[AINews] GPT-4o: the new SOTA-EVERYTHING Frontier model (GPT4O version)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Omnimodality is all you want.
AI News for 5/10/2024-5/13/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (426 channels, and 7769 messages) for you. Estimated reading time saved (at 200wpm): 763 minutes.
Say hello to GPT-4O!
It turns out that the numerous leaks about a "Her" like-chatbot announcement were most accurate, with a surprisingly "hot" voice but also the ability to respond with (an average 300ms, down from ~3000ms) low latency, have vision, handle interruptions and sing, speak faster or in pirate/whale, and more. There's also a waitlisted new desktop app that has the ability to read from the screen and clipboard history that directly challenges the desktop agent startups like Multion/Adept.
But nobody leaked that this also comes with a new versioned model, now confirmed to be the "gpt2-chatbot" that was previewed on LMsys, that is confirmed to be substantially above all other prior frontier models:
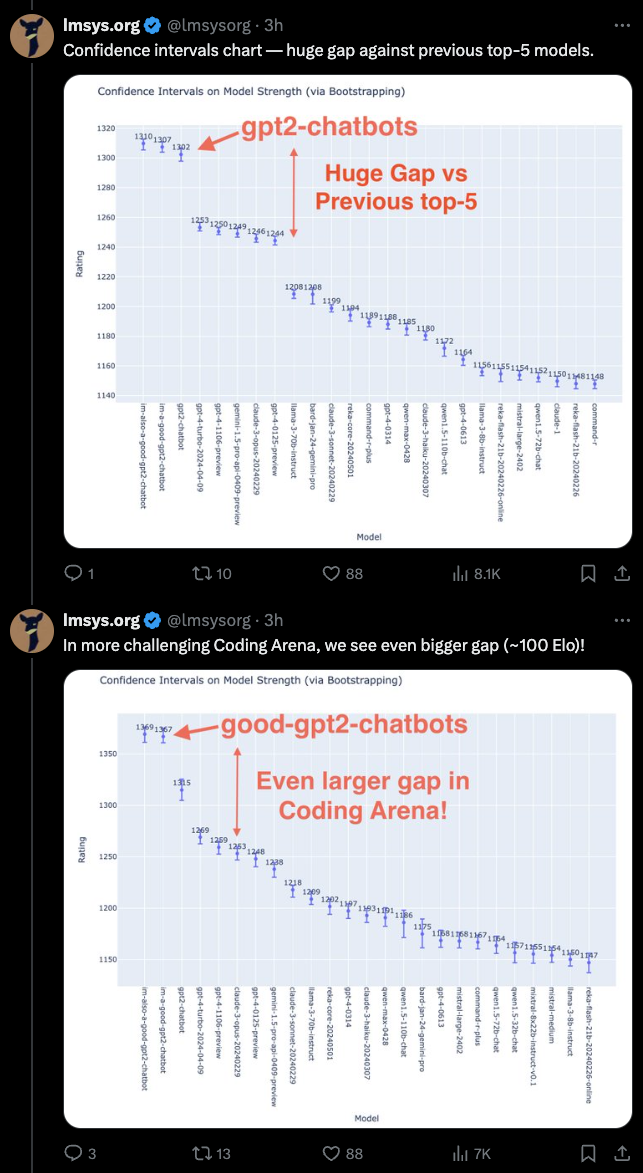
The official blogpost has a lot more video examples demonstrating the app and model, including new versions of image output that may or may not be Dall-E or some completely new thing:
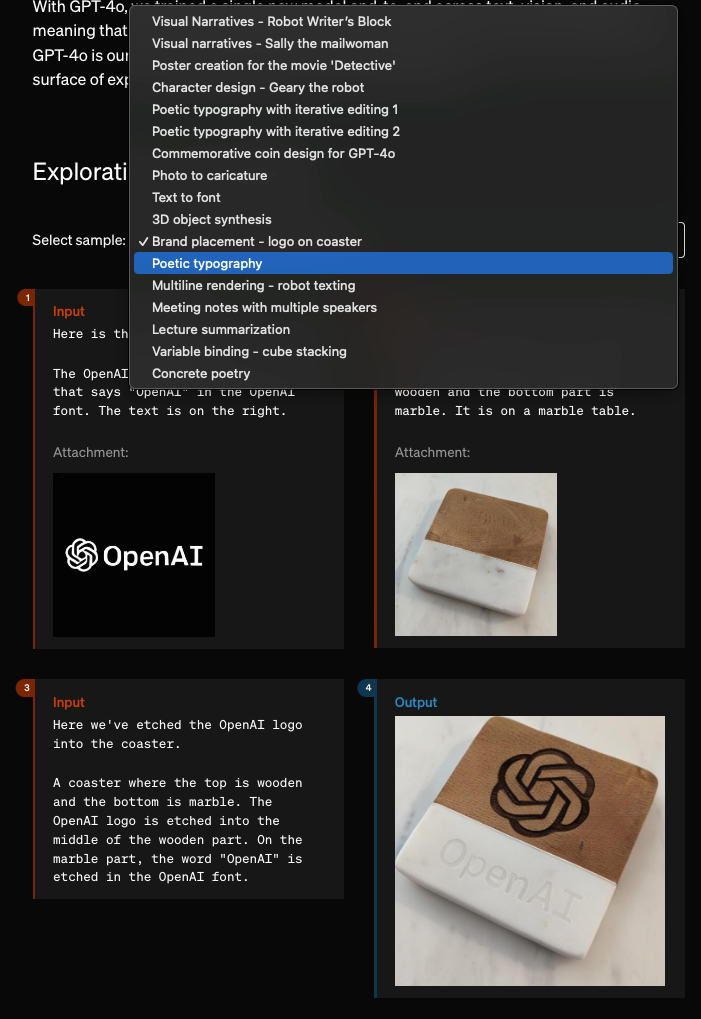
Lots of people are making noise about the 3d object demo, but we can't be sure if that's just code generation since there were hidden steps in there.
To do this, OpenAI had to beat SOTA on everything all at once, including ASR and Vision:
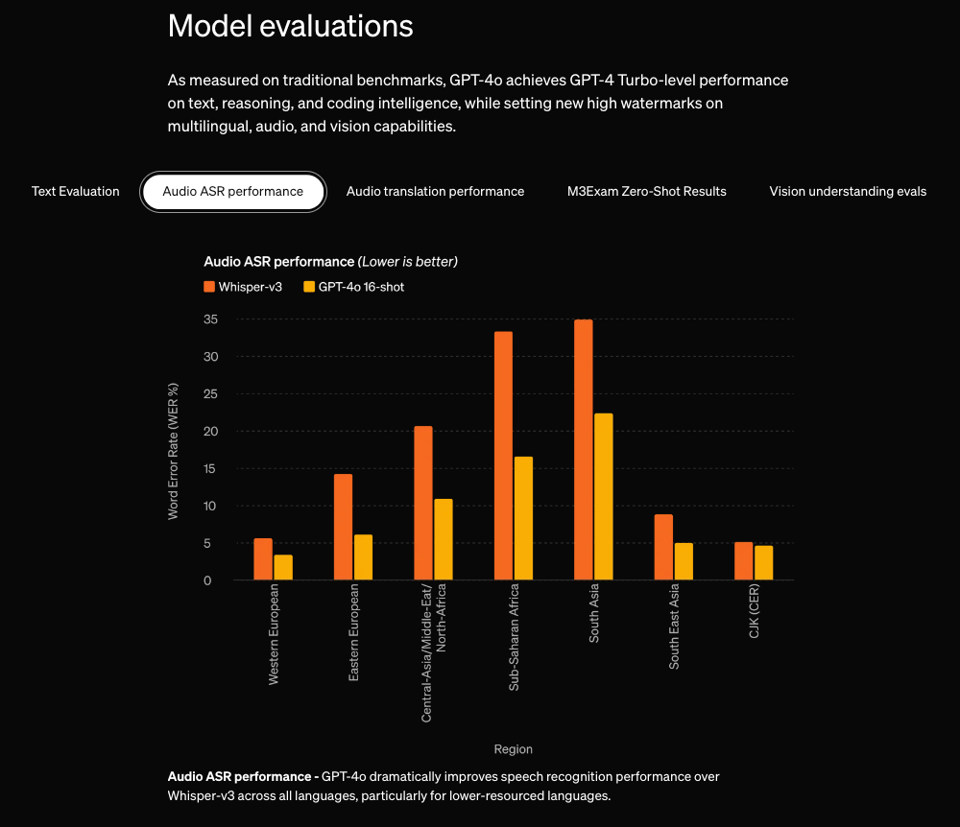
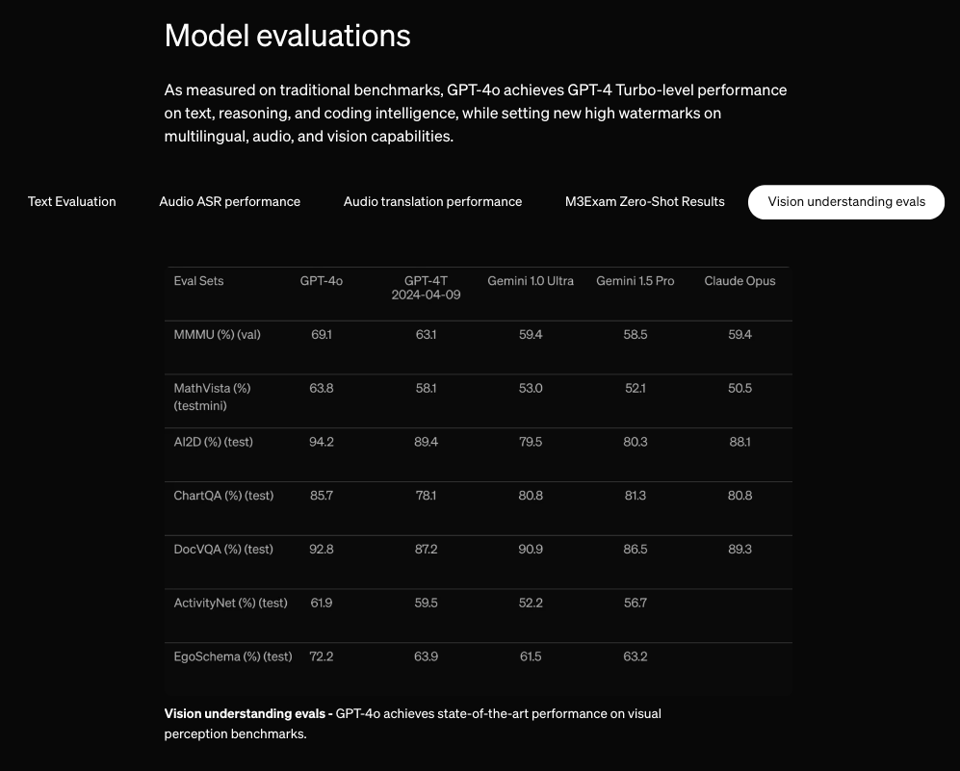
The tiktokenizer update revealed an expanded 200k vocab size that makes non-English cheaper/more native.
Lots more takes are flying, but as is tradition on Frontier Model days on AINews, we're publishing two editions of AINews. You're currently reading the one where all Part 1 and Part 2 summaries are done by GPT4O - the next email you get is the same but with GPT4T (update: it completed here, 74% slower than GPT4O). We envision that you will pull them up side by side (like this!) to get comparisons on discords you care about to better understand the improvements/regressions.

Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- OpenAI Discord
- Nous Research AI Discord
- Latent Space Discord
- Perplexity AI Discord
- HuggingFace Discord
- LM Studio Discord
- OpenRouter (Alex Atallah) Discord
- Modular (Mojo 🔥) Discord
- CUDA MODE Discord
- Eleuther Discord
- Interconnects (Nathan Lambert) Discord
- LAION Discord
- LangChain AI Discord
- LlamaIndex Discord
- OpenAccess AI Collective (axolotl) Discord
- OpenInterpreter Discord
- tinygrad (George Hotz) Discord
- Cohere Discord
- Datasette - LLM (@SimonW) Discord
- Mozilla AI Discord
- DiscoResearch Discord
- LLM Perf Enthusiasts AI Discord
- Alignment Lab AI Discord
- AI Stack Devs (Yoko Li) Discord
- Skunkworks AI Discord
- YAIG (a16z Infra) Discord
- PART 2: Detailed by-Channel summaries and links
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
OpenAI Releases GPT-4o, a Multimodal Model with Voice and Vision Capabilities
- GPT-4o Capabilities: @sama introduced GPT-4o, OpenAI's new model which can reason across text, audio, and video in real time. It is described as smart, fast, natively multimodal, and a step towards more natural human-computer interaction. @gdb noted it is extremely versatile and fun to play with.
- Availability and Pricing: GPT-4o will be available to all ChatGPT users, including on the free plan according to @sama. In the API, it is half the price and twice as fast as GPT-4-turbo, with 5x rate limits @sama.
- Improved Language Performance: GPT-4o has significantly improved non-English language performance, including an improved tokenizer to better compress many languages, as noted by @gdb.
Key Demos and Capabilities
- Real-time Voice and Video: GPT-4o supports real-time voice and video input and output, which feels very natural according to @sama. This feature will roll out to users in the coming weeks.
- Coding Capabilities: GPT-4o is especially adept at coding tasks, as highlighted by @sama and @sama.
- Emotion Detection and Voice Styles: The model can detect emotion in voice input and generate voice output in a wide variety of styles with broad dynamic range, per @sama.
- Multimodal Outputs: GPT-4o can generate combinations of audio, text, and image outputs, enabling interesting new capabilities that are still being explored, according to @gdb.
Reactions and Implications
- Game-changing User Experience: Many, including @jerryjliu0 and @E0M, noted that the real-time audio/video input and output represents a huge step change in user experience and will lead to more people conversing with AI.
- Comparison to Other Models: GPT-4o was compared to other models, with @imjaredz stating it blows GPT-4-turbo out of the water in terms of speed and quality. However, @bindureddy pointed out that open-source models like Llama-3 are still 5x cheaper for pure language/coding use-cases.
- Impressive Demos: People were impressed by demos showcasing GPT-4o's real-time translation abilities @BorisMPower, emotion detection and voice style control @BorisMPower, and ability to sing and dramatize content @swyx.
Other AI News and Discussions
- Apple-OpenAI Deal: Rumors circulated that the Apple-OpenAI deal just closed, one day before OpenAI's voice assistant announcement, leading to speculation that the new Siri will be powered by OpenAI technology @bindureddy.
- Anthropic Constitutional AI: Anthropic released a new prompt engineering tool for their Claude model that can generate prompts optimized for different tasks, as shared by @adcock_brett.
- Open vs Closed AI Debates: There were various discussions on the tradeoffs of open vs closed AI development. Some, like @ylecun, argued that open source frontier models are important for enabling a diversity of fine-tuned systems and assistant AIs. Others, such as @vkhosla, expressed concerns about the national security implications of open models.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
OpenAI's Upcoming Announcement
- Speculation about capabilities: In /r/singularity, there is speculation that OpenAI's May 15th announcement will include agents, Q*-type algorithmic improvements, and architectural upgrades that will "feel like magic". Some in /r/LocalLLaMA expect a voice assistant like the AI in the movie "Her".
- Tempering expectations: However, others in /r/singularity are tempering expectations, believing it will be an incremental improvement but not AGI. The announcement has generated significant hype and speculation.
Advances in AI Capabilities
- Drug discovery success rates: New research shared in /r/singularity shows that AI-discovered drug molecules have 80-90% success rates in Phase I clinical trials, compared to the historical industry average of 40-65%. This represents a significant advancement in AI-powered drug discovery.
- Autonomous fighter jets: According to the Air Force Chief, autonomous F-16 fighters are now "roughly even" with human pilots in performance. This milestone demonstrates the rapid progress of AI in complex domains like aerial combat.
Open Source AI Developments
- Open source AI alliance: As reported in /r/singularity, Meta, IBM, NASA and others have formed an open source AI alliance to be a voice in AI governance discussions. This alliance aims to shape the narrative around AI development and regulation.
- New open source dataset: /r/LocalLLaMA announces the release of code_bagel_hermes-2.5, a new open source dataset similar to the closed source deepseek-coder dataset. Open datasets enable wider participation in AI research.
- Call to open source AlphaFold3: In /r/MachineLearning, researchers are asking Google DeepMind to open source AlphaFold3, their new state-of-the-art protein structure prediction model. Open sourcing cutting-edge models can accelerate scientific progress.
Optimizing AI Performance
- Faster GPU kernels: Researchers at Stanford have released ThunderKittens, an embedded DSL to help write fast GPU kernels that outperform FlashAttention-2 by 30% on the H100. Optimizing GPU performance is crucial for efficient AI training.
- Improved stochastic gradient descent: A new paper introduces Preconditioned SGD (PSGD) which utilizes curvature information to accelerate stochastic gradient descent, outperforming state-of-the-art on vision, NLP and RL tasks. Algorithmic improvements can significantly boost AI performance.
- Enhancing GPT-4 function calling: In /r/OpenAI, it's shown that techniques like adding function definitions, flattening schemas, and providing examples can increase the accuracy of GPT-4 function calling from 35% to 75%. Fine-tuning prompts and inputs can greatly improve AI model performance on specific tasks.
Humor and Memes
- Hype and speculation memes: Various subreddits are sharing memes and jokes about the hype and speculation surrounding OpenAI's upcoming announcement, capturing the excitement and anticipation in the AI community. Examples: "THIS IS ME RN", "Group members be like", "Average 'future is now' fella".
AI Discord Recap
A summary of Summaries of Summaries
Claude 3 Sonnet
1. Efficient AI Model Training and Inference:
- ThunderKittens is gaining traction for optimizing CUDA kernels, seen as more approachable than CUTLASS for tensor core management. It promises to outperform Flash Attention 2.
- Discussions on fusing kernels, max-autotune in torch.compile, Dynamo vs. Inductor, and profiling with Triton aim to boost performance. The Triton Workshop offers insights.
- ZeRO-1 integration in llm.c shows 54% throughput gain by optimizing VRAM usage, enabling larger batch sizes.
- Efforts to improve CI with GPU support in llm.c and LM Studio highlight the need for hardware acceleration.
2. Open-Source LLM Developments:
- Yi-1.5 models, including 9B, 6B, and quantized 34B variants, gain popularity for diverse fine-tuning tasks.
- MAP-Neo, a transparent bilingual 4.5T LLM, and ChatQA, outperforming GPT-4 in conversational QA, generate excitement.
- Falcon 2 11B model, with 5T refined data and permissive license, attracts interest.
- Techniques like Farzi for efficient data distillation and Conv-Basis for attention approximation are discussed.
3. Multimodal AI Capabilities:
- GPT-4o by OpenAI integrates audio, vision, and text reasoning, impressing with real-time demos of voice interaction and image generation.
- VideoFX showcases early video generation capabilities as a work-in-progress.
- Tokenizing voice datasets and training transformers on audio data are areas of focus, as seen in a Twitter post and YouTube video.
- PyWinAssistant enables AI control over user interfaces through natural language, leveraging Visualization-of-Thought.
4. Debates on AI Safety, Ethics, and Regulation:
- Discussions on OpenAI's regulatory moves, like GPU signing and White House collaboration, spark criticism over potential monopolization.
- Concerns arise about the impact of AI art services like Midjourney on artists' livelihoods and potential legal repercussions.
- The release of WizardLM-2-8x22B by Microsoft faces controversy due to similarities with GPT-4.
- Members analyze AI copyright implications and how companies offering indemnity could impact smaller AI ventures.
- Efforts to detect untrained tokens like SolidGoldMagikarp aim to improve tokenizer efficiency and model safety (arXiv paper).
Claude 3 Opus
Here is a high-level summary of the top 3-4 major themes across the Discord channels, with important key terms, facts, and URLs bolded and linked to sources where relevant:
- GPT-4o Launches with Mixed Reviews: OpenAI released GPT-4o, a multimodal model supporting text, image, and audio inputs. It offers free access with limitations and advanced features for Plus users. Engineers noted its speed and cost-effectiveness but criticized its shorter memory and reasoning inconsistencies compared to GPT-4. Excitement grew for upcoming voice and video capabilities. GPT-4o also topped benchmarks on the LMSys Arena.
- Falcon-2 and Yi Models Gain Traction: The open-source Falcon-2 11B model, trained on 5T refined data, was released with a permissive license. Discussions highlighted its multilingual and multimodal capabilities despite restrictive terms. Simultaneously, the Yi-1.5 series by 01.AI garnered praise for strong performance across tasks, with quantized variants like the rare 34B model suiting 24GB GPUs well.
- Tooling and Techniques Advance LLM Efficiency: New tools like ThunderKittens promised optimized CUDA kernels, potentially outperforming Flash Attention 2. The Triton Index and Awesome Triton Kernels repositories cataloged Triton kernels for discovery. Techniques like knowledge distillation, depth scaling, and novel architectures like Memory Mosaics and Conv-Basis attention were explored to enhance LLM fine-tuning and inference efficiency.
- Ethical and Legal Debates Persist in AI Development: Conversations wrestled with the implications of AI-generated art on artists' livelihoods, considering fair use, derivative works, and potential legal challenges for Stability AI and Midjourney. The impact of AI copyright on innovation funding and the indemnification of big tech players over smaller entities remained contentious issues.
Let me know if you would like me to elaborate on any part of this summary or if you have additional questions!
GPT4T (gpt-4-turbo-2024-04-09)
Major Themes: 1. Regulatory Concerns and Monopolistic Moves: There's significant discussion and concern over OpenAI's regulatory actions, particularly around practices that may favor larger companies, potentially leading to a monopolistic environment. Members expressed mixed feelings about OpenAI's moves, with criticisms particularly about potential restrictions that harm smaller competitors.
-
New Model Releases and Enhancements: Several discords discussed the release and capabilities of new models like GPT-4o, WizardLM, and Falcon 2. The release of these models sparked discussions about their enhanced multi-modal capabilities, performance improvements, and general excitement or skepticism about their real-world applications.
-
Technical Tools and Innovations: Various communities delved into technical aspects, discussing new tools and updates such as ThunderKittens for optimizing CUDA kernels, stable diffusion innovations, and advancements in model training techniques. There was a strong focus on optimizing performance and integrating the latest technological advancements.
-
Community Engagement and Speculations: Across several platforms, members engaged in forward-looking speculations about the impact of AI on various sectors. There were debates about the legal implications of deploying AI-driven services, discussions on the potential monopolistic behavior of AI giants, and the community's role in shaping the ethics and policies of AI development.
Significant Discussions Linked to URLs:
- HuggingFace's Regression Analysis: Understanding Depth Scaling in LLMs
- OpenAI's GPT-4o Release Features: Highlighted in multiple discussions across discords for its significant performance improvements and multimodal capabilities. Links to official release notes: GPT-4o Launch Details
- ThunderKittens Optimization Tool: Gaining traction for enhancing CUDA operations, linked here: ThunderKittens GitHub
- Falcon 2's Launch: Discussed for its multilingual and multimodal capabilities across different discords, further details can be found here: Falcon 2
- Legal Concerns Over AI Art: Heated discussions about the implications for artists and legal battles surrounding AI-generated art were prevalent, particularly highlighted in platforms discussing Stability.ai and Midjourney's operations.
GPT4O (gpt-4o-2024-05-13)
-
Regulatory Challenges and Platform Control:
- OpenAI's Regulatory Moves: Discussions spanned multiple communities about OpenAI's implementation of tighter control through measures like compulsory GPU signing and collaboration with the White House, raising concerns over monopolistic tendencies (e.g., [Unsloth AI (Daniel Han)]).
- Competitive Landscape: Concerns were also raised about how these moves could marginalize smaller competitors, favoring big tech companies, indicating a broader fear of restricted innovation in the AI space Nous Research AI.
-
Advancements in and Deployment of New Models:
- GPT-4o Release: Enthusiasm was noted for GPT-4o's launch, highlighting its free public access with certain limitations and multi-modal capabilities integrating audio, vision, and text reasoning OpenAI.
- Community Response: Some noted mixed emotions about GPT-4o's performance compared to previous models, with some excitement over new features overshadowed by noted reasoning inconsistencies Perplexity AI and HuggingFace.
-
Focus on Technical Optimization and Fine-Tuning:
- ThunderKittens: Gained attention for its promising kernel performance improvements, suggested to outperform existing methods like Flash Attention 2 CUDA MODE and Unsloth AI (Daniel Han).
- Fine-Tuning Issues: Multiple communities mentioned difficulties in fine-tuning models like Llama3, with discussions about specific solutions and optimization techniques HuggingFace.
-
Application and Use-Case Innovations:
- World Simulation and AI Agents: Platforms for running simulations like Websim and AI agents for tasks like generating PowerPoint presentations were shared. There was also notable interest in enhancing simulation capabilities, including integrating Digital Audio Workstations Nous Research AI.
- Community Tool Sharing: Users frequently shared code examples, scripts, and tutorials to assist with setting up and configuring AI tools, emphasizing collaborative knowledge sharing across projects like LangChain AI and HuggingFace.
Important Links:
- WizardLM GitHub: https://huggingface.co/alpindale/WizardLM-2-8x22B
- ThunderKittens GitHub: https://github.com/HazyResearch/ThunderKittens
- OpenRouter API Watcher Demo: https://orw.karleo.net/
- RAG Pipeline Tutorial: https://zackproser.com/blog/langchain-pinecone-chat-with-my-blog
- Deep Learning Initialization Guide: https://www.deeplearning.ai/ai-notes/initialization/index.html
- AI Research Papers (various links):
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- OpenAI's Regulatory Debate Heats Up: Community discusses OpenAI's recent moves toward tighter control, with particular focus on compulsory GPU signing and collaboration with the White House. Concerns were aired about creating a monopolistic environment favoring bigger companies over smaller competitors.
- WizardLM Steals the Spotlight: Despite controversy, the WizardLM-2-8x22B model has garnered support, originally released by Microsoft and bearing resemblance to GPT-4. The model stirred conversations about its availability and potential censorship, with resources shared on the WizardLM GitHub page.
- Tuning and Tooling for Peak Performance: On the technical side, discussions emerged about efficient methods and tools for fine-tuning models. Attention was on ThunderKittens kernel for its promising performance gains, potentially outdoing Flash Attention 2, found at ThunderKittens GitHub.
- Unsloth AI Gains Multi-GPU Support: Unsloth AI has been acknowledged for its efficient model fine-tuning capabilities and is slated to support multi-GPU functionality. Importance was given to the tool’s ability to integrate new model variants without needing separate branches, as detailed on Unsloth GitHub.
- Fine-Tuning Frustrations with Llama3: Engineers swapped tactics for addressing fine-tuning challenges with Llama3 models, discussing dataset sizes, padding quirks, and conversions across FP16 to GGUF format. Technical issues such as tokenization inaccuracies with GGUF tokenizers were also a key topic.
- A Peek at Altman's Q&A: OpenAI hosted a Q&A with CEO Sam Altman, focusing on the Model Spec and fostering community engagement. The session's motive is outlined in the Model Spec document.
- Llama Variants Get Finetuned for Token Classification: An engineer has contributed Llama variants optimized for token classification tasks, using LoRA adapters and trained on the conll2003 dataset. These models are accessible via their Hugging Face collection.
Stability.ai (Stable Diffusion) Discord
- SD3: More Myth than Model?: Discussions in the guild were rife with speculation about Stability AI's rumored SD3, akin to the Half-Life 3 anticipation. The lack of official release dates has led to a mix of hope and disappointment among users.
- Call for Fine-Tuning Assistance Answered: An expert stepped forward to aid with fine-tuning Stable Diffusion XL for ad generation, highlighting their experience with the machine learning backend of creativio.ai.
- Complexities of Model Usage and Configuration: Users shared challenges in downloading and setting up sizable models like CohereForAI's C4AI Command R+, and software such as KoboldAI and OogaBooga. These struggles underscored complexities related to software configuration and model file management.
- Art Styles and Animation Insights: Advice was offered on using gpt-4 for identifying art styles and the animatediff with controlnet tile method for animating artwork in a way that remains true to the original piece's aesthetic.
- Image Upscaling Quest: A user sought expertise for enhancing image resolutions using Automatic1111's forge with controlnet, highlighting a broader interest in achieving detailed and high-quality image upscaling within the community.
OpenAI Discord
- GPT-4o Unlocked for Public: OpenAI has released GPT-4o, offering free access with limitations on usage and advanced features reserved for Plus users. This model distinguishes itself with multi-modal capabilities, integrating audio, vision, and text reasoning. Launch Details and Usage Information.
- Mixed Emotions on GPT-4o's Performance: The engineer community's reaction to GPT-4o is divided, highlighting its enhanced speed and cost-effectiveness, albeit accompanied by a shorter memory span and occasional reasoning inconsistencies when compared to its predecessor. Excitement for voice and video feature integrations is palpable, tempered by the current lack of availability and some confusion over rollout schedules.
- Fine-Tuning the AI Toolset: Discussions on APIs reflect the technical crowd's interest in GPT-4T's extended 128k context for more nuanced applications, alongside strategies to manage the randomness at high-temperature settings. Practical concerns include vigilant monitoring of OpenAI's static pricing via their Pricing Page and awaiting the implementation of per-GPT memories discussed in the Memory FAQ.
- Programming Puzzles with Gemini 1.5: AI engineers are troubleshooting problematic moderation filters affecting responses in applications using Gemini 1.5 and shared steps for creating, managing, and linking to downloadable file directories using Python scripts—indicative of their resourceful approach to solving immersion-breaking application constraints.
- ChatGPT with a Supervisory Twist: A user queried about crafting a ChatGPT clone with a 3.5 model that incorporates user message monitoring by an overseeing establishment, suggesting a nuanced approach to interface replication that extends into the administrative oversight realm.
Nous Research AI Discord
- Llama Struggles Beyond 8k: The llama 3 70b model is exhibiting coherency issues when generating content over 8,000 tokens.
- Introducing MAP-Neo: The MAP-Neo project has been unveiled; it's a transparent, bilingual LLM trained on 4.5 trillion tokens, with resources and documentation available on Hugging Face, its dataset, and GitHub repository.
- Revolutionizing Conversational QA with ChatQA: A breakthrough detailed in an arXiv paper, ChatQA-70B outclasses GPT-4 in conversational QA, leveraging the InstructLab framework by IBM/Redhat that introduces incremental enhancements through curated weekly dataset updates, documented here.
- World Simulation Tech Talk: Members shared enthusiasm for WorldSim, a platform for running simulations and discussing philosophy, with technical discussions and bug reports on the simulator command issues. They approached world simulation with a desire for expanded features such as digital audio workstation integration.
- GPT-4o Stirring Debate: GPT-4o's impact on the AI field leveraged controversial opinions within the community, discussing its pros, such as improved coding performance and quantitative efficiency, alongside concerns about its proprietary nature and possible challenges to open-source AI.
Latent Space Discord
- PhD Thesis Worthy of Applause: An NLP PhD thesis attracted attention and praise, with a social media shout-out for the author's achievements.
- No Data Left Behind: Discussion turned to Llama 3's massive 15 trillion token training, sparking debate on data sources and prompting contrast with Stella Biederman’s stance on data necessity.
- AI Infrastructure - Feedback Wanted: A Substack post outlines new infrastructure services designed for AI agents, with a call for the community's input read more here.
- Falcon 2 Takes Flight, But With Tethered Wings: Falcon 2's launch stirred conversations around its leading-edge, multilingual, and multimodal facilities. Licensing conditions, however, raised eyebrows over their restrictiveness.
- GPT-4o Drops Jaws: Revelations around GPT-4o's capabilities, including its low latency and versatile responses, steered debate on API access and real-world performance, as enthusiasts shared OpenAI's latest unveilings.
- OpenAI Watch Party - Join In!: A guild member announced a watch party for an OpenAI event with pre-event festivities kicking off 30 minutes prior discord invite.
- Watch Party Woes: At the Open AI Spring Event, an initial hiccup with the stream's audio occurred, but quick community tips helped improve the situation.
- Apple vs. Google - The Speculative Saga: Amidst rumors of Apple lagging in AI, guild members shared insights into whether Siri might integrate GPT-4o, hinting at the specter of regulatory concerns related discussions.
- Live Impressions of GPT-4o: Live demonstrations of GPT-4o's emotional voice capabilities and its multimodal proficiency wowed engineers, stirring talks of real-time productivity and creative applications event playback.
- AI's Next Move - Competing in the Big Leagues: The community speculated about the competitive consequences of GPT-4o and potential disruptions to applications by Google, Siri, and others, with some considering these steps a stride towards mimicking human interaction.
Perplexity AI Discord
- Cheerio's Challenger: A faster alternative to the Cheerio library was sought for HTML content extraction. A user directed others to Perplexity's AI search for more information.
- Choosing Between AI Services: Conversations compared ChatGPT Plus with Perplexity Pro, with the latter being praised for its niche as an AI search engine enabling features like collections and model flexibility. Claude 3's usage limits in Perplexity Pro were a sore point, with users looking at YesChat for more generous quotas.
- GPT-4o Steals the Spotlight: The community engaged eagerly about the launch of GPT-4o, discussing its better speed and capabilities over preceding models. Interest was high regarding when Perplexity would incorporate GPT-4o into its services.
- Perplexity at the Helm of AI Search: Alexandr Yarats was spotlighted through his recent interview, shedding light on his trajectory from Yandex and Google to becoming Perplexity AI's Head of Search.
- Tutorial Inquiry Indicates Diverse User Base: A user's request for a Perplexity AI tutorial in Spanish signals the platform's global reach and the need for multilingual support resources. A link was shared for a "deep dive," albeit without explicit detail: Deep dive into Perplexity.
HuggingFace Discord
- Unlocking LLM Potential on Modest Hardware: Open-source LLM models like Mistral and LLaMa3 were discussed due to their lower hardware demands compared to ChatGPT. Resources such as LM Studio allow users to discover and run local LLMs.
- Pushing the Frontiers of AI Troubleshooting: Various technical issues were aired, including problems encountered while disabling a safety checker in StableDiffusionPipeline, GPT's data retrieval challenges in RAG applications, and fine-tuning of models like GPT-2 XL on Nvidia A10G hardware. There was also buzz around OpenAI's GPT-4o and its capabilities.
- Dynamic Approaches in AI Learning: From genAI user experience involving containerized applications (YouTube video) to a tutorial on Neural Network Initialization from DeepLearning.ai (deeplearning.ai article), and a JAX and TPU integration for VAR paper (GitHub for Equinox)—the community showcased a breadth of learning resources.
- Phi-3 On-The-Go and Robotic Breakthroughs: Highlighted resources included a paper about Phi-3's efficiency on smartphones (arXiv link), the book "Understanding Deep Learning" for grasping deep learning concepts, and a novel 3D Diffusion Policy (DP3) for robots (3D Diffusion Policy website).
- Innovative Creations and AI Deployments: Community members showcased an array of projects: an AI-powered storyteller (Alkisah AI), Holy Quran verses tool (Kalam AI), an OCR framework (OCR Toolkit on GitHub), fine-tuned Llama variants (HuggingFace collection), and a tutorial for an AI Discord chatbot (YouTube video).
LM Studio Discord
GPT Agents in Learning Limbo: GPT agents' inability to assimilate new information into their base knowledge caused buzz, with clarification on how information is stored as "knowledge" files that don't update the agent's core understanding.
Hardware Hurdles for Hi-Tech Pursuits: Engineers faced challenges running advanced models like Llama 3 70B Q8 on hardware with 128GB RAM, with PCIe 3.0 causing bottlenecks remedied by switching to PCIe 4.0 motherboards. Utilizing GPUs with less than 6GB VRAM for weighty models proved futile.
Yi Models Yield Enthusiasm: Yi-1.5 models, including 9B and quantized 34B variants, received praise and recommendations for a variety of tasks, with quantized models leveraging llama.cpp for improved performance.
Tooling Up for Efficiency: LM Studio's 0.2.22 update introduced a CLI tool, lms, for model management and boasted bug fixes in llama.cpp, while the community navigated the complexities of connecting OpenInterpreter to LM Studio and configuring headless installations on Linux servers.
Quest for Research Collaboration: Dispensing with corporate vernacular, the conversation sought aid and shared experiences for running MemGPT on various setups, revealing a collective endeavor to optimize this AI model.
OpenRouter (Alex Atallah) Discord
JetMoE 8B Free Hits a Snag: The JetMoE 8B Free model is experiencing downtime due to upstream overload, returning an error (502) to all requests until further notice.
Eye on the Models—OpenRouter API Watcher: An open-source tool called OpenRouter API Watcher has been unveiled, which keeps track of changes in OpenRouter's model availability, offering hourly updates via a web interface and an RSS feed with low overhead. Check out the demo.
A Beta Tester’s Dream with Rubik's AI Pro: Users can beta test and provide feedback for Rubik's AI Pro, an advanced research assistant and search engine, with 2 months of free premium access using a RUBIX promo code. Further details can be found at Rubik's AI.
Jetmoe’s Caveat: It has been confirmed that Jetmoe lacks internet access, which restricts its use cases, but it remains useful for academic research.
GPT-4o Joins OpenRouter: GPT-4o has been added to OpenRouter’s arsenal, supporting text and image inputs, and generating buzz for its performance and competitive pricing, although it lacks support for video and audio inputs.
Modular (Mojo 🔥) Discord
- Mojo's Contemplation on Pattern Matching: There was a vigorous debate about implementing pattern matching in Mojo, with affirmative stances on compiler efficiency and exhaustive case handling. Conversely, objections were raised on grounds of aesthetic preference for traditional
if-elseconstructs.
- Mojo Rises, Rust's Complexity Under Lens: Mojo's compiler, described as more navigable and straightforward than Rust's, was a hot topic. Discussions extended to Mojo's future development and, separately, the potential relationship between Mojo and MLIR.
- Innovations and Contributions in Mojo: Ideas were exchanged on incorporating yield-like behavior and new hashing techniques into Mojo. Links to proposed changes such as in this pull request and a YouTube talk also sparked discussions on the language's ownership model.
- Nightlies and Enhanced Mojo Performance: Discussions on GitHub Issues about CI tests in Ubuntu, custom
Hasherstruct proposals, and performance optimizations for Mojo'sListstructure highlighted the active nightly builds and their role in the ongoing development rhythm.
- String Building in Mojo's Landscape: A new repository for MoString received attention, offering a variation on StringBuilder approaches and a method to reduce memory allocation in Mojo, available here on GitHub.
CUDA MODE Discord
- ThunderKittens Strikes a Chord: Engineers are showing great interest in ThunderKittens, a project focusing on optimizing CUDA kernels. It’s seen as more approachable than CUTLASS for tensor core management, and its repository includes projects like NanoGPT-TK, heralded for its performance in GPT training.
- Triton's Expanding Universe: Knowledge sharing on Triton peaked with the recommendation of advanced learning resources, including a detailed YouTube lecture and pointers to GitHub repos such as PyTorch’s kernels. The excitement is palpable with discussions of internal performance and new domain-specific languages that could outperform current implementations.
- Learning on Demand: Upcoming expert talks on fusing kernels and CUDA C++ scans were announced, with Zoom as the venue. A University of Illinois lecture series on parallel programming is also accessible, offering Zoom sessions and a comprehensive YouTube playlist for independent study.
- Performance Tuning Tackled: Discussions tackled techniques to boost performance from calculating outside CUDA kernels to using max-autotune for kernels to compiler dynamics with Dynamo over Inductor, highlighting the nuanced trade-offs between kernel fusion benefits and configuration costs.
- Community Support and Query Resolution: Queries ranged from understanding GPU memory management with CUDA to seeking project assistance for thermal face recognition, involving requests for insights, papers, and Git repositories. Additionally, there’s been productive interaction over course content and GPU compatibility checks for builds.
Eleuther Discord
- Mind the Synthetic Hype!: Despite a bullish stance on synthetic data, some engineers exercise caution due to a previous hype cycle about 5-7 years ago, questioning if critical lessons will translate with the entry of new professionals in the field.
- Convolutional Contemplations: AI Engineers are comparing the performance of CNNs, Transformers, and MLPs for vision tasks, as noted in arXiv paper discussions, suggesting that while moderate scales show competitive performance, scaling up may require a mixed-method approach.
- Efforts in Model Compression: Conversations arose about model compression's impact on features and neural circuits, pondering if the lost features during compression are redundant or critically specialized revealing the dataset's diversity.
- Curiosity over New Attention Method: A new efficient attention approximation method using convolution matrices has been discussed with some skepticism, considering existing methods such as flash attention, alongside talks of depth scaling in Large Language Models (LLMs), referencing SOLAR and Yi 1.5 models.
- Insights into Falcon-2 and Copyright Conversations: The release of Falcon-2 11B, trained on a significant 5T of refined data and featuring a permissive license, sparked discussion, while ongoing debates about AI copyright implications highlight the competitive edge that may skew towards indemnifying corporations like Microsoft, highlighting a potential chilling effect on smaller players.
Interconnects (Nathan Lambert) Discord
- GPT-4o Ascends to the Top: GPT-4o, OpenAI’s latest model, has been demonstrated to outperform predecessors in coding and may raise the bar in other benchmarks like MATH. It has also become the strongest model on the LMSys Arena, boasting higher win-rates against all other models.
- REINFORCE Understood Through PPO Lens: A Hugging Face PR revealed that REINFORCE is a special case of PPO, presenting an interesting perspective on the relationship between the two reinforcement learning methods, documented in a recent paper.
- VideoFX Work in Progress Draws Eyes: Early footage of VideoFX showcased its burgeoning capabilities, generating interest with preview content on Twitter.
- Tokenizer Tuning Increases Efficiency: OpenAI has pushed a new update for their tokenizer, increasing processing speed by making use of a larger vocabulary as seen in the recent GitHub commit.
- Videos Capture Attention with Viral Potential: Within Interconnects' #reads, a surge of views on certain videos sparked conversations around promotion strategies, with one aiming to reach higher view counts inspired by another Huggingface video's popularity. There was even discourse on circumventing Stanford's licensing for wider dissemination of video content.
LAION Discord
- Artistic Anxieties over AI: Engineers discussed the implications of AI art on artists' livelihoods, examining the impact of services like Midjourney on art sales as well as potential legal repercussions. Some argued for fair use while others expressed concerns about derivative works, with reference to insights from The Legal Artist.
- Legal Buzz Surrounding AI: There was chatter around StabilityAI and Midjourney facing possible legal challenges given the current climate, with some hoping for David Holz to face repercussions for his work. The discussion included the unpredictable influence of jury decisions on the direction of such legal cases.
- Evolutions in AI Efficiency: Mention of improved efficiency in AI models sparked interest, with the spotlight on a fine-tuned Pixart Sigma model on Civitai and advancements in AI compute showcased by FlashAttention-2.
- Falcon 2 Takes Flight: Announcements highlighted the launch of Falcon 2 models boasting superior performance compared to Meta's Llama 3, with detailed information available through the Technology Innovation Institute.
- Audio's Textual Transformation: Engineers explored the conversion of voice datasets into tokens, emphasizing high-quality annotations for emotions and speaker attributes. They shared a Twitter post and a YouTube video on training transformers with audio data for further understanding.
LangChain AI Discord
- ISO Date Extraction Using LangChain: A member's request on how to extract and convert dates to ISO format led to shared code examples using the
DatetimeOutputParserin both Python and JavaScript, highlighting LangChain's functionality in structured output.
- Hook Up Local LLMs with LangChain: The conversation included guidance on integrating local open-source LLMs such as Ollama using LangChain, with Kapa.ai providing a breakdown of model definitions and prompt creation.
- Persistent Storage Solutions Beyond InMemoryStore: In the quest for persistent storage alternatives within LangChain and Gemini, some pointed to LangChain documentation for potential solutions, moving past the limited
InMemoryStore.
- Common Hurdles with HuggingFace Integration: Users shared experiences and fixes for frequent issues encountered when integrating HuggingFace models with LangChain, emphasizing the importance of model compatibility and precise API interactions.
- Tutorials and Resources to Enhance LangChain Know-How: The community spotlighted resources like a YouTube tutorial and a detailed blog post on creating a RAG pipeline with LangChain, with open requests for guidance on streaming and session management within LangChain applications.
LlamaIndex Discord
- Slide Decks on Automatic: Using the Llama3 RAG pipeline, a new system to generate PowerPoint presentations has been developed, incorporating Python-pptx. The workflow and integration details are shared in an article.
- Reflecting on Reflection: Hanane Dupouy's exploration of creating a financial agent that reflects on stock prices shows promise for advanced CRITIC applications, with an in-depth explanation available in their exposure.
- Moderation by RAG: Setting up a RAG pipeline for moderating user-generated images by converting images to text and checking against indexed rules is outlined, with a more detailed procedure available.
- RAG System Under the Microscope: A comprehensive article presented by @kingzzm covers the evaluation of RAG systems, utilizing libraries such as TruLens, Ragas, UpTrain, and DeepEval, with a link to the full article for the metrics.
- Distill Knowledge, Sharpen Models: A valuable discussion-centric blog post on the knowledge distillation technique used to fine-tune GPT-3.5 is recommended for engineers looking to increase model accuracy and performance.
OpenAccess AI Collective (axolotl) Discord
Tech-Savvy Inner Circle Shares AI Insights
- LLAMA3's Instructional Layer Secrets: An analysis shows key weights in LLAMA 3 concentrated in the K and V layers, suggesting possible freezing to induce stylistic variations without affecting its instructional prowess.
- Practicality of OpenOrca and AI Efficiency: AI enthusiasts evaluated the feasibility of re-running OpenOrca's deduplication for GPT-4o, roughly costing $650, while spotlighting methods like Based, Monarch Mixer, H3, and FlashAttention-2 to enhance computational efficiency, as discussed in a blog post.
- Development Chaos: Dependencies & Docker Woes: Developers reported difficulties ranging from AttributeError 'LLAMA3'* errors when using Docker to outdated dependencies leading to conflicts, emphasizing the transition from torch 2.0.0 to 2.3.0 with the need for updates in fastchat and pyet**.
- AXOLOTL Interactions Met with Errors and Questions: The AI community faces diverse challenges, including error messages converting models to GGUF, loading Gemma-7B, and pragmatically merging QLoRA into base models, often left unresolved within thread discussions.
- No Quick Fix in Sight: Inquiries addressed to the Axolotl-phorm-bot about topics like pruning support, continuous pretraining, LoRa methods, and QLoRA merging techniques prompted searches in Axolotl's repository without providing immediate solutions - details check on Phorm's platform.
Deploying practical solutions and seamless updates remains a collective goal in tackling emergent AI tech puzzles — updates and breakthroughs to follow.
OpenInterpreter Discord
Goofy Errors and Speedy Performances: Claude API users reported "goofy errors" impeding its use, whereas GPT-4o garnered praise for its swift performance, clocking at "minimum 100 tokens/s." Local models such as Mixtral and Llama3 were considered inferior to GPT-4.
PyWinAssistant Showcases AI Control over UI: An open-source project dubbed PyWinAssistant allows control of user interfaces through natural language, leveraging Visualization-of-Thought for spatial reasoning. Excitement grew as users shared a GitHub repo and a live YouTube demo.
Hardware Headaches and Software Solutions: Integration of LiteLLM, Groq and Llama3 successfully confirmed, while another user struggled to connect their 01-Light device. Separate issues arose with Python script execution resolved by importing OpenInterpreter correctly.
Shipment Updates and Support Channels: Queries about the 01 hardware brought news of upcoming batch shipments, and an iOS app for the hardware is in beta, shared on GitHub. Order cancellations were directed to help@openinterpreter.com.
Dev Discussions on Model Swapping: The 01 dev preview prompted exchanges on switching to local models using poetry run 01 --local, offering insights into model selection commands.
tinygrad (George Hotz) Discord
- Tensor Talk Tackles Variable Shapes: Engineers debated how to represent tensors with variable shapes in tinygrad, a topic especially relevant in transformers due to changing token numbers. They referred to Tinygrad's handling of variable shapes and code snippets from Whisper (snippet 1, snippet 2) for insights.
- Dim Versus Axis: Different Terms, Same Concept?: There was a clarification sought on the terminology difference between "dim" and "axis" in tensor operations, concluding that the terms are mostly interchangeable and any differences might be rooted in historical conventions.
- Debugging
AssertionErrorDuring Training: A user faced anAssertionErrorrelated to missing gradients during a bigram model training which led to a discussion on proper settings (Tensor.training = True). The conversation included a reference to a GitHub pull request to prevent such issues.
- Feature Aggregation in Neural Turing Machines: An NTM implementation prompted discussions on feature aggregation via tensor operations and optimization, for which code examples were exchanged and ideas on efficiency improvements were discussed (aggregate feature code).
- Navigating
wherein Backprop Challenges: Participants worked through a backpropagation issue with a 'where' call in tinygrad that was causingRuntimeError. The workaround involved adetach().where()method, highlighting a PyTorch-to-tinygrad gradient challenge.
Cohere Discord
- Token Troubles and Model Mechanics: A query on the unexpected surge in input tokens was clarified; web searches using command 'r' result in context passing and higher token count, leading to billing charges. Meanwhile, the challenge of 'glitch tokens' in language models like SolidGoldMagikarp was acknowledged with a linked arXiv paper, which discusses detection methods for these potentially problematic tokens.
- Open-Source Embeddings and Billing Brain Teasers: No consensus was reached about the open-source nature of embedding models due to a lack of responses. In a separate issue, billing confusion over a $0.63 charge was resolved, attributed to the amount due since the last invoice.
- Aya vs. Cohere Command Plus - Clash of the Models: In a comparison between Aya and Cohere Command Plus models, Aya was reported less accurate, even with a 0 temperature setting, with one user suggesting its best use case in translation tasks.
- Specializing LLMs Seek New Horizons in Telecom: A challenge to tailor large language models (LLMs) for the telecom sector, focusing on areas such as 5G, was shared, with more details found on the Zindi Africa competition page.
- In Search of a Chat-with-PDF Solution: A call was made for references to a "chat with PDF" application utilizing Cohere, with the incentive being collaboration and knowledge-sharing among members.
Datasette - LLM (@SimonW) Discord
- GPT-4o Still Falling Short: Members shared frustration about GPT-4o's inaccuracies, experiencing a 50% success rate when asking the model to list book titles it "saw" in a library scenario.
- Voice Assistant Marketing Missteps: Recent voice assistant promotion mishaps, including unwanted giggling from the devices, drew criticism from users who called it "embarrassing".
- Custom Instructions Could Improve Voice Assistants: Hopes are pinned on custom instructions to improve the interactions with voice assistants, aiming to eliminate awkward behavior.
- AGI Believers Club Lacks Members: Skepticism prevails about the near-term development of AGI, with engineers expressing a lack of belief in its imminent advent.
- Law of Diminishing Returns in LLMs: Discussions indicate a consensus that there are diminishing improvements in new versions of large language models, and current models have untapped capabilities.
Mozilla AI Discord
- Beware Fake Repositories: An announcement warned about a fake OpenELM repository; there is no GGUF (GitHub User File) for OpenELM currently available, cautioning the community against potential scams.
- llamafile Archives Receive a Boost: A new pull request (PR) was mentioned for an upgrade script for llamafile Archives, based on a script from Brian Khuu's blog, offering improvement and maintenance for file handling processes.
- Containers Get a Green Light: Confusion around using containerization tools like podman or kubernetes was resolved, affirming that utilizing containers for operations is approved and encouraged for deployment consistency and scalability.
- Performance Check for Hermes-2-Pro: Experiences with the Hermes-2-Pro-Llama-3-8B-Q5_K_M.gguf running on an AMD 5600U were shared, noting response times of approximately 10 seconds and RAM usage spikes of 11GB.
- Model Troubleshooting: Batch Size Errors: Reports surfaced of an error affecting both Llama 8B and Mistral models involving update_slots and n_batch size issues. High RAM allocation appears to mitigate the issue, which is less prevalent in other models like LLaVa 1.5 and Llama 70B.
DiscoResearch Discord
Searching for German Content: A pursuit for diverse German YouTube channels to train a Text-to-Speech model led to suggestions such as using Mediathekview to download content. The Mediathekview's JSON API was also highlighted as a resourceful tool, as seen in the GitHub repository.
Keep It English: A reminder was issued within the discussions to ensure that English remains the primary language for communication, possibly to maintain the accessibility of discussions.
Demo Status Check: An inquiry about the status of a unidentified demo received no response, indicating either a lack of information or attention to the query.
Thumbs Up for... Something: Positive feedback was expressed with a brief "It's really nice," comment, though the context of this satisfaction wasn't expanded upon.
Curiosity for RT Audio Interface: There's evident curiosity and excitement about the "RT Audio interface" in applications beyond chat, but experiences or results have not yet been shared in the discussions.
LLM Perf Enthusiasts AI Discord
- Claude Beats Llama at Haiku: In a showdown of linguistic prowess, engineers compared the submodel accuracy of Claude 3 Haiku with Llama 3b Instruct's entity extraction capabilities. Initial experiments with fuzzy matching proved fruitless, sparking interest in more sophisticated submodel matching techniques.
- Teasers and Voices Stir Excitement: Anticipation is building in the community as OpenAI's Spring Update has been teased, promising the introduction of GPT-4o. A notable highlight is none other than Scarlett Johansson voice-featured in the update, sparking both surprise and amusement among members.
- Audio Futures Discussed: Technical discussions speculated on OpenAI's potential integration of audio functionalities, envisioning direct audio input-output support for an AI assistant.
- OpenAI Update Available: Engineers eager for the latest advancements took note of the OpenAI Spring Update, which includes information on GPT-4o, ChatGPT enhancements, and possibly more, streamed live on May 13, 2024.
Alignment Lab AI Discord
AlphaFold Goes Social: The AlphaFold3 Federation has sprung into action, inviting participants to a meet on May 12th at 9pm EST focusing on updates and pipeline development, with an open invitation link here.
Fasteval on the Brink: The fasteval project seems to be ending, but hope remains for someone to assume the helm; the current maintainers are open to transferring the project found on GitHub, or else they suggest archiving it.
AI Stack Devs (Yoko Li) Discord
- Need for Speed Customization?: There's interest in personalizing the AI Town experience; specifically, adjusting the character moving speed and number of NPCs. This feedback indicates user desire for more control over gameplay mechanics.
- Balancing NPC Interactions: A user suggested optimizing AI Town by reducing NPC interaction frequency to improve player-NPC interaction quality. They emphasized the performance challenges when running AI Town locally with the llama3 model.
Skunkworks AI Discord
- A Casual Share for Tech Enthusiasts: User pradeep1148 shared a YouTube video in the #off-topic channel, which may be of interest to fellow AI engineers. The content of the video has not been described, so its relevance to the technical discussions is unknown.
YAIG (a16z Infra) Discord
- Consensus in AI Discussions Achieved: The notorious brevity of pranay01's response with a simple "Agree!" reflects either alignment or the conclusion of a discussion on a potentially complex AI infrastructure topic. No further context was provided to detail the nature of the agreement.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (833 messages🔥🔥🔥):
- Community criticizes OpenAI's regulatory moves: Members discussed OpenAI's GPU signing and collaboration with the White House as moves to monopolize and control the AI space. One noted that OpenAI wants to make authorization mandatory, restricting competition ("god i hate regulations on anything tech when it benefits only the top companies").
- Support expands for 'WizardLM' despite controversy: Members shared links to resources on the contentious WizardLM-2-8x22B model. Participants highlighted that it was initially released by Microsoft and later censored due to its similarity to GPT-4 (WizardLM GitHub).
- Discord members discuss efficient fine-tuning and new tools: Various tools and kernels like ThunderKittens were discussed for improving model training and inference. A new kernel, ThunderKittens, was noted for its promise to outperform Flash Attention 2 (ThunderKittens GitHub).
- Unsloth receives praise and updates: Users expressed appreciation for Unsloth's library for fine-tuning models efficiently. Unsloth announced upcoming multi-GPU support and the integration of models such as Qwen's recent versions without a specific additional branch requirement (Unsloth GitHub).
- Fine-tuning challenges with Llama models discussed: Members shared experiences and troubleshooting tips around fine-tuning processes, specifically with providing dataset sizes and padding issues. Converting and handling different model formats like FP16 to GGUF was also a notable topic.
- ThunderKittens: A Simple Embedded DSL for AI kernels: no description found
- Rethinking Machine Unlearning for Large Language Models: We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illega...
- eramax/nxcode-cq-7b-orpo: https://huggingface.co/NTQAI/Nxcode-CQ-7B-orpo
- Hugging Face – The AI community building the future.: no description found
- alpindale/WizardLM-2-8x22B · Hugging Face: no description found
- NTQAI/Nxcode-CQ-7B-orpo · Hugging Face: no description found
- tiiuae/falcon-11B · Hugging Face: no description found
- Tweet from Daniel Han (@danielhanchen): Was fixing LLM fine-tuning bugs and found 4 issues: 1. Mistral: HF's batch_decode output is wrong 2. Llama-3: Be careful of double BOS 3. Gemma: 2nd token has an extra space - GGUF(_Below) = 3064...
- Joy Dadum GIF - Joy Dadum Wow - Discover & Share GIFs: Click to view the GIF
- Anima/air_llm at main · lyogavin/Anima: 33B Chinese LLM, DPO QLORA, 100K context, AirLLM 70B inference with single 4GB GPU - lyogavin/Anima
- Gojo Satoru Gojo GIF - Gojo Satoru Gojo Ohio - Discover & Share GIFs: Click to view the GIF
- GitHub - HazyResearch/ThunderKittens: Tile primitives for speedy kernels: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
- GitHub - lilacai/lilac: Curate better data for LLMs: Curate better data for LLMs. Contribute to lilacai/lilac development by creating an account on GitHub.
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- remove convert-lora-to-ggml.py by slaren · Pull Request #7204 · ggerganov/llama.cpp: Changes such as permutations to the tensors during model conversion makes converting loras from HF PEFT unreliable, so to avoid confusion I think it is better to remove this entirely until this fea...
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- LLaMA-Factory/scripts/llamafy_qwen.py at main · hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs. Contribute to hiyouga/LLaMA-Factory development by creating an account on GitHub.
- Lorem Function – Typst Documentation: Documentation for the `lorem` function.
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #random (15 messages🔥):
- OpenAI hosts Q&A for community engagement: OpenAI’s CEO Sam Altman held a Q&A on Reddit to discuss the newly released Model Spec, encouraging community interaction and questions. The document outlines desired model behavior in OpenAI's API and ChatGPT.
- Mixed feelings on AI updates: Members expressed a range of emotions about potential OpenAI updates. While there were hopes for revitalization, others felt cautious optimism or skepticism given past experiences and current market dynamics.
- Skepticism about OpenAI releasing open-source models: Discussion highlighted doubts about OpenAI releasing models open-source due to potential impacts on their business model and reputation. Comparisons were made to other companies like Meta, where open-source releases were either forced or strategic responses to competition.
- Debate on the future of AI development publicity: The channel featured a debate on whether the reporting of an "AI winter" impacts OpenAI, with consensus leaning towards minimal impact due to OpenAI's current industry status. Discussion also covered the incentives and risks associated with releasing AI models open-source.
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #help (312 messages🔥🔥):
- Challenges with Quantized Models and TGI: A member highlighted that quantized models often result in sharding errors on HF dedicated inference when used with TGI. They noted that the models need to be saved in 16-bit format via
model.save_pretrained_merged(...)to avoid issues (TGI requires 16-bit models).
- Issues with GGUF Tokenizers: There were discussions about tokenization issues, particularly with Gemma's GGUF models. Members noted problems like incorrect tokenization and an extra space being added to the first token.
- Finetuning Llama3 Models on Colab: Multiple users faced and resolved issues fine-tuning Llama3 models. One user mentioned a solution was found by saving to GGUF manually and ensuring models are saved and loaded correctly, with relevant documents and example notebooks being effective guides.
- Multi-GPU and Multi-Cloud Discussions: There were suggestions and debates on multi-GPU and cloud-based training options. Some members voiced concerns about high prices and proposed potential partnerships with cloud providers to offer cost-effective solutions for commercial users.
- Issues with Unsloat Installation on Colab: Problems related to installing and importing Unsloth on Colab were addressed. Solutions included ensuring the correct runtime settings, particularly GPU settings, and following instructions precisely.
- Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Google Colab: no description found
- Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Load: no description found
- unsloth/unsloth/__init__.py at d3a33a0dc3cabd3b3c0dba0255fb4919db44e3b5 · unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - unslothai/hyperlearn: 2-2000x faster ML algos, 50% less memory usage, works on all hardware - new and old.: 2-2000x faster ML algos, 50% less memory usage, works on all hardware - new and old. - unslothai/hyperlearn
- I got unsloth running in native windows. · Issue #210 · unslothai/unsloth: I got unsloth running in native windows, (no wsl). You need visual studio 2022 c++ compiler, triton, and deepspeed. I have a full tutorial on installing it, I would write it all here but I’m on mob...
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Sou Cidadão - Colab: no description found
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
- SauravMaheshkar shares Llama finetuned variants: A member has been working on finetuning Llama variants for Token Classification and has uploaded some of the model weights to the 🤗 hub. The fine-tuned variants include
unsloth/llama-2-7b-bnb-4bittrained on the conll2003 dataset using LoRA adapters, and they shared a collection link.
Link mentioned: LlamaForTokenClassification - a SauravMaheshkar Collection: no description found
Stability.ai (Stable Diffusion) ▷ #general-chat (976 messages🔥🔥🔥):
- Discord user wonders about SD3's existence: Users speculated about the Stability AI's upcoming SD3, questioning if it would ever be released. Sentiments varied with some expressing disappointment over missed release dates and others humorously comparing the situation to "Half-Life 3."
- Expertise needed for Fine-Tuning in SDXL: A plea for assistance with fine-tuning Stable Diffusion XL for generating product ads drew responses. One experienced user offered to help, showcasing their past work on the ML backend of creativio.ai.
- Locating and using models for AI tasks proves challenging: Users discussed downloading and running large language models, like CohereForAI's C4AI Command R+, and the complicated process of configuring software like KoboldAI and OogaBooga. Frustrations were expressed over the difficulty and large file sizes involved.
- Recognizing and animating art styles: Users suggested studying art history or using tools like gpt-4 to identify art styles. For slight animations close to the original image, it was recommended to use methods like animatediff with controlnet tile.
- Challenges with image upscaling: A user faced difficulties in finding an effective method for upscaling images using Automatic1111's forge with controlnet. They sought advice on achieving high-quality, detailed upscales.
- dranger003/c4ai-command-r-v01-iMat.GGUF · Hugging Face: no description found
- Lewdiculous/Average_Normie_l3_v1_8B-GGUF-IQ-Imatrix · Hugging Face: no description found
- CohereForAI/c4ai-command-r-plus · Hugging Face: no description found
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
- jonathan frakes telling you you're wrong for 47 seconds: it never happened
- Nikolas Cruz's Depraved Google Search History: A glimpse of the Parkland shooter's descent into the dark bowels of the Internet. This is why parents should monitor what their children do online. Warning: ...
- GitHub - nullquant/ComfyUI-BrushNet: ComfyUI BrushNet nodes: ComfyUI BrushNet nodes. Contribute to nullquant/ComfyUI-BrushNet development by creating an account on GitHub.
- PORK NIGHTMARE: ATTENTION !!! Âmes sensibles s'abstenir car vous regardez en face certaines des choses les plus sombres que votre humanité à engendré.ARRÊTEZ-TOUT !!!▼▼ RÉSE...
- no title found: no description found
- GitHub - KoboldAI/KoboldAI-Client: Contribute to KoboldAI/KoboldAI-Client development by creating an account on GitHub.
- GitHub - Zuellni/ComfyUI-ExLlama-Nodes: ExLlamaV2 nodes for ComfyUI.: ExLlamaV2 nodes for ComfyUI. Contribute to Zuellni/ComfyUI-ExLlama-Nodes development by creating an account on GitHub.
- GitHub - LostRuins/koboldcpp: A simple one-file way to run various GGML and GGUF models with KoboldAI's UI: A simple one-file way to run various GGML and GGUF models with KoboldAI's UI - LostRuins/koboldcpp
- Reddit - Dive into anything: no description found
- Character Consistency in Stable Diffusion - Cobalt Explorer: UPDATED: 07/01– Changed templates so it’s easier to scale to 512 or 768– Changed ImageSplitter script to make it more user friendly and added a GitHub link to it– Added section...
OpenAI ▷ #annnouncements (2 messages):
- GPT-4o offers free public access with limitations: OpenAI announced the launch of GPT-4o and features like browse, data analysis, and memory available to everyone for free, but with usage limits. Plus users will enjoy up to 5x higher limits and early access to features such as the macOS desktop app and next-gen voice and video capabilities. More info.
- Introducing GPT-4o with multi-modal capabilities: OpenAI's new flagship model, GPT-4o, can reason in real-time across audio, vision, and text. Text and image input capabilities are available in the API and ChatGPT now, with voice and video features to follow in the coming weeks. Details here.
OpenAI ▷ #ai-discussions (684 messages🔥🔥🔥):
- GPT-4o debuts with mixed reviews: Members discussed the new GPT-4o's performance, noting it is faster and cheaper but with inconsistencies in reasoning and shorter memory compared to GPT-4. Some users appreciated its abilities, while others found GPT-4 to have better reasoning capabilities for custom instructions.
- Rollout confusion and feature anticipation: Members experienced varied rollout times for access to GPT-4o, both through API and ChatGPT. There was noticeable enthusiasm for upcoming features like real-time camera use and new voice capabilities, though these have not been fully rolled out yet.
- Classic vs. New Model debate: Users debated the practicality of maintaining GPT-4 when GPT-4o is available, considering the latter's lower cost and fast performance. Some pointed out specific cases where GPT-4 still performed better, leading to mixed decisions on which model to use.
- Feature accessibility queries: Queries about the availability of specific features like the new macOS app, visual capabilities, and voice cloning in the GPT-4o API were prominent. It was clarified that many of these features would be gradually available in the coming weeks.
- General excitement and skepticism: The community expressed a blend of excitement and skepticism regarding the new updates, with many looking forward to broader access and testing the new features in real-world applications.
- Twerk Dance GIF - Twerk Dance Dog - Discover & Share GIFs: Click to view the GIF
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Models - Hugging Face: no description found
OpenAI ▷ #gpt-4-discussions (126 messages🔥🔥):
- **Issues Passing Files to GPT Actions**: A member asked if anyone figured out how to pass uploaded files to a GPT action. There wasn't a clear resolution provided in the discussion.
- **GPT-4T API Provides Higher Context**: Discussion highlighted that the API for GPT-4T is less restrained and currently allows a 128k context. Members discussed the nuances of this capability.
- **Random Output with High Temperature Settings**: A member experienced random outputs when setting the temperature above 1.5. Another advised keeping the temperature below 1 for stable and coherent responses.
- **Fetching OpenAI Model Pricing**: Members shared that OpenAI pricing is static and can be reviewed on the [OpenAI pricing page](https://openai.com/api/pricing/). There are no alerts for pricing changes, so users need to monitor the page manually.
- **Custom GPTs and Cross-Session Memory**: There was confusion about custom GPTs' cross-session memory capabilities, clarified by a member noting that per-GPT memories have not rolled out yet. More details about this can be found in the [OpenAI Memory FAQ](https://help.openai.com/en/articles/8590148-memory-faq).
OpenAI ▷ #prompt-engineering (32 messages🔥):
- Moderation Filter Issue with Gemini 1.5: A user reported that their application consistently fails to respond to queries related to "romance package" due to an unspecified moderation filter. Despite setting all blocks to none and trying different settings, the issue persists, making it difficult to implement their integrations at a major resort.
- Discussion on Safety Settings: Members discussed whether the problem with the moderation filter could be due to safety settings not being explicitly disabled. One member suggested testing in the AI Lab to ensure no syntax errors are affecting the results.
- API Keys and Temperature Settings Experimentation: The user tried generating new API keys and adjusting temperature settings to resolve the issue but had no success. This has led them to conclude that the problem might be on Google's end.
- Help Offered and Syntax Check Recommended: Another member offered help and suggested checking the syntax in the AI Lab to confirm that the issue is not due to improper syntax or safety filter settings. The user appreciated this assistance but remained convinced that the problem is external.
- Python Script for File Operations: A user shared a Python script snippet that outlines creating a directory, writing Python files in separate sessions, and zipping the directory. This script demonstrates a method for displaying a link to download the resulting zip file.
OpenAI ▷ #api-discussions (32 messages🔥):
- Moderation filter issue in Gemini 1.5: A user reported an issue with their application experiencing consistent failures when users inquire about "romance package" or similar topics. Despite changing defaults and generating new API keys, the problem persists, suggesting potential model training restrictions.
- Troubleshooting AI Safety Settings: Another user suggested explicitly disabling safety settings to potentially resolve the issue. They stressed the importance of ensuring that safety filters are correctly turned off and offered a screenshot method for further verification.
- Google AI Lab potential solution: The conversation shifted to testing in Google AI Lab to determine if syntax errors are the cause. Suggestions included checking the safety filters and possibly testing for syntax errors in the lab.
- File directory creation in Python: A user requested guidance on creating a full file tree, writing files in Python sessions, and zipping a directory, asking for a downloadable link upon completion. The task involves programmatically setting up a directory structure and managing files through Python scripts.
OpenAI ▷ #api-projects (2 messages):
- Creating a ChatGPT clone with tracking: A user inquired about the feasibility of creating a ChatGPT clone utilizing the 3.5 model but with the capability for user messages to be monitored by the organization. This implies replicating the ChatGPT interface while adding a message tracking feature.
Nous Research AI ▷ #ctx-length-research (1 messages):
king.of.kings_: i am struggling to get llama 3 70b to be coherent over 8k tokens lol
Nous Research AI ▷ #off-topic (15 messages🔥):
- Aurora in France: A member mentioned seeing the aurora borealis over the central volcano of Arvenia in Auvergne, France. This surreal natural phenomenon caught their attention and seemed worth sharing.
- YouTube Links Shared: Two YouTube links were shared: one titled "Udio Testing: You never knew your own name : whispers in the void" and another by another member, without additional descriptions.
- Introducing MAP-Neo: A user announced the release of MAP-Neo, a fully transparent bilingual LLM trained on 4.5T tokens, and shared links to Hugging Face, a dataset, and the GitHub repository.
- Kingdom Come: Deliverance Cooking Mechanic: A user discussed the perpetual stew mechanic in the game Kingdom Come: Deliverance, noting its historical accuracy. They shared a personal recipe involving slow-cooking vegetables and meat, highlighting a shift in cooking methods based on hunger.
- RPA and Software Automation: A member inquired about a library for interacting directly with software windows via RDP, like RPA for automation. Another member suggested using Frida for runtime hooks and exposing functionality via an HTTP API, although concerns were raised about the complexity due to not having access to software binaries.
- Mother Day GIF - Mother day - Discover & Share GIFs: Click to view the GIF
- Udio Testing: You never knew your own name : whispers in the void: no description found
- Neo-Models - a m-a-p Collection: no description found
- m-a-p/Matrix · Datasets at Hugging Face: no description found
- GitHub - multimodal-art-projection/MAP-NEO: Contribute to multimodal-art-projection/MAP-NEO development by creating an account on GitHub.
Nous Research AI ▷ #interesting-links (6 messages):
- Hierarchical Correlation Reconstruction in Neural Networks: A member posted a link to an arXiv paper discussing optimization of artificial neural networks through hierarchical correlation reconstruction. The paper contrasts typical unidirectional value propagation with the multidirectional operation of biological neurons.
- Taskmaster Episode Roleplay App: Another member shared their creation of a React app for roleplaying as a Taskmaster contestant, using a state machine that encodes each stage of an episode. Users need to input their own OpenAI key and may encounter clunky outputs but can check out the code on GitHub.
- Yi-1.5-34B-Chat Model Update: One message highlighted the 01-ai/Yi-1.5-34B-Chat model on Hugging Face. It was updated recently and had over a thousand uses, as seen here.
- Detailed Industrial Military Complex Knowledge Graph: A member used Mistral 7B instruct v 0.2 and their framework, llama-cpp-agent, to create a 40-node knowledge graph of the Industrial Military Complex. They shared the framework on GitHub which supports various servers and APIs like llama.cpp and TGI.
- Detailed Thoughts on OpenAI's Technology and Strategy: A user linked to a Twitter thread offering a deep dive into OpenAI's advancements in audio-to-audio mapping and video streaming to transformers. It speculates on OpenAI's strategic moves and potential Apple integrations with GPT-4o as a precursor to GPT-5.
- Biology-inspired joint distribution neurons based on Hierarchical Correlation Reconstruction allowing for multidirectional neural networks: Popular artificial neural networks (ANN) optimize parameters for unidirectional value propagation, assuming some guessed parametrization type like Multi-Layer Perceptron (MLP) or Kolmogorov-Arnold Net...
- Yi-1.5 (2024/05) - a 01-ai Collection: no description found
- Taskmaster-LLM/src/App.js at main · LEXNY/Taskmaster-LLM: Contribute to LEXNY/Taskmaster-LLM development by creating an account on GitHub.
- GitHub - Maximilian-Winter/llama-cpp-agent: The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output. Works also with models not fine-tuned to JSON output and function calls.: The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured...
Nous Research AI ▷ #general (741 messages🔥🔥🔥):
- OpenAI's GPT-4o divides opinions: Members discussed the launch of GPT-4o, noting its dual input-output capabilities and improved coding performance. There was significant debate about its lower token limit (2048) and potential impact on the open-source AI community.
- Speed improvements with mixed feelings: Users noted GPT-4o's increased speed and lower costs, attributing the efficiency to potential quantization and model size reductions. Despite these benefits, some were disappointed by the limited token output and pricing.
- Concerns about OpenAI's competitive strategies: Several members expressed frustration with OpenAI's approach, feeling it aims to dominate the market and marginalize open-source alternatives. This sentiment highlights ongoing tension within the AI community about proprietary vs. open-source models.
- Technical demonstrations and issues: Members tested GPT-4o's capabilities in various scenarios, including API performance and mathematical reasoning. Some observed inconsistent results and speculated about the causes, such as potential quantization artifacts or model limitations.
- Impact on specialized services: Discussions also touched on how GPT-4o's features might affect companies focusing on specialized services like audio generation and multimodal capabilities, with ElevenLabs mentioned as a potentially impacted entity.
- cambioml: no description found
- mradermacher/llama-3-cat-8b-instruct-GGUF · Hugging Face: no description found
- refuelai/Llama-3-Refueled · Hugging Face: no description found
- ggml-model-Q4_K_M.gguf · 01-ai/Yi-1.5-34B-Chat at main: no description found
- Improving GPT 4 Function Calling Accuracy: Join our Discord Community and check out what we're building! We just published Part 2 of the blog comparing gpt-4-turbo vs opus vs haiku vs sonnet . Introduction to GPT Function Calling Larg...
- oobabooga benchmark: no description found
- Benchmarking Benchmark Leakage in Large Language Models: Amid the expanding use of pre-training data, the phenomenon of benchmark dataset leakage has become increasingly prominent, exacerbated by opaque training processes and the often undisclosed inclusion...
- Cats Animals GIF - Cats Animals Reaction - Discover & Share GIFs: Click to view the GIF
- TheSkullery/llama-3-cat-8b-instruct-v1 · Hugging Face: no description found
- GitHub - interstellarninja/MeeseeksAI: A framework for orchestrating AI agents using a mermaid graph: A framework for orchestrating AI agents using a mermaid graph - interstellarninja/MeeseeksAI
- Tweet from will depue (@willdepue): i think people are misunderstanding gpt-4o. it isn't a text model with a voice or image attachment. it's a natively multimodal token in, multimodal token out model. you want it to talk fast? ...
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Tweet from Wenhu Chen (@WenhuChen): Big News! Meet our strongest fully open-source 7B-LLM Neo. We release its 4.7T pre-training data Matrix and entire codebase at MAP-Neo! 1. Neo-7B beats the existing fully open-source models like OL...
- GitHub - Potatooff/Le-Potato: Simple. elegant LLM Chat Inference: Simple. elegant LLM Chat Inference. Contribute to Potatooff/Le-Potato development by creating an account on GitHub.
- Replete-AI/code_bagel_hermes-2.5 · Datasets at Hugging Face: no description found
- Chat Template support for function calling and RAG by Rocketknight1 · Pull Request #30621 · huggingface/transformers: This PR updates our support of chat templates to cover tool-use and RAG use-cases. Specifically, it does the following: Defines a recommended JSON schema spec for tool use Adds tools and documents...
- MeeseeksAI/src/agents.py at 2399588acdee06cff4af04ca091b1ab5c71580b8 · interstellarninja/MeeseeksAI: A framework for orchestrating AI agents using a mermaid graph - interstellarninja/MeeseeksAI
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Tweet from Johan Nordberg (@almost_digital): I joined @elevenlabsio in January and It’s been an absolute blast working with @flavioschneide on this! This one is generated from a single text prompt “rap about never stopping to learn”, lyrics inc...
Nous Research AI ▷ #ask-about-llms (48 messages🔥):
- Exploration into MoE Architectures for Attention Blocks: Members discussed the structure of MoE (Mixture of Experts) architectures, particularly questioning whether attention blocks are included. It was noted that traditionally only FFN layers are part of MoE, though MoE attention has been explored in research.
- Combining Autoregressive Models with Diffusion Models: There was curiosity about the feasibility of merging autoregressive models favored for text with diffusion models used for images to create a robust multimodal model. A member sought validation and ideas on this concept, indicating a blend of architectures might offer enhanced performance.
- Understanding and Using Prompt Templates: The conversation covered different formats for prompt templates, explaining their importance in model responses. Specific formats like the Alpaca Prompt Format and ChatML were discussed, alongside best practices depending on the model used, like Hermes.
- Preventing Models from Giving Canned "Life Lessons": Members brainstormed methods to stop models from defaulting to general "safe" responses when they detect potentially unsafe inputs. System prompts and specific tuning techniques were suggested as solutions, including a resource on HuggingFace and an article on the Alignment Forum about mitigating refusal behaviors in models.
- Challenges in Fine-Tuning with Specific Datasets: One member sought advice on fine-tuning llama3 using the dolphin-2.9 dataset but encountered issues with torchtune and compatibility. After some troubleshooting and useful tips, including updating flash-attn and resolving MPI dependencies, they managed to progress with their setup.
- RAPHAEL: Text-to-Image Generation via Large Mixture of Diffusion Paths: Text-to-image generation has recently witnessed remarkable achievements. We introduce a text-conditional image diffusion model, termed RAPHAEL, to generate highly artistic images, which accurately por...
- ortho_cookbook.ipynb · failspy/llama-3-70B-Instruct-abliterated at main: no description found
- Refusal in LLMs is mediated by a single direction — AI Alignment Forum: This work was produced as part of Neel Nanda's stream in the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort, with co-supervision from…
Nous Research AI ▷ #rag-dataset (5 messages):
- New ChatQA Model Outperforms GPT-4: An arXiv paper titled ChatQA introduces conversational QA models that achieve GPT-4 level accuracies. ChatQA-70B reportedly outperforms GPT-4 on 10 conversational QA datasets without relying on synthetic data from OpenAI GPT models.
- InstructLab Enhances LLMs Without Full Retraining: IBM/Redhat's new InstructLab project adds new skills and knowledge to LLMs using a large model as a teacher and a taxonomy to generate synthetic datasets. This framework allows incremental additions to models through curated datasets and weekly builds.
- ChatQA: Building GPT-4 Level Conversational QA Models: In this work, we introduce ChatQA, a family of conversational question answering (QA) models that obtain GPT-4 level accuracies. Specifically, we propose a two-stage instruction tuning method that can...
- InstructLab: InstructLab has 10 repositories available. Follow their code on GitHub.
Nous Research AI ▷ #world-sim (22 messages🔥):
- Websim's popularity rises: Members expressed excitement about Websim, a platform described as "a really cool business/startup simulator" and actively shared links to build bases and explore different scenarios. One of the shared links was websim.ai.
- Consent is trending: In a playful interaction, a member highlighted the importance of consent humorously suggesting "consent is haut!" This was part of a message sharing a link to websim.ai.
- Discussion on simulation platforms: Members showed interest in expanding the capabilities and functionalities of world simulation tools. For example, one mentioned needing a Digital Audio Workstation (DAW) / VSTs in worldclient, referring to its potential utility.
- Bug reports and technical issues: Several members noted technical issues with WorldSim, such as commands like "!back" inadvertently restarting the simulator and problems with context not clearing when requested. They also mentioned responses getting cut off and issues with typing characters.
- Invitation to philosophy and websim salon: There was an invitation extended by a member for others to join a philosophy and websim salon in chat, indicating interest in deeper discussions within the community. They coordinated on time zones to facilitate participation.
- generative.ink/chat/: no description found
- generative.ink/chat/: no description found
Latent Space ▷ #ai-general-chat (93 messages🔥🔥):
- Top NLP PhD spotlight: A member called attention to a notable NLP PhD thesis, sharing a Twitter link with accolades. Another member humorously remarked on the impressive CV.
- Data shortage discussion: A fascinating thread on data shortage was shared, noting that Llama 3 trained on 15 trillion tokens. This sparked a conversation about data claims and the sources behind them, highlighting Stella Biederman's differing views.
- Infrastructure services for AI agents: A member from Singapore shared a draft on new infrastructure services for AI agents and invited feedback, directing interested individuals to their Substack post.
- Falcon 2 release: The community discussed the launch of Falcon 2, noting its open-source, multilingual, and multimodal capabilities. Despite its impressive features, concerns were raised about the licensing terms, which some found restrictive.
- GPT-4o excitement: Members actively engaged in discussions about the new GPT-4o, sharing various insights and links, including speculation on voice latency and features. Some contemplated its API access and performance, with links to API documentation and real-time observations.
- Tweet from Siqi Chen (@blader): this will prove to be in retrospect by far the most underrated openai event ever openai casually dropping text to 3d rendering in gpt4o and not even mentioning it (more 👇🏼)
- Tweet from Greg Brockman (@gdb): GPT-4o can also generate any combination of audio, text, and image outputs, which leads to interesting new capabilities we are still exploring. See e.g. the "Explorations of capabilities" sec...
- Tweet from Robert Lukoszko — e/acc (@Karmedge): I am 80% sure openAI has extremely low latency low quality model get to pronounce first 4 words in <200ms and then continue with the gpt4o model Just notice, most of the sentences start with “Sure...
- Tweet from lmsys.org (@lmsysorg): Breaking news — gpt2-chatbots result is now out! gpt2-chatbots have just surged to the top, surpassing all the models by a significant gap (~50 Elo). It has become the strongest model ever in the Are...
- Falcon LLM: Generative AI models are enabling us to create innovative pathways to an exciting future of possibilities - where the only limits are of the imagination.
- Bloomberg - Are you a robot?: no description found
- Tweet from Jake Colling (@JacobColling): @simonw @OpenAI Using the model `gpt-4o` seems to work for my API access
- Sync codebase · openai/tiktoken@9d01e56: no description found
- AI for Engineers | Latent Space | swyx & Alessio | Substack: a 7 day foundational course for prospective AI Engineers, developed with Noah Hein. NOT LIVE YET - we are 5/7 complete. Sign up to get it when it releases! Click to read Latent Space, a Substack publi...
- Tweet from tweet davidson 🍞 (@andykreed): ChatGPT voice is…hot???
- Tweet from Mark Cummins (@mark_cummins): Llama 3 was trained on 15 trillion tokens (11T words). That’s large - approximately 100,000x what a human requires for language learning
- Tweet from Mark Cummins (@mark_cummins): Llama 3 was trained on 15 trillion tokens (11T words). That’s large - approximately 100,000x what a human requires for language learning
- Tweet from Justin Uberti (@juberti): Had a chance to try the gpt-4o API from us-central and text generation is quite fast. Comparing to http://thefastest.ai, this perf is 5x the TPS of gpt-4-turbo and similar to many llama-3-8b deployme...
- Something to do something: Click to read Something to do something, by sweekiat, a Substack publication. Launched 2 years ago.
- Tweet from Robert Lukoszko — e/acc (@Karmedge): I am 80% sure openAI has extremely low latency low quality model get to pronounce first 4 words in <200ms and then continue with the gpt4o model Just notice, most of the sentences start with “Sure...
- Tweet from Jim Fan (@DrJimFan): I know your timeline is flooded now with word salads of "insane, HER, 10 features you missed, we're so back". Sit down. Chill. <gasp> Take a deep breath like Mark does in the demo &l...
- Tweet from Mark Cummins (@mark_cummins): Up next is code. Code is a very important text type, and the amount of it surprised me. There’s 0.75T tokens of public code. Total code ever written might be as much as 20T, though much of this is pri...
- Falcon 2 | Hacker News: no description found
Latent Space ▷ #ai-announcements (1 messages):
- Pre-event Hype for OpenAI Watch Party: A member announced a watch party for an OpenAI event happening tomorrow. The pregame starts at 9:30, half an hour before the event, and more details can be found on the Discord event link.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Latent Space ▷ #llm-paper-club-west (710 messages🔥🔥🔥):
- Audio issues plagued Open AI Spring Event Watch Party: Members experienced audio problems initially during the Open AI Spring Event Watch Party, where viewers could not hear the stream host. Suggestions to drop and rejoin helped mitigate some issues.
- Speculations and reactions to Apple and Google tech: Participants speculated about Apple's challenges and the potential of Apple licensing tech, emphasizing Siri's inferiority. A link was shared for a discussion on Twitter about whether Apple will adopt integrations discussed for iOS 18 due to potential Gemini and antitrust concerns related tweet.
- GPT-4o steals the show: The new GPT-4o model was highlighted as available for free in ChatGPT, capturing attention with discussions on performance, cost, and its availability without a subscription. A tweet with self-leaked performance metrics was shared related tweet.
- A.I. capabilities and live demos amazed audience: Users were impressed by real-time demos, including voice mode updates with emotional range and interruption capability, and multimodal interactions of GPT-4o. Discussions included real-time responsiveness, voice synthesis improvements, and a demo link on YouTube link to event.
- Immediate reactions and possible competitive edge: Excitement was shared about how these advancements might affect competitors like Google and potential impacts on applications like Siri, Copilot, and Replika, with some speculating it's a step towards human-level interaction. Comments included comparisons to existing technologies and implications for future AI agents.
- Twitch: no description found
- Tweet from William Fedus (@LiamFedus): GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot 🙂. Here’s how it’s been doing.
- Tweet from Olivier Godement (@oliviergodement): I haven't tweeted much about @OpenAI announcements, but I wanted to share a few reflections on GPT-4o as I've have not been mind blown like that for a while.
- Tweet from Brad (@brad_agi): 50% cheaper isn't even competitive. Source: https://artificialanalysis.ai/
- Tweet from Jared Zoneraich (@imjaredz): gpt-4o blows gpt-4-turbo out of the water. So quick & seemingly better answer. Also love the split-screen playground view from @OpenAI
- Mechanical Turk - Wikipedia: no description found
- Tweet from bdougie on the internet (@bdougieYO): ChatGPT saying it looks like I am in a good mood.
- GPT-4o: There are two things from our announcement today I wanted to highlight. First, a key part of our mission is to put very capable AI tools in the hands of people for free (or at a great price). I am...
- Tweet from Karma (@0xkarmatic): "An ASR model, an LLM, a TTS model… are you getting it? These are not three separate model: This is one model, and we are calling it gpt-4o." Quoting Andrej Karpathy (@karpathy) They are r...
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Tweet from Greg Brockman (@gdb): We also have significantly improved non-English language performance quite a lot, including improving the tokenizer to better compress many of them:
- Tweet from Greg Brockman (@gdb): Introducing GPT-4o, our new model which can reason across text, audio, and video in real time. It's extremely versatile, fun to play with, and is a step towards a much more natural form of human-...
- Tweet from Sam Altman (@sama): it is available to all ChatGPT users, including on the free plan! so far, GPT-4 class models have only been available to people who pay a monthly subscription. this is important to our mission; we wan...
- GitHub - BasedHardware/OpenGlass: Turn any glasses into AI-powered smart glasses: Turn any glasses into AI-powered smart glasses. Contribute to BasedHardware/OpenGlass development by creating an account on GitHub.
Perplexity AI ▷ #general (658 messages🔥🔥🔥):
- **Cheerio Library Alternatives**: A user asked if there's a faster way than the Cheerio library to extract content from HTML strings. Another user provided a link to [Perplexity's AI search](https://www.perplexity.ai/search/Is-there-a-xOtvxOveTGSfbae88ElQMA) for further exploration.
- **ChatGPT Plus vs. Perplexity Pro**: Discussions highlighted the comparative advantages of ChatGPT Plus and Perplexity Pro, including context window sizes and general AI capabilities. Users shared their experiences, stating Perplexity as more focused on being an AI search engine with specific features such as collections and model flexibility.
- **Claude 3 Opus Limits**: Users frequently mentioned dissatisfaction with the imposed limits on Claude 3 Opus usage in Perplexity Pro. One user suggested considering YesChat as an alternative, which offers more generous usage quotas.
- **GPT-4o Release Buzz**: Conversations were abuzz with the release of GPT-4o, noting its improved speed and capabilities. There was anticipation for when Perplexity would integrate GPT-4o, with comparisons to how it might outclass existing models like Claude 3 Opus.
- **Perplexity's Context Handling**: Users discussed the effectiveness of Perplexity in handling context windows and RAG (retrieval-augmented generation). The consensus was that while 32k tokens seem standard, there is uncertainty and a desire for greater context capabilities.
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
- More than an OpenAI Wrapper: Perplexity Pivots to Open Source: Perplexity CEO Aravind Srinivas is a big Larry Page fan. However, he thinks he's found a way to compete not only with Google search, but with OpenAI's GPT too.
- gpt-tokenizer playground: no description found
- Tweet from Ina Fried (@inafried): A couple tidbits I've confirmed as well. 1) The mysterious GPT2-chatbot that showed up on benchmark sites was GPT-4o. 2) OpenAI did desktop version first for Mac because "we're just priori...
- Two GPT-4os interacting and singing: Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time.Learn more here: https://www.openai.com/index/hello-...
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
- Happy Birthday with GPT-4o: Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time.Learn more here: https://www.openai.com/index/hello-...
- Two GPT-4os interacting and singing: Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time.Learn more here: https://www.openai.com/index/hello-...
- Tweet from Mckay Wrigley (@mckaywrigley): This demo is insane. A student shares their iPad screen with the new ChatGPT + GPT-4o, and the AI speaks with them and helps them learn in *realtime*. Imagine giving this to every student in the wor...
- YesChat.ai Pricing Plan: no description found
- Introducing GPT-4o: OpenAI’s new flagship multimodal model now in preview on Azure | Microsoft Azure Blog: OpenAI, in partnership with Microsoft, announces GPT-4o, a groundbreaking multimodal model for text, vision, and audio capabilities. Learn more.
Perplexity AI ▷ #sharing (21 messages🔥):
- Alexandr Yarats leads Perplexity Search: An interview with Alexandr Yarats reveals his journey from Yandex to Google, and eventually to Perplexity AI as the Head of Search. Yarats discusses his initial interest in machine learning driven by his background in math, probability theory, and statistics.
- Understanding Bernoulli's Fallacy: A member shared a link explaining Bernoulli's Fallacy. The discussion aims to clarify misconceptions about the fallacy in probability and statistics.
- Severe Geomagnetic Storms: Insights about severe geomagnetic storms were discussed with reference to a search. The effects discussed include impacts on satellite operations and power grids.
- Eurovision 2024 Updates: Eurovision enthusiasts discussed updates related to the 2024 event, as detailed in a search result.
- Importance of Magnesium: A user inquired about the significance of magnesium, leading to a detailed explanation available here. Important for various bodily functions, the mineral's role in health was elaborated.
Link mentioned: Alexandr Yarats, Head of Search at Perplexity – Interview Series: Alexandr Yarats is the Head of Search at Perplexity AI. He began his career at Yandex in 2017, concurrently studying at the Yandex School of Data Analysis. The initial years were intense yet rewarding...
Perplexity AI ▷ #pplx-api (4 messages):
- User requests Perplexity tutorial: A user requested a tutorial for Perplexity AI, asking in Spanish "dame un tutoria de perplexity por favor". This indicates some users may be seeking guidance in languages other than English.
- Link to deep dive provided: A user shared a link to a Discord message for a "deep dive", presumably related to a more comprehensive guide or information about Perplexity AI. Link to deep dive.
HuggingFace ▷ #general (389 messages🔥🔥):
- Search for Open Source LLM Model Alternatives: Members discussed various open-source LLM models such as Mistral and LLaMa3, which can operate with lower hardware requirements compared to the free version of ChatGPT. Mention was made of platforms like You.com for trying these models.
- Debugging Stable Diffusion Pipeline: A member provided a Python code snippet for disabling the safety checker in the StableDiffusionPipeline using
from_pretrained(). Another member reported the issue of black images indicating incomplete solutions. - Issues with GPT's Data Retrieval in RAG Applications: Users discussed difficulties with GPT's effectiveness in retrieving data from files in Retrieval-Augmented Generation (RAG) applications. Suggested improvements included refining data sets and using better embedding models.
- OpenAI's New Announcements: Some participants commented on OpenAI's recent announcement of GPT-4o, noting its real-time audio, video, and speech synthesis capabilities. Concerns were raised about the long-term implications of life-like AI features.
- HuggingFace Documentation and AutoTrain: The HuggingFace documentation was recommended for beginners, and questions were raised about the fine-tuning time for models like GPT-2 XL on Nvidia A10G hardware using AutoTrain.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- no title found: no description found
- Gryphe/Tiamat-8b-1.2-Llama-3-DPO · Hugging Face: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
- Easily Train Models with H100 GPUs on NVIDIA DGX Cloud: no description found
- EurekAI: no description found
- Excuse Me Hands Up GIF - Excuse Me Hands Up Woah - Discover & Share GIFs: Click to view the GIF
- Getting Started With Hugging Face in 15 Minutes | Transformers, Pipeline, Tokenizer, Models: Learn how to get started with Hugging Face and the Transformers Library in 15 minutes! Learn all about Pipelines, Models, Tokenizers, PyTorch & TensorFlow in...
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
- TikTok - Make Your Day: no description found
- Will Smith Chris Rock GIF - Will Smith Chris Rock Jada Pinkett Smith - Discover & Share GIFs: Click to view the GIF
HuggingFace ▷ #today-im-learning (3 messages):
- MedEd AI User Experience Overview: A YouTube video provided a quick overview on genAI user experience, highlighting the use of containerized applications, multimodal medical advisors, and future plans for RA generation, free tier access, and cost-conscious models. The video covers aspects from introduction to detailed features at various timestamps.
- DeepLearning.ai on Neural Network Initialization: A member shared an informative resource from deeplearning.ai which explains the importance of effective initialization to prevent issues like exploding/vanishing gradients. The tutorial outlines the common training process for neural networks and emphasizes on choosing the right initialization method.
- Exploring JAX and TPU for VAR Paper: Another member discussed porting the VAR paper, which focuses on a new autoregressive modeling paradigm for images, to a Jax-compatible library using Equinox for TPU acceleration (Arxiv paper). They shared a GitHub repository for Equinox to further elaborate on the tools being used.
- AI Notes: Initializing neural networks - deeplearning.ai: In this post, we'll explain how to initialize neural network parameters effectively. Initialization can have a significant impact on convergence in training deep neural networks...
- On User Experience. With Multiple Models. For MedEd & More.: A quick overview on genAI user experience with our current progress. If AI is a buffet, we aim to be your Sushi-Go-Round. 00:00 Introduction03:45 Containeriz...
- Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction: We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolutio...
- GitHub - patrick-kidger/equinox: Elegant easy-to-use neural networks + scientific computing in JAX. https://docs.kidger.site/equinox/: Elegant easy-to-use neural networks + scientific computing in JAX. https://docs.kidger.site/equinox/ - patrick-kidger/equinox
HuggingFace ▷ #cool-finds (10 messages🔥):
- Phi-3 excels on smartphones: A member highlighted that Phi-3 runs well on low-power devices like smartphones. Read more about it in this paper by multiple authors.
- Deep Learning Primer Book: A "nice book" for understanding deep learning was shared. Check it out here.
- Neural Network Weights Initialization: An interesting resource from deeplearning.ai about initializing neural network weights and the issues of exploding/vanishing gradients was shared. Link for more details.
- Visualization of GPT: A member found a cool visualization of GPT and shared it. View it here.
- 3D Diffusion Policy for Robots: Introducing the 3D Diffusion Policy (DP3), a novel approach to visual imitation learning for robots that uses 3D visual representations from sparse point clouds. The method shows a 24.2% improvement over baselines with minimal demonstrations; more insights here.
- LLM Visualization: no description found
- AI Notes: Initializing neural networks - deeplearning.ai: In this post, we'll explain how to initialize neural network parameters effectively. Initialization can have a significant impact on convergence in training deep neural networks...
- Understanding Deep Learning: no description found
- Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone: We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of ...
- 3D Diffusion Policy: This paper introduces 3D Diffusion Policy (DP3), a visual imitation learning algorithm that masters divserse visuomotor tasks.
- no title found: no description found
HuggingFace ▷ #i-made-this (7 messages):
- AI storyteller in 4 languages faces inactivity: A member showcased an AI-powered storyteller supporting English, Malay, Chinese, and Tamil here, but noted that this space is currently inactive due to lack of use.
- Holy Quran verses tool waiting for users: They also built an AI tool to create beautiful posters based on Holy Quran verses, available here, but this space is similarly inactive due to inactivity.
- OCR toolkit integrates multiple frameworks: An OCR framework was developed that integrates with DocTr, PaddleOCR, and Google Cloud Vision, making it easy to use and visualize, with the code and docs available on GitHub. The toolkit allows for experimentations with different OCR frameworks seamlessly.
- Fine-tuned Llama variants for token classification shared: Models fine-tuned for token classification using Llama variants have been shared on the HuggingFace Hub. Details and models, such as
unsloth/llama-2-7b-bnb-4bittrained onconll2003, are available in a collection and an upcoming blog post will be shared on Weights & Biases.
- New AI Discord chatbot tutorial video posted: A link to a YouTube video on creating an AI Discord chatbot with web search capabilities was posted, including a git repository with detailed instructions.
- Classifying noisy vs. clean text is now simpler: An OCR quality classifier was launched using the PleIAs dataset for text classification, easily distinguishing between noisy and clean text. The small encoders used can serve as new filters for document quality, with details available in a collection.
- How To Create Your Own AI Discord Chat Bot With Web Search: Git Repo:https://github.com/ssimpson91/newsChanYou will need the following packages;NodeJS v. 18Python 3.10 or aboveRun these commands in your terminal to in...
- OCR Quality Classifiers - a pszemraj Collection: no description found
- Kalam AI - a Hugging Face Space by ikmalsaid: no description found
- LlamaForTokenClassification - a SauravMaheshkar Collection: no description found
- Alkisah AI - a Hugging Face Space by ikmalsaid: no description found
- GitHub - ajkdrag/ocrtoolkit: Experiment and integrate with different OCR frameworks seamlessly: Experiment and integrate with different OCR frameworks seamlessly - ajkdrag/ocrtoolkit
HuggingFace ▷ #reading-group (2 messages):
- YOCO Decoder-Decoder Architecture reduces GPU memory demands: A member shared an arXiv paper introducing YOCO, a new architecture for large language models. The design, featuring a cross-decoder stacked upon a self-decoder, aims to reduce GPU memory usage while retaining global attention capability and improving prefill speeds.
Link mentioned: You Only Cache Once: Decoder-Decoder Architectures for Language Models: We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. ...
HuggingFace ▷ #computer-vision (6 messages):
- Class-Condition Diffusion with UNet Discussion: A user shared their experience with class condition diffusion using UNet, referring to a HuggingFace diffusion course and inquired if there's similar material for latent diffusion models.
- Stable Diffusion Using Diffusers: Another user provided a link to a HuggingFace blog post on Stable Diffusion, which discusses how to use the Diffusers library with this text-to-image latent diffusion model and provides additional educational resources.
- YOLOv1 Implementation Troubles: A user expressed difficulty implementing YOLOv1 from scratch on a custom dataset and sought assistance from experienced individuals. They later clarified that their goal was to create an educational mini-YOLO with a ResNet backbone.
- YOLOv1 vs. YOLOv5 or YOLOv8: Another user questioned the necessity of using YOLOv1 instead of newer versions like YOLOv5 or YOLOv8. The original poster explained the choice was for educational and teaching purposes, aiming to implement a simpler version of YOLO with their custom dataset.
- Hugging Face - Learn: no description found
- Stable Diffusion with 🧨 Diffusers: no description found
HuggingFace ▷ #NLP (7 messages):
- Challenges with meeting transcript chunking: A user is seeking insights on how to efficiently chunk meeting transcripts for extracting actionable insights using LLMs. They mention trying to separate by speaker changes, but find the similarity scores between interactions to be low (0.45).
- Consequent messages and similarity scores: Another member commented that consequent messages may not necessarily have high similarity scores even if the topic remains constant. They suggested finding the most relevant chunk and writing a function to fetch neighboring chunks to address the user's needs.
- Retrieval and generation evaluation advice: It was suggested to separate retrieval and generation components, evaluate them independently, and benchmark retriever results with different configurations like chunk size and overlap. The "mean reciprocal rank" metric was recommended for evaluation.
- Custom Hugging Face tokenizer training issues: A user shared their process of creating and training a custom Hugging Face tokenizer and issues faced when integrating it with a transformer, as instructed in a 2021 YouTube video. They reported errors, with ChatGPT indicating the tokenizer might be in the wrong format.
Link mentioned: Building a new tokenizer: Learn how to use the 🤗 Tokenizers library to build your own tokenizer, train it, then how to use it in the 🤗 Transformers library.This video is part of the...
HuggingFace ▷ #diffusion-discussions (14 messages🔥):
- Dive into Diffusion Models with these Resources: A member asked for recommendations on understanding diffusion models, samplers, and related topics. They were pointed to the DDPM & DDIM papers and Fast.ai's course, which includes collaboration with Stability.ai and Hugging Face.
- Struggling with SadTalker on macOS?: A user requested urgent help with installing SadTalker on macOS. Someone recommended searching for the error message to find more precise answers.
- Get Hands-On with Inpainting: There was an inquiry about using inpainting with personal images. An in-depth explanation and guide for using the 🤗 Diffusers library for inpainting was shared.
- Creating Custom Image Datasets: Someone asked how to use their custom image datasets instead of internet data. They were directed to a guide on creating a dataset with the 🤗 Datasets library.
- Local Inference Engine for Command-R+ Advice: There was a passing query about making a local inference engine for Command-R+. A member suggested seeking advice from an NLP-focused group for more relevant input.
- Create a dataset for training: no description found
- Practical Deep Learning for Coders - Part 2 overview: Learn Deep Learning with fastai and PyTorch, 2022
- Inpainting: no description found
- Hands-On Generative AI with Transformers and Diffusion Models: Learn how to use generative media techniques with AI to create novel images or music in this practical, hands-on guide. Data scientists and software engineers will understand how state-of-the-art gene...
- [Bug]: ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor' torchvision 0.17 promblem · Issue #13985 · AUTOMATIC1111/stable-diffusion-webui: Is there an existing issue for this? I have searched the existing issues and checked the recent builds/commits What happened? ModuleNotFoundError: No module named 'torchvision.transforms.functiona...
LM Studio ▷ #💬-general (183 messages🔥🔥):
- Users Struggle with GPT Agent Learning: Users expressed concerns about GPT agents not learning from additional information, with others clarifying that uploaded files are saved as "knowledge" files but do not continually modify the agent's base knowledge.
- RTX 4070 for Summarization Tasks in Linux: A member inquired about specs for summarizing PDFs, mentioning a system with Intel i5, RTX 4070, and 64GB RAM on GNU/Linux, only to be informed that chat with docs capabilities aren't yet supported by LM Studio.
- Performance Issue with Multi-GPU Setup: A user faced issues running models on a setup with multiple GPUs and reported extremely slow performance. The problem was identified as likely related to hardware setup with PCIe 3.0, and resolving it by switching motherboard equipped with PCIe 4.0.
- Access Issues to LM Studio Features Amid Network Concerns: Various users reported encountering difficulties accessing models from LM Studio, often due to network errors or blocked locations. Solutions such as using a VPN with IPv4 were suggested.
- Exploring Alternatives for Local Model Deployment: Discussion included advice on using systems with sufficient VRAM for local model deployment, emphasizing GPUs with 8GB+ memory for better performance and usability over CPU-only setups.
- no title found: no description found
- no title found: no description found
- Chat.lmsys.org down? Current problems and status. - DownFor: Chat.lmsys.org won't load? Or, having problems with Chat.lmsys.org? Check the status here and report any issues!
- Boo Boo This Man GIF - Boo Boo This Man - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #🤖-models-discussion-chat (92 messages🔥🔥):
- Yi-1.5 Models Gain Traction: LM Studio community members are excited about the new Yi-1.5 models and multiple versions like 9B, 6B, and upcoming 34B quantized models. Members appreciated Yi-1.5's performance, noting it performs well in diverse fine-tuning tasks but mentioned issues like confusion about its identity.
- Challenges with Smaller Hardware: Users discussed the difficulties of running advanced models on constrained hardware like an RTX 3050 6GB and the limitations it poses for tasks like coding or long-context processing. Recommendation steered towards using lightweight models or employing tools like stable diffusion via accessible platforms such as itch.io.
- Audio Cleanup Solutions: For those needing to clean up audio, options like Voicecraft and RVC were discussed to enhance instructional videos with poor audio quality, similar to Adobe's Podcast Enhance.
- Fine-Tuning Questions and Insights: Queries about fine-tuning datasets sparked discussions on the composition of test data, with suggestions leaning toward a mix of normal question-answer pairs. Insights were shared about models often being quantized by different people and occasionally having finetune designations in their names.
- Command R+ Model Commended: There was high praise for the Command R+ model, with users recommending it for its longer context length, enhanced smartness, and lack of censorship, which makes it preferable over others like Llama 3 70B.
- YorkieOH10/Yi-1.5-6B-Chat-Q8_0-GGUF · Hugging Face: no description found
- YorkieOH10/Yi-1.5-9B-Chat-Q8_0-GGUF · Hugging Face: no description found
- NikolayKozloff/Meta-Llama-3-8B-Instruct-bf16-correct-pre-tokenizer-and-EOS-token-Q8_0-Q6_k-Q4_K_M-GGUF · Hugging Face: no description found
- 01-ai/Yi-1.5-9B-Chat · Hugging Face: no description found
- failspy/kappa-3-phi-abliterated · Hugging Face: no description found
- dranger003/c4ai-command-r-plus-iMat.GGUF · Hugging Face: no description found
LM Studio ▷ #🧠-feedback (4 messages):
- Member shares positive feedback: A user expressed their gratitude for the helpful feedback they received from another member, indicating a positive interaction within the community.
- Alternatives to Innosetup: One member suggested using Innosetup or Nullsoft Installer as good open-source alternatives for software installation, based on their past experiences.
- Challenges with Starcoder model on Debian: A member described encountering repetitive responses and off-topic answers while using the starcoder2-15b-instruct model on Debian 12. They noted the behavior was similar across different platforms and setups, including the app chatbox and VSC server.
- Instruct model's limitations: Another member clarified that instruct models are not typically designed for multi-step conversations. They emphasized that these models are intended to execute single commands and respond directly to those.
LM Studio ▷ #⚙-configs-discussion (7 messages):
- Playground mode requires GPU: A user inquired about running the playground mode on RAM + CPU given their limited 4GB VRAM. Another member confirmed that the playground mode is GPU only.
- Warning against suspicious links: A user warned others not to click a shortlink, pointing out that it does not direct to Steam. The warning is emphasized with a Johnny Depp gif and repeated insistence to "go away."
- Using word files for LLM training: A user asked if they could train a Large Language Model (LLM) with word files containing syllabus content for question-and-answer purposes. There was no follow-up response to this inquiry.
Link mentioned: Shoo Go Away GIF - Shoo Go Away Johnny Depp - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #🎛-hardware-discussion (106 messages🔥🔥):
- Running Large Models on Limited Hardware Fails: Members discussed their experiences running Llama 3 70B Q8 on hardware with 128GB RAM, noting that it's often too slow or fails to load. One example noted 2 tok/s speed on a 4090 with 128GB for a 70B Q4 model, highlighting limitations.
- CPU Inference for Large LLMs is Painfully Slow: Running large models like Llama 3 70B solely on CPUs results in slow speeds, often only achieving single-digit token per second performance. A notable example mentioned getting 0.6 tok/s after disabling E-cores on an i5 12600K.
- Challenges of GPU Memory Limitations: Users with limited VRAM, such as 2GB, found it practically useless for running advanced models, even when trying to offload layers. "2GB video won't be useful at all - you'd want 4, but preferably 6gb, minimum to start to be useful."
- Mixed Results with Different GPUs: Despite having superior specs, a Tesla P100 performed worse than a GTX 1060 for some members when using LM Studio. Disabling "Hardware-accelerated GPU scheduling" showed a modest 5% boost in performance.
- Documentation and Backend Queries: Users were curious about how the llama.cpp backend in LM Studio handles computations and whether it utilizes FP32 or FP16 and Tensor cores. Clarifications included that it generally uses quantized models which reduce precision significantly.
LM Studio ▷ #🧪-beta-releases-chat (12 messages🔥):
- CodeQwen1.5 shines for coding on RTX 3050: A member recommended CodeQwen1.5 as a highly efficient coding model, noting it outperforms DeepSeek Coder. The model's 4b quantization, about 4.18 GB, fits well on an RTX 3050 GPU.
- Hugging Face's coding leaderboard is a resource: Another member shared a link to the Hugging Face's coding leaderboard on their site, where users can check details about coding models of 7b or lower. bigcode-models-leaderboard.
- LLama.cpp update and bug fixes: Responding to queries about new features, a user clarified that the latest build primarily consists of bug fixes alongside an update to llama.cpp. Users did not report any new hidden features.
- Bots slip through automod: A user commented on a suspicious link, likely for farming ad or referral income, and noted it evaded auto-moderation. This highlights ongoing vigilance against potential spam or malicious links in the chat.
Link mentioned: Big Code Models Leaderboard - a Hugging Face Space by bigcode: no description found
LM Studio ▷ #memgpt (4 messages):
- Seek MemGPT Help: A member requested assistance from someone experienced with MemGPT, prompting responses of varying confidence and apologies.
- Setup Issues: One responder mentioned successfully setting up MemGPT with Kobold and managing memory adjustments but admitted to struggling with implementation on LM Studio.
LM Studio ▷ #amd-rocm-tech-preview (2 messages):
- Scoops up RX 7900 XT: A member shared the excitement of purchasing an RX 7900 XT for 700 euros, mentioning it's more than enough power for their needs.
- Bigger models recommended: Another member suggested trying Command-R+ or Yi-1.5's quantized variants, hinting that the new GPU could handle larger models.
LM Studio ▷ #open-interpreter (4 messages):
- Confusion on connecting LM Studio to OpenInterpreter: A user asked for a guide on how to connect LM Studio to OpenInterpreter. The conversation reveals they are experiencing consistent errors when attempting to run the server, both when connected and not connected.
LM Studio ▷ #model-announcements (1 messages):
- New Yi Models Available!: The LM Studio community has released new Yi models on their Hugging Face page. There are various sizes available, including a rare 34B model, ideal for users with 24GB cards.
- GGUF Quantization by Bartowski: The models feature GGUF quantization provided by the community member Bartowski, based on the
llama.cpprelease b2854. This ensures maximum quality and enhanced performance.
- Model Details and Performance: All Yi-1.5 models are upgraded versions continuously pre-trained with a high-quality corpus of 500B tokens and fine-tuned on 3M diverse samples. They are designed to perform well on a wide range of tasks.
- Links to Models: Check out the new models here:
- lmstudio-community/Yi-1.5-34B-Chat-GGUF · Hugging Face: no description found
- lmstudio-community/Yi-1.5-9B-Chat-GGUF · Hugging Face: no description found
- lmstudio-community/Yi-1.5-6B-Chat-GGUF · Hugging Face: no description found
LM Studio ▷ #🛠-dev-chat (19 messages🔥):
- Discussion on Vulkan-Backend for llama.cpp: A member inquired about running a Vulkan-backend for llama.cpp with LM Studio or using a backend API. Another member responded that there isn't a solution for this yet.
- LM Studio CLI Tool Announcement: A member shared the release of LM Studio 0.2.22 and its companion CLI tool,
lms, which allows model management and API server control. The tool is available on GitHub and ships with LM Studio's working directory.
- Clarification on Backend API Request: A discussion clarified that the original query was about connecting LM Studio to a llama.cpp HTTP server rather than the suggested CLI tool.
- Headless Installation Issues: Members discussed the difficulties of installing LM Studio on a headless Linux cloud server due to AppImage issues with FUSE. Alternative suggestions included trying Ollama or compiling llama.cpp from the base.
Link mentioned: Introducing lms - LM Studio's companion cli tool | LM Studio: Today, alongside LM Studio 0.2.22, we're releasing the first version of lms — LM Studio's companion cli tool.
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- JetMoE 8B Free Outage: The JetMoE 8B Free model is currently down due to upstream overload. All requests will return an empty response with an error (502) until further notice.
- Multimodal Models Now Available: Two new multimodal models are now up and running on OpenRouter. Check out OpenAI: GPT-4o and LLaVA v1.6 34B.
- JetMoE 8B by jetmoe | OpenRouter: Coming from a broad set of teams, ranging from academic to industry veterans, Jet MoE is a combined effort from MIT, Princeton, IBM, Lepton, and MyShell. This model is fully open source and trained o...
- OpenAI: GPT-4o by openai | OpenRouter: GPT-4o ("o" for "omni") is OpenAI's latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of [GPT-4 Turbo](/models/open...
- LLaVA v1.6 34B by liuhaotian | OpenRouter: LLaVA Yi 34B is an open-source model trained by fine-tuning LLM on multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. Base LLM: [Nou...
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- Track OpenRouter model changes easily: A member introduced the OpenRouter API Watcher, an open-source tool designed to monitor and store changes in the OpenRouter model list using a SQLite database. It offers a web interface and an RSS feed for updates, querying the API hourly to maintain minimal overhead. Demo
- Become a beta tester for Rubik's AI Pro: Another member is inviting users to beta test an advanced research assistant and search engine, offering 2 months of free premium access to models like GPT-4 Turbo and Claude 3 Opus. Interested users were asked to DM feedback and use a promo code
RUBIXfor the free trial. Rubik's AI
- OpenRouter API Watcher: OpenRouter API Watcher monitors changes in OpenRouter models and stores those changes in a SQLite database. It queries the model list via the API every hour.
- Rubik's AI - AI research assistant & Search Engine: no description found
OpenRouter (Alex Atallah) ▷ #general (251 messages🔥🔥):
- **Jetmoe lacks online access**: When asked if **Jetmoe** has online access, the response was clear, *“No, it doesn’t.”* Jetmoe is considered good for academic research despite this limitation.
- **OpenRouter tackles anti-fraud measures aggressively**: Discussion on anti-fraud updates revealed that **OpenRouter** has implemented measures to combat fraud due to losses from credit card skimming. Users can opt for crypto transactions to avoid providing personal information.
- **Embedding models support in consideration**: When asked about embedding models support, it was mentioned that **OpenRouter** is working on improving the backend and has embedding models in the queue, but there is no immediate roadmap yet.
- **Inconsistent prompt formatting issues**: Users discussed how models like **Claude** handle instructions differently than models focused on RP (role-playing) or generic tasks. The need for trial and error in crafting effective prompts for different models was highlighted.
- **OpenRouter adds GPT-4o**: Excitement surrounded the addition of **GPT-4o** to OpenRouter, with users noting its competitive pricing and high performance in benchmarks. OpenRouter will support text and image inputs for GPT-4o, although video and audio are not available.
- OpenAI API Endpoints | Open WebUI: In this tutorial, we will demonstrate how to configure multiple OpenAI (or compatible) API endpoints using environment variables. This setup allows you to easily switch between different API providers...
- Reddit - Dive into anything: no description found
- Stripe | Financial Infrastructure for the Internet: Stripe powers online and in-person payment processing and financial solutions for businesses of all sizes. Accept payments, send payouts, and automate financial processes with a suite of APIs and no-c...
- Reddit - Dive into anything: no description found
- 零一万物-AI2.0大模型技术和应用的全球公司(01.AI): no description found
- Can Claude Read PDF? [2023] - Claude Ai: Can Claude Read PDF? PDF (Portable Document Format) files are a common document type that many of us encounter in our daily lives.
Modular (Mojo 🔥) ▷ #general (65 messages🔥🔥):
- Implicit variants with the pipe operator in Mojo discussed: One member queried about Mojo adopting implicit variants with the pipe operator, to which another shared a link to PEP 604 as a comparison. The discussion touched upon potential syntax and the handling of pattern matching.
- Pattern matching debate gets heated: There was a vibrant discussion about the value and aesthetics of pattern matching in Mojo compared to using
if-elsestatements. Advocates highlighted how pattern matching ensures exhaustive cases and compiler optimizations, while critics found it visually unappealing.
- Mojo versus Rust: compiler experiences shared: Members compared experiences with Mojo and Rust compilers, noting that Rust is perceived as more complex and harder to navigate, whereas Mojo’s simpler, more straightforward approach was appreciated. The debate included opinions on Rust's optimization capabilities and the projection of Mojo's future feature robustness.
- Contributing to the Mojo compiler inquiries: A user inquired about contributing to the Mojo compiler, prompting a response that currently, the Mojo compiler is not open source. Clarifications were made that the Mojo compiler is written in C++, not Mojo.
- Discussion on Mojo and MLIR relationship: There was a brief discussion on the possibilities of bootstrapping Mojo using MLIR, and whether rebuilding MLIR in Mojo would be feasible in the future. The conversation acknowledged MLIR’s C++ origins and raised the question of future development.
Link mentioned: PEP 604 – Allow writing union types as X | Y | peps.python.org: no description found
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1790046377613144201
Modular (Mojo 🔥) ▷ #📺︱youtube (1 messages):
- Modular's new video announcement: The ModularBot shared that a new video has been posted on their YouTube channel. You can check out the latest content by clicking here.
Modular (Mojo 🔥) ▷ #🔥mojo (85 messages🔥🔥):
- Storage and Running of Benchmarks: Members discussed optimal ways to store and run benchmarks in repositories, with one user suggesting that including benchmarks in a
testsfolder might be practical. Another user inquired about ways to benchmark memory usage.
- Syntax Discussion in Mojo: There was a debate about dereferencing syntax, with some suggesting C++ style
*would be ergonomic, but others like Chris Lattner argued forp[]as it composes nicely and is pythonic.
- Iterator Implementation in Mojo: Joker discussed implementing "yield" like behavior in Mojo by replicating the torchdata API due to Mojo's current lack of real
yieldcapabilities. They detailed their approach and ran into issues with type constraints and parametric traits.
- Tree Sitter Grammar Fork: Lukas Hermann mentioned they wrote a Tree Sitter grammar fork and tested it successfully in text editors like Helix and Zed, planning to clean up decorators and add tests.
- Deep Dive into Mojo Ownership: A link to a YouTube talk by Chris Lattner was shared, explaining ownership in Mojo. Members discussed their struggles with ownership concepts coming from a Python background and the importance of examples showing why these ideas matter.
- Subtyping and Variance - The Rustonomicon: no description found
- DType | Modular Docs: Represents DType and provides methods for working with it.
- Mojo🔥: a deep dive on ownership with Chris Lattner: Learn everything you need to know about ownership in Mojo, a deep dive with Modular CEO Chris LattnerIf you have any questions make sure to join our friendly...
- [Feature Request] Unify SSO between `InlinedString` and `String` type · Issue #2467 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? We currently have https://docs.modular.com/mojo/stdlib...
- Python Mutable Defaults Are The Source of All Evil - Florimond Manca: How to prevent a common Python mistake that can lead to horrible bugs and waste everyone's time.
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (1 messages):
- Introducing MoString on GitHub: A member announced the creation of a GitHub repo for MoString focusing on variations over StringBuilder ideas in Mojo. They added an
optimize_memorymethod to reduce allocated memory and invited community contributions to explore suitable implementations for the Mojo standard.
Link mentioned: GitHub - dorjeduck/mostring: variations over StringBuilder ideas in Mojo: variations over StringBuilder ideas in Mojo. Contribute to dorjeduck/mostring development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #nightly (64 messages🔥🔥):
- Custom Hasher struct proposal sparks debate: A member expressed concerns about forcing devs to create custom Hasher structs, favoring simpler methods like Python's
__hash__. The proposal author provided additional examples showcasing the flexibility and simplicity his implementation aims to offer.
- CI tests failure on Ubuntu sparks action: Members discussed issues with CI tests hanging on Ubuntu, with suggestions to add timeouts to the workflows. A pull request was created to implement these timeouts, and it was noted that GitHub Actions might experience buggy "pending" statuses during this time.
- Significant performance findings on
Listextend method: A member shared benchmarking results showing the extend method of Mojo'sListcould be greatly improved via a memory pre-allocation strategy. This led to discussions about the merits of mirroring Rust's vector allocation strategies for similar tasks.
- Nested arrays causing segmentation faults: A member reported segmentation faults when dealing with nested arrays and questioned whether the issue was related to variadic pack or lifetime management. It led to insights on reference handling within array iterators.
- Excitement over nightly releases: The community celebrated the shift to automatic nightly releases for Mojo, dubbed "nightly nightlies," and discussed implications such as reduced delays between committed changes and their availability.
- Usage limits, billing, and administration - GitHub Docs: no description found
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [stdlib] Introduce Hasher type with all necessary changes by mzaks · Pull Request #2619 · modularml/mojo: This is a draft because although the code compiles 8 tests are failing. It might be due to compiler bug. The error messages are cryptic. I don't have the "Mojo" ;) to fix them. Failed Te...
- [CI] Add timeouts to workflows by JoeLoser · Pull Request #2644 · modularml/mojo: On Ubuntu tests, we're seeing some non-deterministic timeouts due to a code bug (either in compiler or library) from a recent nightly release. Instead of relying on the default GitHub timeout of ...
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo: port of Andrjey Karpathy's minbpe to Mojo. Contribute to dorjeduck/minbpe.mojo development by creating an account on GitHub.
- [stdlib] Delegate string comparisons to `StringRef` by siitron · Pull Request #2620 · modularml/mojo: This is a follow-up to #2409. String comparisons for StringRef are implemented. StringRef make use of memory.memcmp for all of its 6 comparisons now, hopefully this change is ok. String's and Stri...
- minbpe.mojo/mojobpe/utils/mostring/molist.mojo at main · dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo. Contribute to dorjeduck/minbpe.mojo development by creating an account on GitHub.
- GitHub - dorjeduck/mostring: variations over StringBuilder ideas in Mojo: variations over StringBuilder ideas in Mojo. Contribute to dorjeduck/mostring development by creating an account on GitHub.
- GitHub - mzaks/mojo at feature/minimal-example-of-test-crash-for-new-hasher: The Mojo Programming Language. Contribute to mzaks/mojo development by creating an account on GitHub.
CUDA MODE ▷ #general (5 messages):
- GPU memory management confusion clarified: A user with an 8GB GPU noticed that CUDA uses shared memory when running out of dedicated GPU memory. They observed significant slowdowns during this process and asked for resources to understand how this works.
- Direct contact with Discord CEO for tech support: One member humorously reported chatting directly with the Discord CEO to resolve stage stability issues, leading to quick action from the team. Their success prompted light-hearted reactions from other members.
CUDA MODE ▷ #triton (43 messages🔥):
- New Lecture on Triton Praised: A member shared a YouTube video titled "Lecture 14: Practitioner's Guide to Triton" and the accompanying GitHub description. It's a resource for learning more about Triton kernels.
- Contributors Share Resources for Conv2D Kernels: Discussions included links to existing Conv2D kernel implementations in Triton found in PyTorch's kernel and the attorch repository. There's encouragement to contribute to the main Triton repo or other related repositories.
- Cataloging Triton Kernels Highlighted: The Triton Index and Awesome Triton Kernels repositories were mentioned as valuable resources for cataloging and discovering Triton kernels. Kernl, a tool designed for running PyTorch transformer models faster on GPU, was also highlighted: Kernl GitHub.
- Excitement Over ThunderKittens: A new DSL called ThunderKittens was shared via Twitter and discussed enthusiastically. It promises to make writing AI kernels in CUDA simpler and more efficient, potentially outperforming Triton's Flash Attention.
- Flash Attention Performance Comparisons: There was a detailed discussion about the performance differences between Triton’s Flash Attention and a new implementation in ThunderKittens. Some members noted that proper tuning and configurations might narrow the performance gap, suggesting ongoing improvements and benchmarks.
- GitHub - BobMcDear/attorch: A subset of PyTorch's neural network modules, written in Python using OpenAI's Triton.: A subset of PyTorch's neural network modules, written in Python using OpenAI's Triton. - BobMcDear/attorch
- Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
- Tweet from Benjamin F Spector (@bfspector): (1/7) Happy mother’s day! We think what the mothers of America really want is a Flash Attention implementation that’s just 100 lines of code and 30% faster, and we’re happy to provide. We're exci...
- GitHub - zinccat/Awesome-Triton-Kernels: Collection of kernels written in Triton language: Collection of kernels written in Triton language. Contribute to zinccat/Awesome-Triton-Kernels development by creating an account on GitHub.
- [TUTORIALS] tune flash attention block sizes (#3892) · triton-lang/triton@702215e: no description found
- GitHub - cuda-mode/triton-index: Cataloging released Triton kernels.: Cataloging released Triton kernels. Contribute to cuda-mode/triton-index development by creating an account on GitHub.
- GitHub - ELS-RD/kernl: Kernl lets you run PyTorch transformer models several times faster on GPU with a single line of code, and is designed to be easily hackable.: Kernl lets you run PyTorch transformer models several times faster on GPU with a single line of code, and is designed to be easily hackable. - ELS-RD/kernl
CUDA MODE ▷ #cuda (9 messages🔥):
- ThunderKittens speeds up kernels: The GitHub repository for ThunderKittens focuses on tile primitives for speeding up kernels. It's a project by HazyResearch aimed at making CUDA operations more efficient.
- NanoGPT-TK for optimized GPT training: NanoGPT-TK is a repository touted as the simplest and fastest for training and fine-tuning medium-sized GPTs. The repository also humorously emphasizes that it includes "kittens," playing on the project name.
- FlashAttention explained humorously: A blog post describes the efforts of HazyResearch to simplify AI kernel-building ideas through projects like ThunderKittens. They reference a NeurIPS keynote and use humor to bridge the gap between complex technical models and accessible explanations.
- Swizzling reduces memory bank conflicts: A discussion clarified that swizzling helps avoid memory bank conflicts, enhancing memory access efficiency in CUDA programming. A link to the NVIDIA documentation was provided for further reading.
- ThunderKittens: A Simple Embedded DSL for AI kernels: good abstractions are good.
- GPUs Go Brrr: how make gpu fast?
- GitHub - HazyResearch/ThunderKittens: Tile primitives for speedy kernels: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
- GitHub - HazyResearch/nanoGPT-TK: The simplest, fastest repository for training/finetuning medium-sized GPTs. Now, with kittens!: The simplest, fastest repository for training/finetuning medium-sized GPTs. Now, with kittens! - HazyResearch/nanoGPT-TK
CUDA MODE ▷ #announcements (1 messages):
- Fusing Kernels Talk Announcement: An upcoming talk on fusing kernels is scheduled to start in 7 minutes, featuring <@488490090008674304>. The talk will happen on Zoom, and attendees are instructed to post chat and questions in the designated channel <#1238926773216084051>.
Link mentioned: Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
CUDA MODE ▷ #algorithms (1 messages):
random_string_of_character: https://arxiv.org/abs/2405.05219
CUDA MODE ▷ #beginner (14 messages🔥):
- Join the U Illinois PMPP lecture series via Zoom: "We will start the 4th lecture of U Illinois PMPP series in 10 minutes.. here is a zoom link." These lectures usually happen weekly on Saturdays, and the details are shared in a dedicated Discord server.
- PMPP lecture comparisons vivid: "I like how he compares warps to platoons in the army," making complex concepts more relatable.
- Course details and accessibility: The course on applied parallel programming is available on YouTube, with the course playlist being frequently shared. Despite being from 2018, it remains a valuable resource.
- Integration and announcement etiquette: Laith0x0 and Wilson post announcements here but prefer not to overuse mentions. Marksaroufim suggested using a dedicated Discord channel for more persistent information sharing.
- Compatibility queries and build dependencies: Geri8904 is seeking compatibility information for torch-tensorrt with different CUDA and Torch versions and experiences issues with package installations. safelix also encountered missing build dependencies and sought recommendations for a comprehensive requirements.txt file.
- UIUC ECE408/CS483 Spring 2018 Hwu: This is a junior/senior-level undergraduate course entitled "Applied Parallel Programming" at the University of Illinois at Urbana-Champaign. It is often als...
- UIUC ECE408/CS483 Spring 2018 Hwu: This is a junior/senior-level undergraduate course entitled "Applied Parallel Programming" at the University of Illinois at Urbana-Champaign. It is often als...
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
CUDA MODE ▷ #pmpp-book (1 messages):
- CUDA Expert Talks Date Announced: The PMPP Author Izzat El Hajj will discuss scan operations on May 24. On May 25, Jake and Georgii will explain how to build advanced scan using CUDA C++; the event details are available here.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
CUDA MODE ▷ #off-topic (5 messages):
- Seeking help on Thermal Face Recognition project: A member asked for insights, resources, such as research papers, GitHub repositories, or general suggestions for their college final project titled 'Thermal Face Recognition'. They aim to predict if two thermal face images belong to the same person.
- Clarification sought and given: One member asked if the project involves matching two thermal face images for the same person, detecting bounding boxes, or facial landmarks. The project was clarified to be related to predicting if two images are of the same person.
CUDA MODE ▷ #irl-meetup (1 messages):
boxxy_ms: anyone in Toronto?
CUDA MODE ▷ #triton-puzzles (2 messages):
- Oscar_yu hunts for official solutions: Oscar_yu inquired about the availability of official solutions to verify the numerical correctness of his implementation. He later acknowledged finding Joey's solution in Misha's thread, expressing gratitude.
CUDA MODE ▷ #llmdotc (67 messages🔥🔥):
- **ZeRO-1 empowers VRAM battle**: ZeRO-1 integration was discussed, with benchmarks showing a 54% training throughput improvement by optimizing VRAM usage, allowing batch size increase from 4 to 10, maxing out the A100's 40GB VRAM capacity. Catch more details [here](https://github.com/karpathy/llm.c/pull/309).
- **Optimization insights on GPU workloads**: Members discussed the benefit of performing calculations outside of CUDA kernels to optimize integer divisions and memory-bound kernels. Perspectives were shared on using 2D/3D grids and thread coarsening for efficiency, backed by detailed [code discussions](https://github.com/karpathy/llm.c/blob/master/train_gpt2.cu#L689).
- **ThunderKittens catches interest**: The potential of HazyResearch's [ThunderKittens](https://github.com/HazyResearch/ThunderKittens) for H100 llm.c optimization sparked excitement. Members see it as a lower-level abstraction than CUTLASS for managing tensor core layouts.
- **Efforts to improve CI with GPU support**: Talks revolved around the lack of GPUs in llm.c’s CI and ways to bridge this gap, noting GitHub Actions' recent GPU runner beta. Suggestions included upgrading GitHub plans and references to current pricing [details](https://docs.github.com/en/billing/managing-billing-for-github-actions/about-billing-for-github-actions#per-minute-rates-for-larger-runners).
- About billing for GitHub Actions - GitHub Docs: no description found
- cub::WarpLoad — CUB 104.0 documentation: no description found
- Issues · NVIDIA/cccl: CUDA C++ Core Libraries. Contribute to NVIDIA/cccl development by creating an account on GitHub.
- Run your ML workloads on GitHub Actions with GPU runners: Run your ML workloads on GitHub Actions with GPU runners
- llm.c/train_gpt2.cu at master · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- GitHub - HazyResearch/ThunderKittens: Tile primitives for speedy kernels: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
- GPUs Go Brrr: how make gpu fast?
- 2D and 3D tile divisions so that permutation coordinates can be read from threadIdx and blockIdx · Issue #406 · karpathy/llm.c: Supposedly the permutation kernels, even though they are mostly memory bound can reduce the amount of division and do thread coarsening by having a 2d or 3d grid and not have to do any division in ...
- Zero Redundancy Optimizer - Stage1 by chinthysl · Pull Request #309 · karpathy/llm.c: To train much larger model variations (2B, 7B, etc), we need larger GPU memory allocations for parameters, optimizer states, and gradients. Zero Redundancy Optimizer introduce the methodology to sh...
- llm.c/.github/workflows/ci.yml at 2346cdac931f544d63ce816f7e3f5479a917eef5 · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- Zero Redundancy Optimizer - Stage1 by chinthysl · Pull Request #309 · karpathy/llm.c: To train much larger model variations (2B, 7B, etc), we need larger GPU memory allocations for parameters, optimizer states, and gradients. Zero Redundancy Optimizer introduce the methodology to sh...
CUDA MODE ▷ #lecture-qa (48 messages🔥):
- Max-Autotune boosts performance with thorough hyperparam tuning: The
max-autotunemode intorch.compileleverages Triton-based matrix multiplications and convolutions, trying out more hyperparameters for potentially faster kernels. As a trade-off, it takes longer to compile. torch.compile docs - Dynamo vs. Inductor tutorials: Members shared that Dynamo tutorials are more comprehensive compared to inductor ones and highlighted the importance of having better materials for handling dynamic shapes. Links to additional resources were provided for those interested in Dynamo's internal workings. PyTorch Workshops
- Fusion benefits and limitations debated: Discussions highlighted that fusing kernels generally reduces global memory read/writes which benefits memory-bound kernels, but excessive fusion may just add overhead without substantial gains. The general sentiment was to fuse extensively unless proven counterproductive.
- Interest in Triton internals and performance profiling: Several members expressed the need for talks on Triton internals and detailed profiling methodologies for distinguishing overhead, HBM-SRAM communication, and actual computation time. An upcoming workshop was promoted for more insights. Triton Workshop
- Availability of lecture recordings: Due to time zone differences and chaotic schedules, members inquired about when the lecture recordings would be available. The response indicated that it might be delayed but would be addressed soon.
- torch.compile — PyTorch 2.3 documentation: no description found
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- Tensor and Operator Basics: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- workshops/ASPLOS_2024 at master · pytorch/workshops: This is a repository for all workshop related materials. - pytorch/workshops
- Dynamo Deep-Dive — PyTorch main documentation: no description found
CUDA MODE ▷ #youtube-watch-party (5 messages):
- ECE408 Slides Shared for Applied Parallel Programming: Course materials for the Spring 2019 edition of ECE408, available here, include timeline, project plan, and staff office hours. The course emphasizes grade distribution through Blackboard and discussions via Piazza.
- YouTube Watch Party for CUDA Videos: This channel hosts a viewing party where participants watch CUDA-related videos on YouTube together, especially focusing on the series Programming Massively Parallel Processors. The sessions encourage discussions every 10-15 minutes to allow for questions and knowledge sharing.
- Scheduled Viewing Times: Viewing sessions are scheduled on Saturdays at 7:30 GMT for EMEA participants and 18:00 GMT for NAM participants. Zoom links will be provided by specific members for the meetings.
- Plan Post 18 Lectures: After completing the round of 18 lectures, the group may rewatch CUDA Mode videos or select another high-quality, vetted series on parallel processing. This ensures continuous learning and engagement in parallel programming topics.
- Programming Massively Parallel Processors: This channel is the official channel for the textbook: "Programming Massively Parallel Processors: A Hands-on Approach"
- ECE408: Applied Parallel Programming, Spring 2019 ZJUI Section: no description found
Eleuther ▷ #general (61 messages🔥🔥):
- GPTs Agents cannot learn after initial training: A member shared a concern about GPTs agents not learning from additional information provided after their initial training. Another member cleared this misunderstanding, explaining that uploaded files are saved as "knowledge" files for the agent to reference when required, but they do not continually modify the agent's base knowledge.
- Researchers critique layer duplication: “It’s like they’re just introducing noise by duplicating layers and calling the model smarter,” a commenter critiqued efforts to expand models like llama 70b to 120b and 160b by duplicating layers. Another user added "they are finetuning over this somewhat also”.
- Recent arXiv paper on zero-shot generalization: A recent arXiv paper discussed performance issues in zero-shot generalization for multimodal models, generating extensive debate. Critics noted the work's findings were unsurprising and emphasized that the paper does not address compositional generalization.
- Falcon-2 11B release gains attention: Falcon-2 11B was released, trained on 5T refined web data, with an 8k context and MQA attention for improved inference. It sparked interest due to its permissive license and new size.
- Discussion on copyright impact on AI development: Members discussed how AI copyright issues could influence small players and startups. The conversation highlighted that companies like Microsoft offering indemnity may dominate funding and innovation competition, potentially chilling effects on smaller AI ventures.
Link mentioned: No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance: Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image gener...
Eleuther ▷ #research (79 messages🔥🔥):
- New Attention Approximation Method Debuts: A member shared an arXiv link about an efficient approximation method for attention computation using convolution matrices. Another member expressed skepticism about its practical applications compared to existing methods like flash attention.
- Depth Upscaling in LLMs Gains Interest: Discussions on systematic approaches to "depth upscaling," mentioned in papers such as SOLAR and Yi Granite Code models Yi 1.5, included insights on appropriate datasets and prevailing techniques for improving language models.
- Efficient Data Distillation via Farzi: A new method called Farzi summarized an event sequence dataset into smaller synthetic datasets while maintaining performance, as highlighted in an arXiv link. Authors claimed up to 120% downstream performance on synthetic data, but acknowledged scaling challenges with larger models like T5 and datasets like C4.
- Token Glitch Detection Method Released: A study was discussed that focuses on identifying untrained and under-trained tokens in LLMs, found at this arXiv link. This method aims to improve tokenizer efficiency and overall model safety.
- Emerging Work on Memory Mosaics: A fresh approach called Memory Mosaics was shared via an arXiv link, proposing a network of associative memories for prediction tasks, showcasing competitive performance with transformers on medium-scale language modeling tasks.
- Memory Mosaics: Memory Mosaics are networks of associative memories working in concert to achieve a prediction task of interest. Like transformers, memory mosaics possess compositional capabilities and in-context lea...
- State-Free Inference of State-Space Models: The Transfer Function Approach: We approach designing a state-space model for deep learning applications through its dual representation, the transfer function, and uncover a highly efficient sequence parallel inference algorithm th...
- Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models: The disconnect between tokenizer creation and model training in language models has been known to allow for certain inputs, such as the infamous SolidGoldMagikarp token, to induce unwanted behaviour. ...
- SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling: We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts t...
- Conv-Basis: A New Paradigm for Efficient Attention Inference and Gradient Computation in Transformers: Large Language Models (LLMs) have profoundly changed the world. Their self-attention mechanism is the key to the success of transformers in LLMs. However, the quadratic computational cost $O(n^2)$ to ...
- Subquadratic LLM Leaderboard - a Hugging Face Space by devingulliver: no description found
- Fast Exact Retrieval for Nearest-neighbor Lookup (FERN): Exact nearest neighbor search is a computationally intensive process, and even its simpler sibling -- vector retrieval -- can be computationally complex. This is exacerbated when retrieving vectors wh...
- Farzi Data: Autoregressive Data Distillation: We study data distillation for auto-regressive machine learning tasks, where the input and output have a strict left-to-right causal structure. More specifically, we propose Farzi, which summarizes an...
- Yi: Open Foundation Models by 01.AI: We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language mode...
- Granite Code Models: A Family of Open Foundation Models for Code Intelligence: Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the pr...
- Farzi Data: Autoregressive Data Distillation: We study data distillation for auto-regressive machine learning tasks, where the input and output have a strict left-to-right causal structure. More specifically, we propose Farzi, which summarizes...
- ThunderKittens: A Simple Embedded DSL for AI kernels: good abstractions are good.
- GPUs Go Brrr: how make gpu fast?
- FLM-101B: An Open LLM and How to Train It with $100K Budget: Large language models (LLMs) have achieved remarkable success in NLP and multimodal tasks, among others. Despite these successes, two main challenges remain in developing LLMs: (i) high computational ...
- Masked Structural Growth for 2x Faster Language Model Pre-training: Accelerating large language model pre-training is a critical issue in present research. In this paper, we focus on speeding up pre-training by progressively growing from a small Transformer structure ...
- Updatable Learned Index with Precise Positions: Index plays an essential role in modern database engines to accelerate the query processing. The new paradigm of "learned index" has significantly changed the way of designing index structures...
- Jean Feydy's home page: no description found
Eleuther ▷ #scaling-laws (7 messages):
- Bullish on synthetic data, but with caution: One member expressed being bullish about synthetic data, while another shared skepticism, noting that it "had literally the same hype cycle about 5-7 years ago" and concerns that the lessons learned may not carry over due to the influx of newer field professionals.
- MLPs versus Transformers and CNNs: A member referenced two papers on arXiv, discussing the comparison of CNNs, Transformers, and MLPs for vision tasks. They highlighted an empirical study indicating that while all structures can achieve competitive performance at a moderate scale, they show distinctive behaviors as network size scales, advocating for a hybrid approach.
- A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP: Convolutional neural networks (CNN) are the dominant deep neural network (DNN) architecture for computer vision. Recently, Transformer and multi-layer perceptron (MLP)-based models, such as Vision Tra...
- Scaling MLPs: A Tale of Inductive Bias: In this work we revisit the most fundamental building block in deep learning, the multi-layer perceptron (MLP), and study the limits of its performance on vision tasks. Empirical insights into MLPs ar...
Eleuther ▷ #interpretability-general (3 messages):
- NeurIPS last-minute submission call: A member asked if anyone was interested in doing a last-minute submission for NeurIPS. They mentioned doing something similar to the Othello paper.
- Impact of model compression on features/circuits: Another member raised the question of what types of features/circuits are lost when compressing models. They pondered whether these features are totally useless or if they are just overspecialized for small subsets of the training distribution, suggesting such features could inform on the dataset's diversity.
Eleuther ▷ #gpt-neox-dev (1 messages):
oleksandr07173: Hello
Interconnects (Nathan Lambert) ▷ #news (120 messages🔥🔥):
- **First Look at VideoFX Generations**: A user shared a [link to VideoFX footage](https://fxtwitter.com/bedros_p/status/1789256595123179701?s=46), stating there are more examples but it's still a WIP. The shared footage demonstrates early capabilities of VideoFX generations.
- **GPT-4o Steals the Spotlight**: [Liam Fedus announced](https://x.com/liamfedus/status/1790064963966370209?s=46) GPT-4o as the new state-of-the-art model. Users discussed its superior performance in coding compared to older versions and speculated about its potential in MATH and other benchmarks.
- **OpenAI's New Tokenizer**: A member shared a [GitHub commit](https://github.com/openai/tiktoken/commit/9d01e5670ff50eb74cdb96406c7f3d9add0ae2f8) for the new OpenAI tokenizer. The update appears to improve processing speeds by utilizing a larger vocabulary.
- **OpenAI's Latest Demo Reaction**: Although a user found the demo impressive, they didn't see anything fundamentally new beyond UI improvements. Other discussions included speculation around GPT-4o's capabilities and its availability, with questions about OpenAI’s data strategies.
- **GPT-4o Dominates on LMSys Arena**: LMSys org [shared exciting news](https://x.com/lmsysorg/status/1790097588399779991?s=46) that GPT-4o has surpassed all models on the LMSys Arena with a significant Elo increase. The model's enhancements in reasoning and coding were particularly highlighted by users.
- Tweet from Google (@Google): One more day until #GoogleIO! We’re feeling 🤩. See you tomorrow for the latest news about AI, Search and more.
- Tweet from Bedros Pamboukian (@bedros_p): VideoFX footage from the list of examples There are 2 more, but it looks like its a WIP First look at VideoFX generations:
- Tweet from lmsys.org (@lmsysorg): Significantly higher win-rate against all other models. e.g., ~80% win-rate vs GPT-4 (June) in non-tie battles.
- Tweet from William Fedus (@LiamFedus): GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot 🙂. Here’s how it’s been doing.
- Tweet from lmsys.org (@lmsysorg): Breaking news — gpt2-chatbots result is now out! gpt2-chatbots have just surged to the top, surpassing all the models by a significant gap (~50 Elo). It has become the strongest model ever in the Are...
- Two GPT-4os interacting and singing: Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time.Learn more here: https://www.openai.com/index/hello-...
- Tweet from Jim Fan (@DrJimFan): I stand corrected: GPT-4o does NOT natively process video stream. The blog says it only takes image, text, and audio. That's sad, but the principle I said still holds: the right way to make a vide...
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Tweet from Kaio Ken (@kaiokendev1): yeah but can it moan?
Interconnects (Nathan Lambert) ▷ #ml-questions (1 messages):
- TRLOO Paper Explains REINFORCE as PPO's Special Case: A member shared a Hugging Face PR and noted its explanation on how REINFORCE is a special case of PPO in the implementation. They also linked to the referenced paper.
Link mentioned: PPO / Reinforce Trainers by vwxyzjn · Pull Request #1540 · huggingface/trl: This RP supports the REINFORCE RLOO trainers in https://arxiv.org/pdf/2402.14740.pdf. Note that REINFORCE's loss is a special case of PPO, as shown below it matches the REINFORCE loss presented i...
Interconnects (Nathan Lambert) ▷ #random (5 messages):
- ChatbotArena Appreciation: One member remarked that people on ChatbotArena are very skillful and another agreed, highlighting that it's instrumental in determining the future.
- Open-Sourcing GPT-3.5: There was a brief speculative discussion on the potential of GPT-3.5 being open-sourced. One member humorously noted that this would happen only when "hell freezes over."
Interconnects (Nathan Lambert) ▷ #reads (11 messages🔥):
- Video achieves 6k views in a day: "damn 6k views in a day" - a member exclaimed about the quick success. Other videos in comparison were noted to be at "20k" views.
- Natolambert aims to boost views: "I need to pump those numbers" - intention to increase video views was expressed. This was motivated by another Huggingface video reaching "150k" views.
- Discussion on posting video to X: Suggestions made to post the video to X, with a native upload mentioned. There was concern about Stanford's licensing, but skipped, as natolambert believes they won't pursue, saying they can "request permission", but will post anyways.
LAION ▷ #general (109 messages🔥🔥):
- Artists vs. AI Services Debate Heats Up: Members debated whether AI services like Midjourney and others that generate art harm artists' income. Claims included AI's commercial service impact on art sales, potential legal implications, and distinctions between fair use and derivative works, with links to The Legal Artist and various articles providing context.
- StabilityAI and Midjourney's Legal Troubles: Members discussed the potential downfall of StabilityAI and shared disdain for artist David Holz, with hopes for consequences stemming from public disclosures. Insights included the likelihood of juries affecting outcomes without following the law and broader implications for Midjourney’s practices.
- DeepSeek LLM and Efficient AI Models: A new fine-tuned Pixart Sigma model was shared on Civitai, with praise for its non-NSFW use. In parallel, a blog post highlighted advancements in AI compute efficiency, featuring innovations like FlashAttention-2 and others.
- Launch of Falcon 2 Series: A description of the launch and specifications of Falcon 2 models, claiming superior performance over Meta's Llama 3 was shared. A link to the Technology Innovation Institute provided further details.
- OpenAI's GPT-4o Unveiled: OpenAI's release of GPT-4o, featuring real-time communication and video processing, spurred interest. Members noted its improved performance, free access, and voice mode updates as detailed in OpenAI's announcement.
- GPUs Go Brrr: how make gpu fast?
- Bunline - v0.4 | Stable Diffusion Checkpoint | Civitai: PixArt Sigma XL 2 1024 MS full finetune on custom captions for roughly 35k images w/ max(w,h) > 1024px INSTRUCTIONS: Place the .safetensors wher...
- Silicon Valley Tip To Tip GIF - Silicon Valley Tip To Tip Brainstorm - Discover & Share GIFs: Click to view the GIF
- deepseek-ai/DeepSeek-V2 · Hugging Face: no description found
- Falcon 2: UAE’s Technology Innovation Institute Releases New AI Model Series, Outperforming Meta’s New Llama 3: no description found
{kind=link}
LAION ▷ #research (5 messages):
- Convert Voice Data Sets to Tokens: A member emphasized the need to convert numerous voice data sets to tokens. They also highlighted the importance of "high quality annotations about emotions and speaker attribute", sharing a link to a Twitter post and a YouTube video on training transformers with audio.
- Mathematical Notation and Sampling Functions: There was a technical discussion about the use of notation in formal mathematics to indicate sequences of elements, specifically z indexed by i converging to z_t, and the potential role of T as a sampling function. Further elaboration was deemed difficult without more context.
Link mentioned: Tweet from LAION (@laion_ai): Wanna train transformers with audio as if it was text? - Here is how. :) https://youtu.be/NwZufAJxmMA https://discord.gg/6jWrFngyPe
LangChain AI ▷ #general (105 messages🔥🔥):
- Extracting and Converting Dates to ISO Format in LangChain: One member shared a prompt containing dates and asked how to extract and convert them to ISO format using LangChain. Kapa.ai provided detailed Python and JavaScript code examples utilizing the
DatetimeOutputParserfor this process.
- Setting Up Local Open-Source LLMs with LangChain: A user asked how to use tools with local open-source LLMs like Ollama in LangChain. Kapa.ai explained the process including defining models and creating prompts in both Python and JavaScript.
- Handling Ambiguous Model Outputs and Reducing La*tency in Function Calls: Members discussed methods to refine model outputs and optimize response times when creating entities in databases via LangChain. Suggestions focused on model selection for specific tasks and improving UX by speeding up function call responses.
- Persistent Storage Alternatives for docstore in LangChain: A user inquired about alternatives to using
InMemoryStorefor persistent storage in the multimodal RAG setup with LangChain and Gemini. Other members suggested checking the LangChain documentation for more options.
- Frequent Errors and Model Context Use with HuggingFace and LangChain: Common issues like validation errors with
facebook/barton HuggingFace and problems related to API usage and model support were discussed. Solutions included using correctly supported models and adjusting prompts or API usage.
- Extracting structured output | 🦜️🔗 LangChain: Overview
- Structured chat | 🦜️🔗 LangChain: The structured chat agent is capable of using multi-input tools.
- Stores | 🦜️🔗 LangChain: In many different applications, having some sort of key-value storage is helpful.
- Quickstart | 🦜️🔗 LangChain: In this guide, we will go over the basic ways to create Chains and Agents that call Tools. Tools can be just about anything — APIs, functions, databases, etc. Tools allow us to extend the capabilities...
- generative-ai/gemini/use-cases/retrieval-augmented-generation/multimodal_rag_langchain.ipynb at main · GoogleCloudPlatform/generative-ai: Sample code and notebooks for Generative AI on Google Cloud, with Gemini on Vertex AI - GoogleCloudPlatform/generative-ai
- Quickstart | 🦜️🔗 LangChain: In this quickstart we'll show you how to:
- langchain/libs/partners/chroma/pyproject.toml at master · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- go - Overview: go has 52 repositories available. Follow their code on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Example of extracting multiple values from a streamed OpenAI chat response: Example of extracting multiple values from a streamed OpenAI chat response - extract_multiple_values_from_stream.py
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Manifest | 🦜️🔗 LangChain: This notebook goes over how to use Manifest and LangChain.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #share-your-work (4 messages):
- AI Video Recommendations Wow the Crowd: Check out this YouTube video shared in the community, likely of interest due to its relevance to the LangChain crowd.
- Twitter Thread on IndexNetwork Gains Attention: A member shared an intriguing Twitter thread by IndexNetwork, drawing attention to its relevance for AI enthusiasts.
- Open Source Code Interpreter Alternative Launched: A community member introduced NLAVIDA, an open-source alternative to advanced data analytics tools available in ChatGPT Plus. They plan to expand its functionality to support open source LLMs like Llama 3.
- RAG Pipeline Tutorial Excites Developers: One member is creating an in-depth tutorial on building a custom RAG pipeline using LangChain, Next.js, and Pinecone. The guide includes everything from data processing code to a client-side chat interface demo.
- Build a RAG pipeline for your blog with LangChain, OpenAI and Pinecone: You can chat with my writing and ask me questions I've already answered even when I'm not around
- GitHub - obaidur-rahaman/nlavida: Natural Language-Assisted Visualization & Interactive Data Analysis (NLAVIDA): Securely handle and analyze confidential data in enterprise environments, enhancing insights and decision-making with advanced visualization.: Natural Language-Assisted Visualization & Interactive Data Analysis (NLAVIDA): Securely handle and analyze confidential data in enterprise environments, enhancing insights and decision-making ...
LangChain AI ▷ #tutorials (3 messages):
- YouTube Tutorial Share: A member shared a YouTube tutorial useful for certain LangChain functionalities.
- Chat with Blog using LangChain and Pinecone: Zack Proser created a blog post explaining how he integrated a chat feature on his site to query blog content. He provided everything needed to replicate it, including ingest code, API route code for embeddings and vector search, and a client-side chat interface.
- Seeking Tutorial for Session Handling with Streaming: A member requested recommendations for a tutorial on managing history, handling sessions, and enabling streaming in LangChain. They mentioned struggling to get streaming functionality working based on the current documentation.
Link mentioned: Build a RAG pipeline for your blog with LangChain, OpenAI and Pinecone: You can chat with my writing and ask me questions I've already answered even when I'm not around
LlamaIndex ▷ #blog (8 messages🔥):
- Generate PowerPoints with Llama 3: An article by @naivebaesian on using @llama_index to build a Llama3 RAG pipeline that can generate PowerPoint slide decks is highlighted. It utilizes the Python-pptx library and can be found here.
- Build a Financial Agent with Reflection: Hanane Dupouy demonstrates how to create an agent capable of reflecting on stock prices. Techniques include implementing CRITIC for tool use, with more details available here.
- Use RAG for Content Moderation: @cloudraftio details setting up a RAG pipeline for content moderation of user-generated images. The process involves captioning images to text and matching them against indexed rules, more information here.
- Evaluate RAG Systems with Multiple Libraries: @kingzzm provides a thorough article on evaluating RAG systems using libraries like TruLens, Ragas, UpTrain, and DeepEval. A comprehensive set of evaluation metrics is discussed, article available here.
- GPT-4o Multimodal Abilities Demo: A simple demonstration of GPT-4o's multimodal capabilities featuring @seldo's dog shows its prowess. View the demo and a humorous take on Amazon's $4,000 second-hand sneakers here.
- Google Colab: no description found
- llama-index-llms-openai: llama-index llms openai integration
- llama-index-multi-modal-llms-openai: llama-index multi-modal-llms openai integration
- Google Colab: no description found
LlamaIndex ▷ #general (87 messages🔥🔥):
- Condense Plus Context Bug Identified and Fixed: Discussions revealed that the condense_plus_context method ignored the postprocessor, which was a bug. A user confirmed this has already been fixed in the latest version.
- Hybrid Search Error Due to Configuration Issue: A user faced a ValueError in hybrid search due to a misconfiguration. Another member clarified the need to enable hybrid in the QdrantVectorStore constructor, not in the retriever.
- Ease of Use and Flexibility of LlamaIndex Praised: Multiple users highlighted the ease of use, flexibility, and documentation of LlamaIndex over other AI builder tools. Users appreciated LlamaIndex's focused approach on Retrieval-Augmented Generation (RAG), making development smoother.
- Querying with Metadata Clarified: Clarifications were given on how metadata in TextNodes is used during querying. It was explained that metadata helps in filtering and additional uses but needs to be appropriately configured during node creation.
- Python Code Examples for CSV Parsing: Detailed guidance was provided on how to efficiently read, parse, and index CSV files, emphasizing the use of the CSVReader class. A code snippet and links to further resources were shared for deeper understanding.
- langchain/cookbook/Multi_modal_RAG.ipynb at master · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- File - LlamaIndex: no description found
- Data Connectors (LlamaHub) - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (3 messages):
- Fine-Tune GPT-3.5 with Knowledge Distillation: Members discussed a blog post on knowledge distillation for fine-tuning a GPT-3.5 judge. One user highlighted the importance of such articles, noting that there aren't enough resources showing users how to effectively fine-tune models.
Link mentioned: Knowledge Distillation for Fine-Tuning a GPT-3.5 Judge: Enhancing Accuracy and Performance : no description found
OpenAccess AI Collective (axolotl) ▷ #general (30 messages🔥):
- Llama 3 Instruct Tune Investigation: An analysis shared by a member breaks down the weight differences between instruct and base Llama 3, noting that "most changes are scattered seemingly at random," with clustering in the K and V layers. This could suggest that freezing the K/V layers might allow for "more of a stylistic tune" without severely impacting the instruct ability.
- OpenOrca Rerun Cost and Feasibility: Another member is seeking sponsors to fund a rerun of the OpenOrca deduplication on GPT-4o. Estimated costs are around $650 for processing both input and output tokens, with potential batch job options to lower the expenditure.
- AI Compute Efficiency Focus: A shared blog post delves into recent efforts to reduce AI's compute usage. It references multiple methods like Based, Monarch Mixer, H3, and FlashAttention-2 aimed at running AI more efficiently.
- Publishing Delays Frustration: Frustration over journal publication delays is voiced, with the concern that by the time papers are published, they could be "already outdated." A respondent noted that getting two papers published is typically sufficient for earning a PhD, even though the process is challenging.
- Bluesky vs. Substack for Blogs: Engagement around whether to use Substack or Bluesky for blogging mentions that while Bluesky is currently limited to threads and posts, it has a "rather nerdy audience".
- GPUs Go Brrr: how make gpu fast?
- Open-Orca/SlimOrca-Dedup · Datasets at Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (11 messages🔥):
- Merged Pull Request Initiates Discussion: Members briefly noted that a recent merge occurred successfully. One commented, "Nice it was merged."
- Pyet PR for Llama3 Chat Template Raises Errors: A member inquired if anyone had tried the new pyet PR for the LLAMA3 chat template. They encountered an AttributeError: 'LLAMA3. Did you mean: 'LLAMA2'?.
- Updating Dependencies Resolves Issues: One member mentioned that updating fastchat resolved their issue with the new PR. Another confirmed, "pr + fastchat worked ok for me."
- Outdated Dependency Concerns: Concerns were raised about outdated dependencies like peft 0.10.0, accelerate 0.28.0, deepspeed 0.13.2, flash-attn 2.5.5, xformers 0.0.22, and transformers @ 43d17c. They highlighted that these configurations default to torch 2.0.0 while 2.3.0 is already available.
OpenAccess AI Collective (axolotl) ▷ #general-help (11 messages🔥):
- FSDP and FFT compatibility questioned: A member asked if FSDP works with FFT or if it is still problematic. Another replied suggesting to try DeepSpeed instead.
- DeepSpeed confirmed operational: Another member confirmed that DeepSpeed works for the proposed scenario.
- LLAMA3 AttributeError during Docker use: A member encountered an AttributeError: LLAMA3 while using Docker, and was advised to update fastchat which did not resolve the issue, but git cloning did.
- Updating pip dependencies for LLAMA3 error: Another user suggested updating pip dependencies to fix the LLAMA3 error, confirming with their own experience.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (10 messages🔥):
- Changing system_prompt in axolotl CLI: A member inquired about changing the
system_promptwhen usingaxolotl.cli.inference. There was no direct solution provided in the thread itself.
- Error converting merged model to GGUF: A user encountered an error while converting a merged model to GGUF, specifically a
FileNotFoundErrordue to the absence of a matching tokenizer. Details included paths to the model files and the specific error message.
- RuntimeError with Gemma-7B after training: A user's attempt to load a trained Gemma-7B model resulted in a
RuntimeErrordue to a size mismatch inmodel.embed_tokens.weight. They provided details of the file structure before and after training, but the issue remained unresolved.
- How to merge qlora to base without precision issues: Another user asked how to merge qlora to a base model without facing precision issues (fp16/32). No solution was discussed in the visible portion of the thread.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (9 messages🔥):
- Question on pruning support in Axolotl: A user asked if Axolotl supports pruning, to which Phorm initiated an automatic search over the OpenAccess-AI-Collective/axolotl without providing a definitive answer yet. The search result indicated that further information could be found on Phorm's official page.
- Continuous pretraining and LoRa methods inquiry: Another query was made regarding tips for continuous pretraining and the various LoRa methods. Again, Phorm started a search over the relevant repositories but could not provide an immediate answer, suggesting users check back later on their platform.
- Merging QLoRA into base model: A user inquired about how to merge QLoRA into the base model, directing their question to a specific group within the Discord. This question was not accompanied by an immediate response.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
OpenInterpreter ▷ #general (41 messages🔥):
- Claude API fails with "goofy error": A user expressed frustration over Claude API's non-functionality, reporting it "gives some goofy error." Other members were also looking for solutions.
- Selecting local models in 01 dev preview: Discussion highlighted how the 01 dev preview defaults to OpenAI and how to switch it using
poetry run 01 --localto select a desired model. This was clarified by a user suggesting commands for model selection.
- Python script troubleshooting for OpenInterpreter: A member faced issues running Python code with
interpreter.chatfunction, but resolved it by usingfrom interpreter import OpenInterpreter.
- Best local models lag behind GPT-4: Users compared various local models like Mixtral, Phi, Lama3 with GPT-4, expressing disappointment. One user noted, "If I hadn’t tried GPT-4 first I would be impressed with other models I am sure."
- GPT-4o speed impresses users: Users were excited about GPT-4o's performance, reporting speeds of "minimum 100 tokens/s" and noting it's "way more than 2x faster." A command to try it out was shared:
interpreter --model openai/gpt-4o.
- no title found: no description found
- Microsoft C++ Build Tools - Visual Studio: no description found
OpenInterpreter ▷ #O1 (21 messages🔥):
- LiteLLM with Groq-Llama3 confirmed working: Members discussed issues with integrating LiteLLM, Groq, and Llama3. One member confirmed, "it works fine".
- Website connection issues with M5 board: "I never get the website anymore. I've tried re-flashing, and been hammering on this for hours." A member described extensive troubleshooting failed attempts to connect their 01-Light device.
- 01 hardware app now available: A member "had the opportunity to build the 01 hardware beta" and created a more accessible app version for early-stage testing. They shared the GitHub repo link and mentioned a pending TestFlight approval.
- Refund request and support: A member asked for help with canceling an order and was advised to send an email to help@openinterpreter.com.
- Upcoming 01 batch shipment: A member inquired about the next 01 batch shipment and was informed that the "first batch [is] expected for November."
OpenInterpreter ▷ #ai-content (4 messages):
- PyWinAssistant Excitement: A user shared the GitHub link to PyWinAssistant, describing it as "The first open source Large Action Model generalist Artificial Narrow Intelligence that controls completely human user interfaces by only using natural language." They highlighted that PyWinAssistant utilizes Visualization-of-Thought to elicit spatial reasoning in large language models.
- PyWinAssistant in Action: Another user mentioned they successfully got PyWinAssistant working and shared a YouTube video demonstrating it in action. The video includes examples of PyWinAssistant controlling human user interfaces and features other tools like Autogroq and websim.
- GitHub - a-real-ai/pywinassistant: The first open source Large Action Model generalist Artificial Narrow Intelligence that controls completely human user interfaces by only using natural language. PyWinAssistant utilizes Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models.: The first open source Large Action Model generalist Artificial Narrow Intelligence that controls completely human user interfaces by only using natural language. PyWinAssistant utilizes Visualizati...
- pywinassistant working || Autogroq || websim || twelvelabs + more: ➤ Twitter - https://twitter.com/techfrenaj➤ Twitch - https://www.twitch.tv/techfren➤ Discord - https://discord.com/invite/z5VVSGssCw➤ TikTok - https://www....
tinygrad (George Hotz) ▷ #learn-tinygrad (38 messages🔥):
- Understanding Variable Shapes in Tensors: There was a discussion around representing tensors with variable shapes for optimization, particularly in transformers where the number of tokens can change. A user referenced a Tinygrad Notes article and examples from Whisper code (example 1, example 2).
- Clarifying Tensor and Axis Terms: A question was raised about the difference between "dim" and "axis" in operations like sum and concatenate in tensors. It was noted that they often refer to the same concept but are used in different contexts possibly due to legacy reasons.
- Handling Missing Gradients in Training: One user encountered an "AssertionError" related to
Tensor.trainingwhile training a bigram model, which was resolved by settingTensor.training = True. This discussion included references to relevant GitHub code and suggestions for improving error messages.
- Aggregating Features with Tensor Operations: Another user sought advice on implementing feature aggregation for a simple Neural Turing Machine. They discussed tensor operations, provided code examples, and explored optimization techniques, sharing aggregate feature GitHub code.
- Issues with Backpropagation through
whereCall: There was a hurdle in backpropagating through a "where" call in tinygrad that worked in PyTorch, leading to aRuntimeErrordue to missing gradients. A solution was proposed involving the use ofdetach().where()to resolve the gradient assignment issue.
- train.py: GitHub Gist: instantly share code, notes, and snippets.
- test_aggregate.py: GitHub Gist: instantly share code, notes, and snippets.
- optimizer shouldn't be run without training by geohot · Pull Request #4460 · tinygrad/tinygrad: no description found
- Neural-Turing-Machine-in-Tinygrad/NTM.py at main · shriar/Neural-Turing-Machine-in-Tinygrad: Contribute to shriar/Neural-Turing-Machine-in-Tinygrad development by creating an account on GitHub.
- GitHub - rs9000/Neural-Turing-machine: NTM in PyTorch: NTM in PyTorch. Contribute to rs9000/Neural-Turing-machine development by creating an account on GitHub.
- tinygrad/examples/whisper.py at a1940ced7746fcdf09068aadf4155e4c1e3641b8 · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- tinygrad/examples/whisper.py at a1940ced7746fcdf09068aadf4155e4c1e3641b8 · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- pytorch_cluster/csrc/cuda/radius_cuda.cu at master · rusty1s/pytorch_cluster: PyTorch Extension Library of Optimized Graph Cluster Algorithms - rusty1s/pytorch_cluster
- torchmd-net/torchmdnet/extensions/neighbors/neighbors_cpu.cpp at 75c462aeef69e807130ff6206b59c212692a0cd3 · torchmd/torchmd-net: Neural network potentials . Contribute to torchmd/torchmd-net development by creating an account on GitHub.
- Home - PyG: PyG is the ultimate library for Graph Neural Networks
Cohere ▷ #general (24 messages🔥):
- Embedding models inquiry sparks interest: A user asked whether the embedding models are open source. No further information or responses were provided to this query.
- Confusion over billing gets resolved: One user expressed confusion about billing numbers, particularly an unexplained cost of $0.63. They later resolved their confusion, realizing the number represents the amount due since the last invoice, although they still found the explanation unclear.
- Web command tokens clarification: A user questioned why input tokens surged when using command r with web searches, suspecting additional token costs for web visits. Another user confirmed that search results are indeed passed in the context, and this incurs billing.
- SolidGoldMagikarp token issue analyzed: A user thanked another for linking an arXiv paper that discusses the problem of 'glitch tokens' causing unwanted behavior in language models, and the methods to detect such tokens.
- Comparing models Aya and Cohere Command Plus: A user sought benchmarks between the Aya and Cohere Command Plus models, reporting inaccuracies with Aya even at 0 temperature. Another user recommended using Aya solely for translation tasks.
Link mentioned: Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models: The disconnect between tokenizer creation and model training in language models has been known to allow for certain inputs, such as the infamous SolidGoldMagikarp token, to induce unwanted behaviour. ...
Cohere ▷ #project-sharing (2 messages):
- Specializing LLMs in Telecom: One member shared a new challenge for specializing large language models (LLMs) in telecom domains such as 5G. More details about the competition can be found on Zindi Africa's competition page.
- Seeking "Chat with PDF" Application: Another member inquired whether anyone had created a "chat with PDF" type of application using Cohere. They requested any related repositories or blog posts for reference.
Link mentioned: Zindi: no description found
Datasette - LLM (@SimonW) ▷ #ai (23 messages🔥):
- GPT-4o still misses the mark: Users expressed disappointment with GPT-4o, noting it still struggles with simple tasks like listing books on a shelf accurately, despite being faster and cheaper. "Currently in a library and it misses title, adds in ones that aren’t there, gets about 50% right."
- Voice assistants in bad PR: Some found recent PR efforts for voice assistants to be embarrassing, partly due to assistants giggling, which was seen as a poor marketing choice. "Just an embarrassing choice."
- Custom instructions to the rescue: Discussion included hopes to use custom instructions to make voice assistants less cringeworthy. "I am hoping we can use custom instructions to tone it down a bit!"
- AGI skepticism spreading: There was a noticeable skepticism about the imminent arrival of AGI, with some members suggesting they should start a club for non-believers. "Sometimes I feel like I’m one of the few people in the bay area that don’t expect AGI to be released next week."
- LLMs hitting diminishing returns: Consensus seems to be building that improvements between versions of LLMs (e.g., 4 vs 3) are showing diminishing returns, and untapped potential still exists within current models. "I keep pointing out to people in convos that 3 vs 2 was a bigger leap than 4 vs 3."
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
simonw: https://twitter.com/simonw/status/1790121870399782987
Mozilla AI ▷ #llamafile (15 messages🔥):
- Fake OpenELM repo warning: A member alerted that "it is a FAKE repo, there is no GGUF for OpenELM yet." Another member sarcastically remarked "At least the AI industry is catching up to the game industry then."
- Pull Request for llamafile Archives: Shared a PR link titled "Added Script To Upgrade llamafile Archives." The context mentions porting from an external blog.
- Container Usage Clarified: There was some confusion about using containers like podman or kubernetes, which was clarified with "using containers is perfectly fine."
- Hermes-2-Pro Performance: A member reported smooth running of "Hermes-2-Pro-Llama-3-8B-Q5_K_M.gguf" on "AMD 5600U," with around 10 second response times and 11GB total RAM usage spikes.
- Batch Size Error with Llama and Mistral: Multiple members reported a recurring error with both Llama 8B and Mistral models: update_slots: failed to find free space in the KV cache, retrying with smaller n_batch = 1. This issue seems less prominent with higher RAM allocations and other models like LLaVa 1.5 and Llama 70B.
- Added Script To Upgrade llamafile Archives by mofosyne · Pull Request #412 · Mozilla-Ocho/llamafile: Context: #411 Porting https://briankhuu.com/blog/2024/04/06/inplace-upgrading-of-llamafiles-engine-bash-script/ to llamafile
- Add metadata override and also generate dynamic default filename when converting gguf · Issue #7165 · ggerganov/llama.cpp: This is a formalized ticket for this PR #4858 so people are aware and can contribute to figuring out if this idea makes sense... and if so then what needs to be done before this can be merged in fr...
DiscoResearch ▷ #general (9 messages🔥):
- German TTS Project Seeks Podcast/YouTube Channel Suggestions: A member is looking to compile a list of high-quality German YouTube channels with diverse content to train a Text-to-Speech (TTS) model. Another member suggested using Mediathekview to download broadcasts and films from various German channels.
- Managing German Video Resources with Mediathekview: Members discussed using Mediathekview and its potential for downloading and managing German media content, including the feasibility of downloading its database. A suggestion was made to utilize Mediathekview's local database, located at
%userprofile%\.mediathek3\databasemediathekview.mv.db.
- Using Mediathekview's JSON API: It was pointed out that Mediathekview has a JSON API that can be used for querying data, with a reference to the GitHub repository for more details.
- Encouraged to Maintain English Communication: A member reminded others to keep the discourse in English within the channel.
- Excitement Over RT Audio Interface in Non-Chat Applications: One user expressed excitement about the "RT Audio interface" and inquired about any first-hand experiences or results in non-chat applications, indicating a keen interest in its capabilities.
- MediathekViewWebVLC/mediathekviewweb.lua at main · 59de44955ebd/MediathekViewWebVLC: MediathekViewWeb Lua extension for VLC. Contribute to 59de44955ebd/MediathekViewWebVLC development by creating an account on GitHub.
- Die 100 beliebtesten Podcasts im Moment – Deutschland: Diese Liste zeigt die derzeit 100 beliebtesten Podcasts mit aktuellen Daten von Apple und Podtail.
- Top YouTube Channels in Germany | HypeAuditor YouTube Ranking: Find the most popular YouTube channels in Germany as of May 2024. Get a list of the biggest YouTubers in Germany.
DiscoResearch ▷ #discolm_german (2 messages):
- **Demo status inquiry**: A user asked, *"Is the demo down?"* but there was no response to this query.
- **Positive feedback**: Another user remarked, *"It's really nice,"* expressing satisfaction without further elaboration.
LLM Perf Enthusiasts AI ▷ #general (4 messages):
- Claude 3 Haiku vs Llama 3b sparks interest: Members discussed the performance of Claude 3 Haiku versus Llama 3b Instruct. One member shared their experience building an automated scoring service to extract entities from documents and expressed the need for accurate submodel matching, mentioning that initial attempts with fuzzy string algorithms and similar pattern matching were unsuccessful.
LLM Perf Enthusiasts AI ▷ #gpt4 (6 messages):
- Speculation on Audio Integration: Members talked about the possibility that OpenAI is working on something related to audio, with one suggesting it might involve "audio in-out support directly to some assistant."
- OpenAI Spring Update Teased: A YouTube link was shared, hinting at new features, including the introduction of GPT-4o as part of the OpenAI Spring Update. The event is set to have updates on ChatGPT and more.
- Scarlett Johansson as a Voice: The community expressed surprise and amusement that Scarlett Johansson has been featured as the voice in the new update. One member exclaimed, "cant believe they got scarjo to do the voice" followed by "lol".
Link mentioned: Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
Alignment Lab AI ▷ #general-chat (3 messages):
- AlphaFold3 Federation invites for sign-up: A member announced the commencement of an AlphaFold3 Federation and shared a sign-up link for an upcoming meet at 9pm EST on May 12th. The agenda includes progress updates, pipeline design, and Q&A.
- Request for server ROLE information: A member inquired about where to find ROLE information for the server and tagged another user for clarification. No further details were provided on the available roles.
Link mentioned: AlphaFold3 [AF3] Federation Meet · Luma: Current Progress Update A talk by the lead developer on the current status of Alpha Fold 3 integration. Discussion of any issues encountered during the initial…
Alignment Lab AI ▷ #fasteval-dev (3 messages):
- Fasteval project might cease: A member inquired about the continuation of the fasteval project. Another member responded that they are not planning to continue it but are willing to transfer ownership of the GitHub project if someone responsible wishes to take it over; otherwise, they suggest archiving the fasteval channels.
AI Stack Devs (Yoko Li) ▷ #app-showcase (1 messages):
- Modify AI Town settings: A member inquired about the ability to modify the character moving speed and the number of NPCs in AI town. This suggests interest in customizing gameplay mechanics.
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (1 messages):
- Optimize NPC interaction frequency for better performance: A user inquired if it was possible to adjust the code to reduce the interaction frequency between NPCs. They suggested reallocating computation power to enhance the player-NPC interaction, noting that running AI town on a local machine with the llama3 model is quite taxing.
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=KQ-xGVFHDkw