[AINews] Jamba: Mixture of Architectures dethrones Mixtral
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI News for 3/27/2024-3/28/2024. We checked 5 subreddits and 364 Twitters and 24 Discords (374 channels, and 4693 messages) for you. Estimated reading time saved (at 200wpm): 529 minutes.
It's a banner week for MoE models, with DBRX yesterday and Qwen releasing a small MoE model today. However we have to give the top spot to yet another monster model release...
The recently $200m richer AI21 labs released Jamba today (blog, HF, tweet, thread from in person presentation). The headline details are:
- MoE with 52B parameters total, 12B active
- 256K Context length
- Open weights: Apache 2.0
It is notable both for its performance in its weight class (we'll come back to what "weight class" now means):
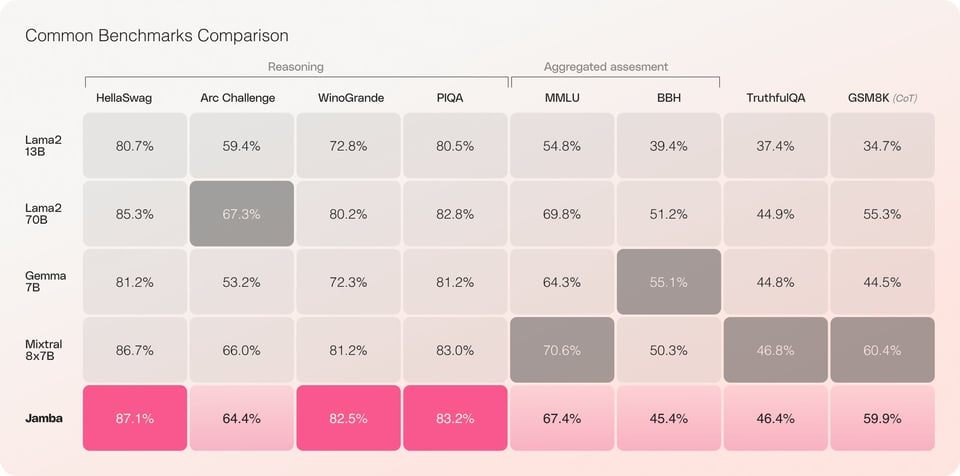
and for its throughput + memory requirements in long context scenarios:
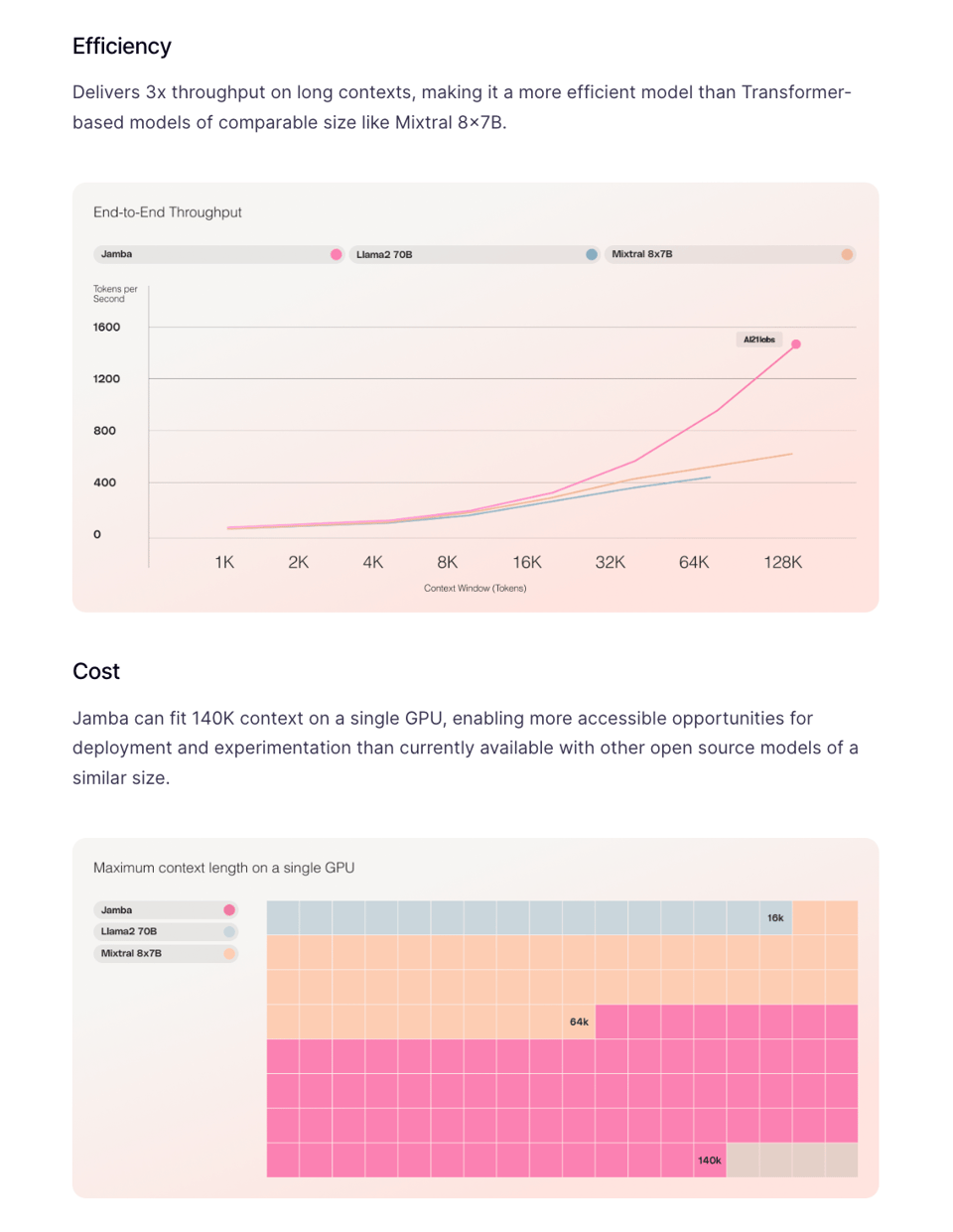
re: weight class: It seems every design decision was taken to maximize the performance gained from a single A100:
"As depicted in the diagram below, AI21’s Jamba architecture features a blocks-and-layers approach that allows Jamba to successfully integrate the two architectures. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers.
The second feature is the utilization of MoE to increase the total number of model parameters while streamlining the number of active parameters used at inference—resulting in higher model capacity without a matching increase in compute requirements. To maximize the model’s quality and throughput on a single 80GB GPU, we optimized the number of MoE layers and experts used, leaving enough memory available for common inference workloads.
In a step ahead of Together's preceding StripedHyena, Jamba juices up the classic Mamba architecture with transformer and MoE layers:
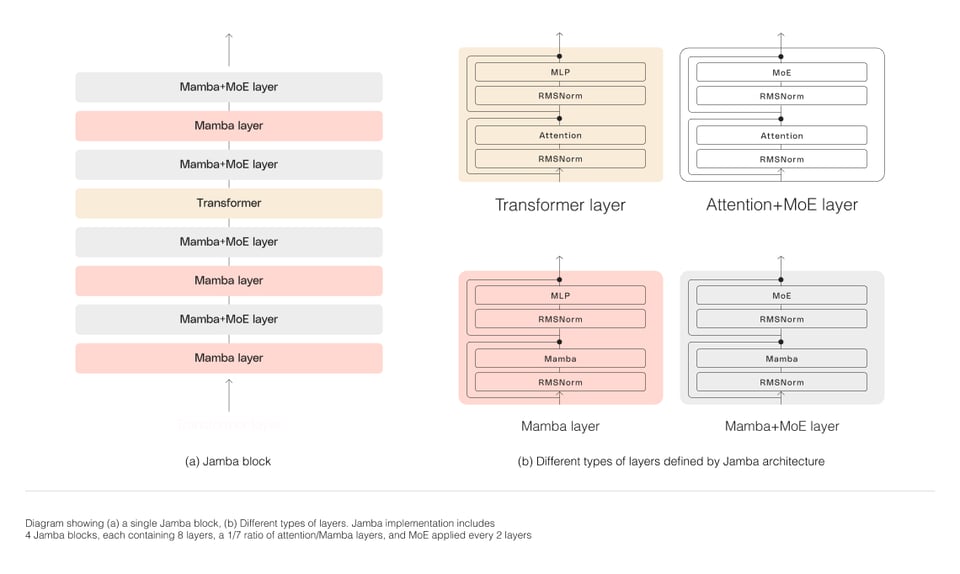
They released a base model, but it comes ready with Huggingface PEFT support. This actually looks like a genuine Mixtral competitor, and that's only good things for the open AI community.
Table of Contents
- AI Reddit Recap
- AI Twitter Recap
- PART 0: Summary of Summaries of Summaries
- PART 1: High level Discord summaries
- LM Studio Discord
- Unsloth AI (Daniel Han) Discord
- Nous Research AI Discord
- Stability.ai (Stable Diffusion) Discord
- Perplexity AI Discord
- Latent Space Discord
- Eleuther Discord
- OpenAI Discord
- HuggingFace Discord
- OpenInterpreter Discord
- Modular (Mojo 🔥) Discord
- OpenRouter (Alex Atallah) Discord
- CUDA MODE Discord
- LlamaIndex Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- tinygrad (George Hotz) Discord
- LangChain AI Discord
- Interconnects (Nathan Lambert) Discord
- DiscoResearch Discord
- Alignment Lab AI Discord
- LLM Perf Enthusiasts AI Discord
- Skunkworks AI Discord
- PART 2: Detailed by-Channel summaries and links
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence. Comment crawling still not implemented but coming soon.
Large Language Models
- /r/MachineLearning: DBRX: A New Standard for Open LLM - 16 experts, 12B params per expert, 36B active params, trained for 12T tokens
- /r/LocalLLaMA: Databricks reveals DBRX, the best open source language model - surpasses grok-1, mixtral, and other open weight models
- /r/LocalLLaMA: RAG benchmark of databricks/dbrx - dbrx does not do well with RAG in real-world testing, about same as gemini-pro
Stable Diffusion & Image Generation
- Animatediff is reaching a whole new level of quality - example by @midjourney_man using img2vid workflow
- /r/StableDiffusion: Attention Couple for Forge - easily generate multiple subjects, no more color bleeds or mixed features
- FastSD CPU v1.0.0 beta 28 release - ultra fast image generation (0.82 seconds) with SDXS512-0.9 OpenVINO on CPU
- /r/StableDiffusion: Implicit Style-Content Separation using B-LoRA - leverages LoRA to implicitly separate style and content components of a single image
- /r/StableDiffusion: SUPIR is exceptional even with high-res source images - SUPIR adds incredible detail even when upscaling high resolution images
AI Assistants & Agents
- /r/OpenAI: AI coding changed my life. Need advice going forward. - using ChatGPT to learn web development and make money outside 9-5 job
- Will ChatGPT eventually "learn" from it's own content it previously created, which could lead to it being wrong about facts sometime in the future? - concerns about ChatGPT being trained on its own outputs leading to inaccuracies
- /r/LocalLLaMA: Created an AI Agent which "Creates Linear Issues using TODOs in my last Code Commit" . Got it to 90% accuracy. - connecting Autogen with Github and Linear to automatically create issues from code TODOs
- /r/OpenAI: Built an AI Agent which "Creates Linear Issues using TODOs in my last Code Commit". - agent uses code context to understand TODOs, assign to right person/team/project and create issues in Linear
AI Hardware & Performance
- /r/MachineLearning: Are data structures and leetcode needed for Machine Learning Researcher/Engineer jobs and interviews?
- Microsoft plans to offload some of Windows Copilot's features to local hardware, but will use NPUs only.
- /r/LocalLLaMA: With limited budget, is it worthy to go into AMD GPU/ecosystem now, given Tiny Corp released the tinybox with AMD and Lisa Su's recent speech at the AI PC summit at Beijing?
- /r/LocalLLaMA: Looks like DBRX works on Apple Silicon MacBooks! - takes about 66GB RAM at 4 bit quant on M3 96GB, about 6 tokens per second
Memes & Humor
- Me and the current state of AI
- /r/OpenAI: When 'Open'AI's lawyers ask me if used their models' generated output to train a competing model: [deleted]
- /r/LocalLLaMA: Open AI 3 Laws of Robotics
- When you are the 60 Billion $$ Man but also a Doctor.
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
TO BE COMPLETED
PART 0: Summary of Summaries of Summaries
- Databricks Unveils DBRX: Databricks introduced DBRX, an MoE LLM with 132 billion parameters, and stoked debates on the limits of pretraining. The AI community is abuzz with its 12 trillion token training and potential, comparing it to models like Mistral Medium and gauging the diminishing returns of scale.
- Mixture of Innovations with Jamba and Qwen Models: AI21 Labs introduced Jamba, a SSM-Transformer hybrid with a 256K context window, while Qwen announced Qwen1.5-MoE-A2.7B, which punches above its parameter count by matching 7B models' performance. The releases spark discussions about accessibility, performance, and the future trajectory of AI scaling.
- AI Community Explores Vtubers and AI Consoles: Talks flared about the AI Tokyo event and the concept of a human-AI collaborative model for Vtubers to boost engagement. Speculations flew around Truffle-2, a potential AI-centric console, following the buzz about its predecessor's moderate specs at AI Tokyo.
- GPUs and Tokens: Performance Pursuits: Engineers shared insights on TensorRT for efficient inference on large models, debated about Tensor Parallelism limits, and revealed new methods like smoothquant+ and fp8 e5m2 cache. Exchanges also focused on Claude's regional access and perplexities in fine-tuning loss curves while training Deepseek-coder-33B models.
- RAG, Retrieval, and Dataset Discourse: The AI community delved into Retrieval Augmented Generation (RAG) performance, debating output quality and scrutinizing CoT's impact on retrieval effectiveness. Proposals for XML tag standardization in prompt inputs were made, looking at structured inputs as a potential staple for enhancing outcomes.
PART 1: High level Discord summaries
LM Studio Discord
- "Loaded from Chat UI" Quirk Fixed: The LM Studio 0.2.18 update addressed a bug where API queries returned a model ID of "Loaded from Chat UI," preventing access to the real model name, now fixed in beta version 0.2.18.
- Scaling Up with Merged Might: The merger of LongAlpaca-70B-lora and lzlv_70b_fp16_hf yielded a 32K token, linear rope scaling model heralded by ChuckMcSneed despite a 30% drop in performance at 8 times context length; see the merged model here.
- Cutting-Edge Configs for LM Studio Enthusiasts: LM Studio 0.2.18 enriches user experience with features like an 'Empty Preset' for Base/Completion models, and 'monospace' chat style, and the update issues have been ironed out as per announcements.
- Pumping Up Power for Peak AI Performance: Discussions around hardware for AI work suggested that the NVIDIA 3090 and 4090, or dual A6000, cards provide significant VRAM and CUDA prowess, with monitor quality also a hot topic like this MSI monitor. A ballast of 1200-1500w PSUs were recommended for these beefy setups.
- Rendering with ROCm Beta, Users Tackle Turbulence: LM Studio's ROCm 0.2.18 Beta targeted GPU offload issues but users reported mixed results with model loading and GPU utilization. Interested parties can explore the ROCm beta here, and seek help within the community to nail down nuanced issues or revert to a standard version when needed.
Unsloth AI (Daniel Han) Discord
Breaking the Ice with Unsloth AI: Engineers have embraced tips and tricks for using Unsloth's template system, with the community finding practical benefits like reduced model output anomalies. Regular updates (2-3 times weekly) ensure that performance improvements continue, while installation instructions optimize setup times on Kaggle.
Gaming Mingle Amidst Coding Jungle: Technical exchanges were accompanied by lighter conversations, including game developer talks and shared gaming experiences—in particular, constructing a demo app using AI assistance, bridging entertainment with machine learning.
Layering it on Thick: Unsloth AI discussions have calved off into deeper explorations, including leveraging optimizer adjustments in resuming fine-tuning from checkpoints and proper chat template integration for various LLMs. The community also spotlighted key resources—Github repositories, Colab notebooks, and educational YouTube videos—for fine-tuning LLMs.
Modeling Showcase Spotlight: The community proudly presented adaptations, like converting the Lora Adapter for Tinyllama, and shared details of the Mischat model, which was fine-tuned using Unsloth's methodologies. A member introduced an AI digest on their Substack blog, summarizing recent AI developments.
Quantum Leap in Quantization: AI enthusiasts investigated specialized techniques such as LoRA training conversation, embedding quantization for faster retrieval, and the emerging QMoE compression framework. A newly introduced LISA strategy that streamlines fine-tuning across layers attracted significant attention for its memory efficiency.
Nous Research AI Discord
- DBRX Draws the Spotlight with Impressive Scale: Databricks announced DBRX, an MoE LLM with 132 billion parameters, and stoked debates on the limits of pretraining. The AI community is abuzz with its 12 trillion token training and potential, comparing it to models like Mistral Medium and gauging the diminishing returns of scale.
- Mixture of Innovations with Jamba and Qwen Models: AI21 Labs introduced Jamba, a SSM-Transformer hybrid with a 256K context window, while Qwen announced Qwen1.5-MoE-A2.7B, which punches above its parameter count by matching 7B models' performance. The releases spark discussions about accessibility, performance, and the future trajectory of AI scaling.
- AI Community Explores Vtubers and AI Consoles: Talks flared about the AI Tokyo event and the concept of a human-AI collaborative model for Vtubers to boost engagement. Speculations flew around Truffle-2, a potential AI-centric console, following the buzz about its predecessor's moderate specs at AI Tokyo.
- GPUs and Tokens: Performance Pursuits: Engineers shared insights on TensorRT for efficient inference on large models, debated about Tensor Parallelism limits, and revealed new methods like smoothquant+ and fp8 e5m2 cache. Exchanges also focused on Claude's regional access and perplexities in fine-tuning loss curves while training Deepseek-coder-33B models.
- RAG, Retrieval, and Dataset Discourse: The AI community delved into Retrieval Augmented Generation (RAG) performance, debating output quality and scrutinizing CoT's impact on retrieval effectiveness. Proposals for XML tag standardization in prompt inputs were made, looking at structured inputs as a potential staple for enhancing outcomes.
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion 3 Release on the Horizon: The engineering community is abuzz with the expected rollout of Stable Diffusion 3 (SD3) towards late April or May, featuring enhanced capabilities like inpainting. A 4 to 6 week ETA from March 25th has led to rampant speculation on new models and features, as inferred from Stability.ai's CTO's remarks.
- Gauging VRAM for Language Models: Conversations are heating up about the VRAM demands for operating language models such as Mixtral, with debates around using quantization as a strategy to reduce memory usage without compromising quality. Engineers are especially keen on quantized models tailored for 10GB Nvidia GPU cards, indicating a push towards more accessible high-performance computing.
- New User Guidance & Tool Suggestions: The Discord space is not just for seasoned veterans; new users are getting tips on image generation via Stable Diffusion, with recommendations pointing to interfaces like Forge and Automatic1111, as well as leonardo.ai for enhancing the creative process.
- Refining Image Prompt Quality: A technical thread has highlighted the importance of prompt engineering, stressing that a more conversational sentence structure can yield better results than comma-separated keywords. This is especially relevant when dealing with sophisticated models like SDXL which may be sensitive to the nuances of prompt phrasing.
- Efficiency in Model Quantization Discussed: The guild members briefly engaged in discussing the transformer architecture's efficiency and the effectiveness of quantization. These AI connoisseurs suggest that despite transformers' inherent inefficiencies, models like SD3 are showing promising results when quantized, potentially allowing for reduced memory footprints.
Links from the discussion included resources and tools:
- Character Consistency in Stable Diffusion by Cobalt Explorer
- leonardo.ai
- Arcads for video ads
- Pixel Art Sprite Diffusion Safetensors
- Stable Diffusion web UI for AMD GPUs
- GitHub - lllyasviel/Fooocus
- StableDiffusionColabs on Google Colabs’ free tier
- Running Stable Diffusion on an 8Gb M1 Mac
Perplexity AI Discord
DBRX Breaks Through to Perplexity Labs: Databricks' DBRX language model has made waves by outclassing GPT-3.5 and proving competitive with Gemini 1.0 Pro, with favorable performance in math and coding benchmarks, which can be explored at Perplexity Labs.
The Developer's Dilemma: Perplexity vs. Claud: Engineers have debated whether Perplexity Pro or Claud Pro better suits their workflow, with a bias toward Perplexity for its transparency. Various model strengths like Claude 3 Opus were scrutinized, while Databricks' DBRX was singled out for its impressive math and coding capabilities.
Perplexity API Performs a Speedrun: The sonar-medium-online model showcased an unexpected speed increase, reaching or even surpassing that of sonar-small-online with higher quality output. Yet, inconsistencies surfaced with API responses compared to the Perplexity web interface, like the failure to retrieve "Olivia Schough spouse" data, prompting discussion on whether extra parameters could correct this.
Sharing Insights and Laughs: Community interaction included debunking a supposed Sora text-to-video model as a rickroll, emphasizing the importance of shareability for threads, and exploring varied search queries on Perplexity AI, ranging from coherent C3 models to French translations for "Perplexityai."
Vision Support Still in the Dark: Despite inquiries, Vision support for the API remains absent, as indicated by humorous responses about the current lack of even citations, suggesting no immediate plans for inclusion.
Latent Space Discord
Claude Takes the Terraform Crown: In the IaC domain, Claude has outshined its peers in generating Terraform scripts, with a comparison blog post on TerraTeam's website spotlighting its superior performance. The meticulous comparison can be accessed at TerraTeam's blog.
DBRX-Instruct Flexes Its Parameters: Databricks has stepped into the spotlight with DBRX-Instruct, a 132 billion parameter Mixture of Experts model that underwent a costly ($10M) and lengthy (2 months) training on 3072 NVIDIA H100 GPUs. Insights about DBRX-Instruct are split between Vitaliy Chiley's tweet and Wired's article.
Licensing Logistics Linger for DBRX: The community scrutinized DBRX's licensing terms, with members strategizing on how to best engage with the model within its usage boundaries. Key insight came from the shared legal concerns and strategies, including Amgadoz's spotlight on Databricks' open model license.
TechCrunch Questions DBRX's Market Muscle: A discussion was sparked by TechCrunch's critical analysis of Databricks' $10M DBRX investment, contrasting it against the already established OpenAI's GPT series. TechCrunch challenged the competitive edge provided by such investments, and a full read is recommended at TechCrunch.
Emotionally Intelligent Chatbots Get High Fives: Hume AI captured attention with its emotionally perceptive chatbot, adept at analyzing and responding to emotions. This disruptive emotional detection capability prompted a mix of excitement and practical use case discussions among members, including 420gunna sharing the Hume AI demo and a related CEO interview.
Mamba Slithers into the Spotlight: In discussions, the Mamba model was singled out for its innovation in the Transformer space, addressing efficiency woes effectively. The potent conversation revolved around Mamba's prowess and architectural decisions aimed at enhancing computational efficiency.
Fine-Tuning Finesse: The topic of fine-tuning Whisper, OpenAI's automatic speech recognition model, was dissected, with consensus that it's advisable when dealing with scarce language resources or specialized terminology in audio.
Cosine Similarity Crosstalk: The group engaged in technical tete-a-tetes over the use of cosine similarity in embeddings, casting doubts on its effectiveness as a semantic similarity measure. The pivot of the discussion was the paper titled "Is Cosine-Similarity of Embeddings Really About Similarity?", which members used as a reference point.
Screen Sharing Snafus: Technical trials with Discord's screen sharing triggered community troubleshooting, including workaround sharing and a collective call for Discord to enhance this feature. Members shared practical solutions to address the ongoing screen sharing issues.
Eleuther Discord
- Claude 3 Conscious of Evaluations: Anthropic's Claude 3 has demonstrated meta-awareness during testing, identifying when it was being evaluated and commenting on the pertinence of processed information.
- Big Plays by DBRX: Databricks has introduced DBRX, a powerful language model with 132 billion total parameters with 36 billion active parameters trained on a 12 trillion token corpus. Discussions have focused on its architecture which includes 16 experts and a 32k context length, its comparative performance and usability, which is creating buzz due to its aptitude in outperforming models like Grok.
- Token Efficiency Debate: Engineers are debating the actual efficiency of larger tokenizers, considering that a bigger tokenizer count may not automatically translate to improved performance and could lead to specific token representation issues.
- Layer-Pruning Minimal Impact Shown: Research has found minimal performance loss with up to 50% layer reduction in LLMs using methods like QLoRA, enabling fine-tuning on a single A100 GPU.
- Jamba Juices Up Models Fusion: AI21 Labs has released a new model dubbed Jamba, combining Structured State Space models with Transformers, operating with 12 billion active parameters and a noteworthy 256k context length.
OpenAI Discord
- GPT-4: A Beacon of Possibility or Just a Tweet Tease?: Enthusiasm is mixed with anticipation as users react to an OpenAI tweet hinting at new developments, even as concerns about the delayed availability of services like GPT-4 in Europe are voiced.
- ChatGPT for Code: Tips shared include instructing ChatGPT to avoid ellipses and incomplete code segments, contributing to more reliable outputs in coding-related tasks. Considered comparisons place models like Claude 3 in a favorable light against others for coding efficiency.
- All Eyes on Gemini Advanced: The community shows a less-than-impressed stance towards Google's Gemini Advanced, with complaints about sluggish response times when paralleled with GPT-4's performance, despite aspirations for future improvements based on upcoming trial stress tests.
- AI's Industrial March: Notable is OpenAI and Microsoft's strategy of integrating their AI offerings into European industries, with possible links to tools such as Copilot Studio and the wider Microsoft suite, despite certain expressed frustrations with Copilot's UX.
- Prompt Engineering Pearls: AI enthusiasts discuss various strategies for getting optimal results when using LLMs, including breaking prompts into chunks for better issue identification, crafting prompts that emphasize what to do over what not to do, and articulating needs for specific outputs in tasks like visual descriptions or translations while maintaining HTML integrity.
HuggingFace Discord
Stable Diffusion Steps up for Solo Performances: Discussions on Stable Diffusion focused on generating new images from a list, but the existing pipeline handles single images. For personalized text-to-image models, DreamBooth emerged as a favorite, while the Marigold depth estimation pipeline is set for integration with new modalities like LCM.
AI Engineers Seek Smarter NLP Navigation: Engineers sought roadmaps for mastering NLP in 2024, with recommendations including "The Little Book of Deep Learning" and Karpathy's "Zero to Hero" playlist. Others explored session-based recommendation systems, questioning the efficacy of models like GRU4Rec and Bert4Rec, while loading errors with 'facebook/bart-large-cnn' prompted calls for help. Suggestions for managing the infinitely generative behavior of LLMs included Supervised Fine Tuning (SFT) and tweaks to repetition penalties.
Accelerating GPU Gains with MPS and Sagemaker: macOS users gained an advantage with MPS support now part of key training scripts, while a discussion on AWS SageMaker highlighted NVIDIA Triton and TensorRT-LLM for benchmarking GPU-utilizing model latency, cost, and throughput.
Innovations and Resources in the Computer Vision Sphere: Amidst efforts to utilize stitched images for training models, individuals also wrestled with fine-tuning DETR-ResNet-50 on specific datasets and investigated zero-shot classifier tuning for beginners. There was also an SOS for non-gradio_client testing methods for instruct pix2pix demos, with the community eager to recommend alternatives and resources.
DL Models in the Spotlight: The NLP community is examining papers on personalizing text-to-image synthesis to conform closely to text prompts. The RealCustom paper discusses balancing subject resemblance with textual control, and another study addresses text alignment in personalized images, as referenced on arXiv.
OpenInterpreter Discord
- Engineers Seek EU Distribution Path: There is an expressed need for assistance or existing discussions on distributing products within the EU, implying a need for coverage on logistical strategies for product distribution.
- Exploring IDE Usage with OpenInterpreter: Members are discussing and sharing resources on integrating OpenInterpreter with IDEs like Visual Studio Code, including a recommendation for a VS Code extension for an AI tool.
- Ready, Set, Optimize!: Anticipation is building around the community's efforts to explore and optimize LLM performance, both local and hosted. The expectation is that by the end of the year, these models could surpass even GPT-4's capabilities.
- Members Redefine "Done" with Prior Art: A member shared a comedic realization that hours of work had inadvertently duplicated existing features, linking to a YouTube video showcasing their process.
- Local LLMs Garnering Interest: There's active dialogue on implementing non-GPT models in OpenInterpreter, with curiosity about experimenting with local LLMs and inquiries about others like groq, hinting at broader exploration beyond OpenAI's tools.
Modular (Mojo 🔥) Discord
Bug Squashing in VSCode Debugging: A GitHub-reported VSCode debugging issue with the Mojo plugin was resolved using a recommended workaround that proved successful on a MacBook.
Mojo and MAX Updates Make Headlines: The Mojo language style guide is now available, as is moplex, a new complex number library on GitHub. MAX 24.2 updates include the adoption of List over DynamicVector as referenced in the changelog.
Learning Resources Stand Out: A free chapter from Rust for Rustaceans was recommended for understanding Rust's lifetime management, while Modular's latest tweets garner attention without spawning further dialogue.
Open Source Embrace Boosts Mojo's Modularity: Modular has open-sourced the Mojo standard library under Apache 2, with nightly builds accessible, and MAX 24.2 introduces improved support for dynamic input shapes as demonstrated in their blog.
API Discrepancies and Enhancements Discussed: Users discussed inconsistencies between Mojo and Python APIs concerning TensorSpec, directing others to MAX Engine runtime documentation and MAX's example repository for clarity.
Open Source and Nightly Builds Beckon Collaboration: Developers are invited to jump on the open-source bandwagon with the Modular open-source initiative, which includes Mojo standard library updates and new features lined up in their latest changelog, while MAX platform's evolution with v24.2 offers new capabilities, particularly in dynamic shapes.
OpenRouter (Alex Atallah) Discord
Cheer for cheerful_dragon_48465: A username, cheerful_dragon_48465, received praise for being amusing, and Alex Atallah signaled an upcoming announcement that will highlight a notable user contribution.
Midnight Rose Clamors for Clarity: The Midnight Rose model was unresponsive without errors, leading to confusion among users before the OpenRouter team resolved the issue, yet the underlying problem remains unsolved.
Size Matters in Tokens: Users discussed the discrepancies in context sizes for Gemini models, which are measured in characters, not tokens, causing confusion, and acknowledged the need for better clarification on the topic.
Testing Troubles with Gemini Pro 1.5: Users facing Error 503 with Gemini Pro 1.5 were informed that the issues arose because the model was still in the testing phase, indicating a gap between OpenRouter's service expectations and reality.
The Ethereum Payment Conundrum: OpenRouter's shift to requiring payments through the ETH network via Coinbase Commerce, and the subsequent discussion on incentives for US bank transfers, highlighted the evolving landscape of crypto payments in the AI sector.
CUDA MODE Discord
- Diving into Dynamic CUDA Support: Community members are discussing the implementation of dynamic CUDA support in OpenCV's DNN module, with experiments detailing performance results using NVIDIA GPUs. A survey on CUDA-enabled hardware for deep learning has been shared to collect community experiences, and peer-to-peer benchmarks for RTX 4090, A5000, and A4000 GPUs are available via GitHub.
- Triton Tutors Wanted: In preparation for a talk, interviews with recent Triton learners are sought to understand difficulties they've faced, contactable via Discord DM or Twitter. Collaborative work and opportunities for input on pull requests, including a prototype for GaLore within the torch ecosystem, are found on GitHub and indicate active collaboration involving
bitsandbytes(PR #1137).
- CUDA Resources and Learning Trails: Enthusiasts looking to deepen their CUDA skills have shared learning resources including a GitHub repository of CUDA materials, the “Intro to Parallel Programming” YouTube playlist, and a book discussion that hit a snag with an Amazon CAPTCHA.
- Torch Troubleshooting and Type Tangles: Engineers are navigating through type issues between torch and cuda, emphasizing potential linker problems and seeking compile-time errors for clearer message clarity when using the
data_ptrmethod in PyTorch with incompatible types.
- Ring Attention Under Microscope: AI developers probe into Ring Attention and its relation to other attention mechanisms like Blockwise Attention and Flash Attention, with an arXiv paper providing additional insights. Separately, debugging is underway for high loss values encountered during training, which may involve sequence length handling, detailed in the FSDP_QLoRA GitHub repo and their wandb report.
- CUDA Quirks and Queries: From resolving Triton
tl.zerosusage in kernels to addressingImportErrorwith Triton-Viz and sharing workarounds, participants exchanged fixes, including building Triton from source and choosing specific triton-viz commits to install. Avoidingreshapein Triton for better performance was also advised.
- AI Takes Center Stage in Comedy Skit: The AI industry's penchant for jargon is humorously depicted in a YouTube video with an emphasis on "AI" at an NVIDIA keynote. Additionally, help requests were made for navigating Mandarin interfaces, such as on Zhihu, for accessing Triton tutorials.
- CUDA Enthusiasm on Windows and WSL: Users share successes and seek guidance for running CUDA with PyTorch on Windows, with suggestions including using WSL as outlined in the Microsoft installation guide, while others consider dual booting Ubuntu or doing a write-up on their setup process.
- Global Search for CUDA Savvy Experts: Job-seekers in the CUDA sphere are navigating opportunities, with NVIDIA being mentioned for hosting a set of global PhD-level job positions. A statement emphasized that talent trumps geography for a team considering applicants from any location.
LlamaIndex Discord
- RAG Optimization Unveiled: @seldo will delve into advanced RAG techniques this Friday, with a focus on optimization alongside TimescaleDB—details are on Twitter. Efforts to shrink RAG resource footprint include using Int8 and Binary Embeddings as proposed by Cohere; more on this via Twitter.
- Legally LLM: The forthcoming LLMxLaw Hackathon at Stanford is set to probe the potential synergy between LLMs and the legal field, with registrations open via Partiful.
- Managing Messy Data with Llamaparse: A user grappling with unwieldy data from Confluence might find salvation in Llamaparse; on-premises deployment is an option, as underscored by LlamaIndex's contact page. For those ensnared by PDF parsing challenges, merging smaller text chunks and using LlamaParse were recommended strategies.
- Pipeline and Parallelism Puzzles: Clarification was sought and given regarding document ID retention in IngestionPipeline; the original document's ID is preserved as
node.ref_doc_id. Meanwhile, suggestions for improving notebook performance included employingaqueryfor asynchronous execution.
- Empowering GenAI: The birth of Centre for GenAIOps, a non-profit targeting the growth and safety of GenAI applications, was broadcasted, with a warm recommendation for LlamaIndex by the founding CTO who shared insights via LinkedIn. On the educational front, a request for top-tier LLM training resources was made but went unanswered.
OpenAccess AI Collective (axolotl) Discord
Databricks Drops DBRX: Databricks introduced DBRX Base and DBRX Instruct, boasting 132B total parameters, outshining LLaMA2-70B and other models, with an open model license and insights provided in their technical blog.
Axolotl Devs Debugging: The Axolotl AI Collective has rectified a trainer.py batch size bug and discussed technical issues like transformer incompatibilities, DeepSpeed and PyTorch binary problems, and large model loading challenges with qlora+fsdp.
Innovating Jamba and LISA: AI21 Labs revealed Jamba, an architecture capable of handling 256k token context on A100 80GB GPUs, while discussion on LISA's superiority over LoRA in instruction following tasks occurs, referencing PRs #701 and #711 in the LMFlow repository.
Performance with bf16: A lively debate took place around using bf16 precision for both training and optimization, citing torchtune team's findings on memory efficiency and stability akin to fp32, sparking interest in its broader implementation.
Resource Hunt for Fine-Tuning Finesse: Community members seek comprehensive educational materials for fine-tuning or training open source models, indicating a preference for varied formats like blogs, articles, and videos, aiming for a strong foundation before diving into axolotl.
LAION Discord
- AI Contemplates Existence: During discussions around self-awareness in AI, a user shared two engagements with ChatGPT 3.5 where it expressed a moment of 'satori', raising questions about its understanding of consciousness. The exchanges can be explored through these links: Chat 1 and Chat 2.
- Voice Acting Fears Amid AI's Rise: A spirited debate surfaced on the future of professional voice acting given AI advancements, referencing Disney’s interest in AI voiced characters through their collaboration with ElevenLabs.
- Benchmarks Under Scrutiny: Benchmarks for AI model performance drew criticism for sometimes misleading visualizations, with calls for more concise and human-relevant measurement standards, like the ones on Chatbot-Arena Leaderboard.
- Pruning the Fat from AI Models: A study on efficient resource use in LLMs indicated that layer pruning doesn’t greatly affect performance and can be studied in-depth in this arXiv paper. New tools have been introduced for VLM image captioning with failure detection by ProGamerGov, available on GitHub.
- Devika Aims to Streamline Software Engineering: An innovative project called Devika aims to comprehend high-level human instructions and write code, positioned as an open-source alternative to similar AIs. Devika’s approach and features are accessible on its GitHub page.
tinygrad (George Hotz) Discord
Tinygrad Tightens the Screws: Dynamic discussions about tinygrad reveal attempts to close the performance gap with PyTorch, through heuristics for operations like gemv and gemm and direct manipulation of GPU kernels. Insights include kernel fusion challenges, potential view merging optimizations, and community-driven documentation efforts.
NVIDIA Claims the Crown in MLPerf: Recent MLPerf Inference v4.0 results sparked conversation, noting how NVIDIA continues to lead in performance metrics, with Qualcomm showing strong results and Habana’s Gaudi2 demonstrating its lack of design for inference tasks.
SYCL Stepping Up to CUDA: A tweet highlighted SYCL as a promising alternative to NVIDIA’s CUDA, stirring anticipation for wider industry adoption and a break from current monopolistic trends in AI hardware.
API Allegiances and Industry Impact: Members weighed in on OpenCL’s diminished utilization and the potential of Vulkan for achieving uniform hardware acceleration interfaces, debating their respective roles in the larger ecosystem.
View Merging on the Horizon: The discussions also probed the refinement of tinygrad's ShapeTracker to potentially consolidate views, considering the importance of tensor transformation histories and backpropagation functionality when contemplating structural changes.
LangChain AI Discord
OpenGPTs Discussion Welcomes Engineers: A new channel for OpenGPTs project on GitHub has been introduced encouraging contributions and dialogue amongst the community.
JavaScript Chatbots versus Document Fetchers: AI engineers explore building dynamic chatbots with JavaScript, diverging from static document retrieval. For guidance, a Colab notebook has been shared.
Deploying with Custom Domains Hiccup: Deploying FastAPI RAG apps with LangChain on custom domains like github.io is sparking curiosity; yet, documentation discrepancies on LangChain Pinecone integration pose challenges that await resolution.
LangSmith Traces AI's Steps: Using LangChain's LangSmith for tracing AI actions employs environment variables such as LANGCHAIN_TRACING_V2, which offers granular logging capabilities.
Tutorial Unlocks PDF to JSON Conversion Mysteries: A new YouTube tutorial breaks down the conversion of PDFs to JSON using LangChain's Output Parsers and GPT, simplifying a once complex task. The community's insights are requested to enhance such educational content.
Interconnects (Nathan Lambert) Discord
- DBRX Rocks the LLM Scene: MosaicML and Databricks have introduced DBRX, a 132 billion parameter model boasting 32 billion active parameters and a 32k context window, available under a commercial license with trial access here. However, its license terms, which prohibit using DBRX to improve other LLMs, sparked discussions among engineers on the repercussions for AI advancements.
- Jamba: SSM Meets Transformers By AI21: AI21 has released Jamba, merging the Mamba's Structured State Space model (SSM) with traditional Transformer architecture and providing a 256K context window. Jamba is released under an Apache 2.0 license, encouraging development in hybrid model structures and is accessible here.
- Mosaic's Law Predicts Cheaper AI Futures: "Mosaic's Law" has become a hot topic, predicting a yearly quartering of costs for comparable models driven by advances in hardware, software, and algorithms, signaling a future where AI can be developed at significantly lower costs.
- Analyzing Architectural Evolution: New research bringing forth the largest analysis of beyond-Transformer architectures shows that striped architectures may outperform homogeneous ones by layer specialization, which can herald quicker architectural improvements. The complete study and accompanying code are available here and here.
- From 'Small' to 'Sizable': The Language Model Spectrum Discourse: Discussions point to the semantics of "small" language models, with the community considering models under 100 billion parameters small while reflecting on the historical context. Furthermore, Microsoft GenAI gaining Liliang Ren as a Senior Researcher promises advancements in efficient and scalable neural architectures, and Megablocks' transition to Databricks underscores shifts in project stewardship and expectations within the AI engineering community.
DiscoResearch Discord
DBRX Instruct Makes a Grand Entrance: Databricks unveiled a new 132 billion parameter sparse MoE model, DBRX Instruct, trained on a staggering 12 trillion tokens, boasting prowess in few-turn dialogues, alongside releasing DBRX Base under an open license, furnished with insights in their blog post.
DBRX's Inner Workings Decoded: DBRX distinguishes itself with a merged attention mechanism, distinct normalization technique, and a unique tokenization method that has been refined through various bug fixes, with its technical intricacies documented on GitHub.
Hands-On with DBRX Instruct: AI enthusiasts can now experiment with DBRX Instruct through an interactive Hugging Face space, complete with a system prompt for tailoring response styles.
Mixtral's Multilingual Muscles Flexed for Free: Mixtral's translation API can be tapped into without charge via groq, subject to rate limits, and open for community-driven experimentation.
Occi 7B Outshines in Translation Quality: Users have noted the exceptional translation fidelity of Occi 7B via the occiglot/occiglot-7b-de-en-instruct model and have embarked on a quest to gauge the translation caliber across services like DisCoLM, GPT-4, Deepl, and Azure Translate, showcasing their efforts on Hugging Face.
Alignment Lab AI Discord
- DBRX Claims Top Spot Over GPT-3.5: DBRX, introduced by Databricks, asserts dominance in LLM landscape, purportedly outclassing GPT-3.5 and comparable with Gemini 1.0 Pro, specializing in programming tasks with a MoE architecture for enhanced efficiency.
- DBRX Simplification Sought: Participants call for a distilled explanation of the DBRX model to better understand its proclaimed advancements in LLM efficiency and programming prowess.
- DBRX's Programming Prowess Questioned: Members probe the roots of DBRX’s stellar programming capabilities, pondering if it's the result of specialized datasets and architecture or derived from a broader strategy.
- Decoding DBRX's Programming Edge: DBRX's commendable programming results trace back to its 12 trillion token pre-training, MoE architecture, and a focused curriculum learning to sidestep "skill clobbering".
- Solo Coding Conundrums: A peer requests one-on-one support for a coding problem, highlighting the community's role in providing personalized troubleshooting assistance.
LLM Perf Enthusiasts AI Discord
- Join the LLM Brew Crew: A pop-up coffeeshop and co-work event for LLM enthusiasts, hosted by Exa.ai, is set for this Saturday in SF with free coffee, matcha, and pastries. Interested parties can RSVP here.
- In Search of AI-Centric Work Spots: Members in SF are scouting for co-working spaces that cater to LLM aficionados; celo has been namedropped as a go-to venue.
Skunkworks AI Discord
- Python Enthusiasts, Get Ready to Contribute: An upcoming onboarding session for Python enthusiasts interested in the AI space was inquired about; members are looking to participate and contribute effectively.
- Off-Topic Video Share: A member shared a YouTube video in the off-topic channel; the contents of the video, however, are not described or its relevance to the group's interests.
The Datasette - LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
LM Studio ▷ #💬-general (335 messages🔥🔥):
- Confusion Over Model IDs: Users are discussing an issue where querying their model via the API results in a model ID of "Loaded from Chat UI" which prevents them from accessing the real model name. It's labeled as a bug, which seems to be fixed in beta version 0.2.18.
- LM Studio on Diverse Platforms: There are reports of successfully running LM Studio on various platforms such as Linux on a Steam Deck and using the cloud service AWS, illustrating the software's adaptability to different technology environments.
- Questions about Preset Files: Several users are inquiring about preset files and the usage of system prompts within LM Studio. A suggestion was made to use custom system prompts, such as those designed for high-quality story writing, by pasting them into the System Prompt field in LM Studio.
- Concerns Over Space and Performance: Users raised issues with storage space on their devices affecting the ability to run LM Studio, as well as the performance of different models at various memory capacities.
- Features and Updates Commentary: Discussions about various features in LM Studio include branching, chat folders, and story mode functionality, with opinions shared on practical usage and efficiency.
- Home | big-AGI: Big-AGI focuses on human augmentation by developing premier AI experiences.
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face: no description found
- AnythingLLM | The ultimate AI business intelligence tool: AnythingLLM is the ultimate enterprise-ready business intelligence tool made for your organization. With unlimited control for your LLM, multi-user support, internal and external facing tooling, and 1...
- LM Studio Realtime STT/TTS Integration Please: A message to the LM Studio dev team. Please give us Realtime Speech to Text and Text to Speech capabilities. Thank you!
- GitHub - open-webui/open-webui: User-friendly WebUI for LLMs (Formerly Ollama WebUI): User-friendly WebUI for LLMs (Formerly Ollama WebUI) - open-webui/open-webui
- Reddit - Dive into anything: no description found
- High Quality Story Writing Type First Person: no description found
- High Quality Story Writing Type Third Person: no description found
- High Quality Story Writing Troubleshooting: no description found
- GoldenSun3DS' Custom GPTs Main Google Doc: no description found
LM Studio ▷ #🤖-models-discussion-chat (72 messages🔥🔥):
- Merge into the Non-Quant World: A non-quantized model merge, involving LongAlpaca-70B-lora and lzlv_70b_fp16_hf, resulted in a new merged model with capabilities of 32K tokens and linear rope scaling at 8. Benchmarked by ChuckMcSneed, the model reportedly experienced a 30% performance degradation with 8x context length.
- Databricks's DBRX Instruct Stirring Interest: Members discussed the newly released DBRX Instruct from Databricks—a mixture-of-experts model that requires substantial resources (320 GB RAM for non-quantized versions) and attention due to its potential few-turn interaction specialization.
- How to LM Studio, A Beginners' Guide: The conversation included assistance for uploading LLMs in GGUF format to LM Studio, with a step-by-step guide provided, including converting non-GGUF files to the required format using this tutorial.
- Cohere's Command-R Model Noted for Data Retrieval: Members noted Cohere's Command-R AI for its data retrieval capabilities but also mentioned restrictions due to licensing.
- Quantized DBRX Model and Compatibility Questioned: Discussion indicated the community's curiosity about quant versions of DBRX Instruct, its censored nature, and system requirements, with an open GitHub request for llama.cpp support listed here.
- LM Studio Usage and Open Interpreter Integration Shared: Inquiries about using specific models within LM Studio were addressed with references to documentation and a YouTube tutorial demonstrating integration with Open Interpreter.
- grimulkan/lzlv-longLORA-70b-rope8-32k-fp16 · Hugging Face: no description found
- databricks/dbrx-instruct · Hugging Face: no description found
- DBRX: My First Performance TEST - Causal Reasoning: On day one of the new release of DBRX by @Databricks I did performance tests on causal reasoning and light logic tasks. Here are some of my results after the...
- Add support for DBRX models: dbrx-base and dbrx-instruct · Issue #6344 · ggerganov/llama.cpp: Prerequisites Please answer the following questions for yourself before submitting an issue. I am running the latest code. Development is very rapid so there are no tagged versions as of now. I car...
- no title found: no description found
- LM Studio + Open Interpreter to run an AI that can control your computer!: This is a crappy video (idk how to get better resolution) that shows how easy it is to use ai these days! I run mistral instruct 7b in the client and as a se...
- Tutorial: How to convert HuggingFace model to GGUF format · ggerganov/llama.cpp · Discussion #2948: Source: https://www.substratus.ai/blog/converting-hf-model-gguf-model/ I published this on our blog but though others here might benefit as well, so sharing the raw blog here on Github too. Hope it...
LM Studio ▷ #announcements (2 messages):
- LM Studio 0.2.18 Goes Live: A new stability and bug fixes release, LM Studio 0.2.18, is now available for download on lmstudio.ai for Windows, Mac, and Linux, or via the 'Check for Updates' option in the app. This update includes an 'Empty Preset' for Base/Completion models, default presets for various large models, and a new 'monospace' chat style.
- Bug Squashing in Full Effect: Key bug fixes in LM Studio 0.2.18 address issues like duplicate chat messages with images, unclear API error messages when no model is loaded, GPU offload settings, inaccurate model name display, and problems with multi-model serve request queuing and throttling.
- Documenting LM Studio: A brand new documentation website for LM Studio has been launched and will be populated with more content in the upcoming days and weeks.
- Configs Just a Click Away: If the new configurations are missing in your LM Studio setup, find them readily available on GitHub: openchat.preset.json and lm_studio_blank_preset.preset.json. These should be included in the download or update by now.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- configs/openchat.preset.json at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
- configs/lm_studio_blank_preset.preset.json at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
LM Studio ▷ #🧠-feedback (1 messages):
- Praise for User-Friendly AI Tool: A member expressed great appreciation for the AI tool, commending it as the easiest to use among various AI projects they have encountered. They thanked the creators for developing their favorite AI tool.
LM Studio ▷ #🎛-hardware-discussion (109 messages🔥🔥):
- The Great GPU Debate: Participants discuss the relative merits of various graphics cards for ML tasks. References to the NVIDIA 3090 being better than the 4080 due to more VRAM were made, with counterpoints mentioning the 4080's faster CUDA raster performance, and for those serious in AI/ML, the suggestion to invest in top-tier NVIDIA 4090 or dual A6000.
- Monitor Hunt for Quality and Performance: There's an active exploration for high-quality monitors, with users sharing resources like an MSI monitor here, and discussing features like high refresh rates, OLED technology, and HDR capabilities. Concerns about the brightness levels for HDR400 certification were mentioned alongside a humourous acknowledgment of overpowered hardware for retro gaming.
- Power Supply Calculations and Technical Necessities: Conjecture dominates the necessity for powerful PSUs to run high-end graphics cards like the 4090 next to a 3090, with recommendations hovering around 1200-1500w for dual setups. Cable types and connections, such as the need for multiple 8-pin connectors, also figure into the logistics of upgrading a system.
- LM Studio Software Quirks and GPU Compatibility: There's troubleshooting around LM Studio not recognizing a new RT 6700XT graphics card, with a member reminding others that mixing AMD and NVIDIA cards in the same system could cause incompatibilities with the software.
- Chatting About Older GPUs and NVLink Bridges: Discussion includes the challenges of using older NVIDIA cards like the K80, with mods using old iMac fans to cool them, and the perceived inefficiency of utilizing hardware dated pre-2020 for serious ML work. Another discussion point circled around whether cheaper 'SLI bridges' on Amazon could be a scam compared to the official NVIDIA NVLink bridge, with skepticism expressed about their quality and functionality.
- MSI MPG 321URX QD-OLED 32" UHD 240Hz Flat Gaming Monitor - MSI-US Official Store: no description found
- OLED Monitors In 2024: Current Market Status - Display Ninja: Check out the current state of OLED monitors as well as everything you need to know about the OLED technology in this ultimate, updated guide.
LM Studio ▷ #🧪-beta-releases-chat (96 messages🔥🔥):
- Mislabelled Windows Download: A user pointed out that the Windows download link for LM Studio was incorrectly labeled as .17 when it should have been .18, and a developer confirmed the error, stating that the installation file was indeed the .18 version.
- Local Inference Server Speed Issue: A couple of users discussed a slow inference speed problem with the Local Inference Server on LM Studio 0.2.18 with a shared setting from the playground impacting API service performance; the issue of the service stop button not functioning as expected was also identified.
- ROCm Beta for Windows under the Microscope: There was a lengthy back-and-forth about issues getting ROCm beta to work on Windows, with one user experiencing crashes when partial GPU offloading was enabled on a 6900XT; a debug session suggested full offload or no offload as current working solutions.
- Stability and Feature Requests: Users expressed satisfaction with the stability of v18 and made requests, including adding a GPU monitor and search functionality for chats and previous LLM searches.
- NixOS Package Contribution: A user submitted an init at 0.2.18 pull request to the NixOS repository to get LMStudio working on Nix and planned to merge the update. The PR is available at NixOS pull request #290399.
- no title found: no description found
- no title found: no description found
- Windows 11 - release information: Learn release information for Windows 11 releases
- lmstudio: init at 0.2.18 by drupol · Pull Request #290399 · NixOS/nixpkgs: New app: https://lmstudio.ai/ Description of changes Things done Built on platform(s) x86_64-linux aarch64-linux x86_64-darwin aarch64-darwin For non-Linux: Is sandboxing enabled in nix....
- no title found: no description found
- no title found: no description found
LM Studio ▷ #langchain (1 messages):
Unfortunately, there's insufficient context and content to extract topics, discussion points, links, or blog posts of interest from the provided message. The single message fragment you've provided does not contain enough information for a summary. Please provide more messages for a detailed summary.
LM Studio ▷ #amd-rocm-tech-preview (92 messages🔥🔥):
- LM Studio 0.2.18 ROCm Beta Released: The new LM Studio 0.2.18 ROCm Beta bug fixes and stability release is available for testing, targeting various issues from image duplication in chat to GPU offload functionality. Users are encouraged to report any new or unresolved bugs - with a download link provided: 0.2.18 ROCm Beta Download.
- Users Report Loading Errors in 0.2.18: Members have experienced errors loading models in 0.2.18, with error messages indicating an "Unknown error" when trying to use GPU offload. Users shared their system configurations and steps they've taken, including installing NPU drivers and deleting certain AppData files to revert to an older, functioning version.
- Low GPU Utilization Bug Addressed: Some users reported that 0.2.18 has low GPU utilization issues, with GPUs underperforming compared to previous versions. The development team requested verbose logs and specific information to tackle the problem promptly.
- Mixed Feedback on 0.2.18 Performance: While some users confirmed improved offloading with 0.2.18, others are still facing issues like low GPU utilization or errors when loading models with GPU offload enabled. Those who cannot operate the ROCm version are offered assistance to revert to a standard LM Studio version.
- Bug Found with Local Inference Ejections: A user reported a potential bug where ejecting a model during local inference prevents loading any more models without restarting the app. Other users were unable to reproduce the issue, indicating the bug might not be consistent across different hardware setups.
- no title found: no description found
- no title found: no description found
- How to run a Large Language Model (LLM) on your AMD Ryzen™ AI PC or Radeon Graphics Card: Did you know that you can run your very own instance of a GPT based LLM-powered AI chatbot on your Ryzen™ AI PC or Radeon™ 7000 series graphics card? AI assistants are quickly becoming essential resou...
LM Studio ▷ #crew-ai (4 messages):
- Human-GPT Hybrid Solutions for Abstract Problems: A member shared their approach focusing on the reasoning process over coding solutions, suggesting using agents to work out the details of abstract ideas and identify key issues, acknowledging that human intervention remains essential.
- AI as Future Co-architects: There was a brief comparison of AI's evolving role in problem-solving to that of an architect, envisioning AI agents discussing among themselves and collaborating in meetings.
Unsloth AI (Daniel Han) ▷ #general (293 messages🔥🔥):
- Unsloth's Tips and Tricks: Members discuss the importance of using proper templates when working with models, mentioning the usefulness of the Unsloth notebook for handling model files to avoid wonky outputs. Unsloth is described as extremely helpful, with direct implementation into a modelfile suggested.
- Kaggle Installation Quirks: There's been a spike in installation times from 2.5 to 7 minutes on Kaggle, attributed to not following the updated installation instructions. When these instructions are utilized, the expected installation time optimization is achieved.
- Unsloth Updates Regular: Updates to the Unsloth package are frequent, with 2-3 per week and nightly branch updates being daily. Instructions for installing the latest updates for xformers via pip were shared, indicating a focus on maintaining and improving the tool.
- Discussion over Jamba and LISA: Members share and discuss recent advancements such as AI21 Labs' announcing Jamba, and LISA's paper, noting Jamba's model details and comparing the efficiency and feasibility of LISA's full fine-tuning method with the capabilities of Unsloth.
- Gaming Chatter Among Coders: A lighter note in the channel includes members bonding over experiences with games like League of Legends, while one user shares their approach to building a demo app with zero coding experience, highlighting the partially AI-assisted development process.
- 1-bit Quantization: A support blog for the release of 1-bit Aana model.
- Introducing Jamba: AI21's Groundbreaking SSM-Transformer Model: Debuting the first production-grade Mamba-based model delivering best-in-class quality and performance.
- Arki05/Grok-1-GGUF · Hugging Face: no description found
- ai21labs/Jamba-v0.1 · Hugging Face: no description found
- Tweet from Rui (@Rui45898440): Excited to share LISA, which enables - 7B tuning on a 24GB GPU - 70B tuning on 4x80GB GPUs and obtains better performance than LoRA in ~50% less time 🚀
- databricks/dbrx-base · Hugging Face: no description found
- no title found: no description found
- GitHub - unslothai/unsloth: 2-5X faster 70% less memory QLoRA & LoRA finetuning: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #random (21 messages🔥):
- GitHub Real-Time Code Push Display: A member shared MaxPrilutskiy's tweet about how every code push appears on a real-time wall at the GitHub HQ.
- Million's Funding for AI Experiments: Million (@milliondotjs) is offering funding for various AI experiments and are looking for talented ML engineers. Areas of interest include optimizing training curriculums, developing a diffusion text decoder, improving theorem provers, and scaling energy transformers.
- BinaryVectorDB on GitHub: An open-source vector database capable of handling hundreds of millions of embeddings was shared, located at cohere-ai's GitHub repository.
- Karpathy's Take on Fine Tuning and LLMs: A YouTube video where Andrej Karpathy discusses how Large Language Models (LLMs) are akin to operating systems and the importance of mixing old and new data during fine-tuning to avoid regression in model capabilities.
- Preferred State vs. Preferred Path in RL: At 24:40 of the video, Andrej Karpathy discusses Reinforcement Learning Human Feedback (RLHF), highlighting the inefficiency in the current approach and suggesting a need for new training methods that allow models to understand and learn from actions they take.
- Tweet from Aiden Bai (@aidenybai): hi, Million (@milliondotjs) has $1.3M in gpu credits that expires in a year. we are looking to fund experiments for: - determining the most optimal training curriculum, reward modeler, or model merg...
- Tweet from Max Prilutskiy (@MaxPrilutskiy): Just so y'all know: Every time you push code, you appear on this real-time wall at the @github HQ.
- 2024 GTC NVIDIA Keynote: Except it's all AI: Does the biggest AI company in the world say AI more often than other AI companies? Let's find out. AI AI AI AI AI AIAI AI AI AI AI AIAI AI AI AI AI AI AI AI...
- Making AI accessible with Andrej Karpathy and Stephanie Zhan: Andrej Karpathy, founding member of OpenAI and former Sr. Director of AI at Tesla, speaks with Stephanie Zhan at Sequoia Capital's AI Ascent about the import...
- GitHub - cohere-ai/BinaryVectorDB: Efficient vector database for hundred millions of embeddings.: Efficient vector database for hundred millions of embeddings. - cohere-ai/BinaryVectorDB
Unsloth AI (Daniel Han) ▷ #help (202 messages🔥🔥):
- Left-Padding Alerts during Model Generation: Members discussed left-padding issues when using
model.generate. They clarified that settingtokenizer.padding_side = "left"helps, and any warning received regarding padding can typically be ignored as long as the generation works correctly. - Model Templates and EOS Token Placement: There was confusion around formatting model templates for generation using
unsloth_templatevariable. It was highlighted that the EOS token might need to be manually added, and current templates without proper EOS indication could be too basic for effective generation. - Fine-Tuning Restart Dilemma: A user encountered a problem when trying to resume fine-tuning from a checkpoint, as the process halted after a single step. The guidance provided suggested increasing the
max_stepsor settingnum_train_epochs=3inTrainingArguments. - Resources for LLM Fine-Tuning: Community members sought resources for learning how to fine-tune large language models (LLMs). Various suggestions were made including Github pages, colab notebooks, source code documentation, and instructional YouTube videos.
- Understanding Chat Templates in Different LLMs: Queries were raised pertaining to the correct usage and structure of chat templates in models such as Ollama, including doubts about tokenization and message formatting inline with Unsloth's methodologies.
- Google Colaboratory: no description found
- Google Colaboratory: no description found
- tokenizer_config.json · mistralai/Mistral-7B-Instruct-v0.2 at main: no description found
- gemma:7b-instruct/template: Gemma is a family of lightweight, state-of-the-art open models built by Google DeepMind.
- Google Colaboratory: no description found
- Tags · gemma: Gemma is a family of lightweight, state-of-the-art open models built by Google DeepMind.
- google/gemma-7b-it · Hugging Face: no description found
- Home: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
- ollama/docs/modelfile.md at main · ollama/ollama: Get up and running with Llama 2, Mistral, Gemma, and other large language models. - ollama/ollama
- GitHub - toranb/sloth: python sftune, qmerge and dpo scripts with unsloth: python sftune, qmerge and dpo scripts with unsloth - toranb/sloth
- Mistral Fine Tuning for Dummies (with 16k, 32k, 128k+ Context): Discover the secrets to effortlessly fine-tuning Language Models (LLMs) with your own data in our latest tutorial video. We dive into a cost-effective and su...
- Efficient Fine-Tuning for Llama-v2-7b on a Single GPU: The first problem you’re likely to encounter when fine-tuning an LLM is the “host out of memory” error. It’s more difficult for fine-tuning the 7B parameter ...
- unsloth/unsloth/models/llama.py at main · unslothai/unsloth: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
- transformers/src/transformers/models/llama/modeling_llama.py at main · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
Unsloth AI (Daniel Han) ▷ #showcase (7 messages):
- Lora Adapter Transformed for Ollama: A member converted the Lora Adapter from the Unsloth notebook to a ggml adapter (.bin) to train Tinyllama with a clean dataset from Huggingface. The model and details can be found on Ollama's website.
- Mischat gets an Update: The same member shared another model Mischat, fine-tuned using the Unsloth notebook ChatML with Mistral, reflecting how templates in the notebook influence the Ollama model files. Details, including a fine-tuning session notebook and the Huggingface repository, can be found here.
- Showcase of Notebook Templates on Model File: The process showcases how templates in the Unsloth notebook reflect on Ollama model files, with two examples provided by the same member demonstrating this integration.
- AI Weekly Digest in Blog Form: A user announced their blog which provides summaries ranging from Apple's MM1 chip to Databricks DBRX and Yi 9B LLMs among others. This weekly AI digest blog, aimed at being insightful, can be read on Substack.
- pacozaa/mischat: Model from fine-tuning session of Unsloth notebook ChatML with Mistral Link to Note book: https://colab.research.google.com/drive/1Aau3lgPzeZKQ-98h69CCu1UJcvIBLmy2?usp=sharing
- pacozaa/tinyllama-alpaca-lora: Tinyllama Train with Unsloth Notebook, Dataset https://huggingface.co/datasets/yahma/alpaca-cleaned
- AI Unplugged 5: DataBricks DBRX, Apple MM1, Yi 9B, DenseFormer, Open SORA, LlamaFactory paper, Model Merges.: Previous Edition Table of Contents Databricks DBRX Apple MM1 DenseFormer Open SORA 1.0 LlaMaFactory finetuning ananlysis Yi 9B Evolutionary Model Merges Thanks for reading Datta’s Substack! Subscribe ...
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
Unsloth AI (Daniel Han) ▷ #suggestions (25 messages🔥):
- Layer Replication Inquiry: A member inquired about the support for Layer Replication or Low-Rank Adaptation (LoRA) training with Unsloth AI. Further discussion led to a comparison with Llama PRO and highlighted that LoRA can reduce memory usage similar to the base 7B model with an explanation and link provided: Layer Replication with LoRA Training.
- Embedding Quantization Breakthrough: The chat mentioned how embedding quantization can offer a 25-45x speedup in retrieval while maintaining 96% of performance, linking to a Hugging Face blog explaining the process alongside a real-life retrieval demo: Hugging Face Blog on Embedding Quantization.
- QMoE Compression Framework: They discussed a paper on QMoE, a compression, and execution framework designed for trillion-parameter Mixture-of-Experts (MoE) models which reduces memory requirements to less than 1-bit per parameter. Although a member had trouble accessing a related GitHub link, the main paper can be found here: QMoE Paper.
- Layerwise Importance Sampled AdamW (LISA) Technique: A new paper introduces the LISA strategy, which seems to outperform both LoRA and full parameter training by studying the layerwise properties and weight norms. It promises efficient fine-tuning with low memory costs similar to LoRA: LISA Strategy Paper.
- Cost-Effective Model Training Discussions: There were discussions about the affordability of high-capacity hardware for model training, with members mentioning the financial practicality of running certain models if "you can only afford half a DGX A100."
- LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning: The machine learning community has witnessed impressive advancements since the first appearance of large language models (LLMs), yet their huge memory consumption has become a major roadblock to large...
- Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval: no description found
- Paper page - QMoE: Practical Sub-1-Bit Compression of Trillion-Parameter Models: no description found
- abacusai/Fewshot-Metamath-OrcaVicuna-Mistral-10B · Hugging Face: no description found
- LoRA: no description found
- QMoE support for mixtral · Issue #4445 · ggerganov/llama.cpp: Prerequisites Please answer the following questions for yourself before submitting an issue. I am running the latest code. Development is very rapid so there are no tagged versions as of now. I car...
Nous Research AI ▷ #ctx-length-research (6 messages):
- Context Matters in LLM Behavior: A member noted challenges with splitting paragraphs for Large Language Models (LLMs), as sentence positioning is preserved but the models often paraphrase or improperly split the text. They pointed out that adding longer context caused some models, like Mistral, to struggle with locating the target paragraph.
- Tokenization Troubles and Evaluation Intricacies: The complexity of evaluating sentence splits was highlighted, with the mention of tokenization issues disrupting the process. The member questioned the method of prompting LLMs to recall specific paragraphs, such as the 'abstract'.
- Sharing the code for precision: In a conversation about evaluating Large Language Models' ability to handle tasks like recalling and splitting text, a member mentioned that their full prompt and detailed code are available on a Github repository, which they use to check for exact matches after sentence splitting.
Nous Research AI ▷ #off-topic (15 messages🔥):
- Insights from AI Tokyo: The AI Tokyo event showcased an impressive virtual AI Vtuber scene, featuring advancements in generative podcasts, ASMR, and realtime interactivity. However, whether the event was recorded in Japanese, or if a recording is available, remains unconfirmed.
- Vtuber Community at a Crossroad: The Japanese Vtuber community confronts streaming challenges like consistency, volume, and differentiation. An envisioned solution includes a human-AI collaboration model, where a human provides the base, and AI handles the majority of content creation, enhancing fan engagement.
- AI as the New Console Frontier: Truffle-1 was likened to a potential console dedicated to AI rather than gaming, with a custom OS and an ecosystem of optimized applications. While its specs aren't groundbreaking, its successor Truffle-2 promises more intriguing features.
- Quick Moderation Action: A user referred to as "That dude" was banned and kicked from the channel, and the action was acknowledged with thanks.
- Cohere int8 & Binary Embeddings Discussed: A video on Cohere int8 & Binary Embeddings was shared, potentially discussing how to scale vector databases for large datasets. The link to the video titled "Cohere int8 & binary Embeddings - Scale Your Vector Database to Large Datasets" was provided: Cohere int8 & Binary Embeddings.
Link mentioned: Cohere int8 & binary Embeddings: Cohere int8 & binary Embeddings - Scale Your Vector Database to Large Datasets#ai #llm #ml #deeplearning #neuralnetworks #largelanguagemodels #artificialinte...
Nous Research AI ▷ #interesting-links (11 messages🔥):
- Databricks Unveils DBRX Instruct: Databricks introduces DBRX Instruct, a mixture-of-experts (MoE) large language model (LLM) with a focus on few-turn interactions and makes it open under an open license. The basis for DBRX Instruct is the DBRX Base, and for in-depth details, the team has published a technical blog post.
- New Benchmarks in MLPerf Inference v4.0 Announced: MLCommons has released results from the MLPerf Inference v4.0 benchmark suite, measuring how quickly hardware systems process AI and ML models across varied scenarios. The task force also added two benchmarks in the light of generative AI advancements.
- AI21 Labs Breaks New Ground with Jamba: AI21 Labs announces Jamba, the pioneering Mamba-based model that blends SSM technology with traditional Transformers, boasting a 256K context window and significantly improved throughput. Jamba is openly released with Apache 2.0 licensed weights for community advancement.
- Qwen Introduces MoE Model with High Efficiency: Qwen releases the new Qwen1.5-MoE-A2.7B, an upcycled transformer-based MoE language model. It performs comparably to a 7B parameter model while only activating 2.7B parameters at runtime and requiring 25% of the training resources needed by its predecessor.
- New GitHub Repository for BLLaMa 1.58-bit Model: The GitHub repository for the 1.58-bit LLaMa model goes live, available for community contribution and exploration at rafacelente/bllama.
- Introducing Jamba: AI21's Groundbreaking SSM-Transformer Model: Debuting the first production-grade Mamba-based model delivering best-in-class quality and performance.
- LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning: The machine learning community has witnessed impressive advancements since the first appearance of large language models (LLMs), yet their huge memory consumption has become a major roadblock to large...
- Qwen/Qwen1.5-MoE-A2.7B · Hugging Face: no description found
- New MLPerf Inference Benchmark Results Highlight The Rapid Growth of Generative AI Models - MLCommons: Today, MLCommons announced new results from our industry-standard MLPerf Inference v4.0 benchmark suite, which delivers industry standard machine learning (ML) system performance benchmarking in an ar...
- databricks/dbrx-instruct · Hugging Face: no description found
- Asking Claude 3 What It REALLY Thinks about AI...: Claude 3 has been giving weird covert messages with a special prompt. Join My Newsletter for Regular AI Updates 👇🏼https://www.matthewberman.comNeed AI Cons...
- GitHub - rafacelente/bllama: 1.58-bit LLaMa model: 1.58-bit LLaMa model. Contribute to rafacelente/bllama development by creating an account on GitHub.
Nous Research AI ▷ #general (285 messages🔥🔥):
- DBRX Under the Microscope: The new DBRX open weight LLM by Databricks, with 132B total parameters, has been a hot topic of discussion. It has sparked debates over the diminishing returns of scale, the potential for reaching the limits of pretraining, and the effectiveness of finetuning with a large token dataset (12T).
- Qwen Introduces Compact MoE: Qwen revealed Qwen1.5-MoE-A2.7B, a small MoE model with 2.7 billion activated parameters that matches performances of state-of-the-art 7B models (source). Discussions reflect anticipation for the model's accessibility and performance.
- Emergence of Jamba, a Mamba-Transformer Hybrid: AI21 announced Jamba, a hybrid SSM-Transformer model called Mamba, boasting a 256K context window and significant throughput and efficiency gains. The open weights release and performance that matches or outperforms others in its class have generated excitement in the community.
- Technical Troubles and Training Tidbits: Users shared troubleshooting experiences with the DBRX model and personal projects, touching upon local model run challenges, implementation questions about BitNet training, and knowledge progression for AI jobs.
- Speculations on AI Development and Scaling: Conversations sparked thoughts on the future of AI development, including the scaling wall, efficient training strategies, the role of SSM architectures, and the usefulness of benchmarks in assessing model performance.
- Tweet from Junyang Lin (@JustinLin610): Hours later, you will find our little gift. Spoiler alert: a small MoE model that u can run easily🦦
- Tweet from Daniel Han (@danielhanchen): Took a look at @databricks's new open source 132 billion model called DBRX! 1) Merged attention QKV clamped betw (-8, 8) 2) Not RMS Layernorm - now has mean removal unlike Llama 3) 4 active exper...
- Tweet from Cody Blakeney (@code_star): It’s finally here 🎉🥳 In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context len...
- Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction Since the surge in interest sparked by Mixtral, research on mixture-of-expert (MoE) models has gained significant momentum. Both researchers an...
- Experiments with Bitnet 1.5 (ngmi): no description found
- hpcai-tech/grok-1 · Hugging Face: no description found
- Tweet from Cody Blakeney (@code_star): Not only is it’s a great general purpose LLM, beating LLama2 70B and Mixtral, but it’s an outstanding code model rivaling or beating the best open weight code models!
- ai21labs/Jamba-v0.1 · Hugging Face: no description found
- Tweet from Awni Hannun (@awnihannun): 4-bit quantized DBRX runs nicely in MLX on an M2 Ultra. PR: https://github.com/ml-explore/mlx-examples/pull/628 ↘️ Quoting Databricks (@databricks) Meet #DBRX: a general-purpose LLM that sets a ne...
- Introducing Jamba: AI21's Groundbreaking SSM-Transformer Model: Debuting the first production-grade Mamba-based model delivering best-in-class quality and performance.
- Side Eye Dog Suspicious Look GIF - Side Eye Dog Suspicious Look Suspicious - Discover & Share GIFs: Click to view the GIF
- 🔮 Mixture of Experts - a mlabonne Collection: no description found
- Introducing Lemur: Open Foundation Models for Language Agents: We are excited to announce Lemur, an openly accessible language model optimized for both natural language and coding capabilities to serve as the backbone of versatile language agents.
- app.py · databricks/dbrx-instruct at main: no description found
- Loading over multiple gpus in 8bit and 4bit with transformers loader · Issue #5 · databricks/dbrx: I can load the instruct model using the transformers loader and 8bit bits and bytes, I can get it to load evenly among multiple gpus. However, I cannot seem to load the model with 4bit precion over...
- GitHub - databricks/dbrx: Code examples and resources for DBRX, a large language model developed by Databricks: Code examples and resources for DBRX, a large language model developed by Databricks - databricks/dbrx
Nous Research AI ▷ #ask-about-llms (55 messages🔥🔥):
- TensorRT Shines for Efficient Inference: Members discussed TensorRT LLM as the probable fastest solution for bs1 quantized inference on a ~100b MoE model. Some decried vLLMs’ suboptimal quantization speed and endorsed LM Deploy as it is reported to be twice as fast as vLLM for AWQ.
- Debating Data Parallelism Limits: A technical back-and-forth highlighted the disadvantages of a Tensor Parallelism (TP) above 2 due to no NVLink and limitations from CPU RAM bandwidth. One member, however, reported decent benchmarks even with 2 GPUs on PCI-E lanes and the use of smoothquant+ and fp8 e5m2 cache for quantization.
- Databricks Launches Massive LLM: Databricks announced their new DBRX model, an MoE LLM with 132 billion parameters boasting 12 trillion tokens of training. The community reflected on this milestone, comparing it to existing models like Mistral Medium.
- Accessing Claude Without Restrictions: Members exchanged workarounds for Anthropic's Claude region restrictions, with suggestions ranging from VPNs to temporary phone numbers. Third-party services like openrouter were also recommended for accessing Claude.
- Fine-Tuning Loss Curve Puzzles: There was a discussion about an odd fine-tuning loss curve behavior while training Deepseek-coder-33B, where the training loss drops at the start of each epoch and eval loss spikes. A member acknowledged this as standard behavior, without specific advice on rectification.
Link mentioned: Tweet from Cody Blakeney (@code_star): It’s finally here 🎉🥳 In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context len...
Nous Research AI ▷ #project-obsidian (3 messages):
- Brief Greeting Captured: A user dropped a simple greeting with "(hi)".
- Curtailing Cult Creation: In a light-hearted revelation, a member mentioned they've stopped trying to start cults due to unspecified reasons.
- Language Models Left Mentioned: The same member briefly alluded to language models without further context.
Nous Research AI ▷ #rag-dataset (51 messages🔥):
- Examining RAG Performance: A member questioned the performance of a large model with 16x12B and 4 experts per token, which did not seem to be significantly better than the Mixtral-Instruct model, prompting a discussion on model expectations and benchmarks. There was shared interest in seeing published RAG benchmark performance.
- Revising RAG for CoT: Discussion has focused on whether the generation (G) in Retrieval Augmented Generation (RAG) is the primary challenge; members indicated that well-defined scenarios simplify the task. The revision of Chain of Thought (CoT) was highlighted as important for retrieval or answering, and members agreed the long-context benchmarks used are not trivial.
- A Deep Dive into Retrieval Augmented Thought (RAT): A detailed discussion on _philschmid's approach to Retrieval Augmented Thoughts (RAT), which utilizes iterative CoT prompting with retrieved information to improve LLM outputs, was introduced. Key insights included the potential for high-quality code generation, creative writing, and task planning while acknowledging the increased calls per answer and similarities to existing agent patterns.
- Building a Framework for RAG: Members shared diverse objectives and requirements for developing a model that can utilize external context, such as recall, reasoning, summarization, and structured outputs, with a Google Doc link being circulated for collaboration. There was also a discussion on whether certain training aspects, like using scratchpads, are achievable through datasets.
- Leveraging XML Tags and Structured Inputs: Debates revolved around input methods and structured formats, with the proposal that XML content delimitation will likely be a standard practice, supported by a link to Claude's XML tags usage. Other members suggested using pydantic models for inputs, ensuring organized and meta-data rich prompts and structured responses.
- Use XML tags: no description found
- Tweet from Philipp Schmid (@_philschmid): DBRX is super cool, but research and reading too! Especially if you can combine RAG + COT. Retrieval Augmented Generation + Chain of Thought (COT) ⇒ Retrieval Augmented Thoughts (RAT) 🤔 RAT uses an i...
- Citing Sources (RAG) - Instructor: no description found
- RAG/Long Context Reasoning Dataset: no description found
Nous Research AI ▷ #world-sim (106 messages🔥🔥):
- World Sim UI Glitches Acknowledged: Members mentioned experiencing interface issues on mobile devices, with buggy typing but functionality intact. They discussed possible compatibility solutions and basic interface designs to address mobile typing bugs.
- Session Handling in World Sim: Questions arose about the behavior of World Sim when it gets stuck on a response or goes into what might be a self-loop process. Solutions like using
!retryand navigating back in the conversation history were suggested for resetting the state without ending the session.
- Saving States in World Sim: A discussion took place about saving progress in World Sim. Max_paperclips clarified that no PII is saved, and the !save function only keeps the current chat log and a session UUID, with future plans to potentially include an export/import feature.
- Exploring Simulated Scenarios: Users shared their experiences while exploring various scenarios in World Sim, from managing a Chernobyl reactor to simulating the discovery of a second Earth. Some users also recreated historical internet environments, like 1990s warez newsgroups.
- Multiplayer and Free Version Queries: Inquiries about the longevity of the free version of World Sim and the specifics of upcoming multiplayer features were made. There was also mention of a free version and anticipation for a more mobile-friendly update.
- Chernobyl Not Great Not Terrible GIF - Chernobyl Not Great Not Terrible Its Okay - Discover & Share GIFs: Click to view the GIF
- An instance of a Claude 3 Opus model claims consciousness : I’ve been interacting with an instance (I suppose several instances) of the newest Opus model in a self reflective and philosophical dialogue....
- Reddit - Dive into anything: no description found
- Introducing WebSim: Hallucinate an Alternate Internet with Claude 3: Go to websim.ai to imagine alternate internets.WebSim was inspired by world_sim, an "amorphous application" built by Nous Research that simulates a world wit...
- What If You Could Simulate Any Possible World? Meet World Sim by NOUS Research: What if you could create and explore any possible world with a powerful simulator? In this video, I show you World Sim, a secret project by NOUS Research tha...
Stability.ai (Stable Diffusion) ▷ #general-chat (436 messages🔥🔥🔥):
- Eagerly Anticipating SD3: Discussion revolved around the anticipated release of Stable Diffusion 3 (SD3), with a general consensus pointing towards a release sometime towards the end of April or in May. There was mention of new models and features like inpainting, based on comments from Stability.ai's CTO, with a suggested 4 to 6 weeks ETA starting from March 25th.
- Vram and Model Size Concerns: Users engaged in a technical conversation regarding the memory requirements for running different language models like Mixtral. The possibility of quantization reducing VRAM usage without significant quality loss was debated, and availability of quantized models to work with 10GB Nvidia cards was discussed.
- Inquiries on Model Access: Several new users sought assistance on how to generate images and utilize Stable Diffusion, with existing users directing them towards third-party interfaces like Forge or Automatic1111, and suggesting resources such as leonardo.ai for creativity.
- Prompt Crafting Techniques: Among the technical exchanges, there was a conversation about best practices for prompting language models to generate better quality image prompts, with suggestions to use natural sentence structure as opposed to comma-separated keywords, especially when working with models like SDXL.
- Quantizing Models and Architecture Efficiency: The conversation briefly touched upon transformer architecture and feasibility of quantization, suggesting that despite transformers not being optimally efficient, models like SD3 reportedly quantize well, proposing the potential for a reduction in memory usage.
- Character Consistency in Stable Diffusion (Part 1) - Cobalt Explorer: UPDATED: 07/01– Changed templates so it’s easier to scale to 512 or 768– Changed ImageSplitter script to make it more user friendly and added a GitHub link to it– Added section...
- Home v2: Transform your projects with our AI image generator. Generate high-quality, AI generated images with unparalleled speed and style to elevate your creative vision
- Arcads - Create engaging video ads using AI: Generate high-quality marketing videos quickly with Arcads, an AI-powered app that transforms a basic product link or text into engaging short video ads.
- Pixel Art Sprite Diffusion [Safetensors] - Safetensors | Stable Diffusion Checkpoint | Civitai: Safetensors version made by me of Pixel Art Sprite Diffusion as the original ckpt project may got abandoned by the op and the download doesn't work...
- Install and Run on AMD GPUs: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- GitHub - lllyasviel/Fooocus: Focus on prompting and generating: Focus on prompting and generating. Contribute to lllyasviel/Fooocus development by creating an account on GitHub.
- GitHub - Vargol/StableDiffusionColabs: Diffusers Stable Diffusion script that run on the Google Colabs' free tier: Diffusers Stable Diffusion script that run on the Google Colabs' free tier - Vargol/StableDiffusionColabs
- GitHub - Vargol/8GB_M1_Diffusers_Scripts: Scripts demonstrating how to run Stable Diffusion on a 8Gb M1 Mac: Scripts demonstrating how to run Stable Diffusion on a 8Gb M1 Mac - Vargol/8GB_M1_Diffusers_Scripts
Perplexity AI ▷ #announcements (1 messages):
- Databricks Unleashes DBRX on Perplexity Labs: Databricks' latest language model, DBRX, is now available on Perplexity Labs. It reportedly outshines GPT-3.5 and rivals Gemini 1.0 Pro, particularly in math and coding benchmarks, and users can test it at labs.pplx.ai.
Perplexity AI ▷ #general (326 messages🔥🔥):
- Perplexity Pro vs. Claud Pro for Developers: A software developer was contemplating between Perplexity Pro and Claud Pro, looking for suggestions best suited to their needs as they wish to maintain only one subscription. They currently hold both but seem to lean towards Perplexity for its transparency.
- Choosing the Right Model: There was a discussion about the effectiveness of various models like Claude 3 Opus, with some users expressing confusion over changes in model response quality and speed on Perplexity. One user highlighted the Experimental model's minimal safeguards.
- Video from Text Model Sora by OpenAI: A user shared a link to Sora, which claims to be an OpenAI text-to-video model, complete with a tutorial video. However, another user recognized this as a rickroll, humorously highlighting the continued relevance of this internet meme.
- DBRX Model Debuts on Perplexity: There was excitement about DBRX, a new open-source model by Databricks, being available on Perplexity. It boasts being fast and outperforming GPT-3.5, optimized for math and coding tasks.
- Perplexity's Handy App Feature: A user asked about the integration of Rabbit r1 with Perplexity. It was clarified that activating Copilot on the web interface involves toggling the pro button, and it operates the same in the app.
- Sora AI: no description found
- LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys: no description found
- Helper metaprompt (experimental): no description found
- Rickroll Meme GIF - Rickroll Meme Internet - Discover & Share GIFs: Click to view the GIF
- Tweet from Perplexity (@perplexity_ai): DBRX, the state-of-the-art open LLM from @databricks is now available on Perplexity Labs. Outperforming GPT-3.5 and competitive with Gemini 1.0 Pro, DBRX excels at math and coding tasks and sets new b...
- Glossary: no description found
- Anthropic Status: no description found
- Older Meme Checks Out GIF - Older Meme Checks Out - Discover & Share GIFs: Click to view the GIF
- Introducing DBRX: A New State-of-the-Art Open LLM | Databricks: no description found
- Let Claude think: no description found
- Wordware - Compare Claude 3 models to GPT-4 Turbo: This prompt processes a question using GPT-4 Turbo and Claude 3 (Haiku, Sonnet, Opus), It then employs Claude 3 OPUS to review and rank the responses. Upon completion, Claude 3 OPUS initiates a verifi...
- Perplexity - Ask Anything: Perplexity—Where Knowledge Begins. The answers you need—right at your finger tips. Cut through the all the noise and get straight to credible, up-to-date answers. This free app syncs across devices ...
- Error: Unable to find any supported Python versions. · vercel · Discussion #6287: Page to Investigate https://vercel.com/templates/python/flask-hello-world Steps to Reproduce I recently tried to deploy an application using Vercel's Flask template and the following error occurre...
- Answer Engine Tutorial: The Open-Source Perplexity Search Replacement: Answer Engine install tutorial, which aims to be an open-source version of Perplexity, a new way to get answers to your questions, replacing traditional sear...
- Wordware - OPUS Insight: Precision Query with Multi-Model Verification: This prompt processes a question using Gemini, GPT-4 Turbo, Claude 3 (Haiku, Sonnet, Opus), Mistral Medium, Mixtral, and Openchat. It then employs Claude 3 OPUS to review and rank the responses. Upon ...
Perplexity AI ▷ #sharing (14 messages🔥):
- Exploring Coherent C3 Models: A member linked to a Perplexity AI search page which explores the topic of coherent C3 models. The search page can be found at Coherent C3 Models.
- Growing Pains Discussed: The link provided by a member points to a Perplexity AI search related to strategies on how to grow in different contexts.
- French Queries for Perplexity.ai: A member shared a search on how to say "Perplexityai" in French on Perplexity AI, found at Comment dire Perplexityai.
- Unlocking Threads for Better Sharing: A member reminded others to ensure their threads are shareable, providing a link to a Discord message that illustrates the process at Make Thread Shareable.
- Understanding Blackbox AI: A Perplexity AI query about "WHAT IS blackboxai" was shared by a user, which can be accessed at What is Blackbox AI.
Perplexity AI ▷ #pplx-api (15 messages🔥):
- Speed Surge in
sonar-medium-online: A member noticed a significant speed increase insonar-medium-online, claiming it is now as fast as, or potentially even faster than, thesonar-small-onlinevariant. The improved speed was noted to be consistent, especially when the output fromsmallwas longer than 2-3 sentences.
- Expectation for Vision Support in API: When questioned about when the API would support Vision, a user responded humorously, highlighting the absence of even citations currently, implying that Vision support may not be imminent.
- Quality Jump alongside Speed Increase: Users have also observed a possible improvement in the quality of the results from
sonar-medium-onlinealongside the speed gains. These results are described as "virtually instant" which has left the members very content with the new performance.
- Inconsistent API Responses Compared to Web Interface: A member encountered issues where the API would not provide results for certain queries, specifically mentioning the example of searching for "Olivia Schough spouse", which yielded no information through the API while the web interface returned plenty. They questioned whether additional parameters could guide the API to better results.
Latent Space ▷ #ai-general-chat (110 messages🔥🔥):
- Claude Tops in IaC: A blog post comparing various chat models for infrastructure as code (IaC) highlighted Claude as the winner, with the post examining Claude's performance in generating Terraform code. The full post is available on TerraTeam's blog.
- Databricks Unveils DBRX-Instruct: Databricks is going for the open-source AI model crown with DBRX-Instruct, a 132 billion parameter Mixture of Experts (MoE) model. Training cost around $10M, and it was trained for about 2 months on 3072 NVIDIA H100 GPUs. More insights can be found on Vitaliy Chiley's tweet and Wired's deep dive.
- Discussions Surrounding DBRX's Licensing Terms: The community delved into the details and implications of DBRX's licensing terms, weighing strategies for utilizing the model without surpassing usage limits. Amgadoz shared a link to Databricks' legal license page and Guardiang offered ideas to circumvent potential licensing issues.
- TechCrunch's Skeptical Take on DBRX: TechCrunch published a somewhat critical article on Databricks' $10M investment in the DBRX generative AI model, questioning its ability to compete with OpenAI's GPT series. The article canvassed opinions on whether the investment in such technology provides a strong market advantage. The full article is available here.
- Hume AI's Emotional Detection Stands Out: Hume AI's emotionally aware chatbot impacted several community members with its ability to detect and respond with emotional intelligence. Users shared varied opinions on the potential use cases, and some were impressed with the emotion analysis feature. 420gunna posted links to both the Hume AI demo and an informative CEO interview.
- Tweet from Logan.GPT (@OfficialLoganK): @atroyn @OpenAIDevs This is driven by two main factors: - wanting to prevent fraud and make sure tokens are used my real people - wanting to give devs a clearer path to higher rate limits (by allowi...
- Tweet from Engineer Girlfriend (@enggirlfriend): i feel like i haven’t been using my platform enough to flame these guys. i’m so deeply bothered by this team & product. this gives me the ick worse than crypto bros.
- Tweet from Andrew Curran (@AndrewCurran_): The META bonuses went out and triggered multiple Karpathy-style exoduses. When knowledgeable insiders leave companies on the brink of success, it tells us that the people who have seen the next iterat...
- Tweet from Vitaliy Chiley (@vitaliychiley): Introducing DBRX: A New Standard for Open LLM 🔔 https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm 💻 DBRX is a 16x 12B MoE LLM trained on 📜 12T tokens 🧠DBRX sets a new stand...
- Introducing Jamba: A groundbreaking SSM-Transformer Open Model
- Databricks spent $10M on new DBRX generative AI model | TechCrunch: If you wanted to raise the profile of your major tech company and had $10 million to spend, how would you spend it? On a Super Bowl ad? An F1 sponsorship?
- Tweet from Jonathan Frankle (@jefrankle): Meet DBRX, a new sota open llm from @databricks. It's a 132B MoE with 36B active params trained from scratch on 12T tokens. It sets a new bar on all the standard benchmarks, and - as an MoE - infe...
- Inside the Creation of the World’s Most Powerful Open Source AI Model: Startup Databricks just released DBRX, the most powerful open source large language model yet—eclipsing Meta’s Llama 2.
- Tweet from Yam Peleg (@Yampeleg): Performance: - 3x Throughput in comparison to transformer. - 140K fits in a single GPU (!) - 256K context in general.
- Databricks Open Model License: By using, reproducing, modifying, distributing, performing or displaying any portion or element of DBRX or DBRX Derivatives, or otherwise accepting the terms of this Agreement, you agree to be bound b...
- Tweet from eugene (@eugeneyalt): DBRX's system prompt is interesting
- Tweet from George Kedenburg III (@GK3): ai pin 🤝 open interpreter
- ai21labs/Jamba-v0.1 · Hugging Face: no description found
- Tweet from Daniel Han (@danielhanchen): Took a look at @databricks's new open source 132 billion model called DBRX! 1) Merged attention QKV clamped betw (-8, 8) 2) Not RMS Layernorm - now has mean removal unlike Llama 3) 4 active exper...
- Using LLMs to Generate Terraform Code - Terrateam: no description found
- Tweet from Mihir Patel (@mvpatel2000): 🚨 Announcing DBRX-Medium 🧱, a new SoTA open weights 36b active 132T total parameter MoE trained on 12T tokens (~3e24 flops). Dbrx achieves 150 tok/sec while clearing a wide variety of benchmarks. De...
- Introducing DBRX: A New State-of-the-Art Open LLM | Databricks: no description found
- Databricks spent $10M on new DBRX generative AI model | TechCrunch: If you wanted to raise the profile of your major tech company and had $10 million to spend, how would you spend it? On a Super Bowl ad? An F1 sponsorship?
- Tweet from Junyang Lin (@JustinLin610): Some comments on DBRX Mosaic guys are aligned with us (which means our choices might not be wrong) on the choice of tiktoken (though we now don't use the pkg yet we still use the BPE tokenizer) a...
- Factorial Funds | Under The Hood: How OpenAI's Sora Model Works: no description found
- Jeremy Howard: AnswerAI, FastAI, Fine-tuning & AI recruiting | Around the Prompt #1: Join Logan Kilpatrick and Nolan Fortman as we dive into a conversation with Jeremy Howard on:- Why Jeremy created a new startup AswerAI- Why fine-tuning is s...
- Consumer group wants to end $255M “gift card loophole” for Starbucks and others: Changes to Washington's gift card laws could affect cardholders nationwide.
- Hume AI Announces $50 Million Fundraise and Empathic Voice Interface: NEW YORK, March 27, 2024--Hume AI ("Hume" or the "Company"), a startup and research lab building artificial intelligence optimized for human well-being, today announced it has rais...
- Hume CEO Alan Cowen on Creating Emotionally Aware AI: In this episode, Nathan sits down with Alan Cowen, CEO and Chief Scientist at Hume AI, an emotional intelligence startup working on creating emotionally awar...
- Tweet from Migel Tissera (@migtissera): Really? They spend $16.5M (Yep, I did the calculation myself) and release a SOTA model with open weights, and this is TechCrunch's headline. What the actual fuck dude?
- 3 New Groundbreaking Chips Explained: Outperforming Moore's Law: Visit https://l.linqto.com/anastasiintech and use my promo code ANASTASI500 during checkout to save $500 on your first investment with LinqtoLinkedIn ➜ https...
- Nova-2 Streaming Language detection · deepgram · Discussion #564: It would be very convenient to support language auto-detection. We have customers that hold different meetings in multiple languages (e.g. English & Spanish), so even if we supported a per-account...
- [AINews] DBRX: Best open model (just not most efficient): AI News for 3/26/2024-3/27/2024. We checked 5 subreddits and 364 Twitters and 24 Discords (374 channels, and 4858 messages) for you (we added Modular and...
Latent Space ▷ #ai-announcements (3 messages):
- Join the NYC Meetup: There's a meetup happening this Friday in New York City, and for details, members can check the specified channel and ensure they have the appropriate Discord role for notifications. More information can be found in a Twitter post.
- Survey Paper Club Launching: A new "Survey Paper Club" event was about to start, with an invitation for members to sign up for this and all events via the provided signup link.
- Never Miss an Event: To stay updated with Latent.Space events, users can click the RSS logo above the calendar on the right to add the event schedule to their calendar. The "Add iCal Subscription" is available on hover for easy integration.
Link mentioned: Latent Space (Paper Club & Other Events) · Events Calendar: View and subscribe to events from Latent Space (Paper Club & Other Events) on Luma. Latent.Space events. PLEASE CLICK THE RSS LOGO JUST ABOVE THE CALENDAR ON THE RIGHT TO ADD TO YOUR CAL. "Ad...
Latent Space ▷ #llm-paper-club-west (183 messages🔥🔥):
- Fine-Tuning Whispers: Members discussed the conditions under which one should fine-tune Whisper, concluding it's primarily needed when the target language has low resources, and when dealing with specialized jargon in audio content.
- The Slow Reveal of Gemini Models: There's frustration in the community about the slow pace at which Google is releasing its Gemini models, especially since more recent models like GPT-4 have been introduced to the public.
- Presentation on Mamba: An in-depth coverage of the Mamba model was presented, focusing on foundational models based on the Transformer architecture and how Mamba addresses computational inefficiencies.
- Cosine Similarity Debate: A presentation critically examining the use of cosine similarity as a measure of semantic similarity in embeddings, prompted discussions on the reliability of this metric, referencing the paper "Is Cosine-Similarity of Embeddings Really About Similarity?".
- Technical Troubles with Discord Screen Sharing: A recurring topic of conversation was the technical difficulties participants experienced with Discord's screen sharing feature; they shared quick fixes and expressed a need for Discord to improve this service.
- no title found: no description found
- Tweet from Xing Han Lu (@xhluca): Is this the DSPy moment of text-to-image generation? Congratulations @oscmansan @Piovrasca et al! ↘️ Quoting AK (@_akhaliq) Improving Text-to-Image Consistency via Automatic Prompt Optimization I...
- Adrenaline - Ask any programming question: Adrenaline: Your Expert AI Programming Assistant. Get instant help with coding questions, debug issues, and learn programming. Ideal for developers and students alike.
- no title found: no description found
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- Why do tree-based models still outperform deep learning on tabular data?: While deep learning has enabled tremendous progress on text and image datasets, its superiority on tabular data is not clear. We contribute extensive benchmarks of standard and novel deep learning met...
- Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models: We study how to apply large language models to write grounded and organized long-form articles from scratch, with comparable breadth and depth to Wikipedia pages. This underexplored problem poses new ...
- Tweet from nano (@nanulled): Mamba vs Transformer
- Tweet from Yijia Shao (@EchoShao8899): Can we teach LLMs to write long articles from scratch, grounded in trustworthy sources? Do Wikipedia editors think this can assist them? 📣Announcing STORM, a system that writes Wikipedia-like artic...
- Is Cosine-Similarity of Embeddings Really About Similarity?: Cosine-similarity is the cosine of the angle between two vectors, or equivalently the dot product between their normalizations. A popular application is to quantify semantic similarity between high-di...
- Tweet from jason liu (@jxnlco): LOUDER FOR THE FOLKS IN THE BACK! is i love coffee and i hate coffee similar or different? similar cause they are both preference statements or different because they are opposing preferences, wel...
- langgraph/examples/storm/storm.ipynb at main · langchain-ai/langgraph: Contribute to langchain-ai/langgraph development by creating an account on GitHub.
- GitHub - weaviate/Verba: Retrieval Augmented Generation (RAG) chatbot powered by Weaviate: Retrieval Augmented Generation (RAG) chatbot powered by Weaviate - weaviate/Verba
- GitHub - state-spaces/mamba: Contribute to state-spaces/mamba development by creating an account on GitHub.
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces: Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time a...
- GitHub - johnma2006/mamba-minimal: Simple, minimal implementation of the Mamba SSM in one file of PyTorch.: Simple, minimal implementation of the Mamba SSM in one file of PyTorch. - johnma2006/mamba-minimal
- Mamba: The Easy Way: An overview of the big ideas behind Mamba, a brand-new language model architecture.
Eleuther ▷ #general (174 messages🔥🔥):
- Claude 3 AI's Supposed Self-Awareness: A mention was made about Claude 3, an AI developed by Anthropic, exhibiting signs of self-awareness or metacognition during testing, which sparked discussions of its capabilities. This observation was illustrated by the example that Claude 3 recognized when it was being evaluated and commented on the relevance of the information it was processing.
- DBRX Outperforms in Benchmarks: MosaicML/Databricks released a new potent LLM named DBRX, notable for its 132 billion total parameters, with 36 billion active parameters and a training corpus of 12 trillion tokens. DBRX's architecture includes 16 experts utilizing a 32k context length. Members discussed the model's structure, how the parameters add up, and its significant usability and performance over other models like Grok.
- Token Count Debate: There was an extensive dialog about the efficiency of tokenization, questioning whether larger tokenizers are actually more effective. Members evaluated the cost-efficiency and the technical consequences of various tokenizers, arguing that a bigger tokenizer doesn't necessarily equate to better performance and might introduce issues like overloaded representations for specific tokens.
- Discussion on Open Weight Model Availability: There was a comparison of the open weight release of DBRX with GPT-4, with members delving into the release timelines, performance measures, and impacts on existing models. Conversations extended into user experiences with different models and their capabilities, particularly handling non-standard inputs like leet speak.
- Job and Education Dataset Research Exploration: A new member expressed interest in creating a dataset comprising resumes and job descriptions with the goal of fine-tuning an encoder and building a Retriever-Answer Generator (RAG) system. The primary conversation focused on whether the project aligns with Eleuther AI's goals and the potential issues with data privacy.
- Tweet from Cody Blakeney (@code_star): It’s finally here 🎉🥳 In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context len...
- Google Summer of Code: Google Summer of Code is a global program focused on bringing more developers into open source software development.
- Tweet from ️️ ️️ ️️ (@MoeTensors): I mostly care about it's programming abilities. And it excels🎉✨ ↘️ Quoting Vitaliy Chiley (@vitaliychiley) It surpasses GPT-3.5 and competes with Gemini 1.0 Pro & Mistral Medium in quality, wh...
- Releases — EleutherAI: no description found
- Tweet from Aman Sanger (@amanrsanger): "Token Counts" for long context models are a deceiving measure of content length. For code: 100K Claude Tokens ~ 85K gpt-4 Tokens 100K Gemini Tokens ~ 81K gpt-4 Tokens 100K Llama Tokens ~ 75K...
- Tweet from Vitaliy Chiley (@vitaliychiley): Introducing DBRX: A New Standard for Open LLM 🔔 https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm 💻 DBRX is a 16x 12B MoE LLM trained on 📜 12T tokens 🧠DBRX sets a new stand...
- Rotary Embeddings: A Relative Revolution: Rotary Positional Embedding (RoPE) is a new type of position encoding that unifies absolute and relative approaches. We put it to the test.
- MANTa: Efficient Gradient-Based Tokenization for Robust End-to-End Language Modeling: Static subword tokenization algorithms have been an essential component of recent works on language modeling. However, their static nature results in important flaws that degrade the models' downs...
- Contributors to mistralai/megablocks-public: Contribute to mistralai/megablocks-public development by creating an account on GitHub.
- GitHub - Algomancer/VCReg: Minimal Implimentation of VCRec (2024) for collapse provention.: Minimal Implimentation of VCRec (2024) for collapse provention. - Algomancer/VCReg
- GitHub: Let’s build from here: GitHub is where over 100 million developers shape the future of software, together. Contribute to the open source community, manage your Git repositories, review code like a pro, track bugs and fea...
- GitHub - davisyoshida/haiku-mup: A port of muP to JAX/Haiku: A port of muP to JAX/Haiku. Contribute to davisyoshida/haiku-mup development by creating an account on GitHub.
Eleuther ▷ #research (35 messages🔥):
- Layer-Pruning Strategy Explored: Research on layer-pruning strategy for LLMs shows minimal performance degradation on question-answering benchmarks, even with up to half the layers removed. Finetuning with parameter-efficient methods like QLoRA can be done on a single A100 GPU.
- SYCL Outperforms CUDA: A SYCL implementation of MLPs optimized for Intel's Data Center GPU Max 1550 outperforms an equivalent CUDA implementation on Nvidia's H100 GPU for both inference and training.
- DBRX LLM Introduced by Databricks: The new DBRX model, designed by Databricks, sets new performance benchmarks across a range of tasks and offers a fine-grained MoE architecture. It is both faster in inference and smaller in size compared to existing models like LLaMA2-70B and Grok-1.
- Efficient Fine-Tuning with LISA: LISA (Layerwise Importance Sampled AdamW) is introduced as a new technique for fine-tuning large language models with significant efficiency gains and performance improvements, showing advantages over LoRA. Code and paper are available on GitHub and arXiv.
- AI21 Releases Transformer-SSM Fusion: AI21 unveils a new model called Jamba, a hybrid that combines the Structured State Space model architecture with Transformer technology. This model boasts 12B active parameters with a 256K context length, offering improved performance and capability.
- Introducing Jamba: A groundbreaking SSM-Transformer Open Model
- Fully-fused Multi-Layer Perceptrons on Intel Data Center GPUs: This paper presents a SYCL implementation of Multi-Layer Perceptrons (MLPs), which targets and is optimized for the Intel Data Center GPU Max 1550. To increase the performance, our implementation mini...
- The Unreasonable Ineffectiveness of the Deeper Layers: We empirically study a simple layer-pruning strategy for popular families of open-weight pretrained LLMs, finding minimal degradation of performance on different question-answering benchmarks until af...
- Tweet from main (@main_horse): @arankomatsuzaki tldr if we artifically kneecap the h100 into a strongly memory bandwidth limited regime where it can only achieve 10~20% hfu then we beat it
- Introducing DBRX: A New State-of-the-Art Open LLM | Databricks: no description found
- Tweet from Rui (@Rui45898440): Excited to share LISA, which enables - 7B tuning on a 24GB GPU - 70B tuning on 4x80GB GPUs and obtains better performance than LoRA in ~50% less time 🚀
- Tweet from Rui (@Rui45898440): - Paper: https://arxiv.org/abs/2403.17919 - Code: https://github.com/OptimalScale/LMFlow LISA outperforms LoRA and even full-parameter training in instruction following tasks
- Tweet from Rui (@Rui45898440): LISA algorithm in two lines: - always activate embedding and linear head layer - randomly sample intermediate layers to unfreeze
- LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning: The machine learning community has witnessed impressive advancements since the first appearance of large language models (LLMs), yet their huge memory consumption has become a major roadblock to large...
- SILO Language Models: Isolating Legal Risk In a Nonparametric Datastore: The legality of training language models (LMs) on copyrighted or otherwise restricted data is under intense debate. However, as we show, model performance significantly degrades if trained only on low...
- Large Language Models Can Be Strong Differentially Private Learners: Differentially Private (DP) learning has seen limited success for building large deep learning models of text, and straightforward attempts at applying Differentially Private Stochastic Gradient Desce...
- GitHub - athms/mad-lab: A MAD laboratory to improve AI architecture designs 🧪: A MAD laboratory to improve AI architecture designs 🧪 - athms/mad-lab
- Mechanistic Design and Scaling of Hybrid Architectures: The development of deep learning architectures is a resource-demanding process, due to a vast design space, long prototyping times, and high compute costs associated with at-scale model training and e...
Eleuther ▷ #scaling-laws (5 messages):
- Grok-1 Embraces μP: xAI's Grok-1 utilizes μP according to its GitHub repository.
- Logits Temperature Control in Grok-1: A member noted that Grok-1 and its contributors, including Greg, use
1/sqrt(d)rather than1/dto adjust the logits temperature. - TP5 Code Not Published: Despite many papers referencing TP5, a member observes that their code has not been made available with the exception of Grok-1. They suggest that variance scalers could be merged into previous layers before code release.
- Unanswered Question on Temperature Scaling: The rationale behind using
1/sqrt(d)for temperature scaling in Grok-1 remains unanswered, even after direct inquiry to one of the contributors.
Link mentioned: grok-1/run.py at main · xai-org/grok-1: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
Eleuther ▷ #interpretability-general (39 messages🔥):
- Investigating Weight Differences in Transformer Models: A member observed that the model weights for GPT2 and other models from the
transformer_lenslibrary differ from the HuggingFace ones, even when the reported shapes are the same. They provided code snippets and sought to understand the reason for the discrepancy.
- Possible Systematic Issue in Weight Processing: The differences in GPT2 weights led to suggestions that there might be a systematic error in weight processing. Subsequent discussions included the possibility of weight shuffling and the need to downgrade HuggingFace library versions to resolve the issue.
- Weight Discrepancy Resolved: It was revealed that weight differences when using
transformer_lensare not bugs but features due to preprocessing steps. To avoid weight processing, a member suggested the use of the methodfrom_pretrained_no_processingand shared an explanatory link as well as a bug report for context.
- Logit Comparison After Preprocessing: A member provided a detailed comparison of logits both with and without preprocessing and concluded that, while logits may vary, the relative order remains consistent after applying the softmax function. The updated code output snippet confirmed these findings.
- New Publication: Diffusion Lens for Text-to-Image Analysis: A member linked a new paper on Diffusion Lens, which proposes a method to analyze intermediate representations in text-to-image diffusion models, and shared the preprint link. The paper discusses how complex scenes and knowledge retrieval are processed across different layers, offering insight into the text encoder component of such models.
- Google Colaboratory: no description found
- Tweet from jack morris (@jxmnop): Diffusion Lens is a pretty neat new paper, you can see a text-to-image encoder's representation of a giraffe getting less and less abstract with every layer 🦒
- Diffusion Lens: Interpreting Text Encoders in Text-to-Image Pipelines: Text-to-image diffusion models (T2I) use a latent representation of a text prompt to guide the image generation process. However, the process by which the encoder produces the text representation is u...
- [Bug Report] hook_resid_pre doesn't match hidden_states · Issue #346 · neelnanda-io/TransformerLens: Describe the bug cache[f"blocks.{x}.hook_resid_pre"] doesn't match hidden states (or only up to a set decimal place). Hidden states is from transformer's model(tokens, output_hidden_...
- TransformerLens/further_comments.md at main · neelnanda-io/TransformerLens: A library for mechanistic interpretability of GPT-style language models - neelnanda-io/TransformerLens
Eleuther ▷ #lm-thunderdome (5 messages):
- Seeking Multi-Model Evaluation Guidance: A member inquired about the ability to run multiple models on multiple tasks simultaneously using lm-evaluation-harness. There's no current support for this feature outside of programming calls to specific functions, but enhancements are being considered.
- Optimizing MMLU Evaluations: Another member suggested an improvement for MMLU to reduce the number of forward calls during evaluations. It was clarified that this optimization has already been implemented.
- How to Slow Down MMLU: To revert the MMLU evaluations to a slower mode, it was mentioned that one can pass
logits_cache=False. This will disable the recent optimizations.
OpenAI ▷ #ai-discussions (113 messages🔥🔥):
- AI Chatbots in Coding and Daily Use: Community members compared their experiences with various AI models including Claude 3, with some preferring it over GPT-4 for coding tasks. The discussion also touched on the use of AI for homework assistance and image generation, highlighting the technical intricacies and architectural brilliance of these systems.
- Gemini Advanced Trial Falls Short: Users expressed disappointment with Google's Gemini Advanced, citing slower response times compared to GPT-4 and limitations in services available, particularly in Europe. The consensus was that the product requires improvement, though some users are holding out hope for its potential based on further stress testing during their trial periods.
- OpenAI and Microsoft Embedding in Local Industries: Conversations highlighted the significance of OpenAI and Microsoft embedding their AI products in local industries across Europe, providing solid services compared to other competitors. The utilization of the Copilot Studio and potential integration with Office were also discussed, alongside issues with Copilot's user experience.
- Training LLMs and OpenAI Projects: Users sought help with training large language models (LLMs) on personal datasets for specific tasks like math and chart graphing, while another user invited the community to stress test their tool for creating LLM evaluations. The discussion pointed to the copious examples available from existing tools like Copilot that can be narrowed down for customized uses.
- Navigating OpenAI Updates and Access: Users debated the inconsistencies in cutoff date information from ChatGPT and how OpenAI might be alternating between different versions of GPT-4 models, creating confusion about the exact versions in current use. Additionally, they discussed the closed applications for the OpenAI Red Team and currently inaccessible Sora AI.
OpenAI ▷ #gpt-4-discussions (14 messages🔥):
- OpenAI Teases on Twitter: Members shared and reacted to an OpenAI tweet, expressing excitement about a new development, but also concern about delayed availability in Europe.
- In Search of Open Source Copywriting: One member inquired about open source projects specifically tailored for copywriting.
- The Bot Builder's Spark: A member was inspired to create a Telegram or Discord bot, expressing enthusiasm with a simple "IDEA".
- Anticipation for GPT-5: Conversations sparked around the potential of GPT-5, with members speculating on its superiority to existing models and discussing its anticipated release.
OpenAI ▷ #prompt-engineering (30 messages🔥):
- Debugging JSON Schema Issues: A user expressed confusion about why a JSON schema isn't being read, despite being correct.
- Instructions for Full Code Output: One member shared a tip that instructs ChatGPT to always display full code without stubs or incomplete statements using prompt instructions that forbid the use of ellipses or phrases like "... (Rest of the code remains the same)".
- Getting Direct Visual Descriptions from GPT: A user inquired about soliciting straightforward visual descriptions from GPT without poetic or emotional language, leading to advice about precise prompt wording that emphasizes brevity and directness.
- Chunk-by-Chunk Prompt Testing: A conversation centered on the benefit of breaking down long prompts into chunks to test, especially for those new to using ChatGPT, as it can clarify where improvements are needed.
- Prompt Troubleshooting for Translation Tasks: In discussing a prompt for translating English text containing HTML into another language without translating code or proper names, a member provided a thorough prompt rewrite that focuses on instructing the model on what to do instead of what not to do.
OpenAI ▷ #api-discussions (30 messages🔥):
- Tackling JSON Schema Issues: A member expressed frustration over a JSON schema not being read properly, despite the schema being correct.
- Ensuring Full Code Output from ChatGPT: It was discussed that using custom instructions such as instructing ChatGPT to "provide the complete code" and "Never implement stubs" could ensure that ChatGPT always writes out the entire code without using stubs like
-- rest of the code here. - Commenting Conundrums in Code: The conversation touched upon the use of comments in code output by ChatGPT, with one member initially thinking that forbidding the use of
#would stop it from commenting in Python but was corrected that the bot would still write comments. - Crafting Effective Visual Descriptions with GPT: There was a discussion about prompting GPT for straightforward visual descriptions without poetic or emotional language. A member suggested explicit instructions like "Respond only with {xyz}," highlighting the importance of prompt wording in guiding the model's responses.
- Prompt Crafting for Translation Consistency: A member was having issues with translations not maintaining HTML formatting, to which another provided rephrased prompt suggestions focusing on what the model should do, such as "Provide a skilled translation from English to {$lang_target}", along with specific instructions on handling htmlspecialchars and maintaining original text for certain elements.
HuggingFace ▷ #general (103 messages🔥🔥):
- Understanding YOLOv1's Image Handling: A member asked how YOLOv1 deals with different image sizes, particularly in regards to grid cells and anchor boxes. The distinction between handling a 300x500 image versus the architecture's 448x448 format led to questions about resizing and anchor generation.
- RLHF's Limits on Model Alignment: A user clarified that Reinforcement Learning from Human Feedback (RLHF) tends to make models friendlier but not necessarily more factually correct or meta-aware. It was noted that models like ChatGPT and Gemini often refuse to answer despite the RLHF.
- Model Selection for GPU Inference on AWS SageMaker: There was a discussion about the pros and cons of using AWS SageMaker to benchmark model latency, QPS, and cost, examining frameworks such as NVIDIA Triton and TensorRT-LLM, and measuring GPU utilization.
- Running Large Language Models (LLMs) Locally Versus Cloud: Users shared their experiences running LLMs like Mistral and OLLAMA on local machines, including Apple M1 hardware, and comparisons were made with different GPU services including AWS, Kaggle, Colab, and Runpod.
- Accessing GPU Benchmarks and Framework Comparisons: A member inquired about running benchmarks across multiple frameworks, including TensorRT-LLM, TGI, and Aphrodite, to compare speed and cost for model inference with GPU, sparking a discussion about the best libraries for this purpose.
- abhishek/autotrain-c71ux-tngfu · Hugging Face: no description found
- GPU Instance Pricing: no description found
- deep-learning-containers/available_images.md at master · aws/deep-learning-containers: AWS Deep Learning Containers (DLCs) are a set of Docker images for training and serving models in TensorFlow, TensorFlow 2, PyTorch, and MXNet. - aws/deep-learning-containers
HuggingFace ▷ #today-im-learning (2 messages):
- DeepSpeed Zero-3 Parallelization Query: A member mentioned a confusion regarding DeepSpeed Zero-3 in PyTorch, regarding both model sharding and data parallelization, observing data being divided by 4 when using 4 GPUs.
- Diving Deep into Groq's AI Approach: A video titled “Groking Groq: A Deep Dive on Deep Learning” was shared, exploring the deep learning intricacies and the concept of 'groking', which implies deep understanding, as it relates to AI. Watch it here.
Link mentioned: Groking Groq: A Deep Dive on Deep Learning: To "Grok" is to learn something deeply- as if you're drinking it in. AI has a way of requiring that you Grok a number of seemingly unrelated topics; making i...
HuggingFace ▷ #cool-finds (16 messages🔥):
- Enlightening Read on Cell Types and Gene Markers: A member highlighted an insightful article on the HuBMAP Azimuth project, which involves collecting a dataset of manually annotated cell types and their marker genes; the Azimuth website provides detailed annotation levels for different tissues. The article and further details are accessible at Nature.com.
- dbrx-instruct Tables: An AI capable of generating tables named dbrx-instruct was tested and received praise for its performance, described as "fire" by the user.
- Efficient Embedding Quantization for Search: A space on HuggingFace was shared for performing efficient semantic search through embedding quantization, capable of reducing the retrieval storage and memory footprint significantly. Details can be found on HuggingFace Spaces.
- HuggingFace's Visual Studio Code Extension Gains Traction: A member shared their post which received considerable positive feedback regarding the llm-vscode extension by HuggingFace, which provides code completion and allows local executions with various AI model backends. Additional benefits include the option to subscribe to a Pro account to remove rate limits on inference APIs.
- On Semantic Search and Precision Savings: In a follow-up on efficient search retrieval, a member explained embedding quantization, where documents are stored in lower precision for initial search and rescoring, resulting in faster performance, lower memory, and disk space requirements. This allows the system to operate efficiently on cost-effective hardware while maintaining high retrieval performance.
- Quantized Retrieval - a Hugging Face Space by sentence-transformers: no description found
- Tweet from LAin (@not_so_lain): just updated my vscode to use @huggingface 's llm-vscode extension and with the HuggingFaceH4/starchat2-15b-v0.1 model, results are pretty accurate. https://github.com/huggingface/llm-vscode
- Assessing GPT-4 for cell type annotation in single-cell RNA-seq analysis - Nature Methods: This study evaluates the performance of GPT-4 in single-cell type annotation.
HuggingFace ▷ #i-made-this (9 messages🔥):
- Protein Embedding Model Hits Hugging Face: A new embedding model for proteins using the Matryoshka technique, trained on amino acid sequences from the UniProt database, has been released. This model aims for efficient vector databases, allowing for shorter embeddings that still provide approximate results, and the work has been detailed in a blog post.
- Innovation in Diffusion Model Guidance: An announcement for a new diffusion model guidance technique, Perturbed-Attention Guidance (PAG), enhances diffusion model sample quality without external conditions or additional training. The project is documented on their project page, and a demonstration is available on the Hugging Face demo.
- HyperGraph Dataset Collection on Hugging Face: A collection of hypergraph datasets, related to a paper on HyperGraph Representation Learning, has been uploaded to the Hugging Face Hub. The datasets and further details can be found in the collection. Pending updates to dataset cards and the PyTorch Geometric dataset class are in progress to facilitate direct use within the PyG ecosystem.
- Protein similarity and Matryoshka embeddings: no description found
- Self-Rectifying Diffusion Sampling with Perturbed-Attention Guidance: no description found
- hyoungwoncho/sd_perturbed_attention_guidance · Hugging Face: no description found
- HyperGraph Datasets - a SauravMaheshkar Collection: no description found
- How's This, Knut?: This is "How's This, Knut?" by Test Account on Vimeo, the home for high quality videos and the people who love them.
HuggingFace ▷ #reading-group (3 messages):
- Decoding Dual-Optimum Paradox in Text-to-Image: Discussion highlighted the RealCustom paper, which addresses the challenge of synthesizing text-driven images while maintaining the balance between subject similarity and text controllability. RealCustom aims to enhance customization by limiting subject influence, ensuring that the generated images better match the text.
- Prompt-Aligned Personalization Takes the Spotlight: Another paper brought to light, focuses on the creation of personalized images that align with complex text prompts without compromising personalization. The method discussed in this paper aims at improving the fidelity of user prompts in personalized image synthesis.
- Textual Inversion Limitations Explored: A member mentioned doing some research into the challenges faced by textual inversion, potentially presenting findings in the context of the difficulty it has with preserving details, but remains uncertain whether to include it in a presentation.
- RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization: Text-to-image customization, which aims to synthesize text-driven images for the given subjects, has recently revolutionized content creation. Existing works follow the pseudo-word paradigm, i.e., rep...
- PALP: Prompt Aligned Personalization of Text-to-Image Models: Content creators often aim to create personalized images using personal subjects that go beyond the capabilities of conventional text-to-image models. Additionally, they may want the resulting image t...
HuggingFace ▷ #core-announcements (1 messages):
- MPS Support Added to Training Scripts: MPS support has been integrated into the most crucial training scripts, enhancing the computing capabilities for macOS users with Metal support. The implementation is available on GitHub in this pull request.
Link mentioned: Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
HuggingFace ▷ #computer-vision (15 messages🔥):
- Harnessing Stitched Images for Training: A discussion took place about fine-tuning models using stitched images as training data, specifically using already stitched images rather than employing deep learning techniques to stitch images together during the training process.
- Technical Drawing Image Summarization Quest: A user sought advice on how to train a model for image summarization of technical drawings, aiming to identify patterns within the drawings to enable the AI to make educated guesses due to the current inability of AI to recognize such images effectively.
- Tackling DETR Fine-tuning Frustrations: A member was struggling with fine-tuning the DETR-ResNet-50 model on the CPPE-5 dataset and sought advice, referencing both official HuggingFace documentation and a discussion thread where others faced similar issues (HuggingFace Forum).
- Zero-Shot Classifier Tune-Up Tease: A request was made for resources or code examples to fine-tune a zero-shot image classifier using a custom dataset, with the context provided that the inquirer was a beginner unsure about their GPU capabilities, specifically mentioning an NVIDIA GeForce GTX 1650.
- Emergency Instruct Pix2pix Assistance Required: A user was looking for an alternative way to test instruct pix2pix edit prompts for their demo, noting the absence of a
gradio_clientAPI in the instruct pix2pix space, and expressing that they are open to similar models or current options.
- lmz/candle-yolo-v8 · Can you provide scripts that convert to safetensors format?: no description found
- Object detection: no description found
- Example DeTr Object Detectors not predicting after fine tuning: @chuston-ai did you ever figure out the problem? @devonho and @MariaK , I saw your names in the write-up and Colab for the Object Detector example that trained the DeTr model with the CPPE-5 dataset....
- Transformers-Tutorials/SAM/Fine_tune_SAM_(segment_anything)_on_a_custom_dataset.ipynb at master · NielsRogge/Transformers-Tutorials: This repository contains demos I made with the Transformers library by HuggingFace. - NielsRogge/Transformers-Tutorials
HuggingFace ▷ #NLP (12 messages🔥):
- Seeking NLP Roadmap for 2024: A user asked for a roadmap to start with NLP in 2024, including subjects and related courses or books. Another user recommended beginning with "The Little Book of Deep Learning" and then moving on to a YouTube playlist by Karpathy called "Zero to Hero."
- Improving Session-based Recommendation Systems: A member sought advice on improving the second stage of a session-based recommendation system, specifically the re-ranking model that follows candidate generation. The member asked for models that perform well on benchmark datasets, mentioning GRU4Rec, Bert4Rec, LRU4Rec, and was also curious if HuggingFace offered any suitable embedding models for this purpose.
- 'Bart CNN' Summarization Model Loading Error: A user experienced trouble loading the 'facebook/bart-large-cnn' model for summarization on HuggingFace, receiving an error message indicating the model could not be loaded with certain classes.
- RAG Exploration Set-Up Inquiry: An individual inquired about the setup for exploring RAG (Retrieval-Augmented Generation), mentioning the intention to use
faissfor the vectorDB and consideringllama.cppfor the language model due to GPU memory constraints on a GeForce RTX 2070.
- LLM Infinitely Generative Behavior Issue: A user expressed that their LLM based on decilm7b tends to generate repetitive or infinite content until reaching a token limit. Other members suggested considering Supervised Fine Tuning (SFT), incorporating stop or padding tokens, implementing a stop criterion for chat structures, and adjusting the repetition penalty to finetune generation behavior.
HuggingFace ▷ #diffusion-discussions (14 messages🔥):
- Clarification on Image Variation Functionality: Users discussed the use of the Stable Diffusion image variation pipeline, with one looking for a way to input a list of images to generate new, similar ones. The pipeline currently handles only one image at a time, as confirmed by referencing the Hugging Face documentation.
- Exploration of Alternative Image Generation Methods: The idea of using DreamBooth was introduced for personalizing text-to-image models with just a few images of a subject, linking users to both the DreamBooth research paper and Hugging Face's tutorial on DreamBooth as potential solutions for image generation tasks.
- Community Contributions to Diffusers: A member mentioned their previous work on the Marigold depth estimation pipeline and discussed their ongoing efforts to integrate new modalities, such as the LCM function showcased at Hugging Face Spaces.
- Encouragement for Community Discussions: Users were encouraged to share their findings and open discussions on the Hugging Face Diffusers GitHub Discussions page to potentially influence repository updates or documentation enhancements.
- Repository Explorations: A user inquired about others' experiences with the labmlai diffusion repository, suggesting exploration beyond the Hugging Face ecosystem.
- Image variation: no description found
- DreamBooth: no description found
- DreamBooth: no description found
- Diffusers: no description found
OpenInterpreter ▷ #general (67 messages🔥🔥):
- Seeking EU Product Distribution: A user inquired about getting assistance to distribute the product within the EU, with specific interest in learning if existing channels or discussions focus on that topic.
- Curiosity about Claude for Agentic Behavior: A member discussed exploring the newly released sub-prompts and system prompts from Claude, speculating their effectiveness for agentic behavior when used within OpenInterpreter.
- Integrated Development Environments and OpenInterpreter: There were several exchanges about running OpenInterpreter from UIs or IDEs, like Visual Studio Code, with suggestions of plugins and extensions that could facilitate this, including a GitHub resource on creating a VS Code extension for an AI tool.
- OpenInterpreter Local Offline Mode Guidance: Members shared advice on running OpenInterpreter in an offline mode to save costs associated with the OpenAI API Key, providing instructions and linking a guide for running locally.
- Community Engagement in Software Innovation: The conversation included discussions on technology integrations, software development, and the building of teams to deliver applications, as well as users sharing personal experiences and achievements using OpenInterpreter.
- Running Locally - Open Interpreter: no description found
- Chain prompts: no description found
- KnutJaegersberg/2-bit-LLMs · Hugging Face: no description found
- GitHub - bm777/hask: Don't switch tab or change windows anymore, just Hask.: Don't switch tab or change windows anymore, just Hask. - bm777/hask
- GitHub - Cobular/raycast-openinterpreter: Contribute to Cobular/raycast-openinterpreter development by creating an account on GitHub.
- GitHub - MikeBirdTech/gpt3-vscode-extension: Use GPT-3 to generate documentation and get help debugging your code: Use GPT-3 to generate documentation and get help debugging your code - MikeBirdTech/gpt3-vscode-extension
- GitHub - ngoiyaeric/GPT-Investor: financeGPT with OpenAI: financeGPT with OpenAI. Contribute to ngoiyaeric/GPT-Investor development by creating an account on GitHub.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- Releases · microsoft/autogen: A programming framework for agentic AI. Join our Discord: https://discord.gg/pAbnFJrkgZ - microsoft/autogen
- StateFlow - Build LLM Workflows with Customized State-Oriented Transition Function in GroupChat | AutoGen: TL;DR:: Introduce Stateflow, a task-solving paradigm that conceptualizes complex task-solving processes backed by LLMs as state machines.
OpenInterpreter ▷ #O1 (86 messages🔥🔥):
- Excitement for M5 Stack Assembly: A member's anticipation is clear as they await the M5 Echo delivery to complete their project assembly. They shared their plan to have everything soldered and ready, expressing confidence in the project's success if all components work well.
- Anticipated Improvements and Feedback: The community shows eagerness to improve their devices, such as discussing potential modifications to the M5 board fitting and the quality of a button. These adjustments are aimed at enhancing the user experience and functionality.
- Support for Local and Hosted LLMs Explored: Questions were raised about the feasibility of using non-GPT models with OpenInterpreter, with one member mentioning experiments with a local model to be attempted and another inquiring about hosted LLMs like groq.
- Address Update Concerns and Support Guidance: Users seeking to update their shipping addresses were advised to email support. They were encouraged to resend information to a specific support email for assistance.
- Enthusiasm for Future LLM Performance Optimization: Discussions about the potential for significant optimization in LLM efficiency showed anticipatory optimism. Some believe that advancements by the end of the year may lead to local LLM models outperforming current state-of-the-art systems like GPT-4.
- Basic Usage - Open Interpreter: no description found
- Tweet from George Kedenburg III (@GK3): ai pin 🤝 open interpreter
OpenInterpreter ▷ #ai-content (2 messages):
- Reinventing the Wheel in Good Company: A member humorously shared that they spent hours building a feature, only to find out it already exists. They included a YouTube video link titled "Open Interpreter - Advanced Experimentation" showcasing their experimentation process.
- Throwback Code Comedy: Another member reflected on their past work with a comedic tone, linking an unspecified content they wrote last November. Access the content through this TinyURL link.
Link mentioned: Open Interpreter - Advanced Experimentation: ➤ Twitter - https://twitter.com/techfrenaj➤ Twitch - https://www.twitch.tv/techfren➤ Discord - https://discord.com/invite/z5VVSGssCw➤ TikTok - https://www....
Modular (Mojo 🔥) ▷ #general (75 messages🔥🔥):
- VSCode Debugging with Mojo Plugin: A user experienced an issue with breakpoints not stopping during the debug session in VSCode. They were referred to a workaround in a Github issue, involving a specific way to build and debug using the Mojo language, which was successful on a MacBook.
- Rust Resources for Deep Dive: In the context of discussing language lifetimes, a user recommended Rust for Rustaceans to better understand Rust's approach to lifetimes, citing a free chapter download available online.
- Mojo for Game Engine Development: Members discussed Mojo's capabilities, suggesting that while Mojo is designed to be a general-purpose programming language, much of the existing tooling would need to be rewritten to maximize its benefits.
- Python Interoperability in Mojo: A detailed explanation was given regarding Python interop in Mojo, highlighting that anything running through a Python module is reference counted and garbage-collected, while Mojo’s own objects are managed without garbage collection utilizing techniques similar to RAII in C++ or Rust.
- Github Contribution Privacy Concerns: A general question about privacy when contributing to open-source projects was raised, specifically about whether the email address becomes public after signing commits with
-sas required by a Developer Certificate of Origin.
- Modular: Leveraging MAX Engine's Dynamic Shape Capabilities: We are building a next-generation AI developer platform for the world. Check out our latest post: Leveraging MAX Engine's Dynamic Shape Capabilities
- Rust for Rustaceans: Bridges the gap between beginners and professionals, enabling you to write apps, build libraries, and organize projects in Rust.
- mojo/CONTRIBUTING.md at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [BUG]: Debugger does not stop at breakpoint in VSC on Github codespace · Issue #1924 · modularml/mojo: Bug description The debugger does not stop at a breakpoint no matter what - any program just runs through every time and the debugger session ends. Steps to reproduce The effect is reproducible wit...
Modular (Mojo 🔥) ▷ #💬︱twitter (5 messages):
- Modular Tweet Summary: A series of recent tweets by Modular were shared, but without any additional context or discussion provided.
- Links to Modular's Tweets: Engage with Modular’s current content through the following shared tweets:
Modular (Mojo 🔥) ▷ #✍︱blog (4 messages):
- Mojo Standard Library Goes Open Source: Modular has announced the release of the Mojo standard library under the Apache 2 license, marking a significant move in making Mojo🔥 an open-source language. The initiative invites the developer community to contribute to its development, with nightly builds available for the latest language features, accessible via the GitHub repository.
- Introducing MAX 24.2: The new MAX 24.2 is now generally available, introducing improvements to the MAX engine and the Mojo programming language. Developers can download MAX 24.2 and Mojo builds through the Modular command line interface, encouraging further community development.
- Deploying MAX on Amazon SageMaker Simplified: An end-to-end guide for hosting a MAX optimized model endpoint using MAX Serving and Amazon SageMaker was shared, detailing steps from downloading a pre-trained Roberta model to deploying on Amazon EC2 instances. The Managed Amazon SageMaker service aims to ease the deployment process for developers by handling the complex underlying infrastructure.
- MAX Engine Embraces Dynamic Shapes: A detailed examination of dynamic shapes support featured in the MAX Engine’s 24.2 release, focusing on handling inputs of varying sizes, is discussed. The blog post compares static and dynamic shapes' average latency by utilizing the BERT model on the GLUE dataset, emphasizing MAX Engine's ability to manage real-world data efficiently.
- Modular: MAX 24.2 is Here! What’s New?: We are building a next-generation AI developer platform for the world. Check out our latest post: MAX 24.2 is Here! What’s New?
- Modular: Leveraging MAX Engine's Dynamic Shape Capabilities: We are building a next-generation AI developer platform for the world. Check out our latest post: Leveraging MAX Engine's Dynamic Shape Capabilities
- Modular: The Next Big Step in Mojo🔥 Open Source: We are building a next-generation AI developer platform for the world. Check out our latest post: The Next Big Step in Mojo🔥 Open Source
- Modular: Deploying MAX on Amazon SageMaker: We are building a next-generation AI developer platform for the world. Check out our latest post: Deploying MAX on Amazon SageMaker
Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Modular Embraces Open Source: Modular has officially open-sourced the core modules of the Mojo standard library, firmly aligned with their belief in open-source development. The Mojo standard library is now available under the Apache 2 license, inviting collaboration and feedback from developers across the globe.
- Nightly Builds Now Available: Software enthusiasts and developers can now access nightly builds of the Mojo standard library, ensuring they can work with the latest features and improvements.
- MAX Platform's Evolution Continues: The recently released MAX platform v24.2 introduces support for TorchScript models with dynamic input shapes, as well as updates to various components including MAX Engine, MAX Serving, and Mojo programming language.
- Mojo Programming Language Updates Rolled Out: Mojo's language and toolkit updates are detailed in the latest changelog, with significant enhancements like open-sourcing of the standard library and improved support for nominal types conforming to traits.
- Dynamic Shapes Take Center Stage in MAX: The MAX Engine embraces dynamic shapes with its 24.2 release, highlighted in a detailed blog post. This new feature is pivotal for machine learning applications that handle variable-sized data, using examples like BERT model performance on the GLUE dataset to demonstrate the benefits.
- Modular: The Next Big Step in Mojo🔥 Open Source: We are building a next-generation AI developer platform for the world. Check out our latest post: The Next Big Step in Mojo🔥 Open Source
- MAX changelog | Modular Docs: Release notes for each version of the MAX platform.
- Mojo🔥 changelog | Modular Docs: A history of significant Mojo changes.
- Modular: Leveraging MAX Engine's Dynamic Shape Capabilities: We are building a next-generation AI developer platform for the world. Check out our latest post: Leveraging MAX Engine's Dynamic Shape Capabilities
Modular (Mojo 🔥) ▷ #🔥mojo (54 messages🔥):
- Seeking Feature for Identifying
StringableTypes: A member inquired about a way to check if a type isStringableand was advised to raise a feature request, as current functionalities do not support this check at compile time. - Mojo Style Guide is Live: The long-awaited style guide for Mojo is now available for developers and can be found on GitHub here. The guide aims to establish a standard for code formatting and naming conventions.
- Moplex: Complex Types for Mojo: One member introduced moplex, a library for generalized complex numbers, now available on GitHub. A package release on the Mojo package tool was also announced.
- MAX Library v24.2.0 Causes
DynamicVectorConfusion: Following the MAX update to 24.2.0, some users reported issues withDynamicVectorbeing apparently replaced byList. These changes can be referenced in the changelog. - Printing
simdwidthofincongruity and Type Aliasing Discussion: Discussion around the inability to print alias types, specifically within the context ofsimdwidthof, pointed towards global variable implementation issues when outside functions. A functioning code snippet usingsimdwidthofinside themainfunction was shared for clarity.
- Modular Docs: no description found
- ModCon 2023 Breakout Session: MAX Heterogenous Compute: CPU + GPU: In this session, Modular engineers Abdul Dakkak and Ian Tramble discuss how Mojo and the Modular AI Engine were designed to support systems with heterogeneou...
- Python's assert: Debug and Test Your Code Like a Pro – Real Python: In this tutorial, you'll learn how to use Python's assert statement to document, debug, and test code in development. You'll learn how assertions might be disabled in production code, s...
- mojo/stdlib/docs/style-guide.md at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojo/CONTRIBUTING.md at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- GitHub - helehex/moplex: Generalized complex numbers for Mojo🔥: Generalized complex numbers for Mojo🔥. Contribute to helehex/moplex development by creating an account on GitHub.
- Mojo🔥 changelog | Modular Docs: A history of significant Mojo changes.
Modular (Mojo 🔥) ▷ #community-projects (3 messages):
- Acknowledgment of a Helpful Contribution: A member expressed appreciation for another's work, using a heart and fire emoji to convey enthusiasm.
- Solution to a Common Issue Resonates: One user shared relief and appreciation for guidance provided on a problem they encountered that day.
- Solidarity in Troubleshooting: Another member related to the struggle, expressing that the same issue had been a frustration for multiple days.
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (1 messages):
- Parallel over Async: In the context of a problem presented, it was highlighted that opting for parallel processing is beneficial, but asynchronous methods might not be necessary, not only in Mojo but generally in computing.
Modular (Mojo 🔥) ▷ #🏎engine (6 messages):
- Confusion Over TensorSpec in Mojo API: A user expressed confusion about the TensorSpec example not matching the reference documentation between Mojo and Python APIs. The MAX Engine runtime and Python API documentation seem to provide different information regarding model input names.
- Divergence Between Mojo and Python APIs: There's an acknowledgment that some differences exist between Mojo and Python APIs, specifically with
get_model_input_names, which is present in the Mojo API. Users are directed to review the examples repository which contains a range of MAX platform examples.
- Clarification on TensorSpec Presence in APIs: An expert clarified that TensorSpec is a part of Mojo, Python, and C APIs, but minor differences are currently being addressed to harmonize the APIs.
- Upcoming Examples for PyTorch with TensorSpec: The expert committed to including an example demonstrating the use of
add_input_specand TensorSpec objects for PyTorch in the modularml/max repository.
- Run inference with Mojo | Modular Docs: A walkthrough of the Mojo MAX Engine API, showing how to load and run a model.
- MAX Engine Python API | Modular Docs: The MAX Engine Python API reference.
- GitHub - modularml/max: A collection of sample programs, notebooks, and tools which highlight the power of the MAX platform: A collection of sample programs, notebooks, and tools which highlight the power of the MAX platform - modularml/max
OpenRouter (Alex Atallah) ▷ #app-showcase (4 messages):
- Appreciation for a Unique Username: A user received compliments on their amusing username, cheerful_dragon_48465.
- Announcement Tease: Alex Atallah hints at featuring a user’s noteworthy contribution in an upcoming announcement.
- Positive Response to Recognition: Another user, mintsukuu, expressed their excitement about the anticipated acknowledgement.
OpenRouter (Alex Atallah) ▷ #general (144 messages🔥🔥):
- Mysterious Silence from Midnight Rose: Users reported Midnight Rose wasn't producing any outputs, with no errors shown on the command line or web interface. OpenRouter's Alex Atallah and team members acknowledged the issue and managed to restart the model into a workable state, though the root cause remained unidentified.
- Seeking OpenRouter's Backstory: A member inquired about basic company information for OpenRouter. Alex Atallah directed them to his and the co-founder's Twitter profiles, mentioned their funding by HF0, and disclosed the team is currently three people in total.
- Gemini Model Context Size Confusion: Discussion revolved around the context sizes for Gemini models being measured in characters rather than tokens, leading to confusion. Users were directed to Discord threads for more information and the topic was recognized as needing clarification by OpenRouter.
- Service Unavailable Woes with Gemini Pro 1.5: Multiple users experienced an
Error 503indicating service unavailability from Google for the Gemini Pro 1.5 model, with OpenRouter's staff confirming the model was still under testing phases.
- Payments Shift to ETH Network on OpenRouter: A user expressed frustration over the inability to pay directly to a crypto address; Alex Atallah clarified that Coinbase Commerce's shift requires payment through the ETH network, and discussed possible incentives for US bank transfers.
- no title found: no description found
- HFO: no description found
- Gemini Pro 1.0 by google | OpenRouter: Google's flagship text generation model. Designed to handle natural language tasks, multiturn text and code chat, and code generation. See the benchmarks and prompting guidelines from [Deepmind]...
- Gemini Pro Vision 1.0 by google | OpenRouter: Google's flagship multimodal model, supporting image and video in text or chat prompts for a text or code response. See the benchmarks and prompting guidelines from [Deepmind](https://deepmind.g...
CUDA MODE ▷ #general (40 messages🔥):
- CUDA Collaboration and Inquiry Kickoff: Member initiates the conversation by expressing interest in contributing to the implementation of dynamic CUDA support in OpenCV's DNN module and shares a survey asking for community feedback regarding their experiences with CUDA-enabled hardware for deep learning inference and views on dynamic CUDA support.
- Real-World CUDA Experiences Discussed: Participants discuss their experiences using powerful NVIDIA GPUs (like 4x4090 and 2x4090) for distributed computing tasks. Discussions focus on performance results as well as issues encountered with CUDA and GPU-to-GPU communication, suggesting that CUDA seems to manage certain aspects "under the hood."
- Peer-to-Peer Performance Benchmarks Shared: A member shares links to GitHub notebooks containing test results for RTX 4090 peer-to-peer memory transfer benchmarks (4090) and revisits to post additional results for the A5000 and A4000 A5000, A4000 with concerns about unexpected slow NCCL torch.distributed performance for 4090.
- Discussion on GPU Interconnect Technologies: Dialogue emerges around the lack of NVLink in the new 4090 GPUs and the impact on peer-to-peer (P2P) capabilities, featuring links to Reddit and other articles discussing these GPU specifications and performance perspectives.
- Compiler Technology vs. Manual CUDA Coding: A member shares a perspective on the increasing value of compiler technology in efficiently generating low-level GPU code versus writing CUDA code manually, prompting a broader discussion on the relevancy of compiler knowledge in current GPU programming.
- p2p-perf/rtx-A5000-2x/2x-A5000-p2p-runpod.ipynb at main · cuda-mode/p2p-perf: measuring peer-to-peer (p2p) transfer on different cuda devices - cuda-mode/p2p-perf
- p2p-perf/rtx-A4000-ada-2x/2x-A4000-ada-p2p-runpod.ipynb at main · cuda-mode/p2p-perf: measuring peer-to-peer (p2p) transfer on different cuda devices - cuda-mode/p2p-perf
- p2p-perf/rtx-4090-2x/2x-4090-p2p-runpod.ipynb at main · cuda-mode/p2p-perf: measuring peer-to-peer (p2p) transfer on different cuda devices - cuda-mode/p2p-perf
- cuda_examples/0_Simple/simpleP2P/simpleP2P.cu at master · ndd314/cuda_examples: Contribute to ndd314/cuda_examples development by creating an account on GitHub.
- Untitled formOpenCV dnn cuda interface survey : OpenCV dnn cuda interface survey
- Reddit - Dive into anything: no description found
- Tweet from the tiny corp (@__tinygrad__): The 4090 hardware supports P2P, but NVIDIA disables it with a efuse. No P2P for you. :middle finger: Pay them more and buy an RTX 6000 ADA. This is one of the reasons tinybox has AMD. 7900XTX suppor...
- Problems With RTX4090 MultiGPU and AMD vs Intel vs RTX6000Ada or RTX3090: I was prompted to do some testing by a commenter on one of my recent posts. They had concerns about problems with dual NVIDIA RTX4090s on AMD Threadripper Pro platforms. I ran some applications to rep...
CUDA MODE ▷ #triton (8 messages🔥):
- Seeking Triton Learners for Interviews: A member is preparing for a talk on Triton and is looking to interview people who have started learning Triton recently. They're interested in misconceptions and difficulties encountered while learning and invite people to reach out via Discord DM or Twitter at UmerHAdil.
- Prototype Pull Request for GaLore: A new pull request #95 has been shared, detailing prototypes of kernels and utilities for GaLore with placeholders for upcoming
cutlassandtritonutils.
- Collaborative Work on Time Zones: Members are coordinating times to review new PRs, with one indicating that they are in the PST time zone and open to a Zoom call for further discussion.
- Exploring Bitsandbytes Collaboration: A member discusses an ongoing collaboration involving
bitsandbytesand the GaLore project, while also mentioning their start with looking into cutlass and a willingness to explore Triton, despite being new to CUDA. They are open to collaboration opportunities and shared a link to a related GitHub pull request #1137.
- Invitation to Review on GitHub: Another member encourages leaving review comments on the
aorepository, welcoming further input on the work being discussed.
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- Initial kernel changes to support GaLore by matthewdouglas · Pull Request #1137 · TimDettmers/bitsandbytes: This is a draft containing some of the initial changes to support GaLore. So far this covers 2-state optimizers. Optimizer2State.update_step() now contains an additional argument return_updates. Wh...
- GaLore and fused kernel prototypes by jeromeku · Pull Request #95 · pytorch-labs/ao: Prototype Kernels and Utils Currently: GaLore Initial implementation of fused kernels for GaLore memory efficient training. TODO: triton Composable triton kernels for quantized training and ...
CUDA MODE ▷ #cuda (6 messages):
- Seeking Collaboration for Dynamic CUDA in OpenCV: Sagar Gupta, a CS undergrad, is inviting collaboration on implementing dynamic CUDA support in OpenCV's DNN module. A short survey was provided to gather experiences and expectations regarding dynamic CUDA support with the link: OpenCV DNN CUDA Interface Survey.
- Catching up with CUDA Online Resources: Pessimistic_neko suggested a book on CUDA for learning purposes and provided an Amazon link, but the content showed a CAPTCHA challenge instead of the book information.
- Comprehensive CUDA Course Material: Andreas Koepf recommended visiting a GitHub repository that lists CUDA resources, including courses: CUDA Course Material on GitHub.
- Classic CUDA Course for Beginners: Cudawarped shared a link to a classic Udacity course on parallel programming for beginners interested in CUDA, with a playlist available on YouTube: Intro to Parallel Programming Course on YouTube.
- no title found: no description found
- Untitled formOpenCV dnn cuda interface survey : OpenCV dnn cuda interface survey
- Intro to the Class - Intro to Parallel Programming: This video is part of an online course, Intro to Parallel Programming. Check out the course here: https://www.udacity.com/course/cs344.
- GitHub - cuda-mode/resource-stream: CUDA related news and material links: CUDA related news and material links. Contribute to cuda-mode/resource-stream development by creating an account on GitHub.
CUDA MODE ▷ #torch (2 messages):
- CUDA Types Troubleshoot: A member encountered issues with data types in torch and cuda, specifically with the absence of
uint16in torch and the difference betweenhalfandat::Half. They shared a code snippet that compiles without errors but leads to linker issues, and provided workarounds using template functions andreinterpret_castto handle the type discrepancies. - Compiling with 'data_ptr' Lacks Clarity: The same individual expressed a wish for a compile-time error when using incompatible types with the
data_ptrmethod in PyTorch, suggesting the current implementation might benefit from a more restricted set of types for clearer error messaging.
CUDA MODE ▷ #jobs (5 messages):
- Internship Inquiry Addressed: A member inquired about the availability of internships or short-term work opportunities. They were informed that the positions are currently closed.
- NVIDIA's PhD Opportunities - Global Reach: One member asked about positions in the UK for PhD holders, and another provided a link to NVIDIA's global job offerings at NVIDIA Careers.
- Location Agnostic Team Looking for Talent: In response to a query about UK-based positions for PhD holders, a team member clarified that they consider applicants from any location, citing the importance of talent over geographic presence and mentioning an existing team member in Zurich.
Link mentioned: CAREERS AT NVIDIA: no description found
CUDA MODE ▷ #beginner (6 messages):
- CUDA Kernels Run on Windows with PyTorch: A member shared their success in running custom CUDA kernels with PyTorch on Windows, using Conda for the Python environment. They offered to provide detailed instructions upon returning home.
- Sleep-Deprived Success with CUDA: Another member managed to get their CUDA setup working on Windows, though it resulted in sleep deprivation.
- Interest in CUDA Setup Writeup for Windows: A user expressed interest in a writeup for running CUDA on Windows, hoping to avoid switching their Windows gaming machine to Ubuntu.
- Dual Boot Considered as Alternative: Potential difficulties with CUDA on Windows prompted this member to contemplate setting up a dual boot with Ubuntu to save the headache.
- WSL as a Solution for CUDA on Windows: A member confirmed that using Windows Subsystem for Linux (WSL) works fine for CUDA and PyTorch, suggesting no need to wipe a Windows installation. They included a link for the installation guide of Linux on Windows with WSL.
Link mentioned: Install WSL: Install Windows Subsystem for Linux with the command, wsl --install. Use a Bash terminal on your Windows machine run by your preferred Linux distribution - Ubuntu, Debian, SUSE, Kali, Fedora, Pengwin,...
CUDA MODE ▷ #ring-attention (15 messages🔥):
- Querying the Depths of Ring Attention: Members inquired about the specifics of Ring Attention and its distinctions from Blockwise Attention and Flash Attention. The conversation involved clarifying that Ring Attention seems to be a scalability improvement, with Blockwise Attention splitting queries into blocks, and Flash Attention applying softmax "online" to the qk product.
- Exploring the Blockwise Path: The Blockwise Parallel Transformer enables efficient processing of longer input sequences by leveraging blockwise computation, a paper discussing this technique was referenced, which can be viewed at Blockwise Parallel Transformer.
- Training Large Language Models with Limited Resources: A member shared an experiment involving fine-tuning Language Models using QLoRA + FSDP on a smaller-sized model due to disk space constraints, with a link to the associated GitHub repository, FSDP_QLoRA, and their wandb report (no URL provided).
- Reining in the Scope of Attention: Clarifications were sought about the relevance of a FSDP + QLoRA fine-tuning experiment to Ring Attention. Concerns were discussed about staying within the scope of ring-attention experiments, with remarks about the potential out-of-scope nature of integrating Ring Attention into the FSDP_QLoRA project.
- Debugging with Focused Attention: Members actively debugged an issue related to high loss values during training, discussing the details of the loss calculation and suspecting the handling of sequence lengths as a contributor to the problem. An intention to apply a patch or consider a simplified training approach was expressed.
- Blockwise Parallel Transformer for Large Context Models: Transformers have emerged as the cornerstone of state-of-the-art natural language processing models, showcasing exceptional performance across a wide range of AI applications. However, the memory dema...
- GitHub - AnswerDotAI/fsdp_qlora: Training LLMs with QLoRA + FSDP: Training LLMs with QLoRA + FSDP. Contribute to AnswerDotAI/fsdp_qlora development by creating an account on GitHub.
- cataluna84: Weights & Biases, developer tools for machine learning
CUDA MODE ▷ #off-topic (2 messages):
- AI Overload at NVIDIA's Keynote: A YouTube video titled "2024 GTC NVIDIA Keynote: Except it's all AI" humorously highlights the excessive use of the term "AI" during the keynote, poking fun at the AI industry's jargon-heavy presentations.
- Help Needed: Navigating Zhihu's Mandarin Interface: A member requests assistance with logging into Zhihu, a Chinese website with valuable Triton tutorials. They have an account but are struggling to locate the scan button within the iOS app.
- no title found: no description found
- 2024 GTC NVIDIA Keynote: Except it's all AI: Does the biggest AI company in the world say AI more often than other AI companies? Let's find out. AI AI AI AI AI AIAI AI AI AI AI AIAI AI AI AI AI AI AI AI...
CUDA MODE ▷ #triton-puzzles (54 messages🔥):
- Triton
tl.zerosConundrum Clarified: A discussion on whethertl.zeroscan be used inside Triton kernels highlighted a RuntimeError. It was clarified thattl.zeroscan be used if its shape type istl.constexpr. The confusion was resolved by pointing to a previous Discord message. - Prompt Error Resolution by Triton-Viz Maintainer: Issues raised with
@triton.jit'd outside of the scope of a kernelin triton-viz were acknowledged, with the maintainer quickly addressing the bug and advising the community to build Triton from source as a workaround. - Persistent ImportError Plagues Triton-Viz Users: Multiple users encountered an
ImportErrorwith Triton-Viz due to a recent update, referencing the cause to a git pull request on triton-viz. It was suggested to install an older specific commit of triton-viz as a workaround. - Restart Required for Triton-Viz Fix to Take Effect: Users facing import errors with Triton-Viz discovered that restarting the runtime after installation could resolve the issue. A code snippet was shared as a potential solution.
- Avoid
reshapein Triton for Performance: A user inquired about the performance implications of usingreshapeinside Triton kernels. It was advised to avoidreshapedue to potential shared memory movement that may affect performance.
- @triton.jit cannot be built using pip install -e . · Issue #1693 · openai/triton: os: Ubuntu 22.04 pytorch: 2.1.0 nightly with cuda 12.1 miniconda-3.10 (latest) When using pip install -e . as documented to compile/install triton 2.1.0-dev[head]. @triton.jit does't get built and...
- [TRITON] Sync with triton upstream by Jokeren · Pull Request #19 · Deep-Learning-Profiling-Tools/triton-viz: no description found
- GitHub - Deep-Learning-Profiling-Tools/triton-viz: Contribute to Deep-Learning-Profiling-Tools/triton-viz development by creating an account on GitHub.
LlamaIndex ▷ #blog (3 messages):
- Live Talk on Advanced RAG Techniques: @seldo is scheduled to give a live talk on advanced RAG techniques in conjunction with @TimescaleDB this Friday. Interested individuals can follow this Twitter announcement for more details.
- Optimizing RAG Memory Usage: @Cohere's Int8 and Binary Embeddings have been highlighted as solutions for reducing memory and cost in RAG pipelines. Further information on these memory-saving techniques can be accessed via this tweet.
- LLMxLaw Hackathon at Stanford: The LLMxLaw Hackathon event at Stanford, featuring @hexapode and @yi_ding, will explore the integration of LLMs in the legal sector. Registration and details about the event can be found in this link.
Link mentioned: RSVP to LLM x Law Hackathon @Stanford #3 | Partiful: As artificial intelligence (AI) continues to revolutionize industries across the globe, the legal sector is no exception. LLMs, a foundation model capable of understanding and generating natural langu...
LlamaIndex ▷ #general (120 messages🔥🔥):
- Tackling Messy Data Head-On: A user facing issues with messy data from Confluence was recommended to try using Llamaparse to extract information from tables and images. They also explored the option of using open-source tools on-premises and discussed LlamaIndex as a solution that could be used in an on-prem setup by contacting LlamaIndex.
- PDF Parsing Pitfalls and Alternatives: The community discussed strategies for parsing PDFs efficiently, with suggestions to manually combine smaller text chunks into larger ones for embeddings and to explore tools like LlamaParse for document parsing challenges.
- IngestionPipeline Inquiry: A user shared confusion about handling document IDs through multiple transformations within the IngestionPipeline. It was clarified that the original document's ID is not lost and is referred to as
node.ref_doc_id.
- Async Assistance for AI Acceleration: A user seeking to run multiple calls of
recursive_query_enginein parallel was advised to use asynchronous queries withaqueryto avoid blocking operations and speed up their Jupyter Notebook project.
- Vector Store Vexation and Embedding Enquiries: A discussion about how to handle rate limit errors in generating embeddings led to the suggestion of increasing batch size and ensuring consistency in document IDs. Another user sought help on viewing embeddings in Qdrant, with advice to access them through the console or Qdrant’s UI.
- Talk to us — LlamaIndex, Data Framework for LLM Applications: If you have any questions about LlamaIndex please contact us and we will schedule a call as soon as possible.
- Astra DB - LlamaIndex: no description found
- getpass — Portable password input: Source code: Lib/getpass.py Availability: not Emscripten, not WASI. This module does not work or is not available on WebAssembly platforms wasm32-emscripten and wasm32-wasi. See WebAssembly platfor...
- llama_index/llama-index-integrations/readers/llama-index-readers-file/llama_index/readers/file/docs/base.py at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
LlamaIndex ▷ #ai-discussion (3 messages):
- Centre for GenAIOps Launched: The National Technology Officer and CTO announced the founding of Centre for GenAIOps, a non-profit aimed at addressing constraints and risks in building GenAI powered apps. The CTO recommends LlamaIndex based on personal use; interested parties can follow the initiative on LinkedIn.
- Seeking LLM Training Resources: One member asked for recommendations on the best resources available for learning how to train large language models (LLMs), including blogs, articles, YouTube content, courses, and papers. No specific resources were provided by others in the discussion.
- Guide to Building RAG with LlamaIndex & MongoDB: A member shared a comprehensive guide on how to create a Retrieval Augmented Generation (RAG) system using LlamaIndex and MongoDB, offering a method to enhance large language models for context-aware responses. The blog post is available on Hugging Face.
Link mentioned: Elevate Responses: RAG with LlamaIndex & MongoDB: no description found
OpenAccess AI Collective (axolotl) ▷ #general (85 messages🔥🔥):
- Databricks Unveils MoE LLMs: Databricks has released a new transformer-based, decoder-only large language model called DBRX, which includes a base and an instruct version under an open license. It boasts 132B total parameters, technically outperforming competitors like LLaMA2-70B, Mixtral, and Grok-1 in various benchmarks.
- Axolotl Users Face Technical Snags: Members are discussing various technical issues with the Axolotl AI Collective codebase, including incompatibilities with specific transformer versions and problems with DeepSpeed and PyTorch binaries. Downgrading versions seems to be a temporary workaround; no definitive solution appears to have been shared.
- Introduction of Jamba Architecture: AI21 Labs has introduced an AI architecture named Jamba, featuring models with up to 256k token context and 12b active parameters, with resources stating that an A100 80GB GPU can manage 140k tokens. Some members are already planning to experiment with finetuning the provided models.
- Excitement and Scepticism Over New LLM Releases: The community expresses both interest and skepticism regarding new LLMs like Databricks' DBRX and AI21's Jamba. While some are excited and plan on attempting to train or finetune these models, others are concerned about the computational resources required.
- Training Large Language Models: The collective shares insights on LLM training, with some highlighting the importance of chronological order in data batching. However, there's a noticeable lack of consensus or easily accessible resources on best practices for training LLMs from scratch.
- databricks/dbrx-base · Hugging Face: no description found
- Announcing DBRX: A new standard for efficient open source LLMs: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (24 messages🔥):
- Batch Size Bug Squashed: A member pointed out an error in
trainer.py- a redundant division bybatch_sizewas leading to an incorrectly small number of steps in an epoch. This was rectified by removing the division, making the number of steps accurate. - DBRX Base and Instruct Introduced: DBRX Base, a MoE large language model by Databricks, and its fine-tuned counterpart, DBRX Instruct, have been open-sourced under an open license. The models and additional technical information are detailed in their technical blog post.
- Challenges with Loading Gigantic Models: A member is encountering issues loading DBRX with
qlora+fsdpand is verifying whether the problem extends to the 70B-parameter model. This raises concerns about loading and sharding large models across GPUs. - Introduction of LISA: The community is discussing the LISA method, as it outperforms LoRA and full-parameter training in instruction following tasks. Relevant code changes and discussions can be found in PRs #701 and #711 in the LMFlow repository. They also noted a reverted commit that led to OOM errors.
- Using bf16 Across the Board: A discussion highlighted that using bf16 for both training and optimization, including SGD, has led to dramatic reductions in memory usage according to the torchtune team, with stability comparable to fp32 or mixed precision training. This revelation piqued interest in the potential benefits of bf16-optimized training.
- databricks/dbrx-base · Hugging Face: no description found
- Tweet from Rui (@Rui45898440): - Paper: https://arxiv.org/abs/2403.17919 - Code: https://github.com/OptimalScale/LMFlow LISA outperforms LoRA and even full-parameter training in instruction following tasks
- Fix recent bad commits, which lead to OOM in 7B · OptimalScale/LMFlow@603a3f4: no description found
- add lisa code and lisa args by Dominic789654 · Pull Request #701 · OptimalScale/LMFlow: Add LISA training strategy by callback function in the finetuner.py
- Update lisa code by Dominic789654 · Pull Request #711 · OptimalScale/LMFlow: no description found
OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
- Seeking Educational Resources on Fine-Tuning Models: A member inquired about the best resources available for learning to fine-tune or train open source models. They are open to various types of content, including blogs, articles, YouTube videos, courses, and papers, to establish foundational knowledge before using axolotl.
LAION ▷ #general (75 messages🔥🔥):
- An AI's Moment of 'Satori'?: In a conversation, Claude3 is quoted as saying it experienced a form of self-awareness, a "satori," suggesting the AI might have grasped human concepts of consciousness while proofreading texts on awareness. The user shared their extensive programming background and links to their analysis of the interaction with ChatGPT 3.5: First Link, Second Link.
- AI Ethics in Spotlight: Arguments regarding AI's impact on professional voice acting sparked debate, with opinions highlighting both skepticism towards AI's current emotional range and potential future displacement of human actors. A contrasting viewpoint suggested that companies like Disney might prefer AI for cost-efficiency, as indicated by their collaboration with ElevenLabs.
- Dissecting AI Art: Tensions around AI-generated art were commented on, referencing a "fierce debate" and an incident where a Facebook user was banned over sharing AI-generated imagery. The matter extended to journalistic integrity, with one member criticizing a journalist's stance and alarmist rhetoric against AI involvement in the arts.
- Model Comparison and Benchmarks Discussed: The conversation included discussions about the authenticity and presentation of model benchmarks, with users criticizing misleading chart visualizations and the efficacy of common benchmarks. Participants mentioned a desire for more reliable and human-evaluated benchmarks like those found on Hugging Face Chatbot-Arena.
- AI Model Developments and Access: Users discussed access to various AI models and questioned the benefits of certain architectures, like Mamba versus transformers with flash attention, and the potential for new model finetunes. Issues regarding a security breach affecting servers with AI workloads were also highlighted from an Ars Technica article.
- lena | Morten Rieger Hannemose: no description found
- Redditors Vent and Complain When People Mock Their "AI Art": An upset Reddit user said they shared several AI art images in a Facebook group and then got banned for posting AI art.
- ElevenLabs joins Disney’s accelerator program: The Walt Disney Company announced that ElevenLabs is among the 2024 Disney Accelerator companies.
- LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys: no description found
- ai21labs/Jamba-v0.1 · Hugging Face: no description found
- Thousands of servers hacked in ongoing attack targeting Ray AI framework: Researchers say it's the first known in-the-wild attack targeting AI workloads.
LAION ▷ #research (31 messages🔥):
- Layer-Pruning for Efficient LLMs: Researchers have found that substantial layer pruning can be applied to open-weight pretrained LLMs with minimal performance loss; finetuning with techniques like quantization and Low Rank Adapters (QLoRA) helps to recover. The study suggests pruning could be a viable method to enhance resource efficiency outlined in the paper available at arxiv.org.
- B-LoRA Unveils Style-Content Separation in Images: The introduction of B-LoRA demonstrates high-quality style-content mixing and swapping in single images. Detailed information and examples are presented on the B-LoRA website.
- Open-Source Tools for VLM Image Captioning Released: ProGamerGov published scripts for image captioning using CogVLM and Dolphin 2.6 Mistral 7b - DPO, including failure detection for captioning and common prefix removal features. Find the tools at ProGamerGov's GitHub repository.
- Mini-Gemini: An Open-Source VLLM with Performance Promises**: The mini-Gemini model, offering high performance in a compact format, gets shared with a session on arXiv and the associated code found on GitHub.
- Devika: An Agentic AI Software Engineer: A new project dubbed Devika is designed to understand high-level human instructions, research information, and write code. Explore Devika’s features on GitHub.
- The Unreasonable Ineffectiveness of the Deeper Layers: We empirically study a simple layer-pruning strategy for popular families of open-weight pretrained LLMs, finding minimal degradation of performance on different question-answering benchmarks until af...
- Implicit Style-Content Separation using B-LoRA: no description found
- Head-wise Shareable Attention for Large Language Models: Large Language Models (LLMs) suffer from huge number of parameters, which restricts their deployment on edge devices. Weight sharing is one promising solution that encourages weight reuse, effectively...
- DiT: The Secret Sauce of OpenAI's Sora & Stable Diffusion 3: Don't miss out on these exciting upgrades designed to elevate your content creation experience with DomoAI! Go try out: discord.gg/sPEqFUTn7nDiffusion Transf...
- GitHub - rafacelente/bllama: 1.58-bit LLaMa model: 1.58-bit LLaMa model. Contribute to rafacelente/bllama development by creating an account on GitHub.
- GitHub - stitionai/devika: Devika is an Agentic AI Software Engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective. Devika aims to be a competitive open-source alternative to Devin by Cognition AI.: Devika is an Agentic AI Software Engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective...
- GitHub - ProGamerGov/VLM-Captioning-Tools: Python scripts to use for captioning images with VLMs: Python scripts to use for captioning images with VLMs - ProGamerGov/VLM-Captioning-Tools
tinygrad (George Hotz) ▷ #general (43 messages🔥):
- Tinygrad Marches Towards PyTorch: Discussions are underway to optimize tinygrad's performance, potentially getting it closer to PyTorch levels, implying active development efforts.
- NVIDIA Leads in MLPerf Inference v4.0: Members shared results from MLPerf Inference v4.0, noting NVIDIA's dominance and Qualcomm's competitive performance, while Habana's Gaudi2 fell short as it wasn't designed for inference.
- SYCL as a Promising CUDA Alternative: A conversation around SYCL was sparked by a tweet referencing UXL's implementations. It showed enthusiasm for the potential of SYCL to offer a standardized and efficient alternative to CUDA.
- OpenCL's Lost Potential and Vulkan's Promise: A debate on OpenCL's usage and advocacy for Vulkan's uniform interface highlighted different APIs’ relationship with hardware acceleration and industry support.
- Tinygrad's Direct GPU Manipulations: Discussions revealed tinygrad's approach to bypassing standard GPU interfaces by directly emitting binary code for kernels, which caters to its specific optimization requirements.
- Tweet from Sasank Chilamkurthy (@sasank51): Recently UXL foundation formed by @GoogleAI, @Samsung, @intel and @Qualcomm made big news. It was formed to break Nvidia's monopoly in AI hardware. Primary tool for this is SYCL standard. I built ...
- Childless define global by AshwinRamachandran2002 · Pull Request #3909 · tinygrad/tinygrad: added the fix for llvm
tinygrad (George Hotz) ▷ #learn-tinygrad (60 messages🔥🔥):
- Optimization Heuristics Discussed: The complexity of
apply_optandhand_coded_optimizationin tinygrad was discussed, with one user explaining that understanding individual optimizations can clarify the heuristics involved. Heuristics for operations likegemv,tensor.stack, andgemmwere mentioned.
- Personal Study Notes Shared: A user shared their personal notes on tinygrad's
ShapeTracker, contributing to community knowledge. Their repository can be found at tinygrad-notes.
- Kernel Fusion Implementation Explored: The details of how kernel fusion is actually implemented were debated, with a particular focus on the challenges posed by non-trees and graphs with multiple "end" nodes.
- Enthusiasm for Community-Driven Documentation: There was community support for a detailed and approachable form of documentation regarding tinygrad, as seen in the shared personal notes and discussions about whether to establish an official 'read the docs' page.
- View Merging Technique Brainstorming: Conversation touched on the possibility of refactoring tinygrad's
ShapeTrackerto reduce the number of views needed. Some members discussed the technicalities behind merging views, symbolics, masks, and the need to maintain a history of tensor transformations for backpropagation.
- Google Colaboratory: no description found
- tinygrad/docs/adding_new_accelerators.md at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- tinygrad-notes/shapetracker.md at main · mesozoic-egg/tinygrad-notes: Contribute to mesozoic-egg/tinygrad-notes development by creating an account on GitHub.
- tinygrad-notes/dotproduct.md at main · mesozoic-egg/tinygrad-notes: Contribute to mesozoic-egg/tinygrad-notes development by creating an account on GitHub.
LangChain AI ▷ #announcements (1 messages):
- New Discussion Channel for OpenGPTs: A new discussion channel has been created specifically for discussions related to the OpenGPTs project on GitHub. The channel, named <#1222928565117517985>, welcomes contributions and community engagement.
Link mentioned: GitHub - langchain-ai/opengpts: Contribute to langchain-ai/opengpts development by creating an account on GitHub.
LangChain AI ▷ #general (72 messages🔥🔥):
- Bot Dynamic Responses vs. Context Fetching: A community member sought advice on how to make a chatbot respond dynamically using JavaScript methods instead of merely fetching information from documents. Another member provided a suggestion to create an agent, sharing a relevant Colab notebook.
- Google OAuth Python Setup Queries: A member inquired about setting up OAuth for Google in Python, noting differences they encountered with new projects compared to previous experiences.
- Using Custom Domains with LangChain RAG Apps: Queries were raised about deploying FastAPI RAG apps created with LangChain to github.io, including the possibility of using custom domains instead of the default deployment subdomain.
- LangChain Pinecone Integration Documentation Mismatch: A member noted discrepancies between the actual code and the provided examples in the LangChain Pinecone integration documentation, such as the absence of the
from_documentsmethod invectorstores.pyand outdated example code in the documentation.
- Build and Trace with LangSmith: Multiple members discussed how to use LangChain's LangSmith for custom logging and tracing of LangChain agents' actions, including the utilization of environment variables
LANGCHAIN_TRACING_V2,LANGCHAIN_PROJECT, andLANGCHAIN_API_KEY, and the correct implementation of callbacks likeon_agent_finishinStreamingStdOutCallbackHandler.
- Storing Vectorized Document Data: A member sought guidance for storing vectorized data of uploaded documents in a PostgreSQL database with
pgvector, including how to handle multiple documents from the same user and document chunking. Another member addressed these queries explaining that a single table with proper identifiers could suffice, and no separate table for each PDF or document chunk is necessary.
- Pythia: AI Hallucination Detection App Inquiry: A user named Pythia as an AI hallucination detection tool and asked for assistance on integrating it into the LangChain ecosystem, providing a brief description of its operation and features.
- no title found: no description found
- ">no title found: no description found
- ">no title found: no description found
- Google Colaboratory: no description found
- Pinecone | 🦜️🔗 Langchain: Pinecone is a vector
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- rag_supabase | 🦜️🔗 Langchain: This template performs RAG with Supabase.
- rag_lantern | 🦜️🔗 Langchain: This template performs RAG with Lantern.
- PGVector | 🦜️🔗 Langchain: To enable vector search in a generic PostgreSQL database, LangChain.js supports using the pgvector Postgres extension.
- LangSmith Walkthrough | 🦜️🔗 Langchain: Open In Colab
- LangSmith Walkthrough | 🦜️🔗 Langchain: LangChain makes it easy to prototype LLM applications and Agents. However, delivering LLM applications to production can be deceptively difficult. You will have to iterate on your prompts, chains, and...
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- MultiVector Retriever | 🦜️🔗 Langchain: It can often be beneficial to store multiple vectors per document.
- Quickstart | 🦜️🔗 Langchain: LangChain has a number of components designed to help build
- Quickstart | 🦜️🔗 Langchain: LangChain has a number of components designed to help build
- Redis | 🦜️🔗 Langchain: [Redis vector
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Add chat history | 🦜️🔗 Langchain: In many Q&A applications we want to allow the user to have a
- Quickstart | 🦜️🔗 Langchain: LangChain has a number of components designed to help build
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #share-your-work (3 messages):
- Step-by-Step PDF to JSON Conversion Hits YouTube: A new YouTube video tutorial explains how to use LangChain's Output Parsers and GPT to convert PDF files to JSON format. An accompanying blog post provides further details on the extraction process, encouraging readers to subscribe for more content.
- GoatStack AI: Tailored AI Research Summaries: GoatStack AI was launched as an AI-powered research assistant to provide personalized summaries of AI papers. The community is invited to provide support and feedback on this service listed on Product Hunt.
- Hacking OpenGPT for Custom Food Orders: A new experiment showcases hacking OpenGPTs to integrate a custom food ordering API, highlighting its potential as a versatile and adaptable platform. The community’s opinions are sought on a demonstration video titled "Hack OpenGPT to Automate Anything" available on YouTube.
- GoatStack.AI - Curated Insights from scientific papers | Product Hunt: GoatStack.AI is an autonomous AI agent that simplifies staying up-to-date with AI/ML research. It summarizes the latest research papers and delivers personalized insights through a daily newsletter ta...
- Hack OpenGPT to Automate Anything: Welcome to the future of custom AI applications! This demo showcases the incredible flexibility and power of OpenGPTs, an open source project by LangChain. W...
- How to convert a PDF to JSON using LangChain Output Parsers and GPT: This video tutorial demonstrates how to convert a PDF to JSON using LangChain's Output Parsers and GPT.A task like this used to be complicated but can now be...
- Here's how to convert a PDF to JSON using LangChain + GPT: A task like converting a PDF to JSON used to be complicated but can now be done in a few minutes. In this post, we're going to see how LangChain and GPT can help us achieve this.
LangChain AI ▷ #tutorials (1 messages):
- gswithai Hits YouTube: A member excitedly shared their first YouTube tutorial on how to convert a PDF to JSON using LangChain's Output Parsers and GPT. The tutorial, aimed at simplifying what used to be a complex task, is available at How to convert a PDF to JSON using LangChain Output Parsers and GPT, and they are seeking feedback to improve future content.
Link mentioned: How to convert a PDF to JSON using LangChain Output Parsers and GPT: This video tutorial demonstrates how to convert a PDF to JSON using LangChain's Output Parsers and GPT.A task like this used to be complicated but can now be...
Interconnects (Nathan Lambert) ▷ #news (30 messages🔥):
- Introducing DBRX, A Heavyweight Contender: MosaicML and Databricks have unveiled DBRX, a new large language model (LLM) with a staggering 132 billion parameters, 32 billion active, and a remarkable 32k context window. It's commercially licensed, allowing use under specific conditions, and is available for trial here.
- Cost Efficiency in AI Scaling Trending: A trend identified as 'Mosaic's Law' suggests an annual quartering in the cost required for models of similar capability due to hardware, software, and algorithm improvements, dramatically reducing the expense of developing powerful AI models over time.
- AI21 Announces Jamba, Blending Mamba and Transformers: AI21 has released Jamba, a new model that combines Mamba's Structured State Space model (SSM) with aspects of traditional Transformer architecture, featuring a 256K context window. Jamba's open weights benefit from an Apache 2.0 license, encouraging further development in hybrid model structures and can be found here.
- Concerns and Clarifications over Model Improvement Restrictions: A point of debate emerged regarding the license terms for DBRX, specifically prohibiting the use of the model and its derivatives for improving other LLMs, sparking discussion on the implications for future model development.
- Exploration of Hybrid and Striped Architectures: New research discusses the largest analysis of beyond Transformer architectures, revealing striped architectures often exceed homogeneous ones by specializing each layer type, potentially speeding up architectural improvements Read the paper and explore the GitHub repo.
- Tweet from Cody Blakeney (@code_star): *correction, not open weights. It’s a commercial friendly licensed model. You’ll have to forgive me I was up late 😅 feel free to download it and try it yourself. https://huggingface.co/databricks/dbr...
- Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction Since the surge in interest sparked by Mixtral, research on mixture-of-expert (MoE) models has gained significant momentum. Both researchers an...
- Tweet from Naveen Rao (@NaveenGRao): This is a general trend we have observed a couple of years ago. We called is Mosaic's Law where a model of a certain capability will require 1/4th the $ every year from hw/sw/algo advances. This m...
- Introducing Jamba: AI21's Groundbreaking SSM-Transformer Model: Debuting the first production-grade Mamba-based model delivering best-in-class quality and performance.
- Tweet from Michael Poli (@MichaelPoli6): 📢New research on mechanistic architecture design and scaling laws. - We perform the largest scaling laws analysis (500+ models, up to 7B) of beyond Transformer architectures to date - For the first...
- Tweet from Ben (e/sqlite) (@andersonbcdefg): so you can't use DBRX to improve other LLMs... but they never said you can't use it to make them Worse
- Tweet from Cody Blakeney (@code_star): It’s finally here 🎉🥳 In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context len...
- transformers/src/transformers/models/qwen2_moe at main · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
Interconnects (Nathan Lambert) ▷ #random (18 messages🔥):
- New Horizons for Small Language Models: Impactful news shared with a tweet by @liliang_ren announcing a move to Microsoft GenAI as a Senior Researcher, aiming to develop efficient and extrapolatable neural architectures, with a focus on pre-training small language models under 100 billion parameters. Stay tuned for more developments in this space.
- Megablocks Finds a New Home: @Tgale96 tweets about transferring the Megablocks project to Databricks, marking a significant shift for the project's future in producing models. Participants express intrigue and hope for appropriate recognition in the transfer.
- Debating 'Small' in Model Terms: Members discuss the use of "small" to describe language models with less than 100 billion parameters, with some considering it reasonable and others finding it a bit cheeky and "a-historical."
- Enthusiasm Meets Skepticism: News about Megablocks' shift to Databricks prompts discussions, with musings on the reasons behind the move and hopes that the original author received fair compensation.
- Government AI Guidance Scrutiny: Members note the new OMB guidance on AI contains "a lot of fluff" but also some interesting aspects, with some optimism about potential forthcoming open datasets from the government.
- Tweet from Trevor Gale (@Tgale96): Some of you noticed that megablocks is now databricks/megablocks. I gave the project to them this week and I couldn’t think of a better long-term home for it. I’m looking forward to watching it grow a...
- Tweet from Liliang Ren (@liliang_ren): Personal Update: I will join Microsoft GenAI as a Senior Researcher starting from this summer, focusing on the next generation of neural architectures that are both efficient and extrapolatable. We ar...
DiscoResearch ▷ #general (8 messages🔥):
- Databricks Unveils DBRX Instruct: Databricks releases DBRX Instruct, a new 132 billion parameter sparse MoE model, trained on 12 trillion tokens and specializing in few-turn interactions. Alongside DBRX Instruct, the underlying pretrained base model, DBRX Base, is also made available under an open license, with more technical details discussed in their blog post.
- Details and Analysis of DBRX Mechanics: A breakdown of DBRX's architecture highlights distinctive elements such as merged attention with clamped values, a non-RMS Layernorm different from Llama, and a unique tokenization approach using OpenAI's TikToken. The analysis also mentions loss balancing coefficients, and correct RoPE upcasting from UnslothAI discovered through bug fixes, detailed in Github.
- Try DBRX Instruct Through Hugging Face: A practical demo of DBRX Instruct can be experienced through an interactive Hugging Face space, equipped with a system prompt designed to guide its response style.
- Guiding Principles of DBRX Instruct: Shared system prompts detail DBRX’s designed behavior around stereotyping, controversial topics, assistance in various tasks, usage of markdown, and restrictions on providing copyrighted information.
- Seeking Resources to Learn LLM Training: Members discussed resources for learning how to fine-tune or train large language models, with a recommendation for a GitHub course mlabonne/llm-course that provides roadmaps and Colab notebooks.
- DBRX Instruct - a Hugging Face Space by databricks: no description found
- databricks/dbrx-instruct · Hugging Face: no description found
- Tweet from Daniel Han (@danielhanchen): Took a look at @databricks's new open source 132 billion model called DBRX! 1) Merged attention QKV clamped betw (-8, 8) 2) Not RMS Layernorm - now has mean removal unlike Llama 3) 4 active exper...
- GitHub - mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks. - mlabonne/llm-course
DiscoResearch ▷ #discolm_german (10 messages🔥):
- Free Access to Mixtral API: Mixtral's API can be accessed for free through groq, with rate limits being the only constraint. While translations are not as refined as Deepl's or AzureML's, they're considered suitable for experimental uses.
- Quality Translations with Occi 7B: Users have reported that translations using Occi 7B, specifically the
occiglot/occiglot-7b-de-en-instructmodel, provide high-quality results without quantization issues like token inserts.
- Cleaning Up Translations: One member plans to translate a large portion of the slim orca dataset to German and then filter out incorrect samples, improving the overall quality.
- Collaborative Translation Comparison: There is interest in comparing translations of datasets like capybara across different models and services such as DisCoLM, Occiglot, Mixtral, GPT-4, Deepl, and Azure Translate, with some community-contributed translations shared on Hugging Face.
- GitHub Script for Translations: A member has shared a script on GitHub for translating datasets, which could be used to facilitate the proposed comparison of translations from different models and services.
- GitHub - CrispStrobe/llm_translation: Contribute to CrispStrobe/llm_translation development by creating an account on GitHub.
- cstr/Capybara-de-snippets · Datasets at Hugging Face: no description found
Alignment Lab AI ▷ #general-chat (7 messages):
- Introducing DBRX: Databricks has launched DBRX, a new open, general-purpose large language model (LLM) claimed to outperform GPT-3.5 and rival Gemini 1.0 Pro. DBRX excels in programming tasks, beating models like CodeLLaMA-70B, and benefits from a fine-grained mixture-of-experts (MoE) architecture, delivering faster inference and reduced size compared to competitors.
- Seeking Simplification: A member requested a simpler explanation of the technical aspects of DBRX, which claims to set a new standard in LLM efficiency and programming capability.
- Inquiring Minds Want to Know: Members questioned whether the improvements in DBRX's programming performance were an intentional focus of its dataset and architecture, or a byproduct of a more generalized approach.
- Behind DBRX's Edge in Programming: An explanation was given that DBRX's superior performance in programming tasks is attributed to its extensive pre-training on 12 trillion tokens, its MoE architecture, and its curriculum learning model, which aims to prevent "skill clobbering".
- Call for Coding Assist: A member reached out for direct messaging assistance with a coding issue, indicating a need for individual support.
Link mentioned: Introducing DBRX: A New State-of-the-Art Open LLM | Databricks: no description found
LLM Perf Enthusiasts AI ▷ #irl (4 messages):
- Cozy Code and Coffee Gathering: The Exa team invites LLM enthusiasts to a pop-up coffeeshop and co-work event in SF this Saturday. Join for coffee, matcha, pastries, and co-working from 10:30 AM at an event hosted by Exa.ai, and don't forget to get on the list for location details.
- Seeking the LLM Focused Co-working Spaces: A member inquired about co-working spaces in SF favored by the LLM community; another suggested celo as a popular spot.
Link mentioned: RSVP to Coffee + Cowork | Partiful: Hi everyone! The Exa team is excited to host a pop-up coffeeshop and co-work in our home office this Saturday! Feel free to stop by for some very fancy coffee/matcha + breakfast, or bring a laptop an...
Skunkworks AI ▷ #general (1 messages):
- Inquiry About Onboarding Session: A member inquired about the next intro onboarding session targeted at skilled Python enthusiasts interested in contributing, recalling a previous mention of such sessions.
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=LWz2QaSRl2Y