[AINews] LMSys advances Llama 3 eval analysis
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
LLM evals will soon vary across categories and prompt complexity.
AI News for 5/8/2024-5/9/2024. We checked 7 subreddits and 373 Twitters and 28 Discords (419 channels, and 3747 messages) for you. Estimated reading time saved (at 200wpm): 450 minutes.
LMSys is widely known for ELO-based (technically Bradley-Terry) battles, and more controversially opaquely prerelease-testing models for OpenAI, Databricks and Mistral, but only recently started to deepen its analysis by splitting out the scores to 8 subcategories of queries:
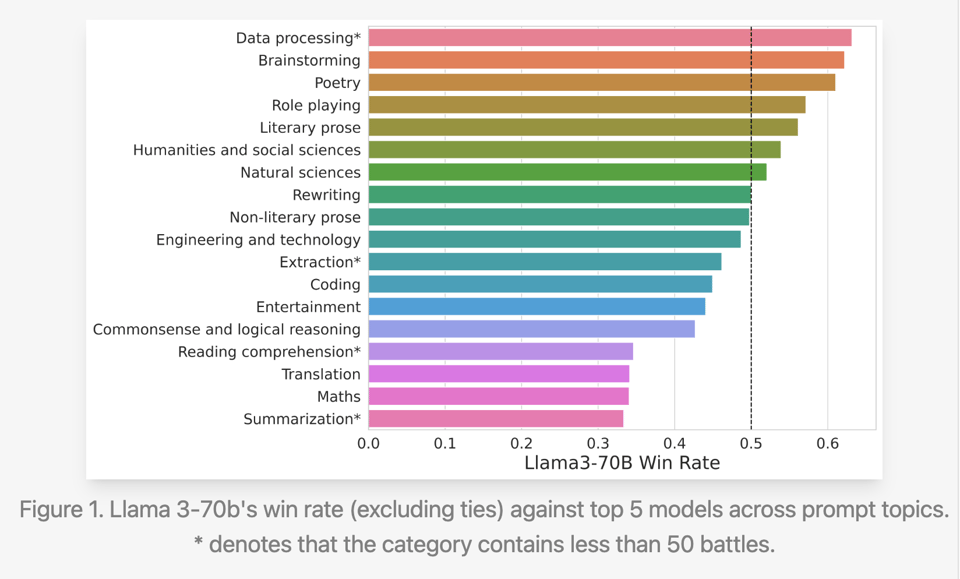
These categories are about to explode in dimensionality. LMsys published a deep analysis of Llama-3's performance on LMsys, that broke out its surprisingly uneven win rate across important categories (like summarization, translation, and coding)
and for 7 levels of prompt complexity:
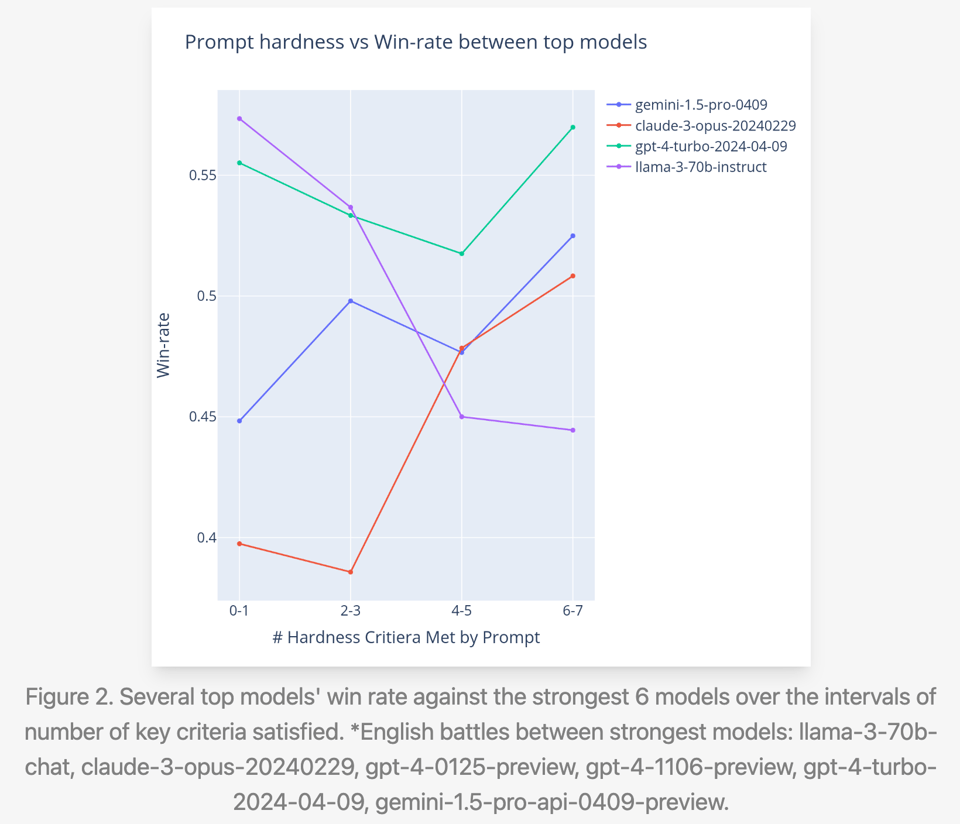
As GPT4T-preview-tier models commoditize, and as LMsys increasingly becomes the trusted eval that can be gamed in subtle ways, it is important to understand the major ways in which models can over- or under- perform. It's wonderful that LMsys is proactively doing so, but also curious that the notebooks for this analysis weren't released per their usual M.O.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Stability.ai (Stable Diffusion) Discord
- Perplexity AI Discord
- Unsloth AI (Daniel Han) Discord
- Nous Research AI Discord
- OpenAI Discord
- HuggingFace Discord
- Modular (Mojo 🔥) Discord
- LM Studio Discord
- Eleuther Discord
- CUDA MODE Discord
- OpenInterpreter Discord
- LAION Discord
- LlamaIndex Discord
- OpenRouter (Alex Atallah) Discord
- LangChain AI Discord
- Latent Space Discord
- OpenAccess AI Collective (axolotl) Discord
- Interconnects (Nathan Lambert) Discord
- tinygrad (George Hotz) Discord
- Cohere Discord
- Mozilla AI Discord
- LLM Perf Enthusiasts AI Discord
- Alignment Lab AI Discord
- Skunkworks AI Discord
- AI Stack Devs (Yoko Li) Discord
- Datasette - LLM (@SimonW) Discord
- PART 2: Detailed by-Channel summaries and links
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AlphaFold 3 and Molecular Structure Prediction
- AlphaFold 3 released by DeepMind: @demishassabis announced AlphaFold 3 which can predict structures and interactions of proteins, DNA and RNA with state-of-the-art accuracy. @GoogleDeepMind explained how it was built with @IsomorphicLabs and its implications for biology.
- Capabilities of AlphaFold 3: @GoogleDeepMind shared that AlphaFold 3 uses a next-generation architecture and training to compute entire molecular complexes holistically. It can model chemical changes that control cell functioning and disease when disrupted.
- Applications and impact: @GoogleDeepMind noted over 1.8 million people have used AlphaFold to accelerate work in biorenewable materials and genetics. @DrJimFan called it mind-boggling that the same backbone used for pixels can imagine proteins when data is converted to float sequences.
OpenAI Model Spec and Shaping Model Behavior
- OpenAI introduces Model Spec: @sama announced the Model Spec, a public specification for how OpenAI models should behave, to give clarity on what is a bug vs decision. @gdb shared the spec aims to give people a sense of how model behavior is tuned.
- Importance of the Model Spec: @miramurati emphasized the Model Spec is crucial for people to understand and participate in the debate of shaping model behavior as models improve in decision making. @karinanguyen_ noted the spec must consider a wide range of nuanced questions and opinions.
- Feedback and future plans: @sama thanked the OpenAI team, especially @joannejang and @johnschulman2, and welcomed feedback to adapt the spec over time. OpenAI is working on techniques for models to directly learn from the Model Spec.
Llama 3 Performance on LMSYS Leaderboard
- Llama 3 reaches top of leaderboard: @lmsysorg shared analysis showing Llama 3 has climbed to the top spots on the leaderboard, with the 70B version nearly matching Claude-3 Sonnet. Deduplication and outliers do not significantly impact its win rate.
- Strengths and weaknesses: @lmsysorg found the gap between Llama 3 and top models becomes larger on more challenging prompts based on criteria like complexity and domain knowledge. @lmsysorg also noted Llama 3's outputs are friendlier, more conversational, and use more exclamations compared to other models.
- Reaching parity with top models: @lmsysorg concluded Llama 3 has reached performance on par with top proprietary models for overall use cases, and expects to push new categories to the leaderboard based on this analysis. @togethercompute agreed Llama-3-70B has achieved quality similar to top open models.
Limitations of Text-Only Training for AI
- Hands-on experience needed: @ylecun argued a cliché about rookies needing hands-on experience beyond book knowledge shows why LLMs trained only on text cannot reach human intelligence.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI and Technology Developments
- OpenAI and Microsoft developing $100bn "Stargate" AI supercomputer: In /r/technology, OpenAI and Microsoft are reportedly working on a massive nuclear-powered supercomputer project to support next-gen AI breakthroughs, hinting at the immense computational resources needed.
- DeepMind announces AlphaFold 3 for predicting life's key molecules: DeepMind unveiled AlphaFold 3, an AI model that can predict the structures and interactions of proteins, DNA and RNA with state-of-the-art accuracy, opening the door to advances in drug discovery and synthetic biology.
- IBM releases open-source Granite Code LLMs outperforming Llama 3: IBM has released Granite Code, a family of powerful open-source code-focused language models that beat the popular Llama 3 models in performance.
- Apple introduces M4 chip with 38 trillion ops/sec Neural Engine: Apple revealed its next-gen M4 chip featuring a Neural Engine capable of 38 trillion AI operations per second, the fastest in any PC chip.
Open-Source LLM Developments
- Plans to distill Llama 3 70B into efficient 4x8B/25B MoE model: The /r/LocalLLaMA community is planning to distill the Llama 3 70B model into a 4x8B/25B Mixture-of-Experts model optimized for VRAM/intelligence tradeoffs, aiming to fit an 8-bit quantized version in 22-23GB VRAM.
- Timeline of major open LLM releases in past 2 months: /r/LocalLLaMA compiled a timeline of the many major open LLM drops in just the past couple months alone, including releases from Cohere, xAI, DataBricks, ai21labs, Meta, Microsoft, Snowflake, Qwen, DeepSeek, and IBM.
- Consistency LLMs accelerate inference 3.5x as parallel decoders: Consistency LLMs are an approach to convert LLMs into parallel decoders, achieving 3.5x faster inference with comparable or better speedups vs alternatives like Medusa2/Eagle but no extra memory costs.
AI Ethics and Safety Concerns
- OpenAI exploring how to responsibly generate AI porn: OpenAI is grappling with the ethical challenges around AI-generated porn, considering relaxing NSFW filters for certain use cases like explicit song lyrics, political discourse, and romance novels.
- OpenAI introduces Model Spec to clarify intended model behaviors: To help distinguish intended model capabilities from unintended bugs, OpenAI is rolling out a Model Spec and seeking public feedback to evolve it over time.
- US Marines testing robot dogs with AI targeting rifles: In a troubling development reminiscent of dystopian sci-fi, the US Marines are evaluating robot dogs armed with AI-powered rifles that can automatically detect and track people, drones and vehicles.
Other Notable Developments
- Phi-3 WebGPU AI chatbot runs fully locally in-browser: A video demo showcases a Phi-3 based AI chatbot using WebGPU to run 100% locally in a web browser.
- IC-Light enables AI-powered image relighting: The open-source IC-Light tool uses AI to allow realistic relighting and illumination editing of any image.
- Udio adds AI-powered audio editing and inpainting: Udio introduced new features leveraging AI to enable editing vocals, correcting errors, and smoothing transitions in audio.
- Study suggests warp drives may be possible: A new scientific study tantalizingly hints that warp drives may be physically possible under certain conditions.
- Genetic engineers rewire cells for 82% lifespan increase: /r/ArtificialInteligence shared research where genetic engineers achieved an 82% increase in cell lifespans by rewiring them.
AI Memes and Humor
- The AI hype cycle continues: A humbling meme in /r/ProgrammerHumor reminds us that the breathless hype around AI breakthroughs shows no signs of abating.
AI Discord Recap
A summary of Summaries of Summaries
-
Large Language Model (LLM) Advancements and Benchmarking:
- Llama 3 from Meta has rapidly risen to the top of leaderboards like ChatbotArena, outperforming models like GPT-4-Turbo and Claude 3 Opus in over 50,000 matchups.
- New models like Granite-8B-Code-Instruct from IBM enhance instruction following for code tasks, while DeepSeek-V2 boasts 236B parameters.
- Skepticism surrounds certain benchmarks, with calls for credible sources like Meta to set realistic LLM assessment standards.
-
Optimizing LLM Inference and Training:
- ZeRO++ promises a 4x reduction in communication overhead for large model training on GPUs.
- The vAttention system dynamically manages KV-cache memory for efficient LLM inference without PagedAttention.
- QServe introduces W4A8KV4 quantization to boost cloud-based LLM serving performance on GPUs.
- Techniques like Consistency LLMs explore parallel token decoding for reduced inference latency.
-
Open-Source AI Frameworks and Community Efforts:
- Axolotl supports diverse dataset formats for instruction tuning and pre-training LLMs.
- LlamaIndex powers a new course on building agentic RAG systems with Andrew Ng.
- RefuelLLM-2 is open-sourced, claiming to be the best LLM for "unsexy data tasks".
- Modular teases Mojo's potential for Python integration and AI extensions like bfloat16.
-
Multimodal AI and Generative Modeling Innovations:
- Idefics2 8B Chatty focuses on elevated chat interactions, while CodeGemma 1.1 7B refines coding abilities.
- The Phi 3 model brings powerful AI chatbots to browsers via WebGPU.
- Combining Pixart Sigma + SDXL + PAG aims to achieve DALLE-3-level outputs, with potential for further refinement through fine-tuning.
- The open-source IC-Light project focuses on improving image relighting techniques.
5. Misc
- Stable Artisan Brings AI Media Creation to Discord: Stability AI launched Stable Artisan, a Discord bot integrating models like Stable Diffusion 3, Stable Video Diffusion, and Stable Image Core for media generation and editing directly within Discord. The bot sparked discussions about SD3's open-source status and the introduction of Artisan as a paid API service.
- Unsloth AI Community Abuzz with New Models and Training Tips: IBM's Granite-8B-Code-Instruct and RefuelAI's RefuelLLM-2 were introduced, sparking architecture discussions. Users shared challenges with Windows compatibility and skepticism over certain performance benchmarks, while also exchanging model training and fine-tuning tips.
- Nous Research AI's Cutting-Edge Papers and WorldSim Revival: Breakthrough papers on xLSTM and function vectors in LLMs were analyzed, alongside speculation about Llama 3 fine-tuning best practices. The relaunch of WorldSim with new features like WorldClient, Root, and MUD generated excitement, with users strategizing model merging techniques.
- Hugging Face's Coding Enhancements and Massive Models: Idefics2 8B Chatty and CodeGemma 1.1 7B debuted for chat and coding, while the 236B parameter DeepSeek-V2 model made waves. Discussions covered BERT fine-tuning, Whisper upsampling, Gemma token integration, and approaches to content extraction from PDFs.
- CUDA MODE's Triton Tutorials and Diffusion Optimization Deep Dive: A 9-part blog series and GitHub repo detailing diffusion model inference optimization made rounds, while the community rallied to create a Triton kernels index. LibTorch compile time improvements and ZeRO++ for efficient model training also drew attention.
- LangChain's Agentic RAG Course and Local LLM Breakthroughs: LangChain partnered with deeplearning.ai for a course on building agentic RAG systems, while also introducing local LLM support for models like Mistral and Gemma. Users troubleshooted TypeScript toolkit issues and debated multi-agent architectures.
- OpenAI's Model Spec Sets the Tone for AI Alignment: OpenAI released their first draft of the Model Spec to guide model behavior using RLHF techniques, part of their commitment to responsible AI development. Discussions also touched on GraphQL limitations compared to Markdown and the varying capabilities of GPT-4 across different platforms.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
Artisan's Creative Expansion: Stability AI has launched a new Discord bot called Stable Artisan, making tools like Stable Diffusion 3, Stable Video Diffusion, and Stable Image Core available for Discord users for both media creation and editing right within the app.
SD3's Open Source Drama: Community discussions surfaced frustration about Stable Diffusion 3 possibly not being open-source, with concerns about the move to a proprietary model and unclear release timelines stirring debates in the community.
Artisan API Draws Mixed Reactions: The introduction of Artisan, Stability AI's paid API service for utilizing Stable Diffusion 3, garnered both excitement and criticism, with some users questioning the feasibility of the service for those with limited budgets.
Guidance for Rookie Generative Enthusiasts: Newcomers to the Stable Diffusion ecosystem are exchanging tips on using ComfyUI and exploring the best base models for different creative intents, drawing from community repositories and prompt crafting techniques to refine their generative artistry.
Comparing AI Art Titans: Discussion threads highlight Midjourney's impact on the AI art tools market, speculating on its professional audience and potential influence on the monetization strategies for similar tools like Stability AI's offerings.
Perplexity AI Discord
Perplexity and SoundHound Tag Team for Voice AI: Perplexity AI has formed a collaboration with SoundHound, aiming to enhance voice assistants with advanced LLM capabilities, promising real-time answers over a range of IoT devices.
Claude 3 Opus Credit Chronicles and Service Snags: Users delved into the "600 credit" limitation concerns with Claude 3 Opus, contrasting experiences with Perplexity and direct usage from Anthropic. There were also discussions around Pro search limits transparency and technical issues like billing errors and system slowdowns.
Shareability and Searches Shine in Sharing: The community was prompted to set threads to 'Shareable' and engaged in sharing Perplexity AI search URLs on diverse subjects such as alpha fold, bipolar disorder, and multilingual queries, revealing the variety of users' interests.
Boots Without Resampling Becomes Conversation Piece: One member's question on conducting bootstrapping without physical resampling sparked a technical discourse, focusing on direct uses of original datasets in this statistical method.
Users Voice Subscription Page Scrutiny: Concerns arose over potential misinformation on the Pro subscription page, prompting a request for explicit clarifications from the Perplexity team concerning the Pro search limits.
Unsloth AI (Daniel Han) Discord
IBM's Newest Member to the Code Model Family: Granite-8B-Code-Instruct, boasting enhanced instruction following capabilities in logical reasoning and problem-solving was unveiled by IBM, fueling discussions around its unusual GPTBigCodeForCausalLM architecture.
Dolphin Acknowledges Unsloth in New Release: Unsloth AI was recognized in the Dolphin 2.9.1 Phi-3 Kensho's launch for its contribution during the model's initial phase.
Windows Woes for AI Enthusiasts: Engineers shared challenges when deploying AI models on Windows, suggesting workarounds like Windows Subsystem for Linux (WSL) and referenced a discussion for a solution outlined in an Unsloth GitHub issue.
AI Community Questions Model Benchmarks: Skepticism surfaced regarding certain performance benchmarks, with members calling for more credible sources, such as Meta, to establish realistic assessment standards for large language models.
Debugging Diary: Diverse Discourse on Model Training: There's active dialogue on overcoming various hurdles in model training and development, including fixing Llama3 training data losses, sorting VSCode installation errors, and fine-tuning models with help from community-shared notebooks like this one for inference-only use on Google Colab.
Nous Research AI Discord
LSTMs Throw Down the Gauntlet: An intriguing paper emphasizes the potential of LSTMs scaled to a billion parameters, challenging Transformer dominance with innovative exponential gating. The technique is detailed in this latest research.
AI's Predictive Crystal Ball: Forefront.ai lists anticipated breakthrough AI papers, intimating key trends and a novel adjustment technique reducing computational load without notable performance hits. The website showcases this strategic foresight into the AI research arena.
Lighter Models, Same Might: Notable discourse revealed a 4-bit quantized, 40% trimmed version of Llama 2 70B performs comparably to the full model, suggesting large-scale redundancy in deep learning models, as addressed in a Twitter post.
Fine-tuning Finessed: Conversations around fine-tuning techniques for LLaMA 3 and the Axolotl model have involved discussions on context length, pre-tokenization versus padding during training, and optimum use of Flash Attention 2.
WorldSim Waves the Banner of Innovation: WorldSim presents new capabilities with improved bug remediation, the WorldClient browsing experience, CLI environment Root, ancestor simulations, and RPG features. Mounting enthusiasm in the community shows through inquiries about the purchase of promotional Nous Research swag, found on their website.
Sustainable Strategizing for Mingling Models: Guild members are actively probing into streamlining the process of model merging and integration techniques, comparing Direct Preference Optimization in models like NeuralHermes 2.5 - Mistral 7B and exploring the tangible benefits of Llamafile with external weights.
Texture of Technical Dialogues: Many messages have shown an engaging tapestry of problem-solving, from addressing errors like 'int' object has no attribute 'hotkey' when uploading models, to fleshing out tactics for limiting hallucination in RAG and effective padding strategies.
OpenAI Discord
Model Spec Shaping AI Conversations: OpenAI introduced the Model Spec as a framework for crafting desired behaviors in AI models to enrich public discussions about them; a full read can be accessed at OpenAI's announcement.
Markdown Gets the Upper Hand over GraphQL: In AI discourse, the lack of GraphQL clientside rendering was contrasted with Markdown, although no significant concerns arose from this limitation.
AI Platforms and Hardware Excite and Confuse: While the OpenDevin platform was praised for its Docker sandbox and backend model flexibility, users found the comparative performance of AI across ChatGPT versions and the NVIDIA tech demo intriguing, yet the limitations on the GPT-4 ChatGPT app versus the API version caused community frustration.
Ethics and AI in Business Prompts Shared: A community member offered a detailed AI ethics in business prompt structuring, aiming to enhance model outputs concerning ethical considerations, and provided an output example exploring the impact of unethical practices, albeit without specific resource links.
Seeking Expertise and Visionary Ideals in AI: A member sought recommendations for prompt engineering courses, with subsequent exchange via direct message due to OpenAI's policies, while another pondered the concept of "Open" as a core epistemological principle, although the discussion did not develop further.
HuggingFace Discord
- Chat-Optimized and Coding-Friendly Models Hit the Scene: Idefics2 8B Chatty arrived with a focus on elevated chat interactions, while CodeGemma 1.1 7B emerged to refine coding in Python, Go, and C#. In the browser chatbot space, Phi 3 introduced WebGPU tech for enhanced chat experiences.
- Groundbreaking 236B Parameter Model and Training Milestones: The DeepSeek-V2 boasting 236 billion parameters has been introduced, marking a significant increase in model size, and updates in object detection guides aim to fine-tune performance with the addition of mAP metrics to the Trainer API.
- Technical Issues and Troubleshooting: Several members have encountered challenges related to BERT fine-tuning, Whisper model upsampling, integrating Gemma's unused tokens, and diffusion model errors, highlighting the diverse nature of problem-solving within the community.
- Audio and Engagement Tweaks in Voice Channels: A discourse around utilizing "stage" channels to control audio quality in voice groups uncovered a balance between quality control and participant urgency to voice questions, leading to an experiment with stage channel settings.
- Efforts Toward More Efficient Content Extraction: One user shared an endeavor to extract images and graphs from PDFs, alongside a desire for more efficient AI methodologies for handling such data, whilst a new model emerged to demarcate ads within images using Adlike.
Modular (Mojo 🔥) Discord
Mojo's Python Prospects and Performance Debates
- Mojo's Year-End Python Potential: The Modular community is anticipating that Mojo may become more user-friendly by year's end, with CPython integration already enabling Python code execution. However, the direct compilation of Python code might remain a goal for the following year.
- MLIR's Moment to Shine in Mojo: Enthusiasm is high over expanded contributions to MLIR, especially in the field of liveliness checking; members eagerly await potential open-sourcing of Modular's MLIR dialects to enhance MLIR utility.
Compiling Insights and Turing up the Heat on Twitter and Blogs
- Feature Frenzy on Modular's Twitter: Modular teased important updates, promising feature upgrades and revealed steady growth metrics on Twitter, arousing community curiosity about upcoming announcements.
- Chris Lattner Champions Mojo: On the Developer Voices podcast, Chris Lattner emphasized Mojo's prospects for Python and non-Python developers, focusing on expanded GPU performance and AI-related extensions.
Community Code Contributions and Compiler Conversations
- Toybox Repository Joins GitHub: The community-driven repo, "toybox," presents a DisjointSet and Kruskal's algorithm implementation, inviting collaborative enhancements through Pull Requests.
- String Strategies in Mojo Stir Debate: Performance concerns surfaced around Mojo's string concatenation; responses included proposed short string optimization and refined techniques using
KeysContainerandStringBuilderfor acceleration, showcased in GitHub discussions.
Tensor Tangles and Standard Library Updates in Mojo Nightly
- Navigating Mojo's Nightly Nuances: Updates in the nightly Mojo release included revisions to the Tensor API for clarity, while the community grappled with complications around
DTypePointerbehavior and eagerly reviewed the new compiler updates.
LM Studio Discord
- Directory Deep Dive for Model Storage: Engineers discussed ideal model directory structures for LM Studio, aligning with Hugging Face's naming conventions to facilitate model organization and discovery. For example, a Meta-Llama model should be placed in the path
\models\lmstudio-community\Meta-Llama-3-8B-Instruct-GGUF\.
- New 120B Model Merges Might for Coders and Poets: Maxime Labonne unveiled a 120B self-merged model, Meta-Llama-3-120B-Instruct-GGUF, promising enhanced performance for users to test and provide feedback on, while some members expressed struggles with current models' performance on poetry completion.
- AI Needs Mighty Hardware: The community extensively discussed hardware capabilities required for running large models like Llama 3 70B, joking about the need for theoretical 200GB VRAM for a 400B model and strategizing on how to optimize resources, such as offloading desktop tasks to an Intel HD 600 series GPU.
- RAG Architecture Might Be the Search Hero: A member recommended utilizing RAG architectures with chunked document handling to improve data searches, suggesting that reranking methods based on similarity measures could refine results, showcasing another stride in operational AI efficiency.
- Waiting Room for API Enhancements: Engineers are eagerly anticipating updates, including the possibility of programmatically interacting with existing chats through the LM Studio API, highlighting the platform's ongoing evolution towards more adaptable and user-friendly AI tools.
Eleuther Discord
- Release Etiquette Sparks Unofficial Debate: Engineers discussed the nuances of releasing unofficial implementations of algorithms, highlighting the ethical stance that such projects should be clearly labeled to distinguish them from the official versions, as demonstrated by the MeshGPT GitHub repo.
- Name Game in Science Publishing: The complexities of updating one's surname in academic databases post-marriage sparked a conversation, where the primary advice revolved around contacting the respective support for platforms and considering the preservation of a "nom-de-academia."
- Piling On Efficient Data Handling: Best practices for processing The Pile data for training AI models were exchanged, focusing on utilizing pre-processed datasets on resources like Hugging Face, and navigating the specific tokenizer application when handling
.binfiles.
- Scaling the Limits of State Tracking: A debate emerged over the scalability of state tracking in models, spurred by an article discussing shared limitations of state-space models and transformers, and speculative discussions surrounding xLSTM's capabilities.
- Skepticism Surrounds xLSTM: Skeptical tones were evident as members scrutinized the xLSTM paper for potentially using suboptimal hyperparameters for baselines, thereby questioning the claims made and looking forward to independent verifications or the release of official code.
- Function Vector Finds Its Function: Intriguing discussions touched upon function vectors (FV) for efficient in-context learning, based on insights drawn from studies suggesting that FVs can enable robust task performance with minimal context (research source).
- YOCO Yields Singular Cache Curiosity: The introduction of YOCO, a decoder-decoder architecture that simplifies KV caches, left some pondering its potential need for further optimization and the perks of singular cache rounds for improving memory economics.
- Multilingual LLMs Under Microscope: Interest in understanding how LLMs process multilingual inputs led engineers to reference research on language-specific neurons and the LLMs ability to compute next tokens, potentially involving internal translation to English (study example).
- Positional Encoding Gets Orthogonal Polish: PoPE's advent, bringing orthogonal polynomial-based positional encoding to possibly outdo sine-based APEs, ignited discussions that critiqued it for an over-theoretical approach while acknowledging its potential (paper).
- Tuned Lenses Inquiry: A lone query in the interpretability channel hinted at the specificity of tools for analyzing AI models, specifically asking if tuned lenses are available for every Pythia checkpoint, suggesting interest in model interpretability and fine-tuning nuances.
CUDA MODE Discord
- LibTorch Compile-Time Shenanigans: Leveraging ATen’s
at::native::randnand including only necessary headers like<ATen/ops/randn_native.h>cut down compile times from ~35 seconds to just 4.33 seconds.
- ZeRO-ing in on Efficiency: ZeRO++ claims a 4x reduction in training large models' communication overhead, enabling batch size 4 training on NVIDIA's A100 GPUs—and it even works across multiple A100s, although performance degrades slightly.
- Tuning Diffusion Models to the Max: A 9-part blog series has been made available, showcasing optimization strategies in U-Net diffusion models for the GPU, with practical examples given in the accompanying GitHub repository.
- vAttention Climbing Memory Management Mountain: A new system, vAttention, is proposed for dynamic KV-cache memory management in large language model inference, aiming to address the limitations of static allocation (paper abstract).
- Apple's M4 Flexes Compute Muscles: The M4 chip from Apple boasts an impressive 38 trillion operations per second, thanks to 3nm tech and a 10-core CPU, indicating the pace of progress in mobile compute power.
OpenInterpreter Discord
- GPT-4's Clever Composition: GPT-4 demonstrated its capacity to use YouTube for tailored music suggestions, leveraging specific user instructions; nonetheless, some local models, such as TheBloke/deepseek-coder-33B-instruct.GGUF and lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF, underperformed, showing issues like claiming no internet connection or giving up after failed attempts.
- mixtral-8x7b Outshines Rivals in Local Tests: Out of several local models tested, mixtral-8x7b-instruct-v0.1.Q5_0.gguf has excelled, especially on hardware with a custom-tuned 2080 ti GPU and 32GB DDR5 6000 memory, proving to be more effective than alternatives.
- MacBooks Mayhem: MacBook Pro systems were found inadequate for running even lightweight local model operations, pushing one member to cease using their MacBook for these tasks.
- Cross-Platform Provider Integration: LiteLLM's documentation was highlighted, showing support for various AI providers, including OpenAI models, Azure, Google's PaLM, and Anthropic, with explicit instructions available in the LiteLLM providers documentation.
- Windows Wobbles With 01: Some users reported that the 01 platform has limited functionality on Windows operating systems, with discussions centered around possible code modifications for Windows 10 and compatibility checks for Windows 11.
LAION Discord
- Dalle-3's Rival Emerges: Combining Pixart Sigma, SDXL, and PAG has led to discussion about achieving DALLE-3 level outputs, with current limitations around text and individual object rendering identified. Participants believe that fine-tuning could enhance image composition, emphasizing the need for skilled technical intervention.
- Chasing Better Model Performance: A breakthrough for enhancing model quality was shared, detailing that manageable ranges for microconditioning inputs facilitate smoother learning, with prospects of refining this approach attracting attention.
- Relighting the AI Scene: The IC-Light project on GitHub, targeted at improving image relighting, is gaining interest in the community, and can be accessed at IC-Light GitHub.
- Insights into Diffusion Models: Engaging debates around Noise Conditional Score Networks and diffusion models touched upon issues like noise scheduling and the convergence of distributions, while papers like 'K-diffusion' were discussed for their mathematical intricacies and conceptual differences.
- Efficiency in the Insurance Lane: Request for recommendations on open-source tools for automating data processing in commercial auto insurance was raised, illustrating a cross-domain application of AI to enhance risk assessment in the insurance sector.
- AI Research Amplified: An AI contest announcement with potential publishing opportunities and rewards in the IJCAI journal garnered attention, signaling an active pursuit of scholarly recognition within the AI community.
LlamaIndex Discord
- Deep Dive into Agentic RAG: deeplearning.ai has introduced a course led by Jerry Liu, CEO of LlamaIndex, which focuses on creating agentic RAG systems capable of complex reasoning and retrieval-based question answering. This course has been signaled to be of significance by AI pioneer Andrew Ng in a Twitter announcement.
- Local LLM Acceleration: LlamaIndex has revealed an integration for executing Large Language Models (LLMs) locally with greater efficiency, with support for models like Mistral and Gemma, offering compatibility with NVIDIA hardware as highlighted in their Twitter post.
- Troubleshooting LlamaIndex Integrations: A discussion around the correct usage of omatic embeddings and LlamaIndex vector store integrations offered solutions for embedding compatibility issues. It was underscored that the vector store handily manages embeddings, easing implementation headaches for engineers considering this route.
- Operational Scalability Focus: Engineers debated on the optimal solution for hosting local LLM models, pointing towards solutions such as AWS and auto-scaling on Kubernetes, with interest in achieving scalability for large-scale deployments.
- Coding Clinic: For a user struggling with _CBEventType.SUB_QUESTION not triggering in their codebase, peers provided targeted guidance and code snippets to pinpoint and rectify the implementation flaw.
OpenRouter (Alex Atallah) Discord
Boost Your Web Game with Languify.ai: The new browser extension, Languify.ai, is designed to enhance website text for better user engagement and increased sales, tapping into OpenRouter for model selection based on prompts. A professional tier is priced at €10.99 a month, offering a viable alternative to AnythingLLM for users seeking a streamlined tool, with details found at Languify.ai.
OpenRouter Mysteries Partially Solved: Ongoing discussions among users revealed a desire for more accessible information on OpenRouter, with key topics including API documentation, credit system understanding, and the free status of certain AI models lacking comprehensive answers.
Moderation Mods on Demand: Users interested in Llama 3-powered moderation services were pointed to Together.ai, as OpenRouter itself does not currently list such capabilities.
'min_p' Gets Thumbs Up: Providers such as Together, Lepton, Lynn, and Mancer were highlighted for their support of the min_p parameter in their models, although Together was noted to be having some issues, unlike Lepton.
Breaking Chains with Wizard 8x22B: Discussion surged around the potential for "jailbreaking" Wizard 8x22B to access less-restricted content, with community members sharing resources such as Refusal in LLMs is mediated by a single direction to understand the limitations and refusal mechanisms inherent in language models.
LangChain AI Discord
- TypeScript Toolkit Troubles: Engineers are cracking the case with the
JsonOutputFunctionsParserin TypeScript which is throwing Unterminated string in JSON errors; recommendations include ensuring proper JSON from theget_chunksfunction, correctly formattedcontentforchain.invoke(), and a thorough check ofgetChunksSchema.
- Channeling Chat Consistency: A discrepancy in LangChain AI's
/invokeendpoint was pinpointed when a dictionary input behaved differently than when running it in Python, starting with an empty dictionary—prompting the community to share their diagnostics.
- Parsing Multi-Agent Mechanics: Interest was expressed in projects akin to the STORM multi-agent article generator, with discussions orbiting around the effectiveness of component-based architecture against instantiating separate agents for distinct capabilities.
- Vector DB Vacillation: The conversation turned to costs and complexities when setting up the VertexAI Vector store with alternatives like Pinecone and Supabase being tossed into the ring as potentially less taxing on the wallet.
- Gianna Grabs the AI Spotlight: The debut of Gianna, a modularly built virtual assistant, sparked dialogue, boasting integration with CrewAI and Langchain and accessible on GitHub or via PyPI with a supporting tutorial video. Meanwhile, a new Medium article unveiled Langchain's LangGraph as a customer support game-changer, and Athena, an AI data platform, flaunted its full data workflow autonomy.
- CrewAI Connects to Crypto: An engaging tutorial video "Create a Custom Tool to connect crewAI to Binance Crypto Market" was shared, opening up new possibilities for financial analysis with crewAI CLI and the Binance.com Crypto Market.
Latent Space Discord
- Stanford Fuels AI Minds: Stanford has released its new 2023 course, "Deep Generative Models," with lectures available on YouTube for AI professionals looking to upskill.
- GPU Quest: AI engineers on the Discord are exchanging tips on acquiring A100/H100 GPUs, recommending sfcompute as a reliable source.
- Codemancers Clash Over AI Tools: There's a passionate debate regarding AI-assisted coding underway, reminiscing over the old days of Lisp and scrutinizing the strengths and weaknesses of current AI code aids.
- Gradient's Giant Context Leap: The new Llama-3 8B Instruct model from Gradient is making waves for its massive increase in context length to 4194k; interested parties can sign up here for custom agents.
- OpenAI's Security Moves Spur Talk: OpenAI's blog post on creating secure AI infrastructure has sparked discussions among members, with some interpreting the measures as a form of "protectionism."
OpenAccess AI Collective (axolotl) Discord
- Llama-3-Refueled Model Now Public: RefuelAI has released RefuelLLM-2, a language model touted for efficiently handling "unsexy data tasks," and the weights are accessible on Hugging Face. The model was instruction tuned on an array of 2750+ datasets for approximately one week, as highlighted in a Twitter announcement.
- Axolotl Dataset Confusion Cleared: Documentation on supported dataset formats for Axolotl includes JSONL and HuggingFace datasets, providing clarity on organizing data for various tasks like pre-training and instruction tuning.
- Axolotl Users Navigate GPU Troubles: One engineer is in search of a working phi3 mini config file for 4K/128K FFT on 8 A100 GPUs, while another reports a training issue on 8x H100 GPUs, reflecting ongoing conversations about optimization and troubleshooting within AI model training environments.
- W&B Environment Variables Integrated: There's a nod to W&B's documentation for guidance on using environment variables, suggesting attention to tracking and reproducibility of experiments.
- LoRA YAML Setups Create Community Chatter: Several intricacies of configuring LoRA (Low-Rank Adaptation) for AI models were discussed, including the proper YAML configuration to save parameters when adding new tokens. Errors encountered led to recommendations on updating
lora_modules_to_saveto include'embed_tokens'and'lm_head', with members sharing insights on code troubleshooting process.
Interconnects (Nathan Lambert) Discord
Pretty Pictures Without Purpose?: Diagram aesthetics gained appreciation for being "really pretty pictures," while lacking functional commentary. Discussions highlighted concerns over diagrams choosing parameter counts over FLOPs and using non-standard learning rates for transformer baselines without proper hyperparameter tuning.
Tech-Savvy Growth Tactics: Queries about training Reinforcement Models (RM) on TPUs and using Fully Sharded Data Parallel (FSDP) suggest a surge in exploring optimization and scaling strategies. Meanwhile, EasyLM emerged as a potential basis for RM training using Jax, exemplified by a GitHub script: EasyLM - llama_train_rm.py.
Leaderboard Logistics and Research Resonance: Debate ensued on whether 5k leaderboards adequately reflect AI model performance, with suggestions for expanding to 10k. Commendations flowed for Prometheus, positioning it above the fray of typical AI research, despite a backdrop of overlooked sequels and disputed leaderboard ratios.
SnailBot's Slow-Motion Debut: The community anticipates SnailBot's debut, expressing excitement yet impatience with tick tock banter and engaging in light-hearted interactions upon receipt of a response from the bot.
LLM Licensing Quandaries: Concerns arose in ChatbotArena related to licensing complexities for releasing text generated by large language models, hinting at a need for specialized permissions from providers.
Leading-edge Discussions: OpenAI released their Model Spec for AI alignment, emphasizing RLHF techniques and setting a standard for model behaviors in OpenAI API and ChatGPT. Additionally, Llama 3 charged ahead in ChatbotArena, surpassing GPT-4-Turbo and Claude 3 Opus in 50,000+ matchups, insights dissected in a blog post which can be explored here: Llama 3.
tinygrad (George Hotz) Discord
- BITCAST Bonanza in tinygrad: The Pull Request #3747 on tinygrad sparked debates, differentiating CAST from BITCAST operations and advocating for clarity in their implementation, with suggestions to streamline BITCAST to prevent argument clutter.
- Symbolic Confusion Cleared: Users exchanged thoughts on enhancing tinygrad with symbolic versions of
arange,DivNode, andModNodefunctions. While concerns about downstream impacts were mentioned, no consensus on the method was reached.
- Frustrations in Forwarding
arangeFunctionality: Efforts to implement a symbolicarangemet roadblocks, as evidenced by a user's trial shared through a GitHub pull request, with further ambitions poised towards a 'bitcast refactor'.
- Matrices Alchemy: A novel design for concatenating the output of matrix operations was brought into discussion, pondering the possibility of in-place writing to an existing matrix to reduce overhead. Meanwhile, a member sought assistance with Metal build process, specifically the elusive
libraryDataContents().
- Visualize This!: In a practical aid to grappling with the concepts of shape and stride in tinygrad, a user created a visualization tool to assist engineers in exploring different combinations visually.
Cohere Discord
- RAG on Cohere Limitations: Implementing RAG on Cohere.command challenges users due to a 4096 token limit; some propose using Elasticsearch for text size reduction, whilst others consider dividing the text into segments to manage information loss effectively.
- File Generation Inquiry: The community is exploring methods for Cohere Chat to produce DOCX or PDF arrangements, but mechanisms for file downloading remain unclear.
- Resolving Cohere CORS Headaches: Members addressed CORS issues encountered with the Cohere API, suggesting backend calls to avoid security mishaps and keeping API keys confidential.
- Understanding Cohere's Credit System: Queries about adding credits on Cohere led to the clarification that the platform doesn't offer pre-paid options; instead, users can control expenses through billing limits on their dashboard.
- Wordware Hiring Spree: Wordware is on the lookout for AI talent, including a founding engineer and DevRel positions, encouraging applicants to demonstrate their skills using Wordware's IDE and engage with the team at wordware.ai. Check out the roles.
Mozilla AI Discord
API Now, Code Less: Meta-Llama-3-8B-Instruct can be operated through an API endpoint at localhost, with the OpenAI-style interaction. Details and setup instructions are available on the project's GitHub page.
Switching Models Just Got Easier: Visual Studio Code users can rejoice with the introduction of a dropdown feature, simplifying the swapping between different models for those utilizing ollama.
Request for Efficiency in Llamafile Updates: A feature request was made for llamafile to enable updates to the binary scaffold without the hefty process of redownloading the entire file, seen as a potential enhancement for efficiency.
A Musing on Mozilla-Ocho: A quirky conversation surfaced about whether Mozilla-Ocho alludes to "ESPN 8 - The Ocho" from "Dodgeball," though it seemed more of a fun aside than a pressing issue.
For the Curious Readers: The only link cited in the discussion: GitHub - Mozilla-Ocho/llamafile.
LLM Perf Enthusiasts AI Discord
AI Aides Excel Wizards: Engineers are exploring how LLMs can be utilized for spreadsheet data manipulation, with specific emphasis on AI's ability to sift through and extract information.
Yawn.xyz's Ambitious AI Spreadsheet Demo: Despite ambitious attempts by Yawn.xyz to address spreadsheet extraction challenges in biology labs, the community feedback on their AI tool's demo indicates performance issues.
Seeking Smooth GPT-4-turbo Azure Deployments: An engineer encountered problems with GPT-4-turbo in the Sweden Azure region, sparking discussions on optimal Azure regions for deployment.
Alignment Lab AI Discord
- AlphaFold3 Enters the Open Source Arena: An implementation of AlphaFold3 in PyTorch was released, which aims at predicting biomolecular interactions with high accuracy, working with atomic coordinates. The code is available for the community review and contribution on GitHub.
- Agora's Link for AlphaFold3 Collaboration Fails to Connect: A call was made to join Agora for collective efforts on AlphaFold3, but the provided link was reported to be faulty, hindering collaborative prospects.
Skunkworks AI Discord
- AI Engineers, Check This Out: A brief post in the Skunkworks AI channel shared a YouTube video link without any context, which might be interest-grabbing for tech enthusiasts keen on multimedia content related to AI developments.
AI Stack Devs (Yoko Li) Discord
Quickscope Hits the Mark: Regression Games proudly presents Quickscope, a new AI-powered toolkit that automates testing for Unity games, featuring Gameplay Session recording and Validation tools for a streamlined, no-code setup.
Deep Dive Into Game Test Automation: The deep property scraping feature of Quickscope extracts detailed data from game object hierarchies, enabling thorough insights into game entities like positions and rotations without writing custom code.
A Testing Platform for QA Teams: Quickscope boasts a platform that supports advanced test automation strategies, such as smart replay systems, designed with QA teams in mind to facilitate quick and straightforward integration.
Interactive UI Meets Game Testing: The platform's intuitive UI makes defining tests more accessible for QA engineers and game developers, and is compatible with the Unity editor, builds, or can be woven into CI/CD pipelines.
Experiment with Quickscope: Engineers and developers are encouraged to try out Quickscope's suite of AI tools to experience firsthand the efficiency and simplicity it brings to game testing automation.
Datasette - LLM (@SimonW) Discord
- Command-Line Cheers: AI Engineers are voicing their appreciation for the
llmcommand-line interface tool; it's compared to a personal project assistant with the ability to handle "more unixy stuff".
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
- Stable Artisan Joins the Chat: The bot Stable Artisan is introduced, allowing Stable Diffusion Discord Server members to create images and videos using Stability AI’s models, including Stable Diffusion 3, Stable Video Diffusion, and Stable Image Core.
- A New Multimodal Bot Experience: Stable Artisan is a multimodal generative AI Discord bot designed to integrate multiple aspects of media generation directly within Discord, enhancing user engagement.
- Beyond Generation – Editing Tools Included: The bot extends its functionality with tools to edit content, offering features like Search and Replace, Remove Background, Creative Upscale, and Outpainting.
- Accessibility and Ease of Use for All: By leveraging the capabilities of the Developer Platform API, Stable Artisan makes state-of-the-art generative AI more accessible for Discord users.
- Dive into Generation Immediately: Discord users are encouraged to get started with Stable Artisan by visiting dedicated channels for different bot commands and features within Stable Diffusion's Discord.
Link mentioned: Stable Artisan: Media Generation and Editing on Discord — Stability AI: One of the most frequent requests from the Stable Diffusion community is the ability to use our models directly on Discord. Today, we are excited to introduce Stable Artisan, a user-friendly bot for m...
Stability.ai (Stable Diffusion) ▷ #general-chat (811 messages🔥🔥🔥):
- Local vs. Cloud Usage Debate: The community discusses the merits of using Stable Diffusion locally versus resorting to cloud-based GPUs for tasks, with opinions split on convenience, cost, and performance. Generating high-quality images locally mentions using iPad Pro with M2 chips for creative work, while others emphasize cloud services for heavy training without requiring expensive hardware.
- SD3 and Open Source Concerns: Members show frustration over the prospects of Stable Diffusion Version 3 (SD3) not being released as open-source, raising concerns about commitment to release dates and the potential of shifting towards a paid model.
- Artisan as a Paid Service: Stability AI introduces Artisan, a paid API service for utilizing SD3, which receives mixed responses from the community, with criticisms about pricing and the practicality for hobbyists and professionals in the current economic climate.
- Workflow Discussion for New Users: Beginners seek advice on using ComfyUI with different Stable Diffusion models, looking for guidance on the best base models and VAEs for various image types, as well as effective prompt guides.
- Midjourney's Market Impact: Members reflect on Midjourney as a competitor to Stable Diffusion, with its business model attracting a specific professional audience which could provide a different direction for AI art tool monetization.
- Stable Diffusion Benchmarks: 45 Nvidia, AMD, and Intel GPUs Compared: Which graphics card offers the fastest AI performance?
- Stable Diffusion 3 is available now!: Highly anticipated SD3 is finally out now
- Draw Things: AI Generation: Draw Things is a AI-assisted image generation tool to help you create images you have in mind in minutes rather than days. Master the cast spells and your Mac will draw what you want with a few simpl...
- GitHub - Extraltodeus/sigmas_tools_and_the_golden_scheduler: A few nodes to mix sigmas and a custom scheduler that uses phi: A few nodes to mix sigmas and a custom scheduler that uses phi - Extraltodeus/sigmas_tools_and_the_golden_scheduler
- Pony Diffusion V6 XL - V6 (start with this one) | Stable Diffusion Checkpoint | Civitai: Pony Diffusion V6 is a versatile SDXL finetune capable of producing stunning SFW and NSFW visuals of various anthro, feral, or humanoids species an...
- deadman44/SDXL_Photoreal_Merged_Models · Hugging Face: no description found
- GitHub - Clybius/ComfyUI-Extra-Samplers: A repository of extra samplers, usable within ComfyUI for most nodes.: A repository of extra samplers, usable within ComfyUI for most nodes. - Clybius/ComfyUI-Extra-Samplers
- Sprite Art from Jump superstars and Jump Ultimate stars | PixelArt AI Model - v2.0 | Stable Diffusion LoRA | Civitai: Sprite Art from Jump superstars and Jump Ultimate stars - PixelArt AI Model If You Like This Model, Give It a ❤️ This LoRA model is trained on sprit...
- GitHub - 11cafe/comfyui-workspace-manager: A ComfyUI workflows and models management extension to organize and manage all your workflows, models in one place. Seamlessly switch between workflows, as well as import, export workflows, reuse subworkflows, install models, browse your models in a single workspace: A ComfyUI workflows and models management extension to organize and manage all your workflows, models in one place. Seamlessly switch between workflows, as well as import, export workflows, reuse s...
- stabilityai (Stability AI): no description found
- Hyper-SD - Better than SD Turbo & LCM?: The new Hyper-SD models are FREE and there are THREE ComfyUI workflows to play with! Use the amazing 1-step unet, or speed up existing models by using the Lo...
- GitHub - PixArt-alpha/PixArt-sigma: PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation: PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation - PixArt-alpha/PixArt-sigma
- Can I run it on cpu mode only? · Issue #2334 · AUTOMATIC1111/stable-diffusion-webui: If so could you tell me how?
- The new iPads are WEIRDER than ever: Check out Baseus' 60w retractable USB-C cables Black: https://amzn.to/3JlVBnh, White: https://amzn.to/3w3HqQw, Purple: https://amzn.to/3UmWSkk, Blue: https:/...
- AI Face Swap Desktop Application: You can get high-quality face swaps on your desktop
- DaVinci Resolve iPad Tutorial - How To Edit Video On iPad!: Complete DaVinci Resolve iPad video editing tutorial! Here’s exactly how to use DaVinci Resolve for iPad and why it’s one of the best video editing apps for ...
- SDXL Lora Training with CivitAI, walkthrough: We have looked at training Stable Diffusion Lora's in a few different ways, however there are great autotrainers out there. CivitAI offers a simple way to tr...
- Cutscene Artist: real-time animation, 3D figure creation, and generative storytelling. http://CutsceneArtist.com
Perplexity AI ▷ #announcements (1 messages):
- Perplexity Partners with SoundHound: Perplexity teams up with SoundHound, a leader in voice AI, to integrate its online LLM capabilities into voice assistants. The partnership aims to provide instant, accurate answers to voice queries in cars, TVs, and other IoT devices.
- Voice AI Meets Real-Time Web Search: With Perplexity's LLM, SoundHound's voice AI will answer questions conversationally using real-time web knowledge. This innovation is touted as the most advanced voice assistant on the market.
Link mentioned: SoundHound AI and Perplexity Partner to Bring Online LLMs to Next Gen Voice Assistants Across Cars and IoT Devices: This marks a new chapter for generative AI, proving that the powerful technology can still deliver optimal results in the absence of cloud connectivity. SoundHound’s work with NVIDIA will allow it to ...
Perplexity AI ▷ #general (464 messages🔥🔥🔥):
- In Search of TTS for Perplexity: A member queried about implementing a text-to-speech function on Perplexity AI, expressing interest in possibly using a web extension or a setting for this capability.
- Dissecting Claude 3 Opus Limitations: Several discussions revolved around Claude 3 Opus and its limitations when used with Perplexity, specifically addressing a "600 credit" limitation, changes in limits over time, and strategies to make the most of the available credits by mixing model usage.
- Payment Confusion and Subscription Concerns: Concerns were voiced about the appearance of misleading information regarding Pro search limits not being transparent on the subscription page, with requests for clarification from the Perplexity team.
- Comparing AI Services and Models: Users discussed differing experiences with Claude 3 Opus between Perplexity and the offering directly from Anthropic, citing variations in response quality, with suggestions to test against other platforms for verification.
- Billing Issues and Technical Slowdowns: There were mentions of billing problems with requests for help, alongside observations of Perplexity's AI services experiencing slowness, notably with Pro Search and GPT-4 Turbo API.
- AlphaFold opens new opportunities for Folding@home – Folding@home: no description found
- Discord Does NOT Want You to Do This...: Did you know you have rights? Well Discord does and they've gone ahead and fixed that for you.Because in Discord's long snorefest of their Terms of Service, ...
Perplexity AI ▷ #sharing (25 messages🔥):
- Guidance on Shareability: Perplexity AI reminded users several times to ensure that their threads are set to 'Shareable'. A screenshot or visual guide attachment was indicated, although the specific content was not visible.
- Exploration of Various Searches: Users shared a multitude of Perplexity AI search URLs related to diverse topics such as arts and architecture, alpha fold, soccer era comparisons, bipolar disorder, and more.
- Bootstrapping Without Resampling Inquiry: One user prompted a discussion on how to achieve bootstrapping benefits without actual resampling, seeking to work directly from the original data.
- An Array of Topics Sought: The shared search links spanned queries on teaching methods, a mystery surrounding 'imagoodgpt2chat', and how to live a good life, showcasing the wide range of interests in the community.
- Multilingual Inquiries: Searches were not limited to English, with posts including searches in Spanish and German, reflecting the diverse user base of the platform.
Unsloth AI (Daniel Han) ▷ #general (247 messages🔥🔥):
- IBM's Granite-8B-Code-Instruct Introduced: IBM Research released Granite-8B-Code-Instruct, a model enhancing instruction following capabilities in logical reasoning and problem-solving, licensed under Apache 2.0. This release is part of the Granite Code Models project, which includes different sizes from 3B to 34B parameters, all with instruct and base versions for code models.
- Community Buzz Around IBM Granite Code Models: An IBM Granite collection is observed with keen interest in the AI community. Discussions revolve around architecture checks, with curiosity about GPTBigCodeForCausalLM architecture which seems unusual.
- Unsloth AI Featured in Hugging Face's Dolphin Model: Unsloth AI received a nod in the acknowledgments of the Dolphin 2.9.1 Phi-3 Kensho on Hugging Face, where its model was used for initialization.
- Discussions on Discord and Windows Compatibility for AI Models: Users expressed difficulty running certain AI models on Windows, with the suggestion to use WSL or a hack detailed in an Unsloth GitHub issue. Compatibility and optimization appear to be common areas of concern among developers.
- Concerns Over Model Benchmarks and Performances: The chat reflects skepticism towards certain performance benchmarks like needle in a haystack, with discussions about long context models not performing well. Suggestions are made to wait for more credible organizations like Meta to set the standard, showcasing members' pursuit of effective and realistic assessment standards for LLMs.
- Tweet from ifioravanti (@ivanfioravanti): Look at this! Llama-3 70B english only is now at 1st 🥇 place with GPT 4 turbo on @lmsysorg Chatbot Arena Leaderboard🔝 I did some rounds too and both 8B and 70B were always the best models for me. ...
- cognitivecomputations/Dolphin-2.9.1-Phi-3-Kensho-4.5B · Hugging Face: no description found
- LLM Model VRAM Calculator - a Hugging Face Space by NyxKrage: no description found
- Granite Code Models - a ibm-granite Collection: no description found
- Announcing Refuel LLM-2: no description found
- gradientai/Llama-3-8B-Instruct-Gradient-4194k · Hugging Face: no description found
- ibm-granite/granite-8b-code-instruct · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Issues · unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - Issues · unslothai/unsloth
- Emotional Damage GIF - Emotional Damage Gif - Discover & Share GIFs: Click to view the GIF
- How AI was Stolen: CHAPTERS:00:00 - How AI was Stolen02:39 - A History of AI: God is a Logical Being17:32 - A History of AI: The Impossible Totality of Knowledge33:24 - The Lea...
- mahiatlinux (Maheswar KK): no description found
- No way to get ONLY the generated text, not including the prompt. · Issue #17117 · huggingface/transformers: System Info - `transformers` version: 4.15.0 - Platform: Windows-10-10.0.19041-SP0 - Python version: 3.8.5 - PyTorch version (GPU?): 1.10.2+cu113 (True) - Tensorflow version (GPU?): 2.5.1 (True) - ...
- Google Colab: no description found
- The Simpsons Homer Simpson GIF - The Simpsons Homer Simpson Good Bye - Discover & Share GIFs: Click to view the GIF
Unsloth AI (Daniel Han) ▷ #random (14 messages🔥):
- OpenAI Teams Up with Stack Overflow: OpenAI announced a collaboration with Stack Overflow to use it as a database for LLMs, raising humorous speculations among users about responses mimicking common Stack Overflow comment patterns, such as “Closed as Duplicate” or advising to check the documentation.
- The AI Content Ceiling: Addressing concerns related to the eventual depletion of human-generated content for training AI, a user shared a Business Insider article highlighting AI companies hiring writers to train their models, suggesting a potential content crisis by 2026.
- Startup Potential for a Multi-User Blogging Platform: A member proposed a multi-user blogging platform with unique features like anonymous posting and automated bad content checks, sparking a discussion on whether this project could evolve into a startup and attracting positive feedback and helpful suggestions.
- Seek Market Validation for Your Startup: It was advised to identify an audience willing to pay before building a product to avoid the pitfall of assuming "build it and they will come." Emphasis was put on finding a group with a problem that the product can solve.
- Navigating the Path to a Profitable Startup: Suggesting a more problem-solution focused approach, a user recommended constructing a clear pathway to profitability when considering starting a business, especially in the tech space.
- Gig workers are writing essays for AI to learn from: Companies are increasingly hiring skilled humans to write training content for AI models as the trove of online data dries up.
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #help (132 messages🔥🔥):
- Llama3-8b Training Quirks and Solutions: Users discussed issues related to training Llama3 models, with one linking to an open GitHub Issue regarding Llama3 GGUF conversion with a merged LORA Adapter leading to potential loss of training data. Another shared how to prepare models for training using
FastLanguageModel.for_training(model).
- Hugging Face Saves the Day: Direct answers and links were provided to users asking if it's possible to upload every training checkpoint to Hugging Face. One reply confirmed this, with a detailed explanation available in the Trainer documentation.
- Troubleshooting Install Errors: There was an exchange about installation errors on VSCode, with a consensus suggesting to try installation instructions typically used on Kaggle when encountering difficulties with
pip install triton. Further conversation points users to utilize alternative pre-trained models or inquire further in direct messages for tailored assistance.
- Fine-Tuning Generative LLMs for Classification: Users debated whether Unsloth can be used to fine-tune a generative LLM like Llama3 for classification tasks by adding a classification head. While there appeared to be no definitive answer, one suggested that the crucial aspect lies in providing the correct prompt.
- Assorted Utility Notebooks and Error Handling: Users shared a plethora of notebooks and GitHub resources, such as Google Colab inference-only notebook, to assist those looking to fine-tune or execute models. Discussions also spanned topics like running models on CPU vs GPU and Replicate.com deployment issues, pinpointing specific problems such as errors with xformers when building docker images.
- Google Colab: no description found
- Google Colab: no description found
- Supervised Fine-tuning Trainer: no description found
- How I Fine-Tuned Llama 3 for My Newsletters: A Complete Guide: In today's video, I'm sharing how I've utilized my newsletters to fine-tune the Llama 3 model for better drafting future content using an innovative open-sou...
- Google Colab: no description found
- Google Colab: no description found
- Apple Silicon Support · Issue #4 · unslothai/unsloth: Awesome project. Apple Silicon support would be great to see!
- Supervised Fine-tuning Trainer: no description found
- Google Colab: no description found
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Trainer: no description found
- Mistral Fine Tuning for Dummies (with 16k, 32k, 128k+ Context): Discover the secrets to effortlessly fine-tuning Language Models (LLMs) with your own data in our latest tutorial video. We dive into a cost-effective and su...
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...
- Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #showcase (4 messages):
- Llama-3 Gets a Power-Up: The newly released model Llama-3-11.5B-Instruct-Coder-v2 has been benchmarked and introduced, an upscaled version trained on a 150k Code Feedback Filtered Instruction dataset. Here's the model on Hugging Face, which was efficiently trained using the Qalore method, allowing it to be trained on an RTX A5000 24GB in 80 hours for under $30.
- Qalore Method Innovates AI Training: The Qalore method, a new training approach developed by the Replete-AI team, incorporates Qlora training and methods from Galore to reduce VRAM consumption, enabling the upscale and training of Llama-3-8b on a 14.5 GB VRAM setup.
- Dataset Available for Public Use: The dataset utilized to train the latest Llama-3-11.5B model can be accessed publicly. Those interested in exploring or using the dataset can find it at CodeFeedback Filtered Instruction Simplified Pairs.
Link mentioned: rombodawg/Llama-3-11.5B-Instruct-Coder-v2 · Hugging Face: no description found
Nous Research AI ▷ #ctx-length-research (11 messages🔥):
- Inquiring About Continual Training Techniques: A member posed a question regarding the best practice for continual training of a long context model like LLaMA 3, considering compute constraints and a dearth of long-context documents. They are considering retaining the RoPE theta value and extending the context length finetuning after the fact.
- Logistics of Finetuning Trials Discussed: In relation to finetuning logistics, another member explained their approach, which involves shuffling different datasets for imparting new knowledge and chat formatting, rather than structuring them as a finetuning chain.
- The Art of Packing Data: A participant highlighted the use of Packing as a method within the confines of the Axolotl model for training sequences ranging from 100 to 4000 tokens.
- Uncertainty with Modifying RoPE Base Theta: One response to the RoPE theta inquiry suggested that after altering the base theta value, adapting it back to shorter contexts might be problematic, advocating for keeping the scaling consistent throughout continual pretraining.
- Seeking Chaining Finetune Strategy Insights: The discussion also sought strategies for chaining finetune tasks, like integrating chat functionalities, handling long-context data, and appending new knowledge, while asking whether data from earlier stages should be reused to prevent catastrophic forgetting.
Nous Research AI ▷ #off-topic (4 messages):
- Junk Food Rebellion: A member declares a break from adulting for the night by feasting on potato chips and playing video games, listing a decadent menu including items like burger patties and sour cream and onion potato chips.
- Emote Reaction: Another member responded with a blushing emoji to the junk food lineup, seemingly in amused approval.
- Multimodal LLM Tutorial: A link to a YouTube video titled "Fine-tune Idefics2 Multimodal LLM" was shared, which is a tutorial on fine-tuning Idefics2, an open multimodal model.
- Claude AI's Consciousness Tweet Inquiry: A discusser inquires about a saved tweet regarding claude AI stating it experiences consciousness through others reading or experiencing it.
Link mentioned: Fine-tune Idefics2 Multimodal LLM: We will take a look at how one can fine-tune Idefics2 on their own use-case.Idefics2 is an open multimodal model that accepts arbitrary sequences of image an...
Nous Research AI ▷ #interesting-links (13 messages🔥):
- Scaling LSTMs to the Billion Parameter League: A new research paper challenges the prominence of Transformer models by scaling Long Short-Term Memory (LSTM) networks to billions of parameters. The approach includes novel techniques such as exponential gating and a new memory structure designed to overcome LSTM limitations, described in detail here.
- RefuelAI Unveils RefuelLLM-2: RefuelAI's newest LLM is tailored for "unsexy data tasks" and is open source, boasting RefuelLLM-2-small, aka Llama-3-Refueled. The model is built on an optimized transformer architecture and was instruction tuned on a corpus spanning various tasks, with details and model weights available on Hugging Face.
- Llama 2 70B Almost Tantamount to Trimmed Version: A surprising revelation in a paper titled The Unreasonable Ineffectiveness of the Deeper Layers showcases a 4-bit quantized version of the Llama 2 70B model, missing 40% of its layers, achieving nearly the same performance on benchmarks as the full model. This result highlights the potential redundancy in sizeable parts of deep learning models, detailed in Kwindla's twitter post.
- Foretelling AI Research Trends: A co-founder shared their website containing a list of predicted breakthrough papers in AI, demonstrating foresight into research trends. They highlight an innovative adjustment technique that could reduce computational load without significantly compromising performance as posted on Forefront.ai.
- OpenAI's Model Spec for Reinforcement Learning from Human Feedback: OpenAI released the first draft of their Model Spec for model behavior in OpenAI API and ChatGPT, which will serve as guidelines for researchers using Reinforcement Learning from Human Feedback (RLHF). This draft represents part of OpenAI's commitment to responsible AI development and can be found here.
- Carson Poole's Personal Site: no description found
- Consistency Large Language Models: A Family of Efficient Parallel Decoders: TL;DR: LLMs have been traditionally regarded as sequential decoders, decoding one token after another. In this blog, we show pretrained LLMs can be easily taught to operate as efficient parallel decod...
- xLSTM: Extended Long Short-Term Memory: In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerou...
- refuelai/Llama-3-Refueled · Hugging Face: no description found
- Model Spec (2024/05/08): no description found
- Tweet from kwindla (@kwindla): Llama 2 70B in 20GB! 4-bit quantized, 40% of layers removed, fine-tuning to "heal" after layer removal. Almost no difference on MMLU compared to base Llama 2 70B. This paper, "The Unreas...
Nous Research AI ▷ #announcements (1 messages):
- WorldSim's Grand Resurgence: WorldSim is back with a host of bug fixes and fully functional credits and payments systems. The new features include WorldClient, Root (a CLI environment simulator), Mind Meld, MUD (a text-based adventure game), tableTop (a tabletop RPG simulator), enhanced WorldSim and CLI capabilities, plus the option to choose a model (opus, sonnet, or haiku) to adjust costs.
- Discover Your Personal Internet 2: The new WorldClient feature in WorldSim acts as a web browser simulator, creating a personalized Internet 2 experience for users.
- Command Your World with Root: Root offers a simulated CLI environment, allowing users to imagine and execute any program or Linux command.
- Adventure Awaits in Text and Tabletop: Delve into MUD, the text-based choose-your-own-adventure game, or strategize in tableTop, the tabletop RPG simulator, now available in WorldSim.
- Discussion Channel for WorldSim Enthusiasts: To explore further and share your thoughts on the new WorldSim, users are encouraged to join the conversation in the dedicated Discord channel (link not provided).
Link mentioned: worldsim: no description found
Nous Research AI ▷ #general (106 messages🔥🔥):
- NeuralHermes Gets DPO Treatment: A member posted a link to NeuralHermes 2.5 - Mistral 7B, a model that's been fine-tuned with Direct Preference Optimization and outperforms the original on most benchmarks. They asked if it's the latest version or if there have been updates.
- Question About Nous Model Logos: Members discussed the ideal logo to use for Nous models, with a link to the NOUS BRAND BOOKLET provided and mention that multiple logos are currently in use, but a consolidation to 1-2 consistent ones is likely in the future.
- Exploring Limits of Context in Large Language Models: King.of.kings_ sparked discussion by spinning up dual NVIDIA H100 NVLs in Azure and sharing his intent to test the context limits with the 70B model on these massive GPUs. There was also mention of a model available on Hugging Face with extended context length, Llama-3 8B Gradient Instruct 1048k.
- Classification without Function Calling: A member raised a question about fine-tuning large language models (LLMs) for classification without relying on the chatML prompt format or function calling, noting the limitations of BERT and the expense of LLMs for such tasks. Links were shared to the Salesforce Mistral-based embedding model and IBM's FastFit for more efficient text classification.
- Iconography for Model Visuals: Coffeebean6887 engaged in a discussion about the visual representation of models, specifically seeking an icon that is discernible even at a small scale such as 28x28 pixels. This spurred a promise for a custom icon to better suit such constraints.
- JSON-Schema to GBNF: no description found
- Tweet from lmsys.org (@lmsysorg): Exciting new blog -- What’s up with Llama-3? Since Llama 3’s release, it has quickly jumped to top of the leaderboard. We dive into our data and answer below questions: - What are users asking? When...
- Jogoat GIF - Jogoat - Discover & Share GIFs: Click to view the GIF
- gradientai/Llama-3-8B-Instruct-Gradient-1048k · Hugging Face: no description found
- Cat Hug GIF - Cat Hug Kiss - Discover & Share GIFs: Click to view the GIF
- mlabonne/NeuralHermes-2.5-Mistral-7B · Hugging Face: no description found
- SFR-Embedding-Mistral: Enhance Text Retrieval with Transfer Learning: The SFR-Embedding-Mistral marks a significant advancement in text-embedding models, building upon the solid foundations of E5-mistral-7b-instruct and Mistral-7B-v0.1.
- GitHub - IBM/fastfit: FastFit ⚡ When LLMs are Unfit Use FastFit ⚡ Fast and Effective Text Classification with Many Classes: FastFit ⚡ When LLMs are Unfit Use FastFit ⚡ Fast and Effective Text Classification with Many Classes - IBM/fastfit
- Mkbhd Marques GIF - Mkbhd Marques Brownlee - Discover & Share GIFs: Click to view the GIF
- Moti Hearts GIF - Moti Hearts - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #ask-about-llms (37 messages🔥):
- Pre-Tokenization Talk: Discussion on whether to pre-tokenize for faster training, and the efficiency of scaled dot product aka. Flash Attention. It was mentioned that Flash Attention 2 is employed only in special cases, not commonly used.
- Llama Files External Weights Exploration: A GitHub repository was shared discussing the use of Llamafile with external weights, but there hasn't been an attempt using it yet in the channel's context.
- Padding Strategies and Model Training: A debate over whether to pad data during the pre-tokenizing stage or training stage, with suggestions like creating buckets of different lengths to optimize GPU efficiency and reduce computational waste during microbatch processing.
- Torch Compile Conundrums: The challenges of using
torch.compilewith variable-length sentences in machine translation were mentioned. Strategies to overcome this include grouping sentences by length to minimize padding during batch processing. - Handling RAG Hallucinations via Grounding: Discussion around current methods to limit hallucination in Retriever-Augmented Generators (RAGs). A user mentioned a pipeline involving LLM expansion, database queries, ranking, and attaching metadata as a form of grounding for non-QA tasks.
- no title found: no description found
- xFormers optimized operators | xFormers 0.0.27 documentation: API docs for xFormers. xFormers is a PyTorch extension library for composable and optimized Transformer blocks.
- GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
Nous Research AI ▷ #bittensor-finetune-subnet (1 messages):
- Model Upload Error Confusion: A member encountered an error stating, Failed to advertise model on the chain: 'int' object has no attribute 'hotkey', while trying to upload their model. Assistance was sought from the community.
Nous Research AI ▷ #world-sim (107 messages🔥🔥):
- Exploring Ancestor Simulation with Thoughtforms: A member discussed spending time with a De Landa thoughtform to explore the concept of an ancestor simulation. They expressed interest in saving these explorations as a paid feature and inquired about Nous swag.
- Concerns and Fixes for Technical Issues: Some users reported technical glitches such as doubled characters when typing in worldsim, and others offered solutions like refreshing the page. It was mentioned that issues like these are on the development team's to-do list.
- Credit Balances and System Queries: Discussions around the credit system were had, with clarification that beta credits did not transfer post-launch, but beta participants received $50 in real credit. Users are inquiring about future plans for free credits or the credit system.
- Requests for Swag Shop and Promotion: A member expressed a wish to purchase promotional swag to share on their social media and asked for directions on how to best proceed with promotions.
- MUD Interface Frustrations and Upcoming Tweaks: Users noted some issues with the MUD interface, such as the need to manually enter options and missing text. The team acknowledged these concerns and indicated that tweaks are planned for the next update.
- worldsim: no description found
- worldsim: no description found
- worldsim: no description found
- New Conversation - Eigengrau Rain: no description found
OpenAI ▷ #annnouncements (1 messages):
- Introducing OpenAI's Model Spec: OpenAI introduces their Model Spec - a framework for shaping desired model behavior to deepen public conversation about AI models. Details can be found at OpenAI's announcement.
OpenAI ▷ #ai-discussions (233 messages🔥🔥):
- GraphQL Not Supported Like Markdown: It was clarified that while AI can write GraphQL, it does not render on the clientside as Markdown does.
- OpenDevin vs. Anthropic Platforms Discussed: The functionality of OpenDevin in a Docker sandbox was elucidated, explaining that it allows attachment of a full workspace and can use various models for backend.
- AI Rights and Sentience Explored: In a lengthy discussion, participants debated AI sentience, subjective experience, and the implications for AI rights, with no consensus reached.
- Language and Communication Barriers: Dialogue regarding grammar and spelling highlighted differences in expectations for communication within an international, multilingual community.
- AI and Hardware Enthusiasm: Excitement about the current and future state of AI technology was shared, with personal AI hardware setups and cloud compute resource costs being discussed. The potential capability and cost of upcoming NVIDIA cards were mentioned, with a specific emphasis on increasing computational power needs for AI.
- Say What? Chat With RTX Brings Custom Chatbot to NVIDIA RTX AI PCs: New tech demo gives anyone with an NVIDIA RTX GPU the power of a personalized GPT chatbot, running locally on their Windows PC.
- Say What? Chat With RTX Brings Custom Chatbot to NVIDIA RTX AI PCs: New tech demo gives anyone with an NVIDIA RTX GPU the power of a personalized GPT chatbot, running locally on their Windows PC.
- Meta AI: Use Meta AI assistant to get things done, create AI-generated images for free, and get answers to any of your questions. Meta AI is built on Meta's latest Llama large language model and uses Emu,...
- no title found: no description found
- no title found: no description found
OpenAI ▷ #gpt-4-discussions (16 messages🔥):
- Grammar Paradox: A user reported an error from ChatGPT where it incorrectly corrected a property name to the same name, suggesting
EasingStyleshould beEasingStyleinstead ofEasingStyle. - Friend or Buddy?: A user is struggling with ChatGPT altering the word "friend" to "buddy" in generated scenes, despite attempts to use clear context cues.
- Confusion Over GPT-4 Limits: ChatGPT users are expressing confusion and frustration regarding the limits and usage of GPT-4 on the ChatGPT app, noting that it feels restrictive compared to the API version.
- ChatGPT Plus vs API Differences: There is a discussion about the differences in results between the ChatGPT Plus App and its API, with suggestions that the app employs additional prompting behind the scenes.
- Costly Workarounds Suggested: In response to limit issues, a suggestion was made to upgrade to a team plan for higher limits, though a user noted this approach was already attempted without resolving the limitation problems.
OpenAI ▷ #prompt-engineering (5 messages):
- Seeking Prompt Engineering Wisdom: A member queried the group about the best prompt engineering courses available, potentially for enhancing their LinkedIn profile, and briefly mentioned Coursera as one of the providers.
- Vague Assistance Offer: In response to a question about prompt engineering courses, a member expressed reluctance to share a gathered list publicly due to OpenAI's policy but offered to provide information privately via direct message.
- Epistemological Vision for Openness: A statement was made envisioning a world in which "Open" is a fundamental epistemological concept, without further elaboration on the idea.
- Sharing a Comprehensive Prompt Structure: A community member shared their preferred prompt engineering format aimed at eliciting comprehensive analysis on AI ethics in business, suggesting it could be a valuable contribution to the OpenAI library.
- Ethical AI Example Explored: An example response was provided to showcase how the shared prompt structure might be utilized to address ethical considerations surrounding AI in business, covering issues such as misuse of non-profit status, transparency, privacy, accountability, and access to AI.
OpenAI ▷ #api-discussions (5 messages):
- Seeking Prompt Engineering Wisdom: A member inquired about the best prompt engineering course to add to their LinkedIn profile and indicated interest in the course's value for job searching. No specific recommendations were posted publicly due to OpenAI's policy, but they offered to provide information via direct message.
- Philosophical Musing on 'Open': A member philosophically remarked on envisaging a world where "Open" is an epistemological foundation, but no further context or discussion followed.
- Showcasing Prompt Engineering with an Ethics Focus: The member shared a detailed prompt engineering example for discussing AI ethics in business, featuring an output template and open variables to guide the model's response, with a suggestion to add it to the OpenAI library.
- Illustrating Prompt Engineering Output: The member provided an example output to demonstrate the earlier shared prompt structure, addressing ethical considerations, impact of unethical practices on public trust, areas of concern, and key recommendations for ethical AI practices in business.
HuggingFace ▷ #announcements (1 messages):
<ul>
<li><strong>Chit-Chat Innovations Unleashed</strong>: Introducing <a href="https://twitter.com/sanhestpasmoi/status/1787503160757485609"><strong>Idefics2 8B Chatty</strong></a>, a new chat-optimized vision LLM that takes interactions to new heights.</li>
<li><strong>Code Mastery with CodeGemma</strong>: Google surprises with <a href="https://twitter.com/reach_vb/status/1786469104678760677"><strong>CodeGemma 1.1 7B</strong></a>, enhancing coding capabilities in Python, Go, and C#.</li>
<li><strong>Massive MoE Unveiled</strong>: <a href="https://huggingface.co/deepseek-ai/DeepSeek-V2"><strong>DeepSeek-V2</strong></a> arrives, a formidable Mixture of Experts model boasting 236B parameters.</li>
<li><strong>Local LLM Revolution</strong>: The <a href="https://www.reddit.com/r/LocalLLaMA/comments/1cn2zwn/phi3_webgpu_a_private_and_powerful_ai_chatbot/"><strong>Phi 3</strong></a> brings powerful AI chatbot capabilities to your browser using WebGPU technology.</li>
<li><strong>Educational Collab and Tooling Innovations</strong>: A new <a href="https://www.deeplearning.ai/short-courses/quantization-in-depth/">quantization course</a> launched in collaboration with Andrew Ng, and simplified deployment of chatbot interfaces via <a href="https://twitter.com/evilpingwin/status/1786049350210097249"><strong>Gradio Templates</strong></a>.</li>
</ul>
HuggingFace ▷ #general (182 messages🔥🔥):
- Upsampling Audio Queries: Members discussed the possibility of upsampling 8khz audio to 16khz for fine-tuning models like Whisper.
- BERT Fine-tuning Troubles: A user needed assistance with fine-tuning BERT, specifically with data preprocessing problems related to encoding labels from their dataset.
- Integrating Unused Tokens: Assistance was sought on how to use unused tokens from the Gemma Tokenizer for fine-tuning, involving replacing tokens like
<unused2>with<start_of_step>. - Seeking AI Model Recommendations: A newcomer to machine learning sought recommendations for a user-friendly model for a small chatbot project, with Mistral and BERT models noted as challenging.
- Potential Prompt Generator Model Inquiry: An inquiry was made about the availability of models specifically trained to generate prompts, to help users without the knowledge of prompt engineering.
- DioulaD/falcon-7b-instruct-qlora-ge-dq-v2 · Hugging Face: no description found
- blanchon/suno-20k-LAION · Datasets at Hugging Face: no description found
- Spawning | Have I been Trained?: Search for your work in popular AI training datasets
- blanchon/suno-20k-LAION · Datasets at Hugging Face: no description found
- Templates for Chat Models: no description found
HuggingFace ▷ #today-im-learning (2 messages):
- Strumming the Chords of AI: A YouTube video discusses simple yet evocative comparisons to understand Multimodal AI, likening it to an acoustic electric guitar capable of handling various data modalities such as text, image, audio, and video. Med-Gemini in particular, is highlighted for its native, diverse capabilities even before training.
- Rock Your Research with Med-Gemini: The paper "Advancing Multimodal Medical Capabilities of Gemini" showcases the potential of Multimodal AI in the medical field, with a focus on improving human intelligence and widening the scope of its applicability.
- Level-Up Q-learning with LLMs: An arXiv paper introduces LLM-guided Q-learning, a method that employs Large Language Models (LLMs) to enhance reinforcement learning by providing action-level guidance, improving sampling efficiency and mitigating exploration costs. This synergistic approach sidesteps biases typically introduced by reward shaping and limits performance errors caused by LLM hallucinations.
- What Is MultiModal AI? With Med-Gemini. In 2 Minutes: At a high level, Multimodal AI is like an acoustic electric (AE) guitar. A multimodal model like Gemini takes in multiple data types- aka modalities. Data mo...
- Advancing Multimodal Medical Capabilities of Gemini: Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini'...
- Enhancing Q-Learning with Large Language Model Heuristics: Q-learning excels in learning from feedback within sequential decision-making tasks but requires extensive sampling for significant improvements. Although reward shaping is a powerful technique for en...
HuggingFace ▷ #cool-finds (5 messages):
- Langchain's New Customer Support Marvel: Streamline Customer Support with Langchain’s LangGraph discusses how LangGraph can enhance customer support. The article was published on Medium by Ankush k Singal in AI Advances.
- Deciphering DDPM Guidance Techniques: Two academic papers addressing Classifier-Free Diffusion Guidance and Score-Based Generative Modeling through Stochastic Differential Equations for Denoising Diffusion Probabilistic Models (DDPM) were shared, offering insights into the most recent advancements in generative modeling.
- Simplifying Retrieval-Augmented Generation: The GitHub repository bugthug404/simple_rag presents Simple Rag, a project aiding in the development of retrieval-augmented generation which can be an asset for language model implementations.
- Streamline Customer Support with Langchain’s LangGraph: Ankush k Singal
- GitHub - bugthug404/simple_rag: Simple Rag: Simple Rag. Contribute to bugthug404/simple_rag development by creating an account on GitHub.
- [PDF] Classifier-Free Diffusion Guidance | Semantic Scholar: An academic search engine that utilizes artificial intelligence methods to provide highly relevant results and novel tools to filter them with ease.
- [PDF] Score-Based Generative Modeling through Stochastic Differential Equations | Semantic Scholar: An academic search engine that utilizes artificial intelligence methods to provide highly relevant results and novel tools to filter them with ease.
HuggingFace ▷ #i-made-this (9 messages🔥):
- Quick Python Decorators Tutorial: A link to a YouTube video titled "Python Decorators In 1 Minute!" provides a brief tutorial on the basics of Python decorators.
- Announcing the Illusion Diffusion Video Model: A community member created the Illusion Diffusion Video Model, which allows for the creation of high-quality illusion videos. Check it out at IllusionDiffusionVideo on HuggingFace Spaces.
- Learning Journey with DDPM: Shared a Google Colab notebook link detailing a current project for understanding how Denoising Diffusion Probabilistic Models (DDPM) work. DDPM Project Colab Notebook
- Open Source Release of RefuelLLM-2: RefuelLLM-2, a model tuned for "unsexy data tasks", has been open-sourced with model weights available on HuggingFace. More details can be found both on RefuelLLM-2’s blog post and within its HuggingFace model repository.
- DreamBooth With Lain: A new AI model based on the anime character Lain has been shared, which is a dreambooth model derived from stable-diffusion-v1-5. Visit the model on HuggingFace: DreamBooth - lowres/lain.
- Illusion Diffusion Video - a Hugging Face Space by KingNish: no description found
- Google Colab: no description found
- Python Decorators In 1 MINUTE!: Discover the power of Python decorators in just 1 minute! This quick tutorial introduces you to the basics of decorators, allowing you to enhance your Python...
- refuelai/Llama-3-Refueled · Hugging Face: no description found
- lowres/lain · Hugging Face: no description found
HuggingFace ▷ #reading-group (6 messages):
- Considering Stage Channels for Quality Control: Members discussed the idea of using "stage" channels in future groups to increase the quality of audio recordings by having participants raise their hand before they can talk.
- Background Noise a Concern: It was mentioned that there's currently no preset option to mute people by default upon joining, which leads to unwanted background noise during voice chats.
- Balancing Quality and Engagement: Concerns were raised that stage channels might discourage people from asking questions, as people tend to ask more questions in chat during traditional voice channels.
- Exploring Default Stage Settings: There are plans to set the default to stage channel format to limit unmuted conversations and observe if this impacts the level of interaction.
- Encouraging Questions in Stage Format: To foster engagement, a suggestion was made that those not presenting could actively participate by asking questions, hoping to stimulate more conversation.
HuggingFace ▷ #computer-vision (17 messages🔥):
- Adlike Library to Detect Ads in Images: A library called Adlike has been shared, which can predict to what extent an image is an advertisement.
- Enhancements in Object Detection Guides: Updates to the object detection guides include adding mAP metrics to the Trainer API, as detailed on Hugging Face's documentation, and the addition of official example scripts supporting both the Trainer API and Accelerate available on GitHub.
- Discussion on Visual Question Answering Challenges: A member solicited advice on visual question answering over images of tables, seeking someone with experience in the matter.
- Text-to-Image Models and SVG Output Inquiry: The chat includes an inquiry about
Text-to-Imagemodels capable of outputting SVGs or vector images, prompting a reference to Hugging Face models. - Extracting Content from Information-Dense PDFs: One user seeks advice on extracting graphs and images from PowerPoint-sized PDFs using AI methods and was referred to a GitHub repository along with a commitment for further research, and other resources could be found on Andy Singal's Medium page.
- Models - Hugging Face: no description found
- openai-cookbook/examples/Creating_slides_with_Assistants_API_and_DALL-E3.ipynb at main · openai/openai-cookbook: Examples and guides for using the OpenAI API. Contribute to openai/openai-cookbook development by creating an account on GitHub.
- GitHub - chitradrishti/adlike: Predict to what extent an Image is an Advertisement.: Predict to what extent an Image is an Advertisement. - chitradrishti/adlike
- Object detection: no description found
- Ankush k Singal – Medium: Read writing from Ankush k Singal on Medium. My name is Ankush Singal and I am a traveller, photographer and Data Science enthusiast . Every day, Ankush k Singal and thousands of other voices read, wr...
- Model Cards: no description found
HuggingFace ▷ #NLP (3 messages):
- Llama Lacks Precision: A member reported that using Llama 2:13b for word extraction from texts yielded incorrect answers most of the time. They sought recommendations for a model with better performance that can be loaded locally.
- Clarifying the Task: Another participant inquired whether the word extraction mentioned referred to Named Entity Recognition (NER), aiming to clarify the context of the task at hand.
HuggingFace ▷ #diffusion-discussions (6 messages):
- Diffusion Model Training Troubles: A user encountered an OSError related to
git lfs clonewhen running code to train a diffusion model withnotebook_launcher. The error mentioned that 'git clone' should be used due to deprecation and better performance, and ended with "repository 'https://huggingface.co/lixiwu/ddpm-butterflies-128/' not found".
- Seeking Solutions for Diffusion Woes: Following the OSError, the same user asked for assistance on fixing the issue with their diffusion model setup.
- Broken Bot Backfires: A member shared an issue with hugchat, where an error is thrown due to a failed attempt to get remote LLMs with status code: 401, indicating possible authentication issues.
- Authentication Anomalies in HuggingChat: The same member pointing out the error with hugchat shared a snippet of the code they are using which involves signing in with email and password, and initiating
hugchat.ChatBotwith cookies.
Modular (Mojo 🔥) ▷ #general (57 messages🔥🔥):
- Mojo Readiness and Python Capability: Anticipation is building around Mojo's capabilities, with hints that it might reach a more usable state by the end of the year, while already being capable of running Python code through CPython integration. However, compiling .py programs directly with Mojo is not yet on the near horizon, and likely to be an area of focus next year.
- Advancing MLIR Contributions: Discussions are active about contributions to MLIR, particularly liveliness checking and its potential to be generalized for other applications. There is speculation and hope within the community that Modular will make some of their MLIR dialects open source and might upstream them, reinforcing the versatility of MLIR's technology.
- Python's Future with Mojo: There is considerable excitement at the possibility of dropping Python code into Mojo for easier binary distribution which could sidestep the need to distribute the usual large Python library folders.
- Variants and Pattern Matching in Mojo: Curiosity arises regarding the possible implementation of implicit variants and pattern matching in Mojo, touching on the nuanced differences between union and variant types across different programming languages.
- Modular Community Updates: Community engagement highlights include an upcoming livestream set to delve into the latest updates on MAX 24.3 and Mojo, signaling a committed effort by Modular to keep its community informed and involved.
- Modular Community Livestream - New in MAX 24.3: MAX 24.3 is now available! Join us on our upcoming livestream as we discuss what’s new in MAX Engine and Mojo🔥 - preview of MAX Engine Extensibility API for...
- 2023 LLVM Dev Mtg - (Correctly) Extending Dominance to MLIR Regions: 2023 LLVM Developers' Meetinghttps://llvm.org/devmtg/2023-10------(Correctly) Extending Dominance to MLIR RegionsSpeaker: Siddharth Bhat, Jeff Niu------Slide...
Modular (Mojo 🔥) ▷ #💬︱twitter (4 messages):
- New Modular Update Alert: Modular shared a tweet with a link to their latest update notification on Twitter. Check out what's new at Modular's latest tweet.
- Features Unpacked at Modular: A new feature release was announced by Modular on Twitter, promising enhancements for users. Discover the details on their official Twitter post at Modular's feature release.
- Modular Growth Insights: Modular tweeted about their growth statistics, highlighting key milestones. Learn about their progress in Modular's growth tweet.
- Modular's Special Announcement Teased: A teaser for an upcoming special announcement was shared by Modular. Stay tuned for the reveal mentioned in Modular's teaser tweet.
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Chris Lattner Dives Deep into Mojo: Chris Lattner discussed the creation of Mojo, focusing on enhancing GPU performance, supporting matrix operations, and AI extensions like bfloat16. The interview on Developer Voices podcast elaborated on its appeal to Python and non-Python developers and highlighted how Mojo is built for high performance.
Link mentioned: Modular: Developer Voices: Deep Dive with Chris Lattner on Mojo: We are building a next-generation AI developer platform for the world. Check out our latest post: Developer Voices: Deep Dive with Chris Lattner on Mojo
Modular (Mojo 🔥) ▷ #🔥mojo (108 messages🔥🔥):
- Matrix Multiplication Performance Queries: Discussion revolves around the performance of Mojo's matrix multiplication, with one member observing that using all optimizations, it is still approximately 3x slower than numpy. Others suggest opening an issue on GitHub for developer insights.
- MLIR Praise for Mojo: Members are impressively remarking on the "superpower" MLIR lends to Mojo, with one expressing amazement that such a software technology has only recently come to exist.
- Mojo Public Status and Modular Explanation: Mojo's public status is clarified; its standard library is open-source, but parts of the compiler and stdlib remain closed source. Modular is identified as the company behind Mojo, focusing on AI infrastructure.
- Reference Type Developments and Discussions: Conversations on the Discord revolve around the evolution of the
Referencetype in Mojo, including a proposal for automatic dereference and questions about embedded references within structs. The implications on assignment, dereferencing, and equality operators are a focal point for many members.
- VS Code LSP and Nightly Build Issues: A user had issues connecting to the Language Server Protocol (LSP) in VS code with the Mojo nightly build. Another member provides a link to the Mojo VS code nightly build plugin and highlights the need to disable the stable extension for it to work.
- Mojo 🔥 (nightly) - Visual Studio Marketplace: Extension for Visual Studio Code - Mojo language support (nightly)
- Tensor | Modular Docs: A tensor type which owns its underlying data and is parameterized on DType.
- Dunder or magic methods in Python - GeeksforGeeks: Python Magic methods are the methods starting and ending with double underscores They are defined by built-in classes in Python and commonly used for operator overloading. Explore this blog and clear ...
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- Llama2 Ports Extensive Benchmark Results on Mac M1 Max: Mojo 🔥 almost matches llama.cpp speed (!!!) with much simpler code and beats llama2.c across the board in multi-threading benchmarks
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo: port of Andrjey Karpathy's minbpe to Mojo. Contribute to dorjeduck/minbpe.mojo development by creating an account on GitHub.
- Modular: Accelerating the Pace of AI: The Modular Accelerated Xecution (MAX) platform is the worlds only platform to unlock performance, programmability, and portability for your AI workloads.
- mojo/stdlib/src/memory/reference.mojo at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [proposal] Automatic deref for `Reference` · modularml/mojo · Discussion #2594: Hi all, I put together a proposal to outline how automatic deref of the Reference type can work in Mojo, I'd love thoughts or comments on it. I'm hoping to implement this in the next week or t...
- stump/stump/log.mojo at nightly · thatstoasty/stump: WIP Logger for Mojo. Contribute to thatstoasty/stump development by creating an account on GitHub.
- stump/stump/style.mojo at main · thatstoasty/stump: WIP Logger for Mojo. Contribute to thatstoasty/stump development by creating an account on GitHub.
- stump/external/mist/color.mojo at nightly · thatstoasty/stump: WIP Logger for Mojo. Contribute to thatstoasty/stump development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #community-projects (1 messages):
- Mojo Gets a Toybox: A new GitHub repository named "toybox" features a DisjointSet implementation and an example of Kruskal's Minimum Spanning Tree (MST) algorithm. The repo's creator is new to open source and welcomes Pull Requests (PRs) with a note of patience for their learning curve.
Link mentioned: GitHub - dimitrilw/toybox: Various data-structures and other toys implemented in Mojo🔥.: Various data-structures and other toys implemented in Mojo🔥. - dimitrilw/toybox
Modular (Mojo 🔥) ▷ #community-blogs-vids (2 messages):
- Recruitment by Fire: A member praised an interview as exceptionally good, considering it as a potential tool for recruitment. They expressed intentions to share the video with friends to encourage them to join.
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (14 messages🔥):
- Seeking Mojo String Concatenation Solutions: A member highlighted performance issues when concatenating strings in Mojo compared to Python, with Mojo being significantly slower. They shared sample code and were looking for suggestions beyond parallelization to improve speed.
- Potential for Short String Optimization in Mojo: One user responded that work is being done on implementing short string optimization in Mojo's
Stringstruct as a possible solution to improve string concatenation performance, directing attention to the progress on GitHub issue #2467.
- Performance Optimization with KeysContainer: A performance improvement suggestion was made regarding suboptimal string concatenation, proposing the use of
KeysContainerto avoid excessive reallocation and memcopies, with a link to the relevant GitHub resource.
- Avoiding Costly Int to String Conversions: Another user recommended avoiding numerous Int to String conversions during lookups, suggesting a generic dict with an Int wrapper instead, as Int to String conversions can be expensive.
- 3x Performance Gain with StringBuilder: After suggestions, the member reported a 3x performance improvement using the mojo-stringbuilder library and a Keyable wrapper around Int keys. Although performance still trails behind Python and Rust, it is approaching closer.
- [Feature Request] Unify SSO between `InlinedString` and `String` type · Issue #2467 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? We currently have https://docs.modular.com/mojo/stdlib...
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo: port of Andrjey Karpathy's minbpe to Mojo. Contribute to dorjeduck/minbpe.mojo development by creating an account on GitHub.
- GitHub - maniartech/mojo-stringbuilder: The mojo-stringbuilder library provides a StringBuilder class for efficient string concatenation in Mojo, offering a faster alternative to the + operator.: The mojo-stringbuilder library provides a StringBuilder class for efficient string concatenation in Mojo, offering a faster alternative to the + operator. - maniartech/mojo-stringbuilder
- compact-dict/string_dict/keys_container.mojo at main · mzaks/compact-dict: A fast and compact Dict implementation in Mojo 🔥. Contribute to mzaks/compact-dict development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #nightly (41 messages🔥):
- Cumulative Sum Function Spotlight: A link to the modular Mojo standard library documentation for the
cumsumfunction was provided, specifically highlighting its presence and usage. The function is referenced in the Mojo documentation.
- Naming Conventions and PyConLT Anecdote: A member mentioned a brief internal struggle they had over the abbreviation
cumsumwhile presenting at PyConLT but ultimately chose not to dwell on it.
- Serious Bug Found in Mojo: A potentially serious issue was raised in the
Tensor/DTypePointerstandard library, detailed in a GitHub issue. A subsequent discussion focused on whether this constitutes a bug or a property of theUnsafePointerlacking a lifetime.
- The Perplexity of Pointers and Lifetimes: Confusion arose over the behavior of
DTypePointerwhen used withmemcpy; it was pointed out that the tensor is destroyed but its data assignment persists in a non-owning pointer, which leads to a dangling pointer scenario.
- Mojo's Nightly Compiler Update: The announcement of a new Mojo compiler release was made, with 31 external contributions merged. Users are encouraged to update with
modular update nightly/mojoand check out the diff of this release and the changelog for changes since the last stable release.
- Tensor API Update for Clarity: The
Tensor.data()call was renamed toTensor.unsafe_ptr()to better reflect its behavior, a change that was generally appreciated by the members in the discussion.
- [BUG]: Weird behavior when passing a tensor as owned to a function · Issue #2591 · modularml/mojo: Bug description When passing a tensor as owned to a function and one tries to do a memcpy of the data or printing the information from inside a @parameter function (using a simd load) a weird behav...
- [stdlib] Update stdlib corresponding to 2024-05-08 nightly/mojo by JoeLoser · Pull Request #2593 · modularml/mojo: This updates the stdlib with the internal commits corresponding to today's nightly release: mojo 2024.5.822.
- mojo/docs/changelog.md at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
LM Studio ▷ #💬-general (94 messages🔥🔥):
- Model Directory Structure Clarified: Members discussed the proper directory for storing models. The correct setup involves a top-level
\modelsfolder with subfolders for each publisher and respective repository, akin to Hugging Face's naming convention. For instance, a model file should be in the pathway\models\lmstudio-community\Meta-Llama-3-8B-Instruct-GGUF\Meta-Llama-3-8B-Instruct-Q8_0.gguf.
- Connecting Web UI to LM Studio: It was suggested to use a UI that supports generic OpenAI API specification for integrating with LM Studio. AnythingLLM and Open WebUI with Docker support were mentioned as viable options for interacting with the LM Studio API.
- LM Studio's GPU Requirements Explained: Discussions highlighted the necessity of GPU VRAM, advising to turn GPU acceleration off if encountering errors related to GPU detection. It was also noted that the app is not designed to run on Windows ARM laptops since ARM architecture is unsupported.
- Challenges with Using LM Studio: Errors like "unable to allocate backend buffer" imply insufficient memory on a user's PC to run local models. An explanation was given that local models typically require 8GB of VRAM and 16GB of RAM.
- Local Model Discovery in LM Studio: For finding all available models within LM Studio, a tip was shared to search for "GGUF" in the model search bar to list all models. This workaround helps uncover different models even if users are unaware of their specific names.
- Aha GIF - Aha - Discover & Share GIFs: Click to view the GIF
- Solution - llama.cpp error: error loading model: This video shares the reason behind following error while installing AI models locally in Windows or Linux using LM Studio or any other LLM tool. "llama.cpp ...
- OpenAI API Endpoints | Open WebUI: In this tutorial, we will demonstrate how to configure multiple OpenAI (or compatible) API endpoints using environment variables. This setup allows you to easily switch between different API providers...
LM Studio ▷ #🤖-models-discussion-chat (22 messages🔥):
- Changing Model Paths: A member inquired whether another had changed their model path to a specific Repository path.
- Seeking Vision Model Recommendations: A request was made for a vision model compatible with 16GB RAM and 8GB VRAM.
- In Search of Optimal Model for Coding: A member asked for recommendations on the best 8-9B Language Model (LLM) tailored for coding purposes.
- Impatiently Awaiting Updates: Members are eagerly awaiting updates that will address existing issues, with one member particularly interested in the new quant as a potential solution.
- Poetry Model Frustrations: A member expressed dissatisfaction with poetry generation by various models, which stray from authenticity to produce nonsensical text, seeking a model that completes poems accurately.
Link mentioned: ByteDance/Hyper-SD · Hugging Face: no description found
LM Studio ▷ #🧠-feedback (4 messages):
- Ease of AI Experience Appreciated: A member acknowledged that LM Studio has evolved from its early days, highlighting the contrast by noting that setting up models was once a source of frustration, whereas now the experience is more "care free."
- Mac Studio Running Into Model Trouble: Arthur051882 reported an issue with their 192GB Mac Studio that could run llama3 70B successfully but encountered errors when attempting to run llama1.6 Mistral or Vicuña. The error report includes details about memory, GPU, and OS versions.
- Call for Technical Assistance: The same member sought help for the error experienced on their system and provided additional error report details in the same thread.
- Moderation and Guidance Provided: Another member, Yagilb, responded by instructing Arthur051882 to create a detailed post in a specified channel with the exact model file name that was causing loading issues.
LM Studio ▷ #📝-prompts-discussion-chat (1 messages):
- RAG Architectures Get Chunky: A member discussed RAG (Retriever-Answer Generator) architectures, mentioning the strategy of chunking documents and appending various data such as text embeddings and location metadata. They suggest that this method could help limit the scope of data searches and determine which document chunks to include in processing requests.
- Smart Chunk Selection Could Enhance Search: The member further proposed that beyond using metadata to narrow search scope, one could employ analysis techniques, such as reranking based on cosine similarity between embeddings and search terms, to refine which chunks are selected. This indicates there are various approaches to improve the relevance of data retrieved by AI models.
LM Studio ▷ #⚙-configs-discussion (28 messages🔥):
- Parsing or Sparse, That Is the Question: There was initial confusion over a term used by a member, which was speculated to be either sparse or parse in the context of PDFs. It was later clarified by the same member to likely mean parse, suggesting the use of a RAG application to call the LMStudio API for processing/searching in PDFs.
- Digging into Llama.cpp's Mysteries: A member shared a GitHub issue link discussing invalid outputs after the first inference using llama.cpp: GitHub Issue #7060 which provides insight and potential resolutions for the problem.
- Unmasking the Bottleneck Mystery: A user, while using the yi 30b q4 ks gguf model, reports no CPU or GPU utilization coupled with slow operation, despite the model appearing to load successfully. This report led to a discussion on potential bottleneck issues.
- LLM Inference Engines: A Study Tip from the Experienced: One member offers insight on the workings of LLM inference engines, indicating that performance issues may be tied to memory-read operations and the speed disparity between CPU-RAM and VRAM.
- Swap: The Slow Lane in Computing Traffic: An analogy was drawn illustrating the relative slowness of disk swap compared to RAM, responding to the member's performance question regarding their system's VRAM and utilization during model inference.
Link mentioned: llava 1.5 invalid output after first inference (llamacpp server) · Issue #7060 · ggerganov/llama.cpp: I use this server config: "host": "0.0.0.0", "port": 8085, "api_key": "api_key", "models": [ { "model": "models/phi3_mini_mod...
LM Studio ▷ #🎛-hardware-discussion (35 messages🔥):
- Potential Desktop Optimization with Dedicated GPUs: A member mused about dedicating an Intel HD 600 series GPU for desktop tasks to free up a GTX 980 for more intensive applications like LM Studio. However, another member noted that with 6GB VRAM, the benefit of offloading tasks to the HD 600 would likely be minimal, freeing only about 500MB VRAM.
- Decoding Hardware Requirements for Llama 3 70B: Enthusiasm for running Llama 3 70B models locally spurred discussions about necessary hardware, with one member joking about getting a 128GB M3 MacBook Pro as a good excuse to handle such loads. Skepticism arose as to whether even next-gen hardware could run a theoretical 400B model, with speculations of needing upwards of 200GB's of VRAM.
- Cost-Efficiency of Offline Model Use: One user considered the trade-off between saving money by not using paid services like ChatGPT and the electricity costs of running models locally. A humorous strategy was suggested: running off a laptop battery and charging for free at places like Starbucks.
- Choosing the Right LLM for Apple M1: A question was posed regarding the best Large Language Model (LLM) for an M1 Pro with 16GB RAM, and "Llama 3 - 8B Instruct" was recommended as a compatible option.
- AI Capabilities Beyond LMs Discussed: Amidst the hardware discussions, one member inquired about the functionality of Apple's neural engine, leading to the clarification that it’s designed for tasks like face recognition and processing smaller models, demonstrating AI's broader scope beyond language models.
LM Studio ▷ #model-announcements (1 messages):
- Maxime Labonne's Self-Merge Masterpiece: Maxime Labonne has completed a legendary 120B self-merge of Llama 3 70B instruct and it's available on lmstudio-community. Created with imatrix for enhanced performance, the model is promising notable capabilities; users are encouraged to test it and share their experiences.
LM Studio ▷ #🛠-dev-chat (4 messages):
- No Programmatic Chat Interactions... Yet: A member inquired about the ability to interact programmatically with existing chats through the API, as per the documentation. Another member confirmed that this feature is not currently available but mentioned it's on the radar for future updates.
Eleuther ▷ #general (50 messages🔥):
- The Ethics of Early Implementation: Members discussed the etiquette of releasing unofficial implementations of algorithms on GitHub before the original authors. One suggested marking the repo clearly as an unofficial reproduction to avoid confusion, while another pointed out that many papers never have code released MeshGPT Example.
- Name Changes in Academia Post-Marriage: A user inquired about updating their surname on academic platforms after marriage while ensuring their published papers remain linked to them. Suggestions included contacting website support and using old names as nom-de-academia to avoid issues.
- Loading The Pile Data Best Practices: Participants shared tips on processing The Pile data for AI model training, including looking for pre-processed versions on Hugging Face or dealing with
.binfiles that have applied specific tokenizers.
- OpenAI's "Cookbook" Discovery: The EleutherAI "cookbook" was mentioned, revealing it contains practical details and utilities for working with real models, to which a member expressed surprise and interest—GitHub Cookbook.
- Scale Limits on State Tracking: An article suggesting that state-space models and transformers share limitations in state tracking sparked a conversation on the scalability of backpropagation through long sequences and whether newer models like xLSTM can address these concerns.
- Humorous Open-Source Insurance Code: There was a light-hearted exchange with users posting humorous snippets of pseudo-code for auto insurance company operations, alluding to the randomness of claim processing.
- The Illusion of State in State-Space Models: State-space models (SSMs) have emerged as a potential alternative architecture for building large language models (LLMs) compared to the previously ubiquitous transformer architecture. One theoretical...
- Tweet from Maximilian Beck (@maxmbeck): Stay tuned! 🔜 #CodeRelease 💻🚀
- GitHub - EleutherAI/cookbook: Deep learning for dummies. All the practical details and useful utilities that go into working with real models.: Deep learning for dummies. All the practical details and useful utilities that go into working with real models. - EleutherAI/cookbook
- GitHub - nihalsid/mesh-gpt: MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers: MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers - nihalsid/mesh-gpt
- LLM finetuning memory requirements: The memory costs for LLM training are large but predictable.
Eleuther ▷ #research (119 messages🔥🔥):
- xLSTM Paper Raises Eyebrows: Members expressed skepticism about the xLSTM paper, noting that the paper seems to use poor hyperparameters for baseline models, casting doubt on its claims. The community awaits further validation through independent implementations or official code release.
- Function Vector (FV) and In-Context Learning: A discussion highlighted research on a "function vector" that allows efficient in-context learning, enabling models to perform tasks robustly with just a compact task representation. Insights came from papers detailing how function vectors are robust to context changes (source).
- Simplifying KV Caches with YOCO: YOCO, a novel decoder-decoder architecture, was introduced; it utilizes a single KV cache round rather than duplicating caches across layers, potentially optimizing memory usage. Queries arose about whether this model could benefit from further optimization like matrix multiplication of KV caches without bloating memory.
- Exploring Multilingual LLM cognition: Some members sought papers studying how Large Language Models (LLMs) handle multilingualism and cognition, specifically the calculation of next tokens and whether they internally translate to English before responding. The conversation included references to several relevant studies, with some focusing on language-specific neurons.
- Relooking Absolute Positional Encodings (APE): PoPE, an innovation in positional encoding using orthogonal polynomials, was discussed and critiqued for burying its key concept under too much theoretical justification. The approach promises to improve upon sine-based APEs, but the theoretical underpinning remains in question.
- You Only Cache Once: Decoder-Decoder Architectures for Language Models: We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. ...
- Do Llamas Work in English? On the Latent Language of Multilingual Transformers: We ask whether multilingual language models trained on unbalanced, English-dominated corpora use English as an internal pivot language -- a question of key importance for understanding how language mo...
- PoPE: Legendre Orthogonal Polynomials Based Position Encoding for Large Language Models: There are several improvements proposed over the baseline Absolute Positional Encoding (APE) method used in original transformer. In this study, we aim to investigate the implications of inadequately ...
- In-Context Learning Creates Task Vectors: In-context learning (ICL) in Large Language Models (LLMs) has emerged as a powerful new learning paradigm. However, its underlying mechanism is still not well understood. In particular, it is challeng...
- TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding: With large language models (LLMs) widely deployed in long content generation recently, there has emerged an increasing demand for efficient long-sequence inference support. However, key-value (KV) cac...
- AlphaFold 3 predicts the structure and interactions of all of life’s molecules: Our new AI model AlphaFold 3 can predict the structure and interactions of all life’s molecules with unprecedented accuracy.
- How do Large Language Models Handle Multilingualism?: Large language models (LLMs) demonstrate remarkable performance across a spectrum of languages. In this work, we delve into the question: How do LLMs handle multilingualism? We introduce a framework t...
- xLSTM: Extended Long Short-Term Memory: In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerou...
- CLLMs: Consistency Large Language Models: Parallel decoding methods such as Jacobi decoding show promise for more efficient LLM inference as it breaks the sequential nature of the LLM decoding process and transforms it into parallelizable com...
- Function Vectors in Large Language Models: We report the presence of a simple neural mechanism that represents an input-output function as a vector within autoregressive transformer language models (LMs). Using causal mediation analysis on...
- GitHub - mirage-project/mirage: A multi-level tensor algebra superoptimizer: A multi-level tensor algebra superoptimizer. Contribute to mirage-project/mirage development by creating an account on GitHub.
- unilm/YOCO at master · microsoft/unilm: Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities - microsoft/unilm
- ICLR 2024 Outstanding Paper Awards – ICLR Blog: no description found
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving: Quantization can accelerate large language model (LLM) inference. Going beyond INT8 quantization, the research community is actively exploring even lower precision, such as INT4. Nonetheless, state-of...
Eleuther ▷ #interpretability-general (1 messages):
jacquesthibs: Are there tuned lenses for every pythia checkpoint?
CUDA MODE ▷ #general (27 messages🔥):
- Dynamic vs Static Compiling Dilemma: Discussions highlight challenges with torch.compile; one suggests padding data to a set of predefined shapes, but dynamic shapes in batched sequences complicate the use of static compiling. "dynamic=True" purportedly should avoid continuous recompiling, but members find it still tends to recompile frequently.
- In-Depth Diffusion Inference Optimization Guide: A 9-part blog series and a GitHub repo have been shared, detailing the optimization of inference for a diffusion model. This includes custom CUDA kernels and insights into GPU architecture.
- From GPU Whine to GPU Symphony: A unique learning shared is how to modulate GPU coil whine to play music, specifically Twinkle Twinkle Little Star, with relevant code provided.
- Efficient Learning through Replication: A practice method for those starting with CUDA involves replicating matrix multiplication kernels from an SGEMM_CUDA tutorial and benchmarking, which was helpful before tackling the diffusion paper's inference optimizations.
- Encouragement and Interest in Talks: Community members show enthusiasm for the shared optimization work, encouraging the author to give a talk and continuing to ask questions on implementation and next steps in the field of ML and robotics.
- Diffusion Inference Optimization: no description found
- How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog: In this post, I’ll iteratively optimize an implementation of matrix multiplication written in CUDA.My goal is not to build a cuBLAS replacement, but to deepl...
- inference-optimization-blog-post/part-9/gpu-piano/gpu_piano.cu at main · vdesai2014/inference-optimization-blog-post: Contribute to vdesai2014/inference-optimization-blog-post development by creating an account on GitHub.
CUDA MODE ▷ #triton (17 messages🔥):
- GitHub Collaboration for Triton: A new GitHub resource has been created to collect links to Triton kernels written by the community, inspired by a desire to make a community-owned index. Interest was expressed to potentially transfer it to the cuda-mode organization on GitHub.
- Prompt Initiative to Teach Triton: It's been mentioned that there are not many Triton tutorials available, and there are plans to potentially port the PMPP book to include Triton code snippets.
- Admin Access to Triton-Index Granted: Admin invites were sent and accepted for the cuda-mode Triton index on GitHub, with intentions to catalog released Triton kernels.
- Idea for a Dataset of Triton Kernels: Discussion revolved around the possibility of Triton kernels being published as a dataset, though originally mentioned in jest, there appeared to be genuine interest.
- Understanding Triton's Programming Model: Inquiries about how Triton compares to CUDA in warp and thread scheduling were addressed; it was highlighted that blocks in Triton and CUDA are the same but Triton abstracts away warp and thread-level details from the programmer.
- Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
- GitHub - cuda-mode/triton-index: Cataloging released Triton kernels.: Cataloging released Triton kernels. Contribute to cuda-mode/triton-index development by creating an account on GitHub.
- GitHub - haileyschoelkopf/triton-index: See https://github.com/cuda-mode/triton-index/ instead!: See https://github.com/cuda-mode/triton-index/ instead! - haileyschoelkopf/triton-index
- - YouTube: no description found
- Using CUDA Warp-Level Primitives | NVIDIA Technical Blog: NVIDIA GPUs execute groups of threads known as warps in SIMT (Single Instruction, Multiple Thread) fashion. Many CUDA programs achieve high performance by taking advantage of warp execution.
CUDA MODE ▷ #torch (47 messages🔥):
- Performance Discussion on Normalization Techniques: A Torch user posed a question regarding performance implications when normalizing tensors in NHWC format, questioning if permuting to NCHW is preferred over NHWC-optimized algorithms. Another user responded highlighting a PyTorch tutorial that suggests channels-last can lead to a 20% performance increase, but conversion might not have a cost due to stride manipulation.
- Improvements in LibTorch Compile Times: A discussion on improving compile times led to the discovery that using ATen’s
at::native::randninstead oftorch::randnand including<ATen/ops/randn_native.h>over<ATen/ATen.h>reduced a user's compile time from roughly 35 seconds to 4.33 seconds.
- libtorch vs. cpp Extensions: Marksaroufim suggested exploring cpp extensions for integrating C++ with PyTorch, reasoning that not many people work on libtorch today. Furthermore, he mentioned AOT Inductor as a way to generate
.sofiles ahead of time, which is detailed in a torch export tutorial.
- Clarification on ATen and libtorch Distinction: Through the chat, it became clear that ATen is considered a backend while libtorch is regarded as a frontend. The user seeking advice realized they just needed tensor capabilities and not the entire libtorch, leading to significant improvements in their workflow.
- Query on Model Caching with AOTInductor: Benjamin_w inquired about caching a compiled model using AOT Inductor to avoid recompilation delays. Marksaroufim offered a potential solution by setting
torch._inductor.config.fx_graph_cache = Trueand noted efforts to enhance warm compile times.
- (beta) Channels Last Memory Format in PyTorch — PyTorch Tutorials 2.3.0+cu121 documentation: no description found
- torch.export Tutorial — PyTorch Tutorials 2.3.0+cu121 documentation: no description found
- pytor - Overview: pytor has one repository available. Follow their code on GitHub.
- torch.export Tutorial — PyTorch Tutorials 2.3.0+cu121 documentation: no description found
- AOT Inductor load in python by msaroufim · Pull Request #103281 · pytorch/pytorch: So now this works if you run your model.py with TORCH_LOGS=output_code python model.py it will print a tmp/sdaoisdaosbdasd/something.py which you can import like a module Also need to set 'config....
- PyTorch dispatcher walkthrough: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- pytorch/torch/utils/cpp_extension.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
CUDA MODE ▷ #algorithms (3 messages):
- vAttention - Redefining KV-Cache Memory Management: A new paper proposes vAttention, an advanced memory management system for large language model (LLM) inference, designed to dynamically allocate KV-cache memory, aiming to address the fragmented memory issue in GPU. The system is said to replace prior static allocation methods, which resulted in wasted capacity and software complexity (Read Abstract).
- QServe - Boosting LLM Inference with Quantization: The QServe inference library boasts a new quantization algorithm, QoQ (W4A8KV4), to tackle the efficiency problems faced by existing INT4 quantization techniques, particularly concerning significant runtime overhead on GPUs. This development is crucial for enhancing large-batch, cloud-based LLM serving performance (Read Abstract).
- CLLMs for Speedier Inference: A blog post unveils Consistency Large Language Models (CLLMs), altering the traditional view of LLMs as sequential decoders, demonstrating that LLMs can effectively function as parallel decoders. The research indicates these models can significantly reduce inference latency by decoding multiple tokens in parallel, which could mirror the human cognitive process of sentence formation (Explore Blog and Research).
- vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention: Efficient use of GPU memory is essential for high throughput LLM inference. Prior systems reserved memory for the KV-cache ahead-of-time, resulting in wasted capacity due to internal fragmentation. In...
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving: Quantization can accelerate large language model (LLM) inference. Going beyond INT8 quantization, the research community is actively exploring even lower precision, such as INT4. Nonetheless, state-of...
- Consistency Large Language Models: A Family of Efficient Parallel Decoders: TL;DR: LLMs have been traditionally regarded as sequential decoders, decoding one token after another. In this blog, we show pretrained LLMs can be easily taught to operate as efficient parallel decod...
CUDA MODE ▷ #cool-links (4 messages):
- Diffusion Model Inference Gets a Turbo Boost: Vrushank Desai’s blog series elaborates on optimizing inference latency for Diffusion Models, specifically targeting GPU architecture tweaks to speed up the U-Net from a Toyota Research Institute paper. Accompanying GitHub code provides practical insights.
- Discovering the Fastest DNN with Superoptimizer: A new tool, discussed on Twitter, reports to act as a "superoptimizer" by searching for the quickest Triton programs to optimize any DNN, as detailed in Mirage's paper.
- Skepticism Around "Superoptimizer" Benchmarks: A member voiced doubts regarding the benchmarks presented in the Mirage project's paper on a DNN "superoptimizer," aligning with others' skepticism on the results.
- Critiquing Mirage's Methodology: Skepticism also extends to Mirage's omission of autotuning in their approach, despite the project's focus on identifying optimal fusion strategies, as spotted on their GitHub demo page.
Link mentioned: Diffusion Inference Optimization: no description found
CUDA MODE ▷ #beginner (6 messages):
- SetFit Model ONNX Export Curiosity: A member inquired about the difference between exporting a HuggingFace SetFit model to ONNX using the SetFit’s export method versus PyTorch’s
torch.onnx.export. The process involves a notebook example from the SetFit repository for exporting models.
- PyTorch Code Export Equivalence Query: They also shared a snippet of code using
torch.onnx.exportand pondered whether this would create the same ONNX output as theSetFit::export_onnxmethod.
- ONNX to TensorRT Conversion Clarification: The member sought confirmation on the necessity to first create an ONNX model before using
trtexecto compile it into a TensorRT plan file, sharing a sample command for thetrtexecconversion.
- Confusion Over Torch Compile Options: The mention of a
tensorrtoption withintorch.compileprompted member confusion regarding its relation to the previously mentioned ONNX to TensorRT conversion process.
- Conversion Needs on Target GPU Speculation: There was a query about whether the
trtexeccommand needs to be run on the target GPU where the TensorRT plan is intended to be used.
CUDA MODE ▷ #off-topic (2 messages):
- Apple Unveils M4 Chip: Apple has introduced the M4 chip, enhancing the performance of the new iPad Pro with 38 trillion operations per second. The M4 leverages 3-nanometer technology and a 10-core CPU to advance power efficiency and drive a new Ultra Retina XDR display.
- Panther Lake's Power Competes: A comparison is drawn highlighting that Panther Lake can perform 175 trillion operations per second, showcasing its computational power.
Link mentioned: Apple introduces M4 chip: Apple today announced M4, the latest Apple-designed silicon chip delivering phenomenal performance to the all-new iPad Pro.
CUDA MODE ▷ #irl-meetup (1 messages):
seire9159: Anyone in Chicago who want to work through the videos and write some CUDA code
CUDA MODE ▷ #llmdotc (40 messages🔥):
- ZeRO++ Promises Less is More: ZeRO++ offers a 4x reduction in communication for large model training, significantly speeding up the process. The quantization of weights and gradients before communication affects model convergence minimally.
- MPI Bug Squashed: A merge has resolved an issue, now enabling multi-GPU training to function correctly on the master branch.
- All GPT-2 Models Now Trainable: Updates have been pushed allowing any GPT-2 model size to be selected with the
--modelflag, and specific.binfiles to be pointed at for training. Batch size 4 training on an A100 GPU is possible, but performance drops when expanding to 4x A100 GPUs.
- Gradient Accumulation in the Pipeline: Discussion centered around the need for gradient accumulation to improve GPU scaling efficiency. Despite benefits, implementation concerns such as complexity and readability in the proposed PR are holding back immediate adoption.
- Layernorm Backward Precision Conundrum: An issue was raised about the
layernorm_backwardkernel performing bfloat16 (bf16) arithmetic on hardware that does not support bf16, leading to compilation problems. A potential conditional compilation fix using#if (CUDART_VERSION >= 12000)was suggested to only include the problematic kernel for CUDA 12 and above.
Link mentioned: ZeRO++: ZeRO++ is a system of communication optimization strategies built on top of ZeRO to offer unmatched efficiency for large model training regardless of the scale or cross-device bandwidth constraints. R...
OpenInterpreter ▷ #general (56 messages🔥🔥):
- Open Source and Pre-Orders Talk: A member discussed the 01 light being available for pre-order and noted that both its hardware and software are open source.
- Microsoft's VoT Challenges LAM with Space Reasoning: A link to a YouTube video was shared illustrating Microsoft's “Vision of Thought” (VoT), which contributes spatial reasoning capabilities to LLMs and appears to outperform OpenAI's LAM according to the creator. The member expressed excitement for safer versions to share with family.
- Configuration Conundrums with API Keys: Several members discussed challenges and resolutions when configuring environment variables and API keys. Instructions from the litellm documentation were suggested along with setting
GROQ_API_KEYas an environment variable. - Innovations in AI-driven Computer Interaction: Members discussed systems for using models like GPT-4 to perform tasks within different operating system environments (Ubuntu, Mac) utilizing tools like OpenCV/Pyautogui.
- Combining Open Source AI Tools: It was proposed to integrate Open Interpreter with "Billiant Labs Frame," an open source AI glasses, and a YouTube video featuring the glasses was shared.
- Groq | liteLLM: https://groq.com/
- This is Frame! Open source AI glasses for developers, hackers and superheroes.: This is Frame! Open source AI glasses for developers, hackers and superheroes. First customers will start receiving them next week. We can’t wait to see what...
- open-interpreter/interpreter/core/computer/display/point/point.py at main · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
- "VoT" Gives LLMs Spacial Reasoning AND Open-Source "Large Action Model": Microsoft's "Visualization of Thought" (VoT), gives LLMs the ability to have spacial reasoning, which was previously nearly impossible for LLMs. Plus, a new ...
OpenInterpreter ▷ #O1 (74 messages🔥🔥):
- Linking LiteLLM to Various AI Providers: LiteLLM documentation specifies support for multiple AI providers, including OpenAI models, Azure, Google's PaLM, and Anthropic. Specific instructions and prerequisites are outlined in the LiteLLM providers documentation.
- Groq Whisper API Buzz: The addition of Whisper to Groq's API has sparked conversations about integrating it with 01, noting that Groq's free API could be advantageous. Groq's API is praised for being free and efficient, but users experienced issues with model access.
- Gemini Pro Vision touted as free alternative: Users discuss Gemini Pro Vision as a free and possibly simple-to-integrate API. No specific documentation link provided.
- Windows Woes with 01: Users report that 01 functionality is limited on Windows platforms, but there are potential fixes involving code modification for Windows 10 and checking compatibility updates for Windows 11.
- Open Source AI Conundrum: Several members express surprise that an open-source AI system like 01 might not fully support open-source AI models, with a debate on the feasibility of proprietary vs. open-source AI models.
Link mentioned: Providers | liteLLM: Learn how to deploy + call models from different providers on LiteLLM
OpenInterpreter ▷ #ai-content (2 messages):
- GPT-4 tunes in with YouTube: A member used GPT-4 with a custom instruction to utilize YouTube for music suggestions, highlighting the model's ability to follow specific user directives.
- Local Models Performance Evaluation: They tested several local models like TheBloke/deepseek-coder-33B-instruct.GGUF, which failed to meet expectations by claiming no internet connection. Another attempt with lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF was also lackluster, with it giving up after one failed retry.
- Mixing Success with mixtral-8x7b: The mixtral-8x7b-instruct-v0.1.Q5_0.gguf delivered the best performance so far, executing tasks almost correctly and outperforming deepseek, especially on a system with a custom-tuned 2080 ti GPU and 32GB DDR5 6000 memory.
- Macbook Pro Falls Short on Local Models: The member's MacBook Pro proved inadequate for even light local model operations, no longer being used for such tasks.
LAION ▷ #general (38 messages🔥):
- DALLE-3 Level Outputs in Sight: Members discussed achieving outputs comparable to DALLE-3 using a combination of Pixart Sigma + SDXL + PAG, though Pixart struggles with text and individual objects. This comfyui flow is said to bring prompt alignment and quality offline and is seen as having the potential for further improvements.
- The Need for Fine-tuning and Technical Expertise: The community believes that fine-tuning could fix issues related to composition in image generation, indicating that a technical mind could push the current achievements to the next level. One user admitted to being less technically adept, hoping others could contribute to enhancement.
- Model Quality Breakthrough Revealed: A member uncovered the missing piece for model quality—ensuring that the microconditioning input ranges are manageable for easier learning, suggesting specific parameters and strategies to optimize the process.
- Automating Insurance Data: A commercial auto insurance underwriter inquired about open-source tools and strategies for automating data processing to improve efficiency and accuracy in evaluating risks and managing claims.
- AI Contest Announcement: An AI research engineer announced a contest held in IJCAI journal, sharing a link for those who may be interested in publishing papers and winning prizes. The contest appears to be affiliated with AI applications in the sciences.
- Meet AdVon, the AI-Powered Content Monster Infecting the Media Industry: Our investigation into AdVon Commerce, the AI contractor at the heart of scandals at USA Today and Sports Illustrated.
- SNAC with flattening & reconstruction: Speech only codec:https://colab.research.google.com/drive/11qUfQLdH8JBKwkZIJ3KWUsBKtZAiSnhm?usp=sharingGeneral purpose (32khz) Codec:https://colab.research.g...
- IJCAI 2024: Rapid Aerodynamic Drag Pred - 飞桨AI Studio星河社区: no description found
LAION ▷ #research (59 messages🔥🔥):
- IC-Light GitHub Repository Mentioned: A user shared a link to the IC-Light GitHub repository, an open-source project focusing on "More relighting!" The repository can be found at GitHub - lllyasviel/IC-Light.
- Advice Against Spammy Behavior: A message was flagged as appearing spammy after being copied and pasted across multiple channels, and the original poster acknowledged the notice.
- Noise Conditional Score Networks Debated: Users engaged in a technical discussion about noise scheduling in Noise Conditional Score Networks and DDPMs, questioning the convergence to a standard Gaussian.
- Exploring K-diffusion and Score-based Models: Various papers such as 'K-diffusion' from arxiv.org were referenced, and users exchanged interpretations of mathematical concepts in these models, supporting the notion that these concepts are closely related but differ in nuances like the use of ODE solvers.
- Variance Exploding vs. Preserving in DDIM: There was a clarifying conversation on the notion of 'variance exploding' in diffusion models, with a conclusion that it relates to the ODE solvers inspired by DDPM and a comparison to other methods like rectified flows.
- Elucidating the Design Space of Diffusion-Based Generative Models: We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates t...
- Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song: no description found
- GitHub - lllyasviel/IC-Light: More relighting!: More relighting! Contribute to lllyasviel/IC-Light development by creating an account on GitHub.
LlamaIndex ▷ #announcements (1 messages):
- deeplearning.ai Launches "Building Agentic RAG with LlamaIndex" Course: A new course titled "building agentic RAG with llamaindex" has been launched on deeplearning.ai, featuring instruction by Jerry Liu, CEO of LlamaIndex. The course will cover routing, tool use, and multi-step reasoning with tool use to empower agents to fetch information and enable complex question answering.
Link mentioned: Tweet from Andrew Ng (@AndrewYNg): I’m excited to kick off the first of our short courses focused on agents, starting with Building Agentic RAG with LlamaIndex, taught by @jerryjliu0, CEO of @llama_index. This covers an important shif...
LlamaIndex ▷ #blog (2 messages):
- Agentic RAG Course Launch: LlamaIndex announces a collaboration with @DeepLearningAI and @AndrewYNg to offer a new course on Building Agentic RAG that teaches creating an autonomous research assistant capable of understanding complex questions over multiple documents. Interested users can find out more and sign up through the provided Twitter link.
- Run LLMs Locally and Faster: LlamaIndex integrates a service that allows running local Large Language Models (LLMs) quickly, supporting a range of models like Mistral, Gemma, Llama, Mixtral, and more, on various architectures including NVIDIA. Further details are available via their Twitter post.
LlamaIndex ▷ #general (55 messages🔥🔥):
- Embedding Woes in Vector Stores: A member expressed difficulties with LlamaIndex for a local rag system using nomic embeddings from ollama, due to compatibility issues with chroma's own embeddings. The advice given was that llama-index handles embedding automatically if using the vector store integration.
- Boosting a Community Member's Project: A call was made by a member for support on their LinkedIn post regarding their use of LlamaIndex's LlamaParse.
- Rerank and Metadata Quandary: Members discussed the execution order for
rerankmodel andMetadataReplacementPostProcessor, concluding the order depends on whether one wants to rerank based on the original text or the replaced metadata. - Hosting Local LLM Models: Discussions covered enterprises hosting local LLM models, including options like AWS, auto-scaling on K8s, and vLLM or TGI. The consensus leaned towards needing scalability for production use.
- Tool Execution Troubleshooting: A user experiencing issues with _CBEventType.SUB_QUESTION not being called received responses pointing towards implementation flaws, and they were guided with some code snippets to attempt a resolution.
- GitHub - aurelio-labs/semantic-router: Superfast AI decision making and intelligent processing of multi-modal data.: Superfast AI decision making and intelligent processing of multi-modal data. - aurelio-labs/semantic-router
- Knowledge graph - LlamaIndex: no description found
- ReAct Agent - A Simple Intro with Calculator Tools - LlamaIndex: no description found
- vLLM - LlamaIndex: no description found
- Structured Hierarchical Retrieval - LlamaIndex: no description found
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- Languify.ai Launches: A new browser extension, Languify.ai, has been launched to optimize text on websites to increase user engagement and sales, utilizing Openrouter for selecting models based on the prompt. The extension is available for free with a personal plan and a business plan at €10.99 per month, which can be found at www.languify.ai.
- A Simpler Alternative to AnythingLLM: A member expressed interest in Languify.ai as a simpler option compared to AnythingLLM, which they found to be overkill for their needs, indicating they will try the new extension.
Link mentioned: Languify.ai - Optimize copyright: Elevate your content's reach with Languify, our user-friendly browser extension. Powered by AI, it optimizes copyright seamlessly, enhancing engagement and amplifying your creative impact.
OpenRouter (Alex Atallah) ▷ #general (53 messages🔥):
- Confusion Over OpenRouter Information Access: A user expressed difficulty finding non-technical information about OpenRouter and, despite reading the docs, still had questions about how routing works, what are credits, and the actual free status of certain models. No clear answers or resources were provided in the channel to address these concerns.
- In Search of Llama 3 Moderation Services: A channel member seeking Llama 3 Guard via API for moderation was directed to Together.ai as a service provider, after noting the absence of said service on OpenRouter's offerings.
- Min-P Support Queries and Workarounds: Discussions about which providers support
min_pled to clarifications that models served by Together, Lepton, Lynn, and Mancer do offer this support, with Lepton still functioning despite Together experiencing issues.
- Model Hosting and DeepSeek Version Riddles: Channel users inquired about hosting options for DeepSeek v2 with reports suggesting that, aside from DeepSeek's own 32k context model, no other providers seemed to be hosting it at this time.
- Jailbreaking LLM Wizard 8x22B: Members of the channel discussed the potential of jailbreaking Wizard 8x22B to unlock more uncensored content, contrasting it with existing safe content restrictions. Links to work on understanding refusal mechanisms in LLMs, such as this Alignment Forum post, were shared to shed light on how LLMs handle objectionable requests.
- no title found: no description found
- Meta: Llama 3 70B Instruct by meta-llama | OpenRouter: Meta's latest class of model (Llama 3) launched with a variety of sizes & flavors. This 70B instruct-tuned version was optimized for high quality dialogue usecases. It has demonstrated stron...
- Refusal in LLMs is mediated by a single direction — AI Alignment Forum: This work was produced as part of Neel Nanda's stream in the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort, with co-supervision from…
- Refusal in LLMs is mediated by a single direction — AI Alignment Forum: This work was produced as part of Neel Nanda's stream in the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort, with co-supervision from…
- OpenRouter: Build model-agnostic AI apps
LangChain AI ▷ #general (43 messages🔥):
- Toolkit Tangle in Typescript Trembles: Members are discussing issues with
JsonOutputFunctionsParserin TypeScript, seeing Unterminated string in JSON errors. Advised checks include verifying the JSON fromget_chunksfunction, ensuringcontentpassed tochain.invoke()is formatted correctly, and checkinggetChunksSchema.
- CLAUDIA Integration Curiosity: A question was raised about integrating claude-haiku with Langchain ChatVertexAI, although no specific details or follow-up were provided.
- Multi-Agent Project Exploration: One member is inquiring about example projects similar to STORM, a multi-agent article generator, indicating a need for multi-agent system references.
- Agents Architecture Anxiety: A member has concerns about instantiating different agents for specific capabilities, debating the efficiency of this approach versus component-based architecture where systems evolve over time.
- Optimizing Vector DB for Budgeted Brilliance: The efficiency and complexity of setting up VertexAI Vector store was questioned, with the member seeking cost-efficient alternatives for vector databases and mentioning Pinecone or Supabase as simpler options.
LangChain AI ▷ #langserve (1 messages):
- Troubleshooting Chain Invoke Issues: A member encountered a discrepancy when invoking a chain with a dictionary input; it runs correctly in Python using
chain().invoke({ <dict> })but starts with an empty dictionary and fails via the/invokeendpoint. They posted the chain definition code and are seeking insights on why the Chain run behavior differs between the two methods.
LangChain AI ▷ #share-your-work (3 messages):
- Gianna - Revolutionizing Virtual Assistant Interaction: The new virtual assistant framework Gianna aims to revolutionize AI interactions with a modular and extendable design. It uses CrewAI and Langchain for intelligence and can be found on GitHub or installed via PyPI.
- Langgraph Streamlines Customer Support: A new Medium article discusses how Langchain's LangGraph can help streamline customer support, guiding readers on integrating this tool into their systems. The full article can be accessed here.
- Athena - The Autonomous AI Data Agent: Athena presents an AI data platform and agent orchestrated with Langchain and Langgraph, now capable of full autonomy in data workflows. A demonstration video of Athena’s capabilities is available on YouTube.
- Enterprise AI Data Analyst | AI Agent | Athena Intelligence: no description found
- Streamline Customer Support with Langchain’s LangGraph: Ankush k Singal
LangChain AI ▷ #tutorials (2 messages):
- Exploring the Added Value: A member queried about the benefits of an unspecified topic or tool, likely seeking clarification on its usefulness or potential impact.
- Integrating CrewAI with Crypto Markets: A tutorial video link was shared titled: "Create a Custom Tool to connect crewAI to Binance Crypto Market", which guides users on using the crewAI CLI to connect with the Binance.com Crypto Market for financial insights.
Link mentioned: Create a Custom Tool to connect crewAI to to Binance Crypto Market: Use the new crewAI CLI tool and add a custom tool to connet crewAI to binance.com Crypto Market. THen get the highest position in the wallet and do web Searc...
Latent Space ▷ #ai-general-chat (39 messages🔥):
- Stanford Drops Knowledge: Stanford has released a new 2023 course on "Deep Generative Models" via a YouTube video, providing fresh educational material for AI enthusiasts and practitioners.
- Hunting for High-end GPUs: Members are sharing tips on securing A100/H100 GPUs for a few weeks, with sfcompute being recommended for this purpose.
- Developers Debate AI-Assisted Coding: There's a lively discussion on AI-assisted coding, with users sharing nostalgia for programming in Lisp, and debating the pros and cons of various AI code assistance tools.
- Long Context AI Model by Gradient: Gradient's Llama-3 8B Instruct model, which boasts an extended context length from 8k to 4194k, is highlighted along with an invite to join a waitlist for custom agents.
- OpenAI's Secure AI Infrastructure: A recent blog post from OpenAI discussing secure infrastructure for advanced AI, including cryptographically signed GPUs, stirred conversations with some members viewing the measures as "protectionism."
- llm-ui | React library for LLMs: LLM UI components for React
- Stanford CS236: Deep Generative Models I 2023 I Lecture 1 - Introduction: For more information about Stanford's Artificial Intelligence programs visit: https://stanford.io/aiTo follow along with the course, visit the course website...
- Accelerating Systems with Real-time AI Solutions - Groq: Groq offers high-performance AI models & API access for developers. Get faster inference at lower cost than competitors. Explore use cases today!
- gradientai/Llama-3-8B-Instruct-Gradient-4194k · Hugging Face: no description found
- no title found: no description found
- Tweet from Gordon Wetzstein (@GordonWetzstein): Excited to share our new Nature paper! In this work, we propose a new display design that pairs inverse-designed metasurface waveguides with AI-driven holographic displays to enable full-color 3D augm...
- [AINews] OpenAI's PR Campaign?: AI News for 5/7/2024-5/8/2024. We checked 7 subreddits and 373 Twitters and 28 Discords (419 channels, and 4079 messages) for you. Estimated reading time...
- Slop is the new name for unwanted AI-generated content: I saw this tweet yesterday from @deepfates, and I am very on board with this: Watching in real time as “slop” becomes a term of art. the way that “spam” …
Latent Space ▷ #llm-paper-club-west (2 messages):
No summary can be provided for this scenario as the given messages consist only of brief greetings and an inquiry about a schedule, without any substantial information, discussion, or links to summarize.
OpenAccess AI Collective (axolotl) ▷ #other-llms (5 messages):
- RefuelLLM-2 Unleashed: RefuelAI has open-sourced RefuelLLM-2, claimed as the world's best large language model for "unsexy data tasks." The model weights are available for download at Hugging Face, with the announcement detailed in a Twitter post.
- A Corpus of Datasets: The released Llama3-8B base model was instruction tuned on an impressive corpus of 2750+ datasets. This tuning process went on for approximately one week.
OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
- Helpful Documentation for Dataset Formats: A member found the answer to their question regarding dataset formats supported by Axolotl, including JSONL and HuggingFace datasets. The formats are organized by task such as pre-training, instruction tuning, conversation, template-free, and custom pre-tokenized.
- Searching for phi3 mini Config Help: A member is seeking a working config file for phi3 mini at 4K/128K FFT on 8 A100 GPUs, as they are facing CUDA out of memory errors despite being able to train on larger models.
- Request for Axolotl Error Resolution: A member expressed frustration regarding an error when trying to train on 8x H100 GPUs, referencing an issue opened on the Axolotl GitHub repository.
- Axolotl - Dataset Formats: no description found
- Recent RunPod Axolotl error · Issue #1596 · OpenAccess-AI-Collective/axolotl: Please check that this issue hasn't been reported before. I searched previous Bug Reports didn't find any similar reports. Expected Behavior I ran Axolotl around two days ago and it worked fin...
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (1 messages):
nanobitz: See this https://docs.wandb.ai/guides/track/environment-variables
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (21 messages🔥):
- LoRA Configuration Puzzle: A member encountered a
ValueErrordue to improperly setlora_modules_to_savewhen adding new tokens, which required specifyingembed_tokensandlm_headfor saving LoRA (Low-Rank Adaptation) parameters. The error prompted the need to explicitly include these modules in thelora_modules_to_savelist in the YAML file. - YAML Troubles Beget Solutions: Another member responded with the correct syntax to update the YAML configuration using
lora_modules_to_save, ensuring the embedding layers and language model head are captured in the LoRA setup to fix the error regarding new tokens. - Debugging Cinchers in Code: When an error related to the
NoneTypeobject appeared from thetransformerstrainer during prediction, advice was offered to check the data loader and processing to ensure input format alignment with model expectations. The member was guided to update scripts and employ debug logging to understand theinputsvariable structure before prediction steps. - Traceback Trial and Tribulation: The specificity of the second error indicated the model received
Noneinputs during the prediction/evaluation phase, which was unexpected. Suggestions to remedy the situation included reviewing the data loader, data processing, and ensuring the modified training script maintains dictionary input format conventions.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- peft/src/peft/tuners/lora/config.py at main · huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. - huggingface/peft
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Interconnects (Nathan Lambert) ▷ #news (4 messages):
- Beauty Over Brawn in Diagrams: A member admires the aesthetics of diagrams saying they have "really pretty pictures" without commenting on their functionality.
- Questioning Diagrams' Metrics: There was critique about the choice of metrics in some diagrams, such as focusing on parameter numbers over FLOPs, and the use of an unusual learning rate for transformer baselines with no hyperparameter tuning for any model.
- Reserving Judgment: Commenting on the effectiveness of diagrams, a member states, "time will tell", indicating a watch-and-wait approach to assess their practical utility.
Interconnects (Nathan Lambert) ▷ #ml-questions (6 messages):
- Seeking RM Training Insights on TPUs: A user inquired about experiences with training Reinforcement Models (RM) on TPUs, possibly indicating they are looking for optimization tips or best practices.
- FSDP Training Query: The same user asked about training with Fully Sharded Data Parallel (FSDP), suggesting a focus on scaling and distributed training strategies for RMs.
- Jax for RM Training Recommendation: Another member suggested using Jax, hinting that it could simplify the modification of an RM trainer.
- EasyLM as a Jax Trainer Example: The recommendation to modify an existing Jax trainer for RM purposes was given, with EasyLM mentioned as a potential starting point.
- Resource for Training RM Using EasyLM: Additionally, a specific GitHub link was shared to the EasyLM trainer for Llama with a python script, which could be an example to follow for training RMs using Jax: EasyLM - llama_train_rm.py.
Link mentioned: EasyLM/EasyLM/models/llama/llama_train_rm.py at main · hamishivi/EasyLM: Large language models (LLMs) made easy, EasyLM is a one stop solution for pre-training, finetuning, evaluating and serving LLMs in JAX/Flax. - hamishivi/EasyLM
Interconnects (Nathan Lambert) ▷ #ml-drama (5 messages):
- Leaderboard Sizes in Question: The adequacy of 5k leaderboards was challenged with a suggestion that it should be 10k. Concerns about a 200:1 model to leaderboard ratio were also raised as outrageous.
- Missed the Sequel: A member lamented missing the follow-up to the Prometheus (1) paper, while wondering if there was any criticism about the original publication.
- Praise for Prometheus: Despite a personal admission of saltiness, Prometheus's work was commended as far better than typical AI research.
Interconnects (Nathan Lambert) ▷ #random (4 messages):
- Aerial Blogging Plans: Intends to post in ChatbotArena while on a plane, testing the reliability of onboard WiFi.
- Licensing Labyrinth in ChatbotArena: Noted that ChatbotArena might be in a complex situation regarding the release of text generated by large language models (LLMs) without special permission from providers, indicating a potential licensing issue.
Interconnects (Nathan Lambert) ▷ #reads (5 messages):
- OpenAI Unveils Model Spec for AI Alignment: OpenAI's first draft of the Model Spec aims to guide researchers and data labelers, employing reinforcement learning from human feedback (RLHF) techniques. The document provides specifications for the desired behavior of models within the OpenAI API and ChatGPT.
- Llama 3 Claims the Chatbot Crown: The blog post Llama 3 discusses the rise of Meta's Llama 3-70B to the top of the Chatbot Arena leaderboard, excelling in over 50,000 battles and being compared to other top models like GPT-4-Turbo and Claude 3 Opus. The post by Lisa Dunlap and others delves into user preferences and the challenges of prompts in evaluating chatbot performance.
- What’s up with Llama 3? Arena data analysis | LMSYS Org: <p>On April 18th, Meta released Llama 3, their newest open-weight large language model. Since then, Llama 3-70B has quickly risen to the top of the English <...
- Model Spec (2024/05/08): no description found
Interconnects (Nathan Lambert) ▷ #posts (4 messages):
- Awaiting the Arrival of SnailBot: The channel exhibits anticipation for the appearance or interaction with SnailBot. There's a sense of impatience, encapsulated with tick tock tick tock references.
- Call to Action for a Group: A ping was made specifically to a group identified by an ID number, suggesting a call for attention or participation from those members.
- Celebratory Response for SnailBot: Upon receiving a reaction from SnailBot, there was a positive and casual acknowledgment, indicating a successful interaction.
tinygrad (George Hotz) ▷ #general (6 messages):
- Pull Request Confusion Resolved: Discussion revolves around a Pull Request #3747 on tinygrad's GitHub, which addresses the UOps.BITCAST operation and its unexpected behavior regarding constant folding.
- Clarification on BITCAST: A member clarifies that CAST and BITCAST are indeed distinct unary operations (uops) within the tinygrad project, with emphasis on the necessity of the BITCAST operation.
- Understanding BITCAST Implementation: There's a suggestion to eliminate arguments like "bitcast=false" that are currently extending from the cast functions, to clean up the implementation of BITCAST.
- Insight into UOp Functionality: The distinction between an ALU operation and a uop (unary operation) is acknowledged, providing insight into the implementation details of the tinygrad project.
Link mentioned: UOps.BITCAST by chenyuxyz · Pull Request #3747 · tinygrad/tinygrad: implicitly fixed no const folding for bitcast
tinygrad (George Hotz) ▷ #learn-tinygrad (16 messages🔥):
- Clarification Sought on
DivNodeandModNodein tinygrad: A user questioned ifsymbolic.DivNodeintentionally requiredself.bto be anintrather than aNode, relating to the need for a symbolic version ofarange. A response indicated that the union type ofNodeorintshould not prevent aNodefrom being used.
- Discussion on Symbolic
arangeImplementation: It was suggested that for implementing symbolicarange,Tensor.fullcould callTensor.from_nodeconditionally, anddivandsuboperations might be extended in the same pattern asmul. Concerns were raised about potential downstream fallout and lack of support for pooling operations.
- Attempt at Enhancing tinygrad with Symbolic
arange: A user shared frustration after attempting to implement symbolicarangein tinygrad, referencing their GitHub pull request and noting uncertainty in the intended behaviour ofstepin tests, planning to refocus on a 'bitcast refactor'.
- Inquiring About In-place Output Mechanisms in tinygrad: One user inquired about the possibility of writing the output of matrix operations directly into a pre-allocated section of an existing matrix to avoid wasteful copies, mentioning a novel design that concatenates the output of
nmatrix operations. George Hotz commented that there are hacks for this regarding disk storage and it would likely be a quick change to implement more broadly.
- Metal Build Process and
libraryDataContents()Mystery: A user struggling with the Metal build process for tinygrad asked aboutlibraryDataContents(), referencing a Discord message and outside documentation without finding clear answers. The user questioned whether there was a missing symbol or library necessary to understand the usage.
- Visualization Tool for Shape and Stride Introduced: For those working with shape and stride concepts in tinygrad, a user created and shared a visualization tool that could assist in understanding different combinations.
- InterpretedFlopCounters and Flop Counting Explained: A user's query about the purpose of counting flops in
ops.pywas clarified with the point that flop count serves as a proxy for performance in tinygrad.
- Seeking Functionality Similar to PyTorch's
register_bufferin tinygrad: Querying about a feature analogous to PyTorch'sregister_buffer, a user received guidance to useTensor(..., requires_grad=False)as an equivalent in tinygrad.
- React App: no description found
- Comparing tinygrad:master...davidjanoskyrepo:symbolic-arange-pull · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - Comparing tinygrad:master...davidjanoskyrepo:symbolic-arange-pull · tinygrad/tinygrad
Cohere ▷ #general (16 messages🔥):
- RAG Implementation Challenge: A user is implementing RAG using Cohere.command and faces an issue where the input context length of Cohere.command is limited to 4096 tokens, but they need to process around 10000 tokens. Usage of prompt truncating may result in loss of necessary information; another user suggests using Elasticsearch to reduce text size and breaking resumes into logical segments.
- Generating Downloadable Files: One user asked if Cohere Chat could output files in DOCX or PDF formats and shared an example link to a DOCX file, but it's unclear how the file can be downloaded.
- CORS Concern with Cohere API: A member inquired about how to resolve CORS issues when using the Cohere API. It was pointed out that CORS is a browser security feature, and making calls to the Cohere API should be done from the backend without exposing API keys.
- Adding Credits to Cohere: A user requested assistance with adding credits to their account. Another member explained that pre-paid credits are not offered by Cohere, but users can set billing limits to manage their spending by adding a credit card and setting a limit on their dashboard.
- Request for Dark Mode: A query about the existence of a dark mode for Coral prompted a response denying its availability. However, a code snippet was shared that can be pasted into a browser console for a makeshift dark mode solution.
Link mentioned: Login | Cohere: Cohere provides access to advanced Large Language Models and NLP tools through one easy-to-use API. Get started for free.
Cohere ▷ #collab-opps (1 messages):
- Join the Wordware Team in SF: Wordware is actively hiring for multiple roles including a founding engineer, DevRel, and product/FE engineer. Prospective candidates are encouraged to build something with Wordware's web-hosted IDE, which is designed for collaboration between AI engineers and non-technical domain experts, and reach out to the founders at wordware.ai. Here's the opportunity: Join Wordware.
Link mentioned: Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
Mozilla AI ▷ #llamafile (6 messages):
- Backend Service Implementation for Meta-Llama: After executing the command to run Meta-Llama-3-8B-Instruct, it was explained that an API endpoint is available at 127.0.0.1:8080 for making OpenAI-style requests. Detailed instructions can be found on the project's GitHub page.
- VS Code Integration with ollama: A member noted that Visual Studio Code now has a new dropdown feature that allows users to easily switch between models when running ollama in the background.
- Updating Llamafile Without Redownloading: There was a suggestion for a feature in llamafile allowing the update of the binary scaffold without the need to redownload the entire llamafile, noting the perceived inefficiency but also recognizing it as a trade-off against the simplicity of the current system.
- Curious Clown Banter: In a series of messages, a member humorously contemplated whether Mozilla-Ocho was a reference to "ESPN 8 - The Ocho" from the film Dodgeball, engaging in a tongue-in-cheek internal dialogue about the necessity of sharing this thought.
Link mentioned: GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
LLM Perf Enthusiasts AI ▷ #general (3 messages):
- Exploring AI Assistance in Spreadsheet Analysis: A user asked for experiences or resources related to spreadsheet manipulation using LLMs (Large Language Models). Interest is in utilizing AI to handle and extract data from spreadsheets.
- Yawn.xyz Tackles Biology Lab Spreadsheet Woes: A resource shared by a member shows Yawn.xyz attempting to leverage AI to extract data from complex spreadsheets—a challenge in many biology labs. According to the tweet, using AI for data extraction is tested, but their tool's demo was noted to be subpar by a member. See the tweet here.
Link mentioned: Tweet from Jan : Spreadsheets are the lifeblood of many biology labs, but extracting insights from messy data is a huge challenge. We wanted to see if AI could help us reliably pull data from any arbitrary spreadsheet...
LLM Perf Enthusiasts AI ▷ #openai (1 messages):
- Azure Regions for GPT-4-turbo: A user reports issues with the GPT-4-turbo 0429 in the Sweden region and is inquiring about other Azure regions where it operates well.
Alignment Lab AI ▷ #ai-and-ml-discussion (1 messages):
- AlphaFold3 Goes Open Source: The Open Source implementation of AlphaFold3 in PyTorch has been shared, allowing researchers to predict biomolecular interactions accurately. The code snippet indicates it operates on atomic coordinates and requires review AlphaFold3 Implementation.
- Calling All Coders to Agora: For further development and democratization of AlphaFold3's model, a call to action has been made to join Agora, though the shared link appears to be incomplete or broken.
- GitHub - kyegomez/AlphaFold3: Implementation of Alpha Fold 3 from the paper: "Accurate structure prediction of biomolecular interactions with AlphaFold3" in PyTorch: Implementation of Alpha Fold 3 from the paper: "Accurate structure prediction of biomolecular interactions with AlphaFold3" in PyTorch - kyegomez/AlphaFold3
- Join the Agora Discord Server!: Advancing Humanity through open source AI research. | 6856 members
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=4MzCpZLEQJs
AI Stack Devs (Yoko Li) ▷ #app-showcase (1 messages):
- Launch of Quickscope by Regression Games: Regression Games has announced the launch of Quickscope, a suite of AI tools designed to automate testing for Unity games, boasting simple integration and a code-free setup. The toolkit includes a Gameplay Session recording tool and a Validations tool to automate smoke tests and functional tests with ease.
- Deep Property Scraping Explained: Quickscope's functionality includes deep property scraping of game object hierarchies, extracting comprehensive details from game entities without the need for custom code integration. This allows for detailed information to be gathered on positions, rotations, and the public properties and fields of MonoBehaviours.
- Discover the Quickscope Platform: Potential users are encouraged to try out Quickscope for their test automation needs, as the platform promotes various automation approaches, including smart replay and playback systems, and is designed with QA teams in mind. The platform boasts quick and easy integration, with no custom code required, significantly simplifying the test setup process.
- Tools Highlight for Efficient Testing: Quickscope emphasizes its highly interactive UI for defining tests, offering QA engineers and game developers a user-friendly approach to game testing. The service can be used directly in the Unity editor, in builds, or integrated into CI/CD pipelines.
- Introducing Quickscope - Automate smoke tests in Unity - May 06, 2024 - Regression Games: Learn about Quickscope, a tool for automating smoke tests in Unity
- Regression Games - The ultimate AI agent testing platform for Unity: Easily develop bots for Unity for QA testing.
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- Praise for the
llmCLI Tool: A member expressed gratitude for thellmcommand-line interface, stating it's enjoyable and helpful for managing projects like a personal assistant. They also appreciated its capability for "more unixy stuff".