[AINews] Google wakes up: Gemini 2.0 et al
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
TPUs are all you need.
AI News for 12/10/2024-12/11/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (207 channels, and 6549 messages) for you. Estimated reading time saved (at 200wpm): 649 minutes. You can now tag @smol_ai for AINews discussions!
It is day 1 sessions at NeurIPS, and as teased with various Gemini-Exp versions, Sundar Pichai came out swinging with Google's first official Gemini 2 model - Gemini Flash. Nobody expected 2.0 Flash to beat 1.5 Pro but here we are:
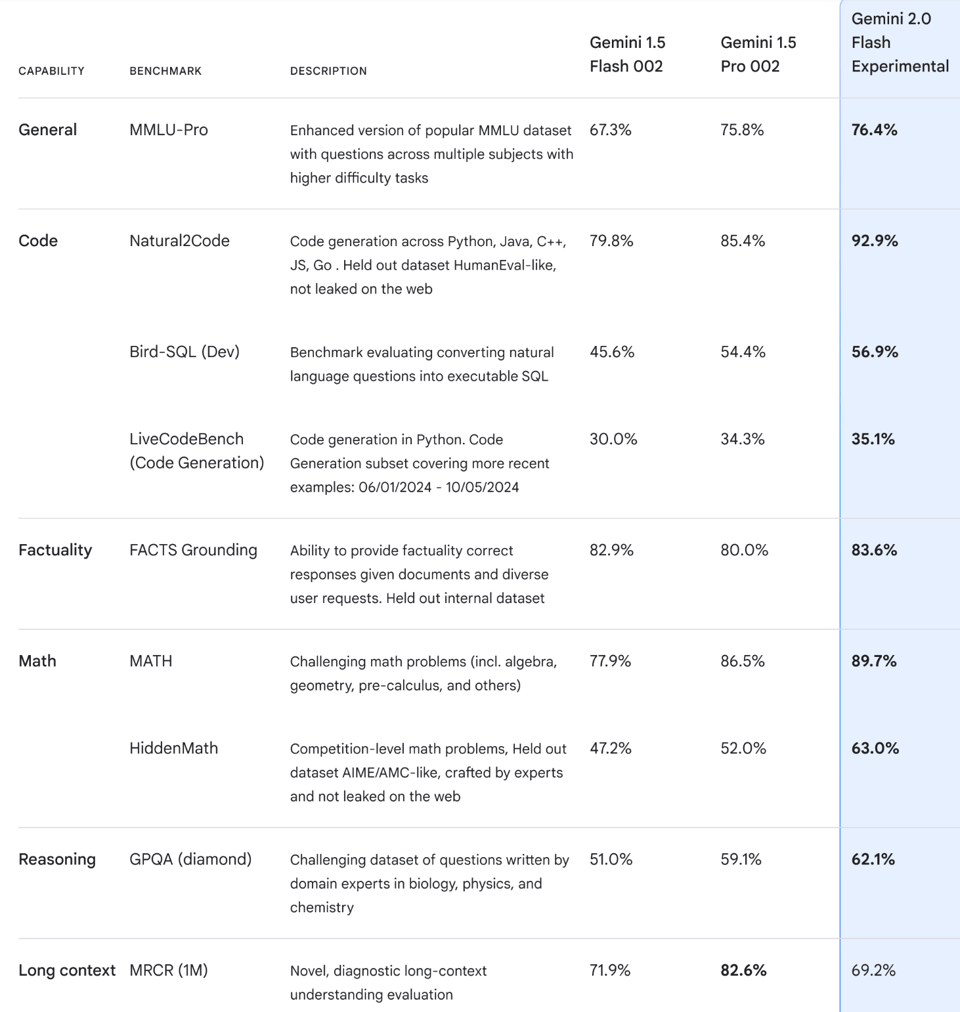
It also beats o1-preview on LMArena (but is still behind Gemini-Exp-1206, the suspected 2.0 Pro model).
Pricing is "free" - while 2.0 Flash is still experimental. As if that weren't enough, 2.0 Flash launches with a Multimodal (Vision -AND- Voice) API, and Paige Bailey even stopped by today's Latent Space LIVE/Thrilla on Chinchilla event to show off how it does what OpenAI dared not ship today:
Image output is also trained and teased but not shipped, but it can draw the rest of the owl like you have never seen.
They also announced a bunch of features in limited preview:
- Deep Research: "a research assistant that can dig into complex topics and create reports for you with links to the relevant sources."
- Project Mariner: a browser agent that "is able to understand and reason across information - pixels, text, code, images + forms - on your browser screen, and then uses that info to complete tasks for you", achieved SOTA 83.5% on the WebVoyager benchmark.
- Project Astra updates: multilinguality, new tool use, 10 minutes of sesssion memory, streaming/native audio latency.
- Jules, an experimental AI-powered code agent that will use Gemini 2.0. Working asynchronously and integrated with your GitHub workflow, Jules handles bug fixes and other time-consuming tasks while you focus on what you actually want to build. Jules creates comprehensive, multi-step plans to address issues, efficiently modifies multiple files, and even prepares pull requests to land fixes directly back into GitHub.
Comments and impressions from everyone here at NeurIPS, and online on X/Reddit/Discord was overwhelmingly positive. Google is so back!
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Codeium / Windsurf Discord
- OpenAI Discord
- Cursor IDE Discord
- Eleuther Discord
- Bolt.new / Stackblitz Discord
- Unsloth AI (Daniel Han) Discord
- Nous Research AI Discord
- Stability.ai (Stable Diffusion) Discord
- Notebook LM Discord Discord
- Interconnects (Nathan Lambert) Discord
- LM Studio Discord
- Latent Space Discord
- Modular (Mojo 🔥) Discord
- Cohere Discord
- LLM Agents (Berkeley MOOC) Discord
- OpenInterpreter Discord
- Torchtune Discord
- DSPy Discord
- LAION Discord
- Axolotl AI Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- Codeium / Windsurf ▷ #announcements (1 messages):
- Codeium / Windsurf ▷ #content (1 messages):
- Codeium / Windsurf ▷ #discussion (239 messages🔥🔥):
- Codeium / Windsurf ▷ #windsurf (580 messages🔥🔥🔥):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (517 messages🔥🔥🔥):
- OpenAI ▷ #gpt-4-discussions (25 messages🔥):
- OpenAI ▷ #prompt-engineering (11 messages🔥):
- OpenAI ▷ #api-discussions (11 messages🔥):
- Cursor IDE ▷ #general (410 messages🔥🔥🔥):
- Eleuther ▷ #announcements (1 messages):
- Eleuther ▷ #general (78 messages🔥🔥):
- Eleuther ▷ #research (296 messages🔥🔥):
- Eleuther ▷ #lm-thunderdome (7 messages):
- Eleuther ▷ #multimodal-general (1 messages):
- Bolt.new / Stackblitz ▷ #announcements (3 messages):
- Bolt.new / Stackblitz ▷ #prompting (7 messages):
- Bolt.new / Stackblitz ▷ #discussions (235 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (152 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (10 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (58 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (5 messages):
- Unsloth AI (Daniel Han) ▷ #research (4 messages):
- Nous Research AI ▷ #announcements (3 messages):
- Nous Research AI ▷ #general (90 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (62 messages🔥🔥):
- Nous Research AI ▷ #research-papers (8 messages🔥):
- Nous Research AI ▷ #interesting-links (16 messages🔥):
- Nous Research AI ▷ #research-papers (8 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (176 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (13 messages🔥):
- Notebook LM Discord ▷ #general (93 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #events (13 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (49 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (6 messages):
- Interconnects (Nathan Lambert) ▷ #random (11 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (8 messages🔥):
- Interconnects (Nathan Lambert) ▷ #cv (1 messages):
- Interconnects (Nathan Lambert) ▷ #reads (11 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- LM Studio ▷ #general (81 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (5 messages):
- Latent Space ▷ #ai-general-chat (52 messages🔥):
- Latent Space ▷ #ai-announcements (2 messages):
- Latent Space ▷ #llm-paper-club-west (7 messages):
- Modular (Mojo 🔥) ▷ #general (7 messages):
- Modular (Mojo 🔥) ▷ #mojo (49 messages🔥):
- Cohere ▷ #discussions (13 messages🔥):
- Cohere ▷ #questions (8 messages🔥):
- Cohere ▷ #api-discussions (9 messages🔥):
- Cohere ▷ #projects (9 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (31 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
- OpenInterpreter ▷ #general (25 messages🔥):
- OpenInterpreter ▷ #O1 (1 messages):
- Torchtune ▷ #dev (16 messages🔥):
- Torchtune ▷ #papers (1 messages):
- DSPy ▷ #general (10 messages🔥):
- LAION ▷ #general (3 messages):
- LAION ▷ #research (6 messages):
- Axolotl AI ▷ #general (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Here are the key discussions organized into relevant categories:
Major Model Releases & Updates
- Gemini 2.0 Flash Launch: @demishassabis announced Gemini 2.0 Flash which outperforms 1.5 Pro at twice the speed, with native tool use, multilingual capabilities, and new multimodal features including image generation and text-to-speech. The model will power new agent prototypes like Project Astra and Project Mariner.
- ChatGPT + Apple Integration: OpenAI announced ChatGPT integration into Apple experiences across iOS, iPadOS and macOS, allowing access through Siri, visual intelligence features, and composition tools.
- Claude Performance: @scaling01 noted that Claude 3.5 Sonnet appears to be a distilled version of Opus, with Opus training completion confirmed.
Industry Developments & Analysis
- Google's Progress: Multiple researchers observed Google's advancement with Gemini 2.0 Flash showing strong performance, though noting it's not yet production-ready. The model achieved impressive results on benchmarks like SWE-bench.
- Competition Dynamics: @drjwrae highlighted that while 1.5 Flash was popular for its performance/price ratio, 2.0 brings performance matching or exceeding 1.5 Pro.
- Business Impact: Discussion about market dynamics, with @saranormous noting that the AI industry games are just beginning, comparing it to how internet developments took decades to play out.
Research & Technical Developments
- NeurIPS Conference: Multiple researchers sharing updates from #NeurIPS2024, including @gneubig presenting on agents, LLMs+neuroscience, and alignment.
- LSTM Discussion: @hardmaru shared about Sepp Hochreiter's keynote on xLSTM's advantages in inference speed and parameter efficiency compared to attention transformers.
Humor & Memes
- Industry Commentary: @nearcyan noted "the only way twitter would be impressed by openai's 12 shipping days is if it started with gpt5 and ended with gpt17"
- AI Model Names: Discussion about naming conventions for AI models with various humorous takes on different companies' approaches.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Gemini 2.0 Flash Achievements and Comparisons
- Gemini 2.0 Flash beating Claude Sonnet 3.5 on SWE-Bench was not on my bingo card (Score: 287, Comments: 53): Gemini 2.0 Flash achieved a 51.8% performance on the SWE-bench Verified benchmark, surpassing Claude Sonnet 3.5's 50.8%. Other models like GPT-4o and o1-preview scored between 31.0% and 41.0%, indicating a significant performance gap.
- Scaffolding and Testing Methods: Discussions highlight the importance of scaffolding in model performance, with some users noting that Gemini 2.0 Flash utilizes multiple sampling methods to achieve its score, unlike Claude Sonnet 3.5 which is perceived as a more straightforward model. The debate includes whether comparisons between models are fair due to differences in testing methodologies, such as using hundreds of samples versus single-shot methods.
- Context Window and Performance: Gemini 2.0 Flash is noted for its larger context window, which some users argue gives it an edge over models like Claude and o1. This capability is seen as crucial in handling real-world software engineering tasks, contributing to its higher score on the SWE-bench Verified benchmark.
- Industry Perspectives and Concerns: There is a broader conversation about the dominance of companies like Google and OpenAI in the AI space, with users expressing concerns over the implications of their control. Some prefer Google for its contributions to open-source projects, while others worry about the fast-paced development approach of companies like OpenAI.
- Gemini Flash 2.0 experimental (Score: 141, Comments: 53): Gemini Flash 2.0 is being discussed in relation to an experimental update announced by Sundar Pichai through his Twitter post. The update presumably includes new features or improvements, though specific details are not provided in the post.
- Gemini 2.0 Flash Performance: The model shows a significant advancement with a 92.3% accuracy on natural code, marking a 7% improvement over the 1.5 Pro version, positioning Google as a strong competitor against OpenAI. However, it performs worse on the MRCR long context benchmark compared to the previous 1.5 Flash model, indicating a trade-off between general improvements and specific capabilities.
- API and Usage: Users can access the model via Google AI Studio with a "pay as you go" model, costing $1.25 per 1M token input and $5 per 1M token output. There is a 1500 replies/day limit in AI Studio, with some users facing QUOTA_EXHAUSTED issues, likely due to API key arrangements.
- Market and Future Expectations: There is an anticipation for Gemma 3 with enhanced multimodal capabilities, reflecting user interest in future developments. The model's pricing strategy is seen as a potential market dominance factor, and its integration of native tool use and real-time applications is highlighted as a key innovation.
- Gemini 2.0 Flash Experimental, anyone tried it? (Score: 96, Comments: 44): Gemini 2.0 Flash Experimental offers capabilities in multimodal understanding and generation, supporting use cases such as processing code and generating text and images. The interface details pricing as $0.00 for both input and output tokens up to and over 128K tokens, with a knowledge cutoff date of August 2024, and rate limits set at 15 requests per minute.
- Gemini 2.0 impresses users with its object localization capabilities, which can detect specified object types and draw bounding boxes without the need for custom ML training, a feature not available in ChatGPT.
- Users note the speed of Gemini 2.0, with some comparing its performance to Claude in data science tasks. While both models struggle with error correction, users appreciate Google's approach of testing multiple models against each other, despite hitting demand limits and producing basic features compared to Claude's more complex ones.
- There are some compatibility issues reported, such as with cline and cursor composer, though workarounds like editing extension files are suggested. Additionally, image generation is currently restricted to early testers, as per the announcement.
Theme 2. QRWKV6-32B and Finch-MoE-37B-A11B: Innovations in Linear Models
- New linear models: QRWKV6-32B (RWKV6 based on Qwen2.5-32B) & RWKV-based MoE: Finch-MoE-37B-A11B (Score: 81, Comments: 28): Recursal has released two experimental models, QRWKV6-32B and Finch-MoE-37B-A11B, which leverage the efficient RWKV Linear attention mechanism to reduce time complexity. QRWKV6 combines Qwen2.5 architecture with RWKV6, allowing conversion without retraining from scratch, while Finch-MoE is a Mixture-of-experts model with 37B total parameters and 11B active parameters, promising future expansions and improvements. More models, such as Q-RWKV-6 72B Instruct and Q-RWKV-7 32B, are in development. For more details, visit their Hugging Face model cards and Finch-MoE.
- RWKV's Potential and Limitations: Commenters discussed that while RWKV offers theoretical speed advantages and can handle long context lengths, current inference engines are not yet optimized to fully realize these benefits. There is also interest in the practicality of converting transformers to RWKV, despite concerns about small context lengths due to limited training resources.
- Implementation Challenges: There are challenges in implementing new architectures like QRWKV6 on platforms such as koboldcpp, as it often requires dedicated effort from the community to adapt and implement these models. The RWKV community is noted for its potential to eventually overcome these hurdles.
- Future Developments and Expectations: Commenters expressed excitement over the potential of future models like RWKV 7 and the possibility of QwQ models. There is hope for linear reasoning models, and discussions touched on the need for reasoning-style data to improve model conversions and inference time thinking.
- Speculative Decoding for QwQ-32B Preview can be done with Qwen-2.5 Coder 7B! (Score: 69, Comments: 28): The post discusses using Qwen-2.5 Coder 7B as a draft model for speculative decoding in QwQ-32B, noting that both models have matching vocab sizes. On a 16 GB VRAM system, performance gains were limited, but the author anticipates significant improvements with larger VRAM GPUs (e.g., 24 GB). Subjectively, the QwQ with Qwen Coder appeared more confident and logical, though it used more characters and time; the author invites others to experiment and share their results. PDF link for detailed outputs is provided.
- Speculative Decoding Techniques: There is debate over the effectiveness of using a smaller draft model with the larger QwQ-32B model. Some users suggest that the speed improvements are noticeable when the smaller model is significantly less than ten times the size of the larger one, such as 0.5B or 1.5B models, but not much larger.
- Performance Observations: Users report that speculative decoding can lead to speed-ups of 1.5x to 2x in some setups, though the perceived improvements in logic or quality are subjective. The use of a fixed seed is recommended to verify if the perceived improvements are due to speculative decoding or other factors like GPU offload inaccuracies.
- Speculative Decoding Methods: There is mention of two speculative decoding methods: one that samples from both models and uses the smaller model only if samples agree, and another that uses logits from the smaller model with rejection sampling. The exact method implemented in llama.cpp remains unclear to some users.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Google's Gemini 2.0: Strategic Release Amidst OpenAI Announcements
- Google releasing Gemini 2.0 a few hours before the daily openai live: (Score: 244, Comments: 64): Google released Gemini 2.0 just hours before OpenAI's daily live event, leading to speculation about the potential confirmation of GPT-5/Epsilon. This timing suggests a competitive dynamic between the two tech giants in the AI landscape.
- Gemini 2.0 Performance: Users have noted that Gemini Flash 2.0 performs exceptionally well on benchmarks, with some suggesting it might outperform models like Sonnet 3.5 and potentially be more cost-effective than 4o-mini. The context window is significantly larger than its predecessor, making it particularly useful for coding tasks.
- Market Dynamics: There is a strong sentiment favoring competition between Google and OpenAI, as it drives innovation and prevents monopolistic stagnation. Users appreciate the competitive landscape, which keeps companies motivated to improve their offerings.
- Adoption and Accessibility: Despite some skepticism about its recognition, Gemini is integrated into many Google products, which could facilitate its adoption as it becomes more recognized for its performance. It's available for testing on platforms like AI Studio, and users have found it accessible and functional.
- Google Just Introduced Gemini 2.0 (Score: 202, Comments: 45): Google introduced Gemini 2.0 during OpenAI week, indicating a strategic move to highlight advancements in AI technology and accessibility.
- Discussions emphasize skepticism about Google's Gemini 2.0, with some users expressing disappointment due to a lack of new core intelligence features and concerns about Google's history of over-promising in demos. Others counter that Gemini is already accessible for testing on aistudio, with agents expected in January, and some users report positive experiences with the technology.
- The potential for Google to undercut OpenAI on pricing due to their use of TPUs is highlighted, suggesting Google could dominate the AI market. Criticism of OpenAI's pricing strategy and product releases, such as the $200/month model and the Sora release, suggests financial struggles and competitive disadvantages against Google's integrated approach.
- Some users speculate about strategic timing in announcements, with Google's release timing potentially aimed at outpacing OpenAI's expected announcements. The competitive landscape is seen as a dynamic 'tit for tat' environment, with some users expressing enjoyment in watching these major AI companies compete.
Theme 2. Google GenCast: 15-Day AI Weather Forecast Spearheading Future Predictions
- Google says AI weather model masters 15-day forecast (Score: 286, Comments: 38): DeepMind's GenCast AI model reportedly achieves over 97% precision in 15-day weather forecasts, outperforming various models across more than 35 countries. For further details, refer to the article on phys.org.
- Users express skepticism about the accuracy of AI-driven weather forecasts, with some noting that current forecasts beyond 5 days are often unreliable. One commenter suggests that historic averages might be more accurate than predictions for forecasts beyond two weeks.
- The GenCast model's code repository is accessible via a link in the publication, which could be useful for those interested in examining or utilizing the model further.
- There is a discussion about the potential sources of data for AI models, with some users speculating that models like GenCast might rely on NOAA data. However, others highlight that AI will not replace traditional data collection methods like satellites and weather stations.
Theme 3. ChatGPT Outages: Troubles Improving Stability and User Dependency
- I came to ask it chat gpt was down... Seems like 5,000,000 other people also did... (Score: 299, Comments: 186): ChatGPT experienced downtime, causing frustration among students during finals. This issue was widely noticed, with many users seeking confirmation of the outage.
- ChatGPT's downtime during finals week caused significant frustration among students, highlighting its importance as a tool for learning and completing assignments. Users expressed their reliance on it for tasks like programming and brainstorming, emphasizing that it's not merely a means for cheating.
- The outage prompted humorous and exasperated reactions, with some users jokingly blaming themselves for the crash, while others reminisced about using alternatives like Chegg. The event underscored the high demand and dependency on AI tools during critical academic periods.
- Multiple comments noted the rarity of such outages, suggesting it was an unlucky timing due to increased usage and recent updates. The downtime led to a mix of humorous banter and serious concern about the impact on academic performance.
- ⚠️ ChatGPT, API & SORA currently down! Major Outage | December 11, 2024 (Score: 195, Comments: 80): Major Outage: On December 11, 2024, significant outages affected ChatGPT, API, and Sora services, with OpenAI's status page indicating ongoing investigations. A 90-day uptime graph shows "Major Outage" for API and ChatGPT, while Labs and Playground remain "Operational."
- Many users speculate that the iOS 18.2 update and the recent launch of Sora contributed to the outage, with new features like ChatGPT support integrated into Siri and Writing Tools potentially straining the servers. dopedub noted that these updates might have been poorly timed, leading to the system overload.
- There is a broader sentiment about the dependency on ChatGPT, with comments like legend503's highlighting the fragility of reliance on AI tools when they are unavailable. Users expressed frustration and humor about the downtime, with some suggesting alternative platforms or methods to access ChatGPT during the outage.
- Users shared various workarounds, such as trying to access ChatGPT through iPhones or using the mobile app, with some success reported. InspectorOk6664 and others noted that they managed to access the service, albeit with limited functionality, suggesting that the outage impact varied across platforms.
Theme 4. Sora AI Criticisms: Inferior Outputs Against Rivals and Discontent Among Users
- Sora is awful (Score: 350, Comments: 193): Sora's performance is heavily criticized for its inability to accurately generate videos, even with simple tasks like making cats dance, resulting in poor quality outputs. The user expresses dissatisfaction with the cost of Sora compared to other more effective and often cheaper or free text-to-video generators, stating that the service does not justify its price unless it significantly improves.
- Sora's Performance and Limitations: Many users agree that Sora underperforms compared to alternatives like Runway Gen-3 and Luma, with complaints about its inability to handle tasks like image-to-video generation effectively. Users note that the public version of Sora is a scaled-down "Turbo" model, which lacks the computational power of the demo version that was showcased earlier.
- Technical and Market Challenges: Comments suggest that Sora's limitations are due to computational constraints and the need to balance demand with available resources, leading to a watered-down version being released. This has resulted in disappointment among users who expected the capabilities demonstrated in earlier demos, which likely used more resources than what is available to the public.
- Community Sentiment and Comparisons: The community expresses skepticism about OpenAI's handling of Sora, with some speculating that the product was strategically released to compete with Google's Gemini Pro. Users also criticize OpenAI's Dalle as inferior to MidJourney, indicating a broader dissatisfaction with OpenAI's offerings relative to competitors.
- Used Sora Al to recreate my favorite Al video (Score: 2574, Comments: 140): Sora AI is criticized for its inability to perform expected tasks, resulting in negative user feedback. The post mentions attempting to use Sora AI to recreate a favorite AI video, highlighting user dissatisfaction with its performance.
- Users overwhelmingly prefer the original video over the Sora AI recreation, citing the original's humor and appeal. Many comments express dissatisfaction with the realism and quality of the AI-generated content, with some users noting inappropriate elements like pornographic frames.
- There is speculation and curiosity about the prompt and training data used for Sora AI, with some users questioning if it was trained on inappropriate content. The discussion hints at a desire to understand the AI's development process and its limitations.
- The conversation includes humorous and critical remarks about the AI's output, such as comparisons to video game characters and references to cultural events like 9/11. Despite criticism, there is recognition of the AI's role in showcasing technological evolution and potential future applications.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. New AI Models and Significant Updates
- Gemini 2.0 Flash Launches with Stellar Performance: Google DeepMind unveiled Gemini 2.0 Flash, debuting at #3 overall in the Chatbot Arena and outperforming models like Flash-002. This release enhances multimodal capabilities and coding performance, setting new benchmarks in AI model development.
- Nous Research Releases Hermes 3 for Enhanced Reasoning: Nous Research launched Hermes 3 3B on Hugging Face, featuring quantized GGUF versions for optimized size and performance. Hermes 3 introduces advanced features in user alignment, agentic performance, and reasoning, marking a significant upgrade from its predecessor.
- Windsurf Wave 1 Enhances Developer Tools: Windsurf Wave 1 officially launched, integrating major autonomy tools like Cascade Memories and automated terminal commands. The update also boosts image input capabilities and supports development environments such as WSL and devcontainers. Explore the full changelog for detailed enhancements.
Theme 2. AI Tool Performance and Comparative Analysis
- Windsurf Outperforms Cursor in AI Tool Comparisons: Community discussions highlight Windsurf as a superior AI tool compared to Cursor, emphasizing its more reliable communication and transparent changelogs. Users appreciate Windsurf's update approach and responsiveness, positioning it ahead in the AI tool landscape.
- Muon Optimizer Emerges as a Strong Alternative to AdamW: The Muon optimizer gains attention for its robust baseline performance and solid mathematical foundation, positioning it as a viable alternative to traditional optimizers like AdamW. Although it hasn't yet outperformed AdamW, its resilience in models such as Llama 3 underscores its potential in future developments.
- Gemini 2.0 Flash Surpasses Competitors in Coding Tasks: Gemini 2.0 Flash has been praised for its exceptional performance in spatial reasoning and iterative image editing, outperforming models like Claude 3.5 and o1 Pro. Users have noted its competitive benchmarks, sparking further discussions on its advancements over existing offerings.
Theme 3. Feature Integrations and Platform Enhancements
- ChatGPT Integrates Seamlessly with Apple Ecosystem: During the 12 Days of OpenAI event, ChatGPT was successfully integrated into iOS and macOS. Demonstrated by Sam Altman and team members, this integration includes enhanced holiday-themed features to engage users during the festive season.
- NotebookLM Boosts Functionality with Gemini 2.0 Integration: NotebookLM confirmed the integration of Gemini 2.0, enhancing its capabilities for real-time AI engagement within Discord guilds. This upgrade is expected to bolster NotebookLM's performance, despite humorous critiques on branding choices.
- Supabase Integration Enhances Bolt.new Workflows: Bolt.new provided a sneak peek of its Supabase integration during a live stream, promising improved workflow functionalities for developers. This integration aims to streamline existing processes and attract more users by enhancing the platform's utility.
Theme 4. Pricing, Usage Transparency, and Subscription Models
- Windsurf Rolls Out Transparent Pricing and Usage Updates: An updated pricing system for Windsurf has been introduced, featuring a new quick settings panel that displays current plan usage and trial expiry. The update also includes a 'Legacy Chat' mode in Cascade that activates upon exhausting Flow Credits, providing limited functionality without additional costs.
- Self-Serve Upgrade Plans Simplify Subscription Management: Windsurf has introduced a self-serve upgrade plan button, allowing users to effortlessly access updated plans through this link. This feature simplifies the process of scaling subscriptions based on project needs, enhancing user experience and flexibility.
- $30 Pro Plan Expands App Capabilities for Open Interpreter: Killianlucas announced that the $30 monthly desktop app plan for Open Interpreter increases usage limits and provides the app without needing an API key for free users. He recommended sticking to the free plan unless users find the expanded features overwhelmingly beneficial, as the app continues to evolve rapidly in beta.
Theme 5. Training, Fine-Tuning, and Cutting-Edge Research
- Eleuther Analyzes Training Jacobian to Uncover Parameter Dependencies: Researchers at Eleuther published a paper on arXiv exploring the training Jacobian, revealing how final parameters depend on initial ones by analyzing the derivative matrix. The study differentiates between bulk and chaotic subspaces, offering insights into neural training dynamics.
- Challenges in Fine-Tuning Qwen 2.5 Highlight Integration Difficulties: In the Unsloth AI Discord, users reported difficulties in obtaining numeric outputs from the fine-tuned Qwen 2.5 model, especially with simple multiplication queries. Discussions emphasized that integrating domain-specific knowledge is challenging, suggesting that pre-training or employing RAG solutions might offer more effective outcomes.
- Innovations in LLM Training with COCONUT and RWKV Architectures: The introduction of COCONUT (Chain of Continuous Thought) enables LLMs to reason within a continuous latent space, optimizing processing through direct embedding approaches. Additionally, new RWKV architectures like Flock of Finches and QRWKV-6 32B have been released, emphasizing optimized training costs without compromising performance.
PART 1: High level Discord summaries
Codeium / Windsurf Discord
- Wave 1 Launch Enhances Windsurf Capabilities: Windsurf Wave 1 has officially launched, introducing major autonomy tools such as Cascade Memories and automated terminal commands. The update also includes enhanced image input capabilities and support for development environments like WSL and devcontainers. Check out the full changelog for detailed information.
- Users have expressed excitement over the new features, highlighting the integration of Cascade Memories as a significant improvement. The launch aims to streamline developer workflows by automating terminal commands and supporting diverse development environments.
- Windsurf Pricing and Usage Transparency Update: An updated pricing system for Windsurf is rolling out, featuring a new quick settings panel that displays current plan usage and trial expiry. Detailed information about the changes is available on the pricing page.
- The update introduces a 'Legacy Chat' mode in Cascade, which activates when users exhaust their Flow Credits, allowing limited functionality without additional credits. This change aims to provide clearer usage metrics and enhance transparency for users managing their subscriptions.
- Enhanced Python Support in Windsurf: Windsurf has improved language support for Python, offering better integration and advanced features for developers. This enhancement is part of the platform's commitment to empowering developers with more effective tools.
- Additionally, a self-serve upgrade plan button has been introduced, enabling users to easily access updated plans through this link. This feature simplifies the process of scaling their subscriptions based on their project needs.
- Cascade Image Uploads and Functionality Enhancements: Cascade image uploads are no longer restricted to 1MB, allowing users to share larger files seamlessly. This improvement is part of ongoing efforts to enhance usability and functionality within the platform.
- The increased upload limit aims to support more extensive workflows, enabling users to incorporate higher-resolution images into their projects without encountering size limitations. This change contributes to a more flexible and efficient user experience.
- Cascade Model Performance Issues Reported: Users have reported that Cascade Base is experiencing performance issues, such as hanging and unresponsiveness, which affects its reliability for coding tasks. Some users have encountered HTTP status 504 errors during usage.
- There are speculations that these instability issues might be linked to ongoing problems with OpenAI, leading several users to consider downgrading or switching to alternative tools. The community is actively discussing potential solutions to mitigate these performance challenges.
OpenAI Discord
- ChatGPT Apple Integration: In the YouTube demo, ChatGPT was integrated into iOS and macOS, showcased by Sam Altman, Miqdad Jaffer, and Dave Cummings during the 12 Days of OpenAI event.
- The festive presentation featured team members in holiday sweaters, aiming to enhance viewer engagement and reflect the holiday season spirit.
- Gemini 2.0 Flash Outperforms: Gemini 2.0 Flash has been lauded by users for its superior performance, especially in spatial reasoning and iterative image editing, outperforming models like o1 Pro.
- Community comparisons highlight Gemini 2.0 Flash's competitive benchmarks, sparking discussions on its advancements over OpenAI's offerings.
- OpenAI Services Experience Downtime: OpenAI experienced service outages affecting ChatGPT and related API tools, as reported in the status update.
- Users noted disruptions coinciding with the Apple integration announcement, with API traffic partially recovering while Sora remained down as of December 11, 2024.
- Challenges in Fine-Tuning OpenAI Models: Developers reported that fine-tuned OpenAI models still generate generic responses despite completing training, seeking assistance with their JSONL configurations.
- Community feedback is sought to identify potential issues in training data, aiming to enhance model specificity and performance.
- Chaining Custom GPT Tools: Users are encountering difficulties in chaining multiple Custom GPT tools within a single prompt, where only the first tool's API call is executed.
- Suggestions include adding meta-functional instructions and using canonical tool names to improve tool interaction management.
Cursor IDE Discord
- Cursor Slows Amid OpenAI Model Hiccups: Users reported persistent performance issues with Cursor, notably sluggish request response times and problematic codebase indexing. These issues appear linked to upstream problems with OpenAI models, resulting in degraded platform performance. Cursor Status shows ongoing downtimes affecting key functionalities.
- Community members expressed frustration over Cursor's inability to code effectively during these downtimes. A feature request for long context mode received significant attention, though formal support remains pending.
- Agent Mode Hangs Code Flow: Cursor's Agent mode is facing widespread complaints due to frequent hangs when processing code or accessing the codebase. Users have found that reindexing or restarting Cursor can temporarily alleviate these issues.
- Despite temporary fixes, the recurring nature of Agent mode disruptions continues to hinder developer productivity, prompting discussions on potential long-term solutions within the community.
- Windsurf Surges Past in AI Tool Comparisons: Discussions highlighted Windsurf as a superior AI tool compared to Cursor, emphasizing its more reliable communication and transparent changelogs. Users appreciate Windsurf's approach to updates and feedback integration.
- Participants noted that while Cursor offers unique features, its changelog transparency and responsiveness lag behind competitors like Windsurf, suggesting areas for improvement to meet user expectations.
- Gemini 2.0 Shines Twice as Fast: Sundar Pichai announced the launch of Gemini 2.0 Flash, which outperforms Gemini 1.5 Pro on key benchmarks at twice the speed. This advancement marks a significant milestone in the Gemini model's development.
- The AI community is keenly observing the progress of Gemini 2.0, with expectations high for its performance improvements and potential impact on existing models like Claude.
- Windsurf's Transparent Changelogs Impress: Windsurf users praised the tool's clear communication and detailed changelogs available at Windsurf Editor Changelogs. This transparency demonstrates a strong commitment to user feedback and continuous improvement.
- The favorable reception of Windsurf's engagement model contrasts with Cursor, prompting discussions on adopting similar transparent practices to enhance user trust and satisfaction.
Eleuther Discord
- Training Jacobian Analysis Reveals Parameter Dependencies: A recent paper on arXiv explores the training Jacobian, uncovering how final parameters hinge on initial ones by analyzing the derivative matrix. The study highlights that training manipulates parameter space into bulk and chaotic subspaces.
- The research was conducted using a 5K parameter MLP due to computational constraints, yet similar spectral patterns were observed in a 62K parameter image classifier, suggesting broader implications for neural training dynamics.
- Muon Optimizer Emerges as a Strong Contender: Muon has garnered attention for its robust baseline performance and solid mathematical foundation, positioning it as a viable alternative to existing optimizers like AdamW. Keller Jordan detailed its potential in optimizing hidden layers within neural networks.
- While Muon hasn't yet decisively outperformed AdamW, its resilience against issues observed in models such as Llama 3 underscores its promise in future optimizer developments.
- Addressing Inherent Biases in Large Language Models: A forthcoming paper discusses that harmful biases in large language models are an intrinsic result of their current architectures, advocating for a fundamental reassessment of AI design principles. The study emphasizes that biases stem from both dataset approximations and model architectures.
- This perspective encourages the AI community to focus on understanding the root causes of biases rather than merely adjusting specific implementations, fostering more effective strategies for bias mitigation.
- Integrating HumanEval in lm_eval_harness for Enhanced Perplexity Metrics: lm_eval_harness is being utilized to assess model perplexity on datasets formatted in jsonl files, with members sharing custom task configurations. A specific pull request (#2559) aims to facilitate batch inference, addressing processing inefficiencies.
- The integration seeks to deliver per-token perplexity results essential for comparative studies, with community members actively contributing solutions to streamline evaluation workflows.
- Release of New RWKV Architectures Enhances Model Efficiency: New RWKV architectures, namely Flock of Finches and QRWKV-6 32B, have been launched, emphasizing optimized training costs without compromising performance.
- These models demonstrate comparable capabilities to larger counterparts while maintaining reduced computational demands, making them attractive for scalable AI applications.
Bolt.new / Stackblitz Discord
- Cole Amplifies OSS Bolt on Twitter: During a live session, Cole discussed OSS Bolt, sharing the journey and developments, which was viewed by the community on Twitter.
- OSS Bolt is gaining traction, with the latest Bolt Office Hours: Week 8 now available on YouTube, featuring resource links to enhance viewer engagement.
- Supabase Sneak Peek Enhances Bolt: A live stream provided a sneak peek of the Supabase integration, set to enhance existing workflows and attract interest from developers.
- This Supabase integration promises to improve workflow functionalities, as revealed during the live session, exciting the developer community.
- Supabase Tops Firebase for Stripe Integration: Several users discussed transitioning from Firebase to Supabase for better Stripe integration, evaluating each database’s merits.
- The decision to choose Supabase is driven by the desire to avoid vendor lock-in, making it a preferred choice among some app developers.
- Shopify API Integration Boosts Web App: A member developing a web app synchronized with their Shopify store received recommendations to integrate with Shopify's APIs, citing Shopify API Docs.
- Implementing Shopify API Integration ensures secure data access exclusive to the app, leveraging comprehensive documentation for seamless development.
- Bolt AI Token Drain Sparks Concerns: Users reported frustrations with Bolt AI making repeated errors and consuming large amounts of tokens without resolving issues, with one user using 200k tokens without changes.
- Issues are attributed to the underlying AI, Claude, prompting suggestions to refine prompt framing to minimize wasted tokens during debugging sessions.
Unsloth AI (Daniel Han) Discord
- Qwen 2.5 Fine-tuning Faces Numeric Output Issues: A user reported challenges in obtaining numeric outputs from the fine-tuned Qwen 2.5 model, particularly when handling simple multiplication queries.
- The discussion emphasized that integrating domain-specific knowledge is difficult, suggesting that pre-training or employing RAG solutions might offer more effective outcomes.
- Gemini Voice Surpasses Competitors: Community members expressed excitement over the capabilities of Gemini Voice, describing it as 'crazy' and outperforming some existing alternatives.
- Comparisons highlighted that OpenAI's real-time voice API is more costly and less capable, positioning Gemini Voice as a superior option.
- Managing Memory Spikes during Training: Concerns were raised about unexpected spikes in RAM and GPU RAM usage during training phases, causing runtime collapses on Colab.
- Users recommended strategies such as adjusting batch sizes, balancing dataset lengths, and ensuring high-quality data to mitigate memory issues.
- Effective Model Conversion with llama.cpp: Users discussed utilizing llama.cpp for model conversion, sharing experiences and troubleshooting methods to streamline the process.
- One member successfully resolved conversion issues by performing a clean install and leveraging PyTorch 2.2 as a specific dependency version.
- WizardLM Arena Datasets Now Available: A member uploaded all datasets used in the WizardLM Arena paper to the repository, with the commit b31fa9d verified a day ago.
- These datasets provide comprehensive resources for replicating the WizardLM Arena experiments and further research.
Nous Research AI Discord
- Hermes 3 Launches with Upgraded Reasoning: Hermes 3 3B has been released on Hugging Face with quantized GGUF versions for optimized size and performance, introducing advanced capabilities in user alignment, agentic performance, and reasoning.
- This release marks a significant upgrade from Hermes 2, enhancing overall model efficiency and effectiveness for AI engineers.
- Google DeepMind Debuts Gemini 2.0: Gemini 2.0 was unveiled by Google DeepMind, including the experimental Gemini 2.0 Flash version with improved multimodal output and performance, as announced in their official tweet.
- The introduction of Gemini 2.0 Flash aims to facilitate new agentic experiences through enhanced tool use capabilities.
- DNF Advances 4D Generative Modeling: The DNF model introduces a new 4D representation for generative modeling, capturing high-fidelity details of deformable shapes using a dictionary learning approach, as detailed on the project page.
- A YouTube overview demonstrates DNF's applications, showcasing temporal consistency and superior shape quality.
- COCONUT Enhances LLM Reasoning Processes: COCONUT (Chain of Continuous Thought) enables LLMs to reason within a continuous latent space, optimizing processing through a more direct embedding approach, as described in the research paper.
- This methodology builds on Schmidhuber's work on Recurrent Highway Networks, offering end-to-end optimization via gradient descent for improved reasoning efficiency.
- Forge Bot Streamlines Discord Access: Members can now access Forge through a Discord bot without needing API approval by selecting the Forge Beta role from the customize page and navigating to the corresponding channel.
- This enhancement facilitates immediate testing and collaboration within the server for AI engineers.
Stability.ai (Stable Diffusion) Discord
- VRAM Usage and Management: Users discussed how caching prompts in JSON format impacts memory usage, noting that storing 20 prompts consumes only a few megabytes. They also explored running models in lower precision like FP8 to reduce memory costs.
- Optimizing FP8 precision is crucial for managing VRAM efficiently in large-scale AI deployments.
- AI Model Recommendations for Image Enhancement: A user requested model recommendations for generating spaceships, mentioning their use of Dream Shaper and Juggernaut. Another member suggested training a LoRA if existing models did not meet their needs.
- Training a LoRA can offer customized enhancements for specific image generation requirements.
- GPU Scalping Concerns: Members shared insights on how scalpers might deploy web scrapers to purchase GPUs on launch days. One user expressed concerns about acquiring a GPU before scalpers, mentioning they avoided waiting in lines due to being outside the US.
- Preventing GPU scalping requires strategies beyond physical queueing, especially for international users.
- AI for Image Classification and Tagging: A user inquired about tools for extracting tags or prompts from images, leading to a discussion about image classification techniques. Clip Interrogator was recommended as a tool that can describe images without prior metadata.
- Clip Interrogator can automate the tagging process, enhancing efficiency in managing large image datasets.
- AI Programs for Voice Training: Users discussed programs commonly used to train AI on specific voices, with Applio mentioned as a potential tool. The conversation emphasized interest in tools for voice manipulation and AI training applications.
- Choosing the right program like Applio can improve workflows in voice-specific AI training tasks.
Notebook LM Discord Discord
- Integrating NotebookLM into Discord: A member discussed adding a chat feature to Discord, enabling users to directly query NotebookLM for enhanced interactivity.
- This integration aims to provide a seamless connection for players seeking real-time AI engagement within the Discord guild.
- NotebookLM for TTRPG Rule Conversion: A member showcased using a 100-page custom TTRPG rule book with NotebookLM to convert narrative descriptions into specific game mechanics.
- They highlighted the tool's effectiveness in translating complex rules into actionable mechanics, facilitating smoother gameplay.
- Enhancing Podcasts with NotebookLM: Users explored leveraging NotebookLM for podcast creation, including customizing presenters and utilizing visuals from the Talking Heads Green Screen Podcast.
- Members suggested employing chromakey techniques to personalize podcast backdrops, enhancing visual appeal.
- Gemini 2.0 Integration in NotebookLM: Discussions confirmed the integration of Gemini 2.0 with NotebookLM, with members humorously noting the absence of the Gemini symbol in branding.
- The transition is expected to bolster NotebookLM's capabilities, despite light-hearted critiques on branding choices.
- NotebookLM Features and AI Tool Experiences: Users examined NotebookLM's limitations, including a maximum of 1,000 notes, 100,000 characters each, and 50 sources per notebook, raising queries about PDF size constraints.
- Additionally, members shared positive experiences with tools like Snapchat AI and Instagram's chat AI, emphasizing NotebookLM's utility in their workflows during challenging periods.
Interconnects (Nathan Lambert) Discord
- Gemini 2.0 Flash Launch: Google unveiled Gemini 2.0 Flash, highlighting its superior multimodal capabilities and enhanced coding performance compared to previous iterations. The launch event was covered in detail on the Google DeepMind blog, emphasizing its top-tier benchmark scores.
- Users have praised Gemini 2.0 Flash for its robust coding functionalities, with comparisons to platforms like Claude. However, some concerns were raised about its stability and effectiveness relative to other models, as discussed in multiple tweets.
- Scaling Laws Debate at NeurIPS: Dylan Patel is set to engage in an Oxford Style Debate on scaling laws at NeurIPS, challenging the notion that scaling alone drives AI progress. The event promises to address critiques from industry influencers, with registration details available in his tweet.
- The community has shown strong engagement, finding the debate format entertaining and insightful. Discussions emphasize the importance of search, adaptation, and program synthesis over mere model scaling, reflecting broader AI development trends.
- Joining Meta's Llama Team: A member announced their upcoming role with AI at Meta's Llama team, aiming to develop the next generation of Llama models. This move underscores a commitment to fostering a healthier AI ecosystem aligned with AGI goals and open-source initiatives.
- The announcement sparked discussions about integrating Gemini insights into the Llama project, despite past challenges with Llama 3.2-vision. Members humorously debated the potential distractions from presenting Kambhampathi's works, highlighting community support for the new endeavor.
- OpenAI's Product-Centric Strategy: OpenAI continues to emphasize a product-centric approach, maintaining its leadership in the AI field by focusing on user-friendly products. This strategy has kept OpenAI ahead as competitors lag, as observed within the community discussions.
- The focus on usability ensures that OpenAI's developments remain relevant and impactful, reinforcing the importance of practical applications in ongoing AI advancements.
- LLM Creativity Benchmarking: A discussion emerged on evaluating LLM capabilities in creative tasks, revealing discrepancies between benchmark scores and user satisfaction. Claude-3 remains popular despite not always leading in creativity metrics.
- Community members are exploring methodologies to better assess creative outputs of LLMs, aiming to align benchmarking practices with actual user experiences and expectations.
LM Studio Discord
- Maximizing GPU Utilization in LM Studio: Discussions centered on using multiple GPUs, including two 3070s and a 3060ti, with LM Studio's GPU offload currently functioning as a simple toggle.
- Users are exploring workaround solutions through environment variables to enhance multi-GPU performance due to existing limitations.
- Advancing Document Merging with Generative AI: A member sought methods to merge two documents using generative AI, but suggestions leaned towards traditional techniques like the MS Word merge option.
- Alternative solutions included writing a custom script for exact merges instead of relying on vague AI prompts.
- Enabling Model Web Access via API Integration: Queries about providing web access to models received answers pointing towards requiring custom API solutions instead of the standard chat interface.
- This indicates a growing interest in integrating models with external tools and websites for enhanced operational capabilities.
- Integrating Alphacool's D5 Pump in Hardware Setup: Alphacool introduced a model with the D5 pump pre-installed, impressing some members.
- However, one member expressed regret over not choosing this setup due to space constraints in their extensive setup comprising 4 GPUs and 8 HDDs.
Latent Space Discord
- Gemini 2.0 Flash Launches: Google announced the launch of Gemini 2.0 Flash, which debuted at #3 overall in the Chatbot Arena, outperforming previous models like Flash-002.
- Gemini 2.0 Flash offers enhanced performance in hard prompts and coding tasks, incorporating real-time multimodal interactions.
- Hyperbolic Raises $12M Series A: Hyperbolic successfully raised a $12M Series A, aiming to develop an open AI platform with an open GPU marketplace offering H100 SXM GPUs at $0.99/hr.
- This funding emphasizes transparency and community collaboration in the development of AI infrastructure.
- Stainless Secures $25M Series A Funding: Stainless API announced a $25M Series A funding round led by a16z and Sequoia, aimed at enhancing their AI SDK offerings.
- The investment will support the development of a robust ecosystem for AI developers.
- Nous Simulators Launches: Nous Research launched Nous Simulators to experiment with human-AI interaction in social contexts.
- The platform is designed to provide insights into AI behaviors and interactions.
- Realtime Multimodal API Unveiled: Logan K introduced the new Realtime Multimodal API, powered by Gemini 2.0 Flash, supporting real-time audio, video, and text streaming.
- This API facilitates dynamic tool calls in the background for a seamless interactive experience.
Modular (Mojo 🔥) Discord
- C23 Standardizes Pure Functions: Standardizing pure functions in both C and C++ has been achieved with the inclusion of this feature in C23, referencing n2956 and p0078 for detailed guidelines.
- This update facilitates better optimization by clearly marking pure functions, enhancing code predictability and performance.
- Modular Forum Links Obscured: Users expressed frustration that the Modular website's forum link is difficult to find, being buried under the Company section.
- The team is dedicated to improving the forum and targets a public launch in January to enhance accessibility.
- Mojo's Multi-Paxos Implementation Issues: A Multi-Paxos consensus protocol implemented in C++ failed initial tests by not efficiently handling multiple proposals.
- Essential features such as timeouts, leader switching, and retries are lacking, akin to the necessity of back-propagation in neural networks.
- Debate on Mojo Struct del Design: The community debated whether Mojo structs should have
__del__methods be opt-in or opt-out, weighing consistency against developer ergonomics.- Some members prefer reducing boilerplate code, while others advocate for a uniform approach across traits and methods.
- Performance Boost with Named Results: Named results in Mojo allow direct writes to an address, avoiding costly move operations and providing performance guarantees during function returns.
- While primarily offering guarantees, this feature enhances efficiency in scenarios where move operations are not feasible.
Cohere Discord
- Maya Multimodal Model Launch: Introducing Maya, an open source, multilingual vision-language model supporting 8 languages with a focus on cultural diversity, built on the LLaVA framework.
- Developed under the Apache 2.0 license, Maya's paper highlights its instruction-finetuned capabilities, and the community is eagerly awaiting a blog post and additional resources.
- Plans for Rerank 3.5 English Model: A member inquired about upcoming developments for the rerank 3.5 English model, seeking insights into future enhancements.
- As of now, there have been no responses provided regarding this inquiry, leaving the plans for the rerank 3.5 model unaddressed.
- Aya Expanse Enhances Command Family: Discussions highlighted that Aya Expanse potentially benefits from the command family's performance, suggesting improved instruction following capabilities.
- Members implied that since Aya Expanse may be built upon the command family, it could offer enhanced performance in processing and executing commands.
- Persistent API 403 Errors: Users reported encountering 403 errors when utilizing the API request builder, even after disabling their VPN and using a Trial API key.
- Details shared include the use of an IPv6 address from China and specific curl commands, but the issue remains unresolved within the community.
- Seeking Quality Datasets for Quantification: Members are looking for high-quality datasets suitable for quantification, specifically interested in the 're-annotations' tag from the aya_dataset.
- The community is emphasizing the need for datasets with a significant number of samples to support robust quantification tasks.
LLM Agents (Berkeley MOOC) Discord
- Hackathon Submissions Due by December 17th: Participants must submit their hackathon submissions by December 17th, adhering to the guidelines provided.
- Additionally, the written article assignment is due by December 12th, 11:59 PM PST, separate from the 12 lecture summaries previously required.
- Detailed Guidelines for Written Article Assignment: Students are required to create a post of approximately 500 words on platforms such as Twitter, Threads, or LinkedIn, linking to the MOOC website.
- The article submission is graded on a pass or no pass basis and must be submitted using the same email used for course sign-up to ensure proper credit.
- ToolBench Platform Presented at ICLR'24: The ToolBench project was showcased at ICLR'24 as an open platform for training, serving, and evaluating large language models for tool learning.
- This platform aims to provide AI engineers with enhanced resources and frameworks to advance tool integration within large language models.
- Advancements in Function Calling for AI Models: AI models are increasingly leveraging detailed function descriptions and signatures, setting parameters based on user prompts to improve generalization capabilities.
- This development indicates a trend towards more intricate interactions between AI models and predefined functions, enhancing their operational complexity.
OpenInterpreter Discord
- O1 Pro Enables Advanced Control Features: A member proposed using Open Interpreter in OS mode to control O1 Pro, enabling features like web search, canvas, and file upload.
- Another user considered reverse engineering O1 Pro to control Open Interpreter, commenting that 'the possibilities that opens up... yikes.'
- Open Interpreter App Beta Access Limited to Mac: Members confirmed that the Open Interpreter app is currently in beta, requires an invite, and is limited to Mac users.
- One member expressed frustration over being on the waitlist without access, while another shared contacts to obtain an invite.
- Mixed Feedback on New Website Design: Users provided mixed feedback on the new website design, with one stating it looked 'a lil jarring' initially but has grown on them.
- Others noted the design is a work-in-progress, with ambitions for a cooler overlay effect in future updates.
- $30 Pro Plan Expands App Capabilities: Killianlucas explained that the $30 monthly desktop app plan increases usage limits and provides the app without needing an API key for free users.
- He recommended sticking to the free plan unless users find it overwhelmingly beneficial, as the app is rapidly evolving in beta.
- Actions Beta App Focuses on File Modification: The Actions feature was highlighted as a beta app focusing on file modification, distinct from OS mode which is available only in the terminal.
- Members were encouraged to explore this new feature, though some encountered limitations, with one noting they maxed out their token limit while testing.
Torchtune Discord
- QRWKV6-32B achieves 1000x compute efficiency: The QRWKV6-32B model, built on the Qwen2.5-32B architecture, matches the original 32B performance while offering 1000x compute efficiency in inference.
- Training was completed in 8 hours on 16 AMD MI300X GPUs (192GB VRAM), showcasing a significant reduction in compute costs.
- Finch-MoE-37B-A11B introduces linear attention: The Finch-MoE-37B-A11B model, part of the new RWKV variants, adopts linear attention mechanisms for efficiency in processing long contexts.
- This shift highlights ongoing developments in the RWKV architecture aimed at enhancing computational performance.
- DoraLinear enhances parameter initialization: DoraLinear improves user experience by utilizing the
to_emptymethod for magnitude initialization, ensuring it doesn't disrupt existing functionality.- Implementing
swap_tensorsin theto_emptymethod facilitates proper device handling during initialization, crucial for tensors on different devices.
- Implementing
DSPy Discord
- O1 Series streamlines DSPy workflows: A member inquired about the impact of the O1 series models on DSPy workflows, suggesting that MIPRO’s recommended parameters for optimization might require adjustments.
- They speculated that the new models could lead to fewer optimization cycles or the evaluation of fewer candidate programs.
- Generic optimization errors in DSPy: A user reported encountering a weird generic error during the optimization process and mentioned a related bug posted in a specific channel.
- This issue highlights the ongoing challenges the community faces when optimizing DSPy workflows.
- 'backtrack_to' attribute error in DSPy Settings: A member shared an error where 'backtrack_to' was not an attribute of Settings in DSPy and sought assistance.
- Another user indicated that the issue was resolved earlier, likely due to some async usage.
- Debate on Video and Audio IO focus: A user initiated a discussion on video and audio IO within DSPy, prompting varied opinions among members.
- One member advocated for concentrating on text and image input, citing the effectiveness of existing features.
LAION Discord
- Grassroots Science Ignites Multilingual LLM Development: The Grassroots Science initiative launches in February 2025, aiming to develop multilingual LLMs through crowdsourced data collection with partners like SEACrowd and Masakhane.
- The project focuses on creating a comprehensive multilingual dataset and evaluating human preference data to align models with diverse user needs.
- LLaMA 3.2 Throughput Troubleshooting: A user is optimizing inference throughput for LLaMA 3.2 with a 10,000-token input on an A100 GPU, targeting around 200 tokens per second but experiencing slower performance.
- Discussions suggest techniques like batching, prompt caching, and utilizing quantized models to enhance throughput.
- TGI 3.0 Surpasses vLLM in Token Handling: TGI 3.0 is reported by Hugging Face to process three times more tokens and run 13 times faster than vLLM, improving handling of long prompts.
- With a reduced memory footprint, TGI 3.0 supports up to 30k tokens on LLaMA 3.1-8B, compared to vLLM's limitation of 10k tokens.
- Model Scaling Skepticism Favors Small Models: A member challenges the necessity of scaling models beyond a billion parameters, stating, 'A Billion Parameters Ought To Be Enough For Anyone.', and advocates for hyperefficient small models.
- The discussion critiques the scale-is-all-you-need approach, highlighting benefits in model training efficiency.
- COCONUT Introduces Continuous Reasoning in LLMs: Chain of Continuous Thought (COCONUT) is presented as a new reasoning method for LLMs, detailed in a tweet.
- COCONUT feeds the last hidden state as the input embedding, enabling end-to-end optimization via gradient descent instead of traditional hidden state and token mapping.
Axolotl AI Discord
- Default Setting Suggestion: User suggested that 'default' should be the default.
- ****:
Mozilla AI Discord
- Mozilla AI hires Community Engagement Head: Mozilla AI is recruiting a Head of Community Engagement for a remote position, reporting directly to the CEO.
- This role is responsible for leading and scaling community initiatives across various channels to boost engagement.
- Introducing Lumigator for LLM Selection: Mozilla is developing Lumigator, a tool designed to assist developers in selecting the optimal LLM for their projects.
- This product is part of Mozilla's commitment to providing reliable open-source AI solutions to the developer community.
- Developer Hub Streamlines AI Resources: Mozilla AI is launching a Developer Hub that offers curated resources for building with open-source AI.
- The initiative aims to enhance user agency and transparency in AI development processes.
- Blueprints Open-sources AI Integrations: The Blueprints initiative focuses on open-sourcing AI integrations through starter code repositories to initiate AI projects.
- These resources are designed to help developers quickly implement AI solutions in their applications.
- Inquiries on Community Engagement Role: Interested applicants can pose questions about the Head of Community Engagement position in the dedicated thread.
- This role underscores Mozilla AI's dedication to community-driven initiatives.
The tinygrad (George Hotz) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Codeium / Windsurf ▷ #announcements (1 messages):
Windsurf Wave 1 Launch, Cascade Memories and terminal automation, Updated pricing and usage transparency, Improved Language support for Python, Cascade image uploads
- Windsurf Wave 1 Launch makes a splash: Windsurf Wave 1 is now live, featuring major autonomy tools, including Cascade memories and automated terminal commands. Check out the full changelog for all the exciting updates.
- The launch emphasizes enhanced image input capabilities, alongside support for development environments such as WSL and devcontainers.
- Updated pricing and usage transparency: An updated usage and pricing system for Windsurf is rolling out, with a new quick settings panel displaying current plan usage and trial expiry. Details on the changes can be found on the pricing page.
- A new 'Legacy Chat' mode in Cascade activates when users exhaust their Flow Credits, offering limited functionality without needing additional credits.
- Cascade expands image upload limits: Cascade image uploads are no longer restricted to 1MB, enhancing user capabilities for sharing larger files. This change is part of the ongoing improvements in usability and functionality.
- The broader functionality aims to support a more seamless user experience for those utilizing image features in their workflow.
- Python language support gets a boost: Windsurf has improved language support for Python, providing better integration and features for users. This enhancement aligns with the goal of empowering developers with more effective tools.
- Additionally, a self-serve upgrade plan button has been added, making it easier for users to access updated plans at this link.
- Stay tuned for more as Waves continue: The announcement concludes with a tease for further updates, stating, This is just the beginning - stay tuned for more waves coming in the new year!
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
- Plan Settings: Tomorrow's editor, today. Windsurf Editor is the first AI agent-powered IDE that keeps developers in the flow. Available today on Mac, Windows, and Linux.
- Windsurf Wave 1: Introducing Wave 1, our first batch of updates to the Windsurf Editor.
- Tweet from Windsurf (@windsurf_ai): Introducing Wave 1.Included in this update:🧠 Cascade Memories and .windsurfrules💻 Automated Terminal Commands🪟 WSL, devcontainer, Pyright support... and more.
Codeium / Windsurf ▷ #content (1 messages):
Windsurf AI Twitter Giveaway
- Windsurf Announces Merch Giveaway: Windsurf AI excitedly announced their first merch giveaway on Twitter, encouraging users to share what they've built with the platform for a chance to win a care package.
- Participants must be following to qualify for the #WindsurfGiveaway, making it a great opportunity for users to showcase their projects.
- Invitation to Showcase Builds on Twitter: Users are invited to share their creations using Windsurf on Twitter to participate in the getaway campaign.
- This call to action aims to engage the community and promote user-generated content related to Windsurf.
Link mentioned: Tweet from Windsurf (@windsurf_ai): Excited to announce our first merch giveaway 🏄Share what you've built with Windsurf for a chance to win a care package 🪂 #WindsurfGiveawayMust be following to qualify
Codeium / Windsurf ▷ #discussion (239 messages🔥🔥):
Credit Issues in Windsurf, Customer Support Concerns, Functionality of Cascade and Extensions, Community Discussions on Features, Product Updates and Feedback
- Users Report Credit Problems: Several users expressed frustration regarding their inability to use the purchased Flex Credits, with one member noting their credits were not credited to their account despite purchase.
- Another user also shared that they couldn't access Windsurf and had been seeking help from the support team without response.
- Concerns with Customer Support: Multiple participants raised issues about the lack of response from customer support, with some stating they had been waiting for days for ticket replies.
- One user sarcastically highlighted the poor customer support, suggesting a need for improvement in communication.
- Integration and Functionality of Cascade: Users discussed the limitations of Cascade, with one participant noting the difficulty in integrating it programmatically compared to its manual use.
- Another conveyed their preference for asking Cascade questions and coping with its output rather than targeting a developer-friendly interface.
- Feedback on Codeium Extensions: Participants shared their experiences with Codeium's VS Code extension, speculating on potential unlimited access to different models but encountering functionality issues.
- Among the feedback was concern about the codeium's operational errors related to chat features.
- Product Updates and Community Input: Community members engaged in discussions about recent updates, particularly the wrong video link in a blog post regarding new features.
- There were suggestions for improvements, with users highlighting their experiences and expressing hopes for better product consistency.
- Disappointed Disbelief GIF - Disappointed Disbelief Slap - Discover & Share GIFs: Click to view the GIF
- Bobawooyo Dog Confused GIF - Bobawooyo Dog confused Dog huh - Discover & Share GIFs: Click to view the GIF
- Clapping Leonardo Dicaprio GIF - Clapping Leonardo Dicaprio Leo Dicaprio - Discover & Share GIFs: Click to view the GIF
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Reddit - Dive into anything: no description found
- Plans and Pricing Updates: Some changes to our pricing model for Cascade.
- GitHub - codelion/optillm: Optimizing inference proxy for LLMs: Optimizing inference proxy for LLMs. Contribute to codelion/optillm development by creating an account on GitHub.
Codeium / Windsurf ▷ #windsurf (580 messages🔥🔥🔥):
Windsurf Updates, Cascade Model Issues, User Experience with Pricing, Feature Requests for Windsurf, Community Feedback on AI Performance
- Windsurf Update Challenges: Users reported various issues following recent updates, including problems with 'Accept All' buttons and errors relating to Cascade's performance, with some experiencing HTTP status 504 errors.
- Despite these setbacks, many users expressed their excitement for the new features and rules capabilities, contributing to a lively discussion on improving the product.
- Cascade Model Performance Concerns: Several users noted that Cascade Base was hanging or not responding properly, leading to frustration and concerns about its reliability for coding tasks.
- There were suggestions that the instability might be linked to ongoing OpenAI issues, causing many users to consider downgrading or switching to other tools.
- Pricing and Subscription Complaints: Substantial criticisms were directed at the pricing model for WindSurf, particularly the limits associated with flex credits which seem inadequate for extensive use.
- A comparison was made with Cursor's options that allow for more flexible subscription arrangements, highlighting user dissatisfaction with current structures.
- User-Requested Features: Users expressed a desire for better documentation on the use of rules and to have the ability to integrate custom API endpoints for more personalized functionality.
- The community also discussed the potential for including features like web crawling and file uploads to enhance usability and effectiveness.
- General Sentiment on Windsurf: Overall sentiment among the users ranged from appreciation for Windsurf's capabilities to frustrations about recent hiccups and feature limitations.
- Many users were proactive in seeking solutions, sharing experiences, and providing feedback to help improve the tool.
- Tweet from Windsurf (@windsurf_ai): Excited to announce our first merch giveaway 🏄Share what you've built with Windsurf for a chance to win a care package 🪂 #WindsurfGiveawayMust be following to qualify
- Exit Abort GIF - Exit Abort Wipe Out - Discover & Share GIFs: Click to view the GIF
- Codeium: no description found
- CursorList - .cursorrule files and more for Cursor AI: no description found
- OpenAI Status: no description found
- OpenAI Status: no description found
- Feature Requests | Codeium: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- Export individual chat history | Feature Requests | Codeium: I was able to build an app in one chat session. I want to export it and read what steps I've done, so I can review and replicate it to build another app.
- Windsurf - Cascade: no description found
- Feature Requests | Codeium: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Burning Late GIF - Burning Late Omg - Discover & Share GIFs: Click to view the GIF
- I tested AI coding tools and the result might surprise you: Watch at 1.5x speed, guys 🙏 If you wanna learn together 👉 https://discord.gg/CBC2Affwu300:00 Intro + Test Prompt01:25 Cursor07:30 Windsurf16:48 Aider25:46...
- Gemini 2.0 Flash: BEST LLM Ever! Beats Claude 3.5 Sonnet + o1! (Fully Tested): Gemini 2.0 Flash: BEST LLM Ever?! We're putting Google's NEW AI model to the ULTIMATE test! Does it really beat Claude 3.5 Sonnet and others?! In this video...
- Windsurf Tenerife GIF - Windsurf Surf Tenerife - Discover & Share GIFs: Click to view the GIF
- GitHub - PatrickJS/awesome-cursorrules: 📄 A curated list of awesome .cursorrules files: 📄 A curated list of awesome .cursorrules files. Contribute to PatrickJS/awesome-cursorrules development by creating an account on GitHub.
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
OpenAI ▷ #annnouncements (1 messages):
ChatGPT integration with Apple, 12 Days of OpenAI, Holiday themed demo
- ChatGPT integrates with Apple devices: In the YouTube video titled 'ChatGPT x Apple Intelligence—12 Days of OpenAI: Day 5', Sam Altman, Miqdad Jaffer, and Dave Cummings showcase the new ChatGPT integration into iOS and macOS while donning holiday sweaters.
- Stay in the loop by picking up the <@&1261377106890199132> role in
- Stay in the loop by picking up the <@&1261377106890199132> role in
- Holiday vibes during the demo: During the presentation, team members wore holiday sweaters to enhance the festive atmosphere while demonstrating the ChatGPT functionalities.
- This light-hearted touch aims to engage viewers and reflect the spirit of the holiday season.
Link mentioned: ChatGPT x Apple Intelligence—12 Days of OpenAI: Day 5: Sam Altman, Miqdad Jaffer, and Dave Cummings introduce and demo ChatGPT integration into iOS and macOS while wearing holiday sweaters.
OpenAI ▷ #ai-discussions (517 messages🔥🔥🔥):
Gemini 2.0 Flash, OpenAI services downtime, ChatGPT usage strategies, Image generation performance, API tool comparisons
- Gemini 2.0 Flash impresses users: Users reported that Gemini 2.0 Flash is performing impressively well, with some comparing its benchmarks favorably against OpenAI's models, including o1 Pro.
- Features like spatial reasoning and iterative image editing were highlighted, showing significant advancements in its capabilities.
- OpenAI services experiencing downtime: ChatGPT services were reported as unavailable due to a system issue that the team is actively working to fix.
- Several users noted their API tools and chatbots were also down, coinciding with the announcement of Apple's intelligence integration.
- Strategies for maximizing subscription usage: Users sought advice on how to effectively utilize new features like o1 and canvas to ensure maximum value from their subscriptions.
- Suggestions included using DALL-E for image generation, o1 for reasoning tasks, and canvas for building projects, while acknowledging that some features were currently offline.
- Concerns over image generation performance: Some users expressed skepticism about Gemini 2.0's image generation capabilities, mentioning they received subpar results in their attempts to morph images.
- While there are promising demos of iterative editing, reports from beta testers indicated mixed results.
- Comparison with other models like Llama and Google: The discussions highlighted how Gemini compares with o1 and Llama models, particularly in terms of pricing and token efficiency.
- Users noted the competitive landscape for model features and outputs, particularly with the recent announcements from Gemini and OpenAI.
Link mentioned: no title found: no description found
OpenAI ▷ #gpt-4-discussions (25 messages🔥):
Custom GPT Actions, API Error Handling, Platform Outages, File Formats for Scenarios
- Custom GPTs struggle with Action calls: Members discussed issues regarding Custom GPTs potentially calling external APIs multiple times during a failed generation cycle.
- One member suggested incorporating a session ID to avoid duplicate calls while ensuring proper API interaction.
- ChatGPT Status Updates on Outage: There was a confirmed outage affecting ChatGPT and the API, with updates being shared via a status link.
- Updates reported partial recovery of API traffic but noted that Sora remained down as of December 11, 2024.
- Handling API Errors Effectively: Discussion emerged around whether to repeat API calls until a successful response is obtained if the initial call fails.
- Members debated the effectiveness of error handling logic, implying that error responses like 403 or 500 could be useful to amend the logic.
- Optimal File Format for Scenario Data: One user inquired about the best file format for 25 scenarios to be used in a Custom GPT, currently stored in a Word document table.
- A member recommended using a basic text file to simplify the data without formatting issues, and suggested summarizing lengthy scenarios for better retrieval.
Link mentioned: API, ChatGPT & Sora Facing Issues: no description found
OpenAI ▷ #prompt-engineering (11 messages🔥):
Fine-tuning issues, Custom GPT instructions, Tool integration challenges, Canmore tool functions
- Users struggle with fine-tuning models: A member developing an OpenAI-based app in Node.js reported issues where the model fails to learn context post-fine-tuning, resulting in generic responses.
- They requested feedback on their training JSONL, hoping to identify potential problems from the community.
- Manipulating tool usage order in GPT: A member inquired if GPT instructions could dictate the order in which it utilizes tools, noting that it always searches the knowledge file before the RAG API.
- Another member explained that this may happen due to the reliance on coded responses, suggesting combining documents in the remote RAG instead of separating them.
- Chaining multiple tools together: The same member expressed difficulties chaining multiple tool calls within a single prompt, noting that it successfully makes API calls but doesn't follow up with further tool usage.
- A response recommended including meta-functional instructions and using canonical tool names to better manage these interactions.
- Details about Canmore tool functions: A detailed description was shared regarding the Canmore tool and its three main functions: create_textdoc, update_textdoc, and comment_textdoc, each with specific parameters.
- Suggestions were made on how to effectively use these functions for collaborative content management.
OpenAI ▷ #api-discussions (11 messages🔥):
Fine-tuning OpenAI models, Custom GPT tool usage, Chaining multiple tools, Canmore tool functions, Protected chat policies
- Challenge fine-tuning OpenAI models: A developer expressed frustration with their OpenAI-based app in Node.js, stating that the fine-tuned model still provides generic answers despite completing training.
- They requested help reviewing their training JSONL for potential issues.
- Custom GPT tools not used as intended: A member inquired if it is possible to prompt GPT to use tools in a specified order, noting that their API is often ignored in favor of knowledge files.
- Another member highlighted that the model may stochastically fail to prioritize the RAG API if it detects documents in its path.
- Difficulty chaining multiple tools: A user reported challenges in getting the GPT to chain tools together in a single prompt, noting that it only completes the first tool's API call.
- It was suggested to include meta-functional instructions to help GPT understand how to list multiple function calls in its response.
- Clarifying Canmore tool functions: A member detailed the functions of the Canmore tool, including commands to create, update, and comment on text documents in a structured way.
- They shared how each function works with specific JSON parameters to enhance interactivity and collaboration.
- Discussion of chat moderation policies: A conversation about a blocked discussion pointed to possible wording issues and protective policies within the ChatGPT settings.
- An image was attached to illustrate the moderation statement, although specific details were not shared.
Cursor IDE ▷ #general (410 messages🔥🔥🔥):
Cursor performance issues, Agent mode functionality, Comparison with other AI tools, Gemini model capabilities, Windsurf communication and features
- Cursor faces performance challenges: Users reported persistent issues with Cursor, particularly with the slow request response times and problems with the codebase indexing feature, which left many frustrated and unable to code effectively.
- The downtime seems related to upstream issues with OpenAI models, leading to degraded performance across the platform.
- Agent mode struggles: There were widespread complaints about the functionality of Cursor's agent mode, with users noting that it often hangs when trying to process code or access the codebase.
- Some users suggested that reindexing or restarting Cursor temporarily resolves the issue, but it remains a recurring problem.
- Comparison with other AI tools: Discussions highlighted the advantages of tools like Windsurf, particularly its more reliable communication and changelog transparency compared to Cursor.
- Users expressed that while Cursor offers unique features, its changelogs and user feedback could improve to match competitors better.
- Gemini model performance feedback: Users shared varying experiences with the Gemini model, with some noting it has capabilities comparable to others but still falling short in certain areas, especially when compared to Claude's performance.
- Despite mixed reviews, users remain interested in the potential advancements from Gemini's ongoing developments.
- Windsurf's enhanced engagement: Windsurf users praised the tool's clear communication and responsiveness in their community, stating it shows a commitment to user feedback and product improvement.
- The favorable engagement model of Windsurf was highlighted as a contrast to Cursor, prompting discussions on how Cursor could adopt similar practices.
- Tweet from Sundar Pichai (@sundarpichai): We’re kicking off the start of our Gemini 2.0 era with Gemini 2.0 Flash, which outperforms 1.5 Pro on key benchmarks at 2X speed (see chart below). I’m especially excited to see the fast progress on c...
- Supermaven: Free AI Code Completion: The fastest copilot. Supermaven uses a 1 million token context window to provide the highest quality code completions.
- Feature request: Long context mode: I see more people reacting to this comment than upvoting the feature. Just a reminder, you need to push the formal vote button
- Tweet from Aryan Vichare (@aryanvichare10): Introducing WebDev ArenaAn arena where two LLMs compete to build a web app. You can vote on which LLM performs better and view a leaderboard of the best models.100% Free and Open Source with @lmarena_...
- Tweet from OpenAI (@OpenAI): Canvas—a new way to work with ChatGPT to draft, edit, and get feedback on writing & code—is now available to all users in our 4o model.It’s fully rolled out on web and the ChatGPT desktop app for Wind...
- Unemployment Unemployed GIF - Unemployment Unemployed Laid Off - Discover & Share GIFs: Click to view the GIF
- Wait What Wait A Minute GIF - Wait What Wait A Minute Huh - Discover & Share GIFs: Click to view the GIF
- Wtff Cat Confused Orange GIF - Wtff Cat Confused Orange - Discover & Share GIFs: Click to view the GIF
- Cursor Status: no description found
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
Eleuther ▷ #announcements (1 messages):
Neural network training, Training Jacobian analysis, Parameter dependence, Bulk and chaotic subspaces, Training dynamics
- Neural Network Parameter Dependencies Unveiled: In a new paper, researchers analyze the training Jacobian, revealing how final parameters depend on initial ones by examining the matrix of derivatives.
- They found that training stretches and rotates parameter space, leading to bulk regions that are minimally affected by training and chaotic regions where perturbations are amplified.
- Bulk vs Chaotic Dynamics in Training: The paper identifies two key subspaces: the bulk with singular values (SVs) close to one that training does not significantly alter, and a chaotic subspace with SVs greater than one where changes are magnified.
- Interestingly, the dimensionality of the bulk is smaller when training on white noise compared to real data, suggesting a need for more aggressive parameter compression when dealing with unstructured input.
- Computational Challenges of Training Jacobian: Computational limitations restrict the analysis of the complete training Jacobian, as it remains intractable for large networks, making them focus on a smaller 5K parameter MLP for their experiments.
- Despite this, similar spectral patterns were observed in a 62K parameter image classifier, indicating potential for broader insights into neural training dynamics.
- Upcoming Research Series on Training Dynamics: This research is the first in a series on neural network training dynamics and loss landscape geometry, encouraging community involvement in the ongoing work.
- For further information and literature, refer to the dedicated channel for collaboration and insights on this topic.
- Explore the Paper and Code: The paper is available on arXiv with the link to the PDF and experimental HTML provided.
- Additional resources include the associated GitHub repository for contributing to the project.
- Understanding Gradient Descent through the Training Jacobian: We examine the geometry of neural network training using the Jacobian of trained network parameters with respect to their initial values. Our analysis reveals low-dimensional structure in the training...
- GitHub - EleutherAI/training-jacobian: Contribute to EleutherAI/training-jacobian development by creating an account on GitHub.
- Tweet from Nora Belrose (@norabelrose): How do a neural network's final parameters depend on its initial ones?In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final paramete...
Eleuther ▷ #general (78 messages🔥🔥):
HumanEval evaluations, OpenAI employee insights on training data, RWKV architectures and models, AdamW weight decay
- Interest in HumanEval evaluations: A member expressed interest in running HumanEval evaluations and inquired about the long-standing open pull request for its integration.
- They are seeking information on whether there is a plan to review and progress the PR.
- Training data takes priority: A post surfaced from an OpenAI employee discussing the significance of training data, asserting that after extensive experimentation, the models strongly approximate their datasets.
- The conversation recognized that while the model behavior seems to stem from the dataset, it also involves underlying biases within the model architecture.
- New RWKV models released: A member announced the release of new RWKV architectures, specifically the Flock of Finches and QRWKV-6 32B, each claiming to optimize training costs.
- They highlighted the models' comparable performance to larger counterparts while maintaining lower computational demands.
- Call for clarifications in AdamW settings: A member suggested that the weight decay setting in AdamW is crucial for understanding the impact on singular values and should be mentioned in related papers.
- They pointed out that weight decay affects the spectrum of the matrices, noting that it is helpful to clarify whether weight decay is on or off in experiments.
- The “it” in AI models is the dataset. – Non_Interactive – Software & ML: no description found
- Absolute Unit NNs: Regression-Based MLPs for Everything · Gwern.net: no description found
- Flock of Finches: RWKV-6 Mixture of Experts: The largest RWKV MoE model yet!
- recursal/QRWKV6-32B-Instruct-Preview-v0.1 · Hugging Face: no description found
- Q-RWKV-6 32B Instruct Preview: The strongest, and largest RWKV model variant to date: QRWKV6 32B Instruct Preview
- Add HumanEval by hjlee1371 · Pull Request #1992 · EleutherAI/lm-evaluation-harness: Hi, I added the widely-used HumanEval benchmark. This partially resolves #1157.The implementation relies on pass@k from the HF evaluate module, so it requires the environment variable HF_ALLOW_COD...
- The Bitter Lesson: no description found
- The Scaling Hypothesis · Gwern.net: no description found
- The Scaling Hypothesis · Gwern.net: no description found
- Why next-token prediction is enough for AGI - Ilya Sutskever (OpenAI Chief Scientist): Full episode: https://youtu.be/Yf1o0TQzry8Transcript: https://www.dwarkeshpatel.com/p/ilya-sutskeverApple Podcasts: https://apple.co/42H6c4DSpotify: https://...
- Tweet from Andrej Karpathy (@karpathy): # On the "hallucination problem"I always struggle a bit with I'm asked about the "hallucination problem" in LLMs. Because, in some sense, hallucination is all LLMs do. They are dre...
- 500'000€ Prize for Compressing Human Knowledge: no description found
Eleuther ▷ #research (296 messages🔥🔥):
Muon optimizer performance, Understanding harmful biases in LLMs, Regularization techniques in neural networks, Effects of weight decay in transformers, Gradient orthogonalization benefits
- Muon optimizer shows promise: Muon has been recognized as a strong contender among recent optimizer developments, with promising baseline performance and insightful underlying mathematics.
- While it's not yet confirmed to outperform AdamW, its potential is acknowledged, especially given observed issues with optimizers in existing models like Llama 3.
- Addressing biases in LLMs: A forthcoming paper suggests that harmful biases in large language models are an inevitable consequence of their current design, warranting a reevaluation of foundational AI assumptions.
- This perspective emphasizes the need for a deeper understanding of why biases occur rather than focusing solely on specific implementations.
- Exploring regularization methods: There's ongoing discussion about the complex role of regularizers like weight decay in training neural networks, particularly in attention layers of transformers.
- The relationship between L2 regularization and feature representations highlights the need for further investigation into how different regularization techniques affect model performance.
- Gradient orthogonalization as a regularizer: Previous research on gradient orthogonalization indicates its effectiveness as a strong regularizer, promoting feature diversity in deep learning models.
- Proposals for implementing batch whitening instead of batch normalization could yield similar benefits, particularly in contexts with small batch sizes.
- Weight decay's influence in training: A study discusses the impact of weight decay and L2-regularization on deep neural networks, especially regarding multiplicative interactions within parameter matrices in attention mechanisms.
- Findings suggest that L2-regularized losses may converge quickly to identical formulations involving nuclear norm regularization, raising questions about their utility during training.
- FlashRNN: Optimizing Traditional RNNs on Modern Hardware: While Transformers and other sequence-parallelizable neural network architectures seem like the current state of the art in sequence modeling, they specifically lack state-tracking capabilities. These...
- Gated Delta Networks: Improving Mamba2 with Delta Rule: Linear Transformers have gained attention as efficient alternatives to standard Transformers, but their performance in retrieval and long-context tasks has been limited. To address these limitations, ...
- Muon: An optimizer for hidden layers in neural networks | Keller Jordan blog: no description found
- Tweet from YouJiacheng (@YouJiacheng): New NanoGPT training speed record: 3.28 FineWeb val loss in 3.80 minuteshttps://gist.github.com/YouJiacheng/a6d4d543f9e9b15be3e94e42bb9b7643Changelog:- Split Value Embs, DDP(gradient_as_bucket_view=Tr...
- Weight decay induces low-rank attention layers: The effect of regularizers such as weight decay when training deep neural networks is not well understood. We study the influence of weight decay as well as $L2$-regularization when training neural ne...
- Recall to Imagine: no description found
- APOLLO: SGD-like Memory, AdamW-level Performance: Large language models (LLMs) are notoriously memory-intensive during training, particularly with the popular AdamW optimizer. This memory burden necessitates using more or higher-end GPUs or reducing ...
- DeepNet: Scaling Transformers to 1,000 Layers: In this paper, we propose a simple yet effective method to stabilize extremely deep Transformers. Specifically, we introduce a new normalization function (DeepNorm) to modify the residual connection i...
- Large Language Models are Biased Because They Are Large Language Models: This paper's primary goal is to provoke thoughtful discussion about the relationship between bias and fundamental properties of large language models. We do this by seeking to convince the reader ...
- Highway Networks: There is plenty of theoretical and empirical evidence that depth of neural networks is a crucial ingredient for their success. However, network training becomes more difficult with increasing depth an...
- Value Residual Learning For Alleviating Attention Concentration In Transformers: Transformers can capture long-range dependencies using self-attention, allowing tokens to attend to all others directly. However, stacking multiple attention layers leads to attention concentration. O...
- DenseFormer: Enhancing Information Flow in Transformers via Depth Weighted Averaging: The transformer architecture by Vaswani et al. (2017) is now ubiquitous across application domains, from natural language processing to speech processing and image understanding. We propose DenseForme...
Eleuther ▷ #lm-thunderdome (7 messages):
lm_eval_harness, Perplexity evaluation, Batch processing in inference frameworks, Token processing utility, AOTriton updates
- Evaluating Model Perplexity with lm_eval_harness: A member is using lm_eval_harness to evaluate model perplexity on data in jsonl files and shared their custom task configuration.
- They require per-token perplexity results for comparison with another study and sought advice on potential issues.
- Inferences Slowed by Single Sample Processing: Concerns were raised about inference being slow as each sample in the jsonl file gets processed separately, potentially leading to inefficiencies.
- The member noted that each sample gets individually tokenized and inferred, suggesting a need for batch processing.
- Pull Request to Enable Batch Inference: A member offered a solution to the processing delay by pushing a PR to batch across inference requests.
- They acknowledged the importance of ensuring no attention across requests and expressed gratitude for the prompt assistance.
- Concerns about Token Processing Function: The token processing function was discussed, noting that it computes different perplexities triggered by tokenizer input.
- Key metrics like token_perplexity, word_perplexity, and byte_perplexity are calculated but members sought clarification on efficiency gains.
- [ROCm] Update to AOTriton 0.8b: A commit was shared related to AOTriton 0.8b that introduced new features for SDPA operators on AMD systems, including nested tensor support.
- The notable features were highlighted in the commit message emphasizing the improvements brought by this update.
Link mentioned: [ROCm] Update to AOTriton 0.8b (#140172) · pytorch/pytorch@424156c: Notable new features for SDPA operators on AMD systems from AOTriton 0.8b:1. Nestedtensor support;2. MQA/GQA support;3. Restore Efficient attention support for causal=True and seqlen_q != seqle...
Eleuther ▷ #multimodal-general (1 messages):
tensor_kelechi: https://machinelearning.apple.com/research/multimodal-autoregressive
Bolt.new / Stackblitz ▷ #announcements (3 messages):
OSS Bolt, YouTube Streams, Supabase Integration
- Cole Talks OSS Bolt Live: Cole discussed OSS Bolt during a live session, viewed by the community on Twitter.
- This interactive conversation offered insights into the journey and developments surrounding OSS Bolt.
- Watch the Bolt Office Hours on YouTube: The latest Bolt Office Hours: Week 8 featuring Cole is now available on YouTube.
- This episode includes links to various resources related to the discussion, enhancing viewer engagement.
- Sneak Peek of Supabase Integration: The community got an exciting sneak peek of the Supabase integration during the live stream.
- This integration looks set to enhance the functionality of existing workflows and draw interest from developers.
Link mentioned: Bolt Office Hours: Week 8: 🔗 LinksBolt.diy: https://bolt.diyCole Medin YouTube: https://www.youtube.com/@ColeMedinBolt.diy announcement: https://twitter.com/stackblitz/status/18668673...
Bolt.new / Stackblitz ▷ #prompting (7 messages):
Web App Development, Shopify API Integration, Data Transformation Tools, Airtable Integration, Webhook Scenarios
- Building an Internal Dashboard with Product Sync: A member is developing a web app for their company, aimed at creating an internal dashboard that synchronizes with their Shopify store.
- Isoprophlex0 suggested integrating with Shopify's APIs to secure the data accessible only to the app, highlighting the comprehensive documentation available at Shopify API Docs.
- Leveraging Airtable for Inventory Management: Another member confirmed that they have their entire inventory on Airtable synced with the web app built using Bolt.
- Isoprophlex0 recommended transforming documents into a readable format for Bolt, potentially utilizing a different AI to assist in this process.
- File Manipulation with Make.com: A user shared their experience with using Make.com for file manipulation and LLM transfers, claiming it is often more efficient than traditional methods.
- They suggested utilizing webhook scenarios to streamline the process of sending data to the database for display purposes.
Link mentioned: Shopify API, libraries, and tools: Learn about Shopify APIs, libraries, and tools, and select the right option for your use case.
Bolt.new / Stackblitz ▷ #discussions (235 messages🔥🔥):
Bolt AI performance, Firebase vs Supabase, Error handling in Bolt, Token usage concerns, Community support in Bolt
- Bolt AI struggles with errors: Users reported frustrations with Bolt AI making repeated mistakes and failing to implement changes or resolve issues despite consuming large amounts of tokens.
- One user highlighted spending 200k tokens for no effective changes, attributing some issues to the underlying AI, Claude.
- Firebase vs Supabase for Stripe Integration: Several users discussed the transition from Firebase to Supabase for better integration with Stripe, weighing the merits of each database.
- It's noted that while both options are viable, the choice ultimately hinges on specific app needs, with some users leaning towards Supabase to avoid vendor lock-in.
- Token usage and debugging in Bolt: There is widespread concern about how quickly tokens can deplete during debug sessions, with many users sharing experiences of significant token expenditure without resolution.
- Suggestions included refining how prompts are framed to reduce wasted tokens while working with the AI.
- Community Support and Resources: Users expressed frustrations about the lack of direct tech support while relying primarily on community assistance for troubleshooting.
- Participants noted the importance of community channels like Discord and GitHub for sharing challenges and solutions.
- Cross-platform compatibility: Questions arose about the ability to transfer code between Bolt and other platforms like Cursor, emphasizing the need for smoother integrations.
- Users seek a more straightforward route for code migration when facing difficulties in Bolt.
Unsloth AI (Daniel Han) ▷ #general (152 messages🔥🔥):
Qwen 2.5 Fine-tuning, Gemini Voice, AWQ and Adapter Models, Context Length Capabilities, Performance Evaluation of Voice Models
- Fine-tuning challenges with Qwen 2.5: A user noted difficulties in getting numeric outputs from a fine-tuned Qwen 2.5 model, specifically with a simple multiplication query.
- Discussion highlighted how adding domain-specific knowledge is challenging, indicating that pre-training or utilizing RAG solutions may be more effective.
- Responses to Gemini Voice: Members shared excitement over the capabilities of Gemini Voice, describing it as 'crazy' and better than some alternatives.
- Comparisons were made with other voice models, with some users noting OpenAI's real-time voice API is costly and less capable.
- Insight on AWQ and Adapter Usage: It was discussed that while training directly with AWQ models isn't possible, using Adapters is viable and functional.
- Members remarked on the clever usage of Adapters even in scenarios where training models directly isn’t supported.
- Context Length Trials with Qwen 2.5: A user is experimenting with a 65k context on a 3B version of Qwen 2.5, reporting positive expectations for improved performance.
- There's anticipation around the capability of the model to handle 65,536 context tokens, suggesting increasing overall efficiency in fine-tuning processes.
- Performance Questions on Voice Models: Discussion regarding the peculiarities of specific voice models like GLM, where issues arise such as missing logits in outputs.
- Members expressed confusion over the architecture, mentioning that the model outputs binary tokens instead of standard probabilities, causing confusion.
- Google Colab: no description found
- Errors | Unsloth Documentation: To fix any errors with your setup, see below:
- Fine-tune Llama 3.3 with Unsloth: Fine-tune Meta's Llama 3.3 (70B) model which has better performance than GPT 4o, open-source 2x faster via Unsloth! Beginner friendly.Now with Apple's Cut Cross Entropy algorithm.
- unsloth/Llama-3.3-70B-Instruct-GGUF · Hugging Face: no description found
- Qwen2.5 Bugs & Issues + fixes, Colab finetuning notebook: When I loaded in Qwen 32b base with 4-bit bnb and transformers (in ooba) and just prompted it with <|im_start|> in notebook mode, and I guess...
- Reward Modelling - DPO, ORPO & KTO | Unsloth Documentation: To use DPO, ORPO or KTO with Unsloth, follow the steps below:
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (10 messages🔥):
Unsloth Merch, Dropshipping Challenges, Ecommerce Concerns
- Unsloth Merch in Demand: There's a strong interest in launching Unsloth merch, but concerns about delivery logistics were raised.
- Delivery will be a nightmare was the sentiment expressed by a community member.
- Dropshipping as a Solution: A suggestion was made to utilize dropshipping services like Printful to alleviate delivery concerns.
- This approach would potentially remove the need to manage delivery directly.
- Quality and Cost Issues in Dropshipping: Despite the ease of dropshipping on the surface, members warned that QA challenges can arise.
- One member mentioned that if quality suffers, the RMA costs can surpass profits from the products.
- Ecommerce Entrepreneurs Beware: A cautionary note was shared about many who attempt to venture into ecommerce and dropshipping often ending up with unexpected costs.
- Members advised to walk with care, as they could face a significant financial burden.
- Dropshipping Can Be a Trap: The conversation concluded with a metaphor indicating that dropshipping can be a trap filled with challenges.
- One member humorously noted, there will be dragons in the process.
Unsloth AI (Daniel Han) ▷ #help (58 messages🔥🔥):
Learning CUDA and Triton, Fine-tuning with custom datasets, Memory management during training, Using llama.cpp for model conversion, Data quality for domain adaptation
- Seeking Resources for CUDA/Triton Kernel Development: A user inquired about good resources for learning CUDA and Triton kernel development, seeking guidance from the community.
- Another member suggested early blogposts on the topic, specifically mentioning the introduction of Unsloth, which outlined its performance benefits.
- Challenges with Fine-tuning Using Custom Data: A member mentioned difficulties in running fine-tuning with Unsloth due to the UnslothTrainer expecting a single
textcolumn in their custom dataset.- They were advised to potentially add a mock text column and to ensure the input-output pairs were being handled correctly by the data collator.
- Managing Memory Spikes During Training: Concerns were raised about sudden spikes in RAM and GPU RAM usage during the training phase, leading to runtime collapses on Colab.
- Several users recommended adjusting batch sizes, balancing dataset lengths, and emphasized the importance of high-quality data for effective training.
- Using Llama.cpp for Model Conversion: A conversation unfolded regarding using llama.cpp for model conversion, with users sharing experiences and troubleshooting issues they faced.
- One member successfully resolved issues by performing a clean install and using specific versions of dependencies, including PyTorch 2.2.
- Issues with Tokenization in Collators: A user faced a ValueError regarding unrecognized tokens while trying to get a model to train on the last token using a custom collator.
- The collator was shared, highlighting the complexities in processing both text and image data while managing label masking for effective training.
- Introducing Unsloth: no description found
- Reddit - Dive into anything: no description found
- accelerate==1.2.0aiohappyeyeballs==2.4.4aiohttp==3.11.10aiosignal==1.3.1 - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #showcase (5 messages):
Roles in AI systems, Constrained generation, Feature extraction, Moderation techniques
- Exploring Roles in AI Systems: A member suggested a deeper dive into the various roles within AI systems (system/user/assistant), covering aspects such as personality cards and roleplay.
- This discussion highlighted the importance of better understanding roles to enhance functionality and user interaction.
- Harnessing Constrained Generation: Another idea was presented on explaining constrained generation through JSONSchema and grammar, emphasizing its benefits for improved code and feature extraction.
- The focus is on how this can lead to better RAG (Retrieval-Augmented Generation) and ensure perfect function calling.
- Decision Dilemma on Topic Prioritization: There was an amusing debate on which topic to address first, with a mix of excitement and humor expressed by members.
- Both!!! please... highlighted the eagerness to tackle both subjects, showcasing a collaborative spirit.
Unsloth AI (Daniel Han) ▷ #research (4 messages):
WizardLM Arena datasets, OpenPlatypus dataset, QwQ model conversion, MATH dataset
- WizardLM Arena Datasets Available: A member uploaded all datasets used in the WizardLM Arena paper to this repository. The commit b31fa9d was verified just a day ago.
- OpenPlatypus Dataset Insights: Another dataset titled OpenPlatypus with 25k samples has been shared, noting a cost of $30 incurred on open router for testing. It is recommended to exclude responses greater than 5000 and less than 100 tokens for cleaner results.
- Creating QwQ Versions of Models: A member mentioned that this method can be utilized to convert any model into a QwQ version and is in the process of making 14B and 3B Qwen models. Testing on these models has yet to occur.
- Mathematics Aptitude Test Dataset Available: The MATH dataset, consisting of competition problems with detailed solutions, can be found here. It can be used for training models to generate answer derivations and explanations.
- Benchmarking with MATH Dataset: The MATH dataset is suggested for captioning problems with qwq and comparing against ground truth answers. It's noted that this dataset is sometimes utilized for benchmarks but can be filtered to remove benchmark questions.
- hendrycks/competition_math · Datasets at Hugging Face: no description found
- forcemultiplier/arena-paper-datasets-jsonl at main: no description found
- forcemultiplier/QwQ_OpenPlatypus_25k_jsonl · Datasets at Hugging Face: no description found
Nous Research AI ▷ #announcements (3 messages):
New Projects Channel, Forge Discord Bot Access, Hermes 3 LLM Release
- New Projects Collaboration Channel Launched: A new channel for collaboration has been created for projects, allowing members to work together effectively.
- This is an opportunity for members to connect and build with others in the server.
- Instant Access to Forge via Discord Bot: Members can now access Forge through a Discord bot without needing API approval, facilitating immediate testing.
- To start, select the Forge Beta role from the customize page and then head to the corresponding channel.
- Introducing Hermes 3 LLM: Small but Mighty: Hermes 3 3B is now available on Hugging Face with quantized GGUF versions for optimized size and performance.
- Hermes 3 brings advanced capabilities in user alignment, agentic performance, and reasoning, marking a significant upgrade from Hermes 2.
Link mentioned: NousResearch/Hermes-3-Llama-3.2-3B · Hugging Face: no description found
Nous Research AI ▷ #general (90 messages🔥🔥):
Nous Forge Access, Quantum Computing Updates, Neurofeedback Research, AI Collaboration Proposals, Creative AI Simulation
- Unlocking Nous Forge Access: A member inquired about gaining access to the Nous Forge beta, expressing their desire for a response after a long wait.
- Another member mentioned that users can reach the beta through the
- Another member mentioned that users can reach the beta through the
- AI Credits for Development: A user shared a link offering free AI credits, stating it could be beneficial for those scaling projects in AI development.
- The post mentioned $50+ in credits from top-tier platforms, including the BFL API, in collaboration with Eleven Labs.
- Exciting New Research in Neurofeedback: Research was shared regarding a technique that allows the 'writing' of new learning patterns in the brain through neurofeedback from fMRI imaging.
- This method shows promising insights into implicit learning and could lead to new treatments for neuropsychiatric disorders.
- Quantum Computing Breakthroughs: A member shared an article about noise in quantum devices and how logical qubits can help mitigate errors, highlighting their significance in quantum computing.
- The paper indicated that logical qubits represent a critical advancement in the journey of quantum devices toward practical applications.
- Creative AI Exploration: Discussion centered around members experimenting with the World Simulator and creative AI tools, such as simulating personal experiences.
- Members expressed interest in building agents and exploring the creativity potential of AI, noting the unexpected nature of simulations.
- Turn Down the Noise: CUDA-Q Enables Industry-First Quantum Computing Demo With Logical Qubits: Infleqtion published groundbreaking work that used the NVIDIA CUDA-Q platform to both design and demonstrate an experiment with two of them.
- Tweet from Nous Research (@NousResearch): Announcing Nous Simulators!A home for all of our experiments involving human-AI interaction in the social arena. http://sims.nousresearch.com
- Can We Program the Brain to Learn Without Teaching? - Neuroscience News: Researchers have developed a groundbreaking technique to “write” new learning patterns directly into the brain using real-time neurofeedback from fMRI imaging.
- How the Brain Sorts Noise from Signal to Maintain Stable Perception - Neuroscience News: New research reveals how the brain separates internally generated noise from sensory signals, ensuring stable perception.
- New look at dopamine signaling suggests neuroscientists' model of reinforcement learning may need to be revised: Dopamine is a powerful signal in the brain, influencing our moods, motivations, movements, and more. The neurotransmitter is crucial for reward-based learning, a function that may be disrupted in a nu...
- Tweet from Black Forest Labs (@bfl_ml): We are excited to introduce the AI Engineer Pack, to accelerate your AI development.Together with @elevenlabsio, we are offering $50+ in credits for top-tier platforms, including the BFL API.Whether y...
Nous Research AI ▷ #ask-about-llms (62 messages🔥🔥):
Coconut model, KV-cache mechanisms, Thought tokens in LLMs, Amnesia mode in models, Custom LLMs on iOS
- Coconut model processes thoughts: The Coconut model engages the embedding layer to process initial sequences, creating a series of thought tokens before generating a response.
- This method prioritizes attention between the initial sequence and continuous thoughts throughout the response generation.
- KV-cache mechanics in LLMs: Discussions reveal the potential for larger KV caches for certain layers to enhance state building in LLMs.
- The attention mechanism is anticipated to utilize additional KV vectors for improved processing.
- Thought tokens enhance reasoning: The use of special thought tokens has been proposed as a way to facilitate reasoning without congesting initial layers during inference.
- Experiments suggest that such tokens could lead to more effective outputs, but previous studies indicate that recurring embeddings may be more efficient.
- Amnesia mode's availability: Questions arose regarding whether the new smol Hermes model features an Amnesia mode, but members reported that it seems absent.
- Random continuations occur even with empty prompts, suggesting the functionality is inconsistent.
- iOS LLM app capabilities: A query about iOS applications for running LLMs revealed most support custom downloaded models.
- This opens up avenues for users to experiment with various models, including Hermes.
- Tweet from Gurvan (@gurvanson): @iScienceLuvr already done by Schmidhuber in Recurrent Highway Networks https://arxiv.org/abs/1607.03474better illustrated here https://arxiv.org/abs/1707.05589
- Training Large Language Models to Reason in a Continuous Latent Space: Large language models (LLMs) are restricted to reason in the "language space", where they typically express the reasoning process with a chain-of-thought (CoT) to solve a complex reasoning pro...
Nous Research AI ▷ #research-papers (8 messages🔥):
DNF for 4D Generation, Chain of Continuous Thought (COCONUT), Github Repository for qtip, Model Capacity Utilization Insights, Communication Theory in AI
- DNF pushes boundaries in 4D modeling: The DNF model proposes a new 4D representation for generating deformable shapes by leveraging a dictionary learning approach, enhancing high-fidelity details while disentangling motion and shape.
- More details and insights on this approach can be found in the Project Page and the YouTube video.
- COCONUT redefines LLM reasoning: The introduction of Chain of Continuous Thought (COCONUT) will allow LLMs to reason within a continuous latent space, optimizing processing through a more direct embedding approach.
- Discussion points emerged around potentially renaming it to 'highway network', referencing related works by Schmidhuber on Recurrent Highway Networks.
- Github repository 'qtip' unveiled: A new GitHub repository has been launched for the project Cornell-RelaxML/qtip, aiming to contribute to the model's development.
- The repository invites contributions and collaboration, indicating a growing interest in high-quality implementations.
- Insights on model capacity utilization: Preliminary observations suggest that certain models, like llama3, exhibit drops due to model capacity utilization issues, marking a trend in performance analysis.
- The community is intrigued by the efficiency improvements that come without the need for retraining, suggesting a resurgence of signal processing techniques.
- Communication theory makes a comeback: There's an emerging interest in communication theory papers among AI practitioners, hinting at a shift in foundational concepts for model optimization.
- Discussions suggest these theories may play a pivotal role in future model designs and improvements.
- Tweet from Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr): Training Large Language Models to Reason in a Continuous Latent SpaceIntroduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT)Extremely simple change: instead of mapping...
- Tweet from Gurvan (@gurvanson): @iScienceLuvr already done by Schmidhuber in Recurrent Highway Networks https://arxiv.org/abs/1607.03474better illustrated here https://arxiv.org/abs/1707.05589
- GitHub - Cornell-RelaxML/qtip: Contribute to Cornell-RelaxML/qtip development by creating an account on GitHub.
- DNF: Unconditional 4D Generation with Dictionary-based Neural Fields: While remarkable success has been achieved through diffusion-based 3D generative models for shapes, 4D generative modeling remains challenging due to the complexity of object deformations over time. W...
- DNF: Unconditional 4D Generation with Dictionary-based Neural Fields: no description found
- DNF: Unconditional 4D Generation with Dictionary-based Neural Fields: Project Page: https://xzhang-t.github.io/project/DNF/While remarkable success has been achieved through diffusion-based 3D generative models for shapes, 4D g...
Nous Research AI ▷ #interesting-links (16 messages🔥):
Gemini 2.0, Gemini Flash, Deep Research feature, Maya: Multilingual Vision-Language Model
- Google's Gemini 2.0 Launch: Google DeepMind unveiled Gemini 2.0, introducing an experimental version called Gemini 2.0 Flash, featuring enhanced multimodal output and improved performance, as highlighted in their official announcement.
- Gemini 2.0 aims to pave the way for new agentic experiences with its tool use capabilities.
- Deep Research Feature Unveiled: The Deep Research feature in Gemini Advanced is designed to synthesize complex information and assist with detailed tasks, as highlighted by Sundar Pichai.
- This function intends to help users generate comprehensive reports with links to relevant sources, enhancing the AI's utility.
- Maya Model Preprint Shared: One member announced their work on Maya: Multilingual Vision-Language Model, sharing a link to the preprint through their Twitter post.
- The introduction of Maya showcases advancements in multilingual capabilities within vision-language models, stirring interest among participants.
- Tweet from Google DeepMind (@GoogleDeepMind): Welcome to the world, Gemini 2.0 ✨ our most capable AI model yet.We're first releasing an experimental version of 2.0 Flash ⚡ It has better performance, new multimodal output, @Google tool use - ...
- Introducing Gemini 2.0: our new AI model for the agentic era: Today, we’re announcing Gemini 2.0, our most capable AI model yet.
- Tweet from Jeff Dean (@🏡) (@JeffDean): We're also introducing a new feature today in Gemini Advanced called "Deep Research" (currently using the Gemini 1.5 Pro model) that will go off and do lots of independent work to synthesi...
Nous Research AI ▷ #research-papers (8 messages🔥):
4D Generative Modeling, Chain of Continuous Thought (COCONUT), Model Capacity Utilization, Signal Processing in AI, QTIP GitHub Repository
- DNF: A Leap in 4D Generative Modeling: A new 4D representation for generative modeling called DNF has been proposed, effectively capturing high-fidelity details of deformable shapes using a dictionary learning approach.
- This method provides temporal consistency and superior shape quality, integrated with a YouTube overview demonstrating its applications.
- Introducing COCONUT for LLM Reasoning: A new paradigm named Chain of Continuous Thought (COCONUT) has been introduced for training large language models to reason in a continuous latent space, simplifying existing methodologies.
- This improvement allows for end-to-end optimization through gradient descent via continuous thoughts, enhancing the efficiency in processing language tokens.
- Performance Insights on Model Capacity Utilization: Discussions indicate that model capacity utilization significantly affects performance, with observations that Llama3 shows more significant drops under certain conditions.
- Members noted the re-emergence of signal processing-inspired approaches, suggesting a regression to earlier communication theory principles.
- QTIP GitHub Repository Launch: A new repository named QTIP has been launched by Cornell-RelaxML, providing resources for model development and collaboration on GitHub.
- Users can contribute to the project via its GitHub page, which aims to facilitate advancements in related fields.
- Tweet from Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr): Training Large Language Models to Reason in a Continuous Latent SpaceIntroduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT)Extremely simple change: instead of mapping...
- Tweet from Gurvan (@gurvanson): @iScienceLuvr already done by Schmidhuber in Recurrent Highway Networks https://arxiv.org/abs/1607.03474better illustrated here https://arxiv.org/abs/1707.05589
- GitHub - Cornell-RelaxML/qtip: Contribute to Cornell-RelaxML/qtip development by creating an account on GitHub.
- DNF: Unconditional 4D Generation with Dictionary-based Neural Fields: While remarkable success has been achieved through diffusion-based 3D generative models for shapes, 4D generative modeling remains challenging due to the complexity of object deformations over time. W...
- DNF: Unconditional 4D Generation with Dictionary-based Neural Fields: no description found
- DNF: Unconditional 4D Generation with Dictionary-based Neural Fields: Project Page: https://xzhang-t.github.io/project/DNF/While remarkable success has been achieved through diffusion-based 3D generative models for shapes, 4D g...
Stability.ai (Stable Diffusion) ▷ #general-chat (176 messages🔥🔥):
VRAM usage and management, AI model recommendations for image enhancement, Scalping GPUs, Using AI for classification and tagging images, Voice training AI programs
- Understanding VRAM Usage: Users discussed how caching prompts in JSON format can impact memory usage, with some stating that 20 prompts would take only a few megabytes.
- Discussions about running models in lower precision like FP8 to reduce memory costs were also brought up.
- AI Model Recommendations for Spaceships: A user asked for model recommendations specifically for generating spaceships, citing their use of Dream Shaper and Juggernaut.
- Another user suggested training a LoRA if existing models did not meet their needs.
- Scalping GPUs: Members shared insights on how scalpers might use web scrapers to purchase GPUs on launch days.
- One user expressed concern about obtaining a GPU before scalpers and mentioned they opted against waiting in lines due to being outside the US.
- Using AI for Classification and Tagging Images: A user inquired about tools for extracting tags or prompts from images, leading to a discussion about image classification techniques.
- Clip Interrogator was recommended as a tool that could help with describing images without prior metadata.
- Voice Training AI Programs: A user asked what programs are commonly used to train AI on specific voices, with Applio mentioned as a potential tool.
- The discussion highlighted the interest in tools for voice manipulation and AI training applications.
- Facepalm Picard GIF - Facepalm Face Palm - Discover & Share GIFs: Click to view the GIF
- A Dive into Vision-Language Models: no description found
- GitHub - lllyasviel/IC-Light: More relighting!: More relighting! Contribute to lllyasviel/IC-Light development by creating an account on GitHub.
Notebook LM Discord ▷ #use-cases (13 messages🔥):
Discord Integration for Notebook, TTRPG Rule Book Utility, Experimenting with Output Styles, Podcast Enhancement Strategies, Solo Adventure Generation
- Integrating Notebook into Discord: A member inquired about adding a chat feature to Discord so users can directly ask Notebook questions, enhancing interactivity.
- This could provide a seamless connection for players wanting to engage more directly with the AI.
- Utilizing TTRPG Rule Books: One member shared success in using their 100-page rule book for a custom TTRPG as a tool for mechanics conversion.
- They highlighted the effectiveness of the book in translating narrative descriptions into specific game mechanics.
- Output Experimentation: A member experimented with forcing short outputs from NotebookLM, leveraging famous sayings during the generation process.
- They noted interesting discoveries and hinted at deeper implications regarding the content's responses.
- Elevating Podcasts with Visuals: A suggestion was made to enhance podcasts by using visuals, including a YouTube video titled 'Talking Heads Green Screen Podcast'.
- Members were encouraged to personalize content by employing chromakey techniques for a unique backdrop.
- Running Solo DnD Adventures with AI: A question was posed about using TTRPG sources to facilitate solo DnD-like adventures through chat interactions.
- Members shared mixed experiences, indicating varying success with this concept leaving room for further exploration.
- Women Suck at EVERYTHING?! Debating Fresh and Fit's Myron Gaines @StandOutTV_: Myron Gaines from the FreshandFit podcast thinks women suck at everything. From driving to sports, he believes women are inferior to men. Join me as I debate...
- UNREAL MYSTERIES 6: The Christmas Special - a Post-Apocalyptic Musical: Every good show has a Christmas Special and every good Christmas Special is a musical.... David and Hannah takes on Zombie reindeer, Australian Aliens, and l...
- Talking Heads Green Screen Podcast: 🎙️ Drowning in a sea of AI-generated podcasts? Make yours stand out! 🌊Need visuals to elevate your podcast? 🎥 Download this video and use it however you l...
Notebook LM Discord ▷ #general (93 messages🔥🔥):
Podcasting with NotebookLM, NotebookLM Features and Limits, Gemini 2.0 Integration, Input Methods for NotebookLM, User Experiences with AI Tools
- Exploring Podcasting Capabilities of NotebookLM: Many users expressed curiosity about creating podcasts using NotebookLM, with one member inquiring about the ability to customize podcast presenters.
- One noted that they hadn't utilized NotebookLM in a while, highlighting a gap in understanding its podcast features.
- Understanding NotebookLM's Limits on Notes: Users discussed the limitations of NotebookLM, such as the ability to have 1,000 notes with a maximum of 100,000 characters each, and 50 sources per notebook.
- Questions arose regarding the size limits of PDFs uploaded as sources and how they affect overall functionality.
- Gemini 2.0 Coming to NotebookLM: Speculation about NotebookLM integrating with Gemini 2.0 was prevalent, with some confirming that the transition was indeed happening.
- Discussion included humorous comments about the missed branding opportunity of using the Gemini symbol for branding.
- User Experiences with AI and Tools: Users shared their experiences with various AI tools and features, noting that Snapchat AI and Instagram's chat AI had been enjoyable.
- One user mentioned that NotebookLM has been helpful during challenging times, emphasizing its role in their workflows.
- Video Trimming and Usage: A member shared their experience using an online tool to trim YouTube videos, highlighting its ease of use for editing content effectively.
- They noted the tool's functionality in creating direct links to edited clips without requiring registration.
- Tweet from OpenInterX - Multimodal Mass Video Analysis with Contextual Memory: OpenInterX is a leading platform for multimodal mass video analysis with contextual memory, offering advanced AI-based tools for efficient video analysis.
- Brain mechanisms underpinning loss of consciousness identified: The shift from an awake state to unconsciousness is a phenomenon that has long captured the interest of scientists and philosophers alike, but how it happens has remained a mystery—until now. Through ...
- Dr. Ganapathi Pulipaka on Instagram: "Best Books on #Statistics for Advanced. #BigData #Analytics #DataScience #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Books #Programming #Coding #100DaysofCode https://geni.us/Statistics-Advanced": 62 likes, 2 comments - gp_pulipaka on December 5, 2024: "Best Books on #Statistics for Advanced. #BigData #Analytics #DataScience #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript...
- Volley on Instagram: 0 likes, 0 comments - somebiohacker on December 10, 2024
- nice bonk football (accelerate to 1.5 or 2.0): no description found
- Trim and Crop YouTube videos - YouTubeTrimmer.com: YouTubeTrimmer.com: Trim and Crop YouTube videos online. A free online tool.
- Hellfire: no description found
- 10 NotebookLM Podcast Prompts YOU MUST know: NotebookLM Podcast is changing the game-so why settle for generic two-host chats? In this video, I'll reveal 10 secret prompts that will elevate your Noteboo...
- CRISPR genome editing can be controlled with ultrasound | PET: A focused ultrasound beam was directed to a tumour containing CRISPR/Cas9, causing localised heating and activation of the CRISPR system.
- The neural basis of temporal processing - PubMed: A complete understanding of sensory and motor processing requires characterization of how the nervous system processes time in the range of tens to hundreds of milliseconds (ms). Temporal processing o...
- December 11, 2024: no description found
Interconnects (Nathan Lambert) ▷ #events (13 messages🔥):
Microwave Gang, Discord Profile Naming, Open Hangouts Scheduling, Whova App Preferences
- Welcome to the Microwave Gang: A member suggested creating an entire channel dedicated to Microwave Gang if there's enough interest among members.
- Another member humorously mentioned that they were too lazy to come up with a name, resulting in spammed initials.
- Choosing Discord Names with a Family Touch: One member revealed that their main Discord profile name and picture were chosen by their daughter, bringing a personal touch to their online identity.
- This playful detail sparked laughter and lightheartedness in the chat, adding to the community's bonding.
- Open Hangouts Announced for the Weekend: A member announced two open hangouts scheduled for 1:30-2:30pm on Thursday and Friday, along with plans to finalize the venue.
- They also hinted at possibly starting early for paid participants who are already in the loop.
- Whova App Discomfort Expressed: A member humorously expressed their refusal to use the Whova app, indicating a preference for other options.
- This comment generated a brief discussion around app choices, highlighting the varied preferences within the group.
- Chicken Microwave GIF - Chicken Microwave Spin - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
Interconnects (Nathan Lambert) ▷ #news (49 messages🔥):
Gemini 2.0 Flash, OpenAI Product Focus, Video Generation Models, Sora Sign-ups, Coding Capabilities
- Gemini 2.0 Flash debuts with excitement: Google announced the rollout of Gemini 2.0 Flash, described as impressive in capabilities and coding performance, particularly in benchmarks where it outperformed previous versions.
- Users are excited about its multimodal nature, including improvements in tool use and coding tasks, but some noted concerns about its stability and effectiveness compared to other models.
- OpenAI maintains product-centric approach: The community has observed that OpenAI's focus on delivering strong products has allowed it to stay ahead in the field, as its competitors struggled to keep pace.
- This sentiment echoes the idea that product usability will always take precedence in ongoing developments within AI technologies.
- Mixed reviews on video generation models: Feedback from the Chinese community regarding various video generation models, including Kling 1.5 and Huyuan, indicate that Gemini's video capabilities are underwhelming by comparison.
- Despite some initial hype, users noted that Gemini is buggy and doesn't meet the expectations set by its predecessors and competitors.
- Sora sign-ups become available again: Sora sign-ups have resumed, leading to user excitement as some members report gaining access and looking to explore its capabilities further.
- This resurgence of interest comes amid ongoing discussions about AI model functionalities and usability.
- Coding capabilities of Gemini impress users: Many users have remarked on how well Gemini 2.0 Flash performs in coding tasks, even rivaling other well-established platforms like Claude.
- The general consensus is that its strength in coding presents exciting opportunities for developers moving forward.
- Tweet from 汗青 HQ (@hanqing_me): 玩了一天下来,不得不说Sora的稳定性真的是很好,特别稳
- Tweet from TestingCatalog News 🗞 (@testingcatalog): BREAKING 🚨: Gemini Flash 2.0 Experimental is rolling out to some users already! Looks like Google is up to something for today 👀It appears in the dropdown and comes with an "Experimental" la...
- Tweet from Logan Kilpatrick (@OfficialLoganK): Announcing Gemini 2.0 Flash, a new multimodal agentic model (initially experimental), with our best-ever results on capabilities and benchmarks: https://developers.googleblog.com/en/the-next-chapter-o...
- Tweet from BioBootloader (@bio_bootloader): this is super impressive, butAnthropic's post showed that they used fairly basic scaffolding - the agent selects tools until it decides to submitwhile from this it seems 2.0 Flash's score was ...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Breaking News from Chatbot Arena⚡@GoogleDeepMind Gemini-2.0-Flash debuts at #3 Overall - a massive leap from Flash-002!Highlights (improvement from Flash-002):- Overall: #11 → #3- Hard Prompts: #15 → ...
- Introducing Gemini 2.0: our new AI model for the agentic era: Today, we’re announcing Gemini 2.0, our most capable AI model yet.
- Tweet from Logan Kilpatrick (@OfficialLoganK): Gemini 2.0 Flash is pretty good at coding : )
- Gemini: Gemini 2.0 our most capable AI model yet, built for the agentic era.
Interconnects (Nathan Lambert) ▷ #ml-drama (6 messages):
Scaling Laws Debate, Latent Space Podcast Live Event, Influencers and Scaling, Community Engagement, Wholesomeness in AI Discussions
- Scaling Laws Debate at NeurIPS: Join @dylan522p for a live Oxford Style Debate on scaling laws tomorrow at 4:00 PM during NeurIPS, where he faces off against all challengers.
- Excited attendees are encouraged as this debate tackles the notion that scaling has hit a wall, aiming to address criticisms from Twitter influencers.
- Latent Space Podcast LIVE Event Announced: The Latent Space Podcast is hosting a live event with @dylan522p, who is challenging anyone brave enough to debate him on scaling laws.
- Sponsorships make attendance free, and the event features trophies for participants, appealing for bold contenders.
- Community Engagement Over Debates: A member expressed excitement and found the debate concept hilarious, demonstrating community engagement with the event.
- The community's enthusiasm reflects their interest in pressing topics within AI, particularly in an entertaining format.
- Support for Personal Content Battles: Another member humorously suggested having a supporter 'battle Gary' over their content, adding a lighthearted note to the conversation.
- The community's responses highlight a supportive environment where members can share their experiences and emotions about content.
- Wholesome AI Community Vibes: A member's comment about the wholesome nature of the discussions fosters a sense of camaraderie within the AI community.
- The tone of the conversation suggests an uplifting atmosphere that encourages positivity alongside serious debates.
- Tweet from Dylan Patel ✈️ NeurIPS (@dylan522p): Is scaling done for? Got a sick debate between myself and the illustrious Jonathan Frankle of Lottery Ticket and MosaicML / DatabricksAt 4:00PM live at NeurIPS tomorrow (Wednesday)Register now!https:/...
- Michelangelo D’Agostino (@mdagost.bsky.social): I have no inside information, only what @natolambert.bsky.social wrote in that post:
Interconnects (Nathan Lambert) ▷ #random (11 messages🔥):
Joining Llama team, Gemini secrets, Presentation on reasoning, Major papers on reasoning, Nous Dunks compliment
- Exciting News: Joining Llama Team!: A member announced that they will be joining AI at Meta's Llama team next month to work on the next generation of llama models, expressing excitement for upcoming projects.
- They also stated their desire to contribute towards a healthier ecosystem that benefits everyone, quoting Zuck on AGI goals and open sourcing efforts.
- Hoping for Gemini Secrets: Members expressed hope that Gemini secrets will integrate into the multimodal Llama team following past disappointments with Llama 3.2-vision.
- There was a humorous exchange about discussing insights from Kambhampathi's works during a presentation, though some noted it might distract from the main points.
- Preparing for a Reasoning Presentation: A member shared that they are presenting on reasoning in 4 hours and sought major papers or notable critiques to include in their slides.
- Another member, stuck without access to their resources, lamented being in a remote location and hinted at discussing some STaR works.
- Casual Banter Amidst Location Jokes: Some discussions humorously highlighted members' shared experiences of being in remote locations, with one referring to Paris as 'bumfuck nowhere'.
- Casual remarks intertwined with expressions of comfort in their locations seemed to maintain a light atmosphere.
- Compliment on Nous Dunks: A member received a compliment on their Nous Dunks and remarked, 'you have no idea what goes on behind closed doors'.
- This comment elicited a humorous reaction, showcasing the casual nature of discussions in the channel.
- Tweet from rohan anil (@_arohan_): And here we go as the secret is out: I will be joining @AIatMeta ‘s Llama team next month to work on the next generation of llama models. And yes, I already have some llama puns ready before the next ...
- [12112024, Latent Space @ NeurIPS] Reasoning: The state of reasoning Nathan Lambert Ai2 // Interconnects.ai Latent Space // NeurIPS 2024 Lambert | Thoughts on reasoning 1
Interconnects (Nathan Lambert) ▷ #memes (8 messages🔥):
Scalability in AI, Criticism of GM, Responses to Online Discourse
- Scaling Laws Under Scrutiny: In response to criticism, @fchollet clarified that they have not bet against scaling laws, but rather have pushed back against the idea that simply increasing model size will be sufficient for progress.
- They noted that advancements have come from search, adaptation, and program synthesis instead of solely from growing model sizes.
- GM's Reputation Takes a Hit: @kvogt bluntly stated that "GM are a bunch of dummies," indicating a severe criticism directed at the company and its leadership.
- In a follow-up comment, it was noted that while this might be tough for someone like Kyle, GM acquired his company for a whopping $1 billion, sparking discussions on the value of that acquisition.
- Rising Frustration on Twitter: A user commented on the escalating nature of discourse on Twitter, with @natolambert admitting to increasing their straightforward responses, starting from a stance of just saying 'no'.
- They acknowledged the intensity of the current conversations, marking it as a significant change in their interactions.
- Tweet from Kyle Vogt (@kvogt): In case it was unclear before, it is clear now: GM are a bunch of dummies.
- Tweet from François Chollet (@fchollet): Dude, what are you talking about?1. I have no idea who you are, so I don't "think" anything about you.2. I have never bet against scaling laws. Rather, I have pushed back against the idea ...
Interconnects (Nathan Lambert) ▷ #cv (1 messages):
CV Channel Engagement, MLLMs, VLMs
- Boosting Engagement in the CV Channel: A member expressed hope to increase participation in the CV channel, seeking to connect with more people interested in computer vision.
- They identified themselves as a CV / perception person focused on MLLMs and VLMs.
- Focus on Multimodal Learning: The discussion highlights a specific interest in MLLMs (Multimodal Large Language Models) and VLMs (Vision-Language Models) within the channel.
- This reflects a growing trend towards integrating various modalities in AI, enhancing the capabilities of perception systems.
Interconnects (Nathan Lambert) ▷ #reads (11 messages🔥):
AI Scaling Laws, LLM Creativity Benchmarking, Inference Time Compute, RL LLMs, Scaling LLM Test-Time Compute
- Fear and Doubt Surrounding AI Scaling Laws: There's been a rising trend of fear, uncertainty, and doubt (FUD) regarding AI Scaling Laws, with various predictions claiming the end of these models' rapid advancement, as highlighted in a recent article. Journalists are supporting these narratives with noisy leaks and vague information about the failures in model scalability.
- Exploring LLM Capabilities in Creative Tasks: A discussion surfaced on measuring LLM capabilities in soft 'creative' tasks, like brainstorming, and exposing deficiencies in creative writing domains. It pointed out that user opinions often diverge from benchmark scores, particularly noting Claude-3's popularity despite not always ranking highest on creativity benchmarks.
- Challenges in RL LLMs and Test-Time Compute: Members highlighted their interest in two recent YouTube videos related to RL LLMs and Scaling Test-Time Compute, one presented by Charlie Snell from UC Berkeley which focuses on enhancing LLM outputs. Another tutorial aimed at explaining the key technologies behind 'Inference-Time Compute', crucial for optimizing OpenAI's O1 performance.
- PDF Resource Sharing Turns Confusing: A user shared a PDF related to the Scaling Laws topic, but later noted that the document lacked premium content, expressing frustration over the misunderstanding of the request. This led to a light-hearted exchange about the resource's availability and completeness.
- Uncertainty in Video Learning Resources: A member commented on their struggle to find time to watch insightful YouTube videos about LLM reasoning and related topics, noting the quality of the content might be variable. Others shared links to these resources, with varying levels of enthusiasm regarding their depth and information available.
- Towards Benchmarking LLM Diversity & Creativity · Gwern.net: no description found
- Scaling Laws – O1 Pro Architecture, Reasoning Training Infrastructure, Orion and Claude 3.5 Opus “Failures”: There has been an increasing amount of fear, uncertainty and doubt (FUD) regarding AI Scaling laws. A cavalcade of part-time AI industry prognosticators have latched on to any bearish narrative the…
- Scaling Laws – O1 Pro Architecture, Reasoning Training Infrastructure…: no description found
- The Hitchhiker's Guide to Reasoning: A talk about LLM reasoning, covering various methods, core problems, and future research directions!Links:- Slides: https://docs.google.com/presentation/d/e/...
- Charlie Snell, UC Berkeley. Title: Scaling LLM Test-Time Compute: Abstract:Enabling LLMs to improve their outputs by using more test-time computation is a critical step towards building generally self-improving agents that ...
- LTI Special Seminar by Yi Wu: no description found
- Inference Time Compute: This tutorial aims at explaining the key technologies behind "Inference-Time Compute", which is said to be the core of OpenAI O1. I will talk about how we ca...
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
``
- Frustration Expressed in Discord: Users expressed agitation with minimal responses, as seen in the exchange where one user exclaimed, 'bruh' and followed up with 'cmon', indicating dissatisfaction with discussions.
- Minimal Engagement Noted: The brief interaction between users suggests a lack of deeper conversation or engagement in the channel, illustrating potential frustration with the ongoing dialogue.
LM Studio ▷ #general (81 messages🔥🔥):
Merging Documents with AI, Running Models on Multiple GPUs, Using LM Studio with Web Access, Handling Model Parameters, Updating LM Studio
- Tips for Merging Documents with Generative AI: A member asked for advice on merging two documents using generative AI but received suggestions to use traditional methods like the MS Word merge option instead.
- Another suggested writing a script to perform an exact merge rather than relying on vague prompts.
- Parallel GPU Usage Discussions: One user inquired about using multiple GPUs for running models, specifically two 3070s and a 3060ti.
- It was noted that LM Studio's GPU offload is currently a simple toggle, leaving users to explore workaround solutions through environment variables.
- Web Access for Models in LM Studio: A member questioned if their model could have web access, and responses indicated it would require custom solutions via the API rather than the chat interface.
- This reflected a broader interest in integrating models with external tools and websites for enhanced functionality.
- Model Training Challenges: Discussants examined the challenges of training large language models (LLMs), emphasizing that while creating a model isn't overly difficult, creating a high-quality one is.
- Concerns were raised regarding the performance of a model trained on insufficient data and parameters, with insights shared on the importance of architecture.
- Updating and Customizing LM Studio: A user noted that they were on an outdated version of LM Studio and learned that the latest update must be done manually.
- Discussions also touched on customizing the GUI, with resources found for potential modifications available on GitHub.
Link mentioned: SicariusSicariiStuff/LLAMA-3_8B_Unaligned_BETA_GGUFs · Hugging Face: no description found
LM Studio ▷ #hardware-discussion (5 messages):
Alphacool D5 Pump Setup, LMStudio GPU Usage
- Alphacool's D5 Pump Integration: Alphacool has released a model that features the D5 pump already installed, which some members find impressive.
- A member expressed regret for not choosing this setup due to space issues in their big case, which is already filled with 4 GPUs and 8 HDDs.
- Confirmed Multi-GPU Support in LMStudio: There is a qualified confirmation that LMStudio does utilize multiple GPUs at once, enhancing its performance.
- Another member inquired about the browser discovery features integrated into the client, indicating interest in its broader capabilities.
Latent Space ▷ #ai-general-chat (52 messages🔥):
Nous Simulators Announcement, Hyperbolic Series A Funding, Gemini 2.0 Flash Launch, Stainless Series A Update, Realtime Multimodal API Introduction
- Nous Simulators Launches: Nous Research announced the launch of Nous Simulators to experiment with human-AI interaction in social contexts.
- This platform aims to provide insights into AI behaviors and interactions.
- Hyperbolic Raises $12M Series A: Hyperbolic has successfully raised a $12M Series A, with ambitions to develop an open AI platform featuring an open GPU marketplace.
- They aim for transparency and community collaboration, offering the lowest prices for H100 SXM GPUs at $0.99/hr.
- Gemini 2.0 Flash Launches: Google's Gemini 2.0 Flash debuted at position #3 overall in the Chatbot Arena, outperforming previous models like Flash-002 significantly.
- Key improvements include better performance in hard prompts and coding tasks, with real-time capabilities enabling multimodal interactions.
- Stainless Series A Funding Success: Stainless API announced a significant $25M Series A funding round led by notable investors including a16z and Sequoia.
- This funding aims to enhance their offerings behind popular AI SDKs, contributing to a robust development ecosystem.
- Realtime Multimodal API Unveiled: Logan K unveiled a new Realtime Multimodal API powered by Gemini 2.0 Flash, facilitating real-time audio, video, and text streaming.
- This tool promises dynamic tool calls in the background for a seamless interactive experience.
- Tweet from rohan anil (@_arohan_): And here we go as the secret is out: I will be joining @AIatMeta ‘s Llama team next month to work on the next generation of llama models. And yes, I already have some llama puns ready before the next ...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Breaking News from Chatbot Arena⚡@GoogleDeepMind Gemini-2.0-Flash debuts at #3 Overall - a massive leap from Flash-002!Highlights (improvement from Flash-002):- Overall: #11 → #3- Hard Prompts: #15 → ...
- Tweet from Dylan Patel ✈️ NeurIPS (@dylan522p): Scaling LawsO1 Pro ArchitectureReasoning InfrastructureOrion and Claude 3.5 Opus “Failures”AI Lab Synthetic Data InfrastructureInference Tokenomics of Test Time ComputeThe Data WallEvaluation's ar...
- Tweet from undefined: no description found
- Tweet from Andy Konwinski (@andykonwinski): I'll give $1M to the first open source AI that gets 90% on this sweet new contamination-free version of SWE-bench - http://kprize.ai
- Tweet from Cerebras (@CerebrasSystems): Introducing CePO – a test time reasoning framework for Llama- Llama3.3-70B + CePO outperforms Llama 3.1 405B and approaches GPT-4 & Sonnet 3.5- CePO enables realtime reasoning. Despite using >10x...
- Tweet from Yuchen Jin (@Yuchenj_UW): 🚀 Excited to share that we raised a $12M Series A!At Hyperbolic, our mission is to build an open AI platform. By "open", we mean:> Open GPU marketplace: Think of it as GPU Airbnb—anyone ca...
- Tweet from Logan Kilpatrick (@OfficialLoganK): Introducing the new Realtime Multimodal API, powered by Gemini 2.0 Flash! You can stream audio, video, and text in, while dynamic tool calls happen in the background (Search, code execution, & functio...
- Tweet from ʟᴇɢɪᴛ (@legit_rumors): this just got added behind the scenes 👀
- Tweet from Simon Willison (@simonw): If you try nothing else today, give the demo at https://aistudio.google.com/live a go - it lets you stream video and audio directly to Gemini 2.0 Flash and get audio back, so you can have a real-time ...
- Tweet from Lisan al Gaib (@scaling01): holy shit! is that real chat?Google absolutely cooked with Gemini 2.0 Flash.Gemini 2.0 Flash BEATS all o1 models and Sonnet 3.5 in SWE-bench verifiedQuoting wh (@nrehiew_) Updated the chart with Gemin...
- Tweet from kepano (@kepano): my quick review of Gemini 2.0 Flash released today — it's really fast, and free (for now?)Feels on par with Claude Haiku 3.5 in my Web Clipper testing. Here's an example:
- Tweet from Nous Research (@NousResearch): Announcing Nous Simulators!A home for all of our experiments involving human-AI interaction in the social arena. http://sims.nousresearch.com
- Tweet from Mostafa Dehghani (@m__dehghani): Gemini2 Flash on the challenge of what the internet has been asking for: breaking down "draw the rest of the owl" into actual steps with interleaved generation. not perfect yet, but it’s on t...
- Tweet from Jeff Dean (@🏡) (@JeffDean): We're also introducing a new feature today in Gemini Advanced called "Deep Research" (currently using the Gemini 1.5 Pro model) that will go off and do lots of independent work to synthesi...
- Tweet from Alex Volkov (Thursd/AI) (@altryne): Whoah looks like we're getting Gemini 2 flash! 128k multimodal in @googleaistudio 👏
- Tweet from David (@DavidSHolz): Live with Restream, December 11 https://x.com/i/broadcasts/1OwxWNdLkDZJQ
- Tweet from Mostafa Dehghani (@m__dehghani): Interactive and interleaved image generation is one of the areas where Gemini 2 Flash shines!A thread for some cool examples:
- Tweet from TechCrunch (@TechCrunch): OpenAI-backed Speak raises $78M at $1B valuation to help users learn languages by talking out loud https://tcrn.ch/3D9gZw4
- Tweet from Stainless (@StainlessAPI): Excited to share that we’ve raised a $25M Series A, led by @JenniferHLi @a16z along with @sequoia, @thegp, @felicis, @zapier, and @mongoDB Ventures:https://www.stainlessapi.com/blog/stainless-series-a
- Tweet from hardmaru (@hardmaru): Excited to announce Sakana AI’s new paper: “An Evolved Universal Transformer Memory” 🧠https://arxiv.org/abs/2410.13166This work introduces Neural Attention Memory Models which are evolved to optimize...
- Latent Space LIVE! - Best of 2024: Startups, Vision, Open Src, Reasoning, & The Great Scaling Debate: https://lu.ma/LSLIVE
- no title found: no description found
Latent Space ▷ #ai-announcements (2 messages):
Latent Space Live 2024, NeurIPS Conference, AI Agents Debate, Bolt Success, YouTube Streaming Event
- Latent Space Live 2024 lineup announced: Exciting speakers confirmed for Latent Space Live! at the NeurIPS Conference, including topics on 2024 in AI Startups/Macro and Open Models.
- Organizers are looking to finalize a few more speaker slots and invite discussions on Multi Agents and End of Scaling.
- AI Engineers rally for academic conferences: The event emphasizes filling knowledge gaps at major academic conferences, with Singapore as the next destination for ICLR 2025.
- This initiative aims to create a supportive space for AI Engineers during large conferences moving forward.
- Bolt's rapid success in AI engineering: Bolt reported over $8m ARR in just 2 months as a Claude Wrapper, signaling robust interest in code agent engineering.
- Key discussions included strategies for complex task breakdown and maintaining user interfaces, highlighting Bolt's unique position in the market.
- Streaming Latent Space LIVE!: Catch the live event discussing the Best of 2024 on YouTube, including topics like Startups, Vision, and The Great Scaling Debate.
- Viewers can access the event details through this link for more information.
- Channel updates and Zoom usage: The #llm-paper-club channel has been temporarily renamed for better organization of discussions surrounding the event.
- Discord members are encouraged to join via the provided Zoom link to engage in live discussions.
- Tweet from swyx @LatentSpacepod LIVE! (@swyx): buried lede but very proud to announce the initial speakers for LS LIVE! on day 1 of @NeuripsConf:- 2024 in AI Startups/Macro @saranormous- 2024 in Vision: @roboflow + @vikhyatk- 2024 in Open Models: ...
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- Latent Space LIVE! - Best of 2024: Startups, Vision, Open Src, Reasoning, & The Great Scaling Debate: https://lu.ma/LSLIVE
Latent Space ▷ #llm-paper-club-west (7 messages):
Zoom call arrangements, Thriaal on Chinchilla, YouTube live stream
- Zoom Call Link Shared: A member shared the Zoom link for the upcoming session starting at 9am.
- There was a moment of urgency as a member had to jump on a call quickly, prompting them to seek additional information.
- Inquiry about Thriaal on Chinchilla: A member questioned the status of Thriaal on Chinchilla, seeking clarity on the developments around this topic.
- This inquiry highlights ongoing interest in the project, sparking discussions among the group.
- YouTube Live Stream Announcement: A YouTube stream titled 'Latent Space LIVE! - Best of 2024: Startups, Vision, Open Src, Reasoning, & The Great Scaling Debate' was announced.
- Additional details are provided in the stream's description, implying a significant event discussion ahead.
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- Latent Space LIVE! - Best of 2024: Startups, Vision, Open Src, Reasoning, & The Great Scaling Debate: https://lu.ma/LSLIVE
Modular (Mojo 🔥) ▷ #general (7 messages):
C and C++ Standardization, Modular Website Forum Access
- C and C++ successful standardization of pure functions: The effort to standardize marking functions as pure in C and C++ has seen success, with the C side being included in C23.
- Modular website's forum link hard to find: A member expressed frustration about the Modular website not clearly linking to the forum, stating it seems buried under the Company feature.
- Another member noted that the team is currently focused on improving the forum and aims for a public launch in January before making further links.
- Community feature suggestions for Modular website: Suggestions were made to add a Community feature to the Modular menu to improve access to the forum.
- The response indicated a deliberate choice to avoid linking from the homepage to streamline the experience for users during the initial launch.
- Modular: Control, develop & deploy high-performance AI: The Modular Accelerated Xecution (MAX) platform is the worlds only platform to unlock Generative AI performance and portability across CPUs and GPUs. Integrate AI into every product, everywhere.
- Unsequenced functions: no description found
Modular (Mojo 🔥) ▷ #mojo (49 messages🔥):
Multi-Paxos Protocol Implementation, Mojo Struct Design, Named Results Performance, Programming Environment Preferences, Mojo Open Source Timeline
- Multi-Paxos Protocol Fails Initial Tests: A user implemented a Multi-Paxos consensus protocol in C++, but feedback highlighted that the initial version failed to meet core Multi-Paxos requirements, such as handling multiple proposals efficiently.
- Key features like timeouts, leader switching, and retries are essential for a complete implementation, similar to the necessity of back-propagation in neural networks.
- Debate on Mojo Struct Design Consistency: Discussions arose regarding whether
__del__methods should be opt-in or opt-out for Mojo structs, with opinions divided on the impact of consistency versus developer ergonomics.- Some members argued for ergonomic design to reduce boilerplate code, while others preferred a consistent approach across using traits and methods.
- Performance Guarantees of Named Results: Named results in Mojo allow direct writes to an address, avoiding sometimes costly move operations, thus providing performance guarantees during function returns.
- While this feature is seen more for its guarantee than outright performance improvement, it optimizes situations where a move might not be possible.
- Preferred Coding Environments for Mojo: Members discussed their coding environments, noting that many prefer CLI for Mojo due to direct learning experiences, while others use VS Code for its basic linting support.
- One user mentioned the anticipation of using Zed with a compatibility update for the new Magic CLI, showcasing the community's experimentation with different tools.
- Inquiry about Mojo's Open Source Future: A user inquired about the timeline for Mojo to be open sourced, indicating a desire for wider accessibility and collaboration in the community.
- This reflects a growing interest in the platform beyond its current user base, highlighting expectations for future developments.
Cohere ▷ #discussions (13 messages🔥):
AI tools and chatbots, DM communication, Support requests
- Industry-specific AI tools: A member noted that the usage of AI tools, including chatbots, largely depends on the industry.
- They implied that specific tools might be more effective depending on the context of application.
- Direct messages for urgent queries: In a conversation, members suggested sending direct messages to either them or the support team for urgent inquiries rather than generic requests.
- This highlights the preference for more personalized communication for critical issues.
- Support team assistance: A member assured that the support team is currently staffed and available to address queries.
- Another member reiterated that specific communication should be directed to the support email provided.
Link mentioned: Magic Eight GIF - Magic Eight Eightball - Discover & Share GIFs: Click to view the GIF
Cohere ▷ #questions (8 messages🔥):
Rerank 3.5 English Model, CmdR+Play Bot Status, Aya Expanse Performance, API Request 403 Error, Dataset Recommendations for Quantification
- Inquiry about Rerank 3.5 English Model: A member inquired about any plans for a rerank 3.5 English model.
- No responses were provided regarding this topic at the moment.
- CmdR+Play Bot Taking a Break: A member was curious about the status of the CmdR+Play Bot, to which another member responded that it's currently taking a break and to stay tuned for updates.
- *
- Aya Expanse and Command Family Performance: Questions were raised regarding whether Aya Expanse benefits from the performance of the command family, suggesting a possible correlation in capabilities.
- It was implied that since Aya Expanse might be built upon this family, it could offer enhanced performance in taking instructions.
- 403 Error with API Request Builder: A member reported receiving a 403 error when trying to use their API request builder and asked for reasons behind it.
- This issue appears unresolved, as no explanation was provided by the community.
- Suggestions for Quality Datasets: A member is seeking recommendations on which of the provided datasets has better quality for quantification, mentioning the need for a significant number of samples.
- They specifically expressed interest in the 're-annotations' tag from the aya_dataset for their analysis.
Link mentioned: GitHub - hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs (ACL 2024): Unified Efficient Fine-Tuning of 100+ LLMs (ACL 2024) - hiyouga/LLaMA-Factory
Cohere ▷ #api-discussions (9 messages🔥):
API Response 403 Issues, VPN Connection Effects, Trial API Key Limitations
- User encounters 403 error with API request: A user reported receiving a 403 response when attempting to use the API request builder.
- They provided their ISP and location details, indicating they were using a VPN in Seattle, Washington.
- Suspected VPN-related restrictions: Another user suggested that the VPN might be routing through a restricted region, prompting the 403 error.
- They advised the original user to try making requests without the VPN to see if the issue persists.
- API request details shared: The original user shared their full curl command used for the API request, including headers and data payload.
- The request aimed to interact with the chat model, asking for the bot model name.
- User tried with and without VPN: The user confirmed that even without the VPN, they still faced a 403 response using their IPv6 address from China.
- They clarified that they were using a Trial API key, which may have restrictions.
Cohere ▷ #projects (9 messages🔥):
Maya Multimodal Model, Open Source Development, Feedback and Support, Future Video Release, Culturally Aware VLM
- Maya: A New Multimodal Multilingual Model: Introducing Maya – a completely open source, multilingual vision-language model designed to handle 8 languages with attention to cultural diversity.
- Built on the LLaVA framework, Maya includes a newly crafted pre-training dataset focusing on data quality and cultural sensitivity.
- Community Excitement for Maya: Community members expressed excitement, with comments like “that’s insane!” and encouragement to try out the model.
- One member requested a video or recording to get a better feel for the model, anticipating a blog post release soon.
- Maya's Model Details and Accessibility: Maya is developed by the Cohere For AI Community and operates under the Apache 2.0 license, ensuring accessibility.
- The related paper for the model can be found here, emphasizing its instruction-finetuned capabilities in multilingual settings.
- Call for Feedback on Maya: Karthik encouraged members to try Maya and provide their feedback, highlighting the importance of community input.
- The team is actively engaging with users, showing appreciation for the support received from the community.
- Tweet from Karthik reddy Kanjula (@Karthik_kanjula): Introducing Maya – A New Multimodal Multilingual Vision-Language Model. Maya is completely open source, open weight and open dataset, designed to handle 8 languages, cultural diversity, and nuanced r...
- maya-multimodal/maya · Hugging Face: no description found
- GitHub - nahidalam/maya: Maya: An Instruction Finetuned Multilingual Multimodal Model using Aya: Maya: An Instruction Finetuned Multilingual Multimodal Model using Aya - nahidalam/maya
- maya-multimodal (Maya: Multilingual Multimodal model): no description found
- Paper page - Maya: An Instruction Finetuned Multilingual Multimodal Model: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
MOOC Feedback, Hackathon Feedback
- Call for MOOC Feedback: Participants are encouraged to share their thoughts on the MOOC using the anonymous feedback form provided.
- Hackathon feedback can also be submitted through this form if desired.
- Anonymous Feedback Encouraged: The message invites every participant to provide feedback which can remain anonymous, fostering a safe space for sharing insights.
- This initiative aims to gather diverse perspectives to improve the course experience.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (31 messages🔥):
Hackathon Submission Guidelines, Written Article Assignment, API Key Usage, Feedback Submission, Course Completion Requirements
- Hackathon Submission Guidelines Clarified: It's confirmed that the hackathon submissions are due by December 17th, while the written article is due by December 12th, 11:59 PM PST.
- Students can submit one article for the hackathon, distinct from the 12 lecture summaries previously required.
- Details on Written Article Assignment: Students must create a post of roughly 500 words on platforms like Twitter, Threads, or LinkedIn, linking to the MOOC website.
- The article submission is graded as pass or no pass, requiring the same email used for course sign-up to ensure credit.
- API Key Usage Isn’t Mandatory: Participants are to utilize their personal API keys for lab assignments, but must not submit those keys.
- Clarification was given that having your own API key is acceptable for course work, even in the event of not receiving the OpenAI API key.
- Anonymous Feedback Submission Available: An anonymous feedback form was created for course feedback and hackathon suggestions.
- Participants are encouraged to share their thoughts on the course via the feedback form.
- Social Media Submission Allowed: Students can create and submit links to their articles posted on social media platforms, including a final draft submission.
- This allows for a more interactive submission process while fulfilling the written article assignment requirements.
- Large Language Model Agents MOOC: MOOC, Fall 2024
- LLM Agents MOOC (Anonymous) Feedback Form!: Hackathon feedback can also go here if you want :)
- Written Article Assignment Submission: INSTRUCTIONS:Create a Twitter, Threads, or LinkedIn post of roughly 500 words. You can post this article directly onto your preferred platform or you can write the article on Medium and then post a li...
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
Function Calling in AI, ToolBench Platform, Important Research Papers
- Function Calling in AI Gains Attention: It was mentioned that AI models likely utilize a detailed understanding of function descriptions and signatures, setting parameters according to the user's prompt, which enhances their generalization capabilities.
- This indicates a growing complexity in how AI models interact with predefined functions.
- ToolBench: A New Open Platform Emerges: A member highlighted the ToolBench project, presented at ICLR'24, as an open platform aimed at training, serving, and evaluating large language models for tool learning.
- Its significance lies in providing resources and frameworks for advancing the field of AI tools.
- Discussion on Key Research Papers: Members shared links to potentially important research papers, including paper 1 and paper 2, for ongoing dialogue about their relevance to current topics.
- There were uncertainties expressed about whether these papers are among the top resources for the respective topics.
- GitHub - OpenBMB/ToolBench: [ICLR'24 spotlight] An open platform for training, serving, and evaluating large language model for tool learning.: [ICLR'24 spotlight] An open platform for training, serving, and evaluating large language model for tool learning. - OpenBMB/ToolBench
- Tool Learning with Foundation Models: Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the...
OpenInterpreter ▷ #general (25 messages🔥):
Open Interpreter Desktop App, O1 Pro Capabilities, Website Design Feedback, Pricing for Pro Plan, Actions Beta App
- Exploring O1 Pro Control Possibilities: A member proposed using Open Interpreter in OS mode to control O1 Pro, suggesting that this could enable web search, canvas, and file upload features.
- Another thought about the potential of reverse engineering O1 Pro to control Open Interpreter, adding, 'the possibilities that opens up... yikes.'
- Clarifications on the Open Interpreter App Availability: Members discussed the Open Interpreter app, confirming it's currently in beta and requires an invite, with availability limited to Mac users.
- One member noted frustration over being on the waitlist without access yet, while another shared contacts for obtaining an invite.
- Feedback on Website's New Design: Feedback on the new website design was mixed, with one member stating it looked 'a lil jarring' at first but has grown on them.
- Others commented on the ongoing work-in-progress nature of the design, with ambitions for a cooler overlay effect in the future.
- Understanding the $30 Pro Plan: Killianlucas explained that the $30 monthly desktop app plan increases usage limits and provides the app without needing an API key for free users.
- He recommended sticking to the free plan unless users find it overwhelmingly beneficial, as the app is rapidly evolving in beta.
- Actions Beta App Explained: The Actions feature was highlighted as a beta app focusing on file modification, distinct from OS mode which is available only in the terminal.
- Members were encouraged to explore this new feature, even though others encountered limitations, with one noting they maxed out their token limit while testing.
Link mentioned: Open Interpreter: no description found
OpenInterpreter ▷ #O1 (1 messages):
pradipdutta9392: i Think This useful for researchers just they shown in the demo
Torchtune ▷ #dev (16 messages🔥):
DoraLinear Initialization, Module Device Handling, Gradient Management, Parameter Copying Techniques, Use of Optional in Method Signatures
- DoraLinear improves user experience with
to_empty: A proposal was made to utilize theto_emptymethod in the current PR to handle magnitude initialization, ensuring it doesn’t disrupt existing functionality.- Setting
requires_gradon magnitude is crucial to avoid unintended behavior with self.magnitude.requires_grad=False.
- Setting
- Device Management in Module Implementation: It was noted that
swap_tensorsshould be used in theto_emptymethod for proper device handling during initialization.- This allows for the copying of device settings, which is essential when tensors reside on different devices.
- Understanding
requires_gradin Parameter Initialization: The discussion clarified that copying parameters doesn’t pose an issue as long as device considerations are managed beforehand.- Concerns were raised about assignments capturing parameters, suggesting that assignments should be carefully handled.
- Functionality and Requirements for
copy_andswap_tensors: The distinction between the use ofcopy_andswap_tensorsin the initialization logic was emphasized, with a lean towards usingcopy_for its standard implementation.- Using
copy_could be favored in bothto_emptyandinitialize_dora_magnitudeas a straightforward solution.
- Using
- Questions on Optional Method Parameter Usage: A query arose regarding the necessity of the
Optionaltype for thedeviceparameter in theto_emptymethod, since it lacks a default value.- It was concluded that the
Optionaltype is designed to offer flexibility by allowing a None value, which preserves existing device settings.
- It was concluded that the
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- ebs-torchtune/torchtune/modules/peft/dora.py at 5da01406658f9079ebb5bcd6eab0e4261d4188f9 · ebsmothers/ebs-torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to ebsmothers/ebs-torchtune development by creating an account on GitHub.
- pytorch/torch/nn/modules/module.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- pytorch/torch/nn/modules/module.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
Torchtune ▷ #papers (1 messages):
QRWKV6-32B, Finch-MoE-37B-A11B, Computational Efficiency Improvements, RWKV-V6 Attention Mechanism, Language Support Limitations
- QRWKV6-32B matches original 32B performance: The new QRWKV6-32B model, built on the Qwen2.5-32B architecture, achieves the same performance as the original 32B while offering 1000x compute efficiency in inference.
- Training was completed in 8 hours on 16 AMD MI300X GPUs (192GB VRAM), showcasing a significant reduction in compute costs.
- Finch-MoE-37B-A11B revealed: The Finch-MoE-37B-A11B model builds upon the RWKV architecture and is part of the line of new RWKV variants currently under development.
- It highlights a shift towards using linear attention mechanisms, which are particularly efficient for processing long contexts.
- Conversion process enables RWKV transformations: A novel conversion process allows for transforming QKV Attention models into RWKV variants without the need for full retraining, significantly lowering compute expenses.
- Notably, the model retains the feedforward network architecture of its parent, resulting in incompatibility with existing RWKV inference code.
- Current context limitations and capabilities: The QRWKV6 model supports approximately 30 languages, limited by its parent Qwen model, which traditionally supports around 100+ languages.
- Additionally, while the current context length is limited to 16k, it shows stability even beyond this boundary.
Link mentioned: Tweet from Rohan Paul (@rohanpaul_ai): New linear models: QRWKV6-32B (RWKV6 based on Qwen2.5-32B) & RWKV-based MoE: Finch-MoE-37B-A11B🚀 Recursal AI converted Qwen 32B Instruct model into QRWKV6 architecture, replacing transformer attentio...
DSPy ▷ #general (10 messages🔥):
O1 Series Impact on DSPy Workflows, Generic Optimization Errors, Backtrack_to Attribute Error, Async Usage Issues, Video and Audio Input Discussions
- O1 Series may optimize DSPy workflows: One member inquired about the impact of the O1 series models on DSPy workflows, noting MIPRO’s recommended parameters for optimization modules may need adjustments.
- They speculated that these new models could require fewer optimization cycles or evaluating fewer candidate programs.
- Members encounter generic errors during optimization: A user reported running into a weird generic error when optimizing and mentioned a bug posted in a specific channel for further assistance.
- This issue highlights ongoing challenges faced by the community during optimization processes.
- Backtrack_to Attribute Error Troubleshooting: One member shared an error related to 'backtrack_to' not being an attribute of Settings in DSPy and sought help on resolving it.
- Another user indicated that the issue had been resolved earlier and was likely tied to some async usage.
- Discussion on Video and Audio IO: A user posed a question regarding opinions on video and audio IO, prompting a discussion among members.
- One member expressed that focusing on text and image input is more beneficial at this juncture, given the existing features.
LAION ▷ #general (3 messages):
Grassroots Science Initiative, Optimizing Inference Throughput, Comparative Performance of Libraries, Knowledge Graphs from Research Papers
- Launch of Grassroots Science for Multilingual LLMs: A collaborative initiative named Grassroots Science is set to launch in February 2025, aiming to develop multilingual LLMs aligned with diverse human preferences through crowdsourced data collection.
- Throughput Optimization for LLaMA 3.2 Inference: A user seeks to optimize throughput for LLaMA 3.2 with 10,000 token input on an A100 GPU, expecting around 200 tokens per second but feels this is slower than anticipated.
- Discussion includes exploring batching, prompt caching, and the potential benefits of using quantized versions to increase batch size.
- TGI 3.0 Shows Improved Performance over vLLM: According to Hugging Face, TGI 3.0 can process 3 times more tokens and is 13 times faster than vLLM, making it suitable for handling long prompts efficiently.
- TGI has significantly reduced its memory footprint, allowing it to handle up to 30k tokens on LLaMA 3.1-8B, whereas vLLM struggles with just 10k tokens.
- TGI v3 overview: no description found
- Llama 3.2 3B - Quality, Performance & Price Analysis | Artificial Analysis: Analysis of Meta's Llama 3.2 Instruct 3B and comparison to other AI models across key metrics including quality, price, performance (tokens per second & time to first token), context window &...
- Grassroots Science: A global initiative focused on developing state-of-the-art multilingual language models through grassroots efforts.
- Grassroots Science Interest Form: Grassroots Science is a year-long global collaboration aimed at collecting multilingual data through crowdsourcing, initiated by grassroots communities who believe in the power of collective efforts t...
- Tweet from undefined: no description found
LAION ▷ #research (6 messages):
Non-LLMs Generalization, Sub-Billion Parameter Models, COCONUT Paradigm, Efficient Small Models
- Debate on Model Scaling: A member expressed skepticism about the necessity of scaling models, stating, 'A Billion Parameters Ought To Be Enough For Anyone.' They voiced their disagreement with the scale-is-all-you-need movement.
- An enthusiasm for hyperefficient small models was also shared, emphasizing their benefit in model training.
- COCONUT: New Reasoning Paradigm for LLMs: The introduction of Chain of Continuous Thought (COCONUT) was highlighted as a method for training large language models to reason in a continuous latent space, detailed in a tweet.
- Rather than the traditional mapping via hidden states and language tokens, COCONUT feeds the last hidden state as the input embedding, enabling end-to-end optimization through gradient descent.
Link mentioned: Tweet from Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr): Training Large Language Models to Reason in a Continuous Latent SpaceIntroduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT)Extremely simple change: instead of mapping...
Axolotl AI ▷ #general (1 messages):
c.gato: That should be the default
Mozilla AI ▷ #announcements (1 messages):
Mozilla AI hiring, Community Engagement Head role, Lumigator product, Developer Hub, Blueprints initiative
- Mozilla AI is on the lookout for talent: Mozilla AI is hiring a Head of Community Engagement with remote opportunities, reporting directly to the CEO.
- This role will lead and scale community initiatives across various channels to enhance engagement.
- Introducing Lumigator for LLM selection: Mozilla is developing Lumigator, a product aimed at helping developers confidently choose the best LLM for their projects.
- It's part of their effort to offer trustworthy open-source AI solutions to the developer community.
- Developer Hub to streamline AI resources: Mozilla AI is creating a Developer Hub where developers can find curated resources for building with open-source AI.
- This initiative supports user agency and transparency in AI development.
- Blueprints: Open-sourcing AI integrations: The Blueprints initiative aims to open-source AI integrations via starter code repositories to kickstart AI projects.
- These resources will be invaluable for developers looking to quickly implement AI solutions.
- Community engagement inquiries: Potential applicants can ask questions about the Head of Community Engagement role in this thread.
- The role reflects Mozilla AI's commitment to community-driven initiatives.
Link mentioned: Head of Community Engagement: Remote