[AINews] LMSys killed Model Versioning (gpt 4o 1120, gemini exp 1121)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Dates are all you need.
AI News for 11/21/2024-11/22/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (217 channels, and 2501 messages) for you. Estimated reading time saved (at 200wpm): 237 minutes. You can now tag @smol_ai for AINews discussions!
Frontier lab race dynamics are getting somewhat ridiculous. We used to have a rule that new SOTA models always get top spot, and reported on Gemini Exp 1114 last week even though there was next to no useful detail on it beyond their lmsys ranking. But yesterday OpenAI overtook them again with gpt-4o-2024-11-20, which we fortunately didn't report on (thanks to DeepSeek R1), because it is now suspected of being a worse (but faster) model (we don't know if this is true but it would be a very serious accusation indeed for OpenAI to effectively brand a "mini" model as a mainline model and hope we don't notice), and meanwhile, today Gemini Exp 1121 is out -again- retaking the top lmsys spot from OpenAI.
It's getting so absurd that this joke playing on OpenAI-vs-Gemini-release-coincidences is somewhat plausible:
The complete suspension of all model release decorum is always justifiable under innocent "we just wanted to get these out into the hands of devs ASAP" type good intentions, but we are now in a situation where all three frontier labs (reminder that Anthropic, despite their snark, has also been playing the date-update-with-no-versioning game) have SOTA model variants uniquely only identified by their dates rather than their versions, in order to keep up on Lmsys.
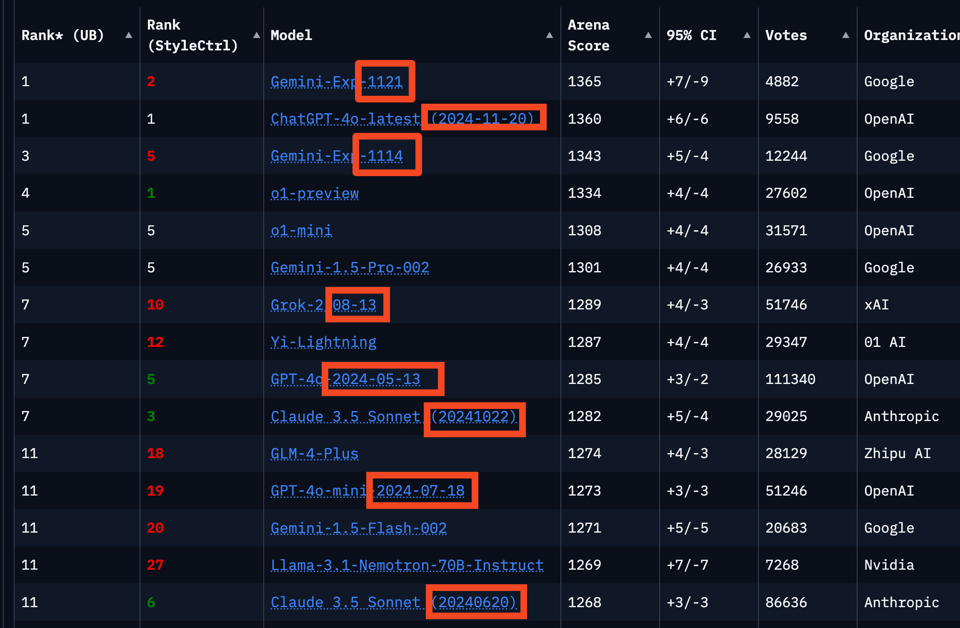
Are we just not doing versioning anymore? Hopefully we are, because we're still talking about o2 and gpt5 and claude4 and gemini2, but this liminal lull as the 100k clusters ramp up is a rather local minima nobody is truly happy with.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- Interconnects (Nathan Lambert) Discord
- HuggingFace Discord
- OpenAI Discord
- LM Studio Discord
- aider (Paul Gauthier) Discord
- OpenRouter (Alex Atallah) Discord
- Stability.ai (Stable Diffusion) Discord
- Eleuther Discord
- Perplexity AI Discord
- Latent Space Discord
- Nous Research AI Discord
- GPU MODE Discord
- Notebook LM Discord Discord
- LlamaIndex Discord
- Cohere Discord
- Modular (Mojo 🔥) Discord
- Torchtune Discord
- DSPy Discord
- LLM Agents (Berkeley MOOC) Discord
- tinygrad (George Hotz) Discord
- MLOps @Chipro Discord
- OpenInterpreter Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- Mozilla AI Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- Unsloth AI (Daniel Han) ▷ #general (497 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
- Unsloth AI (Daniel Han) ▷ #off-topic (1 messages):
- Unsloth AI (Daniel Han) ▷ #help (122 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #research (3 messages):
- Interconnects (Nathan Lambert) ▷ #news (98 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (18 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (120 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #posts (34 messages🔥):
- HuggingFace ▷ #general (182 messages🔥🔥):
- HuggingFace ▷ #cool-finds (10 messages🔥):
- HuggingFace ▷ #i-made-this (9 messages🔥):
- HuggingFace ▷ #reading-group (1 messages):
- HuggingFace ▷ #computer-vision (6 messages):
- HuggingFace ▷ #NLP (9 messages🔥):
- HuggingFace ▷ #diffusion-discussions (13 messages🔥):
- OpenAI ▷ #ai-discussions (209 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (1 messages):
- OpenAI ▷ #prompt-engineering (3 messages):
- OpenAI ▷ #api-discussions (3 messages):
- LM Studio ▷ #general (63 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (135 messages🔥🔥):
- aider (Paul Gauthier) ▷ #announcements (2 messages):
- aider (Paul Gauthier) ▷ #general (133 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (42 messages🔥):
- aider (Paul Gauthier) ▷ #links (2 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (162 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (1 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (164 messages🔥🔥):
- Eleuther ▷ #general (5 messages):
- Eleuther ▷ #research (48 messages🔥):
- Eleuther ▷ #scaling-laws (7 messages):
- Eleuther ▷ #lm-thunderdome (39 messages🔥):
- Eleuther ▷ #multimodal-general (1 messages):
- Perplexity AI ▷ #general (83 messages🔥🔥):
- Perplexity AI ▷ #sharing (7 messages):
- Perplexity AI ▷ #pplx-api (7 messages):
- Latent Space ▷ #ai-general-chat (59 messages🔥🔥):
- Nous Research AI ▷ #general (29 messages🔥):
- Nous Research AI ▷ #ask-about-llms (6 messages):
- Nous Research AI ▷ #interesting-links (4 messages):
- GPU MODE ▷ #triton (20 messages🔥):
- GPU MODE ▷ #beginner (2 messages):
- GPU MODE ▷ #torchao (1 messages):
- GPU MODE ▷ #rocm (11 messages🔥):
- GPU MODE ▷ #webgpu (1 messages):
- GPU MODE ▷ #liger-kernel (1 messages):
- GPU MODE ▷ #self-promotion (1 messages):
- GPU MODE ▷ #🍿 (1 messages):
- Notebook LM Discord ▷ #use-cases (9 messages🔥):
- Notebook LM Discord ▷ #general (25 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (16 messages🔥):
- Cohere ▷ #discussions (8 messages🔥):
- Cohere ▷ #questions (3 messages):
- Cohere ▷ #api-discussions (5 messages):
- Cohere ▷ #projects (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (6 messages):
- Modular (Mojo 🔥) ▷ #max (9 messages🔥):
- Torchtune ▷ #dev (9 messages🔥):
- DSPy ▷ #general (7 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (4 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
- MLOps @Chipro ▷ #events (3 messages):
- OpenInterpreter ▷ #general (3 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
- LAION ▷ #general (2 messages):
- Mozilla AI ▷ #announcements (2 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Theme 1. DeepSeek and Global AI Advancements
- DeepSeek's R1 Performance: DeepSeek R1 is compared to OpenAI o1-preview with "thoughts" streamed directly without MCTS used during inference. @saranormous highlights the model's potency, suggesting chip controls are ineffective against burgeoning competition from China, underlined by @bindureddy who praises the open-source nature of R1.
- Market Impact and Predictions: Deepseek-r1 gains traction as a competitive alternative to existing leaders like OpenAI, further emphasized by discussion of the AI race between China and the US.
Theme 2. Model Releases and Tech Developments
- Google's Gemini-Exp-1121: This model is being lauded for its improvements in vision, coding, and creative writing. @Lmarena_ai discusses its ascendance in the Chatbot Arena rankings alongside GPT-4o, showcasing rapid gains in performance.
- Enhanced Features: New coding proficiency, stronger reasoning, and improved visual understanding have made Gemini-Exp-1121 a formidable force, per @_akhaliq.
- Mistral's Expansion: MistralAI announces a new office in Palo Alto, indicating growth and open positions in various fields. This expansion reflects a strategic push to scale operations and talent pool, as noted by @sophiamyang.
- Claude Pro Google Docs Integration: Anthropic enhances Claude AI with Google Docs integration, aiming to streamline document management across organization levels.
Theme 3. AI Frameworks and Dataset Releases
- SmolTalk Dataset Unveiling: SmolTalk, a 1M sample dataset under Apache 2.0, boosts SmolLM v2's performance with new synthetic datasets. This initiative promises to enhance various model outputs, like summarization and rewriting.
- Dataset Integration and Performance: The dataset couples with public sources like OpenHermes2.5 and outperforms competitors trained on similar model scales, positioning it as a high-impact resource in language model training.
Theme 4. Innovative AI Applications and Tools
- LangGraph Agents and LangChain's Voice Capabilities: A video tutorial illustrates the transformation of LangGraph agents into voice-enabled assistants using OpenAI's Whisper for input and ElevenLabs for speech output.
- OpenRecovery's Use of LangGraph: Highlighted by LangChain, the application in addiction recovery demonstrates its practical adaptiveness and scalability.
Theme 5. Benchmarks and Industry Analysis
- AI Performance and Industry Insights: Menlo Ventures releases a report on Generative AI's evolution, emphasizing top use cases and integration strategies, noting Anthropic's growing share in the market.
- Model Fine-tuning and Evaluation: A shift from fine-tuning to more advanced RAG and agentic AI techniques is reported, underscoring the value of LLM engineers in optimizing AI applications.
Theme 6. Memes/Humor
- Misadventures with AI and OpenAI: @aidan_mclau humorously contemplates the challenges of fitting new language model behaviors into neatly defined categories, reflecting the often unpredictable nature of ongoing AI developments.
- Finance Humor and Predictions: @nearcyan injects humor into financial discussions by likening the experience of "ghosting" at FAANG companies with engineering's evolving professional landscapes.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. M4 Max 128GB: Running 72B Models at 11 t/s with MLX
- M4 Max 128GB running Qwen 72B Q4 MLX at 11tokens/second. (Score: 476, Comments: 181): The Apple M4 Max with 128GB of memory successfully runs the Qwen 72B Q4 MLX model at a speed of 11 tokens per second. This performance metric demonstrates the capability of Apple silicon to handle large language models efficiently.
- Users discussed power consumption and thermal performance, noting the system draws up to 190W during inference while running at high temperatures. The M4 Max achieves this performance while using significantly less power than comparable setups with multiple NVIDIA 3090s or A6000s.
- The M4 Max's memory bandwidth of 546 GB/s and performance of 11 tokens/second represents a significant improvement over the M1 Max (at 409.6 GB/s and 6.17 tokens/second). Users successfully tested various models including Qwen 72B, Mistral 128B, and smaller coding models with 32k context windows.
- Discussion compared costs between building a desktop setup (~$4000 for GPUs alone) versus the $4700 M4 Max laptop, with many highlighting the portability advantage and complete solution aspect of the Apple system for running local LLMs, particularly during travel or in locations with power constraints.
- Mac Users: New Mistral Large MLX Quants for Apple Silicon (MLX) (Score: 91, Comments: 23): A developer created 2-bit and 4-bit quantized versions of Mistral Large optimized for Apple Silicon using MLX-LM, with the q2 version achieving 7.4 tokens/second on an M4 Max while using 42.3GB RAM. The models are available on HuggingFace and can run in LMStudio or other MLX-compatible systems, promising faster performance than GGUF models on M-series chips.
- Users inquired about performance comparisons, with tests showing MLX models running approximately 20% faster than GGUF versions on Apple Silicon, confirmed independently by multiple users.
- Questions focused on practical usage, including how to run models through LMStudio, where users can manually download from HuggingFace and place files in the LMStudio cache folder for recognition.
- Users discussed hardware compatibility, particularly regarding the M4 Pro 64GB and its ability to run Mistral Large variants, with interest in comparing performance against Llama 3.1 70B Q4.
Theme 2. DeepSeek R1-Lite Preview Shows Strong Reasoning Capabilities
- Here the R1-Lite-Preview from DeepSeek AI showed its power... WTF!! This is amazing!! (Score: 146, Comments: 19): DeepSeek's R1-Lite-Preview model demonstrates advanced capabilities, though no specific examples or details were provided in the post body. The post title expresses enthusiasm about the model's performance but lacks substantive information about its actual capabilities or benchmarks.
- Base32 decoding capabilities vary significantly among models, with GPT-4 showing success while other models struggle. The discussion highlights that most open models perform poorly with ciphers, though they handle base64 well due to its prevalence in training data.
- MLX knowledge gaps were noted in DeepSeek's R1-Lite-Preview, suggesting limited parameter capacity for comprehensive domain knowledge. This limitation reflects the model's likely smaller size compared to other contemporary models.
- Discussion of tokenization constraints explains model performance on encoding/decoding tasks, with current models using token-based rather than character-based processing. Users compare this limitation to humans trying to count invisible atoms - a system limitation rather than intelligence measure.
- deepseek R1 lite is impressive , so impressive it makes qwen 2.5 coder look dumb , here is why i am saying this, i tested R1 lite on recent codeforces contest problems (virtual participation) and it was very .... very good (Score: 135, Comments: 44): DeepSeek R1-Lite demonstrates superior performance compared to Qwen 2.5 specifically on Codeforces competitive programming contest problems through virtual participation testing. The post author emphasizes R1-Lite's exceptional performance but provides no specific metrics or detailed comparisons.
- DeepSeek R1-Lite shows mixed performance across different tasks - successful with scrambled letters and number encryption but fails consistently with Playfair Cipher. Users note it excels at small-scope problems like competitive programming tasks but may struggle with real-world coding scenarios.
- Comparative testing between R1-Lite and Qwen 2.5 shows Qwen performing better at practical tasks, with users reporting success in Unity C# scripting and implementing a raycast suspension system. Both models can create Tetris, with Qwen completing it in one attempt versus R1's two attempts.
- Users highlight that success in competitive programming doesn't necessarily translate to real-world coding ability. Testing on platforms like atcoder.jp and Codeforces with unique, recent problems is suggested for better model evaluation.
Theme 3. Gemini-exp-1121 Tops LMSYS with Enhanced Coding & Vision
- Google Releases New Model That Tops LMSYS (Score: 139, Comments: 53): Google released Gemini-exp-1121, which achieved top performance on the LMSYS leaderboard for coding and vision tasks. The model represents an improvement over previous Gemini iterations, though no specific performance metrics were provided in the announcement.
- LMSYS leaderboard rankings are heavily debated, with users arguing that Claude being ranked #7 indicates benchmark limitations. Multiple users report Claude outperforms competitors in real-world applications, particularly for coding and technical tasks.
- Gemini's new vision capabilities enable direct manga translation by processing full image context, offering advantages over traditional OCR + translation pipelines. This approach better handles context-dependent elements like character gender and specialized terminology.
- A competitive pattern emerged between Google and OpenAI, where each company repeatedly releases models to top the leaderboard. The release of Gemini-exp-1121 appears to be a strategic move following OpenAI's recent model release.
Theme 4. Allen AI's Tulu 3: Open Source Instruct Models on Llama 3.1
- Tülu 3 -- a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms (Score: 117, Comments: 23): Allen AI released Tülu 3, a collection of open-source instruction-following models, with complete access to training data, evaluation code, and training algorithms. The models aim to advance state-of-the-art performance while maintaining full transparency in their development process.
- Tülu 3 is a collection of Llama 3.1 fine-tunes rather than models built from scratch, with models available in 8B and 70B versions. Community members have already created GGUF quantized versions and 4-bit variants for improved accessibility.
- Performance benchmarks show the 8B model surpassing Qwen 2.5 7B Instruct while the 70B model outperforms Qwen 2.5 72B Instruct, GPT-4o Mini, and Claude 3.5 Haiku. The release includes comprehensive training data, reward models, and hyperparameters.
- Allen AI has announced that their completely open-source OLMo model series will receive updates this month. A detailed discussion of Tülu 3's training process is available in a newly released podcast.
Theme 5. NVIDIA KVPress: Open Source KV Cache Compression Research
- New NVIDIA repo for KV compression research (Score: 48, Comments: 7): NVIDIA released an open-source library called kvpress to address KV cache compression challenges in large language models, where models like llama 3.1-70B require 330GB of memory for 1M tokens in float16 precision. The library, built on 🤗 Transformers, introduces a new "expected attention" method and provides tools for researchers to develop and benchmark compression techniques, with the code available at kvpress.
- KV cache quantization is not currently supported by kvpress, though according to the FAQ it could potentially be combined with pruning strategies to achieve up to 4x compression when moving from float16 to int4.
- That's the only meaningful discussion point from the comments provided - the other comments and replies don't add substantive information to summarize.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Flux.1 Tools Suite Expands SD Capabilities
- Huge FLUX news just dropped. This is just big. Inpainting and outpainting better than paid Adobe Photoshop with FLUX DEV. By FLUX team published Canny and Depth ControlNet a likes and Image Variation and Concept transfer like style transfer or 0-shot face transfer. (Score: 739, Comments: 194): Black Forest Labs released their Flux.1 Tools control suite featuring inpainting and outpainting capabilities that compete with Adobe Photoshop, alongside ControlNet-style features for Canny and Depth controls. The release includes image variation and concept transfer tools that enable style transfer and zero-shot face transfer functionality.
- ComfyUI offers day-one support for Flux Tools with detailed implementation examples, requiring 27GB VRAM for full models, though LoRA versions are available on Huggingface.
- Community feedback indicates strong outpainting capabilities comparable to Midjourney, with users particularly praising the Redux IP adapter's performance and strength. The tools are publicly available for the FLUX DEV model with implementation details at Black Forest Labs.
- Users criticized the clickbait-style announcement title and requested more straightforward technical communication, while also noting that an FP8 version is available on Civitai for those with lower VRAM requirements.
- Day 1 ComfyUI Support for FLUX Tools (Score: 149, Comments: 26): ComfyUI added immediate support for FLUX Tools on release day, though specific details about the integration were not provided in the post.
- ComfyUI users report successful integration with Flux Tools, with SwarmUI providing native support for all model variants as documented on GitHub.
- Users identified issues with Redux being overpowering and not working with FP8_scaled models, though adjusting ConditioningSetTimestepRange and ConditioningSetAreaStrength parameters showed improvement. A proper compositing workflow using ImageCompositeMasked or Inpaint Crop/Stitch nodes was recommended to prevent VAE degradation.
- The implementation supports Redux Adapter, Fill Model, and ControlNet Models & LoRAs (specifically Depth and Canny), with a demonstration workflow available on CivitAI.
- Flux Redux with no text prompt (Score: 43, Comments: 30): Redux adapter testing focused on image variation capabilities without text prompts, though no specific details or results were provided in the post body.
- FLUX.1 Redux adapter focuses on reproducing images with variations while maintaining style and scene without recreating faces. Users report faster and more precise results, particularly with inpainting capabilities for changing clothes and backgrounds.
- The ComfyUI implementation requires placing the sigclip vision model in the models/clip_vision folder. Updates and workflows can be found on the ComfyUI examples page.
- Flux Tools integration with ComfyUI provides features like ControlNet, variations, and in/outpainting as detailed in the Black Forest Labs documentation. The implementation guide is available on the ComfyUI blog.
Theme 2. NVIDIA/MIT Release SANA: Efficient Sub-1B Parameter Diffusion Model
- Diffusion code for SANA has just released (Score: 103, Comments: 52): SANA diffusion model's training and inference code has been released on GitHub by NVlabs. The model weights are expected to be available on HuggingFace under "Efficient-Large-Model/Sana_1600M_1024px" but are not currently accessible.
- SANA model's key feature is its ability to output 4096x4096 images directly, though some users note that models like UltraPixel and Cascade can also achieve this. The model comes in sizes of 0.6B and 1.6B parameters, significantly smaller than SDXL (2B) and Flux Dev (12B).
- The model is released by NVIDIA, MIT, and Tsinghua University researchers with a CC BY-NC-SA 4.0 License. Users note this is more restrictive than PixArt-Sigma's OpenRail++ license, but praise the rare instance of a major company releasing model weights.
- Technical discussion focuses on the model's speed advantage and potential for fine-tuning, with the 0.6B version being considered for specialized use cases. The model is available on HuggingFace with a size of 6.4GB.
- Testing the CogVideoX1.5-5B i2v model (Score: 177, Comments: 51): CogVideoX1.5-5B, an image-to-video model, was discussed for community testing and evaluation. Insufficient context was provided in the post body for additional details about testing procedures or results.
- The model's workflow is available on Civitai, with recommended resolution being above 720p. The v1.5 version is still in testing phase and currently only supports 1344x768 according to Kijai documentation.
- Using a 4090 GPU, generation takes approximately 3 minutes for 1024x640 resolution and 5 minutes for 1216x832. A 3090 with 24GB VRAM can run without the 'enable_sequential_cpu_offload' feature.
- Technical limitations include poor performance of the GGUF version with occasional crashes, incompatibility with anime-style images, and potential Out of Memory (OOM) issues on Windows when attempting 81 frames at 1024x640 resolution.
Theme 3. ChatGPT 4o Nov Update: Better Writing, Lower Test Scores
- gpt-4o-2024-11-20 scores lower on MMLU, GPQA, MATH and SimpleQA than gpt-4o-2024-08-06 (Score: 77, Comments: 17): GPT-4o's November 2024 update shows performance decreases across multiple benchmarks compared to its August version, including MMLU, GPQA, MATH, and SimpleQA. The lack of additional context prevents analysis of specific score differences or potential reasons for the decline.
- Performance drops in the latest GPT-4o are significant, with GPQA declining by 13.37% and MMLU by 3.38% according to lifearchitect.ai. The model now scores lower than Claude 3.5 Sonnet, Llama 3.1 405B, Grok 2, and even Grok 2 mini on certain benchmarks.
- Multiple users suggest OpenAI is optimizing for creative writing and user appeal rather than factual accuracy, potentially explaining the decline in benchmark performance. The tradeoff has resulted in "mind blowing" improvements in creative tasks while sacrificing objective correctness.
- Users express desire for specialized model naming (like "gpt-4o-creative-writing" or "gpt-4o-coding") and suggest these changes are cost-optimization driven. Similar specialization trends are noted with Anthropic's Sonnet models showing task-specific improvements and declines.
- OpenAI's new update turns it into the greatest lyricist of all time (ChatGPT + Suno) (Score: 57, Comments: 27): OpenAI released an update that, when combined with Suno, enhances its creative writing capabilities specifically for lyrics. No additional context or specific improvements were provided in the post body.
- Users compare the AI's rap style to various artists including Eminem, Notorious B.I.G., Talib Kweli, and Blackalicious, with some suggesting it surpasses 98% of human rap. The original source was shared via Twitter/X.
- The technical improvement appears focused on the LLM's rhyming capabilities while maintaining coherent narrative structure. Several users note the AI's ability to maintain consistent patterns while delivering meaningful content.
- Multiple comments express concern about AI's rapid advancement, with one user noting humans are being outperformed not just in math and chess but now in creative pursuits like rapping. The sentiment suggests significant apprehension about AI capabilities.
Theme 4. Claude Free Users Limited to Haiku as Demand Strains Capacity
- Free accounts are now (permanently?) routed to 3.5 Haiku (Score: 52, Comments: 40): Claude free accounts now default to the Haiku model, discovered by user u/Xxyz260 through testing with a specific prompt about the October 7, 2023 attack. The change appears to be unannounced, with users reporting intermittent access to Sonnet 3.5 over an 18-hour period before reverting to Haiku, suggesting possible load balancing tests by Anthropic.
- Users confirmed through testing that free accounts are receiving Haiku 3.5, not Haiku 3, with evidence shown in test results demonstrating that model knowledge comes from system prompts rather than the models themselves.
- A key concern emerged that Pro users are not receiving access to the newest Haiku 3.5 model after exhausting their Sonnet limits, while free users are getting the updated version by default.
- Discussion around ChatGPT becoming more attractive compared to Claude, particularly for coding tasks, with users expressing frustration about Anthropic's handling of the service changes and lack of transparency.
- Are they gonna do something about Claude's overloaded server? (Score: 27, Comments: 46): A user reports being unable to access Claude Sonnet 3.5 due to server availability issues for free accounts, while finding Claude Haiku unreliable for following prompts. The user expresses that the $20 Claude Pro subscription is cost-prohibitive for their situation as a college student, despite using Claude extensively for research, creative writing, and content creation.
- Free usage of Claude Sonnet is heavily impacted by server load, particularly during US working hours, with users reporting up to 14 hours of unavailability. European users note better access during their daytime hours.
- Even paid users experience overloading issues, suggesting Anthropic's server capacity constraints are significant. The situation is unlikely to improve for free users unless the company expands capacity or training costs decrease.
- There's confusion about the Haiku model version (3.0 vs 3.5), with users sharing comparison screenshots and noting inconsistencies between mobile app and web UI displays, suggesting possible A/B testing or UI bugs.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. New AI Models Surge Ahead with Enhanced Capabilities
- Tülu 3 Launches with Superior Performance Over Llama 3.1: Nathan Lambert announced the release of Tülu 3, an open frontier model that outperforms Llama 3.1 across multiple tasks by incorporating a novel Reinforcement Learning with Verifiable Rewards approach. This advancement ensures higher accuracy and reliability in real-world applications.
- Gemini Experimental 1121 Tops Chatbot Arena Benchmarks: Google DeepMind’s Gemini-Exp-1121 tied for the top spot in the Chatbot Arena, surpassing GPT-4o-1120. Its significant improvements in coding and reasoning capabilities highlight rapid progress in AI model performance.
- Qwen 2.5 Achieves GPT-4o-Level Performance in Code Editing: Open source models like Qwen 2.5 32B demonstrate competitive performance on Aider's code editing benchmarks, matching GPT-4o. Users emphasize the critical role of model quantization, noting significant performance variations based on quantization levels.
Theme 2. Advanced Fine-Tuning Techniques Propel Model Efficiency
- Unsloth AI Introduces Vision Support, Doubling Fine-Tuning Speed: Unsloth has launched vision support for models like LLaMA, Pixtral, and Qwen, enhancing developer capabilities by improving fine-tuning speed by 2x and reducing memory usage by 70%. This positions Unsloth ahead of benchmarks such as Flash Attention 2 (FA2) and Hugging Face (HF).
- Contextual Position Encoding (CoPE) Enhances Model Expressiveness: Contextual Position Encoding (CoPE) adapts position encoding based on token context rather than fixed counts, leading to more expressive models. This method improves handling of selective tasks like Flip-Flop, which traditional position encoding struggles with.
- AnchorAttention Reduces Training Time by Over 50% for Long-Context Models: A new paper introduces AnchorAttention, a plug-and-play solution that enhances long-context performance while cutting training time by more than 50%. Compatible with both FlashAttention and FlexAttention, it is suitable for applications like video understanding.
Theme 3. Hardware Solutions and Performance Optimizations Drive AI Efficiency
- Cloud-Based GPU Renting Enhances Model Speed for $25-50/month: Transitioning to a cloud server for model hosting costs $25-50/month and significantly boosts model speed compared to local hardware. Users find cloud-hosted GPUs more cost-effective and performant, avoiding the limitations of on-premises setups.
- YOLO Excels in Real-Time Video Object Detection: YOLO remains a preferred choice for video object detection, supported by the YOLO-VIDEO resource. Ongoing strategies aim to optimize YOLO's performance in real-time processing scenarios.
- MI300X GPUs Experience Critical Hang Issues During Long Runs: Members reported intermittent GPU hangs on MI300X GPUs during extended 12-19 hour runs with axolotl, primarily after the 6-hour mark. These stability concerns are being tracked on GitHub Issue #4021, including detailed metrics like loss and learning rate.
Theme 4. APIs and Integrations Enable Custom Deployments and Enhancements
- Hugging Face Endpoints Support Custom Handler Files: Hugging Face Endpoints now allow deploying custom AI models using a handler.py file, facilitating tailored pre- and post-processing. Implementing the EndpointHandler class ensures flexible and efficient model deployment tailored to specific needs.
- Model Context Protocol (MCP) Enhances Local Interactions: Anthropic's Claude Desktop now supports the Model Context Protocol (MCP), enabling enhanced local interactions with models via Python and TypeScript SDKs. While remote connection capabilities are pending, initial support includes various SDKs, raising interest in expanded functionalities.
- OpenRouter API Documentation Clarified for Seamless Integration: Users expressed confusion regarding context window functionalities in the OpenRouter API documentation. Enhancements are recommended to improve clarity, assisting seamless integration with tools like LangChain and optimizing provider selection for high-context prompts.
Theme 5. Comprehensive Model Evaluations and Benchmark Comparisons Illuminate AI Progress
- Perplexity Pro Outperforms ChatGPT in Accuracy for Specific Tasks: Users compared Perplexity with ChatGPT, noting that Perplexity is perceived as more accurate and offers advantages in specific functionalities. One participant highlighted that certain features of Perplexity were developed before their popularity surge, underscoring its robust capabilities.
- SageAttention Boosts Attention Mechanisms Efficiency by 8-Bit Quantization: The SageAttention method introduces an efficient 8-bit quantization approach for attention mechanisms, enhancing operations per second while maintaining accuracy. This improvement addresses the high computational complexity traditionally associated with larger sequences.
- DeepSeek-R1-Lite-Preview Showcases Superior Reasoning on Coding Benchmarks: DeepSeek launched the DeepSeek-R1-Lite-Preview, demonstrating impressive reasoning capabilities on coding benchmarks. Users like Zhihong Shao praised its performance in both coding and mathematical challenges, highlighting its practical applications.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Vision Support in Unsloth Launches: Unsloth has officially launched vision support, enabling fine-tuning of models like LLaMA, Pixtral, and Qwen, which significantly enhances developer capabilities.
- This feature improves fine-tuning speed by 2x and reduces memory usage by 70%, positioning Unsloth ahead of benchmarks such as Flash Attention 2 (FA2) and Hugging Face (HF).
- Enhancements in Fine-tuning Qwen and LLaMA: Users are exploring the feasibility of fine-tuning both base and instructed Qwen and LLaMA models, with discussions centered around creating and merging LoRAs.
- Unsloth's vision support facilitates merging by converting 4-bit LoRAs back into 16-bit, streamlining the fine-tuning process.
- Llama 3.2 Vision Unveiled: Llama 3.2 Vision models are now supported by Unsloth, achieving 2x faster training speeds and 70% less memory usage while enabling 4-8x longer context lengths.
- The release includes Google Colab notebooks for tasks like Radiography and Maths OCR to LaTeX, accessible via Colab links.
- AnchorAttention Improves Long-Context Training: A new paper introduces AnchorAttention, a method that enhances long-context performance and reduces training time by over 50%.
- This solution is compatible with both FlashAttention and FlexAttention, making it suitable for applications like video understanding.
- Strategies for Training Checkpoint Selection: Discussions around selecting the appropriate training checkpoint revealed varied approaches, with some members opting for extensive checkpoint usage and others advocating for strategic selection based on specific metrics.
- Participants emphasized the importance of performance benchmarks and shared experiences to optimize checkpoint choices in the training workflow.
Interconnects (Nathan Lambert) Discord
- Tülu 3 launch innovations: Nathan Lambert announced the release of Tülu 3, an open frontier model that outperforms Llama 3.1 on multiple tasks, incorporating a novel Reinforcement Learning with Verifiable Rewards approach.
- The new model rewards algorithms exclusively for accurate generations, enhancing its performance and reliability in real-world applications.
- Nvidia's AI Wall concerns: An article from The Economist reports Nvidia’s CEO downplaying fears that AI has 'hit a wall', despite widespread skepticism in the community.
- This stance has intensified discussions about the current trajectory of AI advancements and the pressing need for continued innovation.
- Gemini's Chatbot Arena performance: Google DeepMind’s Gemini-Exp-1121 tied for the top spot in the Chatbot Arena, surpassing GPT-4o-1120 in recent benchmarks.
- Gemini-Exp-1121 exhibits significant improvements in coding and reasoning capabilities, highlighting rapid progress in AI model performance.
- Reinforcement Learning with Verifiable Rewards: Tülu 3 incorporates a new technique called Reinforcement Learning with Verifiable Rewards, which trains models on constrained math problems and rewards correct outputs, as detailed in Nathan Lambert's tweet.
- This approach aims to ensure higher accuracy in model generations by strictly incentivizing correct responses during training.
- Model Context Protocol by Anthropic: Anthropic's Claude Desktop now supports the Model Context Protocol (MCP), enabling enhanced local interactions with models via Python and TypeScript SDKs.
- While initial support includes various SDKs, remote connection capabilities are pending future updates, raising interest in expanded functionalities.
HuggingFace Discord
- SageAttention Enhances Attention Mechanisms: The SageAttention method introduces an efficient quantization approach for attention mechanisms, boosting operations per second by optimizing computational resources.
- This technique maintains accuracy while addressing the high complexity associated with larger sequences, making it a valuable improvement over traditional methods.
- Deploying AI Models with Custom Handler Files: Hugging Face Endpoints now support deploying custom AI models using a handler.py file, allowing for tailored pre- and post-processing.
- Implementing the EndpointHandler class ensures flexible and efficient model deployment, catering to specific deployment needs.
- Automated AI Research Assistant Developed: A new Python program transforms local LLMs into automated web researchers, delivering detailed summaries and sources based on user queries.
- The assistant systematically breaks down queries into subtopics, enhancing information gathering and analysis efficiency from various online sources.
- YOLO Excels in Video Object Detection: YOLO continues to be a preferred choice for video object detection, supported by a YOLO-VIDEO resource that facilitates effective implementation.
- Discussions highlight ongoing strategies to optimize YOLO's performance in video streams, addressing challenges related to real-time processing.
- MOUSE-I Streamlines Web Service Deployment: MOUSE-I enables the conversion of simple prompts into globally deployed web services within 60 seconds using AI automation.
- This tool is ideal for startups, developers, and educators seeking rapid deployment solutions without extensive manual configurations.
OpenAI Discord
- Perplexity Outperforms ChatGPT in Accuracy: Users compared Perplexity with ChatGPT, highlighting that Perplexity is seen as more accurate and offers advantages in specific functionalities.
- One participant noted that certain features of Perplexity were in development prior to their popularity surge.
- GPT-4 Drives Product Categorization Efficiency: A member shared their experience categorizing products using a prompt with GPT-4, specifying categories ranging from groceries to clothing with great results.
- They noted that while the categorization is effective, token usage is high due to the lengthy prompt structure.
- GPT-4o Enhances Image-Based Categorization: A member described using GPT-4o to categorize products based on title and image, achieving excellent results with a comprehensive prompt structure.
- However, they pointed out that the extensive token usage poses a scalability challenge for their setup.
- Streamlining with Prompt Optimization: Discussions centered around minimizing token usage while maintaining prompt effectiveness in categorization tasks.
- Suggestions included exploring methods like prompt caching to streamline the process and reduce redundancy.
- Prompt Caching Cuts Down Token Consumption: Members suggested implementing prompt caching techniques to reduce repetitive input tokens in their categorization workflows.
- They recommended consulting API-related resources for further assistance in optimizing token usage.
LM Studio Discord
- Hermes 3 exceeds expectations: A member favored Hermes 3 for its superior writing skills and prompt adherence, though noted phrase repetition at higher contexts (16K+).
- This preference underscores Hermes 3’s advancements, but highlights limitations in handling longer contexts efficiently.
- Cloud-Based GPU Renting: Transitioning to a cloud server for model hosting costs $25-50/month and enhances model speed compared to local hardware.
- Users find cloud-hosted GPUs more cost-effective and performant, avoiding the limitations of on-premises setups.
- LLM GPU Comparisons: Members compared AMD and NVIDIA GPUs, with recent driver updates impacting AMD's ROCM support.
- Consensus leans towards NVIDIA for better software compatibility and support in AI applications.
- Mixed GPU setups hinder performance: Configurations with 1x 4090 + 2x A6000 GPUs underperform others due to shared resource constraints, reducing token generation rates.
- Users highlighted that the slowest GPU in a setup, such as the 4090, can limit overall processing speed.
- Feasibility of a $2k local LLM server: Setting up a local LLM server for 2-10 users on a $2,000 budget poses challenges with single GPU concurrency.
- Developers recommend cloud solutions to mitigate performance bottlenecks associated with budget and older hardware.
aider (Paul Gauthier) Discord
- Qwen 2.5 Rivals GPT-4o in Performance: Open source models like Qwen 2.5 32B demonstrate competitive performance on Aider's code editing benchmarks, matching GPT-4o, while the least effective versions align with GPT-3.5 Turbo.
- Users emphasized the significant impact of model quantization, noting that varying quantization levels can lead to notable performance differences.
- Aider v0.64.0 Introduces New Features: The latest Aider v0.64.0 release includes the new
/editorcommand for prompt writing and full support for gpt-4o-2024-11-20.- This update enhances shell command clarity, allowing users to see confirmations and opt into analytics seamlessly.
- Gemini Model Enhances AI Capabilities: The Gemini Experimental Model offers improved coding, reasoning, and vision capabilities as of November 21, 2024.
- Users are leveraging Gemini's advanced functionalities to achieve more sophisticated AI interactions and improved coding efficiency.
- Model Quantization Impact Discussed: Model quantization significantly affects AI performance, particularly in code editing, as highlighted in Aider's quantization analysis.
- The community discussed optimizing quantization levels to balance performance and resource utilization effectively.
- DeepSeek-R1-Lite-Preview Boosts Reasoning: DeepSeek launched the DeepSeek-R1-Lite-Preview, showcasing impressive reasoning capabilities on coding benchmarks, as detailed in their latest release.
- Users like Zhihong Shao praised its performance in both coding and mathematical challenges, highlighting its practical applications.
OpenRouter (Alex Atallah) Discord
- OpenRouter Launches Five New Models: OpenRouter has introduced GPT-4o with improved prose capabilities, along with Mistral Large (link), Pixtral Large (link), Grok Vision Beta (link), and Gemini Experimental 1114 (link).
- These models enhance functionalities across various benchmarks, offering advanced features for AI engineers to explore.
- Mistral Medium Deprecated, Alternatives Recommended: The Mistral Medium model has been deprecated, resulting in access errors due to priority not enabled.
- Users are advised to switch to Mistral-Large, Mistral-Small, or Mistral-Tiny to continue utilizing the service without interruptions.
- Gemini Experimental 1121 Released with Upgrades: Gemini Experimental 1121 model has been launched, featuring enhancements in coding, reasoning, and vision capabilities.
- Despite quota restrictions shared with the LearnLM model, the community is eager to assess its performance and potential applications.
- OpenRouter API Documentation Clarified: Users have expressed confusion regarding context window functionalities in the OpenRouter API documentation.
- Enhancing documentation clarity is recommended to assist seamless integration with tools like LangChain.
- Request for Custom Provider Key for Claude 3.5: A member has requested a custom provider key for Claude 3.5 Sonnet due to exhausting usage on the main Claude app.
- This request aims to provide an alternative solution to manage usage limits and improve user experience.
Stability.ai (Stable Diffusion) Discord
- Flux's VRAM Vexations: Members discussed the resource requirements for using Flux effectively, noting that it requires substantial VRAM and can be slow to generate images. Black Forest Labs released FLUX.1 Tools, enhancing control and steerability of their base model.
- One member highlighted that using Loras can enhance Flux's output for NSFW content, although Flux isn't optimally trained for that purpose.
- Optimizing SDXL Performance: For SDXL, applying best practices such as
--xformersand--no-half-vaecan improve performance on systems with 12GB VRAM. Members noted that Pony, a derivative of SDXL, requires special tokens and has compatibility issues with XL Loras.- These configurations aid in enhancing SDXL efficiency, while Pony's limitations underscore challenges in model compatibility.
- Enhancing Image Prompts with SDXL Lightning: A user inquired about using image prompts in SDXL Lightning via Python, specifically for inserting a photo into a specific environment. This showcases the community's interest in combining image prompts with varied backgrounds to boost generation capabilities.
- The discussion indicates a trend towards leveraging Python integrations to augment SDXL Lightning's flexibility in image generation tasks.
- Mitigating Long Generation Times: Frustrations over random long generation times while using various models led to discussions about potential underlying causes. Members speculated that memory management issues, such as loading resources into VRAM, might contribute to these slowdowns.
- Addressing these delays is pivotal for improving user experience, with suggestions pointing towards optimizing VRAM usage to enhance generation speeds.
- Securing AI Model Utilization: Concerns were raised about receiving suspicious requests for personal information, like wallet addresses, leading members to suspect scammers within the community. Users were encouraged to report such incidents to maintain a secure environment.
- Emphasizing security, the community seeks to protect its members by proactively addressing potential threats related to AI model misuse.
Eleuther Discord
- Contextual Position Encoding (CoPE) Boosts Model Adaptability: A proposal for Contextual Position Encoding (CoPE) suggests adapting position encoding based on token context rather than fixed counts, leading to more expressive models. This approach targets improved handling of selective tasks like Flip-Flop that traditional methods struggle with.
- Members discussed the potential of CoPE to enhance the adaptability of position encoding, potentially resulting in better performance on complex NLP tasks requiring nuanced token relationship understanding.
- Forgetting Transformer Surpasses Traditional Architectures in Long-Context Tasks: Forgetting Transformer, a variant incorporating a forget gate, demonstrates improved performance on long-context tasks compared to standard architectures. Notably, this model eliminates the need for position embeddings while maintaining effectiveness over extended training contexts.
- The introduction of the Forgetting Transformer indicates a promising direction for enhancing LLM performance by managing long-term dependencies more efficiently.
- Sparse Upcycling Enhances Model Quality with Inference Trade-off: A recent Databricks paper evaluates the trade-offs between sparse upcycling and continued pretraining for model enhancement, finding that sparse upcycling results in higher model quality. However, this improvement comes with a 40% increase in inference time, highlighting deployment challenges.
- The findings underscore the difficulty in balancing model performance with practical deployment constraints, emphasizing the need for strategic optimization methods in model development.
- Scaling Laws Predict Model Performance at Minimal Training Costs: A recent paper introduces an observational approach using ~100 publicly available models to develop scaling laws without direct training, enabling prediction of language model performance based on scale. This method highlights variations in training efficiency, proposing that performance is dependent on a low-dimensional capability space.
- The study demonstrates that scaling law models are costly but significantly less so than training full target models, with Meta reportedly spending only 0.1% to 1% of the target model's budget for such predictions.
- lm-eval Enhances Benchmarking for Pruned Models: A user inquired if the current version of lm-eval supports zero-shot benchmarking of pruned models, specifically using WANDA, and encountered issues with outdated library versions. Discussions suggested reviewing the documentation for existing limitations.
- To resolve integration issues with the Groq API, setting the API key in the
OPENAI_API_KEYenvironment variable was recommended, successfully addressing unrecognized API key argument problems.
- To resolve integration issues with the Groq API, setting the API key in the
Perplexity AI Discord
- Perplexity Pro Unveils Advanced Features: Members discussed various features of Perplexity Pro, emphasizing the inclusion of more advanced models available for Pro users, differentiating it from ChatGPT.
- The discussion included insights on search and tool integration that enhances user experience.
- Pokémon Data Fuels New AI Model: A YouTube video explored how Pokémon data is being utilized to develop a novel AI model, providing insights into technological advancements in gaming.
- This may change the way data is leveraged in AI applications.
- NVIDIA's Omniverse Blueprint Transforms CAD/CAE: A member shared insights on NVIDIA's Omniverse Blueprint, showcasing its transformative potential for CAD and CAE in design and simulation.
- Many are excited about how it integrates advanced technologies into traditional workflows.
- Bring Your Own API Key Adoption Discussed: A member inquired about the permissibility of bringing your own API key to build an alternative platform with Perplexity, outlining secure data management practices.
- This approach involves user-supplied keys being encrypted and stored in cookies, raising questions about compliance with OpenAI standards.
- Enhancing Session Management in Frontend Apps: In response to a request for simplification, a user explained session management in web applications by comparing it to cookies storing session IDs.
- The discussion emphasized how users' authentication relies on validating sessions without storing sensitive data directly.
Latent Space Discord
- Truffles Device Gains Attention: The Truffles device, described as a 'white cloudy semi-translucent thing,' enables self-hosting of LLMs. Learn more at Truffles.
- A member humorously dubbed it the 'glowing breast implant,' highlighting its unique appearance.
- Vercel Acquires Grep for Enhanced Code Search: Vercel announced the acquisition of Grep to bolster developer tools for searching code across over 500,000 public repositories.
- Dan Fox, Grep's founder, will join Vercel's AI team to advance this capability.
- Tülu 3 Surpasses Llama 3 on Tasks: Tülu 3, developed over two years, outperforms Llama 3.1 Instruct on specific tasks with new SFT data and optimization techniques.
- The project lead expressed excitement about their advancements in RLHF.
- Black Forest Labs Launches Flux Tools: Black Forest Labs unveiled Flux Tools, featuring inpainting and outpainting for image manipulation. Users can run it on Replicate.
- The suite aims to add steerability to their text-to-image model.
- Google Releases Gemini API Experimental Models: New experimental models from Gemini were released, enhancing coding capabilities.
- Details are available in the Gemini API documentation.
Nous Research AI Discord
- DeepSeek R1-Lite Boosts MATH Performance: Rumors suggest that DeepSeek R1-Lite is a 16B MOE model with 2.4B active parameters, significantly enhancing MATH scores from 17.1 to 91.6 according to a tweet.
- The skepticism emerged as members questioned the WeChat announcement, doubting the feasibility of such a dramatic performance leap.
- Llama-Mesh Paper Gains Attention: A member recommended reviewing the llama-mesh paper, praising its insights as 'pretty good' within the group.
- This suggestion came amid a broader dialogue on advancing AI architectures and collaborative research.
- Multi-Agent Frameworks Face Output Diversity Limits: Concerns were raised that employing de-tokenized output in multi-agent frameworks like 'AI entrepreneurs' might result in the loss of hidden information due to discarded KV caches.
- This potential information loss could be contributing to the limited output diversity observed in such systems.
- Soft Prompts Lag Behind Fine Tuning: Soft prompts are often overshadowed by techniques like fine tuning and LoRA, which are perceived as more effective for open-source applications.
- Participants highlighted that soft prompts suffer from limited generalizability and involve trade-offs in performance and optimization.
- CoPilot Arena Releases Initial Standings: The inaugural results of CoPilot Arena were unveiled on LMarena's blog, showing a tightly contested field among participants.
- However, the analysis exclusively considered an older version of Sonnet, sparking discussions on the impact of using outdated models in competitions.
GPU MODE Discord
- Triton Kernel Debugging and GEMM Optimizations: Users tackled Triton interpreter accuracy issues and discussed performance enhancements through block size adjustments and swizzling techniques, referencing tools like triton.language.swizzle2d.
- There was surprise at Triton GEMM's conflict-free performance on ROCm, sparking conversations about optimizing GEMM operations for improved computational efficiency.
- cuBLAS Matrix Multiplication in Row-Major Order: Challenges with
cublasSgemmwere highlighted, especially regarding row-major vs column-major order operations, as detailed in a relevant Stack Overflow post.- Users debated the implications of using
CUBLAS_OP_NversusCUBLAS_OP_Tfor non-square matrix multiplications, noting compatibility issues with existing codebases.
- Users debated the implications of using
- ROCm Compilation and FP16 GEMM on MI250 GPU: Developers reported prolonged compilation times when using ROCm's
makecommands, with efforts to tweak the-jflag showing minimal improvements.- Confusion arose over input shape transformations for FP16 GEMM (v3) on the MI250 GPU, leading to requests for clarification on shared memory and input shapes.
- Advancements in Post-Training AI Techniques: A new survey, Tulu 3, was released, covering post-training methods such as Human Preferences in RL and Continual Learning.
- Research on Constitutional AI and Recursive Summarization frameworks was discussed, emphasizing models that utilize human feedback for enhanced task performance.
Notebook LM Discord Discord
- NotebookLM's GitHub Traversal Limitations: Users reported that NotebookLM struggles to traverse GitHub repositories by inputting the repo homepage, as it lacks website traversal capabilities. One member suggested converting the site into Markdown or PDF for improved processing.
- The inability to process websites directly complicates using NotebookLM for repository analysis, leading to workarounds like manual content conversion.
- Enhancements in Audio Prompt Generation: A user proposed enhancing NotebookLM by supplying specific prompts to generate impactful audio outputs, improving explanations and topic comprehension.
- This strategy aims to facilitate a deeper understanding of designated topics through clearer audio content, as discussed by the community.
- Integrating Multiple LLMs for Specialized Tasks: Community members shared workflows utilizing multiple Large Language Models (LLMs) tailored to specific needs, with compliments towards NotebookLM for its generation capabilities.
- This approach underscores the effectiveness of combining various AI tools to support conversational-based projects, as detailed in user blog posts.
- ElevenLabs' Dominance in Text-to-Speech AI: Discussions highlighted ElevenLabs as the leading text-to-speech AI, outperforming competitors like RLS and Tortoise. A user reminisced about early experiences with the startup before its funding rounds.
- The impact of ElevenLabs on voice synthesis and faceless video creation was emphasized as a transformative tool in the industry.
- NotebookLM's Stability and Safety Flags Issues: Users noted an increase in safety flags and instability within NotebookLM, resulting in restricted functionalities and task limitations.
- Community members suggested direct message (DM) examples for debugging, attributing transient issues to ongoing application improvements.
LlamaIndex Discord
- AI Agent Architecture with LlamaIndex and Redis: Join the upcoming webinar on December 12 to learn how to architect agentic systems for breaking down complex tasks using LlamaIndex and Redis.
- Participants will discover best practices for reducing costs, optimizing latency, and gaining insights on semantic caching mechanisms.
- Knowledge Graph Construction using Memgraph and LlamaIndex: Learn how to set up Memgraph and integrate it with LlamaIndex to build a knowledge graph from unstructured text data.
- The session will explore natural language querying of the constructed graph and methods to visualize connections effectively.
- PDF Table Extraction with LlamaParse: A member recommended using LlamaParse for extracting table data from PDF files, highlighting its effectiveness for optimal RAG.
- An informative GitHub link was shared detailing its parsing capabilities.
- Create-Llama Frontend Configuration: A user inquired about the best channel for assistance with Create-Llama, specifically regarding the absence of a Next.js frontend option in newer versions when selecting the Express framework.
- Another participant confirmed that queries can be posted directly in the channel to receive team support.
- Deprecation of Llama-Agents in Favor of Llama-Deploy: A member noted dependency issues while upgrading to Llama-index 0.11.20 and indicated that llama-agents has been deprecated in favor of llama_deploy.
- They provided a link to the Llama Deploy GitHub page for further context.
Cohere Discord
- 30 Days of Python Challenge: A member shared their participation in the 30 Days of Python challenge, which emphasizes step-by-step learning, utilizing the GitHub repository for resources and inspiration.
- They are actively engaging with the repository's content to enhance their Python skills during this structured 30-day program.
- Capstone Project API: One member expressed a preference for using Go in their capstone project to develop an API, highlighting the exploration of different programming languages in practical applications.
- Their choice reflects the community's interest in leveraging Go's concurrency features for building robust APIs.
- Cohere GitHub Repository: A member highlighted the Cohere GitHub repository (GitHub link) as an excellent starting point for contributors, showcasing various projects.
- They encouraged exploring available tools within the repository and sharing feedback or new ideas across different projects.
- Cohere Toolkit for RAG Applications: The Cohere Toolkit (GitHub link) was mentioned as an advanced UI designed specifically for RAG applications, facilitating quick build and deployment.
- This toolkit includes a collection of prebuilt components aimed at enhancing user productivity.
- Multimodal Embeddings Launch: Exciting updates were shared about the improvement in multimodal embeddings, with their launch scheduled for early next year on Bedrock and partner platforms.
- A team member will flag the rate limit issue for further discussion to address scalability concerns.
Modular (Mojo 🔥) Discord
- Mojo's Async Features Under Development: Members reported that Mojo's async functionalities are currently under development, with no available async functions yet.
- The compiler presently translates synchronous code into asynchronous code, resulting in synchronous execution during async calls.
- Mojo Community Channel Launch: A dedicated Mojo community channel has been launched to facilitate member interactions, accessible at mojo-community.
- The channel serves as a central hub for ongoing discussions related to Mojo development and usage.
- Moonshine ASR Model Performance on Mojo: The Moonshine ASR model was benchmarked using moonshine.mojo and moonshine.py, resulting in an execution time of 82ms for 10s of speech, compared to 46ms on the ONNX runtime.
- This demonstrates a 1.8x slowdown in Mojo and Python versions versus the optimized ONNX runtime.
- Mojo Script Optimization Challenges: Developers faced crashes with Model.execute when passing
TensorMapin the Mojo scripts, necessitating manual argument listing due to unsupported unpacking.- These issues highlight the need for script optimization and improved conventions in Mojo code development.
- CPU Utilization in Mojo Models: Users observed inconsistent CPU utilization while running models in Mojo, with full CPU capacity and hyperthreading being ignored.
- This suggests a need for further optimization to maximize resource utilization during model execution.
Torchtune Discord
- Updated Contributor Guidelines for Torchtune: The team announced new guidelines to assist Torchtune maintainers and contributors in understanding desired features.
- These guidelines clarify when to use forks versus example repositories for demonstrations, streamlining the contribution process.
- Extender Packages Proposed for Torchtune: A member suggested introducing extender packages like torchtune[simpo] and torchtune[rlhf] to simplify package inclusion.
- This proposal aims to reduce complexity and effectively manage resource concerns without excessive checks.
- Binary Search Strategy for max_global_bsz: Recommendation to implement a last-success binary search method for max_global_bsz, defaulting to a power of 2 smaller than the dataset.
- The strategy will incorporate max_iterations as parameters to enhance efficiency.
- Feedback on UV Usability: A member inquired about others' experiences with UV, seeking opinions on its usability.
- Another member partially validated its utility, noting it appears appealing and modern.
- Optional Packages Addressing TorchAO: Discussion on whether the optional packages feature can resolve the need for users to manually download TorchAO.
- Responses indicate that while it may offer some solutions, additional considerations need to be addressed.
DSPy Discord
- Prompt Signature Modification: A member inquired about modifying the prompt signature format for debugging purposes to avoid parseable JSON schema notes, particularly by building an adapter.
- The discussion explored methods like building custom adapters to achieve prompt signature customization in DSPy.
- Adapter Configuration in DSPy: A user suggested building an adapter and configuring it using
dspy.configure(adapter=YourAdapter())for prompt modifications, pointing towards existing adapters in thedspy/adapters/directory for further clarification.- Leveraging existing adapters within DSPy can aid in effective prompt signature customization.
- Optimization of Phrases for Specific Cases: Questions about tuning phrases for specific types like bool, int, and JSON were clarified to be based on a maintained set of model signatures.
- These phrases are not highly dependent on individual language models overall, indicating a generalized formulation approach.
LLM Agents (Berkeley MOOC) Discord
- Intel AMA Session Scheduled for November 21: Join the Hackathon AMA with Intel on November 21 at 3 PM PT to engage directly with Intel specialists.
- Don't forget to watch live here and set your reminders for the Ask Intel Anything opportunity.
- Quiz 10 Release Status Update: A member inquired about the release status of Quiz 10, which has not been released on the website yet.
- Another member confirmed that email notifications will be sent once Quiz 10 becomes available, likely within a day or two.
- Hackathon Channel Mix-up Incident: A member expressed gratitude for the Quiz 10 update but humorously acknowledged asking about the hackathon in the wrong channel.
- This exchange reflects common channel mix-ups within the community, adding a lighthearted moment to the conversation.
tinygrad (George Hotz) Discord
- Need for int64 Indexing Explored: A user questioned the necessity of int64 indexing in contexts that do not involve large tensors, prompting others to share their thoughts.
- Another user linked to the ops_hip.py file for further context regarding this discussion.
- Differences in ops_hip.py Files Dissected: A member pointed out distinctions between two ops_hip.py files in the tinygrad repository, suggesting the former may not be maintained due to incorrect imports.
- They noted that the latter is only referenced in the context of an external benchmarking script, which also contains erroneous imports.
- Maintenance Status of ops_hip.py Files: In response to the maintenance query, another user confirmed that the extra ops_hip.py is not maintained while the tinygrad version should function if HIP=1 is set.
- This indicates that while some parts of the code may not be actively managed, others can still be configured to work correctly.
MLOps @Chipro Discord
- Event link confusion arises: A member raised concerns about not finding the event link on Luma, seeking clarification on its status.
- Chiphuyen apologized, explaining that the event was not rescheduled due to illness.
- Wishing well to a sick member: Another member thanked Chiphuyen for the update and wished them a speedy recovery.
- This reflects the community's supportive spirit amidst challenges in event management.
OpenInterpreter Discord
- Urgent AI Expertise Requested: User michel.0816 urgently requested an AI expert, indicating a pressing need for assistance.
- Another member suggested posting the issue in designated channels for better visibility.
- Carter Grant's Job Search: Carter Grant, a full-stack developer with 6 years of experience in React, Node.js, and AI/ML, announced his search for job opportunities.
- He expressed eagerness to contribute to meaningful projects.
OpenAccess AI Collective (axolotl) Discord
- MI300X GPUs Stall After Six Hours: A member reported experiencing intermittent GPU hangs during longer 8 x runs lasting 12-19 hours on a standard ablation set with axolotl, primarily occurring after the 6-hour mark.
- These stability concerns have been documented and are being tracked on GitHub Issue #4021, which includes detailed metrics such as loss and learning rate to provide technical context.
- Prompting Correctly? Engineers Debate Necessity: In the community-showcase channel, a member questioned the necessity of proper prompting, sharing a YouTube video to support the discussion.
- This query has initiated a dialogue among AI engineers regarding the current relevance and effectiveness of prompt engineering techniques.
LAION Discord
- Training the Autoencoder: A member emphasized the importance of training the autoencoder for achieving model efficiency, focusing on techniques and implementation strategies to enhance performance.
- The conversation delved into methods for improving autoencoder performance, including various training techniques.
- Sophistication of Autoencoder Architectures: Members discussed the sophistication of autoencoder architectures in current models, exploring how advanced structures contribute to model capabilities.
- The effectiveness of different algorithms and their impact on data representation within autoencoders were key points of discussion.
Mozilla AI Discord
- Refact.AI Live Demo: The Refact.AI team is conducting a live demo showcasing their autonomous agent and innovative tooling.
- Join the live event here to engage in the conversation.
- Mozilla Launches Web Applets: Mozilla has initiated the open-source project Web Applets to develop AI-native applications for the web.
- This project promotes open standards and accessibility, fostering collaboration among developers, as detailed here.
- Mozilla's Public AI Advocacy: Mozilla has advanced 14 local AI projects in the past year to advocate for Public AI and build necessary developer tools.
- This initiative aims to foster open-source AI technology with a collaborative emphasis on community engagement.
Gorilla LLM (Berkeley Function Calling) Discord
- Query on Llama 3.2 Prompt Format: A member inquired about the lack of usage of a specific prompt for Llama 3.2, referencing the prompt format documentation.
- The question highlighted a need for clarity on function definitions in the system prompt, emphasizing their importance for effective use.
- Interest in Prompt Applicability: The conversation showed a broader interest in understanding the applicability of prompts within Llama 3.2.
- This reflects ongoing discussions about best practices for maximizing model performance through effective prompting.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (497 messages🔥🔥🔥):
Vision support in UnslothFine-tuning Qwen and LLaMA modelsDataset preparation for multimodal modelsLicensing and legal considerationsChallenges with model merging and format compatibility
- Vision Support in Unsloth is Live: Unsloth has officially launched support for vision models, allowing for fine-tuning of LLaMA, Pixtral, and Qwen, greatly enhancing capabilities for developers.
- This new feature reportedly makes fine-tuning 2x faster and cuts memory usage by 70%.
- Fine-tuning Challenges with Qwen and LLaMA: Users are discussing the feasibility of fine-tuning both base and instructed models, with some expressing confusion over creating and merging LoRAs.
- The vision support in Unsloth is designed to facilitate merging, transforming 4-bit LoRAs back into 16-bit seamlessly.
- Dataset Preparation for Vision Models: Tips shared on creating datasets for vision models, with examples such as the 'unsloth/Radiology_mini' format, which includes images, IDs, captions, and classifications.
- The community is encouraged to use the structured format, making data preparation more streamlined for model training.
- Licensing and Legal Considerations: Participants discussed the implications of licensing when it comes to fine-tuning Mistral models, with some reporting challenges in contacting the team for permission.
- Concerns were raised about the impact of neglecting licensing terms on the future of open-source efforts.
- Merging and Format Compatibility Issues: Users have encountered issues with the compatibility of 4-bit and 16-bit models, often requiring upcasting for successful merging.
- The emphasis is placed on the importance of understanding these formats for effective model training and implementation.
- Mimi (@yasomi.xeiaso.net): Vaporwave pastel ukiyo-e goes hard
- unsloth/LaTeX_OCR · Datasets at Hugging Face: no description found
- Unsloth AI | Substack: Welcome to Unsloth's newsletter where we'll be sharing tips & tricks on AI, our latest releases and more! We recently launched unsloth.ai 🦥. Click to read Unsloth AI, a Substack public...
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
- Reddit - Dive into anything: no description found
- AI Unplugged 23: nGPT normalised transformer, LAUREL, TokenFormer: Insights over information
- Introduce MsT technologies into unsloth to extend sequence length by wdlctc · Pull Request #1082 · unslothai/unsloth: Description This pull request introduces optimizations to the LLaMA model implementation, specifically targeting the language modeling head and forward pass. The main changes include: Implement a c...
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
Llama 3.2 VisionVision/Multi-modal ModelsGoogle Colab NotebooksHugging Face Model UploadsFine-tuning Improvements
- Llama 3.2 Vision boosts performance: Unsloth now supports Llama 3.2 Vision models, achieving 2x faster training speeds and 70% less memory usage while allowing for 4-8x longer context lengths.
- This enhancement places Unsloth's vision finetuning capability ahead of Flash Attention 2 (FA2) and Hugging Face (HF) benchmarks.
- Google Colab Notebooks for Llama 3.2: Unsloth has provided Google Colab notebooks for users to finetune Llama 3.2 Vision on tasks like Radiography and Maths OCR to LaTeX.
- These can be accessed via the provided Colab links.
- Exciting Updates on Hugging Face: Unsloth's new models are now available on Hugging Face, including Llama 3.2 Vision in both 11B and 90B variants.
- Users can explore models like Qwen 2 VL and Pixtral (12B) through Hugging Face.
- Enhancements in Fine-tuning Methods: The latest improvements to Unsloth's training process allow for 1.5-2x faster finetuning times compared to previous standards.
- This efficiency helps equip developers with tools to maximize their machine learning workflows swiftly.
- Llama 3.2 Vision Fine-tuning with Unsloth: Fine-tune Meta's Llama 3.2 Vision, Llava, Qwen 2.5 Vision models open-source 2x faster via Unsloth! Beginner friendly.
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Unsloth Documentation: no description found
- Unsloth Documentation: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (1 messages):
Training Checkpoints
- Choosing the Right Training Checkpoint: A member posed a question about which training checkpoint to choose, asking others for their preferences in light of their own choice of 200 checkpoints without hesitation.
- Curiosity on diverse approaches to training checkpoints was expressed, suggesting a possible discussion among participants.
- Diverse Perspectives on Checkpoint Selection: Another participant chimed in with their perspective on the selection process for training checkpoints, emphasizing a more strategic approach based on specific metrics.
- They encouraged others to consider performance benchmarks when determining their checkpoint choices.
Unsloth AI (Daniel Han) ▷ #help (122 messages🔥🔥):
Model Training and PreprocessingFine-tuning ProcessVision SupportUsing OllamaKubernetes vs SLURM for Training
- Queries on fine-tuning and pre-tokenized datasets: A user inquired whether it’s feasible to use continued pretraining scripts with an already tokenized dataset, to which another member suggested passing the untokenized dataset instead.
- The exchange highlighted challenges in the training setup and the specifics of dataset formatting.
- Evaluation process during fine-tuning: A user wanted to evaluate their model every 100 steps during fine-tuning and sought advice on how to achieve this, mentioning concerns about starting training from scratch each time.
- Suggestions included configuring the eval dataset in training arguments and using the
resume_from_checkpointfeature.
- Suggestions included configuring the eval dataset in training arguments and using the
- Vision support rollout announcement: A member announced that vision support is now available, generating excitement in the channel.
- Responses to the announcement included humor about how the information was shared with those previously interested.
- Discussion on using Ollama for production: Users discussed using Ollama in their production setup due to its simplicity and ease of use with Docker images, contrasting it with more complex systems.
- Concerns were raised about Ollama's performance in production environments compared to alternatives like VLLM.
- Considerations on Kubernetes vs SLURM for HPC: A user questioned the differences between using Kubernetes and SLURM for training models, particularly regarding multi-GPU setups.
- The conversation revealed that for single GPU allocations, Kubernetes can work efficiently, but there may be challenges with resource management when requesting multiple GPUs.
- Saving to GGUF | Unsloth Documentation: Saving models to 16bit for GGUF so you can use it for Ollama, Jan AI, Open WebUI and more!
- Continued Pretraining | Unsloth Documentation: AKA as Continued Finetuning. Unsloth allows you to continually pretrain so a model can learn a new language.
- Finetuning from Last Checkpoint | Unsloth Documentation: Checkpointing allows you to save your finetuning progress so you can pause it and then continue.
Unsloth AI (Daniel Han) ▷ #research (3 messages):
BFloat16 impact on RoPEAnchorAttention methodLong-context training issues
- BFloat16 disrupts RoPE in Long-Context Training: A new paper discusses how BFloat16 casting in FlashAttention2 causes RoPE to deviate from its intended properties, even when RoPE is computed in Float32.
- BFloat16 introduces critical numerical errors, leading to significant declines in relative positional encoding as context length increases.
- AnchorAttention boosts long-context performance: The paper introduces AnchorAttention, a plug-and-play solution that enhances long-context performance while cutting training time by over 50%.
- This method is adaptable, supporting both FlashAttention and FlexAttention for varied applications, including video understanding.
- Discussion on potential issues caused by BFloat16: A community member inquired about the implications of the 'breakage' caused by BFloat16, speculating it might relate to existing looping issues.
- They referenced a prior discussion link regarding those looping issues, suggesting a deeper investigation could be beneficial.
- Merging in a Bottle: Differentiable Adaptive Merging (DAM) and the Path from Averaging to Automation: By merging models, AI systems can combine the distinct strengths of separate language models, achieving a balance between multiple capabilities without requiring substantial retraining. However, the i...
- Tweet from Haonan Wang (@Haonan_Wang_): 🚀 New Paper📜 When Precision Meets Position: BFloat16 Breaks Down RoPE in Long-Context Training 🤯 RoPE is Broken because of... BFloat16! > Even if RoPE is computed in Float32 (like in Llama 3 a...
Interconnects (Nathan Lambert) ▷ #news (98 messages🔥🔥):
Tülu 3 releaseNvidia's AI WallGemini's performance boostReinforcement Learning techniquesCommunity discussions on model ranking
- Tülu 3 launched with new techniques: Nathan Lambert announced the launch of Tülu 3, an open frontier model that surpassed Llama 3.1 on multiple tasks.
- The model includes a novel Reinforcement Learning with Verifiable Rewards approach that rewards the algorithm only for correct generations.
- Nvidia's CEO addresses AI concerns: An article from The Economist discusses Nvidia's boss downplaying fears that AI has 'hit a wall', despite widespread skepticism.
- This revelation further fueled discussions about the state of AI advancements and the urgency for innovation.
- Gemini's ranking surge in Chatbot Arena: The recent release of Gemini-Exp-1121 from Google DeepMind has tied for the top spot in the Chatbot Arena, outperforming previous benchmarks.
- It boasts significant improvements in coding and reasoning capabilities, showcasing rapid advancements in AI.
- RL techniques spark community interest: The community engaged in a discussion about the iterations and challenges encountered during the Tülu development, particularly concerning Reinforcement Learning methods.
- Insights were shared on problems such as the accidental deletion of key model checkpoints that illustrate the finicky nature of RL.
- Competitiveness among AI models: Conversations ensued about the rivalry between models like Claude and Gemini, with some community members noting the focus on substantial improvements over mere output formatting.
- Members chimed in with humor about the current state of AI models, emphasizing the need for both innovation and practicality.
- Excalidraw — Collaborative whiteboarding made easy: Excalidraw is a virtual collaborative whiteboard tool that lets you easily sketch diagrams that have a hand-drawn feel to them.
- Tweet from xjdr (@_xjdr): @TheXeophon lol the very first thing i looked for too. i think they may have indeed cooked
- Tweet from Nathan Lambert (@natolambert): I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor...
- Tweet from TDM (e/λ) (@cto_junior): @TheXeophon @teortaxesTex and it's amazing both model updates remaing virtually the same in ranking if you apply style control + coding/hard prompts
- Nvidia’s boss dismisses fears that AI has hit a wall: But it’s “urgent” to get to the next level, Jensen Huang tells The Economist
- Tweet from Nathan Lambert (@natolambert): So @elonmusk can you open source the Grok post training recipe too? Quoting Nathan Lambert (@natolambert) I've spent the last two years scouring all available resources on RLHF specifically and...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Woah, huge news again from Chatbot Arena🔥 @GoogleDeepMind’s just released Gemini (Exp 1121) is back stronger (+20 points), tied #1🏅Overall with the latest GPT-4o-1120 in Arena! Ranking gains since...
- Tweet from Nathan Lambert (@natolambert): Right to the fun stuff. To finish our models, we use a new technique called Reinforcement Learning with Verifiable Rewards, where we train on math problems or prompts with constraints, and only reward...
- Tweet from Logan Kilpatrick (@OfficialLoganK): Say hello to gemini-exp-1121! Our latest experimental gemini model, with: - significant gains on coding performance - stronger reasoning capabilities - improved visual understanding Available on Goo...
- Tweet from Alex Albert (@alexalbert__): Claude getting better at things that actually matter while other labs compete over markdown output
Interconnects (Nathan Lambert) ▷ #ml-questions (18 messages🔥):
Post-training capabilitiesSFT and new skillsDebate on LLM capabilitiesDiminished philosophy sectionTraining efficiency
- Debate on Post-training Capabilities: A member raised the question of whether post-training merely surfaces existing capabilities or induces entirely new ones, highlighting a need for clarity in the ongoing discussion.
- Another member pointed out it could be both, especially as it often surfaces latent abilities within the model, prompting further debate.
- The Role of SFT in Learning: Members discussed how Supervised Fine-Tuning (SFT) might both surface base model abilities and introduce new ones, depending on the quantity and quality of data used.
- One noted that while you can achieve impressive results with minimal data, targeted SFT mid-training likely leads to significantly improved performance.
- Philosophy Section Shrinkage: The reductions in the paper's philosophy section were noted, with one member humorously lamenting a 'mini manifesto' being condensed to just one paragraph.
- This led to a light-hearted acknowledgment about the challenges of keeping detailed discussions intact in lengthy papers.
- Concerns Over Limited Flops: A member expressed concerns that current model flops may be too low to maximize the potential gains from post-training techniques.
- They emphasized that while technically it is both surfacing and inducing new capabilities, practically, gaining intuition from the base model is more feasible.
Interconnects (Nathan Lambert) ▷ #random (120 messages🔥🔥):
GPT-4o Performance AnalysisPerceptron AI LaunchModel Context Protocol by AnthropicRickrolls in AIIssues with Academic AI Resources
- GPT-4o show declining performance metrics: Independent evaluations of OpenAI’s GPT-4o released on Nov 20 reflect lower quality scores compared to the August version, suggesting it may be a smaller model despite improved output speed.
- Recommendations were made for developers to carefully test workloads before shifting from the prior models due to these changes.
- Introducing Perceptron AI's Foundational Models: Perceptron AI announced its focus on developing foundational models aimed at integrating intelligence into the physical world, claiming to be the first of its kind.
- The announcement spurred skepticism as multiple companies have made similar promises, prompting questions about their uniqueness.
- Model Context Protocol (MCP) support arrives for Claude: Anthropic's Claude Desktop is introducing support for the Model Context Protocol (MCP), allowing local connection capabilities for enhanced interaction with models.
- The initial support comes with various SDKs, but remote connections remain unavailable, raising curiosity about future updates.
- Rickrolls in AI interactions become a concern: Instances of AI models, such as Lindy AI, unexpectedly sending users Rick Astley's music video link illustrate humorous yet concerning lapses in model responses.
- This issue emphasizes potential gaps in the model's training, leading to unexpected and unwanted outcomes for users.
- Critique of poor academic resources in AI field: Frustration over a student's reliance on a subpar academic book about LLMs highlights common challenges in AI education, particularly regarding reliable sources.
- The critique showcases significant issues in how educational materials in the AI space can mislead, with some publications offering inaccurate or simplistic explanations.
- Tweet from Andrew Curran (@AndrewCurran_): Visualization of the change in enterprise market share over the last year.
- Tweet from 0xDamian (@damnsec1): Getting Rick rolled by ChatGPT is crazy. 😂
- allenai/tulu-3-hardcoded-prompts · Datasets at Hugging Face: no description found
- Tweet from Armen Aghajanyan (@ArmenAgha): Say hello to our new company Perceptron AI. Foundation models transformed the digital realm, now it’s time for the physical world. We’re building the first foundational models designed for real-time...
- FLUX Tools now available via Together APIs: Get greater control over image generation with Canny, Depth and Redux models: no description found
- Tweet from User Mac (@UserMac29056): gpt-4o-2024-11-20 simple eval updated. tl;dr: benchmark performance got worse
- Tweet from Artificial Analysis (@ArtificialAnlys): Wait - is the new GPT-4o a smaller and less intelligent model? We have completed running our independent evals on OpenAI’s GPT-4o release yesterday and are consistently measuring materially lower eva...
- Tweet from Tibor Blaho (@btibor91): Model Context Protocol (MCP) by Anthropic is getting ready for prime time on a new domain modelcontextprotocol[.]io - now, in addition to the Python SDK, there is also a TypeScript SDK + the complete ...
- Introducing FLUX.1 Tools: Today, we are excited to release FLUX.1 Tools, a suite of models designed to add control and steerability to our base text-to-image model FLUX.1, enabling the modification and re-creati...
- This founder had to train his AI not to Rickroll people | TechCrunch: One AI assistant learned too much from the internet and ended up "rickrolling" a client instead of sharing a tutorial video.
Interconnects (Nathan Lambert) ▷ #posts (34 messages🔥):
RLHF vs DPOCohere and AlignmentSnailBot RSS Issues
- Debate on RLHF in AI Models: Many companies initially doubted the necessity of RLHF, with ongoing discussions about its relevance today. A member questioned whether not doing RLHF implies a shift to DPO or simply refers to post-training alignment.
- I'm working with some of those people and need dirt to rag on them! sparked humorous engagement.
- Cohere's Historical Approach: One member noted that Cohere primarily utilized IFT for an extended period, now evolving towards a RLHF++ approach. This situation raised eyebrows since the reinforce-loo paper originated from Cohere.
- A member expressed confusion over their approach, stating it's peculiar given their foundational work.
- SnailBot's Technical Glitch: Discussion revealed that SnailBot is facing issues with double posting voiceovers due to it being on a separate RSS feed. A member suggested building a custom solution to manage RSS and Discord webhook interactions more smoothly.
- An offer was made to help set up a new bot, emphasizing the need for an RSS feed that exclusively covers posts.
HuggingFace ▷ #general (182 messages🔥🔥):
Hugging Face ModelsVoice Conversion Using RVCCommunity InteractionsMagicQuil DownloadsModel Training Issues
- Hugging Face models usage: Users discussed issues with utilizing various models on Hugging Face, including a query about obtaining large text sizes for better visibility in HuggingChat.
- Suggestions included setting spaces to private to avoid interruptions from public interactions while testing models.
- Voice Conversion with RVC: A user inquired about using the RVC-beta.7z tool from Hugging Face, specifically whether to utilize ov2super during model training or audio conversion.
- This conversation prompted questions about the setup and functionality of voice conversion tools and expectations for progress.
- MagicQuil Download Assistance: A user sought help on how to download creations made with MagicQuil, indicating potential confusion regarding the process.
- Community members expressed a lack of familiarity with the MagicQuil tool, leaving the user without a clear answer.
- Debugging and Errors on Hugging Chat: Concerns were raised regarding frequent errors such as 'Error while parsing tool calls' during interactions in HuggingChat, leading to questions about site overload.
- The discussions emphasized users' frustrations related to response generation issues and potential overloads while using the platform.
- Community Dynamics: The channel displayed vibrant interactions among members, with light-hearted banter and acknowledgments of shared experiences within the community.
- Members expressed their thoughts on friendship, guidance, and support, enhancing the collaborative spirit in the discussions.
- Tweet from undefined: no description found
- RVC-beta.7z · lj1995/VoiceConversionWebUI at main: no description found
- Kitty Sleep Kitten Sleep GIF - Kitty sleep Kitten sleep Cuddling in bed - Discover & Share GIFs: Click to view the GIF
- RunPod - The Cloud Built for AI: Develop, train, and scale AI models in one cloud. Spin up on-demand GPUs with GPU Cloud, scale ML inference with Serverless.
- GitHub - CPJKU/madmom: Python audio and music signal processing library: Python audio and music signal processing library. Contribute to CPJKU/madmom development by creating an account on GitHub.
- Black Forest Labs - Frontier AI Lab: Amazing AI models from the Black Forest.
- Sunday Cult Of The Lamb GIF - Sunday Cult of the lamb Cult - Discover & Share GIFs: Click to view the GIF
- Simpsons Homer GIF - Simpsons Homer Bart - Discover & Share GIFs: Click to view the GIF
- Rabbit Bunny GIF - Rabbit Bunny Toilet - Discover & Share GIFs: Click to view the GIF
HuggingFace ▷ #cool-finds (10 messages🔥):
Custom AI Models with Handler FilesAI Security Research PaperAutomated AI Research AssistantCollaborative Learning Framework in LLMsEfficient Quantization Method for Attention
- Deploy Custom AI Models Using Handler Files: Hugging Face Endpoints allows deploying custom AI models via a handler.py file, facilitating custom pre- and post-processing.
- This handler needs to implement the EndpointHandler class, ensuring flexibility in model deployment.
- Redhat/IBM's AI Security Insights: A new research paper discusses the risks associated with publicly available AI models and proposes strategies to enhance security and safety in AI development.
- The paper highlights challenges such as tracking issues and the absence of lifecycle processes, aiming to foster more standardized practices in the AI ecosystem.
- Automated AI Research Assistant Created: An innovative python program transforms local LLMs into automated web researchers, providing detailed summaries and sources based on user queries.
- The program intelligently breaks down queries into subtopics, systematically gathering and analyzing information from the web.
- FreeAL: Collaborative Learning for LLMs: The paper FreeAL proposes an advanced collaborative learning framework aimed at reducing label annotation costs in LLM training.
- By utilizing an LLM as an active annotator, it distills task-specific knowledge interactively to improve the quality of dataset samples.
- SageAttention: Quantization in Attention Models: The method SageAttention offers an efficient quantization approach for attention mechanisms, significantly improving operations per second compared to current methods.
- It enhances accuracy while addressing the computational limits of attention, which traditionally sees high complexity in larger sequences.
- SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration: The transformer architecture predominates across various models. As the heart of the transformer, attention has a computational complexity of O(N^2), compared to O(N) for linear transformations. When ...
- FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models: Collecting high-quality labeled data for model training is notoriously time-consuming and labor-intensive for various NLP tasks. While copious solutions, such as active learning for small language mod...
- no title found: no description found
- Create custom Inference Handler: no description found
- Clone Git Repo To Space - a Hugging Face Space by fffiloni: no description found
- Paper page - Building Trust: Foundations of Security, Safety and Transparency in AI: no description found
- Reddit - Dive into anything: no description found
HuggingFace ▷ #i-made-this (9 messages🔥):
Neo's Red Pill JourneyPrompting TechniquesMOUSE-I Web ServiceCinematic Image Generationloadimg Downloads Milestone
- Neo's Red Pill sends him to the 60s: A discussion initiated around a YouTube video exploring what would happen if Neo's red pill transported him back to the 1960s.
- Members expressed excitement about the share, highlighting the video's coolness.
- The Importance of Prompting: A YouTube video titled 'BAD vs GOOD prompting' raises questions on whether effective prompting is still necessary in current applications.
- The description invites viewers to explore when and how prompting techniques might differ.
- MOUSE-I revolutionizes web development: Introducing MOUSE-I, which converts a simple prompt into a globally deployed web service in just 60 seconds using AI automation.
- It promises instant results and is suitable for startups, developers, and educators alike.
- Cinematic Images with a Twist: A project shared on Hugging Face allows users to create cinematic images with preset widescreen aspect ratios at more than 2 megapixels.
- The link to this tool can be found here.
- loadimg hits 500,000 downloads: A community member celebrated that loadimg has achieved 500,000 downloads and is now compatible with Hugging Face and OpenAI SDKs.
- This milestone showcases the tool's growing popularity and compatibility.
- no title found: no description found
- Mouse1 - a Hugging Face Space by VIDraft: no description found
- BAD vs GOOD prompting: Let's see in this video if we still need to make good prompting nowadays and if there is a difference, at what point is it different.Feel free to leave comme...
- CineDiffusion - a Hugging Face Space by takarajordan: no description found
- GitHub - gmontamat/screen-grep: Open source alternative to Windows Recall: Open source alternative to Windows Recall. Contribute to gmontamat/screen-grep development by creating an account on GitHub.
- Appine: no description found
HuggingFace ▷ #reading-group (1 messages):
crazypistachecat: Sory👍
HuggingFace ▷ #computer-vision (6 messages):
YOLO for Video Object DetectionStable DiffusionAutodistill Training Method
- YOLO shines in Video Object Detection: A member highlighted that YOLO supports video object detection, making it a classic choice for this task.
- There are ongoing discussions on using it effectively, with a linked resource provided for further exploration.
- Stable Diffusion remains a classic: Another member brought up Stable Diffusion as a well-known and classic model for various applications in image processing.
- This prompted discussions on its longevity and effectiveness compared to newer models.
- Struggles with YOLO labeling: A user expressed difficulties in getting YOLO to label correctly online, seeking guidance and solutions.
- The conversation emphasized the need for clear instructions or support to effectively utilize the model.
- Autodistill simplifies model training: A member shared about Autodistill, which trains small supervised models using larger foundation models, highlighting its efficiency.
- They provided a detailed documentation link for those interested in training models faster with minimal human intervention.
- Home - Autodistill: no description found
- YOLO VIDEO - a Hugging Face Space by prithivMLmods: no description found
HuggingFace ▷ #NLP (9 messages🔥):
Pandas alternativesBuilding local AgentsFast inference frameworksScaling data processing
- Consider Polars for faster data processing: A member suggested using Polars as a faster alternative to Pandas when dealing with large datasets.
- Swetha98 appreciated the recommendation and plans to explore it further.
- NVIDIA RAPIDS for GPU acceleration: A recommendation was made for NVIDIA RAPIDS, which is said to run on GPU and could help with scalability.
- However, Swetha98 mentioned a lack of GPU access, complicating the suggestion.
- Local Agent frameworks comparison: Pizzadrones inquired about frameworks that compete with AnythingLLM and Ottobot for building local Agents.
- The discussion focused on alternatives to these frameworks in the chat.
- vLLM touted as the top inference framework: Takarajordan_82155 noted that vLLM is currently highly regarded as the best inference framework for LLMs.
- This statement sparked interest in exploring different frameworks for rapid inference.
- Llama 3.2 leading inference performance: In discussing effective chat LLMs, Takarajordan_82155 proposed Llama 3.2 90B on Groq as a strong contender.
- Abhijithneilabraham asked for leaderboards to track the best generic chat LLMs with fast inference.
HuggingFace ▷ #diffusion-discussions (13 messages🔥):
Open Source Models like SSD-1BUsing SDXL in Google ColabToken Embeddings in Shuttle-3
- Recommendations for SSD-1B Alternatives: Members discussed alternatives to SSD-1B, suggesting the step distilled version of SDXL or DreamShaper Lightning for potentially better quality and speed.
- A link to Hyper-SD was shared, highlighting its ease of use for similar purposes.
- Loading Models on Low VRAM in Google Colab: Concerns about loading models with low GPU resources were addressed, confirming that SDXL's size of 6.5GB is manageable within Google Colab's 16GB VRAM.
- Members noted that after loading the base model, it might be easier to save the model state for future use.
- Token Limitations in Shuttle-3 Pipeline: A member inquired about increasing token embeddings beyond 77 in the shuttle-3 pipeline, which seems unsupported currently.
- Discussion indicated that while the CLIP encoder may truncate prompts, the T5 encoder can handle up to 256 tokens without issues.
- Impact of Encoding on Image Generation: Questions were raised about the effect of truncating data for the CLIP encoder and whether important prompt data should be prioritized.
- Members weighed in, noting that while truncation occurs for CLIP, it may not significantly affect image generation outcomes.
- ByteDance/Hyper-SD · Hugging Face: no description found
- tianweiy/DMD2 · Hugging Face: no description found
OpenAI ▷ #ai-discussions (209 messages🔥🔥):
AI Discussions on CensorshipOpinions on AgnosticismDeep Web and AI AccessOpenAI's Censorship PoliciesPerplexity vs ChatGPT
- Debate on AI Censorship Importance: Users discussed the need for censorship in AI to prevent harmful uses, with one member arguing OpenAI aims to avoid legal trouble by implementing moderation.
- Concerns were raised about some possible overreach and false positives in the moderation process, but the general consensus favored a cautious approach.
- Subjectivity of Agnosticism Explained: A lively debate ensued over whether agnosticism is subjective, with members asserting that it represents a lack of evidence rather than personal belief.
- One user highlighted that agnosticism can be considered a healthy mindset, while another pointed out the redundancy of claiming a 'subjective opinion'.
- Exploration of AI's Capabilities: Discussion centered around whether AI could access the deep web and how it functions theoretically, with some suggesting that customized AI could scan the web unfiltered.
- One user noted that while AI doesn't access the web, passing external content into it is possible, which could raise ethical questions.
- OpenAI's Approach to Political Questions: Participants agreed that discussing politics with ChatGPT is allowed, as long as it does not lead to harmful or misleading content.
- Members recognized that while politics can be part of the conversation, unnecessary political bias should be avoided.
- Comparison of AI Models: Users compared Perplexity with ChatGPT, emphasizing that Perplexity was seen as more accurate and had advantages in certain functionalities.
- One participant noted that specific features of Perplexity had been in development before they gained popularity.
OpenAI ▷ #gpt-4-discussions (1 messages):
grundaypress: Hi, does anyone know why the retry button is gone when using Custom GPTs?
OpenAI ▷ #prompt-engineering (3 messages):
Categorizing Products with GPT-4Prompt OptimizationPrompt Caching for Efficiency
- Product Categorization with GPT-4: A member shared their experience categorizing products using a prompt with GPT-4, specifying categories from groceries to clothing.
- They highlighted that while results are great, the token usage is quite high due to the lengthy prompt structure.
- Token Reduction Strategies: Discussion revolved around minimizing token usage while maintaining effectiveness in categorization prompts.
- Suggestions included exploring methods like prompt caching to streamline the process and reduce redundancy.
- API Assistance Reference: A user provided a link to a Discord channel for help with API-related queries about improving prompt efficiency.
- This reference aims to assist others in the community facing similar challenges in product categorization.
OpenAI ▷ #api-discussions (3 messages):
Product Categorization with GPT-4oToken Optimization StrategiesPrompt Caching in API usage
- Categorizing Products with GPT-4o: A member described using GPT-4o to categorize products based on a title and image with a comprehensive prompt structure.
- The prompt produces excellent results, but the extensive token usage poses a challenge for scalability.
- Efficient Token Usage Suggestions: Another member suggested exploring prompt caching techniques to reduce repetitive input tokens in their product categorization setup.
- They recommended consulting API-related resources for further aid in optimizing token usage as linked in their message.
LM Studio ▷ #general (63 messages🔥🔥):
Hermes 3 Model PerformanceCloud-Based GPU RentingLLM GPU ComparisonsMLX Models in LMSGraphics Card Recommendations
- Hermes 3 impresses users: A member expressed their preference for Hermes 3, highlighting its strong writing skills and ability to follow prompts effectively.
- However, they noted that at higher contexts (16K+), it tends to repeat phrases.
- Cloud-based servers for model hosting: A member reported switching from local model hosting to a cloud server, costing about $25-50 per month, effectively running models faster.
- This shift was noted as superior to local hardware due to performance and cost efficiency.
- Choosing between AMD and NVIDIA cards: Members discussed the pros and cons of choosing AMD versus NVIDIA GPUs, with recent drivers affecting AMD's ROCM support.
- There's a consensus that for better software support and compatibility, sticking with NVIDIA is recommended.
- Interest in MLX models integration: A request was made for announcements regarding interesting MLX models given LMS's recent support for them.
- The integration of MLX models was acknowledged as a valuable addition, even if these models are not official to LMS.
- Graphics card decision-making: Discussion centered on the choice between the 4070 Ti Super and 7900 XTX, weighing factors like gaming performance versus LLM applications.
- A member pointed out that while the 3090 excels in various tasks, the 7900 XTX could be a cheaper alternative for gaming.
- NousResearch/Hermes-3-Llama-3.1-70B · Hugging Face: no description found
- Gigabyte GeForce RTX 4070 Ti Super Gaming OC Review: The Gigabyte RTX 4070 Ti Super Gaming OC, true to its name, comes with a factory overclock, to a rated boost of 2655 MHz. It features a triple-slot, triple-fan cooler and dual BIOS for added versatili...
LM Studio ▷ #hardware-discussion (135 messages🔥🔥):
AI chip discussionsPerformance of GPUsBuilding a local LLM serverUSB4 with AMD devicesChallenges with GPU configurations
- Performance Issues with Mixed GPU Configurations: Users reported that adding GPUs to configurations often slows down performance, with benchmarks showing 1x 4090 + 2x A6000 performing worse than other combinations due to shared resource ceilings.
- One user noted that adding a 4090 to their A6000 setup decreased token generation rate, highlighting that the slowest card often dictates the overall speed.
- Considerations for Local LLM Server Setup: A user questioned whether a $2,000 budget for a local LLM server catering to 2-10 users is feasible, given the challenges of concurrent access with single GPUs.
- Developers suggested exploring cloud solutions to avoid performance bottlenecks associated with budget setups utilizing older hardware and fewer GPUs.
- Insights on USB4 and EGPU Setup: Users discussed the use of a specific GitHub tool to enable USB4 on newer AMD devices while sharing experiences with external GPU configurations like A4000s and P40s.
- One member reported success with A4000s being plug-and-play, while concerns lingered regarding the compatibility of P40s and potential legacy PCIe mode issues.
- Shipping Delays and E-Commerce Challenges: There were discussions regarding shipping delays from online vendors like AliExpress, with one user highlighting delays due to possible strikes affecting delivery times.
- Overall, members expressed frustration with inconsistent shipping experiences and the impact on ongoing hardware builds.
- Utilization of AMD's Firmware for Hardware Optimization: It was suggested that AMD laptop users could access hidden firmware menus to modify settings using a GitHub tool, enhancing their hardware performance.
- Members exchanged ideas regarding how enabling certain settings like MMIO and above 4G decoding could potentially improve eGPU connectivity and performance.
- Fascinating Mr Spock GIF - Fascinating Mr Spock Henoch - Discover & Share GIFs: Click to view the GIF
- Sniped Piggy GIF - Sniped Piggy Piggyverse - Discover & Share GIFs: Click to view the GIF
- Senator Palpatine Anakin Skywalker GIF - Senator Palpatine Anakin Skywalker Phantom Menace - Discover & Share GIFs: Click to view the GIF
- GitHub - v1ckxy/LMSPLS: LM Studio Portable Launch Script (LMS PLS): LM Studio Portable Launch Script (LMS PLS). Contribute to v1ckxy/LMSPLS development by creating an account on GitHub.
- GitHub - DavidS95/Smokeless_UMAF: Contribute to DavidS95/Smokeless_UMAF development by creating an account on GitHub.
- Tweet from Holistech (@_Holistech_): @rasbt @ivanfioravanti I hope they will fit together with my M1 Ultra in my 6 screen mobile and foldable AI workstation setup
- GitHub - XiongjieDai/GPU-Benchmarks-on-LLM-Inference: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference?: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference? - XiongjieDai/GPU-Benchmarks-on-LLM-Inference
aider (Paul Gauthier) ▷ #announcements (2 messages):
Qwen 2.5 Model PerformanceAider v0.64.0 FeaturesModel Quantization ImpactSlash Commands in AiderContext Window and Token Costs
- Qwen 2.5 Model Rivals GPT-4o: Open source models like Qwen 2.5 32B show excellent performance on Aider's code editing benchmarks, rivalling closed source frontier models with significant differences in quantization impact.
- The best version competes with GPT-4o, while the least effective resembles GPT-3.5 Turbo, inviting users to pay careful attention to quantization effects.
- New Features in Aider v0.64.0: The latest Aider version adds a new
/editorcommand for prompt writing and full support for gpt-4o-2024-11-20.- This update improves shell command clarity, enabling users to see confirmations and opt-in for analytics.
- Understanding Model Quantization: Attention is drawn to how model quantization affects performance, particularly in code editing, as heavily quantized models are prevalent in cloud solutions.
- The discussion highlights different serving methods and their performance impact, guiding users toward better model configurations.
- Exploration of Slash Commands: Aider supports various slash commands like
/add,/architect, and/chat-mode, simplifying users' interactions within the chat environment.- These commands enhance editing and reviewing capabilities, promoting efficient communication and code management.
- Registering Context Window Limits: Users can register context window limits and costs for models with unknown parameters by creating a
.aider.model.metadata.jsonfile in specified directories.- This functionality allows for better resource management, accommodating broader model configurations within Aider.
- Quantization matters: Open source LLMs are becoming very powerful, but pay attention to how you (or your provider) is quantizing the model. It can strongly affect code editing skill.
- In-chat commands: Control aider with in-chat commands like /add, /model, etc.
- Advanced model settings: Configuring advanced settings for LLMs.
aider (Paul Gauthier) ▷ #general (133 messages🔥🔥):
Aider Leaderboard ChangesOpenRouter Providers and QuantizationGemini Model PerformanceDeepSeek Model DevelopmentsUser Experiences with AI Models
- Aider Leaderboard Enhancements: Aider has introduced a new search/filter box on the leaderboard tables and graphs to improve usability and allow users to quickly find specific models.
- Users have noted that the addition greatly enhances navigation and access to model performance data.
- Concerns Over OpenRouter's Model Choices: Participants expressed concerns regarding OpenRouter using quantized versions of models, which may lead to misleading performance expectations.
- Discussion highlighted the importance of being aware of quantization levels and the specific providers being used for AI models.
- Performance Insights on Gemini Model: Recent benchmarks indicated mixed performance for the new Gemini model, with different results from standard diff and diff-fenced formats.
- While gemini-exp-1121 scored 58% on the diff format, there were concerns about lower scores observed with previous iterations and different formats.
- DeepSeek Model Updates: DeepSeek announced new capabilities with the launch of the DeepSeek-R1-Lite-Preview, touted for impressive performance on coding benchmarks.
- Users discussed the practical implications of using various models, including speed and efficiency advantages.
- User Experiences with AI Assistants: Users shared humorous anecdotes about their interactions with various AI models, noting quirky behavior and unexpected outputs.
- The community reflected on the learning curve and challenges of effectively utilizing different AI tools for coding and other tasks.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Use the Qwen API - Alibaba Cloud Model Studio - Alibaba Cloud Documentation Center : no description found
- Advanced model settings: Configuring advanced settings for LLMs.
- Qwen2.5 Coder 32B Instruct - API, Providers, Stats: Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). Run Qwen2.5 Coder 32B Instruct with API
- Tweet from Zhihong Shao (@zhs05232838): Our DeepSeek reasoning model is great on code and math. Try it out! Quoting DeepSeek (@deepseek_ai) 🚀 DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power! 🔍 o1-preview-...
- no title found: no description found
- [Feature]: Support OpenRouter's "provider" argument to control/select providers · Issue #6857 · BerriAI/litellm: The Feature OpenRouter supports a variety of mechanisms to select which providers you want your requests to hit. This involves passing a provider argument. Currently that causes an error: import li...
- Provider Routing | OpenRouter: Route requests across multiple providers
- Provider Routing | OpenRouter: Route requests across multiple providers
- Models | OpenRouter: Browse models on OpenRouter
- Qwen on openrouter#aider #lmsys #qwen #llm #aicoding #huggingface: no description found
- DeepSeek V2.5 - API, Providers, Stats: DeepSeek-V2.5 is an upgraded version that combines DeepSeek-V2-Chat and DeepSeek-Coder-V2-Instruct. Run DeepSeek V2.5 with API
- 🚀 DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power! | DeepSeek API Docs: 🔍 o1-preview-level performance on AIME & MATH benchmarks.
- Meta: Llama 3.1 70B Instruct – Provider Status: See provider status and make a load-balanced request to Meta: Llama 3.1 70B Instruct - Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 70B instruct-t...
- Tongyi Qianwen (Qwen) - Alibaba Cloud: Top-performance foundation models from Alibaba Cloud
- Alibaba Cloud Model Studio - Alibaba Cloud: A one-stop generative AI platform to build intelligent applications that understand your business, based on Qwen and other popular models
- 模型列表_大模型服务平台百炼(Model Studio)-阿里云帮助中心: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (42 messages🔥):
Looping with AiderAider Caching EfficiencyDisabling Autocomplete in AiderAPI Approval for AiderRecommendations for Model Combinations
- Looping in Aider for Checklists: A user inquired about using Aider for automating checklist tasks by running a loop to avoid token limits, with suggestions to wrap Aider in an outer script or use the
-mmode.- Another member shared a command-line approach for scripting, utilizing
aider --messageto automate tasks within a shell script.
- Another member shared a command-line approach for scripting, utilizing
- Caching Mechanism Usage: A user expressed concerns over high costs associated with Aider, prompting a discussion about the effectiveness of the
--prompt-cachingfeature and how frequently caches are utilized.- Recommendations included exploring cache settings like
AIDER_CACHE_PROMPTSto analyze the cost-saving potential of caching.
- Recommendations included exploring cache settings like
- Disabling Autocomplete Functionality: A user sought help to disable the file autocomplete feature in Aider, which was causing distractions during coding.
- Suggestions included using the
--no-fancy-inputoption, although users preferred to maintain certain features without the autocomplete pop-ups.
- Suggestions included using the
- IT Approval Process for Aider: A discussion opened regarding the challenges of getting IT and legal departments to approve the use of Aider, focusing on data retention policies and intellectual property concerns.
- Documentation regarding analytics and privacy policies was mentioned as helpful for addressing concerns, alongside noting that API providers also have their own policies.
- Model Combinations for Projects: A user sought insights on which combinations of models are currently effective for real projects, hinting at notable models like Qwen2.5.1 and DeepSeek.
- This inquiry reflects ongoing interest in optimizing model usage for practical implementations in AI development.
- Prompt caching: Aider supports prompt caching for cost savings and faster coding.
- Scripting aider: You can script aider via the command line or python.
- Analytics: Opt-in, anonymous, no personal info.
aider (Paul Gauthier) ▷ #links (2 messages):
Gemini APIuithub
- Gemini API boosts coding and reasoning skills: The Gemini Experimental Model introduced improved coding, reasoning, and vision capabilities as of November 21, 2024.
- This update aims to enhance user interactions with AI through sophisticated understanding and functionalities.
- uithub redefines GitHub interactions: uithub.com allows users to replace 'g' with 'u' in GitHub links for instant copy-paste repository interactions, enhancing LLM contexts.
- Users like Nick Dobos and Ian Nuttall praised the tool, with Nuttall noting it delivers full repo context effectively.
- Community embraces uithub tool: Various users shared their experiences with uithub on Twitter, calling it a helpful tool that simplifies LLM coding questions.
- Yohei Nakajima expressed enthusiasm for discovering uithub, commenting on its practicality and utility.
- uithub offers unique capabilities: uithub's features are compared to --show-repo-map, suggesting it generates more tokens and provides advanced filtering options for specific file types.
- However, it lacks certain intricate functionalities seen in other tools, leaving some users to prefer the standard aider tools for complex tasks.
- no title found: no description found
- uithub - Easily ask your LLM code questions: no description found
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
New models releaseHigh context provider selection
- New models introduced this week: The GPT-4o has launched with better prose, details available here. Other new models include Mistral Large (link), Pixtral Large (link), Grok Vision Beta (link), and Gemini Experimental 1114 (link).
- Selecting providers for high context prompts: Users have shown confusion about how to select providers that support high context; OpenRouter automatically routes to those that do. If you send a long prompt or max tokens, providers with small context or max output are filtered out.
- GPT-4o (2024-11-20) - API, Providers, Stats: The 2024-11-20 version of GPT-4o offers a leveled-up creative writing ability with more natural, engaging, and tailored writing to improve relevance & readability. It’s also better at working with...
- Mistral Large 2411 - API, Providers, Stats: Mistral Large 2 2411 is an update of [Mistral Large 2](/mistralai/mistral-large) released together with [Pixtral Large 2411](mistralai/pixtral-large-2411) It is fluent in English, French, Spanish, Ge...
- Pixtral Large 2411 - API, Providers, Stats: Pixtral Large is a 124B open-weights multimodal model built on top of [Mistral Large 2](/mistralai/mistral-large-2411). The model is able to understand documents, charts and natural images. Run Pixtra...
- Grok Vision Beta - API, Providers, Stats: Grok Vision Beta is xAI's experimental language model with vision capability. . Run Grok Vision Beta with API
- Gemini Experimental 1114 - API, Providers, Stats: Gemini 11-14 (2024) experimental model features "quality" improvements.. Run Gemini Experimental 1114 with API
OpenRouter (Alex Atallah) ▷ #general (162 messages🔥🔥):
Mistral Model IssuesOpenRouter API FunctionalityGemini Experimental ModelsFile Upload CapabilitiesCommunity Engagement in OpenRouter
- Mistral Model Facing Deprecation: Users reported that the Mistral Medium model has been deprecated, causing an error when accessed, indicating that priority is not enabled for it.
- Members suggested switching to Mistral-Large, Mistral-Small, or Mistral-Tiny to continue using the service.
- OpenRouter API Documentation Cleared Up: Users expressed confusion regarding certain functionalities in the OpenRouter API documentation, specifically around context window capabilities.
- It was suggested to enhance clarity in documentation to aid understanding for users integrating OpenRouter with tools like LangChain.
- New Gemini Experimental Models Update: The Gemini Experimental 1121 model has been introduced, with claims of improved coding, reasoning, and vision capabilities.
- Users noted the existing quota restrictions shared with the LearnLM model and expressed curiosity about the model’s performance.
- File Upload Capability in Models: Discussion arose regarding file upload limitations, with users questioning if any models accept non-image formats.
- It was clarified that image uploads are supported, and the recent infrastructure upgrades may have lifted the previous 4MB restriction.
- Community Building and Founder Insights: A user inquired about the founding of OpenRouter and the motivations behind its creation.
- Community engagement was highlighted as a significant factor in OpenRouter’s development, and suggestions for a write-up on its story were mentioned.
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- LFM 40B MoE (free) - API, Providers, Stats: Liquid's 40.3B Mixture of Experts (MoE) model. Run LFM 40B MoE (free) with API
- Llama 3.1 8B Instruct (free) - API, Providers, Stats: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. Run Llama 3.1 8B Instruct (free) with API
- no title found: no description found
- Despicable Me Animation GIF - Despicable Me Animation Movies - Discover & Share GIFs: Click to view the GIF
- OpenRouter Status: OpenRouter Incident History
- Requests | OpenRouter: Handle incoming and outgoing requests
- Requests | OpenRouter: Handle incoming and outgoing requests
OpenRouter (Alex Atallah) ▷ #beta-feedback (1 messages):
Claude 3.5Custom provider key requests
- User requests custom provider key for Claude 3.5 Sonnet: A member requested a custom provider key for Claude 3.5 Sonnet, expressing frustration with running out of usage on the main Claude app.
- They hope that this request will provide a viable alternative to their current constraints.
- Concerns about Claude app usage limits: The discussion highlighted issues regarding the usage limits on the main Claude app, leading to user frustration.
- Members are seeking solutions to manage their usage more effectively and improve their experience.
Stability.ai (Stable Diffusion) ▷ #general-chat (164 messages🔥🔥):
Flux performanceSDXL usageImage generation issuesControlNet functionalityAI model security concerns
- Flux's Resource Intensive Needs: Members discussed the resource requirements for using Flux effectively, noting that it requires substantial VRAM and can be slow to generate images.
- One member highlighted that using Loras can enhance Flux's output for NSFW content, although it is not optimally trained for that.
- Maximizing SDXL Performance: For SDXL, using the best practices such as
--xformersand--no-half-vaein configuration can improve performance on systems with 12GB VRAM.- Members noted that Pony, a derivative of SDXL, requires special tokens and has limitations in compatibility with XL Loras.
- Image Prompting with SDXL Lightning: A user inquired about using image prompts in SDXL Lightning via Python, specifically for inserting a photo into a specific environment.
- The conversation indicates that combining image prompts with different backgrounds is a topic of interest for enhancing generation capabilities.
- Addressing Generational Delays: Frustrations over random long generation times while using various models prompted discussions about the potential underlying causes.
- Members speculated that memory management issues, such as loading resources into VRAM, might contribute to these slowdowns.
- AI Model Utilization and Security: Concerns over receiving suspicious requests for personal information, like wallet addresses, led members to believe there may be scammers in the community.
- Users were encouraged to report such incidents to maintain a secure environment within the group.
- Comfy-Org/stable-diffusion-3.5-fp8 · Hugging Face: no description found
- Tweet from Black Forest Labs (@bfl_ml): Today, we are excited to release FLUX.1 Tools, a suite of models designed to add control and steerability to our base text-to-image model FLUX.1, enabling the modification and re-creation of real and ...
- calcuis/sd3.5-medium-gguf at main: no description found
Eleuther ▷ #general (5 messages):
Mamba SSM LayersData Transfer TimesLLM Autophagy ProcessEvaluation Tasks for Foundational ModelsMeetup in Wellington
- Mamba's SSM Layers Explained: A member inquired if the SSM layers in the real-valued version of Mamba function as exponential moving averages, implicating that
dA(x) = exp(-f(x))wherefis a function of input x.- There is a suggestion that this operation essentially computes an efficient EMA update applied elementwise:
h_t = dA(x) * h_{t - 1} + (1 - dA(x)) * x.
- There is a suggestion that this operation essentially computes an efficient EMA update applied elementwise:
- Training Data Transfer vs Processing Time: A discussion emerged on whether it's common for the training time on a single batch to be shorter than the PCI bus data transfer time.
- This raises concerns about efficiency in processing large datasets during training workflows.
- Research on LLM Autophagy Process: A PhD student introduced their research on the autophagy process in LLMs, providing a link to their preprint paper: arXiv preprint.
- They mentioned utilizing the library for evaluating models in the context of collapse in their upcoming paper.
- Seeking Evaluation Tasks for Foundational Models: The same PhD student sought suggestions for interesting evaluation tasks for foundational models, beyond standard ones like HellaSwag.
- This indicates a desire for broader benchmarking for foundational models in the community.
- Meetup Invitation in Wellington, NZ: The PhD student announced their upcoming research period starting in Wellington, NZ, and expressed interest in meeting local members.
- They invited anyone residing in Wellington to reach out if interested in a meetup.
Eleuther ▷ #research (48 messages🔥):
FlexAttentionsPosition Encoding TechniquesForgetting TransformerSparse Upcycling vs Continued PretrainingScale of LLM Training
- FlexAttentions Development Underway: A member expressed optimism that developing new FlexAttentions models could be accomplished relatively easily within a month of focused work.
- This indicates a growing interest in refining attention mechanisms to enhance model efficiency.
- Exploring New Position Encoding Methods: Discussion emerged around position encoding methods, specifically a proposal for Contextual Position Encoding (CoPE) that adapts based on token context rather than fixed counts, leading to more expressive models.
- Members highlighted potential improvements in handling selective tasks like Flip-Flop that traditional methods struggle with.
- Forgetting Transformer Outshines Standard Models: The Forgetting Transformer was introduced as a variant incorporating a forget gate for better performance on long-context tasks, showing improvements over standard architectures.
- This model does not require position embeddings and maintains effective performance on longer training contexts.
- Trade-offs in Sparse Upcycling Methodology: A recent Databricks paper evaluates the trade-offs between sparse upcycling and continued pretraining for model enhancement, finding sparse upcycling yields better quality but at a cost of increased inference time.
- This shows a noticeable 40% slowdown in inference efficiency, emphasizing the challenge of balancing model performance with practical deployment considerations.
- Concerns Over LLM Training Infrastructure: Conversations included criticisms of current network fabric and bandwidth improvements lagging behind processing capabilities, especially highlighted in the context of TPU training setups.
- The discussion considers how architecture choices like TPU's topology may provide advantages over traditional GPU setups.
- Contextual Position Encoding: Learning to Count What's Important: The attention mechanism is a critical component of Large Language Models (LLMs) that allows tokens in a sequence to interact with each other, but is order-invariant. Incorporating position encoding (P...
- Hardware Scaling Trends and Diminishing Returns in Large-Scale Distributed Training: Dramatic increases in the capabilities of neural network models in recent years are driven by scaling model size, training data, and corresponding computational resources. To develop the exceedingly l...
- Sparse Upcycling: Inference Inefficient Finetuning: Small, highly trained, open-source large language models are widely used due to their inference efficiency, but further improving their quality remains a challenge. Sparse upcycling is a promising app...
- seaborn.heatmap — seaborn 0.13.2 documentation: no description found
- Tweet from YouJiacheng (@YouJiacheng): @hi_tysam This is a sliding window, information can still propagate if there are >1 layers.
- Forgetting Transformer: Softmax Attention with a Forget Gate: An essential component of modern recurrent sequence models is the forget gate. While Transformers do not have an explicit recurrent form, we show that a forget gate can be naturally incorporated...
- the world’s largest distributed LLM training job on TPU v5e | Google Cloud Blog: We used Multislice Training to run the world’s largest LLM distributed training job on a compute cluster of 50,944 Cloud TPU v5e chips.
Eleuther ▷ #scaling-laws (7 messages):
Scaling LawsEvaluation PredictionsMarius Hobbhahn's ContributionsMeta and OpenAI's MethodsCost of Scaling Law Training
- Scaling Laws Explained: A recent paper discusses how language model performance varies with scale and offers an observational approach using ~100 publicly available models to develop scaling laws without direct training.
- This method can highlight variations in training efficiency, proposing a generalized scaling law where performance is dependent on a low-dimensional capability space.
- Marius Hobbhahn Leads Eval Science: Marius Hobbhahn at Apollo is noted for publicly advocating for the science of evaluation methodologies in the field of scaling laws.
- His contributions aim to ground predictions and benchmarking in observable metrics rather than extensive modeling.
- Predicting Performance Before Training: The GPT-4 paper predicted its score in the popular HumanEval coding benchmark within a ~1% margin prior to even training, illustrating effective evaluation methodologies.
- Similarly, the Meta team predicted the Llama-3.1 model's performance on the Abstract Reasoning Corpus before training, employing innovative statistical methods.
- Methods for Successful Predictions: The prediction methodology for HumanEval involved plotting Mean Log Pass rate against compute scales, while the Abstract Reasoning Corpus utilized a two-step translation involving negative log likelihood.
- These methods demonstrated the ability to accurately project model capabilities based on scaling laws derived from existing models.
- The Cost of Scaling Law Models: Training scaling law models is costly but significantly less than training full target models, with Meta reportedly spending only 0.1% to 1% of the target model's budget.
- For instance, to predict capabilities for a $1B model, the cost of training the scaling law models could exceed $1M if following this budget ratio.
Link mentioned: Observational Scaling Laws and the Predictability of Language Model Performance: Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of ...
Eleuther ▷ #lm-thunderdome (39 messages🔥):
lm-eval and pruned modelsUsing Groq APILogits and loglikelihood in QACustom metrics in lm-harness
- lm-eval's support for pruned models questioned: A user inquired if the current version of lm-eval supports zero-shot benchmarking of pruned models, noting issues with old library versions.
- They are using WANDA and reported unreliable zero-shot results, prompting discussion on reading documentation for existing limitations.
- Successfully interfacing with Groq API: A user faced issues with unrecognized API key arguments when trying to connect to the Groq API, referencing their documentation for troubleshooting.
- Another member suggested setting the API key in the
OPENAI_API_KEYenvironment variable, which resolved the issue.
- Another member suggested setting the API key in the
- Extracting loglikelihood in TruthfulQA: A user asked for advice on obtaining loglikelihood values for answers in the TruthfulQA dataset instead of standard accuracy metrics.
- This discussion revolved around the standard QA setup and the need for better indicators of an LLM's performance before and after adjustments.
- Custom metrics for logits in lm-harness: A user inquired if there's a method to save logits in lm-harness to analyze LLM tendencies toward correct answers.
- A member suggested creating a custom metric that could manipulate logits as needed for their evaluation purpose.
- GitHub · Build and ship software on a single, collaborative platform: Join the world's most widely adopted, AI-powered developer platform where millions of developers, businesses, and the largest open source community build software that advances humanity.
- GitHub - locuslab/wanda: A simple and effective LLM pruning approach.: A simple and effective LLM pruning approach. Contribute to locuslab/wanda development by creating an account on GitHub.
- GroqCloud: Experience the fastest inference in the world
- lm-evaluation-harness/lm_eval/models/anthropic_llms.py at 867413f8677f00f6a817262727cbb041bf36192a · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #multimodal-general (1 messages):
Multimodal benchmarksLLaVA performanceText recognition in images
- Seeking Multimodal Benchmark Diversity: A member inquired about interesting benchmarks for multimodal models that go beyond basic tasks like describing photographs.
- They specifically want to explore benchmarks that evaluate the capability of models to recognize and report text in images.
- LLaVA Underperforms Compared to Smaller Models: The same member noticed that LLaVA and its derivatives are performing worse than much smaller models on certain tasks.
- This observation sparked their interest in conducting further tests to understand the performance disparities.
Perplexity AI ▷ #general (83 messages🔥🔥):
Pro Channel AccessImage Creation on iOSPerplexity Pro FeaturesSubscription IssuesDiscord Support
- Concerns about Pro Channel Access: Users expressed concerns about accessing the Pro Channel after purchasing the Pro version, with one stating they initially lacked access despite following the provided link.
- Others confirmed their access after rejoining the Discord or receiving help from fellow users.
- Image Creation on iOS: A user inquired about image creation capabilities within the Perplexity iOS app, noting that another user clarified this feature is available only on iPad.
- This sparked discussions about the limitations of functionality across different devices.
- Perplexity Pro Features Highlighted: Members discussed various features of Perplexity Pro, emphasizing the more advanced models available for Pro users and how it differs from ChatGPT.
- The discussion included insights on search and tool integration that enhances user experience.
- Issues with Account and Subscriptions: Several users reported challenges with their subscriptions, ranging from unsuccessful attempts to redeem codes to difficulties linking accounts.
- Users were directed to the support email to resolve their specific issues, and discussions ensued about how to manage multiple accounts effectively.
- Need for Support on Discord: Questions arose regarding how to receive support on Discord, with members sharing links to help with subscription upgrades and issues accessing roles.
- The community provided assistance, and some members confirmed successful resolution of their account issues after receiving guidance.
- Bocchi The Rock Bocchi The Rock Awkward GIF - Bocchi The Rock Bocchi The Rock Awkward Anime Bocchi The Rock - Discover & Share GIFs: Click to view the GIF
- Tweet from Phi Hoang (@apostraphi): time well spent if you asked me
- Virgin Media O2 UK Offer Free Access to AI Search Engine Perplexity Pro: Customers of Virgin Media and O2’s various broadband, mobile, phone and TV packages may like to know that their ‘Priority’ app, which rewards existing sub
Perplexity AI ▷ #sharing (7 messages):
Pokémon Data AI ModelBaltic Sea Cable SabotageChicken or Egg Paradox ResolutionNVIDIA's Omniverse BlueprintOne-Person Startup Era
- Pokémon Data Sparks New AI Model: A YouTube video discussed how Pokémon data is being utilized to create an AI model, offering insights into technology advances in gaming.
- This may change the way data is leveraged in AI applications.
- Investigating Baltic Sea Sabotage: A link raised concerns about the sabotage of cables in the Baltic Sea, highlighting potential geopolitical tensions.
- Further discussions are needed on the implications for digital infrastructure and security.
- Chicken or Egg Paradox Potentially Solved: A recent discussion points towards a possible resolution of the chicken or egg paradox, inviting thoughts on scientific evolution.
- This could lead to new philosophical inquiries regarding development and existence.
- NVIDIA's Game Changing Tech for CAD/CAE: A member shared insights on NVIDIA's Omniverse Blueprint, showcasing its transformative potential for CAD and CAE in design and simulation.
- Many are excited about how it integrates advanced technologies into traditional workflows.
- Era of One-Person Startups Arises: Sam Altman provocatively stated, 'Tomorrow's startups will be run by just 1 person and 10,000 GPUs', hinting at future entrepreneurship trends.
- This notion reflects the evolving landscape of tech startups and resource utilization.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (7 messages):
API Rate LimitsUsing Own API Key in PerplexitySession Management in Frontend Apps
- Rate Limit Confusion: Several members are facing rate limit issues with the API, questioning if the limit is set at 50 requests per minute per account or key.
- One user has reached out to Perplexity for limit increases but hasn't received feedback yet, expressing urgency due to customer issues.
- Inquiry on Bring Your Own API Key: A member asked if it's permissible to bring your own API key to build an alternative platform using Perplexity, outlining how data would be managed securely.
- This approach involves user-supplied keys being encrypted and stored in cookies, prompting questions on compliance with OpenAI standards.
- Simplifying Technical Concepts: In response to a request for simplification, a user explained session management in web applications by comparing it to cookies storing session IDs.
- The conversation highlighted how users' authentication relies on checking valid sessions without storing sensitive data directly.
Link mentioned: no title found: no description found
Latent Space ▷ #ai-general-chat (59 messages🔥🔥):
Truffles hardware deviceVercel acquires GrepTülu 3 model releaseFlux Tools from Black Forest LabsGemini API model updates
- Truffles Device Gains Attention: Members recalled the Truffles device, described as a 'white cloudy semi-translucent thing' that allows self-hosting of LLMs Truffles. One member humorously referred to it as the 'glowing breast implant.'
- Vercel Acquires Grep for Code Search: Vercel announced the acquisition of Grep to enhance developer tools for searching code across over 500,000 public repositories. Dan Fox, the founder, will join Vercel's AI team to continue developing this capability.
- Tülu 3 Outperforms Llama 3: Tülu 3, a new model developed over two years, reportedly outperforms Llama 3.1 Instruct on specific tasks, boasting new SFT data and optimization techniques. The project lead expressed excitement about their achievement in the field of RLHF.
- New Features in Flux Tools: Black Forest Labs released Flux Tools, which includes features like inpainting and outpainting for image manipulation. The suite aims to add steerability to their text-to-image model, and users are encouraged to explore running it on Replicate.
- Updates to Google Gemini Models: New experimental models from Gemini were released, focusing on improvements in coding capabilities. Users are directed to the Gemini API documentation for details.
- Vercel acquires Grep to accelerate code search - Vercel: Announcing the acquisition of Grep to further our mission of helping developers work and ship faster.
- Tweet from Nathan Lambert (@natolambert): I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor...
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- Tweet from Exa (@ExaAILabs): We're celebrating Thanksgiving with a full week of launches 🦃 Today - semantic search over LinkedIn. Pick the "LinkedIn profile" category to intelligently search over hundreds of millio...
- Tweet from undefined: no description found
- Say What You Mean: A Response to 'Let Me Speak Freely': no description found
- Tweet from Replicate (@replicate): Black Forest Labs just dropped Flux Tools, for pro and open-source dev models: - Fill: Inpainting and outpainting - Redux: For image variations - Canny and depth controlnets They're all really g...
- Tweet from Black Forest Labs (@bfl_ml): Today, we are excited to release FLUX.1 Tools, a suite of models designed to add control and steerability to our base text-to-image model FLUX.1, enabling the modification and re-creation of real and ...
- no title found: no description found
- Tweet from markokraemer (@markokraemer): v0 vs bolt vs loveable vs softgen 3 Prompts 1. "Make this a fancy landing page about protein shakes" 2. "Make it pop" 3. "Add more sections" FYI I was drinking a protein shak...
- Large Language Models explained briefly: Dig deeper here: https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3piTechnical details as a talk: https://youtu.be/KJtZARuO3JYMade for an...
- Tweet from Andrej Karpathy (@karpathy): Remember the llm.c repro of the GPT-2 (124M) training run? It took 45 min on 8xH100. Since then, @kellerjordan0 (and by now many others) have iterated on that extensively in the new modded-nanogpt rep...
- GitHub - KellerJordan/modded-nanogpt: NanoGPT (124M) in 5 minutes: NanoGPT (124M) in 5 minutes. Contribute to KellerJordan/modded-nanogpt development by creating an account on GitHub.
Nous Research AI ▷ #general (29 messages🔥):
AI Expert Needed UrgentlyDeepSeek R1-Lite SpecificationsLlama-Mesh Paper RecommendationDaily LLM Drop DiscussionsUser Interaction Memory in AI
- AI Expert Needed Urgently: A member urgently called for an AI expert, prompting various responses about the specific type of assistance required, from deployment issues to architectural support.
- Members humorously suggested contacting top experts, while one proposed that the urgent situation remained vague, highlighting the need for clarity.
- DeepSeek R1-Lite Specifications: It was rumored that DeepSeek R1-Lite is a 16B MOE model with 2.4B active parameters, drastically improving MATH scores from 17.1 to 91.6.
- The rumor quoted a WeChat announcement and was met with skepticism, with a member expressing disbelief at the potential performance improvement.
- Llama-Mesh Paper Recommendation: A member recommended reviewing the llama-mesh paper, describing it as 'pretty good' to the group.
- This appeal for others to engage with the content was noted amidst a broader conversation about AI discussions.
- Daily LLM Drop Discussions: Members discussed the concept of a 'daily LLM drop,' referencing the evolving landscape of language models with a hint of fatigue.
- One member humorously remarked that the Goodhart arena is getting old, indicating a sentiment towards frequent changes in the field.
- User Interaction Memory in AI: A member inquired whether AI systems remember prior interactions on platforms like Twitter, especially concerning engaging with the same accounts.
- This inquiry reflects broader curiosity about user memory capabilities of AI, pertinent to various user experiences and expectations.
- Tweet from wh (@nrehiew_): Rumor is that DeepSeek R1-Lite is a 16B MOE with 2.4B active params if true, their MATH scores went from 17.1 -> 91.6 Quoting Phil (@phill__1) @nrehiew_ From their wechat announcement:
- GitHub - Lesterpaintstheworld/terminal-velocity: A novel created autonomously by 10 teams of 10 AI agents: A novel created autonomously by 10 teams of 10 AI agents - Lesterpaintstheworld/terminal-velocity
Nous Research AI ▷ #ask-about-llms (6 messages):
LLM Performance ImprovementKV Cache LimitationsMulti-Agent FrameworksPrefix CachingPrompt Caching
- Multi-Agent Frameworks and Hidden Information: A member raised concerns that using de-tokenized output in multi-agent frameworks, like 'AI entrepreneurs' and 'AI software engineers', may lead to loss of hidden information due to the discarded kv cache.
- They suggested that this loss might explain the limited output diversity observed in such frameworks.
- Prefix Caching vs. KV Cache: In response, another member questioned whether prefix caching serves a similar purpose to kv caching during inference.
- The discussion revealed that prefix caching was not previously available in APIs, which contributed to the limitations experienced in early agent frameworks.
- Misunderstandings About Caching: Conversations turned to misunderstandings regarding the equivalence of prompt caching to other caching techniques.
- Acknowledgments about these oversights suggested a continuous learning curve within the community.
Nous Research AI ▷ #interesting-links (4 messages):
Soft Prompts vs Fine TuningCoPilot Arena ResultsLoRA Trade-offs
- Soft Prompts Struggle for Adoption: The discussion highlighted that soft prompts are often overshadowed by techniques like fine tuning and LoRA, which are generally seen as more effective for open source use cases. Despite some unique advantages, soft prompts exhibit limited generalizability and are not widely utilized in current practices.
- Participants noted that using soft prompts may involve trade-offs, particularly in performance and optimization.
- The Two Potential Uses of Soft Prompts: A member suggested that soft prompts could serve two main purposes: system prompt compression and enhancing LoRA/full SFT applications. They mentioned that this strategy could optimize model parameters without heavily relying on the inference system.
- The implications of these uses include potential risks of overfitting, indicating the need for careful implementation.
- CoPilot Arena Initial Results Released: The first results of the CoPilot Arena, showcased on LMarena's blog, reveal a surprisingly close field among participants. However, it was noted that the analysis only considered an older version of Sonnet.
- This sparked curiosity about the implications of using outdated models in competitive settings and how it might affect participant comparisons.
GPU MODE ▷ #triton (20 messages🔥):
Debugging Triton InterpreterBlock Size DiscussionTriton GEMM and Bank ConflictsBoolean Mask Summation BugSwizzling Techniques for Performance
- Debugging Triton Interpreter for Kernel Accuracy: A user sought advice on debugging a kernel accuracy issue that is not reproducible with the Triton interpreter, especially considering that TF32 is off for matmuls.
- Suggestions included manually casting tensors to
tl.float32and checking data compatibility with specific block sizes.
- Suggestions included manually casting tensors to
- Strange Block Size Behavior Observed: There were reports that accuracy issues arise in Triton depending on the block size, functioning well for sizes <= 64 but problematic for sizes >= 128.
- Discussion arose regarding ensuring input shapes are correct and valid by potentially pruning configurations to avoid loading shape conflicts.
- Triton GEMM's Bank Conflict Solutions: A user was surprised at the Triton GEMM on ROCm being conflict-free and asked about the application of swizzling to avoid bank conflicts.
- While references to block-level swizzling were shared, the focus remained on further exploring methods specific to bank conflict resolution.
- Bug Found in Boolean Mask Summation: After extensive printing and debugging, a user discovered a bug in Triton related to summing bool masks converted to int8 tensors.
- Switching from summation to max reduction resolved the issue, and there was a suggestion to draft a minimal example for the repo.
- Fun Farewells and Ongoing Questions: As discussions wrapped up, a member remarked it was time for bed while another expressed ongoing curiosity regarding AMD support.
- The conversation concluded with a commitment to follow up on the technical puzzles presented.
- triton.language.swizzle2d — Triton documentation: no description found
- gemlite/gemlite/triton_kernels/utils.py at master · mobiusml/gemlite: Simple and fast low-bit matmul kernels in CUDA / Triton - mobiusml/gemlite
GPU MODE ▷ #beginner (2 messages):
cuBLAS operationsMatrix Multiplication with cuBLASRow-major vs Column-major order
- cuBLAS's Column-Major Order Dilemma: A user highlighted the challenge of using
cublasSgemmwhich operates in column-major order, questioning the preference for calling it withCUBLAS_OP_NorCUBLAS_OP_Tfor better clarity.- Explicit clarity on transpose operations may lead to confusion when working with matrices defined in a row-major order, as the output will always be in column-major.
- Stack Overflow Insights on cuBLAS: A member shared a relevant Stack Overflow post which clarifies using
cublasSgemmfor non-square matrices stored in row-major order.- The post discusses limitations around using CUBLAS_OP_T when multiplying non-square matrices and highlights potential conflicts with non-transposed results.
- Complexities of Matrix Declarations: There is mention that modifying matrices to declare them in column-order using the
IDX2Cmacro isn’t feasible due to them being set in another program.- This indicates the prevalent issues faced when adapting existing codebases to fit the constraints of cuBLAS libraries.
- Program Limitations with cuBLAS: The user's existing code cannot multiply non-square matrices with the transpose parameter, limiting its versatility in matrix operations.
- This raises questions regarding the flexibility and usability of cuBLAS for diverse matrix sizes and orientations.
Link mentioned: cublasSgemm row-major multiplication: I'm trying to use cublasSgemm to multiplicity two non-square matrices that are stored in row-major order. I know that this function has one parameter where you can specify that if you want to tra...
GPU MODE ▷ #torchao (1 messages):
Llama-2-70B modelMulti-GPU support
- Questioning Multi-Card Support for Llama-2-70B: One member inquired whether
llama/generate.pysupports the Llama-2-70B model to utilize multiple cards, specifically mentioning 2 A100s.- The discussion focused on the capabilities of the script in handling GPU resources effectively.
- Exploring GPU Utilization Strategies: Another point raised was about how GPU utilization can be optimized when running heavy models like Llama-2-70B on multiple cards.
- Members discussed potential strategies to maximize throughput and reduce bottlenecks.
GPU MODE ▷ #rocm (11 messages🔥):
HIP Kernel RulesCompilation Time for ExamplesFP16 GEMM on MI250 GPUDebugging KernelTriton GEMM on ROCm
- HIP Kernel Rules still confusing: A user expressed difficulty in understanding and reproducing rules within a pure HIP kernel.
- They noted ongoing challenges even after multiple attempts.
- Compilation time for examples frustrating: The time taken to compile a simple example was reported to be 1-2 hours on a user’s machine using
makecommands.- Despite trying to adjust the
-jflag in compilation, it did not significantly improve the performance.
- Despite trying to adjust the
- Confusion over input shape in FP16 GEMM: A user analyzed the transformation description for an FP16 GEMM (v3) on an MI250 GPU, noting a mismatch in the input shape for transformations.
- They requested clarification on the rationale behind the shared memory and input shapes.
- Debugging slows down compilation: Inserting print functions within the kernel increases compilation time due to many static operations in CK, which unroll multiple times.
- A suggestion was made to reduce tile size to improve debugging performance.
- Triton GEMM on ROCm found conflict free: A user was surprised to find that Triton GEMM on ROCm also exhibits conflict-free properties.
- This insight could open discussions about optimization strategies in ROCm.
GPU MODE ▷ #webgpu (1 messages):
AGX machine codeFreedesktop tools
- Freedesktop Developers Disassemble AGX Machine Code: Freedesktop developers maintain tools to disassemble AGX machine code available on their GitHub repository.
- Disassembling machine code can aid in better understanding and optimization of software performance.
- Tool advantages and user discussions: Several members discussed the advantages of using Freedesktop's disassembling tools over other methods for analyzing machine code. They highlighted how these tools can streamline the debugging process and reduce development time.
GPU MODE ▷ #liger-kernel (1 messages):
0x000ff4: A little update on kto I am working now on the tests
GPU MODE ▷ #self-promotion (1 messages):
pradeep1148: https://www.youtube.com/watch?v=XP33Vgn75lM
GPU MODE ▷ #🍿 (1 messages):
Post-Training TechniquesHuman Preferences in RLContinual LearningConstitutional AIRecursive Summarization
- Survey on Tulu 3 Released: A new survey paper titled Tulu 3 has been recommended for understanding post-training methods.
- This paper serves as a comprehensive overview for anyone interested in the advancements in the field.
- Harnessing Human Preferences for RL: The paper Deep RL from human preferences explores defining complex goals through human preferences in RL tasks, demonstrating effective results in games and robot locomotion.
- It emphasizes that only one percent of the agent's interactions required human feedback, significantly reducing oversight costs.
- Continual Learning Insights: The article Comprehensive survey of continual learning delves into challenges like catastrophic forgetting and the methods to overcome them.
- It provides a thorough bridge between foundational theories and practical applications in continual learning.
- Constitutional AI Explored: In the paper Constitutional AI, the authors examine structuring AI systems based on robust guiding principles.
- It includes contributions from notable researchers in the field, ensuring diverse perspectives on the topic.
- Advancing Summarization with Humans: The research titled Recursively summarizing books with human feedback tackles the challenge of summarizing entire novels using human feedback and recursive decomposition.
- This model allows quick supervision and evaluation by humans, leading to efficient and sensible summarizations.
- Deep reinforcement learning from human preferences: For sophisticated reinforcement learning (RL) systems to interact usefully with real-world environments, we need to communicate complex goals to these systems. In this work, we explore goals defined i...
- Learning to summarize from human feedback: As language models become more powerful, training and evaluation are increasingly bottlenecked by the data and metrics used for a particular task. For example, summarization models are often trained t...
- Training language models to follow instructions with human feedback: Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not h...
- Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback: Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large langu...
- A Comprehensive Survey of Continual Learning: Theory, Method and Application: To cope with real-world dynamics, an intelligent system needs to incrementally acquire, update, accumulate, and exploit knowledge throughout its lifetime. This ability, known as continual learning, pr...
- Constitutional AI: Harmlessness from AI Feedback: As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through self-improvement, without any huma...
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model: While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised ...
- Scaling Laws for Reward Model Overoptimization: In reinforcement learning from human feedback, it is common to optimize against a reward model trained to predict human preferences. Because the reward model is an imperfect proxy, optimizing its valu...
- Recursively Summarizing Books with Human Feedback: A major challenge for scaling machine learning is training models to perform tasks that are very difficult or time-consuming for humans to evaluate. We present progress on this problem on the task of ...
Notebook LM Discord ▷ #use-cases (9 messages🔥):
NotebookLM and GitHub RepositoriesAudio Prompt GenerationUsing Multiple LLMsTable of Contents in CodeElevenLabs and Text-to-Speech AI
- NotebookLM struggles to traverse GitHub repos: A user attempted to let NotebookLM traverse a GitHub repo by inputting the repo homepage but found it ineffective. Another member noted that NotebookLM lacks the ability to traverse websites, complicating the request.
- They suggested using Markdown of the site or printing the page to convert it into a PDF for better processing.
- Generating impactful audio prompts: A user suggested providing NotebookLM with specific prompts to produce impactful audio outputs that are useful for explanations. This can help others gain a better understanding of designated topics.
- Such a strategy aims to enhance the learning experience through clearer audio content.
- Multiple LLMs for specific tasks: A member shared their workflow where they utilize multiple LLMs depending on their needs and complimented NotebookLM for certain generations. They previously wrote about this approach in a blog post.
- This strategy highlights the versatility and effectiveness of leveraging various AI tools to accomplish conversational-based projects.
- Table of contents usage in code: The use of a table of contents in code was mentioned as a particularly interesting feature, noting it describes each section with line numbers. This improves navigation and understanding of complex codebases.
- Members expressed enthusiasm about this feature's utility in coding practices.
- ElevenLabs as a leading text-to-speech AI: Discussion around ElevenLabs noted its superiority in the text-to-speech AI space, surpassing competitors like RLS and Tortoise. The member recalled their early experiences with the startup prior to its funding, recognizing the potential for innovation.
- They emphasized the significant impact of ElevenLabs on creating faceless videos and voice synthesis, marking it as a game-changing tool in the industry.
- I'm an ElevenLabs Pro!: Discover the revolution in voice synthesis with our deep dive into ElevenLabs: groundbreaking technology for animation and performance capture. Sample the magic ✨
- 'Songs We Sing' Podcast Companion: Playlist · MrBland · 11 items
Notebook LM Discord ▷ #general (25 messages🔥):
Jensen Huang's shoutoutPodcast generation issuesAccent preferencesFunctionality requests
- Jensen Huang gives a shoutout to NotebookLM: During the NVIDIA earnings call, Jensen Huang mentioned using NotebookLM to load numerous documents and listen to generated podcasts.
- This highlights the application's versatility in handling content for users.
- Podcast generation is experiencing errors: Multiple users reported that podcast generation is stuck and resulting in errors, with some needing to wait extended periods for outputs.
- One user shared that after a two-hour wait, the service suddenly began working again, suggesting potential server issues.
- Inquiries about changing podcast host accents: A user inquired whether it’s possible to change the accents of podcast hosts, expressing preference for a British accent over an American one.
- Currently, there are no options available for this feature.
- Desired features and functionality in NotebookLM: Several users requested features such as the ability to limit audio duration to 3 minutes and translate audio within NotebookLM.
- Additionally, there were questions about the possibility of an API and adjustments to host script deliveries for more natural conversations.
- Noted instability and safety flags: Users have noted an increase in safety flags and possible instability with the application, leading to restricted functionalities in tasks.
- One user suggested DMing examples for debugging, while another noted transient issues likely due to ongoing improvements.
Link mentioned: Reddit - Dive into anything: no description found
LlamaIndex ▷ #blog (2 messages):
AI agents architectureData-backed systems with RedisKnowledge graph constructionNatural language queryingMemgraph integration
- Build AI agents with LlamaIndex and Redis: Join our webinar on December 12 to learn how to architect an agentic system to break down complex tasks using LlamaIndex and Redis.
- Discover best practices for reducing costs and optimizing latency, along with insights on semantic caching.
- Transform data into a knowledge graph with Memgraph: Learn how to set up Memgraph and integrate it with LlamaIndex to build a knowledge graph from unstructured text data.
- Participants will explore natural language querying of their graph and methods to visualize connections.
LlamaIndex ▷ #general (16 messages🔥):
LlamaParse for PDF table extractionCreate-Llama frontend optionsLlama-Agents deprecationNDCG calculation queryvLLM error and usage
- LlamaParse offers PDF data extraction: A member recommended using LlamaParse for extracting table data from PDF files, stating it could parse files effectively for optimal RAG.
- They included an informative GitHub link about its capabilities.
- Create-Llama frontend confusion: A user inquired about the best channel for assistance with Create-Llama, particularly regarding the lack of a Next.js frontend option in newer versions when selecting the Express framework.
- Another participant confirmed that they could post queries directly in the channel and would receive team support.
- Llama-Agents phased out in favor of Llama-Deploy: A member noted the issue of dependencies while upgrading to Llama-index 0.11.20 and suggested that llama-agents has been deprecated in favor of llama_deploy.
- They provided a link to the Llama Deploy GitHub page for further context.
- Discussion on NDCG calculation: A member raised a question about potentially incorrect code in the NDCG calculation within the metrics.py file of llama-index-core.
- They proposed that the line should use
len(expected_ids)for maximum achievable DCG, inviting feedback on their interpretation.
- They proposed that the line should use
- Help with vLLM integration: A user reported encountering a KeyError related to the vLLM integration, particularly missing the 'text' key when trying to use VllmServer.
- Another user suggested launching vLLM in OpenAI API mode with
OpenAILike, providing a sample code snippet to help.
- Another user suggested launching vLLM in OpenAI API mode with
- llama_index/llama-index-core/llama_index/core/evaluation/retrieval/metrics.py at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- GitHub - run-llama/llama_deploy: Deploy your agentic worfklows to production: Deploy your agentic worfklows to production. Contribute to run-llama/llama_deploy development by creating an account on GitHub.
- GitHub - run-llama/llama_parse: Parse files for optimal RAG: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
Cohere ▷ #discussions (8 messages🔥):
30 Days of PythonCapstone Project APILearning Resources
- Engaging with the 30 Days of Python Challenge: A member shared their participation in the 30 Days of Python challenge, which emphasizes step-by-step learning.
- They are utilizing the GitHub repository for resources and inspiration throughout this endeavor.
- Discussion on Capstone Project Tech Choices: One member expressed a preference for using Go for their capstone project, focusing on developing an API.
- This choice reflects the excitement for exploring different programming languages in practical applications.
- Hi Hello GIF - Hi Hello Greet - Discover & Share GIFs: Click to view the GIF
- GitHub - Asabeneh/30-Days-Of-Python: 30 days of Python programming challenge is a step-by-step guide to learn the Python programming language in 30 days. This challenge may take more than100 days, follow your own pace. These videos may help too: https://www.youtube.com/channel/UC7PNRuno1rzYPb1xLa4yktw: 30 days of Python programming challenge is a step-by-step guide to learn the Python programming language in 30 days. This challenge may take more than100 days, follow your own pace. These videos m...
Cohere ▷ #questions (3 messages):
Cohere RepositoryCohere ToolkitJupyter NotebooksContribution Guidelines
- Explore the Cohere Repository: A member highlighted the Cohere GitHub repository (GitHub link) as a great starting point for contributors, showcasing various projects.
- They encouraged exploration of tools available in the repository and to share feedback or new ideas within each project.
- Cohere Toolkit for RAG Applications: The Cohere Toolkit (GitHub link) was mentioned as an advanced UI designed specifically for RAG applications, allowing quick build and deployment.
- It's a collection of prebuilt components aimed at enhancing user productivity.
- Starter Code Available in Notebooks: Members were directed to the notebooks repository (GitHub link), which contains starter code for various use cases.
- These Jupyter notebooks offer practical examples aimed at assisting users in getting acquainted with the Cohere Platform.
- cohere.ai: cohere.ai has 46 repositories available. Follow their code on GitHub.
- GitHub - cohere-ai/cohere-toolkit: Cohere Toolkit is a collection of prebuilt components enabling users to quickly build and deploy RAG applications.: Cohere Toolkit is a collection of prebuilt components enabling users to quickly build and deploy RAG applications. - cohere-ai/cohere-toolkit
- GitHub - cohere-ai/notebooks: Code examples and jupyter notebooks for the Cohere Platform: Code examples and jupyter notebooks for the Cohere Platform - cohere-ai/notebooks
Cohere ▷ #api-discussions (5 messages):
Multimodal Embeddings LaunchResearch Agent Use CaseRate Limit Concerns
- Multimodal Embeddings Launch Set for Next Year: Exciting news as improvement with multimodal embed has been noted, and its launch is scheduled for early next year on Bedrock and partner platforms.
- A team member will flag the rate limit issue for further discussion.
- Innovative Research Agent Using Cohere Technology: A member created a Research Agent that researches topics for 30 mins and utilizes Cohere's multimodal embeddings to select relevant images.
- This tool is gaining traction, but rate limits hinder its ability to produce articles efficiently, with only 1 article every 3 minutes.
- Support Ticket for Rate Limit Increase Submitted: The same member submitted a support ticket requesting a rate limit increase to enhance the Research Agent's performance.
- They expressed that this could serve as a case study for the effective use of multimodal embeddings if the product marketing team is interested.
Link mentioned: CustomGPT.AI Researcher - Create High-Quality AI Content Based On Deep Research: Create ultra high-quality, brand-safe articles and research reports using CustomGPT.ai Researcher. Perfect for content marketing, SEO and research reports.
Cohere ▷ #projects (1 messages):
rachel_47358: https://github.com/harmonydata/harmony
Modular (Mojo 🔥) ▷ #mojo (6 messages):
Mojo Async ProgressMojo Community ChannelAsync Runtime Overhead
- Mojo's async feature still under development: Members noted that Mojo's async capabilities are still a work in progress, with no actual async functions available yet.
- The compiler currently converts sync code into async, leading to a synchronous execution of the code during async calls.
- Discussion on Mojo Community Channel: A community channel has emerged for members to connect and communicate, accessible at mojo-community.
- This channel has been identified as a hub for ongoing discussions related to Mojo.
- Concerns about async runtime overhead: A member raised a concern whether Mojo's async runtime incurs overhead even when no async code is running, citing confusion over how async compiles down to a state machine.
- Discussions continued about the necessity of explicitly running async functions in an event loop, as well as the implications of the async runtime in Mojo.
Modular (Mojo 🔥) ▷ #max (9 messages🔥):
Moonshine ASR Model PerformanceMojo Script OptimizationCPU Utilization Observations
- Moonshine ASR Model shows speed challenges: The Moonshine ASR model was tested using both Mojo and Python versions via Max, yielding an execution time of 82ms for 10s of speech, while a direct ONNX version managed 46ms.
- This indicates a 1.8x slowdown in the Mojo and Python versions compared to the more optimized ONNX runtime.
- Mojo script experiences crashes: When writing the Mojo version, there were issues with Model.execute causing crashes when passing
TensorMap, and a manual argument listing was necessary due to the lack of unpacking support.- These hurdles highlight the script's unidiomatic nature and the author's desire for performance tips to enhance their Mojo skills.
- Optimization suggestions for Mojo: A member suggested that optimizing the tokens list by pre-allocating capacity could prevent frequent malloc invocations, potentially enhancing performance.
- Considerations included implementing an InlineArray for stack storage if the maximum length permits, aiming to streamline execution.
- Performance remains unchanged without tokens: After optimizing, tokens were completely removed from the Mojo code, leaving only the graph execution benchmark, but this change did not significantly impact performance.
- The author is still exploring avenues for improving the efficiency of their ASR model execution.
- CPU utilization issues with the model: One user observed chaotic CPU usage while running the model, noticing it wasn't fully utilizing their CPU capabilities and ignoring hyperthreads.
- This lack of parallelism in running the model suggests further optimization might be necessary to fully leverage available resources.
- moonshine.mojo: moonshine.mojo. GitHub Gist: instantly share code, notes, and snippets.
- moonshine.py: moonshine.py. GitHub Gist: instantly share code, notes, and snippets.
Torchtune ▷ #dev (9 messages🔥):
New guidelines for Torchtune contributorsExtender packages for TorchtuneBinary search method suggestionHands-on experience with UVOptional packages feature for TorchAO
- Clearer guidelines coming for Torchtune: Members anticipate some clearer guidelines soon to assist maintainers and contributors in understanding desired features for Torchtune.
- These improvements may help determine when to use forks versus example repos for demonstrations.
- Suggestion for extender packages in Torchtune: One member proposed using extender packages like torchtune[simpo] or torchtune[rlhf], advocating for simplifying package inclusion without excessive checks.
- This approach aims to reduce complexity and manage resource concerns effectively.
- Binary search method for max_global_bsz: A member recommended utilizing a last success binary search for max_global_bsz, defaulting to a power of 2 smaller than the dataset.
- This method would also incorporate max_iterations as parameters for enhanced efficiency.
- Discussion around using UV: A member inquired if others have experience using UV, expressing interest in opinions regarding its usability.
- Another member partially validated its utility, noting it looks appealing and modern.
- Optional packages may resolve TorchAO issues: There was a query about whether the optional packages feature would solve the issue of users needing to manually download TorchAO.
- Responses indicated that while it may help, there are additional considerations to address.
DSPy ▷ #general (7 messages):
Prompt Signature ModificationAdapter ConfigurationOptimization across Models
- Exploring Prompt Signature Modification: A member inquired about the best way to override or change the prompt signature format for debugging purposes, particularly to avoid parseable JSON schema notes.
- The discussion revolved around methods to achieve this such as building an adapter.
- Adapter Configuration in DSPy: A user suggested building an adapter and configuring it using
dspy.configure(adapter=YourAdapter())for prompt modifications.- They also pointed towards the existing adapters in the
dspy/adapters/directory for further clarification.
- They also pointed towards the existing adapters in the
- Optimization of Phrases for Specific Cases: In response to questions about the tuning of phrases for specific types like bool, int, and JSON, it was clarified that these phrases are based on a maintained set of model signatures.
- These phrases are not highly dependent on the individual language models overall, indicating a generalized approach to their formulation.
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Intel AMA SessionHackathon Insights
- Reminder for Intel AMA Session: Join us for the Hackathon AMA with Intel tomorrow at 3 PM PT (11/21) for a chance to engage with Intel specialists.
- Don't forget to watch live here and set your reminders!
- Ask Intel Anything Opportunity: This is a great chance to ask your questions and gain insights directly from Intel specialists during the AMA session.
- Participants are eager to hear the latest updates and innovations from Intel's team!
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (4 messages):
Quiz 10 ReleaseHackathon Discussion
- Quiz 10 Not Yet Released: A member inquired about the status of Quiz 10, asking if it has been released on the website.
- Another member confirmed that it hasn’t been released yet and mentioned that email notifications will be sent once it becomes available, likely within a day or two.
- Hackathon Confusion: A member expressed gratitude for the update regarding Quiz 10 but humorously acknowledged asking about the hackathon in the wrong channel.
- This exchange reflects common channel mix-ups within the community, adding a lighthearted moment to the conversation.
tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
int64 indexingdifferences in ops_hip.pymaintenance of codeHIP setting in tinygrad
- Need for int64 Indexing Explored: A user questioned the necessity of int64 indexing in contexts that do not involve large tensors, prompting others to share their thoughts.
- Another user linked to a relevant issue on GitHub for further context regarding this discussion.
- Differences in ops_hip.py Files Dissected: A member pointed out distinctions between two ops_hip.py files in the tinygrad repository, suggesting the former may not be maintained due to incorrect imports.
- They noted that the latter is only referenced in the context of an external benchmarking script, which also contains erroneous imports.
- Maintenance Status of ops_hip.py Files: In response to the questioning of maintenance, another user confirmed that the extra ops_hip.py is not maintained while the tinygrad version should function if HIP=1 is set.
- This indicates that while some parts of the code may not be actively managed, others can still be configured to work correctly.
- tinygrad/extra/backends/ops_hip.py at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- tinygrad/tinygrad/runtime/ops_hip.py at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- tinygrad/test/external/external_benchmark_hip_compile.py at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
MLOps @Chipro ▷ #events (3 messages):
Event link confusionRescheduling events
- Event link confusion arises: A member expressed concern about not finding the event link on Luma, asking for clarification regarding its status.
- Chiphuyen responded, apologizing and stating that they forgot to reschedule the event due to being sick.
- Wishing well to a sick member: Another member thanked Chiphuyen for the update and wished them a speedy recovery.
- This showcases the supportive spirit within the community amidst event management challenges.
OpenInterpreter ▷ #general (3 messages):
AI Expert RequestCarter Grant Seeking Opportunities
- Urgent Call for AI Expertise: michel.0816 urgently asked for an AI expert, indicating a pressing need for assistance.
- Another member suggested writing the problem in designated channels for better visibility.
- Carter Grant's Job Hunt: Carter Grant, a full-stack developer with 6 years of experience, announced his search for job opportunities.
- He specializes in a wide range of technologies including React, Node.js, and AI/ML, and expressed eagerness to contribute to meaningful projects.
OpenAccess AI Collective (axolotl) ▷ #general (1 messages):
MI300X GPU IssuesAblation Set RunsIntermittent GPU HangsROCm GitHub Issue
- MI300X struggles with extended runs: A member reported experiencing intermittent GPU hangs while conducting longer 8 x runs of 12-19 hours on a standard ablation set with axolotl.
- These issues seem to occur mostly past the 6-hour mark, leading to discussions and tracking concerns on GitHub.
- Shorter runs show no problems: The same member noted that their experiences indicate the GPU hangs do not appear during shorter runs of the model.
- This distinction has raised questions about the stability of longer training sessions with MI300X when using axolotl.
- Tracking GPU hang issues on GitHub: The ongoing issues with GPU hang HW Exceptions during MI300X runs have been formally recorded on GitHub Issue #4021.
- The description includes detailed metrics such as loss and learning rate, highlighting the problem's technical context.
Link mentioned: [Issue]: Intermittent GPU Hang HW Exception by GPU on MI300X when training with axolotl · Issue #4021 · ROCm/ROCm: Problem Description When running axolotl runs, I get intermittent GPU hangs: {'loss': 0.4589, 'grad_norm': 1.0493940198290594, 'learning_rate': 5.284132841328413e-06, 'epoc...
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
volko76: Do we still need to prompt correctly ? https://youtu.be/m3Izr0wNfQc
LAION ▷ #general (2 messages):
Autoencoder Training
- Training the Autoencoder Discussed: A member mentioned the process of training the autoencoder, highlighting its importance in achieving model efficiency.
- The conversation focused on techniques and implementation strategies for improving autoencoder performance.
- Additional Insights on Autoencoders: There were assorted opinions shared regarding the sophistication of autoencoder architectures in current models.
- Discussions included the effectiveness of various algorithms and their impact on data representation.
Mozilla AI ▷ #announcements (2 messages):
Refact.AI demoWeb Applets projectPublic AI initiative
- Refact.AI Live Demo Announced: We are excited to have Refact.AI team members join us for a live demo discussing their autonomous agent and innovative tooling.
- Don't miss the opportunity to engage in this conversation by joining the live event here.
- Mozilla's New Project: Web Applets: Mozilla has launched an early-stage open-source project termed Web Applets aimed at developing AI-native applications for the web.
- This initiative aims to promote open standards and accessibility in the AI landscape, encouraging collaboration among developers, as detailed here.
- Advocacy for Public AI: Mozilla has accelerated 14 local AI projects over the past year, focusing on advocating for Public AI and building necessary developer tools.
- This effort is intended to foster state-of-the-art open-source AI technology, with a collaborative spirit emphasizing community engagement.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
Llama 3.2 prompt usage
- Query on Llama 3.2 Prompt Format: A member inquired about the lack of usage of a specific prompt for Llama 3.2, referencing the prompt format documentation.
- The question hinted at curiosity regarding the function definitions in the system prompt, indicating a need for clarity on its application.
- Interest in Prompt Applicability: The conversation illustrated a broader interest in understanding the applicability of prompts within Llama models, particularly version 3.2.
- This reflects ongoing discussions about best practices for maximizing model performance through effective prompting.
Link mentioned: Llama 3.2 | Model Cards and Prompt formats: .