl/docs/dataset-formats/conversation.qmd at main · axolotl-ai-cloud/axolotl: Go ahead and axolotl questions. Contribute to axolotl-ai-cloud/axolotl development by creating an account on GitHub.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (9 messages🔥):
GPTs AgentsOpenAI Platform's sidebarsCustom chat templates for axolotl trainingAxolotl training setupJinja format for templates
- GPTs Agents cannot learn after initial training: A member shared a concern about GPTs agents not learning from additional information provided after their initial training.
- Another member clarified that uploaded files are saved as "knowledge" files for the agent to reference, but they do not continuously update the agent's base knowledge.
- OpenAI Platform's sidebars changed: Members discussed changes in the sidebars of platform.openai.com, noting that two icons (threads and messages) disappeared.
- They speculated on potential reasons and impacts of this change on user navigation.
- Setting up custom chat templates for axolotl training: A member requested help converting custom chat templates for axolotl training, providing specific configurations they wanted to achieve.
- Another member provided step-by-step guidance, including Jinja template formats and YAML examples for configuring Axolotl.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Interconnects (Nathan Lambert) ▷ #news (31 messages🔥):
OpenAI working on StrawberryNew models in LMSYS arenaStealth releases of models in LMSYS
- OpenAI's Strawberry to Enhance Reasoning: OpenAI is working on new reasoning technology called Strawberry, with similarities to Stanford's Self-Taught Reasoner or STaR developed in 2022, as reported by Reuters.
- Discussion reveals insiders believe it resembles STaR, a method from Stanford.
- LMSYS Brings New Models into the Arena: Jimmy Apples indicates that new models are appearing in the LMSYS arena, spurring community hype.
- Among the models discussed are column-r and column-u, rumored to be from Cohere.
- Stealth Model Releases in LMSYS: Twitter user @btibor91 confirms a trend of stealthily pushing new models to LMSYS Chatbot Arena, mentioning four upcoming models including eureka-chatbot and upcoming-gpt-mini.
- Eureka-chatbot appears to be trained by Google, according to error messages and hints from community members.
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): Seems like there’s a new model in Lmsys arena.
- Tweet from Xeophon (@TheXeophon): Column-U is also jailbreak-able with the same prompt, so its also a cohere model i guess
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): Also a new column-r that seems really good… are we finally seeing shit happen? Quoting Jimmy Apples 🍎/acc (@apples_jimmy) Seems like there’s a new model in Lmsys arena.
- Tweet from Xeophon (@TheXeophon): Column-R is a cohere model, the Command R+ jailbreaks work on it as well.
- Tweet from Tibor Blaho (@btibor91): Looks like it became a new trend to stealthily push new models to LMSYS Chatbot Arena (and mostly non-selectable) for vibe check and hype before release With 4 models upcoming right now, as far as I ...
Interconnects (Nathan Lambert) ▷ #ml-questions (23 messages🔥):
Mistral-7B instruct-tuningOrca3/AgentInstruct paperInFoBench benchmarkWizardArena/ArenaLearning paperChatbotArena competition
- Mistral-7B instruct-tuning scrutinized: Discussion centered around the perceived improvements in the Orca3/AgentInstruct paper over Mistral-7B's instruct-tuning, with curiosity about the strength of Mistral's instruct-finetune dataset.
- Questions were raised about the best-known instruct-tuning for Mistral-7B, hinting that current datasets may not be especially robust.
- InFoBench benchmark divides opinions: The InFoBench (Instruction Following Benchmark) was introduced as a new benchmark, prompting questions about its relevance compared to standard alignment datasets.
- Debate ensued whether benchmarks like EQ Bench and InFoBench matter for highlighting valuable qualities in LMs, given high correlations with existing benchmarks like MMLU performance.
- WizardArena paper and ChatbotArena competition analyzed: Participants discussed the WizardArena/ArenaLearning paper, which details evaluating models using human preference scores, and the related Kaggle competition.
- Interest was shown in multi-turn synthetic interaction generation and evaluations, with specific curiosity about how WizardArena sets up its judging process and multi-turn evaluation.
- Questions about difficulty level predictions: The WizardArena paper mentions using an LM to predict the instruction difficulty level, sparking questions on its accuracy and real-world correlations.
- There was speculation around whether LMs could genuinely predict their own weaknesses, with reference to existing literature on LM self-knowledge.
- Sharp posting rate noticed in discussions: One user acknowledged their high posting rate and encouraged others to join the conversation actively.
- This user seemed eager to engage and share their read-throughs and insights on various papers and benchmarks.
- LMSYS - Chatbot Arena Human Preference Predictions | Kaggle: no description found
- RLHF roundup: Getting good at PPO, charting RLHF’s impact, RewardBench retrospective, and a reward model competition: Things to be aware of if you work on language model fine-tuning.
Interconnects (Nathan Lambert) ▷ #ml-drama (7 messages):
Finite State MachinePaper Rewriting ControversyGoogle Plagiarism
- Finite State Machine for Structured Generation: Outline's finite state machine for structured generation has been up on arXiv for almost a year, according to a post by @remilouf.
- I feel flattered, but still...
- Google accused of rewriting technical report: Brandon Willard reported that some people at Google completely rewrote their technical report, citing it but making ridiculous brief comments about the differences.
- He quoted @remilouf with the term plagiarism to underscore the severity of the issue.
- Tweet from Brandon T. Willard @brandonwillard@fosstodon.org (@BrandonTWillard): Yeah, looks like some people at Google completely rewrote our technical report. Although they did cite it, the brief comments about the differences are ridiculous. Quoting Rémi 〰️ (@remilouf) Plag...
- Tweet from Rémi 〰️ (@remilouf): I feel flattered, but still
Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
OpenAI's revenue speculationsOpenAI Supply Co. shopShopify usageInterconnects merchHackathons and free merch
- VCs speculate OpenAI's revenue from chatbot summaries: Aaron Holmes noted that VCs are circulating a speculative report on OpenAI's revenue, based on chatbot summaries from public web sources.
- For firsthand reporting, he referred to a detailed article published last month.
- OpenAI Supply Co. shop now internal only: The OpenAI Supply Co. shop now requires a login with an @openai.com Microsoft account, as confirmed by B Tibor's post.
- It's likely internal or should not be publicly accessible for now.
- OpenAI merch via Shopify: Discussion about OpenAI merch focused on using Shopify for merchandise stores.
- One member mentioned their own Interconnects Shopify store and showcased products like the Coder Hoodie and Coffee Vessel #1.
- Hackathons for free OpenAI merch: A suggestion was made that attending a hackathon might be a good way to get free OpenAI merch.
- It's a pretty smart way to leverage events for promotional items.
- Tweet from aaron holmes (@aaronpholmes): A lot of VCs are circulating a “report” today that speculates OpenAI’s revenue, based entirely on chatbot summaries of public web sources. If you want firsthand reporting on OpenAI’s revenue numbers, ...
- OpenAI Supply Co.: OpenAI Supply Co.
- Interconnects AI Store: Official merchandise for the Interconects.ai blog for RL bois and gurls.
- Tweet from Tibor Blaho (@btibor91): OpenAI Supply Co. Shopify store now requires login with an @ openai dot com Microsoft account - confirming it's only internal or should not be accessible, for now
Interconnects (Nathan Lambert) ▷ #reads (4 messages):
California AI Bill SB 1047Paywall circumventionArchive.isSilicon Valley debatesFortune article
- California AI Bill SB 1047 sparks fierce debate: The California AI Bill SB 1047, which passed the state’s Senate in May 32-1, is heading to a final vote in August amidst intense lobbying and discourse.
- State senator Scott Wiener described the debate as ‘Jets vs Sharks’, with AI safety experts clashing with top venture capitalists over the bill’s implications.
- Paywall circumvention using Archive.is: A discussion revealed a method to bypass paywalls by using Archive.is, allowing access to content behind paywalls like those on Fortune.
- One user expressed surprise that sites have not yet patched this loophole.
- It's AI's "Sharks vs. Jets"—welcome to the fight over California's AI safety bill: The California state senator behind the controversial SB-1047 AI bill says he didn't anticipate the opposition from Silicon Valley heavy-weights
- California AI bill SB-1047 sparks fierce debate around regulation of …: no description found
LangChain AI ▷ #general (58 messages🔥🔥):
LangChain JS UsageGemini Pro vs APIRAG ErrorsUsing Base64 with APIsOpenAI Embedding Models
- Understanding LangChain JS: invoke, stream, and streamEvents: A user queried about the differences between
invoke,stream, andstreamEventsin LangChain JS, wondering which to use with langgraph for streaming output, where nodes mainly involve tool calls.- In response, a suggestion was made to use agents for various actions such as data collection and API calls.
- Base64 Input Issues with Gemini Pro: A user tested Base64 with Gemini Pro API and encountered an 'invalid input' error, seeking help as the docs only mention File API upload without specifying Base64 format.
- Transitioning from ToolCall to OpenAIToolCall: Users discussed the deprecation of
ToolCalland the need to useOpenAIToolCallinstead, including the addition of anindexproperty.- A user sought guidance on updating the LangChain package and handling unintended default tool calls in 'auto' mode.
- Hallucinations in HuggingFace Models for Chatbots: A user experienced hallucinations with HuggingFace models, where the LLM generated random question/answer pairs.
- Suggestions included switching to openAI-models or FireworksAI models, noting that repetition penalties weren't effective for finetuned llama models.
- Optimal OpenAI Embedding Model: A query was raised regarding the best OpenAI embedding model, with a recommendation for
text-embedding-ada-002being the default in LangChain.
- ToolCall | LangChain.js - v0.2.9: no description found
- How to use a chat model to call tools | 🦜️🔗 Langchain: This guide assumes familiarity with the following concepts:
- How to use few shot examples in chat models | 🦜️🔗 LangChain: This guide assumes familiarity with the following concepts:
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Hippo | 🦜️🔗 LangChain: Transwarp Hippo is an enterprise-level cloud-native distributed vector database that supports storage, retrieval, and management of massive vector-based datasets. It efficiently solves problems such a...
LangChain AI ▷ #share-your-work (1 messages):
LLM Scrapercode generationlocal modelsGitHub project releasewebpage scraping
- LLM Scraper ships with code-generation support: LLM Scraper now includes code-generation support, allowing users to turn any webpage into structured data using local models.
- This new feature is aimed at enhancing the tool's functionality and is available on the project's GitHub page with detailed information and updates.
- Turn any webpage into structured data using LLMs: LLM Scraper enables users to transform any webpage into structured data using Large Language Models (LLMs).
- The GitHub repository provides an overview and contributions documentation on how to utilize this powerful tool.
Link mentioned: GitHub - mishushakov/llm-scraper: Turn any webpage into structured data using LLMs: Turn any webpage into structured data using LLMs. Contribute to mishushakov/llm-scraper development by creating an account on GitHub.
LlamaIndex ▷ #blog (10 messages🔥):
entity deduplicationLlamaCloudGPT-4o for financial reportsmulti-agent workflows with Redisadvanced RAG guide
- Entity Deduplication with Neo4j Cypher Snippet: A seriously cool Cypher snippet by @tb_tomaz and others at @neo4j performs entity deduplication using a combination of text embeddings and word analysis.
- LlamaCloud Streamlines Data Pipeline Management: LlamaCloud now lets you manage your data pipelines all in one place, with new team features enabling multiple users to have a central view of all projects.
- Parsing Financial Reports with GPT-4o: LlamaParse uses multimodal models like GPT-4o to easily extract text, diagrams, and tables from complex financial reports, which text-based parsers struggle with.
- Multi-Agent Workflows with Redis Integration: Thanks to @0xthierry, you can now build production agent systems using Redis Queue as the central message broker to coordinate multi-agent workflows.
- This setup allows agents services to communicate via a central message queue, significantly streamlining the architecture.
- Get Started with Advanced RAG Workflows: A fantastic guide from @kingzzm teaches you how to use LlamaIndex query pipelines to build advanced RAG and agent modules with full visibility.
- The step-by-step guide covers everything from basic to advanced settings, providing essential knowledge for AI engineers.
Link mentioned: blogs/llm/llama_index_neo4j_custom_retriever.ipynb at master · tomasonjo/blogs: Jupyter notebooks that support my graph data science blog posts at https://bratanic-tomaz.medium.com/ - tomasonjo/blogs
LlamaIndex ▷ #general (18 messages🔥):
LlamaIndex KG node deduplicationCombining SQL and PDF embeddingsHandling chat history in FastAPIChunking data for better embeddingsKnowledgeGraphIndex with NebulaGraphStore
- LlamaIndex KG Node Deduplication: A member shared a YouTube video and a Medium article explaining the process of deduplicating nodes in LlamaIndex Knowledge Graph.
- The video provides detailed insights into the technical approach and Rajib emphasizes the importance of knowledge modeling for making unstructured data GenAI ready.
- Combining SQL and PDF Embeddings with LlamaIndex: A user inquired about combining a MySQL database indexed using Manticore search with PDF documents as embeddings, following an example from LlamaIndex documentation.
- The user faced issues using
NLSQLTableQueryEnginebecause Manticore queries differ from MySQL, seeking a best approach to handle this.
- The user faced issues using
- Handling Chat History in FastAPI with LlamaIndex: Discussion on best practices for managing chat history in a multi-user FastAPI backend using LlamaIndex, weighing options between storing dictionaries of chat engines or maintaining chat history for each interaction.
- The consensus leaned towards managing just the chat history, possibly using a simple chat store.
- Smaller Chunk Sizes Enhance Embeddings: Chunking data into smaller sizes can help make embeddings more precise in LlamaIndex, as smaller chunk sizes offer finer-grained details.
- Configuration example provided: setting
Settings.chunk_sizeto 512 with an overlap of 50 and adjustingsimilarity_top_kto 4 for better retrieval accuracy, according to LlamaIndex documentation.
- Configuration example provided: setting
- Issues with NebulaGraphStore in KnowledgeGraphIndex: A member faced issues running a NebulaGraph example notebook for
KnowledgeGraphIndex, as noted in GitHub Issue #14748.- The error
KnowledgeGraphIndex._build_index_from_nodes() got an unexpected keyword argument 'space_name'was raised, and they sought advice on resolving it.
- The error
- Entity De-duplication | LlamaIndex Approach: LlamaIndex released a smart way to de-duplciate the entities of a Knowledge Graph created by a Language model. I looked at their approach…
- LlamaIndex KG | Deduplication of nodes.: In this recording, I explain in details how LlamaIndex is doing the deduplication of the nodes after creating the knowledge graphcode:https://github.com/raji...
- Basic Strategies - LlamaIndex: no description found
- [Bug]: KnowledgeGraphIndex._build_index_from_nodes() got an unexpected keyword argument 'space_name' · Issue #14748 · run-llama/llama_index: Bug Description I'm trying to run this NebulaGraph example. Running this cell: from llama_index.core import KnowledgeGraphIndex kg_index = KnowledgeGraphIndex.from_documents( documents, storage_co...
- SQL Join Query Engine - LlamaIndex: no description found
- Recursive Retriever + Query Engine Demo - LlamaIndex: no description found
OpenInterpreter ▷ #general (13 messages🔥):
OpenInterpreter GUI IntegrationOpenAI OS RumorsPhi-3.1 Model EvaluationInternlm2 ValuationSystem Architecture Documentation Request
- OpenInterpreter Fully Integrated into GUI: OpenInterpreter has been fully integrated into a GUI by a member, featuring branching chats, editable messages, code auto-run, and chat saving.
- Members expressed excitement over the project with others requesting video tutorials or demos to better understand its functionalities.
- Rumors of OpenAI OS Building: A tweet suggests that Sam Altman and OpenAI might be developing their own OS and communication tool, citing increasing evidence.
- This development followed a job opening posted a month ago, stirring discussions in the community.
- Phi-3.1 Model Evaluation: Techfren raised a discussion on the performance of the Phi-3.1 model, noting its promising size and capabilities.
- Member twodogseeds shared insights, indicating that Phi-3.1 offers more than requested but sometimes struggles following
accurately.
- Member twodogseeds shared insights, indicating that Phi-3.1 offers more than requested but sometimes struggles following
- Internlm2 Smashed on Raspi5: Twodogseeds pointed out that 'Internlm2 smashed' received attention, highlighting its performance on Raspi5.
- They mentioned the potential of multi-shot and smash modes for edge devices, especially with IoT applications.
- Request for System Architecture Documentation: A member inquired about available documentation explaining the system-level architecture and breakdown of Open Interpreter.
- No specific documentation was shared in response, indicating a potential gap or need for community-contributed resources.
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): I’m really bored so in case you missed it, a month or so ago they were hiring for this role. Quoting Chubby♨️ (@kimmonismus) The rumor seems to confirm that Sam Altman and OpenAi are building their...
- GitHub - jbexta/AgentPilot: Universal GUI for seamless interaction and management of AI workflows: Universal GUI for seamless interaction and management of AI workflows - jbexta/AgentPilot
OpenInterpreter ▷ #O1 (3 messages):
Meta Ray-Ban JailbreakInstalling O1 on Linux'Interpreter' Not Defined Error
- Meta Ray-Ban Jailbreak Interest: A member expressed excitement about the possibility of jailbreaking Meta Ray-Ban.
- They stated, 'That would be awesome, let me know if you do jailbreak Meta Ray-Ban.'
- O1 Linux Installation Patch: A member shared the steps to install O1 on Linux, mentioning a necessary patch in Poetry.
- They needed to remove a dependency to complete the installation.
- 'Interpreter' Not Defined Error: A member encountered an error message indicating that 'interpreter' is not defined while using O1.
- They reviewed the server code but couldn't find a solution, expressing their frustration.
LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
LLM agentAdding agents in LLMsModular components in chat pipelinesProcessing information using agentsInteracting with external APIs
- How LLM agents work in detail: A user shared a detailed guide explaining how to add agents in Large Language Models (LLMs), focusing on their modular nature and their roles in the Chat pipeline.
- The guide describes the process steps: Input Processing, LLM Interpretation, and using JSON output to invoke agents based on conversation needs.
- Modular components enhance LLM chat pipelines: The detailed guide emphasizes that agents in LLMs act as modular components, performing tasks such as fetching data, processing information, and interacting with external APIs.
- By leveraging the JSON output capability of LLMs, these agents can be seamlessly integrated into the conversation flow to address specific requirements.
Link mentioned: Adding Agents to Large Language Models Guide: Learn how to add agents in large language models using JSON output for flexible, scalable chat pipelines in this detailed guide
LLM Finetuning (Hamel + Dan) ▷ #asia-tz (2 messages):
OpenAI API Key request
- OpenAI API Key request for a chatbot project: A member requested an API key for OpenAI to use in a chatbot project.
- They mentioned needing the key to create a tutorial for the project.
- Seeking unused OpenAI API keys: Same member asked if anyone had an unused OpenAI API key they could share.
- They specified that the key was needed only for a tutorial.
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (1 messages):
healthymonkey: I’ve heard it’s about a year. I really like how easy it is to get H100s on modal lol
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (1 messages):
Credit Denial
- Credits cannot be granted after deadline: Attempts to reach out before the deadline were unsuccessful, resulting in the denial of credits.
- No further details were provided.
- No additional responses: No responses were received within the specified deadline.
LLM Finetuning (Hamel + Dan) ▷ #axolotl (1 messages):
Training Loss IssuesTemplate CorrectnessMeta's Template
- Training Loss Refuses to Drop: A member is experiencing issues with their training loss not decreasing using a specified setup, indicating a potential problem in their method.
- The shared code snippet and output suggest possible issues in dataset loading and prompt formatting.
- Correct Template Verification: A member provided an output example matching the template from Meta's documentation.
- The template follows
type: input_outputwith segments labeled as true or false for training responses.
- The template follows
Link mentioned: Meta Llama 3 | Model Cards and Prompt formats: Special Tokens used with Meta Llama 3. A prompt should contain a single system message, can contain multiple alternating user and assistant messages, and always ends with the last user message followe...
LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (2 messages):
modal erroraxolotl troubleshootingseeking help on slack
- Seeking Help on Slack for Modal Error: A member mentioned an unfamiliar error, speculating it might be specific to modal and suggested asking on Slack.
- Havent seen this error before but my guess is it's modal specific I would ask on their slack.
- Struggling with Modal and Axolotl: Another member chimed in, confirming struggles with both modal and axolotl.
- thanks. I have been struggling both with modal and axolotl.
LLM Finetuning (Hamel + Dan) ▷ #langchain-langsmith (1 messages):
Langsmith evaluationRate limits in OpenAI
- Tackling Rate Limits in Langsmith Evaluation: A user was encountering token rate limits per minute while running Langsmith evaluation tests using OpenAI credits.
- They found that adjusting the max_concurrency parameter helped mitigate the issue.
- Introducing Delays in Experiments: Another part of the conversation involved looking for ways to introduce delays into experiments to avoid hitting rate limits.
- Suggestions were sought for implementing this into the existing basic script.
LLM Finetuning (Hamel + Dan) ▷ #openai (5 messages):
OpenAI Credit ExpirationPetition for Credit Extension
- OpenAI Credits Expire on September 1: OpenAI credits are set to expire on September 1, confirmed by members after a query on the matter.
- One user appreciated the clarification after another member pointed out where to find this information.
- Petition for Extending OpenAI Credits: A user humorously requested a petition to extend the expiry date of OpenAI credits.
LAION ▷ #general (2 messages):
Hugging Face ProfitabilityCambrian-1 Multimodal LLMs
- Hugging Face Achieves Profitability: Hugging Face, a leading platform for developing and sharing machine learning models, announced its profitability with a team of 220 members, maintaining a largely free and open-source platform.
- Chief Clement Delangue shared on X, 'This isn’t a goal of ours because we have plenty of money in the bank but quite excited to see that @huggingface is profitable these days, with 220 team members and most of our platform being free (like model hosting) and open-source for the community!'
- Cambrian-1 Multimodal LLMs Unveiled: The Cambrian-1 family of multimodal LLMs with a vision-centric design was introduced, expanding the capabilities of AI models.
- GitHub - cambrian-mllm/cambrian: Cambrian-1 is a family of multimodal LLMs with a vision-centric design.: Cambrian-1 is a family of multimodal LLMs with a vision-centric design. - cambrian-mllm/cambrian
- Hugging Face Announces Profitability with Free and Open-Source Models – AIM: no description found
LAION ▷ #learning-ml (1 messages):
MagViT2 compatibility with non-RGB motion dataMotion data preprocessing
- MagViT2 for non-RGB motion data: A user inquired if MagViT2 can be used for motion data that are not in RGB format, mentioning their data as 24x3.
- No additional discussions or comments were provided in the messages.
- Motion data preprocessing techniques: Members are exploring various preprocessing techniques for non-RGB motion data to ensure compatibility with existing AI models.
- Further details and specific preprocessing methods were not discussed in the messages.
DiscoResearch ▷ #disco_judge (2 messages):
LLM ArenaOllama modelsWizardLM paperArena Learning methodology
- Introducing OpenArena for LLM Battles: A member shared the launch of OpenArena, a platform for pitting 2 LLMs against each other with a 3rd acting as a judge to enhance dataset quality.
- The platform primarily uses models from Ollama but supports any OpenAI compatible endpoint.
- Foundation of OpenArena in WizardLM Paper: The WizardLM paper introduces 'Arena Learning' - a simulated chatbot arena for evaluating LLMs.
- The methodology includes precise evaluations and consistent offline simulations to improve the LLM through supervised fine-tuning and reinforcement learning.
- GitHub - syv-ai/OpenArena: Contribute to syv-ai/OpenArena development by creating an account on GitHub.
- Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena - Microsoft Research: Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena