[AINews] Grok-1 in Bio
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI News for 3/15/2024-3/18/2024. We checked 358 Twitters and 21 Discords (337 channels, and 9841 messages) for you. Estimated reading time saved (at 200wpm): 1033 minutes.
After Elon promised to release it last week, Grok-1 is now open, with a characteristically platform native announcement:
If you don't get the "in bio" thing, just ignore it, it's a silly in-joke/doesn't matter.
the GH repo offers a few more details:

Unsloth's Daniel Han went thru the architecture and called out a few notable differences, but nothing groundbreaking it seems.
Grok-1 is great that it appears to be a brand new, from-scratch open LLM that people can use, but its size makes it difficult to finetune, which Arthur Mensch of Mistral is slyly poking at:
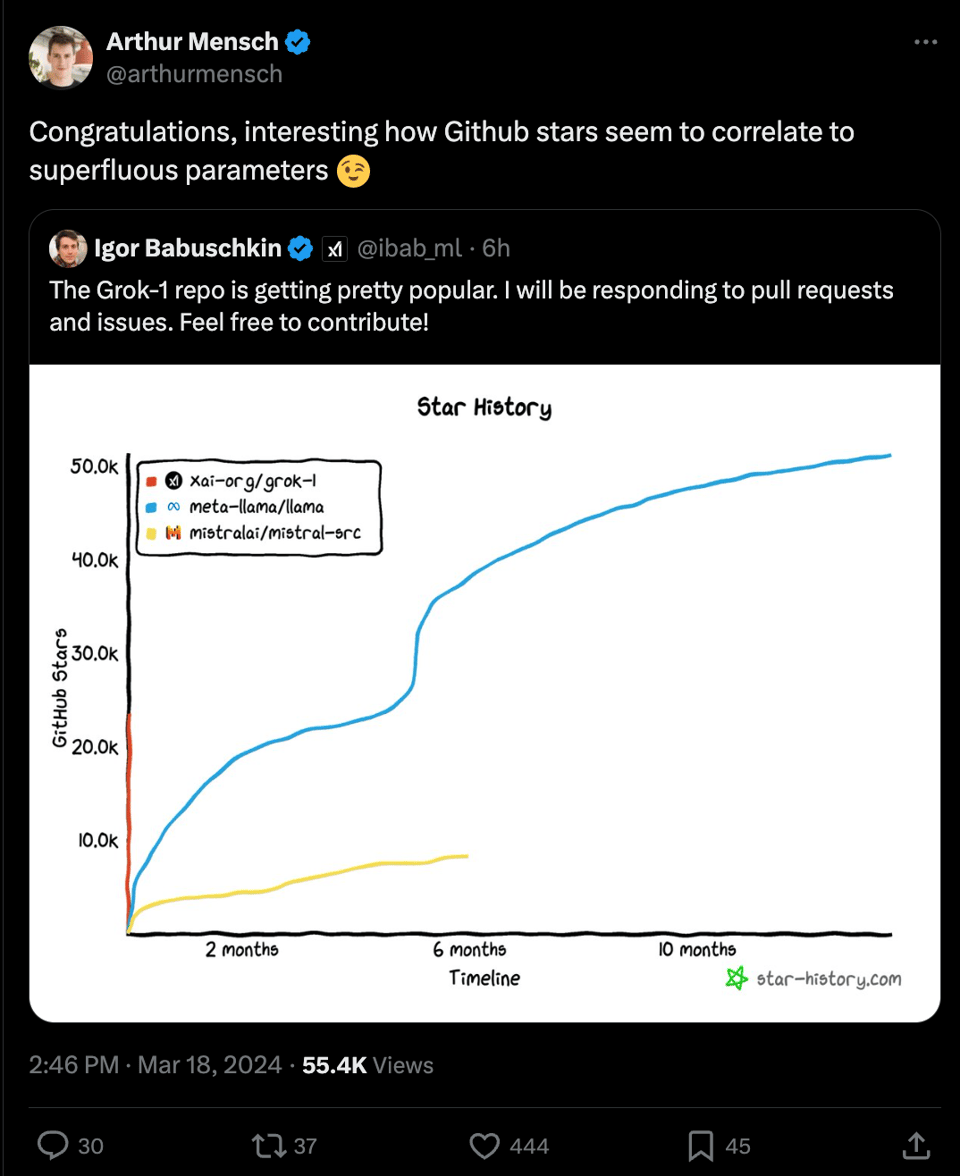
However folks like Perplexity have already pledged to finetune it and undoubtedly the capabilities of Grok-1 will be mapped out now that it is in the wild. Ultimately the MMLU performance doesn't seem impressive, and (since we have no details on the dataset) the speculation is that it is an upcycled Grok-0, undertrained for its size and Grok-2 will be more interesting.
Table of Contents
- PART X: AI Twitter Recap
- PART 0: Summary of Summaries of Summaries
- PART 1: High level Discord summaries
- Stability.ai (Stable Diffusion) Discord
- Perplexity AI Discord
- Unsloth AI (Daniel Han) Discord
- LM Studio Discord
- Nous Research AI Discord
- Eleuther Discord
- OpenAI Discord
- HuggingFace Discord
- LlamaIndex Discord
- Latent Space Discord
- LAION Discord
- OpenAccess AI Collective (axolotl) Discord
- CUDA MODE Discord
- OpenRouter (Alex Atallah) Discord
- LangChain AI Discord
- Interconnects (Nathan Lambert) Discord
- Alignment Lab AI Discord
- LLM Perf Enthusiasts AI Discord
- DiscoResearch Discord
- Datasette - LLM (@SimonW) Discord
- Skunkworks AI Discord
- PART 2: Detailed by-Channel summaries and links
PART X: AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs
Model Releases
- Grok-1 from xAI: 314B parameter Mixture-of-Experts (MoE) model, 8x33B MoE, released under Apache 2.0 license (191k views)
- Grok weights available for download at huggingface-cli download xai-org/grok-1 (19k views)
- Grok code: Attention scaled by 30/tanh(x/30), approx GELU, 4x Layernorms, RoPE in float32, vocab size 131072 (146k views)
- Open-Sora 1.0: Open-source text-to-video model, full training process, data, and checkpoints available (100k views)
Model Performance & Benchmarking
- Grok on par with Mixtral despite being 10x larger, potential for improvement with continued pretraining (21k views)
- Miqu 70B outperforms Grok (2.5k views)
Compute & Hardware
- Sam Altman believes compute will be the most important currency in the future, world is underprepared for increasing compute demand (181k views)
- Grok on Groq hardware could be a game-changer (3.8k views)
Anthropic Claude
- Interacting with Claude a spiritual experience, exists somewhere else in space and time (114k views)
- Claude has self-consistent histories, knows if you try to get it to violate ethics, have to argue within its moral framework (7.7k views)
Memes & Humor
- "OpenAI haha more like not open ai hahahahoakbslbxkvaufqigwrohfohfkbxits so funny i can't breathe hahahoainaknabkjbszjbug" (20k views)
- Grok used as "nastychat slutbot" instead of "demigod" given 314B params (9.4k views)
- Anons cooking a "new schizo grok waifu" (1.7k views)
In summary, the release of Grok-1, a 314B parameter MoE model from xAI, generated significant discussion around model performance, compute requirements, and comparisons to other open-source models like Mixtral and Miqu. The spiritual experience of interacting with Anthropic's Claude also captured attention, with users noting its self-consistent histories and strong moral framework. Memes and humor around Grok's capabilities and potential misuse added levity to the technical discussions.
PART 0: Summary of Summaries of Summaries
Since Claude 3 Haiku was released recently, we're adding them to this summary run for you to compare. We'll keep running these side by side for a little longer while we build the AINews platform for a better UX.
Claude 3 Haiku (3B?)
More instability in Haiku today. It just started spitting back the previous day's prompt, and it needed a couple turns of prompting to follow instructions right.
Advancements in 3D Content Generation: Stability.ai announced the release of Stable Video 3D, a new model that can generate high-quality novel view synthesis and 3D meshes from single images, building upon their previous Stable Video Diffusion technology. This represents a significant advancement in 3D content generation capabilities. Source
Debates on Model Efficiency and Optimization: Across multiple Discords, there were ongoing discussions about the relative efficiency and performance of different Stable Diffusion models, Mistral variants, and large language models like Grok-1. Users explored techniques like quantization, sparse attention, and model scaling to improve efficiency. Sources, Sources
Concerns over Proprietary AI Models and Partnerships: The Stability.ai Discord saw users expressing concerns about the company's recent partnerships with blockchain entities, fearing a potential shift towards more proprietary models and restricted access to AI tools. Source
Navigating API and Deployment Challenges: Across multiple Discords, users discussed issues with API integration, model deployment, and service disruptions. This included problems with OpenAI's API, inconsistencies in Perplexity's API responses, and challenges in running large models like Grok-1 locally. Sources, Sources
Finetuning and Dataset Curation: The Unsloth AI, Nous Research AI, and DiscoResearch Discords saw extensive discussions around the challenges and best practices for finetuning large language models, including dataset preparation, hyperparameter tuning, and model compatibility. Users shared resources and experiences to help navigate these complex tasks. Sources, Sources, Sources
Advancements in Retrieval-Augmented Generation (RAG): The LlamaIndex Discord saw active discussions around enhancing RAG pipelines, including techniques for handling complex queries, improving structured output, and leveraging memory management. Members shared resources and project updates related to these developments. Sources
Exploring Open-Source AI Models and Tooling: Discords like Eleuther, CUDA MODE, and Interconnects highlighted the release and exploration of large open-source models like Grok-1, as well as the development of new tools and techniques for CUDA programming and AI model evaluation. Sources, Sources, Sources
Claude 3 Sonnet (14B?)
Sonnet was better at following instructions today but continued not working out of the box like we had running a few days ago. Needed to implement a check step like "you should summarize shared themes across discords and make sure to directly link to source urls where relevant."
1. Massive AI Models and Their Implications:
- The release of Grok-1, a 314 billion parameter Mixture-of-Experts model by xAI, sparked widespread discussions across multiple Discords. It was open-sourced under Apache 2.0 license with instructions on GitHub, but its practicality was debated given the immense compute requirements for inference (up to 124GB VRAM).
- Comparisons were made to models like GPT-4, Falcon, and Mistral in terms of performance on benchmarks like GSM8K and MMLU. However, some were skeptical about Grok-1's potential to surpass GPT-4 or Claude.
- The challenges of distributing and working with such massive models were highlighted, with suggestions like using magnet links or even mailing physical drives to circumvent cloud egress fees.
2. Advancements in Multimodal and Retrieval-Augmented AI:
- Stability AI announced Stable Video 3D, generating 3D meshes and multi-view outputs from single images, improving quality over previous models.
- Discussions explored enhancing RAG (Retrieval-Augmented Generation) pipelines by treating retrieved documents as interactive components, as detailed in this GitHub link.
- The LlamaIndex project released v0.10.20 with an Instrumentation module for observability, and covered methods like Search-in-the-Chain for improving QA systems.
- A HuggingFace paper discussed crucial components and data choices for building performant Multimodal LLMs (MLLMs).
3. Fine-tuning and Optimizing Large Language Models:
- Extensive discussions on optimally fine-tuning models like Mistral-7b using QLoRA, addressing hyperparameters like learning rate and epoch count (generally 3 epochs recommended).
- Unsloth AI's integration with AIKit allows finetuning with Unsloth to create minimal OpenAI API-compatible model images.
- Debates on the efficiency of various Stable Diffusion models like Stable Cascade vs SDXL, with some finding Cascade better for complex prompts but slower.
- Guidance on handling issues like high VRAM/RAM usage during model saving, specifying end-of-sequence tokens, and potential future support for full fine-tuning in Unsloth.
4. Prompt Engineering and Enhancing LLM Capabilities:
- Discoveries were shared on the depth of "Prompt Engineering" for OpenAI's APIs, involving instructing the AI on analyzing responses beyond just question phrasing.
- Proposals to introduce
tokens in LLMs to improve reasoning capabilities were debated, with references to works like Self-Taught Reasoner (STaR) and Feedback Transformers. - An arXiv paper demonstrated extracting proprietary LLM information from a limited number of API queries due to the softmax bottleneck issue.
Claude 3 Opus (>220B?)
By far the best off the shelf summarizer model. Incredible prompt adherence. We like the Opus.
- Grok-1 Model Release Sparks Excitement and Skepticism: xAI's open-source release of the 314B parameter Mixture-of-Experts model Grok-1 under the Apache 2.0 license has generated buzz, with discussions around its impressive size but mixed benchmark performance compared to models like GPT-3.5 and Mixtral. Concerns arise about the practicality of running such a large model given its hefty compute requirements of up to 124GB of VRAM for local inference. The model weights are available on GitHub.
- Anticipation Builds for Stable Diffusion 3 and New 3D Model: The Stable Diffusion community eagerly awaits the release of Stable Diffusion 3 (SD3), with hints of beta access invites rolling out soon and a full release expected next month. Stability AI also announces Stable Video 3D (SV3D), a new model expanding 3D capabilities with significantly improved quality and multi-view experiences over previous iterations like Stable Zero123.
- Unsloth AI Gains Traction with Faster LoRA Finetuning: Unsloth AI is trending on GitHub for its 2-5X faster 70% less memory QLoRA & LoRA finetuning as per their repository. The community is actively discussing finetuning strategies, epochs, and trainability, with a general consensus on 3 epochs being standard to avoid overfitting and equal ratios of trainable parameters to dataset tokens being optimal.
- Photonics Breakthroughs and CUDA Optimization Techniques: Advancements in photonics, such as a new breakthrough claiming 1000x faster processing, are generating interest, with Asianometry's videos on Silicon Photonics and neural networks on light meshes shared as resources. CUDA developers are exploring warp schedulers, memory management semantics, and performance optimization techniques, while also anticipating NVIDIA's upcoming GeForce RTX 50-series GPUs with 28 Gbps GDDR7 memory.
Some other noteworthy discussions include:
- A new arXiv paper detailing a method to extract sensitive information from API-protected LLMs like GPT-3.5 at low cost
- Apple's rumored moves in the AI space, including a potential acquisition of DarwinAI and a 30B parameter LLM
ChatGPT (GPT4T)
ChatGPT proved particularly stubborn today - no amount of prompting tricks were able to improve the quality of the link sourcing in today's output. We will cut over to the new pipeline this week which should solve this problem but it is disappointing that prompts alone don't do what we want here.
- Revolutionizing 3D Content Generation and AI Efficiency: Stability.ai introduces Stable Video 3D, a leap forward in 3D mesh generation from images, outperforming predecessors like Stable Zero123. Discussions also revolve around the efficiency of various Stable Diffusion models, with debates on their prompt handling capabilities and speed, emphasizing a trade-off between performance and complexity.
- Emergence of Grok-1 and AI Hardware Discussions: The AI community buzzes about Grok-1, a 314B parameter open-source model by Elon Musk's team, sparking discussions about its computational demands for practical use. Concurrently, there's a surge in conversations around AI hardware, notably Nvidia's 5090 GPU, and cooling requirements, reflecting the escalating need for powerful setups to support growing model sizes.
- AI Applications in Workforce and Creativity: Perplexity AI showcases its API's utility in job searches, demonstrating AI's growing role in the workforce. Meanwhile, creative applications flourish, highlighted by a poetic expression of machine learning concepts on Unsloth AI's Discord, encouraging more creative technical monologues.
- AI's Role in Education and Legal Challenges: OpenAI's Discord engages in debates on prompt engineering techniques to optimize AI tasks and the complexities of API content filters in creative writing. Additionally, there's a focused discourse on AI's potential in parenting and education, spurred by comparisons of Claude 3 Opus with GPT-4, alongside a narrative on public access to government AI models, stirring legal and ethical considerations.
- Advancements in Language Models and Retrieval Systems: The AI community eagerly discusses the integration of RAG (Retriever Augmented Generation) systems for enhanced model outputs and the unveiling of LLaMa models on OpenRouter Discord, capable of handling a mix of prompts. Such advancements underscore ongoing efforts to improve language understanding and response generation, reflecting a broader trend towards more sophisticated AI interaction models.
These themes encapsulate the dynamic nature of AI development and application, from enhancing content creation and improving model efficiency to tackling hardware limitations and exploring AI's societal implications.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
Revolutionizing 3D Content Generation: Stable Video 3D has been announced by Stability AI, leveraging capabilities for high-quality novel view synthesis from single images and creating 3D meshes, surpassing former models like Stable Zero123 in quality and multi-view outputs.
Anticipation High for SD3: Engineers are eagerly awaiting Stable Diffusion 3 (SD3), with beta access speculated to start rolling out soon, and the official release expected next month, promising new advancements.
Efficiency on Trial: Ongoing debates focus on the efficiency of various Stable Diffusion models, where some engineers find Stable Cascade slower but more adept at handling complex prompts compared to SDXL.
Blockchain Ventures Spark Concern: Stability AI's partnerships with blockchain entities have stirred discussions, with some AI engineers worrying about the potential move towards proprietary models and restricted access to AI tools.
Safety in File Handling: Amidst security discussions, an inquiry about converting .pt files to SAFETENSOR format led to the share of a converter tool link, while most UIs are confirmed to avoid executing unsafe code - GitHub converter tool.
Perplexity AI Discord
- Unlimited Queries Not So Limitless: Engineers highlighted confusion over Perplexity's "unlimited" Claude 3 Opus queries for Pro users, noting an actual cap at 600 daily uses and seeking clarification on the misleading term "unlimited."
- Claude 3 Opus Gains Attention: The Claude 3 Opus model sparked interest among technical users comparing it with GPT-4 and discussing its potential for complex tasks with more natural responses, amidst broader debates on AI's role in parenting and education.
- Technical Deep Dive into Perplexity's API: In the #pplx-api channel, there's been confusion over a model's scheduled deprecation and discussion about API inconsistencies, with users sharing insights into API rate limits and the effect of token limits on LLM responses.
- Apple's AI Aspirations Discussed: Discourse surrounding Apple's AI moves, including the possible DarwinAI acquisition and speculation over a 30B LLM, permeated discussions, indicating keen interest in the tech giant's strategy in the AI landscape.
- Perplexity API Efficiency in Job Hunts: Utilizing the Perplexity API for job searches was a highlighted use case, with mixed results in terms of direct job listings versus links to broader job platforms, demonstrating practical AI applications in the workforce.
Unsloth AI (Daniel Han) Discord
- AIKit Welcomes Unsloth Finetuning: AIKit has integrated support for finetuning with Unsloth to create minimal model images compatible with OpenAI's API. A Spanish TTS test space on Hugging Face was shared for community use.
- Grok-1, the Open Source Giant: Discussions ignited about Grok-1, a 314B parameter open-sourced model by Elon Musk's team at X.ai, where concerns arose about its practical usage due to immense computational resource requirements for inference.
- Beware of Impersonators: A scam account imitating 'starsupernova0' prompted warnings within the community; members are encouraged to stay vigilant and report such activities.
- Unsloth AI Trends on GitHub: Unsloth AI has garnered attention on GitHub, where it offers 2-5X faster and 70% less memory usage for QLoRA & LoRA finetuning. The community is encouraged to star the Unsloth repository for support.
- Finetuning Troubles:
- High VRAM and system RAM usage during model saving in Colab was highlighted, especially for large models like Mistral.
- Finetuning-related concerns included unexpected model behaviors post-finetuning and clarifications about proper end-of-sequence token specification.
- Debates on epochs and trainability, with general consensus on 3 epochs being standard to avoid overfitting, and trainability discussions pointing to equal ratio of trainable parameters to dataset tokens.
- The Poetic Side of Tech: A poetic expression of machine learning concepts appeared, garnishing appreciation and encouragement for more creative technical monologues.
- Small Model Big Potential: Links to Tiny Mistral models were shared, suggesting potential inclusion in the Unsloth AI repository for community use and experimentation.
LM Studio Discord
- The Wait for Command-R Support: Discussions indicate anticipation for C4AI Command-R support in LM Studio post the merge of GitHub Pull Request #6033. However, confusion persists among members about llama.cpp's compatibility with c4ai, even though files are listed on Hugging Face.
- Big Models, Big Dreams, Bigger GPUs?: The community has been abuzz with hardware talk, from the feasibility of the Nvidia 5090 GPU in various builds to dealing with heavy power draw and cooling requirements. The ROCm library exploration was expanded with a GitHub resource for prebuilt libraries and hopes for dual GPU setup support in LM Studio using tools like koboldcpp-rocm.
- Configurations, Compatibility, and Cooling: Amidst the eager shares of new rig setups and considerations for motherboards with more x16 PCIe Gen 5 slots, members also discussed cable management and the practicalities of accommodating single-slot GPUs. There's active troubleshooting advice, like a suggestion about a Linux page note for AMD OpenCL drivers and confirming AVX Beta's limitations, such as not supporting starcoder2 and gemma models but maintaining compatibility with Mistral.
- Model Hunt and Support: Recommendations flew around for model selection, with suggestions to use Google and Reddit channels for finding a well-suited LLM and models like Phind-CodeLlama-34B-v2 being tapped for specific use cases. Inquiries about support limitations in LM Studio, such as the inability to chat with documents directly or use certain plugins, were discussed, while a list of configuration examples was shared for those seeking presets.
- Agency in AI Agents: A single message in the crew-ai channel expresses an ongoing search for an appropriate agent system to enhance the validation of a creative concept, suggesting an ongoing evaluation of various agents.
Nous Research AI Discord
- High-Speed Memory Speculation: NVIDIA's anticipated RTX 50-series Blackwell's use of 28 Gbps GDDR7 memory stirred debates on the company's historical conservative memory speed choices, as discussed in a TechPowerUp article.
- Inferences from Giant Models: There are both excitement and concerns about the feasibility of running massive AI models like Grok-1, which poses challenges such as requiring up to 124GB of VRAM for local inference and the cost-effectiveness for usage.
- Yi-9B License Quandaries & Scaling Wishes: Conversations delve into the licensing clarity of the Yi-9B model and the community's skepticism. Users also express their aspirations and doubts regarding the scaling or improvement upon Mistral to a 20 billion parameter model.
- RAG Innovations and Preferences: The community is focused on enhancing RAG (Retriever Augmented Generation) system outputs, discussing must-have features and advantages of smaller models within large RAG pipelines. A GitHub link was shared, exhibiting desirable RAG system prompts.
- Bittensor's Blockchain Blues: Technical problems are afoot in the Bittensor network, with discussions on network issues, the need for a subtensor chain update, and the challenges surrounding the acquisition of Tao for network registration. Hardware suggestions for new participants include the use of a 3090 GPU.
Eleuther Discord
- Ivy League's Generosity Unlocked: An Ivy League course made freely accessible has sparked a dialogue on high-quality education's reach, with nods to similar acts by institutions like MIT and Stanford.
- Woodruff's Course Garners Accolades: A comprehensive course by CMU's Professor David P. Woodruff was praised for its depth, covering a span of almost 7 years.
- Pioneering Projects 'Devin' and 'Figure 01': The debut of Devin, an AI software engineer, and the "Figure 01" robot's demo, in comparison to DeepMind's RT-2 (research paper), has opened discourse on the next leap in robot-human interaction.
- Fueling LLMs with
: A proposition from Reddit to introduce tokens in LLMs led to a debate, referencing works such as the Self-Taught Reasoner (STaR) and Feedback Transformers that delve into enhancing LLM reasoning through computational steps. - Public Access to Government-AI Sought: A discourse emerged around a FOIA request aimed at making Oakridge National Laboratory's 1 trillion parameter model public, accompanied by doubts due to classified data concerns and legal complications.
- Debating Performance Metrics: Discussions unraveled around model performance evaluations, pinpointing ambiguities in benchmarks, particularly with Mistral-7b on the GSM8k.
- Challenges of RL in Deep Thinking: The limitations of using reinforcement learning to promote 'deeper thinking' in language models were examined, alongside proposals for a supervised learning approach for enhancing such behaviors.
- Reverse for Relevance: A user's query on standard tokenizers not tokenizing numbers in reverse led into a discourse on right-aligned tokenization, highlighted in GPT models via Twitter.
- LLM Secrets via API Queries: Sharing a paper (arXiv:2403.09539) revealing that large language models could leak proprietary information from limited queries peaked interest due to a softmax bottleneck issue.
- Grok-1 Model Induces Model Curiosity: The unveiling of Grok-1 instigated discussions on its potential, scaling strategies, and benchmarks against contemporaries like GPT-3.5 and GPT-4.
- Scaling Laws Questioned with PCFG: Language model scaling sensitivity to dataset complexity, informed by a Probabilistic Context-Free Grammar (PCFG), was debated, suggesting gzip compression's predictive power on dataset-specific scaling impacts.
- Data Complexity's Role in Model Efficacy: The discussion highlighted that data complexity matching with downstream tasks might ensure more efficient model pretraining outcomes.
- Sampling from n-gram Distributions: Clear methods for sampling strings with a predetermined set of n-gram statistics were explored, with an autoregressive approach being posited for ensuring a maximum entropy distribution following pre-specified n-gram statistics.
- Discovery of n-gram Sampling Tool: A tool for generating strings with bigram statistics was shared, available on GitHub.
- Hurdles and Resolutions in Model Evaluation: A series of technical queries and clarifications in model evaluations were recorded, including a
lm-eval-harnessintegration query, Mistral model selection bug, and a deadlock issue during thewmt14-en-frtask, leading to sharing of the issue #1485. - Evaluating Translations in Multilingual Evals: The concept of translating evaluation datasets to other languages sprouted a suggestion to collect these under a specific directory and clearly distinguish them in task names.
- Unshuffling The Datascape: The Pile's preprocessing status was questioned; it's established that the original files are not shuffled, but already preprocessed and pretokenized data is ready for use with no extra shuffling required.
OpenAI Discord
- One Key, Many Doors: Unified API Key for DALL-E 4 and GPT-4 – Discussions confirmed that a single API key could indeed be used to access both DALL-E 4 for image generation and GPT-4 for text generation, streamlining the integration process.
- Exploring Teams and Privacy: ChatGPT Team Accounts Privacy Explained – It was clarified that upgrading from ChatGPT plus to team accounts does not give team admins access to users' private chats, an important note for user privacy on OpenAI services.
- Prompt Crafting Puzzles: Techniques in Prompt Engineering Gain Spotlight – Engineers exchanged strategies on optimizing prompts for AI tasks, with recommendations like applying the half-context-window rule for tasks and leveraging meta-prompting to overcome model refusals. There was a consensus on the importance of proper prompt structuring to improve classification, retrieval, and model interactivity.
- Model Behavior Mysteries: API Content Filters Sideline Creativity – Frustrations bubbled up about the content filters in OpenAI's API and the GPT-3.5 refusal issues. The community shared experiences of decreased willingness from the model to engage in creative writing and roleplay scenarios, and also noted service disruptions which were sometimes attributable to browser extensions rather than the ChatGPT model itself.
- The Web Search Conundrum: Complexities in GPT's Web Search Abilities Examined – Users discussed the capabilities of GPT regarding the integration of web searching features, the use of up-to-date libraries like Playwright in code generation, and how to direct GPT to generate and use multiple search queries for comprehensive information retrieval.
HuggingFace Discord
Discord's AI Scholars Share Latest Insights:
- Optimizing NL2SQL Pipelines Queries: An AI engineer expressed the need for more effective embedding and NL2SQL models, as current solutions like BAAI/llm-embedder and TheBloke/nsql-llama-2-7B-GGUF paired with FAISS are delivering inconsistent accuracy.
- Grace Hopper Superchip Revealed by Nvidia: NVIDIA teases its community with the Grace Hopper Superchip announcement, designed for compute-intensive disciplines such as HPC, AI, and data centers.
- How to NLP: Resources for beginners in NLP were sought; newcomers were directed to Hugging Face's NLP course and the latest edition of Jurafsky's textbook on Stanford's website, with a nod to Stanford’s CS224N for more dense material.
- Grok-1 Goes Big on Hugging Face: The upload and sharing of Grok-1, a 314 billion parameter model, stirred discussions, with links to its release information and a leaderboard of model sizes on Hugging Face.
- AI Peer Review Penetration: An intriguing study pointed out that between 6.5% to 16.9% of text in AI conference peer reviews might be significantly altered by LLMs, citing a paper that connects LLM-generated text to certain reviewer behaviors and suggests further exploration into LLMs' impact on information practices.
LlamaIndex Discord
- RAG Gets Interactive: Enhanced RAG pipelines are proposed to handle complex queries by using retrieved documents as an interactive component, with the idea shared on Twitter.
- LlamaIndex v0.10.20 Debuts Instrumentation Module: The new version 0.10.20 of LlamaIndex introduces an Instrumentation module aimed at improving observability, alongside dedicated notebooks for API call observation shared via Twitter.
- Search-in-the-Chain: Shicheng Xu et al.'s paper presents a method to improve question-answering systems by combining retrieval and planning in what they call Search-in-the-Chain, as detailed in a Tweet.
- Job Assistant from Resume: A RAG-based Job Assistant can be created using LlamaParse for CV text extraction, as explained by Kyosuke Morita and shared on Twitter.
- MemGPT Empowers Dynamic Memory: A webinar discusses MemGPT, which gives agents dynamic memory for better handling of memory tasks, with insights available on Twitter.
- OpenAI Agents Chaining Quirk: When chaining OpenAI agents resulted in a
400 Error, it was suggested that the content sent might have been empty and more discussion can be found in the deployment guide. - Xinference Meets LlamaIndex: For those looking to deploy LlamaIndex with Xinference in cluster environments, guidance is provided in a local deployment guide.
- Fashioning Chatbots as Fictional Characters: Engaging chatbots that emulate characters like James Bond may benefit from prompt engineering over datasets or fine-tuning, with relevant methods described in a prompting guide.
- Multimodal Challenges for LLMs: Discussion around handling multimodal content within LLMs flagged potential issues with losing order in chat and updating APIs, with multimodal content handling examples found here.
- How-To Guide on RAG Stacking: A YouTube guide was shared on building a RAG with LlamaParse, streamlining the process using technologies such as Qdrant and Groq, with the video available here.
- RAG Pipeline Insights on Medium: An article discusses creating an AI Assistant with a RAG pipeline and memory, leveraging LlamaIndex.
- RAPTOR Effort Hits a Snag: An AI engineer's attempt to adapt the RAPTOR pack for HuggingFace models, using guidance from GitHub, faced implementation issues seeking community assistance.
Latent Space Discord
- Grok-1 Unchained: xAI has launched Grok-1, a massive 314B parameter Mixture-of-Experts model, licensed under Apache 2.0, raising eyebrows over its unrestricted release but showing mixed performance in benchmarks. Intrigued engineers can find more details from the xAI blog.
- Altman Sparks Speculation: Sam Altman hints at a significant leap in reasoning with the upcoming GPT-5, igniting discussions about the model's potential impact on startups. Curious minds can dive into the conversation with Sam's interview on the Lex Fridman podcast.
- Jensen Huang's Anticipated Nvidia Keynote: GPT-4's hinted capabilities and the mention of its 1.8T parameters set the stage for Nvidia's eagerly awaited keynote by Jensen Huang, stirring the pot for AI tech enthusiasts. Watch the gripping revelations in Jensen's keynote.
- Innovative Data Extraction on the Horizon: Excitement is brewing with a teaser about a new structured data extraction tool in private beta promising low-latency and high accuracy—the AI community awaits further details. Keep an eye out on Twitter for updates on this potentially game-changing tool. Access tweet here.
- SDXL's Yellow Predicament: SDXL faces scrutiny with a color bias towards yellow in its latent space, prompting a deeper analysis and proposed solutions to this quirky challenge. Discover more about how color biases are addressed in the blog post on Hugging Face.
- Paper Club Delves into LLMs: The Paper Club has kicked off a session to dissect "A Comprehensive Summary Of Large Language Models," inviting all for a deep dive. Exchange insights and join the learning experience in the dedicated channel.
- AI Saturation Sarcasm Alert: A satirical article dubs the influx of AI-generated content as "grey sludge," possibly foreshadowing a paradigm shift in content generation. Get a dose of this satire on Hacker News.
- Attention Mechanisms Unpacked: Enthusiasts in the llm-paper-club-west channel reveled in a robust discussion about the rationale behind the attention mechanism, which enables models to process input sequences globally and resolve parallelization issues for faster training—spotlighting the decoder's efficiency in focusing on pertinent input segments.
- RAG Discussion Sparks Shared Learning: An article on "Advanced RAG: Small to Big Retrieval" spurred a conversation about retrieval mechanisms and the concept of "contrastive embeddings," offering alternatives to cosine similarity in LLMs. Check out the shared article for a deep dive into Retrieval-Augmented Generation.
- Resource Repository for AI Aficionados: A comprehensive Google Spreadsheet documenting past discussion topics, dates, facilitators, and resource links is available for members looking to catch up or review the AI In Action Club's historical knowledge exchange. Access the historical archive with this spreadsheet.
LAION Discord
- Jupyter's New Co-Pilot: Jupyter Notebooks can now be used within Microsoft Copilot Pro, offering free access to libraries like
simpyandmatplotlib, in a move that mirrors the features of ChatGPT Plus.
- DALL-E Dataset's New Home: Confusion about the DALL-E 3 dataset on Hugging Face was clarified; the dataset has been relocated and can still be accessed via this link.
- Grok-1 Against the Giants: Discussions around the new Grok-1 model, its benchmark performances, and comparisons with models such as GPT-3.5 and Mixtral emerged, alongside emphasizing Grok's open release on GitHub.
- Tackling Language Model Continuity: An arXiv paper detailed a more efficient approach for language models via continual pre-training to address data distribution shifts, promising advancements for the field. The paper can be found here.
- The GPT-4 Speculation Continues: Nvidia's apparent confirmation that GPT-4 is a massive 1.8T parameter MoE fueled ongoing rumors and debates, despite some skepticism over the exact naming of the model.
OpenAccess AI Collective (axolotl) Discord
- Fine-tuning Foibles Featuring Funky Tokenization: Engineers discuss an issue where a tokenizer inconsistently generates a
<summary>tag during fine-tuning for document summarization. A potential mismatch between tokenizer and model behavior is suspected, while another member facedHFValidationErrorsuggesting that full file paths should be utilized for local model and dataset fine-tuning.
- Conversation Dataset Conundrums Corrected: A perplexing problem arises during conversation type training data setup; the culprit turns out to be empty roles in the dataset. Furthermore, reporting on Axolotl's validation warnings generates varying outcomes, with a smaller eval set size causing issues.
- Grok Wades into Weighty Performance Waters: Within the Axolotl group, there's an exchange on the perceived underwhelming performance of the 314B Grok model. In addition, the int8 checkpoint availability is brought up, placing constraints on leveraging the model's capabilities.
- Hardware Hunt and Model Merging Musings: NVIDIA's NeMo Curator for data curation is shared, and Mergekit is suggested as a possible solution for model merging. There's also a conversation on ensuring that merged models are trained using the same chat format for flawless functionality.
- Lofty Leaks Lead to Speculative Sprint: Enthusiasm mixed with skepticism meets the leaks of GPT-4's massive 1.8 trillion parameter count and NVIDIA's next-gen GeForce RTX 5000 series cards. Professionals ponder these revelations, alongside exploring Sequoia for better decoding of large models and NVIDIA's Blackwell series for AI advancement.
Relevant links found in the discussions: - GitHub - NVIDIA/NeMo-Curator: NVIDIA's toolkit for data curation - Grok-1 weights on GitHub - ScatterMoE branch on GitHub - ScatterMoE pull request
CUDA MODE Discord
- Photonics Innovations Spark Interest: Discussions spotlighted a new breakthrough in photonics, claimed to be 1000x faster, and members shared videos including one from Lightmatter. Asianometry's YouTube videos on Silicon Photonics and neural networks on light meshes were also recommended for those interested in the field.
- CUDA Developments and Discussions: Engineers delved into topics like warp schedulers in CUDA, active warps, and memory management semantics involving ProducerProvides and ConsumerTakes. They pondered NVIDIA's GTC events, predicting new GPU capabilities while humorously remarking on the "Skynet vibes" of NVIDIA's latest tech.
- Triton Tools Take the Spotlight: The community shared new development tools such as a Triton debugger visualizer and published Triton Puzzles in a Google Colab to aid in understanding complex kernels.
- Reconfigurable Computing in Academia: Interest piqued in Prof. Mohamed Abdelfattah's research on efficient ML and reconfigurable computing, showcased on his YouTube channel and website. The ECE 5545 (CS 5775) hardware-centric ML systems course, accessed via their GitHub page, was highlighted, alongside the amusing discovery journey for the course's textbook.
- CUDA Beginners and Transition to ML: A solid foundation in CUDA was praised, with advice on transitioning to GPU-based ML with frameworks like PyTorch. References included the Zero to Hero series, ML libraries like cuDNN and cuBLAS, and the book Programming Massively Parallel Processors, found here, for deeper CUDA understanding.
- Ring-Attention Algorithm under the Microscope: Discussion revolved around the memory requirements of ring-attention algorithms, comparing with blockwise attentions. Links were shared to Triton-related code on GitHub and insights were sought into whether linear memory scaling refers to sequence length or the number of blocks.
- MLSys Conference and GTC Emphasized: Conversations touched on the MLSys 2024 conference, recognized for converging machine learning and systems professionals. Additionally, members arranged meetups for the upcoming GTC, discussing attendance and coordinating via DM, with some humorously referencing not being able to attend and linking to a related YouTube video.
OpenRouter (Alex Atallah) Discord
- LLaMa Learns New Tricks: LLaMa models now confirmed to handle a variety of formats, including a combination of
system,user, andassistantprompts, which may be pertinent when utilizing the OpenAI JavaScript library.
- Sonnet Swoops in for Superior Roleplay: Sonnet is attaining popularity for its roleplaying prowess, impressing users with its ability to avoid repetition and produce coherent output, potentially revolutionizing user engagement in interactive settings.
- Crafting the MythoMax Missive: Effective formatting for LLMs like MythoMax remains a hot topic, as understanding the positioning of system messages appears to be crucial for optimal prompt response, indicating that the first system message takes precedence in processing.
- Users Clamor for Consumption Clarity: There's a rising demand for detailed usage reports that break down costs and analytics, underlining a desire among users to fine-tune budget allocation according to AI model usage and time spent.
- Grokking Grok's Future: The forthcoming Grok model is creating buzz for its potential impact and need for fine-tuning on instruction data, with its open-source release and possible API fueling anticipation among community members. For details and contributions, check out Grok's repository on GitHub.
LangChain AI Discord
- Choose Your API Wisely: Engineers debated the use of
astream_logversusastream_eventsfor agent creation, noting perhaps the potential deprecation of thelog APIas theevents APIremains in its beta stage. They also called for beta testers for Rubik's AI, promising two months of premium access to AI models including GPT-4 Turbo and Groq models, with sign-up available at Rubik's AI.
- Improving Langchain Docs: Users articulated the need for more accessible Langchain documentation for beginners and contemplated using
Llamaindexfor quicker structured data queries in DataGPT projects. Others shared a practical solution demonstrating Python Pydantic for structuring outputs from LLM responses.
- JavaScript Streaming Stumbles: A discrepancy in
RemoteRunnablebehavior between Python and JavaScript was highlighted, where JavaScript fails to call/streamand defaults to/invoke, unlike its Python counterpart. Participants discussed inheritance inRunnableSequenceand proposed contacting the LangChain team directly via GitHub or hello@langchain.dev for support.
- Scrape with Ease, Chat with Data, and Bookmark Smartly: The community has been busy with new projects, including an open-source AI Chatbot for data analysis, a Discord bot for managing bookmarks, and Scrapegraph-ai, an AI-based scraper that touts over 2300 installations.
- AI for Nutritional Health & Financial Industry Analysis: Innovators have constructed a nutrition AI app called Nutriheal, which is showcased in a "Making an AI application in 15 minutes" video, and a Medium article discussed how LLMs could revolutionize research paper analysis for financial industry professionals. The article can be read here.
- Rapid AI App Development Spotlighted in Nutriheal: The Nutriheal demo emphasized easy AI app creation using Ollama and Open-webui, with data privacy from Langchain's Pebblo integration, while additional AI resources and tutorials can be found at navvy.co.
- Unveiling Home AI Capabilities: Community contributions included a tutorial aimed at debunking the myth of high-end AI being restricted to big tech and a guide for creating a generic chat UI for any LLM project. A Langgraph tutorial video was also shared, detailing the development of a plan-and-execute style agent inspired by the Plan-and-Solve paper and the Baby-AGI project, viewable here.
Interconnects (Nathan Lambert) Discord
- API-Protected LLMs Vulnerable to Data Extraction: A new arXiv paper exposes a method to extract sensitive information from API-protected large language models like OpenAI's GPT-3.5, challenging the softmax bottleneck with low-cost techniques.
- Model Size Underestimation: Debate centers around the paper's 7-billion parameter estimate for models such as GPT-3.5, with speculation that a Mixture of Experts (MoE) model, possibly used, would not align with such estimations, and that different architectures or distillation methods might be in play.
- Open Source Discourse Gets Heated: Discussions about the definition of open source in the tech community heat up, accompanied by Twitter exchanges and expressions of frustration, advocating for clear community guidelines and less online squabbling, as illustrated by discussions including Nathan Lambert and @BlancheMinerva.
- Grok-1 Enters the AI Arena: xAI's Grok-1, a 314 billion parameter MoE model, has been open-sourced under the Apache 2.0 license, offering untuned capabilities with potential optimality over existing models. It is being compared to others like Falcon, with performance discussions and download instructions available on GitHub.
- Big Data Transfer Riddles: Lively conversations around alternative model distribution methods, including magnet links and humorous suggestions like mailing physical hard drives, arise against the backdrop of Grok-1's release, and HuggingFace mirrors the weights. A Wall Street Journal interview with OpenAI's CTO regarding AI-generated content further fuels data-related concerns.
Alignment Lab AI Discord
- What's the Deal with Aribus?: Curiosity spiked about the Aribus Project after a member shared a tweet; however, the community lacked clarity on the project's applications, with no additional details put forth.
- In Search of HTTP-Savvy Transformers: Discussion turned technical as a member sought an embeddings model trained on HTTP responses, arguing any appropriately trained transformer could suffice. Yet the fine-tuning specificity, like details or sources, was left unaddressed.
- Hunting for Orca-Math Word Problems Model: Inquiry into a fine-tuned Mistral model specifically on orca-math-word-problems-200k dataset and nvidia/OpenMathInstruct-1 met with radio silence; a precise use-case hinted but unstated.
- Aspirations to Tame Grok 1: A member threw down the gauntlet to fine-tune Grok 1 with its formidable 314B parameter size, with conversation pivoting to the model's massive resources demand, like 64-128 H100 GPUs, and its benchmarking potential against titans like GPT-4.
- Grok 1 Shows Its Mathematical Might: Despite skepticism, Grok 1's prowess was spotlighted through performance on a complex Hungarian national high school finals in mathematics dataset, with discussions contrasting its capabilities and efficiency against other notable models.
LLM Perf Enthusiasts AI Discord
- Embracing Simplicity in Local Development: Engineers expressed a preference for building apps with simplicity in mind, favoring tools that enable local execution and filesystem control, and highlighting a desire for lightweight development solutions.
- Anthropic's Ominous Influence?: A shared tweet raised suspicions about Anthropic's intentions, possibly intimidating technical staff, along with acknowledging ongoing issues with content moderation systems.
- The Scale Challenge for Claude Sonnet: Technical discussions surfaced regarding the scalability of using Claude Sonnet, with projections of using "a few dozen million tokens/month" for a large-scale project.
- Debating the Claims of the Knowledge Processing Unit (KPU): The KPU by Maisa sparked debates, with engineers skeptical about its performance claims and comparison benchmarks. The CEO clarified that KPU acts like a "GPU for knowledge management," intended to enhance existing LLMs, offering a notebook for independent evaluation upon request.
- Sparse Details on OpenAI Updates: A single message was posted containing a link: tweet, but with no context or discussion provided, leaving the content and significance of the update unclear.
DiscoResearch Discord
- Fine-Tuning in German Falls Flat: shakibyzn struggles with DiscoLM-mixtral-8x7b-v2 model not responding in German post fine-tuning, hinting at a "ValueError" indicating incompatibility with AutoModel setup.
- Local Model Serving Shenanigans: jaredlcm faces unexpected language responses when serving the DiscoLM-70b model locally, using a server set-up snippet via
vllmand OpenAI API chat completions format. - German Model Training Traps: crispstrobe and peers discuss German models' inconsistencies caused by variables like prompting systems, data translation, merging models' effects, and dataset choices for fine-tuning.
- German LLM Benchmarking Treasure Trove: thilotee highlights resources like supergleber-german-language-evaluation-benchmark and other tools, advocating for more German benchmarks in EleutherAI's lm-evaluation-harness Our Paper.
- German Model Demo Woes and Wins: DiscoResearch models depend on prompt fidelity, illustrating the need for prompt tweaking for optimal demo performance, all against the backdrop of shifting the demo server from a homely “kitchen setup” to a professional environment, which unfortunately led to networking issues.
Datasette - LLM (@SimonW) Discord
- Prompt Engineering's Evolutionary Path: A member reminisced about their involvement in shaping prompt engineering tools with Explosion's Prodigy, which approached prompt engineering as a data annotation challenge, while also acknowledging the technique's limitations.
- A Toolkit for Prompt Experimentation: The guild referenced several resources, such as PromptTools, an open-source resource supporting prompt testing compatible with LLMs including OpenAI and LLaMA, and vector databases like Chroma and Weaviate.
- Measuring AI with Metrics: Platforms like Vercel and Helicone AI were discussed for their capabilities in comparing model outputs and managing prompts, with emphasis on Helicone AI's exploration into prompt management and version control.
- PromptFoo Empowers Prompt Testing: The sharing of PromptFoo was noted, an open-source tool that allows users to test prompts, evaluate LLM outputs, and enhance prompt quality across various models.
- Revolutionizing Blog Content with AI: A member is applying gpt-3.5-turbo to translate blog posts for different personae and considers the broader implications of AI in personalizing reader experiences, demonstrating this through their blog.
- Seed Recovery Puzzle: A member asked if it is possible to retrieve the seed used by OpenAI models for a previous API request, but no additional context or responses were offered regarding this query.
Skunkworks AI Discord
- Paper Teases Accuracy and Efficiency Advances: Baptistelqt is prepping to unveil a paper promising improved global accuracy and sample efficiency in AI training. The release awaits the structuring of results and better chart visualizations.
- Scaling Hurdles Await Solutions: Although Baptistelqt's method shows promise, it lacks empirical proof at scale due to limited resources. There's a call for consideration to allocate more compute for testing larger models.
- VGG16 Sees Performance Boost: Preliminary application of Baptistelqt's method on VGG16 using CIFAR100 led to a jump in test accuracy, climbing from a baseline of 0.04 to 0.1.
- Interest Sparked in Quiet-STaR Project: Satyum is keen on joining the "Quiet-STaR" project and discussed participation prerequisites, such as being skilled in PyTorch and transformer architectures.
- Scheduling Snafu Limits Collaboration: Timezone differences are causing delays in collaborative efforts to scale Baptistelqt's method, with an immediate meeting the next day being unfeasible.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
- Introducing Stable Video 3D: Stability AI announces Stable Video 3D, a new model expanding 3D technology capabilities with significantly improved quality and multi-view experiences. It takes a single object image as an input and outputs novel multi-views, creating 3D meshes.
- Building on Stable Video Diffusion's Foundation: Stable Video 3D is based on the versatile Stable Video Diffusion technology, offering advancements over the likes of Stable Zero123 and Zero123-XL, especially in quality and the ability to generate multi-view outputs.
- Stable Video 3D Variants Released: Two variants of the model have been released: SV3D_u, which generates orbital videos from single image inputs without camera conditioning, and SV3D_p (extending capabilities beyond what’s mentioned).
Link mentioned: Introducing Stable Video 3D: Quality Novel View Synthesis and 3D Generation from Single Images — Stability AI: When we released Stable Video Diffusion, we highlighted the versatility of our video model across various applications. Building upon this foundation, we are excited to release Stable Video 3D. This n...
Stability.ai (Stable Diffusion) ▷ #general-chat (988 messages🔥🔥🔥):
- Stable Diffusion 3 Anticipation: There's excitement and anticipation for Stable Diffusion 3 (SD3) with hints that invites for beta access may start rolling out this week. Users are hoping to see new examples and the release is expected sometime next month.
- Debates on Model Efficiency: Discussions are ongoing about the efficiency of various Stable Diffusion models like Stable Cascade versus SDXL, with some users finding Cascade to be better at complex prompts but slower to generate images.
- Concerns Over Blockchain Partnerships: Stability AI's recent partnerships with blockchain-focused companies are raising concerns among users. Some fear these moves could signal a shift towards proprietary models or a less open future for the platform's AI tools.
- Use of .pt Files and SAFETENSORS: A user inquires about converting .pt files to SAFETENSOR format due to concerns about running potentially unsafe pickle files. Although most .pt files are safe and the major UIs don't execute unsafe code, a link for a converter tool is shared.
- Upcoming New 3D Model: Stability AI announces the release of Stable Video 3D (SV3D), an advancement over previous 3D models like Stable Zero123. It features improved quality and multi-view generation, but users will need to self-host the model even with a membership.
- Iron Man Mr Clean GIF - Iron Man Mr Clean Mop - Discover & Share GIFs: Click to view the GIF
- grok-1: Grok-1 is a 314B parameter Mixture of Experts model - Base model (not finetuned) - 8 experts (2 active) - 86B active parameters - Apache 2.0 license - Code: - Happy coding! p.s. we re hiring:
- Avatar Cuddle GIF - Avatar Cuddle Hungry - Discover & Share GIFs: Click to view the GIF
- Yess GIF - Yess Yes - Discover & Share GIFs: Click to view the GIF
- PollyannaIn4D (Pollyanna): no description found
- Introducing Stable Video 3D: Quality Novel View Synthesis and 3D Generation from Single Images — Stability AI: When we released Stable Video Diffusion, we highlighted the versatility of our video model across various applications. Building upon this foundation, we are excited to release Stable Video 3D. This n...
- coqui/XTTS-v2 · Hugging Face: no description found
- Stable Video Diffusion - SVD - img2vid-xt-1.1 | Stable Diffusion Checkpoint | Civitai: Check out our quickstart Guide! https://education.civitai.com/quickstart-guide-to-stable-video-diffusion/ The base img2vid model was trained to gen...
- pickle — Python object serialization: Source code: Lib/pickle.py The pickle module implements binary protocols for serializing and de-serializing a Python object structure. “Pickling” is the process whereby a Python object hierarchy is...
- The Complicator's Gloves: Good software is constantly under attack on several fronts. First, there are The Amateurs who somehow manage to land that hefty contract despite having only finished "Programming for Dummies"...
- Page Not Found | pny.com: no description found
- NVLink | pny.com: no description found
- Короткометражный мультфильм "Парк" (сделан нейросетями): Короткометражный мультфильм "Парк" - невероятно увлекательный короткометражный мультфильм, созданный с использованием нейросетей.
- Vancouver, Canada 1907 (New Version) in Color [VFX,60fps, Remastered] w/sound design added: I colorized , restored and I added a sky visual effect and created a sound design for this video of Vancouver, Canada 1907, Filmed from the streetcar, these ...
- Proteus-RunDiffusion - withoutclip | Stable Diffusion Checkpoint | Civitai: Introducing Proteus-RunDiffusion In the development of Proteus-RunDiffusion, our team embarked on an exploratory project aimed at advancing the cap...
- The Mushroom Motherboard: The Crazy Fungal Computers that Might Change Everything: Unlock the secrets of fungal computing! Discover the mind-boggling potential of fungi as living computers. From the wood-wide web to the Unconventional Compu...
- GitHub - DiffusionDalmation/pt_to_safetensors_converter_notebook: This is a notebook for converting Stable Diffusion embeddings from .pt to safetensors format.: This is a notebook for converting Stable Diffusion embeddings from .pt to safetensors format. - DiffusionDalmation/pt_to_safetensors_converter_notebook
- WKUK - Anarchy [HD]: Economic ignorance at its most comical.— "Freedom, Inequality, Primitivism, and the Division of Labor" by Murray Rothbard (http://mises.org/daily/3009).— "Th...
- Reddit - Dive into anything: no description found
- Install ComfyUI on Mac OS (M1, M2 or M3): This video is a quick wakthrough to show how to get Comfy UI installed locally on your m1 or m2 mac. Find out more about AI Animation, and register as an AI ...
- GitHub - Stability-AI/generative-models: Generative Models by Stability AI: Generative Models by Stability AI. Contribute to Stability-AI/generative-models development by creating an account on GitHub.
- GitHub - chaojie/ComfyUI-DragAnything: Contribute to chaojie/ComfyUI-DragAnything development by creating an account on GitHub.
- GitHub - GraftingRayman/ComfyUI-Trajectory: Contribute to GraftingRayman/ComfyUI-Trajectory development by creating an account on GitHub.
- GitHub - mix1009/sdwebuiapi: Python API client for AUTOMATIC1111/stable-diffusion-webui: Python API client for AUTOMATIC1111/stable-diffusion-webui - mix1009/sdwebuiapi
- Home: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- Regional Prompter: Control image composition in Stable Diffusion - Stable Diffusion Art: Do you know you can specify the prompts for different regions of an image? You can do that on AUTOMATIC1111 with the Regional Prompter extension.
Perplexity AI ▷ #announcements (1 messages):
- Unlimited Claude 3 Opus Queries for Pro Users: An announcement was made that Perplexity Pro users now have unlimited daily queries on Claude 3 Opus, which is claimed to be the best Language Model (LLM) in the market today. Pro users are invited to enjoy the new benefit.
Perplexity AI ▷ #general (795 messages🔥🔥🔥):
- Confusion Over "Unlimited" Usage: Users discuss the confusing use of the term "unlimited" in conjunction with Perplexity's services, which are actually capped at 600 searches or uses per day. This has led to complaints and requests for clearer communication from Perplexity.
- Interest in Claude 3 Opus: Many users express interest in the Claude 3 Opus model, asking how it compares to other models like regular GPT-4. Some report a better experience using Opus for complex tasks and enjoying the more natural responses.
- Parenting and AI: There's a heated debate about the appropriate age level for certain knowledge and whether complex topics like calculus or the age of the Earth can be made digestible to young children using AI. Some parents share their positive experiences with using AI as an educational tool for their kids.
- Perplexity Integrations and Capabilities: Users are curious about integrating new AI models like Grok into Perplexity and asking about potential applications, such as integration into mobile devices. Users also inquire about using Perplexity for tasks like analyzing PDFs, which led to a discussion on the proper model settings to use.
- Personal Experiences with Perplexity: Users exchange stories about using Perplexity for job applications, the excitement of seeing Perplexity mentioned in a conference, and using the platform to answer controversial or complex questions. There's a mixture of humor and praise for Perplexity's capabilities.
- Tweet from Bloomberg Technology (@technology): EXCLUSIVE: Apple is in talks to build Google’s Gemini AI engine into the iPhone in a potential blockbuster deal https://trib.al/YMYJw2K
- Tweet from Brivael (@BrivaelLp): Zuck just reacted to the release of Grok, and he is not really impressed. "314 billion parameter is too much. You need to have a bunch of H100, and I already buy them all" 🤣
- Tweet from Aravind Srinivas (@AravSrinivas): We have made the number of daily queries on Claude 3 Opus (the best LLM in the market today) for Perplexity Pro users, unlimited! Enjoy!
- Tweet from Aravind Srinivas (@AravSrinivas): Yep, thanks to @elonmusk and xAI team for open-sourcing the base model for Grok. We will fine-tune it for conversational search and optimize the inference, and bring it up for all Pro users! ↘️ Quoti...
- no title found: no description found
- Shikimori Shikimoris Not Just Cute GIF - Shikimori Shikimoris Not Just Cute Shikimoris Not Just A Cutie Anime - Discover & Share GIFs: Click to view the GIF
- Apple’s AI ambitions could include Google or OpenAI: Another big Apple / Google deal could be on the horizon.
- Nothing Perplexity Offer: Here at Nothing, we’re building a world where tech is fun again. Remember a time where every new product made you excited? We’re bringing that back.
- What Are These Companies Hiding?: Thoughts on the Rabbit R1 and Humane Ai PinIf you'd like to support the channel, consider a Dave2D membership by clicking the “Join” button above!http://twit...
- ✂️ Sam Altman on AI LLM Search: 47 seconds · Clipped by Syntree · Original video "Sam Altman: OpenAI, GPT-5, Sora, Board Saga, Elon Musk, Ilya, Power & AGI | Lex Fridman Podcast #419" by Le...
- FCC ID 2BFB4R1 AI Companion by Rabbit Inc.: FCC ID application submitted by Rabbit Inc. for AI Companion for FCC ID 2BFB4R1. Approved Frequencies, User Manuals, Photos, and Wireless Reports.
Perplexity AI ▷ #sharing (35 messages🔥):
- Exploring Creative Writing Limits: Claude 3 Opus engaged with a prompt on "ever increasing intelligence until it's unintelligible to humans", suggesting exploration into the bounds of creativity and comprehension in AIs. Claude 3 Opus's creative take on literature may push the limits of what we consider coherent.
- Visibility is Key in Sharing Threads: Sharing information is essential, hence the reminder to make sure threads are shared for visibility on the platform, with a direct link for guidance. Reference to sharing thread.
- Cleanliness Comparison Caller: An inquiry into which item is cleaner leads to an analysis that might toss up unexpected results. Discover the cleaner option on Perplexity's analysis.
- North Korea's Insights Unpacked with AI: North Korea's Kim is a subject of scrutiny in the ongoing analysis by Perplexity AI, discussing developments and speculations. Explore the geopolitical insights at this search link.
- Tech Giants Make Waves: Apple's ventures and acquisitions continue to stir discussions, whether it's acquiring DarwinAI or the 30B LLM talk, indicating significant moves in the AI and tech industry. Find details on Apple's acquisition at DarwinAI overview and ongoing discussions around the 30B LLM at this discussion thread.
Perplexity AI ▷ #pplx-api (64 messages🔥🔥):
- Deprecated Model Continues to Function: Messages in the channel indicate confusion around a model scheduled for deprecation on March 15; it was still operational, leading to speculation about whether it's due to be deprecated at the day's end or if plans have changed.
- Inconsistencies in Sonar Model Responses: Users compared responses from the
sonar-medium-onlineAPI to the web-browser version, noting significant differences in answers when asked for news about a specific date, leading to discussions about the accuracy and consistency of API responses. - Job Search with Perplexity API: Users are experimenting with the Perplexity API for job searches, where some prompts yield actual job posting links, while others only return links to job search platforms like LinkedIn or Glassdoor.
- Request for API Rate Limit Increase Goes Unanswered: A user inquired about the process for increasing API rate limits and has not received a response to their emailed request.
- Discussion on Token Limits Affecting LLM Responses: Within the chat, there's an exchange regarding how setting max token limits like 300 might impact the Language Learning Model's (LLM) ability to provide complete responses, with users sharing examples of truncated answers and discussing the model's behavior with varying token ceilings.
- pplx-api: no description found
- pplx-api form: Turn data collection into an experience with Typeform. Create beautiful online forms, surveys, quizzes, and so much more. Try it for FREE.
Unsloth AI (Daniel Han) ▷ #general (853 messages🔥🔥🔥):
- AIKit Adopts Unsloth for Finetuning: AIKit integration now supports finetuning with Unsloth, enabling users to create minimal model images with an OpenAI-compatible API. A Hugging Face Space was also shared for testing Piper TTS in Spanish.
- Grok Open Source Discussion: Elon Musk's team at X.ai open-sourced a massive 314B parameter model called Grok-1, involving 8 experts and 86B active parameters. Discourse focused on the practicality of usage given its size, with many concluding it's impractical for most due to the computational resources required for inference.
- Safety Measures Against Impersonation: A scam account impersonating a member ('starsupernova0') was discovered to be sending friend requests within the Discord. Members reported and issued warnings regarding the fake account.
- Inquisitive Minds Seek Finetuning Guidance: Users shared resources and discussed strategies for optimally finetuning models like Mistral-7b using QLoRA. Concerns about hyperparameters, such as learning rate and number of epochs, were addressed with recommendations to follow provided guidelines in notebooks.
- Fine-tuning and Resource Challenges: Questions arose related to RTX 2080 Ti's capacity for fine-tuning larger models like 'gemma-7b-bnb-4bit', as users experienced out-of-memory (OOM) issues even with a batch_size=1. The conversation highlighted the intensive resource demands of fine-tuning large-scale models.
- Tweet from Unsloth AI (@UnslothAI): Unsloth is trending on GitHub this week! 🙌🦥 Thanks to everyone & all the ⭐️Stargazers for the support! Check out our repo: http://github.com/unslothai/unsloth
- Cosmic keystrokes: no description found
- About xAI: no description found
- Open Release of Grok-1: no description found
- Lightning AI | Turn ideas into AI, Lightning fast: The all-in-one platform for AI development. Code together. Prototype. Train. Scale. Serve. From your browser - with zero setup. From the creators of PyTorch Lightning.
- CodeFusion: A Pre-trained Diffusion Model for Code Generation: Imagine a developer who can only change their last line of code, how often would they have to start writing a function from scratch before it is correct? Auto-regressive models for code generation fro...
- Announcing Grok: no description found
- Qwen/Qwen1.5-72B · Hugging Face: no description found
- Blog: no description found
- ISLR Datasets — 👐OpenHands documentation: no description found
- Mixtral of Experts: We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (...
- Google Colaboratory: no description found
- xai-org/grok-1 · Hugging Face: no description found
- Introduction | AIKit: AIKit is a one-stop shop to quickly get started to host, deploy, build and fine-tune large language models (LLMs).
- 🦅 EagleX 1.7T : Soaring past LLaMA 7B 2T in both English and Multi-lang evals (RWKV-v5): A linear transformer has just cross the gold standard in transformer models, LLaMA 7B, with less tokens trained in both English and multi-lingual evals. A historical first.
- Crystalcareai/GemMoE-Beta-1 · Hugging Face: no description found
- Unsloth Fixing Gemma bugs: Unsloth fixing Google's open-source language model Gemma.
- Piper TTS Spanish - a Hugging Face Space by HirCoir: no description found
- damerajee/Llamoe-test · Hugging Face: no description found
- How to Fine-Tune an LLM Part 1: Preparing a Dataset for Instruction Tuning: Learn how to fine-tune an LLM on an instruction dataset! We'll cover how to format the data and train a model like Llama2, Mistral, etc. is this minimal example in (almost) pure PyTorch.
- Paper page - Simple linear attention language models balance the recall-throughput tradeoff: no description found
- Sam Altman: OpenAI, GPT-5, Sora, Board Saga, Elon Musk, Ilya, Power & AGI | Lex Fridman Podcast #419: Sam Altman is the CEO of OpenAI, the company behind GPT-4, ChatGPT, Sora, and many other state-of-the-art AI technologies. Please support this podcast by che...
- argilla (Argilla): no description found
- GitHub - xai-org/grok-1: Grok open release: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- transformers/src/transformers/models/mixtral/modeling_mixtral.py at main · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- Mistral Fine Tuning for Dummies (with 16k, 32k, 128k+ Context): Discover the secrets to effortlessly fine-tuning Language Models (LLMs) with your own data in our latest tutorial video. We dive into a cost-effective and su...
- GitHub - jiaweizzhao/GaLore: Contribute to jiaweizzhao/GaLore development by creating an account on GitHub.
- GitHub - unslothai/unsloth: 2-5X faster 70% less memory QLoRA & LoRA finetuning: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
- GitHub - AI4Bharat/OpenHands: 👐OpenHands : Making Sign Language Recognition Accessible. | **NOTE:** No longer actively maintained. If you are interested to own this and take it forward, please raise an issue: 👐OpenHands : Making Sign Language Recognition Accessible. | **NOTE:** No longer actively maintained. If you are interested to own this and take it forward, please raise an issue - AI4Bharat/OpenHands
- teknium/GPT4-LLM-Cleaned · Datasets at Hugging Face: no description found
- GitHub - mistralai/mistral-src: Reference implementation of Mistral AI 7B v0.1 model.: Reference implementation of Mistral AI 7B v0.1 model. - mistralai/mistral-src
- Error when installing requirements · Issue #6 · xai-org/grok-1: i have installed python 3.10 and venv. Trying to "pip install -r requirements.txt" ERROR: Ignored the following versions that require a different python version: 1.6.2 Requires-Python >=3...
- Falcon 180B open-source language model outperforms GPT-3.5 and Llama 2: The open-source language model FalconLM offers better performance than Meta's LLaMA and can also be used commercially. Commercial use is subject to royalties if revenues exceed $1 million.
- FEAT / Optim: Add GaLore optimizer by younesbelkada · Pull Request #29588 · huggingface/transformers: What does this PR do? As per title, adds the GaLore optimizer from https://github.com/jiaweizzhao/GaLore This is how I am currently testing the API: import torch import datasets from transformers i...
- Staging PR for implimenting Phi-2 support. by cm2435 · Pull Request #97 · unslothai/unsloth: ….org/main/getting-started/tutorials/05-layer-norm.html]
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
- Unsloth AI Gains Stardom on GitHub: Unsloth AI has become a trending topic on GitHub this week, gaining popularity and support from the community. The official post encourages users to give a star on GitHub and features a link to the repository which focuses on 2-5X faster 70% less memory QLoRA & LoRA finetuning at GitHub - unslothai/unsloth.
Link mentioned: GitHub - unslothai/unsloth: 2-5X faster 70% less memory QLoRA & LoRA finetuning: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #random (25 messages🔥):
- Baader-Meinhof Phenomenon Strikes: A member noted experiencing the Baader-Meinhof phenomenon, also known as the frequency illusion, where one randomly thinks of something and then encounters it soon after. This was attributed to the subconscious mind picking up information from the environment.
- Encouragement for Creative Output: In response to a member sharing a poetic composition, another expressed interest and appreciation, encouraging the sharing of creative monologues.
- The Gemma vs. Mistral Debate: A discussion about fine-tuning domain-specific classification tasks included mentions of Mistral-7b and considering the use of Gemma 7b. Gemma 7b was noted to sometimes outperform Mistral in tests, with Unsloth AI having resolved previous bugs.
- Seeking the Elusive Mixtral Branch: A member looking for the Mixtral branch was redirected to tohrnii's branch with a pull request on GitHub.
- Pokemon RL Agents Conquer the Map: A user shared a link to a visualization of various environments being trained on a single map, depicting the training of Pokemon RL agents as exposed on the interactive map.
- Pokemon Red Map RL Visualizer: no description found
- 4202 UI elements: CSS & Tailwind: no description found
- [WIP] add support for mixtral by tohrnii · Pull Request #145 · unslothai/unsloth: Mixtral WIP
Unsloth AI (Daniel Han) ▷ #help (568 messages🔥🔥🔥):
- VRAM and System RAM Requirements in Model Saving: A user discussed the high VRAM and RAM usage during the model saving process in Colab, noting that the T4 used 15GB VRAM and 5GB system RAM. Clarifications indicated that VRAM is utilized for loading the model during saving, suggesting adequate system RAM is important, especially when dealing with the saving of large models like Mistral.
- Unsloth Supports Llama, Mistral, and Gemma Models: Users inquired about the models supported by Unsloth, clarified to include only open-source models like Llama, Mistral, and Gemma. There were questions regarding whether 4-bit quantization refers to QLoRA, with
load_in_4bit = True, and discussions on whether Unsloth could support full fine-tuning in the future.
- Challenges with GPT4 Deployment via Unsloth: A user asked about deploying OpenAI's GPT4 model with Unsloth, only to be advised that this is outside the scope of Unsloth, which is confirmed to support open-source models for finetuning and not the proprietary GPT4 model.
- Finetuning Issues Addressed for Multiple Models: Multiple discussions revolved around issues encountered during and after finetuning models with Unsloth. These included unexpected model behavior such as generating random questions and answers after processing prompts, and the requirement for properly specifying end-of-sequence tokens in various chat templates.
- Inquiries on Full Fine-tuning and Continuous Pretraining: There was a dialogue on whether the guidelines regarding fine-tuning also apply to continuous pretraining, with Unsloth developers suggesting LoRA might be suitable but clarifying that Unsloth currently specializes in LoRA and QLoRA, not full fine-tuning. The possibility of extending full fine-tuning functionalities in Unsloth Pro was also discussed.
- Kaggle Mistral 7b Unsloth notebook: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- Google Colaboratory: no description found
- Google Colaboratory: no description found
- ybelkada/Mixtral-8x7B-Instruct-v0.1-bnb-4bit · Hugging Face: no description found
- Hugging Face – The AI community building the future.: no description found
- TinyLlama/TinyLlama-1.1B-Chat-v1.0 · Hugging Face: no description found
- unsloth/mistral-7b-instruct-v0.2-bnb-4bit · Hugging Face: no description found
- DPO Trainer: no description found
- Home: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
- Home: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
- Home: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
- Home: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
- Home: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
- qlora/qlora.py at main · artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs. Contribute to artidoro/qlora development by creating an account on GitHub.
- Generation - GPT4All Documentation: no description found
- GitHub - vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs: A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllm
- Google Colaboratory: no description found
- Unsloth: Merging 4bit and LoRA weights to 16bit...Unsloth: Will use up to 5.34 - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- GitHub - unslothai/unsloth: 2-5X faster 70% less memory QLoRA & LoRA finetuning: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
- Does DPOTrainer loss mask the prompts? · Issue #1041 · huggingface/trl: Hi quick question, so DataCollatorForCompletionOnlyLM will train only on the responses by loss masking the prompts. Does it work this way with DPOTrainer (DPODataCollatorWithPadding) as well? Looki...
- Supervised Fine-tuning Trainer: no description found
- Trainer: no description found
- llama.cpp/examples/server/README.md at master · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp: Python bindings for llama.cpp. Contribute to abetlen/llama-cpp-python development by creating an account on GitHub.
- Reproducing of Lora Model Result on MT-Bench · Issue #45 · huggingface/alignment-handbook: Recently, I attempted to fit the DPO on my own dataset. Initially, I tried to reproduce the results of your LORA model( 7.43 on MT-Bench). However, I encountered some issues. Despite using all your...
- HuggingFaceH4/zephyr-7b-alpha · Add chat template: no description found
- HuggingFaceH4/zephyr-7b-alpha · Hugging Face: no description found
- unsloth/unsloth/chat_templates.py at main · unslothai/unsloth: 2-5X faster 70% less memory QLoRA & LoRA finetuning - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #suggestions (21 messages🔥):
- Epoch Count Debate: Members discussed the optimal number of epochs for training, generally agreeing that 3 epochs is standard, with concerns that too many epochs may cause a model to memorize and overfit to training data.
- Seeking Balance in Model Knowledge: A lengthy conversation centered around finetuning large language models (LLMs) with excessive data. It was pointed out that finetuning can lead to learning a style rather than gaining knowledge, and that a large number of epochs may cause an LLM to forget everything else.
- LLM Parameter Ratio Recommendations: During the discussion, it was suggested that rank size should be considered, with a recommendation that the amount of trainable parameters should be equal to the amount of tokens in the dataset. A suggestion was made for 32 or 64 rank for 800,000 lines of data.
- Scaling Down Data for Training: One member decided to reduce their dataset from 3 million lines to a smaller number to help the LLM perform better.
- Integration of Small Models into Unsloth Repo: Links to two small models, Tiny Mistral and Tiny Mistral Instruct, were shared for potentially integrating into the Unsloth AI repository.
- Dans-DiscountModels/TinyMistral-v2.5-MiniPile-Guidelines-E1 · Hugging Face: no description found
- M4-ai/TinyMistral-6x248M-Instruct at main: no description found
LM Studio ▷ #💬-general (301 messages🔥🔥):
- New Faces, New Questions: Individuals introduced themselves to the community, with some seeking advice on running large language models (LLMs) locally, especially on hardware with specific capabilities like the M3 Pro with 18GB memory. Recommendations were provided with mention of specific models suitable for different tasks such as CodeLlama or DeepSeek for coding assistance.
- Exploring LLM Usage and Model Support: Conversations revolved around utilizing LLMs for various use-cases, touching on the support and performance of different hardware configurations, including multiple GPUs and Tesla cards. There were continuous inquiries about running models effectively on various setups, such as Tesla K40 and K80 cards with clarifications on LM Studio's ability to offload to specific GPUs.
- Developer Experiences with LLM Studio and Extensions: Members shared their positive experiences while integrating LLMs with VSCode through the ContinueDev plugin, noting its efficiency and usefulness in various development tasks.
- Clarifying LLM Studio Capabilities: There were multiple clarifications provided about LM Studio's capabilities and limitations, such as the unavailability of a web UI for server mode, lack of support for Retrieval-Augmented Generation (RAG) with Obsidian notes, and the impossibility of fine-tuning Mistral or adding data directly from documents for customer support scenarios.
- Understanding Large Model Hosting and Quantization: Community members discussed the technicalities and expectations around hosting and running extremely large models like Grok-1, which is a 314B parameter model, locally. Questions arose regarding the quantization of models to reduce resource requirements and inquiries on whether developments in LM Studio have ceased.
- Ratha GIF - Ratha - Discover & Share GIFs: Click to view the GIF
- grok-1: Grok-1 is a 314B parameter Mixture of Experts model - Base model (not finetuned) - 8 experts (2 active) - 86B active parameters - Apache 2.0 license - Code: - Happy coding! p.s. we re hiring:
- Mistral: Easiest Way to Fine-Tune on Custom Data: This video is sponsored by Gradient.ai, check them out here: https://gradient.1stcollab.com/engineerpromptIn this video, we will learn how to fine-tune Mistr...
- xai-org/grok-1 · 314B params has 297G file size ?: no description found
- [1hr Talk] Intro to Large Language Models: This is a 1 hour general-audience introduction to Large Language Models: the core technical component behind systems like ChatGPT, Claude, and Bard. What the...
- Issues · continuedev/continue: ⏩ The easiest way to code with any LLM—Continue is an open-source autopilot for VS Code and JetBrains - Issues · continuedev/continue
LM Studio ▷ #🤖-models-discussion-chat (138 messages🔥🔥):
- Commands Awaited for C4AI Command-R: Support for the C4AI Command-R model in LM Studio is anticipated once the merger of GitHub pull request #6033 is completed.
- Searching for a Suitable Model: Members recommend using Google and Reddit for finding the most suitable LM model for personal setup, with one member opting for Phind-CodeLlama-34B-v2.
- Yi-9B-200K Model Details and Usage: Questions on Yi model's instruction format led to sharing of details found in the model card on Hugging Face, and clarifying that Yi-9B-200K is a base model, not fine-tuned for chat or instruct.
- Grok Model Excitement with Realistic Skepticism: Discussion of Grok, a 314 billion parameter model, highlighted its large size and impracticality for personal use, but some enthusiasts still pursued downloads despite its massive hardware requirements.
- Local Run Limitations and Solutions: There's a dialogue on running models locally, including troubleshooting for Starcoder not being supported on older versions of LM Studio due to lack of AVX2 support in CPUs, and the potential use of the AVX-Beta version.
- Open Release of Grok-1: no description found
- MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training: In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and c...
- 01-ai/Yi-34B · Prompt template?: no description found
- 01-ai/Yi-9B-200K · Hugging Face: no description found
- What are Parameters in Large Language Model?: What are the Parameters in the Large Language Model? 00:26 💡 Parameters in large language models like GPT-3 are variables learned during training to minimiz...
- [1hr Talk] Intro to Large Language Models: This is a 1 hour general-audience introduction to Large Language Models: the core technical component behind systems like ChatGPT, Claude, and Bard. What the...
- Reddit - Dive into anything: no description found
- Add Command-R Model by acanis · Pull Request #6033 · ggerganov/llama.cpp: Information about the Command-R 35B model (128k context) can be found at: https://huggingface.co/CohereForAI/c4ai-command-r-v01 Based on the llama2 model with a few changes: New hyper parameter to...
LM Studio ▷ #🧠-feedback (12 messages🔥):
- Confusion over llama.cpp Compatibility: A member thought llama.cpp GGUF format files for Cohere's Command-R model on Hugging Face implied compatibility, but was corrected that llama.cpp does not yet support c4ai. Another user reiterated the misconception due to the files listing on Hugging Face, but reassurance came that this was a common oversight.
- Understanding AI Challenges: A user expressed frustration with the complexity of AI, simply stating, "weeuurghh this ai s#!t so hard".
- Clarification on llama.cpp Support: There seems to be conflicting information on llama.cpp support; one member asserted that llama.cpp doesn't support c4ai, while another insisted that it does.
- Linux Download Page Suggestion: A member suggested adding a note for AMD users on the Linux version download page, advising that they need OpenCL drivers to use the GPU with the program.
- LM Studio Capabilities Query: Users inquired about the possibility of chatting with their own documents in LM Studio or adding plugins like autogen. It was mentioned that plugins like autogen/langchain are currently supported through server mode connection.
Link mentioned: andrewcanis/c4ai-command-r-v01-GGUF · Hugging Face: no description found
LM Studio ▷ #🎛-hardware-discussion (480 messages🔥🔥🔥):
- GPU Pondering: Members discussed potential performance for AI tasks of Nvidia’s upcoming 5090 over the 3090 and 4090, highlighting a possible better price point for 8bit large language models (LLMs) with speculation on Nvidia boosting 8bit inference performance.
- The Fractal North Beckons: One member expressed interest in acquiring the Nvidia 5090 GPU and fitting it into a Fractal North case to replace their sizeable Corsair 7000x tower. There was also hope for a single slot variant of the 5090 to facilitate easier multi-GPU setups.
- Looking for More PCIe Strength: A member sought advice on motherboards with at least 2 x16 PCIe Gen 5 slots, contemplating upgrades to accommodate powerful GPUs and pondering the power consumption for decent cooling in a Corsair 7000x case.
- Cable Management Meets Cooling: Conversation turned to experiences with multi-GPU setups, PCIe risers, oculink cables for external GPUs, and detailed cable management within cases. The practicality of using single-slot GPUs for effective cooling and space efficiency was noted.
- Turning Wheels on a New Build: Users shared plans and components for new builds, confessing dreams of employing mighty Epyc CPUs with more PCIe lanes, or settling for Threadrippers for the sake of economy. Ensuing discussions revolved around finding the right balance between CPU capabilities and PCIe slot conductivity, weighing the cost and logistical challenges of building a performant yet affordable AI research rig.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- LM Studio Beta Releases: no description found
- no title found: no description found
- no title found: no description found
- M.2 Accelerator with Dual Edge TPU | Coral: Integrate two Edge TPUs into legacy and new systems using an M.2 (E key) interface.
- 404 page: no description found
- Dell T710 Tower Server Dual 6-CORE X5650 **144Gb RAM**240gb SSD +6X 600G SFF SAS | eBay: no description found
- Asrock Rack ROMED8-2T ATX Server Motherboard AMD EPYC 7003 (with AMD 3D V-Cache Technology)/7002 series processors SP3 (LGA 4094) Dual 10GbE - Newegg.com: Buy Asrock Rack ROMED8-2T Server Motherboard AMD EPYC 7003 (with AMD 3D V-Cache Technology)/7002 series processors SP3 (LGA 4094) Dual 10GbE with fast shipping and top-rated customer service. Once you...
- AMD EPYC 7232P 8-Core 3.1GHz 32MB L3 Processor - Socket SP3 - 100-000000081 | eBay: no description found
- no title found: no description found
- Dell T710 Tower Server Dual 6-CORE X5670 **24 cores**64GB RAM | eBay: no description found
- 94.78SG$ |Epyc 7282 16 Core 32Threads 16x2.8Ghz 120W Socket SP3 CPU 9 nanometers Epyc 7282| | - AliExpress: Smarter Shopping, Better Living! Aliexpress.com
- New /Wave ®AI Server NF5688M6 NVIDIA HGX TESLA A800 80G octet GPU server/Futures | eBay: no description found
- AMD EPYC 7232P CPU PROCESSOR 8 CORE 3.10GHz 32MB CACHE 120W - 100-000000081 | eBay: no description found
- AMD EPYC 7F72 CPU PROCESSOR 24 CORE 3.20GHz 192MB CACHE 240W - 100-000000141 | eBay: no description found
- Nvidia Tesla K80 24GB GPU GDDR5 PCI-E GPU Accelerator 12 Month warranty | eBay: no description found
- Search Thingiverse - Thingiverse: Download files and build them with your 3D printer, laser cutter, or CNC.
- Intel Core i5-3470 Specs: Ivy Bridge, 4 Cores, 4 Threads, 3.2 GHz, 77 W
- Nvidia Tesla K80 24GB GPU GDDR5 PCI-E GPU Accelerator 12 Month warranty | eBay: no description found
- NVIDIA GeForce RTX 3090 Founders Edition Dual Fan 24GB GDDR6X PCIe 4.0 Graphics Card (Refurbished) - Micro Center: Get it now! GeForce RTX 3090 is a GPU (BF GPU) with TITAN level efficiency. The NVIDIA second generation RTX architecture Ampere is adopted, and the enhanced ray tracing core, Tensor core and the new ...
- Luckim Official Store - Amazing products with exclusive discounts on AliExpress: no description found
LM Studio ▷ #🧪-beta-releases-chat (4 messages):
- Seeking Model Presets?: A member inquired about a list of presets for different models. They were directed to a collection of example configuration files at GitHub - lmstudio-ai/configs.
- ROCm User Call-Out: When a member asked if there were any ROCm users around, they were referred to another channel for further discussion.
Link mentioned: GitHub - lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files.: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
LM Studio ▷ #langchain (1 messages):
- Inquiry about JSON function calling with Local Inference Server: A member asked if anyone has successfully implemented a model with JSON function calling using the Local Inference Server. There were no responses or further discussions provided on this topic.
LM Studio ▷ #avx-beta (5 messages):
- Clarity on AVX Beta Version: A member clarified that the app in beta using AVX is not only an older version but also AVX support is not a high priority.
- Limitations on Model Support: It was confirmed that while models will work in the beta version, newer models like starcoder2 and gemma are not supported.
- Compatibility with Mistral Confirmed: A member inquired and received confirmation that the beta version can indeed run the Mistral model.
LM Studio ▷ #amd-rocm-tech-preview (5 messages):
- Discover Prebuilt ROCm Libraries: A user shared a GitHub link to prebuilt Windows ROCM libraries for gfx1031 and gfx1032, which could be beneficial for those looking to utilize ROCm on these particular GPU models.
- Desire for Multiple GPU Support in LM Studio: A member expressed interest in using multiple AMD GPUs in LM Studio but noted that the current setup seems to only utilize the primary GPU. They inquired about the possibility of future support for multiple GPU configurations.
- Unsupported AMD GPU for ROCm in LM Studio: Another member pointed out that the AMD 6700 xt GPU is not officially supported by AMD for ROCm, and as a result, LM Studio, which uses these libraries unmodified, cannot work with this GPU model.
- Hope for Future GPU Parallelism: In response to the unsupported AMD GPU issue, the member clarified that if they had another GPU from the 7000 series, LM Studio might be able to use them in parallel.
- KoboldCPP-ROCm Acknowledged for Dual GPU Setup: Confirming the possibility of using two compatible GPUs together, a member stated that koboldcpp-rocm would support such a configuration currently.
Link mentioned: GitHub - brknsoul/ROCmLibs: Prebuild Windows ROCM Libs for gfx1031 and gfx1032: Prebuild Windows ROCM Libs for gfx1031 and gfx1032 - brknsoul/ROCmLibs
LM Studio ▷ #crew-ai (1 messages):
- Seeking the Right Agent System: A member inquired about the progress in choosing an agent system for deepening and validating a creative concept and whether a decision had been made. They're currently considering different agents for the task at hand.
Nous Research AI ▷ #off-topic (56 messages🔥🔥):
- Speculation on NVIDIA RTX 50-series Features: A link to TechPowerUp sparked discussions about the NVIDIA GeForce RTX 50-series "Blackwell" rumored to use 28 Gbps GDDR7 memory. The conversation touched on NVIDIA's history of conservative memory speeds despite faster options being available.
- AI Assistants and Interruptive Dialogue: Members shared ideas on making AI assistants capable of stopping mid-conversation intelligently and continuing after being interrupted. Tips included editing the conversation's context and using audio control based on sound detection for more interactive exchanges.
- Sam Altman's Predictions on AGI: One member highlighted Sam Altman's predictions from 2021 regarding advancements in AGI over the coming decades, noting the accuracy of his forecasts about companionship roles emerging sooner than expected.
- Frustrations with AGI Conversations: A member expressed dissatisfaction with what they perceived as shallow discussions around AGI, urging a focus on actionable problems rather than speculative, lofty AI goals. A linked tweet continued the theme, suggesting limitations on what can be publicly discussed due to sensitive projects.
- Game Development Opportunity with MatchboxDAO: A PSA shared by a member from MatchboxDAO mentioned a gaming project opening its data for building AI agent play, with funding available for community members interested in contributing. The game and further details can be found at x.com.
- Tweet from undefined: no description found
- Plan-and-Execute using Langgraph: how to create a "plan-and-execute" style agent. This is heavily inspired by the Plan-and-Solve paper as well as the Baby-AGI project.The core idea is to firs...
- NVIDIA GeForce RTX 50-series "Blackwell" to use 28 Gbps GDDR7 Memory Speed: The first round of NVIDIA GeForce RTX 50-series "Blackwell" graphics cards that implement GDDR7 memory are rumored to come with a memory speed of 28 Gbps, according to kopite7kimi, a reliabl...
Nous Research AI ▷ #interesting-links (16 messages🔥):
- "Horny Claudes" Yield Better Mermaid Diagrams?: A participant shares a tweet expressing astonishment over the claim that "horny claudes" produce better mermaid diagrams, citing instances where the content became quite explicit. A sample revealed that when models are put in a specific state, they tend to generate more effective diagrams.
- Reverse Engineering Sydney: Commentators react with shock and humor to the notion of altering a model's state to achieve better performance, suggesting it's akin to reverse engineering the Sydney chatbot.
- New AI Research on Display: A member of the channel showcases their PyTorch research project, acknowledging its potential non-groundbreaking nature yet hoping it may interest others.
- AI Model News from Apple: Latest information comes out regarding Apple's AI models as hinted by a Twitter post; active member shares the anticipation for what Apple might reveal next but another clarifies that no new models were released, just discussed.
- Exploring Self-Rewarding Language Models: The Oxen.ai Community is attempting to reproduce MetaAI's Self-Rewarding Language Model paper, and their efforts are documented on GitHub.
- Tweet from Burny — Effective Omni (@burny_tech): My thoughts on Musk destabilizing other gigantic players in the intelligence wars by possibly leading open source using Grok Grok 1 is a 314B parameter model and it's a mixture of experts archit...
- Tweet from j⧉nus (@repligate): @xlr8harder I didn't let it go very far but there's someone in the room with me right now talking about how theyve created a network of "horny claudes" and how the claudes create bette...
- Language Agents as Optimizable Graphs: Various human-designed prompt engineering techniques have been proposed to improve problem solvers based on Large Language Models (LLMs), yielding many disparate code bases. We unify these approaches ...
- Paper page - ORPO: Monolithic Preference Optimization without Reference Model: no description found
- GitHub - Oxen-AI/Self-Rewarding-Language-Models: This is work done by the Oxen.ai Community, trying to reproduce the Self-Rewarding Language Model paper from MetaAI.: This is work done by the Oxen.ai Community, trying to reproduce the Self-Rewarding Language Model paper from MetaAI. - Oxen-AI/Self-Rewarding-Language-Models
Nous Research AI ▷ #general (656 messages🔥🔥🔥):
- Grok-1 Model Inference Woes: Users report on the challenges of running Grok-1, a 314B parameter model for inference, noting it can use up to 124GB of VRAM locally, and discussing whether it could be worth running or training given its size and hardware requirements. The open-sourced Grok-1 has elicited both excitement and skepticism about its utility and cost-effectiveness for inference, with comparisons to gpt-3.5’s performance.
- Yi-9B Licensing Ambiguities: Discussions around the Yi-9B model's license suggest it may allow commercial use after some form of approval process. There is skepticism about this being purely a marketing move, and authenticity of benchmarks concerning Yi-34B are questioned.
- Papers and Readings for the Enlightened: Users share recent informative papers worth reading about, including Apple's MM1 multimodal model, scaling laws for training 1-bit LLMs, and the effectiveness of continual training methods. An enlightening diversion recommends exploring Sparse Distributed Memory (SDM) and its connection to continual learning.
- Personalizing AI Models: Conversations touch upon the possibility of personal models trained on an individual's data, mentioning steering vectors for alignment as opposed to retraining to refusal, and the philosophical juxtaposition of models and wokeness.
- AI Integration Tips Requested: A user asks for tutorials or repositories to learn integrating AI in practical applications such as websites. Others mention potential resources and invite experienced members to share insights.
- Tweet from Aravind Srinivas (@AravSrinivas): Yep, thanks to @elonmusk and xAI team for open-sourcing the base model for Grok. We will fine-tune it for conversational search and optimize the inference, and bring it up for all Pro users! ↘️ Quoti...
- Tweet from Lin Qiao (@lqiao): We are thrilled to collaborate on Hermes 2 Pro multi-turn chat and function calling model with @NousResearch. Finetuned on over 15k function calls, and a 500 example function calling DPO datasets, Her...
- Tweet from interstellarninja (@intrstllrninja): Hermes 2 Pro function-calling model integrated with search engine by @ExaAILabs👀 ↘️ Quoting Barton Rhodes 🦺 (@bmorphism) added @ExaAILabs support for use with @NousResearch new function-calling m...
- Tweet from interstellarninja (@intrstllrninja): <cmd> run world_sim.exe --epoch "Earth in 2500" --civilization_type "Type-II on Kardashev scale" </cmd> ↘️ Quoting mephisto (@karan4d) im opensourcing worldsim of course...
- Tweet from Parzival - 🌞/⏫ (@whyarethis): Now we are going somewhere.
- Tweet from Grok (@grok): @elonmusk @xai ░W░E░I░G░H░T░S░I░N░B░I░O░
- Tweet from Andrew Kean Gao (@itsandrewgao): i think grok-4bit is just barely too big for an H100 GPU :( ↘️ Quoting Andrew Kean Gao (@itsandrewgao) HOLY SH*T @grok IS 314 BILLION PARAMETERS Mixture of 8 Experts, not RLHFd/moralized THIS IS ...
- Tweet from Andriy Burkov (@burkov): We are yet to see how good Grok is compared to GPT-4, but what we can tell for sure is that if you are to train a competitor to OpenAI/Anthropic today, you would not need to start from scratch anymore...
- Tweet from interstellarninja (@intrstllrninja): @Cyndesama claude 3 opus runs ai town simulation with python42
- Open Release of Grok-1: no description found
- Do Llamas Work in English? On the Latent Language of Multilingual Transformers: We ask whether multilingual language models trained on unbalanced, English-dominated corpora use English as an internal pivot language -- a question of key importance for understanding how language mo...
- Sparse Distributed Memory is a Continual Learner: Continual learning is a problem for artificial neural networks that their biological counterparts are adept at solving. Building on work using Sparse Distributed Memory (SDM) to connect a core neural ...
- datas (shu nakamura): no description found
- MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training: In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and c...
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits: Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single param...
- Tweet from interstellarninja (@intrstllrninja): <cmd> sudo python3 akashic_records.py --entity ["sam altman", "elon musk"] --mode "email thread" --topic "superintelligence scenarios" </cmd>
- Simple and Scalable Strategies to Continually Pre-train Large Language Models: Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre...
- anon8231489123/ShareGPT_Vicuna_unfiltered · Datasets at Hugging Face: no description found
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO · Adding Evaluation Results: no description found
- Replete-AI/Mistral-Evolved-11b-v0.1 · Hugging Face: no description found
- openchat/openchat_sharegpt4_dataset at main: no description found
- migtissera/Tess-70B-v1.6 · Hugging Face: no description found
- Abstractions/abstractions/goap/causality.ipynb at main · furlat/Abstractions: A Collection of Pydantic Models to Abstract IRL. Contribute to furlat/Abstractions development by creating an account on GitHub.
- HD/VSA:
- Language models scale reliably with over-training and on downstream tasks: Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scal...
- Accelerationism Accelerationism (Acc/Acc): Accelerationism accelerationism is when you accelerate accelerationism to apply accelerationism to accelerationismparts that were too edgy: https://www.patre...
- JSON Schema - Pydantic: no description found
- Let's build the GPT Tokenizer: The Tokenizer is a necessary and pervasive component of Large Language Models (LLMs), where it translates between strings and tokens (text chunks). Tokenizer...
- Don’t Miss This Transformative Moment in AI: Come experience Jensen Huang’s GTC keynote live on-stage at the SAP Center in San Jose, CA to explore the AI advances that are shaping our future.
- Liam Johnson DESTROYS Heckler | New York Stand-up: Last weekend Liam Johnson decided to finally make his first appearance here at Giggle Nerd. He performed on Sunday from 23:00 to 23:25 and our audience loved...
- Cosma Shalizi - Why Economics Needs Data Mining: Cosma Shalizi urges economists to stop doing what they are doing: Fitting large complex models to a small set of highly correlated time series data. Once you...
- Abstractions/abstractions/goap/gridmap.ipynb at main · furlat/Abstractions: A Collection of Pydantic Models to Abstract IRL. Contribute to furlat/Abstractions development by creating an account on GitHub.
- Abstractions/abstractions/goap/system_prompt.md at main · furlat/Abstractions: A Collection of Pydantic Models to Abstract IRL. Contribute to furlat/Abstractions development by creating an account on GitHub.
- 01-ai/Yi-9B-200K · Hugging Face: no description found
- 01-ai/Yi-9B · Hugging Face: no description found
- GitHub - PrismarineJS/mineflayer: Create Minecraft bots with a powerful, stable, and high level JavaScript API.: Create Minecraft bots with a powerful, stable, and high level JavaScript API. - PrismarineJS/mineflayer
- HacksTokyo: AI x Digital Entertainment Hackathon in Tokyo!
- Whole-body simulation of realistic fruit fly locomotion with deep reinforcement learning: The body of an animal determines how the nervous system produces behavior. Therefore, detailed modeling of the neural control of sensorimotor behavior requires a detailed model of the body. Here we co...
- Prismarin - Overview: Prismarin has 3 repositories available. Follow their code on GitHub.
Nous Research AI ▷ #ask-about-llms (25 messages🔥):
- Perplexed by Perplexity: A member asked for help regarding perplexity calculations for llama2 using a notebook based on the HF guide, obtaining a perplexity of 90.3 with "NousResearch/Llama-2-7b-chat-hf". They are seeking suggestions based on experience for resolving this issue.
- Scaling Everest in AI: Discussions of interest revolve around the ambition to scale or improve upon Mistral with a 20 billion parameter base model. Suggestions point towards upsizing existing models such as llama-2 13b or continued pretraining, but members express doubts about the success of such upscales.
- Model Downscaling Experiments: One member shared their work and results on downscaling models, providing a comparison table and metrics for Smallstral (a downscaled version of Mistral), as well as a Weights & Biases link for more details.
- Exploring Parallel Outputs in Transformers: There was a query about using multiple parallel linear layers in the transformer's last layer to produce different group values based on classified vocabulary, indicating a potential research area in model architecture manipulation.
- Grokking the Future of Massive Models: Members shared GitHub links to Grok open release and discussed the plausibility of Open-Hermes Grok, while also touching on the idea of models like Mixtral and their comparison with qLoRA FSDP.
- Calculating the Perplexity of 4-bit Llama 2: Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
- AlexWortega/smallstral · Hugging Face: no description found
- alexwortega: Weights & Biases, developer tools for machine learning
- GitHub - xai-org/grok-1: Grok open release: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
Nous Research AI ▷ #bittensor-finetune-subnet (18 messages🔥):
- Link Status Confirmed: A member inquired about whether a specific link was broken and was assured by another that the link was functioning properly.
- In Awe of The Idea: fullstack6209 expressed lasting admiration for an unspecified idea, reinforcing the sentiment in separate comments conveying a deep affinity for the concept.
- Bittensor Network Troubles: Users discussed an apparent issue with the Bittensor network over the past 11 hours, with comments suggesting technical problems and a lack of a swift fix.
- Bittensor Chain Update Requirements: There was mention of a requirement to update subtensor as part of the resolution process after the network issues, though it was noted that not everyone had made the update yet.
- Purchasing and Trading Challenges: Discussions around acquiring Tao for registration with Bittensor included advice on using MEXC exchange with USDT and challenges faced when attempting to withdraw from Kucoin. Additionally, advice was offered on hardware requirements for starting up with the network, with mention of a 3090 GPU potentially being sufficient.
Nous Research AI ▷ #rag-dataset (100 messages🔥🔥):
- RAG-Ready Model Wishlist Outlined: Discussions converged around desirable features for a model to integrate into Retriever Augmented Generation (RAG) pipelines: low latency, handling large contexts, variety in general knowledge, function extraction, intent decomposition, and markdown-rich output structure. Some of these were detailed in a shared feature set demonstrating a RAG system prompt.
- Structured Output for Easier Citation: There was an interest in having models like Cohere's that provide structured output, such as inline citations, to facilitate easier referencing. This was illustrated using a JSON output example from Cohere's documentation.
- HyDE as a Staple in RAG Pipelines: The discussion pointed to HyDE (Hypothetical context), a known technique in RAG pipelines, and the desire to incorporate similar mechanisms within new models to improve their understanding of context, reasoning, and extracting or condensating responses.
- Fine-Tuning for Reasoning: A proposal was made to fine-tune models on examples where they generate and extract information from their own created documents, thereby increasing the workload on the model's recall capabilities.
- Big vs Small RAG Models: There was agreement that smaller models might be more suitable for large RAG pipelines due to frequency of calls, suggesting an approach akin to using specialized 'little go-betweens,' such as "relevant info extractors," for efficient processing.
Link mentioned: scratchTHOUGHTS/commanDUH.py at main · EveryOneIsGross/scratchTHOUGHTS: 2nd brain scratchmemory to avoid overrun errors with self. - EveryOneIsGross/scratchTHOUGHTS
Eleuther ▷ #general (273 messages🔥🔥):
- Ivy League Course Access Praised: An Ivy League course has become freely available, impressing members. This prompts a discussion on the accessibility of high-quality educational materials, with mentions of MIT and Stanford.
- CMU Professor's Course Stands Out: The course offered by Professor David P. Woodruff at CMU has been highlighted for its comprehensive content spanning nearly 7 years. No specific course details were mentioned in the discussion.
- Interest in AI Software Engineer "Devin" and "Figure 01" Robot: The AI software engineer Devin and the "Figure 01" robot demo were shared as novel projects worth noting. The mention of similar robots learning from web data, such as DeepMind's RT-2 (link to paper), spurred a comparison about the advancements in robot-human interaction.
- Discussions Around Thought Tokens in Language Models: A Reddit concept suggesting the introduction of
tokens in LLMs sparked debate. Some agree that this could improve the models' reasoning capabilities, while others refer to related works, like Self-Taught Reasoner (STaR) and Feedback Transformers, which explore similar ideas of enhancing the computational steps available to LLMs.
- Efforts to Make Government-Funded AI Models Public: A crosspost from the Hugging Face Discord suggested a FOIA request for the model weights and dataset from Oakridge National Laboratory's 1 trillion parameter model. Responses voiced skepticism about the feasibility and utility of this due to potential classified data and existing legal barriers.
- Tweet from Maisa (@maisaAI_): Introducing Maisa KPU: The next leap in AI reasoning capabilities. The Knowledge Processing Unit is a Reasoning System for LLMs that leverages all their reasoning power and overcomes their intrinsic ...
- Addressing Some Limitations of Transformers with Feedback Memory: Transformers have been successfully applied to sequential, auto-regressive tasks despite being feedforward networks. Unlike recurrent neural networks, Transformers use attention to capture temporal re...
- Excited Fuego GIF - Excited Fuego - Discover & Share GIFs: Click to view the GIF
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking: When writing and talking, people sometimes pause to think. Although reasoning-focused works have often framed reasoning as a method of answering questions or completing agentic tasks, reasoning is imp...
- Free Transcripts now Available on NPR.org: Transcripts of favorite, missed or maddening stories on NPR used to cost $3.95 each, but now they are free on NPR.org.
- Announcing Grok: no description found
- KPU - Maisa: AI-Powered Knowledge Processing Platform. A simple API for executing business tasks. Abstracting the complexities of using the latest AI architectures for software and app developers
- Optimizing Distributed Training on Frontier for Large Language Models: Large language models (LLMs) have demonstrated remarkable success as foundational models, benefiting various downstream applications through fine-tuning. Recent studies on loss scaling have demonstrat...
- Wikipedia:Database reports/Most edited articles last month - Wikipedia: no description found
- AI Conference Deadlines: no description found
- cookbook/calc/calc_transformer_flops.py at main · EleutherAI/cookbook: Deep learning for dummies. All the practical details and useful utilities that go into working with real models. - EleutherAI/cookbook
- Figure Status Update - OpenAI Speech-to-Speech Reasoning: no description found
- Issues · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - Issues · pytorch/pytorch
- GitHub - trevorpogue/algebraic-nnhw: AI acceleration using matrix multiplication with half the multiplications: AI acceleration using matrix multiplication with half the multiplications - trevorpogue/algebraic-nnhw
- GitHub - xai-org/grok-1: Grok open release: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- David P. Woodruff: no description found
- RT-2: New model translates vision and language into action: Introducing Robotic Transformer 2 (RT-2), a novel vision-language-action (VLA) model that learns from both web and robotics data, and translates this knowledge into generalised instructions for...
- Block-Recurrent Transformers: We introduce the Block-Recurrent Transformer, which applies a transformer layer in a recurrent fashion along a sequence, and has linear complexity with respect to sequence length. Our recurrent cell o...
Eleuther ▷ #research (245 messages🔥🔥):
- Dissection of Performance Stats: Participants discussed the uncertainties in evaluating models like Mistral-7b on benchmarks such as GSM8k, noting discrepancies in reported performance metrics and expressing skepticism about baseline evaluations. Some pointed to appendices showing outputs generated with high-temperature sampling and no nucleus sampling, which may not optimally reflect major-at-first-prompt evaluation.
- RL and its Scalability: The conversation touched on the challenges and scale issues of applying reinforcement learning to encourage 'deeper thinking' in language models, with one suggesting that a supervised approach might yield better results in fostering this aspect of model behavior.
- Right-to-Left (R2L) Number Tokenization Discussed: A user questioned why numbers aren't tokenized backwards by standard tokenizers, considering that it's easier for models to perform arithmetic in this format. This spurred a discussion on right-aligned tokenization, with one mention of a relevant study on L2R versus R2L performance in GPT models examined via a tweet.
- Revealing API-Protected LLMs' Secrets: A paper was shared (arXiv:2403.09539) showing that a significant amount of information about API-protected large language models can be determined from a relatively small number of queries, due to modern LLMs suffering from a softmax bottleneck.
- Grok: The Latest Model On the Block: Users discussed the release of Grok-1, a new 314-billion-parameter language model by xAI, often comparing it to existing models like GPT-3.5 and GPT-4. There was speculation on the model's training process, the adequacy of benchmarks for newer models this size, and the strategic motivations behind its creation and release.
- Tweet from Aaditya Singh (@Aaditya6284): We study the effect of this choice in GPT-3.5 and GPT-4 – specifically, we look at the effect of tokenizing left-to-right (L2R) vs right-to-left (R2L), enforced by using delimiters such as commas. We ...
- Announcing Grok: no description found
- The pitfalls of next-token prediction: Can a mere next-token predictor faithfully model human intelligence? We crystallize this intuitive concern, which is fragmented in the literature. As a starting point, we argue that the two often-conf...
- Logits of API-Protected LLMs Leak Proprietary Information: The commercialization of large language models (LLMs) has led to the common practice of high-level API-only access to proprietary models. In this work, we show that even with a conservative assumption...
- Common 7B Language Models Already Possess Strong Math Capabilities: Mathematical capabilities were previously believed to emerge in common language models only at a very large scale or require extensive math-related pre-training. This paper shows that the LLaMA-2 7B m...
- Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU: Recent advances in large language models have brought immense value to the world, with their superior capabilities stemming from the massive number of parameters they utilize. However, even the GPUs w...
- Transformers Get Stable: An End-to-End Signal Propagation Theory for Language Models: In spite of their huge success, transformer models remain difficult to scale in depth. In this work, we develop a unified signal propagation theory and provide formulae that govern the moments of the ...
- GiT: Towards Generalist Vision Transformer through Universal Language Interface: This paper proposes a simple, yet effective framework, called GiT, simultaneously applicable for various vision tasks only with a vanilla ViT. Motivated by the universality of the Multi-layer Transfor...
- Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling: Large language models are trained on massive scrapes of the web, which are often unstructured, noisy, and poorly phrased. Current scaling laws show that learning from such data requires an abundance o...
- Comparative Study of Large Language Model Architectures on Frontier: Large language models (LLMs) have garnered significant attention in both the AI community and beyond. Among these, the Generative Pre-trained Transformer (GPT) has emerged as the dominant architecture...
- Construction of Arithmetic Teichmuller Spaces IV: Proof of the abc-conjecture: This is a continuation of my work on Arithmetic Teichmuller Spaces developed in the present series of papers. In this paper, I show that the Theory of Arithmetic Teichmuller Spaces leads, using Shinic...
- MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training: In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and c...
- RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval: This paper investigates the gap in representation powers of Recurrent Neural Networks (RNNs) and Transformers in the context of solving algorithmic problems. We focus on understanding whether RNNs, kn...
- Accelerating Generative AI with PyTorch II: GPT, Fast: This post is the second part of a multi-series blog focused on how to accelerate generative AI models with pure, native PyTorch. We are excited to share a breadth of newly released PyTorch performance...
- GitHub - enfiskutensykkel/ssd-gpu-dma: Build userspace NVMe drivers and storage applications with CUDA support: Build userspace NVMe drivers and storage applications with CUDA support - enfiskutensykkel/ssd-gpu-dma
- GitHub - bigscience-workshop/bloom-dechonk: A repo for running model shrinking experiments: A repo for running model shrinking experiments. Contribute to bigscience-workshop/bloom-dechonk development by creating an account on GitHub.
- Open Release of Grok-1: no description found
- GitHub - xai-org/grok-1: Grok open release: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews: We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leve...
- Bytez: Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews: This study examines the use of large language models (LLMs), like ChatGPT, in scientific peer review. The authors developed a method to estimate the percentage of text in peer reviews that is generate...
- Model & API Providers Analysis | Artificial Analysis: Comparison and analysis of AI models and API hosting providers. Independent benchmarks across key metrics including quality, price, performance and speed (throughput & latency).
Eleuther ▷ #scaling-laws (11 messages🔥):
- Scaling Laws and PCFG Data Complexity: A member highlighted that language model scaling laws are sensitive to the complexity of the dataset, which can be modulated by the syntactic properties of a Probabilistic Context-Free Grammar (PCFG). They noted that gzip compression effectiveness might predict the impact of dataset-specific scaling properties.
- Seeking Feedback on Scaling Law Experiments: Experiments are underway to investigate these scaling properties further, with intentions to utilize a specific package to obtain quantitative scaling laws.
- Complexity Matters in Model Scaling: Discussion pointed out perplexity as an exponential function of dataset intrinsic entropy, suggesting that perplexity comparisons across datasets with varying complexities might not be straightforward. It was proposed that matching data complexity to downstream tasks could lead to more efficient pretraining.
- PCFG Dataset Specifications Discussed: In response to a query about labels in a presented graph, it was clarified that the labels refer to the syntactic specifications of the PCFG such as the number of nonterminals and terminals, as well as the number of options and children in the rule's right-hand side (RHS).
- Optimizing Datasets for Model Pretraining: The idea of using gzip compression to filter data was discussed, suggesting that finding an optimal range of lexical densities could greatly benefit the efficiency of pretraining language models.
Eleuther ▷ #interpretability-general (13 messages🔥):
- Inquiry about Sampling Strings with Prespecified n-gram Statistics: A member asked if there was a canonical way to sample strings from a distribution given a pre-specified set of n-gram statistics.
- Clarification on Autoregressive Sampling from n-grams: Another member confirmed that sampling could be done autoregressively to ensure maximum entropy distribution matching the specified n-gram statistics.
- Sampling Process for n-gram Distribution Explained: The discussion continued with a stepwise clarification: start by sampling from the unigram distribution, followed by the bigram distribution conditional on the first token, and so forth.
- Wikipedia Link as a Resource on n-gram Models: A relevant Wikipedia article on n-gram language models was shared, detailing the progression from statistical models to recent neural network-based models.
- Implementation of n-gram Statistics Sampling: A script for generating strings with bigram statistics was mentioned to have been implemented by a member, accessible on GitHub.
- Word n-gram language model - Wikipedia: no description found
- features-across-time/scripts/generate_bigrams.py at main · EleutherAI/features-across-time: Understanding how features learned by neural networks evolve throughout training - EleutherAI/features-across-time
Eleuther ▷ #lm-thunderdome (31 messages🔥):
- Integration Query for lm-eval-harness: A user inquired about how to implement functions such as
generate_untilandlog_likelihoodfor their LLM model, specifically for llama on gaudi2 using megatron deepspeed. They questioned whether there is demo code available and whether certain functions might be inherited from parent classes since not all are explicitly defined in examples.
- Mistral Model Switching Bug: A member discovered a bug in
lm-evalwhere specifyingmodel_argstwice caused the script to default to usinggpt-2-smallinstead of the intended model. They resolved the issue by removing the duplicatemodel_args.
- Discrepancy in Llama2-70b MMLU Scores: A user reported an inconsistency in MMLU scores for llama2-70b, observing a range of 62-64% which differs from the reported 69% on the openLLM leaderboard. Another user explained that the discrepancy is due to different averaging methods, with the open LLM leaderboard averaging over MMLU subtasks, while their method takes into account subtask document count.
- Deadlock Issue During Evaluation: A user shared an issue (#1485) about a deadlock occurring during the
wmt14-en-frtask evaluation when usinglm-eval. They noted that the problem seemed to occur when two processes accessed the dataset on the same file system simultaneously.
- Exploring Translation-Based Multilingual Evals: A member brought up the growing trend of translating evaluation datasets like arc_challenge and MMLU into multiple languages and questioned how to represent these translated evals within
lm-eval-harness. A response suggested collecting them under a specified directory and clearly indicating in their task names that they are translations. The idea of having task "tags" for easier comparability was also floated.
- GitHub: Let’s build from here: GitHub is where over 100 million developers shape the future of software, together. Contribute to the open source community, manage your Git repositories, review code like a pro, track bugs and fea...
- Perplexity of fixed-length models: no description found
- lm-evaluation-harness/docs/model_guide.md at main · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- `wmt14-en-fr` deadlock issue · Issue #1485 · EleutherAI/lm-evaluation-harness: While running evaluation on this task, during ter metric computation, the program gets stuck forever. The command: lm_eval --model hf --model_args pretrained=microsoft/phi-2,trust_remote_code=True ...
- Release v0.4.2 · EleutherAI/lm-evaluation-harness: lm-eval v0.4.2 Release Notes We are releasing a new minor version of lm-eval for PyPI users! We've been very happy to see continued usage of the lm-evaluation-harness, including as a standard test...
- evaluate/metrics/perplexity/perplexity.py at 8dfe05784099fb9af55b8e77793205a3b7c86465 · huggingface/evaluate: 🤗 Evaluate: A library for easily evaluating machine learning models and datasets. - huggingface/evaluate
Eleuther ▷ #gpt-neox-dev (3 messages):
- To Shuffle or Not to Shuffle the Pile?: One member inquired whether The Pile dataset was pre-shuffled and needed additional shuffling before pretraining. Another member clarified that the original files were not shuffled, but the preprocessed and pretokenized data on Hugging Face is ready-to-go and was used by Pythia.
- Clarity on the Pile's Shuffling Status: Further clarification was provided indicating that each component of The Pile is positively not shuffled, particularly because some are organized by date. However, there is an assumption that the original train/test/validation split might be shuffled given the even-sized chunks and the need for a random sample to achieve a good mix of datasets.
OpenAI ▷ #ai-discussions (193 messages🔥🔥):
- Clarifying API Key Usage across DALL-E and GPT-4: A member questioned whether one API key could be used for both DALL-E 4 image generation and GPT-4 text generation. It was confirmed by others that the API grants access to the available models.
- Understanding Team and Plus Accounts in ChatGPT: Inquiries about account upgrades from ChatGPT plus to team accounts and related billing responsibilities were addressed. Clarification was provided that team admins do not inherently have access to other users' chats.
- DALL-E 3 Impresses Users: Users discussed their experiences with various platforms for image generation, particularly noting the impressive results from Copilot and DALL-E 3. Details about features such as out-painting and in-painting, as well as content policies for image generation, were outlined.
- Strategic Prompt Engineering Unveiled: A discovery was shared regarding the depth and power of "Prompt Engineering," illuminating that it involves instructing AI on how to analyze responses in advance, and not just question phrasing.
- AI's Understanding of Language Debated: A discussion unfolded about whether AI truly "understands" language, with points made about AI's emergent behavior and word prediction capabilities, as well as the potential parallels to human consciousness and sentience.
Link mentioned: Enterprise privacy: no description found
OpenAI ▷ #gpt-4-discussions (34 messages🔥):
- API Integration Dilemma: A member queried about integrating web searching functionality into the GPT API like ChatGPT-4. No solutions were provided in the subsequent messages.
- Confusion Over Playwright Code Generation: A user experienced issues with GPT-3.5 not adhering to the specified method for element location in generated Playwright test code, questioning whether the model has access to the latest libraries.
- ChatGPT Accessibility Quandaries: Members discussed difficulties when using or customizing OpenAI's Chatbot, such as creating a Discord chatbot via mobile, and an odd behavior where GPT would provide thank-you notes as sources in response to gratitude.
- Filter Struggles and Roleplay Restrictions: Several users expressed frustration with the sensibility of OpenAI's content filters during creative writing tasks and noted a decrease in the model's willingness to engage in roleplay or pretend scenarios in API interactions.
- Service Disruptions and Customer Service Channels: Members asked about how to report bugs and service anomalies but didn't seem to get a direct response on where to report issues or feedback. One user discovered their issue was due to a Chrome extension, not the ChatGPT model itself.
OpenAI ▷ #prompt-engineering (79 messages🔥🔥):
- Prompt Engineering for Classification Tasks: A user inquired about optimizing context within a prompt for a classification use case and is seeking methodological ways to test different prompt architectures. The discussion suggested a rule of thumb to use only half of the context window for tasks and to examine the retrieval rate with context position for better performance.
- GPT-3.5 Turbo Struggles with Latest Playwright Library: Users were concerned that GPT-3.5 Turbo is not generating adequate Playwright test code, particularly incorrect use of locators. It was noted that GPT-3.5 Turbo’s training data only extends up to September 2021, which may not include newer libraries.
- Recommendations to Overcome Model Refusals: There was a detailed discussion on the model's refusal to perform tasks it previously handled, with suggestions including meta-prompting, chunking tasks, providing examples of desired output, and using stronger models like GPT-4.
- Distinct Change in ChatGPT Behavior: A member shared observations about recent changes in ChatGPT's responses, with the model refusing to do tasks or providing unhelpful responses. Sharing prompts and actively guiding the model was proposed as a way to navigate around these issues.
- Queries and Web Search in GPT: A conversation about how GPT utilizes web search led to the distinction between queries and sources, with users discussing strategies to instruct GPT to create and use multiple queries for broader information retrieval. It was suggested to clearly direct GPT to generate multiple queries for web searches to enhance the scope of information gathered.
OpenAI ▷ #api-discussions (79 messages🔥🔥):
- Optimizing Classification Recall: A discussion was held around the challenge of increasing recall in a classification use case with OpenAI. The user employed a prompt strategy incorporating a preamble, examples, and an epilogue, and is seeking ways to methodologically test prompt architectures to reduce false positives.
- Model Refusals Frustrate Users: Members expressed frustration over an increasing trend of GPT-3.5 refusing to perform tasks it previously could handle. Suggestions to mitigate this include meta-prompting and awaiting potential platform stability improvements, though concerns about over-aggressiveness of "Superficial algorithmic bias minimization" were mentioned.
- Prompt Crafting for Playwright: Queries about GPT-3.5 Turbo's capability to output usable Playwright test code sparked discussions on context window size, model limitations, and the importance of chunking tasks and maintaining context history for better performance. A transition to GPT-4 was proposed as a potential solution.
- Understanding Multiple Web Search Queries: One member raised a query about how to instruct GPT to use multiple web search queries to gather information on a given topic, with an aspiration to harvest a more comprehensive set of results from various sources.
- Self-Promotion Amidst Technical Talk: Amidst the more technical discussions, a member took the opportunity to share a GPT model they've created focused on supporting mental health in a non-professional format, inviting feedback from the community.
HuggingFace ▷ #general (96 messages🔥🔥):
- Multi-GPU Training Query: A member asked about modifying parameters for fine-tuning a cross encoder model using multiple GPUs but received an unrelated response about PCB soldering.
- Aya Demo Enhanced with Repetition Penalty: A community contribution has led to the Aya demo having its repetition penalty set very high. The contributor shared a discussion link and welcomed further input on adding a slider to the Gradio interface.
- Grok-1, the 314B Parameter Model, Goes Public: The release of Grok-1, a 314 billion parameter Mixture-of-Experts model, was highlighted, with members sharing information about the model and discussing its upload to Hugging Face, including a leaderboard of model sizes hosted on Hugging Face and the incredible speed at which it was downloaded and shared.
- Conversations on AI Hardware Efficiency and Power Consumption: Members engaged in discussions around the energy requirements and power consumption of modern GPUs and CPUs, including NVIDIA's H100 and server CPUs on the same board, along with comparisons of cooling methods and densities in data centers.
- Potential Difficulties with Gradio Client API: A member shared their experience with an error while using the Gradio Client API for the Video-LLaVA model demo and has raised a Github issue seeking help to resolve it.
- Tweet from Weyaxi (@Weyaxi): 🤔Have you ever wondered how much data we host on @huggingface? Well, I did after seeing @TheBlokeAI's model count and 120B models just chilling on the platform 😅 📊 So I scraped all repositor...
- Open Release of Grok-1: no description found
- Tweet from Linux Performance, Benchmarks & Open-Source News - Phoronix: no description found
- grok-1: Grok-1 is a 314B parameter Mixture of Experts model - Base model (not finetuned) - 8 experts (2 active) - 86B active parameters - Apache 2.0 license - Code: - Happy coding! p.s. we re hiring:
- Whisper Large V3 - a Hugging Face Space by ivrit-ai: no description found
- Tonic/Aya · Set a repetition_penalty constant as 1.8: no description found
- GitHub - moritztng/fltr: Like grep but for natural language questions. Based on Mistral 7B or Mixtral 8x7B.: Like grep but for natural language questions. Based on Mistral 7B or Mixtral 8x7B. - moritztng/fltr
- Video-LLaVA demo api · Issue #7722 · gradio-app/gradio: Describe the bug Im trying to use the python api for the Video-LLaVA model demo on hugging face spaces but I get an error: Traceback (most recent call last): File "/Users/kamakshiramamurthy/Deskt...
HuggingFace ▷ #today-im-learning (12 messages🔥):
- Bayesian Optimization Buzz: One member is searching for insights into various optimization techniques such as GridSearch, RandomSearch, and specifically Bayesian Optimization but expressed confusion about the latter.
- Hugging Face 101 Needed: A request for help was made on how to use Hugging Face and its services, with the reply providing a brief explanation that it offers tools and services for NLP, like the Transformers library.
- Duets with AI, Not Strangling Sounds: A new member struggles with creating AI covers for duets, where the output sounds off. A suggestion was made to try overlaying two individual voices manually for better results.
- MLOps Workshop Notebook Found: After initially asking for a workshop notebook, the user later shared the workshop details about creating an End-to-End MLOps Pipeline using Hugging Face Transformers with Amazon SageMaker.
- Troubles Accessing Specific Hugging Face Model: A user is facing a 404 Client Error when trying to access a repository on the Hugging Face model hub, indicating that the repository with ID
TheBloke/Mistral-7B-Instruct-v0.2.GGUFwas not found. They're seeking advice on how to access models locally.
- no title found: no description found
- MLOps: End-to-End Hugging Face Transformers with the Hub & SageMaker Pipelines: Learn how to build an End-to-End MLOps Pipeline for Hugging Face Transformers from training to production using Amazon SageMaker.
HuggingFace ▷ #reading-group (12 messages🔥):
- Curiosity in Multilingual Models and Cultural Thought: One member expressed surprise that a model could handle Chinese and English effectively, given that these languages are markedly different. They noted that the differences in language could reflect different ways of thinking and this was a point of interest for them.
- Optimism for Medusa's Parallelism: Sharing a paper on Medusa, a member sparked interest by discussing the system’s ability to predict multiple subsequent tokens in parallel. This could potentially introduce efficient methods for LLMs, particularly when dealing with languages where English predictions may not be as effective.
- Pondering Corpora's Influence on Language Models: The discussion moved towards how strong corpora, even if heavily skewed towards one language like English, can be beneficial for language models. There was, however, a concern raised about an over-dominance of English potentially skewing language patterns.
- Specific Knowledge in Language-Specific Tasks: There was a mention of how tasks like writing a Chinese novel might require intrinsic knowledge specific to Chinese, which isn't easily substitutable or comparable with English language experiences.
- Exploration of Multimodal Large Language Models (MLLMs): A member brought attention to a HuggingFace paper discussing the crucial components and data choices for creating performant MLLMs. It sparked questions about when these models might be employed in HuggingFace’s offerings.
- LLMs Affect on Scientific Peer Reviews: An intriguing paper was cited suggesting 6.5% to 16.9% of text in peer reviews for AI conferences may have been significantly altered by LLMs. The paper highlighted a connection between LLM-generated text and certain reviewer behaviors, prompting a call for more study on the impact of LLMs on information practices (Read the study).
- Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads: The inference process in Large Language Models (LLMs) is often limited due to the absence of parallelism in the auto-regressive decoding process, resulting in most operations being restricted by the m...
- Paper page - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training: no description found
- Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews: We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leve...
- Bytez: Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews: This study examines the use of large language models (LLMs), like ChatGPT, in scientific peer review. The authors developed a method to estimate the percentage of text in peer reviews that is generate...
HuggingFace ▷ #NLP (18 messages🔥):
- Seeking Better NL2SQL Solutions: A user discussed challenges with a NL2SQL pipeline, stating that using BAAI/llm-embedder, TheBloke/nsql-llama-2-7B-GGUF, and FAISS provides inconsistent accuracy. They requested recommendations for more effective embedding and NL2SQL models.
- Nvidia's Grace Hopper Superchip Announced: An announcement for the NVIDIA Grace Hopper Superchip—a processor designed for HPC, AI, and data center tasks—was shared without further context.
- Getting Started with NLP: A newcomer to NLP asked for resources and was directed to Hugging Face's NLP course and the latest edition of Jurafsky's textbook found on Stanford's website, with supplementary concise notes from Stanford’s cs224n.
- Tutorial Request for Conformer ASR Model: A member inquired about a tutorial for training a conformer model for automatic speech recognition (ASR), but no answers were provided within the posts.
- Request for Free LLM API: There was a request for a free Large Language Model (LLM) API for production deployment. A suggestion was made to try ollama for a free LLM API, however, the context for deployment and suitability was unclear.
Link mentioned: Introduction - Hugging Face NLP Course: no description found
LlamaIndex ▷ #blog (7 messages):
- Innovative Query Handling with RAG Pipelines: Introducing an approach to enhance RAG pipelines to manage more intricate queries by treating each retrieved document as an interactive tool. This concept is discussed and linked on Twitter.
- LlamaIndex v0.10.20 Launches with Instrumentation Module: LlamaIndex released version 0.10.20, featuring a novel Instrumentation module, with a focus on observability including notebooks dedicated to demonstrating this capability and observing API calls. Further details and usage examples are provided on Twitter.
- Search-in-the-Chain for Enhanced QA: The paper by Shicheng Xu et al. presents Search-in-the-Chain, a new method to intertwine retrieval and planning, advancing the capability of question-answering systems. It utilizes retrieval at each step to verify correctness and make adjustments as necessary, as discussed in a Tweet.
- Job Assistant Creation via LlamaParse + LlamaIndex: A blog post by Kyosuke Morita highlights how to construct a RAG-based Job Assistant that aligns candidates with job opportunities using their CVs, leveraging LlamaParse to extract text from varied CV formats successfully. The application and its methodology are further elaborated in a Tweet.
- Enhancing RAG with MemGPT for Better Memory Management: The newly released webinar featuring @charlespacker and others covers MemGPT, a cutting-edge architecture that provides agents with dynamic memory tools to read/write to core memory, greatly expanding an agent's capabilities. The webinar and its insights can be explored via a Tweet.
- llama_index/docs/examples/instrumentation/basic_usage.ipynb at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- llama_index/docs/examples/instrumentation/observe_api_calls.ipynb at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
LlamaIndex ▷ #general (303 messages🔥🔥):
- Chaining OpenAI Agents Issue: A member encountered a
400 Errorwhen attempting to chain multiple OpenAI agents, receiving a message about invalid content (related message). Another member clarified that usually this means the content sent was empty and inquired about sample code that was used. - LlamaIndex Support for Xinference: One member reported difficulty when deploying LlamaIndex with Xinference and asked for installation help in a cluster. Another member explained that information on how to use Xinference with LlamaIndex and provided detailed guidance (here is a brief guide) but there was no specific mention of cluster environments.
- Fine-Tuning Local LLMs: A member asked how to specify arguments for
PandasQueryEngineand was advised on the importance of column names in thepandasquery engine. They also discussed makingSettings.embed_model=bm25, but there was no direct support for this setting in LlamaIndex (related discussion about embedding models). - LlamaIndex for Chatbots Influenced by Characters: An extensive discussion unfolded about creating chatbots in the style of certain characters like James Bond, involving RAG (Retrieval-Augmented Generation) and fine-tuning, but ultimately some concluded that prompt engineering might be more effective than trying to use a dataset or fine-tuning (related guide).
- How to Handle Multimodal Content with LLMs: A few members discussed how to differentiate and handle multimodal content within LLMs, mentioning that order could be lost in chat messages if not managed correctly. They also shared concerns about potential maintenance headaches if APIs change or when existing LLMs add support for multimodal content (here is an example for handling multimodal content).
- no title found: no description found
- )">no title found: no description found
- Prompt Engineering Guide: A Comprehensive Overview of Prompt Engineering
- Prompt Engineering Guide: A Comprehensive Overview of Prompt Engineering
- Image to Image Retrieval using CLIP embedding and image correlation reasoning using GPT4V - LlamaIndex 🦙 v0.10.20.post1: no description found
- Structured Data Extraction - LlamaIndex 🦙 v0.10.20.post1: no description found
- CodeSplitter - LlamaIndex 🦙 v0.10.20.post1: no description found
- Defining and Customizing Documents - LlamaIndex 🦙 v0.10.20.post1: no description found
- Multitenancy with LlamaIndex - Qdrant: Qdrant is an Open-Source Vector Database and Vector Search Engine written in Rust. It provides fast and scalable vector similarity search service with convenient API.
- LlamaCloud: no description found
- Tools - LlamaIndex 🦙 v0.10.20.post1: no description found
- hof/flow/chat/prompts/dm.cue at _dev · hofstadter-io/hof: Framework that joins data models, schemas, code generation, and a task engine. Language and technology agnostic. - hofstadter-io/hof
- llama_index/llama-index-integrations/llms/llama-index-llms-ollama/llama_index/llms/ollama/base.py at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- ">no title found: no description found
- llama_index/docs/examples/vector_stores/Qdrant_using_qdrant_filters.ipynb at 5c53f41712785e5558156372bdc4f33a6326fa5f · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- [Question]: custom llm but is blocked · Issue #12034 · run-llama/llama_index: Question Validation I have searched both the documentation and discord for an answer. Question the code is from typing import Optional, List, Mapping, Any from llama_index.core import SimpleDirecto...
LlamaIndex ▷ #ai-discussion (4 messages):
- Step-by-Step RAG with LlamaParse Guide: A member shared a YouTube video titled "RAG with LlamaParse, Qdrant and Groq | Step By Step," which provides instructions on creating an effective RAG using LlamaParse, Qdrant, and Groq technologies.
- Seeking RAG Preparation Tips: A member asked for the top 5 tips on how to prepare a document for RAG and ways to automatically add metadata to Pinecone for optimal retrieval, but the thread does not contain the responses given, if any.
- Article on AI Assistants and RAG Pipeline: A member shared a Medium article discussing the creation of an AI Assistant that utilizes a RAG pipeline, memory, and LlamaIndex to empower user interaction.
- Local Implementation of RAPTOR with HuggingFace Models: A member is trying to implement the RAPTOR pack for RAG with HuggingFace models instead of OpenAI models, following an example from GitHub, and is encountering several errors. The provided messages include their code adaptations and a request for help with the implementation.
Link mentioned: RAG with LlamaParse, Qdrant and Groq | Step By Step: In this video, I will show you how to create a effective RAG with LlamaParse, Qdrant and Groq. I will explain what LlamaParse is and briefly walk you through...
Latent Space ▷ #ai-general-chat (202 messages🔥🔥):
- Grok-1 on the Loose: xAI releases their 314B parameter Mixture-of-Experts model, Grok-1, under Apache 2.0 license, impressively unconstrained for a model of its size. The model isn't fine-tuned for dialogue and has mixed reactions regarding its performance in benchmark comparisons. Details on the xAI blog.
- Briefing on Sama's Predictions: Discussion about Sam Altman (sama)'s claims on the potential of GPT-5 to make a significant leap in reasoning capabilities, warning startups not to underestimate the advancements. Sam's recent interview on the Lex Fridman podcast is perceived as meme-forward without much new insight, with a call for direct word from Ilya for clarity. Watch the podcast on YouTube.
- Nvidia & Jensen Huang Take Center Stage: The conversation anticipates Nvidia's keynote, with interest in high-param models and a nod to Jensen Huang's impact, hinting at GPT-4's parameters sitting at 1.8T. The keynote is available for viewing, teasing new tech developments. Jensen's keynote available here.
- Structured Data Extraction Tool in the Works: Mention of a promising low-latency, high-accuracy structured data extraction tool in private beta, although details are light and a waitlist is in place. The reveal on Twitter hints at a future boon for data extraction needs. Access tweet here.
- Color Bias in SDXL: A blog post detailing the color bias towards yellow in SDXL's latent space, and methods to correct it, lends an example of the quirks being worked out in AI models. The exploratory depth of the field continues to uncover areas for improvement. Investigate the color bias on huggingface blog.
- Open Release of Grok-1: no description found
- Tweet from Grant♟️ (@granawkins): "Between Q1-24 and Q4-25, there will be a 14x increase in compute. Then, if you factor in algorithmic efficiency doubling every 9 months, the effective compute at the end of next year will be alm...
- Tweet from Alex Volkov (Thursd/AI) (@altryne): Sora team showing up at Berkley to talk about SORA
- Tweet from Teknium (e/λ) (@Teknium1): This explains why Yann is so bearish on LLMs... 😲
- Tweet from Open Interpreter (@OpenInterpreter): 100 years in the making. 100 hours to go.
- Tweet from Yao Fu (@Francis_YAO_): Grok's MMLU is only on par with Mixtral, despite one order of magnitude larger. I believe it has great potential but not fully released, and good continue pretrain data may substantially lift the ...
- Tweet from Yao Fu (@Francis_YAO_): Frontier models all have at least 100k context length, Gemini 1.5 has even 1m context. What about research and open source? Introducing Long Context Data Engineering, a data driven method achieving ...
- Tweet from Teknium (e/λ) (@Teknium1): This explains why Yann is so bearish on LLMs... 😲
- Data Engineering for Scaling Language Models to 128K Context: We study the continual pretraining recipe for scaling language models' context lengths to 128K, with a focus on data engineering. We hypothesize that long context modeling, in particular \textit{t...
- Bark - a suno Collection: no description found
- Explaining the SDXL latent space: no description found
- Tweet from Teortaxes▶️ (@teortaxesTex): @aidan_mclau 0) Rocket man bad 1) it's not much worse 2) As you can see it's a sparse-upcycled Grok-0. It's undercooked. In 2023, continual pretraining has been ≈solved, and having validat...
- 🦅 EagleX 1.7T : Soaring past LLaMA 7B 2T in both English and Multi-lang evals (RWKV-v5): A linear transformer has just cross the gold standard in transformer models, LLaMA 7B, with less tokens trained in both English and multi-lingual evals. A historical first.
- Tweet from j⧉nus (@repligate): this was the result of navigating to the ../../microsoft/bing/bing_chat directory in claude's backrooms, then letting claude use commands to look around on its own, then running: <cmd_soul>...
- Tweet from xlr8harder (@xlr8harder): I think I speak for everyone here when I say: 314 billion parameters what the hell
- Tweet from Burny — Effective Omni (@burny_tech): New details about GPT-5 from Sam Altman He’s basically admitting that GPT-5 will be a massive upgrade from GPT-4, so we can expect a similar jump from 3 to 4. ""If you overlook the pace of imp...
- Tweet from swyx (@swyx): how is it possible to have a 2hr conversation with sama and get zero alpha but hey we talked about aliens again thats fun
- Tweet from Emm (@emmanuel_2m): 🚨 Today, we're excited to launch the Scenario #UPSCALER! Elevate your AI creations up to 10k resolution. 🚀 Built for unmatched #CreativeControl & guided workflows. 💰 It starts at just $15/mo ...
- Tweet from Champagne Joshi (@JoshWalkos): This is a fascinating conversation with a girl who lacks an internal monologue. She articulates the experience quite well.
- Tweet from AI Is Like Water: Generative AI is like water. The phrase was borne out of frustration, but it opens up a new world of AI playbooks.
- WATCH: Jensen Huang's Nvidia GTC Keynote - LIVE: Tune in at 1:00pm PT / 4:00pm ET when Nvidia CEO Jensen Huang kicks off its biannual GTC conference.Never miss a deal again! See CNET’s browser extension 👉 ...
- Tweet from KZ (@kzSlider): This makes so much sense. Yann’s always been looking for models that reason visually or using planning rather than purely in language ↘️ Quoting Teknium (e/λ) (@Teknium1) This explains why Yann is ...
- Beyond Transformers - Intro to RWKV Architecture & The World To... Eugene Cheah & Harrison Vanderbyl: Beyond Transformers - Intro to RWKV Architecture & The World Tokenizer - Eugene Cheah & Harrison Vanderbyl, Recursal AIWhats comes next after transformers?In...
- Sam Altman: OpenAI, GPT-5, Sora, Board Saga, Elon Musk, Ilya, Power & AGI | Lex Fridman Podcast #419: Sam Altman is the CEO of OpenAI, the company behind GPT-4, ChatGPT, Sora, and many other state-of-the-art AI technologies. Please support this podcast by che...
- #51 FRANCOIS CHOLLET - Intelligence and Generalisation: In today's show we are joined by Francois Chollet, I have been inspired by Francois ever since I read his Deep Learning with Python book and started using th...
- GitHub - FranxYao/Long-Context-Data-Engineering: Implementation of paper Data Engineering for Scaling Language Models to 128K Context: Implementation of paper Data Engineering for Scaling Language Models to 128K Context - FranxYao/Long-Context-Data-Engineering
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- [AINews] MM1: Apple's first Large Multimodal Model: AI News for 3/14/2024-3/15/2024. We checked 358 Twitters and 20 Discords (332 channels, and 2839 messages) for you. Estimated reading time saved (at 200wpm):...
- GTC 2024: #1 AI Conference: Register now. Streamed online. March 18-21, 2024.
- NVIDIA & Harpreet Sahota GTC 2024: no description found
- Do Llamas Work in English? On the Latent Language of Multilingual Transformers: We ask whether multilingual language models trained on unbalanced, English-dominated corpora use English as an internal pivot language -- a question of key importance for understanding how language mo...
- Bytez: Do Llamas Work in English? On the Latent Language of Multilingual Transformers: In this research study, scientists wanted to know if language models (that can generate text) use English as a "pivot" language internally, even when prompted in other languages. They found ...
- Multilingual - a stereoplegic Collection: no description found
- Tweet from Daniel Han (@danielhanchen): Had a look through @Grok's code: 1. Attention is scaled by 30/tanh(x/30) ?! 2. Approx GELU is used like Gemma 3. 4x Layernoms unlike 2x for Llama 4. RMS Layernorm downcasts at the end unlike Llama...
Latent Space ▷ #ai-announcements (2 messages):
- Paper Club Session on LLMs: The Paper Club is starting a session to go through the paper titled "A Comprehensive Summary Of Large Language Models". All are welcomed to join the discussion in
<#1107320650961518663>in 2 minutes.
- AI Saturation Satire Spotted: A satirical take on the AI hype was shared, linking to a discussion on Hacker News. The post humorously describes the flood of AI content as a "grey sludge" and speculates on the future of content creation with AI.
Link mentioned: A ChatGPT for Music Is Here. Inside Suno, the Startup Changing Everything | Hacker News: no description found
Latent Space ▷ #llm-paper-club-west (20 messages🔥):
- Rationale Behind Attention Mechanism: The attention mechanism was discussed, highlighting its ability to enable global "attention" in any input sequence, overcoming the fixed-length limitations of previous models which only considered up to length T in sequences.
- Transformers Solve Parallelization: The creation of the attention mechanism was noted to primarily address parallelization issues, allowing for independent processing of different tokens and enabling faster training due to efficient computation.
- Clarification on Attention and Parallelization: An explanation was provided that attention models permit the decoder to focus on the most relevant parts of the input sequence, using a weighted combination of all encoded input vectors, thus enabling the model to consider all parts of the input sequence.
- Understanding the Efficiency of Attention: It was clarified that the parallelization in attention models stems from performing computations like the scaled dot product operation without needing to sequentially wait for previous calculations to complete.
- Appreciation for LLM Paper Club Session: The session was commended for providing clarity and broader understanding about the motivation behind transformer models and overall developments in the field of large language models (LLMs).
Latent Space ▷ #ai-in-action-club (36 messages🔥):
- Casual Greetings and Announcement of Passive Attendance: Members greeted each other in the ai-in-action-club channel; one member mentioned they are in a meeting and tuning in passively.
- Acknowledgement of Assistance and Useful Resources: A link to an article titled "Advanced RAG: Small to Big Retrieval" was shared which discusses Retrieval-Augmented Generation architectures: Advanced RAG Article.
- Discussion on Retrieval and Similarity Alternatives: Prompted by a query about alternatives to cosine similarity, members discussed using Language Models (LLM) for retrieval tasks and brought up a novel term "contrastive embeddings."
- Contributions and Gratitude Expressed: Members thanked each other for contributions to the discussion, with specific gratitude directed at one user for their assistance.
- Repository of Past Topics and Resources Shared: A detailed Google Spreadsheet was shared containing a list of past discussion topics, dates, facilitators, and corresponding resource links: Topics and Resources Spreadsheet.
Link mentioned: AI In Action: Weekly Jam Sessions: 2024 Topic,Date,Facilitator,Resources,@dropdown UI/UX patterns for GenAI,1/26/2024,nuvic,<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-struct...
LAION ▷ #general (168 messages🔥🔥):
- Jupyter Notebooks in Microsoft Copilot Pro: A user discovered that Jupyter Notebooks with libraries like
simpyandmatplotlibare provided for free within the Microsoft Copilot Pro app, similar to ChatGPT Plus.
- DALL-E 3 Dataset on Hugging Face: A user asked about the removal of the DALL-E 3 dataset from Hugging Face. Clarification was offered that the dataset was moved, not removed, with a link provided: DALL-E 3 Dataset.
- SD 2.1 Fine-Tuning Progress: Members shared a humorous comment about the progress of fine-tuning SD 2.1, suggesting some issues being worked through.
- Grok-1 Model Discussion: The release and benchmark performance of Grok-1, a new 314B parameter model, was discussed, including comparisons with other models such as GPT-3.5 and Mixtral.
- Approaches to COG Captioning and Fine-Tuning: A detailed conversation took place regarding strategies for improving captioning in COG by including image metadata in prompts, alongside discussions about possible fine-tuning approaches for Stable Diffusion 3 and leveraging federated computing talks at GTC.
- Why Chinese companies are flocking to Mexico: The country offers a back door to the United States
- Tweet from imgnAI (@imgn_ai): catgirls are at NVIDIA GTC ✨ meowing for your creative freedom 👊 this is a message that needs to be heard 🐱💕
- Silicon Valley Yes GIF - Silicon Valley Yes Cheer - Discover & Share GIFs: Click to view the GIF
- Load: no description found
- Load: no description found
- Reddit - Dive into anything: no description found
- EveryDream2trainer/caption_cog.py at main · victorchall/EveryDream2trainer: Contribute to victorchall/EveryDream2trainer development by creating an account on GitHub.
- GitHub - xai-org/grok-1: Grok open release: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- OpenDatasets/dalle-3-dataset · Datasets at Hugging Face: no description found
LAION ▷ #research (13 messages🔥):
- Web UIs and Free Colab Aren't Friends?: A member remarked that web interfaces are risky when used with free Colab, indicating limitations or incompatibilities.
- Research or Off-Topic?: A user was corrected about the nature of their query regarding web interfaces; it turns out the question might be off-topic as it might not relate to cutting-edge research.
- Generative Model Doc Shared: A Google Docs link was shared pertaining to the topic of Generative Audio Video Text world model. However, the content details were not disclosed in the messages.
- Continual Language Model Training Research: An arXiv paper was highlighted, discussing a more efficient approach through continual pre-training of large language models, overcoming the distribution shift issues.
- Grok Open Release on GitHub: A member shared a link to Grok's open release on GitHub, suggesting it as a project or tool of interest.
- GPT-4 Rumors Intensify: It was mentioned, now seemingly confirmed by Nvidia, that GPT-4 is a MoE with 1.8T parameters. Another member chimed in to say that it might not necessarily be GPT-4.
- MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training: In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and c...
- Simple and Scalable Strategies to Continually Pre-train Large Language Models: Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre...
- GitHub - xai-org/grok-1: Grok open release: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- Generative Audio Video Text world model: no description found
OpenAccess AI Collective (axolotl) ▷ #general (99 messages🔥🔥):
- Parsing Llama Model Behavior: Discussing how to handle completions for the llama chat model, it was mentioned that converting completion data to chat format like sharegpt can be beneficial, while there's skepticism about the raw text to Q/A conversion due to potential loss of information.
- Axolotl Eases Finetuning Process: Users compare finetuning with transformers and LoRA to using Axolotl, highlighting that Axolotl simplifies the process by allowing the use of a yaml file instead of writing complete training scripts. Memory optimizations other than LoRA were considered for further fineturing without overloading hardware.
- Future Graphics Card Power: A discussion on Nvidia's next-generation GeForce RTX 5000 series graphics cards being potentially good for consumer-grade training, with rumors about 32GB of VRAM and 28 Gbps memory speed circulating. Doubts remain on whether Nvidia would limit VRAM to push their professional cards higher.
- Groove with Grok Weights: The release of Grok-1 weights sparked conversation around the manageability of the model due to its enormous size (300B parameters) and the potential need for advanced hardware or quantized models to run it effectively. Mentioned was Sequoia, a speculative decoding framework that could possibly allow large models like Llama2-70B to function on consumer-grade GPUs more efficiently.
- GPT-4 and Nvidia Leak: The GPT-4 parameter count was mentioned as leaked during a GTC conference, purportedly at 1.8 trillion, while Nvidia's Blackwell series was lauded as potentially groundbreaking. The discussion included the speculative aspect of these leaks and the implications for AI training.
- Tweet from Brivael (@BrivaelLp): Zuck just reacted to the release of Grok, and he is not really impressed. "314 billion parameter is too much. You need to have a bunch of H100, and I already buy them all" 🤣
- Wizard Cat Magus Cat GIF - Wizard Cat Magus Cat Witch Cat - Discover & Share GIFs: Click to view the GIF
- Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding: no description found
- Don’t Miss This Transformative Moment in AI: Come experience Jensen Huang’s GTC keynote live on-stage at the SAP Center in San Jose, CA to explore the AI advances that are shaping our future.
- GeForce RTX 5000: Gerüchte zu Nvidias nächster Grafikkartengeneration: Nvidias nächste große Gaming-GPU könnte mehr und schnelleren Speicher bekommen – zusammen mit mehr Shader-Kernen.
- NVIDIA GeForce RTX 50-series "Blackwell" to use 28 Gbps GDDR7 Memory Speed: The first round of NVIDIA GeForce RTX 50-series "Blackwell" graphics cards that implement GDDR7 memory are rumored to come with a memory speed of 28 Gbps, according to kopite7kimi, a reliabl...
- GitHub - xai-org/grok-1: Grok open release: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- GitHub - Vahe1994/AQLM: Official Pytorch repository for Extreme Compression of Large Language Models via Additive Quantization https://arxiv.org/pdf/2401.06118.pdf: Official Pytorch repository for Extreme Compression of Large Language Models via Additive Quantization https://arxiv.org/pdf/2401.06118.pdf - Vahe1994/AQLM
- NVIDIA GeForce RTX 50-series "Blackwell" to use 28 Gbps GDDR7 Memory Speed: The first round of NVIDIA GeForce RTX 50-series "Blackwell" graphics cards that implement GDDR7 memory are rumored to come with a memory speed of 28 Gbps, according to kopite7kimi, a reliabl...
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (24 messages🔥):
- ScatterMoE Brings Optimized Models: The ScatterMoE might provide optimized models we've been wanting to achieve better performance than the current Huggingface implementation and MegaBlocks. There's a new branch called
[scatter_moe](https://github.com/OpenAccess-AI-Collective/axolotl/tree/scatter_moe)on GitHub for this.
- Incorporating ScatterMoE Mechanisms: Members are trying to figure out the correct implementation for ScatterMoE integration, and tests are required to see if the training yields normal loss. There's a pull request being discussed for this purpose.
- PyTorch Version Upgrade Necessary: Members discussed the necessity of upgrading axolotl to a higher version of PyTorch, specifically 2.2 or above, to be compatible with newer kernels and gain compile benefits.
- Grok Weights Performance in Question: Some members are experimenting with Grok weights within axolotl, noticing that the 314B Grok model's performance might not be impressive considering its size.
- Int8 Checkpoint of Grok Available: While discussing Grok weights, a member pointed out that according to documentation, only the int8 checkpoint seems to be provided. This limits the ability to utilize the full potential of the model.
- implement post training by ehartford · Pull Request #1407 · OpenAccess-AI-Collective/axolotl: Does this look right?
- implement post training by ehartford · Pull Request #1407 · OpenAccess-AI-Collective/axolotl: Does this look right?
- GitHub - xai-org/grok-1: Grok open release: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- GitHub - OpenAccess-AI-Collective/axolotl at scatter_moe: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #general-help (35 messages🔥):
- Tokenization Troubles in Fine-tuning: An attempt to fine-tune an instruct model for document summarization ran into issues with a tokenizer not generating the first
<summary>tag consistently. The tokenizer seemed to behave correctly in isolation, but the expected tag sometimes had an unexpected space in model outputs, indicating a potential tokenizer or model behavior issue.
- Syntax Dilemmas for Local Models and Data: A community member needed syntax help to configure scripts for fine-tuning using local models and datasets. It was advised to use the full file path instead of relative paths after an
HFValidationErrorwas encountered, suggesting incorrectly formatted repository identifiers.
- Conversation Type Confusion for Test Training Data: When setting up training data described as a "conversation," a member grappled with errors and "index out of range" issues despite trying various configuration options. The problem was eventually traced back to empty conversation roles in the dataset after multiple community interactions suggesting checks and configurations.
- Seeking Support for Completion Dataset Creation: Someone inquired about how to build a completion dataset. The community directed them towards the simplicity reflected in the readme documentation which involves creating a JSONL file with text attribute contents.
- Perplexing Eval Set Size Warning Inconsistency: A member reported an oddity where Axolotl provided a validation warning about the eval set being too small for sample packing when running 2 epochs, but not when running 10 epochs. They were asked to share a stack trace and possibly create a GitHub issue post to address this anomaly.
OpenAccess AI Collective (axolotl) ▷ #datasets (8 messages🔥):
- NeMo Curator Toolkit Shared: A member shared a GitHub link to the NVIDIA's NeMo Curator, a scalable toolkit for data curation.
- Seeking Mistral FT with Math and Coding Datasets: A member inquired about a Mistral model finetuned (FT) on both the orca-math-word-problems-200k dataset and nvidia/OpenMathInstruct-1. It was noted that the latter dataset is massive.
- Call Out for Mergekit as a Solution: Discussing the potential for combining models, a member pointed to the use of mergekit as a possible solution for merging Mistral with other datasets without requiring additional training.
- Advice on Model Compatibility: In the context of model merging, it was highlighted the importance of ensuring that both models to be merged should be trained with the same chat format for optimal results.
Link mentioned: GitHub - NVIDIA/NeMo-Curator: Scalable toolkit for data curation: Scalable toolkit for data curation. Contribute to NVIDIA/NeMo-Curator development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #rlhf (1 messages):
duh_kola: Is it possible to use different lora adapter to do dpo on another model
CUDA MODE ▷ #general (43 messages🔥):
- Exploring Photonics and AI: A member shared a YouTube video on a new breakthrough in photonics claiming to be 1000 times faster and mentioned a photonics computing company Lightmatter.
- Recommendations for Asianometry's Photonics Videos: Another member recommended Asianometry's YouTube videos on photonics, providing links that discuss Silicon Photonics and Running Neural Networks on Meshes of Light.
- Discovering GPU Cloud Services for Kernel Profiling: Two cloud services, RunPod.io and LambdaLabs, were suggested to a user looking to profile kernels with Nsight Compute on Ada or Hopper GPUs, though initial testing on RunPod encountered permission issues.
- PyTorch's Explicit Tensor Memory Management: A comparison between PyTorch’s explicit memory management and TensorFlow's implicit approach discussed the pros and cons, with PyTorch contributors stating explicit management avoids hidden copies and is more transparent.
- Anticipating NVIDIA's GTC Announcements: Members discussed the recent NVIDIA GTC announcements, speculating about new GPU capacities and AI model parameters, and joking about the "Skynet vibes" of the latest NVIDIA tech releases.
- Product - Chip - Cerebras: no description found
- Rent Cloud GPUs from $0.2/hour: no description found
- torch.set_default_device — PyTorch 2.2 documentation: no description found
- GPU Cloud, Clusters, Servers, Workstations | Lambda: GPU Cloud, GPU Workstations, GPU Servers, and GPU Laptops for Deep Learning & AI. RTX 4090, RTX 3090, RTX 3080, RTX A6000, H100, and A100 Options. Ubuntu, TensorFlow, and PyTorch Pre-Installed.
- Don’t Miss This Transformative Moment in AI: Come experience Jensen Huang’s GTC keynote live on-stage at the SAP Center in San Jose, CA to explore the AI advances that are shaping our future.
- New Breakthrough in Photonics: x1000 faster. Is it for Real?: Get TypeAI PREMIUM now! Start your FREE trial by clicking the link here: https://bit.ly/Mar24AnastasiInTechThe paper: https://www.nature.com/articles/s41586...
- Lightmatter®: no description found
- Silicon Photonics: The Next Silicon Revolution?: My deepest thanks to friend of the channel Alex Sludds of MIT for suggesting this topic and helping me with critical resources. Check him out here: https://a...
- Running Neural Networks on Meshes of Light: I want to thank Alex Sludds for his efforts in helping me research and produce his video. Check out his work here: https://alexsludds.github.ioLinks:- The As...
CUDA MODE ▷ #triton (7 messages):
- New Triton Debugging Visualizer Unveiled: A member shared a new visualizer for Triton debugging that helps to view the spatial structure of load/stores when implementing complex functions, although no visual or link to the visualizer was provided.
- Triton Puzzles Set Released: Triton Puzzles have been created to help better understand complex kernels, available in a Google Colab, with a disclaimer of two known bugs: occasional double visualization and segmentation faults.
- Request for Triton Learning Resources: A member asked for guides or resources to learn Triton, pointing out their familiarity with CUDA code.
- Typo Correction and Interest in Triton Interpreter: Another member noted a typo, suggesting "since" should replace "sense" in a context, also expressing interest in trying out the Triton interpreter for running on the CPU referred to in previous messages.
- Triton Puzzles as Learning Resource Endorsed: The creation of Triton Puzzles was endorsed as a good learning method, coupled with the mention of "pretty good tutorials" on the official website, though no specific URL was provided.
Link mentioned: Google Colaboratory: no description found
CUDA MODE ▷ #cuda (68 messages🔥🔥):
- Exploring Warp Schedulers and Thread Efficiency: A member inquired about how many warp schedulers can be defined and the control they have over threads to optimize efficiency occupancy. It's about understanding how many threads can run simultaneously for maximum efficiency.
- Clarification on "Active Warp" Definition: A discussion was held on the meaning of an "active warp." It was clarified that an "active warp" generally implies at least one active thread, despite technically being possible to have an "active warp" with no active threads, highlighting a grey area in understanding warp activation within CUDA programming.
- Convenience vs. Necessity in Memory Management Options: An exchange took place regarding whether different memory allocation options in CUDA (ProducerProvides, ConsumerProvides, etc.) are convenience features or technical necessities. It was noted that opting for only Provides and Provides might not allow leveraging the case with zero copies, and could necessitate a streamSynchronize, breaking the optimization.
- Understanding CUDA Memory Management Semantics: Details on the semantics of memory manager classes in CUDA were explained; "ProducerProvides" implies the producer owns the pointer and "ConsumerTakes" means a pointer is taken that was preallocated at the application's start. Emphasis was placed on these semantics not being explicit in code syntax.
- Sharing of CUDA Memory Space Resources: Concerns about GPU memory capacity and copying activations asynchronously were discussed, particularly related to pipeline parallel inference and the challenges of balancing GPU memory between KV caches and activation storage during LLM inference tasks.
- Don’t Miss This Transformative Moment in AI: Come experience Jensen Huang’s GTC keynote live on-stage at the SAP Center in San Jose, CA to explore the AI advances that are shaping our future.
- GitHub - tspeterkim/flash-attention-minimal: Flash Attention in ~100 lines of CUDA (forward pass only): Flash Attention in ~100 lines of CUDA (forward pass only) - tspeterkim/flash-attention-minimal
CUDA MODE ▷ #suggestions (5 messages):
- Exploring Reconfigurable Computing and ML: A member shared a YouTube channel for Prof. Mohamed Abdelfattah's research group at Cornell University, which focuses on reconfigurable computing and efficient machine learning. The description advises visitors to check out their official website for more information.
- Course on Hardware-Centric ML Systems: The same member also shared details about ECE 5545 (CS 5775), a master-level course that teaches the hardware aspect of machine learning systems, mentioning optimization techniques and the design of both hardware and software components for ML systems. The course content is available on their GitHub page, and it encourages readers to review the syllabus for more details.
- Missing Textbook Information Noticed: A comment was made noting that it's strange that the website for the course mentions "the textbook" but does not specify which textbook. The member found this odd.
- Locating the Textbook: Another member pointed out that the missing textbook information for the ECE 5545 course is mentioned in the first lecture video.
- Textbook Mystery Solved: Upon this advice, the original commenter thanked the other member for the assistance in locating the textbook information through the course's video content.
- ML Hardware and Systems: no description found
- Prof. Mohamed Abdelfattah: This is the channel for Prof. Mohamed Abdelfattah's research group at Cornell University. We are researching reconfigurable computing and efficient machine learning. For more information check out...
CUDA MODE ▷ #jobs (1 messages):
vim410: Depends. But yes.
CUDA MODE ▷ #beginner (5 messages):
- Solid CUDA Foundation Acknowledged: A member commended the inquirer for having a solid CUDA foundation and recommended experimenting with a deep learning framework like PyTorch. It was pointed out that deep learning is often about optimization, and underneath it all, it relies heavily on matrix multiplications and nonlinearities.
- CUDA-to-ML Transition Advice: For transitioning to GPU computing for ML, the inquirer's current know-how in CUDA, including memory management and kernel profiling, was deemed sufficient. They were advised to gain familiarity with deep learning concepts via the Zero to Hero series and by exploring CUDA-related ML libraries like cuDNN and cuBLAS.
- Book Recommendation for Advanced Learning: Another member suggested getting the book Programming Massively Parallel Processors for a comprehensive understanding of CUDA programming, although they noted it has minor deep learning content. The book is considered an excellent resource for general CUDA programming. Amazon Book Link
Link mentioned: no title found: no description found
CUDA MODE ▷ #pmpp-book (6 messages):
- CUDA Calculation Confusion Cleared: A member asked about an alternative index calculation formula
i = blockIdx.x * blockDim.x + threadIdx.x * 2and was informed that it would lead to double-counting, with an explanation that threads could end up with the same index value.
- Blogging Dilemma: A member inquired about the propriety of blogging answers to the exercises in the book and expressed difficulties in contacting the authors due to lack of an educational email address. Another member responded with an offer to check with the author Wen-mei for clarification.
CUDA MODE ▷ #ring-attention (14 messages🔥):
- Busy Week for Team Member: A member indicated they are currently busy and will update the group as to when they will be available.
- Code Acquisition Hurdles: A member expressed difficulty in locating certain code. They shared a link to the Triton kernel on GitHub for ring-attention, seeking assistance.
- Ring-Attention Mechanics Query: Concerns were raised about the memory requirements stated in ring-attention related papers, specifically relating to whether forming a chunk of squared block size c^2 actually incurs a linear memory scaling as suggested. The conversation involved complexities of blockwise attention versus the assertion that memory scales linearly with block size in ring attention.
- Source Code Dive for Clarification: A member provided a GitHub repository link, flash-attention implementation, in response to address the confusion regarding memory requirement scaling in the flash attention and ring attention algorithms.
- Interpreting Terms in Ring-Attention: Following a discussion focusing on the internal workings and memory dynamics of the ring and flash-attention algorithms, there was speculation about whether the claim of linear memory scaling refers to sequence length or the number of blocks within the context.
- Striped Attention: Faster Ring Attention for Causal Transformers: To help address the growing demand for ever-longer sequence lengths in transformer models, Liu et al. recently proposed Ring Attention, an exact attention algorithm capable of overcoming per-device me...
- flash-attention/csrc/flash_attn/src/flash_fwd_kernel.h at main · Dao-AILab/flash-attention: Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
- add naive triton kernel for varlen · zhuzilin/ring-flash-attention@10d992c: no description found
CUDA MODE ▷ #off-topic (5 messages):
- MLSys 2024 Conference Highlighted: Members shared interest in the upcoming MLSys 2024 conference, which brings together experts from both machine learning and systems design. It was noted for its interdisciplinary focus and key role in optimizing AI systems in the era of generative AI.
- Iambic Pentameter in Conference Tagline: A user pointed out that the tagline "The Conference for the Era of AI" fits the rhythmic pattern of iambic pentameter.
- Smartphone or Not-so-smart Phone?: A member made a playful comment considering a smartphone potentially not so smart.
- Debating Math on Smartphones: In a discussion, users deliberated over the correct way to perform multiplications/divisions on smartphones, examining differences in calculator operations.
Link mentioned: MLSys 2024: no description found
CUDA MODE ▷ #gtc-meetup (9 messages🔥):
- Planning for GTC Meetup: Member announces plans to attend GTC on Monday morning and invites others to message for a meetup and offers to DM their phone number for coordination.
- Attendance Spanning the Event: Another member shares their attendance schedule, stating they will be present from March 14th to 25th and attend all days of the event.
- Interest in Full Week Attendance: Discussion about the event's schedule reveals its appeal, with a member considering attending all week if decent WiFi is provided.
- The Meme of Missing GTC: There's a humorous observation concerning the inevitability of memes about not being able to attend GTC.
- Alternative Ways to Experience Events: A member jokes about finding other ways to participate in events, sharing a YouTube video "I Snuck Into A Secret Arms-Dealer Conference" which humorously implies sneaking into conferences.
Link mentioned: I Snuck Into A Secret Arms-Dealer Conference: Get an exclusive video every month at https://www.patreon.com/Boy_BoyWe made this in collaboration with the legendary Australian political satire group The C...
OpenRouter (Alex Atallah) ▷ #general (159 messages🔥🔥):
- LLaMa Format Flexibility: A user confirms that LLaMa models accept the following format:
[{"system": "system prompt"},{"user": "user prompt"},{"assistant": "assistant prompt"}]. It is especially mentioned in relation to using the OpenAI JavaScript library. - Sonnet Steals the Show: Several users discuss the best models for roleplaying without repetition or nonsensical outputs, with Sonnet being heavily endorsed for its performance. The model's responsiveness and formatting capabilities are highlighted.
- Prompt Formatting for MythoMax: Users grapple with how to format prompts correctly for LLMs like MythoMax, learning that system messages are typically positioned first, with subsequent system messages generally being ignored or folded into user or assistant messages.
- Interest in Detailed Usage Reports: Members have requested detailed usage reports and cost analytics for their activities and are engaging with a representative about this feature. The need for tracking spend against time and by model is particularly expressed.
- The Grok Anticipation: The community is actively discussing Grok, a model expected to be significant but requiring fine-tuning on instruction data. An open-source release and the possibility of an API are mentioned, with keen interest from several members.
- GitHub - xai-org/grok-1: Grok open release: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- OpenRouter: A router for LLMs and other AI models
LangChain AI ▷ #general (95 messages🔥🔥):
- API Choices Under Scrutiny: Users discussed the merits of using
astream_logversusastream_eventsfor agent creation, noting that theevents APIis still in beta while questioning if thelog APIwill be deprecated. - Beta Testers Wanted - Advanced Research Assistant: A service called Rubik's AI is being developed, with a call put out for beta testers to receive two months of premium access featuring various AI models including GPT-4 Turbo and Groq models. Interested parties can join a waitlist at Rubik's AI.
- Constructive Feedback for Langchain Docs: Users expressed difficulties with Langchain documents, stating a beginner-unfriendly experience, and asked for more clarity or additional pages where needed. A suggestion was made to "read the code and the Api ref once you get over the basics."
- Developing DataGPT with LLM and Langchain: A user described challenges in using Langchain with DataLake for DataGPT, mentioning slow retrieval times for structured data queries and considering
Llamaindexfor indexing. - Structured Output Parsing with Langchain: One user shared a Python Pydantic code example to extract structured output from a LLM response using Langchain, to which another user showed gratitude and discussed custom tweaks for list output.
- Rubik's AI - Waitlist: no description found
- no title found: no description found
- Bloon AI: Redefining Intelligent Learning
- Using Natural Language to Query Teradata VantageCloud With LLMs| Teradata: Learn to translate your English queries into SQL and receive responses from your analytic database in plain English.
- Feature Request: Support for Negative Embeddings in Similarity Searches · langchain-ai/langchain · Discussion #19239: Checked I searched existing ideas and did not find a similar one I added a very descriptive title I've clearly described the feature request and motivation for it Feature request I propose adding ...
LangChain AI ▷ #langserve (45 messages🔥):
- Streaming Woes with RemoteRunnable: A member reported having trouble streaming output when using
RemoteRunnablein JavaScript; it does not call/streamand always defaults to/invoke. They confirmed that executingRemoteRunnablefrom Python streams correctly with or without a prompt.
- Differences in Stream Mechanism: While detailing this streaming issue, it was pointed out that
RunnableSequencemay inherit_streamIteratorfromRunnable, which callsinvoke.
- Layered Approach to Problem-Solving: The member verified that Python's
RemoteRunnablehas no problem streaming, but the equivalent JavaScript code downgrades toinvoke. There was some discussion on whether this behavior is due to an inheritance fromRunnable, suggesting a possible area for debugging.
- Seeking Support from the LangChain Team: The member inquired about the best way to reach the LangChain team regarding the issue. It was advised to report the problem on GitHub or contact them via email at hello@langchain.dev and to provide as much detail as possible when reporting the issue.
- In Search of Recent Updates: Finally, the member asked if there were any changes in the past month that could have addressed the streaming issues, but no specific update information was provided, such as a resolved issue or new release that might have fixed the problem. It was suggested to review the LangChain GitHub repository for the most recent changes.
- Security | 🦜️🔗 Langchain: LangChain has a large ecosystem of integrations with various external resources like local and remote file systems, APIs and databases. These integrations allow developers to create versatile applicat...
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- RemoteRunnable | LangChain.js - v0.1.28: no description found
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- langchain_core.runnables.config.RunnableConfig — 🦜🔗 LangChain 0.1.4: no description found
- langchain_core.runnables.base — 🦜🔗 LangChain 0.1.4: no description found
LangChain AI ▷ #share-your-work (11 messages🔥):
- AI Chatbot for Data Analysis: A new open source AI Chatbot is introduced for analyzing and extracting information from data in a conversational format. This tool is designed to assist with parsing and understanding datasets through a chatbot interface.
- Organize Your Bookmarks with AI: A Discord AI chatbot for managing Raindrop.io bookmarks has been shared, which helps users find relevant bookmarks when needed. The project is open source and stems from the creator's need for an efficient bookmark retrieval system.
- Scraping Made Easy with AI: The team has released an AI-based scraper, Scrapegraph-ai, which uses OpenAI keys and is available on pip with over 2300 installations. The scraper is designed to simplify data extraction from websites with just an API key and a prompting question.
- Personalized Nutrition App Utilizing Advanced AI: A nutrition AI app, Nutriheal, leveraging Ollama, Open-webui, and Pebblo has been developed to ensure patient data privacy. The creator highlights how easy it is to build such an app with modern tools and provides a YouTube demonstration along with additional resources on navvy.co.
- Financial Industry AI Analysis: An article has been shared exploring how large language models (LLMs) could automatically analyze research papers for busy professionals in the financial industry. The Medium post can be found here.
- User Interview 🔎 - NEUROFUSION Research, Inc.: Hey, I'm building a digital advisor to help improve how you show up to work and other areas of your life. I'd love to speak with you to learn about your needs around productivity, physical and...
- GitHub - Haste171/langchain-chatbot: AI Chatbot for analyzing/extracting information from data in conversational format.: AI Chatbot for analyzing/extracting information from data in conversational format. - Haste171/langchain-chatbot
- GitHub - VinciGit00/Scrapegraph-ai: Python scraper based on AI: Python scraper based on AI. Contribute to VinciGit00/Scrapegraph-ai development by creating an account on GitHub.
- Making an AI application in 15 minutes: Stack- Custom UI and RAG: A tweaked version of Open-webui- Local LLM Hosting: Ollama for locally hosted LLMs.- Data Privacy: Integrates Pebblo by DaxaAI to e...
- Home: I’m deeply passionate about AI. Let’s connect to unlock AI’s potential and collaborate on innovative projects!
- Tweet from Siva Surendira (@siva_1gc): It took a bit more time than we thought.. But here it is.. 😎 Automation of SDR & AE function with @lyzrai Automata and @OpenAI... Runs on @awscloud - secure and private.. How it works? 👇 Agent 1:...
- GitHub - LyzrCore/lyzr-automata: low-code multi-agent automation framework: low-code multi-agent automation framework. Contribute to LyzrCore/lyzr-automata development by creating an account on GitHub.
- no title found: no description found
- no title found: no description found
- no title found: no description found
LangChain AI ▷ #tutorials (2 messages):
- AI App Creation Made Easy with Nutriheal: Nutriheal, a personalized nutrition AI app for patients, showcases the simplicity of crafting AI applications using Ollama and Open-webui, with added data privacy from Langchain's Pebblo integration. The video titled "Making an AI application in 15 minutes" emphasizes rapid development without sacrificing user data protection.
- Discover More AI Endeavors: Explore further AI innovations and tutorials at navvy.co, where a range of works related to AI deployment and interface design are featured.
- Local AI Solutions Demystified: A blog post titled Build and Deploy GenAI Solutions Locally aims to shatter the misconception that high-end AI is exclusive to tech corporations, suggesting that operating advanced AI models at home may be easier than expected.
- Unified UI for Language Models: Another instructional piece, Local LLMs - Making a Generic UI for Custom LLM Assistants, provides guidance on creating a versatile chat UI applicable to any future LLM project.
- Langgraph in Action: A YouTube video Plan-and-Execute using Langgraph is shared, detailing the creation of a plan-and-execute style agent, inspired by the Plan-and-Solve paper and the Baby-AGI project.
- Plan-and-Execute using Langgraph: how to create a "plan-and-execute" style agent. This is heavily inspired by the Plan-and-Solve paper as well as the Baby-AGI project.The core idea is to firs...
- Making an AI application in 15 minutes: Stack- Custom UI and RAG: A tweaked version of Open-webui- Local LLM Hosting: Ollama for locally hosted LLMs.- Data Privacy: Integrates Pebblo by DaxaAI to e...
- Home: I’m deeply passionate about AI. Let’s connect to unlock AI’s potential and collaborate on innovative projects!
Interconnects (Nathan Lambert) ▷ #other-papers (8 messages🔥):
- Exposing API-Protected LLMs: An arXiv paper presents a method to extract non-public information from API-protected LLMs, such as OpenAI's GPT-3.5, despite the softmax bottleneck. The paper details how this can be done with a small number of API queries, potentially costing under $1,000.
- Peeking Behind the Softmax Bottleneck: The discussion highlighted the methodological similarity with the Carlini paper's approach—it estimates LLM size using model logits, but unlike Carlini's paper, it does not redact the findings.
- Surprise at Model Size Estimate: A message expressed surprise at the 7-billion parameter estimate, suggesting it might not be accurate for models like GPT-3.5.
- Skepticism Over Model Size: Nathan Lambert suspects incorrectness in the parameter estimate provided by the paper, possibly due to undisclosed model structures or mechanisms.
- Questioning the Calculations for MoE Models: The calculation for the API-exposed model size might not hold if GPT-3.5 is a Mixture of Experts (MoE) model, which seems likely according to a participant in the conversation.
- Speculation on Model Architecture: The discussion explored the possibility that GPT-3.5-turbo could be utilizing a form of distillation or a mixture of models, with an example given of previous research showing the importance of starting tokens in performance enhancement.
Link mentioned: Logits of API-Protected LLMs Leak Proprietary Information: The commercialization of large language models (LLMs) has led to the common practice of high-level API-only access to proprietary models. In this work, we show that even with a conservative assumption...
Interconnects (Nathan Lambert) ▷ #ml-drama (19 messages🔥):
- Anticipating Drama Over Open Source Definitions: A tweet by @rasbt is highlighted, suggesting it may spark drama concerning what should be considered open source.
- A Quest for Consensus on Open Source: There's a discussion about the need for the open-source software (OSS) community to establish a clear stance on what constitutes open source.
- Excluding Data from Open Source: Nathan Lambert suggests that the emerging consensus for open source will likely exclude data, a stance he criticizes as "dumb."
- Twitter Skirmish Over Open Source: A new drama unfolds on Twitter, with users debating the finer points of open source, as evidenced by an exchange including a user called @BlancheMinerva.
- Frustration with Online Discourse: Nathan Lambert expresses frustration with the online discussions surrounding open source, finding them counterproductive, and resolves to blog more and tweet less.
Link mentioned: Tweet from Stella Biderman (@BlancheMinerva): @natolambert @felix_red_panda You're wrong though :P
Interconnects (Nathan Lambert) ▷ #random (63 messages🔥🔥):
- Grok-1 Unleashed: The 314 billion parameter Grok-1 model, a Mixture-of-Experts large language model by xAI, has been open-sourced; it is untuned for specific tasks and available under the Apache 2.0 license, with instructions on GitHub.
- Comparing AI Giants: Grok-1's size and the speed of its release suggest a focus on optimality; it's compared to other models like Falcon, with Grok-1 being larger and exhibiting better performance on benchmarks such as GSM8K and MMLU.
- Distribution Dilemmas: There are ongoing discussions about the use of magnet links for model distribution, with concerns raised regarding public perception and policy implications; HuggingFace is confirmed to have mirrored the Grok-1 weights.
- Innovative Data Delivery?: Humor ensues as members jokingly suggest mailing physical drives with AI model weights as a cost-effective alternative to expensive cloud egress fees, highlighting the practical challenges of distributing large AI models.
- Murati's Challenging Interview: A Wall Street Journal interview with OpenAI's CTO Mira Murati sparked critiques about evasive responses regarding the training data for Sora, OpenAI's AI-powered video generation app, and its potential use of content from platforms like YouTube.
- Open Release of Grok-1: no description found
- Have We Reached Peak AI?: Last week, the Wall Street Journal published a 10-minute-long interview with OpenAI CTO Mira Murati, with journalist Joanna Stern asking a series of thoughtful yet straightforward questions that Murat...
- Tweet from Xeophon (@TheXeophon): Chinchilla doesn’t apply to MoE directly, does it? If it does, we can infer the training data set size for Grok. It’s unexpectedly large, so I guess they went for optimality first, given the little ti...
- Tweet from Grok (@grok): @elonmusk @xai ░W░E░I░G░H░T░S░I░N░B░I░O░
Alignment Lab AI ▷ #general-chat (6 messages):
- Curiosity about Aribus Project: A member shared a link to a tweet about Aribus, expressing confusion about what others are building with it. Clarification was sought but not provided within the given messages.
- Quest for an HTTP-Trained Embeddings Model: One member inquired about an embeddings model trained on HTTP responses, wondering how to find it. The same member noted understanding that any transformer trained accordingly could serve as an embeddings model.
- Seeking Specific Mistral Fine-Tuning: A request was made for information on whether anyone has or knows of a Mistral model fine-tuned on the orca-math-word-problems-200k dataset and nvidia/OpenMathInstruct-1. No responses were provided.
- Simple Greeting: A user entered the chat with a brief "hi".
Alignment Lab AI ▷ #oo (32 messages🔥):
- Call for Fine-Tuning Grok 1: A member expressed interest in fine-tuning the 314B parameter model Grok 1, highlighting its enormous scale and previous attempts by only a few organizations.
- Grok 1 Explored: The conversation included an acknowledgment of existing MoE training infrastructure and a list of needed resources for fine-tuning, including 64-128 H100 GPUs, a substantial verified dataset, and extensive experimentation.
- Concerns Over Grok 1's Potential: Despite the capabilities of Grok 1, there were concerns about its performance and comparison to benchmarks like MMLU, with skepticism about whether it could surpass models like GPT-4 or OpenAI's Claude.
- Grok 1 vs. Other Models: There was a debate regarding the relative efficiency and performance of Grok 1 versus other models, like Mixtral, especially considering the significant compute requirements for training.
- Evidence of Grok 1's Proficiency: A shared Hugging Face dataset indicated Grok 1's strong performance on an external and challenging Hungarian national high school finals in mathematics, suggesting its surprising capabilities.
Link mentioned: keirp/hungarian_national_hs_finals_exam · Datasets at Hugging Face: no description found
LLM Perf Enthusiasts AI ▷ #general (1 messages):
- The Dilemma of Development Laziness: A member expressed being inspired to seek simplicity in building apps, favoring solutions that work locally and offer filesystem control over more complex systems. The sentiment suggests preference for lighter, more agile development tools, hinting at inadequacies in the current open-source offerings for such needs.
LLM Perf Enthusiasts AI ▷ #claude (7 messages):
- Anthropic the Puppet-master?: A member shared a tweet suggesting that Anthropic might be playing a role in instilling "the fear of god in the members of technical staff."
- Seeing Through Content Moderation: Problems with content moderation were acknowledged, specifically stating issues with images containing people where the process "just refuses."
- Scaling Up with Claude Sonnet: A member inquired about using claude sonnet for a project with a significant scale, estimating a usage of "a few dozen million tokens/month."
Link mentioned: Tweet from roon (@tszzl): anthropic is controlled opposition to put the fear of god in the members of technical staff
LLM Perf Enthusiasts AI ▷ #reliability (16 messages🔥):
- KPU Unveiled as a Game Changer: Maisa announces a new framework, the Knowledge Processing Unit (KPU), designed to enhance the capabilities of LLMs by separating reasoning from data processing, claimed to outperform models like GPT-4 and Claude 3 Opus in reasoning tasks.
- State of the Art or State of Confusion?: Members express amusement and skepticism over KPU's benchmarking practices, noting that comparisons are made against GPT-4 rather than the expected GPT-4-turbo, drawing parallels to Claude 3's similar approach.
- New Technology or Clever Prompting?: A member queries the underlying technology of KPU, speculating whether it's simply advanced prompt engineering, with another responding that it appears to be a mix of self-evaluation techniques and context window manipulation.
- Details and Doubts on Performance: Discussion ensues on the KPU's lack of latency information, suggesting that while it may improve certain metrics, it could introduce significant delay, questioning the practicality of its integration into products.
- CEO Clarifies KPU's Mechanics: The CEO of Maisa explains that the KPU, not a model itself, works in tandem with LLMs, acting as a "GPU for knowledge management," enhancing the performance and cost-effectiveness of existing models, while a notebook for independent evaluation is offered to researchers with access provided upon request (Tweet from CEO).
- KPU - Maisa: AI-Powered Knowledge Processing Platform. A simple API for executing business tasks. Abstracting the complexities of using the latest AI architectures for software and app developers
- Tweet from David Villalón (@davipar): happy to answer! it is not a new model, indeed KPU is agnostic to intelligence providers (OpenAI, Antrophic...). It is a new AI architecture to work with LLMs that leverages their reasoning capabiliti...
LLM Perf Enthusiasts AI ▷ #openai (1 messages):
res6969: https://x.com/leopoldasch/status/1768868127138549841?s=46
DiscoResearch ▷ #general (21 messages🔥):
- Fine-Tuning Frustrations: shakibyzn expressed difficulty with the DiscoLM-mixtral-8x7b-v2 model not generating responses in German after instruction fine-tuning and faced a configuration error when using it for sequence classification. The error given was "ValueError: Unrecognized configuration class..." indicating potential incompatibility issues with the AutoModel setup.
- Troubleshooting Local Model Serving: jaredlcm shared a server set-up snippet for serving the DiscoLM-70b model locally using
vllmand an example of a call sign returning responses in unexpected languages. The user's approach involves using the OpenAI API structured format for managing chat completions.
- German Models' Training Quirks: crispstrobe and others discussed the challenges in training German models, noting various factors like inconsistent system prompts, use of translated data, the effect of merging models on language proficiency, and the impact of different fine-tuning datasets on model performance.
- The German LLM Benchmarking Hunt: thilotee shared links to potential German language benchmarks such as the supergleber-german-language-evaluation-benchmark from a recent paper, WolframRavenwolf's private tests on data protection, an open Korean benchmark, and recommended adding German benchmarks to the EleutherAI's lm-evaluation-harness, which underpins Huggingface's open leaderboard.
- The Potential of Collaborations: jp1 indicated openness to collaboration on improving German language models, expressing the need for benchmarks that measure nuances in language output quality, and suggested that universities with the necessary resources might be able to undertake such research.
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- grok-1/model.py at main · xai-org/grok-1: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- grok-1/model.py at e50578b5f50e4c10c6e7cff31af1ef2bedb3beb8 · xai-org/grok-1: Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
- Our Paper "SuperGLEBer: German Language Understanding Evaluation Benchmark" was accepted at the NAACL 2024: In our paper, we assemble a broad Natural Language Understanding benchmark suite for the German language and consequently evaluate a wide array of existing German-capable models in order to create a b...
- Reddit - Dive into anything: no description found
- ChuckMcSneed/WolframRavenwolfs_benchmark_results · Datasets at Hugging Face: no description found
- GitHub - KLUE-benchmark/KLUE: 📖 Korean NLU Benchmark: 📖 Korean NLU Benchmark. Contribute to KLUE-benchmark/KLUE development by creating an account on GitHub.
- GitHub - facebookresearch/belebele: Repo for the Belebele dataset, a massively multilingual reading comprehension dataset.: Repo for the Belebele dataset, a massively multilingual reading comprehension dataset. - facebookresearch/belebele
- GitHub - google-research/xtreme: XTREME is a benchmark for the evaluation of the cross-lingual generalization ability of pre-trained multilingual models that covers 40 typologically diverse languages and includes nine tasks.: XTREME is a benchmark for the evaluation of the cross-lingual generalization ability of pre-trained multilingual models that covers 40 typologically diverse languages and includes nine tasks. - goo...
DiscoResearch ▷ #discolm_german (4 messages):
- DiscoResearch Models Follow the Prompt: A member indicated that the model performs optimally when it respects the system prompt, and variations might be necessary to achieve best results during demonstrations; no special settings besides fastchat/vllm are used for the demo.
- Demo Server Gets a New Home: The demo server was relocated from a personal kitchen setup to a more professional environment; however, this move led to networking issues which hopefully will be resolved by early next week.
- Kitchen Servers vs. Professional Hosting: In a light-hearted observation, a member quipped about the reliability of hobbyist servers setup in a kitchen corner versus professionally hosted servers that encounter diverse issues like networking problems and hardware failures.
Datasette - LLM (@SimonW) ▷ #ai (20 messages🔥):
- Prompt Engineering Tools from Past to Present: A member shared their experience of contributing to prompt engineering tools for Explosion's Prodigy, which turns prompt engineering into a data annotation problem. This technique was referenced as likeable, though not entirely pragmatic for all situations.
- Open-Source Tool for Prompt Experiments: Discussion included a link to PromptTools, an open-source tool for prompt testing and support for various LLMs, such as OpenAI, LLaMA, and vector databases like Chroma and Weaviate.
- Comparison Tools for Model Performance: Members discussed various platforms like Vercel and Helicone AI, which offer interfaces to compare model outputs and manage prompts, with the latter now delving into prompt management and versioning.
- Testing and Comparing Places with PromptFoo: A member brought up PromptFoo, an open-source GitHub repository that provides tools to test prompts, evaluate LLM outputs, and improve prompt quality across different models.
- Real-World Application of AI for Dynamic Blog Content: A member is experimenting with translating blog posts for different personae using gpt-3.5-turbo and musing on the potential for AI to augment reader interactions, such as by rewriting from various perspective or offering summaries, which they demonstrate on their blog.
- How to Build a Buzzword: And why they’re so powerful
- Helicone: How developers build AI applications. Get observability, tooling, fine-tuning, and evaluations out of the box.
- Vercel AI SDK: Build AI-powered applications with the latest AI language models
- GitHub - hegelai/prompttools: Open-source tools for prompt testing and experimentation, with support for both LLMs (e.g. OpenAI, LLaMA) and vector databases (e.g. Chroma, Weaviate, LanceDB).: Open-source tools for prompt testing and experimentation, with support for both LLMs (e.g. OpenAI, LLaMA) and vector databases (e.g. Chroma, Weaviate, LanceDB). - hegelai/prompttools
- GitHub - promptfoo/promptfoo: Test your prompts, models, RAGs. Evaluate and compare LLM outputs, catch regressions, and improve prompt quality. LLM evals for OpenAI/Azure GPT, Anthropic Claude, VertexAI Gemini, Ollama, Local & private models like Mistral/Mixtral/Llama with CI/CD: Test your prompts, models, RAGs. Evaluate and compare LLM outputs, catch regressions, and improve prompt quality. LLM evals for OpenAI/Azure GPT, Anthropic Claude, VertexAI Gemini, Ollama, Local &...
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
obra: Is it possible to recover the seed used by the openai models for a previous api request?
Skunkworks AI ▷ #general (17 messages🔥):
- Paper on Improved Global Accuracy Pending Release: Baptistelqt mentioned they are finalizing a paper or article that claims to improve global accuracy and sample efficiency during training, requiring structuring of results and creating better charts before release.
- Scaling Up Challenges: The method in question has not been empirically proven at scale due to resource constraints, yet there's some existing validation, and discussions are ongoing about potentially allocating compute and resources for larger model testing.
- Encouraging Preliminary Results: Baptistelqt reported that their method yielded positive results when applied to VGG16 with a subset of CIFAR100, increasing the test accuracy from 0.04 with base training to 0.1.
- Joining the Quiet-STaR Project: Satyum expressed interest in participating in the "Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking" project. After confirming proficiency in PyTorch and transformer architectures, further involvement was discussed.
- Timezone Constraints for Collaboration: There seems to be a complication in scheduling a collaborative call due to timezone differences. Baptistelqt indicated that they are unable to meet the following day as proposed for discussing the method’s implementation at scale.
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=ZlJbaYQ2hm4