[AINews] RWKV "Eagle" v5: Your move, Mamba
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI Discords for 1/27-28/2024. We checked 20 guilds, 297 channels, and 10073 messages for you. Estimated reading time saved (at 200wpm): 826 minutes. We are pinning our GPT4T version to 1106 for now, given the slight regression in summarization quality from last week's A/B test (More research to be performed, stay tuned)
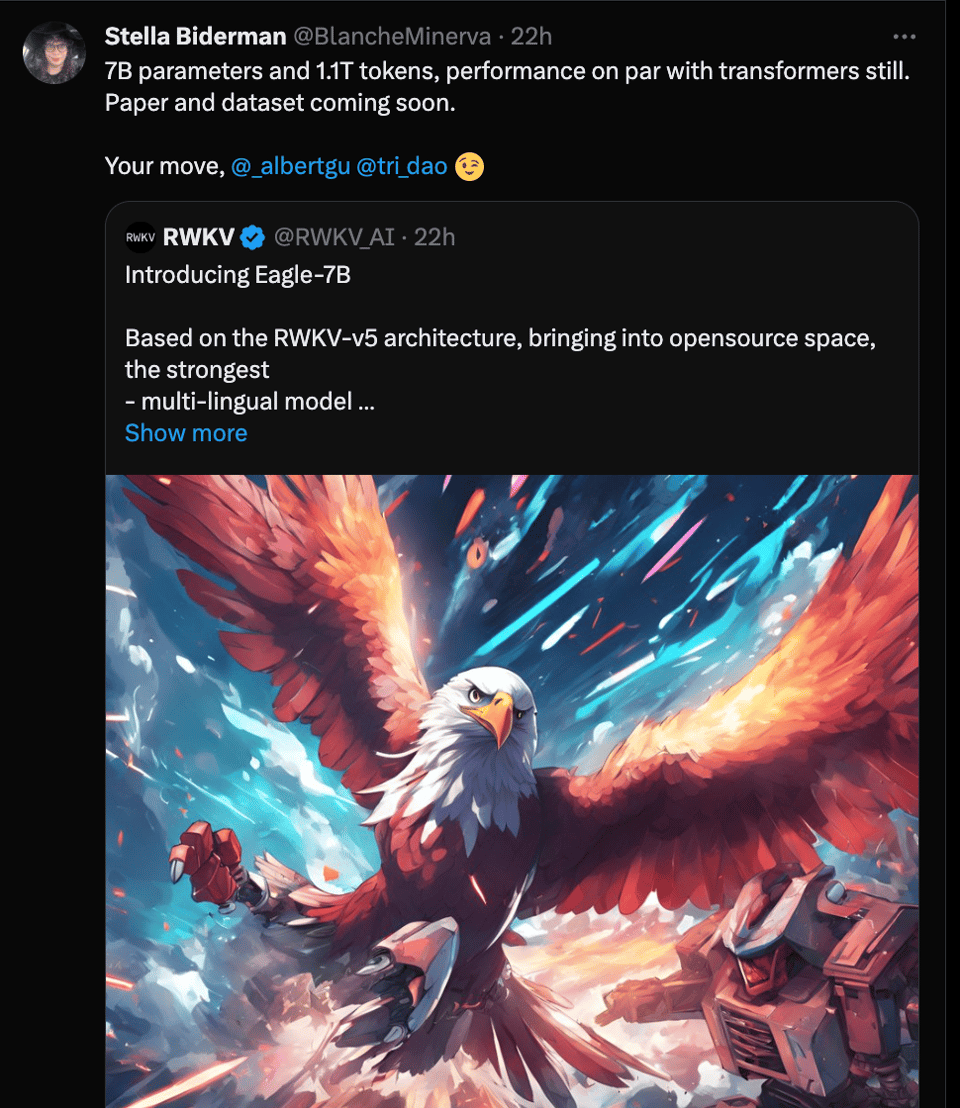
RWKV v5 ("Eagle") was released this weekend, with better-than-mistral-7b-size evals, and an acknowledgement that it trades off English performance for multilingual capabilities. Stella from EleutherAI (who has supported RWKV from the beginning - see the RWKV pod on Latent Space) put it best:
In other news, there's much speculation about miqu-1-70b, which could be a leak or distillation of Mistral-Medium (not proven either way). There's also more discussion about the Bard upset on the LMsys board.
--
Table of Contents
- PART 1: High level Discord summaries
- TheBloke Discord Summary
- Nous Research AI Discord Summary
- OpenAI Discord Summary
- LM Studio Discord Summary
- Eleuther Discord Summary
- Mistral Discord Summary
- HuggingFace Discord Summary
- LangChain AI Discord Summary
- LAION Discord Summary
- Perplexity AI Discord Summary
- LlamaIndex Discord Summary
- Latent Space Discord Summary
- DiscoResearch Discord Summary
- Alignment Lab AI Discord Summary
- AI Engineer Foundation Discord Summary
- PART 2: Detailed by-Channel summaries and links
- TheBloke ▷ #general (1395 messages🔥🔥🔥):
- TheBloke ▷ #characters-roleplay-stories (578 messages🔥🔥🔥):
- TheBloke ▷ #training-and-fine-tuning (71 messages🔥🔥):
- TheBloke ▷ #coding (27 messages🔥):
- Nous Research AI ▷ #ctx-length-research (10 messages🔥):
- Nous Research AI ▷ #off-topic (187 messages🔥🔥):
- Nous Research AI ▷ #interesting-links (57 messages🔥🔥):
- Nous Research AI ▷ #general (607 messages🔥🔥🔥):
- Nous Research AI ▷ #ask-about-llms (51 messages🔥):
- OpenAI ▷ #ai-discussions (164 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (75 messages🔥🔥):
- OpenAI ▷ #prompt-engineering (299 messages🔥🔥):
- OpenAI ▷ #api-discussions (299 messages🔥🔥):
- LM Studio ▷ #💬-general (316 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (74 messages🔥🔥):
- LM Studio ▷ #🧠-feedback (5 messages):
- LM Studio ▷ #🎛-hardware-discussion (144 messages🔥🔥):
- LM Studio ▷ #🧪-beta-releases-chat (6 messages):
- LM Studio ▷ #autogen (7 messages):
- Eleuther ▷ #general (108 messages🔥🔥):
- Eleuther ▷ #research (131 messages🔥🔥):
- Eleuther ▷ #lm-thunderdome (29 messages🔥):
- Eleuther ▷ #gpt-neox-dev (34 messages🔥):
- Mistral ▷ #general (92 messages🔥🔥):
- Mistral ▷ #deployment (3 messages):
- Mistral ▷ #finetuning (16 messages🔥):
- Mistral ▷ #showcase (18 messages🔥):
- Mistral ▷ #random (3 messages):
- Mistral ▷ #la-plateforme (17 messages🔥):
- HuggingFace ▷ #general (70 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (7 messages):
- HuggingFace ▷ #cool-finds (1 messages):
- HuggingFace ▷ #i-made-this (10 messages🔥):
- HuggingFace ▷ #reading-group (8 messages🔥):
- HuggingFace ▷ #diffusion-discussions (6 messages):
- HuggingFace ▷ #computer-vision (9 messages🔥):
- HuggingFace ▷ #NLP (22 messages🔥):
- HuggingFace ▷ #diffusion-discussions (6 messages):
- LangChain AI ▷ #general (77 messages🔥🔥):
- LangChain AI ▷ #langserve (8 messages🔥):
- LangChain AI ▷ #langchain-templates (1 messages):
- LangChain AI ▷ #share-your-work (8 messages🔥):
- LangChain AI ▷ #tutorials (1 messages):
- LAION ▷ #general (89 messages🔥🔥):
- LAION ▷ #research (5 messages):
- Perplexity AI ▷ #general (52 messages🔥):
- Perplexity AI ▷ #sharing (15 messages🔥):
- Perplexity AI ▷ #pplx-api (14 messages🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (57 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (35 messages🔥):
- Latent Space ▷ #llm-paper-club (2 messages):
- DiscoResearch ▷ #general (4 messages):
- DiscoResearch ▷ #embedding_dev (1 messages):
- DiscoResearch ▷ #discolm_german (10 messages🔥):
- Alignment Lab AI ▷ #general-chat (1 messages):
- Alignment Lab AI ▷ #oo (5 messages):
- AI Engineer Foundation ▷ #general (1 messages):
PART 1: High level Discord summaries
TheBloke Discord Summary
- Miqu's Mysterious Origins Spark Debate: Discussions center around the true origin of miqu-1-70b, oscillating between theories of it being a leaked Mistral Medium or a fine-tuned Llama 2 model. Performance assessments vary, with some users finding it superior to Mistral 7b, while others expected more.
- In Search of the Optimal Training Sample Size: An elusive LIMA paper hints that fine-tuning a base model with 1,000 high-quality prompts outshines the same model fine-tuned with 52,000 mixed-quality prompts, sparking discussions on effective sample sizes for various fine-tuning tasks within the community.
- Fine-Tuning Techniques and Benchmarks Garner Interest: Topics ranged from sequential fine-tuning strategies aimed at preserving general capabilities while enhancing performance on specific tasks, to quantizing models like Kunoichi-DPO-v2-7B for potential performance boosts. Tools and frameworks like Deepspeed, Axolotl, and QLoRA were discussed for their utility in fine-tuning operations.
- Modelling Tools and Approaches for Coding Challenges: The community shared resources and discussions about leveraging models for coding and complex reasoning tasks. Recommendations included LangChain for local modeling and GPT-4 for tasks requiring deeper insights, with additional mentions of methods to address Clang issues in Windows using CMake.
- Roleplay and Storytelling Models Under Scanner: Discourse on fine-tuning roleplay story-writing models spotlighted the potential of base models like L2 13B and SOLAR. Tips were shared for enhancing model training, including ZeRO configurations for Deepspeed over FSDP, and the selection of tools for enhancing role-play model interactions, like XTTSv2 for text-to-speech applications.
Noteworthy Projects and Resources:
- The llamafile project for creating portable APE files.
- Ensemble of tools and frameworks for AI engineering, including polyglot frameworks like LangChain and GPT-4, alongside specific guides and courses for transitioning from predictive to generative AI modeling, with Andrej Karpathy’s zero to hero series being a prime recommendation.
Nous Research AI Discord Summary
- RoPE Theta Settings Influence LLM Extrapolation: Following recent discussions,
@dreamgenand@euclaisehave highlighted the impact of Rotary Position Embedding (RoPE) theta settings on LLMs' extrapolation capabilities. A study, Scaling Laws of RoPE-based Extrapolation, suggests that fine-tuning RoPE-based LLMs like Mistral Instruct v0.2 with adjustedrope_thetavalues can significantly enhance performance.
- Mistral Speed Boost Changes the AI Game:
@carsonpooleshared that after tuning, Mistral and Mixtral kernels showcased notable speed improvements, making Mistral Tuna a more efficient choice over cuBLAS implementations. This adjustment brings down the cost of 1M tokens dramatically, positioning Mistral and Mixtral as frontrunners in the AI modeling efficiency race.
- Eagle 7B Flies High with Multilingual Mastery: The launch of Eagle 7B, built on the RWKV-v5 architecture and boasting a 7.52B parameter count, has stirred excitement. It not only outpaces all 7B class models in multi-lingual benchmarks but also rivals top-tier models in English evaluations with lower inference costs, as detailed in Eagle 7B's Launch post.
- SentencePiece Decoding Dilemma Addressed: An important discovery was shared by
.ben.comregarding SentencePiece leading to suppressed spaces in decoded tokens, potentially troubling for data parsing. A comprehensive decoding of the entire response for each chunk was suggested as a workaround, mitigating the "I hate computers" frustration points commonly encountered in model outputs.
- Exploring Tokenizer and Configuration Nuances in LLMs: Technical discussions around implementing appropriate tokenizers for Mixtral Instruct and fine-tuning configurations for models like OpenHermes using
axolotlwere brought into focus. Specifically, a JavaScript tokenizer for LLaMA was recommended by@_3sphereto ensure accurate token counts, while a YAML snippet for OpenHermes tuning highlighted the precise adjustments required for optimized model training.
OpenAI Discord Summary
- GPT-3.5 vs. GPT-4: A Casual Debate: Users
@vantagesp,@xenowhiz, and@eskcantadelved into the nuanced differences in casualness between GPT-3.5 and GPT-4, exploring prompt influences through shared conversations and examples at this link. - Tech Woes and Wins with ChatGPT: Technical advice was sought by
@gegex__for executing Python functions via ChatGPT, with guidance offered on integrating ChatGPT with DALL-E 3 for artistic purposes and ChatGPT's game development applications in Unreal Engine. - Customization Complications: Complaints about GPT's erratic search function in custom knowledge bases by
@blckreaperand technical hitches faced while updating behaviors in Custom GPTs highlighted the platform's sometimes inconsistent performance and usability issues. - Exploring Advanced GPT Features: The community examined using GPT's "@-calling" feature for complex integrations and narrative creations, alongside querying the utility of GPT-4's "laziness" and the mechanisms behind GPT model switching for enriched interaction experiences.
- Innovating with Prompt Engineering: Discussions ranged from clarification of Rule 7 to deep dives into prompt variables, SudoLang utility, and the effectiveness of the EmotionPrompt technique in Automated Prompt Engineering (APE), with an intriguing mention of the Hindsight of Consciousness Prompt Technique initiated by
@mad_cat__.
Key Document Mentioned: The community shared OpenAI's December 17th, 2023 Prompt Engineering Guide, a resource loaded into GPT for those exploring advanced prompt engineering strategies.
LM Studio Discord Summary
- Diving into Uncensored AI: Within LM Studio, Dolphin models were highlighted for their ability to manage uncensored content, a sought-after feature for text-based adventures. Efforts to integrate SillyTavern for smoother experiences and CogVLM for vision models into LM Studio underline an eagerness to push AI's boundaries in content creation.
- GPU Grind for LLM Intensifies: The best GPU debate for large language models (LLMs) stirred up attention, spotlighting the RTX 4060 Ti, RTX 3090, and AMD 7900 XTX as contenders. A notable discussion centered around the affordability and VRAM adequacy of NVIDIA's P40 for LLM tasks, balanced with concerns over its outdated nature LM Studio.
- Battle with Beta Bugs: Challenges sprout in LM Studio's beta releases with reports of issues like AVX2 instruction incompatibility and unresponsiveness when models reside on iCloud Drive without local caching. These hurdles highlight potential areas of improvement for system requirements and storage handling optimizations LM Studio.
- Hardware Hoopla Heightens: Discussions in LM Studio delved into Mixtral model requirements, suggesting 52GB of VRAM for optimal performance, and quizzed over quantization's impact on model performance. The dialogue also spotlighted ongoing explorations to maximize hardware configurations within budget constraints for LLM efficiency.
- Linux GPU Acceleration Angst: Users reported GPU acceleration issues on Linux with specific mention of Radeon 7900XTX difficulties, shedding light on the constant back-and-forth in optimizing AI workloads across different operating systems and hardware setups. The community's readiness to assist underscored the collaborative spirit in tackling these tech hurdles LM Studio.
- Autogen Anomalies Addressed: Reports of server errors in Autogen Studio and disparate behavior between Autogen and TextGen-webui indicate ongoing challenges in seamless AI application development. The community's pivot to troubleshooting and suggestions like exploring NexusRaven-V2 for function calling exhibits a proactive stance towards solving complex AI integration issues LM Studio.
Eleuther Discord Summary
- Flash-Attention Adaptation for Jax: Discussions about porting flash-attention to Jax are foregrounded by challenges related to dependencies on PyTorch with CUDA, leading to considerations for forking and modifying the original repository to accommodate Jax bindings. This adaptation aims to manage the compatibility issues between torch-cuda and jax-cuda due to cuda version conflicts.
- T5 Models Missing Flash Attention: Concerns have been raised about the absence of flash attention implementation in T5 models, marking it as a significant gap in leveraging this technology within that particular framework.
- AI Expert Opinions Versus Media Representations: The discordance between AI experts' insights and media portrayals, particularly involving figures like Gary Marcus, sparks debate over the impact of academic rivalries and media misrepresentations on public understanding. This discussion highlights the Gell-Mann Amnesia effect and the challenges of conveying accurate AI advancements.
- Existential Risks and Silicon Valley Preppers: A diverging conversation emerges around existential risks and the culture of prepping, underscored by skepticism towards the motivations behind such activities. Yet, evidence points toward high-profile figures like Larry Page and Mark Zuckerberg investing in secluded refuges, stirring a complex dialogue on readiness versus skepticism toward catastrophic events.
- Seeking 2023 News Datasets for Model Training: The demand for up-to-date news datasets for model training in 2023 and possibly January 2024 is evident, with current resources like the common crawl dump from December being deemed unsuitable due to its unfiltered nature. Suggestions for alternatives, like scraping PROQUEST, indicate a proactive search for viable datasets.
- Embedding Strategies and Activation Mechanisms in LLMs Discussed: A rich dialogue happens around the transition from tying to untying word embeddings in large language models (LLMs), activation beacon mechanisms for maintaining information over long sequences, and the investigation of post-training sparsification techniques like SliceGPT. This discussion is enlivened by critiques of current benchmarks' construction, notably the MMMU benchmark, and shows a growing interest in self-play research projects.
- Language Model Evaluation Harness Insights: Tweaks to the LM evaluation harness, including seed changes and the incorporation of the RWKV library, highlight an ongoing effort to assess language models consistently. These adjustments, alongside discussions about per example metrics and the repetition penalty's impact, stress the community’s dedication to refining evaluation strategies.
- GPT-NeoX Development Hurdles and Solutions: Efforts to address GPT-NeoX developmental challenges, such as Apex build troubles and multi-node deployment obstacles, illustrate a communal commitment to making the tool more accessible and efficient across various architectures. The notion of creating an opinionated Apex fork and setting up a build pipeline for scalability and ease points toward proactive solutions for future-proofing and wider architecture support.
Mistral Discord Summary
- Embedding Mistral Models for Offline Use:
@mahmoodbashar08explored embedding Mistral models into Python scripts for offline application, with@vhariationalrecommending the use of quantized models for hardware constraints, including a GGUF model hosted on Hugging Face. The discussion reveals a growing interest in leveraging Mistral models beyond online APIs.
- Deployment Dilemmas for Mistral8x7b Solved: For deploying Mistral8x7b on cloud platforms or local servers, users are steered towards Mistral's self-deployment guides, indicating a preference for cost-effective, DIY deployments as highlighted by
@vhariational's response to@rolexx6326Mistral's self-deployment documentation.
- Fine-Tuning Large Language Models (LLMs) with (Q)LoRAs: In the #finetuning channel,
@sadaisystemssought advice on the practical aspects of fine-tuning LLMs, indicating a preference for real-world, executable knowledge over theoretical papers. Discussions also revolved around the complexity of integrating Retrieval-Augmented Generation (RAG) for processing book-length pdfs into Mistral's LLM, with budget and project scope being critical factors in consultancy considerations.
- GitHub Copilot Alternatives and Open Sourcing Plans: Discourse in the #showcase channel introduced alternatives to GitHub Copilot, notably Tabby/Continue, with links provided to their GitHub repositories.
@hugoduprezalso announced initiatives to open source a discussed project, reflecting a trend towards community-driven development and knowledge sharing.
- Exploring Frontend Alternatives and Integrations for Mistral API: The demand for a ChatGPT-like interface utilizing Mistral API saw suggestions ranging from building custom UIs to leveraging third-party interfaces like HuggingChat and Librechat, indicating a collaborative effort within the community to enhance user experience with Mistral models.
HuggingFace Discord Summary
- Understanding Hugging Face's Automodel Queries and Collaborations: In the #general channel, clarifications were provided on deploying auto-trained models, data rights, and the costs involved, with references to Hugging Face’s terms of service. An invitation for a collaborative project in Trading AI or Poker AI was also put forward, alongside an announcement for an offline community meetup in Chennai focused on LLMs.
- Deep Dive into Audio, Law, and Manufacturing: The #today-im-learning and #reading-group channels featured discussions ranging from audio basics and the physics of sound (ciechanow.ski/sound) to a literature review on AI in law (medium article) and inquiries about machine learning in manufacturing.
- Innovations and Insights in AI Shared: Users in the #i-made-this and #diffusion-discussions channels presented various projects such as ML security concerns, the FumesAI demo, and the new WhiteRabbitNeo-33B-v1 model with a prompt enhancement feature, addressing the cybersecurity discussions in Twitter Space and citing a broken link in clip retrieval attempts.
- Exploring the Landscape of NLP and Computer Vision: The #NLP and #computer-vision channels fostered discussions on in-context learning, the effectiveness of few-shot learning, and the feasibility of automatic model importation using CI/CD or MLOps techniques. There was also a dialogue about shifting text generation models for Russian support and troubleshooting ONNX conversion issues.
- Trend Watch in HuggingFace Spaces and Model Experimentation: The #cool-finds channel highlighted a trending YouTube video exploring Meta's Text to Audio capabilities in HuggingFace spaces. Additionally, discussions in the #diffusion-discussions and #computer-vision channels touched upon practical concerns like compute issues on Colab for Pro users and the pursuit of effective Clip Retrieval tools.
LangChain AI Discord Summary
- OpenAI Unveils New Toys for AI Enthusiasts: OpenAI has dropped an exciting update featuring new embedding models, an updated GPT-4 Turbo, a text moderation model, and more, alongside API usage management enhancements. Highlight of the update includes price reduction for GPT-3.5 Turbo and the introduction of two new embedding models, details of which are spilled here.
- Dot Annotation Drama and Python’s Saving Grace:
hiranga.gjourneyed from confusion with dot annotation in LangServe's production environment to discovering a temporary fix with quadruple curly braces, and finally finding solace in Python’s f-strings to handle nested data access issues, embodying the trial-and-error spirit of coding.
- Base64 Encoded Images for LangChain?: User
@nav1106inquires about the feasibility of using base64 strings in place of URLs forimage_urltype inputs inHumanMessagecontent within LangChain, suggesting an alternative approach to image input handling.
- Semantic Routes and AI Conversational Enhancements:
@andysingalshares insights on the Semantic Router's transformative influence on AI dialogues through LangChain technology, supported by a deep dive blog post. Meanwhile, a debate about semantic routing's underpinnings pointed to James Briggs’ work as foundational, with references including a keynote video.
- Roll Your Own ChatGPT UI with a Blend of ChainLit, LangChain, Ollama & Mistral: A new tutorial shared by
datasciencebasicspromises to guide enthusiasts on creating a ChatGPT-esque UI locally using a mix of ChainLit, LangChain, Ollama, and Mistral, with the how-to session available here.
LAION Discord Summary
- Google's Bard Edges Out GPT-4: Google's Bard has overtaken GPT-4, securing the second spot on the AI leaderboard, sparking conversations around its implications on future AI developments. The milestone was shared via a tweet announcement.
- New AI Model Redefines Text-to-Image Synthesis: A novel AI, surpassing DALL-E 3 and SDXL, was introduced, showcasing superior performance in handling complex text-to-image tasks. Comprehensive details and comparisons were discussed, with further information accessible through Reddit, the paper on arXiv, and the model's code on GitHub.
- Eagle 7B Takes Flight Over Traditional Transformers: With a spotlight on efficiency and multilingual capabilities, Eagle 7B introduces an era for the RWKV-v5 architecture, detailed in a blog post. It highlights its green credentials and proficiency across over 100 languages.
- AI Enhancements in Video Games and Art Creation Sparks Vigorous Debate: Discussions encapsulated the potential of smaller LLMs in game development and Pixart-α's balance between realism and style in AI-generated art. PixArt-α's GitHub repository became a focal point of interest, found here.
- AI's Expanding Role in Digital Moderation and Search Engine Accuracy Examined: The community mused over AI's evolving utility in online content moderation through sentiment analysis and its differential performance in Bing versus Google's search AI integrations. These conversations underline a burgeoning reliance on AI to enhance digital experiences and information reliability.
Perplexity AI Discord Summary
- Enhancing Integrations with Copilot and API: Discussions highlighted queries on integrating Copilot with the Perplexity API, centered around limitations to online models only. A link for further information provided essential details.
- Perplexity's Subscription Model Insights: Users sought clarification on what happens post-subscription, learning GPT-3.5 reverts as the default model, as detailed by community members and further supported by insights from
@icelavamanand@brknclock1215.
- Technical Workarounds and Model Preferences Discussed: Amidst exploring Perplexity AI's utility, users like
@akhil_pulse_energyengaged in discussions about leveraging Google search operators for fresher content through PPLX APIs and expressed a preference for online LLMs for web-like accuracy.
- Perplexity AI as a Learning and Creative Tool: Users shared experiences using Perplexity AI, highlighting its effectiveness in learning coding, identifying healthful berries in North America, and creatively generating humorous content to roast scammers. Pertinent resources include screenshots of coding help and a tutorial on Perplexity Collections as an AI research tool.
- API Credits and Support Concerns Addressed: Instances of users not receiving API credits for Perplexity Pro were mentioned, alongside a general inquiry about the presence of source URLs in API responses. Suggestions included directly emailing support for resolution and exploring discussion forums for further clarity.
LlamaIndex Discord Summary
- Enterprise RAG Systems Made Easier: A comprehensive guide to building enterprise-level Retrieval-Augmented Generation (RAG) systems was shared by
@rungalileo, addressing both algorithmic and system components. This deep dive can be found here. - AI Engineers Face Seven Challenges on LLM OSes: Highlighting seven key challenges for AI engineers, such as improving accuracy and optimizing parallel execution in large-scale intelligent agents, additional insights are provided here.
- Knowledge Graphs Enhance RAG Pipelines:
@chiajy2000detailed the integration of knowledge graphs (KGs) into RAG pipelines, improving query responses with graph-related techniques. Learn more and view the diagram here. - Overcoming PDF and Asynchronous Issues in LlamaIndex: Solutions to common problems such as async support for PostgreSQL in LlamaIndex, and PDF parsing with tools like pdfminer, pymupdf, and opencv for complex documents were discussed, aiding users like
@ziggyrequrvand@rnovikov. - Multi-Retriever Chaining Clarified:
@akshay_1addressed multi-retriever chaining in LlamaIndex, confirming the feasibility of using various retrievers (vector, keyword, BM25) together, with Haystack mentioned as a viable platform for implementation.
Latent Space Discord Summary
- Exploring RLHF/DPO for Structured Data: Discussions led by
@sandgorgonquestion the applicability of RLHF/DPO techniques beyond high-temperature cases, specifically for structured data, without reaching a consensus or citing specific studies.
- Mixed Reception for 4turbo's Creative Capabilities:
@jozexotic's inquiry into 4turbo's creative headings reveals a regression in performance compared to previous iterations, as confirmed by@swyxio's performance comparison.
- Photography Meets AI:
@slonois embarking on a digital photography learning journey using AI tools from Adobe and custom coding for photo management and enhancement, demonstrating a practical application of AI in creative fields.
- Persistent "Laziness" in ChatGPT:
@btdubbinshighlights ongoing issues with ChatGPT, including incomplete code generation and placeholder content, sparking discussions on improving ChatGPT's performance through the use of API calls.
- Eastern LLM Paper Club Focuses on Self-Rewarding Models: An upcoming session of the Eastern LLM Paper Club, announced by
@ivanleomk, will delve into self-rewarding language models. Interested individuals can register for the event here.
DiscoResearch Discord Summary
- Choosing the Right Model for World Knowledge: Discord user
@aslawlietignited a conversation around choosing between Mixtral 8x7b, Yi-34b, and LLaMA-2-70b for world knowledge applications, but conclusions remain elusive as the community didn’t provide a definitive recommendation.
- CUDA Programming with Jeremy Howard: An opportunity to dive into CUDA programming with Jeremy Howard was shared by
@rasdani, inviting members to a scheduled Discord event that promises insights into CUDA programming, with the session also being recorded for those unable to attend live.
- Evaluating AI with Grounded Artificial Datasets: A new paper from Microsoft introduces grounded artificial datasets for Retrieval-Augmented Generation (RAG), as shared by
@bjoernp, offering new perspectives and metrics for AI evaluation, potentially informing future research and development strategies.
- Mysterious 80k: A cryptic message from
sebastian.bodzain the #embedding_dev channel simply reads “>80k”, leaving the context and significance open to interpretation but possibly indicating a significant benchmark or dataset size of interest.
- DiscoLM and Ollama Integration Puzzle: Discussions in #discolm_german revolve around finding the optimal setup for integrating DiscoLM German with Ollama, with
@jannikstdlsharing both inquiries and initial code templates leading to lackluster LLM responses.
Alignment Lab AI Discord Summary
- 2023's News Under the Microscope:
@danfosingis on the hunt for 2023 news datasets, including materials up to January 2024, highlighting a particular need within the AI alignment community. The quest was noted in the general-chat channel, alongside a mention of challenges posting in another specific channel. - Dedication to Communication:
autometahas taken to sending 10 DMs to ensure their message is heard, showcasing a high level of dedication to engagement within the community. - Isolation or Integration?: Amidst conversations about where dialogues are taking place,
ilovescienceandtekniumpondered the presence of discussions outside their current forum, concluding that no, the conversations are centralized right where they are, with a touch of light-hearted emoji banter to seal the confirmation.
AI Engineer Foundation Discord Summary
- Seeking the Best AI Tools: User
@kudos0560sparked a conversation inquiring about the best open source tools for AI development, mentioning Mistral as a notable option and inviting community recommendations.
The Skunkworks AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Datasette - LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Ontocord (MDEL discord) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
TheBloke ▷ #general (1395 messages🔥🔥🔥):
- Debate Over Miqu's Origin: There's ongoing speculation about whether miqu-1-70b is a leaked Mistral Medium or a fine-tuned Llama 2 model. Critiques of its performance and comparisons to existing models, such as Mistral 7b, are mixed, with some users reporting superior performance and others noting it performs worse than expected.
- Analysis and Benchmarks Shared: Users shared various analyses comparing miqu to other models like Mistral and RWKV, showing mixed results on performance, especially across different bit quantizations (Q2, Q4, Q5). There's a consensus that higher bit quantizations offer improved performance.
- Performance Discussions on Various Hardware: Different hardware setups were discussed, including M2 Ultra, Macbook M3 Max, Epyc servers, and GPU rigs featuring Nvidia's A100 and 4090 cards. User experiences highlight the computational costs and speed differences between hardware when running AI models like miqu.
- TabbyAPI and Model Running Challenges: Users discussed the challenges and techniques for running models using tools like TabbyAPI, llama.cpp, and exl2, debating the efficiency and speed of each approach. Concerns were raised about costs associated with running models on platforms like Runpod, emphasizing the trade-off between hardware investment and operational costs.
- Discussion Over RWKV and New Model Developments: The recent updates and capabilities of RWKV models were briefly mentioned, hinting at their potential for scaling and application. The community shared tools and projects designed to facilitate model execution and deployment, indicating a collective effort towards enhancing model accessibility and performance.
Links mentioned:
- Chat with Open Large Language Models: no description found
- 🦅 Eagle 7B : Soaring past Transformers with 1 Trillion Tokens Across 100+ Languages: A brand new era for the RWKV-v5 architecture and linear transformer's has arrived - with the strongest multi-lingual model in open source today
- How to play with the Raven model?: no description found
- Tweet from nisten (@nisten): @JagersbergKnut False alarm, this looks to be just a frankenstein with layers duplicated but also weights individually widened by either duplicating or quadrupling. Albeit it does run, in my early t...
- Panchovix/goliath-120b-exl2 · Hugging Face: no description found
- miqudev/miqu-1-70b at main: no description found
- alpindale/miqu-1-70b-pytorch · Hugging Face: no description found
- miqudev/miqu-1-70b · Hugging Face: no description found
- Dial Up Internet - Sound Effect (HD): Source Attribution:https://www.youtube.com/watch?v=UsVfElI-7oo🎹 For more sound effects/music for your videos check out Artlist (Get 2 free extra months when...
- Tweet from nisten (@nisten): @JagersbergKnut 👀👀👀 wtf just did a full weights stats dump, nono arch is mixtral even though it says llama (my own 2xMoE is same. 80 layers , 8 expers, shapes are bigger too some 2x some 4x bigge...
- There’s something going on with AI startups in France | TechCrunch: Artificial intelligence, just like in the U.S., has quickly become a buzzy vertical within the French tech industry.
- How to mixtral: Updated 12/22 Have at least 20GB-ish VRAM / RAM total. The more VRAM the faster / better. Grab latest Kobold: https://github.com/kalomaze/koboldcpp/releases Grab the model Download one of the quants a...
- GitHub - dyu/ffi-overhead: comparing the c ffi (foreign function interface) overhead on various programming languages: comparing the c ffi (foreign function interface) overhead on various programming languages - GitHub - dyu/ffi-overhead: comparing the c ffi (foreign function interface) overhead on various programm...
- GitHub - itsme2417/PolyMind: A multimodal, function calling powered LLM webui.: A multimodal, function calling powered LLM webui. - GitHub - itsme2417/PolyMind: A multimodal, function calling powered LLM webui.
- GitHub - josStorer/RWKV-Runner: A RWKV management and startup tool, full automation, only 8MB. And provides an interface compatible with the OpenAI API. RWKV is a large language model that is fully open source and available for commercial use.: A RWKV management and startup tool, full automation, only 8MB. And provides an interface compatible with the OpenAI API. RWKV is a large language model that is fully open source and available for c...
- GitHub - theroyallab/tabbyAPI: An OAI compatible exllamav2 API that's both lightweight and fast: An OAI compatible exllamav2 API that's both lightweight and fast - GitHub - theroyallab/tabbyAPI: An OAI compatible exllamav2 API that's both lightweight and fast
- /g/ - /lmg/ - Local Models General - Technology - 4chan: no description found
- Significant performance degradation from Exllamav2 0.12 update · Issue #5383 · oobabooga/text-generation-webui: Describe the bug I'm not entirely sure if this bug is caused by ooba or exllamav2 itself, but ever since the commit from 2 days ago that upgraded Exllamav2, my generations are significantly slower...
- Solving olympiad geometry without human demonstrations - Nature: A new neuro-symbolic theorem prover for Euclidean plane geometry trained from scratch on millions of synthesized theorems and proofs outperforms the previous best method and reaches the performance of...
- /g/ - /lmg/ - Local Models General - Technology - 4chan: no description found
TheBloke ▷ #characters-roleplay-stories (578 messages🔥🔥🔥):
- Model Comparison and Fine-Tuning Decisions:
@dreamgenquestions the merit of fine-tuning role-play story-writing models on L2 13B versus SOLAR, pointing out a lack of recent L2 13B fine-tunes from entities like Nous Research. They emphasize the importance of base model quality for fine-tuning, assessable through the general reception of fine-tunes from a particular base model.
- Model Training Technicalities Discussed:
@jondurbinadvises@dreamgenon training large models, highlighting the use of Deepspeed over FSDP and mentioning personal preferences towards ZeRO 2 for its speed advantage over ZeRO 3. This discussion also touched upon the inefficiencies and potential bugs when trying to increase sequence lengths during training.
- Quantization Queries and Benchmark Interests:
@theyallchoppableinquires about the decision-making process behind quantizing a model and the straightforwardness of quantization. They also show interest in comparing their model, Kunoichi-DPO-v2-7B with others on benchmarks, questioning the impact of recently added calibrations on performance variations.
- Recommendations for Roleplay Models and Tools for TTs: Users debate the best models for role-playing, with suggestions ranging from Mixtral to Goliath 120B models. The conversation extends to tools for text-to-speech (TTS) applications, with
@stoop poopsmentioning XTTSv2 as an option for quality-conscious users.
- Frankenmodel Skepticism and Model Performance Criteria:
@sanjiwatsukiexpresses skepticism towards frankenmodels unless they accomplish what SOLAR did, meanwhile engaging in a discussion with@reinman_and@doctorshotgunabout the benefits and limitations of models ranging from 7B to 120B for roleplay and story writing. Specific attention is paid to the models' abilities to follow intricate character cards and maintain coherence in longer contexts.
Links mentioned:
- mistralai/Mistral-7B-Instruct-v0.2 · Hugging Face: no description found
- Shame Go T GIF - Shame Go T Game Of Thrones - Discover & Share GIFs: Click to view the GIF
- Chain-of-Verification Reduces Hallucination in Large Language Models: Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language models. We study the ability of language models to deliberate on the responses t...
- aiconfig/cookbooks/LLaMA-Guard/llama_guard_cookbook.ipynb at main · lastmile-ai/aiconfig: AIConfig is a config-based framework to build generative AI applications. - lastmile-ai/aiconfig
- SanjiWatsuki/Kunoichi-DPO-v2-7B · Hugging Face: no description found
- GitHub - mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks. - GitHub - mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.
- Project Atlantis - AI Sandbox: no description found
- Importance matrix calculations work best on near-random data · ggerganov/llama.cpp · Discussion #5006: So, I mentioned before that I was concerned that wikitext-style calibration data / data that lacked diversity could potentially be worse for importance matrix calculations in comparison to more "...
TheBloke ▷ #training-and-fine-tuning (71 messages🔥🔥):
- Searching for Fine-Tuning Sample Size Guidelines:
@superking__mentioned seeking an article elucidating the required high-quality samples for various fine-tuning tasks, sparking interest in the topic among other users. Although the exact document remained elusive, a reference to the LIMA paper was made, indicating that a base model fine-tuned with 1,000 high quality prompts outperformed the same model fine-tuned with 52,000 mixed quality prompts.
- Discussion on Sequential Fine-Tuning Across Diverse Tasks:
@sadaisystemsdetailed an experimental setup for sequentially fine-tuning a model on diverse tasks like question answering and coding, aiming to improve performance without compromising general abilities. This sparked interest in creating organized learning paths, similar to human education systems, as suggested by@kquant.
- QLoRA Fine-Tuning for Distinct Tasks Proposal:
@sadaisystemscontemplated using QLoRA for sequential fine-tuning on different tasks and sought community suggestions for widely recognized tasks that could potentially lead to a research paper. The strategy involves using the Mistral-Instruct v0.2 model as a base for experimentation.
- Axolotl Stuck During Dataset Saving Process:
@flashmanbahadurencountered an issue where Axolotl hangs after the "Saving the dataset" phase while running the example Mistral 7b config.yml, suspecting a problem with Accelerate and CUDA.
- Inquiry About Training Models for Specific Programming Languages:
@Naruto08inquired about training models for specific programming languages like Rust or Go on a 24GB GPU system, with@superking__suggesting a possible 10b model might be feasible and advising to check out fine-tuning toolkits like Axolotl and Unsloth.
TheBloke ▷ #coding (27 messages🔥):
- APE Files Project Deserves More Attention:
@righthandofdoomhighlighted the llamafile project that creates APE files, which can run anywhere, expressing a wish for it to gain more popularity. - Choosing Between LangChain and GPT-4 for Complex Reasoning:
@djstraylightand@bartowski1182discussed using LangChain for local modeling and contacting GPT-4 for tasks requiring deeper insights. They noted GPT-4's substantial advantage in handling heavy lifting and reducing the need for prompt engineering. - GPT-4's Vision Capabilities Open New Potential: In a conversation about model capabilities,
@djstraylightand@bartowski1182extolled the virtues of GPT-4-vision for its proficiency in interpreting images, with hopes for future implementations in video analysis. - Solving Clang Issues on Windows with CMake:
@spottyluckoffered a workaround for issues when forcing Clang in Windows using CMake, suggesting the addition of a specific target toCMAKE_C_FLAGSandCMAKE_CXX_FLAGS. - Learning Generative AI From the Ground Up:
@4n7m4nexpressed an interest in transitioning from predictive to generative AI modeling.@dirtytigerxrecommended Andrej Karpathy’s zero to hero series and the nanoGPT project on GitHub for comprehensive learning, highlighting the similarity to time series analysis but with different implementations.
Links mentioned:
- Neural Networks: Zero To Hero: no description found
- GitHub - karpathy/nanoGPT: The simplest, fastest repository for training/finetuning medium-sized GPTs.: The simplest, fastest repository for training/finetuning medium-sized GPTs. - GitHub - karpathy/nanoGPT: The simplest, fastest repository for training/finetuning medium-sized GPTs.
Nous Research AI ▷ #ctx-length-research (10 messages🔥):
- Curiosity About Model Scaling and RoPE Settings:
@dreamgeninquired about the reason behind some models, specifically Mistral Instruct v0.2, opting for increasedrope_thetavalues instead of employing rope scaling. The query also covered experimentation with the amount of fine-tuning required for effective scaling. - Insights from Recent Research on RoPE-based LLMs:
@euclaiseshared a related paper discussing the extrapolation capabilities of Large Language Models (LLMs) using Rotary Position Embedding (RoPE). The research suggests that fine-tuning RoPE-based LLMs with variousrope_thetavalues significantly impacts extrapolation performance. - Debating the Efficacy of RoPE Theta Adjustment: Following the discussion and the shared research,
@dreamgenpondered whether settingrope_thetato 1M is superior to dynamic rope scaling for addressing extrapolation issues in LLMs. - Theoretical Limitations of Default RoPE Settings:
@euclaisementioned that the defaultrope_thetavalue is nearly the theoretical worst, implying significant room for optimization in LLM performance through parameter adjustments. - Exploratory Ideas for Mixed Theta Training:
@dreamgenproposed an innovative fine-tuning approach using a mix ofrope_thetavalues (500 and 1M) for training examples. The idea is to choose the most appropriaterope_thetabased on the input length during inference.
Links mentioned:
Scaling Laws of RoPE-based Extrapolation: The extrapolation capability of Large Language Models (LLMs) based on Rotary Position Embedding is currently a topic of considerable interest. The mainstream approach to addressing extrapolation with ...
Nous Research AI ▷ #off-topic (187 messages🔥🔥):
- AI Innovations in Off-Topic Chatter:
@carsonpoolerevealed significant speed improvements in Mistral and Mixtral kernels after extensive tuning, with Mistral Tuna showing a dramatic speedup compared to cuBLAS implementations. The improvements bring down the cost of 1M tokens significantly compared to market competitors.
- Multilingual Musings on LLMs: A rich discussion unfolded between
@Error.PDFand@n8programs, highlighting the nuanced views on the future of Large Language Models (LLMs), the potential of transformers, and architectural needs for achieving AGI, shifting effortlessly between English and Spanish to accommodate language preferences.
- Gary Marcus's Predictions Stir Debate:
@Error.PDFshared a sarcastic remark about Gary Marcus's predictions, igniting a conversation about the evolution of GPT models and whether attention mechanisms alone can drive future advancements in LLMs.
- EleutherAI Logs Provide Insight:
@_3sphereshared a link to a discussion on Llama, the Meta AI's large language model, now with official Vulkan support, highlighting the community's efforts in exploring new frontiers in AI.
- Portality Offers a Glimpse into 3D Worlds:
@erichallahanintroduced Portality.ai, a project that promises to create private 3D portals using cutting-edge AI, showcasing the latest in 3D Gaussian Splatting technology. The project encourages community participation and is looking to democratize 3D scene creation.
Links mentioned:
- Portality: Take reality with you
- Bellebows Happy Dog GIF - Bellebows Happy Dog Dog - Discover & Share GIFs: Click to view the GIF
- Luna Crunchycat GIF - Luna Crunchycat Nerd - Discover & Share GIFs: Click to view the GIF
- Cat Cat Meme GIF - Cat Cat meme Funnt cat - Discover & Share GIFs: Click to view the GIF
- Dog Dog With Butterfly On Nose GIF - Dog Dog with butterfly on nose Dog with butterfly - Discover & Share GIFs: Click to view the GIF
- Rat Spin GIF - Rat spin - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- Cat Nyash GIF - Cat Nyash Meow - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #interesting-links (57 messages🔥🔥):
- Deepseek's System Prompt Magic:
.ben.comshared a template for a system prompt for the Deepseek Coder model, highlighting the necessity of handling both default and provided system prompts for consistency. More details can be found in the discussion.
- Counterfactual Prompting for Aligning LLMs:
gabriel_symeintroduced a paper on counterfactual prompting as a method to align large language models' response styles without human intervention. The paper offers insights into enhancing models' generation styles innately (Download PDF).
- Exploring Infinite Context Scaling in LLMs: A discussion initiated by
euclaiseabout a paper proposing a novel approach that enables infinite context scaling in large language models sparked mixed reactions. While it was mentioned to improve roleplay and chat agents, facts retention is a question (Study more here).
- Exllamav2 Enhancements and GitHub Release:
.ben.comdiscussed the benefits of using Exllamav2 for Large Language Models (LLMs), including a 2x throughput increase on a 3090ti GPU and the release of an OpenAI API compatible LLM inference server based on Exllamav2 on GitHub.
- Eagle 7B's Remarkable Achievement:
nonameusrhighlighted the launch of Eagle 7B, a 7.52B parameter model built on the RWKV-v5 architecture. It outperforms all 7B class models in multi-lingual benchmarks and approaches top-tier model performance in English evaluations, while boasting a significantly lower inference cost (Find out more).
Links mentioned:
- 🦅 Eagle 7B : Soaring past Transformers with 1 Trillion Tokens Across 100+ Languages: A brand new era for the RWKV-v5 architecture and linear transformer's has arrived - with the strongest multi-lingual model in open source today
- Aligning Large Language Models with Counterfactual DPO: Advancements in large language models (LLMs) have demonstrated remarkable capabilities across a diverse range of applications. These models excel in generating text completions that are contextually c...
- Tweet from BlinkDL (@BlinkDL_AI): RWKV-5 "Eagle" 7B: beats Mistral-7B at multilingual, reaches Llama2-7B level at English, while being 100% attention-free RNN and only trained 1.1T tokens. Gradio Demo: https://huggingface.co/s...
- internlm/internlm2-math-20b · Hugging Face: no description found
- exllamav2/examples/multiple_caches.py at master · turboderp/exllamav2: A fast inference library for running LLMs locally on modern consumer-class GPUs - turboderp/exllamav2
- GitHub - bjj/exllamav2-openai-server: An OpenAI API compatible LLM inference server based on ExLlamaV2.: An OpenAI API compatible LLM inference server based on ExLlamaV2. - GitHub - bjj/exllamav2-openai-server: An OpenAI API compatible LLM inference server based on ExLlamaV2.
- Reddit - Dive into anything: no description found
- GitHub - TryForefront/tuna: Contribute to TryForefront/tuna development by creating an account on GitHub.
Nous Research AI ▷ #general (607 messages🔥🔥🔥):
- SentencePiece Decoding Solved:
.ben.comdiscovered that SentencePiece suppresses leading spaces in all tokenizer decodes, leading to "I hate computers" moments. A workaround involves decoding the entire response for every chunk, ensuring no loss of spaces.
- Mamba Model Discussions: After a query by
nonameusrabout the existence of mamba models,_3sphereshared links to state-spaces on GitHub and HuggingFace, revealing models with a cap at 2.8b.
- Model Preference Debate: Discussion on the superior option for world knowledge among Mixtral 8x7b, Yi-34b, and LLaMA-2-70b ensued, with
n8programssuggesting based on experience that Mixtral may lack in-depth world knowledge compared to the others. Benchmarks and further testing were hinted at as means to a definitive answer.
- Quantization Techniques Explored: Several members, including
mihai4256andn8programs, exchanged insights on 2 bit quantization in models, especially in context of platforms like Twitter showcasing advancements and the implications for model efficiency and size.
- Intriguing Emerging Model - 'Miqu': Conversations around a potentially new 70B model named 'Miqu', described on HuggingFace, fueled speculations around its origins and capabilities. Various tests, including comparisons and translations, were conducted to understand its similarity to Mistral medium and ponderings on its structure, possibly hinting at a Mistral and LLaMA merge.
Links mentioned:
- NobodyExistsOnTheInternet/unmixed-mixtral · Hugging Face: no description found
- Are Emergent Abilities of Large Language Models a Mirage?: Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models that are present in larger-scale models. What makes emergent abilities intriguin...
- Tweet from AK (@_akhaliq): Microsoft presents SliceGPT Compress Large Language Models by Deleting Rows and Columns paper page: https://huggingface.co/papers/2401.15024 show that SliceGPT can remove up to 25% of the model par...
- Tweet from Weyaxi (@Weyaxi): Impressive results, but I think it's due the RAG. Also, I believe Google is intentionally censoring the model even after it generates the answer. I asked it to generate a model card for Bard, but ...
- There’s something going on with AI startups in France | TechCrunch: Artificial intelligence, just like in the U.S., has quickly become a buzzy vertical within the French tech industry.
- Think About It Use Your Brain GIF - Think About It Use Your Brain Use The Brain - Discover & Share GIFs: Click to view the GIF
- miqudev/miqu-1-70b · Hugging Face: no description found
- Tweet from nion (@ubernion): mistral-70b-instruct is coming, strap in.
- Uploading dataset compressing images: Hey! I’m having some trouble uploading a VQA dataset to the hub via python’s DatasetDict.push_to_hub(). Everything seems to work perfectly except the images, they seem to be converted from png to jpg....
- state-spaces (State Space Models): no description found
- Tweet from Mike Soylu (@mikesoylu): @nisten Not a torrent leak so obviously fake 🙄
- Tweet from Andrew Carr (e/🤸) (@andrew_n_carr): @main_horse Looks like some quants just landed on HF
- Tweet from Pedro Domingos (@pmddomingos): LLMs are a System 1 solution to a System 2 problem.
- llama.cpp/gguf-py/gguf/constants.py at 6db2b41a76ee78d5efdd5c3cddd5d7ad3f646855 · ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- Tweet from nisten (@nisten): @JagersbergKnut 👀👀👀 wtf just did a full weights stats dump, nono arch is mixtral even though it says llama (my own 2xMoE is same. 80 layers , 8 expers, shapes are bigger too some 2x some 4x bigge...
- exibings/rsvqa-lr · Datasets at Hugging Face: no description found
- miqudev/miqu-1-70b · Please upload the full model first: no description found
- GitHub - ggerganov/llama.cpp at 6db2b41a76ee78d5efdd5c3cddd5d7ad3f646855: Port of Facebook's LLaMA model in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
Nous Research AI ▷ #ask-about-llms (51 messages🔥):
- Finding the Right Tokenizer for Mixtral Instruct:
@giulio123456asked about computing token numbers for prompts for Mixtral Instruct.@_3sphererecommended any tokenizer implementation and specifically shared a JavaScript tokenizer for LLaMA, warning about off-by-one errors.
- Fine-Tuning OpenHermes with Axolotl:
@filippob82shared a YAML configuration snippet for fine-tuning OpenHermes usingaxolotl, which was confirmed to work by@teknium. This discussion points towards specific configurations needed to adjust tokens for model training.
- Exploring Machine Unlearning for Character Behavior:
@lorenzoroxyoloraised questions on machine unlearning, aiming to let a model, like one simulating Harry Potter, forget certain knowledge like writing Python code. Resources like a paper on unlearning training data and a discussion on knowledge forgetting techniques were highlighted in the conversation.
- Interest in Prometheus Rating Model:
@.afg1inquired about the application specifics of the Prometheus rating model for evaluating summaries without a direct model answer, linking to the relevant arXiv paper. The question addresses whether it's feasible to assess a summary with an unrelated good summary as a reference.
- Temperature Setting in OpenHermes 2.5:
@realsedlyfasked if OpenHermes 2.5 supports a temperature setting of 0, to which@tekniumconfirmed positively. This query reflects user exploration of model behavior under different temperature settings for output generation.
Links mentioned:
- NeurIPS 2023 - Machine Unlearning | Kaggle: no description found
- NeurIPS 2023 - Machine Unlearning | Kaggle: no description found
- Who's Harry Potter? Approximate Unlearning in LLMs: Large language models (LLMs) are trained on massive internet corpora that often contain copyrighted content. This poses legal and ethical challenges for the developers and users of these models, as we...
- GitHub - belladoreai/llama-tokenizer-js: JS tokenizer for LLaMA: JS tokenizer for LLaMA. Contribute to belladoreai/llama-tokenizer-js development by creating an account on GitHub.
OpenAI ▷ #ai-discussions (164 messages🔥🔥):
- GPT-3.5 vs GPT-4 Casualness Discussed: Users like
@vantagesp,@xenowhiz, and@eskcantadebated the perceived differences in casualness between GPT-3.5 and GPT-4, discussing how prompts could influence the models' outputs. They shared specific prompts and received advice on achieving more natural or casual responses, leading to a shared conversation at this link.
- Challenges Integrating Physical Actions with ChatGPT:
@gegex__sought advice on triggering Python functions, such as turning off lights, through ChatGPT API calls, with users like@luguiand@a1vxproviding step-by-step guidance, including API documentation.
- Leveraging GPT-4 for Artistic Endeavors:
@aridelta_arktheythemadvertised an upcoming lecture and poetry reading event with a focus on the future of intelligence, providing the event details and Instagram video for further insight.
- Integrating GPT-4 with External Tools for Enhanced Functionality:
@s4lvininquired about the process of integrating GPT-4 with DALL-E 3 for image generation in ChatGPT Plus, leading to discussion about utilizing the function call feature for seamless model integration.
- Exploring the Use of ChatGPT in Game Development: Queries were raised by
@mragentssharkregarding the deployment of ChatGPT for Unreal Engine tasks, with participants like@ash8496and@beanz_and_ricesharing their experiences and views on the utility of ChatGPT in game development environments.
Links mentioned:
- Life After Life: A Video Lecture & Poetry ReadingGray Area Happy Hour: no description found
- delta.ark on Instagram: "looking pretty filmic at this point, even though it's just a game -- come see it at gray area on Thursday: 42 likes, 1 comments - delta.ark on January 9, 2024: "looking pretty filmic at this point, even though it's just a game -- come see it at gray area on ..."
OpenAI ▷ #gpt-4-discussions (75 messages🔥🔥):
- Navigating GPT's Custom Knowledge Pitfalls:
@blckreaperexpressed frustration when GPT failed to locate information within a document, despite explicitly being instructed to use its search function. After a brief argument, it finally located the required data, highlighting the intermittent efficacy of GPT's retrieval capability from custom knowledge bases. - Custom GPT Creation Hiccups: Several users including
.lightforgedand@steved3reported encountering technical issues when attempting to update or save new behaviors within Custom GPTs on the platform, suggesting a widespread problem that's been ongoing since Tuesday, with community threads dedicated to resolving these errors. - Exploring GPT's "@-calling" Feature for Enhanced Integrations: Users like
@serenejayand@darthgustavdiscussed utilizing the new @-calling feature to leverage multiple GPTs within a single conversation for creating complex narratives or combining functionalities, despite some initial confusion on its operational mechanics. - GPT-4 Acting "Lazy"? Investigating User Experience: Instances of GPT-4 providing unsatisfactory responses or advising users to search Bing instead of answering directly were reported by
@d_smoov77,@_ezee_, and@jasonat, with suggestions to check special instructions for potential misconfigurations as a remedy. - Confusions and Curiosities Around GPT Model Switching: The conversation between
_odaenathusand@eskcantaclarifies misunderstandings around the persistence of the @-model switching functionality, while@scargianotes that the model remains switched without needing to re-@ in every prompt, underlining the flexibility and potential confusion in interacting with multiple models.
OpenAI ▷ #prompt-engineering (299 messages🔥🔥):
- Rule Reminder and Clarification:
@an_analystwas reminded by@darthgustav.about Rule 7 prohibiting self-promotion, soliciting, or advertising on the channel.@darthgustav.further clarified the rule, noting exceptions include API, Custom GPTs, and Plugin Channels.
- Exploration of Variable Types in Prompting:
@madame_architectqueried about using different symbols for variables in prompts, leading to a discussion with@darthgustav.about syntax indications for various data types and their stochastic behaviors.
- Prompt Engineering Techniques Discussed:
@madame_architectmentioned learning something new from an "emotionprompt" blog post regarding its effectiveness in APE (automated prompt engineering). This spurred a broader conversation about understanding model attention mechanisms for better prompt engineering.
- Self Critique Technique Highlighted: Amid discussing prompting techniques,
@mad_cat__introduced a concept he termed as Hindsight of Consciousness Prompt Technique, leading to feedback from@darthgustav.about testing for efficacy against control prompts. This evolved into a discussion about "self critique" as a known prompting technique, with both embracing the potential for further exploration.
- Technical Queries and Assistance: The channel served as a platform for technical exchanges, ranging from advice on overcoming model limitations in generating content (
@a1vxdiscussing model "laziness") to strategies for handling JSON timeouts (@novumclassicum). Members provided insights, referenced OpenAI guides, and shared personal experiences to aid in troubleshooting and exploration.
Links mentioned:
OpenAI's Dec 17th, 2023 Prompt Engineering Guide: OpenAI dropped the Prompt Engineering guide today. Guide: https://platform.openai.com/docs/guides/prompt-engineering It is loaded into this GPT if you don’t want to do that yourself. This GPT also h...
OpenAI ▷ #api-discussions (299 messages🔥🔥):
- Rule Clarification for
an_analyst:@darthgustav.explains that posting URLs may conflict with Rule 7, which prohibits self-promotion, solicitation, or advertising, except in channels designated for API, Custom GPTs, and Plugins. - Prompt Variables Explained:
@madame_architectqueries about the use of brackets in prompts, leading to a discussion with@darthgustav.on different brackets indicating different data types and their expected impacts on model output. - SudoLang and ParallelDrive Discussion:
@madame_architectand@bambooshootsshare insights about SudoLang, stored on ParallelDrive GitHub, suggesting it as a comprehensive method to guide LLMs beyond natural language with coded syntax. - EmotionPrompt Strategy Revealed:
@madame_architecthighlights the utility of EmotionPrompt for Automated Prompt Engineering (APE), referring to increased performance rates and suggesting it be incorporated into Memories.txt to prime model agents for specific tasks. mad_cat__Explores a New Prompt Technique:@mad_cat__introduces the idea of a Hindsight of Consciousness Prompt Technique aimed at making the model reflect on and explain its erroneous responses rather than simply apologizing.
Links mentioned:
OpenAI's Dec 17th, 2023 Prompt Engineering Guide: OpenAI dropped the Prompt Engineering guide today. Guide: https://platform.openai.com/docs/guides/prompt-engineering It is loaded into this GPT if you don’t want to do that yourself. This GPT also h...
LM Studio ▷ #💬-general (316 messages🔥🔥):
- In Search of Uncensored Adventure:
@hirquitickeinquired about using an uncensored text adventure model within LM Studio, seeking a model that doesn't impose moral judgments.@dagbssuggested Dolphin models as a versatile choice, specifically for handling uncensored content, and recommended SillyTavern for seamless integration with LM Studio.
- Discovering New Models: Amidst discussions,
@agcobra1reported a leak of Mistral Medium on Hugging Face (HF Hub) and shared a link (here) but expressed uncertainty regarding its authenticity and compatibility with LM Studio. The group discussed the risks of using unverified models, warning about potential poisoning.
- Troubleshooting and Optimization Tips Shared: Users encountered various issues, such as models talking to themselves,
@cloakedman, or needing specific deployment advice,@broski_1337.@dagbsprovided users with specific advice on using ChatML and adjusting pre-prompts for better results, as well as recommending different UIs for Android users looking for an easy setup.
- Exploring the Integration of Vision and Multi-Modal Models: Participants showed interest in integrating vision models into LM Studio, with
@sumo_79925seeking advice on which vision models excel in different areas.@heyitsyorkieresponded with a link to CogVLM, a leading vision model on GitHub, stressing that currently, LM Studio mainly facilitates text generation.
- Anticipation for Future AI Developments and Applications: The channel reflected excitement about the potential for future multimodal models in LM Studio, allowing for a seamless generation of images from text prompts. Users discussed the merits of various image generation models such as Stable Diffusion and DALL-E for creative projects, indicating a strong interest in developing more versatile and powerful tools for AI-driven content creation.
Links mentioned:
- How to Run Stable Diffusion: A Tutorial on Generative AI: Explore generative AI with our introductory tutorial on Stable Diffusion. Learn how to run the deep learning model online and locally to generate detailed images.
- PsiPi/NousResearch_Nous-Hermes-2-Vision-GGUF · Hugging Face: no description found
- AI-Sweden-Models/gpt-sw3-20b-instruct-4bit-gptq · Hugging Face: no description found
- The unofficial LMStudio FAQ!: Welcome to the unofficial LMStudio FAQ. Here you will find answers to the most commonly asked questions that we get on the LMStudio Discord. (This FAQ is community managed). LMStudio is a free closed...
- GitHub - THUDM/CogVLM: a state-of-the-art-level open visual language model | 多模态预训练模型: a state-of-the-art-level open visual language model | 多模态预训练模型 - GitHub - THUDM/CogVLM: a state-of-the-art-level open visual language model | 多模态预训练模型
- GitHub - Mintplex-Labs/anything-llm: Open-source multi-user ChatGPT for all LLMs, embedders, and vector databases. Unlimited documents, messages, and users in one privacy-focused app.: Open-source multi-user ChatGPT for all LLMs, embedders, and vector databases. Unlimited documents, messages, and users in one privacy-focused app. - GitHub - Mintplex-Labs/anything-llm: Open-source...
LM Studio ▷ #🤖-models-discussion-chat (74 messages🔥🔥):
- GPU Choices for LLM Enthusiasts: Users are discussing the best GPU options for running large language models (LLMs), with mentions of the RTX 4060 Ti, RTX 3090, and AMD's 7900 XTX.
@hexacubeis considering upgrading to accommodate better performance for text generation, while@jayjay70shares their setup of dual 4060 TIs for handling LLMs.
- P40 as a Budget Option for LLMs: Discussion around using NVIDIA's P40 GPU for LLM tasks highlights its affordability and ample VRAM despite being older and not intended for gaming.
@dagbsand@heyitsyorkienote that while it's a budget-friendly option, it's becoming outdated, especially with its lack of support for newer operating systems like Windows 11.
- Multi-GPU Support and Model Preferences: The conversation reveals that LM Studio doesn't currently support multiple GPUs, but users, including
@dagbsand@hexacube, are experimenting with various setups to optimize performance. Preferences for models vary, with@dagbsciting a blend of power and speed needs met by different models.
- LLM Community Resources and Developments: Users share resources like the LLM leaderboard at https://chat.lmsys.org and arXiv for the latest research and developments in the field.
@dagbsand@msz_mgsexpress interest in staying on top of new techniques and models, indicating a vibrant community eager for innovation.
- Technical Discussions and Optimizations: The chat includes technical considerations like VRAM requirements, system RAM, and the practicalities of running LLMs on different hardware setups.
@dagbsprovides a rule of thumb for VRAM allocation based on model size, and@hexacubeexplores the feasibility of using a Tesla P40 alongside a newer GPU for specific tasks.
Links mentioned:
- Chat with Open Large Language Models: no description found
- Reddit - Dive into anything: no description found
- Artificial Intelligence authors/titles recent submissions: no description found
LM Studio ▷ #🧠-feedback (5 messages):
- AVX2 Instruction Support Required for LM Studio:
@.thesherbetshared a JSON error indicating their platform does not support AVX2 instructions, preventing the use of LM Studio.@kadesharsuggested trying the beta version of LM Studio, which requires only AVX support.
- LM Studio Unresponsive with Models on iCloud Drive:
@tamina7974reported that LM Studio becomes unresponsive and shows a white screen when there is a model in the directory on iCloud Driver not cached to the local drive.
- Unknown Error Code 42 in LM Studio:
@bypassproductionencountered an unknown error (Exit code: 42) when using LM Studio, asking for advice on how to fix the problem. The diagnostic info includes sufficient RAM and a GPU that supports AVX2.
LM Studio ▷ #🎛-hardware-discussion (144 messages🔥🔥):
- Mixtral Model and VRAM Requirements Discussed:
@heyitsyorkieadvised that for running Mixtral in q6 format, a minimum of 52GB's of VRAM is required, contrary to@roscopeko's query about using 48Gb of VRAM with 3x4060TI. DDR5 RAM was recommended for better performance, indicating 2-3 tok/s speed increase over DDR4.
- CPU Considerations for Running LLMs: A new generation i5 was deemed insufficient by
@heyitsyorkie, who suggested that a faster CPU, like an i9, would prevent it from being a bottleneck when running large language models.
- VRAM vs System Performance:
@roscopekoinquired about the most cost-effective VRAM options, leading to a discussion highlighting the Nvidia 4060TI and used 3090 as optimal choices based on cost per GB of VRAM, despite differences in performance and heat generation.
- Quantization and Model Performance Insights Offered:
@aswarpdetailed the trade-offs made when quantizing large language models, emphasizing a balance between model size, computational efficiency, and potential declines in accuracy, and prompted a discussion on the suitability of quantized models for specific applications.
- Hardware Recommendations for Running LLMs: Suggestions ranged from maximizing VRAM within budget constraints to considering Mac Studio with 192GB RAM for its efficiency and cost-effectiveness in running LLMs, as shared by
@heyitsyorkieand@roscopeko. Various configurations, including a blend of AMD and Nvidia GPUs, were debated, with a consensus on the importance of compatibility and the challenges of mixing different GPU brands.
Links mentioned:
- Mixtral LLM: All Versions & Hardware Requirements – Hardware Corner: no description found
- TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF · Hugging Face: no description found
- AI/ML/DL GPU Buying Guide 2024: Get the Most AI Power for Your Budget: Welcome to the ultimate AI/ML/DL GPU Buying Guide for 2024!In this comprehensive guide, I'll help you make informed choices when selecting the ideal graphics...
- Model Quantization in Deep Neural Networks | HackerNoon: To get your AI models to work on laptops, mobiles and tiny devices quantization is essential
- Model Quantization & Quantization-Aware Training: Ultimate Guide: Learn how model quantization and quantization-aware training can help preserve your model’s accuracy while achieving INT8 performance.
- AMD OpenCL - openSUSE Wiki: no description found
- Feature: Integrate with unified SYCL backend for Intel GPUs by abhilash1910 · Pull Request #2690 · ggerganov/llama.cpp: Motivation: Thanks for creating llama.cpp. There has been quite an effort to integrate OpenCL runtime for AVX instruction sets. However for running on Intel graphics cards , there needs to be addi...
LM Studio ▷ #🧪-beta-releases-chat (6 messages):
- Yi-VL Support Announced: User
n8programsexcitedly shared that yi-vl support has just dropped. This notable update seems to be a awaited feature within the community.
- Linux GPU Acceleration Troubleshooting:
Adrian-1111reported issues with GPU acceleration on Linux Mint 21.03, using a Radeon 7900XTX. Despite trying various settings, the GPU does not seem to be recognized, hinting at a possible driver issue.
- Community Steps Up to Assist: Following
Adrian-1111's query,jedd1provided a series of troubleshooting questions, andheyitsyorkiesuggested posting in a Linux-specific channel for better visibility, indicating the helpful and collaborative nature of the community.
- Adrian Provides Detailed Feedback: In response,
Adrian-1111elaborated on the problem stating they're using Linux version 0.2.10 (Beta V6), and the issue persists across allgpu_layerssettings. They also mentioned the modelTheBloke • mistral instruct v0 2 7B q6_k ggufis operational without GPU offload, albeit less efficiently.
- New Beta Release Fixes for Windows Users:
yagilbwelcomed feedback on the latest Windows 0.2.11 Beta V1 release, which addresses several key issues, including OpenCL not working, VRAM capacity estimates showing 0, and a fix for app startup issues. The release is available for download, with a call to the community for feedback on these fixes.
Links mentioned:
no title found: no description found
LM Studio ▷ #autogen (7 messages):
- Autogen Studio Update Leads to Errors:
@jayjay70reported encountering a server error in Autogen Studio after updating it, specifying a complaint about the 'messages' array having a content field that's empty. They noted this as an old error and were still looking for a fix.
- New User Faces Same Autogen Error:
@fiveofknivesechoed@jayjay70's issue, facing the exact same error message in Autogen Studio, marking their difficulty as a newcomer to the platform.
- Autogen vs. TextGen-webui Behavior Noted:
@jayjay70found that TextGen-webui, when used with Autogen Studio, didn't produce the same errors, pinpointing the issue to running on LM Studio.
- Question about Autogen Studio Config Files:
@jayjay70inquired about the locations of Autogen Studio's config files, mentioning they are using it within a conda virtual environment (venv) installed via PIP.
- Autogen Studio's Error Handling Capability:
@jayjay70shared an experience with Autogen Studio attempting to fix an error by installing the missing Pillow library automatically while using Stable Diffusion via TextGen-webui.
- NexusRaven-V2 GitHub Repository Suggested:
@jgglobalsuggested exploring the NexusRaven-V2 GitHub repository for function calling, sharing a link to its GitHub page.
Links mentioned:
GitHub - nexusflowai/NexusRaven-V2: Contribute to nexusflowai/NexusRaven-V2 development by creating an account on GitHub.
Eleuther ▷ #general (108 messages🔥🔥):
- Flash-Attention Jax Porting Woes:
@nshepperdis contemplating the best strategy to package a Jax port of flash-attention, considering the complications arising from dependencies on pytorch with cuda. They suggest forking the original repo to remove pytorch specifics in favor of Jax bindings, highlighting the predicament of not having both torch-cuda and jax-cuda installed simultaneously due to cuda version compatibility issues.
- The Absence of Flash Attention in T5 Models:
@rallio.expressed surprise upon discovering that there's no implementation of flash attention for T5 models, pointing out a perceived gap in the technology's application.
- AI Expertise and Media Misinterpretations:
@exiraeand others discuss the influence of AI experts like Gary Marcus in the media, critiquing how academic rivalries and misinterpretations can dilute the public's understanding of AI's capabilities and risks. This notion is expanded upon with references to the Gell-Mann Amnesia effect by@.msklarand comments on the misalignment of expertise and media representation by@catboy_slim_, highlighting the complexity of conveying accurate AI advancements to the public.
- Concerns Around X-Risks and Prepping Culture: The discourse ventures into existential risks (X-risks) and the culture around prepping for catastrophic events. Discussions range from critiques of the prepper mindset by
@catboy_slim_and@the_alt_man, highlighting skepticism towards the efficacy and motivations of prepping, to@rallio.advocating for readiness against existential threats, supported by examples of high-profile individuals like Larry Page and Mark Zuckerberg allegedly investing in secluded refuges.
- Searching for Current News Datasets for Model Training:
@danfosinginquires about datasets containing news from 2023 and potentially January 2024 for training models, highlighting a noticeable scarcity in available quality datasets for recent news. They mention the unsuitability of the common crawl dump from December due to its unfiltered nature, with@sparetime.suggesting a scraper for PROQUEST as a potential alternative source with newer content.
Links mentioned:
- Inside Mark Zuckerberg’s Top-Secret Hawaii Compound: Meta CEO Mark Zuckerberg is building a sprawling, $100 million compound in Hawaii—complete with plans for a huge underground bunker. A WIRED investigation reveals the true scale of the project—and its...
- Reclusive Google co-founder Larry Page reportedly hiding out in Fiji: The reclusive billionaire and Google co-founder has stayed mostly on the heart-shaped Tavarua island in Fiji.
Eleuther ▷ #research (131 messages🔥🔥):
- Wondering About the Future of Embedding Tying in LLMs: Discussion pivots on when and why language models moved from tying to untying word embeddings.
@maxmaticalinquires about the transition timeline, while@catboy_slim_suggests that at large model scales, the benefits of tying embeddings become negligible and possibly detrimental.
- Exploring Activation Beacon Mechanism in Transformers:
@leegao_provides a comprehensive explanation of how Activation Beacon with a sliding window approach can enhance pre-trained models' ability to condense activations and maintain information over long sequences. The method requires fine-tuning but promises fixed max space/time usage due to self-attention being confined to up to L tokens.
- MMMU Benchmark Raises Concerns:
@avi.aicriticizes the MMMU benchmark for what they perceive as poorly constructed questions, especially in non-STEM areas, with an example from sociology that seems misconstrued. The incident sparks a broader discussion on the integrity and construction of benchmarks in AI research.
- Interest Surges in Self-Play Projects: Following
@rybchuk's inquiry about interest in a self-play project, multiple users, including@sumo43,@joiboitoi, and@sparetime., express their interest and available compute resources for reproducing the SPIN project, highlighting a collective interest in deepening research in self-play mechanisms.
- SliceGPT Promises Efficient Model Sparsification:
@pizza_joeshares a paper on SliceGPT, a post-training sparsification technique that effectively reduces model size by slicing weight matrices and retaining significant task performance with a smaller compute and memory footprint.@leegao_critiques it, pointing out the accuracy-compression tradeoff might not be favorable for smaller models like LLaMA.
Links mentioned:
- SliceGPT: Compress Large Language Models by Deleting Rows and Columns: Large language models have become the cornerstone of natural language processing, but their use comes with substantial costs in terms of compute and memory resources. Sparsification provides a solutio...
- Firefly Monte Carlo: Exact MCMC with Subsets of Data: Markov chain Monte Carlo (MCMC) is a popular and successful general-purpose tool for Bayesian inference. However, MCMC cannot be practically applied to large data sets because of the prohibitive cost ...
- In-Context Language Learning: Arhitectures and Algorithms: Large-scale neural language models exhibit a remarkable capacity for in-context learning (ICL): they can infer novel functions from datasets provided as input. Most of our current understanding of whe...
- Paper page - Cure the headache of Transformers via Collinear Constrained Attention): no description found
- SeamlessM4T: Massively Multilingual & Multimodal Machine Translation: What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation...
- MMMU: no description found
- Tweet from Charles Foster (@CFGeek): > Transformers significantly outperform neural sequence models with recurrent or convolutional representations on ICLL tasks […] we provide evidence that their ability to do so relies on specialize...
Eleuther ▷ #lm-thunderdome (29 messages🔥):
- Seeding Changes in LM Evaluation Harness:
@hailey_schoelkopfand@baber_discussed changes in the seeding for few-shot sampling in the LM evaluation harness, moving from seed42to1234. This change, aimed at improving consistency, might affect results upon rerun.
- Consistency Over Time in LM Evaluation Harness:
@.johnnysandsis updating their main copy of the LM evaluation harness and is concerned about ensuring consistent results over time. They are considering updating to the latest main branch despite potential changes to test results.
- Discussion on Repetition Penalty in LM Evaluation Harness:
@harrisonvraised concerns about the impact of disabling repetition penalty on evaluation scores for language models.@hailey_schoelkopfstated that for Hugging Face models, the setting can be passed, but it is not enabled by default.
- Incorporating RWKV Library into LM Evaluation Harness:
@picocreatoris looking into integrating the RWKV pip library into the LM evaluation harness, inquiring about the handling of logprob outputs and the necessity to disable settings like top_p and top_k for loglikelihood-based scoring.@hailey_schoelkopfclarified that logprob should be the sum of per-token loglikelihood.
- Per Example Metrics in LM Evaluation Harness:
@Goyiminquired if it is possible to compute and output metrics per example in the evaluation harness instead of aggregated metrics.@baber_explained that using—log_sampleswill log results for each sample along with all its metadata.
Links mentioned:
- GitHub: Let’s build from here: GitHub is where over 100 million developers shape the future of software, together. Contribute to the open source community, manage your Git repositories, review code like a pro, track bugs and fea...
- lm-evaluation-harness/lm_eval/models/gguf.py at 97a67d27c09857e5698cbae730750cf84cd987f3 · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/evaluator.py at e81d3cce155e93ba2445068767c738891ad97024 · jonabur/lm-evaluation-harness): A framework for few-shot evaluation of autoregressive language models. - jonabur/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/models/huggingface.py at 97a67d27c09857e5698cbae730750cf84cd987f3 · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- Comparing jonabur:master...EleutherAI:master · jonabur/lm-evaluation-harness: A framework for few-shot evaluation of autoregressive language models. - Comparing jonabur:master...EleutherAI:master · jonabur/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/evaluator.py at e81d3cce155e93ba2445068767c738891ad97024 · jonabur/lm-evaluation-harness): A framework for few-shot evaluation of autoregressive language models. - jonabur/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/api/task.py at 97a67d27c09857e5698cbae730750cf84cd987f3 · EleutherAI/lm-evaluation-harness): A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #gpt-neox-dev (34 messages🔥):
- Apex Build Troubles and Solutions:
@catboy_slim_opened a conversation about the less-than-ideal process of building Apex, suggesting a shift to using prebuilt binaries due to the long build times of newer Apex versions in a Docker environment. They highlighted the need for a prebuilt Apex wheel, especially for the ppc64le architecture used at ORNL Summit, to bring the Docker build time under half an hour.
- Cross-architecture Compatibility Concerns: Discussions revolved around making GPT-NeoX compatible across different architectures, with
@tastybucketofricerevealing that GPT-NeoX is already running on ORNL Summit's ppc64le.@catboy_slim_considered setting up prebuilt wheels for Apex to ease installation and address compatibility issues.
- Multi-node Deployment Hurdles:
@dayofthepenguin_91344shared issues faced while setting up NeoX on a new cluster, particularly when extending training across two nodes using apdshlauncher. Following the advice of@tastybucketofrice, who suggested checking container launches and considering an OpenMPI deepspeed multinode runner, a working solution involved adapting a hack to ensure the virtual environment setting on each rank.
- Creating an Opinionated Apex Fork with Prebuilt Wheels:
@catboy_slim_shared a link to a prebuilt Apex wheel and voiced support for creating a fork of Apex with only necessary kernels, to simplify the build process and make the setup more developer-friendly. They also mentioned automating the build process for Apex and making it available as a Python package.
- Future-proofing and Architecture Support Tactics: The discussion included plans for future-proofing by setting up a build pipeline for Apex, which would also address the daunting task of building Apex from scratch.
@catboy_slim_expressed readiness to support additional architectures as needed but highlighted a focus on linux_x86_64 and ppc64le, mentioning the relative ease of supporting the latter due to available Nvidia CUDA containers.
Links mentioned:
- [BUG] RuntimeError: Ninja is required to load C++ extensions · Issue #1687 · microsoft/DeepSpeed: Hi, I am getting the following error when running pretrain_gpt.sh DeepSpeed C++/CUDA extension op report NOTE: Ops not installed will be just-in-time (JIT) compiled at runtime if needed. Op compati...
- Release apex-0.1-cp310-cp310-linux_x86_64-141bbf1 · segyges/not-nvidia-apex: Releases a prebuilt apex wheel. Python 3.10, linux_x86_64, apex commit 141bbf1
- gpt-neox/Dockerfile at python-version-update · segyges/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the DeepSpeed library. - segyges/gpt-neox
Mistral ▷ #general (92 messages🔥🔥):
- Embedding Models into Scripts for Offline Use:
@mahmoodbashar08inquired about embedding Mistral models into a Python script for offline use, and@vhariationaladvised downloading open-weight models and possibly using quantized versions for constrained hardware, such as the GGUF model available on Hugging Face. - Inference Package Choices Expand: Several users, including
@mrdragonfoxand@ethux, discussed various inference packages like ollama, ooba, and vllm, highlighting the availability of many with OpenAI-compatible endpoints and hinting at the constant growth in the variety of inference tools available. - Demand for Mistral Medium Weights: Queries about accessing Mistral's medium weights surfaced, with
@.mechapasking for their location. However,@ethuxconfirmed these are still closed source, noting this is understandable given their beta status. - Running Models in Server Mode for Efficiency: In response to
@mahmoodbashar08's question about loading models efficiently in node llama cpp,@tom_lrdrecommended running the model in server mode for persistent access via a local API, suggesting this as a common approach among many applications. - Speculations Around a Potential Mistral Model Leak: The discussion led by
@akshay_1and@ethuxabout a possible model related to Mistral hinted at a leak.@ethuxclarified the uncertainty around the authenticity and whether it was Mistral-led or a fine-tuned version by another entity, evoking curiosity and caution regarding unofficial information.
Links mentioned:
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Client code | Mistral AI Large Language Models.): We provide client codes in both Python and Javascript.
- miqudev/miqu-1-70b · Hugging Face: no description found
- Open The Vault Gta Online GIF - Open The Vault Gta Online Vault Robbery - Discover & Share GIFs: Click to view the GIF
Mistral ▷ #deployment (3 messages):
- Seeking Deployment Wisdom for Mistral8x7b: User
@rolexx6326inquired about deploying Mistral8x7b on AWS, Azure, GCP, or a local server. They shared adocker pullcommand from Replicate and expressed interest in offering a self-hosted AI model solution with a ChatGPT-like interface for companies.
- A Path to Self-Deployment Found:
@vhariationalpointed@rolexx6326towards Mistral's self-deployment documentation, mentioning that while big cloud vendors offer managed inference solutions, they tend to be more costly than DIY deployments.
Mistral ▷ #finetuning (16 messages🔥):
- Seeking Guidance on LLM Fine-Tuning:
@sadaisystemsis looking for comprehensive resources, excluding papers, on fine-tuning Large Language Models using (Q)LoRAs, with a focus on the practical aspects. - Consultant Request for RAG Implementation:
@brentnhunteris in search of a consultant to build a Retrieval-Augmented Generation (RAG) system for ingesting book-length PDFs into Mistral’s LLM on a modest budget. The expectation and budget specifics were initially unclear. - Clarifying RAG and Budget Expectations:
@mrdragonfoxseeks clarification on@brentnhunter's budget for the project, whether it's under $50k or $10k, and explains that RAG operates differently by embedding data into a vector storage outside of the LLM for semantic search. - System Requirements Elaborated by Inquiry: Following queries,
@brentnhunterdetails his system that combines a full-stack setup and an API for voice-activated Q&A sessions, aiming to integrate it with RAG to process two book-length PDFs. - Budget and Scope Considerations for Consultancy:
@mrdragonfox, discussing as a potential consultant, highlights the importance of budget details and project specifics for determining the feasibility and interest in providing consultancy for@brentnhunter’s RAG project.
Mistral ▷ #showcase (18 messages🔥):
- Confusion and Clarification on Copilot Alternatives:
@amagicalbooksought details on GitHub for a project, leading to a mention of Copilot alternatives by@mrdragonfox. They specifically mentioned Tabby/Continue, causing some confusion that was later clarified by@vhariationalwith links to Tabby and Continue.
- The Debate on Self-Research vs. Spoonfeeding Information: A debate ensued between
@mrdragonfoxand@vhariationalregarding whether directly providing answers or encouraging self-research benefits the questioner more.@mrdragonfoxexpressed a preference for encouraging self-research to improve problem-solving skills.
- Plans to Open Source Discussed Project: In response to a query about the availability of a project on GitHub,
@hugoduprezmentioned plans to open source the project and promised to keep the community updated.
- Announcement of Arithmo2-Mistral-7B Model:
@ajindalintroduced the Arithmo2-Mistral-7B model which shows improvement on GSM8K, GSM8K PoT, and MATH benchmarks over its predecessor. Links to the model and LoRA adapter are shared on Hugging Face and detailed information can be found on the project's GitHub page.
Links mentioned:
- upaya07/Arithmo2-Mistral-7B · Hugging Face: no description found
- upaya07/Arithmo2-Mistral-7B-adapter · Hugging Face: no description found
- GitHub - akjindal53244/Arithmo: Small and Efficient Mathematical Reasoning LLMs: Small and Efficient Mathematical Reasoning LLMs. Contribute to akjindal53244/Arithmo development by creating an account on GitHub.
Mistral ▷ #random (3 messages):
- DoubleMint Dives into the Metaverse with Xbox's CFO: DoubleMint shared a YouTube video titled "I asked XBOX's CFO about the Metaverse, XBOX in 2030, VR, & tech's future," discussing the future of human-computer interaction, virtual reality, and the metaverse with Xbox's CFO.
- Offline Community Meetup in Chennai:
@lokeshkannanannounced an offline community meetup in Chennai on Saturday, Feb 3rd, focusing on "Building using open-source LLMs". The meetup seeks speakers with experience in building products or solutions using open-source LLM models, catering to an audience of product managers, data scientists, and principal engineers, with options to join via Zoom for overseas participants.
Links mentioned:
I asked XBOX's CFO about the Metaverse, XBOX in 2030, VR, & tech's future: in this mess of a video I chat with Kevin about the future of human-computer-interaction and nerd out about virtual reality, the metaverse, and some other st...
Mistral ▷ #la-plateforme (17 messages🔥):
- Seeking a ChatGPT Alternative with Mistral API:
@adams3996inquired about a frontend alternative to the ChatGPT subscription, utilizing the Mistral API for access on any computer.@ethuxresponded, confirming that while there isn't a ChatUI equivalent for Mistral API, users could build their own UI using the API key. - Documentation and API Clarifications by Mistral Community:
@vhariationalhighlighted potential inconsistencies in Mistral's documentation regarding generative endpoints and suggested corrections related to the use of Mistral models in the documentation. They provided a direct link to the documentation for reference. - Alternatives for Mistral API Interface:
@vhariationaland@chrisbouvardsuggested third-party interfaces such as HuggingChat and platforms operated by Poe and Fireworks.ai, which utilize Mistral models, offering potential solutions for users looking for front-end interfaces. - Model Specifications and Corrections:
@mrdragonfoxclarified model names and capabilities, stating that "small is the 8x7b moe" and that "tiny is 7b", correcting mislabelings and confirming no existence of a "medium" Mistral model. - Librechat as a Mistral Interface Option:
@fersingbintroduced Librechat, mentioning it as an unexplored option that supports Mistral integration, potentially offering another alternative for users seeking an interface for Mistral API.
Links mentioned:
Endpoints | Mistral AI Large Language Models): We provide different endpoints with different price/performance tradeoffs. Our endpoints depend on internal models.
HuggingFace ▷ #general (70 messages🔥🔥):
- Hugging Face Autotrain Queries Resolved:
@rishit_kapoorasked about downloading, deploying, rights to data, and costs related to Hugging Face's auto-trained models.@vishyouluckconfirmed that auto-trained models can be deployed and later used for inference, and clarified data rights by pointing towards open-source licensing, while@vipitisreferenced the terms of service, indicating private uploads are not used by Hugging Face without exception.
- RAG Expert Assistance Offered:
@the_aureoresponded to@skyward2989's request for help with RAG, encouraging direct messaging for advice.
- Dataset Sharding Discussed for Performance: In a discussion about dataset performance,
@lhoestqconfirmed to@kopylthat splitting datasets into shards and processing them with multiple processes does speed up operations. However, they also mentioned enabling multiprocessing only if explicitly requested to avoid unwarranted behaviors.
- Collaborative Creation of AI Models in Gaming and Trading:
@wondeysexpressed interest in starting projects related to Trading AI or Poker AI, inviting collaboration from the community.
- Upcoming Offline Community Meetup in Chennai:
@lokeshkannanannounced an offline community meetup in Chennai focused on building products/solutions using open-source Large Language Models (LLMs), calling for speakers to share their experiences with an audience of product managers, data scientists, and principal engineers.
Links mentioned:
- ChitraGPT - a Hugging Face Space by VishalMysore: no description found
- Accelerated inference on AMD GPUs supported by ROCm: no description found
- Terms of Service – Hugging Face: no description found
- Spaces - Hugging Face: no description found
- TURNA - a Hugging Face Space by boun-tabi-LMG: no description found
- TURNA: A Turkish Encoder-Decoder Language Model for Enhanced Understanding and Generation: The recent advances in natural language processing have predominantly favored well-resourced English-centric models, resulting in a significant gap with low-resource languages. In this work, we introd...
- Process:): no description found
- diffusers/examples/text_to_image/train_text_to_image_sdxl.py at main · kopyl/diffusers: 🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - kopyl/diffusers
- diffusers/examples/text_to_image/train_text_to_image.py at main · huggingface/diffusers): 🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - huggingface/diffusers
- Map speedup by kopyl · Pull Request #6745 · huggingface/diffusers: Speed up 2nd mapping in examples/text_to_image/train_text_to_image_sdxl.py (computing VAE). Testing on 833 samples of this dataset: lambdalabs/pokemon-blip-captions Mine: 1m 48s Current implementat...
- import functoolsimport gcimport loggingimport mathimport osimport rand - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- root@55cb7f729062:/workspace# lsHF_HOME Untitled.ipynb pycache dataset- - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Fix multi gpu map example by lhoestq · Pull Request #6415 · huggingface/datasets: use orch.cuda.set_device instead of CUDA_VISIBLE_DEVICES add if name == "main" fix #6186
HuggingFace ▷ #today-im-learning (7 messages):
- A Quick Take on Audio Basics:
@not_lainmentioned that the initial unit on audio basics felt slightly off but advised not to dwell on it too much. - Discover the Physics of Sound:
@vipitisshared a highly informative and interactive blog about the physics of sound at ciechanow.ski/sound, highlighting its interactive elements to better understand sound propagation. - Completion of 🤗 Audio Course:
@not_lainannounced the completion of an audio course provided by 🤗, receiving congratulations from@lunarflu. - The Importance of Personas in Projects:
@mad_cat__shared insights on the underestimated role of personas in the development and execution of projects, emphasizing its crucial importance. - Automated Testing for LLMOps:
@miko_alfound and shared a link to learn.deeplearning.ai, focusing on Automated Testing for LLMOps, suggesting it as a resource worth exploring.
Links mentioned:
- DLAI - Learning Platform: deeplearning.ai learning platform
- Sound – Bartosz Ciechanowski: Interactive article explaining how sound works.
HuggingFace ▷ #cool-finds (1 messages):
- Trending HF Spaces Explored in New Video: User
@devspotshared a YouTube video titled "Meta's Text to Audio is INSANE - MAGNet, Moondream & ZeroShape!" The video offers a brief exploration of the latest trending HuggingFace spaces, validating the functionality of 3-4 different AI apps.
Links mentioned:
Meta's Text to Audio is INSANE - MAGNet, Moondream & ZeroShape!: A brief video about some of the trending huggingfac spaces of the past weeks. In this video, we explore 3-4 different AI apps and validate their functionalit...
HuggingFace ▷ #i-made-this (10 messages🔥):
- ML Security Alert by 4n7m4n:
@4n7m4nshared their blog post on ML security, highlighting a threat via Google Colaboratory that can compromise your Google Drive data. The post, titled Careful Who You Colab With, serves as a cautionary tale for ML researchers and educators using Google Colab.
- FumesAI Demos Image Models:
@myg5702introduced the FumesAI demo on Hugging Face, showcasing image models in action. Check out the demo here for a practical application of these models.
- Gantrithor Demo by Stroggoz:
@stroggozshared a YouTube video of themselves using Gantrithor, an app for labeling 10,000 documents from the conll dataset within 5 minutes, leading to an NER model with 86% accuracy. The app and its capabilities are previewed here.
- AI Simmons Art Bell Show:
@.plotused Mistral, Ollama, and Coqui to simulate an Art Bell call-in radio show, creating a unique AI-generated exploration of the unexplained. The YouTube video of this creation, titled "Open Lines - AI Art Bell v.04 Riding the Wire", can be viewed here.
- SoniTranslate Project:
@R~S~developed a project utilizing transformers, Whisper, Openvoice, Bark, VITs, Wav2vec2, and Pyannote for synchronizing translation on video segments. This open-source project, available on GitHub, aims to overlay translated text at corresponding timestamps on videos.
- Discover Your Vogue Fashion Twin with tony_assi's Tool:
@tony_assishared a fun AI tool that matches users with a fashion collection look-alike from 90K images across 1700 collections on Vogue Runway. Interested users can try the tool at Hugging Face Spaces.
Links mentioned:
- Image Models Demo - a Hugging Face Space by FumesAI: no description found
- Vogue Fashion Look A Like - a Hugging Face Space by tonyassi: no description found
- Careful Who You Colab With:: abusing google colaboratory
- Open Lines - AI Art Bell v.04 Riding the Wire: 🌌 Riding the Wire - Unraveling the Unexplained with Art Bell AI 🌌👽 Welcome to a cosmic journey on the airwaves! In this AI-generated edition of "Riding th...
- Gantrithor Demo Labelling NER: In this video we have some randomized predictions of entities from an untrained tiny BERT transformer.We show that a fairly accurate (86% accuracy) model can...
- GitHub - R3gm/SoniTranslate: Synchronized Translation for Videos: Synchronized Translation for Videos. Contribute to R3gm/SoniTranslate development by creating an account on GitHub.
HuggingFace ▷ #reading-group (8 messages🔥):
- Seeking Machine Learning in Manufacturing Reads: User
@gschwepp_84093inquired about recommended readings on the application of machine learning algorithms in manufacturing, seeking suggestions from the community.
- AI in Law Presentation Preview:
@chad_in_the_houseshared a preview of their upcoming presentation on AI in law, providing a medium article that outlines the challenges of using AI in legal contexts and the current state of research in this area. The post indicates a detailed exploration of the difficulties in replacing human judgment in law with algorithms.
- Simplifying Argumentative Logic in Law: Further,
@chad_in_the_housementioned plans to simplify the content on argumentative logic in their presentation on AI in law, indicating that the complexity took significant effort to grasp. This illustrates the intricate nature of the topic being addressed.
- Interest in Stream Diffusion: User
@skyward2989raised the question of the community's interest in stream diffusion, potentially hinting at discussions on recent advances or applications in that area.
- Learning GPU Programming for AI Applications:
@skyward2989also expressed a desire to learn about GPU programming and low-level operations such as writing CUDA kernels, seeking resources for beginners in this technical area. This could prompt sharing of educational resources and advice on starting projects to learn GPU programming.
Links mentioned:
Literature Review on AI in Law: This blog was inspired by Owl from the Laion Discord server. Thanks for the discussions! In this blog, my main goal is to go through why…
HuggingFace ▷ #diffusion-discussions (6 messages):
- Colab Compute Quandary for Pros:
@iloveh8expressed confusion on why they run out of Colab compute as a Pro user, despite opening many tabs but not running any code. - Seeking a Good Clip Retrieval Tool:
@pawanp3is in search of a reliable Clip Retrieval tool for querying the LAION-5B dataset. They found clip-retrieval on GitHub, but noted the backend URL appears to be broken. - WhiteRabbitNeo-33B-v1 Announced:
@compscifutureshighlighted the release of WhiteRabbitNeo-33B-v1 model by Migel Tissera, featuring a "Prompt Enhancement" feature and available at WhiteRabbitNeo.com. An invitation to join their Discord server was also extended. - Cybersecurity Insights via Twitter Space:
@compscifuturesshared a link to a Twitter Space (Twitter Space link) discussing cybersecurity with Migel Tissera, author of WhiteRabbitNeo. - Query on OpenAI Framework:
@amir_martinez.veered off-topic by inquiring if anyone had access to an OpenAI framework, without specifying what exactly they were looking for.
Links mentioned:
- WhiteRabbitNeo/WhiteRabbitNeo-33B-v1 · Hugging Face: no description found
- GitHub - rom1504/clip-retrieval: Easily compute clip embeddings and build a clip retrieval system with them: Easily compute clip embeddings and build a clip retrieval system with them - GitHub - rom1504/clip-retrieval: Easily compute clip embeddings and build a clip retrieval system with them
HuggingFace ▷ #computer-vision (9 messages🔥):
- Automatic Model Importation Discussed:
@iloveh8sparked a conversation on the feasibility of automating the importation of new models from Hugging Face to enhance use cases. They inquired about applying CI/CD or MLOps techniques to seamlessly integrate the best models for specific applications.
- Skepticism on Automating Model Selection:
@johko990raised concerns about the complexities of automatically choosing the "best" model due to varying benchmarks and the unique requirements of specific use cases. They suggested that minor improvements in model performance might not justify switching models frequently.
- Agreement on Approach Caution: Echoing
@johko990's sentiments,@gugaimeconcurred that constantly chasing the latest model based on leaderboard standings could be ill-advised, suggesting that such decisions should not be made lightly.
- Concept of Dynamic Model Merging/Updating Introduced:
@iloveh8likened their idea to dynamic model merging/updating and AutoML for pretrained diffusion generative models, indicating a desire for more autonomous and adaptive model management.
- Reference to Depth Anything Model:
@johko990shared a link to the Depth Anything model on Hugging Face, illustrating an example of advanced models available on the platform which could potentially fit into such an automated importation system.
- Inquiry on AutoTrain Settings for LoRA:
@b1gb4nginquired about the settings for LoRA training within Hugging Face's AutoTrain, specifically the number of epochs required for training on 10 images, indicating user interest in detailed configuration information for model training processes.
Links mentioned:
Depth Anything: no description found
HuggingFace ▷ #NLP (22 messages🔥):
- Demystifying In-context Learning:
@stroggozasked about in-context learning, to which@vipitisresponded, explaining it as providing a model with a few examples at the start of the prompt for few-shot learning. They also shared the GPT-3 paper for further reading. - Few-shot Learning: A Double-Edged Sword:
@vipitiswarned that while one-shot/few-shot learning can significantly enhance output accuracy, it also makes models prone to over-reliance on prompt context, leading to potential hallucinations, especially concerning code models. - Finding the Right Keyword Extraction Model on Hugging Face:
@shashwat_g27sought a model for extracting keywords from sentences, leading@vipitisto suggest training a span prediction model.@stroggozfurther recommended exploring KeyBERT and shared a link to a keyword extractor model on the Hugging Face platform. - Transitioning Text Generation Models for Russian Support:
@cherrykoroldiscussed switching from GPT-2 to rugpt for Russian language support, aiming to develop a question-and-answer system. - Troubleshooting ONNX Conversion Issues with Hugging Face Models:
@denisjannotreported successfully fine-tuning a model and converting it to ONNX. However, they encountered an issue where the ONNX model's responses mirrored the input exactly, a problem not present in the pre-conversion model.
Links mentioned:
- Language Models are Few-Shot Learners: Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in a...
- transformer3/H1-keywordextractor · Hugging Face: no description found
- Models - Hugging Face: no description found
HuggingFace ▷ #diffusion-discussions (6 messages):
- Colab Compute Confusion:
@iloveh8expressed confusion about running out of compute on Colab as a pro user, despite not running any code on the multiple open tabs they have. - Seeking Clip Retrieval Tools:
@pawanp3is in search of a good Clip Retrieval tool for the LAION-5B dataset, mentioning a broken link to a potentially useful tool they found. - WhiteRabbitNeo’s New Features:
@compscifutureshighlighted Migel Tissera's authoring of the WhiteRabbitNeo-33B-v1 model, now live with a "Prompt Enhancement" feature, and shared a link to a Cybersecurity model discussion on Twitter Spaces. - Enthusiasm for WhiteRabbitNeo:
@chad_in_the_houseexpressed enthusiasm for the WhiteRabbitNeo model, calling it awesome. - Off-Topic Inquiry About OpenAI Framework:
@amir_martinez.shifted the topic by inquiring if anyone has the OpenAI framework, indicating a lack of context or additional information about their request.
Links mentioned:
- WhiteRabbitNeo/WhiteRabbitNeo-33B-v1 · Hugging Face: no description found
- GitHub - rom1504/clip-retrieval: Easily compute clip embeddings and build a clip retrieval system with them: Easily compute clip embeddings and build a clip retrieval system with them - GitHub - rom1504/clip-retrieval: Easily compute clip embeddings and build a clip retrieval system with them
LangChain AI ▷ #general (77 messages🔥🔥):
- OpenAI's New Embedding Models and API Tools:
@capit0shared a link to OpenAI's blog post announcing new embedding models, an updated GPT-4 Turbo preview model, updated GPT-3.5 Turbo model, a text moderation model, and new API usage management tools. The post also highlighted a reduction in prices for GPT-3.5 Turbo and introduced two new embedding models viewable here.
- Chroma Troubleshooting Galore:
@sheldadafaced multiple issues with Chroma in http-only client mode leading to a RuntimeError, indicating that it can only run with 'chromadb.api.fastapi.FastAPI' as the chroma_api_impl. Helpful suggestions came from others, including switching to pg-vector for simplicity and Docker support as discussed by@johnny2x2.
- Exploring LangChain for Unique Integrations: Multiple users, including
@nullbit0and@mikdad, discussed integrating various tools with LangChain for applications like multi-agent systems and combining Hugging Face with OpenAI. Additionally,@techexplorer0sought advice for creating a local conversational RAG chatbot with memory and context handling.
- Interest in Open Sourcing Solutions and Project Ideas:
@caleb_solencouraged open sourcing a self-querying retriever system as it could lead to recognition and opportunities in the domain. Meanwhile,@johnny2x2floated an idea about leveraging personal GPU resources for inferencing as a local service, suggesting a self-regulated market based on users' available resources.
- OpenAI Embedding Function Errors and Solutions:
@sheldadareported an AttributeError with 'OpenAIEmbeddingFunction' not having an 'embed_query' attribute while working with LangChain's self-querying retrieval system. Despite suggestions and troubleshooting steps offered by@johnny2x2, including the correct usage of libraries and potential reinstallations, the problem persisted without a clear resolution.
Links mentioned:
- OpenAI | 🦜️🔗 Langchain: Let’s load the OpenAI Embedding class.
- New embedding models and API updates: We are launching a new generation of embedding models, new GPT-4 Turbo and moderation models, new API usage management tools, and soon, lower pricing on GPT-3.5 Turbo.
- 🧪 Usage Guide | Chroma: Select a language
- langchain/docs/docs/integrations/retrievers/self_query/chroma_self_query.ipynb at master · langchain-ai/langchain: ⚡ Building applications with LLMs through composability ⚡ - langchain-ai/langchain
LangChain AI ▷ #langserve (8 messages🔥):
- Dot Annotation Struggle in Production:
hiranga.gencountered errors when using dot annotation in prompts for production, despite it working in tests. The issue was related to accessing nested data within a JSON request object. - Plea for Help with LangServe:
hiranga.greached out to users with expertise in LangServe, hoping to resolve issues related to using nested data and adding complex structures like arrays or calculated functions in their project. - Quadruple Curly Braces Revelation: Discovering that quadruple curly braces
{{variable.nestedVar}}solved their issue temporarily,hiranga.gshared this tip, hinting at it as a possible workaround for escaping characters when using nested data in prompts. - Back to Square One: Unfortunately, the quadruple curly braces trick didn’t solve the problem as hoped.
hiranga.gshared an error message indicating that the expected variables were missing, highlighting the ongoing struggle to correctly set up their system. - Eureka with Python’s f-strings: Ultimately,
hiranga.gfound that using Python’s f-strings resolved their issues with accessing nested data in LangChain, expressing relief but also frustration over the time taken to resolve what turned out to be a simple fix.
LangChain AI ▷ #langchain-templates (1 messages):
- Inquiry about Image Input Handling: User
@nav1106asked if it's possible to set an input variable forHumanMessagecontent with the typeimage_urlto use a base64 string of an image instead. They seek to replace the standard image URL with a base64 encoded image string.
LangChain AI ▷ #share-your-work (8 messages🔥):
- The Semantic Router Shaping AI Conversations:
@andysingalintroduces an enlightening exploration into the impact of the Semantic Router on AI conversations and LangChain technology. The transformative potential is highlighted in their blog post.
- Seeking AI for YouTube and Podcast Summaries:
@moneyj2kis in search of an AI application that can summarize YouTube watch history and podcasts, then input the summaries into note-taking apps like Obsidian or Notion. No direct suggestions were provided in the conversion.
- Introducing a Reverse Job Board for AI Talents:
@sumoddshared their creation, Neural Network, a free reverse job board tailored for individuals interested in working with AI. It allows engineers and creatives to make free profiles for exposure to companies seeking AI talent.
- Simpler Google Sheets Download with Python:
@johnny2x2shared a Python snippet for downloading Google Sheets as CSV files with ease, using therequestsandpandasmodules. This code snippet represents a practical tool for data handling.
- Debate on Semantic Routing's Foundations: A discussion ensued between
@v7__vand@andysingalregarding the omission of NeMo Guardrails in the discussion about Semantic Router's impact.@v7__vcited James Briggs' work as foundational, prompting@andysingalto consider reevaluating their resources, including a particular YouTube video by Briggs.
Links mentioned:
- NEW AI Framework - Steerable Chatbots with Semantic Router: Semantic Router is a superfast decision layer for your LLMs and agents that integrates with LangChain, improves RAG, and supports OpenAI and Cohere.Rather th...
- Unlocking the Future of AI Conversations: The Semantic Router’s Impact on LangChain: Ankush k Singal
- Neural Network - an initiative by Convergent Software: A reverse job board to connect AI engineers with organizations
LangChain AI ▷ #tutorials (1 messages):
- DIY ChatGPT-like UI with ChainLit, LangChain, Ollama & Mistral: A new tutorial video titled "Create Chat UI Using ChainLit, LangChain, Ollama & Mistral 🧠" has been shared by
datasciencebasics. The video guides viewers through the process of creating a simple ChatGPT-like UI on their local computer, instructing them to follow along by cloning a specific repository.
Links mentioned:
Create Chat UI Using ChainLit, LangChain, Ollama & Mistral 🧠: In this video, I am demonstrating how you can create a simple ChatGPT like UI in locally in your computer. You can follow along with me by cloning the repo l...
LAION ▷ #general (89 messages🔥🔥):
- AI Models and Game Development Challenges: Discussion led by
@vrus0188and@nx5668about the size of Language Learning Models (LLMs) required for NPCs in games, suggesting that smaller 2B models could suffice for basic NPC interactions, but more sophisticated and consistent behavior might require at least 7B models. This exchange exemplifies the considerable resources needed for NPCs in 2D RPGs, hinting that such technological advancements may not be imminent.
- Pixart and Model Evaluations Heat Up:
@qwerty_qwerand@pseudoterminalxengage in a conversation about Pixart-α, a model designed for generating professional watercolor historical paintings, reflecting users' ongoing experiments and discussions regarding the balance between realism and artistic style in AI-generated images. The conversation includes a shared link to PixArt-α's GitHub repository, highlighting community interest in improving AI's ability to handle specific artistic requests.
- AI's Role in Moderation Tools: A lighthearted but insightful exchange among users, particularly
@pseudoterminalx,@chad_in_the_house, and@astropulse, discusses the innovative use of AI for sentiment analysis to ease the process of moderating user interactions online. The contribution underscores AI's potential in identifying problematic content, suggesting a future where AI moderates digital spaces more prominently.
- Comparative Discussions on Search Engine AI Integrations: Users
@SegmentationFaultand@qwerty_qwerdebate over the effectiveness of Bing's and Google's AI integrations, with contrasting views on their capabilities in providing accurate information and search results. This conversation reflects the broader community's interest in the evolving landscape of AI-enhanced search tools.
- Efforts to Enhance AI Model Training and Fine-Tuning: Users express ongoing endeavors to improve AI models, with
@pseudoterminalxdiscussing refinements in their model training processes, and@thejonasbrothersproviding insights into the challenges and nuances associated with fine-tuning Pixart and SDXL. These discussions exemplify the community's dedication to pushing the boundaries of AI image synthesis and model sophistication.
Links mentioned:
- Tweet from Pablo Pernías (@pabloppp): Cool and fun use of Würstchen v3's Face ControlNet: Club bathroom selfie :P You'll be able to play with it really soon ^__^
- Pixart-α - a Hugging Face Space by PixArt-alpha: no description found
- GitHub - PixArt-alpha/PixArt-alpha: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis - GitHub - PixArt-alpha/PixArt-alpha: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synth...
- PASD Magnify - a Hugging Face Space by fffiloni: no description found
- csslc/ccsr – Run with an API on Replicate: no description found
LAION ▷ #research (5 messages):
- Google's Bard Surpasses GPT-4:
@vrus0188announced that Google's Bard has climbed to the second spot on the leaderboard, overtaking GPT-4. Here's the announcement on Twitter. - New AI Beats DALL-E 3 and SDXL in Text-to-Image:
@vrus0188shared info about a new model that excels at text-to-image tasks, specifically highlighting its superiority in handling multiple objects and text-image semantic alignment. The model's details are discussed in a Reddit post, with the paper available on arXiv and the code on GitHub. - Collaborative AI Paper Enhances RLHF Performance:
@vrus0188highlighted a paper co-authored by teams from ETH Zurich, Google, and Max Plank Institute aiming to improve Reinforcement Learning from Human Feedback (RLHF) strategies. The paper's discussion can be found on Reddit. - Eagle 7B: A Model Soaring Above Transformers:
@top_walk_townintroduced Eagle 7B, a highly efficient 7.52B parameter model built on the RWKV-v5 architecture, noted for its green credentials and multilingual proficiency. Further insights are offered in a detailed blog post.
Links mentioned:
- 🦅 Eagle 7B : Soaring past Transformers with 1 Trillion Tokens Across 100+ Languages: A brand new era for the RWKV-v5 architecture and linear transformer's has arrived - with the strongest multi-lingual model in open source today
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Perplexity AI ▷ #general (52 messages🔥):
- Warm Welcome for Newcomers:
@kudos0560received a warm welcome from fellow users, including@mares1317, upon joining the Discord channel. No specific topics or links were shared, just greetings. - Questions about API and Copilot Integration:
@lennard.inquired about the possibility of using the Copilot with the API, with@icelavamanresponding and providing a link for further information. The discussion indicated that Copilot functionality is limited to online models only. - Perplexity Users Discuss Model Versions: Users, including
@victor5296, engaged in discussions about the specifics of GPT-4 models used by Perplexity, with@icelavamanproviding clarification and links. The conversation included queries about using GPT-4 turbo and addressed issues with connectivity. - Subscription Model Queries and Concerns:
@minister_pluffersasked if ChatGPT4 remains available after a subscription ends, leading to a clarification that GPT-3.5 becomes the default model post-subscription. Additional context was provided by@icelavamanand@brknclock1215. - Support and Service Accessibility Issues: Users like
@dapperduff,@krayziejim, and@yuki.uedareported experiencing technical issues, including outages and unresponsive support tickets.@ok.alexoffered assistance and directed users to share more detailed information privately for further help.
Links mentioned:
- What model does Perplexity use and what is the Perplexity model?: Dive deep into Perplexity's technical details with our comprehensive FAQ page. From the nuances of AI models like GPT-4 and Claude 2 to token limits and AI profiles, get concise answers to optimize yo...
- Add Perplexity AI as official search option: Please either add Perplexity AI as one of the search engine options, or as an official browser extension. Chrome already has the latter. Thank you.
Perplexity AI ▷ #sharing (15 messages🔥):
- Perplexity AI Shines in Specific Searches and Combining Overviews: User
@rainlain666expressed appreciation for Perplexity AI's ability to find specific websites, pictures, and videos and combine them into a comprehensive overview for any query.
- Learning Coding Better with Perplexity than Paid Alternatives:
@fortunate1utilized Perplexity for learning coding in Ninja Trader 8 Code Editor and found it more effective than another AI service they pay for. They shared screenshots of the AI's responses at and .
and .
- Discovering the Top 5 Healthy Berries in North America:
@geordiemilnefound information on Perplexity AI about the top 5 berries in North America that contain antioxidants and other healthful elements, sharing a result link for further reading.
- Using Perplexity AI to Roast Scammers with Humor:
@gumby2411created a collection with a custom AI prompt on Perplexity AI for generating humorous warnings about scam posts, including vent cleaner and work-from-home scams, without directly accusing the poster. The link to the scam buster tool can be found.
- Tutorial on Leveraging Perplexity Collections:
@parthdasawantshared a YouTube video titled "Tutorial: Perplexity Collections," which provides insights on how to use 'Collections' in Perplexity as a AI research tool. The tutorial is meant to guide users through grouping threads around specific topics effectively. Watch the tutorial.
Links mentioned:
Tutorial: Perplexity Collections: Uncover the power of 'Collections' in Perplexity, a top-tier AI research tool. This tutorial guides you through effectively grouping threads around specific ...
Perplexity AI ▷ #pplx-api (14 messages🔥):
- Seeking Fresher News with PPLX APIs:
@akhil_pulse_energyis trying to fetch the most recent news articles through PPLX APIs but ends up getting articles over a year old.@brknclock1215suggests using Google search operators likeafter:yyyy-mm-ddin the query to potentially yield newer results.
- In Search of the Best Model for Web-like Accuracy:
@akhil_pulse_energyinquires about the best model to use for results similar to web accuracy, to which@icelavamanrecommends using online LLMs as they are the only ones with internet access, thus closest to the web version.
- API Credits Issue for Perplexity Pro:
@defektivexreports not receiving API credits for Perplexity Pro and is advised by@me.lkto email support with account details. Defektivex mentions having already sent an email the previous night.
- Looking for Perplexity API Alternatives:
@defektivexexpresses a need for an API version of the Perplexity web version for his research workflows and discusses alternatives.@brknclock1215observes a shift in Perplexity's stance towards being more receptive to feedback about including sources in API responses.
- Query on Source URLs in Responses:
@Srulikinquires if response from the API includes source URLs.@mares1317responds with a link directing to further discussion but provides no direct answer in the quoted content.
LlamaIndex ▷ #blog (3 messages):
- Building Enterprise RAG Just Got Easier:
@rungalileooffers a deep dive into the architecture for building enterprise-level Retrieval-Augmented Generation (RAG) systems, covering both algorithmic and system-level components. Discover more in this comprehensive guide here.
- Seven Key Challenges for AI Engineers on LLM OSes: Identifying seven crucial challenges that AI engineers face while building large-scale intelligent agents, including improving accuracy and optimizing parallel execution, offers valuable insights into the advancements needed in AI engineering. Further exploration can be found here.
- Enhancing RAG with Knowledge Graphs:
@chiajy2000explains how to incorporate knowledge graphs (KGs) into a RAG pipeline, addressing a common query among users and showcasing various graph-related techniques. Visual learners can appreciate the included diagram and deeper details here.
LlamaIndex ▷ #general (57 messages🔥🔥):
- Azure Configuration Mistake Spotted:
@warpwinghad trouble integrating Llama Index with Azure Open AI due to an ordering error in their code.@cheesyfishesidentified the mistake as creating the index before setting the global service context, which@warpwingacknowledged with gratitude.
- Async Support Confirmed for Postgres: In response to
@rnovikov's inquiry,@cheesyfishesconfirmed that LlamaIndex does support async PostgreSQL drivers, specifically mentioning that the postgres vector store is fully implemented with async methods.
- RAG Stack Guidance Offered by Akshay:
@akshay_1offered assistance to anyone struggling with their RAG stack, engaging with@techexplorer0who faced issues with context loss in Contextchatengine after a few interactions. Akshay probed for more details about the model being used for troubleshooting.
- PDF Parsing Solutions Suggested: For
@ziggyrequrv, who was looking for ways to parse complex PDFs,@akshay_1recommended using tools like pdfminer and pymupdf, and exploring opencv options like tesseract for handling images, links, and other elements within PDFs.
- Multi-Retriever Chaining Possible: In response to
@anupamamaze's question on whether it's feasible to chain multiple types of retrievers (vector, keyword, and BM25) for LlamaIndex or similar applications,@akshay_1confirmed its possibility, specifically mentioning Haystack as a platform where this can be implemented.
Latent Space ▷ #ai-general-chat (35 messages🔥):
- RLHF/DPO for Structured Data Inquiry:
@sandgorgonexplores whether RLHF/DPO is applicable beyond high-temperature use cases, seeking insights on its relevance for structured data. No definitive answers or papers were cited. - New 4turbo Gets Mixed Reviews: After
@jozexotic's inquiry about the new 4turbo's creative headings,@swyxioconfirmed the same settings were used, yet the results were deemed a regression, as detailed in a comparison of GPT4 Turbo's performance over time here. - Digital Photography Learning Journey with AI Assistance:
@slonoembarks on learning digital photography, planning to utilize AI tools from Adobe and others, alongside custom code, to enhance learning and manage photographs. - Discussion on ChatGPT's 'Laziness' Problem Remains:
@btdubbinsraises concerns that ChatGPT hasn't overcome its 'laziness,' citing issues with incomplete code generation and placeholder content. This prompts suggestions on using API calls for better performance. - Perplexity Search Engine Faces Critique: Perplexity as a default search option receives a setback after a trial, as
@swyxioshares a user's quick return to Google over it. Meanwhile,@guardiangdefends Perplexity's diverse model offerings, suggesting that Copilot could offer a superior experience.
Links mentioned:
- Tweet from undefined: no description found
- Tweet from Jay Hack (@mathemagic1an): The jump from langchain => DSPy feels similar to the declarative => imperative shift that PyTorch/Chainer introduced to deep learning in the late 2010s Suddenly there was much more flexibility ...
- Tweet from zachary (@wenquai): i was so pumped about @perplexity_ai as a default search option in Arc browser tried it for about 30 min immediately set it back to Google
- Qdrant: Open Source Vector Search Engine and Vector Database (Andrey Vasnetsov): CMU Database Group - ML⇄DB Seminar Series (2023)Speakers: Andrey Vasnetsov (Qdrant)September 11, 2023https://db.cs.cmu.edu/seminar2023/#db1Sponsors:Google DA...
- Tweet from Q (@qtnx_): what we know for now - anon on /lmg/ posts a 70b model name miqu saying it's good - uses the same instruct format as mistral-instruct, 32k context - extremely good on basic testing, similar answe...
- Tweet from swyx (@swyx): A/B test: GPT4 Turbo for summarizing >100k words Same prompts, ~same corpus, different models. Nov 2023: https://buttondown.email/ainews/archive/ainews-gpt4turbo-ab-test-gpt-4-1106-preview/ Jan 2...
- Tweet from zachary (@wenquai): i was so pumped about @perplexity_ai as a default search option in Arc browser tried it for about 30 min immediately set it back to Google
Latent Space ▷ #llm-paper-club (2 messages):
- Eastern LLM Paper Club Meeting on Self-Rewarding Language Models:
@ivanleomkannounced the Eastern Paper Club session for Friday SGT 6-7pm, focusing on the self-rewarding language models paper. Register for the event and add it to your calendar to stay updated on future Latent.Space events.
- No Additional Context from _bassboost:
_bassboost's message doesn't provide context relevant to the discussion of LLM papers or related topics.
Links mentioned:
LLM Paper Club (Asia Edition!) · Luma: Asia-timezone friendly version of the Latent.Space x EugeneYan.com LLM Paper Club! This week we'll be covering the new Self-Rewarding Language Models paper (...
DiscoResearch ▷ #general (4 messages):
- World Knowledge Dilemma: User
@aslawlietseeks advice on choosing between Mixtral 8x7b, Yi-34b, and LLaMA-2-70b for world knowledge applications, but no clear recommendation was provided in the given messages. - Jeremy Howard's CUDA Programming Intro:
@rasdanishared an invite to Jeremy Howard's introduction to CUDA programming, scheduled for 21:00 at this Discord event. The session will also be recorded for later viewing. - New Grounded Artificial Datasets Paper:
@bjoernplinked to a new paper by Microsoft on grounded artificial datasets for Retrieval-Augmented Generation (RAG), highlighting its relevance to ongoing discussions and pointing out proposed quality evaluation metrics.
Links mentioned:
- RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture: There are two common ways in which developers are incorporating proprietary and domain-specific data when building applications of Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) an...
- Tritt dem CUDA MODE-Discord-Server bei!: CUDA reading group | 3393 Mitglieder
DiscoResearch ▷ #embedding_dev (1 messages):
sebastian.bodza: >80k
DiscoResearch ▷ #discolm_german (10 messages🔥):
- In Search of the Optimal DiscoLM Setup with Ollama: User
@jannikstdlasked the community for advice on integrating DiscoLM German with Ollama, focusing on finding the most effective modelfile configuration. - Template Troubles Lead to Lackluster LLM Responses:
@jannikstdlshared their initial template code for Ollama which resulted in the LLM only responding with `
Alignment Lab AI ▷ #general-chat (1 messages):
- Seeking 2023 News Datasets:
@danfosingis looking for datasets that include news articles from 2023 and possibly January 2024. They also mentioned an inability to post in another specific channel (<#1117625732189933650>).
Alignment Lab AI ▷ #oo (5 messages):
- Dedicated DM Grind:
autometamentioned they've sent like 10 DMs to a recipient, emphasizing their commitment to the "grind". - In Search of Missing Discussions:
ilovescienceinquired if discussions were happening elsewhere, withtekniumconfirming that no, discussions were not occurring in another location. This was succinctly followed by a solitary emoji fromteknium, indicating perhaps a light-hearted acknowledgment of the situation.
AI Engineer Foundation ▷ #general (1 messages):
- Open Source AI Tools Inquiry: User
@kudos0560asked the community for recommendations on the best open source tools for AI development, highlighting Mistral as a good option. They invited others to share their preferences.