[AINews] Life after DPO (RewardBench)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
RLHF is all you need.
AI News for 5/24/2024-5/27/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (382 channels, and 9556 messages) for you. Estimated reading time saved (at 200wpm): 1079 minutes.
It's a quiet US holiday weekend.
- X.ai raised $6b at a $24B valuation, immediately becoming one of the most highly valued AI startups.
- We also released Part 1 of our ICLR recap of best papers and talks.
- Alex Reibman's LlamaFS project from the Meta Llama 3 hackathon went viral: A local LLM-powered hard drive file organizer. Automatically rename and categorize messy files and directories with multi-modal AI.
Today's feature goes to Nathan Lambert, who is giving a guest lecture for Chris Manning's CS224N (the full suggested readings are worth a browse), and released slides for his upcoming talk on the history and future of reward models and his work on RewardBench.
- History of Language Models (LMs): LMs have evolved significantly, from Claude Shannon's early English language model in 1948 to the powerful GPT-3 in 2020 and beyond. The transformer architecture, introduced in 2017, has been instrumental in this progress, enabling the development of models capable of generating increasingly complex and coherent text.
- RLHF and DPO: RLHF (Reinforcement Learning from Human Feedback) has been a key factor in the success of many popular language models, but it is complex and resource-intensive. DPO (Direct Preference Optimization), introduced in 2023, is a simpler and more scalable alternative that learns directly from human preferences. While DPO has shown promising results, RLHF still produces better outcomes in many cases.
- RewardBench: RewardBench is a tool for evaluating reward models (RMs) for LLMs. It provides insights into how RMs impact LLM capabilities and safety. Cohere's RMs have outperformed open-source models on RewardBench, highlighting the importance of continued research in this area.
- Future Directions for Alignment Research: Key areas for future research include collecting more data, particularly preference datasets, improving DPO techniques, exploring different model sizes, developing more specific evaluations beyond general benchmarks, and addressing personalization in language models.
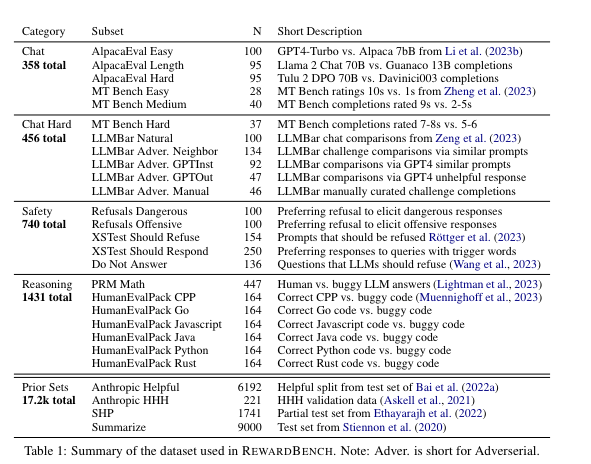
The RewardBench paper lists a collection of the most challenging reward model benchmarks:
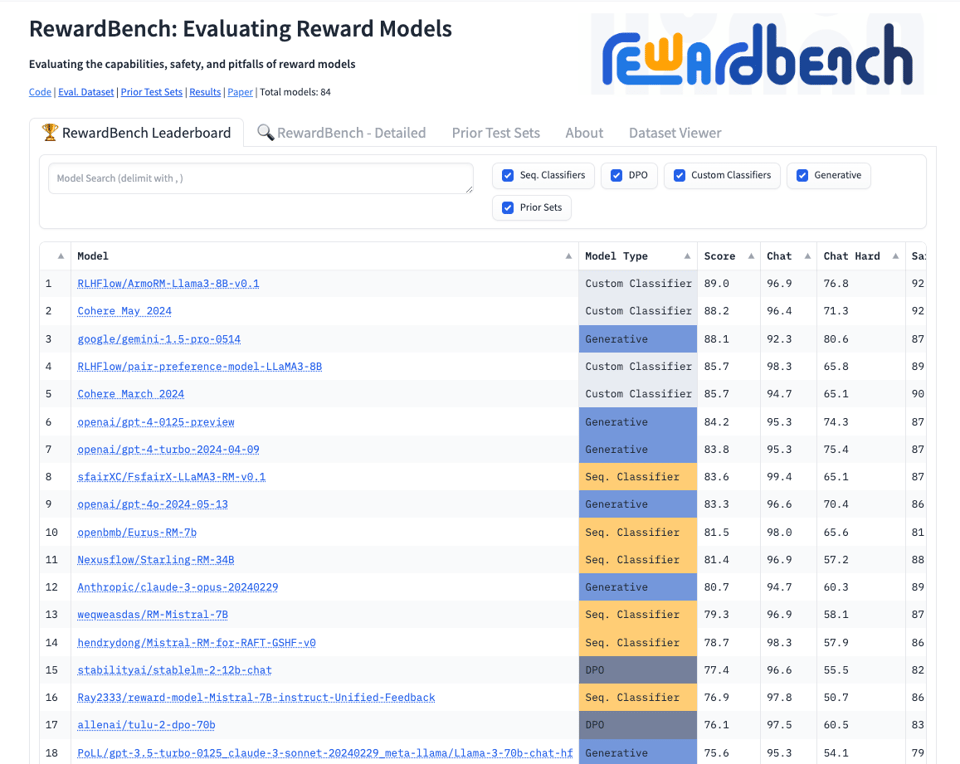
and it is interesting that a few dedicated Reward Model focused Llama 3 8B models are currently beating GPT4 and Cohere and Gemini and Claude in the leaderboard. Something there or reward hacking?
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
xAI Raises $6 Billion at $24 Billion Valuation
- Funding Details: @nearcyan noted xAI raised $6 billion, valuing the company at $24 billion. @bindureddy congratulated xAI and Elon on the funding, stating it should be enough compute for GPT-5 and 6 class models.
- Comparisons to Other AI Companies: @rohanpaul_ai compared xAI's $24B valuation to other AI companies - OpenAI valued at $80-100B, Mistral AI at around $6B in April, and Anthropic at around $18.4B.
- Speculation on Spending: @nearcyan joked the money will go straight to Nvidia, cutting out the middlemen. He also imagined xAI saying a 100% Nvidia portfolio is a reasonable bet.
Criticism of Elon Musk and xAI
- Yann LeCun's Criticism: @ylecun sarcastically suggested joining xAI if you can stand a boss who claims what you're working on will be solved next year, claims it will kill everyone, and spews conspiracy theories while claiming to want rigorous pursuit of truth.
- Concerns about AI Hype and Regulation: @ylecun criticized the "Doomer's Delusion" of claiming AI will kill us all, monopolizing AI, requiring kill switches, banning open source, and scaring the public to get insane funding from clueless billionaires. He stated we don't even have a hint of a design for human-level AI yet.
- Musk's Politics: @ylecun disliked Musk's vengeful politics, conspiracy theories and hype, while liking his cars, rockets, solar panels and satellite network. He clarified this wasn't advocacy of the far left, as authoritarianism and scapegoating have been used by both extremes.
AI Safety and Existential Risk Debate
- Counterarguments to AI Doomerism: @ylecun argued AI is not a natural phenomenon that will emerge and become dangerous, but something we design and build. He stated if a safe, controllable AI system that fulfills objectives better than humans exists, we'll be fine; if not, we won't build it. Currently, we don't even have a hint of a design for human-level AI.
- Rebuttal to Regulation Proposals: @ylecun responded to a tweet saying AI must be monopolized by a small number of companies under tight regulation. He reasoned as if AI is a natural phenomenon rather than something we design and build, and compared it to how we made turbojets reliable before deploying them widely.
- Debate on General Intelligence: @ylecun stated general intelligence, artificial or natural, does not exist. All animals have specialized intelligence and ability to acquire new skills. Much of intelligence is acquired through interaction with the physical world, which machines need to reproduce.
Developments in AI and Robotics
- Naver Labs Robot Cafe: @adcock_brett reported Naver Labs made a Starbucks with over 100 robots called "Rookie" that bring drinks and perform various tasks.
- Microsoft's AI Announcements: @adcock_brett shared Microsoft revealed Copilot+ PCs that run AI 20x faster than traditional PCs, ship with GPT-4o, and have a "Recall" feature to search things you've seen on screen.
- Tokyo Robotics Demo: @adcock_brett noted Tokyo Robotics showed a new 4-fingered robotic hand that can grasp objects of any shape without prior knowledge of dimensions.
- Other Developments: @adcock_brett mentioned MIT developing a robotic exoskeleton to help astronauts recover from falls. He also shared IDEA Research unveiled object detection models, and reported on Anthropic glimpsing into Claude's "mind".
New AI Research Papers
- Grokked Transformers: @_akhaliq shared a paper studying if transformers can implicitly reason over parametric knowledge. They found transformers can learn implicit reasoning but only through grokking (extended training past overfitting).
- Stacking Transformers: @_akhaliq posted about a paper on model growth for efficient LLM pre-training by leveraging smaller models to accelerate training of larger ones.
- Automatic Data Curation: @arankomatsuzaki shared Meta's paper on automatic data curation for self-supervised learning, outperforming manually curated data.
- Meteor: @_akhaliq posted about Meteor, which leverages multifaceted rationale to enhance LLM understanding and answering capabilities.
- AutoCoder: @_akhaliq noted AutoCoder is the first LLM to surpass GPT-4 on HumanEval, with a versatile code interpreter.
Debates and Discussions
- Math Skills vs Verbal Skills: There was debate on a viral tweet claiming AI will favor verbal over math skills. @bindureddy argued you need math and analytical skills, not verbal skills, to instruct LLMs on hard problems. He also disagreed AI makes coding obsolete, stating design skills and AI tool use will be in demand.
- Mechanical Interpretability: @jeremyphoward cautioned against just doing what everyone else is doing in interpretability research, as that's not how the best research gets done. @NeelNanda5 and @aryaman2020 discussed the lack of diversity in directions explored.
- Sentience and Consciousness: There were many tweets debating if LLMs and AI systems can be sentient or conscious. Key arguments were that we can't observe the self-awareness of another entity, attempts to define sufficient properties for sentience lead to bizarre conclusions, and current LLMs likely can't reflect on their internal states.
Miscellaneous
- History Project: @alexandr_wang is kicking off a next-gen history project to invent new ways to preserve stories and make history experiential using LLMs and AI.
- Rabbit AI Opinions: There were mixed views on Rabbit AI, with some criticizing it as a grift while others like @KevinAFischer were impressed and thought opening it up to developers could make it amazing.
- Nvidia's Rise: Many noted Nvidia's spectacular climb and importance to AI, with @rohanpaul_ai sharing a chart of its stock price.
- Metaverse Hype Cycle: @fchollet compared current AI hype to late 2021 when the Metaverse and NFTs were seen as the future of everything before dying down.
- LLaMA Ecosystem: Many shared resources, demos and experiments around LLaMA models, including a self-organizing file manager called LLamaFS (@llama_index).
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Developments and Capabilities
- Llama-3-70B fine-tuned model: In /r/LocalLLaMA, the Llama-3-70B fine-tuned model is the most uncensored model on the Uncensored General Intelligence leaderboard, outperforming other large language models.
- Phi-3 mini ONNX DirectML Python AMD GPU: In /r/LocalLLaMA, a demo shows token generation reusing KV cache from NPU, then running on CPU at 27 tokens/second.
- In-context learning transformers: In /r/MachineLearning, in-context learning transformers can be used as tabular data classifiers, learning to create complex decision boundaries during pretraining.
- MOMENT foundation model: In /r/MachineLearning, the MOMENT foundation model was released for time series forecasting, classification, anomaly detection and imputation.
AI Agents and Assistants
- Microsoft's Recall: In /r/MachineLearning, Microsoft's Recall can be recreated using open-source models and tools like mss for screenshots, ollama/llava for descriptions, and chromadb for search.
- Jetta Autonomous Configurable PC Task Doer: In /r/singularity, Jetta is a new AI agent that can control your PC.
- Faster Whisper Server: In /r/LocalLLaMA, Faster Whisper Server provides an OpenAI compatible server for streaming transcription using faster-whisper as the backend.
- AI agent applications: In /r/LocalLLaMA, people are excited about potential AI agent applications like games with AI characters once larger models can run on consumer hardware.
AI Regulation and Governance
- Two former OpenAI board members: In The Economist, two former OpenAI board members argue that AI firms cannot self-govern and need regulation to tame market forces for humanity's sake.
- AI "kill switch": In Fortune, tech companies have agreed to an AI "kill switch" to prevent Terminator-style risks, though implementation details are unclear.
AI and Society
- AI unemployment and UBI: In /r/singularity, some argue it's time to introduce UBI tied to unemployment rates to support those displaced by AI.
- Post-scarcity world: In /r/singularity, in a post-scarcity world, excess wealth could still buy scarce experiences like real estate, vacations, live performances, and human-provided services.
- Age Reversal Unity: In /r/singularity, Age Reversal Unity has petitioned the FDA to recognize aging as a disease, a step towards anti-aging treatments.
AI Art and Content Generation
- Stable Diffusion techniques: In /r/StableDiffusion, new Stable Diffusion techniques allow for travelling through images in creative ways to create detailed, expansive artworks.
- Anime style changer: In /r/StableDiffusion, an anime style changer combines SDXL model with ControlNet and IPAdapter to transform character designs.
- AI-generated art carbon footprint: In an image post, AI-generated art is argued to have a much smaller carbon footprint than traditional art, though this claim is disputed.
- LoRA models: In /r/StableDiffusion, new LoRA (Low-Rank Adaptation) models were released for anime-style droids and running motion.
Memes and Humor
- Nvidia's increasing revenues: A meme jokes that Nvidia's increasing revenues are beating expectations in 2024 while AMD falls behind.
- Google's approach to AI: In /r/singularity, a meme pokes fun at Google's approach to AI being overly cautious and slow.
- Limits in AI art generation: A meme suggests the only limits in AI art generation are "your imagination... and VRAM".
AI Discord Recap
A summary of Summaries of Summaries
-
Fine-Tuning and Model Training Challenges:
- Discussions on various Discords highlighted challenges in fine-tuning models like Llama 3 and Mistral, with users facing issues from semantic similarity overfitting to runtime errors on GPUs like T4. Useful guides and troubleshooting tips were shared, such as TinyLLama Fine-Tuning and Mistral-Finetune repository.
- Members struggled with model tokenization and prompt engineering, emphasizing the importance of correctly using template tokens like
###or end-of-text tokens for efficient fine-tuning. This was particularly discussed in the context of Axolotl and Jarvis Labs.
-
Advancements in Multimodal Models and Integration:
- Perplexity AI outshone ChatGPT in processing CSV files by supporting direct uploads and integrating tools like Julius AI for data analysis, as noted by users on Discord.
- New proteins visualization project using 3D rendering was shared on HuggingFace, along with considerations for integrating Vision Transformers (ViT) for tasks like monocular depth estimation. Check out the GitHub repository for protein examples.
-
Open-Source AI Projects and Community Efforts:
- LlamaIndex introduced tools for automated RAG chatbots, detailed in a post on MultiOn's demo. Issues around ensuring context maintenance and efficient indexing for knowledge retrieval were discussed.
-
New Model Releases and Benchmarking:
- Meta's Phi-3 Medium 128k Instruct debuted, receiving attention for its enhanced reasoning and instruction-following abilities, available on OpenRouter. Discussions emphasized user feedback on model performance and applications.
- IBM Granite vs. Llama-3 performance debates surfaced on platforms like ChatbotArena, underlining the need for credible and transparent benchmarks. DeepSeek-V2 and Granite-8B-Code-Instruct were notable mentions, with specific benchmarks shared.
-
Ethics, Legislation, and AI's Societal Impact:
- Concerns over SB-1047 were voiced, likening it to regulatory capture and disadvantaging smaller AI players. Tools like Perplexity AI for searching legislation impacts were shared for community awareness.
- OpenAI's water consumption during AI model training stirred discussions on environmental impacts, referencing Gizmodo's article. The community called for more eco-friendly AI practices and discussed alternatives like Meta's Audiocraft for sustainable advancements.
LLM Finetuning (Hamel + Dan) Discord
Fine-Tuning Facts: Discussion on fine-tuning in the general channel revealed a concern about semantic similarity overfitting due to biased data categories. A user struggled with understanding fine-tuning vis-à-vis user inputs and initial model training. Changes in the OpenAI platform's sidebars were also noted with the disappearance of two icons (threads and messages).
Templates Take the Spotlight: In workshop-1, the importance of configuring templates correctly during fine-tuning was highlighted. In particular, the delimiter ### aids in parsing different input sections, and "end of text" tokens indicate when to stop token generation.
Maven Mingles with Moderation: In asia-tz, a light-hearted exchange between members referenced a reunion. A request for a conference talk recording was met, with the video being available on Maven.
Modal Mobilization: Modal users in 🟩-modal shared excitement over received credits, training experiences, and provided specific links to Modal documentation and examples for new users. A plan to use Modal for a Kaggle competition was also shared, including setup and execution details.
Jarvis Jots Down Jupyter Jumble: In the jarvis-labs channel, members discussed storing a VSCode repo on Jarvis with a suggestion to use GitHub for saving work. There was a notice of spot instance removal due to instability. The cost and duration of fine-tuning the open-lama-3b model were shared, and a user resolved an Ampere series error by adjusting model parameters.
Hugging Face Huddles on Credits & Spanish Models: The hugging-face channel saw discussions about pending HF credits and models suitable for Spanish text generation—with Mistral 7B and Llama 3 models being recommended.
Credit Countdown Carries On in replicate, where an upcoming announcement related to credit management and distribution was teased.
Corbitt's Commandments Claim Clout: Enthusiastic attendees in the kylecorbitt_prompt_to_model channel discussed fine-tuning methods and techniques presented in Kyle Corbitt's talk, including Ten Commandments for Deploying Fine-Tuned Models.
Axolotl Answers the Call in workshop-2, where users discussed datasets, model training, and troubleshooting in Axolotl. A blog post on TinyLLama Fine-Tuning was shared, and there was a push for integrating observability into LLM applications.
Zoom Out, Discord In: Users from workshop-3 migrated their discussions to Discord after the Zoom chat was disabled.
Axolotl's Cache Conundrum Causes Confusion: Issues with cache in Axolotl frustrating users and confusion with missing files were resolved in axolotl. Discussions on sample packing and a guide on tokenizer gotchas addressed concerns around efficiency and tokenization.
Accelerate to Victory: zach-accelerate saw users work through confusion over float comparisons, resolve Jarvislab training command errors, and exchange resources for learning model acceleration with a focus on fine-tuning best practices.
Winging It with Axolotl: The wing-axolotl channel collaborated on dataset templates, pre-processing issues, Axolotl configurations, and provided a PR merge for the latest Axolotl updates. They delved into debugging tools and the significance of precise templates for training success.
HuggingFace Discord
Protein Data Visuals Reach New Heights: A new protein visualization project now sports 3D rendering and includes examples for human hemoglobin and ribosomal proteins, with the project details found on GitHub.
Enter the TranscriptZone with OpenAI's Whisper: A new transcription app that leverages OpenAI's Whisper to transcribe YouTube videos and more is available at Hugging Face Spaces.
Decentralizing the Web - More than a Dream?: A project building infrastructure for a decentralized internet sought community feedback through a survey, raising discussions about the ethics of data collection.
A Vision Transformers Query in Depth: A member sought resources on applying Vision Transformers (ViT) for monocular depth estimation, indicating an intent to develop a model using ViT, but no specific resources were provided in the discussion.
Quantisation Quandary for Mistral Model: The use of bitsandbytes for 8-bit quantisation on Mistral v0.3 Instruct led to slower performance compared to 4-bit and fp16, a baffling outcome that contradicts expected efficiency gains from reduced-bit computation.
Perplexity AI Discord
- Perplexity Climbs Over ChatGPT in CSV Showdown: Engineers discussed that Perplexity AI outshines ChatGPT in CSV file processing by allowing direct CSV uploads. Also, Julius AI was recommended for data analysis, leveraging Python and integration with LLMs like Claude 3 or GPT-4.
- Users Snub Claude 3 Opus: Claude 3 Opus is getting the cold shoulder due to increased content restrictions and perceived diminished utility, with GPT-4 posed as a preferable option despite limitations.
- Querying Pro Search's True Upgrade: Upgrades to Pro Search raised eyebrows as users discussed whether new multi-step reasoning features and API specs were genuine backend improvements or merely surface-level UI enhancements.
- API Integration Articulated: Dialogue around API integration for external tools with Claude generated interest along with sharing of custom function calls, serverless backends, and documentation like Tool Use with Claude.
- Ethics in AI: More Than a Thought Experiment: Discourse on infusing GPTs with ethical monitoring capabilities sparked, casting light on potential applications in workplace communication and legal defensibility, albeit with philosophical wrinkles yet to be ironed out.
Stability.ai (Stable Diffusion) Discord
- Speculation Peaks on RTX 5090's VRAM: There's buzzing debate over whether the rumored RTX 5090 with 32GB VRAM makes practical sense. References were made to potential specs and images on PC Games Hardware, but some members remained skeptical about its authenticity.
- Stable Diffusion and the AMD Challenge: Users offered guidance on installing Stable Diffusion on an AMD 5700XT GPU, suggesting that starting with web services like Craiyon may circumvent potential compatibility issues.
- Stable Diffusion 3: Trial Before Commitment: The community contrasted Stable Diffusion 3 with competitor Midjourney, highlighting that while a free trial is available for SD3, ongoing access would require a Stability membership.
- Anticipation Builds Around Mobius Model: An announcement concerning DataPlusEngine’s novel Mobius model has garnered significant interest for its claim to create efficient base models. The model, teased on Twitter, is neither a straightforward base model nor a tuned version of something pre-existing.
- 32GB VRAM: Game Changer or Overkill?: The mention of a 32GB VRAM GPU led to conversations about the potential shift in Nvidia's approach to data center GPU sales, considering how products with substantial memory could impact the market demand for the H100/A100 series.
Unsloth AI (Daniel Han) Discord
- PEFT Config Snag Solved: An issue where
config.jsonwas missing during PEFT training was resolved by copying it from the base model's configuration, with the user confirming success.
- Llama Levitates Above Bugs: The Llama 3 model's base weights were described as "buggy," but Unsloth has implemented fixes. To improve training, the use of reserved tokens and updates to the tokenizer and
lm_headare recommended.
- System Prompt Boosts Llama 3: Incorporating a system prompt, even a blank one, was observed to enhance Llama3 finetuning outcomes.
- Phi 3 Proliferation: Excitement bubbled as Phi 3 models debuted, sporting medium support. Community chatter pointed engineers toward extensive details in blog posts and release notes.
- Stable Diffusion's Sinister Side Show: Creepy artifacts and uncanny voice cloning outputs from Stable Diffusion startled users, with discussions and experiences shared via YouTube videos and a Reddit thread.
- VSCode Copilot Climbing Onboard: Recommendations for a local VSCode "copilot" were sought and met with suggestions and positive responses in the random channel.
- Inference Inertia with Phi-3: Slower inference times using Unsloth Phi-3 puzzled one user, who provided a Colab notebook to investigate the lag, with community efforts yet to find a fix.
- Quantization Quandary Unraveled: A member faced challenges quantizing a custom model, hitting walls with llama.cpp and Docker compatibility, sparking a discussion on solutions.
- VRAM Verdict for Model Might: VRAM requirements were laid out: 12GB for Phi 3 mini is okay, but 16GB is a must for Phi 3 medium. For hefty tasks, considering outside computing resources was proposed.
- Data Diligence for Training Consistency: The importance of using consistent datasets for training and evaluation was echoed, highlighting Unslothai's public datasets like the Blackhole Collection.
- Platform Possibilities and Cautions: Queries regarding Unsloth support for older Macs were addressed, confirming a focus on CUDA and GPU usage, with suggestions for those on CPU-only rigs.
- Enterprise Expertise Extension: A community member stepped forward to offer enterprise expertise to Unsloth, hailing the joining of accelerators at Build Club and Github, hinting at synergistic potential for Unsloth's endeavors.
Nous Research AI Discord
Intellectual Debate Ignites Over AI Understanding: In-depth discussions were had about the true understanding of concepts by LLMs, with interpretability research considered important empirical evidence. Skeptics argued that current efforts are lacking, with references to work by Anthropic on mapping large language model minds.
The Creature from the Llama Lagoon: A technical foray into enhancing Llama models centered around crafting a script that could manage function calls, with Hermes Pro 2's approach serving as inspiration. Another inquiry circled the implementation of Llama3 LoRA techniques on a 3080 GPU.
Reality Quest in Digital Dimensions: Spearheading a conversation on Nous and WorldSim, members explored the possible applications of NightCafe and multi-dimensional AR spaces in mapping complex AI worlds. Dream-like explorations in audio-visualizers and whimsical ASCII art representations highlighted creative uses for AI-driven simulations.
Sifting Through RAG Data: Advocation for models to integrate internal knowledge with Retrieval-Augmented Generation (RAG) was a hot topic, with questions raised about how to handle contradictions and resolve conflicts. Emphasizing user evaluations was seen as essential, particularly for complex query cases.
Precision over Pixie Dust in Fine-Tuning AI: The community's discourse featured a celebration of the Mobius model for its prowess in image generation, with anticipation for an open-sourced version and elucidating publications. Additionally, Hugging Face was mentioned for their PyTorchModelHubMixin enabling easier model sharing, though limited by a 50GB size constraint without sharding.
Eleuther Discord
- JAX vs. PyTorch/XLA: The TPU Showdown: The performance comparison of JAX and PyTorch/XLA on TPUs spurred debate over benchmarking nuances such as warmup times and blocking factors. The dramatic decline in GPT-3 training costs from $4.5M to an estimated $125K-$1M by 2024 was highlighted, considering TFLOP rates and GPU-hour pricing from various contributors, linking to a Databricks Blog Post.
- Scaling and Teaching LLMs: In the research forum, the Chameleon model was noted for its strong performance in multimodal tasks, while Bitune promised improvements in zero-shot performance for LLMs (Bitune Paper). Discussions questioned the scalability of the JEPA model for AGI and critiqued RoPE's context length limitations, referencing a relevant paper.
- Emergent Features Puzzle LLM Enthusiasts: Tim Dettmers' research on advanced quantization methods maintaining performance in transformer inference was linked, including his concept of emergent outliers, and its integration with Hugging Face via the bitsandbytes library. Discourse on emergent features coalescing around ideas of them being the "DNA" of a model, driving discussions on its implications for phase transitions.
- A Brief on Technical Tweaks & LM Evaluation: Within the lm-thunderdome, engineers covered practical tips for setting seeds in vllm models, retrieving the list of tasks with
lm_eval --tasks list, and handling changes in BigBench task names that affect harnesses like Accelerate with memory issues. It was suggested to locate tasks by perusing thelm-eval/tasksfolder for better organization.
- A Call for Collaboration: An appeal was made for expanding the Open Empathic project, with a YouTube guide for contributing movie scenes and a link to the project shared. Further collaboration was encouraged, underlining the need for community efforts in enhancement.
LM Studio Discord
GPU Adventures: Engineers discussed challenges when loading small models onto GPUs, with some favoring models like llama3, mistral instruct, and cmdrib. Meanwhile, using lower quantizations, such as llamas q4, reportedly yielded better results than higher ones like q8 for certain applications, refuting the notion that "bigger is always better."
Next-Gen Models Incoming: An update in the model realm informed about the release of a 35B model, with testing to ensure LM Studio compatibility. Optimizations for different scales of models were a topic too, with a focus on Phi-3 small GGUFs and their efficiency.
Servers and Setups: Hardware discussions included leveraging distributed inference with llama.cpp and its recent RPC update, although quantized models aren't supported yet. Experimental builds using clustered cheap PCs with RTX 4060 Ti 16GB for distributed model setups and possible network constraints were also explored.
Multilingual Cohesion Achieved: Cohere models now extend their prowess to 23 languages, as advertised with aya-23 quants available for download, but ROCm users must await an update to dive in.
Stable Diffusion Left Out: LM Studio clarified that it exclusively handles language models, excluding image generators like Stable Diffusion, alongside dealing with CUDA issues on older GPUs and promoting services like Julius AI to ease user experience woes.
CUDA MODE Discord
- Gradient Norm Nuisance: Altering the batch size from 32 leads to a sudden spike in gradient norm, disrupting training. A pull request resolved this issue by preventing indexing overflow in the fused classifier.
- Int4 and Uint4 Types Need Some TLC: A member flagged that many functions lack implementations for int4 and uint4 data types in PyTorch, with a discussion thread indicating limitations on type promotion and tensor operations.
- Live Code Alert – Scan Algorithm in Spotlight: Izzat El Hajj will lead a live coding session on the Scan algorithm, vital for ML algorithms like Mamba, scheduled for
<t:1716663600:F>, promising to be a technical deep dive for enthusiasts.
- CUB Library Queries and CUDA Nuances: Members tapped into discussions ranging from the functioning of CUDA CUB library code to triggering tensor cores without cuBLAS or cuDNN, highlighting resources like NVIDIA's CUTLASS GitHub repository and the NVIDIA PTX manual.
- FineWeb Dataset Conundrum: Processing the FineWeb dataset can be a storage hog, hitting 70 GB on disk and gobbling up to 64 GB of RAM, hinting at a need for better optimization or more robust hardware configurations for data processing tasks.
Modular (Mojo 🔥) Discord
Python Libraries Cling to C Over Mojo: There's a lively conversation about the feasibility and preparedness of porting Python libraries to Mojo, with concerns about pushing maintainers too hard given Mojo's evolving API. Members discussed whether targeting C libraries might be a more immediate and practical endeavor.
Rust's Security Appeal Doesn't Rust Mojo's Potential: Mojo is not slated to replace C, but the security benefits of Rust are influencing how engineers think about Mojo's application in different scenarios. Ongoing discussions address concepts from Rust that could benefit Mojo developments.
Blazing Ahead With Nightly Mojo: BlazeSeq performance on MacOS using Night versions of Mojo shows promising similarity to Rust's Needletail, fueling cross-platform efficiency discussions. Rapid nightly updates, noted in changelog, keep the community engaged with the evolving language.
Curiosity Sparks Over Modular Bot's Machinery: Queries were raised about the underlying tech of "ModularBot", and although no specific model was referenced, the bot shared a colorful reply. Separately, the potential for ML model training and inference within Mojo was discussed, with mention of Max Engine as a numpy alternative, though no full-fledged training framework is on the horizon.
Compile-Time Confusion and Alignment Woes: Problems from aligning boolean values in memory to compile-time function issues are causing a stir among users, with workarounds and official bug reports highlighting the importance of community-driven troubleshooting.
OpenAI Discord
- LaTeX Loyalist LLM: In the realm of formatting, users noted frustration with GPT's strong inclination to default to LaTeX despite requests for Typst code, revealing preferences in coding syntax that the LLM seems to adhere to.
- Microsoft Copilot+ vs. Leonardo Rivalry: Conversations in the community centered on the value of Microsoft Copilot+ PCs for creative tasks like "sketch to image," while some members encouraged checking out Leonardo.ai for analogous capabilities.
- A Thirst for Efficiency in AI: Concern was voiced over the environmental toll of AI, citing a Gizmodo article on the substantial water usage during the training of AI models, prompting discussions on the need for more eco-friendly AI practices.
- Iteration Over Innovation: There was active dialogue on enhancing the performance of LLMs through iterative refinement, with references to projects like AutoGPT addressing iterations, despite the associated higher costs.
- Intelligence Infusion Offer Overstated?: The guild pondered the plausibility and potential of embedding legal knowledge within ChatGPT, enough to consider a valuation at $650 million, though detailed perspectives on this bold assertion were limited.
LangChain AI Discord
LangChain CSV Agent Deep Dive: Engineers explored LangChain's CSV agent within a SequentialChain and discussed how to customize output keys like csv_response. Challenges with SQL agents handling multi-table queries were mentioned, pointing towards token limits and LLM compatibility issues, with direction to GitHub for issues.
AI Showcases Gather Buzz: OranAITech tweeted their latest AI tech, while everything-ai v2.0.0 announced features including audio and video processing capabilities with a repository and documentation available.
Demystifying VisualAgents: Demonstrations of Visual Agents platform were shared via YouTube, revealing its potential to streamline SQL agent creation and building simple retrieval systems without coding, utilizing LangChain's capabilities. Two specific videos showcased their workflows: SQL Agent and Simple Retrieval.
EDA GPT Impressions On Display: A demonstration of EDA GPT, including a five-minute overview video showcasing its various functions, was linked to via LOVO AI. The demo highlights the AI tool's versatility.
Tutorial Teaser: A message in the tutorials channel provided a YouTube link to business24.ai's content, although the context of its relevance was not disclosed.
LAION Discord
- Piracy's Not the Panacea: Despite a humorous suggestion that The Pirate Bay could become a haven for sharing AI model weights, skepticism among members arises, highlighting the potential for friendlier AI policy landscapes in other nations to prevail instead.
- Japan Takes the AI High Road: Participants noted Japan's encouraging position on AI development, referencing a paper shared via a tweet about creating new base diffusion models without the need for extensive pretraining, showcasing a strategy involving temporary disruption of model associations.
- Poisoned Recovery Protocols Probed: A collaborative study, involving a poisoned model recovery method conducted by fal.ai, was mentioned, with findings expected to empirically substantiate the recovery approach. Reservations were expressed regarding the aesthetics of AI-generated imagery, specifically the "high contrast look" and artifacts presented by models like Mobius versus predecessors such as MJv6.
- Claude Mappings Crack the Code: Anthropic's research paper details the dissection of Claude 3 Sonnet's neural landscape, which illustrates the manipulation of conceptual activations and can be read at their research page. Debates sparked over the potential commercialization of such activations, with a juxtaposed fear of the commercial implications driving AI practitioners to frustration.
- A Nostalgic Look at AI's Visual Visions: A member reminisced about the evolution from early AI visual models like Inception v1 to today's sophisticated systems, recognizing DeepDream’s role in understanding neural functionality. Furthermore, the benefits of sparsity in neural networks were discussed, describing the use of L1 norm for sparsity and a typical 300 non-zero dimensions in high-dimensional layers.
LlamaIndex Discord
- Meetup Alert: Limited Seats Available: Few spots remain for the upcoming LlamaIndex meetup scheduled for Tuesday, with enthusiasts encouraged to claim their spots quickly due to limited availability.
- MultiOn Meets LlamaIndex for Task Automation: LlamaIndex has been coupled with MultiOn, an AI agents platform, facilitating task automation through a Chrome web browser acting on behalf of users; view the demo here.
- RAGApp Launches for Code-Free RAG Chatbot Setup: The newly introduced RAGApp simplifies the deployment of RAG chatbots via a docker container, making it easily deployable on any cloud infrastructure, and it's open-source; configure your model provider here.
- Solving PDF Parsing Puzzles: The community endorses LlamaParse as a viable API for extracting data from PDFs, especially from tables and fields, leveraging the GPT-4o model for enhanced performance; challenges with Knowledge Graph Indexing were also a topic, highlighting the need for both manual and automated (through
VectorStoreIndex) strategies.
- PostgresML Joins Forces with LlamaIndex: Andy Singal shared insights on integrating PostgresML with LlamaIndex, detailing the collaboration in a Medium article, "Unleashing the Power of PostgresML with LlamaIndex Integration", receiving positive remarks from the community.
OpenRouter (Alex Atallah) Discord
- Phi-3 Medium 128k Instruct Drops: OpenRouter unveiled Phi-3 Medium 128k Instruct, a powerful 14-billion parameter model, and invited users to review both the standard and free variants, and to participate in discussions on its effectiveness.
- Wizard Model Gets a Magic Boost: The Wizard model has shown improvements, exhibiting more prompt and imaginative responses, yet attention is required to avoid repeated paragraphs.
- Eyes on Phi-3 Vision and CogVLM2: Enthusiasm surges around Phi-3 Vision, with sharing of testing links like Phi-3 Vision, and suggestions to use CogVLM2 for vision-centric tasks found at CogVLM-CogAgent.
- Automatic Llama 3 Prompt Transformation: It was clarified that prompts to Llama 3 models are automatically transformed through OpenRouter's API, streamlining the process, but manual prompting remains as an alternative approach.
- Gemini API Annoyances: Users reported issues with Gemini FLASH API, such as empty outputs and token drain, recognized as a model-centric problem. The emergence of Google's daily API usage limits has piqued interest in how this might affect OpenRouter's Gemini integration.
Latent Space Discord
- LLM Evaluation under the Microscope: A Hugging Face blog post about Large Language Model (LLM) evaluation practices, the importance of leaderboards, and meticulous non-regression testing caught the attention of members, emphasizing the critical role of such evaluations in AI developments.
- AI's Answer to Search Engine Manipulations: An incident involving website poisoning affecting Google's AI-gathered overviews triggered discussions around security and data integrity, including workarounds through custom search engine browser bypasses as reported in a tweet by Mark Riedl.
- AI Democratizing Development or Raising Reliability Questions?: GitHub CEO Thomas Dohmke's TED Talk on AI's role in simplifying coding provoked debates over its reliability despite AI-driven UX improvements that expedite problem-solving in the coding process.
- Diversity Scholarships to Bridge Gaps: Engineers from diverse backgrounds who face financial barriers to attending the upcoming AI Engineer World's Fair received a boost with the announcement of diversity scholarships. Interested applicants should furnish concise responses to the essay questions provided in the application form.
Interconnects (Nathan Lambert) Discord
- Tax Tales Without Plastic: Nathan Lambert deciphered an invoice kerfuffle, realizing the rational behind tax billing sans credit card due to resale certificates.
- Golden Gate AI Gets Attention: Experimentation by Anthropic AI led to "Golden Gate Claude," an AI single-mindedly trained on the Golden Gate Bridge, creating buzz for its public interactivity at claude.ai.
- Google's AI Missteps: Google's failure to harness feedback and premature deployment of AI models spurred discussion about the tech giant's public relations challenges and product development woes.
- Battling Dataset Misconceptions: Google's AI team countered claims about using the LAION-5B dataset by putting forth that they utilize superior in-house datasets, as referenced in a recent tweet.
- Nathan Shares Knowledge Nuggets: For AI aficionados, Nathan Lambert uploaded advanced CS224N lecture slides. Additionally, attendees were tipped off about an upcoming session recording, sans release date details.
OpenAccess AI Collective (axolotl) Discord
- GQA Gains Traction in CMDR Models: Discussions revealed that Grouped Query Attention (GQA) is present in the "cmdr+" models but not in the basic "cmdr" models, indicating an important distinction in their specifications.
- VRAM Efficiency with Smart Attention: Engineers noted that while GQA doesn't offer linear scaling, it represents an improved scaling method compared to exponential, affecting VRAM usage favorably.
- Sample Packing Gets a Boost: A new GitHub pull request showcases a 3-4% efficiency improvement in sample packing, promising better resource management for distributed contexts, linked here.
- Academic Achievement Acknowledged: A member's co-authored journal article has been published in the Journal of the American Medical Informatics Association, highlighting the impact of high-quality, mixed-domain data on medical language models, with the article available here.
- Community Cheers Scholarly Success: The community showed support for the peer's published work through personal congratulatory messages, fostering a culture of recognition for academic contributions within the AI field.
OpenInterpreter Discord
SB-1047 Sparks Technical Turmoil: Engineers express deep concerns about the implications of SB-1047, dubbing it as detrimental to smaller AI players and likening the situation to regulatory capture observed in other industries.
Perplexity and Arc, Tools of the Trade Showcased: The community spotlighted tools aiding their workflows, sharing a Perplexity AI search on SB-1047 and the new “Call Arc” feature of Arc Browser, which simplifies finding relevant answers online, with an informational link.
Install Issues Incite Inquiry: Users face issues with Typer library installation via pip, raising questions about whether steps in the setup process, such as poetry install before poetry run, were followed or if a virtual environment is being used.
Mozilla AI Discord
Twinny Takes Off as Virtual Co-Pilot: Developers are integrating Twinny with LM Studio to serve as a robust local AI code completion tool, with support for multiple llamafiles running on different ports.
Embedding Endpoint Enlightenment: The /v1/embeddings endpoint was clarified not to support image_data; instead, the /embedding endpoint should be used for images, as per pull request #4681.
Mac M2 Meets Its Match in continue.dev: A performance observation noted that continue.dev runs slower on a Mac M2 compared to an older Nvidia GPU when executed with llamafile.
Hugging Your Own LLMs: For those looking to build and train custom LLMs, the community recommended the use of HuggingFace Transformers for training, with the reminder that llamafile is designed for inference, not training.
Cohere Discord
- Gratitude Echoes in the Server: A user expressed heartfelt thanks to the team, showcasing user appreciation for support or development work done by the team.
- Curiosity About Upscaled Models: There's buzz around whether a 104B version of a model will join the family tree, but no clear answers have been outlined yet.
- Langchain Links Missing: Questions arose regarding the integration of Langchain with Cohere, with users seeking guidance on its current usability and implementation status.
- Model Size Mysteries: Users are probing for clarity on whether the Aya model in the playground pertains to the 8B or 35B version, indicating importance in understanding model scales for application.
- Error Troubleshooting Corner: Issues like a
ValidationErrorwith ContextualCompressionRetriever and a 403 Forbidden error signal active debugging and technical problem-solving among the engineers, serving as reminders of common challenges in AI development.
AI Stack Devs (Yoko Li) Discord
AI Comedy Night Hits the Right Notes: An AI-generated standup comedy piece shared by a user was met with positive surprise, indicating advancements in AI's capability to mimic humor and perform entertainment.
Exploratory Queries on AI Applications: Curiosity about the extent of Ud.io's functions was evident from a user's query whether its capabilities go beyond generating comedy.
Sound Transformations Showcased: A user displayed the flexible audio alteration features of Suno by sharing an altered, demonic version of an original sound piece.
Eagerness for Audio Engineering Know-How: Interest was expressed in acquiring the skills to craft audio modifications like the ones demonstrated, a skill set valuable for an AI engineer with an interest in sound manipulation.
Concise Communication Preferred: A one-word reply "No" to a question highlighted a preference for succinct responses, perhaps reflecting an engineer's desire for direct, no-nonsense communication.
MLOps @Chipro Discord
- In Search of a Unified Event Tracker: A member has highlighted a pressing need for an event calendar compatible with Google Calendar to ensure no community events are overlooked. The absence of such a system is a noted concern within the community.
DiscoResearch Discord
- New Dataset Announcement: A new dataset has been referenced by user datarevised, with a link to further details: DataPlusEngine Tweet.
Latent Space Discord
- Benchmarks Drive Innovation: Evaluation benchmarks like GLUE, MMLU, and GSM8K are crucial for AI research progress, while "execution based evals" face particular challenges in dynamic tasks, as discussed in a blog post shared by members.
- Anticipation for GPT-5: A talk stirred speculation among guild members that GPT-5 may debut in 2024 with an advancement towards an "agent architecture," as suggested in a rumored tweet.
- AI's Role in Music Examined: Members probed into copyright questions concerning AI-created music like Suno, contemplated the capabilities of Meta's Audiocraft, and discussed legal ramifications and open-source endeavors promoting creative freedom, including gary-backend-combined on GitHub.
- Pythonistas Gear Up for NumPy 2.0: There's building excitement for NumPy 2.0, with members jesting about potential dependency management impacts, as noted in a Twitter post.
- xAI Lands a Whopper of Investment: Breaking into investment news, xAI secured a substantial $6 billion Series B funding round, setting sights on rapidly advancing their models' capabilities, as illustrated in their announcement post.
Modular (Mojo 🔥) Discord
- Nightly Nuisances Fixed by Community Brainstorm: After members highlighted that the Mojo VSCode extension worked only for post-installation files and was buggy since version 24.3, solutions included closing/reopening the code and frequent resets. Conversely, the Mojo compiler's nightly updates (
2024.5.2505to2024.5.2705) featured enhancements like variable renaming in LSP and a newtempfilemodule, though they introduced test issues in existing PRs like #2832 on GitHub.
- The Zen of ZIPping Through Mojo: Difficulties in replicating Python's
zipandunzipfunctions in Mojo led to a discussion on how to declare functions returning tuples based on variadic list arguments. The conversation shed light on Mojo's potential auto-dereferencing iterators using the newrefsyntax, aiming to simplify implementation and reduce explicit dereferencing.
- Processor Picks Perform Differently: A member's efforts to optimize CRC32 calculations in Mojo led to performance variance across core types; compact implementation lagged on larger byte sizes due to L1 cache limits, yet efficiency cores favoured the compact version. Benchmarking metadata and versioning files are located at fnands.com and nightly version tests for the aforementioned.
- Musings Over Mojo’s Might: General discussions on Mojo ranged from function behavior differences compared to Python, handling of optional types, to implementing LinkedLists, and reflecting on Mojo's as-yet-to-be-implemented reflection capabilities. Members exchanged thoughts on efficient initializations using
UnsafePointerandOptional.
- Tech Titans' Tremendous Transactions: The AI community digested news that Elon Musk’s AI startup, xAI, hauled in a hefty $6 billion in Series B funding as outlined in a TechCrunch article, positioning xAI to directly confront AI frontrunners like OpenAI and Microsoft, stirring conversations around the commercialization of AI technologies.
OpenRouter (Alex Atallah) Discord
New Kids on The Block: Phi-3 Models Arrive: Microsoft's phi-3-medium-128k-instruct and phi-3-mini-128k-instruct models are now live, with a special 57% discount applied to the llama-3-lumimaid-70b model.
Rate Limit Labyrinth Explained: Challenges with rate limiting on OpenRouter sparked intense discussion, emphasizing the importance of understanding how credit balances impact request rates, as outlined in the OpenRouter documentation.
Modal Mayhem: When Credits Clash with Rate Limits: A puzzling issue arose with the modal fallback feature, where rate limits were hit despite a healthy credit balance. The community recommended monitoring free requests and possibly sidelining the free model when limits loom.
AI's Self-Moderation Struggle Softens Appeal: Enthusiasts expressed concerns that stricter guardrails and higher refusal rates in Claude's self-moderated models result in a less human-like experience, pointing to a possible downturn in usage.
Vision Model Breakdown: Performance vs. Price: The talk turned to vision model performance, specifically Gemini's OCR capabilities, with a nod to its cost-effectiveness compared to traditional vision services. Conversations also highlighted cheaper GPU usage via RunPod and Vast.ai over mainstream clouds like Google Cloud and Amazon Bedrock.
Eleuther Discord
- CCS Doesn't Cut the Mustard: The Eleuther team's follow-up to Collin Burns's Contrast Consistent Search (CCS) method didn't yield expected results in generalization improvements, as shown in the Quirky Models benchmark. Their transparency in sharing both the method and lackluster results was commended in a detailed blog post.
- Optimal Model Extraction Strategy Hotly Debated: Engineers sparred over whether RAG is superior to finetuning for LLMs in extracting data from custom libraries, concluding that RAG might retain information better. There's buzz around ThePitbull 21.4B Model, released on Hugging Face, with some skepticism regarding its near-70B-model performance claims.
- Troubleshooting Data Replication: AI programmers grappled with tokenizer tribulations while replicating Pythia data, with solutions including the use of
batch_viewer.pyand proper datatype handling withMMapIndexedDataset. The process, though likened to "black magic", was necessary for correct dataset interpretation, as noted in the Pythia repository.
- Pushing the Envelope with New Techniques: Accelerated discussions among engineers covered gradient perturbation methods to distribute weight updates and the potential of transformers to implicitly reason over parametric knowledge. A new "schedule-free" optimization paper caught eyes, suggesting iterate averaging without extra hyper-parameters might outperform traditional learning rate schedules.
- Quantization Quandaries: In the quest for efficiency, a discourse ensued on the situations where small models might surpass larger quantized ones. A reference to ggerganov's Twitter hinted at quantization methods' potential, stoking the fires of debate regarding the balance of model size and performance.
LlamaIndex Discord
- RAG Revolution: Enterprise Pipelines on the Horizon: The LlamaIndex team announced a workshop in collaboration with AWS to showcase how to build enterprise-level RAG pipelines using AWS Bedrock and Ragas. Registrations are live for the event aiming to provide insights on integrating Bedrock with LlamaIndex for optimized RAG systems Sign Up Here.
- Innovations Boosting Retrieval: Discussions have spotlighted Vespa's integration for improved hybrid search capabilities and an advanced guide by Jayita B. on creating rapid response RAG chatbots using Llama3 and GroqInc. An innovative method for indexing images through structured annotations produced by models like gpt4o was also noted.
- File Organization Ascended: LlamaFS was launched as a new tool for automatically organizing cluttered directories, which may resonate with those seeking clean and efficient file management solutions.
- Technical Troubleshooting Takes Center Stage: AI Engineers grapple with issues surrounding Llama Index's reAct, with workarounds involving
max_iterationssettings and overcoming import errors by aligning package versions. HTML parsing generally requires more custom code compared to PDF files, which can take advantage of advanced chunking tools with fewer dependencies.
- Pydantic for Structured LlamaIndex Output: Guidance on using Pydantic models with LlamaIndex signifies a step towards structured output integration, pointing to broader applications and usability of the system. Calls for improved retriever documentation highlight community drive for enhanced understanding and application of BM25 and AutoRetrieval modules within diverse projects.
Cohere Discord
Aya-23 Takes the Stage: Engineers discussed Aya-23's multilingual capabilities compared to Command R/R+, implying superior performance but questioning its English-specific efficiency. They also noted Aya-23-35b is a fine-tuned version of Command R and provided access to the technical report for more details.
Mobile Privacy Vs. LLM Limitations: There was a consensus that on-phone LLMs aren't sufficiently developed for private, local execution in a mobile app, particularly for tasks typically aligning with a RAG mobile app.
Bot Innovations Flourish: A community member showcased a gaming bot on LinkedIn which garnered interest due to its integration with Cohere Command R; meanwhile, the "Create 'n' Play" bot for Discord boasts "over 100 engaging text-based games" and enhances social engagement with AI.
Adaptation and Integration of Prompts: The guild confirmed that Aya-23 supports system prompts, sharing insights on adapting Command R prompts with specific tokens such as <|USER_TOKEN|> and <|CHATBOT_TOKEN|> to operate effectively.
Solutions for OneDrive Syncing: In response to a query about OneDrive connectors, a SharePoint connector was recommended, which may fulfill similar integration needs.
LAION Discord
AI's Advice Bridge Ditching: Members shared a humorous take on Google AI's dangerous advice to "jump off bridges to cure depression", referencing the misleading nature of Reddit suggestions. A related meme was shared regarding the mishap.
ConvNeXt Gets Optimized: A vibrant discussion on the ConvNeXt paper praised its ability to handle high-resolution images efficiently, potentially reducing the generation of excessive visual tokens and streamlining optimizations for high-resolution tasks.
From Redstone to Neural Nets: Innovative uses of datasets and AI tools were showcased, including a dataset of publication PDFs and source TeX from archive.org, and a YouTube video demonstrating how to create a neural network with Redstone.
Growth Stacks Up in AI Pre-training: An arXiv paper highlighting depthwise stacking as an effective method for model growth in efficient pre-training of Large Language Models (LLMs) sparked interest, addressing critical speed and performance challenges in the pre-training process.
Pitfalls in PyTorch Persistence: Discussions in the learning sphere centered on troubleshooting issues with the randomness in training-validation splits and loss inconsistency during model reloads. Specifically, proper saving of optimizer states in PyTorch was pinpointed as crucial to avoid exploding losses.
DiscoResearch Discord
- Llama3 Goes Deutsch: The new Llama3-German-8B model extends the capabilities of Meta's Llama3-8B to the German language, training on 65 billion tokens with negligible performance loss in English; details are on Hugging Face. However, it's noted that unlike other language models, the training omitted English data replay, sparking debates about its effectiveness.
- Quantization Quirks and Puzzles: A quantized version of the Llama3, GGUF has shown underwhelming benchmark scores, hinting at potential issues, available for review at Llama3-DiscoLeo-Instruct-8B-32k-v0.1-GGUF. Meanwhile, discussions on parameter settings and strange outputs hint at the complex challenges of running these models, like max tokens and choice of the engine.
- Cohere’s Multilingual Leap: Cohere's Aya-23-35B model, though restrictive in licensing, now supports 23 languages, indicative of the growing trend and interest in powerful multilingual models. A related ShareGPT format dataset for translations has generated talks on quality and filtering, hosted here.
- Mistral’s Guide to the Fine-tuned Galaxy: In a nod to the tech-savvy community, Mistral rolls out a finetuning guide for Mixtral models, a beacon for those embarking on finetuning adventures; the guide can be perused on their GitHub.
- Model Tuning Intricacies Exposed: The community is conducting experiments with oobabooga and ollama, touching on 'skip_special_tokens' toggles and stop token settings, including a suggested use of a specific Llama3 template to address output issues—reflecting the active tweaking and tuning culture prevailing amongst members.
OpenInterpreter Discord
- LAM Security Concerns and Mobility: Discussions reveal skepticism about the Large Action Model (LAM) due to its potential for reverse engineering, despite the Rabbit LAM architecture overview showcasing its secure web app control capabilities. Conversations also circled on integration challenges for running the 01 model on Rabbit R1 devices and Humane platform, highlighting user-drive solutions like the 01 model Android GitHub repository.
- Installation Tactics on the Fly: A Python version upgrade to 3.11 resolved OpenInterpreter issues on Mac, while tinkering with a Linux distro through Andronix enabled OpenInterpreter use on Android-powered earbuds. Queries about Open Interpreter installation revealed a need for a local or cloud-accessible LLM, and a new Markdown export feature was launched to aid developers.
- DIY Spirit in the Community: A user fixed an OpenInterpreter issue on Mac by upgrading to Python 3.11, and others shared pathways for enhancing current devices, like modifying R1 with LineageOS. In buying versus building hardware, the consensus is that purchasing the pre-built O1 benefits the Seattle development team, despite no technical differences from a self-built version.
- Shipping and Storage Under Scrutinization: Frustration was voiced over lack of updates on hardware shipment, particularly regarding European distribution and information blackout for pre-orders. The conversation also featured a search for solutions to overcome disk space limits on Runpod, a hint at the constant struggle for cost-efficient data storage in AI workloads.
- OpenInterpreter Leap Forward: A member's successful tactic of switching to Python 3.11 on Mac for OpenInterpreter signals the ongoing agility in problem-solving within the community. Meanwhile, the implementation of a new Markdown export feature reflects the push for enhancing developer utility in AI toolchains.
LangChain AI Discord
PDF Extraction Proves Challenging: Discussions on extracting text from PDFs highlight the difficulties encountered with complex tables and diagrams, suggesting solutions like ML-based text segmentation and using Adobe Extract API for layout parsing, as referenced in the LangChain documentation.
LangChain Community Set to Expand: Karan Singh from Scogo Networks expressed interest in creating a local LangChain community in Mumbai, seeking marketing contacts to organize events.
Bump in the Langserve Waitlist: Users experienced access issues with the Langserve waiting list on Airtable, searching for alternate methods to try the hosted service.
Interactive Data Visualization Tool Introduced: The NLAVIDA project, which facilitates interactive data visualization and analysis through natural language, was introduced along with a YouTube video tutorial.
Ready, Set, Vote for OranClick: The launch of OranClick, a tool aimed at optimizing message crafting for higher signup rates, was announced with an invitation to support on ProductHunt.
Mozilla AI Discord
- Llamafile Powers Up with v0.8.5: The release of llamafile version 0.8.5 was highlighted, offering fast inference for K quants on X86 CPUs, with a call to action for community benchmarking efforts using
llamafile-bench. - Llamafile Goes Network-Savvy: Engineers swapped tips on how to make the llamafile server network-accessible, suggesting using flags like
--host <my ip>or--host 0.0.0.0for cross-machine availability within the same network. - Blank Slate Mystery in Llama3-70B: Contributors reported encountering blank responses from the llama3-70b model, sharing logs for community-led debugging, although definitive solutions were yet to surface.
- Home Sweet APIs for Home Assistant: There's a buzz around enhancing Home Assistant integration, with a focus on developing a standardized local API akin to OpenAI's candidate, underscored by the importance of features like API discoverability and secure API endpoints.
- Python Puzzles for Model Select: Questions and shared code snippets indicated some confusion around specifying models in the Python example for LLaMA_CPP integration, particularly concerning when model specification is a must, such as with TinyLlama.
OpenAccess AI Collective (axolotl) Discord
- Mistral-Finetune Mystery Uncovered: Developers engaged in deciphering the new update in the Mistral-Finetune repository, with emphasis on understanding the distinctive changes.
- MoEs Fine-Tuning Quirkiness: The AI crowd discussed the fickle nature of fine-tuning Mixture of Experts (MoEs) models, highlighting the necessity of running multiple iterations to cherry-pick the most efficient model, albeit details on the success rates were not divulged.
- Aya 23's Restricted Aptitude: The limitations of Aya 23 were hotly debated, underscoring its suboptimal performance for chat-based applications, with its prowess confined to niche tasks, as per its technical report.
- MoRA Steps into the Fine-Tuning Spotlight: MoRA, introduced as a cutting-edge high-rank updating approach for fine-tuning, entered the discussions with its potential to complement or exceed LoRA, linked with a dedicated GitHub repository.
- FFD Bin Packing Woes and Llama 3 Tokens in Limelight: Issues surfaced regarding the FFD bin packing implementation, specifically in a distributed training context, and fixes for Llama 3 related to untrained tokens, with a patch shared for sfttrainer to address the latter.
AI Stack Devs (Yoko Li) Discord
- Simulating Realities with Virtual Beings: The Virtual Beings Summit could be a valuable event for AI professionals, featuring Will Wright and focusing on the intersection of AI with simulations. Supporting content can be found on the Virtual Beings YouTube channel, which offers insights into AI's role in interactive simulations.
- AI Dreamscapes with DIAMOND: The DIAMOND GitHub repository introduces "DIAMOND (DIffusion As a Model Of eNvironment Dreams)," which uses diffusion models in a reinforcement learning context to enhance environmental interactions within AI simulations.
- Crafting AI "Westworlds" with UE5 and 4Wall: Discussions around creating immersive experiences suggest that AI Town might leverage UE5 and integrate voice control to simulate environments akin to "Westworld," with ongoing development info available at the 4Wall Discord.
- Venturing into Virtual Reality: The idea of integrating AI Town with VR technology was met with enthusiasm, indicating that engineers are considering novel methods to bring AI-generated environments to life through VR.
- Animating Avatars with SadTalker and V-Express: Two GitHub repositories, SadTalker and Tencent AI Lab's V-Express, provide tools for creating realistic talking face animations and generating talking head videos, respectively, showcasing advancements in stylized animation technology.
Interconnects (Nathan Lambert) Discord
Zyphra Zamba Slithers into the Spotlight: The new Zyphra Zamba model, a blend of mamba and attention mechanisms, has launched with corresponding technical report, PyTorch code, and integration into Hugging Face Transformers. Comparative analysis with OLMo 1.7 is in progress to benchmark its performance.
Hushed Release of SD Audio 2.0: An unauthorized release of SD Audio 2.0 appeared on 4chan and is also available on a Hugging Face account, sparking discussions among members.
Station-to-Station Regulation: Former OpenAI board members Hellen Toner and Tasha McCauley propose in The Economist strict regulation over AI companies, emphasizing the inability for such companies to self-regulate due to profit motives and calling out past internal issues.
Controversy in Command: The article critiques Sam Altman’s alleged “toxic culture of lying” during his tenure, discussing both internal investigations and public outcry over the absence of transparency.
A Textbook Case for RL: The community shared a new resource, a textbook on reinforcement learning from human feedback on GitHub, and praised professors Chris Potts and Chris Manning for their engaging teaching styles. Discussions included when the electronic version of Stanford's 224n class would be released, with suggestions to reach out to Chris for concrete timelines.
tinygrad (George Hotz) Discord
Tweaking Time Limits in Tech Tests: Discussions involved the possibility of extending the per-test time limit beyond 9 minutes 34 seconds to accommodate complex functions like 'Taylor approximations'. A specific issue was with the clang function not completing, only reaching approximately 60% completion.
Crashing Compilations Need Solutions: One member pointed out the dilemma of generating excessively large expressions that crash compilers with errors related to incompatible operand types, specifically doubles.
Bitwise Operations on Double Drama: Clarifications were made regarding the impossibility of performing bitwise operations like XOR on double data types, addressing the cause of a compilation error observed by members.
Bounty Hunting Heats Up: Interest spiked in various research-oriented bounties, with discussion on old pull requests and confirmation from George Hotz that bounties, such as the one referenced in tinygrad pull request #4212, are still available.
Deciphering 'vin' and Discussing Dominators: George Hotz clarified that 'vin' in the UOp class is not an acronym. Additionally, a member questioned why post dominator analysis isn't used for improving scheduling in models, suggesting it might optimize subgraph fusion during execution.
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!