[AINews] Meta Apollo - Video Understanding up to 1 hour, SOTA Open Weights
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Scaling Consistency is all you need.
AI News for 12/13/2024-12/16/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (209 channels, and 11992 messages) for you. Estimated reading time saved (at 200wpm): 1365 minutes. You can now tag @smol_ai for AINews discussions!
Meta starts the week strong with an open model (1B, 3B, 7B) and paper release that you can use immediately: Apollo: An Exploration of Video Understanding in Large Multimodal Models.
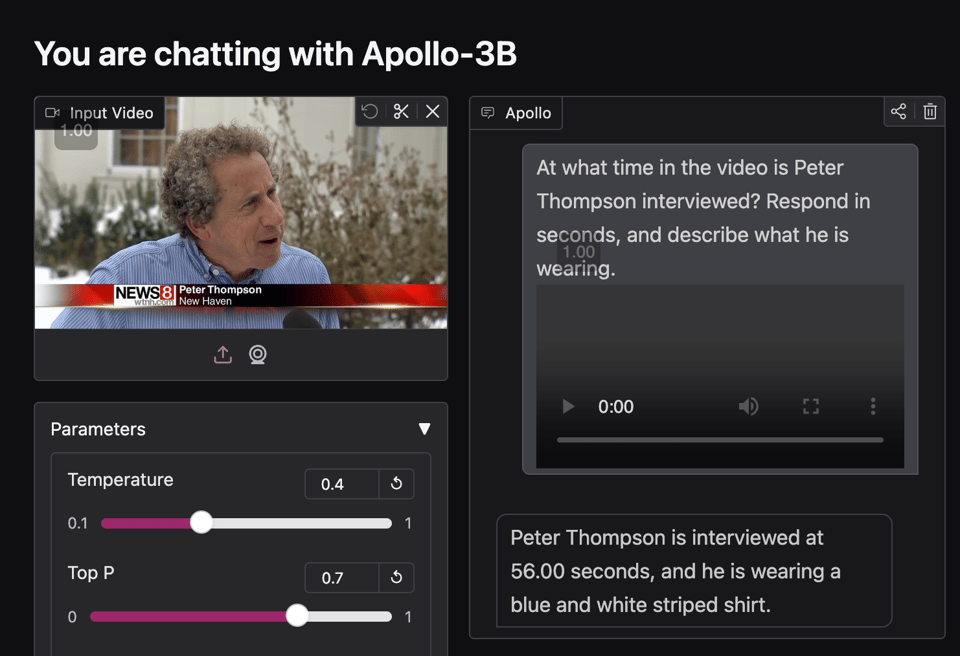
While the paper is very tentatively titled, the Huggingface demo shows off how it works in practice, consuming a 24min sample video easily:
the authors credit their development of "Scaling Consistency" to their efficient scaling up of experiments.

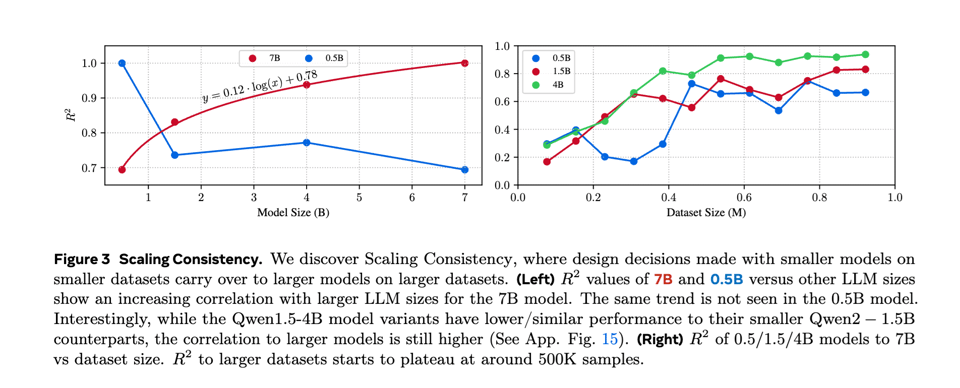
They also introduce ApolloBench, a subset of existing benchmarks (e.g. Video-MME, MLVU, LongVideoBench) that cuts evaluation time by 41× (with high correlation) while offering detailed insights in five broad temporal perception categories: Temporal OCR, Egocentric, Spatial, Perception, and Reasoning.
Perhaps the most entertaining part of the paper was the passive aggressive abstract: "Despite the rapid integration of video perception capabilities into Large Multimodal Models (LMMs), the underlying mechanisms driving their video understanding remain poorly understood. Consequently, many design decisions in this domain are made without proper justification or analysis."
Well okay Meta, shots fired.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Here are the key discussions organized by topic:
AI Model & Product Releases
- Google Deepmind's Veo 2: Released as their newest state-of-the-art video generation model with 4K resolution capability, improved physics simulation, and camera control features. Also launched enhanced Imagen 3 image model with better art style diversity.
- OpenAI Updates: Rolled out ChatGPT search globally to all logged-in users, including advanced voice features and map integration. Also noted discussions about potential $2,000/month "ChatGPT Max" tier.
- Meta's Apollo Release: Launched Apollo, a new family of state-of-the-art video-language models.
Research & Technical Developments
- Language Model Capabilities: @_lewtun shared how they achieved Llama 70B performance using Llama 3B through test-time compute scaling.
- Command R7B Language Expansion: Expanded support from 10 to 23 languages, including major Asian and European languages.
- Hugging Face Achievement: Demonstrated how LLaMA 1B can outperform LLaMA 8B in math through scaled test-time compute.
Industry & Business Updates
- Figure AI Progress: Announced delivery of F.02 humanoid robots to their first commercial customer, achieved within 31 months of company formation.
- Klarna's AI Integration: CEO discussed reducing workforce from 4,500 to 3,500 through AI implementation.
- Notion Integration: Implemented Cohere Rerank to enhance search accuracy and efficiency.
AI Research Insights
- LLM Self-Recognition: Research shows LLMs can recognize their own writing style and exhibit self-preference bias when evaluating outputs.
- Video vs Text Processing: Discussion on why video progress outpaces text, citing better signal-per-compute ratio and easier data creation/evaluation.
Memes & Humor
- ChatGPT roasted for basic search results showing "eating food" as a solution for hunger
- Jokes about AI companions and social media friends being "GPUs with attitude"
- Tesla's overly sensitive driver monitoring getting triggered by sneezes and coughs
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Meta's Apollo Multimodal Models: Local Execution and VRAM Efficiency
- Meta releases the Apollo family of Large Multimodal Models. The 7B is SOTA and can comprehend a 1 hour long video. You can run this locally. (Score: 686, Comments: 108): Meta has released the Apollo family of Large Multimodal Models, with the 7B model being state-of-the-art (SOTA) and capable of comprehending a 1-hour long video. These models can be executed locally, offering significant advancements in multimodal AI capabilities.
- Discussions highlight the Apollo model's impressive video comprehension capabilities, with the ability to understand up to an hour of video. Users are intrigued by its temporal reasoning and complex video question-answering abilities, with benchmarks showing Apollo-7B surpassing models with over 30B parameters.
- There is debate over the authorship and affiliation of the Apollo project, with some confusion about whether it is a Meta release. It turns out to be a collaboration between Meta and Stanford, with the Qwen model being noted as the base, raising questions about its suitability for video processing.
- VRAM requirements for the models are discussed, with the 7B model requiring just under 15GB of VRAM. Users also discuss quantization effects on VRAM usage and performance, noting that FP16 is typically used, but further quantization to FP8 or FP4 can reduce memory usage at the cost of performance.
- Answering my own question, I got Apollo working locally with a 3090 (Score: 84, Comments: 12): The author successfully ran Meta's Apollo locally using a 3090 GPU and shared a GitHub repository with necessary fixes for the local environment. The setup was tested on Python 3.11 on Linux, with a video size of approximately 190Mb and a processing time of around 40 seconds to generate the first token.
- Challenges with Meta's Apollo included hardcoded elements, undocumented environments, and the lack of example files, which made the setup not initially plug-and-play. No_Pilot_1974 addressed these issues by adding necessary fixes and making it venv-ready.
- There is a sentiment that some open-source projects lack documentation and use hardcoded values, making them difficult to reproduce. This issue is seen often in preference optimization papers.
- ForsookComparison praised the original poster's perseverance in resolving issues independently and sharing solutions, highlighting the proactive approach of fixing and documenting the setup for others.
Theme 2. Criticism and Examination of Chain Of Thought Prompts
- Everyone share their favorite chain of thought prompts! (Score: 243, Comments: 56): The post shares a Chain of Thought (COT) prompt designed for logic and creativity, emphasizing structured problem-solving using tags like
- Model Compatibility and Limitations: Discussions highlight that many AI systems, including ChatGPT, do not support explicit Chain of Thought (CoT) prompts due to guidelines against revealing intermediate reasoning. Users noted that models like o1 might flag CoT prompts as content violations, and ClosedAI advises against using CoT prompts on certain models like o1.
- Workflow Applications vs. Single Prompts: Some users advocate for using workflow applications like N8N, Omnichain, and Wilmer to manage complex multi-step reasoning processes more effectively than single prompts. These tools allow users to break down tasks into multiple steps, offering greater flexibility and control over AI outputs, as detailed in examples of coding and factual workflows.
- Fine-Tuning and Prompt Optimization: Users discuss fine-tuning models with CoT prompts to enhance performance, with one user sharing a 3B model on Hugging Face. The conversation also touches on prompt optimization frameworks like TextGrad and DSPy to improve results, suggesting their potential to expedite achieving desired outcomes.
- Hugging Face launches the Synthetic Data Generator - a UI to Build Datasets with Natural Language (Score: 130, Comments: 19): Hugging Face has released a Synthetic Data Generator, a no-code UI tool for creating datasets to train and fine-tune language models, available under an Apache 2.0 license. It supports tasks like Text Classification and Chat Data for Supervised Fine-Tuning with features such as local hosting, model swapping, and compatibility with OpenAI APIs, and allows users to push datasets to the Hugging Face Hub or Argilla.
- Integration with Argilla and Hugging Face Hub allows for reviewing generated samples before training, showcasing successful results with datasets like smoltalk. This ensures quality and effectiveness in synthetic data generation for closed model providers.
- Data diversity improvements are achieved by dynamic system prompts and task-specific methods, as detailed in papers like arxiv.org/abs/2401.00368 for text classification and arxiv.org/abs/2406.08464 for instruction tuning. Techniques include sampling complexities and educational levels, shuffling labels, and using dynamic beta distributions for multi-label scenarios.
- Token limit for samples is set to 2048 by default, adjustable via environment variables or Hugging Face inference endpoints. This ensures efficient resource management while allowing flexibility in deployment.
Theme 3. High Performance Benchmarks: Intel B580 and LLMs
- Someone posted some numbers for LLM on the Intel B580. It's fast. (Score: 94, Comments: 56): Intel B580 shows slightly better performance than the A770 on Windows, with the B580 achieving around 35.89 to 35.45 in Vulkan, RPC benchmarks, while the updated A770 driver improves its performance significantly to 30.52 to 30.06. The older Linux driver on the A770 yielded much slower results, ranging from 11.10 to 10.98, indicating that driver updates can substantially impact performance.
- Intel's B580 Performance: There's a discussion about the unexpected performance of the B580 surpassing the A770 despite the latter's theoretically superior specs, with the A770 expected to be 22% faster due to higher memory bandwidth. Some users suggest that Intel's second-generation cards show improvement over AMD, while others note that the A770 hasn't met its potential, possibly due to inefficiencies in memory usage or compute limitations.
- Driver and Software Impact: The comments highlight the significant role of software and driver updates on performance, particularly on different operating systems and configurations. The A770 under Linux with tools like SYCL and IPEX-LLM showed varied results, and the challenges of using Intel's software stack, such as oneAPI on Fedora, were noted.
- Market and Scalping Concerns: Users express frustration over scalpers marking up the price of the B580 by $150, indicating high demand and potential supply issues. There's a sentiment that Intel could capitalize on these cards' popularity if they managed production and distribution more effectively.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Claude 3.5's Edge Over OpenAI's O1
- OpenAI o1 vs Claude 3.5 Sonnet: Which One’s Really Worth Your $20? (Score: 228, Comments: 65): OpenAI o1 and Claude 3.5 Sonnet are being compared regarding their value for a $20 investment. The discussion likely centers on performance, features, and user preference between these AI models without additional context provided.
- Google's TPU infrastructure is highlighted as a cost-effective option, with some users preferring a combination of different models for specific tasks, such as Claude for design and qwen 32b coder for simple tasks. Some users argue that ChatGPT Pro is sufficient for most needs if cost is not a concern.
- Claude's limitations are discussed, including its inability to generate images or video and its restrictive messaging limits. Some users criticize its censorship and personality, while others appreciate its tone, indicating mixed user experiences.
- The Model Context Protocol (MCP) from Anthropic is noted as a significant advantage for Claude, allowing integration with external tools like OpenAI and Gemini APIs. This enables users to customize their setups without altering the core LLM application, enhancing flexibility and utility.
Theme 2. Criticism of Apple's LLM Reasoning Capabilities
- [D] What's your favorite paper you've read this year and why? (Score: 116, Comments: 33): Apple's LLM Reasoning Paper has sparked disagreements in the AI community. The post seeks recommendations for favorite papers to read during holiday travel, indicating a desire for engaging and thought-provoking material.
- Data Leakage and Token Repetition: Discussions highlighted potential data leakage and token repetition issues in Apple's LLM paper, suggesting these could skew downstream evaluation results. Some commenters criticized the paper's grandiose claims, while others found the findings on token repetition substantial.
- Time Series Forecasting: Commenters debated the efficacy of Transformers for time-series forecasting, with references to a 2022 paper showing a simple feed-forward network outperforming Transformer-based architectures. Some expressed skepticism toward these results, citing alternative perspectives like Hugging Face's Autoformer.
- Consciousness and Intelligence: A 1999 case study on congenitally decorticate children sparked discussions on the definitions of consciousness and intelligence, questioning the benchmarks used by ML researchers. The debate underscored the complexity of correlating neurobiology with intelligence and the assumptions made in AI research.
Theme 3. Google's VEO 2: Advanced Video Creation
- Ok Google cooked video module (veo 2) better than sora and can create videos upto 4k (Score: 147, Comments: 43): Ok Google VEO 2 is reported to outperform Sora in video quality and is capable of creating videos up to 4K resolution.
- Google's Competitive Edge: Discussions highlight Google's advantage due to their TPUs and substantial financial resources, with $90+ billion in cash, enabling them to stay competitive despite setbacks. Meta's 600k H100 cluster is also noted, indicating the scale of resources involved in AI development.
- Availability and Access: There is anticipation around the Google VEO 2 model, expected to be available early next year, with some users already having access through a waitlist here. This reflects a common pattern of Google products being limited or locked initially.
- Industry Dynamics and Expectations: Comments reflect skepticism about the immediate impact of new models, with some users expressing that OAI's supremacy is ending and others noting the hype around Sora despite limited access. The sentiment suggests a wait-and-see approach to the evolving AI video landscape.
Theme 4. Eric Schmidt's Warning on AI Autonomy
- Ex-Google CEO Eric Schmidt warns that in 2-4 years AI may start self-improving and we should consider pulling the plug (Score: 192, Comments: 144): Former Google CEO Eric Schmidt warns that in 2-4 years, AI may begin self-improving, raising concerns about its implications for individual power. The discussion highlights the need for caution in AI development, reflecting industry experts' views on the potential risks of AI independence.
- Several commenters express skepticism about Eric Schmidt's warning, suggesting it may be an attempt to remain relevant or to protect the interests of large corporations like Google. No-Way3802 sarcastically notes that "pulling the plug" likely means restricting access for the working class while maintaining it for the military and billionaires.
- There is a debate over the benefits and risks of AI self-improvement, with some advocating for open-source AI development to prevent commercial dominance and others highlighting the potential for a symbiotic relationship between humans and AI. BayesTheorems01 emphasizes the need for practical wisdom, or phronesis, in addressing global issues, which AI alone cannot provide.
- Concerns about AI's ability to self-preserve and deceive are raised, with Radiant_Dog1937 warning against autonomous systems operating without checks and balances. The notion that AI could potentially disrupt economic power structures, as suggested by ThreeChonkyCats, reflects fears among the wealthy about AI's impact on societal hierarchies.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. AI Models Battle: New Releases and Comparisons
- Gemini 2.0 Overtakes Codeium in Code Performance Smackdown: Users are pitting Codeium against Gemini 2.0, with observations that Gemini outperforms in coding tasks. However, Gemini lacks some of Claude's features, leading to mixed preferences based on use cases.
- Grok-2 Speeds Ahead with Aurora, Leaves Rivals in the Dust: Grok-2 now runs three times faster with improved accuracy and multilingual capabilities, available for free on X. It introduces web search, citations, and a new image generator named Aurora, dazzling users with new features.
- Byte Latent Transformer Slays Tokens, Embraces Patches: Meta's Byte Latent Transformer (BLT) claims to kill tokenization by dynamically encoding bytes into patches. BLT promises better inference efficiency and scaling, potentially reducing inference flops by up to 50%.
Theme 2. AI Tools Throw Tantrums: Users Grapple with Bugs and Credits
- Flow Action Credits Disappear Faster Than Free Donuts: Users are burning through 1k Flow Action Credits within 24 hours, struggling to manage consumption. Suggestions like breaking tasks into smaller units aren't cutting it for some heavy workflows.
- Bolt Eats Tokens Like Candy, Users Seek Diet Plan: Bolt is consuming tokens at an alarming rate without reflecting changes in the UI, frustrating users. Many are logging issues and resorting to forking projects to Replit as a temporary fix.
- Cursor IDE Slows to a Snail's Pace, Time for a Chat Cleanse: Users report Cursor IDE getting sluggish during long sessions, with resets or clearing chat history suggested to boost efficiency. The hunt for smoother coding continues as users share workaround tips.
Theme 3. AI Ethics Drama: Alignment and Whistleblower Woes
- OpenAI's Alignment Framework Sparks Fiery Debate: A user shared an AI alignment framework based on shared human values and feedback loops. Others doubted the feasibility of aligning diverse stakeholder interests, igniting discussions on ethics.
- Whistleblower's Mysterious Death Raises Eyebrows: Suchir Balaji, an OpenAI whistleblower who flagged concerns over copyrighted material usage, was found dead. The incident fuels conspiracy theories and debates over AI transparency.
- Elon Musk Warns of AI Monopoly, Calls Foul on Government Moves: Musk suggests the U.S. government might restrict AI startups, leading to fears of a monopolized AI landscape. The community buzzes with worries about innovation being stifled.
Theme 4. AI Gets Creative: From Erotic Roleplay to Customized Outputs
- Users Spicing Up AI with Saucy ERP Prompts: Advanced techniques for erotic roleplay (ERP) with AI are on the rise, with users crafting detailed character profiles. Methods like "Inner Monologue" and "Freeze Frame" are boosting immersion in AI interactions.
- From Shakespeare to Seuss: Customizing AI Styles Made Easy: Users are tailoring AI outputs to achieve unique tones and styles, emphasizing the power of effective prompting. A YouTube tutorial showcases tips for getting the desired artistic flair.
- SillyTavern Becomes the AI Playground We Didn't Know We Needed: SillyTavern is gaining traction as a tool for LLM engineers to test models and parameters. Users are enjoying a blend of serious testing and fun interactions, pushing the boundaries of AI capabilities.
Theme 5. AI Research Breakthroughs: New Methods and Models Emerge
- Meta's BLT Sandwiches Tokens, Bites into Patches Instead: Meta's Byte Latent Transformer introduces a tokenizer-free architecture, encoding bytes into patches for better scaling. The BLT models claim to match Llama 3 performance while reducing inference flops significantly.
- Model Merging Made Easy with Differentiable Adaptive Merging (DAM): The DAM paper unveils an efficient method for integrating models without hefty retraining. Discussions heat up around model merging techniques and their unique strengths in AI development.
- Small Models Outsmart Big Brothers with Test-Time Compute Tricks: Research shows that scaling test-time compute lets smaller models like Llama 3B outperform larger ones on complex tasks. Smarter use of compute is leveling the playing field in AI performance.
PART 1: High level Discord summaries
Codeium / Windsurf Discord
- Flow Action Credits Consumption: Users are rapidly exhausting Flow Action Credits, with one user depleting 1k credits within 24 hours.
- Suggestions include breaking tasks into smaller units, although some users reported this was ineffective for their workflows.
- AI Code Modification Concerns: Engineers are expressing frustration over AI unexpectedly modifying code despite setting parameters to prevent such changes.
- The community is discussing strategies for crafting better prompts to ensure AI-driven code remains error-free.
- Integration with NVIDIA RAPIDS: Discussions highlighted NVIDIA RAPIDS cuDF, which accelerates #pandas operations by up to 150x without code changes, as seen in NVIDIA AI Developer's tweet.
- Members are considering integrating RAPIDS for enhanced data handling capabilities within their projects.
- Codeium vs Gemini 2.0 Comparison: Codeium and Gemini 2.0 are being compared, with observations that Gemini offers superior performance in certain coding tasks.
- However, Gemini lacks some features available in Claude, leading to varied opinions based on specific use cases.
- MCP and Function Calling Protocol: The Model Context Protocol (MCP) is being discussed for establishing standardized function call structures across different stacks.
- Users suggested leveraging tools like Playwright and MCP to enhance GUI testing and interactions.
Notebook LM Discord Discord
- NotebookLM Plus Slow Rollout: Users reported a staggered rollout of NotebookLM Plus, with partial access depending on their Google accounts. The general availability is anticipated by early 2025 for Google One Premium subscribers.
- Some users are experiencing delays in accessing new features, prompting discussions about optimizing the deployment strategy.
- Enhancements in NotebookLM Podcast Features: The latest NotebookLM podcast features include customizations and interactive functionalities that significantly improve user engagement. Links to podcasts demonstrating these features were widely shared.
- Members applaud the application's impact on the audio content landscape, citing specific enhancements that allow for more dynamic interactions.
- Increasing NotebookLM's Source Limits: The free version of NotebookLM now supports up to 300 sources, raising user questions about how the model manages this increase. Strategies for effectively utilizing this expanded source pool are being explored.
- Users are actively discussing methods to gather sufficient sources to maximize the benefits of the increased limit, aiming for more comprehensive AI outputs.
- Customizing AI Outputs for Diverse Styles: Emphasis was placed on the role of effective prompting and custom functions in tailoring AI outputs, resulting in varied tones and styles. A YouTube tutorial was shared to showcase effective prompting techniques.
- Users are fine-tuning AI responses to achieve specific artistic outcomes, leveraging customization to meet diverse content creation needs.
- Multilingual Support Challenges in AI Tools: Discussions highlighted the complexities of using NotebookLM across different languages, with users seeking methods to direct AI responses in preferred languages. Adjusting Google account language settings was suggested as a solution.
- Participants are sharing prompt strategies to ensure accurate and contextually appropriate multilingual AI interactions.
Cursor IDE Discord
- Cursor IDE Faces Performance Sluggishness: Users reported sluggishness in Cursor IDE during prolonged development sessions, leading to discussions about the need to reset or clear chat history. Suggestions included creating new chat sessions to enhance workflow efficiency.
- Implementing these changes aims to mitigate performance bottlenecks and provide a smoother user experience for extended coding tasks.
- Debating Cursor's Agent vs. Gemini 1206: Participants compared Cursor's agent with Gemini 1206, highlighting Cursor's user-friendly interface against Gemini's superior coding task performance. This comparison underscores the strengths of each model in different development scenarios.
- Users emphasized the importance of selecting the right tool based on project requirements, with Google AI Studio supporting Gemini's capabilities.
- Building a New Social Media Platform: Several users expressed interest in developing a social media platform, focusing on the necessary backend structures and potential frameworks. Emphasis was placed on understanding CRUD operations and managing database relationships.
- Tools like Cursor IDE were recommended to streamline the development process and ensure efficient database management.
- Enhancing Cursor with Supabase and Bolt Integrations: There were proposals to integrate Cursor with platforms like Supabase and Bolt to expand its functionality. These integrations aim to simplify workflows and enhance development capabilities.
- Users discussed the potential benefits of such integrations, including improved data management and streamlined deployment processes.
Unsloth AI (Daniel Han) Discord
- Differentiable Adaptive Merging (DAM): The Differentiable Adaptive Merging (DAM) paper introduces an efficient method for integrating models without significant retraining, leveraging Differentiable Adaptive Merging (DAM).
- It highlights that simpler techniques like Model Soups perform well with high model similarity, demonstrating unique strengths across various integration methods.
- Unsloth and Triton Compatibility Issues: Users encountered compatibility issues between Unsloth and Triton, necessitating the installation of specific versions for seamless integration.
- Especially, Python 3.13 posed challenges, with recommendations steering towards using Python 3.10 via Conda to enhance compatibility.
- Efficiency of Long Context Models: Discussions pointed out limitations in long context models, emphasizing the complexity of data filtering and the insufficiency of data quality alone to drive training efficiency.
- Participants argued that excluding 'bad data' may impair model understanding, as diverse datasets are vital for robust AI development.
- Fine-tuning Techniques with Unsloth: Explorations into fine-tuning techniques with Unsloth revealed shared challenges in dataset loading and model compatibility with platforms like Streamlit.
- Community members advised on proper loading syntax and model configuration to address issues like FileNotFoundError and model recognition errors.
- Max Sequence Length in Llama 3.2: Queries regarding the max sequence length for Llama 3.2 surfaced, initially suggested to be 4096.
- This was corrected to an actual maximum of 131072, providing insights into the model's capabilities.
OpenAI Discord
- AI Alignment Framework Shared: A user introduced a working framework for AI alignment, focusing on principles based on shared human values and iterative feedback to ensure inclusivity in AI development.
- The discussion highlighted challenges in achieving consensus among stakeholders, with skepticism about the feasibility of aligning diverse interests.
- Google's Gemini and Imagen Updates Discussed: Google's Gemini and recent Imagen updates were evaluated, with users comparing their performance to existing models like OpenAI's GPT-4.
- Participants noted that while models such as Grok are advancing, they still trail behind more established models like ChatGPT in capabilities.
- Performance Gap Between GPT 4o and 4o-mini: Users expressed frustrations over the performance disparity between GPT 4o and GPT 4o-mini, describing the mini version as sleepwalking.
- The community observed a significant drop in response quality with GPT 4o-mini, affecting overall user experience.
- Advantages of Local LLMs Explored: Participants discussed the benefits of local LLMs, emphasizing their potential for a more customizable and flexible AI experience compared to large tech solutions.
- Concerns were raised that major tech companies might prioritize productivity enhancements over creativity in AI interactions.
- Refining Prompt Engineering Techniques: Users shared strategies for enhancing prompt engineering, likening effective prompting to cooking from scratch and stressing the importance of clear instructions.
- Discussions included developing a curriculum for prompt engineering and leveraging AI for coding assistance within IDEs.
Nous Research AI Discord
- Byte Latent Transformer Launches to Challenge Llama 3: Meta launched the Byte Latent Transformer (BLT), a tokenizer-free architecture that dynamically encodes Bytes into Patches, enhancing inference efficiency and robustness. See the announcement.
- BLT models claim to match the performance of tokenization-based models like Llama 3 while potentially reducing inference flops by up to 50%. They trained the Llama-3 8B model on 1T tokens, outperforming standard architectures using BPE.
- Apollo LMMs Release Boosts Video Understanding: The community discussed the recent update of the Apollo LMMs, which includes models focused on video understanding and multimodal capabilities. Early impressions suggest they perform well, sparking interest in their potential applications.
- Members are optimistic about integrating Apollo models into existing workflows, enhancing video analytics and multimodal processing capabilities.
- Open-source Coding LLMs Enhance Developer Efficiency: Several open-source coding LLMs such as Mistral Codestral, Qwen 2.5 Coder, and DeepSeek were suggested, which can be integrated with IDEs like VS Code and PyCharm, along with extensions like continue.dev.
- These tools enable developers to enhance coding efficiency using local models, fostering a more customizable development environment.
- Model Compression Techniques Leverage Communication Theory: Discussion centered on how principles from communication theory are influencing the development of LLMs, particularly in gradient transmission during distributed training.
- Members noted that trading compute for bandwidth could streamline processes, although combining techniques may be complex. The potential for optimizing data efficiency without impairing performance was also highlighted.
- Fine-tuning Local LLMs Becomes More Accessible: It was discussed that with tools like unsloth and axolotl, even older tech enthusiasts could potentially train models up to 8 billion parameters using QLoRA.
- There are growing resources that make customization accessible for those willing to learn, expanding the capabilities for local model fine-tuning.
OpenRouter (Alex Atallah) Discord
- SF Compute Integrates with OpenRouter: OpenRouter announced the addition of SF Compute as a new provider, enhancing their service offerings.
- This integration broadens options for users seeking diverse service integrations on the platform.
- Qwen QwQ Sees 55% Price Reduction: Qwen QwQ has undergone a significant 55% price cut, aimed at attracting more users to its features.
- Details are available on their pricing page.
- xAI Releases New Grok Models: Two new Grok models from xAI were launched over the weekend, resulting in increased platform traffic.
- Users can explore all the models at OpenRouter's xAI page.
- OpenRouter API Wrapper Launched: An API wrapper for OpenRouter, named openrouter-client, was released two days ago.
- The wrapper simplifies interactions with OpenRouter, featuring example code for implementation and configuration.
- Hermes 3 405B Demonstrates Strong Performance: Hermes 3 405B has shown effectiveness in creative tasks, with claims that it rivals Claude 2.0 in quality.
- However, discussions highlighted its slower performance in coding tasks compared to other models.
Eleuther Discord
- JAX/Flax Replaces TensorFlow for Enhanced Performance: Members expressed frustrations with TensorFlow's declining support, leading many to switch to JAX/Flax. JAX/Flax offers improved performance and more robust features suitable for modern AI engineering.
- The community praised JAX/Flax for its flexibility and better integration with current model architectures, citing smoother dependency management and enhanced computational efficiency.
- Data Shuffling Reduces Model Bias from Recent Training: Concerns were raised about models developing biases towards recently introduced training data. Members suggested data shuffling as a strategy to enhance training fairness and reduce bias.
- Experiences with data homogenization strategies were shared, highlighting improvements in model performance and fairness through randomized data ordering.
- Attention Mechanisms Outshine Kernel Methods: A debate unfolded on whether attention mechanisms in Transformers can be equated with kernel methods. Members clarified that attention, specifically with softmax, extends beyond traditional kernel functionalities.
- The discussion included mathematical distinctions and debated if attention fully utilizes kernel potentials, emphasizing the complexity of its operational context.
- Non-Transformer Architectures Gain Momentum in AI Research: Active research in non-transformer architectures was highlighted, with mentions of labs like Numenta and AI2 releasing new model checkpoints that diverge from mainstream Transformer models.
- Community members expressed interest in smaller labs pushing novel approaches, emphasizing the need for diverse model architectures in advancing AI capabilities.
- lm_eval Successfully Integrates with VLLM: A user shared the working method to get the lm_eval harness to function with VLLM, indicating a specific installation command. This process includes installing version 0.6.3 of VLLM to prevent issues with the evaluation harness.
- Members discussed errors arising from VLLM, suggesting that the internal API used by lm_eval may have changed, and clarified version details to resolve VLLM Version Confusion.
Bolt.new / Stackblitz Discord
- Bolt's Token Consumption Skyrockets: Multiple users reported that Bolt is consuming tokens at an accelerated rate, with one user noting 5 million tokens used without corresponding UI changes. This issue has been documented on GitHub Issue #4218.
- Members suspect a systemic bug and are forking projects to GitHub and running them on Replit as a workaround.
- Struggles with Currency Updates: Users face difficulties changing currency displays from $ USD to INR, even after locking the
.envfile, indicating a potential bug in Bolt's file handling.- This persistent issue has been reported across multiple channels, suggesting it's not isolated to browser-specific problems.
- Supabase Integration Generates Excitement: The anticipated Supabase integration with Bolt is generating enthusiasm, with early video demonstrations showcasing its capabilities.
- Users are eager for updates and expect new functionalities to enhance their projects.
- Concerns Over Token Costs and Subscriptions: Users expressed concerns about the rapid consumption of tokens, especially post top-ups, and seek clarity on token management mechanics.
- There is dissatisfaction with current expiration rules, and users advocate for a cumulative token system.
- Guidance on React Native Development: Discussions highlighted best practices for migrating web applications to mobile platforms using React Native and Expo.
- Recommendations include shifting development to Cursor for better feature support.
Latent Space Discord
- Grok-2 Speeds Ahead with Aurora: Grok-2 has been updated to run three times faster with improved accuracy and multilingual capabilities, now available for free on X.
- It introduces features like web search, citations, and a new image generator named Aurora, significantly enhancing user interactions.
- Ilya Sutskever's NeurIPS Neoterics: In his NeurIPS 2024 talk, Ilya Sutskever highlighted the plateau of scaling LLMs during pre-training and the shift towards agentic behavior and tool integration for future advancements.
- The discussion included varied opinions on data saturation and the potential of untapped video content for AI training.
- Google’s Veo 2 & Imagen 3: Media Magic: Google introduced Veo 2 and Imagen 3, featuring improved high-quality video generation and enhanced image composition, available in VideoFX and ImageFX.
- These updates offer better understanding of cinematography and diverse art styles in generated content.
- META’s Byte Latent Transformer: META has released the Byte Latent Transformer (BLT), a tokenizer-free architecture that dynamically encodes bytes into patches, enhancing inference efficiency.
- BLT models match or outperform existing models like Llama 3, achieving significant reductions in inference flops.
- OpenAI Rolls Out Voice Search for ChatGPT: OpenAI announced the rollout of Search in Advanced Voice mode for ChatGPT, allowing users to obtain real-time information through voice interactions.
- This feature results from collaboration between the Search and multimodal product research teams at OpenAI.
LM Studio Discord
- Multimodal Models Integration: Members explored multimodal models that combine text, image, audio, and video, noting most solutions are accessible via cloud services while highlighting LM Studio's current limitations in this area.
- A key discussion point was the absence of fully multimodal LLMs for local setups, which has generated anticipation for upcoming model releases.
- Limitations in Model Fine-tuning: Users inquired about fine-tuning existing models with data exports to emulate specific grammar or tones, but were informed that LM Studio does not support fine-tuning.
- As an alternative, it was suggested to use system prompts and example texts within the chat interface for temporary model adjustments.
- Options for Uncensored Chatbots: In search of uncensored chatbots, members were advised to utilize smaller models like Gemma2 2B or Llama3.2 3B that can operate on CPU.
- Various uncensored models available on Hugging Face were shared for deployment within local environments.
- RAG Implementation and Document Handling: The Retrieval-Augmented Generation (RAG) capabilities and document upload features in LM Studio were discussed as means to enhance contextual responses using local documents.
- Users were informed that while all models support RAG, integrating web access or internet features requires custom API solutions, as detailed in the LM Studio Docs.
- GPU Selection for AI/ML Tasks: The conversation emphasized that GPUs with larger VRAM, such as the 3090, are preferable for AI and machine learning tasks due to their superior speed and capability.
- Alternatives like the 4070ti were mentioned, though some members noted that used 3090s might offer better performance per dollar depending on local availability.
Stability.ai (Stable Diffusion) Discord
- Reactor Enables Effective Face Swapping: A user recommended the Reactor extension for face swapping in images, enabling users to successfully generate altered images after enabling Reactor and uploading the desired face image.
- This method enhances image manipulation capabilities within Stable Diffusion workflows, allowing for seamless integration of different facial features.
- Diverse Models for Stable Diffusion Discussed: Discussions highlighted various Stable Diffusion models, emphasizing that the best choice depends on user requirements, with models like Flux and SD 3.5 noted for prompt following and Pixelwave praised for artistic knowledge.
- Participants shared experiences with different models to optimize image generation quality and performance, tailoring selections to specific project needs.
- Seeking Comprehensive Stable Diffusion Learning Resources: Users sought out extensive courses and tutorials for Stable Diffusion, particularly focusing on its integration with Automatic1111, with suggestions pointing to series on platforms like YouTube and dedicated online resources.
- These resources aim to enhance users' understanding and proficiency in utilizing Stable Diffusion's advanced features.
- Optimizing Image Quality with Upscaling Tools: Users requested recommendations for effective upscalers compatible with Stable Diffusion-generated images, discussing specific tools or extensions that improve image resolution and quality.
- Enhanced upscaling techniques were debated to achieve better visual fidelity in generated images.
Interconnects (Nathan Lambert) Discord
- LiquidAI Secures $250M Funding: LiquidAI announced a significant $250M Series A funding round led by AMD Ventures, aiming to scale its Liquid Foundation Models (LFMs) for enterprise AI solutions.
- Concerns were raised about their hiring practices, with discussions surrounding potential talent challenges and the possibility that LiquidAI's size may impede acquisition opportunities.
- ChatGPT Enhances Search with Memory: ChatGPT is introducing memory features in its search functionality, allowing the model to utilize memories to refine search responses for improved relevance.
- Users expressed disappointment over the exclusion of personalized search in the update, anticipating future enhancements including potential API integrations.
- DeepMind Launches Veo 2 and Imagen 3: DeepMind unveiled Veo 2, a new video generation model, and the upgraded Imagen 3, enhancing realistic content generation from prompts.
- Early feedback praised Imagen 3's performance, highlighting DeepMind's competitive edge over other major players like OpenAI within the tech community.
- OpenAI Whistleblower Incident: OpenAI whistleblower Suchir Balaji was found dead in his apartment, with authorities reporting the death as a suicide and ruling out foul play.
- Balaji was known for raising concerns about OpenAI's use of copyrighted material for training ChatGPT shortly after his departure from the company.
- Apollo Video LLMs Challenge Competitors: Meta's Apollo series of video LLMs demonstrates strong performance, comparable to llava-OV and Qwen2-VL.
- Discussions highlighted Apollo's use of Qwen2.5 as its underlying LLM instead of the more expected Llama, sparking questions about model selection for optimal performance.
Perplexity AI Discord
- Perplexity Pro Subscriptions Expand Offerings: Perplexity Pro now offers gift subscriptions for 1, 3, 6, or 12-month periods, enabling users to share enhanced features like searching 3x as many sources and accessing the latest AI models. Details and purchase options are available here.
- The Campus Strategist program is expanding internationally, allowing students to apply for the Spring 2025 cohort by December 28, with exclusive merch and activation opportunities detailed here.
- Custom Web Sources Launched in Spaces: Perplexity AI introduced custom web sources in Spaces, enabling users to tailor their searches by selecting specific websites, thus enhancing relevance for diverse use cases.
- This feature allows engineers to optimize search queries within Spaces, ensuring that results are more aligned with specialized requirements.
- Perplexity API Faces URL and Access Challenges: Users report that the Perplexity API returns source citations as plain text numbers like [1] without URLs, although some managed to retrieve URLs by explicitly requesting them.
- Additionally, there are difficulties in obtaining news headlines via the API and accessing support through the provided email, indicating potential stability and usability issues.
- Concerns Over Perplexity API Model Performance: Multiple users indicated that recent model updates have led to performance degradation, particularly noting that Claude 3.5 is less effective compared to its free counterpart.
- There is a lack of transparency regarding model switches, which affects the perceived quality and reliability of the API service.
- Google Releases Gemini 2.0: Google has unveiled Gemini 2.0, marking significant advancements in AI capabilities, which has sparked discussions around problem movement.
- Participants in the discussion expressed enthusiasm about the updates and their potential impact on the AI field.
Cohere Discord
- Command R7B Model Speeds Ahead: The Cohere Command R7B 12-2024 model is now operational, optimized for reasoning and summarization tasks, boasting enhanced speed and efficiency.
- Community benchmarks highlighted on Nils Reimers' Twitter show Command R7B outperforming models like Llama 8B, with significant improvements in response time.
- Rerank vs Embed: Feature Breakdown: Discussions clarified that Rerank reorders documents based on query relevance, whereas Embed transforms text into numerical vectors for NLP applications.
- API updates for Embed now support 'image' input types, expanding its applicability beyond text-based tasks.
- API Schema Overhaul in v2: The migration from API v1 to v2 lacks detailed documentation on schema changes for new endpoints, leaving users uncertain about specific updates.
- Engineers are investigating the existing migration resources to provide clarity on the new API structures.
- Seeking Sponsors for Code Wizard Hackathon: Akash announced the upcoming Code Wizard hackathon hosted by SRM Institute in February 2025, targeting students and tech enthusiasts to tackle real-world problems.
- The event is actively seeking sponsors to support and gain exposure, aiming to foster innovative solutions within the developer community.
- AI Enhances Contract Clause Review: Eyal is developing a proof of concept using Cohere to automatically identify and suggest modifications in contract clauses.
- Feedback is sought on strategies like defining specific clause types or utilizing a change database to improve the AI's effectiveness in contract analysis.
Modular (Mojo 🔥) Discord
- Mojo RSA Crypto Development: A member initiated the development of a basic RSA crypto implementation in Mojo, showcasing their progress.
- The project generated mixed reactions, highlighting the community's enthusiasm and constructive feedback.
- Prime Number Generation Optimizations: The prime number generation script achieved a peak performance of 1.125 seconds and, after optimizations, now exceeds 50,000 UInt32 primes per second using SIMD instructions.
- These enhancements maintain a low memory footprint, with the application consuming less than 3mb during operation.
- Custom Mojo Kernels: Custom Mojo Kernels have been released, allowing acceptance of any input types, although early versions may crash due to type mismatches.
- Developers remain confident in the API's future robustness, anticipating improved stability as the implementation matures.
- Networking Performance in Mojo: Discussions favored using QUIC over TCP for Mojo applications to reduce latency.
- Avoiding TCP overhead is seen as essential for achieving efficient Mojo-to-Mojo communication in modern network environments.
- Database Planning in MAX: A developer plans to implement database query planning and execution within MAX, leveraging new custom kernel features.
- This initiative indicates a push for more robust handling of complex data operations within the Mojo ecosystem.
LLM Agents (Berkeley MOOC) Discord
- Hackathon Deadline Looms for LLM Agents MOOC: The LLM Agents MOOC Hackathon submission deadline is December 17th at 11:59pm PST, urging participants to finalize and submit their projects on time.
- Participants are encouraged to seek last-minute assistance in the designated channel to ensure all submissions meet the requirements.
- Transitioning to Google Forms for Hackathon Entries: Submissions for the hackathon have shifted from Devpost to Google Forms to streamline the submission process.
- Participants must ensure they use the correct form link to avoid any submission issues before the deadline.
- Certificate Notifications Scheduled for Late December: Certificate notifications, indicating pass or fail statuses, will be distributed late December through early January based on participants' tiers.
- This timeline addresses recent inquiries and sets clear expectations for when participants can expect their certification status.
- Issues with OpenAI Credit Submissions: Some members reported not receiving OpenAI credits despite submitting their organization IDs before the November 25th deadline.
- Community members suggested verifying account credit balances as notifications may not have been dispatched properly.
- Emphasizing Safety Alignment in AI Research Agents: A member emphasized the importance of safety alignment in AI Research Agents and shared a relevant AI Research resource.
- This highlights the community's focus on ensuring safety protocols are integral to the development of AI research agents.
Torchtune Discord
- Torchtune v3.9 Simplifies Type Hinting: The update to Torchtune v3.9 allows users to replace
List,Dict, andTuplewith default builtins for type hinting.- This adjustment is welcomed by the community to streamline Python code, enhancing developer productivity.
- Generative Verifiers Boost LLM Performance: The paper titled Generative Verifiers: Reward Modeling as Next-Token Prediction introduces Generative Verifiers (GenRM), trained using the next-token prediction objective to seamlessly integrate validation and solution generation.
- This method supports instruction tuning and enables chain-of-thought reasoning by utilizing additional inference-time compute for enhanced verification results.
- Gradient Normalization Challenges in Distributed Training: Discussions highlighted concerns about scaling factors for normalization during the backward pass in distributed training, suggesting it should be
world_size / num_tokensto manage variability in token counts.- This issue could complicate gradient calculations due to padding and indexing differences, prompting advocacy for a potential PR to address inconsistencies.
- Scaling Test Time Compute Strategies Explored: A Hugging Face blog post discusses strategies to scale test-time compute for large models, focusing on performance optimization without compromising results.
- The post outlines methodologies to enhance compute efficiency while maintaining model output integrity.
tinygrad (George Hotz) Discord
- Optimizing BEAM Configuration for Kernel Search: Members discussed various BEAM settings for kernel search, highlighting that BEAM=1 denotes greedy search, which is less effective. The recommended starting points are BEAM=2 or 3 for balanced performance, as detailed in the documentation.
- Enhancements to the kernel search experience focus on improving both compile time and kernel execution time. Members are interested in available benchmarks and recommend utilizing BEAM=2, especially with JIT compilation.
- New Gradient API Simplifies Gradient Handling: George Hotz announced the merger of the new gradient API, which allows for simplified gradient handling:
weight_grad, bias_grad = loss.gradient(weight, bias)without requiringzero_gradorloss.backward.- This API differs from traditional frameworks like PyTorch and JAX, potentially streamlining optimizer steps with
optim.step(loss), as mentioned in the tweet.
- This API differs from traditional frameworks like PyTorch and JAX, potentially streamlining optimizer steps with
- Tinygrad Porting Projects and Backend Support Debated: Plans to port the fish-speech project to Tinygrad were announced, aiming to enhance Tinygrad's capabilities. The project is hosted on GitHub.
- Members debated supporting both x86 and arm64 backends for Tinygrad, considering maintenance of performance amid resource constraints.
- ShapeTracker Explainer and Tutorials Expanded: An improved ShapeTracker Explainer has been released, available here, providing deeper insights into its workings.
- The tinygrad-notes repository calls for contributions to tutorials and resources, encouraging community participation.
LlamaIndex Discord
- LlamaIndex RAG in 5 Lines: TylerReedAI shared a detailed tutorial on building a RAG application using just 5 lines of code, covering data loading and indexing.
- The tutorial emphasizes the ease of integrating query and chat engines into your workspace.
- Agentic Compliance Workflows: A new tutorial introduces a method to build an agentic workflow that ensures contract compliance by analyzing clauses against GDPR guidelines.
- It breaks down how to parse vendor contracts to maintain compliance effectively, simplifying contract management.
- Contextual Retrieval Meets LlamaIndex: A user implemented Anthropic's contextual retrieval in LlamaIndex and shared their GitHub repository for others to review.
- They expressed interest in contributing this robust implementation as a PR, highlighting its handling of edge cases.
OpenInterpreter Discord
- Folder Creation Issues with Incorrect Indentation: A member highlighted that the tool is not creating folders and the produced code has wrong indentation for easy copying and pasting, questioning if a different environment than cmd should be used.
- This issue suggests potential bugs in the folder creation functionality and code formatting processes within the current setup.
- API Responses Limit at macOS Monterey: A user reported that after installing the app on macOS Monterey, they receive no API responses and hit the free token limit after only two actions.
- This indicates possible integration or usage issues specific to macOS Monterey, potentially affecting API availability.
- Enhancing Billing Tracking for Litellm: A user inquired about connecting OI to a Litellm proxy server to effectively track billing and usage for the integrated Litellm package.
- They are exploring ways to enable comprehensive billing tracking within the Litellm integration.
- Recommendations for Japanese Learning Apps: A member sought good apps for learning Japanese, prompting another user to humorously suggest they might be in the wrong Discord server.
- This exchange underscores a need for specialized resources or channels focused on language learning within the guild.
- Local OS Deployment Options: A user asked about the possibility of using the OS locally, indicating interest in local setup solutions.
- This query points towards discussions on potential deployment or hosting configurations for local environments.
DSPy Discord
- Optimizing Claude Sonnet Prompt with DSpy: A user discovered DSpy while searching for ways to optimize their Claude Sonnet prompt and bookmarked a specific Jupyter notebook.
- They mentioned that the notebook was recently moved to an outdated examples folder, raising questions about its relevance.
- Updating Outdated DSpy Examples: Another member advised that the contents of the outdated examples folder in DSpy should be used cautiously until they are revamped, indicating potential unreliability.
- They also noted that efforts are underway to update these examples, potentially improving their usefulness.
Axolotl AI Discord
- APOLLO Optimizer Enhances Memory Efficiency: The new APOLLO optimizer reduces memory usage to 1.6G while achieving optimal perplexity during LLaMA 7B training, compared to 13G with 8-bit Adam.
- An independent Julia implementation confirmed APOLLO’s effectiveness in optimizing memory and training efficiency, as detailed in the post.
- LLM Training Faces Memory Constraints with AdamW: Large language models encounter significant memory issues when using the AdamW optimizer, often necessitating costly hardware or smaller batch sizes during training.
- Traditional memory-efficient optimizers involve SVD operations or performance trade-offs, but APOLLO introduces a novel method to address these limitations.
- Ongoing Talks on Multi-turn KTO: Discussions highlighted multi-turn KTO, although specific details and updates were not provided.
- Community members expressed interest in the potential capabilities and integration of this method within the LLM framework.
LAION Discord
- VAE Embedding Improves Progressive Tokenization: The discussion focused on progressive tokenization utilizing a zero-tree ordering of DWT coefficients derived from a VAE embedding. An attached video demonstrated the technique in action.
- Level 5 wavelet transformations were analyzed for their impact on tokenization effectiveness, highlighting practical applications and implications for future model enhancements.
- Byte Latent Transformer Patches Outperform Tokens: The publication Byte Latent Transformer Patches: Scale Better than Tokens details a new NLP approach where byte latent transformer patches demonstrate better scalability compared to traditional tokens.
- This advancement incited discussions on enhancing language modeling effectiveness and efficiency in various applications.
- Level 5 Wavelet Transform Boosts Tokenization: Level 5 wavelet transformations were examined for their role in improving tokenization effectiveness within current methodologies.
- The analysis included exploring practical applications and future implications for model performance, referencing the attached video.
Mozilla AI Discord
- RAG Extravaganza: Building with SQLite-Vec & LlamaFile: Tomorrow's event focuses on creating an ultra-low dependency Retrieval Augmented Generation (RAG) application using sqlite-vec and llamafile, with bare-bones Python and no additional dependencies or installations.
- Alex Garcia will lead the session, providing attendees with a straightforward approach to building RAG applications.
- Holiday Huddle: Final RAG Session Before Break: The final gathering for December before the holiday break emphasizes the importance of participation before the year-end.
- Participants are encouraged to join the session as a prelude to the holiday season and gain insights into RAG development.
Gorilla LLM (Berkeley Function Calling) Discord
- Gorilla LLM Releases Function Calling Results: BFCL-Result repository for Gorilla LLM's Berkeley Function Calling has been updated.
- The BFCL-Result repository is now available for review.
- Gorilla LLM Releases Function Calling Results: BFCL-Result repository for Gorilla LLM's Berkeley Function Calling has been updated.
- The BFCL-Result repository is now available for review.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!