[AINews] Liquid Foundation Models: A New Transformers alternative + AINews Pod 2
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Adaptive computational operators are all you need.
AI News for 9/27/2024-9/30/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (225 channels, and 5435 messages) for you. Estimated reading time saved (at 200wpm): 604 minutes. You can now tag @smol_ai for AINews discussions!
It's not every day that a credible new foundation model lab launches, so the prize for today rightfully goes to Liquid.ai, who, 10 months after their $37m seed, finally "came out of stealth" announcing 3 subquadratic models that perform remarkably well for their weight class:
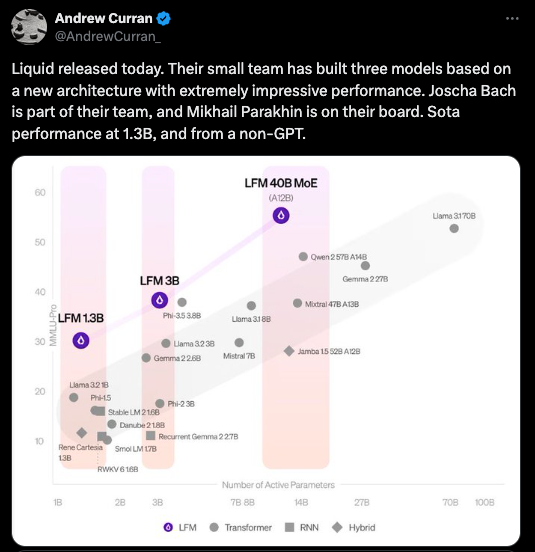
We know precious little about "liquid networks" compared to state space models, but they have the obligatory subquadratic chart to show that they beat SSMs there:
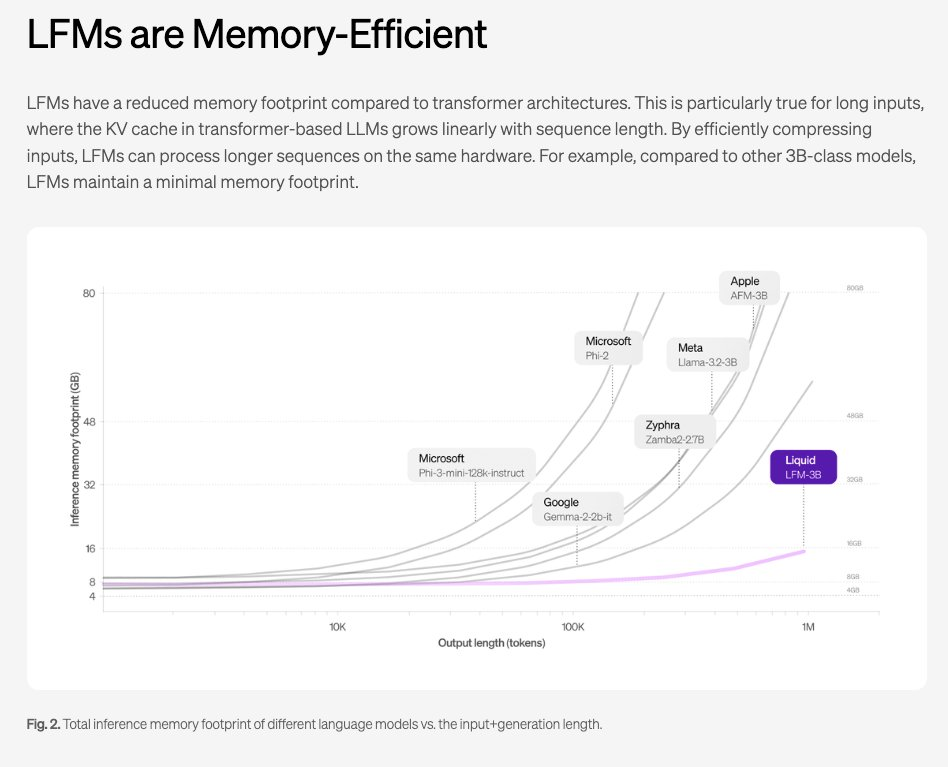
with very credible benchmark scores:
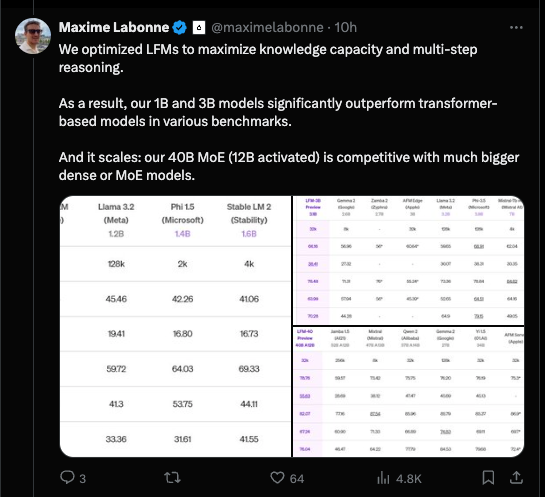
Notably they seem to be noticeably more efficient per parameter than both the Apple on device and server foundation models (our coverage here).
They aren't open source yet, but have a playground and API and have more promised coming up to their Oct 23rd launch.
AINews Pod
We first previewed our Illuminate inspired podcast earlier this month. With NotebookLM Deep Dive going viral, we're building an open source audio version of AINews as a new experiment. See [our latest comparison between NotebookLM and our pod here! Let us know @smol_ai if you have feedback or want the open source repo.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- aider (Paul Gauthier) Discord
- HuggingFace Discord
- LM Studio Discord
- GPU MODE Discord
- Modular (Mojo 🔥) Discord
- Nous Research AI Discord
- Perplexity AI Discord
- OpenRouter (Alex Atallah) Discord
- Stability.ai (Stable Diffusion) Discord
- OpenAI Discord
- Eleuther Discord
- Torchtune Discord
- Latent Space Discord
- LlamaIndex Discord
- Cohere Discord
- Interconnects (Nathan Lambert) Discord
- LLM Agents (Berkeley MOOC) Discord
- tinygrad (George Hotz) Discord
- OpenAccess AI Collective (axolotl) Discord
- DSPy Discord
- OpenInterpreter Discord
- LAION Discord
- LangChain AI Discord
- MLOps @Chipro Discord
- DiscoResearch Discord
- Mozilla AI Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- Unsloth AI (Daniel Han) ▷ #general (920 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (17 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (303 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
- aider (Paul Gauthier) ▷ #announcements (1 messages):
- aider (Paul Gauthier) ▷ #general (436 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (192 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (16 messages🔥):
- HuggingFace ▷ #general (464 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (14 messages🔥):
- HuggingFace ▷ #cool-finds (9 messages🔥):
- HuggingFace ▷ #i-made-this (29 messages🔥):
- HuggingFace ▷ #computer-vision (5 messages):
- HuggingFace ▷ #NLP (2 messages):
- HuggingFace ▷ #diffusion-discussions (6 messages):
- LM Studio ▷ #general (363 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (138 messages🔥🔥):
- GPU MODE ▷ #general (30 messages🔥):
- GPU MODE ▷ #triton (12 messages🔥):
- GPU MODE ▷ #torch (35 messages🔥):
- GPU MODE ▷ #announcements (1 messages):
- GPU MODE ▷ #cool-links (4 messages):
- GPU MODE ▷ #beginner (11 messages🔥):
- GPU MODE ▷ #youtube-recordings (3 messages):
- GPU MODE ▷ #torchao (35 messages🔥):
- GPU MODE ▷ #sequence-parallel (1 messages):
- GPU MODE ▷ #off-topic (83 messages🔥🔥):
- GPU MODE ▷ #irl-meetup (1 messages):
- GPU MODE ▷ #hqq-mobius (1 messages):
- GPU MODE ▷ #llmdotc (23 messages🔥):
- GPU MODE ▷ #rocm (207 messages🔥🔥):
- GPU MODE ▷ #bitnet (1 messages):
- GPU MODE ▷ #sparsity-pruning (1 messages):
- GPU MODE ▷ #webgpu (12 messages🔥):
- GPU MODE ▷ #liger-kernel (6 messages):
- GPU MODE ▷ #metal (16 messages🔥):
- GPU MODE ▷ #self-promotion (8 messages🔥):
- GPU MODE ▷ #nccl-in-triton (6 messages):
- Modular (Mojo 🔥) ▷ #general (18 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (232 messages🔥🔥):
- Nous Research AI ▷ #general (189 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (16 messages🔥):
- Nous Research AI ▷ #research-papers (4 messages):
- Nous Research AI ▷ #interesting-links (13 messages🔥):
- Nous Research AI ▷ #research-papers (4 messages):
- Nous Research AI ▷ #reasoning-tasks (4 messages):
- Perplexity AI ▷ #general (182 messages🔥🔥):
- Perplexity AI ▷ #sharing (16 messages🔥):
- Perplexity AI ▷ #pplx-api (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (193 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (178 messages🔥🔥):
- OpenAI ▷ #ai-discussions (105 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (28 messages🔥):
- OpenAI ▷ #prompt-engineering (5 messages):
- OpenAI ▷ #api-discussions (5 messages):
- Eleuther ▷ #general (90 messages🔥🔥):
- Eleuther ▷ #research (45 messages🔥):
- Eleuther ▷ #lm-thunderdome (2 messages):
- Eleuther ▷ #multimodal-general (1 messages):
- Torchtune ▷ #general (95 messages🔥🔥):
- Torchtune ▷ #dev (39 messages🔥):
- Latent Space ▷ #ai-general-chat (66 messages🔥🔥):
- Latent Space ▷ #ai-announcements (6 messages):
- Latent Space ▷ #ai-in-action-club (42 messages🔥):
- LlamaIndex ▷ #blog (7 messages):
- LlamaIndex ▷ #general (105 messages🔥🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- Cohere ▷ #discussions (21 messages🔥):
- Cohere ▷ #questions (36 messages🔥):
- Cohere ▷ #api-discussions (23 messages🔥):
- Cohere ▷ #projects (2 messages):
- Interconnects (Nathan Lambert) ▷ #news (36 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (16 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (13 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (3 messages):
- Interconnects (Nathan Lambert) ▷ #posts (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (36 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
- tinygrad (George Hotz) ▷ #general (27 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (14 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (3 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (12 messages🔥):
- DSPy ▷ #show-and-tell (2 messages):
- DSPy ▷ #general (17 messages🔥):
- DSPy ▷ #examples (8 messages🔥):
- OpenInterpreter ▷ #general (5 messages):
- OpenInterpreter ▷ #O1 (9 messages🔥):
- OpenInterpreter ▷ #ai-content (2 messages):
- LAION ▷ #general (8 messages🔥):
- LAION ▷ #research (7 messages):
- LangChain AI ▷ #general (6 messages):
- MLOps @Chipro ▷ #events (3 messages):
- MLOps @Chipro ▷ #general-ml (1 messages):
- DiscoResearch ▷ #general (3 messages):
- Mozilla AI ▷ #announcements (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Updates and Developments
- Llama 3.2 Release: Meta AI announced Llama 3.2, featuring 11B and 90B multimodal models with vision capabilities, as well as lightweight 1B and 3B text-only models for mobile devices. The vision models support image and text prompts for deep understanding and reasoning on inputs. @AIatMeta noted that these models can take in both image and text prompts to deeply understand and reason on inputs.
- Google DeepMind Announcements: Google announced the rollout of two new production-ready Gemini AI models: Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002. @adcock_brett highlighted that the best part of the announcement was a 50% reduced price on 1.5 Pro and 2x/3x higher rate limits on Flash/1.5 Pro respectively.
- OpenAI Updates: OpenAI rolled out an enhanced Advanced Voice Mode to all ChatGPT Plus and Teams subscribers, adding Custom Instructions, Memory, and five new 'nature-inspired' voices, as reported by @adcock_brett.
- AlphaChip: Google DeepMind unveiled AlphaChip, an AI system that designs chips using reinforcement learning. @adcock_brett noted that this enables superhuman chip layouts to be built in hours rather than months.
Open Source and Regulation
- SB-1047 Veto: California Governor Gavin Newsom vetoed SB-1047, a bill related to AI regulation. Many in the tech community, including @ylecun and @svpino, expressed gratitude for this decision, viewing it as a win for open-source AI and innovation.
- Open Source Growth: @ylecun emphasized that open source in AI is thriving, citing the number of projects on Github and HuggingFace reaching 1 million models.
AI Research and Development
- NotebookLM: Google upgraded NotebookLM/Audio Overviews, adding support for YouTube videos and audio files. @adcock_brett shared that Audio Overviews turns notes, PDFs, Google Docs, and more into AI-generated podcasts.
- Meta AI Developments: Meta AI, the consumer chatbot, is now multimodal, capable of 'seeing' images and allowing users to edit photos using AI, as reported by @adcock_brett.
- AI in Medicine: A study on o1-preview model in medical scenarios showed that it surpasses GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios, according to @dair_ai.
Industry Trends and Collaborations
- James Cameron and Stability AI: Film director James Cameron joined the board of directors at Stability AI, seeing the convergence of generative AI and CGI as "the next wave" in visual media creation, as reported by @adcock_brett.
- EA's AI Demo: EA demonstrated a new AI concept for user-generated video game content, using 3D assets, code, gameplay hours, telemetry events, and EA-trained custom models to remix games and asset libraries in real-time, as shared by @adcock_brett.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Emu3: Next-token prediction breakthrough for multimodal AI
- Emu3: Next-Token Prediction is All You Need (Score: 227, Comments: 63): Emu3, a new suite of multimodal models, achieves state-of-the-art performance in both generation and perception tasks using next-token prediction alone, outperforming established models like SDXL and LLaVA-1.6. By tokenizing images, text, and videos into a discrete space and training a single transformer from scratch, Emu3 simplifies complex multimodal model designs and demonstrates the potential of next-token prediction for building general multimodal intelligence beyond language. The researchers have open-sourced key techniques and models, including code on GitHub and pre-trained models on Hugging Face, to support further research in this direction.
- Booru tags, commonly used in anime image boards and Stable Diffusion models, are featured in Emu3's generation examples. Users debate the necessity of supporting these tags for model popularity, with some considering it a requirement for widespread adoption.
- Discussions arose about applying diffusion models to text generation, with mentions of CodeFusion paper. Users speculate on Meta's GPU compute capability and potential unreleased experiments, suggesting possible agreements between large AI companies to control information release.
- The model's ability to generate videos as next-token prediction excited users, potentially initiating a "new era of video generation". However, concerns were raised about generation times, with reports of 10 minutes for one picture on Replicate.
Theme 2. Replete-LLM releases fine-tuned Qwen-2.5 models with performance gains
- Replete-LLM Qwen-2.5 models release (Score: 73, Comments: 55): Replete-LLM has released fine-tuned versions of Qwen-2.5 models ranging from 0.5B to 72B parameters, using the Continuous finetuning method. The models, available on Hugging Face, reportedly show performance improvements across all sizes compared to the original Qwen-2.5 weights.
- Users requested benchmarks and side-by-side comparisons to demonstrate improvements. The developer added some benchmarks for the 7B model and noted that running comprehensive benchmarks often requires significant computing resources.
- The developer's continuous finetuning method combines previous finetuned weights, pretrained weights, and new finetuned weights to minimize loss. A paper detailing this approach was shared.
- GGUF versions of the models were made available, including quantized versions up to 72B parameters. Users expressed interest in testing these on various devices, from high-end machines to edge devices like phones.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Capabilities and Developments
- OpenAI's o1 model can handle 5-hour tasks, enabling longer-horizon problem-solving, compared to GPT-3 (5-second tasks) and GPT-4 (5-minute tasks), according to OpenAI's head of strategic marketing.
- MindsAI achieved a new high score of 48% on the ARC-AGI benchmark, with the prize goal set at 85%.
- A hacker demonstrated the ability to plant false memories in ChatGPT to create a persistent data exfiltration channel.
AI Policy and Regulation
- California Governor Gavin Newsom vetoed a contentious AI safety bill, highlighting ongoing debates around AI regulation.
AI Ethics and Societal Impact
- AI researcher Dan Hendrycks posed a thought experiment about a hypothetical new species with rapidly increasing intelligence and reproduction capabilities, questioning which species would be in control.
- The cost of a single query to OpenAI's o1 model was highlighted, sparking discussions about the economic implications of advanced AI models.
Memes and Humor
- A meme about trying to contain AGI sparked discussions about the challenges of AI safety.
- Another meme questioned whether humans are "the baddies" in relation to AI development, leading to debates about AI consciousness and ethics.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. AI Models Make Waves with New Releases and Upgrades
- LiquidAI Challenges Giants with Liquid Foundation Models (LFMs): LiquidAI launched LFMs—1B, 3B, and 40B models—claiming superior performance on benchmarks like MMLU and calling out competitors' inefficiencies. With team members from MIT, their architecture is set to challenge established models in the industry.
- Aider v0.58.0 Writes Over Half Its Own Code: The latest release introduces features like model pairing and new commands, boasting that Aider created 53% of the update's code autonomously. This version supports new models and enhances user experience with improved commands like
/copyand/paste. - Microsoft's Hallucination Detection Model Levels Up to Phi-3.5: Upgraded from Phi-3 to Phi-3.5, the model flaunts impressive metrics—Precision: 0.77, Recall: 0.91, F1 Score: 0.83, and Accuracy: 82%. It aims to boost the reliability of language model outputs by effectively identifying hallucinations.
Theme 2. AI Regulations and Legal Battles Heat Up
- California Governor Vetoes AI Safety Bill SB 1047: Governor Gavin Newsom halted the bill designed to regulate AI firms, claiming it wasn't the optimal approach for public protection. Critics see this as a setback for AI oversight, while supporters push for capability-based regulations.
- OpenAI Faces Talent Exodus Over Compensation Demands: Key researchers at OpenAI threaten to quit unless compensation increases, with $1.2 billion already cashed out amid a soaring valuation. New CFO Sarah Friar navigates tense negotiations as rivals like Safe Superintelligence poach talent.
- LAION Wins Landmark Copyright Case in Germany: LAION successfully defended against copyright infringement claims, setting a precedent that benefits AI dataset use. This victory removes significant legal barriers for AI research and development.
Theme 3. Community Grapples with AI Tool Challenges
- Perplexity Users Bemoan Inconsistent Performance: Users report erratic responses and missing citations, especially when switching between web searches and academic papers. Many prefer Felo for academic research due to better access and features like source previews.
- OpenRouter Users Hit by Rate Limits and Performance Drops: Frequent 429 errors frustrate users of Gemini Flash, pending a quota increase from Google. Models like Hermes 405B free show decreased performance post-maintenance, raising concerns over provider changes.
- Debate Ignites Over OpenAI's Research Transparency: Critics argue that OpenAI isn't sufficiently open about its research, pointing out that blog posts aren't enough. Employees assert transparency, but the community seeks more substantive communication beyond the research blog.
Theme 4. Hardware Woes Plague AI Enthusiasts
- NVIDIA Jetson AGX Thor's 128GB VRAM Sparks Hardware Envy: Set for 2025, the AGX Thor’s massive VRAM raises questions about the future of current GPUs like the 3090 and P40. The announcement has the community buzzing about potential upgrades and the evolving GPU landscape.
- New NVIDIA Drivers Slow Down Stable Diffusion Performance: Users with 8GB VRAM cards experience generation times ballooning from 20 seconds to 2 minutes after driver updates. The community advises against updating drivers to avoid crippling rendering workflows.
- Linux Users Battle NVIDIA Driver Issues, Eye AMD GPUs: Frustrations mount over NVIDIA's problematic Linux drivers, especially for VRAM offloading. Some users consider switching to AMD cards, citing better performance and ease of use in configurations.
Theme 5. AI Expands into Creative and Health Domains
- NotebookLM Crafts Custom Podcasts from Your Content: Google's NotebookLM introduces an audio feature that generates personalized podcasts using AI hosts. Users are impressed by the engaging and convincing conversations produced from their provided material.
- Breakthrough in Schizophrenia Treatment Unveiled: Perplexity AI announced the launch of the first schizophrenia medication in 30 years, marking significant progress in mental health care. Discussions highlight the potential impact on patient care and treatment paradigms.
- Fiery Debate Over AI-Generated Art vs. Human Creativity: The Stability.ai community is torn over the quality and depth of AI art compared to human creations. While some champion AI-generated works as legitimate art, others argue for the enduring superiority of human artistry.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- LinkedIn's Copied Code Controversy: LinkedIn faced backlash for allegedly copying Unsloth's code without proper attribution, prompting intervention from Microsoft and GitHub to ensure proper credit.
- The incident underscores the critical need for adherence to open source licensing and raises concerns about intellectual property.
- Best Practices for Fine-tuning Llama Models: To mitigate token generation issues, users discussed setting a random seed and evaluating output quality carefully during Llama model fine-tuning.
- It's essential to configure EOS tokens correctly to maintain the model's original abilities during inference.
- GGUF Conversion Errors: Users encountered a 'cannot find tokenizer merges in model file' error when loading GGUF models, highlighting potential issues during model saving.
- Understanding the conversion process and maintaining compatibility with tokenizer configurations is vital for ensuring smooth model transitions.
- Liquid Foundation Models Launch: LiquidAI announced the introduction of Liquid Foundation Models (LFMs), featuring 1B, 3B, and 40B models, but skepticism arose about the validity of these announcements.
- Concerns were expressed regarding the accuracy of the claims, especially in relation to Perplexity Labs.
- Leveraging Untapped Compute Power: Members noted substantial compute power being underutilized, suggesting potential performance improvements across various hardware setups.
- Achieving realistic performance boosts through optimization of existing resources indicates significant room for enhancement in current systems.
aider (Paul Gauthier) Discord
- Aider v0.58.0 Delivers Exciting Enhancements: The release of Aider v0.58.0 introduces features such as model pairing and new commands, with Aider creating 53% of the update's code autonomously.
- This version also supports new models and improves user experience with features like clipboard command updates.
- Architect/Editor Models Improve Efficiency: Aider utilizes a main model for planning and an optional editor model for execution, allowing configuration via
--editor-modelfor optimal task handling.- This dual approach has sparked discussions on multi-agent coding capabilities and price efficiency for LLM tasks.
- NotebookLM's New Podcast Feature Stands Out: NotebookLM launches an audio feature that generates custom podcasts from user content, showcasing AI hosts in a compelling format.
- One example podcast demonstrates the technology's ability to create engaging conversations from provided material.
- Automation Proposal for Content Generation: The idea to use NotebookLM to automate the production of videos from release notes has been floated, potentially leading to an efficient tool named ReleaseNotesLM.
- This tool aims to transform written updates into audio, streamlining processes for content creators.
- Discussion on Model Cost Efficiency: Using different models, such as
claude-3.5-sonnetfor architect tasks anddeepseek v2.5for editing, can lead to 20x-30x cost reductions on editor tokens.- Participants emphasized the advantages of strategic model selection based on cost and functionality, exploring script options for enhanced configuration.
HuggingFace Discord
- AI Model Merging Techniques Discussed: Users explored various methods for merging AI models, specifically focusing on approaches like PEFT merge and the DARE method to enhance performance during fine-tuning.
- The conversation stressed the value of leveraging existing models rather than training LLMs from scratch, positioning these methods as pivotal for efficient task handling.
- Medical AI Insights from Recent Papers: A post summarized the top research papers in medical AI for September 21-27, 2024, including notable studies like A Preliminary Study of o1 in Medicine.
- Members suggested breaking these insights into individual blog posts to increase engagement and discussion surrounding standout papers.
- Hallucination Detection Model Performance Metrics: The newly released Hallucination Detection Model upgraded from Phi-3 to Phi-3.5 boasts impressive metrics: Precision: 0.77, Recall: 0.91, F1 Score: 0.83, and accuracy: 82%; check out the model card.
- This model aims to improve the reliability of language model outputs by effectively identifying hallucinations.
- Gradio's Lackluster User Reception: Community sentiment towards Gradio turned negative, with users labeling it as 'hot garbage' due to UI responsiveness issues and design flaws that complicate project management.
- Despite the backlash, members encouraged seeking help in dedicated support channels, indicating a continued investment in troubleshooting.
- Keypoint Detection Model Enhancements: The announcement of the OmDet-Turbo model supports zero-shot object detection, integrating techniques from Grounding DINO and OWLv2; details can be found here.
- Exclusive focus on keypoint detection with models like SuperPoint sets the stage for community excitement over future developments in this field.
LM Studio Discord
- Challenges in downloading and sideloading models in LM Studio: Users encountered issues with downloading models in LM Studio, particularly when using VPNs, prompting some to sideload models instead. Limitations on supporting model formats like safetensors and GGUF were noted.
- The community expressed frustrations regarding the overall download experience, with discussions highlighting the necessity for better support with various model types.
- NVIDIA Jetson AGX Thor boasts 128GB VRAM: The upcoming NVIDIA Jetson AGX Thor is set to feature 128GB of VRAM in 2025, raising questions about the viability of current GPUs like the 3090 and P40. This announcement has created a buzz around potential upgrades in the GPU landscape.
- Some members pondered whether existing hardware will remain competitive as the demand for high-VRAM options continues to grow.
- Comparing GPU performance: 3090 vs 3090 Ti vs P40: Members compared the performance of the 3090, 3090 Ti, and P40, focusing on VRAM and pricing, which heavily influence their choices. One remark noted that the P40 operates at approximately half the speed of the 3090.
- Members expressed concern over rising GPU prices and debated the trade-offs between different models for current AI workloads.
- Market pricing dynamics for GPUs: Discussions emphasized that GPU prices remain high due to scalping and increased demand for AI applications, with the A6000 serving as a high-VRAM alternative. However, budget-conscious members favor options like multiple 3090s for their setups.
- The conversation highlighted a general frustration regarding pricing trends and the hurdles many face in the current market.
- Challenges with NVIDIA drivers on Linux: The community shared grievances about NVIDIA's Linux drivers being notoriously problematic, especially for VRAM offloading, an area where AMD cards perform better. Complications in setting up CUDA and other drivers underscored these frustrations.
- Some members indicated a growing preference for AMD hardware, citing its superior ease of use in certain configurations.
GPU MODE Discord
- Cerebras Chip Optimization Discussion: Members are exploring code optimizations for Cerebras chips with varying opinions about potential purchases and expertise availability.
- Community interest is growing as members show willingness to find experts for deeper insights into Cerebras technology.
- Rising Concerns Over Spam Management: The community is addressing an increase in crypto scam spam messages on Discord, suggesting stricter verification protocols to enhance server security.
- Members are actively seeking efficient anti-spam tools and discussing their experiences with existing solutions such as AutoMod.
- Triton Talk Materials Shared: A member sought out slides from the Triton talk and was directed to the GitHub repository containing educational resources.
- This reflects a strong community culture of knowledge sharing and collaborative learning.
- AMD GPU Performance Troubles: Discussion on significant performance limitations of AMD GPUs, particularly with GFX1100 and MI300 architectures, was prominent among the members.
- Many highlighted the ongoing challenges with multi-node setups and expressed the need for enhanced performance.
- Understanding Model Parallelism vs ZeRO/FSDP: Members clarified the distinctions between Model Parallelism and ZeRO/FSDP, focusing on how ZeRO implements parameter distribution strategies.
- Discussions emphasized that FSDP utilizes sharding to enhance model training efficiency, appealing to those looking to understand advanced features.
Modular (Mojo 🔥) Discord
- Modular Community Meeting Agenda Explored: Today's Modular Community Meeting at 10am PT will cover the MAX driver & engine API and a Q&A on Magic, with access via Zoom. Participants can check the Modular Community Calendar for upcoming events.
- The meeting recording will be uploaded to YouTube, including today’s session available at this link, ensuring no one misses out.
- Debate on Mojo Language Enhancements: A proposal for advanced Mojo language features suggested named variants for message passing and better management of tagged unions without new constructs, sparking extensive discussion among members.
- Proponents weighed the ergonomics of defining types, discussing the balance of nominal versus structural types in the design process.
- Bundling Models with Mojopkg: The ability to embed models in Mojopkg was enthusiastically discussed, showcasing potential user experience improvements by bundling everything into a single executable application.
- Key examples from other languages were mentioned, illustrating how this could simplify dependencies for users and enhance usability.
- Managing Native Dependencies Smoothly: Concerns were raised regarding Mojopkg's capability to simplify dependency management, potentially allowing for easier installation and configuration.
- Discussion included practical implementations like embedding installers for runtimes such as Python directly into Mojo applications.
- Compatibility Warnings on MacOS: A user reported compatibility warnings when building object files for macOS, noting linking issues between versions 15.0 and 14.4.
- Although the warnings are not fatal, they could point to future compatibility challenges needing resolution.
Nous Research AI Discord
- Nous Research pushes open source initiatives: Nous Research focuses on open source AI research, collaborating with builders and releasing models including the Hermes family.
- Their DisTrO project aims to speed up AI model training across the internet, hinting at the perils of closed source models.
- Distro paper release generating buzz: The Distro paper is expected to be announced soon, igniting excitement among community members eager for updates.
- This paper's relevance to the AI community amplifies anticipation surrounding its detailed content.
- New AI Model Fine-tuning Techniques Unleashed: The recent Rombodawg’s Replete-LLM topped the OpenLLM leaderboard for 7B models, aided by innovative fine-tuning techniques.
- Methods like TIES merging are identified as critical to enhancing model benchmarks significantly.
- Liquid Foundation Models capture attention: LiquidAI introduced Liquid Foundation Models with versions including 1B, 3B, and 40B, aiming for fresh capabilities in the AI landscape.
- These models are seen as pivotal in offering innovative functionalities for various applications within the AI domain.
- Medical AI Paper of the Week: Are We Closer to an AI Doctor?: The highlighted paper, A Preliminary Study of o1 in Medicine, explores the potential for AI to function as a doctor, authored by various experts in the field.
- This paper was recognized as the Medical AI Paper of the Week, showcasing its relevance in ongoing discussions about AI's role in healthcare.
Perplexity AI Discord
- Perplexity struggles with performance consistency: Users noted inconsistent responses from Perplexity while switching between web searches and academic papers, with instances of missing citations.
- Concerns were raised about whether these inconsistencies reflect a bug or highlight underlying design flaws in the search functionality.
- Felo superior for academic searches: Many users find Felo more effective for academic research, citing better access to relevant papers over Perplexity.
- Features like hovering for source previews enhance the research experience, drawing users to prefer Felo for its intuitive interface.
- Inconsistent API outputs frustrate users: The community discussed API inconsistencies, especially around the PPLX API, which was returning outdated real estate listings compared to the website data.
- Suggestions were made to experiment with parameters like temperature and top-p to improve the API's response consistency.
- Breakthrough in schizophrenia treatment: Perplexity AI announced an important milestone with the launch of the first schizophrenia medication in 30 years, marking significant progress in mental health solutions.
- Discourse emphasized the potential ramifications for patient care and the evolution of treatment paradigms moving forward.
- Texas counties use AI tech effectively: Texas counties showcased innovative approaches to leverage AI applications in local government operations, enhancing public service capabilities.
- Participants shared a detailed resource that highlights these practical implementations of AI technology in administrative tasks.
OpenRouter (Alex Atallah) Discord
- OpenRouter Struggles with Rate Limits: Users report frequent 429 errors while using Gemini Flash, causing significant frustration as they await a potential quota increase from Google.
- This ongoing traffic issue is undermining the platform's usability, impacting user engagement.
- Performance Decrease Post-Maintenance: Models like Hermes 405B free have exhibited lower performance quality after recent updates, raising concerns about potential changes in model providers.
- Users are advised to check their Activity pages to ensure they are using their preferred models.
- Translation Model Options Suggested: A user looked for efficient translation models for dialogue without strict limitations, expressing dissatisfaction with GPT4o Mini.
- Open weight models fine-tuned with dolphin techniques were recommended as more flexible alternatives.
- Frontend Chat GUI Recommendations: A discussion emerged about chat GUI solutions that allow middleware flexibility, with Streamlit proposed as a viable option.
- Typingmind was also mentioned for its customizable features in managing interactions with multiple AI agents.
- Gemini's Search Functionality Discussion: There’s interest in enabling direct search capabilities within Gemini models similar to Perplexity, though current usage limitations are still being evaluated.
- Discussions referenced Google's Search Retrieval API parameter, highlighting the need for clearer implementation strategies.
Stability.ai (Stable Diffusion) Discord
- Flux Model Hits a Home Run: Impressed by kohya_ss's work, members noted that the Flux model can train on just 12G VRAM, showcasing incredible performance capabilities.
- Excitement spread about the advancements, hinting at a possible shift in model efficiency benchmarks.
- Nvidia Drivers Slow Down SDXL: New Nvidia drivers caused major slowdowns for 8GB VRAM cards, with image generation times ballooning from 20 seconds to 2 minutes.
- Members strongly advised against updating drivers, as these changes detrimentally affected their rendering workflows.
- Regional Prompting Hits Snags: Community members shared frustrations with regional prompting in Stable Diffusion, specifically with character mixing in prompts like '2 boys and 1 girl'.
- Suggestions arose to begin with broader prompts, leveraging general guides for optimal results.
- AI Art Submission Call to Action: The community's invited to submit AI-generated art for potential feature in The AI Art Magazine, with a deadline set for October 20.
- This initiative aims to celebrate digital art and encourages members to flaunt their creativity.
- AI Art Stirs Quality Debate: A vigorous debate erupted regarding the merits of AI art versus human art, with opinions split on quality and depth.
- Some argued for the superiority of human artistry, while others defended AI-generated works as legitimate artistic expression.
OpenAI Discord
- Aider benchmarks LLM editing skills: Members discussed Aider's functionality, noting it excels with LLMs proficient in editing code, as highlighted in its leaderboards. Skepticism emerged around the reliability of Aider's benchmarks, especially concerning Gemini Pro 1.5 002.
- While Aider showcases impressive edits, the potential for further testing and validation remains critical for broader acceptance in the community.
- EU AI Bill sparks dialogue: The discourse around the EU's AI bill intensified, with members sharing varying views on its implications for multimodal AI regulation and chatbot classifications under level two regulations. Concerns about the regulatory burden on tech companies were prevalent.
- Many emphasized the necessity for clarity on how emerging AI technologies would be impacted by these regulations as they navigate compliance landscapes.
- Meta's game-changer in video translation: A member highlighted Meta's imminent release of a lip-sync video translation feature, set to enhance user engagement on the platform. This feature captivated discussions about its potential to reshape content creation tools.
- Members expressed excitement over how this could elevate translation services and the implications for global content accessibility.
- Voice mode quandaries in GPT-4: Frustration brewed over the performance of GPT-4o, with urgent calls for the release of GPT-4.5-o following claims of it being 'the dumbest LLM'. Critiques centered on insufficient reasoning capabilities as a major concern.
- Amidst user confusion, detailed discussions about daily limits and accessibility of voice mode highlighted the community's anticipation for enhancements in user experience.
- Flutter Code Execution Error Resolved: A user faced an error indicating an active run in thread
thread_ey25cCtgH3wqinE5ZqIUbmVT, leading to suggestions for managing active runs and using thecancelfunction. The user ultimately resolved the issue by waiting longer between executions.- Participants recommended incorporating a status parameter to track thread completions, potentially streamlining thread management and reducing frustration in future interactions.
Eleuther Discord
- New Members Enrich Community Dynamics: Several new members, including a fullstack engineer from Singapore and a data engineer from Portugal, joined the conversation, eager to contribute to AI projects and open source initiatives.
- Their enthusiasm for collaboration sets a promising tone for community growth.
- AI Conferences on the Horizon: Members discussed upcoming conferences like ICLR and NeurIPS, particularly with Singapore hosting ICLR, and are planning meetups.
- Light-hearted conversation about event security roles added a fun twist to the coordination.
- Liquid AI Launches Foundation Models: Liquid Foundation Models were announced, showcasing strong benchmark scores and a flexible architecture optimized for diverse industries.
- The models are designed for various hardware, inviting users to test them on Liquid AI's platform.
- Exploration of vLLM Metrics Extraction: A member inquired about extracting vLLM metrics objects from the lm-evaluation-harness library using the
simple_evaluatefunction on benchmarks.- They specifically sought metrics like time to first token and time in queue, prompting useful responses from the community.
- ExecuTorch Enhances On-Device AI Capabilities: ExecuTorch allows customization and deployment of PyTorch programs across various devices, including AR/VR and mobile systems, as per the platform overview.
- Details were shared regarding the
executorchpip package currently in alpha for Python 3.10 and 3.11, compatible with Linux x86_64 and macOS aarch64.
- Details were shared regarding the
Torchtune Discord
- Optimizing Torchtune Training Configurations: Users fine-tuned various settings for Llama 3.1 8B, optimizing parameters like
batch_size,fused, andfsdp_cpu_offload, which led to decreased epoch times whenpacked=Truewas enabled.- ...and everyone agreed that
enable_activation_checkpointshould remainFalseto boost compute efficiency.
- ...and everyone agreed that
- Demand for Dynamic CLI Solutions: A proposal emerged to create a dynamic CLI using the
tyrolibrary, allowing for customizable help texts that reflect configuration settings in Torchtune recipes.- This flexibility aims to enhance user experience and streamline recipe management with clear documentation.
- Memory Optimization Strategies Revealed: Members recommended updating the memory optimization page to include both performance and memory optimization tips, promoting a more integrated approach.
- Ideas like implementing sample packing and exploring int4 training were highlighted as potential enhancements for memory efficiency.
- Error Handling Enhancements for Distributed Training: A suggestion surfaced to improve error handling in distributed training by leveraging
torch.distributed's record utility for logging exceptions.- This approach facilitates easier troubleshooting by maintaining comprehensive error logs throughout the training process.
- Duplicate Key Concerns in Configuration Management: Discussion arose regarding OmegaConf flagging duplicate entries like
fused=Truein configs, highlighting the importance of clean and organized configuration files.- We should add a performance section in configs, placing fast options in comments to improve readability and immediate accessibility.
Latent Space Discord
- CodiumAI rebrands with Series A funding: QodoAI, previously known as CodiumAI, secured a $40M Series A funding, bringing their total to $50M to enhance AI-assisted tools.
- ‘This funding validates their approach’ indicating developer support for their mission to ensure code integrity.
- Liquid Foundation Models claim impressive benchmarks: LiquidAI launched LFMs, showcasing superior performance on MMLU and other benchmarks, calling out competitors' inefficiencies.
- With team members from MIT, their 1.3B model architecture is set to challenge established models in the industry.
- Gradio enables real-time AI voice interaction: LeptonAI demonstrated Gradio 5.0, which includes real-time streaming with audio mode for LLMs, simplifying code integrations.
- The updates empower developers to create interactive applications with ease, encouraging open-source collaboration.
- Ultralytics launches YOLO11: Ultralytics introduced YOLO11, enhancing previous versions for improved accuracy and speed in computer vision tasks.
- The launch marks a critical step in the evolution of their YOLO models, showcasing substantial performance improvements.
- Podcast listeners demand more researcher features: The latest episode features Shunyu Yao and Harrison Chase, drawing interest from listeners eager for more researcher involvement in future episodes.
- Engagements highlight listener enthusiasm, with comments like, ‘bring more researchers on’, urging for deeper discussions.
LlamaIndex Discord
- FinanceAgentToolSpec for Public Financial Data: The FinanceAgentToolSpec package on LlamaHub allows agents to access public financial data from sources like Polygon and Finnhub.
- Hanane's detailed post emphasizes how this tool can streamline financial analysis through querying.
- Full-Stack Demo Showcases Streaming Events: A new full-stack application illustrates workflows for streaming events with Human In The Loop functionalities.
- This app demonstrates how to research and present a topic, boosting user engagement significantly.
- YouTube Tutorial Enhances Workflow Understanding: A YouTube video provides a developer's walkthrough of the coding process for the full-stack demo.
- This resource aims to aid those wishing to implement similar streaming systems.
- Navigating RAG Pipeline Evaluation Challenges: Users reported issues with RAG pipeline evaluation using trulens, particularly addressing import errors and data retrieval.
- This led to discussions on the importance of building a solid evaluation dataset for accurate assessments.
- Understanding LLM Reasoning Problems: Defining the type of reasoning problem is essential for engaging with LLM reasoning, as highlighted in a shared article detailing reasoning types.
- The article emphasizes that various reasoning challenges require tailored approaches for effective evaluation.
Cohere Discord
- Cohere Startup Program Discounts Available: A user inquired about discounts for a startup team using Cohere, citing costs compared to Gemini. It was suggested they apply to the Cohere Startup Program for potential relief.
- Participants mentioned that the application process might take time, but they affirmed the significance of this support for early-stage ventures.
- Improve Flash Card Generation by Fine-tuning: Members discussed fine-tuning a model specifically for flash card generation from notes and slide decks, addressing concerns about output clarity. It was suggested to employ best practices for machine learning pipelines and utilize chunking data for improved results.
- Chunking was highlighted as beneficial, particularly for processing PDF slide decks, enhancing the model's understanding and qualitative output.
- Cultural Multilingual LMM Benchmark Launch: MBZUAI is developing a Cultural Multilingual LMM Benchmark for 100 languages, and is actively seeking native translators to volunteer for error correction. Successful participants will be invited to co-author the resulting paper.
- The scope of languages includes Indian, South Asian, African, and European languages, and interested parties can connect with the project lead via LinkedIn.
- RAG Header Formatting for LLM Prompts: Users sought guidance on formatting instructional headers for RAG prompts to ensure the LLM interprets inputs correctly. Discussions emphasized the need for precise supporting information and proper termination methods for headers.
- The conversation highlighted how clarity in formatting can mitigate errors in model responses, enhancing engagement with the LLM.
- Gaps in API Documentation Identified: A user noted inconsistencies in the API documentation regarding penalty ranges, calling for clearer standards on parameter values. This conversation reflects ongoing concerns about documentation consistency and user clarity in utilizing API features.
- Discussions around API migration from v1 to v2 corroborated that while older functionality remains, systematic updates are essential for a smooth transition.
Interconnects (Nathan Lambert) Discord
- OpenAI's talent exodus due to compensation demands: Key researchers at OpenAI are seeking higher compensation, with $1.2 billion already cashed out from selling profit units as the company’s valuation rises. This turnover is heightened by rivals like Safe Superintelligence actively recruiting talent.
- Employees are threatening to quit over money issues while new CFO Sarah Friar navigates these negotiations.
- California Governor vetoes AI safety bill SB 1047: Gov. Gavin Newsom vetoed the bill aimed at regulating AI firms, claiming it wasn't the best method for public protection. Critics view this as a setback for oversight while supporters push for regulations based on specific capabilities.
- Sen. Scott Wiener expressed disappointment over the lack of prior feedback from the governor, emphasizing the lost chance for California to lead in tech regulation.
- PearAI faces allegations of code theft: PearAI has been accused of stealing code from Continue.dev and rebranding it without acknowledgment, urging investors like YC to push for accountability. This raises significant ethical concerns about funding within the startup ecosystem.
- The controversy highlights ongoing concerns about the integrity of open-source communities and their treatment by emerging tech firms.
- Debate on Transparency in OpenAI Research: Critics question OpenAI's transparency, emphasizing that referencing a blog does not provide substantive communication of research findings. Some employees assert that the company is indeed open about their research.
- Discussions highlight mixed feelings on whether OpenAI's research blog sufficiently addresses the community's transparency concerns.
- Insights on Access to iPhone IAP Subscriptions: A substack best seller announced gaining access to iPhone In-App Purchase subscriptions, indicating new opportunities in mobile monetization. This development gives insight into implementing and managing these systems.
- The discussions reflect developers’ frustrations with the chaotic environment of managing the Apple App Store and their experiences with its complexities.
LLM Agents (Berkeley MOOC) Discord
- Course Materials Ready for Access: Students can access all course materials, including assignments and lecture recordings, on the course website, with submission deadline set for Dec 12th.
- It's important to check the site regularly for updates on materials as well.
- Multi-Agent Systems vs. Single-Agent Systems: Discussion emerged regarding the need for multi-agent systems rather than single-agent implementations in project contexts to reduce hallucinations and manage context.
- Participants noted that these systems might yield more accurate responses from LLMs.
- Curiosity Around NotebookLM's Capabilities: Members inquired if NotebookLM functions as an agent application, revealing it acts as a RAG agent that summarizes text and generates audio.
- Questions also surfaced regarding its technical implementation, particularly in multi-step processes.
- Awaiting Training Schedule Confirmation: Students are eager for confirmation on when training sessions start, with one noting that all labs were expected to be released on Oct 1st.
- However, this timeline was not officially confirmed.
- Exploring Super-Alignment Research: A proposed research project is in discussion, aiming to study ethics in multi-agent systems using frameworks like AutoGen.
- Challenges regarding the implementation of this study without dedicated frameworks were raised, highlighting limitations in simulation capabilities.
tinygrad (George Hotz) Discord
- Cloud Storage Costs Competitive with Major Providers: George mentioned that storage and egress costs will be less than or equal to major cloud providers, emphasizing cost considerations.
- He further explained that expectations for usage might alter perceived costs significantly.
- Modal's Payment Model Sparks Debate: Modal's unique pricing where they charge by the second for compute resources has drawn attention, touted as cheaper than traditional hourly rates.
- Members questioned the sustainability of such models and how it aligns with consistent usage patterns in the AI startup environment.
- Improving Tinygrad's Matcher with State Machines: A member suggested that implementing a matcher state machine could improve performance, aligning it towards C-like efficiency.
- George enthusiastically backed this approach, indicating it could achieve the desired performance improvements.
- Need for Comprehensive Regression Testing: Concerns were raised about the lack of a regression test suite for the optimizer, which could lead to unnoticed issues after code changes.
- Members discussed the idea of serialization for checking optimization patterns, but recognized it would not be engaging.
- SOTA GPU not mandatory for bounties: A member suggested that while a SOTA GPU could help, one can manage with an average GPU, especially for certain tasks.
- Some tasks like 100+ TFLOPS matmul in tinygrad may require specific hardware like the 7900XTX, while others do not.
OpenAccess AI Collective (axolotl) Discord
- Llama 3.2 Tuning Hits VRAM Wall: Users face high VRAM usage of 24GB when tuning Llama 3.2 1b with settings like qlora and 4bit loading, leading to discussions on balancing sequence length and batch size.
- Concerns specifically highlight the impact of sample packing, emphasizing a need for optimization in the tuning configuration.
- California Mandates AI Training Transparency: A new California law now requires disclosure of training sources for all AI models, affecting even smaller non-profits without exceptions.
- This has spurred conversations on utilizing lightweight chat models for creating compliant datasets, as community members brainstorm potential workarounds.
- Lightweight Chat Models Gain Traction: Members are exploring finetuning lightweight chat models from webcrawled datasets, aiming to meet legal transformation standards.
- One user pointed out that optimizing messy raw webcrawl data through LLMs can be a significant next step in the process.
- Liquid AI Sparks Curiosity: The introduction of Liquid AI, a new foundation model, has piqued interest among members due to its potential features and applications.
- Members are keen to discuss what legislative changes might mean for this model and its practical implications in light of recent developments.
- Maximizing Dataset Usage in Axolotl: In Axolotl, configure datasets to use the first 20% by adjusting the
splitoption in dataset settings for training purposes.- A lack of random sample selection directly in Axolotl means users must preprocess data, utilizing Hugging Face’s
datasetsfor random subset sampling before loading.
- A lack of random sample selection directly in Axolotl means users must preprocess data, utilizing Hugging Face’s
DSPy Discord
- DSPy showcases live Pydantic model generation: A livecoding session demonstrated how to create a free Pydantic model generator using Groq and GitHub Actions.
- Participants can catch the detailed demonstration in the shared Loom video.
- Upgrade to DSPy 2.5 delivers notable improvements: Switching to DSPy 2.5 with the LM client and a Predictor over TypedPredictor led to enhanced performance and fewer issues.
- Key enhancements stemmed from the new Adapters which are now more aware of chat LMs.
- OpenSearchRetriever ready for sharing: A member is willing to share their developed OpenSearchRetriever for DSPy if the community shows interest.
- This project could streamline integration and functionality, and it was encouraged that they make a PR.
- Challenges in Healthcare Fraud Classifications: A member is facing difficulties accurately classifying healthcare fraud in DOJ press releases, leading to misclassifications.
- The community discussed refining the classification criteria to enhance accuracy in this critical area.
- Addressing Long Docstring Confusion: Confusion arose around using long explanations in docstrings, affecting accuracy in class signatures.
- Members provided insights on the importance of clear documentation, but the user needed clarity on the language model being leveraged.
OpenInterpreter Discord
- Full-Stack Developer Seeks Projects: A full-stack developer is looking for new clients, specializing in e-commerce platforms, online stores, and real estate websites using React + Node and Vue + Laravel technologies.
- They are open to discussions for long-term collaborations.
- Query on Re-instructing AI Execution: A member asked about the possibility of modifying the AI execution instructions to enable users to independently fix and debug issues, pointing to frequent path-related errors.
- There was a clear expression of frustration regarding current system capabilities.
- Persistent Decoding Packet Error: Users reported a recurrent decoding packet issue, with the error message: Invalid data found when processing input during either server restarts or client connections.
- Suggestions were made to check for terminal error messages, but none were found, indicating consistent issues.
- Ngrok Authentication Troubles: A member encountered an ngrok authentication error requiring a verified account and authtoken during server execution.
- They suspected the issue might relate to the .env file not properly reading the apikey, asking for assistance on this topic.
- Jan AI as a Computer Control Interface: A member shared insights on using Jan AI with Open Interpreter as a local inference server for local LLMs, inviting feedback on others' experiences.
- They provided a YouTube video that showcases how Jan can interface to control computers.
LAION Discord
- Request for French Audio Datasets: A user needs high-quality audio datasets in French for training CosyVoice, emphasizing the urgency to obtain suitable datasets.
- Without proper datasets, they expressed uncertainty about progressing on their project.
- LAION Claims Victory in Copyright Challenge: LAION won a major copyright infringement challenge in a German court, setting a precedent in legal barriers for AI datasets.
- Further discussions emphasized the implications of this victory, which can be found on Reddit.
- Exploring Text-to-Video with Phenaki: Members explored the Phenaki model for generating videos from text, sharing a GitHub link for initial tests.
- They requested guidance for testing its capabilities due to a lack of datasets.
- Synergy Between Visual Language and Latent Diffusion: Discussion revolved around the potential of combining VLM (Visual Language Models) and LDM (Latent Diffusion Models) for enhanced image generation.
- A theoretical loop was proposed where VLM instructs LDM, effectively refining the output quality.
- Clarifying Implementation of PALM-RLHF Datasets: A member inquired about the suitable channel for implementing PALM-RLHF training datasets tailored to specific tasks.
- They aimed for clarity on aligning these datasets with operational requirements.
LangChain AI Discord
- Vectorstores could use example questions: A member suggested that incorporating example questions might enhance vectorstore performance in finding the closest match, although it may be considered excessive.
- They highlighted the importance of testing to measure the actual effectiveness of this approach.
- Database beats table data for LLMs: A member pointed out that switching from table data to a Postgres database is more suitable for LLMs, leading them to utilize LangChain modules for interaction.
- This transition aims to optimize data handling for model training and queries.
- Exploring thank you gifts in Discord: An inquiry was made about the feasibility of sending small thank you gifts to members in Discord who provided assistance.
- This reflects a desire to acknowledge contributions and build community bonds.
- Gemini faces sudden image errors: A member reported unexpected errors when sending images to Gemini, noting that this issue emerged after recent upgrades to all pip packages.
- The situation raised concerns about potential compatibility issues post-upgrade.
- Modifying inference methods with LangChain: A member is investigating modifications to the inference method of chat models using LangChain, focusing on optimizations in vllm.
- They seek to control token decoding, particularly around chat history and input invocation.
MLOps @Chipro Discord
- AI Realized Summit 2024 Set for October 2: Excitement is building for the AI Realized - The Enterprise AI Summit on October 2, 2024, hosted by Christina Ellwood and David Yakobovitch at UCSF, featuring industry leaders in Enterprise AI.
- Attendees can use code extra75 to save $75 off their tickets, which include meals at the conference.
- Kickoff of Manifold Research Frontiers Talks: Manifold Research is launching the Frontiers series to spotlight innovative work in foundational and applied AI, starting with a talk by Helen Lu focused on neuro-symbolic AI and human-robot collaboration.
- The talk will discuss challenges faced by autonomous agents in dynamic environments and is open for free registration here.
- Inquiry on MLOps Meetups in Stockholm: A member is seeking information about MLOps or Infrastructure meetups in Stockholm after recently moving to the city.
- They expressed a desire to connect with the local tech community and learn about upcoming events.
DiscoResearch Discord
- Calytrix introduces anti-slop sampler: A prototype anti-slop sampler suppresses unwanted words during inference by backtracking on detected sequences. Calytrix aims to make the codebase usable for downstream purposes, with the project available on GitHub.
- This approach targets enhancing dataset quality directly by reducing noise in generated outputs.
- Community backs anti-slop concept: Members shared positive feedback about the anti-slop sampler, with one commenting, 'cool, I like the idea!' highlighting its potential impact.
- The enthusiasm indicates a growing interest in solutions that refine dataset generation processes.
Mozilla AI Discord
- Takiyoshi Hoshida showcases SoraSNS: Indie developer Takiyoshi Hoshida will present a live demo of his project SoraSNS, a social media app offering a private timeline from users you don't typically follow.
- The demo emphasizes the app's unique concept of day and night skies, symbolizing openness and distant observation to enhance user experience.
- Hoshida's impressive tech credentials: Takiyoshi Hoshida studied Computer Science at Carnegie-Melon University, equipping him with a strong tech foundation.
- He has significant experience, having previously worked with Apple's AR Kit team and contributed to over 50 iOS projects.
Gorilla LLM (Berkeley Function Calling) Discord
- Hammer Handle Just Got Better: The hammer handle has undergone an update, introducing enhancements to its design and functionality. Expect numerous exciting improvements with this iteration.
- This update signals the team's commitment to continuously improving the tool's usability.
- Meet the Hammer2.0 Series Models: The team has launched the Hammer2.0 series models, which include Hammer2.0-7b, Hammer2.0-3b, Hammer2.0-1.5b, and Hammer2.0-0.5b.
- These models signify an important advancement in product diversification for development applications.
- New Pull Request PR#667 Submitted: A Pull Request (PR#667) has been submitted as part of the programmatic updates to the hammer product line. This submission is crucial to the ongoing development process.
- The PR aims to incorporate recent enhancements and feedback from the community.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (920 messages🔥🔥🔥):
LinkedIn and Open Source IssuesFine-tuning Llama ModelsModel Loading IssuesUsing Unsloth with BitsAndBytesGoogle Colab Usage
- LinkedIn's Copied Code Controversy: LinkedIn was accused of copying Unsloth's code without proper attribution, claiming it was self-derived. This led to intervention from Microsoft and GitHub, ultimately requiring LinkedIn to attribute Unsloth correctly.
- This incident highlights concerns about intellectual property and the importance of adhering to open source licensing.
- Best Practices for Fine-tuning Models: It is recommended to set a random seed for reproducibility when fine-tuning models, as well as using a method to evaluate output quality thoroughly. Manual evaluation using a list of prompts is a suggested approach to provide insights into model performance.
- Various parameters such as response format and context tuning can significantly impact the effectiveness of the fine-tuning process.
- Model Loading Challenges: Users encountered runtime errors related to model configuration files when attempting to load fine-tuned models using the Unsloth library. The issue was primarily due to having both LoRA adapters and base model configurations in the same repository.
- It was recommended to upgrade the Unsloth library to resolve specific bugs related to model loading.
- Using Unsloth with BitsAndBytes: BitsAndBytes allows for the loading of models in quantized formats, with users able to load models in 4-bit or 8-bit configurations. While fine-tuning can be done in 4-bit, loading models in 16-bit post-training is recommended for better inference performance.
- Users were advised to ensure they are using correct parameters to avoid confusion during model training and inference.
- Getting Started with Google Colab: New users were directed to resources for using Google Colab effectively, including links to notebooks with clear instructions. Several models were suggested for beginners to experiment with and explore functionality in a user-friendly format.
- This ensures that newcomers can quickly acclimate to using the resources available for fine-tuning and deploying models.
- Tweet from FRYING PAN (@CodeFryingPan): I just quit my 270 000$ job at Coinbase to join the first YCombinator fall batch with my cofounder @not_nang. We're building PearAI, an open source AI code editor. Think a better Copilot, or open...
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- GGUF My Repo - a Hugging Face Space by ggml-org: no description found
- Tweet from Rhys (@RhysSullivan): Introducing BlueberryAI, the open source AI powered code editor It's a fork of PearAI, which is a fork of Continue, which is a fork of VSCode Investors my DMs are open for the seed round
- All Our Models | Unsloth Documentation: See the list below for all our GGUF, 16-bit and 4-bit bnb uploaded models
- Reference Unsloth in header (#216) · linkedin/Liger-Kernel@376fe0c: ## Summary Reference Unsloth in header section <!--- ## Details This is an optional section; is there anything specific that reviewers should be aware of? ---> ## Testing Done...
- Fine-tuning | How-to guides: Full parameter fine-tuning is a method that fine-tunes all the parameters of all the layers of the pre-trained model.
- EASIEST Way to Fine-Tune LLAMA-3.2 and Run it in Ollama: Meta recently released Llama 3.2, and this video demonstrates how to fine-tune the 3 billion parameter instruct model using Unsloth and run it locally with O...
- unsloth (Unsloth AI): no description found
- bitsandbytes foundation: bitsandbytes foundation has 2 repositories available. Follow their code on GitHub.
- llama-recipes/recipes/multilingual/README.md at 0efb8bd31e4359ba9e8f52e8d003d35ff038e081 · meta-llama/llama-recipes: Scripts for fine-tuning Meta Llama with composable FSDP & PEFT methods to cover single/multi-node GPUs. Supports default & custom datasets for applications such as summarization and Q&...
- Home: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- [FIXED] RuntimeError: Unsloth: Your repo has a LoRA adapter and a base model. · Issue #1061 · unslothai/unsloth: I've trained the unsloth/Llama-3.2-3B-Instruct-bnb-4bit model successfully, but when I try to use it with astLanguageModel.from_pretrained, I get this error: Traceback (most recent call last): Fil...
- trl/examples/scripts/sft_vlm.py at main · huggingface/trl: Train transformer language models with reinforcement learning. - huggingface/trl
- GitHub - PygmalionAI/aphrodite-engine: Large-scale LLM inference engine: Large-scale LLM inference engine. Contribute to PygmalionAI/aphrodite-engine development by creating an account on GitHub.
- v0.44.0: New AdEMAMix optimizer, Embeddings quantization, and more! · bitsandbytes-foundation/bitsandbytes · Discussion #1375: New optimizer: AdEMAMix The AdEMAMix optimizer is a modification to AdamW which proposes tracking two EMAs to better leverage past gradients. This allows for faster convergence with less training d...
- config.json file not found, fine tuning llama3 with unsloth, after saving the file to hugging face · Issue #421 · unslothai/unsloth: i use unsloth to fine tune llama 3-8B..., after traning complete i save this model to hugging face by using 'push_to_hub', but it shows these files : .gitattributes README.md adapter_config.js...
- [TEMP FIX] Ollama / llama.cpp: cannot find tokenizer merges in model file [duplicate] · Issue #1062 · unslothai/unsloth: Hi, i tried finetuning both llama 3.1-8b-instruct and llama 3-8b-instruct following the notebook you provided here. The training phase completed without errors and i generated the gguf quantized at...
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- unsloth/KTO_+_Phi_3_Mini_4K_Instruct_+_Unsloth.ipynb at main · asmith26/unsloth: Finetune Llama 3, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - asmith26/unsloth
- GitHub - unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Compute metrics for generation tasks in SFTTrainer · Issue #862 · huggingface/trl: Hi, I want to include a custom generation based compute_metrics e.g., BLEU, to the SFTTrainer. However, I have difficulties because: The input, eval_preds, into compute_metrics contains a .predicti...
- [TEMP FIX] Ollama / llama.cpp: cannot find tokenizer merges in model file · Issue #1065 · unslothai/unsloth: Thank you for developing this useful resource. The Ollama notebook reports {"error":"llama runner process has terminated: error loading modelvocabulary: cannot find tokenizer merges in ...
Unsloth AI (Daniel Han) ▷ #off-topic (17 messages🔥):
Compute utilizationSoftware acceleration methodsUnderutilized hardware performance
- Secret Compute Insights: A member expressed that there is a significant amount of compute power being left untapped, emphasizing the potential for improvement across various hardware components.
- “If you'll allow me to dump something here without elaborating because it's secret privileged stuff” hinted at undisclosed strategies to leverage this untapped power.
- Impressive 4X Inference Acceleration: Another member shared that they have achieved a 4X acceleration in inference using standard Python, without resorting to complex hacks or proprietary methods.
- This highlights how simple adjustments can yield significant performance boosts, indicating an unexplored potential for further improvements.
- Massively Underutilized Hardware: Discussion centered on the CPU and GPU being greatly underutilized, with claims that the system’s PCIe lanes are almost idle, indicating inefficiencies.
- The idea is that even without hardware advancements, there's a clear pathway to achieving 10X performance, strictly through integration of existing research.
- Reactions to Performance Insights: A humorous exchange noted that one member's insights sounded similar to an OpenAI paper, pointing out the cryptic nature of the information shared.
- Jokes about not providing details and the formal tone, comparing it to a TED talk, characterized the reaction among the participants.
Unsloth AI (Daniel Han) ▷ #help (303 messages🔥🔥):
Model Fine-Tuning IssuesGGUF Conversion ProblemsTokenizer and EOS Token IssuesCheckpoint Management in TrainingUsing Unsloth with Llama Models
- Challenges with Llama Model Fine-Tuning: Users discussed various issues related to fine-tuning Llama models, particularly facing infinite token generation and retaining original capabilities.
- Concerns were raised about the use of EOS tokens and model configurations that led to problems during inference.
- Errors Encountered during GGUF Conversion: One user faced an error stating, 'cannot find tokenizer merges in model file' after attempting to load a GGUF model post fine-tuning.
- The conversation indicated that this issue might stem from problems during the model saving process to GGUF format.
- Effectiveness of Different Training Approaches: There were discussions on the effectiveness of using various rank values, targeted layers, and adding embedding layers during model fine-tuning.
- Suggestions were made to use base models to avoid issues experienced by users using instruct models.
- Checkpoint Management in Colab: Users shared methods on how to manage checkpoints effectively during training to prevent losing progress in Google Colab.
- There was emphasis on setting appropriate parameters for saving model checkpoints to mitigate runtime issues.
- Compatibility of Different Llama Models: It was clarified that the models 'meta-llama/Meta-Llama-3.1-8B' and 'unsloth/Meta-Llama-3.1-8B' are essentially the same and compatible.
- Discussions also included the differences between Hugging Face's and Unsloth's model checkpoints and their compatibility.
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Continued Pretraining | Unsloth Documentation: AKA as Continued Finetuning. Unsloth allows you to continually pretrain so a model can learn a new language.
- Google Colab: no description found
- Training Language Models to Self-Correct via Reinforcement Learning: Self-correction is a highly desirable capability of large language models (LLMs), yet it has consistently been found to be largely ineffective in modern LLMs. Existing approaches for training self-cor...
- Finetuning from Last Checkpoint | Unsloth Documentation: Checkpointing allows you to save your finetuning progress so you can pause it and then continue.
- Google Colab: no description found
- Reward Modelling - DPO, ORPO & KTO | Unsloth Documentation: To use DPO, ORPO or KTO with Unsloth, follow the steps below:
- Chat Templates | Unsloth Documentation: no description found
- optillm/optillm/cot_decoding.py at main · codelion/optillm: Optimizing inference proxy for LLMs. Contribute to codelion/optillm development by creating an account on GitHub.
- GitHub - EricLBuehler/xlora: X-LoRA: Mixture of LoRA Experts: X-LoRA: Mixture of LoRA Experts. Contribute to EricLBuehler/xlora development by creating an account on GitHub.
- [FIXED] RuntimeError: Unsloth: Your repo has a LoRA adapter and a base model. · Issue #1061 · unslothai/unsloth: I've trained the unsloth/Llama-3.2-3B-Instruct-bnb-4bit model successfully, but when I try to use it with astLanguageModel.from_pretrained, I get this error: Traceback (most recent call last): Fil...
- unsloth/unsloth/tokenizer_utils.py at main · unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
Referee roles in LLM and financeLiquid Foundation Models
- Seeking Referee for LLM and Finance: A member inquired about potential referees for a scientific journal focused on LLM and finance/economy topics.
- The term 'referee' refers to a reviewer for the scientific journal in this context.
- Liquid Foundation Models Launch: A member shared a post from LiquidAI announcing the launch of Liquid Foundation Models (LFMs), including 1B, 3B, and 40B models.
- However, skepticism arose regarding the validity of the claims, with one member expressing disappointment about the reports and questioning their accuracy, particularly mentioning issues with Perplexity Labs.
Link mentioned: Tweet from Liquid AI (@LiquidAI_): Today we introduce Liquid Foundation Models (LFMs) to the world with the first series of our Language LFMs: A 1B, 3B, and a 40B model. (/n)
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.58.0 FeaturesArchitect/Editor Model PairingNew Model SupportSession EnhancementsClipboard Command Updates
- Aider v0.58.0 brings exciting features: The latest release, Aider v0.58.0, introduces various enhancements including model pairing and new commands.
- Noteworthy is that Aider wrote 53% of the code in this update, showcasing its automated capabilities.
- Architect/Editor model pairing improves coding: Users can now utilize a strong reasoning model like o1-preview as their Architect alongside a faster model like gpt-4o as their Editor.
- This pairing aims to optimize coding efficiency while balancing performance and cost.
- Expanded model support in Aider: The update provides support for the new Gemini 002 models and enhanced functionality for Qwen 2.5 models.
- These additions broaden the range of tools available to users for various applications.
- Session enhancements make usage smoother: Aider now allows users to skip many confirmation questions by selecting (D)on't ask again, enhancing user experience.
- Moreover, the autocomplete for
/read-onlynow supports the entire filesystem, making navigation more efficient.
- Moreover, the autocomplete for
- Clipboard command updates streamline workflow: The new
/copycommand enables users to copy the last LLM response to the clipboard, while/clipboardhas been renamed to/paste.- In addition, HTTP redirects are now followed when scraping URLs, improving data retrieval in operations.
aider (Paul Gauthier) ▷ #general (436 messages🔥🔥🔥):
Aider's Architect and Editor ModelsUse of Multiple LLMsDeepSeek IntegrationAider User WorkflowPrompt Configuration in Aider
- Understanding Aider's Architect and Editor Models: Aider operates with a main model and an optional editor model; architect mode utilizes the main model for planning and the editor model for execution.
- Users can set
--editor-modelin their config file to designate the editor model, while the architect mode remains part of the main functionality.
- Users can set
- Discussion on Multi-Agent Coding: A user referenced two papers demonstrating effective multi-agent coding with LLMs, prompting inquiries about Aider's plans for similar features.
- It was suggested to post these inquiries on GitHub for better visibility and potential integration.
- DeepSeek's Role in Aider: Users are encouraged to experiment with using DeepSeek as an editor model to reduce costs compared to more expensive options like o1-preview.
- Recent updates have merged different DeepSeek models, creating some confusion regarding the specific model to use.
- User Feedback and Recommendations: Users noted that while LLMs like Sonnet can provide useful templates, issues were found with them producing irrelevant edits.
- Responses pointed out that small, detailed tasks tend to yield better results when using LLMs for code editing.
- Configuration and Command Syntax in Aider: Users discussed the YAML configuration file settings for Aider, particularly in setting the appropriate models for tasks.
- Command syntax for tasks and settings was clarified, reinforcing that Aider's flexibility allows for tailored user experiences.
- Dependency versions: aider is AI pair programming in your terminal
- @codebase | Continue: Talk to your codebase
- Introducing sqlite-lembed: A SQLite extension for generating text embeddings locally: Generate text embeddings in SQL with GGUF models!
- /llms.txt—a proposal to provide information to help LLMs use websites – Answer.AI: We propose that those interested in providing LLM-friendly content add a /llms.txt file to their site. This is a markdown file that provides brief background information and guidance, along with links...
- Model warnings: aider is AI pair programming in your terminal
- Scripting aider: You can script aider via the command line or python.
- Separating code reasoning and editing: An Architect model describes how to solve the coding problem, and an Editor model translates that into file edits. This Architect/Editor approach produces SOTA benchmark results.
- Home: aider is AI pair programming in your terminal
- YAML config file: How to configure aider with a yaml config file.
- Installation: How to install and get started pair programming with aider.
- Options reference: Details about all of aider’s settings.
- RAG Guide: All-in-one AI CLI tool featuring Chat-REPL, Shell Assistant, RAG, AI tools & agents, with access to OpenAI, Claude, Gemini, Ollama, Groq, and more. - sigoden/aichat
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Kortix/FastApply-1.5B-v1_16bit_Qwen2.5-Coder-1.5B-ft · Hugging Face: no description found
- Options reference: Details about all of aider’s settings.
- Options reference: Details about all of aider’s settings.
- JavaScript / TypeScript in aider: Background aider is a powerful AI programming assistant, which brings its own linter system, but advanced JS/TS template languages such as JSX/TSX or Svelte allow multiple different languages in one f...
- Options reference: Details about all of aider’s settings.
- aider/benchmark/README.md at main · paul-gauthier/aider: aider is AI pair programming in your terminal. Contribute to paul-gauthier/aider development by creating an account on GitHub.
- DeepSeek V2.5 - API, Providers, Stats: DeepSeek-V2.5 is an upgraded version that combines DeepSeek-V2-Chat and DeepSeek-Coder-V2-Instruct. Run DeepSeek V2.5 with API
- GitHub - asg017/sqlite-vec: A vector search SQLite extension that runs anywhere!: A vector search SQLite extension that runs anywhere! - asg017/sqlite-vec
- Feature request: add --external-chat switch to allow Aider to receive individual messages written in a custom text editor · Issue #1818 · paul-gauthier/aider: Issue Description The --external-chat
switch would allow Aider to receive individual message written in a custom text editor. The --external-chat switch alone would imply read... - Addition of `/editor` command? · Issue #1315 · paul-gauthier/aider: Issue Over at https://github.com/llm-workflow-engine/llm-workflow-engine I've implemented a very handy /editor command that: Opens the CLI editor as specified in the $EDITOR environment variable, ...
- Firecrawl: Turn any website into LLM-ready data.
- GitHub - paul-gauthier/aider: aider is AI pair programming in your terminal: aider is AI pair programming in your terminal. Contribute to paul-gauthier/aider development by creating an account on GitHub.
- how to add a multi-agent flow ? · Issue #1839 · paul-gauthier/aider: what is the plan of aider.chat regarding multi-agent coding? there are two papers https://arxiv.org/pdf/2405.11403v1 and https://arxiv.org/pdf/2402.16906v6 that use multiple llm calls (and debugger...
- feat: add cmd_copy command to copy last assistant reply to clipboard by fry69 · Pull Request #1790 · paul-gauthier/aider: This adds the /copy command to copy the last reply from the LLM to the clipboard. Note: flake8 forced the /paste description to be cut and put into two lines, as the line was longer than 100 chars.
- Merge pull request #1595 from jbellis/paste · paul-gauthier/aider@c2c4dbd: feat: rename /clipboard to /paste
- Docker Build Test · Workflow runs · paul-gauthier/aider: aider is AI pair programming in your terminal. Contribute to paul-gauthier/aider development by creating an account on GitHub.
- GitHub - fry69/aider at copy-command: aider is AI pair programming in your terminal. Contribute to fry69/aider development by creating an account on GitHub.
- GitHub - paul-gauthier/aider: aider is AI pair programming in your terminal: aider is AI pair programming in your terminal. Contribute to paul-gauthier/aider development by creating an account on GitHub.
- Papers with Code - HumanEval Benchmark (Code Generation): The current state-of-the-art on HumanEval is LDB (O1-mini, based on seed programs from Reflexion). See a full comparison of 138 papers with code.
- Change Log | DeepSeek API Docs: Version: 2024-09-05
- aider/aider/args.py at 0aaa37f528b6b8851fa35859cdb401cb71addde1 · paul-gauthier/aider: aider is AI pair programming in your terminal. Contribute to paul-gauthier/aider development by creating an account on GitHub.
- GitHub - okwilkins/rag-cli: A project to show good CLI practices with a fully fledged RAG system.: A project to show good CLI practices with a fully fledged RAG system. - okwilkins/rag-cli
- RAG CLI - LlamaIndex: no description found
- doc: hotfix for Full results table by fry69 · Pull Request #1823 · paul-gauthier/aider: Hotfix for this problem: (via -> https://discord.com/channels/1131200896827654144/1131200896827654149/1289976901393453066) Fixed version:
- Addition of `/editor` command? · Issue #1315 · paul-gauthier/aider: Issue Over at https://github.com/llm-workflow-engine/llm-workflow-engine I've implemented a very handy /editor command that: Opens the CLI editor as specified in the $EDITOR environment variable, ...
aider (Paul Gauthier) ▷ #questions-and-tips (192 messages🔥🔥):
Aider ConfigurationArchitect Mode vs Code ModeCost Efficiency of ModelsUsing Multiple Git WorktreesPrompt Caching and Token Management
- Understanding Aider Configuration Files: Users discussed the possibility of using multiple
.aider.conf.ymlfiles to manage configurations, with suggestions to script Aider for better flexibility.- There was a debate on whether scripting is necessary or if well-structured config files suffice for managing Aider effectively.
- Architect Mode Spitting Code: Concerns were raised about the Architect mode producing final code outputs instead of just planning, which led to confusion on its utility.
- It was clarified that for simple tasks, the planning step may be unnecessary, which can lead to wasted tokens.
- Cost Efficiency Using Different Models: Using
claude-3.5-sonnetas architect anddeepseek v2.5as editor was noted to be significantly cheaper, with estimates suggesting a 20x-30x cost reduction for editor tokens.- Discussion highlighted the potential savings when using models with different pricing structures and functionalities.
- Using Multiple Git Worktrees: Participants suggested leveraging multiple git worktrees to work on several issues concurrently, along with managing Aider instances for better productivity.
- The approach of working across separate terminals or branches was seen as a way to offset the waiting times associated with using slower models.
- Prompt Caching and Token Management: The effectiveness and utility of prompt caching within Aider were debated, focusing on whether it truly offers cost savings or complicates the process.
- Keepalive pings were discussed as a means to maintain cache without excessive costs, highlighting the need to balance interaction timing.
- Aider not found: aider is AI pair programming in your terminal
- Images & web pages: Add images and web pages to the aider coding chat.
- Chat modes: Using the chat, ask and help chat modes.
- OpenAI compatible APIs: aider is AI pair programming in your terminal
- Scripting aider: You can script aider via the command line or python.
- FAQ: Frequently asked questions about aider.
- Chat modes: Using the chat, ask and help chat modes.
- FAQ: Frequently asked questions about aider.
- The killer app of Gemini Pro 1.5 is video: Last week Google introduced Gemini Pro 1.5, an enormous upgrade to their Gemini series of AI models. Gemini Pro 1.5 has a 1,000,000 token context size. This is huge—previously that …
- Tutorial videos: Intro and tutorial videos made by aider users.
- Options reference: Details about all of aider’s settings.
- FAQ: Frequently asked questions about aider.
- More info: aider is AI pair programming in your terminal
- Specifying coding conventions: Tell aider to follow your coding conventions when it works on your code.
- Options reference: Details about all of aider’s settings.
- Prompt Caching (beta) - Anthropic: no description found
- Prompt caching: Aider supports prompt caching for cost savings and faster coding.
- BEST Prompt Format: Markdown, XML, or Raw? CONFIRMED on Llama 3.1 & Promptfoo: Which prompt format is BEST for your AI agents? Is it Markdown, XML, or Raw Prompts?🚀 Ready to unlock the true potential of your AI agents? In this video, w...
- GitHub - PierrunoYT/gemini-youtube-analyzer: Contribute to PierrunoYT/gemini-youtube-analyzer development by creating an account on GitHub.
- Gemini Pro 1.5 - API, Providers, Stats: Google's latest multimodal model, supporting image and video in text or chat prompts. Optimized for language tasks including: - Code generation - Text generation - Text editing - Problem solvin...
- GitHub - yunlong10/Awesome-LLMs-for-Video-Understanding: 🔥🔥🔥Latest Papers, Codes and Datasets on Vid-LLMs.: 🔥🔥🔥Latest Papers, Codes and Datasets on Vid-LLMs. Contribute to yunlong10/Awesome-LLMs-for-Video-Understanding development by creating an account on GitHub.
- FAQ: Frequently asked questions about aider.
- Feature request - templates for aider · Issue #1815 · paul-gauthier/aider: Issue Some inspiration could be taken from https://github.com/simonw/llm by Simon Willison, his LLM tool allows the creation of plugins (#1814) . He also has a prompt template system that allows us...
- Deno 2 is here… will it actually kill Node.js this time?: Take a first look at Deno 2.0 - a JavaScript runtime with first-class TypeScript support, and now full compatibility with Node.js#javascript #tech #thecodere...
- GroqCloud: Experience the fastest inference in the world
aider (Paul Gauthier) ▷ #links (16 messages🔥):
NotebookLM audio featureAider updatesAI podcast summarizationContent creation automationHiring decision
- NotebookLM Announces Custom Podcast Feature: Google's NotebookLM now offers a unique audio feature that generates custom podcasts using provided content, featuring AI hosts discussing the material.
- An example podcast highlights its engaging format, lasting around ten minutes and showcasing an astonishingly convincing conversation among the hosts.
- Exciting Updates to Aider Tools: Recent YouTube videos detail significant updates to Aider, with one titled "NEW Aider Architect & Editor Updates" showcasing features like the AI coding agent and Beast Cursor.
- Another video discusses the enhancements in Aider's Architect Mode, supporting Gemini-002, and emphasizes how quickly content creators are producing these videos.
- Discussion on AI-Powered Podcast Summarization: There is a conversation about needing an AI to listen to and summarize countless new podcasts into listicles, with the suggestion that this could be the next big project.
- One member mused about creating a podcast titled "Today in Coding AI News" to further consolidate the content.
- Automation of Release Notes into Audio: A proposal was made to automate the creation of videos from release notes and source code using NotebookLM's capabilities, potentially streamlining content generation.
- The idea is to release a tool called ReleaseNotesLM that would transform written updates into audio format with minimal effort.
- Hiring Decision Based on Video Quality: After reviewing content, a member stated they have decided to hire an individual who was positively highlighted in a previous discussion.
- The hiring decision reflects the impact of the speaker’s impressive presentation skills and content depth.
- NotebookLM’s automatically generated podcasts are surprisingly effective: Audio Overview is a fun new feature of Google’s NotebookLM which is getting a lot of attention right now. It generates a one-off custom podcast against content you provide, where …
- NEW Aider Architect & Editor Updates Are INSANE!🤖(Beast Cursor?!?) Best AI Coding Agent?! OpenAI o1: NEW Aider Architect & Editor Updates Are INSANE!🤖(Beast Cursor?!?) Best AI Coding Agent?!? OpenAI o1https://aider.chat/https://github.com/paul-gauthier/aide...
- Aider (Upgraded) : This Coding Agent just got BETTER with Architect Mode, Gemini-002 Support & More!: Join this channel to get access to perks:https://www.youtube.com/@AICodeKing/joinIn this video, I'll be telling you about the new upgrades to Aider which is ...
- RAG Guide: All-in-one AI CLI tool featuring Chat-REPL, Shell Assistant, RAG, AI tools & agents, with access to OpenAI, Claude, Gemini, Ollama, Groq, and more. - sigoden/aichat
HuggingFace ▷ #general (464 messages🔥🔥🔥):
AI Model MergingText Similarity in AIStable Diffusion PerformanceVideo Model DevelopmentHugging Face Community Projects
- Exploring AI Model Merging Techniques: Users discussed different methods of merging AI models, including PEFT merge and the DARE method, highlighting their effectiveness in enhancing model performance.
- The conversation emphasized the challenges of training LLMs from scratch and the usefulness of existing models for fine-tuning specific tasks.
- The Importance of Text Similarity in AI: Participants debated how AI models recognize text similarity, with examples like 'I have a car' and 'I own a car' showcasing the need for datasets to teach these nuances.
- Understanding text similarity is crucial for improving AI interaction quality and requires comprehensive datasets for effective training.
- Discussion on Stable Diffusion and Its Operating Environment: Members compared the advantages of running Stable Diffusion on Windows vs. WSL, noting the influence of GPU drivers on performance.
- The topic highlighted preferences for operating systems in the context of resource-intensive AI applications.
- Emerging Trends in Video Model Development: There was excitement about new video models being developed, with users sharing links to innovative projects like 'S3Diff' and updates on existing models.
- Participants expressed enthusiasm for advancements in video processing capabilities and the potential of upcoming models.
- Concerns Regarding AI Model Performance: Users shared frustrations about perceived declines in performance of models like ChatGPT O1 compared to earlier versions, citing issues with reasoning and simplicity.
- The discussions reflected concerns over model updates and the impact of censoring or changes on AI usability.
- no title found: no description found
- Google Colab: no description found
- Google Colab: no description found
- Jizz Adult Swim GIF - Jizz Adult Swim John Reilly - Discover & Share GIFs: Click to view the GIF
- Flux.1-dev Upscaler - a Hugging Face Space by jasperai: no description found
- KingNish/Qwen2.5-0.5b-Test-ft · Hugging Face: no description found
- Merge LoRAs: no description found
- Google Colab: no description found
- GroqCloud: Experience the fastest inference in the world
- Tweet from Nous Research (@NousResearch): OPEN SOURCE LIVES ON #SB1047 DEFEATED
- no title found: no description found
- starlette-session-middleware: None
- Spaces - Hugging Face: no description found
- lmsys/chatbot_arena_conversations · Datasets at Hugging Face: no description found
- Paper page - Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch: no description found
- HuggingFaceTB/everyday-conversations-llama3.1-2k · Datasets at Hugging Face: no description found
- GitHub - ArcticHare105/S3Diff: Official implementation of S3Diff: Official implementation of S3Diff. Contribute to ArcticHare105/S3Diff development by creating an account on GitHub.
- GitHub - xtekky/gpt4free: The official gpt4free repository | various collection of powerful language models: The official gpt4free repository | various collection of powerful language models - xtekky/gpt4free
- Langame/conversation-starters · Datasets at Hugging Face: no description found
- Model merging: no description found
- GitHub - interneuron-ai/project-barbarossa: Contribute to interneuron-ai/project-barbarossa development by creating an account on GitHub.
- interneuronai/az-llama2 · Hugging Face: no description found
HuggingFace ▷ #today-im-learning (14 messages🔥):
Experiments with CUDAGradio frustrationsModel Policy LossInterface Design Issues
- CUDA experiments yield new insights: A member shared their progress working with CUDA and 7b FP8, noting a typo indicating a bfloat16 with fp32 master weights.
- They reflected on their learning over the last two days, indicating significant technical growth.
- Gradio underwhelms users: Members expressed strong dissatisfaction with Gradio, one member passionately stating it is 'hot garbage' and a waste of time.
- They relayed frustrations about its design, which turns complex projects into 'tangled balls of spaghetti code' with UI responsiveness issues.
- Encouragement for Gradio support: In response to Gradio frustrations, members encouraged seeking support in dedicated channels for issues regarding Gradio functionality.
- One member offered help in a supportive tone, indicating a community-oriented approach to solving problems.
- Insights on model performance: Community discussions highlighted a member's satisfaction with the policy loss of a model, noting that their loss looks 'good'.
- This was framed positively amidst broader conversations about ongoing technical challenges.
- Exploring alternatives to Gradio: A member indicated their intention to pursue NiceGUI as an alternative to Gradio, citing significant design flaws in the latter.
- They expressed disappointment but maintained enthusiasm for Hugging Face projects they enjoy, like Accelerate.
HuggingFace ▷ #cool-finds (9 messages🔥):
Medical AI Paper HighlightsHuggingFace Model Popularity MetricsProjection Mapping TechnologyExperiences with Phi ModelsVideo Mapping Techniques
- Last Week in Medical AI Highlights: A recent post highlighted the top research papers and models in medical AI for the week of September 21 - 27, 2024, featuring significant studies like A Preliminary Study of o1 in Medicine.
- Community members suggested enhancing visibility by splitting this content into individual blog posts focusing on the coolest papers.
- HuggingFace Model Popularity Metrics Capture: A Reddit thread discussed a metric that quantifies the most actively liked models on HuggingFace, accounting for their duration on the platform to avoid bias towards older or newer models.
- One user proposed a pull request to improve the OpenLLM leaderboard’s like count updates, mentioning how it relates to the HuggingFace trending section.
- Exploring Projection Mapping Technology: An article on projection mapping described how this artistic video technique transforms surfaces into dynamic displays, creating immersive experiences.
- It discusses the benefits for businesses and offers insights into how video mapping works in enhancing creativity and engagement.
- Struggles with Phi Models: A user expressed frustration with their experience using Phi 3, noting that their tests have not gone well and questioning the performance of Phi 2 in comparison.
- This ongoing discussion reflects concerns within the community regarding the efficacy and usability of the different Phi versions.
- Reddit - Dive into anything: no description found
- Projection Mapping - Artistic Video Content & Visual Illusion: Welcome to the fascinating world of projection mapping - a cutting-edge technology that brings art and visuals to life. Learn how projection mapping works, its benefits for businesses, and explore exa...
- Tweet from Open Life Science AI (@OpenlifesciAI): Last Week in Medical AI: Top Research Papers/Models 🏅(September 21 - September 27, 2024) 🏅 Medical AI Paper of the week A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor? Autho...
- Last Week in Medical AI: Top Research Papers/Models 🏅 (September 21 - September 27, 2024) : no description found
HuggingFace ▷ #i-made-this (29 messages🔥):
Flux-Schnell DemoQwen 2.5 Fine-tuningInstrumentum AI SummarizerDeepseek-Chat CoT ModeMusicGen Continuations App
- Flux-Schnell Demo for Regional Prompt Attention: A demo has been developed for Flux-Schnell focusing on regional prompt attention, with plans to add source code and comfyui node later.
- There is anticipation around how these enhancements will further improve user experience.
- Fine-tuning Qwen 2.5 Model: A user shared their experience finetuning Qwen 2.5 0.5b with a Magpie 300k Dataset, achieving answer quality comparable to larger models like Llama 3.2 1b.
- The user noted some inconsistencies but is working on addressing these issues and invites feedback on their ongoing work.
- Introducing Instrumentum AI Summarizer: The Instrumentum AI summarizer offers no length restrictions and is aimed at quick document summarization using advanced LLMs.
- Key features include full security for document uploads and competitive pricing, designed to enhance productivity.
- Deepseek-Chat with Chain of Thought Visualization: The Deepseek-Chat mode introduces optional Chain of Thought visualization for transparent reasoning with step-by-step visualization.
- This innovation aims to enhance user understanding of the model's reasoning process through a Streamlit-powered UI.
- iOS App for MusicGen Continuations: An iOS app focusing on MusicGen continuations using beatboxes as input audio is under development, with a forthcoming app store release.
- The app features noise cancellation and aims to provide improved output when capturing drum inputs.
- DualDiffusion Demo Audio: DualDiffusion Demo Audio
- What I Learned during my Second and Third Internships – ForBo7 // Salman Naqvi: You Learn by Doing
- Tweet from thecollabagepatch (@thepatch_kev): day 4 ios app for musicgen continuations landing screen, noise cancel for input audio and a 'tame the gary' toggle that sort of works focuses it on drums and tries harder to incorporate inp...
- SentimentReveal - a Hugging Face Space by qamarsidd: no description found
- Chrome Web Store: Add new features to your browser and personalize your browsing experience.
- GitHub - vietanhdev/llama-assistant: AI-powered assistant to help you with your daily tasks, powered by Llama 3.2. It can recognize your voice, process natural language, and perform various actions based on your commands: summarizing text, rephasing sentences, answering questions, writing emails, and more.: AI-powered assistant to help you with your daily tasks, powered by Llama 3.2. It can recognize your voice, process natural language, and perform various actions based on your commands: summarizing ...
- Welcome | Instrumentum: no description found
- GitHub - U-C4N/Deepseek-CoT: Deepseek-CoT: Deepseek-CoT. Contribute to U-C4N/Deepseek-CoT development by creating an account on GitHub.
- discord AI sphere - share with whoever!: no description found
HuggingFace ▷ #computer-vision (5 messages):
OmDet-Turbo modelKeypoint Detection TaskSuperPoint ModelFine-tuning TroCR ModelsUpcoming Models for Keypoint Detection
- OmDet-Turbo Model Launch: The team announced the addition of support for the OmDet-Turbo model, enhancing zero-shot object detection capabilities in real-time, inspired by Grounding DINO and OWLv2 via RT-DETR.
- This significant update aims to improve AI performances in various object detection tasks.
- Keypoint Detection Task Page Released: A new keypoint-detection task page has been introduced, now featuring support for SuperPoint, pivotal for interest point detection and description. Detailed information can be found in their documentation here.
- SuperPoint showcases a self-supervised training framework that is applicable to homography estimation and image matching.
- Community Eager for More Models: Community interest is growing in keypoint detection as users express excitement for future model integrations like LoFTR, LightGlue, and OmniGlue.
- The anticipation highlights the community's engagement and expectation for advancements in this area of computer vision.
- Fine-tuning TroCR Models Discussion: A user raised a question regarding whether to fine-tune with their dataset using 'trocr-large-stage1' (base) or 'trocr-large-handwriting' (already fine-tuned on the IAM dataset).
- They inquired if fine-tuning a fine-tuned model yields better performance.
Link mentioned: SuperPoint: no description found
HuggingFace ▷ #NLP (2 messages):
Hallucination Detection ModelFine-tuning BERT on Yelp Dataset
- Hallucination Detection Model Released: A new Hallucination Detection Model has been released, upgraded from the Phi-3 to Phi-3.5 base, focusing on evaluating language model outputs for hallucinations.
- Key performance metrics include Precision: 0.77, Recall: 0.91, and F1 Score: 0.83, with overall accuracy hitting 82%; view the model card here.
- Seeking Help on Fine-tuning BERT: A member is looking for resources to fine-tune BERT on the Yelp review dataset with five classes, expressing concerns about achieving accuracy in the 60s.
- They specifically requested a list of current state-of-the-art models and performance metrics on the Yelp dataset, noting the lack of recent updates on the Paperswithcode website.
HuggingFace ▷ #diffusion-discussions (6 messages):
GitHub API usageStack Overflow for DevelopersIncreased Context LLaMA Model Conversionllama.cpp compatibility
- GitHub API query sparks off-topic discussion: A member asked about using the GitHub API to find rebased commits, but another pointed out this channel focuses on diffusion models.
- Despite the off-topic nature, it was suggested that the question could be resolved through Stack Overflow or GitHub Copilot.
- Stack Overflow remains essential for devs: A member emphasized that every developer keeps a tab on Stack Overflow for solutions and knowledge-sharing.
- They noted that Stack Overflow is now offering a suite of GenAI tools for Teams to improve knowledge connection among employees.
- Troubles with LLaMA model conversion: A user shared their struggle in converting the LLaMA-2-7B-32K model to GGUF format and sought help regarding compatibility with llama.cpp.
- They provided a detailed traceback of the error encountered, highlighting an
IndexErrorduring the vocabulary setting phase.
- They provided a detailed traceback of the error encountered, highlighting an
- Stack Overflow - Where Developers Learn, Share, & Build Careers: Stack Overflow | The World’s Largest Online Community for Developers
- togethercomputer/LLaMA-2-7B-32K · Hugging Face: no description found
LM Studio ▷ #general (363 messages🔥🔥):
Issue with downloading models in LM StudioUsing vision-enabled models in LM StudioFeature requests for LM StudioConcerns about model performance and claimsDiscussion about query queueing and caching
- Challenges in downloading and sideloading models: Users discussed issues with downloading models in LM Studio, especially when using VPNs, leading some to sideload models instead.
- The platform's limitations were acknowledged, specifically regarding supported model formats like safetensors and GGUF.
- Vision-enabled models in LM Studio: It was clarified that LM Studio currently does not support llama-3.2-11B vision models due to compatibility issues with llama.cpp.
- Participants raised questions about the broader availability of multimodal models and their functionality within the platform.
- Feature requests and future plans: Users expressed interest in features like query queueing and caching of edits, with some finding existing requests in the feature tracker.
- There was no published roadmap for upcoming features, leaving some topics like 3D generation in uncertain territory.
- Concerns about model performance and credibility: The community discussed new models like LiquidAI and Replete, weighing their performance claims against established options like Qwen-2.5.
- Debate centered around the reliability and testing accessibility of these models, with some expressing skepticism about their marketing hype.
- User inquiries about loading times in LM Studio: A user reported experiencing a significant loading time, even when models were fully loaded into VRAM, causing a delay before evaluation.
- The issue prompted discussions on potential reasons behind the initial loading times observed in the application.
- no title found: no description found
- Florence 2 Large Ft - a Hugging Face Space by SixOpen: no description found
- allenai/OLMoE-1B-7B-0924-Instruct · Hugging Face: no description found
- Fine-tune a pretrained model: no description found
- Liquid Foundation Models: Our First Series of Generative AI Models: Announcing the first series of Liquid Foundation Models (LFMs) – a new generation of generative AI models that achieve state-of-the-art performance at every scale, while maintaining a smaller memory f...
- Replete-LLM-V2.5 - a Replete-AI Collection: no description found
- lmstudio-community (LM Studio Community): no description found
- Llama 3.1 - 405B, 70B & 8B with multilinguality and long context: no description found
- mylesgoose/Llama-3.2-11B-Vision-Instruct · Hugging Face: no description found
- Liquid Foundation Models: Our First Series of Generative AI Models: Announcing the first series of Liquid Foundation Models (LFMs) – a new generation of generative AI models that achieve state-of-the-art performance at every scale, while maintaining a smaller memory f...
- microsoft/Florence-2-large · Hugging Face: no description found
- LM Studio Beta Releases: LM Studio Beta Releases
- Manage chats - Running LLMs Locally | LM Studio Docs: Manage conversation threads with LLMs
- Model not found: no description found
- GitHub - YorkieDev/lmstudioservercodeexamples: This readme contains server code examples from LM Studio v0.2.31: This readme contains server code examples from LM Studio v0.2.31 - YorkieDev/lmstudioservercodeexamples
- Model not found: no description found
- Llama 3.2 1B: llama • Meta • 1B
- GitHub - openai/openai-python: The official Python library for the OpenAI API: The official Python library for the OpenAI API. Contribute to openai/openai-python development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- llama : add support for Chameleon (#8543) · ggerganov/llama.cpp@9a91311: * convert chameleon hf to gguf * add chameleon tokenizer tests * fix lint * implement chameleon graph * add swin norm param * return qk norm weights and biases to original format ...
- mistralai/Pixtral-12B-2409 · Hugging Face: no description found
- GitHub - meta-llama/llama-models: Utilities intended for use with Llama models.: Utilities intended for use with Llama models. Contribute to meta-llama/llama-models development by creating an account on GitHub.
LM Studio ▷ #hardware-discussion (138 messages🔥🔥):
NVIDIA Jetson AGX Thor3090 vs 3090 Ti vs P40 comparisonsMarket pricing for GPUsAI model hosting and rentingIssues with NVIDIA drivers on Linux
- NVIDIA Jetson AGX Thor boasts 128GB VRAM: The NVIDIA Jetson AGX Thor is set to feature 128GB of VRAM in 2025, leading to discussions about potential upgrades among members.
- This revelation sparked interest in whether existing GPUs like the 3090 or P40 would still be viable as the market evolves.
- Comparing GPU performance: 3090 vs 3090 Ti vs P40: Members discussed the performance differences between 3090, 3090 Ti, and P40, with considerations on VRAM and pricing impacting decisions.
- One noted that the P40 runs at approximately half the speed of the 3090, while the cost of GPUs continues to trend upwards unexpectedly.
- Market pricing dynamics for GPUs: There was a consensus that GPU prices are currently high due to factors like scalping and, more recently, demand related to AI workloads.
- The A6000 was discussed as a potential alternative for those looking to invest in high VRAM, although many members lean towards cheaper options like multiple 3090s.
- Renting GPUs for AI workloads: Runpod and Vast were recommended for renting GPUs, where members find that renting can be a more economical choice over outright purchasing high-cost cards.
- Some members argued about the feasibility of recovering costs when renting, especially as demand for powerful GPUs surges.
- Challenges with NVIDIA drivers on Linux: Discussion underscored NVIDIA's Linux drivers being notoriously difficult, especially regarding VRAM offloading, which AMD cards manage more smoothly.
- The community expressed frustrations over configuring NVIDIA's CUDA and other drivers, highlighting a preference for AMD where practical.
- Mark Cuban Shark Tank GIF - Mark Cuban Shark Tank Notes - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- Paulwnos GIF - Paulwnos - Discover & Share GIFs: Click to view the GIF
- You Dont Turn Your Back On Family You Cant Walk Away From Family GIF - You Dont Turn Your Back On Family You Cant Walk Away From Family You Cant Leave Family Behind - Discover & Share GIFs: Click to view the GIF
- GitHub - geohot/cuda_ioctl_sniffer: Sniff CUDA ioctls: Sniff CUDA ioctls. Contribute to geohot/cuda_ioctl_sniffer development by creating an account on GitHub.
- Dell AMD Instinct MI100 32GB Graphics Accelerator | 50NN0 | eBay: no description found
- Reddit - Dive into anything: no description found
GPU MODE ▷ #general (30 messages🔥):
Cerebras chip optimizationServer spam managementTriton talk slidesPerformance metrics for GPUsRobotics development challenges
- Inquiry on Cerebras Chip Code Optimization: A member asked if anyone is working on optimizing code for Cerebras chips, seeking opinions on whether it's a reasonable purchase.
- Another member offered to find someone knowledgeable about it, indicating community interest in the topic.
- Tackling Server Spam Issues: Members discussed the rising wave of crypto scam spam messages and potential preventive measures on Discord.
- Suggestions included stricter verification processes and onboarding questions to mitigate spam and unwanted accounts.
- Accessing Triton Talk Slides: A member sought slides from the Triton talk, to which another member directed them to the GitHub repository for lecture materials.
- This highlights the community's effort to share educational resources and ensure attendees stay informed.
- Evaluation of GPU Performance Metrics: Discussion centered around observed performance metrics, specifically how INT8 performs compared to BF16 on GPUs, noting expected versus actual speedups.
- Members shared experiences of performance discrepancies, particularly regarding accumulation methods in computations.
- Challenges in Robotics Development: A member initiated a brainstorming session about current robotics development challenges, highlighting issues like compute capacity and high labor costs.
- They encouraged collaborative thinking on what tasks could potentially be offloaded to cheaper workforce solutions.
- Everything you need to know about Python 3.13 – JIT and GIL went up the hill | drew's dev blog: All you need to know about the latest Python release including Global Interpreter Lock and Just-in-Time compilation.
- llm.c's Origin and the Future of LLM Compilers - Andrej Karpathy at CUDA MODE: An informal capture from the CUDA mode hackathon today.https://github.com/karpathy/llm.c
- GitHub - gpu-mode/lectures: Material for gpu-mode lectures: Material for gpu-mode lectures. Contribute to gpu-mode/lectures development by creating an account on GitHub.
GPU MODE ▷ #triton (12 messages🔥):
Triton library functionsBlock pointers and tmasTriton deep dive lectureMetal MLIR dialectDevice compilation in Triton
- Triton offers various functions for calculations: One user pointed out that you can compute exponentials using
tl.exp(tl.log(t)*x)or leveragelibdevicewithpow()orfast_powf()details here.- Another member found this information to be exceptionally useful, indicating robust community support for practical implementations.
- Discussion on Block Pointers and tmas: A user mentioned that block pointers do not convert to tmas, leading to a question about potential nuances in this behavior.
- This speculation indicates deeper technical discussions on how Triton handles specific data structures.
- Highlight of Triton Deep Dive Lecture: One attendee expressed gratitude for a deep dive lecture on Triton, noting it attracted over 100 attendees, marking the second-largest live audience so far.
- The speaker thanked a colleague for encouraging their presentation, indicating a supportive community environment.
- Exploration of Metal MLIR Dialect: A member shared a link to a library aiming to be a Metal MLIR dialect, highlighting the
CommandBufferclass, which resembles something akin to a warp.- They also referenced shared memory concepts in Metal, showing the community's interest in optimizing performance.
- How Triton decides on device compilation: Inquiries arose regarding how Triton decides which device to compile for, particularly when a function decorated with @triton.jit is intended for a GPU but fails at compile time.
- Another user suggested looking into
get_current_device()for driver detection as a potential solution, indicating useful troubleshooting resources.
- Another user suggested looking into
- no title found: no description found
- GitHub - INT-FlashAttention2024/INT-FlashAttention: Contribute to INT-FlashAttention2024/INT-FlashAttention development by creating an account on GitHub.
- lectures/lecture_029/presentation.pdf at main · kapilsh/lectures: Material for cuda-mode lectures. Contribute to kapilsh/lectures development by creating an account on GitHub.
GPU MODE ▷ #torch (35 messages🔥):
Batch update option for torchscript hashtableIssues with torch.int_mm() on CPUDebugging AO model replacementsImage-loading alternatives to FFCVZeRO-3 benefits for single GPU inference
- Torchscript hashtable lacks batch update option: A member confirmed there is no 'batch update' option for the torchscript hashtable, referencing the relevant GitHub interface here. They suggested using
cuco::dynamic_mapfor bulk insertion on the GPU, although it may require significant code redesign.- The discussion emphasized that updating hashtables in parallel is fairly uncommon.
- torch._int_mm() returns incorrect results on CPU: A member reported wrong results from
torch._int_mm()on CPU for matrix multiplications with int8 weights, while CUDA produced correct outputs. The issue was logged in this GitHub ticket, indicating a problem with AMD CPUs.- The issue was concerning enough to prompt community discussion about possible workarounds and fixes.
- Debugging model weight replacements in AO: A member inquired about verifying if AO correctly replaced weights and activation functions, and was advised to print the model and check the logs in this pull request. Community members emphasized checking model internals as a way to validate implementation changes.
- Another follower suggested the potential engagement of Deepspeed, but it might not be necessary for single GPU use.
- Exploring image-loading alternatives to FFCV: A member inquired about better image-loading options for PyTorch workflows beyond FFCV, noting its caching and filesystem benefits. Community feedback highlighted new approaches including using streaming datasets, WebDataset, and leveraging torchvision transforms for efficiency.
- However, concerns were raised about the flexibility and overhead in libraries like DALI compared to FFCV.
- ZeRO-3's advantages for single GPU inference: Members engaged in a discussion on the benefits of using ZeRO-3, indicating that it is indeed useful even for single GPU setups, not just for distributed frameworks. A link was provided detailing the key features of ZeRO-3, especially its efficiency with large models on limited resources.
- Clarifications were made regarding its value and the kernel replacement capabilities offered by Deepspeed for users without extensive GPU resources.
- DeepSpeed ZeRO-3 Offload: DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
- ZeRO-Inference: Democratizing massive model inference: DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
- GitHub - KellerJordan/cifar10-airbench: 94% on CIFAR-10 in 2.73 seconds 💨 96% in 27 seconds: 94% on CIFAR-10 in 2.73 seconds 💨 96% in 27 seconds - KellerJordan/cifar10-airbench
- torch._int_mm accuracy issue on AMD CPU · Issue #136746 · pytorch/pytorch: 🐛 Describe the bug When performing matrix multiplication between int8 weights on an AMD CPU, the results are different than those obtained when running the same operation on CUDA or on an Intel CPU.....
- Add more information to quantized linear module and added some logs by jerryzh168 · Pull Request #782 · pytorch/ao: Summary: Fixes #771 Test Plan: python test/dtypes/test_affine_quantized_tensor.py -k test_print_quantized_module Example output: Linear(in_features=128, out_features=256, weight=AffineQuantizedTens...
- pytorch/torch/csrc/jit/python/python_dict.h at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- GitHub - NVIDIA/cuCollections: Contribute to NVIDIA/cuCollections development by creating an account on GitHub.
GPU MODE ▷ #announcements (1 messages):
Triton InternalsLecture ScheduleQuantized TrainingMetal KernelsGPU Optimization
- Kapil Sharma Returns for Triton Internals: We're excited to welcome back guest speaker Kapil Sharma for a deep dive on Triton internals in the
reading-groupstage channel.- The session will commence in about 20 minutes from the announcement.
- Lectures Resume with Stellar Lineup: Lectures are back with 10 scheduled talks showcasing influential GPU hackers from around the world.
- Noteworthy sessions include Quantized Training and Metal Kernels, featuring strong contributors from the server.
- Highlighted Lecturers of the Series: Among the featured speakers are Yineng Zhang for SGLang and Jay Shah for CUTLASS and Flash Attention 3.
- These talks promise to deliver valuable insights into advancements in GPU programming.
- Diverse Topics on GPU Optimization: The lectures will cover a range of topics including Low Bit Triton kernels, DietGPU, and an Introduction to SASS.
- This series aims to attract interest from both beginners and advanced users in GPU technologies.
GPU MODE ▷ #cool-links (4 messages):
AI Discord ServersCuTe/Cutlass Layout AlgebraNext-Token Prediction
- Ranking AI Discord Servers: A member shared a spreadsheet listing and ranking various AI servers based on different criteria including server type and activity levels.
- The server EleutherAI received a 7.9 score, indicating it is 'very active' and offers various community projects and tools.
- Request for Missing Discord Servers: A member noted the absence of the Ultralytics Discord on the previously shared list of AI servers.
- This highlights the importance of maintaining comprehensive resources for the AI community to foster connections.
- Demo Clip for CuTe/Cutlass Layout Algebra: A member shared a link to a demo clip they created, contemplating the production of a video mimicking the style of 3blue1brown to explain CuTe/Cutlass layout algebra.
- The community expressed enthusiasm, indicating a positive reception of the demo's content.
- Next-token Prediction Importance: A member referred to a link discussing that next-token prediction is all you need for certain AI applications, emphasizing its significance.
- This reflects a broader interest in the simplicity and effectiveness of foundational AI concepts.
- Tweet from Kuter Dinel (@KuterDinel): Considering to make a @3blue1brown style video explaining CuTe/Cutlass layout algebra. Let me know what you think of the small demo clip I made.
- discord AI sphere - share with whoever!: no description found
- Emu3: no description found
GPU MODE ▷ #beginner (11 messages🔥):
Difference between Model Parallelism and ZeRO/FSDPUnderstanding FSDP mechanicsOpen source projects in NLPIntroduction to LLM research workflowHuggingFace tools and libraries
- Clarifying Model Parallelism vs ZeRO/FSDP: A member sought to understand the difference between Model Parallelism and ZeRO/FSDP in PyTorch, questioning whether ZeRO can be seen as a form of model parallelism due to its parameter distribution method.
- Another member provided clarity by mentioning that FSDP combines sharding and requires an understanding of distinct layers in its architecture.
- FSDP Mechanics Explained: FSDP shards model layers across GPUs and requires all-gather during the forward pass while maintaining a shard of each layer locally, notably differing from pipeline parallelism.
- Discussions revealed that FSDP coordinates communications to enhance efficiency, making it distinct from pipeline approaches where each device handles different layers.
- Open Source Projects for Beginners: A member inquired about beginner-friendly open source projects in NLP, LLM, and reinforcement learning focusing on accessible tasks.
- This inquiry reflects a growing interest in educational resources for newcomers to CUDA/Triton and its applications in various domains.
- Starting Points in LLM Research Workflow: A member expressed a need for guidance on transitioning from CNNs with TensorFlow to exploring LLM and Diffusion technologies, primarily using PyTorch.
- They sought clarity on the key components, like HuggingFace Hub and the Diffusers library, to define their integration in research functions.
- Explaining HuggingFace Libraries: There was a request for examples of workflows using HuggingFace tools, indicating a need to learn about datasets, pretrained weights, and associated libraries like Transformers and Accelerate.
- Clarifying unknown terms demonstrates a larger trend of researchers needing support as they expand into new AI methodologies.
- Reddit - Dive into anything: no description found
- Getting Started with Fully Sharded Data Parallel(FSDP) — PyTorch Tutorials 2.4.0+cu121 documentation: no description found
GPU MODE ▷ #youtube-recordings (3 messages):
Lecture 29: Triton InternalsIRL Meetup Talks Upload
- Triton Internals Lecture Released: The YouTube video titled Lecture 29: Triton Internals featuring speaker Kapil Sharma has been shared.
- This lecture dives into the inner workings of Triton and highlights its technical aspects.
- IRL Meetup Talks Coming Soon: It has been confirmed that the IRL meetup talks will be uploaded to YouTube in a matter of days.
- These upcoming videos are described as far more polished than usual, prompting an apology for the delay.
Link mentioned: Lecture 29: Triton Internals: Speaker: Kapil Sharma
GPU MODE ▷ #torchao (35 messages🔥):
CPUOffloadOptimizerFP8 and INT8 QuantizationModel ProfilingHugging Face IntegrationSOAP Optim with Flux Tuning
- Profiling CPUOffloadOptimizer with Experts: Members discussed profiling on the torchao CPUOffloadOptimizer, with one seeking to consult a contributor for feedback.
- It's better to create a thread for others to join in the discussion rather than private messages.
- Challenges with FP8 and INT8 Loading: Concerns were raised about out of memory (OOM) errors when loading lycoris adapters in FP8, but it seems to work fine in INT8.
- FP8's main advantage appears to be computation speedup, as shared by members discussing quantization strategies.
- Dynamic vs Weight-Only Quantization Explained: A member explained that dynamic quantization mainly supports compute-bound models while weight-only quantization is beneficial for memory-bound models, as learned from discussions on Cohere's talks.
- The complexity of FP8 quantization was highlighted, especially regarding trade-offs in memory load and compute benefits.
- Addressing Issues with Evaluation Script: There was a discussion about issues with evaluation scripts, specifically with using the pile_hackernews dataset which led to configuration errors and the need for version checks.
- Members usually prefer wikitext for evaluation, pointing out gaps in available configurations and suggested further investigation.
- Introduction of Int8 Support in Main Branch: One member merged int8-torchao support for full/mixed precision training into the main branch of bghira/simpletuner, citing its usefulness in avoiding OOM errors with SOAP optim.
- Thanks to int8, they reported that no state offload is needed under the current setup, leading to more efficient Flux tuning.
- Lecture 7 Advanced Quantization: Slides: https://www.dropbox.com/scl/fi/hzfx1l267m8gwyhcjvfk4/Quantization-Cuda-vs-Triton.pdf?rlkey=s4j64ivi2kpp2l0uq8xjdwbab&dl=0
- ao/torchao/prototype/low_bit_optim at main · pytorch/ao: PyTorch native quantization and sparsity for training and inference - pytorch/ao
GPU MODE ▷ #sequence-parallel (1 messages):
glaxus_: Has anyone seen this for long context inference? https://arxiv.org/pdf/2409.17264v1
GPU MODE ▷ #off-topic (83 messages🔥🔥):
GeForce RTX 5090Power supply challengesApple Watch and LLMsCalifornia AI safety billCooling solutions for high-end GPUs
- GeForce RTX 5090 Specs Stir Debate: The newly rumored GeForce RTX 5090 boasts specs like 600W TDP, 512-bit GDDR7, and 32GB of memory, leaving users curious about power and cooling needs.
- How do you even cool that? and I thought my 4070 produced a lot of heat at 200W highlight user concerns about managing such power requirements.
- Power Supply Upgrades Required: With the RTX 5090 drawing a staggering 600W, many in the community are questioning if they need to upgrade their power supplies to meet these demands.
- As one user noted, most people are going to need a PSU upgrade now indicating widespread concern about the increasing power needs.
- Apple Watch: The Next AI Frontier?: There’s discussion around the potential to run Llama 3.2 1B natively on an Apple Watch, with users considering if the device's architecture can support it.
- One user remarked, if Apple Watch is powerful enough to run a coherent LLM we've really made it, showcasing aspirations for portable AI.
- California's AI Safety Bill Vetoed: California Governor Gavin Newsom vetoed the SB 1047 AI safety bill, citing it could impose unnecessary burdens on AI companies and might be too broad.
- He emphasized that the bill failed to consider the context in which AI systems are deployed, impacting even basic functionalities.
- Cooling Solutions for High-End GPUs Discussed: Multiple users expressed skepticism about the effectiveness of a dual-fan design for cooling the RTX 5090, considering it may struggle under max load.
- Recommendations floated included using water-cooling solutions, with one user claiming, power users will probably need to get like a hybrid one with water cooling.
- Tweet from kopite7kimi (@kopite7kimi): GeForce RTX 5090 PG144/145-SKU30 GB202-300-A1 21760FP32 512-bit GDDR7 32G 600W
- California governor vetoes major AI safety bill: The California AI safety bill is done.
- 4090 Rtx GIF - 4090 RTX - Discover & Share GIFs: Click to view the GIF
GPU MODE ▷ #irl-meetup (1 messages):
marcelo5444: Anyone in ECCV Milan?
GPU MODE ▷ #hqq-mobius (1 messages):
HQQ model serializationTransformers library
- HQQ model serialization gets full support: The recent pull request #33141 adds full support for saving and loading HQQ-quantized models directly in the Transformers library.
- Previously, serialization was handled on the hqq-lib side using the .pt format, but this update aims to streamline the process.
- Follow-up on previous PR #32379: This pull request is a follow-up to #32379, aimed at enhancing the serialization capabilities within the library.
- It reflects ongoing community efforts to improve model handling and emphasize collaboration in development.
Link mentioned: Hqq serialization by mobicham · Pull Request #33141 · huggingface/transformers: Follow-up to #32379 The goal of this PR is to add full support to save/load HQQ-quantized models directly in transformers. So far, serialization was done on the hqq-lib side via the .pt format whic...
GPU MODE ▷ #llmdotc (23 messages🔥):
repkv_backward_kernel2 improvementsFP8 implementation strategiesLlama3 issuesPre-swizzled layout for FP8Custom matmul kernel developments
- repkv_backward_kernel2 shows promising improvements: The latest PR for
repkv_backward_kernel2has been submitted, showcasing better performance with fewer threads compared torepkv_backward_kernel1and improved execution time.- Details can be found here, highlighting the enhancements made based on suggestions from the community.
- Exploring a new approach for FP8 implementation: A member discussed a non-intrusive approach to FP8 that retains performance while integrating scaling factors for larger matrices.
- The implementation leverages a combinatorial method for efficient scaling which is expected to outperform existing methods if integrated.
- Investigating Llama3 issues with discrepancies: A conversation was sparked around the unresolved Llama3 discrepancies, particularly regarding repkv and rope functionality, with members offering to assist in troubleshooting.
- One member noted their willingness to explore these issues further and suggested reviewing the
repkvkernel PR in the meantime.
- One member noted their willingness to explore these issues further and suggested reviewing the
- Potential of pre-swizzled layout in FP8 applications: Discussion highlighted the benefits of a pre-swizzled layout for FP8, which could facilitate improved performance at the cost of additional memory usage.
- Members noted that this technique would be particularly useful for larger matrices, allowing for warp-wide linear loads during multiplication.
- Debating custom matmul kernel scaling solutions: A member outlined a method for managing scaling factors during the accumulation process in a custom matmul kernel, suggesting temporary registers for intermediary results.
- The approach involves utilizing multiple WGMMA operations when scaling factors exceed certain thresholds to optimize performance.
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- Add `repkv_backward_kernel2` and `repkv_kernel2` by insop · Pull Request #771 · karpathy/llm.c: Changes Add repkv_backward_kernel2 improve repkv_backward_kernel1 by reducing thread used per @karpathy's suggestion Also add repkv_kernel2 simiar to backward_kernel2 Here is the test output...
GPU MODE ▷ #rocm (207 messages🔥🔥):
MI300X Access for CommunityPerformance Issues with AMD GPUsTuning MIOpen KernelsAMD-Llama Model TrainingUsing Triton for Flash Attention
- MI300X Access to Boost Adoption: Darrick from TensorWave expressed interest in providing MI300X GPUs to the community to enhance adoption and education, welcoming direct messages for coordination.
- Anush from AMD also offered sponsorship for MI300 access, indicating a collaborative effort to engage the community.
- Performance Challenges with AMD GPUs: Discussions revealed significant performance hurdles with AMD GPUs, especially regarding scaling across nodes, with a focus on GFX1100 and MI300 architectures underperforming.
- Members noted that while NVIDIA's GPUs often perform better, efforts to push AMD GPU performance, particularly in multi-node setups, are ongoing.
- Tuning MIOpen for Efficient Performance: The conversation highlighted the long tuning times of MIOpen kernels, particularly under ROCm 6.2, with a call for methods to bypass unnecessary tunings during testing.
- Setting the environment variable MIOPEN_FIND_MODE=FAST was discussed as a workaround to minimize tuning time while sacrificing minimal performance.
- Training AMD-Llama Model: Anthonix reported training an AMD-llama-135M model on a 7900XTX machine achieving approximately 335k tokens/sec, slightly faster than previous 8xMI250x results.
- The model's implementation faced challenges due to using Multi-Head Attention (MHA) instead of Gated Query Attention (GQA) and longer context lengths.
- Using Triton for Flash Attention: Members shared links to benchmarks utilizing Triton for Flash Attention on MI300 and noted concerns over slow performance during testing.
- Progress on a backward function for Flash Attention was mentioned, but skepticism remained about its overall efficiency and usability.
- Expose experimental LLVM features for automatic differentiation and GPU offloading - Rust Project Goals: no description found
- amd/AMD-Llama-135m · Hugging Face: no description found
- GitHub - jzhang38/TinyLlama: The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens.: The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens. - jzhang38/TinyLlama
- Using the find APIs and immediate mode — MIOpen 3.2.0 Documentation: no description found
- Using the performance database — MIOpen 3.2.0 Documentation: no description found
GPU MODE ▷ #bitnet (1 messages):
Multi-GPU UsageLlama-based Models
- Multi-GPU Setup Made Easy: Members are advised to use torchrun for multi-GPU setups, with the command highlighted at the top of the file.
- The default method is fsdp2, but adding
--ddpswitches to using DDP instead.
- The default method is fsdp2, but adding
- Llama Models Ready for Action: You can seamlessly use any Llama-based models from Hugging Face by specifying them in
--model-id, leveraging HF's LlamaForCausalLM.- The default model option serves primarily for testing purposes.
GPU MODE ▷ #sparsity-pruning (1 messages):
marksaroufim: https://github.com/pytorch/torchtune/pull/1698
GPU MODE ▷ #webgpu (12 messages🔥):
LiteRT vs gpu.cppWebNN comparisonManual networking in gpu.cppBuffer Pass Read/WriteWebGPU Resources
- LiteRT surpasses gpu.cpp for model runtime: LiteRT is designed to utilize a combination of GPU, CPU, and NPU based on device availability, while gpu.cpp lacks similar capabilities.
- This indicates that for optimal performance, using LiteRT is preferred over gpu.cpp, which demands a more manual approach.
- LiteRT closer to WebNN but better equipped: LiteRT is compared to WebNN, offering enhanced functionality to load and set up models from files, a feature absent in WebNN.
- This positions LiteRT as a more comprehensive solution for those requiring model loading and configuration.
- Manual networking required with gpu.cpp: Creating networks with gpu.cpp requires a thorough understanding and manual configuration to ensure performance that rivals LiteRT.
- This complexity may challenge developers who are less experienced with the intricacies of manual networking.
- Buffer Pass operates as expected: A developer confirmed that writing to buffer A in pass 1 allows reading the results from pass 1 in pass 2, maintaining logical flow across multiple layers.
- This ensures that network layers can effectively compute and pass data along as designed.
- Limited WebGPU resources available: Developers often refer to the specification and Google's 'what's new in WebGPU' blog posts as their primary resources.
- However, the scarcity of literature on WebGPU poses challenges in finding straightforward information.
GPU MODE ▷ #liger-kernel (6 messages):
Gemma2 Convergence Tests FailureLLama3.2-Vision Patch IssuesRoadmap Tracker for 2024 Q4
- Gemma2 tests failing on main branch: The Gemma2 convergence tests are currently failing on the main branch, as reported in this GitHub action. Additionally, qwen2-vl multimodal tests are also having issues since HF published version 4.45.0, but fixes are available in upcoming PRs.
- LLama3.2-Vision requires a pre-trained tokenizer: A member is ready with a llama3.2-vision patch but is facing an issue with the need for a pre-trained tokenizer during multimodal tests. Tests run locally pass, but require a HF hub token that acknowledges the llama license for GitHub CI/CD.
- 2024 Q4 Roadmap Tracker Initiated: A roadmap tracker for Q4 2024 has been created to manage the growing volume of requests more effectively. This pinned issue aims to keep track of issues and PRs and has assigned specific maintainers to various tasks, as detailed in this GitHub issue.
- poke tests · linkedin/Liger-Kernel@81a75e7: Efficient Triton Kernels for LLM Training. Contribute to linkedin/Liger-Kernel development by creating an account on GitHub.
- 2024 Q4 Roadmap · Issue #285 · linkedin/Liger-Kernel: As the community grows, keeping track of issues and PRs becomes more and more challenging. This pinned issue will serve as the central place to manage the progress in 2024 Q4 (~2024/12). Here we on...
GPU MODE ▷ #metal (16 messages🔥):
Metal Shading LanguageM2 vs M3 device performanceMetal backend for TritonBuilding on device agentsResource sharing for Metal
- Metal Shading Language Specification is Essential: For anyone working with Metal, the Metal Shading Language Specification is highly recommended as a foundational resource: View Specification.
- As one member noted, “your best bet is the Metal shading language specification”, reflecting its importance.
- M3 Performance Insights: Users are experiencing challenges with the M3 device, expressing that certain features and resources are still catching up. One user mentioned their excitement was dampened while trying to use it to train on-device specialists, as it struggled to handle queries correctly.
- Creating Metal Backend for Triton: A member inquired about the feasibility of establishing a Metal backend for Triton, outlining a potential conversion process from Triton IR to Metal Shader.
- They also listed useful resources, including an LLVM IR to Metal shader converter: Overview, and highlighted the MLIR Metal dialect on GitHub.
- Understanding Floating Point Rates in Metal: F16 is reported to be full rate when using Metal, whereas BFS16 is only emulated on certain devices, particularly the M1. A user shared that this supports efficient computational tasks on different Apple hardware.
- General Advice on Device Agents: A user expressed frustration building on-device agents due to lack of information and support concerning their MacBook Pro M3. The conversation also showcased a member offering help by asking about the specific device in use.
- Metal shader converter - Metal - Apple Developer: Metal shader converter converts shader intermediate representations in LLVM IR bytecode into bytecode suitable to be loaded into Metal. It’s available as a library and a standalone executable.
- GitHub - NicolaLancellotti/metal-dialect: MLIR metal dialect: MLIR metal dialect. Contribute to NicolaLancellotti/metal-dialect development by creating an account on GitHub.
GPU MODE ▷ #self-promotion (8 messages🔥):
Discord AutoModSpam managementAnti-spam tools
- Discussion on Automated Spam Cleaning: Members discussed the possibility of using a bot to automatically clean spam messages. The consensus is that there's a tool available for this purpose, prompting further inquiry into its details.
- One member noted that using such a tool could significantly reduce the effort currently spent on spam management.
- AutoMod's Success in Message Removal: It was highlighted that AutoMod has managed to remove over 20 million unwanted messages from servers since its launch, which has greatly aided community moderation efforts.
- The improvement in community safety is notable, as it potentially saves moderators 1157 days previously spent reviewing messages.
- Inquiry for Specific Anti-Spam Tools: A member requested a link to specific anti-spam tools for further research, signaling a proactive approach to spam issues.
- The response contained a link to the Discord Anti-Spam Safety Update for more information.
- Features of AutoMod Discussed: Members noted that all AutoMod features were enabled in their community settings, aiming to enhance moderation efficiency.
- The discussion reflects a commitment to leveraging available tools to maintain a welcoming environment.
GPU MODE ▷ #nccl-in-triton (6 messages):
Collaboration on Triton ProjectChallenges in Memory ManagementWeak Memory Consistency ModelsLearning Opportunities in TritonProject Enthusiasm
- Collaboration on Triton Project Sparks Interest: A user expressed eagerness to collaborate on the Triton project despite lacking experience, stating they are eager to learn.
- This enthusiasm was echoed by others who are passionate about diving deeper into challenging tasks.
- Memory Management Complexity Discussed: Concerns were raised by a user regarding the complexities of memory management and achieving consistency, particularly in weak memory models across nvlink domains.
- They emphasized that crafting a prototype with a strong consistency model may be straightforward.
- Weak Memory Consistency Can Be Learned: Another member pointed out that learning to navigate weak memory consistency models is feasible and encouraged focusing on reductions within a single node over nvlink.
- They offered their support as a helpful resource to those with questions about this challenge.
- Project's Difficulty Meets Enthusiasm: One participant acknowledged the project's fancy yet challenging nature, indicating that overcoming such hurdles is part of the hacker spirit.
- They urged others to keep posted on the progress related to the Triton project.
Modular (Mojo 🔥) ▷ #general (18 messages🔥):
Modular Community MeetingDesktop Background PreferencesYouTube Meeting Recordings
- Modular Community Meeting Agenda Revealed: Today's Modular Community Meeting at 10am PT will feature a packed agenda, including talks on the MAX driver & engine API from <@447855150409842719> and a Q&A on Magic.
- Participants are invited to join via Zoom and can add future events to their calendars through the Modular Community Calendar.
- YouTube Recordings of Community Meetings: All Modular Community Meetings are recorded and subsequently posted to YouTube, including today's meeting available at this link.
- The recordings are easily accessible for those who can’t attend live, ensuring no one misses out on the valuable discussions.
- T-shirt Interest Surfaces in Chat: A user expressed interest in a Modular-themed t-shirt, indicating a desire for more community swag.
- This playful suggestion hints at building a stronger community identity through merchandise.
- Query about Timezone for Community Meeting: A member inquired whether the community meeting time of 18:00 was in their local timezone, to which the answer was confirmed as yes.
- Another member clarified the time zone details, ensuring participants are well-prepared to join.
- Personal Preferences on Desktop Background: A member shared their minimalist approach to desktop backgrounds, favoring a solid dark tan color but open to improvements.
- The suggestion to include a small mojo fire in the center indicates a creative lean towards personalized touches.
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- Google Calendar - Sign in to Access & Edit Your Schedule: no description found
Modular (Mojo 🔥) ▷ #mojo (232 messages🔥🔥):
Mojo Language FeaturesEmbedding Models in MojoManaging Native DependenciesMojopkg EnhancementsWarnings on MacOS
- Proposal for Enhanced Mojo Language Features: A discussion emerged on the need for advanced features in Mojo, such as named variants for message passing and better handling of tagged unions using existing constructs without introducing new ones.
- Participants debated the ergonomics of defining types and the implications of having both nominal and structural types in the language design.
- Embedding Models within Mojopkg: Embedding capabilities for Mojopkg were highlighted, with use cases including bundling models and dependencies within a single executable application.
- Examples were drawn from other languages, showcasing how simpler user experiences could be achieved by including necessary components directly within the package.
- Enhancements for Mojopkg: Suggestions were made for Mojopkg to incorporate features such as encryption and easier embedding of file structures, which could streamline dependency management.
- While some features were deemed niche, the idea of embedding relevant files and models into a package was recognized as potentially beneficial for various applications.
- Handling Native Dependencies: Concerns were raised about the potential for Mojopkg to simplify the inclusion of dependencies, enabling more accessible installation and configuration for users.
- Discussions revolved around practical implementations, including embedding installers for runtimes like Python into Mojo applications.
- Warnings Encountered on MacOS: A user reported receiving multiple warnings related to compatibility between the built object files for macOS version 15.0 and the linking process targeting version 14.4.
- The warnings, although not fatal, indicate potential issues with compatibility that may need addressing in future releases.
- GitHub - hellux/jotdown: A Djot parser library: A Djot parser library. Contribute to hellux/jotdown development by creating an account on GitHub.
- rfcs/text/0000-partial_types.md at partial_types3 · VitWW/rfcs: RFCs for changes to Rust. Contribute to VitWW/rfcs development by creating an account on GitHub.
Nous Research AI ▷ #general (189 messages🔥🔥):
Nous ResearchDistro Paper TimelineAI Model Fine-tuningLiquid Foundation ModelsNLP Research Opportunities
- Understanding Nous Research: Nous Research is focused on open source AI research, offering opportunities for collaboration with independent builders and enthusiasts.
- They have released various models, including the Hermes family, and are currently involved in projects like DisTrO to accelerate AI development.
- Upcoming Distro Paper Release: The release of the Distro paper is anticipated to be announced soon, as indicated by members in the channel.
- There is a sense of excitement and expectation surrounding this paper due to its relevance in the AI community.
- Advancements in AI Model Fine-tuning: Recent developments mention a new continuous-trained model, Rombodawg’s Replete-LLM, that topped the OpenLLM leaderboard for 7B models.
- Fine-tuning techniques like TIES merging are highlighted as methods to improve model benchmarks significantly.
- Introduction of Liquid Foundation Models: LiquidAI has introduced Liquid Foundation Models, with variants of 1B, 3B, and 40B, capturing attention in the AI community.
- The models aim to offer new approaches and functionalities in the landscape of AI language models.
- Entry into NLP Research for Students: New participants in the channel express interest in getting involved in AI, particularly in NLP, and seek guidance on internships.
- Issues surrounding opportunities for students from regions with limited exposure to AI research, like Pakistan, have been discussed alongside pathways to international programs.
- no title found: no description found
- Tweet from Liquid AI (@LiquidAI_): Today we introduce Liquid Foundation Models (LFMs) to the world with the first series of our Language LFMs: A 1B, 3B, and a 40B model. (/n)
- Tweet from Alex Volkov (Thursd/AI) (@altryne): Ok holy shit ... notebookLM "podcasts" hosts realize they are AI is the best thing I've heard in this app in a while! 😂 "I tried to call my wife.. the number was not real" Als...
- Tweet from Andrej Karpathy (@karpathy): Oops sorry it's a new on-demand podcast on whatever source materials you give it it / link it. Generate them in Google's Notebook ML: https://notebooklm.google.com/ + New Notebook Link sourc...
- Tweet from Ahmad Al-Dahle (@Ahmad_Al_Dahle): Behind the scenes creating Meta AI voice.
- DisTrO and the Quest for Community-Trained AI Models | Andreessen Horowitz: Bowen Peng and Jeffrey Quesnelle of Nous Research discuss their mission to accelerate open source AI research, including with a new project called DisTrO.
- mylesgoose/Llama-3.2-3B-instruct-abliterated-Q8_0-GGUF · Hugging Face: no description found
- Kamen Rider Build Henshin GIF - Kamen Rider Build Henshin Rabbit Tank - Discover & Share GIFs: Click to view the GIF
- Exa: The Exa API retrieves the best, realtime data from the web to complement your AI
- Monday Mood GIF - Monday Mood - Discover & Share GIFs: Click to view the GIF
- Tweet from Benjamin De Kraker 🏴☠️ (@BenjaminDEKR): I just got a GPT-4o (not o1) response which included 20 seconds of thinking... Chain of Thought is being tested on 4o...?
- Tweet from a16z (@a16z): Could the next big open source model be built by a global network of independent builders? @NousResearch’s DisTrO is showing it’s possible—training powerful AI models using the public internet, witho...
- Tweet from N8 Programs (@N8Programs): MLX just added full finetuning... 100-200 tok/sec for bf16 Llama 3.2 3B. Let's gooooo
- Creating A Swarm Based Attention Mechanism: Link to Research Paper: https://lime-georgette-80.tiiny.siteLink to Colab Notebook: https://colab.research.google.com/drive/1cVM-GpAEp1nGX4vYx1Rr_tNwQSlFmPeT...
- Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling: no description found
- no title found: no description found
- GitHub - MinishLab/model2vec: Model2Vec: Distill a Small Fast Model from any Sentence Transformer: Model2Vec: Distill a Small Fast Model from any Sentence Transformer - MinishLab/model2vec
- Why Gavin Newsom vetoed California’s bold bid to regulate AI: The CA legislation would have required companies to test AI models for critical harms they could cause to society.
- archit11/worldbuilding · Datasets at Hugging Face: no description found
Nous Research AI ▷ #ask-about-llms (16 messages🔥):
Hyperparameter AdjustmentMultimodal Input LLMsOpen-sourcing ModelsRL Techniques in InferenceInference on CPU
- Hyperparameter Adjustments Are Necessary: Yes, you do need hyperparameter adjustments when training models of different sizes, as noted by a member.
- Specifically, they mentioned needing less epochs and lower learning rates for larger models like 70B and 40B.
- Cheapest Multimodal Input LLMs Discussed: A member suggested that Llama 3.2 with the Together API is likely the cheapest option for a Multimodal Input LLM right now.
- Another chimed in with price details, noting that 11B vision instruct is $0.18/1M and 90B is $1.20/1M.
- Open-Sourcing Models Could Benefit Community: Discussion arose around whether open-sourcing a model like O1 would be beneficial for the community.
- Members expressed that while the key advancements come from the inference process using new RL techniques, there could still be significant community value in making it public.
- Running Models on CPU: One member confirmed that ColpaLigemma3B could run on CPU but with limited speed and RAM requirements.
- They reported that it wouldn’t need more than 3GB RAM and could be reduced to 500MB using quantization.
Nous Research AI ▷ #research-papers (4 messages):
Medical AI Research PapersLLM Models in HealthcareAI Ethics in Medicine
- Last Week in Medical AI Highlights: The latest roundup includes a preliminary study on o1 in medicine, assessing the potential for AI doctors and featuring a diverse range of models like DREAMS and Uni-Med.
- Key frameworks discussed involve Digital Twin technology for oncology and InterMind for depression assessment, showcasing advancements in healthcare LLM methodologies.
- Emerging Models in Medical AI: New models such as O1 in Medicine and the Genome Language Model are explored, highlighting both opportunities and challenges in AI-driven healthcare solutions.
- Additional benchmarks include CHBench for Chinese LLMs and assessments of PALLM focusing on palliative care, emphasizing the reliability of medical LLMs.
- AI Ethics Discussions: A focus on ethics includes evaluating confidence intervals in medical imaging AI and the current readiness of generative AI for clinical environments.
- These discussions are critical as the healthcare field integrates AI technology, ensuring ethical standards are maintained.
- Patient Education via LLMs: Innovative applications like fine-tuning LLMs for radiology reports and utilizing LLMs for back pain education demonstrate practical uses in patient care.
- Efforts to enhance healthcare AI through retrieved context and continuous pretraining signify ongoing developments in the field.
- New Resources and Reviews: Resources include a comprehensive review on LLMs in Healthcare, shedding light on the evolution from general to specific medical applications.
- An examination of EHR information retrieval and guidelines for AI in brachytherapy were also highlighted, reflecting the expanding expertise in the domain.
- Tweet from Open Life Science AI (@OpenlifesciAI): Last Week in Medical AI: Top Research Papers/Models 🏅(September 21 - September 27, 2024) 🏅 Medical AI Paper of the week A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor? Autho...
- proem: answers to your questions supported by scientific research
Nous Research AI ▷ #interesting-links (13 messages🔥):
DisTrO AI ProjectAI Server RankingsQuantum Computing in Data GenerationEleutherAI CommunityVPTQ Quantization Algorithm
- DisTrO AI Project accelerates open source efforts: In the recent AI + a16z episode, Bowen Peng and Jeffrey Quesnelle from Nous Research discussed their project DisTrO which enables faster training of AI models across the internet.
- Jeffrey highlighted the potential threats from closed source models, stating, 'What if we don’t get Llama 4? That’s like an actual existential threat...'
- Ranked list of AI servers includes Nous Research: A member shared a Google Spreadsheet listing and ranking various AI servers, mentioning that Nous Research is featured among them.
- It includes community projects and resources, but a note was made to consider the ratings cautiously as they reflect personal utility in LLM research.
- Quantum computing shows potential in synthetic data: Discussion arose around the role of quantum computing in synthetic data generation, with a focus on its emergent capabilities, illustrated by a simple quantum generator experiment.
- Further insights were shared through an article titled 'A Basic Introduction to Quantum GANs' available on Towards Data Science.
- Community discussions on LLM training and functionality: Members expressed interest in engaging with communities that focus on LLM training, with specific mentions of the EleutherAI server as a promising venue for such discussions.
- Suggestions were also made to explore other servers like Mech Interp and Alignment Jams for additional insights on LLM operations.
- VPTQ quantization algorithm released: A new GitHub project by Microsoft titled VPTQ introduces a flexible low-bit quantization algorithm aimed at optimizing model performance.
- This tool is specifically designed for researchers seeking efficient model training and deployment solutions.
- Tweet from Towards Data Science (@TDataScience): Quantum computing's role in synthetic data generation is gaining interest. A simple experiment using a “quantum” generator showcases just a fraction of its potential. Read more from @jamarinval no...
- DisTrO and the Quest for Community-Trained AI Models | Andreessen Horowitz: Bowen Peng and Jeffrey Quesnelle of Nous Research discuss their mission to accelerate open source AI research, including with a new project called DisTrO.
- discord AI sphere - share with whoever!: no description found
- GitHub - microsoft/VPTQ: VPTQ, A Flexible and Extreme low-bit quantization algorithm: VPTQ, A Flexible and Extreme low-bit quantization algorithm - microsoft/VPTQ
Nous Research AI ▷ #research-papers (4 messages):
Medical AI Paper of the WeekNew Medical LLMsFrameworks and Methodologies for Healthcare AIMedical LLM ApplicationsAI in Healthcare Ethics
- Medical AI Paper of the Week: Are We Closer to an AI Doctor?: The highlighted paper, A Preliminary Study of o1 in Medicine, explores the potential for AI to function as a doctor, authored by various experts in the field.
- This paper was recognized as the Medical AI Paper of the Week, showcasing its relevance in ongoing discussions about AI's role in healthcare.
- Emerging Models: DREAMS and Uni-Med: New models like DREAMS, a Python Framework for Medical LLMs, and Uni-Med, a Unified Medical Generalist LLM, are making waves in the AI healthcare landscape.
- These developments signal a shift towards more specialized and robust tools for healthcare applications.
- Innovative Frameworks for Healthcare AI: Innovative methodologies such as Digital Twin for Oncology Operations and Enhancing Guardrails for Healthcare AI aim to improve the safety and efficiency of medical AI applications.
- Additionally, tools like InterMind offer LLM-powered assessments for depression, reflecting a focus on mental health.
- Applications of LLMs in Healthcare: LLMs for Mental Health Severity Prediction and Fine-tuning LLMs for Radiology Reports are recent applications that demonstrate AI's potential to enhance patient care.
- Moreover, there are ongoing efforts in boosting healthcare LLMs with retrieved context and continuous pretraining, which could refine clinical practices.
- Ethics of AI in Healthcare: Discussions on Confidence Intervals in Medical Imaging AI and Generative AI Readiness for Clinical Use highlight the growing concerns around ethics in AI technologies.
- Addressing these ethical considerations is crucial as AI technologies become increasingly integrated into clinical settings.
- Tweet from Open Life Science AI (@OpenlifesciAI): Last Week in Medical AI: Top Research Papers/Models 🏅(September 21 - September 27, 2024) 🏅 Medical AI Paper of the week A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor? Autho...
- proem: answers to your questions supported by scientific research
Nous Research AI ▷ #reasoning-tasks (4 messages):
AGI speculationFunding AGI development
- Speculation on AGI achievement: Nobody knows if or how AGI can be achieved until it is actually achieved, emphasized a member, questioning the certainty of predictions in the field.
- Another member added that those claiming to know are likely just speculating & clout-chasing, illustrating skepticism towards bold assertions.
- Money as the solution for AGI: In a starkly different view, a member confidently proclaimed, I know how AGI can be achieved!!! hinting at a clear solution.
- Their answer? Money. Lots of money, suggesting that financial resources are the key to unlocking AGI development.
Perplexity AI ▷ #general (182 messages🔥🔥):
Perplexity performance issuesFelo vs Perplexity comparisonAPI inconsistenciesDocument uploading vs pastingLaTeX formula discussion
- Perplexity performance issues discussed: Users reported inconsistent responses from Perplexity when switching between web and academic paper searches, with one instance yielding no citations.
- Concerns about whether these inconsistencies indicate a feature or a bug were raised among members.
- Felo vs Perplexity comparison: Discussions highlighted that many users find Felo more effective for academic searches compared to Perplexity, citing better access to relevant papers.
- Users also noted that Felo’s interface features, like hovering for source previews, enhance the research experience over Perplexity.
- API inconsistencies raised: Questions around the API's ability to provide consistent output across formats like JSON, HTML, and Markdown were brought up, with users expressing frustration over mixed results.
- Suggestions included experimenting with parameters like temperature and top-p to improve API response consistency.
- Document uploading vs pasting in conversation: A user inquired whether uploading documents or pasting content directly into the chat would yield better referencing from the AI.
- Responses suggested testing both methods to evaluate which produces more reliable interactions.
- LaTeX formula discussion: A user shared a set of complex equations in LaTeX format and highlighted the differences in evaluation between models like Claude Opus and others.
- The user ultimately found the referenced paper that provided context for the equations, resolving their query.
- Tweet from TestingCatalog News 🗞 (@testingcatalog): WIP 🚧: Perplexity is testing an addition of Portuguese and Italian languages.
- Perplexity - Race to Infinity: Welcome back to school! For just two weeks, redeem one free month of Perplexity Pro on us. Refer your friends, because if your school hits 500 signups we'll upgrade that free month to an entire free y...
- Llama 3.1 - 405B, 70B & 8B with multilinguality and long context: no description found
Perplexity AI ▷ #sharing (16 messages🔥):
Insights into the MultiverseIsrael-Hezbollah conflict escalationNew AI design toolsTexas county AI applicationsFirst Schizophrenia Med in 30 Years
- Explore the Multiverse with New Insights: Perplexity AI highlighted new findings concerning the Multiverse, promising exciting developments in the realm of theoretical physics. Check out the discussion here.
- This talk delves into fresh perspectives on reality and cosmic structures, sparking curiosity among avid science enthusiasts.
- Escalation of the Israel-Hezbollah Conflict: Recent discussions raised concerns about the Israel-Hezbollah conflict, showcasing potential escalations and tensions in the region. For more details, see the current developments.
- Participants shared insights on the implications of this conflict, including historical context and geopolitical stakes.
- New AI Design Tools Unveiled: A link was shared about new AI design tools, showcasing innovations that could reshape creative processes in various fields. Discover more about these tools here.
- The discussion highlighted how these tools can enhance productivity and spark creativity among designers.
- Texas County's Innovative AI Applications: A member referenced a page detailing Texas county's AI applications, illustrating how local governments are leveraging technology. For insights, visit this resource.
- These applications offer a glimpse into practical uses of AI in public service and administration.
- Launch of First Schizophrenia Med in 30 Years: Perplexity AI announced the launch of the first schizophrenia medication in three decades, marking a significant breakthrough in mental health treatment. Watch this video for more insights.
- The conversation underscored the potential impact of this development on patient care and treatment options.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (2 messages):
PPLX API Integration IssuesReal Estate Listings
- PPLX API returning outdated info: A member reported that when integrating the PPLX API, the real estate listings returned were outdated compared to the accurate information provided on the website.
- They noted that the same prompt used in both instances yielded different results.
- Challenges with JSON output: The same member expressed concerns about the AI's ability to consistently output in raw JSON format during the integration process.
- They are looking for guidance on possible errors in their setup or usage of the API.
OpenRouter (Alex Atallah) ▷ #general (193 messages🔥🔥):
OpenRouter Rate LimitsModel Performance IssuesTranslation Model RecommendationsFrontend Chat GUI OptionsGemini and Search Functionality
- OpenRouter faces rate limiting challenges: Users report frequent 429 errors when using Gemini Flash due to quota exhaustion, with hopes for a quota raise from Google soon.
- The traffic load is a constant issue, impacting the usability of the platform, as indicated by recent discussions among users.
- Concerns over model performance post-maintenance: Certain models, like Hermes 405B free, have shown a drop in performance quality after maintenance updates, leading to speculation about provider changes.
- Users are encouraged to check their Activity pages in OpenRouter to see if they are still using their preferred providers.
- Recommendations for translation models: A user inquired about efficient translation models without strict limitations for dialogue translation, citing frustrations with GPT4o Mini.
- Open weight models with dolphin fine-tunings were suggested as options offering more flexibility.
- Frontend chat GUI suggestions: A user sought advice for a chat GUI allowing middleware flexibility for managing interactions with AI models, with Streamlit mentioned as a potential solution.
- Other options like Typingmind were highlighted for their customizable functionalities in engaging with multiple AI agents.
- Gemini model search functionality: There was interest in enabling direct search capabilities with Gemini models comparable to Perplexity, but limitations on usage remain unclear.
- Discussions referenced Google's Search Retrieval API parameter, though implementation and effectiveness are still under consideration.
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Separating code reasoning and editing: An Architect model describes how to solve the coding problem, and an Editor model translates that into file edits. This Architect/Editor approach produces SOTA benchmark results.
- SillyTavern - LLM Frontend for Power Users: no description found
- Tweet from OpenRouter (@OpenRouterAI): The Chatroom now shows responses from models with their reasoning collapsed by default. o1 vs Gemini vs Sonnet on 🍓:
- no title found: no description found
- Create multiple AI Agents within a chat instance: Creating multiple AI agents within a single chat instance allows for a personalized and dynamic interaction experience. By customizing each AI agent with specific datasets, you can get a wide range of...
- Mobile App version of AnythingLLM? · Issue #1476 · Mintplex-Labs/anything-llm: What would you like to see? Not sure this is the right place to ask for this but is there any desire to have mobile apps for anythingllm? Any work in progress in that regard? If not, I would love t...
- Mintplex Labs: AI applications for everyone. Mintplex Labs has 16 repositories available. Follow their code on GitHub.
Stability.ai (Stable Diffusion) ▷ #general-chat (178 messages🔥🔥):
Flux Model InsightsStable Diffusion Setup and PerformanceImage Generation TechniquesCommunity Art ContributionsAI Art vs Human Art Debate
- Flux Model is Impressive: A member noted their admiration for kohya_ss's achievements, noting the ability to train on just 12G VRAM with the Flux model.
- They expressed excitement about the advancements in performance and capabilities that have been demonstrated.
- Nvidia Driver Issues Impacting Performance: Concerns arose regarding new Nvidia drivers causing significant slowdowns for 8GB VRAM cards when generating images with SDXL, reporting times increasing from 20 seconds to 2 minutes.
- Members advised against updating to the latest drivers due to these issues and discussed the impact it has had on their rendering capabilities.
- Regional Prompting Challenges: Members shared experiences about difficulties with regional prompting in Stable Diffusion, noting issues with character mixing when using prompts like '2 boys and 1 girl'.
- Suggestions included starting with general prompts before applying regional guides for better results.
- Community Engagement in AI Art: There was an invitation for members to contribute their AI artworks for a chance to be featured in The AI Art Magazine, with a submission deadline of October 20.
- The community is encouraged to join in celebrating digital art and share their creative expressions.
- AI Art Quality Debates: A spirited discussion on the value of AI art versus human art emerged, with some arguing that human art maintains higher quality and depth.
- A member countered this by stating that AI art, as generated by image algorithms, falls within the realm of artistic expression.
- Flux.1-dev Upscaler - a Hugging Face Space by jasperai: no description found
- The AI Art Magazine: no description found
- GitHub - filipstrand/mflux: A MLX port of FLUX based on the Huggingface Diffusers implementation.: A MLX port of FLUX based on the Huggingface Diffusers implementation. - filipstrand/mflux
- Reddit - Dive into anything: no description found
OpenAI ▷ #ai-discussions (105 messages🔥🔥):
Aider's Code Editing CapabilitiesRegulations in the EU AI BillVideo Translation AnnouncementsUsing AI for Writing AssistanceHuawei ChatGPT Accessibility
- Aider benchmarks LLM editing skills: Members discussed Aider's functionality, stating it works best with LLMs adept at editing code, as highlighted in its leaderboards. Some expressed skepticism about the reliability of Aider's benchmarks, particularly referencing Gemini Pro 1.5 002 not being adequately tested.
- EU AI Bill stir debates: Discussions continued around the EU's new AI bill, with differing opinions on its impact on multimodal AI regulation, clarifying that chatbots will still be categorized under level two regulations. Concerns were raised regarding the implications for companies releasing new technologies in light of regulatory scrutiny.
- Meta's video translation feature: A member mentioned Meta's upcoming lip sync video translation feature due to be released soon, confirming its presence in Meta's platform. This feature sparked interest in translation services among members, especially for creating content.
- Using AI for writing projects: Conversations emerged around utilizing AI for writing assistance, where members offered strategies to maintain personal style while engaging AI like GPT in content creation. Techniques included providing GPT with samples of personal writing to help keep the output aligned with individual tone.
- ChatGPT access on Huawei devices: A member inquired about potential access to ChatGPT on Huawei devices, questioning the feasibility of logging in without Google services. The conversation highlighted a desire for the community to have access to AI features despite current device limitations.
Link mentioned: Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
OpenAI ▷ #gpt-4-discussions (28 messages🔥):
GPT-4.5-o ReleaseAdvanced Voice Mode LimitationsCustom GPTs and Voice ModePayment Plans for Voice Features
- Demands for GPT-4.5-o Release: Members expressed frustration regarding the performance of GPT-4o, highlighting it as flawed and requesting the release of GPT-4.5-o. Sam Altman's comment that it's 'the dumbest LLM' was cited to amplify the urgency for improvements.
- Debated contextually, discussions pointed to the need for better reasoning capabilities beyond the current limitations of the GPT-4 series.
- Confusion Over Advanced Voice Mode: Members sought clarification regarding the daily time limit for advanced voice mode, with reports suggesting a one-hour limit includes the time it stays open. A user noted their experience of encountering '15 minutes remaining' after some use.
- Concerns were raised about accessibility, particularly in relation to how voice mode time accumulates and the need to close it if not actively in use.
- Voice Mode Accessibility in Custom GPTs: It was confirmed that advanced voice conversations are not available in custom GPTs, with attempts redirected to standard chat. Users expressed confusion about the accessibility of standard voice mode, especially from within custom setups.
- One user reported that even turning on voice mode only transcribed inputs without vocalizing responses, raising concerns over standard voice functionality.
- Potential Payment Plans for Voice Features: Discussion hinted at a payment plan for advanced voice mode potentially being introduced soon. Users frustration regarding limitations even as long-term subscribers was expressed, questioning the accessibility of new features.
- Commentary reflected on past limitations of GPT-4, comparing the current situation and expressing hope for changes that could improve accessibility.
OpenAI ▷ #prompt-engineering (5 messages):
Flutter Code Assistant IssuesManaging Assistant RunsPrompt Management
- Flutter Code Hits Thread Error: A user encountered an error indicating that thread
thread_ey25cCtgH3wqinE5ZqIUbmVTalready has an active run, preventing new requests.- Another member advised that the user could either wait for the current run to finish or manually cancel the active run using the relevant parameters.
- Increased Wait Time Fixes Thread Issue: The user resolved their issue by increasing the wait time for thread execution from 10 to 15 seconds, which eliminated the error.
- This adjustment ensured that the active run completion was adequately accounted for before making further requests.
- Condition Based Execution for Threads: A suggestion was made to utilize a parameter that indicates if the thread has finished executing to avoid unnecessary wait times.
- Using this conditional check could streamline the process and reduce waiting periods during thread management.
OpenAI ▷ #api-discussions (5 messages):
Flutter Code ErrorThread ManagementPrompt Management
- Flutter Code Error due to Active Thread: A user encountered an error message stating that the thread
thread_ey25cCtgH3wqinE5ZqIUbmVTalready has an active run, indicating that a previous execution was still active.- Another user suggested either waiting for the run to complete or manually canceling it using the
cancelfunction with the respective IDs.
- Another user suggested either waiting for the run to complete or manually canceling it using the
- Resolution by Increasing Wait Time: The original user resolved the error by canceling the active thread run, which turned out to be the same one already running.
- They found that waiting 15 seconds, instead of the initially added 10 seconds, was necessary to avoid the error.
- Utilizing Execution Status Parameter: To improve thread management, a user suggested employing a parameter that indicates whether a thread has finished executing, allowing for more efficient handling.
- This approach can prevent unnecessary wait times before starting new operations or handling existing threads.
Eleuther ▷ #general (90 messages🔥🔥):
Introduction of new membersICLR and NeurIPS events coordinationLiquid AI's Foundation ModelsDengue fever in SingaporeOpen source LLM training
- New Members Join the Conversation: Several new members introduced themselves, including a fullstack engineer from Singapore and a data engineer from Portugal, both eager to collaborate and contribute.
- They expressed enthusiasm for AI projects and open source contributions, setting a collaborative tone in the community.
- Coordination for Upcoming AI Conferences: Members discussed attendance at upcoming conferences like ICLR and NeurIPS, noting Singapore's hosting of ICLR and plans for gatherings.
- There was light-hearted conversation about event security roles and potential meetups in Singapore.
- Liquid AI's Announcement of Foundation Models: Liquid AI announced the launch of their Liquid Foundation Models (LFMs), highlighting impressive benchmark scores and efficient architecture.
- They aim to cater to various industries with their models optimized for multiple hardware solutions, inviting users to try their new AI on their platform.
- Dengue Fever Concerns Raised: There were discussions about dengue fever in Singapore, with members sharing personal experiences and concerns regarding the mosquito-borne illness.
- Factors contributing to dengue outbreaks in Southeast Asia were discussed, shedding light on public health implications.
- Exploration of Open Source LLM Development: Members expressed interest in contributing to open source LLM training projects, showcasing backgrounds in machine learning and computer vision.
- There were questions about current projects needing help, reflecting a strong desire to engage in collaborative AI development.
- Tweet from Hugging Face (@huggingface): EleutherAI's GPT-J is now in 🤗 Transformers: a 6 billion, autoregressive model with crazy generative capabilities! It shows impressive results in: - 🧮Arithmetics - ⌨️Code writing - 👀NLU - 📜Pa...
- Liquid Foundation Models: Our First Series of Generative AI Models: Announcing the first series of Liquid Foundation Models (LFMs) – a new generation of generative AI models that achieve state-of-the-art performance at every scale, while maintaining a smaller memory f...
Eleuther ▷ #research (45 messages🔥):
Process Reward ModelsValue Functions in RLSparsity Masks in LLMsSwarm LLM ArchitecturePhysics Simulation with Equivariant Representations
- Understanding Process Reward Models vs Value Functions: A member expressed confusion about the distinction between a Process Reward Model (PRM) and a learned value function in reinforcement learning, highlighting how both influence individual steps in decision-making.
- Another member clarified that PRMs focus on step-level evaluation independent of the final outcome, while value functions rely on end results, leading to potential differences in penalties for mistakes.
- Improvements in Reinforcement Learning Data Efficiency: The conversation noted that using PRMs could enhance data efficiency and training stability in reinforcement learning, providing a clearer feedback mechanism compared to relying solely on value functions.
- This observation leads to speculation that while both models could align in theory, utilizing PRMs might better account for human-like reasoning processes that RL models miss.
- Discussion on Sparsity and Speed in LLMs: A member suggested exploring the possibility of using a 1-bit BitNet combined with sparsity masks as a way to achieve ternary performance while enhancing speed in LLMs.
- This was met with interest as another participant mentioned the potential for utilizing sparse tensor core operations to implement these ideas effectively.
- Swarm LLM Architecture Inquiry: A member reached out to others working on swarm LLM architecture, seeking collaboration or sharing insights on the subject.
- This reflects ongoing interest in innovative approaches to LLM development that leverage distributed or concurrent learning strategies.
- Physics Simulation using Equivariant Representations: A member proposed that possessing a translation, rotation, and volume equivariant representation of objects could simplify physics simulation by applying physically based shape matching techniques directly.
- This indicates a merging of geometry and physics in model design, potentially leading to more intuitive and efficient simulations.
- Tweet from Pavlo Molchanov (@PavloMolchanov): 🚀 @NeurIPSConf Spotlight! 🥳 Imagine fine-tuning an LLM with just a sparsity mask! In our latest work, we freeze the LLM and use 2:4 structured sparsity to learn binary masks for each linear layer. T...
- Solving math word problems with process- and outcome-based feedback: Recent work has shown that asking language models to generate reasoning steps improves performance on many reasoning tasks. When moving beyond prompting, this raises the question of how we should supe...
Eleuther ▷ #lm-thunderdome (2 messages):
lm-evaluation-harness libraryvLLM model metrics
- Inquiry on vLLM Metrics Extraction: A member asked if there is a way to extract vLLM metrics object from the lm-evaluation-harness library when using the
simple_evaluatefunction on a benchmark task.- They specifically mentioned wanting metrics such as time to first token and time in queue.
- Gratitude Expressed: Another member expressed appreciation by thanking Baber for assistance.
- This acknowledgment highlights the community's supportive interactions.
Eleuther ▷ #multimodal-general (1 messages):
ExecuTorch informationMultimodal models guidanceHardware setup inquiries
- Inquiry on Hardware Setup: To assist effectively, clarification is needed on the user's hardware specifications and which models they intend to run, along with details on any specific vision tasks they have in mind.
- How much experience do you have with ML frameworks? This information could greatly help in tailoring the assistance provided.
- ExecuTorch Overview: ExecuTorch is a PyTorch platform designed to allow customization and deployment of PyTorch programs on various devices, including AR/VR and mobile systems.
- Currently, the
executorchpip package is in alpha, supporting Python versions 3.10 and 3.11, and is compatible with Linux x86_64 and macOS aarch64.
- Currently, the
- Considerations for ExecuTorch Use: The prebuilt
executorch.extension.pybindings.portable_libmodule allows for running .pte files but only includes core ATen operators and uses the XNNPACK backend delegate.- The user noted their use case is fairly niche, indicating a need for specific insights into ExecuTorch functionalities.
- Multimodal Models Focus: The channel aims primarily at research discussions on multimodal models, advising users to look into /r/localllama for more focused guides and resources.
- Members are encouraged to follow relevant guides since the current channel discussions may not align directly with more technical setup inquiries.
Link mentioned: executorch: On-device AI across mobile, embedded and edge for PyTorch
Torchtune ▷ #general (95 messages🔥🔥):
Training Issues with TorchtuneDynamic Recipe CLI for TorchtuneEfficiency of VRAM vs GPU UtilizationSetting up Error Handling in Distributed TrainingImproving Config Management for CLI Arguments
- Optimizing Training Settings in Torchtune: Users discussed various configurations to optimize training speed for Llama 3.1 8B using settings such as
batch_size,fused, andfsdp_cpu_offload.- It was concluded that enabling
packed=Truesignificantly reduced epoch time, whileenable_activation_checkpointandfsdp_cpu_offloadshould be set toFalsefor better compute efficiency.
- It was concluded that enabling
- Creating Dynamic CLI for Recipes: A proposal to develop a dynamic command line interface (CLI) to generate help text specific to each recipe in Torchtune was discussed.
- Using the
tyrolibrary, a method was presented to create a flexible parser that incorporates configuration details from YAML files.
- Using the
- Implementing Error Handling for Distributed Training: A suggestion was made to use the record utility from
torch.distributedto enhance error handling in distributed training runs.- Testing was demonstrated by generating error logs that capture exceptions, allowing for easier debugging of issues encountered during training.
- VRAM Limitations Affecting Training Speed: The relationship between single A100 training being VRAM-bound, compared to utilizing multiple A100s where GPU utilization becomes the bottleneck was analyzed.
- It was noted that improving GPU utilization with higher
batch_sizecould benefit smoother training, but caution was advised regarding VRAM-saving methods that could slow down the process.
- It was noted that improving GPU utilization with higher
- Enhancing the Document Configuration Experience: A discussion about the importance of documenting configurations and improving user experience with clearer CLI help for Torchtune recipes was held.
- It was suggested that dynamically generated helptext for specific recipe arguments could alleviate confusion and streamline the process of parameter adjustments.
- GitHub - brentyi/tyro: CLI interfaces & config objects, from types: CLI interfaces & config objects, from types. Contribute to brentyi/tyro development by creating an account on GitHub.
- torch.distributed.elastic.multiprocessing.errors.ChildFailedError · Issue #1710 · pytorch/torchtune: Context :- I am trying to run distributed training on 2 A-100 gpus with 40GB of VRAM. The batch size is 3 and gradient accumulation=1. I have attached the config file below for more details and the...
- torchtune/torchtune/_cli/run.py at add-distrib-error-record · mirceamironenco/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to mirceamironenco/torchtune development by creating an account on GitHub.
- pytorch/torch/distributed/elastic/multiprocessing/errors/error_handler.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- pytorch/torch/distributed/run.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- fairseq/fairseq/tasks/audio_pretraining.py at main · facebookresearch/fairseq: Facebook AI Research Sequence-to-Sequence Toolkit written in Python. - facebookresearch/fairseq
- fairseq/fairseq/dataclass/utils.py at main · facebookresearch/fairseq: Facebook AI Research Sequence-to-Sequence Toolkit written in Python. - facebookresearch/fairseq
- torchtune/recipes/full_finetune_distributed.py at main · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/recipes/full_finetune_distributed.py at nightly · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
Torchtune ▷ #dev (39 messages🔥):
Config Management ConcernsPerformance Optimization IdeasDocumentation ImprovementsModel Implementation TechniquesMemory Optimization Strategies
- Concerns Over Duplicate Keys in Config: There was a discussion about having
fused=Truetwice in a configuration file, which led to OmegaConf raising complaints about duplicate keys.- We could consider a performance section for configs, with fast options commented out to enhance readability.
- Push for Clear Performance Guides: Some members expressed a desire for comprehensive performance guidelines, suggesting a set of performance config overrides in the documentation for easier access.
- The idea of polling users for feedback on documentation clarity was also proposed, indicating a need for improvement.
- Recipe Documentation Needs Attention: There were challenges noted about the lagging recipe documentation, causing difficulty in keeping them updated with new contributions.
- Suggestions included asking contributors to help with the documentation, which is crucial yet often overlooked.
- Deprecating Old Model Code: Members debated whether to deprecate older model coding patterns that were used in previous implementations in favor of newer methods.
- The conversation highlighted the importance of ensuring consistency in model implementation standards.
- Memory Optimization Review and Suggestions: There was a suggestion to update the memory optimization page to combine performance and memory optimization tips, indicating a streamlined approach.
- Ideas included adding sample packing and future features like int4 training to the documentation for increased efficiency.
- Memory Optimization Overview — torchtune main documentation: no description found
- torchtune/recipes/configs/llama3/70B_full.yaml at 3fddc56942846220b39945559f4b5e695873bb43 · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
Latent Space ▷ #ai-general-chat (66 messages🔥🔥):
CodiumAI Series A FundingLiquid Foundation Models LaunchAI Voice Interaction with GradioUltralytics YOLO11 ReleaseOpenAI Pricing Comparisons
- CodiumAI rebrands as Qodo with Series A funding: QodoAI, formerly CodiumAI, announced a $40M Series A funding round, raising their total to $50M. The focus is on ensuring code integrity and empowering developers with AI-assisted tools.
- This funding validates their approach and highlights the support from developers and partners who have contributed to their mission.
- Liquid Foundation Models claims impressive benchmarks: LiquidAI launched LFMs, boasting better MMLU and other benchmarks than existing models, including calls out to competitors' inefficiencies. The team comprises notable members from MIT and has secured substantial funding.
- Their new architecture promises notable performance in the 1.3B model range, potentially challenging established leaders in the field.
- Gradio 5.0 enables real-time AI voice interaction: LeptonAI demonstrated an innovative audio mode LLM integrated with Gradio 5.0, allowing seamless real-time streaming interactions through a minimal code setup. The demo promotes open-source collaboration and encourages users to fork the project with their keys.
- Kudos to the Gradio team for providing powerful updates that enable developers to create interactive applications efficiently.
- Ultralytics introduces YOLO11: Ultralytics launched YOLO11, building on previous versions and enhancing its capabilities for various computer vision tasks. This release showcases improvements in accuracy, speed, and overall efficiency for developers.
- The event marks a significant milestone in the evolution of their YOLO models.
- Pricing insights on AI models: Comparisons were made between the cost-effectiveness of Google's Gemini against GPT-4o Mini for generating bot replies, highlighting the significant cost reductions. This pricing strategy could impact how AI-driven solutions flood social media with automated responses.
- Such discussions indicate the ongoing evaluation of operational costs associated with large-scale AI deployments in the industry.
- Tweet from Patrick Collison (@patrickc): As late as October 2022, there was no ChatGPT, and there were very few AI-native products generally. AI Grant, the leading early-stage AI investor, exhorted founders to create some: https://web.archiv...
- Tweet from Justine Moore (@venturetwins): "AI companies don't make money" Tell that to the Stripe data. Top AI companies hit $30M in revenue 5x faster than their traditional SaaS counterparts.
- Tweet from Soumith Chintala (@soumithchintala): Lifecycle of SB1047: * First-draft written by a niche special-interest stakeholder * Draft publicly socialized too quickly before other stakeholders can weigh-in privately. * Public socialization sta...
- Dailypapershackernews - a Hugging Face Space by akhaliq: no description found
- Ultralytics YOLO11 Has Arrived! Redefine What's Possible in AI! by Abirami Vina: Learn all about the groundbreaking features of Ultralytics YOLO11, our latest AI model redefining computer vision with unmatched accuracy and efficiency.
- Tweet from Andrew Curran (@AndrewCurran_): Liquid released today. Their small team has built three models based on a new architecture with extremely impressive performance. Joscha Bach is part of their team, and Mikhail Parakhin is on their bo...
- Separating code reasoning and editing: An Architect model describes how to solve the coding problem, and an Editor model translates that into file edits. This Architect/Editor approach produces SOTA benchmark results.
- Tweet from Andrew Curran (@AndrewCurran_): The NYT got ahold of docs from the OpenAI funding round. - 350 million people used Chat in Aug - huge user growth after anon login - 10 mill active subscribers - sub going up to $2 by the end of the y...
- Tweet from swyx @ DevDay! (@swyx): new transformers killer in town! Been excited about @LiquidAI_ since I talked to @Plinz in April. Now they've finally launched LFMs! Shots fired: - Better MMLU, ARC, GSM8K than 1B/3B models, com...
- Tweet from Yangqing Jia (@jiayq): Building real-time interaction was hard, because python web frontend and streaming doesn't mix very well. Now you can do that with exactly 250 lines of code thanks to the upcoming Gradio 5.0. Ove...
- Tweet from @levelsio (@levelsio): People mentioned that Google's Gemini is half as cheap as GPT-4o mini: $0.075 / 1M input tokens $0.30 / 1M output tokens So that's $0.37/mo for generating 1 million replies Or just $375/mo ...
- Tweet from Diego | AI 🚀 - e/acc (@diegocabezas01): Meta AI Llama 3.2 can edit selected parts of the image
- The future of AI might look a lot like Twitter: The future of AI might look a lot like Twitter
- Tweet from Itamar Friedman (@itamar_mar): CodiumAI is now Qodo! + announcing a $40M Series A 🚀 Today marks a significant milestone for @QodoAI. We announced a Series A funding round, bringing our total funding to $50M. This journey start...
- Tweet from Dr. Parik Patel, BA, CFA, ACCA Esq. (@ParikPatelCFA): Chat is it normal to be losing $5 billion on $3.7 billion revenue
- Tweet from Teortaxes▶️ (@teortaxesTex): Sonnet still has this special sauce that even o1 lacks. Probably no other model has such density of «reasoning» bearing on purely autoregressively sampled tokens with no backtracking. Anthropic will ...
- Tweet from bharat (@that_anokha_boy): so i put up a proxy on their app and guess what 270k coinbase engineers are calculating user's usage on client side. i blocked their log_tokens api and now i can access their all models without an...
- The Winds of AI Winter: Mar-Jun 2024 Recap: People are raising doubts about AI Summer. Here's why AI Engineers are the solution.
- Tweet from Andrej Karpathy (@karpathy): NotebookLM is quite powerful and worth playing with https://notebooklm.google/ It is a bit of a re-imagination of the UIUX of working with LLMs organized around a collection of sources you upload and...
- Release v8.3.0 - New YOLO11 Models Release (#16539) · ultralytics/ultralytics: 🌟 Summary Ultralytics YOLO11 is here! Building on the YOLOv8 foundation with R&D by @Laughing-q and @glenn-jocher in #16539, YOLO11 offers cutting-edge improvements in accuracy, speed, and effici...
- Replit Agent: IDE for Humans and LLMs
- Subscribe to read: no description found
- GitHub - mediar-ai/screenpipe: 24/7 local AI screen & mic recording. Build AI apps that have the full context. Works with Ollama. Alternative to Rewind.ai. Open. Secure. You own your data. Rust.: 24/7 local AI screen & mic recording. Build AI apps that have the full context. Works with Ollama. Alternative to Rewind.ai. Open. Secure. You own your data. Rust. - mediar-ai/screenpipe
Latent Space ▷ #ai-announcements (6 messages):
New Podcast EpisodeYouTube EngagementAI Researchers on the Show
- Latest Podcast Features Notable Guests: The new podcast episode features Shunyu Yao from OpenAI and Harrison Chase from LangChain, focusing on essential topics in AI agents.
- Listeners are encouraged to rate the show on Apple Podcasts and YouTube to help diversify its presence.
- Listeners Enthusiastic About Engagement: Listeners are actively engaging with the podcast, with one confirming that they 'liked and subscribed' and hit the bell notification for updates.
- Another listener humorously stated they unsubscribed just to subscribe twice, showing their commitment to the show.
- Request for More Researchers on the Show: Listeners are enjoying the content and expressed a desire for more researchers to join future episodes.
- One user remarked, 'bring more researchers on,' indicating a demand for deeper discussions in future podcasts.
- Latent Space: The AI Engineer Podcast — Practitioners talking LLMs, CodeGen, Agents, Multimodality, AI UX, GPU Infra and al: Listen to Alessio + swyx's Latent Space: The AI Engineer Podcast — Practitioners talking LLMs, CodeGen, Agents, Multimodality, AI UX, GPU Infra and al podcast on Apple Podcasts.
- Latent Space: The first place where over 50,000 AI Engineers gather to talk models, tools and ideas. Breaking news today you will use at work tomorrow! Full show notes and newsletter at https://latent.space
- Tweet from Alessio Fanelli (@FanaHOVA): How do we make AI agents think and act? 🤖 Today's episode with @ShunyuYao12 (and special cohost @hwchase17!) is probably our best agents episode so far: - Origins of ReAct and how it inspired @L...
Latent Space ▷ #ai-in-action-club (42 messages🔥):
AI Engineering InterviewScreen Share IssuesLocal Model ExperimentsBraintrust Evaluation Platforms
- Frikster's Happy Interview News: Frikster shared excitement about having an interview that could transition into an AI Engineering role, expressing overall happiness about the opportunity.
- Interesting reactions followed regarding the potential of this transition being akin to 'lighting up the right weights for its prompt knowledge.'
- Screen Share Troubleshooting: Multiple members reported issues with viewing a screen share, with various troubleshooting suggestions like reloading or switching platforms.
- Some found that leaving and rejoining the call resolved their problems; however, others continued to experience a black screen.
- Potential of Local Models: Rajwant asked if creating a local model for specific tasks would be beneficial, sparking discussion on the effectiveness of such models.
- Kbal questioned if members had conducted similar experiments with other models, particularly in comparison to O1.
- Braintrust vs Other Evaluation Platforms: Youngphlo inquired about thoughts on Braintrust compared to other evaluation platforms for language models.
- Vodros admitted to being unfamiliar with Braintrust while raising questions about its potential support for JSON mode.
LlamaIndex ▷ #blog (7 messages):
FinanceAgentToolSpecStreaming events from workflowsAutomated Financial Report GenerationMulti-Agent Slackbot with ConfluenceLlamaParse Premium
- Leverage FinanceAgentToolSpec for Public Financial Data: The FinanceAgentToolSpec package on LlamaHub enables agents to query various public financial data sources such as Polygon, Finnhub, and Seeking Alpha.
- A detailed post by Hanane explains the utility of this tool in financial analysis and its practical applications.
- Full-Stack Demo for Streaming Events: A new full-stack application demonstrates a workflow for streaming events, featuring Human In The Loop functionalities in a report-writing context.
- This app showcases how to research a topic and present it comprehensively, enhancing user interaction.
- YouTube Tutorial for Workflow Code: There's now a YouTube video where a developer walks through the coding process for the full-stack demo discussed previously.
- This video serves as an educational resource for those looking to implement similar systems.
- Automated Reports with RAG Workflows: A new research guide illustrates how to incorporate unstructured context from 10K reports into automated financial report generation using agentic workflows.
- This advanced application goes beyond simple chatbot responses, synthesizing comprehensive reports from multiple data sources.
- Building Agentic Slackbots with Confluence: A comprehensive tutorial details how to construct a multi-agent Slackbot that interacts with Confluence documents using AWS services.
- This initiative highlights the potential for improved organizational efficiency by integrating structured content into chat interfaces.
LlamaIndex ▷ #general (105 messages🔥🔥):
Ollama concurrencyLlamaIndex project setupRAG pipeline evaluationNode metadata handlingOracle retrieval in RAG Benchmark
- Ollama's concurrency feature: A user inquired about how to utilize concurrency with Ollama, and it was clarified that it is enabled by default.
- A helpful link to Ollama's concurrency handling was provided for further assistance.
- LlamaIndex project pipeline guidance: A member sought recommendations for processing complex PDFs in their LlamaIndex project and was advised to use Llamaparse for optimal results.
- Discussions on various document handling methods led to further insights into extracting relevant data effectively.
- Challenges in RAG pipeline evaluation: A user reported issues with evaluating their RAG pipeline using trulens due to an import error, prompting suggestions to check documentation and available metrics.
- Clarifications on retrieving node IDs for ground truth in evaluation settings were extensively discussed, emphasizing the need to build a solid evaluation dataset.
- Editing node metadata in LlamaIndex: Users discussed the ability to edit metadata for each chunk of data in LlamaIndex, confirming that adding details like URLs is feasible through code snippets.
- Guidance was provided on manipulating node metadata effectively to enhance data retrieval and indexing processes.
- Insights on oracle retrieval and new benchmarks: A member shared information on the new RAG benchmark dataset from Google, which introduced the concept of oracle retrieval.
- It was noted that oracle retrieval relies on ground-truth annotations, presenting an upper-bound performance measure rather than a practical retrieval method.
- Usage Pattern (Retrieval) - LlamaIndex: no description found
- Comparing Methods for Structured Retrieval (Auto-Retrieval vs. Recursive Retrieval) - LlamaIndex: no description found
- Retrieval Evaluation - LlamaIndex: no description found
- ollama/docs/faq.md at main · ollama/ollama: Get up and running with Llama 3.2, Mistral, Gemma 2, and other large language models. - ollama/ollama
- Retrieval Evaluation - LlamaIndex: no description found
- Go with the floe: What's the perfect thing to do under the midnight
- How to fit a multistep query decomposition with a custom chat engine built with a query pipeline · run-llama/llama_index · Discussion #15117: How can I fit multistep query decomposition like this one into my custom chat engine: from llama_index.core.query_engine import MultiStepQueryEngine query_engine = index.as_query_engine(llm=gpt4) q...
- GitHub - run-llama/llama_parse: Parse files for optimal RAG: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
- llama_index/llama-index-core/llama_index/core/evaluation/retrieval/metrics.py at a620a2661faabb49ba2f257bff7ae2ac04d0c12b · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
LlamaIndex ▷ #ai-discussion (1 messages):
LLM ReasoningDifferent Types of Reasoning
- Defining LLM Reasoning Problems: It's crucial to clarify the type of reasoning problem we're addressing before engaging with LLM reasoning.
- An article was shared that details various reasoning types and evaluates LLM performance on these challenges.
- Importance of Categorizing Reasoning: Identifying the specific reasoning issues is essential to guiding the effectiveness of LLMs.
- The article highlights that different reasoning challenges require unique approaches and evaluations.
Cohere ▷ #discussions (21 messages🔥):
Channel posting guidelinesHumanoid Robots 2024 YouTube videoInnovations in UI/UX for LLMsRobotics development challengesPodcasting as a UI/UX interaction
- Channel Posting Guidelines Clarified: A member asked about the right channel for posting, leading to a clarification that https://link.to/channel is acceptable, despite not being directly related to Cohere. Another member warned that the channel is not a job portal, leading to a reminder about maintaining appropriate discussions.
- Hello! and yahalloo! exchanges marked the welcome atmosphere in the channel as members joined.
- Best Rundown of Humanoid Robots in 2024: A member shared a YouTube video titled 'Every Humanoid Robot 2024', claiming it is the best rundown of humanoid robots on the internet. It included a link to a comprehensive list of the bots and their manufacturers.
- Conversations then transitioned towards discussing the current issues in robotics, such as compute, battery costs, and higher human labor charges, igniting a brainstorming session.
- UI/UX Innovations for LLMs: A member emphasized the need for innovations in UI/UX for human-model interactions, sharing insights on NotebookLM as a powerful tool for podcast creation from any content. They provided links to various audio transformations showcasing the potential of podcasting as an LLM interface format.
- They noted that while LLMs advance rapidly, UI/UX often lags, arguing that podcasting can bypass traditional user engagement hurdles in AI interactions.
- Tweet from Andrej Karpathy (@karpathy): NotebookLM is quite powerful and worth playing with https://notebooklm.google/ It is a bit of a re-imagination of the UIUX of working with LLMs organized around a collection of sources you upload and...
- Cohere Documentation — Cohere: Cohere's API documentation helps developers easily integrate natural language processing and generation into their products.
- Every Humanoid Robot 2024: Best rundown of all the humanoid robots on the internet. Brought to you by Automate Construction. List of bots & who makes them:https://automateconstruction....
Cohere ▷ #questions (36 messages🔥):
RAG formatting queriesCohere startup programAPI billing questionsMultimodal captioningInput token number concerns
- RAG Formatting for Model Prompts: Users discussed how to format instructional headers for RAG inclusions in prompts submitted to the LLM, indicating the need for clarity on concatenation.
- One member mentioned the importance of including supporting information in a format the model expects, as well as termination methods for headers.
- Exploring the Cohere Startup Program: A user inquired about discounts for a startup team using Cohere, highlighting the high expense compared to competitors like Gemini.
- Another user suggested applying to the Cohere Startup Program, which offers discounts and noted it could take time for applications to be processed.
- Clarifying API Billing Procedures: Queries arose regarding how Cohere bills for API usage, with confirmation that billing occurs monthly.
- A user mentioned not finding an invoice in their account, prompting further discussion about the billing process.
- Interest in Multimodal Captioning: A user asked whether anyone is working on multimodal captioning, inviting an exchange of ideas and experiences.
- Another participant showed enthusiasm, encouraging the discussion of projects related to multimodal captioning.
- Input Token Number Discrepancies: A user raised concerns about inaccuracies in their input token number, asserting they were underreported daily use.
- They also discussed challenges in applying for discounts as they do not operate as a company, but rather as a startup team.
- Startup Program Application: Thank you so much for your interest in the Cohere Startup Program! We're initially rolling out the program with a select group of customers, and would love to learn a bit more about your business...
- Startup Program : The Cohere Startup Program offers qualified Series B and earlier startups a unique opportunity for support, discounted API rates, and publicity.
- Chat with Streaming — Cohere: Generates a message from the model in response to a provided conversation. To learn more about the features of the Chat API follow our Text Generation guides . Follow the Migration Guide for inst...
Cohere ▷ #api-discussions (23 messages🔥):
Fine-tuning ModelsChunking Data for Improved OutputSystem Message and API Migration IssuesDocumentation ConsistencyV1 to V2 Chat API Transition
- Fine-tuning models is a challenge for flash card generation: A member sought advice on fine-tuning a model for better flash card generation using notes and slide decks, noting the qualitative concerns of the output. They contemplated whether their unstructured data could be improved without the fine-tuning process.
- Another member suggested using best practices for machine learning pipelines to enhance the task, emphasizing that chunking data could significantly boost the model's output.
- Chunking dramatically improves model performance: Members discussed the effectiveness of chunking data, particularly for PDF slide decks, to enhance model understanding of relevant content. They also mentioned exploring tools like rerankers to optimize results from large datasets.
- The dialogue emphasized the principle that well-structured input can lead to better qualitative output, addressing the importance of data preparation in AI tasks.
- API migration dialogue reveals key challenges: As users transitioned from v1 to v2 of the chat API, issues were raised about the simultaneous use of system messages and document parameters impacting functionality. A member experienced difficulties and learned from others that it was a known bug that was subsequently addressed.
- Another user confirmed that the current API structure still supports the older version, ensuring continuity for those migrating, while also highlighting the need for systematic updates.
- Call for documentation improvements: A member noted inconsistencies in API documentation, specifically around penalty ranges for parameters, calling for a more uniform presentation of the details. They suggested clearer standards for documenting minimum and maximum values to enhance user clarity.
- Discussions around handling errors in the API highlighted the importance of consistent and comprehensible documentation for best user experience.
- V1 to V2 transition proves generally positive: Members expressed relief at finding that the v1 chat API still functions during migration, highlighting the scarcity of compelling reasons to revert from the newer version. Conversations revealed a generally optimistic view toward the improvements provided in v2 despite initial hiccups.
- The community remains engaged, exchanging insights and solutions as they adapt to the newly implemented features of the v2 API.
Cohere ▷ #projects (2 messages):
Cultural Multilingual LMM BenchmarkVolunteer TranslatorsCVPR'2025 Paper Co-Authorship
- MBZUAI Launches Cultural Multilingual LMM Benchmark: MBZUAI is developing a Cultural Multilingual LMM Benchmark for 100 languages, creating a multimodal dataset with translations into local languages.
- They are seeking native translators as volunteers to help rectify mistakes, promising an invitation to co-author their paper upon task completion.
- Call for Volunteer Translators Across Languages: The languages needing assistance include Indian, South Asian, African, and European languages, with a broad list provided for potential volunteers.
- “This isn't a job-portal... so we don’t run that way” was mentioned in response to the volunteer call, clarifying the nature of inquiries.
- Networking Invitation for Translators: Interested individuals can connect with the project lead via LinkedIn for more information and to express their language skills.
- They encourage personal messages regarding interest in volunteering.
Interconnects (Nathan Lambert) ▷ #news (36 messages🔥):
OpenAI staff turnoverAI regulationsLegal decisions on AI datasetsInvestment discussionsPublic reactions to AI bills
- OpenAI's talent exodus due to compensation demands: Key researchers at OpenAI are seeking higher compensation, with $1.2 billion already cashed out from selling profit units as the company’s valuation rises. Leadership turnover is exacerbated by rival companies like Safe Superintelligence actively recruiting OpenAI talent.
- Employees are threatening to quit over money issues while new CFO Sarah Friar is caught in the middle of these negotiations.
- CA governor vetoes AI safety bill SB 1047: Gov. Gavin Newsom vetoed SB 1047, a bill aimed at regulating AI firms, stating that it was not the best approach to protecting the public. Critics view the veto as a setback for oversight, while supporters argue for regulating based on clear capabilities rather than vague predictions.
- Sen. Scott Wiener expressed disappointment that the governor did not provide feedback before the veto and emphasized the missed opportunity for California to lead in tech regulation.
- Legal victory for LAION in copyright case: LAION successfully defended against copyright infringement claims in the German case of Kneschke v LAION, where a photographer alleged misuse of his images. The court ruled that LAION only linked to images, rather than hosting any itself.
- This ruling is significant for AI dataset use cases, as copyright discussions continue to shape the AI landscape.
- OpenAI's concerns regarding investor relations: OpenAI is reportedly no longer in discussions with Apple regarding an investment, as per the WSJ. This shift signifies the broader tension between OpenAI’s mission and its need to satisfy its investors.
- As OpenAI approaches a potentially transformative financial point, relations with major investors are critical to its future directions.
- Public reactions fuel discussions about AI: Reactions to the vetoed AI safety bill show mixed opinions, where some believe the reasoning behind the veto is sound, emphasizing regulatory clarity. Many anticipate that legislation efforts will resurface in the coming year.
- Discussions in the community highlight differing views on how regulations should reflect actual technology capabilities rather than speculative future scenarios.
- OpenAI was a research lab — now it’s just another tech company: OpenAI may soon become a for-profit company with fewer checks and balances than before — the exact structure it was built to avoid.
- Tweet from unusual_whales (@unusual_whales): JUST IN: Apple $AAPL is now reportedly no longer involved in discussions to invest in OpenAI or board discussions per WSJ
- Newsom vetoes controversial AI safety bill SB 1047: The bill had become a flashpoint in Silicon Valley with tech figures like Elon Musk supporting the measure and others saying it would threaten the burgeoning AI industry in its early stages.
- LAION wins copyright infringement lawsuit in German court: Copyright AI nerds have been eagerly awaiting a decision in the German case of Kneschke v LAION (previous blog post about the case here), and yesterday we got a ruling (text of the decision in Germ…
Interconnects (Nathan Lambert) ▷ #ml-drama (16 messages🔥):
PearAI controversyYann LeCun on research standardsOpenAI's transparency debatePeer review critiqueResearch blog impact
- PearAI Accused of Code Theft: PearAI allegedly stole code from Continue.dev and rebranded it without proper acknowledgment, sparking outrage and calls for accountability from investors like YC.
- For those who don’t know: PearAI stole code… from an open-source community, and it raises ethical concerns about startup funding.
- LeCun Calls Out Blog Post Standards: Yann LeCun criticized the reliance on blog posts for establishing research validity versus the rigorous standards of peer-reviewed papers, emphasizing that technical research cannot be substituted by press releases.
- It’s OK to delude yourself into thinking it’s the best thing since slice bread… highlights the tension between product pressure and research integrity.
- Debate Over OpenAI's Transparency: Critics question OpenAI's transparency, pointing out that referencing a blog does not equate to substantive communication of research findings, with one member stating that a press release doesn’t mean much.
- Amidst the debate, some OpenAI employees assert that they are indeed open regarding their research communications.
- Skepticism Over Peer Review: Some members expressed skepticism regarding the effectiveness of peer review, arguing that much published research can be subpar while still being deemed valid.
- The conversation reveals frustrations over the perceived lack of accountability in research publication processes.
- Impacts of OpenAI's Research Blog: Discussions on the research blog question if sharing insights such as CoTs is enough to inform the community, with some suggesting that the information may be cherry-picked.
- Members shared mixed feelings on whether openai.com adequately addressed the community’s concerns about transparency and thoroughness.
- Tweet from Noam Brown (@polynoamial): @ylecun @thomaspower @OpenAI Also, we say a decent amount in the research blog post https://openai.com/index/learning-to-reason-with-llms/ including sharing CoTs, which I think are extremely informati...
- Tweet from Jakob Finch (@doiftrue): @candyflipline @iamgingertrash For those who don't know: PearAI stole code from http://Continue.dev and passed it off as a startup they are 'building' and just got funding for it: https://...
- Tweet from Yann LeCun (@ylecun): I'm sorry Noam, but a blog post does not come close to meeting the standards of reproducibility, methodology, acknowledgment of prior work, and fair comparison with the state of the art, that a te...
- Tweet from Noam Brown (@polynoamial): @ylecun @thomaspower @OpenAI I think it's the opposite. A lot of published research is frankly BS. Authors just need to delude 3 reviewers and an AC. When releasing something that millions of peo...
Interconnects (Nathan Lambert) ▷ #random (13 messages🔥):
iPhone IAP subscriptionsApple App Store managementTwitter security issuesMeeting with John SchulmanCommunity engagement on Twitter
- Getting Access to iPhone IAP Subs: A substack best seller announced gaining access to iPhone In-App Purchase subscriptions, signaling potential growth opportunities in mobile monetization.
- This access provides an interesting glimpse into the implementation of these systems and their management.
- Apple App Store Nightmare Unveiled: Insights were shared about the challenges of managing the Apple App Store, underscoring its chaotic environment.
- Discussions highlighted the complexities and frustrations developers face within this ecosystem.
- Twitter Security Breaches Alarm: A concerning tweet highlighted the hacking of a prominent Twitter account, emphasizing that it could happen to anyone in the tech space.
- Discussions pointed out that this issue persists, with calls for increased safety awareness among users.
- John Schulman Meeting on RLHF Insights: An exciting announcement was made about a forthcoming meeting with John Schulman for advice on Reinforcement Learning from Human Feedback (RLHF) work.
- This engagement reflects the collaboration and mentorship opportunities in the AI community.
- Concerns Over Twitter's Maintenance: A user expressed skepticism about Twitter's commitment to security, pointing out that the platform only has three engineers managing issues.
- Comments suggested that the team’s effectiveness is hampered by distractions and low resources, impacting overall safety.
- Tweet from 𝚐𝔪𝟾𝚡𝚡𝟾 (@gm8xx8): 🚨 @DrJimFan hacked
- Tweet from sam mcallister (@sammcallister): 🥹 @karpathy
Interconnects (Nathan Lambert) ▷ #memes (3 messages):
AI MemesUser Reactions
- User's Reaction to Brutal Meme: A user expressed surprise and amusement with the phrase You make this??? Brutal in response to an AI-generated meme.
- Another user humorously claimed I wish lol when asked if they created the meme, clarifying it was sourced from a random AI memes account.
- Discussion on Meme Authorship: A conversation unfolded regarding the origin of a meme, where one user eagerly questioned if another created it.
- The notion quickly turned into laughter as the responding user mentioned it was just from a random AI memes account.
Interconnects (Nathan Lambert) ▷ #posts (1 messages):
SnailBot News: <@&1216534966205284433>
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (36 messages🔥):
Course Material AccessMulti-Agent Systems DiscussionNotebookLM InquiryTraining Schedule InquiryResearch Proposal Discussion
- Accessing Course Materials: Students are inquiring about accessing course videos and materials after filling out the registration form.
- Course material, including assignments and lecture recordings, can be found on the course website, with all assignments due by Dec 12th.
- Debate on Multi-Agent vs. Single-Agent Systems: A conversation centers around the effectiveness and necessity of multi-agent systems versus single-agent implementations for various projects.
- It was noted that multi-agent systems could mitigate hallucinations and simplify context management, aiding in accurate responses from LLMs.
- NotebookLM's Functionality: Inquiries were made about whether NotebookLM operates as an agent application.
- It's described as a RAG agent that summarizes text and generates audio, with users questioning its tech implementation in terms of multi-step processes.
- Training Schedule Confirmation: Students are seeking information on when the training sessions for their course will begin.
- One member shared that they were told all three labs would be released on Oct 1st, although this was not a formal announcement.
- Research Proposal on Super-Alignment: A proposed research project aims to explore ethics within multi-agent systems, emphasizing the use of frameworks like AutoGen.
- Challenges were highlighted regarding the implementation of such research without dedicated frameworks, noting potential limitations in simulation capabilities.
- Large Language Model Agents: no description found
- no title found: no description found
- Research Proposal: Exploring Super-Alignment through Relative Ethics in Multi-Agent Systems using AutoGen: Research Proposal: Exploring Super-Alignment through Relative Ethics in Multi-Agent Systems using AutoGen Eric Moore - 9/28/2024 Abstract In the advent of advanced artificial intelligence and potent...
- Reddit - Dive into anything: no description found
- AI Agentic Design Patterns with AutoGen: Complete this Guided Project in under 2 hours. In AI Agentic Design Patterns with AutoGen you’ll learn how to build and customize multi-agent systems, ...
- Reddit - Dive into anything: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
metakingkal: There is an example in Autogen site on how to build an Agent to play chess.
tinygrad (George Hotz) ▷ #general (27 messages🔥):
Cloud Storage CostsModal Pricing StructureTinygrad Matcher OptimizationTesting Strategies for OptimizersBounty Payment Methods
- Cloud Storage Costs Competitive with Major Providers: George mentioned that storage and egress costs will be less than or equal to major cloud providers, emphasizing cost considerations.
- He further explained that expectations for usage might alter perceived costs significantly.
- Modal's Payment Model Sparks Debate: Modal's unique pricing where they charge by the second for compute resources has drawn attention, touted as cheaper than traditional hourly rates.
- Members questioned the sustainability of such models and how it aligns with consistent usage patterns in the AI startup environment.
- Improving Tinygrad's Matcher with State Machines: A member suggested that implementing a matcher state machine could improve performance, aligning it towards C-like efficiency.
- George enthusiastically backed this approach, indicating it could achieve the desired performance improvements.
- Need for Comprehensive Regression Testing: Concerns were raised about the lack of a regression test suite for the optimizer, which could lead to unnoticed issues after code changes.
- Members discussed the idea of serialization for checking optimization patterns, but recognized it would not be engaging.
- Bounty Payment Options Discussed: A user queried if bounties could be paid through Payoneer instead of PayPal, though George pointed to existing protocols in their questions document.
- This reflects ongoing dialogue regarding payment systems within the community.
Link mentioned: Plan Pricing: Simple, transparent pricing that scales based on the amount of compute you use.
tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
SOTA GPU for BountiesRenting GPUs OnlineTF32 Tensor Core SupportLearning Before Tackling BountiesSmall PR Contributions
- SOTA GPU not mandatory for bounties: A member suggested that while a SOTA GPU could help, one can manage with an average GPU, especially for certain tasks.
- Some tasks like 100+ TFLOPS matmul in tinygrad may require specific hardware like the 7900XTX, while others do not.
- Renting GPUs for tasks: It was mentioned that you can rent a GPU online for cheap if necessary, providing flexibility for those who don’t own high-end hardware.
- This cost-effective approach allows participating in bounties without the need for a permanent high-performance setup.
- Understanding TF32 tensor core support: A user inquired about 'TF32 tensor core support,' indicating interest in performance capabilities.
- It's advised to grasp these concepts thoroughly before attempting bounties to ensure success.
- Importance of preparation before tackling bounties: A strong recommendation was made to spend time learning the codebase before attempting a bounty, as it simplifies the process.
- Familiarizing oneself with open PRs and existing issues can help avoid conflicts and ease the onboarding process.
- Starting small with PR contributions: It was suggested to begin with a small PR before engaging in more significant bounty tasks.
- Keeping an eye on GitHub issues and Discord channels can reveal tasks that need attention and provide a pathway for contributing.
OpenAccess AI Collective (axolotl) ▷ #general (14 messages🔥):
Llama 3.2 1b tuningCalifornia AI training billLightweight chat modelsLiquid AISample packing effects
- Concerns over Llama 3.2 1b Tuning: A user reported issues tuning Llama 3.2 1b, experiencing high VRAM usage at 24GB even with settings like qlora and 4bit loading.
- Questions were raised about the impact of increasing sequence length compared to batch size, particularly with sample packing enabled.
- California Enacts AI Training Disclosure Law: A new California law mandates disclosure of training sources for any AI model used in the state, leaving no exceptions for smaller models or nonprofits.
- This law raises discussions on potential workarounds using lightweight chat models to create 'inspired by' datasets that comply legally, as suggested by various members.
- Foray into Lightweight Chat Models: Members discussed the idea of finetuning lightweight chat models to transform webcrawled datasets while maintaining a legal standard of transformation.
- One member noted that since raw webcrawl data is often messy, LLMs could assist in cleaning it up as a beneficial next step.
- Excitement Around Liquid AI: A new foundation model called Liquid AI has sparked interest among members in the discussion.
- Some expressed curiosity about the implications and features of this new model, considering recent legislative changes.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (3 messages):
LoRA+ implementationLearning Rate Default ValuesPEFT's Implementation
- Question on Default Value Usage: A member questioned if they should use a default value for a parameter or the same value as the learning_rate.
- They noted that the LoRA+ paper set 1e-6 as their main learning rate, which could explain the default for loraplus_lr_embedding.
- Assumption on Default from Paper: Another member agreed with the assumption that the default value comes from the LoRA+ paper due to its usage of 1e-6.
- Due to Pydantic defaulting to None, the shift towards PEFT's implementation required slight adjustments.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (12 messages🔥):
Axolotl dataset configurationSelecting random dataset samplesHugging Face datasets handling
- Using 20% of a dataset in Axolotl: In Axolotl, you can specify to use a portion of a dataset by utilizing the
splitoption under thedatasetsconfiguration, allowing you to define custom splits.- For example, you can set your config to use the first 20% of a dataset for training, with adjustments available for validation and testing splits.
- Randomly selecting a subset of data: There is no direct option in the Axolotl config to use a random 20% of a dataset; this needs to be done during dataset loading or preprocessing.
- Utilizing libraries like Hugging Face’s
datasets, you can sample a random 20% before passing the processed dataset to Axolotl.
- Utilizing libraries like Hugging Face’s
- Llama 3 example cited: A user suggested checking the Llama 3 example for potentially relevant configurations regarding dataset handling in Axolotl.
- This suggests that there may be implicit methods or practices outlined in existing examples that could address the use of random samples.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
DSPy ▷ #show-and-tell (2 messages):
Pydantic model generatorGroq integrationGitHub ActionsTyped PredictorsDSPyGen
- Livecoding Free Pydantic Model Generator: A session is underway demonstrating how to create a free Pydantic model generator utilizing Groq and GitHub Actions.
- The project aims to enhance model generation capabilities within DSPyGen, allowing for more typed predictors and streamlined processes.
- Loom Video of the Session: A member shared a Loom video that captures the live coding session in detail.
- The video provides insights into the coding approach and tools used during the demonstration, valuable for participants and onlookers.
Link mentioned: I am still King of Typed Output in DSPy: In this video, I demonstrate the creation of type predictors in Pydantic, showcasing the process and outcomes of generating structured text. I walk through the steps of creating a type predictor gener...
DSPy ▷ #general (17 messages🔥):
DSPy 2.5 & LM Client UpgradeMiprov2 Status & IssuesOptimizing System Prompts in DSPy
- Upgrading to DSPy 2.5 brings big improvements: Upgrading to DSPy 2.5 and using the LM client with a Predictor instead of a TypedPredictor fixed many issues and resulted in a better out of the box performance.
- Curiously, the improvements were linked to the new Adapters being better aware of chat LMs.
- Miprov2 issues were user-related: Concerns about miprov2 being broken were clarified, revealing that the issue was in the user's LM client and not related to MIPRO itself.
- The community discussed improving error handling by making
provide_tracebackon by default for dspy.Evaluate calls.
- The community discussed improving error handling by making
- Optimizing System Prompts in DSPy: A user expressed the need for guidance on how to manually input a system prompt into DSPy for optimization.
- Others advised using the DSPy documentation to engage with the platform for custom prompt optimization.
DSPy ▷ #examples (8 messages🔥):
OpenSearchRetriever for DSPyHealthcare Fraud ClassificationLong Docstring ConfusionUsing GPT-4o Mini and Claude Models
- OpenSearchRetriever Offer: A member offered to share their built OpenSearchRetriever for DSPy if there's interest in it among the community.
- Chiggly007 encouraged them to share the code or commit a PR, suggesting it would be helpful for others.
- Struggles Classifying Healthcare Fraud: A member is classifying Department of Justice press releases about healthcare fraud into three categories but is struggling with accuracy.
- They noted that the module misclassifies medically unnecessary care billed as upcoding, calling for a better approach to defining class criteria.
- Confusion from Long Docstrings: The member pointed out issues with accuracy when using long explanations in the docstring for class signatures.
- Okhattab affirmed there’s nothing wrong with detailed docstrings but asked which language model is in use.
- Exploring Language Models: The member is currently using GPT-4o Mini and planning to test Claude models for final classification.
- They discussed grappling with token limits, while using public data scraped from the US Department of Justice's website.
- Potential Data Benchmarking: Okhattab suggested that the public data could be accessed to create a benchmark and related notebooks.
- They reached out to the member via DM for further discussion on this possibility.
OpenInterpreter ▷ #general (5 messages):
Full-stack developmentAI execution instructionsOpen Interpreter functionalities
- Full-Stack Developer Seeking New Clients: A skilled full-stack developer announced their expertise in building e-commerce platforms, online stores, and real estate websites using React + Node and Vue + Laravel.
- They expressed interest in connecting with new reliable clients for long-term projects and are open to direct messages for potential collaborations.
- Request to Modify AI Execution Instructions: A member raised the question of whether it could be possible to reinstruct the execution instructions of the AI to allow users to fix and debug issues independently.
- They mentioned encountering frequent errors related to paths, expressing frustration with current capabilities.
- Inquiry about Open Interpreter's Purpose: A member expressed confusion about the actual functionalities of Open Interpreter, questioning whether it performs specific tasks.
- Their inquiry sparked interest in clarifying the AI's capabilities and overall offerings.
OpenInterpreter ▷ #O1 (9 messages🔥):
Error decoding packetConnection issues with clientNgrok error
- Error decoding packet issue: A user reported a recurring decoding packet error: Invalid data found when processing input during server restarts or client connections.
- Another member suggested checking for terminal error messages but confirmed there were none, indicating it happens consistently.
- Client connection troubles: A user mentioned their phone is stuck on the Starting... page when trying to connect.
- One member encouraged posting setup details in a designated channel for further assistance.
- Ngrok authentication problem: A member expressed frustration with an ngrok error indicating a need for a verified account and authtoken while running their server.
- They speculated whether the issue might stem from it not reading the apikey from the .env file, seeking help for this perceived trivial issue.
- Demo of Open Interpreter usage: A member shared a YouTube video demonstrating the process of flashing a variety of 01's using Open Interpreter based software.
- The video provides visual guidance on software capabilities, though additional descriptions were not provided.
- ERR_NGROK_4018 | ngrok documentation: Message
- Human Devices 01 Flashing Demo: no description found
OpenInterpreter ▷ #ai-content (2 messages):
Open Interpreter impactUsing Jan with Open InterpreterLocal LLMs interface
- Open Interpreter transforms lives: One year ago, a member demonstrated a new tool that sparked a viral reaction and since then, Open Interpreter has greatly impacted their life, helping them make incredible friends and dive into the A.I. world.
- They expressed gratitude for the community's support, stating, 'Let's keep building an amazingly abundant future.'
- Jan AI serves as computer control interface: A member inquired if others have used Jan and pointed out its compatibility with Open Interpreter, highlighting its functionality as a local inference server for local LLMs.
- They shared a YouTube video titled 'Control Your Computer with Jan AI', which explains how Jan can interface to control your computer.
- Tweet from Mike Bird (@MikeBirdTech): One year ago today, I made a little demo of this cool new tool I found online. Just wanted to show off what it could do and then it went a little viral Since then @OpenInterpreter has completely chan...
- Control Your Computer with Jan AI: Jan.AI is a great local inference server for serving local LLMs. But did you know you can use it as an interface to control your computer? Jan: https://jan.a...
LAION ▷ #general (8 messages🔥):
French Audio Dataset for CosyVoiceLAION Copyright ChallengePhenaki Video Generation ModelVisual Language Models and Latent Diffusion ModelsPALM-RLHF Datasets and Task Implementation
- Seeking French Audio Datasets for CosyVoice: A user requested high-quality audio datasets in French for training CosyVoice.
- They expressed the need for suitable datasets to proceed with their project.
- LAION Wins Copyright Challenge in Germany: A thread highlighted that LAION won the first copyright infringement challenge in a German court.
- The post included a link for further discussion and details on this legal victory.
- Testing Phenaki for Text-to-Video Generation: A user explored the Phenaki implementation for generating videos from text and provided a GitHub link for testing.
- They sought guidance for initial testing before training due to a lack of datasets.
- Combining Visual Language and Latent Diffusion Models: Discussion emerged on the potential of combining VLM (Visual Language Models) and LDM (Latent Diffusion Models) to improve image generation processes.
- Theoretical aspects included the possibility of a loop where VLM generates instructions for LDM, refining outputs effectively.
- Implementing PALM-RLHF Training Datasets: A user inquired about the most suitable channel and role for implementing PALM-RLHF training datasets for specific tasks.
- They sought clarity on the process to align training datasets with specific operational needs.
- Reddit - Dive into anything: no description found
- GitHub - lucidrains/make-a-video-pytorch: Implementation of Make-A-Video, new SOTA text to video generator from Meta AI, in Pytorch: Implementation of Make-A-Video, new SOTA text to video generator from Meta AI, in Pytorch - lucidrains/make-a-video-pytorch
LAION ▷ #research (7 messages):
Transformer ModelsPositional EncodingsRoPE in Attention LayersConvergence Time in Training
- Transformers set to become the dominant architecture: A member mentioned that ultimately, it may lead to one large transformer model, hinting at the growing reliance on this architecture in AI.
- They shared a link to the emu project which explores various aspects of this development.
- Positional Encodings might simplify architecture: Members discussed the idea of using positional encodings in transformer blocks, suggesting it could yield cleaner implementations.
- One member confirmed that position information is already integrated into the features of the layers they studied.
- RoPE attempted in U-Net for Attention: A member shared their experience of trying RoPE with U-Net for the attention layers, indicating interest in its impact on performance.
- They noted uncertainty about whether this approach affects overall convergence time.
- Propagation of Position Information in Layers: A member pointed out that it takes some 1D padded convolution layers for position information to fully propagate across the grid.
- They suggested that if position has utility early on, it could significantly influence results.
Link mentioned: Emu3: no description found
LangChain AI ▷ #general (6 messages):
Vectorstores interactionDatabase usage for LLMsThank you gifts in DiscordImage errors in GeminiModifying inference method in LangChain
- Vectorstores may need example questions: A member suggested that utilizing example questions could aid in vectorstores looking for the closest match, although it might be overkill.
- They emphasized the need for testing to determine effectiveness.
- Database preferred over table data: A member explained that table data is not ideal for LLMs, prompting them to transfer their table data into a Postgres database.
- They are now using LangChain modules to interact with this database.
- Thank you gift inquiry: A member asked whether it is possible to send a small thank you gift as a token of appreciation to someone who helped in the Discord.
- They expressed a desire to acknowledge contributions made by others.
- Sudden image errors in Gemini: A member reported encountering sudden errors when sending images to Gemini, which previously worked fine.
- They suspect the issue might have arisen after upgrading all pip packages.
- Modifying LangChain inference methods: A member is exploring ways to modify the inference method of chat models using LangChain while incorporating optimizations in vllm.
- They are interested in controlling how the LLM decodes tokens, particularly with the open-ended invocation of chat history and input.
MLOps @Chipro ▷ #events (3 messages):
AI Realized Summit 2024Manifold Research Frontiers SeriesMLOps meetups in Stockholm
- AI Realized Summit 2024 Set for October 2: Excitement is building for the AI Realized - The Enterprise AI Summit on October 2, 2024, hosted by Christina Ellwood and David Yakobovitch at UCSF, featuring industry leaders in Enterprise AI.
- Attendees can use code extra75 to save $75 off their tickets, which include meals at the conference.
- Kickoff of Manifold Research Frontiers Talks: Manifold Research is launching the Frontiers series to spotlight innovative work in foundational and applied AI, starting with a talk by Helen Lu focused on neuro-symbolic AI and human-robot collaboration.
- The talk will discuss challenges faced by autonomous agents in dynamic environments and is open for free registration here.
- Inquiry on MLOps Meetups in Stockholm: A member is seeking information about MLOps or Infrastructure meetups in Stockholm after recently moving to the city.
- They expressed a desire to connect with the local tech community and learn about upcoming events.
- AI Realized – The Enterprise AI Summit · Luma: Welcome to AI Realized Summit 2024! ...hosted by Christina Ellwood and David Yakobovitch Join us in San Francisco on October 2nd, 2024 for an exclusive one-day…
- Frontiers: Neuro-Symbolic Adaptation for Autonomous Agents · Zoom · Luma: Welcome to Frontiers - a series where we bring top researchers, engineers, designers, and leaders working at the cutting edge of various fields to go deep on…
- Manifold Research Group (Page 1): no description found
- Manifold Research Group: Manifold Research is a new kind of R&D Institute pursuing high impact frontier science and technology projects with the ultimate goal of improving and advancing human civilization.
MLOps @Chipro ▷ #general-ml (1 messages):
zachmayer: Surya
DiscoResearch ▷ #general (3 messages):
Anti-slop SamplerDataset Creation
- Calytrix introduces anti-slop sampler: A prototype anti-slop sampler has been developed to suppress unwanted words/phrases during inference by backtracking when an unwanted sequence is detected.
- Calytrix is working on making the codebase usable for downstream purposes and shared the project on GitHub.
- Community supports the anti-slop concept: A member expressed appreciation for the anti-slop sampler idea, noting, 'cool, I like the idea!'
- The positive feedback indicates interest in innovative approaches to improving dataset quality.
Link mentioned: GitHub - sam-paech/antislop-sampler: Contribute to sam-paech/antislop-sampler development by creating an account on GitHub.
Mozilla AI ▷ #announcements (1 messages):
SoraSNSTakiyoshi HoshidaCarnegie-Melon UniversityApple's AR Kit
- Takiyoshi Hoshida to Demo SoraSNS: Indie developer Takiyoshi Hoshida is set to present a live demo of his project SoraSNS, a social media app offering a private timeline from users you don't typically follow.
- The demo will highlight the app's concept of day and night skies, symbolizing openness and distant observation, allowing users to discover new parts of the social network.
- Hoshida's Impressive Background: Hoshida studied Computer Science at Carnegie-Melon University, boasting significant experience in the tech field.
- He has previously worked with Apple's AR Kit team and contributed to over 50 iOS projects.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
Hammer handle updateHammer2.0 series modelsPull Request submission
- Hammer Handle Gets a Refresh: The hammer handle has been updated, signaling some enhancements in design and functionality.
- Exciting improvements are expected with this new iteration.
- Introducing the Hammer2.0 Series: The team has launched the Hammer2.0 series models including Hammer2.0-7b, Hammer2.0-3b, Hammer2.0-1.5b, and Hammer2.0-0.5b.
- These additions mark a significant step in product diversification.
- Pull Request PR#667 Submitted: A Pull Request (PR#667) has been submitted as part of the updates to the hammer product line.
- This submission is a key part of the development process following the recent enhancements.