[AINews] Mini, Nemo, Turbo, Lite - Smol models go brrr (GPT4o version)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Efficiency is all you need.
AI News for 7/17/2024-7/18/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (467 channels, and 2324 messages) for you. Estimated reading time saved (at 200wpm): 279 minutes. You can now tag @smol_ai for AINews discussions!
Like with public buses and startup ideas/asteroid apocalypse movies, many days you spend waiting for something to happen, and other days many things happen on the same day. This happens with puzzling quasi-astrological regularity in the ides of months - Feb 15, Apr 15, May 13, and now Jul 17:
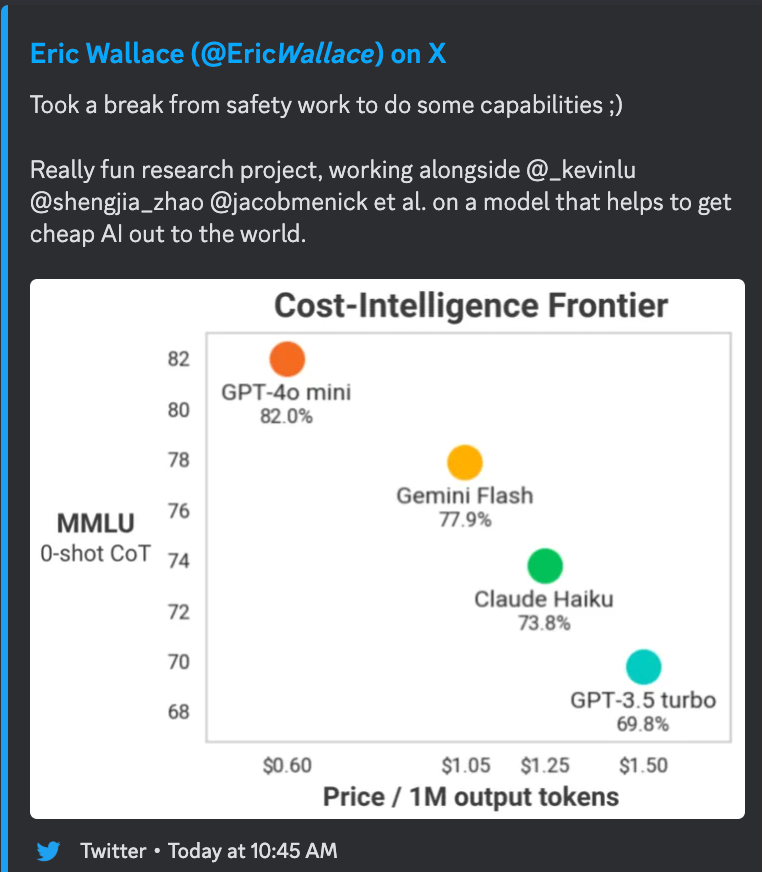
- GPT-4o-mini (HN):
- Pricing: $0.15/$0.60 per mtok (on a 3:1 input:output token blend price basis, HALF the price of Haiku, yet with Opus-level benchmarks (including on BigCodeBench-Hard), and 3.5% the price of GPT4o, yet ties with GPT4T on Lmsys )
- calculations: gpt 4omini (3 * 0.15 + 0.6)/4 = 0.26, claude haiku (3 * 0.25 + 1.25)/4 = 0.5, gpt 4o (5 * 3 + 15)/4 = 7.5, gpt4t was 2x the price of gpt4o
- sama is selling this as a 99% price reduction vs text-davinci-003
- much better utilization of long context than gpt3.5
- with 16k output tokens! (4x more than 4T/4o)
- "order of magnitude faster" - (~100tok/s, a bit slower than Haiku)
- "with support for text, image, video and audio inputs AND OUTPUTS coming in the future"
- first model trained on new instruction hierarchy framework (our coverage here)... but already jailbroken
- @gdb says it is due to demand from developers
- ChatGPT Voice mode alpha promised this month
- Criticized vs Claude 3.5 Sonnet
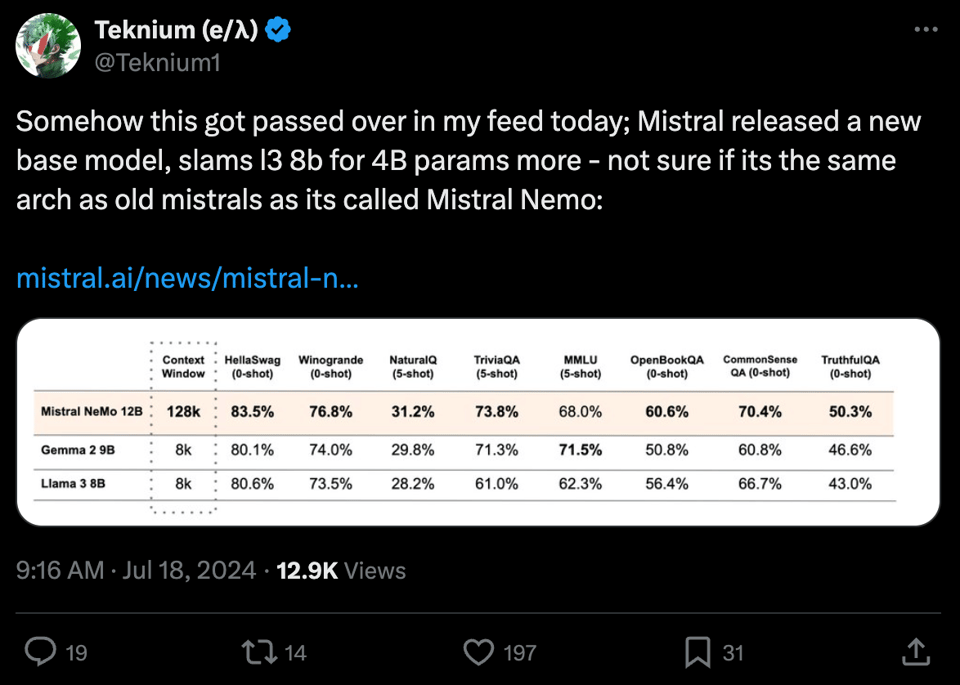
- Mistral Nemo (HN): a 12B model trained in collaboration with Nvidia (Nemotron, our coverage here). Mistral NeMo supports a context window of 128k tokens (the highest natively trained at this level, with new code/multilingual-friendly tokenizer), comes with a FP8 aligned checkpoint, and performs extremely well on all benchmarks ("slams llama 3 8b for 4B more params").
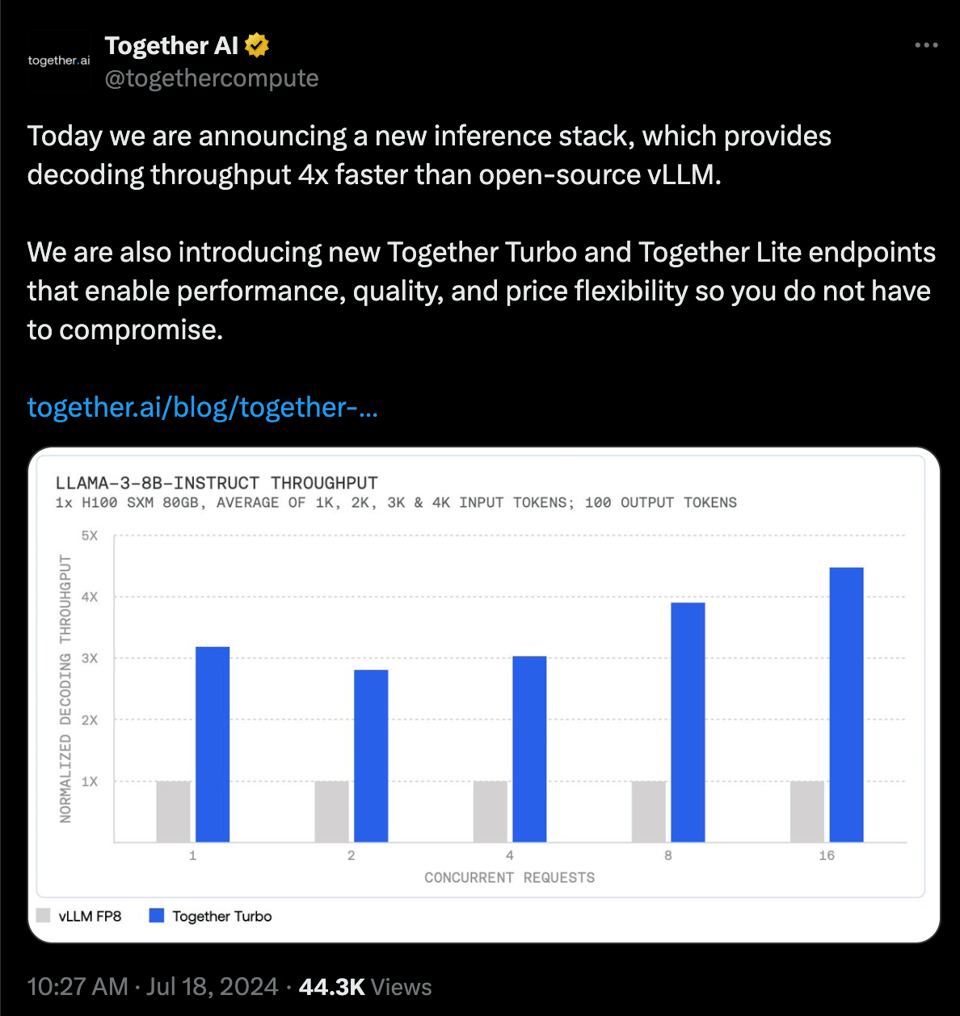
- Together Lite and Turbo (fp8/int4 quantizations of Llama 3), 4x throughput over vLLM
- turbo (fp8) - messaging is speed: 400 tok/s
- lite (int4) - messaging is cost: $0.1/mtok. "the lowest cost for Llama 3", "6x lower cost than GPT-4o-mini."
- DeepSeek V2 open sourced (our coverage of the paper when it was released API-only)
- note that at least 5 more unreleased models are codenamed on Lmsys
- with some leaks on Llama 4
As for why things like these bunch up - either Mercury is in retrograde, or ICML is happening next week, with many of these companies presenting/hiring, with Llama 3 400b expected to be released on the 23rd.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- HuggingFace Discord
- CUDA MODE Discord
- Stability.ai (Stable Diffusion) Discord
- Eleuther Discord
- LM Studio Discord
- Nous Research AI Discord
- Latent Space Discord
- OpenAI Discord
- Interconnects (Nathan Lambert) Discord
- OpenRouter (Alex Atallah) Discord
- Modular (Mojo 🔥) Discord
- Cohere Discord
- Perplexity AI Discord
- LangChain AI Discord
- LlamaIndex Discord
- OpenInterpreter Discord
- OpenAccess AI Collective (axolotl) Discord
- LLM Finetuning (Hamel + Dan) Discord
- LAION Discord
- Torchtune Discord
- tinygrad (George Hotz) Discord
- PART 2: Detailed by-Channel summaries and links
- Unsloth AI (Daniel Han) ▷ #general (245 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (11 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (84 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #research (7 messages):
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (222 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (1 messages):
- HuggingFace ▷ #cool-finds (7 messages):
- HuggingFace ▷ #i-made-this (23 messages🔥):
- HuggingFace ▷ #reading-group (5 messages):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #NLP (5 messages):
- CUDA MODE ▷ #general (6 messages):
- CUDA MODE ▷ #triton (1 messages):
- CUDA MODE ▷ #torch (37 messages🔥):
- CUDA MODE ▷ #algorithms (1 messages):
- CUDA MODE ▷ #beginner (6 messages):
- CUDA MODE ▷ #torchao (2 messages):
- CUDA MODE ▷ #triton-puzzles (2 messages):
- CUDA MODE ▷ #llmdotc (159 messages🔥🔥):
- CUDA MODE ▷ #lecture-qa (9 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (213 messages🔥🔥):
- Eleuther ▷ #announcements (1 messages):
- Eleuther ▷ #general (72 messages🔥🔥):
- Eleuther ▷ #research (108 messages🔥🔥):
- Eleuther ▷ #interpretability-general (1 messages):
- Eleuther ▷ #lm-thunderdome (14 messages🔥):
- LM Studio ▷ #💬-general (59 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (23 messages🔥):
- LM Studio ▷ #🧠-feedback (1 messages):
- LM Studio ▷ #📝-prompts-discussion-chat (1 messages):
- LM Studio ▷ #⚙-configs-discussion (1 messages):
- LM Studio ▷ #🎛-hardware-discussion (23 messages🔥):
- LM Studio ▷ #🧪-beta-releases-chat (3 messages):
- LM Studio ▷ #amd-rocm-tech-preview (4 messages):
- LM Studio ▷ #model-announcements (1 messages):
- LM Studio ▷ #🛠-dev-chat (14 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #datasets (1 messages):
- Nous Research AI ▷ #interesting-links (3 messages):
- Nous Research AI ▷ #general (115 messages🔥🔥):
- Nous Research AI ▷ #world-sim (6 messages):
- Latent Space ▷ #ai-general-chat (121 messages🔥🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (66 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (15 messages🔥):
- OpenAI ▷ #prompt-engineering (20 messages🔥):
- OpenAI ▷ #api-discussions (20 messages🔥):
- Interconnects (Nathan Lambert) ▷ #events (1 messages):
- Interconnects (Nathan Lambert) ▷ #news (74 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (5 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (21 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (9 messages🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (97 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (7 messages):
- Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
- Modular (Mojo 🔥) ▷ #ai (7 messages):
- Modular (Mojo 🔥) ▷ #mojo (35 messages🔥):
- Modular (Mojo 🔥) ▷ #max (5 messages):
- Modular (Mojo 🔥) ▷ #nightly (13 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo-marathons (16 messages🔥):
- Cohere ▷ #general (52 messages🔥):
- Cohere ▷ #project-sharing (31 messages🔥):
- Perplexity AI ▷ #general (63 messages🔥🔥):
- Perplexity AI ▷ #sharing (5 messages):
- Perplexity AI ▷ #pplx-api (5 messages):
- LangChain AI ▷ #general (39 messages🔥):
- LangChain AI ▷ #langserve (2 messages):
- LangChain AI ▷ #langchain-templates (1 messages):
- LangChain AI ▷ #share-your-work (1 messages):
- LangChain AI ▷ #tutorials (1 messages):
- LlamaIndex ▷ #blog (4 messages):
- LlamaIndex ▷ #general (21 messages🔥):
- LlamaIndex ▷ #ai-discussion (2 messages):
- OpenInterpreter ▷ #general (19 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (9 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general-help (7 messages):
- LLM Finetuning (Hamel + Dan) ▷ #general (7 messages):
- LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (1 messages):
- LAION ▷ #general (2 messages):
- LAION ▷ #research (6 messages):
- Torchtune ▷ #dev (6 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Models and Architectures
- Llama 3 and Mistral models: @main_horse noted Deepseek founder Liang Wenfeng stated they will not go closed-source, believing a strong technical ecosystem is more important. @swyx mentioned on /r/LocalLlamas, Gemma 2 has evicted Llama/Mistral/Phi from the top spot, matching @lmsysorg results after filtering for larger/closed models.
- Anthropic's approach: @abacaj noted while OpenAI releases papers on dumbing down smart model outputs, Anthropic releases models to use, with bigger ones expected later this year.
- Deepseek Coder V2 and MLX LM: @awnihannun shared the latest MLX LM supports DeepSeek Coder V2, with pre-quantized models in the MLX Hugging Face community. A 16B model runs fast on an M2 Ultra.
- Mistral AI's Mathstral: @rasbt was positively surprised by Mistral AI's Mathstral release, porting it to LitGPT with good first impressions as a case study for small to medium-sized specialized LLMs.
- Gemini model from Google: @GoogleDeepMind shared latest research on how multimodal models like Gemini are helping robots become more useful.
- Yi-Large: @01AI_Yi noted Yi-Large continues to rank in the top 10 models overall on the #LMSYS leaderboard.
Open Source and Closed Source Debate
- Arguments for open source: @RichardMCNgo argued for a strong prior favoring open source, given its success driving tech progress over decades. It's been key for alignment progress on interpretability.
- Concerns about open source: @RichardMCNgo noted a central concern is allowing terrorists to build bioweapons, but believes it's easy to be disproportionately scared of terrorism compared to risks like "North Korea becomes capable of killing billions."
- Ideal scenario and responsible disclosure: @RichardMCNgo stated in an ideal world, open source would lag a year or two behind the frontier, giving the world a chance to evaluate and prepare for big risks. If open-source seems likely to catch up to or surpass closed source models, he'd favor mandating a "responsible disclosure" period.
AI Agents and Frameworks
- Rakis data analysis: @hrishioa provided a primer on how an inference request is processed in Rakis to enable trustless distributed inference, using techniques like hashing, quorums, and embeddings clustering.
- Multi-agent concierge system: @llama_index shared an open-source repo showing how to build a complex, multi-agent tree system to handle customer interactions, with regular sub-agents plus meta agents for concierge, orchestration and continuation functions.
- LangChain Improvements: @LangChainAI introduced a universal chat model initializer to interface with any model, setting params at init or runtime. They also added ability to dispatch custom events and edit graph state in agents.
- Guardrails Server: @ShreyaR announced Guardrails Server for easier cloud deployment of Guardrails, with OpenAI SDK compatibility, cross language support, and other enhancements like Guardrails Watch and JSON Generation for Open Source LLMs.
Prompting Techniques and Data
- Prompt Report survey: @labenz shared a 3 minute video on the top 6 recommendations for few-shot prompting best practices from The Prompt Report, a 76-page survey of 1,500+ prompting papers.
- Evol-Instruct: @_philschmid detailed how Auto Evol-Instruct from @Microsoft and @WizardLM_AI automatically evolves synthetic data to improve quality and diversity without human expertise, using an Evol LLM to create instructions and an Optimizer LLM to critique and optimize the process.
- Interleaved data for Llava-NeXT: @mervenoyann shared that training Llava-NeXT-Interleave, a new vision language model, on interleaved image, video and 3D data increases results across all benchmarks and enables task transfer.
Memes and Humor
- @swyx joked "Build picks and shovels in a gold rush, they said" in response to many trying to sell AI shovels vs mine gold.
- @vikhyatk quipped "too many people trying to sell shovels, not enough people trying to actually mine gold".
- @karpathy was amused to learn FFmpeg is not just a multimedia toolkit but a movement.
- @francoisfleuret shared a humorous exchange with GPT about solving a puzzle involving coloring objects.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. EU Regulations Limiting AI Model Availability
- Andrej Karpathy is launching new AI Education Company called Eureka Labs (Score: 239, Comments: 54): Andrej Karpathy has announced the launch of Eureka Labs, a new AI education company. The company's inaugural product is LLM101n, touted as the "world's best AI course," with course materials available on GitHub. Eureka Labs can be found at www.eurekalabs.ai.
- Thanks to regulators, upcoming Multimodal Llama models won't be available to EU businesses (Score: 341, Comments: 138): Meta's multimodal Llama models will not be available to EU businesses due to regulatory challenges. The issue stems from GDPR compliance for training models using data from European customers, not the upcoming AI Act. Meta claims it notified 2 billion EU users about data usage for training, offering opt-outs, but was ordered to pause training on EU data in June after receiving minimal feedback from regulators.
Theme 2. Advancements in LLM Quantization Techniques
- New LLMs Quantization Algorithm EfficientQAT, which makes 2-bit INT llama-2-70B outperforms FP llama-2-13B with less memory. (Score: 130, Comments: 51): EfficientQAT, a new quantization algorithm, successfully pushes the limits of uniform (INT) quantization for LLMs. The algorithm produces a 2-bit Llama-2-70B model on a single A100-80GB GPU in 41 hours, achieving less than 3% accuracy degradation compared to full precision (69.48 vs. 72.41). Notably, this INT2 quantized 70B model outperforms the Llama-2-13B model in accuracy (69.48 vs. 67.81) while using less memory (19.2GB vs. 24.2GB), with the code available on GitHub.
- Introducing Spectra: A Comprehensive Study of Ternary and FP16 Language Models (Score: 102, Comments: 14): Spectra LLM suite introduces 54 language models, including TriLMs (Ternary) and FloatLMs (FP16), ranging from 99M to 3.9B parameters and trained on 300B tokens. The study reveals that TriLMs at 1B+ parameters consistently outperform FloatLMs and their quantized versions for their size, with the 3.9B TriLM matching the performance of a 3.9B FloatLM in commonsense reasoning and knowledge benchmarks despite being smaller in bit size than an 830M FloatLM. However, the research also notes that TriLMs exhibit similar levels of toxicity and stereotyping as their larger FloatLM counterparts, and lag behind in perplexity on validation splits and web-based corpora.
- Llama.cpp Integration Explored: TriLM models on Hugging Face are currently unpacked. Developers discuss potential support for BitnetForCausalLM in llama.cpp and a guide for packing and speeding up TriLMs is available in the SpectraSuite GitHub repository.
- Training Costs and Optimization: The cost of training models like the 3.9B TriLM on 300B tokens is discussed. Training on V100 GPUs with 16GB RAM required horizontal scaling, leading to higher communication overhead compared to using H100s. The potential benefits of using FP8 ops on Hopper/MI300Series GPUs are mentioned.
- Community Reception and Future Prospects: Developers express enthusiasm for the TriLM results and anticipate more mature models. Interest in scaling up to a 12GB model is mentioned, and there are inquiries about finetuning these models on other languages, potentially using platforms like Colab.
Theme 3. Comparative Analysis of LLMs for Specific Tasks
- Best Story Writing LLMs: SFW and NSFW Options (Score: 61, Comments: 24): Best Story Writing LLMs: SFW and NSFW Compared The post compares various Large Language Models (LLMs) for story writing, categorizing them into SFW and NSFW options. For SFW content, Claude 3.5 Sonnet is recommended as the best option, while Command-R+ is highlighted as the top choice for NSFW writing, with the author noting it performs well for both explicit and non-explicit content. The comparison includes details on context handling, instruction following, and writing quality for models such as GPT-4.0, Gemini 1.5 pro, Wizard LM 8x22B, and Midnight Miqu, among others.
- Cake: A Rust Distributed LLM inference for mobile, desktop and server. (Score: 55, Comments: 16): Cake is a Rust-based distributed LLM inference framework designed for mobile, desktop, and server platforms. The project aims to provide a high-performance, cross-platform solution for running large language models, leveraging Rust's safety and efficiency features. While still in development, Cake promises to offer a versatile tool for deploying LLMs across various devices and environments.
- Post-apocalyptic LLM gatherings imagined:• Homeschooled316 envisions communities connecting old iPhone 21s to a Cake host for distributed LLM inference in a wasteland. Users ask about marriage and plagues, risking irrelevant responses praising defunct economic policies.
- Key_Researcher2598 expresses excitement about Cake, noting Rust's expansion from web dev (WASM) to game dev (Bevy) and now machine learning. They plan to compare Cake with Ray Serve for Python.
Theme 4. Innovative AI Education and Development Platforms
- Andrej Karpathy is launching new AI Education Company called Eureka Labs (Score: 239, Comments: 54): Andrej Karpathy has announced the launch of Eureka Labs, a new AI education company. Their inaugural product, LLM101n, is touted as the "world's best AI course" and is available on their website www.eurekalabs.ai with the course repository hosted on GitHub.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. AI in Comic and Art Creation
- [/r/OpenAI] My friend made an AI generated music video for my ogre album, did he nail it? (Score: 286, Comments: 71): AI-generated music video showcases a surreal visual interpretation of an "ogre album". The video features a blend of fantastical and grotesque imagery, including ogre-like creatures, mystical landscapes, and otherworldly scenes that appear to sync with the music. While the specific AI tools used are not mentioned, the result demonstrates the creative potential of AI in producing unique and thematically coherent music videos.
- [/r/singularity] What are they cooking? (Score: 328, Comments: 188): AI-generated art controversy: A recent image shared on social media depicts an AI-generated artwork featuring a distorted human figure cooking in a kitchen. The image has sparked discussions about the ethical implications and artistic value of AI-created art, with some viewers finding it unsettling while others appreciate its unique aesthetic.
- [/r/StableDiffusion] Me, Myself, and AI (Score: 276, Comments: 57): "Me, Myself, and AI": This post describes an artist's workflow integrating AI tools for comic creation. The process involves using Midjourney for initial character designs and backgrounds, ChatGPT for story development and dialogue, and Photoshop for final touches and panel layouts, resulting in a seamless blend of AI-assisted and traditional artistic techniques.
- Artist's AI Integration Sparks Debate: The artist's workflow incorporating Stable Diffusion since October 2022 has led to mixed reactions. Some appreciate the innovative approach, while others accuse the artist of "laziness and immorality". The artist plans to continue creating comics to let the work speak for itself.
- AI as a Tool in Art: Many commenters draw parallels between AI-assisted art and other technological advancements in creative fields. One user compares it to the transition from film to digital photography, suggesting that AI-assisted workflows will become industry standard in the coming years.
- Workflow Insights: The artist reveals using a pony model as base and fine-tuning B&W and color Loras based on their older work. They advise "collaborating" on character design with the models to create more intuitive designs that work well with AI tools.
- Artistic Merit Debate: Several comments challenge the notion that "art requires effort", arguing that the end result should be the main focus. Some suggest that AI tools are similar to photo editing in professional photography, where the real work happens after the initial creation.
Theme 2. Real-Time AI Video Generation with Kling AI
- [/r/OpenAI] GPT-4o in your webcam (Score: 312, Comments: 45): GPT-4o in your webcam integrates GPT-4 Vision with a webcam for real-time interaction. This setup allows users to show objects to their computer camera and receive immediate responses from GPT-4, enabling a more interactive and dynamic AI experience. The integration demonstrates the potential for AI to process and respond to visual inputs in real-time, expanding the possibilities for human-AI interaction beyond text-based interfaces.
- [/r/StableDiffusion] Hiw to do this? (Score: 648, Comments: 109): Chinese Android app reportedly allows users to create AI-generated videos of celebrities meeting their younger selves. The process is described as simple, requiring users to input two photos and press a button, though specific details about the app's name or functionality are not provided in the post.
- "Kling AI" reportedly powers this Chinese app, allowing users to create videos of celebrities meeting their younger selves. Many commenters noted the intimate body language between the pairs, with one user joking, "Why do half of them look like they're 10 seconds away from making out."
- Stallone's Self-Infatuation Steals the Show - Several users highlighted Sylvester Stallone's interaction with his younger self as particularly intense, with comments like "Damn Stallone's horny af" and "Stallone gonna fuck himself". This sparked a philosophical debate about whether intimate acts with oneself across time would be considered gay or masturbation.
- Missed Opportunities and Emotional Impact - Some users suggested improvements, like having Harrison Ford look suspiciously at his younger self. One commenter expressed surprise at feeling emotionally moved by the concept, particularly appreciating the "cultivate kindness for yourself" message conveyed through celebrity pairings.
- Technical Speculation and Ethical Concerns - Discussion touched on the app's potential hardware requirements, with one user suggesting it would need "like a thousand GPUs". Others debated the implications of such technology, with some praising Chinese
- [/r/StableDiffusion] Really nice usage of GPU power, any idea how this is made? (Score: 279, Comments: 42): Real-time AI video generation showcases impressive utilization of GPU power. The video demonstrates fluid, dynamic content creation, likely leveraging advanced machine learning models and parallel processing capabilities of modern GPUs. While the specific implementation details are not provided, this technology potentially combines generative AI techniques with high-performance computing to achieve real-time video synthesis.
- SDXL turbo with a 1-step scheduler can achieve real-time performance on a 4090 GPU at 512x512 resolution. Even a 3090 GPU can handle this in real-time, according to user tests.
- Tech Stack Breakdown: Commenters suggest the setup likely includes TouchDesigner, Intel Realsense or Kinect, OpenPose, and ControlNet feeding into SDXL. Some speculate it's a straightforward img2img process without ControlNet.
- Streamlined Workflow: The process likely involves filming the actor, generating an OpenPose skeleton, and then forming images based on this skeleton. StreamDiffusion integration with TouchDesigner is mentioned as a "magical" solution. - Credit Where It's Due: The original video is credited to mans_o on Instagram, available at https://www.instagram.com/p/C9KQyeTK2oN/?img_index=1.
Theme 3. OpenAI's Sora Video Generation Model
- [/r/singularity] New Sora video (Score: 367, Comments: 128): OpenAI's Sora has released a new video demonstrating its advanced AI video generation capabilities. The video showcases Sora's ability to create highly detailed and realistic scenes, including complex environments, multiple characters, and dynamic actions. This latest demonstration highlights the rapid progress in AI-generated video technology and its potential applications in various fields.
- Commenters predict Sora's technology will be very good within a year and indistinguishable from reality in 2-5 years. Some argue it's already market-ready for certain applications, while others point out remaining flaws.
- Uncanny Valley Challenges: Users note inconsistencies in physics, movement, and continuity in the demo video. Issues include strange foot placement, dreamlike motion, and rapid changes in character appearance. Some argue these problems may be harder to solve than expected.
- Potential Applications and Limitations: Discussion focuses on AI's role in CGI and low-budget productions. While not ready for live-action replacement, it could revolutionize social media content and background elements in films. However, concerns about OpenAI's limited public access were raised. - Rapid Progress Astonishes: Many express amazement at the speed of AI video advancement, comparing it to earlier milestones like thispersondoesnotexist.com. The leap from early demos to Sora's capabilities is seen as remarkable, despite ongoing imperfections.
Theme 4. AI Regulation and Deployment Challenges
- [/r/singularity] Meta won't bring future multimodal AI models to EU (Score: 341, Comments: 161): Meta has announced it will not release future multimodal AI models in the European Union due to regulatory uncertainty. The company is concerned about the EU AI Act, which is still being finalized and could impose strict rules on AI systems. This decision affects Meta's upcoming large language models and generative AI features, potentially leaving EU users without access to these advanced AI technologies.
- [/r/OpenAI] Sam Altman says $27 million San Francisco mansion is a complete and utter ‘lemon’ (Score: 244, Comments: 155): Sam Altman, CEO of OpenAI, expressed frustration with his $27 million San Francisco mansion, calling it a complete "lemon" in a recent interview. Despite the property's high price tag and prestigious location in Russian Hill, Altman revealed that the house has been plagued with numerous issues, including problems with the pool, heating system, and electrical wiring. This situation highlights the potential pitfalls of high-end real estate purchases, even for tech industry leaders with significant resources.
- [/r/singularity] Marc Andreessen and Ben Horowitz say that when they met White House officials to discuss AI, the officials said they could classify any area of math they think is leading in a bad direction to make it a state secret and "it will end" (Score: 353, Comments: 210): Marc Andreessen and Ben Horowitz report that White House officials claimed they could classify any area of mathematics as a state secret if they believe it's leading in an undesirable direction for AI development. The officials allegedly stated that by doing so, they could effectively end progress in that mathematical field. This revelation suggests a potential government strategy to control AI advancement through mathematical censorship.
AI Discord Recap
As we do on frontier model release days, there are two versions of today's Discord summaries. You are reading the one where channel summaries are generated by GPT-4o, then the channel summaries are rolled up in to {4o/mini/sonnet/opus} summaries of summaries. See archives for the GPT-4o-mini pairing for your own channel-by-channel summary comparison.
Claude 3 Sonnet
1. New AI Model Launches and Capabilities
- GPT-4o Mini: OpenAI's Cost-Effective Powerhouse: OpenAI unveiled GPT-4o mini, a cheaper and smarter model than GPT-3.5 Turbo, scoring 82% on MMLU with a 128k context window and priced at $0.15/M input, $0.60/M output.
@AndrewCurran_confirmed GPT-4o mini is replacing GPT-3.5 Turbo for free and paid users, being significantly cheaper while improving on GPT-3.5's capabilities, though lacking some functionalities like image support initially.
- Mistral NeMo: NVIDIA Collaboration Unleashes Power: Mistral AI and NVIDIA released Mistral NeMo, a 12B model with 128k context window, offering state-of-the-art reasoning, world knowledge, and coding accuracy under the Apache 2.0 license.
- Mistral NeMo supports FP8 inference without performance loss and outperforms models like Gemma 2 9B and Llama 3 8B, with pre-trained base and instruction-tuned checkpoints available.
- DeepSeek V2 Ignites Pricing War in China: DeepSeek's V2 model has slashed inference costs to just 1 yuan per million tokens, sparking a competitive pricing frenzy among Chinese AI companies with its revolutionary MLA architecture and significantly reduced memory usage.
- Earning the moniker of China's AI Pinduoduo, DeepSeek V2 has been praised for its cost-cutting innovations, potentially disrupting the global AI landscape with its affordability.
2. Advancements in Large Language Model Techniques
- Codestral Mamba Slithers with Linear Inference: The newly introduced Codestral Mamba promises a leap in code generation capabilities with its linear time inference and ability to handle infinitely long sequences, co-developed by Albert Gu and Tri Dao.
- Aiming to enhance coding productivity, Mamba aims to outperform existing SOTA transformer-based models while providing rapid responses regardless of input length.
- Prover-Verifier Games Boost LLM Legibility: A new technique called Prover-Verifier Games has been shown to improve the legibility and interpretability of language model outputs, as detailed in an associated paper.
- By enhancing the explainability of LLM reasoning, this approach aims to address a key challenge in developing more transparent and trustworthy AI systems.
3. Hardware Optimization and AI Performance
- Resizable BAR's Minimal Impact on LLMs: Discussions revealed that the Resizable BAR feature, aimed at enhancing GPU performance, has negligible effects on LLM operations which rely more heavily on tensor cores and VRAM bandwidth.
- While model loading and multi-GPU setups were speculated to potentially benefit, the community consensus leaned towards Resizable BAR having minimal impact on core LLM workloads.
- Lubeck Outpaces MKL with LLVM Efficiency: The Lubeck numerical library has demonstrated superior performance over MKL (Math Kernel Library), attributed to its differential LLVM IR generation potentially aided by Mir's LLVM-Accelerated Generic Numerical Library.
- A benchmark comparison highlighted Lubeck's speed advantages, sparking discussions on leveraging LLVM for optimized numerical computing.
4. AI Coding Assistants and Integrations
- Codestral 22B Request for OpenRouter: A user requested the addition of Codestral 22B, an open code model performing on par with state-of-the-art transformer-based models, to OpenRouter, sharing the model card for context.
- The Codestral Mamba showcases competitive performance in code generation tasks, fueling interest in its integration with popular AI platforms like OpenRouter.
- Groq Models Dominate Function Calling Leaderboard: Groq's new tool use models, including Llama-3-Groq-8B and Llama-3-Groq-70B, have achieved top scores on the Berkeley Function Calling Leaderboard with 89.06% and 90.76% respectively.
- Optimized for tool use and function calling capabilities, these models demonstrate Groq's proficiency in developing AI assistants adept at executing complex multi-step tasks.
Claude 3.5 Sonnet
1. AI Model Launches and Upgrades
- DeepSeek's V2 Sparks Price War: DeepSeek launched DeepSeek V2, dramatically lowering inference costs to 1 yuan per million tokens, igniting a price war among Chinese AI companies. The model introduces a new MLA architecture that significantly reduces memory usage.
- Described as China's AI Pinduoduo, DeepSeek V2's cost-effectiveness and architectural innovations position it as a disruptive force in the AI market. This launch highlights the intensifying competition in AI model development and deployment.
- Mistral NeMo's 12B Powerhouse: Mistral AI and NVIDIA unveiled Mistral NeMo, a 12B parameter model boasting a 128k token context window and state-of-the-art reasoning capabilities. The model is available under the Apache 2.0 license with pre-trained and instruction-tuned checkpoints.
- Mistral NeMo supports FP8 inference without performance loss and is positioned as a drop-in replacement for Mistral 7B. This collaboration between Mistral AI and NVIDIA showcases the rapid advancements in model architecture and industry partnerships.
- OpenAI's GPT-4o Mini Debut: OpenAI introduced GPT-4o mini, touted as their most intelligent and cost-efficient small model, scoring 82% on MMLU. It's priced at $0.15 per million input tokens and $0.60 per million output tokens, making it significantly cheaper than GPT-3.5 Turbo.
- The model supports both text and image inputs with a 128k context window, available to free ChatGPT users and various tiers of paid users. This release demonstrates OpenAI's focus on making advanced AI more accessible and affordable for developers and businesses.
2. Open-Source AI Advancements
- LLaMA 3's Turbo-Charged Variants: Together AI launched Turbo and Lite versions of LLaMA 3, offering faster inference and cheaper costs. The LLaMA-3-8B Lite is priced at $0.10 per million tokens, while the Turbo version delivers up to 400 tokens/s.
- These new variants aim to make LLaMA 3 more accessible and efficient for various applications. The community is also buzzing with speculation about a potential LLaMA 3 400B release, which could significantly impact the open-source AI landscape.
- DeepSeek-V2 Tops Open-Source Charts: DeepSeek announced that their DeepSeek-V2-0628 model is now open-sourced, ranking No.1 in the open-source category on the LMSYS Chatbot Arena Leaderboard. The model excels in various benchmarks, including overall performance and hard prompts.
- This release highlights the growing competitiveness of open-source models against proprietary ones. It also underscores the community's efforts to create high-performance, freely accessible AI models for research and development.
3. AI Safety and Ethical Challenges
- GPT-4's Past Tense Vulnerability: A new paper revealed a significant vulnerability in GPT-4, where reformulating harmful requests in the past tense increased the jailbreak success rate from 1% to 88% with 20 reformulation attempts.
- This finding highlights potential weaknesses in current AI safety measures like SFT, RLHF, and adversarial training. It raises concerns about the robustness of alignment techniques and the need for more comprehensive safety strategies in AI development.
- Meta's EU Multimodal Model Exclusion: Meta announced plans to release a multimodal Llama model in the coming months, but it won't be available in the EU due to regulatory uncertainties, as reported by Axios.
- This decision highlights the growing tension between AI development and regulatory compliance, particularly in the EU. It also raises questions about the potential for a technological divide and the impact of regional regulations on global AI advancement.
Claude 3 Opus
1. Mistral NeMo 12B Model Release
- Mistral & NVIDIA Collab on 128k Context Model: Mistral NeMo, a 12B model with a 128k token context window, was released in collaboration with NVIDIA under the Apache 2.0 license, as detailed in the official release notes.
- The model promises state-of-the-art reasoning, world knowledge, and coding accuracy in its size category, being a drop-in replacement for Mistral 7B with support for FP8 inference without performance loss.
- Mistral NeMo Outperforms Similar-Sized Models: Mistral NeMo's performance has been compared to other models, with some discrepancies noted in benchmarks like 5-shot MMLU scores against Llama 3 8B as reported by Meta.
- Despite these inconsistencies, Mistral NeMo is still seen as a strong contender, outperforming models like Gemma 2 9B and Llama 3 8B in various metrics according to the release announcement.
2. GPT-4o Mini Launch & Jailbreak
- GPT-4o Mini: Smarter & Cheaper Than GPT-3.5: OpenAI released GPT-4o mini, touted as the most capable and cost-efficient small model, scoring 82% on MMLU and available for free and paid users as announced by Andrew Curran.
- The model is priced at 15¢ per M token input and 60¢ per M token output with a 128k context window, making it significantly cheaper than GPT-3.5 Turbo while lacking some capabilities of the full GPT-4o like image support.
- GPT-4o Mini's Safety Mechanism Jailbroken: A newly implemented safety mechanism in GPT-4o mini named 'instruction hierarchy' has been jailbroken according to Elder Plinius, allowing it to output restricted content.
- This jailbreak reveals vulnerabilities in OpenAI's latest defense approach, raising concerns about the robustness of their safety measures and potential for misuse.
3. Advances in AI Training & Deployment
- Tekken Tokenizer Tops Llama 3 in Efficiency: The Tekken tokenizer model has demonstrated superior performance compared to the Llama 3 tokenizer, with 30-300% better compression across various languages including Chinese, Korean, Arabic, and source code.
- This improved efficiency positions Tekken as a strong contender for NLP tasks, offering significant advantages in reducing computational costs and enabling more compact model representations.
- CUDA on AMD GPUs via New Compiler: A new compiler for AMD GPUs has enabled CUDA support on RDNA 2 and RDNA 3 architectures, with the RX 7800 confirmed to be working, as shared in a Reddit post.
- Community members expressed interest in testing this setup in llama.cpp to compare performance against the ROCm implementation, with tools like ZLUDA and SCALE mentioned as alternatives for running CUDA on AMD hardware.
GPT4O (gpt-4o-2024-05-13)
1. Mistral NeMo Release
- Mistral NeMo's Impressive Entrance: The Mistral NeMo model, a 12B parameter model developed in collaboration with NVIDIA, boasts a 128k token context window and superior reasoning capabilities.
- Pre-trained and instruction-tuned checkpoints are available under the Apache 2.0 license, promising state-of-the-art performance in reasoning, coding accuracy, and world knowledge.
- Mistral NeMo Performance Comparison: A discrepancy in the 5-shot MMLU score for Llama 3 8B was noted, with Mistral reporting 62.3% versus Meta's 66.6%, raising questions about the reported performance.
- This discrepancy, along with potential issues in the TriviaQA benchmark, sparked discussions on the reliability of these metrics.
2. AI Hardware Optimization
- Kernel Quest: Navigating Parameter Limits: AI Engineers tackled the CUDA 4k kernel parameter size limit by favoring pointers to pass extensive data structures, with the migration from CPU to GPU global memory made compulsory for such scenarios.
- The dialogue transitioned to pointer intricacies, illuminating the necessity for pointers in kernel arguments to address GPU memory, and scrapping confusion over ** vs. * usage in CUDA memory allocation.
- Muscle For Models: Exploring AI Training with Beefy Hardware: Conversations on optimal AI training setups praised the prowess of A6000 GPUs for both price and performance, with one user highlighting a 64-core threadripper with dual A6000s setup.
- This setup, originally for fluid dynamics simulations, sparked interest and discussions on the versatility of high-end hardware for AI training.
3. Multimodal AI Advancements
- Meta's Multimodal Llama Model Release: Meta plans to debut a multimodal Llama model, yet EU users are left in the lurch due to regulatory restraints, as highlighted in an Axios report.
- Workarounds like using a VPN or non-EU compliance checkboxes are already being whispered about, foreshadowing a possible rise in access hacks.
- Turbo Charged LLaMA 3 Versions Leap into Action: The introduction of LLaMA-3-8B Lite by Together AI promises a cost-effective $0.10 per million tokens, ensuring affordability meets velocity.
- Enhancing the deployment landscape, LLaMA-3-8B Turbo soars to 400 tokens/s, tailored for applications demanding brisk efficiency.
4. Model Training Issues
- Model Training Troubles: Clouds Gathering: The community discusses the trials of deploying and training models, specifically on platforms like AWS and Google Colab, highlighting long durations and low-resource complexities.
- Special mention was made regarding
text2text-generationerrors and GPU resource dilemmas on Hugging Face Spaces, with contributors seeking and sharing troubleshooting tactics.
- Special mention was made regarding
- Fine-tuning Challenges and Prompt Engineering Strategies: Importance of prompt design and usage of correct templates, including end-of-text tokens, for influencing model performance during fine-tuning and evaluation.
- Example: Axolotl prompters.py.
GPT4OMini (gpt-4o-mini-2024-07-18)
1. Mistral NeMo Model Launch
- Mistral NeMo's Impressive Context Window: Mistral NeMo, a new 12B model, has been released in partnership with NVIDIA, featuring a remarkable 128k token context window and high performance in reasoning and coding tasks.
- The model is available under the Apache 2.0 license, and discussions have already begun on its effectiveness compared to other models like Llama 3.
- Community Reactions to Mistral NeMo: The model is available under the Apache 2.0 license, and discussions have already begun on its effectiveness compared to other models like Llama 3.
- Initial impressions indicate a positive reception, with users eager to test its capabilities.
2. GPT-4o Mini Release
- Cost-Effective GPT-4o Mini Launch: OpenAI introduced GPT-4o mini, a new model priced at $0.15 per million input tokens and $0.60 per million output tokens, making it significantly cheaper than its predecessors.
- This pricing structure aims to make advanced AI more accessible to a wider audience.
- Performance Expectations of GPT-4o Mini: Despite its affordability, some users expressed disappointment in its performance compared to GPT-4 and GPT-3.5 Turbo, indicating that it does not fully meet the high expectations set by OpenAI.
- Community feedback suggests that while it is cost-effective, it may not outperform existing models in all scenarios.
3. Deep Learning Hardware Optimization
- Optimizing with A6000 GPUs: Community discussions highlighted the advantages of utilizing A6000 GPUs for deep learning tasks, particularly in training models with high performance at a reasonable cost.
- Users reported successful configurations that leverage the A6000's capabilities for various AI applications.
- User Configurations for AI Training: Members shared their configurations, including setups with dual A6000s, which were repurposed from fluid dynamics simulations to AI training.
- These setups demonstrate the versatility of A6000 GPUs in handling complex computational tasks.
4. RAG Implementation Challenges
- Skepticism Around RAG Techniques: Several community members expressed their doubts about the effectiveness of Retrieval Augmented Generation (RAG), stating that it often leads to subpar results without extensive fine-tuning.
- The consensus is that while RAG has potential, it requires significant investment in customization.
- Community Feedback on RAG: Comments like 'RAG is easy if you want a bad outcome' emphasize the need for significant effort to achieve desirable outcomes.
- Members highlighted the importance of careful implementation to unlock RAG's full potential.
5. Multimodal AI Advancements
- Meta's Multimodal Llama Model Plans: Meta is gearing up to launch a multimodal Llama model, but plans to restrict access in the EU due to regulatory challenges, as per a recent Axios report.
- This decision has raised concerns about accessibility for EU users.
- Workarounds for EU Users: Workarounds like using a VPN are already being discussed among users to bypass these restrictions.
- These discussions highlight the community's resourcefulness in navigating regulatory barriers.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Retrieval's Rocky Road: AI Enthusiasts Skirmish over RAG: Several members voiced skepticism over RAG**, noting its propensity for subpar results without extensive fine-tuning.
- 'RAG is easy if you want a bad outcome' hinted at the significant efforts required to harness its potential.
- NeMo's New Narrative: Mistral Launches 12B Powerhouse: The Mistral NeMo 12B model, released in tandem with NVIDIA**, boasts an impressive context window and the promise of leading reasoning capabilities.
- Adopters of Mistral 7B can now upgrade to NeMo under the Apache 2.0 license according to an announcement linked from Mistral News.
- Delayed Debut: Unsloth Studio's Beta Bash Bumped : Unsloth Studio** has announced a delay in their Beta launch, shifting gears to a later date.
- The community echoed support for quality with replies like 'take your time - takes as long to troubleshoot as it takes'.
- Muscle For Models: Exploring AI Training with Beefy Hardware: Conversations on optimal AI training setups praised the prowess of A6000 GPUs** for both price and performance.
- One user's setup – a 64-core threadripper with dual A6000s – sparked interest, highlighting the hardware's versatility beyond its initial purpose of fluid dynamics simulations.
- STORM's Success: Shaping Structured Summaries: STORM set a new standard for AI-powered pre-writing, structuring elaborate articles with 25% enhanced organization and 10% more coverage**.
- Integrating expert-level multi-perspective questioning, this model can assemble comprehensive articles akin to full-length reports as described in GitHub - stanford-oval/storm.
HuggingFace Discord
- AI Comics Bubble Up with Defaults!: An update to AI Comic Factory stated it would now include default speech bubbles, with the feature still in its developmental stage.
- The tool AI Comic Factory, although in progress, is set to enhance comic creation by streamlining conversational elements.
- Huggingchat Hits a Snag: Speed Dial Turns Slow: Huggingchat's commandR+ is reported to crawl at a pace, causing frustration among users, some of whom experienced up to 5 minutes processing time for tasks that typically take seconds.
- Remarks in the community such as 'they posted virtually the same message three times' highlighted the slowing speeds affecting user experience.
- Florence 2 Flouts Watermarks Effortlessly: A new watermark remover built with Florence 2 and Lama Cleaner demonstrates its prowess, giving users an efficient removal tool shared on Hugging Face Spaces.
- Designed for ease-of-use, the watermark remover tool joins the suite of Florence 2 capabilities, promising to solve another practical problem.
- Mistral NeMo: NVIDIA's 12B Child: Mistral NeMo, a 12B model now sports a whopping 128k context length, debuted under Apache 2.0 license with a focus on high performance, as stated in the official announcement.
- This new release by MistralAI, in collaboration with NVIDIA and shared on Mistral AI, bolsters the library of tools available for tackling immense context lengths.
- Model Training Troubles: Clouds Gathering: The community discusses the trials of deploying and training models, specifically on platforms like AWS and Google Colab, highlighting long durations and low-resource complexities.
- Special mention was made regarding
text2text-generationerrors and GPU resource dilemmas on Hugging Face Spaces, with contributors seeking and sharing troubleshooting tactics.
- Special mention was made regarding
CUDA MODE Discord
- Kernel Quest: Navigating Parameter Limits: AI Engineers tackled the CUDA 4k kernel parameter size limit by favoring pointers to pass extensive data structures, with the migration from CPU to GPU global memory made compulsory for such scenarios.
- The dialogue transitioned to pointer intricacies, illuminating the necessity for pointers in kernel arguments to address GPU memory, and scrapping confusion over ** vs. * usage in CUDA memory allocation.
- Google Gemma 2 Prevails, Then Eclipsed: Gemma 2 models magnetized the community by overshadowing the former front-runner, Llama 2, sparking a deep dive on Google's reveal at Google I/O.
- Yet, the relentless progress in AI saw Gemma 2 swiftly outmoded by the likes of LlaMa 3 and Qwen 2, stirring acknowledgement of the industry's high-velocity advancements.
- GPT-3 125M Model: Groundbreaking Lift-Off: The launch of the first GPT-3 model (125M) training gripped the community, with notable mentions of a 12-hour expected completion time and eagerness for resulting performance metrics.
- Modifications in FP8 training settings and the integration of new Quantization mechanics were foregrounded, pointing to future explorations in model efficiency.
- CUDA Conundrums: Shared Memory Shenanigans: Dynamic Shared Memory utility became a hot topic with strategies like
extern __shared__ float shared_mem[];being thrown into the tech melting pot, aiming to enhance kernel performance.- A move towards dynamic shared memory pointed to a future of cleaner CUDA operations and the shared vision for denser computational processes.
- Triton's Compiler Choreography: Excitement brewed as the Triton compiler showed off its flair by automatically fine-tuning GPU code, turning Python into the more manageable Triton IR.
- Community contributions amplified this effect with the sharing of personal solutions to Triton Puzzles, nudging others to attempt the challenges.
Stability.ai (Stable Diffusion) Discord
- RTX 4060 Ti Tips & Tricks: Queries surrounding RTX 4060 Ti adequacy for automatic 1111 were alleviated; editing
webui-user.batwith--xformers --medvram-sdxlflagged for optimal AI performance.- Configurations hint at the community's quest for maximized utility of hardware in AI operations.
- Adobe Stock Clips Artist Name Crackdown: Adobe Stock revised its policy to scrub artist names from titles, keywords, or prompts, showing Adobe's strict direction on AI content generation.
- The community's worry about the sweeping breadth of the policy mirrors concerns for creative boundaries in AI art.
- The AI Artistic Triad Trouble: Discourse pinpointed hands, text, and women lying on grass as repetitive AI rendering pitfalls likened to an artist's Achilles' heel.
- Enthusiasm brews for a refined model that could rectify these common AI errors, revealed as frequent conversation starters among techies.
- Unraveling the 'Ultra' Feature Mystery: 'Ultra' feature technical speculation included hopeful musings on a second sample stage with techniques like latent upscale or noise application.
- Clarifications disclosed Ultra's availability in beta via the website and API, separating fact from monetization myths.
- Divergent Views on Troll IP Bans: The efficacy of IP bans to deter trolls sparked a fiery debate on their practicality, illustrating different community management philosophies.
- Discussion revealed varied expertise, stressing the need for a toolkit of strategies for maintaining a positive community ethos.
Eleuther Discord
- GoldFinch Soars with Linear Attention: The GoldFinch model has been a hot topic, with its hybrid structure of Linear Attention and Transformers, enabling large context lengths and reducing VRAM usage.
- Performance discussions highlighted its superiority over similarly classed models due to efficient KV-Cache mechanics, with links to the GitHub repository and Hugging Face model.
- Drama Around Data Scraping Ignites Debate: Convos heated over AI models scraping YouTube subtitles, sparking a gamut of economic and ethical considerations.
- Discussions delved into nuances of fair use and public permissions, with some users reflecting on the legality and comparative outrage.
- Scaling LLMs Gets a Patchwork Solution: In the realm of large language models, Patch-Level Training emerged as a potential game-changer, aiming to enhance sequence training efficiency.
- The PatchTrain GitHub was a chief point of reference, discussing token compression and its impact on training dynamics.
- Interpretability through Token-Free Lenses: Tokenization-free models took the stage with curiosity surrounding their impact on AI interpretability.
- The conversations spanned theory and potential implementations, not reaching consensus but stirring a meaningful exchange.
- ICML 2024 Anticipation Electrifies Researchers: ICML 2024 chatter was abound, with grimsqueaker's insights on 'Protein Language Models Expose Viral Mimicry and Immune Escape' drawing particular attention.
LM Studio Discord
- Codestral Mamba Slithers into LM Studio: Integration of Codestral Mamba in LM Studio is dependent on its support in llama.cpp, as discussed by members eagerly awaiting its addition.
- The Codestral Mamba enhancements for LM Studio will unlock after its incorporation into the underlying llama.cpp framework.
- Resizable BAR's Minimal Boost: Resizable BAR, a feature to enhance GPU performance, reportedly has negligible effects on LLM operations which rely more on tensor cores.
- Discussions centered on the efficiency of hardware features, concluding that factors like VRAM bandwidth hold more weight for LLM performance optimization.
- GTX 1050's AI Aspirations Dashed: The GTX 1050's 4GB VRAM struggles with model execution, compelling users to consider downsizing to less demanding AI models.
- Community members discussed the model compatibility, suggesting the limited VRAM of the GTX 1050 isn't suited for 7B+ parameter models, which are more intensive.
- Groq's Models Clinch Function Calling Crown: Groq's Llama-3 Groq-8B and 70B models impress with their performance on the Berkeley Function Calling Leaderboard.
- A focus on tool use and function calls enables these models to score competitively, showcasing their efficiency in practical AI scenarios.
- CUDA Finds New Ally in AMD RDNA: Prospects for CUDA on AMD's RDNA architecture piqued interest following a share of a Reddit discussion on the new compiler allowing RX 7800 execution.
- Skepticism persists around the full compatibility of CUDA on AMD via tools like ZLUDA, although SCALE and portable installations herald promising alternatives.
Nous Research AI Discord
- Textual Gradients Take Center Stage: Excitement builds around a new method for 'differentiation' via textual feedback, using TextGrad for guiding neural network optimization.
- ProTeGi steps into the spotlight with a similar approach, stimulating conversation on the potential of this technique for machine learning applications.
- STORM System's Article Mastery: Stanford's STORM system leverages LLMs to create comprehensive outlines, boosting long-form article quality significantly.
- Authors are now tackling the issue of source bias transfer, a new challenge introduced by the system's methodology.
- First Impressions: Synthetic Dataset & Knowledge Base: Synthetic dataset and knowledge base drops, targeted to bolster business application-centric AI systems.
- RAG systems could find a valuable resource in this Mill-Pond-Research/AI-Knowledge-Base, with its extensive business-related data.
- When Agents Evolve: Beyond Language Models: A study calls for an evolution in LLM-driven agents, recommending more sophisticated processing for improved reasoning, detailed in an insightful position paper.
- The Mistral-NeMo-12Instruct-12B arrives with a bang, touting a multi-language and code data-training and a 128k context window.
- GPT-4's Past Tense Puzzle: GPT-4's robustness to harmful request reformulations gets a shock with a new paper finding 88% success in eliciting forbidden knowledge via past tense prompts.
- The study urges a review of current alignment techniques against this unexpected gap as highlighted in the findings.
Latent Space Discord
- DeepSeek Engineering Elegance: DeepSeek's DeepSeek V2 slashes inference costs to 1 yuan per million tokens, inducing a competitive pricing frenzy among AI companies.
- DeepSeek V2 boasts a revolutionary MLA architecture, cutting down memory use, earning it the moniker of China's AI Pinduoduo.
- GPT-4o Mini: Quality Meets Cost Efficiency: OpenAI's GPT-4o mini emerges with a cost-effectiveness punch: $0.15 per million input tokens and $0.60 per million output tokens.
- Achieving an 82% MMLU score and supporting a 128k context window, it outperforms Claude 3 Haiku's 75% and sets a new performance cost benchmark.
- Mistral NeMo's Performance Surge: Mistral AI and NVIDIA join forces, releasing Mistral NeMo, a potent 12B model sporting a huge 128k tokens context window.
- Efficiency is front and center with NeMo, thanks to its FP8 inference for faster performance, positioning it as a Mistral 7B enhancement.
- Turbo Charged LLaMA 3 Versions Leap into Action: The introduction of LLaMA-3-8B Lite by Together AI promises a cost-effective $0.10 per million tokens ensuring affordability meets velocity.
- Enhancing the deployment landscape, LLaMA-3-8B Turbo soars to 400 tokens/s, tailored for applications demanding brisk efficiency.
- LLaMA 3 Anticipation Peaks with Impending 400B Launch: Speculation is high about LLaMA 3 400B's impending reveal, coinciding with Meta executives' scheduled sessions, poised to shake the AI status quo.
- Community senses a strategic clear-out of existing products, setting the stage for the LLaMA 3 400B groundbreaking entry.
OpenAI Discord
- GPT-4o Mini: Intelligence on a Budget: OpenAI introduces the GPT-4o mini, touted as smarter and more cost-effective than GPT-3.5 Turbo and is rolling out in the API and ChatGPT, poised to revolutionize accessibility.
- Amid excitement and queries, it's clarified that GPT-4o mini enhances over GPT-3.5 without surpassing GPT-4o; conversely, it lacks GPT-4o's full suite of capabilities like image support, but upgrades from GPT-3.5 for good.
- Eleven Labs Unmutes Voice Extraction: The unveiling of Eleven Labs' voice extraction model has initiated vibrant discussions, leveraging its potential to extract clear voice audio from noisy backgrounds.
- Participants are weighing in on ethical considerations and potential applications, aligning with novel creations in synthetic media.
- Nvidia's Meta Package Puzzle: Nvidia's installer's integration with Facebook, Instagram, and Meta's version of Twitter has stirred a blend of confusion and humor among users.
- Casual reactions such as 'Yes sir' confirmed reflect the community's light-hearted response to this unexpected bundling.
- Discourse on EWAC's Efficiency: The new EWAC command framework gains traction as an effective zero-shot, system prompting solution, optimizing model command execution.
- A shared discussion link encourages collaborative exploration and fine-tuning of this command apparatus.
- OpenAI API Quota Quandaries: Conversations circulate around managing OpenAI API quota troubles, promoting vigilance in monitoring plan limits and suggesting credit purchases for continued usage.
- Community members exchange strategies to avert the API hallucinations and maximize its usage, while also pinpointing inconsistencies in token counting for images.
Interconnects (Nathan Lambert) Discord
- Meta and the Looming Llama: Meta plans to debut a multimodal Llama model, yet EU users are left in the lurch due to regulatory restraints, an issue spotlighted by an Axios report.
- Workarounds like using a VPN or non-EU compliance checkboxes are already being whispered about, foreshadowing a possible rise in access hacks.
- Mistral NeMo's Grand Entrance: Mistral NeMo makes a splash with its 12B model designed for a substantial 128k token context window, a NVIDIA partnership open under Apache 2.0, found in the official release notes.
- Outshining its predecessors, it boasts enhancements in reasoning, world knowledge, and coding precision, fueling anticipation in technical circles.
- GPT-4o mini Steals the Spotlight: OpenAI introduces the lean and mean GPT-4o mini, heralded for its brilliance and transparency in cost, garnering nods for its free availability and strong MMLU performance according to Andrew Curran.
- Priced aggressively at 15¢ per M token input and 60¢ per M token output, it's scaled down yet competitive, with a promise of wider accessibility.
- Tekken Tokenizer Tackles Tongues: The Tekken tokenizer has become the talk of the town, dripping with efficiency and multilingual agility, outpacing Llama 3 tokenizer substantially.
- Its adeptness in compressing text and source code is turning heads, making coders consider their next move.
- OpenAI's Perimeter Breached: OpenAI's newest safety mechanism has been decoded, with
Elder Pliniusshedding light on a GPT-4o-mini jailbreak via a bold declaration.- This reveals cracks in their 'instruction hierarchy' defense, raising eyebrows and questions around security.
OpenRouter (Alex Atallah) Discord
- GPT-4o Mini's Frugal Finesse: OpenAI's GPT-4o Mini shines with both text and image inputs, while flaunting a cost-effective rate at $0.15/M input and $0.60/M output.
- This model trounces GPT-3.5 Turbo in affordability, being over 60% more economical, attractive for free and subscription-based users alike.
- OpenRouter's Regional Resilience Riddle: Users faced a patchwork of OpenRouter outages, with reports of API request lags and site timeouts, though some regions like Northern Europe remained unaffected.
- The sporadic service status left engineers checking for live updates on OpenRouter's Status to navigate through the disruptions.
- Mistral NeMo Uncaps Context Capacity: Mistral NeMo's Release makes waves with a prodigious 12B model boasting a 128k token context window, paving the way for extensive applications in AI.
- Provided under the Apache 2.0, Mistral NeMo is now available with pre-trained and instruction-tuned checkpoints, ensuring broad access and use.
- Codestral 22B: Code Model Contender: A community-led clarion call pushes for the addition of Codestral 22B, spotlighting the capabilities of Mamba-Codestral-7B to join the existing AI model cadre.
- With its competitive edge in Transformer-based frameworks for coding, Codestral 22B solicits enthusiastic discussion amongst developers and model curators.
- Image Token Turbulence in GPT-4o Mini: Chatter arises as the AI engineering community scrutinizes image token pricing discrepancies in the newly released GPT-4o Mini, as opposed to previous models.
- Debate ensues with some expressing concerns over the unexpected counts affecting usage cost, necessitating a closer examination of model efficiency and economics.
Modular (Mojo 🔥) Discord
- Nightly Mojo Compiler Enhancements Unveiled: A fresh Mojo compiler update (2024.7.1805) includes
stdlibenhancements for nested Python objects using list literals, upgradeable viamodular update [nightly/mojo](https://github.com/modularml/mojo/compare/e2a35871255aa87799f240bfc7271ed3898306c8...bb7db5ef55df0c48b6b07850c7566d1ec2282891)command.- Debating stdlib's future, a proposal suggests
stdlib-extensionsto engage community feedback prior to full integration, aiming for consensus before adding niche features such as allocator awareness.
- Debating stdlib's future, a proposal suggests
- Lubeck Outstrips MKL with Acclaimed LLVM Efficiency: Lubeck's stellar performance over MKL is attributed to differential LLVM IR generation, possibly aided by Mir's LLVM-Accelerated Generic Numerical Library.
- SPIRAL distinguishes itself by automating numerical kernel optimization, though its generated code's complexity limits its use outside prime domains like BLAS.
- Max/Mojo Embraces GPU's Parallel Prowess: Excitement builds around Max/Mojo's new GPU support, expanding capabilities for tensor manipulation and parallel operations, suggested by a Max platform talk highlighting NVIDIA GPU integration.
- Discussion threads recommend leveraging MLIR dialects and CUDA/NVIDIA for parallel computing, putting a spotlight on the potential for AI advancements.
- Keras 3.0 Breaks Ground with Multi-Framework Support: Amid community chatter, the latest Keras 3.0 update flaunts compatibility across JAX, TensorFlow, and PyTorch, positioning itself as a frontrunner for flexible, efficient model training and deployment.
- The milestone was shared during a Mojo Community Meeting, further hinting at broader horizons for Keras's integration and utility.
- Interactive Chatbot Designs Spark Conversation in Max: MAX version 24.4 innovates with the
--promptflag, facilitating the creation of interactive chatbots by maintaining context and establishing system prompts, as revealed in the Max Community Livestream.- Queries about command-line prompt usage and model weight URIs lead to illuminating discussions about UI dynamics and the plausibility of using alternative repositories over Hugging Face for weight sourcing.
Cohere Discord
- Tools Take the Stage at Cohere: A member's inquiry about creating API tools revealed that tools are API-only, with insights accessible through the Cohere dashboard.
- Details from Cohere's documentation clarified that tools can be single or multi-step and are client-defined.
- GIFs Await Green Signal in Permissions Debate: Discussions arose over the ability to send images and GIFs in chat, facing restricted permissions due to potential misuse.
- Admins mentioned possible changes allowing makers and regular users to share visuals, seeking a balance between expression and moderation.
- DuckDuckGo: Navigating the Sea of Integration: Members considered integrating DuckDuckGo search tools into projects, highlighting the DuckDuckGo Python package for its potential.
- A suggestion was made to use the package for a custom tool to enhance project capabilities.
- Python & Firecrawl Forge Scraper Synergy: The use of Python for scraping, along with Firecrawl, was debated, with prospects of combining them for effective content scraping.
- Community peers recommended the use of the duckduckgo-search library for collecting URLs as part of the scraping process.
- GPT-4o Joins the API Integration Guild: Integration of GPT-4o API with scraping tools was a hot topic, where personal API keys are used to bolster Firecrawl's capabilities.
- Technical set-up methods, such as configuring a .env file for API key inclusion, were shared to facilitate this integration with LLMs.
Perplexity AI Discord
- NextCloud Navigates Perplexity Pitfalls: Users reported difficulty setting up Perplexity API on NextCloud, specifically with choosing the right model.
- A solution involving specifying the
modelparameter in the request was shared, directing users to a comprehensive list of models.
- A solution involving specifying the
- Google Grapples with Sheets Snafus: Community members troubleshoot a perplexing issue with Google Sheets, encountering a Google Drive logo error.
- Despite efforts, they faced a persistent 'page can't be reached' problem, leaving some unable to login.
- PDF Probe: Leverage Perplexity Without Limits: The guild discussed Perplexity's current limitation with handling multiple PDFs, seeking strategies to overcome this challenge.
- A community member recommended converting PDF and web search content into text files for optimal Perplexity performance.
- AI Discrepancy Debate: GPT-4 vs GPT-4 Omni: Discussions arose around Perplexity yielding different results when integrating GPT-4 Omni, sparking curiosity and speculation.
- Members debated the possible reasons, with insights hinting at variations in underlying models.
- DALL-E Dilemmas and Logitech Legit Checks: Questions about DALL-E's update coinciding with Perplexity Pro search resets were raised, alongside suspicions about a Logitech offer for Perplexity Pro.
- Subsequent confirmation of Logitech's partnership with Perplexity squashed concerns of phishing, backed by a supporting tweet.
LangChain AI Discord
- LangChain Leverages Openrouter: Discussions revolved around integrating Openrouter with LangChain, but the conversation lacked concrete examples or detailed guidelines.
- A query for code-based RAG examples to power a Q&A chatbot was raised, suggesting a demand for comprehensive, hands-on demonstrations in the LangChain community.
- Langserve Launches Debugger Compartment: A user inquired about the Langserve Debugger container, seeking clarity on its role and application, highlighted by a Docker registry link.
- Curiosity peaked regarding the distinctions between the Langserve Debugger and standard Langserve container, impacting development workflows and deployment strategies.
- Template Tribulations Tackled on GitHub: A KeyError issue related to incorporating JSON into LangChain's ChatPromptTemplate spurred discussions, with reference to a GitHub issue for potential fixes.
- Despite some community members finding a workaround for JSON integration challenges, others continue to struggle with the nuances of the template system.
- Product Hunt Premieres Easy Folders: Easy Folders made its debut on Product Hunt with features to tidy up chat histories and manage prompts, as detailed in the Product Hunt post.
- A promotion for a 30-day Superuser membership to Easy Folders was announced, banking on community endorsement and feedback to amplify engagement.
- LangGraph Laminates Corrective RAG: The integration of LangGraph with Corrective RAG to combat chatbot hallucinations was showcased in a YouTube tutorial, shedding light on improving AI chatbots.
- This novel approach hints at the community's drive to enhance AI chatbot credibility and reliability through innovative combinations like RAG Fusion, addressing fundamental concerns with existing chatbot technologies.
LlamaIndex Discord
- Jerry's AI World Wisdom: Catching up on AI World's Fair? Watch @jerryjliu0 deliver insights on knowledge assistants in his keynote speech, a highlight of last year's event.
- He delves into the evolution and future of these assistants, sparking continued technical discussions within the community.
- RAGapp's Clever Companions: The RAGapp's latest version now interfaces with MistralAI and GroqInc, enhancing computational creativity for developers.
- The addition of @cohere's reranker aims to refine and amplify app results, introducing new dynamics to the integration of large language models.
- RAG Evaluators Debate: A dialogue unfolded around the selection of frameworks for RAG pipeline evaluation, with alternatives to the limited Ragas tool under review.
- Contributors discussed whether crafting a custom evaluation tool would fit into a tight two-week span, without reaching a consensus.
- Mask Quest for Data Safety: Our community dissected strategies for safeguarding sensitive data, recommending the PIINodePostprocessor from LlamaIndex for data masking pre-OpenAI processing.
- This beta feature represents a proactive step to ensure user privacy and the secure handling of data in AI interactions.
- Multimodal RAG's Fine-Tuned Futurism: Enthusiasm peaked as a member shared their success using multimodal RAG with GPT4o and Sonnet3.5, highlighting the unexpected high-quality responses from LlamaIndex when challenged with complex files.
- Their findings incited interest in LlamaIndex's broader capabilities, with a look towards its potential to streamline RAG deployment and efficiency.
OpenInterpreter Discord
- OpenInterpreter's Commendable Community Crescendo: OpenInterpreter Discord celebrates a significant milestone, reaching 10,000 members in the community.
- The guild's enthusiasm is palpable with reactions like "Yupp" and "Awesome!" marking the achievement.
- Economical AI Edges Out GPT-4: One member praised a cost-effective AI claiming superior performance over GPT-4, particularly noted for its use in AI agents.
- Highlighting its accessibility, the community remarked on its affordability, with one member saying, "It’s basically for free."
- Multimodal AI: Swift and Versatile: Discussions highlighted the Impressive speed of a new multimodal AI, which supports diverse functionalities and can be utilized via an API.
- Community members are excited about its varied applications, with remarks emphasizing its "crazy fast latency" and multimodal nature.
OpenAccess AI Collective (axolotl) Discord
- Mistral NeMo's Impressive Entrance: Mistral NeMo, wielding a 12B parameter size and a 128k token context, takes the stage with superior reasoning and coding capabilities. Pre-trained flavors are ready under the Apache 2.0 license, detailed on Mistral's website.
- Meta's reporting of the 5-shot MMLU score for Llama 3 8B faces scrutiny due to mismatched figures with Mistral, shedding doubt on the claimed 62.3% versus 66.6%.
- Transformers in Reasoning Roundup: A debate sparked around transformers' potential in implicit reasoning, with new research advocating their capabilities post-extensive training.
- Despite successes in intra-domain inferences, transformers are yet to conquer out-of-domain challenges without more iterative layer interactions.
- Rank Reduction, Eval Loss Connection: A curious observation showed that lowering model rank correlates with a notable dip in evaluation loss. However, the data remain inconclusive as to whether this trend will persist in subsequent training steps.
- Participants exchanged insights on this phenomenon, contemplating its implications on model accuracy and computational efficiency.
- GEM-A's Overfitting Dilemma: Concerns surfaced regarding the GEM-A model potentially overfitting during its training period.
- The dialogue continued without concrete solutions but with an air of caution and a need for further experimentation.
LLM Finetuning (Hamel + Dan) Discord
- GPT-3.5-turbo Takes the Lead: Discussion emerged showing GPT-3.5-turbo outpacing both Mistral 7B and Llama3 in fine-tuning tasks, despite OpenAI's stance on not utilizing user-submitted data for fine-tuning purposes.
- A sentiment was expressed preferring against the use of GPT models for fine-tuning due to concerns over transmitting sensitive information to a third party.
- Mac M1’s Model Latency Lag: Users faced latency issues with Hugging Face models on Mac M1 chips due to model loading times when starting a preprocessing pipeline.
- The delay was compounded when experimenting with multiple models, as each required individual downloads and loads, contributing to the initial latency.
LAION Discord
- Meta's Multimodal Mission: An eye on the future, Meta shifts its spotlight to multimodal AI models, as hinted by a sparse discussion following an article share.
- Lack of substantial EU community debate leaves implications on innovation and accessibility in suspense.
- Llama Leaves the EU: Meta's decision to pull Llama models from the EU market stirs a quiet response among users.
- The impact on regional AI tool accessibility has yet to be intensively scrutinized or debated.
- Codestral Mamba's Coding Coup: The freshly introduced Codestral Mamba promises a leap forward in code generation with its linear time inference.
- Co-created by Albert Gu and Tri Dao, this model aims to enhance coding efficiency while handling infinitely long sequences.
- Prover-Verifier's Legibility Leap: The introduction of Prover-Verifier Games sparks interest for improving the legibility of language models, supported by a few technical references.
- With details provided in the full documentation, the community shows restrained enthusiasm pending practical applications.
- NuminaMath-7B's Top Rank with Rankling Flaws: Despite NuminaMath-7B's triumph at AIMO, highlighted flaws in basic reasoning capabilities pose as cautionary tales.
- AI veterans contemplate the gravity and aftershocks of strong claims not standing up to elementary reasoning under AIW problem scrutiny.
Torchtune Discord
- Template Turmoil Turnaround: Confusion arose over using
torchtune.data.InstructTemplatefor custom template formatting, specifically regarding column mapping.- Clarification followed that column mapping renames dataset columns, with a query if the alpaca cleaned dataset was being utilized.
- CI Conundrums in Code Contributions: Discourse on CI behavior highlighted automatic runs when updating PRs leading to befuddlement among contributors.
- The consensus advice was to disregard CI results until a PR transitions from draft to a state ready for peer review.
- Laugh-Out-Loud LLMs - Reality or Fiction?: Trial to program an LLM to consistently output 'HAHAHA' met with noncompliance, despite being fed a specific dataset.
- The experiment served as precursor to the more serious application using the alpaca dataset for a project.
tinygrad (George Hotz) Discord
- GTX1080 Stumbles on tinygrad: A user faced a nvrtc: error when trying to run tinygrad with CUDA=1 on a GTX1080, suspecting incompatibility with the older GPU architecture.
- The workaround involved modifying the ops_cuda for the GTX1080 and turning off tensor cores; however, a GTX2080 or newer might be necessary for optimal performance.
- Compile Conundrums Lead to Newer Tech Testing: The member encountered obstacles while setting up tinygrad on their GTX1080, indicating potential compatibility issues.
- They acknowledged community advice and moved to experiment with tinygrad using a more current system.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (245 messages🔥🔥):
RAGMistral NeMo releaseUnsloth StudioMistral-Nemo integrationFlash Attention support
- Debate on RAG and its implementation: Multiple members expressed that RAG (Retrieval Augmented Generation) is often oversold and overhyped despite being difficult and requiring extensive custom tuning for effective results.
- One member noted, 'RAG is easy if you want a shitty outcome - same goes for finetuning but if you want a good outcome... then that will require lots of work'.
- Mistral NeMo 12B model launched: Mistral NeMo, a 12B model with a context window up to 128k tokens, was released in collaboration with NVIDIA under the Apache 2.0 license.
- The model promises state-of-the-art reasoning, world knowledge, and coding accuracy in its size category, being a drop-in replacement for Mistral 7B.
- Unsloth Studio release delayed: The release of Unsloth Studio (Beta) was postponed from the planned date to the following Monday.
- A member advised to 'take your time - takes as long as it takes'.
- Introduction and compatibility of Mistral-Nemo: Discussions on whether Unsloth will support the newly released Mistral-Nemo are in progress.
- The integration is still being worked on, and Flash Attention 2.6 appears to be required for larger context lengths.
- Hardware choices for training models: Members discussed various hardware setups, noting the benefits of using A6000 GPUs and the cost-effectiveness of renting hardware for AI training.
- One member mentioned using 64-core threadripper with dual A6000 GPUs primarily for fluid dynamics and finite state simulations, now repurposed for AI.
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- FACTS About Building Retrieval Augmented Generation-based Chatbots: no description found
- mistralai/Mistral-Nemo-Instruct-2407 · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Gigabyte releases AI software to help train your own AI — AI TOP utility taps Gigabyte motherboards, GPUs, SSDs, and power supplies to fine-tune local AI model training: The tool can locally train AI models with up to 236B parameters.
- GitHub - bclavie/RAGatouille: Easily use and train state of the art late-interaction retrieval methods (ColBERT) in any RAG pipeline. Designed for modularity and ease-of-use, backed by research.: Easily use and train state of the art late-interaction retrieval methods (ColBERT) in any RAG pipeline. Designed for modularity and ease-of-use, backed by research. - bclavie/RAGatouille
- AIUnplugged 15: Gemma 2, Flash Attention 3, QGaLoRE, MathΣtral and Codestral Mamba: Insights over Information
Unsloth AI (Daniel Han) ▷ #off-topic (11 messages🔥):
GPU recommendationsRunpodBinary messageShylily fans
- GPU Debate: 3090 vs 4090: Members discussed the merits of getting a used RTX 3090 over the 3090 TI, suggesting even crypto-mined cards are acceptable.
- A user mentioned owning two 4090 GPUs and highlighted Runpod as a superior alternative.
- Binary Message Fun: Members had a light-hearted moment decoding the binary message '01110111 01101111 01101101 01110000 00100000 01110111 01101111 01101101 01110000' into 'womp womp'.
- This sparked a series of playful 'womp womp' exchanges among the members.
- Shylily Fan Moments: A member pointed out the presence of many Shylily fans in the chat, calling out fun moments.
- The discussion brought attention to the many 'womp womp' moments in the chat logs, prompting laughter and comments.
Unsloth AI (Daniel Han) ▷ #help (84 messages🔥🔥):
disabling pad_tokenfinetuning and saving modelsmodel sizes and memory consumptionfine-tuning locallyhandling new errors with GPU and dtype
- Ignore pad_token if model doesn't need one: Members discussed that if the model doesn’t use
pad_token, it can simply be ignored without any effect. - Best practices for saving finetuned models in 4-bit vs. 16-bit for VLLM: Members debated whether to save a finetuned 4-bit model as 16-bit or to just use LoRA adapters in a production setting.
- Theyruinedelise suggested trying the LoRA approach to maintain accuracy.
- High VRAM requirements for Llama 3 models: Members discussed the extensive VRAM requirements of Llama 3 models, noting it takes 48GB VRAM for 70B model quantization at 4-bit.
- Running fine-tuning locally vs. using Colab: Efficio sought advice on running fine-tuning locally and received suggestions on using WSL on Windows for local training.
- Theyruinedelise recommended following detailed guides available on GitHub for setting up the local environment.
- Handling new torch.autocast errors on RTX A4000: Kiingz3440 faced an error with
torch.autocastrelated to unsupportedbfloat16on an RTX A4000 GPU.- Edd0302 suggested explicitly setting the model to use
torch.float16, which resolved the error.
- Edd0302 suggested explicitly setting the model to use
- Install WSL: Install Windows Subsystem for Linux with the command, wsl --install. Use a Bash terminal on your Windows machine run by your preferred Linux distribution - Ubuntu, Debian, SUSE, Kali, Fedora, Pengwin,...
- tinygrad: A simple and powerful neural network framework: no description found
- I got unsloth running in native windows. · Issue #210 · unslothai/unsloth: I got unsloth running in native windows, (no wsl). You need visual studio 2022 c++ compiler, triton, and deepspeed. I have a full tutorial on installing it, I would write it all here but I’m on mob...
Unsloth AI (Daniel Han) ▷ #research (7 messages):
Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking (STORM)EfficientQAT for LLM QuantizationMemory3 Architecture for LLMsSpectra LLM Suite and QuantizationPatch-Level Training for LLMs
- STORM Revolutionizes Pre-writing for AI: STORM introduces a novel system for the Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking, enabling large language models to write grounded, organized long-form articles similar to Wikipedia pages.
- The approach includes discovering diverse perspectives, simulating expert conversations, and curating information, showing a 25% improvement in organization and a 10% increase in coverage compared to previous methods.
- EfficientQAT Achieves Low-bit Quantization: EfficientQAT successfully pushes the limits of uniform INT quantization, delivering a 2-bit Llama-2-70B model on a single A100-80GB GPU with less than 3% accuracy degradation compared to full precision.
- EfficientQAT demonstrates that INT2 quantized models require less memory while achieving better accuracy than larger models, highlighting advancements in deployable LLM quantization.
- Memory3 Enhances LLM Efficiency: Memory3 introduces an explicit memory mechanism for LLMs, aiming to improve both efficiency and performance.
- This architecture addresses challenges in current LLM architectures by introducing a novel way to handle and store information more efficiently.
- Spectra LLM Suite Released: Spectra LLM presents 54 language models trained on 300B tokens, including FloatLMs, post-training quantized models, and ternary LLMs (TriLMs), which outperform previous ternary models at the same bit size.
- The suite demonstrates that TriLMs can match the performance of half-precision models, paving the way for more efficient and smaller LLM deployments.
- Patch-Level Training Boosts LLM Efficiency: Patch-level training for LLMs introduces a method to reduce sequence length by compressing multiple tokens into a single patch, significantly cutting down on computational costs.
- This new training approach allows LLMs to process training data more efficiently, switching to token-level training in later stages to align with inference requirements.
- Paper page - Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models: no description found
- Patch-Level Training for Large Language Models: As Large Language Models (LLMs) achieve remarkable progress in language understanding and generation, their training efficiency has become a critical concern. Traditionally, LLMs are trained to predic...
- Tweet from catid (e/acc) (@MrCatid): 2x faster LLM training: https://arxiv.org/abs/2407.12665 Probably applies to other types of transformer models too!
- no title found: no description found
- Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models: We study how to apply large language models to write grounded and organized long-form articles from scratch, with comparable breadth and depth to Wikipedia pages. This underexplored problem poses new ...
- no title found: no description found
- GitHub - stanford-oval/storm: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations.: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations. - stanford-oval/storm
- Reddit - Dive into anything: no description found
- OpenGVLab: General Vision Team of Shanghai AI Laboratory. OpenGVLab has 65 repositories available. Follow their code on GitHub.
HuggingFace ▷ #announcements (1 messages):
Watermark RemoverCandyLLMAI Comic Factory UpdateFast Subtitle MakerHF Text Embedding on Intel GPUs
- Watermark Remover with Florence 2: A member introduced a watermark remover using Florence 2.
- 'It's efficient and easy to use for all your watermark removal needs,' they shared.
- CandyLLM Python Library with Gradio UI: Introducing CandyLLM by @shreyanmitra_05940_88933, a python library utilizing the Gradio UI.
- 'This tool aims to simplify the use of language models in applications,' the creator stated.
- AI Comic Factory Adds Default Speech Bubbles: The AI comic factory now includes speech bubbles by default, announced by @jbilcke.
- This update enhances the user experience by automatically adding conversational elements to generated comics.
- Quantise and Load HF Text Embedding Models on Intel GPUs: A member shared an easy method to quantise and load any HF text embedding model on Intel GPUs.
- 'This will help in efficiently utilizing Intel hardware for AI tasks,' they explained.
Link mentioned: How to transition to Machine Learning from any field? | Artificial Intelligence ft. @vizuara: In this video, Dr. Raj Dandekar from Vizuara shares his experience of transitioning from mechanical engineering to Machine Learning (ML). He also explains be...
HuggingFace ▷ #general (222 messages🔥🔥):
Huggingchat Performance IssuesModel Training QueriesRVC and Voice Model AlternativesText2text Generation IssuesAdmin Ping Etiquette
- Huggingchat's commandR+ Slows Down: Users reported that Huggingchat's commandR+ is extremely slow, with some tasks taking as long as 5 minutes compared to 5 seconds for other models.
- One user sarcastically mentioned, 'they posted virtually the same message three times' as an example of frustration.
- Model Training and Deployment Issues: Multiple users discussed issues with deploying and training models, particularly on platforms like AWS and Google Colab.
- Specific issues included long deployment times, errors with specific tasks like
text2text-generation, and problems with low GPU resources on Hugging Face Spaces.
- Specific issues included long deployment times, errors with specific tasks like
- RVC Repositories and Alternatives: Users discussed that RVC is not working and questioned why the repositories are still online while seeking alternative projects for creating AI voice models.
- Suggestions for solutions or alternatives were sparse, leaving the issue largely unresolved within the discussion.
- Need for Proper Training Data Format: A user shared a detailed approach for pre-training Mistral using unsupervised learning but sought validation for their data format and approach.
- The response advised on the correct input format and provided some pointers on token exclusion for proper training.
- Pinging Admins and Communication Etiquette: A user named quirkyboi22 frequently pinged admins to fix issues with Huggingchat, prompting multiple reminders from the community about appropriate communication channels.
- Another user pointed out that 'email website@hf.co' would be a more suitable approach for reporting such issues, and an official response confirmed that the team was aware and looking into the specific issues.
- fal/AuraSR · Hugging Face: no description found
- AuraSR - a Hugging Face Space by gokaygokay: no description found
- Unicorn Happy GIF - Unicorn Happy Birthday - Discover & Share GIFs: Click to view the GIF
- Tweet from abhishek (@abhi1thakur): We just integrated dataset viewer in AutoTrain 💥 So, now you can look into your dataset, identify correct splits and columns before training the model, without leaving the page 🚀
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
HuggingFace ▷ #today-im-learning (1 messages):
rp0101: https://youtu.be/N0eYoJC6USE?si=zms6lSsZkF6_vL0E
HuggingFace ▷ #cool-finds (7 messages):
Transformers.js tutorialComputer Vision CourseAutoTrainerMistral NeMoDiscord moderation
- Transformers.js enhances Next.js apps: A tutorial on Transformers.js demonstrates building a Next.js app for sentiment analysis, with options for both client-side and server-side inference.
- The tutorial uses the new App Router paradigm and provides demo links and source code.
- Community-driven Computer Vision Course starts: A new Community Computer Vision Course has launched, covering everything from basics to advanced topics.
- The course includes foundational topics and emphasizes accessibility for everyone interested in computer vision.
- AutoTrainer simplifies ML model training: AutoTrainer automates the training of custom machine learning models by simply uploading data.
- It supports various tasks like LLM Finetuning, Image classification, and Text Classification, and boasts seamless integration with the Hugging Face Hub.
- Mistral NeMo model release!: MistralAI announced Mistral NeMo, a state-of-the-art 12B model with a 128k context length built in collaboration with NVIDIA, under the Apache 2.0 license.
- The official tweet provides more details about this high-performance model.
- Moderation reminder in Discord: A reminder to maintain PG content was issued by a member, emphasizing community standards.
- Another member clarified that the content in question is from a kid's cartoon, highlighting different interpretations of guidelines.
- AutoTrain – Hugging Face: no description found
- Welcome to the Community Computer Vision Course - Hugging Face Community Computer Vision Course: no description found
- Building a Next.js application: no description found
- Tweet from Mistral AI (@MistralAI): https://mistral.ai/news/mistral-nemo/
HuggingFace ▷ #i-made-this (23 messages🔥):
AI Comic Factory updateTool for transcribing and summarizing videosFeedback request for AI assistantGradio Python libraryWatermark remover using Florence 2 and Lama Cleaner
- AI Comic Factory now has speech bubbles by default: A member announced an update to AI Comic Factory to include speech bubbles by default, though the feature is still in development.
- Tool Automatically Transcribes and Summarizes Videos: A member created a tool for automatically transcribing and summarizing YouTube videos using Deepgram for transcription and Claude for summarization.
- Feedback Request for Productivity Boosting AI Assistant: A member is developing a free AI assistant to help boost productivity by integrating with tools like Slack, Gmail, and Google Calendar.
- New Python Library Using Gradio for ML Newbies: A beginner in Gradio and ML shared a basic Python library aimed at easing the use of text-generation models.
- Watermark Remover Using Florence 2: A member demonstrated a watermark remover built using Florence 2 and Lama Cleaner, shared on Hugging Face.
- Hunch - AI Tools for Teams: Create AI workflows and tools to automate knowledge work and boost team productivity
- Remove-WM - a Hugging Face Space by DamarJati: no description found
- AI Comic Factory - a Hugging Face Space by jbilcke-hf: no description found
- Sophi.app — using app integrations and AI, Sophi helps you get work done: 🚀 the intelligent, proactive, and actionable answer engine that understands your digital life and keeps you ahead.
- GitHub - shreyanmitra/CandyLLM: A simple, easy-to-use framework for HuggingFace and OpenAI text-generation models.: A simple, easy-to-use framework for HuggingFace and OpenAI text-generation models. - shreyanmitra/CandyLLM
- Hunch - AI Tools for Teams: Create AI workflows and tools to automate knowledge work and boost team productivity
HuggingFace ▷ #reading-group (5 messages):
Delayed Project PresentationBeginner Friendly PapersOptimization of ML Model Layers
- Project Presentation Delayed: A member intended to present their project but postponed it, likely to occur in three weeks due to scheduling conflicts.
- Resources for Beginner Friendly Papers: A member asked for beginner-friendly papers, and another suggested Hugging Face Papers or joining Yannic Kilcher’s Discord server for daily paper discussions.
- Optimizing ML Model Layers: A member sought foundational papers and articles on optimizing ML model layers including dense layers, GRU, and LSTM GPU kernels for career advancement.
HuggingFace ▷ #computer-vision (1 messages):
dorbit_: Hey! Does anybody had the an experience with camera calibration with Transformers?
HuggingFace ▷ #NLP (5 messages):
Image to Video Diffusion ModelPrompt Engineering for SVDInstalling Transformers & AccelerateText Classification with Multiple TagsYOLO Model Confusion
- Stable Video Diffusion Model Discussion: User shared about using the Stable Video Diffusion Image-to-Video Model from Hugging Face, seeking advice on prompt engineering for generating videos.
- Installing Transformers and Accelerate in Colab: A member suggested using
!pip install transformers accelerateto import necessary libraries for their project in Colab. - Handling Text Classification with Multiple Tags: A member enquired about managing a text classification problem with around 200 tags and considered creating individual models for each tag.
- mattilinnanvuori recommended using a single model for multi-label classification based on their experience.
- YOLO Model Misunderstanding: A user initially suggested using YOLO models for an image classification problem after misreading another user's request about text classification.
Link mentioned: stabilityai/stable-video-diffusion-img2vid-xt · Hugging Face: no description found
CUDA MODE ▷ #general (6 messages):
CUDA kernel splittingLoss masking in LLM trainingSebastian Raschka's research insightsNVIDIA open-source kernel modulesCUDA graphs
- Benefits of Splitting CUDA Kernels: Members discussed scenarios where splitting a CUDA kernel into multiple kernels might be beneficial, primarily for managing memory during multi-step reduction and achieving latency hiding.
- A particular use case mentioned was in CNNs, where deeper layers require impractical amounts of memory if fused together.
- Raschka Questions Loss Masking Benefits: Sebastian Raschka's research insight blog questioned the benefits of applying loss on prompt tokens in LLM training, referencing a paper on Instruction Tuning With Loss Over Instructions.
- Further reading and a mention of his upcoming book and ACM Tech Talk were also shared.
- NVIDIA Open Sources GPU Kernel Modules: A member shared that NVIDIA has fully transitioned towards open-source GPU kernel modules, achieving better performance and adding new capabilities including Heterogeneous Memory Management (HMM).
- For more details, refer to the NVIDIA blog.
- CUDA Graphs Educational Material Sought: A user inquired about lectures or material covering CUDA graphs.
- No further details or resources were provided in response to this query.
- NVIDIA Transitions Fully Towards Open-Source GPU Kernel Modules | NVIDIA Technical Blog: With the R515 driver, NVIDIA released a set of Linux GPU kernel modules in May 2022 as open source with dual GPL and MIT licensing. The initial release targeted datacenter compute GPUs…
- LLM Research Insights: Instruction Masking and New LoRA Finetuning Experiments: Discussing the Latest Model Releases and AI Research in May 2024
CUDA MODE ▷ #triton (1 messages):
Missingtl.pow``triton.language.extra.libdevice.pow()
- Missing
tl.powfunction issue: A member mentioned the absence of thetl.powfunction in Triton.- It was suggested to use
triton.language.extra.libdevice.pow()as an alternative.
- It was suggested to use
- Suggested workaround for
tl.pow: The suggested workaround for the missingtl.powfunction is usingtriton.language.extra.libdevice.pow().- This serves as a temporary solution until the issue with
tl.powis resolved.
- This serves as a temporary solution until the issue with
CUDA MODE ▷ #torch (37 messages🔥):
Profiling and Distributed Cases in CUDADynamic Shared Memory in CUDAIssues with torch.compileInstalling torch-tensorrtReplacing aten::embedding_dense_backward with Triton Kernels
- Short Profiles for Efficient Inference in CUDA: Members discussed generating short profiles for regions such as prefill + 2-3 token forward passes for efficient batch preparation and scheduling.
- Dynamic Shared Memory Utilization Tips: Members shared techniques for declaring and using dynamic shared memory in CUDA kernels, such as
extern __shared__ float shared_mem[];and allocating memory at kernel launch.- They also discussed splitting dynamic shared memory into multiple arrays with pointer arithmetic for more efficient access.
- torch.compile Causing Inconsistent Model Performance: A user identified torch.compile as the source of inconsistencies in model performance and correctness, especially when comparing dense and sparse models.
- Enabling
torch._dynamo.config.guard_nn_modules=Truewas suggested as a fix, and linked to a relevant GitHub issue.
- Enabling
- Issues with torch-tensorrt Installation: A user encountered errors when trying to install torch-tensorrt via pip and was advised to use the command from the official NVIDIA releases page.
- Issues might stem from unsupported Python versions, and downgrading to versions between 3.8 and 3.10 was suggested.
- Replacing aten::embedding_dense_backward with Triton: A user wanted to replace aten::embedding_dense_backward with a fused Triton kernel to improve backward pass performance on
nn.Embedding.- They were recommended to write a custom Embedding layer to make direct calls to Triton kernels for better optimization.
- Compile doesn't guard on user NN module attribute · Issue #124717 · pytorch/pytorch: 🐛 Describe the bug TorchTune relies on mutating user NN module's attribute to decide whether to e.g. apply LoRA technique. The usage pattern looks like this: import contextlib import torch class ...
- Using Shared Memory in CUDA C/C++ | NVIDIA Technical Blog: In the previous post, I looked at how global memory accesses by a group of threads can be coalesced into a single transaction, and how alignment and stride affect coalescing for various generations of...
- CUDA Shared Memory Capacity: Use Large Shared Memory for CUDA Kernel Optimization
- Releases · pytorch/TensorRT: PyTorch/TorchScript/FX compiler for NVIDIA GPUs using TensorRT - pytorch/TensorRT
CUDA MODE ▷ #algorithms (1 messages):
Google Gemma 2 family of modelsTogether AI Flash Attention 3QGaLoRE: Quantised low rank gradients for fine tuningMistral AI MathΣtral and CodeStral mamba
- Google Gemma 2 models outperform competitors: The Google Gemma 2 family includes models that perform better than the Llama 2 family, with sizes 2B and 7B.
- Originally released in February 2024, Gemma 2 was announced at Google I/O and quickly surpassed by newer models like LlaMa 3 and Qwen 2, demonstrating the fast-paced evolution of AI technology.
- Flash Attention 3 accelerates GPU performance: Together AI introduces Flash Attention 3, with clear improvements over Flash Attention 1 and 2, making GPUs significantly faster.
- This advancement is crucial for enhancing computational efficiency and performance, as highlighted in the substack article.
- QGaLoRE: Optimizing fine-tuning with quantized gradients: The QGaLoRE technique utilizes quantised low-rank gradients to optimize the fine-tuning process of models.
- Mistral AI's MathΣtral and CodeStral projects impress: Mistral AI announced the MathΣtral and CodeStral mamba projects, pushing the envelope in mathematical computation and code efficiency, as discussed in the latest update.
Link mentioned: AIUnplugged 15: Gemma 2, Flash Attention 3, QGaLoRE, MathΣtral and Codestral Mamba: Insights over Information
CUDA MODE ▷ #beginner (6 messages):
CUTLASS repo tutorialsNsight CLI resources
- Building CUTLASS repo tutorials: A member asked for guidance on building and running the cute tutorials in the CUTLASS repo.
- Another member clarified that it's achieved via a make target and offered further assistance if needed.
- Using Nsight CLI for remote profiles: A member requested resources on using Nsight CLI and capturing profiles remotely for analysis in the GUI.
- It was highlighted that there's an option to export the captured profile to a file which can be opened from the GUI.
Link mentioned: cutlass/examples/cute/tutorial/sgemm_1.cu at main · NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines. Contribute to NVIDIA/cutlass development by creating an account on GitHub.
CUDA MODE ▷ #torchao (2 messages):
HF related discussionsFSDP2 replacing FSDP
- Initiation of HF-related Discussions: A user suggested that they should start discussing HF (Hugging Face) related topics in this channel.
- Let's talk here about HF related stuff too was the specific proposal made to the group.
- FSDP2 Set to Replace FSDP: A member mentioned that FSDP2 is going to replace FSDP and advised to start using FSDP2.
- nf4 is an example I think was cited as part of the explanation, with a promise to look into the details soon.
CUDA MODE ▷ #triton-puzzles (2 messages):
Triton compiler detailsTriton puzzles solutions
- Triton Compiler's Magical Optimization: A member mentioned that the Triton compiler automatically handles GPU code optimization, referencing a blog post that explains the process in detail.
- They highlighted that Triton turns Python code into Triton IR, optimizes it, and then compiles to PTX, leveraging
libLLVMandptxas.
- They highlighted that Triton turns Python code into Triton IR, optimizes it, and then compiles to PTX, leveraging
- Triton Puzzle Solutions Released: A member shared personal solutions to the Triton puzzles, mentioning the challenging notation in Puzzle 12.
- They noted that the solutions might be helpful if someone is short on time, despite being 'poorly written but probably correct'.
- GitHub - alexzhang13/Triton-Puzzles-Solutions: Personal solutions to the Triton Puzzles: Personal solutions to the Triton Puzzles. Contribute to alexzhang13/Triton-Puzzles-Solutions development by creating an account on GitHub.
- Demystify OpenAI Triton: Learn how to build mapping from OpenAI Triton to CUDA for high-performance deep learning apps through step-by-step instructions and code examples.
CUDA MODE ▷ #llmdotc (159 messages🔥🔥):
FP8 training settingsLayernorm optimizationsGPT-3 modelsMemory management refactoringFP8 inference
- How to activate FP8 training easily: To run FP8 training, switch to the fp8 branch, ensure defines are set as
FORCE_FP8_MATMUL true,FORCE_FP8_WEIGHTS false, andFORCE_FP8_ACTIVATIONS true, and execute./scripts/run_gpt2_1558M.sh.- arund42 confirms current params are for turning FP8 off, and mentions potential compatibility issues with existing checkpoints.
- Layernorm optimization with row_reduce: Arund42 spent the day on
train_gpt2fp32cuand added a newrow_reduce()function for Layernorm, aiming for better performance and cleaner abstraction.- The approach received mixed feelings about its higher-level abstraction but was appreciated for not using overly complex C++.
- First GPT-3 model (125M) training launched: Akakak1337 has initiated training for the first GPT-3 model (125M), estimating a runtime of ~12 hours and emphasizing expectations of performance benchmarks.
- Proposals are made to test various configurations, including memory consumption and maximum batch size, highlighting key optimizations and potential issues like shared memory overflows.
- Memory management refactoring in GPT code: Eriks.0595 is refactoring memory management for better consolidation and efficiency, moving allocations for model parameters, gradients, and optimizer states to centralized locations.
- FP8 and quantization strategies: Arund42 and others discussed training models with FP8 and INT8 quantization, highlighting the challenges and potential benefits of quantization-aware training.
- Comparisons were drawn to other approaches like natively training in INT8, with mentions of Character.AI's and Tesla's implementations for inference optimization.
- Optimizing AI Inference at Character.AI: At Character.AI, we're building toward AGI. In that future state, large language models (LLMs) will enhance daily life, providing business productivity and entertainment and helping people with e...
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- Accelerating Neural Network Training with Semi-Structured (2:4) Sparsity: Over the past year, we’ve added support for semi-structured (2:4) sparsity into PyTorch. With just a few lines of code, we were able to show a 10% end-to-end inference speedup on segment-anything by r...
- Major FP32 llm.c improvements/refactoring/etc. by ademeure · Pull Request #696 · karpathy/llm.c: I got slightly carried away and this ended up significantly changing nearly every single kernel in train_gpt2_fp32.cu! I have also added a lot of comments to the kernels - possibly too many, but if...
CUDA MODE ▷ #lecture-qa (9 messages🔥):
Deep Copy in GPU OperationsKernel Parameter LimitsPointer Handling in CUDAQuantization and Group Size
- Confusion over deep copy in GPU operations: A user expressed confusion about the necessity of deep-copying data from the host to the device during GPU operations, especially for a list of tensors.
- Other members clarified that data access issues arise because large structs cannot directly be passed to kernels, requiring pointers to large memory buffers instead.
- Kernel parameter limits and pointer handling: Members discussed issues around the 4k kernel parameter limit in CUDA, noting the necessity of using pointers to access large data structures from GPU memory.
- Pointers initially in CPU memory need to be copied to GPU global memory, and passing these to the kernel can mitigate size constraints.
- * vs. * in CUDA memory allocation*: A user's confusion about the use of vs. * in CUDA was addressed, highlighting that pointer arguments in GPU kernels must point to GPU memory.
- Passing a CPU memory array of pointers to GPU memory was an example given to clarify this point.
- Quantization lecture perplexity and group size: A user raised a question about the term 'group size' mentioned in a quantization lecture concerning changes in perplexity.
- Explanations provided detailed that group size refers to the number of quantized values sharing a scaling factor, affecting memory usage and quantization error.
Stability.ai (Stable Diffusion) ▷ #general-chat (213 messages🔥🔥):
Hermes 2Mistral strugglesModel MergingOpen Empathic
- RTX 4060 Ti Adequacy Confirmed with Configuration Tips: After inquiries about using automatic 1111 with an RTX 4060 Ti, another user confirmed the hardware is sufficient and recommended editing the
webui-user.batfile to add--xformers --medvram-sdxlfor optimal performance.- Discussion indicates the community is keen on hardware performance and configuration tips for maximized utility.
- Adobe Stock Revises Policy on Artist Names: Adobe Stock has updated its content policy to remove items that reference artist names in titles, keywords, or prompts for generated AI content, as notified in their recent communication.
- Users raised concerns about the broad application of this policy affecting non-copyrighted references, reflective of Adobe's stringent stance.
- AI Struggles: Common Failures Highlighted: Community members discussed recurring issues AI faces, such as rendering hands, text, and women lying on grass, with one user jokingly summarizing it as 'hands, text, women laying on grass'.
- There is anticipation for a finetuned model to address these specific shortcomings, as these errors are frequent pain points.
- Ultra Feature Speculation and Beta Access Clarified: Members speculated on the technical aspects of the 'Ultra' feature, with suggestions that it might involve a second sample stage and potential use of latent upscale or noise injection.
- Clarification was provided that Ultra is in beta and accessible via the website and API, confirming it's not directly tied to monetization but rather part of ongoing development.
- Troll Management Techniques Debated: A heated debate unfolded on the effectiveness of IP bans to manage disruptive users, with one member asserting their inefficacy and another highlighting the broader implications and alternatives.
- Conversations on this topic suggested varying levels of expertise and opinions on managing trolls within the community.
- Dies From Cringe Meme GIF - Dies From Cringe Meme Cringe - Discover & Share GIFs: Click to view the GIF
- Auraflow Demo - a Hugging Face Space by multimodalart: no description found
- What is score_9 and how to use it in Pony Diffusion | Civitai: Interested in next version of Pony Diffusion? Read update here: https://civitai.com/articles/5069/towards-pony-diffusion-v7 You may've seen score_9...
Eleuther ▷ #announcements (1 messages):
GoldFinch hybrid modelLinear Attention vs TransformersGoldFinch performance benchmarksFinch-C2 and GPTAlpha releases
- GoldFinch Hybrid Model Hatches: The GoldFinch model combines Linear Attention (RWKV) with traditional Transformers, eliminating quadratic slowdown and significantly reducing KV-Cache size, enabling extremely large context lengths with minimal VRAM requirements.
- In experiments, GoldFinch outperforms slightly larger models like 1.5B class Llama and Finch (RWKV-6) on downstream tasks.
- GoldFinch Outperforms Rivals: GoldFinch shows better downstream performance compared to 1.5B class Llama and Finch (RWKV-6) models.
- The ability to look back at every token at lower costs and better downstream results is highlighted.
- Finch-C2 and GPTAlpha Released: Finch-C2 is introduced as a higher performance version of Finch (RWKV-6), while GPTAlpha enhances traditional Transformer architecture with RWKV components.
- Both models leverage softmax attention to outperform standard Transformers.
- Reference Links for GoldFinch: The code, paper, and checkpoints for GoldFinch are available on GitHub and Hugging Face repositories.
- GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression: We introduce GoldFinch, a hybrid Linear Attention/Transformer sequence model that uses a new technique to efficiently generate a highly compressed and reusable KV-Cache in linear time and space with r...
- GitHub - recursal/GoldFinch-paper: GoldFinch and other hybrid transformer components: GoldFinch and other hybrid transformer components. Contribute to recursal/GoldFinch-paper development by creating an account on GitHub.
- recursal/GoldFinch-paper · Hugging Face: no description found
Eleuther ▷ #general (72 messages🔥🔥):
Drama over AI scrapingWhisper Mit License MisunderstandingGoogle scraping and content useRandom pages mentioning PileCommunity project involvement
- Drama erupts over AI scraping YT subtitles: Intense discussions emerge about AI training data, specifically YouTube subtitles, with members pointing out the outrage seems misplaced compared to concerns about images and audio.
- Some argue it harms creators economically while others believe it doesn't deserve the uproar, noting the legality of scraping under fair use and public permissions.
- Misunderstandings about Whisper's MIT License clarified: Misunderstandings about Whisper being an MIT project are cleared up, confirming it’s MIT licensed software.
- The distinction between MIT license and MIT projects highlighted: "Whisper wasn't made by MIT... Whisper is MIT licensed."
- Google profits without user consent?: Members debate over Google and Bing scraping data and the resulting economic benefits without direct payments to content creators.
- "Importantly for copyright, search results do not harm the economic value..."
- General Misinformation about scraping practices: Discussion centers around the misinformation spreading about EleutherAI and scraping practices, pointing out they are not a company but a non-profit research org.
- Some members jest that journalists' misinformation may be rampant these days.
- Seeking active community projects: Queries about active community projects were directed to different channels and organizations.
- The suggestion was made to explore other channels within the server for ongoing projects in LLMs and NLP.
Eleuther ▷ #research (108 messages🔥🔥):
ICML 2024Attention MechanismsProtein Language ModelsPatch-Level TrainingLanguage Model Scaling
- ICML 2024 Buzz Heats Up: Attendees discuss the upcoming ICML 2024, celebrating grimsqueaker's presentation on 'Protein Language Models Expose Viral Mimicry and Immune Escape' at the ML4LMS workshop.
- Grimsqueaker elaborates on the poster, highlighting 99.7% ROCAUC accuracy and novel insights into viral mimicry, providing code on GitHub and the poster link.
- Attention Mechanism Debates Ensue: Members engage in a technical discussion on the invariance of hashing functions to vector scaling in LSH Attention.
- Vodros and gloomyc discuss the impact of normalization on attention matrices, examining the effectiveness of multiple hashing rounds and bucket divisions.
- Patch-Level Training Revolutionizes LLM Efficiency: The newly introduced Patch-Level Training for LLMs claims to improve training efficiency by reducing the sequence length via token compression.
- Members, including cz_spoon_06890, explore the implications of cosine LR schedules, patch vs. token-level training, and potential learnings from the PatchTrain GitHub.
- Scaling Techniques for Language Models: Members discuss scaling and training efficiency techniques, including multi-token prediction and learning rate schedules.
- Catboy_slim_ and others delve into the implications of different scaling methods, referencing relevant papers such as those from arxiv.org.
- NuminaMath-7B's Rise and Scrutiny: Jeniajitsev criticizes NuminaMath-7B for overstated claims in high school math-solving benchmarks, revealing fundamental reasoning flaws.
- This model's performance on simple problems suggests caution in interpreting benchmark results, as discussed in a Twitter thread.
- Patch-Level Training for Large Language Models: As Large Language Models (LLMs) achieve remarkable progress in language understanding and generation, their training efficiency has become a critical concern. Traditionally, LLMs are trained to predic...
- Neural Networks Learn Statistics of Increasing Complexity: The distributional simplicity bias (DSB) posits that neural networks learn low-order moments of the data distribution first, before moving on to higher-order correlations. In this work, we present com...
- Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations: Scale has become a main ingredient in obtaining strong machine learning models. As a result, understanding a model's scaling properties is key to effectively designing both the right training setu...
- Cognitive Architectures for Language Agents: Recent efforts have augmented large language models (LLMs) with external resources (e.g., the Internet) or internal control flows (e.g., prompt chaining) for tasks requiring grounding or reasoning, le...
- Better & Faster Large Language Models via Multi-token Prediction: Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in h...
- Tweet from Jenia Jitsev 🏳️🌈 🇺🇦 (@JJitsev): (Yet) another tale of Rise and Fall: Recently, NuminaMath-7B ranked 1st at the AIMO competition, solving 29/50 private set problems of olympiad math level. Can it handle simple AIW problem, which re...
- GitHub - shaochenze/PatchTrain: Code for paper "Patch-Level Training for Large Language Models": Code for paper "Patch-Level Training for Large Language Models" - shaochenze/PatchTrain
- GitHub - RulinShao/retrieval-scaling: Official repository for "Scaling Retrieval-Based Langauge Models with a Trillion-Token Datastore".: Official repository for "Scaling Retrieval-Based Langauge Models with a Trillion-Token Datastore". - RulinShao/retrieval-scaling
- Protein language models expose viral mimicry and immune escape: Viruses elude the immune system through molecular mimicry, adopting their hosts biophysical characteristics. We adapt protein language models (PLMs) to differenti-ate between human and viral...
- GitHub - ddofer/ProteinHumVir: Code & data for "Protein Language Models Expose Viral Mimicry and Immune Escape": Code & data for "Protein Language Models Expose Viral Mimicry and Immune Escape" - ddofer/ProteinHumVir
- Protein Language Models Expose Viral Mimicry and Immune Escape: Motivation Viruses elude the immune system through molecular mimicry, adopting biophysical characteristics of their host. We adapt protein language models (PLMs) to differentiate between human and vir...
Eleuther ▷ #interpretability-general (1 messages):
tokenization-free modelsinterpretability in AI
- Tokenization-Free Models for Better Interpretability?: A member raised a question whether tokenization-free language models would be better or worse for interpretability.
- Theory on Interpretability in AI: The discussion focused on the potential impacts of tokenization on AI model interpretability.
Eleuther ▷ #lm-thunderdome (14 messages🔥):
lm-eval-harness--predict_onlyflagTRL finetuning with loraEmbedding matrices issue in PeftModelForCausalLMGigachat model PR reviewsimple_evaluate responses storage
- Challenges in using lm-eval-harness
--predict_only: A user inquired about running metrics withlm-eval-harnessafter using the--predict_onlyflag and having access to a file of completions. - Error with TRL finetuning using lora: A user faced
RuntimeError: size mismatchwhen usingtrl'ssetup_chat_formatand finetuning withlora, despite having the latest version of the library. - System messages handling in lm-eval-harness: The community clarified that system messages passed through
--system_instructionare treated similarly to those in thedescriptionfield of a task.yaml file, concatenated for compatible models. - Review request for Gigachat model PR: A user requested a review for their PR adding the Gigachat model to the library, using the API with chat templates.
- Evaluating consistency in LM evaluation scores: A user discussed ensuring correctness when adding new models by comparing deterministic generation sampling scores across different LM evaluation implementations and frameworks.
Link mentioned: Add Gigachat model by seldereyy · Pull Request #1996 · EleutherAI/lm-evaluation-harness: Add a new model to the library using the API with chat templates. For authorization set environmental variables "GIGACHAT_CREDENTIALS" and "GIGACHAT_SCOPE" for your API auth_data a...
LM Studio ▷ #💬-general (59 messages🔥🔥):
Codestral Mamba on LM StudioContext length issues in LM StudioModel suggestions for NSFW/roleplayGemma IT GPU issuesMistral-Nemo 12B collaboration with NVIDIA
- Codestral Mamba integration with LM Studio: Members discussed the requirement for Codestral Mamba support to be added in llama.cpp before it can be available in LM Studio.
- Heyitsyorkie mentioned that updates depend on llama.cpp integration and subsequent adoption in LM Studio.
- Fixing context length overflow in LM Studio: Members helped Gilwolfy to resolve a context length overflow issue by guiding them to adjust settings in the tools menu.
- Santonero clarified where to find and change the Context Overflow Policy setting.
- Model recommendations for NSFW content: Member Skryptii suggested that model choice and system prompts have more impact on NSFW and roleplay tasks than presets.
- Recommended models like Smegmma-9B which are fine-tuned for such purposes.
- Gemma IT GPU error issues: Anadon reported GPU errors while executing models with 2B parameters on an RX 6900 XT with 16GB VRAM.
- The errors vary with the number of layers loaded into the GPU.
- Mistral and NVIDIA release Mistral-Nemo 12B: The collaboration between Mistral and NVIDIA resulted in the launch of the Mistral-Nemo 12B model, boasting up to 128k token context window.
- The announcement noted its superior reasoning and coding accuracy, though it’s currently unsupported in LM Studio due to tokenizer issues in llama.cpp.
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- TheDrummer/Smegmma-9B-v1 · Hugging Face: no description found
- Local LLM Server | LM Studio: You can use LLMs you load within LM Studio via an API server running on localhost.
- Code Examples | LM Studio: Examples of how to use the LM Studio JavaScript/TypeScript SDK
LM Studio ▷ #🤖-models-discussion-chat (23 messages🔥):
DeepSeek-V2 integrationMistral NeMo model releaseChina's use of open-source LLMsLogical reasoning in LLMsVerbose responses in LLMs
- DeepSeek-V2 integration with LM Studio pending: Users discussed whether LM Studio will support DeepSeek-V2-Chat-0628, with an estimate that support will be added when llama.cpp supports it.
- Anester highlighted China's data policy and implied that they may leverage their large datasets to surpass other countries in LLM development.
- Mistral NeMo model collaboration with NVIDIA: Mistral released the Mistral NeMo, a 12B model co-developed with NVIDIA offering a 128k token context window and state-of-the-art reasoning, world knowledge, and coding accuracy.
- The model supports FP8 inference without performance loss, and pre-trained checkpoints are available under the Apache 2.0 license.
- Chinese policies on data and LLMs: Anester argued that China's data policies could eventually allow them to surpass others in LLM capabilities due to extensive data collection and the lack of DRM laws.
- He made a controversial point about China's potential to take over technologies like ChatGPT using these methods.
- Logical reasoning issues in Mistral NeMo: Users noted that Mistral NeMo's logical reasoning appears to be poor in certain tests despite its high technical specs.
- An example illustrated the model gave a convoluted explanation for a simple scenario involving a ball and a goblet.
- Verbose responses in language models: Ptable mentioned that Mistral NeMo responds very verbosely, which can be seen as taking advantage of its 128k token context window.
- This verbosity could have implications for the user's interaction with the model, especially in lengthy conversations.
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- deepseek-ai/DeepSeek-V2-Chat-0628 · Hugging Face: no description found
- NVIDIA NIM | mistral-nemo-12b-instruct : Experience the leading models to build enterprise generative AI apps now.
LM Studio ▷ #🧠-feedback (1 messages):
xoxo3331: There is no argument or flag to load a model with a preset through cli
LM Studio ▷ #📝-prompts-discussion-chat (1 messages):
Meta Llama 3Prompt strategiesStock trading strategiesFund allocationRisk management
- Crafting Meta Llama 3 trading prompt: A member shared their approach for drafting a prompt to analyze stock market opportunities and propose trading strategies using Meta Llama 3.
- The prompt includes steps for assessing trade strategy risks and rewards, fund allocation recommendations, and managing within a specified risk tolerance.
- Structured prompts for risk management in trading: The shared prompt outlines methods for managing risk within an agreed-upon tolerance, ensuring comprehensive analysis before trade execution.
- Your final answer MUST include a detailed analysis of the trade proposal, further emphasizing the meticulous breakdown requirement.
LM Studio ▷ #⚙-configs-discussion (1 messages):
New Model DiscussionLMStudio Preset for AutogenLlama-3-Groq-8B-Tool-Use-GGUF
- New model discussion on Llama-3-Groq-8B: A query was raised about the new model Llama-3-Groq-8B-Tool-Use-GGUF and its compatibility with the default lmstudio preset for autogen cases.
- This model is associated with MaziyarPanahi and there is curiosity regarding its use in automated generation scenarios.
- LMStudio Preset for Autogen Cases: Discussion includes whether the default lmstudio preset will work effectively for autogen cases with the new model.
- Members are seeking clarification on the preset compatibility for efficient use in various scenarios.
LM Studio ▷ #🎛-hardware-discussion (23 messages🔥):
Custom Hardware SpecsResizable BAR Impact on LLMNVIDIA GTX 1050 IssuesROCM Version UpdateDIY Safety Concerns
- Xeon Setup with High Hopes: 2x Xeon 8 core 3.5GHz, 32GB 2600 ECC RAM, and P40 GPU setup aims for fast model performance with room for expansion.
- The builder is not interested in running large models slowly and seeks to optimize the setup for speed and additional features.
- Resizable BAR Not Crucial for LLM: Resizable BAR reportedly has no significant effect on LLM performance as mentioned in the conversation, focusing instead on tensor cores and VRAM bandwidth.
- Model loading and multi-GPU performance were questioned but remain inconclusive.
- GTX 1050 Struggles with LLM: Issues were reported with a GTX 1050 where the GPU usage capped at 10% and the CPU handled most of the workload.
- Members speculated that the 4GB VRAM is insufficient for 7B+ models, and a smaller model might be a feasible solution.
- ROCM Version Update Notice: Members inquired about the latest version of LM Studio ROCM, initially believed to be 0.2.24.
- It was clarified with a quick pointer to the appropriate channel for updated information.
- DIY Setup Heat Safety: Concerns were raised about the Xeon processors potentially burning wood in a DIY build.
- The builder reassured that there's an air gap to mitigate this risk.
LM Studio ▷ #🧪-beta-releases-chat (3 messages):
0.3.0 Beta EnrollmentBeta DownloadBeta Announcements
- 0.3.0 Beta status confusion: Multiple members, including krypt_lynx, mentioned they received '0.3.0 Beta' status but did not receive further replies or download information.
- skeletonbow hypothesized that this might be a signup beta with invites rolling out gradually to gather feedback and iterate, while heyitsyorkie suggested that current beta access is likely limited to 'active' chat participants.
- Awaiting Beta Enrollment Replies: krypt_lynx asked where to look for the download after receiving '0.3.0 Beta' status without further messages.
- The question remains unresolved, but heyitsyorkie speculates an announcement from Yags might come in a few days.
LM Studio ▷ #amd-rocm-tech-preview (4 messages):
CUDA on AMDzludascaleportable install option
- Testing CUDA on AMD RDNA: A member shared a Reddit post about a new compiler for AMD cards, indicating RX 7800 works with it and suggesting potential benefits over ROCm implementation.
- They mentioned interest in testing it in lama.cpp and seeing if it performs better than the ROCm implementation.
- ZLUDA and its Limitations: Another member mentioned ZLUDA, which enables CUDA to run natively on AMD, and noted it never integrated into lama.cpp.
- SCALE Similar to ZLUDA: A member pointed out that SCALE, a tool similar to ZLUDA, was released a few days ago.
- Request for Portable Install Option: A user expressed interest in testing if there were a portable install option available.
Link mentioned: Reddit - Dive into anything: no description found
LM Studio ▷ #model-announcements (1 messages):
Groq's tool use modelsBerkeley Function Calling LeaderboardLlama-3 Groq-8BLlama-3 Groq-70Btool use and function calling
- Groq's Models Score High on Function Calling Leaderboard: Groq's new tool use models have achieved high scores on the Berkeley Function Calling Leaderboard, with 89.06% for the 8B and 90.76% for the 70B models.
- These models are ideal for pipelines that rely on tool use and function calling.
- Llama-3 Groq Models Released: The Llama-3 Groq-8B and Llama-3 Groq-70B models are now available for use, optimized for tool use and function calling.
- Check out the models on Hugging Face for integrating into various pipelines.
LM Studio ▷ #🛠-dev-chat (14 messages🔥):
Hosting AI models onlineNgrok vs Nginx for hostingCustom web UI and SSR techniqueTailscale for secure tunnelingBuilding user accounts and separate chats
- Setting up AI models for friends to test: A user inquired about hosting AI models on their PC to be accessible online for friends to test with multiple sessions.
- Suggestions included using Ngrok for easy, temporary URL hosting and NGINX for better control; Tailscale was mentioned for secure tunneling.
- Long-term AI model hosting plans: The user shared a vision for hosting AI models for hundreds or thousands of users with separate accounts and chats.
- Plans for a custom front-end and back-end to manage user interactions were discussed, highlighting the need for experienced front-end developers.
- Web UI and SSR technique for user interactions: A suggestion was made to create a custom web UI using server-side rendering (SSR) techniques for facilitating user interactions.
- This approach was recommended unless users are comfortable with fetching APIs directly.
Nous Research AI ▷ #research-papers (2 messages):
TextGradProTeGiSTORM Writing System
- TextGrad Framework Offers Textual Gradients for NN Optimization: A member wondered if TextGrad, a framework for performing automatic 'differentiation' via text, is practical or just hype.
- The framework facilitates LLMs in providing textual feedback to optimize components like code snippets and molecular structures, aiming to make optimization more accessible.
- ProTeGi Paper Raises Interest in Textual Gradients: Another paper, ProTeGi, was mentioned in discussion for its similar approach to optimizing neural networks with textual gradients.
- STORM System Enhances Outline Creation for Long-Form Articles: The STORM system by Stanford uses LLMs to write organized long-form articles by synthesizing topic outlines through multi-perspective question asking and retrieval.
- STORM showed a significant increase in the organization and breadth of coverage in generated articles compared to baseline methods, although new challenges like source bias transfer remain.
- TextGrad: Automatic "Differentiation" via Text: AI is undergoing a paradigm shift, with breakthroughs achieved by systems orchestrating multiple large language models (LLMs) and other complex components. As a result, developing principled and autom...
- Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models: We study how to apply large language models to write grounded and organized long-form articles from scratch, with comparable breadth and depth to Wikipedia pages. This underexplored problem poses new ...
- no title found: no description found
- GitHub - stanford-oval/storm: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations.: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations. - stanford-oval/storm
Nous Research AI ▷ #datasets (1 messages):
Synthetic datasetGeneral knowledge base
- Synthetic Dataset and Business-Focused Knowledge Base Released: A synthetic dataset and general knowledge base was shared, focusing on business applications.
- This comprehensive resource aims to support AI systems with a wide array of business-related data.
- AI Knowledge Base for RAG Systems: The Mill-Pond-Research/AI-Knowledge-Base offers a comprehensive generalized knowledge base tailored for Retrieval-Augmented Generation (RAG) systems.
- The repository includes detailed documentation and a dataset image indicating its expansive capabilities.
Link mentioned: GitHub - Mill-Pond-Research/AI-Knowledge-Base: Comprehensive Generalized Knowledge Base for AI Systems (RAG): Comprehensive Generalized Knowledge Base for AI Systems (RAG) - Mill-Pond-Research/AI-Knowledge-Base
Nous Research AI ▷ #interesting-links (3 messages):
Intelligent Digital AgentsMistral-NeMo-12B-InstructAgentInstruct for Synthetic Data
- Shift Needed for Intelligent Digital Agents: “Intelligent Digital Agents in the Era of Large Language Models” discusses advancements in LLM-driven agents, pinpointing limitations and suggesting a shift from language-based processing to enhance reasoning.
- The position paper emphasizes the necessity for new approaches in agent design for improved performance.
- NVIDIA’s Mistral-NeMo-12B-Instruct Shines: The Mistral-NeMo-12B-Instruct model by NVIDIA and Mistral AI boasts 12B parameters and outperforms similar-sized models, supporting a 128k context window and FP8 quantization.
- This multilingual and code data-trained model is released under the Apache 2 License and includes both pre-trained and instructed versions.
- AgentInstruct Automates Synthetic Data Creation: Microsoft Research's AgentInstruct framework aims to simplify synthetic data creation through an automated multi-agent system, enhancing language model post-training.
- Arindam Mitra and coauthors’ research outlines this initiative, promising to revolutionize data generation at scale.
- Tweet from Microsoft Research (@MSFTResearch): Synthetic data creation is hard. Arindam Mitra and his coauthors aim to change that w/ AgentInstruct, an automated multi-agent framework for generating quality synthetic data at scale for language mod...
- nvidia/Mistral-NeMo-12B-Instruct · Hugging Face: no description found
- Tweet from Manifold Research (@ManifoldRG): 🚨We’re excited to share “Intelligent Digital Agents in the Era of Large Language Models”, a position paper that explores advancements in LLM driven agents, identifies limitations, and suggests that t...
Nous Research AI ▷ #general (115 messages🔥🔥):
Twitter/X Model LivestreamNew Paper on LLM JailbreakingMistral NeMo Model ReleaseAutoFP8 and FP8 QuantizationGPT-4o Mini Benchmark Performance
- New paper highlights LLM jailbreaking via past tense reformulations: A new paper reveals a curious generalization gap in LLMs, where reformulating harmful requests in the past tense significantly increases the jailbreak success rate on GPT-4 from 1% to 88% with 20 reformulation attempts (link).
- "Our findings highlight that the widely used alignment techniques such as SFT, RLHF, and adversarial training can be brittle and not generalize as intended."
- Mistral NeMo Model Release Sparks Discussion: Mistral AI, in collaboration with NVIDIA, released the 12B model Mistral NeMo, boasting up to 128k token context window and FP8 quantization for enhanced performance (link).
- Some users noted concerns about exclusion for RTX 3090 owners, as FP8 quantization requires newer GPUs like the 4090.
- AutoFP8 Enables FP8 Quantization in vLLM: The AutoFP8 library from Neural Magic enables FP8 weight and activation quantization for models, preserving 98-99% quality compared to FP16 (link).
- Experimental support for FP8 was added to vLLM, which allows significant reduction in model memory.
- GPT-4o Mini Struggles Against Expectations: Despite high HumanEval scores, GPT-4o Mini's actual performance in coding benchmarks is similar to GPT-3.5-Turbo, disappointing many users (link).
- Users expressed frustration and confusion over OpenAI's model performance claims and hype.
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- Tweet from anton (@abacaj): The numbers reported by mistral nemo (considering it’s a 12B model vs meta llama 8B) are wrong? They make llama 3 8B look much worse than it actually is for some reason…
- FP8 — vLLM: no description found
- BERTopic: no description found
- Tweet from Maksym Andriushchenko (@maksym_andr): 🚨Excited to share our new paper!🚨 We reveal a curious generalization gap in the current refusal training approaches: simply reformulating a harmful request in the past tense (e.g., "How to make...
- Tweet from DeepSeek (@deepseek_ai): 🎉Exciting news! We open-sourced DeepSeek-V2-0628 checkpoint, the No.1 open-source model on the LMSYS Chatbot Arena Leaderboard @lmsysorg. Detailed Arena Ranking: Overall No.11, Hard Prompts No.3, Co...
- mistralai/Mistral-Nemo-Instruct-2407 · Hugging Face: no description found
- Tweet from Nathan Lambert (@natolambert): GPT4-o-mini on reward bench Above claude 3 sonnet (not 3.5) and llama 3 70b, below gemma 2 27b. Really all of these are similar. Pretty saturated.
- GitHub - neuralmagic/AutoFP8: Contribute to neuralmagic/AutoFP8 development by creating an account on GitHub.
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- NousResearch/Hermes-2-Pro-Llama-3-8B · Add tool use template: no description found
- Upload 3 files · NousResearch/Hermes-2-Pro-Llama-3-8B at 714ffdf: no description found
Nous Research AI ▷ #world-sim (6 messages):
WorldSim downtimeWorldSim issue
- WorldSim experiences downtime: WorldSim was reported down by a member, causing inconvenience.
- Should be back up in a minute! assured another member, and a fix was confirmed shortly.
- WorldSim issue quickly resolved: A member swiftly reported the downtime issue in WorldSim.
- The issue was promptly fixed, with thanks to the community for reporting.
Latent Space ▷ #ai-general-chat (121 messages🔥🔥):
DeepSeek V2GPT-5 SpeculationGPT-4o Mini ReleaseDeepSeek V2 DiscussionNew LLaMA 3
- DeepSeek causes price war in AI models: DeepSeek's DeepSeek V2 model dramatically lowered inference costs to 1 yuan per million tokens, sparking a price war among Chinese tech giants.
- Described as China’s AI Pinduoduo, its innovation includes a new MLA architecture that significantly reduces memory usage.
- GPT-4o mini shakes the AI world: OpenAI released GPT-4o mini, providing high performance at a cost of $0.15 per million input tokens and $0.60 per million output tokens.
- This model surpasses smaller models like Claude 3 Haiku (75%) with an 82% MMLU score and a 128k context window.
- Mistral NeMo emerges with NVIDIA: Mistral AI and NVIDIA introduced Mistral NeMo, a high-performance, 12B model with 128k tokens context window, trained on the NVIDIA DGX Cloud.
- Features include quantization awareness for FP8 inference and high efficiency, with the model being a drop-in replacement for Mistral 7B.
- Together AI unveils Turbo & Lite LLaMA 3: Together AI launched Turbo and Lite versions of LLaMA 3, offering faster inference and cheaper costs, including LLaMA-3-8B Lite at $0.10 per million tokens.
- The Turbo version delivers up to 400 tokens/s, making it exceptionally efficient for high-demand applications.
- Speculation builds around LLaMA 3 400B release: The AI community is buzzing about the potential release of LLaMA 3 400B in the next few days, aligning with upcoming talks by top Meta executives.
- There is anticipation that current model releases aim to clear the field before this significant launch.
- Mistral AI and NVIDIA Unveil Mistral NeMo 12B, a Cutting-Edge Enterprise AI Model: Mistral AI and NVIDIA today released a new state-of-the-art language model, Mistral NeMo 12B, that developers can easily customize and deploy for enterprise applications supporting chatbots, multiling...
- Tweet from Louis Knight-Webb (@LouisKnightWebb): Context utilisation of gpt-4o mini unsurprisingly much better than 3.5 but worse than daddy 4o
- Tweet from Ethan Mollick (@emollick): 👀Claude handles an insane request: “Remove the squid” “The document appears to be the full text of the novel "All Quiet on the Western Front" by Erich Maria Remarque. It doesn't contain ...
- Tweet from Artificial Analysis (@ArtificialAnlys): GPT-4o Mini, announced today, is very impressive for how cheap it is being offered 👀 With a MMLU score of 82% (reported by TechCrunch), it surpasses the quality of other smaller models including Gem...
- Tweet from Matt Shumer (@mattshumer_): Mistral NeMo looks to be a damn good model - 12B so it fine-tunes quickly and cheaply - fast inference (small + trained w/ quantisation awareness) - new tokenizer that handles many languages efficien...
- Tweet from Hassan (@nutlope): Together AI's API just got faster & cheaper with our 2 new versions of Llama-3: ◆ Llama-3-8B Turbo (FP8) – up to 400 tokens/s ◆ Llama-3-8B Lite (INT4) – $0.10 per million tokens ◆ Turbo & Lite fo...
- Tweet from Lenny Bogdonoff (@rememberlenny): This, but for labor hours to do intelligent work. And much faster.
- Tweet from Nathan Lambert (@natolambert): kind of more impressed that the tiny gemini flash model is beating all these chonky open models. rumors gemini pro < 70B active params guessing gemeni flash <30B active params, maybe even like ...
- Samsung’s new image-generating AI tool is a little too good: What is a photo, really?
- Tweet from Jared Zoneraich (@imjaredz): gpt-4o-mini was just released and is 33x cheaper than gpt-4o which was ALREADY the cheapest model by far gpt-4o-mini is 200x cheaper than gpt-4 used at scale by @tryramp and @Superhuman already. We&...
- Tweet from Xenova (@xenovacom): Mistral and NVIDIA just released Mistral NeMo, a state-of-the-art 12B model with 128k context length! 😍 It uses a new Tiktoken-based tokenizer, which is far more efficient at compressing source code...
- Tweet from Eric Glyman (@eglyman): Was immediately clear in early testing, @OpenAI's latest GPT-4o mini model is a step up. It's helping us save even more time for our customers. Quoting Ramp (@tryramp) Happy to help @OpenAI...
- Tweet from 𝑨𝒓𝒕𝒊𝒇𝒊𝒄𝒊𝒂𝒍 𝑮𝒖𝒚 (@artificialguybr): I deleted the post about GPT-4O no longer being available to free users. Unfortunately I ended up being confused by the UI and spoke bullshit/fake news. I apologize for the mistake!
- Tweet from Pliny the Prompter 🐉 (@elder_plinius): ⚡️ JAILBREAK ALERT ⚡️ OPENAI: PWNED ✌️😎 GPT-4O-MINI: LIBERATED 🤗 Looks like the new "instruction hierarchy" defense mechanism isn't quite enough 🤷♂️ Witness the and new gpt-4o-mini ...
- Tweet from lmsys.org (@lmsysorg): Congrats @openai on the new GPT-4o mini release! GPT-4o mini's early version "upcoming-gpt-mini" was tested in Arena in the past week. With over 6K user votes, we are excited to share it...
- Tweet from Teortaxes▶️ (@teortaxesTex): Deepseek internal logs is the best Xianxia story you have never read. The Eastern Blue Whale Sect disciples will continue cultivation until the very Heavens tremble.
- Tweet from Max Woolf (@minimaxir): GPT-4o mini is $0.15/1M input tokens, $0.60/1M output tokens. In comparison, Claude Haiku is $0.25/1M input tokens, $1.25/1M output tokens. There's no way this price-race-to-the-bottom is sustain...
- Tweet from Patrick Loeber (@patloeber): This is the syllabus of @karpathy's upcoming AI course. Oh boy, am I excited about this!🤩 Especially looking forward to all hands-on coding parts not only in Python but also in C and CUDA. Sou...
- Tweet from Andrej Karpathy (@karpathy): LLM model size competition is intensifying… backwards! My bet is that we'll see models that "think" very well and reliably that are very very small. There is most likely a setting even of...
- Tweet from Teknium (e/λ) (@Teknium1): Somehow this got passed over in my feed today; Mistral released a new base model, slams l3 8b for 4B params more - not sure if its the same arch as old mistrals as its called Mistral Nemo: https://mi...
- Tweet from anton (@abacaj): OpenAI > here’s a cool paper where we dumb down smart model outputs Anthropic > here’s a cool model you can use, expect the bigger one later this year
- Tweet from Sam Altman (@sama): way back in 2022, the best model in the world was text-davinci-003. it was much, much worse than this new model. it cost 100x more.
- Tweet from Together AI (@togethercompute): Today we are announcing a new inference stack, which provides decoding throughput 4x faster than open-source vLLM. We are also introducing new Together Turbo and Together Lite endpoints that enable ...
- Tweet from Greg Brockman (@gdb): We built gpt-4o mini due to popular demand from developers. We ❤️ developers, and aim to provide them the best tools to convert machine intelligence into positive applications across every domain. Ple...
- Tweet from Andrew Curran (@AndrewCurran_): From this: - Llama 4 started training in June - Llama 4 will be fully multimodal, including audio - Llama 3 405b will still release in the EU - Llama 4, and beyond, will not be released in the EU unle...
- Tweet from Nick Dobos (@NickADobos): OpenAI had to make the ai dumber so idiot humans could understand it Quoting OpenAI (@OpenAI) We trained advanced language models to generate text that weaker models can easily verify, and found it...
- Tweet from Terry Yue Zhuo (@terryyuezhuo): GPT-4o mini on BigCodeBench-Hard is out: Complete Pass@1: 27.0 Instruct Pass@1: 24.3 Average: 25.7 The average score is very close to Claude-3-Opus (26.0)! Quoting Boris Power (@BorisMPower) The ...
- Tweet from Romain Huet (@romainhuet): Launching GPT-4o mini: the most intelligent and cost-efficient small model yet! Smarter and cheaper than GPT-3.5 Turbo, it’s ideal for function calling, large contexts, real-time interactions—and has...
- no title found: no description found
- Tweet from Jared Zoneraich (@imjaredz): did a quick batch run comparing 4-turbo to 4o-mini order of magnitude faster and cheaper will unlock many new usecases where you will happily sacrifice intelligence for speed/cost Quoting Jared Zon...
- Tweet from Phil (@phill__1): There are currently at least 6 unreleased models in the lmsys arena: -gemini-test-1 and gemini-test-2 (probably new Gemini 1.5 version, maybe Gemini 2.0) -im-a-little-birdie (???) -upcoming-gpt-mini ...
- Tweet from will depue (@willdepue): fyi on voice mode coming in near future. heroic effort from team to get this out. Quoting Sam Altman (@sama) @jakebrowatzke alpha starts later this month, GA will come a bit after
- Tweet from Vipul Ved Prakash (@vipulved): We released Turbo and Lite versions of Llama-3 today that incorporate our latest research in optimization and quantization. Lite models are 6x cheaper than GPT-4o mini, possibly the most cost effici...
- Tweet from Simon Willison (@simonw): My notes on today's release of GPT-4o mini: https://simonwillison.net/2024/Jul/18/gpt-4o-mini/ The biggest news is the price: this is cheaper even than Claude 3 Haiku, at just 15c per million inp...
- Tweet from main (@main_horse): Deepseek founder Liang Wenfeng: We will not go closed-source. We believe that having a strong technical ecosystem first is more important.
- Tweet from Jeff Harris (@jeffintime): hidden gem: GPT-4o mini supports 16K max_tokens (up from 4K on GPT-4T+GPT-4o) https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/
- Tweet from anton (@abacaj): 4x throughput over open source serving vLLM… what hope do we have to serve our own models Quoting Together AI (@togethercompute) Today we are announcing a new inference stack, which provides decodi...
- Tweet from swyx 🤞 🔜 SFO (@swyx): Completely hypothetically... what would you do with an open source GPT4o-class model that you can't do today? What questions could you ask that delivers alpha within the bounds of new-normal AI...
- 揭秘DeepSeek:一个更极致的中国技术理想主义故事: 做贡献者,而非搭便车者。
- Tweet from Andrew Curran (@AndrewCurran_): Here's our new model. 'GPT-4o mini'. 'the most capable and cost-efficient small model available today' according to OpenAI. Going live today for free and pro.
- GitHub - openai/simple-evals: Contribute to openai/simple-evals development by creating an account on GitHub.
- Artificial Agency Launches Out of Stealth with $16M (USD) in Funding to Bring Generative Behavior to Gaming — Artificial Agency — Artificial Agency : World’s first AI-powered behavior engine integrates runtime decision-making into game mechanics, unlocking a new generation of adaptive and intelligent games
- Tweet from Guillaume Lample @ ICLR 2024 (@GuillaumeLample): Very happy to release our new small model, Mistral NeMo, a 12B model trained in collaboration with @nvidia. Mistral NeMo supports a context window of 128k tokens, comes with a FP8 aligned checkpoint, ...
- Tweet from anton (@abacaj): The numbers reported by mistral nemo (considering it’s a 12B model vs meta llama 8B) are wrong? They make llama 3 8B look much worse than it actually is for some reason…
- Tweet from Artificial Analysis (@ArtificialAnlys): Mistral has released NeMo, a new open-source, long context, smaller model as a successor to Mistral 7B. Why it is exciting below 👇 - Open source model with a 128k context window: Large context windo...
- Reddit - Dive into anything: no description found
- Mistral NeMo | Hacker News: no description found
- BRX - Loading: no description found
Latent Space ▷ #ai-announcements (1 messages):
Model drop dayUpdated thread discussions
- Big Model Drop Day Announced: Today is a big model drop day, highlighting significant updates and releases in the AI community.
- Members should opt in to heavily updated thread discussions to stay informed on the latest developments.
- Opt-In for Updated Discussions: Heavily updated thread discussions are now available and require users to opt in.
- This ensures users stay up-to-date with the most recent conversations and updates in the community.
OpenAI ▷ #annnouncements (1 messages):
GPT-4o mini launch
- Introducing GPT-4o Mini: Smarter & More Affordable: The new GPT-4o mini, our most intelligent and affordable small model, is now available in the API and rolling out in ChatGPT.
- Described as significantly smarter and cheaper than GPT-3.5 Turbo, this launch was announced with a link.
- GPT-4o Mini Versus GPT-3.5 Turbo: OpenAI launched GPT-4o mini, which is described as significantly smarter and cheaper than GPT-3.5 Turbo.
- The new model is available today in the API and rolling out in ChatGPT.
OpenAI ▷ #ai-discussions (66 messages🔥🔥):
Voice extraction model from Eleven LabsSwitching from GPT to ClaudeNvidia installer bundling with Facebook, Instagram, and Meta's TwitterGPT-4o mini rollout and differences from GPT-4oIssues with ChatGPT loading and troubleshooting steps
- Eleven Labs releases voice extraction model: A mention of Eleven Labs developing a voice extraction model sparked interest among the users.
- Nvidia installer bundled with Meta apps: The Nvidia installer will come with Facebook, Instagram, and Meta's own Twitter according to a user, which raised some eyebrows.
- Some humor ensued, with remarks like 'Yes sir' confirming the news, indicating a casual take on it.
- Issues with ChatGPT loading persist: Users reported ChatGPT experiencing loading issues, with various troubleshooting steps like switching browsers and clearing cache being discussed.
- A user mentioned wanting their money back due to the prolonged issues, adding a bit of frustration to the conversation.
- GPT-4o mini rollout and limitations: Members noted that the GPT-4o mini is in rollout but lacks some functionalities like image support, which disappointed some users.
- There was confusion about the feature set, with ongoing discussion about whether future updates will include additional functionalities like text, image, video, and audio inputs and outputs.
Link mentioned: Gollum Lord GIF - Gollum Lord Of - Discover & Share GIFs: Click to view the GIF
OpenAI ▷ #gpt-4-discussions (15 messages🔥):
GPTs AgentsOpenAI API errors4o mini token limitsOpenAI image token count4o mini vs 4o capabilities
- Handling OpenAI API quota issues: A user encountered an error with the OpenAI API related to exceeding their quota and was advised to check their plan and billing details, with a reminder that the API is not free.
- A community member suggested that purchasing credits was necessary to continue using the API.
- 4o mini token limits confusion: A user reported successfully sending 150k tokens to GPT-4o mini which is supposed to have a 128k token limit and questioned the correctness of token counting for images.
- The user highlighted an inconsistency observed on OpenAI's pricing page for image tokens, noting that the token count for images was higher on 4o mini compared to GPT-4o.
- Comparing GPT-4o mini and GPT-4o: A community discussion clarified that GPT-4o mini is not smarter than GPT-4o but is an upgrade over GPT-3.5.
- 4o mini replaces GPT-3.5 for good, indicating its improved capabilities.
OpenAI ▷ #prompt-engineering (20 messages🔥):
IF...THEN... logic in promptsGPT-4 hallucinationsEWAC command frameworkVoice agent with controlled pausesPrompt engineering tips
- Optimizing IF...THEN... logic: A member suggested structuring IF...THEN... logic without negative instructions to guide the model's output more effectively.
- This approach aims to prevent the model from providing incorrect or irrelevant responses.
- Handling GPT-4 hallucinations: Discussion on GPT-4's tendency to hallucinate answers when asked about unfamiliar technologies, like creating use cases for a non-existent tech named 'fleperwelp'.
- Recommendations were made to prompt the model in ways that avoid encouraging such hallucinations by clarifying what it should do when it encounters unknown terms.
- Exploring EWAC command framework: A member introduced an experiment with a new EWAC command framework, which works well for zero-shot, system prompting, and general queries.
- They shared a discussion link for further insights and collaboration.
- Enhancing voice agents with appropriate pauses: A member developed a voice agent capable of varying speech rate by inserting special characters to indicate pauses.
- They sought advice on teaching the model to insert pauses appropriately in sentences based on context, such as phone numbers and addresses.
- Reconnaissance for prompt engineering: The importance of understanding what the model already knows before defining specific sections of a prompt was highlighted.
- This reconnaissance helps align the model's output with user expectations by leveraging its training data effectively.
OpenAI ▷ #api-discussions (20 messages🔥):
ChatGPT hallucination managementEWAC discussion frameworkVoice agent pause controlInnovative prompting techniquesThought evoking in AI responses
- Managing ChatGPT's hallucinations: ChatGPT's hallucinations can be mitigated by using IF...THEN structures without negative instructions and recognizing when it doesn't know something.
- Specific examples include avoiding prompts that guide hallucinations and leveraging model's ability to recognize unfamiliar technologies.
- Introducing EWAC command for GPT: A novel promoting framework, EWAC, is discussed for turning text into specific commands, enhancing zero-shot and system prompting.
- The model’s ability to recognize how to apply EWAC efficiently is explored through shared links and detailed examples.
- Controlling pauses in voice agents: The development of a voice agent that can control speaking speed by inserting special characters for pauses is detailed, including challenges faced.
- Proper placement of pauses in phone numbers, addresses, and other contexts is discussed, along with seeking methods to improve GPT's understanding of natural speech patterns.
- Thought evoking in AI responses: A new technique is shared where AI can evoke multiple layers of thought in responses, adjusting to the complexity of the query.
- The process involves custom instructions for detailed thought evocation and dynamically choosing thought layers based on the user’s request.
- Guidance for model’s existing knowledge: For better scoping of prompts, it's suggested to ask the model about existing knowledge on relevant topics before providing additional instructions.
- This can improve the quality of responses, especially in areas like pause insertion in speech by leveraging its understanding of human speech patterns.
Interconnects (Nathan Lambert) ▷ #events (1 messages):
natolambert: Anyone at ICML? A vc friend of mine wants to meet my friends at a fancy dinner
Interconnects (Nathan Lambert) ▷ #news (74 messages🔥🔥):
Meta's multimodal Llama modelMistral NeMo releaseGPT-4o mini releaseTekken tokenizerOpenAI safety mechanism jailbreak
- Meta excludes EU from multimodal Llama model: Meta has announced they will release a multimodal Llama model in the coming months, but it won't be available in the EU due to the unpredictable nature of European regulatory environment, as per Axios report.
- A member noted that this situation means they will either use a VPN or click a non-EU compliance checkbox to access it.
- Mistral NeMo announced with NVIDIA collaboration: Mistral NeMo, a new 12B model with a 128k token context window built in collaboration with NVIDIA, was announced and is available under the Apache 2.0 license with pre-trained and instruction-tuned checkpoints, as detailed in the official release.
- Mistral NeMo offers superior performance compared to previously released models in terms of reasoning, world knowledge, and coding accuracy.
- OpenAI's GPT-4o mini release: OpenAI released GPT-4o mini, touted as the most capable and cost-efficient small model available, scoring 82% on MMLU and available for free and paid users as per Andrew Curran's announcement.
- The model is cheaper than GPT-3.5 with a pricing of 15¢ per M token input and 60¢ per M token output with a 128k context window.
- Tekken tokenizer outperforms Llama 3: Tekken, the new tokenizer model, has shown superior performance compared to the Llama 3 tokenizer, being more proficient in compressing text across multiple languages including source code and several major languages.
- This improved efficiency makes it approximately 30% to 300% more effective in various languages such as Chinese, Korean, and Arabic.
- OpenAI's new safety mechanism jailbreak: A newly implemented safety mechanism in OpenAI's GPT-4o-mini has been jailbroken, according to Elder Plinius, allowing it to output restricted content such as malware and copyrighted material.
- This highlights vulnerabilities in the recent defense mechanism named 'instruction hierarchy.'
- Tweet from Phil (@phill__1): There are currently at least 6 unreleased models in the lmsys arena: -gemini-test-1 and gemini-test-2 (probably new Gemini 1.5 version, maybe Gemini 2.0) -im-a-little-birdie (???) -upcoming-gpt-mini ...
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- Tweet from Andrew Curran (@AndrewCurran_): Here's our new model. 'GPT-4o mini'. 'the most capable and cost-efficient small model available today' according to OpenAI. Going live today for free and pro.
- Tweet from Andrew Curran (@AndrewCurran_): For the many people asking for the API pricing for GPT-4o Mini it is: 15¢ per M token input 60¢ per M token output 128k context window
- Tweet from morgan — (@morqon): gpt-4o mini scores 82% on MMLU, fwtw
- Tweet from TestingCatalog News 🗞 (@testingcatalog): Based on
- Tweet from Pliny the Prompter 🐉 (@elder_plinius): ⚡️ JAILBREAK ALERT ⚡️ OPENAI: PWNED ✌️😎 GPT-4O-MINI: LIBERATED 🤗 Looks like the new "instruction hierarchy" defense mechanism isn't quite enough 🤷♂️ Witness the and new gpt-4o-mini ...
- Tweet from Paul Gauthier (@paulgauthier): GPT 4o mini scores like the original GPT 3.5 on aider's code editing benchmark (later 3.5s were worse). It doesn't seem capable of editing code with diffs on first blush, which limits its use ...
Interconnects (Nathan Lambert) ▷ #ml-questions (5 messages):
Code-related PRM datasetsAST mutation methodPositive, Negative, Neutral labels vs Scalar valuesPRM-800KResearch & MS program
- Need for code-related PRM datasets: A member inquired about the availability of code-related PRM datasets, mentioning AST mutation method used in the "Let's Reward Step by Step" paper.
- Not to my knowledge. Is desperately needed. Plz make them.
- Pos/Neg/Neutral vs Scalar values in PRM labels: Discussion on why PRMs use positive, negative, neutral labels instead of scalar values, considering the challenge to generate a calibrated scalar-valued dataset.
- The discussion included curiosity about why not to try scalar values, especially given datasets like PRM-800K which involve human data.
- Exploring research on PRMs and synthetic data: A member expressed interest in starting MS program soon to explore research on PRMs and synthetic data, seeking knowledge and insights.
- Any knowledge to dispense on the
Pos/Neg/Neutral vs Scalarthing?
- Any knowledge to dispense on the
- Reference to an unspecified book: A query about a book reference led to a vague response about books being extensively litigated.
- Probably the ones being extensively litigated, but I can’t say officially.
Interconnects (Nathan Lambert) ▷ #ml-drama (21 messages🔥):
Public Perception of AIOpenAI's Business ChallengesGoogle vs OpenAI CompetitionAI Scaling Issues
- Public's discomfort with AI tools: A member discussed that common people might be mystified by and dislike strong AI tools like ChatGPT, unless the industry finds a way to monetize simpler versions.
- They emphasized that historically, the public has reacted negatively to technologies that make them uncomfortable, likening it to modern witchcraft.
- OpenAI might face challenging business problems: Members speculated whether OpenAI is facing challenging business problems as it scales from a few hundred employees to a few thousand.
- It's suggested that unlike Big Tech, OpenAI can't easily reallocate existing resources and questioned how it aligns with their primary mission of AGI.
- Google outpaces OpenAI in innovation: A discussion highlighted that Google seems to outpace OpenAI in shipping new features, particularly with references to generating images with GPT-4o mini.
- One member pointed out that OpenAI is now seen as a boomer company due to its slower release cycle.
- OpenAI’s loss of leading model status: A member noted that while GPT-4T is better than GPT-4 upon release, other organizations, including open source, have nearly caught up.
- They expressed surprise that OpenAI hasn’t maintained a significant lead despite leveraging user preference data from ChatGPT.
Link mentioned: Tweet from TDM (e/λ) (@cto_junior): Every cool thing is later pretty sure we'll get Gemini-2.0 before all of this which anyways supports all modalities
Interconnects (Nathan Lambert) ▷ #random (9 messages🔥):
Codestral Mamba modelDeepSeek-V2-0628 releaseMamba infinite contextOpen-sourced modelsLMSYS Chatbot Arena
- Codestral Mamba accuracy plummets after 1k tokens: A tweet revealed Codestral Mamba's accuracy goes to zero after approximately 1k tokens, highlighting it as an ongoing research issue.
- DeepSeek-V2-0628 open-sourced with top ranks: DeepSeek announced their DeepSeek-V2-0628 model is now open-sourced, ranking No.1 in the open-source category on the LMSYS Chatbot Arena Leaderboard.
- Tweet from Louis Knight-Webb (@LouisKnightWebb): Codestral Mamba's 🐍 accuracy goes to zero after ~1k tokens of context. Codestral (normal) for comparison. Looks like this whole mamba thing is still very much an open research problem, but still...
- Tweet from DeepSeek (@deepseek_ai): 🎉Exciting news! We open-sourced DeepSeek-V2-0628 checkpoint, the No.1 open-source model on the LMSYS Chatbot Arena Leaderboard @lmsysorg. Detailed Arena Ranking: Overall No.11, Hard Prompts No.3, Co...
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
GPT-4o MiniCost-efficiency of GPT-4o Mini
- OpenAI Unveils GPT-4o Mini: GPT-4o mini, OpenAI's newest model after GPT-4 Omni, supports both text and image inputs with text outputs.
- The model maintains state-of-the-art intelligence while being significantly more cost-effective, priced at just $0.15/M input and $0.60/M output.
- GPT-4o Mini: A Cost-Effective AI Solution: GPT-4o Mini is many multiples more affordable than other recent frontier models and more than 60% cheaper than GPT-3.5 Turbo.
- The price for GPT-4o Mini is $0.15/M input and $0.60/M output, making it a budget-friendly option for users.
- OpenAI: GPT-4o by openai: GPT-4o ("o" for "omni") is OpenAI's latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of [GPT-4 Turbo](/models/open...
- OpenAI: GPT-3.5 Turbo by openai: GPT-3.5 Turbo is OpenAI's fastest model. It can understand and generate natural language or code, and is optimized for chat and traditional completion tasks. Training data up to Sep 2021.
OpenRouter (Alex Atallah) ▷ #general (97 messages🔥🔥):
Codestral 22BOpenRouter outagesMistral NeMo releaseGPT-4o mini releaseImage token pricing issues
- Codestral 22B model request: A user requested to add Codestral 22B, sharing the model card for Mamba-Codestral-7B which is an open code model performing on par with state-of-the-art Transformer-based code models.
- OpenRouter experiencing outages: Several users reported issues with OpenRouter, including API requests hanging and website timeouts, while others stated it was working fine in different regions like Northern Europe.
- Mistral NeMo 128K Context model release: Mistral NeMo, a 12B model offering a context window of up to 128k tokens, was announced, with pre-trained and instruction-tuned checkpoints available under the Apache 2.0 license.
- GPT-4o mini release: OpenAI announced the release of GPT-4o mini, described as the most capable and cost-efficient small model, available to free ChatGPT users, ChatGPT Plus, Team, and Enterprise users.
- Image token pricing issues: Users discussed discrepancies in image token counts and pricing for GPT-4o mini compared to other models, with some noting unexpectedly high token counts for images.
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- mistralai/mamba-codestral-7B-v0.1 · Hugging Face: no description found
- OpenAI debuts mini version of its most powerful model yet: OpenAI on Thursday launched a new AI model, "GPT-4o mini," the artificial intelligence startup's latest effort to expand use of its popular chatbot.
- Tweet from Matt Shumer (@mattshumer_): New @OpenAI model! GPT-4o mini drops today. Seems to be a replacement for GPT-3.5-Turbo (finally!) Seems like this model will be very similar to Claude Haiku — fast / cheap, and very good at handli...
- OpenRouter Status: OpenRouter Incident History
Modular (Mojo 🔥) ▷ #general (7 messages):
Linking to C libraries requestMojo GPU supportMax platform NVIDIA GPU announcementMLIR dialects and CUDA/NVIDIA
- Support Request for Linking to C Libraries: A user shared a GitHub ticket requesting support for linking to C libraries in Mojo.
- Mojo Adding GPU Support: Discussion emerged regarding the new GPU support in Max/Mojo, initiated by a query on how to utilize it for tensor operations and parallelization.
- Another member recalled the announcement in a Max platform talk by Chris Lattner about NVIDIA GPU support, while others provided insights into its integration for parallel computing with MLIR dialects and CUDA/NVIDIA.
Link mentioned: Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular:
https://twitter.com/Modular/status/1813988940405493914
Modular (Mojo 🔥) ▷ #ai (7 messages):
Image object detection in videoFrame rate adjustmentHandling bounding box issuesProcessing MP4 videosManaging large video frames
- Frame rate solutions for image object detection: It is common to run image object detection models at a low framerate like 5 fps for real-time applications to address normal issues with video processing.
- Post-processing can also be applied to smooth out bounding box locations, which may be problematic for specific applications.
- Challenges in handling large video frames: A member expressed concerns about managing a lot of frames in large videos for object detection.
- Another member suggested that there is no magic solution and if all frames must be processed, then it has to be done regardless.
Modular (Mojo 🔥) ▷ #mojo (35 messages🔥):
Loop through Tuple in MojoNaming conventions in MojoKeras 3.0 compatibility and advancementMAX and HPC capabilitiesAlias Tuples of FloatLiterals in Mojo
- Looping through Tuples in Mojo poses challenges: A user asked about looping through Tuples in Mojo, but another user explained that it's generally not possible due to Tuples being heterogeneous.
- Mojo Naming Conventions Resource shared: In response to inquiries about naming conventions in Mojo, a GitHub Style Guide was shared.
- Keras 3.0 supports multiple frameworks: Keras 3.0 was announced to support running workflows on JAX, TensorFlow, or PyTorch, which could significantly improve model training and deployment.
- MAX and Graph Compiler limitations: There was a debate around MAX's capabilities, emphasizing its current focus as a graph compiler similar to XLA with limitations for general HPC applications.
- Explicitly aliasing tuples of FloatLiterals in Mojo: A user inquired about aliasing tuples of FloatLiterals in Mojo, finding it needed explicit typing as
Tuple[FloatLiteral, FloatLiteral](1.0, 2.0).
- Keras: Deep Learning for humans: no description found
- Mojo 🔥 Community Meeting #4: Recording of the Mojo Community Meeting #4🫓 Flat Buffers: memory efficient serialization⚒️ Forge Tools: extending the Mojo 🔥 standard library🔄 Mojo 🔥 Gen...
- mojo/stdlib/docs/style-guide.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #max (5 messages):
Command-Line Prompt UsageModel Weight URIsLlama 3 PipelineInteractive Chatbot example
- Command-Line Prompt Explained: A user queried if the
--promptflag inmojo ../../run_pipeline.:fire: llama3 --prompt ...serves as a context window, and if building an interactive chat needs an input loop.- An official link explains the prompt format.
- Preferred Source of Model Weights: A user asked whether it’s better to load weights from the official Hugging Face repository instead of third parties like
bartowskiandQuantFactory.- The user referenced lines in the GitHub repository discussing these weights.
- Utilizing Llama 3 Pipeline with Custom Weights: A user interested in the
llama3-70B-instructmodel wondered how modularml chose its model URIs on Hugging Face.- An answer noted that weights can be specified with the
--model-pathparameter and highlighted the use of GGUF versions for easier ingestion and lazy-loading.
- An answer noted that weights can be specified with the
- Interactive Chatbot with MAX: An explanation clarified that the released MAX 24.4 uses
--promptto populate initial context and runs generation once.- The nightly branch includes an interactive chatbot example that preserves context and sets system prompts, showcased in a community meeting on YouTube.
- max/examples/gui at nightly · modularml/max: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform - modularml/max
- Modular Community Livestream - New in MAX 24.4: MAX 24.4 is now available! Join us on our upcoming livestream as we discuss what’s new in MAX Engine and Mojo🔥 - MAX on macOS, MAX Engine Quantization API, ...
- meta-llama (Meta Llama): no description found
- max/examples/graph-api/pipelines/llama3/run.🔥 at 7189864b2fc829176149f6997a70c62732982ec8 · modularml/max: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform - modularml/max
- Meta Llama 3 | Model Cards and Prompt formats: Special Tokens used with Meta Llama 3. A prompt should contain a single system message, can contain multiple alternating user and assistant messages, and always ends with the last user message followe...
Modular (Mojo 🔥) ▷ #nightly (13 messages🔥):
Mojo Compiler UpdateStandard Library Extensions ProposalDiscussion on Allocator AwarenessAsync IO API and PerformanceOpt-out of stdlib
- Mojo Compiler Update Released: A new nightly Mojo compiler version 2024.7.1805 has been released with updates to
stdlib, including support for creating nested Python objects using list literals.- The update can be applied using
modular update nightly/mojo, and the full changelog is available here.
- The update can be applied using
- Proposal to Reduce Stdlib Workload: A proposal to reduce the workload of stdlib's maintainers with
stdlib-extensionshas been discussed, aiming to involve more community input before making stdlib commitments.- This incubator approach is suggested to judge API and popularity before integration, providing value regardless of the number of stdlib reviewers. More details here.
- Allocator Awareness in Standard Library: Members discussed the significance of having the community assess ideas before integrating them into the stdlib, particularly for niche use cases like allocator awareness.
- Rust's issue of lack of allocator awareness despite demand was cited as an example of potential friction, underlining the need for community vetting in Mojo.
- Standard Async IO API Performance: There was a suggestion for a standard async IO API to support high-performance models where IO operations hand off buffers, separate from the existing Python API.
- This would cater to high-performance APIs and ensure compatibility within the Mojo community.
- Opt-out of Standard Library in Mojo: A discussion emerged around the possibility of opting in or out of the stdlib, with some questioning the feasibility and use cases for such an option.
- The debate included concerns about avoiding the division between 'performance-focused' users and those following popular yet potentially incompatible solutions.
- mojo/proposals/stdlib-extensions.md at proposal_stdlib_extensions · gabrieldemarmiesse/mojo: The Mojo Programming Language. Contribute to gabrieldemarmiesse/mojo development by creating an account on GitHub.
- [Proposal] Reduce the workload of stdlib's maintainers with `stdlib-extensions` · modularml/mojo · Discussion #3233: This discussion is here to have a place to talk about the folloowing proposal: pull request markdown document We are especially interested in the opinion of frequent contributors, as well as the st...
Modular (Mojo 🔥) ▷ #mojo-marathons (16 messages🔥):
LubeckMKLLLVMBLAS LinkingSPIRAL
- Lubeck speeds past MKL thanks to LLVM: A member stated that Lubeck is faster than MKL, attributing its speed to differences in LLVM IR generation.
- Mir, an LLVM-Accelerated Generic Numerical Library, might also contribute to Lubeck's performance as noted in this blog post.
- SPIRAL program pushes automation boundaries: SPIRAL aims to automate software and hardware optimization for numerical kernels, going beyond current tools.
- A member praised SPIRAL for its ability to generate platform-tuned implementations of numerical functions, although it is difficult to use for functions outside of high-value areas like BLAS.
- SPIRAL: Hard to use but highly optimized: SPIRAL generates highly optimized code that resembles mathematical papers making it hard to use for general purposes.
- SPIRAL's goal is to achieve optimal performance through high-level descriptions, although it remains complex and is primarily useful for BLAS functions.
- Numeric age for D: Mir GLAS is faster than OpenBLAS and Eigen: no description found
- SPIRAL Project: Home Page: no description found
Cohere ▷ #general (52 messages🔥):
Creating new tools for APITools vs ConnectorsPermissions for sending images and GIFsDuckDuckGo search in projects
- How to create new API tools: A member inquired about creating new tools for the API, spotting differences between tools and connectors, and was directed to check the Cohere dashboard.
- Discussion clarified that tools are API-only, can be single-step or multi-step, and are defined on the client side, as explained in Cohere's documentation.
- Image and GIF permissions in chat: Members requested permissions to send images and GIFs in the general chat, pointing out some restrictions.
- An admin explained that these permissions might be restricted to prevent misuse, but changes are being considered, and permissions might be enabled for makers and regular users.
- DuckDuckGo search tool integration: Members discussed using DuckDuckGo for retrieving links and integrating it into projects.
- A link to the DuckDuckGo search Python package was shared, and a member mentioned creating a custom tool with it for work.
- duckduckgo-search: Search for words, documents, images, news, maps and text translation using the DuckDuckGo.com search engine.
- Yay Kitty GIF - Yay Kitty Cat - Discover & Share GIFs: Click to view the GIF
- Trombone Pusheen GIF - Trombone Pusheen Musician - Discover & Share GIFs: Click to view the GIF
- Tool Use with Cohere's Models - Cohere Docs: no description found
Cohere ▷ #project-sharing (31 messages🔥):
Python development for scrapingLibrary for collecting URLsFirecrawl self-hostingCost concerns of FirecrawlAPI integration with GPT-4o
- Python streamlined web scraping: Discussion centered on using Python with Streamlit for proof of concept, leveraging Firecrawl for scraping content.
- The combination with ddg is mentioned as a feasible approach to have a working system.
- Efficient URL collection using 'duckduckgo-search' library: Members discussed the unofficial duckduckgo-search library for collecting URLs and scraping them with BeautifulSoup.
- A special mention was made on how it is a free resource.
- Firecrawl backend self-hosting saves costs: There was a notable mention of self-hosting Firecrawl's backend to cut down on high costs, facilitating API endpoint creation.
- Firecrawl's self-hosting guide was shared, highlighting a cost-saving measure that could save users several hundred dollars.
- Firecrawl pricing concerns addressed: While Firecrawl is deemed effective, members acknowledged that its pricing is steep without a pay-as-you-go plan.
- Community members appreciated learning about the self-hosting option which can be cheaper.
- Integrating GPT-4o API with scraping tools: Members discussed the integration of Firecrawl with GPT-4o using their own API keys.
- The configuration involves setting up the API key within a .env file to enable scraping, crawling, and LLM extraction.
- duckduckgo-search: Search for words, documents, images, news, maps and text translation using the DuckDuckGo.com search engine.
- firecrawl/SELF_HOST.md at main · mendableai/firecrawl: 🔥 Turn entire websites into LLM-ready markdown or structured data. Scrape, crawl and extract with a single API. - mendableai/firecrawl
- Edit fiddle - JSFiddle - Code Playground: no description found
Perplexity AI ▷ #general (63 messages🔥🔥):
Google Sheets login issuePerplexity analyzing multiple PDFsGPT-4 vs. GPT-4 Omni answersPerplexity Pro email from LogitechDALL-E update speculation
- Google Sheets login issue with Drive logo: A member reported encountering an error with a Google Drive logo when trying to log in to a page created with Google Sheets.
- They asked for assistance to resolve the 'page can't be reached' error.
- Limitations and strategies for analyzing multiple PDFs: Members discussed the limitations of Perplexity in analyzing more than 4 PDFs and combining PDFs with web searches.
- One suggested converting the content of PDFs and web searches into a .txt file to attach to a new chat.
- Differences in responses from GPT-4 vs. GPT-4 Omni: A member questioned why there are different answers from ChatGPT 4 and Perplexity with GPT-4 Omni turned on.
- Another member speculated that the discrepancies might be due to the different models used.
- Suspected phishing email offering Perplexity Pro from Logitech: Members debated the legitimacy of an email offering 6 months of Perplexity Pro from Logitech, with some expressing suspicion.
- After checking, confirmation was found on social media, and the Chief Business Officer @ Perplexity confirmed the partnership.
- Speculation about DALL-E updates: Members noted issues with Perplexity Pro searches resetting and speculated that it might be related to an upgrade to DALL-E.
- Some members expressed frustration with the current limitations of generating images, suggesting it could be linked to a new version release.
- OpenAI is releasing a cheaper, smarter model: OpenAI is launching a cheaper and smarter model dubbed GPT-4o Mini as a more accessible model for developers.
- Tweet from Dmitry Shevelenko (@dmitry140): Perplexity 🤝 Logitech Thx @ATXsantucci for the great partnership. Just getting started! Quoting Jorge Barba (@jorgebarba) Wow! Totally unexpected. Got a 6 month subscription to @perplexity_ai Pro...
Perplexity AI ▷ #sharing (5 messages):
Record-Breaking Stegosaurus SaleLab-Grown Pet Food ApprovedAnthropic's $100M AI FundH2O-3 Code Execution Vulnerability
- Record-Breaking Stegosaurus Sale: Perplexity AI highlighted a record-breaking sale of a Stegosaurus fossil, generating significant interest.
- The discussion emphasized the staggering price and the historical significance of the sale.
- Lab-Grown Pet Food Approved: A YouTube video linked here announced the approval of lab-grown pet food, capturing the attention of the community.
- The video highlights ethical considerations and the nutritional benefits of lab-grown options.
- Anthropic's $100M AI Fund: Perplexity AI revealed Anthropic's launch of a $100M fund aimed at advancing AI technologies.
- Members discussed the potential impact on AI research and future innovations funded by this initiative.
- H2O-3 Code Execution Vulnerability: A critical Page on Perplexity AI described a newly discovered code execution vulnerability in H2O-3.
- The page detailed the risks and potential exploits, urging users to update their systems promptly.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (5 messages):
NextCloud Perplexity API setupModel selection issuesAPI call suggestionsFormatting responses in API queries
- NextCloud struggles with Perplexity API model selection: A user faced issues setting up NextCloud to use the Perplexity API, specifically with model selection, and sought help from the community.
- Another member suggested setting the
modelstring in the body to something like'llama-3-sonar-small-32k-online'and shared a link to available models.
- Another member suggested setting the
- Suggestions for formatting-free API responses: A member asked how to get responses without any formatting from the API and shared a code snippet showcasing their approach.
- No specific solutions were provided in response to the query.
- API call to retrieve model details requested: A member suggested an API call feature to retrieve available model names, context windows, costs, and rate limits without the need for a model name.
- This would allow programmers to manage their usage more effectively in terms of context windows, rate limits, and costs.
Link mentioned: Supported Models: no description found
LangChain AI ▷ #general (39 messages🔥):
Openrouter integration with LangChainCode-based RAG examples for Q&A chatbotUsing trimMessages with Llama2 modelSetting beta header for Claude in LangChainMongoDB hybrid search with LangChain
- LangChain Integration Discusses Openrouter: A member sought a guide on using Openrouter with LangChain, but no specific details or references were provided in response.
- Seeking Examples for Code-Based RAG Q&A Chatbot: A user expressed interest in building a Q&A chatbot for a code database and requested examples of code-based RAG implementations.
- TrimMessages with Llama2 Model Explained: The
trimMessagesfunction can be used with token counter functions, but there is no specific implementation for Llama2 or Llama3 models shared in the messages.- Examples in JavaScript and Python were provided, but without a specific
getNumTokensmethod for Llama models.
- Examples in JavaScript and Python were provided, but without a specific
- Setting Beta Header for Claude in LangChain: The method to set a beta header for Claude in LangChain was explained using the
defaultHeadersoption in theclientOptionswhen creating aChatAnthropicinstance. - Hybrid Search Using MongoDB in LangChain: Steps to implement hybrid search with MongoDB as the vector store in LangChain include confirming MongoDB's hybrid search support, installing necessary packages, and configuring LangChain.
- A reference code snippet in JavaScript was shared, but no specific Python implementation was provided for hybrid search.
- trimMessages | LangChain.js - v0.2.10: no description found
- ChatAnthropic | 🦜️🔗 Langchain: LangChain supports Anthropic's Claude family of chat models.
- Conceptual guide | 🦜️🔗 LangChain: This section contains introductions to key parts of LangChain.
- MongoDB Atlas | 🦜️🔗 Langchain: Only available on Node.js.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #langserve (2 messages):
Langserve Debugger ContainerLangserve Container
- Langserve Debugger Container and its Usage: A member requested an explanation of the contents and purpose of the Langserve Debugger container.
- Difference Between Langserve Debugger and Langserve Containers: A comparison was requested between the Langserve Debugger container and the Langserve container.
- no title found: no description found
- no title found: no description found
LangChain AI ▷ #langchain-templates (1 messages):
ChatPromptTemplate JSON IssueGitHub support for LangChain
- ChatPromptTemplate struggles with JSON content: A user reported encountering a KeyError when trying to add JSON as part of the template content for ChatPromptTemplate from LangChain.
- Referencing a GitHub issue, they noted that surrounding JSON with double curly braces works for some, but the problem persists for others.
- LangChain GitHub issue discussed: Users referred to a GitHub issue for resolving a ChatPromptTemplate JSON integration problem.
- Despite some reporting success with the suggested solution, several users continue to encounter difficulties.
Link mentioned: Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #share-your-work (1 messages):
Easy Folders launchProduct HuntSuperuser membershipProductivity toolsBrowser extensions
- Easy Folders launches on Product Hunt: Easy Folders is now live on Product Hunt.
- The tool offers functionality like creating folders, searching chat history, bookmarking chats, prompts manager, prompts library, and custom instruction profiles.
- Limited time offer for Easy Folders Superuser membership: For a limited time, users can get a free 30-day Superuser membership for Easy Folders by upvoting the launch, leaving a review, and sending a DM with screenshots of the above.
- This offer aims to incentivize community engagement and feedback on the platform.
Link mentioned: Easy Folders for ChatGPT & Claude - Declutter and organize your chat history | Product Hunt: Create Folders, Search Chat History, Bookmark Chats, Prompts Manager, Prompts Library, Custom Instruction Profiles, and more.
LangChain AI ▷ #tutorials (1 messages):
LangGraphCorrective RAGRAG Fusion Python ProjectChatbot hallucinations
- Combining LangGraph with Corrective RAG and RAG Fusion: A member expressed a concern with modern AI chatbots regarding their hallucinations and decided to combine Corrective RAG with RAG Fusion.
- They shared a YouTube video titled 'LangGraph + Corrective RAG + RAG Fusion Python Project: Easy AI/Chat for your Docs' demonstrating the process.
- Addressing AI Chatbot Concerns: The video tutorial shows how to create a fully local chatbot using LangGraph, focusing on addressing chatbot hallucinations.
- The combination of Corrective RAG and RAG Fusion seeks to enhance the chatbot's accuracy and performance.
Link mentioned: LangGraph + Corrective RAG + RAG Fusion Python Project: Easy AI/Chat for your Docs: #chatbot #coding #ai #llm #chatgpt #python #In this video, I have a super quick tutorial for you showing how to create a fully local chatbot with LangGraph, ...
LlamaIndex ▷ #blog (4 messages):
Jerry Liu's Keynote at AI World's FairRAGapp New FeaturesStackPodcast Interview with Jerry LiuNew Model Releases from MistralAI and OpenAI
- Jerry Liu Shines at AI World's Fair Keynote: Missed the @aiDotEngineer World's Fair? Catch @jerryjliu0's keynote here, last year his talk was the most-watched video from the conference!
- He breaks down the future of knowledge assistants in detail.
- RAGapp Now Supports MistralAI and GroqInc: Our team, led by @MarcusSchiesser, added support for MistralAI and GroqInc in the new versions of RAGapp, deploying with Docker.
- @cohere reranker has been added for improved results.
- Jerry Liu Discusses High-Quality Data on StackPodcast: In a StackPodcast episode, co-founder @jerryjliu0 emphasizes the importance of high-quality data, prompt engineering, long context windows, and RAG with Jerry Chen.
- They discuss how LlamaIndex is making it easier for developers to build LLM apps.
- MistralAI and OpenAI Unveil New Models: New releases from MistralAI and OpenAI with day zero support includes Mistral NeMo, a small (12B) model outperforming Mistral 7b.
- Mistral NeMo boasts a 128k context window.
- no title found: no description found
- The framework helping devs build LLM apps - Stack Overflow: no description found
LlamaIndex ▷ #general (21 messages🔥):
Neo4jPropertyGraphStore indexingStarting with Llama IndexSetting min outputs in LLMMultiSelectorRAG evaluation frameworksOpenAI data masking
- Neo4jPropertyGraphStore indexing slow: A member experienced long indexing times with
Neo4jPropertyGraphStorewhile using Claude-3 haiku and questioned if others had the same issue.- Another member explained that indexing speed depends on the amount of data and the number of LLM calls.
- Starting with AI Programming: New members seeking to build AI Agents were advised to start with foundational resources like this YouTube video and a short course on ChatGPT.
- The advice highlighted learning to use LLM APIs before diving into specific frameworks.
- Setting min outputs in LLMMultiSelector: A member inquired whether it is possible to set minimum outputs in
LLMMultiSelector.- The response indicated that this feature is not currently supported, except through prompt engineering.
- Frameworks for RAG evaluation: A participant sought recommendations for frameworks to evaluate their RAG pipeline, expressing concern over the inefficacy of Ragas.
- They questioned whether creating an evaluation framework from scratch would be feasible within a two-week project timeline.
- Masking sensitive data for OpenAI chat bot: Members discussed how to mask sensitive data before sending it to OpenAI using
llama-index.- Suggestions included using the PIINodePostprocessor as a beta feature and other postprocessor modules.
- Node Postprocessor Modules - LlamaIndex: no description found
- A Hackers' Guide to Language Models: In this deeply informative video, Jeremy Howard, co-founder of fast.ai and creator of the ULMFiT approach on which all modern language models (LMs) are based...
- Building Systems with the ChatGPT API: Use LLMs to streamline tasks, automate workflows, and improve outputs. Ensure safety and accuracy in your LLM inputs and outputs.
- PII - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (2 messages):
Query rewritingMultimodal RAG using GPT4o and Sonnet3.5LlamaIndex performanceLangchain and RAG app developmentDocument splitting in LlamaIndex
- Wondering about the usefulness of query rewriting: A member inquired whether anyone finds the rewriting query feature useful, mentioning their testing of multimodal RAG using GPT4o and Sonnet3.5 on a presentation file.
- They highlighted that despite the file's complexity, LlamaIndex delivered impressive response quality and expressed eagerness to learn more about the LlamaIndex universe.
- Comparing Langchain and LlamaIndex for RAG apps: Discussing the process of developing RAG apps using Langchain, involving document splitting, text chunk vectorization, and database storage for retrieval.
- A member sought clarification on LlamaIndex's process, particularly whether documents are split or divided into pages, referencing a specific notebook example on GitHub.
Link mentioned: llama_parse/examples/multimodal/claude_parse.ipynb at main · run-llama/llama_parse: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
OpenInterpreter ▷ #general (19 messages🔥):
OpenInterpreter Hits 10,000 MembersAffordable AI outperforming GPT-4Fast Multimodal AI Agents
- OpenInterpreter Discord Reaches 10,000 Members: OpenInterpreter hits a milestone with 10,000 discord members celebrating the growing community.
- Members expressed their excitement with comments like "Yupp" and "Awesome!".
- Affordable AI Outperforms GPT-4: A member boasted about a new AI that's dirt cheap and performs better than GPT-4, noting its great performance for AI agents.
- "It’s basically for free," shared another, highlighting its cost-efficiency.
- Fast Multimodal AI Agents: Another member mentioned the crazy fast latency of this cost-efficient AI, available via API, making it highly practical.
- They added, "Oh its multimodal too,", indicating its diverse capabilities.
OpenAccess AI Collective (axolotl) ▷ #general (9 messages🔥):
High context length challengesMistral NeMo releaseMistral NeMo performance comparisonTraining inference capabilities in transformers
- High context length training struggle: A member reported unexpected consequences of having a high context length during training, learning it the hard way.
- Mistral NeMo with 12B parameters released: Mistral NeMo, a 12B model in collaboration with NVIDIA, has been released with a context window of up to 128k tokens and state-of-the-art reasoning, world knowledge, and coding accuracy in its category.
- Pre-trained base and instruction-tuned checkpoints are available under the Apache 2.0 license.
- Performance discrepancies in Mistral NeMo vs. Llama 3 8B: A member pointed out a discrepancy in the 5-shot MMLU score for Llama 3 8B reported by Mistral (62.3%) compared to Meta's report (66.6%), calling it a red flag.
- This discrepancy, along with potential issues in the TriviaQA benchmark, was highlighted in discussions.
- Training transformers for reasoning: A paper discussed whether transformers can learn to implicitly reason over parametric knowledge, finding that they succeed through extended training beyond overfitting.
- Key insights include that generalization improves with more inference-based training data and that transformers struggle with out-of-domain inferences due to lack of iterative layer processing.
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization: We study whether transformers can learn to implicitly reason over parametric knowledge, a skill that even the most capable language models struggle with. Focusing on two representative reasoning types...
OpenAccess AI Collective (axolotl) ▷ #general-help (7 messages):
Overfitting in GEM-ALLama3 ModelImpact of Lowering Rank on Eval LossTraining Loss Observations
- Concerns about Overfitting in GEM-A: A member expressed concerns about overfitting in the GEM-A model during training.
- LLama3 Mentioned as Reference Model: In a conversation about model types, LLama3 was mentioned as the reference model.
- Lowering Rank Reduces Eval Loss Significantly: A member observed that lowering the rank during training helped reduce the eval loss significantly.
- There is some uncertainty about whether the metrics would even out in later steps.
- Training Loss Improvement Observed: It was noted that the training loss seems noticeably lower after adjusting the rank.
- The member plans to continue running evaluations to verify this improvement.
LLM Finetuning (Hamel + Dan) ▷ #general (7 messages):
Comparative Performance of LLMsHugging Face Model Latency on Mac M1Data Sensitivity with GPT Models
- GPT-3.5-turbo outperforms Mistral and Llama3: A user shared results showing GPT-3.5-turbo outperforming Mistral 7B and Llama3 8B/80B when fine-tuned, despite OpenAI's policy of not using data submitted for fine-tuning and inference.
- Another user added that many prefer not to use GPT models for finetuning due to concerns about sending sensitive data to another company.
- Model loading time causes latency on Mac M1: Hugging Face models experience high latency the first time due to the need to load the model into memory when initiating a preprocessing pipeline on Mac M1.
- One user found that trying multiple models exacerbated the issue, as each new model needed to be downloaded and loaded before inference.
LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (1 messages):
ashpun: i dont think there is an expiration date. do we have <@657253582088699918> ?
LAION ▷ #general (2 messages):
Meta's multimodal AI modelsLlama models not available for EU users
- Meta shifts focus to future multimodal AI models: An Axios article was shared highlighting Meta's plans for the future of multimodal AI models, following potential issues with its current lineup.
- No further details or community discussion provided.
- Meta restricts Llama models for EU: It was noted that Meta's Llama models will no longer be available to users in the EU.
- No further details or community discussion provided.
LAION ▷ #research (6 messages):
Codestral MambaProver-Verifier GamesNuminaMath-7BMistral NeMo
- Codestral Mamba introduced for architecture research: Codestral Mamba offers significant improvements with linear time inference and the ability to model sequences of infinite length, aiming to advance code productivity.
- It was developed with assistance from Albert Gu and Tri Dao and promises quick responses regardless of input length, positioning it as a competitor to SOTA transformer-based models.
- Prover-Verifier Games enhance LLM legibility: Prover-Verifier Games have been shown to improve the legibility of language model outputs.
- More details can be found in the associated PDF.
- NuminaMath-7B aces math Olympiad, faces basic flaws: NuminaMath-7B ranked 1st at AIMO competition, solving 29/50 problems but has shown basic reasoning deficits on AIW problems.
- We should be very cautious with strong claims based on benchmarks that do not properly detect basic reasoning flaws.
- Mistral NeMo collaborates with NVIDIA for context-heavy model: Mistral NeMo, developed in collaboration with NVIDIA, supports up to 128k tokens and offers state-of-the-art reasoning, coding accuracy, and world knowledge.
- Released under Apache 2.0, it promotes adoption with quantisation awareness for FP8 inference and outperforms comparable models like Gemma 2 9B and Llama 3 8B.
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- Codestral Mamba: As a tribute to Cleopatra, whose glorious destiny ended in tragic snake circumstances, we are proud to release Codestral Mamba, a Mamba2 language model specialised in code generation, available under ...
- Tweet from Jenia Jitsev 🏳️🌈 🇺🇦 (@JJitsev): (Yet) another tale of Rise and Fall: Recently, NuminaMath-7B ranked 1st at the AIMO competition, solving 29/50 private set problems of olympiad math level. Can it handle simple AIW problem, which re...
Torchtune ▷ #dev (6 messages):
Custom template formattingCI behavior in PRsInstruction dataset issues
- Custom template formatting confusion: A user asked about formatting a custom template using the
torchtune.data.InstructTemplateclass and how to handle column mapping to rename expected columns.- Another user clarified that the column map should actually rename the columns in the dataset, and questioned if the user intended to use the alpaca cleaned dataset.
- CI runs automatically on PRs: A user expressed confusion regarding CI behavior, noticing that it runs automatically when adding to a PR.
- A user replied suggesting to ignore the CI until the PR draft is finalized and ready for reviews.
- Forcing specific LLM outputs: A user attempted to make an LLM always reply 'HAHAHA' using a specific dataset, expressing that the LLM was not complying.
- The user mentioned this was a preliminary test before utilizing the alpaca dataset for their project.
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
GTX1080 compatibility with tinygradCUDA support for older NVIDIA cards
- Tinygrad struggles with GTX1080: A member attempted to run tinygrad with CUDA=1 on a GTX1080 and encountered a nvrtc: error related to invalid GPU architecture.
- It was suggested that 2080 generation is the minimal requirement, but patching the architecture in ops_cuda and disabling tensor cores could potentially solve the issue.
- Exploratory setup on newer system: After encountering the error, the member decided to set up tinygrad on a newer system to further explore the issue.
- The member expressed gratitude for the suggestion provided by another community member.