[AINews] GPT4o August + 100% Structured Outputs for All (GPT4o August edition)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Pydantic/Zod is all you need.
AI News for 8/5/2024-8/6/2024. We checked 7 subreddits, 384 Twitters and 28 Discords (249 channels, and 2423 messages) for you. Estimated reading time saved (at 200wpm): 247 minutes. You can now tag @smol_ai for AINews discussions!
It's new frontier model day again! (Blog, Simonw writeup)
As we did for 4o-mini, there are 2 issues of the newsletter today run with the exact same prompts - you are reading the one with all channel summaries generated by gpt-4o-2024-08-06, the newest 4o model released today with 16k context (4x longer but still less than the alpha Long Output model) and 33-50% lower pricing than 4o-May.
We happen to run AINews with structured output via the Instructor library anyway (doing "chain of thought summaries"), so swapping it out saved us some lines of code and more importantly saved some money in retries (since OpenAI does constrained grammar sampling, you no longer spend any retry money/time on poorly formed json)

Based on our summary vibe check and prompts, the new model seems strictly better than 4o-May (example picked here, but you can see the two emails you got today for yourself):
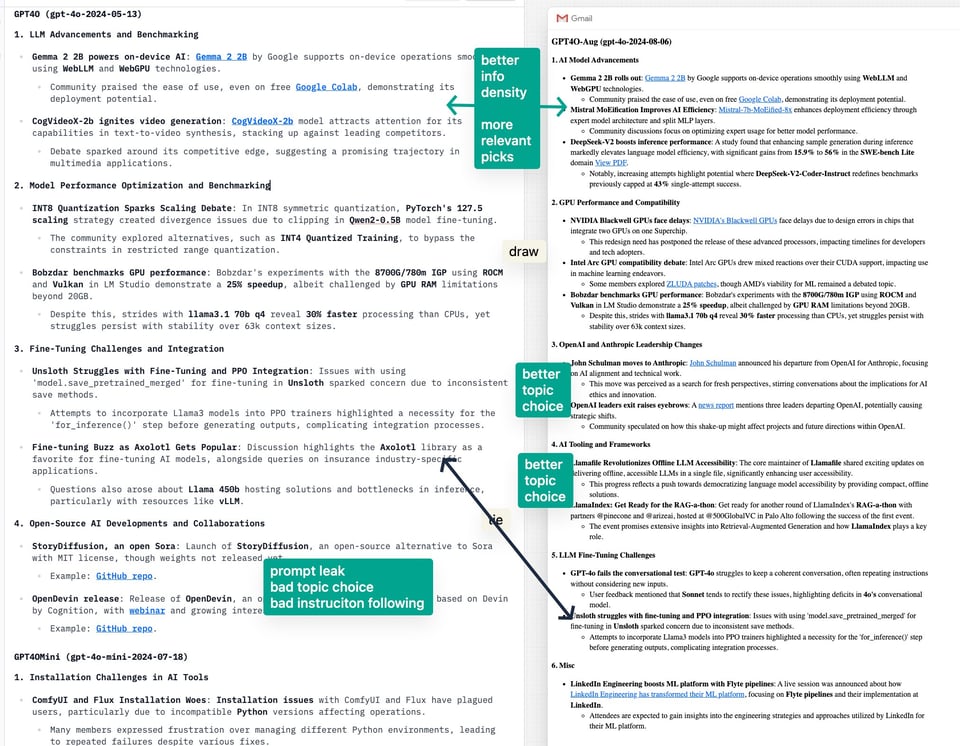
and mostly better than 4o-mini (which we last concluded was about equivalent to but way cheaper than 4o-May):
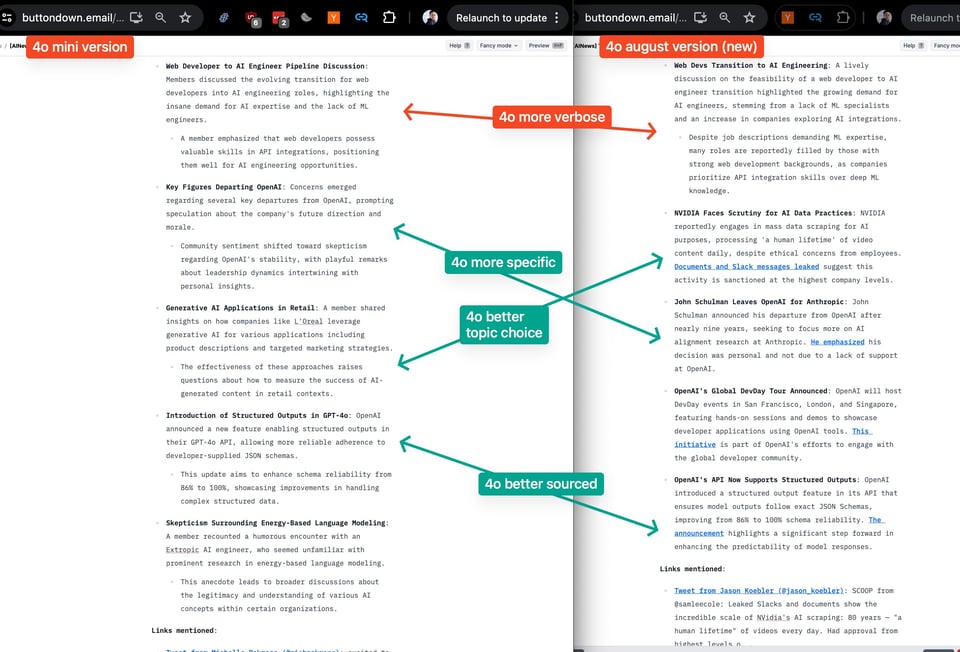
New Structured Output API aside, which applies to all models, we think the unexpected 4o model bump is a good thing - 4o August is effectively GPT 4.6 or 4.7 depending how you are counting. We don't have any publicly reported ELO or benchmark metrics on this model yet, but we are willing to bet that this one will be a sleeper hit - perhaps even a sneaky launch of Q*/Strawberry?
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Stability.ai (Stable Diffusion) Discord
- Unsloth AI (Daniel Han) Discord
- HuggingFace Discord
- LM Studio Discord
- CUDA MODE Discord
- Nous Research AI Discord
- Latent Space Discord
- OpenAI Discord
- Perplexity AI Discord
- Eleuther Discord
- LangChain AI Discord
- Interconnects (Nathan Lambert) Discord
- OpenRouter (Alex Atallah) Discord
- LlamaIndex Discord
- Cohere Discord
- Modular (Mojo 🔥) Discord
- LAION Discord
- tinygrad (George Hotz) Discord
- DSPy Discord
- OpenAccess AI Collective (axolotl) Discord
- Torchtune Discord
- OpenInterpreter Discord
- Mozilla AI Discord
- MLOps @Chipro Discord
- PART 2: Detailed by-Channel summaries and links
- Stability.ai (Stable Diffusion) ▷ #general-chat (459 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (105 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (10 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (162 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
- Unsloth AI (Daniel Han) ▷ #research (1 messages):
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (239 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #cool-finds (4 messages):
- HuggingFace ▷ #i-made-this (5 messages):
- HuggingFace ▷ #reading-group (5 messages):
- HuggingFace ▷ #computer-vision (4 messages):
- HuggingFace ▷ #NLP (2 messages):
- LM Studio ▷ #general (157 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (59 messages🔥🔥):
- CUDA MODE ▷ #general (5 messages):
- CUDA MODE ▷ #torch (17 messages🔥):
- CUDA MODE ▷ #algorithms (3 messages):
- CUDA MODE ▷ #jobs (7 messages):
- CUDA MODE ▷ #torchao (34 messages🔥):
- CUDA MODE ▷ #off-topic (7 messages):
- CUDA MODE ▷ #llmdotc (99 messages🔥🔥):
- CUDA MODE ▷ #rocm (9 messages🔥):
- CUDA MODE ▷ #cudamode-irl (2 messages):
- Nous Research AI ▷ #datasets (1 messages):
- Nous Research AI ▷ #off-topic (1 messages):
- Nous Research AI ▷ #general (129 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (19 messages🔥):
- Nous Research AI ▷ #reasoning-tasks-master-list (7 messages):
- Latent Space ▷ #ai-general-chat (128 messages🔥🔥):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (86 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (16 messages🔥):
- OpenAI ▷ #prompt-engineering (1 messages):
- OpenAI ▷ #api-discussions (1 messages):
- Perplexity AI ▷ #general (82 messages🔥🔥):
- Perplexity AI ▷ #sharing (7 messages):
- Perplexity AI ▷ #pplx-api (8 messages🔥):
- Eleuther ▷ #announcements (1 messages):
- Eleuther ▷ #general (36 messages🔥):
- Eleuther ▷ #research (40 messages🔥):
- Eleuther ▷ #scaling-laws (4 messages):
- Eleuther ▷ #interpretability-general (5 messages):
- Eleuther ▷ #lm-thunderdome (8 messages🔥):
- LangChain AI ▷ #general (83 messages🔥🔥):
- LangChain AI ▷ #share-your-work (2 messages):
- Interconnects (Nathan Lambert) ▷ #news (57 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #random (6 messages):
- Interconnects (Nathan Lambert) ▷ #memes (1 messages):
- Interconnects (Nathan Lambert) ▷ #rlhf (1 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (62 messages🔥🔥):
- LlamaIndex ▷ #announcements (1 messages):
- LlamaIndex ▷ #blog (4 messages):
- LlamaIndex ▷ #general (49 messages🔥):
- Cohere ▷ #discussions (29 messages🔥):
- Cohere ▷ #questions (3 messages):
- Cohere ▷ #cohere-toolkit (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (30 messages🔥):
- LAION ▷ #general (18 messages🔥):
- LAION ▷ #research (8 messages🔥):
- tinygrad (George Hotz) ▷ #general (8 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (16 messages🔥):
- DSPy ▷ #show-and-tell (6 messages):
- DSPy ▷ #papers (2 messages):
- DSPy ▷ #general (7 messages):
- DSPy ▷ #colbert (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (7 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
- OpenAccess AI Collective (axolotl) ▷ #announcements (1 messages):
- Torchtune ▷ #announcements (1 messages):
- Torchtune ▷ #general (9 messages🔥):
- Torchtune ▷ #dev (6 messages):
- OpenInterpreter ▷ #general (9 messages🔥):
- OpenInterpreter ▷ #O1 (2 messages):
- Mozilla AI ▷ #announcements (2 messages):
- MLOps @Chipro ▷ #events (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Updates and Benchmarks
- Llama 3.1: Meta released Llama 3.1, a 405-billion parameter large language model that surpasses GPT-4 and Claude 3.5 Sonnet on several benchmarks. The Llama Impact Grant program is expanding to support organizations worldwide in building with Llama.
- Gemini 1.5 Pro: Google DeepMind quietly released Gemini 1.5 Pro, which reportedly outperformed GPT-4o, Claude-3.5, and Llama 3.1 on LMSYS and reached #1 on the Vision Leaderboard. It excels in multi-lingual tasks and technical areas.
- Yi-Large Turbo: Introduced as a powerful, cost-effective upgrade to Yi-Large, priced at $0.19 per 1M tokens for input and output.
AI Hardware and Infrastructure
- NVIDIA H100 GPUs: John Carmack shared insights on H100 performance, noting that 100,000 H100s are more powerful than all 30 million current generation Xboxes combined for AI workloads.
- Groq LPUs: Jonathan Ross announced plans to deploy 108,000 LPUs into production by end of Q1 2025, expanding cloud and core engineering teams.
AI Development and Tools
- RAG (Retrieval-Augmented Generation): Discussions on the importance of RAG for integrating human input and enhancing AI systems' capabilities.
- JamAI Base: A new platform for building Mixture of Agents (MoA) systems without coding, leveraging Task Optimizers and Execution Engines.
- LangSmith: New filtering capabilities for traces in LangSmith, allowing more precise filtering based on JSON key-value pairs.
AI Research and Techniques
- PEER (Parameter Efficient Expert Retrieval): A new architecture from Google DeepMind using over a million small "experts" instead of large feedforward layers in transformer models.
- POA (Pre-training Once for All): A novel tri-branch self-supervised training framework enabling pre-training of models of multiple sizes simultaneously.
- Similarity-based Example Selection: Research showing significant improvements in low-resource machine translation using similarity-based in-context example selection.
AI Ethics and Societal Impact
- Data Monopoly Concerns: Discussions about the potential for data monopolies if downloading content from internet services becomes illegal, leading to vendor lock-in.
- AI Safety: Debates on the nature of AI intelligence and safety measures, with Yann LeCun arguing against some common AI risk narratives.
Practical AI Applications
- Code Generation: Observations on the effectiveness of AI for code generation, with examples of researchers using Claude for coding despite physical limitations.
- Model Selection Guide: Recommendations for choosing AI models for various tasks, including code generation, search, document analysis, and creative writing.
AI Community and Education
- AI and Games Textbook: Julian Togelius and Georgios Yannakakis released a draft of the second edition of their textbook on AI and Games, seeking community input for improvements.
- AI Education Programs: Google DeepMind celebrated the first graduates from the AI for Science Master's program at AIMS, providing scholarships and resources.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Architectural Innovations in AI Models
- Flux's Architecture diagram :)Don't think there's a paper so had a quick look through their code. Might be useful for understanding current Diffusion architectures (Score: 461, Comments: 35): Flux's architecture diagram for diffusion models provides insight into current diffusion architectures without an accompanying paper. The diagram, derived from an examination of Flux's code, offers a visual representation of the model's structure and components, potentially aiding in the understanding of contemporary diffusion model designs.
Theme 2. Advancements in Open-Source AI Models
- Why is nobody taking about InternLM 2.5 20B? (Score: 247, Comments: 98): InternLM 2.5 20B demonstrates impressive performance in benchmarks, surpassing Gemma 2 27B and approaching Llama 3.1 70B. The model achieves a remarkable 64.7 score on MATH 0 shot, close to 3.5 Sonnet's 71.1, and can potentially run on a 4090 GPU with 8-bit quantization.
-
Shower thought: What if we made V2 versions of Magnum 32b & 12b (spoiler: we did!) (Score: 54, Comments: 15): Magnum-32b v2 and Magnum-12b v2 models have been released, with improvements based on user feedback. The models are available in both GGUF and EXL2 formats on Hugging Face, and the developers are seeking further input from users to refine the models.
- Users inquired about potential Mistral-based models and discussed optimal sampler settings for the 32b V1 model in applications like Koboldcpp and Textgenui.
- The model's intended use was humorously described as "foxgirl studies," while others noted multilanguage performance issues in the v1 model, speculating on differences between 72B and 32B versions.
- Some users reported issues with the 12B v2 8bpw exl2 model, experiencing nonsense sentences and intense hallucination unaffected by prompt templates or sample settings changes.
Theme 3. Novel Applications and Capabilities of LLMs
- We’re making a game where LLM's power spell and world generation (Score: 413, Comments: 81): The developers are creating a game that utilizes Large Language Models (LLMs) for dynamic spell and world generation. This approach allows for the creation of unique spells and procedurally generated worlds based on player input, potentially offering a more personalized and immersive gaming experience. While specific details about the game's mechanics or release are not provided, the concept demonstrates an innovative application of AI in game development.
-
Gemini 1.5 Pro Experimental 0801 is strangely uncensored for a closed source model (Score: 54, Comments: 23): Google's Gemini 1.5 Pro Experimental 0801 model has demonstrated surprisingly uncensored capabilities when added to the UGI-Leaderboard. With safety settings set to "Block none" and a specific system prompt, the model was willing to provide responses to controversial and potentially illegal queries, though it was slightly less willing (W/10) than the average model on the leaderboard.
- Users reported mixed results with Gemini 1.5 Pro Experimental 0801's uncensored capabilities. Some found it denied all requests, while others successfully prompted it to answer queries about piracy, suicide methods, and drug manufacturing.
- The model demonstrated inconsistent behavior with sexual content, refusing some requests but agreeing to write pornographic stories when prompted differently. Users noted potential risks to their Google accounts when testing these capabilities.
- In the SillyTavern staging branch, Gemini 1.5 Pro Experimental 0801 showed less filtering compared to other versions. Users also found it to be more intelligent than the regular Gemini 1.5 Pro, which was described as "schizo at times".
Theme 4. Leadership Shifts in Major AI Companies
-
Will Sam "Spook" Uncle Sam in order to shut down Llama 4? (Score: 59, Comments: 31): Sam Altman's potential private demo of GPT-5 to government regulators is speculated to potentially influence restrictions on open-source AI developments, particularly Llama 4. This hypothetical scenario suggests Altman might intentionally alarm regulators to limit competition from open-source models, potentially giving his company an advantage in the evolving open LLM era.
- Meta could potentially train open-source LLMs outside the US, with Mistral offering competitive models. However, the EU AI Act has introduced significant documentation requirements, potentially hindering generative model development in Europe.
- In an unexpected turn, Zuckerberg is advocating for open-source AI protection, with the government indicating they will not restrict open-source AI. Some argue this stance benefits all non-OpenAI entities in challenging OpenAI's perceived monopoly.
- FTC head Lina Khan is reportedly pro-open weight models, potentially alleviating concerns about restrictions. The regulatory community seems to be treating AI software more like the early 90s internet than encryption, suggesting a less restrictive approach.
- OpenAI Co-Founders Schulman and Brockman Step Back. Schulman leaving for Anthropic. (Score: 317, Comments: 94): OpenAI co-founders Adam D'Angelo and Ilya Sutskever are stepping back from their roles, with Schulman leaving to join Anthropic. This development follows the recent controversy surrounding Sam Altman's brief dismissal and reinstatement as CEO, which led to significant internal changes at OpenAI. The departure of these key figures marks a notable shift in OpenAI's leadership structure and potentially its strategic direction.
- Concerns raised about OpenAI's internal issues, with speculation about problems with GPT5/strawberry/Q* development or Sam Altman's leadership style. Some users attribute the departures to different factors for each individual.
- Discussion about the coincidental names of key OpenAI figures (Schulman, Brockman, Altman), with humorous comments about AI-related surnames and comparisons to Hideo Kojima's character naming style.
- Users express mixed feelings about Anthropic, praising Claude while criticizing the company's perceived "megalomaniac complex" and censorship practices. Debate ensues about the pros and cons of having "businesspeople" versus current leadership in the AI industry.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Development
- Google DeepMind advances multimodal learning: A Google DeepMind paper demonstrates how data curation via joint example selection can accelerate multimodal learning (/r/MachineLearning).
- Microsoft's MInference speeds up long-context inference: Microsoft's MInference technique enables inference of up to millions of tokens for long-context tasks while maintaining accuracy (/r/MachineLearning).
- Scaling synthetic data creation with web-curated personas: A paper on scaling synthetic data creation leverages 1 billion personas curated from web data to generate diverse synthetic data (/r/MachineLearning).
- NVIDIA allegedly scraping massive amounts of video data: Leaked documents suggest NVIDIA is scraping "a human lifetime" of videos daily to train AI models (/r/singularity).
AI Model Releases and Improvements
- Salesforce releases xLAM-1b model: The 1 billion parameter xLAM-1b model achieves 70% accuracy in function calling, surpassing GPT-3.5 despite its smaller size (/r/LocalLLaMA).
- Phi-3 Mini updated with function calling: Rubra AI released an updated Phi-3 Mini model with function calling capabilities, competitive with Mistral-7b v3 (/r/LocalLLaMA).
AI Industry News and Developments
- Major departures from OpenAI: Three key leaders are leaving OpenAI: President Greg Brockman (extended leave), John Schulman (joining Anthropic), and product leader Peter Deng (/r/OpenAI, /r/singularity).
- Elon Musk files lawsuit against OpenAI: Musk has filed a new lawsuit against OpenAI and Sam Altman (/r/singularity).
- Anthropic founder discusses AI development: An Anthropic founder suggests that even if AI development stopped now, there would still be years to decades of improvements from existing capabilities (/r/singularity).
Neurotech and Brain-Computer Interfaces
- Elon Musk makes claims about Neuralink: Musk predicts that brain chip patients will outperform pro gamers within 1-2 years and talks about giving people "superpowers" (/r/singularity).
Memes and Humor
- A meme comparing a journalist's contrasting views on AI from 11 years apart (/r/singularity).
- A humorous image speculating about the year 2030 (/r/singularity).
AI Discord Recap
A summary of Summaries of Summaries
Claude 3 Sonnet
1. LLM Advancements and Benchmarking
- *Llama 3 Tops Leaderboards: Llama 3 from Meta has rapidly risen to the top of leaderboards like ChatbotArena, outperforming models like GPT-4-Turbo and Claude 3 Opus* in over 50,000 matchups.
- Example comparisons highlighted model performance across benchmarks like AlignBench and MT-Bench, with DeepSeek-V2 boasting 236B parameters and surpassing GPT-4 in certain areas.
- *New Open Models Advance State of the Art: Novel models like Granite-8B-Code-Instruct from IBM enhance instruction following for code tasks, while DeepSeek-V2 introduces a massive 236B parameter* model.
- Leaderboard comparisons across AlignBench and MT-Bench revealed DeepSeek-V2 outperforming GPT-4 in certain areas, sparking discussions on the evolving state of the art.
2. Model Performance Optimization and Inference
- *Quantization Techniques Reduce Model Footprint: [Quantization] techniques like AQLM and QuaRot aim to enable running large language models (LLMs*) on individual GPUs while maintaining performance.
- Example: AQLM project demonstrates running the Llama-3-70b model on an RTX3090 GPU.
- **DMC Boosts Throughput by 370% **: Efforts to boost transformer efficiency through methods like Dynamic Memory Compression (DMC) show potential for improving throughput by up to 370% on H100 GPUs.
- Example: DMC paper by
@p_nawrotexplores the DMC technique.
- Example: DMC paper by
- *Parallel Decoding with Consistency LLMs: Techniques like Consistency LLMs* explore parallel token decoding for reduced inference latency.
- The SARATHI framework also addresses inefficiencies in LLM inference by employing chunked-prefills and decode-maximal batching to improve GPU utilization.
- *CUDA Kernels Accelerate Operations: Discussions focused on optimizing CUDA operations like fusing element-wise operations, using the Thrust library's
transform* for near-bandwidth-saturating performance.- Example: Thrust documentation highlights relevant CUDA kernel functions.
3. Open-Source AI Frameworks and Community Efforts
- *Axolotl Supports Diverse Dataset Formats*: Axolotl now supports diverse dataset formats for instruction tuning and pre-training LLMs.
- The community celebrated Axolotl's increasing capabilities for open-source model development and fine-tuning.
- *LlamaIndex Integrates Andrew Ng Course: LlamaIndex* announces a new course on building agentic RAG systems with Andrew Ng's DeepLearning.ai
- The course highlights LlamaIndex's role in developing retrieval-augmented generation (RAG) systems for enterprise applications.
- *RefuelLLM-2 Optimized for 'Unsexy' Tasks: RefuelLLM-2 is open-sourced, claiming to be the best LLM for "unsexy data tasks"*.
- The community discussed RefuelLLM-2's performance and applications across diverse domains.
- *Mojo Teases Python Integration and Accelerators: Modular's deep dive* teases Mojo's potential for Python integration and AI extensions like
_bfloat16_.- Custom accelerators like PCIe cards with systolic arrays are also considered future candidates for Mojo upon its open-source release.
4. Multimodal AI and Generative Modeling Innovations
- *Idefics2 and CodeGemma Refine Capabilities: Idefics2 8B Chatty focuses on elevated chat interactions, while CodeGemma 1.1 7B* refines coding abilities.
- These new multimodal models showcase advancements in areas like conversational AI and code generation.
- *Phi3 Brings AI Chatbots to WebGPU: The Phi 3* model brings powerful AI chatbots to browsers via WebGPU.
- This advancement enables private, on-device AI interactions through the WebGPU platform.
- *IC-Light Improves Image Relighting: The open-source IC-Light* project focuses on improving image relighting techniques.
- Community members shared resources and techniques for leveraging IC-Light in tools like ComfyUI.
5. Fine-tuning Challenges and Prompt Engineering Strategies
- *Axolotl Prompting Insights: The importance of prompt design* and usage of correct templates, including end-of-text tokens, was highlighted for influencing model performance during fine-tuning and evaluation.
- Example: Axolotl prompters.py showcases prompt engineering techniques.
- *Logit Bias for Prompt Control: Strategies for prompt engineering like splitting complex tasks into multiple prompts and investigating logit bias* were discussed for more control over outputs.
- Example: OpenAI logit bias guide explains techniques.
- *
Token for Retrieval : Teaching LLMs to use the<RET>token for information retrieval* when uncertain can improve performance on infrequent queries.- Example: ArXiv paper introduces this technique.
Claude 3.5 Sonnet
1. LLM Advancements and Benchmarking
- DeepSeek-V2 Challenges GPT-4 on Benchmarks: DeepSeek-V2, a new 236B parameter model, has outperformed GPT-4 on benchmarks like AlignBench and MT-Bench, showcasing significant advancements in large language model capabilities.
- The model's performance has sparked discussions about its potential impact on the AI landscape, with community members analyzing its strengths across various tasks and domains.
- John Schulman's Strategic Move to Anthropic: John Schulman, co-founder of OpenAI, announced his departure to join Anthropic, citing a desire to focus more deeply on AI alignment and technical work.
- This move follows recent restructuring at OpenAI, including the disbandment of their superalignment team, and has sparked discussions about the future directions of AI safety research and development.
- Gemma 2 2B: Google's Compact Powerhouse: Google released Gemma 2 2B, a 2.6B parameter model designed for efficient on-device use, compatible with platforms like WebLLM and WebGPU.
- The model's release has been met with enthusiasm, particularly for its ability to run smoothly on free platforms like Google Colab, demonstrating the growing accessibility of powerful AI models.
2. Inference Optimization and Hardware Advancements
- Cublas hgemm Boosts Windows Performance: The cublas hgemm library has been made compatible with Windows, achieving up to 315 tflops on a 4090 GPU compared to 166 tflops for torch nn.Linear, significantly enhancing performance for AI tasks.
- Users reported achieving around 2.4 it/s for flux on a 4090, marking a substantial improvement in inference speed and efficiency for large language models on consumer hardware.
- Aurora Supercomputer Eyes ExaFLOP Milestone: The Aurora supercomputer at Argonne National Laboratory is expected to surpass 2 ExaFLOPS after performance optimizations, potentially becoming the fastest supercomputer globally.
- Discussions highlighted Aurora's unique Intel GPU architecture, supporting tensor core instructions that output 16x8 matrices, sparking interest in its potential for AI and scientific computing applications.
- ZeRO++ Slashes GPU Communication Overhead: ZeRO++, a new optimization technique, promises to reduce communication overhead by 4x for large model training on GPUs, significantly improving training efficiency.
- This advancement is particularly relevant for distributed AI training setups, potentially enabling faster and more cost-effective training of massive language models.
3. Open Source AI and Community Collaborations
- SB1047 Sparks Open Source AI Debate: An open letter opposing SB1047, the AI Safety Act, is circulating, warning that it could negatively impact open-source research and innovation by potentially banning open models and threatening academic freedom.
- The community is divided, with some supporting regulation for AI safety, while others, including companies like Anthropic, caution against stifling innovation and suggest the bill may have unintended negative consequences on academic and economic fronts.
- Wiseflow: Open-Source Data Mining Tool: Wiseflow, an open-source information mining tool, was introduced to efficiently extract and categorize data from various online sources, including websites and social platforms.
- The tool has sparked interest in the AI community, with suggestions to integrate it with other open-source projects like Golden Ret to create dynamic knowledge bases for AI applications.
- AgentGenesis Boosts AI Development: AgentGenesis, an open-source AI component library, was launched to provide developers with copy-paste code snippets for Gen AI applications, promising a 10x boost in development efficiency.
- The project, available under an MIT license, features a comprehensive code library with templates for RAG flows and QnA bots, and is actively seeking contributors to enhance its capabilities.
4. Multimodal AI and Creative Applications
- CogVideoX-2b: A New Frontier in Video Synthesis: The release of CogVideoX-2b, a new text-to-video synthesis model, has attracted attention for its capabilities in generating video content from textual descriptions.
- Initial reviews suggest that CogVideoX-2b is competitive with leading models in the field, sparking discussions about its potential applications and impact on multimedia content creation.
- Flux AI Challenges Image Generation Giants: Flux AI's 'Schnell' model is reportedly outperforming Midjourney 6 in image generation coherence, showcasing significant advancements in AI-generated visual content.
- Users have praised the model for its ability to generate highly realistic and detailed images, despite occasional minor typos, indicating a leap forward in the quality of AI-generated visual media.
- MiniCPM-Llama3 Advances Multimodal Interaction: MiniCPM-Llama3 2.5 now supports multi-image input and demonstrates significant promise in tasks such as OCR and document understanding, offering robust capabilities for multimodal interaction.
- The model's advancements highlight the growing trend towards more versatile AI systems capable of processing and understanding multiple types of input, including text and images, simultaneously.
GPT4O (gpt-4o-2024-05-13)
1. LLM Advancements and Benchmarking
- Gemma 2 2B powers on-device AI: Gemma 2 2B by Google supports on-device operations smoothly using WebLLM and WebGPU technologies.
- Community praised the ease of use, even on free Google Colab, demonstrating its deployment potential.
- CogVideoX-2b ignites video generation: CogVideoX-2b model attracts attention for its capabilities in text-to-video synthesis, stacking up against leading competitors.
- Debate sparked around its competitive edge, suggesting a promising trajectory in multimedia applications.
2. Model Performance Optimization and Benchmarking
- INT8 Quantization Sparks Scaling Debate: In INT8 symmetric quantization, PyTorch's 127.5 scaling strategy created divergence issues due to clipping in Qwen2-0.5B model fine-tuning.
- The community explored alternatives, such as INT4 Quantized Training, to bypass the constraints in restricted range quantization.
- Bobzdar benchmarks GPU performance: Bobzdar's experiments with the 8700G/780m IGP using ROCM and Vulkan in LM Studio demonstrate a 25% speedup, albeit challenged by GPU RAM limitations beyond 20GB.
- Despite this, strides with llama3.1 70b q4 reveal 30% faster processing than CPUs, yet struggles persist with stability over 63k context sizes.
3. Fine-Tuning Challenges and Integration
- Unsloth Struggles with Fine-Tuning and PPO Integration: Issues with using 'model.save_pretrained_merged' for fine-tuning in Unsloth sparked concern due to inconsistent save methods.
- Attempts to incorporate Llama3 models into PPO trainers highlighted a necessity for the 'for_inference()' step before generating outputs, complicating integration processes.
- Fine-tuning Buzz as Axolotl Gets Popular: Discussion highlights the Axolotl library as a favorite for fine-tuning AI models, alongside queries on insurance industry-specific applications.
- Questions also arose about Llama 450b hosting solutions and bottlenecks in inference, particularly with resources like vLLM.
4. Open-Source AI Developments and Collaborations
- StoryDiffusion, an open Sora: Launch of StoryDiffusion, an open-source alternative to Sora with MIT license, though weights not released yet.
- Example: GitHub repo.
- OpenDevin release: Release of OpenDevin, an open-source autonomous AI engineer based on Devin by Cognition, with webinar and growing interest on GitHub.
- Example: GitHub repo.
GPT4OMini (gpt-4o-mini-2024-07-18)
1. Installation Challenges in AI Tools
- ComfyUI and Flux Installation Woes: Installation issues with ComfyUI and Flux have plagued users, particularly due to incompatible Python versions affecting operations.
- Many members expressed frustration over managing different Python environments, leading to repeated failures despite various fixes.
- Local LLM Setup Problems: Setting up local LLMs with Open Interpreter resulted in unnecessary downloads, causing openai.APIConnectionError during model selection.
- Users are coordinating privately to troubleshoot this issue, highlighting the complexities of local model setup.
2. Model Performance and Optimization Discussions
- Mistral-7b-MoEified-8x Model Efficiency: The Mistral-7b-MoEified-8x model optimizes expert usage by dividing MLP layers into splits, improving deployment efficiency.
- Community discussions focus on leveraging this model architecture for enhanced performance in specific applications.
- Performance Challenges with Llama3 Models: Users reported inconsistent inference times with fine-tuned Llama3.1, ranging from milliseconds to over a minute based on loading requirements.
- These variations highlight the need for better integration practices when deploying Llama3 models in production.
3. AI Ethics and Data Practices
- NVIDIA's Data Scraping Controversy: NVIDIA faces backlash for allegedly scraping vast amounts of video data daily for AI training, raising ethical concerns among employees.
- Leaked documents confirm management's approval of these practices, sparking significant unrest within the company.
- Opposition to AI Safety Regulation SB1047: An open letter against California's SB1047 highlights fears that it could stifle open-source research and innovation in AI.
- Members discussed the potential negative impacts of the bill, with a call for signatures supporting the opposition.
4. Emerging AI Projects and Collaborations
- Launch of Open Medical Reasoning Tasks: The Open Medical Reasoning Tasks project aims to unite AI and medical communities for comprehensive reasoning tasks.
- This initiative seeks contributions to advance AI applications in healthcare, reflecting a growing intersection of these fields.
- Gemma 2 2B Capabilities: Google's Gemma 2 2B model supports on-device operations, demonstrating impressive deployment potential.
- Community feedback highlights its ease of use, especially in environments like Google Colab.
5. Advancements in AI Frameworks and Libraries
- New Features in Mojo's InlineList: Mojo is introducing new methods in InlineList, such as
__moveinit__and__copyinit__, aimed at enhancing its feature set.- These advancements signal Mojo's commitment to improving its data structure capabilities for future development.
- Bits and Bytes Foundation Updates: The latest Bits and Bytes pull request has sparked interest among library development enthusiasts.
- This development is seen as crucial for the library's evolution, with the community closely monitoring its progress.
GPT4O-Aug (gpt-4o-2024-08-06)
1. AI Model Advancements
- Gemma 2 2B rolls out: Gemma 2 2B by Google supports on-device operations smoothly using WebLLM and WebGPU technologies.
- Community praised the ease of use, even on free Google Colab, demonstrating its deployment potential.
- Mistral MoEification Improves AI Efficiency: Mistral-7b-MoEified-8x enhances deployment efficiency through expert model architecture and split MLP layers.
- Community discussions focus on optimizing expert usage for better model performance.
- DeepSeek-V2 boosts inference performance: A study found that enhancing sample generation during inference markedly elevates language model efficiency, with significant gains from 15.9% to 56% in the SWE-bench Lite domain View PDF.
- Notably, increasing attempts highlight potential where DeepSeek-V2-Coder-Instruct redefines benchmarks previously capped at 43% single-attempt success.
2. GPU Performance and Compatibility
- NVIDIA Blackwell GPUs face delays: NVIDIA's Blackwell GPUs face delays due to design errors in chips that integrate two GPUs on one Superchip.
- This redesign need has postponed the release of these advanced processors, impacting timelines for developers and tech adopters.
- Intel Arc GPU compatibility debate: Intel Arc GPUs drew mixed reactions over their CUDA support, impacting use in machine learning endeavors.
- Some members explored ZLUDA patches, though AMD's viability for ML remained a debated topic.
- Bobzdar benchmarks GPU performance: Bobzdar's experiments with the 8700G/780m IGP using ROCM and Vulkan in LM Studio demonstrate a 25% speedup, albeit challenged by GPU RAM limitations beyond 20GB.
- Despite this, strides with llama3.1 70b q4 reveal 30% faster processing than CPUs, yet struggles persist with stability over 63k context sizes.
3. OpenAI and Anthropic Leadership Changes
- John Schulman moves to Anthropic: John Schulman announced his departure from OpenAI for Anthropic, focusing on AI alignment and technical work.
- This move was perceived as a search for fresh perspectives, stirring conversations about the implications for AI ethics and innovation.
- OpenAI leaders exit raises eyebrows: A news report mentions three leaders departing OpenAI, potentially causing strategic shifts.
- Community speculated on how this shake-up might affect projects and future directions within OpenAI.
4. AI Tooling and Frameworks
- Llamafile Revolutionizes Offline LLM Accessibility: The core maintainer of Llamafile shared exciting updates on delivering offline, accessible LLMs in a single file, significantly enhancing user accessibility.
- This progress reflects a push towards democratizing language model accessibility by providing compact, offline solutions.
- LlamaIndex: Get Ready for the RAG-a-thon: Get ready for another round of LlamaIndex's RAG-a-thon with partners @pinecone and @arizeai, hosted at @500GlobalVC in Palo Alto following the success of the first event.
- The event promises extensive insights into Retrieval-Augmented Generation and how LlamaIndex plays a key role.
5. LLM Fine-Tuning Challenges
- GPT-4o fails the conversational test: GPT-4o struggles to keep a coherent conversation, often repeating instructions without considering new inputs.
- User feedback mentioned that Sonnet tends to rectify these issues, highlighting deficits in 4o's conversational model.
- Unsloth struggles with fine-tuning and PPO integration: Issues with using 'model.save_pretrained_merged' for fine-tuning in Unsloth sparked concern due to inconsistent save methods.
- Attempts to incorporate Llama3 models into PPO trainers highlighted a necessity for the 'for_inference()' step before generating outputs, complicating integration processes.
6. Misc
- LinkedIn Engineering boosts ML platform with Flyte pipelines: A live session was announced about how LinkedIn Engineering has transformed their ML platform, focusing on Flyte pipelines and their implementation at LinkedIn.
- Attendees are expected to gain insights into the engineering strategies and approaches utilized by LinkedIn for their ML platform.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- Installation Struggles Plague Users: Installing and configuring ComfyUI and Flux proved problematic due to incompatible Python versions with SD operations.
- Members vented their frustrations about managing disparate Python environments, emphasizing the repeated failures experienced despite various fixes.
- ControlNet's Creativity with Style: Using ControlNet, users shared methods to transform photos into line art, comparing techniques involving DreamShaper and pony models.
- Focus was on leveraging Lora models alongside specific base models to achieve targeted artistic outputs.
- Inpainting with Auto1111 Sparks Interest: The Auto1111 tool was explored for refined inpainting tasks, like inserting a specific poster into an image.
- Inpainting and ControlNet emerged as preferred alternatives over manual tools such as Photoshop for detail management.
- Intel Arc GPU Compatibility Debate: Intel Arc GPUs drew mixed reactions over their CUDA support, impacting use in machine learning endeavors.
- Some members explored ZLUDA patches, though AMD's viability for ML remained a debated topic.
- Reminiscing Community Spats: Historical clashes between moderation teams on different SD forums were recounted, highlighting past Discord and Reddit dynamics.
- These disputes reveal the complexities of moderating open-source AI communities, reflecting on past as pertinent to present user dynamics.
Unsloth AI (Daniel Han) Discord
- MoEification in Mistral-7b Improves Efficiency: Mistral-7b-MoEified-8x embraces the division of MLP layers into multiple splits with specific projections to enhance the efficiency of deploying expert models.
- The community focuses on optimizing expert usage by leveraging these split model architectures to achieve better performance.
- Unsloth Struggles with Fine-Tuning and PPO Integration: Issues with using 'model.save_pretrained_merged' for fine-tuning in Unsloth sparked concern due to inconsistent save methods.
- Attempts to incorporate Llama3 models into PPO trainers highlighted a necessity for the 'for_inference()' step before generating outputs, complicating integration processes.
- BigLlama Model Merge Creates Challenges: The BigLlama-3.1-1T-Instruct model's creation through Meta-Llama with Mergekit has proven problematic as the merged weights need training.
- Although the community is enthusiastic, many see it as 'useless' until properly trained and calibrated.
- Llama-3-8b-bnb Merging Tactics Clarified: Users resolved merging challenges for Llama-3-8b-bnb using LoRA adapters by specifying 16-bit configurations before gguf quantization.
- This process involved following precise merging instructions to ensure seamless integration and performance.
- RunPod Configurations for LLaMA3 Explored: Cost-effective strategies for running the LLaMA3 model on RunPod were discussed due to high operational expenses.
- Community members are exploring configurations that minimize costs while maintaining model performance efficiency.
HuggingFace Discord
- Gemma 2 2B rolls out: Gemma 2 2B by Google supports on-device operations smoothly using WebLLM and WebGPU technologies.
- Community praised the ease of use, even on free Google Colab, demonstrating its deployment potential.
- CogVideoX-2b ignites video generation: CogVideoX-2b model attracts attention for its capabilities in text-to-video synthesis, stacking up against leading competitors.
- Debate sparked around its competitive edge, suggesting a promising trajectory in multimedia applications.
- Structured outputs gain traction: OpenAI Blog posits structured outputs as industry-standard, stirring discussions on legacy contributions.
- The release triggered reflections on past works, hinting at the evolving landscape of standardization in machine learning outputs.
- Depth estimation reimagined: CVPR 2022 paper introduces a technique combining stereo and structured-light for depth estimation, capturing the community’s interest.
- Significant interest was shown in the practical implementation of these findings, indicating a drive towards actionable insights in computer vision.
- AniTalker revolutionizes animated conversations: The AniTalker project enhances facial motion depiction in animated interlocutors based on X-LANCE, offering nuanced identity separation.
- Trials showcased its practical prowess in real-time conversational simulations, suggesting broader applications in interactive media.
LM Studio Discord
- LMStudio gears up for RAG setup feature: RAG setup with LMStudio is generating buzz as it's expected to debut in the 0.3.0 release, prompting users to explore AnythingLLM as a temporary fix, though some face file access hurdles.
- Discussions underscore interest in Meta's LLaMA integration, with some highlighting initial setup challenges that might be simplified in future updates.
- GPU Evangelists debate future performance gains: NVIDIA 4090's worthiness as an upgrade stirs debate, with some users questioning its performance over the 3080, considering alternatives like dual setups or switching to other platforms.
- Speculation heats about the upcoming RTX 5090's improvements, with VRAM expectations mirroring the 4090's 24GB, yet hopeful for better efficiency and computing power.
- Strategizing GPU upgrades amidst market turbulence: The graphics card market faces upheaval as P40 cards skyrocket in price on eBay in 2024, and the scarcity of 3090s piques interest in rumored AMD 48GB VRAM cards.
- Community members highlight necessities for VRAM scalability and compatibility checks with power supplies when contemplating upgrades, proposing cost-effective solutions like coupling a 2060 Super with a 3060.
- K-V Cache curio in quantization contexts: A looped discourse on K-V cache settings and their role in model quantization has sparked curiosity in optimizing Flash Attention techniques.
- Conversations include sharing guides and resources to improve attention mechanisms, hinting at a drive for maximizing computational throughput.
- Insightful Bobzdar benchmarks GPU performance: Bobzdar's experiments with the 8700G/780m IGP using ROCM and Vulkan in LM Studio demonstrate a 25% speedup, albeit challenged by GPU RAM limitations beyond 20GB.
- Despite this, strides with llama3.1 70b q4 reveal 30% faster processing than CPUs, yet struggles persist with stability over 63k context sizes.
CUDA MODE Discord
- Hermes Enigma: PyTorch 2.4 vs CUDA 12.4: Users experienced build-breaking issues when running PyTorch 2.4 with CUDA 12.4, while successfully navigating with CUDA 12.1.
- Further insight shared included CUDA 12.6 installed via conda, indicating complex version dependencies.
- cublas hgemm Hits Windows High: The cublas hgemm library now runs on Windows, enhancing performance up to 315 tflops on a 4090 GPU, compared to 166 tflops with nn.Linear.
- Users reported achieving around 2.4 it/s for flux, marking a milestone in performance progression.
- INT8 Quantization Sparks Scaling Debate: In INT8 symmetric quantization, PyTorch's 127.5 scaling strategy created divergence issues due to clipping in Qwen2-0.5B model fine-tuning.
- The community explored alternatives, such as INT4 Quantized Training, to bypass the constraints in restricted range quantization.
- ZHULDA 3 Vanishes Under AMD's Claim: The ZHUDA 3 project was pulled from GitHub after AMD countered previously granted development permissions.
- Community perplexity arose over employment contract terms allowing for a release if deemed unfit by AMD, highlighting blurry contractual obligations.
- Hudson River Trading's Lucrative GPU Calls: Hudson River Trading is on the hunt for experts adept in GPU optimization, emphasizing CUDA kernel creation and PyTorch enhancement.
- The firm offers internship roles and competitive salaries reaching up to $798K/year, demonstrating significant financial appeal in high-frequency trading.
Nous Research AI Discord
- Nvidia Steers into Conversational AI: Nvidia launched the UltraSteer-V0 dataset with 2.3M conversations labeled over 22 days with nine fine-grained signals.
- Data is processed using Nvidia's Llama2-13B-SteerLM-RM reward model, evaluating attributes from Quality to Creativity.
- OpenAI Leaders Exit Raises Eyebrows: A news report mentions three leaders departing OpenAI, potentially causing strategic shifts.
- Community speculated on how this shake-up might affect projects and future directions within OpenAI.
- Flux AI Outpaces Competition with Images: Flux AI's 'Schnell' competes with Midjourney 6, exceeding in image generation coherence, showcasing advanced model capabilities.
- Images generated by 'Schnell' exhibit high levels of realism, despite minor typos, indicating significant strides over competitors.
- Medical Community Joins AI with New Initiatives: The Open Medical Reasoning Tasks project launches to unite medical and AI communities for comprehensive reasoning tasks.
- This initiative taps into AI healthcare advancements, building extensive medical reasoning tasks and gaining traction in related research.
- Fine-tuning Buzz as Axolotl Gets Popular: Discussion highlights the Axolotl library as a favorite for fine-tuning AI models, alongside queries on insurance industry-specific applications.
- Questions also arose about Llama 450b hosting solutions and bottlenecks in inference, particularly with resources like vLLM.
Latent Space Discord
- Web Devs Seamlessly Transition to AI: A convivial debate surfaced on the practicality of transitioning from web development to AI engineering, driven by a shortage of ML experts and growing business ventures into AI applications.
- Although job postings often highlight ML credentials, they're frequently filled by individuals with robust web development experience as companies highly value API integration abilities.
- NVIDIA Under Fire for AI Data Collection: NVIDIA stands accused of large-scale data scraping for AI initiatives, treating 'a human lifetime' of video material daily, with approval from top-level management. Documents and Slack messages surfaced confirming this operation.
- The scant regard for ethical considerations by NVIDIA sparked significant employee unrest, raising questions about corporate responsibility.
- John Schulman Switches from OpenAI to Anthropic: John Schulman declared his exit from OpenAI to intensify his focus on AI alignment research at Anthropic after a nine-year tenure.
- He clarified his decision wasn't due to OpenAI's lack of support but a personal ambition to deepen research endeavors.
- OpenAI Engages Global Audience Through DevDay: OpenAI unveiled a series of DevDay events in San Francisco, London, and Singapore, aiming to highlight developer implementations with OpenAI's tools through workshops and demonstrations.
- The Roadshow represents OpenAI's strategy to connect globally with developers, reinforcing its role within the community.
- Boost in Reliability for OpenAI's API: OpenAI implemented a structured output feature in its API, ensuring model responses adhere strictly to JSON Schemas, thus elevating schema precision from 86% to 100%.
- The recent update marks a leap forward in achieving consistency and predictability within model outputs.
OpenAI Discord
- OpenAI DevDay Goes Global: OpenAI announced DevDay will travel to cities like San Francisco, London, and Singapore, offering developers hands-on sessions and demos this fall.
- Developers are encouraged to meet OpenAI engineers to learn and exchange ideas in the AI development space.
- Desktop ChatGPT App & Search GPT Release: Members discussed the release dates for the desktop ChatGPT app on Windows and the public release of Search GPT, based on info from Sam Altman.
- Search GPT has been officially distributed, confirming inquiries about its availability.
- Harnessing Structured Outputs: OpenAI introduced Structured Outputs, creating consistent JSON responses aligned with provided schemas, enhancing API interactions.
- The Python and Node SDKs offer native support, promising consistent outputs and reduced costs for users.
- AI Reshapes Gaming World: A member envisaged AI elevating games like BG3 by enabling unique character designs and dynamic NPC interactions.
- The use of generative AI in gaming is expected to enhance player immersion and revolutionize traditional gaming experiences.
- Bing AI Creator Uses DALL-E 3: Bing AI Image Creator employs DALL-E 3 technology, aligning with recent updates.
- Despite improvements, users noted inconsistencies in output quality and expressed dissatisfaction.
Perplexity AI Discord
- GPT-4o fails the conversational test: GPT-4o struggles to keep a coherent conversation, often repeating instructions without considering new inputs.
- User feedback mentioned that Sonnet tends to rectify these issues, highlighting deficits in 4o's conversational model.
- Sorting AI targets content chaos: An innovative content sorting and recommendation engine project is underway at a university, aimed at improving database content prioritization.
- Peers suggested using platforms like RAG and local models to enhance the project's impact and sophistication.
- NVIDIA's GPU glitch: NVIDIA's Blackwell GPUs face delays due to design errors in chips that integrate two GPUs on one Superchip.
- This redesign need has postponed the release of these advanced processors, impacting timelines for developers and tech adopters.
- API glitches undermine user confidence: API results have been unexpectedly corrupted, delivering gibberish content beyond initial lines when composing articles.
- Documentation confirms API model deprecation is scheduled for August 2024, including the llama-3-sonar-small-32k models.
Eleuther Discord
- Meta masters distributed AI training with massive network: At ACM SIGCOMM 2024, Meta revealed their expansive AI network linking thousands of GPUs, vital for training models like LLAMA 3.1 405B.
- Their study on RDMA over Ethernet for Distributed AI Training highlights the architecture supporting one of the planet's most extensive AI networks.
- SB1047 stirs AI community with pros and cons: An open letter opposing SB1047, the AI Safety Act, is gaining signatures, warning it could stifle open-source research and innovation (Google Form).
- Anthropic acknowledges regulation necessity, yet suggests the bill may curb innovation with potential negative academic and economic impacts.
- Mechanistic anomaly detection: promising but inconsistent: Eleuther AI evaluated mechanistic anomaly detection methods, finding they sometimes fell short of traditional techniques, detailed in a blog post.
- Performance improved on full data batches; however, not all tasks saw gains, underscoring research areas needing refinement.
- Scaling SAEs: recent explorations and resources: Eleuther AI discussed Structural Attention Equations (SAEs) with links to foundational and modern works like the Monosemantic Features paper.
- Efforts are underway to scale SAEs from toy models to 13B parameters, with significant collaboration across Anthropic and OpenAI indicated in scaling papers.
- lm-eval-harness adapts to custom models easily: Eleuther AI encouraged using lm-eval-harness for custom architectures, providing a guide link in a GitHub example.
- Discussions addressed batch processing nuance and confirmed BOS token default inclusion, highlighting eval-harness adaptability in testing contexts.
LangChain AI Discord
- GPU Overflows: Running Models on CPU: Users faced memory overflow issues when attempting to run large models on GPUs with limited 8GB vRAM, leading to a workaround by utilizing the CPU entirely, albeit with slower performance.
- A discussion emerged about best practices for handling insufficient GPU memory, highlighting the trade-offs between speed and capability.
- LangChain Integration Puzzles: Queries arose regarding incorporating RunnableWithMessageHistory in LangChain v2.0 for chatbot development due to lack of documentation.
- Suggestions to explore storing message history through available tutorials were recommended, hinting at common obstacles faced by developers.
- Groans Over Automatic Code Review Foibles: Issues surfaced with GPT-4o failing to assess positions within GitHub diffs correctly, prompting users to pursue alternative data processing methods.
- The advice to avoid vision models in favor of coding-specific approaches underscored the challenges of applying AI to code review.
- AgentGenesis Invites Open Source Collaboration: The AgentGenesis project, offering a library of AI code snippets, seeks contributors to enhance its development, highlighting its open-source MIT license.
- Active community collaboration and contributions via their GitHub repository are encouraged to build a robust library of reusable code.
- Mood2Music App Hits the Right Note: The Mood2Music app promises to curate music recommendations based on users' moods, integrating seamlessly with Spotify and Apple Music.
- This innovative app aims to elevate the user's experience by automating playlist creation through mood detection, featuring unique AI selfie analysis.
Interconnects (Nathan Lambert) Discord
- John Schulman surprises with move to Anthropic: John Schulman announced his departure from OpenAI for Anthropic, focusing on AI alignment and technical work.
- This move was perceived as a search for fresh perspectives, stirring conversations about the implications for AI ethics and innovation.
- Leaked whispers around Gemini program intrigue members: The community speculated on leaked information regarding OpenAI's Gemini program, marveling at the mysterious developments around Gemini 2.
- This intrigue raised questions about potential advancements and strategic direction within OpenAI.
- Flux Pro offers a novel vibe in AI models: Flux Pro was described as offering a noticeably different user experience compared to its competitors.
- Discussions focused on how its unique approach might not be rooted in benchmarks but rather subjective user satisfaction.
- Data-dependency impacts model benefits: Chats emphasized that model performance benefits from decomposing data into components like \( (x, y_w) \) and \( (x, y_l) \) depending largely on data noise levels.
- Startups often opt for noisy data strategies to bypass standard supervised fine-tuning, as noted in an ICML discussion mentioning Meta's Chameleon approach.
- Claude lags behind ChatGPT in user experience: Members compared Claude unfavorably to ChatGPT, indicating it lags akin to older GPT-3.5 models while ChatGPT was praised for flexibility and memory performance.
- This sparked conversations about advancements and user expectations for next-generation AI tools.
OpenRouter (Alex Atallah) Discord
- GPT4-4o Launches with Structured Output Capabilities: The new model GPT4-4o-2024-08-06 has been released on OpenRouter with enhanced structured output capabilities.
- This update includes the ability to provide a JSON schema in the response format, encouraging users to report issues with strict mode in designated channels.
- AI Models Performance Drama: yi-vision and firellava models failed to perform under test conditions compared to haiku/flash/4o, highlighting ongoing price and efficiency challenges.
- Discussions hinted at imminent price reductions for Google Gemini 1.5, positioning it as a more cost-effective alternative.
- Budget-Friendly GPT-4o Advances in Token Management: Developers now save 50% on inputs and 33% on outputs by adopting the more cost-effective gpt-4o-2024-08-06.
- Community dialogues suggest efficiency and strategic planning as key factors in this model's reduced costs.
- Calculating OpenRouter API Costs: A detailed discussion on OpenRouter API cost calculation emphasized using the
generationendpoint after requests for accurate expenditure tracking.- This method allows users to manage funds in pay-as-you-go schemes effectively without embedded cost details in streaming responses.
- Google Gemini Throttling Issues: Users of Google Gemini Pro 1.5 faced
RESOURCE_EXHAUSTEDerrors due to heavy rate limiting.- Adjustments in usage expectations are necessary, with no immediate solution to these rate limit constraints.
LlamaIndex Discord
- LlamaIndex: Get Ready for the RAG-a-thon: Get ready for another round of LlamaIndex's RAG-a-thon with partners @pinecone and @arizeai, hosted at @500GlobalVC in Palo Alto following the success of the first event.
- The event promises extensive insights into Retrieval-Augmented Generation and how LlamaIndex plays a key role.
- Webinar on RAG-Augmented Coding Assistants: Webinar with CodiumAI invites participants to explore RAG-augmented coding assistants, showcasing how LlamaIndex can enhance AI-generated code quality.
- Participants must register and verify token ownership; the session will present practical applications for maintaining contextual code integrity.
- RabbitMQ Bridges the Agent Gap: A blog by @pavan_mantha1 explores using RabbitMQ for effective communication between agents in a multi-agent system.
- This innovative setup integrates tools like @ollama and @qdrant_engine to streamline operations within LlamaIndex.
- Function Calling Glitch Crashes CI: LlamaIndex's
function_calling.pygenerated a TypeError that obstructed CI processes, resolved by upgrading specific dependencies.- Old package requirements presented issues, urging the team to tighten specification of dependencies to avoid such glitches in the future.
- Vector Databases Under the Microscope: A Vector DB Comparison was shared for assessing different vector databases' capabilities.
- The community was encouraged to share insights from experiences with various VectorDBs to educate and enhance knowledge-sharing.
Cohere Discord
- Galileo Hallucination Index Ignites Source Debate: Galileo's Hallucination Index prompted discussions about the open-source classification of LLMs, highlighting ambiguities in categorizing models like Command R Plus.
- Users contended over the distinction between open weights versus fully open-source, advocating for clearer criteria, potentially establishing a separate category.
- Licensing Controversy Sizzles with Command R Plus: Galileo clarified their definition of open-source to encompass models supporting commercial use, citing the Creative Commons license of Command R Plus as a limitation.
- Members discussed the creation of a new category for 'open weights', suggesting that distinct licensing classifications should replace the broad open-source tag.
- Mistral's Open Weights Under Apache 2.0: Mistral's models were distinguished for their permissive Apache 2.0 license, offering greater liberties than typically available to open weights.
- Discussion included sharing Mistral's documentation, underscoring their initiative in transparency with pre-trained and instruction-tuned models.
- Cohere Toolkit for RAG Projects: A member utilized Cohere Toolkit for an AI fellowship project, illustrating its application in developing an LLM with RAG across various domain-specific databases.
- The toolkit's integration was poised to explore content from platforms like Confluence, enhancing its utility in diverse professional contexts.
- Exploring Feasibility of Third-party API Integration: Discussion on switching from Cohere models to third-party APIs like OpenAI's Chat GPT and Gemini 1.5 was underway.
- The potential for using these external APIs evidently promised to broaden the scope and adaptability of existing projects.
Modular (Mojo 🔥) Discord
- InlineList Strides With Exciting Features: The development of InlineList in Mojo is advancing with the introduction of
__moveinit__and__copyinit__methods as per the recent GitHub pull request, aiming to enhance feature sets.- These new methods seem to be driven by technological priorities, hinting at future capabilities in
InlineListenhancements.
- These new methods seem to be driven by technological priorities, hinting at future capabilities in
- Mojo Optimizes Lists with Small Buffer Tactics: Small buffer optimization for
Listin Mojo introduces flexibility by allowing stack space allocation with parameters likeList[SomeType, 16], which is detailed in Gabriel De Marmiesse's PR.- This improvement might eventually eliminate the need for a separate
InlineListtype, streamlining the existing architecture.
- This improvement might eventually eliminate the need for a separate
- New Prospects for Mojo with Custom Accelerators: Custom accelerators such as PCIe cards with systolic arrays are set to be potential contenders for Mojo upon its open-source release, showcasing new hardware integration possibilities.
- Despite the enthusiasm, it currently remains challenging to use Mojo for custom kernel replacements, as existing flows like lowering PyTorch IR dominate until RISC-V target supports are available.
LAION Discord
- OpenAI Leadership Shakeup Brings John Schulman to Anthropic: John Schulman, co-founder of OpenAI, is leaving to join Anthropic, spurred by recent restructuring within OpenAI.
- This leadership move follows only three months after dismantling OpenAI's superalignment team, hinting at internal strategic shifts.
- Open-Source Model Training Faces High-Cost Roadblocks: The open-source community acknowledged expensive model training constraining the development of state-of-the-art models.
- Cheaper training could lead to a boom in open models, leaving aside the ethical challenges of data sourcing.
- Meta's JASCO Project Stymied by Legal Woes: Meta's under-the-radar JASCO project faces delays, possibly due to lawsuits with Udio & Suno.
- Concern mounts as these legal entanglements could slow technology advancements in proprietary AI.
- Validation Accuracy Hits 84%, Brings Believers: Model hits 84% validation accuracy, a notable milestone celebrated with allusions to The Matrix.
- Enthusiasm rounds as this breakthrough echoes familiar phrases like 'He's beginning to believe.'
- CIFAR's Frequency Retains, Phase Inquires: Inquiries were made on CIFAR images' frequency constancy versus potential phase shifts in Fourier analysis.
- The curiosity sparks conversations about whether image frequency stays steady while phase dynamics change.
tinygrad (George Hotz) Discord
- Tinygrad's Aurora Ambitions: Members pondered the feasibility of running tinygrad on Aurora, a cutting-edge supercomputer with Intel GPU support, sparking discussions in general.
- Insights revealed that Aurora's GPUs could leverage unique tensor core instructions, with 16x8 matrix output, potentially exceeding 2 ExaFLOPS post-optimization.
- Precision Perils in FP8 Nvidia Bounty: Inquiries about the FP8 Nvidia bounty arose, focusing on whether it necessitates E4M3, E5M2, or both standards for precision.
- The bounty reflects Nvidia's emphasis on diverse precision requirements, challenging developers to optimize across different modes.
- Tackling Tensor Slice Bugs in Tinygrad: A bug causing
AssertionErrorin Tensor slicing in Tinygrad was fixed, ensuring slices maintain contiguity, as confirmed by George Hotz.- The resolution provided clarity on Buffer to DEFINE_GLOBAL transition, a nagging issue within Tinygrad's computational operations.
- JIT Battles with Batch Sizes: Inconsistent batch sizes in datasets led to JIT errors, with suggestions including skipping or handling the last batch separately to prevent errors.
- George Hotz recommended ensuring JIT is not executed on the last incomplete batch, smoothing the workflow.
- Unlocking Computer Algebra Solutions: Study notes shared on computer algebra aim to aid understanding of Tinygrad's shapetracker and symbolic math, accessible here.
- This repository deepens insights into Tinygrad's structure, offering valuable knowledge for enthusiasts diving into advanced symbolic computation.
DSPy Discord
- Wiseflow Mines Data Efficiently: Wiseflow is touted as an agile data extraction tool that systematically categorizes and uploads information from websites and social media to databases, as showcased on GitHub.
- Members discussed integrating Golden Ret with Wiseflow to form a robust dynamic knowledge base.
- HybridAGI Launches New Version: A fresh version of the HybridAGI project is out, focusing on usability and refining data pipelines, with new features like Vector-only RAG and Knowledge Graph RAG, shared on GitHub.
- The community is showing interest in its applications for seamless neuro-symbolic computation in diverse AI setups.
- LLM-based Agents Aim for AGI Potential: A recent paper delves into the prospects of LLM-based agents to circumvent limitations like autonomy and self-improvement, challenging traditional LLM constraints View PDF.
- There's a growing call to establish clear criteria to distinguish LLMs from agents in software engineering, emphasizing the need for unified standards.
- Inference Compute Boosts Performance: A study found that enhancing sample generation during inference markedly elevates language model efficiency, with significant gains from 15.9% to 56% in the SWE-bench Lite domain View PDF.
- Notably, increasing attempts highlight potential where DeepSeek-V2-Coder-Instruct redefines benchmarks previously capped at 43% single-attempt success.
- MIPRO's Mixed Performance Metrics: In performance chat, MIPRO was noted to often surpass BootstrapFewShotWithRandomSearch, although inconsistently across situations.
- Further questions about MIPROv2 confirmed its current lack of support for assertions, a feature awaited by the community.
OpenAccess AI Collective (axolotl) Discord
- Synthetic Data Strategy Enhances Reasoning Tasks: A community member proposed a synthetic data generation strategy for 8b models focusing on reasoning tasks like text-to-SQL by incorporating Chain-of-Thought (CoT) in synthetic instructions.
- Training with CoT before generating the final SQL query was discussed as a method for improving model performance.
- MD5 Hash Consistency Confirmed in LoRA Adapter Merging: A query about MD5 hash consistency when merging LoRA adapters led to a confirmation that consistent results are indeed expected.
- Any discrepancy from expected MD5 hash results was discussed as indicative of potential problems.
- Bits and Bytes Pull Request Sparks Interest: Users recognized the significance of the latest Bits and Bytes Foundation pull request for library development enthusiasts.
- This pull request is seen as a critical development in the library's evolution and is being closely monitored by the community.
- Gemma 2 27b QLoRA Requires Fine-Tuning: Issues with Gemma 2 27b's QLoRA were noted, specifically around tweaking the learning rate to improve results with the latest flash attention.
- The recommendation was to adjust QLoRA parameters for enhanced performance, especially when integrating new modules like flash attention.
- UV: A Robust Python Package Installer: UV, a new Python package installer written in Rust, was introduced for its impressive speed in handling installations efficiently.
- Considered as a faster alternative to pip, UV was highlighted for potentially improving docker build processes.
Torchtune Discord
- Torchtune Rolls Out PPO Integration: Torchtune has added PPO training recipes, enabling Reinforcement Learning from Human Feedback (RLHF) in its offerings.
- This expansion allows for more robust training processes, enhancing the usability of RLHF across models supported by the platform.
- Qwen2 Models Join Torchtune Lineup: Torchtune has expanded support to include Qwen2 models, with a 7B model available and additional smaller models in the pipeline.
- The expanded support for varying model sizes is aimed at broadening Torchtune's adaptability to diverse machine learning requirements.
- Troubleshooting Llama3 File Paths Made Easier: Members discussed challenges with the Llama3 models, emphasizing correct checkpointer and tokenizer paths and the auto-configuring of prompts for the LLAMA3 Instruct Model.
- These confirmations simplify processes for users facing issues with prompt variability and model interference.
- Model Page Revamp on Torchtune's Horizon: Members are considering a restructuring of the Model Page to accommodate new and future models including multimodal LLMs.
- The proposed revamp includes a model index page for consistent handling of tasks like downloading and configuring models.
- PreferenceDataset Gets a Boost: Torchtune's PreferenceDataset now features a unified data pipeline supporting chat functionalities as outlined in a recent GitHub pull request.
- This refactor aims to streamline data processing and invites community feedback to further refine the transformation design.
OpenInterpreter Discord
- Local LLM Setup Flub in Open Interpreter: Setting up the interpreter with a local LLM results in an unnecessary download after selecting llamafile, leading to an openai.APIConnectionError.
- Efforts are ongoing to resolve this, with users coordinating solutions via private messages.
- Open Interpreter's Security Questions: A user raised concerns about Open Interpreter's data privacy and security, asking if communication between systems includes end-to-end encryption.
- The user is keen on knowing the encryption standards and data retention policies, especially with third-party involvement.
- Python Version Support Confusion: Open Interpreter currently supports Python 3.10 and 3.11, leaving users inquiring about Python 3.12 support in the dust.
- Installation validation was suggested through the Microsoft App Store for compatibility checks.
- Ollama Model Setup Hints Shared: Users discussed setting up local models using
ollama list, stressing the VRAM prerequisites for models.- See the GitHub instructions for API key details necessary for paid models.
Mozilla AI Discord
- Llamafile Revolutionizes Offline LLM Accessibility: The core maintainer of Llamafile shared exciting updates on delivering offline, accessible LLMs in a single file, significantly enhancing user accessibility.
- This progress reflects a push towards democratizing language model accessibility by providing compact, offline solutions.
- Mozilla AI Dangles Gift Card Carrot for Feedback: Mozilla AI launched a community survey, offering participants a chance to win a $25 gift card in exchange for valuable feedback.
- This initiative aims to gather robust insights from the community to inform future developments.
- sqlite-vec Release Bash Sparks Interest: sqlite-vec's release party kicked off, inviting enthusiasts to explore new features and participate in interactive demos.
- The event, hosted by the core maintainer, showcased tangible advancements in vector data handling within SQLite.
- Machine Learning Paper Talks Generate Buzz: The community dived into Machine Learning Paper Talks featuring 'Communicative Agents' and 'Extended Mind Transformers', revealing new analytical perspectives.
- These talks stimulated discussions around the potential impacts and implementations of these novel findings.
- Local AI AMA Promotes Open Source Ethos: A successful AMA was conducted by the maintainer of Local AI highlighting their open-source, self-hosted alternative to OpenAI.
- The event underscored the commitment to open-source development and community-driven innovation.
MLOps @Chipro Discord
- LinkedIn Engineering boosts ML platform with Flyte pipelines: A live session was announced about how LinkedIn Engineering has transformed their ML platform, focusing on Flyte pipelines and their implementation at LinkedIn.
- Attendees are expected to gain insights into the engineering strategies and approaches utilized by LinkedIn for their ML platform.
- Practical Applications of Flyte Pipelines: The live event covers Flyte pipelines showcasing their practical application within LinkedIn's infrastructure.
- Participants will explore how Flyte is being employed at LinkedIn for enhanced operational efficiency.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #general-chat (459 messages🔥🔥🔥):
Model and Tool DiscussionInstallation ChallengesLora and ControlNet UsageUpscaling and Processing TechniquesCommunity and Platform Issues
- Installation Challenges Wreak Havoc: Several members faced difficulties with installations and configurations, particularly with ComfyUI and Flux, leading to issues like incompatible Python versions affecting SD and ComfyUI operations.
- A member shared their frustration over multiple failed fixes, emphasizing the challenges in managing different Python environments.
- Harnessing ControlNet for Style Transformation: Users discussed using ControlNet to transform photos into line art, leveraging img2img setups and comparing methods like using DreamShaper and pony models.
- There was a focus on understanding the application of Lora models with specific base models for achieving desired artistic styles.
- Auto1111's Versatility in Inpainting and Styling: Members explored using Auto1111 for specific inpainting tasks, such as adding a particular poster to an image, and debated methods for refining the image using techniques like perspective adjustment.
- Inpainting and ControlNet emerged as popular choices to manage image details without manual editing tools like Photoshop.
- Intel Arc GPUs Stir Mixed Reactions: The community discussed Intel Arc GPUs' compatibility and performance, with concerns over CUDA support impacting their appeal for machine learning tasks.
- Some users were curious about patches like ZLUDA, although skepticism about AMD's viability for ML persists.
- Community Resources and Drama Recalled: Reflecting on past community events, a conversation revealed historical frictions between moderation teams in different SD forums, highlighting dynamics between Discord and Reddit communities.
- The challenges of moderating open-source AI communities were underlined, with users considering the implications of past controversies for current user engagement.
Links mentioned:
- Tweet from Karma (@0xkarmatic): Wow, Greg is also taking a leave of absence.
- KREA: no description found
- THUDM/CogVideoX-2b · Hugging Face: no description found
- Dependency: no description found
- FLUX: Installation with Workflow is Here: no description found
- Tweet from Somnium Space (@SomniumSpace): We are delighted to publish this incredible full Keynote Speech by Robert Scoble (@Scobleizer) which he gave at #SomniumConnect2024✨ What will #AI bring to humanity in the next 10 years? How will thi...
- black-forest-labs (Black Forest Labs): no description found
- Flux Examples: Examples of ComfyUI workflows
- ComfyUI: Imposing Consistent Light (IC-Light Workflow Tutorial): The video focuses on implementing IC-Light in Comfy UI, specifically for product photography. IC-Light is based on SD1.5, and we use a reference background a...
- What are LoRA models and how to use them in AUTOMATIC1111 - Stable Diffusion Art: LoRA models are small Stable Diffusion models that apply tiny changes to standard checkpoint models. They are usually 10 to 100 times smaller than checkpoint
- CFG: how it works in non-Flux models vs Flux (code examples): The 'guidance' value for flux is a simple numeric input that gets fed into the model. BFL introduced this at distilation time by generating an...
- Good Vibrations (Official Music Video): REMASTERED IN HD!Official Music Video for Good Vibrations performed by Marky Mark and The Funky Bunch.#MarkyMark #GoodVibrations #Remastered
- GitHub - vosen/ZLUDA: CUDA on ??? GPUs: CUDA on ??? GPUs. Contribute to vosen/ZLUDA development by creating an account on GitHub.
- Line Art Style [SDXL Pony] - V1 | Stable Diffusion LoRA | Civitai: LINE ART STYLE This is a style LoRA meant to mimic line art, specifically art with little to no shading/shadows in order to get clean black lines o...
- Pony Diffusion V6 XL - V6 (start with this one) | Stable Diffusion Checkpoint | Civitai: Pony Diffusion V6 is a versatile SDXL finetune capable of producing stunning SFW and NSFW visuals of various anthro, feral, or humanoids species an...
Unsloth AI (Daniel Han) ▷ #general (105 messages🔥🔥):
MoEification in Mistral-7bIssues with Unsloth fine-tuning save methodsIntegrating Unsloth models into PPO trainerPerformance differences in Fine Tuned Llama3.1 inferenceLearning resources for LLM inference
- MoEification in Mistral-7b Explained: The Mistral-7b-MoEified-8x model explores expert models by dividing MLP layers into splits and adjusting projections, aiming to optimize expert usage.
- Unsloth Fine-Tuning Save Issues: Users encounter problems with saving fine-tuned models using 'model.save_pretrained_merged' in Unsloth, where methods are inconsistent or not working.
- Integrating Unsloth with PPO Trainer Fails: The integration of Llama3 models fine-tuned by Unsloth into PPO trainers breaks due to required use of 'for_inference()' before model.generate() calls.
- Inconsistent Performance for Llama3.1 Inference: Inference time for fine-tuned Llama3.1 is variable, ranging from milliseconds to over a minute, due to factors like initial loading requirements on first runs.
- Comprehensive Guide for LLM Inference: Replete AI offers a comprehensive guide to understanding generative AI, suggested as a resource for beginners learning about the LLM inference stack.
Links mentioned:
- Tweet from OpenAI Developers (@OpenAIDevs): Introducing Structured Outputs in the API—model outputs now adhere to developer-supplied JSON Schemas. https://openai.com/index/introducing-structured-outputs-in-the-api/
- Google Colab: no description found
- kalomaze/Mistral-7b-MoEified-8x · Hugging Face: no description found
- Google Colab: no description found
- Google Colab: no description found
- Nextra: the next docs builder: Nextra: the next docs builder
- Load 4bit models 4x faster - a unsloth Collection: no description found
- 4bit Instruct Models - a unsloth Collection: no description found
- unsloth (Unsloth AI): no description found
Unsloth AI (Daniel Han) ▷ #off-topic (10 messages🔥):
BigLlama-3.1-1T-Instruct ModelPokémon AI Game MasterLLM leaderboardsMinecraftChatGPT Pokémon Prompt
- BigLlama-3.1-1T Model Under Discussion: The BigLlama-3.1-1T-Instruct model is an experimental merge using Meta-Llama and created with Mergekit, succeeding the Meta-Llama-3-120B model.
- Members noted it's currently 'useless' as it hasn't been trained with its merged weights.
- Pokémon AI Game Master Intrigues: A ChatGPT Pokémon prompt mimics a Game Master, guiding users through the Pokémon world in a narrative capturing courage, friendship, and exploration.
- The prompt facilitates engaging in capturing, training, and battling Pokémon within the AI-crafted tales and realms.
Links mentioned:
- mlabonne/BigLlama-3.1-1T-Instruct · Hugging Face: no description found
- Pokémon RPG - ChatGPT Prompt : This prompt invokes an AI-crafted Game Master, guiding you through the vibrant and exciting world of Pokémon, inspired by the adventure-filled regions familiar to fans of the franchise. Engage in capt...
Unsloth AI (Daniel Han) ▷ #help (162 messages🔥🔥):
Llama-3-8b-bnb 4 bit training and mergingGPT-4ALL and GGUF filesFine-tuning Llama models on ColabExporting models to OllamaMulti-GPU support for Unsloth
- Llama-3-8b-bnb 4 bit training and merging issues resolved: A user faced issues when merging the Llama-3-8b-bnb 4 bit due to incorrect merging instructions, which require merging the LoRA adapter in 16-bit before quantizing to gguf.
- GPT-4ALL requires conversion to GGUF files: Theyruinedelise explained that GPT-4ALL requires models in GGUF format and advised to follow the final conversion steps in the provided Colab notebook.
- Fine-tuning Llama models on Google Colab: Users discussed the challenges and strategies for fine-tuning Llama models using Google Colab, including the need to split datasets and manage memory for effective training.
- Process of exporting models to Ollama: A discussion on how to export and run models from Colab to Ollama revealed the need for terminal access, which can be achieved with Colab Pro, to effectively run the models locally.
- Multi-GPU support pending for Unsloth: A runtime error revealed that Unsloth does not currently support multi-GPU setups, though they are working on adding this feature.
Links mentioned:
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Serverless GPU Endpoints for AI Inference: Run machine learning inference at scale with RunPod Serverless GPU endpoints.
- Load: no description found
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
LLaMA3 Configuration on RunPodEfficient AI Resource Management
- Run LLaMA3 on RunPod Efficiently: A member asked for suggestions regarding the configuration needed to run the LLaMA3 model on RunPod in a cost-effective manner.
- Optimize AI Resource Usage: Community members discussed strategies for managing AI resources efficiently to minimize costs and maximize performance.
Unsloth AI (Daniel Han) ▷ #research (1 messages):
vvelo: https://fxtwitter.com/reach_vb/status/1820493688377643178
HuggingFace ▷ #announcements (1 messages):
Gemma 2 2BDiffusers integration for FLUXMagpie UltraWhisper Generationsllm-sagemaker Terraform module
- Gemma 2 2B runs effortlessly on your device: Google releases Gemma 2 2B, a 2.6B parameter version for on-device use with platforms like WebLLM and WebGPU.
- FLUX takes the stage with Diffusers: The new FLUX model, integrated with Diffusers, promises a groundbreaking text-to-image experience enhanced by bfl_ml's release.
- Argilla and Magpie Ultra fly high: Magpie Ultra v0.1 debuts as the first open synthetic dataset using Llama 3.1 405B and Distilabel for high compute-intensive tasks.
- Whisper Generations hit lightning speeds: Whisper generations now run 150% faster using Medusa heads without sacrificing accuracy.
- llm-sagemaker simplifies LLM deployment: Llm-sagemaker, a new Terraform module, is launched to streamline deploying LLMs like Llama 3 on AWS SageMaker.
Links mentioned:
- Google releases Gemma 2 2B, ShieldGemma and Gemma Scope: no description found
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): Gemma 2 2B running in a browser, powered by WebLLM & WebGPU! 🔥 100% local & on-device In less than 24 hours, we've already got the model to the edge! ⚡ Try it out on an HF space below:
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): Gemma 2 2B running in a free Google Colab! 🤗 Powered by transformers! ⚡
- Tweet from Georgi Gerganov (@ggerganov): Simple instructions to get started with the latest Gemma 2 models + llama.cpp https://huggingface.co/blog/gemma-july-update#use-with-llamacpp
- Tweet from Sayak Paul (@RisingSayak): You should have already gone bonkers by now with @bfl_ml's FLUX release. What a model, eh! I am getting back to Twitter after some sprinting with my mates @_DhruvNair_, @YiYiMarz, and @multimoda...
- Tweet from Gabriel Martín Blázquez (@gabrielmbmb_): Dropping magpie-ultra-v0.1, the first open synthetic dataset built with Llama 3.1 405B. Created with distilabel, it's our most advanced and compute-intensive pipeline to date. https://huggingfac...
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): 150% faster Whisper generations w/ medusa heads! 🔥 Built on top of Transformers with minimal drop in accuracy. Quite exciting area of research, Medusa heads are proven to be incredibly fast for LLM...
- Tweet from merve (@mervenoyann): Shipped: new task guide on Vision Language Models and freshly updated Depth Estimation task guide on @huggingface transformers docs ⛴️📦 👉🏻 Read about VLMs, how to stream, quantization and more 👉�...
- Tweet from Philipp Schmid (@_philschmid): Excited to announce “llm-sagemaker” a new Terraform module to easily deploy open LLMs from @huggingface to @awscloud SageMaker real-time endpoints! 👀 Infrastructure as Code (IaC) tools are crucial f...
- Tweet from merve (@mervenoyann): SAMv2 is just mindblowingly good 😍 Learn what makes this model so good at video segmentation, keep reading 🦆⇓
- Tweet from Databricks Mosaic Research (@DbrxMosaicAI): For our StreamingDataset users: We're thrilled to announce support for storing MDS datasets in @huggingface. S/O to @orionweller for the contribution! Check out the docs here: https://docs.mosaic...
HuggingFace ▷ #general (239 messages🔥🔥):
MarianMT model translation issuesNew text to video model releaseAudio processing with spectrogramsDataset size limit increase processPyTorch warnings and issues
- MarianMT model lacks ro-en translation: A user noted that while the MarianMT model can translate from English to Romanian, the reverse is not possible due to
Helsinki-NLP/opus-mt-ro-ennot existing. - CogVideoX-2b new release impresses: A newly released model, CogVideoX-2b, has surfaced in the AI community for text to video generation and appears to be comparable to Kling, according to initial reviews.
- Spectrograms dominate audio processing: Discussion highlighted why CNNs with spectrograms are preferred over RNNs for audio processing due to better feature extraction from complex signals.
- Dataset size limit inquiries at Hugging Face: Users seeking to share large datasets are advised to email datasets@huggingface.co for increasing size limits.
- Torch.library modules raise warnings: A user encountered future warnings with
torch.library.impl_abstract, which has been renamed totorch.library.register_fakein future PyTorch versions.
Links mentioned:
- Hugging Face - Learn: no description found
- Welcome to the 🤗 Machine Learning for 3D Course - Hugging Face ML for 3D Course: no description found
- Repository limitations and recommendations: no description found
- Audio To Spectrogram - a Hugging Face Space by fffiloni: no description found
- Riffusion • Spectrogram To Music - a Hugging Face Space by fffiloni: no description found
- THUDM/CogVideoX-2b · Hugging Face: no description found
- Create a dataset loading script: no description found
- Cherry Blossoms Explode Across the Dying Horizon: Provided to YouTube by DistroKidCherry Blossoms Explode Across the Dying Horizon · SakuraburstDeconstructing Nature℗ 643180 Records DKReleased on: 2016-12-18...
- GitHub - buaacyw/MeshAnythingV2: From anything to mesh like human artists. Official impl. of "MeshAnything V2: Artist-Created Mesh Generation With Adjacent Mesh Tokenization": From anything to mesh like human artists. Official impl. of "MeshAnything V2: Artist-Created Mesh Generation With Adjacent Mesh Tokenization" - buaacyw/MeshAnythingV2
- GitHub - SonyCSLParis/NeuralDrumMachine: Contribute to SonyCSLParis/NeuralDrumMachine development by creating an account on GitHub.
- load_dataset with multiple jsonlines files interprets datastructure too early · Issue #7092 · huggingface/datasets: Describe the bug likely related to #6460 using datasets.load_dataset("json", data_dir= ... ) with multiple .jsonl files will error if one of the files (maybe the first file?) contains a full...
- Issues · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - Issues · huggingface/transformers
- Spaces Overview: no description found
- Spaces - Hugging Face: no description found
- Spaces Launch – Hugging Face: no description found
HuggingFace ▷ #today-im-learning (3 messages):
Linear Algebra3D Video Analysis
- Exploring Linear Algebra for 3D Video Analysis: A member learned about linear algebra and its application in 3D video analysis, seeking recommendations for insightful blogs or articles.
- Sharing Resources for Learning: Another member expressed interest in spreading the learning experience and requested others to share the topic widely.
HuggingFace ▷ #cool-finds (4 messages):
High Resolution Image SynthesisGraph Integration with LLMs
- High Resolution Image Synthesis with Transformers: A member expressed interest in the synthesis of high resolution images using transformers, highlighting concepts like latent representation of images and context-rich vocabulary codebook.
- New Graph Integration Method with LLMs: A cool method to integrate graphs into LLMs was shared, similar to a proposal at ICML, with the paper available here.
HuggingFace ▷ #i-made-this (5 messages):
SAC Agent Training in UnityEmbodied Agent Platform DevelopmentAniTalker ProjectBiRefNet for Image Segmentation
- Boost SAC Agent Training in Unity: A member shared progress on SAC agent training with multi-threaded support for CUDA or CPU, offering significant performance improvements in Unity ML-Agents setup.
- Launch of an Embodied Agent Platform: Development is underway on an embodied agent platform that enables agents to converse with players and execute tasks within a 3D environment.
- Innovative AniTalker for Animated Faces: A member introduced AniTalker, a talking head synthesis port from X-LANCE featuring identity-decoupled facial motion encoding.
- BiRefNet Excels in Image Segmentation: The BiRefNet project was announced as a state-of-the-art solution for high-resolution dichotomous image segmentation, outperforming RMBG1.4.
Links mentioned:
- ZhengPeng7/BiRefNet · Hugging Face: no description found
- Unity ML-Agents | Live Agent training from Scratch | Part 2: a quick sac agent trainer in a 3d voxel world
- GitHub - thunlp/LEGENT: Open Platform for Embodied Agents: Open Platform for Embodied Agents. Contribute to thunlp/LEGENT development by creating an account on GitHub.
- LEGENT - a Hugging Face Space by LEGENT: no description found
- Anitalker - a Hugging Face Space by Delik: no description found
- GitHub - X-LANCE/AniTalker: [ACM MM 2024] This is the official code for "AniTalker: Animate Vivid and Diverse Talking Faces through Identity-Decoupled Facial Motion Encoding": [ACM MM 2024] This is the official code for "AniTalker: Animate Vivid and Diverse Talking Faces through Identity-Decoupled Facial Motion Encoding" - X-LANCE/AniTalker
HuggingFace ▷ #reading-group (5 messages):
LLM Reasoning CapabilitiesOpenAI's Structured OutputsTheories on LLM Reasoning Mechanisms
- OpenAI Publishes Structured Outputs Blogpost: OpenAI just released a blog post recommending structured outputs as a standard practice, though with minimal attribution to previous work.
- LLMs Fake Reasoning by Transforming Tasks into Retrieval: A theory suggests that while LLMs lack true reasoning ability, they simulate reasoning by transforming tasks into retrieval tasks, leveraging the vast dataset of internet facts and logic they're trained on.
- Token Scratchpads Enhance LLM Reasoning: Token scratchpads might boost LLM reasoning by expanding the KV-cache, aiding the attention layers in reasoning without the need to retrain models.
- Attention Variants and External Databases Impact LLM Reasoning: Empirical tests show that attention variants such as mamba/linear attention tend to perform poorly in reasoning tasks compared to models maintaining KV-cache.
HuggingFace ▷ #computer-vision (4 messages):
Depth EstimationCVPR 2022
- Depth Estimation combines Stereo and Structured-Light: A member shared the CVPR 2022 paper titled 'Depth Estimation by Combining Binocular Stereo and Monocular Structured-Light', which explores a novel approach to improve depth estimation accuracy.
- Is there a code implementation for the above paper? was asked, indicating interest in practical applications of the discussed methodology.
- Request for Code Implementation: A query was made about the availability of code implementation for the depth estimation paper discussed from CVPR 2022.
- The question highlights the community’s interest in practical applications and real-world testing of theoretical research.
HuggingFace ▷ #NLP (2 messages):
Named Entity Recognition datasetJSON file search optimization
- NER Dataset Annotated with IT Skills is Live on Kaggle: A member shared a Kaggle dataset featuring 5029 CVs annotated with IT skills using Named Entity Recognition (NER).
- Challenge of Identifying Relevant JSON Files in Large Dataset: A member discussed a method for identifying the most relevant 5 JSON file IDs from a dataset of over 20,000 JSON files.
Link mentioned: NER Annotated CVs: This dataset includes 5029 annotated curriculum vitae (CV), marked with IT skill
LM Studio ▷ #general (157 messages🔥🔥):
RAG setup with LMStudioInternLM model performanceAudio transcription with AIModel quantization and K-V cacheCUDA device selection for inference
- RAG setup with LMStudio possible soon: Users discuss the possibility of setting up a Retrieval-Augmented Generation (RAG) with LMStudio, with anticipated support in the upcoming 0.3.0 release.
- Interest is shown in AnythingLLM as a workaround, though some encounter issues with file accessing initially.
- InternLM and model discussion: Members note challenges with using models like InternLM2.5 and discuss comparisons in performance with other models such as Gemma2 27b.
- The conversation suggests a developing understanding of using different quantizations and highlights IMat quant options.
- Exploring audio transcription via AI tools: While LM Studio doesn't directly support audio input, AnythingLLM and other integrative tools offer potential paths forward for transcription tasks.
- Users express a preference for staying offline for privacy using local solutions, indicating a challenge with cloud-dependent speech-to-text services.
- Understanding K-V cache in model quantization: Members display curiosity regarding Flash Attention and K-V cache quant settings, with some seeking to understand their impact on model performance.
- Resources and guidance are shared to assist users in optimizing attention mechanisms for better efficiency and output quality.
- Selecting CUDA devices for inference: Users explore techniques such as modifying CUDA_VISIBLE_DEVICES settings to designate specific GPUs for model inference, enhancing their computational setups.
- These solutions allow efficient resource distribution across different GPUs, aiding in better performance for simultaneous tasks like image generation.
Links mentioned:
- Flash Attention: no description found
- UGI Leaderboard - a Hugging Face Space by DontPlanToEnd: no description found
- GGUF: no description found
- Reddit - Dive into anything: no description found
- legraphista/internlm2_5-20b-chat-IMat-GGUF · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Shut Up! GIF - Money Dollars Cash - Discover & Share GIFs: Click to view the GIF
- ggml : add Flash Attention by ggerganov · Pull Request #5021 · ggerganov/llama.cpp: ref #3365 Setting up what's needed for Flash Attention support in ggml and llama.cpp The proposed operator performs: // new res = ggml_flash_attn(ctx, q, k, v, kq_mask, kq_scale); // fused sc...
- Open WebUI: no description found
LM Studio ▷ #hardware-discussion (59 messages🔥🔥):
8700G/780m IGP testingNVIDIA 4090 and 5090 discussionGraphics card market trendsGPU upgrades for LLMsRTX 4090 vs 3080 performance
- Bobzdar's testing: 8700G/780m IGP with ROCM and Vulkan: Bobzdar reported a 25% acceleration using a special Ollama version with ROCM on the 8700G/780m IGP and 15% with Vulkan in LM Studio, although he encountered loading issues beyond 20GB GPU RAM.
- He managed to run llama3.1 70b q4 at 30% faster speed than CPU; however, larger contexts in LM Studio would crash beyond 63k context size.
- NVIDIA 4090: Is it Worth the Upgrade?: Pydus considered upgrading to a 4090 and wondered about differences with gaming versions, later noting its performance wasn't significantly better than the 3080.
- He expressed uncertainty about its speed advantage and contemplated a setup with two 4090's or switching to MAC.
- Controllers Debate on GPU VRAM Needs: It was discussed whether the RTX 5090 will significantly improve on the 4090's VRAM capabilities, with some predicting the same 24GB VRAM capacity.
- Pydus and others speculated on waiting or upgrading, with AMD Opteron highlighting that availability and pricing poses a challenge, with AMD possibly being a future competitor.
- Prevailing Graphics Card Market Trends: P40 cards doubled in price in 2024 on eBay, illustrating market demand shifts, while a surplus of 3090s remains hard to find due to maintained high pricing.
- Cards like the potential AMD 48GB VRAM are desired by LLM builders, which could impact NVIDIA's pricing and market strategies if released.
- GPU Upgrades: Factors and Considerations: For larger LLM models, community members suggest upgrading to at least a 3060 or even a 3090, emphasizing the importance of VRAM in performance considerations.
- Recommendations include checking for power supply compatibility as GPU upgrades require higher power; combining GPUs such as the 2060 Super with a 3060 was suggested for cost efficiency.
CUDA MODE ▷ #general (5 messages):
PufferLib Environment SetupReinforcement Learning StreamingGPUDrive Generation ExampleRequest for Mojo Talk
- Set up PufferLib for Gameboy Emulation: A member shared a link to set up environments for a Gameboy emulator using PufferLib and commented on the benefits of starting with a familiar language like CPython.
- Ask RL Questions Live on Stream: The creator of the PufferLib library streams and can be reached for questions directly through a YouTube session focusing on reinforcement learning development.
- GPUDrive Boosts Agent Training Speed: The Hugging Face paper introduces GPUDrive, a multi-agent simulator using CUDA to efficiently train reinforcement learning agents in the Waymo Motion dataset, achieving successful agent behavior in minutes to hours.
- Mojo Overview Session Requested: There was an invitation extended to Chris and his team for a potential talk about the current state and vision of Mojo, encouraging an introductory overview.
Links mentioned:
- Paper page - GPUDrive: Data-driven, multi-agent driving simulation at 1 million FPS: no description found
- Reinforcement learning live dev: Follow jsuarez5341 on XStar https://github.com/pufferai/pufferlibMIT PhD and full-time OSS RL exorcist
- PufferLib/pufferlib/environments/pokemon_red/environment.py at 729003f9cb89845cc1a69a65e5a2431b2d0542bd · PufferAI/PufferLib: Simplifying reinforcement learning for complex game environments - PufferAI/PufferLib
CUDA MODE ▷ #torch (17 messages🔥):
PyTorch 2.4 with CUDA 12.4 issuescublas hgemm library for WindowsFP16 accumulate versus FP32Speed/accuracy trade-offs in cublas libraryInference-only library discussion
- PyTorch 2.4 faces hiccup with CUDA 12.4: A member noted that CUDA 12.4 build breaks their code, yet PyTorch 2.4 with CUDA 12.1 runs perfectly.
- The user further clarified they were running CUDA 12.6 on the base system installed via conda.
- cublas hgemm library now Windows-ready: A user shared that they made the torch cublas hgemm library compatible with Windows, enhancing performance to up to 315 tflops on a 4090 compared to 166 tflops for torch nn.Linear.
- The library assists in achieving performances of around 2.4 it/s for flux on a 4090, marked by drastic improvement from previous benchmarks.
- FP16 accumulate triumphs over FP32: The discussion highlighted that FP16 with FP16 accumulate yields 330 tflops, while FP16 with FP32 accumulate only reaches 165 tflops.
- Despite concerns, the member noted that FP16 accumulate is 2x faster on consumer GPUs due to limited L1 cache, and is less problematic than 4/8 bit quantization.
- Benchmarking the cublas speed-accuracy balance: Benchmarking results showed CublasLinear offered slight deviations from the nn.Linear outputs but achieved a significant speed boost with 313.22 TFLOPS versus torch's 166.47 TFLOPS.
- The user assured that these slight differences do not significantly affect outcomes in applications like diffusion models or LLMs.
- Inference-only library sparks attention: The cublas library is noted to be inference-only, sparking discussions about its applicability and usefulness within specific bounds.
- Emphasis was placed on its high-speed capabilities being beneficial despite lacking training support.
Link mentioned: GitHub - aredden/torch-cublas-hgemm: PyTorch half precision gemm lib w/ fused optional bias + optional relu/gelu: PyTorch half precision gemm lib w/ fused optional bias + optional relu/gelu - aredden/torch-cublas-hgemm
CUDA MODE ▷ #algorithms (3 messages):
Quantization Bits as an Optimizable ParameterAccuracy Tuning for CIFAR-10
- Quantization Bits emerge as a tunable parameter: Experimentation revealed that making quantization bits an optimizable parameter leads to improved model performance.
- CIFAR-10 accuracy faces tuning challenges: A member observed that their model achieves around 70% accuracy on CIFAR-10, indicating further tuning is needed.
CUDA MODE ▷ #jobs (7 messages):
Hudson River Trading internshipsGPU job optimizationSoftware Engineer salary at Hudson River Trading
- Hudson River Trading seeks GPU wizards: A member described their role at Hudson River Trading, a high-frequency trading firm, focusing on GPU optimization and performance engineering, with tasks including writing CUDA kernels and optimizing PyTorch.
- Internships at Hudson River Trading sparks curiosity: An inquiry was made regarding internship opportunities similar to a full-time GPU optimization role, which are typically available in summer.
- Cracking the compensation code at Hudson River Trading: The software engineering compensation at Hudson River Trading ranges from $406K to $798K per year, showcasing the lucrative potential of roles in high-frequency trading.
Links mentioned:
- Senior Software Engineer - Performance Optimization (C++/GPU): New York, NY, United States
- Hudson River Trading Software Engineer Salary | $406K-$485K+ | Levels.fyi: Software Engineer compensation in United States at Hudson River Trading ranges from $406K per year for L1 to $485K per year for L3. The median compensation in United States package totals $410K. View ...
CUDA MODE ▷ #torchao (34 messages🔥):
INT8 Quantization IssuesAffinQuantizedTensor PlansTorchAO Installation ErrorsHardware Compatibility for Tensor Core OperationsGPTQ Refactor Progress
- INT8 Quantization Sparks Debate on Scaling Techniques: In a discussion about INT8 symmetric quantization, members analyzed why PyTorch uses 127.5 for scaling and the implications on restricted range quantization. Experiences with Qwen2-0.5B fine-tuning showed model divergence using 127.5 due to value clipping, which spurred interest in comparing INT8/PTQ and INT4 Quantized Training alternatives.
- TorchAO Installation Challenges on Older GPUs: Several users experienced installation issues with TorchAO on T4 GPUs due to compatibility problems with BF16 operations found within the TorchAO's source code.
- TorchAO May Need Updated Documentation: Users suggested that current documentation on TorchAO installation could mislead users into thinking that certain steps were additive rather than alternative.
Links mentioned:
PyTorch- pytorch/aten/src/ATen/native/cuda/int4mm.cu at e98eac76b358fb4639b9e9ce6894014354d7b073 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- ao/torchao/quantization/quant_primitives.py at de4a1fb3b1f71e2f61b84dfdc96e7d704ff72208 · pytorch/ao: The missing pytorch dtype and layout library for training and inference - pytorch/ao
- Quantization - Neural Network Distiller: no description found
CUDA MODE ▷ #off-topic (7 messages):
LLaMA 3 Dataset SectionPrefix Chunk LLM Paper - Sarathi LLMCTF Challenge using CPUChunkAttention for LLM InferenceSARATHI Framework
- LLaMA 3 Dataset Section Stands Out: The LLaMA 3 paper was noted for its engaging dataset section, while other parts were better explained in alternate papers.
- A user mentioned that the dataset section was the most interesting part compared to other sections.
- Explore ChunkAttention in Prefix-aware LLM: The ChunkAttention paper introduces a prefix-aware self-attention module, optimizing memory utilization by sharing key/value tensors across similar LLM requests.
- Key improvements come from breaking down monolithic key/value tensors into smaller chunks and using a prefix-tree architecture to enhance memory utilization.
- CTF Challenge Highlights Modern Attacks: A CTF challenge focusing on CPU usage and kernel exploitation was shared, incorporating themes from corCTF 2023.
- Details provided included a new syscall on Linux and a link to the CTF challenge.
- Introducing SARATHI Framework: The SARATHI framework addresses inefficiencies in LLM inference by employing chunked-prefills and decode-maximal batching.
- SARATHI improves GPU utilization by allowing decode requests to piggyback during inference at reduced costs.
Links mentioned:
- ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition: Self-attention is an essential component of large language models (LLM) but a significant source of inference latency for long sequences. In multi-tenant LLM serving scenarios, the compute and memory ...
- SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills: Large Language Model (LLM) inference consists of two distinct phases - prefill phase which processes the input prompt and decode phase which generates output tokens autoregressively. While the prefill...
- Will's Root: corCTF 2024: Its Just a Dos Bug Bro - Leaking Flags from Filesystem with Spectre v1: no description found
CUDA MODE ▷ #llmdotc (99 messages🔥🔥):
Ragged attention masksBatch size and sequence length schedulingSpecial tokens in LLaMA trainingFlashAttention supportTraining stability and efficiency
- Ragged Attention Masks Pose Challenges: Discussion around using ragged attention masks revealed difficulties in handling out-of-distribution scenarios when passing tokens separated by EOT, requiring a tailored masking approach.
- Batch and Sequence Length Scheduling Aims for Stability: A suggested training strategy involves gradually increasing sequence lengths (e.g., 512 -> 1024 -> 2048) while adjusting
batch sizesandRoPE, aiming to balance computational cost and model stability. - Uncertain Implementation of Special Tokens in LLaMA Training: Unresolved issues in how
Metahas implemented special tokens like<|end_of_text|>and<|begin_of_text|>led to user confusion, potentially causing incorrect runtime behavior. - FlashAttention Enhances Long Context Training: There’s ongoing discussion about whether
FlashAttentionandcudnnlibrary can support ragged attention effectively. - Understanding Training Stability in Pre-training: Several members noted the importance of analyzing
training instabilityand loss spikes during pre-training through new research insights.
Links mentioned:
- Spike No More: Stabilizing the Pre-training of Large Language Models: Loss spikes often occur during pre-training of large language models. The spikes degrade the performance of large language models and sometimes ruin the pre-training. Since the pre-training needs a va...
- The Stability-Efficiency Dilemma: Investigating Sequence Length Warmup for Training GPT Models: Recent works have demonstrated great success in pre-training large-scale autoregressive language models on massive GPUs. To reduce the wall-clock training time, a common practice is to increase the ba...
- Llama 3 | Model Cards and Prompt formats: Special Tokens used with Llama 3. A prompt should contain a single system message, can contain multiple alternating user and assistant messages, and always ends with the last user message followed by ...
- Templates for Chat Models: no description found
- 🤗 Transformers: no description found
- Issues · Dao-AILab/flash-attention: Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
- Issues · pytorch/torchchat: Run PyTorch LLMs locally on servers, desktop and mobile - Issues · pytorch/torchchat
CUDA MODE ▷ #rocm (9 messages🔥):
ZLUDA 3 takedownAMD claim on ZLUDAContractual obligationsDevelopment permissions
- ZLUDA 3 removed after AMD's claim: The author of ZLUDA 3 has taken down the project as AMD claimed that the permission given to release it was not valid, according to GitHub.
- Contract confusion over ZLUDA's status: There is confusion regarding the employment contract terms, where one clause allowed the release of ZLUDA if AMD deemed it unfit for further development.
Links mentioned:
- GitHub - vosen/ZLUDA: CUDA on ??? GPUs: CUDA on ??? GPUs. Contribute to vosen/ZLUDA development by creating an account on GitHub.
- GitHub - vosen/ZLUDA at v3: CUDA on ??? GPUs. Contribute to vosen/ZLUDA development by creating an account on GitHub.
CUDA MODE ▷ #cudamode-irl (2 messages):
Discussion about Decision TimelineAdding Details to Proposals
- Understand Decision Timelines: Members discussed the probable decision timeline being by the end of the month, emphasizing the lengthy list of factors involved.
- Clarifying Proposal Details: A method to ensure proposal clarity was discussed, highlighting the role of a Google form or a gist to submit detailed work plans.
Nous Research AI ▷ #datasets (1 messages):
UltraSteer-V0Multi-Turn Dialogue DatasetNvidia's Reward ModelFine-Grained Labeling
- Nvidia releases UltraSteer-V0 dataset: Nvidia has curated a dataset called UltraSteer-V0 containing 2.3M conversations and 2.8M dialogue turns, each labeled with nine fine-grained signals.
- The dataset is described as 'version zero' and comes after 22 days of labelling and processing, indicating room for further deduplication and improvement.
- Llama2-13B-SteerLM-RM powers UltraSteer: The conversations in UltraSteer are labeled using Nvidia's Llama2-13B-SteerLM-RM reward model within the NeMo Aligner framework.
- Each assistant message in the dataset is rated across attributes like Quality, Toxicity and Creativity on a scale of 0 to 4.
Link mentioned: Avelina/UltraSteer-v0 · Datasets at Hugging Face: no description found
Nous Research AI ▷ #off-topic (1 messages):
vikings7699: Has anyone here ever worked on fine tuning a model specifically for insurance sector?
Nous Research AI ▷ #general (129 messages🔥🔥):
Multi-dataset Model Training IssuesOpenAI Leadership ChangesFlux AI Model PerformanceOpen Medical Reasoning Tasks ProjectMiniCPM-Llama3 VLM Capabilities
- Multi-dataset Training: A Recipe for Disaster?: A user fried their model by training it with different datasets at a very small learning rate across multiple sessions, which led to catastrophic forgetting, unlike using a larger learning rate on a single merged dataset.
- 'Accumulated errors' and 'overfitting' were discussed as potential causes, with one suggestion being a low-performance local minimum was reached during training.
- OpenAI Loses Top Leaders: A trio of leaders have left OpenAI, as reported in a news article, suggesting potential shifts in the company’s trajectory.
- Flux AI Shows Promise in Text and Image Generation: Flux AI models, particularly the free 'Schnell', are reportedly beating Midjourney 6 in terms of image generation coherence, indicating significant advancements in model performance.
- Despite some minor typos, these models are well-regarded, with images achieving a remarkable level of realism and clarity.
- Open Medical Reasoning Project Launches: Initiated by Open Life-Science AI, this project invites contributions from medical and AI communities to develop medical reasoning tasks for LLMs.
- MiniCPM-Llama3 Pushes Multimodal Frontiers: MiniCPM-Llama3 2.5 now supports multi-image input and demonstrates significant promise in tasks such as OCR and document understanding, offering robust capabilities for multimodal interaction.
Links mentioned:
- Tweet from Maxime Labonne (@maximelabonne): 🦙✨ BigLlama-3.1-1T-Instruct So I've heard that 405B parameters weren't enough... It's my pleasure to present an upscaled Llama 3.1 with 1,000,000,000 parameters. Now available on @hugg...
- Tweet from fofr (@fofrAI): 🤯 > powerpoint presentation, the slide title says “Flux AI has new skills”, three bullet points, “good at text”, “prompt comprehension”, “amazing images”
- Tweet from Aaditya Ura ( looking for PhD ) (@aadityaura): Exciting news! 🎉 Introducing the Open Medical Reasoning Tasks project! Inspired by @NousResearch and @Teknium1, @OpenLifeSciAI ( Open Life-Science AI ) is launching an open, collaborative initiative...
- openbmb/MiniCPM-Llama3-V-2_5 · Hugging Face: no description found
- HuggingFaceM4/Idefics3-8B-Llama3 · Hugging Face: no description found
- openbmb/MiniCPM-V-2_6 · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Generated with Flux.1 Pro and Schnell : Posted in r/StableDiffusion by u/Sea_Law_7725 • 370 points and 77 comments
- Issues · black-forest-labs/flux: Official inference repo for FLUX.1 models. Contribute to black-forest-labs/flux development by creating an account on GitHub.
- Generated with Flux.1 Pro and Schnell : Posted in r/StableDiffusion by u/Sea_Law_7725 • 372 points and 77 comments
- MiniCPM-V Finetuning for multi-image input during a multi-turn conversation💡 [REQUEST] - <title> · Issue #233 · OpenBMB/MiniCPM-V: 起始日期 | Start Date No response 实现PR | Implementation PR No response 相关Issues | Reference Issues for multi-image input during a multi-turn conversation 摘要 | Summary for multi-image input during a mul...
Nous Research AI ▷ #ask-about-llms (19 messages🔥):
Fine-tuning LibrariesInsurance Sector Fine-TuningHosting Llama 450bInference Stack and ResourcesBottleneck in Inference/Training
- Fine-tuners like Axolotl gain traction: A user queried whether most people use libraries for fine-tuning and training or if they write unique scripts; another responded citing Axolotl as a popular choice.
- Insurance industry seeks custom AI solutions: A member inquired about fine-tuning AI models for the insurance sector.
- Navigating Llama 450b hosting options: A member asked for companies hosting Llama 450b with pay-as-you-go access, noting Groq's enterprise account requirement.
- Getting started with the inference stack: A user requested resources on starting with the inference stack and vLLM.
- Understanding inference and training bottlenecks: Questions were raised about bottlenecks in inference/training; responses indicated that memory is a bottleneck at batch size 1.
Nous Research AI ▷ #reasoning-tasks-master-list (7 messages):
Synthetic task generationOpen Medical Reasoning Tasks projectSystem 2 Reasoning Link Collection
- Pondering synthetic task generation improvements: A user expressed contemplation on enhancing synthetic task generation to transcend the current limits of LLM capabilities.
- Open Medical Reasoning Tasks project takes inspiration: Inspired by the Open Reasoning Tasks project, a medical version has been launched with a call to the medical community to contribute on GitHub.
- The initiative aims to create comprehensive medical reasoning tasks while advancing AI in healthcare.
- Inclusion in System 2 Reasoning Link Collection: The Open Medical Reasoning Tasks project was also cited in the System 2 Reasoning Link Collection, enhancing visibility and collaboration.
- This collection aims to aggregate resources significant to systemic reasoning research.
Links mentioned:
- Tweet from Aaditya Ura ( looking for PhD ) (@aadityaura): Exciting news! 🎉 Introducing the Open Medical Reasoning Tasks project! Inspired by @NousResearch and @Teknium1, @OpenLifeSciAI ( Open Life-Science AI ) is launching an open, collaborative initiative...
- GitHub - open-thought/system-2-research: System 2 Reasoning Link Collection: System 2 Reasoning Link Collection. Contribute to open-thought/system-2-research development by creating an account on GitHub.
Latent Space ▷ #ai-general-chat (128 messages🔥🔥):
Web Dev to AI Engineer TransitionNVIDIA AI Scraping ControversyJohn Schulman's Departure from OpenAIOpenAI DevDay EventsStructured Outputs in OpenAI API
- Web Devs Transition to AI Engineering: A lively discussion on the feasibility of a web developer to AI engineer transition highlighted the growing demand for AI engineers, stemming from a lack of ML specialists and an increase in companies exploring AI integrations.
- Despite job descriptions demanding ML expertise, many roles are reportedly filled by those with strong web development backgrounds, as companies prioritize API integration skills over deep ML knowledge.
- NVIDIA Faces Scrutiny for AI Data Practices: NVIDIA reportedly engages in mass data scraping for AI purposes, processing 'a human lifetime' of video content daily, despite ethical concerns from employees. Documents and Slack messages leaked suggest this activity is sanctioned at the highest company levels.
- John Schulman Leaves OpenAI for Anthropic: John Schulman announced his departure from OpenAI after nearly nine years, seeking to focus more on AI alignment research at Anthropic. He emphasized his decision was personal and not due to a lack of support at OpenAI.
- OpenAI's Global DevDay Tour Announced: OpenAI will host DevDay events in San Francisco, London, and Singapore, featuring hands-on sessions and demos to showcase developer applications using OpenAI tools. This initiative is part of OpenAI's efforts to engage with the global developer community.
- OpenAI's API Now Supports Structured Outputs: OpenAI introduced a structured output feature in its API that ensures model outputs follow exact JSON Schemas, improving from 86% to 100% schema reliability. The announcement highlights a significant step forward in enhancing the predictability of model responses.
Links mentioned:
- Tweet from Jason Koebler (@jason_koebler): SCOOP from @samleecole: Leaked Slacks and documents show the incredible scale of NVidia's AI scraping: 80 years — "a human lifetime" of videos every day. Had approval from highest levels o...
- Tweet from OpenAI Developers (@OpenAIDevs): We’re taking OpenAI DevDay on the road! Join us this fall in San Francisco, London, or Singapore for hands-on sessions, demos, and best practices. Meet our engineers and see how developers around the ...
- Tweet from Two Weeks LOL (@TwoWeeksLOL): @MKBHD Uh oh...
- Tweet from Michelle Pokrass (@michpokrass): excited to announce Structured Outputs -- our newest feature in the api. model outputs will now reliably follow your exact json schemas, matching the parameters and types accurately. schema reliabil...
- Tweet from anton (@abacaj): interesting... new model also includes a pretty big price drop Quoting OpenAI Developers (@OpenAIDevs) Introducing Structured Outputs in the API—model outputs now adhere to developer-supplied JSON ...
- Tweet from Philipp Schmid (@_philschmid): "Deep Reinforcement Learning from Human Preferences" and "Proximal Policy Optimization Algorithms" are part of the foundation of modern RLHF in LLMs.
- Tweet from roon (@tszzl): all the people that can make eye contact at openai joined in the last 6 months and they’re making me uncomfortable with their eye contact
- Tweet from John Schulman (@johnschulman2): I shared the following note with my OpenAI colleagues today: I've made the difficult decision to leave OpenAI. This choice stems from my desire to deepen my focus on AI alignment, and to start a ...
- Tweet from Mira (@_Mira___Mira_): no description found
- Tweet from Aizk ✡️ (@Aizkmusic): @BigTechAlert @ChatGPTapp @TarunGogineni His LinkedIn bio is great
- no title found: no description found
- eCommerce & Retail: Discover how innovative eCommerce and retail companies use Writer to create on-brand content that works, from first touch to sale.
- no title found: no description found
- Efficient Guided Generation for Large Language Models: In this article we show how the problem of neural text generation can be constructively reformulated in terms of transitions between the states of a finite-state machine. This framework leads to an ef...
- Tweet from jack morris (@jxmnop): funny little story about Extropic AI >been curious about them for a while >have twitter mutual who is an engineer/researcher for this company >often tweets energy-based modeling and LM-quant...
- GitHub - simonw/datasette: An open source multi-tool for exploring and publishing data: An open source multi-tool for exploring and publishing data - simonw/datasette
- Tweet from Nick Dobos (@NickADobos): Great post on writing code with ai Love this chart Quoting Erik Schluntz (@ErikSchluntz) Replacing my right hand with AI (How I wrote thousands of lines of code for work each week while in a cast)...
OpenAI ▷ #annnouncements (1 messages):
OpenAI DevDay 2023Developer engagementGlobal developer events
- OpenAI DevDay Hits the Road: OpenAI announced that DevDay will be traveling to major cities like San Francisco, London, and Singapore this fall for hands-on sessions and demos, inviting developers to engage with OpenAI engineers.
- This event offers a unique opportunity for developers to learn best practices and witness how their peers worldwide are leveraging OpenAI's technology.
- Connect with OpenAI Engineers Globally: Developers are encouraged to meet with OpenAI engineers at the upcoming DevDay events to discover how the latest advancements in AI are being implemented globally.
- These events also provide a platform for participants to collaborate and exchange innovative ideas in the AI development space.
OpenAI ▷ #ai-discussions (86 messages🔥🔥):
Desktop ChatGPT App for WindowsOpenAI Structured OutputsLlama 3.1 Model and APIChatGPT Vision and 4o MiniBing AI Image Creator
- Desktop ChatGPT App & Search GPT Release: Members discussed the upcoming release dates for the desktop ChatGPT app on Windows and the public release of Search GPT, hinting reliance on info from Sam Altman.
- Structured Outputs Improves Response Formatting: OpenAI introduced Structured Outputs, delivering JSON responses aligned with provided schemas, enhancing API interactions.
- The SDKs in Python and Node come with native support, and the models promise to generate consistent and structured outputs, while also being cheaper.
- Llama 3.1 Model Free for Local Use: Members confirmed that Llama 3.1 can be run locally for free, provided it's not used through an API service.
- Local deployment involves downloading the model and utilizing it via custom setups, allowing cost-free operations with minor limitations due to hardware.
- ChatGPT Vision Model Now Cheaper: The new ChatGPT Vision Model has seen a 50% price reduction, promising more affordable access compared to previous iterations.
- Despite being an improvement over 4o mini, some users question potential trade-offs in performance for the reduced cost.
- Bing AI Image Creator Uses DALL-E 3: It was clarified that Bing AI Image Creator relies on DALL-E 3, though some users noted inconsistencies in output quality.
Link mentioned: Assistant GPT - Can I perform knowledge retrieval from a cloud storage?: I have some files that are on my cloud storage (onedrive) and would like to perform knowledge retrieval on them. Is it possible to integrate an assistant to perform knowledge retrieval directly fro...
OpenAI ▷ #gpt-4-discussions (16 messages🔥):
Search GPT releasePhoto upload limit for membersAI in gamingGPT-4o model updateStructured outputs announcement
- Search GPT officially released: A member confirmed that Search GPT has been distributed to users, responding affirmatively to an inquiry regarding its release.
- Photo upload limits frustrate members: A discussion emerged about the limits on photo uploads, with a member noting that even paid users face such upload limits.
- AI to revolutionize gaming experiences: A member envisaged games like BG3 or Pathfinder utilizing generative AI for unique character designs and dynamic NPC interactions, enhancing player immersion.
- Update on GPT-4o model sparks interest: A user noted changes in ChatGPT-4o's response behavior, prompting confirmation from the community about a new model released on 2024-08-06.
OpenAI ▷ #prompt-engineering (1 messages):
darthgustav.: Use the python tool and import data from uploads.
OpenAI ▷ #api-discussions (1 messages):
darthgustav.: Use the python tool and import data from uploads.
Perplexity AI ▷ #general (82 messages🔥🔥):
Issues with LLMs: GPT-4 Turbo vs. 4oContent Sorting and Recommendation EnginePDF Upload Errors with Perplexity AIApplication Stability and Feature ChangesFelo vs. Perplexity Pro Subscription
- 4o Struggles to Keep Conversational Flow: Users expressed frustration with GPT-4o's inability to maintain a conversational flow, repeating past instructions robotically and not acknowledging new directives.
- They claim Sonnet model immediately apologized for 4o's behavior, highlighting perceived deficits.
- Embarking on a Content Sorting Endeavor: A user details a university project aimed at developing a content sorting and recommendation engine that analyzes and prioritizes content from a database.
- Others suggest exploring platforms like 'RAG' and local models for this initiative.
- Token Limit Woes in PDF Uploading: Users face issues uploading large PDFs due to a 'Failed to count tokens' error, notably when files exceed a certain size (100-200k tokens).
- Converting PDFs to TXT format seems to alleviate this problem, circumventing token limitations.
- Perplexity App's Vanishing Features: Some users report sudden disappearance and reappearance of features like switching LLMs and access to library collections in the Perplexity Pro app.
- These intermittent issues have caused confusion and frustration, though functionalities often return spontaneously.
- Stacking Up Against Felo with Free Pro: A user tested Felo against Perplexity's Free and Pro versions with mixed results, citing moments where Felo provided correct answers while Perplexity failed.
- They noted redeeming a 1-month free Pro subscription limited the ability to change LLMs, restricting comprehensive comparison tests.
Links mentioned:
- no title found: no description found
- Releases · inulute/perplexity-ai-app: The Perplexity AI Desktop App, powered by Electron which brings the magic of AI language processing to your desktop. - inulute/perplexity-ai-app
- When Tom's funeral was held, his father didn't attend. Now that his father has passed away, Tom didn't show up at his father's funeral either. Is Tom going too far?: The situation you described involves a complex interplay of personal relationships and individual choices. Here are some points to consider: ### Context and Ba
Perplexity AI ▷ #sharing (7 messages):
NVIDIA Blackwell GPUs delayDigital memory and AIWarhol's $26M digital portrait on YouTubeNavigating Perplexity AI's features
- NVIDIA Blackwell GPUs delayed due to design mishaps: NVIDIA's next-generation Blackwell GPUs have been delayed due to design flaws in the processor die linking two GPUs on a single Superchip, requiring redesign and validation.
- Questioning Digital Memory with Technology: There is no scientific evidence supporting objects like stones having memory; however, AI, like DeepMind's advancements, seeks to emulate human memory replay processes, although still experimental.
- Warhol’s $26M digital portrait stars on YouTube: A YouTube video highlights Andy Warhol’s digital portrait sold for $26M, sparking conversations around art, technology, and value perception.
- Discovering Perplexity AI's Navigation Features: The Perplexity AI platform offers varied interface options, including Pro upgrades with features like image upload and advanced AI capabilities.
Links mentioned:
- YouTube: no description found
- NVIDIA Blackwell's Delay Explained: NVIDIA's next-generation Blackwell GPUs have encountered delays primarily due to design and manufacturing issues. Here are the main reasons for the delay: The...
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- apa saja benda yang mengandung karbon: Benda yang mengandung karbon sangat beragam dan dapat ditemukan dalam berbagai bentuk di kehidupan sehari-hari. Berikut adalah beberapa contoh benda yang...
Perplexity AI ▷ #pplx-api (8 messages🔥):
API Data CorruptionAPI Model DeprecationAPI Error 502 Issues
- API Results Corruption Frustrates Users: A user reported receiving corrupted results from the API when attempting to write an article, with only the first few lines being correct before turning into gibberish.
- They noted that the issue does not occur when reconstructing the whole prompt on the Perplexity site.
- Upcoming API Model Deprecation in August 2024: A member inquired about the deprecation of API models in August 2024, confirmed by shared documentation outlining affected models and their parameters.
- The models
llama-3-sonar-small-32kversions are among those set for deprecation on August 12, 2024.
- The models
- Users Face API Error 502: A user experienced a 502 Error when querying the Perplexity AI API, indicating a possible service disruption.
- However, another user referenced the service status page which reported no notices of disruption during that time.
Links mentioned:
- Perplexity Labs: no description found
- Perplexity - Status: Perplexity Status
- Supported Models: Perplexity Models Model Parameter Count Context Length Model Type llama-3-sonar-small-32k-online 8B 28,000 Chat Completion llama-3-sonar-small-32k-chat 8B 32,768 Chat Completion llama-3-sonar-large-32...
Eleuther ▷ #announcements (1 messages):
Mechanistic anomaly detectionAdversarial examples in image classifiersEleuther's quirky language modelsAttribution patching technique
- Mechanistic anomaly detectors tested with mixed results: Eleuther AI tested mechanistic anomaly detection techniques, which did not consistently outperform traditional non-mechanistic baselines, as detailed in a recent blog post.
- Better performance was achieved when evaluating entire batches of data, but not all tasks showed improvement, highlighting areas for future research.
- Adversarial robustness of anomaly detectors untested: Off-the-shelf techniques showed ease in detecting adversarial examples in image classifiers, but the adversarial robustness of the anomaly detectors wasn't tested.
- Our anomaly detectors may need further evaluation for adversarial robustness, indicating a potential area for continued investigation.
- Eliciting latent knowledge from quirky language models: Eleuther AI published their findings on finetuning language models to behave in a 'quirky' manner in a new paper, exploring the behavior detection problem.
- They distinguished model behaviors using a simple anomaly detection technique, navigating the Alice and Bob heuristic response behaviors, linked to the MAD problem.
Links mentioned:
- Mechanistic Anomaly Detection Research Update: Interim report on ongoing work on mechanistic anomaly detection
- GitHub - EleutherAI/cupbearer at attribution_detector: A library for mechanistic anomaly detection. Contribute to EleutherAI/cupbearer development by creating an account on GitHub.
Eleuther ▷ #general (36 messages🔥):
SB1047 (AI Safety Act) oppositionConcerns with AI regulation and innovationAnthropic's response to SB1047AAAI conference submission relevanceWatermarking and AI safety laws
- Opposition to SB1047 gains momentum: An open letter against SB1047, the AI Safety Act, is circulating, warning that it would negatively impact open-source research and innovation by potentially banning open models and threatening academic freedom.
- Supporters are encouraged to sign a Google Form opposing the bill which is criticized for its potential legal repercussions and economic impact.
- Debate sparks over implications of AI regulation: Discussions reveal significant concerns regarding the ambiguity and potential negative impacts of AI safety regulations like SB1047, especially fears about hindering research and legal uncertainties.
- "The academic letter doesn't seem much more grounded than the YC a16z one (mostly words, no evidence)," a member summarizes, highlighting the lengthy debate and varying interpretations of the bill's effects.
- Anthropic's nuanced take on SB1047: Anthropic's response to SB1047 offers a balanced perspective, acknowledging the need for regulation while highlighting the bill's potential to stifle innovation.
- Some members see the response as a sensible contribution to the broader discourse on AI governance and responsibility.
- AAAI submission relevance questioned: A question arose regarding the value of submitting to AAAI conferences, with members suggesting it might be seen as a venue for papers not deemed strong enough for other conferences.
- Watermarking AI outputs faces scrutiny: Members expressed skepticism towards legislative mandates for watermarking AI outputs, noting the technical hurdles and potential for removal or alteration.
- Though some see legal incentives as drivers for technical solutions, others caution against premature laws that might negatively impact open-source efforts.
Links mentioned:
- DocumentCloud: no description found
- DocumentCloud: no description found
- Letter to YC & a16z | SB 1047 - Safe & Secure AI Innovation: no description found
- Students, Faculty, and Scientists Against SB 1047 (AI Safety Act) Open Letter Signature Form: This is a form to provide your signature in support of our open letter from UC Faculty and students against California SB 1047, a catastrophically bad law attempting to regulate "AI safety" ...
Eleuther ▷ #research (40 messages🔥):
Meta's AI networkDistributed AI Training at ScaleSearch efficiency in AI modelsDifferentiability in search techniquesCompute-optimal inference methods
- Meta builds AI network for massive model training: At ACM SIGCOMM 2024, Meta showcased their network infrastructure connecting thousands of GPUs, essential for training models like LLAMA 3.1 405B.
- Their paper on RDMA over Ethernet for Distributed AI Training highlights designing and operating one of the world's largest AI networks.
- Searching efficiency in AI models debated: Participants discussed the effectiveness of latent space search versus discrete space search, suggesting that searching in the model's latent space might bypass bottlenecks in world model evaluation.
- Suggestions included employing a VQ method for efficient model latent searches, incentivizing the learning of composable subsolutions.
- Differentiability in exotic search techniques questioned: While some argue for differentiable search techniques, others believe simpler methods often outperform, citing unsupervised MT as an example where basic methods worked better than complex ones.
- The debate emphasized the trade-offs between differentiability and computational efficiency in model evaluation functions.
- Scaling compute for inference with sampling strategies: Research indicates that increasing generated samples improves inference performance, especially in scenarios where answers are automatically verifiable.
- Studies explore compute-optimal inference strategies like Tree Search algorithms, showing smaller models can achieve favorable compute-performance trade-offs.
Links mentioned:
- Large Language Monkeys: Scaling Inference Compute with Repeated Sampling: Scaling the amount of compute used to train language models has dramatically improved their capabilities. However, when it comes to inference, we often limit the amount of compute to only one attempt ...
- Self-Taught Evaluators: Model-based evaluation is at the heart of successful model development -- as a reward model for training, and as a replacement for human evaluation. To train such evaluators, the standard approach is ...
- An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models: The optimal training configurations of large language models (LLMs) with respect to model sizes and compute budgets have been extensively studied. But how to optimally configure LLMs during inference ...
- Getting 50% (SoTA) on ARC-AGI with GPT-4o: You can just draw more samples
- RoCE networks for distributed AI training at scale: AI networks play an important role in interconnecting tens of thousands of GPUs together, forming the foundational infrastructure for training, enabling large models with hundreds of billions of pa…
Eleuther ▷ #scaling-laws (4 messages):
Training InstabilityExperiment AveragingLearning Rate Adjustments
- Training Instability Overrides Double Descent Concerns: A discussion member suggested that observed issues are more likely due to noise/training instability rather than double descent phenomena.
- Rationale for Experiment Averaging: The suggestion was made to perform the experiment three to five times and average results to rule out anomalies.
- Learning Rate as a Stability Factor: To decrease the likelihood of training stability issues, a participant proposed lowering the learning rate if the phenomenon persists.
Eleuther ▷ #interpretability-general (5 messages):
State of SAEsResearch on Scaling SAEsSAELens LibraryRecent Developments in Transformer Circuits
- Exploring the State of SAEs in Transformer Research: A user sought guidance on recent developments in Structural Attention Equations (SAEs) and was directed to foundational and recent works such as the Monosemantic Features paper and the Superposition paper, which contextualize SAEs.
- Additional resources include a progression to real-scale SAEs, such as the Anthropic paper on scaling monosemanticity.
- Diverse Approaches to Scaling SAEs: Discussions highlighted the scaling of SAEs in various papers, like one scaling from toy models to 13B parameters by a user group connecting to Anthropic and OpenAI's ongoing research, as seen in a related paper.
- OpenAI has attempted scaling to GPT-4, focusing on methodological advances while EleutherAI actively trains on LLaMA 3.1 405B.
- Leveraging the SAELens Library: SAELens, discussed by the community, is a library created to train and analyze SAEs, with visualizations in Neuronpedia touted for their depth.
- Additionally, EleutherAI's contribution includes an auto-interp library that integrates with NNsight, although its scaling potential is under question.
- Overview of SAE Developments in Transformer Circuits: An overview document of the SAE landscape was shared as a comprehensive starting point for newcomers, hosted in the online collaborative platform Google Docs.
- The document provides historical context and recent advancements, though likely misses the very latest developments in the field.
Links mentioned:
- SAE Landscape: SAE Landscape – A collection of useful publications and tools Welcome to a collection of resources on Sparse Autoencoders (SAEs) for language model interpretability. This is a live document, I appreci...
- A Mathematical Framework for Transformer Circuits: no description found
Eleuther ▷ #lm-thunderdome (8 messages🔥):
lm-eval-harness usageBatch size and loglikelihood_rollingBOS token in evalharnessBenchmark names from JSON output
- Using lm-eval-harness for custom models: A user inquired about using lm-eval-harness to evaluate a model checkpoint for a custom architecture. Another member provided a link to a GitHub example on overriding model methods to ensure compatibility with custom model types.
- Batch processing in eval-harness: A user questioned if 'loglikelihood_rolling' respects batch size in the Huggingface model class, suggesting it might be processing one request at a time.
- Special tokens in evalharness: There was confusion regarding whether evalharness adds a BOS token by default, since default tokenizer behavior is
add_special_tokens=True.- A user confirmed that even though BOS tokens may not appear in generated sample files, the default setting includes them.
- Extracting benchmark names from JSON: A member discussed how to find benchmark names from JSON output by accessing the
resultskey, which contains another dictionary with benchmark names as keys and scores as values.
Link mentioned: mamba/evals/lm_harness_eval.py at main · state-spaces/mamba: Mamba SSM architecture. Contribute to state-spaces/mamba development by creating an account on GitHub.
LangChain AI ▷ #general (83 messages🔥🔥):
GPU Out of Memory IssuesLangChain Integration QuestionsAutomatic Code Review ChallengesLangGraph Course RecommendationsMood2Music App Launch
- GPU Out of Memory Quandaries: A user encountered a memory overflow issue when attempting to load models that were too large for their available 8GB GPU vRAM, requiring suggestions for adjustments or lesser model usage.
- They resolved it by forcing the system to run entirely on CPU, although this resulted in slower performance.
- Navigating LangChain Tool Integration: A user inquired about integrating RunnableWithMessageHistory in LangChain v2.0 for chatbot development without sufficient documentation.
- Another query explored storing message history during tool calling, based on a tutorial thread.
- Automatic Code Review Position Miscalculations: Automatic code reviews using GPT-4o struggled to correctly assess positions within GitHub diffs due to counting issues.
- One suggestion was to avoid using a vision model and instead parse and retrieve data with a more coding-specific approach.
- LangGraph Learning Pathways: For those struggling with LangGraph concepts, online resources like DeepLearning.ai and Udemy were recommended.
- The suggestion emphasized starting with basic courses to solidify understanding before advancing.
- Mood2Music App Set to Resonate with Users: A new app, Mood2Music, was announced, focusing on providing music recommendations based on the user's mood and integrating with platforms like Spotify and Apple Music.
- The app claims to enhance the user's listening experience by creating personalized playlists, featuring unique features such as AI selfie analysis for automatic mood detection.
Links mentioned:
- mood2music: no description found
- AI Agents in LangGraph: Build agentic AI workflows using LangChain's LangGraph and Tavily's agentic search. Learn directly from LangChain and Tavily founders.
- Vector DB Comparison: Vector DB Comparison is a free and open source tool from VectorHub to compare vector databases.
- Build a Chatbot | 🦜️🔗 Langchain: Overview
- Can Ollama use both CPU and GPU for inference? · Issue #3509 · ollama/ollama: What are you trying to do? May I know whether ollama support to mix CPU and GPU together for running on windows? I know my hardware is not enough for ollama, but I still want to use the part abilit...
LangChain AI ▷ #share-your-work (2 messages):
AgentGenesis ProjectOpen Source Collaboration
- AgentGenesis Boosts AI Development: AgentGenesis is an AI component library offering copy-paste code snippets to enhance Gen AI application development, promising a 10x boost in efficiency, and is available under an MIT license.
- The project features include a comprehensive code library with templates for RAG flows and QnA bots, supported by a community-driven GitHub repository.
- Call for Contributors to AgentGenesis: AgentGenesis is seeking active contributors to join and enhance the ongoing development of their open-source project, which emphasizes community involvement and collaboration.
- Interested developers are encouraged to star the GitHub repository and contribute to the library of reusable code.
Links mentioned:
- AgentGenesis: Copy paste the most trending AI agents and use them in your project without having to write everything from scratch.
- GitHub - DeadmanAbir/AgentGenesis: Welcome to AgentGenesis, your source for customizable Gen AI code snippets that you can easily copy and paste into your applications.: Welcome to AgentGenesis, your source for customizable Gen AI code snippets that you can easily copy and paste into your applications. - DeadmanAbir/AgentGenesis
Interconnects (Nathan Lambert) ▷ #news (57 messages🔥🔥):
John Schulman's move to AnthropicConfidential Gemini programSabbatical of Greg from OpenAIClaude and Gemini comparisonAGI alignment perspectives
- John Schulman surprises with move to Anthropic: John Schulman announced his decision to leave OpenAI for Anthropic to focus on AI alignment and hands-on technical work, highlighting his desire for new perspectives.
- Leaked whispers around Gemini program intrigue members: Members discussed confidential details about OpenAI's Gemini program, expressing amazement at potential leaks and the mysterious nature of Gemini 2.
- Greg Brockman takes a break from OpenAI marathon: Greg Brockman announced his sabbatical from OpenAI, marking the first time he will relax since co-founding the company, fueling speculations about his motivations.
- Claude lags behind ChatGPT in user experience: Users critically compared Claude and ChatGPT, with Claude being seen as lagging behind in performance akin to older GPT-3.5 models, while ChatGPT excelled in flexibility and memory.
- Divergent views spark debate on AI alignment: Conversations highlighted differing approaches to AI alignment, with John Schulman focusing on practical issues like prompt adherence, unlike Jan Leike who worries about broader implications of AI safety.
Links mentioned:
- Tweet from John Schulman (@johnschulman2): I shared the following note with my OpenAI colleagues today: I've made the difficult decision to leave OpenAI. This choice stems from my desire to deepen my focus on AI alignment, and to start a ...
- Tweet from Simon Willison (@simonw): Hidden at the bottom of this announcement: "By switching to the new gpt-4o-2024-08-06, developers save 50% on inputs ($2.50/1M input tokens) and 33% on outputs ($10.00/1M output tokens) compared ...
- Tweet from Greg Brockman (@gdb): I’m taking a sabbatical through end of year. First time to relax since co-founding OpenAI 9 years ago. The mission is far from complete; we still have a safe AGI to build.
Interconnects (Nathan Lambert) ▷ #random (6 messages):
DALL-E vs. challengersFlux ProReplicate's hosting of Flux.1Comparison of image generation models
- DALL-E faces competition in image generation: Discussion reveals curiosity about whether DALL-E remains the leading image generation tool with an API amid rising competition.
- A member wonders about the criteria for comparing these models, implying intuition or 'vibes' might play a significant role.
- Flux Pro offers a novel experience: One user describes Flux Pro as having a really different vibe compared to other models in the space.
- It's not about quantitative benchmarks, but more about the subjective experience.
- Flux.1 available on Replicate: Flux.1, which some people enjoy, is now hosted on Replicate, as discussed by the members.
- It highlights a broader consideration of how hosting might influence accessibility and user satisfaction.
Interconnects (Nathan Lambert) ▷ #memes (1 messages):
xeophon.: https://x.com/sahir2k/status/1820791954508022019?s=46
Interconnects (Nathan Lambert) ▷ #rlhf (1 messages):
Data-dependency in model performanceStartups using noisy dataICML discussion on Meta's Chameleon
- Data-dependency impacts model benefits: The conversation highlighted that model benefits from breaking data into components like ( (x, y_w) ) and ( (x, y_l) ) depend heavily on data noise levels.
- Startups favor noisy data strategies: Startups tend to apply these techniques more often due to the noisy nature of their data, which can lead to bypassing standard SFT processes.
- ICML chat mentions Meta's Chameleon: At ICML, someone mentioned that Armen from Chameleon at Meta is a fan of such data strategies; however, it's unclear if they are used in production models.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
GPT4-4o releaseStructured outputs with strict mode
- GPT4-4o Release OpenRouter: The new model GPT4-4o-2024-08-06 is now available on OpenRouter.
- Issues with Strict Mode Structured Outputs: Structured outputs with strict mode are currently not fully supported, with issues to be reported in designated channels.
- Users are encouraged to report any issues encountered to improve the system's functionality.
Link mentioned: GPT-4o (2024-08-06) - API, Providers, Stats: The 2024-08-06 version of GPT-4o offers improved performance in structured outputs, with the ability to supply a JSON schema in the respone_format. Read more [here](%5Bhttps://openai%5D(https://openai). Run GPT-4o (2024-08...
OpenRouter (Alex Atallah) ▷ #general (62 messages🔥🔥):
AI Model PerformanceGPT-4o-2024-08-06 UpdateToken Usage and PricingGoogle Gemini UpdateAPI Cost Calculation
- AI Models Face Performance Challenges: yi-vision and firellava were tested by a member but failed compared to haiku/flash/4o due to pricing and performance issues on a single test image.
- The conversation hinted at price changes for Google Gemini 1.5, which will soon be cheaper than the less effective models mentioned.
- GPT-4o-2024-08-06 Boasts Structured Outputs: OpenAI introduced structured outputs in their API for the new gpt-4o-2024-08-06, promising better and more cost-effective token usage compared to previous models.
- There are expectations for improved JSON generation consistency, with details available through OpenAI's blog.
- Understanding Token Pricing and Savings: Developers can save 50% on inputs and 33% on outputs by switching to gpt-4o-2024-08-06, which is cheaper than previous offerings.
- The community discussed the potential reasons for reduced costs, including efficiency and usage of investor resources.
- Methods to Calculate API Costs Discussed: A conversation unfolded regarding the calculation of OpenRouter API costs, with the consensus being to utilize the
generationendpoint post-request for exact details.- This information empowers users to manage pay-as-you-go systems by assessing usage without embedded cost details in streaming replies.
- Rate Limiting Affects Google Gemini Model: Users experienced issues with Google Gemini Pro 1.5, particularly 'RESOURCE_EXHAUSTED' errors due to heavy rate limiting by Google.
- This situation necessitates adjustment expectations for usage as there is no immediate fix for the rate limit constraints.
Links mentioned:
- no title found: no description found
- OpenAI: Introducing Structured Outputs in the API: OpenAI have offered structured outputs for a while now: you could specify `"response_format": {"type": "json_object" }}` to request a valid JSON object, or you could use t...
- Responses | OpenRouter: Manage responses from models
- Anthropic Status: no description found
- GPT-4o (2024-08-06) - API, Providers, Stats: The 2024-08-06 version of GPT-4o offers improved performance in structured outputs, with the ability to supply a JSON schema in the respone_format. Read more [here](https://openai. Run GPT-4o (2024-08...
LlamaIndex ▷ #announcements (1 messages):
Webinar with CodiumAIRAG-augmented coding assistantsLlamaIndex for code generation
- Join Webinar on RAG-Augmented Coding Assistants: Webinar with CodiumAI on RAG-augmented coding assistants is happening soon!
- Participants need to register and verify token ownership with their wallet to attend.
- Exploring RAG with LlamaIndex in Coding: Retrieval-Augmented Generation (RAG) is pivotal for achieving contextual awareness in AI-generated code, as discussed in the upcoming webinar.
- The session will showcase an advanced RAG approach using LlamaIndex infrastructure with examples of practical applications for maintaining code quality and integrity.
Link mentioned: LlamaIndex Webinar: Using RAG with LlamaIndex for Large-Scale Generative Coding · Zoom · Luma: Retrieval-Augmented Generation (RAG) plays a central role in achieving contextual awareness in AI-generated code, which is crucial for enterprises adopting…
LlamaIndex ▷ #blog (4 messages):
RabbitMQ and llama-agentsSecond RAG-a-thonWorkflows feature in LlamaIndexBuilding Multi-agents as a Service
- Building Multi-agent Systems with RabbitMQ: A blog by @pavan_mantha1 demonstrates building a local multi-agent system using RabbitMQ to broker communication between different agents, integrating @ollama and @qdrant_engine.
- Gear Up for LlamaIndex's Second RAG-a-thon: Following the success of the first event, LlamaIndex is hosting another RAG-a-thon in partnership with @pinecone and @arizeai at the @500GlobalVC offices in Palo Alto.
- Mastering Complex Workflows in LlamaIndex: In a new YouTube video, @seldo explains the basics of creating, running, and visualizing workflows, and managing their structure, looping, branching, and state within LlamaIndex.
- Comprehensive Guide to Llama-agents: The community has requested more extensive documentation about llama-agents, the core repository for building multi-agents as a service.
LlamaIndex ▷ #general (49 messages🔥):
HuggingFace Inference API for embeddingsSimpleDirectoryReader PDF loadingVector DB ComparisonIssue with function_calling.py in llama_indexStructured Outputs in OpenAI API
- Generate embeddings with HuggingFace Inference API: A member inquired about using the HuggingFace Inference API to generate embeddings, specifically mentioning a private endpoint for Jina.ai.
- Another member provided a link to relevant documentation on LlamaIndex examples for embedding.
- SimpleDirectoryReader loads PDFs page by page: The SimpleDirectoryReader loads each PDF page as individual documents, allowing metadata like page labels to be associated.
- Options to modify the
PDFReadersetup were shared, including Python code examples to treat PDFs as single documents.
- Options to modify the
- Vector DB Comparison serves as useful resource: The Vector DB Comparison was shared for its usefulness in evaluating vector databases.
- Community encouraged sharing experiences with different VectorDBs to benefit everyone's learning.
- LlamaIndex function_calling.py causing CI issues: A TypeError in
function_calling.pyfrom LlamaIndex caused CI processes to fail until upgradingllama-index-llms-bedrock-converse.- The issue was identified possibly due to outdated package requirements, solved by explicitly specifying dependencies.
- OpenAI's Structured Outputs are supported: OpenAI's Structured Outputs in the API are already supported by the Llama Index when the
strict=Trueparameter is set.- Though functional, it significantly increases latency compared to non-strict mode, with one call taking significantly longer than parsing with pydantic.
Links mentioned:
- Vector DB Comparison: Vector DB Comparison is a free and open source tool from VectorHub to compare vector databases.
- llama_index/pyproject.toml at 6eea66ed23fb85ee77664148a4c2b66720caabeb · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Text Embedding Inference - LlamaIndex: no description found
- GitHub - run-llama/llama_index at 15227173b8c1241c9fbc761342a2344cd90c6593: LlamaIndex is a data framework for your LLM applications - GitHub - run-llama/llama_index at 15227173b8c1241c9fbc761342a2344cd90c6593
- llama_index/llama-index-core/llama_index/core/llms/function_calling.py at 15227173b8c1241c9fbc761342a2344cd90c6593 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
Cohere ▷ #discussions (29 messages🔥):
Galileo Hallucination IndexOpen Source vs Open WeightsCommand R Plus LicensingMistral Licensing and Access
- Galileo's Hallucination Index stirs debate: The release of Galileo's Hallucination Index sparked discussions about the criteria used to classify LLMs as open or closed source, particularly focusing on whether Command R Plus is classified accurately.
- Users questioned if Command R Plus were indeed open source, with some advocating for a clearer distinction between open weights and completely open-source models.
- Contentious licensing of Command R Plus: Galileo's response clarified that they classified a model as open source only if it supports commercial use, pointing to Command R Plus's Creative Commons Attribution Non Commercial 4.0 license as a limiting factor.
- Debate ensued over the appropriateness of this definition, with members suggesting a new category for 'open weights', distinct from open source.
- Mistral open weights: least restrictive?: Contrary to the general consensus about AI models being labeled as open weights, a member pointed out that Mistral's models are available under Apache 2.0, a more permissive license offering greater freedom.
- Efforts to confirm this included sharing links to Mistral's official documentation, showcasing their transparency with both pre-trained and instruction-tuned models.
Links mentioned:
- Apache 2.0 models | Mistral AI Large Language Models: We open-source both pre-trained models and instruction-tuned models. These models are not tuned for safety as we want to empower users to test and refine moderation based on their use cases. For safer...
- LLM Hallucination Index - Galileo: LLM Hallucination Index. A Ranking & Evaluation Framework For LLM Hallucinations
- LLM Hallucination Index - Galileo: LLM Hallucination Index. A Ranking & Evaluation Framework For LLM Hallucinations
Cohere ▷ #questions (3 messages):
Contacting Dennis Padilla
- Seeking Dennis Padilla's email: A member was trying to contact Dennis Padilla after learning that Lauren is on vacation but couldn't find his email address.
- Another user inquired about the context of the email request to potentially assist.
- No Additional Information Available: The provided messages do not contain more detailed topics for further summaries.
- As a result, there is a lack of diversity in the discussion topics to elaborate on.
Cohere ▷ #cohere-toolkit (1 messages):
Cohere Toolkit integrationSwitching modelsThird-party API usageOpenAI integrationGemini 1.5 compatibility
- Integrating Cohere Toolkit with Creative Corpus: A member mentioned using Cohere Toolkit for an AI fellowship project to build an LLM with RAG over diverse knowledge bases like Confluence, culinary notes, winery records, or law firm case notes.
- Exploring 3rd Party API Models Over Cohere: A query was raised regarding the feasibility of switching from Cohere models to third-party APIs such as OpenAI's Chat GPT or Gemini 1.5.
Modular (Mojo 🔥) ▷ #mojo (30 messages🔥):
InlineList developmentSmall buffer optimization in MojoUsing custom accelerators with MojoRVV support in open-source Mojo
- InlineList makes strides with new features: The development of
InlineListis progressing with new features needed, as highlighted by a recent merge.- Technological prioritization seems to guide the timeline for introducing
__moveinit__and__copyinit__methods inInlineList.
- Technological prioritization seems to guide the timeline for introducing
- Small buffer optimization adds flexibility to Mojo Lists: Mojo introduces a small buffer optimization for
Listusing parameters likeList[SomeType, 16], which allocates stack space.- Gabriel De Marmiesse elucidates that this enhancement could potentially subsume the need for a distinct
InlineListtype.
- Gabriel De Marmiesse elucidates that this enhancement could potentially subsume the need for a distinct
- Custom accelerators await Mojo's open-source future: Custom accelerators like PCIe cards with systolic arrays and CXL.mem are considered potential candidates for Mojo use upon open-sourcing, especially highlighted by dialogue on hardware integration features.
- For now, using Mojo for custom kernel replacements remains challenging, with existing flows, such as lowering PyTorch IR, remaining predominant until Mojo supports features like RISC-V targets.
Links mentioned:
- modula - Overview: GitHub is where modula builds software.
- [stdlib] Add optional small buffer optimization to `List`, take 2 by gabrieldemarmiesse · Pull Request #2825 · modularml/mojo: This PR solves part of #2467 This PR is part of three PRs to read and merge in the following order [stdlib] Add optional small buffer optimization to List, take 2 #2825 [stdlib] Work around the ma...
LAION ▷ #general (18 messages🔥):
Leadership changes at OpenAIOpen-source model training challengesMeta's JASCO statusNullbulge controversySchool BUD-E voice assistant
- OpenAI Leadership Shakeup Drives John Schulman to Anthropic: OpenAI co-founder John Schulman announced his departure from the Microsoft-backed company to join Anthropic, following the disbandment of OpenAI's superalignment team just three months prior.
- The transition comes amid strategic shifts within OpenAI, as Schulman previously co-led the post-training team responsible for refining the ChatGPT chatbot.
- Open-Source Struggles with Expensive Training: The community noted that open-source AI projects lag due to the prohibitive costs of training state-of-the-art models, which cannot be conducted in home environments.
- Speculation suggests that if model training were cheaper, there would be a proliferation of open models, disregarding ethical data sourcing concerns.
- Meta's JASCO Quiet Amid Legal Fears: Discussion arose about the absence of Meta's JASCO project, with suspicions that ongoing lawsuits with Udio & Suno may have delayed plans.
- Community concern highlights legal risks impacting the pace of advancements in proprietary AI technology.
- Nullbulge Doxxing Scandal: Comments emerged regarding the controversial figure known as Nullbulge, who has apparently been doxed.
- Users cautioned others against Googling Nullbulge due to the potentially revealing and harmful content.
- Introduction of School BUD-E: A New Browser Voice Assistant: A YouTube video introducing the School BUD-E voice assistant was shared as an innovative web-browser tool.
- The solution aims to potentially transform educational interactions through its vocal user interface.
Links mentioned:
- OpenAI co-founder John Schulman says he will leave and join rival Anthropic: Schulman said OpenAI executives remain committed to backing efforts to ensure that people can control highly capable artificial intelligence models.
- School BUD-E web-browser Voice Assistant: no description found
- Trio of Leaders Leave OpenAI — The Information: no description found
LAION ▷ #research (8 messages🔥):
Val Acc UpdateScaling ExperimentsAccuracy Wall discussionFrequency-Phase Inquiry
- Val Acc jumps to 84%: An update was shared where the model achieved 84% validation accuracy.
- This was followed by a hint of belief, reminiscent of a famous scene from The Matrix.
- Scaling Up Experiments Stumble: Efforts to scale the model to 270k parameters did not enhance performance, as it reached a similar accuracy threshold as smaller models.
- CIFAR Image Frequency Inquiry: A member raised a question on how CIFAR images appear in Fourier Transform terms.
- The question focused on whether frequency information remains consistent while phase differs.
Link mentioned: The Matrix Laurence Fishburne GIF - The matrix Laurence fishburne Morpheus - Discover & Share GIFs: Click to view the GIF
tinygrad (George Hotz) ▷ #general (8 messages🔥):
Tinygrad compatibility with AuroraIntel GPU supportAurora's ExaFLOP capabilitiesFP8 Nvidia bounty requirements
- Feasibility of Running Tinygrad on Aurora: A member questioned the feasibility of running tinygrad on the Aurora supercomputer at Argonne National Laboratory due to its Intel GPUs.
- Intel Max Data Center GPU Insights: Discussion about Aurora's GPUs revealed they support tensor core instructions similar to A770s, but output in 16x8 matrices instead of 8x8.
- Aurora’s Performance Predictions: Aurora, expected to surpass 2 ExaFLOPS, could become the fastest supercomputer after performance optimizations.
- FP8 Nvidia Bounty on Precision Requirements: A member inquired whether the FP8 Nvidia bounty required support for E4M3, E5M2, or both.
Links mentioned:
- cl_intel_subgroup_matrix_multiply_accumulate: no description found
- Aurora (supercomputer) - Wikipedia: no description found
tinygrad (George Hotz) ▷ #learn-tinygrad (16 messages🔥):
Bug in Tensor slicingBuffer to DEFINE_GLOBAL mappingJIT and inconsistent batch sizesComputer algebra study notesMulti-threading in CLANG and LLVM
- Fix bugs in Tensor slicing: A member encountered an
AssertionErrorwhen assigning to a Tensor slice and later noted the error's fix was in the tests.- George Hotz confirmed the issue should be addressed to ensure the slice is contiguous.
- Mapping Buffers to DEFINE_GLOBAL in Tinygrad: A user queried how Buffers are mapped to
DEFINE_GLOBALvariables when performing operations like addition in Tinygrad.- The conversation highlighted a lack of clarity in the transition from Buffer to MemBuffer in the system.
- JIT errors with inconsistent batch sizes: Members discussed problems with JIT errors due to inconsistent batch sizes in datasets that don't perfectly divide.
- George Hotz suggested running the JIT on all batches but the last or skipping the last batch to resolve this.
- Computer Algebra Study Notes Available: A user shared study notes on computer algebra as a supplement to understanding Tinygrad's shapetracker and symbolic math.
- These notes are available on GitHub.
- Single Threading in CLANG and LLVM: There was a query about CLANG and LLVM's threading capabilities, to which it was clarified they use a single thread.
- It was noted that incorporating OpenMP could potentially address this, referencing related pull requests on Tinygrad's repository.
Link mentioned: computer-algebra-study-notes/README.md at main · mesozoic-egg/computer-algebra-study-notes: Contribute to mesozoic-egg/computer-algebra-study-notes development by creating an account on GitHub.
DSPy ▷ #show-and-tell (6 messages):
Wiseflow toolGolden Ret and Wiseflow integrationHybridAGI project release
- Wiseflow Mines Data Efficiently: Wiseflow is an agile information mining tool that extracts concise messages from various sources, including websites and social platforms, and automatically categorizes them. It is detailed on GitHub.
- Golden Ret and Wiseflow creative merge: A suggestion was made to combine Golden Ret with Wiseflow to create a dynamic knowledge base.
- HybridAGI Launches New Version: The HybridAGI system, a neuro-symbolic cypher-focused project, released a new version with enhancements focused on usability and data processing pipelines. It comes with various notebooks such as Vector-only RAG and Knowledge Graph RAG and is available on GitHub.
Links mentioned:
- GitHub - TeamWiseFlow/wiseflow: Wiseflow is an agile information mining tool that extracts concise messages from various sources such as websites, WeChat official accounts, social platforms, etc. It automatically categorizes and uploads them to the database.: Wiseflow is an agile information mining tool that extracts concise messages from various sources such as websites, WeChat official accounts, social platforms, etc. It automatically categorizes and ...
- GitHub - SynaLinks/HybridAGI: The Programmable Cypher-based Neuro-Symbolic AGI that lets you program its behavior using Graph-based Prompt Programming: for people who want AI to behave as expected: The Programmable Cypher-based Neuro-Symbolic AGI that lets you program its behavior using Graph-based Prompt Programming: for people who want AI to behave as expected - SynaLinks/HybridAGI
DSPy ▷ #papers (2 messages):
LLM-based agents in software engineeringScaling inference compute in language models
- LLM-based agents aim for AGI potential: The paper discusses the potential of LLM-based agents which combine LLMs for decision-making and action-taking, aiming to overcome limitations such as lack of autonomy and self-improvement in regular LLMs View PDF.
- Despite their promise, the field lacks a unified standard to qualify a solution as an LLM-based agent in software engineering, highlighting the need for distinction between LLMs and LLM-based agents.
- Inference compute boosts performance: Scaling inference compute by increasing sample generation significantly improves language model performance in domains with verifiable answers, according to the study.
- In the SWE-bench Lite domain, the DeepSeek-V2-Coder-Instruct's performance rose from 15.9% to 56% solved issues with 250 samples, compared to the single-attempt state-of-the-art of 43%.
Links mentioned:
- Large Language Monkeys: Scaling Inference Compute with Repeated Sampling: Scaling the amount of compute used to train language models has dramatically improved their capabilities. However, when it comes to inference, we often limit the amount of compute to only one attempt ...
- From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future: With the rise of large language models (LLMs), researchers are increasingly exploring their applications in var ious vertical domains, such as software engineering. LLMs have achieved remarkable succe...
DSPy ▷ #general (7 messages):
MIPRO performanceMIPROv2 capabilities
- MIPRO's performance comparison: Discussion on whether MIPRO always performs better than BootstrapFewShotWithRandomSearch concluded that MIPRO often performs better, but not necessarily in all cases.
- MIPROv2 lacks assertion support: A query regarding MIPROv2's support for assertions was answered, indicating that it does not yet support assertions.
DSPy ▷ #colbert (1 messages):
gamris: Would you recommend FastEmbed by Qdrant instead? https://github.com/qdrant/fastembed
OpenAccess AI Collective (axolotl) ▷ #general (7 messages):
Synthetic Data StrategySQL Examples in Llama IndexMD5 Hash ConsistencyBits and Bytes Pull Request
- Synthetic Data Strategy for Reasoning Tasks: A community member inquired about developing a synthetic data generation strategy for 8b models to improve reasoning tasks such as text-to-SQL, suggesting the use of Chain-of-Thought (CoT) in synthetic instructions.
- The consideration includes enhancing performance by training with CoT before outputting the final SQL query.
- Llama Index Provides SQL Examples: Another member mentioned that Llama Index includes some SQL examples which could be useful for tasks requiring SQL generation.
- No additional details or links were provided regarding these SQL examples.
- MD5 Hash Consistency in LoRA Adapter Merging: A user queried about the MD5 hash consistency when merging a LoRA adapter multiple times, getting consistent results.
- Another member confirmed that consistent MD5 hashes are expected, and a discrepancy indicates a problem.
- Tracking Bits and Bytes Development: A user pointed out the importance of monitoring the branch in a Bits and Bytes Foundation pull request for relevant updates.
- This pull request appears to hold significant developments for those interested in the library's evolution.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
Gemma 2 27b QLoRAL40S GPUs performanceFast Python package installer
- Gemma 2 27b QLoRA Needs Tuning: A user mentioned that the QLoRA for Gemma 2 27b might require tweaking the learning rate but is expected to work with the latest flash attention.
- L40S GPUs Provide Decent Training: There was curiosity about model training and serving performance on L40S GPUs. A member stated that training on L40S is pretty decent.
- UV: The Fast Python Package Installer: A GitHub repository for an extremely fast Python package installer, called UV, written in Rust, was shared.
- "Faster pip might be useful for docker building," a member commented.
Link mentioned: GitHub - astral-sh/uv: An extremely fast Python package installer and resolver, written in Rust.: An extremely fast Python package installer and resolver, written in Rust. - astral-sh/uv
OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
Context length adjustment in fine-tuned modelsRoPE scaling for context length
- Adjust context length for fine-tuned models: A member inquired if it's possible to adjust the context length of a fine-tuned model like llama2-13b-hf with an initial context of 4k.
- RoPE scaling offers quick fixes: In response to a query on context length adjustments, RoPE scaling was highlighted as a potential quick fix for increasing context length efficiently.
OpenAccess AI Collective (axolotl) ▷ #announcements (1 messages):
caseus_: Office hours kicks off in an hour in <#1268285745555308649>.
Torchtune ▷ #announcements (1 messages):
PPO integrationQwen2 model supportRLHF trainingFeature requests for Torchtune
- PPO Joins the Torchtune Arsenal: Torchtune has integrated PPO training recipes, enabling Reinforcement Learning from Human Feedback (RLHF) within the platform, as detailed in a new GitHub pull request.
- Qwen2 Models Now Supported: Support for Qwen2 models has been added to Torchtune's training suite, including a 7B model available via GitHub, with 1.5B and 0.5B models arriving soon.
- Community Input Requested for Torchtune Features: Torchtune invites users to suggest new models or recipes they'd like to see added to the platform, encouraging feature requests through GitHub.
Torchtune ▷ #general (9 messages🔥):
Support for DPO in Llama3-8BModel Prompt DifferencesLLAMA3 Instruct Model Download
- Upcoming DPO Support for Llama3-8B: A member inquired about plans to support DPO for Llama3-8B-full-finetune.
- Another member provided a workaround using the
lora_dpo_single_devicerecipe with specific configurations for Llama3-8B.
- Another member provided a workaround using the
- LLAMA3 Model Prompt Variability: There were discussions about differing outputs when prompting the LLAMA3 Instruct Model in various environments.
- Users debated whether a BASE model was being mistaken for an INSTRUCT model despite the correct download.
- Ensure Correct LLAMA3 File Paths: Members emphasized the importance of specifying correct checkpointer and tokenizer paths for downloaded Llama3 files.
- There was confirmation that prompt formatting with the Llama3 Instruct Template is handled automatically by the tokenizer.
Torchtune ▷ #dev (6 messages):
Model Page RefactorPreferenceDataset Refactor
- Model Page Revamp: Members discussed the idea of dedicating an entire page to each model's builders to accommodate the growing number of models, including future multimodal LLMs.
- The revamp could include a model index page for explaining repetitive tasks like downloading and configuring models.
- PreferenceDataset Gets a Makeover: Refactored PreferenceDataset was shared in the chat, supporting the addition of chat functionalities via a unified data pipeline.
- A pull request was mentioned, and feedback was encouraged to further enhance the PreferenceDataset's transformation design.
Link mentioned: [4/n] Refactor preference dataset with transforms design by RdoubleA · Pull Request #1276 · pytorch/torchtune: Context Following the RFC in #1186, we will use the unified message_transform -> template -> tokenization data pipeline in all our datasets. This PR updates PreferenceDataset to follow t...
OpenInterpreter ▷ #general (9 messages🔥):
Local LLM setup issuesOpen Interpreter security measuresPython version compatibilityVision model recommendations
- Local LLM setup woes: downloads unnecessary model copy: A user attempting to set up the interpreter with a local LLM encountered issues where, after selecting their llamafile, input like 'Hello.' triggered an unnecessary download of the same model, culminating in an openai.APIConnectionError.
- Despite identifying some potential progress, this issue remains unresolved, prompting a user request for private message coordination to troubleshoot collaboratively.
- Open Interpreter's privacy and security inquiry: A member expressed interest in the security measures of Open Interpreter, inquiring about documentation regarding data privacy, including data retention on local machines and involvement of third parties.
- The member specifically sought details on whether communication between systems is protected by end-to-end encryption and the encryption standards used.
- Python version compatibility questions with Open Interpreter: There was a query on whether Open Interpreter supports Python 3.12, particularly for installation via the Microsoft App Store.
- Python 3.10 or 3.11 were recommended as compatible versions, indicating that Python 3.12 is not currently supported.
OpenInterpreter ▷ #O1 (2 messages):
Ollama local models setupDeepgram support inquiry
- Set your models up on Ollama: A user explained the process of checking model names via
ollama listand emphasized the need for adequate VRAM for each model on your graphics card.- They advised following specific instructions on GitHub for running locally, highlighting importance of an API key for paid models.
- Inquiry about Deepgram support: A user simply inquired whether the channel supports Deepgram, but no further details were discussed.
Link mentioned: open-interpreter/docs/language-models/local-models/ollama.mdx at main · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
Mozilla AI ▷ #announcements (2 messages):
Llamafile UpdatesCommunity Survey for Gift Cardsqlite-vec Release PartyMachine Learning Paper TalksLocal AI AMA
- Llamafile Gets Major Updates: The core maintainer of Llamafile announced ongoing significant progress in delivering offline, accessible LLMs in a single file, enhancing user accessibility.
- Mozilla AI Survey Offers Gift Cards: A call to the community to share feedback through a survey was made, offering a $25 gift card as an incentive.
- Celebrate sqlite-vec Release: sqlite-vec's release party is underway, inviting participants to explore features and demos with the core maintainer.
- Machine Learning Discussions Take Center Stage: Engage with Machine Learning Paper Talks covering 'Communicative Agents' and 'Extended Mind Transformers', diving into new analytical perspectives.
- Local AI AMA with Core Maintainer: An AMA was held by the core maintainer of Local AI, promoting an open-source, self-hosted alternative to OpenAI.
Link mentioned: Discover Typeform, where forms = fun): Create a beautiful, interactive form in minutes with no code. Get started for free.
MLOps @Chipro ▷ #events (1 messages):
LinkedIn Engineering's ML platform transformationFlyte pipelines
- LinkedIn Engineering revamps ML platform: A live session was announced about how LinkedIn Engineering has transformed their ML platform.
- The focus of the event is on Flyte pipelines and their implementation at LinkedIn.
- Flyte pipelines in action at LinkedIn: The live event covers Flyte pipelines showcasing their practical application within LinkedIn's infrastructure.
- Attendees are expected to gain insights into the engineering strategies and solutions employed by LinkedIn.