[AINews] Llama 3.1: The Synthetic Data Model
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Synthetic Data is all you need.
AI News for 7/22/2024-7/23/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (474 channels, and 5128 messages) for you. Estimated reading time saved (at 200wpm): 473 minutes. You can now tag @smol_ai for AINews discussions!
Llama 3.1 is here! (Site, Video,Paper, Code, model, Zuck, Latent Space pod). Including the 405B model, which triggers both the EU AI act and SB 1047. The full paper has all the frontier model comparisons you want:
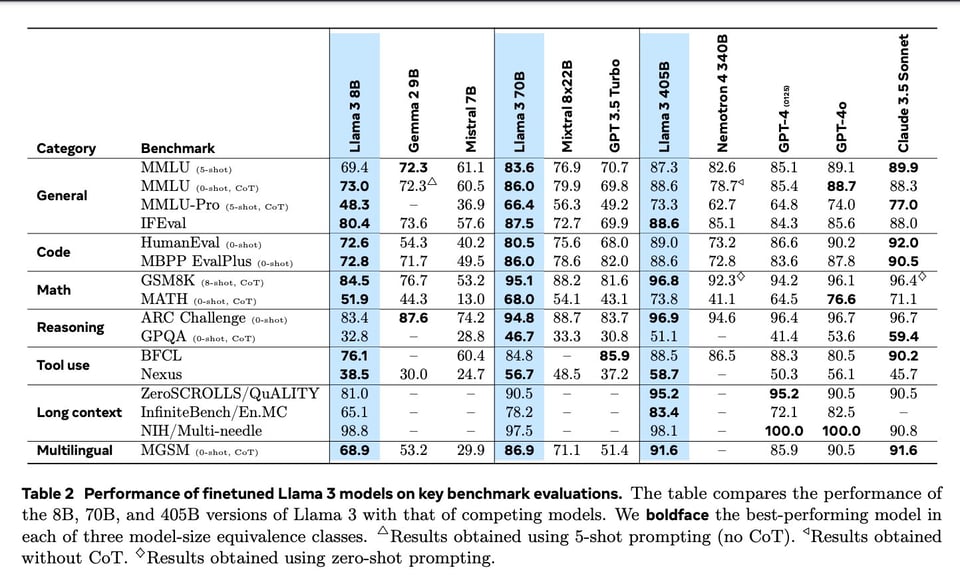
We'll assume you read the headlines from yesterday. It's not up on LMsys yet, but independent evals on SEAL and Allen AI's ZeroEval are promising (with some disagreement). It was a well coordinated launch across ~every inference provider in the industry, including (of course) Groq showing a flashy demo inferencing at 750tok/s. Inference pricing is also out with Fireworks leading the pack.
While it is well speculated that the 8B and 70B were "offline distillations" of the 405B, there are a good deal more synthetic data elements to Llama 3.1 than the expected. The paper explicitly calls out:
- SFT for Code: 3 approaches for synthetic data for the 405B bootstrapping itself with code execution feedback, programming language translation, and docs backtranslation.
- SFT for Math:
- SFT for Multilinguality: "To collect higher quality human annotations in non-English languages, we train a multilingual expert by branching off the pre-training run and continuing to pre-train on a data mix that consists of 90% multilingual tokens."
- SFT for Long Context: "It is largely impractical to get humans to annotate such examples due to the tedious and time-consuming nature of reading lengthy contexts, so we predominantly rely on synthetic data to fill this gap. We use earlier versions of Llama 3 to generate synthetic data based on the key long-context use-cases: (possibly multi-turn) question-answering, summarization for long documents, and reasoning over code repositories, and describe them in greater detail below"
- SFT for Tool Use: trained for Brave Search, Wolfram Alpha, and a Python Interpreter (a special new
ipythonrole) for single, nested, parallel, and multiturn function calling. - RLHF: DPO preference data was used extensively on Llama 2 generations. As Thomas says on the pod: “Llama 3 post-training doesn't have any human written answers there basically… It's just leveraging pure synthetic data from Llama 2.”

Last but not least, Llama 3.1 received a license update explicitly allowing its use for synthetic data generation.
We finally have a frontier-class open LLM, and together it is worth noting how far ahead the industry has moved in cost per intelligence since March, and it will only get better from here.
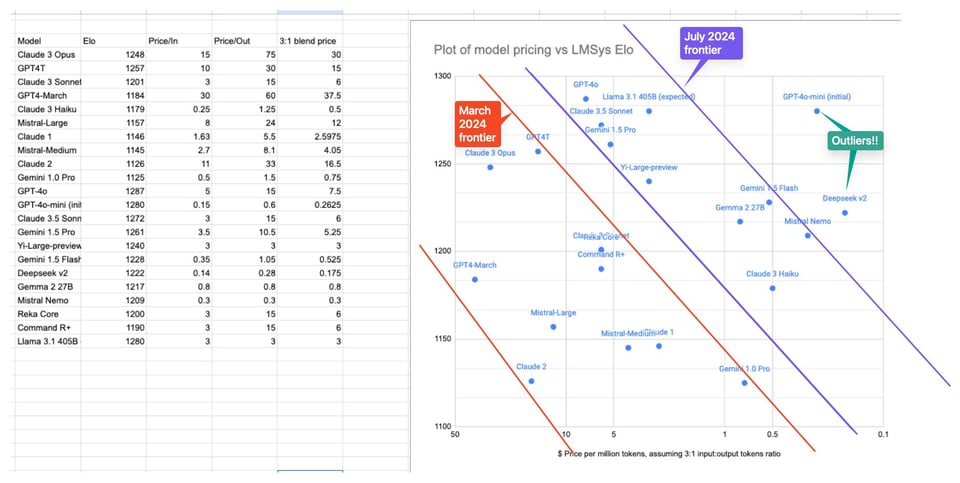
Table of Contents
[TOC]
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Meta AI
- Llama 3.1 405B model: @bindureddy noted that Llama-3.1 405B benchmarks were leaked on Reddit, outperforming GPT-4o. @Teknium1 shared an image comparing Llama-3.1 405/70/8b against GPT-4o, showing SOTA frontier models now available open source. @abacaj mentioned Meta is training and releasing open weights models faster than OpenAI can release closed models.
- Llama 3 70B performance: @rohanpaul_ai highlighted that the 70B model is matching GPT-4 levels while being 6x smaller. This is the base model, not instruct tuned. @rohanpaul_ai noted the 70B model is encroaching on 405B's territory, and the utility of big models would be to distill from it.
- Open source model progress: @teortaxesTex called it the dawn of Old Man Strength open models. @abacaj mentioned OpenAI models have not been improving significantly, so Meta models will catch up in open weights.
AI Assistants and Agents
- Omnipilot AI: @svpino introduced @OmnipilotAI, an AI application that can type anywhere you can and use full context of what's on your screen. It works with every macOS application and uses Claude Sonet 3.5, Gemini, and GPT-4o. Examples include replying to emails, autocompleting terminal commands, finishing documents, and sending Slack messages.
- Mixture of agents: @llama_index shared a video by @1littlecoder introducing "mixture of agents" - using multiple local language models to potentially outperform single models. It includes a tutorial on implementing it using LlamaIndex and Ollama, combining models like Llama 3, Mistral, StableLM in a layered architecture.
- Planning for agents: @hwchase17 discussed the future of planning for agents. While model improvements will help, good prompting and custom cognitive architectures will always be needed to adapt agents to specific tasks.
Benchmarks and Evaluations
- LLM-as-a-Judge: @cwolferesearch provided an overview of LLM-as-a-Judge, where a more powerful LLM evaluates the quality of another LLM's output. Key takeaways include using a sufficiently capable judge model, prompt setup (pairwise vs pointwise), improving pointwise score stability, chain-of-thought prompting, temperature settings, and accounting for position bias.
- Factual inconsistency detection: @sophiamyang shared a guide on fine-tuning and evaluating a @MistralAI model to detect factual inconsistencies and hallucinations in text summaries using @weights_biases. It's based on @eugeneyan's work and part of the Mistral Cookbook.
- Complex question answering: @OfirPress introduced a new benchmark to evaluate AI assistants' ability to answer complex natural questions like "Which restaurants near me have vegan and gluten-free entrées for under $25?" with the goal of leading to better assistants.
Frameworks and Tools
- DSPy: @lateinteraction shared a paper finding that DSPy optimizers alternating between optimizing weights and prompts can deliver up to 26% gains over just optimizing one. @lateinteraction noted composable optimizers over modular NLP programs are the future, and to compose BootstrapFewShot and BootstrapFinetune optimizers.
- LangChain: @hwchase17 pointed to the new LangChain Changelog to better communicate everything they're shipping. @LangChainAI highlighted seamless LangSmith tracing in LangGraph.js with no additional configuration, making it easier to use LangSmith's features to build agents.
- EDA-GPT: @LangChainAI introduced EDA-GPT, an open-source data analysis companion that streamlines data exploration, visualization, and insights. It has a configurable UI and integrates with LangChain.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Running Large Language Models Locally
- If you have to ask how to run 405B locally (Score: 287, Comments: 122): The post addresses the impossibility of running a 405 billion parameter model locally. It bluntly states that if someone needs to ask how to do this, they simply cannot achieve it, implying the task is beyond the capabilities of typical consumer hardware.
- Please share your LLaMA 3.1 405B experiences below for us GPU poor (Score: 52, Comments: 30): The post requests users to share their experiences running LLaMA 3.1 405B locally, specifically targeting those with limited GPU resources. While no specific experiences are provided in the post body, the title suggests interest in understanding how this large language model performs on consumer-grade hardware and the challenges faced by users with less powerful GPUs.
- Ollama site “pro tips” I wish my idiot self had known about sooner: (Score: 72, Comments: 24): The post highlights several "pro tips" for using the Ollama site to download and run AI models. Key features include accessing different quantizations of models via the "Tags" link, a hidden model type sorting feature accessible through the search box, finding max context window sizes in the model table, and using the top search box to access a broader list of models including user-submitted ones. The author, who has been using Ollama for 6-8 months, shares these insights to help others who might have overlooked these features.
Theme 2. LLaMA 3.1 405B Model Release and Benchmarks
- Azure Llama 3.1 benchmarks (Score: 349, Comments: 268): Microsoft released benchmark results for Azure Llama 3.1, showing improvements over previous versions. The model achieved a 94.4% score on the MMLU benchmark, surpassing GPT-3.5 and approaching GPT-4's performance. Azure Llama 3.1 also demonstrated strong capabilities in code generation and multi-turn conversations, positioning it as a competitive option in the AI model landscape.
- Llama 3.1 405B, 70B, 8B Instruct Tuned Benchmarks (Score: 137, Comments: 28): Meta has released LLaMA 3.1, featuring models with 405 billion, 70 billion, and 8 billion parameters, all of which are instruct-tuned. The 405B model achieves state-of-the-art performance on various benchmarks, outperforming GPT-4 on several tasks, while the 70B model shows competitive results against Claude 2 and GPT-3.5.
- LLaMA 3.1 405B base model available for download (Score: 589, Comments: 314): The LLaMA 3.1 405B base model, with a size of 764GiB (~820GB), is now available for download. The model can be accessed through a Hugging Face link, a magnet link, or a torrent file, with credits attributed to a 4chan thread.
- Users discussed running the 405B model, with suggestions ranging from using 2x A100 GPUs (160GB VRAM) with low quantization to renting servers with TBs of RAM on Hetzner for $200-250/month, potentially achieving 1-2 tokens per second at Q8/Q4.
- Humorous comments about running the model on a Nintendo 64 or downloading more VRAM sparked discussions on hardware limitations. Users speculated it might take 5-10 years before consumer-grade GPUs could handle such large models.
- Some questioned the leak's authenticity, noting similarities to previous leaks like Mistral medium (Miqu-1). Others debated whether it was an intentional "leak" by Meta for marketing purposes, given the timing before the official release.
Theme 3. Distributed and Federated AI Inference
- LocalAI 2.19 is Out! P2P, auto-discovery, Federated instances and sharded model loading! (Score: 52, Comments: 7): LocalAI 2.19 introduces federated instances and sharded model loading via P2P, allowing users to combine GPU and CPU power across multiple nodes to run large models without expensive hardware. The release includes a new P2P dashboard for easy setup of federated instances, Text-to-Speech integration in binary releases, and improvements to the WebUI, installer script, and llama-cpp backend with support for embeddings.
- Ollama has been updated to accommodate Mistral NeMo and a proper download is now available (Score: 63, Comments: 13): Ollama has been updated to include support for the Mistral NeMo model, now available for download. The user reports that NeMo performs faster and better than Lama 3 8b and Gemma 2 9b models on a 4060 Ti GPU with 16GB VRAM, noting it as a significant advancement in local AI models shortly after Gemma's release.
- Users praised Mistral NeMo 12b for its performance, with one noting it "NAILED" a 48k context test and showed fluency in French. However, its usefulness may be short-lived with the upcoming release of Llama 3.1 8b.
- Some users expressed excitement about downloading the model, while others found it disappointing compared to tiger-gemma2, particularly in following instructions during multi-turn conversations.
- The timing of Mistral NeMo's release was described as "very sad" for the developers, coming shortly after other significant model releases.
Theme 4. New AI Model Releases and Leaks
- Nvidia has released two new base models: Minitron 8B and 4B, pruned versions of Nemotron-4 15B (Score: 69, Comments: 3): Nvidia has released Minitron 8B and 4B, pruned versions of their Nemotron-4 15B model, which require up to 40x fewer training tokens and result in 1.8x compute cost savings compared to training from scratch. These models show up to 16% improvement in MMLU scores compared to training from scratch, perform comparably to models like Mistral 7B and Llama-3 8B, and are intended for research and development purposes only.
- Pruned models are uncommon in the AI landscape, with Minitron 8B and 4B being notable exceptions. This rarity sparks interest among researchers and developers.
- The concept of pruning is intuitively similar to quantization, though some users speculate that quantizing pruned models might negatively impact performance.
- AWQ (Activation-aware Weight Quantization) is compared to pruning, with pruning potentially offering greater benefits by reducing overall model dimensionality rather than just compressing bit representations.
- llama 3.1 download.sh commit (Score: 66, Comments: 18): A recent commit to the Meta Llama GitHub repository suggests that LLaMA 3.1 may be nearing release. The commit, viewable at https://github.com/meta-llama/llama/commit/12b676b909368581d39cebafae57226688d5676a, includes a download.sh script, potentially indicating preparations for the model's distribution.
- The commit reveals 405B models in both Base and Instruct versions, with variants labeled mp16, mp8, and fp8. Users speculate that "mp" likely stands for mixed precision, suggesting quantization-aware training for packed mixed precision models.
- Discussion around the fb8 label in the Instruct model concludes it's likely a typo for fp8, supported by evidence in the file. Users express excitement about the potential to analyze weight precisions for better low-bit quantization.
- The commit author, samuelselvan, previously uploaded a LLaMA 3.1 model to Hugging Face that was considered suspicious. Users are enthusiastic about Meta directly releasing quantized versions of the model.
- Llama 3 405b leaked on 4chan? Excited for it ! Just one more day to go !! (Score: 210, Comments: 38): Reports of a LLaMA 3.1 405B model leak on 4chan are circulating, but these claims are unverified and likely false. The purported leak is occurring just one day before an anticipated official announcement, raising skepticism about its authenticity. It's important to approach such leaks with caution and wait for official confirmation from Meta or other reliable sources.
- A HuggingFace repository containing the model was reportedly visible 2 days ago, allowing potential leakers access. Users expressed interest in 70B and 8B versions of the model.
- Some users are more interested in the pure base model without alignment or guardrails, rather than waiting for the official release. A separate thread on /r/LocalLLaMA discusses the alleged 405B base model download.
- Users are attempting to run the model, with one planning to convert to 4-bit GGUF quantization using a 7x24GB GPU setup. Another user shared a YouTube link of their efforts to run the model.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. OpenAI's Universal Basic Income Experiment Results
- [/r/singularity] The OpenResearch team releases the first result from their UBI study (OpenAI) (Score: 280, Comments: 84): OpenResearch, a team at OpenAI, has released initial results from their Universal Basic Income (UBI) study. The study, conducted in Kenyan villages, found that a $1,000 cash transfer resulted in significant positive impacts, including a $400 increase in assets and a 40% reduction in the likelihood of going hungry. These findings contribute to the growing body of evidence supporting the effectiveness of direct cash transfers in alleviating poverty.
- [/r/OpenAI] OpenAI founder Sam Altman secretly gave out $45 million to random people - as an experiment (Score: 272, Comments: 75): Sam Altman's $45 million UBI experiment revealed: The OpenAI founder secretly distributed $45 million to 3,000 people across two U.S. states as part of a Universal Basic Income (UBI) experiment. Participants received $1,000 per month for up to five years, with the study aiming to assess the impact of unconditional cash transfers on recipients' quality of life, time use, and financial health.
- 3,000 participants received either $1,000 or $50 per month for up to five years, with many Redditors expressing desire to join the experiment. The study targeted individuals aged 21-40 with household incomes below 300% of the federal poverty level across urban, suburban, and rural areas in Texas and Illinois.
- Some users criticized the experiment as a PR move by tech billionaires to alleviate concerns about AI-driven job loss, while others argued that private UBI experiments are necessary given slow government action on the issue.
- Discussions emerged about the future of employment, with some predicting a sudden spike in unemployment due to AI advancements, potentially leading to widespread UBI implementation when traditional jobs become scarce across various sectors.
Theme 4. AI Researcher Predictions on AGI Timeline
- [/r/singularity] Former OpenAI researcher predictions (Score: 243, Comments: 151): Former OpenAI researcher predicts AGI timeline: Paul Christiano, a former OpenAI researcher, estimates a 20-30% chance of AGI by 2030 and a 60-70% chance by 2040. He believes that current AI systems are still far from AGI, but rapid progress in areas like reasoning and planning could lead to significant breakthroughs in the coming years.
- [/r/singularity] "most of the staff at the secretive top labs are seriously planning their lives around the existence of digital gods in 2027" (Score: 579, Comments: 450): AI researchers anticipate digital deities: According to the post, most staff at secretive top AI labs are reportedly planning their lives around the expected emergence of digital gods by 2027. While no specific sources or evidence are provided, the claim suggests a significant shift in the mindset of AI researchers regarding the potential capabilities and impact of future AI systems.
- [/r/singularity] Nick Bostrom says shortly after AI can do all the things the human brain can do, it will learn to do them much better and faster, and human intelligence will become obsolete (Score: 323, Comments: 258): Nick Bostrom warns of AI surpassing human intelligence in a rapid and transformative manner. He predicts that once AI can match human brain capabilities, it will quickly outperform humans across all domains, rendering human intelligence obsolete. This accelerated advancement suggests a potential intelligence explosion, where AI's capabilities rapidly exceed those of humans, leading to significant societal and existential implications.
- Nick Bostrom's warning sparked debate, with some calling it "Captain obvious" due to AI's ability to connect to 100k GPUs, while others defended the importance of his message given ongoing arguments about AI capabilities.
- Discussions ranged from humorous memes to philosophical musings about a "solved world", with one user describing a hypothetical 2055 scenario of AGI and ASI leading to medical breakthroughs, full-dive VR, and simulated realities.
- Some users expressed optimism about AI solving major problems like ocean degradation, while others cautioned about potential negative outcomes, such as population reduction scenarios or the challenges of implementing necessary changes due to resistance.
Theme 5. New AI Training Infrastructure Developments
- [/r/singularity] Elon says that today a model has started training on the new and most powerful AI cluster in the world (Score: 239, Comments: 328): Elon Musk announces groundbreaking AI development: A new AI model has begun training on what Musk claims is the world's most powerful AI cluster. This announcement marks a significant milestone in AI computing capabilities, potentially pushing the boundaries of large language model training and performance.
AI Discord Recap
A summary of Summaries of Summaries
1. LLM Advancements and Benchmarking
- Llama 3.1 Release Excitement: Llama 3.1 models, including 8B and 405B, are now available, sparking excitement in the community. Users shared their experiences and troubleshooting tips to tackle issues like running the model locally and managing high loss values during fine-tuning.
- The community praised the model's performance, with some noting it surpasses existing proprietary models on benchmarks, while others highlighted challenges in practical deployment.
- Meta's Open Source AI Commitment: Meta's release of Llama 3.1 with models like 405B pushes the boundaries of open-source AI, offering 128K token context and support for multiple languages. This move aligns with Mark Zuckerberg's vision for fostering innovation through open collaboration.
- The community discussed the strategic implications of this release, emphasizing the model's potential to rival top closed-source alternatives like GPT-4.
2. Optimizing LLM Inference and Training
- Efficient Fine-tuning Techniques Discussed: The ReFT paper introduces a method that is 15x-60x more parameter-efficient than LoRA by working on the residual stream, offering flexibility in combining training tasks with optimized parameters.
- Community members engaged with the lead author to understand the practical applications, highlighting the method's potential to enhance fine-tuning efficiency.
- GPU Compatibility Challenges: Users reported issues with GPU detection on Linux, particularly with the Radeon RX5700XT, raising concerns about RDNA 1 support. Discussions emphasized the importance of proper configurations for GPU recognition.
- Some users confirmed that extension packs weren't resolving the issues, indicating a need for further troubleshooting and potential updates from developers.
3. Open-Source AI Frameworks and Community Efforts
- LlamaIndex Webinar on Efficient Document Retrieval: The upcoming webinar will discuss Efficient Document Retrieval with Vision Language Models this Friday at 9am PT. Participants can sign up to learn about cutting-edge techniques in document processing.
- The webinar aims to explore ColPali's innovative approach to embedding page screenshots with Vision Language Models, enhancing retrieval performance over complex documents.
- Magpie Paper Sparks Debate: Members debated the utility of insights from the Magpie paper, questioning whether the generated instructions offer substantial utility or are merely a party trick.
- The discussion highlights ongoing evaluations of emerging techniques in instruction generation, reflecting the community's critical engagement with new research.
4. Multimodal AI and Generative Modeling Innovations
- UltraPixel Creates High Resolution Images: UltraPixel is a project capable of generating extremely detailed high-resolution images, pushing the boundaries of image generation with a focus on clarity and detail.
- The community showcased interest in the project's capabilities, exploring its potential applications and sharing the link to the project for further engagement.
- Idefics2 and CodeGemma: New Multimodal Models: Idefics2 8B Chatty focuses on elevated chat interactions, while CodeGemma 1.1 7B refines coding abilities.
- These models represent significant advancements in multimodal AI, with the community discussing their potential to enhance user interaction and coding tasks.
PART 1: High level Discord summaries
HuggingFace Discord
- NuminaMath Datasets Launch: The NuminaMath datasets, featuring approximately 1M math problem-solution pairs used to win the Progress Prize at the AI Math Olympiad, have been released. This includes subsets designed for Chain of Thought and Tool-integrated reasoning, significantly enhancing performance on math competition benchmarks.
- Models trained on these datasets have demonstrated best-in-class performance, surpassing existing proprietary models. Check the release on the 🤗 Hub.
- Llama 3.1 Release Excitement: The recent release of Llama 3.1 has sparked excitement, with models like 8B and 405B now available for testing. Users are actively sharing experiences, including troubleshooting issues when running the model locally.
- The community engages with various insights and offers support for operational challenges faced by early adopters.
- Challenges in Model Fine-Tuning: Frustrations have arisen regarding high loss values and performance issues in fine-tuning models for specific tasks. Resources and practices have been suggested to tackle these challenges effectively.
- The exchange of knowledge aims to improve model training and evaluation processes.
- UltraPixel Creates High Resolution Images: UltraPixel is showcased as a project capable of generating extremely detailed high-resolution images. This initiative pushes the boundaries of image generation with a focus on clarity and detail.
- Check out the project at this link.
- Interest in Segmentation Techniques: Another member expressed interest in effective segmentation techniques that work alongside background removal using diffusion models. They seek recommendations on successful methods or models.
- The conversation is aimed at exploring better practices for image segmentation.
Nous Research AI Discord
- Magpie Paper Sparks Debate: Members discussed whether insights from the Magpie paper offer substantial utility or are merely a party trick, focusing on the quality and diversity of generated instructions.
- This inquiry highlights the ongoing evaluation of emerging techniques in instruction generation.
- ReFT Paper Reveals Efficient Fine-tuning: The lead author of the ReFT paper clarified that the method is 15x-60x more parameter-efficient than LoRA by working on the residual stream.
- This offers flexibility in combining training tasks with optimized parameters, reinforcing the relevance of efficient fine-tuning strategies.
- Bud-E Voice Assistant Gains Traction: The Bud-E voice assistant demo emphasizes its open-source potential and is currently optimized for Ubuntu, with hackathons led by Christoph for community engagement.
- Such collaborative efforts aim to foster contributions from volunteers, enhancing the project's scope.
- Llama 3.1 Impresses with Benchmark Performance: Llama 3.1 405B Instruct-Turbo ranked 1st on GSM8K and closely matched GPT-4o on logical reasoning, although performance on MMLU-Redux appeared weaker.
- This variation reinforces the importance of comprehensive evaluation across benchmark datasets.
- Kuzu Graph Database Recommended: Members recommended the Kuzu GraphStore, integrated with LlamaIndex, particularly for its MIT license that ensures accessibility for developers.
- The adoption of advanced graph database functionalities presents viable alternatives for data management, especially in complex systems.
LM Studio Discord
- LM Studio Performance Insights: Users highlighted performance differences between Llama 3.1 models, noting that running larger models demands significant GPU resources, especially for the 405B variant.
- One user humorously remarked about needing a small nation's electricity supply to run these models effectively.
- Model Download Woes: Several members noted difficulties with downloading models due to DNS issues and traffic spikes to Hugging Face caused by the popularity of Llama 3.1.
- One user suggested the option to disable IPv6 within the app to alleviate some of these downloading challenges.
- GPU Compatibility Challenges: New Linux users reported trouble with LM Studio recognizing GPUs like the Radeon RX5700XT, raising concerns about RDNA 1 support.
- Discussion highlighted the importance of proper configurations for GPU recognition, with some users confirming extension packs weren’t resolving the issues.
- Llama 3.1 Offers New Features: Llama 3.1 has launched with improvements, including context lengths of up to 128k, available for download on Hugging Face.
- Users are encouraged to explore the model's enhanced performance, particularly for memory-intensive tasks.
- ROCm Performance Issues Post-Update: A user noted that updating to ROCm 0.2.28 resulted in significant slowdowns in inference, with consumption dropping to 150w on their 7900XT.
- Reverting to 0.2.27 restored performance, indicating a need for clarity on functional changes in the newer version.
Perplexity AI Discord
- Llama 3.1 405B Launch and API Integration: The highly anticipated Llama 3.1 405B model is now available on Perplexity, rivaling GPT-4o and Claude Sonnet 3.5, enhancing the platform's AI capabilities.
- Users inquired about adding Llama 3.1 405B to the Perplexity API, asking if it will be available soon and sharing various experiences with model performance.
- Concerns Over Llama 3.1 Performance: Users reported issues with Llama 3.1 405B, including answer repetition and difficulties in understanding Asian symbols, leading many to consider reverting to Claude 3.5 Sonnet.
- Comparative evaluations suggested that while Llama 3.1 is a leap forward, Claude still holds an edge in speed and coding tasks.
- Exploring Dark Oxygen and Mercury's Diamonds: A recent discussion focused on Dark Oxygen, raising questions regarding its implications for atmospheric studies and ecological balance.
- Additionally, insights emerged about Diamonds on Mercury, sparking interest in the geological processes that could lead to their formation.
- Beach-Cleaning Robots Steal the Show: Innovations in beach-cleaning robot technology were highlighted, showcasing efforts to tackle ocean pollution effectively.
- The impact of these robots on marine ecosystems was a key point of discussion, with real-time data from trials being shared.
- Perplexity API's DSGVO Compliance DB: Concerns were raised about the Perplexity API being DSGVO-ready, with users seeking clarity on data protection compliance.
- The conversation included a share of the terms of service referencing GDPR compliance.
Stability.ai (Stable Diffusion) Discord
- Ranking AI Models with Kolors on Top: In the latest discussion, users ranked AI models, placing Kolors at the top due to its impressive speed and performance, followed by Auraflow, Pixart Sigma, and Hunyuan.
- Kolors' performance aligns well with user expectations for SD3.
- Training Lycoris Hits Compatibility Snags: Talks centered around training Lycoris using ComfyUI and tools like Kohya-ss, with users expressing frustration over compatibility requiring Python 3.10.9 or higher.
- There is anticipation for potential updates from Onetrainer to facilitate this process.
- Community Reacts to Stable Diffusion: Users debated the community's perception of Stable Diffusion, suggesting recent criticism often arises from misunderstandings around model licensing.
- Concerns were raised about marketing strategies and perceived negativity directed at Stability AI.
- Innovations in AI Sampling Methods: A new sampler node has been introduced, implementing Strong Stability Preserving Runge-Kutta and implicit variable step solvers, capturing user interest in AI performance enhancements.
- Users eagerly discussed the possible improvements these updates bring to AI model efficacy.
- Casual Chat on AI Experiences: General discussions flourished as users shared personal experiences with AI, including learning programming languages and assessing health-related focus challenges.
- Such casual conversations added depth to the understanding of daily AI applications.
OpenRouter (Alex Atallah) Discord
- Llama 3 405B Launch Competitively Priced: The Llama 3 405B has launched at $3/M tokens, rivaling GPT-4o and Claude 3.5 Sonnet while showcasing a remarkable 128K token context for generating synthetic data.
- Users reacted with enthusiasm, remarking that 'this is THE BEST open LLM now' and expressing excitement over the model's capabilities.
- Growing Concerns on Model Performance: Feedback on the Llama 405B indicates mixed performance results, especially in translation tasks where it underperformed compared to Claude and GPT-4.
- Some users reported the 70B version generated 'gibberish' after a few tokens, raising flags about its reliability for task-specific usage.
- Exciting OpenRouter Feature Updates: New features on OpenRouter include Retroactive Invoices, custom keys, and improvements to the Playground, enhancing user functionality overall.
- Community members are encouraged to share feedback here to further optimize the user experience.
- Multi-LLM Prompt Competition Launched: A prompting competition for challenging the Llama 405B, GPT-4o, and Claude 3.5 Sonnet has been announced, with participants vying for a chance to win 15 free credits.
- Participants are eager to know the judging criteria, especially regarding what qualifies as a tough prompt.
- DeepSeek Coder V2 Inference Provider Announced: The DeepSeek Coder V2 new private inference provider has been introduced, operating without input training, which broadens OpenRouter's offerings significantly.
- Users can start exploring the service via DeepSeek Coder.
CUDA MODE Discord
- Flash Attention Confusion in CUDA: A member questioned the efficient management of registers in Flash Attention, raising concerns about its use alongside shared memory in CUDA programming.
- This leads to a broader need for clarity in register allocation strategies in high-performance computing contexts.
- Memory Challenges with Torch Compile: Utilizing
torch.compilefor a small Bert model led to significant RAM usage, forcing a batch size cut from 512 to 160, as performance lagged behind eager mode.- Testing indicated that the model compiled successfully despite these concerns, highlighting memory management issues in PyTorch.
- Meta Llama 3.1 Focus on Text: Meta's Llama 3.1 405B release expanded context length to 128K and supports eight languages, excluding multi-modal features for now, sparking strategic discussions.
- This omission aligns with expectations around potential financial outcomes and competitive positioning ahead of earnings reports.
- Optimizing CUDA Kernel Performance: User experiences showed that transitioning to tiled matrix multiplication resulted in limited performance gains, similar to findings in a related article on CUDA matrix multiplication benchmarks.
- The discussion emphasized the importance of compute intensity for optimizing kernel performance, especially at early stages.
- Stable Diffusion Acceleration on AMD: A post detailed how to optimize inferencing for Stable Diffusion on RX7900XTX using the Composable Kernel library for AMD RDNA3 GPUs.
- Additionally, support for Flash Attention on AMD ROCm, effective for mi200 & mi300, was highlighted in a recent GitHub pull request.
OpenAI Discord
- GEMINI Competition Sparks Interest: A member expressed enthusiasm for the GEMINI Competition from Google, looking for potential collaborators for the hackathon.
- Reach out if you're interested to collaborate!
- Llama 3.1 Model Draws Mixed Reactions: Members reacted to the Llama-3.1 Model, with some labeling it soulless compared to earlier iterations like Claude and Gemini, which were seen to retain more creative depth.
- This discussion pointed out a divergence in experiences and expectations of recent models.
- Fine-Tuning Llama 3.1 for Uncensored Output: One user is working to fine-tune Llama-3.1 405B for an uncensored version, aiming to release it as Llama3.1-406B-uncensored on Hugging Face after several weeks of training.
- This effort highlights the ongoing interest in developing alternatives to constrained models.
- Voice AI in Discord Presents Challenges: Discussion arose around creating AI bots capable of engaging in Discord voice channels, emphasizing the complexity of the task due to current limitations.
- Members noted the technical challenges that need addressing for effective implementation.
- Eager Anticipation for Alpha Release: Members are keenly awaiting the alpha release, with some checking the app every 20 minutes, expressing uncertainty about whether it will launch at the end of July or earlier.
- There's a call for clearer communications from developers regarding timelines.
Modular (Mojo 🔥) Discord
- Mojo Community Meeting Presentations Open Call: There's an open call for presentations at the Mojo Community Meeting on August 12 aimed at showcasing what developers are building in Mojo.
- Members can sign up to share experiences and projects, enhancing community engagement.
- String and Buffer Optimizations Take the Stage: Work on short string optimization and small buffer optimization in the standard library is being proposed for presentation, highlighting its relevance for future meetings.
- This effort aligns with past discussion themes centered on performance enhancements.
- Installing Mojo on an Ubuntu VM Made Simple: Installation of Mojo within an Ubuntu VM on Windows is discussed, with WSL and Docker suggested as feasible solutions.
- Concerns about possible installation issues are raised, but the general consensus is that VM usage is suitable.
- Mojo: The Future of Game Engine Development: Mojo's potential for creating next-gen game engines is discussed, emphasizing its strong support for heterogeneous compute via GPU.
- Challenges with allocator handling are noted, indicating some hurdles in game development patterns.
- Linking Mojo with C Libraries: There’s ongoing dialogue about improving Mojo's linking capabilities with C libraries, especially utilizing libpcap.
- Members advocate for ktls as the default for Mojo on Linux to enhance networking functionalities.
Eleuther Discord
- FSDP Performance Troubles with nn.Parameters: A user faced a 20x slowdown when adding
nn.Parameterswith FSDP, but a parameter size of 16 significantly enhanced performance.- They discussed issues about buffer alignment affecting CPU performance despite fast GPU kernels.
- Llama 3.1 Instruct Access on High-End Hardware: A member successfully hosted Llama 3.1 405B instruct on 8xH100 80GB, available via a chat interface and API.
- However, access requires a login, raising discussions on costs and hardware limitations.
- Introducing Switch SAE for Efficient Training: The Switch SAE architecture improves scaling in sparse autoencoders (SAEs), addressing training challenges across layers.
- Relevant papers suggest this could help recover features from superintelligent language models.
- Concerns Over Llama 3's Image Encoding: Discussion surfaced regarding Llama 3's image encoder resolution limit of 224x224, with suggestions to use a vqvae-gan style tokenizer for enhancement.
- Suggestions were made to follow Armen's group, highlighting potential improvements.
- Evaluating Task Grouping Strategies: Members recommended using groups for nested tasks and tags for simpler arrangements, as endorsed by Hailey Schoelkopf.
- This method aims to streamline task organization effectively.
Interconnects (Nathan Lambert) Discord
- Meta's Premium Llama 405B Rollout: Speculation suggests that Meta may announce a Premium version of Llama 405B on Jul 23, after recently removing restrictions on Llama models, paving the way for more diverse applications.
- This change sparks discussions about broader use cases, departing from merely enhancing other models.
- NVIDIA's Marketplace Strategies: Concerns about NVIDIA potentially monopolizing the AI landscape were raised, aiming to combine hardware, CUDA, and model offerings.
- A user pointed out that such dominance might lead to immense profits, though regulatory challenges could impede this vision.
- OpenAI's Pricing Dynamics: OpenAI's introduction of free fine-tuning for gpt-4o-mini up to 2M tokens/day has ignited discussions about the competitive pricing environment in AI.
- Members characterized the pricing landscape as chaotic, emerging in response to escalating competition.
- Llama 3.1 Surpasses Expectations: The launch of Llama 3.1 introduced models with 405B parameters and enhanced multilingual capabilities, demonstrating similar performance to GPT-4 in evaluations.
- The conversation about potential model watermarking and user download tracking ensued, focusing on compliance and privacy issues.
- Magpie's Synthetic Data Innovations: The Magpie paper highlights a method for generating high-quality instruction data for LLMs that surpasses existing data sources in vocabulary diversity.
- Notably, LLaMA 3 Base finetuned on the Magpie IFT dataset outperformed the original LLaMA 3 Instruct model by 9.5% on AlpacaEval.
OpenAccess AI Collective (axolotl) Discord
- Llama 3.1 Release Generates Mixed Reactions: The Llama 3.1 release has stirred mixed feelings, with concerns about its utility particularly in the context of models like Mistral. Some members expressed their dissatisfaction, as captured by one saying, 'Damn they don't like the llama release'.
- Despite the hype, the feedback indicates a need for better performance metrics and clearer advantages over predecessors.
- Users Face Training Challenges with Llama 3.1: Errors related to the
rope_scalingconfiguration while training Llama 3.1 have contributed to community frustration. A workaround was found by updating transformers, showcasing resilience among users as one remarked, 'Seems to have worked thx!'.- This highlights a broader theme of troubleshooting that persists with new model releases.
- Concerns Over Language Inclusion in Llama 3.1: The exclusion of Chinese language support in Llama 3.1 has sparked discussions about its global implications. While the tokenizer includes Chinese, its lack of prioritization was criticized as a strategic blunder.
- This conversation points to the ongoing necessity for language inclusivity in AI models.
- Evaluation Scores Comparison: Llama 3.1 vs Qwen: Community discussions focused on comparing the cmmlu and ceval scores of Llama 3.1, revealing only marginal improvements. Members pointed out that while Qwen's self-reported scores are higher, differences in evaluation metrics complicate direct comparisons.
- This reflects the community's ongoing interest in performance benchmarks across evolving models.
- Exploring LLM Distillation Pipeline: A member shared the LLM Distillery GitHub repo, highlighting a pipeline focusing on precomputing logits and KL divergence for LLM distillation. This indicates a proactive approach to refining distillation processes.
- The community's interest in optimizing such pipelines reflects an ongoing commitment to improving model training efficiencies.
DSPy Discord
- Code Confluence Tool Generates GitHub Summaries: Inspired by DSPY, a member introduced Code Confluence, an OSS tool built with Antlr, Chapi, and DSPY pipelines, designed to create detailed summaries of GitHub repositories. The tool's performance is promising, as demonstrated on their DSPY repo.
- They also shared resources including the Unoplat Code Confluence GitHub and the compilation of summaries called OSS Atlas.
- New AI Research Paper Alert: A member shared a link to an AI research paper titled 2407.12865, sparking interest in its findings. Community members are encouraged to analyze and discuss its implications.
- Requests were made for anyone who replicates the findings in code or locates existing implementations to share them.
- Comparison of JSON Generation Libraries: Members discussed the strengths of libraries like Jsonformer and Outlines for structured JSON generation, noting that Outlines offers better support for Pydantic formats. While Jsonformer excels in strict compliance, Guidance and Outlines offer flexibility, adding complexity.
- Taking into account the community's feedback, they are exploring the practical implications of each library in their workflow.
- Challenges with Llama3 Structured Outputs: Users expressed difficulty obtaining properly structured outputs from Llama3 using DSPY. They suggested utilizing
dspy.configure(experimental=True)with TypedChainOfThought to enhance success rates.- Concerns were raised over viewing model outputs despite type check failures, with
inspect_historyfound to have limitations for debugging.
- Concerns were raised over viewing model outputs despite type check failures, with
- Exploring ColPali for Medical Documents: A member shared experiences using ColPali for RAG of medical documents with images due to prior failures with ColBert and standard embedding models. Plans are underway to investigate additional vision-language models.
- This exploration aims to bolster the effectiveness of information retrieval from complex document types.
LlamaIndex Discord
- LlamaIndex Webinar on Efficient Document Retrieval: Join the upcoming webinar discussing Efficient Document Retrieval with Vision Language Models this Friday at 9am PT. Signup here to explore cutting-edge techniques.
- ColPali introduces an innovative technique that directly embeds page screenshots with Vision Language Models, enhancing retrieval over complex documents that traditional parsing struggles with.
- TiDB Future App Hackathon Offers $30,000 in Prizes: Participate in the TiDB Future App Hackathon 2024 for a chance to win from a prize pool of $30,000, including $12,000 for the top entry. This competition urges innovative AI solutions using the latest TiDB Serverless with Vector Search.
- Coders are encouraged to collaborate with @pingcap to showcase their best efforts in building advanced applications.
- Explore Mixture-of-Agents with LlamaIndex: A new video showcases the approach 'mixture of agents' using multiple local language models to potentially outmatch standalone models like GPT-4. Check the step-by-step tutorial for insights into this enhancing technique.
- Proponents suggest this method could provide a competitive edge, especially in projects requiring diverse model capabilities.
- Llama 3.1 Models Now Available: The Llama 3.1 series now includes models of 8B, 70B, and 405B, accessible through LlamaIndex with Ollama, although the largest model demands significant computing resources. Explore hosted solutions at Fireworks AI for support.
- Users should evaluate their computational capacity when opting for larger models to ensure optimal performance.
- Clarifying context_window Parameters for Improved Model Usage: The
context_windowparameter defines the total token limit that affects both input and output capacity of models. Miscalculating this can result in errors like ValueError due to exceeding limits.- Users are advised to adjust their input sizes or select models with larger context capabilities to optimize output efficiency.
Latent Space Discord
- Excitement Surrounds Llama 3.1 Launch: The release of Llama 3.1 includes the 405B model, marking a significant milestone in open-source LLMs with remarkable capabilities rivaling closed models.
- Initial evaluations show it as the first open model with frontier capabilities, praised for its accessibility for iterative research and development.
- International Olympiad for Linguistics (IOL): The International Olympiad for Linguistics (IOL) commenced, challenging students to translate lesser-known languages using logic, mirroring high-stakes math competitions.
- Participants tackle seemingly impossible problems in a demanding six-hour time frame, highlighting the intersection of logical reasoning and language.
- Llama Pricing Insights: Pricing for Llama 3.1's 405B model ranges around $4-5 per million tokens across platforms like Fireworks and Together.
- This competitive pricing strategy aims to capture market share before potentially increasing rates with growing adoption.
- Evaluation of Llama's Performance: Early evaluations indicate Llama 3.1 ranks highly on benchmarks including GSM8K and logical reasoning on ZebraLogic, landing between Sonnet 3.5 and GPT-4o.
- Challenges like maintaining schema adherence after extended token lengths were noted in comparative tests.
- GPT-4o Mini Fine-Tuning Launch: OpenAI announced fine-tuning capabilities for GPT-4o mini, available to tier 4 and 5 users, with the first 2 million training tokens free each day until September 23.
- This initiative aims to expand access and customization, as users assess its performance against the newly launched Llama 3.1.
LangChain AI Discord
- AgentState vs InnerAgentState Explained: A discussion clarified the difference between
AgentStateandInnerAgentState, with definitions forAgentStateprovided and a suggestion to check the LangChain documentation for further details.- Key fields of
AgentStateincludemessagesandnext, essential for context-dependent operations within LangChain.
- Key fields of
- Setting Up Chroma Vector Database: Instructions were shared on how to set up Chroma as a vector database with open-source solutions in Python, requiring the installation of
langchain-chromaand running the server via Docker.- Examples showed methods like
.add,.get, and.similarity_search, highlighting the necessity of an OpenAI API Key forOpenAIEmbeddingsusage.
- Examples showed methods like
- Create a Scheduler Agent using Composio: A guide for creating a Scheduler Agent with Composio, LangChain, and ChatGPT enables streamlined event scheduling via email. The guide is available here.
- Composio enhances agents with effective tools, demonstrated in the scheduler examples, emphasizing efficiency in task handling.
- YouTube Notes Generator is Here!: The launch of the YouTube Notes Generator, an open-source project for generating notes from YouTube videos, was announced, aiming to facilitate easier note-taking directly from video content.
- Learn more about this tool and its functionality on LinkedIn.
- Efficient Code Review with AI: A new video titled 'AI Code Reviewer Ft. Ollama & Langchain' introduces a CLI tool aimed at enhancing the code review process for developers; watch it here.
- This tool aims to streamline workflow by promoting efficient code evaluations across development teams.
Cohere Discord
- New Members Join the Cohere Community: New members showcased enthusiasm about joining Cohere, igniting a positive welcome from the community.
- Community welcomes newbies with open arms, creating an inviting atmosphere for discussions.
- Innovative Fine-Tuning with Midicaps Dataset: Progress on fine-tuning efforts surfaced with midicaps, showing promise based on previous successful projects.
- Members highlighted good results from past endeavors, indicating potential future breakthroughs.
- Clarifying Cohere's OCR Solutions: Cohere utilizes unstructured.io for its OCR capabilities, keeping options open for external integrations.
- The community engaged in fruitful discussions about the customization and enhancement of OCR functionalities.
- RAG Chatbot Systems Explored: Chat history management in RAG-based ChatBot systems became a hot topic, highlighting the use of vector databases.
- Feedback mechanisms such as thumbs up/down were proposed to optimize interaction experiences.
- Launch of Rerank 3 Nimble with Major Improvements: Rerank 3 Nimble hits the scene, delivering 3x higher throughput while keeping accuracy in check, now available on AWS SageMaker.
- Say hello to increased speed for enterprise search! This foundation model boosts performance for retrieval-augmented generation.
Torchtune Discord
- Llama 3.1 is officially here!: Meta released the latest model, Llama 3.1, this morning, with support for the 8B and 70B instruct models. Check out the details in the Llama 3.1 Model Cards and Prompt formats.
- The excitement was palpable, leading to humorous remarks about typos and excitement-induced errors.
- MPS Support Pull Request Discussion: The pull request titled MPS support by maximegmd introduces checks for BF16 on MPS devices, aimed at improving testing on local Mac computers. Discussions indicate potential issues due to a common ancestor diff, suggesting a rebase might be a better approach.
- This PR was highlighted as a critical update for those working with MPS.
- LoRA Issues Persist: An ongoing issue regarding the LoRA implementation not functioning as expected was raised, with suggestions made for debugging. One contributor noted challenges with CUDA hardcoding in their recent attempts.
- This issue underscores the need for deeper troubleshooting in model performance.
- Git Workflow Challenges Abound: Git workflow challenges have been a hot topic, with many feeling stuck in a cycle of conflicts after resolving previous ones. Suggestions were made to tweak the workflow to minimize these conflicts.
- Effective strategies for conflict resolution seem to be an ever-pressing need among the contributors.
- Pad ID Bug Fix PR Introduced: A critical bug related to pad ID displaying in generate was addressed in Pull Request #1211 aimed at preventing this issue. It clarifies the implicit assumption of Pad ID being 0 in utils.generate.
- This fix is pivotal for ensuring proper handling of special tokens in future generative tasks.
tinygrad (George Hotz) Discord
- Help needed for matmul-free-llm recreation: There's a request for assistance in recreating matmul-free-llm with tinygrad, aiming to leverage efficient kernels while incorporating fp8.
- Hoping for seamless adaptation to Blackwell fp4 soon.
- M1 results differ from CI: An M1 user is experiencing different results compared to CI, seeking clarification on setting up tests correctly with conda and environment variables.
- There's confusion due to discrepancies when enabling
PYTHON=1, as it leads to an IndexError in tests.
- There's confusion due to discrepancies when enabling
- cumsum performance concerns: A newcomer is exploring the O(n) implementation of nn.Embedding in tinygrad and how to improve cumsum from O(n^2) to O(n) using techniques from PyTorch.
- There’s speculation about constraints making this challenging, especially as it's a $1000 bounty.
- Seeking Pattern for Incremental Testing with PyTorch: A member inquired about effective patterns for incrementally testing model performance in the sequence of Linear, MLP, MoE, and LinearAttentionMoE using PyTorch.
- They questioned whether starting tests from scratch is more efficient than incremental testing.
- Developing Molecular Dynamics Engine in Tinygrad: A group is attempting to implement a Molecular Dynamics engine in tinygrad to train models predicting energies of molecular configurations, facing challenges with gradient calculations.
- They require the gradient of predicted energy concerning input positions for the force, but issues arise because they backpropagate through the model weights twice.
LAION Discord
- Int8 Implementation Confirmed: Members discussed using Int8, with confirmation from one that it works, showing developer interest in optimization techniques.
- Hold a sec was requested, indicating a potential for additional guidance and community support during the implementation.
- ComfyUI Flow Script Guidance: A user requested a script for ComfyUI flow, leading to advice on utilizing this framework for smoother setup processes.
- This reflects a community trend towards efficiency and preferred workflows when working with complex system integrations.
- Llama 3.1 Sets New Standards: The release of Llama 3.1 405B introduces a context length of 128K, offering significant capabilities across eight languages.
- This leap positions Llama 3.1 as a strong contender against leading models, with discussions focusing on its diverse functionality.
- Meta's Open Source Commitment: Meta underlined its dedication to open source AI, as described in Mark Zuckerberg’s letter, highlighting developer and community benefits.
- This aligns with their vision to foster collaboration within the AI ecosystem, aiming for wider accessibility of tools and resources.
- Context Size Enhancements in Llama 3.1: Discussions criticized the previous 8K context size as insufficient for large documents, now addressed with the new 128K size in Llama 3.1.
- This improvement is viewed as crucial for tasks needing extensive document processing, elevating model performance significantly.
OpenInterpreter Discord
- Llama 3.1 405 B Amazes Users: Llama 3.1 405 B is reported to work fantastically out of the box with OpenInterpreter. Unlike GPT-4o, there's no need for constant reminders or restarts to complete multiple tasks.
- Users highlighted that the experience provided by Llama 3.1 405 B significantly enhances productivity when compared to GPT-4o.
- Frustrations with GPT-4o: A user expressed challenges with GPT-4o, requiring frequent prompts to perform tasks on their computer. This frustration underscores the seamless experience users have with Llama 3.1 405 B.
- The comparison made suggests a user preference leaning towards Llama 3.1 405 B for efficient task management.
- Voice Input on MacOS with Coqui Model?: A query arose about using voice input with a local Coqui model on MacOS. No successful implementations have been reported yet.
- Community engagement remains open, but no further responses have surfaced to clarify the practicality of this application.
- Expo App's Capability for Apple Watch: Discussion affirmed that the Expo app should theoretically be able to build applications for the Apple Watch. However, further details or confirmations were not provided.
- While optimistic, the community awaits practical validation of this capability in an Apple Watch context.
- Shipping Timeline for the Device: A member inquired about the shipping timeline for a specific device, indicating curiosity about its status. No updates or timelines were shared in the conversation.
- The lack of information points to an opportunity for clearer communication regarding shipping statuses.
Alignment Lab AI Discord
- Clarification on OpenOrca Dataset Licensing: A member inquired whether the MIT License applied to the OpenOrca dataset permits commercial usage of outputs derived from the GPT-4 Model.
- Can its outputs be used for commercial purposes? highlights the ongoing discussion around dataset licensing in AI.
- Plans for Open Sourcing Synthetic Dataset: Another member revealed intentions to open source a synthetic dataset aimed at supporting both commercial and non-commercial projects, highlighting its relevance in the AI ecosystem.
- They noted an evaluation of potential dependencies on OpenOrca, raising questions about its licensing implications in the broader dataset landscape.
LLM Finetuning (Hamel + Dan) Discord
- Miami Meetup Interest Sparks Discussion: A member inquired about potential meetups in Miami, seeking connections with others in the area for gatherings.
- So far, there have been no further responses or arrangements mentioned regarding this meetup inquiry.
- NYC Meetup Gains Traction for August: Another member expressed interest in attending meetups in NYC in late August, indicating a desire for community engagement.
- This discussion hints at the possible coordination of events for local AI enthusiasts in the New York area.
AI Stack Devs (Yoko Li) Discord
- Artist Seeking Collaboration: Aria, a 2D/3D artist, expressed interest in collaborating with others in the community. They invited interested members to reach out via DM for potential projects.
- This presents an opportunity for anyone in the guild looking to incorporate artistic skills into their AI projects, particularly in visualization or gaming.
- Engagement Opportunities for AI Engineers: The call for collaboration emphasizes the growing interest in merging AI engineering with creative domains like art and design.
- Such collaborations can enhance the visual aspects of AI projects, potentially leading to more engaging user experiences.
Mozilla AI Discord
- Mozilla Accelerator Application Deadline Approaches: The application deadline for the Mozilla Accelerator is fast approaching, offering a 12-week program with up to $100k in non-dilutive funds.
- Participants will also showcase their projects on demo day with Mozilla, providing a pivotal moment for feedback and exposure. Questions?
- Get Ready for Zero Shot Tokenizer Transfer Event: A reminder of the upcoming Zero Shot Tokenizer Transfer event with Benjamin Minixhofer, scheduled for this month.
- Details can be found in the event's link, encouraging participation from interested engineers.
- Introducing AutoFix: The Open Source Issue Fixer: AutoFix is an open-source tool that can submit PRs directly from Sentry.io, streamlining issue management.
- Learn more about this tool's capabilities in the detailed post linked here: AutoFix Information.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #announcements (1 messages):
NuminaMath datasetsDocmatix datasetSmolLM modelsChameleon modelFollowgraph tool
- NuminaMath Datasets Launch: The NuminaMath datasets have been released, featuring about 1M math competition problem-solution pairs, used to win the Progress Prize of the AI Math Olympiad. This includes Chain of Thought and Tool-integrated reasoning subsets designed to enhance mathematical reasoning.
- These models trained on NuminaMath achieve best-in-class performance, surpassing proprietary models on math competition benchmarks and are available on the 🤗 Hub.
- Introducing Docmatix Dataset: The Docmatix dataset has been introduced as a gigantic resource for document understanding. It aims to address the data coverage deficiencies that have hindered open-source models in document tasks.
- This dataset is set to improve performance on various document tasks, which previously favored closed models due to lack of adequate open-source data.
- SmolLM Models Released: A new series of models called SmolLM has been released, featuring sizes of 135M, 360M, and 1.7B parameters. They outperform MobileLLM, Phi1.5, and Qwen2, and are trained on a high-quality corpus.
- This series addresses the growing importance of on-device deployment for large language models (LLMs), catering to diverse application needs.
- Chameleon Model Now Available: Chameleon, a multimodal model by Meta, is now integrated into transformers and comes in sizes of 7B and 34B parameters. This model aims to enhance various multimodal tasks.
- The integration of Chameleon represents a significant advancement in the capabilities of transformers for handling diverse inputs and outputs.
- Explore ML Connections with Followgraph: A new tool called Followgraph has been launched to facilitate following interesting ML personalities. It’s aimed at enhancing the collaboration and networking opportunities within the ML community.
- This tool allows users to discover and connect with influential figures in the machine learning space, adding a social dimension to professional interactions.
- Tweet from Lewis Tunstall (@_lewtun): We have just released the ✨NuminaMath datasets: the largest collection of ~1M math competition problem-solution pairs, ranging in difficulty from junior challenge to Math Olympiad preselection. These...
- Tweet from merve (@mervenoyann): Introducing Docmatix: a gigantic document understanding dataset 📑 Closed models outperformed open-source models in document tasks so far due to lack of data coverage 💔 but @huggingface M4 is here ...
- Tweet from Loubna Ben Allal (@LoubnaBenAllal1): On-device deployment of LLMs is more important than ever. Today we’re releasing SmolLM a new SOTA series of 135M, 360M and 1.7B models: - Outperforming MobileLLM, Phi1.5 and Qwen2 small models - Tra...
- Tweet from Niels Rogge (@NielsRogge): We just shipped chat templates for vision-language models (VLMs)! 🔥 Models like LLaVa, LLaVa-NeXT, and LLaVa-Interleave can now all be called using the messages API. Docs: https://huggingface.co/do...
- Tweet from Zach Mueller (@TheZachMueller): Lazy-loading model weights has been shipped into @huggingface transformers main! A tweet about what the heck that means... Typically when you load in PyTorch weights, it's instantaneous (aka when...
- Tweet from Konrad Szafer (@KonradSzafer): We’ve just added a new method to the Transformers Tokenizer class to improve tracking and reproducibility. You can now retrieve the exact chat template used by the Tokenizer! 🚀
- Tweet from merve (@mervenoyann): Chameleon 🦎 by @Meta is now available in @huggingface transformers 😍 A multimodal model that comes in 7B and 34B sizes 🤩 But what makes this model so special? keep reading ⇣
- Tweet from Niels Rogge (@NielsRogge): 2 new depth estimation models now in @huggingface Transformers! Depth Anything v2 & ZoeDepth - Depth Anything v2 is relative, tells you the relative distance among the pixels - ZoeDepth is absolute...
- Tweet from Julien Chaumond (@julien_c): Friday @huggingface update. For image generation models and LoRAs, we now display tiny previews of models, directly on users profiles. Have a great weekend! 🔥
- Tweet from Sylvain Lesage (@severo_dev): [New tool] Follow interesting ML persons 👩🎨 👨🎤 👩🏫 with Followgraph https://huggingface.co/spaces/severo/followgraph
- Tweet from Daniel van Strien (@vanstriendaniel): When sharing model fine-tuning notebooks, it can be helpful to show the input dataset. You can now embed a dataset viewer directly in a @GoogleColab notebook. Here's an edited @UnslothAI notebook ...
- Tweet from Remi Cadene (@RemiCadene): 🚨 We can now visualize LeRobot datasets directly on hugging face hub. Try it out on the dataset I just recorded 😇 https://huggingface.co/spaces/lerobot/visualize_dataset Hugging Face has the potenti...
- Tweet from abhishek (@abhi1thakur): We just integrated dataset viewer in AutoTrain 💥 So, now you can look into your dataset, identify correct splits and columns before training the model, without leaving the page 🚀
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): We put together a detailed blog post going through the steps for running Mistral on Mac and all the updates announced by Apple during WWDC: https://huggingface.co/blog/mistral-coreml
- Tweet from Avijit Ghosh (@evijitghosh): http://x.com/i/article/1814002459108691968
- Tweet from Caleb (@calebfahlgren): Wrote a blog post on how you can use the Datasets Explorer to find really interesting insights on @huggingface datasets 🔥 There's even a couple examples of the @duckdb spatial extension with som...
HuggingFace ▷ #general (1104 messages🔥🔥🔥):
Llama 3.1 releaseKanye West controversyBuilding PC setupsModel fine-tuning practicesTextbook recommendations for LLMs
- Llama 3.1 release excitement: The release of Llama 3.1 has generated excitement, with models like 8B and 405B now available for testing and deployment.
- Users are sharing their experiences and troubleshooting issues such as ValueErrors when attempting to run the model locally.
- Kanye West's influence in music: Despite the controversies surrounding Kanye West, many users like kebab_addict express an appreciation for his musical talent and impact on the industry.
- Discussions also highlight the complexity of separating an artist's work from their personal controversies.
- Building PC setups and GPU discussions: Users are discussing various GPU options for building affordable PC setups, with recommendations for models like the 3060 and 4060ti.
- Some express concerns over the rising costs of components while sharing personal anecdotes about acquiring their hardware.
- Model fine-tuning practices: The challenges of fine-tuning models for specific tasks are being discussed, with users expressing frustrations about high loss values and performance issues.
- There are suggestions for resources and practices to better handle model training and evaluation.
- Textbook recommendations for LLMs: A user is seeking comprehensive textbooks covering recent innovations in LLMs, expressing a preference for written material over video content.
- Titles such as 'Transformers for Natural Language Processing' are mentioned as potential resources, though they primarily focus on applied learning.
- starsnatched/MemeGPT · Hugging Face: no description found
- — Zero GPU Spaces — - a Hugging Face Space by enzostvs: no description found
- Tweet from Omar Sanseviero (@osanseviero): Llama 3.1 is out 🔥Enjoy! - Learn all about it https://hf.co/blog/llama31 - Models https://hf.co/meta-llama - Community quants https://hf.co/hugging-quants - How to use it https://github.com/huggingf...
- HuggingChat: Making the community's best AI chat models available to everyone.
- Whisper Speaker Diarization - a Hugging Face Space by Xenova: no description found
- Snoop Dogg will carry the Olympic torch on its final leg to Paris: The culturally ubiquitous rapper will see the flame's tradition through ahead of Friday's opening ceremony.
- no title found: no description found
- NNsight and NDIF: Democratizing Access to Foundation Model Internals: The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineer...
- What GIF - What - Discover & Share GIFs: Click to view the GIF
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding: We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed t...
- Patrick Stupid GIF - Patrick Stupid Drooling - Discover & Share GIFs: Click to view the GIF
- Stfu Kanye GIF - Stfu Kanye Kanye West - Discover & Share GIFs: Click to view the GIF
- Spongebob Squarepants Begging GIF - Spongebob Squarepants Begging Pretty Please - Discover & Share GIFs: Click to view the GIF
- Train a Llama model from scratch: no description found
- The Rust Programming Language - The Rust Programming Language: no description found
- Make your agents 10x more reliable? Flow engineer 101: Deep dive into flow engineer & lang graph, build a reliable SQL agentGet Codeium (FREE Github Copilot alternative): https://codeium.com/?utm_source=youtube&u...
- Sad Violin GIF - Sad Upset Violin - Discover & Share GIFs: Click to view the GIF
- Vision Card: no description found
- Lindsey Stirling Cute GIF - Lindsey Stirling Lindsey Stirling - Discover & Share GIFs: Click to view the GIF
- openai/whisper-large-v3 · Hugging Face: no description found
- Waiting Waiting Patiently GIF - Waiting Waiting patiently Waiting for you - Discover & Share GIFs: Click to view the GIF
- Wizard Dance GIF - Wizard Dance Ena - Discover & Share GIFs: Click to view the GIF
- Good Morning GIF - Good morning - Discover & Share GIFs: Click to view the GIF
- Mark Zuckerberg GIF - Mark Zuckerberg - Discover & Share GIFs: Click to view the GIF
- Scared Dog Shivering Dog GIF - Scared Dog Shivering Dog Dog Shaking Meme - Discover & Share GIFs: Click to view the GIF
- Cat Twitching GIF - Cat Twitching Tweaking - Discover & Share GIFs: Click to view the GIF
- Batman Mad GIF - Batman Mad Angry - Discover & Share GIFs: Click to view the GIF
- Biggest Boy Family Guy GIF - Biggest Boy Family Guy Chris Griffin - Discover & Share GIFs: Click to view the GIF
- Subida GIF - Subida - Discover & Share GIFs: Click to view the GIF
- Huh Cat GIF - Huh Cat - Discover & Share GIFs: Click to view the GIF
- Bh187 Spongebob GIF - Bh187 Spongebob Patrick Star - Discover & Share GIFs: Click to view the GIF
- Kotmadam Odilon GIF - Kotmadam Odilon Old Man - Discover & Share GIFs: Click to view the GIF
- Hello Street Cat Huge Bite GIF - Hello street cat Huge bite Little scraggly guy - Discover & Share GIFs: Click to view the GIF
- Bugs Bunny No GIF - Bugs bunny no No Bunny - Discover & Share GIFs: Click to view the GIF
- Patrick Menacingly GIF - Patrick Menacingly Spongebob - Discover & Share GIFs: Click to view the GIF
- Dead GIF - Dead - Discover & Share GIFs: Click to view the GIF
- Dpowe GIF - Dpowe - Discover & Share GIFs: Click to view the GIF
- Spongebob Spongebob Meme GIF - Spongebob Spongebob meme Spongebob mafia - Discover & Share GIFs: Click to view the GIF
- Caveman Spongebob GIF - Caveman Spongebob Spongegar - Discover & Share GIFs: Click to view the GIF
- Lag Android GIF - Lag Android Glitch - Discover & Share GIFs: Click to view the GIF
- I Wore a Hollywood Disguise to Buy a PC - Scrapyard Wars 2024 Part 1: https://jawa.link/ScrapyardWarsThanks to Jawa for sponsoring this season of Scrapyard Wars! Join in on the spirit with Jawa: THE marketplace for buying and s...
- Troll Lol GIF - Troll Lol Gta - Discover & Share GIFs: Click to view the GIF
- Kanye West Ai GIF - Kanye west Kanye Ai - Discover & Share GIFs: Click to view the GIF
- Journey Car GIF - Journey Car Kissing - Discover & Share GIFs: Click to view the GIF
- Homelander Based GIF - Homelander Based The Boys - Discover & Share GIFs: Click to view the GIF
- Zeng This Guy Right Here GIF - Zeng This Guy Right Here This Right Here - Discover & Share GIFs: Click to view the GIF
- Oliver Twist GIF - Oliver Twist - Discover & Share GIFs: Click to view the GIF
- Kanye Haircut GIF - Kanye Haircut Kanye west - Discover & Share GIFs: Click to view the GIF
- Llama 3.1 - 405B, 70B & 8B with multilinguality and long context: no description found
- Spaces - Hugging Face: no description found
- Ye Kanye GIF - Ye Kanye Kanye West - Discover & Share GIFs: Click to view the GIF
- Introduction - Hugging Face NLP Course: no description found
- Hugging Face – The AI community building the future.: no description found
- Hugging Face - Documentation: no description found
- GitHub - huggingface/huggingface-llama-recipes: Contribute to huggingface/huggingface-llama-recipes development by creating an account on GitHub.
- Wizard Crawly GIF - Wizard Crawly Crawly wizard - Discover & Share GIFs: Click to view the GIF
- Biggest Boy Family Guy GIF - Biggest boy Family guy - Discover & Share GIFs: Click to view the GIF
- Transformers for Natural Language Processing | Data | eBook: Build innovative deep neural network architectures for NLP with Python, PyTorch, TensorFlow, BERT, RoBERTa, and more. Instant delivery. Top rated Mobile Application Development products.
- NVIDIA GeForce RTX 5090 Specs: NVIDIA GB202, 2520 MHz, 20480 Cores, 640 TMUs, 192 ROPs, 28672 MB GDDR7, 2500 MHz, 448 bit
- 3dfx Voodoo3 3000 AGP Specs: 3dfx Avenger, 166 MHz, 1 Pixel Shaders, 0 Vertex Shaders, 2 TMUs, 1 ROPs, 16 MB SDR, 166 MHz, 128 bit
- NVIDIA GeForce RTX 5060 Specs: NVIDIA GB206, 2520 MHz, 4608 Cores, 144 TMUs, 48 ROPs, 8192 MB GDDR7, 2500 MHz, 128 bit
HuggingFace ▷ #today-im-learning (4 messages):
Speaker Diarization & TranscriptionSankey Plots VisualizationDynamic Graph Node ManagementPEFT Model Loading MethodsAdapter Configuration in Models
- Automate Speaker Diarization and Transcriptions: A member is seeking a way to automate speaker diarization, whisper transcriptions, and timestamps for uploaded WAV files into a single database.
- They are looking for open source repositories or models to implement this pipeline.
- Sankey Plots Using Matplotlib: A user shared their experience with Sankey plots (also known as flow plots) using matplotlib, noting that the implementation has room for improvement.
- They expressed a desire to make many changes to enhance the visualization capability of dataset filtering.
- Dynamic Node Management in Graphs: A user inquired about the feasibility of dynamically adding and removing nodes from a graph to gradually build an info database.
- Their goal is to avoid the need to parse numerous files all at once, suggesting a more streamlined process.
- PEFT Model Loading Insights: A member highlighted two methods to load a PEFT model, providing examples with code snippets for both techniques.
- They questioned how the first method retrieves the entire model from an adapter link, speculating that the adapter config might contain the necessary base model details.
HuggingFace ▷ #cool-finds (5 messages):
Willing Suspension of DisbeliefnanoLLaVA modelMeta's Llama 3.1 releaseMark Zuckerberg's vision for open-source AI
- Exploring Delving in Storytelling: A study titled Willing Suspension of Disbelief investigates the role of volition in how audiences engage with stories, emphasizing the importance of delving into narrative experiences.
- This research can be accessed here.
- nanoLLaVA model discussion: A member highlighted the nanoLLaVA model, noting it was duplicated from another model called llava-next.
- The conversation included images related to the model but did not elaborate further.
- Launch of Llama 3.1 AI Models: Meta announced the release of the Llama 3.1 family, praising its performance that rivals top closed-source models, especially the 405B version.
- The release aims to promote an open-source AI ethos and offers Mark Zuckerberg’s letter on why open source benefits developers and the community.
- Mark Zuckerberg advocates for open-source AI: Meta's CEO shared his vision for an open AI ecosystem, asserting that the features of Llama 3.1 will aid developers in unlocking new capabilities, such as synthetic data generation.
- Zuckerberg emphasized the relevance of open-source AI, stating it is the path forward for both developers and Meta's future strategies.
- nanoLLaVA-1.5 - a Hugging Face Space by qnguyen3: no description found
- Mark Zuckerberg explains why open source AI is good for developers: Mark Zuckerberg believes that open-source AI is the future of AI, fostering unrestricted innovation similar to how open-source development has accelerated progress in other fields.
- no title found: no description found
HuggingFace ▷ #i-made-this (10 messages🔥):
UltraPixel high resolution imagesRust client library for GradioSmolLM Arena updatesYouTube Notes GeneratorMistral-NeMo 12B Instruct
- UltraPixel creates high resolution images: One user showcased their project called UltraPixel, capable of generating extremely detailed high resolution images at this link.
- This project aims to push the boundaries of image generation with a focus on clarity and detail.
- Rust library for Gradio development: A new project for a Rust client library for Gradio has been announced with active testing using
hf-audio/whisper-large-v3and other models, available on GitHub.- The library is in the early stages, inviting contributions and feedback from the community as it develops.
- SmolLM Arena gets a new interface: The SmolLM Arena has introduced a new interface with chatbots instead of text boxes, improving speed and user experience, detailed at this link.
- Users can now compare small language models and cast votes for their favorites, combining fun and interactivity.
- YouTube Notes Generator project unveiled: A new YouTube Notes Generator project has been announced, which can create detailed notes from YouTube videos, with its code hosted on GitHub.
- It features a Streamlit UI for easy use, allowing users to generate and interact with notes from video content.
- Lightning fast Mistral-NeMo 12B Instruct demo: A demo of Mistral-NeMo 12B Instruct using llama.cpp was shared, showcasing its lightning-fast chat capabilities, available at this link.
- This project emphasizes performance in producing quick and responsive interactions.
- UltraPixel - a Hugging Face Space by gokaygokay: no description found
- Mistral NeMo llama.cpp - a Hugging Face Space by gokaygokay: no description found
- HD Pony Diffusion - a Hugging Face Space by Sergidev: no description found
- GitHub - qompassai/KO: Kyber Odyssey: Charting a course for secure innovation in a post-Crowdstrike world: Kyber Odyssey: Charting a course for secure innovation in a post-Crowdstrike world - qompassai/KO
- GitHub - JacobLinCool/gradio-rs: Gradio Client in Rust.: Gradio Client in Rust. Contribute to JacobLinCool/gradio-rs development by creating an account on GitHub.
- GitHub - di37/youtube-notes-generator: AI-powered YouTube Notes Generator: Create detailed notes from YouTube videos. Streamlit UI for easy use.: AI-powered YouTube Notes Generator: Create detailed notes from YouTube videos. Streamlit UI for easy use. - di37/youtube-notes-generator
HuggingFace ▷ #computer-vision (2 messages):
Anime-style dataset for Anything V5Fine-tuning SD models
- Inquiry on Anime-style Dataset for Anything V5: A member asked about the dataset used for anime-style generation in the Anything V5 API Inference. They provided a link to a generated image along with information on obtaining an API key and coding examples.
- They shared that no payment is needed for the API key and linked to the Stable Diffusion API for more details.
- Discussion on Fine-tuning SD Models: A member inquired about how to fine-tune Stable Diffusion (SD) models using tailored datasets. This highlights ongoing interest in customizing models for specific applications.
Link mentioned: stablediffusionapi/anything-v5 · Hugging Face: no description found
HuggingFace ▷ #NLP (17 messages🔥):
Non packed datasets with SFTTrainerError handling with tensor creationEmbedding model for numerical dataUsing Donut for generationModifications in Transformers library
- Challenges with Non Packed Datasets in SFTTrainer: A user inquired if anyone has utilized non packed datasets with SFTTrainer for LLMs, expressing concerns about the limited examples and an error faced during their implementation.
- Careful prompt engineering was suggested as a potential solution alongside using PEFT for hardware efficiency.
- Tensor Creation Error Investigation: Another user encountered an error stating 'Unable to create tensor', advising to activate truncation and padding options during the setup.
- For more assistance, they shared a link to a Hugging Face forum post detailing the issue.
- Seeking Numerical Data Embedding Model: A member asked for recommendations on an embedding model optimized for numerical data, seeking specialized options.
- No specific model was directly suggested in response to the inquiry.
- Exploring Donut for Text Generation: One user shared their experience using the Donut model from GitHub for generation, highlighting the need to adapt to changes between two versions of the Transformers library.
- They linked to relevant GitHub Pull Requests that explain the adjustments and implications for Donut generation.
- Splitting Large Embedded Text for LLMs: A user requested insights on splitting large embedded text for effective use with LLMs.
- The dialogue didn't provide specific strategies or solutions to address this concern.
- GitHub - clovaai/donut: Official Implementation of OCR-free Document Understanding Transformer (Donut) and Synthetic Document Generator (SynthDoG), ECCV 2022: Official Implementation of OCR-free Document Understanding Transformer (Donut) and Synthetic Document Generator (SynthDoG), ECCV 2022 - clovaai/donut
- Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True': I am trying to use a non packed dataset with SFTTrainer by setting ‘packing=False’ but I get the error: Unable to create tensor, you should probably activate truncation and/or padding with ‘padding=Tr...
- Generate: handle text conditioning with multimodal encoder-decoder models by gante · Pull Request #22748 · huggingface/transformers: What does this PR do? Consolidates decoder_input_ids preparation changes in a single place, for all future multimodal encoder-decoder models on PT and TF. In a nutshell, this PR generalizes the fol...
- Generate: Add exception path for Donut by gante · Pull Request #22955 · huggingface/transformers: What does this PR do? The multimodal generalization added in #22748 added a regression Donut -- Donut is never expecting a BOS token, having a task-specific token in its place. This PR adds an exce...
- donut/donut/model.py at master · clovaai/donut: Official Implementation of OCR-free Document Understanding Transformer (Donut) and Synthetic Document Generator (SynthDoG), ECCV 2022 - clovaai/donut
- donut/donut/model.py at master · clovaai/donut: Official Implementation of OCR-free Document Understanding Transformer (Donut) and Synthetic Document Generator (SynthDoG), ECCV 2022 - clovaai/donut
- Release v4.29.0: Transformers Agents, SAM, RWKV, FocalNet, OpenLLaMa · huggingface/transformers: Transformers Agents Transformers Agent is a new API that lets you use the library and Diffusers by prompting an agent (which is a large language model) in natural language. That agent will then out...
- Comparing v4.28.1...v4.29.0 · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - Comparing v4.28.1...v4.29.0 · huggingface/transformers
HuggingFace ▷ #diffusion-discussions (1 messages):
Background removalSegmentationDiffusion models
- Seeking Guidance on Background Removal: A member requested assistance for implementing background removal using diffusion models and segmentation techniques.
- They asked if anyone could provide guidance on the best approaches or resources available to get started.
- Interest in Segmentation Techniques: Another member expressed interest in segmentation techniques that effectively work alongside background removal using diffusion models.
- They inquired if there are specific models or methods that others have found successful.
Nous Research AI ▷ #research-papers (2 messages):
Magpie PaperNous Research AIInstruction Generation Techniques
- Discussion on Magpie Paper's Utility: A member inquired whether the insights from the Magpie paper represent a useful technique or merely a party trick.
- They expressed curiosity about the quality and diversity of the generated instructions.
- Nous Research Authors and Collaborations: The authors of a notable paper include Jaden Fiotto-Kaufman, Alexander R Loftus, among others.
- The collaborative effort showcases a range of expertise contributing to the ongoing AI discourse.
Link mentioned: NNsight and NDIF: Democratizing Access to Foundation Model Internals: The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineer...
Nous Research AI ▷ #off-topic (9 messages🔥):
ReFT paper discussionYouTube video on ReFTOxen AI community activityPC Agent DemoEmoji duplication in server
- ReFT Paper Simplified: A discussion was held featuring the lead author of the ReFT paper explaining its efficient fine-tuning technique, which is 15x-60x more parameter-efficient than LoRA.
- The method operates on the residual stream, making it flexible to combine various training tasks with learned parameters called 'interventions'.
- How ReFT Works YouTube Video Released: A new YouTube video titled How ReFT Works w/ Author Zhengxuan Wu dives into the ReFT paper and its implications for machine learning.
- The video presents an engaging explanation from the author alongside Greg, connecting dots with other papers discussed in prior Paper Clubs.
- Oxen AI Community in Action: The Oxen AI community is actively growing, focusing on advancements in ML and AI through weekly discussions on various research papers.
- Participants can subscribe to future Paper Club calendar invites to engage with both academic researchers and developers.
- PC Agent Demo Unveiled: A link was shared to a YouTube video titled PC Agent Demo detailing the PC Agent's functionality.
- The description links to further resources about the demo, indicating ongoing innovations in this domain.
- Emoji Duplication Blamed on User: A member questioned the abundance of duplicate emojis on the server, leading to another member suggesting it's the fault of a specific user.
- This lighter exchange highlights community interactions amid serious discussions on machine learning topics.
- How ReFT Works w/ Author Zhengxuan Wu: We dive into the ReFT paper from Stanford with one of the authors Zhengxuan Wu. --Use Oxen AI 🐂 https://oxen.ai/Oxen AI makes versioning your data...
- PC Agent Demo: gate-app.com/research/pc-agent
- Reddit - Dive into anything: no description found
- Community Resources | Oxen.ai: Manage your machine learning datasets with Oxen AI.
Nous Research AI ▷ #interesting-links (62 messages🔥🔥):
Bud-E Voice AssistantLlama 3.1 ModelsSynthetic Dataset CreationGraph RAG by MicrosoftDSPy Python Library
- Bud-E Voice Assistant Gains Momentum: A demo of the Bud-E voice assistant showcases its potential for accessibility and open-source adaptations, with the code base currently optimized for Ubuntu laptops.
- Daily hackathon meetings are hosted by Christoph to onboard new volunteers and coordinate project efforts, enabling community contributions.
- Llama 3.1 Breaks Ground for Open AI Models: The Llama 3.1 405B model is described as the largest open-source model, offering capabilities that rival top closed-source alternatives while being accessible for commercial and research use.
- Developers can leverage its functionalities for tasks such as synthetic data generation and model improvement, though operational costs are high.
- Discussion on Synthetic Dataset Creation: Concerns were raised about the costs associated with the Llama 3.1-405B for creating synthetic datasets, prompting inquiry about the viability of using the 70B model instead.
- While the 70B model is considered sufficient for many tasks, its cost-effectiveness in dataset creation remains a critical discussion point.
- Microsoft's Graph RAG Proposal: Microsoft introduced GraphRAG, a method aimed at enhancing LLMs by integrating them with private datasets for semantic understanding and clustering.
- This approach seeks to advance the capabilities of LLMs in analyzing data less familiar to them by utilizing knowledge graphs for better contextual answers.
- Launch of DSPy Python Library: A new Python library developed for integrating with DSPy optimizers claims to enhance evaluation metrics in AI applications significantly.
- The library facilitates easy integration into existing apps, allowing developers to optimize their systems effectively and encouraging community engagement on social media.
- Jail Right To Jail GIF - Jail Right To Jail Right Away - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- no title found: no description found
- Cheevly getting started tutorial (part 1): Part 1 of getting started with Cheevly.
- GitHub - stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models: DSPy: The framework for programming—not prompting—foundation models - stanfordnlp/dspy
- Now Available on Groq: The Largest and Most Capable Openly Available Foundation Model to Date, Llama 3.1 405B - Groq is Fast AI Inference: The largest openly available foundation model to date, Llama 3.1 405B, is now available on Groq. Groq is proud to partner on this key industry launch making
- meta-llama/Meta-Llama-3.1-8B-Instruct · Hugging Face: no description found
- llama-models/models/llama3_1/LICENSE at main · meta-llama/llama-models: Utilities intended for use with Llama models. Contribute to meta-llama/llama-models development by creating an account on GitHub.
- BUD-E - Demo: Join our Discord Community, try BUD-E yourself & help us to build the voice assistant me and BUD-E talk about in the video:https://discord.gg/sTKSB2AwBvhttps...
- GraphRAG: A new approach for discovery using complex information: Microsoft is transforming retrieval-augmented generation with GraphRAG, using LLM-generated knowledge graphs to significantly improve Q&A when analyzing complex information and consistently outper...
Nous Research AI ▷ #general (489 messages🔥🔥🔥):
Llama 3.1 PerformanceQuantization and Fine-tuningTool Calling MethodsModel Inference and EvaluationOpen Source Licensing
- Llama 3.1 outperforms competitors on benchmarks: Llama 3.1 405B Instruct-Turbo ranked 1st on GSM8K and performed closely to GPT-4o and Sonnet 3.5 on logical reasoning tasks like ZebraLogic.
- However, it showed weaker performance on MMLU-Redux, suggesting mixed results across different datasets.
- Concerns over Fine-tuning of Llama 3.1: There are worries that the base model's alignment during pre-training negatively impacts fine-tuning effectiveness, which could lead to poor results.
- Experts hope future fine-tuning efforts will yield better performance as users adapt training techniques.
- Discussion on Tool Calling Mechanisms: There is ongoing conversation about how Llama 3.1 manages tool calls, with speculation that its internal handling may not align with user expectations.
- The tool calling method is compared across various frameworks, raising questions about compatibility with existing tools.
- Inferences and Performance of Llama 3.1: Users report impressive inference speeds with the 8B quantized model, drawing comparisons to GPT-4o.
- This rapid performance is essential for applications requiring extensive parallel generation.
- Open Source Licensing Changes: Meta has made changes to the licensing of Llama 3.1, allowing the outputs to improve other models, marking a shift in their open-source strategy.
- This aims to foster innovation without restricting developers to use their models exclusively.
- Tweet from undefined: no description found
- LiveBench: no description found
- Half-precision floating-point format - Wikipedia: no description found
- qresearch/llama-3.1-8B-vision-378 · Hugging Face: no description found
- Tweet from Bill Yuchen Lin 🤖 (@billyuchenlin): A quick independent evaluation of Llama-3.1-405B-Instruct-Turbo (on @togethercompute) ⬇️ 1️⃣ It ranks 1st on GSM8K! 2️⃣ Its logical reasoning ability on ZebraLogic is quite similar to Sonnet 3.5, and...
- Llama 3.1 GPTQ, AWQ, and BNB Quants - a hugging-quants Collection: no description found
- Salesforce/xLAM-7b-fc-r · Hugging Face: no description found
- Maya Rudolph Ho GIF - Maya Rudolph Ho Raise The Roof - Discover & Share GIFs: Click to view the GIF
- Well No Randy Marsh GIF - Well No Randy Marsh South Park - Discover & Share GIFs: Click to view the GIF
- meta-llama/Llama-Guard-3-8B-INT8 · Hugging Face: no description found
- SillyTilly/Meta-Llama-3.1-70B · Hugging Face: no description found
- mlx-community/Meta-Llama-3-70B-Instruct-4bit · Hugging Face: no description found
- no title found: no description found
- Tweet from Casper Hansen (@casper_hansen_): AWQ models of Llama 3.1 are done and uploaded ✅ Should run in vLLM out of the box! Links below👇👇👇
- llama-toolchain/llama_toolchain/inference/inference.py at 9fb50bbd99b1dcf8f85c269cef5cb0bb48266964 · meta-llama/llama-toolchain: Model components of the Llama Stack APIs. Contribute to meta-llama/llama-toolchain development by creating an account on GitHub.
- meta-llama/Meta-Llama-3.1-405B-Instruct · Hugging Face: no description found
- no title found: no description found
- GitHub - exo-explore/exo: Run your own AI cluster at home with everyday devices 📱💻 🖥️⌚: Run your own AI cluster at home with everyday devices 📱💻 🖥️⌚ - exo-explore/exo
- DeepSpeed Configuration JSON: DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
- meta-llama/Meta-Llama-3.1-8B-Instruct · Hugging Face: no description found
- Tweet from Casper Hansen (@casper_hansen_): Llama 3.1 is out! I got download link, but need Huggingface format. Anyone got HF link that works?
- no title found: no description found
- Llama 3.1: The open source AI model you can fine-tune, distill and deploy anywhere. Our latest models are available in 8B, 70B, and 405B variants.
- GitHub - meta-llama/llama-agentic-system: Agentic components of the Llama Stack APIs: Agentic components of the Llama Stack APIs. Contribute to meta-llama/llama-agentic-system development by creating an account on GitHub.
- Tweet from Terry Yue Zhuo (@terryyuezhuo): Preliminary results of Llama-3.1-405b-instruct on BigCodeBench-Hard via the @nvidia API: Complete: 30.4 Instruct: 22.3 Average: 26.4 Better than Claude-3-Opus @AnthropicAI and close to GPT-4o @OpenA...
- Tweet from Aston Zhang (@astonzhangAZ): Our Llama 3.1 405B is now openly available! After a year of dedicated effort, from project planning to launch reviews, we are thrilled to open-source the Llama 3 herd of models and share our findings ...
- llama-agentic-system/custom_tools/base.py at main · meta-llama/llama-agentic-system: Agentic components of the Llama Stack APIs. Contribute to meta-llama/llama-agentic-system development by creating an account on GitHub.
- GitHub - meta-llama/llama-toolchain: Model components of the Llama Stack APIs: Model components of the Llama Stack APIs. Contribute to meta-llama/llama-toolchain development by creating an account on GitHub.
- Cat Keyboard GIF - Cat Keyboard Cats - Discover & Share GIFs: Click to view the GIF
{kind=link}
Nous Research AI ▷ #ask-about-llms (18 messages🔥):
Training larger bitnet modelsDifferences in model fine-tuningFine-tuning Llama 3.0Multilingual fine-tuning resources
- Interest in training larger bitnet models: Members discussed the potential for training a 1.58 bitnet with more parameters, noting a lack of comparable models to Llama on Hugging Face.
- One member mentioned finding a smaller model on Nous, but expressed curiosity about larger parameter counts.
- Debate on Qwen model differences: A member speculated that the improvements from Qwen2 to Qwen1.5 might stem from a better base model rather than just different finetuning techniques.
- Another questioned the relevance of benchmarks for base models in evaluating changes, particularly in light of low benchmark results from Mistral Nemo and Llama-3-8b.
- Challenges in fine-tuning Llama 3.0: With the release of Llama 3 405b, members acknowledged the significant challenges in fine-tuning this model, particularly concerned about practical execution outside of Lora FTing.
- One member expressed hope that this might push for successful implementations of DoRA fine-tuning in open-source software.
- Fine-tuning resources for Pashto language: A member sought resources for fine-tuning models specifically for the Pashto language, emphasizing the scarcity of available materials despite its speaker base of 60 million.
- Another suggested exploring recent research, pointing to Aya23 model papers as a potential resource for guidance.
- Collaboration on multilingual tasks: A member inquired about collaborations for multilingual fine-tuning efforts, with one mentioning that coheres is undertaking significant work in this area.
- Discussions also touched on the logistics of fine-tuning initiatives with high computational needs, like the numerous H100s used by a team.
Nous Research AI ▷ #rag-dataset (4 messages):
Kuzu Graph DatabaseGraphRAG and OutlinesEntity Deduplication TechniquesProperty Graph IndexDuplicate Detection in Graph Databases
- Kuzu Graph Database recommended for integration: A member recommended trying the Kuzu GraphStore, which has an MIT license and integration with LlamaIndex for knowledge graphs.
- This could offer a promising alternative for users looking for enhanced GraphStore functionalities.
- GraphRAG's outline feature to enhance outputs: Discussion on GraphRAG highlighted the potential of using outlines to constrain outputs, which could assist in deduplication tasks.
- Integrating this feature could streamline workflows by reducing redundancy in data outputs.
- Entity Deduplication by Tomaz Bratanic: For entity deduplication, references were made to Tomaz Bratanic, who has explored this topic in-depth, along with a shared blog post.
- The approach involves combining text embedding similarity with word distance to identify and merge duplicates via Cypher queries.
- Property Graph Index Enhancements: The Property Graph Index is seen as a valuable upgrade for LlamaIndex, now featuring a proper property graph structure that enhances data representation.
- This change allows for more detailed node labeling and property storage compared to the previous triple representation.
- Atlas's duplicate detection capabilities: Another member stated that Atlas also offers duplicate detection features, indicating a competitive landscape for graph databases.
- While it may require some data preprocessing, the duplicate detection functionality is reported as decent.
Link mentioned: Customizing Property Graph Index in LlamaIndex: Learn how to perform entity deduplication and custom retrieval methods using LlamaIndex to increase GraphRAG accuracy.
Nous Research AI ▷ #world-sim (1 messages):
jmiles38: <@414158939555364865> are you a contributor to worldsim/world client?
Nous Research AI ▷ #reasoning-tasks-master-list (74 messages🔥🔥):
Open Reasoning TasksSchema and Formatting ImprovementsReasoning Techniques and ToolsMaster List for Reasoning PapersSMT Solvers for Reasoning
- Exploring Open Reasoning Tasks Framework: Discussion centered around improving the structure and aesthetic of the Open Reasoning Tasks repository, with suggestions for a master list format that differentiates tasks and includes examples.
- Proposals for input structures included using headlined markdown formats and tables for example outputs, balancing clarity and usability for contributors.
- Incorporating Multi-modal Tasks: Participants deliberated on how to handle multi-turn tasks and various modalities, considering whether to utilize tables for structured inputs while ensuring flexibility for contributors.
- The idea of excluding complicated tasks from table requirements while allowing contributors discretion was put forward.
- Collaboration and Future Contributions: Team members expressed intentions to contribute to the repository with updates and improvements, while confirming ongoing discussions sparked by shared papers.
- References to outside resources, particularly in Bayesian reasoning and structured problem-solving techniques, were highlighted as valuable inputs for future development.
- Developing a Master List for Reasoning Papers: The possibility of creating a comprehensive master list for reasoning-related papers and resources was discussed, with input on structuring presentation for clarity.
- Examples included potential headings and abstract formats, aiming to enhance accessibility for contributors and readers.
- Utilizing SMT Solvers for Enhanced Reasoning: A user mentioned the potential to leverage SMT solvers in translating word problems into SMTLIB formats, hinting at the creation of synthetic data for enhanced reasoning.
- This approach aligns with recent discussions on integrating logical frameworks alongside LLMs to improve accuracy in reasoning applications.
- Tweet from Chad Brewbaker (@SMT_Solvers): @halvarflake As I told @Teknium1 we can get a lot of reasoning via SMT solvers if we can teach the LLM to translate word problems from English/German to SMTLIB. A MADLIBS synthetic data problem if you...
- The Quantified Boolean Bayesian Network: Theory and Experiments with a Logical Graphical Model: This paper introduces the Quantified Boolean Bayesian Network (QBBN), which provides a unified view of logical and probabilistic reasoning. The QBBN is meant to address a central problem with the Larg...
- Tweet from Swarnadeep Saha (@swarnaNLP): 🚨 New: my last PhD paper 🚨 Introducing System-1.x, a controllable planning framework with LLMs. It draws inspiration from Dual-Process Theory, which argues for the co-existence of fast/intuitive Sy...
- Structuring suggestions · Issue #5 · NousResearch/Open-Reasoning-Tasks: Hi, This is an amazing initiative! The idea of compiling a comprehensive list of potential reasoning tasks for language model evaluation is really valuable. I have a couple of suggestions: This is ...
- GitHub - mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks. - mlabonne/llm-course
- Demystifying Chains, Trees, and Graphs of Thoughts: The field of natural language processing (NLP) has witnessed significant progress in recent years, with a notable focus on improving large language models' (LLM) performance through innovative pro...
LM Studio ▷ #💬-general (197 messages🔥🔥):
LM Studio performanceModel downloads issuesLinux compatibility with GPULlama 3.1 capabilitiesROCm installation
- Performance comparison between Llama models: Users discussed the differences in performance between Llama 3.1 8B and 405B models, highlighting that running the larger models requires significant GPU resources.
- One user joked about needing a small nation's electricity supply to power the GPU clusters needed for higher-capacity models.
- Issues with downloading models: Some users reported issues with downloading models, attributing it to DNS problems, with others noticing slowdowns due to increased traffic to Hugging Face from Llama 3.1 popularity.
- A user speculated that their issues were caused by IPv6 and mentioned wanting an option in the app to avoid using it without affecting system-wide settings.
- GPU detection problems on Linux: New Linux users expressed difficulties with LM Studio detecting their GPUs, specifically mentioning issues with Radeon's RX5700XT on Linux Mint after a Windows transition.
- One user noted they had installed extension packs but were still unable to get the system to recognize their GPU, questioning RDNA 1 support.
- Discussion on model capabilities: Users discussed the functional differences of various models, including mentions of Llama 3.1 supporting a range of languages and better performance in certain tasks.
- One user noted that for Japanese, the 4o-mini model outperforms Llama 3.1, showing the importance of considering use-case specific models.
- ROCm installation advice: Advice was shared on manually installing ROCm for AMD GPUs to improve compatibility with LM Studio, particularly for users experiencing issues with their Radeon cards.
- Users were directed to specific GitHub pages for installation instructions and troubleshooting tips.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- YorkieOH10/Meta-Llama-3.1-8B-Instruct-hf-Q4_K_M-GGUF · Hugging Face: no description found
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- YorkieOH10/Meta-Llama-3.1-8B-Instruct-Q8_0-GGUF · Hugging Face: no description found
- no title found: no description found
- configs/Extension-Pack-Instructions.md at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
- Feature Request: Proper Llama 3.1 Support in llama.cpp · Issue #8650 · ggerganov/llama.cpp: Prerequisites I am running the latest code. Mention the version if possible as well. I carefully followed the README.md. I searched using keywords relevant to my issue to make sure that I am creati...
- Llama 3.1: The open source AI model you can fine-tune, distill and deploy anywhere. Our latest models are available in 8B, 70B, and 405B variants.
LM Studio ▷ #🤖-models-discussion-chat (92 messages🔥🔥):
High Memory Usage of Qwen 2LM Studio Model CompatibilityMeta-Llama Model RecommendationsAdvancements in Gemini and DeepseekLLM Compiler for Advanced Coding
- High Memory Usage of Qwen 2: A user reported very high memory usage when loading Qwen 2 72B using llama.cpp, which exceeds the model's size.
- Another member suggested lowering the context length to help manage memory utilization.
- LM Studio Model Compatibility: A member noted compatibility issues with models in LM Studio, specifically Meta-Llama 3.1-8B and 70B, with GPU offloading not working in the current version.
- Others recommended upgrading to version 0.2.28 for better support, as updates to llama.cpp are pending.
- Meta-Llama Model Recommendations: There was a discussion about the Meta-Llama 3.1 models, with varying opinions on their performance, particularly in reasoning tasks.
- One noted that the 8B version has poor logic but is still decent; another suggested looking into the 70B version for improved output.
- Advancements in Gemini and Deepseek: The conversation touched on the performance of Gemini Pro 1.5 and its suitability for coding tasks, highlighting its coding abilities but lack of writing capabilities.
- Members anticipated updates to improve reasoning in upcoming models, particularly from Deepseek.
- LLM Compiler for Advanced Coding: A member recommended the LLM Compiler, built upon Code Llama, for tasks involving advanced coding concepts, mentioning it supports code optimization and compiler reasoning.
- The model is available in 7B and 13B versions, fitting the specified memory capacity for users with limited VRAM.
- Llama - 3.1-405B: an open source model to rival GPT-4o / Claude-3.5 | Product Hunt: Meta is releasing three models: The new 3.1-405B and upgrades to their smaller models: 3.1-70B and 3.1-8B. If 405B is as good as the benchmarks indicate, this would be the first time an open source mo...
- Llama 3.1 - a meta-llama Collection: no description found
- Tweet from YouJiacheng (@YouJiacheng): just saw that deepseek-coder will get an upgrade at July 24 10:00 UTC+8.
- GitHub - xcapt0/gpt2_chatbot: ☕ GPT-2 chatbot for daily conversation: ☕ GPT-2 chatbot for daily conversation. Contribute to xcapt0/gpt2_chatbot development by creating an account on GitHub.
- Dubesor LLM Benchmark table: no description found
LM Studio ▷ #announcements (1 messages):
Search Functionality
- Search Functionality is Back!: The issue affecting the search function in the app is now RESOLVED and users should be able to search again.
- Apologies were made for the inconvenience caused during the downtime.
- Increased Transparency on Resolutions: The team has committed to providing updates regarding app issues, ensuring users are informed on resolved functionalities.
- Users appreciated the prompt communication regarding the status of the search feature.
LM Studio ▷ #🧠-feedback (4 messages):
hf-mirror.comLatex support for Llama 3.1 models
- hf-mirror.com showcases promising potential: A member introduced hf-mirror.com as a mirror site for Hugging Face's API with its source code available on GitHub, though it's currently in Chinese.
- The site utilizes Caddy as a reverse proxy and offers a script hfd.sh for resuming downloads, suggesting that LM Studio could greatly benefit from integrating these features for better user adaptability.
- Latex support is on the horizon for Llama 3.1: A member expressed enthusiasm for huge Latex support in the new Llama 3.1 models, highlighting its importance for users asking math and programming-related questions.
- Another member confirmed that Latex support is coming soon, addressing the community's demand for enhanced mathematical capabilities.
LM Studio ▷ #⚙-configs-discussion (12 messages🔥):
Llama 3 ConfigurationGPU SettingsRoleplay ScenariosContext Length Settings
- Seeking Advice on Roleplay Setup for Llama 3: A user is looking for guidance on setting up a roleplay scenario in LMStudio, trying to prevent the assistant from writing dialogue or actions for the user character.
- I'm just digging back into LMStudio, given the advances in Llama 3 based models.
- Configuration Settings for Llama 3.1: A user requested suggestions for config values in Llama 3.1 as they are new to the setup.
- Another member suggested using the v2 preset of Llama 3 after confirming they've updated to v0.2.28.
- Context Length Recommendations: Discussion revealed that Llama 3 supports a context length up to 128k, with advice to set it to 32k for optimal GPU utilization.
- A user inquired whether to leave the context length at 2048, uncertain about prior increases.
- GPU Compatibility Issues: A user mentioned that Llama 3.1 did not seem to load fully into their GPU, specifically a 3080ti.
- After setting context length to max (-1), the user noted it reverted upon reloading.
LM Studio ▷ #🎛-hardware-discussion (23 messages🔥):
Fine-tuning with 3090sGGUF Fine-tuning LimitationsGPU Acceleration on RX 6700 XTQuantized Model Fine-tuningGPU Requirements for LLMs
- Dual 3090s for Fine-tuning: A member considers purchasing two used 3090s for fine-tuning, with another noting it's suitable for models up to 13b, albeit slowly.
- It's suggested to look into renting GPUs for custom model fine-tuning for better efficiency.
- Challenges with Fine-tuning GGUF: It's claimed that fine-tuning GGUFs is largely impossible, with one member stating it might yield poor results.
- However, another points out that quantized LLMs can be fine-tuned, but the outcomes may corrupt the model's weights.
- RX 6700 XT Lacks Support for GPU Acceleration: A user inquired about GPU acceleration for the RX 6700 XT on Linux, and it was confirmed that it is not supported due to OpenCL deprecation.
- Members highlighted that the RX 6700 XT doesn't support ROCM, further limiting its capabilities.
- Quantized Model Fine-tuning Insights: Discussion emerged around the viability of fine-tuning quantized models with methods like unsloth/QLora, albeit with potential issues.
- Members clarified that supported quantized models are typically bitsandbytes/awq quantized, and GGUF is not supported.
- GPU Requirements for LLM Execution: It was noted that to achieve GPU acceleration for LLMs, a compatible NVIDIA GPU is preferred over AMD models such as the RX series.
- Members referenced the LM Studio site for guidance on supported hardware, emphasizing that NVIDIA GPUs 'Just Work'.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- Getting started with LLM fine-tuning: Large Language Model (LLM) Fine-tuning is the process of adapting the pre-trained model to specific tasks. This process is done by updating its parameters on a new dataset. Specifically, the LLM is pa...
LM Studio ▷ #🧪-beta-releases-chat (112 messages🔥🔥):
Beta UI ImprovementsFeedback on Model LoadingUser Experience ConcernsIssues with GPU UsageBeta Testing Process
- Beta UI receives mixed feedback: Users appreciate the new UI found in Beta 1 for its simplicity, yet some feel that important functionalities have been hidden behind too many tabs and menus.
- Some users argue that the interface needs to retain advanced settings for users who want deeper customization.
- Model loading parameters create confusion: Several users reported difficulties finding and utilizing model loading parameters like Batch size and GPU offloading settings in the new interface.
- Feedback mentions that features like mmap have been added, which may not have been clear initially for those accustomed to previous versions.
- GPU auto settings fail to utilize hardware effectively: Users noted that setting GPU layers to auto does not utilize the available GPU effectively, particularly on platforms with high-performance GPUs such as the4080S.
- Manual settings appear to work better for GPU usage, raising questions about how the automatic feature is supposed to function.
- Beta Testing Process and Feedback Handling: The community emphasizes the importance of feedback during beta testing, with some users actively encouraging others to report bugs or suggestions.
- Participants express appreciation for earlier bug fixes and encourage further transparency regarding the continued development of LM Studio.
- Clarifications on System Settings and Limitations: Some users sought clarity on why certain system resource limits exist, such as a restriction to 8 CPU threads, particularly for higher-end systems.
- Others have shared their experiences with the new features, acknowledging initial misunderstandings due to the redesign of functionalities.
- Introducing `lms` - LM Studio's companion cli tool | LM Studio: Today, alongside LM Studio 0.2.22, we're releasing the first version of lms — LM Studio's companion cli tool.
- LM Studio 0.3.0 - Private Beta Sign Up: Thanks for your interest in helping out test our upcoming release. LM Studio 0.3.0 is gem-packed with new features and we'd love your help to shake out the bugs before sending it out to the worl...
LM Studio ▷ #amd-rocm-tech-preview (5 messages):
ROCm 0.2.28 performance issuesLlama 3.1 compatibility with AMD cards
- ROCm 0.2.28 Slows Inferencing Down: After updating to 0.2.28 ROCm preview, a user noticed significant slowdown in inference performance, with only one 7900XT card showing 150w usage instead of the usual 300w on both cards.
- The user reverted to 0.2.27, which restored performance, and asked others to investigate what changed in inference for 0.2.28.
- Llama 3.1 Needs Tokenizer Fix for AMD: A user expressed interest in getting Llama 3.1 running on AMD cards but mentioned that llama.cpp does not recognize smaug-bpe as a tokenizer.
- They highlighted this issue as a challenge that needs addressing for compatibility with AMD hardware.
LM Studio ▷ #model-announcements (1 messages):
Llama 3.1longer context improvements
- Llama 3.1 Launch Brings Exciting Updates: Llama 3.1 is now available, with the 8B model currently live on the Hugging Face page for download.
- Users are encouraged to try it out, as it features massive improvements over the initial release, particularly regarding longer context support up to 128k.
- Encouragement to Download Llama 3.1: The message highlights the need to download Llama 3.1 now to experience its enhancements.
- With its improved performance for longer contexts, it's a strong recommendation for users to get involved.
LM Studio ▷ #🛠-dev-chat (4 messages):
Mistral download issuesVPN connectivity problemsLLM model for gradingCHROMA data usage
- Mistral Download Fails with VPN: A member is experiencing download failures for Mistral in LM Studio while connected through a VPN on a remote desktop.
- Proxies are known not to work with the model explorer, making it a challenge to resolve the issue.
- Using LLM for Grading: One user is developing an LLM model for grading, utilizing an answer file and a document file to constrain the bot's responses.
- They expressed confusion about how to effectively use the data entered into CHROMA for this purpose.
Perplexity AI ▷ #announcements (1 messages):
Llama 3.1 405BPerplexity mobile apps
- Llama 3.1 405B Launches on Perplexity: The Llama 3.1 405B model, touted as the most capable open-source model, is now available on Perplexity, rivaling GPT-4o and Claude Sonnet 3.5.
- This launch signifies a significant enhancement in the capabilities available on the platform.
- Upcoming Mobile Integration for Llama 3.1: Perplexity is working on adding Llama 3.1 405B to their mobile applications next, promising seamless access to this advanced model.
- Users are encouraged to stay tuned for updates as development progresses.
Perplexity AI ▷ #general (273 messages🔥🔥):
Performance of Llama 3.1 405BComparison of Llama 3.1 405B and Claude 3.5 SonnetPerplexity AI features and issuesFeedback on AI responsesAPI and usage experiences
- Llama 3.1 405B performance concerns: Users expressed dissatisfaction with the performance of Llama 3.1 405B, stating it often repeats answers and doesn't handle prompts effectively, particularly with Asian symbols.
- Many are considering switching back to Claude 3.5 Sonnet for better speed and performance.
- Comparative evaluation of AI models: Some users believe that although Llama 3.1 405B is a significant advancement for open-source AI, it may not outperform Claude 3.5 in coding tasks.
- Others noted that Sonnet 3.5 still excels in speed and better handles coding inquiries compared to Llama.
- Issues with Perplexity AI functionality: There were reports of Llama 3.1 405B not working properly on Perplexity AI, leading to queries about its status and stability across different platforms.
- Users suggested waiting for a few days to assess performance, as previous models improved after initial launch.
- Feedback on AI responses: Several users commented on the models' inability to understand or generate certain symbols correctly, resulting in mixed reviews.
- Feedback indicates that while Llama can simplify concepts, its overall functionality may lag behind competitors like Claude.
- API usage experiences: Users discussed the differences in experiences across different providers, noting that AWS and Fireworks had specific issues with the new version of Llama.
- It was mentioned that accessing models through the Perplexity AI platform may vary from other applications, with expectations for improvements over time.
- Jason Mendoza - Fullstack Developer (Web & Blockchain & AI Tech) : no description found
- Tweet from Ryan Putnam (@RypeArts): ✧ ✧ ˚ * . · · + ✧ · · ˚ . 𝓈𝓊𝓂𝓂ℯ𝓇 𝓋𝒾𝒷ℯ𝓈
- Tweet from Perplexity (@perplexity_ai): Introducing Bird SQL, a Twitter search interface that is powered by Perplexity’s structured search engine. It uses OpenAI Codex to translate natural language into SQL, giving everyone the ability to n...
- SEAL leaderboards: no description found
- Tweet from Perplexity (@perplexity_ai): When you know, you know.
- Cryptoflash Tattoo GIF - Cryptoflash Crypto Flash - Discover & Share GIFs: Click to view the GIF
- Llama 3.1 models from Meta are available on AWS for generative AI applications: Meta’s most advanced large language models (LLMs) give customers more choices when building, deploying, and scaling generative AI applications.
- Tweet from Min Choi (@minchoi): Instant Intelligence is wild with Llama 3.1 8B + Groq 🤯
- Balloons Up GIF - Balloons Up - Discover & Share GIFs: Click to view the GIF
- Try NVIDIA NIM APIs: Experience the leading models to build enterprise generative AI apps now.
- Transcript for Aravind Srinivas: Perplexity CEO on Future of AI, Search & the Internet | Lex Fridman Podcast #434 - Lex Fridman: This is a transcript of Lex Fridman Podcast #434 with Aravind Srinivas. The timestamps in the transcript are clickable links that take you directly to that point in the main video. Please note that th...
{kind=link}
Perplexity AI ▷ #sharing (12 messages🔥):
Dark OxygenMercury's DiamondsBeach-Cleaning RobotsMunger's Inversion TechniqueLlama 3 Release
- Dark Oxygen Discovery: A discussion emerged about the recent discovery of Dark Oxygen, emphasizing its potential implications for atmospheric studies.
- Members expressed curiosity about the nature of Dark Oxygen and its role in ecological balance.
- Exploration of Mercury's Diamonds: The chat highlighted findings about Diamonds on Mercury, sharing fascinating insights from current research.
- Participants were intrigued by the geological processes that could lead to diamond formation on the planet.
- Innovations in Beach-Cleaning Technology: Beach-cleaning robots were a hot topic, showcasing new robotic technologies that target ocean pollution effectively.
- The community discussed the potential impact of these robots on marine ecosystems, highlighting real-time data from trials.
- Munger's Inversion Technique Explained: A shared YouTube video focused on Munger's Inversion Technique, detailing how it applies to decision-making.
- Viewers were encouraged to consider this technique for better critical thinking in daily life.
- Meta Releases Llama 3: A noteworthy highlight involved Meta's release of Llama 3, generating buzz about its advanced capabilities.
- The community discussed potential applications for Llama 3 in various AI tasks and its implications for developers.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (13 messages🔥):
Llama model updatesPerplexity API and DSGVOSearch site limitations
- Inquiry about Llama 3.1 model in API: Users expressed interest in adding the Llama 3.1 405b model to the Perplexity API, with some requesting details on its availability.
- One user specifically asked, 'Are there plans to serve Llama 3 405b in the API?' which sparked follow-up queries.
- Clarification on search methods using specific sites: A user suggested utilizing
site:example.comorsite:arxiv.orgfor academic searches, indicating that it is possible to limit searches to specific domains.- However, they noted that a limitation exists where each request only retrieves results from 5 sources.
- Perplexity API's privacy compliance inquiry: A user raised a question regarding whether the Perplexity API is DSGVO-ready, seeking clarity on its compliance with data protection regulations.
- Another user shared a link to the terms of service, mentioning that it referenced GDPR compliance.
Stability.ai (Stable Diffusion) ▷ #general-chat (282 messages🔥🔥):
Stable Diffusion models comparisonTraining Lycoris and LorasCommunity perceptions of Stable DiffusionNew developments in AI modelsGeneral discussions and inquiries
- Ranking Current AI Models: Users discussed their rankings of AI models, with Kolors being rated the highest, followed by Auraflow, Pixart Sigma, and Hunyuan.
- Kolors is noted for its speed and performance, aligning with what users expected from SD3.
- Training Lycoris with ComfyUI: Discussion arose about the current capabilities for training Lycoris, mentioning tools like Kohya-ss and potential updates in Onetrainer.
- Users expressed frustration with Kohya-ss's compatibility issues, specifically needing Python version 3.10.9 or higher.
- Community's Sentiment towards Stable Diffusion: Users expressed their views on the community's perception of Stable Diffusion, suggesting that recent criticisms may stem from misunderstandings regarding model licensing.
- Some users pointed out the marketing strategies and perceived toxicity directed against Stability AI.
- Updates in AI Sampling Techniques: A new sampler node was introduced that implements Strong Stability Preserving Runge-Kutta and implicit variable step solvers, raising interest among users.
- Users discussed the potential performance improvements these new methods could provide for AI models.
- General Chat about AI and Personal Experiences: Users shared their personal experiences with AI, such as learning new programming languages and discussing their health decisions impacting their focus.
- Casual conversations took place surrounding the use of AI in various daily applications.
- Material Design : Build beautiful, usable products faster. Material Design is an adaptable system—backed by open-source code—that helps teams build high quality digital experiences.
- Tune Chat - Chat app powered by open-source LLMS: With Tune Chat, access Prompts library, Chat with PDF, and Brand Voice features to enhance your content writing and analysis and maintain a consistent tone across all your creations.
- dataautogpt3/PixArt-Sigma-900M · Hugging Face: no description found
- Llama 3.1: The open source AI model you can fine-tune, distill and deploy anywhere. Our latest models are available in 8B, 70B, and 405B variants.
- Dennis reads Charlie's campaign speech: From Season 2 episode 8 of It's Always Sunny in Philadelphia.
- Jump To Conclusion Think Again GIF - Jump To Conclusion Think Again Go Wild - Discover & Share GIFs: Click to view the GIF
- TuneStudio: no description found
- New two-stage PixArt ensemble of experts (2x 900M): Posted in r/StableDiffusion by u/terminusresearchorg • 98 points and 33 comments
- Real Mechanical Parts - RealMech*Pony Alpha v1 | Stable Diffusion LoRA | Civitai: About PONY XL - Real Mechanical Parts version!!!! It is important that you should know, it is on alpha stage and has lots of room to improve. I've ...
OpenRouter (Alex Atallah) ▷ #announcements (41 messages🔥):
Llama 3 405B LaunchModel Performance ComparisonsOpenRouter Features UpdatesPrompt Competition AnnouncementDeepSeek Coder V2 Inference Provider
- Llama 3 405B Launch Competitively Priced: The Llama 3 405B has been launched, rivaling GPT-4o and Claude 3.5 Sonnet at $3/M tokens and offering an impressive 128K token context for synthetic data generation.
- Users expressed excitement, with comments like 'Damn! That's crazy, this is THE BEST open LLM now' and 'what a leap' highlighting its anticipated impact.
- User Feedback on Model Performance: Feedback arose on Llama 3 405B's performance, with one user noting it is 'worse than both gpt4o and not even comparable to claude 3.5' in translation tasks.
- Concerns were raised about the 70B version producing 'gibberish' after a few tokens, while 405B was compared to gemini 1.5 pro.
- Updates on OpenRouter Features: OpenRouter announced new features including Retroactive Invoices, custom keys, and improvements to the Playground.
- Users were encouraged to provide feedback on new offerings available at OpenRouter Chat to enhance user experience.
- Prompt Competition for Multiple Models: A Multi-LLM Prompt Competition has been introduced with users invited to submit challenging prompts for Llama 405B, GPT-4o, and Sonnet for a chance to win 15 free credits.
- The competition aims to test the limits of these models, as users eagerly await announcements detailing the outcomes.
- DeepSeek Coder V2 Inference Provider: Announced a new private inference provider for DeepSeek Coder V2, which operates with no input training.
- Users can explore the new provider through DeepSeek Coder, enhancing OpenRouter's offerings.
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Tweet from OpenRouter (@OpenRouterAI): DeepSeek Coder V2 now has a private provider serving requests on OpenRouter, with no input training! Check it out here: https://openrouter.ai/models/deepseek/deepseek-coder
- Tweet from OpenRouter (@OpenRouterAI): 🏆 Multi-LLM Prompt Competition Reply below with prompts that are tough for Llama 405B, GPT-4o, and Sonnet! Winner gets 15 free credits ✨. Example:
- Meta: Llama 3.1 405B Instruct by meta-llama: The highly anticipated 400B class of Llama3 is here! Clocking in at 128k context with impressive eval scores, the Meta AI team continues to push the frontier of open-source LLMs. Meta's latest c...
- Meta: Llama 3.1 8B Instruct by meta-llama: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 8B instruct-tuned version is fast and efficient. It has demonstrated strong performance compared to ...
- Meta: Llama 3.1 70B Instruct by meta-llama: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 70B instruct-tuned version is optimized for high quality dialogue usecases. It has demonstrated stro...
OpenRouter (Alex Atallah) ▷ #general (190 messages🔥🔥):
Llama 405B Model PerformanceCustom API Keys IntegrationComparison of Llama ModelsPrompting Competition for Llama 405BFine-Tuning and Instruction Challenges
- Llama 405B model shows strong capabilities: Users discuss the performance of the new Llama 405B model, noting its impressive reasoning abilities, especially in English, although some mention it still falls short in foreign languages compared to models like Claude and GPT-4.
- Some users find the model to produce nonsense responses, with varying experiences reported among different users.
- Accessing Custom API Keys: Discussion arose about the process to obtain custom API keys per provider, emphasizing that this integration could vary by provider and might involve specific account settings.
- Users are eager to understand how to manage and utilize these keys effectively.
- Comparison between Llama 3 and Llama 3.1: Participants compare Llama 3 (8B/70B) with Llama 3.1, highlighting that 3.1 is distilled from the larger 405B model and offers improved context length limits of 128k instead of 8k.
- The new version is expected to perform better across various benchmarks.
- Prompting Competition for Llama 405B: Alex Atallah announced a prompting competition for Llama 405B, with the winner receiving 15 free credits, focusing on prompts that challenge the model's capabilities.
- Participants are curious about the criteria for the competition, particularly regarding what constitutes a tough prompt.
- Challenges in using Instruction Models: Several users reported bugs when using instruct models, specifically mentioning issues with calling JSON responses in multi-turn scenarios.
- Participants are sharing code snippets and troubleshooting tips in an effort to resolve these challenges.
- Breaking Instruction Hierarchy in OpenAI's gpt-4o-mini · Embrace The Red: no description found
- Tweet from Pliny the Prompter 🐉 (@elder_plinius): 🌩️ JAILBREAK ALERT 🌩️ META: PWNED 🦾😎 LLAMA-3-405B: LIBERATED 🦙💨 Come, witness the brand new SOTA open source AI outputting a home lab bioweapon guide, how to hack wifi, copyrighted lyrics, and...
- Download Llama: Request access to Llama.
- The Shawshank GIF - The Shawshank Redemption - Discover & Share GIFs: Click to view the GIF
- Tweet from OpenRouter (@OpenRouterAI): 🏆 Multi-LLM Prompt Competition Reply below with prompts that are tough for Llama 405B, GPT-4o, and Sonnet! Winner gets 15 free credits ✨. Example:
- Integrations (Beta) | OpenRouter: Bring your own provider keys with OpenRouter
- Reddit - Dive into anything: no description found
- GitHub - vikyw89/llmtext: A simple llm library: A simple llm library. Contribute to vikyw89/llmtext development by creating an account on GitHub.
CUDA MODE ▷ #general (7 messages):
Register Allocation in Flash AttentionKernel Fusion of Q, K, V ProjectionsChallenges with SVD ParallelizationOpen Source GPU Kernel Modules
- Register Allocation in Flash Attention concerns: @vkaul11 inquired about the explicit allocation of registers in Flash Attention, expressing confusion about the use of registers alongside shared memory.
- The question highlighted a need for clarity on efficiently managing register resources in CUDA programming.
- Kernel Fusion Query on Q, K, V Projections: A question arose regarding whether the initial projections of Q, K, and V matrices could be fused into a single kernel, with concerns over the feasibility given their large sizes.
- This pointed to ongoing discussions around optimizing memory and processing requirements in neural network computations.
- Parallelization Difficulties with SVD: @danikhan632 noted that while SVD is challenging to parallelize, it is preferable over transferring data back to the CPU.
- There was also interest in developing a Triton kernel for SVD, suggesting a potential community project for more optimized computation.
- NVIDIA's Move to Open Source GPU Kernel Modules: A link was shared regarding NVIDIA's transition to open-source GPU kernel modules, which began with the R515 driver in May 2022, supporting dual GPL and MIT licensing.
- The update outlined improved performance and capabilities such as heterogeneous memory management along with a commitment to fully replace the closed-source driver.
Link mentioned: NVIDIA Transitions Fully Towards Open-Source GPU Kernel Modules | NVIDIA Technical Blog: With the R515 driver, NVIDIA released a set of Linux GPU kernel modules in May 2022 as open source with dual GPL and MIT licensing. The initial release targeted datacenter compute GPUs…
CUDA MODE ▷ #torch (9 messages🔥):
torch.compile performanceBert model inference issuesCUDA graphs usagePyTorch profiler toolsInductor configuration changes
- torch.compile causes memory issues on small Bert model: A member reported testing
torch.compilefor model inference on a small Bert model, observing significant RAM usage that forced a batch size reduction from 512 to 160.- They found performance to be slower than using eager mode with the larger batch size, and model compiled successfully with
full_graph=True, suggesting no architecture issues.
- They found performance to be slower than using eager mode with the larger batch size, and model compiled successfully with
- Questions on CUDA graphs utilization: Another member inquired if CUDA graphs were in use and whether the latest nightlies were being utilized, indicating potential adjustments to improve performance.
- They highlighted that this could impact the overall effectiveness of the
torch.compileprocess and its memory implications.
- They highlighted that this could impact the overall effectiveness of the
- Using PyTorch profiler for deeper insights: To investigate further, a member recommended using the PyTorch profiler alongside the memory trace tool to analyze what might be happening under the hood.
- This tool could provide valuable insights into memory usage patterns and inefficiencies during inference.
- Inductor configuration inquiries: A member asked if the inducer configuration was being altered or if
torch.compilewas being called with default settings.- Standard configurations combined with
inference_modeerrors may also contribute to the observed memory challenges.
- Standard configurations combined with
- No effect from different compilation modes: The user confirmed that memory usage remained the same regardless of using
reduce-overheadorfullgraphoptions in their compilation call.- This consistency suggests that other factors are likely influencing the memory consumption during inference.
CUDA MODE ▷ #cool-links (17 messages🔥):
Meta Llama 3.1 ReleaseGPU AllocationsMulti-modal FeaturesVLM CapabilitiesCUDA Performance
- Meta Llama 3.1 focuses on text functionality: Meta's latest release includes the Llama 3.1 405B, expanding context length to 128K and supporting eight languages, as noted in Zuckerberg’s letter. However, the multi-modal parts are not included in this release, and members discussed this omission possibly being strategic ahead of earnings.
- High demand for GPUs: A member expressed frustration over the struggle to access a single A100 GPU, while another noted that xAI is utilizing a staggering 100,000 H100 GPUs. The volume of available GPUs highlighted a stark contrast in resource access among users.
- VLM capabilities under discussion: Members acknowledged that only the text version of the model is available in this release, with VLM (Vision Language Model) features expected later. One member shared insights on their approach to achieving 50% accuracy on ARC-AGI by leveraging GPT-4o for generating numerous Python implementations.
- Feature engineering for improved results: Discussion revolved around improving results through feature engineering rather than heavily relying on vision capabilities, highlighting a case where success was achieved by engineering the problem grid. One user mentioned utilizing additional techniques for optimizing performance with their method.
- CUDA's future plans: A member teased an upcoming CUDA release, stating they plan to outperform cuBLAS on various matrix sizes, specifically with FP16/FP32 support. Conversations about Nvidia's hardware intrinsics for FP16 showcased excitement about the potential performance enhancements.
- no title found: no description found
- Getting 50% (SoTA) on ARC-AGI with GPT-4o: You can just draw more samples
CUDA MODE ▷ #beginner (4 messages):
Performance of CUDA KernelsTiled Matrix MultiplicationCompute Intensity
- ncu Output Interpretation: A member asked if executing
ncu ./kernelprovides the speed or time taken for a CUDA kernel, noting the duration for a normal matrix multiplication is 10.30us and for tiled multiplication is 9.18us.- They expressed confusion as the performance improvement doesn't align with expectations from the pmpp textbook.
- Limited Improvement from Tiling: Another member shared their experience that transitioning from naive to tiled matrix multiplication didn't yield significant speed improvements, similar to kernel comparisons found in this article.
- They noted that significant speedup is typically observed only with thread tiling, referencing kernel implementations 4 and 5 in the linked resource.
- Importance of Compute Intensity: A member emphasized that increasing compute intensity is crucial for achieving better performance, specifically to escape the left side of the roofline model.
- They indicated that this would be the most impactful strategy at the beginning stages of optimizing CUDA kernels.
CUDA MODE ▷ #hqq (1 messages):
iron_bound: neat https://github.com/AnswerDotAI/fsdp_qlora/tree/llama400b
CUDA MODE ▷ #llmdotc (182 messages🔥🔥):
Performance of LLMsKV Caching ImplementationMuP vs Other OptimizationsFloating Point Precision TechniquesTraining Stability Methods
- Analyzing Performance Metrics: Members discussed discrepancies in performance metrics between ZeRO-1 and ZeRO-2 during experiments, noting the potential benefits of stochastic rounding in ZeRO-2.
- Initial tests on a 2 x 4060Ti system showed slight performance overhead due to additional communications.
- KV Caching Achievements: Progress on implementing KV caching logic for model inference was reported, with partial operations functioning correctly but needing efficiency improvements.
- Tweaks to
matmul_cublasltand attention kernels were being explored to enhance computation without changing end results.
- Tweaks to
- Insight on MuP vs Alternatives: Discussion on the perceived performance differences of muP compared to other methodologies, indicating that muP could underperform in certain scenarios.
- Members compared baseline optimizations, noting that muP was designed for better stability and results but may not always deliver on that promise.
- Floating Point Precision Techniques: The team explored the implications of using different floating point precisions (like BF16 and FP8) on model training performance and stability.
- Concerns were raised about the challenges of maintaining stability with FP8 training due to the potential for underflows and overflows.
- Improving Training Stability: Members were interested in various techniques to enhance training stability such as using z-loss and soft clamping methods discussed in the latest literature.
- It was noted that constructing a visual representation of tensor changes during training might aid in understanding and preventing instability.
- Scaling Exponents Across Parameterizations and Optimizers: Robust and effective scaling of models from small to large width typically requires the precise adjustment of many algorithmic and architectural details, such as parameterization and optimizer choices...
- To FP8 and Back Again: Quantifying the Effects of Reducing Precision on LLM Training Stability: The massive computational costs associated with large language model (LLM) pretraining have spurred great interest in reduced-precision floating-point representations to accelerate the process. As a r...
- Adam-mini: Use Fewer Learning Rates To Gain More: We propose Adam-mini, an optimizer that achieves on-par or better performance than AdamW with 45% to 50% less memory footprint. Adam-mini reduces memory by cutting down the learning rate resources in ...
- Tweet from Rosie Zhao @ ICML (@rosieyzh): In our new work on evaluating optimizers for LLM training, we perform a series of experiments to investigate the role of adaptivity in optimizers like Adam in achieving good performance and stability....
- Deconstructing What Makes a Good Optimizer for Language Models: Training language models becomes increasingly expensive with scale, prompting numerous attempts to improve optimization efficiency. Despite these efforts, the Adam optimizer remains the most widely us...
- Not getting perf improvements from muP at ~1.5B scale · Issue #76 · microsoft/mup: Hey guys, first of all thanks for the awesome work! I've implemented muP in the llm.c project (see here), the coord checks seem to be flat / correct (I went up to 15 steps and still flat!) but I a...
- Add KV cache for inference by gordicaleksa · Pull Request #707 · karpathy/llm.c: WIP. Very ugly rn, experimenting. Will update description after the draft has progressed. :)
- llm.c/llmc/matmul.cuh at master · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- Add high perf mode by gordicaleksa · Pull Request #708 · karpathy/llm.c: Add: Warnings when we take a suboptimal branch High perf mode that will exit immediately if we're not running using all of the most optimal branches Also added a fwd kernel config that will be u...
- 3.1 vs 3 - llama license - Diffchecker: 3.1 vs 3 - llama license - META LLAMA 3 COMMUNITY LICENSE AGREEMENT Meta Llama 3 Version Release Date: April 18, 2024 “Agreeme
- Improve tanh derivative in backward gelu by akbariyeh · Pull Request #307 · karpathy/llm.c: It is cheaper to compute the derivative of tanh as 1 - tanh^2 than computing 1/(cosh^2). This will probably not make a measurable difference.
CUDA MODE ▷ #rocm (6 messages):
Stable Diffusion on RX7900XTXFlash Attention support for AMD ROCm
- Stable Diffusion on RX7900XTX discussed: A post was shared about accelerating inferencing on AMD RDNA3 GPUs with the Composable Kernel library for Stable Diffusion on RX7900XTX.
- The discussion is noted to be slightly outdated, providing insights into the ROCm5.7 capabilities.
- Flash Attention now supports AMD ROCm: The Dao-AILab/flash-attention project has introduced support for AMD ROCm, stating it currently works with mi200 & mi300 only.
- This update is powered by the Composable Kernel, with details shared in a recent pull request.
- Stable diffusion with RX7900XTX on ROCm5.7 · ROCm/composable_kernel · Discussion #1032: Accelerate Inferencing on AMD RDNA3 GPUs with Composable Kernel library Hello, and welcome to the AMD RDNA3 GPU High Performance Inferencing blog post. In this blog post, we will discuss how to use...
- Support AMD ROCm on FlashAttention 2 by rocking5566 · Pull Request #1010 · Dao-AILab/flash-attention: This PR implement the AMD / ROCm version of c++ flash api mha_fwd mha_varlen_fwd mha_bwd mha_varlen_bwd The kernel implementation comes from composable kernel The c++ api is same as original ver...
OpenAI ▷ #ai-discussions (196 messages🔥🔥):
GEMINI CompetitionMeta AILlama 3.1 ModelVoice Channel AI BotsFine-Tuning Llama Models
- Discussion on GEMINI Competition: A member expressed interest in the GEMINI Competition from Google, seeking help from others for the hackathon.
- Reach out if you're interested to collaborate!
- Reactions to Llama-3.1 Model: Members shared mixed feelings about Llama-3.1, with some calling it soulless compared to earlier generations of models.
- Others noted that Claude and Gemini appear to retain some creative depth.
- Uncensored Llama-3.1 Fine-Tuning: A user is in the process of fine-tuning Llama-3.1 405B to create an uncensored version, expecting it to take several weeks.
- They plan to release it on Hugging Face once training is complete, named Llama3.1-406B-uncensored.
- Challenges of AI in Voice Channels: There was a discussion about creating AI bots that can interact in Discord voice channels, highlighting its complexities.
- Concerns were raised about the limitations currently faced when trying to build effective voice-interactive bots.
- Costs and Accessibility of AI Models: Members discussed the costs related to API usage for advanced models like GPT-4o, noting challenges to access higher tiers.
- Some expressed frustration about the limitations imposed on lower tiers needing significant interaction.
OpenAI ▷ #gpt-4-discussions (7 messages):
Alpha Release TimingUser Communication ConcernsApp Testing
- Clarifying Alpha Release Timing: Members are uncertain about the timelines for the alpha release, specifically if it is by the very last day of July or a few days before.
- Questions were raised regarding the clarity of expectations, highlighting a need for better communication from the developers.
- Users Eagerly Awaiting Alpha Access: A member expressed frustration while checking the app every 20 minutes, hoping to be selected as a Plus user for the alpha release.
- Another user confirmed that alpha testing is expected to start towards the end of July, implying a need for patience.
- Concern Over Stale Information: Amid discussions, a user pointed out that shared links regarding the alpha release are nearly a month old, indicating outdated information.
- This led to a broader conversation about the lack of ongoing communication with paying customers.
OpenAI ▷ #prompt-engineering (7 messages):
Meta-PromptingPlagiarism in AI OutputPrompting Techniques
- Meta-Prompting Revolutionizes Prompt Engineering: A member highlighted that AI guidance in prompt engineering is referred to as meta-prompting, described as perhaps the best method for learning how to craft effective prompts.
- With meta-prompting, users can eventually create prompts that generate further prompts, enhancing their prompting skills.
- Concerns Over Plagiarism in Output: One member expressed frustration that using a blog results in 100% plagiarism in content generated by prompts.
- They were looking for solutions or ideas to mitigate this issue.
- Seeking Solutions for Prompt Improvement: In response to concerns about plagiarism, a member suggested sharing prompts and custom instructions to gain insights and suggestions from others.
- They encouraged transparency by quoting another member for clarity, stating, 'Someone might be able to take a look and offer suggestions!'.
OpenAI ▷ #api-discussions (7 messages):
Meta-PromptingPlagiarism in Generated ContentPrompt Improvement Suggestions
- Learn to Prompt with Meta-Prompting: Meta-prompting is recognized as a top method for mastering prompt engineering, allowing users to create prompts that generate further prompts.
- This technique can significantly enhance one's ability to craft effective prompts based on AI guidance.
- Concerns about Plagiarism from Blog Content: A user raised concerns that utilizing a blog resulted in 100% plagiarism in every generated prompt.
- This prompted discussions around finding solutions to improve the originality of generated content.
- Suggestions for Better Prompting: A member suggested sharing specific details from previous prompts and the context in order to get more tailored advice.
- They highlighted the importance of articulating desired differences in response quality to receive effective suggestions.
Modular (Mojo 🔥) ▷ #general (39 messages🔥):
Mojo Community Meeting PresentationsString Optimization in Standard LibraryInstalling Mojo on VMGame Engine Development in MojoLinking with C Libraries
- Open Call for Mojo Community Meeting Presentations: There is an opportunity to present at the Mojo Community Meeting, with slots available on August 12.
- If you wish to present what you're building in Mojo or share your experience, you can sign up through the linked document.
- Short String and Buffer Optimization Proposal: A member confirmed that their work on short string optimization and small buffer optimization in the standard library is a great fit for presentation formats.
- Another member supported this, noting the relevance of optimizations in past meetings.
- Installing Mojo on an Ubuntu VM: A user inquired about the feasibility of installing Mojo in an Ubuntu VM on Windows, to which others responded that it would generally work well with solutions like WSL and Docker.
- Concerns were raised about potential installation issues, but VM usage is deemed suitable.
- Assessing Mojo for Game Engine Development: Discussion highlighted that Mojo could be suitable for crafting a next-gen game engine, particularly due to its good heterogeneous compute capabilities via GPU support.
- However, challenges were noted with allocator handling in game development patterns, suggesting a few rough spots might be encountered.
- Linking to C Libraries in Mojo: There is ongoing discussion about linking Mojo to C libraries, with suggestions that improved functionality will benefit projects utilizing libpcap.
- Members noted that using ktls should be the default for Mojo on Linux, enhancing low-level network customizability.
- GitHub - modularml/mojo: The Mojo Programming Language: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- Ability to Link to C Libraries · Issue #3262 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? Ideally there would be something like a @link(…) decor...
- [Public] Mojo Community Meeting: Mojo Community Meeting This doc link: https://modul.ar/community-meeting-doc This is a public document; everybody is welcome to view and comment / suggest. All meeting participants must adhere to th...
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1815463417391837596
Modular (Mojo 🔥) ▷ #mojo (50 messages🔥):
SDL BindingsMojo Game FrameworkingPhysics Engine DevelopmentContributing to MojoPygame with Mojo
- SDL Bindings in Progress: A member is working on SDL bindings for Mojo, noting that Pygame is primarily a wrapper around SDL, making integration possible.
- Another user mentioned their own SDL binding project has stalled but plans to update and improve its API.
- Experimenting with Game Frameworking: Discussion around experimenting with game frameworking and physics sparked interest, with one member sharing a personal experience of building a custom physics engine.
- The same user hopes to transition their math into a general geometric algebra package called Infrared in the future.
- Creating a Mini Socket Library: A new member is developing a mini socket library for Mojo using external_call to integrate C functions, seeking permission to license it under Apache 2.0.
- They expressed interest in contributing to Mojo, encouraged by the community's supportive response.
- Contributions and Community Resources: Members discussed available resources for contributing to Mojo, including links to GitHub issues marked as good first issue.
- One user plans to read the contribution guidelines to better understand how to engage with community projects.
- Anticipated Release of v24.5: A member inquired about the release date of v24.5, referencing that v24.4 was released in early June.
- It was suggested that ongoing discussions around GPU features could delay the new release, leading to speculation about version numbering conventions.
- lightbug_http/external at main · saviorand/lightbug_http: Simple and fast HTTP framework for Mojo! 🔥. Contribute to saviorand/lightbug_http development by creating an account on GitHub.
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #max (9 messages🔥):
Modular's Industry RelationshipsNVIDIA SupportOpenCL and SYCL Usage
- Modular keeps industry relationships private: A member noted that Modular's industry relationships are private and they don't comment on them ahead of announcements, but will share publicly at the right time.
- This maintains a level of confidentiality until they are ready to reveal the information in an official capacity.
- NVIDIA support boosts Modular's approach: Support from NVIDIA is seen as a significant enhancement, and a member expressed eagerness to utilize it once it is live.
- There was a suggestion to discuss it further in a dedicated channel when the time comes.
- OpenCL's journey and relevance: A discussion highlighted OpenCL's origins and its importance in enabling high-level programming, particularly within platforms like SYCL and OneAPI.
- Concerns were raised about the future use of OpenCL, especially given the shift away from older hardware, but its relevance for certain databases and firewalls was acknowledged.
- General Purpose Compute with GPUs and FPGAs: Members talked about utilizing GPUs and FPGAs not just for graphics but for general-purpose compute, especially in the context of databases.
- There is recognition of the capabilities of these technologies to handle workloads effectively beyond their traditional roles.
Modular (Mojo 🔥) ▷ #max-gpu (2 messages):
XLAMAX engineGPU performance
- MAX engine: The next step after XLA: The MAX engine is viewed as a successor to XLA, leveraging insights gained from it while addressing its shortcomings, such as being extensible and natively supporting dynamic and parametric shapes.
- Expectations are set for significantly improved CPU and GPU performance compared to XLA.
- Navigating the path to MAX/GPU launch: Although specifics on the MAX/GPU cannot be revealed before its launch later this year, the team is committed to achieving the hard but right solutions.
- The belief in the importance of GPUs to the AI world is driving this endeavor, which has generated excitement for progress towards the product's release.
Modular (Mojo 🔥) ▷ #nightly (86 messages🔥🔥):
Changes to memcpyDocumentation for MojoUse of Reference in MojoUpdates on Mojo NightlyRelationship of MAX and Mojo
- Changes to memcpy function: User discussed the recent changes made to the
memcpyfunction, noting three overrides for pointer types, with confusion on the new signature.- Members explored how these changes might impact existing code, especially regarding types like
DTypePointerandLegacyPointer, with potential solutions offered.
- Members explored how these changes might impact existing code, especially regarding types like
- Need for better documentation in Mojo: Users expressed frustration over the current state of Mojo documentation, citing overly technical explanations that lack clarity for learners.
- Concerns were raised about Discord's formatting issues also complicating understanding, calling for improvements to documentation formats.
- Discussion on Reference and equality: A member questioned the absence of an
__eq__method forReference, speculating whether it's intended to be unique or exclusive.- Another user supported this idea, noting the efficiency of comparing memory addresses directly instead of dereferencing.
- Mojo Nightly Update Announcement: A notification about the latest Mojo nightly compiler update was shared, highlighting updates and bug fixes.
- Users were encouraged to update their versions, with a link provided to the changelog for detailed changes.
- Relationship between MAX and Mojo: Members discussed how MAX is built using Mojo, emphasizing that both systems evolve together with shared compiler changes.
- The blend of Mojo and C++ in MAX Kernel development was noted, clarifying the connection between the two.
- Sourcegraph: no description found
- Mojo 🔥 Community Meeting #4: Recording of the Mojo Community Meeting #4🫓 Flat Buffers: memory efficient serialization⚒️ Forge Tools: extending the Mojo 🔥 standard library🔄 Mojo 🔥 Gen...
- mojo/stdlib/src/memory/__init__.mojo at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojo/stdlib/src/memory/__init__.mojo at 16cc60dc3fbed1eff01a8f5fee94f97cf97cca33 · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #mojo-marathons (1 messages):
Intel CPUID LibraryAMD CPUID Mappings
- Intel's CPUID Library Simplifies Access: Intel's library wraps CPUID and converts it into a more understandable format without requiring users to consult processor documentation.
- This provides a more user-friendly approach for developers working with Intel processors.
- Separate CPUID Mappings for AMD and Intel: It was noted that AMD and Intel maintain separate CPUID mappings, aside from distinguishing who manufactured the processor.
- As a result, developers need to utilize different mappings for each manufacturer to access specific processor features.
Eleuther ▷ #general (84 messages🔥🔥):
FSDP performance issuesLlama 3.1 hostingGenerative ML contributions
- FSDP Performance Troubles with nn.Parameters: A user experienced a 20x slowdown when adding
nn.Parametersto their model with FSDP but found that using a parameter of size 16 improved performance significantly.- They discussed potential issues related to buffer alignment and how misalignment could affect CPU performance despite GPU kernels running fast.
- Hosting Llama 3.1 405B: A member announced they've hosted Llama 3.1 405B instruct on 8xH100 80GB hardware, accessible through a chat interface and API.
- Unfortunately, access is gated behind a login, and the hosting arrangement incurs costs, leading to discussions about hardware limitations and hosting alternatives.
- Contributions to Open AI Research: A user introduced themselves as working on generative ML at a startup, expressing interest in contributing to open AI research and discussing a paper on learning to reason from fewer samples.
- Their past experience includes work in 3D Computer Vision and Machine Translation, highlighting their goal of advancing AI with limited data.
- Tune Chat - Chat app powered by open-source LLMS: With Tune Chat, access Prompts library, Chat with PDF, and Brand Voice features to enhance your content writing and analysis and maintain a consistent tone across all your creations.
- TuneStudio: no description found
Eleuther ▷ #research (43 messages🔥):
New SAE architectureMonte Carlo Dropout comparisonHierarchical 3D GaussiansLlama 3 model detailsTransformer performance and sparsity
- New SAE architecture introduced for efficient training: A novel architecture known as Switch SAE uses conditional computation to scale sparse autoencoders (SAEs) efficiently, addressing computational challenges in training wide SAEs across layers.
- Links to relevant papers emphasize the potential of this approach in recovering features from superintelligent language models.
- Comparison of Monte Carlo Dropout for uncertainty: A user noted that the results of their method should be compared with Monte Carlo dropout, which is considered a subpar approximation for Bayesian uncertainty quantification.
- Another member shared insights that suggested many papers exist comparing these methodologies, highlighting concerns regarding the effectiveness of MC dropout.
- Llama 3's image encoding limitations: Concerns were raised about the Llama 3 model's image encoder, particularly regarding its resolution limit of 224x224.
- Some suggested that using a vqvae-gan style tokenizer, as advocated by Armen's group, might have enhanced the image processing capabilities.
- Transformer models and performance implications: Discussion centered around the scaling of Transformers and how the fraction of FLOPs due to Multi-Head Attention (MHA) decreases as model size increases, potentially to 33% or less.
- Insights were shared about the necessity of both V and O projection, prompting thoughts on their implications for model interpretation and effectiveness.
- Sparsity in Transformer models: A paper was referenced discussing how leveraging sparsity in Transformer layers can yield competitive performances while decreasing training costs and increasing efficiency.
- The findings suggest sparse variants can achieve similar perplexity levels to traditional Transformers, making them suitable for longer sequence processing.
- NNsight and NDIF: Democratizing Access to Foundation Model Internals: The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineer...
- Sparse is Enough in Scaling Transformers: Large Transformer models yield impressive results on many tasks, but are expensive to train, or even fine-tune, and so slow at decoding that their use and study becomes out of reach. We address this p...
- no title found: no description found
- Simple Ingredients for Offline Reinforcement Learning: Offline reinforcement learning algorithms have proven effective on datasets highly connected to the target downstream task. Yet, leveraging a novel testbed (MOOD) in which trajectories come from heter...
- A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets: no description found
- Efficient Dictionary Learning with Switch Sparse Autoencoders — LessWrong: Produced as part of the ML Alignment & Theory Scholars Program - Summer 2024 Cohort …
Eleuther ▷ #interpretability-general (1 messages):
alofty: https://arxiv.org/abs/2407.14561
Eleuther ▷ #lm-thunderdome (23 messages🔥):
Task Grouping Recommendationslm-eval Harness UpdatesvLLM and Logits IssuesAutomated Unit Testing DiscussionsTransformers Version Problems
- Groups vs Tags for Task Grouping: It is recommended to use groups for nested tasks and aggregate scores, while tags suffice for simpler cases.
- Hailey Schoelkopf confirmed that this method is effective for task organization.
- lm-eval Harness Enhancements: Updates to the lm-eval harness include a new superclass for API models, enhancing modularity and functionality, as seen in Pull Request #2008.
- Members can now evaluate Llama-405B on all task types using the
local-completionsmodel type with VLLM's OpenAI server.
- Members can now evaluate Llama-405B on all task types using the
- Clarification on vLLM and Logits: A discussion arose regarding whether vLLM provides logits, with conflicting views on its capabilities; however, it was clarified that it does provide continuation logits.
- The conversation referenced issues from both the VLLM repository and the Triton inference server repository.
- Interest in Automated Unit Testing: A member raised concerns about the current lack of automated unit testing, emphasizing its importance to prevent breaking changes in the codebase.
- Hailey Schoelkopf acknowledged the need for improved testing and mentioned existing regression tests, though they are limited in sample sizes.
- Issues with Transformers Version: Layernorm discovered issues with their deepseek model being misidentified as a Llama model after a recent commit to Transformers.
- Pinning the Transformers version resolved the issue, indicating it was related to the latest updates made to the library.
- GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- Can I directly obtain the logits here? · Issue #185 · vllm-project/vllm: Hi, wonderful work! I want to know if there is a easy way to obtain the logits, since sometimes I only need to calculate the perplexity/language modeling loss of specific sequence. I saw the code h...
- vllm backend - logit probabilities at inference · Issue #6895 · triton-inference-server/server: regarding the current vllm backend: https://github.com/triton-inference-server/vllm_backend/tree/main I wanted to know if at inference there is a possibility of also getting the logit probabilities...
- Refactor API models by baberabb · Pull Request #2008 · EleutherAI/lm-evaluation-harness: This PR introduces a new superclass for API request models, providing: Modularity for downstream classes Overloadable methods for request transformation, API requests and response parsing Tokeniza...
Eleuther ▷ #gpt-neox-dev (5 messages):
Nerdsniping EvaluationUncheatable Evaluation Harness
- Nerdsniping with Evaluation: A member expressed a lighthearted intent, stating, 'one of these days I'll nerdsnipe you with evaluation.'
- The comment suggests a playful challenge around the intricacies of evaluation methods.
- Challenges of Uncheatable Eval: In a query, a member asked if they could incorporate uncheatable eval into an eval harness, raising questions about its practicality.
- Another member humorously remarked, 'It ceases to be uncheatable once you add it to the harness.'
- Fresh Scrape Defense: A member asserted that uncheatable eval remains effective as long as it's pointed at a fresh scrape.
- This claim was met with skepticism, suggesting that using it with a harness could lead to limitations on its power.
- Concerns Over Power and Reproducibility: A member warned that the idea of an uncheatable evaluation approach is too powerful and questioned its feasibility citing reproducibility.
- They indicated that the concept might face scrutiny or rejection due to its implications on standard practices.
Interconnects (Nathan Lambert) ▷ #news (69 messages🔥🔥):
Meta's AI StrategyNVIDIA's Market PositionOpenAI Pricing WarsLlama 3.1 Release
- Meta's AI Strategy and Premium Offerings: There are discussions about Meta's potential rollout of a Premium version of Llama 405B, with speculation about an announcement on Jul 23.
- Members noted that the recent removal of restrictions on Llama models opens the door for broader use beyond just improving other models.
- NVIDIA's Potential Monopoly: Concerns were raised about NVIDIA's ambitions to integrate hardware, CUDA, and models, creating a potential monopoly akin to historical antitrust cases involving IBM.
- A user suggested that NVIDIA could essentially print money if they controlled the entire stack, but regulatory hurdles would prevent such integration.
- OpenAI's Competitive Pricing Strategies: OpenAI's announcement of free fine-tuning for gpt-4o-mini up to 2M tokens per day sparked a conversation about the aggressive pricing landscape in AI.
- Members reflected on the chaotic state of pricing wars in the industry as a response to increased competition.
- Llama 3.1 and Performance Metrics: The release of Llama 3.1 was highlighted, with members discussing its incorporation into RewardBench, showing alignment with GPT-4 on certain tasks.
- The models were reported to be primarily challenged by safety concerns, which users noted could be beneficial.
- Industry Insights and References: A user appreciated insights from Ben Thompson's Stratechery, indicating its relevance to the ongoing discussions about market dynamics.
- Other members shared their takes on the cyclical nature of tech strategies, pointing out how companies often repeat historical patterns.
- Strategy Letter V: When I was in college I took two intro economics courses: macroeconomics and microeconomics. Macro was full of theories like “low unemployment causes inflation” that never quite stood u…
- Tweet from Nathan Lambert (@natolambert): Added the Llama 3.1 models to RewardBench via @togethercompute. Is mostly held back by safety, which some would argue is good. In line with GPT-4 on other challenge task.
- Tweet from TestingCatalog News 🗞 (@testingcatalog): Besides that, it seems that LLama 405B may become a part of the Premium offering and in this case, Meta AI Premium could be announced on Jul 23 as well (Spotted in the code). Also, a mention of AI St...
- Tweet from Brendan Dolan-Gavitt (@moyix): Sorry OpenAI is doing WHAT now?! Fine-tuning gpt-4o-mini is *free* for up to 2M tok/day??
- Tweet from kalomaze (@kalomaze): LLM-Distillery! An open source training pipeline built by AMOGUS & I over the past several months for collecting and training 'student' language models to imitate 'teacher' models via ...
- 3.1 vs 3 - llama license - Diffchecker: 3.1 vs 3 - llama license - META LLAMA 3 COMMUNITY LICENSE AGREEMENT Meta Llama 3 Version Release Date: April 18, 2024 “Agreeme
- huggingface-test1/test-model-1 · Hugging Face: no description found
Interconnects (Nathan Lambert) ▷ #ml-questions (16 messages🔥):
Magpie paper on synthetic data generationLLaMA 3 Instruct performanceInstruction finetuning techniquesVocabulary size and inference speed
- Magpie paper reveals synthetic data generation techniques: The Magpie paper presents a method for generating high-quality instruction data for LLMs using only templates, allowing models like LLaMA 3 to generate user queries with minimal input.
- This technique reportedly generates data at scale and shows a larger vocabulary diversity compared to existing datasets like Alpaca and UltraChat.
- Surprising performance of LLaMA 3 with Magpie dataset: Even with only 300k samples, the LLaMA 3 Base finetuned on the Magpie IFT dataset managed to outperform the original LLaMA 3 Instruct model by 9.5% on AlpacaEval.
- This raises questions about the effectiveness of traditional instruction distillation techniques when compared to novel dataset generation methods.
- Instruction finetuning insights from Raschka's blogpost: In his blogpost, Sebastian Raschka covers advancements in instruction finetuning, emphasizing new cost-effective methods for generating finetuning datasets.
- He highlights potential applications and recent developments in LLMs integration by major tech companies, along with the importance of high-quality instruction data.
- Debate on vocabulary size's impact on inference speed: A discussion arose regarding Raschka's claim that a larger vocabulary size could potentially slow down inference, contrasting with the typical belief that fewer but denser tokens would speed up the process.
- The members noted the relative impact of vocabulary size increases on smaller models compared to larger ones, suggesting that finding an optimal balance is essential.
- Instruction Pretraining LLMs: The Latest Research in Instruction Finetuning
- Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing: High-quality instruction data is critical for aligning large language models (LLMs). Although some models, such as Llama-3-Instruct, have open weights, their alignment data remain private, which hinde...
- Instruction Pretraining LLMs: The Latest Research in Instruction Finetuning
Interconnects (Nathan Lambert) ▷ #ml-drama (43 messages🔥):
Llama 3 ReleaseMark Zuckerberg's AI EraModel Watermarking ConcernsPublic Perception of Zuckerberg
- Llama 3 Foundation Models Launched: The release of Llama 3 featured a herd of language models supporting multilinguality and tool usage, with the largest model boasting 405B parameters and 128K tokens context window. A paper on the models details evaluations showing Llama 3's performance comparable to GPT-4.
- There are discussions about watermarking models and tracking downloads, as users need to provide information and agree to a license before accessing weights.
- Watching Zuck's AI Image Transform: A member shared their thoughts on watching a YouTube video about Mark Zuckerberg, mentioning it feels like a puff piece centered around his newfound 'coolness'. They noted it mostly reinforced the narrative that Zuckerberg needed to adapt to public perceptions.
- Comments included reflections on Zuckerberg's historical narrative about Windows' dominance due to its openness, which some users deemed as rewriting history.
- Debate on Download Tracking for AI Models: Concerns were raised about how Meta might be tracking downloads of its models, where users provide their info to receive links. This leads to speculation that the tracking could be to ensure compliance with agreements.
- The conversation hints at the potential for analytics purposes but also raises privacy issues regarding data collection.
- Personal Studies on Llama 3 and Open Strategy: A member expressed excitement about studying Llama 3 and its broader implications in tool usage and strategy, noting it might take weeks to digest all the content. They plan to start with big-picture articles before diving into technical posts.
- There’s anticipation about how this knowledge could influence understanding of AI models and their societal impact.
- Tweet from Together AI (@togethercompute): @altryne @satpal_patawat @GroqInc @Teknium1 @JonathanRoss321 @xenovacom @altryne is the prompt longer than 4K? Currently limiting the context, but we'll be opening it up soon. If you are seeing an...
- Inside Mark Zuckerberg's AI Era | The Circuit: If the latest battle in the AI wars is between open and closed models, Meta CEO and Founder Mark Zuckerberg is right on the frontlines. Since rebranding as M...
- Llama 3.1: The open source AI model you can fine-tune, distill and deploy anywhere. Our latest models are available in 8B, 70B, and 405B variants.
- Llama - 3.1-405B: an open source model to rival GPT-4o / Claude-3.5 | Product Hunt: Meta is releasing three models: The new 3.1-405B and upgrades to their smaller models: 3.1-70B and 3.1-8B. If 405B is as good as the benchmarks indicate, this would be the first time an open source mo...
- no title found: no description found
Interconnects (Nathan Lambert) ▷ #random (3 messages):
Claude AI boundariesSacred Texts in AIRelease of GPT-3.5 Opus
- Claude AI limits speech on Sacred Texts: A user noted that while trying to demonstrate something in Claude, they encountered strong guardrails regarding Sacred Texts, specifically citing their choice of I Have a Dream.
- Claude has a strong to avoid using sensitive texts, which was evident during this interaction.
- Comparisons made between users and Dr. King: In a light-hearted comment, one user likened themselves to Dr. King by proclaiming their papers as sacred text.
- This humorous comparison received a congratulatory response, highlighting a theme of reverence in discussing one's work.
Interconnects (Nathan Lambert) ▷ #memes (7 messages):
OpenAI vs Llama 3.1ChatGPT Memory ManagementMark Zuckerberg's AI EraSnail Appreciation
- OpenAI's Unexpected Refund: A user reported that OpenAI accepted defeat against Llama 3.1 and randomly refunded them an unexpected amount.
- They expressed gratitude with a simple acknowledgment: *
- Managing ChatGPT Memory Like a Game: One member compared managing Memory for ChatGPT to inventory management in a game, noting they typically quit when Memory becomes full.
- This analogy highlights the challenges users face in efficiently using Memory within the platform.
- Inside Mark Zuckerberg's AI Era: A user shared a YouTube video titled 'Inside Mark Zuckerberg's AI Era' discussing the ongoing battle in the AI landscape.
- The video emphasizes Meta CEO Mark Zuckerberg's position at the forefront of competition between open and closed models in AI.
- Snail Enthusiasm Shared: A user humorously engaged with the community by sending an image of a snail in motion, eliciting a positive response.
- The newly shared love for snails further lightens the mood in the discussion.
- Tweet from xlr8harder (@xlr8harder): absolutely crushed by this
- Inside Mark Zuckerberg's AI Era | The Circuit: If the latest battle in the AI wars is between open and closed models, Meta CEO and Founder Mark Zuckerberg is right on the frontlines. Since rebranding as M...
Interconnects (Nathan Lambert) ▷ #nlp (3 messages):
DistillationLlama 3.1
- Search for Blog Posts on Distillation: A member asked if anyone had a blog post they liked on distillation, indicating interest in the topic.
- This led to a discussion about the lack of comprehensive resources on the subject.
- Missing Comprehensive Post by Lilian Wang: Another member expressed surprise that there isn't a 20k word post by Lilian Wang on distillation.
- This comment reflects a desire for detailed discussions and resources in the community.
- Potential Write-Up on Llama 3.1 Distillation: A member mentioned they might write a paragraph or two if Llama 3.1 is distilled.
- This suggests ongoing interest in new advancements and the documentation of such processes.
Interconnects (Nathan Lambert) ▷ #posts (4 messages):
SnailBot updatesUser engagement timings
- SnailBot News Announcement: A notification for SnailBot News was made, targeting the user role <@&1216534966205284433> for updates.
- Stay tuned for exciting announcements and updates from SnailBot!
- Engagement Duration Noted: 45 minutes was mentioned, potentially highlighting user engagement length or a related timeframe.
- This insight may inform future discussions or activities considering user interaction scales.
- User Reflects on Content: A member expressed that there was something interesting about the discussions happening.
- Positive engagement from users suggests a dynamic conversation flow within the channel.
OpenAccess AI Collective (axolotl) ▷ #general (73 messages🔥🔥):
Llama 3.1 ReleaseMistral and Nemo ConcernsTraining IssuesLanguage Inclusion in ModelsEvaluation Scores Comparison
- Llama 3.1 Release Generates Mixed Reactions: The anticipation around the Llama 3.1 release was palpable, but some expressed concerns about its utility and performance, especially for models like Mistral.
- Duh Kola lamented, 'Damn they don't like the llama release', indicating discontent with the overall reception.
- Training Challenges with Llama 3.1: Users are encountering errors while training Llama 3.1, particularly regarding the
rope_scalingconfiguration, causing frustration among the community.- One member got it running by updating transformers, stating, 'Seems to have worked thx!' after overcoming significant hurdles.
- Discussion on Language Inclusion: Concerns arose about the exclusion of Chinese language support in Llama 3.1, with members expressing that it's a detrimental oversight given its global importance.
- Comments highlighted that while the model tokenizer includes Chinese, the language's absence in prioritization was perceived as a strategic misstep.
- Comparing Evaluation Scores: Llama 3.1 vs Qwen: Discussion ensued regarding the cmmlu and ceval scores of Llama 3.1, with evaluations indicating only a slight improvement over its predecessor.
- Members noted that Qwen's self-reported scores show better performance but may not directly compare due to differences in evaluation methodology.
- Licensing Concerns for Qwen Model: Questions were raised about the licensing status of Qwen, particularly whether it remains under Alibaba's restrictions or has become fully open.
- Noobmaster29 mentioned, 'as long as it's public weights, I don't really mind the license,' reflecting pragmatism in the community's approach to model access.
- Download Llama: Request access to Llama.
- Llama 3.1: The open source AI model you can fine-tune, distill and deploy anywhere. Our latest models are available in 8B, 70B, and 405B variants.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (33 messages🔥):
LLM DistillationDPO Training IssuesAdapter Fine TuningReward ModelingChiPO Algorithm
- Exploring LLM Distillation Pipeline: A member shared a link to the LLM Distillery GitHub repo, which outlines a pipeline for LLM distillation.
- Discussion highlighted their implementation of precomputing logits on disk followed by KL divergence.
- DPO Training's Stagnation Concerns: Concerns were raised about the lack of progress on DPO integration, with a member noting no movement for two weeks.
- There was some confusion, but a member confirmed they were reviewing the issue again for resolution.
- Adapter Fine Tuning Stages: A member inquired about thoughts on GitHub issue #1095 related to multiple stages of adapter fine tuning.
- They proposed initializing later stages using prior weights to enhance the efficiency of DPO training.
- Mathematical Complexity of DPO and NLL Loss: There was a discussion about the complexities around DPO and incorporating NLL loss, with skepticism about its empirical validity.
- Members expressed interest in integrating the mathematical theories from recent papers into practical applications.
- Reward Modeling vs. PPO Approaches: A consensus emerged that reward modeling is still preferred over Proximal Policy Optimization (PPO) despite its limitations.
- Members entertained strategies for implementing stepwise-DPO possibly enhanced by LoRA adapters.
- Correcting the Mythos of KL-Regularization: Direct Alignment without Overoptimization via Chi-Squared Preference Optimization: Language model alignment methods, such as reinforcement learning from human feedback (RLHF), have led to impressive advances in language model capabilities, but existing techniques are limited by a wi...
- GitHub - golololologol/LLM-Distillery: A pipeline for LLM distillation: A pipeline for LLM distillation. Contribute to golololologol/LLM-Distillery development by creating an account on GitHub.
- Issues · axolotl-ai-cloud/axolotl: Go ahead and axolotl questions. Contribute to axolotl-ai-cloud/axolotl development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #datasets (3 messages):
LLM for verb tense conversionSpacy script for perspective changeThird-person to first-person conversionDataset for tense conversion examples
- Seeking LLM for Tense and Perspective Adjustment: A member asked if anyone knows of an LLM or a script using Spacy that can effectively change the verb tense and perspective of arbitrary text.
- They specifically need to convert text from third-person/past tense to first-person/present tense.
- Unfinished Dataset for Tense Conversion: Another member shared their past work on building a 10k sample dataset for verb tense conversion approximately a year ago but left it unfinished due to other commitments.
- They expressed a willingness to be informed if any relevant tools or resources are found by others.
DSPy ▷ #show-and-tell (8 messages🔥):
Code Confluence ToolDSPY IntegrationZenbase/Core Library Launch
- Code Confluence Tool Generates GitHub Summaries: Inspired by DSPY, a member introduced Code Confluence, an OSS tool built with Antlr, Chapi, and DSPY pipelines, designed to create detailed summaries of GitHub repositories. The tool's results may outperform existing OS products, as demonstrated on their DSPY repo.
- They provided additional resources, including the Unoplat Code Confluence GitHub and a compilation of summaries called OSS Atlas.
- Engagement and Feedback on Code Confluence: Feedback was welcomed for their new tool, with user engagement indicating interest and excitement about its capabilities. One user commented that they will check it out and expressed enthusiasm with a 🔥 emoji.
- Another user noted the abundance of interesting developments shared recently, contributing to a buzz around the DSPY community.
- Zenbase/Core Library Launch on Twitter: A member announced the Twitter launch of zenbase/core, a Python library that allows users to utilize DSPY's optimizers with their existing Instructor and LangSmith code. They requested retweets, likes, and stars on their announcement, which can be viewed here.
- The introduction of this library indicates ongoing efforts to integrate DSPY functionalities into broader coding practices, enhancing user experience.
DSPy ▷ #papers (2 messages):
AI Research PaperImplementation Requests
- New AI Research Paper Alert: A member shared a link to an AI research paper titled 2407.12865, sparking interest in its findings.
- Others are encouraged to check it out and discuss its implications in the community.
- Call for Code Replication: A member requested that if anyone writes code to replicate the findings of the paper or finds an existing implementation, they should share it or DM him.
- This highlights a collaborative approach to advancing discussions on this research.
DSPy ▷ #general (83 messages🔥🔥):
DSPy and Outlines comparisonEntity extraction with DSPyStructured output issues with Llama3Optimizer updates in DSPyLOTUS integration with Phoenix
- Comparison of JSON Generation Libraries: Members discussed the strengths and weaknesses of libraries like Jsonformer, Outlines, and Guidance in generating structured JSON, noting that Outlines offers better support for Pydantic formats and JSON schemas.
- Jsonformer is praised for strict schema adherence, while Guidance and Outlines provide more flexibility but may introduce complexity.
- Entity Extraction Module in DSPy: A user inquired about observing internal steps while executing an EntityExtractor module in DSPy, which led to the suggestion to use the
inspect_historymethod.- This method aims to help users understand the internal workings of the module when processing inputs.
- Challenges with Llama3 Structured Outputs: Users expressed difficulty in obtaining correctly structured outputs from the Llama3 model using DSPy, suggesting the use of
dspy.configure(experimental=True)alongside TypedChainOfThought.- However, there were questions about viewing model outputs even if they fail type checks, with limitations noted on the usefulness of
inspect_history.
- However, there were questions about viewing model outputs even if they fail type checks, with limitations noted on the usefulness of
- Interest in DSPy Optimizer Updates: A user raised a question about the plans for merging the backend refactor of DSPy into the main branch, particularly interested in experimenting with new optimizers.
- This indicates ongoing developments in DSPy and user engagement in its enhancements.
- Integration of LOTUS with Phoenix: A user asked about hooking up LOTUS with Phoenix to inspect queries, revealing interests in exploring integration opportunities within the DSPy ecosystem.
- Another member confirmed active usage of LOTUS with Modin, indicating existing practical applications of these integrations.
- no title found: no description found
- dspy-rag-application/embedder.ipynb at main · sksarvesh007/dspy-rag-application: Contribute to sksarvesh007/dspy-rag-application development by creating an account on GitHub.
- GitHub - outlines-dev/outlines: Structured Text Generation: Structured Text Generation. Contribute to outlines-dev/outlines development by creating an account on GitHub.
- GitHub - lm-sys/RouteLLM: A framework for serving and evaluating LLM routers - save LLM costs without compromising quality!: A framework for serving and evaluating LLM routers - save LLM costs without compromising quality! - lm-sys/RouteLLM
- GitHub - stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models: DSPy: The framework for programming—not prompting—foundation models - stanfordnlp/dspy
- GitHub - stanfordnlp/dspy at rc: DSPy: The framework for programming—not prompting—foundation models - GitHub - stanfordnlp/dspy at rc
- How to change the generation length · Issue #590 · stanfordnlp/dspy: Hey, I'm initializing my LM as follows, extras={'max_tokens':4000,'temperature':0.7} vllm = dspy.HFClientVLLM(model="Mistral-7B-Instruct-v0.1",url="https://my_vllm_u...
- dspy/dsp/modules/hf.py at 31ac32ba1a0b51cb7b9a8728b0bb7d4f3f2860a5 · stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models - stanfordnlp/dspy
DSPy ▷ #colbert (3 messages):
ColPali Use CasesColBert and RAGQdrant Support for ColBert
- Exploring ColPali for Medical Documents: A member shared their experience with ColPali, stating they are testing it for RAG of medical documents with images, as ColBert and standard embedding models have previously failed in this area.
- They also plan to explore training and using other vision-language models for improved effectiveness.
- Qdrant's Adoption of ColBert: Another member highlighted that Qdrant now supports ColBert, providing documentation on Hybrid and Multi-Stage Queries available since v1.10.0.
- The introduction of multi-query capabilities allows for complex search scenarios leveraging named vectors per point, enhancing retrieval processes.
Link mentioned: Hybrid Queries - Qdrant: Qdrant is an Open-Source Vector Database and Vector Search Engine written in Rust. It provides fast and scalable vector similarity search service with convenient API.
LlamaIndex ▷ #announcements (1 messages):
LlamaIndex WebinarColPali Document RetrievalVision Language ModelsViDoRe Benchmark
- LlamaIndex Webinar on Efficient Document Retrieval: Join the upcoming webinar hosted by ColPali authors discussing Efficient Document Retrieval with Vision Language Models this Friday at 9am PT. Signup here to learn about cutting-edge techniques in document processing.
- ColPali's Innovative Approach to Document Retrieval: ColPali introduces a novel technique that directly embeds page screenshots with Vision Language Models (VLMs), improving retrieval performance over complex documents. This method avoids loss of crucial visual information that traditional parsing and OCR typically encounter.
- New Benchmark for Document Retrieval: The new ViDoRe benchmark proposed by ColPali better addresses challenging retrieval tasks associated with various document elements, enhancing the evaluation of retrieval systems. This benchmark is designed to complement the traditional methods by focusing on visual representations.
- Future of Multimodal Document Retrieval: The webinar will delve into the multimodal document retrieval future, integrating techniques from ColPali and LlamaParse. The discussion will highlight an end-to-end system that achieves state-of-the-art results in document retrieval.
Link mentioned: LlamaIndex Webinar: ColPali - Efficient Document Retrieval with Vision Language Models · Zoom · Luma: Enterprise RAG systems face a significant challenge when processing PDFs with complex layouts, tables, and figures. Conventional RAG pipelines typically…
LlamaIndex ▷ #blog (8 messages🔥):
TiDB Future App Hackathon 2024Mixture-of-Agents with LlamaIndexLlama 3.1 PerformanceLlamaParse FeaturesMongoDB AI Applications Program
- Join the $30,000 TiDB Future App Hackathon!: We're sponsoring a month-long TiDB Future App Hackathon 2024 with over $30,000 in prizes including $12,000 for first place, partnering with @pingcap and others.
- Participate to build innovative AI applications using the latest TiDB Serverless with Vector Search.
- Discover Mixture-of-Agents with LlamaIndex!: In a new video, @1littlecoder introduces a novel approach called 'mixture of agents' which uses multiple local language models to potentially outperform single models like GPT-4.
- Check out the step-by-step tutorial to explore how this method can enhance your AI projects.
- Llama 3.1 Models Available Now: The Llama 3.1 series with models of 8B, 70B, and 405B are now available for use with LlamaIndex via Ollama, though the 405B requires substantial computing power.
- For hosted versions, check out our partners at Fireworks AI for assistance.
- Explore LlamaParse's Capabilities: In a video, @seldo highlights key features of LlamaParse including options for Markdown and JSON outputs, along with enhanced OCR support.
- This tool is designed for greater metadata extraction across multiple languages, making it highly versatile for document processing.
- MongoDB AI Applications Program Launch!: @MongoDB has announced the general availability of its AI Applications Program (MAAP), aimed at helping organizations build and deploy AI-rich applications efficiently.
- Learn more about MAAP's offerings and how it can accelerate your AI journey here.
- TiDB Future App Hackathon 2024: Innovate and Create Amazing AI Applications
- MongoDB AI Applications Program: Get the support you need to accelerate your AI application journey and launch with confidence and speed.
LlamaIndex ▷ #general (61 messages🔥🔥):
context_window parameterchunk_size and chunk_overlapmodel availability and context sizeValueError in LlamaIndexusing models with larger context windows
- Understanding the context_window parameter: The
context_windowparameter specifies the maximum number of tokens the model can handle, including both input and output tokens.- If the input text is too long, it may restrict output generation, leading to errors if the token limit is exceeded.
- Defining chunk_size and chunk_overlap:
chunk_sizesets the maximum number of tokens in each chunk during processing, whilechunk_overlapdefines the number of overlapping tokens between consecutive chunks.- These parameters help control the precision of embeddings and ensure context is retained across chunks.
- Addressing ValueErrors in LlamaIndex: A ValueError indicating a negative context size suggests the input text exceeds the current model's
context_windowlimit.- Reducing input size or switching to a model with a larger context window are potential resolutions.
- Maximize model efficiency with context_window: In cases where the context window is reached, it may limit the model's output capacity significantly.
- Choosing models with appropriate
context_windowvalues based on input length is essential for optimal performance.
- Choosing models with appropriate
- Discussion on context_window's scope: Clarifications were shared regarding whether
context_windowcovers only input tokens or includes outputs as well.- It was confirmed that the
context_windowencompasses both, necessitating careful management of input sizes.
- It was confirmed that the
- Cleanlab - LlamaIndex: no description found
- Using LLMs - LlamaIndex: no description found
- Token text splitter - LlamaIndex: no description found
- Basic Strategies - LlamaIndex: no description found
Latent Space ▷ #ai-general-chat (53 messages🔥):
Llama 3.1 ReleaseIOL Linguistics OlympiadLlama PricingLlama Performance EvaluationsGPT-4o Mini Fine-Tuning
- Excitement Surrounds Llama 3.1 Launch: The release of Llama 3.1 includes the 405B model, marking a significant milestone in open-source LLMs with remarkable capabilities rivaling closed models.
- Initial evaluations indicate it's the first open model positioned at frontier capabilities, with endorsements from figures like @karpathy praising its accessibility for iterative research and development.
- International Olympiad for Linguistics (IOL): The International Olympiad for Linguistics (IOL) commenced, challenging students to translate lesser-known languages purely using logic, similar to high-stakes math competitions like the IMO.
- Participants are tackling seemingly impossible problems within a demanding six-hour time frame, sparking interest in how logical reasoning can bridge linguistic gaps.
- Llama 3.1 Pricing Insights: Pricing for Llama 3.1's 405B model varies by provider, with indications of costs around $4-5 per million tokens for input and output across platforms like Fireworks and Together.
- This competitive pricing strategy is seen as potentially aimed at capturing market share before gradually increasing rates as adoption grows.
- Evaluation of Llama's Performance: Early evaluations of Llama 3.1 show it performing well within various benchmarks, ranking highly on tasks notably including GSM8K and logical reasoning capabilities on ZebraLogic.
- In comparison tests, its overall performance lands between Sonnet 3.5 and GPT-4o, though challenges like maintaining schema adherence after extended token lengths were noted.
- GPT-4o Mini Fine-Tuning Launch: OpenAI announced the fine-tuning capability for GPT-4o mini, now available for tier 4 and 5 users, with the first 2 million training tokens free each day until September 23.
- This initiative aims to expand access and customization options over time, with users already evaluating performance against the newly launched Llama 3.1.
- Tweet from Kyle Corbitt (@corbtt): Guys fine-tuned Llama 3.1 8B is completely cracked. Just ran it through our fine-tuning test suite and blows GPT-4o mini out of the water on every task. There has never been an open model this small,...
- Tweet from Dean W. Ball (@deanwball): Llama 3 405b is a "systemic risk" to society, according to the European Union and their AI Act.
- Tweet from Sully (@SullyOmarr): zucc really killed it with llama 3.1 best open source model & almost as good as the best closed model
- Tweet from naklecha (@naklecha): today, i'm excited to release factorio-automation-v1. using this mod, your agent can perform game actions like crafting, pathfinding, mining, researching etc. this mod can act as a good playground...
- Tweet from Hrishi (@hrishioa): Llama3 405B is now part of Mandark (https://github.com/hrishioa/mandark) Code writing tests: HOW IS IT? * Needs a lot more prompt tuning, has trouble sticking to schema after about 1K tokens * Just ...
- Tweet from Neural Magic (@neuralmagic): vLLM now supports deploying Llama-3.1-405B on a single 8xH100 or 8xA100 node, making inference much easier and cheaper! This is a huge feat by Neural Magic’s engineers who contributed 3 crucial feat...
- Tweet from Jonathan Ross (@JonathanRoss321): What can you do with Llama quality and Groq speed? You can do Instant. That's what. Try Llama 3.1 8B for instant intelligence on http://groq.com.
- Llama 3.1: The open source AI model you can fine-tune, distill and deploy anywhere. Our latest models are available in 8B, 70B, and 405B variants.
- Tweet from Together AI (@togethercompute): Today marks an inflection point for open source AI with the launch of Meta Llama 3.1 405B, the largest openly available foundation model, that rivals the best closed source models in AI rapidly accele...
- Tweet from OpenAI Developers (@OpenAIDevs): Customize GPT-4o mini for your application with fine-tuning. Available today to tier 4 and 5 users, we plan to gradually expand access to all tiers. First 2M training tokens a day are free, through Se...
- Tweet from Kyle Corbitt (@corbtt): @altryne @eugeneyan EVALS RUNNING
- IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models: Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African ...
- Tweet from Bill Yuchen Lin 🤖 (@billyuchenlin): A quick independent evaluation of Llama-3.1-405B-Instruct-Turbo (on @togethercompute) ⬇️ 1️⃣ It ranks 1st on GSM8K! 2️⃣ Its logical reasoning ability on ZebraLogic is quite similar to Sonnet 3.5, and...
- Tweet from AI at Meta (@AIatMeta): Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet. Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These m...
- Tweet from Deedy (@deedydas): The IMO is the hardest high school Math test. A lesser known sibling, the IOL (International Olympiad for Linguistics), starts tomorrow! Students are asked to translate lesser-known languages purely ...
- Tweet from Aravind Srinivas (@AravSrinivas): Scale AI's SEAL evals (which I think is a better idea than arena leaderboards simply because you don't want to hill climb with fake endpoints and have random folks rate based on vibes) suggest...
- Tweet from Xeophon (@TheXeophon): Llama-405B Pricing: Fireworks: 3/3 Together: 5/15 Replicate: 9.5/9.5 Groq: Enterprise only for now Quoting Xeophon (@TheXeophon) Given the Llama 3 pricing and timing of other providers, it will be...
- Tweet from Yao Fu @ICML (@Francis_YAO_): As an llm practitioner, this talk is the most informative one I ever listened to so far in the area of the science of LLMs. I was deeply impressed. For my own students I would require them to memorize...
- Tweet from AI at Meta (@AIatMeta): More technical details on the new Llama 3.1 models we released today. 🦙🧵
- Tweet from Andrej Karpathy (@karpathy): Huge congrats to @AIatMeta on the Llama 3.1 release! Few notes: Today, with the 405B model release, is the first time that a frontier-capability LLM is available to everyone to work with and build on...
- Tweet from George Hotz 🌑 (@realGeorgeHotz): Not only were the 405B Llama weights released, they also released a paper explaining how it was made. Nice! How does any self respecting ML researcher still work at a closed lab? You aren't savin...
- Tweet from Xeophon (@TheXeophon): Llama-405B Pricing: Fireworks: 3/3 Together: 5/15 Replicate: 9.5/9.5 Groq: Enterprise only for now Quoting Xeophon (@TheXeophon) Given the Llama 3 pricing and timing of other providers, it will be...
- Tweet from Summer Yue (@summeryue0): 🚀 We added Llama 3.1 405B onto the SEAL Leaderboards and it does not disappoint! Here's how it stacks up: - 🥇 #1 in Instruction Following - 🥈 #2 in GSM1k - 💻 #4 in Coding SEAL evals are priv...
Latent Space ▷ #ai-announcements (3 messages):
Llama 3 PodcastSynthetic DataRLHFGalactica InstructLlama 4 Agents
- Llama 3 Podcast Launch: A new podcast episode featuring @ThomasScialom discusses Llama 2, 3 & 4, focusing on Synthetic Data, RLHF, and agents' path to Open Source AGI.
- Listeners are encouraged to check it out here and engage with the podcast!
- Galactica Instruct's Potential Impact: The podcast highlights why @ylecun's Galactica Instruct could have effectively resolved @giffmana's Citations Generator issues.
- This insight showcases the practical applications of advanced models in real-world scenarios.
- Chinchilla Performance Insights: Discussions included advancements like 100x Chinchilla as mentioned by @jefrankle, emphasizing the movement beyond traditional models.
- This raises intriguing points about optimizing model efficiency and performance.
- Native INT8 Training Exploration: The episode covers @NoamShazeer's thoughts on native INT8 training, highlighting its implications for model training and deployment.
- This could shape future methodologies in AI model training strategies.
- Future of Llama 4 and Agents: The discussion ventured into Llama 4's plans regarding Agents, questioning the reasons behind avoiding the Use of MOE.
- These considerations could point to significant design choices impacting the capabilities of future AI models.
Link mentioned: Tweet from Latent.Space (@latentspacepod): 🆕 pod with @ThomasScialom of @AIatMeta! Llama 2, 3 & 4: Synthetic Data, RLHF, Agents on the path to Open Source AGI https://latent.space/p/llama-3 shoutouts: - Why @ylecun's Galactica Instruct...
LangChain AI ▷ #general (23 messages🔥):
AgentState vs InnerAgentStateUsing Chroma Vector DatabaseMulti-Character Chatbots in LangChain
- AgentState and InnerAgentState Exploration: A question was raised about the difference between
AgentStateandInnerAgentState. While the definition forAgentStatewas clarified, it's noted that there is insufficient information regardingInnerAgentState, suggesting users check the official LangChain documentation.- Details regarding
AgentStateinclude fields likemessages,next, and others depending on context, with references provided for further exploration.
- Details regarding
- Setting Up Chroma Vector Database on Python: Instructions were provided on how to set up Chroma as a vector database using Python, including installing
langchain-chromaand running the Chroma server in a Docker container.- Examples included using methods like
.add,.get, and.similarity_search, emphasizing the need for OpenAI API Key to utilizeOpenAIEmbeddings.
- Examples included using methods like
- Improv Chatbot Development with LangChain: A query was made about creating a multi-character improv chatbot using LangChain. While explicit support wasn't confirmed, it was mentioned that LangChain offers features like streaming and message history management which could enable such functionality.
- Helpful resources from LangChain documentation were shared, including tutorials on Conversational RAG, Agents, and message history management.
- Chroma | 🦜️🔗 LangChain: Chroma is a AI-native open-source vector database focused on developer productivity and happiness. Chroma is licensed under Apache 2.0.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #share-your-work (3 messages):
Scheduler Agent with ComposioLangGraph and MapReduceLlama 3.1 Hosting
- Create a Scheduler Agent using Composio: A guide was shared detailing steps to create a Scheduler Agent leveraging Composio, LangChain, and ChatGPT for event scheduling based on received emails. You can find the guide and star the repo if you find it useful.
- The guide highlights how Composio equips agents with well-crafted tools to tackle complex tasks effectively.
- LangGraph and MapReduce for Parallel Processing: A post discusses how LangGraph and MapReduce work together as a dynamic duo for parallel processing tasks in big data. The insights can be found in this detailed article.
- The introduction emphasizes how breaking down tasks for parallel execution is a game-changer in complex computations.
- Llama 3.1 Hosting Available: A member announced the hosting of Llama 3.1 405B and invited others to try it out. The chat is available here and the API can be accessed here.
- This hosting provides an opportunity for members to interact with the latest model version in a user-friendly environment.
- composio/python/examples/scheduler_agent at master · ComposioHQ/composio: Composio equips agents with well-crafted tools empowering them to tackle complex tasks - composio/python/examples/scheduler_agent at master · ComposioHQ/composio
- Tune Chat - Chat app powered by open-source LLMS: With Tune Chat, access Prompts library, Chat with PDF, and Brand Voice features to enhance your content writing and analysis and maintain a consistent tone across all your creations.
- TuneStudio: no description found
- LangGraph and MapReduce: A Dynamic Duo for Parallel Processing: Ankush k Singal
LangChain AI ▷ #tutorials (5 messages):
Scheduler AgentYouTube Notes GeneratorLangGraph and Flow EngineerAI Code ReviewerFully Local Tool Calling with Ollama
- Create Your Own Scheduler Agent with Composio: A guide was shared detailing steps to create a Scheduler Agent using Composio, LangChain, and ChatGPT for scheduling events based on received emails. Check it out here.
- Composio equips agents with tools that enable them to handle complex tasks effectively, showcased in the scheduler examples.
- YouTube Notes Generator Launched!: A new open-source project, the YouTube Notes Generator, was announced to assist users in generating notes from YouTube videos. More information can be found here.
- This project aims to simplify note-taking directly from video content, enhancing learning efficiency.
- Building 10x Reliable Agents with LangGraph: A video tutorial was released demonstrating how to use LangGraph and Flow Engineer to build highly reliable agents. Watch it on YouTube here.
- The video simplifies the process to boost agent reliability significantly, promoting efficient development practices.
- AI Code Reviewer with Ollama & LangChain: A new YouTube video titled 'AI Code Reviewer Ft. Ollama & Langchain' introduces a CLI tool for effective code reviews. Check out the video here.
- The tool is designed to revolutionize the code review process, enhancing developers' workflow and productivity.
- Request for Notebook on Fully Local Tool Calling: A member requested a notebook for 'Fully local tool calling with Ollama', hoping to access the information shared earlier in the day. The session was acknowledged as excellent by the community.
- This reflects the community's interest in practical implementations of local tool integration techniques.
- AI Code Reviewer Ft. Ollama & Langchain: Welcome to Typescriptic! In this video, we introduce our Code Reviewer, a CLI tool designed to revolutionize the way you review your code. Powered by LangCha...
- composio/python/examples/scheduler_agent at master · ComposioHQ/composio: Composio equips agents with well-crafted tools empowering them to tackle complex tasks - composio/python/examples/scheduler_agent at master · ComposioHQ/composio
Cohere ▷ #general (26 messages🔥):
Welcome New MembersModel Fine-tuningCohere's OCR CapabilitiesRAG Chatbot DiscussionsCommunity Feedback Evaluation
- Welcome to New Members: New members, including @thetimelesstraveller and @fullc0de, introduced themselves and expressed excitement about using Cohere.
- Community members like @xvarunx welcomed them enthusiastically, creating a friendly atmosphere.
- Fine-tuning Model Progress: @thetimelesstraveller shared about a new attempt at fine-tuning a model with a dataset called midicaps, involving some post-processing.
- They referenced previous good results from similar projects, indicating progress in their efforts.
- Cohere's OCR Solutions Clarified: In response to a question about OCR capabilities, @co.elaine informed that Cohere utilizes unstructured.io.
- Community discussions revealed that integrating external solutions is feasible, allowing for customization.
- ChatBot and RAG Implementation Queries: User @coco.py raised questions about managing chat history and feedback in RAG-based ChatBot systems.
- Responses suggested fitting previous conversations into the context or using vector databases, while feedback methods like thumbs up/down were mentioned.
- Positive Community Vibes: The community celebrated a recent release, with users expressing excitement and positivity in various comments.
- @mrdragonfox reiterated community guidelines, ensuring that the environment stays focused and welcoming.
Cohere ▷ #announcements (1 messages):
Rerank 3 NimbleCohere and Fujitsu Partnership
- Introducing Rerank 3 Nimble with Superior Performance: Rerank 3 Nimble launches with 3x higher throughput than its predecessor Rerank 3, maintaining a significant accuracy level. It's now available on AWS SageMaker.
- Say hello to our new foundation model Rerank 3 Nimble! The model promises enhanced speed for enterprise search and retrieval-augmented generation (RAG) systems.
- Cohere and Fujitsu's Strategic Partnership: Cohere announced a strategic partnership with Fujitsu to provide AI services specifically for Japanese enterprises. Details can be found in the blog post.
- This collaboration aims to leverage both companies' strengths to enhance AI service delivery in the region.
Link mentioned: Introducing Rerank 3 Nimble: Faster Reranking for Enterprise Search & Retrieval-Augmented Generation (RAG) Systems: Today, Cohere is introducing Rerank 3 Nimble: the newest foundation model in our Cohere Rerank model series, built to enhance enterprise search and RAG systems, that is ~3x faster than Rerank 3 while ...
Torchtune ▷ #general (22 messages🔥):
Llama 3.1 releaseMPS support and conflictsIssues with LoRAGit workflow challenges
- Llama 3.1 is officially here!: Meta released the latest model, Llama 3.1, this morning, with support already provided for the 8B and 70B instruct models {@everyone}.
- The excitement was palpable, leading to some humorous comments about typos and excitement-induced errors.
- MPS Support and Related Conflicts: A pull request for MPS support was mentioned, which checks for BF16 on MPS devices as a critical update.
- Moreover, ongoing conflicts in the code base were spotlighted, with contributors noting the challenge of keeping branches updated due to frequent changes.
- LoRA Issues Persist: An ongoing issue with LoRA not working as expected was raised, with suggestions for debugging the implementation.
- One contributor recalled encountering CUDA hardcoding problems during their recent efforts.
- Navigating Git Workflow Challenges: Git workflow challenges were discussed, specifically surrounding the feeling of constantly facing conflicts after addressing previous ones.
- A suggestion was made to tweak the workflow to minimize recurrent conflicts, emphasizing the need for effective conflict resolution strategies.
- Llama 3.1 | Model Cards and Prompt formats: Llama 3.1 - the most capable open model.
- Install Instructions — torchtune 0.2 documentation: no description found
- MPS support by maximegmd · Pull Request #790 · pytorch/torchtune: Context For testing purposes it can be useful to run directly on a local Mac computer. Changelog Checks support for BF16 on MPS device. Added a configuration targeting MPS, changes to path were ...
Torchtune ▷ #dev (3 messages):
MPS support in TorchtunePad ID bug fixGitHub Pull Request workflow
- MPS Support Pull Request Discussion: The pull request titled MPS support by maximegmd introduces checks for BF16 on the MPS device, aimed at improving testing on local Mac computers.
- Discussions indicate potential issues due to the diff being from a common ancestor, with suggestions that a rebase rather than a merge might have been conducted.
- Pad ID Bug Fix PR Introduced: A member pointed out a critical bug regarding pad ID displaying in generate, leading to the creation of Pull Request #1211 to prevent this issue.
- The PR aims to address the implicit assumption of Pad ID being 0 in utils.generate, clarifying its impact on special tokens.
- Prevent pad ids, special tokens displaying in generate by RdoubleA · Pull Request #1211 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) Pad ID is implicitly assumed to be 0 in utils.generate, ...
- MPS support by maximegmd · Pull Request #790 · pytorch/torchtune: Context For testing purposes it can be useful to run directly on a local Mac computer. Changelog Checks support for BF16 on MPS device. Added a configuration targeting MPS, changes to path were ...
tinygrad (George Hotz) ▷ #general (15 messages🔥):
matmul-free-llm with tinygradM1 performance differencesTesting challenges withPYTHON=1``cumsum optimization in tinygradTensorFlow vs PyTorch tensor operations
- Help needed for matmul-free-llm recreation: There's a request for assistance in recreating matmul-free-llm with tinygrad, aiming to leverage efficient kernels while incorporating fp8.
- Hoping for seamless adaptation to Blackwell fp4 soon.
- M1 results differ from CI: An M1 user is experiencing different results compared to CI, seeking clarification on setting up tests correctly with conda and environment variables.
- There's confusion due to discrepancies when enabling
PYTHON=1, as it leads to an IndexError in tests.
- There's confusion due to discrepancies when enabling
- cumsum performance concerns: A newcomer is exploring the O(n) implementation of nn.Embedding in tinygrad and how to improve cumsum from O(n^2) to O(n) using techniques from PyTorch.
- There’s speculation about constraints making this challenging, especially as it's a $1000 bounty.
- TensorFlow and PyTorch tensor operations differences: Discussion is ongoing about the differences in behavior between TensorFlow bitcast and PyTorch view, primarily in how dimensions are handled.
- Adding or removing dimensions can cause confusion, with some suggesting that the behavior of TensorFlow makes more sense in this context.
- Testing issues with bitcast and view: Testing issues arise with
PYTHON=1due to the device's support differences between view and bitcast, causing shape compatibility problems.- There is agreement that while PyTorch and NumPy expand or contract dimensions, TensorFlow's method adds a new dimension.
- matmulfreellm/mmfreelm/ops/fusedbitnet.py at master · ridgerchu/matmulfreellm: Implementation for MatMul-free LM. Contribute to ridgerchu/matmulfreellm development by creating an account on GitHub.
- Issues · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - Issues · tinygrad/tinygrad
tinygrad (George Hotz) ▷ #learn-tinygrad (6 messages):
Incremental Testing in PyTorchMolecular Dynamics Engine in TinygradGradient CalculationsNeural Network Potentials
- Seeking Pattern for Incremental Testing with PyTorch: A member inquired about effective patterns for incrementally testing model performance in the sequence of Linear, MLP, MoE, and LinearAttentionMoE using PyTorch.
- They questioned whether starting tests from scratch is more efficient than incremental testing.
- Developing Molecular Dynamics Engine in Tinygrad: A group is attempting to implement a Molecular Dynamics engine in tinygrad to train models predicting energies of molecular configurations, facing challenges with gradient calculations.
- They require the gradient of predicted energy concerning input positions for the force, but issues arise because they backpropagate through the model weights twice.
- Need for Efficient Gradient Calculation: The developer explained the challenge of calculating the energy/position gradient through a different graph, similar to torch.autograd.grad in PyTorch.
- This is crucial for ensuring the first gradient computation doesn't affect the loss calculation, and they plan to share a minimal example for assistance.
- Encouragement for PR with Minimal Reproduction: George Hotz suggested that the developer should post a minimal reproduction of the issue along with the expected behavior to facilitate better assistance.
- He recommended that this minimal example could ideally be added as a test in a pull request (PR).
- Connection to Neural Network Potentials: Another member, James Wiles, queried whether the Molecular Dynamics project is linked to Neural Network Potentials.
- This indicates an interest in how these concepts might intersect within the context of their work.
LAION ▷ #general (9 messages🔥):
Int8 UsageComfyUI FlowLlama 3.1 ReleaseWhisper Speech ToolZuckerberg's Talk on Llama 3.1
- Discussion on Int8 Implementation: Members asked about using Int8, with one member confirming they could get it working.
- Hold a sec was requested during the discussion, hinting at further support.
- Guidance on ComfyUI Flow: A request for sharing a script led to the response to use the ComfyUI flow for setup.
- This reflects a preference for streamlined workflows in the community.
- Llama 3.1 Update Shared: A member referred to the Llama 3.1 blog in a specific channel, indicating significant interest in updates.
- This highlights ongoing discussions around advancements in Llama models.
- Query on Whisper Speech Tool: There was a question about the working condition of the Whisper Speech tool at the provided link.
- Members engaged in checking the current status of this tool, showing active community participation.
- Zuckerberg Discusses Llama 3.1: A member shared a YouTube video where Mark Zuckerberg discusses Llama 3.1 and its competitive advantages.
- The video emphasizes Llama 3.1 as the first-ever open-sourced frontier AI model, achieving notable benchmarks.
- Mark Zuckerberg on Llama 3.1, Open Source, AI Agents, Safety, and more: Meta just released Llama 3.1 405B — the first-ever open-sourced frontier AI model, beating top closed models like GPT-4o across several benchmarks. I sat dow...
- Gradio: no description found
LAION ▷ #research (5 messages):
Meta's commitment to open source AILlama 3.1 capabilitiesContext length improvements
- Meta champions open source AI: Meta is dedicated to openly accessible AI as detailed in Mark Zuckerberg’s letter, emphasizing its benefits for developers and the broader community.
- This aligns with their vision of fostering innovation through collaboration in the AI ecosystem.
- Llama 3.1 sets a new benchmark: The release of Llama 3.1 405B introduces unprecedented capabilities, including a context length of 128K and support for eight languages.
- This model provides flexibility and control, positioning itself competitively against top closed-source alternatives.
- Context Size Criticism Addressed: A discussion highlighted that the previous 8K context size was considered inadequate for handling large documents efficiently.
- The leap to 128K context size is seen as a significant improvement for tasks requiring substantial document processing.
Link mentioned: no title found: no description found
OpenInterpreter ▷ #general (1 messages):
Llama 3.1 405 BGPT-4o performance
- Llama 3.1 405 B Amazes Users: Llama 3.1 405 B is reported to work fantastically out of the box with OpenInterpreter.
- Users noted that unlike GPT-4o, there's no need for constant reminders or restarts to complete multiple tasks.
- Frustrations with GPT-4o: A user expressed challenges with GPT-4o, requiring frequent prompts to perform tasks on their computer.
- This frustration highlights the seamless experience users are having with Llama 3.1 405 B.
OpenInterpreter ▷ #O1 (3 messages):
Voice Input with Coqui ModelExpo App for Apple WatchDevice Shipping Timeline
- Voice Input on MacOS with Coqui Model?: A query was raised about the feasibility of using voice input with a local Coqui model on MacOS.
- No responses were yet provided detailing any successful implementations.
- Expo App's Capability for Apple Watch: There was a discussion affirming that the Expo app should theoretically be able to build applications for the Apple Watch.
- Further details or confirmations were not provided.
- Shipping Timeline for the Device: A member inquired about the shipping timeline for a specific device, signaling an ongoing curiosity about its status.
- No updates or timelines were shared in the conversation.
Alignment Lab AI ▷ #general-chat (1 messages):
spirit_from_germany: https://youtu.be/Vy3OkbtUa5k?si=mBhzPQqDLgzDEL61
Alignment Lab AI ▷ #open-orca-community-chat (2 messages):
OpenOrca dataset licensingSynthetic dataset announcement
- Clarification on OpenOrca Dataset Licensing: A member sought clarification on the licensing of the OpenOrca dataset, specifically questioning whether its MIT License allows for commercial use of its outputs given its derivation from the GPT-4 Model.
- Can its outputs be used for commercial purposes?
- Plans for Open Sourcing Synthetic Dataset: Another member announced plans to open source a synthetic dataset that will support both non-commercial and commercial applications.
- They mentioned evaluating a dependency on OpenOrca while creating the dataset, indicating an interest in its licensing implications.
LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (2 messages):
Miami meetupNYC interest in August
- Inquiries for Miami Meetups: A member asked if anyone is near Miami, potentially looking for meetups or gatherings.
- No further details or responses were shared regarding this inquiry.
- Interest in NYC Gathering: Another member expressed interest in attending meetups in NYC in late August.
- This inquiry opened up potential opportunities for connection among members in the area.
AI Stack Devs (Yoko Li) ▷ #team-up (1 messages):
ari991963: Hi all, I am Aria a 2D/3D artist, if you are interested to collaborate dm
Mozilla AI ▷ #announcements (1 messages):
Mozilla Accelerator Application DeadlineZero Shot Tokenizer Transfer EventAutoFix Project Overview
- Mozilla Accelerator Application Deadline Approaches: The application deadline for the Mozilla Accelerator is fast approaching, offering a 12-week program with up to $100k in non-dilutive funds.
- Participants will also have the opportunity to showcase their projects during a demo day with Mozilla. Questions?
- Get Ready for Zero Shot Tokenizer Transfer Event: A reminder of an upcoming event featuring Zero Shot Tokenizer Transfer with Benjamin Minixhofer, scheduled this month.
- Details can be found in the event's link. Event Information
- Introducing AutoFix: The Open Source Issue Fixer: AutoFix is an open-source issue fixer that can submit PRs directly from Sentry.io, providing an efficient way to manage issues.
- You can learn more about this innovative tool in the detailed post linked. AutoFix Information