[AINews] Llama 3.1 Leaks: big bumps to 8B, minor bumps to 70b, and SOTA OSS 405b model
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
TODO: ONELINE SUBTITLE
AI News for 7/19/2024-7/22/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (474 channels, and 7039 messages) for you. Estimated reading time saved (at 200wpm): 765 minutes. You can now tag @smol_ai for AINews discussions!
We know it's coming tomorrow (with Soumith's ICML keynote), so we really tried to avoid discussing the leaks since we're going to be covering it tomorrow, but Llama 3.1 is leaking like a sieve (weights, evals, model card) that is leaky, so unfortunately it is all the community is talking about today, despite a lot of it being repeats of the first Llama 3 release in April.
Apart from the well telegraphed 405B dense model release, here are the diffs to Llama 3.1 as far as we can tell, mostly from the model card spells out the various priorities they had:
- "The Llama 3.1 instruction tuned text only models (8B, 70B, 405B) are optimized for multilingual dialogue use cases and outperform many of the available open source and closed chat models on common industry benchmarks."
- Explicitly advertising "Multilingual text and code as an output modality
- every model bumped up to 128k context length (up from 8k)
- Training utilized a cumulative of 39.3M GPU hours of computation on H100-80GB (TDP of 700W): 1.5m for 8B, 7m for 70B, 31M for 405B.
- Llama 3.1 was pretrained on ~15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 25M synthetically generated examples.
- sizable bumps to the 8B and 70B benchmarks (MMLU from 65 to 73 for the 8B (+8 points), and from 81 to 86 for the 70B (+5 points), and MATH from 29 to 52 (+23 points) for the 8B
We made a diff spreadsheet to visualize - TLDR, HUGE bump for the 8B, across the board and instruct 70b is mildly better. 405B is still behind flagship models.:
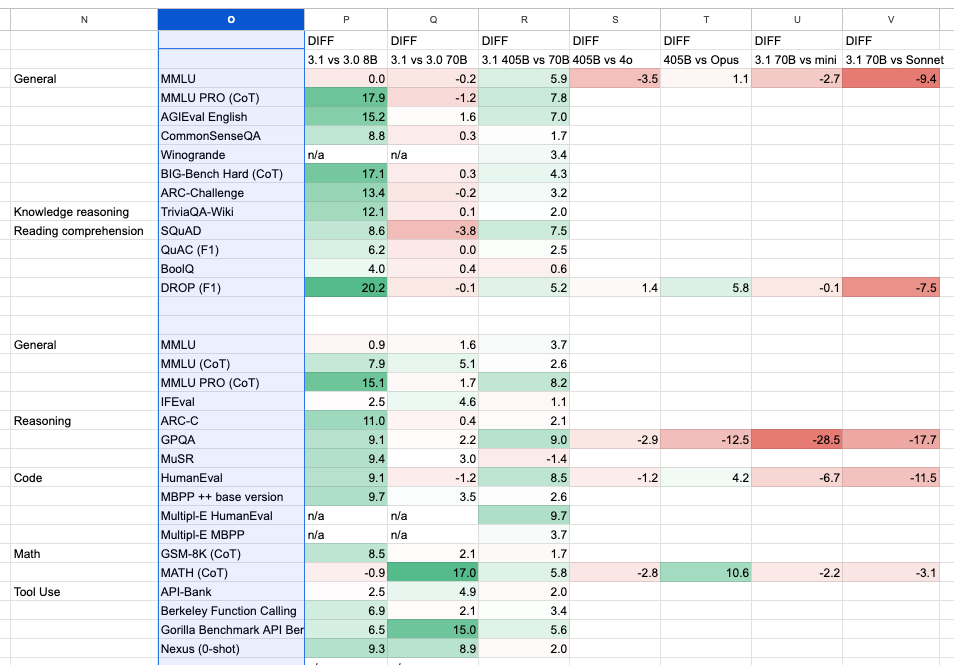
However some independently run evals have Llama 3.1 70b doing better than GPT 4o - jury still out.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
GPT-4o Mini Release and Performance
- GPT-4o Mini Launch: @adcock_brett announced the release of GPT-4o mini, a compact and cost-efficient version of the GPT-4o model, with pricing at 15 cents per million input tokens and 60 cents per million output tokens, over 60% cheaper than GPT-3.5 Turbo.
- Strong Performance: @swyx highlighted GPT-4o mini's impressive performance, achieving 82 MMLU at $0.15/mtok, outperforming models that were state-of-the-art just 3 months ago.
- Reasoning Deficits: @JJitsev tested GPT-4o mini on AIW problems and found basic reasoning deficits and lack of robustness on simple problem variations, performing worse than Llama-3-8B despite similar compute scale.
Synthetic Data and Model Performance
- Surpassing Teachers: @_philschmid shared that the AI-MO team's winning dataset with a fine-tuned @Alibaba_Qwen 2 model approaches or surpasses GPT-4o and Claude 3.5 in math competitions, demonstrating the potential of synthetic datasets to enable models to outperform their teachers.
- NuminaMath Datasets: @_lewtun introduced the NuminaMath datasets, the largest collection of ~1M math competition problem-solution pairs, which were used to win the 1st Progress Prize of the AI Math Olympiad. Models trained on NuminaMath achieve best-in-class performance among open weight models.
Reasoning and Robustness Benchmarks
- Comprehensive Reasoning Task List: @Teknium1 suggested creating a master list of reasoning tasks for people to contribute to, aiding dataset builders in targeting tasks that improve reasoning capabilities.
- Illusion of Strong Performance: @JJitsev argued that current benchmarks overlook clear deficits in SOTA LLMs, creating an illusion of strong performance for models that manage to score high, despite their inability to perform basic reasoning robustly.
Memes and Humor in the AI Community
- Meme Potential: @kylebrussell shared a meme, suggesting its potential impact in the AI community.
- AI-Generated Humor: @bindureddy shared an AI-generated image, highlighting the role of AI in creating humorous content and providing a break from serious topics.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. AI-Powered Mathematics Training
- NuminaMath datasets: the largest collection of ~1M math competition problem-solution pairs (Score: 53, Comments: 1): NuminaMath unveils massive math dataset: The NuminaMath collection, featuring approximately 1 million math competition problem-solution pairs, has been released on the Hugging Face Hub. This dataset, accompanied by models and a technical report, represents the largest collection of its kind, potentially advancing AI capabilities in mathematical problem-solving.
Theme 2. Local LLM Resource Optimization
- large-model-proxy allows to run multiple LLMs on different ports of the same machine while automatically managing VRAM usage by stopping/starting them when needed. (Score: 68, Comments: 10): large-model-proxy is a tool that enables running multiple Large Language Models (LLMs) on different ports of the same machine while automatically managing VRAM usage. The proxy dynamically stops and starts models as needed, allowing users to efficiently utilize their GPU resources without manual intervention. This solution addresses the challenge of running multiple memory-intensive LLMs on a single machine with limited VRAM.
- The author developed large-model-proxy to efficiently manage multiple LLMs in their workflow. It automates VRAM management and model starting/stopping, making it easier to script and utilize various models without manual intervention.
- A user points out that Ollama offers similar functionality, allowing multiple models to run concurrently with automatic unloading/loading based on VRAM availability, without the need for multiple ports or config file editing.
- Another developer mentions using Python and OpenResty Lua scripts to proxy OpenAI API requests and manage LLaMa.cpp instances on demand, expressing interest in the VRAM management aspect of large-model-proxy.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. LLaMA 3 405B Model Release and Implications
- [/r/singularity] Looks like we’re getting LLama3 405B this week (Score: 443, Comments: 113): LLaMA 3 405B model imminent: Meta's AI research team is expected to release the LLaMA 3 405B model this week, according to insider information. This new model is anticipated to be a significant upgrade from its predecessors, potentially rivaling or surpassing the capabilities of GPT-4.
Theme 2. AI in Healthcare: Improving Cancer Detection
- [/r/singularity] GPs use AI to boost cancer detection rates in England by 8% (Score: 203, Comments: 25): AI-assisted cancer detection in England has led to an 8% increase in referrals for suspected cancer. General practitioners using the C the Signs tool have referred 92,000 more patients for urgent cancer checks over a two-year period. This AI system helps doctors identify potential cancer symptoms and determine appropriate next steps, demonstrating the potential of AI to enhance early cancer detection in primary care settings.
Theme 3. LocalLLaMA Advancements and Applications
- [/r/StableDiffusion] On the same day, two people stole my design and app, and posted them as their own. (Score: 259, Comments: 195): Plagiarism strikes AI developer: The creator of a virtual dress try-on Chrome extension using LocalLLaMA reports that two individuals copied their design and application, presenting them as original work on the same day. This incident highlights the ongoing challenges of intellectual property protection in the rapidly evolving field of AI development and application.
- Two individuals allegedly copied OP's virtual dress try-on Chrome extension, sparking debate about intellectual property in AI development. Many users pointed out that similar products already exist, questioning OP's claim to originality.
- Users highlighted that the project, using fal.ai API, could be recreated in 15 minutes with basic inputs and a button. This ease of replication raised questions about the value of simple AI implementations and the need for more robust barriers to entry.
- Discussion centered on the importance of open-sourcing projects and properly crediting ideas. Some argued that ideas cannot be copyrighted, while others emphasized the need to acknowledge inspirations, even for simple implementations.
AI Discord Recap
A summary of Summaries of Summaries
1. LLM Model Releases and Benchmarks
- DeepSeek-V2 Tops Benchmarks: DeepSeek-V2, a 236B parameter MoE model (21B activated per token), is praised for its excellent performance and cost-efficiency at $0.14 per input token, outperforming GPT-4 in some areas like AlignBench and MT-Bench.
- The model's impressive 1-bit quantization results for DeepSeek-V2-Chat-0628 showed optimized CPU performance, ranking #7 globally on LMSYS Arena Hard. Users noted its strong performance in multilingual tasks.
- Llama 3.1 Leak Sparks Excitement: Leaked evaluations for Llama 3.1 suggest its 8B, 70B, and 405B models might outperform current state-of-the-art models, even before instruct tuning, with the 70B model noted as being very close to leading models.
- The leak revealed a 405B model distilled into 8B and 70B versions with 128k context. Community members expressed excitement about potential capabilities, especially after instruct tuning is applied.
2. AI Infrastructure and Optimization
- Elon Musk's Memphis Supercluster Announcement: Elon Musk announced the launch of the Memphis Supercluster, claiming it to be the world's most powerful AI training cluster with 100k liquid-cooled H100s on a single RDMA fabric.
- However, fact-checks revealed discrepancies in power usage and GPU availability, suggesting that the facility is not yet fully operational as claimed.
- Advances in Model Quantization: Discussions highlighted advancements in model quantization techniques, with AQLM and QuaRot aiming to run large language models (LLMs) on individual GPUs while maintaining performance.
- An example shared was the AQLM project successfully running Llama-3-70b on an RTX3090, showcasing significant progress in making large models more accessible on consumer hardware.
3. AI Model Performance and Efficiency
- Implicit CoT boosts GPT-2 performance: Implicit Chain-of-Thought (CoT) internalizes steps by removing intermediate stages and finetuning, enabling GPT-2 Small to solve 9-by-9 multiplication with 99% accuracy.
- This method also enhances Mistral 7B, achieving over 50% accuracy on GSM8K without intermediate steps.
- ReFT shocks with parameter efficiency: ReFT achieves 15x-60x more parameter efficiency than LoRA and fine-tunes models like Llama 2 7B in under a minute on an A10 with ~100 examples.
- Greg Schoeninger discussed its practical applications and challenges, diving deeper in a YouTube video.
- DeepSeek impresses with 1-bit quant results: 1-bit quantization for DeepSeek-V2-Chat-0628 showed impressive CPU optimization, ranking #7 globally on LMSYS Arena Hard (link).
- kotykd queried the model’s coherence and performance changes from previous versions.
4. Knowledge Graphs and Retrieval-Augmented Generation (RAG)
- Triplex cuts KG costs by 98%: Triplex from SciPhi.AI cuts knowledge graph extraction costs by 98%, outperforming GPT-4 at 1/60th the price by using local graph building with SciPhi's R2R.
- R2R supports multimodal data and hybrid search, optimizing knowledge graphs and Microsoft’s method using deeper adjacency matrices for more efficient RAG.
- Deploying RAG app to production: A member shared a tutorial on using MongoDB Atlas with LangChain to build a RAG implementation.
- The tutorial covers setting up the environment, storing data, creating search indices, and running vector search queries.
- Improving RAG via Deasie Workshop: A YouTube session with Deasie cofounders covers advanced parsing and metadata for improved RAG.
- Parsing and metadata enhancements are highlighted as key techniques for boosting RAG performance.
5. Community Contributions and Open-Source Projects
- Nemotron-340B bounty sparks interest: Nathan offered a bounty starting at $75 for converting Nemotron-340B to HuggingFace with FP8 quantization and multi-node implementation.
- The bounty has skyrocketed to over $2,000, with considerable interest from the synthetic data community.
- OpenRouter Provider for GPTScript Now Available: A new OpenRouter provider for GPTScript has been announced, with an image and detailed description on GitHub.
- This tool contributes significantly to the development of GPTScript applications.
- Bud-E presents new demo with open-source goals: A demo of the Bud-E voice assistant was shared, showcasing the vision of a future where everyone has access to highly capable, open-source systems for the cost of electricity.
- The code base currently optimized for Ubuntu will be restructured for clean separation between client, server, and interchangeable ASR, TTS, LLM components.
PART 1: High level Discord summaries
Nous Research AI Discord
- Implicit CoT boosts GPT-2 performance: Implicit Chain-of-Thought (CoT) internalizes steps by removing intermediate stages and finetuning, enabling GPT-2 Small to solve 9-by-9 multiplication with 99% accuracy.
- This method also enhances Mistral 7B, achieving over 50% accuracy on GSM8K without intermediate steps.
- ReFT shocks with parameter efficiency: ReFT achieves 15x-60x more parameter efficiency than LoRA and fine-tunes models like Llama 2 7B in under a minute on an A10 with ~100 examples.
- Greg Schoeninger discussed its practical applications and challenges, diving deeper in a YouTube video.
- DeepSeek impresses with 1-bit quant results: 1-bit quantization for DeepSeek-V2-Chat-0628 showed impressive CPU optimization, ranking #7 globally on LMSYS Arena Hard (link).
- kotykd queried the model’s coherence and performance changes from previous versions.
- Graphs boost RAG performance: Triplex from SciPhi.AI cuts knowledge graph extraction costs by 98%, outperforming GPT-4 at 1/60th the price by using local graph building with SciPhi's R2R.
- R2R supports multimodal data and hybrid search, optimizing knowledge graphs and Microsoft’s method using deeper adjacency matrices for more efficient RAG.
- QuietStar sparks auto-generated prompts: QuietStar inspired a discussion about LLMs generating subsequent prompts in parallel, aiming to enhance their reasoning capabilities dynamically.
- Participants debated adapting LLM architectures for better token-level reasoning through intermediate representations and type systems.
HuggingFace Discord
- Hermes 2.5 outperforms Hermes 2: After adding code instruction examples, Hermes 2.5 appears to perform better than Hermes 2 in various benchmarks.
- Hermes 2 scored a 34.5 on the MMLU benchmark whereas Hermes 2.5 scored 52.3.
- Mistral has struggles expanding beyond 8k: Members stated that Mistral cannot be extended beyond 8k without continued pretraining and this is a known issue.
- They pointed to further work on mergekit and frankenMoE finetuning for the next frontiers in performance.
- Discussion on Model Merging Tactics: A member suggested applying the difference between UltraChat and base Mistral to Mistral-Yarn as a potential merging tactic.
- Others expressed skepticism, but this member remained optimistic, citing successful past attempts at what they termed "cursed model merging".
- Open Empathic Project Plea for Assistance: A member appealed for help in expanding the categories of the Open Empathic project, particularly at the lower end.
- They shared a YouTube video on the Open Empathic Launch & Tutorial that guides users to contribute their preferred movie scenes from YouTube videos, as well as a link to the OpenEmpathic project itself.
- SmolLM Arena Launches: A new project called SmolLM Arena has been launched, allowing users to compare various Small Language Models (<1.7B params).
- The arena features a chatbot interface, runs faster, and includes usage instructions for a smoother user experience.
Modular (Mojo 🔥) Discord
- Mojo 2.0: Socket Implementation: Discussions centered around various socket implementations for Mojo, focusing on platform-specific challenges like Windows sockets.
- Members also highlighted the potential of using Rust’s socket implementation and discussed the importance of accommodating SCTP for future protocols.
- Debate on Dual Stack Sockets: Dual stack sockets were preferred for new server sockets, allowing both IPv4 and IPv6 connections, mirroring Python’s implementation.
- There was a consensus on using
io_uringfor Linux for handling high-performance workloads.
- There was a consensus on using
- Flat Buffers Shine in Community Meeting: The Mojo 🔥 Community Meeting #4 covered topics like Flat Buffers for memory-efficient serialization and updates on Forge Tools.
- Discussions highlighted optimizing data handling and extending the Mojo standard library.
- Newton's Method for Float Literals: A member shared an implementation of Newton’s Method for Float Literals in Mojo, prompting detailed discussions on capturing keywords for numerical equations.
- This led to conversations on closures and solving complex numerical problems within Mojo.
- Mojo GPU: Eyeing the Summer: Former XLA team from Google has joined Mojo, bringing new insights into AI infrastructure development.
- Mojo GPU support is expected to be available this summer, enhancing computational capabilities.
Stability.ai (Stable Diffusion) Discord
- ComfyUI recommended over Forge: Multiple users suggested switching from Forge to ComfyUI for a better experience, citing issues with Forge's functionality and compatibility.
- Users praised ComfyUI for having significantly more tools and features, although noting it has a more complex node-based interface.
- Comparing Forge to Easy Diffusion: A user noted that while Forge is faster than Easy Diffusion, it lacks some features and outputs errors when upscaling.
- Others commented on upscaling issues and resolutions not being handled properly in Forge, suggesting alternatives.
- Using Latent mode for Regional Prompter: Guidance was provided on using Latent mode instead of Attention mode for Regional Prompter to prevent character blending.
- Detailed prompts and clarifications were shared for improving the use of Latent mode with multiple character LoRAs.
- VRAM and GPU compatibility issues: Discussions covered VRAM requirements for stable diffusion and issues with VRAM on GPUs, particularly with AMD cards.
- Solutions included using local installations and cloud GPUs for those with limited home GPU capability.
- Errors with upscaling in Forge: Users encountered 'NoneType' errors when upscaling images with Forge.
- Suggestions included switching to hi-res fix and alternative upscaling tools like real-ESRGAN.
CUDA MODE Discord
- SVD CUDA Implementation Woes: A user inquired about how cusolver/hipSolver performs SVD as most implementations found were just wrappers for closed-source solutions.
- A GitHub repository was referenced for insights, mentioning methods like Gram-Schmidt, Householder reflections, and Givens rotations.
- Building with LLMs: Year in Review: A video and blog post summarized lessons from a year of practitioners working with LLMs, highlighting tactical, operational, and strategic insights.
- The author created a visual TLDR to make the series more accessible, emphasizing the value of watching the video for a better understanding.
- Triton Profiling Tools: Members discussed tools suitable for profiling Triton kernels, specifically for tasks like peak memory usage.
- nsight-compute and nsight-systems were recommended for detailed profiling, with a note that nvprof should be avoided as it has been succeeded by these tools.
- FP16 vs FP32 Performance on A100: Discussions focused on why FP16 performance in A100 is 2x that of FP32, despite the seemingly expected ratio from computational complexity being around 2.8x (Ampere Architecture Whitepaper).
- Members investigated if the performance issue might be I/O-bound rather than computation bound, discussing hardware architecture and overheads.
- CUDA MODE IRL Invites on September 21st: CUDA MODE team members were invited to an IRL event on September 21st in San Francisco, coinciding with PyTorch devcon, including potential talk on llm.c for 20 minutes.
- Logistics and details for the event were shared via Google Document.
LM Studio Discord
- Parsing GGUF file metadata in C#: A user announced the parsing of GGUF file metadata in C#, introducing a console tool designed to report metadata and offer statistics.
- Initially intended as a ShellExtension for file properties, the developer faced registration issues and opted to focus on the console tool.
- Quantization demystified: A detailed explanation on the quantization process (q5, q6, f16) aimed to help fit large models on older hardware.
- Discussions included how q5 is more quantized than q8, with insights on running large models on limited VRAM using devices like a Dell laptop with RTX 3050.
- Hugging Face API disrupts LM Studio search: LM Studio's search functionality broke due to issues with the Hugging Face API, causing numerous troubleshooting attempts by users.
- The issue was eventually resolved, restoring search capabilities within the app.
- Nexusflow launches Athese model: Nexusflow introduced the Athese model, showing impressive results and potentially being the current SOTA for its size.
- The model demonstrates exceptional multilingual performance, making it suitable for users beyond English-speaking communities.
- Creating Discord bot with LM Studio: A developer shared a blog post regarding making a Discord bot with LM Studio.js.
- The post includes a tutorial and source code available on GitHub, detailing necessary modifications for private responses.
Perplexity AI Discord
- Chrome Restart Fixes Pro Image Generation Issue: A user resolved an issue of generating only one image with a Pro subscription by restarting their Chrome browser. Pro users can expect smoother image generation after this fix.
- Community members noted the need for better error handling within the image generation feature to avoid relying on browser restarts.
- GPTs Agents Struggle Post Training: Discussion emerged about GPTs agents being unable to learn from new information after their initial training phase.
- Suggestions to overcome this included incremental updates and community-driven patches for enhanced adaptability.
- Perplexity API Clarifications on Token Billing: Perplexity API now charges for both inbound and outbound tokens, as discussed in a recent thread.
- Users expressed concerns over billing transparency and asked for detailed documentation to better understand these charges.
- YouTube Tests its Conversational AI Features: Perplexity AI covered YouTube's testing of new AI conversational capabilities to assess their efficacy in enhancing user engagement.
- Initial community responses were mixed, with some excited about the potential for better interaction and others skeptical about the AI's conversational depth.
- OpenAI Introduces GPT-4.0 Mini: OpenAI's GPT-4.0 Mini debuted, offering a scaled-down version focused on accessibility without compromising on sophisticated functionalities.
- Early feedback highlighted its impressive balance between compute efficiency and performance, making it suitable for a wider range of applications.
OpenAI Discord
- 4O Mini outshines Sonnet 3.5: 4O Mini can solve complex questions that even the entire Claude family struggles with, showing its superior capabilities.
- This generates excitement among users for the potential of GPT-4o mini to phase out GPT-3.5 and dominate advanced use cases.
- Finetuning multimodal models for coral reef research: A user inquired about finetuning multimodal models to study coral reefs, but another suggested using Azure AI's Custom Vision Service for better accuracy.
- No specific models or datasets were cited, highlighting a need for more tailored recommendations in this area.
- API lacks real-time voice integration: A discussion highlighted that OpenAI’s new voice features are available in ChatGPT but not in the API, generating concerns about functional limitations.
- Members noted the significant latency and quality differences, with opinions leaning towards ChatGPT being more suited for end-user real-time interactions.
- Improving ChatGPT response modifications: A user faced challenges instructing ChatGPT to modify only specific text parts without rewriting entire responses, a common issue among users.
- Suggestions included using the 'Customize ChatGPT' section in settings, and sharing detailed custom instructions for better accuracy.
- ChatGPT Voice vs API Text-to-Speech: Concerns were raised about the latency and quality differences between ChatGPT's new voice feature and the API’s Text-to-Speech endpoint.
- Members suggested potential improvements and alternative solutions but acknowledged the current limitations of the API for real-time application.
OpenRouter (Alex Atallah) Discord
- Rankings Page Slows Due to Migration: The rankings page will be slow to update over the weekend and often present stale data while the migration to new infrastructure occurs.
- Users should expect delays and inaccuracies in rankings during this timeframe.
- OpenRouter Provider for GPTScript Now Available: A new OpenRouter provider for GPTScript has been announced, with an image and detailed description on GitHub.
- This tool contributes significantly to the development of GPTScript applications.
- Dolphin Llama 70B's Performance Issues: Using Dolphin Llama 70B at 0.8-1 temperature led to erratic behavior in a 7k token context chat, producing incoherent content split between code and unrelated output.
- Another member noted similar issues with Euryale 70B's fp8 quantized models, suggesting potential problems stemming from the quantization process.
- DeepSeek's Low Cost and Efficiency: DeepSeek v2, a 236B parameter MoE model (21B activated per token), is praised for its excellent performance and cost-efficiency at $0.14 per input token.
- “DeepSeek’s pricing is very competitive, and it seems to be hugely profitable,” explaining their strategy of using high batch sizes and compression techniques.
- Leaked Information on Llama 3.1 405B: Llama 3.1 405B Base apparently leaked early due to a misstep on HuggingFace, sparking discussions about its extended context capabilities via RoPE scaling.
- Members are excited, anticipating software updates for efficient utilization and eager for the official instruct model release.
Cohere Discord
- Harnessing LLMs for RPG Games: The community showed interest in using LLMs for classifications, JSON, and dialogue generation in RPG projects, with CMD-R emerging as a top choice due to its strict instruction adherence.
- After successful tests, members discussed further enhancements and integration possibilities, expanding AI's role in RPG gameplay.
- Structured Outputs in Cohere API: Cohere announced that Command R and Command R+ can now produce structured outputs in JSON format, enhancing integration and data analysis for downstream applications.
- This new feature is thoroughly documented here and aims to streamline data workflows for developers.
- New Enterprise AI Services from Cohere and Fujitsu: Cohere and Fujitsu formed a strategic partnership to deliver new enterprise AI services in Japan, as detailed in their blog.
- This collaboration targets improved AI service accessibility and performance for various applications, highlighting advancements in the Cohere toolkit.
- Interactive Multiplayer Text Games with Command R+: A member introduced Command R+, a Discord app for creating and playing multiplayer text games, enhancing the social and interactive aspects of gaming communities.
- This app was showcased on Product Hunt, offering unlimited possibilities for engaging community experiences.
- Developer Office Hours 2.0 Launched: Cohere hosted another Developer Office Hours session, discussing new API features, toolkit updates, and recent Cohere For AI research papers.
- The community was invited to join these sessions to discuss updates, share insights, and connect over various initiatives.
Eleuther Discord
- Nemotron-340B bounty sparks interest: Nathan offered a bounty starting at $75 for converting Nemotron-340B to HuggingFace with FP8 quantization and multi-node implementation.
- The bounty has skyrocketed to over $2,000, with considerable interest from the synthetic data community.
- Hypernetworks and the scaling law debate: Hypernetworks face constraints due to scaling laws, needing to be less than O(scaling_law(output_model_compute)(target_error)) to achieve target error.
- Discussion focused on the necessity for the task predicting the neural network being simpler or having a 'nice' scaling law to be effective.
- Feature Contamination and OOD Generalization: A paper on out-of-distribution generalization details that neural networks suffer from feature contamination, affecting generalization.
- Relevant discussions highlighted the significant roles of inductive biases and SGD dynamics in creating a potential unified theory to explain these model failures.
- Scaling Exponents Across Parameterizations and Optimizers: A tweet about scaling exponents discussed findings across optimizers and models, involving over 10,000 models.
- Key insights: O(1/n) LR schedule outperformed mUP, successful hparam transfer across configurations, and a new Adam-atan2 optimizer was proposed to avoid gradient underflow issues.
- MATS 7.0 Applications Open: Neel Nanda and Arthur Conmy have opened applications for their Winter MATS 7.0 streams, with a deadline on August 30th. Announcement and admissions doc provided.
- The MATS program emphasizes its unique contribution to fostering mechanistic interpretability research.
Interconnects (Nathan Lambert) Discord
- Nemotron-4-340B conversion to HuggingFace: Nathan Lambert offers a paid bounty of $75 to convert nvidia/Nemotron-4-340B-Instruct to HuggingFace.
- This effort aims to unlock synthetic permissive data for distillation projects, requiring both FP8 quantization and multi-node implementation.
- Llama-3 and 3.1 leaks spark excitement: Rumors and leaks about Llama-3 405b and Llama 3.1 models, including benchmarks, were widely discussed, referencing Azure's GitHub and Reddit.
- Leaked benchmarks show Llama 3.1 outperforming GPT-4 in several areas, excluding HumanEval, sparking conversation on its potential superiority.
- ICML 2024 celebrates Faithfulness Measurable Models: Andreas Madsen announced their ICML 2024 spotlight on a new approach for interpretability: Faithfulness Measurable Models, claiming 2x-5x better explanations and accurate faithfulness metrics.
- A user pointed out its resemblance to a 2021 NeurIPS paper, emphasizing the need for improved literature reviews in submissions.
- Meta AI's potential premium offerings: Speculation arose that Llama 405B might be part of a premium offering from Meta AI, hinted by snippets of code and a tweet by Testing Catalog.
- The buzz includes the possible Meta AI API platform, AI Studio, with announcements expected on July 23.
- Surprising Effectiveness of UltraChat: Discussion noted that the Zephyr paper significantly filtered UltraChat data from 1.5M to 200k, questioning the data quality.
- Despite the rigorous filtering, UltraChat was surprisingly effective, leading to further inquiries about its generation process.
Latent Space Discord
- Langfuse Outshines Langsmith: Anecdotal feedback from users suggests that Langfuse is performing better than Langsmith, with positive experiences shared about its ease of self-hosting and integration.
- Clemo_._, the founder, encouraged more community interaction, emphasizing their commitment to maintaining a great OSS solution.
- GPT-4o Mini Enables AI-generated Content: OpenAI's new GPT-4o mini model costs $0.15 per 1M input tokens, making it possible to create dynamic AI-generated content supported entirely by ads.
- Discussion includes the potential impact on web content, hypothesizing a shift towards more AI-generated outputs.
- Harvey AI Rumors and Predictions: Rumors and skepticism about Harvey AI's viability emerged, with some calling it a 'smoke and mirrors company'.
- Debates ensued about the challenges facing vertical AI startups, including dependency on big AI labs and the industry's current cycle.
- Elon Musk's Memphis Supercluster: Elon Musk announced the launch of the Memphis Supercluster, claiming it to be the world's most powerful AI training cluster with 100k liquid-cooled H100s on a single RDMA fabric.
- However, fact-checks reveal discrepancies in power usage and GPU availability, suggesting that the facility is not yet fully operational.
- LLaMA 3.1 Leaks Spark Excitement: Leaked evaluations for LLaMA 3.1 suggest that its 8B, 70B, and 405B models might outperform current state-of-the-art models, even before instruct tuning.
- These leaks have led to widespread anticipation and speculation about the future capabilities of open-source AI models.
OpenAccess AI Collective (axolotl) Discord
- Triplex Cuts KG Costs by 98%: SciPhi's new Triplex model slashes knowledge graph creation costs by 98%, outperforming GPT-4 at a fraction of the cost.
- The model extracts triplets from unstructured data and operates locally, making affordable, accessible knowledge graphs a reality.
- Mistral 12b Tokenizer Troubles: Multiple members raised issues with Mistral 12b's tokenizer, which outputs text without spaces despite its promising metrics.
- The outputs were criticized as 'garbage', likely tied to special token handling problems.
- LLaMA 3.1 Benchmarks Impress: Members lauded the benchmarks for LLaMA 3.1, highlighting stellar performances by the 8B and 70B models.
- The 70B model was noted to be particularly very close behind the leading models, even outperforming some expectations.
- DeepSpeed Zero-3 Compatibility Fix: A user solved DeepSpeed Zero-3 compatibility issues involving a ValueError tied to
low_cpu_mem_usage=Trueand customdevice_mapsettings.- The problem was fixed by deleting the accelerate config, resuming error-free setup.
- Axolotl Training Hits GPU Roadblocks: Training errors in Axolotl traced back to GPU memory roadblocks, as noted by Phorm.
- Troubleshooting steps included reducing batch size, adjusting gradient accumulation, and switching to mixed precision training.
LangChain AI Discord
- Hermes 2.5 outperforms Hermes 2: After adding code instruction examples, Hermes 2.5 appears to perform better than Hermes 2 in various benchmarks.
- Hermes 2 scored a 34.5 on the MMLU benchmark whereas Hermes 2.5 scored 52.3.
- Triplex slashes knowledge graph creation costs: The newly open-sourced Triplex by SciPhi.AI reduces knowledge graph creation costs by 98%, outperforming GPT-4 at 1/60th the cost.
- Triplex, a finetuned version of Phi3-3.8B, extracts triplets from unstructured data, enhancing RAG methods like Microsoft's Graph RAG.
- Deploying RAG app to production: A member shared a tutorial on using MongoDB Atlas with LangChain to build a RAG implementation.
- The tutorial covers setting up the environment, storing data, creating search indices, and running vector search queries.
- LangChain beginner-friendly article published: A user shared a Medium article about LangChain and its components, aimed at beginners interested in understanding its applications.
- Imagine having a virtual assistant that can handle complex tasks through simple natural language commands, the article delves into why these components are important.
- AI-powered function builder for TypeScript: A new project called AI Fun was developed at a hackathon to build LLM-powered functions for TypeScript.
- The project leverages AI to automate and simplify TypeScript function building processes.
LAION Discord
- Bud-E presents new demo with open-source goals: A demo of the Bud-E voice assistant was shared, showcasing the vision of a future where everyone has access to highly capable, open-source systems for the cost of electricity.
- The code base currently optimized for Ubuntu will be restructured for clean separation between client, server, and interchangeable ASR, TTS, LLM components.
- Join the BUD-E discord server for collaboration: Volunteers are invited to join the new BUD-E discord server to help develop the voice assistant further and contribute new skills akin to Minecraft Mods.
- Daily Online-Hackathon meetings will occur every day at 9 PM CEST to onboard new volunteers and coordinate project work.
- Switch Back to Epochs for Plotting Loss Curves: A member initially plotted their loss curves with wall-clock time but found it more meaningful to measure model learning efficiency by switching back to epochs.
- The member found WandB useful for this purpose but admitted the initial change was incorrect and a 'foolish' decision.
- Mem0 Introduces Smart Memory Layer for LLMs: Mem0 has released a memory layer for Large Language Models, enabling personalized AI experiences with features like user, session, and AI agent memory, and adaptive personalization.
- For more information on integration and features, view the GitHub page for Mem0.
- Datadog Publishes SOTA Results in Time Series Modeling: Datadog has published state-of-the-art results on time series modeling and is actively recruiting for research roles.
- Datadog's foundation models aim to handle time series data effectively by identifying trends, parsing high-frequency data, and managing high-cardinality data.
LlamaIndex Discord
- PostgresML Boosts Reranking: PostgresML for reranking enhances search result relevancy with additional parameters for precise control.
- A guest blog explains how a managed index approach optimizes reranking in practical applications.
- LLMs as Production Judges: A session with Yixin Hu and Thomas Hulard discussed deploying LLMs as judges in production systems.
- This session covered key concepts and practices behind RAG evaluation for development.
- Merlinn: Open-source On-call Copilot: Merlinn introduces an AI-powered Slack assistant for incident management.
- It integrates with observability and incident management tools like Datadog.
- Multimodal RAG Simplified with Ollama and Qdrant: Pavan Mantha presents an article on setting up multimodal RAG with Ollama and Qdrant.
- The guide includes steps for ingesting audio/video sources and indexing data through text transcription.
- Improving RAG via Deasie Workshop: A YouTube session with Deasie cofounders covers advanced parsing and metadata for improved RAG.
- Parsing and metadata enhancements are highlighted as key techniques for boosting RAG performance.
DSPy Discord
- GPT4o-mini Model Struggles with Verbosity: GPT4o-mini has been reported to be verbose and repetitive, impacting data extraction compared to GPT3.5-turbo.
- This issue causes significant inefficiencies in data pipelines, necessitating better model tuning or alternative approaches.
- DSPy Tracing Release Enhances Workflow: The new DSPy tracing feature is now available, offering efficient tracking of modules, predictions, LMs, and retrievers (documentation here).
- This update is expected to streamline debugging and performance tracking significantly.
- TypedPredictors Compatibility Limited: GPT-4o and Sonnet-3.5 uniquely handle complex pydantic class generation, whereas other models fall short.
- This limitation calls for careful selection of models based on project requirements, especially in handling intricate data structures.
- Joint Optimization in DSPy Yields Big Gains: A new DSPy paper reveals that alternating between prompt optimization and finetuning results in up to 26% performance gains.
- The study validates the efficiency of a dual optimization strategy over single-method approaches (paper link).
- Reliability of DSPy Optimizers Discussed: The BootstrapFewShotWithRandomSearch optimizer is highlighted as a reliable and straightforward starting point.
- Members debated the reliability of various optimizers, pointing out BootstrapFewShotWithRandomSearch for its simplicity and robustness.
tinygrad (George Hotz) Discord
- George Hotz Spurs OpenPilot Insights: George Hotz shared OpenPilot model run analysis focusing on documenting kernel changes and potential slowdowns.
- He mentioned that the task should be accessible for anyone technically inclined but noted that some beginners might overlook initial problem-solving.
- Debate on Bitcast Shapes in Tinygrad: Tyoc213 questioned if the
bitcastfunction in Tinygrad should align with TensorFlow'sbitcast, especially regarding shape differences.- George Hotz and members agreed that syncing Tinygrad with TensorFlow/Torch/Numpy was sensible and Tyoc213 committed to the necessary updates.
- Promising PRs in Tinygrad: George Hotz recognized a pull request by Tyoc213 as highly promising and noteworthy for its thorough testing.
- Tyoc213 appreciated the acknowledgment and revealed plans to align it further with other framework standards.
- Tinygrad Weekly Meeting Highlights: Chenyuy shared the agenda for the Monday meeting, detailing updates on tinybox, hcopt speed recovery, and MCTS search enhancements.
- Discussions also included better search features, conv backward fusing, fast Llama improvements, and various bounties aimed at kernel and driver improvements.
- Debate Over Viability of Tinygrad: Members debated Tinygrad's viability versus PyTorch, with questions on whether to switch now or wait for version 1.0.
- The discussion reflected productivity concerns and was notably fueled by a detailed YouTube implementation tutorial on Shapetrackers.
OpenInterpreter Discord
- First Day Update at Crowdstrike: Vinceflibustier shared a lighthearted update about their first day at Crowdstrike, mentioning they pushed a small update and took the afternoon off.
- The message ended with a peace sign emoji, creating a casual and friendly tone.
- Python Subinterpreters in Python 3.12: A member shared a tutorial on Python subinterpreters detailing enhancements in GIL control and parallelism for Python 3.12 and a preview of changes in 3.13.
- The tutorial discusses changes to CPython's global state, aimed at improving parallel execution and suggests familiarity with Python basics.
- Meta Llama 3.1 Repository Leak: AlpinDale confirmed that Meta Llama 3.1 includes a 405B model distilled into 8B and 70B, with 128k context and noted that the 405B model can't draw unicorns.
- The repository was accidentally made public ahead of time, retaining the same architecture as Llama 3, with the instruct tuning possibly being safety aligned.
- Deepseek Chat v2 6.28 Outperforms Deepseek Coder: A member mentioned that the Deepseek chat v2 6.28 update performs incredibly well, even surpassing the Deepseek coder and being more cost-effective than the 4o mini.
- The update underscores Deepseek chat v2 6.28's improved performance metrics and cost advantages.
- Launch of Pinokio's Augmentoolkit on GitHub: Pinokio's new Augmentoolkit has been released on GitHub for public access, featuring tools to enhance AI applications.
LLM Finetuning (Hamel + Dan) Discord
- Finetuning with GPT models proves costly: Finetuning GPT models is rare due to high costs and vendor lock-in. This involves expensive API calls and dependency on specific company infrastructure.
- A discussion in the #general channel highlighted how these factors deter many from adopting finetuning practices.
- OpenAI credits remain elusive: Issues in receiving OpenAI credits have been reported, with members providing details like organizational ID org-EX3LDPMB5MSmidg3TrlPfirU and multiple form submissions.
- Despite following the process, credits are not being allocated, as detailed in the #openai channel.
- Exploring Openpipe with alternate providers: Inquiries were made on using Openpipe with providers like Replicate or Modal, aside from OpenAI or Anthropic.
- Discussions focused on integrating models from Replicate while ensuring compatibility with existing systems, as seen in the #openpipe channel.
- East Coast Meetup scheduled for late August: A proposition for a late August meetup in New York was made in the #east-coast-usa channel.
- Members are considering the logistics for this informal gathering.
LLM Perf Enthusiasts AI Discord
- OpenAI Scale Tier Confusion: Discussion on the new OpenAI Scale Tier left many puzzled, particularly regarding the throughput per second (TPS) calculations for different models.
- Queries centered around the calculation of 19 TPS on the pay-as-you-go tier in comparison to GPT-4-o's throughput of about 80 TPS.
- Websim seeks Founding AI Engineer: Websim is on a mission to create the world's most adaptable platform for software creation, empowering individuals to solve their own challenges.
- The company is hiring a Founding AI Engineer to establish systems for rapidly iterating on non-deterministic programs targeting automated product development.
Alignment Lab AI Discord
- Insightful Year of Building with LLMs: A user shared a video and blog post summarizing a three-part series on lessons learned by practitioners building with LLMs for a year.
- The summary highlights tactical, operational, and strategic insights, with a recommendation to consume the content via video for better understanding.
- BUD-E Voice Assistant Invites Collaboration: A user shared a YouTube video showcasing a demo of the open-source BUD-E voice assistant, inviting others to join their new Discord server for collaboration.
- Daily online hackathons will begin at 9 PM CEST to onboard new volunteers and coordinate project work.
AI Stack Devs (Yoko Li) Discord
- Artist Aria Calls for Creative Collaboration: Aria introduced themselves as a 2D/3D artist looking for collaboration opportunities in the AI community.
- They invited interested members to direct message them for potential partnership projects.
- No Additional Topics Available: There were no other significant topics discussed or shared in the provided message history.
- This summary reflects the lack of further technical discussions, announcements, or noteworthy events.
MLOps @Chipro Discord
- Clarify Target Audience Needs: A member raised a query regarding the target audience and the main goals behind the communication strategy.
- The discussion brought up the need to craft different approaches for engineers, aspiring engineers, devrels, and solution architects when discussing products.
- Strategic Communication for Roles: Various communication strategies were explored for effectively engaging engineers, devrels, solution architects, and aspiring engineers.
- Participants agreed that each role necessitates uniquely tailored messages to clearly convey product features and benefits.
DiscoResearch Discord
- Lessons from 1 Year of Building with LLMs: Lessons from 1 Year of Building with LLMs detail tactical, operational, and strategic insights from six practitioners.
- A visual TLDR video accompanies the series, making the lessons more digestible.
- TLDR Series Heroic Entry: The TLDR series provides in-depth, actionable advice for those deeply involved with LLMs, as shared by six authors.
- The series is recommended by its authors as a vital resource for LLM practitioners.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!