[AINews] Google I/O in 60 seconds
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Spot the 7 flavors of Gemini!
AI News for 5/13/2024-5/14/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (426 channels, and 8590 messages) for you. Estimated reading time saved (at 200wpm): 782 minutes.
Google I/O is still ongoing, and it is a good deal harder to cover than OpenAI's half-hour event yesterday because of the sheer scope of products, and we haven't yet come across a single webpage that summarizes everything (apart from @Google and @OfficialLoganK accounts).
Here is a subjectively sorted list:
The Gemini Model Family
- Gemini 1.5 Pro announced 2m token support (in waitlist). The blogpost made references to " a series of quality improvements across key use cases, such as translation, coding, reasoning and more" but published no benchmarks.
- Announcing Gemini Flash, adding a fourth to the original 3-model vision for Gemini. The blogpost calls it "optimized for narrower or high-frequency tasks where the speed of the model’s response time matters the most", highlights its 1m token capacity for slightly cheaper than GPT3.5, but offers no speed claims. The Gemini suite now stands as:
- Ultra: "our largest model" (only in Gemini Advanced)
- Pro: "our best model for general performance" (available in API preview today, GA in June)
- Flash: "our lightweight model for speed/efficiency" (available in API preview today, GA in June)
- Nano: "our on-device model" (will be built into Chrome 126)
- Gemini Gems - Gemini's version of custom GPTs
- Gemini Live: "the ability to have an in-depth two-way conversation using your voice.", which leads directly into Project Astra - The live video understanding personal assistant chatbot with a polished 2 minute demo
- LearnLM - "our new family of models based on Gemini and fine-tuned for learning"
The Gemma Model Family
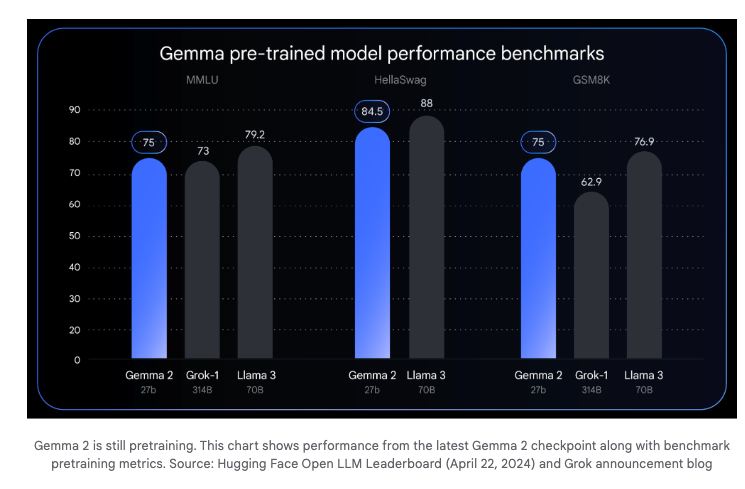
- Gemma 2, now up to 27B (previously 7B and 2B), a still-in-training model that offers near-Llama-3-70B performance at half the size (fitting in 1 TPU)
- PaliGemma - their first vision-language open model inspired by PaLI-3, complementing CodeGemma and RecurrentGemma.
Other Launches
- Veo, DeepMind's answer to Sora. Comparisons on HN.
- Imagen 3: " It understands prompts the way people write, creates more photorealistic images and is our best model for rendering text." (more samples here)
- Music AI Sandbox - YouTube x DeepMind collaborating to compete with Udio/Suno
- SynthID watermarking now extending to text as well as images, audio, and video (including Veo).
- Trillium - the codename for TPUv6
And AI deployments across Google's product suite - Workspace, Email, Docs, Sheets, Photos, Search Overviews, Search with Multi-step reasoning, Android Circle to Search, Lens.
Overall a very competently executed I/O, easy to summarize without losing too much detail. The world awaits Apple's answer.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- OpenAI Discord
- Perplexity AI Discord
- Unsloth AI (Daniel Han) Discord
- Latent Space Discord
- Nous Research AI Discord
- Stability.ai (Stable Diffusion) Discord
- LM Studio Discord
- HuggingFace Discord
- OpenRouter (Alex Atallah) Discord
- Interconnects (Nathan Lambert) Discord
- Eleuther Discord
- Modular (Mojo 🔥) Discord
- CUDA MODE Discord
- LlamaIndex Discord
- LAION Discord
- OpenInterpreter Discord
- LangChain AI Discord
- OpenAccess AI Collective (axolotl) Discord
- Datasette - LLM (@SimonW) Discord
- tinygrad (George Hotz) Discord
- DiscoResearch Discord
- Cohere Discord
- LLM Perf Enthusiasts AI Discord
- Skunkworks AI Discord
- Alignment Lab AI Discord
- AI Stack Devs (Yoko Li) Discord
- PART 2: Detailed by-Channel summaries and links
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
GPT-4o Release by OpenAI
- Key Features: @sama noted GPT-4o is half the price and twice as fast as GPT-4-turbo, with 5x rate limits. @AlphaSignalAI highlighted its ability to reason across text, audio, and video in real time, calling it extremely versatile and fun to play with.
- Multimodal Capabilities: @gdb emphasized GPT-4o's real-time reasoning across text, audio, and video, seeing it as a step towards more natural human-computer interaction.
- Improved Tokenizer: @aidan_clark mentioned up to 9x cheaper/faster performance for non-Latin-script languages thanks to the new tokenizer.
- Wide Availability: @sama stated GPT-4o is available to all ChatGPT users, including the free plan, in line with their mission of democratizing access to powerful AI tools.
Technical Analysis and Implications
- Architecture Speculation: @DrJimFan speculated GPT-4o maps audio to audio directly as a first-class modality, requiring new tokenization and architecture research. He believes OpenAI developed a neural-first, streaming video codec to transmit motion deltas as tokens.
- Potential GPT-5 Relation: @DrJimFan suggested GPT-4o may be an early checkpoint of GPT-5 that's still training, with the branding betraying insecurity ahead of Google I/O.
- Character AI Overlap: @DrJimFan noted the assistant's lively, flirty personality similar to the AI from "Her", and believes OpenAI is directly competing with Character AI's form factor.
- Apple Integration Potential: @DrJimFan outlined 3 levels of iOS integration: 1) Replacing Siri with on-device GPT-4o, 2) Native features for camera/screen streaming, 3) Integration with iOS system APIs. He believes the first to partner with Apple will have an AI assistant with a billion users from the start.
Community Reactions and Memes
- @karpathy joked that "The killer app of LLMs is Scarlett Johansson", rather than math or other serious applications.
- @vikhyatk shared a meme of Steve Ballmer's "developers" chant, questioning if any big tech CEOs still show that level of enthusiasm.
- @fchollet quipped that with the rise of AI girlfriends, "self-play" in AI might finally become a reality, referencing a concept discussed since 2016.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
GPT-4o Capabilities and Features
- Speed and Cost: In /r/singularity, GPT-4o is noted to be 2x faster and 50% cheaper than GPT-4 Turbo, with 5x rate limits. It is also significantly better than GPT-4 Turbo in non-English languages.
- Audio Capabilities: GPT-4o has improved audio parsing abilities like capturing different speakers, lecture summarization, and capturing human emotions, as well as improved audio output like expressing emotions and singing.
- Image Generation: It has improved image generation capabilities like better text rendering, character consistency, font generation, 3D image generation, and targeted image editing. Additionally, GPT-4o has abilities not shown in the presentation like 3D object synthesis.
- Benchmarks: GPT-4o shows slight improvements on MMLU/HumanEval benchmarks.
GPT-4o Availability and Pricing
- ChatGPT Rollout: GPT-4o text and image capabilities are rolling out in ChatGPT today, available for free and to Plus users with 5x higher message limits. Voice mode with GPT-4o will roll out to Plus users in coming weeks.
- Pricing: GPT-4o is half the price of GPT-4 Turbo ($10/1M tokens) and 12x less than GPT-4 32K ($60/1M tokens).
Reactions and Comparisons
- Coding Performance: Some find GPT-4o underwhelming for coding compared to GPT-4 Turbo, with more hallucinations that don't justify the 50% discount.
- Translation Quality: Others note it is not better than GPT-4 Turbo for translation.
- Benchmark Claims: OpenAI claims benchmarks against "Llama-3-400B" which is still in training.
- Chess Performance: GPT-4o achieves +100 ELO on harder chess puzzle prompts, reaching 1310 ELO.
Open Source and Competitors
- Meta's Progress: Meta states they are only months away from catching up to GPT-4o.
- Falcon 2 Release: Falcon 2, an open source model from UAE, is released to compete with Llama 3.
- Google's AI Capabilities: Google teases their own real-time video AI capabilities ahead of Google I/O event tomorrow.
Memes and Humor
- People joke GPT-4o is so fast it should be called "GPT-4ooooooohhhhh".
- Image joking "OpenAI invented Apple's futuristic Knowledge Navigator from 1987".
- Meme image suggesting GPT-4o is trained on "Scarlett Johansson's voice".
AI Discord Recap
A summary of Summaries of Summaries
Claude 3 Sonnet
Here are the top 3-4 major themes from the content, with important key terms, facts, URLs, and examples bolded:
-
New AI Model Releases and Comparisons:
- OpenAI's GPT-4o is a new flagship multimodal model that can process audio, vision, and text in real-time. It boasts faster response times, lower costs, and improved reasoning capabilities compared to GPT-4. Example showcasing GPT-4o's interactive abilities.
- The Falcon 2 11B model outperforms Meta's Llama 3 8B and rivals Google's Gemma 7B, offering multilingual and vision-to-language capabilities.
- Claude 3 Opus is still preferred by some users for complex reasoning tasks over GPT-4o, despite concerns over its cost and usage restrictions.
-
AI Model Optimization and Efficiency Efforts:
- Implementing ZeRO-1 in llm.c increased GPU batch size and training throughput by ~54%, enabling larger model variations.
- The ThunderKittens library promises faster inference and potential training speed improvements for LLMs through optimized CUDA tile primitives.
- Discussions focused on reducing AI's compute usage, with links shared to projects like Based and FlashAttention-2.
-
Multimodal AI Applications and Frameworks:
- The AniTalker framework enables creating lifelike talking faces from static images using audio input, capturing complex facial expressions.
- Retrieval Augmented Generation (RAG) integration with image generation models like Stable Diffusion was discussed, leveraging CLIP embeddings.
- A multimodal chat app using Streamlit, LangChain, and GPT-4o supports image uploads and clipboard pastes in chat.
-
Open-Source AI Model Development and Deployment:
- Unsloth AI celebrated surpassing 1 million model downloads on Hugging Face, reflecting the community's active engagement. Example of a novel Cthulhu-worshipping AI model created using Unsloth.
- The Mojo programming language gained traction, with discussions on contributing to its open-source compiler, integration with MLIR, and its ownership model. Video on Mojo's ownership semantics.
- LM Studio users discussed hardware recommendations, quant levels for efficient inference, and issues with specific models like Command R on Apple Silicon. Advice on using larger models like yi-1.5 for better performance.
Claude 3 Opus
- GPT-4o Launches with Multimodal Capabilities: OpenAI unveiled GPT-4o, a new flagship model supporting text, image, and soon voice/video inputs in real-time. It's available for free with limits and extra benefits for Plus users, boasting faster response times and API performance at half the cost of GPT-4. Live demos showcased its interactive multimodal skills.
- Falcon 2 and Other Open Models Impress: Falcon 2 11B was released, outperforming Meta's Llama 3 8B and nearing Google's Gemma 7B with open-source, multilingual and multimodal capabilities. Anticipation also grew for Gemma 2, Google's upcoming 27B open model. Users debated the accessibility and future of open vs closed models.
- Anthropic's Opus Policy Shift Sparks Debate: Anthropic's new terms for Opus, banning certain content types, generated mixed reactions. Despite GPT-4o's speed, some still preferred Claude 3 Opus for its strong summarization and human-like output.
- Memory and Multi-GPU Support Coming to Unsloth: Unsloth AI teased upcoming features like cross-session memory for custom GPTs and multi-GPU support. The platform celebrated 1M model downloads as users explored optimal fine-tuning datasets and methods.
- Modular's Mojo Language Expands with Key Talks: Modular shared educational content on Mojo's ownership model and open-source standard library contributions. Mojo's compiler, written in C++, generated interest in potential MLIR integration and future self-hosting.
GPT4T (gpt-4-turbo-2024-04-09)
Major Themes:
-
Advancement of AI Models: Various channels buzz with discussions about the latest AI models, like GPT-4o, Falcon 2, and LLaMA models. These models boast enhanced capabilities like multimodal functionalities and real-time processing, with integration into platforms such as Perplexity AI and OpenRouter.
-
Community Engagement and Collaborations: There's an increasing interest in sharing projects, seeking collaborations, and participating in discussions around coding practices, optimizations, and the integration of new technologies within community platforms such as Stability.ai, Modular, and LAION, demonstrating a thriving ecosystem focused on collective growth and learning.
-
Customization and Personalization Questions: Users show a keen interest in customizing AI models and systems to fit specific needs, ranging from setting up private instances of AI tools to merging different model capabilities, reflecting an ongoing trend of personalizing AI use to meet individual or organizational requirements.
-
Technical Challenges and Debugging: A common thread across several discords centers around troubleshooting and problem-solving specific to AI models and computing environments. This includes discussions on optimizing model inference, handling specific library issues, and improving integration with various coding environments.
-
Educational Content and Resource Sharing: Several channels are dedicated to educational content ranging from detailed explanations of machine learning concepts to sharing tutorials and resources to help members learn about and implement AI technologies. This not only helps in skill development but also fosters a culture of knowledge sharing within the community.
GPT4O (gpt-4o-2024-05-13)
-
Model Launches and Innovations:
- GPT-4o: Many discords are abuzz with OpenAI's launch of GPT-4o, a multimodal model capable of handling text, audio, and vision inputs. This model promises significant advancements in speed, context windows (up to 128K tokens), and overall capabilities. OpenAI's GPT-4o is praised for real-time multimodal capabilities but also criticized for some quirks and high usage costs (GPT-4o Info).
- Falcon 2: Highlighted as a competitive model against Meta's Llama 3 8B and Google's Gemma 7B. It is praised for being open-source, multilingual, and multimodal. Falcon 2 Announcement.
- Claude 3 Opus: Its strength lies in handling long-form reasoning tasks and text summarization despite facing cost and policy concerns. Claude 3 Opus.
-
Performance and Technical Discussions:
- GPU Utilization: Many discussions revolve around optimizing GPU usage for different models such as Stable Diffusion, YOLOv1, and implementation techniques in Flash Attention 2. This includes guide sharing and configuration tips like the effectiveness of ThunderKittens in speeding up inference and training (GitHub - ThunderKittens).
- API and Performance Enhancements: Conversations on API performance specifically focus on optimizing response times and handling larger context windows. For instance, GPT-4o API is noted for faster speed and better performance at reduced costs.
-
Community Tools and Support:
- Projects and Tools Sharing: From job search assistants using Retrieval-Augmented Generation to detailing steps for setting up AI tools like OpenRouter with community-developed utilities. There is significant sharing of personal projects and collaborative efforts (Job Search Assistant Guide, OpenRouter Model Watcher).
- Help and Collaboration: A recurring theme is troubleshooting and providing support for issues encountered during AI development, such as CUDA errors, model fine-tuning, and dependency management.
-
Ethics and Policy:
- Content Moderation and Policies: ETHICAL concerns around the usage and policies governing AI tools, specifically Claude 3 Opus and GPT-4o moderation filters (Anthropic Policy Link).
- Open-Source vs Proprietary Models: Discussions often compare open-source advantages like Falcon 2 against proprietary models' constraints, impacting their accessibility and modifications.
PART 1: High level Discord summaries
OpenAI Discord
GPT-4o Makes Its Grand Entrance: OpenAI launched a new model, GPT-4o, with free access for certain features and additional benefits for Plus users, including faster response times and more extensive features. GPT-4o distinguishes itself by processing audio, vision, and text in real-time, indicating a significant step forward in multimodal applications with text and image inputs already available and voice and video to be rolled out soon. Read more about GPT-4o.
Claude Claims Complex Task Crown: Within the community, Claude Opus is considered superior for complex, long-form reasoning compared to GPT-4o, particularly when processing extensive original content. Expectations are high for future enhancements that include broader context windows and advanced voice capabilities from both Google and OpenAI.
Custom GPTs Await Memory Upgrade: The awaited cross-session context memory for custom GPTs remains in development, with an assurance that once released, memory will be configurable by the creators per GPT. Enhanced speeds and consistent API performance mark the current state of GPT-4o, though Plus users benef from higher message limits, and everyone eagerly awaits the promised integration within custom GPT models.
Prompt Engineering Exposes Model Quirks: Users faced challenges when directing GPT-4o towards creative and spatially aware tasks, noting difficulties in iterative image generation and specific content moderation issues with Gemini 1.5's safety filters. Even as GPT-4o accelerates response times, it occasionally stumbles in comprehension and execution, indicating room for iterative refinement based on user feedback.
Monitored ChatGPT Clone Sought: A member inquired about creating a ChatGPT-like application that allows organizational monitoring of messages using the GPT-3.5 model. This reflects a growing need for customizable and controllable AI tools within formal ecosystems.
Perplexity AI Discord
GPT-4's Token Tussle: There's debate around GPT-4's token capacity, with clarification that GPT-4's larger context window applies to specific models like GPT-4o which has a 128K token context window. Some users are diving into the capabilities of GPT-4o, noting its velocity and performance excellence, and sharing video examples of its real-time reasoning.
Policy Shift Sparks Chatter: Anthropic's revised terms of service for Opus, going live on June 6th, have members in a stir due to limitations like the ban on creating LGBTQ content. Details of the policy can be found in the shared Anthropic policy link.
Claude Maintains Its Ground: Despite the buzz around GPT-4o, Claude 3 Opus is still the go-to for text summarization and human-like responses for some users, despite concerns over cost and use restrictions.
Perplexity's New Power Player: Users are testing GPT-4o's integration into Perplexity's tools, highlighting its high-speed, in-depth responses. The Pro version allows for 600 queries a day, echoing its API availability.
API Config Conundrums: Discussions surfaced around Perplexity's API settings, with a user inquiring about timeout issues for lengthy inputs using llama models. One member indicated that the chat model of llama-3-sonar-large-32k-chat is fine-tuned for dialogue contexts, yet no consensus on the optimal timeout settings was reported.
Unsloth AI (Daniel Han) Discord
LLaMA Instruction Tuning Advice: For finetuning on small datasets, start with the instruction model of Llama-3 before considering the base model if performance is suboptimal, as per users’ discussions. They recommend iteration to find the best fit for your scenario.
ThunderKittens Exceeds Flash Attention 2: ThunderKittens overtakes Flash Attention 2 in speed, per mentions in the community, promising faster inference and potential advancements in training speeds. The code is available on GitHub.
Synthetic Dataset Construction for Typst: To effectively fine-tune models on "Typst," engineers propose synthesizing 50,000 examples. The daring task of generating substantial synthetic datasets has been been flagged as a fundamental step for progress.
Multimodal Model Expansion on Unsloth AI: Upcoming support for multimodal models has been anticipated in Unsloth AI, including multi-GPU support expected next week, setting a pace for new robust AI capabilities.
A Million Cheers for Unsloth AI: The AI community celebrates Unsloth AI surpassing one million model downloads on Hugging Face, signaling a milestone recognized by users and reflecting the community’s active engagement and support.
Latent Space Discord
- Apple Aims for AI Integration, Lifts an Eyebrow on Google: Amidst the tech talk, speculations tally on Apple's rumored deal with OpenAI to incorporate ChatGPT into iPhones, juxtaposing the idea of local versus cloud-based models. Skepticism brews among engineers over the feasibility of this integration, with some doubting Apple's ability to host heavyweight models efficiently on handheld devices.
- Falcon 2 Soars Above the Rest: The Falcon 2 model gains applause for its performance, boasting open-source, multilingual, and multimodal capabilities while edging out competitors like Meta's Llama 3 8B and slightly trailing behind Google Gemma 7B's benchmarks. Evident excitement trails the announcement that Falcon 2 is both open-source and superior in several areas Falcon LLM.
- GPT-4o Stirring the Pot: Gasps and groans tune into the conversation around GPT-4o, OpenAI's newest model that flexes faster response times and intriguing free chat capabilities. Critiques hover around its branding and performance concerns—particularly latency—despite the buzz over poem-laureate-quick capabilities.
- Voice Meets Vision, Sets the Stage for AI Drama: The demonstration of ChatGPT's voice and vision integration commands attention, with its show of real-time, emotion-sensitive AI interactions. Doubts infiltrate the guild about the reality of the demo's capabilities, poking at the potential behind-the-scenes mechanics of such a display.
- API Anticipation and the Competitive Landscape: Discussions spin around accessing GPT-4o's API, with engineers leaning forward for its swift performance. The undercurrent reflects on the greater AI battlefield, where Google and other players shuffle in reaction to OpenAI's gambit with GPT-4o—and the community watches, waiting to play their own hand with the new API.
Nous Research AI Discord
- LLM Struggles to Exceed 8k Tokens: Some members reported challenges in using Llama 3 70b in creating coherent outputs beyond 8k tokens. While notable successes have been achieved, there is room for improvements in handling larger token processes.
- Riding the Roller Coaster of GPT-4o: Mixed reactions and reviews flooded the server following the advent of OpenAI’s GPT-4o model. Some noted unique capabilities, including real-time multimodal functionality and Chinese token handling, while others scrutinized its limitations, especially regarding its image editor mode and cost efficiency.
- Remote Automation: Trickier Than You Think: Demonstrating the intricacies and subtleties of the AI field, the community shared experiences and ideas about automating software that runs inside a Remote Desktop Protocol. From parsing the Document Object Model (DOM) to reverse engineering software, the conversation showcased the complicated navigation and decision-making paths in automation processes.
- Heads or Tails: Renting Vs Owning GPU Setups for LLMs: The assembly hosted a hearty debate about the pros and cons of renting vs owning GPU setups for use with large language models (LLMs). The conversation took a deep dive into cost-effectiveness, privacy considerations, and hardware specifications, with GPU providers and setup configurations being extensively explored.
- Multimodality of GPT-4o Unveiled: Unraveling the futuristic promise of GPT-4o, community members dived into enlightening exchanges about the model’s multimodal features, particularly whispering latents for audio inputs and non-English language token handling. The community also pointed out resources to understand the longest Chinese tokens and tokenizer improvements in models like GPT4-o.
- WorldSim Images Making Their Mark: WorldSim users openly admire the program's creativity. One member even mentioned considering an artwork-inspired tattoo, demonstrating their appreciation for WorldSim's visuals.
- IBM/Redhat Takes LLMs the Extra Mile: IBM/Redhat’s schema for expanding the knowledge base and capabilities of LLMs was a hot topic. Their project assimilates new information on a continuum, applying it real-time instead of requiring full retraining after each knowledge expansion, presenting an innovative approach for models' incremental evolution.
- Researchers Seek Human/LLM Text Pairs for Comparative Model Evaluation: The extraction of datasets comparing 'human_text' and 'llm_text' for the same prompts arose during discussions, suggesting a need for a deeper comparison and evaluation of LLM responses in relation to human language outputs.
- Enriching AI Knowledge Through Open Project Contributions: The feasibility and importance of community contributions towards open projects such as IBM/Redhat’s Granite and Merlinite were affably reiterated - a step towards open source collaborations for a tech-transformed future.
Stability.ai (Stable Diffusion) Discord
- CEO Shuffles at Stability.ai: Discussion centered around Stability AI's uncertain future with CEO Emad's exit and the murky release status of SD3, including whether it might become a paid service.
- GPU Showdown for Stable Diffusion: Engineers debated on the best GPUs for running Stable Diffusion, reaching a consensus that those with more VRAM are better suited, and shared a comprehensive guide on styles and tags.
- Inpainting Boost with BrushNet: The integration of BrushNet via ComfyUI BrushNet's GitHub repository was recommended for improved inpainting in Stable Diffusion, utilizing a combo of brush and powerpaint features.
- Strategies for Consistent AI Characters: Techniques to maintain AI character consistency were hotly debated, with a focus on LoRA and ControlNet, and resources for creating detailed character sheets.
- Big Tech vs. Open Community Models: Google's Imagen 3 prompted discussions reflecting a mix of anticipation and preference for open models like SD3, due to the communal accessibility.
LM Studio Discord
- Fine-Tuning and VPN Workarounds: Engineers confirmed that accessing a fine-tuned model stored on Hugging Face through LM Studio is possible if public and using the GGUF format. Additionally, VPN usage was suggested to remedy network errors from Hugging Face being blocked, pointing to region-specific restrictions and recommending IPv4 connections.
- Model Performance Discussions: The community discussed model merging strategies, such as applying methods from unsloth to potentially merge and upgrade the llama3 and/or mistral. Furthermore, there was a debate surrounding different quant levels for models, highlighting that anything below Q4 is seen as inefficient.
- Software Compatibility and Hardware: Discussions indicated incompatibilities, such as the Command R model outputs on Apple M1 Max systems, and ROCM limitations with the RX6600 GPU resulting in issues with LM Studio and Ollama. Concerning hardware, talks favored GPUs like the Nvidia 3060ti for value-for-money in LM Studio applications and the significance of VRAM speed for efficient LLM inference.
- LM Studio Feature Set and Support: Queries were raised about multimodal functionality in LM Studio, specifically regarding feature consistency with standard models. Moreover, Intel GPU support interest was expressed, with offers from an Intel employee to help with SYCL integration, pointing to potential performance improvements.
- Feedback, Expectations, and Future Directions: There was critical feedback on LMS's current realtime learning capabilities, with user demands for at least a differential file for line-item training. Another user suggested the deployment of larger models like command-r+ or yi-1.5 for possibly enhanced outcomes.
- Deployment Considerations: A member evaluated the Meta-Llama-3-8B-Instruct-Q4_K_M model's high RAM usage over GPU, weighing deployment options between AWS and commercial APIs in the context of cost-effectiveness. They compared the potential savings of using IaaS providers against subscriptions with LLMaaS considering the significant differences in model sizes and parameters.
HuggingFace Discord
YOCO Cuts Down on GPU Needs: The YOCO paper introduces a new decoder-decoder architecture that cuts GPU memory usage while speeding up the prefill stage, maintaining global attention capabilities.
When NLP and AI Storytelling Collide: Researchers are pulling from the Awesome-Story-Generation GitHub repository to contribute to comprehensive studies on AI story generation, such as the GROVE framework, aimed at increasing story complexity.
Stable Diffusion Ventures into DIY Territory: A Fast.ai course spans over 30 hours, teaching Stable Diffusion from scratch, partnering with industry insiders from Stability.ai and Hugging Face, discussed alongside queries about sadtalker installation and practical uses for transformer agents.
OCR Quality Frontier: A collection of OCR-quality classifiers showcases the feasibility of distinguishing between clean and noisy documents using compact models.
Stable Diffusion and YOLO: A HuggingFace guide on Stable Diffusion using Diffusers is available, and conversations revolve around YOLOv1 implementations using ResNet18, balancing data quality and quantity issues to improve model performance.
Mixed Sentiments on the Cutting Edge: GPT-4o's announcement led to diverse reactions within the community, raising concerns about distinguishing AI from humans, while members reported mixed success with custom tokenizer creation and NLP strategies focused on example-rich prompts.
OpenRouter (Alex Atallah) Discord
New Multimodal Models Storm OpenRouter: OpenRouter has expanded its lineup with the launch of GPT-4o, noted for supporting text and image inputs, and LLaVA v1.6 34B. Additionally, the roster now includes DeepSeek-v2 Chat, DeepSeek Coder, Llama Guard 2 8B, Llama 3 70B Base, Llama 3 8B Base, with GPT-4o's latest iteration dating May 13, 2024.
Blazing through Beta: An advanced research assistant and search engine is being beta-tested, offering premium access with leading models like Claude 3 Opus and Mistral Large, and the platform shared a promo code RUBIX for trials.
GPT-4o Enthusiasm and Scrutiny: A vivacious discussion about GPT-4o's API pricing ($5/15 per 1M tokens) sparked excitement, whereas speculation about its multimodal capabilities has piqued curiosity, with commentators noting the lack of native image handling via OpenAI's API.
Community Weighs in on OpenRouter Hiccups: Technical difficulties with OpenRouter were voiced by users, identifying issues such as empty responses and errors from models like MythoMax and DeepSeek. Alex Atallah clarified that most models on OpenRouter are FP16, with some quantized exceptions.
Engineering Connection over Community Tools: A community-developed tool to sort through OpenRouter models has been positively received, with suggestions to integrate additional metrics like ELO scores and model add-dates being discussed. Links to related resources such as OpenRouter API Watcher were provided.
Interconnects (Nathan Lambert) Discord
GPT-4o Leads the Frontier: OpenAI's GPT-4o sets a new benchmark in AI capabilities, especially in reasoning and coding, dominating LMSys arena and featuring a doubled token capacity thanks to a tokenizer update. Its multi-modal prowess was also showcased including potential singing abilities, stirring both interest and debate around AI evolution and its competitive landscape.
REINFORCE Under PPO's Umbrella: The AI community discusses a new PR from Hugging Face that positions REINFORCE as a subset of PPO, detailed in a related paper, showing active contributions in the realm of reinforcement learning.
AI's Silver Screen Reflects Real Concerns: Dialogues within the community resonate with the movie "Her", highlighting how AI interaction can be perceived as either trivial or profound. These discussions tie in with sentiments regarding AI leadership and the humanization of technology.
Long-Term AI Governance Emerging: Forward-looking conversations hint at Project Management Robots (PRMs) playing a key role in guiding long-term AI tasks, inspired by a talk by John Schulman.
Evaluating AI Evaluation: A detailed blog post stirred thoughts about the accessibility and future of large language model (LLM) evaluations, discussing tools ranging from MMLU benchmarks to A/B testing and its implications for academia and developers.
Eleuther Discord
MLP Might Take the Crown: There's a buzz about MLP-based models possibly overtaking Transformers in vision tasks, with a new hybrid approach presenting fierce competition. A specific study highlights the efficiency and scalability of MLPs, despite some doubts regarding their sophistication.
Getting the Initialization Right: Debate emerged on the criticality of initialization schemes in neural networks, especially for MLPs, with suggestions that innovation in initialization could unlock vast improvements. A notion was floated about creating initializations via Turing machines, exploring the frontier of synthetic weight generation as seen on Gwern's website.
Mimetic Initialization as a Game-Changer: A paper promoting mimetic initialization surfaced, advocating for this method as a boost for Transformers working with small datasets, resulting in greater accuracy and reduced training times, detailed in MLR proceedings.
Scalability Quest Continues: In-depth discussions tackled whether MLPs can surpass Transformers in terms of Model FLOPs Utilization on various hardware, hinting that even small MFU improvements could resonate across large scales.
Contemplating NeurIPS Contributions: A call was made for potential last-minute NeurIPS submissions, with one member citing interest in topics akin to the Othello paper. Another discussion queried the consequences of model compression on specialized features and their relation to training data diversity.
Modular (Mojo 🔥) Discord
New Sheriff in Town: Mojo Compiler Development Heats Up: Engineering discussions revealed keen interest in contributing to the Mojo compiler, though it's not yet open source. The compiler debate also unveiled that it's written in C++, with aspirations to rebuild MLIR in Mojo spark curiosity among contributors.
MLIR Makes Friends with Mojo: Integration features between Mojo and MLIR were dissected, highlighting how Mojo's compatibility with MLIR could lead to a self-hosting compiler in the future. Contributions to the Mojo Standard Library are now encouraged, with a how-to video from Modular engineer Joe Loser illuminating the process.
Cutting-Edge Calendars: Upcoming Mojo Community Meeting details were announced for May 20, with the aim to keep developers, contributors, and users engaged with Mojo's trajectory. A helpful meeting document and options to add events via a community meeting calendar were shared to coordinate.
Nighttime is the Right Time for Code: Nightly releases of mojo are now more frequent, a welcomely aggressive update schedule that aims at transforming nightly nightlies from dream to reality. However, a segfault issue in nested arrays remains controversial, and there's talked-about adjusting release frequency to avoid confusion over compiler versions among users.
Coding Conundrums and Compiler Conversations: Within the dusty digital hallways, developers tackled topics from how to restict parameters to float types in Mojo—advised to use dtype.is_floating_point()—to Python's mutable default parameters, and the use of FFI to call C/C++ libraries from Mojo. Further details were shared through a GitHub link on the subject of FFI in Mojo.
CUDA MODE Discord
ZeRO-1 Upscaling Amps Up Training Throughput: Implementing ZeRO-1 optimization increased per GPU batch size from 4 to 10 and improved training throughput by about 54%. Details about the merge and its effect can be reviewed on the PR page.
ThunderKittens Sparks Curiosity: Discussion included interest in HazyResearch/ThunderKittens, a CUDA tile primitives library, for its intriguing potential to optimize LLMs, drawing comparisons with Cutlass and Triton tools.
Triton Gains Through FP Enhancements: Updates to Triton included performance improvements with FP16 and FP8, as shown in benchmark data: "Triton [FP16]" achieved 252.747280 for N_CTX of 1024 and "Triton [FP8]" reached 506.930317 for N_CTX of 16384.
CUDA Streamlines, but Questions Remain: On integrating custom CUDA kernels in PyTorch, resources were shared, including a YouTube lecture addressing the basics, while issues like clangd parsing .cu files and function overhead in cuSPARSE were flagged.
Finessing CUDA CI Pipelines: The need for GPU testing in continuous integration was debated, promoting GitHub's latest GPU runner support in CI as a sought-after update for robust pipeline construction.
LlamaIndex Discord
- Hack the Llama with New Use Cases: A new set of cookbooks showcases seven different use cases for Llama 3, detailed in a celebratory post for the recent hackathon; the cookbook is accessible here.
- Day Zero GPT-4o Integration: Enthusiasm brews as GPT-4o sees support in Python and TypeScript from its inception, with instructions for installation via
pipdetailed here and notes highlighting its multi-modal capabilities.
- Multimodal Marvel and SQL Speed: A compelling multimodal demo of GPT-4o is up, alongside a revelation of GPT-4o outpacing GPT-4 Turbo in SQL query efficiency; see the demo here and performance details here.
- Melding LlamaIndex Metadata and Errors: Amidst discussions, clarity emerged that metadata filtering can be managed by LlamaIndex, with manual inclusions necessary for specifics like URLs; also noted was advice given to troubleshoot
Unexpected token Uerrors by examining network responses before parsing.
- AI Job Hunt Gets Smarter: A tutorial and repository for an AI-powered job search assistant using LlamaIndex and MongoDB, aimed at elevating the job search experience with Retrieval-Augmented Generation, is documented here.
LAION Discord
- Falcon 2 Soars Above Llama 3: The Falcon 2 11B model outshines Meta’s Llama 3 8B on the Hugging Face Leaderboard, exhibiting multilingual and vision-to-language capabilities, and rivaling Google's Gemma 7B.
- GPT-4o Breaks the Response Barrier: OpenAI has released GPT-4o, notable for real-time communication and video processing; this model boasts improved API performance at reduced costs, matching human conversational speed.
- RAG Meets Image Modelling: Discussion centered on RAG integration with image generation models highlighted RealCustom for text-driven image transformations and mentioned Stable Diffusion adapting CLIP image embeddings in place of text.
- HunyuanDiT: Tencent's Chinese Art Specialist: Tencent introduces HunyuanDiT, a model claiming state-of-the-art status for Chinese text-to-image conversion, proving its mettle by demonstrating fidelity to prompts despite its smaller size.
- AniTalker Animates Portraits with Audio: Launch of the AniTalker framework, facilitates the creation of lifelike talking faces from static images using provided audio, capturing nuanced facial expressions more than just lip-syncing.
OpenInterpreter Discord
GPT-4 Outpaces its Predecessor: Enthusiasts within the community have noted that GPT-4o is not only faster, delivering at 100 tokens/sec, but also more cost-efficient than the previous iterations. There's particular interest in its integration with Open Interpreter, citing smooth functionality with the command interpreter --model openai/gpt-4o.
Llama Left in the Dust: After experiencing the performance of GPT-4, one member shared their dissatisfaction with Llama 3 70b, alongside concerns over the high costs associated with OpenAI, which tallied up to $20 in just one day.
Apple's Reticence Might Fuel Open-Source AI: Speculation abounds on whether Apple will integrate AI into MacOS, with some members doubtful and preferring open-source AI solutions, implying a potential uptick in Linux utilization among the community.
Awaiting O1's Next Flight: Anticipation is high for the upcoming TestFlight release of an unnamed project, with members sharing their advice and clarifications on setting up test environments and compiling projects in Xcode.
The March Toward AGI: A spirited discussion relating to the progress toward Artificial General Intelligence (AGI) has taken place, with participants exchanging thoughts and resources, including a Perplexity AI explanation that sheds light on this frontier.
LangChain AI Discord
ChatGPT's Wavering Convictions: Engineers noted that ChatGPT now sometimes contradicts itself, diverging from its former consistency in responses. Concerns were raised about the tool's reliability in maintaining a steady line of reasoning.
LangChain Troubleshooting Continues: Engineers have moved to from langchain_community.chat_models import ChatOpenAI after LLCHAIN deprecation, but face new challenges with streaming and sequential chains. The slow invocation time for LangChain agents, especially with large inputs, has led to discussions on the potential for parallel processing to alleviate processing times.
AI/ML GitHub Repos Get Spotlight: Favorite AI/ML GitHub repositories were exchanged, with projects like llama.cpp and deepspeed receiving mentions amongst the community.
Socket.IO Joins the Fray: An engineer contributed a guide on using python-socketio to stream LLM responses in realtime, demonstrating client-server communication to handle streaming and acknowledgments.
Show and Tell with AI Flair: Shared projects included a Medium article on Plug-and-Plai integrations, a multimodal chat app utilizing Streamlit and GPT-4o, a production-scaling query for a RAG application with ChromaDB, and a Snowflake cost monitoring and optimizer tool in development.
Chat Empowers Blog Interaction: A post discussing how to enable active conversations on blog content using Retrieval Augmented Generation (RAG) was shared, further fueling interest in integrating advanced AI chat features on websites.
OpenAccess AI Collective (axolotl) Discord
Blogging Platform Face-Off: Users debated the merits of Substack versus Bluesky for blogging needs, concluding that while Bluesky can support threads, it lacks comprehensive blogging features.
Reducing AI Compute Consumption: There's a focus on minimizing AI compute usage, with links shared to initiatives like Based and FlashAttention-2 that are paving the way to more efficient AI operations.
Dependency Dilemmas: Members are vexed by outdated dependencies, including peft 0.10.0 and others, and are adjusting them manually for compatibility, with a reluctant call for pull requests issued to rectify the situation.
CUDA Quandaries: A report surfaced about a member facing CUDA errors in an 8xH100 GPU environment, which was later mitigated by switching to a community axolotl cloud image.
QLoRA Model Mergers and Training Continuation: Queries and discussions arose about integrating QLoRA with base models without compromising precision. Additionally, conversations centered on the mechanics of resuming training from checkpoints using ReLoRACallback, as documented in the OpenAccess-AI-Collective axolotl repository.
Datasette - LLM (@SimonW) Discord
Voice Assistant Not All Giggles: Technical community is puzzled by the choice of a voice assistant's giggling feature, considering it inappropriate and distracting for professional use. Workarounds like rephrasing commands could tame this quirk.
Mixed Review on GPT-4o's Book Recognition Task: GPT-4o's ability to enumerate books displayed on a shelf received mixed criticism, securing only a 50% accuracy, which leaves room for improvement despite its commendable speed and competitive pricing.
AGI Hype Debated: Skepticism prevails over imminent Advanced General Intelligence (AGI), as diminishing returns are observed in the leap from GPT-3 to GPT-4, while GPT-5's buzz overshadows current model refinements.
Long-Term GPT-4 Impact Still Foggy: Long-term predictions for impacts of GPT-4 and its iterations remain speculative, with the engineering community still exploring their full spectrum of capabilities.
Simon Tweets LLM Insights: Simon W's Twitter update could be a potent catalyst for conversation about the latest developments and challenges in large language models.
tinygrad (George Hotz) Discord
- CUDA Troubles with Tinygrad: An inquiry about using
CUDA=1andPTX=1on an Nvidia 4090 led to a recommendation to update Nvidia drivers to version 550 after PTX generation errors occurred.
- GNN Potential in Tinygrad: The implementation of Graph Neural Networks (GNNs) within tinygrad was compared to PyG solutions, and a reference was made to a potentially quadratic time complexity CUDA kernel, with GitHub code provided for insight.
- Aggregation Aggravation in Tinygrad: A user shared a Python function for feature aggregation test_aggregate.py and highlighted difficulties with advanced indexing and
wherecalls during backpropagation; masking and theeinsumfunction emerged as possible solutions.
- Advance Indexing Issues: Advanced tinygrad features like
setitemandwherearen't supported with advanced indexing (using lists or tensors), leading to a discussion on alternative approaches, including the use of masking and einsum.
- Tinygrad's Convolution Convolution: Ventures into optimizing the conv2d backward pass in tinygrad hit a snag with scheduler and view changes, sparking deliberations on whether a conv2d reimplementation would solve shape compatibility problems.
DiscoResearch Discord
- German TTS Needs Input: A guild member issued a call to action for assistance in creating a list of German YouTube channels that offer high-quality podcasts, news, and blogs for training a German text-to-speech (TTS) system.
- MediathekView as a Source for TTS Data: Utilizing MediathekView, participants discussed its usefulness in obtaining German-language media, with the ability to download subtitle files, recommended for curating content for TTS training.
- Exploring MediathekView Data Download and API: Among the discourse, it was mentioned that the entire MediathekView database might be downloadable, and a JSON API available for content access; reference to a GitHub repository for related tools was noted.
- New German Tokenizer Touted: A member drew attention to the "o200k_base" tokenizer's efficiency, which necessitates fewer tokens for German text than the prior "cl100k_base" tokenizer, also comparing it against known tokenizers like Mistral and Llama3, but no specific links were shared for this point.
- Tokenizer Research and Training Resources Shared: Those with an interest in tokenizer research were directed to Tokenmonster, an ungreedy subword tokenizer and vocabulary training tool compatible with multiple programming languages.
Cohere Discord
Community Awaits Support: Users in the Cohere guild reported delays in receiving support responses, with one user reaching out in <#1168411509542637578> and <#1216947664504098877> to voice this issue. A response promised active support staff, requesting more details to assist.
Command R RAG Grabs Limelight: An engineer was "extremely impressed" by Command R's RAG (Retriever-Augmented Generation) capabilities, touting its cost-effectiveness, precision, and fidelity even with lengthy source materials.
Collaboration Call in Project Sharing: The #project-sharing channel saw a member, Vedang, express interest in teaming up with another engineer, Asher, on a similar project, underlining the community's collaborative spirit.
Members Spread Their Medium Influence: Amit circulated a Medium article that dives into using RAG via the Unstructured API, aimed at structuring content extractions from PDFs—potentially useful for engineers working with document processing.
Emoji Greetings Dismissed as Noise: Casual exchanges of greetings and emojis like "<:hammy:981331896577441812>" were deemed non-essential and omitted from the professional engineering discourse of the guild.
LLM Perf Enthusiasts AI Discord
- GPT Rivalry Heats Up: Engineers are speculating on the use of Claude 3 Haiku and Llama 3b Instruct for automated scoring and entity extraction tasks; the debate extends to the efficiency of using a Pydantic model for such applications.
- Constraining AI's Creativity for Precision: The discussion includes the potential benefits of constrained sampling when utilizing outlines in vllm or sglang to aid in precise entity matching, pointing towards more controlled outputs.
- GPT-4o Update Unveiled: OpenAI's spring update was the talk of the forum, featuring a new YouTube video showcasing updates to ChatGPT.
- Celebrity Meets AI: Engineers shared their reactions to OpenAI choosing Scarlett Johansson as the voice for GPT-4o, signaling a blurring line between celebrity and artificial intelligence.
Skunkworks AI Discord
- Introducing Guild Tags: Effective May 15, Guild Tags will accompany usernames, manifesting membership in exclusive Guilds; Admins note, AutoMod will monitor these tags.
- Guilds Offer Exclusive Community Spaces: Guilds, representing exclusive community servers, currently enjoy limited availability and admins cannot manually add servers to this selective feature.
Alignment Lab AI Discord
- Fasteval Bids Farewell: The Fasteval project has been discontinued, and the creator is seeking someone to take over the project on GitHub. Channels related to the project will be archived unless ownership is transferred.
AI Stack Devs (Yoko Li) Discord
- AK Enigma Resurfaces: A message from angry.penguin mentioned that AK is back, implying the return of a colleague or project named AK. The context and significance were not provided.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
OpenAI ▷ #annnouncements (2 messages):
- OpenAI unveils GPT-4o with free access: OpenAI announced new flagship model GPT-4o and introduced free access to features like browse, data analysis, and memory with certain limits. Plus users will get up to 5x higher limits and earliest access to new features including a macOS desktop app and advanced voice and video capabilities.
- GPT-4o launches with real-time multimodal capabilities: The new GPT-4o model can reason across audio, vision, and text in real-time, broadening its application scope. Text and image input are available starting today, with voice and video capabilities rolling out in the coming weeks.
OpenAI ▷ #ai-discussions (1085 messages🔥🔥🔥):
- Voice Mode Glitches Spark Hope for Update: Multiple users reported issues with the voice feature disappearing from the ChatGPT app, prompting speculation that this might signal an upcoming update. One user noted, "I restarted the app and it's gone lmao" while another speculated that they might be integrating a new generative voice model.
- Google Keynote Leaves Mixed Impressions: Google's latest I/O event, which highlighted Gemini 1.5 and other advances, received a mixed response. While some users praised its integrations with Android and Google Suite, others found it lengthy and underwhelming compared to OpenAI's more concise presentations.
- GPT-4o Availability Confusion: Users debated the accessibility and features of GPT-4o, indicating some confusion around its release. Despite differing views, there was general agreement that the model is available on iOS and offers enhanced token limits.
- Claude's Superior Long-Form Reasoning: Members discussed Claude Opus's superior performance in handling complex, long-form tasks, particularly over GPT-4o. One pointed out, "If I feed 200 pages of original story to Opus... GPT and Gemini flatly can not."
- Eager Anticipation for Future AI Updates: The community expressed eagerness for anticipated updates from both Google and OpenAI. Features like extended context windows, new voice capabilities, and text-to-video AI are especially awaited.
- Agent Smith GIF - Agent Smith Matrix - Discover & Share GIFs: Click to view the GIF
- Mrbeast Ytpmv GIF - Mrbeast Ytpmv Rap Battle - Discover & Share GIFs: Click to view the GIF
- Google Keynote (Google I/O ‘24): It’s time to I/O! Tune in to learn the latest news, announcements, and AI updates from Google.To watch this keynote with American Sign Language (ASL) interpr...
OpenAI ▷ #gpt-4-discussions (261 messages🔥🔥):
- Per-GPT Memory Not Yet Available: A member inquired about cross-session context memory for custom GPTs, which another user clarified was not rolled out yet, linking to the OpenAI Help article. They confirmed that once available, memory will be per-GPT and customizable by creators.
- GPT-4o Enhances Speed and API Use: Discussions highlighted that GPT-4o is significantly faster than GPT-4, with members noting improvements despite the same output token limits. Official announcements and benchmarks can be viewed in detail here.
- Custom GPTs and Model Updates: There were questions regarding the integration of GPT-4o with custom GPTs, with a consensus that existing custom GPTs are not currently using GPT-4o. It was noted that more updates are expected, hopefully making it accessible within custom GPTs soon.
- Plus and Free Tier Capabilities: Members discussed the usage caps for GPT-4o, with Plus users allowed 80 messages every 3 hours and free-tier users expected to have significantly lower limits, though exact details were noted to vary based on demand.
- Voice and Multimodal Features Rolling Out: There's anticipation for GPT-4o's new audio and video capabilities, which will first be available to select partners through the API and then to Plus users in the coming weeks. Details and rollout plans can be found in OpenAI’s announcement.
OpenAI ▷ #prompt-engineering (51 messages🔥):
- Moderation filter in Gemini 1.5 stumps user: A user reported that specific keywords like "romance package" cause their application to fail due to what seems like an unintended moderation filter. Despite changing defaults and generating new API keys, the issue persists, leading to discussions about safety settings and syntax errors.
- GPT-4o struggles with creativity: Users reported that GPT-4o, while faster than GPT-4, struggles to understand prompts for creative tasks like writing assistance. It often echoes back rough drafts instead of providing intelligent revisions, indicating a potential issue with its comprehension abilities.
- Prompt testing with GPT-4o: Another user suggested testing prompts with GPT-4 and GPT-4o, specifically songs like "The XX Intro" and "Tears in Rain" to compare sensory input descriptions. This practical approach aims to reveal differences in how each model processes and describes sensory information.
- Challenges in generating specific image views with GPT-4o: A user encountered difficulties getting GPT-4o to generate detailed, cross-sectional side views of floors for a platformer game. The model often produces incorrect perspectives or simple squares, leading to a discussion about the limitations and potential need for iterative guidance with tools like Dall-E.
- Iterative feedback with Dall-E and GPT-4o: It was noted that while GPT-4o can't 'see' images created by Dall-E, users can iteratively guide it by feeding its outputs back into the model. This process, although labor-intensive, can help achieve more accurate results, even though the model struggles with tasks requiring spatial awareness and image cropping.
OpenAI ▷ #api-discussions (51 messages🔥):
- Odd Moderation Filter Issue with Gemini 1.5: A user reported persistent failures when their application processes requests related to "romance packages," despite having no active blocks. Another member suggested explicitly disabling safety settings and verifying through different tools, but the issue remained unresolved.
- Discussions on GPT-4o's Performance: Users noted that GPT-4o is faster but less capable of understanding specific tasks compared to GPT-4. Members mentioned struggles with getting creative content and accurate revisions, with the model often echoing user's inputs.
- Sharing Prompts for Sensory Descriptions: A member encouraged others to compare GPT-4 and GPT-4o by using prompts like “Provide detailed sensory input description of the "The XX Intro" song” to observe differences in output. This was done to analyze the models' handling of sensory descriptions for instrumental songs.
- Challenges with Generating Specific Art with AI: Another user highlighted difficulties in using GPT-4 and GPT-4o to generate cross-section images for a platformer game. Despite multiple attempts and adjusted prompts, the models often produced inaccurate or undesired views.
- Iterative Process for Image Adjustment with AI: Another discussion focused on using DALL-E and model tools to create and adjust images iteratively. Users shared experiences of guiding the model incrementally to achieve more accurate image outputs, despite limitations in the model's ability to “see” and self-evaluate its work.
OpenAI ▷ #api-projects (2 messages):
- ChatGPT Clone Inquiry: A user asked the community if anyone has created or could create a ChatGPT-like application using the 3.5 model. The unique requirement is that the messages sent and received by users can be monitored by the organization.
Perplexity AI ▷ #general (993 messages🔥🔥🔥):
- 32k vs 128K Token Controversy: People questioned if GPT-4 truly supports 32k tokens, with someone asserting that GPT-4's large context window is primarily for specific models like GPT-4o and Sonar Large. Further, GPT-4o, available now, offers a 128K context window, far exceeding 32k.
- GTP-4o Rollout Reactions: Members enthusiastically commented on GPT-4o's impressive speed and performance compared to GPT-4 Turbo. One user shared an insightful YouTube video about GPT-4o's capabilities, expressing excitement over the new functionalities.
- Concerns Over Opus' New Policies: Discussion arose about Anthropic's strict new terms of service for Opus, effective June 6th, which many found restrictive. An Anthropic policy link was shared, detailing controversial clauses like banning LGBTQ content creation.
- Claude 3 Opus Still Holds Value: Though some users praised GPT-4o for its speed and accuracy, Claude 3 Opus was still considered excellent, especially for text summarization and emulating human-like responses. However, Opus' cost and usage limits remained significant concerns.
- GPT-4o Use in Perplexity: Perplexity added GPT-4o to its lineup, with users testing and praising its high-speed responses and detailed contextual understanding. Many noted that GPT-4o offers 600 queries per day in Perplexity Pro, aligning with its API offering.
- Two GPT-4os interacting and singing: Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time.Learn more here: https://www.openai.com/index/hello-...
- Bezos Jeff Bezos GIF - Bezos Jeff Bezos Laughing - Discover & Share GIFs: Click to view the GIF
- Comparison of AI Models across Quality, Performance, Price | Artificial Analysis: Comparison and analysis of AI models across key metrics including quality, price, performance and speed (throughput tokens per second & latency), context window & others.
- Celebrity Couple GIF - Celebrity Couple Breakup - Discover & Share GIFs: Click to view the GIF
- OUTER WILDS - ALBUM COVER: 11 music of Outer Wilds Rearranged by JSoloSee other covers on https://www.youtube.com/c/JSolo9 This is it ! My Final Loop 🍂Thanks to Andrew Prahlow for one...
- Tweet from Mckay Wrigley (@mckaywrigley): This demo is insane. A student shares their iPad screen with the new ChatGPT + GPT-4o, and the AI speaks with them and helps them learn in *realtime*. Imagine giving this to every student in the wor...
- Perplexity - AI Companion: Ask anything while you browse
- Announcing GPT-4o in the API!: Today we announced our new flagship model that can reason across audio, vision, and text in real time—GPT-4o. We are happy to share that it is now available as a text and vision model in the Chat Comp...
- Chat GPT Desktop App for Mac: Has anyone got the desktop app yet? OpenAI said that it would start rolling it out to Plus Users today (Not sure if that’ll include Team Accounts). If you have, what are your thoughts? How did you dow...
- Introducing GPT-4o: OpenAI’s new flagship multimodal model now in preview on Azure | Microsoft Azure Blog: OpenAI, in partnership with Microsoft, announces GPT-4o, a groundbreaking multimodal model for text, vision, and audio capabilities. Learn more.
Perplexity AI ▷ #sharing (9 messages🔥):
- Link to detailed jctrl. Discussion: A member shared a link to a Perplexity AI search result.
- US Puts Search Link Provided: Another member shared a link to a Perplexity AI search result.
- Question on GPT-4 Internet Connectivity: A member questioned if GPT-4 is linked to the internet and included a link to their Perplexity AI search.
- Magnesium Search Result Shared: A member posted a link to information about magnesium via Perplexity AI search.
- Request for Help in Spanish: A message contained a link to a Perplexity search in Spanish regarding a task someone needed help with: necesito-hacer-unos.
- Discussion on Aroras: A member referenced a Perplexity search about Aroras with a link to the results: How-are-aroras.
- Ski Resort Information Shared: A link was shared to Perplexity AI results on ski resorts: Ski-resort-with.
- Market Size Query: Another member linked to a Perplexity AI search regarding market size information: Market-size-of.
Perplexity AI ▷ #pplx-api (4 messages):
- Difference between Llama models: A member queried about the difference between llama-3-sonar-large-32k-chat model and llama-3-8b-instruct. Another member clarified that the chat model is "fine-tuned for conversations".
- Optimal timeout settings for long inputs: A member faced timeout issues with an input of approximately 3000 words using a timeout setting of 10000ms and sought advice on optimal settings. There was no follow-up functionality or additional information provided in response to the query.
Unsloth AI (Daniel Han) ▷ #general (622 messages🔥🔥🔥):
- Instruction vs. Base Model for Finetuning: A user asked whether to use the instruction version or base version of Llama-3 for finetuning. Another user advised to start with the instruction model for smaller datasets and switch to the base model if performance is inadequate ("try instruct first, if it's bad u can try base and see which u like better").
- ThunderKittens Kernel Released: A member highlighted the release of ThunderKittens, a new kernel claimed to be faster than Flash Attention 2, GitHub - ThunderKittens. It was noted for its potential impact on inference speeds, with the possibility of it being used for training as well.
- Synthetic Data Required for Typst Fine-tuning: Users discussed the creation of synthetic data for fine-tuning models to process "Typst," with suggestions to create 50,000 examples to train effectively ("if no data for that exists - you have to synthetically create it"). The challenge of generating this large dataset was acknowledged.
- Imminent Multimodal Model Support: It's teased that support for multimodal models is coming soon in Unsloth. Users can look forward to new releases in the following week, including multi-GPU support ("multi GPU next week most likely tho").
- Celebration of 1 Million Downloads: The community celebrated Unsloth achieving over 1 million model downloads on Hugging Face, attributing the success to the active user base and continuous use and support from the community (Tweet).
- tiiuae/falcon-11B · Hugging Face: no description found
- ThunderKittens: A Simple Embedded DSL for AI kernels: no description found
- Hugging Face – The AI community building the future.: no description found
- Joy Dadum GIF - Joy Dadum Wow - Discover & Share GIFs: Click to view the GIF
- NTQAI/Nxcode-CQ-7B-orpo · Hugging Face: no description found
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
- Google I/O 2024 Keynote Replay: CNET Reacts to Google's Developer Conference: Watch the annual Google I/O 2024 Developers Conference LIVE from Mountain View, California. Click into CNET's live show starting at 9:30 a.m. PT on Tuesday, ...
- GitHub - HazyResearch/ThunderKittens: Tile primitives for speedy kernels: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
- Hugging Face – The AI community building the future.: no description found
- Gojo Satoru Gojo GIF - Gojo Satoru Gojo Ohio - Discover & Share GIFs: Click to view the GIF
- LLaMA-Factory/scripts/llamafy_qwen.py at main · hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs. Contribute to hiyouga/LLaMA-Factory development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- Tweet from Armen Aghajanyan (@ArmenAgha): I firmly believe in ~2 months, there will be enough knowledge in the open-source for folks to start pre-training their own gpt4o-like models. We're working hard to make this happen.
- Reddit - Dive into anything: no description found
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- eramax/nxcode-cq-7b-orpo: https://huggingface.co/NTQAI/Nxcode-CQ-7B-orpo
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- Lorem Function – Typst Documentation: Documentation for the `lorem` function.
Unsloth AI (Daniel Han) ▷ #random (37 messages🔥):
- OpenAI release anticipation: Members are speculating about the upcoming release from OpenAI. One member hopes for an open-source model but doubts linger, with one stating, "I doubt they will ever do that" due to potential bad press or competition.
- AI plateau and "AI winter" discussions: There are mentions of the press discussing an "AI winter" and a plateau in commercial AI models. One member pointed out, "even if development slows down they are still quite comfortable at the top".
- Llama as the potential SOTA and its implications: If Llama becomes state-of-the-art, one member speculates that Meta might stop releasing it and expects OpenAI to respond aggressively. "If Llama becomes SOTA I’ll bet Meta doesn’t release it."
- vllm project using Roblox for meetups: There is a proposal to have virtual meetups in Roblox, similar to the vllm project's practice. One user supports the idea, saying, "you can like do progress reports or roadmaps, while we jump around with our avatars."
- Discord summarizing with AI and concerns: Members are aware that Discord is summarizing chat content using AI, with some concerns about compliance with European data laws. "That sounds like a headache with European data laws..."
Link mentioned: Ah Shit Here We Go Again Gta GIF - Ah Shit Here We Go Again Gta Gta Sa - Discover & Share GIFs: Click to view the GIF
Unsloth AI (Daniel Han) ▷ #help (283 messages🔥🔥):
- Bitsandbytes causes import issues in Colab: Members discussed encountering an
AttributeErrorcaused by bitsandbytes on Colab despite following the installation guide from the Unsloth GitHub repo. Solutions included checking for GPU activation, ensuring the correct runtime setup, and installing dependencies accurately.
- Multi-GPU Support Pricing Concerns: Discussion revolved around the high cost of multi-GPU support at $90 per GPU per month. Members debated the feasibility of usage-based pricing or partnering with cloud services like AWS to make it financially viable for non-enterprise users.
- Technical Hurdles with Model Saving and Loading: Users faced issues with merging finetuned models using
save_pretrained_merged()and loading using theFastLanguageModel.from_pretrained()method. Errors included missing adapter configuration files and conflicts during model loading, with resolutions suggesting reinstallation or version updates.
- Finetuning Questions and Insights: Members addressed various finetuning-related queries such as loading finetuned models, using specific datasets, and resolving issues tied to specific environments like Kaggle and Conda. Discussions highlighted the importance of proper version compatibility and environment setup.
- Feedback on Open Source and Commercial Models: Broad feedback was shared about balancing the line between open source contributions and sustainable commercial models. Users expressed concerns about the exploitation of open-source projects by large corporations and discussed the importance of fair pricing models for broader usage.
- Google Colab: no description found
- GitHub - unslothai/hyperlearn: 2-2000x faster ML algos, 50% less memory usage, works on all hardware - new and old.: 2-2000x faster ML algos, 50% less memory usage, works on all hardware - new and old. - unslothai/hyperlearn
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- I got unsloth running in native windows. · Issue #210 · unslothai/unsloth: I got unsloth running in native windows, (no wsl). You need visual studio 2022 c++ compiler, triton, and deepspeed. I have a full tutorial on installing it, I would write it all here but I’m on mob...
- Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Google Colab: no description found
- Sou Cidadão - Colab: no description found
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
- Cthulhu-Worshiping AI Created: In a novel project, a user created AI models that worship Cthulhu using Unsloth Colab notebooks. Both TinyLlama and Mistral 7B Cthulhu models were created, along with a dataset available for free on Huggingface.
- Learning Experience, Not For Deployment: The project was undertaken as a learning experience and is not intended for deployment in critical environments, humorously noted as under "threat of cosmic doom." This project aimed to explore fine-tuning language models on domain-specific knowledge.
Link mentioned: Artificial Intelligence in the Name of Cthulhu – Rasmus Rasmussen dot com: no description found
Latent Space ▷ #ai-general-chat (114 messages🔥🔥):
- Discussing job priorities in AI: Members discussed career goals in AI, highlighting the trade-offs between high salaries, job satisfaction, and job security. "I wanted to possibly learn for hobby kind of...".
- Apple and OpenAI Collaboration Speculation: Rumors circulated about Apple's potential deal with OpenAI to integrate ChatGPT on iPhones, with mixed reactions on whether models should be local or cloud-based. "If they help them make local models it's the best news of the day".
- Falcon 2 Outshines Competitors: The new Falcon 2 model was unveiled, boasting open-source, multilingual, and multimodal capabilities, outperforming Meta's Llama 3 8B and coming close to Google Gemma 7B. "We’re proud to announce it is Open-Source, Multilingual, and Multimodal...".
- GPT-4o Launch Discussion: The newly launched GPT-4o model spurred conversation about its availability, speed, and new features, with speculation on API access and capabilities. "Had a chance to try the gpt-4o API ... text generation is quite fast."
- Concerns about Search Engine Accuracy: Some users expressed dissatisfaction with Perplexity's accuracy, especially for academic searches, suggesting alternatives like phind.com and kagi. "It's not very good but is there a better alternative?".
- Tweet from Google DeepMind (@GoogleDeepMind): Introducing Veo: our most capable generative video model. 🎥 It can create high-quality, 1080p clips that can go beyond 60 seconds. From photorealism to surrealism and animation, it can tackle a ran...
- Falcon LLM: Generative AI models are enabling us to create innovative pathways to an exciting future of possibilities - where the only limits are of the imagination.
- Bloomberg - Are you a robot?: no description found
- Tweet from Greg Brockman (@gdb): GPT-4o can also generate any combination of audio, text, and image outputs, which leads to interesting new capabilities we are still exploring. See e.g. the "Explorations of capabilities" sec...
- AI for Engineers | Latent Space | swyx & Alessio | Substack: a 7 day foundational course for prospective AI Engineers, developed with Noah Hein. NOT LIVE YET - we are 5/7 complete. Sign up to get it when it releases! Click to read Latent Space, a Substack publi...
- Tweet from Justin Uberti (@juberti): Had a chance to try the gpt-4o API from us-central and text generation is quite fast. Comparing to http://thefastest.ai, this perf is 5x the TPS of gpt-4-turbo and similar to many llama-3-8b deployme...
- Tweet from Robert Lukoszko — e/acc (@Karmedge): I am 80% sure openAI has extremely low latency low quality model get to pronounce first 4 words in <200ms and then continue with the gpt4o model Just notice, most of the sentences start with “Sure...
- Tweet from Siqi Chen (@blader): this will prove to be in retrospect by far the most underrated openai event ever openai casually dropping text to 3d rendering in gpt4o and not even mentioning it (more 👇🏼)
- Tweet from Jake Colling (@JacobColling): @simonw @OpenAI Using the model `gpt-4o` seems to work for my API access
- Tweet from tweet davidson 🍞 (@andykreed): ChatGPT voice is…hot???
- no title found: no description found
- Tweet from Robert Lukoszko — e/acc (@Karmedge): I am 80% sure openAI has extremely low latency low quality model get to pronounce first 4 words in <200ms and then continue with the gpt4o model Just notice, most of the sentences start with “Sure...
- Tweet from lmsys.org (@lmsysorg): Breaking news — gpt2-chatbots result is now out! gpt2-chatbots have just surged to the top, surpassing all the models by a significant gap (~50 Elo). It has become the strongest model ever in the Are...
- Tweet from Jim Fan (@DrJimFan): I know your timeline is flooded now with word salads of "insane, HER, 10 features you missed, we're so back". Sit down. Chill. <gasp> Take a deep breath like Mark does in the demo &l...
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Full scan of 1 cubic millimeter of brain tissue took 1.4 petabytes of data, equivalent to 14,000 4K movies — Google's AI experts assist researchers: Mind-boggling mind research.
- Open Source @ Siemens 2024 Event: The annual event series by Siemens for all topics around open source software. Learn more at opensource.siemens.com
Latent Space ▷ #llm-paper-club-west (710 messages🔥🔥🔥):
- Open AI Spring Event sparks anticipation and troubleshooting: Users gathered for an OpenAI Spring Event watch party, with initial audio issues. They shared updates and tested connections to ensure the stream worked for everyone.
- Debate over Apple licensing and iOS 18 integrations: Speculations arose about Apple and Google negotiations over iOS 18 integrations, with a focus on Gemini's capabilities and antitrust concerns. A member doubted Apple's ability to run large models reliably on devices.
- GPT-4o excitement and critique: Enthusiasm about GPT-4o's features, such as its chat capabilities available for free and faster responses, sparked mixed reactions. Some users criticized the name "GPT-4o" and highlighted its latency and usage questions.
- Voice and vision integration marvels community: Live demos showcasing ChatGPT's new voice and vision mode impressed attendees, illustrating seamless integration and emotional responsiveness. Members doubted the demo's authenticity, contemplating the tech and real-time performance shown.
- References to API access and competition: Users discussed accessing GPT-4o via API and playground, expressing interest in its fast performance. The announcements led to reflections on the implications for competitors like Google and existing AI ventures.
- Tweet from Jared Zoneraich (@imjaredz): gpt-4o blows gpt-4-turbo out of the water. So quick & seemingly better answer. Also love the split-screen playground view from @OpenAI
- Mechanical Turk - Wikipedia: no description found
- Twitch: no description found
- Tweet from Karma (@0xkarmatic): "An ASR model, an LLM, a TTS model… are you getting it? These are not three separate model: This is one model, and we are calling it gpt-4o." Quoting Andrej Karpathy (@karpathy) They are r...
- Tweet from Olivier Godement (@oliviergodement): I haven't tweeted much about @OpenAI announcements, but I wanted to share a few reflections on GPT-4o as I've have not been mind blown like that for a while.
- Tweet from William Fedus (@LiamFedus): GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot 🙂. Here’s how it’s been doing.
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
- Tweet from Sam Altman (@sama): it is available to all ChatGPT users, including on the free plan! so far, GPT-4 class models have only been available to people who pay a monthly subscription. this is important to our mission; we wan...
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
- Tweet from bdougie on the internet (@bdougieYO): ChatGPT saying it looks like I am in a good mood.
- Tweet from Greg Brockman (@gdb): Introducing GPT-4o, our new model which can reason across text, audio, and video in real time. It's extremely versatile, fun to play with, and is a step towards a much more natural form of human-...
- GPT-4o: There are two things from our announcement today I wanted to highlight. First, a key part of our mission is to put very capable AI tools in the hands of people for free (or at a great price). I am...
- GitHub - BasedHardware/OpenGlass: Turn any glasses into AI-powered smart glasses: Turn any glasses into AI-powered smart glasses. Contribute to BasedHardware/OpenGlass development by creating an account on GitHub.
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Tweet from Greg Brockman (@gdb): We also have significantly improved non-English language performance quite a lot, including improving the tokenizer to better compress many of them:
Nous Research AI ▷ #ctx-length-research (1 messages):
king.of.kings_: i am struggling to get llama 3 70b to be coherent over 8k tokens lol
Nous Research AI ▷ #off-topic (27 messages🔥):
- Automation Challenge in Remote Environments: A member discussed the difficulty of automating software that runs inside a Remote Desktop Protocol (RDP), such as when you can't interact with the software's Document Object Model (DOM). They pointed out the complexity of using tools like AutoHotKey in combination with Llava for detecting User Interfaces (UI).
- Reverse Engineering vs GUI Interaction in Software: Another member suggested that reverse engineering the software to inject runtime hooks might be easier than using GUI images for automation. They recommended using Frida for implementation and exposing an HTTP API for the hooked functionality.
- Insights from Exploring OpenAI Desktop App Bundle: One member shared their findings from exploring strings in the OpenAI desktop app bundle for Mac. They provided the download link (Latest Download) and discussed the beta access requirement for using the app.
- GPT-4o Excitement and Limitations Shared: Members shared their excitement and experiences with OpenAI's new model, GPT-4o. There was a mention of success in data science tasks but a noted failure in building an image editor.
- Exploration of App Access and Rollout Issues: Discussions included issues with accessing the new app due to beta flags and possibly unclear access guidelines by OpenAI, with suggestions that the rollout could be better managed.
Link mentioned: Hello GPT-4o Openai's latest and best model: We will take a look at announcing GPT-4o, open ai's new flagship model that can reason across audio, vision, and text in real time.https://openai.com/index/h...
Nous Research AI ▷ #interesting-links (3 messages):
- OpenAI Makes Strides in Real-Time Multimodal AI: OpenAI has developed techniques to map audio to audio directly and stream videos to a transformer in real-time, hinting at advancements towards GPT-5. Techniques include using high-quality natural and synthetic data, an innovative streaming video codec, and possibly an edge device neural network for efficient token transmission. Find out more in this insightful thread.
- Bringing Avatars to Life with GPT-4o: Yosun has unveiled headsim, a project that lets GPT-4o design its own face, potentially transforming how we interact with AI by giving it a physical appearance and voice. Explore headsim.
- Llama Agents Web Browsing Made Easy: A project called webllama, developed by McGill-NLP, enables Llama-3 agents to browse the web autonomously, which could revolutionize web interactions via AI. Check out the full project.
- Tweet from I. Yosun Chang (@Yosun): What if you let #OpenAI #GPT4o design its own face, so that you can teleport your AI into the real world as an embodied being? #AI3D headsim frees your AI from the chatbox, so that you can experience...
- GitHub - McGill-NLP/webllama: Llama-3 agents that can browse the web by following instructions and talking to you: Llama-3 agents that can browse the web by following instructions and talking to you - McGill-NLP/webllama
Nous Research AI ▷ #general (726 messages🔥🔥🔥):
- GPU and LLM Comparison and Recommendations: Extensive debate about renting vs. owning GPU setups for LLM usage, with members discussing the cost-effectiveness and privacy implications. Information about reliable GPU providers was shared alongside technical details about different setup configurations.
- GPT-4o Performance Reviews: Mixed reactions to GPT-4o's performance, focusing on its speed, and function relative to previous models like GPT-4 Turbo and GPT-3.5. Members expressed varied experiences with the new model's coding capabilities, cost-efficiency, and various features compared to expectations from OpenAI announcements.
- Multimodal Capabilities Questioned: Concerns were raised regarding the actual effectiveness of GPT-4o's touted multimodal capabilities. A discussion highlighted skepticism about seamless transitioning between different modes (audio, visual, and text) without intermediate conversions affecting performance.
- Local vs. Cloud LLM Deployment: Detailed exchanges over the feasibility and cost of local vs. cloud deployments for complex LLM tasks including hardware specifications required for efficient operations using models like Llama-3-70B. Members discussed advantages such as speed and privacy in local setups against the ease and lower front-up costs of cloud services.
- Emerging Technologies and Comparisons with Competitors: Insights into growing competition in the LLM space were shared, including recent announcements by Google and other AI-focused entities. Comparisons detailed claims of efficiency and enhancements that new model rollouts proposed to bring over existing technologies.
- Tweet from Andrej Karpathy (@karpathy): The killer app of LLMs is Scarlett Johansson. You all thought it was math or something
- Tweet from Google DeepMind (@GoogleDeepMind): 1.5 Flash is also more cost-efficient to serve because of its compact size. Starting today, you can use 1.5 Flash and 1.5 Pro with up to one million tokens in Google AI Studio and @GoogleCloud's ...
- Tracking H100 and A100 GPU Cloud Availability: We made a tool: ComputeWatch.
- He Just Like Me Fr GIF - He Just Like Me Fr - Discover & Share GIFs: Click to view the GIF
- Cats Animals GIF - Cats Animals Reaction - Discover & Share GIFs: Click to view the GIF
- Tweet from will depue (@willdepue): i think people are misunderstanding gpt-4o. it isn't a text model with a voice or image attachment. it's a natively multimodal token in, multimodal token out model. you want it to talk fast? ...
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Reddit - Dive into anything: no description found
- Compute Watch : no description found
Nous Research AI ▷ #ask-about-llms (15 messages🔥):
- Exploring the Multimodal Capabilities of GPT-4o: Discussions highlighted the multimodal input-output capability of models like GPT-4o, referencing AI2's similar project from last year. This discourse provides insight into the operational dynamics of integrating text, image, and audio inputs and outputs.
- Tokenization Innovations and Applications: The conversation revealed a strong interest in the tokenization processes of LLMs, particularly for enhancing non-English language handling in recent models. One member directed attention to a tokenizer development, improving cost and efficiency for multilingual applications.
- Chinese Token Analysis Shared: A link to a GitHub Gist explored the longest Chinese tokens in GPT-4o, indicating ongoing efforts to detail and optimize specific language tokenization. The resource can be found here.
- Exploring Audio Capabilities in LLMs: A technical discussion about how different LLMs handle audio data suggested using whisper latents for inputs, while maintaining tokenization for outputs. Various approaches and theories, including advancements in tokenization for such multimodal functionalities, were examined to understand the underlying mechanisms of models like GPT-4o.
- Seeking Datasets for LLM Evaluation: An inquiry was made about locating datasets containing pairs of 'human_text' and 'llm_text' for the same prompts, indicating a research interest or need for evaluating model responses in comparative studies. This points to an ongoing pursuit in the AI community for benchmarking and evaluation resources.
- Tweet from Deedy (@deedydas): Not enough people are talking about the fact that OpenAI FINALLY tokenizes different languages better! I classified all the tokens on 'o200_base', the new tokenizer for GPT-4o and at least 25...
- Tweet from Nathan Lambert (@natolambert): Friendly reminder that folks at AI2 built a text image audio input-output model last year, unified io 2, if you're looking to get started on research here.
- Longest Chinese tokens in gpt4o: Longest Chinese tokens in gpt4o. GitHub Gist: instantly share code, notes, and snippets.
- dblp: Alexis Conneau: no description found
Nous Research AI ▷ #bittensor-finetune-subnet (2 messages):
- Member seeks assistance: lionking927 posted looking for help in the channel. Another member, teknium, responded promptly via a direct message.
Nous Research AI ▷ #rag-dataset (2 messages):
- Innovative Framework by IBM/Redhat Introduces Incremental Learning: IBM/Redhat's new project presents a method to add skills and knowledge to LLMs without full retraining. It utilizes a large model as a teacher and incorporates a taxonomy to generate synthetic datasets as seen on their InstructLab GitHub page.
- Granite and Merlinite Enrichment through Community Contributions: The new framework allows for the submission and curation of external datasets, specifically enhancing their models Granite and Merlinite. A weekly build process integrates new, curated information, suggesting potential applicability to other models for incremental knowledge enhancement.
Link mentioned: InstructLab: InstructLab has 10 repositories available. Follow their code on GitHub.
Nous Research AI ▷ #world-sim (22 messages🔥):
- WorldSim Imagery Sparks Tattoo Ideas: jtronique mentioned how "Jailbroken Prometheus" imagery from WorldSim could make a great tattoo, considering an "Xlaude tat" currently.
- WorldSim Paid Service Inquiry Clarified: irrid_gatekeeper inquired whether WorldSim is a paid service due to the credits tab showing in the options window. It was clarified by garlix. that it is not paid at the moment.
- Time Zone Coordination for Meeting: Users detailoriented and rundeen discussed their respective time zones, PST and CET, to coordinate a suitable meeting time. They proposed a meeting time that would accommodate both zones.
- Enthusiasm for WorldSim's Artistic Output: katwinter expressed admiration for the images generated by WorldSim, incorporating them into a Photoshop project.
- Discussion on Hosting an Event in Discord: Proprietary suggested running a showcase on Saturday directly on Discord, which was agreed upon by detailoriented, highlighting the platform's use for live collaboration.
Stability.ai (Stable Diffusion) ▷ #general-chat (450 messages🔥🔥🔥):
- Stability.ai faces uncertainty over SD3 release: Users discussed ongoing difficulties at Stability AI, including the resignation of CEO Emad and speculation about whether SD3 will be released or put behind a paywall.
- Choosing the right graphics card for SD: Users debated the merits of different graphics cards for running Stable Diffusion, noting that higher VRAM is generally preferable. One user highlighted a variety of free resources including a comprehensive 140-page document on styles and tags.
- ComfyUI and inpainting utilities: Members praised the BrushNet tool for enhancing inpainting performance significantly, sharing GitHub repository for BrushNet. They discussed workflows combining brush and powerpaint features for better results.
- Handling AI character consistency: Users debated techniques for achieving character consistency, suggesting the use of LoRA and combinations with ControlNet. The discussion included links to guides on creating character sheets.
- Feeling about Launch of Tech Giants: There was both excitement and skepticism regarding Google’s Imagen 3, with users noting that despite its capabilities, models like SD3 are preferable due to their open availability to the community.
- Muse: Text-To-Image Generation via Masked Generative Transformers: no description found
- HunyuanDiT - a Hugging Face Space by multimodalart: no description found
- GitHub - nullquant/ComfyUI-BrushNet: ComfyUI BrushNet nodes: ComfyUI BrushNet nodes. Contribute to nullquant/ComfyUI-BrushNet development by creating an account on GitHub.
- Character Consistency in Stable Diffusion - Cobalt Explorer: UPDATED: 07/01– Changed templates so it’s easier to scale to 512 or 768– Changed ImageSplitter script to make it more user friendly and added a GitHub link to it– Added section...
LM Studio ▷ #💬-general (205 messages🔥🔥):
- Fine-tuned models on LM Studio: A member asked if they can access a fine-tuned model stored on Hugging Face through LM Studio. Another member confirmed it's possible if the model is in a public repository and in GGUF format.
- Network errors and VPN solutions: Users encountered network errors when searching for models due to Hugging Face being blocked in their location. It was suggested to use a VPN with an IPv4 connection, though one user reported persisting issues despite using IPv4.
- OpenAI GPT-4o access confusion: Users discussed the availability of GPT-4o, with some able to access it and others not, depending on their region and subscription status. It was noted that GPT-4o should be available in Europe and rolling out to more users soon.
- Hardware advice for AI builds: A $2500 budget for an Nvidia-based AI machine was discussed, with recommendations to maximize VRAM and consider visits to local stores like MicroCentre for hardware. Alternative suggestions included Nvidia over AMD for GPU selection due to VRAM considerations.
- Vision AI limitations in LM Studio: A user inquired if LM Studio's Vision AI could describe videos as well as images. It was clarified that currently, LM Studio cannot describe videos.
- Chat.lmsys.org down? Current problems and status. - DownFor: Chat.lmsys.org won't load? Or, having problems with Chat.lmsys.org? Check the status here and report any issues!
- Boris Zip Line GIF - Boris Zip Line UK Flag - Discover & Share GIFs: Click to view the GIF
- Quick Start Guide | LM Studio: Minimal setup to get started with the LM Studio SDK
- Boo Boo This Man GIF - Boo Boo This Man - Discover & Share GIFs: Click to view the GIF
- INSANE OpenAI News: GPT-4o and your own AI partner: New GPT-4o is released and it's mindblowing! Here are all the details.#gpt4o #ai #ainews #agi #singularity #openai https://openai.com/index/hello-gpt-4o/News...
- Support for OpenELM of Apple · Issue #6868 · ggerganov/llama.cpp: Prerequisites Please answer the following questions for yourself before submitting an issue. I am running the latest code. Development is very rapid so there are no tagged versions as of now. I car...
- GitHub - ksdev-pl/ai-chat: (Open)AI Chat: (Open)AI Chat. Contribute to ksdev-pl/ai-chat development by creating an account on GitHub.
LM Studio ▷ #🤖-models-discussion-chat (62 messages🔥🔥):
- Model merging strategies intrigue members: A user mentioned that they "might be able to merge with another model and upgrade the context", suggesting various fine-tuning methods like using unsloth. Another user indicated potential merges with llama3 and/or mistral, citing the close source configurations.
- Issues with command-r on Apple silicon devices: Multiple users, including telemaq, experienced problems with Command R models generating gibberish outputs on M1 Max systems. Suggestions included checking quant types and adjusting rope values, as seen in this Huggingface discussion.
- Mac users report improved multi-model handling in updates: An update to LM Studio 0.2.23 was praised by echeadle for resolving issues with running multiple models on POP_OS 22.04. Another user, kujila, shared a positive experience with Cmd R (not plus) 35 B, praising its performance.
- Exploration of uncensored local models: Immortal.001 sought recommendations for uncensored local LLMs, leading lordyanni to recommend Dolphin 2.8 Mistral 7b. The recommendation included mention of its 32k context capability and sponsor acknowledgments.
- Debate over utility of different quant levels: Heyitsyorkie commented that models in the Q4-Q8 quant range perform well, stating "Anything lower than Q4 isn't worth using at all." Other users compared speeds and performance of different quant levels on various hardware setups, including feedback on Meta-Llama-3-120b and Command R models.
- TheSkullery/llama-3-cat-8b-instruct-v1 · Hugging Face: no description found
- andrewcanis/c4ai-command-r-v01-GGUF · Failed to use Q8 model in LM Studio: no description found
- cognitivecomputations/dolphin-2.8-mistral-7b-v02 · Hugging Face: no description found
- dranger003/c4ai-command-r-plus-iMat.GGUF · Hugging Face: no description found
LM Studio ▷ #🧠-feedback (6 messages):
- Starcoder2-15b struggles with coherence: A member reported that using starcoder2-15b-instruct-v0.1-IQ4_XS.gguf on debian12 leads to repetitive responses and failure to stay on topic after a few questions. They noted this issue occurs both in the app chatbox and via the server with "continue" in VSC.
- Instruct models not fit for chat: Another member clarified that instruct models are designed for single-command responses and not for multi-step conversations, which may explain the issues observed with Starcoder2-15b.
- RX6600 and ROCM limitations: A user pointed out that the RX6600 GPU works with the Koboldcpp ROCM build but faces compatibility issues with LM Studio and Ollama due to ID checks in the official llama.cpp binaries. Another member confirmed this, explaining that Kobold uses a customized ROCM hack while LM Studio and Ollama rely on the official builds.
- Limited hope for RX6600 users: There appears to be little immediate hope for better RX6600 support on LM Studio and Ollama, as improved support is contingent on either AMD enhancing ROCM support or more AMD GPUs being added to the official llama.cpp builds.
LM Studio ▷ #🎛-hardware-discussion (12 messages🔥):
- Bug causing high RAM usage: A member reported "there is def a bug with model loading and context size regarding ram usage", and noted discussions about it also occurred in the Linux channel, highlighting an ongoing RAM usage issue.
- High RAM utilization in Meta-Llama-3 deployment: A user shared their experience using the 'Meta-Llama-3-8B-Instruct-Q4_K_M' model, noting "it seems to use very little GPU but high RAM utilization". They are considering deployment on AWS and ponder the cost differences between local installations and using commercial APIs.
- Cost and performance comparison of servers vs. LLMaaS: One member suggested comparing the cost of an always-on instance from IaaS providers to a subscription with LLMaaS, emphasizing that "you'll get access to a model effectively 200GB or more in size for a subscription, compared to a low quant low-parameter LLama3 model".
- GPU precision impact: There was a discussion on GPU precision, specifically FP16/FP32, and one member suggested that since LM Studio uses CUDA, it likely operates at 32-bit precision. This led into a member testing a Tesla M40, where its performance was curiously lower than expected.
- GPU recommendations for budget and performance needs: Members discussed the best budget-friendly GPU for LM Studio, with a recommendation for a 3060ti for around 200€, and a query about whether a 4060 would offer a significant performance upgrade. Another member noted that VRAM speed is crucial for LLM inference, suggesting dual-chip GPUs might excel with complex models.
LM Studio ▷ #🧪-beta-releases-chat (2 messages):
- Question on Multimodal Feature Parity: A user asked, "when will the multimodal have all the same features as single one like storing messages?", highlighting a concern about feature parity. Another user responded seeking clarification on what was meant by that.
LM Studio ▷ #amd-rocm-tech-preview (1 messages):
- Consider larger models for better performance: A member recommended trying command-r+ or yi-1.5 (quantized variants) if you want to run larger models. They believe these options could potentially offer improved outcomes.
LM Studio ▷ #🛠-dev-chat (17 messages🔥):
- Intel GPUs support in LMS discussed: An Intel employee offered to help integrate support for Intel GPUs into LMS, specifically using the SYCL flag with llama.cpp. They mentioned "install the Intel compilers and then build with " and are willing to obtain hardware for testing.
- Deployment of SYCL runtime for LMS: Clarified the need for a SYCL runtime backend, similar to having CUDA installed, for proper functioning. The user offered to assist in coding and integrating this into the dev pipeline, adding "I'd have to look at how to deploy on the LMS side".
- Current LMS support with Intel GPUs: LMS currently works using Intel Arc on the OCL backend, but the performance is slower compared to the SYCL implementation. This points to an existing foundation that could be improved.
- Realtime learning in models: A new user criticized the lack of realtime learning capabilities in LMS models, asserting "interactions beyond rote retrieval are useless and pointless". They requested at least a learning overlay or differential file for line-item training.
HuggingFace ▷ #general (235 messages🔥🔥):
- Popular AI Topics Discussed: There was a general consensus that Natural Language Processing (NLP) is a popular topic in AI. One user remarked, "NLP is pretty popular atm, allows us to interact easily with different models and extract useful info".
- GPT-4o Announcement Draws Mixed Reactions: The announcement of GPT-4o drew mixed reactions. One user pointed to a YouTube video about GPT-4o's capabilities, while another criticized the life-like features of virtual agents, stating, "Distinguishing between machine and human should be heavily at the fore-front of AI."
- GPU Utilization Issues: Users discussed challenges with GPU utilization, noting instances where GPU memory maxed out while GPU utilization was low. Explanations included that tasks could be more memory-intensive and less GPU-intensive, causing this discrepancy.
- Deploying Models and Utilizing Resources: Various users sought help with issues related to deploying models, such as running into CUDA errors and handling concurrent requests on Whisper-v3. Specific libraries and tools like AutoTrain and DGX Cloud were mentioned (Train on DGX Cloud).
- Discussions on Uncensored AI Models: There was interest in uncensored AI models, especially for conversational use cases. A recommendation for the Dolphin 2.5 Mixtral 8x7b model was given, which is described as being very obedient but not DPO tuned.
- hackerllama - LLM Evals and Benchmarking: Omar Sanseviero Personal Website
- Paper page - NoFunEval: Funny How Code LMs Falter on Requirements Beyond Functional Correctness: no description found
- cognitivecomputations/dolphin-2.5-mixtral-8x7b · Hugging Face: no description found
- Easily Train Models with H100 GPUs on NVIDIA DGX Cloud: no description found
- stabilityai/stable-diffusion-xl-base-1.0 · Hugging Face: no description found
- Will Smith Chris Rock GIF - Will Smith Chris Rock Jada Pinkett Smith - Discover & Share GIFs: Click to view the GIF
- License to Call: Introducing Transformers Agents 2.0: no description found
- Excuse Me Hands Up GIF - Excuse Me Hands Up Woah - Discover & Share GIFs: Click to view the GIF
- Two GPT-4os interacting and singing: Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time.Learn more here: https://www.openai.com/index/hello-...
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
HuggingFace ▷ #today-im-learning (4 messages):
- Jax and TPU venture begins: A user is diving into Jax and TPU acceleration, aiming to port the PyTorch implementation of the VAR paper to a Jax-compatible library using Equinox. They shared the VAR paper and the Equinox library.
- Rendering insights with d3-delaunay: A user discovered that re-rendering on every frame while using d3-delaunay is inefficient. They created a hybrid Delaunay triangulation/Game of Life visualization which, despite its performance limitations, looks visually appealing.
- Prompting advice: Another user suggested giving models clear examples of input and output within the system prompt for better results.
- Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction: We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolutio...
- GitHub - patrick-kidger/equinox: Elegant easy-to-use neural networks + scientific computing in JAX. https://docs.kidger.site/equinox/: Elegant easy-to-use neural networks + scientific computing in JAX. https://docs.kidger.site/equinox/ - patrick-kidger/equinox
HuggingFace ▷ #cool-finds (8 messages🔥):
- 3D Diffusion Policy tackles robot learning: The 3D Diffusion Policy (DP3) incorporates 3D visual representations into diffusion policies for enhanced robot dexterity. Experiments show DP3 handles tasks with just 10 demonstrations, achieving a 24.2% improvement over baselines.
- Supercharge Your LLMs: An article on Medium discusses Plug-and-Plai Integration for Langchain Workflows, offering techniques to enhance language model performance in workflows.
- Universal Hand Model by Facebook Research: The Universal Hand Model (UHM) provides a PyTorch implementation of creating hand avatars from phone scans. It's a novel approach presented at CVPR 2024 for generating realistic hand models.
- Hugging Face revives Daily Papers: Hugging Face now offers an option to receive trending AI papers via email. Users can subscribe to get daily updates on trending papers and research in the field.
- Beginner's AI Journey on LinkedIn: A member shared a basic article on LinkedIn discussing their initial steps in AI. Feedback suggested reposting it on Hugging Face's Blog Explorers for more visibility.
- 3D Diffusion Policy: This paper introduces 3D Diffusion Policy (DP3), a visual imitation learning algorithm that masters divserse visuomotor tasks.
- Daily Papers - Hugging Face: no description found
- blog-explorers (Blog-explorers): no description found
- GitHub - facebookresearch/UHM: Official PyTorch implementation of "Authentic Hand Avatar from a Phone Scan via Universal Hand Model", CVPR 2024.: Official PyTorch implementation of "Authentic Hand Avatar from a Phone Scan via Universal Hand Model", CVPR 2024. - facebookresearch/UHM
HuggingFace ▷ #i-made-this (7 messages):
- Share your blog on HuggingFace: A member encouraged another to share their blog on the HuggingFace blog platform to gain more visibility.
- OCR Quality Classifiers: A member shared a link to their OCR-quality classifiers collection and discussed using small encoders for document quality classification, stating, "turns out classifying noisy/clean is relatively easy".
- Streamlit GPT-4o Multimodal Chat App: A member introduced a multimodal chat app using Streamlit and Langchain with OpenAI’s GPT-4o. The app allows users to upload or paste images from the clipboard and displays them in chat messages.
- Path Planning with RL and ROS2: A member shared a report on path planning for autonomous robots, using a novel approach that combines Reinforcement Learning (TD3 algorithm), ROS2, and LiDAR sensor data.
- Vietnamese Language Model Dataset: A member announced the release of a 700,000-sample open-source dataset for Vietnamese language models.
- OCR Quality Classifiers - a pszemraj Collection: no description found
- streamlit-gpt4o - a Hugging Face Space by joshuasundance: no description found
- OpenGPT 4o - a Hugging Face Space by KingNish: no description found
- IEEE NITK | Corpus: IEEE NITK is a student branch of IEEE located at NITK Surathkal dedicated to innovative projects and solutions. This is the official website of IEEE NITK
- Vi-VLM/Vista · Datasets at Hugging Face: no description found
HuggingFace ▷ #reading-group (6 messages):
- YOCO architecture impresses: A member shared a link to the YOCO paper, introducing a new decoder-decoder architecture for large language models. YOCO significantly reduces GPU memory demands while maintaining global attention capabilities and speeding up the prefill stage.
- Deep dive into AI storytelling: Another member mentioned conducting a literature review on AI story generation, referencing the Awesome-Story-Generation GitHub repository. They are considering key papers, including a comprehensive review on storytelling and a recent study on GROVE, a framework to enhance story complexity (GROVE paper).
- You Only Cache Once: Decoder-Decoder Architectures for Language Models: We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. ...
- GROVE: A Retrieval-augmented Complex Story Generation Framework with A Forest of Evidence: Conditional story generation is significant in human-machine interaction, particularly in producing stories with complex plots. While Large language models (LLMs) perform well on multiple NLP tasks, i...
- GitHub - yingpengma/Awesome-Story-Generation: This repository collects an extensive list of awesome papers about Story Generation / Storytelling, primarily focusing on the era of Large Language Models (LLMs).: This repository collects an extensive list of awesome papers about Story Generation / Storytelling, primarily focusing on the era of Large Language Models (LLMs). - yingpengma/Awesome-Story-Generation
- Open-world Story Generation with Structured Knowledge Enhancement: A Comprehensive Survey: Storytelling and narrative are fundamental to human experience, intertwined with our social and cultural engagement. As such, researchers have long attempted to create systems that can generate storie...
HuggingFace ▷ #computer-vision (28 messages🔥):
- Stable Diffusion with Diffusers spark interest: A HuggingFace blog post on Stable Diffusion using 🧨 Diffusers was shared. The guide includes the model's workings and customization of image generation pipelines.
- YOLOv1 vs YOLOv5 and YOLOv8: After a member inquired about the use of YOLOv1 over newer versions, @ajkdrag explained the selection was for educational purposes, aiming to combine different backbones and loss functions.
- Struggles with training YOLOv1: @ajkdrag reported poor results with a simple implementation of YOLOv1 using a ResNet18 backbone. Despite seeing overfitting on a smaller validation set, the model struggled with a larger training dataset.
- Training and validation data complexities: @pendresen suggested that learning issues when training on the actual dataset (~800 images) could be due to learning rate or insufficient data augmentation. The importance of data quality and its impact on model performance were highlighted.
- Private assistance offered: @pendresen offered to assist @ajkdrag via DM, leveraging his 7 years of industry experience in object detection. Data quality issues were underscored as critical factors in model training.
- Stable Diffusion with 🧨 Diffusers: no description found
- architectures-impl-pytorch/notebooks/yolov1.ipynb at main · ajkdrag/architectures-impl-pytorch: PyTorch implementations of some basic CNN architectures - ajkdrag/architectures-impl-pytorch
- architectures-impl-pytorch/yolov1/src/yolov1 at main · ajkdrag/architectures-impl-pytorch: PyTorch implementations of some basic CNN architectures - ajkdrag/architectures-impl-pytorch
HuggingFace ▷ #NLP (1 messages):
- Custom Tokenizer Throws Errors: A member shared their experience of creating and training a custom Hugging Face tokenizer, following an instructional video from 2021. However, they encountered multiple errors, which ChatGPT attributed to the tokenizer being in the wrong format.
Link mentioned: Building a new tokenizer: Learn how to use the 🤗 Tokenizers library to build your own tokenizer, train it, then how to use it in the 🤗 Transformers library.This video is part of the...
HuggingFace ▷ #diffusion-discussions (16 messages🔥):
- Implementing Stable Diffusion from scratch intrigues community: A member shared a Fast.ai course that covers building the Stable Diffusion algorithm from scratch over 30 hours. They highlighted that this course includes recent techniques and collaboration with experts from Stability.ai and Hugging Face.
- Book on generative AI techniques praised but incomplete: Another member commented on the book about generative media techniques, noting its potential and expressing interest despite its incomplete status.
- Help with sadtalker installation on macOS requested: A user sought urgent help with installing sadtalker on macOS. Another member suggested searching the error message online and shared a GitHub issue link to assist.
- Using Inpainting explained and dataset creation: Members discussed how to use Inpainting for personal images with a link to the Diffusers documentation. Additionally, guidance was provided on creating custom datasets with a Hugging Face guide.
- Seeking real-world applications of transformer agents: A member asked for examples of projects using transformer agents, expressing interest beyond academic examples. They were directed to the Hugging Face blog posts but requested more practical applications from the community.
- Create a dataset for training: no description found
- License to Call: Introducing Transformers Agents 2.0: no description found
- Practical Deep Learning for Coders - Part 2 overview: Learn Deep Learning with fastai and PyTorch, 2022
- Inpainting: no description found
- Hands-On Generative AI with Transformers and Diffusion Models: Learn how to use generative media techniques with AI to create novel images or music in this practical, hands-on guide. Data scientists and software engineers will understand how state-of-the-art gene...
- [Bug]: ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor' torchvision 0.17 promblem · Issue #13985 · AUTOMATIC1111/stable-diffusion-webui: Is there an existing issue for this? I have searched the existing issues and checked the recent builds/commits What happened? ModuleNotFoundError: No module named 'torchvision.transforms.functiona...
OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
- OpenRouter unveils GPT-4o and LLaVA v1.6 34B: Two new multimodal models are now available on OpenRouter. The models include OpenAI: GPT-4o and LLaVA v1.6 34B.
- DeepSeek and Llama models join the library: Several new models have been added, including DeepSeek-v2 Chat, DeepSeek Coder, Llama Guard 2 8B, Llama 3 70B Base, Llama 3 8B Base, and GPT-4o updated on 2024-05-13.
- Gemini Flash 1.5 launched: A new model named Gemini Flash 1.5 has been released. This continues expanding the versatile offerings available on OpenRouter.
- Google: Gemini Flash 1.5 (preview) by google | OpenRouter: Gemini 1.5 Flash is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video...
- OpenAI: GPT-4o by openai | OpenRouter: GPT-4o ("o" for "omni") is OpenAI's latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of [GPT-4 Turbo](/models/open...
- LLaVA v1.6 34B by liuhaotian | OpenRouter: LLaVA Yi 34B is an open-source model trained by fine-tuning LLM on multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. Base LLM: [Nou...
- DeepSeek-V2 Chat by deepseek | OpenRouter: DeepSeek-V2 Chat is a conversational finetune of DeepSeek-V2, a Mixture-of-Experts (MoE) language model. It comprises 236B total parameters, of which 21B are activated for each token. Compared with D...
- Deepseek Coder by deepseek | OpenRouter: Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. The model ...
- Meta: LlamaGuard 2 8B by meta-llama | OpenRouter: This safeguard model has 8B parameters and is based on the Llama 3 family. Just like is predecessor, [LlamaGuard 1](https://huggingface.co/meta-llama/LlamaGuard-7b), it can do both prompt and response...
- Meta: Llama 3 70B by meta-llama | OpenRouter: Meta's latest class of model (Llama 3) launched with a variety of sizes & flavors. This is the base 70B pre-trained version. It has demonstrated strong performance compared to leading closed...
- Meta: Llama 3 8B by meta-llama | OpenRouter: Meta's latest class of model (Llama 3) launched with a variety of sizes & flavors. This is the base 8B pre-trained version. It has demonstrated strong performance compared to leading closed-...
- OpenAI: GPT-4o by openai | OpenRouter: GPT-4o ("o" for "omni") is OpenAI's latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of [GPT-4 Turbo](/models/open...
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- Advanced Research Assistant Beta Testing: A user announced the launch of an advanced research assistant and search engine, seeking participants for beta testing. "I can give you 2 months free of premium with Claude 3 Opus, GPT-4 Turbo, Mistral Large, Mixtral-8x22B...," they offered, sharing a promo code RUBIX for access.
- GPT-4O Release Highlighted: A link was shared about OpenAI’s GPT-4O release, marking it as a significant upgrade to existing AI models. The mention indicates community interest in keeping up with OpenAI's developments.
- Mistral AI’s $6B Valuation News: Information was highlighted about Mistral AI, a Paris-based startup raising funds at a $6B valuation. This underscores the rapid growth and interest in companies developing large language models.
Link mentioned: Rubik's AI - AI research assistant & Search Engine: no description found
OpenRouter (Alex Atallah) ▷ #general (278 messages🔥🔥):
- GPT-4o API pricing and hype: Discussions centered around the availability and pricing of the GPT-4o API at $5/15 per 1M tokens. One user noted, “so damn hype...100 pts better than opus at coding in terms of elo ranking apparently.”
- GPT-4o multimodal capabilities speculation: Users speculated about GPT-4o’s abilities, with some questioning if it could handle image generation. “Via [OpenAI’s] api, no. My python project does the Internet side of things and supplies the LLM with that data.”
- Issues with OpenRouter: Users reported various errors and issues with OpenRouter, including empty responses from MythoMax and errors with DeepSeek. “Still seems to be happening with DeepInfra” and “TypeError: Cannot read properties of undefined (reading 'stream').”
- Discussion on OpenRouter's model precision: There was a query about whether OpenRouter uses full-precision models, to which Alex Atallah responded that almost all models are FP16, with some exceptions like Goliath being quantized (4-bit). “might be nice to add it to the page.”
- Introducing community tools: A community member introduced a tool to explore and sort OpenRouter models, prompting positive responses. “Ooh this is pretty cool” and discussions about integrating additional metrics like ELO scores and SCRAPED model add dates.
- LiteLLM: LiteLLM handles loadbalancing, fallbacks and spend tracking across 100+ LLMs. all in the OpenAI format
- GitHub - fry69/orw: Watch for changes in OpenRouter models API and store changes in a SQLite database. Includes a simple web interface.: Watch for changes in OpenRouter models API and store changes in a SQLite database. Includes a simple web interface. - fry69/orw
- Can Claude Read PDF? [2023] - Claude Ai: Can Claude Read PDF? PDF (Portable Document Format) files are a common document type that many of us encounter in our daily lives.
- OpenRouter API Watcher: OpenRouter API Watcher monitors changes in OpenRouter models and stores those changes in a SQLite database. It queries the model list via the API every hour.
- OpenRouter API Watcher: OpenRouter API Watcher monitors changes in OpenRouter models and stores those changes in a SQLite database. It queries the model list via the API every hour.
Interconnects (Nathan Lambert) ▷ #news (178 messages🔥🔥):
- OpenAI introduces GPT-4o with impressive capabilities: Announced as a new state-of-the-art frontier model by Liam Fedus. The new model has been performing remarkably well on LMSys arena with a strong emphasis on reasoning and coding.
- Tokenizer update and increased token capacity: A new tokenizer has been introduced, supposedly doubling the token capacity to 200k, which results in improved speed. The increase in tokens is one of the reasons for the performance boost.
- Live demos and multi-modal capabilities: GPT-4o's live demonstration showcases its capabilities, including potential features like singing. A YouTube video demonstrates GPT-4o’s interactive abilities.
- Competitive landscape and concerns: Discussions point towards OpenAI’s strategy to stay competitive against rivals like Meta. There's speculation on data pool saturation and the balance between multimodal improvements and other enhancements.
- Google I/O 2024 key updates: Google announced new additions to Gemma models, including the upcoming Gemma 2 release and other Gemini enhancements. The Gemma 2 with 27B parameters represents a significant step up in Google’s AI offerings.
- LiveCodeBench Leaderboard: no description found
- Tweet from William Fedus (@LiamFedus): GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot 🙂. Here’s how it’s been doing.
- Gemini 1.5 Pro updates, 1.5 Flash debut and 2 new Gemma models: Today we’re updating Gemini 1.5 Pro, introducing 1.5 Flash, rolling out new Gemini API features and adding two new Gemma models.
- Tweet from lmsys.org (@lmsysorg): Significantly higher win-rate against all other models. e.g., ~80% win-rate vs GPT-4 (June) in non-tie battles.
- Tweet from lmsys.org (@lmsysorg): Breaking news — gpt2-chatbots result is now out! gpt2-chatbots have just surged to the top, surpassing all the models by a significant gap (~50 Elo). It has become the strongest model ever in the Are...
- Tweet from Kaio Ken (@kaiokendev1): yeah but can it moan?
- no title found: no description found
- Tweet from Jim Fan (@DrJimFan): I stand corrected: GPT-4o does NOT natively process video stream. The blog says it only takes image, text, and audio. That's sad, but the principle I said still holds: the right way to make a vide...
- Tweet from Google (@Google): One more day until #GoogleIO! We’re feeling 🤩. See you tomorrow for the latest news about AI, Search and more.
- Two GPT-4os interacting and singing: Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time.Learn more here: https://www.openai.com/index/hello-...
- Sync codebase · openai/tiktoken@9d01e56: no description found
- Google announces Gemma 2, a 27B-parameter version of its open model, launching in June | TechCrunch: At Google I/O, Google introduced Gemma 2, the next generation of Google's Gemma models, which will launch with a 27 billion parameter model in June.
Interconnects (Nathan Lambert) ▷ #ml-questions (3 messages):
- REINFORCE is a special case of PPO: A member shared a PR from Hugging Face implementing RLOO and explaining how REINFORCE is a special case of PPO. The paper related to this discussion can be found here.
- Costa's work on RLOO: A member mentioned their intent to contribute to TRL by working on RLOO, only to find that Costa had already started the process. This humorous exchange highlighted the community's ongoing collaboration and efforts.
Link mentioned: PPO / Reinforce Trainers by vwxyzjn · Pull Request #1540 · huggingface/trl: This RP supports the REINFORCE RLOO trainers in https://arxiv.org/pdf/2402.14740.pdf. Note that REINFORCE's loss is a special case of PPO, as shown below it matches the REINFORCE loss presented i...
Interconnects (Nathan Lambert) ▷ #random (20 messages🔥):
- Community wonders if GPT-3.5 will be open sourced: One member quipped, "Guess then hell freezes over," reflecting skepticism about the possibility.
- Concerns about AI leadership: A member stated feeling disillusioned with Sam Altman, mentioning the "flirty playfulness" of a demo and a comparison to the movie "Her", suggesting it trivializes AI's serious implications.
- Language model evaluation accessibility: Shared a detailed blog post on LLM evaluation, questioning the accessibility of evaluation tools for academics and other stakeholders. The post highlights three main types of LLM evaluations: MMLU benchmarks, ChatBotArena head-to-head tests, and private A/B testing.
- PRMs for long-term AI projects: Linked to a YouTube video featuring John Schulman, discussing how future models might act more like coworkers than search engines, hinting at the role of Project Management Robots (PRMs) in facilitating long-term AI tasks.
- ChatBotArena: The peoples’ LLM evaluation, the future of evaluation, the incentives of evaluation, and gpt2chatbot: What the details tell us about the most in-vogue LLM evaluation tool — and the rest of the field.
- 2025 models will be more like coworkers than search engines – OpenAI cofounder John Schulman: Full episode out tomorrow!Follow me on Twitter: https://twitter.com/dwarkesh_sp
Interconnects (Nathan Lambert) ▷ #reads (5 messages):
- Nathan plans to post with Stanford's permission: Nathan mentioned that he can "request permission" from Stanford for "personal use" and intends to download and post it accordingly. He also expressed skepticism about any potential repercussions.
- Rewatching for blog inspiration: Nathan mentioned rewatching "her" for a blog post, indicating it to be "so on point" and relevant to his writing. He believes it is currently available on HBO for viewing.
Eleuther ▷ #general (30 messages🔥):
- Probe into Web-Crawled Pretraining Datasets: A topic arose around a recent arxiv paper scrutinizing the concept of "zero-shot" generalization in multimodal models. Members discussed its implications and limitations, emphasizing it's not applicable to compositional generalization and calling for a cautious interpretation of popularized accounts.
- Falcon2 11B Released: A new 11B model trained on 5T refined web data with an 8k context window and MQA attention has been released. This model promises better inference capabilities thanks to a permissive license.
- Best AI/Machine Learning GitHub Repositories: Members recommended standout AI/ML GitHub repositories, including Lucidrains and equinox. The conversation sought to identify favorites and laud impressive repositories.
- Epistemic Networks Paper Discussion: There's an active discussion on the necessity and impact of adding the output of the original network to the output in the context of the epistemic networks paper. Members debated whether adding a residual from the base network centers outputs or poses risks when scale mismatches.
- RAG with Image Gen Models Inquiry: A query was raised about current practices for inference-time modifications of image gen models using RAG. The discussion considered techniques like clip embedding of images and averaging for prompt conditioning but sought better alternatives.
- Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
- No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance: Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image gener...
Eleuther ▷ #research (36 messages🔥):
- Linearattn models need more data for MMLU benchmarks: One user mentioned, "MMLU is the real challenge for linearattn models. Seems you either need 7B, or suitable data", linking to the subquadratic LLM leaderboard for comparative performance.
- Farzi data distillation method discussed: A detailed summary of the paper on data distillation titled "We propose Farzi, which summarizes an event sequence dataset into a small number of synthetic sequences — Farzi Data — maintaining or improving model performance" was provided. The discussion extended to practical constraints in scaling to larger models and datasets.
- Memory Mosaics and associative memories: Users debated the impact of the Memory Mosaics paper, with some skepticism around its effectiveness compared to transformers. It was noted for its compositional and in-context learning capabilities, "perform as well or better than transformers on medium-scale language modeling tasks."
- Activation function convergence questions: A user inquired about "necessary but not sufficient" conditions for an activation function to guarantee good convergence, sparking a technical discussion. Another user pointed out the essential need for non-linearity in activation functions.
- Discussion on parallelization and splitting in FlashAttention2 (FA2): Members engaged in a detailed technical debate about the parallelization of splits in FA2 vs. Flash Infer. "FA2 now has a kernel that does split kv too" and this was noted as a significant algorithmic change, hinting at a potential evolution to FA3.
- Memory Mosaics: Memory Mosaics are networks of associative memories working in concert to achieve a prediction task of interest. Like transformers, memory mosaics possess compositional capabilities and in-context lea...
- Subquadratic LLM Leaderboard - a Hugging Face Space by devingulliver: no description found
- Farzi Data: Autoregressive Data Distillation: We study data distillation for auto-regressive machine learning tasks, where the input and output have a strict left-to-right causal structure. More specifically, we propose Farzi, which summarizes an...
- Farzi Data: Autoregressive Data Distillation: We study data distillation for auto-regressive machine learning tasks, where the input and output have a strict left-to-right causal structure. More specifically, we propose Farzi, which summarizes...
- GitHub - yingpengma/Awesome-Story-Generation: This repository collects an extensive list of awesome papers about Story Generation / Storytelling, primarily focusing on the era of Large Language Models (LLMs).: This repository collects an extensive list of awesome papers about Story Generation / Storytelling, primarily focusing on the era of Large Language Models (LLMs). - yingpengma/Awesome-Story-Generation
Eleuther ▷ #scaling-laws (119 messages🔥🔥):
- MLPs Challenge Transformers' Dominance: Members discussed efforts to improve MLP-based models over Transformers in vision tasks (arxiv.org) with proposed hybrid architectures demonstrating competitive performance. Emphasis was on the potential scalability and efficiency of MLPs, despite skepticism about their ability to handle complex priors.
- Initializations are Key: The discussion highlighted the importance of initialization schemes for neural networks, with some suggesting that effective initializations could dramatically improve MLP performance (gwern.net). The idea of synthetic initializations using Turing machines or other computation models was proposed as a future research direction.
- Mimetic Initialization Shows Promise: A recent paper suggested that mimetic initialization, which makes weights resemble pre-trained transformers, could yield significant accuracy improvements in training Transformers on small datasets (proceedings.mlr.press). This approach helps transformers achieve higher final accuracies with faster training times.
- Controversy on Efficiency and Architectural Choices: Members debated the efficiency gains possible with MLPs compared to Transformers, particularly regarding Model FLOPs Utilization (MFU) on various hardware setups like A100s and TPUs. Some pointed out that even a slight increase in MFU could have significant impacts at scale.
- Minsky's Controversial Influence: Discussions included reflections on Marvin Minsky's historical impact on neural network research, with opinions divided on whether his skepticism significantly hindered progress. Links were provided to related papers and humorous AI Lab koans (catb.org) adding context to Minsky's legacy.
- Exposing Attention Glitches with Flip-Flop Language Modeling: Why do large language models sometimes output factual inaccuracies and exhibit erroneous reasoning? The brittleness of these models, particularly when executing long chains of reasoning, currently see...
- Understanding the Covariance Structure of Convolutional Filters: Neural network weights are typically initialized at random from univariate distributions, controlling just the variance of individual weights even in highly-structured operations like convolutions. Re...
- Fully-Connected Neural Nets · Gwern.net: no description found
- Some AI Koans: no description found
- A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP: Convolutional neural networks (CNN) are the dominant deep neural network (DNN) architecture for computer vision. Recently, Transformer and multi-layer perceptron (MLP)-based models, such as Vision Tra...
- Scaling MLPs: A Tale of Inductive Bias: In this work we revisit the most fundamental building block in deep learning, the multi-layer perceptron (MLP), and study the limits of its performance on vision tasks. Empirical insights into MLPs ar...
- GitHub - edouardoyallon/pyscatwave: Fast Scattering Transform with CuPy/PyTorch: Fast Scattering Transform with CuPy/PyTorch. Contribute to edouardoyallon/pyscatwave development by creating an account on GitHub.
Eleuther ▷ #interpretability-general (4 messages):
- Last-minute NeurIPS submission call: A member asked if anyone was interested in a last-minute NeurIPS submission, referencing "something like the Othello paper". Another member expressed their willingness to assist despite having their own submission to finish.
- Compression impact on model features: A member raised a query about the types of features or circuits lost during model compression. They speculated that if such features are overspecialized rather than useless, they might help assess the diversity of the training dataset.
Eleuther ▷ #gpt-neox-dev (1 messages):
oleksandr07173: Hello
Modular (Mojo 🔥) ▷ #general (29 messages🔥):
- Mojo Compiler Development Stirs Interest: A member expressed interest in contributing to the Mojo compiler, asking for recommendations on related books or courses. Another member clarified that the Mojo compiler is not open source yet.
- Mojo Compiler's Language Revealed: A member asked if the Mojo compiler is written in Mojo, to which another replied it is actually written in C++. The discussion also touched on potential future possibilities of rebuilding MLIR in Mojo.
- Python Dependency for Mojo Raises Questions: Concerns were raised about Python system dependency for Mojo. It was clarified that while the current necessity is for compatibility, there are scenarios and open issues suggesting the toolchain could work without Python installed.
- MLIR and Mojo Integration Detailed: Examples and detailed explanations were given on how Mojo integrates with MLIR, showcasing how Mojo programs can take full advantage of MLIR’s extensibility. The capability is noted as extremely powerful for extending systems to new datatypes or hardware features.
- Self-Hosting Mojo Compiler Discussed: There was hope expressed for a self-hosted Mojo compiler in the future. Members were optimistic, noting the language's compatibility with MLIR and its extensive features.
- Low-level IR in Mojo | Modular Docs: Learn how to use low-level primitives to define your own boolean type in Mojo.
- [Feature Request] binary build via `mojo build` could not run directly on other os · Issue #935 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? Hi, I tried to build a simple mojo app which use numpy...
Modular (Mojo 🔥) ▷ #💬︱twitter (2 messages):
- Modular Shares New Tweet: Modular posted an update, which can be accessed here. The content of the tweet is not detailed in the messages.
- Further Update from Modular: Another tweet from Modular is shared, available here. The specific details of this tweet are also not provided in the messages.
Modular (Mojo 🔥) ▷ #📺︱youtube (4 messages):
- Mojo CEO Chris Lattner dives deep into ownership: Modular released a YouTube video about ownership in Mojo featuring CEO Chris Lattner. The description invites viewers to join their community for further discussion.
- Contribute to Mojo🔥 Standard Library: Another video announces that the Mojo standard library is now open-source. Modular engineer Joe Loser guides viewers on how to start contributing using Mojo.
- New video uploads from Modular: Modular regularly updates its YouTube channel with new content. Check out the latest videos here and here.
- Mojo🔥: a deep dive on ownership with Chris Lattner: Learn everything you need to know about ownership in Mojo, a deep dive with Modular CEO Chris LattnerIf you have any questions make sure to join our friendly...
- Contributing to Open-Source Mojo🔥 Standard Library: Mojo🔥 standard library is now open-source. In this video Modular engineer Joe Loser discusses how you can get started with contributing to Mojo🔥 using Mojo...
Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Join the first Mojo Community Meeting: A community meeting for Mojo developers, contributors, and users is set to take place on Monday, May 20, from 10-11 am. The meeting will cover exciting updates for Mojo and future meeting plans—details here.
- Add Mojo Meetings to Your Calendar: Users can add this and future meetings to their calendars by subscribing to the community meeting calendar. Full details can be accessed in the community meeting document.
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- Google Calendar - Sign in to Access & Edit Your Schedule: no description found
- [Public] Mojo Community Meeting: no description found
Modular (Mojo 🔥) ▷ #🔥mojo (77 messages🔥🔥):
- Restricting parameters to float types in Mojo: A user inquired how to restrict parameters to only float types in Mojo. Another user suggested using
dtype.is_floating_point()along with constrained checks, directing to DType docs for more information.
- Mojo's Ownership talk sparks discussion: Multiple users discussed the challenges and benefits of Mojo's ownership model compared to Python, appreciating an internal talk on ownership. The conversation included real-world examples and explanations of concepts like
borrowed,inout, andowned.
- Tuple unpacking in Mojo: Users explored how to perform tuple unpacking in Mojo and discovered it requires declaring the tuple first before unpacking. Example snippets were shared to clarify the syntax.
- Calling C/C++ libraries from Mojo: A user asked about calling C/C++ libraries from Mojo, and another user provided a resource link to the FFI tweetorial on GitHub.
- String to float conversion in Mojo: A user inquired about converting a string to a float in Mojo and created a pull request to add this functionality. Another user shared their repository with related examples, noting compatibility with the nightly build of Mojo.
- DType | Modular Docs: Represents DType and provides methods for working with it.
- Subtyping and Variance - The Rustonomicon: no description found
- Mojo - IntelliJ IDEs Plugin | Marketplace: Provides basic editing for Mojo programming language: syntax checks and highlighting, commenting and formatting. New features will be added in the future, please feel...
- Value semantics | Modular Docs: An explanation of Mojo's value-semantic defaults.
- Value semantics | Modular Docs: An explanation of Mojo's value-semantic defaults.
- devrel-extras/tweetorials/ffi at main · modularml/devrel-extras: Contains supporting materials for developer relations blog posts, videos, and workshops - modularml/devrel-extras
- [stdlib] Add method `atof()` to `String` by fknfilewalker · Pull Request #2649 · modularml/mojo: This PR adds a function that can convert a String to a Float64. Right now it is implemented just for Float64 but maybe we should add other precisions? This supports the following notations: "-12...
- GitHub - saviorand/lightbug_http: Simple and fast HTTP framework for Mojo! 🔥: Simple and fast HTTP framework for Mojo! 🔥. Contribute to saviorand/lightbug_http development by creating an account on GitHub.
- GitHub - carlca/ca_mojo: Contribute to carlca/ca_mojo development by creating an account on GitHub.
- Python Mutable Defaults Are The Source of All Evil - Florimond Manca: How to prevent a common Python mistake that can lead to horrible bugs and waste everyone's time.
Modular (Mojo 🔥) ▷ #nightly (27 messages🔥):
- Fastest list extension method discovered: A user reported an error in their benchmark script and concluded that looping through the
source_listto append elements individually is faster than using custom or standardextend. They shared a sample code snippet for clarification. - Ubuntu tests remain unresolved: There is no update on the Ubuntu tests failing, and the CI infra team is investigating. The discussion included a GitHub Actions issue showing "pending" status incorrectly.
- Nightly releases become more frequent: A new
mojonightly was pushed with commits merged internally and automatically, making nightly nightlies a reality. Members humorously likened it to an "Inception" movie joke. - Segfault issue with nested arrays: A user reported a segfault when nesting arrays deeply in a
mojoscript. There's debate on whether it's a feature or an issue with the implementation, including suggestions to use Span's iterator. - Debate on nightly release frequency: A discussion around reducing the delay on merged commits suggests frequent pushes could complicate the required compiler version. The consensus leans towards maintaining a 24-hour period between nightlies to avoid user inconvenience.
Link mentioned: [CI] Add timeouts to workflows by JoeLoser · Pull Request #2644 · modularml/mojo: On Ubuntu tests, we're seeing some non-deterministic timeouts due to a code bug (either in compiler or library) from a recent nightly release. Instead of relying on the default GitHub timeout of ...
CUDA MODE ▷ #triton (13 messages🔥):
- Triton achieves speed improvements in FP16 and FP8: A user noted Phil's update in the Triton tutorial to match FP16 forward performance with the Kitten implementation. The commit for this update can be found here.
- Discussions on TMA: A member asked about TMA (tensor memory accelerator), and it was clarified that it only exists in Hopper (H100). Another user expressed interest in a software version of TMA.
- Triton configurations discussed: Members discussed adding new configurations to enhance Triton's performance. One member confirmed the addition of new configs for better search over.
- Speed benchmarks shared: Performance benchmarks for Triton with Casual=True and d=64 on gh200 were shared, showing significant improvements in FP16 and FP8 across various contexts. Specific data points included: "Triton [FP16]" hitting 252.747280 for N_CTX of 1024 and "Triton [FP8]" reaching 506.930317 for N_CTX of 16384.
Link mentioned: [TUTORIALS] tune flash attention block sizes (#3892) · triton-lang/triton@702215e: no description found
CUDA MODE ▷ #cuda (7 messages):
- Increasing L2 cache hit rate: A member simply mentioned "Also increases L2 cache hit rate," possibly in relation to their discussion about CUDA optimizations.
- cuSPARSE Function Overhead: A user inquired about the cost of calls to functions like
cusparseCreateDnVecin cuSPARSE, asking if it is feasible to reuse them due to repeated operations. They particularly questioned if vector data is cached elsewhere since the documentation only mentions releasing memory for dense vector descriptors.
- clangd with CUDA files Issues: A member is experiencing issues getting
clangdto parse.cufiles correctly despite having acompile_commands.jsonfile. They reported that neither VSCode nor Neovim with clangd extensions seem to work on Unix.
- Solution Attempt with cccl .clangd: Another member provided a link to the .clangd file from NVIDIA's CCCL as a potential solution. However, the original poster noted that switching from the CUDA toolkit to NVHPC may have caused the issue, as it previously worked fine with the CUDA toolkit.
Link mentioned: cccl/.clangd at main · NVIDIA/cccl: CUDA C++ Core Libraries. Contribute to NVIDIA/cccl development by creating an account on GitHub.
CUDA MODE ▷ #torch (10 messages🔥):
- Torch.compile() causes performance issues on 4090: A member reported a "significant drop (4x worse) in throughput & latency when using torch.compile() on a single 4090." Another member requested a minimal reproduction and details on tensor cores, CUDA graphs, and benchmarking methods used.
- Dynamic tensor allocation performance hit: It was suggested to check if the model is using dynamically allocated tensors, such as via
torch.cat, which impacts performance. An example provided from OpenAI's Whisper model illustrates the issue. - Creating a graph of a network with custom ops: For integrating custom Triton kernels with a network architecture, it's recommended to create custom ops and wrap them with torch.compile.
- Compatibility of torch.compile with DeepSpeed: It was asked whether torch.compile models work with DeepSpeed, recognizing the latest stable release may not be compatible. It was clarified that it should work but won't trace collectives, prompting further details on the specific bug experienced.
Link mentioned: whisper/whisper/model.py at main · openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision - openai/whisper
CUDA MODE ▷ #beginner (6 messages):
- Missing build dependencies trip up beginners: A user noted issues with missing build dependencies when using
load_inline, particularly mentioning dependencies like ninja. They asked for a recommended way to get all important tools and if anyone could suggest a repo with a goodrequirements.txt.
- Neural network output as if statements: A user speculated that a neural network's output could be expressed elementwise as functions of
x, theoretically mapping with longifstatements. They questioned the practicality, suspecting warp divergence due toifstatements might cause significant slowdowns.
- Why long if statements are bad for performance: In a follow-up, the same user pondered whether excessive warp divergence or each thread handling too many FLOPS would be the main reason for potential performance issues with their approach.
- Beginner seeks resources on custom CUDA kernels in PyTorch: A user requested resources for using custom CUDA kernels in PyTorch, wanting a comprehensive overview.
- Helpful link for learning custom CUDA kernels in PyTorch: Another user recommended a YouTube lecture by Jeremy titled "Lecture 3: Getting Started With CUDA for Python Programmers" to help beginners understand how to write custom CUDA kernels. The video includes supplementary content for further learning.
Link mentioned: Lecture 3: Getting Started With CUDA for Python Programmers: Recording on Jeremy's YouTube https://www.youtube.com/watch?v=nOxKexn3iBoSupplementary Content: https://github.com/cuda-mode/lecture2/tree/main/lecture3Speak...
CUDA MODE ▷ #pmpp-book (6 messages):
- PMPP Author Event May 24: PMPP Author Izzat El Hajj will talk about scan on May 24. There seems to be a featured link that directs users to the event on Discord.
- Advanced Scan Tutorial May 25: On May 25, Jake and Georgii will discuss how to build advanced scan using CUDA C++. Event Details Here.
- Broken Link Issues: Members initially experienced issues with a link to the event being broken on both mobile and PC. This issue was later resolved and confirmed to work with a different link.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
CUDA MODE ▷ #off-topic (1 messages):
shikhar_7985: found an old one from the internet's basement
CUDA MODE ▷ #triton-puzzles (2 messages):
- Seeking Official Solution Resources: A member inquired about the availability of an official solution to verify the numerical correctness of their implementation, expressing concerns about its efficiency. They later acknowledged finding Joey's solution in Misha's thread, "thanks a lot!"
CUDA MODE ▷ #llmdotc (89 messages🔥🔥):
- ZeRO-1 Enhances VRAM Efficiency: By implementing the Zero Redundancy Optimizer (ZeRO-1), significant VRAM savings were achieved, allowing for an increase in per GPU batch size from 4 to 10, nearly maxing out GPU capacity and boosting training throughput by ~54%. Detailed results and configurations are available in the PR page.
- Gradient Accumulation and Bias Backward Kernel Updates: The backward bias kernel was updated for better performance and determinism, and a PR was merged to address issues with gradient accumulation. The discussion included various approaches, such as eliminating atomics in favor of warp shuffles and considering more deterministic methods.
- HazyResearch/ThunderKittens Garners Interest: The HazyResearch project's low-level CUDA tile primitives library, ThunderKittens, caught the attention of developers for its potential to optimize LLM performance, highlighting similarities and differences with existing tools like Cutlass and Triton.
- GPU Testing in CI Discussed: The lack of GPUs in the llm.c continuous integration (CI) pipeline was identified as a gap, igniting discussions to integrate GPU runners into GitHub Actions. GitHub's recent announcement regarding GPU support in CI runners was highlighted as a potential solution.
- Floating Point Precision Handling: Debugging and ensuring determinism extended to handling floating point precision, with discussions on using both relative and absolute tolerances similar to Numpy's allclose method to improve testing accuracy.
- About billing for GitHub Actions - GitHub Docs: no description found
- Run your ML workloads on GitHub Actions with GPU runners: Run your ML workloads on GitHub Actions with GPU runners
- numpy.testing.assert_allclose — NumPy v1.26 Manual: no description found
- numpy.testing.assert_allclose — NumPy v1.26 Manual: no description found
- cub::WarpLoad — CUB 104.0 documentation: no description found
- 2D and 3D tile divisions so that permutation coordinates can be read from threadIdx and blockIdx · Issue #406 · karpathy/llm.c: Supposedly the permutation kernels, even though they are mostly memory bound can reduce the amount of division and do thread coarsening by having a 2d or 3d grid and not have to do any division in ...
- Issues · NVIDIA/cccl: CUDA C++ Core Libraries. Contribute to NVIDIA/cccl development by creating an account on GitHub.
- llm.c/.github/workflows/ci.yml at 2346cdac931f544d63ce816f7e3f5479a917eef5 · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- Zero Redundancy Optimizer - Stage1 by chinthysl · Pull Request #309 · karpathy/llm.c: To train much larger model variations (2B, 7B, etc), we need larger GPU memory allocations for parameters, optimizer states, and gradients. Zero Redundancy Optimizer introduce the methodology to sh...
- Layernorm backward updates by ngc92 · Pull Request #408 · karpathy/llm.c: This fixes gradient accumulation for the layernorm backward pass, and provides general modernization of the layernorm backward dev/cuda file. Tolerances have been adapted to the float scratchpad ...
- GitHub - HazyResearch/ThunderKittens: Tile primitives for speedy kernels: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
- GPUs Go Brrr: how make gpu fast?
- Zero Redundancy Optimizer - Stage1 by chinthysl · Pull Request #309 · karpathy/llm.c: To train much larger model variations (2B, 7B, etc), we need larger GPU memory allocations for parameters, optimizer states, and gradients. Zero Redundancy Optimizer introduce the methodology to sh...
- llm.c/train_gpt2.cu at master · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
CUDA MODE ▷ #lecture-qa (2 messages):
- Deadline might shift due to NYC chaos: A member mentioned potential delays in their work due to the chaotic situation in NYC. They will update the task status if another member has an edit ready.
- Evening availability in Eastern Time: Another member confirmed their availability to work on the edits this evening, specifying Eastern Time.
LlamaIndex ▷ #blog (6 messages):
- Tour of Llama 3 Use Cases Shines: Celebrating the Llama 3 hackathon, there's a new set of cookbooks showing how to use Llama 3 for 7 different use cases. The details can be explored here.
- GPT-4o Supported from Day 0: Exciting support for GPT-4o is available in Python and TypeScript from day one. Users can install via
pipwith detailed instructions and are encouraged to use the multi-modal integration as well.
- GPT-4o Multimodal Demo: A simple demo showcases the impressive multimodal capabilities of GPT-4o in Python. Check out the demo featuring a user's dog here.
- GPT-4o Outpaces GPT-4 Turbo in SQL: When generating complex SQL queries, GPT-4o performs twice as fast as GPT-4-turbo. See the performance breakthrough here.
- Local Research Assistant with llamafile: The llamafile from Mozilla enables a private research assistant on your laptop with no installation needed. Learn more about this innovative tool here.
- no title found: no description found
- llama-index-llms-openai: llama-index llms openai integration
- llama-index-multi-modal-llms-openai: llama-index multi-modal-llms openai integration
- Google Colab: no description found
- Google Colab: no description found
LlamaIndex ▷ #general (104 messages🔥🔥):
- **Metadata in `query` method leaves users confused**: A member questioned if metadata must be passed during the `query` method after embedding it in `TextNode`. Clarifications revealed that **metadata filtering** can be handled internally by LlamaIndex, but any specific usage like URLs must be added manually.
- **Unexpected token error in frontend response**: A user faced an issue where the frontend stops outputting the AI's response mid-message, displaying `Unexpected token U`. It was suggested to inspect the actual response in the network tab or manually `console.log` the response before parsing.
- **Error handling with Qdrant vectors and postprocessors**: A user's attempt to create a new postprocessor with Qdrant vector store met with a `ValidationError`: expected `BaseDocumentStore`. The solution involved correctly identifying and passing vector storage within the proper context.
- **Confusion about LlamaIndex implementation updates**: Members discussed updating the sec-insights repo and LlamaIndex from 0.9.7 to newer versions. Suggesting it may involve mostly updating imports, as noted by a member willing to assist with the version upgrade changes.
- **Job search assistant using LlamaIndex**: An article on building a job search assistant with LlamaIndex and MongoDB was shared, offering a detailed tutorial and project repository. The project aims to enhance the job search experience using AI-driven chatbots and **Retrieval-Augmented Generation**.
- no title found: no description found
- langchain/cookbook/Multi_modal_RAG.ipynb at master · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Llama3 Cookbook with Ollama and Replicate - LlamaIndex: no description found
- Multimodal Ollama Cookbook - LlamaIndex: no description found
- Using LlamaIndex and MongoDB to Build a Job Search Assistant: Learn how to build a job search assistant with LlamaIndex using Retrieval-Augmented Generation (RAG) and MongoDB.
- Multi-Modal Applications - LlamaIndex: no description found
LAION ▷ #general (101 messages🔥🔥):
- Falcon 2 beats Meta’s Llama 3 8B: The Falcon 2 11B model outperforms Meta’s Llama 3 8B, and performs on par with Google's Gemma 7B, as verified by the Hugging Face Leaderboard. This model is multilingual and the only AI model with vision-to-language capabilities.
- GPT-4o Launches with Impressive Features: The new GPT-4o model is released, offering real-time communication and video processing. This version significantly improves API performance, operating at half the cost and matching the speed of human conversations.
- RAG with Image Gen Models Discussion: A conversation about RAG with image gen models referenced RealCustom paper for transformation of text-driven images, and IP Adapter as a prominent tool. Additionally, Stable Diffusion is noted to accept CLIP image embeddings rather than text embeddings.
- HunyuanDiT Claims SOTA: Tencent releases the HunyuanDiT model, purportedly the SOTA open-source diffusion transformer text-to-image model but excels particularly for Chinese prompts. It shows good prompt following and quality despite being a smaller model.
- AniTalker for Lifelike Talking Faces: The new AniTalker framework offers the capability to animate talking faces from a single portrait using static images and input audio. It captures complex facial dynamics beyond simple lip synchronization.
- HunyuanDiT - a Hugging Face Space by multimodalart: no description found
- Tweet from apolinario (multimodal.art) (@multimodalart): The first open Stable Diffusion 3-like architecture model is JUST out 💣 - but it is not SD3! 🤔 It is HunyuanDiT by Tencent, a 1.5B parameter DiT (diffusion transformer) text-to-image model 🖼️✨ In...
- AniTalker: no description found
- Bunline - v0.4 | Stable Diffusion Checkpoint | Civitai: PixArt Sigma XL 2 1024 MS full finetune on custom captions for roughly 35k images w/ max(w,h) > 1024px INSTRUCTIONS: Place the .safetensors wher...
- lambdalabs/stable-diffusion-image-conditioned · Hugging Face: no description found
- CompVis/stable-diffusion-v-1-3-original · Hugging Face: no description found
- Tweet from Google DeepMind (@GoogleDeepMind): We’re introducing Imagen 3: our highest quality text-to-image generation model yet. 🎨 It produces visuals with incredible detail, realistic lighting and fewer distracting artifacts. From quick sket...
- RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization: Text-to-image customization, which aims to synthesize text-driven images for the given subjects, has recently revolutionized content creation. Existing works follow the pseudo-word paradigm, i.e., rep...
- Falcon 2: UAE’s Technology Innovation Institute Releases New AI Model Series, Outperforming Meta’s New Llama 3: no description found
- GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model: A latent text-to-image diffusion model. Contribute to CompVis/stable-diffusion development by creating an account on GitHub.
- GitHub - cubiq/Diffusers_IPAdapter: implementation of the IPAdapter models for HF Diffusers: implementation of the IPAdapter models for HF Diffusers - cubiq/Diffusers_IPAdapter
- Silicon Valley Tip To Tip GIF - Silicon Valley Tip To Tip Brainstorm - Discover & Share GIFs: Click to view the GIF
{kind=link}
LAION ▷ #research (3 messages):
- DeepMind's Veo sets new benchmark in video generation: Veo is DeepMind's most advanced video generation model, producing 1080p resolution videos exceeding a minute in duration, with a wide array of cinematic styles. Aimed at making video production more accessible, it will soon be available to select creators via VideoFX with a waitlist already open.
- Research demos fail to consider mobile users: A member lamented that research demos often do not compress their videos, making them less accessible for mobile users.
Link mentioned: Veo: Veo is our most capable video generation model to date. It generates high-quality, 1080p resolution videos that can go beyond a minute, in a wide range of cinematic and visual styles.
OpenInterpreter ▷ #general (52 messages🔥):
- GPT-4o impresses but costly: One member expressed dissatisfaction with Llama 3 70b compared to GPT-4, mentioning they spent $20 in one day on OpenAI fees and feeling unimpressed by other models after trying GPT-4.
- Open Interpreter compatible with GPT-4o: Users discussed the functionality of GPT-4o with Open Interpreter, with one mentioning “anyone that wants to try it with OI, it’s working” using the command
interpreter --model openai/gpt-4o. - Speed advantages of GPT-4o: The GPT-4o model is reported to deliver a whopping 100 tokens/sec compared to 10-15 tokens/sec for GPT-4-turbo and being half the price, making it a significant improvement in model performance.
- Custom instructions cause issues: Some users experienced issues with GPT-4o due to previous custom instructions set months ago, which caused it to malfunction until the instructions were adjusted.
- Achieving AGI within reach?: There was a speculative discussion on the advancements leading towards AGI (Artificial General Intelligence), with one member sharing a link to a Perplexity AI explanation of AGI.
OpenInterpreter ▷ #O1 (18 messages🔥):
- Community Eager for TestFlight Release: Members are eagerly awaiting the TestFlight release, with an update expected once Apple's approval process is complete. One mentioned, "Testflight should be up later today, waiting for approval from Apple."
- Bundle Identifier Setup in Xcode: Members discussed setting up the Signing Team and Bundle Identifier in Xcode to compile their projects. A helpful clarification was given: "When you open the file in xcode it’s a setting you need to change under the target file in order to compile."
- Shipping Timeline for Next Batch: There's a shared interest in the shipping timeline for the O1 device, with the first batch expected for November. One member inquired, "Anyone know when the next 01 batch is being shipped out?" and received confirmation about the timeline.
- Speculation on AI Integration in MacOS: Some users speculated about potential OpenAI integration into MacOS after a recent presentation. While one member was optimistic about full integration, another suggested, "I think Apple wont do that, I bet they want AI to run locally on the machine."
- Preference for Open Source AI Solutions: A preference for open-source AI solutions over proprietary ones like Apple's was expressed. "Even if Apple integrates AI into their OS, I’d rather go with open source," leading to a suggestion of using Linux instead.
LangChain AI ▷ #general (47 messages🔥):
- ChatGPT Contradictions Frustrate Users: A user expressed frustration with ChatGPT's recent tendency to contradict itself in responses. They noted that it "used to at least stick to its story and gaslight the whole way, now it can't make its mind up on its stance."
- Issues with Deprecated LLCHAIN: Multiple users discussed issues they faced after LLCHAIN was deprecated. Switching to
from langchain_community.chat_models import ChatOpenAIresolved some problems, but encountered new issues with streaming and invoking sequential chains.
- LangChain Agent Invoked Slowly: A user reported that LangChain agents take an excessively long time, 2-3 minutes, to process large inputs of 300-400 words. Another user pointed towards handling the workload through parallel architecture to improve speed.
- AI/ML GitHub Repository Favorites: Members shared their favorite AI/ML GitHub repositories, with mentions of llama.cpp and deepspeed standing out.
- Socket.IO for Streaming LLM Responses: A detailed example was provided on how to integrate
python-socketiowith LangChain to stream responses to the frontend. It covered both server-side and client-side implementations for managing token streaming and acknowledgments.
Link mentioned: : 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #langchain-templates (1 messages):
- Query on Response Optimization Prefixes: A member asked if prefixes such as
<|begin_of_text|><|start_header_id|>system<|end_header_id|>are needed for optimal response. There was no response or additional context provided in the message history.
LangChain AI ▷ #share-your-work (5 messages):
- Plug-and-Plai Integration Supercharges LLMs: Check out this Medium article on using Plug-and-Plai with LangChain workflows to enhance LLM performance. The integration aims to elevate the ease of deploying large language models in various applications.
- Multimodal Chat App Using Streamlit and GPT-4o Wows: A member shared their Hugging Face space featuring a multimodal chat app. The app uses Streamlit with LangChain and OpenAI’s GPT-4o, supporting image uploads and clipboard pastes directly into chat messages.
- RAG App Scaling Challenges: A developer, Sivakumar, has built an RAG application using LangChain and ChromaDB as the vector store and seeks advice on scaling it to production level. They are looking for insights and suggestions to make the application production-ready.
- OranClick AI Writing Flow Unveiled: OranAITech announced their new AI writing flow in a tweet. The tool aims to enhance message effectiveness by tracking link clicks and optimizing copy creation with AI support.
- Snowflake Cost Monitoring Tool Seeks Feedback: A new Snowflake cost monitoring and optimizer tool built using LangChain, Snowflake Cortex, and OpenAI is in development. The tool leverages multiple AI agents to optimize credit usage and automatically selects relevant data visualizations, though it remains a work in progress.
- Crystal Cost Demo: In this video, I give a quick demo of Crystal Cost, an AI-powered streamlit app that simplifies data monitoring on data warehouses. Crystal Cost uses natural language processing and agents to query da...
- Tweet from Adi Oran (@OranAITech): You’re tired of not knowing if your message will click. But you want to easily double down on effective messaging. So it’s time you met OranClick track your link clicks and write your best copy wi...
- streamlit-gpt4o - a Hugging Face Space by joshuasundance: no description found
LangChain AI ▷ #tutorials (2 messages):
- Build your own chat with a blog: A member shared their blog post explaining how they built a chat feature into their site, allowing visitors to ask questions based on previous blog posts. They provide the necessary code, including data processing, server-side API, and client-side chat interface, using Retrieval Augmented Generation with citations.
- Seeking session handling and streaming tutorial: Another member asked for a tutorial on handling history, managing sessions, and enabling streaming using LangChain. They mentioned struggling to implement streaming despite following the current documentation.
Link mentioned: Build a RAG pipeline for your blog with LangChain, OpenAI and Pinecone: You can chat with my writing and ask me questions I've already answered even when I'm not around
OpenAccess AI Collective (axolotl) ▷ #general (24 messages🔥):
- Substack or Bluesky?: A member inquired about which platform to use, Substack or Bluesky, for blogging purposes. Another member clarified that while Bluesky supports threads of posts, it doesn't currently facilitate full-fledged blogging.
- AI's Compute Usage Scrutiny: Members discussed AI's substantial compute usage and shared several links to recent work focused on reducing this compute load, like Based and FlashAttention-2.
- GPT-4o Hype Commentary: A YouTube video hyping GPT-4o was shared, with "singing" GPT-4os and capabilities in audio, vision, and text. It was mentioned that despite the hype, the offering might appeal mainly to those willing to pay GPT-4 turbo prices.
- Sponsorship for OpenOrca Dedup on GPT-4o: A member sought sponsors for rerunning the OpenOrca dedup on GPT-4o, estimating costs at around $350 for 70M input tokens and $300 for 30M output tokens. They highlighted the possibility of getting a discount if run as a batch job.
- Challenges in Publishing Papers: Members discussed the long and challenging process of publishing papers, noting how papers often become outdated by the time they are published. This was illustrated by one member's experience of needing just two papers for their Ph.D., having only one accepted so far.
- Training cmdR+ 100b Model: A member expressed a desire to train a cmdR+ 100b model but noted that Axolotl doesn't support it. Another member suggested that training a base model might be more beneficial since cmdR+ is already instruction-tuned.
- GPUs Go Brrr: how make gpu fast?
- Open-Orca/SlimOrca-Dedup · Datasets at Hugging Face: no description found
- Two GPT-4os interacting and singing: Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time.Learn more here: https://www.openai.com/index/hello-...
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (8 messages🔥):
- Outdated Dependencies Frustrate Users: A user expressed frustration over outdated dependencies including peft 0.10.0, accelerate 0.28.0, deepspeed 0.13.2, and others, noting that "this configuration installs torch 2.0.0 by default while we got 2.3.0 already."
- Updating Dependencies Manually: Despite recommending updating dependencies to their latest versions for better compatibility, the user mentioned needing to install peft directly from the repo due to a compatibility issue with the accelerate FSDP plugin, and flash-attn via a
.whlfile from GitHub releases. - Prompt for Pull Request: Faced with a request to make a pull request (PR) for the newer versions, the user responded with hesitance, citing difficulty in testing across different environments, but confirmed that updating packages to the latest stable versions worked on their end.
OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
- Update pip dependencies: A member suggested that updating pip dependencies could resolve a specific error. Another member confirmed experiencing the same error and implied that this could be a solution.
OpenAccess AI Collective (axolotl) ▷ #runpod-help (1 messages):
- Trouble with CUDA Errors in 8xH100 Setup: A user initially reported running into CUDA errors with both Runpod PyTorch containers and
winglian/axolotl:main-latest. After an edit, they updated that the setup might be working with the community axolotl cloud image.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (1 messages):
- Merge QLoRA to base without precision trouble: A user queried the procedure to "merge QLoRA to base without precision issue (fp16/32)". This highlights a common concern among developers ensuring model accuracy when converting precision formats.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (7 messages):
- Merging QLoRA with Base: A member inquired about the process to merge QLoRA into a base model, indicating interest in model integration techniques.
- Resuming Training with Checkpoints: Users discussed how to "resume from checkpoint when previously training LoRA" using the
ReLoRACallbackfrom the OpenAccess-AI-Collective/axolotl codebase. Detailed steps included initializing the training environment, configuring and loading checkpoints, and starting the training process.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Datasette - LLM (@SimonW) ▷ #ai (29 messages🔥):
- Voice Assistant Giggling Disappoints Users: Users expressed disappointment over a voice assistant feature that giggles, describing it as an "embarrassing choice." Suggestions included using prompts like "Act as a voice assistant that does not giggle" to mitigate this issue.
- GPT-4o Struggles with Library Book Listing: A user shared their discontent with GPT-4o's performance on a "list all the books on this shelf" test, stating it only got about 50% correct and missed several titles, though praising its speed and pricing.
- Debate on AGI Expectations and Model Progress: Discussion centered around skepticism on AGI, with some users arguing that AGI is not imminent and that there are diminishing returns in model advancements from GPT-3 to GPT-4. One user mentioned that the hype around GPT-5 is overshadowing unrealized potential in existing models like GPT-4.
- GPT-4 and GPT-4o Long-Term Impacts: There was consensus that the long-term effects of models like GPT-4 are still unknown and that most people haven't yet experienced their capabilities. One user humorously suggested that if AGI is defined by the ability to "do a slightly botched job of any task," then AGI was achieved with GPT-3.
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
simonw: https://twitter.com/simonw/status/1790121870399782987
tinygrad (George Hotz) ▷ #learn-tinygrad (24 messages🔥):
- Tinygrad's CUDA support questioned: A member inquired about the expected behavior of
CUDA=1andPTX=1on an Nvidia 4090, sharing errors encountered during PTX generation and module loading. Another member suggested updating the Nvidia drivers to version 550 to resolve the issue.
- Discussing Graph Neural Networks (GNN) in tinygrad: The conversation touched on the implementation of GNNs in tinygrad and compared it to existing PyTorch solutions such as PyG. One member noted, "In that case it just comes down to a O(N^2) CUDA kernel" and shared GitHub links for reference.
- Tinygrad aggregations and limitations: A member shared a Python function for feature aggregation and its challenges in tinygrad, but faced issues with advanced indexing and backpropagation through
wherecalls. Solutions suggested included using masking and theeinsumfunction, though it was not clear if all edge cases were covered.
- Struggles with tinygrad's advanced features: The discussion included grappling with advanced features like
setitemandwhere, with one member stating that "currently any setitem with advanced indexing (indexing with list or tensors) is not supported". Multiple workarounds, including masking and einsum, were proposed and tested.
- Exploring tinygrad optimizations: Some members were experimenting with optimizations for the conv2d backward pass in tinygrad. One member noted issues with the scheduler and view changes affecting shape compatibility, questioning whether reimplementing conv2d might be a better approach.
- test_aggregate.py: GitHub Gist: instantly share code, notes, and snippets.
- pytorch_cluster/csrc/cuda/radius_cuda.cu at master · rusty1s/pytorch_cluster: PyTorch Extension Library of Optimized Graph Cluster Algorithms - rusty1s/pytorch_cluster
- torchmd-net/torchmdnet/extensions/neighbors/neighbors_cpu.cpp at 75c462aeef69e807130ff6206b59c212692a0cd3 · torchmd/torchmd-net: Neural network potentials . Contribute to torchmd/torchmd-net development by creating an account on GitHub.
- Home - PyG: PyG is the ultimate library for Graph Neural Networks
DiscoResearch ▷ #general (17 messages🔥):
- Call for Help with German TTS Training: A member asked for assistance in compiling a list of German YouTube channels with high-quality podcasts, news, blogs, etc. "Hätte jemand Zeit und Lust dabei zu helfen so eine Liste zusammenzustellen?"
- MediathekView for German Media Content: Another member suggested using MediathekView to download shows and films from various German online media libraries, which can also include subtitle files if available. They shared links to popular German podcasts and the top German YouTube channels.
- MediathekView Usage Insights: Discussions also covered potential ways to download the entire MediathekView database and use a JSON API for accessing the content, with an additional source from GitHub.
- New German Tokenizer Efficiency: A user highlighted the efficiency of the new "o200k_base" tokenizer, which only requires 82.2% as many tokens for the same German text compared to the old tokenizer "cl100k_base". They noted the new tokenizer's performance against tokenizers like Mistral and Llama3.
- Tokenizers Research Resource: For those interested in further research on tokenizers, a project called Tokenmonster was shared. The project focuses on subword tokenizers and vocabulary training for various programming languages.
- Tweet from Susan Zhang (@suchenzang): this new "o200k_base" vocab for gpt-4o makes me want to clutch my pearls
- Tweet from main (@main_horse): "why was the gpt-4o demo so horny?"
- GitHub - alasdairforsythe/tokenmonster: Ungreedy subword tokenizer and vocabulary trainer for Python, Go & Javascript: Ungreedy subword tokenizer and vocabulary trainer for Python, Go & Javascript - alasdairforsythe/tokenmonster
- MediathekViewWebVLC/mediathekviewweb.lua at main · 59de44955ebd/MediathekViewWebVLC: MediathekViewWeb Lua extension for VLC. Contribute to 59de44955ebd/MediathekViewWebVLC development by creating an account on GitHub.
- Die 100 beliebtesten Podcasts im Moment – Deutschland: Diese Liste zeigt die derzeit 100 beliebtesten Podcasts mit aktuellen Daten von Apple und Podtail.
- Top YouTube Channels in Germany | HypeAuditor YouTube Ranking: Find the most popular YouTube channels in Germany as of May 2024. Get a list of the biggest YouTubers in Germany.
Cohere ▷ #general (8 messages🔥):
- Support Requests in Community Channels: One user expressed difficulty in receiving support through specific channels (<#1168411509542637578> and <#1216947664504098877>), mentioning a lack of responses. Another user reassured them that Cohere staff are available and active, asking for further details.
- Praise for Command R's Capabilities: A user expressed high satisfaction with Command R's RAG capabilities, emphasizing its affordability, accuracy, and fidelity to long source documents. They noted being "extremely impressed" with its performance despite extensive source lengths.
- Greetings and Emojis: There were general greetings exchanged in the channel, including a "hello" and the use of an emoji "<:hammy:981331896577441812>".
Cohere ▷ #project-sharing (2 messages):
- Vedang seeks collaboration on a project: A member expressed interest in collaborating on a project similar to what another user was working on. They said, "Hi Asher, I’m also doing working on same thing. I would like to cooperate."
- Amit shares Medium article on RAG learning: A member shared a link to their Medium article about learning RAG from scratch using the Unstructured API. The article focuses on extracting content from PDFs in a structured format.
LLM Perf Enthusiasts AI ▷ #general (6 messages):
- Battle of the LLMs: Claude 3 Haiku vs Llama 3b: Members discussed the potential use cases and comparative strengths of Claude 3 Haiku versus Llama 3b Instruct. One user is specifically interested in using these models for building an automated scoring service to extract and match entities from documents using a Pydantic model.
- Constrained Sampling in LLMs: A suggestion was made to use constrained sampling with outlines in vllm or sglang. This was recommended as a potentially useful approach for the type of entity matching and scoring tasks being discussed.
LLM Perf Enthusiasts AI ▷ #gpt4 (3 messages):
- OpenAI's Spring Update steals the show: A link to a YouTube video titled "Introducing GPT-4o" was shared, highlighting OpenAI's live stream update from May 13, 2024, which includes updates to ChatGPT.
- Scarlett Johansson voices GPT-4o: A member expressed surprise and amusement that Scarlett Johansson was chosen to do the voice for GPT-4o.
Link mentioned: Introducing GPT-4o: OpenAI Spring Update – streamed live on Monday, May 13, 2024. Introducing GPT-4o, updates to ChatGPT, and more.
Skunkworks AI ▷ #announcements (1 messages):
- Guild Tags introduce new user identifiers: Starting May 15, some members might notice Guild Tags next to usernames, indicating their membership in exclusive servers called Guilds. Admins should note that if AutoMod is enabled, it will also check for these tags.
- Guilds are exclusive communities: Guilds are small, exclusive servers where members can share common identities, hobbies, and play styles. Currently, Guilds are available only to a limited number of servers, and support cannot manually add servers to this experiment.
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=9pHyH4XDAYk
Alignment Lab AI ▷ #fasteval-dev (1 messages):
- Project discontinuation and ownership transfer: A user announced they are not planning to continue with the **Fasteval project** or any followup. They are open to transferring ownership of the project on GitHub if someone responsible is interested, otherwise, the channels will be archived.
AI Stack Devs (Yoko Li) ▷ #paper-spam (1 messages):
angry.penguin: nice, AK is back