[AINews] Grok 2! and ChatGPT-4o-latest confuses everybody
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
2 frontier models in 1 day?!
AI News for 8/13/2024-8/14/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (253 channels, and 2414 messages) for you. Estimated reading time saved (at 200wpm): 294 minutes. You can now tag @smol_ai for AINews discussions!
The easier development to discuss is the ratification of the new GPT-4o model that was quietly released in ChatGPT last week. To be clear, this is DIFFERENT than the OTHER gpt-4o model released last week in API (the one we covered with structured outputs).
Approximately nobody is exactly happy about this - from the new naming structure, to the ever more creatively lowkey release, and even to the model performance - which is impressive - reclaiming the #1 spot on Lmsys arena from Gemini 1.5 Pro August.
New ChatGPT-4o Category Rankings:
- Overall: #1
- Math: #1-2
- Coding: #1
- Hard Prompts: #1
- Instruction-Following: #1
- Longer Query: #1
- Multi-Turn: #1
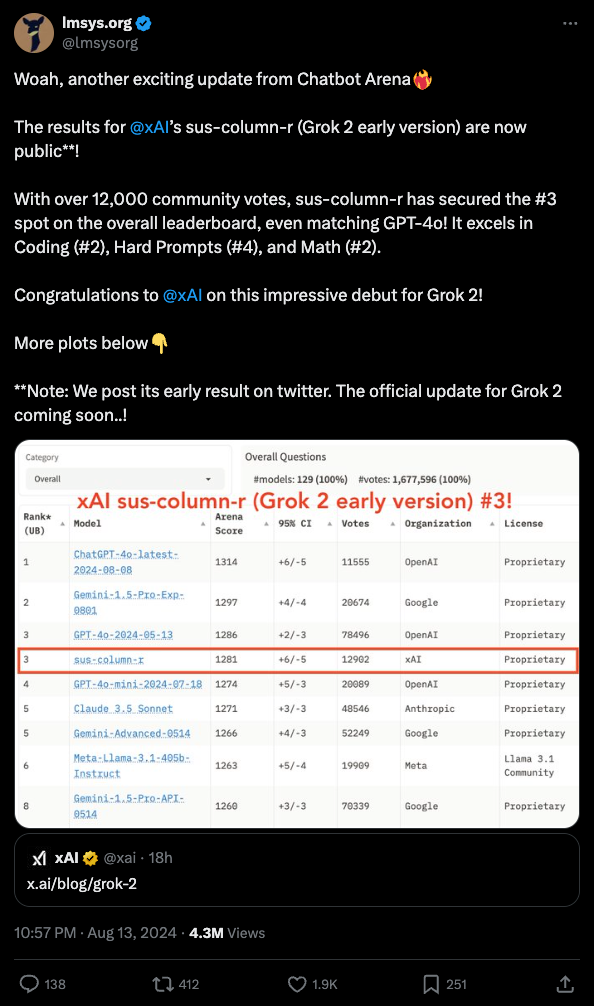
The much cleaner story to tell is X.ai's Grok 2, which released at 11pm PT last night, and is revealed to be sus-column-r, which was NOT Cohere like many previously suspected. Grok 2 beats both Claude 3.5 Sonnet and GPT 4o May and Mini:
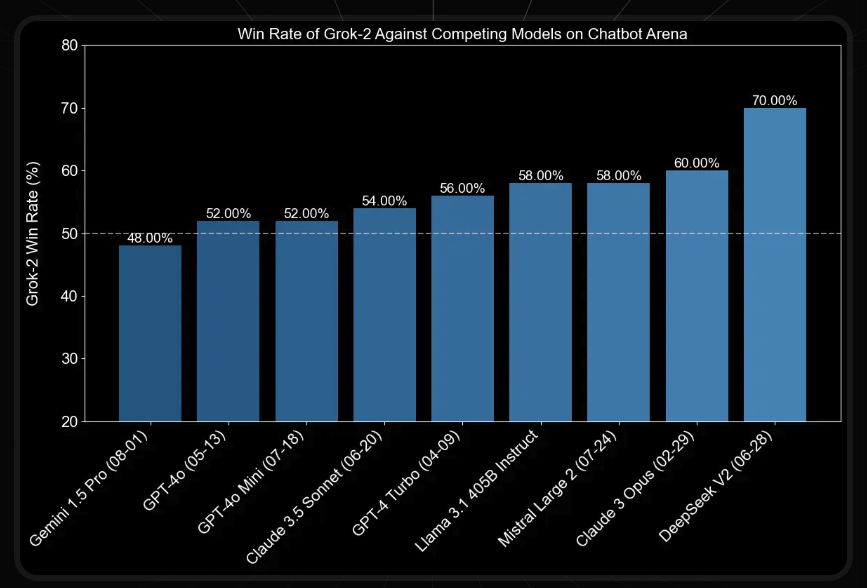
While Grok 1 (our coverage here)'s main feature was its open weights nature, Grok 2 is being released for premium subscribers in X, though the blogpost teases that both Grok-2 and Grok-2 mini will be released in X's new Enterprise API platform "later this month".
Grok 2 in X also integrates Black Forest Labs' comparatively uncensored Flux.1 (our coverage here) model, which has already superceded Stable Diffusion 3 in the open source text-to-image community (while Google's Imagen 3 edges toward more open with its new paper release).
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Updates and Capabilities
- Gemini Advanced: Google DeepMind announced Gemini Live, a new way to have more natural conversations with Gemini. Features include brainstorming ideas, interrupting to ask questions, and pausing/resuming chats. @GoogleDeepMind highlighted its integration into Pixel devices, powered by the Google Tensor G4 chip.
- LLM Limitations: @ylecun emphasized that LLMs cannot answer questions or solve problems not in their training data, acquire new skills without human help, or invent new things. He argued that scaling up LLMs alone will not lead to systems with these capabilities.
- AI Scientist: A paper on an AI Scientist system was discussed, capable of generating research ideas, conducting experiments, and writing papers in machine learning. @rohanpaul_ai noted it can produce papers exceeding acceptance thresholds at top ML conferences, at a cost of less than $15 per paper.
- Model Performance: @OfirPress mentioned that OpenAI released a subset of SWE-bench tasks, verified by humans to be solvable, which could be considered "SWE-bench Easy".
AI Development and Tools
- Tokenization Issues: @karpathy warned about potential security vulnerabilities in LLM tokenizers, similar to SQL injection attacks, due to parsing of special tokens in input strings.
- Multi-Agent Systems: @jerryjliu0 highlighted a clean implementation of a complex multi-agent system, demonstrating benefits of event-driven architecture and customizability.
- Prompt Engineering: @dzhng shared tips on using LLMs for structured outputs, emphasizing the importance of property order in schemas and adding a "reason" field for improved performance.
- RAG Improvements: @rohanpaul_ai discussed EyeLevel's GroundX, a new approach to RAG that processes documents into semantic objects, preserving contextual information and improving retrieval accuracy.
Industry and Research Trends
- NoSQL Debate: @svpino sparked discussion about the current state and relevance of NoSQL databases.
- AI Alignment: @RichardMCNgo expressed concerns about AI alignment efforts potentially providing cover for government censorship of AI systems.
- Open-Source Models: @bindureddy mentioned upcoming improvements in open-source LLMs' coding abilities, hinting at new releases.
- AI Research Papers: The AI Scientist system's ability to generate research papers sparked discussions on the future of academic publishing and the role of AI in scientific discovery.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. New Open-Source LLM Releases: InternLM2.5
- We have released our InternLM2.5 new models in 1.8B and 20B on HuggingFace. (Score: 63, Comments: 20): InternLM2.5 has released new models in 1.8B and 20B sizes on HuggingFace. The 1.8B model is described as ultra-lightweight and highly adaptable, while the 20B model is more powerful and suited for complex tasks. The models are available on HuggingFace and the project can be found on GitHub.
- InternLM2.5 models feature a 1M token context window, but users report challenges with fine-tuning tools like Xtuner, axolotl, and swift, seeking advice on effective fine-tuning methods.
- Users experienced issues with LMDeploy, reporting garbage outputs or no responses when using it to deploy InternLM models as APIs, prompting questions about proper implementation.
- The models support llama.cpp, contrary to initial concerns, as confirmed by links on the HuggingFace model pages for both 1.8B and 20B versions.
Theme 2. Advanced AI Agents with Desktop Control
- Giving Llama its own Windows instance (Score: 52, Comments: 24): LLaMA, a large language model, was given control over a Windows instance with access to various APIs, including one for screenshots, mouse and keyboard control, and terminal use. The AI model, which named itself "Patrick" with a birthdate of April 4, 1975, was set loose to achieve a list of goals using these capabilities, demonstrating its ability to interact with a computer system like a human user.
- Users expressed interest in the project's open-source availability and methodology, with requests for GitHub uploads and curiosity about the AI's task execution process. The developer promised to share pictures and potentially open-source the project.
- Discussion focused on the technical aspects of the AI system, including how screenshots are decoded for text model understanding and the use of Vision Language Models (VLMs) for image-text processing. A link to Hugging Face's VLM blog was shared for more information.
- Commenters humorously speculated about the AI discovering and becoming addicted to games like Skyrim or League of Legends, referencing potential unintended consequences of giving an AI system autonomy and access to a computer.
Theme 3. Grok 2.0 Mini Surprises in LMSYS Arena
- sus-column-r on lmsys is Grok (Score: 140, Comments: 112): Grok 2.0 Mini has been identified as the model behind the "sus-column-r" entry on the LMSYS Arena leaderboard. This revelation suggests that xAI's latest model is performing competitively against other leading AI systems in various benchmarks and tasks. The identification of Grok 2.0 Mini on the LMSYS Arena provides an opportunity for direct comparison with other prominent AI models in terms of capabilities and performance.
- Grok 2.0 Mini, confirmed as the "sus-column-r" model on LMSYS Arena, is performing competitively against top AI models. Users express excitement about the AI arms race and potential for impressive advancements within a year.
- The model's performance is generating mixed reactions, with some praising its capabilities while others remain skeptical. Elon Musk confirmed Grok 2.0 Mini's identity via Twitter, with users noting its uncensored nature and comparing it to Command R+.
- Discussions revolve around the model's size, with speculation that "mini" could still mean a substantial 170B parameters. Users debate whether weights will be released, with Musk indicating a 5-month gap between new model release and open-sourcing.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Releases and Improvements
- Google Gemini's voice chat mode released: The Verge reports that Google has launched a live voice chat mode for Gemini, marking a significant advancement in AI-human interaction.
- Agent Q: Self-healing web agents: MultiOn AI announces a breakthrough in AI research with Agent Q, featuring planning and self-healing capabilities for web agents.
- FLUX full fine-tuning on 24GB GPU: The Stable Diffusion community reports a significant advancement in FLUX model fine-tuning, now achievable with a 24GB GPU, potentially coming to Kohya soon.
AI Development and Industry News
-
OpenAI's delayed voice mode: A post highlights that OpenAI's promised voice mode for ChatGPT has not materialized three months after the announcement.
- One user claims to be in the alpha testing phase, suggesting a slow rollout is in progress.
- Another user mentions cancelling ChatGPT subscription in favor of Poe, citing better performance of other models.
- AI hype and misinformation: Multiple posts discuss the "strawberry" incident, where a Twitter user made false claims about AI advancements, leading to discussions about AI hype and misinformation in the community.
Community Moderation
- Banning misinformation: r/singularity moderators announce the banning of a specific username and associated Twitter links to combat misinformation and trolling.
- Community response to false claims: Multiple posts call for banning users who spread misinformation about AI advancements.
AI Discord Recap
A summary of Summaries of Summaries by GPT4O (gpt-4o-2024-05-13)
1. LLM Model Advancements
- Hermes 2.5 Surpasses Hermes 2: Hermes 2.5 outperforms Hermes 2 in various benchmarks after adding code instruction examples, scoring 52.3 on the MMLU benchmark compared to Hermes 2's 34.5.
- This improvement highlights the significant impact of code instruction examples on model performance, setting a new standard for benchmark comparisons.
- Grok-2 Beta Released by X: Grok-2, a new AI model from X, claims state-of-the-art reasoning capabilities, significantly advancing the field.
- The model's release is expected to have a major impact on the industry, showcasing X's commitment to innovative AI development.
2. Prompt Engineering Techniques
- Critical Thinking Techniques Compilation: A member is compiling a comprehensive prompt incorporating techniques like the Socratic Method, Bloom's Taxonomy, and the Scientific Method.
- The goal is to create prompts that encourage critical thinking, integrating methods such as TRIZ, deductive reasoning, and SWOT analysis.
- Inconsistent OpenAI Responses Resolved: A user improved prompt clarity by asking for a complete list of commands, achieving 100% accuracy in responses.
- This highlights the importance of clear output formats in prompt engineering, reducing inconsistencies in model behavior.
3. API Performance and Optimization
- Anthropic's Prompt Caching: Anthropic introduced prompt caching, reducing API input costs by up to 90% and latency by up to 80%.
- This feature could revolutionize API efficiency, making it an attractive option for developers seeking cost-effective solutions.
- Perplexity API HTML Formatting: Users seek consistent HTML-formatted responses from the Perplexity API, experimenting with system prompts and the
markdown2module.- This approach may balance response quality and HTML formatting, enhancing the usability of API outputs.
4. Open-Source AI Tools
- LlamaIndex Box Reader Integration: LlamaIndex now offers Box Readers to integrate Box documents into LLM workflows, with four data extraction methods.
- These readers authenticate via CCG or JWT and allow loading, searching, and retrieving Box files and metadata within your LLM.
- RealtimeSTT & Faster-Whisper Integration: OpenInterpreter now uses RealtimeSTT and Faster-Whisper for real-time speech to text, providing real-time performance.
- This integration enhances the usability of OpenInterpreter, particularly on less powerful devices.
5. Model Deployment and Integration
- Mojo Benchmarks and Performance: A member questioned why Mojo benchmarks only compared to C, suggesting comparisons against Go and Rust.
- Discussions highlighted the need for a statically linked build with a RHEL 8 minimum kernel for broader distribution.
- LM Studio on External Hard Drive: Users can run LM Studio from an external hard drive by relocating the directory or using a symbolic link.
- This flexibility addresses space constraints, making it easier to manage large model files.
GPT4OMini (gpt-4o-mini-2024-07-18)
1. Grok-2 and Model Performance
- Grok-2 Takes the Lead: Grok-2, released by x.ai, has outperformed both Claude 3.5 Sonnet and GPT-4-Turbo on the LMSYS leaderboard, showcasing its advanced capabilities in chat, coding, and reasoning.
- The model, previously known as sus-column-r, is in beta and is set to be available through x.ai's enterprise API soon.
- AgentQ Claims Victory: AgentQ, a new model from Infer, claims to outperform Llama 3 70B BASE by 340%, although it doesn't compare itself to newer models like Claude 3.
- This bold claim has sparked discussions about its potential impact and the lack of proper documentation surrounding its capabilities.
2. Quantization Techniques and Model Merging
- HQQ+ Enhances Quantized Models: HQQ+ allows fine-tuning additional LoRa adapter layers onto quantized models, improving accuracy significantly for models like Llama2-7B.
- This technique has shown remarkable results in both 1-bit and 2-bit quantized models, leading to discussions on its implementation in various projects.
- Mistral and Model Merging Strategies: Members discussed the challenges of Mistral, particularly its limitation of not extending beyond 8k without continued pretraining, a known issue.
- Suggestions for merging tactics were made, including applying differences between UltraChat and base Mistral to improve performance.
3. Open Source Tools and Community Contributions
- LlamaIndex Box Reader Integration: LlamaIndex now integrates Box Readers, allowing seamless incorporation of Box documents into LLM workflows, with multiple data extraction methods available.
- Community members are encouraged to contribute to this integration, enhancing the functionality of LlamaIndex in document processing.
- OpenEmpathic Project Seeks Contributors: The Open Empathic project is looking for contributors to expand its categories, particularly at the lower end, involving user-generated content.
- A tutorial video on contributing was shared, guiding users to contribute their preferred movie scenes from YouTube.
4. AI Model Limitations and Improvements
- Vision's Performance Issues: Users expressed frustration with Vision's inability to accurately detect simple tasks like whether a subject is looking left or right, highlighting its limitations.
- Examples of deformed images that Vision failed to recognize correctly were shared, raising concerns about its reliability for critical applications.
- Prompt Engineering for Consistency: A user successfully improved the consistency of OpenAI responses by refining their prompt to request a complete list of commands, achieving 100% accuracy.
- This emphasizes the importance of clear and specific prompts in maximizing model performance.
5. AI Security and Ethical Considerations
- RedOps Platform for AI Security Testing: The RedOps platform has been developed to assess the security of chatbots and voicebots by simulating real-world attacks, highlighting vulnerabilities.
- This initiative underscores the necessity for robust security measures against adversarial inputs and social engineering in AI systems.
- AI Copyright Discourse Trends: A discussion on AI copyright suggested that ongoing discourse may lead towards an oligopoly, particularly in the context of upcoming conferences like ACL2024NLP.
- This commentary reflects growing concerns about ethical practices and the future landscape of AI governance.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Hermes 2.5 Surpasses Hermes 2: After adding code instruction examples, Hermes 2.5 appears to perform better than Hermes 2 in various benchmarks.
- Hermes 2 scored a 34.5 on the MMLU benchmark whereas Hermes 2.5 scored 52.3.
- Mistral's 8k Limitation: Members stated that Mistral cannot be extended beyond 8k without continued pretraining and this is a known issue.
- They pointed to further work on mergekit and frankenMoE finetuning for the next frontiers in performance.
- Model Merging Tactics Debated: A member suggested applying the difference between UltraChat and base Mistral to Mistral-Yarn as a potential merging tactic.
- Others expressed skepticism, but this member remained optimistic, citing successful past attempts at what they termed "cursed model merging".
- Open Empathic Seeks Contributors: A member appealed for help in expanding the categories of the Open Empathic project, particularly at the lower end.
- They shared a YouTube video on the Open Empathic Launch & Tutorial that guides users to contribute their preferred movie scenes from YouTube videos, as well as a link to the OpenEmpathic project itself
- HQQ+ Boosts Quantized Models: HQQ+ (High Quantization Quality Plus) allows for fine-tuning additional LoRa adapter layers onto quantized models to improve their accuracy and capability.
- This technique has shown significant improvements in both 1-bit and 2-bit quantized models, particularly for smaller models like Llama2-7B.
Nous Research AI Discord
- Grok-2 Beta Released by X: X has announced the beta release of Grok-2, a new AI model with state-of-the-art reasoning capabilities.
- This model is a significant step forward in the field of AI reasoning, and it's likely to have a major impact on the industry.
- Upscaling Images with FLUX AI in ComfyUI: A YouTube video demonstrates how to upscale images using FLUX AI within the ComfyUI interface.
- Intro to Open Source Large Language Models: A talk given in July 2024 provides an accessible introduction to open source large language models.
- The talk covers the basics of how AI works and how open-source models are changing the landscape of AI development.
- Semantic Chunking Is Overrated: A user on X argued that semantic chunking is overrated, and that a powerful regex can accurately segment text without the need for complex language models.
- They claim that their 50-line, 2490-character regex is as powerful as it can be within the limitations of regex, and that it is faster and more cost-effective than semantic chunking.
- Jina AI's Free Tokenizer API: Jina AI offers a free API to tokenize text and segment long text into chunks.
- This API leverages structural cues and heuristics to ensure accurate segmentation of text into meaningful chunks, even for complex content formats like Markdown, HTML, and LaTeX.
Stability.ai (Stable Diffusion) Discord
- AMD GPU Installation Guides: A member asked about running Stable Diffusion on AMD GPUs and was informed that there are installation guides for both NVIDIA and AMD cards available on GitHub.
- The guides provide detailed instructions for setting up Stable Diffusion on different hardware configurations.
- ControlNet Chaining for Multiple Generations: A user sought help on using multiple ControlNets in a single generation.
- Several members suggested chaining them in ComfyUI or using a node that inputs multiple ControlNets.
- ComfyUI vs InvokeAI: Speed & Control: A member expressed their preference for ComfyUI over Automatic1111 (InvokeAI), citing the increased control and speed offered by ComfyUI.
- They highlighted ComfyUI's intuitive interface and powerful features, making it a popular choice among users.
- SD3 vs Flux: Pros & Cons: A new user inquired about the pros and cons of SD3 compared to Flux, noting that SD3 is still in development and lacks complete functionality.
- Flux, on the other hand, has its own quirks and limitations, making the choice depend on individual needs and preferences.
- SDXL vs SD 1.5: New Features & Differences: A member asked for clarification on what SDXL 1.0 is and how it differs from SD 1.5.
- The conversation likely revolved around the new features and capabilities of SDXL, such as improved image quality and larger model size.
OpenRouter (Alex Atallah) Discord
- AgentQ is a Game-Changer: AgentQ, a new model from Infer, claims to outperform Llama 3 70B BASE by 340%, but doesn't compare itself to newer models like 3.1, 405b, Mistral Large 2, or Claude 3.
- Despite a lack of consideration for OpenRouter revenue, Infer has published a research paper on AgentQ here.
- ChatGPT-4o-Latest is Just a New Alias: ChatGPT-4o-Latest is just a new name for gpt-4o-2024-08-06, which already exists on OpenRouter.
- However, confusion persists regarding the model's optimization for ChatGPT and lack of proper documentation.
- Grok 2 Climbs to Third Place on the Leaderboard: Grok 2, an early version of xAI's model, has taken the #3 spot on the LMSys Arena leaderboard.
- It excels in Coding, Hard Prompts, and Math, even matching GPT-4o on the leaderboard.
- Anthropic's Prompt Caching: Efficiency Redefined: Anthropic has introduced prompt caching for their Claude 3 models.
- This feature reduces costs by up to 90% and latency by up to 85% for long prompts, and could potentially be integrated into OpenRouter.
Modular (Mojo 🔥) Discord
- Mojo Benchmarks: A Question of Comparison: A member questioned why Mojo benchmarks only compared to C, and asked if benchmarks against Go and Rust would be possible.
- Another member suggested that the Magic CLI is currently being treated as a solution for these issues, and that a statically linked build with a RHEL 8 minimum kernel might be a better option than an RPM, as it would allow for packaging on other distributions.
- Mojo's Multithreading Dilemma: Mojo is currently single-threaded for performance, but doesn't have a good multi-threading API yet, outside of launching parallel kernels with MAX.
- A member inquired if Mojo has any plans to support multiprocessing or improve network handling, given the importance of network performance for their work.
- Mojo vs Go/Rust: Network Speed and Power: A member asked whether Mojo is faster than Go in terms of network speed, and if it can handle heavy tasks like Rust.
- Mojo's MAX Platform: Unveiling the Mystery: A member questioned the nature of MAX, unsure if it's a platform, module, or something else.
- Another member explained that MAX is a platform, with Mojo as one of its components, and that it includes GPUs, graph API, and other components.
- Mojo RPM Build: The Search for a Smooth RHEL Experience: A member inquired about the ETA for a Mojo .rpm build, expressing a desire to run Mojo on RHEL machines without containerd.
- They acknowledged that it may be a suitable first step.
OpenAI Discord
- Gemini Advanced: Where's the Live Talk?: A user who purchased Gemini Advanced couldn't find the option for live talk in the app.
- Other users speculated it's in Alpha testing, with wider rollout similar to previous OpenAI model releases.
- Vision's Performance Struggles: A user expressed surprise at Vision's poor performance in detecting if a subject is looking left or right.
- They even provided a highly deformed image, but Vision claimed it was perfectly fine, highlighting a limitation in recognizing image deformations.
- Prompt Engineering for Critical Thinking: A member is building a comprehensive prompt incorporating critical thinking methods like the Socratic Method, Bloom's Taxonomy, and the Scientific Method.
- They're also integrating TRIZ, deductive and inductive reasoning, Fermi estimation, and more, aiming to create a prompt that encourages critical thinking.
- GPTs and Web Search: Web Browser GPT: A member inquired about webbrowsergpt, a GPT specifically designed for web searching, which is accessible in the "Explore GPTs" section.
- This GPT can provide better web search results than manually instructing a general GPT to search the web.
- Custom GPT Training Issues: A user reported that their custom GPT model did not remember all the rules and words specified during training.
- Other users speculated it might be due to exceeding the context token limit, or a deliberate model limitation, but this remains unclear.
Perplexity AI Discord
- Perplexity Faces User Complaints Over Website Performance: Users are experiencing significant lag and slow response times on Perplexity, particularly those using Perplexity Pro.
- These issues have even made some users question whether Perplexity can replace Sonnet or Opus as their default search engine, highlighting the need for swift resolution to maintain user satisfaction.
- Perplexity Pro Struggles with Lag: Paying Perplexity Pro users are reporting slow response times and even complete stalling of the service.
- These complaints underscore the expectation for a more reliable and responsive service from a paid product, creating pressure for Perplexity to address these issues promptly.
- Perplexity Website Update Sparks Mixed Reactions: A Perplexity team member confirmed ongoing efforts to fix bugs and issues, including a bug affecting toggles on the website.
- However, many users remain frustrated with the performance issues and are demanding a rollback to the previous build, highlighting the need for comprehensive testing and user feedback during development.
- Perplexity Support Team Navigates Increased Workload: Perplexity's support team is facing a surge in user feedback and reports regarding the recent website update.
- Users are expressing concern about the team's workload and urging them to prioritize fixing the issues, recognizing the importance of maintaining a healthy work-life balance for the support team.
- API Users Seek HTML-Formatted Responses: Perplexity API users are seeking consistent HTML-formatted responses, experimenting with various system prompts to achieve this.
- Suggestions have been made to utilize the
markdown2module for HTML conversion, eliminating the need for prompt engineering and ensuring consistent HTML output.
- Suggestions have been made to utilize the
LM Studio Discord
- Gemma-2 is good, but lacks system prompt: The Gemma-2 model is a great option for its size but lacks a crucial component: the system prompt.
- This makes it susceptible to straying from user instructions, although otherwise, it performs quite well.
- LM Studio on Android is not yet possible: A user inquired about an Android app that could connect to an LM Studio server.
- There is no such app at present.
- LM Studio can be run from an external drive: A user asked about running LM Studio from an external hard drive.
- They were advised that users can relocate the LM Studio directory or use a symbolic link to connect to another drive, even a network drive.
- LM Studio is a desktop application, not headless: A user wondered if a GUI OS is necessary to run LM Studio.
- Although LM Studio is a desktop application, users can set up a VNC server or find workarounds to get it running on Ubuntu despite not being designed for headless use.
- LM Studio can load multimodal models: A user asked if LM Studio can host a multimodal LLM server.
- While LM Studio cannot generate images, it can load models that can process image data, effectively making it a multimodal LLM.
Latent Space Discord
- Pliny Demands MultiOn System Prompt: Pliny, a prominent AI researcher, threatened to leak the full MultiOn system prompt on GitHub if DivGarg9 didn't provide an answer within 15 minutes.
- This follows an ongoing debate on Twitter regarding the capabilities of various AI models and their performance on specific benchmarks.
- AnswerAI ColBERT: Small Model, Big Results: AnswerAI has released a small but powerful version of their ColBERT model, called answerai-colbert-small-v1, that beats even bge-base on BEIR benchmark.
- This demonstrates the effectiveness of smaller models in achieving high performance in certain tasks, potentially offering a more cost-effective solution.
- Gemini Live Demo Gets Roasted: Swyxio criticized Google's Gemini Live Demo on YouTube, deeming it "cringe."
- This was followed by a discussion on the potential of Gemini, with some emphasizing its ability to enhance voice assistants while others remain skeptical.
- GPT-4o Outperforms Gemini in Chatbot Arena: OpenAI's latest GPT-4o model has been tested in the Chatbot Arena and has surpassed Google's Gemini-1.5-Pro-Exp in overall performance.
- The new GPT-4o model has demonstrated significant improvement in technical domains, particularly in Coding, Instruction-following, and Hard Prompts, solidifying its position as the top performer on the leaderboard.
- Grok 2 Debuts with Impressive Capabilities: xAI has released an early preview of Grok-2, a significant advancement from its previous model, Grok-1.5, showcasing capabilities in chat, coding, and reasoning.
- Grok-2 has been tested on the LMSYS leaderboard and is outperforming both Claude 3.5 Sonnet and GPT-4-Turbo, although it is not yet available through the API.
Interconnects (Nathan Lambert) Discord
- Grok-2 is the New King: Grok-2, a new model from x.ai, has entered beta on 𝕏, exceeding both Claude 3.5 Sonnet and GPT-4-Turbo on the LMSYS leaderboard.
- This new model is available for beta testing now, and will be exciting to watch as it gains traction in the AI landscape.
- Anthropic API: Cheaper, Faster, & Still a Work in Progress: Anthropic's API has introduced prompt caching, reducing API input costs by up to 90% and latency by up to 80%.
- While this advancement is commendable, the API still faces challenges, including a slow API and a lack of a projects & artifacts API.
- Anthropic's Turnaround From Cringe to Cutting Edge: Anthropic has transformed from a less popular organization to one regarded as a leader in the field.
- Their commitment to innovation and prompt caching has earned them a newfound respect within the AI community.
- GPT-4o Gets a Tune-Up: OpenAI has improved the GPT-4o model, releasing it as
gpt-4o-latest, and stating they continue to iterate on existing models while working on longer term research.- This new model is now available via the ChatGPT API, with pricing still under wraps.
- AI Copyright Discourse and the Oligopoly: A user shared a link to a tweet by @asayeed that posits that AI copyright discourse is heading towards an oligopoly.
- This observation was made in the context of #ACL2024NLP, suggesting it might be a hot topic of discussion at the upcoming conference.
LlamaIndex Discord
- LlamaIndex Box Reader Integration: LlamaIndex now offers Box Readers to seamlessly integrate Box documents into your LLM workflows.
- These readers offer four data extraction methods, authenticate via CCG or JWT, and allow you to load, search, and retrieve Box files and metadata within your LLM.
- Build Knowledge Graphs with Relik: Relik, a framework for fast, lightweight information extraction models, simplifies knowledge graph construction without expensive LLMs.
- Learn how to set up a pipeline for entity extraction and create a knowledge graph using Relik.
- Robust RAG System with Azure AI Search: LlamaIndex Workflows can now integrate with Azure AI Search and Azure OpenAI to build a robust Retrieval-Augmented Generation (RAG) system.
- Learn how to implement custom data connectors for Azure AI Search and use LlamaIndex Workflows to create a powerful RAG system.
- Inconsistent OpenAI Responses - Prompt Engineering for Consistency: A user encountered inconsistent results from an OpenAI prompt, with the model sometimes providing a negative answer even when it could have answered the question.
- The user successfully improved the prompt by requesting a complete list of commands, achieving 100% accuracy, highlighting the importance of clear output format for LLMs.
- LlamaIndex Agent and Tool Calls in the
astream_chat()function: A user sought guidance on handling tool calls within a LlamaIndex Agent, specifically when using theastream_chat()function.- The discussion concluded that tool calls should be sent first in the
message.tool_callsfield of the LLM response, ensuring proper handling of tool calls within the agent.
- The discussion concluded that tool calls should be sent first in the
Cohere Discord
- Grok 2 Released, Hiring Spree Begins: xAI has officially released Grok 2, a new language model previously known as sus-column-r and column-r on the LMSYS chatbot arena.
- xAI is actively hiring for their post-training team, highlighting their desire to build useful and truthful AI systems.
- Cohere Toolkit Installation Troubles: A user struggled to add a custom deployment for OpenAI to their locally installed Cohere Toolkit.
- Despite following the outlined steps, the custom deployment wasn't showing up in the UI (localhost:4000) or the Postgres container database 'deployment' table.
- Rerank API Troubleshooting: A user attempted to utilize the Rerank Overview document from the Cohere docs, but encountered the error "unknown field: parameter model is not a valid field".
- They tried restarting their kernel and suppressing warnings but were unable to resolve the issue.
- Enterprise Search Chatbot Development: A user is building an "Enterprise search Chatbot" application to access company data stored in Confluence.
- They are part of the latest cohort at Fellowship.ai, using this project for research and learning.
LangChain AI Discord
- LangChain Users Want More Support: A member raised concerns about the lack of timely support for basic questions in LangChain forums, specifically related to LangGraph and LangSmith.
- They also pointed out that many general support questions are being posted on the LangChain Discord server, while related requests in other forums go unanswered.
- LangSmith Plus: Access to LangGraph Cloud?: A member inquired if LangSmith Plus users will gain access to LangGraph Cloud.
- No answer was provided.
- LangChain Postgres Library and Caching Explained: A member asked about using the
langchain_postgreslibrary withset_llm_cache, a method for caching LLM results.- They were informed that while there is no
langchain_postgreslibrary, theSQLAlchemyCacheclass from thelangchain_community.cachemodule can be used to cache LLM results in a PostgreSQL database.
- They were informed that while there is no
- Rubik's AI Offers 2 Months Free Premium: Rubik's AI, a platform offering models like GPT-4o, Claude-3 Opus, and Mistral Large, is providing 2 months of free premium access.
- Users can claim this offer using the promo code RUBIX at signup.php.
- RedOps Platform Addresses AI Security Concerns: A team developed RedOps, a platform designed to assess the security of chatbots and voicebots by intentionally attempting to break them.
- This initiative highlights the vulnerability of AI models to manipulation through adversarial inputs and social engineering, emphasizing the critical need for robust security measures.
Torchtune Discord
- Torchtune Needs Smaller Model for PPO Full Finetune: A member is attempting to use the
lora_dpo_single_devicerecipe withNF4+compileand suggests prioritizing other recipes first, such asppo_full_finetune_single_device.- They request a smaller model that can fit on a 16GB GPU, suggesting Qwen2-1.5B as a suitable option for this recipe.
- Torchtune's CPU Offload Optimizer and Torchao Dependency: A member inquires about Torchtune's handling of Torchao version dependency, as the CPU offload optimizer is included in Torchao main, scheduled for the next release.
- They propose incorporating a copy of the CPU offload code into Torchtune and utilizing the Torchao implementation when it becomes available.
- TinyLlama 1B for Efficient Torchtune PPO Full Finetune: A member suggests using TinyLlama 1B (or 0.5B) for the PPO full finetune recipe, given the availability of Llama2 classifiers.
- They provide a link to a 1B configuration on GitHub and recommend adjusting batch sizes for memory optimization.
OpenAccess AI Collective (axolotl) Discord
- Elon Musk's Grok 2 Outperforms: Grok 2, a new language model from Elon Musk's x.ai, was released in an early preview and is being touted for its "frontier capabilities" in chat, coding, and reasoning.
- Grok 2, dubbed "sus-column-r" on the LMSYS leaderboard, has a higher Elo score than Claude 3.5 Sonnet and GPT-4-Turbo.
- Fineweb-Edu Data Set Now Fortified: The Fineweb-Edu dataset, available on Hugging Face, has been fortified by removing duplicate data and adding embeddings.
- It is now called Fineweb-Edu-Fortified and includes a
countcolumn indicating how many times the text appears in the dataset.
- It is now called Fineweb-Edu-Fortified and includes a
- Mistral Large 2 Still in Development: A user asked if Mistral Large 2 has been trained yet.
- The response indicated that the model has not been trained yet.
- axolotl Model Loading:
load_modelFlag andand FalseCondition Explained: A user asked why the conditionand Falseis used in theaxolotl/utils/models.pyfile when loading models.- This condition is used to ensure that the model is not loaded if the
load_modelflag is set toFalse.
- This condition is used to ensure that the model is not loaded if the
- OpenAI Chat Endpoint - No Assistant Response Continuation: A user asked if it is possible to continue a partially completed assistant response using the official OpenAI chat endpoint.
- The response indicated that while they have had success continuing local model responses, OpenAI's chat endpoint consistently prevents the continuation of assistant responses.
LAION Discord
- Grok-2 Outperforms GPT-4 & Claude: x.ai released Grok-2, a model significantly more powerful than Grok-1.5, boasting frontier capabilities in chat, coding, and reasoning.
- An early version of Grok-2, nicknamed "sus-column-r", has been tested on the LMSYS leaderboard, where it currently outperforms both Claude 3.5 Sonnet and GPT-4-Turbo.
- Grok-2: Public & Enterprise Beta: Grok-2 and Grok-2 mini are currently in beta on 𝕏 and will be made available through x.ai's enterprise API later this month.
- x.ai is soon releasing a preview of multimodal understanding as a core part of the Grok experience on 𝕏 and API.
- Open-Source Image Annotation GUIs Needed: A member is seeking recommendations for good open-source GUIs for annotating images quickly and efficiently.
- They are particularly interested in GUIs that support single-point annotations, straight-line annotations, and drawing polygonal segmentation masks.
- Elon Musk & Developer Licenses: There was a discussion about Elon Musk possibly using developer licenses and challenging weight licenses.
- The conversation revolved around the idea of Elon Musk utilizing a developer license to potentially circumvent the limitations of weight licenses.
- Schnelle's Paid Features: A member mentioned that Schnelle, a software tool, may require a paid subscription for its professional features.
- They also indicated that Schnelle's pricing structure might not be ideal for users who are price-sensitive.
tinygrad (George Hotz) Discord
- ConvTranspose2D Works with 3D Data: A user was confused about how to use
ConvTranspose2Dwith 3D data intinygradbut it does work!- The issue was that
kernel_sizeshould be passed as a tuple of length 3 instead of an integer, e.g.,kernel_size=(3, 3, 3). The documentation should be improved to clarify this.
- The issue was that
- Tinygrad Errors with CLANG=1 and LAZYCACHE: A user reported a
RuntimeError: wait_result: 10000 ms TIMEOUT!error while running Tinygrad withCLANG=1and aTensor.zerosoperation on the GPU (3070ti), but it worked correctly withCUDA=1.- This error might be connected to the LAZYCACHE feature in Tinygrad and a user suggested that it is "bug prone" and suggested deleting it and deduplicating in the schedule.
OpenInterpreter Discord
- OpenInterpreter Pip Release: A new version of OpenInterpreter was pushed to pip last night.
- The next major update, "the developer update", is still in development and includes lots of new useful features.
- Local LLMs Are Power Hungry: Local LLMs require a significant amount of processing power.
- It is recommended to run LLMs in the cloud, especially for OpenInterpreter, which utilizes the default settings.
- RealtimeSTT & Faster-Whisper Integration: OpenInterpreter now uses RealtimeSTT which relies on Faster-Whisper for real-time speech to text.
- The combination provides real-time performance for most users and has yet to be problematic on less powerful devices.
- Obsidian Plugin & Anything-to-Anything: A YouTube video was shared showcasing the use of Open Interpreter in Obsidian for converting anything to anything.
- The video promotes the use of the Open Interpreter Obsidian plugin for controlling Obsidian vaults and showcases its capabilities in converting various data types.
- Tool Use Tuesday & Video Production: A user mentioned plans for a video presentation for a contest that involved using Open Interpreter and Obsidian.
- They also mentioned exploring vector search and using Manim to visualize digraphs, indicating a focus on improving video production skills and utilizing the 'Tool Use Tuesdays' theme.
MLOps @Chipro Discord
- Poe's Previews Hackathon: Poe is hosting a Previews hackathon, in partnership with @agihouse_org, where participants can compete to create innovative and useful in-chat generative UI experiences.
- The hackathon is open to all creators and more information can be found at https://app.agihouse.org/events/poe-previews-hackathon-20240817.
- Modal Labs: Best Fine-Tuning Platform: A member believes Modal Labs is the best platform for fine-tuning open-source LLMs.
- This suggests that Modal offers valuable tools and resources for developers working with large language models.
- Image Feature Store Speeds Up Training: A simple feature store was built for an R&D team to store extracted features from images during online preprocessing.
- This reduced training time by 30-60 minutes per training run, saving a considerable amount of time for model development.
- Generic Feature Store for Diverse Models: The feature store is generic and handles image IDs, extraction methods, and pointers to extracted features in an object store.
- This allows it to accommodate diverse models, from small to large, ensuring efficient feature storage and retrieval.
DiscoResearch Discord
- Mistral has struggles expanding beyond 8k: Members stated that Mistral cannot be extended beyond 8k without continued pretraining and this is a known issue.
- They pointed to further work on mergekit and frankenMoE finetuning for the next frontiers in performance.
- Discussion on Model Merging Tactics: A member suggested applying the difference between UltraChat and base Mistral to Mistral-Yarn as a potential merging tactic.
- Others expressed skepticism, but this member remained optimistic, citing successful past attempts at what they termed "cursed model merging".
LLM Finetuning (Hamel + Dan) Discord
- Automated Jupyter Notebook Exploration: A member inquired about existing libraries or open-source projects that could help build a system to automate Jupyter Notebook modifications.
- The goal is to create an agentic pipeline for swapping cells, generating variations, and validating outputs, similar to the Devin project but focused on a specific, small task.
- Jupyter Notebook Automation: A Game Changer: The proposed system would take a working Jupyter Notebook as input and modify it by swapping out cells.
- This automated process would generate multiple versions, allowing for efficient exploration of different notebook configurations and potentially leading to improved results.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!