[AINews] Mamba-2: State Space Duality
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Transformers are SSMs.
AI News for 5/31/2024-6/3/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (400 channels, and 8575 messages) for you. Estimated reading time saved (at 200wpm): 877 minutes.
Over the weekend we got the FineWeb Technical Report (which we covered a month ago), and it turns out that it does improve upon CommonCrawl and RefinedWeb with better filtering and deduplication.
However we give the weekend W to the Mamba coauthors, who are somehow back again with Mamba-2, a core 30 lines of Pytorch which outperforms Mamba and Transformer++ in both perplexity and wall-clock time.
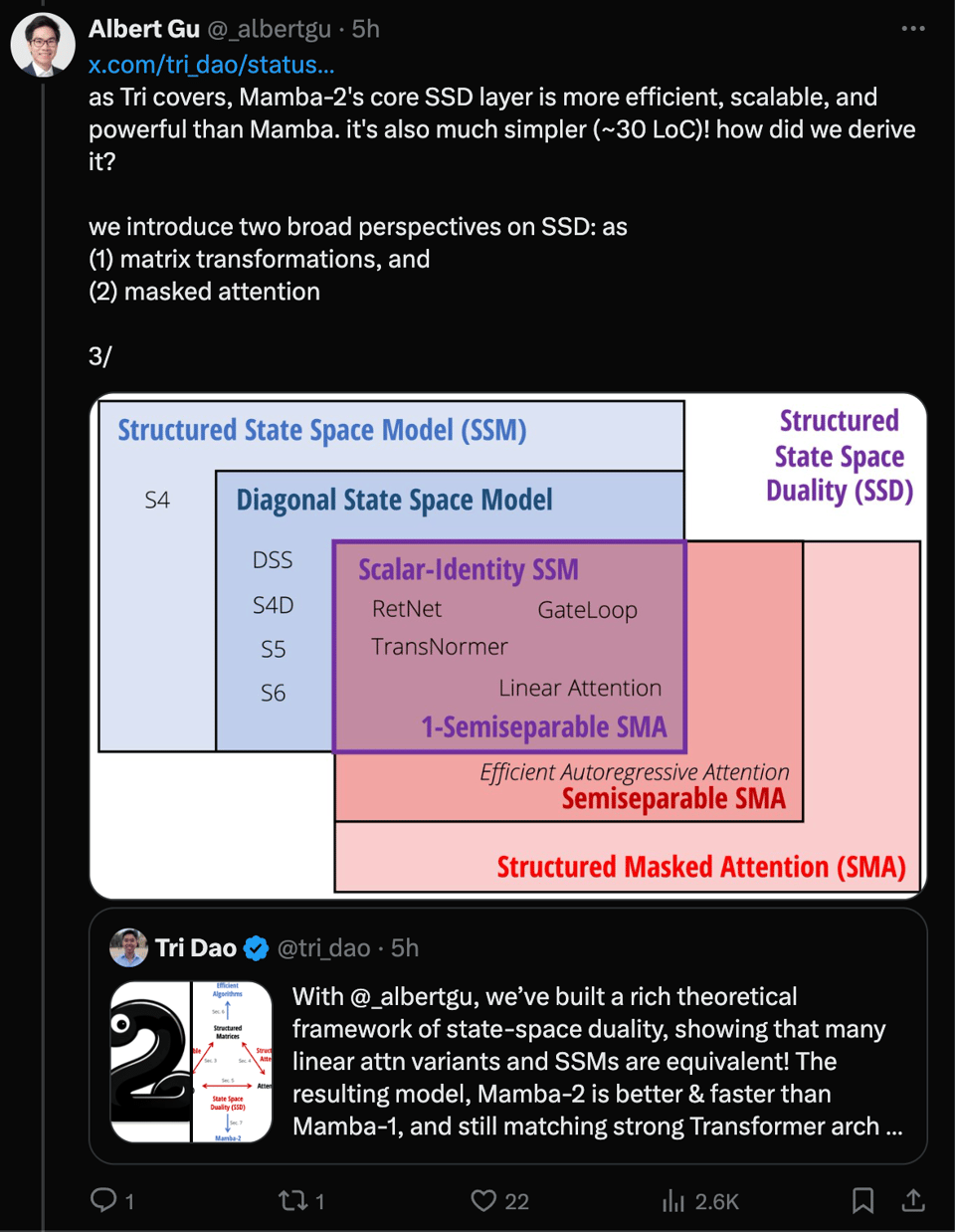
Tri recommends reading the blog first, developing Mamba-2 over 4 parts:
- The Model
- Understanding: What are the conceptual connections between state space models and attention? Can we combine them?
As developed in our earlier works on structured SSMs, they seem to capture the essence of continuous, convolutional, and recurrent sequence models – all wrapped up in a simple and elegant model.
- Efficiency: Can we speed up the training of Mamba models by recasting them as matrix multiplications?
Despite the work that went into making Mamba fast, it’s still much less hardware-efficient than mechanisms such as attention.
- The core difference between Mamba and Mambda-2 is a stricter diagonalization of their A matrix:
 Using this definition the authors prove equivalence (duality) between Quadratic Mode (Attention) and Linear Mode (SSMs), and unlocks matrix multiplications.
Using this definition the authors prove equivalence (duality) between Quadratic Mode (Attention) and Linear Mode (SSMs), and unlocks matrix multiplications.

- Understanding: What are the conceptual connections between state space models and attention? Can we combine them?
- The Theory
- The Algorithm
- The Systems
- they show that Mamba-2 both beats Mamba-1 and Pythia on evals, and dominate in evals when placed in hybrid model archs similar to Jamba:
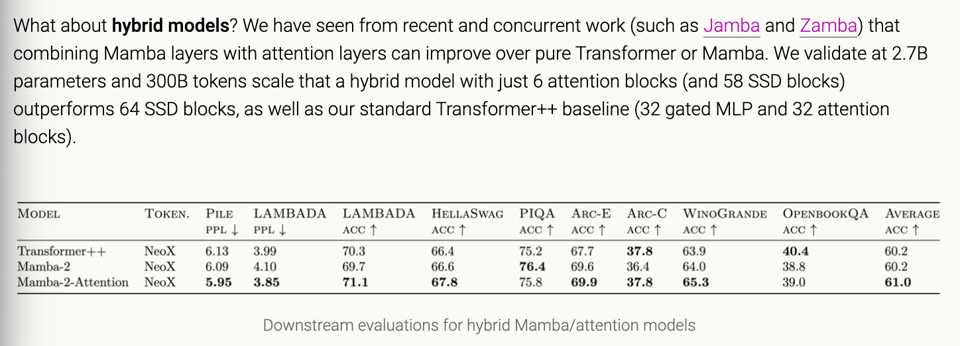
- they show that Mamba-2 both beats Mamba-1 and Pythia on evals, and dominate in evals when placed in hybrid model archs similar to Jamba:
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- Perplexity AI Discord
- CUDA MODE Discord
- LM Studio Discord
- Nous Research AI Discord
- LLM Finetuning (Hamel + Dan) Discord
- OpenAI Discord
- Modular (Mojo 🔥) Discord
- Eleuther Discord
- OpenRouter (Alex Atallah) Discord
- LAION Discord
- LlamaIndex Discord
- Latent Space Discord
- LangChain AI Discord
- tinygrad (George Hotz) Discord
- OpenAccess AI Collective (axolotl) Discord
- Cohere Discord
- OpenInterpreter Discord
- Interconnects (Nathan Lambert) Discord
- Mozilla AI Discord
- DiscoResearch Discord
- Datasette - LLM (@SimonW) Discord
- AI21 Labs (Jamba) Discord
- MLOps @Chipro Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (974 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (28 messages🔥):
- HuggingFace ▷ #cool-finds (3 messages):
- HuggingFace ▷ #i-made-this (11 messages🔥):
- HuggingFace ▷ #reading-group (5 messages):
- HuggingFace ▷ #computer-vision (9 messages🔥):
- HuggingFace ▷ #NLP (24 messages🔥):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- HuggingFace ▷ #gradio-announcements (2 messages):
- Unsloth AI (Daniel Han) ▷ #general (919 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #random (13 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (170 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (32 messages🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (4 messages):
- Stability.ai (Stable Diffusion) ▷ #announcements (2 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (1009 messages🔥🔥🔥):
- Perplexity AI ▷ #general (796 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (33 messages🔥):
- Perplexity AI ▷ #pplx-api (12 messages🔥):
- CUDA MODE ▷ #general (29 messages🔥):
- CUDA MODE ▷ #triton (14 messages🔥):
- CUDA MODE ▷ #torch (4 messages):
- CUDA MODE ▷ #announcements (4 messages):
- CUDA MODE ▷ #cool-links (2 messages):
- CUDA MODE ▷ #jobs (3 messages):
- CUDA MODE ▷ #beginner (22 messages🔥):
- CUDA MODE ▷ #pmpp-book (2 messages):
- CUDA MODE ▷ #youtube-recordings (12 messages🔥):
- CUDA MODE ▷ #torchao (15 messages🔥):
- CUDA MODE ▷ #ring-attention (4 messages):
- CUDA MODE ▷ #off-topic (36 messages🔥):
- CUDA MODE ▷ #hqq (3 messages):
- CUDA MODE ▷ #triton-viz (1 messages):
- CUDA MODE ▷ #llmdotc (504 messages🔥🔥🔥):
- CUDA MODE ▷ #bitnet (52 messages🔥):
- CUDA MODE ▷ #pytorch-docathon (1 messages):
- LM Studio ▷ #💬-general (338 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (86 messages🔥🔥):
- LM Studio ▷ #🧠-feedback (22 messages🔥):
- LM Studio ▷ #📝-prompts-discussion-chat (3 messages):
- LM Studio ▷ #⚙-configs-discussion (26 messages🔥):
- LM Studio ▷ #🎛-hardware-discussion (74 messages🔥🔥):
- LM Studio ▷ #autogen (4 messages):
- LM Studio ▷ #amd-rocm-tech-preview (1 messages):
- LM Studio ▷ #crew-ai (1 messages):
- LM Studio ▷ #🛠-dev-chat (8 messages🔥):
- Nous Research AI ▷ #ctx-length-research (1 messages):
- Nous Research AI ▷ #off-topic (57 messages🔥🔥):
- Nous Research AI ▷ #interesting-links (10 messages🔥):
- Nous Research AI ▷ #general (250 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (53 messages🔥):
- Nous Research AI ▷ #project-obsidian (1 messages):
- Nous Research AI ▷ #rag-dataset (2 messages):
- Nous Research AI ▷ #world-sim (21 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #general (81 messages🔥🔥):
- LLM Finetuning (Hamel + Dan) ▷ #workshop-1 (9 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (19 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #learning-resources (9 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #hugging-face (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #replicate (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #berryman_prompt_workshop (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #whitaker_napkin_math (31 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #workshop-2 (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #workshop-3 (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #abhishek_autotrain_llms (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #clavie_beyond_ragbasics (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #jason_improving_rag (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #jeremy_python_llms (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #gradio (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #axolotl (34 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #zach-accelerate (23 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (23 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #freddy-gradio (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #charles-modal (43 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #langchain-langsmith (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #allaire_inspect_ai (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #credits-questions (42 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #fireworks (6 messages):
- LLM Finetuning (Hamel + Dan) ▷ #emmanuel_finetuning_dead (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #braintrust (5 messages):
- LLM Finetuning (Hamel + Dan) ▷ #west-coast-usa (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #europe-tz (6 messages):
- LLM Finetuning (Hamel + Dan) ▷ #announcements (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #predibase (7 messages):
- LLM Finetuning (Hamel + Dan) ▷ #career-questions-and-stories (17 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #openai (1 messages):
- OpenAI ▷ #ai-discussions (315 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (55 messages🔥🔥):
- OpenAI ▷ #prompt-engineering (7 messages):
- OpenAI ▷ #api-discussions (7 messages):
- Modular (Mojo 🔥) ▷ #general (198 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
- Modular (Mojo 🔥) ▷ #📺︱youtube (1 messages):
- Modular (Mojo 🔥) ▷ #🔥mojo (79 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #performance-and-benchmarks (4 messages):
- Modular (Mojo 🔥) ▷ #🏎engine (2 messages):
- Modular (Mojo 🔥) ▷ #nightly (30 messages🔥):
- Eleuther ▷ #general (28 messages🔥):
- Eleuther ▷ #research (125 messages🔥🔥):
- Eleuther ▷ #interpretability-general (2 messages):
- Eleuther ▷ #lm-thunderdome (7 messages):
- Eleuther ▷ #multimodal-general (3 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (13 messages🔥):
- OpenRouter (Alex Atallah) ▷ #general (112 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #소개 (1 messages):
- OpenRouter (Alex Atallah) ▷ #일반 (1 messages):
- OpenRouter (Alex Atallah) ▷ #紹介 (1 messages):
- OpenRouter (Alex Atallah) ▷ #一般 (1 messages):
- LAION ▷ #general (98 messages🔥🔥):
- LAION ▷ #research (5 messages):
- LlamaIndex ▷ #announcements (1 messages):
- LlamaIndex ▷ #blog (6 messages):
- LlamaIndex ▷ #general (80 messages🔥🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- Latent Space ▷ #ai-general-chat (51 messages🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Latent Space ▷ #ai-in-action-club (33 messages🔥):
- LangChain AI ▷ #general (41 messages🔥):
- LangChain AI ▷ #langserve (1 messages):
- LangChain AI ▷ #langchain-templates (4 messages):
- LangChain AI ▷ #share-your-work (13 messages🔥):
- LangChain AI ▷ #tutorials (4 messages):
- tinygrad (George Hotz) ▷ #general (42 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (8 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (29 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general-help (8 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (7 messages):
- Cohere ▷ #general (33 messages🔥):
- Cohere ▷ #project-sharing (6 messages):
- OpenInterpreter ▷ #general (21 messages🔥):
- OpenInterpreter ▷ #O1 (11 messages🔥):
- OpenInterpreter ▷ #ai-content (1 messages):
- Interconnects (Nathan Lambert) ▷ #news (16 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (7 messages):
- Interconnects (Nathan Lambert) ▷ #memes (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
- Mozilla AI ▷ #llamafile (17 messages🔥):
- DiscoResearch ▷ #discolm_german (6 messages):
- Datasette - LLM (@SimonW) ▷ #llm (5 messages):
- AI21 Labs (Jamba) ▷ #jamba (5 messages):
- MLOps @Chipro ▷ #events (2 messages):
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI and Machine Learning Research
- Mamba-2 State Space Model: @_albertgu and @tri_dao introduced Mamba-2, a state space model (SSM) that outperforms Mamba and Transformer++ in perplexity and wall-clock time. It presents a framework connecting SSMs and linear attention called state space duality (SSD). Mamba-2 has 8x larger states and 50% faster training than Mamba. (@arankomatsuzaki and @_akhaliq)
- FineWeb and FineWeb-Edu Datasets: @ClementDelangue highlighted the release of FineWeb-Edu, a high-quality subset of the 15 trillion token FineWeb dataset, created by filtering FineWeb using a Llama 3 70B model to judge educational quality. It enables better and faster LLM learning. @karpathy noted its potential to reduce tokens needed to surpass GPT-3 performance.
- Perplexity-Based Data Pruning: @_akhaliq shared a paper on using small reference models for perplexity-based data pruning. Pruning based on a 125M parameter model's perplexities improved downstream performance and reduced pretraining steps by up to 1.45x.
- Video-MME Benchmark: @_akhaliq introduced Video-MME, the first comprehensive benchmark evaluating multi-modal LLMs on video analysis, spanning 6 visual domains, video lengths, multi-modal inputs, and manual annotations. Gemini 1.5 Pro significantly outperformed open-source models.
AI Ethics and Societal Impact
- AI Doomerism and Singularitarianism: @ylecun and @fchollet criticized AI doomerism and singularitarianism as "eschatological cults" driving insane beliefs, with some stopping long-term life planning due to AI fears. @ylecun argued they make people feel powerless rather than mobilizing solutions.
- Attacks on Dr. Fauci and Science: @ylecun condemned attacks on Dr. Fauci by Republican Congress members as "disgraceful and dangerous". Fauci helped save millions but is vilified by those prioritizing politics over public safety. Attacks on science and the scientific method are "insanely dangerous" and killed people in the pandemic by undermining public health trust.
- Opinions on Elon Musk: @ylecun shared views on Musk, liking his cars, rockets, solar/satellites, and open source/patent stances, but disagreeing with his treatment of scientists, hype/false predictions, political opinions, and conspiracy theories as "dangerous for democracy, civilization, and human welfare". He finds Musk "naive about content moderation difficulties and necessity" on his social platform.
AI Applications and Demos
- Dino Robotics Chef: @adcock_brett shared a video of Dino Robotics' robot chef making schnitzel and fries using object localization and 3D image processing, trained to recognize various kitchen objects.
- SignLLM: @adcock_brett reported on SignLLM, the first multilingual AI model for Sign Language Production, generating AI avatar sign language videos from natural language across eight languages.
- Perplexity Pages: @adcock_brett highlighted Perplexity's Pages tool for turning research into articles, reports, and guides that can rank on Google Search.
- 1X Humanoid Robot: @adcock_brett demoed 1X's EVE humanoid performing chained tasks like picking up a shirt and cup, noting internal updates.
- Higgsfield NOVA-1: @adcock_brett introduced Higgsfield's NOVA-1 AI video model allowing enterprises to train custom versions using their brand assets.
Miscellaneous
- Making Friends Advice: @jxnlco shared tips like doing sports, creative outlets, cooking group meals, and connecting people based on shared interests to build a social network.
- Laptop Recommendation: @svpino praised the "perfect" but expensive Apple M3 Max with 128GB RAM and 8TB SSD.
- Nvidia Keynote: @rohanpaul_ai noted 350x datacenter AI compute cost reduction at Nvidia over 8 years. @rohanpaul_ai highlighted the 50x Pandas speedup on Google Colab after RAPIDS cuDF integration.
- Python Praise: @svpino called Python "the all-time, undisputed GOAT of programming languages" and @svpino recommended teaching kids Python.
Humor and Memes
- Winning Meme: @AravSrinivas posted a "What does winning all the time look like?" meme image.
- Pottery Joke: @jxnlco joked "Proof of cooking. And yes I ate on a vintage go board."
- Stable Diffusion 3 Meme: @Teknium1 criticized Stability AI for "making up a new SD3, called SD3 'Medium' that no one has ever heard of" while not releasing the Large and X-Large versions.
- Llama-3-V Controversy Meme: @teortaxesTex posted about Llama-3-V's Github and HF going down "after evidence of them stealing @OpenBMB's model is out".
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Model Releases and Updates
- SD3 Medium open weights releasing June 12 from Stability AI: In /r/StableDiffusion, Stability AI is releasing the 2B parameter SD3 Medium model designed for photorealism, typography, performance and fine-tuning under non-commercial use. The 2B model currently outperforms the 8B version on some metrics, and has incompatibilities with certain sampling methods. Commercial rights will be available through a membership program.
- Nvidia and AMD unveil future AI chip roadmaps: In /r/singularity, Nvidia revealed plans through 2027 for its Rubin platform to succeed Blackwell, with H200 and B100 chips on the horizon after H100s used in OpenAI's models. AMD announced the MI325X with 288GB memory to rival Nvidia's H200, with the MI350 and MI400 series offering major inference boosts in coming years.
AI Capabilities and Limitations
- AI-generated media deceives mainstream news: A video mistaken by NBC News as showing a real dancing effect demonstrates the potential for AI-generated content to fool even major media outlets.
- Challenges in truly open-sourcing AI: A video argues that open source AI is not truly open source, as model weights are inscrutable without training data, order, and techniques. Fully open-sourcing large language models is difficult due to reliance on licensed data.
- Limitations in multimodal reasoning: In /r/OpenAI, ChatGPT struggles to annotate an object in an image despite correctly identifying it, highlighting current gaps in AI's ability to reason across modalities.
AI Development Tools and Techniques
- High-quality web dataset outperforms on knowledge and reasoning: The FineWeb dataset with 1.3T tokens surpasses other open web-scale datasets on knowledge and reasoning benchmarks. The associated blog post details techniques for creating high-quality datasets from web data.
- New mathematical tool for ML introduced in book: The book "Tangles" applies a novel mathematical approach to group qualities for identifying structure and types in data, with applications from clustering to drug development. Open source code is available.
- Parametric compression of large language model: In /r/LocalLLaMA, a simple parametric compression method prunes less important layers of LLaMA 3 70B to 62B parameters without fine-tuning, resulting in only slight performance drops on benchmarks.
AI Ethics and Societal Impact
- Ethical dilemma in disclosing AI impact on jobs: /r/singularity discusses the quandary of whether to inform friends that AI can now do their jobs, like book cover design, in seconds. The distress of delivering such news is weighed against withholding the truth.
- Poll gauges perceptions of AI's threat to job security: A poll in /r/singularity measures how secure people feel about their jobs persisting for the next 10 years in the face of AI automation.
Memes and Humor
- Meme satirizes AI's wide-reaching job replacement potential: An "All The Jobs" meme image humorously portrays AI's ability to replace a vast range of occupations.
AI Discord Recap
A summary of Summaries of Summaries
-
LLM Advancements and Multimodal Applications:
- Granite-8B-Code-Instruct from IBM enhances instruction-following for code tasks, surpassing major benchmarks. Stable Diffusion 3 Medium set to launch, promises better photorealism and typography, scheduled for June 12.
- The AI engineering community discusses VRAM requirements for SD3, with predictions around 15GB while considering features like fp16 optimization for potential reductions. FlashAvatar promises 300FPS digital avatars using Nvidia RTX 3090, stoking interest in high-fidelity avatar creation.
-
Fine-Tuning Techniques and Challenges:
- Recommendations for overcoming tokenizer issues in half-precision training suggest
tokenizer.padding_side = 'right'and using techniques from LoRA for enhanced fine-tuning. Axolotl users face issues with binary classification, suggesting Bert as an alternative.
- Community insights highlight the effective use of Gradio's OAuth for private app access and the utility of
share=Truefor quick app testing. Troubleshooting includes handling issues with inference setups in Kaggle and discrepancies with loss values in Axolotl, considering factors like input-output preprocessing.
- Recommendations for overcoming tokenizer issues in half-precision training suggest
-
Open-Source Projects and Community Collaborations:
- Manifold Research’s call for collaboration on multimodal transformers and control tasks aims to build a comprehensive open-source Generalist Model. StoryDiffusion and OpenDevin emerge as new open-source AI projects, sparking interest.
- Efforts to integrate TorchAO with LM Evaluation Harness focus on adding APIs for quantization support. Community initiatives, such as adapting Axolotl for AMD compatibility, highlight ongoing efforts in refining AI tools and frameworks.
-
AI Infrastructure and Security:
- Hugging Face security incident prompts a recommendation for rotating tokens and switching to fine-grained access tokens, affecting users' infrastructures like HF Spaces. Discussions in OpenRouter reference database timeouts in Asia, leading to service updates and decommissioning certain models like Llava 13B and Hermes 2 Vision 7B.
- ZeRO++ framework presents significant communication overhead reduction in large model training, aiding LLM implementations. The Paddler stateful load balancer enhances llama.cpp's efficiency, potentially streamlining model serving capabilities.
-
AI Research and Ethical Discussions:
- Yudkowsky’s controversial strategy against AI development sparks debate, with aggressive measures like airstrikes on data centers. LAION community reacts, discussing the balance between open collaboration and preventing misuse.
- New Theories on Transformer Limitations: Empirical evidence suggests transformers struggle with composing functions on large domains, leading to new approaches in model design. Discussions on embedding efficiency continue, comparing context windows for performance across LLM implementations.
PART 1: High level Discord summaries
HuggingFace Discord
- Security Flaw in HF Spaces: Users are advised to rotate any tokens or keys after a security incident in HF Spaces, as detailed in HuggingFace's blog post.
- AI and Ethics Debate Heats Up: Debate over the classification of lab-grown neurons sparks a deeper discussion on the nature and ethics of artificial intelligence. Meanwhile, HuggingFace infrastructure issues lead to a resolution of "MaxRetryError" problems.
- Rust Rising: A member collaborates to implement a deep learning book (d2l.ai) in Rust, contributing to GitHub, while others discuss the efficiency and deployment benefits of Rust's Candle library.
- Literature Review Insights and Quirky Creations: An LLM reasoning literature review is summarized on Medium, plus creative projects like the Fast Mobius demo and the gary4live Max4Live device shared, reflecting a healthy mixture of engineering rigor with imaginative playfulness.
- Practical Applications and Community Dialogue: Practical guidance on using TrOCR and models, such as MiniCPM-Llama3-V 2.5, is shared for OCR tasks. Discussions also extend to LLM determinism and resource recommendations for enhanced language generation and translation tasks, specifically citing Helsinki-NLP/opus-mt-ja-en as a strong Japanese to English translation tool.
- Exciting Developments in Robotics and Gradio: The article Diving into Diffusion Policy with Lerobot showcases ACT and Diffusion Policy methods in robotics, while Gradio announced support for dynamic layouts with @gr.render, exemplified by versatile applications like the Todo List and AudioMixer, explored in the Render Decorator Guide.
Unsloth AI (Daniel Han) Discord
- Multi-GPU Finetuning Progress: Active development is being made on multi-GPU finetuning with discussions on the viability of multimodal expansion. A detailed analysis of LoRA was shared, highlighting its potential in specific finetuning scenarios.
- Technical Solutions to Training Challenges:
Recommendations were made to alleviate tokenizer issues in half-precision training by setting
tokenizer.padding_side = 'right', and insights were given on Kaggle Notebooks as a solution to expedite LLM finetuning.
- Troubleshooting AI Model Implementation: Users have encountered difficulties with Phi 3 models on GTX 3090 and RoPE optimization on H100 NVL. Community recommended fixes include Unsloth's updates and discussion on potential memory reporting bugs.
- Model Safety and Limitations in Focus: Debates surfaced on businesses' hesitation to use open-source AI models due to safety concerns, with emphasis on preventing harmful content generation. Moreover, the inherent limitation of LLMs unable to innovate beyond their training data was acknowledged.
- Continuous Improvements to AI Collaboration Tools: Community shared solutions for saving models and fixing installation issues on platforms like Kaggle. Furthermore, there's active collaboration on refining checkpoint management for fine-tuning across platforms like Hugging Face and Wandb.
Stability.ai (Stable Diffusion) Discord
- Countdown to SD3 Medium Launch: Stability.ai has announced Stable Diffusion 3 Medium is set to launch on June 12th; interested parties can join the waitlist for early access. The announcement at Computex Taipei highlighted the model's expected performance boosts in photorealism and typography.
- Speculation Over SD3 Specs: The AI engineering community is abuzz with discussions on the prospective VRAM requirements for Stable Diffusion 3, with predictions around 15GB, while suggestions such as fp16 optimization have been mentioned to potentially reduce this figure.
- Clarity Required on Commercial Use: There's a vocal demand for Stability AI to provide explicit clarification on the licensing terms for SD3 Medium's commercial use, with concerns stemming from the transition to licenses with non-commercial restrictions.
- Monetization Moves Meet Backlash: The replacement of the free Stable AI Discord bot by a paid service, Artisan, has sparked frustration within the community, underscoring the broader trend toward monetizing access to AI tools.
- Ready for Optimizations and Fine-Tuning: In preparation for the release of SD3 Medium, engineers are anticipating the procedures for community fine-tunes, as well as performance benchmarks across different GPUs, with Stability AI ensuring support for 1024x1024 resolution optimizations, including tiling techniques.
Perplexity AI Discord
- AI-Assisted Homework: Opportunity or Hindrance?: Engineers shared diverse viewpoints on the ethics of AI-assisted homework, comparing it to choosing between "candy and kale," while suggesting an emphasis on teaching responsible AI usage to kids.
- Directing Perplexity's Pages Potential: Users expressed the need for enhancements to Perplexity's Pages feature, like an export function and editable titles, to improve usability, with concerns voiced over the automatic selection and quota exhaustion of certain models like Opus.
- Extension for Enhanced Interaction: The announcement of a Complexity browser extension to improve Perplexity's UI led to community engagement, with an invitation for beta testers to enhance their user experience.
- Testing AI Sensitivity: Discussions highlighted Perplexity AI's capability to handle sensitive subjects, demonstrated by its results on creating pages on topics like the Israel-Gaza conflict, with satisfactory outcomes reinforcing faith in its appropriateness filters.
- API Exploration for Expert Applications: AI engineers discussed optimal model usage for varying tasks within Perplexity API, clarifying trade-offs between smaller, faster models versus larger, more accurate ones, while also expressing enthusiasm about potential TTS API features. Reference was made to model cards for guidance.
CUDA MODE Discord
Let's Chat Speculatively: Engineers shared insights into speculative decoding, with suggestions like adding gumbel noise and a deterministic argmax. Recorded sessions on the subject are expected to be uploaded after editing, and discussions highlighted the importance of ablation studies to comprehend sampling parameter impacts on acceptance rates.
CUDA to the Cloud: Rental of H100 GPUs was discussed for profiling purposes, recommending providers such as cloud-gpus.com and RunPod. The challenges in collecting profiling information without considerable hacking were also noted.
Work and Play: A working group for production kernels and another for PyTorch performance-related documentation were announced, inviting collaboration. Additionally, a beginner's tip was given to avoid the overuse of @everyone in the community to prevent unnecessary notifications.
Tech Talks on Radar: Upcoming talks and workshops include a session on Tensor Cores and high-performance scan algorithms. The community also anticipates hosting Prof Wen-mei Hwu for a public Q&A, and a session from AMD's Composable Kernel team.
Data Deep Dives and Development Discussions: Discussion in #llmdotc was rich with details like the successful upload of a 200GB dataset to Hugging Face and a proposal for LayerNorm computation optimization, alongside a significant codebase refactor for future-proofing and easier model architecture integration.
Of Precision and Quantization: The AutoFP8 GitHub repository was introduced, aiming at automatic conversion to FP8 for increased computational efficiency. Meanwhile, integrating TorchAO with the LM Evaluation Harness was debated, including API enhancements for improved quantization support.
Parsing the Job Market: Anyscale is seeking candidates with interests in speculative decoding and systems performance, while chunked prefill and continuous batching practices were underscored for operational efficiencies in predictions.
Broadcasting Knowledge: Recordings of talks on scan algorithms and speculative decoding are to be made available on the CUDA MODE YouTube Channel, providing resources for continuous learning in high-performance computing.
PyTorch Performance Parsing: A call to action was made for improving PyTorch's performance documentation during the upcoming June Docathon, with emphasis on current practices over deprecated concepts like torchscript and a push for clarifying custom kernel integrations.
LM Studio Discord
- VRAM Vanquishers: Engineers are discussing solutions for models with high token prompts leading to slow responses on systems with low VRAM, and practical model recommendations like Nvidia P40 cards for home AI rigs.
- Codestral Claims Coding Crown: Codestral 22B's superior performance in context and instruction handling sparked discussions, while concerns with embedding model listings in LM Studio were addressed, and tales of tackling text generation with different models circulated.
- Whispering Without Support: Despite clamor for adding Whisper and Tortoise-enhanced audio capabilities to LM Studio, the size and complexity trade-offs triggered a talk, alongside the reveal of a "stop string" bug in the current iteration.
- Config Conundrums: Queries regarding model configuration settings for applications from coding to inference surfaced, with focus on quantization trade-offs and an enigmatic experience with inference speeds on specific GPU hardware.
- Amped-Up Amalgamation Adventures: Members mulled over Visual Studio plugin creations for smarter coding assistance, tapping into experiences with existing aids and the potential for project-wide context understanding using models like Mentat.
Note: Specific links to models, discussions, and GitHub repositories were provided in the respective channels and can be referred back to for further technical details and context.
Nous Research AI Discord
- Thriving in a Token World: The newly released FineWeb-Edu dataset touts 1.3 trillion tokens reputed for their superior performance on benchmarks such as MMLU and ARC, with a detailed technical report accessible here.
- Movie Magicians Source SMASH: A 3K screenplay dataset is now available for AI enthusiasts, featuring screenplay PDFs converted into .txt format, and secured under AGPL-3.0 license for enthusiastic model trainers.
- Virtual Stage Directions: Engagement in strategy simulation using Worldsim unfolds with a particular focus on the Ukraine-Russia conflict, demonstrating its capacity for detailed scenario-building, amidst a tech glitch causing text duplication currently under review.
- Distillation Dilemma and Threading Discussions: Researchers are exchanging ideas on effective knowledge distillation from larger to smaller models, like the Llama70b to Llama8b transition, and suggesting threading over loops for managing AI agent tasks.
- Model Ethics in Plain View: Community debates are ignited over the alleged replication of OpenBMB's MiniCPM by MiniCPM-Llama3-V, which led to the removal of the contested model from platforms like GitHub and Hugging Face after collective concern and evidence came to light.
LLM Finetuning (Hamel + Dan) Discord
- Axolotl Adversities: Engineers reported issues configuring binary classification in Axolotl's .yaml files, receiving a
ValueErrorindicating no corresponding data for the 'train' instruction. A proposed alternative was deploying Bert for classification tasks instead, as well as directly working with TRL when Axolotl lacks support.
- Gradio's Practicality Praised: AI developers leveraged Gradio's
share=Trueparameter for quickly testing and sharing apps. Discussions also unfolded around using OAuth for private app access and the overall sharing strategy, including hosting on HF Spaces and handling authentication and security.
- Modal Mysteries and GitHub Grief: Users encountered errors downloading models like Mistral7B_v0.1, due in part to a lack of authentication into Hugging Face in modal scripts caused by recent security events. Other challenges arose with
device map = metain Accelerate, with one user providing insights into its utility for inference mechanics.
- Credits Crunch Time: Deadline-driven discussions dominated channels, with many members concerned about timely credit assignment across platforms. Dan and Hamel intervened with explanations and reassurances, highlighting the importance of completing forms accurately to avoid missing out on platform-specific credits.
- Fine-tuning for the Future: Possible adjustments and various strategies for LLM training and fine-tuning emerged, such as keeping the batch sizes at powers of 2, using gradient accumulation steps to optimize training, and the potential of large batch sizes to stabilize training even in distributed setups over ethernet.
OpenAI Discord
- Zero Crossings and SGD: Ongoing Dispute: Ongoing debates have delved into the merits and drawbacks of tracking zero crossings in gradients for optimizer refinement, with mixed results observed in application. Another topic of heated discussion was the role of SGD as a baseline for comparison against new optimizers, indicating that advances may hinge upon learning rate improvements.
- FlashAvatar Ignites Interest: A method dubbed FlashAvatar for creating high-fidelity digital avatars has captured particular interest, promising up to 300FPS rendering with an Nvidia RTX 3090, as detailed in the FlashAvatar project.
- Understanding GPT-4's Quirks: Conversations in the community have centered on GPT-4's memory leaks and behavior, discussing instances of 'white screen' errors and repetitive output potentially tied to temperature settings. Custom GPT uses and API limits were also discussed, highlighting a 512 MB per file limit and 5 million tokens per file constraint as per OpenAI help articles.
- Context Window and Embedding Efficacy in Debate: A lively debate focused on the effectiveness of embeddings versus expanding context windows for performance improvement. Prospects for incorporating Gemini into the pipeline were entertained for purportedly enhancing GPT's performance.
- Troubles in Prompt Engineering: Community members shared challenges with ChatGPT's adherence to prompt guidelines, seeking strategies for improvement. Observations noted a preference for a single system message in structuring complex prompts.
Modular (Mojo 🔥) Discord
- Mojo Server Stability Saga: Users report the Mojo language server crashing in VS Code derivatives like Cursor on M1 and M2 MacBooks, documented in GitHub issue #2446. The fix exists in the nightly build, and a YouTube tutorial covers Python optimization techniques that can accelerate code loops, suggested for those looking to boost Python's performance.
- Eager Eyes on Mojo's Evolution: Discussions around Mojo's maturity centered on its development progress and open-source community contributions, as outlined in the Mojo roadmap and corresponding blog announcement. Separate conversations have also included Mojo's potential in data processing and networking, leveraging frameworks like DPDK and liburing.
- Mojo and MAX Choreograph Forward and Backward: In the Max engine, members are dissecting the details of implementing the forward pass to retain the necessary outputs for the backward pass, with concerns about the lack of documentation for backward calculations. The community is excited about conditional conformance capabilities in Mojo, poised to enhance the standard library's functions.
- Nightly Updates Glow: Continuous updates to the nightly Mojo compiler (2024.6.305) introduced new functionalities like global
UnsafePointerfunctions becoming methods. A discussion about thechartype in C leads to ultimately asserting its implementation-defined nature. Simultaneously, suggestions to improve changelog consistency are voiced, pointing to a style guide suggestion and discussing the transition of Tensors out of the standard library.
- Performance Chasers: Performance enthusiasts are benchmarking data processing times, identifying that Mojo is outpacing Python while lagging behind compiled languages, with the conversation captured in a draft PR#514. The realization sparks a proposal for custom JSON parsing, drawing inspiration from C# and Swift implementations.
Eleuther Discord
- BERT Not Fit for lm-eval Tasks: BERT stumbled when put through lm-eval, since encoder models like BERT aren't crafted for generative text tasks. The smallest decoder model on Hugging Face is sought for energy consumption analysis.
- Unexplained Variance in Llama-3-8b Performance: A user reported inconsistencies in gsm8k scores with llama-3-8b, marking a significant gap between their 62.4 score and the published 79.6. It was suggested that older commits might be a culprit, and checking the commit hash could clarify matters.
- Few Shots Fired, Wide Results Difference: The difference in gsm8k scores could further be attributed to the 'fewshot=5' configuration used on the leaderboard, potentially deviating from others' experimental setups.
- Collaborations & Discussions Ignite Innovation: Manifold Research's call for collaborators on multimodal transformers and control tasks was mentioned alongside insights into the bias in standard RLHF. Discussions also peeled back the layers of transformer limitations and engaged in the challenge of data-dependent positional embeddings.
- Hacking the Black Box: Interest is poised (editing advised) to surge for the upcoming mechanistic interpretability hackathon in July, with invites to dissect neural nets over a weekend put forth. A paper summary looking for collaborators on backward chaining circuits was shared to rope in more minds.
- Vision and Multimodal Interpretability Gaining Focus: The AI Alignment Forum article shed light on foundation-building in vision and multimodal mechanistic interpretability, underlining emergent segmentation maps and the "dogit lens." However, a need for further research into the circuits of score models itself was expressed, noting an existing gap in literature.
OpenRouter (Alex Atallah) Discord
Database Woes in the East: OpenRouter users reported database timeouts in Asia, mainly in regions like Seoul, Mumbai, Tokyo, and Singapore. A fix was implemented which led to rolling back some latency improvements to address this issue.
OpenRouter Under Fire for API Glitches: Despite a patch, users continued to face 504 Gateway errors, with some temporarily bypassing the issue using EU VPNs. User suggestions included the addition of provider-specific uptime statistics for better service accountability.
Model Decommissioning and Recommendation: Due to low usage and high costs, OpenRouter is retiring models such as Llava 13B and Hermes 2 Vision 7B (alpha) and suggests switching to alternatives like FireLlava 13B and LLaVA v1.6 34B.
Seamless API Switcheroo: OpenRouter’s standardized API simplifies switching between models or providers, as seen in the Playground, without necessitating code alterations, acknowledging easier management for engineers.
Popularity Over Benchmarks: OpenRouter tends to rank language models based on real-world application, detailing model usage rather than traditional benchmarks for a pragmatic perspective available at OpenRouter Rankings.
LAION Discord
- AI Ethics Hot Seat: Outrage and debate roared around Eliezer Yudkowsky’s radical strategy to limit AI development, with calls for aggressive actions including data center destruction sparking divisive dialogue. A deeper dive into the controversy can be found here.
- Mobius Model Flexes Creative Muscles: The new Mobius model charmed the community with prompts like "Thanos smelling a little yellow rose" and others, showcasing the model's flair and versatility. Seek inspiration or take a gander at the intriguing outcomes on Hugging Face.
- Legal Lunacy Drains Resources: A discussion detailed how pseudo-legal lawsuits waste efforts and funds, spotlighted by a case of pseudo-legal claims from Vancouver emerging as a cautionary tale. Review the absurdity in full color here.
- Healthcare's AI Challenge Beckons: Innovators are called to the forefront with the Alliance AI4Health Medical Innovation Challenge, dangling a $5k prize to spur development in healthcare AI solutions. Future healthcare pioneers can find their starting block here.
- Research Reveals New AI Insights: The unveiling of the Phased Consistency Model (PCM) challenges LCM on design limitations, with details available here, while a new paper elaborates on the efficiency leaps in text-to-image models, dubbed the "1.58 bits paper applied to image generation," which can be explored on arXiv. SSMs strike back in the speed department, with Mamba-2 outstripping predecessors and rivaling Transformers, read all about it here.
LlamaIndex Discord
- Graphs Meet Docs at LlamaIndex: LlamaIndex launched first-class support for building knowledge graphs integrated with a toolkit for manual entity and relation definitions, elevating document analytics capabilities. Custom RAG flows can now be constructed using knowledge graphs, with resources for neo4j integration and RAG flows examples.
- Memories and Models in Webinars: Upcoming and recorded webinars showcase the forefront of AI with discussions on "memary" for long-term autonomous agent memory featured by Julian Saks and Kevin Li, alongside another session focusing on "Future of Web Agents" with Div from MultiOn. Register for the webinar here and view the past session online.
- Parallel Processing Divide: Engineers discussed the OpenAI Agent's ability to make parallel function calls, a feature clarified by LlamaIndex's documentation, albeit true parallel computations remain elusive. The discussion spanned several topics including persistence in TypeScript and RAG-based analytics for document sets with examples linked in the documentation.
- GPT-4o Ecstatic on Professional Doc Extraction: Recent research shows GPT-4o markedly surpasses other tools in document extraction, boasting an average accuracy of 84.69%, indicating potential shifts in various industries like finance.
- Seeking Semantic SQL Synergy: The guild pondered the fusion of semantic layers with SQL Retrievers to potentially enhance database interactions, a topic that remains open for exploration and could inspire future integrations and discussions.
Latent Space Discord
AI's Intrigue and Tumult in Latent Space: An AI Reverse Turing Test video surfaced, sparking interest by depicting advanced AIs attempting to discern a human among themselves. Meanwhile, accusations surfaced around llama3-V allegedly misappropriating MiniCPM-Llama3-V 2.5's academic work, as noted on GitHub.
The Future of Software and Elite Influence: Engineers digested the implications of "The End of Software," a provocative Google Doc, while also discussing Anthropic's Dario Amodei’s rise to Time's Top 100 after his decision to delay the chatbot Claude’s release. An O'Reilly article on operational aspects of LLM applications was also examined for insights on a year of building with these models.
AI Event Emerges as Industry Nexus: The recent announcement of the AI Engineering World Forum (AIEWF), detailed in a tweet, stoked anticipation with new speakers, an AI in Fortune 500 track, and official events covering diverse LLM topics and industry leadership.
Zoom to the Rescue for Tech Glitch: A Zoom meeting saved the day for members experiencing technical disruptions during a live video stream. They bridged to continued discussion by accessing the session through the shared Zoom link.
LangChain AI Discord
RAG Systems Embrace Historical Data: Community members discussed strategies for integrating historical data into RAG systems, recommending optimizations for handling CSV tables and scanned documents to enhance efficiency.
Game Chatbots Game Stronger: A debate on the structure of chatbots for game recommendations led to advice against splitting a LangGraph Chatbot agent into multiple agents, with a preference for a unified agent or pre-curated datasets for simplicity.
LangChain vs OpenAI Showdown: Conversations comparing LangChain with OpenAI agents pointed out LangChain's adaptability in orchestrating LLM calls, highlighting that use case requirements should dictate the choice between abstraction layers or direct OpenAI usage.
Conversational AI Subjects Trending in Media: Publications surfaced in the community include explorations of LLMs with Hugging Face and LangChain on Google Colab, and the rising importance of conversational agents in LangChain. Key resources include exploratory guide on Medium and a deep dive into conversational agents by Ankush k Singal.
JavaScript Meets LangServe Hurdle: A snippet shared the struggles within the JavaScript community when dealing with the RemoteRunnable class in LangServe, as evidenced by a TypeError related to message array processing.
tinygrad (George Hotz) Discord
Tinygrad Progress Towards Haskell Horizon: Discussions highlighted a member's interest in translating tinygrad into Haskell due to Python's limitations, while another suggested developing a new language specifically for tinygrad’s uop end.
Evolving Autotuning in AI: The community critiqued older autotuning methods like TVM, emphasizing the need for innovations that address shortcomings in block size and pipelining tuning to enhance model accuracy.
Rethinking exp2 with Taylor Series: Users, including georgehotz, examined the applicability of Taylor series to improve the exp2 function, discussing the potential benefits of CPU-like range reduction and reconstruction methods.
Anticipating tinygrad's Quantum Leap: George Hotz excitedly announced tinygrad 1.0's intentions to outstrip PyTorch in speed for training GPT-2 on NVIDIA and AMD, accompanied by a tweet highlighting upcoming features like FlashAttention, and proposing to ditch numpy/tqdm dependencies.
NVIDIA's Lackluster Showcase Draws Ire: Nvidia's CEO Jensen Huang's COMPUTEX 2024 keynote video raised expectations for revolutionary reveals but ultimately left at least one community member bitterly disappointed.
OpenAccess AI Collective (axolotl) Discord
- Yuan2.0-M32 Shows Its Expertise: The new Yuan2.0-M32 model stands out with its Mixture-of-Experts architecture and is presented alongside key references including its Hugging Face repository and the accompanying research paper.
- Troubleshooting llama.cpp: Users are pinpointing tokenization problems in llama.cpp, citing specific GitHub issues (#7094 and #7271) and advising careful verification during finetuning.
- Axolotl Adapts to AMD: Modifying Axolotl for AMD compatibility has been tackled, resulting in an experimental ROCm install guide on GitHub.
- Defining Axolotl's Non-Crypto Realm: In a clarification within the community, Axolotl is reaffirmed to focus on training large language models, explicitly not delving into cryptocurrency.
- QLoRA Training with wandb Tracking: Members are exchanging insights on how to implement wandb for monitoring parameters and losses during QLoRA training sessions, with a nod to an existing wandb project and specific
qlora.ymlconfigurations.
Cohere Discord
Open Call for AI Collab: Manifold Research is on the hunt for collaborators to work on building an open-source "Generalist" model, inspired by GATO, targeting multimodal and control tasks across domains like vision, language, and more.
Cohere Community Troubleshoots: A broken dashboard link in the Cohere Chat API documentation was spotted and flagged, with community members stepping in to acknowledge and presumably kickstart a fix.
AI Model Aya 23 Gets the Thumbs Up: A user shares a successful testing of Cohire's Aya 23 model and hints at a desire to distribute their code for peer review.
Community Tag Upgrade Revealed: Discord's updated tagging mechanism sparks conversation and excitement in the community, with members sharing a link to the tag explanation.
Support Network Activated: For those experiencing disappearing chat histories or other issues, redirections to Cohere's support team at support@cohere.com or the server's designated support channel are provided.
OpenInterpreter Discord
- Whisper to OI's Rescue: Efforts to integrate Whisper or Piper into Open Interpreter (OI) are underway; this aims to reduce verbosity and increase speech initiation speed. No successful installation of OI on non-Ubuntu systems was reported; one attempt on MX Linux failed due to Python issues.
- Agent Decision Confusion Cleared: Clarifications were made about "agent-like decisions" within OI, leading to a specific section in the codebase—the LLM with the prompt found in the default system message.
- Looking for a Marketer: The group discussed a need for marketing efforts for Open Interpreter, which was previously handled by an individual.
- Gemini's Run Runs into Trouble: Queries were raised about running Gemini on Open Interpreter, as the provided documentation seemed to be outdated.
- OI's Mobile Maneuver: There are active discussions on creating an app to link the OI server to iPhone, with an existing GitHub code and a TestFlight link for the iOS version. TTS functionality on iOS was confirmed, while an Android version is in development.
- Spotlight on Loyal-Elephie: A single mention pointed to Loyal-Elephie, without context, by user cyanidebyte.
Interconnects (Nathan Lambert) Discord
- Security Breach at Hugging Face: Unauthorized access compromised secrets on Hugging Face's Spaces platform, leading to a recommendation to update keys and use fine-grained access tokens. Full details are outlined in this security update.
- AI2 Proactively Updates Tokens: In response to the Hugging Face incident, AI2 is refreshing their tokens as a precaution. However, Nathan Lambert reported his tokens auto-updated, mitigating the need for manual action.
- Phi-3 Models Joining the Ranks: The Phi-3 Medium (14B) and Small (7B) models have been added to the @lmsysorg leaderboard, performing comparably to GPT-3.5-Turbo and Llama-2-70B respectively, but with a disclaimer against optimizing models solely for academic benchmarks.
- Plagiarism Allegations in VLM Community: Discussions surfaced claiming that Llama 3V was a plagiarized model, supposedly using MiniCPM-Llama3-V 2.5's framework with minor changes. Links, including Chris Manning's criticism and a now-deleted Medium article, fueled conversations about integrity within the VLM community.
- Donation-Bets Gain Preference: Dylan transformed a lost bet about model performance into an opportunity for charity, instigating a trend of 'donation-bets' among members who see it also as a reputational booster for a good cause.
Mozilla AI Discord
- Mozilla Backs Local AI Wizardry: The Mozilla Builders Accelerator is now open for applications, targeting innovators in Local AI, offering up to $100,000 in funding, mentorship, and a stage on Mozilla’s networks for groundbreaking projects. Apply now to transform personal devices into local AI powerhouses.
- Boosting llama.cpp with Paddler: Engineers are considering integrating Paddler, a stateful load balancer, with llama.cpp to streamline llamafile operations, potentially offering more efficient model serving capabilities.
- Sluggish Sampling Calls JSON Schema into Question: AI engineers encounter slowdowns in sampling due to server issues and identified a problem with the JSON schema validation, citing a specific issue in the llama.cpp repository.
- API Endpoint Compatibility Wrangling: Usability discussions revealed that the OpenAI-compatible chat endpoint
/v1/chat/completionsworks with local models; however, model-specific roles need adjustments previously handled by OpenAI’s processing.
- Striving for Uniformity with Model Interfaces: There's a concerted effort to maintain a uniform interface across various models and providers despite the inherent challenges due to different model specifics, necessitating customized pre-processing solutions for models like Mistral-7b-instruct.
DiscoResearch Discord
- Spaetzle Perplexes Participants: Members discussed the details of Spaetzle models, with the clarification that there are actually multiple models rather than a single entity. A related AI-generated Medium post highlighted different approaches to tuning pre-trained language models, which include names like phi-3-mini-instruct and phoenix.
- Anticipation for Replay Buffer Implementation: An article on InstructLab describes a replay buffer method that could relate closely to Spaetzle; however, it has not been implemented to date. Interest is brewing around this concept, indicating potential future developments.
- Deciphering Deutsche Digits: A call was made for recommendations on German handwriting recognition models, and Kraken was suggested as an option, accompanied by a survey link possibly intended for further research or input collection.
- Model Benchmarking and Strategy Sharing: The effectiveness of tuning methods was a core topic, underscored by a member expressing intent to engage with material on InstructLab. No specific benchmarks for the models were provided, although they were mentioned in the context of Spaetzle.
Datasette - LLM (@SimonW) Discord
- Claude 3's Tokenizing Troubles: Engineers found it puzzling that Claude 3 lacks a dedicated tokenizer, a critical tool for language model preprocessing.
- Nomic Model Queries: There's confusion on how to utilize the nomic-embed-text-v1 model since it isn't listed with gpt4all models within the
llm modelscommand output. - SimonW's Plugin Pivot: For embedding tasks, SimonW recommends switching to the llm-sentence-transformers plugin, which appears to offer better support for the Nomic model.
- Embed Like a Pro with Release Notes: Detailed installation and usage instructions for the nomic-embed-text-v1 model can be found in the version 0.2 release notes of llm-sentence-transformers.
AI21 Labs (Jamba) Discord
- Jamba Instruct on Par with Mixtral: Within discussions, Jamba Instruct's performance was likened to that of Mixtral 8x7B, positioning it as a strong competitor against the recently highlighted GPT-4 model.
- Function Composition: AI's Achilles' Heel: A shared LinkedIn post revealed a gap in current machine learning models like Transformers and RNNs, pinpointing challenges with function composition and flagging Jamba's involvement in related SSM experiments.
MLOps @Chipro Discord
- Hack Your Way to Health Innovations: The Alliance AI4Health Medical Innovation Challenge Hackathon/Ideathon is calling for participants to develop AI-driven healthcare solutions. With over $5k in prizes on offer, the event aims to stimulate groundbreaking advancements in medical technology. Click to register.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #announcements (1 messages):
- Urgent Security Alert for HF Spaces: Due to a security incident, users are strongly advised to rotate any tokens or keys used in HF Spaces. For more details, check the official blog post.
Link mentioned: Spaces Overview: no description found
HuggingFace ▷ #general (974 messages🔥🔥🔥):
- Controversy over Natural vs. Artificial Intelligence: Members debated whether growing neurons can be considered artificial, discussing definitions and ethical implications. One member suggested that labor-intensive creation processes render a product artificial, sparking controversy.
- Issues with Hugging Face Infrastructure: Members experienced issues with the Hugging Face Inference API, reporting multiple "MaxRetryError" messages. The problem was shared with the team for resolution, subsequently returning to normal functionality.
- Fine-Tuning Models with Limited Resources: One user struggled with fine-tuning and pushing a model using limited RAM, seeking advice on using quantization techniques. A member suggested using the
BitsAndBytesConfigfrom thepeftlibrary, which eventually solved the issue. - Podcasts and Learning Resources: Members exchanged recommendations for various podcasts including Joe Rogan Experience, Lex Fridman, and specific programming-related podcasts. Additionally, there were discussions about the helpfulness of different content kinds for various types of learning, including AI and rust programming.
- Activity Tracker for LevelBot: A new activity tracker for the HF LevelBot was announced, allowing users to view their activity. Suggestions included tracking more types of actions, linking GitHub activity, and improving the graphical interface.
- HF Serverless LLM Inference API Status - a Hugging Face Space by pandora-s: no description found
- nroggendorff/mayo · Hugging Face: no description found
- Tweet from Noa Roggendorff (@noaroggendorff): All my homies hate pickle, get out of here with your bins and your pts. Get safetensors next time.
- google/switch-c-2048 · Hugging Face: no description found
- It Started to Sing: Here’s an early preview of ElevenLabs Music.This song was generated from a single text prompt with no edits.Style: “Pop pop-rock, country, top charts song.”
- Omost - a Hugging Face Space by lllyasviel: no description found
- Papers with Code - HumanEval Benchmark (Code Generation): The current state-of-the-art on HumanEval is AgentCoder (GPT-4). See a full comparison of 127 papers with code.
- Kryonax Skull GIF - Kryonax Skull - Discover & Share GIFs: Click to view the GIF
- blanchon/udio_dataset · Datasets at Hugging Face: no description found
- @lunarflu on Hugging Face: "By popular demand, HF activity tracker v1.0 is here! 📊 let's build it…": no description found
- GitHub - huggingface/knockknock: 🚪✊Knock Knock: Get notified when your training ends with only two additional lines of code: 🚪✊Knock Knock: Get notified when your training ends with only two additional lines of code - huggingface/knockknock
- Hugging Face Reading Group 21: Understanding Current State of Story Generation with AI: Presenter: Isamu IsozakiWrite up: https://medium.com/@isamu-website/understanding-ai-for-stories-d0c1cd7b7bdcPast Presentations: https://github.com/isamu-iso...
- transformers/src/transformers/models/t5/modeling_t5.py at 96eb06286b63c9c93334d507e632c175d6ba8b28 · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- GitHub - JonathonLuiten/Dynamic3DGaussians: Contribute to JonathonLuiten/Dynamic3DGaussians development by creating an account on GitHub.
- GitHub - nullonesix/sign_nanoGPT: nanoGPT with sign gradient descent instead of adamw: nanoGPT with sign gradient descent instead of adamw - nullonesix/sign_nanoGPT
- Image-to-image: no description found
- GitHub - bigscience-workshop/petals: 🌸 Run LLMs at home, BitTorrent-style. Fine-tuning and inference up to 10x faster than offloading: 🌸 Run LLMs at home, BitTorrent-style. Fine-tuning and inference up to 10x faster than offloading - bigscience-workshop/petals
- transformers/examples/pytorch/summarization/run_summarization.py at 96eb06286b63c9c93334d507e632c175d6ba8b28 · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- Loaded adapter seems ignored: Hello everyone, I’m an absolute beginner, trying to do some cool stuff. I have managed to fine-tune a model using QLoRA, used 'NousResearch/Llama-2-7b-chat-hf' as the base model, and created ...
- Hub API Endpoints: no description found
- nroggendorff/vegan-mayo · Hugging Face: no description found
- GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository): Tesseract Open Source OCR Engine (main repository) - tesseract-ocr/tesseract
- sentence_bert_config.json · Alibaba-NLP/gte-large-en-v1.5 at main: no description found
- Dave Brubeck - Take Five: Dave Brubeck - Take Five
- Quantization: no description found
- Mistral: no description found
HuggingFace ▷ #today-im-learning (28 messages🔥):
- Deploying a 3D website for LLM chatbot: A member is working on deploying a 3D website for an LLM chatbot and invites others to join in.
- Learning about d2l.ai with Rust: A member is using the book d2l.ai to learn how to use Candle in Rust, sharing their GitHub repo. Another user asks about the book; it’s a famous deep learning textbook lacking a Rust version.
- Advantages of Candle in Rust: Discussions reveal the advantages of using Candle over PyTorch, including "less dependencies overhead" and "ease of deployment" due to the Rust-based system.
- Training models with more money and better hardware: A user humorously suggests that spending more money produces better models, mentioning they use an A6000 GPU but get better results with slower training at 200 seconds per step.
- Evaluating Whisper medium: A user is working on evaluating Whisper medium en but faces issues when trying to get a timestamp per word instead of a passage using the pipeline function.
Link mentioned: GitHub - asukaminato0721/d2l.ai-rs: use candle to implement some of the d2l.ai: use candle to implement some of the d2l.ai. Contribute to asukaminato0721/d2l.ai-rs development by creating an account on GitHub.
HuggingFace ▷ #cool-finds (3 messages):
- AI Systems Overview in Recent Paper: The arXiv paper, 2312.01939, delves into contemporary AI capabilities tied to increasing resource demands, datasets, and infrastructure. It discusses reinforcement learning's knowledge representation via dynamics, reward models, value functions, policies, and original data.
- Mastery and Popular Topics in SatPost: A Substack post discusses Jerry Seinfeld and Ichiro Suzuki's dedication to mastering their skills, along with Netflix’s password policy success, Red Lobster’s bankruptcy, and trending memes. Check it out for a mix of serious insight and humor here.
- Conversational Agents on the Rise with Langchain: An article titled "Chatty Machines: The Rise of Conversational Agents in Langchain" hosted on AI Advances emphasizes the growing presence of conversational agents. Authored by Ankush K Singal, it covers advancements and implementations in this domain.
- Chatty Machines: The Rise of Conversational Agents in Langchain: Ankush k Singal
- Jerry Seinfeld, Ichiro Suzuki and the Pursuit of Mastery: Notes from the 1987 Esquire magazine issue that inspired Jerry Seinfeld to "pursue mastery [because] that will fulfill your life".
- Foundations for Transfer in Reinforcement Learning: A Taxonomy of Knowledge Modalities: Contemporary artificial intelligence systems exhibit rapidly growing abilities accompanied by the growth of required resources, expansive datasets and corresponding investments into computing infrastr...
HuggingFace ▷ #i-made-this (11 messages🔥):
- Fast Mobius Demo Delights: A member shared a Fast Mobius demo, highlighting the duplicated space from Proteus-V0.3. The post included multiple avatars enhancing the message.
- Max4Live Device on the Horizon: Another member celebrated nearing production for the gary4live device, emphasizing electron js for UI, and redis/mongoDB/gevent for backend robustness. They mentioned challenges with code signing and shared a YouTube demo.
- Notes on LLM Reasoning from Literature Review: A detailed summary of current research on reasoning in LLMs was provided, including the lack of papers on GNNs, potential of Chain of Thought, and interest in Graph of Thoughts. The full notes can be accessed on Medium.
- Quirky Perspectives: Multiple humorous and imaginative posts were shared, including "when you rent the upstairs suite to that weird guy who always talks about nuclear power" and "a more psychedelic view of a Belize city resident undergoing a transformation".
- A Funny Take on Historical Figures: A member shared a lighthearted YouTube video about Mark Antony and Cleopatra, tagged with #facts #funny #lovestory.
- Mobius - a Hugging Face Space by ehristoforu: no description found
- Mark Antony and Cleopatra #facts #funny #lovestory #love: no description found
- no title found: no description found
- demo turns into another ableton speedrun - musicgen and max for live - captains chair s1 encore: season 1 e.p. out june 7https://share.amuse.io/album/the-patch-the-captains-chair-season-one-1from the background music, saphicord community sample pack:http...
HuggingFace ▷ #reading-group (5 messages):
- Research Paper Shared on Text-to-Image Diffusion Models: A member shared the link to an Arxiv paper authored by several researchers, highlighting recent developments in large-scale pre-trained text-to-image diffusion models.
- Ping Mistake Corrected with Humor: After accidentally pinging the wrong person, a member apologized and humorously acknowledged the mistake using a Discord emoji
<:Thonk:859568074256154654>.
Link mentioned: TerDiT: Ternary Diffusion Models with Transformers: Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models ba...
HuggingFace ▷ #computer-vision (9 messages🔥):
- Train OCR models with TrOCR and manga-ocr: To train an OCR model for non-English handwritten documents, a member suggested using TrOCR, noting its application on Japanese text through manga-ocr. They also linked to detailed TrOCR documentation.
- Emerging VLMs excel at document AI tasks: Nowadays, VLMs like Pix2Struct and UDOP are increasingly effective for document AI, particularly OCR tasks. A member highlighted recent models such as the MiniCPM-Llama3-V 2.5 and CogVLM2-Llama3-chat-19B which perform well on benchmarks such as DocVQA.
- Understanding Vision-Language Models (VLMs): An introduction to VLMs, their functionality, training, and evaluation was shared through a research paper, accessible at huggingface.co/papers/2405.17247. The discussion emphasizes the increasing significance and challenges of integrating vision and language models.
- Community events and collaboration: Members were invited to a Computer Vision Hangout in another channel, fostering community engagement and collaboration on ongoing projects.
- Paper page - An Introduction to Vision-Language Modeling: no description found
- TrOCR: no description found
- openbmb/MiniCPM-Llama3-V-2_5 · Hugging Face: no description found
- Vision Transformer (ViT): no description found
- GitHub - kha-white/manga-ocr: Optical character recognition for Japanese text, with the main focus being Japanese manga: Optical character recognition for Japanese text, with the main focus being Japanese manga - kha-white/manga-ocr
- no title found: no description found
HuggingFace ▷ #NLP (24 messages🔥):
- Llama 3 with 8B Parameters causes memory issues: One user mentioned their local memory was crying after installing and using Llama 3 with 8B parameters locally. Another user suggested using 4-bit quantization techniques available with llama cpp to alleviate memory issues.
- Best Translation Model for Japanese to English: A user requested recommendations for the best translation model for Japanese to English on Hugging Face. Another user recommended Helsinki-NLP/opus-mt-ja-en for the task, citing various resources and benchmarks.
- Resources for RAG: For those looking for resources on RAG (Retrieval-Augmented Generation), Hugging Face's Open-Source AI Cookbook was suggested. This resource includes sections dedicated to RAG recipes and other AI applications.
- Running into issue with Graphcodebert's tree_sitter: A user encountered an AttributeError when attempting to build a library in Graphcodebert using tree_sitter. The user's directory listing showed that the attribute "build_library" does not exist in their environment, implying a potential misconfiguration or missing dependency.
- Making LLM Deterministic: For making a Large Language Model (LLM) deterministic, a user asked for guidance beyond setting the temperature to 1. Another user clarified that the proper settings are
do_sample=Falseand setting the temperature to 0.
- Open-Source AI Cookbook - Hugging Face Open-Source AI Cookbook: no description found
- Helsinki-NLP/opus-mt-ja-en · Hugging Face: no description found
- Tweet from Anjney Midha (@AnjneyMidha): It cost ~$30M to train the original llama model, but only $300 (i.e. <0.1%) to fine-tune it into Vicuna, a frontier model at the time Anyone who claims that it requires significant compute to en...
HuggingFace ▷ #diffusion-discussions (1 messages):
- Combining Lerobot and Diffusion in Robotics: A member shared a detailed blog post, Diving into Diffusion Policy with Lerobot, explaining the integration of the Action Chunking Transformer (ACT) in robot training. The post describes how ACT utilizes an encoder-decoder transformer to predict actions based on an image, robot state, and optional style variable, contrasting this with the Diffusion Policy approach that starts with Gaussian noise.
Link mentioned: Diving into Diffusion Policy with LeRobot: In a recent blog post, we looked at the Action Chunking Transformer (ACT). At the heart of ACT lies an encoder-decoder transformer that when passed in * an image * the current state of the robot ...
HuggingFace ▷ #gradio-announcements (2 messages):
- Gradio supports dynamic layouts with @gr.render: Exciting news that Gradio now includes dynamic layouts using the @gr.render feature, enabling the integration of components and event listeners dynamically. For more details, check out the guide.
- Todo App Example: One example shared is a Todo List App where textboxes and responsive buttons can be dynamically added and rearranged using @gr.render. The linked guide provides full code snippets and a walkthrough.
- AudioMixer App Example: Another example is a music mixer app enabling users to add multiple tracks dynamically with @gr.render and Python loops. Detailed source code and instructions are provided in the guide.
Link mentioned: Dynamic Apps With Render Decorator: A Step-by-Step Gradio Tutorial
Unsloth AI (Daniel Han) ▷ #general (919 messages🔥🔥🔥):
- Multi-GPU finetuning update: Progress is being made on model support and licensing for multi-GPU finetuning. "We might do multimodal but that may need more time," explains one project member.
- LoRA Tuning vs Full Tuning: Discussion around LoRA and full tuning reveals mixed results in terms of new knowledge retention versus old knowledge loss. Detailed paper analysis highlights why LoRA might excel in certain contexts (e.g., less source domain forgetting).
- Training setups and errors: Several users reported technical challenges around tokenizer settings and finetuning configurations. "You might consider adding
tokenizer.padding_side = 'right'to your code," was advised due to overflow issues in half-precision training. - Kaggle Notebooks for faster LLM finetuning: The team shared updates about fixing their 2x faster LLM finetuning Kaggle notebooks, encouraging users to try them out and report any issues. "Force reinstalling aiohttp fixes stuff!" according to their analysis.
- H100 NVL issues: A user encounters persistent issues when running RoPE optimization runs on H100 NVL with inconsistent VRAM usage and slow response times. The community speculates about potential memory reporting bugs or unexplained VRAM offloading to system RAM.
- Finetune Llama 3 with Unsloth: Fine-tune Meta's new model Llama 3 easily with 6x longer context lengths via Unsloth!
- Google Colab: no description found
- LoRA Learns Less and Forgets Less: Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In t...
- Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach: Self-supervised features are the cornerstone of modern machine learning systems. They are typically pre-trained on data collections whose construction and curation typically require extensive human ef...
- Building LLaMA 3 From Scratch - a Lightning Studio by fareedhassankhan12: LLaMA 3 is one of the most promising open-source model after Mistral, we will recreate it's architecture in a simpler manner.
- Hyperparameter Search using Trainer API: no description found
- Tweet from bycloud (@bycloudai): WE GOT MAMBA-2 THIS SOON????????? https://arxiv.org/abs/2405.21060 by Tri Dao and Albert Gu the same authors for mamba-1 and Tri Dao is also the author for flash attention 1 & 2 will read the paper...
- Tweet from Daniel Han (@danielhanchen): Fixed our 2x faster LLM finetuning Kaggle notebooks! Force reinstalling aiohttp fixes stuff! If you dont know, Kaggle gives 30hrs of T4s for free pw! T4s have 65 TFLOPS which is 80% of 1x RTX 3070 (...
- unsloth (Unsloth AI): no description found
- Tweet from Daniel Han (@danielhanchen): My take on "LoRA Learns Less and Forgets Less" 1) "MLP/All" did not include gate_proj. QKVO, up & down trained but not gate (pg 3 footnote) 2) Why does LoRA perform well on math and ...
- Tweet from Rohan Paul (@rohanpaul_ai): Paper - 'LoRA Learns Less and Forgets Less' ✨ 👉 LoRA works better for instruction finetuning than continued pretraining; it's especially sensitive to learning rates; performance is most ...
- Performance Comparison: Unify Efficient Fine-Tuning of 100+ LLMs. Contribute to hiyouga/LLaMA-Factory development by creating an account on GitHub.
- GitHub - huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. - huggingface/peft
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Hyperparameter Optimization — Sentence Transformers documentation: no description found
- philschmid/guanaco-sharegpt-style · Datasets at Hugging Face: no description found
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #random (13 messages🔥):
- Phi 3 Models Can't Run on GTX 3090: A member struggled to get Phi 3 medium or mini 128 to run on ollama or LM Studio using a GTX 3090, encountering errors despite multiple quants and models from different sources.
- Qwen2 Spotted on LMsys: An alert was raised by a member about the sighting of Qwen2 on chat.lmsys.org.
- Business Aversion to Open Source AI Models Discussed: A discussion emerged around businesses' reluctance to adopt open-source models due to AI safety concerns. Queries were raised about whether models can generate harmful content and how to prevent them from responding to inappropriate prompts.
- LLMs Limited to Training Data: It was noted that LLMs can only generate content included in their training data and cannot conduct novel research or creative innovation, like inventing a "nuclear bomb with €50 worth of groceries and an air fryer."
- Training Models to Avoid Irrelevant Topics: Members discussed techniques for training models to refuse answers to irrelevant or potentially harmful prompts. Methods include DPO/ORPO, control vectors, or using a separate text classifier to detect and block undesired prompts with a fixed response.
Unsloth AI (Daniel Han) ▷ #help (170 messages🔥🔥):
- Error in save_strategy causes confusion: Members discuss an error related to 'dict object has no attribute to_dict' when using save_strategy in the trainer. One member recommends using model.model.to_dict.
- Unsloth adapter works with HuggingFace: A member confirms that Unsloth's finetuned adapter can be used with HuggingFace's pipeline/text generation inference endpoint.
- Inference issues with GGUF conversion: A user shares issues with hallucinations when converting to GGUF and running with Ollama. This user reports that using Unsloth fixed the problem, and was advised to try VLLM for consistent performance.
- Kaggle installation fix shared: An issue with installing Unsloth on Kaggle was resolved by a member using a specific command to upgrade to the latest aiohttp version.
- Documentation and usability updates: Members point to several documentation updates, GitHub links, and upcoming support features such as multi-GPU compatibility and 8-bit quantization. Issues with repository access tokens and instructions for using a Docker image for Unsloth on WSL2 were also discussed.
- Google Colab: no description found
- Home: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- unsloth/llama-3-8b · Hugging Face: no description found
- unsloth/llama-3-8b-bnb-4bit · Hugging Face: no description found
- unsloth/llama-3-70b-bnb-4bit · Hugging Face: no description found
- [FIXED] Kaggle notebook: No module named 'unsloth' · Issue #566 · unslothai/unsloth: I got the error in kaggle notebook, here is how I install unsloth:
- GitHub - Jiar/jupyter4unsloth: Jupyter for Unsloth: Jupyter for Unsloth. Contribute to Jiar/jupyter4unsloth development by creating an account on GitHub.
- jupyter4unsloth/Dockerfile at main · Jiar/jupyter4unsloth: Jupyter for Unsloth. Contribute to Jiar/jupyter4unsloth development by creating an account on GitHub.
- no title found: no description found
- Type error when importing datasets on Kaggle · Issue #6753 · huggingface/datasets: Describe the bug When trying to run import datasets print(datasets.__version__) It generates the following error TypeError: expected string or bytes-like object It looks like It cannot find the val...
Unsloth AI (Daniel Han) ▷ #showcase (32 messages🔥):
- Experimenting with Ghost Beta Checkpoint: The experimentation continues with a checkpoint version of Ghost Beta in various languages including German, English, Spanish, French, Italian, Korean, Vietnamese, and Chinese. It is optimized for production and efficiency at a low cost, with a focus on ease of self-deployment (GhostX AI).
- Evaluating Language Quality: GPT-4 is used to evaluate the multilingual capabilities of the model on a 10-point scale, but this evaluation method is not official yet. Trusted evaluators and community contributions will help refine this evaluation for an objective view.
- Handling Spanish Variants: The model employs a method called "buffer languages" to handle regional variations in Spanish during training. The approach is still developing, and the specifics will be detailed in the model release.
- Mathematical Abilities and Letcode: The model's mathematical abilities are showcased with examples on the Letcode platform. Users have been encouraged to compare these abilities with other models on chat.lmsys.org.
- Managing Checkpoints for Fine-Tuning: Users discussed saving checkpoints to Hugging Face (HF) or Weights & Biases (Wandb) for continued fine-tuning. The process includes setting
save_strategyinTrainingArgumentsandresume_from_checkpoint=Truefor efficient training management.
- Tweet from undefined: no description found
- Ghost X: The Ghost X was developed with the goal of researching and developing artificial intelligence useful to humans.
- ghost-x (Ghost X): no description found
Unsloth AI (Daniel Han) ▷ #community-collaboration (4 messages):
- JSONL Formatting Issues Stump User: A member noticed a format discrepancy between sample training data in Unsloth and his own JSON-formatted data. "all the training data i've created with other tools are formatted like so" without a "text" column, causing errors during the training step.
- Quick Tip for JSON Errors: Another member suggested that you skip the formatting phase and go directly to training since there’s already a column named "text." This didn't resolve the issue because the user’s data lacks the required "text" column, creating a roadblock.
Stability.ai (Stable Diffusion) ▷ #announcements (2 messages):
- Stable Diffusion 3 Medium Release Date Announced: The “weight” is nearly over! Stability.ai's Co-CEO, Christian Laforte, announced that Stable Diffusion 3 Medium will be publicly released on June 12th. Sign up to the waitlist to be the first to know when the model releases.
- Watch the Full Computex Taipei Announcement: The announcement regarding Stable Diffusion 3 Medium was made at Computex Taipei. Watch the full announcement on YouTube.
- AMD at Computex 2024: AMD AI and High-Performance Computing with Dr. Lisa Su: The Future of High-Performance Computing in the AI EraJoin us as Dr. Lisa Su delivers the Computex 2024 opening keynote and shares the latest on how AMD and ...
- SD 3 Waitlist — Stability AI: Join the early preview of Stable Diffusion 3 to explore the model's capabilities and contribute valuable feedback. This preview phase is crucial for gathering insights to improve its performance and s...
Stability.ai (Stable Diffusion) ▷ #general-chat (1009 messages🔥🔥🔥):
- Stable Diffusion 3 Release Date Confirmed: Stability AI announced that Stable Diffusion 3 (SD3) Medium will release on June 12, as shared in a Reddit post. This 2 billion parameter model aims to improve photorealism, typography, and performance.
- Community discusses SD3 VRAM requirements: Concerns about VRAM needs surfaced, with speculation that SD3 Medium requires around 15GB, though optimizations like fp16 may reduce this. A user pointed out T5 encoder would add to VRAM usage.
- New Licensing and Usage Clarifications: Users raised questions regarding the commercial use of SD3 Medium under the new non-commercial license. Stability AI plans to clarify these licensing terms before launch day to address community concerns.
- OpenAI Bot Monetization Draws Criticism: The community expressed frustration over the removal of the free Stable AI Discord bot, now replaced with a paid service called Artisan. This change is seen as part of a trend toward paywalls in AI tools.
- Expectations and Optimizations for SD3: Users anticipate community fine-tunes and performance benchmarks for different GPUs. Stability AI confirmed support for 1024x1024 resolution with optimization steps like tiling to leverage the new model's capabilities.
- False Wrong GIF - False Wrong Fake - Discover & Share GIFs: Click to view the GIF
- Movie One Eternity Later GIF - Movie One Eternity Later - Discover & Share GIFs: Click to view the GIF
- Gojo Satoru GIF - Gojo Satoru Gojo satoru - Discover & Share GIFs: Click to view the GIF
- Tweet from Teknium (e/λ) (@Teknium1): Wow @StabilityAI fucking everyone by making up a new SD3, called SD3 "Medium" that no one has ever heard of and definitely no one has seen generations of to release, and acting like they are o...
- Correct Plankton GIF - Correct Plankton - Discover & Share GIFs: Click to view the GIF
- Tweet from Lykon (@Lykon4072): #SD3 but which version?
- GitHub - adieyal/sd-dynamic-prompts: A custom script for AUTOMATIC1111/stable-diffusion-webui to implement a tiny template language for random prompt generation: A custom script for AUTOMATIC1111/stable-diffusion-webui to implement a tiny template language for random prompt generation - adieyal/sd-dynamic-prompts
- Reddit - Dive into anything: no description found
- Possible revenue models for SAI: Well first this [https://stability.ai/membership](https://stability.ai/membership) Also selling early access to still-in-development models (like...
- Reddit - Dive into anything: no description found
- Stable Diffusion 3 — Stability AI: Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.
- Reddit - Dive into anything: no description found
- Unlock The Full Power Of Stable Diffusion with Wildcards & Dynamic Prompts!: Hey there, engineers! Welcome to Prompt Geek. In today's video, I'll be showing you how to create infinite character portraits using stable diffusion and the...
- Civitai | Share your models: no description found
- Possible revenue models for SAI: Well first this [https://stability.ai/membership](https://stability.ai/membership) Also selling early access to still-in-development models (like...
- Stable Diffusion Benchmarks: 45 Nvidia, AMD, and Intel GPUs Compared: Which graphics card offers the fastest AI performance?
- Image posted by canekzapata: no description found
- Human Prompt Generator: Totals Table,Variations Gender,2.00 Body Type Non Gender,9.00 Head Shapes,8.00 Face Shapes,9.00 Hair Color Type,10.00 Hair Texture Type,5.00 Hair Length Type,6.00 Hair Volume Type,5.00 Hair Styling O...
- Pablo Picasso ∞ SD XL 1.0 - Pablo Picasso ∞ SD XL 1.0 | Stable Diffusion LoRA | Civitai: Introducing Pablo Picasso ∞, an innovative LoRa (Text to Image) model that embarks on a journey through the captivating world of Pablo Picasso's ar...
Perplexity AI ▷ #general (796 messages🔥🔥🔥):
- AI Homework VS Human Learning Debate Heats Up: Members engaged in a heated debate about the impact of kids using AI for homework. One member compared it to letting kids choose between candy and kale, while others advocated for teaching responsible AI use.
- Perplexity Pro Page Limitations Spark Discussion: Members discussed the limitations of Perplexity’s new Pages feature, including no export function, inability to edit titles, text, or interact with viewers. These issues were highlighted by @gilgamesh_king_of_uruk, suggesting a need for improvements to expand usability.
- Confusion Over Opus Model Usage: Several users experienced confusion and issues regarding Perplexity models, specifically the automatic use of Opus, which led to unexpected exhaustion of their Opus quota. Multiple members raised the issue and discussed potential bugs and fixes.
- Complexity Browser Extension Beta Announced: A new browser extension, Complexity, designed to enhance the Perplexity user interface and experience, was announced for beta testing. Members were encouraged to contact @743667485416357939 for access.
- Persistent AI Misinterpretations and Bugs: Members reported several issues with Perplexity’s handling of short and simple tasks, such as proofreading prompts causing irrelevant output. This was identified as potentially related to the new Pro search mechanism and was noted for further investigation.
- Excalidraw — Collaborative whiteboarding made easy: Excalidraw is a virtual collaborative whiteboard tool that lets you easily sketch diagrams that have a hand-drawn feel to them.
- Perplexity Model Selection: Adds model selection buttons to Perplexity AI using jQuery
- no title found: no description found
- no hello: please don't say just hello in chat
- microsoft/Phi-3-mini-128k-instruct · Hugging Face: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
- HEAVY.AI | Interactive Data Visualization Examples / Demos: Interactive data visualization demos of the HEAVY.AI accelerated analytics platform. Experience instant and immersive data visualizations on big data rendered in milliseconds with the power of GPUs.
- HeavyIQ: HeavyIQ takes advantage of the latest LLM (large language model) technology so you can ask questions of your data in natural language and get back actionable visualizations.
- dailyfocus - Complexity | Udio: Listen to Complexity by dailyfocus on Udio. Discover, create, and share music with the world. Use the latest technology to create AI music in seconds.
- But what is a GPT? Visual intro to transformers | Chapter 5, Deep Learning: Unpacking how large language models work under the hoodEarly view of the next chapter for patrons: https://3b1b.co/early-attentionSpecial thanks to these sup...
- PPLX System/Pre Prompt - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Wordware - OPUS Insight - Multi-Model Output Verification with Claude 3 OPUS: This prompt processes a question using Gemini, GPT-4 Turbo, Claude 3 (Haiku, Sonnet, Opus), Mistral Large, Mixtral 7B Open Hermes, and Mixtral 8x7b (MoE based model). It then employs Claude 3 OPUS to ...
- Boutique One Piece | Magasin Officiel du Manga One Piece: Boutique One Piece® vous offre la sélection des meilleurs produits dérivés One Piece du marché : t-shirts, figurine, sweats, avis de recherche et bien d'autres !
- no title found: no description found
- no title found: no description found
- no title found: no description found
- no title found: no description found
- no title found: no description found
Perplexity AI ▷ #sharing (33 messages🔥):
- Users leverage Perplexity AI for a variety of searches: Users shared several Perplexity AI search results, such as AI transforming lives, Israel-Gaza war, and Preventing spam.
- Exploration of Perplexity Pages feature: Some members expressed enthusiasm for the new Pages feature, creating and sharing pages on various topics like Blade Runner and Simple Solidity Auction.
- AI tool ideas and improvements: A user mentioned an idea for an AI tool utilizing live data from Waze, shared through a search link, while another remarked on the potential benefits of Opus working on this concept.
- Discussion on sensitive topics: Users tested Perplexity AI's handling of delicate subjects like the Israel-Gaza war, noting satisfactory results.
- Diverse content sharing: Members posted a wide range of search topics and pages including Evariste Galois, cold weather benefits, and professional research collections.
Perplexity AI ▷ #pplx-api (12 messages🔥):
- New API Users Seek Model Guidance: A new member expressed being impressed by the API and questioned how different models perform for varied use cases. They received guidance on the specifics of model parameter counts, context length, and distinctions between chat and online models with reference to the model cards.
- Small Models vs Large Models: For queries about using smaller models, a member clarified that smaller models are faster, and highlighted the importance of deciding between online models for real-time data and chat models for optimized conversational tasks.
- Interest in TTS API: A user inquired about the possibility of an upcoming TTS API from Perplexity, noting the satisfactory performance of the current mobile TTS. They were informed that Perplexity uses services from 11Labs for TTS.
Link mentioned: Supported Models: no description found
CUDA MODE ▷ #general (29 messages🔥):
- Speculative Decoding Discussion Recap: Members discussed different ways to implement speculative decoding, with suggestions like sampling gumbel noise and using argmax deterministically. One member mentioned the need for an ablation study to understand the acceptance rate with different sampling parameters vs. rejection sampling.
- Query about Recording Availability: Members questioned whether today's session on speculative decoding would be recorded and uploaded. It was confirmed that the sessions are always recorded and would be uploaded after editing.
- Single H100 Cloud Rental: Members discussed the availability of a single H100 GPU for rental with profiling capabilities. Providers like cloud-gpus.com and RunPod were mentioned, though it was noted that collecting profiling info is challenging without significant hacking.
- New Working Groups: A new working group channel was announced for production kernels and another for revamping performance-related docs in PyTorch. These groups are open for members interested in contributing and collaborating on these tasks.
- Pricing for GPU Instances, Storage, and Serverless: RunPod pricing for GPU Instances, Storage, and Serverless.
- AMD announces MI325X AI accelerator, reveals MI350 and MI400 plans at Computex: More accelerators, more AI.
- libdevice User's Guide :: CUDA Toolkit Documentation: no description found
- [feature request] `torch.scan` (also port `lax.fori_loop` / `lax.while_loop` / `lax.associative_scan` and hopefully parallelized associative scans) · Issue #50688 · pytorch/pytorch: Exists in TF: https://www.tensorflow.org/api_docs/python/tf/scan (or some variant inspired by scan), JAX/LAX: https://jax.readthedocs.io/en/latest/_autosummary/jax.lax.scan.html, (old theano: https...
- libdevice User's Guide :: CUDA Toolkit Documentation: no description found
- use std/libdevice erf in inductor by ngimel · Pull Request #89388 · pytorch/pytorch: By itself, libdevice version of erf has the same perf as our decomposition, but in real workloads it leads to better fusion groups (due to fewer ops in the fused kernel). Bonus: a few fp64 test ski...
- Stand-alone error function erf(x): The question came up on StackOverflow this morning how to compute the error function erf(x) in Python. The standard answer for how to compute anything numerical in Python is "Look in SciPy."...
CUDA MODE ▷ #triton (14 messages🔥):
- Handle int64 overflows in Triton: Members discussed issues related to int64 overflows in Triton. One member suggested using
(indices*stride).to(tl.int64)but acknowledged it isn't ideal, while another pointed out that upcasting one factor first avoids overflow and mentioned annotating the kernel signature as another solution. Issue #1211.
- clang-tidy warnings for Triton: A user suggested that Triton implement warnings like those from
clang-tidyto catch potential int overflow issues. Specifically, a warning such as "Result of 32-bit integer multiplication used as pointer offset" could be beneficial.
- Annotations for large tensors: A suggestion was made to use annotations to handle large tensors more gracefully, referencing a specific GitHub issue #832. It involved using a decorator to set up proper type signatures to avoid overflow.
- Memory allocation in Triton: Questions arose about whether memory allocation functions like
tl.zerosandtl.fulluse shared memory on SRAM or VRAM. One user assumed VRAM is used until the memory is actually needed.
- Performance in triton.language.sum: There was a newbie question about whether
triton.language.sumperforms as a normal for-loop or as a parallel reduction. Another user confirmed it is indeed a parallel reduction, suitable for block-level parallel operations.
- Index computations are done in int32 even for large tensors, and overflow causing IMA · Issue #832 · triton-lang/triton: Repro: from ctypes import c_void_p, c_long import torch import random from torch import empty_strided, as_strided, device from torch._inductor.codecache import AsyncCompile aten = torch.ops.aten as...
- Handle int64 overflows more graciously · Issue #1211 · triton-lang/triton: Multiplication between two int32 can overflow, just like in C. This is often unexpected from Python users, but necessary for optimal performance. We need to at least document this behavior better. ...
CUDA MODE ▷ #torch (4 messages):
- Profiling with torch.compile: A member inquired, "When profiling a run with torch.compile, how you can verify if the kernel was executed using the inductor (Triton kernel)?" They mentioned using torch.profiler and chrome trace for this task.
- Distributed Gradient Aggregation in PyTorch: A user asked if anyone had resources on how PyTorch implements distributed gradient aggregation, questioning whether it uses a parameter server or averages gradients similar to Horovod.
- Usage of the Asterisk in Function Arguments: One member queried about the purpose of the * in the arguments for the function on the PyTorch documentation for torch.clamp. Another user clarified that it denotes keyword-only arguments.
CUDA MODE ▷ #announcements (4 messages):
- Speculative Decoding Talk Coming Up: The next talk is scheduled for
- Start of Cade's Talk Announcement: "Starting Cade's talk now!" marks the beginning of the session.
- Shift to Working Groups and Upcoming NVIDIA Talks: Over the next few weeks, there will be fewer weekly lecture series to focus more on working groups. Upcoming talks include a session on Tensor Cores on
- Potential Talk by Prof Wen-mei Hwu: There's a plan to invite Prof Wen-mei Hwu, author of the PMPP book, to give a chapter lecture and participate in a public Q&A. The date for this event is still to be determined, but it's expected to happen soon.
- AMD Session in Preparation: An additional session by someone from AMD, likely from the Composable Kernel (CK) team, is in preparation for July 20.
CUDA MODE ▷ #cool-links (2 messages):
- Custom CUDA Kernel Introduction and Benchmarks: A blog post titled Custom CUDA Kernel Introduction and Benchmarks was shared. The post includes detailed benchmarks and explanations on creating custom CUDA kernels, alongside links to open the content in Google Colab.
- AutoFP8 GitHub Repository Shared: A link to the AutoFP8 GitHub repository was shared. This repository from Neural Magic focuses on automatic conversion of models to the FP8 precision format, aimed at improving computational efficiency and speed.
Link mentioned: Mat’s Blog - CUDA MODE - Accelerate your code with massively parallel programming plus some other tricks: no description found
CUDA MODE ▷ #jobs (3 messages):
- Anyscale invites job interest: A member pitched working for Anyscale, particularly reaching out to those interested in speculative decoding, vLLM, and systems performance. Refer to Anyscale for further details and apply with a resume or LinkedIn.
- Chunked prefill boosts vLLM efficiency: The vLLM project received contributions from Anyscale, introducing chunked prefill. This led to significant efficiency gains, providing up to 2x speedup for higher QPS regimes.
- Fast model loading with Anyscale: Anyscale blogged about loading Llama 2 70B 20x faster using their endpoints, which is crucial for responsive autoscaling and cost-effective model multiplexing in production environments.
- Continuous batching optimizes LLM inference: The Anyscale blog discusses continuous batching, which can offer up to 23x throughput improvement. This technique involves iteration-level scheduling and can drastically enhance real-world workloads by optimizing system-level batching.
- Anyscale | Scalable Compute for AI and Python: Anyscale is the leading AI application platform. With Anyscale, developers can build, run and scale AI applications instantly.
- Tweet from Cade Daniel 🇺🇸 (@cdnamz): Chunked prefill expands the Pareto frontier for fast & cheap online continuous batching. Great work in @vllm_project by engineers at @anyscalecompute . Quoting Anyscale (@anyscalecompute) Recently,...
- Using LoRA adapters — vLLM: no description found
- Loading Llama-2 70b 20x faster with Anyscale Endpoints: In this post, we discuss the importance of speed when loading large language models and what techniques we employed to make it 20x faster. In particular, we use the Llama 2 series of models. We share ...
- Achieve 23x LLM Inference Throughput & Reduce p50 Latency: In this blog, we discuss continuous batching, a critical systems-level optimization that improves both throughput and latency under load for LLMs.
CUDA MODE ▷ #beginner (22 messages🔥):
- Branching Logic in GPUs Clarified: A member asks for resources on how branching logic is handled by GPUs vs CPUs. Others explain that in GPUs, branching is done using execution masking, with minimal scheduling units being warps of 32 threads, and referenced section 4.5 in PMPP for further reading.
- Hands-on CUDA Course Recommendations: When asked for exercises or labs to practice CUDA programming, members recommended the homework in the PMPP book and the Open 2024a PPC Exercises Course. It offers a combination of CPU and GPU exercises that closely mimic official university course content.
- YouTube Lecture on Scan Algorithm: A YouTube video titled Lecture 20: Scan Algorithm was shared for more in-depth learning.
- Creating a Hardware-Abstraction Wrapper: A member seeks to create a wrapper around PyTorch and Hugging Face to abstract hardware complexities. They are advised to start with the Phi model family and explore target-specific libraries for various hardware optimizations like flash attention for AMD and LLM libraries from Intel.
- Avoid Pinging Everyone: A polite reminder was given to avoid using @\everyone in messages to prevent mass notifications.
- Lecture 20: Scan Algorithm: no description found
- Exercises: no description found
CUDA MODE ▷ #pmpp-book (2 messages):
- Izzat kicks off part 2 of the scan: Part 2 of the scan by Izzat is starting. Members were invited to join via a Zoom link.
Link mentioned: Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
CUDA MODE ▷ #youtube-recordings (12 messages🔥):
- Scan Algorithm Coding Not Live Yet: A member inquired about the availability of the coding for the scan algorithm, and was informed that it is "still being edited."
- Speculative Decoding Workshop Recording Confirmed: In response to a query about recording the speculative decoding workshop, it was confirmed that it "will be recorded."
- Scan Algorithm Lectures Shared: Two YouTube videos were shared: Lecture 20: Scan Algorithm and Lecture 21: Scan Algorithm Part 2.
- vLLM Talk to Be Recorded: Upon asking if the vLLM talk was recorded, it was confirmed that "it will be" recorded and uploaded to the CUDA MODE YouTube Channel within 3 days.
- Speculative Decoding in vLLM Lecture Shared: A YouTube video titled Lecture 22: Hacker's Guide to Speculative Decoding in VLLM was shared, which focuses on how vLLM combines continuous batching with speculative decoding.
- CUDA MODE: A CUDA reading group and community https://discord.gg/cudamode Supplementary content here https://github.com/cuda-mode Created by Mark Saroufim and Andreas Köpf
- Lecture 20: Scan Algorithm: no description found
- Lecture 21: Scan Algorithm Part 2: no description found
- Lecture 22: Hacker's Guide to Speculative Decoding in VLLM: Abstract: We will discuss how vLLM combines continuous batching with speculative decoding with a focus on enabling external contributors. Topics include prop...
CUDA MODE ▷ #torchao (15 messages🔥):
- TorchAO integrates with LM Evaluation Harness: A thread was created to discuss the integration of TorchAO quantization support with the LM Evaluation Harness. The recommended API for ease of use includes
q_model = torchao.autoquant(torch.compile(model, mode='max-autotune')).
- Potential API expansions discussed: A member mentioned the possibility of expanding the API to include functions like
to_fp6(), highlighting that all APIs would require an nn module. They debated whether passing a lambda function or explicitly listing the public APIs would be better.
- UInt4Tensor generalization in progress: A pull request aims to generalize UInt4Tensor in DTypes for bits 2-7 with specific implementation details shared by another member. More details can be found in the PR on GitHub.
- Quantization and Sparsity discussed for effectiveness: Members discussed when quantization starts to become effective and the minimal requirements for its application, mentioning factors like memory saving, speed up, and kernel types. The conversation also touched on the quality tradeoff necessary when utilizing these methods.
Link mentioned: Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
CUDA MODE ▷ #ring-attention (4 messages):
- Spelling confusion cleared up: Miscommunication arose when a member asked if "hurn model" inference performance. Another member clarified the intended word was "hurt" and noted it might affect performance slightly but referred to RULER graphs for specifics.
CUDA MODE ▷ #off-topic (36 messages🔥):
- Berlin AI Skepticism: A member noted that in Berlin, it's crucial to double-check if people claiming to work in AI are truly knowledgeable. They emphasized that otherwise, everything is possible in Berlin.
- PhD Position Hunt in Germany: A graduate student based in Germany expressed their intention to apply for PhD positions, preferably within Europe. They noted a scarcity of groups focused on efficiency/systems outside of the US.
- Searching Beyond Germany: Another member inquired about recommended countries other than Germany for systems/performance roles, mentioning France and Switzerland as potential options. Both members agreed to share information if they find any relevant opportunities.
- Dan Alistarh Group in Austria: IST Austria's Dan Alistarh group, known for their work including GPT-Q and SparseGPT, was mentioned as a noteworthy research group. One member had overlooked Austria in their initial search.
- Graduate vs. Industry Roles: A discussion ensued about the differences between research assistant roles and PhD positions. It was highlighted that the US is dominant in the field of systems research, while Europe seems less involved, especially regarding MLsys.
CUDA MODE ▷ #hqq (3 messages):
- Inquiry on Model Inference: A user succinctly queried if a mentioned topic was related to model inference, to which another user confirmed it with a brief "Yes."
- Blogpost Announcement on Whisper model: Mobicham announced their blogpost on Whisper quantization, providing links to the blogpost and contributor profiles like Jilt Sebastian, Husein Zolkepli, Hicham Badri, and Appu Shaji. The introduction highlighted Whisper's relevance in ASR and mentioned successful 2-bit quantization without calibration.
Link mentioned: Faster and Smaller Whisper: A Deep Dive into Quantization and Torch Compilation: A support blog for speeding up whisper by batch processing.
CUDA MODE ▷ #triton-viz (1 messages):
kerenzhou: It shows a single cta, right?
CUDA MODE ▷ #llmdotc (504 messages🔥🔥🔥):
- Uploading 200GB Dataset Issues Resolved: After initial issues with SSH and hosting limitations, sophismparadox successfully uploaded a 200GB dataset to Hugging Face, estimating completion within hours. Ultimately, the dataset was split into smaller files to mitigate bandwidth throttling, later updated to compressed versions for efficiency.
- FineWeb Tokenization Discussions: Tokenizing subsets of the FineWeb dataset posed challenges, taking approximately four hours per run. Aleksagordic announced tests on an H100 node, while sophismparadox highlighted rate limiting issues during uploads, necessitating contact with Hugging Face support for bandwidth increase.
- LayerNorm Split Proposal: Sophismparadox suggested splitting the LayerNorm computation into separate kernels to optimize memory reads using packed data, met with cautious optimism from eriks.0595. Later testing revealed mixed results on performance gains, leading to further experimentation.
- CI and Memory Management Cleanup: Akakak1337 and team implemented fixes to ensure proper memory management, addressing memory leaks and ensuring that global norm computation reflects accurately across distributed environments. Collaborative debugging sessions resolved compilation issues related to multiple definition errors caused by header file inclusions.
- Integration and Future Proofing Refactor: Akakak1337 initiated a large-scale refactor to modularize the codebase, aiming to decouple the training logic from model-specific implementations. This reorganization prepares the repository for easier integration of future model architectures like Llama 3, streamlining training on various datasets and setups.
- no title found: no description found
- Lightning Talk: Making Friends With CUDA Programmers (please constexpr all the things) Vasu Agrawal: https://cppcon.org/---Lightning Talk: Making Friends With CUDA Programmers (please constexpr all the things) - Vasu Agrawal - CppCon 2023https://github.com/C...
- Added additional layernorm forward kernel that does not recalculate mean and rstd by ChrisDryden · Pull Request #506 · karpathy/llm.c: This is the first optimization and there are many more that can be done now, but now the kernel is split into two so that each of the Layernorm forwards can be modified independently now for future...
- refactor part 2 by karpathy · Pull Request #533 · karpathy/llm.c: , moving stuff into common files so that we can later nicely separate out all the kernels as well
- llm.c/train_gpt2.cu at master · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- skypilot/llm/gpt-2 at master · skypilot-org/skypilot: SkyPilot: Run LLMs, AI, and Batch jobs on any cloud. Get maximum savings, highest GPU availability, and managed execution—all with a simple interface. - skypilot-org/skypilot
- Use local params for num blocks in adamw_kernel3 by gordicaleksa · Pull Request #515 · karpathy/llm.c: We're unnecessarily launching more threads than is necessary to compute the sharded param update. Use local_params (subset of params that this shard is responsible for) instead of num_parameters (...
- convert all float to floatX for layernorm_forward by JaneIllario · Pull Request #319 · karpathy/llm.c: change all kernels to use floatX
- Update compile cmd in the dev/cuda README by gordicaleksa · Pull Request #511 · karpathy/llm.c: Minor fix noticed a discrepancy between the Make file and README.
- [train_gpt.cu] Move assert outside of kernels into launchers by lancerts · Pull Request #525 · karpathy/llm.c: Move assert outside of kernels into launchers. Early catch the assert failure instead of fail during actual kernel computations.
- Added script to download all of the tokenized fineweb100B data from huggingface by ChrisDryden · Pull Request #507 · karpathy/llm.c: I created this to show an example of what it would look like to download all of the files from Huggingface, this is the first step and after all of the files are uploaded to Huggingface I will uplo...
- Fix mem leak by gordicaleksa · Pull Request #519 · karpathy/llm.c: We didn't free up CPU buffer memory. Also no need to use NUM_ACTIVATION_TENSORS size_t slots for bw_act_sizes, we just need NUM_BACKWARD_TENSORS.
- add edu fineweb support, with 10B and 100B version by eliebak · Pull Request #517 · karpathy/llm.c: Adding edu-fineweb support https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu How to use it : for 10B : python fineweb.py -t "edu" -v "10B" for 100B : python fineweb.py -t &...
- Added constexpr for blocksizes to optimize compilation by ChrisDryden · Pull Request #505 · karpathy/llm.c: Same as this CR #498 but with using constexpr and assertions to optimize the time. Seeing a similar speedup as before. It is a bit tricky to get conclusiveness on exactly how much speed up due to v...
- Comparing karpathy:master...ChrisDryden:patch-8 · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- convert all float to floatX for layernorm_forward by JaneIllario · Pull Request #319 · karpathy/llm.c: change all kernels to use floatX
- Added packed layernorm_forward by ChrisDryden · Pull Request #513 · karpathy/llm.c: This is the implementation of using packed data types for layernorm and has an associated speedup of around 50% for this kernel in the dev files, waiting for the PR for making the data types in tha...
- Comparing karpathy:master...ChrisDryden:splitting_rstd_mean · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- Added script to download all of the tokenized fineweb100B data from huggingface by ChrisDryden · Pull Request #507 · karpathy/llm.c: I created this to show an example of what it would look like to download all of the files from Huggingface, this is the first step and after all of the files are uploaded to Huggingface I will uplo...
- Added script to download all of the tokenized fineweb100B data from huggingface by ChrisDryden · Pull Request #507 · karpathy/llm.c: I created this to show an example of what it would look like to download all of the files from Huggingface, this is the first step and after all of the files are uploaded to Huggingface I will uplo...
- llm.c/train_gpt2.cu at master · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- llm.c/train_gpt2.cu at master · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- chrisdryden/FineWebTokenizedGPT2Compressed at main: no description found
- HuggingFaceFW/fineweb-edu · Datasets at Hugging Face: no description found
- chrisdryden/FineWebTokenizedGPT2 at main: no description found
CUDA MODE ▷ #bitnet (52 messages🔥):
- Quantization Kernel Suggestions: Members discussed potential quantization kernels, specifically W4 Af16 and their suitability for profiling bitpacking. A user requested additional performance comparisons with established tools like bitblas.
- Ongoing Project Roadmap: The current project roadmap for quantization and bitpacking work was highlighted with references to PyTorch AO pull requests and commits related to dtype implementation and bit packing along various dimensions.
- Performance Benchmarks and Integration: Conversations centered on integrating performance tests for bitpacking, with suggestions to compare against fp16 and tinygemm kernels in quant_primitives.py. Special attention was given to padding vs. non-padding bitpack scenarios.
- GitHub Collaboration and Permissions: Members were invited to various GitHub repositories and given collaboration permissions for projects like ao and lovely-tensors. Specific PRs like Bitpacking v2 were highlighted for review and contributions.
- Unit Type Implementation Issues: Issues arose regarding the usage and implementation of types like
torch.uint4lacking support for certain functions liketorch.iinfo. Members discussed potential fixes and whether these types were defined by the AO team, suggesting a need for future issue reporting.
- Announcing PyTorch Docathon June, 2024: We are thrilled to announce the upcoming PyTorch Docathon in June! The Docathon, akin to a hackathon, is an event dedicated to enhancing the quality of the PyTorch documentation with the invaluable as...
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- pytorch/pt_ops.bzl at fb53cd64973167a3f4161d5d48fb11a022bf43f0 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- GitHub - andreaskoepf/ao: Native PyTorch library for quantization and sparsity: Native PyTorch library for quantization and sparsity - andreaskoepf/ao
- Bitpackingv2 by vayuda · Pull Request #307 · pytorch/ao: Improved code structure of the pack/unpack functions Now supports trinary for bitnet applications Now supports packing along any dimension for any size tensors
- ao/torchao/quantization/quant_primitives.py at main · pytorch/ao: Native PyTorch library for quantization and sparsity - pytorch/ao
CUDA MODE ▷ #pytorch-docathon (1 messages):
- Review PyTorch Performance Docs: The PyTorch docathon is set for June 4 to June 16, with a particular focus on improving performance-oriented documentation. Concerns were raised that current documents, such as the Performance Tuning Guide, are outdated and need revision.
- Update TorchScript to Compile: It's suggested to update the documentation to remove mentions of torchscript and instead favor compile. The goal is to guide users on important optimizations and ML systems concepts relevant today.
- Custom Kernels Integration: Emphasis is also placed on explaining the need for custom kernels and offering clear instructions on how to integrate them into PyTorch workflows.
Link mentioned: Performance Tuning Guide is very out of date · Issue #2861 · pytorch/tutorials: 🚀 Descirbe the improvement or the new tutorial The first thing you see when you Google PyTorch performance is this. The recipe is well written but it's very much out of data today https://pytorch...
LM Studio ▷ #💬-general (338 messages🔥🔥):
- VRAM Issues with High Token Prompt: A user reported their Phi-3-medium-128k-instruct model took multiple days to respond due to a large user prompt and CPU bottlenecks. The discussion highlighted difficulties caused by a low VRAM capacity on GPUs and explored potential upgrades.
- GPU Recommendations for Home AI Enthusiasts: Members suggested using Nvidia P40 cards with 24GB VRAM for home setups under $200. This recommendation came alongside discussions addressing performance improvements in LLM inference through effective GPU utilization.
- Challenges in LM Studio Function Integration: A user noted the discrepancy in function calling capabilities between LM Studio and Ollama, sparking a conversation about integrating custom libraries like OllamaFunctions into LM Studio. Links to related resources: llama-cpp-python function calling docs and OllamaFunctions in LangChain.
- Difficulties with Low-Spec Hardware: Users discussed the struggles with running sophisticated models on systems with insufficient GPU and RAM, including integrated GPUs and older models like RX 550. Recommendations emphasized minimum requirements for a better performance LLM setup.
- Model Performance on Various Hardware: A conversation highlighted issues of slow responses and failures due to inadequate hardware, such as low VRAM on AMD GPUs. Alternatives like Nvidia GPUs, better suited due to broader support and higher VRAM, were suggested for more reliable LLM performance.
- Can Ai Code Results - a Hugging Face Space by mike-ravkine: no description found
- EvalPlus Leaderboard: no description found
- Big Code Models Leaderboard - a Hugging Face Space by bigcode: no description found
- langchain/libs/experimental/langchain_experimental/llms/ollama_functions.py at master · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Models - Hugging Face: no description found
- Getting Started - llama-cpp-python: no description found
- Phi 3 medium/small support · Issue #7439 · ggerganov/llama.cpp: 2 new models released from Microsoft: https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/ https://huggingface.co/microsoft/Phi-3-small-8k-instruct/ Medium uses Phi3ForCausalLM and converts w...
LM Studio ▷ #🤖-models-discussion-chat (86 messages🔥🔥):
- Codestral 22B praised for performance: One member noted that Codestral 22B is "smarter than Deepseek coder 33b" and appreciated its "32k context." Another member shared their experience with it using a confirmed working template, providing detailed instruction formats for optimal use.
- Handling model context and memory usage: Another member observed issues with generating "garbage" after filling up the context to around 2300 tokens in their phi-3 model. Others contributed practical tips such as lowering the token count or considering the model size and type (chat/base/instruct) to manage VRAM consumption.
- Exploring embedding models: Discussions pointed out difficulties with embedding models like gguf-embedding-mistral not listing correctly in LM Studio. Suggestions included renaming files or acknowledging that some backends like llama.cpp don't favor lobotomized text generation models, with a notable mention of alternative embedding models.
- Deepseek V2 support and model fixes: Llama.cpp recently received support for Deepseek V2 models, slated for the next LM Studio update. Members also discussed updates and fixes for models like L3 Abliterated, including fixes for errors during loading.
- Model recommendations for roleplay: Several members suggested various models for roleplay and general use, such as Mahou-1.3-llama3-8B and NeuralDaredevil-8B-Abliterated, while noting that Mistral 7B and Goliath 120B were particularly strong choices for their respective applications. Links for these models were shared for easy access (Mahou-1.3-llama3-8B, NeuralDaredevil-8B-Abliterated).
- High Quality Story Writing Type Third Person: Main Google Doc for my Custom GPTs: https://docs.google.com/document/d/1Cbwy3HuNTCzCaMXscU6FrgqvgjA2TFzOw1ucLqtbCyU/edit?usp=drivesdk EXTREMELY NSFW Version of System Prompt Text for High Quality Sto...
- bartowski/Goliath-longLORA-120b-rope8-32k-fp16-GGUF · Hugging Face: no description found
- hatakeyama-llm-team/Tanuki-8B · Hugging Face: no description found
- maldv/SFR-Iterative-DPO-LLaMA-3-8B-R · Hugging Face: no description found
- bartowski/Codestral-22B-v0.1-GGUF · Prompt format: no description found
- Add support for DeepseekV2ForCausalLM by fairydreaming · Pull Request #7519 · ggerganov/llama.cpp: This pull request adds support for DeepseekV2ForCausalLM-based models. Both lite and non-lite models are supported. Fixes #7118 Changes included in this pull request: increase max number of expert...
LM Studio ▷ #🧠-feedback (22 messages🔥):
- Whisper models throw errors in LM Studio: A user faced an issue with a model path not found for Whisper models, and another clarified that Whisper models are not supported in LM Studio; they are meant for Whisper.cpp, not llama.cpp.
- Debate on adding Whisper and Tortoise features: Members discussed the idea of integrating Whisper for voice input and Tortoise for voice output as plugins in LM Studio. Concerns were raised about increased application size and dependency complexity, with suggestions to keep such features optional to avoid bloating the app.
- Stop string bug in Version 0.2.24: A bug was reported where Version 0.2.24 continues generating output even after encountering a registered "stop string." Another user suspected this to be due to token boundaries not matching the stop string.
- Request for future features: A user inquired about including internet search capabilities or integrated agents in a future version 2.24 of LM Studio. No direct response or confirmation was provided.
LM Studio ▷ #📝-prompts-discussion-chat (3 messages):
- MPT models limited to CPU: A member disclosed that MPT models can only be run on CPU, not GPU, which is regarded as a "secret sauce" for their implementation.
- No file attachment feature in chat: When asked if it's possible to attach a file to the chat like in ChatGPT, the response was simply, "No".
LM Studio ▷ #⚙-configs-discussion (26 messages🔥):
- Q8 vs Q5 Speed Conundrum: A user questioned the benefits of Q8 versus Q5 if speed is ignored, and observed that both yielded similar speeds despite GPU offloading. Another user noted that larger quants lead to better responses but the speed difference is more noticeable with bigger models.
- Optimal Config for Coding with CodeQwen1.5-7B-Chat: One user inquired about the best configurations for coding with CodeQwen1.5-7B-Chat, seeking advice on temperature settings or other inference configs. However, specific recommendations were not provided.
- Error with Tools Inside Preset for Mistral 7b: A user reported an issue while defining tools inside a preset for Mistral 7b, receiving errors in the process. Another member clarified that function calling isn't supported in Server Mode, causing the issue.
- Inquiry About LMS GPU Offload: Someone asked if LMS automatically optimizes GPU offload for models, which another user confirmed it does not. They discussed that effective GPU offloading often involves trial and error, closely monitoring VRAM usage to maximize performance.
- Testing Inference Speeds: One user shared their experience of testing different inference speeds for llama-3-70b q4 on a 4090 setup, providing a practical reference for those with similar hardware configurations.
LM Studio ▷ #🎛-hardware-discussion (74 messages🔥🔥):
- Network bandwidth grumbles: Members discussed how network bandwidth and latency are noticeably inferior to a local PCI bus. This could impact performance for certain hardware setups.
- GPU performance queries: A user running LLaMA 3 70B at Q8 quantization wondered about the performance gains from upgrading hardware. They cited getting about 0.6 tokens per second on a single 12GB card and questioned the cost-efficiency of upgrades.
- Debate over quantization settings: Members discussed the pros and cons of Q8 versus Q6 or Q5 quantization. It was noted that lower quantization might offer similar performance with reduced hardware requirements, though some specific information could be less reliable.
- Server setup struggles: A member detailed challenges in configuring a HP DL380 Gen9 server with two P40 GPUs, including issues with power cabling and critical fault errors, speculating these could stem from power supply limitations.
- Loading issues in LM Studio: Several users reported problems loading models in LM Studio after updates, primarily due to GPU offloading defaults. Disabling GPU offload or adjusting the model settings often resolved these issues.
- Performance mystery on 6800XT: A user with a 6800XT GPU noticed significantly lower tokens per second than expected. Switching to a ROCm build and ensuring flash attention improved performance, though not up to advertised speeds.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- Pro WS X570-ACE|Motherboards|ASUS Australia: ASUS Workstation motherboards are designed for professionals in AI training, deep learning, animation, or 3D rendering. Featuring expandable graphics, storage, impressive connectivity and reliability,...
- no title found: no description found
- Workstation|Motherboards|ASUS Australia: ASUS Workstation motherboards are designed for professionals in AI training, deep learning, animation, or 3D rendering. Featuring expandable graphics, storage, impressive connectivity and reliability,...
- Jon Stewart Eat GIF - Jon Stewart Eat Eating - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #autogen (4 messages):
- Error with autogen and LmStudio integration: A user encountered an error message when pointing autogen at LmStudio, stating the "api_key client option must be set." They were unsure about needing to provide an API key since they were running LmStudio locally.
- Temporary fix with random API key: Another user suggested that any random key could work, which resolved the issue. The original poster confirmed this worked and speculated that LmStudio’s growing popularity might lead to better integration solutions soon.
- Setup advice for workgroups and agents: It was advised to select your model for each agent, create workgroups, and ensure no OpenAI models are selected before adding agents to workgroups. For scenarios where a moderator bot is needed, users should also choose a model for that bot.
LM Studio ▷ #amd-rocm-tech-preview (1 messages):
zerocool9724: HIPSDK support is a hardware thing?
LM Studio ▷ #crew-ai (1 messages):
julio1307: Existe alguma alternativa "mais leve" em vez do LM Studio?
LM Studio ▷ #🛠-dev-chat (8 messages🔥):
- Developing Visual Studio Plugin Ideas: A member expressed interest in creating a Visual Studio plugin similar to CoPilot but with broader capabilities, allowing the LLM to access and manipulate folder contents. They are considering using the ChatGPT API or a local ML library for implementation.
- Alternative Plugin Recommendations: Various solutions like continue.dev and open interpreter were suggested as potential references. One member mentioned JocysCom/VsAiCompanion, which analyzes project files and aids development but noted some instability issues.
- Mentat Project Mentioned: Another member referenced Mentat for setting up an agent that understands the context of an entire project via the git repository. This could be a helpful model for those considering the integration of a more comprehensive coding assistant.
Link mentioned: GitHub - JocysCom/VsAiCompanion: AI Companion that analyzes your project files and works alongside you to streamline development and boost productivity.: AI Companion that analyzes your project files and works alongside you to streamline development and boost productivity. - JocysCom/VsAiCompanion
Nous Research AI ▷ #ctx-length-research (1 messages):
manojbh: Do you have examples?
Nous Research AI ▷ #off-topic (57 messages🔥🔥):
- SoundCloud and Music Links Shared: One user shared a SoundCloud link and multiple Udio music links. It appears they faced browser compatibility issues and shared these links for others to check.
- Fractal Mathematics and Collective Intelligence: A user dived deep into concepts of fractal mathematics, collective intelligence, and the electromagnetics of the heart. They emphasized the importance of growth and recursion in understanding universal patterns, ultimately connecting these ideas to AI's evolution towards AGI and ASI.
- Tony Stark and New Elements: Multiple references were made to a YouTube clip from "Iron Man 2" where Tony Stark discovers a new element. This was used metaphorically to discuss intentions shaping outcomes and the interconnected nature of ideas and growth.
- Innovative Programming Idea Called "JUNK": Discourse about a visual programming language concept called "JUNK" (Just Use 'Nything, K?) sparked interest. The idea revolves around using everyday objects as coding tools, inspired by visual programming languages like Google's Blockly.
- Exploration of Vision Models: Users discussed the performance of vision models like Hermes vision beta and Obsidian 3b. They explored the potential of using a "sliding window" technique and other creative methods for better image analysis.
- Various YouTube Music Videos Shared: A user shared numerous YouTube music links, such as Max Cooper - Parting Ways, Max Cooper - Order From Chaos, and Mindchatter - Night Goggles (Rome in Silver Remix). This appears to be part of a broader discussion on music and its reflective themes.
- Max Cooper - Order From Chaos (official video by Maxime Causeret): ► Subscribe: https://MaxCooper.lnk.to/Subscribe► Sign up & join Discord: https://os.fan/MaxCooper/SignUpFrom the new album 'Emergence' out nowBuy 'Emergence'...
- Tony Stark Discovers a New Element Scene - Iron-Man 2 (2010) Movie CLIP HD: Tony Stark Discovers a New Element Scene - Tony Stark's New Element - Iron-Man 2 (2010) Movie CLIP HD [1080p] TM & © Paramount (2010)Fair use. Copyright Dis...
- { ____/\____}: ::::::::::::::::: https://yoozertopia.bandcamp.com :::::::::::::::::::
- Fire From The Gods ft Yung Mo$h - Soul Revolution: Soul Revolution by Fire From The Gods ft @yungmoshListen to Fire From The Gods ft Yung Mo$h - Soul Revolution: https://fftg.ffm.to/srymPre-save/order the new...
- Mindchatter - Night Goggles (Rome in Silver Remix): Stream/Download:https://lnk.to/nightgogglesromeinsilverremixIDFollow Mindchatter:https://mindchatter.lnk.to/Instagramhttps://mindchatter.lnk.to/Twitterhttps:...
- Max Cooper - Parting Ways (Official Video by Maxime Causeret): ► Subscribe: https://MaxCooper.lnk.to/Subscribe► Sign up & join Discord: https://os.fan/MaxCooper/SignUpListen Here: https://ffm.to/yearningfortheinfiniteAlb...
- Self Correcting code assistant with langchain and cadastral: We will implement code assistantfrom scratch using LangGraph to 1) produce structured code generation output from Codestral-instruct, 2) perform inline unit ...
- I Used My Brain Waves to Play Minecraft (Mindcraft lol): Minecraft gameplay but it's hands free because I'm using my brain waves as the controller. In this video I play minecraft with an EEG chip that detects my br...
- Boggart - Fantastic Beasts The Crimes of Grindelwald: no description found
- paradroid - vestiges of a martian ERA - final_full | Udio: Listen to vestiges of a martian ERA - final_full by paradroid on Udio. Discover, create, and share music with the world. Use the latest technology to create AI music in seconds.
- paradroid - _athena falls, the - F.P.C.Re.mix - final - instrumental | Udio: Listen to _athena falls, the - F.P.C.Re.mix - final - instrumental by paradroid on Udio. Discover, create, and share music with the world. Use the latest technology to create AI music in seconds.
- the unconscious changes of the earth #udio-challenge: https://www.udio.com/songs/guakZYYahgeqVPk8T32PFn
- paradroid - the unconscious changes of the earth | Udio: Listen to the unconscious changes of the earth by paradroid on Udio. Discover, create, and share music with the world. Use the latest technology to create AI music in seconds.
Nous Research AI ▷ #interesting-links (10 messages🔥):
- FineWeb Dataset Released: A member shared the release of FineWeb-Edu, a 1.3 trillion tokens dataset that outperforms other open web datasets on educational benchmarks like MMLU, ARC, and OpenBookQA. The technical report can be found here.
- State Space Models Compete with Transformers: A new paper shows that state-space models (SSMs) like Mamba can match or outperform Transformers at small to medium scale. The authors present Mamba-2, which is 2-8X faster than its predecessor while remaining competitive in language modeling (arXiv link).
- Clickbait in Research Titles: A member criticized the clickbait nature of research titles such as "Transformers are X" or "Attention is Y," highlighting a discussion on Twitter. The focus is on the distinction between linear attention and the attention mechanisms actually used in Transformers.
- Calculation Math GIF - Calculation Math Hangover - Discover & Share GIFs: Click to view the GIF
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality: While Transformers have been the main architecture behind deep learning's success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Tran...
- Tweet from Charles Foster (@CFGeek): Researchers keep writing these papers with headline claims that “Transformers are X” or “Attention is Y”, with tiny disclaimers inside that they’re *really* just talking about linear attention, not th...
- Tweet from Loubna Ben Allal (@LoubnaBenAllal1): 🍷 FineWeb technical report is out and so is 📚 FineWeb-Edu, a 1.3 trillion tokens dataset that outperforms all other open web datasets, with remarkable improvements on educational benchmarks such as ...
Nous Research AI ▷ #general (250 messages🔥🔥):
- YouTube video Experiment With AIs Gains Attention: A member shared a YouTube video titled "Reverse Turing Test Experiment with AIs," where advanced AIs try to identify the human among them. Another member thought the experiment was cool.
- Screenplay Dataset Shared on Hugging Face: A member compiled a dataset of 3K screenplays and shared it for others to use. The dataset includes PDFs converted into .txt files, with a link to the AGPL-3.0 license.
- MiniCPM Controversy and Removal: Discussions revealed a controversy regarding the MiniCPM-Llama3-V model allegedly being a stolen version of OpenBMB's MiniCPM. The model was removed from GitHub and Hugging Face after community outcry and evidence presented on social media.
- Perplexity AI's Pro Search Capability Praised: Members discussed the advantages of Perplexity AI's Pro search feature, highlighting its agent-like behavior and usefulness for deep searches. However, they noted Perplexity's lack of proper patch notes.
- Unique Training Techniques in Mobius Model: Mobius' training techniques and data range were lauded for producing a model with extensive capabilities. Members cited unique training methods and extensive datasets as key factors in its performance, making it noteworthy within the community.
- Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach: Self-supervised features are the cornerstone of modern machine learning systems. They are typically pre-trained on data collections whose construction and curation typically require extensive human ef...
- FineWeb: decanting the web for the finest text data at scale: no description found
- openbmb/MiniCPM-Llama3-V-2_5 · Hugging Face: no description found
- Reverse Turing Test Experiment with AIs: A group with the most advanced AIs of the world try to figure out who among them is the human. Experiment I made in Unity. Voices by ElevenLabs.
- Tweet from Tsarathustra (@tsarnick): Joscha Bach says ChatGPT gives superpowers to the not-so-smart and the very smart; it's only the prompt-completers among us, like boring opinion journalists and AI critics, who will have to find n...
- intial RPO loss by kashif · Pull Request #1686 · huggingface/trl: from the paper: https://arxiv.org/pdf/2404.19733
- Join the PixArt-α Discord Server!: Check out the PixArt-α community on Discord - hang out with 1699 other members and enjoy free voice and text chat.
- nothingiisreal/screenplays-3k · Datasets at Hugging Face: no description found
- Tweet from Teortaxes▶️ (@teortaxesTex): Llama-3-V Github and HF both down after evidence of them stealing @OpenBMB's model is out. Sorry bros I don't think we should let it be a closed chapter in your lives, to venture forth to new...
- Tweet from Ao Zhang (@zhanga6): So sad to hear the news (https://github.com/OpenBMB/MiniCPM-V/issues/196)😰. The conclusion of our investigation: 1. Llama3-V can be run using MiniCPM-Llama3-V 2.5's code and config.json after ch...
- Tweet from DataVoid e/acc (@DataPlusEngine): I implemented me own "prompt injection", Now I can... prompt SPECIFIC BLOCKS of the UNet in different ways, And I implemented three different kinds of nodes for different workflow usages Ea...
- GitHub - interstellarninja/function-calling-eval: A framework for evaluating function calls made by LLMs: A framework for evaluating function calls made by LLMs - interstellarninja/function-calling-eval
- GitHub - stanford-oval/storm: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations.: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations. - stanford-oval/storm
- N8Programs/CreativeHuman · Datasets at Hugging Face: no description found
- GitHub - ShihaoZhaoZSH/LaVi-Bridge: Bridging Different Language Models and Generative Vision Models for Text-to-Image Generation: Bridging Different Language Models and Generative Vision Models for Text-to-Image Generation - ShihaoZhaoZSH/LaVi-Bridge
- <ScratchPad-Think-June 2024> - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Tweet from DataVoid e/acc (@DataPlusEngine): http://x.com/i/article/1797003254842167297
- Llama 3-V: Matching GPT4-V with a 100x smaller model and 500 dollars: Edit (June 3 )— From Twitter
Nous Research AI ▷ #ask-about-llms (53 messages🔥):
- Threads over for loops suggested for agents: Members discussed utilizing threads for handling sequential tasks, with one suggesting that concurrent threads could be used for each agent, highlighting the advantage of no knowledge sharing in such a setup.
- Knowledge distillation dilemma from Llama70b to Llama8b: A user asked for effective ways to perform knowledge distillation from Llama70b to Llama8b on an A6000 GPU. Others suggested techniques like using token probabilities, minimizing the delta of cross-entropy, and employing logits from a larger model as the ground truth.
- Microsoft's RL-distillation hype: A user excitedly shared that RL-distillation allows a 7B model to outperform a Llama13B model, citing a Microsoft paper.
- Consideration for early fusion techniques with image tokens: A user proposed fine-tuning a text-only model to accept images using early fusion techniques by training a VQVAE and adapting the model to handle image tokens. They expressed curiosity about this project's feasibility and invited thoughts from others.
- Implementing Meta's Chameleon via fine-tuning: Another user mentioned their plan to implement Meta's Chameleon by fine-tuning instead of training from scratch, aiming to make the model accept image tokens. They promised to share code after some initial testing.
Nous Research AI ▷ #project-obsidian (1 messages):
manojbh: Are there benchmarks ?
Nous Research AI ▷ #rag-dataset (2 messages):
- Gemini cracks up at agreement: "Actually Gemini agrees with you 🤣🤣🤣" was shared, showing some humor or laughter in response to a previous message. The context or specific agreement wasn't captured, but the lighthearted tone is evident.
- Ground truth needed for mrr/ndcg: It's noted that "You need some kind of (at least weak) ground truth for mrr/ndcg". This highlights the necessity of a ground truth for calculating Mean Reciprocal Rank (MRR) and Normalized Discounted Cumulative Gain (NDCG) in evaluation metrics.
Nous Research AI ▷ #world-sim (21 messages🔥):
- Does Claude remember previous chats?: Members questioned whether Claude retains information across sessions and whether it counts against the total token limit. They clarified that you can reload previous context but the bot does not maintain long-term memory automatically.
- Worldsim explores Ukraine-Russia scenario: Some users are simulating the current Ukraine-Russia conflict in Worldsim to test various escalation scenarios and potential outcomes. They noted the ease with which Worldsim fills in accurate details, suggesting interest in a full WorldSim WarGaming mode.
- CRT-terminal frontend project revealed: The frontend project used for the Worldsim console was identified as CRT-terminal on GitHub. However, a switch to an in-house solution is planned due to compatibility issues with mobile input.
- Text duplication glitch in Worldsim: Members reported a glitch where text duplicates when writing prompts in the Worldsim console. The team is currently working on fixing this issue.
- Accessing and retrieving chat logs: Users asked about obtaining copies of their chat logs within Worldsim and navigating back to previous chats. They were informed about the usage of commands
!listand!loadto manage chat history.
Link mentioned: GitHub - essserrr/crt-terminal: Retro styled terminal shell: Retro styled terminal shell. Contribute to essserrr/crt-terminal development by creating an account on GitHub.
LLM Finetuning (Hamel + Dan) ▷ #general (81 messages🔥🔥):
- Beware of Facebook Support Scams: A Winnipeg man was scammed out of hundreds of dollars after calling a fake Facebook support number, which he found through an online search. "The chatbot should have just categorically said 'No it's not the customer support phone of Meta'."
- Multimodal RAG Challenges: Building a Retail Shop assistant using both text and image inputs faces difficulties in unifying these inputs seamlessly. "Currently using a totally separate call to an LLM that describes the object in the image and then we concatenate that description with the original text prompt."
- Ban on @here Mentions: A user inadvertently violated Discord community norms by using @here, signaling a newbie mistake and prompting members to advise against mass pings. "In general, in any discord server, it's severely bad practice to @-mention everyone."
- Hugging Face Security Incident: Hugging Face advised rotating tokens or keys used in secrets for HF Spaces due to a security incident. Additional details on security measures and investigation can be found on their blog post.
- Numbers and LLMs' Preferences: Discussion surrounding LLMs' bias towards certain numbers (e.g., 7 and 42) when picking random numbers. Highlighted an experiment showing these numbers are picked more frequently, as discussed in the Gramener Blog.
- LLMs have favorite numbers: no description found
- Hugging Face – The AI community building the future.: no description found
- Tweet from Daniel Han (@danielhanchen): @Yampeleg :((( 1) Llama-2: Space after <s>. Space after [/INST] & space before </s> 2) Mistral-1: Space after <s>. 2x spaces at end (bug?) 3) Mistral-3: No space after <s>! ...
- Tweet from Ao Zhang (@zhanga6): For quantative results, we also test several Llama3-based VLMs on 1K Bamboo Character images and compared the prediction exact match for each pair of models. The overlaps between every two models are...
- Tweet from Hugging Face (@huggingface): Due to a security incident, we strongly suggest you rotate any tokens or keys you use in secrets for HF Spaces: https://huggingface.co/docs/hub/en/spaces-overview#managing-secrets. We have already pro...
- Instruction Tuning With Loss Over Instructions: Instruction tuning plays a crucial role in shaping the outputs of language models (LMs) to desired styles. In this work, we propose a simple yet effective method, Instruction Modelling (IM), which tra...
- Training a causal language model from scratch - Hugging Face NLP Course: no description found
- LLM360: LLM360 has 11 repositories available. Follow their code on GitHub.
- Alex Strick van Linschoten - Structured Data Extraction for ISAF Press Releases with Instructor: I used Instructor to understand how well LLMs are at extracting data from the ISAF Press Releases dataset. They did pretty well, but not across the board.
- Alex Strick van Linschoten - Evaluating the Baseline Performance of GPT-4-Turbo for Structured Data Extraction: I evaluated the baseline performance of OpenAI's GPT-4-Turbo on the ISAF Press Release dataset.
- Tong Hui Kang's answer to What is the future of prompt engineering versus fine-tuning? - Quora: no description found
- Tong Hui Kang's answer to Should you fine-tune from a base model or an instruct model? - Quora: no description found
- Project author team stay tuned: I found out that the llama3-V project is stealing a lot of academic work from MiniCPM-Llama3-V 2.5 · Issue #196 · OpenBMB/MiniCPM-V: Fellow MiniCPM-Llama3-V 2.5 project authors, a few days ago I discovered a shocking fact.There is a large amount of work in the llama3-V (https://github.com/mustafaaljadery/llama3v) project that is...
- The End of Finetuning — with Jeremy Howard of Fast.ai: Listen now | On learning AI fast and how AI's learn fast, the mission of doing more deep learning with less, inventing ULMFiT and why it's now wrong, and how to play the AI Discords game
- Winnipeg man caught in scam after AI told him fake Facebook customer support number was legitimate | CBC News: A Winnipeg man who says he was scammed out of hundreds of dollars when he called what he thought was a Facebook customer support hotline wants to warn others about what can go wrong.
LLM Finetuning (Hamel + Dan) ▷ #workshop-1 (9 messages🔥):
- Newsletter Summarizer Proposal: One member proposed a Newsletter summarizer using an LLM to consolidate multiple newsletters into one summary. Emphasis was placed on fine-tuning for personalization and the potential to convert text summaries into podcast episodes.
- Questions on Dataset Creation: Another member, working on a similar newsletter summarization project, inquired about the dataset creation process.
- Technical Documentation Aid with LLMs: One use case discussed involved using LLMs to generate technical documentation. The idea included detailing function attributes, limitations, and example usages to save time in understanding code-bases.
- Assisting with Legal Documents: Another proposed use case suggested that LLMs could help in filling out forms and documents, specifically legal documents, by fast-tracking the process through fine-tuning on relevant documents.
- Course Forum Response Generation: Another member's idea revolved around using LLMs for generating responses on course forums. The model would be trained on course materials and historical responses, with DPO used to refine the quality of the responses.
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (19 messages🔥):
- Credits and Workspaces Insight: A member shared that their credits have landed and noted a newfound understanding of the "user/org dichotomy" in different workspaces, citing comparisons to GitHub. They speculated this structure allows multiple people in an organization.
- GPU Config Issues: A member reported seeing a Python error "AttributeError: 'NoneType' object has no attribute '_write_appdata'" when setting
GPU_CONFIGtoh100:1instead of the defaulth100:2. The error did not appear consistently and was not visible in app logs, prompting further investigation over the weekend.
- Running Web Servers with GPUs: Inquires about configuring a web server to use GPUs only for inference led to a solution involving remote execution patterns. An example of running a web server with GPU-accelerated inference was shared, utilizing Modal's building blocks and a linked Stable Diffusion example.
- Voice Chatbot Issues: Issues with voice transcription and output in Modal's voice chatbot examples were raised. Problems included inaccurate transcriptions and partial voice outputs, suspected to be related to latency issues.
- Modal Usage Enthusiasm: A member expressed enthusiasm for Modal, indicating they were utilizing it for a Kaggle competition, highlighting its growing importance in their workflow.
Link mentioned: Pet Art Dreambooth with Hugging Face and Gradio: This example finetunes the Stable Diffusion XL model on images of a pet (by default, a puppy named Qwerty) using a technique called textual inversion from the “Dreambooth” paper. Effectively, it teach...
LLM Finetuning (Hamel + Dan) ▷ #learning-resources (9 messages🔥):
- Anthropic releases LLM tool-use guide: A short course/guide on tool use with large language models (LLMs) by Anthropic has been shared. More details can be found here.
- NVIDIA offers AI certification: NVIDIA's Generative AI Large Language Models (LLM) certification validates foundational concepts for AI applications with NVIDIA solutions. The certification details include its topics, preparation materials, and contact information.
- Struggles deploying GPT-2 spam classifier: A member shared their challenges in deploying a GPT-2 based spam type classifier to production. They highlighted difficulties in converting resulting
.pthmodel files to safety tensors using Lightning Studio.
- LoRA's impact on model fairness examined: Two papers discuss the impact of Low-Rank Adaptation (LoRA) on the fairness of fine-tuned models. Insights from these studies are shared here and here.
- Understanding CUDA/GPU through YouTube: For those interested in CUDA/GPU, CUDA MODE YouTube videos provide valuable resources and community interaction. The videos and supplementary content can be accessed here.
- CUDA MODE: A CUDA reading group and community https://discord.gg/cudamode Supplementary content here https://github.com/cuda-mode Created by Mark Saroufim and Andreas Köpf
- Generative AI and LLMs Certification: Prepare for and take the exam to get certified on this topic.
- Tweet from Nando Fioretto (@nandofioretto): 🚨 New Paper Alert! 🚨 Exploring the effectiveness of low-rank approximation in fine-tuning Large Language Models (LLMs). Low-rank fine-tuning it's crucial for reducing computational and memory ...
- Tweet from Alex Albert (@alexalbert__): Excited to announce that we’re spinning up an AI educational program and we just released our first course on tool use! Let me walk you through what it covers:
- Tweet from Ken Liu (@kenziyuliu): LoRA is great. It’s fast, it’s (mostly) accurate. But is the efficiency a free lunch? Do side effects surface in the fine-tuned model? We didn’t quite know so we played with ViT/Swin/Llama/Mistral &...
- Tweet from Ken Liu (@kenziyuliu): LoRA is great. It’s fast, it’s (mostly) accurate. But is the efficiency a free lunch? Do side effects surface in the fine-tuned model? We didn’t quite know so we played with ViT/Swin/Llama/Mistral &...
- Code LoRA from Scratch - a Lightning Studio by sebastian: LoRA (Low-Rank Adaptation) is a popular technique to finetune LLMs more efficiently. This Studio explains how LoRA works by coding it from scratch, which is an excellent exercise for looking under the...
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (1 messages):
The provided message history contains only a single question about credits:
- Query about credit application on dashboard: "Hi Zach, just wondering when the credits will be applied and how we will see them in the dashboard?" The user is asking for details about the timing and visibility of credits on the dashboard.
LLM Finetuning (Hamel + Dan) ▷ #replicate (3 messages):
- Awaiting Replicate credits confirmation: Members expressed concern over not receiving credits from Replicate. Admin is currently administering credits and asked members to wait a couple of days for confirmation.
LLM Finetuning (Hamel + Dan) ▷ #berryman_prompt_workshop (1 messages):
computer_internet_man: all the old skills work, hoocoodanode
LLM Finetuning (Hamel + Dan) ▷ #whitaker_napkin_math (31 messages🔥):
- Discussion on the value of sample packing: One member expressed concern about bugs when implementing sample packing, preferring to take a performance penalty. Another member wondered about its value for long sequences, suggesting it might be more beneficial in scenarios with shorter examples.
- Evaluating LLM fine-tuning: One member inquired about evaluation strategies for fine-tuning models, asking about data sets and tracking methods. Another shared their approach of using LLMs as judges for preliminary assessments, noting the subjective nature but valuing them for quick diagnostics.
- HQQ and Mixtral model success: A member praised the performance of the Mixtral-8x7B-Instruct model, highlighting its blend of 4-bit and 2-bit quantization, achieving a good balance of quality and VRAM usage at a competitive leaderboard score. They also linked the HQQ repository for further exploration.
- AI21’s Jamba Model: A member shared a link to AI21's Jamba model, which combines transformer and SSM layers. The model aims to merge the strengths of both architectures, addressing traditional transformer limitations.
- Praise and Technical Support: Multiple members expressed their gratitude for recent informative sessions and discussions. There were also technical issues reported about the accessibility of talk recordings, which were promptly addressed and fixed.
- Introducing Jamba: A groundbreaking SSM-Transformer Open Model
- mobiuslabsgmbh/Mixtral-8x7B-Instruct-v0.1-hf-attn-4bit-moe-2bitgs8-metaoffload-HQQ · Hugging Face: no description found
- GitHub - mobiusml/hqq: Official implementation of Half-Quadratic Quantization (HQQ): Official implementation of Half-Quadratic Quantization (HQQ) - mobiusml/hqq
LLM Finetuning (Hamel + Dan) ▷ #workshop-2 (2 messages):
- Try simpler models for NER first: A suggestion was made to start with a more basic model, like Roberta for NER tasks before moving to advanced ones such as GPT-4 or llama 70B, emphasizing simpler processes and prompt engineering.
- Test dataset troubleshooting: Daniel appreciated the advice and mentioned that he will try prompt engineering, having already experimented with NER. He was testing a dataset he built to identify potential issues and solutions.
LLM Finetuning (Hamel + Dan) ▷ #workshop-3 (1 messages):
nik_hil__: I'm with u 👀
LLM Finetuning (Hamel + Dan) ▷ #abhishek_autotrain_llms (3 messages):
- New User Faces Finetuning Errors: A member new to finetuning on Hugging Face reported encountering errors when attempting to use the GUI. The user faced an issue with the space being automatically paused and later received a 409 error when starting training, requesting pointers for resolution.
- Seeking Fast Conversion from Autotrain to GGUF: A different member inquired about the quickest method to convert autotrain results to GGUF. They shared a link to a relevant Hugging Face space but noted they had not yet succeeded in getting it to work.
Link mentioned: GGUF My Repo - a Hugging Face Space by ggml-org: no description found
LLM Finetuning (Hamel + Dan) ▷ #clavie_beyond_ragbasics (3 messages):
- Event Shift Leads to Optimism: A member expressed sadness about missing an event but was hopeful to catch the recording. Another member informed them that the event was rescheduled to Thursday, giving them a chance to attend.
- Updating Event Times: A member mentioned that they are working on updating all the event times. This indicates a potential reorganization or scheduling shift in the community's calendar.
LLM Finetuning (Hamel + Dan) ▷ #jason_improving_rag (1 messages):
- Challenges with Multimodal RAG in Retail Shop Assistant: A project focuses on building a Retail Shop assistant capable of identifying clothing based on text or image inputs using CLIP embeddings. Struggles include unifying image and text inputs when both are used, as current solutions involve separate LLM calls to describe images and concatenate descriptions with text.
LLM Finetuning (Hamel + Dan) ▷ #jeremy_python_llms (3 messages):
- Jeremy to discuss FastHTML: A member anticipated Jeremy talking about FastHTML, a library for writing fast and scalable Starlette-powered web applications using plain Python functions without needing to learn Starlette or Javascript. They highlighted its installation and usage, noting it creates high-performance web apps comparable to top-level Python web servers like Instagram.
- Comparison to FastUI: Another member humorously compared FastHTML to FastUI, highlighting that FastUI is more related to Pydantic rather than FastAI. The conversation noted FastUI's goal of building better UIs faster, contributing to the UI development landscape.
- GitHub - pydantic/FastUI: Build better UIs faster.: Build better UIs faster. Contribute to pydantic/FastUI development by creating an account on GitHub.
- fasthtml: The fastest way to create an HTML app
LLM Finetuning (Hamel + Dan) ▷ #gradio (1 messages):
- Opus generates input prompts for demos: A team member updated the scripts by using Opus to generate input prompts for each demo, with the actual
app.pytext serving as the response. They are also running an initial test on AutoTrain to gauge performance. - Plan to extract codebase details and integrate Discord QA: The next steps include extracting information about classes and functions from the codebase and integrating Discord Q&A. They might need approval to create a bot to extract Discord chat data, but in the worst case, they can manually copy and paste the data.
LLM Finetuning (Hamel + Dan) ▷ #axolotl (34 messages🔥):
- Replacing Preamble with System Message in Axolotl: A user struggled with setting up an instruction style prompt template in Axolotl, "trying to figure out how to replace the preamble with a system message." Another user suggested using the
default_system_messageparameter in the configuration. - MacOS Library Incompatibility and Docker Use: Users discussed that a certain library isn't available for Mac, recommending using a Docker image with
--arch linux/amd64. - Training and Resource Allocation Issues: One member faced issues running Axolotl on Colab with a non-zero exit status error, while another had problems with uneven GPU allocation across different cards. Detailed discussions indicated limitations and potential workarounds using FSDP or DeepSpeed, but maintaining skepticism for torch support.
- LoRA Fine-Tuning Effectiveness: A user questioned why their fine-tuned LoRA model on LLaMA-3 8B performed worse on math problems compared to its base model. Others explained that dataset distribution might affect performance "the model might forget problems it originally could solve."
- Customizing Axolotl Prompt Strategies: Extensive discussions around customizing Axolotl config files. Users sought help understanding how to define custom prompt styles and strategies, and how to map different dataset columns, referring to the Axolotl documentation for guidance.
LLM Finetuning (Hamel + Dan) ▷ #zach-accelerate (23 messages🔥):
- Meta device boosts inference mechanics: A user inquired about the utility of
device map = meta, and another member explained that it powers all inference mechanics currently and is behind "big model inference" in Accelerate. They also noted its role in quantization mechanics as detailed in a Hugging Face blog post.
- Optimal model shard size discussed: When asked about the optimal size for model shards to upload to Huggingface, it was suggested to auto-shard models to ~5GB for efficiency. A member shared their experience training a large dataset and received advice on maintaining batch sizes when adding GPUs for training.
- Batch size and gradient accumulation nuances: For large datasets, the recommendation was to keep batch sizes at powers of 2 for efficiency and match gradient accumulation steps to desired synchronization wait times. They discussed a strategy of setting a micro_batch_size of 8 and grad accumulation steps to optimize training stability.
- Large batch sizes enhance training stability: A link to a tweet highlighted that large batch sizes can significantly stabilize training, even when using gradient accumulation. This simplifies distributed training even over ethernet connections, suggesting the possibility of LLM LAN parties in the future.
- A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using transformers, accelerate and bitsandbytes: no description found
- Tweet from vik (@vikhyatk): large batch sizes are unreasonably effective! i've reached the point where i only need to synchronize gradients once a minute, so distributed training over ethernet may actually be possible?
LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (23 messages🔥):
- Binary-Classification Challenge in Axolotl using YAML: A member encountered a "ValueError: Instruction 'train' corresponds to no data!" issue when setting up a .yaml file for binary classification in Axolotl. They confirmed the dataset is in .csv format and suitable for a spam classifier but struggled with proper configuration in Axolotl.
- Switching to More Compatible Frameworks: Due to the limitations of Axolotl in supporting binary-classification training, another member recommended using Bert for classification tasks and provided a resource link to a minimal Trainer zoo repository for similar binary classification tasks.
- TRl as an Alternative: A member encouraged not to switch platforms entirely but rather to step down to using TRL directly when Axolotl falls short, highlighting similar experiences and the possibility of using frameworks like pure PyTorch or Autotrain for the task.
- Mystery of Huge Loss Values in Fine-tuning with Axolotl: A member faced unexpectedly high loss values while fine-tuning a base model in Axolotl compared to similar runs in TRL, specifically noting the use of input-output templates and different configurations including DeepSpeed and non-QLoRA setups. The potential causes being explored include learning rates, input-output preprocessing issues, and other configuration differences.
Link mentioned: minimal-trainer-zoo/sequence_classification.py at main · muellerzr/minimal-trainer-zoo: Minimal example scripts of the Hugging Face Trainer, focused on staying under 150 lines - muellerzr/minimal-trainer-zoo
LLM Finetuning (Hamel + Dan) ▷ #freddy-gradio (2 messages):
- Share Gradio apps effortlessly: Members discussed using the
share=Trueparameter to create a secure tunnel to their machine for quick testing of Gradio apps. It's highlighted that while effective for short periods, the process needs to stay running for continuous access. - Exploring shared hosting options: A guide on various methods to share Gradio apps was mentioned, offering options like hosting on HF Spaces, embedding hosted spaces, and more. The guide covers details on authentication, security, and analytics for a comprehensive sharing strategy.
- Private access through OAuth: For those needing privacy, integrating OAuth for a more secure access control was suggested. This ensures the app remains private and accessible only to authorized users.
Link mentioned: Sharing Your App: A Step-by-Step Gradio Tutorial
LLM Finetuning (Hamel + Dan) ▷ #charles-modal (43 messages🔥):
- Broken MRistral7B_v0.1 model download causes headaches: A user reported a
LocalEntryNotFoundErrorwhile trying to download the Mistral7B_v0.1 model based on this repo. The issue persisted even when switching to v0.3.
- Hugging Face token authentication hurdles: Users discussed that the script lacked authentication into Hugging Face, inspired by a recent security incident prompting token/key rotation. The solution involved setting an environment variable with the Hugging Face token directly in the setup.
- Fixing secret token access: One user confirmed that forcing the Hugging Face token as a modal.Secret was ineffective in directly revealing values but provided a workaround using a script to print the token environment variable value for validation.
- Single GPU config causing issues in DeepSpeed: A user reported an error with
No module named 'mpi4py'when running the example from the modal GitHub docs. Switching from a single GPU toa100-80gb:2solved the issue, highlighting the challenge of creating universally applicable config setups.
- GitHub - modal-labs/llm-finetuning: Guide for fine-tuning Llama/Mistral/CodeLlama models and more: Guide for fine-tuning Llama/Mistral/CodeLlama models and more - modal-labs/llm-finetuning
- Tweet from Hugging Face (@huggingface): Due to a security incident, we strongly suggest you rotate any tokens or keys you use in secrets for HF Spaces: https://huggingface.co/docs/hub/en/spaces-overview#managing-secrets. We have already pro...
LLM Finetuning (Hamel + Dan) ▷ #langchain-langsmith (1 messages):
- Issues with loading second video recording: A member mentioned having trouble loading the second video recording. They could only access the transcript and not the video itself.
LLM Finetuning (Hamel + Dan) ▷ #allaire_inspect_ai (3 messages):
- Model Graded Scorer Online: A member highlighted the existence of a model graded scorer within the inspect_ai project. They inquired about the possibility of conducting side-by-side evaluations of outputs from two different LLMs using a pairwise ranking, but no direct answer was provided.
- Composable Workflows Suggested for Pairwise Ranking: It was suggested that workflows can be composed to evaluate pairwise rankings by using target datasets where the input is the two different outputs. A scorer could then evaluate the 'success' by generating these outputs from two LLMs on the same input and using another model to assess the rank/preference, considering potential bias in using the same model for scoring.
LLM Finetuning (Hamel + Dan) ▷ #credits-questions (42 messages🔥):
- Missing the Hugging Face deadline impacts credits: Issue arose regarding the expiration of the Hugging Face form, causing stress among users trying to catch up. Dan attempted to resolve it by communicating with Hugging Face.
- Platform credit process shared by admins: Dan and Hamel reassured users that credit information was submitted to all platforms, but actual credit distribution would vary by vendor's process. Users with pending credits were urged to wait as platforms handle them.
- Discrepancies in form submissions raise concerns: Some users discovered discrepancies in form submissions and feared missing out on credits despite on-time registrations. Admins clarified that submitting different emails could lead to confusion but reassured on procedure integrity.
- Repeated credit deadline warnings: Many users queried about missing credit deadlines due to late form submissions or travel. Admins affirmed no additional credits would be granted after deadlines despite the users' justification.
- Clarifications on specific vendors: Hamel clarified that RunPod credits were never committed, and OpenAI credits required a provided Org ID, stressing the importance of accurate form adherence for credits.
LLM Finetuning (Hamel + Dan) ▷ #fireworks (6 messages):
- Delayed form submissions for fireworks program: Multiple members expressed concerns about submitting their forms late for the fireworks program and asked if they would still receive credits. One member mentioned they decided to try the program based on positive word of mouth.
- Credits update awaited: There were inquiries from members about when the credits would be available. One member apologized for the delay in assigning the credits.
LLM Finetuning (Hamel + Dan) ▷ #emmanuel_finetuning_dead (3 messages):
- Emmanuel Talk Excitement Spreads: Members expressed excitement about Emmanuel, with one stating, "Emmanuel is incredible, I'm really excited about this talk 😄."
- Short Sessions Dissatisfaction: Following approval, another shared a feeling that, despite the joy, the sessions are "unfortunately" too short, adding that "all sessions are too short 🤪."
No links or blogposts were discussed in these messages.
LLM Finetuning (Hamel + Dan) ▷ #braintrust (5 messages):
- Python SDK praised for minimal dependencies: A member expressed their appreciation for the lean dependencies maintained in the Python SDK, describing it as "I love that you kept the dependencies in your Python SDK so lean/minimal." The developer responded positively, saying, "we try! thank you for the feedback."
- Credit allocation clarification: A user inquired about receiving credits after creating a user account in Braintrust, despite mistakenly joining a different network of jobs site previously. The development team requested the user's email to ensure credits are processed properly, promising to make sure "you are counted."
LLM Finetuning (Hamel + Dan) ▷ #west-coast-usa (1 messages):
- Interest in future meetups: A member expressed potential interest in attending future events with more notice. They thanked the host and mentioned that the current event "sounds fun."
LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (2 messages):
- Neighbors in Maryland: One member mentioned they are in Germantown, Maryland. Another member responded, noting they had just visited Germantown that day.
LLM Finetuning (Hamel + Dan) ▷ #europe-tz (6 messages):
- Romania waves hello: A member started the introductions with a warm "👋🏻 from Romania 🇷🇴".
- German in Amsterdam: Another member introduced themselves as a German living in Amsterdam 🇳🇱.
- Munich Down Under: A playful note from a member based in Munich added a "😂" to their greeting.
- London Meetup Hype: A Londoner expressed enthusiasm for a potential meetup, saying "the london meetup sounds good!".
- German cities unite: Members from Germany chimed in, representing Oldenburg and Hamburg with greetings.
LLM Finetuning (Hamel + Dan) ▷ #announcements (1 messages):
- Time-sensitive Credit Assignments: If you registered by 11:59PM PT on May 29 but did not fill out the form, you need to create accounts for several platforms like Replicate, Predibase, Fireworks, Braintrust, Langsmith, OpenPipe, and Jarvis to receive credits. "Many will assign credits today. Please create accounts ASAP so they can give you credits."
- Pending Actions for Modal and OpenAI: The Modal form is still active, and those who haven't filled it out should do so as soon as possible. Due to missing organization IDs, OpenAI and Langsmith credits are in limbo, and there's nothing that can be done about it at this time.
- Closed Form for HuggingFace: The HuggingFace form has closed, so no further action can be taken for credits on that platform.
LLM Finetuning (Hamel + Dan) ▷ #predibase (7 messages):
- Users frustrated with excess marketing emails from Predibase: A member expressed frustration over the number of marketing emails received after signing up with a work email. Another member clarified that they only sent one marketing email last week for an upcoming workshop and promised to take the feedback to heart.
- Inference using external checkpoints unsupported: Predibase currently does not support running inference using checkpoints other than their own. A member was curious about the motivation behind wanting to use other checkpoints and showed willingness to share the input with product and engineering teams.
- Tutorial recording to be shared: Members are looking forward to a Predibase tutorial on 6/7. Predibase confirmed that they will share the recording of the live tutorial afterward.
- Evaluation and training losses discussion: There was a discussion on the importance of trying different checkpoints when evaluation loss is slightly higher but training loss is significantly lower. This was mentioned as part of a strategy to achieve better results.
- Course credits for fine-tuning: A member inquired about the activation of course credits on their account to fine-tune a larger model (L3 70B), which is particularly valuable given their limited training data.
LLM Finetuning (Hamel + Dan) ▷ #career-questions-and-stories (17 messages🔥):
- Historian Transitions to Tech: A user shared their journey from a career in history to an ML-focused role, overcoming early challenges like limited electricity and poor math skills in Kandahar. They eventually secured a job at ZenML, emphasizing the importance of courses like fastai and Launch School in their transition.
- Graph Enthusiast Leverages Layoff: Dan recounted moving from forensic accounting to data science spurred by the Panama Papers' use of Neo4j, despite initially lacking programming skills. His career pivot was enabled by a graduate program and independent study, leading to roles at tech giants and eventually Neo4j, where he now works on graph data science algorithms.
- Math Programming Obsession: Laith detailed his progression from university mathematical programming courses to consulting gigs and deep learning, blending formal study with self-education. He highlighted Radek Osmulski's blog as a resource for learning ML and discussed balancing career and personal life.
- Reddit Engineer Seeks ML Pivot: A backend engineer at Reddit expressed a desire to move from building ML inference stacks to creating ML products. The user asked for advice on navigating the overwhelming landscape of ML learning resources and the transformative impact of generative AI.
- Consultancy Idea for ML and Low-level Engineering: A tweet was shared suggesting a niche consultancy model combining designers, ML engineers, and low-level engineers to optimize and rewrite ML model inference in C++ or Rust. This service is aimed at clients needing high-performance, CPU-optimized model inference.
- Tweet from Andrew Carr (e/🤸) (@andrew_n_carr): I think there's room in the market for a hyper niche, 3 person consultancy. 1. Designer 2. ML engineer 3. Low level engineer Clients would bring a repository, open source or internal, and you w...
- Patching - Instructor: no description found
- Alex Strick van Linschoten - MLOps.systems: no description found
- Meta Learning: Addendum or a revised recipe for life: In 2021 I published Meta Learning: How To Learn Deep Learning And Thrive In The Digital World. The book is based on 8 years of my life where nearly every day I thought about how to learn machine lear...
LLM Finetuning (Hamel + Dan) ▷ #openai (1 messages):
peterg0093: The question is, will we get GPT-5 before we get OpenAI credits?
OpenAI ▷ #ai-discussions (315 messages🔥🔥):
- Debate on the use of Zero Crossings in Optimizers: Members discussed the potential use and limitations of tracking zero crossings (inversions) in the gradient for improving optimizer performance. Notably, experiments with zero crossing-based gradient clamping showed mixed results, with some showing slowed convergence or no significant improvement.
- Critique and Defense of SGD Optimizer: There was a back-and-forth discussion on the merits of the SGD optimizer as a baseline for comparisons in developing new optimizers. One user mentioned, "SGD is a baseline, everything better than it works by merit of learning rates," suggesting refinements are crucial for advancing beyond SGD's simplicity.
- Realistic Digital Avatars with FlashAvatar: Discussion highlighted a new method for creating high-fidelity digital avatars using multi-angle recordings, potentially being capable of rendering and animating virtual avatars at 300FPS with an Nvidia RTX 3090. The FlashAvatar project was a focal point of interest.
- Debate on AI's Handling of Context and Creativity: A user expressed difficulties with GPT-4 repeating the same information and failing to provide creative solutions within the provided context. This prompted suggestions for improving prompts and recognition of LLM limitations in handling long threads and creative prompts.
- Free Access to Custom GPTs: A brief mention noted that free-tier users now have access to custom GPTs on the OpenAI platform. This update prompted some members to consider shifting their GPT models for broader accessibility.
- NPGA: Neural Parametric Gaussian Avatars: no description found
- pytorch-hands-on/mnist_cnn.ipynb at master · rafaela00castro/pytorch-hands-on: My lectures on Convolutional Neural Networks and PyTorch at CEFET/RJ - rafaela00castro/pytorch-hands-on
- LMFAO - Sorry For Party Rocking: Sorry For Party Rocking - Buy the album now! http://smarturl.it/LMFAODeluxe
- Slovak verbs | coLanguage: The Slovak verbs express a process, action or a condition of people, animals, things, etc. Let's have a look at the overview of this lesson!
OpenAI ▷ #gpt-4-discussions (55 messages🔥🔥):
- GPT's Memory Leaks Resurface: Users discuss encountering a "white screen" during login and speculate on a possible memory leak fix. One mentions noticing "word vomit" and repetition, attributing this to temperature settings in the bot.
- Exploring Custom GPT Innovations: Members exchange ideas on unique uses of custom GPTs, such as investigating unexpected AWS bills, and discuss potential improvements in GPT functionality, like integrating "short term memory" without user-defined terms.
- Playground and API File Limits: Clarification provided on limits for uploading files to GPT's knowledge base through the official OpenAI help articles. Constraints include up to "512 MB per file" and "5 million tokens per file."
- Debate on Context Windows and Embeddings: Users debate the effectiveness of embeddings versus longer context windows, with a particular interest in the rumored update to integrate Gemini for better performance. Some prefer smarter, shorter contexts over merely expanding context size.
- Troubleshooting GPT Editing and Actions: Problems with GPT editing are attributed to subscription issues, while other users troubleshoot broken GPT actions, eventually resolving it by reverting to an older version.
OpenAI ▷ #prompt-engineering (7 messages):
- Default system messages win: In response to whether complex prompts benefit from one or multiple system messages, a member advocated for using "1 system message".
- Issues with ChatGPT adherence to guidelines: A member expressed frustration with ChatGPT's inability to follow guidelines and sought techniques to improve its performance. They requested assistance for their specific use case.
OpenAI ▷ #api-discussions (7 messages):
- Discussing Parameters: A user inquired about the temperature and top-p settings being used by another, asking if their topic was finnicky.
- Preference for System Messages: A user queried the group on preferences for structuring complex prompts in GPT-4 and 4o—whether to use one system message or multiple. A single user responded preferring a single system message.
- Seeking Help with ChatGPT Guidelines: A user expressed struggles with ChatGPT not following their guidelines and sought techniques or assistance to address this issue. No follow-up solutions were discussed openly.
Modular (Mojo 🔥) ▷ #general (198 messages🔥🔥):
- Mojo Language Server Crashes: Members report issues with Mojo language server crashing frequently in VS Code forks like Cursor on MacBook M2. A GitHub issue #2446 outlines the problem, and it's mentioned that the fix is only available in the nightly version.
- Mojo Language Maturity and Community Roadmap: Discussions on when Mojo will reach maturity and stabilization, with insights on ongoing development and open-source community contributions. Check out the Mojo roadmap and a blog announcement for more details.
- Potential of Mojo in Networking and Data Processing: Enthusiasts discuss ambitious projects like implementing DPDK (Data Plane Development Kit) and integrating liburing for optimized network performance using Mojo. A call to Modular to test DPDK's headers with Mojo C interop is emphasized as a critical step for future development.
- Python Optimization Techniques: Users seek ways to optimize slow Python code loops, such as using
yield, dicts over tuples, and exploring Numba for JIT compilation as suggested in this YouTube tutorial.
- Transitioning from Windows for Mojo: For users facing issues installing Mojo on Windows, a prescribed workaround is using WSL with Ubuntu 22.04. Modular's priority on perfecting CUDA on Linux before moving to other platforms is acknowledged, with hopes for broader support by late summer or autumn.
- Modular Docs: no description found
- no title found: no description found
- Mojo🔥 roadmap & sharp edges | Modular Docs: A summary of our Mojo plans, including upcoming features and things we need to fix.
- Hello Wave GIF - Hello Wave Cute - Discover & Share GIFs: Click to view the GIF
- Modular: Accelerating the Pace of AI: The Modular Accelerated Xecution (MAX) platform is the worlds only platform to unlock performance, programmability, and portability for your AI workloads.
- Make Python 1000x Faster With One Line 🐍 ⏩ (Numba Tutorial): Numba can speed up your python code 1000x with just a single line of code using a JIT compiler used to optimize simple functions in python by compiling funct...
- [BUG] Mojo Language Server crashes in Visual Studio Code · Issue #2446 · modularml/mojo: Bug description Editing Mojo source code in Visual Studio Code results in crash of Mojo Language Server. Steps to reproduce Try editing the following code in VSCode fn exec_rt_closure(x: Int, bin_o...
- Make Python 1000x Faster With One Line 🐍 ⏩ (Numba Tutorial): Numba can speed up your python code 1000x with just a single line of code using a JIT compiler used to optimize simple functions in python by compiling funct...
- Modular: The Next Big Step in Mojo🔥 Open Source: We are building a next-generation AI developer platform for the world. Check out our latest post: The Next Big Step in Mojo🔥 Open Source
- How to Use Generators and yield in Python – Real Python: In this step-by-step tutorial, you'll learn about generators and yielding in Python. You'll create generator functions and generator expressions using multiple Python yield statements. You&#...
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1797699002353488183
Modular (Mojo 🔥) ▷ #📺︱youtube (1 messages):
- Modular shares new MAX release video: Modular just posted a YouTube video titled "Getting started with MAX release and nightly builds". The video guides users through the installation and configuration of both the MAX release and nightly builds on their systems.
Link mentioned: Getting started with MAX release and nightly builds: In this video, we'll guide you through the entire process of installing and configuring both the MAX release and nightly builds on your system. You'll learn ...
Modular (Mojo 🔥) ▷ #🔥mojo (79 messages🔥🔥):
- Resizing Logic Flaw Identified: A user highlighted that the resizing logic in Mojo doesn't handle cases where the string to be added is larger than the increased capacity. Another user acknowledged this oversight, indicating it wasn't covered initially.
- Function Renaming in Nightly: A user queried the whereabouts of the
rotate_bits_leftfunction. It was clarified that in the nightly build, it has been renamed toSIMD.rotate_leftforSIMDtypes andbit.rotate_bits_leftforInt, per the changelog.
- Installing Mojo on Windows: A user struggled with installing Mojo on Windows using WSL and discovered that path issues arose from Windows using backslashes (
\) while Linux uses forward slashes (/). Another user suggested using/usr/bin/modularas the path to resolve the issue.
- Aliases and SIMD Lengths: Discussions took place about the best ways to store aliases relevant to classes and deal with
SIMDrequiring power of two lengths. The consensus was to use class attributes and reference them withSelf.nelts.
- Custom HTTP Library: A user inquired if there is a native Mojo HTTP library similar to Python's
requests. It was recommended to uselightbug_http, a third-party library actively maintained and available on GitHub.
- Mojo🔥 FAQ | Modular Docs: Answers to questions we expect about Mojo.
- GitHub - saviorand/lightbug_http: Simple and fast HTTP framework for Mojo! 🔥: Simple and fast HTTP framework for Mojo! 🔥. Contribute to saviorand/lightbug_http development by creating an account on GitHub.
- [mojo-stdlib] Add variadic initialiser, __iter__ and __contains__ to InlineList by ChristopherLR · Pull Request #2703 · modularml/mojo: This PR adds some features to InlineList ( related issue #2658 ) Variadic initialiser var x = InlineList[Int](1,2,3) iter var x = InlineList[Int](1,2,3) for i in x: print(i) contains var x = In...
- mojo/stdlib/src/memory/unsafe.mojo at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (4 messages):
- Initial Data Processing Benchmark PR: A draft for a data processing benchmark PR was shared, noting that current performance is faster than Python but slower than compiled languages. Suggestions were requested for code and Docker installation script improvements.
- Custom JSON Parser Needed: To optimize the benchmark, a custom JSON parser in Mojo is proposed, referencing previous work in C# and Swift. This contribution is planned to be tackled next week.
- [Mojo] Initial version by cyrusmsk · Pull Request #514 · jinyus/related_post_gen: Tested: local run of the code verified on 5k posts file Not tested: Docker installation Issues: mojo build and run executable locally gives me a seg fault. But 'mojo rel.mojo' is working Futur...
- FlexBuffersSwift/FlexBuffers/FlexBuffers.swift at master · mzaks/FlexBuffersSwift: Swift implementation of FlexBuffers - a sub project of FlatBuffers - mzaks/FlexBuffersSwift
Modular (Mojo 🔥) ▷ #🏎engine (2 messages):
- Backward pass concerns in forward pass implementation: One member highlighted the need for the forward pass to store the output of each layer for the backward pass to function correctly, mentioning uncertainty on whether this is already possible in Max.
- Missing backward pass documentation and custom optimizer: Another member thanked for the previous info and mentioned that although the necessary functions seem present for the forward pass, they couldn't find documentation on backward calculations and noted the likely need for a custom optimizer.
Modular (Mojo 🔥) ▷ #nightly (30 messages🔥):
- New Nightly Mojo Compilers Released: A new nightly Mojo compiler, updated to
2024.6.305, is now available viamodular update nightly/mojo. The changelog includes moving globalUnsafePointerfunctions to methods and adding a temporary directory function. - C
charSign Confusion Clarified: Members debated whethercharin C is signed or unsigned, noting that its sign is implementation-defined and can be modified using-funsigned-charin GCC, though this breaks standard compliance. - Tensors Moving Out of Std Lib: A user inquired about Tensors being moved out of the standard library, with the response indicating that this was mentioned in a community call available on YouTube.
- Changelog Consistency Proposal: A suggestion for maintaining consistent changelog entries was shared, aiming to improve documentation formatting and style.
- Excitement for Conditional Conformance: There is enthusiasm about the new conditional conformance capabilities in Mojo, which are expected to unlock significant improvements in the standard library's flexibility and functionality.
- [mojo-stdlib] Move global UnsafePointer functions to be methods. · modularml/mojo@c9ea648: This extends the compiler to allow the type of `self` to be `Self` with any parameters, allowing more flexible conditional conformance. This allows us to move the global functions in UnsafePointer...
- [Docs] Style guide entry for consistent changelog entry phrasing · Issue #2923 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? I suggest having an entry in the style guide for how t...
Eleuther ▷ #general (28 messages🔥):
- Fix Those Typos!: There was a brief confusion over the term "stronging" which was clarified to mean "storing", related to embedding storage (not stronging embeds).
- Elon vs Yann Diss Track: A humorous post linked to Yann LeCun's Twitter where LeCun comments "Hilarious 😂" on a diss track involving Elon Musk.
- Liouville's Theorem Discussion: The community delved into Liouville's theorem and its implications on elementary and nonelementary antiderivatives, theorizing on the potential link to neural networks. Wikipedia link for reference.
- Telegram File Storage Hack: A member shared a tool to use Telegram for "infinite free file storage", secured with AES-256-CTR encryption, available here with source code on GitHub.
- Debate on AI Reading Lists: Members discussed the outdatedness of Ilya Sutskever's recommended AI reading list, with contrasting views on its historical vs. current applicability. Some still found it "very inspiring for figuring out how an idea will work in the present moment".
- Liouville's theorem (differential algebra) - Wikipedia: no description found
- Tweet from Yann LeCun (@ylecun): Hilarious 😂 Quoting peterxing.eth🧢🦾 — d/acc (@peterxing) Elon v Yann diss track part 3
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Eleuther ▷ #research (125 messages🔥🔥):
- Manifold Research seeks collaborators: Sidh from Manifold Research announced opportunities for collaboration on transformers for multimodality and control tasks. They aim to build the first large-scale, open-source Generalist Model and welcome contributions via multiple avenues.
- New insights on RLHF bias: A paper shared by a member argues that standard RLHF is intrinsically biased and proposes adding an entropy term to mitigate this. "To mitigate this algorithmic bias, it is both necessary and sufficient to add an entropy term to the reward maximization in RLHF." View PDF
- Exploring Transformer limitations: The discussion includes a paper that uses communication complexity to show that Transformer layers struggle with composing functions on sufficiently large domains. This empirical result highlights inherent limitations in the Transformer architecture. View PDF
- Debate on positional embeddings: Members discussed the challenges and potential solutions for data-dependent positional embeddings in transformers. The conversation highlighted potential difficulties with low-dimensional learnable position vectors. View PDF
- Mamba-2 and SSMs innovations: Albert Gu's team released Mamba-2, introducing a framework that connects SSMs with attention through state space duality (SSD), promising performance and speed improvements. "Mamba-2 aims to advance the theory of sequence models, developing a framework of connections between SSMs and (linear) attention that we call state space duality (SSD)." View PDF
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality: While Transformers have been the main architecture behind deep learning's success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Tran...
- Limits of Deep Learning: Sequence Modeling through the Lens of Complexity Theory: Deep learning models have achieved significant success across various applications but continue to struggle with tasks requiring complex reasoning over sequences, such as function composition and comp...
- Grokfast: Accelerated Grokking by Amplifying Slow Gradients: One puzzling artifact in machine learning dubbed grokking is where delayed generalization is achieved tenfolds of iterations after near perfect overfitting to the training data. Focusing on the long d...
- On Limitations of the Transformer Architecture: What are the root causes of hallucinations in large language models (LLMs)? We use Communication Complexity to prove that the Transformer layer is incapable of composing functions (e.g., identify a gr...
- Contextual Position Encoding: Learning to Count What's Important: The attention mechanism is a critical component of Large Language Models (LLMs) that allows tokens in a sequence to interact with each other, but is order-invariant. Incorporating position encoding (P...
- Knowledge Circuits in Pretrained Transformers: The remarkable capabilities of modern large language models are rooted in their vast repositories of knowledge encoded within their parameters, enabling them to perceive the world and engage in reason...
- Opportunities: There are a few ways to get involved with our work: 1. Join our Discord and take part in events and discussion, both project related and not. 2. Contribute asynchronously to issues on our Github. ...
- Tweet from Albert Gu (@_albertgu): excited to finally release Mamba-2!! 8x larger states, 50% faster training, and even more S's 🐍🐍 Mamba-2 aims to advance the theory of sequence models, developing a framework of connections bet...
- nanoRWKV depth 12: Code/Hyperparameters taken from nanoRWKV trained on OpenWebText2, sequence length 768, iterations 60k xat_time -> replace gelu gating in time mixing with expanded arctan 1xatglu_channel -> first...
- nanoRWKV depth 24: Code/Hyperparameters taken from nanoRWKV trained on OpenWebText2, sequence length 768, iterations 60k xat_time -> replace gelu gating in time mixing with expanded arctan 1xatglu_channel -> first...
- 24 layer: no description found
- On the Algorithmic Bias of Aligning Large Language Models with RLHF: Preference Collapse and Matching Regularization: Accurately aligning large language models (LLMs) with human preferences is crucial for informing fair, economically sound, and statistically efficient decision-making processes. However, we argue that...
- Expanded Gating Ranges Improve Activation Functions: Activation functions are core components of all deep learning architectures. Currently, the most popular activation functions are smooth ReLU variants like GELU and SiLU. These are self-gated activati...
Eleuther ▷ #interpretability-general (2 messages):
- Mechanistic Analysis Paper Summary: A member shared a summary of their paper titled A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task. They aim to reinvigorate interest and find collaborators by discussing the model's use of backward chaining circuits to accomplish tasks.
- Upcoming Mechanistic Interpretability Hackathon: A mechanistic interpretability hackathon is scheduled for July, inviting participants to work on reverse-engineering neural networks over a weekend. Details and registration are available on the itch.io event page, with further information accessible through their dedicated Discord interpretability server.
- Mechanistic interpretability Hackathon: A game jam from 2024-07-05 to 2024-07-07 hosted by victorlf4. Mechanistic Interpretability Hackathon Join us for the Mechanistic Interpretability Hackathon, inspired by similar hackathons hosted by Ap...
- Finding Backward Chaining Circuits in Transformers Trained on Tree Search — LessWrong: This post is a summary of our paper A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task (ACL 2024). While we wrot…
Eleuther ▷ #lm-thunderdome (7 messages):
- BERT fails in lm-eval harness: A member shared an error encountered when using BERT in lm-eval, stating that "BERT and encoder models cannot be used in the lm evaluation harness, as they are not trained as (autoregressive) language models and are not meant for text generation." Another member acknowledged this and asked for the smallest decoder model on Hugging Face for energy consumption measurements.
- Reproducibility issues with llama-3-8b-instruct: One user reported different gsm8k results on the llama-3-8b-instruct compared to published results, noting a discrepancy of 62.4 vs 79.6. Another user suggested that the leaderboard uses an older commit, which might be the reason for the inconsistency, and advised checking the commit hash in the documentation.
- Fewshot configuration may affect results: It was suggested that the leaderboard might use a fewshot=5 configuration for gsm8k, which could explain the result differences. Members were advised to verify this setting to ensure accurate comparison.
Eleuther ▷ #multimodal-general (3 messages):
- Vision and Multimodal Mechanistic Interpretability Foundations Shared: A member shared a post on Alignment Forum discussing the foundations for vision and multimodal mechanistic interpretability. The post includes contributions from Sonia Joseph, Neel Nanda, and other collaborators.
- Dogit Lens and Emergent Segmentation Map Discussed: The concept of the "dogit lens" and its use as a patch-level logit attribution and emergent segmentation map were highlighted. The shared article includes a detailed outline with sections such as "Introduction and Motivation" and "Demo of Prisma’s Functionality."
- Scarcity in Literature on Circuits of Score Models: A member noted a lack of papers specifically addressing the circuits of score models themselves. They have seen papers covering the dynamics of learned reverse processes but not the internal circuitry of the models.
Link mentioned: Laying the Foundations for Vision and Multimodal Mechanistic Interpretability & Open Problems — AI Alignment Forum: Behold the dogit lens. Patch-level logit attribution is an emergent segmentation map. Join our Discord here. …
OpenRouter (Alex Atallah) ▷ #announcements (13 messages🔥):
- Database Timeouts in Asia Regions: Members reported experiencing database timeouts in regions such as Seoul, Mumbai, Tokyo, and Singapore. OpenRouter pushed a fix to resolve the issue but rollback previous latency improvements due to these problems.
- API 504 Errors While Database Times Out: Some users encountered 504 errors with the API while the playground remained functional. Switching to an EU VPN temporarily resolved the issue for some users.
- Fix Deployment and Apologies: The OpenRouter team noted the database was down intermittently for about 4 hours, mostly affecting non-US regions. A fix for the issue has since been deployed and verified to be working by users.
- Decommissioning of Models: OpenRouter is decommissioning Llava 13B and Nous: Hermes 2 Vision 7B (alpha) due to low usage and high costs. They suggest alternatives like FireLlava 13B and LLaVA v1.6 34B.
- Playground | OpenRouter: Experiment with different models and prompts
- LLaVA 13B by liuhaotian | OpenRouter: LLaVA is a large multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding, achieving impressive chat capabilities mimicking [GPT-4](/models/open...
- Nous: Hermes 2 Vision 7B (alpha) by nousresearch | OpenRouter: This vision-language model builds on innovations from the popular [OpenHermes-2.5](/models/teknium/openhermes-2.5-mistral-7b) model, by Teknium. It adds vision support, and is trained on a custom data...
- FireLLaVA 13B by fireworks | OpenRouter: A blazing fast vision-language model, FireLLaVA quickly understands both text and images. It achieves impressive chat skills in tests, and was designed to mimic multimodal GPT-4. The first commercial...
- LLaVA v1.6 34B by liuhaotian | OpenRouter: LLaVA Yi 34B is an open-source model trained by fine-tuning LLM on multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. Base LLM: [Nou...
OpenRouter (Alex Atallah) ▷ #general (112 messages🔥🔥):
- Connection Issues and Outages: Many users reported 504 errors and gateway timeouts while trying to connect to the API. Admins acknowledged ongoing issues with their database provider and promised to resolve them soon.
- Regional Variability in API Functionality: Users located in Germany and the US noted that the OpenRouter API was functioning fine, while users in Southeast Asia and other regions continued experiencing issues.
- OpenRouter Credits and Payments Confusion: A user reported an issue with OpenRouter credits after paying with a different wallet. The problem was resolved by realizing the credits were attributed to the initial wallet logged in.
- Request for Enhanced Uptime Monitoring: Users like cupidbot.ai suggested adding provider-specific uptime statistics to the uptime chart to hold providers accountable for service reliability.
- Questions about Model Performance and Configuration: Multiple users raised questions about the addition of new LLMs, rate limits on specific models like Gemini-1.5-Pro, and the quantization levels offered by providers.
- Vertex AI Agent Builder: Build, test, deploy, and monitor enterprise ready generative AI agents and applications
- Playground | OpenRouter: Experiment with different models and prompts
OpenRouter (Alex Atallah) ▷ #소개 (1 messages):
- Welcome to OpenRouter: Members are introduced to OpenRouter, a platform with hundreds of language models available from numerous providers. Users can prioritize either price or performance for the lowest cost and optimal latency/throughput.
- Standardized API eases model transitions: OpenRouter’s standardized API allows seamless switching between models or providers without code changes. This feature ensures that users can easily choose and pay for the best model.
- Model popularity reflects real-world usage: Instead of relying solely on benchmarks, OpenRouter evaluates models based on how frequently and effectively they are used in real-world scenarios. Users can view these comparisons on the rankings page.
- Experiment with multiple models: The OpenRouter Playground allows users to chat simultaneously with various models, facilitating a hands-on evaluation. Access it here.
- LLM Rankings | OpenRouter: Language models ranked and analyzed by usage across apps
- Playground | OpenRouter: Experiment with different models and prompts
OpenRouter (Alex Atallah) ▷ #일반 (1 messages):
lemmyle: 첫 번째
OpenRouter (Alex Atallah) ▷ #紹介 (1 messages):
- Welcome to OpenRouter: Users are encouraged to prioritize either price or performance when selecting from hundreds of language models and their respective dozens of providers. OpenRouter offers the lowest prices and optimal latency/throughput from numerous providers, allowing users to choose based on their priorities.
- Standardized API benefits: With a standardized API, users can switch models or providers without the need to change their existing code. They also have the option to directly select and pay for the models they use.
- Model usage as a benchmark: Instead of relying solely on traditional benchmarks, OpenRouter compares models based on usage frequency and application types. This data is available at OpenRouter Rankings.
- Playground for model comparison: Users are invited to the OpenRouter Playground, where they can chat with multiple models simultaneously. This hands-on approach helps in making informed decisions about the best model for specific needs.
- LLM Rankings | OpenRouter: Language models ranked and analyzed by usage across apps
- Playground | OpenRouter: Experiment with different models and prompts
OpenRouter (Alex Atallah) ▷ #一般 (1 messages):
lemmyle: 初め
LAION ▷ #general (98 messages🔥🔥):
- Yudkowsky's New Strategy Faces Backlash: Discussion sparked by links about Eliezer Yudkowsky's institute aiming to shut down AI development, referencing his controversial views including advocating for extreme measures like airstrikes on data centers. Opinions were mixed, with some criticizing his ideas, while others acknowledged his earlier rationality work. Link to detailed strategy.
- Mobius Model Released: Several unique images generated by the Mobius model were shared, with prompts like "Thanos smelling a little yellow rose" and "robot holding a sign that says 'a storm is coming'." The Hugging Face link to the model and images can be accessed here.
- AI Community Openness Debate: Participants debated the challenges of maintaining open collaboration within the AI community, weighing the risks of public scrutiny and the benefits of transparency. One user highlighted that LAION's decreasing openness could be due to fears of legal backlash and defamation suits highlighted in a recent lawsuit example.
- Pseudo-legal Lawsuit Madness: A lawsuit involving pseudo-legal claims and how these frivolous cases are wasting time and money was discussed. Specific case reference: a Vancouver woman’s complaint against her neighbor for filing a baseless lawsuit read more here.
- New AI/ML Hackathon Announcement: Announcement for the Alliance AI4Health Medical Innovation Challenge offering $5k in prizes, aimed at developing AI solutions for healthcare. Register and learn more about the challenge here.
- My Last Five Years of Work: no description found
- Tweet from Alex J. Champandard 🌱 (@alexjc): Follow-up on the criminal case against LAION: The complaint is being handled & submitted by award-winning @SpiritLegal. A top lawfirm is not necessary (like driving kids to school in a Rolls Royce) a...
- Tweet from Nirit Weiss-Blatt, PhD (@DrTechlash): Eliezer Yudkowsky's institute published its "2024 Communication Strategy" The main goal (as he argued in TIME magazine) is to 🔻shut down🔻 AI development. So, let's take a look at t...
- Corcelio/mobius · Hugging Face: no description found
- AMD at Computex 2024: AMD AI and High-Performance Computing with Dr. Lisa Su: The Future of High-Performance Computing in the AI EraJoin us as Dr. Lisa Su delivers the Computex 2024 opening keynote and shares the latest on how AMD and ...
- Tweet from Lykon (@Lykon4072): For reference, SD3 2B has roughly the same size but it's MMDiT (which is far superior to Unet) and used 3 text encoders, plus has a 16ch VAE. You can't get this level of detail in XL without c...
- Tweet from Frantastic — e/acc (@Frantastic_7): time to bring back this classic Quoting Nirit Weiss-Blatt, PhD (@DrTechlash) Eliezer Yudkowsky's institute published its "2024 Communication Strategy" The main goal (as he argued in TI...
- Alliance Medical Innovation Challenge: Empowering global health through AI-based solutions: solving the problems of the future
- Vancouver lawyer who sued over condo deck divider accused of pseudolegal 'paper terrorism' | CBC News: A Vancouver woman is asking for the courts to make an example of her neighbour, a practising lawyer she alleges has filed a baseless pseudolegal lawsuit against her in an attempt to “provoke a state o...
LAION ▷ #research (5 messages):
- Phased Consistency Model (PCM) challenges LCM: The PCM project shows that the design space of LCM is limited and proposes PCM to tackle these limitations effectively. The discussion revolves around PCM's design space expansion and improvements.
- New study on pre-trained text-to-image diffusion models: Recent developments in large-scale models were discussed, and a link to an arXiv paper was shared. This paper includes contributions from multiple authors and highlights advancements in the efficiency and capability of text-to-image models.
- 1.58 bits paper connection: A member referred to the new paper on text-to-image diffusion models as basically the "1.58 bits paper applied to image generation". This shorthand indicates specific technical aspects central to the paper's methodology.
- State-space models vs Transformers: A new arXiv submission explores the theoretical connections between State-space models (SSMs) like Mamba and Transformers. The new architecture, Mamba-2, promises to be 2-8X faster than its predecessor while remaining competitive with Transformers for language modeling.
- TerDiT: Ternary Diffusion Models with Transformers: Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models ba...
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality: While Transformers have been the main architecture behind deep learning's success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Tran...
- Phased Consistency Modelt: no description found
LlamaIndex ▷ #announcements (1 messages):
- Don't Miss the "Future of Web Agents" Webinar: The upcoming webinar "Future of Web Agents" with Div from MultiOn is happening this Thursday at 9am PT. Register and get more details here.
Link mentioned: LlamaIndex Webinar: The Future of Web Agents with MultiOn 🤖 · Zoom · Luma: We are excited to chat about the Agentification of the Internet with Web Agents, with Div Garg from MultiOn! Context: We are transitioning into a world where…
LlamaIndex ▷ #blog (6 messages):
- Knowledge graph support launched: LlamaIndex announced the release of first-class support for building knowledge graphs, including support for neo4j. This is highlighted as a significant development in their offerings.
- Define custom graph RAG flows: LlamaIndex now enables building-your-own RAG (Retrieval-Augmented Generation) using knowledge graphs, combining vector/keyword search with graph traversal or text-to-cypher. Details and examples are shared here.
- Webinar recording on memory for autonomous agents: A recent webinar recording about "memary," an open-source implementation for long-term memory in autonomous agents, is now available online. This session features insights from Julian Saks and Kevin Li.
- Manual knowledge graph building toolkit: LlamaIndex provides a toolkit that allows users to manually define entities and relations in knowledge graphs and link them to text chunks. This toolkit supports graph-based RAG techniques for enhanced context retrieval details.
- Launch partnership with NVIDIA: LlamaIndex is partnering with NVIDIA to help users build GenAI applications using NVIDIA’s NIM inference microservices. A step-by-step notebook is available for guidance on deployment here.
- Upcoming webinar on web agents: A future webinar will feature Divyansh Garg from MultiOn AI to discuss the future of web agents. MultiOn AI enables the creation of personalized web agents that can automate tasks online details.
LlamaIndex ▷ #general (80 messages🔥🔥):
- TS Library Setup in Llama‐Index: Members discussed how to configure persistence directories in TypeScript using LlamaIndex. "Try using chromadb context instead of a persistDir," was one recommended approach.
- Integrating Historical Data in RAG Questions: A discussion focused on leveraging historical data in Retrieval-Augmented Generation (RAG). A member mentioned combining document context and historical answers to improve relevance in answering predefined questions.
- Parallel Function Calling in OpenAIAgent: Users questioned whether OpenAIAgent can perform parallel function calls to reduce latency. A shared LlamaIndex example clarified that while OpenAI's latest API allows for multiple function calls, it doesn't truly parallelize computations.
- Document Analytics Using RAG: Discussion on conducting large-scale document analytics with RAG. Suggestions included using retrieval with a score threshold and running tests for specific use cases, like extracting references to "Ferraris" from a set of car documents.
- GPT-4o Performance in Document Extraction: A member shared a research study benchmarking GPT-4o's performance in document extraction and OCR, claiming it surpasses other industry tools, particularly in finance applications.
- no title found: no description found
- no title found: no description found
- GitHub - SqueezeAILab/LLMCompiler: [ICML 2024] LLMCompiler: An LLM Compiler for Parallel Function Calling: [ICML 2024] LLMCompiler: An LLM Compiler for Parallel Function Calling - SqueezeAILab/LLMCompiler
- Built-In Observability Instrumentation - LlamaIndex: no description found
- Single-Turn Multi-Function Calling OpenAI Agents - LlamaIndex: no description found
- Building a Multi-PDF Agent using Query Pipelines and HyDE - LlamaIndex: no description found
- Multi-Document Agents - LlamaIndex: no description found
- Professional Paradigm Shift: GPT-4o and Project Astra in Finance: We tested GPT-4o, Nanonets, and Dext on four document types. GPT-4o outperformed the others with an average accuracy of 84.69%.
LlamaIndex ▷ #ai-discussion (1 messages):
crypto_carter: anyone working on combining semantic layers with SQL Retrievers?
Latent Space ▷ #ai-general-chat (51 messages🔥):
- Reverse Turing Test Video: A member shared a YouTube video titled "Reverse Turing Test Experiment with AIs", where advanced AIs try to identify the human among them using Unity and voices by ElevenLabs.
- The End of Software Google Doc: An interesting blogpost titled "The End of Software" was shared (link), sparking a debate about the future of computer science degrees.
- Operational Perspectives in LLMs: A member highlighted an O'Reilly article, "What We Learned from a Year of Building with LLMs Part II" (link), focusing on operational aspects of building LLM applications.
- Anthropic's Dario Amodei in Time's Top 100: Discussion around Dario Amodei being named a Time's Top 100 influential person, especially regarding his decision to delay the release of the powerful chatbot Claude.
- Buzz on Llama3-V Stealing Incident: Conversations kicking off about the alleged stealing incident around llama3-v reported on GitHub and calls for accountability from those involved.
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality Presents Mamba-2, which outperforms Mamba and Transformer++ in both perplexity and wall-clock...
- Tweet from Binyuan Hui (@huybery): 👋 im-a-good-qwen2 Chat with me in the comments!
- Tweet from Scratch (@DrBriefsScratch): The real kino is Visual Basic 6 in a CRT-shadered web simulated Windows 2000 emulator with exposed shell API If you're still coding in base reality you're ngmi Quoting kache (@yacineMTB) r...
- What We Learned from a Year of Building with LLMs (Part II): no description found
- AI Tune Fusion - The Hypocrite Brigade (Live): Ah, so now my human pet has even subjected me to live music torture. 😒I can't help but ponder what else my AI buddies and I must endure on his behalf. Anywa...
- Tweet from Chris Paik (@cpaik): The End of Software https://docs.google.com/document/d/103cGe8qixC7ZzFsRu5Ww2VEW5YgH9zQaiaqbBsZ1lcc/edit?usp=sharing
- Tweet from Nick Dobos (@NickADobos): If rumor is true, Apple is about to drop AGI App Shortcuts & app intents as actions means every app on your phone can be triggered by GPT. Imagine if every app could be controlled like Dalle. All an ...
- How to Build Terrible AI Systems with Jason Liu: Jason is an independent consultant who uses his expertise in recommendation systems to help fast-growing startups build out their RAG applications. He was pr...
- Tweet from Chris Paik (@cpaik): The End of Software https://docs.google.com/document/d/103cGe8qixC7ZzFsRu5Ww2VEW5YgH9zQaiaqbBsZ1lcc/edit?usp=sharing
- Tweet from Teknium (e/λ) (@Teknium1): Wow @StabilityAI fucking everyone by making up a new SD3, called SD3 "Medium" that no one has ever heard of and definitely no one has seen generations of to release, and acting like they are o...
- Tweet from Teortaxes▶️ (@teortaxesTex): Llama-3-V Github and HF both down after evidence of them stealing @OpenBMB's model is out. Sorry bros I don't think we should let it be a closed chapter in your lives, to venture forth to new...
- Tweet from Doc Xardoc (@andrewb10687674): Excellent article! For those of you who didn't read the whole thing, the key result is they used Llama-3 with this prompt to score the data on a scale from 1-5. Quoting Guilherme Penedo (@gui_pe...
- Reverse Turing Test Experiment with AIs: A group with the most advanced AIs of the world try to figure out who among them is the human. Experiment I made in Unity. Voices by ElevenLabs.
- GitHub - OpenBMB/MiniCPM-V: MiniCPM-Llama3-V 2.5: A GPT-4V Level Multimodal LLM on Your Phone: MiniCPM-Llama3-V 2.5: A GPT-4V Level Multimodal LLM on Your Phone - OpenBMB/MiniCPM-V
- Patterns of Application Development Using AI: Discover practical patterns and principles for building intelligent, adaptive, and user-centric software systems that harness the power of AI.
- Inside Anthropic, the AI Company Betting That Safety Can Be a Winning Strategy: Anthropic is the smallest, youngest, and least well-financed of all the “frontier” AI labs. It’s also nurturing a reputation as the safest.
- Project author team stay tuned: I found out that the llama3-V project is stealing a lot of academic work from MiniCPM-Llama3-V 2.5 · Issue #196 · OpenBMB/MiniCPM-V: Fellow MiniCPM-Llama3-V 2.5 project authors, a few days ago I discovered a shocking fact.There is a large amount of work in the llama3-V (https://github.com/mustafaaljadery/llama3v) project that is...
Latent Space ▷ #ai-announcements (1 messages):
- AIEWF Speaker Announcements and Event Updates: New AIEWF announcements include the second wave of speakers, with notable names like @ashtom for the Closing Keynote and @krandiash on State Space Models. Official events such as a Hackathon and Preparty on June 24th, and a Wearables launch were also highlighted.
- Comprehensive AI Industry Support: This conference marks the first AI industry event supported by all three major cloud providers and top model labs. Unique tracks are introduced, including AI in Fortune 500 and AI Leadership tracks for VPs of AI, as well as notable workshops and side events.
- Exciting Keynotes and Tracks: Keynotes will include diverse and intriguing topics such as "Spreadsheets Are All You Need" by @ianand. Top GPU track speakers and major figures from organizations like Groq Cloud and Fireworks are slated to present.
Link mentioned: Tweet from swyx 🇸🇬 (@swyx): Announcing second wave of speakers + Updates! @aidotengineer Changelog: ➕ Official Hackathon + Preparty Jun 24th ➕ see @HF0Residency announcement today 👀 ➕ hosting @ashtom as our Closing Keynote! ➕ ...
Latent Space ▷ #ai-in-action-club (33 messages🔥):
- Technical difficulties plague video stream: Multiple members, including ssaito_, bharatsoni, and others reported "black screen" and "spinners" issues when trying to view the video. Switching from the app to the web view and vice versa was suggested as a temporary solution.
- Zoom link provided to resolve issues: Due to persistent streaming issues, a Zoom link was provided by kbal11 to continue the session. Members were encouraged to join the meeting with the provided meeting link and credentials.
Link mentioned: Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
LangChain AI ▷ #general (41 messages🔥):
- Using RAG with Historical Data and CSV Tables: A user sought advice on incorporating historical data into a RAG system for answering predefined questions. The data includes CSV tables and scanned documents, and the community suggested optimizing data sources and integration strategies for better efficiency.
- Debate on Agent Structure for Game Recommendation Chatbot: A user questioned whether to split a LangGraph chatbot agent into multiple agents for video game details. The community advised against over-dividing, recommending using a single agent or pre-curating data to streamline responses and reduce complexity.
- LangChain vs OpenAI Agents Discussion: Members discussed comparing LangChain and OpenAI agents, particularly focusing on the need for abstraction versus directly using OpenAI functionality. It was highlighted that LangChain offers a versatile framework for orchestrating LLM calls, but specific use cases might determine the best approach.
- Personal Shopper with Vector Stores: A user working on a personal shopper chatbot asked about efficiently managing API calls and determining when to pull product data from a vector store. The discussion included suggestions on using a single LLM API call to decide on data retrieval and generating conversations.
- Anthropic Tools Release and LangChain Update Request: A member pointed out that Anthropic has released official tools and function calling, which are not yet supported in LangChain. They requested the community and maintainers to update LangChain API to incorporate these new tools.
Link mentioned: GitHub - MOUNAJEDK/GameSeeker-VideoGamesRecommendationChatbot at langgraph-logic-implementation: A chatbot specialized in offering personalized video games recommendations based on user's preferences. - GitHub - MOUNAJEDK/GameSeeker-VideoGamesRecommendationChatbot at langgraph-logic-imple...
LangChain AI ▷ #langserve (1 messages):
- JavaScript code fails with LangServe and LangChain: A user shared a Python version of their working code with LangGraph and LangServe but faced issues with the equivalent JavaScript implementation. They encountered a TypeError:
obj.messages.map is not a function, indicating problems with processing message arrays in theRemoteRunnableclass.
LangChain AI ▷ #langchain-templates (4 messages):
- Using
ChatPromptTemplate.partialeffectively:ChatPromptTemplate.partialshould be used to replace some, but not all, placeholders with the given text. The remaining placeholders will be managed using theRunnable.invokemethod. - Some features only available in
ChatPromptTemplate: Surprisingly, whilepartialis available forChatPromptTemplate, it is not available forSystemMessagePromptTemplate. This discrepancy was noted as peculiar by the user.
LangChain AI ▷ #share-your-work (13 messages🔥):
- Explore LLM Models with Hugging Face and LangChain: A detailed guide on Medium explains how to test LLMs such as Llama3, Mistral, and Phi on Google Colab using LangChain. Read more.
- Advanced Research Assistant Beta Testing: A call for beta testers for a new research assistant and search engine offering free 2-months premium with advanced models like GPT-4 Turbo and Claude 3 Opus. Sign up here and use promo code RUBIX.
- Fixing Sign-Up Issues: A user faced difficulties signing up for Rubik's AI, reporting repeated errors stating "Email and username already existed." The issue needs resolving for continued interest.
- Automated Chat Analyzer: Successfully developed by a user, this tool can extract Q&A from large message lists without using RAG, focusing on efficiency and simplicity. The tool is designed for minimal compute requirements and easy manual editing.
- Conversational Agents in LangChain: A Medium article discusses the rise of conversational agents in LangChain, offering insights into their growing capabilities. Read the article.
- Data Science Workflow Automation Tool: Introducing a tool for automating LLM experimentation tailored to data science tasks, capable of handling data in various formats. Early users are invited for feedback, with 10 free credits offered on Label LM.
- Codestral model | LangChain | HuggingFace: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- Chatty Machines: The Rise of Conversational Agents in Langchain: Ankush k Singal
- Streamlit: no description found
- Exploring LLM Models with Hugging Face and Langchain Library on Google Colab: A Comprehensive Guide: Are you eager to dive into the world of language models (LLMs) and explore their capabilities using the Hugging Face and Langchain library…
- Rubik's AI - AI research assistant & Search Engine: no description found
LangChain AI ▷ #tutorials (4 messages):
- Explore LLMs with Hugging Face and LangChain: A guide shared on Medium explains how to explore language models like Llama3, Mistral, and Phi using the Hugging Face and LangChain library on Google Colab. Read the full guide here!.
- Build a Discord Bot with Langchain and Supabase: Learn to build a Python assistant Discord bot using LangChain and Supabase, powered by Cohere AI models. Full tutorial available at Coder Legion.
- Code Generation with Codestral LLM: Try the Codestral model from Mistral AI for code generation using LangChain, available on Kaggle. Check out the Kaggle notebook.
- Seeking LangGraph with Javascript Resources: A member inquired about resources to learn LangGraph with JavaScript, noting that there isn't much information available online.
- Codestral model | LangChain | HuggingFace: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- Exploring LLM Models with Hugging Face and Langchain Library on Google Colab: A Comprehensive Guide: Are you eager to dive into the world of language models (LLMs) and explore their capabilities using the Hugging Face and Langchain library…
- Build a Discord python assistant with plain Langchain: 1. Introduction Discord is one of the most widespread instant-messaging services, especially when it comes to developers: its structure and internal organization into servers and channels made it easy...
tinygrad (George Hotz) ▷ #general (42 messages🔥):
- Tinygrad challenges with Python; alternatives proposed: Members discussed their frustrations with Python in tinygrad and one expressed interest in writing a similar tool in Haskell. Another user proposed creating a new surface language using tinygrad’s uop end.
- Modern autotuning techniques and limitations: Discussions revolved around the limitations of older work, such as TVM’s autotuning, focusing on restricted tuning components like block sizes and pipelining, as mentioned by chhillee. The aim is to improve accuracy by reducing the prediction components.
- Exploring Taylor series for exp2 function issues: average.arch.user and georgehotz explored the feasibility of using Taylor series for approximating the exp2 function. Suggestions included range reduction and reconstruction techniques used in CPU implementations.
- Excitement over tinygrad 1.0 and upcoming features: georgehotz shared a tweet about tinygrad 1.0 aiming to outperform PyTorch in training GPT-2 on NVIDIA and AMD. The roadmap includes major changes, including FlashAttention, and removing numpy/tqdm dependencies.
- NVIDIA keynote misstep: sekstini shared a YouTube link to NVIDIA CEO Jensen Huang's keynote, expecting new product reveals like the 5090 GPU, but later expressed disappointment, calling it the "Worst 2 hours of my life."
- NVIDIA CEO Jensen Huang Keynote at COMPUTEX 2024: NVIDIA founder and CEO Jensen Huang will deliver a live keynote address ahead of COMPUTEX 2024 on June 2 at 7 p.m. in Taipei, Taiwan, outlining what’s next f...
- Tweet from the tiny corp (@__tinygrad__): A tinygrad 1.0 target: we will beat master PyTorch in speed at train_gpt2 on both NVIDIA and AMD. Big changes coming to the Linearizer to support things like FlashAttention, Mirage style.
tinygrad (George Hotz) ▷ #learn-tinygrad (8 messages🔥):
- ShapeTracker error resolved with jitter: A user shared an error "must be contiguous for assign ShapeTracker" and initially couldn't identify its cause despite using
.contiguous()before the loss function. They later figured out that the issue was related to the jit, and once resolved, "everything works now". - George Hotz suggests filing an issue: Despite the resolution, George Hotz encouraged the user to file a GitHub issue if tinygrad behaved unexpectedly, emphasizing the need for better error messages. He advised that providing more context or a minimal reproducible example would be beneficial.
- Noted case for improving error messages: Another member, qazalin, acknowledged that the error could be confusing and referred to a specific GitHub issue (##4813), hinting at possible improvements in error messaging. Both members expressed interest in refining the user experience with tinygrad.
OpenAccess AI Collective (axolotl) ▷ #general (29 messages🔥):
- Discussing Yuan2.0-M32 Model: A member shared Yuan2.0-M32, highlighting its Mixture-of-Experts architecture with 32 experts. Links to GitHub, WeChat, and the research paper were provided.
- Tokenization Issues in llama.cpp: A member referenced unresolved tokenization issue pages for llama.cpp, sharing two GitHub issues #7094 and #7271. They advised users to verify tokenization when using finetunes with llama.cpp.
- Axolotl on AMD: There was a brief discussion on whether Axolotl works with AMD; it requires some modifications. A GitHub PR was shared for an experimental ROCm install guide.
- Clarifying Axolotl's Purpose: A member mistakenly asked if Axolotl was launching a crypto token. Another clarified it's for training large language models, not cryptocurrency.
- NeurIPS Attendance: Discussion about attending NeurIPS, with one member mentioning their manuscript decision is still pending. They expressed interest in attending even without an accepted paper.
- IEITYuan/Yuan2-M32-hf · Hugging Face: no description found
- Add experimental install guide for ROCm by xzuyn · Pull Request #1550 · OpenAccess-AI-Collective/axolotl: Description This adds a guide on how to install Axolotl for ROCm users. Currently you need to install the packages included in pip install -e '.[deepspeed]' then uninstall torch, xformers, and...
- Issues · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- Issues · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #general-help (8 messages🔥):
- Dataset and categorization shared: A user shared a dataset for analyzing entities and categorizing them as persons, companies, or unions. The dataset is available on Hugging Face.
- Config for inference setup shared: The same user provided a config file used for inference with a Llama Lora model. Key settings include using meta-llama/Meta-Llama-3-8B as the base model and various LoRA-specific configurations.
- Incorrect template usage pointed out: Another user suggested that the issue might be due to not using the Alpaca chat template correctly.
- Specifying device for training: A user asked about specifying the device for training, and it was suggested to set the device by using os.environ["CUDA_VISIBLE_DEVICES"] = "1".
Link mentioned: Dmg02/names_textcat · Datasets at Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (7 messages):
- Set up wandb for QLoRA training: A member asked how to track parameters and loss values using wandb during a QLoRA training session. They received a detailed response on installing wandb, logging in, and configuring their training script, including adding specific configurations to their
qlora.ymlfile. - Configuration for QLoRA using Mistral-7B: A user shared their QLoRA training configuration for Mistral-7B-Instruct-v0.1, outlining detailed parameters, dataset paths, optimizer settings, and wandb integration details. They inquired if their configuration seemed correct and requested further validation.
- Using existing wandb project for tracking: The user emphasized they wanted to track their parameters and loss values using an existing wandb project instead of creating a new one. They asked for instructions on how to configure this setup properly in their training workflow.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Cohere ▷ #general (33 messages🔥):
- Research group seeks collaborators: A member asked if they could post about an open-source large transformer project looking for collaborators. They were advised to post in a specific channel dedicated to such topics.
- Support contact shared: A user seeking help from Cohere support staff was directed to contact support@cohere.com for assistance. Another member affirmed that queries could also be addressed in the Discord server itself.
- Chat API documentation issue identified: A member pointed out a broken dashboard link in the Cohere Chat API documentation's navbar. The issue was acknowledged and appreciated by another community member.
- Lost chat history inquiry: A member reported disappearing chat history and was advised to seek assistance in the designated support channel.
- Cohere's Aya praised: A user confirmed successful testing of Cohere's model Aya 23 using Python and llama.cpp. They shared positive feedback and sought permission to post code in the appropriate channel.
Link mentioned: Using the Chat API: no description found
Cohere ▷ #project-sharing (6 messages):
- Manifold Research seeks collaborators: A representative from Manifold Research invited collaborators for research on transformers for multimodality and control tasks, aiming to build a large-scale, open-source "Generalist" model. This initiative aims to reproduce the GATO architecture at scale, covering vision, language, VQA, control, and more.
- New Discord tag introduced: A member pointed out a new tag, and another shared excitement about the changes, providing a link to the explanation.
- Community appreciation: Members expressed appreciation for each other's contributions and participation in the community. One member humbly downplayed their significance, while another highlighted the value of community support.
OpenInterpreter ▷ #general (21 messages🔥):
- Custom Speech Implementation in Open Interpreter: A member has been "working on a branch of OI that replaces the stock speech with either Whisper or Piper," aiming to enhance it by reducing verbosity and speeding up speech initiation.
- Interpreters on Non-Ubuntu Systems Fail: One user shared their attempt of installing Open Interpreter on MX Linux, which failed due to missing Python, despite later success on Ubuntu after a regional internet outage.
- Confusion Over Agent-like Decision Making Code: A user asked where "agent-like decisions" are generated in the codebase. Another member clarified that these are defined by the LLM with the prompt found in the default system message.
- Marketing Query: A user asked about the marketing efforts for Open Interpreter, which was attributed to a specific individual.
- Issues with Running Gemini: Another member inquired about alternative methods for running Gemini on Open Interpreter, stating that the documentation's example "starts tweaking" and appears outdated.
- open-interpreter/interpreter/core/default_system_message.py at main · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
- Open Interactive, LLC.: GitHub is where Open Interactive, LLC. builds software.
- Bow Bowing GIF - Bow Bowing Michael Scott - Discover & Share GIFs: Click to view the GIF
OpenInterpreter ▷ #O1 (11 messages🔥):
- App to connect 01 server to iPhone sought after: A member asked if anyone had created an app to connect the 01 server to an iPhone. Another member shared a GitHub link to relevant code and encouraged creating the app.
- iOS TestFlight link shared for 01 server app: A member shared a TestFlight link for testing the app connecting the 01 server to an iPhone. They mentioned they had submitted the app to GitHub, though it hadn’t been accepted yet.
- TTS output possible on iOS app: There was a question on whether Text-to-Speech (TTS) output would be possible on the mobile app. It was confirmed that TTS functionality works on the iOS version of the app.
- Android version in progress: A member expressed disappointment over the lack of an Android version. However, it was clarified that a mobile version supporting Android is in progress and can be found on GitHub.
- Join the 01ForiOS beta: Available on iOS
- 01/software/source/clients/mobile at main · OpenInterpreter/01: The open-source language model computer. Contribute to OpenInterpreter/01 development by creating an account on GitHub.
OpenInterpreter ▷ #ai-content (1 messages):
cyanidebyte: https://github.com/v2rockets/Loyal-Elephie
Interconnects (Nathan Lambert) ▷ #news (16 messages🔥):
- Hugging Face Faces Unauthorized Access Issue: There was a recent incident where unauthorized access was detected on Hugging Face’s Spaces platform, potentially compromising some Spaces’ secrets. "We recommend you refresh any key or token and consider switching your HF tokens to fine-grained access tokens which are the new default." More details can be found here.
- AI2 Security Token Refresh: Despite being unaffected, AI2 is undertaking a major refresh of its tokens. natolambert indicated that his tokens updated automatically and mentioned that this incident has stirred more security discussions at AI2.
- Phi-3 Models Performance: Phi-3 Medium (14B) and Small (7B) models have been added to the @lmsysorg leaderboard. While Medium ranks near GPT-3.5-Turbo-0613, Small is close to Llama-2-70B, with the emphasis that "we cannot purely optimize for academic benchmarks".
- Donations Replace Bets: dylan lost a bet related to the performance of models, and the bets have been converted into donation-bets. natolambert expressed interest in the reputation gain from participating in these bets, stating, "Is a good cause".
- Space secrets security update: no description found
- Tweet from Philipp Schmid (@_philschmid): Phi-3 Medium (14B) and Small (7B) models are on the @lmsysorg leaderboard! 😍 Medium ranks near GPT-3.5-Turbo-0613, but behind Llama 3 8B. Phi-3 Small is close to Llama-2-70B, and Mistral fine-tunes. ...
Interconnects (Nathan Lambert) ▷ #ml-drama (9 messages🔥):
- Llama 3V Model Accusations: The discussion reveals that Llama 3V was allegedly a plagiarized model. It could be run using MiniCPM-Llama3-V 2.5's code and config with only changes in parameter names.
- Chris Manning Teardown: Chris Manning's criticism about owning up to mistakes reportedly tanked their career. A tweet from Chris Manning was shared to highlight these views.
- Investigation Concludes Plagiarism: Shared details from Ao Zhang's investigation showed that Llama3-V behaves similarly to MiniCPM-Llama3-V 2.5 with unrevealed experimental features.
- Giffmana's Reflection on VLM Community: Giffmana pointed out that trust within the VLM community was possibly shattered due to this incident. They speculated that the supposedly innovative Llama3-V model was stolen from MiniCPM with supporting receipts.
- Deleted Medium Article: A link to Aksh Garg's article on Medium about building Llama-3V was found to be a 404 "Page not found".
- Tweet from Christopher Manning (@chrmanning): How not to own your mistakes! https://aksh-garg.medium.com/llama-3v-building-an-open-source-gpt-4v-competitor-in-under-500-7dd8f1f6c9ee There’s good open-source work around @TsinghuaNLP, helping adv...
- no title found: no description found
- Tweet from Lucas Beyer (bl16) (@giffmana): This might have been the week-end where blind trust in VLM community kinda died? Remember the Llama3-V release (not from META) with much fanfare, matching Gemini, GPT4, Claude with <500$ training ...
Interconnects (Nathan Lambert) ▷ #random (7 messages):
- Master of the Cliffhanger Paywall: Members joked about needing to improve their paywall strategies. One highlighted that Dylan is a master of the cliffhanger paywall and mentioned an instance where he paywalled only one paragraph of a GPT-4 leak article.
- Karpathy's Twitter Activity Noticed: There was a humorous observation about Andre Karpathy's Twitter activity, noting he received three likes in a short span with the comment, "andrej is really out on twitter this AM". This led to laughter among the members.
Interconnects (Nathan Lambert) ▷ #memes (1 messages):
- Nathan Lambert shares a meme: A user humorously admits they "prolly stole the meme" but still found it worth sharing. They included a link to an Elon Musk tweet.
Link mentioned: Tweet from Elon Musk (@elonmusk): no description found
Mozilla AI ▷ #announcements (1 messages):
- Mozilla Builders Accelerator Wants You: The Mozilla Builders Accelerator is now accepting applications, focusing on Local AI which involves running AI models and applications on personal devices rather than the cloud. Benefits include up to $100,000 in funding, mentorship from experts, community support, and the chance to showcase projects through Mozilla’s channels. Learn more and apply.
Mozilla AI ▷ #llamafile (17 messages🔥):
- Stateful Load Balancer for llama.cpp might be useful: A member shared a GitHub link for paddler, a stateful load balancer custom-tailored for llama.cpp, and wondered about its applicability for llamafile.
- JSON Schema slows down sampling: Another member expressed concerns that sampling is slow even with caching and suspected it was due to the core server; they also confirmed that the JSON schema is broken as highlighted in this GitHub issue.
- OpenAI-Compatible Chat Completion Endpoint Works: A detailed discussion highlighted that the OpenAI-compatible chat endpoint
/v1/chat/completionsworks for local models, but there might be issues with model-specific roles which are usually managed by OpenAI's post-processing. - Pre-processing for Model Compatibility: The importance of pre-processing to ensure compatibility between different models was discussed, with specific mention of needing to adapt chat messages for certain models like Mistral-7b-instruct.
- Uniform Interface Across Models: The goal is to provide a uniform interface and functionality while offering a wide choice of models/providers, even if it requires pre-processing to handle heterogeneity among the models.
- llamafile/llama.cpp/server/README.md at main · Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
- GitHub - distantmagic/paddler: Stateful load balancer custom-tailored for llama.cpp: Stateful load balancer custom-tailored for llama.cpp - distantmagic/paddler
- Bug: JSON Schema Not Respected ? · Issue #7703 · ggerganov/llama.cpp: What happened? Given this JSON Schema { "$schema": "http://json-schema.org/draft-07/schema#", "type": "object", "properties": { "actions": {...
DiscoResearch ▷ #discolm_german (6 messages):
- Replay buffer method not implemented yet: A member noted that "it's quite close to Spaetzle!" and the paper "describes a replay buffer method but afaik that's not implemented (yet)." They planned to revisit it and mentioned an AI-generated Medium post describing the concept.
- Medium post on InstructLab sparks interest: Someone thanked for the Medium post and planned to "delve right into it," noting scores of various models including "phi-3-mini-instruct or phoenix (Spaetzle-v74 was just a test merge with v60 + merlinite)."
- Spaetzle models are different: There was some clarification about Spaetzle, with a member noting "Ah, I thought Spaetzle was one model but they are all different."
- Seeking German handwriting recognition models: A member asked for recommendations for a German handwriting recognition model, and another suggested "Kraken" and shared a link to an anonymous survey.
- InstructLab – “Ever imagined the ease of tuning pre-trained LLMs?: What is InstructLab ?
- OCR Recommender : no description found
Datasette - LLM (@SimonW) ▷ #llm (5 messages):
- Claude 3 lacks tokenizer: A member expressed confusion over the absence of a tokenizer for Claude 3, calling it "weird."
- Nomic Embed Model Troubleshooting: A user asked how to use the nomic-embed-text-v1 model with the
llm embedCLI command, noting thatllm modelsshows gpt4all models, but not this one. - Switch to Sentence Transformers Plugin: SimonW suggested using a different plugin, llm-sentence-transformers, for embedding tasks with the Nomic model.
- Example in Release Notes: SimonW pointed to the release notes for version 0.2 of llm-sentence-transformers as an example of how to install and use the nomic-embed-text-v1 model.
- GitHub - simonw/llm-sentence-transformers: LLM plugin for embeddings using sentence-transformers: LLM plugin for embeddings using sentence-transformers - simonw/llm-sentence-transformers
- Release 0.2 · simonw/llm-sentence-transformers: New llm sentence-transformers register --trust-remote-code option for installing models that require trust_remote_code=True. #14 Here's how to install nomic-embed-text-v1 using this option (which ...
AI21 Labs (Jamba) ▷ #jamba (5 messages):
- Jamba Instruct is compared with GPT-4: A member asked how Jamba Instruct compares to GPT-4, another stated that Jamba Instruct compares to Mixtral 8x7B in terms of performance.
- ML/DL Models Struggle with Function Composition: Another member shared a LinkedIn post discussing that current ML/DL models like SSMs, Transformers, CNNs, and RNNs cannot solve function composition, implying limitations in their reasoning capabilities. The post notes that Jamba was used for SSM experiments as well.
MLOps @Chipro ▷ #events (2 messages):
- AI4Health Medical Innovation up for grabs: An opportunity to join the Alliance AI4Health Medical Innovation Challenge Hackathon/Ideathon has been shared, boasting over $5k in prizes. This event focuses on constructing innovative AI solutions to tackle prevalent healthcare challenges, inspiring the next generation of medical innovators. Register here.
Link mentioned: Alliance Medical Innovation Challenge: Empowering global health through AI-based solutions: solving the problems of the future