[AINews] How Carlini Uses AI
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
An open mind is all you need.
AI News for 8/2/2024-8/5/2024. We checked 7 subreddits, 384 Twitters and 28 Discords (249 channels, and 5970 messages) for you. Estimated reading time saved (at 200wpm): 685 minutes. You can now tag @smol_ai for AINews discussions!
Congrats to Groq's shareholders' net worth going up while everyone else's goes down (and Intel's CEO prays). Nicholas Carlini of DeepMind is getting some recognition (and criticism) as one of the most thoughtful public writers on AI with a research background. This year he has been broadening out from his usual adversarial stomping grounds with his benchmark for large language models and made waves this weekend with an 80,000 word treatise on How He Uses AI, which we of course used AI to summarize:
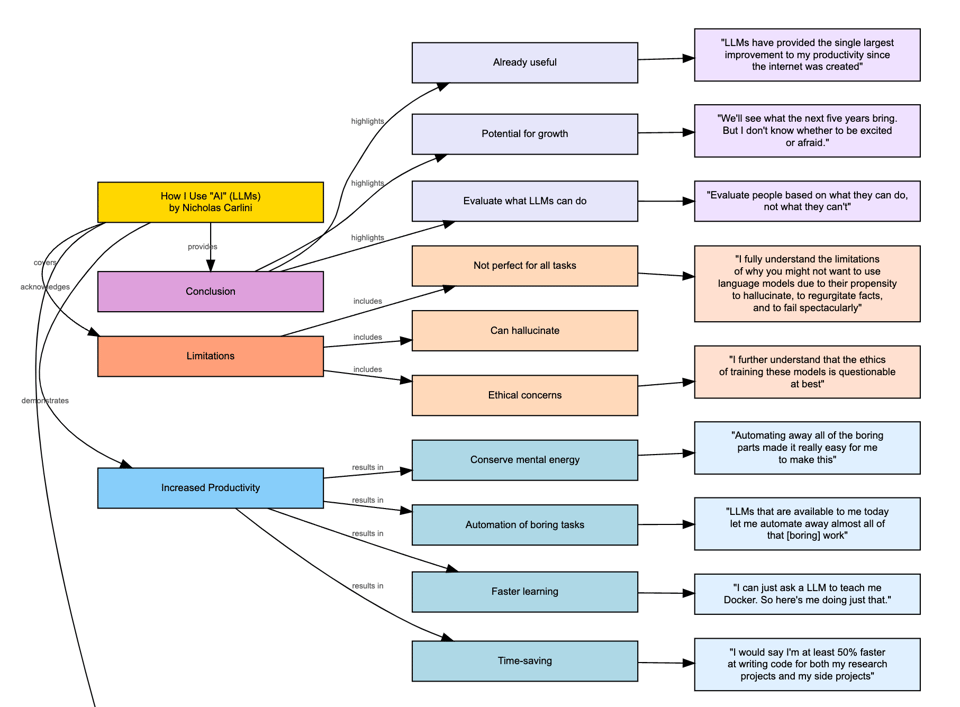
as well as usecases:
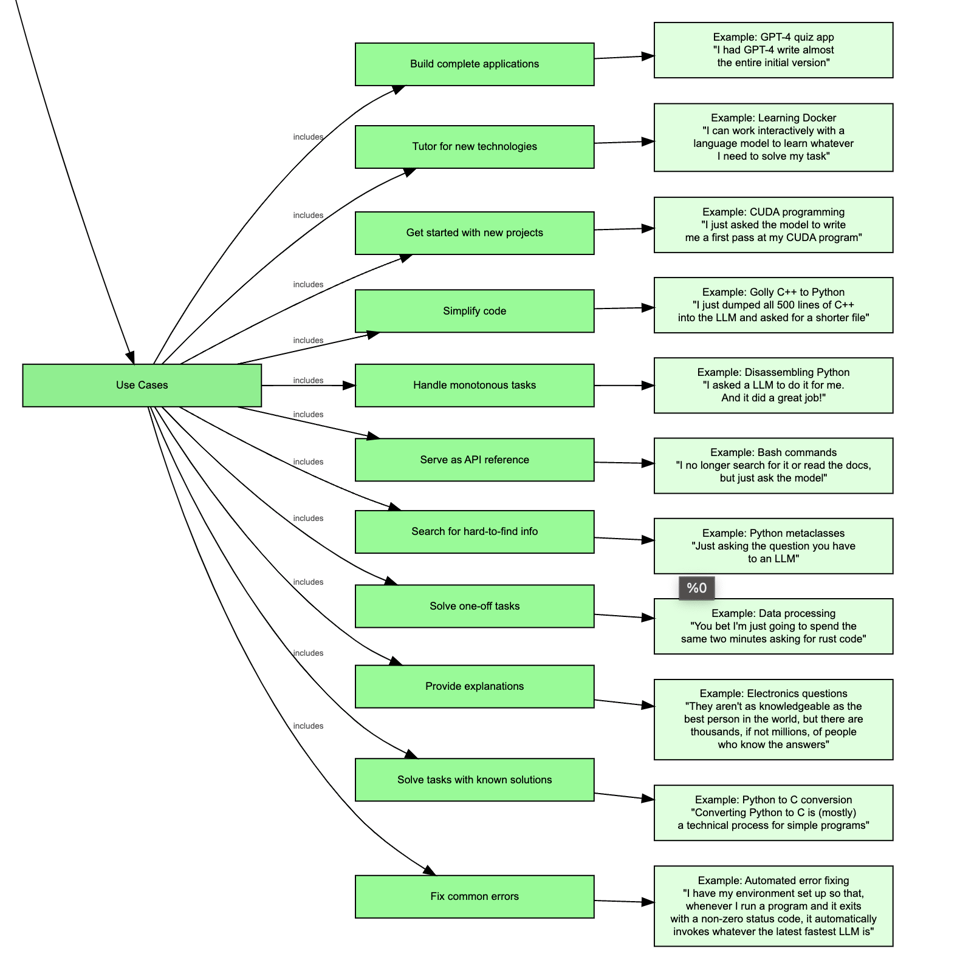
And, impressively, he says that this is "less than 2%" of the usecases for LLMs he has had (that's 4 million words of writing if he listed everything).
Chris Dixon is known for saying "What the smartest people do on the weekend is what everyone else will do during the week in ten years". When people blow wind on the setting AI Winter saying it hasn't produced enough measurable impact at work, they may simply be too short term oriented. Each of these is at least worth polished tooling, if not a startup.
New: we are experimenting with smol, tasteful ads specifically for help AI Engineers. Please click through to support our sponsors, and hit reply to let us know what you'd like to see!
[Sponsored by Box] Box stores docs. Box can also extract structured data from those docs. Here’s how to do it using the Box AI API..
swyx comment: S3's rigidity is Box's opportunity here. The idea of a "multimodal Box" - stick anything in there, get structured data out - makes all digital content legible to machines. Extra kudos to the blogpost for also showing that this solution -like any LLM-driven one- can fail unexpectedly!
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI and Robotics Developments
- Figure AI: @adcock_brett announced the launch of Figure 02, described as "the most advanced humanoid robot on the planet," with more details coming soon.
- OpenAI: Started rolling out 'Advanced Voice Mode' for ChatGPT to some users, featuring natural, real-time conversational AI with emotion detection capabilities.
- Google: Revealed and open-sourced Gemma 2 2B, scoring 1130 on the LMSYS Chatbot Arena, matching GPT-3.5-Turbo-0613 and Mixtral-8x7b despite being much smaller.
- Meta: Introduced Segment Anything Model 2 (SAM 2), an open-source AI model for real-time object identification and tracking across video frames.
- NVIDIA: Project GR00T showcased a new approach to scale robot data using Apple Vision Pro for humanoid teleoperation.
- Stability AI: Introduced Stable Fast 3D, generating 3D assets from a single image in 0.5 seconds.
- Runway: Announced that Gen-3 Alpha, their AI text-to-video generation model, can now create high-quality videos from images.
AI Research and Development
- Direct Preference Optimization (DPO): @rasbt shared a from-scratch implementation of DPO, a method for aligning large language models with user preferences.
- MLX: @awnihannun recommended using lazy loading to reduce peak memory use in MLX.
- Modality-aware Mixture-of-Experts (MoE): @rohanpaul_ai discussed a paper from Meta AI on a modality-aware MoE architecture for pre-training mixed-modal, early-fusion language models, achieving substantial FLOPs savings.
- Quantization: @osanseviero shared five free resources for learning about quantization in AI models.
- LangChain: @LangChainAI introduced Denser Retriever, an enterprise-grade AI retriever designed to streamline AI integration into applications.
AI Tools and Applications
- FarmBot: @karpathy likened FarmBot to "solar panels for food," highlighting its potential to automate food production in backyards.
- Composio: @llama_index mentioned Composio as a production-ready toolset for AI agents, including over 100 tools for various platforms.
- RAG Deployment: @llama_index shared a comprehensive tutorial on deploying and scaling a "chat with your code" app on Google Kubernetes Engine.
- FastHTML: @swyx announced starting an app using FastHTML to turn AINews into a website.
AI Ethics and Societal Impact
- AI Regulation: @fabianstelzer drew parallels between current AI regulation efforts and historical restrictions on the printing press in the Ottoman Empire.
- AI and Job Displacement: @svpino humorously commented on the recurring prediction of AI taking over jobs.
Memes and Humor
- @nearcyan shared a meme about Mark Zuckerberg's public image change.
- @nearcyan joked about idolizing tech CEOs.
- @lumpenspace made a humorous comment about the interpretation of diffusion as autoregression in the frequency domain.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. The Data Quality vs. Quantity Debate in LLM Training
- Since this is such a fast moving field, where do you think LLM will be in two years? (Score: 61, Comments: 101): In the next two years, the poster anticipates significant advancements in Large Language Models (LLMs), particularly in model efficiency and mobile deployment. They specifically inquire about potential reductions in parameter count for GPT-4-level capabilities and the feasibility of running sophisticated LLMs on smartphones.
- Synthetic data generation is becoming crucial as organic data runs out. The Llama 3 paper demonstrated successful techniques, including running generated code through ground truth sources to strengthen prediction abilities without model collapse.
- Researchers anticipate growth in multimodal domains, with models incorporating image/audio encoders for better world understanding. Future developments may include 4D synthetic data (xyzt data associated with text, video, and pictures) and improved context handling capabilities.
- Model efficiency is expected to improve significantly. Predictions suggest 300M parameter models outperforming today's 7B models, and the possibility of GPT-4 level capabilities running on smartphones within two years, enabled by advancements in accelerator hardware and ASIC development.
- "We will run out of Data" Really? (Score: 61, Comments: 67): The post challenges the notion of running out of data for training LLMs, citing that the internet contains 64 ZB of data while current model training uses data in the TB range. According to Common Crawl, as of June 2023, the publicly accessible web contains ~3 billion web pages and ~400 TB of uncompressed data, but this represents only a fraction of total internet data, with vast amounts existing in private organizations, behind paywalls, or on sites that block crawling. The author suggests that future model training may involve purchasing large amounts of private sector data rather than using generated data, and notes that data volume will continue to increase as more countries adopt internet technologies and IoT usage expands.
- Users argue that freely accessible and financially easily accessible data may run out, with companies realizing the value of their data and locking it down. The quality of internet data is also questioned, with some suggesting that removing Reddit from training data improved model performance.
- The 64 ZB figure represents total worldwide storage capacity, not available text data. Current models like GPT-4 have trained on only 13 trillion tokens (about 4 trillion unique), while estimates suggest over 200 trillion text tokens of decent quality are publicly available.
- A significant portion of internet data is likely video content, with Netflix accounting for 15% of all internet traffic in 2022. Users debate the value of this data for language modeling and suggest focusing on high-quality, curated datasets rather than raw volume.
Theme 2. Emerging AI Technologies and Their Real-World Applications
- Logical Fallacy Scoreboard (Score: 118, Comments: 61): The post proposes a real-time logical fallacy detection system for political debates using Large Language Models (LLMs). This system would analyze debates in real-time, identify logical fallacies, and display a "Logical Fallacy Scoreboard" to viewers, potentially improving the quality of political discourse and helping audiences critically evaluate arguments presented by candidates.
- Users expressed interest in a real-time version of the tool for live debates, with one suggesting a "live bullshit tracker" for all candidates. The developer plans to run the system on upcoming debates if Trump doesn't back out.
- Concerns were raised about the AI's ability to accurately detect fallacies, with examples of inconsistencies and potential biases in the model's judgments. Some suggested using a smaller, fine-tuned LLM or a BERT-based classifier instead of large pre-trained models.
- The project received praise for its potential to defend democracy, while others suggested improvements such as tracking unresolved statements, categorizing lies, and distilling the 70B model to 2-8B for real-time performance. Users also requested analysis of other politicians like Biden and Harris.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Capabilities and Advancements
- Flux AI demonstrates impressive text and image generation: Multiple posts on r/StableDiffusion showcase Flux AI's ability to generate highly detailed product advertisements with accurate text placement and brand consistency. Examples include a Tide PODS Flavor Bubble Tea ad and a Hot Pockets "Sleepytime Chicken" box. Users note Flux's superior text generation compared to other models like Midjourney.
- OpenAI decides against watermarking ChatGPT outputs: OpenAI announced they won't implement watermarking for ChatGPT-generated text, citing concerns about potential negative impacts on users. The decision sparked discussions about detection methods, academic integrity, and the balance between transparency and user protection.
AI Ethics and Societal Impact
- Debate over AI's impact on jobs: A highly upvoted post on r/singularity discusses the potential effects of AI on employment, reflecting ongoing concerns about workforce disruption.
- AI-powered verification and deepfakes: A post on r/singularity highlights the increasing sophistication of AI-generated images for verification purposes, raising questions about digital identity and the challenges of distinguishing between real and AI-generated content.
AI in Education and Development
- Potential of AI tutors: A detailed post on r/singularity explores the concept of AI tutors potentially enhancing children's learning capabilities, drawing parallels to historical examples of intensive education methods.
AI Industry and Market Trends
- Ben Goertzel on the future of generative AI: AI researcher Ben Goertzel predicts that the generative AI market will continue to grow, citing rapid development of high-value applications.
AI Discord Recap
A summary of Summaries of Summaries
1. LLM Advancements
- Llama 3 performance issues: Users reported issues with Llama 3's tokenization approach, particularly with EOS and BOS token usage leading to inference challenges. Participants speculated that missing tokens in inference could lead to out-of-distribution contexts during training, prompting a reassessment of documentation.
- Members agreed on the need for a reassessment of documentation to address these tokenization bugs, emphasizing the importance of accurate token handling.
- Claude AI offers code fixes: Members discussed using Claude AI to upload
output.jsonfor code fixes without file access, as outlined in this Medium article. Despite the potential, skepticism remained about the empirical effectiveness of this approach.- Skepticism remained about the empirical effectiveness of this approach, highlighting the need for more evidence-based results to validate its utility.
2. Model Performance Optimization
- Optimizing LLM inference speed: Suggestions for speeding up LLM inference included using torch.compile and comparing performance with tools like vLLM. The ongoing discussion highlights the interest in improving efficiency and performance for large language models.
- Members expressed keen interest in enhancing efficiency while handling large language models, exploring various tools and techniques.
- Mojo enhances data processing pipelines: Discussions highlighted the potential of Mojo for integrating analytics with database workloads, enabling quicker data handling through JIT compilation and direct file operations.
- Members mentioned compatibility with PyArrow and Ibis, suggesting a promising future for a robust data ecosystem within the Mojo framework.
3. Fine-tuning Challenges
- Challenges with fine-tuning multilingual models: Users shared their experiences with fine-tuning models like Llama 3.1 and Mistral with diverse datasets, encountering output relevance issues due to possibly incorrect prompt formatting. Suggestions urged reverting to standard prompt formats to ensure proper dataset handling.
- Participants emphasized the importance of using standard formats to avoid issues, highlighting the need for consistent prompt formatting.
- LoRA training issues: A user reported poor results from their SFTTrainer after trying to format datasets with concatenated text and labels, questioning potential misconfiguration. Clarifications pointed to correct column usage yet failed to resolve the underlying issue.
- Clarifications pointed to correct column usage but failed to resolve the underlying issue, indicating a need for further investigation into the dataset configuration.
4. Open-Source AI Developments
- Introducing DistillKit: Arcee AI announced DistillKit, an open-source tool for distilling knowledge from larger models to create smaller, powerful models. The toolkit combines traditional training techniques with novel methods to optimize model efficiency.
- The toolkit focuses on optimizing models to be efficient and accessible, combining traditional training techniques with novel distillation methods.
- OpenRouter launches new models: OpenRouter rolled out impressive new models, including Llama 3.1 405B BASE and Mistral Nemo 12B Celeste, which can be viewed at their model page. The addition of Llama 3.1 Sonar family further expands application capabilities.
- The new entries cater to diverse needs and adapt to community feedback for continual updates, enhancing the utility of OpenRouter's offerings.
5. Multimodal AI Innovations
- CatVTON redefines virtual try-on methods: A recent arXiv paper introduced CatVTON, a method that significantly reduces training costs by directly concatenating garment images. This innovation promises realistic garment transfers, revolutionizing virtual try-on tech.
- This method eliminates the need for a ReferenceNet and additional image encoders, maintaining realistic garment transfers while reducing costs.
- Open Interpreter speech recognition proposal: A user proposed implementing a speech recognition method in a native language, facilitating translation between English and the local tongue. They cautioned about translation errors, dubbing it Garbage in, Garbage out.
- The approach raised concerns about the potential pitfalls of translation errors, emphasizing the need for accurate input to ensure reliable output.
PART 1: High level Discord summaries
LM Studio Discord
- LM Studio suffers from performance hiccups: Multiple users reported issues with LM Studio version 0.2.31, particularly problems starting the application and models not loading correctly. Downgrading to earlier versions like 0.2.29 was suggested as a potential workaround.
- Users confirmed that performance inconsistencies persist, urging the community to explore stable versions to maintain workflow.
- Model download speeds throttle down: Users experienced fluctuating download speeds from LM Studio's website, with reports of throttled speeds as low as 200kbps. Suggestions include waiting or retrying downloads later due to typical AWS throttling issues.
- The conversation underscored the need for patience during high-demand download times, further stressing the importance of checking connection stability.
- AI wants to control your computer!: Discussion arose about whether AI models, particularly OpenInterpreter, could gain vision capabilities to control PCs, pointing to the limitations of current AI understanding. Participants expressed concerns about potential unforeseen behaviors from such integrations.
- The debate highlighted the need for careful consideration before implementing AI control mechanisms on local systems.
- Multi-modal models create curious buzz: Interest in multi-modal models available for AnythingLLM sparked discussions among users, emphasizing exploration of uncensored models. Resources like UGI Leaderboard were recommended for capability comparisons.
- Participants stressed the importance of community-driven exploration of advanced models to enhance functional versatility.
- Dual GPU setups draw mixed views: Conversations about dual 4090 setups suggest benefits of splitting models across cards for improved performance, yet caution users about programming requirements for effective utilization. Concerns persist regarding the struggle of a single 4090 with larger models.
- Members preferred discussing the balance between power and ease of use when considering multi-GPU configurations.
HuggingFace Discord
- Diving into Hugging Face Model Features: Users shared insights about various models on Hugging Face such as MarionMT for translations and the TatoebaChallenge for language support.
- Concerns about model limitations and the necessity for better documentation sparked a broader discussion.
- Speeding Up LLM Inference Techniques: Optimizing LLM inference became a hot topic, with suggestions like using torch.compile and evaluating performance with tools such as vLLM.
- Members expressed keen interest in enhancing efficiency while handling large language models.
- CatVTON Redefines Virtual Try-On Methods: A recent arXiv paper introduced CatVTON, a method that significantly reduces training costs by directly concatenating garment images.
- This innovation promises realistic garment transfers, revolutionizing virtual try-on tech.
- Gradient Checkpointing Implementation in Diffusers: Recent updates now include a method for setting gradient checkpointing in Diffusers, allowing toggling in compatible modules.
- This enhancement promises to optimize memory usage during model training.
- Identifying Relationships in Tables Using NLP: Members are exploring NLP methods to determine relationships between tables based on their column descriptions and names.
- This inquiry suggests a need for further exploration in the realm of relational modeling with NLP.
Stability.ai (Stable Diffusion) Discord
- Flux Model Rockets on GPUs: Users reported image generation speeds for the Flux model ranging from 1.0 to 2.0 iterations per second depending on GPU setup and model version.
- Some managed successful image generation on lower VRAM setups using CPU offloading or quantization techniques.
- ComfyUI Installation Hacks: Discussions revolved around the installation of Flux on ComfyUI, recommending the use of the
update.pyscript instead of the manager for updates.- Helpful installation guides were shared for newcomers to smoothly set up their environments.
- Stable Diffusion Model Showdown: Participants detailed the different Stable Diffusion models: SD1.5, SDXL, and SD3, noting each model's strengths while positioning Flux as a newcomer from the SD3 team.
- The higher resource demands of Flux compared to traditional models were highlighted in the discussions.
- RAM vs VRAM Showdown: Adequate VRAM is critical for Stable Diffusion performance, with users recommending at least 16GB VRAM for optimal results, overshadowing the need for high RAM.
- The community advised that while RAM assists in model loading, it's not a major factor in generation speeds.
- Animation Tools Inquiry: Participants queried about tools like Animatediff for video content generation, seeking the latest updates on available methods.
- Current suggestions highlight that while Animatediff is still useful, newer alternatives may be surfacing for similar tasks.
CUDA MODE Discord
- Epoch 8 Accuracy Spikes: Members noted a surprising spike in accuracy scores after epoch 8 during training, raising questions on expected behaviors.
- Looks totally normal reassured another member, indicating no cause for concern.
- Challenges with CUDA in DRL: Frustrations arose around creating environments in CUDA for Deep Reinforcement Learning with PufferAI suggested for better parallelism.
- Participants stressed the complexities involved in setup, emphasizing the need for robust tooling.
- Seeking Winter Internship in ML: A user is urgently looking for a winter internship starting January 2025, focused on ML systems and applied ML.
- The individual highlighted previous internships and ongoing open source contributions as part of their background.
- Concerns Over AI Bubble Bursting: Speculation about a potential AI bubble began circulating, with contrasting views on the long-term potential of investments.
- Participants noted the lag time between research outcomes and profitability as a key concern.
- Llama 3 Tokenization Issues: Inconsistencies in Llama 3's tokenization approach were discussed, specifically regarding EOS and BOS token usage leading to inference challenges.
- Participants agreed on the need for a reassessment of documentation to address these tokenization bugs.
Unsloth AI (Daniel Han) Discord
- Unsloth Installation Issues Persist: Users faced errors when installing Unsloth locally, particularly regarding Python compatibility and PyTorch installation, with fixes such as upgrading pip.
- Some solved their issues by reconnecting their Colab runtime and verifying library installations.
- Challenges with Fine-tuning Multilingual Models: Users shared their experiences fine-tuning models like Llama 3.1 and Mistral with diverse datasets, encountering output relevance issues due to possibly incorrect prompt formatting.
- Suggestions urged reverting to standard prompt formats to ensure proper dataset handling.
- LoRA Training Stumbles on Dataset Format: A user reported poor results from their SFTTrainer after trying to format datasets with concatenated text and labels, questioning potential misconfiguration.
- Clarifications pointed to correct column usage yet failed to resolve the underlying issue.
- Memory Issues with Loading Large Models: Loading the 405B Llama-3.1 model on a single GPU resulted in memory challenges, prompting users to note the necessity of multiple GPUs.
- This highlights a common understanding that larger models demand greater computational resources for loading.
- Self-Compressing Neural Networks Optimize Model Size: The paper on Self-Compressing Neural Networks discusses using size in bytes in the loss function to achieve significant reductions, requiring just 3% of the bits and 18% of the weights.
- This technique claims to enhance training efficiency without the need for specialized hardware.
Perplexity AI Discord
- Perplexity's Browsing Capabilities Under Fire: Users reported mixed experiences with Perplexity's browsing, noting struggles in retrieving up-to-date information and strange behaviors when using the web app.
- Conversations highlighted inconsistencies in model responses, particularly for tasks like coding queries that are essential for technical applications.
- Breakthrough in HIV Research with Llama Antibodies: Researchers at Georgia State University engineered a hybrid antibody that combines llama-derived nanobodies with human antibodies, neutralizing over 95% of HIV-1 strains.
- This hybrid approach takes advantage of the unique properties of llama nanobodies, allowing greater access to evasive virus regions.
- Concerns Over Model Performance: Llama 3.1 vs. Expectations: Users found that the Llama 3.1-sonar-large-128k-online model underperformed in Japanese tests, providing less accurate results than GPT-3.5.
- This has led to calls for the development of a sonar-large model specifically optimized for Japanese to improve output quality.
- Uber One Subscription Frustration: A user criticized the Uber One offer as being limited to new Perplexity accounts, indicating it serves more as a user acquisition tactic than a genuine benefit.
- Debates about account creation to capitalize on promotions raised important questions about user management in AI services.
- API Quality Concerns with Perplexity: Multiple users shared issues with the Perplexity API, mentioning unreliable responses and the return of low-quality results when querying recent news.
- Frustrations arose over API outputs, which often appeared 'poisoned' with nonsensical content, urging a demand for improved model and API performance.
OpenAI Discord
- OpenAI DevDay Hits the Road: OpenAI is taking DevDay on the road this fall to San Francisco, London, and Singapore for hands-on sessions, demos, and best practices. Attendees will have the chance to meet engineers and see how developers are building with OpenAI; more info can be found at the DevDay website.
- Participants will interact with engineers during the events, enhancing technical understanding and community engagement.
- AI's Global Threat Discussion: A heated debate unfolded regarding the perception of AI as a global threat, highlighting government behavior concerning open-source AI versus superior closed-source models. Concerns about potential risks rise in light of expanding AI capabilities.
- This issue was emphasized as viewpoints regarding AI's implications become increasingly polarized.
- Insights on GPT-4o Image Generation: Discussions revealed insights into GPT-4o's image tokenization capabilities, with the potential for images to be represented as tokens. However, practical implications and limitations remain blurry in the current implementations.
- Mentioned resources include a tweet from Greg Brockman discussing the team's ongoing work in image generation with GPT-4o.
- Prompt Engineering Hurdles: Users reported ongoing challenges in producing high-quality output when utilizing prompts with ChatGPT, often leading to frustration. The difficulty lies in defining what constitutes high-quality output, complicating interactions.
- Members shared experiences illustrating the importance of crafting clear, open-ended prompts to improve results.
- Diversity and Bias in AI Image Generation: Concerns arose about racial representation in AI-generated images, with specific prompts prompting refusals due to terms of service guidelines. Members exchanged successful strategies to ensure diverse representation by explicitly including multiple ethnic backgrounds in their prompts.
- The discussion also revealed negative prompting effects where attempts to restrict traits produced undesirable results. Recommendations centered around crafting positive, detailed descriptions to enhance output quality.
Latent Space Discord
- AI Engineer Demand Soars: The need for AI engineers is skyrocketing as companies seek generalist skills, particularly from web developers who can integrate AI into practical applications.
- This shift highlights the gap in high-level ML expertise, pushing web devs to fill key roles in AI projects.
- Groq Raises $640M in Series D: Groq has secured a $640 million Series D funding round led by BlackRock, boosting its valuation to $2.8 billion.
- The funds will be directed towards expanding production capacity and enhancing the development of next-gen AI chips.
- NVIDIA's Scraping Ethics Under Fire: Leaked information reveals NVIDIA's extensive AI data scraping, amassing 'a human lifetime' of videos daily and raising significant ethical concerns.
- This situation has ignited debates on the legal and community implications of such aggressive data acquisition tactics.
- Comparing Cody and Cursor: Discussions highlighted Cody's superior context-awareness compared to Cursor, with Cody allowing users to index repositories for relevant responses.
- Users appreciate Cody's ease of use while finding Cursor's context management cumbersome and complicated.
- Claude Introduces Sync Folder Feature: Anthropic is reportedly developing a Sync Folder feature for Claude, enabling batch uploads from local folders for better project management.
- This feature is anticipated to streamline the workflow and organization of files within Claude projects.
Nous Research AI Discord
- Recommendations on LLM as Judge and Dataset Generation: A user inquired about must-reads related to current trends in LLM as Judge and synthetic dataset generation, focusing on instruction and preference data, highlighting the latest two papers from WizardLM as a starting point.
- This discussion positions LLM advancements as crucial in understanding shifts in model applications.
- Concerns Over Claude Sonnet 3.5: Users reported issues with Claude Sonnet 3.5, noting its underperformance and increased error rates compared to its predecessor.
- This raises questions about the effectiveness of recent updates and their impact on core functionalities.
- Introduction of DistillKit: Arcee AI announced DistillKit, an open-source tool for distilling knowledge from larger models to create smaller, powerful models.
- The toolkit combines traditional training techniques with novel methods to optimize model efficiency.
- Efficient VRAM Calculation Made Easy: A Ruby script was shared for estimating VRAM requirements based on bits per weight and context length, available here.
- This tool aids users in determining maximum context and bits per weight in LLM models, streamlining VRAM calculations.
- Innovative Mistral 7B MoEification: The Mistral 7B MoEified model allows slicing individual layers into multiple experts, aiming for coherent model behavior.
- This approach enables models to share available expert resources equally during processing.
OpenRouter (Alex Atallah) Discord
- Chatroom Gets a Fresh Look: The Chatroom has been launched with local chat saving and a simplified UI, allowing better room configuration at OpenRouter. This revamped platform enhances user experience and accessibility.
- Users can explore the new features to enhance interaction within the Chatroom.
- OpenRouter Announces New Model Variants: OpenRouter rolled out impressive new models, including Llama 3.1 405B BASE and Mistral Nemo 12B Celeste, which can be viewed at their model page. The addition of Llama 3.1 Sonar family further expands application capabilities.
- The new entries cater to diverse needs and adapt to community feedback for continual updates.
- Mistral Models Now on Azure: The Mistral Large and Mistral Nemo models are now accessible via Azure, enhancing their utility within a cloud environment. This move aims to provide better infrastructure and performance to users.
- Users can leverage Azure's capacity while accessing high-performance AI models effortlessly.
- Gemini Pro Undergoes Pricing Overhaul: The pricing for Google Gemini 1.5 Flash will be halved on the 12th, making it more competitive against counterparts like Yi-Vision and FireLLaVA. This shift could facilitate more user engagement in automated captioning.
- Community feedback has been crucial in shaping this transition as users desire more economical options.
- Launch of Multi-AI Answers: The Multi-AI answer website has officially launched on Product Hunt with the backing of OpenRouter. Their team encourages community upvotes and suggestions to refine the service.
- Community contributions during the launch signify the importance of user engagement in the development process.
Modular (Mojo 🔥) Discord
- Mojo speeds up data processing pipelines: Discussions highlight the potential of Mojo for integrating analytics with database workloads, enabling quicker data handling through JIT compilation and direct file operations.
- Members mentioned compatibility with PyArrow and Ibis, suggesting a promising future for a robust data ecosystem within the Mojo framework.
- Elixir's confusing error handling: Members discussed Elixir's challenge where libraries return error atoms or raise exceptions, leading to non-standardized error handling.
- A YouTube video featuring Chris Lattner and Lex Fridman elaborated on exceptions versus errors, providing further context.
- Mojo debugger lacks support: A member confirmed that the Mojo debugger currently does not work with VS Code, referencing an existing GitHub issue for debugging support.
- Debugging workflows appear to be reliant on print statements, indicating a need for improved debugging tools.
- Performance woes with Mojo SIMD: Concerns surfaced about the performance of Mojo's operations on large SIMD lists, which can lag on select hardware configurations.
- A suggestion arose that using a SIMD size fitting the CPU's handling capabilities can enhance performance.
- Missing MAX Engine comparison documentation: A user reported difficulty locating documentation that compared the MAX Engine with PyTorch and ONYX, especially across models like ResNet.
- The query highlights a gap in available resources for users seeking comparison data.
Eleuther Discord
- Claude AI Offers Code Fixes: Members discussed starting a new chat with Claude AI to upload
output.json, enabling it to provide code fixes directly without file access, as outlined in this Medium article.- Despite the potential, skepticism remained about the empirical effectiveness of this approach.
- Enhancing Performance through Architecture: New architectures, particularly for user-specific audio classification, can significantly improve performance using strategies like contrastive learning to maintain user-invariant features.
- Additionally, adapting architectures for 3D data was discussed as a means to ensure performance under transformations.
- State of the Art in Music Generation: Queries about SOTA models for music generation included discussions around an ongoing AI music generation lawsuit, with members favoring local execution over external dependencies.
- This conversation reflects a growing trend toward increased control in music generation applications.
- Insights on RIAA and Labels: The relationship between RIAA and music labels was scrutinized, highlighting how they influence artist payments and the industry structure, demanding more direct compensation methods.
- Concerns surfaced about artists receiving meager royalties relative to industry profits, suggesting a push for self-promotion.
- HDF5 for Efficient Embedding Management: Discussions continued on the relevance of HDF5 for loading batches from large embedding datasets, reflecting ongoing efforts to streamline data management techniques.
- This indicates a persistent interest in efficient data usage within the AI community.
LangChain AI Discord
- Ollama Memory Error Chronicles: A user reported a ValueError indicating the model ran out of memory when invoking a retrieval chain despite low GPU usage with models like aya (4GB) and nomic-embed-text (272MB).
- This raises questions about resource allocation and memory management in high-performance setups.
- Mixing CPU and GPU Resources: Discussions centered on whether Ollama effectively utilizes both CPU and GPU during heavy loads, with users noting the expected fallback to CPU didn't occur as anticipated.
- Users emphasized the importance of understanding fallback mechanisms to prevent inference bottlenecks.
- LangChain Memory Management Insights: Insights were shared about how LangChain handles memory and object persistence, focusing on evaluating inputs for memory efficiency across sessions.
- Queries for determining suitable information for memory storage were testing grounds for different model responses.
- SAM 2 Fork: CPU Compatibility in Action: A member initiated a CPU-compatible fork of the SAM 2 model, displaying prompted segmentation and automated mask generation, with aspirations for GPU compatibility.
- Feedback regarding this endeavor is being actively solicited on the GitHub repository.
- Jumpstart Your AI Voice Assistant: A tutorial video titled 'Create a custom AI Voice Assistant in 8 minutes! - Powered by ChatGPT-4o' guides users through building a voice assistant for their website.
- The creator provided a demo link offering potential users hands-on experience before signing up for the service.
LlamaIndex Discord
- Build ReAct Agents with LlamaIndex: You can create ReAct agents from scratch leveraging LlamaIndex workflows for enhanced internal logic visibility.
- This method allows you to ‘explode’ the logic, ensuring a deeper understanding and control over agentic systems.
- Terraform Assistant for AI Engineers: Develop a Terraform assistant using LlamaIndex and Qdrant Engine aimed at aspiring AI engineers, with guidance provided here.
- The tutorial gives practical insights and a framework for integrating AI within the DevOps space.
- Automated Payslip Extraction with LlamaExtract: LlamaExtract allows high-quality RAG on payslips through automated schema definition and metadata extraction.
- This process significantly enhances data handling capabilities for payroll documents.
- Scaling RAG Applications Tutorial: Benito Martin outlines how to deploy and scale your chat applications on Google Kubernetes, emphasizing practical strategies here.
- This resource addresses content scarcity on productionizing RAG applications in detail.
- Innovative GraphRAG Integration: The integration of GraphRAG with LlamaIndex enhances intelligent question answering capabilities, as discussed in a Medium article.
- This integration leverages knowledge graphs to improve context and accuracy of AI responses.
Interconnects (Nathan Lambert) Discord
- Bay Area Events Generate Buzz: Members expressed a desire for updates on upcoming events in the Bay Area, with some noting personal absences.
- The ongoing interest hints at a need for better communication around local gatherings.
- Noam Shazeer Lacks Recognition: Discussion arose around the absence of a Wikipedia page for Noam Shazeer, a key figure at Google since 2002.
- Members reflected on Wikipedia can be silly, highlighting the ironic oversight of impactful professionals.
- Skepticism of 30 Under 30 Awards Validity: A member critiqued the 30 Under 30 awards as catering more to insiders than genuine merit, suggesting special types of people seek such validation.
- This struck a chord among members who noted the often superficial recognition those awards bestow.
- Debate on Synthetic Data Using Nemotron: A heated discussion emerged about redoing synthetic data leveraging Nemotron for fine-tuning Olmo models.
- Concerns were raised over the potential hijacking of the Nemotron name and criticisms of AI2's trajectory.
- KTO Outperforms DPO in Noisy Environments: The Neural Notes interview discussed KTO's strength over DPO when handling noisy data, suggesting significant performance gains.
- Adaptations from UCLA reported KTO's success against DPO with human preferences indicating a 70-30% edge.
LAION Discord
- Synthetic Datasets Spark Controversy: Members debated the effectiveness of synthetic datasets versus original ones, noting they can accelerate training but may risk misalignment and lower quality.
- Concerns were voiced about biases, prompting calls for more intentional dataset creation to avoid generating a billion useless images.
- FLUX Model Performance Divides Opinions: Users shared mixed views on the FLUX model's ability to generate artistic outputs; some praised its capability while others were disappointed.
- Discussion pointed out that better parameter settings could enhance its performance, yet skepticism remained regarding its overall utility for artistry.
- CIFAR-10 Validation Accuracy Hits 80%: 80% validation accuracy achieved on the CIFAR-10 dataset using only 36k parameters, treating real and imaginary components of complex parameters as separate.
- Tweaks to architecture and dropout implementation resolved previous issues, resulting in a more robust model with nearly eliminated overfitting.
- Ethical Concerns in Model Training: Discussions heated up around the ethical implications of training on copyrighted images, sparking anxiety over copyright laundering in synthetic datasets.
- Some proposed that while synthetic data has advantages, stricter scrutiny may impose regulations on training practices within the community.
- Stable Diffusion Dataset Availability Questioned: A user expressed frustration over the unavailability of a Stable Diffusion dataset, which hindered their progress.
- Peers clarified that the dataset isn't strictly necessary for utilizing Stable Diffusion, offering alternative solutions.
DSPy Discord
- Adding a Coding Agent to ChatmanGPT Stack: A member is seeking recommendations for a coding agent to add to the ChatmanGPT Stack, with Agent Zero suggested as a potential choice.
- Looking for an effective addition to enhance coding interactions.
- Golden-Retriever Paper Overview: A shared link to the paper on Golden-Retriever details how it efficiently navigates industrial knowledge bases by improving on traditional LLM fine-tuning challenges, particularly with a reflection-based question augmentation step.
- This method enhances retrieval accuracy by clarifying jargon and context prior to document retrieval. Read more in the Golden-Retriever Paper.
- Livecoding in the Voice Lounge: A member announced their return and mentioned livecoding sessions in the Voice Lounge, signaling a collaborative coding effort ahead.
- Members look forward to joining forces in this engaging setup.
- AI NPCs Respond and Patrol: Plans are underway for developing AI characters in a C++ game using the Oobabooga API for player interaction, focusing on patrolling and response functions.
- The necessary components include modifying the 'world' node and extending the NPC class.
- Exporting Discord Chats Made Easy: A user successfully exported Discord channels to HTML and JSON using the DiscordChatExporter tool, generating 463 thread files.
- This tool streamlines chat organization, making it easier for future reference. Check out the DiscordChatExporter.
OpenInterpreter Discord
- Open Interpreter runs on local LLM!: A user successfully integrated Open Interpreter with a local LLM using LM Studio as a server, gaining access to the OI system prompt.
- They found the integration both interesting and informative, paving the way for local deployments.
- Troubleshooting Hugging Face API integration: Users faced challenges while setting up the Hugging Face API integration in Open Interpreter, encountering various errors despite following the documentation.
- One user expressed gratitude for support, hoping for a resolution to their integration issues.
- Executing screenshot commands becomes a chore: Concerns arose as users questioned why Open Interpreter generates extensive code instead of executing the screenshot command directly.
- A workaround using the 'screencapture' command confirmed functionality, alleviating some frustrations.
- Speech recognition in multiple languages proposed: A user proposed implementing a speech recognition method in a native language, facilitating translation between English and the local tongue.
- They cautioned about translation errors, dubbing it Garbage in, Garbage out.
- Electra AI shows promise for AI on Linux: A member unveiled Electra AI, a Linux distro built with AI capabilities that are free for use, highlighting its potential for integration.
- They noted that Electra AI offers three flavors: Lindoz, Max, and Shift—all available for free.
Cohere Discord
- Cohere Support for CORS Issues: To address the CORS problems on the billing page, community members suggested emailing support@cohere.com for help, including organization's details in the inquiry.
- This support method aims to resolve issues that have hindered user payments for services.
- GenAI Bootcamp Seeks Cohere Insights: Andrew Brown is exploring the potential of Cohere for a free GenAI Bootcamp, which seeks to reach 50K participants this year.
- He highlighted the need for insights beyond documentation, especially regarding Cohere's cloud-agnostic capabilities.
- Benchmarking Models with Consistency: A member inquired about keeping the validation subset consistent while benchmarking multiple models, emphasizing the importance of controlled comparisons.
- Discussions reinforced the necessity of maintaining consistent validation sets to enhance the accuracy of comparisons.
- Rerank Activation on Azure Models: Cohere announced the availability of Rerank for Azure Models, with integration potential for the RAG app, as detailed in this blog post.
- Members showed interest in updating their toolkit to utilize Rerank for Azure users.
- Clarification on Cohere Model Confusion: A user who paid for the Cohere API found only the Coral model available and faced confusion regarding accessing the Command R model.
- In response, a member clarified that Coral is indeed a version of Command R+ to ease the user’s concerns.
tinygrad (George Hotz) Discord
- tinygrad 0.9.2 introduces exciting features: The recent release of tinygrad 0.9.2 brings notable updates like faster gemv, kernel timing, and improvements with CapturedJit.
- Additional discussions included enhancements for ResNet and advanced indexing techniques, marking a significant step for performance optimization.
- Evaluating tinygrad on Aurora supercomputer: Members discussed the feasibility of running tinygrad on the Aurora supercomputer, stressing concerns over compatibility with Intel GPUs.
- While OpenCL support exists, there were queries regarding performance constraints and efficiency on this platform.
- CUDA performance disappoints compared to CLANG: Members noted that tests in CUDA run slower than in CLANG, prompting an investigation into possible efficiency issues.
- This discrepancy raises important questions about the execution integrity of CUDA, especially in test_winograd.py.
- Custom tensor kernels spark discussion: A user shared interest in executing custom kernels on tensors, referencing a GitHub file for guidance.
- This reflects ongoing enhancements in tensor operations within tinygrad, showcasing community engagement in practical implementation.
- Bounties incentivize tinygrad feature contributions: The community has opened discussions on bounties for tinygrad improvements, such as fast sharded llama and optimizations for AMX.
- This initiative encourages developers to actively engage in enhancing the framework, aiming for broader functionality.
Torchtune Discord
- PPO Training Recipe Now Live: The team has introduced an end-to-end PPO training recipe to integrate RLHF with Torchtune, as noted in the GitHub pull request.
- Check it out and try it out!
- Qwen2 Model Support Added: Qwen2 model support is now included in training recipes, with the 7B model available in the GitHub pull request.
- Expect the upcoming 1.5B and 0.5B versions to arrive soon!
- LLAMA 3 Tangles with Generation: Users successfully ran the LLAMA 3 8B INSTRUCT model with a custom configuration, generating a time query in 27.19 seconds at 12.25 tokens/sec, utilizing 20.62 GB of memory.
- However, there's a concern about text repeating 10 times, and a pull request is under review to address unexpected ending tokens.
- Debugging Mode Call for LLAMA 3: Concerns arose regarding the absence of a debugging mode that displays all tokens in the LLAMA 3 generation output.
- A member suggested that adding a parameter to the generation script could resolve this issue.
- Model Blurbs Maintenance Anxiety: Members expressed concerns about keeping updated model blurbs, fearing the maintenance could be overwhelming.
- One proposed using a snapshot from a model card or whitepaper as a minimal blurb solution.
OpenAccess AI Collective (axolotl) Discord
- bitsandbytes Installation for ROCm Simplified: A recent pull request enables packaging wheels for bitsandbytes on ROCm, streamlining the installation process for users.
- This PR updates the compilation process for ROCm 6.1 to support the latest Instinct and Radeon GPUs.
- Building an AI Nutritionist Needs Datasets: A member is developing an AI Nutritionist and considers fine-tuning GPT-4o mini but seeks suitable nutrition datasets like the USDA FoodData Central.
- Recommendations include potential dataset compilation from FNDDS, though it's unclear if it's available on Hugging Face.
- Searching for FFT and Baseline Tests: A member expressed interest in finding FFT or LORA/QLORA for experimentation with a 27b model, mentioning good results with a 9b model but challenges with the larger one.
- Caseus suggested a QLORA version for Gemma 2 27b might work with adjustments to the learning rate and the latest flash attention.
- Inquiry about L40S GPUs Performance: A member asked if anyone has trained or served models on L40S GPUs, seeking insights about their performance.
- This inquiry highlights interest in the efficiency and capabilities of L40S GPUs for AI model training.
- Discussion on DPO Alternatives in AI Training: A member questioned whether DPO remains the best approach in AI training, suggesting alternatives like orpo, simpo, or kto might be superior.
- This led to an exchange of differing opinions on the effectiveness of various methods in AI model training.
MLOps @Chipro Discord
- Triton Conference Registration Now Open!: Registration for the Triton Conference on September 17, 2024 at Meta Campus, Fremont CA is now open! Sign up via this Google Form to secure your spot.
- Attendance is free, but spots are limited, so early registration is encouraged.
- Information Required for Registration: Participants must provide their email, name, affiliation, and role to register. Additional optional questions include dietary preferences like vegetarian, vegan, kosher, and gluten-free.
- Pro tip: Capture what attendees hope to take away from the conference!
- Google Sign-In for Conference Registration: Attendees are prompted to sign in to Google to save their progress on the registration form. All responses will be emailed to the participant's provided address.
- Don't forget: participants should never submit passwords through Google Forms to ensure security.
Mozilla AI Discord
- Llamafile boosts offline LLM access: The core maintainer of Llamafile reports significant advancements in enabling offline, accessible LLMs within a single file.
- This initiative improves accessibility and simplifies user interactions with large language models.
- Community excited about August projects: A vibrant discussion has ignited around ongoing projects for August, encouraging community members to showcase their work.
- Participants have the chance to engage and share their contributions within the Mozilla AI space.
- sqlite-vec release party on the horizon: An upcoming release party for sqlite-vec will allow attendees to discuss features and engage with the core maintainer.
- Demos and discussions are set to unfold, creating opportunities for rich exchanges on the latest developments.
- Exciting Machine Learning Paper Talks scheduled: Upcoming talks featuring topics such as Communicative Agents and Extended Mind Transformers will include distinguished speakers.
- These events promise valuable insights into cutting-edge research and collaborative opportunities in machine learning.
- Local AI AMA promises open-source insights: A scheduled Local AI AMA with the core maintainer will offer insights into this self-hostable alternative to OpenAI.
- This session invites attendees to explore Local AI's capabilities and directly address their queries.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!