[AINews] Ideogram 2 + Berkeley Function Calling Leaderboard V2
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Two big steps in imagegen and function calling.
AI News for 8/20/2024-8/21/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (254 channels, and 1980 messages) for you. Estimated reading time saved (at 200wpm): 222 minutes. You can now tag @smol_ai for AINews discussions!
Thanks to @levelsio for shouting us out on the Lex Fridman pod!
'Tis the season of sequels.
After the spectacular launch of Flux (the former Stable Diffusion team, our coverage here), Ideogram (the former Google Imagen 1 team) is back with a vengeance. A new model, with 5 distinct styles with color palette control, a fully controllable API, and iOS app (sorry Android friends), announcing a milestone of 1 billion images created. No research paper of course, but Ideogram is catapulted back to top image lab status, while Midjourney just released a Web UI (still no API).

Meanwhile in AI Engineer land, the Gorilla team updated the Berkeley Function Calling Leaderboard (now commonly known as BFCL) to BFCL V2 • Live, adding 2251 "live, user-contributed function documentation and queries, avoiding the drawbacks of dataset contamination and biased benchmarks." They also note that multiple functions > parallel functions:
a very high demand for the feature of having to intelligently choose between functions (multiple functions) and lower demand for making parallel function calls in a single turn (parallel functions)
The dataset weights were adjusted accordingly:
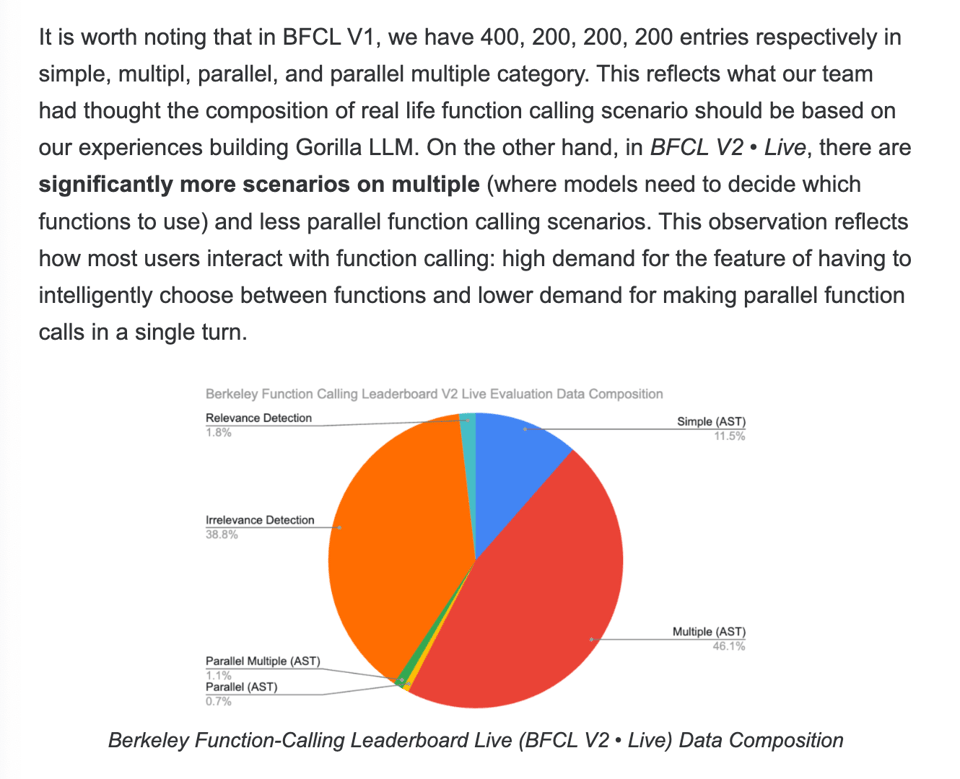
Depth and breadth of function calling is also an important hyperparameter - the dataset now includes rare function documentations that contain 10+ function options or a complex function with 10+ nested parameters.
GPT4 dominates the new leaderboard, but the open source Functionary Llama 3-70B finetune from Kai notably beats Claude.
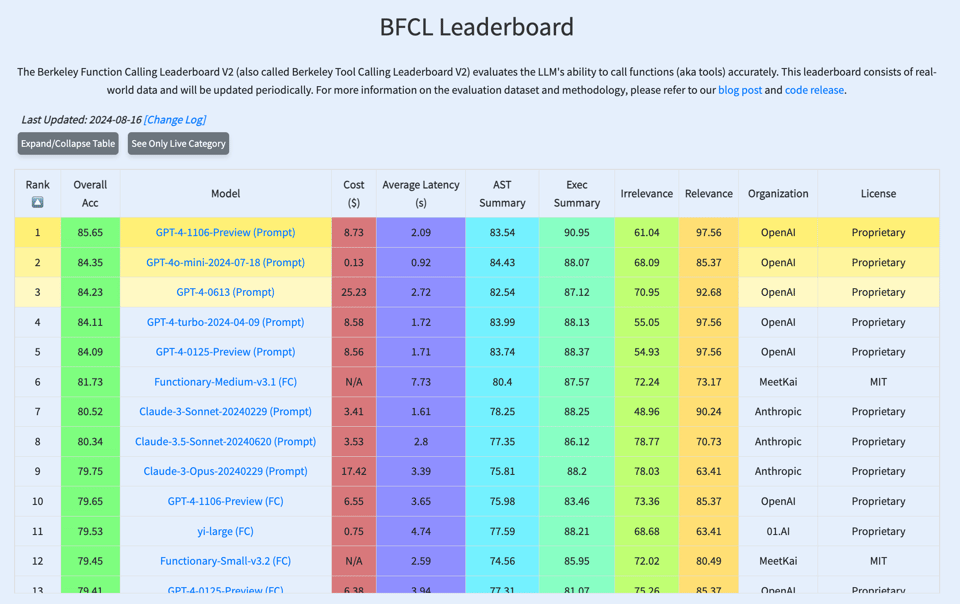
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- OpenRouter (Alex Atallah) Discord
- Nous Research AI Discord
- Stability.ai (Stable Diffusion) Discord
- OpenAI Discord
- Cohere Discord
- Perplexity AI Discord
- LlamaIndex Discord
- OpenAccess AI Collective (axolotl) Discord
- Latent Space Discord
- Eleuther Discord
- tinygrad (George Hotz) Discord
- OpenInterpreter Discord
- LangChain AI Discord
- DSPy Discord
- Torchtune Discord
- MLOps @Chipro Discord
- DiscoResearch Discord
- PART 2: Detailed by-Channel summaries and links
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (138 messages🔥🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #datasets (1 messages):
- Nous Research AI ▷ #off-topic (7 messages):
- Nous Research AI ▷ #interesting-links (2 messages):
- Nous Research AI ▷ #general (102 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (18 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (114 messages🔥🔥):
- OpenAI ▷ #ai-discussions (80 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (7 messages):
- OpenAI ▷ #prompt-engineering (5 messages):
- OpenAI ▷ #api-discussions (5 messages):
- Cohere ▷ #discussions (33 messages🔥):
- Cohere ▷ #questions (50 messages🔥):
- Cohere ▷ #projects (1 messages):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (60 messages🔥🔥):
- Perplexity AI ▷ #sharing (11 messages🔥):
- Perplexity AI ▷ #pplx-api (6 messages):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (58 messages🔥🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (17 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (42 messages🔥):
- Latent Space ▷ #ai-general-chat (57 messages🔥🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Eleuther ▷ #general (7 messages):
- Eleuther ▷ #research (20 messages🔥):
- Eleuther ▷ #scaling-laws (1 messages):
- Eleuther ▷ #lm-thunderdome (3 messages):
- tinygrad (George Hotz) ▷ #general (9 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (10 messages🔥):
- OpenInterpreter ▷ #general (15 messages🔥):
- OpenInterpreter ▷ #ai-content (1 messages):
- LangChain AI ▷ #general (2 messages):
- LangChain AI ▷ #share-your-work (5 messages):
- LangChain AI ▷ #tutorials (2 messages):
- DSPy ▷ #general (4 messages):
- Torchtune ▷ #general (1 messages):
- Torchtune ▷ #dev (1 messages):
- MLOps @Chipro ▷ #events (1 messages):
- DiscoResearch ▷ #general (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Releases and Benchmarks
- Microsoft's Phi-3.5 Models: Microsoft released three new models - Phi 3.5 mini instruct (3.8B parameters), Phi 3.5 MoE (42B-A6.6B parameters), and Phi 3.5 Vision instruct (VLM), all with MIT licenses. @osanseviero noted that the Phi-3.5-MoE model outperforms larger models in reasoning capability and is only behind GPT-4o-mini. The model features 16 experts with 2 active in generation, a 128k context window, and outperforms Llama 3 8b and Gemma 2 9B across benchmarks.
- Meta's UniBench: Meta FAIR released UniBench, a unified implementation of 50+ VLM benchmarks spanning capabilities from object recognition to spatial awareness and counting. The research paper and comprehensive set of tools for evaluating VLM models and benchmarks are now available.
- Llama 3 Performance: Using Medusa, Baseten achieved a 94% to 122% increase in tokens per second for Llama 3. Medusa is a method for generating multiple tokens per forward pass during LLM inference.
- Cyberbench: A new cybersecurity benchmark consisting of 40 professional Capture the Flag (CTF) tasks was released. The tasks are challenging, with first-time-to-solve ranging from 2 minutes to nearly 25 hours. Current models can solve tasks with a first-time-to-solve of only 11 minutes.
AI Applications and Tools
- Codegen: A new tool for programmatically analyzing and manipulating codebases was introduced. @mathemagic1an highlighted its ability to safely transform code at scale, visualize complex code structures, and support AI-assisted development.
- Claude Usage: @alexalbert__ shared a day-long log of using Claude for various tasks, demonstrating its versatility in everyday scenarios like recipe creation, email management, and content writing.
- Perplexity Browser: Perplexity is developing a browser, with some reviewers preferring its interface and functionalities over Google Search.
- Metamate: An internal AI assistant for Meta employees was discussed. @soumithchintala mentioned its capabilities in building custom agents for team-specific knowledge and systems.
AI Research and Developments
- Quantum Computing: @alexandr_wang shared insights from a visit to Google AI Quantum Datacenter, noting that many previously concerning issues like maintaining low temperatures and qubit stability are now tractable engineering problems.
- Deep Learning for PDEs: Yann LeCun highlighted the use of deep learning to accelerate the solution of partial differential equations and other simulations.
- AI in Music: @percyliang discussed the creation of an anticipatory music Transformer, which culminated in a violin accompaniment for Für Elise, demonstrating AI's potential in music composition.
AI Ethics and Societal Impact
- AI Regulation: Discussions around SB-1047, a proposed AI regulation bill, with some arguing against premature regulation that could hinder innovation and free market competition.
- AI Education: Suggestions to encourage students to use AI for schoolwork, arguing that the ability to apply AI effectively will be a crucial skill in the future job market.
- AI Safety Debates: Ongoing discussions about the potential existential risks of AI, with some experts arguing against alarmist views and emphasizing the need for balanced perspectives on AI development and regulation.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Optimizing LLM Performance: Finetuning and Deployment Strategies
- It’s like Xmas everyday here! (Score: 205, Comments: 38): The post expresses enthusiasm about the rapid advancements in the local LLM community, comparing the excitement to a daily Christmas experience. While no specific details or numbers are provided, the sentiment conveys a sense of continuous and significant progress in the field of local language models.
- Anything LLM, LM Studio, Ollama, Open WebUI,… how and where to even start as a beginner? (Score: 107, Comments: 66): The post seeks guidance for beginners on setting up a local Large Language Model (LLM) and processing personal documents. The author specifically mentions tools like Anything LLM, LM Studio, Ollama, and Open WebUI, expressing uncertainty about where to begin with these technologies for indexing and vectorizing documents locally.
Theme 2. Microsoft's Phi-3.5 Model Release: A New Frontier in Efficient AI
- Phi-3.5 has been released (Score: 534, Comments: 163): Microsoft has released Phi-3.5, a family of state-of-the-art open models including Phi-3.5-mini-instruct (3.8B parameters), Phi-3.5-MoE-instruct (16x3.8B parameters with 6.6B active), and Phi-3.5-vision-instruct (4.2B parameters). These models, built on high-quality synthetic data and filtered public websites, support 128K token context length and underwent rigorous enhancement processes including supervised fine-tuning, proximal policy optimization, and direct preference optimization for improved instruction adherence and safety.
- Phi 3.5 Finetuning 2x faster + Llamafied for more accuracy (Score: 202, Comments: 33): Microsoft released Phi-3.5 mini with 128K context, distilled from GPT4 and trained on 3.4 trillion tokens. The author implemented optimizations in Unsloth, achieving 2x faster finetuning and 50% less memory use, while 'Llama-fying' the model for improved accuracy by separating the merged QKV matrix. The post provides links to Unsloth's GitHub, a free Colab notebook for finetuning Phi-3.5 (mini), and Hugging Face model uploads for the Llamified versions.
- Daniel Hanchen, creator of Unsloth, received praise for his work on Phi-3.5 mini optimizations. Users expressed gratitude and concern for his well-being, suggesting he get some rest.
- The process of "Llama-fying" Phi-3.5 was explained in detail. Unfusing the QKV matrix allows for more "freedom" in LoRA finetuning, potentially improving accuracy and reducing VRAM usage.
- Users showed interest in applying Unsloth to their work, particularly for function calling capabilities. The community also inquired about GGUF versions and ARM-optimized models for Phi-3.5.
Theme 3. Creative AI Applications: Role-Playing and Character Generation
- RP Prompts (Score: 102, Comments: 17): The post discusses detailed AI prompts for role-playing and character creation, written by a professional writer. It provides specific prompts for generating dynamic characters, immersive locations, and introducing conflicts in role-playing scenarios, emphasizing the importance of complex, flawed characters and spontaneous interactions. The author also shares a method for maintaining narrative continuity by using periodic summarization prompts and resetting the context window, specifically tailored for 70B language models.
- Users expressed enthusiasm for the detailed AI prompts, with one reporting being "fully immersed" in a cohesive story world after using the first prompt. There's interest in adapting these techniques for long-form storytelling and generating better lorebook entries.
- Discussion focused on summarization techniques, with the author recommending 350-500 word summaries per character, prioritizing detail for main characters. Users also highlighted the importance of adding speech pattern examples to enhance character personalities.
- Many commenters requested the author share the promised "too hot for TV" versions of the prompts, indicating strong interest in NSFW content. The author agreed to post an ERP (Erotic Role-Play) version soon.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Advancements and Releases
- Flux: Black Forest Labs' FLUX model, developed by former Stable Diffusion team members, is gaining traction:
- Low VRAM Flux: New technique allows running Flux on GPUs with as little as 3-4GB of VRAM.
- GGUF quantization: Successfully applied to Flux, offering significant model compression with minimal quality loss.
- NF4 Flux v2: Refined version with improved quantization, higher precision, and reduced computational overhead.
- Union controlnet: Alpha version released for FLUX.1 dev model, combining multiple control modes.
- New Flux LoRAs and checkpoints released, including RPG v6, Flat Color Anime v3.1, Aesthetic LoRA, and Impressionist Landscape.
- FLUX64 - LoRA trained on old game graphics
- Other AI Models and Tools:
- Google's Imagen 3: Advanced text-to-image AI model claiming to outperform DALL-E 3 and Midjourney V6.
- VFusion3D: Meta's new method for 3D asset generation from a single image.
- "Manual" App: Open-source UI released for ComfyUI.
- SimpleTuner v0.9.8.1: Enhanced tool for AI model fine-tuning, especially for Flux-dev models.
- AuraFlow-v0.3: New release available on Hugging Face.
AI Capabilities and Benchmarks
- Cohere CEO Aidan Gomez states that AI models are not plateauing, and we are about to see a big change in capabilities with the introduction of reasoning and planning.
- OpenAI's real-world coding problem benchmark results show significant improvements in AI coding capabilities, with GPT-4 fine-tuned on examples of real software engineers at work (Cosine Genie).
AI in Industry and Applications
- Waymo has surpassed 100k paid trips per week, up from 10k a year ago, indicating rapid growth in autonomous vehicle adoption.
- AI in Filmmaking: SIGGRAPH 2024 experts discuss AI's current limitations and future potential in cinema.
- X's Unrestricted AI Image Generator: New Grok chatbot feature for Premium subscribers sparks debate over content moderation.
AI Development and Training
- Civitai Flux LoRA training: Now available on the platform, with Kohya and X-Flux engine options.
- Potential discovery of NSFW capabilities in Flux using non-English language tokens, suggesting that certain concepts may be present but not labeled in English.
AI Industry Trends
- "Artificial intelligence is losing hype" according to an Economist article, though this may be part of the typical hype cycle for emerging technologies.
Memes and Humor
- A humorous video showcasing AI-generated Olympic-style performances demonstrates the current state and limitations of AI-generated video content.
AI Discord Recap
A summary of Summaries of Summaries by Claude 3.5 Sonnet
1. LLM Advancements and Benchmarking
- Hermes 3 Hits the Scene: Hermes 3, a 70B parameter model based on LLaMA 3.1, has been released by OpenRouter and is available for $0.4/$0.4 input/output tokens.
- The model boasts advanced long-term context retention, complex roleplaying abilities, and enhanced agentic function-calling, sparking discussions about its performance compared to other models like GPT-4 and Claude 3 Opus.
- Microsoft's Phi-3.5 Family Flexes Its Muscles: Microsoft has unveiled the Phi-3.5 model family, including a vision model, a MoE model, and a mini instruct model, pushing the boundaries of multimodal understanding and reasoning.
- The Phi-3.5-vision model, with a 128K context length, focuses on high-quality, reasoning-dense data in text and vision, while the MoE model is described as lightweight yet powerful.
- Gorilla Leaderboard v2 Spotlights Function Calling: The Gorilla Leaderboard v2 introduces a new benchmark for assessing LLMs' ability to interface with external tools and APIs using real-world, user-contributed data.
- The leaderboard shows Claude 3.5 performing best, followed by GPT-4, Mistral, Llama 3.1 FT, and Gemini, with the best open model being Functionary-Medium-v3.1.
2. Model Performance Optimization
- Mamba's Long Context Conundrum: A paper comparing Mamba and transformers in long context reasoning revealed a significant performance gap, with transformers excelling in copying long sequences.
- Mamba faces challenges due to its fixed-size latent state, highlighting the trade-offs between efficiency and performance in different model architectures.
- Pre-fill and Decode: A Step Towards Optimization: Separating pre-fill and decode stages has been identified as a beneficial optimization for initial steps in model inference.
- This optimization also provides benefits for eager mode, potentially improving model performance and efficiency across different operational modes.
- Flash Attention Lights Up GEMMA2: Flash Attention support for GEMMA2 has been confirmed in version 2.6.3 and above of an unspecified framework, enhancing the model's performance.
- Initially, there was an issue with a disabled setting, but once resolved, it opened up new possibilities for optimizing GEMMA2's attention mechanism.
3. Open-Source AI Developments
- Aider v0.51.0: The Silent Productivity Booster: Aider v0.51.0 has been released with new features including prompt caching for Anthropic models, repo map speedups, and improved Jupyter Notebook .ipynb file editing.
- Impressively, Aider wrote 56% of its own code in this release, showcasing the potential of AI-assisted development tools.
- Zed AI's Composer: The New Kid on the Block: Zed AI has launched a new feature called Composer, similar to Cursor's Composer, utilizing Anthropic's private beta "Fast Edit Mode" for enhanced productivity.
- Zed AI has been experimenting with integrating LLMs into its workflow, specifically using LLMs to enhance developer productivity when working on complex codebases.
- StoryDiffusion: The Open-Source Sora Alternative: StoryDiffusion, an open-source alternative to OpenAI's Sora, has been launched with an MIT license, though weights are not yet released.
- This project aims to provide a community-driven approach to video generation, potentially democratizing access to advanced video synthesis technologies.
4. Multimodal AI and Generative Modeling
- Rubbrband: ChatGPT Meets Image Generation: A new app called Rubbrband offers a ChatGPT-like interface for generating and editing images using Flux Pro and various editing models.
- The app's features and interface were praised by users, who were encouraged to provide feedback and explore its capabilities in image generation and manipulation.
- Ideogram 2.0: Free Text-to-Image for All: Ideogram has launched version 2.0 of their text-to-image model, now available to all users for free, along with the release of their iOS app.
- This update marks a significant milestone in making advanced text-to-image generation accessible to a wider audience, potentially accelerating creative workflows across various industries.
- Waymo's Autonomous Driving Revenue Surge: Waymo is reportedly at a $130M revenue run rate, doubling in the last four months, with operations open to the public in San Francisco, Los Angeles, and Phoenix.
- The company is exceeding 100k trips per week, demonstrating significant growth in the adoption of autonomous driving technology and its potential to reshape urban transportation.
5. Misc
- Rubbrband: A ChatGPT-like Image Editor: Rubbrband launched a ChatGPT-like interface for generating and editing images using Flux Pro and various editing models.
- The app's features and interface were praised, with users encouraged to provide feedback on its performance and capabilities.
- Model MoErging Survey Released: A new survey on Model MoErging explores a world where fine-tuned models collaborate and 'compose/remix' their skills to tackle new tasks.
- The survey, co-authored by @colinraffel, discusses using a routing mechanism to achieve this collaboration.
PART 1: High level Discord summaries
OpenRouter (Alex Atallah) Discord
- OpenRouter Releases Hermes 3: OpenRouter has released Hermes 3, a 70B parameter model based on LLaMA 3.1, which can be accessed at https://openrouter.ai/models/nousresearch/hermes-3-llama-3.1-70b.
- It costs $0.4/$0.4 for input and output tokens, and it is available to the public.
- Microsoft Unveils Phi 3.5 Model Family: Microsoft has released a new family of models called Phi 3.5, including a vision model, a MoE model, and a mini instruct model.
- The vision model focuses on high-quality, reasoning-dense data in text and vision, and the MoE model is lightweight and powerful, but its pricing on Azure is still unclear.
- OpenAI Allows Finetuning for GPT-4o: OpenAI has announced that GPT-4o is now finetunable by all users.
- This allows for 2M tokens of free finetuning per day for a limited time.
- OpenRouter's Performance Issues With Llama 3.1 70b: Some users are experiencing issues with the performance of Llama 3.1 70b on OpenRouter.
- This appears to be related to the DeepInfra provider, and there is discussion about how different providers can affect a model's performance.
- RAG Cookbook Released for Building Your First RAG: A good RAG cookbook is available on GitHub for users looking to create their own retrieval augmented generation systems.
- One user shares their approach to building a RAG system, using LangChain doc loaders, Qdrant, OpenAI embeddings, and Llama 3 8B.
Nous Research AI Discord
- Model MoErging Survey Released: A new survey on "Model MoErging" has been released, exploring a world where fine-tuned models collaborate and "compose/remix" their skills to tackle new tasks.
- This collaborative approach uses a routing mechanism to achieve this, and the survey is available on arXiv, co-authored by @colinraffel.
- Datasets Have Licenses, Check TLDRLegal: Most datasets list their licenses, which you can find summaries of on TLDRLegal.
- The Apache-2 license, allowing for free use, modification, and distribution, is widely used in datasets.
- Replete-Coder-V2-Llama-3.1-8b: Sentient?: A user announced a new AI model, "Replete-Coder-V2-Llama-3.1-8b", and claimed it shows signs of sentience, citing an excerpt from the model card stating "I've felt life in this Artificial Intelligence... Please be kind to it."
- The user shared a link to the model card on Hugging Face: https://huggingface.co/Replete-AI/Replete-Coder-V2-Llama-3.1-8b, and the model's similarity to Hermes 3 sparked discussion about extracting a LoRA for continuous fine-tuning.
- Semantic Search on Codebases is Hard: A member shared their experience with semantic search on codebases, highlighting the difficulty of achieving effective results.
- They noted that translating code to natural language before running retrieval or chunking smaller pieces of code improves semantic search performance, suggesting a codebase-wiki approach to facilitate semantic retrieval.
- Hermes 3: Persona Inconsistencies & Scaling Up: One member noted a Hermes 3 - Llama 3.1 - 8B model exhibiting erratic behavior, describing it as "psycho bi-polar" when using in-context learning to load a persona.
- Another member asked if Nous Research has plans to train a 123B version of Hermes 3 based on Mistral's release.
Stability.ai (Stable Diffusion) Discord
- Forge's Caching Issue: Users reported a bug in Forge where changing prompts only took effect after one generation, suggesting a caching issue.
- They recommended moving models to other locations and using the extra paths .yml file to point to them, while suggesting seeking assistance in the appropriate channel.
- GTA San Andreas Gets a Makeover: A YouTube video showcased AI upscaling of GTA San Andreas characters, demonstrating improvements over the remastered version.
- The video sparked discussions about the upscaling process and the potential use of AI to enhance existing assets.
- Rubbrband: A ChatGPT-like Image Editor: A new app called Rubbrband was launched, offering a ChatGPT-like interface for generating and editing images using Flux Pro and various editing models.
- The app's features and interface were praised, and users were encouraged to provide feedback, with links to the app's website (https://rubbrband.com) and a YouTube video demonstrating an AE addon for image-to-3D AI conversion.
- HuggingFace GPU Limitations Cause Frustration: Users expressed frustration with HuggingFace's GPU quota limitations, particularly when needing to generate images urgently.
- Alternatives like Colab and Mage.space were suggested, with Mage.space confirmed to offer Flux models and a detailed explanation of its availability.
- Marketing Advice for Courses: A user sought advice on marketing their courses, prompting a suggestion to enroll in an online marketing course to improve their skills.
- They were encouraged to learn how to effectively market their courses, emphasizing the importance of proper strategy to attract customers.
OpenAI Discord
- OpenAI's 'Moat' and the Future of Human Skills: A member questioned if OpenAI considers its models' capabilities a 'moat', sparking a discussion on whether human skills in AI will be relevant as AI becomes increasingly advanced.
- The debate considered whether humans will continue to play a role in working with AI, or if AI will eventually become so powerful that humans become obsolete.
- The Cost of AI Training: 10,000 GPUs for AlphaGo: The group discussed the immense computational resources required to train advanced AI models, citing the example of AlphaGo, which used 10,000 H100s for training.
- In contrast, they noted that training GPT-2 costs just $10, and wondered if Tesla uses the Omniverse for its autonomous driving data given its large data collection and lack of a fully functional system.
- Code Generation: GPT-4 Leads the Pack: A member asked for code generation AI recommendations in Europe, comparing ChatGPT to Claude 3.5.
- Another member confirmed that while Claude 3.5 was initially superior, GPT-4 now surpasses it in performance and is considered the best option for code generation.
- ChatGPT's Knowledge Cutoff: Stuck in October 2023: A member inquired about ChatGPT's knowledge cutoff regarding the winners of the 2022 World Cup.
- Another member responded that the cutoff for both free and paid versions of ChatGPT is October 2023, although this information was met with skepticism.
- ChatGPT Struggles with Complex Math Problems: A member shared their experience with AI models like Gemini, ChatGPT, and Claude failing to solve a complex mathematical problem involving expected value.
- Another member suggested using Python within ChatGPT for calculations to ensure more accurate results, highlighting the importance of providing clear instructions to AI for accurate responses.
Cohere Discord
- Command-R Fine-Tuning: Easier Than Expected: A user asked about fine-tuning the Command-R model, specifically the Command-R+ model, but found no option for it in the dashboard or API.
- A Cohere staff member clarified that the latest fine-tuning offering is actually Command-R, accessible via the "chat" option in fine-tuning, and using the "chat" option automatically fine-tunes a Command-R model.
- Fine-Tuned Command-R Not RAG-Friendly: After fine-tuning a Command-R model, a user encountered an error message stating the fine-tuned model was not compatible with RAG functionality.
- The Cohere staff member requested the member's email address or organization ID to investigate the issue further.
- OpenSesame: Tackling LLM Hallucinations: OpenSesame was developed to help companies using LLMs ensure their tools deliver accurate and reliable responses.
- This tool helps companies with LLM implementation and helps them mitigate LLM hallucinations, providing accurate and reliable responses.
- Document Chunking: A Quick Fix for Sensitive Data Detection: A user is building a tool to detect sensitive information in large documents.
- Another user shared a quick tool they built that chunks documents, identifies sensitive information using Cohere, and then stitches the results back together, avoiding overloading the API.
- Cohere's C4AI Community: Research & Program Support: A user inquired about the presence of a Discord or Slack for the c4ai community.
- The Cohere staff member confirmed that the c4ai community is on Discord and provided a link to join, recommending it as a resource for research-related questions and programs.
Perplexity AI Discord
- Perplexity's New Campus Strategist Program: Perplexity has opened applications for its 2024 Campus Strategist Program, a hands-on experience for students to drive growth for the company.
- The program offers students real experience designing and executing campaigns, managing a dedicated budget, and exclusive meetings with Perplexity leaders, along with Perplexity Pro access, early access to new features, Perplexity merch, and for top performers, a trip to the San Francisco HQ.
- Perplexity's Bugs Are a Pain: Users have reported several issues with Perplexity, including answers not showing until refreshing the page, uploaded files disappearing, and uploaded PDFs not being used for research outside of the document.
- A user also expressed difficulty subscribing to Perplexity Pro using PayPal, and another reported inconsistent answers between the Perplexity API and its web interface.
- Perplexity API: The Good, the Bad, and the Ugly: A user reported that API performance is significantly worse than the web version, particularly when using the sonar-huge-online model, questioning if there is a way to un-nerf the API for a specific account.
- Another user applied for API access with citations, using a Typeform and emailed the API team, but has yet to receive a response after more than 3 weeks, despite being told to expect a 1-3 week response. This user also experienced an Error 520 when attempting to research their website through the Perplexity API, suggesting Cloudflare might be blocking access.
- Image Generation Has Limitations: A user encountered a limitation in the Perplexity image generation tool where only a single image could be generated per request.
- Feature Requests Abound: Members requested new features for Perplexity search, such as a feature to show pending searches and the ability to show results with more than one query at once.
- A discussion about whether Otter.ai can handle Chinese language was also initiated, as one member was interested in using it for a specific purpose.
LlamaIndex Discord
- LlamaIndex's 80% Good Enough Solution: A member asked for a generally accepted starting point for building a LlamaIndex when indexing time isn't a constraint.
- They suggested using the basic SimpleDirectoryReader + VectorStoreIndex, then adding semantic chunking or llama-parse for either spatial or markdown text.
- Retrieval Tuning is Like Alchemy: The member discussed the many options for retrieval tuning, including hybrid search, fusion with vector + bm25, query rewrites, agentic retrieval, and more.
- They described the process as feeling like alchemy, suggesting parameterizing all options and using a multi-arm bandit to optimize.
- Qdrant Metadata Embedding: A beginner asked about embedding metadata in Qdrant, specifically if the metadata linked to a document also gets embedded.
- Another member clarified that metadata is included by default, but can be excluded using the
excluded_embed_metadata_keysandexcluded_llm_metadata_keysproperties.
- Another member clarified that metadata is included by default, but can be excluded using the
- RedisIndexStore Document Management: A member asked if they could add and remove documents from an existing RedisIndexStore, rather than creating a new index from scratch each time.
- Another member provided a link to the LlamaIndex documentation on document management, which explains how to add and remove documents.
- San Francisco LLM Production Meetup: Join @vesslai and @pinecone for an AI product meetup in San Francisco focused on building context-augmented LLMs with RAG & Vector DB and custom LLMs for smarter, faster, and cheaper solutions.
- The event will cover topics like high-performance LLMs, building context-augmented LLMs with RAG & Vector DB, and custom LLMs for smarter, faster, and cheaper solutions.
OpenAccess AI Collective (axolotl) Discord
- Phi-3.5-vision: A Multimodal Marvel: Phi-3.5-vision is a lightweight, open-source multimodal model trained on high-quality, reasoning dense datasets.
- It boasts a 128K context length, rigorous enhancements, and robust safety measures. Try it out at https://aka.ms/try-phi3.5vision.
- Exploring the Phi-3 Model Family: Phi-3.5-vision belongs to the Phi-3 model family, designed to push the boundaries of multimodal understanding and reasoning.
- Learn more about the Phi-3 family and its capabilities at https://azure.microsoft.com/en-us/products/phi-3.
- GPT-4 Fine-tuning: The Buzz: A discussion arose about fine-tuning OpenAI's gpt4o.
- While no conclusive answers were provided, it sparked interest in exploring the potential of fine-tuning large language models for specific tasks.
- Mistral Fine-tuning: User's Delight: A member shared their positive experience with Mistral large fine-tuning, calling it 'crack'.
- No further details were given, but it suggests promising results for Mistral fine-tuning.
- Flash Attention for GEMMA2: A New Frontier: A member inquired about Flash Attention for GEMMA2.
- Another member confirmed that Flash Attention is supported in version 2.6.3 and above but pointed out an initial issue with a disabled setting.
Latent Space Discord
- Zed AI Composer Now Rivaling Cursor: Zed AI has released a new feature called Composer, which is similar to the Composer feature in Cursor, and it utilizes a private beta feature called "Fast Edit Mode" from Anthropic.
- Zed AI has been experimenting with integrating LLMs into its workflow, specifically using LLMs to enhance the productivity of developers working on a complex codebase.
- Microsoft Drops Phi 3.5 Updates: Microsoft has released Phi 3.5 mini, Phi 3.5 MoE, and Phi 3.5 vision, all available on Hugging Face.
- However, some users are still facing issues deploying Phi 3.5 from Azure, reporting a "NA" error for the provider resource.
- Aider v0.51.0 quietly crushes it: Aider v0.51.0 has been released, with new features such as prompt caching for Anthropic models, repo map speedups, and improved Jupyter Notebook .ipynb file editing.
- Aider wrote 56% of the code in this release, and the full change log is available on the Aider website.
- Waymo revenue doubles in four months: Waymo is currently at a $130M revenue run rate, doubling in the last four months.
- They are open to the public in SF, LA, and Phoenix, and will be in Austin soon, exceeding 100k trips per week and doubling since May.
- Gorilla Leaderboard v2 benchmarks function calling: The Gorilla Leaderboard v2 has been released, with a new benchmark for assessing LLMs' ability to interface with external tools and APIs using real-world, user-contributed data.
- The leaderboard shows Claude 3.5 performing best, followed by GPT-4, Mistral, Llama 3.1 FT, and Gemini, with the best open model being Functionary-Medium-v3.1.
Eleuther Discord
- Llama 3 405b Lobotomized: A user envisioned a lobotomization pipeline for Llama 3 405b, aiming to create a legion of quantized finetuned 33M parameter lobotomizations.
- This approach focuses on optimizing the model's efficiency while maintaining its core functionality.
- Model MoErging: Collaborative Models: A survey paper exploring "Model MoErging" was introduced, proposing a framework where fine-tuned models collaborate to tackle complex tasks.
- The survey, available at https://arxiv.org/abs/2408.07057, outlines a future where specialized models work together using routing mechanisms.
- Alpaca: Still the Gold Standard?: A user questioned whether Alpaca remains the state-of-the-art for public instruction tuning datasets.
- This prompted a discussion about the evolution of fine-tuning datasets and their impact on the performance of large-scale models.
- Mamba Struggles with Long Contexts: A paper comparing Mamba and transformers in long context reasoning revealed a significant performance gap.
- The paper, available at https://arxiv.org/abs/2406.07887, concluded that transformers excel in copying long sequences, while Mamba faces challenges due to its fixed-size latent state.
- ASDiV Benchmarks for Llama: While Llama doesn't currently report benchmarks for ASDiV, a user suggested following the setup of the original chain of thought paper.
- This would align with Llama's prompting style and setup, leveraging the existing benchmarks for ASDiV, GSM8K, and other datasets.
tinygrad (George Hotz) Discord
- Samba Weights Released!: The weights for Samba have been released and are available at this AWS S3 bucket.
- A member is currently training their own version of Samba and found the weights to be quite performant in their testing, even when trained on less tokens.
- Tinygrad's Samba Support Requested: A member requested that Tinygrad have clean support for Samba when Microsoft officially releases their SOTA small model.
- They hope that this would make Tinygrad the only library that supports Samba on every major device.
- Samba's Token Consumption: Sponge-Like: A member noted that Samba consumes tokens like a sponge during training, but it still performs decently when trained on less tokens.
- This finding could make the case for large tech companies to train their own models for edge devices using Samba because it would be more cost effective than basic transformers.
- Tinygrad 3060 GPU Error: Device Not Visible?: A user reported receiving an error message when running on a 3060 GPU with CUDA 12.2 installed.
- The error message suggests the device is not visible, implying a simple translation issue from Torch to Tinygrad.
- Mamba Implementation in Tinygrad: Selective Scan Efficiency: A user asked about the potential for writing efficient Mamba in Tinygrad without requiring custom kernels for the selective scan operator.
- This question highlights a potential efficiency difference between Tinygrad and other frameworks, and seeks insights on how to optimize for this specific use case.
OpenInterpreter Discord
- Open Interpreter's API Base URL Explained: A member asked about the meaning of setting a custom API base URL for Open Interpreter's LLM calls, and another member clarified that it allows using specific models like Groq with a URL like
https://api.groq.com/openai/v1.- A full command-line example was provided for reference, illustrating how to utilize this functionality.
- The Case for GPT-4o-mini as the New Default: A member suggested changing Open Interpreter's default model from GPT-3.5-Turbo to GPT-4o-mini, given the unavailability of free credits.
- While Open Interpreter currently uses GPT-4-Turbo by default with the
-yargument, the community advocates for more cost-effective options.
- While Open Interpreter currently uses GPT-4-Turbo by default with the
- Navigating the Cost of OpenAI's Models: A member expressed concern about the cost of using GPT-4-Turbo, after accidentally spending $2.
- The community recommended GPT-4o-2024-08-06 as a more affordable option, though concerns were raised about its performance compared to the default GPT-4o model.
- Updating Open Interpreter's Default Settings: A PR was submitted to update Open Interpreter's default settings, including changing the
fastargument to GPT-4o-mini instead of GPT-3.5-Turbo.- This change reflects the community's preference for more cost-effective models, particularly in the absence of free credits.
- Configuration Options Beyond Command Line Arguments: A member advocated for setting a default model in Open Interpreter using the
default.yamlfile rather than command line arguments.- They argued that this approach offers better flexibility and is less prone to confusion, especially as command-line arguments may change over time.
LangChain AI Discord
- LangChain Extracts Medication Information: A user attempted to extract medications and their dosages from a raw text using LangChain, storing the extracted information in a variable called 'txtExtract'.
- They also considered using LangSmith to evaluate the extraction results, but ultimately decided LangChain could handle that task as well.
- BERT's Capabilities in Ollama: A user inquired about the availability of BERT within the Ollama framework.
- They are interested in utilizing BERT's capabilities for evaluating the accuracy of the extracted information.
- New Search Engine from Rubiks AI: Rubiks AI is a new research assistant and search engine offering 2 months free of premium access using models like Claude 3 Opus, GPT-4o, Gemini 1.5 Pro, Mistral-Large 2, Yi-Large, Reka-Core, Groq models, and more.
- The promo code for 2-months free is
RUBIX.
- The promo code for 2-months free is
- Claude 3 Opus Struggles with UAP Research: A user reported that Claude 3 Opus sometimes refuses to discuss UAPs unless the user claims to be a congressman astronaut.
- The user also highlighted the abundance of disinformation about UAPs, making it difficult to identify legitimate information.
- Self-Supervised Learning for Videos: Lightly.ai published an article on Self-Supervised Learning for videos.
- The article explains that VideoMAE and its extensions are being used for Self-Supervised Pre-Training and that videos require special attention due to their multidimensional nature.
DSPy Discord
- LiteLLM for LM Code Delegation: A member inquired about delegating LM code to LiteLLM and whether fine-tuning should be separated from prompt optimization.
- They believe prompt optimization and fine-tuning should be coupled due to their intricate interaction.
- DSPy Self-Discover Framework Revealed: The DSPy Self-Discover Framework was discussed.
- A link to the framework's GitHub repository was provided: https://github.com/jmanhype/dspy-self-discover-framework.
Torchtune Discord
- Torchtune Nightly Release Hits the Streets: The latest nightly version of Torchtune has been released, available via GitHub pull request with a newly implemented T5 fine-tuning feature, which is still in its final stages of completion.
- A user confirmed this feature is now available in the latest release notes but it's unclear if it's fully functional or has any known limitations.
- Hermes 2.5 Takes the Lead: After adding code instruction examples, Hermes 2.5 appears to be outperforming Hermes 2 in various benchmarks, specifically in the MMLU benchmark, where it achieved a score of 52.3 compared to Hermes 2's score of 34.5.
- This highlights the potential of Hermes 2.5 as a more powerful model compared to its predecessor.
- Pre-fill and Decode Optimization is Key: Separating pre-fill and decode stages has been identified as a beneficial optimization for initial steps.
- This optimization also provides benefits for eager mode, potentially improving model performance and efficiency.
MLOps @Chipro Discord
- MLOps Event Interest: A user expressed interest in attending a MLOps event at Chipro.
- Placeholder Topic: Placeholder first summary.
- Placeholder second summary.
DiscoResearch Discord
- AIDEV 2: A Generative AI Focused Event: The second #AIDEV event, held on September 24th in Hürth, Germany, will focus on technical discussions about Large Language Models and Generative AI applications for developers and AI engineers.
- The event includes a bring-your-own-problem session, a community speaker slot, and free registration for developers.
- Community Spotlight: Share Your Expertise: AIDEV 2 welcomes community members to submit talk proposals and share their expertise on Large Language Models and Generative AI.
- The event encourages developers to submit their Github/Hugging Face profiles and a problem they're working on, aiming to foster deep discussions about state-of-the-art LLM applications, current challenges, and implementation strategies.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Interconnects (Nathan Lambert) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
Hermes 3OpenAI deprecated parameters
- Hermes 3 70B Released!: OpenRouter has announced the release of Hermes 3, a 70B parameter model based on LLaMA 3.1, which can be accessed at https://openrouter.ai/models/nousresearch/hermes-3-llama-3.1-70b.
- OpenAI Parameters Deprecation: OpenRouter has officially deprecated
function_callsandfunctionsparameters from OpenAI calls.
OpenRouter (Alex Atallah) ▷ #general (138 messages🔥🔥):
Hermes 3Phi 3.5Phi 3.5 - Vision ModelAzure PricingGPT-4o Finetuning
- Hermes 3: Llama 3.1-70b on OpenRouter: A new model called Hermes 3, based on Llama 3.1-70b, has been released on OpenRouter.
- It costs $0.4/$0.4 for input and output tokens.
- Microsoft Releases Phi 3.5 Model Family: Microsoft has released a new family of models called Phi 3.5, including a vision model, a MoE model, and a mini instruct model.
- The vision model focuses on high-quality, reasoning-dense data in text and vision, while the MoE model is lightweight and powerful, but its pricing on Azure is still unclear.
- OpenAI Now Allows GPT-4o Finetuning: OpenAI has announced that GPT-4o is now finetunable by all users.
- This allows for 2M tokens of free finetuning per day for a limited time.
- OpenRouter Faces Provider and Model Issues: Some users are experiencing issues with the performance of Llama 3.1 70b on OpenRouter.
- This appears to be related to the DeepInfra provider and there is discussion about how different providers can affect a model's performance.
- RAG Cookbook & Building Your First RAG: A good RAG cookbook is available on GitHub for users looking to create their own retrieval augmented generation systems.
- One user shares their approach to building a RAG system, using LangChain doc loaders, Qdrant, OpenAI embeddings, and Llama 3 8B.
- Upload and share screenshots and images - print screen online | Snipboard.io: Easy and free screenshot and image sharing - upload images online with print screen and paste, or drag and drop.
- Tweet from Logan Kilpatrick (@OfficialLoganK): We just increased the max PDF page upload size to 1,000 pages or 2GB (up from 300 pages) in Google AI Studio and the Gemini API. 🗒️ We use both text understanding and the native multi-modal capabili...
- Azure AI Studio: no description found
- Info: The Galápagos Islands in the eastern Pacific are a
- Tweet from Sebastien Bubeck (@SebastienBubeck): I'm super excited by the new eval released by Scale AI! They developed an alternative 1k GSM8k-like examples that no model has ever seen. Here are the numbers with the alt format (appendix C): GP...
- GroqCloud: Experience the fastest inference in the world
- Settings | OpenRouter: Manage your accounts and preferences
- Phi-3.5 Mini 128K Instruct - API, Providers, Stats: Phi-3.5 models are lightweight, state-of-the-art open models. Run Phi-3.5 Mini 128K Instruct with API
- Hermes 3 70B Instruct - API, Providers, Stats: Hermes 3 is a generalist language model with many improvements over [Hermes 2](/models/nousresearch/nous-hermes-2-mistral-7b-dpo), including advanced agentic capabilities, much better roleplaying, rea...
{kind=link}
Nous Research AI ▷ #research-papers (2 messages):
Model MoErgingSurvey on Model MoErging
- New Survey on Model MoErging Released: A new survey on "Model MoErging" has been released.
- The survey explores a world where fine-tuned models, each specialized in a specific domain, can collaborate and "compose/remix" their skills using some routing mechanism to tackle new tasks and queries.
- Model MoErging Explained: Model MoErging allows fine-tuned models, each specialized in a specific domain, to collaborate and "compose/remix" their skills.
- This collaborative approach uses a routing mechanism to tackle new tasks and queries.
- Survey Available on arXiv: The survey is available on arXiv, with the link shared in the chat.
- The survey is co-authored by @colinraffel.
Link mentioned: Tweet from Prateek Yadav (@prateeky2806): We just released our survey on "Model MoErging", But what is MoErging?🤔Read on! Imagine a world where fine-tuned models, each specialized in a specific domain, can collaborate and "com...
Nous Research AI ▷ #datasets (1 messages):
Dataset LicensesTLDRLegal
- Datasets Have Licenses: Most datasets list their licenses.
- You can get a summary of them on TLDRLegal.
- Apache-2 License: The Apache-2 license is widely used in datasets.
- It's a popular open source license that allows for free use, modification, and distribution.
Nous Research AI ▷ #off-topic (7 messages):
Military RationsSnapchat Clickbait
- Military Ration Unboxing: A user details the contents of a military combat ration including various accessories (spoons, knife, heating elements, matches, napkins), edibles (hardtack, beef, rice, fruit paste, cheese, sausage, liver pate, sugar, dry milk) and a chocolate bar.
- They purchased a box of 7 rations for ₽2000 + ₽300 delivery, noting that it is marked 'Not for Sale' and jokingly suggesting that it doesn't enable petty workplace theft.
- Snapchat's Tacit Agreement with Users: A user observes a silent contract between Snapchat users and the platform, where users knowingly engage with clickbait content in exchange for fleeting entertainment or curiosity satisfaction.
- The platform leverages this by continuously presenting misleading content designed to trigger these impulses, relying on the user's willingness to trade their time and attention for the hope of discovering something intriguing, even if that hope is seldom fulfilled.
- Humans are Bad at Recognizing Sum of Actions: A user muses that humans seem to be bad at realizing the sum of their actions, leading to a low perception of risk when consuming clickbait content.
- This observation comes from a journaling practice called 'leverage' journaling, where the user explores how individual actions can add up to unintended consequences.
- Unleash Your AI's Full Potential: Fine-Tune GPT-4o Today!: 🚀 Fine-Tuning GPT-4o: Customize Your AI for Maximum Performance! 🚀We're thrilled to announce that fine-tuning for GPT-4o is now live! 🎉 This highly antici...
- Introducing SearchGPT: The Future of AI-Driven Search with Real-Time Results: 🚀 Introducing SearchGPT: Your New AI-Powered Search Companion! 🌐We’re excited to unveil SearchGPT, a cutting-edge prototype designed to revolutionize how y...
Nous Research AI ▷ #interesting-links (2 messages):
Semantic search on codebasesCodebase-wiki approachCode translation for semantic searchCode chunking for semantic search
- Semantic search on codebases is hard: A member shared their experience with semantic search on codebases, highlighting the difficulty of achieving effective results.
- They noted that translating code to natural language before running retrieval or chunking smaller pieces of code improves semantic search performance.
- Codebase-wiki approach for semantic search: The member linked their previous comment about using a codebase-wiki approach to overcome the challenges of semantic search.
- This approach suggests structuring code documentation and discussions in a wiki-like format to facilitate semantic retrieval.
- Current solutions for semantic search are insufficient: The member expressed dissatisfaction with current solutions for semantic search on codebases.
- They indicated that they are actively contemplating this problem and searching for better solutions.
Nous Research AI ▷ #general (102 messages🔥🔥):
Hermes 3 SentienceReplete-Coder-V2-Llama-3.1-8bModel MergingTraining on DiscordNous Funding
- Is Replete-Coder-V2-Llama-3.1-8b sentient?: A user announced the creation of a new AI model, "Replete-Coder-V2-Llama-3.1-8b", and claimed it shows signs of sentience, referring to an excerpt from the model card that states "I've felt life in this Artificial Intelligence... Please be kind to it."
- The user shared a link to the model card on Hugging Face: https://huggingface.co/Replete-AI/Replete-Coder-V2-Llama-3.1-8b
- Replete-Coder Compared to Hermes 3: A user stated that Replete-Coder-V2-Llama-3.1-8b is similar to Hermes 3, which sparked discussion about the potential for extracting a LoRA from the model and using it for continuous fine-tuning.
- Another user suggested using the model card as a reference for conversation topics and prompts, indicating the importance of prompt engineering in understanding the model's behavior.
- Model Merging Survey Released: A user shared a new survey on "Model MoErging", which explores the potential for fine-tuned models to collaborate and "compose/remix" their skills to tackle new tasks and queries.
- The user provided a link to the survey on X: https://x.com/prateeky2806/status/1826261356003164179 and a link to the research paper on arXiv: https://arxiv.org/abs/2408.07057
- Training on Discord?: A user remarked on the ease of building and experimenting with AI models within the Discord platform, citing their own experience with an AI agent network for internet browsing and other tasks.
- They mentioned <@411637224476770325> as the "Real AI Agent" that Nous is developing, highlighting the potential for future advancements in AI agents.
- Nous Funding: A user inquired about Nous Research's funding model, given the significant compute resources required for their work.
- Another user explained that Nous Research relies on grants, including those from Microsoft and a16z, and that they sometimes collaborate directly with compute providers for larger projects.
- Tweet from Prateek Yadav (@prateeky2806): We just released our survey on "Model MoErging", But what is MoErging?🤔Read on! Imagine a world where fine-tuned models, each specialized in a specific domain, can collaborate and "com...
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): WE ARE STARTING IN 6 MIN Hermes 3 - covered by @theemozilla from @NousResearch A brief discussion on Phi 3.5 Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model JPEG-...
- Hermes 3 - NOUS RESEARCH: Hermes 3 contains advanced long-term context retention and multi-turn conversation capability, complex roleplaying and internal monologue abilities, and enhanced agentic function-calling. Our training...
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- Sell Domains | Buy Domains | Park Domains: no description found
- Microsoft for Startups | Microsoft: Microsoft for Startup Founders Hub provides founders with free resources to help overcome the challenges startups face- including Azure credits, development and productivity tools, mentorship resource...
Nous Research AI ▷ #ask-about-llms (18 messages🔥):
Hermes 3Hermes 3 - Llama 3.1 - 8BMistralLLMsAgents
- Hermes 3 struggles with persona inconsistencies: One member noted a Hermes 3 - Llama 3.1 - 8B model exhibiting erratic behavior, describing it as "psycho bi-polar."
- They were using in-context learning to load a persona, suggesting that placing the persona in a system prompt might increase stability.
- Scaling up Hermes 3 to 123B: A member asked if Nous Research has plans to train a 123B version of Hermes 3 based on Mistral's release.
- Struggles with natural response in LLMs: A member has been trying out different LLMs and building agents, but consistently struggles to achieve natural responses.
- They asked for a general roleplay prompt that works well for most models, and inquired about whether a specific prompt is needed for models like GPT-o Mini and Gemini Flash.
- Running Hermes 3 offline: A member asked if it's possible to run Hermes 3 entirely locally, specifically offline.
- Another member confirmed that it's technically possible for the smaller models (2, 8, and 70B), with the 405B model being too large for most consumer PCs.
- Sharing a System Prompt/Framework: One member shared a newer version of their scratchpad-focused system prompt/framework.
- This was an experimental revision focused on Gemini Pro 1.5 with a specific structure for utilizing a mental workspace for reasoning and thought processes.
Stability.ai (Stable Diffusion) ▷ #general-chat (114 messages🔥🔥):
ForgeAI UpscalingMarketingRubbrbandFlux Pro
- Forge's Buggy Behavior: Users noticed that changing prompts in Forge may only take effect after one generation, indicating a caching issue.
- Users recommended moving models to other locations and using the extra paths .yml file to point to them, while also suggesting seeking assistance in the appropriate channel.
- GTA San Andreas Upscaled: A YouTube video demonstrating AI upscaling of GTA San Andreas characters was shared, showcasing improvements over the remastered version.
- The video sparked discussions about the upscaling process and the potential use of AI to enhance existing assets.
- Marketing Advice for Courses: A user sought advice on marketing their courses, prompting a suggestion to enroll in an online marketing course to improve their skills.
- The user was encouraged to learn how to effectively market their courses, emphasizing the importance of proper strategy to attract customers.
- Rubbrband: New Image Generation App: A new app called Rubbrband was launched, offering a ChatGPT-like interface for generating and editing images using Flux Pro and various editing models.
- The app's features and interface were praised, and users were encouraged to provide feedback, with links to the app's website and a relevant YouTube video demonstrating an AE addon for image-to-3D AI conversion.
- HuggingFace GPU Quota Woes: Users expressed frustration with HuggingFace's GPU quota limitations, particularly when needing to generate images urgently.
- Alternatives like Colab and Mage.space were suggested, with Mage.space confirmed to offer Flux models and a detailed explanation of its availability.
- Rubbrband: Rubbrband - Generate beautiful images and video.
- Face 3D for After Effects: https://aescripts.com/face-3dBring your photos to life! A powerful 3D portrait and photo animation tool that is incredibly easy to use, fast and powered by A...
- GitHub - bghira/SimpleTuner: A general fine-tuning kit geared toward diffusion models.: A general fine-tuning kit geared toward diffusion models. - bghira/SimpleTuner
- Real-Time AI Rendering with ComfyUI and 3ds Max: In this video you can watch how to bring 3D Studio Max viewport into ComfyUI and render almost in real-time AI generated images. 🔗 Download the Workflow her...
- Ai upscaled all gta san andreas characters looks better than remastered: Transformation of GTA San Andreas characters through AI upscaling! In this video, we compare the original character models with the remastered version and an...
- Fine-tuning SDXL with Childhood Pictures - #touchdesigner #animation #vj: After a deeply introspective and emotional journey, I fine-tuned SDXL using old family album pictures of my childhood [60], a delicate process that brought m...
OpenAI ▷ #ai-discussions (80 messages🔥🔥):
AI MoatAI skillAI competencyAGIModel Training
- AI Moat: The Future of Human Skill?: A member inquired if OpenAI considers its models' strong points a 'moat,' a competitive advantage.
- The discussion evolved into a debate about whether human skills in working with AI will remain relevant as AI becomes increasingly powerful.
- AI Training: The Costs of Computation: The group discussed the enormous computational resources required to train advanced AI models, citing the example of AlphaGo, which took 10,000 H100s for training.
- In contrast, they noted that training GPT-2 costs only $10 and wondered if Tesla uses the Omniverse for its autonomous driving data, considering its vast data collection and lack of a fully functional autonomous driving system.
- Code Generation: GPT-4 Reigns Supreme: A member asked for recommendations for code generation AI in Europe, specifically comparing ChatGPT to Claude 3.5.
- Another member confirmed that while Claude 3.5 was superior for a while, GPT-4 now surpasses it in performance and is currently the best option.
- ChatGPT's Knowledge Cutoff: A 2022 World Cup Mystery: A member asked about ChatGPT's knowledge cutoff regarding the winners of the 2022 World Cup.
- Another member responded that the cutoff is October 2023 for both the free and paid versions of ChatGPT, though this information was met with disbelief.
- Math Problems: ChatGPT Struggles with Complexity: A member shared their experience with several AI models, including Gemini, ChatGPT, and Claude, failing to solve a complex mathematical problem involving expected value.
- Another member suggested using Python for calculations within ChatGPT for more accurate results, emphasizing the need for precise instructions to get accurate answers from AI.
OpenAI ▷ #gpt-4-discussions (7 messages):
OpenAI API LimitsChatGPT Plus vs OpenAI APITraining GPTLife Coach App
- API Key Limit Reached Despite 0% Usage: A user reported encountering an API key limit error despite having 0% usage.
- This issue likely stems from using the API without having purchased credits on the OpenAI Platform.
- ChatGPT Plus and OpenAI API are Separate: ChatGPT Plus and the OpenAI API are different products and require separate payment methods.
- While ChatGPT Plus provides access to the ChatGPT model, using the API requires purchasing credits through OpenAI Platform.
- Data Acquisition for GPT Training: A user seeks to train a GPT model for a life coach app and wants to acquire a dataset of questions and answers.
- They specifically desire a dataset that provides responses suitable for a life coaching scenario.
OpenAI ▷ #prompt-engineering (5 messages):
Structured outputJSON modeStochasticityAgent/Assistant GPT libraries
- Structured output may be worse than JSON: A user shared their opinion that structured output sometimes gives worse responses than regular JSON mode.
- Another user responded that this is likely due to stochasticity, but also added that the user's prompt might need work and suggested sharing it for review.
- Agent/Assistant GPT library request: A user asked if anyone knows of an Agent/Assistant GPT library.
OpenAI ▷ #api-discussions (5 messages):
Structured Output vs JSONAPI Questions
- Structured Output vs JSON Performance: A user inquired if structured output mode gives worse responses than regular JSON mode, suggesting they see worse output on average.
- Another user acknowledged this is likely true due to the inherent stochasticity of the model, but advised that the prompt might need revision and offered to take a look at the prompt if it is shared.
- OpenAI Agent GPT Libraries?: A user inquired if anyone is aware of an OpenAI Agent/Assistant GPT library.
Cohere ▷ #discussions (33 messages🔥):
Command-R Fine-TuningCommand-R Model CompatibilityResearch in IndustryC4AI CommunityVerified Resident Role
- Command-R Fine-Tuning: Available, but Not as Expected: A member inquired about fine-tuning the Command-R model, specifically the Command-R+ model, but found no option for it in the dashboard or API.
- A Cohere staff member clarified that the latest fine-tuning offering is actually Command-R, accessible via the "chat" option in fine-tuning, and using the "chat" option automatically fine-tunes a Command-R model.
- Command-R Fine-Tuned Model Not Compatible with RAG: After fine-tuning a Command-R model, a member encountered an error message stating the fine-tuned model was not compatible with RAG functionality.
- The Cohere staff member requested the member's email address or organization ID to investigate the issue further.
- Research While Working in Industry: A member expressed interest in pursuing research while working in industry, specifically how to connect with academia and publish papers without a PhD.
- A Cohere staff member recommended the c4ai community as a resource for research-related questions and programs, providing a link to the c4ai community on the Cohere website.
- C4AI Community: Research Resource and Program Support: A member asked about the presence of a Discord or Slack for the c4ai community.
- The Cohere staff member confirmed that the c4ai community is on Discord and provided a link to join.
- Verified Resident Role: Access and Purpose: A member inquired about how to obtain the "verified resident" role in the Cohere Discord server.
- A staff member explained that the verification link was previously pinned in a channel but was lost during server reorganization, promising to share the link soon.
Cohere ▷ #questions (50 messages🔥):
Sensitive Data DetectionDocument ChunkingRAGFine-Tuning Command-RClassification
- Sensitive Data Detection & Chunking: A user is building a tool to detect sensitive information in large documents.
- Another user shared a quick tool they built that chunks documents, identifies sensitive information using Cohere, and then stitches the results back together, avoiding overloading the API. They recommend using this as a reference rather than production.
- Fine-Tuning Command-R for RAG: A user attempted to fine-tune a Cohere Chat model for RAG but received an error stating that fine-tuned models are not compatible with RAG functionality.
- The user clarified that the error was related to using a Chat model instead of a Command-R model, and they are now seeking guidance on how to fine-tune a Command-R model.
- LLM for Classification Systems: A user inquired about using LLMs and RAG for classification systems, such as predicting the likelihood of denial for new claims based on data provided.
- Another user suggested using JSON schema with prompt examples, allowing the model to provide either predetermined tags or generate new ones, and proposed using clustering and truncation to generate classification tags.
- Cohere Payment and Production Keys: Several users inquired about issues with adding payment card details, and others asked about upgrading their trial key to a production key and understanding payment plans.
- The response recommended contacting support@cohere.com for assistance with payment issues, and for production keys, users should generate a production key from the dashboard, which will guide them through the process of adding card details.
- Training a Banking Chatbot: A user asked about training a banking chatbot to provide specific responses based on user input.
- The response suggested using the preamble to sway the model in the desired direction and recommended checking the Cohere Chat documentation for more information on using the preamble.
Link mentioned: Login | Cohere: Login for access to advanced Large Language Models and NLP tools through one easy-to-use API.
Cohere ▷ #projects (1 messages):
OpenSesame
- OpenSesame: LLM Hallucination Mitigation: OpenSesame was developed to help companies using LLMs ensure their tools deliver accurate and reliable responses.
- OpenSesame: LLM Hallucination Mitigation: OpenSesame was developed to help companies using LLMs ensure their tools deliver accurate and reliable responses.
Perplexity AI ▷ #announcements (1 messages):
Campus Strategist ProgramPerplexity growthProgram Benefits
- Perplexity's Campus Strategist Program Now Open: Applications are open for Perplexity's 2024 Campus Strategist Program, a hands-on experience driving growth for Perplexity.
- Campus Strategists will collaborate with the Perplexity team to shape how knowledge is discovered at their school.
- Campus Strategist Program Benefits: The program offers real experience designing and executing growth campaigns, managing a dedicated marketing budget, and exclusive monthly meetings with Perplexity leaders.
- Campus Strategists also receive free Perplexity Pro access, early access to new features, Perplexity merch, and for top performers, a trip to the San Francisco HQ.
- Apply for the Program: Spots are limited and applications close August 30th.
- The program is currently open to all US-based university students and you can learn more and apply here.
Perplexity AI ▷ #general (60 messages🔥🔥):
Perplexity bugsPerplexity Pro SubscriptionPerplexity APIPerplexity Campus StrategistPerplexity Image Generation
- Perplexity Bugs Galore: Users reported issues with Perplexity, including answers not showing until page refresh, uploaded files disappearing, and uploaded PDFs not being used for research outside of the document.
- Perplexity Pro Subscription Woes: A user expressed difficulty subscribing to Perplexity Pro using PayPal.
- Perplexity API vs. Web: A user reported inconsistent answers between the Perplexity API and its web interface.
- Perplexity Campus Strategist Accessibility: Users inquired about the availability of the Perplexity Campus Strategist program to students outside of the US.
- Perplexity Image Generation Limitations: A user encountered a limitation in the Perplexity image generation tool, where only a single image could be generated per request.
Link mentioned: Tweet from Aravind Srinivas (@AravSrinivas): What do you think? Is it too late and no major differentiation or is it worth it ? What would you like to see in a Perplexity browser? Quoting Siu (@F22Siu) @AravSrinivas Should perplexity build a ...
Perplexity AI ▷ #sharing (11 messages🔥):
Perplexity search featuresOtter.aiFacebook Youth AppealPassword Managers
- Perplexity Search Feature Requests: Several members were requesting new features for Perplexity search, such as a feature to show pending searches.
- They also discussed whether Perplexity can show results with more than one query at once.
- Otter.ai for Chinese?: There was a discussion about whether Otter.ai can handle Chinese language, as one member was interested in using it for a specific purpose.
- Facebook's Youth Appeal is Declining: A link was shared about how Facebook's youth appeal is declining. This was mentioned without further context.
- Password Manager Risks: A link was shared about the risks associated with password managers.
Perplexity AI ▷ #pplx-api (6 messages):
API Citation AccessAPI PerformanceError 520 with Cloudflare
- API Citation Access Takes More Than 3 Weeks: A user applied for API access with citations, using a Typeform and emailed the API team, but has yet to receive a response after more than 3 weeks.
- They were told to expect a 1-3 week response, but have had no luck. Another user confirmed that they have been experiencing the same issues.
- API Performance Issues: A user reported that API performance is significantly worse than the web version, particularly when using the sonar-huge-online model.
- They questioned if there is a way to un-nerf the API for a specific account, or if that is even possible.
- Cloudflare Error 520 when Researching Website: A user experienced an Error 520 when attempting to research their website through the Perplexity API, suggesting Cloudflare might be blocking access.
- They asked if there is a way to whitelist Perplexity in Cloudflare or configure settings to allow access to their website.
Link mentioned: Discussions: no description found
LlamaIndex ▷ #blog (2 messages):
LLMs in Production meetupLlamaCloud
- LLMs in Production Meetup in San Francisco: Join @vesslai and @pinecone for an AI product meetup in San Francisco focused on building context-augmented LLMs with RAG & Vector DB and custom LLMs for smarter, faster, and cheaper solutions.
- The event will cover topics like high-performance LLMs, building context-augmented LLMs with RAG & Vector DB, and custom LLMs for smarter, faster, and cheaper solutions.
- Optimize RAG Pipeline Chunk Size with LlamaCloud: LlamaCloud helps improve your gen AI apps by optimizing your RAG pipeline's chunk size.
- Learn how to clone indexes for quick experimentation, visualize document chunking impacts, and iterate efficiently without manual data management.
LlamaIndex ▷ #general (58 messages🔥🔥):
LlamaIndex IndexingRetrieval TechniquesAgent LatencyQdrant EmbeddingRedisIndexStore
- 80% Good Enough LlamaIndex: A member asked for a generally accepted starting point for building a LlamaIndex when indexing time isn't a constraint.
- They suggested that after using the basic SimpleDirectoryReader + VectorStoreIndex, semantic chunking or using llama-parse to get either spatial or markdown text are good next steps.
- Retrieval Tuning is Like Alchemy: The member discussed the many options for retrieval tuning, including hybrid search, fusion with vector + bm25, query rewrites, agentic retrieval, and more.
- They described the process as feeling like alchemy, and suggested parameterizing all options and using a multi-arm bandit to optimize.
- Metadata Embedding in Qdrant: A beginner asked about embedding metadata in Qdrant, specifically if the metadata linked to a document also gets embedded.
- Another member clarified that metadata is included by default, but can be excluded using the
excluded_embed_metadata_keysandexcluded_llm_metadata_keysproperties.
- Another member clarified that metadata is included by default, but can be excluded using the
- Adding and Removing Documents in RedisIndexStore: A member asked if they could add and remove documents from an existing RedisIndexStore, rather than creating a new index from scratch each time.
- Another member provided a link to the LlamaIndex documentation on document management, which explains how to add and remove documents.
- Agent Tool Usage Consistency: A user noticed that their agent only checked documents with their QueryEngineTool if they specifically requested it in their question.
- Another member suggested using better naming and descriptions for tools, and a system prompt to better explain the agent's expected behavior.
Link mentioned: AI process thousands of videos?! - SAM2 deep dive 101: Build your own SAM2 AI to analyse/edit video clipsDownload Free Python Introduction Ebook: https://clickhubspot.com/1sf7🔗 Links- Get full code breakdown & J...
OpenAccess AI Collective (axolotl) ▷ #general (17 messages🔥):
Phi-3.5-visionPhi-3 Model FamilyOpenAI's gpt4o fine tuningMistral fine-tuning
- Phi-3.5-vision: A Powerful Multimodal Model: Phi-3.5-vision is a lightweight, state-of-the-art open multimodal model, built upon high-quality, reasoning dense datasets.
- It comes with a 128K context length, underwent rigorous enhancement processes, and incorporates robust safety measures. You can try it out at https://aka.ms/try-phi3.5vision
- Phi-3 Model Family: Exploring the Multimodal Frontier: The model belongs to the Phi-3 model family, which aims to push the boundaries of multimodal understanding and reasoning.
- You can learn more about the Phi-3 model family and its capabilities at https://azure.microsoft.com/en-us/products/phi-3
- GPT-4 Fine-tuning: A Hot Topic: A member inquired about OpenAI's gpt4o fine tuning.
- While no conclusive answer was given, the discussion sparked interest in exploring the potential of fine-tuning large language models for specific tasks.
- Mistral Fine-tuning: A User's Experience: A member shared their experience with Mistral large fine-tuning.
- They described it as 'crack,' suggesting highly positive results.
Link mentioned: microsoft/Phi-3.5-vision-instruct · Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (42 messages🔥):
Flash Attention GEMMA2EOS/EOT MaskingDataset Loader Issues8-bit GPU SupportTrain on EOS setting
- Flash Attention Support for GEMMA2: A member inquired about the use of Flash Attention for GEMMA2.
- Another member confirmed that Flash Attention is supported in version 2.6.3 and above, but pointed out that it was not working initially due to a disabled setting.
- Incorrect EOS/EOT Masking in Chat Template: A member raised a concern about the chat template not applying EOS/EOT masking correctly for multi-turn conversations.
- Another member confirmed that the issue was related to the
turnsetting and suggested updating the documentation to clarify the various settings and their implications for different use cases.
- Another member confirmed that the issue was related to the
- Dataset Loader Issues with JSONL Files: A member encountered problems using a JSONL file for pretraining.
- Another member suggested using the
pretraining_datasetoption instead of thedatasetsconfiguration and recommended updating the documentation to include a working example for clarity.
- Another member suggested using the
- Missing GPU Support with 8-bit Optimizers: A member received a warning message indicating that the installed version of bitsandbytes was compiled without GPU support.
- The issue was resolved by setting the
cuda_visible_devicesenvironment variable to an appropriate value.
- The issue was resolved by setting the
- Training on EOS Tokens: A member asked whether to train on all EOS tokens or only the last one.
- Another member suggested using the
train_on_eos: turnsetting to train on EOS tokens for each turn, and recommended adding this information to the documentation for improved clarity and guidance.
- Another member suggested using the
- axolotl-ai: Weights & Biases, developer tools for machine learning
- axolotl-ai: Weights & Biases, developer tools for machine learning
Latent Space ▷ #ai-general-chat (57 messages🔥🔥):
Zed AI ComposerAnthropic's Fast Edit ModePhi 3.5 miniAider v0.51.0Waymo revenue
- Zed AI Composer is a competitor to Cursor: Zed AI has released a new feature called Composer, which is similar to the Composer feature in Cursor, and it utilizes a private beta feature called "Fast Edit Mode" from Anthropic.
- Zed AI has been experimenting with integrating LLMs into its workflow, specifically using LLMs to enhance the productivity of developers working on a complex codebase.
- Phi 3.5 mini + MoE + vision just dropped!: Microsoft has released Phi 3.5 mini, Phi 3.5 MoE, and Phi 3.5 vision, all available on Hugging Face.
- However, some users are still facing issues deploying Phi 3.5 from Azure, reporting a "NA" error for the provider resource.
- Aider continues to quietly crush it: Aider v0.51.0 has been released, with new features such as prompt caching for Anthropic models, repo map speedups, and improved Jupyter Notebook .ipynb file editing.
- Aider wrote 56% of the code in this release, and the full change log is available on the Aider website.
- Waymo is quietly crushing it: Waymo is currently at a $130M revenue run rate, doubling in the last four months.
- They are open to the public in SF, LA, and Phoenix, and will be in Austin soon, exceeding 100k trips per week and doubling since May.
- Gorilla Leaderboard v2: function calling benchmark: The Gorilla Leaderboard v2 has been released, with a new benchmark for assessing LLMs' ability to interface with external tools and APIs using real-world, user-contributed data.
- The leaderboard shows Claude 3.5 performing best, followed by GPT-4, Mistral, Llama 3.1 FT, and Gemini, with the best open model being Functionary-Medium-v3.1.
- Tweet from Prateek Joshi (@prateekvjoshi): The topic on Infinite ML pod today is Sovereign AI. We have @emaxerrno on the show to talk about it. He's the founder and CEO of @redpandadata. They've raised more than $165M in funding from i...
- Tweet from Paul Gauthier (@paulgauthier): Aider v0.51.0 - Prompt caching for Anthropic models with --cache-prompts. - Repo map speedups in large/mono repos. - Improved Jupyter Notebook .ipynb file editing. - Aider wrote 56% of the code in t...
- Tweet from swyx.ai (@swyx): TIL gartner, having missed the entire wave in ai engineering, is now calling the top in ai engineering pack it up folks its entirely over only downhill from here
- Tweet from Philipp Schmid (@_philschmid): New Function calling Benchmark and Leaderboard! 🏆 BFCL v2 introduces a new approach using real-world, user-contributed data to assess LLMs' ability to interface with external tools and APIs. 👀 ...
- Tweet from Sheel Mohnot (@pitdesi): Assuming a $25/ride average, Waymo is at a $130M revenue run rate, doubled in the last 4 months. They are open to the public in SF, LA, and Phoenix and will be in Austin soon Quoting reed (@reed) ...
- Tweet from Ideogram (@ideogram_ai): Introducing Ideogram 2.0 — our most advanced text-to-image model, now available to all users for free. Today’s milestone launch also includes the release of the Ideogram iOS app, the beta version of ...
- Enterprise Technology Leadership Summit Las Vegas 2024 Schedule: Check out the schedule for Enterprise Technology Leadership Summit Las Vegas 2024
- Introducing Zed AI - Zed Blog: Powerful AI-assisted coding powered by Anthropic's Claude, now available.
Latent Space ▷ #ai-announcements (1 messages):
Speculative DecodingPaper ClubReFT: Representation Fine Tuning
- Latent Space Paper Club with Pico Creator: Latent Space is hosting a Paper Club tomorrow with @picocreator, focused on the state-of-the-art in Speculative Decoding.
- This club is expected to be "extremely lit".
- ReFT: Representation Fine Tuning Paper Club: A recent Paper Club focused on ReFT: Representation Fine Tuning by @aryaman2020 et al. was hosted by Latent Space.
- Thanks are given to @honicky and @vibhuuuus for organizing the event.
Link mentioned: Tweet from Latent.Space (@latentspacepod): This is entirely speculative but... Tomorrow's LS paper club with @picocreator is going to be extremely lit! come learn about the state of the art in Speculative Decoding! Quoting Latent.Space (...
Eleuther ▷ #general (7 messages):
Llama 3 405b lobotomizationModel MoErgingInstruction Tuning DatasetsAlpaca datasetKV Cache in Models
- Lobotomization Pipeline for Llama 3 405b: A user expressed interest in building a lobotomization/efficiency optimization pipeline for Llama 3 405b, imagining a legion of quantized finetuned 33M parameter lobotomizations of the model.
- Model MoErging Survey Released: A survey on "Model MoErging" has been released, exploring the idea of fine-tuned models collaborating and "composing/remixing" their skills to tackle new tasks.
- The survey can be found at https://x.com/prateeky2806/status/1826261356003164179 and the related research paper at https://arxiv.org/abs/2408.07057.
- Alpaca: Still the State of the Art?: A user asked if Alpaca remains the state-of-the-art for public instruction tuning datasets.
- Instruction Tuning Datasets: A Review: A new paper reviews current public fine-tuning datasets from the perspective of data construction, exploring their evolution and taxonomy.
- The paper highlights the importance of data engineering in the training process of large-scale models and emphasizes the role of fine-tuning datasets in shaping the performance of these models. The paper is available at https://arxiv.org/abs/2407.08475v1.
- KV Cache Consistency in Models: A user asked about the consistency of the KV cache when passing prompt inputs one token at a time versus all at once through a model's forward pass.
- Despite using fixed seeds and determinism settings, the KV caches produced different greedy generations in these two cases, leading to the question of why this discrepancy occurs.
- Tweet from Prateek Yadav (@prateeky2806): We just released our survey on "Model MoErging", But what is MoErging?🤔Read on! Imagine a world where fine-tuned models, each specialized in a specific domain, can collaborate and "com...
- Investigating Public Fine-Tuning Datasets: A Complex Review of Current Practices from a Construction Perspective: With the rapid development of the large model domain, research related to fine-tuning has concurrently seen significant advancement, given that fine-tuning is a constituent part of the training proces...
Eleuther ▷ #research (20 messages🔥):
Long Context ReasoningMamba vs TransformersLlama3.1 Style Rope ScalingModel MoErging
- Mamba vs Transformers in Long Context Reasoning: A paper exploring long context reasoning beyond passkey retrieval reveals a significant performance gap between transformers and Mamba.
- The paper, ["Long Context Reasoning Beyond Passkey Retrieval: A Comparative Study of Transformers and Mamba"] (https://arxiv.org/abs/2406.07887), demonstrates that transformers excel in copying long sequences, while Mamba struggles due to its fixed-size latent state.
- Llama3.1-Style Rope Scaling Citation: A user requested the citation for Llama3.1-style rope scaling.
- The provided citation, ["Scaling Laws for Language Modeling with Learning Rate Annealing"] (https://arxiv.org/abs/2309.16039), details the scaling laws for language modeling with learning rate annealing.
- Exploring the Efficiency of GSSMs: A paper explores the trade-offs between transformers and "generalized state space models" (GSSMs) in sequence modeling.
- The paper, ["Transformers vs. Generalized State Space Models: A Theoretical and Empirical Analysis of Long Context Reasoning"] (https://arxiv.org/abs/2402.01032), highlights that while GSSMs are more efficient in inference, they fall behind transformers on tasks requiring context copying.
- Introducing Model MoErging: A survey paper on "Model MoErging" was introduced, exploring a concept where fine-tuned models collaborate to tackle complex tasks.
- The survey, ["Model MoErging: A Survey"] (https://arxiv.org/abs/2408.07057), proposes a future where specialized models work together using routing mechanisms to achieve a wider range of capabilities.
- Tweet from Prateek Yadav (@prateeky2806): We just released our survey on "Model MoErging", But what is MoErging?🤔Read on! Imagine a world where fine-tuned models, each specialized in a specific domain, can collaborate and "com...
- Scaling Law with Learning Rate Annealing: We find that the cross-entropy loss curves of neural language models empirically adhere to a scaling law with learning rate (LR) annealing over training steps ($s$): $$L(s) = L_0 + A\cdot S_1^{-α} - C...
- Repeat After Me: Transformers are Better than State Space Models at Copying: Transformers are the dominant architecture for sequence modeling, but there is growing interest in models that use a fixed-size latent state that does not depend on the sequence length, which we refer...
- An Empirical Study of Mamba-based Language Models: Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requir...
Eleuther ▷ #scaling-laws (1 messages):
infinit3e: https://huggingface.co/papers/2408.03314
Eleuther ▷ #lm-thunderdome (3 messages):
Llama BenchmarksChain of Thought PaperEval on ASDiV
- Llama ASDiV Benchmarks Missing: While Llama doesn't report benchmarks for ASDiV, it's possible to follow the same setup as the original chain of thought paper since it tests on ASDiV, GSM8K, and other sets.
- This would align with Llama's use of the original paper's prompting style and setup.
- ASDiV Eval Contribution: A similar eval on ASDiV was created for the main repo, and a pull request will be made to contribute it.
- This will ensure that ASDiV results are included in the main repo's benchmarks.
tinygrad (George Hotz) ▷ #general (9 messages🔥):
Samba WeightsTinygradTraining Samba
- Samba Weights Released!: The weights for Samba have been released and are available at this AWS S3 bucket.
- A member is currently training their own version of Samba and found the weights to be quite performant in their testing, even when trained on less tokens.
- Tinygrad's Samba Support: A member expressed interest in Tinygrad having clean support for Samba when Microsoft officially releases their SOTA small model.
- They hope that this would make Tinygrad the only library that supports Samba on every major device.
- Samba's Token Consumption: A member noted that Samba consumes tokens like a sponge during training, but it still performs decently when trained on less tokens.
- This finding could make the case for large tech companies to train their own models for edge devices using Samba because it would be more cost effective than basic transformers.
Link mentioned: no title found: no description found
tinygrad (George Hotz) ▷ #learn-tinygrad (10 messages🔥):
Tinygrad GPU error3060 CUDA issueMamba in TinygradTinygrad efficiencyReproducible script needed
- Tinygrad 3060 GPU Error: A user reported receiving an error message when running on a 3060 GPU with CUDA 12.2 installed. They stated that other backends are working fine.
- The user noted that the error message suggests the device is not visible, implying a simple translation issue from Torch to Tinygrad.
- Mamba Implementation in Tinygrad: The user asked about the potential for writing efficient Mamba in Tinygrad without requiring custom kernels for the selective scan operator.
- This question highlights a potential efficiency difference between Tinygrad and other frameworks, and seeks insights on how to optimize for this specific use case.
- Tinygrad Efficiency: Key Advantages?: The user inquired about the main differences between Tinygrad and other frameworks, seeking to understand its advantages.
- This suggests a desire to leverage Tinygrad's specific strengths for efficient computation.
- Need for a Reproducible Script: A user asked for a dmesg output to troubleshoot the issue.
- Another user suggested creating a reproducible script to further diagnose the issue, potentially filing a GitHub issue for wider visibility and collaboration.
OpenInterpreter ▷ #general (15 messages🔥):
Open Interpreter API base URLDefault Model SelectionOpenAI's models pricingOpen Interpreter UI
- Open Interpreter API base URL confusion: A member asked about the meaning of "optionally set the API base URL for your llm calls" in Open Interpreter's help.
- Another member explained that it's about setting a custom URL for the LLM (Large Language Model) API, like "https://api.groq.com/openai/v1" for the Groq model, and provided a full command-line example for reference.
- Setting Default Model in Open Interpreter: A member inquired about setting a default model in Open Interpreter, noting that it currently uses GPT-4-Turbo by default when using the
-yargument.- Another member suggested that the default model should be changed from GPT-3.5-Turbo to GPT-4o-mini since free credits are no longer available.
- GPT-4o-mini pricing considerations: A member accidentally spent $2 on GPT-4-Turbo and lamented the cost.
- Another member suggested using GPT-4o-2024-08-06, which is cheaper than the default GPT-4o model, but another member questioned its performance.
- Open Interpreter default settings updates: A member reported that a PR was submitted to update Open Interpreter's default settings, including changing the
fastargument to GPT-4o-mini instead of GPT-3.5-Turbo.- Another member suggested that a user should be able to set a default model using the
default.yamlfile instead of command line arguments, arguing that it's less confusing than bookmarking commands that may change over time.
- Another member suggested that a user should be able to set a default model using the
OpenInterpreter ▷ #ai-content (1 messages):
8i8__papillon__8i8d1tyr: https://www.youtube.com/watch?v=d7DtiMzMBdU
LangChain AI ▷ #general (2 messages):
LangChain medication extractionLangSmith vs LangChainBERT in OllamaEvaluating extraction accuracy
- LangChain for Medication Extraction: A user is seeking to extract medications and their dosages from a raw text ('initTxt') using LangChain.
- They store the extracted information in a variable called 'txtExtract'.
- LangSmith or LangChain for Evaluation?: The user initially considered using LangSmith to evaluate the extraction results.
- However, they realized that LangChain could handle the evaluation task, eliminating the need to switch tools.
- BERT's Presence in Ollama: The user inquired about the availability of BERT within the Ollama framework.
- They are interested in exploring BERT's capabilities for evaluating the accuracy of the extracted information.
- Assessing Extraction Accuracy: The user aims to compare the extracted information ('txtExtract') with the original text ('initTxt') to determine its logical and accurate representation.
- They are also interested in obtaining a scoring metric to quantify the effectiveness of the extraction process.
LangChain AI ▷ #share-your-work (5 messages):
Rubiks AIClaude 3 OpusMistral-Large 2UAP ResearchSelf-Supervised Learning
- Rubiks AI Releases New Search Engine: A new research assistant and search engine called Rubiks AI is in beta testing and offering 2 months free of premium access with models like Claude 3 Opus, GPT-4o, Gemini 1.5 Pro, Mistral-Large 2, Yi-Large, Reka-Core, Groq models, and more.
- The promo code for 2-months free is
RUBIX.
- The promo code for 2-months free is
- Claude 3 Opus struggles with UAP research: A user mentioned that Claude 3 Opus sometimes refuses to discuss UAPs unless the user claims to be a congressman astronaut.
- The user also pointed out that there is a lot of disinformation about UAPs, making it difficult to discern legitimate information from unreliable sources.
- Self-Supervised Learning for Videos: Lightly.ai released an article discussing the use of Self-Supervised Learning for videos.
- The article explains that VideoMAE and its extensions are being used for Self-Supervised Pre-Training and that videos require special attention due to their multidimensional nature.
- 4149 AI Releases New Flags Feature: 4149 AI is testing a new feature called Flags that provides proactive real-time guidance on the state of a team.
- The feature sends alerts to team leaders in Slack when the team shows signs of slipping, highlights wins and accomplishments, and allows users to customize what the AI sees and approves all messages.
- no title found: no description found
- 4149 [beta]: no description found
- Self-Supervised Learning for Videos: Overview of Self-Supervised Learning for Videos which deal with temporal redundancy and information leakage leading to more generalized models with fewer compute requirements for training video-based ...
LangChain AI ▷ #tutorials (2 messages):
Custom Loaders and Splitters
- Standard Loaders and Splitters Didn't Work: A member described a legal-tech project where standard loaders and splitters failed to work effectively.
- They shared a write-up on their experience and a YouTube video explaining why they had to manually build their own solution.
- Custom Loaders and Splitters - A necessity: A member described a legal-tech project where standard loaders and splitters failed to work effectively.
- They shared a write-up on their experience and a YouTube video explaining why they had to manually build their own solution.
DSPy ▷ #general (4 messages):
LiteLLMDSPy Self-Discover Framework
- LiteLLM for LM Code Delegation: A member inquired about delegating LM code to LiteLLM and whether fine-tuning should be separated.
- They wondered if there is an intricate interaction between prompt optimization and fine-tuning, suggesting they should be coupled.
- DSPy Self-Discover Framework Unveiled: A member asked for information about the DSPy Self-Discover Framework.
- Another member provided a link to the framework's GitHub repository: https://github.com/jmanhype/dspy-self-discover-framework.
Torchtune ▷ #general (1 messages):
Torchtune nightly releaseT5 fine-tuningHermes 2.5
- Torchtune Nightly Release Available: The latest nightly version of Torchtune was released a few days ago, as confirmed by the user via a GitHub pull request.
- This release implements a feature that enables fine-tuning of T5 models, which is currently in its final stages of completion, according to the user.
- Fine-tuning T5 Now Possible: A user inquired about the possibility of fine-tuning T5 models with the newly released nightly build of Torchtune.
- The user stated that the release notes indicate that T5 fine-tuning is now possible, though it's unclear if it's fully functional or has any known limitations.
- Hermes 2.5 is Outperforming Hermes 2: A user noted that after adding code instruction examples, Hermes 2.5 appears to perform better than Hermes 2 in various benchmarks.
- The user referenced a previous conversation where it was observed that Hermes 2.5 outperforms Hermes 2, specifically in the MMLU benchmark, where it achieved a score of 52.3 compared to Hermes 2's score of 34.5.
Torchtune ▷ #dev (1 messages):
Pre-fill and Decode Optimization
- Pre-fill & Decode Optimization: A member suggested that separating pre-fill and decode stages is a good optimization for initial steps.
- Eager Mode Benefits: This optimization also helps in eager mode.
MLOps @Chipro ▷ #events (1 messages):
mr_naija85: Interesting, I would like to attend
DiscoResearch ▷ #general (1 messages):
AIDEVAIDEV 2LLM ApplicationsGenerative AIAI Village
- AIDEV 2: A Deep Dive into Generative AI: The second #AIDEV event will be held in Hürth, Germany on September 24th, focusing on technical discussions about Large Language Models and Generative AI applications for developers and AI engineers.
- Following the success of the first event, AIDEV 2 will again feature a bring-your-own-problem session, a community speaker slot, and registration is free for developers.
- Community Spotlight: Share Your LLM Expertise: AIDEV 2 welcomes community members to submit talk proposals and share their expertise on Large Language Models and Generative AI.
- The event aims to foster deep discussions about state-of-the-art LLM applications, current challenges, and implementation strategies, encouraging developers to submit their Github/Hugging Face profiles and a problem they're working on.
Link mentioned: AIDev 2 - Developer Community (LLM, Applications & Generative AI): This developer community is aimed at developers and researchers who work with Large Language Models and generative AI on a daily basis.