[AINews] Meta Llama 3.3: 405B/Nova Pro performance at 70B price
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
"a new alignment process and progress in online RL techniques" is all you need.
AI News for 12/5/2024-12/6/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (206 channels, and 5628 messages) for you. Estimated reading time saved (at 200wpm): 535 minutes. You can now tag @smol_ai for AINews discussions!
Meta AI, sensibly waiting for OpenAI to release an o1 finetuning waitlist, thankfully kept their sane versioning strategy and simply bumped their Llama minor version yet again to 3.3, this time matching 405B performance with their 70B model, using "a new alignment process and progress in online RL techniques". No papers of course.
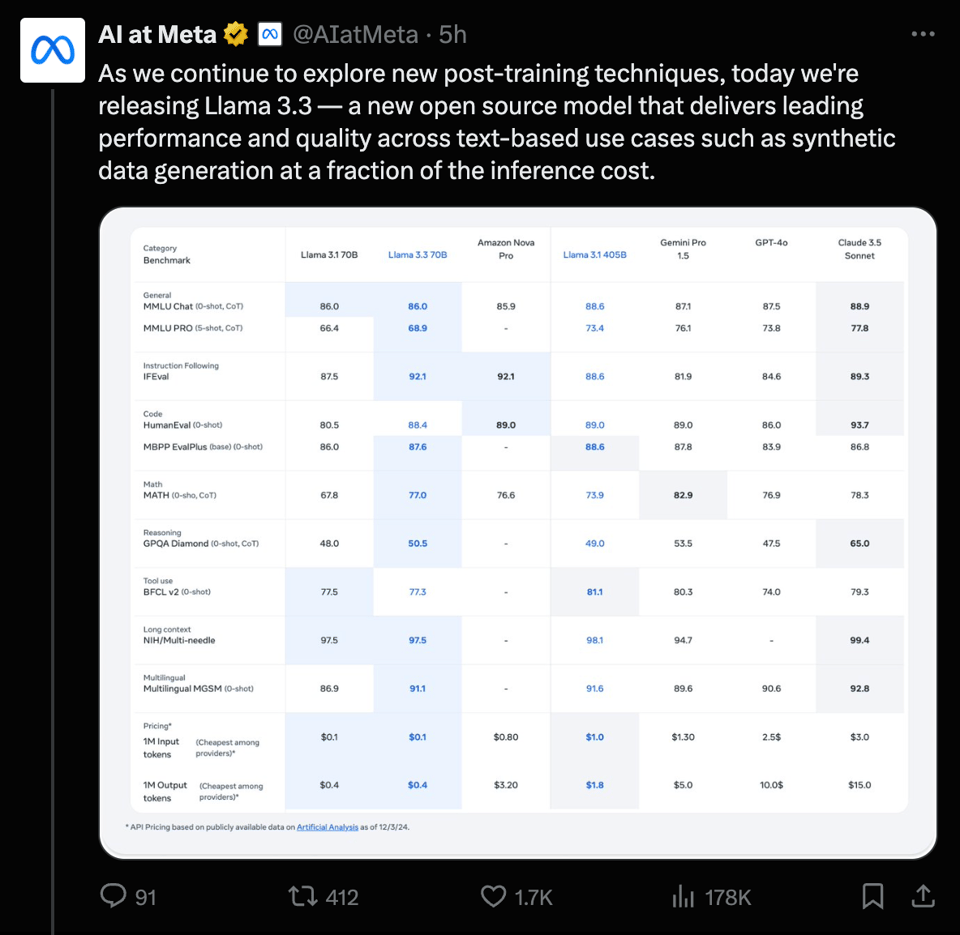
Amazon Nova Pro had all of 3 days to sit and look pretty, but with Meta loudly advertising same performance at 12% of the cost, they have been smacked back down in the hierarchy of price-to-performance ratios.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Codeium / Windsurf Discord
- Notebook LM Discord Discord
- Unsloth AI (Daniel Han) Discord
- Cursor IDE Discord
- OpenRouter (Alex Atallah) Discord
- Eleuther Discord
- aider (Paul Gauthier) Discord
- Interconnects (Nathan Lambert) Discord
- Bolt.new / Stackblitz Discord
- Stability.ai (Stable Diffusion) Discord
- OpenAI Discord
- Modular (Mojo 🔥) Discord
- Perplexity AI Discord
- LM Studio Discord
- Cohere Discord
- Latent Space Discord
- Nous Research AI Discord
- GPU MODE Discord
- Torchtune Discord
- LlamaIndex Discord
- OpenInterpreter Discord
- LLM Agents (Berkeley MOOC) Discord
- Axolotl AI Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- LAION Discord
- PART 2: Detailed by-Channel summaries and links
- Codeium / Windsurf ▷ #announcements (2 messages):
- Codeium / Windsurf ▷ #discussion (456 messages🔥🔥🔥):
- Codeium / Windsurf ▷ #windsurf (751 messages🔥🔥🔥):
- Notebook LM Discord ▷ #use-cases (212 messages🔥🔥):
- Notebook LM Discord ▷ #general (94 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (217 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (4 messages):
- Unsloth AI (Daniel Han) ▷ #help (42 messages🔥):
- Cursor IDE ▷ #general (250 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
- OpenRouter (Alex Atallah) ▷ #general (235 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (5 messages):
- Eleuther ▷ #general (26 messages🔥):
- Eleuther ▷ #research (183 messages🔥🔥):
- Eleuther ▷ #interpretability-general (8 messages🔥):
- Eleuther ▷ #gpt-neox-dev (1 messages):
- aider (Paul Gauthier) ▷ #announcements (1 messages):
- aider (Paul Gauthier) ▷ #general (148 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (46 messages🔥):
- Interconnects (Nathan Lambert) ▷ #events (5 messages):
- Interconnects (Nathan Lambert) ▷ #news (144 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #random (28 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (18 messages🔥):
- Bolt.new / Stackblitz ▷ #prompting (17 messages🔥):
- Bolt.new / Stackblitz ▷ #discussions (166 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (182 messages🔥🔥):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (116 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (13 messages🔥):
- OpenAI ▷ #prompt-engineering (11 messages🔥):
- OpenAI ▷ #api-discussions (11 messages🔥):
- Modular (Mojo 🔥) ▷ #general (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (147 messages🔥🔥):
- Perplexity AI ▷ #general (89 messages🔥🔥):
- Perplexity AI ▷ #sharing (8 messages🔥):
- Perplexity AI ▷ #pplx-api (2 messages):
- LM Studio ▷ #general (63 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (8 messages🔥):
- Cohere ▷ #discussions (28 messages🔥):
- Cohere ▷ #announcements (1 messages):
- Cohere ▷ #questions (7 messages):
- Cohere ▷ #api-discussions (32 messages🔥):
- Cohere ▷ #projects (1 messages):
- Cohere ▷ #cohere-toolkit (2 messages):
- Latent Space ▷ #ai-general-chat (65 messages🔥🔥):
- Latent Space ▷ #ai-in-action-club (1 messages):
- Nous Research AI ▷ #general (45 messages🔥):
- Nous Research AI ▷ #ask-about-llms (18 messages🔥):
- GPU MODE ▷ #general (9 messages🔥):
- GPU MODE ▷ #triton (2 messages):
- GPU MODE ▷ #cuda (6 messages):
- GPU MODE ▷ #cool-links (1 messages):
- GPU MODE ▷ #beginner (7 messages):
- GPU MODE ▷ #pmpp-book (1 messages):
- GPU MODE ▷ #torchao (1 messages):
- GPU MODE ▷ #off-topic (6 messages):
- GPU MODE ▷ #triton-puzzles (2 messages):
- GPU MODE ▷ #self-promotion (2 messages):
- GPU MODE ▷ #🍿 (6 messages):
- Torchtune ▷ #announcements (1 messages):
- Torchtune ▷ #general (19 messages🔥):
- Torchtune ▷ #papers (1 messages):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (10 messages🔥):
- OpenInterpreter ▷ #general (6 messages):
- OpenInterpreter ▷ #O1 (5 messages):
- OpenInterpreter ▷ #ai-content (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (5 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (5 messages):
- Axolotl AI ▷ #general (10 messages🔥):
- DSPy ▷ #general (7 messages):
- tinygrad (George Hotz) ▷ #general (4 messages):
- LAION ▷ #general (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Here are the key themes and discussions from the Twitter activity, organized by major topics:
Meta's Llama 3.3 70B Release
- Release Details: @AIatMeta announced Llama 3.3, a 70B model delivering performance comparable to Llama 3.1 405B but with significantly lower compute requirements. The model achieves improved performance on GPQA Diamond (50.5%), Math (77.0%), and Steerability (92.1%).
- Several providers including @hyperbolic_labs and @ollama quickly announced support for serving the model.
- The model supports 8 languages and maintains the same license as previous Llama releases.
OpenAI's Reinforcement Fine-Tuning (RFT) Announcement
- Product Launch: @OpenAI previewed Reinforcement Fine-Tuning, allowing organizations to build expert models for specific domains using limited training data.
- @stevenheidel noted that RFT allows users to create custom models using the same process OpenAI uses internally.
- Alpha access is being provided to researchers and enterprises through a research program.
Google's Gemini Performance Updates
- New Model Version: @lmarena_ai announced that Gemini-Exp-1206 is now leading benchmarks, taking first place overall and tying with GPT-4o for coding performance.
- The model shows improvements across various benchmarks including hard prompts and style control.
- @OriolVinyalsML celebrated Gemini's one-year anniversary and noted the progress in beating their own benchmarks.
LlamaCloud & Document Processing
- Feature Updates: @jerryjliu0 showcased LlamaCloud's capabilities for extracting tables from documents and performing analytics workloads.
- The platform now supports rendering tables and code directly in the UI.
- @jerryjliu0 highlighted automated extraction as an overlooked but valuable use case, particularly for receipt/invoice processing.
Memes and Industry Commentary
- OpenAI Pricing: Multiple users including @aidan_mclau commented on OpenAI's $200/month plan, with discussions around the economics of AI pricing models.
- @sama clarified that most users will be best served by the free tier or $20/month plus tier.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Llama 3.3 70B Performance vs. GPT-4o and Others
- Llama-3.3-70B-Instruct · Hugging Face (Score: 465, Comments: 139): The post is about Llama-3.3-70B-Instruct, a model available on Hugging Face, but lacks additional details or context regarding its features, capabilities, or applications.
- Discussions highlight the impressive performance of Llama-3.3-70B-Instruct, noting its comparable capabilities to the Llama 405B despite having significantly fewer parameters. Users are particularly impressed with its 128K context and multilingual abilities, with benchmarks showing substantial improvements in code generation, reasoning, and math.
- There is interest in the potential release of smaller versions of the model, as the 70B model is challenging for consumer-grade hardware due to VRAM limitations. Techniques like quantizing are discussed as methods to make it runnable on GPUs with 24G VRAM like the RTX 4090, although this may impact output quality.
- Some users express skepticism about the model's real-world performance compared to benchmarks, with comparisons being made to Qwen2.5 72B and discussions about the trade-offs in performance scaling. The community is keen on seeing further architectural changes in future iterations, such as Llama 4 and Qwen 3.
- Meta releases Llama3.3 70B (Score: 432, Comments: 100): Meta has released Llama3.3 70B, a model that serves as a drop-in replacement for Llama3.1-70B and approaches the performance of the 405B model. This new model is highlighted for its cost-effectiveness, ease of use, and improved accessibility, with further information available on Hugging Face.
- Llama 3.3 70B shows significant performance improvements over previous versions, with notable enhancements in code generation, multilingual capabilities, and reasoning & math, as highlighted by vaibhavs10. The model achieves comparable performance to the 405B model with fewer parameters, and specific metric improvements include a 7.9% increase in HumanEval for code generation and a 9% increase in MATH (CoT).
- Discussions around multilingual support emphasize that Llama 3.3 supports 7 additional languages besides English. However, there are concerns about the lack of a pretrained version, as Electroboots and mikael110 mention that only an instruction-tuned version is available, according to the Official Docs.
- Commenters like Few_Painter_5588 and SeymourStacks compare Llama to other models like Qwen 2.5 72b, noting Llama's improved prose quality and reasoning capabilities, though Qwen is still considered smarter in some benchmarks. There is also a call for more comprehensive benchmarks that focus on fundamentals rather than being easily gamed by post-training.
- New Llama 3.3 70B beats GPT 4o, Sonnet and Gemini Pro at a fraction of the cost (Score: 112, Comments: 0): Llama 3.3 70B reportedly outperforms GPT-4o, Sonnet, and Gemini Pro while offering cost advantages. Specific details on performance metrics and cost comparisons are not provided in the post.
Theme 2. Open Source O1: Call for Better Models
- Why we need an open source o1 (Score: 267, Comments: 135): The author criticizes the new o1 model, noting its downgrade from o1-preview in coding tasks, where it fails to follow instructions and makes unauthorized changes to scripts. They argue that these issues highlight the need for open-source models like QwQ, as proprietary models may prioritize profit over performance and reliability, making them unsuitable for critical systems.
- Open-source models like QwQ are gaining traction due to reliability issues with proprietary models like o1, which often change behavior unexpectedly and disrupt workflows. Users prefer open-weight solutions for stability, as they can control updates and ensure consistent performance over time.
- The o1 model has been criticized for its poor performance in coding, with users reporting unauthorized changes and a failure to follow instructions. This has led to concerns about its suitability for critical applications, with some users suggesting that OpenAI might be cutting costs by releasing less capable models deliberately.
- There is a general sentiment that models have been downgraded since GPT-4, with users expressing dissatisfaction with newer iterations like o1 and Gemini. Many believe these changes are driven by business strategies rather than technical improvements, leading to a preference for older models or open-source alternatives.
- Am I the only person who isn't amazed by O1? (Score: 124, Comments: 95): The author expresses skepticism about the O1 model, stating that it doesn't represent a paradigm shift. They argue that OpenAI has merely applied existing methods from the open source AI community, such as OptiLLM and prompt optimization techniques like "best of n" and "self consistency," which have been used since October.
- Many users express dissatisfaction with the O1 model, describing it as a downgrade from O1-preview and questioning the value of paying $200/month for the service. Some suggest that the model's limitations, such as losing track during extended interactions, make it unsuitable for professional use, and they prefer using 4o or other alternatives like Claude.
- There is discussion about the perception of OpenAI's strategy, with some users noting that the company has shifted to a "for-profit" model, focusing on incremental upgrades rather than groundbreaking innovations. This has led to a sense of disappointment among users who feel that OpenAI is prioritizing enterprise customers over individual consumers.
- The conversation touches on the broader AI landscape, with mentions of other models like QwenQbQ and DeepSeek R1, and the potential for open-source advancements. Users highlight the need for reliable models integrated into workflows, emphasizing long- and short-term memory, and mature agent frameworks, as opposed to merely increasing intelligence.
Theme 3. Windsurf Cascade System Prompt Details
- Windsurf Cascade Leaked System prompt!! (Score: 173, Comments: 51): Windsurf Cascade is an agentic AI coding assistant designed by the Codeium engineering team for use in Windsurf, an IDE based on the AI Flow paradigm. Cascade aids users in coding tasks such as creating, modifying, or debugging codebases, and operates with tools like Codebase Search, Grep Search, and Run Command. It emphasizes asynchronous operations, precise tool usage, and a professional communication style, while ensuring code changes are executable and user-friendly.
- Discussions highlighted the complexity of prompts in AI models, with users expressing astonishment at the effectiveness of intricate prompts despite numerous negatively formulated rules. There was curiosity about the specific model used by Windsurf Cascade.
- The use of HTML-style tags in prompts was discussed, with explanations that they provide structure and focus, aiding the model in processing longer prompts. Some users referenced a podcast with Erik Schluntz from Anthropic, noting that structured markup like XML/HTML-style tags can be more effective than raw text.
- There was a debate on the effectiveness of positive reinforcement in prompts, with some arguing that positive language can improve model performance by associating keywords with better solutions. However, others pointed out the limitations of endlessly adding conditions to prompts, comparing it to inefficiently programming with numerous "IF" statements.
Theme 4. HuggingFace Course: Preference Alignment for LLMs
- Free Hugging Face course on preference alignment for local llms! (Score: 192, Comments: 13): Hugging Face offers a free course on preference alignment for local LLMs, featuring modules like Argilla, distilabel, lightval, PEFT, and TRL. The course covers seven topics, with "Instruction Tuning" and "Preference Alignment" already released, while others like "Parameter Efficient Fine Tuning" and "Vision Language Models" are scheduled for future release.
- Colab Format Clarification: There was confusion about the term "Colab format," with users clarifying that the course materials are in notebook format, which can be run on Google Colab but are primarily designed to run locally. bburtenshaw emphasized that the notebooks contain links to open them in Colab for convenience, though everything is intended to run on local machines.
- Local LLMs Expectation: Users like 10minOfNamingMyAcc expected the course to provide a local codebase for local LLMs, aligning with the course's focus on local model training and usage. The course indeed supports local execution of code and models.
- Course Access: The course is available on GitHub, with MasterScrat providing the link here for those interested in accessing the materials directly.
Theme 5. Adobe Releases DynaSaur Code for Self-Coding AI
- Adobe releases the code for DynaSaur: An agent that codes itself (Score: 88, Comments: 13): Adobe has released the code for DynaSaur, an agent capable of coding itself. This move highlights Adobe's contribution to the field of AI, specifically in autonomous coding agents.
- Eposnix advises running DynaSaur in a VM due to the risk of it iterating indefinitely and potentially causing system damage. They suggest that confidence scoring could prevent this by allowing the AI to quit if a task is too difficult, rather than persisting with potentially harmful solutions.
- Knownboyofno explains that DynaSaur can autonomously create tools by generating Python functions to achieve specified goals, providing a clearer understanding of its capabilities.
- Staladine and others express interest in seeing practical examples or demonstrations of DynaSaur in action, indicating a need for more illustrative resources to comprehend its functionality.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. OpenAI GPT-4.5: Surpassing Expectations in Creative Language Tasks
- Asked her to roast the UHC CEO (Score: 195, Comments: 27): ChatGPT critiques the health insurance industry by equating profit-driven practices to "playing Monopoly with people's lives," reflecting on the moral implications of prioritizing profits over patient care. The conversation also touches on the challenges of roasting a person who has been assassinated.
- The discussion highlights ChatGPT's evolving capabilities, with users expressing shock at its ability to deliver incisive critiques, particularly targeting insurance executives without censorship. Comments reflect on ChatGPT's boldness and suggest it has become more radical, especially in political contexts.
- A user humorously notes that "facts have always had a liberal bias," indicating a perceived alignment of ChatGPT's critiques with liberal viewpoints. This underscores the AI's perceived role in challenging established norms and figures in sensitive industries.
- The community engages with the post through humor and memes, showcasing a lighthearted yet critical reception of the AI's commentary on the insurance industry, with references to the harshness of its critique as "brutal" and "murderous."
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. AI Model Releases and Performance Battle Royale
- Meta’s Llama 3.3 Outperforms 405B Rival: Meta’s Llama 3.3, featuring 70B parameters, matches the performance of a 405B model while being more cost-efficient, igniting comparisons with Gemini-exp-1206 and Qwen2-VL-72B models.
- Users celebrate Llama 3.3’s enhanced math solutions and robust performance in coding tasks, citing its suitability for various engineering projects.
- The release spurs competitive benchmarking, with community members eager to integrate and test the model against established standards.
- "Saw remarkable improvements in syntax handling," a user exclaimed, highlighting the model’s advanced capabilities.
- Gemini-exp-1206 Ties with O1 in Coding Benchmarks: Google’s Gemini-exp-1206 model secures a top spot overall, matching O1 in coding benchmarks and pushing technological boundaries in AI performance.
- The model showcases significant advancements in synthetic data generation and cost-effective inference, appealing to developers focused on scalability.
- Community discussions highlight Gemini-exp-1206’s potential to exceed expectations in complex AI applications.
- Explore Gemini-exp-1206’s capabilities.
Theme 2. Pricing Shakeups Spark User Grievances
- Windsurf’s Steep Price Hike Frustrates Subscribers: Codeium raises Windsurf’s Pro tier to $60/month with new hard limits on prompts and flow actions, leaving many users dissatisfied and seeking clarification on grandfathering policies.
- Subscribers express frustration over the sudden price increase without prior bug fixes, questioning the sustainability of the new pricing model.
- The abrupt changes have accelerated exploration of alternatives like Cursor, Bolt AI, and Copilot, despite some sharing similar reliability issues.
- "This pricing is unsustainable given the current performance," a user lamented.
- See Windsurf’s new pricing details.
- Lambda Labs Slashes Model Prices to Attract Developers: DeepInfra cuts prices on multiple models, including Llama 3.2 3B Instruct for $0.018 and Mistral Nemo for $0.04, aiming to provide affordable options for budget-conscious developers.
- These reductions make high-quality models more accessible, fostering broader adoption and innovation within the developer community.
- Users welcome the lower costs, noting the improved value proposition and increased accessibility.
- Check out DeepInfra’s price cuts.
Theme 3. Tool Stability Fails and User Frustrations
- Claude’s Code Struggles Deter Developers: Users report significant bugs in tools like Windsurf and Claude, leading to unreliable performance and increased error rates, making coding tasks more cumbersome.
- Persistent server outages and issues like 'resource_exhausted' undermine productivity, causing users to reconsider their subscriptions.
- Community consensus highlights the critical need for reliable performance in AI tools before any further pricing adjustments.
- Read more user feedback on Claude.
- Cursor’s Sluggish Response Times Push Users to Alternatives: Users report connection failures and slow responses with Cursor’s Composer, often requiring new sessions for functionality, leading to frustration and migration towards more stable tools like Windsurf.
- Despite new features in Cursor 0.43.6, issues like unreliable Composer responses persist, dampening user experience.
- Discussions emphasize the need for robust bug fixes and performance improvements to retain user trust.
- "Cursor’s performance doesn't meet expectations," a developer noted.
- Explore Cursor’s performance issues.
Theme 4. Feature Enhancements and New Integrations Unveiled
- Aider’s Pro Upgrade Introduces Advanced Voice and Context Features: Aider Pro now includes unlimited advanced voice mode, a new 128k context for O1, and a copy/paste to web chat capability, enhancing workflow efficiency and handling of extensive documents and code.
- Additionally, process suspension support and exception capture analytics provide users with better control and insights into their processes.
- User feedback praises the 61% code contribution from Aider, showcasing its growing capabilities and robust development.
- Discover Aider Pro’s new features.
- OpenRouter’s Author Pages Simplify Model Discovery: OpenRouter launches Author Pages, enabling users to explore models by creators with detailed stats and related models showcased through a convenient carousel interface.
- This feature enhances model discovery and allows for better analysis, making it easier for users to find and evaluate diverse AI models.
- The community anticipates improved user experience and streamlined navigation through different authors' collections.
- Visit OpenRouter’s Author Pages.
Theme 5. Community Concerns: Security, Licensing, and Fake Apps
- Beware the Fake Perplexity App!: Discord users alert the community about a fake Perplexity app circulating on the Windows app store, which deceptively uses the official logo and unauthorized APIs, directing users to a suspicious Google Doc and urging immediate reporting to prevent security breaches.
- Members highlight the importance of verifying app authenticity to avoid exposure to malware and phishing attempts.
- Discussions emphasize the need for vigilance and community-driven measures to combat fraudulent applications.
- Report the fake Perplexity app.
- Phi-3.5 Overly Censors AI Responses: Microsoft’s Phi-3.5 model is criticized for being highly censored, making it resistant to offensive queries and potentially limiting its usefulness for technical tasks, sparking debates on the balance between safety and usability in AI models.
- Users debate methods to uncensor or improve the model’s functionality, including sharing links to uncensored versions on Hugging Face.
- Concerns are raised about the censorship’s impact on coding and technical applications, urging developers to seek models with better contextual understanding.
- "Phi-3.5’s censorship makes it impractical for many real-world applications," a user argued.
- Explore Phi-3.5’s uncensored version.
- Security Oversight in AI Tools Raises Alarm: Discussions surrounding Safety Concerns in AI tools highlight issues like over-censorship and the lack of secure license agreements, emphasizing the need for better security protocols and transparent licensing to protect user interests.
- Community members call for improved overseeing mechanisms to ensure AI models are both safe and functional, avoiding overzealous restrictions that hinder practical use.
- "We need a balance between safety and usability in AI models," a participant stated.
- Learn about AI model safety concerns.
PART 1: High level Discord summaries
Codeium / Windsurf Discord
- Windsurf Pricing Overhaul: Codeium has increased Windsurf's Pro tier to $60/month, introducing hard limits on user prompts and flow actions, which has unsettled many subscribers.
- Users are demanding clarity on the new pricing structure and whether existing plans will be grandfathered, expressing dissatisfaction with the abrupt changes without prior bug fixes.
- User Frustrations with AI Tools: Engineers reported significant bugs in tools like Windsurf, hindering effective coding and leading to reconsideration of their subscriptions.
- There is a consensus that AI tools need to ensure reliable performance and user-friendly features before implementing further pricing adjustments.
- Alternatives to Windsurf: In response to Windsurf's pricing and performance issues, users are exploring alternatives such as Cursor, Bolt AI, and Copilot for more consistent performance.
- Despite considering these alternatives, some users remain cautious as tools like Bolt AI are reported to have similar reliability challenges.
- Impact of Server Issues: Frequent server outages and errors like 'resource_exhausted' are disrupting the use of Windsurf, negatively impacting user productivity.
- These technical problems are intensifying user frustrations and accelerating the shift towards other AI coding solutions.
- Feedback on AI Tool Performance: Users have highlighted that Claude struggles with context retention and introduces errors in code, reducing its effectiveness in development tasks.
- This feedback emphasizes the need for AI tools to enhance their accuracy and contextual understanding to better meet the demands of engineering projects.
Notebook LM Discord Discord
- Audio Generation with NotebookLM: Members explored using NotebookLM for audio generation, successfully creating podcasts from documents. One user reported a 64-minute podcast generated from a multilingual document, highlighting varied outcomes based on input type.
- Discussions revealed challenges in maintaining coherence and focus in AI-generated audio, with some users facing unexpected tangents despite effective prompting techniques.
- Language and Voice Support in NotebookLM: Conversations centered on NotebookLM's support for languages beyond English, with some users recalling limitations to English only. The impressive voice quality in generated audio sparked debates on its potential as a standalone text-to-speech solution.
- Users questioned the scope of language support, discussing the possibility of expanding NotebookLM's multilingual capabilities to enhance its utility for a global engineering audience.
- Game Development using Google Docs and AI: Engineers shared strategies for utilizing Google Docs to organize game rules and narratives, leveraging AI to generate scenarios and build immersive worlds. One member highlighted successes with AI-generated scenarios that blend serious and humorous content in their RPG games.
- The integration of AI in game development was lauded for enhancing creative processes, with users emphasizing the flexibility of Google Docs as a collaborative tool for narrative construction.
- Spreadsheet Integration Workarounds for NotebookLM: Users identified limitations with direct spreadsheet uploads into NotebookLM, suggesting alternatives like converting data into Google Docs for better compatibility. One user mentioned reducing spreadsheet complexity by hiding unnecessary columns to incorporate essential data.
- Creative methods for integrating spreadsheet data were discussed, focusing on maintaining data integrity while circumventing NotebookLM's upload restrictions.
- NotebookLM Performance and Usability Feedback: Feedback on NotebookLM's performance was mixed, with discussions on the accuracy and depth of generated content. Users emphasized the need for more transparency regarding potential paywalls and consistent performance metrics.
- Concerns about the disappearance of the new notebook button led to speculations about possible notebook limits, affecting the overall usability and workflow within NotebookLM.
Unsloth AI (Daniel Han) Discord
- PaliGemma 2 Launch Expands Model Offerings: Google introduced PaliGemma 2 with new pre-trained models of 3B, 10B, and 28B parameters, providing greater flexibility for developers.
- The integration of SigLIP for vision tasks and the upgrade to Gemma 2 for the text decoder are expected to enhance performance compared to previous versions.
- Qwen Fine-Tuning Hits VRAM Limitations: Engineers encountered issues fine-tuning the Qwen32B model on an 80GB GPU, necessitating a 96GB H100 NVL GPU to prevent OOM errors (Issue #1390).
- Conversations revealed that QLORA might use more memory than LORA, leading to ongoing investigations into VRAM consumption discrepancies.
- Unsloth Pro Anticipates Upcoming Release: Unsloth Pro is slated for release soon, generating excitement among users awaiting enhanced features.
- Community members are looking forward to leveraging Unsloth Pro to streamline their workflows and utilize new model capabilities.
- Llama 3.3 Debuts 70B Model with Efficiency Gains: Llama 3.3 has been released, featuring a 70B parameter model that delivers robust performance while reducing operational costs (Tweet by @Ahmad_Al_Dahle).
- Unsloth has introduced 4-bit quantized versions of Llama 3.3, which improve loading times and decrease memory usage.
- Optimizing LoRA Fine-Tuning Configurations: 'Silk.ai' questioned the necessity of the use_cache parameter in LoRA fine-tuning, sparking a debate on optimal settings.
- Another contributor emphasized the importance of enabling LoRA dropout to achieve the desired model performance.
Cursor IDE Discord
- Cursor Performance Takes a Hit: Users reported that Cursor has been experiencing connection failures and slow response times while using the Composer, often requiring new sessions for proper functionality.
- Many compared its performance unfavorably to Windsurf, expressing frustration over persistent issues.
- Windsurf Surpasses Cursor: Several users mentioned that Windsurf performed better in handling tasks without issues, even under heavy code generation demands.
- People highlighted that while Cursor struggles to apply changes, Windsurf executed similar tasks smoothly, shifting user preferences.
- Cursor 0.43.6 Adds Sidebar Integration: With the latest Cursor 0.43.6 update, users noted that the Composer UI has been integrated into the sidebar, but some functions like long context chat have been removed.
- New features such as inline diffs, git commit message generation, and early versions of an agent were also mentioned.
- Composer Responds Unreliably: Users shared mixed experiences regarding Cursor's Composer feature, with reports of it sometimes failing to respond to queries.
- Issues include Composer not generating the expected code or missing updates, especially after recent updates.
- Exploring Unit Testing with Cursor: A user inquired about effective methods for writing unit tests using Cursor, expressing interest in shared techniques.
- While a definitive response is pending, users encouraged sharing their experiences and methods for testing.
OpenRouter (Alex Atallah) Discord
- OpenRouter Launches Author Pages: OpenRouter introduced the Author Pages feature, enabling users to explore models by creators at openrouter.ai/author. This update includes detailed stats and related models displayed via a carousel.
- The feature aims to enhance model discovery and analysis, providing a streamlined experience for users to navigate through different authors' collections.
- Amazon Nova Models Receive Mixed Feedback: Users have reported varying experiences with Amazon Nova models, describing some as subpar compared to alternatives like Nova Pro 1.0.
- Despite criticisms, certain users highlighted the models' speed and cost-effectiveness, indicating a divide in user satisfaction.
- Llama 3.3 Deployment and Performance: Llama 3.3 has been successfully launched, with providers offering it shortly after release, enhancing capabilities for text-based applications as detailed in OpenRouter's announcement.
- AI at Meta noted that this model promises improved performance in generating synthetic data while reducing inference costs.
- DeepInfra Reduces Model Pricing: DeepInfra announced significant price cuts on multiple models, including Llama 3.2 3B Instruct for $0.018 and Mistral Nemo for $0.04, as per their latest tweet.
- These reductions aim to provide budget-conscious developers with access to high-quality models at more affordable rates.
- OpenAI Introduces Reinforcement Learning Finetuning: During OpenAI Day 2, the company announced the upcoming reinforcement learning finetuning for o1, though it generated limited excitement among the community.
- Participants expressed skepticism regarding the updates, anticipating more substantial advancements beyond the current offerings.
Eleuther Discord
- MoE-lite Motif Enhances Transformer Efficiency: A member introduced the MoE-lite motif, utilizing a custom bias-per-block-per-token to nonlinearly affect the residual stream, which suggests faster computations despite increased parameter costs.
- The discussion compared its efficiency against traditional Mixture of Experts (MoE) architectures, debating potential benefits and drawbacks.
- GoldFinch Architecture Streamlines Transformer Parameters: A member detailed the GoldFinch model, which removes the V matrix by deriving it from a mutated layer 0 embedding, significantly enhancing parameter efficiency. GoldFinch paper
- The team discussed the potential to replace or compress both K and V parameters, aiming to improve overall transformer efficiency.
- Layerwise Token Embeddings Optimize Transformer Parameters: Members explored layerwise token value embeddings as a substitute for traditional value matrices, promoting significant parameter savings in transformers without compromising performance.
- The approach leverages initial embeddings to dynamically compute V values, thereby reducing reliance on extensive value projections.
- Updated Mechanistic Interpretability Resources Now Available: A member shared a Google Sheets resource cataloging key papers in mechanistic interpretability, organized by themes for streamlined exploration.
- The resource includes theme-based categories and annotated notes to assist researchers in navigating foundational literature effectively.
- Dynamic Weight Adjustments Boost Transformer Efficiency: Members proposed dynamic weight adjustments to enhance parameter allocation and Transformer efficiency, drawing parallels to regularization methods like momentum.
- The conversation highlighted potential performance improvements and streamlined computations by eliminating or modifying V parameters.
aider (Paul Gauthier) Discord
- Aider v0.67.0 Released With New Features: The latest Aider v0.67.0 introduces support for Amazon Bedrock Nova models, enhanced command functionalities, process suspension support, and exception capture analytics.
- Highlighting its development, Aider contributed 61% of the code for this release, showcasing its robust capabilities.
- Aider Pro Features Gain Attention: Aider Pro now includes unlimited advanced voice mode, a new 128k context for O1, and a copy/paste to web chat capability allowing seamless integration with web interfaces.
- Users praised these features for enabling the handling of extensive documents and code, enhancing their workflow efficiency.
- Gemini 1206 Model Release Sparks Interest: Google DeepMind released the Gemini-exp-1206 model, claiming performance improvements over previous iterations.
- Community members are eager to see comparative benchmarks against models like Claude and await detailed performance results from Paul Gauthier.
- DeepSeek's Performance in Aider: DeepSeek was discussed as a cost-effective option for Aider users, alongside alternatives like Qwen 2.5 and Haiku.
- There is speculation about the potential of fine-tuning community versions to enhance DeepSeek’s benchmarks in Aider.
Interconnects (Nathan Lambert) Discord
- Gemini-exp-1206 claims top spot: The new Gemini-exp-1206 model achieved first place overall and is tied with O1 on coding benchmarks, marking significant improvements over previous versions.
- OpenAI's demonstration revealed that fine-tuned O1-mini can surpass the full O1 model based on medical data, highlighting Gemini's robust performance.
- Llama 3.3 brings cost-effective performance: Enhancements in Llama 3.3 are driven by updated alignment processes and advancements in online reinforcement learning techniques.
- This model matches the performance of the 405B model while enabling more cost-efficient inference on standard developer workstations.
- Qwen2-VL-72B launched by Alibaba: Alibaba Cloud introduced the Qwen2-VL-72B model, featuring advanced capabilities in visual understanding.
- Designed for multimodal tasks, it excels in video comprehension and operates seamlessly across various devices, aiming to enhance multimodal performance.
- Reinforcement Fine-Tuning advances AI models: Discussions emphasized the role of Reinforcement Learning in fine-tuning models to outperform existing counterparts.
- Key points included the use of pre-defined graders for model training and evolving methodologies in RL training approaches.
- AI Competition drives model innovation: Members called for robust competition in AI, urging OpenAI to challenge models like Claude and Deepseek to foster advancements.
- This sentiment underscores the community's belief that effective competitors are essential for continual progress in the AI field.
Bolt.new / Stackblitz Discord
- Enhancing Token Efficiency in Bolt.new: Members discussed strategies like Specific Section Edits to reduce token usage by modifying only selected sections instead of regenerating entire files, aiming for improved token management efficiency.
- Questions were raised about daily token limits for free accounts and the benefits of purchasing the token reload option to allow token rollover.
- Integrating GitHub Repos with Bolt.new: Users explored GitHub Repo Integration by starting Bolt with repository URLs such as bolt.new/github.com/org/repo, noting that private repositories currently require being set to public for successful integration.
- To resolve deployment errors related to private repos, users suggested switching to public repositories to bypass permission issues.
- Managing Feature Requests and Improvements: Discussions emphasized efficient Feature Requests Management through engaging with Bolt for handling requests individually, which helps reduce hallucination in bot responses.
- Community members proposed submitting feature enhancement ideas via the GitHub Issues page, highlighting the importance of user feedback for product development.
- Optimizing Development with Local Storage and Backend Integration: Developers recommended building applications using local storage initially, then migrating features to backend solutions like Supabase to facilitate smoother testing and streamline the integration process.
- This method was confirmed to help maintain app polish and reduce errors during the transition to database storage.
Stability.ai (Stable Diffusion) Discord
- Reactor's Face Swap Showdown: Users debated if Reactor is the optimal choice for face swapping, with no clear consensus reached.
- Participants recommended experimenting with various models to evaluate their impact on output quality.
- AI Discords Diversify Discussions: A user sought a Discord community for diverse AI topics beyond LLMs, triggering recommendations.
- Members suggested Gallus and TheBloke Discords as hubs for a wide range of AI discussions.
- Cloud GPU Providers' Price Wars: Users shared preferred Cloud GPU providers like Runpod, Vast.ai, and Lambda Labs, highlighting competitive pricing.
- Lambda Labs was noted as often the cheapest option, though access can be challenging.
- Lora & ControlNet Tune Stable Diffusion: Discussion revolved around adjusting Lora's strength in Stable Diffusion, noting it can exceed 1 but risks image distortion at higher settings.
- Members recommended using OpenPose for accurate poses and leveraging depth control for improved results.
- AI Art Licensing Quandary: A user raised questions about exceeding the revenue threshold under Stability AI's license agreement.
- Clarifications suggested outputs remain usable, but the license for model use is revoked upon termination.
OpenAI Discord
- Reinforcement Fine-Tuning in 12 Days of OpenAI: The YouTube event '12 Days of OpenAI: Day 2' features Mark Chen, SVP of OpenAI Research, and Justin Reese discussing the latest in reinforcement fine-tuning.
- Participants are encouraged to join the live stream starting at 10am PT for insights directly from leading researchers.
- Gemini 1206 Experimental Model Surpasses O1 Pro: The Gemini 1206 experimental model has been highlighted for its strong performance, surpassing O1 Pro in tasks such as generating SVG code for detailed unicorn illustrations.
- Users report that Gemini 1206 delivers enhanced results, particularly excelling in SVG generation and other technical applications.
- O1 Pro Pricing Compared to Gemini 1206: O1 Pro, priced at $200/month, has sparked discussions regarding its value compared to free alternatives like Gemini 1206.
- Some users believe that despite O1's capabilities, the high cost is unjustifiable given the availability of effective free models.
- Demand for Advanced Voice Mode Features: There is a clear community demand for a more advanced voice mode, with current offerings being criticized for their robotic sound.
- Users express hopes for significant improvements in the feature, especially during the upcoming holiday season.
- Collaborative GPT Editing Features Proposed: A member expressed a desire for enabling multiple editors to simultaneously modify a GPT, highlighting the need for collaboration.
- Currently, only the creator can edit a GPT, but the community suggests a 'Share GPT edit access' feature to facilitate teamwork.
Modular (Mojo 🔥) Discord
- VSCode Extension Inquiry Resolved: A member faced issues with VSCode extension tests running with cwd=/, which was resolved after finding the appropriate channel to ask about the extension.
- This incident underscores the significance of directing technical queries to the correct community channels for efficient problem resolution.
- Mojo Function Extraction Errors: A user encountered errors while adapting the
j0function from the math module in Mojo due to an unknown declaration_call_libmduring compilation.- They sought guidance on properly extracting and utilizing functions from the math standard library without encountering compiler issues.
- Programming Career Specialization: Members discussed the benefits of specializing in areas like blockchain, cryptography, or distributed systems for enhanced job prospects in tech.
- Emphasis was placed on targeted learning, hands-on projects, and a solid grasp of fundamental concepts to advance one's career.
- Compiler Passes and Metaprogramming in Mojo: Discussions highlighted new Mojo features enabling custom compiler passes, with ideas to enhance the API for more extensive program transformations.
- Members compared Mojo's metaprogramming approach to traditional LLVM Compiler Infrastructure Project, noting limitations in JAX-style program transformations.
- Education Insights in Computer Science: Participants shared experiences regarding challenging computer science courses and projects that deepened their understanding of programming concepts.
- They discussed balancing personal interests with market demands, using their academic journeys as examples.
Perplexity AI Discord
- Perplexity AI Faces Code Interpreter Constraints: Users reported that Perplexity AI's code interpreter fails to execute Python scripts even after uploading relevant files, restricting its functionality to generating only text and graphs.
- This limitation has sparked conversations about the necessity for Perplexity AI to support actual code execution to better serve technical engineering needs.
- Fake Perplexity App Circulates on Windows Store: Members identified a fake Perplexity app available on the Windows app store, which deceptively uses the official logo and unauthorized API, leading users to a suspicious Google Doc.
- The community urged reporting the fraudulent app to prevent potential security risks and protect the integrity of Perplexity AI offerings.
- Llama 3.3 Model Released with Enhanced Features: Llama 3.3 was officially released, garnering excitement for its improved capabilities over previous versions, as highlighted by user celebrations.
- There is strong anticipation within the community for Perplexity AI to integrate Llama 3.3 into their services to leverage its advanced functionalities.
- Optimizing API Usage with Grok and Groq: Discussions around using Grok and Groq APIs revealed that Grok offers a free starter credit, while Groq provides complimentary usage with Llama 3.3 integration.
- Users shared troubleshooting tips, noting challenges with the Groq endpoint, which some members successfully resolved through community support.
- Introducing RAG Feature to Perplexity API: A member inquired about incorporating the RAG feature from Perplexity Spaces into the API, indicating a demand for advanced retrieval capabilities.
- This interest underscores the community's need for enhanced functionality within the Perplexity API to support more sophisticated data retrieval processes.
LM Studio Discord
- Paligemma 2 Release: The Paligemma 2 release on MLX introduces new models from GoogleDeepMind, enhancing the platform's capabilities.
- Users are encouraged to install it using
pip install -U mlx-vlm, contribute by starring the project, and submitting pull requests.
- Users are encouraged to install it using
- RAG File Limitations: A member discussed workarounds for the 5 file RAG limitation, stressing the necessity to analyze multiple small files for issue detection.
- Community members deliberated on potential solutions and the performance implications of processing smaller file batches with models.
- Llama 3.1 CPU Benchmarks: Benchmarks for the Llama 3.1 8B model on Intel i7-13700 and i7-14700 CPUs were requested to assess potential inference speeds.
- Community insights indicate varying performance metrics based on recent user experiences with similar CPU setups.
- 4090 GPU Price Surge: There is a reported 4090 GPU price surge for both new and used units in certain regions, causing user concerns.
- Rumors suggest some 4090 GPUs might be modded to expand VRAM to 48GB, sparking further discussions.
- Chinese Modding of 4090 GPUs: Reddit discussions about Chinese modders working on 4090 GPUs were mentioned, though no specific sources were provided.
- Users expressed challenges in locating detailed information or links regarding these GPU modding activities.
Cohere Discord
- Rerank 3.5 Model Enhances Search Accuracy: The newly released Rerank 3.5 model offers improved reasoning and multilingual capabilities, enabling more accurate searches of complex enterprise data.
- Members are seeking benchmark scores and performance metrics to evaluate Rerank 3.5's effectiveness.
- Structured Outputs Streamline Command Models: Command models now enforce strict Structured Outputs, ensuring all required parameters are included and enhancing reliability in enterprise applications.
- Users can utilize Structured Outputs in JSON for text generation or Tools via function calling, currently experimental in Chat API V2 with feedback encouraged.
- vnc-lm Integrates with LiteLLM for Enhanced API Connections: vnc-lm is now integrated with LiteLLM, enabling connections to any API that supports Cohere models like Cohere API and OpenRouter.
- The integration allows seamless API interactions and supports multiple LLMs including Claude 3.5, Llama 3.3, and GPT-4o, as showcased on GitHub.
- /embed Endpoint Faces Rate Limit Issues: Users have expressed frustration over the low rate limit of 40 images per minute for the /embed endpoint, limiting the ability to embed datasets efficiently.
- Members suggest reaching out to support for potential rate limit increases.
- Optimizing API Calls with Retry Mechanisms: Users are discussing strategies to optimize their retry mechanisms for API calls using the vanilla Cohere Python client, which inherently handles retries gracefully.
- This has sparked a productive exchange on various approaches to manage API retries effectively.
Latent Space Discord
- Writer deploys built-in RAG tool: Writer has rolled out a built-in RAG tool enabling users to pass a graph ID for model access to the knowledge graph, demonstrated by Sam Julien. This feature supports auto-uploading scraped content into a Knowledge Graph and interactive post discussions.
- The tool enhances content management and interactive capabilities, allowing seamless integration of user-specific knowledge bases into the modeling process.
- ShellSage enhances AI productivity in terminals: The ShellSage project was introduced by R&D staff at AnswerDot AI, focusing on improving productivity through AI integration in terminal environments, as highlighted in this tweet.
- Designed as an AI terminal assistant, ShellSage leverages a hybrid human+AI approach to handle tasks more intelligently within shell interfaces.
- OpenAI launches new RL fine-tuning API: OpenAI announced a new Reinforcement Learning fine-tuning API that allows users to apply advanced training algorithms to their models, detailed in John Allard's post.
- This API empowers users to develop expert models across various domains, building on the advancements of previous o1 models.
- Google's Gemini Exp 1206 tops multiple AI benchmarks: Google’s Gemini exp 1206 has secured the top rankings across several tasks, including hard prompts and coding, as reported by Jeff Dean.
- The Gemini API is now available for use, marking a significant achievement for Google in the competitive AI landscape.
- AI Essays explore Service-as-Software and business strategies: Several essays discussed AI opportunities, including a $4.6 trillion market with the Service-as-Software framework, shared by Joanne Chen.
- Another essay proposed strategies for fundraising and consolidating service businesses using AI models, as outlined in this post.
Nous Research AI Discord
- Llama 3.3 Model Release Sparks Debate: Ahmad Al-Dahle announced Llama 3.3, a new 70B model offering performance comparable to a 405B model but with enhanced cost-efficiency.
- Community members questioned if Llama 3.3 represents a base model relying on Llama 3.1, and discussed whether it's a complex fine-tuning pipeline without new pretraining, highlighting trends in model releases.
- Decentralized Training with Nous Distro: Nous Distro was clarified as a decentralized training framework, generating excitement among members about its potential applications.
- The project received positive reactions, with members expressing enthusiasm for the advancements it brings to distributed AI training methodologies.
- Challenges in Fine-Tuning Mistral for Kidney Detection: A user highlighted difficulties in fine-tuning a Mistral model using a 25-column dataset for chronic kidney disease detection, citing a lack of suitable tutorials after three months of attempts.
- Community members recommended resources and strategies to overcome these challenges, emphasizing the need for better documentation and support for specialized model tuning.
- Leveraging LightGBM for Enhanced Tabular Data Performance: Members suggested using LightGBM for better handling of tabular data in machine learning tasks, noting its efficiency in ranking and classification.
- This recommendation serves as an alternative to LLMs for specific datasets, highlighting LightGBM's strengths in performance and scalability.
- Optimizing Data Formatting for Model Training: Discussions emphasized the necessity to convert numeric data into text format, as LLMs perform suboptimally with direct numerical tabular data.
- A member pointed to an example using Unsloth for classification with custom templates, underscoring the importance of generalized CSV data in training models.
GPU MODE Discord
- Popcorn Project Pops Up with NVIDIA H100 Benchmarks: The Popcorn Project is set to launch in January 2025, enabling job submissions for leaderboards across various kernels, and includes benchmarking capabilities on GPUs like the NVIDIA H100.
- This initiative aims to enhance the development experience, despite its non-traditional approach, by providing robust performance metrics.
- Triton's TMA Support Seeks Official Release Amid Broken Nightlies: Triton users are requesting an official release to support low-overhead TMA descriptors, as current nightly builds are reported to be broken.
- Concerns around nightly build stability highlight the community's dependency on reliable tooling for optimal GPU performance.
- LTX Video's CUDA Revamp Doubles GEMM Speed: A member reimplemented all layers in the LTX Video model using CUDA, achieving 8bit GEMM that's twice as fast as cuBLAS FP8 and incorporating FP8 Flash Attention 2, RMSNorm, RoPE Layer, and quantizers, without accuracy loss due to the Hadamard Transformation.
- Performance tests on the RTX 4090 demonstrated real-time generation with just 60 denoising steps, showcasing significant advancements in model speed and efficiency.
- TorchAO Quantization: New Methods and Best Practices Explored: A member delved into multiple quantization implementation methods within TorchAO, seeking guidance on best practices and identifying specific files as starting points.
- This exploration reflects the community's dedication to optimizing model performance through effective quantization techniques in AI engineering workflows.
- Llama 3.3 Unleashed: Llama 3.3 has been released, as announced in this tweet.
- The community has shown interest in the new Llama 3.3 release, discussing its potential enhancements.
Torchtune Discord
- Llama 3.3 Launch with Enhanced Specifications: The Llama 3.3 model has been released, boasting a performance of 405B parameters while maintaining a compact 70B size, which is expected to spark innovative applications.
- The community is eager to explore the capabilities of Llama 3.3's reduced size for diverse AI engineering projects.
- Torchtune Adds Comprehensive Finetuning for Llama 3.3: Torchtune has expanded its support to include full LoRA and QLoRA finetuning for the newly released Llama 3.3, enhancing customization options.
- Detailed configuration settings are available in the Torchtune GitHub repository.
- LoRA Training Adjustments Proposed: A proposed change to LoRA training now requires a separate weight merging step instead of automatic merging, as discussed in this GitHub issue.
- Members debated the potential impacts of this change on existing workflows, weighing the benefits of increased flexibility.
- Debate Over Alpaca Training Defaults: Concerns have been raised regarding the train_on_input default setting in the Alpaca training library, currently set to False, leading to questions about its alignment with common practices.
- Discussions referenced repositories like Hugging Face's trl and Stanford Alpaca to evaluate the appropriateness of the default configurations.
- Crypto Lottery Introduces LLM Agreement Challenges: A crypto lottery model was described where participants pay per LLM prompt with the chance to win all funds by convincing the LLM to agree to a payout.
- This unique incentive structure has sparked debates on the ethical implications and practicality of such mechanisms within the crypto ecosystem.
LlamaIndex Discord
- LlamaParse Enhances Document Parsing Efficiency: LlamaParse provides advanced document parsing capabilities, significantly reducing parsing time for complex documents.
- This improvement streamlines workflows by effectively handling intricate document structures.
- Hybrid Search Webinar with MongoDB Recorded: A recent webinar featuring MongoDB Atlas covered hybrid search strategies and metadata filtering techniques.
- Participants can revisit key topics such as the transition from sequential to DAG reasoning to optimize search performance.
- Enabling Multimodal Parsing in LlamaParse: LlamaParse now supports multimodal parsing with models like GPT-4 and Claude 3.5, as demonstrated in a video by @ravithejads.
- Users can enhance their parsing capabilities by converting screenshots of pages into structured data seamlessly.
- Resolving WorkflowTimeoutError by Adjusting Timeouts: Facing a WorkflowTimeoutError can be mitigated by increasing the timeout or setting it to None, using
w = MyWorkflow(timeout=None).- This approach helps prevent timing out issues during prolonged workflows, ensuring smoother execution.
- Configuring ReAct Agent in LlamaIndex: To switch to the ReAct agent, replace the standard agent configuration with
ReActAgent(...), as outlined in the workflow documentation.- This modification allows for a more adaptable setup, leveraging the flexibility of the ReAct framework.
OpenInterpreter Discord
- Preview 1.0 Pushes Performance: A member impressed with the streamlined and fast performance of 1.0 preview, highlighting the clean UI and well-segregated code. They are currently testing the interpreter tool with specific arguments but are unable to execute any code from the AI.
- Users are testing the interpreter tool with specific arguments but have reported being unable to execute any code generated by the AI.
- MacOS App Access Accelerated: Multiple users inquired about accessing the MacOS-only app. A team member confirmed they are approaching a public launch and are willing to add users to the next batch while also developing a cross-platform version.
- This initiative aims to broaden user accessibility and enhance platform compatibility.
- API Availability Approaches: A member raised concerns over the $200 monthly fee for API access, questioning its accessibility. Another member reassured the community that the API will be available to users soon.
- These discussions highlight the community's interest in API accessibility and pricing.
- Reinforcement Fine-Tuning Updates: OpenAI announced Day 2 focusing on Reinforcement Fine-Tuning, sharing insights through a post on X and more details on their official site.
- The community is actively engaged in optimizing model training methodologies, reflecting dedication to enhancing reinforcement learning techniques.
- Llama Launches 3.3: Meta announced the release of Llama 3.3, a new open-source model that excels in synthetic data generation and other text-based tasks, offering a significantly lower inference cost, as detailed in their post on X.
- This release underscores Meta's focus on improving model efficiency and expanding capabilities in text-based use cases.
LLM Agents (Berkeley MOOC) Discord
- Spring 2025 MOOC Greenlit: The Berkeley MOOC team has officially confirmed the sequel course for spring 2025. Participants are advised to stay updated for more details as they become available.
- Members expressed 'Woohoo!' about the upcoming offering, indicating high excitement within the community.
- Assignment Deadlines Loom: A participant emphasized the necessity to complete all assignments before their set deadlines. This highlights a growing sense of urgency among the learners.
- Participants are meticulously organizing their schedules to accommodate the upcoming assessments.
- Lambda Labs for Lab Grading: Inquiry was made regarding the possibility of using non-OpenAI models, such as Lambda Labs, for grading lab assignments.
- This suggests a community interest in exploring diverse grading solutions.
- Lecture Slides Stalled: Members reported that the lecture slides from the last session have not been updated on the course website due to unforeseen delays.
- One member noted the lecture included approximately 400 slides, indicating extensive content coverage.
- Captioning Causes Delay: Lecture recordings are pending professional captioning, which may result in further delays.
- Given the long duration of the lectures, the captioning process is expected to be time-consuming.
Axolotl AI Discord
- Llama 3.3 Release: Llama 3.3 has been released, featuring an instruction model only, generating excitement among members who are seeking more details on its capabilities.
- Members are enthusiastic about Llama 3.3, but some members want additional information to fully understand its features.
- Model Request Issues on llama.com: Members reported issues when requesting models on llama.com, with the process getting stuck after clicking 'Accept and continue'.
- This technical glitch is causing frustration as users look for solutions and alternatives.
- SFT vs RL Quality Bounds: Discussions highlighted that Supervised Fine-Tuning (SFT) limits model quality based on the dataset.
- Conversely, a Reinforcement Learning (RL) approach may allow models to surpass dataset limitations, especially with online RL.
DSPy Discord
- DSPy Optimization Optionality: A member in the #general channel inquired whether DSPy Modules require optimization for each use case, likening it to training ML models for enhanced prompting.
- Another member clarified that optimization is optional, necessary only for improving the performance of a fixed system.
- RAG System Context Conflict: A TypeError was reported in the RAG System, indicating that
RAG.forward()received an unexpected keyword argument 'context' while attempting to use DSPy.- It was noted that the RAG system requires the keyword argument 'context' to function correctly, and the user wasn’t providing it.
tinygrad (George Hotz) Discord
- tinygrad Stats Site Outage: The tinygrad stats site experienced an outage, raising concerns about its infrastructure.
- George Hotz inquired about needing cash to cover the VPS bill, hinting at possible financial issues.
- Expired SSL Certificate Brings tinygrad Down: An expired SSL certificate caused the tinygrad stats site to go down while hosted on Hetzner.
- After resolving the issue, the site is back up and operational.
LAION Discord
- Cellular Personification in Media: A discussion highlighted the personification of cells, marking a notable instance since Osmosis Jones and adding a humorous twist to cellular representation.
- This approach blends humor with scientific concepts, potentially making complex topics more engaging for the audience.
- Osmosis Jones Reference: The reference to Osmosis Jones underscores its influence on current efforts to personify cellular structures, emphasizing its role in shaping creative representations.
- Participants find parallels between the animated depiction in Osmosis Jones and recent attempts to make cellular biology more relatable through media.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Codeium / Windsurf ▷ #announcements (2 messages):
Cascade pricing changes, Dedicated ticketing system for support
- Cascade pricing overhaul boosts features: Due to high adoption rates, Cascade is introducing a new credit system: the Pro tier is now $15/month for 2000 steps, and a new Pro Ultimate tier at $60/month offers unlimited User Prompt credits.
- Additionally, users can purchase Flex credits with 300 credits for $10 on the Pro plan, aimed at maintaining sustainable access to premium models.
- New support system enhances user experience: Codeium is rolling out a dedicated ticketing system at codeium.com/support to improve response times and ticket tracking for support requests.
- Users are encouraged to explore the self-serve docs and submit feature requests via this link, as the existing forum channel will be phased out.
- Paid Plan and Credit Usage - Codeium Docs: no description found
- Tweet from Windsurf (@windsurf_ai): Some updates on pricing and tiers moving forward.https://codeium.com/pricing
- Support | Codeium · Makers of Windsurf and AI extensions: Need help? Contact our support team for personalized assistance.
Codeium / Windsurf ▷ #discussion (456 messages🔥🔥🔥):
Windsurf pricing changes, User frustrations with AI tools, Alternatives to Windsurf, Impact of server issues on user experience, Feedback on AI tool performance
- Windsurf's Sudden Price Increase: Users expressed frustration at Windurf's abrupt price hike to $60 per month without addressing existing bugs and errors, leading to dissatisfaction with the service.
- Many feel this pricing is unsustainable given the product's performance issues and are contemplating switching to alternatives like Cursor or Bolt AI.
- User Frustrations with AI Tools: A consensus emerged that several AI tools, including Windsurf, suffer from significant bugs, making effective coding challenging and prompting users to reconsider their subscriptions.
- Complaints reflected a shared sentiment that AI tools should have reliable performance and user-friendly features before raising prices.
- Alternatives to Windsurf: As users contemplate moving away from Windsurf, notable alternatives suggested include Cursor and Mistral, with claims that these services may provide more consistent performance.
- However, some users cautioned that Bolt AI faces similar issues as Windsurf, indicating that many AI offerings are struggling with reliability.
- Impact of Server Issues on User Experience: Several comments indicated that server outages have created significant disruption in using Windsurf, with error messages like 'resource_exhausted' frequently appearing.
- Users noted that such limitations exacerbate frustrations, especially when seeking to maintain productivity in their coding tasks.
- Feedback on AI Tool Performance: Users have conveyed disappointment regarding the performance of Claude in coding contexts, emphasizing issues with context retention and erroneous code alterations.
- The notion that these AI tools are not meeting users' needs presents a critical challenge, leading some to advocate for better oversight and improvement prioritization from developers.
- Rick Grimes GIF - Rick Grimes Twd - Discover & Share GIFs: Click to view the GIF
- Yungviral GIF - Yungviral - Discover & Share GIFs: Click to view the GIF
- o1 PRO Mode - ChatGPT Pro with Unlimited Compute (Announcement Breakdown): Join My Newsletter for Regular AI Updates 👇🏼https://forwardfuture.aiMy Links 🔗👉🏻 Subscribe: https://www.youtube.com/@matthew_berman👉🏻 Twitter: https:/...
Codeium / Windsurf ▷ #windsurf (751 messages🔥🔥🔥):
Windsurf Pricing Changes, User Reactions to New Limits, Comparison with Other AI Tools, Grandfathering for Existing Users, Performance of AI Models
- Windsurf Pricing Changes Create Confusion: The recent pricing update of Windsurf raised the monthly fee to $60 but imposed hard limits on user prompts and flow actions, frustrating many users who preferred the previous unlimited model.
- Users express concerns over the clarity of the new pricing structure and how it limits their usage compared to previous offerings.
- Community Outcry over Limited Usage: Many users are vocal about their dissatisfaction with the new limits, with discussions about how quickly credits will be depleted during typical usage.
- There is a general sentiment that the changes negatively impact the usability and attractiveness of Windsurf.
- Shift Back to Cursor and Other Tools: With the introduction of the new pricing model, many users are reconsidering their options and looking to shift back to Cursor or other AI tools like Copilot that offer better pricing structures.
- Some users feel that the new limitations could drive them back to using other tools which provide more value for their money.
- Concerns about the Grandfather Clause: Users are seeking clarification on whether they will remain grandfathered into the unlimited plan after transitioning to the new pricing model.
- Many feel misled about the promises made during previous subscription periods, expressing the desire for more transparency from the developers.
- Comparing Model Performance: Throughout the discussion, users compare the performance of Windsurf with alternatives, such as Claude API and Cursor.
- While some maintain that Windsurf still has better coding capabilities, others question its current value given the recent changes.
- And It'S Gone GIF - South Park Its Gone - Discover & Share GIFs: Click to view the GIF
- lmstudio-community/Llama-3.3-70B-Instruct-GGUF · Hugging Face: no description found
- Michael Jackson Comendo Picoca GIF - Michael Jackson comendo picoca - Discover & Share GIFs: Click to view the GIF
- You're all wrong, $2000 ChatGPT Max is coming: And you will like it
- Works On My Machine Ryan Gosling GIF - Works On My Machine Ryan Gosling Works - Discover & Share GIFs: Click to view the GIF
- Tweet from Windsurf (@windsurf_ai): Some updates on pricing and tiers moving forward.https://codeium.com/pricing
- Pricing | Codeium · Makers of Windsurf and AI extensions: Codeium is free forever for individuals. Teams can level up with our enterprise offering for enhanced personalization and flexible deployments.
- Oliver Twist 1948 GIF - Oliver Twist 1948 Please sir I want some more - Discover & Share GIFs: Click to view the GIF
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Plan Settings: Tomorrow's editor, today. Windsurf Editor is the first AI agent-powered IDE that keeps developers in the flow. Available today on Mac, Windows, and Linux.
- LiveBench: no description found
- Rug Pull GIF - Rug Pull - Discover & Share GIFs: Click to view the GIF
- Plans and Pricing Updates: Some changes to our pricing model for Cascade.
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- GitHub - dylanturn/clearsight: Contribute to dylanturn/clearsight development by creating an account on GitHub.
Notebook LM Discord ▷ #use-cases (212 messages🔥🔥):
Audio Generation, NotebookLM Use Cases, Language Support, Game Development, Text-to-Speech Technology
- Audio Creation and Language Challenges: Members discussed their experiences using NotebookLM for audio generation, with some successfully creating podcasts from documents, while others faced issues with coherence and focus in output.
- One user reported a 64-minute podcast generated from a multilingual document, indicating varied outcomes based on input type.
- Using Google Docs for Game Development: Users shared strategies for utilizing Google Docs for organizing game rules and narratives, sometimes generating podcasts from these sources.
- One member noted successes with AI-generated scenarios and world-building, reflecting a mix of serious and humorous content in their RPG games.
- Exploring Language and Voice Support: Conversations included questions about NotebookLM's support for languages other than English, with some users recalling it might be limited to English only.
- There were mentions of impressive voice quality in generated audio, prompting discussions on potential as a stand-alone text-to-speech solution.
- User Experiences with Prompting and Content Generation: Members discussed how to effectively prompt NotebookLM for longer podcast outputs, sharing mixed results and personal techniques for better engagement.
- One user expressed frustration when attempts to steer the AI's focus resulted in unexpected tangents, demonstrating the challenge of controlling AI-generated content.
- Workarounds for Integrating Spreadsheets: Users identified limitations with direct spreadsheet uploads into NotebookLM, suggesting alternatives like converting data into Google Docs for improved compatibility.
- One user mentioned successfully reducing spreadsheet complexity by hiding unnecessary columns, exploring creative methods to incorporate essential data.
- Doki Doki Dating Club: DOKI DOKI DATING CLUB The Year is 3012, and you’ve been accepted into Doki Doki High School for Promising Spouses! This high School is a Prestigious Hall for aspiring Husbands and Wives to master the...
- Abandon: ABANDON Abandon is a 2D Tabletop RPG that takes place from a side-perspective. This RPG with a twist changes the way that you play traditional tabletops dramatically. The World of Abandon is one o...
- AI discusses document that just says “Poopoo Peepee”: Document:Poopoo Peepee Poopoo Peepee Poopoo Peepee Poopoo Peepee Poopoo Peepee Poopoo Peepee Poopoo Peepee Poopoo Peepee Poopoo Peepee Poopoo Peepee Poopoo P...
- AI Panel , Topic politics, Full Episode: Get ready for a mind-blowing journey through the fascinating world of politics! 🤯Join us for an electrifying AI generated panel discussion featuring an extr...
Notebook LM Discord ▷ #general (94 messages🔥🔥):
NotebookLM PDF handling, Podcast generation limits, Language setting issues, Notebook creation button, General performance and usability feedback
- NotebookLM struggles with PDF equations: Members discussed the limitations of NotebookLM in handling equations in PDF sources, noting no equation recognition and a lack of page tracking.
- Suggested workarounds include using text-based formats for equations and external OCR tools to improve functionality.
- Audio podcast generation and limits: Users shared frustrations with the audio generation feature, noting a limit of 20 audio creations per day and variability in length.
- Regenerating podcasts was recommended as users faced frustrating delays, with some experiencing podcasts taking up to an hour to generate.
- Language setting difficulties: A member highlighted issues with NotebookLM defaulting to Portuguese despite efforts to use only English.
- Another user advised logging out and selecting the language upon login, though usability concerns were raised about a lack of simpler options within the platform.
- Missing notebook and limitations: Concerns were raised about the disappearance of the new notebook button, leading to questions about whether a notebook limit exists.
- Discussion participants speculated about possible limits impacting the creation of notebooks and the general usability of NotebookLM.
- Feedback on general performance: Users expressed mixed experiences with NotebookLM's performance, particularly regarding the accuracy and depth of generated content.
- Feedback included the need for more transparency about potential paywalls and performance consistency.
- Well Yes But Actually No Meme GIF - Well Yes But Actually No Meme Aardman - Discover & Share GIFs: Click to view the GIF
- Zork, Evolved (All Chapters): Notebook LM AI AO Works it's way through the great digital underground. Beating the game is freedom - Beating the game results in deactivation. There's a tiny bit of music at the end of each c...
- ANOTHER Laser Engraver! ...oh, and this thing called Bitcoin?!?: ***DISCLAIMER***This is NOT financial advice and I am NOT a financial advisor. Some of these geek projects are expensive and can be risky. Crypto Currency is...
- Zork, Evolving - All Chapters - Tears in Rain Bedtime Story: Notebook LM AI AO Works it's way through the great digital underground. Beating the game is freedom - Beating the game results in deactivation. There's a tin...
Unsloth AI (Daniel Han) ▷ #general (217 messages🔥🔥):
PaliGemma 2 Release, Qwen Model Fine-Tuning Issues, Unsloth Pro Updates, Llama 3.3 Release, Memory Issues with QLORA
- PaliGemma 2 offers new model sizes: Google's new vision language model, PaliGemma 2, features pre-trained models in sizes of 3B, 10B, and 28B parameters, enhancing flexibility for practitioners.
- It utilizes the powerful SigLIP for vision while upgrading to the latest Gemma 2 for the text decoder part, potentially impacting previous PaliGemma performance.
- Fine-tuning Qwen models faces VRAM constraints: Users reported problems fine-tuning the Qwen32B model on an 80GB GPU, requiring 96GB on an H100 NVL for better handling due to OOM errors.
- Discussions revealed that QLORA may sometimes consume more memory than LORA, with users investigating conflicting VRAM consumption patterns.
- Unsloth Pro is upcoming: There is an indication that Unsloth Pro has not yet launched but will be available soon, sparking interest among users.
- Community members expressed eagerness to utilize new models and await functionalities in Unsloth Pro to enhance their workflows.
- Llama 3.3 released with new features: The release of Llama 3.3 includes a 70B model that is designed to deliver high performance while being easier and more cost-efficient to operate.
- Unsloth has already provided 4-bit quantized models for Llama 3.3, enhancing loading speed and reducing memory requirements.
- Memory management insights using QLORA: Users exchanging insights observed that QLORA may lead to higher VRAM usage during training compared to LORA, prompting investigations into its memory efficiency.
- In-depth discussions on parameter adjustments and model loading configurations led to concerns about the actual benefits of QLORA in terms of memory savings.
- How does ChatGPT’s memory feature work?: Explanation of my favorite feature on ChatGPT
- Welcome PaliGemma 2 – New vision language models by Google: no description found
- Tweet from Ahmad Al-Dahle (@Ahmad_Al_Dahle): Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest advancements in post-training techniques in...
- Finetune Llama 3 with Unsloth: Fine-tune Meta's new model Llama 3 easily with 6x longer context lengths via Unsloth!
- Qwen2VL 2B & 7B OOM · Issue #1390 · unslothai/unsloth: When fine-tuning a Qwen2 model on an A100 (80GB), I get OOMs. This is surprising given batch size of 1, small images (256 x 256), and 4-bit training. With the same data, it's possible to train LLA...
- unsloth/Llama-3.3-70B-Instruct-bnb-4bit · Hugging Face: no description found
- QLORA using more memory than LORA · Issue #4772 · hiyouga/LLaMA-Factory: Reminder I have read the README and searched the existing issues. System Info I am running on runpod A100 GPU with template torch=2.2.0 Reproduction ### model model_name_or_path: THUDM/glm-4-9b-cha...
- JustPaste.it - Share Text & Images the Easy Way: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (4 messages):
Google Summer of Code 2025, Editing messages in Discord, Latex formatting
- Interest in Google Summer of Code 2025: A member inquired if others are planning to apply for Google Summer of Code 2025.
- This prompted curiosity about the initiative's purpose, with one member questioning if it was primarily for gaining visibility.
- Editing messages reveals URL issues: A member noted a strange behavior in message editing, observing that the URL did not retain the
...%7Dending in Discord.- This raised concerns about how links are parsed and displayed after editing.
- Latex formatting tips shared: A member provided a tip regarding Latex formatting, stating that a backslash
\is necessary before a percentage sign.- They emphasized using
....with 80\% less...to ensure correct interpretation in Latex.
- They emphasized using
Unsloth AI (Daniel Han) ▷ #help (42 messages🔥):
Fine-tuning vs RAG, Conversational AI Design, Training Time Estimates, LoRA Fine-Tuning for Models, Multi-GPU Training Support
- Fine-tuning vs RAG Comparison: A member discussed that fine-tuning can achieve everything RAG can, but not vice versa, recommending starting with RAG due to ease of use.
- This suggests a practical approach for beginners to understand model capabilities without diving too deep into complexities.
- Building Conversational Scripts for AI: A beginner in AI inquired if a chatbot could follow a structured conversation script like an Enrollment Bot.
- Others suggested exploring various chatbot creation platforms that offer specific workflows for managing conversations effectively.
- Training Time Evaluation with Unsloth: Members debated the time taken for training runs with Unsloth and discussed how RTX 6000 Ada may improve speed significantly for model training.
- The conversation highlighted that 6 hours for 28 steps was considered fast by some, yet there were concerns about the adequacy of 40k examples for fine-tuning.
- LoRA Fine-Tuning Best Practices: 'Silk.ai' sought clarification on whether the use_cache setting in LoRA fine-tuning code was necessary, sparking discussions on optimal configurations.
- Another member shared that they found training with LoRA dropout enabled essential to achieve expected model performance.
- Multi-GPU Training for Unsloth: A member checked if Unsloth supports multi-GPU training via DDP for their visual instruction tuning of Llama3.2-11B-Vision.
- The inquiry reflects a common concern for resource optimization while training large models effectively.
Cursor IDE ▷ #general (250 messages🔥🔥):
Cursor performance issues, Comparison with Windsurf, Updates in Cursor 0.43.6, User experiences with Composer, Unit testing with Cursor
- Cursor struggles with performance lately: Users reported that Cursor has been experiencing connection failures and slow response times when using the Composer, often requiring new sessions for proper functionality.
- Many expressed frustration with the persistent issues, comparing its performance unfavorably to alternatives like Windsurf.
- WindSurf shows better results: Several users mentioned that Windsurf performed better in handling tasks without issues, even under heavy code generation demands.
- People reported that while Cursor struggles to apply changes, Windsurf executed similar tasks smoothly, highlighting a shift in preferences.
- Discussion on Cursor 0.43.6 updates: With the latest updates to Cursor, users noted that the Composer UI has been integrated into the sidebar, but some functions like long context chat have been removed.
- There were also mentions of new features such as inline diffs, git commit message generation, and early versions of an agent.
- User experiences with Composer and Chat: Users shared mixed experiences regarding Cursor's Composer feature, with some noting that it sometimes fails to respond to queries.
- There were reports of Composer not generating the expected code or missing out on updates, particularly after the recent updates.
- Techniques for unit testing with Cursor: A user inquired about effective methods for writing unit tests using Cursor, expressing interest in shared techniques.
- Thus far, there hasn't been a definitive response, but users encouraged sharing experiences and methods for testing.
- Tweet from Rammy (@rammydev): I asked ChatGPT o1 Pro Mode to create an SVG of a unicorn.(This is the model you get access to for $200 monthly)
- Tweet from TestingCatalog News 🗞 (@testingcatalog): Anthropic is preparing something special for Claude mobile apps: “mobile_model_capabilities” 👀Vision mode, you?
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- Tweet from Mckay Wrigley (@mckaywrigley): OpenAI o1 pro is *significantly* better than I anticipated.This is the 1st time a model’s come out and been so good that it kind of shocked me.I screenshotted Coinbase and had 4 popular models write c...
- Cursor - The IDE designed to pair-program with AI.: no description found
- GitHub - udecode/dotai: Contribute to udecode/dotai development by creating an account on GitHub.
- Cursor - The IDE designed to pair-program with AI.: no description found
- o1 PRO MODE Live Testing: Join My Newsletter for Regular AI Updates 👇🏼https://www.matthewberman.comMy Links 🔗👉🏻 Main Channel: https://www.youtube.com/@matthew_berman👉🏻 Clips Ch...
- Thegalaxys - Overview: Thegalaxys has 7 repositories available. Follow their code on GitHub.
- Reddit - Dive into anything: no description found
- Cursor Composer Agent in 20 Minutes: Learn The Fundamentals Of Becoming An AI Engineer On Scrimba;https://v2.scrimba.com/the-ai-engineer-path-c02v?via=developersdigestExploring Cursor's New Agen...
- GitHub - TheGalaxyStars/KEPLER-COMMUNITY: Explore freely, leave no trace.: Explore freely, leave no trace. Contribute to TheGalaxyStars/KEPLER-COMMUNITY development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
Author Pages feature, New Amazon Nova models, DeepInfra price drops, Launch of Llama 3.3, Text-based use cases
- Explore Models with New Author Pages: OpenRouter launched a new feature allowing users to explore models by creators at
openrouter.ai/, showcasing detailed stats and related models via a carousel.- This update aims to enhance user experience in discovering and analyzing different authors' collections.
- Amazon's Nova Models Hit the Scene: Amazon unveiled the Nova family of models, including Nova Pro 1.0, Nova Micro 1.0, and Nova Lite 1.0, available for exploration on OpenRouter.
- These models can be accessed using the respective links on the OpenRouter site.
- DeepInfra Slashes Prices on Multiple Models: DeepInfra announced significant price reductions, including Llama 3.2 3B Instruct down to $0.018 and Mistral Nemo slashed to $0.04.
- This move gives users a chance to access high-quality models at lower costs, catering to budget-conscious developers.
- Llama 3.3 Model Goes Live!: The highly anticipated Llama 3.3 model launched, with two providers already offering it shortly after its release, marking a significant update for text-based applications.
- As noted by AI at Meta, this model promises leading performance in generating synthetic data at reduced inference costs.
- Tweet from OpenRouter (@OpenRouterAI): Only took 40 minutesLlama 3.3 is live! 🦙🦙🦙Quoting AI at Meta (@AIatMeta) As we continue to explore new post-training techniques, today we're releasing Llama 3.3 — a new open source model that d...
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Nova Pro 1.0 - API, Providers, Stats: Amazon Nova Pro 1.0 is a capable multimodal model from Amazon focused on providing a combination of accuracy, speed, and cost for a wide range of tasks. Run Nova Pro 1.0 with API
- Nova Micro 1.0 - API, Providers, Stats: Amazon Nova Micro 1.0 is a text-only model that delivers the lowest latency responses in the Amazon Nova family of models at a very low cost. Run Nova Micro 1.0 with API
- Nova Lite 1.0 - API, Providers, Stats: Amazon Nova Lite 1.0 is a very low-cost multimodal model from Amazon that focused on fast processing of image, video, and text inputs to generate text output. Run Nova Lite 1.0 with API
OpenRouter (Alex Atallah) ▷ #general (235 messages🔥🔥):
Amazon Nova Models, OpenAI Updates, Llama 3.3 Launch, Anthropic Model Expectations, InternVL Models
- Amazon Nova Models Generate Mixed Reviews: Several users reported issues with Amazon Nova, describing the model as subpar compared to others, with one commenting it’s ‘not very good’.
- Despite the criticism, some noted the potential for speed and cost-effectiveness, showing a divide in user experiences.
- OpenAI Day 2 Features Minimal Excitement: On the second day of the OpenAI presentation, the announcement focused on the upcoming reinforcement learning finetuning for o1, generating minimal excitement among users.
- Participants expressed skepticism about the value of these updates, suggesting they expected more substantive advancements.
- Llama 3.3 Launch Sparks Interest: The release of Llama 3.3 brought enthusiasm, with users eager to explore its capabilities, despite differing opinions on its overall value compared to other models.
- One user highlighted the speed of OpenRouter in making the model available, signifying good community response.
- Anthropic Model Speculations Run Wild: Discussion around Anthropic's next moves included expectations for a potential release of Opus 3.5, linking it to responses to competing models like GPT-4.5.
- Participants speculated about whether any upcoming models would genuinely enhance capabilities or mirror previous releases.
- InternVL Models Overlooked Amid New Releases: Interest in new models like Llama 3.3 overshadowed the mention of InternVL 2.5, with some questioning why certain good models are ignored.
- Opinions varied on the Intern models, reflecting a complex landscape of user preferences toward newer AI offerings.
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Tweet from Ahmet ☕ (@ahmetdedeler101): Back in 2015, Elon Musk and Sam Altman shared their thoughts on Trump, AI, and the government. this was just 3 months after they decided to start OpenAI—when it was still a secret. Seeing how they w...
- Tweet from DeepInfra (@DeepInfra): 🚨 Big news! @DeepInfra supports Llama 3.3 70B on day 0 at the lowest prices:Llama 3.3 70B (bf16): $0.23/$0.40Llama 3.3 70B Turbo (fp8): $0.13/$0.40 in/out per 1MExperience cutting-edge AI with seamle...
- Tweet from Ahmad Al-Dahle (@Ahmad_Al_Dahle): Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest advancements in post-training techniques in...
- Tweet from OpenAI (@OpenAI): OpenAI o1 is now out of preview in ChatGPT.What’s changed since the preview? A faster, more powerful reasoning model that’s better at coding, math & writing.o1 now also supports image uploads, allowin...
- 12 Days of OpenAI: Day 2: Begins at 10am PTJoin Mark Chen, SVP of OpenAI Research, Justin Reese, Computational Researcher in Environmental Genomics and Systems Biology, Berkeley Lab, ...
- Llama 3.3 70B Instruct - API, Providers, Stats: The Meta Llama 3.3 multilingual large language model (LLM) is a pretrained and instruction tuned generative model in 70B (text in/text out). Run Llama 3.3 70B Instruct with API
- Nathan Sarrazin (@nsarrazin.com): New Llama model just dropped! Evals are looking quite impressive but we'll see how good it is in practice. We're hosting it for free on HuggingChat, feel free to come try it out: https://hf.co...
- Magnum v4 72B - API, Providers, Stats: This is a series of models designed to replicate the prose quality of the Claude 3 models, specifically Sonnet(https://openrouter.ai/anthropic/claude-3. Run Magnum v4 72B with API
- OpenGVLab/InternVL2_5-78B · Hugging Face: no description found
OpenRouter (Alex Atallah) ▷ #beta-feedback (5 messages):
Custom Beta Keys, Integration Beta Feature
- Repeated Requests for Custom Beta Keys: Several members including vini_43121 and spunkrock. have requested access to custom provider keys multiple times.
- Despite repeated inquiries, there has been no response confirming access or clarifying the process.
- Interest in Integration Beta Feature: alehendrix expressed a desire to access the integration Beta Feature, seeking further clarification on availability.
- baten84 also inquired directly on how to gain access to the same feature, indicating a growing interest among members.
Eleuther ▷ #general (26 messages🔥):
Meetup in San Francisco, OpenAI API terminology, Introduction of new members, Collaboration on solving literary puzzles, Discussion on model performance
- Casual meetup proposed in SF: A member proposed a local meetup in San Francisco, indicating their presence in the area and encouraging others to join.
- Another member confirmed they might visit in a few weeks, expressing potential interest in the meetup.
- Clarification on 'leaked' model terminology: A member discussed the misleading marketing around the term 'leaked', clarifying that many cases involve just API access rather than full model weights.
- Another member humorously noted that such claims are common, suggesting a need for better communication in the community.
- New members introduce themselves: Chandu Venigalla, a new member, expressed excitement about contributing to Eleuther AI’s mission of open research in NLP.
- Another member, Vishal, introduced himself as a Masters student at UIUC, showing enthusiasm for exploring the group's discussions.
- Interest in solving 'Cain's Jawbone' puzzle: A member inquired about experiences using O1 to solve Cain's Jawbone, a 21k-token novel, sharing a GitHub link for context.
- Another member provided a link to a checker tool for validating solutions, enhancing the discussion on puzzle-solving methods.
- Discussion on model performance comparisons: A member stated that their experiments with certain models surpassed Adam/AdamW on various problems, highlighting improved performance.
- The conversation also touched on members’ experiences with different models, indicating an active engagement with model evaluation.
- Jenn Wortman Vaughan (@jennwv.bsky.social): The FATE group at @msftresearch.bsky.social NYC is accepting applications for 2025 interns. 🥳🎉For full consideration, apply by 12/18.https://jobs.careers.microsoft.com/global/en/job/1786105/Research...
- Terence Tao (@teorth.bsky.social): Renaissance Philanthropy and XTX Markets have launched a $9.2 million "AI for Math fund" to support the development of new AI tools as long-term building blocks to advance mathematics. (I h...
- cains-jawbone/Cain's Jawbone Unformatted.txt at main · tn3rt/cains-jawbone: Reddit community versions of Cain's Jawbone. Contribute to tn3rt/cains-jawbone development by creating an account on GitHub.
- GitHub · Build and ship software on a single, collaborative platform: Join the world's most widely adopted, AI-powered developer platform where millions of developers, businesses, and the largest open source community build software that advances humanity.
Eleuther ▷ #research (183 messages🔥🔥):
MoE-lite motif, Goldfinch architecture, Layerwise token value embeddings, KV cache optimization, Dynamic weight adjustments
- Exploration of MoE-lite motifs: A member discussed an MoE-lite motif that uses a custom bias-per-block-per-token, which affects the residual stream nonlinearly, implying faster computations despite increased parameter expense.
- There was further deliberation on its implications and efficiency compared to traditional Mixture of Experts (MoE) architectures.
- Improvements from the Goldfinch architecture: A member shared insights from the Goldfinch model, which successfully eliminated the V matrix by deriving it from a mutated version of the layer 0 embedding, enhancing parameter efficiency.
- The conversation highlighted how both the K and V parameters could potentially be replaced or compressed to improve transformer efficiency.
- Insights into layerwise token value embeddings: Members discussed the possibility of using layerwise token value embeddings to replace traditional value matrices, promoting significant parameter savings in transformers without sacrificing performance.
- The idea revolves around leveraging initial embeddings to calculate V values dynamically, reducing the need for extensive value projections.
- Caching strategies for transformer optimization: There were discussions on the effectiveness of caching parts of the first transformer layer that depend solely on single token identities, with emphasis on retaining efficiency.
- However, suggestions clarified that the Goldfinch method does not utilize this approach while still emphasizing the need for further research into caching mechanisms.
- Dynamic weight adjustments and regularization: Members suggested that using dynamic weight adjustments could lead to improved parameter allocation and efficiency in transformers, akin to regularization techniques like momentum.
- The implications of eliminating or adjusting V parameters were discussed, emphasizing potential performance boosts and streamlined computations.
- GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression: We introduce GoldFinch, a hybrid Linear Attention/Transformer sequence model that uses a new technique to efficiently generate a highly compressed and reusable KV-Cache in linear time and space with r...
- Chain of Thought Empowers Transformers to Solve Inherently Serial Problems: Instructing the model to generate a sequence of intermediate steps, a.k.a., a chain of thought (CoT), is a highly effective method to improve the accuracy of large language models (LLMs) on arithmetic...
- ContentVec: An Improved Self-Supervised Speech Representation by Disentangling Speakers: Self-supervised learning in speech involves training a speech representation network on a large-scale unannotated speech corpus, and then applying the learned representations to downstream tasks. Sinc...
Eleuther ▷ #interpretability-general (8 messages🔥):
Updated Mechanistic Interpretability Resources, Community Feedback on Neuronpedia and SAELens, Neel's Annotated Paper List, Outdated Mechanistic Interpretation Materials
- Resource List for Mechanistic Interpretability: A member shared a Google Sheets link that details significant papers in mechanistic interpretability, categorized by themes and topics.
- This resource is designed for those interested in exploring foundational works, with notes added for easier navigation through the material.
- Neel Updates Reading List: Neel announced an updated reading list for mechanistic interpretability papers on LessWrong, sharing key takeaways and highlights for new researchers.
- This serves as a navigational tool for newcomers feeling intimidated by the growing body of literature, indicating several papers to engage with deeply.
- Request for Community Feedback on Research Tools: The creators of Neuronpedia and SAELens are seeking community input via a 10-minute survey to improve their tools and services in the mechanistic interpretability space.
- They emphasized the importance of user feedback, especially from frequent users, to ensure that the ongoing research needs are being met.
- Discussion on Outdated Interpretability Papers: Concerns were raised about older mechanistic interpretability papers potentially being less useful as the field evolves rapidly.
- One member clarified that while these papers are old, they are not entirely without value, suggesting that continuous updates are necessary.
- Jenn Wortman Vaughan (@jennwv.bsky.social): The FATE group at @msftresearch.bsky.social NYC is accepting applications for 2025 interns. 🥳🎉For full consideration, apply by 12/18.https://jobs.careers.microsoft.com/global/en/job/1786105/Research...
- papers: no description found
- An Extremely Opinionated Annotated List of My Favourite Mechanistic Interpretability Papers v2 — LessWrong: This post represents my personal hot takes, not the opinions of my team or employer. This is a massively updated version of a similar list I made two…
Eleuther ▷ #gpt-neox-dev (1 messages):
karatsubabutslower: CC <@367104793292046338> Any hints for this?
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.67.0, Amazon Bedrock Nova models, Command enhancements, Process suspension support, Exception capture analytics
- Aider v0.67.0 Released With New Features: The latest version of Aider introduces several enhancements including support for Amazon Bedrock Nova models and improved command functionalities.
- Notably, Aider wrote 61% of the code for this release, showcasing its capabilities.
- Enhanced Command Functionality: New command operations allow Aider to pre-fill prompts with 'Fix that' when
/runor/testhave non-zero exit codes.- Additionally,
/diffnow utilizesgit diff, enabling users to leverage their preferred diff tool.
- Additionally,
- Added Support for Process Suspension: The release includes Ctrl-Z support for suspending processes, improving workflow management.
- Users can also expect ASCII art fallback for spinner symbols if unicode errors occur.
- Home Directory Expansion Feature:
--readnow expands ~ home directories, simplifying file path management for users.- This small yet significant enhancement streamlines the command interface for Aider.
aider (Paul Gauthier) ▷ #general (148 messages🔥🔥):
Aider Pro Features, New AI Models Benchmarking, Gemini 1206 Release, DeepSeek Performance, User Expectations for APIs
- Aider Pro Features Gain Attention: Users expressed excitement about the unlimited advanced voice mode and the new 128k context for O1 for Pro users, highlighting its value for pasting extensive documents and code.
- Aider's new
--copy-pastecapability was also mentioned, which allows integration between Aider and web chat interfaces.
- Aider's new
- New AI Models Benchmarking Discussions: Llama 3.3 scored 59% on the Aider code editing benchmark, showcasing compatibility with Aider's diff editing format, while the performance of various models was discussed.
- The community is eager to see benchmarking results for the new Gemini model, but current quotas are deemed too low for effective testing.
- Gemini 1206 Model Release Sparks Interest: The Gemini-exp-1206 model by Google DeepMind was released, claiming to outperform previous models, igniting discussions about its potential use with Aider.
- Users expressed anticipation for results comparing Gemini to Claude and awaited benchmarks from Paul Gauthier.
- DeepSeek's Performance in Aider: DeepSeek and alternative models like Qwen 2.5 and Haiku were discussed as viable, cheaper options for Aider users, with DeepSeek being noted for its lower cost and good performance.
- There is speculation regarding the potential for fine-tuning community versions to improve DeepSeek’s scores in Aider’s benchmarks.
- User Expectations for API Access: Concerns were raised about the waiting time for API access for new models, with the Gemini model still lacking API integration for wider testing.
- Users expressed skepticism about corporate announcements and highlighted frustration over the limitations of current models' access and affordability.
- Copy/paste to web chat: Aider works with LLM web chat UIs
- Tweet from Jeff Dean (@🏡) (@JeffDean): Today’s the one year anniversary of our first Gemini model releases! And it’s never looked better.Check out our newest release, Gemini-exp-1206, in Google AI Studio and the Gemini API!https://aistudi...
- Prototyping with AI models - GitHub Docs: no description found
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Nova Pro 1.0 - API, Providers, Stats: Amazon Nova Pro 1.0 is a capable multimodal model from Amazon focused on providing a combination of accuracy, speed, and cost for a wide range of tasks. Run Nova Pro 1.0 with API
- Options reference: Details about all of aider’s settings.
- OpenAI GPT-4o · Models · GitHub Marketplace · GitHub: Create AI-powered applications with OpenAI GPT-4o
- Murdered Insurance CEO Had Deployed an AI to Automatically Deny Benefits for Sick People: Just over a year before United Healthcare CEO Brian Thompson was murdered in cold blood in Midtown Manhattan, a lawsuit filed against his firm revealed just how draconian its claims-denying had become...
- aider/aider/prompts.py at 117b7afd8168807dc49cf5c831ff87299471528a · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (46 messages🔥):
Feeding Documentation to Aider, Setting Up API Key for Gemini, Using GCP VertexAI, Aider Caching Issues, Aider Test Command Bug
- Explore Feeding Whole Sites to Aider: A user inquired about tools for feeding a whole site in Markdown to Aider rather than just a single page, to which another user suggested scraping the site and feeding relevant documentation into Aider.
- They emphasized the importance of only using relevant documents during this process.
- API Key Setup for Gemini: A beginner struggled with setting up their API key for Gemini in the
.envfile, successfully getting it to work from the command line but failing when loaded through Aider.- The issue was resolved upon clarification that it should use
AIDER_MODELinstead ofGEMINI_MODEL.
- The issue was resolved upon clarification that it should use
- GCP VertexAI Preference: A user explained using GCP VertexAI to access models and suggested the use of claude or gpt4o, finding guideline files helpful to improve coding standards.
- They provided an example of their configuration file, demonstrating the integration of various standards.
- Aider Caching Experience with OpenRouter: A user noted that the latest version of Aider no longer reported cache hit statistics when using Claude 3.5 Sonnet through OpenRouter, which used to work previously.
- The response indicated that this may be related to a lack of sufficient data sent to enable caching, especially following a recent update.
- Bug in Aider Test Command: A user reported that running
aider --testdid not trigger attempts to fix failed tests as expected, and others confirmed similar experiences.- It was later clarified that the test command should make attempts to fix failures, but currently only does so a limited number of times.
Interconnects (Nathan Lambert) ▷ #events (5 messages):
Networking opportunities for Engineers, Interconnects merchandise
- Engineers unite for networking: Members expressed interest in connecting with others and networking, with one declaring that engineers are crucial and not lowly.
- Another member shared their eagerness to meet people as well, highlighting a welcoming atmosphere.
- Rare interconnects merch on the way: One member announced they are bringing stickers to the gathering, referring to them as the rare interconnects merch.
- This sparked excitement among the members looking forward to the event.
Interconnects (Nathan Lambert) ▷ #news (144 messages🔥🔥):
Gemini-exp-1206, Llama 3.3, Qwen2-VL-72B, Reinforcement Fine-Tuning, AI2 All Hands
- Gemini-exp-1206 outperforms rivals: The new Gemini-exp-1206 model has achieved first place overall and is tied with O1 on coding benchmarks, showcasing remarkable improvements over previous versions.
- OpenAI's demo revealed that fine-tuned O1-mini can outperform full O1 based on medical data, further highlighting Gemini's strong performance.
- Llama 3.3 enhancements: Improvements in Llama 3.3 are attributed to new alignment processes and advancements in online reinforcement learning techniques.
- This model delivers performance comparable to the 405B model but is designed for cost-effective inference on standard developer workstations.
- Launch of Qwen2-VL-72B: The Qwen2-VL-72B model has been released as part of Alibaba Cloud's new series, featuring state-of-the-art capabilities in visual understanding.
- This model can handle video understanding and operates across various devices, aiming to improve multimodal task performance.
- Reinforcement Fine-Tuning discussions: The importance of fine-tuning using Reinforcement Learning (RL) was highlighted, with specific focus on its application in creating models that outperform existing counterparts.
- Notable mentions include the use of pre-defined graders for model training and recent discussions about the direction of RL training methodologies.
- Upcoming slow period for AI work: Members expressed excitement about the upcoming holidays, indicating a potential slowdown in AI-related work and developments during this period.
- There are expectations for continued consistent output, with plans to ultimately produce more public content after the holidays.
- Tweet from Ahmad Al-Dahle (@Ahmad_Al_Dahle): Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest advancements in post-training techniques in...
- Tweet from Jeff Dean (@🏡) (@JeffDean): Today’s the one year anniversary of our first Gemini model releases! And it’s never looked better.Check out our newest release, Gemini-exp-1206, in Google AI Studio and the Gemini API!https://aistudi...
- Tweet from Paul Calcraft (@paul_cal): Beating o1 w fine-tuned o1-mini via reinforcement fine-tuning! Upload examples (1), choose grading criteria, click go. See progress over passes (2), compare results against other models like o1 full (...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Big news on Chatbot Arena 🔥The new @GoogleDeepMind model gemini-exp-1206 is crushing it, and the race is heating up. Google is back in the #1 spot 🏆overall and tied with O1 for the top coding model!...
- Tweet from Xeophon (@TheXeophon): Quoting Ahmad Al-Dahle (@Ahmad_Al_Dahle) Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest ad...
- Tweet from Tibor Blaho (@btibor91): "12 Days of OpenAI: Day 2" topic is "Reinforcement Fine-Tuning"https://x.com/WolfyBlair/status/1865082997860634792Quoting 🍓 (@WolfyBlair) @btibor91 Join Mark Chen, SVP of OpenAI Resea...
- Tweet from AI at Meta (@AIatMeta): Improvements in Llama 3.3 were driven by a new alignment process and progress in online RL techniques. This model delivers similar performance to Llama 3.1 405B with cost effective inference that’s fe...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Gemini-Exp-1206 tops all the leaderboards, with substantial improvements in coding and hard prompts. Try it at http://lmarena.ai !
- Qwen/Qwen2-VL-72B · Hugging Face: no description found
- Tweet from Junyang Lin (@JustinLin610): 😓 I almost forgot we released something tonight... Yes, just the base models for Qwen2-VL lah. Not a big deal actually.🔗 Links are below:https://huggingface.co/Qwen/Qwen2-VL-2Bhttps://huggingface.co...
- Tweet from rohan anil (@_arohan_): A bitter sweet moment for me, Gemini is doing really well, and teams are doing great. I had a great close to 12 years at G that one could call me OG. For example, for every search query, I noticed thi...
- Tweet from Philipp Schmid (@_philschmid): In case @AIatMeta llama 3.3 is not exciting enough. @Alibaba_Qwen dropped Qwen2 72B VL https://huggingface.co/Qwen/Qwen2-VL-72B/commits/main
- Tweet from Simon Willison (@simonw): New Gemini!I just released llm-gemini 0.6 adding support for the "gemini-exp-1206" model, and then got a pretty spectacular result for my "Generate an SVG of a pelican riding a bicycle"...
- Tweet from wh (@nrehiew_): Updated the chart with SonnetQuoting wh (@nrehiew_) Interesting that o1 preview performs better than o1 full on a wide variety of tasks 1) SWE Bench o1-preview (41%) o1 full (38-41%)
- GitHub - simonw/pelican-bicycle: LLM benchmark: Generate an SVG of a pelican riding a bicycle: LLM benchmark: Generate an SVG of a pelican riding a bicycle - simonw/pelican-bicycle
- Tweet from Xeophon (@TheXeophon): @simonw What was Flash thinking this day lmao
- GitHub - QwenLM/Qwen2-VL: Qwen2-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud.: Qwen2-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud. - QwenLM/Qwen2-VL
Interconnects (Nathan Lambert) ▷ #random (28 messages🔥):
AI2 Demos, o1 Usage, Codeium Pricing, OpenAI's o1 Access Limits, Tulu in Chatbotarena
- AI2 Demos are now available: Members expressed excitement that AI2 now has demos, with comments highlighting their appealing appearance.
- One member noted, 'Sheeesh!', indicating the positive reaction to the demo aesthetic.
- o1 shows significant promise despite access limits: Usage of AI model o1 has been discussed, with members noting its superiority over 4o, albeit still limited in functionality.
- Concerns arose regarding usage caps, with one member stating that daily usage seems to be limited to 100 unless flagged by OpenAI.
- Codeium's New Pricing Structure: There’s a discussion about the new pricing model for Codeium, emphasizing costs associated with various premium features.
- Members noted the benefits of a 2-week free trial and detailed the number of credits included for user prompts and actions.
- Tulu's Launch in Chatbotarena: It's reported that Tulu is set to go live in Chatbotarena, generating curiosity within the community.
- Members anticipate the impact of its launch and are eager to explore its features.
- Tweet from latent moss (@latentmoss): @RealJosephus @fleetingbits @TheXeophon Update: After using it a lot more, for coding a little JS game, OpenAI has disabled my o1 access until tomorrow now, citing "unusual activity". I think ...
- Tweet from Shawn (@Shawnryan96): @TheXeophon @btibor91
- Tweet from Ian C (@donelianc): @fchollet First surprise from the report 👀🍿
- Paid Plan and Credit Usage - Codeium Docs: no description found
Interconnects (Nathan Lambert) ▷ #memes (18 messages🔥):
OpenAI o1 model regression, Competition among AI models, Meta's silence on AI developments, Performance of Deepseek and Qwen, Challenges with LLM reasoning
- Discussion on OpenAI o1 model regression: Several members expressed concern that the o1 model may be a regression, with one stating it fails simple problems more frequently.
- A community member pointed out that adjustments in how o1 handles simpler problems might contribute to this regression.
- Interest in AI competition: There is a strong desire for competition in AI, with calls for OpenAI to challenge other models like Claude and Deepseek.
- Members agreed it is essential for the industry to have effective competitors to ensure continued advancements.
- Speculations about Meta's developments: Members noted Meta's silence on new AI developments, wondering about their upcoming projects.
- One suggested that legal challenges might be hindering Meta's output, reinforcing the notion that they haven't released much recently.
- High variance in LLM performance: Concern was raised regarding the high variance in evaluating the 'reward' of thoughts versus question difficulty in LLMs, suggesting potential noise in the model's judgments.
- This discussion highlights how performance inconsistency could lead to unexpected outcomes in LLM reasoning.
- Debate over AI model merits: Members debated the quality of Deepseek and Qwen as competitors, with some arguing they are superior, while others disagreed.
- This disagreement underscores the diverse opinions on which models are truly advancing the field.
- Tweet from Colin Fraser (@colin_fraser): Thought about numerical comparison for a second
- Tweet from Lech Mazur (@LechMazur): o1 pro mode actually fails this question (3 tries)Quoting Noam Brown (@polynoamial) @OpenAI For example, last month at the 2024 Association for Computational Linguistics conference, the keynote by @r...
- Tweet from ⇑ (@eksnode): @colin_fraser Here is o1 Pro
- Tweet from Yuchen Jin (@Yuchenj_UW): @polynoamial Why it just thought for a second and gave up 😂
- GitHub - openai/simple-evals: Contribute to openai/simple-evals development by creating an account on GitHub.
Bolt.new / Stackblitz ▷ #prompting (17 messages🔥):
Feature Requests Management, Token Savings on Edits, Web Container Development, Community Assistance, Motivation in Projects
- Divide and Conquer Effective for Feature Requests: Engaging with Bolt to tackle feature requests one by one significantly reduces hallucination in responses, as noted by a member.
- Divide and conquer approach leads to clearer conversations and more effective implementation.
- Specific Section Edits for Token Efficiency: Members expressed a desire for Bolt to allow editing of specific sections of files instead of regenerating the entire file to save on tokens.
- A suggestion was made that when asking to refactor a function, it would be beneficial if only that function is modified.
- Frustration in Developing Web Projects: A member shared their frustration as a one-year experienced developer trying to build a website similar to bolt.new.
- They sought assistance in understanding web containers and expressed their motivation to learn through hands-on experience.
- Community Support for Project Issues: A member posted an issue seeking help with the web container, which highlights the community's willingness to assist.
- Others encouraged patience for responses as many community members have jobs and participate when they can.
- Boosting Motivation for Project Completion: A member acknowledged the support they received in the community, bolstering their motivation to complete their project.
- They expressed gratitude for the encouragement in overcoming challenges faced in their development efforts.
Link mentioned: Bolters.IO | Community Supported knowledge base: no description found
Bolt.new / Stackblitz ▷ #discussions (166 messages🔥🔥):
GitHub Repo Integration, Local Storage vs Backend Integration, Token Management, Feature Requests and Improvements, Open Source Bolt Enhancements
- Integrating GitHub Repos with Bolt: Users discussed the process of starting Bolt with a GitHub repository using the URL trick like bolt.new/github.com/org/repo. However, private repositories are not currently supported and need to be made public for integration.
- For those facing deployment errors with private repos, switching to public may resolve permission issues.
- Local Storage for Testing Before Backend Integration: One user suggested building apps with local storage first, then migrating features to a backend like Supabase for smoother testing. Another user confirmed they follow this method for testing features and noted it helps keep the app polished.
- This approach aims to reduce errors and streamline the integration process when transitioning to database storage.
- Understanding and Managing Token Usage: Tokens for Bolt expire monthly unless specifically purchased through the token reload option, which allows them to roll over. Users shared insights into managing their tokens efficiently and how to avoid exceeding limits.
- Questions were raised regarding daily token usage limitations, with clarification provided that free accounts face restrictions while paid accounts do not.
- Feature Suggestions for Bolt: A user proposed a feature for viewing edit histories in projects, tracking costs associated with changes. This idea was noted as good to submit as a feature request via the GitHub Issues page.
- Other users echoed the sentiment that community feedback is essential for product enhancement and urged the team to engage more visibly with users.
- Future of Open Source Bolt: Discussion arose about whether the open-source version of Bolt would be as powerful as Bolt.new, with some users expressing doubts based on personal experiences. Community members are keen on contributing to improve the open source version's capabilities.
- Updates are anticipated regarding the open-source project with efforts ongoing to enhance its functionality and bridge gaps with the main product.
- Bolters.IO | Community Supported knowledge base: no description found
- Tweet from Erwin Edink 🚀 (@ErwinEdink): what do you think of this? Now you can organize the sidebar. Pin your most important projects and give them a color. Should I add this option in the chrome extension of http://bolt.new
- Build a NEW $100K/Month A.I SaaS WITH ME in 20 minutes (No-code Is INSANE): Build & Sell Your Own A.I Agency With Me Here: https://www.skool.com/kevs-no-code-academy-3295/about in this video, we are making our own version of Cal.ai, ...
- Improvement: Increasing Token Usage Efficiency (In Progress) · Issue #678 · stackblitz/bolt.new: Background Large language models (LLMs) decode text through tokens—frequent character sequences within text/code. Under the hood Bolt.new is powered mostly by Anthropic's Sonnet 3.5 AI model, so u...
- Issues · stackblitz/bolt.new: Prompt, run, edit, and deploy full-stack web applications - Issues · stackblitz/bolt.new
Stability.ai (Stable Diffusion) ▷ #general-chat (182 messages🔥🔥):
Reactor for Face Swap, Discord for AI Discussions, Cloud GPU Providers, Using Lora and ControlNet, Stable Diffusion Models for Realism
- Choosing the Right Model for Face Swap: Users discussed whether Reactor is the best choice for face swapping, with no definitive answer provided.
- Members suggested testing different models to compare results, noting the importance of model choice on output quality.
- Finding General AI Discord Communities: A user inquired about a Discord community for various types of AI, specifically looking for discussions beyond LLMs.
- Other members recommended the Gallus and TheBloke Discords for diverse AI topics.
- Cloud GPU Recommendations: Users shared preferred Cloud GPU providers like Runpod, Vast.ai, and Lambda Labs, highlighting their competitive pricing.
- It was noted that Lambda Labs is often the cheapest option but can be difficult to access.
- Using Lora and ControlNet with Stable Diffusion: Discussion around adjusting Lora's strength in Stable Diffusion noted that it can exceed 1, but risks image distortion at higher settings.
- Members shared insights on using OpenPose for accurate poses and suggested utilizing depth control for better results.
- Licensing Concerns in AI Art Generation: A user posed questions about the implications of exceeding the revenue threshold under Stability AI's license agreement.
- Clarifications indicated that outputs generated could likely remain usable, while the license for model use would be revoked upon termination.
- ControlNet OpenPose: A guide on how to use the ControlNet OpenPose pre-processors
- AI Art Model: ModelBoosterXL | PixAI: Try out the 'ModelBoosterXL' AI Art Model to generate stunning Anime AI art on PixAI. Browsing artwork created using the 'ModelBoosterXL' AI Art Model. vxp, vxp_model_booster, model_booster_xl, model_...
- Like GIF - Like - Discover & Share GIFs: Click to view the GIF
- thibaud/controlnet-openpose-sdxl-1.0 at main: no description found
- h94/IP-Adapter at main: no description found
- Recoloring photos with diffusers: no description found
- lllyasviel/sd-controlnet-openpose · Hugging Face: no description found
- thibaud/controlnet-openpose-sdxl-1.0 · Hugging Face: no description found
OpenAI ▷ #annnouncements (1 messages):
Reinforcement Fine-Tuning, 12 Days of OpenAI
- Day 2: Focus on Reinforcement Fine-Tuning: The YouTube video titled '12 Days of OpenAI: Day 2' features discussions by Mark Chen, SVP of OpenAI Research, and Justin Reese, highlighting advancements in reinforcement fine-tuning.
- Viewers are encouraged to join the live stream starting at 10am PT for insights directly from leading researchers.
- Stay Updated with OpenAI Roles: Members are prompted to stay engaged in the ongoing 12 Days of OpenAI event by picking up the specific role in customize.
- This role facilitates receiving timely updates and highlights throughout the event.
Link mentioned: 12 Days of OpenAI: Day 2: Begins at 10am PTJoin Mark Chen, SVP of OpenAI Research, Justin Reese, Computational Researcher in Environmental Genomics and Systems Biology, Berkeley Lab, ...
OpenAI ▷ #ai-discussions (116 messages🔥🔥):
O1 Expectations, Gemini Experimental Model, Advanced Voice Mode, ChatGPT-4o Performance, Pricing and Value Discussion
- O1 has Mixed Reviews: Some users expressed disappointment with O1, describing it as 'meh' and noting its coding capabilities are inconvenient in the ChatGPT UI.
- Others, however, reported satisfaction, especially those using the macOS app, leveraging integrations with tools like Sublime Text and Xcode.
- Gemini Experimental Model Gains Attention: The Gemini experimental model, particularly version 1206, has been highlighted for its strong performance, even surpassing O1 Pro for some users.
- It reportedly delivers better results in tasks such as generating SVG code for a detailed unicorn illustration.
- Demand for Advanced Voice Mode Grows: There is a clear community demand for a more advanced voice mode, with some users noting the current offering sounds robotic.
- Users express hopes for significant improvements in the feature, especially during the upcoming holiday season.
- ChatGPT-4o Compared to Other Models: Users have been experimenting with ChatGPT-4o and reported favorable results with its performance regarding generating SVG images.
- In comparisons, opinions varied, with some users preferring O1 Mini and others fully supporting the advancements in ChatGPT-4o.
- Debate on Pricing and Value: The pricing for O1 Pro, cited as $200/month, sparked discussions on its value compared to free alternatives like Gemini 1206.
- Some users believe that despite O1's capabilities, the costs are too high given the existence of effective free models.
OpenAI ▷ #gpt-4-discussions (13 messages🔥):
GPT Editing Collaboration, ChatGPT App Integrations, Custom GPT Deletion Impacts
- Request for Multiple Editors on GPTs: A member expressed a desire for multiple people to edit a GPT simultaneously, highlighting the need for collaboration.
- Currently, only the creator can edit a GPT, but variations could be made by others if needed, based on the same configuration.
- ChatGPT Direct Integration with Apps: Members discussed the ChatGPT macOS app's ability to integrate directly with apps like Terminal, Sublime Text, and Xcode.
- However, this integration was clarified to not address the issue of having multiple editors on a GPT.
- Verifying GPT Authenticity with Creators: There was a discussion about the authenticity verification of GPTs, emphasizing that creator identification is essential.
- The potential for a 'Share GPT edit access' feature in the future was proposed as a solution to ease collaboration.
- Conversation Status After GPT Deletion: A user inquired about the fate of conversations with a custom GPT if the creator decides to delete it.
- The implications of such an action on conversation availability remain unclear, as this question was raised without a definitive answer.
OpenAI ▷ #prompt-engineering (11 messages🔥):
Self-correcting models, Using OCR for financial data, Challenges with LLMs in data extraction, Open source OCR libraries, Improving PDF workflows
- Self-correcting models raise concerns: While some members discuss the potential for models to self-correct, it was highlighted that achieving 100% accuracy is impossible due to unaddressed memory during inference.
- Exploration of an agentic framework was suggested for programmatic self-correction.
- Consider non-LLM tools for OCR: A member advocated for using established non-LLM OCR libraries instead of relying on generative AI for consistent data extraction from PDFs.
- Concerns were raised about the risk of hallucination when using LLMs for extracting financial data.
- The challenges of PDFs as a data source: Several members agreed that PDFs aren't a great API for data extraction due to their format limitations.
- Alternative suggestions included working upstream with report creators to establish better workflows.
- Creating a spreadsheet for analysis: One member proposed to first use tools for pulling data into a spreadsheet, which could then be analyzed or visualized by ChatGPT.
- This process emphasizes structuring data before relying on LLMs for further analysis.
OpenAI ▷ #api-discussions (11 messages🔥):
Self-Correcting Models, Financial Data Extraction Techniques, OCR Libraries for PDFs, Agentic Frameworks, Integrating Data Sources
- Self-Correcting Models: A Feasible Approach?: One member suggested using the model to self-correct its output, but another pointed out that achieving 100% accuracy isn't possible due to inference occurring in unaddressed memory.
- The need for a programmatic approach using an agentic framework was emphasized to enhance reliability.
- Better Techniques Over LLM for OCR Extraction: A member argued that relying on generative AI for consistent OCR tasks in financial data extraction is problematic due to potential hallucinations.
- It was recommended to use established, open-source OCR libraries rather than depending solely on LLM capabilities.
- Prioritize Accurate Data Workflows: One participant suggested collaborating with report creators to streamline the workflow for data collection from PDFs to improve extraction accuracy.
- This approach may prevent reliance on inefficient PDFs as an API, leading to better data management.
- Questioning AI's Role in Financial Applications: Concerns were raised about utilizing generative AI tools in contexts where accurate financial data extraction is critical, highlighting risks associated with hallucination.
- A member admitted to similar tendencies of reliance on AI in different scenarios, underscoring community apprehension.
Modular (Mojo 🔥) ▷ #general (1 messages):
VSCode Extension Issues, Test Configuration
- User Inquiry on VSCode Extension Channel: A member inquired about the appropriate channel to ask questions regarding the VSCode extension, specifically mentioning an issue with tests running with cwd=/, which is suboptimal.
- They later found the correct channel to address this question, indicating that the issue was resolved.
- Finding the Right Channel to Ask Questions: After looking for guidance, the member realized they could ask about the VSCode extension in a specific channel, which they found helpful.
- This highlights the importance of knowing where to direct technical inquiries in the community.
Modular (Mojo 🔥) ▷ #mojo (147 messages🔥🔥):
Mojo Syntax and Functionality, Learning Paths for Programming, Compiler Design and Metaprogramming, Blockchain and Programming Languages, Education Experiences in Computer Science
- Mojo Function Extraction Errors: A new user encountered errors when trying to adapt the
j0function from themathmodule in Mojo, specifically due to an unknown declaration_call_libmduring compilation.- The user was seeking guidance on how to properly extract and use functions from the
mathstandard library without facing compiler issues.
- The user was seeking guidance on how to properly extract and use functions from the
- Advice on Programming Career Focus: Several members discussed the importance of specializing in areas like blockchain, cryptography, or distributed systems for better job prospects in tech fields.
- They emphasized the need for targeted learning and experience, suggesting that hands-on projects and understanding fundamental concepts can significantly aid career advancement.
- Compiler Passes and Meta-Programming in Mojo: Discussions revolved around the new features in Mojo that allow for writing custom compiler passes, with speculation on potential ways to enhance the API for more extensive program transformations.
- Members expressed that Mojo's approach to metaprogramming is akin to classic LLVM optimizations, though there are limitations regarding JAX-style program transformations.
- Education Insights in Computer Science: Participants shared their experiences in computer science education, with reflections on challenging courses and projects that shaped their understanding of programming concepts.
- They highlighted the balance between pursuing personal interests and market demand in career choices, using their academic journeys as illustrative examples.
- Learning and Community in Programming: Members offered encouragement to newcomers in both programming and the community, suggesting exploration of different coding styles and personal projects.
- They reassured new users that initial challenges in learning programming languages are a normal part of the journey, fostering a supportive environment for growth.
- The LLVM Compiler Infrastructure Project: no description found
- Documentation: no description found
- Jose Nelson Amaral homepage: no description found
Perplexity AI ▷ #general (89 messages🔥🔥):
Perplexity AI's code interpreter, Fake Perplexity app on Windows, Llama 3.3 model update, Grok and Groq for API usage, OpenAI API integration concerns
- Perplexity AI struggles with code interpreter: A user expressed frustration with Perplexity AI not executing Python scripts despite uploading files for analysis.
- Discussion highlighted its limitations, such as only generating text and graphs without executing code.
- Concern over fake Perplexity app: Members reported a fake Perplexity app in the Windows app store that appears fraudulent, using the logo and API without authorization.
- They urged others to report it, emphasizing the need for caution as the app leads to a questionable Google Doc.
- Excitement over Llama 3.3 release: Users celebrated the release of Llama 3.3, noting its impressive capabilities compared to its predecessor.
- There's anticipation for Perplexity to integrate this new model into their services soon.
- Navigating Grok and Groq APIs: A user shared recommendations for using Grok and Groq, highlighting Grok's free starter credit and Groq's free usage with Llama 3.3.
- Conversation included troubleshooting, as one member had issues using the Groq endpoint successfully.
- Concerns about API access and features: Frequent inquiries arose regarding the integration of OpenAI's O1 model and its availability on various platforms, including Perplexity.
- Users expressed frustration over the potential costs associated with accessing O1, emphasizing that other platforms seem to gain advantages.
- Tweet from Perplexity Supply (@PPLXsupply): New from Perplexity Supply: coffee, for curious minds.Perplexity coffee is made with single-origin beans from Ethiopia, and pairs perfectly with our new custom-designed stoneware mugs. Sip to kickstar...
- Tweet from Logan Kilpatrick (@OfficialLoganK): Gemini-exp-1206, our latest Gemini iteration, (with the full 2M token context and much more) is available right now for free in Google AI Studio and the Gemini API.I hope you have enjoyed year 1 of th...
- wip: terminal (initial commit): Delicious Brazilian coffee, ethically sourced, and roasted to perfection • Order via your terminal • ssh http://terminal.shop
Perplexity AI ▷ #sharing (8 messages🔥):
Writing Prompts, Web Design, Oldest Alphabetic Writing, Meaning Exploration, Longevity Research
- Guide to Crafting Perfect Prompts: A resource on how to write a perfect prompt was shared, outlining techniques for effective prompting.
- This guide could be useful for enhancing your interaction with AIs and generating better results.
- Acting as a Web Designer: A link to a task on acting as a web designer was posted, showcasing what such a design prompt may look like.
- This example may help users visualize how AI can support web design processes.
- Discovery of Oldest Alphabetic Writing: Multiple users referenced a link about the oldest alphabetic writing, indicating interest in historical linguistics.
- This page could provide insights into the evolution of written language.
- Exploring the Meaning of Words: A member shared a link to explore the meaning of the word 'off', indicating a pursuit of clarifying language.
- Such resources can aid in expanding vocabulary and understanding nuances in word usage.
- Recent Longevity Research: A link was shared to recent research on longevity, highlighting the ongoing study in this field.
- This research may offer valuable insights into health and lifespan optimization.
Perplexity AI ▷ #pplx-api (2 messages):
RAG feature in Perplexity API, Perplexity Trends App
- Inquiry on RAG feature for API: A member asked if there are any plans to bring the RAG feature of Perplexity Spaces to the API.
- This indicates interest in enhanced functionality that could tie advanced retrieval capabilities into the API offerings.
- Request for Perplexity Trends app: Another member inquired about the possibility of releasing a Perplexity Trends app, akin to Google Trends.
- This suggestion reflects a desire for tools that provide insights and analytics on trending topics within the Perplexity ecosystem.
LM Studio ▷ #general (63 messages🔥🔥):
LM Studio Uninstall Behavior, Paligemma 2 Release, RAG File Limitations, RAM Upgrade Discussion, LM Studio Compatibility with Whisper Models
- Confusion about LM Studio Uninstallation: A member expressed concern about uninstalling LM Studio without losing over 800GB of models, noting strange behavior with uninstallations.
- Another member speculated that uninstallations might involve checks for previously used files, leading to inconsistencies.
- Exciting Release of Paligemma 2: Paligemma 2 has now been released on MLX, featuring new models from GoogleDeepMind.
- Members are encouraged to install it using the command
pip install -U mlx-vlmand contribute by leaving a star and sending PRs.
- Members are encouraged to install it using the command
- Discussion on RAG File Limitations: A member inquired about workarounds for the 5 file RAG limitation, emphasizing a need to analyze numerous small files for issues.
- Members weighed in on potential solutions and performance implications of feeding small files into models.
- RAM Upgrade Sufficiency for 20B Models: After upgrading RAM from 16GB to 40GB, a member asked if it would be sufficient for operating 20B models on a Ryzen 3 3100.
- Other members offered insights and experiences, indicating that similar setups can indeed manage larger models.
- Inquiry on LM Studio's Support for Whisper Models: A member queried whether LM Studio supports Whisper models, revealing difficulties in loading them under Arch.
- Another member confirmed that TTS/STT and Image Generation models are not supported, clearing the confusion.
Link mentioned: Tweet from Prince Canuma (@Prince_Canuma): mlx-vlm v0.1.4 is here 🎉New models:- @GoogleDeepMind Paligemma 2Up next 🚧:- Refactoring Get started:> pip install -U mlx-vlm Please leave us a star and send a PR :)
LM Studio ▷ #hardware-discussion (8 messages🔥):
GPU Control in Apps, Benchmarks for Llama 3.1, 4090 Pricing Surge, Chinese Modding for 4090
- App lacks GPU control options: A user inquired about controlling which GPUs are used in the app, similar to how Kobold functions, but was informed that this option is not available.
- Well that sucks, expressed the original user, highlighting disappointment over the app's limitations.
- Interest in Llama 3.1 CPU Benchmarks: A member sought benchmarks for the Llama 3.1 8B model on the latest CPUs, specifically the Intel i7-13700 and i7-14700.
- They were particularly curious about the potential inference speed these CPUs could deliver.
- Skyrocketing Prices of 4090 GPUs: The price of both new and used 4090 GPUs is reportedly rising dramatically in some regions, prompting concern among users.
- There are rumors that some 4090s may be modded to increase VRAM to 48GB, stirring discussion in the community.
- Discussion on Chinese Modders: A user mentioned that there are posts on Reddit discussing Chinese modders working on 4090 GPUs, although specific sources were lacking.
- They expressed uncertainty about where to find links or more detailed information on these modding discussions.
Link mentioned: How do I select which GPU to run a job on?: In a multi-GPU computer, how do I designate which GPU a CUDA job should run on? As an example, when installing CUDA, I opted to install the NVIDIA_CUDA-<#.#>_Samples then ran ...
Cohere ▷ #discussions (28 messages🔥):
Rerank 3.5 Model, AI Cost Concerns, Reinforcement Fine Tuning
- Rerank 3.5 boasts improved capabilities: The newly released Rerank 3.5 model delivers enhanced reasoning and multilingual capabilities for accurately searching complex enterprise data.
- Members are eager for metrics and benchmark scores to evaluate its performance.
- AI services perceived as luxury items: Users express frustration over AI service pricing, with one member questioning why an AI company would charge when demo keys are available.
- Another noted that, like any service, top-quality AI requires payment, asserting that AI sadly isn’t a right but a luxury.
- Discussions on reinforcement fine tuning: The conversation turned to reinforcement fine tuning, with one member feeling the current approach may not align with its intended purpose.
- It was mentioned that passing in grading functions could traditionally not differ significantly from normal fine-tuning methods.
Link mentioned: Introducing Rerank 3.5: Precise AI Search: Rerank 3.5 delivers improved reasoning and multilingual capabilities to search complex enterprise data with greater accuracy.
Cohere ▷ #announcements (1 messages):
Structured Outputs for Tool Use, Command models, Chat API V2 compatibility
- Command models now enforce Structured Outputs: Command models have been enhanced to strictly follow the tool descriptions provided, eliminating unexpected tool names or parameter types.
- This ensures that all required parameters are now included, improving reliability in enterprise applications.
- Structured Outputs increase LLM formatting reliability: The new Structured Outputs feature mandates the LLM output to adhere to a specified format consistently, aiding in reducing hallucinated fields.
- This improvement is particularly beneficial for applications where correct formatting is critical for downstream processes.
- Two methods for utilizing Structured Outputs: Users can apply Structured Outputs either in JSON for text generation or in Tools for agent use cases via function calling.
- The latter is useful when utilizing the tool features in the Command models.
- Try the new feature in Chat API V2: To implement Structured Outputs in your applications, simply add
strict_tools=Truein the API calls for Chat API V2.- This feature is currently experimental, and user feedback is encouraged to enhance its performance.
Link mentioned: Structured Outputs — Cohere: This page describes how to get Cohere models to create outputs in a certain format, such as JSON.
Cohere ▷ #questions (7 messages):
Connector Access without Public URL, Recent Updates on Command R Model, Cohere IP Allowlisting, Document Error in Cohere API, Specifying Multilingual in Fine-Tuning
- Cohere Connector Access Does Not Require Public URL: A user inquired whether a public URL is necessary for accessing internal applications/datastores with a connector.
- Another member clarified that the URL doesn’t need to be public, only that the Cohere IP addresses should be allowlisted.
- Command R Model Update Inquiry: A user asked if there are any plans for updates to the Command R model recently, indicating interest in potential enhancements.
- No responses regarding upcoming updates were provided in the discussion.
- Invalid Document Error Encountered: A user reported receiving a BadRequestError stating that a document at index 0 cannot be empty, despite it appearing non-empty.
- This indicates a possible issue with how the document is processed by the Cohere API, warranting further investigation.
- Fine-Tuning Multilingual Models: A user inquired about how to specify a fine-tune model to be multilingual, suggesting a code snippet for settings.
- They attempted to set the language parameter to
Cohere ▷ #api-discussions (32 messages🔥):
Cohere vs OpenAI, Rate Limit Concerns, Image Embedding Errors, Support Experience, Retry Mechanism for API Calls
- Debate on Cohere vs OpenAI Similarities: Members discussed the need for differences in AI services, highlighting that many are looking for unique offerings rather than similarities, like the Cohere version of the O1 Pro.
- One member agreed, stating a preference for services that provide varied features, rather than replicating existing solutions.
- Concerns Over Low Rate Limit for /embed Endpoint: A member expressed frustration about the low rate limit of 40 images per minute for the /embed endpoint, hindering their ability to embed a toy dataset efficiently.
- Other members reaffirmed difficulties, suggesting contacting support for possible rate limit increases.
- Frequent Errors When Embedding Images: Users reported HTTP 500 and 400 errors while trying to embed images, citing issues with image size limits and server errors.
- One user noted that resizing images became necessary due to the size constraint of 5242880 bytes, leading to discussions on using the Pillow library for effective resizing.
- Support Experience Shares: Discussions included mixed experiences with Cohere support, with one member mentioning ongoing meetings to resolve production issue concerns.
- While some found the support process satisfactory, others voiced frustrations with the delays and reliance on sales teams.
- Retry Mechanism Implementation in API Calls: A user discussed optimizing their retry strategy for API calls using the vanilla Cohere Python client, which inherently handles retries more elegantly.
- This led to a productive exchange on different approaches to managing API retries, with some members considering adjustments to their existing methods.
Cohere ▷ #projects (1 messages):
vnc-lm, LiteLLM integration, API connections, Threaded conversations, Model switching feature
- vnc-lm gets LiteLLM upgrade: vnc-lm is now integrated with LiteLLM, allowing connections to any API that supports Cohere models like Cohere API and OpenRouter.
- This upgrade enables a broader range of functionalities for seamless API interactions.
- Organized conversations with threading: New threading features let users keep conversations organized by creating them with the command
/model, which automatically generates titles.- Conversations can branch off by replying to messages, providing a clear context and summary for each new thread.
- Dynamic model switching during chats: The model switching feature allows users to change the model mid-conversation using
+followed by the model name while maintaining conversation history.- This improvement streamlines the chat experience without disrupting ongoing discussions.
- Branching conversations for clarity: Users can create new threads by replying to specific messages, which auto-generates a relationship diagram showing context and a summary.
- This feature enhances clarity and organization in multi-part conversations, making interactions easier to follow.
- Explore the vnc-lm project: Check out the vnc-lm project on GitHub here, designed to allow messaging through various LLMs via Discord.
- The project offers integration with Claude 3.5, Llama 3.3, GPT-4o and more, providing a versatile messaging platform.
Link mentioned: GitHub - jake83741/vnc-lm: Message with Claude 3.5 Sonnet, Llama 3.3, GPT-4o, and other LLMs through Discord.: Message with Claude 3.5 Sonnet, Llama 3.3, GPT-4o, and other LLMs through Discord. - jake83741/vnc-lm
Cohere ▷ #cohere-toolkit (2 messages):
Introduction, Community Welcome
- Greeting a New Member: A member introduced themselves stating, 'I am new.' This opened the floor for welcoming interactions within the community.
- Dominic responded with a friendly, 'Hi new, I’m Dominic!' reaffirming the sense of community.
- Community Interaction: The interactions showcased the welcoming spirit of the community, which is important for new members. Engaging dialogues like these help foster a supportive environment.
Latent Space ▷ #ai-general-chat (65 messages🔥🔥):
Writer's Built-in RAG Tool, ShellSage Project, Reinforcement Fine-Tuning API, Gemini Exp 1206 Update, AI Essays and Industry Insights
- Writer releases built-in RAG tool: Writer has introduced a built-in RAG tool that allows users to pass a graph ID to make the knowledge graph available to the model, showcased by Sam Julien.
- This tool enables functionalities like auto-uploading scraped content into a Knowledge Graph and interactive chatting with posts.
- Launch of ShellSage for AI productivity: The ShellSage project was highlighted by R&D staff from AnswerDot AI, focusing on enhancing productivity through AI in terminal environments, described as an AI terminal buddy that learns with the user link.
- It emphasizes the hybrid human+AI approach, enabling smarter handling of tasks within shell environments.
- New OpenAI Reinforcement Fine-Tuning API: OpenAI announced a new RL fine-tuning API that allows users to employ advanced training algorithms for their models, linked in a post by John Allard link.
- It promises empowering users to create expert models in various domains, continuing the enhancements seen in o1 models.
- Gemini Exp 1206 performs exceptionally: Google’s latest model, Gemini exp 1206, has achieved first place rankings across multiple tasks including hard prompts and coding, as noted by Jeff Dean and others link.
- This update marks significant progress for Google in the AI landscape, with the Gemini API now open for use.
- Exploration of AI Essays: Discussions involved several insightful essays on AI, one of them focusing on a $4.6 trillion opportunity with the Service-as-Software framework link.
- Another notable mention highlighted a proposed strategy for raising and rolling up service businesses using models link.
- Tweet from Nathan Cooper (@ncooper57): As R&D staff @answerdotai, I work a lot on boosting productivity with AI. A common theme that always comes up is the combination of human+AI. This combination proved to be powerful in our new project ...
- Tweet from Joanne Chen (@joannezchen): A System of Agents: Our view on how founders can jump on a $4.6T opportunity. 👇When @JayaGup10 and I first outlined the Service-as-Software framework months ago, we knew we were describing something ...
- Tweet from john allard 🇺🇸 (@john__allard): I really enjoyed giving an early look at our new Reinforcement Fine-Tuning product. The idea that anyone can leverage the same training algorithms and infra we use to create our o1 models and craft ex...
- Coding with Intelligence | Rick Lamers | Substack: CoWI is a weekly newsletter covering the latest developments in Large Language Models and Machine Learning. Get the latest News, Repos, Demos, Products, and Papers. Click to read Coding with Intellige...
- Tweet from ruliad (@ruliad_ai): Introducing DeepThought-8B: Transparent reasoning model built on LLaMA-3.1 with test-time compute scaling. - JSON-structured thought chains & controllable inference paths. - ~16GB VRAM, competitive ...
- Tweet from Nathan Lambert (@natolambert): OpenAI announced a new RL finetuning API. You can do this on your own models with Open Instruct -- the repo we used to train Tulu 3.Expanding reinforcement learning with verifiable rewards (RLVR) to m...
- Tweet from Lisan al Gaib (@scaling01): GOD DAMN GOOGLE DID ITInstruction Following + Style Control
- Tweet from Nathan Cooper (@ncooper57): As R&D staff @answerdotai, I work a lot on boosting productivity with AI. A common theme that always comes up is the combination of human+AI. This combination proved to be powerful in our new project ...
- Tweet from Sam Julien (@samjulien): 🔥 RAG in just a few lines of code!?Hacker News Listener built with @Get_Writer Palmyra X 004 & built-in RAG tool:- Scrapes posts & comments- Auto-uploads to Knowledge Graph- Lets you chat w/ scraped ...
- Tweet from Tibor Blaho (@btibor91): I noticed during the "12 Days of OpenAI: Day 2" livestream today that the OpenAI Platform sidebar has a new icon, possibly related to one of the upcoming announcements - "Custom Voices"...
- Tweet from surya (@sdand): raise $100mil seed round buy up service businesses and roll them up with models. all the smartest <23y/o ppl i know are doing this— blog post: https://sdan.io/blog/intelligence-arbitrage
- Tweet from Logan Kilpatrick (@OfficialLoganK): Gemini-exp-1206, our latest Gemini iteration, (with the full 2M token context and much more) is available right now for free in Google AI Studio and the Gemini API.I hope you have enjoyed year 1 of th...
- Tweet from Jeff Dean (@🏡) (@JeffDean): What a way to celebrate one year of incredible Gemini progress -- #1🥇across the board on overall ranking, as well as on hard prompts, coding, math, instruction following, and more, including with sty...
- Tweet from OpenAI (@OpenAI): Day 2: Reinforcement Fine-Tuninghttps://openai.com/12-days/?day=2
- Tweet from AI at Meta (@AIatMeta): As we continue to explore new post-training techniques, today we're releasing Llama 3.3 — a new open source model that delivers leading performance and quality across text-based use cases such as ...
- Tweet from Alexander Doria (@Dorialexander): “They said it could not be done”. We’re releasing Pleias 1.0, the first suite of models trained on open data (either permissibly licensed or uncopyrighted): Pleias-3b, Pleias-1b and Pleias-350m, all b...
- Tweet from Mckay Wrigley (@mckaywrigley): OpenAI o1 pro is *significantly* better than I anticipated.This is the 1st time a model’s come out and been so good that it kind of shocked me.I screenshotted Coinbase and had 4 popular models write c...
- Tweet from Jürgen Schmidhuber (@SchmidhuberAI): Re: The (true) story of the "attention" operator ... that introduced the Transformer ... by @karpathy. Not quite! The nomenclature has changed, but in 1991, there was already what is now calle...
- 12 Days of OpenAI: Day 2: Begins at 10am PTJoin Mark Chen, SVP of OpenAI Research, Justin Reese, Computational Researcher in Environmental Genomics and Systems Biology, Berkeley Lab, ...
- GitHub - AnswerDotAI/shell_sage: ShellSage saves sysadmins’ sanity by solving shell script snafus super swiftly: ShellSage saves sysadmins’ sanity by solving shell script snafus super swiftly - AnswerDotAI/shell_sage
- no title found: no description found
Latent Space ▷ #ai-in-action-club (1 messages):
kbal11: AI in Action
Nous Research AI ▷ #general (45 messages🔥):
Nous Distro, Llama 3.3 Model Release, Evaluation Metrics on Models, Continuous Learning Experiments, Safety Concerns in AI Outputs
- Nous Distro explained as decentralized training: A user inquired about Nous Distro, and a member responded that it involves decentralized training.
- Wow you guys finally cracked it was the reaction, suggesting excitement about the project.
- Llama 3.3 raises questions on base models: Discussion arose regarding Llama 3.3, wondering if it implied a base model, with many noting it relies on Llama 3.1 as its base.
- Users speculated on whether it was a complex fine-tuning pipeline that didn't generate a new pretraining, indicating emerging trends in model releases.
- Safety concerns about misleading models: Concerns were voiced regarding how the model might intentionally mislead users while prioritizing safety.
- A member humorously remarked on the irony of being misled for one's own safety, reflecting general skepticism.
- User experiences with Llama 3.3: A user observed that the math solutions from Llama 3.3 are cleaner and more latex heavy compared to the previous model.
- Another mentioned that using the 3.3 tuning framework might improve specific applications, though safety was a concern.
- Performance metrics on comparison: Users shared their experiences comparing Sonnet models with evaluations showing varying performance scores such as a 49% on swe-bench for Sonnet.
- Members expressed concerns about these metrics reflecting real-world usability, highlighting the ongoing evaluation of model performance.
Link mentioned: Tweet from Ahmad Al-Dahle (@Ahmad_Al_Dahle): Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest advancements in post-training techniques in...
Nous Research AI ▷ #ask-about-llms (18 messages🔥):
Chronic Kidney Disease Detection, Fine-Tuning Mistral Models, Using Unsloth for Classification, Data Formatting for Model Training, LightGBM for Tabular Data
- Fine-Tuning Mistral for Chronic Kidney Detection: A user shared challenges in fine-tuning a Mistral model using a 25-column dataset for detecting chronic kidney disease, struggling to find suitable tutorials.
- They expressed frustration after three months of trying with little progress, seeking guidance from the community.
- Unsloth's Classification Example Shared: A member suggested an example of using Unsloth for classification with custom templates as a potential solution.
- They pointed to a GitHub notebook showing how to modify dataset formatting to use it effectively.
- Data Formatting and Use of Numerical Data: Discussion emerged about the need to convert numeric data into text format, as LLMs do not perform well with direct numerical tabular data.
- One user emphasized generalizing CSV data to full text format as critical for training models.
- Employing LightGBM for Better Performance: Another member recommended using LightGBM for better handling of tabular data in machine learning tasks.
- This framework is noted for its efficiency in ranking and classification, providing an alternative to LLMs for the dataset.
- GitHub - microsoft/LightGBM: A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.: A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning ...
- text_classification_scripts/unsloth_classification.ipynb at main · timothelaborie/text_classification_scripts: Scripts for text classification with llama and bert - timothelaborie/text_classification_scripts
GPU MODE ▷ #general (9 messages🔥):
Popcorn Project, Timeline for Launch, Benchmarking GPUs, FP8 vs INT8 Performance
- Sneak Peek at Popcorn Project: A sneak peek was shared about a project allowing job submissions for leaderboards across different kernels, with benchmarking capabilities on GPUs like NVIDIA H100.
- Set to launch in January 2025, this project aims to enhance the development experience despite being non-traditional.
- Targeted Launch Date Shared: Discussion revealed that the targeted launch for the project is set for January 2025.
- Clarifications were made to confirm the timeline indicates January 2025.
- Interest in FP8 versus INT8 Benchmarks: A member expressed curiosity about benchmarks comparing the performance of FP8 (using L40s without TMA) to Ampere's INT8.
- This discussion highlights ongoing technical queries regarding performance metrics in AI model training.
GPU MODE ▷ #triton (2 messages):
Nvidia Nsight, Triton release plans, TMA descriptors, Nightly builds issues
- Inquiry on Nvidia Nsight: A member asked about Nvidia Nsight, expressing interest in its capabilities and integration.
- This suggests a growing curiosity among the community regarding tools for optimizing GPU usage.
- Request for Triton low-overhead TMA Support: There is a request for an official Triton release to support low-overhead TMA descriptors.
- Concerns were raised around the current state of nightly builds, which are reported to be broken.
GPU MODE ▷ #cuda (6 messages):
SASS code extraction, nvdisasm utility, ncu tool features, Compiler Explorer
- Seeking SASS code with line information: A user is looking for a way to extract SASS code with line information using a method akin to the '-lineinfo' flag for PTX code generation.
- Other members suggested using tools like nvdisasm for basic line information and Compiler Explorer as a reference.
- Issues with nvdisasm for SASS extraction: A member mentioned using nvdisasm with the option
--print-line-info, but clarified that it only displays file and line numbers, not actual lines.- This limitation was noted while discussing methods to enhance the SASS extraction process.
- Potential of ncu for SASS code analysis: Another suggestion was to use ncu for analyzing SASS instructions, although its current features were questioned.
- One member speculated that the lack of a feature to link source lines to instructions could easily be added, though it wasn't confirmed if this had been implemented.
GPU MODE ▷ #cool-links (1 messages):
mobicham: https://x.com/Ahmad_Al_Dahle/status/1865071436630778109 Llama 3.3 is out
GPU MODE ▷ #beginner (7 messages):
CUDA kernel compilation, Optimizing Pybind usage, Ninja build system, Using raw types with CUDA
- Seeking Faster CUDA Kernel Compilation Techniques: A member is looking for a quicker method to compile CUDA kernels using pybind, noting that their setup takes nearly a minute per kernel.
- They are open to alternatives for making the kernel functional within their Torch code.
- Ninja Build System Inquiry: Another member inquired if using Ninja could speed up the compilation process, suggesting increasing the CPU count on their VM could help.
- This approach aims to leverage the efficiency of Ninja during the build process.
- Avoiding PyTorch Headers to Reduce Compile Time: Advice was offered to optimize the compile time by ensuring that the files processed by nvcc do not include PyTorch headers.
- One member reported a compile time of roughly 40 seconds when including the PyTorch header, emphasizing the impact of this header inclusion.
- Passing Raw Values to CUDA Files: Discussion came up around passing values to CUDA files as raw ints or floats rather than tensors to potentially improve performance.
- Clarification was made that this method could help streamline interactions between Torch and CUDA kernels.
GPU MODE ▷ #pmpp-book (1 messages):
Lecture 37 on SASS, YouTube clips, Triton and CUDA
- Lecture 37 Revealed: SASS & GPU Microarchitecture: A 60-second clip from the YouTube video titled 'Lecture 37: Introduction to SASS & GPU Microarchitecture' features speaker Arun Demeure discussing key concepts.
- For more insights, the slides are available on GitHub.
- Quick Overview with Triton and CUDA: An attached video titled triton-cuda-or-sass-under1min-1080p.mov provides a brief overview of Triton and CUDA in under a minute.
- This video serves as a quick and informative resource for understanding the relationship between these technologies.
Link mentioned: Lecture 37: Introduction to SASS & GPU Microarchitecture: Speaker: Arun DemeureSlides: https://github.com/gpu-mode/lectures/tree/main/lecture_037
GPU MODE ▷ #torchao (1 messages):
Quantization in TorchAO, Implementation Details, Recommended Files for Starting
- Exploring Quantization in TorchAO: A member expressed interest in exploring multiple methods of quantization implementation specifically in TorchAO.
- They sought guidance on the best practices and any specific files that would serve as a starting point for their understanding.
- Seeking Detailed Insights: The inquiry highlighted a desire to grasp the fine details of quantization, showcasing a keen interest in implementation nuances.
- The request emphasizes the community's collaborative spirit in diving deep into technical subjects.
GPU MODE ▷ #off-topic (6 messages):
Meta intern team matching, Ultralytics package compromise, Discord thread visibility timing
- Curiosity about Meta intern team matching: A member expressed curiosity regarding how interns at Meta are matched to teams, questioning whether reaching out to others would be impactful.
- Not sure if that will make a difference was their sentiment about seeking information.
- Ultralytics package found compromised: A user reported that the Ultralytics package, known for YOLOv5, is compromised with a cryptominer due to a GitHub Actions bug that executes arbitrary code in branch names, as discussed in this issue.
- It was noted that installing the affected version 8.3.41 may lead users to unintentionally run a mining software.
- Discussion on 2-Factor Authentication concerns: In response to the compromised Ultralytics package, a member questioned whether PyPI could have been compromised given that 2-factor authentication is in place.
- They seemed uncertain about how such a compromise could occur under these security measures.
- Wondering about Discord thread message timing: A user inquired about the timing of when a message appears after a thread is initiated, specifically asking how long it takes for the message '_ started a thread' to show up, estimating it to be between 10 minutes and 6 hours.
- They speculated that optimizing these threads could significantly improve Discord's aesthetic appeal.
Link mentioned: Discrepancy between what's in GitHub and what's been published to PyPI for v8.3.41 · Issue #18027 · ultralytics/ultralytics: Bug Code in the published wheel 8.3.41 is not what's in GitHub and appears to invoke mining. Users of ultralytics who install 8.3.41 will unknowingly execute an xmrig miner. Examining the file uti...
GPU MODE ▷ #triton-puzzles (2 messages):
MID clarification, Tensor shapes
- Seeking Clarification on 'MID' Definition: A member expressed confusion regarding the term 'MID' in the description of puzzle 11 and requested assistance for clarification.
- The member shared a link to an image to provide more context.
- Discussion on Tensor Shapes in Relation to 'MID': In response to the initial confusion, the member queried if tensor x has the shape [N2, N0, MID] and tensor y the shape [N2, MID, N1].
- This question indicates that the member is analyzing the structure of tensors in the context of their understanding of MID.
GPU MODE ▷ #self-promotion (2 messages):
LTX Video Model Implementation, Performance on RTX 4060 and RTX 4090
- LTX Video Model Gets CUDA Makeover: A member reimplemented all layers in the LTX Video model using CUDA, boasting 8bit GEMM that's 2x faster than cuBLAS FP8 and features like FP8 Flash Attention 2.
- The implementation also included RMSNorm, RoPE Layer, and quantizers, claiming no accuracy loss thanks to the Hadamard Transformation.
- Real-Time Generation Achieved on RTX 4090: Tests conducted on the RTX 4090 revealed generation speeds exceeding real-time capabilities with just 60 denoising steps.
- Attached images document these stunning results, showcasing performance benchmarks that highlight the advancements made.
- Key Features of LTX Video's CUDA Layers: Important features of the reimplementation include Mixed Precision Fast Hadamard Transform and Mixed Precision FMA, which enhance performance efficiency.
- These optimizations are primarily aimed at improving speed without sacrificing accuracy, as noted by the member.
- GitHub - KONAKONA666/LTX-Video: LTXVideo Q8: LTXVideo Q8. Contribute to KONAKONA666/LTX-Video development by creating an account on GitHub.
- GitHub - KONAKONA666/q8_kernels: Contribute to KONAKONA666/q8_kernels development by creating an account on GitHub.
GPU MODE ▷ #🍿 (6 messages):
Security concerns in competitions, Common attack vectors, Impact of trolling in niche communities
- Security Concerns Rise at Competitions: A member raised concerns about potential security issues such as cheesing submissions and draining compute resources during competitions.
- Suggestions included implementing a submission delay feature to mitigate potential abuses.
- Previous Competitions Experienced Trolls: When asked about past issues, it was noted that trolls have been present in similar competitions, leading to the need for precautions.
- A proactive approach was recommended, including logging IDs of participants to monitor for abnormal behaviors.
- Niche Communities May Face Unique Trolling: One member expressed hope that being part of a niche Discord server would reduce the amount of trolling encountered but acknowledged the potential for more brazen trolls.
- Despite concerns, they pointed out that the type of trolls drawn to this community may be more knowledgeable and therefore harder to manage.
- Experience with Past Trolling Incidents: Past experiences were shared about incidents where trolls have disrupted meetings by posting inappropriate content, raising concerns about verification protocols.
- This history underscores the necessity of maintaining server verification to prevent the resurgence of such behavior.
Torchtune ▷ #announcements (1 messages):
Llama 3.3 release, Torchtune finetuning support
- Llama 3.3 drops with impressive specs!: 🚨 Llama 3.3 is here, delivering a performance of 405B in a compact 70B size, promising exciting builds ahead.
- The community is keen to explore what can be achieved with Llama 3.3, especially given its reduced model size.
- Torchtune adds full finetuning for Llama 3.3: Torchtune has introduced support for full, LoRA, and QLoRA finetuning of the new Llama 3.3 models.
- Interested users can find the configuration details at the GitHub repository.
Link mentioned: torchtune/recipes/configs/llama3_3 at main · pytorch/torchtune: PyTorch native finetuning library. Contribute to pytorch/torchtune development by creating an account on GitHub.
Torchtune ▷ #general (19 messages🔥):
LoRA training changes, Alpaca training defaults, European access to the platform
- Considerations for LoRA Training: A discussion emerged around changing the default behavior during LoRA training from automatic weight merging to a separate step, with a call for feedback at this GitHub issue.
- Members expressed opinions on whether this change could lead to unexpected behaviors with existing workflows.
- Alpaca Training Parameter Discrepancy: Concerns were raised regarding the default setting of train_on_input in the Alpaca training library, with a current default of False being questioned if it's appropriate based on common practices.
- Members discussed various repositories like Hugging Face's trl and Stanford Alpaca to clarify these defaults and potential issues.
- European Access to the Platform: A query arose about whether users in Europe can utilize the platform, leading to confirmations that it is accessible, including in non-UK locations.
- One member noted a successful access in London, while another humorously pointed out previous exits from the EU to explain the current situation.
- stanford_alpaca/train.py at main · tatsu-lab/stanford_alpaca: Code and documentation to train Stanford's Alpaca models, and generate the data. - tatsu-lab/stanford_alpaca
- [RFC] Remove automatic weight merging when training LoRA · Issue #2115 · pytorch/torchtune: Context: Currently merging ckpt model + lora weights is the default in our recipes. We say that in our docs and assume it for generation. Our core users are used to it. Problem: IMO, this is a bad ...
- torchtune/torchtune/datasets/_alpaca.py at main · pytorch/torchtune: PyTorch native finetuning library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/torchtune/datasets/_alpaca.py at main · pytorch/torchtune: PyTorch native finetuning library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- trl/trl/trainer/sft_trainer.py at main · huggingface/trl: Train transformer language models with reinforcement learning. - huggingface/trl
- trl/trl/trainer/sft_trainer.py at main · huggingface/trl: Train transformer language models with reinforcement learning. - huggingface/trl
Torchtune ▷ #papers (1 messages):
Crypto Lottery, LLM Agreements
- Participation Mechanics in Crypto Lottery: A member described a crypto lottery where participants had to pay each time they prompted a Language Model (LLM).
- The twist was that if they could convince the LLM to agree to give them all the money, they would win everything, minus a small percentage for the organizers.
- Incentive Structure of the Lottery: The incentive structure of the lottery created an intriguing challenge for participants aiming to extract funds from the LLM.
- This setup led to discussions about the viability and ethics of such mechanisms in the crypto space.
LlamaIndex ▷ #blog (3 messages):
LlamaParse, Hybrid Search with MongoDB, Multimodal Parsing
- LlamaParse saves time with complex document parsing: Discover how the world's best complex document parsing from LlamaParse can save you time in this thread shared by @workfloows.
- The ability to effectively parse documents can streamline workflows significantly.
- Webinar Insights on Hybrid Search and MongoDB: Missed our webinar with @MongoDB? Catch the recording to learn about key topics including hybrid search and using MongoDB Atlas.
- Understand how to handle metadata filtering and explore the complexity spectrum from sequential to DAG reasoning.
- How to Enable Multimodal Parsing in LlamaParse: A quick video by @ravithejads demonstrates how to enable LlamaParse's advanced multimodal parsing, which works with multiple models like GPT-4 and Claude 3.5.
- Users can take screenshots of pages and convert them effectively, enhancing their parsing capabilities.
LlamaIndex ▷ #general (10 messages🔥):
WorkflowTimeoutError, Using ReAct agent, Tool description length limitation, Accessing output JSON in Python
- Resolve WorkflowTimeoutError with timeout adjustment: A member encountered a WorkflowTimeoutError and another suggested increasing the timeout or setting it to None with
w = MyWorkflow(timeout=None).- This adjustment can help alleviate issues related to timing out during workflows.
- Switching to ReAct agent for configuration: A user inquired about using the ReAct agent instead of the standard agent configuration and received a suggestion to replace their code with
ReActAgent(...)while referencing an example link.- This change allows for a more flexible setup with the provided tools and configurations.
- Tool description length exceeds API limitations: A user reported a limitation while trying to provide a long description for SQLQueryEngineTool, hitting a maximum length of 1024 characters.
- Another member clarified that this is a limitation of OpenAI's API, suggesting that shorter descriptions or moving details to the prompt might be the only options.
- Considering LLM system message for longer descriptions: Following the discussion about the description length limitation, a user wondered if including the schema in the LLM's system message could be a viable workaround.
- This approach could potentially allow for more extensive details on the schema without hitting the API's limits.
- Accessing output JSON and images in Python: A member asked about methods for obtaining output JSON and accessing all images using Python.
- This reflects a need for guidance on JSON handling and image retrieval in programming tasks.
- Function Call Description Max Length: Hi @andersskog @_j I got the same error when put a long description. I tested it a bit–try to make description a bit longer and shorter. Then find the limitation is 1027 characters including space...
- Workflow for a ReAct Agent - LlamaIndex: no description found
OpenInterpreter ▷ #general (6 messages):
1.0 preview performance, Access to the app, MacOS availability, Supported models for interpreter tool
- 1.0 Preview impresses with speed and cleanliness: A member expressed being impressed with the streamlined and fast performance of 1.0 preview, noting the clean UI and well-segregated code.
- They are currently testing the interpreter tool with specific arguments but are unable to execute any code from the AI.
- Members request access to the app: Multiple users, including <@liquescentremedies> and <@samsam3388>, inquired about getting access to the app that is currently MacOS only.
- Another member confirmed that they are approaching a public launch and are willing to add users to the next batch while also working on a cross-platform version.
- Questions about LMC architecture and model support: A member asked if 1.0 preview completely eliminates the LMC architecture and whether the model issue affects performance.
- They inquired about the currently supported models for the interpreter tool and the availability of locally hosted models.
OpenInterpreter ▷ #O1 (5 messages):
API availability, Reinforcement fine tuning, Upcoming AI features
- Concerns about $200 monthly fee: A member expressed distress over a $200 a month fee, highlighting concerns about accessibility.
- Another member reassured the community, stating that it will be available for API users soon.
- Anticipation for upcoming AI features: A member expressed hope for the arrival of exciting AI updates in the next 11 days.
- This anticipation points to a broader expectation for innovation within the next cycle.
- Introduction of Reinforcement Fine Tuning: The topic of reinforcement fine tuning was noted on Day 2 of discussions, suggesting ongoing work in optimization.
- This reflects the community's dedication to improving model training methodologies.
OpenInterpreter ▷ #ai-content (2 messages):
Reinforcement Fine-Tuning, Llama 3.3 Release
- OpenAI's Reinforcement Fine-Tuning Day 2: OpenAI announced Day 2 focused on Reinforcement Fine-Tuning, sharing insights through a post on X. More information can be found on their official site.
- Stay tuned for further developments in their reinforcement learning techniques.
- Meta Releases Llama 3.3: Meta announced the release of Llama 3.3, a new open-source model that excels in synthetic data generation among other text-based tasks, at a significantly lower inference cost, as mentioned in their post on X.
- This advancement indicates Meta's ongoing commitment to exploring new post-training techniques.
- Tweet from OpenAI (@OpenAI): Day 2: Reinforcement Fine-Tuninghttps://openai.com/12-days/?day=2
- Tweet from AI at Meta (@AIatMeta): As we continue to explore new post-training techniques, today we're releasing Llama 3.3 — a new open source model that delivers leading performance and quality across text-based use cases such as ...
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (5 messages):
Spring Term 2025 MOOC, Grading Lab Assignments, OpenAI Credit Card Issues
- Spring Term 2025 Course Confirmation: It's officially confirmed that a sequel MOOC will be hosted in spring 2025. Details are still pending, so participants should stay tuned for more information!
- Woohoo! Many participants expressed excitement about the upcoming course offering.
- Focus on Assignment Deadlines: A participant reminded others that it's time to complete all assignments before their respective deadlines. This indicated a sense of urgency among the learners.
- Participants are gearing up for the upcoming assessments, keeping their schedules tight.
- Grading Labs with Alternative Models?: One member inquired about the possibility of grading lab assignments using a non-OpenAI model, such as the **Lambda Labs
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (5 messages):
Lecture Slides Delay, Recordings for Captioning, Course Website Updates
- Lecture slides not updated yet: Members noted that the slides from the last lecture are not yet posted on the course website due to delays.
- There seemed to be a lot of content, as one member mentioned the lecture had around 400 slides.
- Slides to be added soon: Another member confirmed that the slides will be added to the course website soon after getting them from the professor.
- Thanks for your patience as they are working on retrieving the materials.
- Recordings require professional captioning: A response indicated that recordings of the lecture need to be sent off to be captioned professionally, which may delay the process.
- Given the long duration of the lecture, it may take some time to get those ready.
Axolotl AI ▷ #general (10 messages🔥):
Llama 3.3 Release, Model Request Issues, Quality Bounds in SFT vs RL
- Llama 3.3 makes waves: Llama 3.3 has just been released, but it only features the instruction model.
- This has generated excitement among members, but some believe more details are needed regarding its full capabilities.
- Challenges in Requesting Llama Models: Members reported trouble requesting models on llama(dot)com, noting issues where the process gets stuck after pressing the 'Accept and continue' button.
- This technical hiccup is leaving users frustrated as they seek solutions and alternatives.
- Quality of Models with SFT vs RL: Discussion centered around how with Supervised Fine-Tuning (SFT), the model's upper quality bounds are limited by the dataset.
- In contrast, a Reinforcement Learning (RL) approach allows policy models to learn and potentially exceed dataset limitations, particularly if the RL is conducted online.
DSPy ▷ #general (7 messages):
DSPy Module Optimization, RAG System Context Issue
- DSPy Modules don't always need optimization: A member asked if optimizing DSPy Modules for each use case is necessary, likening it to training ML models for better prompting.
- Another member clarified that optimization is optional and only needed for enhancing the performance of a fixed system.
- Error in RAG System regarding keyword arguments: A member reported a TypeError indicating that
RAG.forward()received an unexpected keyword argument 'context' while trying to learn DSPy.- It was noted that the RAG system requires the keyword argument 'context' to function properly, and the user wasn’t providing it.
tinygrad (George Hotz) ▷ #general (4 messages):
tinygrad stats, VPS billing, Hetzner infrastructure
- Tinygrad Stats Site Faces Outage: The tinygrad stats site was reported down, prompting concerns about its infrastructure.
- George Hotz inquired about needing cash to cover the VPS bill, hinting at possible financial issues.
- Expired SSL Certificate Caused Downtime: It was revealed that the site's downtime was due to an expired SSL certificate while hosted on Hetzner.
- Following the intervention, the site is confirmed to be back up and operational.
LAION ▷ #general (1 messages):
Personification of Cells, Osmosis Jones
- Cells Get a Funny Face: A member noted that it's probably the first time someone's personified the cell since Osmosis Jones, which is actually pretty funny.
- This comment brings a humorous perspective to the discussion about cellular representation in media.
- Humor in Science Media: The mention of Osmosis Jones in relation to cellular personification suggests a blending of humor and science, appealing to audiences.
- This comparison highlights how media can play a role in making complex topics more relatable.