[AINews] LLaDA: Large Language Diffusion Models
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Chinese AI is all you need?
AI News for 2/14/2025-2/17/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (211 channels, and 11039 messages) for you. Estimated reading time saved (at 200wpm): 1163 minutes. You can now tag @smol_ai for AINews discussions!
There was something today for everyone.
Ahead of the expected Grok 3 release late tonight on a US holiday, today was a notable day of small things. Either:
- the big model releases of the day were the two StepFun models, Step-Video-T2V (30B Text to Video with remarkable coherence, including the famously hard ballerinas that Sora gets wrong) and Step-Audio-Chat, a 132B voice to voice model
- or you could look at Scale AI's EnigmaEval (very hard multimodal puzzles) or Cambridge's ZeroBench (100 manually-curated multi-step visual reasoning questions) evals where current frontier models score 0.
- or you could look at Schulman and Zoph's latest talk on post-training.
But we choose to award today's title story to LLaDA: Large Language Diffusion Models, the first text diffusion model scaled up to be competitive with autoregressive models like Llama 3 8B.

This is a "white whale" alternative LLM architecture that has only been speculated about but never successfully scaled up til now. The main trick is adapting diffusion to predict uniformly masked tokens, producing text in a diffusion process:
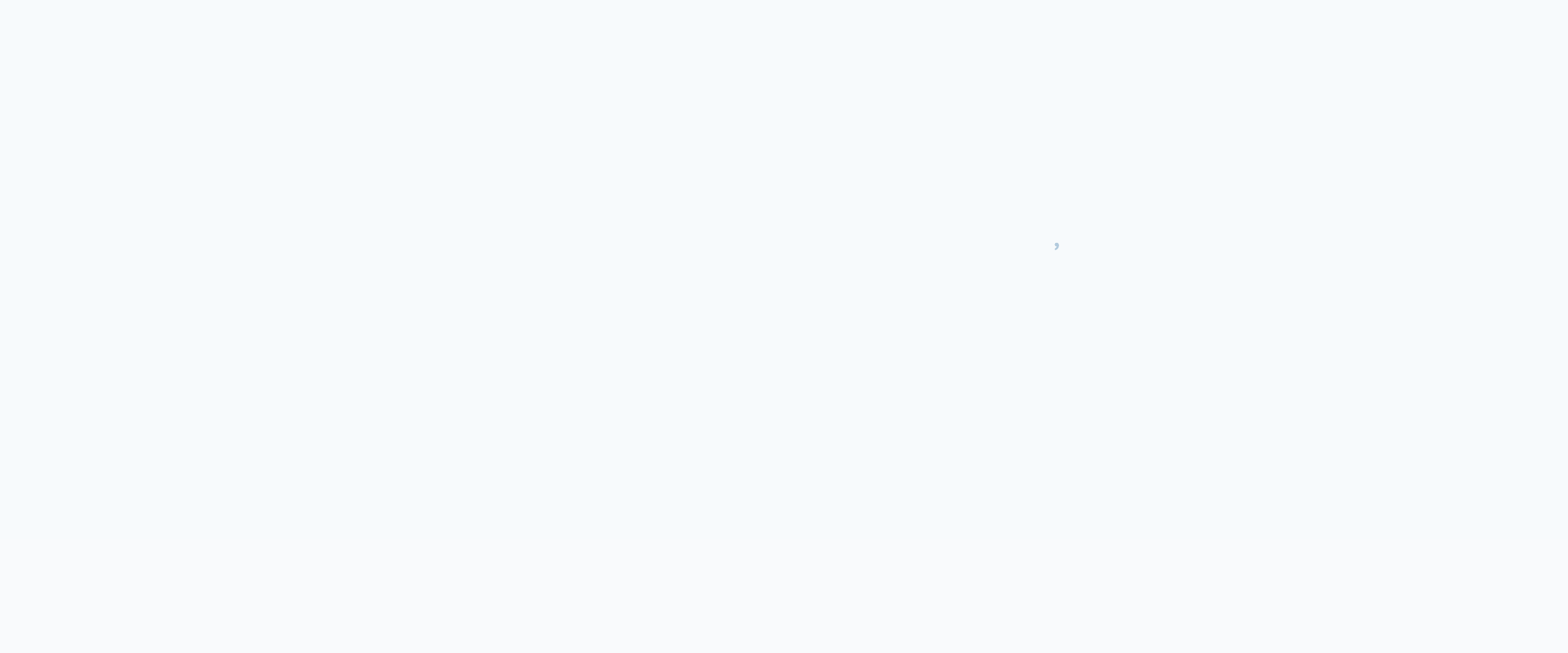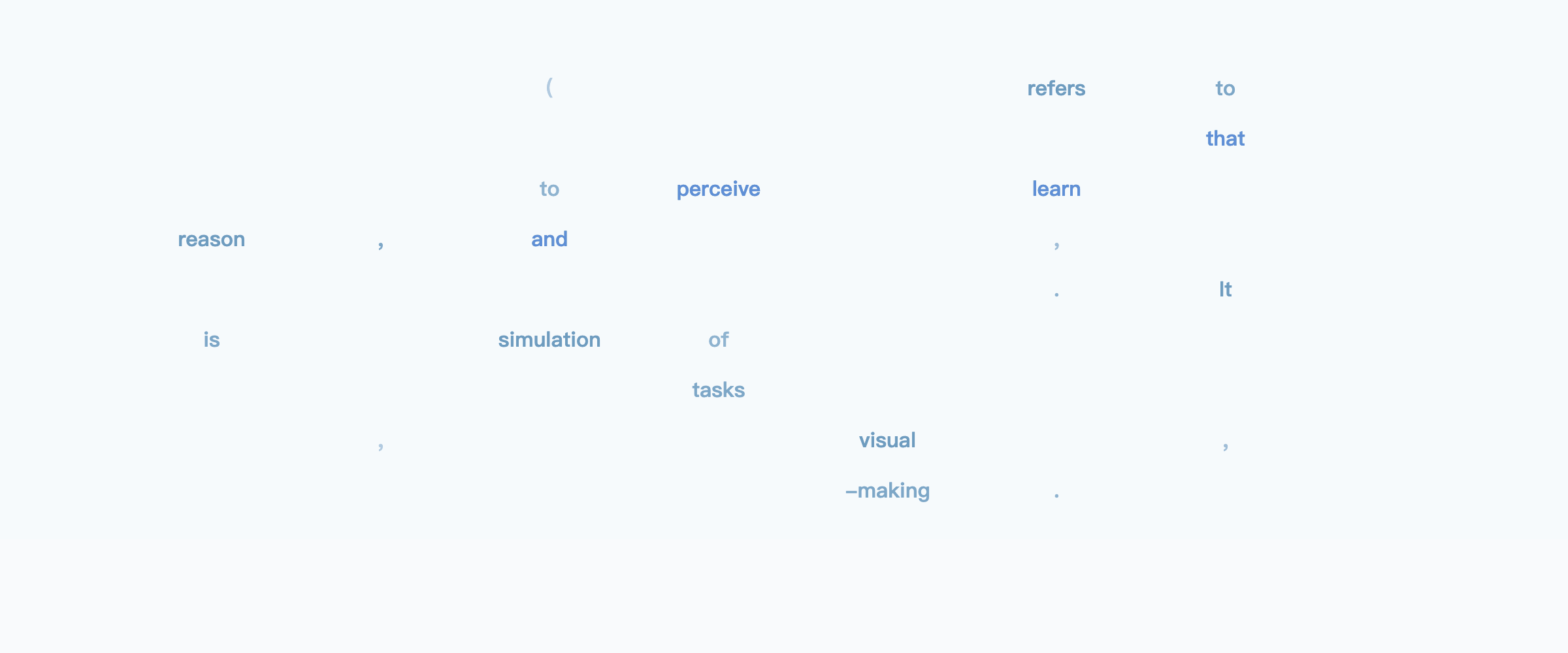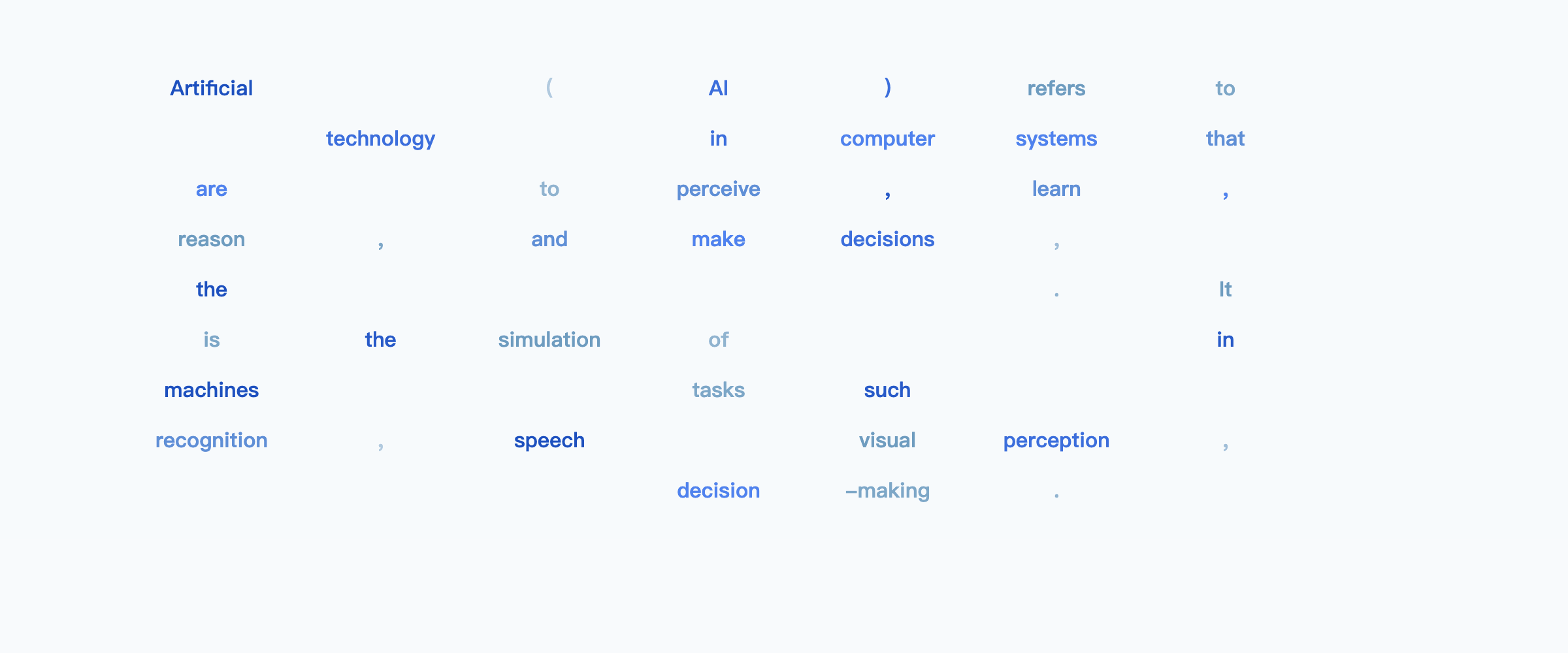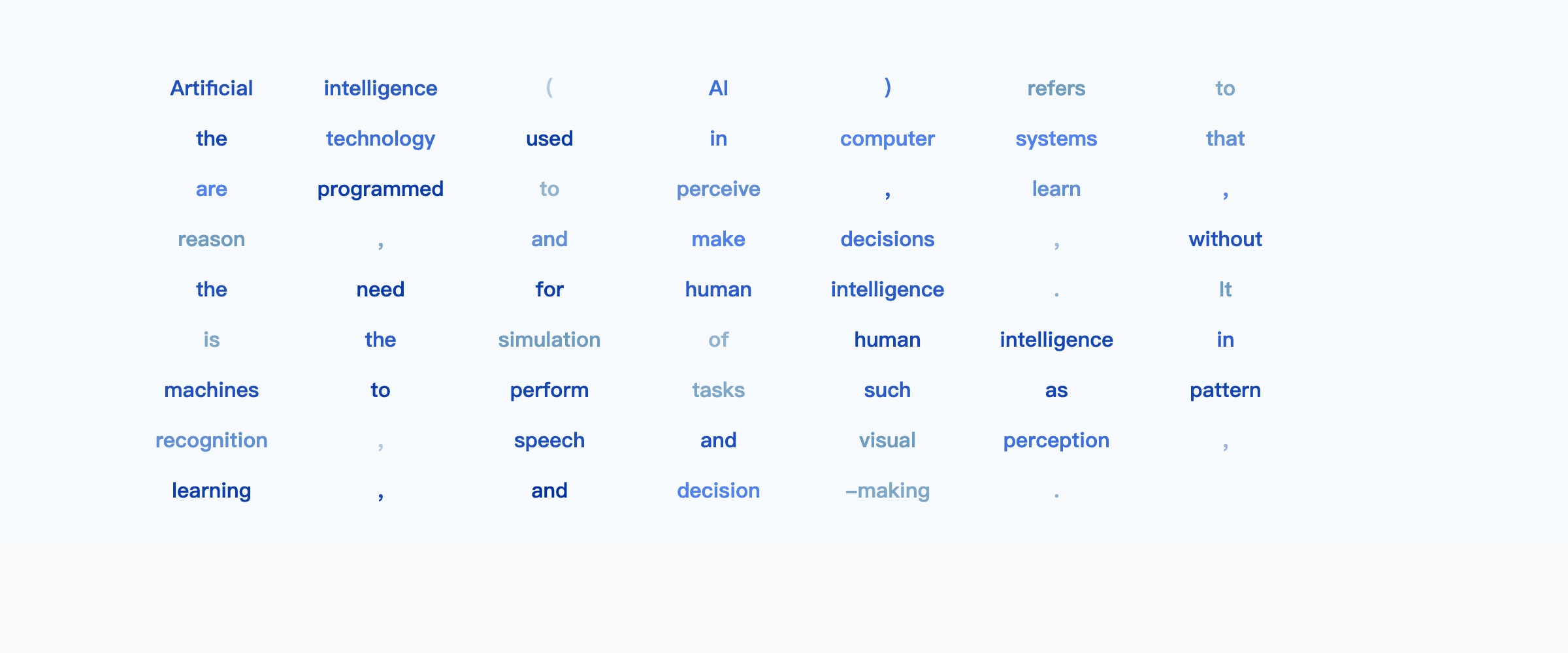
For those used to text streaming in from left to right, diffusion doesn't seem very practical... until you try to infill between preset text structures and word choices that you desire, or create coherent long form story structures. LLaDA could be the start of something much bigger here.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
AI Model & Research Releases
- LLaDA (Large Language Diffusion Model) 8B: @arankomatsuzaki announced the release of LLaDA, an 8B parameter diffusion language model trained from scratch, which rivals LLaMA3 8B in performance but on 7x fewer tokens (2T tokens). @_akhaliq highlighted that LLaDA uses a diffusion model approach for text generation, differing from traditional left-to-right methods. @omarsar0 further detailed LLaDA's characteristics, noting its competitive performance, scalability, breakthrough of the reversal curse, and capability for multi-turn dialogue and instruction-following. @iScienceLuvr emphasized LLaDA-8B surpassing Llama-2 7B and performing on par with Llama-3 8B on standard benchmarks, trained on 2.3 trillion tokens and 0.13 million H800 GPU hours. @gallabytes questioned the "diffusion" aspect, noting the absence of SDE, probability flow, or noise, despite acknowledging its impressiveness as a new approach. @maximelabonne expressed surprise at the comeback of diffusion models in language.
- Step-Video-T2V 30B: @arankomatsuzaki shared the open-source release of Step-Video-T2V, a 30B text-to-video model capable of generating up to 204 frames, highlighting its high quality videos with strong motion dynamics and consistent content. @_akhaliq also discussed the Step-Video-T2V Technical Report, detailing the practice, challenges, and future of video foundation models. @reach_vb announced the release of a 30B text to video model from @StepFun_ai, also mentioning a Turbo model for faster inference and that it's MIT licensed.
- Step-Audio 130B: @_akhaliq announced Step-Audio, a 130 billion parameter multimodal LLM for understanding and generating human speech, and @reach_vb asked "chat, is this for real?" about a 132B parameter end to end Speech LM, describing it as "voice in, voice out 🤯", and noting it is APACHE 2.0 LICENSED.
- Mistral Saba: @sophiamyang announced Mistral Saba, MistralAI's first regional language model with 24B parameters, trained on datasets from the Middle East and South Asia, supporting Arabic and Indian-origin languages, especially Tamil and Malayalam. @sophiamyang noted it is available via API
mistral-saba-2502on la Plateforme and custom training is offered.
Benchmarks & Performance
- LLaDA Performance: @iScienceLuvr noted LLaDA 8B surpasses Llama-2 7B and performs on par with Llama-3 8B on standard zero/few-shot learning tasks. @arankomatsuzaki highlighted LLaDA's performance rivaling LLaMA3 8B despite less training data.
- ZSEval Benchmark: @lateinteraction introduced ZSEval, a new LLM benchmark using multiplayer games to pit models against each other on knowledge, reasoning, and planning, also testing self-improvement capability using DSPy optimization.
- GPQA Score Improvement: @casper_hansen_ questioned why SFT on a dataset with 99.9% math boosts GPQA score from 45.30% to 62.02%, asking if the base model is weak in math or if GPQA Diamond is math-adjacent.
- Arabic Benchmark Performance of Mistral Saba: @sophiamyang mentioned strong performance of Mistral Saba on Arabic benchmarks.
Tools & Libraries
- OmniParser Update: @reach_vb announced Microsoft's silent update to OmniParser, a screen parsing tool, noting it is 60% faster than v1 with sub-second latency on a 4090. @mervenoyann highlighted the improved and faster OmniParser as a groundbreaking screenshot parser for web automation, open-source and pluggable with models like Qwen2.5VL, DeepSeek R1, 4o/o1/o3 mini.
- Ollama Model Downloads: @ollama confirmed seeing downloads of models from Ollama going to major cloud hosts and @ollama confirmed Ollama is written in Go.
- LangGraph.js with MongoDB: @LangChainAI announced a webinar on using MongoDB's data platform with LangGraph.js to build JavaScript AI agents, covering Node.js integration and state persistence.
- Arch AI-Native Proxy: @_akhaliq introduced Arch, an AI-native proxy for agents, built by Envoy contributors, with features like edge guardrails, task routing & function calling, and observability.
China & DeepSeek Focus
- DeepSeek's Rise: @teortaxesTex noted Wenfeng from DeepSeek boosting the Chinese stock market by ~$1.3 trillion, suggesting DeepSeek narrative did what no stimulus could. @teortaxesTex described a CCTV report on Hangzhou tech including DeepSeek, Unitree, DeepRobotics, and Game Science, highlighting the contrast between advanced tech and nostalgic transmission. @teortaxesTex listed DeepSeek along with Tencent, Xiaomi, Huawei, Alibaba as crucial technology leaders represented at a Beijing symposium, with Wenfeng as the sole AI wing representative.
- Wenfeng's Influence: @teortaxesTex stated Wenfeng will inspire generations of Asian autists and @teortaxesTex suggested Wenfeng's boyish looks are appropriate for an anime/manga adaptation, better than Dr. Stone. @teortaxesTex confirmed Liang Wenfeng met Xi Jinping, noting his consistent suit and pose in meetings with Party elites.
- Chinese Tech Symposium: @teortaxesTex analyzed the Beijing symposium as deeply symbolic, noting inclusion of Wenfeng and Xingxing, absence of Baidu and ByteDance, reconciliation with Jack Ma, and the presidency of Wang Huning. @teortaxesTex mentioned Wang Huning, author of Xi Jinping Thought, presiding over the tech symposium.
Perplexity Deep Research & Usage
- Deep Research Launch & Usage: @AravSrinivas stated Deep Research usage on Perplexity is 🚀, accounting for a significant fraction of search qps. @AravSrinivas plugged Perplexity as offering practically unlimited deep research agents. @AravSrinivas demoed Deep Research as a small business incorporation legal consultant, highlighting its accessibility compared to expensive human consultants. @AravSrinivas showcased Perplexity Deep Research as a Product Manager for roadmap planning, envisioning AI employees/interns in companies. @AravSrinivas presented Perplexity Deep Research writing an investment memo like Bill Ackman, using $UBER as an example.
- Deep Research Issues & Improvements: @AravSrinivas acknowledged inaccuracy in financial queries on Perplexity Deep Research, citing examples like old bitcoin prices and company market caps, promising fixes and more trustworthy data sources. @AravSrinivas invited feedback on Deep Research, asking for demo requests and pain points, mentioning potential support for longer reports and academic sources. @hrishioa shared tips for using Deep Research, including chatting before searching for context. @hrishioa provided examples of Deep Research with and without prompt crafting, and using o1pro instead of o3minihigh.
AI & Society, Ethics, and Future
- AI Robotics Breakthrough: @adcock_brett declared this is the breakthrough year for AI Robotics we have been waiting for, stating 10 years ago was too early. @adcock_brett expressed a dream for humanoids to build and fly eVTOLs. @Meta announced Meta's AI can now read minds with 80% accuracy using non-invasive brain activity recordings, highlighting its potential for people with brain lesions and the synergy between neuroscience and AI.
- ASI and Existential Risk: @teortaxesTex asserted "my personal ASI will be giving me as many monsters (AND of the flavor I want) as I decide. anything else is extinction event". @sama mentioned "trying GPT-4.5 has been much more of a 'feel the AGI' moment" among high-taste testers. @teortaxesTex quipped about an "ASI Hail Mary" saving a crashing empire.
- AI in Law & Services: @finbarrtimbers suggested if Harvey (AI law firm) is the future of law, the natural conclusion is to launch their own law firm and dominate the vertical. @finbarrtimbers expressed bearishness on service companies like law firms increasing margins like software companies. @andersonbcdefg stated it is "impossible* to make a law firm that is also a tech company that rewards non-lawyers with equity" due to ownership rules.
- Bias and Viewpoints in LLMs: @fabianstelzer argued LLMs are media publishers and will have viewpoints, seeing bias as a feature, not a bug, and predicting emergence of "FOX news & a NYT model".
- AI Safety & Ethics: @mmitchell_ai noted interest in their paper advocating "Fully Autonomous AI Agents Should Not Be Developed". @teortaxesTex identified "Safetyism" as one of three Great Filter events on the road to mature humanity.
- Future of AI Development: @omarsar0 predicted we will stop caring about the specific models powering AI systems, with product or dev experience becoming the winning factor. @ClementDelangue called for a return to a more open, transparent & collaborative AI, reminiscent of 2016-2020.
Humor/Memes
- Grok 3 Hype: @aidan_mclau made a dark humor joke: "a man died to tell us how good grok 3 really is never forget", reaching over a million impressions. @marktenenholtz encouraged hype for Grok 3 release, anticipating what a "cracked team can ship with a significantly bigger cluster than GPT-4". @teortaxesTex commented "small if true with 60k GPUs I can see Grok 3 actually failing to secure primacy even for a day".
- ChatGPT-4o Coding Prowess: @_akhaliq shared impressive code generated by ChatGPT-4o for a bouncing balls simulation, and @_akhaliq showcased another ChatGPT-4o code for a rotating ASCII sphere, contrasting it with an original test by @flavioAd. @mckbrando simply stated "i have no idea what we did but the new chatgpt is like cool now".
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Zonos: Open Weight Voice Cloning Model
- Zonos, the easy to use, 1.6B, open weight, text-to-speech model that creates new speech or clones voices from 10 second clips (Score: 330, Comments: 80): Zonos is a 1.6B parameter open-weight text-to-speech model that can generate new speech or clone voices from clips as short as 10 seconds. It runs efficiently on 8GB VRAM and is easy to set up on Linux using Docker, with a Windows-friendly fork available, although not vouched for by the author. The model and its hybrid version are available on Hugging Face, and the author recommends using Ocenaudio for editing voice samples.
- Users discuss the technical setup of Zonos, including using Docker on both Linux and Windows, and the necessity of WSL2 for Windows users to enable Docker with the Nvidia Container Toolkit. Some users report issues with docker-compose.yml and needing to adjust network_mode and ports for proper operation.
- There is debate over the performance and quality of Zonos compared to ElevenLabs, with some users finding Zonos less natural and expressive, while others appreciate its cost-effectiveness and potential for voice cloning. Users note that espeak is used for phonemization, which may affect performance in non-English languages.
- Discussions highlight the limitations and potential improvements of Zonos, such as the 30-second output cap and the need for better emphasis and emotion control in generated speech. The community is anticipating future updates and improvements, with some users expressing interest in using Zonos for applications like sillytavern and comparing it to other models like Kokoro and Fairseq.
Theme 2. OpenArc Python API Enhances Intel Inference
- Today I am launching OpenArc, a python serving API for faster inference on Intel CPUs, GPUs and NPUs. Low level, minimal dependencies and comes with the first GUI tools for model conversion. (Score: 279, Comments: 44): OpenArc is a newly launched lightweight inference engine designed to leverage Intel hardware acceleration using Optimum-Intel from Transformers. It features a strongly typed API with four endpoints, native chat templates, and a pydantic model for maintaining exposed parameters. Aimed at owners of Intel accelerators and edge devices, OpenArc offers a low-level approach to context management and promotes API call design patterns for interfacing with LLMs locally. Future updates include an OpenAI proxy, docker compose examples, and support for multi-GPU execution.
- Vendor Lock-In Concerns: Users expressed concerns about vendor lock-in, emphasizing the importance of being able to run models on diverse hardware such as Apple, Intel, Nvidia, and AMD. The ability to operate LLMs without GPU dependency would facilitate local execution, breaking the Nvidia dominance in the market.
- Performance and Compatibility: There is interest in how OpenVINO performs compared to llama.cpp, with discussions highlighting that OpenVINO uses a unique graph representation for quantization, which is not directly comparable to llama.cpp. Anecdotal evidence suggests OpenVINO is faster at higher precisions, and efforts are underway to benchmark its performance with newer models.
- Community and Collaboration: Several users praised the project and expressed interest in future updates, particularly the Docker compose examples for testing on low-cost Intel VPS. There is also a call for collaboration, especially from those working on similar projects targeting Intel platforms, with one user specifically mentioning work on multi-system model hosting and distributed fine-tuning.
Theme 3. DeepSeek-R1: MoE Model CPU Performances
- DeepSeek-R1 CPU-only performances (671B , Unsloth 2.51bit, UD-Q2_K_XL) (Score: 120, Comments: 59): DeepSeek-R1, a 671B model, shows promising CPU-only inference performance due to its MoE nature, with tests conducted on various CPUs like Xeon w5-3435X and TR pro 5955wx. Using Unsloth's 2.51-bit quantization yields better quality and speed compared to 1.58-bit, achieving 4.86 tok/s on the Xeon w5-3435X. kTransformer offers a nearly 2x performance gain by using a mix of CPU and GPU, although it limits context length by VRAM. The author is seeking additional CPU performance data and notes that STREAM benchmark results were lower than expected, with updates planned for kTransformer v0.3 and prompt processing rates.
- Performance Comparisons: Users are discussing the performance of various CPUs, including Xeon w5-3435X, Epyc Rome, and Threadripper 5965wx, with a focus on memory bandwidth and the impact of CCDs. Xeon Sapphire Rapids shows lower than expected real bandwidth, while Epyc Rome offers good value with DDR4 memory, achieving ~160GB/s on STREAM.
- Optimization Techniques: Suggestions for optimizing speed include experimenting with thread counts, avoiding KV cache quantization, and using flags like
--no-mmap --mlockto improve prompt ingestion speeds. CheatCodesOfLife provides detailed performance comparisons for different cache types and quantization settings. - Quantization and Speed: The 2.51-bit quantization method by Unsloth is highlighted for its superior performance over 1.58-bit, and users report varying speeds with different setups. Notably, thereisonlythedance mentions achieving 6 tokens per second with a partial offload, while others note the effects of hardware upgrades on performance improvements.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. Nvidia GPUs: Compute Doubling in 10 Months Raises Questions
- Nvidia compute is doubling every 10 months (Score: 481, Comments: 37): NVIDIA's compute power is projected to double every 10 months, as illustrated by a graph showing exponential growth in FLOP/s from 2020 to 2024 across GPU generations: Hopper, Ampere, Volta, and Pascal. The data indicates a projected growth rate of 2.3x per year, with a confidence interval between 2.2 and 2.5x.
- Users questioned the accuracy of NVIDIA's compute power projections, suggesting that the figures may involve comparing different precision levels (e.g., FP16 to FP8), which can exaggerate perceived performance gains. There was curiosity about the specific types of FLOPS being referenced, with assumptions leaning towards Tensor FLOPS likely in FP16.
- Discussions compared the growth rate to Moore's Law, noting that while Moore's Law pertains to transistor counts, NVIDIA's projections encompass both performance and production scale. Users highlighted that the chart reflects total installed power, not just the power of individual GPUs, which can be misleading if production quantities increase.
- There was skepticism about whether the growth rate would outstrip demand, with comments indicating that demand for compute is growing even faster than supply. Users inquired about the status of Blackwell GPUs and their potential to sustain this growth, reflecting on the need for more compute in areas like video processing.
Theme 2. Advances in Video-to-Video AI: Hunyuan's Harry Potter Anime
- Harry Potter Anime 2024 - Hunyuan Video to Video (Score: 683, Comments: 69): The post mentions the Harry Potter Anime 2024 transformation utilizing the Hunyuan Video-to-Video model. However, no further details or context are provided in the post body.
- Users expressed interest in the workflow and rendering details, with requests for information on GPU usage and the time taken for rendering. Inner-Reflections shared a link to a Lora model and mentioned the potential of controlnets to improve results.
- Concerns were raised about consistency and character design, noting issues like Ron’s hair color and lack of facial expressions. DaddyKiwwi and FourtyMichaelMichael discussed the challenge of maintaining style consistency, possibly due to rendering limitations.
- Neither_Sir5514 and others highlighted a preference for 2D art styles with lower frame rates, contrasting with the less appealing 2.5D Pixar-like styles. Liquidphantom added that anime typically runs at 12fps for action and 8fps for dialogue, emphasizing the suitability of this technology for animation.
Theme 3. Open-Source Video Model Step-Video-T2V: High Demand, High Innovation
- New Open-Source Video Model: Step-Video-T2V (Score: 330, Comments: 63): The post introduces Step-Video-T2V, a new open-source video model. No additional details or context were provided in the post body.
- VRAM Requirements and Optimization: The Step-Video-T2V model requires 80GB of VRAM for optimal performance, but discussions suggest that with quantization and optimizations, it might run on 24GB of VRAM. Integration into the Diffusers library is anticipated to enhance optimization capabilities.
- Technical Details and Resources: The model is described as having 30 billion parameters with a deep compression VAE achieving 16x16 spatial and 8x temporal compression ratios. Resources such as the code and weights are available on GitHub and Hugging Face.
- VRAM Innovations: A linked article discusses SanDisk's new HBF memory that could enable up to 4TB of VRAM on GPUs, which might be beneficial for read-heavy tasks but less so for training due to higher latency compared to HBM. There's speculation about a mixed HBF/HBM architecture for GPUs to balance computation and storage needs.
Theme 4. AI Agent Apply Hero: Mass Job Applications and its Impact
- AI Agent Apply Hero has done over 1.6M Job Applications (Score: 301, Comments: 30): AI Agent Apply Hero has submitted over 1.6 million job applications using Claude to power their models, demonstrating significant advancements in AI capabilities. The Reddit post highlights the rapid progress and potential of AI technologies in the coming years.
- Commenters expressed skepticism about the effectiveness of AI Agent Apply Hero, suggesting it creates unnecessary noise and questioning its success rate in securing jobs. Deep_Area_3790 and DaShibaDoge highlighted concerns about the impact on the job application process and the actual outcomes of the 1.6 million applications.
- Some users, like EngineeringSmooth398 and Halbaras, criticized companies for the cumbersome job application processes, arguing that AI tools might highlight the redundancy and inefficiency of current systems. literum suggested a potential future where AI could manage job applications more efficiently, similar to how companies use AI for resume reviews.
- Funny_Ad_3472 humorously pointed out the disconnect between automated applications and the human element, noting the oddity of being called for interviews for jobs one doesn't remember applying to due to AI automation.
Theme 5. AI Image Restoration: Upscaling the Windows XP Bliss Wallpaper
- Iconic Windows XP Bliss Wallpaper from 800x600 to 8K (7680x4320) - Outpaint and Upscale with Flux Dev (Score: 170, Comments: 22): Iconic Windows XP 'Bliss' Wallpaper has been upscaled from 800x600 resolution to 8K (7680x4320) using AI tools such as Flux Dev. This showcases the application of AI in enhancing classic digital imagery.
- Discussions highlight the original location of the 'Bliss' image and note that many high-quality images of the site already exist, questioning the necessity of AI upscaling. External_Waltz_8927 and others critique the AI-generated 8K image for its lack of detail, suggesting that improper settings, such as excessive denoising, may degrade image quality.
- LatentSpacer shares a detailed workflow for image upscaling using AI, including a link to the process and emphasizes the importance of adjusting settings like denoising and tile size. The final image is shared here, with minor retouching done in Photopea to remove artifacts.
- The conversation also references an archived high-resolution original of the 'Bliss' image available in PNG format at archive.org. There is a discussion on the original photo's camera, the Mamiya RB67, and its large negative format, which offers considerable detail, suggesting its use in AI prompts for better quality outputs.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. Grok 3 Ignites AI Debate: Musk's Claims Meet Community Skepticism
- Musk Hypes Grok 3 as "Smartest AI on Earth": Elon Musk teased the upcoming release of Grok 3, proclaiming it 'the smartest AI on Earth' and scheduling a live demo, creating a buzz but also skepticism among users about its practical utility and potential biases. Concerns arose about Grok 3 being overly tailored for cultural preferences rather than genuine intelligence, as the OpenAI board firmly rejected Musk's $97.4 billion bid to control the company, stating “OpenAI is not for sale.” (Bloomberg Report)
- Users Speculate Grok 3's Capabilities: Enthusiasts are eagerly awaiting Grok 3, with one user optimistically stating, 'if Grok 3 is 10x better, it's game over', while referencing a tweet from Sam Altman teasing improvements to ChatGPT-4o. However, some express concern about Grok potentially becoming a propaganda tool depending on its programming, and anticipate evaluating its performance against existing AI models like O1.
- Grok's Potential Political Leanings Spark Concern: Users voiced apprehension that Grok, backed by Elon Musk, might exhibit biases reflecting his political views, emphasizing the need for balanced censorship in AI and the avoidance of political narratives. Discussions centered on whether AI should influence political opinions, with hopes for Grok 3 to perform well technically, yet worries it could become a propaganda instrument.
Theme 2. DeepSeek Models Drive Performance and Ethical Discussions
- DeepSeek R1 Races to Reasoning Crown: Users are comparing DeepSeek R1 favorably against O3 Mini High, finding R1 superior for reasoning tasks, noting a tweet from Nebius AI Studio touting DeepSeek R1's performance endpoint reaching 60+ tokens/second. While R1 excels in reasoning, O3 Mini High is noted for consistency across scenarios.
- DeepSeek R1's Reasoning Tokens Raise Questions on OpenRouter: Users on OpenRouter observed irregularities with the free DeepSeek R1 model, where reasoning tokens appeared unexpectedly in the response content instead of separate fields. The OpenRouter team is addressing these issues to refine the behavior of open-source reasoning models, referencing DeepSeek's GitHub for usage guidelines.
- DeepSeek Debated as Potential CCP Project: The LM Studio community engaged in light debate about whether DeepSeek is a CCP project, discussing its funding and rapid AI advancements. Speculation arose that the fast pace of AI development might lead to unforeseen breakthroughs, and some users expressed concerns about potential censorship in DeepSeek influenced by training data and web interface settings, as reported by Aider users.
Theme 3. Llama 3.2 Challenges VRAM Limits and Sparks Quantization Solutions
- Llama 3.2 Gobbles VRAM: Hugging Face users are grappling with Llama 3.2 models requiring 20GB VRAM for local use, prompting exploration of quantization techniques like EasyQZ to run larger models on GPUs with limited VRAM. Performance benchmarks are shared, with a 9B model surprisingly outperforming much larger models.
- Unsloth Optimizes Llama 3.2 Fine-tuning: Unsloth AI highlights its ability to fine-tune Llama 3.2 with extended context lengths up to 32k tokens, demonstrating a significant advancement in handling longer sequences. They also fixed bugs in Phi-4, and offer tutorials for fine-tuning Llama 3.2 and Phi-4 (Unsloth Blog, Unsloth Blog Phi-4, YouTube Tutorial).
- Torchtune Community Enhances Llama 3.3 Tokenizer: The Torchtune community reached consensus on adding a 'tool' option to the Llama3 tokenizer to ensure backward compatibility with 'ipython', showcasing collaborative improvements. This update reflects ongoing efforts to refine and adapt models for diverse applications and maintain compatibility.
Theme 4. RAG vs Fine-tuning Debate Intensifies: Efficiency and Application Focus Emerge
- Fine-tuning Dominates RAG for Performance: Unsloth AI Discord members found fine-tuning significantly outperforms RAG when sufficient training data is available, leading to superior performance in LLM applications. One member suggested that RAG may become niche, with fine-tuning becoming the dominant approach for most use cases.
- RAG Faces Repomap Roadblocks in Large Codebases: Aider users discussed the inefficiencies of RAG and Repomap in large repositories, observing diminishing returns as codebase size increases, with suggestions for hybrid scoring using BM25 and RAG to improve search. A blog post about RAG for codebases with 10k repos was referenced, outlining methods to bridge LLMs' context gaps.
- Perplexity Deep Research Challenges Traditional Search: Perplexity AI launched Deep Research, a feature for in-depth research reports via multiple searches and source analysis, offering 5 queries per day for free users and 500 for Pro users. User critique highlights limitations and occasional hallucinations compared to OpenAI offerings, yet hopes remain for future improvements (Perplexity Blog).
Theme 5. Community-Driven Tooling and Optimization Efforts Advance AI Development
- Unsloth's Hiring Challenges Seek Deep Learning Problem Solvers: Unsloth AI launched five challenges offering salaries up to $500K/year for experts in deep learning optimizations, seeking community contributions in areas like Griffin and FSDP2. This initiative aims to accelerate advancements in critical technical domains through open community engagement.
- OpenRouter Charts Real-Time Data and Tooltip Extension Debuts: OpenRouter enhanced its throughput and latency charts with real-time updates via Google AI's Vertex (OpenRouter Announcement), and introduced the Versatile AI Tooltip Chrome extension for quick text processing using OpenRouter models. The extension focuses on efficient summarization and translation (Chrome Web Store).
- Cursor IDE Users Innovate with MCP Server Setups: Cursor IDE users are actively sharing innovative MCP server setups, including Brave Search and Sequential Thinking, detailed in this YouTube video, to enhance coding workflows and documentation. These setups are reported to improve coding process reliability significantly.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Unsloth Announces Hiring Challenges: Unsloth has announced five challenges offering salaries up to $500K/year for problem-solvers in deep learning optimizations.
- The company seeks community contributions for advancements in Griffin, FSDP2, and other technical areas.
- Users Skeptical about AI Agents: Discussions arose about the definition of AI agents, with some suggesting they are merely well-crafted prompts rather than groundbreaking tech.
- Members expressed concerns about the hype surrounding AI agents, stressing the importance of practicality over marketing language.
- CUDA OOM Errors Plague Users: Members discussed experiencing CUDA out-of-memory (OOM) errors mid-training, potentially due to data imbalance.
- Despite using similar settings, even data variance can lead to spikes in VRAM load, complicating resolution efforts.
- Fine Tuning Beats RAG in Performance: Members found that fine tuning can significantly outperform RAG with sufficient training data, improving overall performance in LLM applications.
- One member suggested that RAG may be delegated to niche uses, fine tuning will continue to predominate.
- SCION Optimizer Proposed: A new optimizer, SCION, was suggested, which could potentially train large neural networks without using Adam, requiring less memory while improving results.
- This sparked discussions about the practical applications of SCION in model training while efficiently managing computational resources.
Perplexity AI Discord
- Perplexity's Deep Research Unveiled: Perplexity AI launched Deep Research, a feature enabling in-depth research reports via multiple searches and source analysis, capped at 5 queries per day for non-subscribers, and 500 for Pro users.
- Deep Research is accessible on the Web and will soon be available on iOS, Android, and Mac, receiving high marks on expert-level tasks like Humanity’s Last Exam, as outlined in the official blog.
- Users Critique Deep Research Limitations: Users are drawing comparisons between Perplexity Pro and You.com, noting that Deep Research is limited and occasionally hallucinates responses, leading some to consider alternatives with more accessible pricing.
- Despite concerns and unfavorable comparisons to OpenAI's offerings as expressed on the subreddit, members remain hopeful about future improvements to Perplexity’s features.
- Sonar API's Missing Citations Exposed: Members report that the Sonar API fails to return citations as expected, despite references appearing in the output, sparking confusion about its functionality.
- A user clarified that citations are separate and require correct access, as explained in the Perplexity documentation.
- DeepSeek's Impact Sparks Debate: Members are exploring the potential impact of DeepSeek on AI methodologies, recognizing its ability to reshape current practices, as described on the Perplexity AI page.
- While some emphasize benefits in AI depth, others are wary of integration difficulties.
- Ethereum's Spectra Upgrade Highlighted: The community shared and discussed the recent Ethereum Spectra upgrade, noting its key changes and enhancements to the network's architecture.
- Conversations centered around the potential effects on decentralized applications (dApps) and the broader Ethereum ecosystem, which were summarized on Perplexity AI's page.
HuggingFace Discord
- HF Users Grapple With Llama 3.2's VRAM Demand: Hugging Face users are discussing local model usage, noting that the Llama 3.2 model requires 20GB VRAM, with exploration into quantization options like EasyQZ to fit larger models on GPUs with lower VRAM.
- Performance metrics for various models are being exchanged, showcasing the impressive capabilities of a 9B model that's outperforming models much larger in size.
- Science News Bot Joins the Fray: The Science News Bot launched on GitHub, ready to deliver the latest in scientific advancements and research.
- The team behind Mini PyTorch has released a lightweight alternative for PyTorch enthusiasts and developers, available on GitHub.
- MultiLingual NER Model Shows Promise: The GLiNER-MoE-MultiLingual model, a zero-shot Named Entity Recognition (NER) model, showcases advanced NER capabilities, trained for one epoch using the NOMIC-MOE architecture and is accessible here.
- Optimized SwarmFormer now features local windowed attention and token-to-cluster gating, enhancing computational efficiency for mobile and edge environments.
- Differential Privacy Gains Traction!: A member launched a blog series dedicated to Differential Privacy, starting with an introductory post titled Differential Privacy!! But Why? available here.
- The series emphasizes the critical balance between extracting insights from data and protecting individual privacy in various contexts.
- HF Course Participants Await New Units: Participants in the Hugging Face Agents Course celebrated completing Unit 1 and receiving certificates, while new learners sought guidance on accessing course materials via the official Hugging Face page.
- Community members are proposing the formation of study groups, and bonus materials plus subsequent units are expected to be released periodically.
Codeium (Windsurf) Discord
- Windsurf Surfs Up with Patch 1.3.4: The Windsurf 1.3.4 patch is out, squashing bugs in Cascade write tools and fixing message cancellation issues. Details can be found in the changelog.
- Key fixes include better Cascade Base credit handling and clearer auth login error messages.
- Model Context Protocol Gets Cascade Support: Cascade now supports the Model Context Protocol (MCP), enabling tool calls to configured MCP servers which should get setup using the hammer icon.
- This feature is available to all individual plans, with each MCP tool call costing one flow act.
- JetBrains Extension Users Holding Breath: Users want updates to the JetBrains extension, especially to refresh the model list for tools like DeepSeek and Gemini 2.0 Flash.
- A dev responded by saying updates are incoming, highlighting ongoing maintenance for Codeium extensions due to enterprise user needs.
- Windsurf Waves Frustration on Codeium Extension: Users are salty that Windsurf has overshadowed the original Codeium extension, lamenting the lack of feature parity.
- Some users are so frustrated they are looking at alternatives like Qodo.
- Cascade's Auto-Save: Accidental Savior or Sinister Saboteur?: Reports show Cascade auto-applies changes without asking, creating confusion about code edits.
- The suggested workaround is starting new conversation histories to dodge auto-suggestions.
LM Studio Discord
- Qwen MLX Model Causes Headaches: Users reported a
ModuleNotFoundErrorwhen loading the Qwen MLX model on Macbook Ultra, suggesting updates tomlx-engine/0.6.0might help.- Despite attempts to fix the problem, including removing specific directories, the issue persisted even with the latest version.
- RX580 Performance Falters: The RX580 GPU faces limitations when running LLMs, with recommendations leaning towards newer models boasting ROCm support for improved performance.
- Users are encouraged to use cloud services such as vast.ai to evaluate the performance of GPU models without significant upfront investments.
- DeepSeek labeled as CCP project: The community lightly debated whether DeepSeek is a CCP project, and its funding amid rapid advancements in AI tech.
- The group speculated that the pace of AI advancements may lead to unexpected breakthroughs.
- API Key Woes Plague Local Server Users: Users expressed frustration with the local server API requiring an OpenAI API key in LM Studio.
- Chat participants suggested code modifications to efficiently bypass API key requirements for local setups.
- 4060 Ti Crushes It: The RTX 4060 Ti stands out for its efficient handling of AI models, particularly regarding tokens per second.
- Comparisons reveal that the RTX 3090 also performs admirably, especially for running larger models.
aider (Paul Gauthier) Discord
- Grok 3 Hype Builds: Enthusiasts anticipate the upcoming release of Grok 3, with speculation about its capabilities and performance improvements; there are reports of early access to Grok 3, including a voice mode called Ara.
- One user speculated about the potential improvements, stating, 'if Grok 3 is 10x better, it's game over', while referencing a tweet from Sam Altman teasing improvements to ChatGPT-4o.
- R1 Battles O3 Mini High for Reasoning Crown: Users are weighing DeepSeek R1 and O3 Mini High, finding R1 preferable for reasoning capabilities; the discussion mentioned a tweet from Nebius AI Studio touting DeepSeek R1's performance endpoint reaching 60+ tokens/second.
- Feedback indicates that while R1 excels in certain reasoning tasks, O3 Mini High offers more consistency across various scenarios.
- RAG Faces Repomap Roadblocks: Participants are grappling with inefficiencies of RAG and Repomap in expansive repositories, observing diminishing returns as the codebase swells; one suggestion involved hybrid scoring using BM25 and RAG to boost search results.
- Discussion touched on a blog post about RAG for codebases with 10k repos, outlining methods to bridge LLMs' context gaps.
- Gemini Flash 2.0 Surprises with Speed: Anecdotal evidence indicates that Gemini Flash 2.0 delivers faster, cost-effective solutions with surprisingly robust reasoning and math skills compared to Sonnet.
- This revelation ignited comparisons and discussions among users evaluating different AI models for performance and efficiency.
- Aider Hit with Pesky Bugs: Following recent updates, Aider users are reporting bugs, specifically command parsing snags and
.dockerfilehandling hiccups.- The community also voiced concerns about potential censorship in DeepSeek, influenced by training data and web interface settings.
OpenAI Discord
- Grok's Potential Political Slant Sparks Debate: Users voiced concerns that Grok, backed by Elon Musk, might exhibit biases reflecting his political views and actions on Twitter, emphasizing the necessity of reasonable censorship in AI and the avoidance of political narratives.
- The discussions touched on whether AI should influence political opinions, with some hoping Grok 3 would perform well against existing AI while others worried it could become a propaganda tool depending on its programming.
- AI-Generated Code Raises Security Alarms: Users highlighted the risks of relying on AI-generated code due to potential security vulnerabilities like unsafe string concatenation, stressing the importance of critical code review by developers.
- The discussion emphasized that poor coding practices from AI could introduce vulnerabilities into applications if not thoroughly vetted by human experts.
- GPT Store Action Requires Privacy Policy: A member reported encountering an error stating 'Public actions require valid privacy policy URLs' when attempting to publish in the GPT Store.
- Another member suggested that filling in the privacy policy field in actions could resolve this issue.
- Multi-Agent Systems Circumvent Token Limits: Members discussed the limitations of token output streams in AI interactions, sharing frustration and experiences about how it affects their projects.
- It was suggested that using multi-agent setups could help sidestep token limitations when generating longer outputs, while noting the potential of MCP (Model Context Protocol) to streamline API interactions.
Stability.ai (Stable Diffusion) Discord
- SD 1.7.0 Outshines 1.10: Users reported that Stable Diffusion 1.7.0 is more efficient than 1.10, featuring faster loading times and improved prompt adherence.
- In contrast, users found version 1.10 would often generate unsatisfactory images, citing longer load times and erratic results.
- Optimal LORA Training Disclosed: For better LORA training, aim for approximately 50-150 images of your subject, as discussed among users.
- The community also recommends tools like Koyha LORA to streamline the training process for specific styles.
- Local AI > Online AI?: Users advocated for running AI models locally, highlighting greater control and customization compared to online services.
- They advised that an NVIDIA GPU with at least 8GB VRAM and 32GB of RAM is necessary for optimal performance.
- Mastering Image Generation: Discussions covered effective image creation methods, including employing regional prompting and optimizing word order in prompts for better outcomes.
- Clarity in prompt structuring was emphasized as a key factor in achieving superior image results.
- ComfyUI: Power with Complexity: While acknowledging that ComfyUI can be intimidating for new users, the community recognizes its flexibility and extensive capabilities in image generation workflows.
- Convenient tools like drag-and-drop image uploading simplify AI generation tasks.
Cursor IDE Discord
- Claude's Performance Nosedives: Users reported that Claude's performance has slowed down significantly and its context awareness has decreased over the past few days, leading some to believe it has been 'nerfed'. One user suggested to try Anthropic's new Thinking model and turn on Thinking in model settings to see Claude's thought process, described in this tweet.
- Members expressed frustration and began exploring alternative models and noted it may be experiencing internal changes without a formal model update, according to this reddit thread.
- MCP Server Setups Spark Innovation: Users shared various MCP server setups, highlighting the use of Brave Search and Sequential Thinking to improve performance, detailed in this YouTube video. These setups reportedly enhance the reliability and documentation of the coding process.
- A user also sought a basic 'hello world' example for MCP, indicating a demand for more accessible resources, and another shared a link about Tavily MCP.
- Grok 3's Release Generates Curiosity: The launch of Grok 3 has sparked interest, with users curious about its performance versus existing models and there is speculation about backend updates that might align it with newer Llama versions.
- Users expressed eagerness to test Grok 3 to validate its abilities after previous disappointing launches. News of the roll out discussed in this tweet.
- Cursor's Task Handling Faces Scrutiny: Concerns have been raised about Cursor's ability to manage extensive tasks and process larger files efficiently, especially in agent mode, even for users with unlimited tokens. Users may need to consider alternatives due to these limitations. You can view models via this link.
- One user shared PearAI, an open source AI-powered code editor as one possible alternative. Another user shared a tweet testing multiple AI tools to convert a simple Figma UI design into code.
- Free Trial Exploits Alarm Cursor Users: Users are concerned about potential exploits that allow abuse of Cursor's free trial, leading to conversations about security and oversight. There is a tutorial and script to use Cloudflare to renew Cursor indefinitely as shown in this tweet.
- The community is frustrated by these issues, urging the Cursor team to be vigilant against misuse and one user shared a GitHub repo for auto signing into Cursor.
OpenRouter (Alex Atallah) Discord
- OpenRouter's Real-Time Charts Get a Jolt: OpenRouter's throughput and latency charts now update in real time, thanks to Google AI's Vertex enhancements, as detailed in their announcement.
- They also released llms.txt, a comprehensive resource to chat with the docs (llms.txt and full version).
- AI Tooltip Extension is Born: The Versatile AI Tooltip Chrome extension lets users quickly process text using OpenRouter models, requiring just an API key for setup.
- It focuses on summarizing articles and translating text snippets affordably, with details available on the Chrome Web Store.
- Toledo1 Offers AI on Demand: The Toledo1 platform provides private AI assistant chats on a pay-per-question basis, combining multiple AIs for accuracy.
- It features client-side search with easy installation, promising enterprise-grade security without subscription fees via Toledo1.
- DeepSeek R1's Reasoning Raises Eyebrows: Users noticed inconsistencies with the DeepSeek R1 free model where reasoning tokens appeared unexpectedly in the response content rather than as separate fields.
- The OpenRouter team is tracking solutions to manage the behavior of open-source reasoning models, with usage recommendations found on DeepSeek's GitHub.
- Data Privacy Becomes a Hot Potato: Concerns were raised about forced routing to specific countries potentially violating data protection laws, advocating for region-based routing options for compliance.
- OpenRouter acknowledged the need and is exploring options to support EU-specific routing for better legal compliance, especially with current discussions around OpenAI SDK.
Interconnects (Nathan Lambert) Discord
- Musk's Grok 3 Sparks Debate: Elon Musk announced the release of Grok 3 with a live demo scheduled, touting it as the 'smartest AI on Earth', spurring mixed reactions regarding its alignment with practical user needs and 'based'-ness. The live demo is scheduled for Monday night at 8 PM PT.
- Some concerns were raised about the model being overly tweaked for cultural biases, and the OpenAI board rejected Musk's $97.4 billion bid to control the company, stating, “OpenAI is not for sale.” The board emphasized that they unanimously turned down Musk’s attempts to disrupt competition, as reported by Bloomberg.
- Mistral Saba aims for Regional AI: Mistral Saba, a 24B parameter model, is designed for the Middle East and South Asia, emphasizing custom-trained capabilities to improve language representation, nuance, and cultural context. Mistral AI introduced it as One of the many custom-trained models to serve specific geographies, markets, and customers.
- This move highlights a trend towards tailoring AI models for specific regional markets instead of depending on general-purpose models, showcasing how regional nuance is becoming more important for specialized applications.
- Tencent's Hunyuan LLM Turbo-S to Debut: Tencent is planning to publicly release their Hunyuan LLM Turbo-S and a video generation model, HunyuanVideo I2V, expected in Q1 2025, as tweeted by 青龍聖者.
- This announcement reflects Tencent's ambition to strengthen its position in the competitive AI field, particularly in video technologies, potentially reshaping AI applications in media and entertainment.
- GRPO pairs with SFT!: Members noted that GRPO isn’t meant to replace SFT; rather, both should be utilized together for optimal results. Trelis Research tweeted a teaser for a video on GRPO vs SFT.
- This collaborative approach to model training is favored among users seeking to maximize model performance by leveraging the strengths of both GRPO and SFT techniques.
- LLaDA Challenges Autoregressive Models: The paper introduces LLaDA, a diffusion model that challenges traditional autoregressive models (ARMs) by showcasing its capabilities in scalability and instruction-following abilities, detailed in Large Language Diffusion Models.
- The introduction of LLaDA prompts discussion and scrutiny within the AI community regarding its classification as a diffusion model, with observations noting the absence of traditional diffusion characteristics.
Eleuther Discord
- Data URIs Spark AI Image Generation: A member explored training AI to generate images using Data URIs or Base64 encoding, allowing images to be stored without external linking, but noted that this method typically shows up as a blob in user interfaces.
- The discussion highlights a trade-off between ease of storage and display quality when using Data URIs for AI-generated images.
- Child Prodigies Inform AI Advancement: A conversation arose regarding the commonality of child prodigies in areas like Math and Chess, suggesting these fields might be promising for AI advancements.
- Another member speculated that music might also fit this mold, questioning why it isn't classified as 'easy'.
- NovelAI Unlocks Sampler Secrets: NovelAI's understanding of sampling methods has evolved due to their decision to provide a wide variety of sampler algorithms, pushing developers to figure out the intricacies involved.
- This contrasts with other organizations that initially did not offer complex samplers and thus lacked a reason to invest significant efforts into understanding them.
- Repetition Penalty Remains Tricky: The repetition penalty in text generation is a statistical method to mitigate common issues encountered with less skilled authors, who tend to overuse repetition in their writing.
- While skilled authors can successfully utilize repetition for dramatic effect, distinguishing good repetition from bad remains a challenge in developing sampler policies.
- DEQs Depth Defies RNN Time: Discussion around DEQs highlights their relationship with recurrent structures, focusing on the implications of weight tying and the potential for hidden layers to converge to fixed points.
- Participants noted that, unlike RNNs which handle time variation, DEQs emphasize depth and can utilize implicit differentiation methods for backpropagation.
Nous Research AI Discord
- DeepHermes Delivers on Reasoning: Users are reporting that the DeepHermes model follows instructions better than current R1 distillates, and has been reported as the first usable general-purpose reasoning model. One DeepHermes-3 user reported a processing speed of 28.98 tokens per second on a MacBook Pro M4 Max consumer hardware, according to VentureBeat.
- It was suggested that reasoning tasks and datasets could further enhance this performance.
- Call to Open Source Older Models: Concerns were voiced over Anthropic's decision to potentially delete Claude 3 without plans to open-source it, despite its age. It was argued that releasing older models could foster goodwill and benefit the company's reputation in the open-source community.
- Members pointed to previous work from Clement Delangue, CEO of Hugging Face, who discusses Open AI, DeepSeek and innovation at his company in this Youtube video.
- Reinforcement Learning (RL) Boosts LLMs: Insights were shared about how Reinforcement Learning (RL) and rewards effectively enhance LLMs, particularly regarding alignment tools. Historical references indicated that researchers were aware of these techniques long before other companies adopted similar strategies.
- Google Chief Scientist Jeff Dean discussed his 25 years at Google, from PageRank to AGI in this video.
- Debate on Model Training Costs: A discussion surfaced regarding the costs involved in training a 1B model, with estimates ranging from thousands to tens of thousands of dollars for a complete setup. While it's feasible to train on consumer GPUs, advancements in data and architectures may affect the overall cost efficiency over time.
- One participant mentioned the possibility of achieving a 1.5B model for around $200 to $1,000 through careful data selection and training strategies, linking to 1.5-Pints Technical Report.
- LLaDA Diffusion Model Challenges LLMs: The LLaDA paper introduces a diffusion model that redefines the landscape of large language models (LLMs) by providing a principled generative approach for probabilistic inference. LLaDA shows strong scalability and competes with leading LLMs.
- LLaDA's remarkable performance in in-context learning and multi-turn dialogue, positions it as a competitive alternative to established models like GPT-4o.
Yannick Kilcher Discord
- Splines Show Promise in AI: Discussions highlighted the potential of using NURBS and splines in AI models for enhanced function approximation and reduced overfitting, contrasting with traditional polynomials, further research can be found in NeuralSVG: An Implicit Representation for Text-to-Vector Generation.
- Participants explored the importance of smoothness and topology in developing new AI methodologies, aiming for better generalization capabilities.
- UltraMem Boosts Inference Speed: The UltraMem architecture, detailed in the paper Ultra-Sparse Memory Network, utilizes large-scale, ultra-sparse memory layers to improve inference speed and model performance.
- This architecture potentially offers advantages over traditional MoE approaches while maintaining computational efficiency.
- Community Seeks Paper Discussion Hosts: Members are actively encouraging increased participation in hosting paper discussions to enrich perspectives within the group, the logistics are discussed in #paper-discussion.
- Suggestions included developing a hierarchical tree of seminal papers with dependency links to streamline understanding and knowledge advancement.
- Mistral's Saba Speaks Many Languages: MistralAI introduced Mistral Saba, a 24 billion parameter regional language model, trained on datasets from the Middle East and South Asia.
- The model excels in Arabic and South Indian languages like Tamil and Malayalam, focusing on regional linguistic nuances.
- OpenAI Drafts Robot Ethics Guide: OpenAI has released its 50 laws of robotics, defining safe AI behaviors and modern AI ethics guidelines, expanding Asimov's original three rules.
- The document aims to align AI models with human values and safety, contributing to ongoing discussions on AI responsibility.
Cohere Discord
- Cohere API Might Get OpenAI Compatibility: A member inquired about Cohere API compatibility with OpenAI which received feedback and referral to the product teams, with no definitive timeline given.
- A separate member is building a deep research clone compatible with various AI models, requiring only the base URL and model specification for LLM provider initialization.
- Community Debates Moderation Models: Members debated the effectiveness of moderation models, expressing dissatisfaction with Llamaguard and seeking better alternatives for their specific use cases.
- Some are using OpenAI's omni moderation but hope that Cohere releases new models soon.
- Troubleshooting Technical Glitches: One member reported a ModuleNotFoundError for the cohere package after a fresh install, which was suggested to be an environment issue.
- Another user reported a log in error and shared a screenshot, anticipating community assistance given the unclear error context.
- Aya-8b Integration Stumbles Upon Issues: A member integrating the Cohere Aya-8b model into their application encountered API support problems for the specific model version.
- A sample request using the c4ai-aya-expanse-8b model was shared, with reference to relevant resources for troubleshooting, while other members experienced timeout issues with the Rerank API.
- Embed API Rate Limits: The Embed API production rate limit is 2,000 calls per minute, regardless of the number of tokens embedded, effectively limiting it to 2000 documents total per minute.
- Users humorously tested the AI for color preferences, but the AI stated that it has no personal preferences.
Latent Space Discord
- Perplexity Debuts Deep Research Agent: The new Perplexity Deep Research Agent provides a free tier and a $20/month expert researcher option, generating reports in about three minutes.
- User feedback highlights decent output but suggests follow-on capabilities could better 'leverage deep research', with more potential improvements to be made.
- Musk Teases Grok 3 Release: Elon Musk announced the upcoming Grok 3 launch with a live demo, boldly claiming it to be the 'smartest AI on Earth', but skepticism remains.
- Community members expressed mixed reactions, balancing enthusiasm with caution given the competitive landscape and Grok's previous performance issues.
- StepFun Opens Multimodal Models: StepFun has open-sourced Step-Video-T2V, a 30B text-to-video model needing 80G VRAM, and their Step-Audio-Chat model which is available on Hugging Face.
- Evaluations show that the audio chat model strongly outperforms competitors, highlighting enhanced capabilities in multimodal AI.
- Zed Predicts Next Edit: Zed introduced a new edit prediction model called Zeta that is designed to boost developer productivity by anticipating code edits.
- Although the community appreciates open-source initiatives, some question if Zeta will rival established tools like Cursor and Copilot in terms of performance.
- Eliza Inspires Nostalgia: Members recalled Eliza's impact as an early AI therapist and discussed a related podcast episode.
- Participants speculated on its potential impact if released today, referencing $100B in funding as a hypothetical, inspired by Gary Marcus's remark.
MCP (Glama) Discord
- MCP Servers Enhance Workflows: Members discussed several MCP servers, including those for sequential thinking, filesystem access, web search, and GitHub repository evaluation.
- These tools provide enhanced functionalities to streamline various tasks and improve efficiency.
- Glama Website Experiences Outage: Users reported issues accessing the Glama website due to a network outage in the IAD region, where it is hosted.
- The issues, including slow loading times and timeouts, were eventually resolved.
- Prompt Tool Recommendations Shared: A user sought recommendations for prompt management tools in MCP environments; suggestions included LLMling, MCP-llms-txt for documentation, and Langfuse.
- These tools aim to assist with better prompting and workflow maintenance.
- SSE Wrappers Development Challenges: Developers discussed the challenges of creating SSE wrappers for MCP servers, particularly concerning communication without modifying existing server code.
- Neon's MCP Server Simplifies DB Management: Daniel from Neon introduced Neon's MCP Server that allows users to manage databases using natural language via the Neon API.
- This simplifies database workflows by using Large Language Models (LLMs) for interaction.
Modular (Mojo 🔥) Discord
- MAX Could Simplify NumPy: A member speculated that a NumPy written in Mojo would be simpler than the C version by outsourcing the work to MAX.
- Another member agreed that this approach could lead to significant improvements in efficiency and maintainability.
- Community Courts Polars: A user requested the Discord link for Polars, a DataFrame library powered by Rust.
- The prompt response confirms Polars' relevance and existing awareness within the Mojo community.
- Mojo Eyes GPU, Including Metal: Discussion arose around Mojo's plans to compile code for GPUs, with potential support for Apple's Metal API.
- The ultimate strategy involves implementing MAX drivers for a wide range of hardware, including Apple Silicon, opening doors for broader compatibility.
- AI Assistants Join Mojo Refactoring: A user explored using AI to refactor a large Python project into Mojo, particularly for smaller classes and for its reasonable Mojo knowledge.
- Another member recommended experimenting with
Gemini 2.0 Flashvariants, but advised that fully automating the process would be difficult.
- Another member recommended experimenting with
- Mojo Needs Error Clarity: Users emphasized the need to improve the clarity of Mojo's error messages to aid in navigating the language.
- One member pointed out that Mojo's borrow checker adds extra complexity when transitioning code from other languages, often necessitating a complete re-architecture.
Torchtune Discord
- FSDP steps in for Deepspeed Zero: A member inquired about using Deepspeed Zero with Torchtune, but ebsmothers clarified they use FSDP which is equivalent to ZeRO-3.
- Another member suggested using distributed recipes for capabilities associated with Zero without extra setup.
- GRPO PR Needs Some TLC: Participants discussed the progress of the GRPO PR, noting the need for unit tests and an experimental components folder to house various datasets (see PR #2398).
- Emphasis was placed on maintaining backward compatibility while making generation changes.
- Tool Role Enters Llama3.3: A consensus formed around adding a 'tool' option to the Llama3 tokenizer, providing backward compatibility with 'ipython' (see tokenizer.py).
- Contributors actively debated the implications of introducing a new tokenizer builder and meticulously handling model version checks.
- Dependency Concerns Inflate Dev Environment: Members expressed concerns about the growing list of optional dependencies in the dev environment, particularly those related to logging frameworks.
- A proposal was made to categorize dependencies, enabling users to install only the logging framework they need, thereby minimizing unnecessary bloat.
- Clipping/Winsorization Saves RLHF: It was suggested to add clipping or winsorization options to the
rlhf.get_batch_log_probsfunction to fix issues with dropping end-of-sequence tokens due to logarithmic behavior.- This was identified as a potential improvement in handling log probabilities.
tinygrad (George Hotz) Discord
- Tensor Operations Flexibilized: Members proposed that
Tensor.trilandtriushould accept aTensorfor the diagonal instead of anint, allowing greater flexibility in custom kernels for blockwise attention in KV-cache-space.- psychofauna advocated for an ideal signature of
int | Tensorto streamline the management of multiple diagonals across dimensions.
- psychofauna advocated for an ideal signature of
- Tinygrad Bugfix Bounties Kickoff: A user announced a PR for a bugfix bounty, noting the task's simplicity based on their analysis of test failures.
- They suggested that the test in question may represent a fix or a typo, pending further review of recent commits.
- HEVC Decoder Utility Hunt: Following up on the HEVC decoder, a user inquired about utilities for command queue management, referencing the helpfulness of a previously used ioctl sniffer.
- nimlgen mentioned the existence of code for dumping queues, though it may require adjustments for current use.
- Attention Implementation Almost There: A member reported implementing the full
com.microsoft.Attentionby adapting existing code fromextra/models/llama.pyand evaluating against top Hugging Face repositories.- The implementation passed 201 out of 250 tests, with failures primarily due to numerical inaccuracies across various quantization formats.
- Tinychat Fortified for Mobile: A user announced enhancements to Tinychat, specifically targeting stability on WASM for mobile devices, with changes documented in their PR.
- They are currently cleaning up the code in preparation for merging and have invited inquiries about the updates.
LlamaIndex Discord
- LlamaParse Reveals All!: @mesudarshan showcased LlamaParse's capabilities, emphasizing its multiple parsing modes and parsing audio/images, further enhanced by a JSON mode, as detailed here.
- He gave a full breakdown of its features at this link.
- LlamaIndex.TS Slims Down!: LlamaIndex.TS received an update that slims it down to make it easier to ship, greatly enhancing its usability, with improvements detailed here.
- The release makes it faster for developers to integrate LlamaIndex into Typescript based LLM Apps.
- Roll out Sales Outreach Agent with LlamaIndex: A tutorial for an Automated Sales Outreach Agent, which crafts outreach emails and manages meeting schedules based on responses, was shared leveraging @llama_index workflows with demos here and here.
- The agent helps generate outreach emails and schedule meetings.
- LLM Consortium Answers!: Massimiliano Pippi introduced an implementation of @karpathy's concept of an LLM Consortium, allowing multiple LLMs to respond to questions and compare answers, explained more fully here and here.
- The project explores collaborative LLM responses.
- Mistral Saba Small Model Debuts: Mistral AI launched Mistral Saba, a new Arabic-focused model, which LlamaIndex immediately supported, which users can install using
pip install llama-index-llms-mistralai, more info.- It provides a small model that specializes in Arabic.
Nomic.ai (GPT4All) Discord
- Hunting Nomic Embed Text V2 Source: A member sought the source code and training data for Nomic Embed Text V2 without immediate success, until another member shared the GitHub repository and Hugging Face page.
- The discussion highlighted the importance of clear documentation and discoverability for open-source projects.
- DeepSeek Model Binding Binds Up: A user reported errors loading the DeepSeek-R1-Distill-Qwen-1.5B-Q4_0.gguf model, suggesting issues with potentially outdated python bindings**.
- Another member proposed updating the llama.cpp library to resolve the conflict.
- LocalDoc Data Dumps?: A user questioned if enabling LocalDoc** in GPT4All sends data to the cloud, and how to disable it after initial use.
- The solution involves deselecting the Enable Data Lake setting to prevent data sharing.
- Code Llama Template Tangles: A user requested assistance in configuring a chat template for the Code Llama** model.
- A basic example for a message template was shared, emphasizing the potential need for the model's specific repository or full name for improved support.
- Tooling Around with Models: A member inquired about verifying a model's effective use of tools during execution.
- The advice given was to consult the model developer's documentation to confirm if the model was specifically trained on tool calling.
LLM Agents (Berkeley MOOC) Discord
- Berkeley RDI Internships Seek Talent: The Berkeley Center for Responsible, Decentralized Intelligence (RDI) has openings for internships for UC Berkeley students, with focuses on Marketing and Web Development and applications reviewed on a rolling basis via this link and
samanthaguo@berkeley.edu.- The roles involve developing marketing strategies, managing social media, enhancing their website, and producing multimedia content for their YouTube channel; skills in design tools, GitHub, and multimedia production are preferred.
- Navigating CS294/194-280 Course Enrollment: Students can enroll in CS194-280 (class number 33840) and CS294-280 (class number 33841) through CalCentral, with a petition form available for those waitlisted.
- While late enrollment is accepted, queries about the course should be directed to Edstem instead of emailing staff.
- DeepSeek Reasoning Discussion is Scheduled: A discussion on DeepSeek's reasoning method and GRPO took place to discuss integrating GRPO style reasoning into smaller models.
- The study group also covered Lecture 3 by Prof Yu Su in the weekly forum.
- FinRL-DeepSeek Webinar Premieres CVaR-PPO Extension: The FinRL-DeepSeek webinar on February 25 will present an extension of CVaR-PPO that incorporates trading recommendations and risk assessments generated by LLMs, with open-source code, data, and AI trading agents provided.
- Backtesting results on the Nasdaq-100 will be shared.
- Quiz 3 Expected Soon: Members inquired about the release date of Quiz 3, which has been delayed due to scheduling issues.
- It is now expected to be available early next week.
DSPy Discord
- DSPy Code Golf Competition Kicks Off: Members discussed engaging in DSPy code golf, suggesting a competitive game around creating concise DSPy solutions and sharing quick hacks.
- A member noted it's a fun excuse to spend some time on neat coding challenges and linked to a tweet by Omar Khattab (@lateinteraction) showcasing DSPy usage.
- Qwen 0.5B Wrangling JSON Output: A member sought guidance on securing JSON outputs for a multi-label classification task using Qwen 0.5B, focusing on the necessary configurations.
- Another member recommended using DSPy's JSONAdapter for proper JSON output formatting and provided example code.
- Custom DSPy Implementation Emerges: A member shared their forked and customized implementation of Parlant with DSPy support, ensuring working JSON outputs.
- They offered an example run that can be integrated into the Parlant server for optimal performance.
- Constant Parameter Placement Pondered: Clarification was requested on whether constant parameters should be included in the signature docstring or as an InputField in the pipeline setup.
- The discussion included considerations for the impact on mipro and bootstrapfewshotrandomsearch optimization processes.
- MIpro Feedback Loop Strategies: A question arose on passing feedback to MIpro regarding incorrect answers, beyond just treating the number as a minor metric.
- The inquiry sought methods for effectively communicating the reasons for incorrect outputs to improve the model's performance.
MLOps @Chipro Discord
- FinRL-DeepSeek Webinar Announced: A webinar on FinRL-DeepSeek Algorithmic Trading has been announced, showcasing an extension of CVaR-PPO that integrates trading recommendations and risk evaluations from LLMs, scheduled for February 25 at 8PM CST, at this registration link.
- The webinar promises access to open-source code, data, trading agents, and backtesting results on the Nasdaq-100, emphasizing the availability of AI agents for deployment.
- Inquiry about Webinar Recording: A member inquired about accessing recordings of the FinRL-DeepSeek webinar.
- This suggests significant interest in the webinar's content, particularly for individuals unable to attend the live session.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!