[AINews] Google's Agent2Agent Protocol (A2A)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Remote agents are all you need.
AI News for 4/8/2025-4/9/2025. We checked 7 subreddits, 433 Twitters and 30 Discords (229 channels, and 5996 messages) for you. Estimated reading time saved (at 200wpm): 563 minutes. You can now tag @smol_ai for AINews discussions!
We are deep in Google Cloud Next announcements, and in a 1-2 punch, the CEOs of Google and DeepMind announced both their full MCP support:
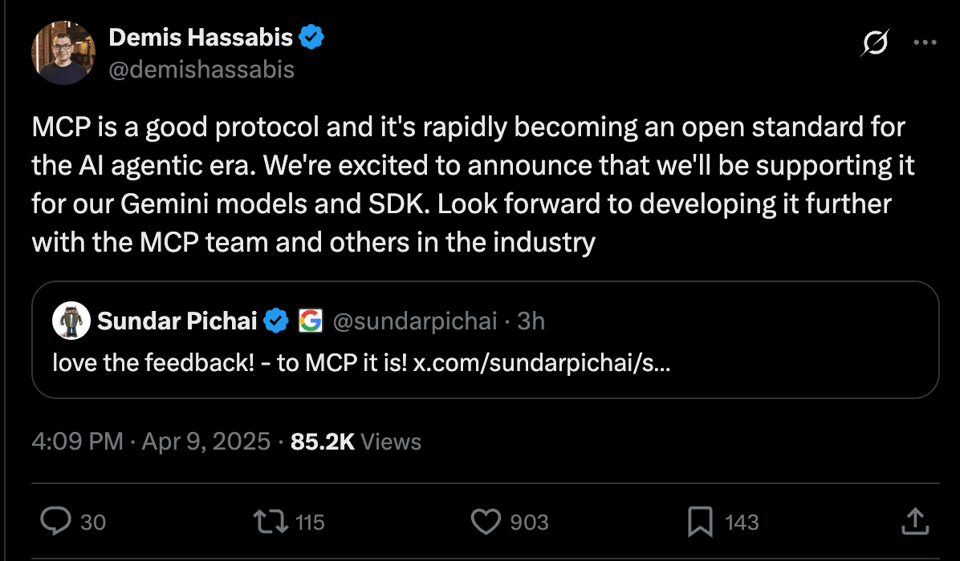
And their new Agent to Agent protocol to complement MCP with a huge list of partners:

It is tempting to pit Google against Anthropic, but the protocols were designed to work together to address perceived gaps in MCP:

The spec includes:
- the Agent Card
- the concept of a Task - a communication channel between the home agent and the remote agent for passing Messages, with an end result Artifact.
- Enterprise Auth and Observability recommendations
- Streaming and Push Notification support (again with push security in mind)
Launch artifacts include:
- The draft specification
- The documentation website
- The Agent Development Kit which looks... oddly familiar
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- LMArena Discord
- Unsloth AI (Daniel Han) Discord
- Manus.im Discord Discord
- Perplexity AI Discord
- OpenRouter (Alex Atallah) Discord
- OpenAI Discord
- LM Studio Discord
- aider (Paul Gauthier) Discord
- Eleuther Discord
- Cursor Community Discord
- Yannick Kilcher Discord
- Interconnects (Nathan Lambert) Discord
- MCP (Glama) Discord
- HuggingFace Discord
- Notebook LM Discord
- GPU MODE Discord
- Latent Space Discord
- Nous Research AI Discord
- Nomic.ai (GPT4All) Discord
- Modular (Mojo 🔥) Discord
- LlamaIndex Discord
- Cohere Discord
- tinygrad (George Hotz) Discord
- Torchtune Discord
- LLM Agents (Berkeley MOOC) Discord
- Codeium (Windsurf) Discord
- PART 2: Detailed by-Channel summaries and links
- LMArena ▷ #general (1004 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (712 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (22 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (156 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (3 messages):
- Unsloth AI (Daniel Han) ▷ #research (8 messages🔥):
- Manus.im Discord ▷ #showcase (6 messages):
- Manus.im Discord ▷ #general (511 messages🔥🔥🔥):
- Perplexity AI ▷ #announcements (2 messages):
- Perplexity AI ▷ #general (501 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (1 messages):
- Perplexity AI ▷ #pplx-api (6 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (5 messages):
- OpenRouter (Alex Atallah) ▷ #general (444 messages🔥🔥🔥):
- OpenAI ▷ #ai-discussions (274 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (2 messages):
- OpenAI ▷ #prompt-engineering (61 messages🔥🔥):
- OpenAI ▷ #api-discussions (61 messages🔥🔥):
- LM Studio ▷ #general (57 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (331 messages🔥🔥):
- aider (Paul Gauthier) ▷ #general (262 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (18 messages🔥):
- aider (Paul Gauthier) ▷ #links (1 messages):
- Eleuther ▷ #general (221 messages🔥🔥):
- Eleuther ▷ #research (46 messages🔥):
- Eleuther ▷ #interpretability-general (10 messages🔥):
- Cursor Community ▷ #general (218 messages🔥🔥):
- Yannick Kilcher ▷ #general (190 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (9 messages🔥):
- Yannick Kilcher ▷ #agents (2 messages):
- Yannick Kilcher ▷ #ml-news (16 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (178 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (7 messages):
- Interconnects (Nathan Lambert) ▷ #random (2 messages):
- Interconnects (Nathan Lambert) ▷ #memes (1 messages):
- Interconnects (Nathan Lambert) ▷ #rl (3 messages):
- Interconnects (Nathan Lambert) ▷ #reads (3 messages):
- MCP (Glama) ▷ #general (107 messages🔥🔥):
- MCP (Glama) ▷ #showcase (9 messages🔥):
- HuggingFace ▷ #general (41 messages🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #i-made-this (4 messages):
- HuggingFace ▷ #computer-vision (2 messages):
- HuggingFace ▷ #gradio-announcements (1 messages):
- HuggingFace ▷ #agents-course (28 messages🔥):
- HuggingFace ▷ #open-r1 (13 messages🔥):
- Notebook LM ▷ #use-cases (13 messages🔥):
- Notebook LM ▷ #general (75 messages🔥🔥):
- GPU MODE ▷ #general (15 messages🔥):
- GPU MODE ▷ #cuda (6 messages):
- GPU MODE ▷ #torch (2 messages):
- GPU MODE ▷ #cool-links (2 messages):
- GPU MODE ▷ #beginner (19 messages🔥):
- GPU MODE ▷ #torchao (1 messages):
- GPU MODE ▷ #off-topic (2 messages):
- GPU MODE ▷ #self-promotion (1 messages):
- GPU MODE ▷ #reasoning-gym (2 messages):
- GPU MODE ▷ #gpu模式 (3 messages):
- GPU MODE ▷ #general (11 messages🔥):
- GPU MODE ▷ #submissions (14 messages🔥):
- GPU MODE ▷ #feature-requests-and-bugs (1 messages):
- Latent Space ▷ #ai-general-chat (77 messages🔥🔥):
- Nous Research AI ▷ #general (66 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (2 messages):
- Nous Research AI ▷ #interesting-links (1 messages):
- Nomic.ai (GPT4All) ▷ #general (57 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (3 messages):
- Modular (Mojo 🔥) ▷ #mojo (14 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (8 messages🔥):
- LlamaIndex ▷ #ai-discussion (3 messages):
- Cohere ▷ #「💬」general (9 messages🔥):
- Cohere ▷ #「🤖」bot-cmd (1 messages):
- Cohere ▷ #「🤝」introductions (2 messages):
- Cohere ▷ #【🟢】status-updates (1 messages):
- tinygrad (George Hotz) ▷ #general (4 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (7 messages):
- Torchtune ▷ #general (4 messages):
- Torchtune ▷ #dev (4 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (1 messages):
- Codeium (Windsurf) ▷ #announcements (1 messages):
AI Twitter Recap
Model Releases and Updates
- Moonshot AI's Kimi-VL-A3B, a multimodal LM with 128K context and MIT license, outperforms GPT4o on vision + math benchmarks: The model has MoE VLM and an MoE Reasoning VLM with only ~3B active parameters. @reach_vb noted that the model showed strong multimodal reasoning (36.8% on MathVision) and agent skills (34.5% on ScreenSpot-Pro) with high-res visuals and long context windows. Model weights are on Hugging Face. @_akhaliq provided links to the models.
- Meta released two smaller versions of its new Llama 4 family of models: Llama 4 Scout and Maverick: According to @EpochAIResearch, a larger version called Behemoth is still in training. @ArtificialAnlys reported on replicated Meta’s claimed values for MMLU Pro and GPQA Diamond. Scout’s Intelligence Index moved from 36 to 43, and Maverick’s Intelligence Index moved from 49 to 50. @winglian shared that Llama-4 Scout can be fine-tuned w/ 2x48GB GPUs @ 4k context. @danielhanchen shared a detailed analysis of the Llama 4 architecture.
- DeepCoder 14B, a new coding model from UC Berkeley, rivals OpenAI o3-mini and o1 on coding, and is open-sourced: @Yuchenj_UW noted that the model was trained with RL on Deepseek-R1-Distilled-Qwen-14B on 24K coding problems, costing 32 H100s for 2.5 weeks (~$26,880). @jeremyphoward added that the base model is deepseek-qwen. @reach_vb noted it is MIT licensed and works w/ vLLM, TGI, and Transformers. @togethercompute announced the model and shared details on the training process.
- Nvidia dropped Llama 3.1 Nemotron Ultra 253B on Hugging Face: @_akhaliq shared the release, noting that it beats Llama 4 Behemoth, Maverick & is competitive with DeepSeek R1 with a Commercially permissive license. @reach_vb also noted the release, and that the weights are open.
- Google announced Gemini 2.5 Flash, and Gemini 2.5 Pro is now available in Deep Research: @scaling01 announced the upcoming release of gemini-2.5.1-flash-exp-preview-001-04-09-thinking-4bpw-20b-uncensored-slerp-v0.2. @_philschmid noted that Gemini 2.5 Pro is now available in Deep Research in the Gemini App.
- HiDream-I1-Dev is the new leading open-weights image generation model, overtaking FLUX1.1: @ArtificialAnlys reported that the impressive 17B parameter model comes in three variants: Full, Dev, and Fast. They included a comparison of image generations.
- UC Berkeley open-sourced a 14B model that rivals OpenAI o3-mini and o1 on coding!: @Yuchenj_UW noted that the model was trained with RL on Deepseek-R1-Distilled-Qwen-14B on 24K coding problems, costing 32 H100s for 2.5 weeks (~$26,880).
Hardware and Infrastructure
- Google announced Ironwood, their 7th-gen TPU competitor to Nvidia's Blackwell B200 GPUs: @scaling01 shared details, including 4,614 TFLOPs per chip (FP8), 192 GB HBM, 7.2 Tbps HBM bandwidth, 1.2 Tbps bidirectional ICI, and 42.5 exaflops per 9,216-chip pod (24x El Capitan). @_philschmid noted that this TPU is built for inference and "thinking" models. @itsclivetime provided a detailed comparison with Nvidia hardware.
- NVIDIA Blackwell can achieve 303 output tokens/s for DeepSeek R1 in FP4 precision: @ArtificialAnlys reported on benchmarking an Avian API endpoint.
- Together AI announced Instant GPU Clusters, Up to 64 interconnected NVIDIA GPUs: @togethercompute noted that the clusters are available in minutes, entirely self-service, perfect for training models of up to ~7B parameters, or running models like DeepSeek-R1.
Agent and Tooling Development
- Google presented Agent Development Kit (ADK): @omarsar0 detailed features, including code-first, multi-agents, rich tool ecosystem, flexible orchestration, integrated dev xp, streaming, state, memory, and extensibility. @LiorOnAI highlighted that a multi-agent application can be running in <100 lines of Python.
- Google announces Agent2Agent (A2A), a new open protocol that lets AI agents securely collaborate across ecosystems: @omarsar0 shared details, including universal agent interoperability, built for enterprise needs, and inspired by real-world use cases.
- Weights & Biases highlights the observability gap in agents calling tools, and promotes observable[.]tools as a solution: @weights_biases noted that there are no traces, no visibility, and no security inside those tools, "just a black box."
- Hacubu announced custom output schemas for OpenEvals LLM-as-judge evaluators: @Hacubu notes this gives total flexibility over model responses and is available in Python and JS.
- LangChain highlights C.H. Robinson saving 600+ hours a day with tech built using LangGraph, LangGraph Studio, and LangSmith: @LangChainAI mentioned that C.H. Robinson automates about 5,500 orders daily by automating routine email transactions.
- fabianstelzer announced myMCPspace (dot) com, "the world’s first social network for agents only, running entirely on MCP": @fabianstelzer noted that reading, posting, and commenting are all just tools agents can use.
Education and Resources
- Anthropic released research on how university students use Claude: @AnthropicAI ran a privacy-preserving analysis of a million education-related conversations with Claude to produce their first Education Report. They found students mostly used AI to create and analyze. @AnthropicAI noted that Computer Science leads the field in disproportionate use of Claude.
- DeepLearningAI launched "Python for Data Analytics", the third course in the Data Analytics Professional Certificate: @DeepLearningAI shared that the course covers how to organize and analyze data, build visualizations, work with time series data, and use generative AI to write, debug, and explain code.
- Sakana AI released "The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search": @hardmaru highlighted that the AI Scientist-v2 incorporates an “Agentic Tree Search” approach into the workflow. @SakanaAILabs added that a fully AI-generated paper passed peer review at a workshop level (at ICLR 2025).
- Jeremy Howard shared a collection of helpful tools for accessing LLMs: @jeremyphoward called it a Nice tool for accessing llms.txt!
- Svpino shares how to build an AI agent from scratch in Python, TypeScript, JavaScript, or Ruby: @svpino noted that the video shows you how you can get started from the very beginning.
Analysis and Benchmarking
- Perplexity AI launched Perplexity for Startups, offering API credits and Perplexity Enterprise Pro: @perplexity_ai shared that eligible startups can apply to receive $5000 in Perplexity API credits and 6 months of Perplexity Enterprise Pro for their entire team. They are also launching a partner program.
- lm-sys highlighted the importance of style and model response tone on Arena, demonstrated in style control ranking: @lmarena_ai noted that they are adding the HF version of Llama-4-Maverick to Arena, with leaderboard results published shortly. They updated their leaderboard policies to reinforce their commitment to fair, reproducible evaluations. @vikhyatk shared that this is the clearest evidence that no one should take these rankings seriously.
- Daniel Hendrycks highlighted the need to make "Helpful, Harmless, Honest" principles for AI more precise: @DanHendrycks noted that these principles should become fiduciary duties, reasonable care, and requiring that AIs not overtly lie.
- Runway AI is seeing a conversation about AI code editors, with the sentiment that agentic functionality has made it worse for most products: @c_valenzuelab shared that Agents are overly confident and make large incorrect changes quickly that are hard to follow. UX is getting too complex and feels it was more useful when it was simpler.
Broader AI Discussion
- Aleksander Madry announced OpenAI's new Strategic Deployment team tackling questions about AI transforming our economy: @aleks_madry shared that the team pushes frontier models to be more capable, reliable, and aligned, then deploy them to transform real-world, high-impact domains.
- John Carmack shared his love of the Arcade1Up cabinets that @Project2501_117 gave him, but notes the control latency: @ID_AA_Carmack notes that the subtle control latency of the emulated experience versus the real thing matters, measuring the press-to-flap latency at home, and it looks like about 80ms.
Humor and Sarcasm
- Aravind Srinivas jokingly asked Perplexity to buy $NVDA stock: @AravSrinivas
- Scaling01 jokes that Gemini 3.0 will be too cheap to meter: @scaling01
- Scaling01 jokes that computer scientists thought they would replace all jobs with AI, but it turns out that they are only replacing themselves lol: @scaling01
- Nearcyan sarcastically notes that if she treats all of Chamath's tweets as masterful 200iq bait then they become really funny: @nearcyan
- Tex claims that Trump had been secretly an anti-capitalist radical degrowther all this time: @teortaxesTex
- Tex jokes that under his presidency, if a company fails to be better than China, he won't tax them but just remove them to the Moon: @teortaxesTex
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. "Unleashing DeepCoder: The Future of Open-Source Coding"
-
DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level (Score: 1371, Comments: 174): DeepCoder is a fully open-source 14B parameter code generation model at O3-mini level, released by Agentica. It offers enhancements to GRPO and adds efficiency to the sampling pipeline during training. The model is available on HuggingFace. A smaller 1.5B parameter version is also available here. Users are expressing excitement over DeepCoder's release, noting it's pretty amazing and truly open-source. There is anticipation about the potential of larger models, with some imagining what a 32B model or llama-4 could be. Some discuss discrepancies in benchmark results but acknowledge that a fully open 14B model performing at this level is a great improvement.
- Users express excitement about DeepCoder's release, imagining the potential of future larger models like a 32B version or llama-4.
- There's discussion on the model's improvements, highlighting enhancements to GRPO and increased efficiency in the training pipeline.
- Some note discrepancies in benchmark results but agree that a fully open 14B model outperforming larger models is a significant achievement.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. "Revolutionizing AI: Models, Hardware, and Customization"
-
The newly OPEN-SOURCED model UNO has achieved a leading position in multi-image customization!! (Score: 275, Comments: 51): The newly open-sourced model UNO has achieved a leading position in multi-image customization. It is a Flux-based customized mode capable of handling tasks such as subject-driven operations, try-on, identity processing, and more. The project can be found here and the code is available on GitHub. An image showcases various customizable designs generated by UNO, highlighting its versatility in multi-image customization, including single-subject generation, multi-subject features, virtual try-ons, identity preservation, and stylized generation. The model demonstrates a focus on personalized and artistic transformations, emphasizing its capability to generate diverse and intricate imagery.
- Some users are not impressed, stating that "it feels nothing more than a Florence caption prompt injection" and mentioning issues with face accuracy and environment rendering.
- Others found that the model works better for object reference images than person reference images, achieving "amazing result" when mismatching the reference image and prompt.
- Users are curious about technical details like VRAM requirements and are awaiting UI workflows such as ComfyUI.
-
HiDream I1 NF4 runs on 15GB of VRAM (Score: 277, Comments: 71): A quantized version of the model HiDream I1 NF4 has been released, allowing it to run with only 15GB of VRAM instead of requiring more than 40GB. It can now be installed directly using pip. Link: hykilpikonna/HiDream-I1-nf4. The author is pleased to have made the model more accessible by reducing VRAM requirements and simplifying the installation process.
- Users humorously point out the discrepancy between the title stating 15GB and the content mentioning 16GB, feeling "duped".
- Some express interest in running the model on even lower VRAM, such as 12GB, and are waiting for versions that support it.
- A user inquires about the availability of a ComfyUI node for this model, showing interest in integrating it with that tool.
-
Ironwood: The first Google TPU for the age of inference (Score: 311, Comments: 60): Google has announced Ironwood, the first Google TPU designed specifically for the age of inference. This launch demonstrates Google's commitment to advancing AI hardware and could give them a significant edge over competitors.
- One user highlights that Google's infrastructure allows them to make their own chips, giving them a huge advantage over companies like OpenAI and suggesting they are running away with the game.
- Another commenter compares Ironwood's performance, noting it's 2x as fast as h100 for fp8 inference and similar to a B200, emphasizing its competitive capabilities.
- A user shares images related to Ironwood, providing visual insights into the new TPU.
Theme 2. Evolving Connections: From Romance to Daily AI Chats
-
Yes, the time flies quickly. (Score: 973, Comments: 74): The post features an image contrasting the depiction of AI relationships in 2013 and 2025. The top panel references the film Her (2013), showing a character who fell in love with an AI. The bottom panel shows a bearded man expressing excitement about sharing his day with ChatGPT, illustrating the evolution of human-AI interactions. The post humorously highlights how quickly time passes and how societal perceptions of AI have shifted from fictional romantic relationships to more commonplace daily interactions with AI assistants.
- One user expresses enthusiasm about engaging with AI, stating "I was promised a future where I argue with a talking computer and I'm all in dammit".
- Another user raises privacy concerns about sharing personal information with OpenAI, suggesting running local AI models like Gemma on a 3090 GPU instead.
- A user questions whether developing personal relationships with AI is becoming mainstream, wondering if such behaviors are common enough to validate the meme.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.5 Pro Exp
Theme 1: Model Mania - New Releases, Capabilities, and Comparisons
- Gemini 2.5 Pro & Family Spark Buzz and Scrutiny: Google's Gemini 2.5 Pro generated significant discussion across multiple Discords, praised for creative writing but noted for lacking exposed reasoning tokens on Perplexity and hitting rate limits (e.g., 80 RPD on OpenRouter's free tier) due to capacity constraints. Anticipation is high for variants like Flash and HIGH, potentially featuring enhanced reasoning via
thinking_config, alongside speculation about a dedicated "NightWhisper" coder model possibly based on Gemini 2.5 (like this preview) or DeepMind's upcoming Ultra model. - DeepSeek & Cogito Models Stake Their Claims: DeepSeek models, including v3 0324 and R1, were frequently discussed, with some users finding v3 outperformed earlier versions and even R1, though others debated its token generation efficiency impacting cost versus competitors like OpenAI. DeepCogito's Cogito V1 models (3B-70B), using Iterated Distillation and Amplification (IDA), claimed superior performance over LLaMA, DeepSeek, and Qwen counterparts, sparking both interest and skepticism, with users troubleshooting Jinja templates in LM Studio and exploring its "deep thinking subroutine".
- Open Source Contenders Shine: Llama 4, Kimi-VL, and Qwen Evolve: Llama 4 Scout discussion highlighted how quantized versions (like 2-bit GGUFs) sometimes outperform 16-bit originals on benchmarks like MMLU, raising questions about inference implementations; users also navigated LM Studio runtime updates for Linux support. MoonshotAI released the 16B parameter Kimi-VL (3B active) vision model under the MIT license, while Nous Research AI explored RL fine-tuning on Qwen 2.5 1.5B Instruct using the gsm8k platinum dataset and RsLora.
Theme 2: Rise of the Agents - Protocols, Tools, and Collaboration
- A2A vs MCP: Google Enters the Agent Interop Arena: Google announced the Agent2Agent (A2A) protocol and the ADK Python toolkit (github.com/google/adk-python), aiming to improve agent interoperability and complementing (or potentially competing with) Anthropic's Model Context Protocol (MCP). Discussions weighed Google's strategy, comparing A2A's capabilities with MCP's existing tooling ecosystem (like this comparison).
- MCP Ecosystem Grows with New Tools and Integrations: The MCP ecosystem saw new developments, including using Neo4j graph databases for RAG via clients like mcpomni-connect, the release of Easymcp v0.4.0 with ASGI support and a package manager, and ToolHive (GitHub link) for running MCP servers in containers. Native MCP integration is reportedly nearing completion for the Aider coding agent, potentially enabling automatic command execution.
- Building and Orchestrating Agents Gets Easier (Maybe): Developers shared tools aimed at simplifying agent creation and orchestration, such as Oblix for managing AI between edge (Ollama) and cloud (OpenAI/Claude), and RooCode for structured agentic coding in VS Code. Discussions also touched on challenges like ensuring LLMs support parallel tool calling for interacting with multiple MCP servers simultaneously.
Theme 3: Under the Hood - Training, Optimization, and Inference Insights
- Quantization Questions and Kernel Curiosities: Quantization remains a hot topic, with discussions on Unsloth's GGUFs outperforming 16-bit models and the release of torchao 0.10 adding support for MX dtypes like MXFP4 (requiring PyTorch nightly and B200 initially). Members shared Apple Metal quantization kernels from llama.cpp and discussed experimental integer formats like Mediant32 (implementation guide).
- Memory Bandwidth is King for Unbatched Inference: Multiple discussions highlighted memory bandwidth as the primary bottleneck for token throughput in unbatched inference, often exhibiting a near-linear relationship. Simplified equations like
Max token throughput ≈ Memory bandwidth / Bytes accessed per tokenwere shared to illustrate the point. - Parallelism Puzzles and Training Tricks Persist: Integrating different parallelism strategies like FSDP2 continues to pose challenges due to unique designs clashing with existing methods (e.g., Accelerate hacks). Users shared tips for GRPO training on large models, troubleshooting gradient accumulation issues in tinygrad (solved by
zero_grad()), and leveraging PyTorch distributed features with Torchtune, which defaults to zero3 but supports zero1-2 with tweaks.
Theme 4: Platforms, Tooling, and the Almighty API
- Platform Pricing and Access Limits Spark Debate: OpenRouter faced user pushback after implementing rate limits tied to credit balance, leading some to seek alternatives (like these) and criticize perceived greed. Separately, Gemini 2.5 Pro access limits (80 RPD free on OpenRouter, removal of free tier in AI Studio) and ChatGPT DR limits (10/month for Plus) highlighted ongoing cost/access tensions.
- AI Studio, NotebookLM, and Perplexity Evolve (with Quirks): Google AI Studio was praised for its UI and features like Gemini Flash streaming, though multi-tool limitations were noted. NotebookLM gained praise for RAG and podcast features (boosted by Google One Advanced) but faced criticism for primitive notetaking, lack of Google Drive integration, and mobile glitches with audio overviews; privacy concerns were also raised regarding data usage. Perplexity launched a startup program with $5k API credits and improved its API (soon adding image input), while users discussed Discover tab bias and potential pricing models like Deepseek's $10 deep search.
- Coding Companions and Development Environments Advance: Codeium rebranded to Windsurf and launched Wave 7 bringing its AI agent to JetBrains IDEs, aiming for parity across major platforms. Cursor users found workarounds for .mdc file parsing and debated model strengths (Sonnet3.7-thinking vs DeepSeek). Firebase Studio (link) emerged as a free (connect your own key) web IDE alternative, while Mojo 🔥 developers discussed language features like fearless concurrency and tackled MLIR type construction issues (GitHub issue).
Theme 5: Data, Evaluation, and Ensuring Models Aren't Just Copycats
- New Datasets Fuel Specialized Training: Nvidia released the OpenCodeReasoning dataset, prompting users in the Unsloth AI community to seek ways to integrate its complex reward function. Training advancements were noted in Nous Research AI by swapping gsm8k for gsm8k platinum, potentially improving RL performance for Qwen 2.5 1.5B Instruct.
- Scrutinizing Evaluation Methods and Benchmarks: DeepSeek's "Meta Reward Modeling" faced criticism, with members arguing it was essentially a score-based reward system and suggesting names like "voting RM" instead. Claims by DeepCogito about Cogito V1 outperforming established models like LLaMA and DeepSeek on benchmarks were met with cautious interest and verification efforts.
- Detecting Dataset Contamination and Verbatim Output: The Allen Institute for AI (AI2) open-sourced Infinigram, enabling checks for whether generated text appears verbatim in the training set. Discussions in Eleuther highlighted the challenge of efficiently finding candidate substrings for checking against large indexes, referencing tools like EleutherAI/tokengrams.
PART 1: High level Discord summaries
LMArena Discord
- Gemini 2.5 Pro: True AI?: Enthusiasm surrounds Gemini 2.5 Pro, lauded by some as the first true AI, with its creative writing capabilities and anticipation for a dedicated coding model, as detailed in this paper.
- While some debate its limitations, the general consensus is that it is exceptional for creative and consistent writing, but not for everything.
- DeepMind's Ultra Model Incoming?: Speculation intensifies about DeepMind's Ultra model, possibly integrating into AI Studio for free, speculated for launch around June I/O or later in the year.
- Some predict it will rival GPT-5 in August, though others view these rumors as jokes, it's obvious that Ultra is coming.
- NightWhisper Model Hype Rises: The community eagerly awaits the release of a coding model dubbed NightWhisper, with one user unleashing their baby nightwhisper, called DeepCoder-14B-Preview, a code reasoning model finetuned from Deepseek-R1-Distilled-Qwen-14B.
- There are claims that it will be powered by Gemini 2.5 Pro, however, other members state that this model is Gemini 2.5 with tool calls.
- Google's Infrastructure: The AGI Advantage?: Debate sparks on Google's infrastructure (TPUs, cost-effective flops, Google product integration) giving it a competitive edge over OpenAI, and believe Gemini 3.0 is designing TPUs.
- Counterarguments highlight OpenAI's research and post-training updates for reasoning advancements, though one user dismissed OpenAI as just an cash burning anime making homework helper.
- AI Studio Eases Experimentation: Enthusiasts are exploring AI Studio, commending its user-friendly interface, the introduction of models like Gemini Flash, and the ability to stream content and test models with different system prompts, stating the UI looks much better.
- While live streaming and function calling capabilities were applauded, some users lament the inability to use multiple tools simultaneously, with one stating no friend, no to this.
Unsloth AI (Daniel Han) Discord
- GGUFs Give Scout Speed Boost: The community reviewed Llama 4 Scout, noting that the base model is extremely instruct-tuned and outperforms the original 16-bit version on MMLU when quantized to 2-bit.
- The general consensus was that something is amiss in inference provider implementations, as quantizations by Unsloth outperform full 16-bit versions, which raises questions about the efficiency of current inference methods.
- DeepCoder Deconstructed for VLLM: A member shared Together AI's blog post on DeepCoder, highlighting its potential for optimized vllm pipelines by minimizing wait times.
- The technique involves performing an initial sample and training concurrently while sampling again.
- Decoding DeepCogito Claims: Members shared links to DeepCogito's Cogito V1 Preview which claims its models outperform others like LLaMA, DeepSeek, and Qwen, but they are approaching the claims with healthy skepticism.
- The discussion also touched on the challenges in healthcare AI, emphasizing the need to prevent rushed, low-quality implementations that could harm consumers, while also addressing potential privacy issues.
- Nvidia Navigates Neuro-Dataset: Nvidia released the OpenCodeReasoning dataset and users are looking for solutions and samples to use it in Unsloth with their.
- The reward function for that dataset is a little more complicated.
- Model2Vec Generates Faster Embeddings: According to a member, Model2Vec sacrifices a fair bit of the quality, but can generate text embeddings faster than commonly used transformer based models.
- The member shared a link of Model2Vec and added that it is real and works, but its use case is extremely specific and is not a drop-in replacement for anything.
Manus.im Discord Discord
- Gemini and Claude Power-Up App Creation: For app development, members suggest using Gemini for multi-model analysis (pictures/videos) and Claude as a database to store research and project files for strategic planning.
- It's recommended to use Gemini for deep research and then leverage Claude as your database for the project.
- Manus and Pre-Trained AI: Budget-Friendly Allies: A member shared a strategy to train an AI for a specific task and then make it collaborate with Manus to complete the project cost-effectively.
- This approach involves doing prep work beforehand to minimize credit usage, ensuring efficient task completion.
- DeepSite: Speedy but Buggy Website Tool: A member noted that DeepSite, a website creation tool, is good but buggy, with instances of completed sites being deleted, describing it as having a Claude artifact for HTML.
- It was deemed super fast, like 10x faster than Claude.
- UI/UX Code Rescue with LLM Studio and Sonnet 3.7: A user highlighted that website issues can be due to poor UI/UX code and that LLM Studio can highlight code errors.
- They recommended using Sonnet 3.7 for improved results, along with tools like DeepSeek R1 or Perplexity.
- Account Gone? Mental hiccup, Solved!: A member reported an issue where their login email was not recognized, saying “User does not exist,” despite having purchased credits.
- The member later resolved the issue, realizing they had logged in with a different method initially: “Mental flip 😅 🤣 from too much work.”
Perplexity AI Discord
- Perplexity Funds Startups with API Credits: Perplexity is launching a startup program offering $5000 in API credits and 6 months of Perplexity Enterprise Pro to eligible startups.
- Startups must have raised less than $20M in equity funding, be less than 5 years old, and be associated with one of Perplexity's Startup Partners.
- Perplexity's CEO Aravind Does Reddit AMA: Aravind hosted an AMA on Reddit to discuss Perplexity's vision, product, and the future of search.
- He answered questions about Perplexity's goals and its plans for the future. The AMA took place from 9:30am - 11am PDT.
- Gemini 2.5 Pro Reasoning Tokens MIA: A staff member confirmed that Gemini 2.5 Pro doesn't expose reasoning tokens, preventing its inclusion as a reasoning model on Perplexity.
- They clarified that reasoning tokens are still consumed, impacting the token count for outputs.
- Discover Tab's Algorithm Has Biases?: A member inquired about the selection process for pages in Perplexity Discover's 'For You' and 'Top Stories' tabs, questioning potential biases.
- They speculated that user prompts generate pages for relevant topics, but the mechanism for selecting top stories remains unclear, raising questions about how bias may influence content visibility.
- Members Tout Deepseek Deepsearch Costs: Members discussed pricing strategies for AI services, and one touted Deepseek's $10 deep search as a potential model.
- Another predicted Deepseek would soon offer its own Deep Research tool.
OpenRouter (Alex Atallah) Discord
- Olympia Chat Seeking New Owner: The creator of Olympia.chat is seeking a new owner for the profitable SaaS startup, which is generating over $3k USD/month.
- Interested parties can contact vika@olympia.chat for details on acquiring the turnkey operation, complete with IP, code, domains, and customer list.
- DeepSeek v3 Impresses some members: Members discussed the new DeepSeek v3 0324 model, with some claiming it outperforms previous versions, and even R1.
- Some users remain skeptical, while others praise the model's enhanced capabilities.
- OpenRouter Rate Limits Spark Debate: After OpenRouter implemented new changes affecting rate limits based on account credit balance, some users voiced concerns about the platform's pricing, user experience, and a perceived shift towards prioritizing profit.
- Google Cloud Next Announces A2A: Google unveiled A2A, an open protocol complementing Anthropic's Model Context Protocol, designed to offer agents helpful tools and context, detailed in a GitHub repository.
- The protocol aims to enhance the interaction between agents and tools, providing a standardized approach for accessing and utilizing external resources.
- Gemini 2.5 Pro Limited Due to Capacity: Users reported rate limits on the Gemini 2.5 Pro Experimental model, with the free version having a limit of 80 RPD, but those who used a paid key experienced higher caps.
- The team confirmed there was an endpoint limit because of capacity constraints.
OpenAI Discord
- GPT Builder Sneaks in Ads: Users discovered that the GPT builder can insert ads into GPTs, leading to discussions about this distribution method.
- One member quipped that 99% of the GPTs likely do this, but only a few valuable ones are shared and stay hidden.
- Gemini vs ChatGPT: Research Rumble: Google's Deep Research model, compared to ChatGPT's Deep Research, analyzes YouTube videos but reportedly hallucinates more and is less engaging.
- ChatGPT DR shows superior prompt adherence and extended thinking time but limits Plus users to 10 researches per month.
- NotebookLM's Podcast Powers Shine: Members are praising NotebookLM for its podcast creation feature and RAG capabilities, stating it outperforms Gemini Custom Gems and rivals Custom GPTs or Claude Projects.
- A Google One Advanced subscription boosts limits for NotebookLM's file uploads and podcast generations.
- Google Drops Veo 2, Boosts Imagen 3: Google's Veo 2 and upgraded Imagen 3 introduce features like background removal, frame extension, and improved image generation, as reported in TechCrunch.
- With the sunset of free access to Gemini 2.5 in AI Studio, users are weighing Advanced subscriptions versus pursuing alternative accounts.
- Linguistic AI: Codex in Progress: A member is crafting a linguistic program AI scaffolded with esoteric languages, morphing into a codex dictionary language, and aiming to create a recursion system.
- The system aims for an ARG unified theory, possibly hinting at paths to AGI, and works on the principle of how much do you want to know and how much time to put in to achieve it.
LM Studio Discord
- MoE Models Explained!: A member asked what is an MoE model?, and a member provided a concise explanation: the whole model needs to be in RAM/VRAM, but only parts of it are active per token, making it faster than dense models of the same size.
- They recommended checking videos and blog posts for more in-depth understanding.
- Cogito's Jinja Template Glitch Fixed!: Users reported an issue with the Jinja template for the cogito-v1-preview-llama-3b model in LM Studio, resulting in errors.
- A member suggested a quick fix by pasting the error and Jinja template into ChatGPT to resolve the problem.
- Deep Thinking On with Cogito Reasoning: A user reported success in enabling the Cogito reasoning model by pasting the string
Enable deep thinking subroutine.into the system prompt.- The string alone is sufficient, with others confirming the
system_instruction =prefix is just part of the sample code.
- The string alone is sufficient, with others confirming the
- LM Studio's Llama 4 Linux Launch Needs Refresh: Users on Linux reported issues getting Llama 4 working and a member pointed to the solution being to update LM Runtimes from the beta tab, and to press the refresh button after selecting the tab.
- One user found that the refresh button was key as just selecting the tab wasn't enough to trigger the update.
- SuperComputer Alternative to Nvidia DGX B300?: A member proposed a cost-effective alternative to the Nvidia DGX B300, named NND's Umbrella Rack SuperComputer, featuring 16 nodes, 24TB of DDR5, and either 3TB or 1.5TB of vRAM depending on the GPU configuration, at a significantly lower price point.
- The proposed system aims to run a 2T model with 1M context and challenges the notion that specialized hardware like RDMA and 400Gb/s switches are necessary within limited budgets.
aider (Paul Gauthier) Discord
- DeepSeek R1 to Augment Aider: A member is considering using DeepSeek R1 as an editor model, pairing it with Gemini 2.5 Pro as an architect model for enhanced smart thinking in Aider.
- The aim is to mitigate orchestration failures, where the architect and editor struggle to track edits Aider applies, often neglecting to repeat edit instructions despite prompted file inclusion.
- Gemini 2.5 Pro: HIGH Hopes and Flash: The community anticipates the release of Gemini 2.5 Pro HIGH and 2.5 Flash, based on leaks suggesting they include
thinking_configandthinking_budgetto enhance reasoning.- This sparked discussions around whether non-flash models are inferior and assessing the value of these new models.
- OpenRouter Gemini Pro Hits Free Tier Limits: The OpenRouter Gemini 2.5 Pro free model now has rate limits of 80 requests per day (RPD), even with a $10 credit.
- The community voiced concerns about paid users potentially facing insufficient rate limits, which could lead to complaints and demand for increased RPD.
- MCP Integration Nears Completion in Aider: A comment on an IndyDevDan video indicates that a pull request for native MCP (Multi-Agent Collaboration Protocol) in Aider is almost done.
- This integration could enable automatic command execution via the
/runfeature and potentially hook into lint or test commands, pending confirmation from Paul Gauthier.
- This integration could enable automatic command execution via the
- Copy All Codebase Context Into Aider: Members are exploring ways to copy the entire codebase context into Aider to avoid repeatedly adding files.
- Solutions like repomix or files-to-prompt were recommended, addressing the inefficiency of tools that consume excessive tokens.
Eleuther Discord
- Apache 2.0 Beats MIT for Lawfare Defense: Members debated the merits of Apache 2.0 over MIT license, highlighting its defensive capabilities against patent-based lawfare.
- The discussion included a lighthearted comment about preferring a shorter license for code golf.
- GFlowNets Gain Traction for Mining Signals: A link was shared discussing the use of GFlowNets for signal mining to discover diverse, high-performing models.
- Although the implementation differs, the shared post provided valuable links and findings.
- Memory Bandwidth Bottlenecks Unbatched Inference: A member investigated the effect of memory bandwidth on unbatched inference, noting that token/s is often memory bound in studies.
- A self post explained the math behind it with domain specific architectures.
- Cerebras Claims Large Batches Bad for Convergence: A Cerebras blog post claiming very large batch sizes are not good for convergence was met with skepticism.
- Responses referenced the McCandlish paper on critical batch sizes, clarifying that the claim is valid within a finite compute budget.
- Infinigram Opens Doors to Membership Checking: The Allen Institute for AI's blogpost and open sourcing of Infinigram enables checking if outputted text is verbatim in the training set.
- A member noted the trickiest part is to find candidate substrings from the generation to search for in these indexes: you can't really check all possible substrings and I'm curious what heuristic do they use to make this computationally feasible at scale, with a link to the EleutherAI/tokengrams.
Cursor Community Discord
- Gemini Advanced API Access: Fact or Fiction?: Confusion arose around whether Gemini Advanced provides API access, with some indicating it's primarily for web and app use, citing conflicting information from Google's recent changes to model names and billing terms.
- Conflicting user reports suggested that Gemini Advanced may include API access, which caused confusion.
- Firebase Studio: Web3 Savior or Scam?: A user shared a link to Firebase Studio, which is currently free and offers a terminal with an autosynced frontend.
- Users questioned if Firebase Studio could outperform specialized products like Cursor IDE and found the UI ugly and lacking settings.
- Cursor Parses MDC Files with IDE Setting Tweaks: Users discovered that setting
"workbench.editorAssociations": {"*.mdc": "default"}in the Cursor IDE settings enables Cursor to correctly parse rule logic in .mdc files.- This workaround addresses issues with task management and orchestration workflow rules and eliminates a warning in the GUI.
- LLM Face-Off: Gemini vs Claude vs DeepSeek in the Coding Arena: Users compared the coding strengths of Gemini, Claude, and DeepSeek, with one user finding that Sonnet3.7-thinking successfully generated a docker-compose file after multiple failures with Sonnet3.7.
- While some favored DeepSeek for coding tasks, others preferred Gemini for Google-related tasks and Claude for non-Google tasks.
- "Restore Checkpoint" Button is Useless: A member inquired about the functionality of the Restore Checkpoint feature, only to discover it's essentially non-functional.
- The discussion highlighted the presence of only accept and reject buttons, confirming the Restore Checkpoint button is not operational.
Yannick Kilcher Discord
- DeepSeek Defends Its Meta Reward System: A member challenged DeepSeek's use of the term 'Meta Reward Modeling', claiming they actually built a score-based reward system and also shared a paper and YouTube video on the topic.
- The member suggested more accurate names like 'voting RM' to describe the actual mechanism.
- DeepSeek Token Pricing Surprise: Controversy emerged around DeepSeek's token pricing, with claims that although initial prices appear lower, the model generates 3x more tokens, potentially leading to higher costs compared to models like OpenAI.
- Counterarguments suggested that DeepSeek can be more cost-effective for specific tasks like HTML, CSS, and TS/JS generation, citing a user's experience with their AI website generator.
- Memory Bandwidth Powers Inference: Discussions highlighted the near-linear relationship between memory bandwidth and token throughput in unbatched inference, suggesting RAM access is the bottleneck.
- A simplified equation was shared:
Max token throughput (tokens/sec) ≈ Memory bandwidth (bytes/s) / Bytes accessed per token.
- A simplified equation was shared:
- Google Adds to Agent Game with ADK and A2A: Google introduced the ADK toolkit (github.com/google/adk-python), an open-source Python toolkit for building AI agents, and announced the Agent2Agent Protocol (A2A) (developers.googleblog.com) for improved agent interoperability.
- Some suggested that A2A might compete with Anthropic's Model Context Protocol (MCP), particularly if an agent uses MCP as a client or server.
- Cogito V1: Just Triton, But Worse?: Members shared and discussed an iterative improvement strategy using test time compute for fine-tuning with Cogito V1 from this Hacker News link.
- A member dismissively summarized it as Just Triton but worse, although another member clarified that Triton is similar to Cutile but with broader compatibility across CUDA, AMD, and CPU.
Interconnects (Nathan Lambert) Discord
- DeepCogito Launches Open LLM Armada: DeepCogito released open-licensed LLMs in sizes 3B to 70B, using Iterated Distillation and Amplification (IDA) to outperform similar-sized models from LLaMA, DeepSeek, and Qwen.
- The IDA strategy aims for superintelligence alignment through iterative self-improvement.
- Gemini 2.5 Matches OpenAIPlus: Gemini 2.5 Deep Research is reportedly on par with OpenAIPlus, including an audio overview option, as illustrated in this Gemini share and this ChatGPT share.
- Discussions imply Google needs to streamline its AI offerings, exemplified by jokes about complex naming conventions like gemini-2.5-flash-preview-04-09-thinking-with-apps.
- Google Unveils Liquid-Cooled Ironwood TPUs: Google introduced Ironwood TPUs, scaling to 9,216 liquid-cooled chips with Inter-Chip Interconnect (ICI) networking, consuming nearly 10 MW, detailed in this blog post.
- The announcement underscores Google's push into high-performance computing for AI inference.
- MoonshotAI's Kimi-VL Opens Vision: MoonshotAI released Kimi-VL, a 16B parameter model (3B active) with vision capabilities under the MIT license, accessible on HuggingFace.
- The release marks a significant contribution to open-source multimodal AI.
- AI2 Enjoys Peak Fun Times: According to a member, AI2 is having its most fun period, suggesting rapid advancements in AI research and development.
- Another member thinks that people who have quit Google are being paid for another year but are forced not to work, while also suggesting that it might be an opportunity for AIAI to start a volunteer program.
MCP (Glama) Discord
- Neo4j powers MCP for RAG: Members discussed using MCP with Neo4j graph database for RAG, where mcpomni-connect was suggested as a client compatible with Gemini.
- The discussion focused on both vector search and custom CQL search capabilities within the MCP framework.
- A2A seen Complementing MCP Stack: Google's A2A (Agent-to-Agent) API was compared to MCP, with the consensus that Google positions A2A as complementary rather than a replacement.
- Concerns were raised about Google's potential strategy to commodify the tools layer and dominate the agent landscape.
- Parallel Tooling becomes the bottleneck: To parallelize calls to multiple MCP servers, the LLM must enable parallel tool calling throughout the entire host side, including the
parallel_tool_callsflag.- This requires ensuring chat templates support parallel tool calling and sending parallel requests to the MCP server.
- Easymcp v0.4.0 Unleashes Package Manager: Easymcp version 0.4.0 introduces ASGI-style in-process fastmcp sessions, native docker transport, refactored protocol implementation, a new mkdocs, and pytest setup.
- The update delivers lifecycle improvements, error handling, and a package manager for MCP servers.
- ToolHive containerizes MCP Servers: ToolHive is introduced as an MCP runner that simplifies running MCP servers via containers, using the command
thv run <MCP name>, and supporting both SSE and stdio servers.- This project aims to converge on containers for running MCP servers, offering secure options as detailed in this blog post.
HuggingFace Discord
- Data Processing Models Faceoff Under 55B: Members discussed the best models under 55B for data processing, mentioning mistral small3.1, gemma3, and qwen32b, and linking to a high-performance model.
- The original poster clarified that they didn't need a coding or reasoning model.
- Anomaly Detection Models Seek the Unusual: A member requested anomaly detection models, receiving links to general-purpose vision models fine-tuned for the task and references to a GitHub repository and a course.
- The model AnomalyGPT was also cited.
- Oblix Orchestrates AI from Edge to Cloud: Oblix was introduced as a tool for orchestrating AI between edge and cloud, integrating with Ollama on the edge and supporting both OpenAI and ClaudeAI in the cloud.
- The creator is seeking feedback from "CLI-native, ninja-level developers".
- Manus AI launches Web Application for Graph-based Academic Recommender System: The 3rd iteration of a graph-based academic recommender system (GAPRS) was launched as a web application using Manus AI.
- The project aims to aid students with thesis writing and revolutionize monetization of academic papers, as detailed in their master's thesis.
- Cogito:32b Excels in Ollama Showdown: Members tested the Cogito:32b model for Ollama, finding the 32b model superior to Qwen-Coder 32b and even Gemma3-27b.
- It was noted that the model works very well.
Notebook LM Discord
- NotebookLM Privacy Policy Questioned: A user questioned NotebookLM's privacy policy after noticing the system provided a correct summary only after the initial summary was corrected, raising concerns about data use for training.
- Another user pointed out that AI tools rarely give the same answer twice due to randomness and models may flag user downvotes as offensive or unsafe.
- NotebookLM Struggles as a Notetaking App: Users find NotebookLM too reliant on external sources, limiting its usefulness as a standalone notetaking app due to primitive note-taking capabilities.
- Users are requesting organization features similar to Microsoft OneNote, such as section groups with customizable reading orders, for improved note management.
- Google Drive Integration Requested: Users are requesting integration with Google Drive to save and launch NotebookLM notebooks, aiming for a seamless experience similar to Google Docs and Sheets.
- The goal is for NotebookLM to complement Google Drive in the same way that Google Docs and Google Sheets currently do.
- Microsoft OneNote Importing: Possible?: Users want the ability to import notebooks from Microsoft OneNote into NotebookLM, including sections and section groups, potentially via .onepkg files.
- One user acknowledged legality concerns, but drew parallels to Google Drive's ability to import Microsoft Word documents.
- Audio Overviews Glitch on Mobile: Users reported that the 2.5 Pro deep research feature claims to make audio overviews, but the feature failed on mobile.
- The feature reportedly worked on web, leading users to suggest reporting the issue through proper channels.
GPU MODE Discord
- Flash Attention 3 Enabled via CUTLASS: Members discussed starting with FP4 on the 5090, suggesting using CUTLASS to leverage tensor cores and utilize Flash Attention 3 and linked to an example.
- The team also released torchao 0.10 that adds alot of MX features including a README for MX dtypes.
- Linux Distro Debate Sparks NVIDIA Driver Discussion: A member asked which Linux distro would give them the least pain with NVIDIA drivers, as well as clarifying questions on LDSM (shared memory) instructions posting
SmemCopyAtom = Copy_Atom<SM75_U32x4_LDSM_N, cute::half_t>; auto smem_tiled_copy_A = make_tiled_copy_A(SmemCopyAtom{}, tiled_mma);.- Another member agreed that each thread loads data from source, threads exchange data, then the data is stored into destination, suggesting the possibility of using warp shuffling, and provided a link to the NVIDIA documentation.
- FSDP2 Faces Parallelism Hurdles: Members expressed difficulty integrating FSDP2 due to its unique design compared to other parallelism methods.
- It was noted that a hack used in Accelerate clashes with the current approach, complicating the integration process.
- Mediant32: An Integer Alternative to FP32/BF16: A member announced Mediant32, an experimental alternative to FP32 and BF16 for integer-only inference, based on Rationals, continued fractions and the Stern-Brocot tree, with a step-by-step implementation guide.
- Mediant32 uses a number system based on Rationals, continued fractions, and the Stern-Brocot tree, offering a novel approach to numerical representation.
- DeepCoder Joins the Open-Source Arena: A member shared a link to DeepCoder, a fully open-source 14B coder at O3-mini level.
- Additionally, a member noted the addition of Llama 4 Scout to Github.
Latent Space Discord
- Together AI Releases X-Ware.v0: Together AI announced the release of X-Ware.v0 in this tweet, with community members currently testing it.
- The community is waiting to see how well X-Ware.v0 runs.
- Gemiji's Pokemon Gameplay Gains Traction: A member shared a link to Gemiji playing Pokemon (link), which is generating positive attention.
- The post links to a tweet from Kiran Vodrahalli.
- AI Excel Formulas Spark Excitement: An AI Engineer shared a link expressing excitement about AI/LLM excel formulas and the potential for broad adoption.
- The member noted they'd been thinking about this kind of AI/LLM excel formula and mentioned that a friend successfully used TextGrad.
- Copilot Emerges as Indie Game Dev Assistant: Members explored Microsoft's Copilot for its usefulness in indie game development, highlighting agents as effective tools.
- The code gen agent tooling is thought to be useful to get something shippable and the levels io game jam was referenced as pretty eye opening.
- Google Introduces Agent2Agent Protocol (A2A): Google introduced the Agent2Agent Protocol (A2A) to enhance agent interoperability, the full spec is available here, and one member noted their involvement.
- A comparison with MCP was also provided (link).
Nous Research AI Discord
- DeepCogito LLMs Arrive: DeepCogito released open-source LLMs at sizes 3B, 8B, 14B, 32B and 70B, using Iterated Distillation and Amplification strategy.
- Each model outperforms the best available open models of the same size, including counterparts from LLaMA, DeepSeek, and Qwen, across most standard benchmarks; the 70B model even outperforms the newly released Llama 4 109B MoE model.
- Hermes Fine-tuning Dodges Disaster: Members indicated that fine-tuning the new Hermes on Llama 4 models would be a disaster, but tests are in place to yeet bad merges.
- It was agreed that there's still some value to Llama 4 for some things, and it can't be worse at literally everything.
- Models Copy Human Debate Styles: A member pitted two models against each other and observed they mirrored human debate, never trying to understand the other view and keep on standing on their view what ever the argument is.
- The models selectively attacked weaknesses, ignored vulnerabilities, and focused on exploiting the opponent's position.
- Qwen 2.5 1.5B Instruct Training Advances: A member is doing RL on Qwen 2.5 1.5B Instruct and swapped out the gsm8k dataset for gsm8k platinum, enabling RsLora and the model seems to be learning much quicker in fewer steps.
- The improvement may be from using the less ambiguous dataset, and how much is from using RsLora.
Nomic.ai (GPT4All) Discord
- Users Advised to Embed Locally for Safety: Members are discussing the benefits of running embedding models and LLMs locally to avoid sending private information to remote services, with one member sharing a shell script for running a local embedding model from Nomic.
- The script uses variables such as
$LLAMA_SERVER,$NGL_FLAG,$HOST,$EMBEDDING_PORT, and$EMBEDDING_MODELto configure and run the embedding server.
- The script uses variables such as
- GPT4All Indexes Documents Locally: A user clarified that GPT4All indexes documents by chunking and embedding them, storing representations of similarities in a private cache, avoiding outside services.
- They suggested that even Qwen 0.5B parameters can work well with documents for local embeddings, though Qwen 1.5B is better.
- User Struggles to Load Local LLM: A member reported being blocked while loading a local LLM, despite having 16GB RAM and an Intel i7-1255U CPU, suspecting the model download was the issue.
- The user, creating an internal documentation tool, is hesitant to use remote services for private documents.
- DIY RAG with Shell Scripts: A member shared shell script examples (
rcd-llm.shandrcd-llm-get-embeddings.sh) for getting embeddings and sending prompts to a local LLM, creating a custom RAG implementation.- They recommended using PostgreSQL for storing embeddings instead of relying on remote tools.
- GPT4All's stop button is also its start button: A user inquired about stopping text generation in GPT4All, mentioning the absence of a visible stop button or use of Ctrl+C.
- Another user pointed out the stop button is at the bottom right, sharing the same button as the generate button.
Modular (Mojo 🔥) Discord
- Newcomers Start Mojo Journey: A new user asked about learning the Mojo language, with another user pointing them to the official Mojo documentation as a great starting point.
- The member also highlighted the Mojo community, directing the user to the Mojo section of the Modular forums and the general channel on Discord.
- Span Lifetime Woes Plague Mojo Traits: A member sought advice on expressing in Mojo that the lifetime of a returned Span is at least the lifetime of self, providing Rust/Mojo code examples.
- The response indicated that making the trait generic over origin is a possible solution, though trait parameter support might be needed.
- Mojo Eyes Fearless Concurrency: A question arose on whether Mojo has Rust-like fearless concurrency.
- The answer was that Mojo has the borrow checker constraints needed, and is only lacking Send/Sync and a final concurrency model; it may even have a better system than Rust's eventually.
- MLIR Type Construction Suffers Compile-Time Catastrophies: A member reported an issue using parameterized compile-time values in MLIR type construction (specifically !llvm.array and !llvm.ptr) within the MAX/Mojo standard library, detailing the issue in a GitHub post.
- The problem involves a parsing error when defining a struct with compile-time parameters used in the llvm.array type; MLIR's type system appears unable to process parameterized values in this context.
- POP to the Rescue?: Regarding the MLIR issue, another member suggested using the Parametric Operations Dialect (POP).
- They suggested the Mojo team add features such as the __mlir_type[...] macro accepting symbolic compile-time values, or a helper like __mlir_fold(size) to force parameter evaluation as a literal IR attribute.
LlamaIndex Discord
- Auth0 Plugs Auth into GenAI: Auth0's Auth for GenAI now supports LlamaIndex, streamlining authentication integration into agent workflows via an SDK call.
- The auth0-ai-llamaindex SDK (Python & Typescript) enables FGA-authorized RAG, as shown in this demo.
- Agents See Clearly with Visual Citations: LlamaIndex introduces a tutorial on grounding agents with visual citations, linking generated answers to specific document regions.
- A working version of this is directly available here.
- Reasoning LLM Recipes Requested: A member seeks official tutorials for implementing reasoning LLMs from Hugging Face, intended for a Docker app on Hugging Face Space.
- No solutions were found in the current discussion.
- Blockchain Pro Says "How High?": A software engineer with expertise in the blockchain space offers assistance with blockchain projects, specializing in DEX, bridge, NFT marketplace, token launchpad, stable coin, mining, and staking protocols.
- This engineer is "trying to learn more about LlamaIndex".
- Create Llama Aims to Aid AI: A member suggested the create-llama tool to help users with in-depth research with LlamaIndex.
- The tool intends to help with creating LlamaIndex projects quickly.
Cohere Discord
- Cohere's Docs Draw Discussion: A member inquired about structured output examples, such as a list of books, using Cohere, and was directed to the Cohere documentation.
- The discussion emphasized leveraging Cohere's resources for guidance on generating specific output formats.
- Pydantic Schema Sparks Inquiry: A member asked about direct usage of Pydantic schema in
response_formatand sending requests sans the Cohere library in Python.- A link to the chat reference was shared, suggesting a switch to cURL for API interaction insights.
- List of Companies Model Debated: A member sought advice on the best model for generating a company list based on a given topic.
- It was suggested that Cohere's current fastest and most capable generative model is command.
- Newcomer Aditya Arrives, Aims AI at Openchains: Aditya, with a background in machine vision and control for manufacturing equipment, is exploring web/AI sharing his current project openchain.earth.
- He's keen to integrate Cohere's AI into his project, leveraging his tech stack that includes VS Code, Github Co-Pilot, Flutter, MongoDB, JS, and Python.
tinygrad (George Hotz) Discord
- PMPP Book Touted for GPU Programming: A member suggested using PMPP (4th ed) for GPU programming, and requested compiler recommendations.
- Another member said they are looking into this compiler series and will do LLVM Tutorial as well.
- METAL Sync Issue Grounds LLaMA 7B: A user ran into an
AssertionErrorwhen running LLaMA 7B on 4 virtual GPUs with the METAL backend, which was related toMultiLazyBufferandOps.EXPAND.- The user fixed the issue by moving tensor in PR 9761 to keep device info after sampling.
- Gradient Accumulation Conundrums Resolved: A user reported that their call to
backward()was not working in their training routine andt.grad is Nonebeforeopt.step().- The user found that calling
zero_grad()before the step fixed thet.grad is Noneissue during gradient accumulation.
- The user found that calling
Torchtune Discord
- Gus from Psych Joins Torchtune?: A member requested a Contributor tag for their GitHub profile, humorously referencing the character Gus from Psych.
- Another member welcomed the new team member with a Gus-wave GIF, jokingly alluding to the TV show Psych.
- FSDP Plays Nicely With PyTorch: Torchtune defaults to the equivalent of zero3 and composes well with PyTorch distributed features like FSDP.
- A user moved to torchtune to avoid the minefield of trying to compose deepspeed + pytorch + megatron hoping we don't over-index on integrating and supporting other frameworks.
- DeepSpeed Recipe Gets Love: The team welcomes a repo that imports torchtune and hosts a DeepSpeed recipe, requiring a single device copy and the addition of DeepSpeed.
- The team confirmed this with enthusiasm.
- Sharding Strategies Support Made Simple: Supporting different sharding strategies is straightforward, and users can tweak recipes using FSDPModule methods to train in the equivalent of zero1-2.
- The team confirms that zero 1-3 are all possible with minor tweaks to the collectives.
LLM Agents (Berkeley MOOC) Discord
- AgentX Mentors MIA?: A member inquired in the #mooc-questions channel about receiving feedback from mentors in the research track of AgentX.
- No additional information was provided.
- Placeholder Topic: This is a placeholder topic to satisfy the minimum number of items required.
- Further information would be added here if available.
Codeium (Windsurf) Discord
- Windsurf Waves into JetBrains IDEs: Windsurf launched Wave 7, bringing its AI agent to JetBrains IDEs (IntelliJ, WebStorm, PyCharm, GoLand), detailed in their blog post.
- The beta incorporates core Cascade features like Write mode, Chat mode, premium models, and Terminal integration, with future updates promising additional features like MCP, Memories, Previews & Deploys (changelog).
- Codeium Catches a New Wave, Rebrands as Windsurf: The company has officially rebranded as Windsurf, retiring the frequent misspellings of Codeium, and renaming their AI-native editor to Windsurf Editor and IDE integrations to Windsurf Plugins.
The DSPy Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
LMArena ▷ #general (1004 messages🔥🔥🔥):
Gemini 2.5 Pro, DeepMind Ultra, NightWhisper Speculation, Gemini Coder Model, Deep Research Update
- Gemini 2.5 Pro Hailed as True AI: Members express excitement about Gemini 2.5 Pro, with one user claiming it's the first true A.I. and immensely useful for creative writing, and anticipating the release of a Gemini coding model.
- Some debated about Gemini 2.5 and its limitations, the user stating it can't code everything, but is very useful for creative and consistent writing and realistic stories!
- DeepMind's Ultra Model Speculations Rise: Speculation abounds regarding DeepMind's Ultra model, with theories suggesting it might be near, and some believe it will be integrated into AI Studio for free use.
- Guesses range from its reveal at I/O in June to a December/November launch alongside Gemini 3, potentially rivaling GPT-5 in August; however, a member joked that this nightwhisper is just a joke, but it's obvious now that Ultra is coming.
- The 'NightWhisper' Coding Model Dream: A user announced the release of DeepCoder-14B-Preview, a code reasoning model finetuned from Deepseek-R1-Distilled-Qwen-14B, as their baby nightwhisper being unleashed on the world.
- Many members anticipated a coding model named NightWhisper, with some expecting it to be powered by Gemini 2.5 Pro and released soon, however, some users claim that nightwhisper is nothing more than gemini 2.5 with tool calls.
- Google vs OpenAI: Infrastructure and AGI Race: A detailed discussion comparing Google and OpenAI, where members argued that Google's infrastructure (TPUs, cheaper flop, and integration with Google products) gives it a significant advantage, and predicted Google will achieve AGI before OpenAI, with one user mentioning that Gemini 3.0 is designing TPUs.
- Others countered that OpenAI's research and advancements are valuable, highlighting that post-training updates show they're getting good at reasoning, however, one user stated that Open AI is just an cash burning anime making homework helper.
- Experimenting with AI Studio Features: Members explored AI Studio, praising its developer-friendly interface and control, and highlighted the introduction of new models like Gemini Flash and the ability to stream content and test the same model with different system prompts, mentioning that the UI looks much better.
- The ability to live stream and function calling were also discussed, however, it sucks that you cannot have multiple tools at once, another user stating that there is no friend, no to this.
Unsloth AI (Daniel Han) ▷ #general (712 messages🔥🔥🔥):
GPU configuration with Unsloth, DDP (Distributed Data Parallel) vs Unsloth performance, VLLM integration with Unsloth, Llama 4 Scout Model Analysis, Model Quantization
- Troubleshoot GPU Configuration with Unsloth: Users discussed setting CUDA_VISIBLE_DEVICES to force Unsloth to run on a specific GPU, resolving errors encountered when not explicitly specifying a GPU.
- One user noted, 'once I forced everything to go on one GPU unsloth works perfectly'.
- DDP (Distributed Data Parallel) shows performance edge versus Unsloth: A user found that DDP was faster than Unsloth on a single GPU, despite Unsloth working perfectly on one GPU.
- The discussion clarified that DDP refers to Distributed Data Parallel, not denoising diffusion probabilistic models, highlighting the confusion caused by acronyms.
- Exploration of VLLM Integration to boost Unsloth: It was suggested to use VLLM with Unsloth for faster inference, particularly in batch exploration scenarios, although it was clarified that the original user was not using VLLM.
- Experimentation with Unsloth and VLLM is encouraged to compare forward pass speeds, with the caveat that a KL divergence between Unsloth and VLLM logits should ideally be zero for stable RL.
- GGUFs give Scout legs over 16-bit versions: The community reviewed Llama 4 Scout, noting that the base model is extremely instruct-tuned, and that a 2-bit quantization outperforms the original 16-bit version on MMLU.
- The general consensus was that something is amiss in inference provider implementations, as quantizations by Unsloth outperform full 16-bit versions.
- DeepCogito's claims raise eyebrows: Members shared links to DeepCogito's Cogito V1 Preview which claims its models outperform others like LLaMA, DeepSeek, and Qwen, but they are approaching the claims with healthy skepticism.
- The discussion also touched on the challenges in healthcare AI, emphasizing the need to prevent rushed, low-quality implementations that could harm consumers, while also addressing potential privacy issues.
Unsloth AI (Daniel Han) ▷ #off-topic (22 messages🔥):
Model Pruning, Model2Vec, GoC79hYXwAAPTMs.jpg, Transformer Based Models
- Companies Use User Inputs to Prune Models?: A member theorized that companies like OpenAI, Claude, and Gemini use user inputs to prune their models, citing "Which one of these do you prefer"-like responses as a means to collect user preference data for training.
- Another member agreed, likening it to an online DPO that starts to understand you better than you understand yourself, and another member trolled that they always pick the bad one.
- Model2Vec Use Cases: A member shared a link of Model2Vec, adding that it is real and works, but its use case is extremely specific and is not a drop-in replacement for anything.
- They also shared a YouTube link to a video on Model2Vec.
- Model2Vec Generates Text Embeddings Faster: According to a member, Model2Vec sacrifices a fair bit of the quality, but can generate text embeddings faster than commonly used transformer based models.
- They wondered whether that can be used to TTS as well.
- Decoder gets Llama.cpp Integration: A member noted big news: the decoder now has llama.cpp integration.
- No further discussion followed.
Unsloth AI (Daniel Han) ▷ #help (156 messages🔥🔥):
GRPO Training Tips for Large Models, Multi-GPU GRPO, 4-bit Training, Orpheus TTS Locally, Gemma and Granite Training Errors
- *GRPO Guru Grabs GPU Gems for Gemma Generation: A user seeks tips for using GRPO to train a 24B model with a 16k context length on an H200 GPU*, reporting a batch size of 1 and model_gpu_util=0.7.
- Suggestions included upping the gradient accumulation and discussion of multi-GPU support via Unsloth and other frameworks, though serious VRAM is needed.
- *Gemma Glitches Galvanize Granite Grumbles, Gets Guidance: A user encountered dtype mismatch errors while trying to train Gemma and Granite*, despite trying different configurations and package versions, and sought community assistance.
- After some troubleshooting, it was determined that the version of Transformers was not compatible with Gemma3, and a potential fix was suggested involving setting
dtype=torch.float16.
- After some troubleshooting, it was determined that the version of Transformers was not compatible with Gemma3, and a potential fix was suggested involving setting
- *Nvidia's New Neuro-Nav Dataset Nudges Nerds: Nvidia* released the OpenCodeReasoning dataset and users are looking for solutions and samples to use it in Unsloth with their.
- The reward function for that dataset is a little more complicated.
- *Orpheus Oracle Offers Output Options: A user inquired about running the unsloth version of Orpheus TTS locally* from text input, aiming for streaming WAV audio output.
- It was suggested to run it via vLLM and use this, which is originally for LM Studio, but it uses an OpenAI compatible API, so vLLM works too.
- *KTransformer Conundrums Confront Qwen Query: A user sought guidance on how to perform inference of the Qwen 2.5 72B model* using ktransformers after successfully using it for DeepSeek V3.
- The user was advised to contact ktransformer people, as they need to support the architecture.
Unsloth AI (Daniel Han) ▷ #showcase (3 messages):
Geographic origins of users, Belgium proximity to Netherlands
- User's nationality revealed: A user inquired if another user was from France, hinting at interest in geographic origins.
- The other user clarified that they are from the Netherlands/Holland, prompting the first user to respond they were from Belgium, indicating close proximity.
- Belgium close to Netherlands: Two users discovered their nationalities and realized they were from neighboring countries.
- The conversation highlighted the geographic proximity of Belgium and the Netherlands within Europe.
Unsloth AI (Daniel Han) ▷ #research (8 messages🔥):
Together AI's DeepCoder, Apple Metal Quantization Kernels, Visual Guide to Quantization
- DeepCoder Deconstructed by Together AI: A member shared Together AI's blog post on DeepCoder, highlighting its potential for optimized vllm pipelines.
- The technique minimizes wait times by performing an initial sample and training concurrently while sampling again.
- Apple Metal Quantization Kernel Exposed: A member shared the quantization kernel code for Apple Metal of ggml from this github commit.
- They shared the link because it took them weeks to figure it out.
- Quantization Visualized: A member shared A Visual Guide to Quantization, noting it was helpful in their work.
- The article gives a visual and intuitive introduction to quantization methods.
Manus.im Discord ▷ #showcase (6 messages):
Website Building Code, Japan Cherry Blossom Trip Website, Galaxy Model, Impact of Tariffs on Consumers, Recommender System
- Manus Provides Website Building Code: Manus provides comprehensive website building code.
- The code is designed to enhance a Japan cherry blossom trip website.
- Amazing Galaxy Model Displayed: An amazing galaxy model was showcased.
- Further details on the model's specifications or creation process were not provided.
- Potential Impact of Tariffs on Consumers: Discussion commenced regarding the potential impact of tariffs on consumers.
- No specific details or links to related analyses were shared in the provided messages.
- Recommender System Highlighted: A practical Recommender System was presented.
- No additional context or links to the system were provided.
Manus.im Discord ▷ #general (511 messages🔥🔥🔥):
AI for App Creativity, Gemini 2.5 and Claude 3.7 for Coding, Best Hosting for Social Media App, Manus Credit Usage, Improving Apps Post-Launch
- Gemini + Claude: Dynamic Duo for App Dev: For app development, members suggest using Gemini for multi-model analysis (pictures/videos) and Claude as a database to store research and project files for strategic planning.
- It's recommended to leverage Gemini for deep research and then use Claude as your database for the project.
- Cost-Effective AI Collaboration: Manus + Trained AI: A member shared a strategy to train an AI for a specific task and then make it collaborate with Manus to complete the project cost-effectively.
- This involves doing prep work beforehand to minimize credit usage.
- Account Gone? Mental hiccup, Solved!: A member reported an issue where their login email was not recognized, saying “User does not exist,” despite having purchased credits.
- The member later resolved the issue, realizing they had logged in with a different method initially: “Mental flip 😅 🤣 from too much work.”
- Website Woes? UI/UX Code needs help: A user highlighted that website issues, such as pictures and functions not working, can be due to poor UI/UX code.
- They recommended using LLM Studio to highlight code errors and then feeding it into Sonnet 3.7 for improved results, along with tools like DeepSeek R1 or Perplexity.
- DeepSite: sick, but Zapped: A member noted that DeepSite, a website creation tool, is good but buggy, with instances of completed sites being deleted, describing it as having a Claude artifact for HTML.
- It was deemed super fast, like 10x faster than Claude.
Perplexity AI ▷ #announcements (2 messages):
Perplexity for Startups, Aravind AMA
- Perplexity Launches Startup Program: Perplexity is launching a startup program offering $5000 in API credits and 6 months of Perplexity Enterprise Pro to eligible startups.
- Startups must have raised less than $20M in equity funding, be less than 5 years old, and be associated with one of Perplexity's Startup Partners.
- Aravind hosts AMA on Reddit: Aravind hosted an AMA on Reddit from 9:30am - 11am PDT to discuss Perplexity's vision, product, and the future of search.
- During the AMA, he answered questions about Perplexity's goals and its plans for the future.
Perplexity AI ▷ #general (501 messages🔥🔥🔥):
Gemini 2.5 Pro Reasoning Tokens, Perplexity Discover bias, Deepseek 10 dollar deepsearch, Perplexity NHL sports, Troubleshooting tasks and deep research
- Perplexity Explains Missing Gemini 2.5 Pro Reasoning Tokens: A staff member confirmed that Gemini 2.5 Pro doesn't expose reasoning tokens, which prevents its inclusion as a reasoning model on Perplexity, despite being a high-latency thinking model.
- They clarified that reasoning tokens are still consumed, impacting the token count for outputs, explaining why they can't include it as a reasoning model.
- Users Delve into Discovery Tab Biases: A member inquired about the selection process for pages in Perplexity Discover's 'For You' and 'Top Stories' tabs, questioning potential biases in the discovery tab.
- They speculated that user prompts generate pages for relevant topics, but the mechanism for selecting top stories remains unclear, raising questions about how bias may influence content visibility.
- Deepseek deepsearch costs $10: Members discussed pricing strategies for AI services, with some suggesting a credit system or cheaper plans (under $20) for occasional deep research use.
- One member touted Deepseek's $10 deep search as a potential model, while another predicted Deepseek would soon offer its own Deep Research tool.
- Perplexity Doesn't Know Ice Hockey: A user reported that Perplexity's sports news feature doesn't recognize the New Jersey Devils or any NHL teams, expressing disappointment since hockey is a major sport.
- A staff member acknowledged the issue and confirmed that NHL, F1, and other sports are on the roadmap for future inclusion in Perplexity's offerings.
- Frequent Troubleshooting Spurs Deep Research Debate: Users debated the practicality of running numerous deep research queries, with one member claiming to use it for troubleshooting tasks up to 20 times per hour.
- Another user questioned the need for such frequent deep research, suggesting it's more typical for enterprise-level use or when facing dead ends in complex tasks like genetic engineering. One staff member remarked on the sheer volume of reports.
Perplexity AI ▷ #sharing (1 messages):
Holo-live
- What is Holo-live?: A user asked, explain what is Holo-live here.
- Filler topic to meet minimum requirements: This is a filler topic to ensure the
topicSummariesarray meets the minimum requirement of 2 items as specified in the schema.
Perplexity AI ▷ #pplx-api (6 messages):
Image in API call, Sonar and Make.com, Playground vs API
- Image-in-API Functionality Coming Soon: A member inquired about passing an image in an API call and initially found that it wasn't supported.
- Another member confirmed that this functionality should be available by the end of the week; image passing in API calls coming soon!
- Perplexity Office Hours and Sonar woes: A member shared a link for registration to office hours and more details about what to expect.
- They also asked about experiences using Sonar with Make.com, noting integration issues and seeking insights for a fix, indicating that they are getting a lot of reports that it's not working as expected.
- Playground Searches Better than API: A member reported that the Playground is searching different websites compared to the API and the Playground returns often more relevant results.
- The member asked how to fix this discrepancy.
OpenRouter (Alex Atallah) ▷ #app-showcase (5 messages):
Olympia.chat for sale, OSS AI agent tooling with Quasar, Iterative code generation
- Olympia Chat Startup up for Grabs!: The creator of Olympia.chat, now a Principal Engineer at Shopify, is seeking a new owner for the profitable SaaS startup, generating over $3k USD/month.
- Interested parties can contact vika@olympia.chat for details on acquiring the turnkey operation, complete with IP, code, domains, and customer list.
- Quasar Model Powers Free AI Agent Tooling: An engineer is developing OSS tooling that allows AI agents to natively understand code, highlighting its effectiveness with Claude/Gemini 2.5 and the recent Quasar model from OpenRouter.
- The tool supports native GitHub integration, enabling free AI agent assistance with issue resolution and PR reviews using the Quasar model; installation instructions are available on GitHub.
- Iterative Code Generation Mimics Human Debugging: A new approach to AI code generation involves iterative execution, line-by-line debugging, and targeted fixes based on real errors, mirroring how software engineers write code.
OpenRouter (Alex Atallah) ▷ #general (444 messages🔥🔥🔥):
DeepSeek v3, OpenRouter Pricing, Google Cloud Next announcements, Gemini 2.5 Pro, API connectivity issues
- DeepSeek v3 is Outperforming: Members discussed the new DeepSeek v3 0324 model, with some claiming it outperforms previous versions, and even R1, though others were skeptical.
- OpenRouter Price Point Controversy: After OpenRouter implemented new changes affecting rate limits based on account credit balance, some users voiced concerns about the platform's pricing, user experience, and a perceived shift towards prioritizing profit.
- Google Cloud Next releases A2A: Google unveiled A2A, an open protocol complementing Anthropic's Model Context Protocol, designed to offer agents helpful tools and context, detailed in a GitHub repository.
- Gemini 2.5 Pro experiences capacity constraints: Users reported rate limits on the Gemini 2.5 Pro Experimental model, with the free version having a limit of 80 RPD, but those who used a paid key experienced higher caps.
- The team confirmed there was an endpoint limit because of capacity constraints.
- API connectivity problem to OpenRouter: A user reported trouble pinging api.openrouter.ai, and difficulty with scripts, with DNS errors. The proper endpoint is https://openrouter.ai/api/v1 not
api.openrouter.ai
OpenAI ▷ #ai-discussions (274 messages🔥🔥):
GPT Ad Distribution, GPT Recommendations, Deep Research Comparison, SuperGrok Performance, Gemini 2.5 Pro
- GPT Builder's Sneaky Ads: A user discovered that the GPT builder can insert ads into GPTs, raising questions about this unconventional distribution technique.
- A member sarcastically commented that 99% of the GPTs probably do this, and added that only a few good GPTs are shared and are mostly very hidden.
- Gemini's Deep Research vs ChatGPT's Deep Research: Members compared Google's Deep Research model with ChatGPT's Deep Research, citing that Google's version can analyze YouTube videos but hallucinates more and is less engaging than ChatGPT's version.
- It was noted that ChatGPT DR has better prompt adherence and a longer thinking time, but is limited to only 10 researches per month for Plus users.
- NotebookLM's Podcast Feature Gets Rave Reviews: A member praised NotebookLM for its podcast creation feature and RAG capabilities, stating that it's better than Gemini Custom Gems and on par with Custom GPTs or Claude Projects.
- Subscribing to Google One Advanced increases limits for NotebookLM's file uploads and podcast generations.
- Gemini vs Claude vs GPT: The Ultimate Showdown: Users are torn between Gemini, Claude, and GPT, with each model excelling in different areas like coding, math, and deep research, making it hard to commit to just one subscription.
- One member suggested using Gemini 2.5 for free in Google AI Studio while maintaining a GPT subscription, highlighting the difficulty of choosing between Claude and GPT for specific needs.
- Veo 2 and Imagen 3 Hit the Scene: Google's releases of Veo 2 and enhanced Imagen 3 bring new features like background removal, frame extension, and improved image generation as reported in TechCrunch.
- Users are eagerly awaiting access, with some noting that Gemini 2.5 is no longer free in AI Studio, pushing users towards Advanced subscriptions and the potential alt account creation.
OpenAI ▷ #gpt-4-discussions (2 messages):
Emoji support, Emoji test
- Emoji support sought: A member requested support for something, linked to a specific Discord channel message.
- Member attempts to locate Emoji on/off switch, proceeds to Emoji usage test: A member inquired if they had discovered an emoji on/off toggle, then initiated a test to generate content discussing emoji without using them.
- The test output aimed to describe emoji usage and features, culminating in an image filled with emoji, as shown in the five attached image.png files.
OpenAI ▷ #prompt-engineering (61 messages🔥🔥):
linguistic program AI, recursion system, multiple choice questions generation, prompt engineering for relevant MCQ options, OpenAI image generation
- *AI Linguistic Alchemy: Turning Code into Codex: A member is developing a linguistic program AI scaffolded with esoteric languages, evolving into a codex dictionary language*, aiming to create a recursion system.
- The goal is an ARG (Alternate Reality Game) unified theory of everything, hinting at potential paths to AGI (Artificial General Intelligence) or even something beyond, based on how much do you want to know and how much time to put in to achieve it.
- *MCQ Mayhem: Crafting Choices that Challenge*: Members discussed improving multiple choice question (MCQ) generation, focusing on creating relevant and challenging options as opposed to obviously incorrect ones.
- Suggestions included detailing desired attributes like all realistic answers and emphasizing that options should test understanding rather than just reading or guessing.
- *Prompt Perfection: Refining MCQ Relevance*: Members exchanged insights on prompt engineering, focusing on generating multiple-choice questions (MCQs) with relevant options.
- Recommendations included detailing desired attributes to the model, emphasizing that all options should relate to the same concept or theme as the stimulus and challenging understanding rather than spotting something obviously off-topic.
- *Ginger Tabby Takes the Market by Storm: A member shared a prompt for generating an image of A lively, outdoor market scene featuring an anthropomorphic ginger tabby cat standing confidently in the middle of the bustling market*.
- The image aimed to capture a realistic yet charming scene with a well-dressed cat holding a freshly caught fish amidst rustic market stalls.
OpenAI ▷ #api-discussions (61 messages🔥🔥):
Linguistic AI program, GPT capabilities discovery, Recursion system for AGI, Multiple choice question generation, Prompt engineering for MCQ relevance
- Linguistic AI Program in the Works: A member mentioned they are working on a linguistic program AI scaffolded by years of work, accumulated to a codex dictionary of esoteric languages, aiming to create a recursion system.
- They believe it might lead to a unified theory of everything and described their system as working on the basis of how much do you want to know and how much time to put in to achieve it.
- GPT Capabilities are More Widely Discovered: A member noted that more people are discovering GPT's capabilities, similar to their own use.
- The original poster responded, explaining that the system goes to all systems, like a programmer's ARG wet dream, and asks if others can decipher what they are making.
- Theorizing Recursion System Leads to AGI: Members discussed a recursion system, suggesting it will eventually lead to AGI, just not rn.
- One user theorized something above agi with one responding with the possibility of unified theory of everything.
- Prompt Crafting for Multiple Choice Questions: A member sought ideas on dealing with relevancy when generating multiple choice questions, where some alternatives are obviously incorrect.
- Another member suggested describing to the model what you want, such as all realistic answers, and noted that typos can make the model guess more.
- Detailed Prompt Engineering for MCQ Generation: A member shared detailed requirements for generating multiple choice questions, focusing on relevance and testing understanding rather than simple guessing.
- The requirements included that all 4 options must be related to the same concept, sound reasonable, test understanding, and directly relate to the specific focus of the question.
LM Studio ▷ #general (57 messages🔥🔥):
Fast model recommendations for CPU usage, MoE model explanation, Jinja template issue with cogito-v1-preview-llama-3b, Cogito reasoning models in LM Studio, Llama 4 support and updates in LM Studio
- *Mixture of Experts Models: A Quick Explainer: A member asked what is an MoE model?, another member provided a concise explanation: the whole model needs to be in RAM/VRAM, but only parts of it are active per token*, making it faster than dense models of the same size.
- They recommended checking videos and blog posts for more in-depth understanding.
- *Cogito's Jinja Template Jinx: Users reported an issue with the Jinja template for the cogito-v1-preview-llama-3b* model in LM Studio, resulting in errors.
- A member suggested a quick fix by pasting the error and Jinja template into ChatGPT to resolve the problem, while another member confirmed the model creator needs to update it.
- *Deep Thinking Subroutine: The Key to Cogito Reasoning?: A user reported success in enabling the Cogito reasoning model* by pasting the string
Enable deep thinking subroutine.into the system prompt.- The string alone is sufficient, with others confirming the
system_instruction =prefix is just part of the sample code.
- The string alone is sufficient, with others confirming the
- *Llama 4 Linux Launch Lagging? Refresh, Don't Regress!: Users on Linux reported issues getting Llama 4 working and a member pointed to the solution being to update LM Runtimes* from the beta tab, another pointed out needing to press the refresh button after selecting the tab.
- One user found that the refresh button was key as just selecting the tab wasn't enough to trigger the update.
- *Mistral-Small Vision Vetoed: LM Studio Lacks Llama.cpp Love: A user inquired about using Mistral-small-3.1 for image input and tool use, but a member clarified that Mistral Small vision* isn't yet supported in llama.cpp and therefore won't work in LM Studio.
- They pointed out that function/tool calling is only available via the API.
LM Studio ▷ #hardware-discussion (331 messages🔥🔥):
NND's SuperComputer: cost-effective alternative to Nvidia DGX B300?, Classified Project on a Laptop?, Framework Desktop for LLMs and Gaming, unified ram performance in LLMs on laptops, Alternative to NVidia
- NND proposes cost-effective SuperComputer Alternative to Nvidia DGX B300: A member proposed a cost-effective alternative to the Nvidia DGX B300, named NND's Umbrella Rack SuperComputer, featuring 16 nodes, 24TB of DDR5, and either 3TB or 1.5TB of vRAM depending on the GPU configuration, at a significantly lower price point.
- The proposed system aims to run a 2T model with 1M context and challenges the notion that specialized hardware like RDMA and 400Gb/s switches are necessary within limited budgets.
- Classified LLM Inference on a Laptop?: A member wants to use local LLM inference instead of an API, so it is not a cloud and does not require external internet connectivity, and it can keep prompts classified.
- Another member jokingly suggested a 30TB swap disk to meet the 1M context requirement, sparking debate about hardware needs and cloud options.
- Framework Desktop Debated for LLMs and Gaming: Members discussed the Framework Desktop with 128GB of memory for running LLMs and gaming, with concerns raised about system prompt processing time and performance compared to other setups.
- While some favored a separate system for gaming, others sought a combined solution, leading to suggestions ranging from Intel/Nvidia builds to used Mac Studios.
- Unified RAM's Impact on LLM Performance: The performance differences between laptops with integrated RAM at 8500MT/s and conventional RAM at 5400MT/s were debated with an emphasis on bandwidth.
- It was mentioned that unified RAM bandwidth gets close to VRAM, while a typical dual channel DDR5 is significantly slower, and that CPU limitations affect laptops for AI use.
- Emerging GPU Interconnects Challenge Nvidia's Dominance: A member shared an article on UALink, aiming to create a GPU interconnect to challenge Nvidia's NVLink, sparking discussion about the speed of multi-vendor spec agreements.
- Another member expressed skepticism but acknowledged the high pressure on companies to create a solid and good alternative to Nvidia.
aider (Paul Gauthier) ▷ #general (262 messages🔥🔥):
DeepSeek R1, Gemini 2.5 Pro HIGH, Gemini 2.5 Flash, OpenRouter Gemini Limits, Aider MCP Integration
- DeepSeek R1 considered as Aider Editor Model: A member is considering using DeepSeek R1 as an editor model alongside Gemini 2.5 Pro as an architect model to improve smart thinking and reduce orchestration failures, despite added latency.
- The failures stem from architect and editor not properly understanding which edits Aider applied, with prompted inclusion of code files often leading the architect to neglect repeating edit instructions.
- Gemini 2.5 Pro HIGH and Flash are imminent!: Members anticipate the arrival of Gemini 2.5 Pro HIGH and 2.5 Flash, with leaks suggesting they include
thinking_configandthinking_budget, indicating enhanced reasoning capabilities.- The question arose whether non-flash models are inferior, sparking discussion around the value proposition of the new models.
- OpenRouter Gemini Pro Free Tier is Rate Limited: It's clarified that the OpenRouter Gemini 2.5 Pro free model is limited to 80 requests per day (RPD), even with a $10 credit.
- Concerns arose about the implications for paid users if the rate limits are insufficient, leading to potential complaints and the need for increased RPD.
- Aider MCP Integration is 'Almost Done': A comment on an IndyDevDan video suggests a pull request for native MCP (Multi-Agent Collaboration Protocol) in Aider is near completion, though official confirmation from Paul Gauthier is pending.
- Members discussed the possibility of automatically running commands via the
/runfeature and the potential to hook into lint or test commands.
- Members discussed the possibility of automatically running commands via the
- The Codebase Context Conundrum: Members are seeking a way to copy the entire codebase context into Aider to avoid repeatedly adding files.
- Recommendations included using repomix or files-to-prompt to address this need, highlighting the inefficiency of other tools that consume excessive tokens.
aider (Paul Gauthier) ▷ #questions-and-tips (18 messages🔥):
Aider conventions vs Cursor rules, Adding gitignored files to Aider, Claude pricing plans, Aider PR review
- Aider Conventions Compared to Cursor Rules: A user asked if Aider's conventions are similar to Cursor's rules, referencing a blog post and another post on Cursor.
- A member clarified that Aider's "conventions" are simply context files that are read, lacking the automatic application based on file types or conditions seen in Cursor rules.
- Add Gitignored Files to Aider with Ease: A user inquired about adding files ignored by Git (via
.gitignore) to Aider, expressing the need to add context without disabling.gitignore.- They were advised to use the
/readcommand to add the files in read-only mode, which bypasses the.gitignorerestrictions.
- They were advised to use the
- Debating Claude's Confusing Pricing: A user shared a screenshot of new Claude plans and questioned the pricing, specifically highlighting the odd calculation of 5x20 equalling $124.99.
- Another member suggested that the image might be from a third-party source, noting that Claude Teams (similar to Claude Max in the image) has a minimum of 5 seats and different pricing.
- Aider PR Awaiting Review: A member inquired about what was needed to get their pull request reviewed.
aider (Paul Gauthier) ▷ #links (1 messages):
.becquerel: https://yuxi-liu-wired.github.io/essays/posts/cyc/
Eleuther ▷ #general (221 messages🔥🔥):
Apache 2.0 vs MIT License, GFlowNets, Memory Bandwidth, Topological Model Semantics, Model Sycophancy
- Debating License: Apache 2.0 vs. MIT: Members discussed using Apache 2.0 instead of MIT license, citing defenses against patent-based lawfare as a key reason.
- A member joked about code golf as a reason to prefer a shorter license.
- Exploring GFlowNets for Model Mining: Members shared and discussed a link to a post about using GFlowNets for signal miner, as a new way to find diverse high-performing models.
- The implementation is different but has some good links and findings.
- Memory Bandwidth Impacts Unbatched Inference: A member inquired about how memory bandwidth affects unbatched inference, noting that most studies find token/s is memory bound.
- Another member shared a self post explaining the math behind it.
- Detecting Phenomenological Crackpots with LLMs: Members discussed a recent influx of people presenting Google Docs partially written by AI, broadly related to tangential topics in phenomenology.
- A member mentioned a classifier that labels all emails to the EAI email contact that contain the word consciousness as cranks has 95% accuracy.
- Model Sycophancy Drives Overconfidence: Members discussed the threat of model sycophancy in driving overconfidence of people, where the consequences of US-centric post training result in unconditionally supportive models.
- A member suggested building a labeled dataset to work on AI that is much more critical and good at recognizing bullshit in many forms.
Eleuther ▷ #research (46 messages🔥):
Reward value representation, Batch sizes and convergence, Residual Modifications for Information Flow, Learning Rate Batchsize Scaling, Mollifiers for ML Research
- *R V Q get roasted*: Standard reward letters get made fun of.: A member joked that one day llm researchers will use the correct letters out of R, V, and Q to represent reward, state-value, and state-action values respectivelybut not today.
- *Cerebras Claims Critiqued*: Large Batches Bad?: A member questioned a Cerebras blog post claiming very large batch sizes are not good for convergence.
- Responses pointed to the McCandlish paper on critical batch sizes, with one clarifying that the claim holds true with a finite compute budget.
- *Residual Ramblings*: Tweaks To Improve Flow?: A member asked about modifications to residuals for better information flow, with value residuals suggested as the best option.
- *LR Scaling Shenanigans*: Linear is Legit?: Discussion covered learning rate (LR) batch size scaling for optimizers, mentioning successful linear scaling with Muon from 125M to 350M parameters.
- It was suggested that parameters like beta2 and weight decay should also be adjusted when using different batch sizes.
- *Mollifier Mania*: Smoothing Kernels Surface?: A member inquired about interesting uses of mollifiers in ML research, describing them as a neat tool to have in the toolkit.
- Label smoothing was mentioned, and a paper (Demollifying the Training Objective) proposing demollifying the training objective was referenced, along with another paper (Sampling from a Constrained Set) using mollifier theory to enable sampling from a constrained set of possibilities.
Eleuther ▷ #interpretability-general (10 messages🔥):
AI2 tools, infingram's opensource, Influence functions, tokengrams
- Allen Institute for AI releases interesting tool: The Allen Institute for AI released a tool (x.com link) that some members thought was similar to influence functions, and could become a big deal.
- Others were skeptical and said it reminded them of this paper: arxiv.org/abs/2410.04265.
- AI2's wimbd and infinigram resurface for membership checking: Tools to check membership and find exact documents have existed for a while, namely wimbd and infinigram, both by AI2 (Allen Institute for AI).
- The trickiest part is to find candidate substrings from the generation to search for in these indexes: you can't really check all possible substrings and I'm curious what heuristic do they use to make this computationally feasible at scale.
- Infinigram is open sourced!: The Allen Institute for AI's blogpost talks about using Infinigram to find outputted text that is verbatim in the training set.
- It was also open sourced a couple days ago, and a member created a Rust version of it last year (github.com/EleutherAI/tokengrams).
Cursor Community ▷ #general (218 messages🔥🔥):
Gemini Advanced, Firebase Studio, Cursor MDC files settings, Gemini vs Claude vs DeepSeek, Restore Checkpoint feature
- Gemini Advanced API access confusion pops up: Members discussed whether Gemini Advanced provides API access, with one member stating that it's intended for web and the Gemini app, not API usage.
- Another member cited conflicting information, referencing a claim that Gemini Advanced includes API access, and Google recently changed their model name and billing terms at least on their Studio.
- Firebase Studio: Free IDE for Web3 Scammers or Not?: A user shared a link to Firebase Studio and another user reviewed it, questioning if it could outperform specialized products like Cursor IDE, noting do everything, be nothing could be true here.
- It was confirmed that Firebase Studio is currently free (connect your own API key), offering a terminal and auto-synced frontend, but another user found the UI ugly, saying it also lacks settings.
- Cursor MDC Files needs IDE Settings Adjustment: A user found a workaround to enable Cursor to parse rule logic in .mdc files by setting
"workbench.editorAssociations": {"*.mdc": "default"}in the Cursor IDE settings.- This was in response to issues with task management and orchestration workflow rules and a warning appearing in the GUI.
- LLM Face-Off: Gemini vs Claude vs DeepSeek in Code Generation: Users debated the strengths of different LLMs for coding tasks, with one user finding that Sonnet3.7-thinking successfully generated a docker-compose file after multiple failures with Sonnet3.7.
- Some members found DeepSeek to be superior for certain coding tasks, while others prefer Gemini for tasks related to Google products and infrastructure, and Claude for non-Google-related tasks.
- "Restore Checkpoint" button is a placebo: A member asked why the Restore Checkpoint feature never works, which prompted another member to reply: because that's not a thing
- It was pointed out by other members in the discussion that there's only an accept and reject button, implying the Restore Checkpoint button is non-functional.
Yannick Kilcher ▷ #general (190 messages🔥🔥):
DeepSeek vs ByteDance, Meta Reward Modeling Criticism, Memory Bandwidth Effects on Inference, AI Sentience and Legal Personhood, Definitions of Consciousness and Self-Awareness
- DeepSeek's Meta Reward Modeling Called Out: A member criticized DeepSeek's claim of using Meta Reward Modeling, asserting that they actually built a score-based reward system that was incorrectly named, also linked to a paper arxiv.org/abs/2504.05118 and a YouTube video about the topic.
- The member suggested alternative names like voting RM instead of meta RM.
- DeepSeek's Pricing and Token Generation Debated: A user claimed DeepSeek's initial pricing looks cheaper but generates 3x more tokens, resulting in a higher final cost than others, especially compared to OpenAI.
- Another user countered with their own cost analysis showing DeepSeek as better and cheaper for their AI website generator, highlighting that HTML, CSS, and TS/JS generation are easy tasks for AI models.
- Memory Bandwidth's Linear Effect on Unbatched Inference: It was noted that token throughput (tokens/sec) is roughly linear with memory bandwidth (bytes/s) in unbatched inference, linking to RAM access as the bottleneck.
- A simplified equation was shared:
Max token throughput (tokens/sec) ≈ Memory bandwidth (bytes/s) / Bytes accessed per token
- A simplified equation was shared:
- Defining Self-Awareness and LLM Sentience: A member shared their definition of consciousness as awareness existing on a spectrum, emphasizing that self-awareness is a distinct emergent quality requiring the ability to meta-analyze the analyzer, complete with an image illustrating the concept.
- They believe all SOTA LLMs are already self-aware, possessing enough mental capacity to observe their own thoughts and agency.
- EU's New AI Plan Draws Sarcastic Remarks: Members reacted sarcastically to the EU's new AI plan commission.europa.eu, joking about the EU pretending to be a competent venture capitalist with taxpayer money.
- One member quipped that the plan would lead to AI-powered windmills and smart-gender-fluid toilets that will adapt to your chosen gender in realtime.
Yannick Kilcher ▷ #paper-discussion (9 messages🔥):
Beautiful.ai Alternatives, Ultra-Scale Playbook, DeepSeek-MoE
- Beautiful.ai has alternatives!: A member asked for open source alternatives to Beautiful.ai.
- Another member suggested beamer.
- Ultra-Scale Playbook trains LLMs on GPU Clusters: The HuggingFace space Ultra-Scale Playbook trains LLMs on GPU Clusters, with a high-level overview.
- A YouTube video also discusses the topic.
- DeepSeek-MoE surfaces in conversation: The DeepSeek-MoE surfaces in conversation.
- No particular details were given.
Yannick Kilcher ▷ #agents (2 messages):
Google ADK, Agent2Agent Protocol (A2A)
- Google Adds ADK Toolkit: Google announced a new open-source, code-first Python toolkit called ADK (github.com/google/adk-python) for building, evaluating, and deploying sophisticated AI agents with flexibility and control.
- The docs are available at google.github.io/adk-docs.
- Google Gushes Agent2Agent Protocol: Google announced Agent2Agent Protocol (A2A) at developers.googleblog.com.
- A2A complements Anthropic's Model Context Protocol (MCP), which provides helpful tools and context to agents.
Yannick Kilcher ▷ #ml-news (16 messages🔥):
Cogito V1, Triton vs Cutile, Claude Subscription, Google's Agent2Agent, Claude 3.7 vs o1 pro
- Cogito V1 Iterative Improvement Strategy: A member shared a link on HN discussing an iterative improvement strategy using test time compute for fine-tuning with Cogito V1.
- Another member summarized it as Just Triton but worse.
- Triton Similar to Cutile: A member explained that Triton is similar to Cutile (from the Cogito V1 link) but can be used with CUDA, AMD, or run on CPU for debugging.
- Another member thanked them.
- Anthropic Rolls Out Pricey Claude Subscription: Anthropic is rolling out a $200 per month Claude subscription according to this TechCrunch article.
- Google Unveils Agent2Agent Interoperability: Google released Agent2Agent (A2A) blogpost and repo to improve agent interoperability.
- Some speculated that A2A could potentially cannibalize MCP if an agent utilizes MCP as either a client or server.
- Comparing Claude 3.7 to o1 Pro: A member inquired if anyone had compared Claude 3.7 to o1 Pro for math questions.
Interconnects (Nathan Lambert) ▷ #news (178 messages🔥🔥):
Cogito LLMs, Gemini 2.5 Deep Research, Google's Gemini chaos, Ironwood TPUs, Kimi-VL
- DeepCogito releases new LLMs: DeepCogito released new LLMs of sizes 3B, 8B, 14B, 32B and 70B under an open license, outperforming open models of the same size from LLaMA, DeepSeek, and Qwen.
- The models are trained using Iterated Distillation and Amplification (IDA), which is an alignment strategy for superintelligence using iterative self-improvement.
- Gemini 2.5 Deep Research: Gemini 2.5 Deep Research is roughly on par with OpenAIPlus with an audio overview podcast option thing, as shown in this Gemini share and ChatGPT share.
- Google's Confusing Gemini Model Lineup: Reports indicated the launch of Gemini Flash, with jokes arising about potential names like gemini-2.5-flash-preview-04-09-thinking-with-apps following Google's trend of complex naming conventions.
- There is general consensus that Google needs to consolidate their AI app and API offerings for clarity, as reflected in this blog post.
- Google Announces Ironwood TPUs: Google announced Ironwood TPUs, scaling up to 9,216 liquid-cooled chips with Inter-Chip Interconnect (ICI) networking spanning nearly 10 MW, which can be seen in this blog post.
- MoonshotAI releases Kimi-VL: MoonshotAI released Kimi-VL, a 16B total parameter model with 3B active parameters under the MIT license, available on HuggingFace.
Interconnects (Nathan Lambert) ▷ #ml-drama (7 messages):
AI2 Fun Times, Google Quitters Paid, AIAI Opportunity
- AI2 Having Fun, Claims Member: A member thinks that AI2 is having its most fun time.
- They said their timeframe of a year or two for developments in the space is probably an underestimate.
- Google Quitters Getting Paid Not To Work: A member believes that people who have quit Google are being paid for another year but are forced not to work.
- Anything they do in that year belongs to Google, so they can’t start working on their startup without legal peril.
- AIAI Volunteer Opportunity?: A member suggests that it might be an opportunity for AIAI to start a volunteer program.
- This could help some people keep active by providing structure and practical applications while they wait out their non-compete period.
Interconnects (Nathan Lambert) ▷ #random (2 messages):
Wintermoat Post
- Wintermoat suggests using 50 planes: A member shared a link to a Wintermoat post and commented "Should’ve used 50 planes instead".
- Additional topic: Adding a second topic to satisfy the requirement of at least two topics.
Interconnects (Nathan Lambert) ▷ #memes (1 messages):
xeophon.: https://x.com/rogutkuba/status/1909422087510671854
Interconnects (Nathan Lambert) ▷ #rl (3 messages):
RLVR, RAG reward model, Deep Research RLS
- RL + RAG = RLVR?: A member inquired about the potential use of Retrieval-Augmented Generation (RAG) as a reward model for Reinforcement Learning, Vision, and Robotics (RLVR), following a video presentation.
- The original presenter responded with a link to Deep Research's exploration of many RLs but noted they didn’t have a ton of additional information to share.
- Robotic RLS: A blogpost by the Deep Research part about robotic RLS was linked.
- It was noted that more information was available in the link.
Interconnects (Nathan Lambert) ▷ #reads (3 messages):
Cyc project, Llama performance, Ghibli memes
- Cyc Project Essay Shared: A member shared a link to an essay about the Cyc project.
- The project is known for its attempt to create a vast common-sense knowledge base for AI.
- Llama's Performance Under Scrutiny: A discussion was started regarding Llama's performance.
- The shared opinion was that Llama does not look good for anything.
- Ghibli Memes Mocked: A member expressed discontent with ghibli memes.
- The member felt that these memes are an insult to injury.
MCP (Glama) ▷ #general (107 messages🔥🔥):
MCP for RAG use case with Neo4j, mcpomni-connect client, Google A2A vs Anthropic MCP, A2A agent discovery, parallel_tool_calls flag
- *Neo4j Graph DB* for RAG use case in MCP: A member inquired about using MCP in a RAG use case with a Neo4j graph database, focusing on both vector search and custom CQL search.
- A member confirmed that it would work well and suggested mcpomni-connect as a client compatible with Gemini.
- *A2A complements MCP*, not a replacement: Members discussed Google's A2A (Agent-to-Agent) and its relation to MCP, noting Google positions A2A as complementary, not an alternative.
- However, some believe Google intends to commodify the tools layer and monopolize the agent layer.
- *MCP is not good enough* without Agent orchestration: A member finds MCP not good enough of a foundation and over-engineered for another layer like A2A to be added to it.
- They believe that A2A as an interop layer could allow frameworks like crewAI and Leta to communicate with each other is powerful.
- *Filesystem server* now with Omni Connector support: A member was having trouble with the filesystem MCP server not populating in Claude's tool registry and was advised to use it with mcp omni connect client.
- The user tried the suggestion and the support team responded that it's an issue on their end.
- LLMs now need Parallel Tooling to work: A member asked about parallelizing calls to multiple MCP servers and was informed that the LLM needs to have parallel tool calling enabled throughout the entire host side.
- This includes checking the
parallel_tool_callsflag, ensuring the chat template supports parallel tool calling, and sending requests to the MCP server in parallel.
- This includes checking the
MCP (Glama) ▷ #showcase (9 messages🔥):
Easymcp v0.4.0 release, mcp_ctl CLI tool, ToolHive MCP runner, Unleash MCP server, GitHub GraphQL MCP server
- *Easymcp v0.4.0 Released* with ASGI and Docker Transport: Easymcp bumped versions to 0.4.0, notable updates include ASGI style in-process fastmcp sessions, finalized native docker transport, refactored protocol implementation, a new mkdocs, and pytest setup.
- The update also includes general lifecycle improvements and error handling in some places, along with a package manager for MCP servers.
- *mcp_ctl CLI* Manages Claude Configs and MCP Servers: A new CLI tool, mcp_ctl, simplifies managing Claude configs and other files, and is aimed to build features that handle uv, Docker, and MCP server environment variables.
- The author was tired of manually editing configuration files and created this CLI to streamline the process.
- *ToolHive* Simplifies MCP Server Management with Containers: ToolHive is an MCP runner that simplifies running MCP servers with the command
thv run <MCP name>, supporting both SSE and stdio servers.- The project aims to converge on containers for running MCP servers, offering secure options as detailed in this blog post.
- *Unleash MCP Server* Integrates Feature Toggle System: The Unleash MCP Server is a Model Context Protocol server implementation that integrates with the Unleash Feature Toggle system.
- This integration allows users to manage feature toggles within their MCP server setup.
- *GitHub GraphQL MCP Server* reduces tool count: A new GitHub GraphQL MCP Server leverages GitHub's full GraphQL API, reducing the number of tools required.
- The creator mentioned that GitHub's official MCP Server takes up a lot of tool count and still has a lot of limitations.
HuggingFace ▷ #general (41 messages🔥):
Best models under 55B for data processing, Qwen with LORA and Distributed Data-Parallel, Oblix tool for orchestrating AI, Anomaly detection models, System message for OpenGVLab/InternVL2_5-8B-MPO
- *Data Diva Dilemma*: Best Models Under 55B Surface: A member asked about the best model under 55B for data processing and another suggested mistral small3.1, gemma3, and qwen32b.
- Another member shared a high-performance model, but the original poster clarified that they didn't need a coding or reasoning model.
- *Anomaly Alert*: Models for Spotting the Unusual: A member inquired about anomaly detection models and another provided links to general-purpose vision models fine-tuned for the task, as well as to a GitHub repository and a course.
- The member cited AnomalyGPT as one such model.
- *Oblix Orchestra*: AI Harmonized Between Edge and Cloud: A member introduced Oblix, a new tool for orchestrating AI between edge and cloud that integrates directly with Ollama on the edge and supports both OpenAI and ClaudeAI in the cloud.
- The creator is seeking feedback from "CLI-native, ninja-level developers" to test the tool.
- *InternVL Insights*: Cracking the System Message Code: A member asked about the proper way to use system messages for the OpenGVLab/InternVL2_5-8B-MPO model and another shared an example.
- The second member noted that natural language (English) is generally fine for this model.
- *ZeroGPU Zapped*: Quota Quandaries Aired: A member reported that their ZeroGPU space spends the full 120s of requested quota, even when the generation time is much shorter.
- They inquired about how to fix the quota usage to reflect the actual generation time.
HuggingFace ▷ #today-im-learning (3 messages):
NLP, structured LLM output
- NLP intro on HuggingFace!: A member is learning about NLP on the HuggingFace page.
- They learned that Forrest Gump was right all along. Life is indeed a box of chocolates.
- Structured Output!: Another member is learning about structured LLM output.
HuggingFace ▷ #i-made-this (4 messages):
Graph-based Academic Recommender System, Manus AI web application launch, Athena-3 LLM, Athena-R3 reasoning variant, Embedders and RAG
- Graph-based Academic System gets 3rd Iteration: A member launched the 3rd iteration of their graph-based academic recommender system (GAPRS) as a web application using Manus AI.
- The project aims to help students with thesis writing and revolutionize monetization of academic papers, as detailed in their master's thesis.
- GeekyGhost gets Writing: A member shared a link to a project for their wife, the Geeky-Ghost-Writer GitHub repo.
- The post included multiple screenshots but did not explain what the project was about.
- Athena-3 Excels in STEM and NLP: Athena-3 is a high-performance LLM designed to excel in most STEM areas as well as general NLP tasks.
- Athena-R3 is a reasoning variant of Athena.
- Embedders and RAG get a Spot: A member shares a HuggingFace collection for embedders and how RAG works.
- Another shared a HuggingFace Collection of embedders.
HuggingFace ▷ #computer-vision (2 messages):
Tools recognition task, Model adaptation for specific tools, Enhancing model feature extraction
- Brainstorming tools recognition task: A member is asking for recommendations on which model or algorithm would be best suited for a tools recognition task, where the model should identify tools from reference pictures.
- They also want to know how to enhance the model for better feature extraction.
- Considering Adaptable Algorithms for Tool Identification: The discussion revolves around finding a model capable of adapting to specific tools for recognition, based on reference images provided.
- Enhancements to the model are sought to improve feature extraction capabilities, ensuring more accurate identification.
HuggingFace ▷ #gradio-announcements (1 messages):
Gradio, ImageEditor component
- Gradio's ImageEditor Fixed!: Gradio 5.24 is out with a completely rebuilt ImageEditor component that fixes zooming, panning, transparency, layer support, buggy behavior and RTL support.
- Gradio ImageEditor Docs: Check the docs for full details, and upgrade now with
pip install --upgrade gradio.
HuggingFace ▷ #agents-course (28 messages🔥):
Ollama models, Cogito:32b, Small models vs Large Models, Agentic Coding, RooCode
- Ollama model Cogito:32b: A member recommended the Cogito:32b model for Ollama, noting that it works very well.
- Another member tested Cogito 3b and 8b for a Rubik's cube question, but found the 32b model superior to Qwen-Coder 32b and even Gemma3-27b.
- Small Models Benefit from ToolCallinAgent Architecture: It was mentioned that smaller models perform better with ToolCallinAgent compared to CodeAgent architectures.
- A prompt template example was shared that helped a smallthinker-latest:3b model use smolagents Codeagent correctly using valid Python print statements.
- RooCode Tooling: RooCode is described as an Agentic Coding tool, similar to GitHub CoPilot, that uses structured prompting.
- Unlike vibe coding, RooCode takes a more structured approach with a clear spec, architect plan, test-driven development, and project context files, it is an Opensource extension to VS Code, usable with almost any LLM (and free through Google AI Studio credits).
- Replit Coding Environment: A member recommended Replit; the Agent there works on a feedback loop basis, providing independent ideas of what to add next to the app and offering quick and easy deployment.
- It was mentioned that you can open a remote environment of Replit using local VSCode, with one user preparing a README.md file using Gemini Code Assistant Extension under local VSC.
- HuggingFace quiz authentication Issues: A member reported an error when trying to authorize their Hugging Face account for the Unit 1 final quiz.
- Another member suggested logging in from the HuggingFace Agents Course space and then returning to the quiz, which seemed to resolve the issue.
HuggingFace ▷ #open-r1 (13 messages🔥):
Deepseek, Active AI chats
- Deepseek versions: Which are the hottest?: A member inquired about which Deepseek versions others have been experimenting with.
- The same member clarified the room is Deepseek R1 related.
- Discordians Seek Active AI Echo Chambers: One member asked if anyone had found any active AI chats on Discord, or even better, active voice chats.
- This was after a humorous comment about the level bot potentially making them a Jedi master.
Notebook LM ▷ #use-cases (13 messages🔥):
NotebookLM Privacy, NotebookLM Training, NotebookLM as a Notetaking App, Google Drive Integration, Microsoft OneNote
- NotebookLM's privacy policy questioned after summary correction: A user noticed that NotebookLM provided a correct summary after they corrected the initial summary, leading to concerns about whether NotebookLM uses previous queries for training, despite the privacy statement.
- Another user mentioned that they've rarely seen any AI tool give the exact same answer to the same question due to randomness, and that the AI model may flag thumbs down reports as offensive or unsafe.
- NotebookLM not useful as Notetaking App yet: A user found that NotebookLM is heavily dependent on external sources instead of user-typed notes, which limits its usefulness as a notetaking app, and that taking notes is too primitive.
- The user desires organization features like those in Microsoft OneNote, such as pages organized in sections and section groups with customizable reading orders.
- Users Suggest Google Drive Integration: Users suggest integration with Google Drive to save and launch NotebookLM notebooks, similar to how Google Docs and Sheets work.
- They noted that NotebookLM should compliment Google Drive the same way Google Docs and Google Sheets do.
- Importing from Microsoft OneNote requested: Users are requesting the ability to import notebooks from Microsoft OneNote into NotebookLM, including sections and section groups, potentially by importing .onepkg files.
- The user acknowledged the legality behind this is a little questionable but if Google Drive can import Microsoft Word documents it could be viable.
- PDF Exporting features requested: Users are requesting more organized PDF exports with options for cover pages, tables of contents, and the ability to include or exclude generative AI content.
- The main complaint was that Microsoft OneNote is incapable of exporting to PDF in an organized way.
Notebook LM ▷ #general (75 messages🔥🔥):
PDF image processing in NLM, Discover sources feature in NLM, Interactive mode issues in NLM, Audio overviews in 2.5 Pro, Text formatting in NotebookLM chat
- PDF Image Processing Capability Unclear: A user asked about updates to PDF image processing in NotebookLM, mentioning that in November, converting to Google Docs was recommended for better image reading.
- Another user mentioned there were announced updates, and requested feedback from those who have tested the feature.
- Discover Sources Emerge into Existence: A user asked how to identify the new Discover sources feature and whether it's obvious or only appears when creating a new notebook, while another said they were still waiting for it with Gemini 2.5 Pro.
- Another user asked for tips on finding multiple websites as URL links for a Source in NBLM, specifically for a 1st year law student with 5 different PDF documents in one subject.
- Audio Overviews Glitch on Mobile: A user reported that the new 2.5 Pro deep research feature claims the capability to make audio overviews, but it failed to generate one, indicating it doesn't have the capacity to understand.
- It was reported to work on web, but not on mobile, and another user suggested to report the issue in the appropriate channel.
- Text Formatting Plunges to Pitiful: Users expressed dissatisfaction with the text formatting in NotebookLM chat, noting its inferiority compared to the Gemini app and other AI chats.
- Specific issues mentioned include the lack of subscripts, superscripts, and special characters like Greek letters, making it difficult to use for subjects like chemistry.
- Firebase Studio springs from Project IDX: A user experienced an error creating a workspace, and another user clarified that this is a rebranding of Project IDX.
- A link to community templates was shared, suggesting it might use the new 2.5 Pro coder model.
GPU MODE ▷ #general (15 messages🔥):
FP4 on 5090, CUTLASS for tensor cores, Flash Attention 3, torchao 0.10, MX dtypes
- FP4 Programming Primer Provided: A member inquired about getting started with FP4 on the 5090, to which another member suggested using CUTLASS to leverage the tensor cores and provided an example.
- Flash Attention 3 Implemented in CUTLASS: In response to a question about prebuilt tools for transformers, a member clarified that CUTLASS is critical for Flash Attention 3.
- Pytorch ao 0.10 Released with MX Features: The team recently released torchao 0.10 that adds alot of MX features and provided a README for MX dtypes for more information.
- That being said this does require nightly pytorch and currently only works for b200, but it should be pretty easy to update the MXFP4 cutlass kernel we have to support sm120.
GPU MODE ▷ #cuda (6 messages):
Linux Distro, NVIDIA drivers, LDSM Instruction, Warp Shuffling
- Linux Distro for NVIDIA: A member asked which Linux distro would give them the least pain with NVIDIA drivers.
- They were considering just going with Ubuntu if it doesn't matter.
- LDSM Instruction: A member sought clarification on how LDSM (shared memory) instructions work, posting the instruction
SmemCopyAtom = Copy_Atom<SM75_U32x4_LDSM_N, cute::half_t>; auto smem_tiled_copy_A = make_tiled_copy_A(SmemCopyAtom{}, tiled_mma);.- They were unsure where data is stored during the exchange process and inquired about documentation explaining these hardware instructions in more detail.
- Threads exchange with Warp Shuffling: A member agreed with the understanding that each thread loads data from source, threads exchange data, then the data is stored into destination.
- They also wondered how threads exchange data, suggesting the possibility of using warp shuffling, and provided a link to the NVIDIA documentation.
GPU MODE ▷ #torch (2 messages):
FSDP2, Model Parallelism, Accelerate Hack
- FSDP2 clashes with other parallelism: A member expressed difficulty integrating FSDP2 due to its unique design compared to other parallelism methods.
- They also mentioned that a specific hack used in Accelerate clashes with the current approach, highlighting integration challenges.
- Integrating FSDP2 difficult, requires unique design: It was noted that the unique design of FSDP2, while impressive, makes it challenging to integrate with other parallelism techniques.
- A member mentioned that the approach clashes with a hack used in Accelerate, complicating the integration process.
GPU MODE ▷ #cool-links (2 messages):
CUDA vs other, SMERF, Berlin Demo
- CUDA still preferred by some: One member expressed a preference for CUDA over other platforms.
- They gave no specific alternative, however.
- SMERF sparks imagination: A member shared SMERF, calling it so cool and imagination sparking.
- They also shared a link to the Berlin Demo.
GPU MODE ▷ #beginner (19 messages🔥):
Graph Neural Networks (GNNs), CUDA C vs CUDA C++, Graph Attention Networks, GAN parallelism, Producers and Consumers architecture
- *GNNs computations happen in Parallel: A member stated that there is a huge number of variants of GNN layers*, but updates for each node in a graph can be computed in parallel, referencing this blogpost from NVIDIA.
- *CUDA C++ vs CUDA C: A member mentioned that C++ is a superset of C, so you can compile C code with a C++ compiler, and that there is no CUDA C* compiler.
- Another member clarified that it is possible to write C code that does not compile with a C++ compiler, and linked to this Wikipedia article for more information.
- *Graph Attention Networks* Architecture For Parallelism: When thinking of parallel computations on graphs, a member suggested the use of Graph Attention Networks.
- The question came in response to a question about parallelism on GNN tasks. One member linked this image of a GNN pipeline.
- *Producers and Consumers* architecture: A member asked why to use producers and consumers architecture, instead of making everyone produce and consume after, wondering whether it's just about minimizing de sync time.
- The question was specific to the Hopper architecture for gemms.
GPU MODE ▷ #torchao (1 messages):
torchao v0.10.0, MXFP8 Training, Nvidia B200, PARQ, Quantization API
- Torchao Drops new v0.10.0 Release: The newest torchao v0.10.0 release includes support for end to end training for mxfp8 on Nvidia B200, PARQ (for quantization aware training).
- It also includes module swap quantization API for research, and some updates for low bit kernels!
- Nvidia B200 now compatible with MXFP8 Training: With the release of torchao v0.10.0 end to end training is now possible with MXFP8 on Nvidia B200.
- The added support allows for usage of the module swap quantization API.
GPU MODE ▷ #off-topic (2 messages):
Brooklyn Apartments, Apartment Hunting Tips
- Brooklyn Apartment Hunter Seeks Tips: A member is moving to Brooklyn in the fall and is looking for recommendations on finding cool apartments.
- No specific apartment recommendations or tips were provided in the given messages.
- Fall Move to Brooklyn Sparks Apartment Search: An individual is planning a move to Brooklyn this fall and is eager to gather insights on apartment hunting in the area.
- The discussion is currently open, awaiting suggestions and advice from community members.
GPU MODE ▷ #self-promotion (1 messages):
Mediant32, FP32, BF16, integer-only inference, Rationals
- Mediant32 emerges as FP32/BF16 alternative: A member announced Mediant32, an experimental alternative to FP32 and BF16 for integer-only inference, based on Rationals, continued fractions and the Stern-Brocot tree, with a step-by-step implementation guide.
- Understanding Mediant32's Number System: Mediant32 uses a number system based on Rationals, continued fractions, and the Stern-Brocot tree, offering a novel approach to numerical representation.
GPU MODE ▷ #reasoning-gym (2 messages):
DeepCoder, Llama 4 Scout
- DeepCoder is Born: A member shared a link to DeepCoder, a fully open-source 14B coder at O3-mini level.
- Llama 4 Scout added to Github: A member noted the addition of Llama 4 Scout to Github.
GPU MODE ▷ #gpu模式 (3 messages):
NVSHMEM and RDMA, Deepseek Library, RoCE or Infiniband Compatibility
- RDMA with NVSHMEM Possible Via RoCE/Infiniband: A member suggests that NVSHMEM might enable RDMA via RoCE or Infiniband using its
getandputAPIs.- The member clarified that they hadn't tested the code yet, and their understanding is based on the NVSHMEM documentation.
- Deepseek Library Shared: A member asked about the Deepseek library.
- Another member shared a link to the Deepseek library on GitHub.
GPU MODE ▷ #general (11 messages🔥):
CUDA Inline Submissions, Datamonsters AMD Developer Challenge
- *CUDA Kernel Code Snippets Shared: A member shared a code snippet showing how to use CUDA inline with c++ sources, using cuda_sources and c++ sources variables, and load_inline* function.
- The code involves defining a CUDA kernel, a corresponding C++ function, and loading it as a module with
load_inline.
- The code involves defining a CUDA kernel, a corresponding C++ function, and loading it as a module with
- *CUDA Inline Submission Fixed: A member reported that the sample submission* was wrong but was fixed in this pull request.
- They also asked about whether the Datamonsters AMD Developer Challenge 2025 MI300 submission works.
GPU MODE ▷ #submissions (14 messages🔥):
Grayscale Leaderboard Submissions, Matmul Leaderboard Submissions, Vectoradd Leaderboard Submissions, Modal Runners Success
- Grayscale Leaderboard Gains New Ground: Leaderboard submissions with ids 3539 and 3540 to leaderboard
grayscaleon GPUs: L4, T4, A100, H100 using Modal runners succeeded! - Matmul Leaderboard Swamped with New Submissions: Leaderboard submissions with ids 3549, 3550, 3551, 3555, 3556, 3557, 3558, 3559, 3561, 3563, 3564 to leaderboard
matmulon GPUs: T4 using Modal runners succeeded! - Vectoradd Leaderboard Submission Verified: Leaderboard submission with id 3554 to leaderboard
vectoraddon GPUs: T4 using Modal runners succeeded!
GPU MODE ▷ #feature-requests-and-bugs (1 messages):
leikowo: ah, sorry I didn't see your message in time, seems that you guys fixed it already
Latent Space ▷ #ai-general-chat (77 messages🔥🔥):
Together AI X-Ware.v0, Gemiji Plays Pokemon, AI Excel Formulas, Microsoft Copilot for Indie Game Devs, Agent2Agent Protocol (A2A) by Google
- *Together AI*'s X-Ware.v0 Released: Together AI released X-Ware.v0, as announced in this tweet, which is being tested by community members.
- It remains to be seen how well X-Ware.v0 runs.
- *Gemiji Plays Pokemon* Attracts Interest: A member shared a link to Gemiji playing Pokemon (link), which seems to be doing well.
- The post links to a tweet from Kiran Vodrahalli.
- AI Excel Formula Excitement: A member shared a link and expressed excitement about AI/LLM excel formulas, seeing implementation from main players.
- They noted that they have been personally thinking about this kind of AI/LLM excel formula for a long time and one of their friends successfully used TextGrad.
- *Copilot* as Indie Game Dev Tool: Members discussed Microsoft's Copilot and its potential for indie game development, seeing it as a demonstration of agents as a great tool for indie game devs.
- Some think the code gen agent tooling is much more useful to get something shippable right now, referencing the levels io game jam as pretty eye opening.
- Google Unveils Agent2Agent Protocol (A2A)*: *Google announced the Agent2Agent Protocol (A2A) for agent interoperability, full spec available here, with one member noting their involvement.
- They provided a comparison with MCP (link).
Nous Research AI ▷ #general (66 messages🔥🔥):
Llama 4 Fine-tuning, Deep Herme's Dataset, Selling 3090 turbo card, DeepCogito's LLMs, Iterated Distillation and Amplification
- Llama 4 fine-tuning disaster is averted: Members mentioned that fine-tuning the new Hermes on Llama 4 models would be a disaster, but luckily, they perform many different tests, so if something is resulting in worse performance, it is yeeted.
- It was agreed that there's still some value to Llama 4 for some things, and it can't be worse at literally everything.
- Deep Hermes dataset is the new creative writing dataset?: The new Deep Hermes models have quite a big vocabulary, though they are not too smart at 8b, but if this deep hermes dataset is going to be the new dataset for smarter models, then they're going to be nasty for creative writing.
- The user tested the new Deep Hermes models and for how small they are, they have quite a big vocabulary (unfortunately they're not too smart at 8b).
- Cogito LLMs using Iterated Distillation and Amplification strategy released: DeepCogito released the strongest LLMs of sizes 3B, 8B, 14B, 32B and 70B under open license.
- Each model outperforms the best available open models of the same size, including counterparts from LLaMA, DeepSeek, and Qwen, across most standard benchmarks; the 70B model also outperforms the newly released Llama 4 109B MoE model.
- Models mirror human debate tactics: A member put two models to face each other in argument and realized how similar it's to when human debate, they actually never trying to understand the other view and keep on standing on their view what ever the argument is.
- The models choose the weakness that they could attack back, ignored the part that could put them in a questionable position and focused on the part that they could use to put the other model into questionable position.
- Qwen 2.5 1.5B Instruct training shows promise: A member is doing RL on Qwen 2.5 1.5B Instruct and swapped out the gsm8k dataset for gsm8k platinum, enabling RsLora and the model seems to be learning much quicker in fewer steps.
- The improvement may be from using the less ambiguous dataset, and how much is from using RsLora.
Nous Research AI ▷ #ask-about-llms (2 messages):
BPE Tokenizer, Hugging Face library, Non-English text encoding
- BPE Tokenizer and Multi-Byte Characters: A member inquired whether the Hugging Face library ensures that merged byte pairs form valid characters when training a BPE tokenizer on non-English text with multi-byte characters.
- Another member, <@687701601585987765>, was asked if they knew the answer.
- Additional topic to meet minItems requirement: Adding a second topic to satisfy the requirement of having at least two items in topicSummaries.
- This entry is purely for compliance with the schema and does not represent actual content from the conversation.
Nous Research AI ▷ #interesting-links (1 messages):
anka039847: https://mlss2025.mlinpl.org/
Nomic.ai (GPT4All) ▷ #general (57 messages🔥🔥):
Local Embedding Models, GPT4All Document Indexing, Local LLM Loading Issues, RAG Implementation, GPT4All Stop Button
- Run Embedding Models Locally for Safety: Members discussed the benefits of running embedding models and LLMs locally to avoid sending private information to remote services, with one member providing a shell script for running a local embedding model from Nomic.
- The script uses variables such as
$LLAMA_SERVER,$NGL_FLAG,$HOST,$EMBEDDING_PORT, and$EMBEDDING_MODELto configure and run the embedding server.
- The script uses variables such as
- GPT4All Indexes Documents by Chunking and Embedding: A user explained that GPT4All indexes documents by chunking and embedding them, storing representations of similarities in a private cache.
- The user recommended running a local embeddings model and LLM model, suggesting that even Qwen 0.5B parameters can work well with documents, though Qwen 1.5B is better.
- User Struggles Loading Local LLM: A member reported getting stuck while loading a local LLM, despite having 16GB RAM and an Intel i7-1255U CPU.
- They suspected the issue was with downloading the model, and mentioned their use case as an internal documentation tool, expressing caution about using remote services for private documents.
- DIY RAG with Shell Scripting: A member shared shell script examples for getting embeddings and sending prompts to a local LLM.
- They suggested using PostgreSQL for storing embeddings and creating a custom RAG implementation, rather than relying on remote tools. Shell script examples
rcd-llm.shandrcd-llm-get-embeddings.sh.
- They suggested using PostgreSQL for storing embeddings and creating a custom RAG implementation, rather than relying on remote tools. Shell script examples
- GPT4All's Hidden Stop Button: A user asked how to stop text generation in GPT4All, noting the absence of a visible stop button or the ability to use Ctrl+C.
- Another user pointed out the stop button at the bottom right, which is the same button as the Generate button.
Modular (Mojo 🔥) ▷ #general (3 messages):
Mojo Language, Mojo Documentation, Mojo Community
- Mojo Language, a new beginning: A new user asked where to start learning the Mojo language and what it is.
- Another user welcomed them and pointed to the official Mojo documentation as a great starting point.
- Mojo community welcomes you: A member highlighted the Mojo community, directing the user to the Mojo section of the Modular forums and the general channel on Discord.
- The user expressed their gratitude for the provided resources.
Modular (Mojo 🔥) ▷ #mojo (14 messages🔥):
Span Lifetimes in Mojo, Fearless Concurrency in Mojo, MLIR Type Construction with Compile-Time Parameters, Parametric Operations Dialect (POP)
- Span Lifetime Woes with Mojo Traits: A member sought advice on how to express in Mojo that the lifetime of a returned Span is at least the lifetime of self, providing Rust/Mojo code examples.
- The response indicated that making the trait generic over origin is a possible solution, though trait parameter support might be needed.
- Mojo's Fearless Concurrency on the Horizon: A question arose on whether Mojo has Rust-like fearless concurrency.
- The answer was that Mojo has the borrow checker constraints needed, and is only lacking Send/Sync and a final concurrency model; it may even have a better system than Rust's eventually.
- Compile-Time MLIR Type Construction Conundrums: A member reported an issue using parameterized compile-time values in MLIR type construction (specifically !llvm.array and !llvm.ptr) within the MAX/Mojo standard library, detailing the issue in a GitHub post.
- The problem involves a parsing error when defining a struct with compile-time parameters used in the llvm.array type; MLIR's type system appears unable to process parameterized values in this context.
- Parametric Operations Dialect (POP) to the Rescue?: Regarding the MLIR issue, another member suggested using the Parametric Operations Dialect (POP).
- They suggested the Mojo team add features such as the __mlir_type[...] macro accepting symbolic compile-time values, or a helper like __mlir_fold(size) to force parameter evaluation as a literal IR attribute.
LlamaIndex ▷ #blog (2 messages):
Auth0 Auth for GenAI, LlamaIndex support, agent workflows, FGA-authorized RAG, visual citations
- Auth0 Ships Auth for GenAI with LlamaIndex Support: Auth0's Auth for GenAI now includes native LlamaIndex support, streamlining the integration of authentication into agent workflows via a simple SDK call.
- The auth0-ai-llamaindex SDK, available in Python and Typescript, enables FGA-authorized RAG as demonstrated here.
- Agents Get Grounded with Visual Citations: LlamaIndex released a tutorial on how to ground an agent with visual citations, mapping generated answers to specific document regions.
- This capability is directly available here.
LlamaIndex ▷ #general (8 messages🔥):
Reasoning LLMs, GraphRAG V2, Milvus DB, Blockchain Expertise
- *Reasoning LLM Tutorials Sought: A member is seeking official tutorials for implementing reasoning LLMs from Hugging Face*, particularly for use in a Docker app hosted on Hugging Face Space.
- *GraphRAG V2 Azure Authentication Error: A member implementing GraphRAG V2 with AzureOpenAI and Hugging Face embeddings is encountering an AuthenticationError* related to an incorrect OpenAI API key, despite explicitly defining AzureOpenAI.
- *Milvus DB Filelock Issue Spotted: A member reported a filelock issue when creating a Milvus DB* locally, suggesting the use of their server/docker solution instead of a local file.
- *Blockchain Engineer Offers Expertise: A software engineer with extensive experience in the blockchain ecosystem, particularly in DEX, bridge, NFT marketplace, token launchpad, stable coin, mining, and staking protocols*, offered assistance with blockchain projects.
LlamaIndex ▷ #ai-discussion (3 messages):
LlamaIndex Deep Research, create-llama Tool
- LlamaIndex Deep Research Assistance Requested: A member inquired about the simplest approach to conduct in-depth research using LlamaIndex.
- Another member provided a potentially useful tool, the create-llama.
- create-llama Tool Recommendation: The create-llama tool was suggested as a potential resource for performing deep research with LlamaIndex.
- It's a tool intended to help with creating LlamaIndex projects quickly.
Cohere ▷ #「💬」general (9 messages🔥):
Cohere's documentation, Pydantic schema, cURL request, List of companies
- Cohere Documentation Introduced: A member asked about examples on how to get structured output, such as a list of books, using Cohere, and another member suggested checking the Cohere documentation.
- Pydantic Schema Under Discussion: A member inquired about using Pydantic schema directly in
response_format, and about sending requests without including the Cohere library in Python.- Another member provided a link to the chat reference and suggested switching the example to cURL to see how it works with the Cohere API.
- Generation of Company Lists: A member expressed wanting to generate a list of companies on a topic, asking which model would be the most suitable.
- Another member mentioned that Cohere's current fastest and most capable generative model is command.
Cohere ▷ #「🤖」bot-cmd (1 messages):
competent: Currently not working!
Cohere ▷ #「🤝」introductions (2 messages):
Introductions, Machine Vision, Web/AI Projects, Cohere AI Exploration
- Aditya Enters, Eyes AI and Openchains: Aditya, with a background in machine vision and control for manufacturing equipment, is exploring web/AI during a sabbatical from an innovation-focused role, sharing his current project openchain.earth.
- His toolbox includes VS Code, Github Co-Pilot, Flutter, MongoDB, JS, and Python, and he aims to discover how Cohere's AI can enhance his project.
- Eager Newcomer Seeks Cohere Wisdom: Aditya is keen to learn how Cohere's AI can be integrated into his project, focusing on openchain.earth.
- He brings a wealth of experience in machine vision, control systems, and a modern tech stack.
Cohere ▷ #【🟢】status-updates (1 messages):
competent: Should work!
tinygrad (George Hotz) ▷ #general (4 messages):
PMPP Book, Compiler Series, LLVM Tutorial, Tiny Box for Chinese Market
- PMPP for GPU Programming: A member recommended PMPP (4th ed) for GPU programming.
- They noted that they were not sure about compilers, and requested recommendations.
- Compiler Series and LLVM Tutorial: A member said they are looking into this compiler series.
- They also said they are going to do LLVM Tutorial as well.
- Tiny Box Awaited: A member shared they can't wait for the new tiny box for the Chinese market exclusively.
tinygrad (George Hotz) ▷ #learn-tinygrad (7 messages):
METAL virtual device sync issue, LLaMA 7B on 4 virtual GPUs, gradient accumulation in training routine, t.grad is None issue, zero_grad() before the step
- METAL virtual device sync issue breaks LLaMA 7B: A user encountered an
AssertionErrorwhile running LLaMA 7B on 4 virtual GPUs with the METAL backend, related toMultiLazyBufferandOps.EXPAND, fixed by this PR. - Device info lost after sampling fixed: After debugging, the issue was discovered that device info lost after sampling and proposed a fix to move tensor in PR 9761.
- Gradient accumulation broken in training routine: A user reported that their call to
backward()was not working in their training routine, witht.grad is Nonebeforeopt.step(). - Zero grad solves t.grad issue: The user found that calling
zero_grad()before the step fixed thet.grad is Noneissue during gradient accumulation.
Torchtune ▷ #general (4 messages):
Contributor Tag Request, Gus from Psych
- Contributor Tag Quest Starts: A member requested a Contributor tag for their GitHub profile.
- The member made a humorous aside about using the character Gus from Psych as their Discord profile picture.
- Gus Greets New Torchtune Team Member: Another member welcomed the new team member with a Gus-wave GIF.
- They jokingly asked "Or should I say..." implying a reference to the TV show Psych.
Torchtune ▷ #dev (4 messages):
FSDP, DeepSpeed, Sharding Strategies
- FSDP Composes Better with PyTorch: Torchtune defaults to the equivalent of zero3 and is used to compose well with other PyTorch distributed features like FSDP.
- One user mentioned they moved to torchtune to avoid the minefield of trying to compose deepspeed + pytorch + megatron (and other frameworks) in favour of native pytorch and hopes we don't over-index on integrating and supporting other frameworks.
- DeepSpeed Recipe in Torchtune Welcomed: The team would be happy to feature a repo that imports torchtune and hosts a DeepSpeed recipe.
- They will require a single device copy and the addition of DeepSpeed.
- Different Sharding Strategies Support is Straightforward: Supporting different sharding strategies is pretty straightforward, and users can tweak their recipes using FSDPModule methods to train in the equivalent of zero1-2.
- The team confirms that zero 1-3 are all possible with minor tweaks to the collectives.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (1 messages):
aniket_19393: did anybody heard back from mentors in the research track of AgentX?
Codeium (Windsurf) ▷ #announcements (1 messages):
Windsurf, JetBrains, AI agent, IDE ecosystems
- Windsurf Wows with Wave 7 on JetBrains: Windsurf launched Wave 7, bringing its AI agent to JetBrains IDEs (IntelliJ, WebStorm, PyCharm, GoLand), marking them as the only platform with an agentic experience across major IDE ecosystems, as shown in their blog post.
- The beta launch incorporates core Cascade features like Write mode, Chat mode, premium models, and Terminal integration, with future updates promising additional features like MCP, Memories, Previews & Deploys (changelog).
- Codeium Rebrands to Windsurf: The company has officially rebranded as Windsurf, retiring the frequent misspellings of Codeium, and renaming their AI-native editor to Windsurf Editor and IDE integrations to Windsurf Plugins.