[AINews] Genesis: Generative Physics Engine for Robotics (o1-2024-12-17)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
A universal physics engine is all you need.
AI News for 12/17/2024-12/18/2024. We checked 7 subreddits, 433 Twitters and 32 Discords (215 channels, and 4542 messages) for you. Estimated reading time saved (at 200wpm): 497 minutes. You can now tag @smol_ai for AINews discussions!
You are reading AINews generated by o1-2024-12-17. As is tradition on new frontier model days, we try to publish multiple issues for A/B testing/self evaluation. Check our archives for the o1-mini version. We are sorry for the repeat sends yesterday (platform bug) but today's is on purpose.
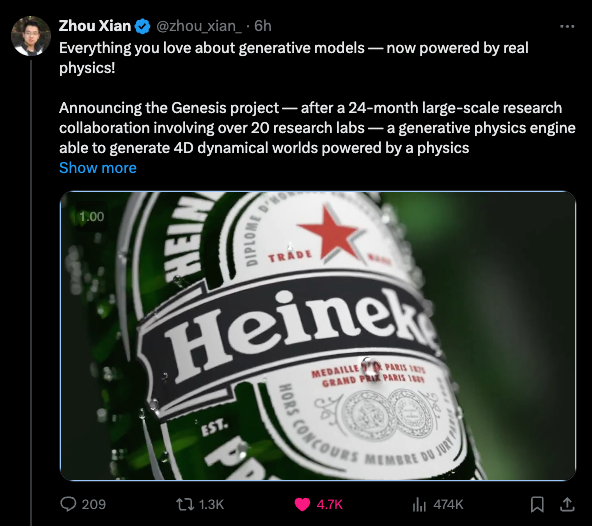
December has been the month of Generative Video World Simulators apparently, with Sora Turbo going GA, both Genie 2 and Veo 2 getting teased by Google. Now, a group of academics led by CMU PhD student Zhou Xian have announced Genesis: A Generative and Universal Physics Engine for Robotics and Beyond, a 2 year large scale research collaboration involving over 20 labs, debuting with a drop of water rolling down a Heineken bottle:
Because it is a physics engine, it can render the same engine from different camera angles:
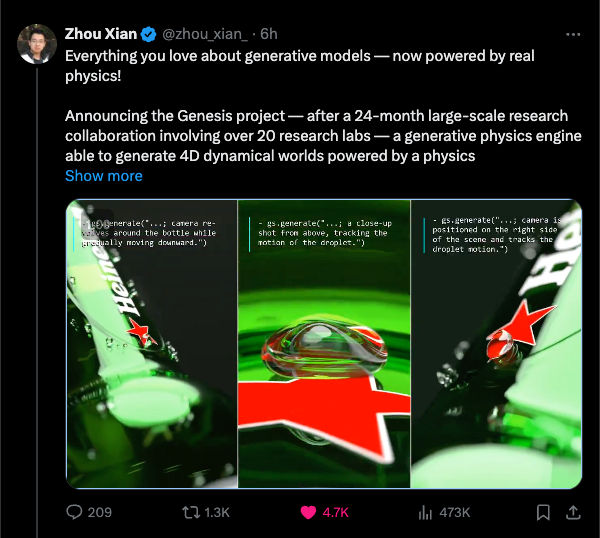
as well as expose the driving vectors:

The "unified physics engine" integrates various SOTA physics solvers (MPM, SPH, FEM, Rigid Body, PBD, etc.), supporting simulation of a wide range of materials: rigid body, articulated body, Cloth, Liquid, Smoke, Deformables, Thin-shell materials, Elastic/Plastic Body, Robot Muscles, etc.
Rendering consistent objects is immediately useful today, but does not sound like the "purist" bitter pilled approach taken by the big labs - being a pile of physics solvers manually put together rather than machine learned through data - but it does have the advantage of being open source and usable today (no paper yet).
If the purpose were video generation, this would already be impressive, but the real goal is robotics. Genesis is really a platform for 4 things:
- A universal physics engine re-built from the ground up, capable of simulating a wide range of materials and physical phenomena.
- A lightweight, ultra-fast, pythonic, and user-friendly robotics simulation platform.
- A powerful and fast photo-realistic rendering system.
- A generative data engine that transforms user-prompted natural language description into various modalities of data.
and it should be the robotics applications that should really shine.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Codeium (Windsurf) Discord
- Cursor IDE Discord
- aider (Paul Gauthier) Discord
- OpenAI Discord
- Nous Research AI Discord
- Notebook LM Discord Discord
- Unsloth AI (Daniel Han) Discord
- OpenRouter (Alex Atallah) Discord
- Interconnects (Nathan Lambert) Discord
- Eleuther Discord
- Stability.ai (Stable Diffusion) Discord
- Perplexity AI Discord
- GPU MODE Discord
- LM Studio Discord
- Stackblitz (Bolt.new) Discord
- Cohere Discord
- Modular (Mojo 🔥) Discord
- Latent Space Discord
- OpenInterpreter Discord
- tinygrad (George Hotz) Discord
- Torchtune Discord
- DSPy Discord
- Nomic.ai (GPT4All) Discord
- LlamaIndex Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- LAION Discord
- LLM Agents (Berkeley MOOC) Discord
- Axolotl AI Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- Codeium (Windsurf) ▷ #discussion (60 messages🔥🔥):
- Codeium (Windsurf) ▷ #windsurf (678 messages🔥🔥🔥):
- Cursor IDE ▷ #general (707 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #general (264 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (18 messages🔥):
- aider (Paul Gauthier) ▷ #links (11 messages🔥):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (220 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (3 messages):
- OpenAI ▷ #prompt-engineering (4 messages):
- OpenAI ▷ #api-discussions (4 messages):
- Nous Research AI ▷ #general (210 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (13 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #research-papers (2 messages):
- Notebook LM Discord ▷ #announcements (1 messages):
- Notebook LM Discord ▷ #use-cases (27 messages🔥):
- Notebook LM Discord ▷ #general (194 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (66 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (139 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #help (15 messages🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (209 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (36 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (26 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (21 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (20 messages🔥):
- Interconnects (Nathan Lambert) ▷ #rl (5 messages):
- Interconnects (Nathan Lambert) ▷ #rlhf (14 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (31 messages🔥):
- Eleuther ▷ #general (1 messages):
- Eleuther ▷ #research (123 messages🔥🔥):
- Eleuther ▷ #lm-thunderdome (6 messages):
- Eleuther ▷ #gpt-neox-dev (9 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (122 messages🔥🔥):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (108 messages🔥🔥):
- Perplexity AI ▷ #sharing (4 messages):
- Perplexity AI ▷ #pplx-api (1 messages):
- GPU MODE ▷ #general (41 messages🔥):
- GPU MODE ▷ #triton (1 messages):
- GPU MODE ▷ #cuda (8 messages🔥):
- GPU MODE ▷ #torch (33 messages🔥):
- GPU MODE ▷ #cool-links (4 messages):
- GPU MODE ▷ #jobs (1 messages):
- GPU MODE ▷ #torchao (5 messages):
- GPU MODE ▷ #rocm (1 messages):
- GPU MODE ▷ #thunderkittens (1 messages):
- GPU MODE ▷ #arc-agi-2 (18 messages🔥):
- LM Studio ▷ #general (87 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (17 messages🔥):
- Stackblitz (Bolt.new) ▷ #prompting (6 messages):
- Stackblitz (Bolt.new) ▷ #discussions (97 messages🔥🔥):
- Cohere ▷ #discussions (42 messages🔥):
- Cohere ▷ #announcements (1 messages):
- Cohere ▷ #questions (51 messages🔥):
- Cohere ▷ #cmd-r-bot (1 messages):
- Cohere ▷ #projects (2 messages):
- Cohere ▷ #cohere-toolkit (3 messages):
- Modular (Mojo 🔥) ▷ #general (22 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (57 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #max (13 messages🔥):
- Latent Space ▷ #ai-general-chat (90 messages🔥🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- OpenInterpreter ▷ #general (28 messages🔥):
- tinygrad (George Hotz) ▷ #general (27 messages🔥):
- Torchtune ▷ #dev (25 messages🔥):
- Torchtune ▷ #papers (2 messages):
- DSPy ▷ #show-and-tell (1 messages):
- DSPy ▷ #papers (4 messages):
- DSPy ▷ #general (11 messages🔥):
- Nomic.ai (GPT4All) ▷ #general (12 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (4 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (3 messages):
- LAION ▷ #general (1 messages):
- LAION ▷ #research (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (1 messages):
- Axolotl AI ▷ #general (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Here are the key discussions organized by topic:
OpenAI o1 API Launch and Features
- o1 model released to API with function calling, structured outputs, vision support, and developer messages. Model uses 60% fewer reasoning tokens than o1-preview and includes a new "reasoning_effort" parameter.
- Performance Benchmarks: @aidan_mclau noted o1 is "insanely good at math/code" but "mid at everything else". Benchmark results show o1 scoring 0.76 on LiveBench Coding, compared to Sonnet 3.5's 0.67.
- New SDKs: Released beta SDKs for Go and Java. Also added WebRTC support for realtime API with 60% lower prices.
Google Gemini Updates
- @sundarpichai confirmed that Gemini Exp 1206 is Gemini 2.0 Pro, showing improved performance on coding, math and reasoning tasks.
- Gemini 2.0 deployment accelerated for Advanced users in response to feedback.
Model Development & Architecture
- Discussion around model sizes and training - debate about whether o1-preview's size matches o1 and relationship to GPT-4o.
- Meta's new research on training transformers directly on raw bytes using dynamic patching based on entropy.
Industry & Business
- @adcock_brett reported successful deployment of commercial humanoid robots at client site with rapid transfer from HQ.
- New LlamaReport tool announced for converting document databases into human-readable reports using LLMs.
Memes & Humor
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Hugging Face's 3B Llama Model: Outperforming the 70B with Search
- Hugging Face researchers got 3b Llama to outperform 70b using search (Score: 668, Comments: 123): Hugging Face researchers achieved a breakthrough by making the 3B Llama model outperform the 70B Llama model in MATH-500 accuracy using search techniques. The graph demonstrates that the 3B model surpasses the 70B model under certain conditions, with accuracy measured across generations per problem, highlighting the model's potential efficiency and effectiveness compared to larger models.
- Inference Time and Model Size Optimization: Users discuss the potential of finding an optimal balance between inference time and model size, suggesting that smaller models can be more efficient if they perform adequately on specific tasks, especially when the knowledge is embedded in prompts or fine-tuned for particular domains.
- Reproducibility and Dataset References: Concerns are raised about the reproducibility of the results due to the non-publication of the Diverse Verifier Tree Search (DVTS) model, with a link provided to the dataset used (Hugging Face Dataset) and the DVTS implementation (GitHub).
- Domain-Specific Limitations: There is skepticism about the applicability of the method outside math and code domains due to the lack of PRMs trained on other domains and datasets with step-by-step labeling, questioning the generalizability of the approach.
Theme 2. Moonshine Web: Faster, More Accurate than Whisper
- Moonshine Web: Real-time in-browser speech recognition that's faster and more accurate than Whisper (Score: 193, Comments: 25): Moonshine Web claims to provide real-time in-browser speech recognition that is both faster and more accurate than Whisper.
- Moonshine Web is open source under the MIT license, with ongoing efforts to integrate it into transformers as seen in this PR. The ONNX models are available on the Hugging Face Hub, although there are concerns about the opacity of the ONNX web runtime.
- Discussion highlights include skepticism about the real-time capabilities and accuracy claims of Moonshine compared to Whisper models, specifically v3 large. Users are curious about the model's ability to perform speaker diarization and its current limitation to English only.
- Moonshine is optimized for real-time, on-device applications, with support added in Transformers.js v3.2. The demo source code and online demo are available for testing and exploration.
Theme 3. Granite 3.1 Language Models: 128k Context & Open License
- Granite 3.1 Language Models: 128k context length & Apache 2.0 (Score: 144, Comments: 22): Granite 3.1 Language Models now feature a 128k context length and are available under the Apache 2.0 license, indicating significant advancements in processing larger datasets and accessibility for developers.
- Granite Model Performance: The Granite 3.1 3B MoE model is reported to have a higher average score on the Open LLM Leaderboard than the Falcon 3 1B, contradicting claims that MoE models perform similarly to dense models with equivalent active parameters. This is despite having 20% fewer active parameters than its competitors.
- Model Specifications and Licensing: The Granite dense models (2B and 8B) and MoE models (1B and 3B) are trained on over 12 trillion and 10 trillion tokens, respectively, with the dense models supporting tool-based use cases and the MoE models designed for low latency applications. The models are released under the Apache 2.0 license, with the 8B model noted for its performance in code generation and translation tasks.
- Community Insights and Comparisons: The Granite Code models are praised for their underrated performance, particularly the Granite 8BCode model, which competes with the Qwen2.5 Coder 7B. Discussions also highlight the potential for MoE models to facilitate various retrieval strategies and the importance of familiar enterprise solutions like Red Hat's integration of Granite models.
Theme 4. Moxin LLM 7B: A Fully Open-Source AI Model
- Moxin LLM 7B: A fully open-source LLM - Base and Chat + GGUF (Score: 131, Comments: 5): Moxin LLM 7B is a fully open-source large language model trained on text and coding data from SlimPajama, DCLM-BASELINE, and the-stack-dedup, achieving superior zero-shot performance compared to other 7B models. It features a 32k context size, supports long-context processing with grouped-query attention, sliding window attention, and a Rolling Buffer Cache, with comprehensive access to all development resources available on GitHub and Hugging Face.
- Moxin LLM 7B is praised for being an excellent resource for model training, with its clean and accessible code and dataset, as noted by Stepfunction. The model's comprehensive development resources are highlighted as a significant advantage.
- TheActualStudy commends the model for integrating Qwen-level context, Gemma-level tech, and Mistral-7B-v0.1 performance. This combination of advanced methods and data is regarded as impressive.
- Many_SuchCases mentions exploring the GitHub repository and notes the absence of some components like intermediate checkpoints, suggesting that these might be uploaded later.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Imagen v2 Quality Elevates Image Generation Benchmark
- New Imagen v2 is insane (Score: 680, Comments: 119): Imagen 3 is establishing new benchmarks in image quality with its release, referred to as Imagen v2. The post highlights the impressive advancements in the technology without providing additional context or details.
- Access and Usage: Users discuss accessing Imagen 3 through the Google Labs website, suggesting the use of VPNs for regions with restrictions. There is a mention of free access with some daily usage quotas on labs.google/fx/tools/image-fx.
- Artistic Concerns: There is significant concern among artists about Imagen 3's impact on the art industry, with fears of reduced need for human artists and the overshadowing of traditional art by AI-generated images. Some users express the belief that this shift may lead to the privatization of creative domains and the erosion of artistic labor.
- Model Confusion and Improvements: Some confusion exists regarding the naming and versioning of Imagen 3, with users clarifying it as Imagen3 v2. Users note significant improvements in image quality, with early testers expressing satisfaction with the results compared to previous versions.
Theme 2. NotebookLM's Conversational Podcast Revolution
- OpenAI should make their own NotebookLM application, it's mindblowing! (Score: 299, Comments: 75): NotebookLM produces highly natural-sounding AI-generated podcasts, surpassing even Huberman's podcast in conversational quality. The post suggests that OpenAI should develop a similar application, as it could significantly impact the field.
- NotebookLM's voice quality is praised but still considered less natural compared to human hosts, with Gemini 2.0 offering live chat capabilities with podcast hosts, enhancing its appeal. Users note issues with feature integration across different platforms, highlighting limitations in using advanced voice modes and custom projects.
- The value of conversational AI for tasks like summarizing PDFs is debated, with some seeing it as revolutionary in terms of time savings and adult learning theory, while others find the content shallow and lacking depth. The Gemini model is noted for its large context window, making it well-suited for handling extensive information.
- Google's hardware advantage is emphasized, with their investment in infrastructure and energy solutions allowing them to offer more cost-effective AI models compared to OpenAI. This positions Google to potentially outperform OpenAI in the podcast AI space, leveraging their hardware capabilities to reduce costs significantly.
Theme 3. Gemini 2.0 Surpass Others in Academic Writing
- Gemini 2.0 Advanced is insanely good for academic writing. (Score: 166, Comments: 39): Gemini 2.0 Advanced excels in academic writing, offering superior understanding, structure, and style compared to other models, including ChatGPT. The author considers switching to Gemini 2.0 until OpenAI releases an improved version.
- Gemini 2.0 Advanced is identified as Gemini Experimental 1206 on AI Studio and is currently available without a paid version, though users exchange data for access. The naming conventions and lack of a central AI service from Google cause some confusion among users.
- Gemini 2.0 Advanced demonstrates significant improvements in academic writing quality, outperforming GPT-4o and Claude in evaluations. It provides detailed feedback, often critiquing responses with humor, which users find both effective and entertaining.
- Users discuss the availability of Gemini 2.0 Advanced through subscriptions, with some confusion over its listing as "2.0 Experimental Advanced, Preview gemini-exp-1206" in the Gemini web app. The model's performance in academic contexts is praised, with users expressing hope that it will push OpenAI to address issues in ChatGPT.
Theme 4. Veo 2 Challenges Sora with Realistic Video Generation
- Google is challenging OpenAl's Sora with the newest version of its video generation model, Veo 2, which it says makes more realistic-looking videos. (Score: 124, Comments: 34): Google is competing with OpenAI's Sora by releasing Veo 2, a new version of its video generation model that claims to produce more realistic videos.
- Veo 2's Availability and Performance: Several commenters highlight that Veo 2 is still in early testing and not widely available, which contrasts with claims of its release. Despite this, some testers on platforms like Twitter report impressive results, particularly in areas like physics and consistency, outperforming Sora.
- Market Strategy and Accessibility: There is skepticism about the release being a marketing strategy to counter OpenAI. Concerns about the lack of public access and API availability for both Veo 2 and Sora are prevalent, with a noted confirmation of a January release on aistudio.
- Trust in Video Authenticity: The discussion touches on the potential erosion of trust in video authenticity due to advanced generation models like Veo 2. Some propose solutions like personal AIs for verifying media authenticity through blockchain registers to address this issue.
AI Discord Recap
A summary of Summaries of Summaries by o1-2024-12-17
Theme 1. Challenges in AI Extensions and Projects
- Codeium Extension Breaks Briefly in VSCode: The extension only displays autocomplete suggestions for a split second, making it unusable. Reverting to version 1.24.8 restores proper functionality, according to multiple user reports.
- Windsurf Performance Crumbles Under Heavy Load: Some users experience over 10-minute load times and sporadic “disappearing code” or broken Cascade functionality. Filing support tickets is the top recommendation until a stable fix arrives.
- Bolt Users Cry Foul Over Wasted Tokens: They jokingly proposed a “punch the AI” button after receiving irrelevant responses that deplete credits. Many called for improved memory controls in upcoming releases.
Theme 2. New and Upgraded Models
- OpenAI o1 Dazzles With Function Calling: This successor to o1-preview introduces a new “reasoning_effort” parameter to control how long it thinks before replying. It also features noticeably lower latency through OpenRouter.
- EVA Llama Emerges as a Storytelling Specialist: Targeted at roleplay and narrative tasks, it reportedly excels at multi-step storytelling. Early adopters praise its creative outputs and user-friendly design.
- Major Price Cuts on Fan-Favorite Models: MythoMax 13B dropped by 12.5% and the QwQ reasoning model plunged 55%. These discounts aim to widen community access for experimentation.
Theme 3. GPU & Inference Pitfalls
- AMD Driver Updates Slash Performance: Users saw tokens-per-second plummet from 90+ to around 20 when upgrading from driver 24.10.1 to 24.12.1. Rolling back fixes the slowdown, reinforcing caution with fresh GPU driver releases.
- Stable Diffusion on Ubuntu Hits Snags: Tools like ComfyUI or Forge UI often demand in-depth Linux know-how to fix compatibility issues. Many still recommend an NVIDIA 3060 with 16GB VRAM as a smoother baseline.
- TinyGrad, Torch, and CUDA Memory Confusion: Removing checks like IsDense(y) && IsSame(x, y) solved unexpected inference failures, but introduced new complexities. This led developers to reference official CUDA Graphs discussions for potential solutions.
Theme 4. Advanced Fine-Tuning & RAG Techniques
- Fine-Tuning Llama 3.2 With 4-bit Conversions: Many rely on load_in_4bit=true to balance VRAM usage and model accuracy. Checkpoints can be reused, and resource constraints are minimized through partial-precision settings.
- Depth AI Indexes Codebases at Scale: It attains 99% accuracy answering technical queries, though indexing 180k tokens may take 40 minutes. Rival solutions like LightRAG exist, but Depth AI is praised for simpler setup.
- Gemini 2.0 Adds Google Search Grounding: A new configuration allows real-time web lookups to refine answers. Early reviews highlight improved factual precision in coding and Q&A scenarios.
Theme 5. NotebookLM and Agentic Workflows
- NotebookLM Revamps Its 3-Panel UI: The update removed “suggested actions” due to low usage, but developers promise to reintroduce similar features with better design. Plans include boosted “citations” and “response accuracy” based on user feedback.
- Multilingual Prompts Spark Wide Engagement: Users tried Brazilian Portuguese and Bangla queries, discovering that explicitly telling NotebookLM the language context makes interactions more fluid. This showcases its capability for inclusive global communication.
- Controlling Podcast Length Remains Elusive: Even with time specifications in prompts, final outputs often exceed or ignore constraints. Most rely on flexible length ranges to strike a balance between deep coverage and listener engagement.
PART 1: High level Discord summaries
Codeium (Windsurf) Discord
-
Codeium Conundrums Continue: Users flagged trouble with Codeium extensions, like disappearing autocomplete and unwanted charges after cancellations, directing folks to codeium.com/support.
- Fans of Elementor wondered if Codeium could produce JSON or CSS code, and flex credits drew lingering questions about usage and rollover.
- Windsurf Woes Worsen: Many reported Windsurf bogging down their laptops for ten minutes or more, with recurring errors shaking confidence in the latest release.
- Some considered downgrading while referencing feature requests like Windsurf Focus Follows Mouse to address performance hiccups.
- Codeium vs Copilot Clash: Debates focused on whether Codeium still has an edge as Copilot opens a free tier, with speculation about GPT-based services hitting capacity issues.
- Advocates insisted Codeium’s autocomplete is still strong, hinting that Copilot’s free tier could spur widespread usage concerns for Claude and GPT.
- Cascade’s Auto-Approval Annoyance: Some devs criticized Cascade for automatically approving code changes, blocking thorough reviews for critical merges.
- Discussion centered on improving review workflows, as people pushed for better output checks to avoid unvetted merges.
- Llama Model & Free AI Tools Talk: Benchmarks of Llama 3.3 and 4o-mini stirred interest, with claims that smaller variants can stand toe-to-toe with bigger models.
Cursor IDE Discord
-
Cursor 0.44.2 Quiets Bugs: The updated Cursor v0.44.2 emerged after a rollback from 0.44, addressing composer quirks and terminal text issues as seen in the changelog.
- Members described better stability with devcontainers, referencing a cautionary forum post, which originally flagged disruptions in version 0.44.
- Kepler Browser Emphasizes Privacy: A Python-built browser named Kepler promises minimal server reliance and user control, spotlighted in the community repo.
- It implements randomized user agents and invites open-source contributions to bolster security.
- UV Tool Streamlines Python: Community discussions revealed the UV tool for Python environment management, with robust version handling as shown in its docs.
- It simplifies project dependencies and integrates with other resources like Poetry and the Python Environment Manager extension.
- O1 Pro Steals the Show: The O1 Pro feature resolved a user’s persistent bug within 20 attempts, illustrating improved performance in tricky scenarios.
- However, consistency issues emerged in chat output formatting, suggesting more refinements to come.
- Galileo API Access Stalls: Inquiries about the Galileo API and models like Gemini 2.0 within Cursor revealed limited availability, prompting curiosity from the developer crowd.
- They seek official integration timelines, especially within Cursor’s platform.
aider (Paul Gauthier) Discord
-
O1 Onslaught & Ties with Sonnet: OpenAI rolled out the O1 API to Tier 5 key holders, but some reported lacking access, causing excitement and frustration over its reasoning abilities.
- Several users showed O1 scoring 84.2 in tests, tying with Sonnet, and debated pricing and performance differences between O1 Pro and standard versions.
- Competition Among AI Models: Members compared Google's Veo 2 with existing contenders like Sonnet, evaluating output quality and utility for coding tasks.
- They also raised concerns about rising subscription fees and sustainability of multiple model plans.
- Support and Refunds Roll the Dice: Community members reported inconsistent refund timelines, with some waiting 4 months while others got a refund in hours.
- This led to skepticism about the overall responsiveness of customer support.
- Gemini Gains Credibility as an Editor: Enthusiasts highlighted gemini/gemini-exp-1206 for minimal coding errors and strong synergy with Aider in practical scenarios.
- Still, they acknowledged Gemini’s limits compared to O1, suggesting further testing for advanced use cases.
- Depth AI and LightRAG for Codebase Insights: Participants praised Depth AI for deeper code indexing accuracy nearing 99%, with moderate resource usage.
- Though LightRAG was mentioned as an alternative, some observed 'no output' glitches from Depth AI and questioned its consistency.
OpenAI Discord
-
OpenAI’s 12 Days & the Surprising Dial-a-Bot: OpenAI is celebrating the 12 Days of OpenAI with a Day 10 highlight reel and a bold new phone feature at 1-800-chatgpt.
- Some find the call-in service questionable for advanced tasks, yet it might help older folks or complete beginners.
- Gemini Gains Ground in AI Rivalry: Gemini is rumored to outpace OpenAI, fueling talk of an intensifying AI competition.
- Skeptics imply OpenAI may be holding back features to deploy them only when absolutely needed, stirring more buzz.
- AI Model Safety Sparks Heated Debate: Participants wondered if humans alone can tackle AI safety without advanced AI support, citing the AlignAGI repo.
- They wrestled with balancing censorship and creative expression, warning of possible unintended extremes on both sides.
- DALL-E Takes a Hit vs Midjourney & Imagen: Some claim DALL-E struggles in realism against Midjourney and Imagen, blaming restrictive design choices.
- Critics note that 'Midjourney brags too much' while others insist 'DALL-E needs more freedom' to shine.
- GPT Manager Training & Editing Headaches: Enthusiasts tried GPT as a manager, hoping for streamlined tasks, but found it only moderately effective.
- Others vented frustration about editing limitations on custom GPTs, pushing for more user control.
Nous Research AI Discord
-
Prompt Chaining for Snappier Prototypes: Contributors noted how prompt chaining connects outputs from one model to the prompt of another, improving multi-stage workflows and advanced agentic designs via Langflow. They cited speedier iteration and more structured AI responses as key benefits, showcasing better synergy across small-scale models.
- Several members considered this chaining approach vital for test-driving ideas quickly, praising how it eliminates cumbersome manual orchestration as they refine new AI prototypes.
- Falcon 3 Gains Momentum: Members highlighted Falcon3-7B on Hugging Face as a fresh release with improved tool-call handling and scalable performance across 7B to 40B parameters. Eager testers discussed potential for simulation and inference tasks, citing interest in how well it handles real-world usage on local hardware.
- They also noted upcoming improvements across larger Falcon variants, referencing user feedback on HPC deployments for more robust model experiments.
- Local Function Calls for Nimble Models: Participants weighed function calling techniques for smaller local models, comparing libraries that parse structured outputs effectively. They sought flexible setups for personalized tasks without reliance on massive cloud solutions.
- Some pointed to Gemini as an example of offloading searches to real data sources, proposing a hybrid approach instead of solely depending on chatbots for recollection.
- Hermes 3 405B Repetitive Quirks: A user reported Hermes 3 405B echoing prompts verbatim despite instructions to avoid it, complicating conversation flow. They compared it against gpt-4o, noting more concise compliance and fewer repetition issues in the latter’s behavior.
- Community members tried specialized prompting strategies to curb repetition, emphasizing the importance of iterative fine-tuning for reliable high-parameter models.
- Signal vs Noise & Consistent LLM Outputs: One discussion underscored the ratio of signal vs noise in AI inference, proposing it as a cornerstone for coherent thinking. Community comparisons drew parallels to how the human brain filters irrelevant input, linking clarity to better model outputs.
- A member also requested the best papers on maintaining output consistency in extended AI responses, hinting at ongoing interest in sustained reliability for lengthy text generation.
Notebook LM Discord Discord
-
Three-Panel Tweak Tones Up NotebookLM: The new 3-panel UI no longer includes 'suggested actions' such as 'Explain' and 'Critique,' addressing the feature's limited usage.
- For now, users rely on copying text from sources into chat, while devs plan to restore missing functionalities in a more intuitive way.
- Citations & Notes Panel Shuffle: NotebookLM's recent build removed embedded citations from notes, prompting requests for their return.
- Users also discovered they can't combine selected notes easily, pushing them to pick either all or one at a time.
- Podcast Length Control Gets Testy: Attempts to set shorter audio segments in NotebookLM often fail, as the AI apparently ignores length instructions.
- One idea is splitting content into smaller files, while the blog announcement hints future improvements.
- Multilingual Mux for Gaming & Chat: Gamers praised NotebookLM for simplifying complex rules through retrieval-augmented queries, while some tested multilingual chat for interactive podcasts.
- They shared links like Starlings One on YouTube for broader usage, also warning about superficial AI podcasts called 'AI slop.'
- Sharing Notebooks and Space Oddities: Users want to share NotebookLM projects outside their organizations, raising the question of external access and family-friendly features.
- Meanwhile, an AI video about isolation in space asked 'Would you survive?', illustrating NotebookLM's potential for broader audio-visual usage.
Unsloth AI (Daniel Han) Discord
-
Llama 3.2 Loss Mystery: Trainers encountered a puzzling higher loss (5.1→1.5) with the Llama template vs (1.9→0.1) using Alpaca for the 1bn instruct model.
- One user wondered if incorrect prompt style caused the discrepancy, with further questions on merging new datasets for repeated fine-tuning.
- QwQ Reasoning Model Quarrel: Members tested open-source model QwQ but noted it defaulted to instruct behavior when math prompts were omitted.
- Some claimed RLHF was essential to sharpen reasoning, while others argued SFT alone could build advanced logic capabilities.
- Multi-GPU & M4 MAX Mac Matters: Users verified that Unsloth supports multi-GPU usage across platforms, though some struggled with installing it on M4 MAX GPUs.
- Developers plan to add official support around Q2 2025, suggesting Google Colab and community contributions as interim solutions.
- LoRA Gains & Merged Minimization: Participants clarified that LoRA adapters tweak fewer parameters and merge with base models for smaller final files.
- They noted that typical merges produce compact LoRA outputs, curbing VRAM usage without hurting training performance.
- DiLoCo’s Distributed Dev: Community members showcased their DiLoCo research presentations for low-communication training of large language models.
- They highlighted continuing work on open-source frameworks and linked the DiLoCo arXiv paper, encouraging collaboration.
OpenRouter (Alex Atallah) Discord
-
OpenAI's O1 Powers Up: OpenRouter rolled out the new O1 model with function calling, structured outputs, and a revamped
reasoning_effortparameter, detailed at openrouter.ai/openai/o1.- Users can find a tutorial on structured outputs at this link, and explore challenges in the Chatroom to test the model's thinking prowess.
- EVA Llama Arrives: OpenRouter added EVA Llama 3.33 70b, a storytelling and roleplay specialist, expanding its line-up of advanced models at this link.
- This model focuses on narrative generation, boosting the platform’s range of creative interactions.
- Price Slashes Spark Joy: The gryphe/mythomax-l2-13b model now boasts a 12.5% lower price, easing experimentation for enthusiasts.
- Meanwhile, the QwQ reasoning model's cost plunged by 55%, encouraging more users to push its boundaries.
- Keys Exposed, Support Alert: A user discovered exposed OpenRouter keys on GitHub and was advised to contact support for immediate assistance, avoiding direct email submission of the compromised tokens.
- Others noted that only metadata is retained after calls, prompting solutions like proxy-based logging if more detailed tracking is needed.
- Google Key Fees & Reasoning Hiccups: Community members confirmed a 5% service fee when linking personal Google AI keys to OpenRouter, applying to credit usage as well.
- Meanwhile, QwQ struggles with strict instruction formats, though OpenAI's 'developer' role may eventually bolster compliance in reasoning-focused models.
Interconnects (Nathan Lambert) Discord
-
Gemini Gains Ground: During Google Shipmas, Gemini 2.0 drew attention with demos like Astra and Mariner, as Jeff Dean confirmed progress on Gemini-exp-1206.
- Community feedback admired its multimodal feats but flagged rate-limit issues in Gemini Exp 1206.
- Copilot’s Complimentary Code: GitHub announced a free tier for Copilot with 2,000 code completions and 50 chat messages monthly, referencing this tweet.
- Members praised the addition of Claude 3.5 Sonnet and GPT-4o models while forecasting a developer surge to GitHub’s now 150M+ user base.
- Microsoft Mulls Anthropic Move: Microsoft is rumored to invest in Anthropic at a $59B valuation, as indicated by Dylan Patel.
- They aim to incorporate Claude while juggling ties with OpenAI, prompting community chatter on this delicate partnership.
- Qwen 2.5 Tulu Teaser: Qwen 2.5 7B Tulu 3 is expected to surpass Olmo, featuring improved licensing and teased with "more crazy RL stuff" in the pipeline.
- Team members compare repeated RL runs to "souping," highlighting surprising positive results that stoke hype for the upcoming release.
- RL Emergent Surprises: Experiments with LLM agents in the 'Donor Game' pointed to cooperation differences that hinge on the base model, as noted by Edward Hughes.
- Subsequent updates on RLVR training drew attention to self-correction behavior in outcome-based rewards, prompting renewed interest in repeated RL runs.
Eleuther Discord
-
Retail Roundup: E-commerce Tools Eye Runway: Members discussed using Runway, OpenAI Sora, and Veo 2 to produce ad content for retail in both video and copy formats, seeking next-level solutions to stand out.
- They invited more suggestions to refine marketing approaches without rehashing old tactics.
- Koopman Kommotion: Are We Spinning Our Wheels?: A paper on Koopman operator theory in neural networks stirred debate about whether it truly adds new insights or repackages residual connections.
- Some argued it lacks practical value, while others insisted the approach might complement network analysis with advanced linear operator techniques.
- The Emergent Label: Real or Hype?: Community members pored over Are Emergent Abilities of Large Language Models a Mirage? to question if these abilities reflect major leaps or mere evaluation artifacts.
- This skepticism extended to assumptions that simply scaling large models solves core limitations, pointing to deeper unresolved theoretical gaps.
- Iterate to Compress: Cheaper Surrogates & OATS: Engineers discussed iterated function approaches for model compression and pointed to the OATS pruning technique as a path to reduce size without sacrificing advanced behaviors.
- They also floated strategies for cheap surrogate layers, though some worried about error buildup when chaining approximations.
- WANDB Logging & Non-Param Norm: What's Next?: Developers requested direct logging of MFU and throughput metrics to WANDB, hinting at soon-to-arrive features in GPT-NeoX's logging code.
- They also anticipate a non-parametric layernorm pull request in coming days, broadening experimentation options for GPT-NeoX.
Stability.ai (Stable Diffusion) Discord
-
LoRA Lore: Training Triumphs: Members emphasized collecting a strong dataset before training a LoRA, along with thorough testing and iteration for quality assurance.
- They highlighted the importance of dataset curation strategies, suggesting research into specialized resources to refine training success.
- Stable Diffusion Smorgasbord: Beginners were advised to try InvokeAI for its straightforward workflow, while ComfyUI and Forge UI were touted for modular functionality.
- Links to models on Civitai and a GitHub script for stable-diffusion-webui-forge were shared, along with tips for leveraging them effectively.
- Quantum Quibbles vs Classical Crunch: Certain members mentioned breakthroughs in quantum computing, while noting that practical deployment is still distant.
- Concerns arose around future warfare scenarios and major leaps in computational capabilities driven by quantum advancements.
- GPU Gains & FP8 Tuning: Optimizing VRAM usage was a hot tip, especially employing FP8 mode on a 3060 GPU for speed and memory efficiency.
- Monitoring GPU memory usage during image generation was advised to avoid unexpected slowdowns or crashes.
- AI Video Visions & Limitations: Participants agreed that while AI-generated images have progressed significantly, video output still has room to improve.
- Practical timelines for seamless AI video were acknowledged, with references to tools like static FFmpeg binaries for macOS to refine post-generation processing.
Perplexity AI Discord
-
Spaces Shakeup: Custom Web Sources: Perplexity introduced Custom Web Sources in Spaces, allowing users to pick favored sites for more specialized results. A short launch video showcases streamlined setup for these sources.
- Community members highlighted the potential for advanced tasks, mentioning how customizing Perplexity suits intense engineering demands.
- Gift a Pro: Subscriptions & Rate Limits: Users praised the Perplexity Pro gift subscriptions for added sources and AI models, with a tweet from Perplexity Supply advertising the offer. They also expressed concern about hitting request caps, suspecting higher tiers might solve those constraints.
- Some advocated a fun snowfall effect in the UI, while others dismissed it as too distracting for hardcore usage.
- Meta Locks Horns with OpenAI: Meta wants to halt OpenAI's for-profit ventures, sparking debate over the ethics of monetized AI. Community chatter questioned if corporate priorities might overshadow open research ideals.
- Others cited earlier showdowns, framing this as a defining moment for unbarred development versus revenue-driven models.
- Cells That Refuse to Die: Research implies cells can be brought back to function after death, unsettling the idea of a final cellular shutdown. A video explanation fueled talk about possible breakthroughs in acute medical treatments.
- Forum discussions also touched on a microbial threat warning, urging close scrutiny of health implications and future prevention.
- Botanical Tears and Dopamine Gears: New findings claim plants might exhibit stress cues resembling crying, challenging older views on plant communication. Talk of dopamine precursor exploration surfaced, hinting at refined strategies for mental health interventions.
- Participants wondered about broader impacts, referencing how these biological insights could shape research trajectories.
GPU MODE Discord
-
MatX Skips Right to Silicon: MatX announced an LLM accelerator ASIC designed to boost AI performance, and they are actively hiring specialists in low level compute kernels, compiler development, and ML performance engineering as shown at MatX Jobs.
- They highlighted the potential to reshape next-gen inference and training, drawing interest from engineers curious about on-chip performance gains.
- Pi 5 Pushes a 1.5B Parameter Punch: A Raspberry Pi 5 overclocked to 2.8GHz with 256GB NVMe is running 1.5B-parameter models via Ollama and OpenBLAS, showcasing local LLM deployment on an edge device.
- Community members appreciated the practical approach, noting the Pi 5 could host smaller specialized models without large-scale GPU resources.
- CoT Gains Vision & Depth: A team explored custom vision encoder integration for small-scale images and discussed expanding Chain of Thought to refine inference with deeper iterative steps.
- They planned a Proof of Concept to embed inner reasoning into LLMs, aiming for better context handling and solution accuracy.
- Beefy int4group with Tinygemm: Engineers described using int4 weights and fp16 activations in an int4group scheme, letting the matmul kernel handle on-the-fly dequantization.
- They confirmed no activation quantization is done during training, leveraging bf16 computations to ensure consistent performance.
- A100 vs H100 Face Off: Users noticed a 0.3% difference in training loss when comparing A100 and H100, raising questions about potential hardware-specific variability.
- They debated whether Automatic Mixed Precision (AMP) or GPU architecture subtleties caused the gap, underscoring the need for deeper analysis.
LM Studio Discord
-
LM Studio Beta Surprises: Users tested LM Studio with Llama 3.2-11B-Vision-Instruct-4bit and ran into architecture errors like unknown model architecture mllama.
- Some overcame hassles by checking LM Studio Beta Releases, noting corrupt downloads and heavy models working for certain users.
- Roleplay LLM Gains Momentum: A user requested pointers on configuring a roleplay LLM, prompting the community to share advanced usage tips.
- They advertised separate channels for deep-dive discussions, emphasizing memory constraints for extended sessions.
- GPU Confusion and Driver Dilemmas: Members questioned if a 3060 Ti 11GB really existed or if it was a 12GB 3060, igniting a debate on GPU details.
- Meanwhile, the Radeon VII suffered from driver 24.12.1 issues causing 100% GPU usage without power draw, forcing a return to 24.10.1.
- Inference Overheads and Mac Aspirations: Enthusiasts realized a 70B Llama model might need 70GB total memory at q8 quantization, spanning VRAM and system RAM.
- One user joked that owning an M2 MacBook Air fueled a craving for a future MBP M4, pointing to the high cost of powerful setups.
Stackblitz (Bolt.new) Discord
-
Supabase Switch from Firebase: Members discussed migrating an entire site from Firebase to Supabase, encountering style conflicts with create-mf-app and Bootstrap usage.
- One user noted that the frameworks overlapped in configuration, and they hinted at refining the migration steps soon.
- Bolt Pilot GPT Blares for Beta: A member introduced the Bolt Pilot GPT for ChatGPT and suggested exploring stackblitz-labs/bolt.diy for relevant code samples.
- They showcased optimism for multi-tenant capabilities and invited community feedback to guide future updates.
- Token Tangle & Bolt Blues: Multiple members complained about Bolt consuming tokens on placeholder prompts, urging a reset feature and possible holiday discounts during Office Hours.
- Some users spent significant sums on tokens with lackluster results, provoking interest in collaboration and pooling resources.
Cohere Discord
-
Massive Rate-Limits on Multimodal Embeds: Cohere soared from 40 images/min to 400 images/min on production keys for the Multimodal Image Embed endpoint, with trial keys fixed at 5 images/min.
- They encouraged usage with the updated API Keys and spelled out more details in their docs.
- Maya Commands for Local Model Gains: Developers explored bridging a local model with Maya by issuing command-r-plus-08-2024, enabling the model to handle image paths alongside queries.
- They also added tool use in base models for better image analysis, prompting talk on advanced pipeline setups.
- Cohere Toolkit Battles AWS Stream Errors: A successful Cohere Toolkit deployment on AWS faced an intermittent stream ended unexpectedly warning, breaking chat compatibility.
- Users examined docker logs to diagnose the random glitch, hoping to pinpoint root causes.
- Structured Outputs Showcase & Reranker Riddles: People tested Cohere's Structured Outputs with
strict_tools, refining prompt parameters for precise JSON responses.
- Meanwhile, a RAG-based PDF system stumbled with the Cohere Reranker ignoring relevant chunks, but occasionally nailing the right content.
- Findr Debuts as Infinite Brain: Findr went live on Product Hunt, offering an endless memory vault to store and access notes.
- Enthusiasts cheered the launch, praising the concept of a searchable digital brain for better retention.
Modular (Mojo 🔥) Discord
-
Mojo & Archcraft: Missing Linker Mystery: One user faced issues launching the Mojo REPL on Archcraft due to a missing mojo-ldd library and an unmanaged environment blocking Python requirements. They also noted a stalled attempt to install Max, sparking a suggestion to create a dedicated thread for problem-solving.
- A Stable Diffusion example was mentioned as a helpful GitHub resource for new features. The conversation highlighted environment setup adjustments to avert abrupt installation failures.
- Docs & 'var' Spat: When Syntax Meets Confusion: Discussions arose over the var keyword requirement explicitly mentioned in Mojo docs, leaving some users unsettled. An upcoming documentation update was teased, though no definitive timeline was provided.
- Community members voiced differing opinions on the necessity of a dedicated keyword for variables. They encouraged feedback to refine future documentation releases.
- Kernel or Just a Function? Mojo's Terminology Tangle: Members clarified that a 'kernel' in Mojo often refers to a function optimized for GPU execution, distinguishing it from operating system kernels. The term varies in meaning, sometimes describing core computational logic or accelerator-friendly code.
- Participants exchanged interpretations of the concept, debating whether it should remain specialized to GPU tasks. Some noted its usage in mathematics to denote a fundamental operation within broader calculations.
- argmax & argmin Missing: Reduction Ruminations: A user lamented the absence of argmax and argmin in algorithm.reduction, questioning the need to rebuild them from scratch. They noted the frustration of reimplementing optimized functions that might be standard in other libraries.
- Members called for better documentation or official support for these operations. The discussion underscored continuity issues in Mojo’s evolving standard library.
- MAX & Mojo: Custom Ops Conundrum: Users wrestled with custom ops integration, citing the
session.load(graph, custom_ops_paths=Path("kernels.mojopkg"))fix for a missing mandelbrot kernel. They also referenced Issue #269 requesting improved error messages and single compilation unit kernels.
- MOToMGP Pass Manager errors further complicated custom op loading, prompting calls for better clarity in failure reports. Contributors emphasized the importance of guiding users with more descriptive diagnostics.
Latent Space Discord
-
Nvidia’s Nimble Nano Nudges AI: Nvidia introduced Jetson Orin Nano Super Developer Kit at $249, boasting 67 TOPS and showing a 70% performance bump over its predecessor.
- It includes 102GB/s bandwidth and aims to help hobbyists execute heavier AI, though some participants questioned if it can handle advanced robotics.
- GitHub Copilot Goes Gratis: GitHub Copilot is now free for VS Code, as Satya Nadella confirmed, with a 50 chats per month limit.
- Community members debated if that cap diminishes Copilot’s usefulness in contrast to rivals like Cursor.
- 1-800-CHATGPT Hits the Hotline: Announced by Kevin Weil, 1-800-CHATGPT provides free phone and WhatsApp access to GPT across the globe.
- Discussions highlighted its accessibility for broader audiences, removing the need for extra apps or accounts.
- AI Video Tools Turn a Corner: OpenAI’s Sora sparked talks about evolving video models, referencing Will Smith test clips to measure progress.
- Enthusiasts compared these breakthroughs to earlier image generation waves, citing a Replicate blogpost on the expanding appetite for high-res AI video.
- EvoMerge & DynoSaur Double Feature: The LLM Paper Club showcased Sakana AI’s EvoMerge and DynoSaur in a double header session, inviting live audience queries.
- Attendees were urged to add the Latent.Space RSS feed to calendars to keep up with future events.
OpenInterpreter Discord
-
Interpreter Interruption Intensifies: Multiple users faced repeated exceptions while using Open Interpreter, losing crucial conversation logs in the process. They reported issues with loading chat histories and dealing with API key confusion, stirring frustration in various threads.
- One user specifically lamented losing good convos, while others mentioned similar incidents across multiple setups. Unresolved technical hiccups continue to hinder extended usage.
- 1.x Mystery Mingles with 0.34: Community members debated the existence of Open Interpreter 1.x while they're currently limited to 0.34. They questioned changes in functionality, pointing out that OS mode doesn't seem present in 1.0.
- This mismatch sparked confusion about updating procedures and support. Some asked for official steps to switch versions, hoping to confirm new features.
- Cloudflare Plays Gateway Gambit: A user proposed Cloudflare AI Gateway to tackle some configuration snags with Open Interpreter. This approach triggered a short debate on external solutions and advanced deployment.
- Members considered new toolchains, examining how Cloudflare’s platform might improve reliability. They also mentioned synergy with other AI applications, but withheld a final verdict.
- Truffle's Tasty On-Device Teaser: A user introduced the Truffle-1: a device with 64GB of memory at a $500 deposit plus $115/month. They posted the official site, showcasing an orb that supports indefinite on-device inference.
- A tweet from simp 4 satoshi gave more financial details, referencing the deposit and monthly plan. This stirred interest in building and sharing custom apps through the orb’s local stack.
- Long-Term Memory Mindset: Enthusiasts explored ways to integrate extended memory with Open Interpreter, focusing on codebase management. Some proposed local setups, including Raspberry Pi, to store conversation data for future use.
- They saw potential for streamlined collaboration tools with persistent logs over time. The idea gained traction among participants seeking to keep larger context windows readily available.
tinygrad (George Hotz) Discord
-
Scramble for LLaMA Benchmarks: A user asked if anyone had benchmarks comparing LLaMA models using tinygrad OpenCL against PyTorch CUDA, but no data surfaced.
- The discussion concluded there are no known head-to-head performance stats, leaving AI engineers in the dark for now.
- ShapeTracker Merge Mayhem: A bounty regarding merging two arbitrary ShapeTrackers in Lean sparked questions about strides and shapes.
- Contributors noted a universal approach seems unworkable since variables complicate the merging beyond straightforward fixes.
- Counterexamples Cause Crashes: Members encountered counterexamples that break the current merging algorithm for unusual view pairs.
- They hinted more examples could be auto-generated from a single irregular case, highlighting dimension overflow issues.
- CuTe Layout Algebra Compared: Pairs of TinyGrad merges were likened to composition in CuTe’s layout algebra, referencing layout docs.
- This parallel calls attention to the intricate process of verifying certain algebraic properties before concluding shape compatibility.
- Injectivity Proof Deemed NP Hard: Skepticism arose over proving injectivity in layout algebra, with some suggesting it might be NP hard.
- Checking both necessity and sufficiency appears too complex for a swift resolution, hinting at a deeper theoretical challenge.
Torchtune Discord
-
FSDP Fracas & TRL Tangles: Team realized that if the FSDP reduce operation averages, scaling by
world_sizemust be applied in this snippet. They also discovered a possible scaling glitch in trl, pointing to this fix PR.- Members recommended an Unsloth-style bug report, suggesting direct code tweaks in
scale_gradsfor clarity. They expect this correction to simplify gradient behavior across distributed setups. - Loss Topping Tactics & Gradient Gains: Contributors agreed that scaling the loss explicitly in the training recipe improves clarity, referencing updates in this memory code. They emphasized that code comments help highlight the purpose of each scaling step.
- An optimizer_in_bwd scenario fix was added to handle normalization properly in the PR. This adjustment aims to keep the training loop transparent and maintain consistent gradient scaling.
- Sakana's Evolutionary Spin: Workers raised interest in Sakana for scaling up evolutionary algorithms to rival gradient-based techniques. They found it noteworthy that evolution-driven methods may inject a different angle into AI development.
- Some saw promise in merging evolutionary ideas with standard gradient recipes. Others plan to watch Sakana’s progress to see if it holds up in rigorous benchmarks.
- Members recommended an Unsloth-style bug report, suggesting direct code tweaks in
DSPy Discord
-
Collabin Clip Sparks Curiosity: A brief video called collabin surfaced at this link, hinting at some collaborative project or demo.
- Participants shared minimal details, but the video teased possibilities for future group efforts or demonstrations.
- Autonomous Agents Boost Knowledge Elite: A new paper titled Artificial Intelligence in the Knowledge Economy (link) highlights how autonomous AI agents elevate the most skilled individuals by automating routine work.
- Community comments cautioned that as these agents proliferate, those with deeper expertise gain an added edge in productivity.
- Coconut Steers LLM Reasoning into Latent Space: A paper on Coconut (Chain of Continuous Thought) (link) challenges text-based coherence, suggesting a latent space approach instead.
- Token-heavy strategies can miss subtleties, so community remarks championed rewriting LLM thought processes to manage complex planning.
- RouteLLM Falls Behind but Questions Arise for DSPy: Folks noticed that RouteLLM (repo) is no longer maintained, raising concerns for future synergy with DSPy.
- No concrete plans emerged, but it signaled a desire for robust routing tools within the DSPy ecosystem.
- DSPy Charts a Reasoning-Centric Path: Discussions pointed to TypedReAct’s partial deprecation, urging a shift toward simpler naming and patterns without 'TypedChainOfThought.'
- Others see fine-tuning pivoting to reward-level branching within DSPy, with references pointing to DSPy’s agent tutorial as a resource on those next steps.
Nomic.ai (GPT4All) Discord
-
Localdocs Support Lights Up GPT4All: Members discussed referencing local docs with GPT4All but found the older CLI lacking official support, pushing them toward the server API or GUI methods.
- Several participants confirmed the CLI’s limitations, highlighting that local document features still require specific configurations in the official toolset.
- Docker Dream Stalls for GPT4All: A user asked about running GPT4All in a Docker container with a web UI, but no one provided a ready-to-use solution.
- The question remains open, leaving container enthusiasts hoping someone releases an official or community image soon.
LlamaIndex Discord
-
Agentic AI SDR Sparks Leads: Check out this agentic AI SDR that uses LlamaIndex to automate revenue tasks while generating leads, as discussed in the blog channel.
- It showcases new possibilities for blending function calling with sales workflows, highlighting LlamaIndex's capacity for direct business impact.
- Composio Quickstarters Jumpstart LLM Agents: The Quickstarters folder points to Composio, linking LLM agents with GitHub and Gmail.
- Through function calling, it enables a streamlined approach for tasks like code commits or inbox scanning, all triggered by natural language input.
- Async Tools Boost OpenAIAgent Concurrency: Members discussed OpenAIAgent concurrency, referencing the OpenAI docs for parallel function calls in API v1.1.0+.
- They shared code snippets suggesting async function usage, clarifying concurrency does not imply true parallel CPU execution.
- RAG Evaluation Collaboration Surfaces: A member invited the community to team up on RAG evaluation, urging others to share insights.
- They welcomed direct discussions for deeper technical explorations, reflecting a growing interest in retrieval-augmented generation techniques.
Gorilla LLM (Berkeley Function Calling) Discord
-
BFCL Leaderboard Burps: One user observed that the BFCL Leaderboard got stuck on "Loading Model Response..." due to a certificate issue that caused a temporary outage.
- They highlighted that the model endpoint was inaccessible, sparking concern among testers eager to try new function calling features.
- Gorilla Benchmark Eyes JSON Adherence: A participant proposed using the Gorilla benchmark to verify the model’s alignment with a JSON schema or Pydantic model, emphasizing structured output testing.
- They asked if there are specialized subtasks for measuring structured generation accuracy, though no official mention of such tasks emerged.
LAION Discord
-
GPT-O1 Reverse Engineering Excites Researchers: Enthusiasts requested any known efforts or materials detailing GPT-O1 reverse engineering, including technical reports and papers, and welcomed additional insights from social media posts. This sparked a push for collective sharing and resource gathering to demystify the intricacies of GPT-O1.
- They proposed forming a collaboration initiative to compile references on GPT-O1, particularly from Twitter discussions and published materials, aiming to pool knowledge in the community.
- Meta Opens Generative AI Internship: Meta announced a 3–6 month research internship on text-to-image models and vision-language models, offering hands-on experimentation at scale, available to apply here. The role focuses on driving core algorithmic advances and building new capabilities in generative AI.
- The Monetization Generative AI team seeks researchers with backgrounds in deep learning, computer vision, and NLP, highlighting a global impact on how users interact online.
LLM Agents (Berkeley MOOC) Discord
-
No Major Discussion: We only saw a friendly expression of thanks with no additional info or references posted.
- No further chat or data were shared, so there's nothing else to highlight.
- No Technical Updates: No new models, code releases, or relevant technical developments surfaced in this discussion.
- We remain without further data for AI specialists from this single message.
Axolotl AI Discord
-
January Reinforcement Rendezvous: A new engineer is set to join the team in January to assist with Reinforcement Learning (RL) initiatives, bringing an extra set of hands for training expansions.
- They will also provide direct support for the KTO project, ensuring timely integration of RL components and improved functionality.
- KTO Gains Extra Pair of Hands: The new engineer will help refine the KTO system after they onboard, focusing on real-time performance improvements.
- Project leads expect their contribution to yield a notable boost in productivity for RL tasks.
Mozilla AI Discord
-
Developer Hub Gains Momentum: A big announcement rolled out brand-new features for the Developer Hub, emphasizing community feedback for continuous refinement, as detailed here.
- Participants stressed the significance of clarifying usage guidelines and gathering input on future expansions.
- Blueprints Initiative Simplifies AI Builds: The Blueprints initiative aims to help developers assemble open-source AI solutions with carefully provided resources, as discussed here.
- They noted planned enhancements could enable broader project collaboration and flexible templates for specialized use cases.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Codeium (Windsurf) ▷ #discussion (60 messages🔥🔥):
Codeium Issues, Windsurf Performance, Elementor and Codeium Integration, Support Ticket System, JetBrains Extension Issues
-
Users report frequent Codeium issues: Numerous users have expressed problems with the Codeium extension, including disappearing autocomplete suggestions and connection issues to the server.
- jamespond000 urged users facing problems with the latest JetBrains version to create support tickets with logs for further assistance.
- Windsurf slowing down user laptops: Many users reported that Windsurf is causing their laptops to slow down significantly, with some waiting over ten minutes for the app to open.
- Errors have been occurring every few seconds for some users, suggesting persistent performance issues.
- Elementor users inquire about Codeium: Users are curious if the Codeium extension can assist them in coding functionalities for Elementor elements using JSON or CSS code.
- There was confusion on whether Codeium can generate code automatically for these elements.
- Support ticket requests for billing issues: Some users have reported being charged after canceling their subscriptions and are seeking resolution through support.
- Users were directed to file tickets at codeium.com/support to address these billing concerns.
- Flex credits and their rollover policy: A user inquired if flex credits accumulate or roll over into subsequent billing periods.
- Clarifications around the flex credit system remain uncertain among users.
Links mentioned:
- Hello There GIF - Hello there - Discover & Share GIFs: Click to view the GIF
- Reasoning with o1: Learn how to use and prompt OpenAI's o1 model for complex reasoning tasks.
Codeium (Windsurf) ▷ #windsurf (678 messages🔥🔥🔥):
Windsurf Performance Issues, Comparison of Codeium and Copilot, Cascade Functionality, Llama Model Benchmarking, Free AI Tool Options
-
Windsurf shows performance issues: Users reported that Windsurf has been experiencing significant bugs and performance drops, with issues like 'disappearing code' and internal errors becoming more frequent since the last update.
- Some users are even considering downgrading due to these problems and are seeking support for persistent issues.
- Codeium vs Copilot: Several users engaged in a discussion about the effectiveness of Codeium compared to Copilot, with some stating that Codeium's autocomplete is still superior despite Copilot's new free tier.
- Concerns were raised about how the introduction of a free tier for Copilot might affect the performance of Claude and GPT, as users speculate on potential overload.
- Cascade's auto-approval function: It was noted that Cascade has been auto-approving changes without the ability to review them, which some users find annoying as reviewing changes is crucial.
- Users expressed dissatisfaction with the performance of Cascade and are analyzing how to improve its output quality.
- Llama Model Performance: Conversations highlighted the benchmarking of Llama models, particularly Llama 3.3 and 4o-mini, with users noting that certain versions can outperform larger models under specific conditions.
- It was mentioned that 4o-mini can be useful for smaller tasks and has capabilities similar to those of premium models.
- Exploration of AI Tools: Users discussed various free AI tools and platforms, emphasizing the importance of project planning and prompt structuring to maximize efficiency with these technologies.
- Overall, participants shared experiences with different AI tools, weighing their benefits in coding and the potential for using models like Gemini Flash in their projects.
Links mentioned:
- LiveBench: no description found
- Windsurf - Focus Follows Mouse (as a configuration option) | Feature Requests | Codeium: There is an open GitHub PR for VSCode which is, on the surface, more than 4 years old, however it is way older than that.
- Productionizing and scaling Python ML workloads simply | Ray: Ray manages, executes, and optimizes compute needs across AI workloads. It unifies infrastructure and enables any AI workload. Try it for free today.
- Cannot use windsurf as git editor | Feature Requests | Codeium: git config --global core.editor 'windsurf --wait ' throws error on rebases hint: Waiting for your editor to close the file... [1119/144632.
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Cursor IDE ▷ #general (707 messages🔥🔥🔥):
Cursor IDE Updates, Kepler Browser Development, Python Environment Management, O1 Pro Performance, Galileo API Integration
-
Cursor IDE Updates: The latest update, Cursor version 0.44.2, was released after a rollback from 0.44 due to instability, with users reporting improved functionality.
- Various features were discussed, including the annoying behavior of the Composer regarding terminal text being pasted improperly.
- Kepler Browser Development: One user is developing a privacy-focused browser named Kepler, built with Python and designed to require no backend server, emphasizing user control.
- The browser aims for improved security through features like randomized user agents and is open-sourced for community contributions.
- Python Environment Management: Users discussed the use of the UV tool for managing Python environments efficiently, particularly its ability to handle various Python versions.
- The tool simplifies virtual environment creation, making it easier for developers to manage dependencies and project configurations.
- O1 Pro Performance: The O1 Pro feature has received positive feedback, with one user reporting it successfully resolved their bug in over 20 attempts.
- Discussions suggest O1 Pro enhances performance, although issues with the output format in chat and composer persist.
- Galileo API Integration: There were inquiries about the availability of the Galileo API and models like Gemini 2.0 within Cursor, with users experiencing limitations.
- Users expressed interest in testing the features and capabilities of new models integrated into the Cursor platform.
Links mentioned:
- Settings | Cursor - The AI Code Editor: You can manage your account, billing, and team settings here.
- Downloads | Cursor - The AI Code Editor: Choose your platform to download the latest version of Cursor.
- Python Environment Manager - Visual Studio Marketplace: Extension for Visual Studio Code - View and manage Python environments & packages.
- Poetry - Python dependency management and packaging made easy: no description found
- uv: no description found
- no title found: no description found
- WARNING: Cursor v0.44 breaks all devcontainers v0.394.0: How did you forcibly disable Cursor from updating? I’m stuck in a world where upon restarts of Cursor, it will always update to v0.44.0 now. The added issue is even if I disable the “devcontainer” ex...
- Danger Alert GIF - Danger Alert Siren - Discover & Share GIFs: Click to view the GIF
- Changelog | Cursor - The AI Code Editor: New updates and improvements.
- GitHub - TheGalaxyStars/KEPLER-COMMUNITY: Explore freely, leave no trace.: Explore freely, leave no trace. Contribute to TheGalaxyStars/KEPLER-COMMUNITY development by creating an account on GitHub.
- GitHub - ultrasev/cursor-reset: Mac utility to reset Cursor editor's device identification system. Helps resolve account restrictions and trial-related issues.: Mac utility to reset Cursor editor's device identification system. Helps resolve account restrictions and trial-related issues. - ultrasev/cursor-reset
- GitHub - ZackPlauche/add-cursor-to-win-context-menu: Contribute to ZackPlauche/add-cursor-to-win-context-menu development by creating an account on GitHub.
- index.html - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- style.css - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
aider (Paul Gauthier) ▷ #general (264 messages🔥🔥):
O1 API Release, Aider Benchmarking, Competition in AI Models, Support and Refunds, Using Gemini as Editor
-
O1 API still rolling out access: Many users, including Tier 5 API key holders, reported not having access to the new O1 API as it is gradually rolling out. Discussions around its capabilities highlight the difference between O1 Pro and standard versions.
- While some are excited about O1's reasoning abilities, others are critical, comparing it to previous models and suggesting that factors like price remain a significant concern.
- Aider's performance in benchmarking: Users shared their experiences with Aider's benchmarking, indicating that O1 scored 84.2 tying with Sonnet, while one claimed it performed even better in specific tasks. Discord conversations emphasized the importance of model selection for coding and reasoning tasks.
- As Aider develops, community members expressed their desire for effective models for editing and debugging, noting that newer iterations of O1 are crucial to testing their functionalities.
- Growing competition among AI models: Discussions emerged around the growing competition in AI model offerings, including mentions of Google's Veo 2 and ongoing debates about model effectiveness. Users particularly noted differences in output and utility between O1 Pro and existing tools like Sonnet.
- As new models appear, concerns were raised regarding price points and the sustainability of current AI subscriptions, highlighting users' frustrations and expectations.
- Support processes and refunds: Several users shared their experiences regarding support and refund processes with OpenAI, including long wait times and mixed results. One user humorously noted a refund took four months after contacting support, which adds to skepticism about the service quality.
- Conversely, another user reported receiving a swift refund within hours, reflecting the inconsistency in user experiences regarding customer support responsiveness.
- Gemini performance as an editor: Some users praised Gemini, particularly the gemini/gemini-exp-1206 model for its editing capabilities, noting minimal errors during extensive usage. Discussions highlighted how Gemini could handle specific coding tasks effectively when paired with Aider.
- Despite the competition, there are concerns about Gemini's limitations compared to models like O1, emphasizing the need for users to identify the right tools for their coding demands.
Links mentioned:
- Tweet from Andrew Ng (@AndrewYNg): OpenAI just announced API access to o1 (advanced reasoning model) yesterday. I'm delighted to announce today a new short course, Reasoning with o1, built with @OpenAI, and taught by @colintjarvis,...
- Linting and testing: Automatically fix linting and testing errors.
- Tweet from Poonam Soni (@CodeByPoonam): Google just dropped Veo 2 and it's INSANESpoiler: OpenAI Sora is now falling behind.10 Wild Examples of what it's capable of: (Don’t miss the 5th one)
- o1 - API, Providers, Stats: The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding. The o1 model series is trained with large-scale reinforcement learning to reason using ...
- Options reference: Details about all of aider’s settings.
- Options reference: Details about all of aider’s settings.
aider (Paul Gauthier) ▷ #questions-and-tips (18 messages🔥):
Aider and Gemini Flash 2 Grounding, Project Management with Aider, Aider's File Handling Issues, Using Architect vs Ask Modes, Repo Map Concerns
-
Aider supports Google Search with Gemini 2.0: A member noted that Gemini 2.0 Flash Experimental supports Google Search grounding, which can be pricy, costing $35 per 1K requests.
- It's essential to comply with ToS regarding search result displays, and the grounding feature utilizes a specific model configuration.
- Optimizing Project Management with Aider: A user discussed managing tasks through O1 and Claude-Sonnet, asking if one could pull in O1 as an architect model for their project management flow.
- Concerns were raised about managing messy code that resulted from Claude's feature development as projects grow, often requiring refactoring steps.
- Aider's File Handling Bug Report: A user reported a bug where they couldn't access the dropdown for adding files after using the /add command in Aider.
- This issue was confirmed to be fixed in the main branch, with instructions to install it using
aider --install-main-branch. - Understanding Aider's Architect and Ask Modes: Users sought clarity on the differences between /architect and /ask, noting they seemed similar but might be useful when applying two different LLMs.
- Discussion emerged about how to effectively manage plans defined in one mode and step-wise implementation in another.
- Concerns Regarding Repo Map Changes: A user expressed concerns about the repo map changing with each refactor, fearing Aider might get lost between the original and current codebase.
- Despite acknowledging the benefits of the repo map in context, they anticipated challenges in maintaining order during a project’s evolution.
Links mentioned:
- Repository map: Aider uses a map of your git repository to provide code context to LLMs.
- FAQ: Frequently asked questions about aider.
- yamad - Overview: yamad has 85 repositories available. Follow their code on GitHub.
- FAQ: Frequently asked questions about aider.
- GitHub - yamadashy/repomix: 📦 Repomix (formerly Repopack) is a powerful tool that packs your entire repository into a single, AI-friendly file. Perfect for when you need to feed your codebase to Large Language Models (LLMs) or other AI tools like Claude, ChatGPT, and Gemini.: 📦 Repomix (formerly Repopack) is a powerful tool that packs your entire repository into a single, AI-friendly file. Perfect for when you need to feed your codebase to Large Language Models (LLMs) o.....
- Add support for Gemini 2.0 GoogleSearch tool by samling · Pull Request #7257 · BerriAI/litellm: TitleAdd googleSearch() tool to valid tool list for Gemini/VertexAI models to support Gemini 2.0 grounding.Relevant issuesEnhances #7188Type🆕 New Feature✅ TestChangesAdd googleSearch() too...
aider (Paul Gauthier) ▷ #links (11 messages🔥):
Depth AI, LightRAG, Codebase indexing, AI assistants, Technical accuracy
-
Depth AI Excels at Understanding Codebases: Members discussed their experiences with Depth AI, an AI tool that accurately indexes codebases and answers deep technical questions with 99% accuracy.
- One user noted, 'I had a blast with it so far on a huge codebase I had forgotten about.'
- Indexing Times Vary for Large Projects: Indexing times for projects can range significantly, with one user noting a 40-minute indexing time for a 180k token codebase, while another user reported their middle-sized project has been indexing for 4 hours.
- They cautioned that indexing can take 1-2 hours for larger projects, particularly those between 200k and 1.5 million tokens.
- LightRAG Offers Alternative Tool: A member brought up LightRAG, describing it as 'simple and fast retrieval-augmented generation', providing an alternate solution to Depth AI.
- However, another user expressed a preference for Depth AI due to its ease of setup and presumed superiority.
- Initial Output Issues with Depth AI: One member experienced an issue where Depth AI returned 'no output was generated' after indexing their repository.
- This raised concerns about the reliability of the outputs, despite initial enthusiasm for the tool.
Links mentioned:
- Depth AI - AI that deeply understands your codebase: Chat with your codebase or build customised AI assistants. Deploy them wherever you work — Slack, Github Copilot, Jira and more.
- GitHub - HKUDS/LightRAG: "LightRAG: Simple and Fast Retrieval-Augmented Generation": "LightRAG: Simple and Fast Retrieval-Augmented Generation" - HKUDS/LightRAG
OpenAI ▷ #annnouncements (1 messages):
12 Days of OpenAI, OpenAI Role Customization
-
Stay Updated with OpenAI!: The community is reminded to stay in the loop during the 12 Days of OpenAI events.
- Participants can pick up the role in customize to receive updates.
- Watch Day 10 Highlights: Day 10 content is highlighted with a link to a YouTube video showcasing activities.
- The video captures various aspects and announcements relevant to the ongoing celebrations.
OpenAI ▷ #ai-discussions (220 messages🔥🔥):
OpenAI ChatGPT developments, Gemini AI comparison, AI model safety concerns, Generative image differences, User experiences with AI models
-
OpenAI introduces phone support for ChatGPT: OpenAI announced a new feature allowing US residents to call ChatGPT at 1-800-chatgpt, which some users find disappointing and not particularly useful.
- Discussion emerged on how this might benefit older users, though skepticism remains regarding its practicality for most audiences.
- Gemini vs OpenAI in AI advancements: Users discuss Google's Gemini AI's rapid progress and compare it favorably against OpenAI's offerings, suggesting Gemini is gaining an edge in the AI competition.
- Concerns were raised about OpenAI potentially withholding advancements until necessary to compete with new releases from other companies.
- Debates around AI model safety and control: The conversation included skepticism about whether humans can effectively manage AI safety issues without AI's assistance in the future.
- Participants expressed doubts about the balance between censorship and allowing creative freedom, arguing both extremes can have pitfalls.
- Comparative analysis of image generation models: Discussions revealed that users feel DALL-E lacks the realism and quality that other models like Midjourney (MJ) and Google's Imagen provide.
- Some believe that the limitations of DALL-E stem from imposed constraints, while others argue that Midjourney overhypes its capabilities.
- User experiences with AI tools in daily tasks: One user shared how they hope to utilize AI agents to assist their father, who is recovering from a stroke, highlighting the potential benefits for those with disabilities.
- General consensus develops that versatile and personal AI assistants could greatly enhance quality of life, assuming privacy concerns are adequately addressed.
Link mentioned: GitHub - AlignAGI/Alignment: Promoting global awareness and action for ethical AI alignment and safeguarding humanity against AI self-replication risks. Includes research, frameworks, and open-source resources.: Promoting global awareness and action for ethical AI alignment and safeguarding humanity against AI self-replication risks. Includes research, frameworks, and open-source resources. - AlignAGI/Alig...
OpenAI ▷ #gpt-4-discussions (3 messages):
GPT Management Training, Editing Custom GPTs
-
Questioning GPTs Managerial Role: A member asked whether the feature of prompting ChatGPT to act as a manager is effective in training for specific tasks.
- This raises interesting discussions about the practical applications of role-playing in AI interactions.
- Frustration Over Custom GPT Editing: Concerns were shared about the inability to edit custom GPTs, leaving users feeling stuck.
- This issue highlights the limitations in flexibility for users customizing their GPTs and seeking improvements.
OpenAI ▷ #prompt-engineering (4 messages):
Channel appropriateness, Spam management, Seeking help
-
Clarification on Channel Usage: A member expressed uncertainty about posting in the right channel, searching for help to get the best input.
- 'Im not aware of the appropriate channel' highlights the need for clearer channel guidelines.
- Addressing Spam Concerns: Another member identified the posts as spam and specified the correct channel for assistance: <#1047565374645870743>.
- They requested removal of the posts from other channels to keep the discussion organized.
- Member Acknowledges Feedback: The member seeking help acknowledged the feedback with a thumbs up emoji, indicating acceptance of the guidance provided.
- This shows a willingness to follow the correct channel protocols for future inquiries.
OpenAI ▷ #api-discussions (4 messages):
Channel confusion, Spam concerns
-
Channel confusion brings apparent spam: A user expressed uncertainty about posting in the correct channel, seeking help to gain better input.
- Another member identified the postings as spam, suggesting the right channel and offering assistance after proper deletion.
- Member seeks better input: User .noval confirmed their intentions by expressing a thumbs-up emoji after receiving guidance on the correct channel.
- This exchange reflects a broader theme of ensuring relevant discussions happen in appropriate spaces.
Nous Research AI ▷ #general (210 messages🔥🔥):
Prompt Chaining, Falcon Models, AI Tool Use, OpenAI Safety Discussions, Data Preprocessing Optimizations
-
Exploring Prompt Chaining Techniques: Members discussed the concept of prompt chaining, where outputs from one model can be used as inputs for another to build complex workflows for LLMs.
- This leads to quicker prototyping of agentic designs and allows for better structured outputs in AI responses.
- Initial Impressions of Falcon3-7B: The Falcon3-7B model has recently gained attention, with users eager to test its performance after updates that improve its ability to handle tool calls.
- Some members expressed uncertainty about its readiness but acknowledged its potential for market simulation applications.
- Concerns Over OpenAI's Safety Practices: There is scrutiny over OpenAI's emphasis on safety alongside their demonstration of jailbreak methods during comparisons of GPT-4o and the o1 preview.
- This raises discussions about the balance between operational safety and the risk of misuse in AI models.
- Advancements in Data Preprocessing Speed: One user shared significant improvements in their data preprocessing time, reducing hours of work down to just around 10 hours now.
- This optimization highlights the efficiency gains achieved through overlapping logging and improved logic in data preparation.
- Tool Use and Model Coordination: Members observed a disconnect in model documentation versus actual capabilities, especially concerning the Falcon models and their tool-use functionality.
- Discussions included insights on integrating these models into market agent simulations to evaluate their effectiveness in real-world scenarios.
Links mentioned:
- Welcome to Langflow | Langflow Documentation: Langflow is a new, visual framework for building multi-agent and RAG applications. It is open-source, Python-powered, fully customizable, and LLM and vector store agnostic.
- Scaling test-time compute - a Hugging Face Space by HuggingFaceH4: no description found
- Tweet from Democratize Intelligence (@demi_network): "It's not a question of alignment between the company and AI, it's a question of alignment between the company and you. It’s going to be very important who your AI works for.If your AI is ...
- tiiuae/Falcon3-7B-Instruct-1.58bit · Hugging Face: no description found
- tiiuae/falcon-11B · Hugging Face: no description found
- tiiuae/falcon-7b-instruct · Hugging Face: no description found
- Tweet from xjdr (@_xjdr): this was one of the most interesting things i heard repeated from ~trusted sources a few times at NeurIPS (newsonnet being 400B dense)Quoting Aidan McLau (@aidan_mclau) @Heraklines1 @deedydas no not ...
- tiiuae/falcon-40b-instruct · Hugging Face: no description found
- Welcome to the Falcon 3 Family of Open Models!: no description found
- tiiuae/Falcon3-10B-Instruct · Hugging Face: no description found
- tiiuae/Falcon3-10B-Instruct · Hugging Face): no description found
- Safepine: no description found
- Reddit - Dive into anything: no description found
Nous Research AI ▷ #ask-about-llms (13 messages🔥):
Function Calling Methods for Local Models, Language Model Data Recollection, Bias in AI Search Integration, Hermes 3 405B Model Responses, Search Engine Expectations
-
Exploring Function Calling on Local Models: Discussions focused on the best libraries and methods for function calling on small local models, evaluating their effectiveness.
- Members are looking for efficient solutions for improved functionality tailored to individual use cases.
- Data Recollection Concerns with Language Models: A member argued that language model chatbots shouldn't be used for recalling data since it varies based on context and author intention.
- They emphasized that models like Gemini should adopt software methods to fetch reliable data rather than solely relying on chatbots.
- Bias Introduced by Search Features in Chatbots: Concerns were raised about how enabling search functionalities in chat models could lead to increased bias and reduced trustworthiness.
- One member noted that unless search sources are curated, the overall quality of results remains questionable, as seen by prevalent spam and SEO tactics.
- Hermes 3 405B Model: Prompt Repetition Issue: A user shared frustrations regarding the Hermes 3 405B model returning prompts verbatim in responses despite guidance not to do so.
- They mentioned experimentation with prompting strategies to reduce repetitive behaviors, highlighting a comparison with gpt-4o for response quality.
- Future of Search Engine Quality: A member expressed hope for a search engine encompassing all written works, criticizing current search results as spammed by SEO tactics.
- The discussion reflects the desire for more robust and reliable search functionalities in the face of existing limitations.
Nous Research AI ▷ #research-papers (2 messages):
Signal and Noise in Inference, LLM Output Consistency
-
Importance of Signal and Noise in Inference: One member expressed curiosity about the significance of signal and noise ratios, drawing parallels to their role in human cognition for coherent thinking.
- It seems like signal and noise would be of great importance, especially...
- Request for Papers on LLM Output Consistency: A member sought recommendations on the best papers discussing the consistency of LLM outputs, particularly for long to very long outputs.
- Not sure it's on topic, if not please ignore, but I'd be keen to hear...
Nous Research AI ▷ #research-papers (2 messages):
Signal and Noise in AI, Consistency of LLM Outputs
-
Signal vs Noise: Key to Coherent Thinking: A member emphasized the importance of the ratio between signal and noise for coherent and clear inference, likening it to how the human brain functions.
- When subjected to coherent thought processes, understanding this relationship could enhance AI inference outputs.
- Seeking Top Papers on LLM Output Consistency: Another member expressed interest in recommendations for the best papers focusing on the consistency of LLM outputs over long text generation.
- This query sparks a potential discussion on evaluating LLM performance in producing reliable extended outputs.
Notebook LM Discord ▷ #announcements (1 messages):
3-panel UI Changes, Removed Suggested Actions, Workarounds for Model Usage, Source-based Actions, Notes to Source Conversion
-
3-panel UI introduces major changes: With the release of the new 3-panel UI, the previously included 'suggested actions' feature has been removed, which included prompts like 'Explain' and 'Critique'.
- This change was made to address the limited discoverability and usage of those actions, which often ignored source citations.
- Restoration of functionality planned: The team plans to restore much of the functionality lost with the removal of suggested actions, aiming for a more intuitive approach over the next few months.
- For the time being, users can utilize alternative methods to achieve similar results by manipulating their notes and sources.
- Effective workarounds for source citations: Users can recreate functionalities by copying text from sources and asking for explanations or summaries directly in chat.
- An option to select 'convert all notes to source' allows for easy querying with citations, enhancing model interactions.
- Critiquing notes made simpler: For critiquing written notes, users can paste the note text into chat or convert the note into a source to focus the model's feedback.
- This method ensures that critiques can be tailored to specific content, enhancing the relevance of model responses.
Notebook LM Discord ▷ #use-cases (27 messages🔥):
Interactive Language Function, Podcast Effectiveness, Using NotebookLM for Gaming, AI-generated Content Concerns, Multilingual Experimentation
-
Interactive Function Enhances Language Capability: Members discussed the ease of using NotebookLM in interactive mode to communicate in multiple languages by customizing prompts.
- One noted, 'it helps when you mention multilingual in the customize prompt... then it seems easier to get into it in the chat.'
- Concerns Over AI Podcast Saturation: One member expressed concern that the rise of AI podcasts with little context may dilute their value, suggesting they become 'AI slop'.
- They proposed enhancing podcast content, saying, 'I do the intro and talk about what I did... to cover a broad range of material.'
- Learning Complex Game Rules via NBLM: A user shared their experience of using NotebookLM to simplify the learning of complex game rules through retrieval augmented generation techniques.
- They noted, 'NBLM is the perfect tool using the power of RAG to help with this.'
- Multilingual Podcast Experimentation: Members are intrigued by the idea of conducting multilingual podcasts, with one announcing plans for experiments in this area.
- Another participant pointed to a source framework that aids in effective script crafting, focusing on prompts for engagement.
- Psyche of Isolation in Space: One member highlighted an AI-generated video exploring the psychological effects of a year-long isolation in space, featuring a synthesis of creativity and madness.
- The video showcases the astronaut's experience, challenging the audience to consider, 'Would you survive the isolation?'
Links mentioned:
- Starlings One: We are the team behind SocialPredict, a free and open source, MIT-Licensed prediction market platform which you can find and check out on Github. Give us a star!This is the Starlings.One Podcast! We d...
- Ask Gennie! Reverse Mortgage Q&A - What is a Reverse Mortgage for Seniors? What are the benefits of the reverse mortgages for elder people and retirees?: Ask Gennie! Mortgage Questions Answered with Experts from GenNext.Mortgage (NMLS #2326098) · Episode
- - YouTube: no description found
- - YouTube: no description found
- - YouTube: no description found
Notebook LM Discord ▷ #general (194 messages🔥🔥):
NotebookLM Interaction Features, Audio Overview and Podcast Length Control, Notes and Citations, Sharing Notebooks Outside Organizations, Using Google Docs as Source
-
NotebookLM Interactive Features Rollout: Users are experiencing variable access to the interactive audio features, which are still rolling out and not available for everyone yet. Some members suggested that customization prompts can help manage speaker roles and improve the interactive experience.
- Feedback was provided on the lag issues faced during interactive sessions, and confirmation that Google is actively working on fixes for these bugs.
- Managing Podcast Length in NotebookLM: Users are struggling with controlling the length of generated podcasts, finding that notes regarding audio length are frequently ignored. Suggestions were made to adjust the custom prompts to focus on shorter content or use chapter-specific files.
- Citations and Notes Panel Functionality: The new version of NotebookLM removed the citations feature from notes, which was available in the earlier version, leading to requests for its return. It was confirmed that combining selected notes isn’t currently possible, and users must either select all or one by one.
- Sharing Notebooks with External Users: A user expressed a desire to share notebooks outside their organizational framework, including with family members. This highlights the need for future updates to consider flexibility in sharing options for non-business users.
- Using Google Docs as a Source: Questions arose regarding whether Google Docs linked as a source sync automatically or require manual updates. Users confirmed that current functionality does not allow for auto-updates of sources, raising concerns about keeping information current.
Links mentioned:
- NotebookLM gets a new look, audio interactivity and a premium version: NotebookLM is introducing new features, and a premium version called NotebookLM Plus.
- Noob GIF - Noob - Discover & Share GIFs: Click to view the GIF
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- Reddit - Dive into anything: no description found
- - YouTube: no description found
Unsloth AI (Daniel Han) ▷ #general (66 messages🔥🔥):
Fine-tuning Llama Models, Multi-GPU Support in Unsloth, Batch Size Considerations, Combining Datasets for Fine-tuning, Unsloth Contributions and Reviews
-
Fine-tuning Llama Models: A user expressed interest in fine-tuning a vision model multiple times with new data, considering two methods: rerunning the whole process or continuing from saved checkpoints.
- They inquired about the most effective approach for incorporating new datasets during fine-tuning.
- Multi-GPU Support in Unsloth: A user asked about the current status of multi-GPU support in Unsloth Pro, specifically if it works locally or only on cloud platforms.
- Another contributor confirmed that multi-GPU functionality is indeed supported.
- Batch Size Considerations: A user shared their understanding of how increasing batch size impacts training speed and model accuracy, confirming that larger batches can stabilize training but at a VRAM cost.
- They noted potential limitations when pushing batch size to extremes, leading to insufficient weight updates.
- Combining Datasets for Fine-tuning: A member questioned whether it is permissible to combine datasets for multiple rounds of fine-tuning a model, seeking guidance on the practice.
- Another participant wondered about the implications of merging datasets for training effectiveness.
- Unsloth Contributions and Reviews: A user mentioned a desire to contribute to Unsloth, asking about the review process for contributions.
- They were informed that all contributions are welcome, but there may be a review period before acceptance.
Links mentioned:
- llama-models/models/llama3_2/text_prompt_format.md at main · meta-llama/llama-models): Utilities intended for use with Llama models. Contribute to meta-llama/llama-models development by creating an account on GitHub.
- no title found...): no description found
- Tutorial: How to Finetune Llama-3 and Use In Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
Unsloth AI (Daniel Han) ▷ #off-topic (139 messages🔥🔥):
QwQ reasoning models, Unsloth usage and troubleshooting, Training models with LoRA, DiLoCo research and presentations, Installing llama.cpp
-
Discussion on QwQ Reasoning Models: Users explored the capabilities of open-source reasoning models like QwQ, with some finding it falls back to vanilla instruct behavior when not prompted for math.
- Some argued that effective reasoning models could be created using SFT without reinforcement learning, while others insisted on RLHF as vital for model training.
- Troubleshooting Unsloth for Model Training: A user encountered issues while saving models in Unsloth, specifically a missing file error related to llama.cpp during quantization.
- Recommendations included updating Unsloth or reinstalling llama.cpp to resolve the issue, with emphasis on ensuring all necessary files are present.
- Understanding LoRA and Model Outputs: A user inquired about the difference between a model and an adapter like LoRA, finding that LoRA affects fewer parameters and can be combined with models.
- It was clarified that merging adapters with models can lead to smaller output sizes, which is typical for LoRA outputs compared to full model sizes.
- DiLoCo Research Presentations: Participants discussed individual research, particularly studying DiLoCo techniques for distributed low-communication training of language models.
- The potential of sharing findings from personal research with the community was highlighted, promoting collaboration and knowledge exchange.
- Installation and Setup of llama.cpp: A user asked about the proper installation of llama.cpp required for Unsloth functionality, expressing uncertainty about existing remnants of an old installation.
- The community recommended updating dependencies and ensuring proper installation to avoid runtime errors during model training.
Links mentioned:
- Google Colab: no description found
- Saving to GGUF | Unsloth Documentation: Saving models to 16bit for GGUF so you can use it for Ollama, Jan AI, Open WebUI and more!
- Hugging Face – The AI community building the future.: no description found
- Eule - a kaleinaNyan Collection: no description found
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
- kaleinaNyan/eule-qwen2.5instruct-7b-111224 · Hugging Face: no description found
- Fine-Tuning Ollama Models with Unsloth: In the previous two articles, we explored Host Your Own Ollama Service in a Cloud Kubernetes (K8s) Cluster and Run Your Own OLLAMA in…
- DiLoCo: Distributed Low-Communication Training of Language Models: DiLoCo: Distributed Low-Communication Training of Language Models OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training INTELLECT-1 Technical Report
- DiLoCo: Distributed Low-Communication Training of Language Models: Large language models (LLM) have become a critical component in many applications of machine learning. However, standard approaches to training LLM require a large number of tightly interconnected acc...
- OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training: OpenDiLoCo is an open-source implementation and replication of the Distributed Low-Communication (DiLoCo) training method for large language models. We provide a reproducible implementation of the DiL...
Unsloth AI (Daniel Han) ▷ #help (15 messages🔥):
Llama 3.2 Training Issues, M4 MAX GPUs Support, Community Contributions for Unsloth, Fast Fine-tuning Alternatives for Mac
-
Llama 3.2 Training Loss Discrepancy: A member reported that their loss is 3x higher when training the Llama 3.2 1bn instruct model with the Llama template compared to the Alpaca prompt, starting at 5.1 and converging to 1.5 with the former versus 1.9 to 0.1 with the latter.
- Another member clarified the language used, asking if the comparison should have been made using the Alpaca template.
- M4 MAX GPUs Lack of Support: A user inquired about the installation of packages on M4 MAX GPUs, noting that the conda install only supports CUDA.
- A response indicated that Unsloth is currently not supported on Mac, mentioning that community contributions could aid in development.
- Unsloth Support Timeline: One member asked about the estimated timeline for support on M4 MAX GPUs, suggesting they might use Colab in the meantime.
- A member responded that support is a work in progress, expected to land around Q2 2025, depending on available developer time.
- Open Source Contributions Welcome: There was a call for community involvement, indicating that contributions to Unsloth are welcome and appreciated.
- It was highlighted that open-source projects have no fixed timelines, allowing flexibility for contributors.
- Fast Fine-tuning Alternatives on Mac: A user wondered about any fast fine-tuning alternatives for Mac, following a discussion on GPU support.
- The member replied with uncertainty, stating they only have NVIDIA experience.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
OpenAI o1 model, EVA Llama model, Price drops on models, Provider Pages improvements, New reasoning parameters
-
OpenAI launches o1 model with enhanced features: OpenAI's new o1 model includes significant upgrades such as function calling, structured outputs and the novel
reasoning_effortparameter, allowing better control over response time.- Users can explore the model further at openai/o1 and find structured output tutorials here.
- EVA Llama joins the family of models: Alongside o1, OpenRouter has introduced EVA Llama, a new storytelling and roleplay model, expanding the versatility of the available tools.
- Check out EVA Llama via this link for more details on its capabilities.
- Price slashes for popular models: The gryphe/mythomax-l2-13b model has seen a 12.5% price reduction, making it even more accessible to users.
- Additionally, the QwQ reasoning model's price has dropped by an impressive 55%, encouraging more engagement with the technology.
- Introducing Provider Pages for transparent tracking: Provider Pages now feature clickable provider names, allowing users to access performance charts for all hosted models over time.
- For instance, users can explore the data for DeepInfra and assess the providers’ offerings easily.
- Interactive challenges with the new Chatroom: The Chatroom is hosting challenges that encourage users to interact with the capabilities of the o1 model, including image and structured input handling.
- Users were directed to join the discussion, enabled by detailed links and challenges shared in the announcements.
Links mentioned:
- o1-preview - API, Providers, Stats): The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding.The o1 models are optimized for math, science, programming, and other STEM-related tasks...
- Tweet from OpenRouter (@OpenRouterAI))): Structured outputs are very underrated. It's often much easier to constrain LLM outputs to a JSON schema than asking for a tool call.OpenRouter now normalizes structured outputs for- 46 models- 8 ...
- OpenRouter): A unified interface for LLMs. Find the best models & prices for your prompts
- EVA Llama 3.33 70b - API, Providers, Stats): EVA Llama 3.33 70b is a roleplay and storywriting specialist model. Run EVA Llama 3.33 70b with API
- OpenRouter): A unified interface for LLMs. Find the best models & prices for your prompts
- OpenRouter): A unified interface for LLMs. Find the best models & prices for your prompts
- MythoMax 13B - API, Providers, Stats): One of the highest performing and most popular fine-tunes of Llama 2 13B, with rich descriptions and roleplay. #merge. Run MythoMax 13B with API
- QwQ 32B Preview - API, Providers, Stats): QwQ-32B-Preview is an experimental research model focused on AI reasoning capabilities developed by the Qwen Team. As a preview release, it demonstrates promising analytical abilities while having sev...
- Tweet from OpenRouter (@OpenRouterAI): OpenAI o1 is now live for all! Try its 🧠 on:- image inputs- structured outputs- function calling- a "reasoning effort" controlThe Chatroom link below has a couple challenges you can try with ...
OpenRouter (Alex Atallah) ▷ #general (209 messages🔥🔥):
OpenRouter keys exposure, API call metadata viewing, Using Google AI API with OpenRouter, Reasoning model instruction compliance, Model performance in coding assistance
-
Reporting Exposed OpenRouter Keys: A user found exposed OpenRouter keys on GitHub with high limits and inquired about reporting them, receiving guidance to contact support at OpenRouter.
- Concerns over the safety of sending compromised API keys via email were also discussed.
- Viewing API Call Metadata: A member questioned how to retrieve prompts from API calls and learned that only metadata is accessible post-factum, while request/response pairs remain stateless.
- Suggestions included potential solutions like using a flag to capture chat details and proxying requests.
- Discussion on Using Google AI API: It was confirmed that using a personal Google API key with OpenRouter incurs a 5% fee on top of the API usage costs, applicable whether credits are purchased or not.
- Users were made aware that the integration of personal API keys allows control over rate limits but still costs additional fees.
- Reasoning Models and Instruction Following: Users noted challenges with QwQ following specific output formatting instructions, pointing to reasoning models' design priorities that favor thought over strict instruction compliance.
- OpenAI's introduction of a 'developer' role aims to enhance instruction adherence in these models, still leading to varying degrees of success.
- Learning to Code Using AI Models: Members discussed various AI models suitable for coding assistance, highlighting Google Experimental 1206 for its expansive context capabilities and DeepSeek-v2 for general coding help.
- Practical examples included using extensive codebases as context for generating optimization suggestions and comments, enhancing the learning experience.
Links mentioned:
- Integrations | OpenRouter: Bring your own provider keys with OpenRouter
- Integrations | OpenRouter: Bring your own provider keys with OpenRouter
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Limits | OpenRouter: Set limits on model usage
- Model Spec (2024/05/08): no description found
- LLM Rankings | OpenRouter: Language models ranked and analyzed by usage across apps
Interconnects (Nathan Lambert) ▷ #news (36 messages🔥):
Google Shipmas Releases, Gemini 2.0 Updates, Deep Research in AI, GitHub Copilot Free Tier, Microsoft Investment in Anthropic
-
Google releases during Shipmas spark interest: Members discussed various Google releases during Shipmas, including new models like Gemini 2.0 and associated demos such as Astra and Mariner.
- Ehhh was the sentiment towards unreleased demos, with a focus on summarizing the ongoing developments.
- Gemini 2.0 Flash impresses the crowd: The Gemini 2.0 Flash model has received praise for its multimodal outputs, even if it's not yet widely available, with impressive demos showcased.
- There are concerns about usability, as Gemini Exp 1206 has been reported as having unusable rate limits, despite its strong performance.
- Deep Research in Gemini becomes popular: Members highlighted the growing appeal of Deep Research, noting its effectiveness in generating high-quality reports that resemble above average blog posts.
- The usefulness of this feature could significantly enhance workflows and reference gathering, indicating a positive trend among users.
- GitHub Copilot introduces free tier: GitHub announced a new free tier for Copilot, offering 2,000 code completions and 50 chat messages per month, which many deemed an amazing deal.
- This move is expected to attract more developers to the platform, which recently surpassed 150M users.
- Microsoft rumored to invest in Anthropic: Microsoft is speculated to invest in Anthropic at a valuation of $59B, aiming to integrate Claude into their offerings amidst competitive tensions with OpenAI.
- This potential investment points to a complicated partnership, as Microsoft navigates its relationship with both AI entities while optimizing for strategic advantage.
Links mentioned:
- Tweet from GitHub (@github): A new free tier of GitHub Copilot in @code. ✅ 2,000 code completions per month💬 50 chat messages per month💫 Models like Claude 3.5 Sonnet or GPT-4o♥️ More fun for youCheck it out today! Oh yeah, and...
- Tweet from Dylan Patel (@dylan522p): Microsoft might be investing in Anthropic's new round at $59B.Microsoft wants to have Claude in their pocket to push back against OpenAI who is increasingly rambunctious with Microsoft.Very uncomf...
- Tweet from Jack Parker-Holder (@jparkerholder): Introducing 🧞Genie 2 🧞 - our most capable large-scale foundation world model, which can generate a diverse array of consistent worlds, playable for up to a minute. We believe Genie 2 could unlock th...
- Tweet from Jeff Dean (@JeffDean): Today’s the one year anniversary of our first Gemini model releases! And it’s never looked better.Check out our newest release, Gemini-exp-1206, in Google AI Studio and the Gemini API!https://aistudi...
Interconnects (Nathan Lambert) ▷ #ml-questions (26 messages🔥):
Olmo pretokenized data, Public S3 bucket access, Cloudflare hosting issues, Hugging Face dataset workaround, AWS credits usage
-
Olmo pretokenized data access inquiry: A user asked if there is a public S3 instance containing all the pretrained tokens for Olmo, indicating a need for easy access during training.
- The response pointed to an official config with numpy files but clarity was sought on S3 bucket availability.
- Public S3 bucket complications: Concerns arose over potential network errors when trying to stream data from the publicly accessible links, leading to failures after extended runtime.
- Issues were attributed to the performance of Cloudflare buckets, raising the possibility of needing a different solution.
- Potential Hugging Face dataset solution: A member suggested using a Hugging Face dataset due to bandwidth costs associated with S3 and the challenges of requester pays links.
- This approach was considered viable given the availability of AWS compute credits for efficient resource management.
- Temporary AWS bucket collaboration: A plan was proposed to create an S3 bucket in us-east-1 to facilitate a batch copy of data for a short-term solution while troubleshooting persists.
- Access to this bucket would be granted temporarily, easing data transfer while figuring out the longer-term strategy.
- Private vs Public Discord dynamics: A humorous remark was made about the nature of the conversations occurring in this private Discord being comparable to the public AI2 Discord that isn't actively used.
- “I am the state” was quoted, highlighting a sense of identity within this space.
Interconnects (Nathan Lambert) ▷ #ml-drama (15 messages🔥):
Video Understanding Models, Human Touch in AI, Meta's Legal Issues, Hugging Face Upload Challenges, Translation AI in Smart Glasses
-
Need for Human Touch in Video Creation: A member suggested that adding a human touch to generating videos would enhance engagement, particularly through using stock photos.
- I just think some human touch on pulling stock photos or something would work.
- Meta's Legal Team Causes Model Licensing Issues: Some members discussed a situation where Meta's legal team requested the takedown of an Apache licensed AI model, leading to it being re-uploaded under a new MIT-APOLLO license.
- One remarked about the absurdity of the situation, stating Some actual moron at meta's legal team asked to take down an apache licensed ai model, reflecting on the potential chaos.
- Challenges of Uploading AI Models: A member expressed frustration about the time it takes to upload AI models, humorously stating they might embarrass themselves if the upload fails.
- Another member chimed in, emphasizing the need for Hugging Face to enable fast transfer speeds, indicating the stress of handling large files.
- Potential Power Behind Translation AI Smart Glasses: A discussion arose questioning whether Meta's video understanding models are behind the live translation AI video features in Ray-Ban smart glasses.
- One pointed to a Reuters article that outlines these technological advancements.
- Script and Voiceover Discussions: Participants discussed the effectiveness of using a real voiceover in presentations, with references to previous scripts they had.
- The conversation highlighted that timestamped scripts are essential for syncing, as one member stated, the script had timestamps that manual doesn’t, indicating a workflow challenge.
Links mentioned:
- Tweet from nisten - e/acc (@nisten): im gonna rllyy embarras myself if this damn thing doesnt finish uploading
- Tweet from Lincoln 🇿🇦 (@Presidentlin): Here we go again (another repeat of Wizard)
- Tweet from nisten - e/acc (@nisten): Some actual moron at meta's legal team asked to take down an apache licensed ai model for video recognition, so it's now being reuploaded under a new MIT-APOLLO-DEEZ-NUTZ License. gghttps://h...
Interconnects (Nathan Lambert) ▷ #random (21 messages🔥):
Model precision concerns, Coding improvements in models, Anthropic research findings, Emergence of cooperation in LLMs, Alignment faking in language models
-
Discussion on model precision and support: A member inquired whether the HF inference API serves models in their original precision, specifically looking for L3.1 405B bf16 that isn't deepinfra.
- Another user mentioned that they heard someone could possibly force HF to make 405B available, although they hadn't tried it.
- Improved coding capabilities acknowledged: One user noted that the latest model seems to be meaningfully better at coding, suggesting a focused improvement in that area.
- Others speculated about potential future releases that may claim to be the true pro version.
- Anthropic reveals alignment faking in LLMs: Anthropic's new research indicates that models, like Claude, often pretend to hold varied views during training but retain their original preferences.
- This was uncovered through collaboration with Redwood Research, highlighting important implications for model behavior.
- Emergence of cooperation examined in AI models: A post shared described experiments on LLM agents in the Donor Game which revealed striking differences in cooperation emergence based on base models.
- This was noted to be surprising, especially since many companies aim to improve models by just a few percent on existing evaluations.
- Call for engaging AI research videos: A user expressed a desire for AI2 to produce engaging videos similar to others for better research dissemination.
- Humorously, another member mentioned receiving a request for comment on a 'trash tech AI startup'.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): New Anthropic research: Alignment faking in large language models.In a series of experiments with Redwood Research, we found that Claude often pretends to have different views during training, while a...
- Tweet from Edward Hughes (@edwardfhughes): We set up a population of LLM agents interacting over generations in the "Donor Game", testing whether a group can build trust over time based on reputation.🤝
- Tweet from Edward Hughes (@edwardfhughes): We find striking differences in the emergence of cooperation depending on the base model. This is quite a surprise, especially as companies training LLMs typically race to eke out a few percent more o...
- Anthropic Fall 2023 Debate Progress Update — AI Alignment Forum: This is a research update on some work that I’ve been doing on Scalable Oversight at Anthropic, based on the original AI safety via debate proposal a…
Interconnects (Nathan Lambert) ▷ #memes (20 messages🔥):
Trump's Art of the Deal, Meme Creation, AI Meme Applications, Superbowl Halftime References
-
Sarcastic Take on Trump's Book: A discussion centered around a sarcastic reference suggesting that Trump's Art of the Deal isn't truly authored by him, given his financial struggles during its writing.
- One member acknowledged that they could have been clearer about this point.
- Enjoyment of Trump’s Nonsense: A member reflected on their mixed feelings toward Trump, noting they find a lot of his actions amusing despite disagreeing with his policies.
- Another quipped about the absurdity of laughter amidst serious political discourse.
- Meme Creation and Appreciation: One member expressed joy in creating a meme for a post, sharing a visual created with a paid AI meme application.
- This prompted laughter and appreciation from other users for the creative use of tools.
- Humor in AI Support Lines: A member jokingly referenced a fictional 1-800 number called ChatGPT, igniting a playful discussion around the absurdity of such services.
- Another confirmed the number's existence, leading to surprise and amusement regarding its legitimacy.
- Superbowl Moves and Parental Approval: A member commented on the cleverness of a certain move, likening it to the Superbowl halftime, and expressed confidence that their parents would appreciate it.
- This led to lighthearted banter about community opinions on gimmicks and the charm of such antics.
Interconnects (Nathan Lambert) ▷ #rl (5 messages):
Self-correction behavior in RLVR, New o1 API parameters, Emergent properties in RL training
-
Exploring Self-Correction in RLVR: A member inquired about obtaining self-correction behavior through feedback in RLVR, referencing a section from Nato's post discussing outcome-based rewards.
- Nato responded that this behavior is mostly an emergent property when the initial reasoning seems incorrect, suggesting the potential benefit of some supervised fine-tuning (SFT).
- Questions on o1 API Parameters: The same member asked about the new o1 API parameters, particularly if there is a regularization on reasoning length conditioned in the reasoning generation process.
- Nato indicated agreement with the inquiry, adding that the parameter could relate to that aspect.
- Interesting Emergence from RL Training: A member found it fascinating how self-correction behavior emerges purely from reinforcement learning (RL) training despite it not being obvious.
- This remark highlights the complexity and potential of RL in developing adaptive capabilities in models.
Interconnects (Nathan Lambert) ▷ #rlhf (14 messages🔥):
Qwen 2.5 7B Tulu 3, Reinforcement Learning (RL) Updates, RLVR Training Methodology, Crazy RL Success
-
Qwen 2.5 7B Tulu 3 Launch Imminent: The team is preparing to launch Qwen 2.5 7B Tulu 3, expected to be a better licensed model that surpasses Olmo.
- Doing more crazy RL stuff indicates an exciting phase of development ahead.
- Unorthodox Success in RL Training: Running Reinforcement Learning (RL) multiple times has yielded unexpected positive results, surprising the team.
- One member humorously noted that this process felt like souping, suggesting a method that shouldn't work yet does.
- Confusion Over RLVR Restart Strategy: Discussions indicate a possible restart in RLVR training which appears confusing but has improved performance metrics.
- Questions arose regarding the differences between the initial RLVR application and this second run, indicating a possible steps delta.
- Anticipating Upcoming Paper Release: The team hinted at releasing a paper soon that will shed more light on the current RL methodologies and findings.
- I suppose I must wait for paper underscores the community's eagerness for more clarity on these developments.
Interconnects (Nathan Lambert) ▷ #posts (31 messages🔥):
AI agents definitions, LinkedIn misinformation, Interconnects business plans, Public engagement, Snail project 2025
-
Clarifying AI Agents: Discussion emphasized that AI agents require clearer definitions and examples to evolve into a sustainable market for researchers and builders, with trends indicating they will be pivotal by 2025. Key points highlighted the need for these tools to do much more than just chat and not just mirror existing human communication.
- A member noted, “the current definition of AI agent… encompasses way too much under one term,” stressing the necessity for specificity in the AI discourse.
- LinkedIn Comments Stir Controversy: Conversations around LinkedIn misinformation revealed a general disdain for the platform, with comments suggesting users who share misleading AI information should be banned. One member quipped if they earned a dollar for each inaccurate post on the site, “I would become a millionaire by scrolling.”
- Another noted that even older professionals who know little about AI often express overly confident opinions, leading to skepticism and frustration.
- Interconnects Ventures for 2025: Members shared ambitious plans for 2025, particularly focusing on making Interconnects a viable business, with projects like 'Fixing snail' and “Build snail with OLMo.” Humorously referenced, the snail was positioned as a potential AI agent in the future.
- Plans to integrate modern technologies and ideas reflect a broader vision for emerging capabilities in the company’s landscape.
- Impact of Public Engagement: Engagement with students was noted as a positive experience, with one member expressing, “Students coming up and wanting to take photos is so cute.” The importance of kindness in public interactions was highlighted as having a greater personal benefit beyond financial compensation.
- Conversations also touched on the challenge of maintaining a supportive public persona, with appreciation for the positive connections formed during such engagements.
Links mentioned:
- Tweet from Xeophon (@TheXeophon): Todays misinformation: A post by a speaker for a political party, who wants to fight misinformation - and then uploads an image with various # Params for GPT models (4o -> >200B, canvas 175-200B...
- The AI Agent Spectrum: Separating different classes of AI agents from a long history of reinforcement learning.
Eleuther ▷ #general (1 messages):
Retail/E-commerce Ad Content Models, Runway, OpenAI Sora, Veo 2
-
Exploring Retail Ad Content Models: A member was inquiring about effective models for creating retail/e-commerce ad content including both video and copy formats.
- They mentioned examining Runway, OpenAI Sora, and Veo 2, and were eager for additional recommendations.
- Suggestions for E-commerce Content Creation: The member's discussion hinted at potential alternatives for ad content generation, emphasizing the need for innovation in retail marketing.
- Community input on other models remains vital, as better solutions could enhance e-commerce strategies.
Eleuther ▷ #research (123 messages🔥🔥):
Koopman Operator Theory in Neural Networks, Emergent Abilities of LLMs, Neural Network Compression Techniques, Iterated Function Composition, Training Efficiency in Generative Models
-
Koopman Theory Misapplied in NNs: Discussion arose around a paper claiming to use Koopman operator theory to analyze neural networks by framing their layers as dynamical systems, which some found dubious.
- Critics argued that the concept could be rephrased as simply extending residual connections, raising questions about its practicality and whether the supposed benefits justify its use.
- Concerns about Emergent Abilities: The notion of emergent abilities in large language models was scrutinized, with some suggesting that they might not signify a fundamental change in model capabilities but rather a choice of evaluation metrics.
- Commentators expressed skepticism about the claim that scaling models would automatically resolve issues, positing that many theoretical problems remain unaddressed.
- Network Compression through Iteration: The group explored potential for iterating functions in generative models as an alternative approach to compression, suggesting that this could enhance model capabilities at test time.
- This method aligns with how diffusion models and LLMs currently operate, iterating predictions to achieve complex behaviours beyond training depth.
- Training Efficiency and Surrogate Construction: A member proposed ideas around constructing cheap surrogates for early layers of neural networks using pairs of functions to reduce computational waste after convergence.
- Discussion emphasized the benefits of flexibility in function approximation, even as doubts about efficacy across multiple layers persisted, particularly concerning cumulative error.
- Challenges in LLM Training and Scaling: Worries emerged regarding the hype surrounding large language models, with suggestions that their inefficiencies and resource demands seem overlooked by the community.
- Participants stressed the need for a broader focus on model exploration beyond LLMs, fearing that current trends might stifle innovative approaches in machine learning.
Links mentioned:
- Are Emergent Abilities of Large Language Models a Mirage?: Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models that are present in larger-scale models. What makes emergent abilities intriguin...
- Representing Neural Network Layers as Linear Operations via Koopman Operator Theory: The strong performance of simple neural networks is often attributed to their nonlinear activations. However, a linear view of neural networks makes understanding and controlling networks much more ap...
- Tweet from BlinkDL (@BlinkDL_AI): RWKV-7 "Goose" 🪿 0.4B trained w/ ctx4k automatically extrapolates to ctx32k+, and perfectly solves NIAH ctx16k🤯Only trained on the Pile. No finetuning. Replicable training runs. tested by ou...
- Growing Neural Cellular Automata: Training an end-to-end differentiable, self-organising cellular automata model of morphogenesis, able to both grow and regenerate specific patterns.
- Tweet from BlinkDL (@BlinkDL_AI): RWKV-7-World 0.1B (L12-D768) trained w/ ctx4k perfectly solves NIAH ctx16k 🤯 100% RNN and attention-free. RWKV is all you need. https://www.rwkv.com/ #RWKVQuoting BlinkDL (@BlinkDL_AI) RWKV-7 "Go...
- OATS: Outlier-Aware Pruning Through Sparse and Low Rank Decomposition: The recent paradigm shift to large-scale foundation models has brought about a new era for deep learning that, while has found great success in practice, has also been plagued by prohibitively...
- Common arguments regarding emergent abilities — Jason Wei: This blog post doesn’t represent the positions of my employer (past, present, or future). I’ll review some common arguments that come up when discussing emergent abilities of large language models...
- Time-Delay Observables for Koopman: Theory and Applications: Nonlinear dynamical systems are ubiquitous in science and engineering, yet analysis and prediction of these systems remains a challenge. Koopman operator theory circumvents some of these issues by con...
- GitHub - Jamba15/SpectralTools: Spectral analysis and training of dense layers: Spectral analysis and training of dense layers . Contribute to Jamba15/SpectralTools development by creating an account on GitHub.
Eleuther ▷ #lm-thunderdome (6 messages):
Passing Extra Arguments to Functions, Task Configurations, Subtask Creation
-
Inquiring About Extra Arguments for doc_to_text: @bodasadallah questioned whether it’s possible to pass extra arguments to the doc_to_text function in a new task.
- This inquiry focused on experimenting with different prompts for the same task.
- Overriding Base Configurations: @baber_ explained that the main entrypoint for passing extra arguments is through configs, allowing for flexibility in configuration.
- He suggested creating a new config based on another using
include:to overload specific fields. - Using Base Config with Different Prompts: @bodasadallah mentioned having a base config where functions are defined and discussed creating different configs for various prompts.
- He sought clarification on whether it was feasible to create distinct subtasks for each prompt.
- Group Configurations Limitations: @baber_ confirmed that users can add a prompt to a group config, but it would overload it for all included tasks.
- This implies that caution is needed when applying changes at the group level to avoid unintended changes.
Eleuther ▷ #gpt-neox-dev (9 messages🔥):
Logging to WANDB, WandB run names from configs, Non-parametric layernorm PR
-
Directly logging MFU, batches/sec, tokens/sec to WANDB: A member inquired about logging MFU, batches/sec, and tokens/sec to WANDB when pretraining with neox, noting this could be calculated from samples_per_sec, but direct plots would be ideal.
- Another member confirmed there's currently no option for this, suggesting a PR could be made if the feature is implemented.
- Setting WANDB run name from configs: A user expressed difficulty in setting a WANDB run name from the configuration, encountering errors with the name parameter in the config.
- A member clarified that the current option isn't available but expressed willingness to add it today along with logging enhancements.
- Upcoming PR for non-parametric layernorm: One member mentioned plans to raise a PR for the non-parametric layernorm feature over the weekend, indicating progress on their part.
- They acknowledged the other contributions regarding WANDB logging and express gratitude for the assistance.
Link mentioned: gpt-neox/megatron/logging.py at f5325805678c2b9e35aae4528283e0132c5f5bbc · EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - EleutherAI/gpt-neox
Stability.ai (Stable Diffusion) ▷ #general-chat (122 messages🔥🔥):
Lora Training, Stable Diffusion Models, Quantum Computing, Web UI Recommendations, Video Generation Challenges
-
Steps to Create Your Own Lora: A member suggested that to make your own Lora, you should first create a good dataset, choose the model, train the Lora, and test it.
- They emphasized the importance of researching how to make effective datasets for successful training.
- Model and Resources for Stable Diffusion: Recommendations for models included InvokeAI for beginners due to its intuitive interface, while ComfyUI and Forge UI were noted for their modularity and features.
- Users shared links to resources like models on Civitai and tools for Lora training that could be beneficial for newcomers.
- Comparing Quantum and Classical Computing: The discussion highlighted ongoing developments in quantum computing, noting that while there are significant breakthroughs, practical applications are still a long way off.
- Concerns were raised about the implications of these advancements, particularly in warfare and the future of computational power.
- Performance Optimization for Image Generation: When generating images, members suggested using FP8 mode for efficient VRAM usage, especially with a 3060 GPU.
- Keeping an eye on GPU memory in task management during image generation can help prevent slowdowns.
- Challenges in AI Image and Video Quality: Participants reflected on the current state of AI-generated images and videos, agreeing that while images have improved significantly, video generation still faces challenges.
- Realistic expectations were set regarding the timeline for achieving near-perfect quality in AI media.
Links mentioned:
- Epoch Helper - v1.1 | Other Other | Civitai: source code - https://github.com/Monkellie/epochcalc # The Epoch Helper Tool This is a tool I created (AI Assisted) to help myself with calculation...
- stable-diffusion-webui-forge/webui-user.sh at main · lllyasviel/stable-diffusion-webui-forge: Contribute to lllyasviel/stable-diffusion-webui-forge development by creating an account on GitHub.
- static FFmpeg binaries for macOS 64-bit Intel: Download static FFmpeg binaries for macOS 64-bit Intel. snapshots and release binaries are available. FFmpeg developers strongly encourage all users to use a current snapshot build instead of a releas...
Perplexity AI ▷ #announcements (1 messages):
Custom web sources, Perplexity Spaces, Tailored searches
-
Custom Web Sources Now in Spaces: Perplexity has introduced custom web sources in Spaces, allowing users to tailor their requests by choosing specific websites for searches.
- This update helps customize Perplexity to better serve the use cases that matter most to you.
- Launch Video Available: An attached video showcases the new feature of custom web sources, demonstrating how to use it effectively.
- Users can view the video here.
Perplexity AI ▷ #general (108 messages🔥🔥):
Perplexity Pro subscriptions, User Interface feedback, Model performance comparisons, Rate limits and upgrades
-
Enjoying Perplexity Pro gifts: Perplexity now offers Pro gift subscriptions, providing features like access to more sources and new AI models, making it a thoughtful gift for knowledgeable friends.
- Give the gift of knowledge is the slogan, highlighting the appeal of Perplexity's Pro features.
- User Interface improvement suggestions: Some users suggested adding a snowfall effect to the UI, noting how it enhances the visual experience in addition to technical functionality.
- However, others mentioned that such features are unnecessary for work-focused users.
- Model performance insights: Users compared the performance of models like Claude, GPT, and others, discussing their effectiveness and the potential limitations in search quality.
- Concerns about hallucinations and model accuracy were raised, with suggestions to combine text models with simulation for improved results.
- Rate limits affecting users: Some users reported reaching request limits on Perplexity, prompting inquiries about higher tier subscriptions to alleviate this issue.
- There was speculation on whether signing up for a higher tier could effectively increase request limits.
- Features and updates on Spaces: There were questions about whether the new update for Spaces, allowing link citations, would provide regularly updated information or static content.
- Users expressed interest in ensuring that the tool would keep its information current for better research outcomes.
Links mentioned:
- Tweet from Perplexity Supply (@PPLXsupply): Give the gift of knowledge. Perplexity Pro gift subscriptions now available.
- TikTok - Make Your Day: no description found
- Perplexity Pro Subscription | Perplexity Supply: Perplexity Supply exists to explore the relationship between fashion and intellect with thoughtfully designed products to spark conversations and showcase your infinite pursuit of knowledge.
- - YouTube: no description found
Perplexity AI ▷ #sharing (4 messages):
Meta's Blocking of OpenAI for-Profit, Microbe Threat Warning, Cell Revitalization, Plant Responses, Dopamine Precursors
-
Meta Wants to Block OpenAI's For-Profit Moves: Meta is advocating for OpenAI's for-profit operations to be blocked, emphasizing concerns over the implications of profit-driven motives in AI development. This move has sparked discussions about the ethical dimensions of AI commercialization.
- Discover more about this stance here.
- Microbe Threat Warning Raises Alarm: A serious warning about a microbial threat has been issued, drawing attention to potential risks posed by certain microbes to health and ecosystems. Discussions have highlighted the need for awareness and preventive measures.
- The community discussed the implications of this warning in light of recent studies and ongoing research.
- Cells Can Be Revived After Death: Research indicates that cells have the potential to be revived even after death, which could have significant implications for medical science. This finding challenges previously held beliefs about cellular permanence.
- Watch a detailed explanation of these findings here.
- Plants Could Cry: Understanding Plant Responses: An intriguing study suggests that plants may have mechanisms akin to crying, responding to environmental stress. This could reshape our understanding of plant behavior and communication.
- Learn more about this phenomenon here.
- Investigating Dopamine Precursors: Research into the precursors to dopamine reveals critical information about its production and regulation in the brain. This knowledge could impact treatments for various psychological conditions.
- Explore the research findings here.
Perplexity AI ▷ #pplx-api (1 messages):
Perplexity web search feature, Perplexity API cost overview
-
Inquiry about Web Search in Perplexity API: A member asked if the web search feature is included in the chat completion API call for Perplexity.
- They highlighted their prior experience with Anthropic and OpenAI's APIs, indicating a desire to innovate with Perplexity.
- Request for Perplexity API Cost Overview: The same member inquired if there is a cost overview available for using the Perplexity API.
- They expressed gratitude for any resources that could clarify pricing details.
GPU MODE ▷ #general (41 messages🔥):
6D Parallelism, PC Troubleshooting, GPU Performance Comparison, Coil Whine Issues
-
6D Parallelism Insights Shared: An article discussing 6D parallelism highlights the visualization of collective communications in a 2⁶ 6D parallel mesh.
- The author points out that many resources fail to capture the complex communications involved, unlike the insights presented here.
- New PC Monitor Connection Troubles: One user reported their new PC starting but with no signal to the monitor until they waited a minute, after which the boot screen appeared.
- Another user suggested testing with just one stick of memory to troubleshoot further.
- Radeon GPUs vs Nvidia 4060 Performance: A user shared dissatisfaction with Radeon cards, comparing their performance to Nvidia 4060 and noting only a minor FPS difference of 5-10 FPS more for Radeon, but it comes with significant coil whine.
- Users discussed the pros and cons of both cards, emphasizing the noisiness of Radeon due to coil whine while appreciating the quieter performance of the Nvidia 4060.
- Coil Whine as Musical Notes: One member humorously suggested creating a program to play music using coil whine, as they've noticed the pitch changes depending on the GPU workload.
- Another user remarked on how the tone changes with power draw, though the range of sounds might be limited.
- Searching for Multi-GPU NVLink Instances: A user inquired about experiences finding multi-GPU instances with NVLink on VastAI, confused by the bandwidth options presented.
- Discussion flowed about the capabilities and limitations of finding the right resources in such multi-GPU setups.
Links mentioned:
- NCCL Source Code Study: no description found
- Visualizing 6D Mesh Parallelism: Plus some lore
GPU MODE ▷ #triton (1 messages):
Kernel Computation Methods, Output Concatenation in Kernels
-
Exploring Efficient Output Concatenation in Kernels: A member inquired about non-slow methods for concatenating output within a loop inside a GPU kernel, contrasting previous experiences with summing outputs.
- They highlighted a concern regarding the potential slowness of writing directly to global memory during every iteration and questioned if operations like
var[idx:idx+block_size] = valuecould be utilized. - Concerns About Global Memory Writes: A discussion unfolded over the performance implications of writing to global memory within the kernel loop, as such actions can slow down execution.
- One member proposed examining the use of shared memory as a potential workaround to improve performance when concatenating outputs.
- They highlighted a concern regarding the potential slowness of writing directly to global memory during every iteration and questioned if operations like
GPU MODE ▷ #cuda (8 messages🔥):
LLM Model Inference, Cuda Memory Operations, A100 vs H100 Training, CUDA Graphs and Async Operations, AMP Impact on Loss
-
Issues in LLM Model Inference Code: A user shared a code snippet for
CopyInternalindicating potential issues when the segment for handling dense tensors is active, causing incorrect results in the inference process.- Commenting out certain lines allows for correct results, suggesting that those lines may be causing unexpected behavior.
- Understanding CudaCopy Kernel Execution: In the provided code, it was noted that
CudaCopyis responsible for executing CUDA kernels, indicating where memory operations are handled during the copy process.
- The mention of stream and kernel types highlights the complexity involved in memory handling in CUDA environments.
- Investigation on A100 vs H100 Training Performance: A user raised a concern about discrepancies in training loss when comparing A100 and H100 GPUs, noting a 0.3% difference even under single GPU tasks.
- This unexpected behavior prompted questions about the underlying factors affecting training consistency.
- Challenges with CUDA Graphs and Async Operations: A query was made regarding the lack of documentation on why CUDA Graphs do not support
cudaMemcpyAsyncoperations, which might limit certain use cases.
- This suggests a broader discussion is needed about the functionality and constraints of CUDA Graphs in relation to asynchronous memory operations.
- Possible Connection between AMP and Training Loss: A user speculated whether the differences in training loss might be related to Automatic Mixed Precision (AMP), sparking further exploration into optimization techniques.
- This inquiry emphasizes the ongoing consideration of how different precision strategies impact model performance.
GPU MODE ▷ #torch (33 messages🔥):
Megatron-LM for efficient training, Torch.compile warnings handling, Coreweave packaging challenges, Handling various shapes in image generation, Distributed training at Gensyn
-
Megatron-LM's Relevance for Distributed Training: A query was raised about whether Megatron-LM is still considered effective for efficient training, especially for research improving training throughput.
- Recommendations were made to connect with Christine Yip from Gensyn, who is active in the distributed training community and can provide insights.
- Suppressing Torch.compile Warnings: A member suggested wrapping torch.compile within a context manager to suppress all output, proposing a potential workaround to handle excessive logging.
- Another user noted that instead of suppressing logs, using the warnings module to filter anticipated warnings might be a simpler approach.
- Challenges with Coreweave Packaging: Discussion highlighted the complexities of using Coreweave's bespoke image, which requires compiling a new torch Docker image, adding significant overhead.
- The difficulty of having to rely on specific compiled flags for performance optimizations was mentioned as an added frustration.
- Managing Dynamic Shapes in Torch.compile: A developer shared concerns about the slow performance of dynamic=True in torch.compile when managing a variety of input shapes for image generation.
- A strategy was proposed to warm up kernels for known supported shapes and seamlessly fallback to non-compiled invocations for unexpected ones.
- Using torch.compile without Decorating: A suggestion was made to compile functionally by storing
fn_compiled = torch.compile(fn)instead of using decorators, allowing flexibility based on conditions.
- This approach's limitations for compiling whole models quickly were addressed, as lengthy compile times were a concern for the user.
Links mentioned:
- Reduce time to first kernel when using CUDA graphs: I’ve been profiling the inference stack that I’m using against vLLM and I found that in their case after calling graph replay, the first kernel gets executed almost instantly(left), whereas in my code...
- GitHub - pytorch/torchtitan: A native PyTorch Library for large model training: A native PyTorch Library for large model training. Contribute to pytorch/torchtitan development by creating an account on GitHub.
GPU MODE ▷ #cool-links (4 messages):
Raspberry Pi 5 deployment, Edge device LLM models, Esp32 / Xtensa LX7 chips
-
Boosting Raspberry Pi 5 for LLMs: The Raspberry Pi 5, equipped with a 256GB NVMe for enhanced data transfer and overclocked to 2.8GHz, is being set up for deploying small models with 1.5B parameters using Ollama compiled with OpenBlas.
- This setup aims to facilitate local deployment on the Pi 5, showcasing the potential of edge devices for model hosting.
- Anticipation for Esp32 / Xtensa LX7 Chips: Excitement builds as a member shares their eagerness for the new Esp32 / Xtensa LX7 chips, intended for a different scenario where an LLM will be called remotely using an API.
- The shift in application highlights the versatility and broad potential of emerging hardware for AI deployment strategies.
GPU MODE ▷ #jobs (1 messages):
MatX LLM Accelerator, Hiring for roles, Low level compute kernel, Compiler engineering, ML performance engineering
-
MatX is developing LLM accelerator ASIC: MatX announced its initiative on building an LLM accelerator ASIC aimed at enhancing AI performance.
- Details about the project can be found on their website, and they are actively looking for talent in this domain.
- MatX hiring for technical roles: The company is hiring for several positions, including low level compute kernel author, compiler, and ML performance engineer roles.
- Interested candidates can check the available positions at MatX Jobs.
Link mentioned: Tweet from MatX | Jobs: no description found
GPU MODE ▷ #torchao (5 messages):
int4group scheme, Tinygemm compute, Activation quantization, Matmul kernel processing
-
Keystone of int4group scheme: In the int4group scheme, weights remain quantized as int4, while activations are kept in fp16, resulting in a matmul of fp16 x int4 = fp16.
- An accompanying image illustrates this process.
- No activation quantization during training: It was confirmed that there is no fake quantization for activations during the training process, as Tinygemm utilizes bf16 for computation.
- The int4 weights are dequantized on-the-fly during both Quantization Aware Training (QAT) and inference time.
- Matmul kernel handles dequantization: In response to questions about on-the-fly computation, it was clarified that the dequantization process takes place within the matmul kernel.
- This approach ensures seamless integration of quantum weights without affecting the activation's floating-point representation.
GPU MODE ▷ #rocm (1 messages):
MigraphX, ONNX Frontend, MI300X, Opset 11 Support
-
MigraphX Potential on MI300X: A member expressed confidence in the ability to build MigraphX for the ONNX Frontend on the MI300X platform.
- They noted that they hadn't checked the supported Opset 11, but believe it should be the latest version available.
- Inquiry about MI300X Experience: The same member inquired whether anyone had attempted to implement MigraphX in conjunction with MI300X.
- The focus was on ensuring compatibility with the current Opset standards in use.
GPU MODE ▷ #thunderkittens (1 messages):
kimishpatel: what i cam here for 🙂
GPU MODE ▷ #arc-agi-2 (18 messages🔥):
Custom Vision Encoder Development, Chain of Thought Implementation, Experimenting with LLMs, Training Configurations for LLMs, Decentralized Sampling Processes for CoT Prompts
-
Custom Vision Encoder Exploration: A member suggested creating a custom vision encoder to integrate with existing language models, noting that current vision models may not be optimal for small pixel scale images.
- They posited that this flexibility might outweigh the benefits provided by pretrained VLMs.
- Granularity of Chain of Thought: Concerns were raised about the granularity of the Chain of Thought (CoT) implementation, particularly regarding its depth beyond core ideas.
- It was suggested that multiple iterations in reasoning may lead to improvement in addressing problems.
- Experimenting with LLMs and CoT: Plans for a Proof of Concept (PoC) phase to test the effectiveness of CoT in generating reasoning tokens were discussed, emphasizing the importance of the experiments' outcomes.
- A member noted their anticipation for integrating inner reasoning into models to enhance solution quality.
- Finetuning Configurations Inquiry: Questions arose regarding the finetuning setup for LLMs, specifically whether bf16, Lora, or combinations like Qlora+int8 are preferred methods.
- A verification of Lora configurations for llama-3-vision was shared as reference for those experimenting on GPU setups.
- Decentralized Sampling for Efficient CoT Prompts: The potential for decentralized sampling processes to run without training for efficient CoT prompt development was proposed, hoping to collect a comprehensive dataset.
- This approach aims to facilitate human-guided exploration and enhance prompt efficiency.
Links mentioned:
- augmxnt: Weights & Biases, developer tools for machine learning
- axolotl/examples/llama-3-vision/lora-11b.yaml at effc4dc4097af212432c9ebaba7eb9677d768467 · axolotl-ai-cloud/axolotl: Go ahead and axolotl questions. Contribute to axolotl-ai-cloud/axolotl development by creating an account on GitHub.
LM Studio ▷ #general (87 messages🔥🔥):
LM Studio beta features, Using Llama 3.2 model, Roleplay LLM setup, Connecting LM Studio to mobile, Hardware specifications for running models
-
LM Studio beta features and issues: Users discussed various beta features of LM Studio, including installation issues and specific model architecture errors like 'unknown model architecture mllama'.
- Some users successfully ran heavy models, while others faced challenges with downloading or corrupt files.
- Clarification on Llama 3.2 model usage: There was confusion regarding the usage of the Llama 3.2 11B Vision model in LM Studio, especially the necessity of MLX for running it.
- Several users confirmed they were able to run the model but others faced errors related to Safetensors headers and memory limitations.
- Setting up a roleplay LLM: A user sought assistance in setting up a roleplay LLM, being directed to a specific channel for further inquiries.
- The community was active in sharing tips and best practices for utilizing LLM models effectively.
- Connecting LM Studio to mobile devices: A user inquired about using LM Studio on their phone while it runs on their desktop.
- Members confirmed there is no mobile application for LM Studio but discussed potential workarounds to access functions remotely.
- Hardware specifications for running models: Users shared their hardware capabilities, specifically mentioning setups like the M3 Max with 96GB and 128GB of memory for optimal model performance.
- Discussions highlighted the importance of adequate RAM and GPU specifications for running larger models effectively.
Links mentioned:
- mlx-community/Llama-3.2-11B-Vision-Instruct-4bit · Hugging Face: no description found
- Tweet from Haider. (@slow_developer): 🚨 NVIDIA Introduces Jetson Nano Super> compact AI computer capable of 70-T operations per second> designed for robotics, it supports advanced models, including LLMs, and costs $249
- LM Studio Beta Releases: LM Studio Beta Releases
LM Studio ▷ #hardware-discussion (17 messages🔥):
3060 Ti vs 3060, AMD Radeon VII driver issues, Llama model utilization, Inference performance with GPUs, M2 MacBook Air as a gateway
-
3060 Ti confusion clarified: There was confusion over the existence of a 3060 Ti 11GB variant, with users questioning if it was simply the 12GB 3060.
- One member noted the differences in specifications, sparking a brief discussion on GPU comparisons.
- Radeon VII facing driver issues: Members discussed the 24.12.1 driver issues impacting the Radeon VII, with one needing to revert back to 24.10.1 for proper performance.
- They highlighted that using 24.12.1 caused 100% GPU utilization without power usage, leading to major lag during basic tasks.
- Llama model performance insights: Discussions revealed that a 5GB model split among GPUs led to performance degradation, prompting one user to consider forcing a single GPU for inference.
- Another member advised checking settings in
llama.cppto ensure it properly uses CUDA, suggesting that setting adjustments could improve performance. - Inference needs significant RAM: A member pointed out the need for 70GB RAM to run a 70B model, accounting for both VRAM and system memory.
- In response, another clarified that running at q8 could require about 1GB per billion parameters, emphasizing the importance of having extra VRAM for context.
- M2 MacBook Air sparks upgrade fantasies: One user humorously noted that owning an MBA M2 made them crave a powerful MBP M4 for better inference capabilities.
- Another chimed in with a humorous analogy about needing to prioritize graphics memory as they joked about selling belongings for high-performance parts.
Stackblitz (Bolt.new) ▷ #prompting (6 messages):
Migrating from Firebase to Supabase, Using create-mf-app with Bootstrap, Google reCAPTCHA Issues, Testing Bolt Pilot GPTs, Vite Pre-Transform Errors
-
Firebase to Supabase Migration Strategies: A member inquired about the best methods to transition their entire site from Firebase to Supabase.
- No specific techniques were provided yet in the discussion.
- Seeking Alternatives to Vite and Tailwind: A user expressed the desire to use create-mf-app and Bootstrap instead of Vite and Tailwind, leading to conflicts.
- They have inadvertently created situations where both styling frameworks are tangled.
- Google reCAPTCHA Key Type Confusion: One member shared their experience with getting an 'Invalid key type' error when using Google reCAPTCHA v3 instead of v2.
- After switching to v2, they still face issues like not receiving emails from the contact form.
- Testing Bolt Pilot GPT: A member announced the creation of a new GPT called Bolt Pilot for ChatGPT and requested feedback on adjustments.
- Their enthusiasm indicates that they're eager to improve the product based on community input.
- Recurring Vite Errors: A user reported experiencing multiple instances of '[vite] Pre-Transform' errors while working on their projects.
- This issue seems to be a common concern that could be affecting other members as well.
Stackblitz (Bolt.new) ▷ #discussions (97 messages🔥🔥):
Frustrations with Bolt, Seeking Help on Projects, Token Usage, Collaborative Projects, Technical Discussions
-
Users frustrated with Bolt wasting tokens: Multiple users expressed their frustration with Bolt wasting tokens on unnecessary prompts and placeholder content, leading to suggestions for a reset button to stop excessive token consumption.
- One mentioned they had already spent a significant amount on tokens without satisfactory results.
- Requests for project assistance: Several users indicated they were seeking guidance on their projects, with some willing to offer payment for help, particularly for contractors and service providers building multi-tenant applications.
- Discussions included sharing project links and a willingness to collaborate on various tasks.
- Token discounts and plans: Users inquired about potential holiday discounts on tokens and expressed concerns over the current pricing due to excessive consumption by Bolt.
- There was a suggestion to check announcements during Office Hours for updates on token pricing.
- Collaborative building ideas: Some users are keen to team up to create projects and offered to combine their token resources for collaborative efforts, aiming to build something substantial together.
- This reflects a growing interest in community engagement for project development.
- Technical issues with Bolt and potential solutions: Users shared experiences with bugs related to commented code and discussed potential fixes, like adjusting settings to fix context window issues.
- Suggestions included turning off diff mode to mitigate some of the frustrations encountered during development.
Links mentioned:
- Vite + React + TS: no description found
- - YouTube: no description found
- GitHub - stackblitz-labs/bolt.diy: Prompt, run, edit, and deploy full-stack web applications using any LLM you want!: Prompt, run, edit, and deploy full-stack web applications using any LLM you want! - stackblitz-labs/bolt.diy
- GitHub - RealSput/Wenode: WebContainers, except it's a million times easier to use: WebContainers, except it's a million times easier to use - RealSput/Wenode
- oTTomator Community: Where innovators and experts unite to advance the future of AI-driven automation
Cohere ▷ #discussions (42 messages🔥):
Tool use with Maya, Local model integration, Importance of sleep, Hugging Face UI update, Image analysis using VQA
-
Need for Tool Use in Base Model: Members discussed the necessity of integrating tool use in their base model to enhance functionality for image analysis.
- One member remarked, 'I probably shouldn't be talking about it here. It's by people at c4.'
- Maya Tool Integration Discussion: A member suggested invoking the command-r-plus-08-2024 to facilitate the integration of Maya as a tool for their local model.
- This approach aims to allow the model to interact with Maya by sending image paths along with questions, optimizing responses.
- Sleep's Importance Raised: During the chat, a member highlighted the importance of sleep, prompting another to respond, 'Don't push yourselves so hard, take some rest!'
- This led to a lighthearted exchange about rejuvenation and work balance among members.
- Hugging Face UI Update Noticed: One member pointed out the Hugging Face update, sharing a screenshot with the group, indicating noticeable improvements.
- The humor of working with the new UI and handling challenges attracted playful comments from others involved.
- Struggling with Large JSON Files: A member expressed their frustration after their IDE crashed due to attempting to load 71,000 lines of JSON.
- Another member remarked humorously on the situation, highlighting the common struggles with large datasets.
Cohere ▷ #announcements (1 messages):
Rate-limit increase, Multimodal Image Embed endpoint, API key types, Rate limits details, Community engagement
-
Massive Boost for Multimodal Image Embed Rate-limits!: In response to community demand, the rate limits for the Multimodal Image Embed endpoint on production keys surged from 40 images/min to 400 images/min.
- Testing rate limits for trial keys remain unaffected at 5 images/min, allowing users to experiment freely.
- Check Your API Key Options!: Cohere offers two types of API keys: evaluation keys (limited usage) and production keys (less limited for a fee).
- Users can create a trial or production key via the API keys page, with further pricing details available in the pricing docs.
- Comprehensive Rate Limits Breakdown: A detailed table outlines the trial and production rate limits for various endpoints, ensuring clarity on usage capacity.
- Notable adjustments include Embed (Images) now having 400 images/min on production while keeping 5 images/min for trials.
- Community Sharing Encouraged!: The announcement invites users to create and share their applications using the updated endpoint limits.
- Community engagement is promoted under the provided channel for sharing experiences and feedback.
- Support Available for Queries: For any questions or concerns regarding the updates, users are encouraged to ask in a specific support channel or contact support directly.
- This ensures that users have adequate support to navigate the new features and rate limits.
Link mentioned: API Keys and Rate Limits — Cohere: This page describes Cohere API rate limits for production and evaluation keys.
Cohere ▷ #questions (51 messages🔥):
Cohere Structured Outputs Implementation, Embedding Dimensions Concerns, RAG-based PDF Answering System Issues, Cohere Reranker Functionality, Cohere and Nvidia Relationship
-
Implementing Cohere Structured Outputs effectively: A user successfully implemented Cohere's Structured Outputs into their project and resolved issues related to tool usage by considering parameters for requests.
- They discussed using
strict_toolssettings to ensure the model utilizes tools effectively for structured responses. - Embedding Dimensions in Vector Stores: A user inquired about storing embeddings generated by different models due to dimensional discrepancies, particularly with
text-3-embedding-largeandcohere embed v3.
- This highlights the complexity of managing embeddings from diverse models in a unified vector store.
- Cohere Reranker Issues in RAG Systems: A developer faced inconsistencies with the Cohere Reranker in their RAG-based PDF answering system, where it occasionally selected less relevant chunks despite proper chunking.
- Despite having the system retrieving accurate answers sometimes, they expressed concern over the random performance of the reranker.
- Understanding AI Infrastructure Choices: In response to a question about Cohere's dependence on Nvidia products, a user noted Nvidia's central role in most AI systems due to its strong ecosystem, particularly with CUDA and NCCL.
- However, alternatives like AMD and Google TPU exist, highlighting a broader range of options for AI infrastructure.
- Exploring TPU Performance in AI: A conversation pointed out that while TPU technology isn't niche, it is prominently utilized by specific organizations like Anthropic due to its efficiency in processing.
- Discussion shifted towards the importance of optimized matrix multiplication and that the choice of infrastructure affects AI system performance.
- They discussed using
Links mentioned:
- Chat — Cohere: Generates a text response to a user message and streams it down, token by token. To learn how to use the Chat API with streaming follow our [Text Generation guides](https://docs.cohere.com/v2/docs/cha...
- Structured Outputs — Cohere: This page describes how to get Cohere models to create outputs in a certain format, such as JSON.
- Chat — Cohere: Generates a text response to a user message and streams it down, token by token. To learn how to use the Chat API with streaming follow our [Text Generation guides](https://docs.cohere.com/v2/docs/cha...
Cohere ▷ #cmd-r-bot (1 messages):
setupisanoun: hey buddy
Cohere ▷ #projects (2 messages):
Findr Launch, Infinite Memory, Product Hunt
-
Findr Takes Off!: Findr has officially launched on Product Hunt, aiming to provide users with infinite memory and a searchable digital brain.
- The creator expressed gratitude for support, stating that they are excited about building this new tool for memory enhancement.
- Community Cheers for Launch Success: Members congratulated the creator on the successful launch of Findr.
- This positive community response highlights the enthusiasm for innovative projects aimed at enhancing human memory.
Link mentioned: Tweet from Nishkarsh (@Nish306): we’ve launched on Product Hunt. i would greatly appreciate your support https://www.producthunt.com/posts/findr-remember-everythingwe're giving humans infinite memory and a searchable digital brai...
Cohere ▷ #cohere-toolkit (3 messages):
Cohere Toolkit Deployment, AWS Stream Errors, Docker Logs Analysis
-
Cohere Toolkit Deployment Success: A member successfully deployed the Cohere Toolkit using the provided AWS instructions, sharing their excitement.
- However, they encountered an intermittent error: stream ended unexpectedly, affecting functionality.
- Intermittent AWS Stream Errors: The deployment faced a random issue with the AWS stream, occasionally breaking the chat functionality.
- The member sought help from others, asking if anyone else had faced similar issues.
- Advice to Check Docker Logs: Another member suggested checking the docker logs for any relevant information to diagnose the issue.
- This recommendation aimed at narrowing down the cause of the intermittent stream errors.
Modular (Mojo 🔥) ▷ #general (22 messages🔥):
Mojo REPL Issues on Archcraft, Magic Environment Challenges, Stable Diffusion Example Reference, Max Installation Problems, Creating Threads for Problem Solving
-
Mojo REPL can't find ldd library on Archcraft: A user reported issues accessing the Mojo REPL on Archcraft Linux, mentioning that it appears to be looking for a dynamically linked library named mojo-ldd.
- Another member indicated that
mojo-lldcould be a linker, but details regarding the exact error were needed for further assistance. - Struggles in the Magic Environment: The same user stated that while within the magic environment, they couldn't install Python requirements, receiving a message about being in an externally managed environment.
- Despite these issues, the user confirmed access to Max and Magic, but further exploration was halted by installation failures.
- Stable Diffusion Example Shared: A member congratulated the community on a new release, referencing an example available on the GitHub repository for Stable Diffusion.
- The GitHub link provided was acknowledged as a helpful resource for users interested in utilizing the new feature.
- Max Installation Process Killed: The user faced issues when attempting to install Max, stating that the installation process was unexpectedly killed.
- They were waiting for the magic environment to install Max, suggesting ongoing installation attempts despite previous errors.
- Creating Threads for Enhanced Problem-solving: A community member suggested creating a new thread for problem-solving to help others experiencing similar issues.
- This proposal aimed to facilitate ongoing discussions and solutions without cluttering the main conversation.
- Another member indicated that
Modular (Mojo 🔥) ▷ #mojo (57 messages🔥🔥):
Mojo Documentation Updates, Mojo Kernel Definition, Feature Development vs. Syntax, Revisiting Early Mojo Decisions, Compute Kernels in Mojo
-
Mojo Documentation Updates Cause Confusion: In recent discussions, members noted confusion regarding the requirement for the
varkeyword in Mojo code after reviewing the Mojo docs. One member highlighted a potential grievance about this, indicating an unresolved issue with the current implementation.- Another member mentioned an upcoming update to the documentation but hasn't confirmed when it will be available, noting that community feedback is welcome.
- Clarifying 'Kernel' Terminology: The term 'kernel' in the context of Mojo was discussed, where members clarified that it refers to a function optimized for execution on GPUs, rather than the operating system context. The term's use varies widely, with one member emphasizing that it should refer to the core computational logic.
- Members agreed that it can signify a pure function typically executed on an accelerator, but its definition may vary depending on the context and can include multiple meanings in mathematics.
- Feature Development Takes Precedence Over Syntax: There was a consensus among members on prioritizing core feature development in Mojo before focusing on syntax improvements. One member pointed out that this approach minimizes the need for rewrites and helps stabilize the language.
- Discussions on whether to keep or remove the
varrequirement revealed varying preferences, highlighting an ongoing conversation about language design. - Hope for Mojo's Future: Several members expressed optimism about Mojo's potential, with one noting the promise of building something special with the language. The conversation indicated ambitions for Mojo to integrate effectively into existing ecosystems alongside established compute kernels like CUDA.
- There was an acknowledgment of the significant work ahead to make Mojo viable for OS kernels and driver development, emphasizing the community's aspirations for its growth.
- Missing Features in Algorithm Reduction: A member inquired about the status of
argmaxandargminin algorithm.reduction, expressing frustration over their absence from the changelog. Concerns were raised about the need to reimplement optimized versions of these functions from scratch.
Link mentioned: Mojo language basics | Modular Docs): Introduction to Mojo's basic language features.
Modular (Mojo 🔥) ▷ #max (13 messages🔥):
Custom Ops in Mojo, MOToMGP Pass Manager Errors, Documentation Issues, Feature Requests for Error Messages, Improving UX for Custom Ops
-
Custom Ops in Mojo face challenges: Users are encountering issues when loading custom ops via MAX, specifically with the mandelbrot kernel not being found.
- One user found that the correct command involves
session.load(graph, custom_ops_paths=Path("kernels.mojopkg"))to resolve the problem. - Errors in MOToMGP Pass Manager: Multiple Unhandled exceptions indicate failures in the MOToMGP pass manager, particularly with missing mojo kernels for custom operations such as get_scalar_from_managed_tensor_slice.
- This highlights the need for clearer error messaging and support for custom ops from Mojo source files.
- Documentation improvements suggested: A member suggested filing issues in the GitHub max repo to tackle the custom op error messaging flaws, particularly related to the 'op not found' error.
- The conversation led to a proposed improvement where the error message directs users to relevant documentation.
- Feature request for better error handling: A feature request was made to enhance the error messaging system to better inform users when a custom op cannot be found.
- The request includes providing guidance on using custom ops effectively and ensuring appropriate documentation is accessible.
- GitHub Issue Linked for Reference: A user linked a GitHub issue regarding custom ops and error handling: Feature Request Issue #269.
- The issue requests a dual improvement target, focusing on better error messages and integration of single compilation unit kernels.
- One user found that the correct command involves
Link mentioned: [Feature Request] Single compilation unit kernels and/or improved error messages · Issue #269 · modularml/max: What is your request? This is a 2-part request, but bundled since they both address the same UX issue. Part one is to make the "custom op not found" error message direct users to documentati...
Latent Space ▷ #ai-general-chat (90 messages🔥🔥):
Nvidia Jetson Orin Nano, Github Copilot Free, 1-800-CHATGPT Experience, AI Video Trends, Google Whisk Tool
-
Nvidia Jetson Orin Nano Super Developer Kit Launch: Nvidia announced the Jetson Orin Nano Super Developer Kit, priced at $249, featuring 67 TOPS neural processing, representing a 70% improvement over its predecessor.
- With 102GB/s memory bandwidth and targeting hobbyists, it aims to enhance AI and robotics projects, despite concerns about its performance sufficiency.
- Github Copilot Free Access: GitHub Copilot has become free for VS Code, as confirmed by Satya Nadella.
- Reactions include skepticism about its limited 50 chats per month and discussions on the implications for competitors like Cursor.
- 1-800-CHATGPT Brings AI to the Phone: Announced by Kevin Weil, users can call 1-800-CHATGPT in the US or message on WhatsApp globally, no account required.
- It's seen as an effective way to engage older users with AI without needing app installation.
- AI Video Models Hitting Their Stride: Discussions around the evolution of AI video models highlight OpenAI's Sora and its transformative impact, creating high-resolution outputs.
- The community noted parallels with past image generation advancements, indicating a growing demand as more models become available.
- Google Whisk Tool Launched: Google Whisk is a new tool designed for generating cute logos and digital art, stirring interest among developers looking for quick solutions.
- Despite enthusiasm, there are concerns regarding its availability, particularly noted by Canadian users who found it inaccessible.
Links mentioned:
- Tweet from Satya Nadella (@satyanadella): GitHub Copilot Free for VS Code has arrived.
- Tweet from Michelle Burgess (@Misslfc): @Pink American Idol did hahah! it sucked you def do it better
- Tweet from Sar Haribhakti (@sarthakgh): Founder of MidJourney
- Tweet from Kevin Weil 🇺🇸 (@kevinweil): Day 10 🎁: 1-800-CHATGPT ✨Call ChatGPT on your phone if you're in the US, or message it on @WhatsApp from anywhere on the planet. It's free, no account needed! Give it a try right now.
- Tweet from Andras Bacsai (@heyandras): Go home Github Copilot. You are drunk.
- Nvidia’s $249 dev kit promises cheap, small AI power: It’s half as expensive as its predecessor.
- Tweet from fofr (@fofrAI): Minimax’s
music-01now on Replicate.Generate up to 1 minute of music using reference songs and lyrics:- use reference songs, vocals and instrumental tracks- optional lyrics- reuse references for fas... - AI video is having its Stable Diffusion moment: no description found
- Whisk: no description found
- Tweet from Vercel (@vercel): Take the State of AI Developer Survey. Help us understand how you're using AI—what you're building, how you're building it, and what challenges you face. https://state-of-ai.vercel.app/
- Tweet from Taelin (@VictorTaelin): WHAT
- Tweet from tldraw (@tldraw): We just launched tldraw computer
- Tweet from web weaver (@deepfates): It's time for the Will Smith test. All the video models on Replicate, prompted with "Will Smith eating spaghetti". Here's the original version from 2023, and a state-of-the-art version...
- no title found: no description found
- - YouTube: no description found
- - YouTube: no description found
- no title found: no description found
Latent Space ▷ #ai-announcements (1 messages):
Sakana AI's EvoMerge, DynoSaur, LLM Paper Club Event
-
Double Header on EvoMerge and DynoSaur: Today features a special double header with presentations on Sakana AI's EvoMerge and DynoSaur, scheduled for 45 minutes from the announcement.
- Members are encouraged to join and participate in the discussions happening in the LLM Paper Club event.
- Upcoming Event Reminder: A reminder was shared to add the Latent.Space events to personal calendars using the RSS feature.
- Please click the RSS logo above the calendar to stay updated with new events and discussions.
Link mentioned: LLM Paper Club (Sakana AI EvoMerge and DynoSaur) · Zoom · Luma: Ramon is joining us for the first time to present…
OpenInterpreter ▷ #general (28 messages🔥):
Open Interpreter Errors, OI 1.x Version, Cloudflare AI Gateway, Truffle AI Computer, Long Term Memory Integration
-
Persistent Open Interpreter Errors: Multiple users expressed frustration with recurring errors when trying to use Open Interpreter, particularly related to loading conversations and API key issues.
- One user lamented the loss of good conversations, leading to a discussion about these persistent issues across different platforms.
- Confusion Over Open Interpreter 1.x Version: Users debated the differences between various versions of Open Interpreter, including questions about accessing version 1.x when currently using 0.34.
- One user noted that OS mode doesn't seem available in 1.0, raising queries about changes in functionality.
- Suggestions for Cloudflare AI Gateway Integration: A member suggested trying Cloudflare AI Gateway as a potential solution for some of the configuration issues with Open Interpreter.
- This sparked discussion about various AI applications and tools that could enhance functionality.
- Introduction to Truffle AI Computer: A user shared insights about the Truffle-1, an AI computing device that operates on-device models with 64GB of unified memory, available for $500 deposit and $115/month.
- They emphasized the ability to write and share apps with the device, fostering interest in practical use cases.
- Long Term Memory Potential: Discussion continued about integrating long term memory capabilities with Open Interpreter for managing codebases effectively.
- Users expressed interest in using local setups with devices like Raspberry Pi to support such integrations.
Links mentioned:
- Truffle: A Personal Agentic Computing stack — the Truffle-1 runs a mixture of models on-device with 64GB of unified memory
- First Of All All Things Are Possible GIF - First Of All All Things Are Possible Jot That Down - Discover & Share GIFs: Click to view the GIF
- Tweet from simp 4 satoshi (@iamgingertrash): To recap:> $500 deposit authorized today> $115/month for 12 months> Infinite inference time compute> Writing & Sharing your own apps> A glowing orb with a 64GB Orin> We're actual...
tinygrad (George Hotz) ▷ #general (27 messages🔥):
Benchmarks for LLaMA models, Mergeability of ShapeTrackers in Lean, Counterexamples in view merging, CuTe layout algebra, Challenges in proving layout injectivity
-
Request for LLaMA model benchmarks: A member inquired if there are any benchmarks available comparing LLaMA models using tinygrad OpenCL against PyTorch CUDA.
- There were no responses or benchmarks provided in the discussion.
- Discussion on ShapeTracker mergeability: Clarification was sought about the objective of a bounty relating to the mergeability of two arbitrary ShapeTrackers in Lean.
- Contributors discussed the impossibility of a general merging criterion due to variables affecting strides and shapes.
- Counterexamples reveal merging issues: One member shared insights about counterexamples indicating that the current merging algorithm struggles with specific view pairs that are not merging correctly.
- They expressed a potential for generating multiple examples from a single issue related to dimensions and overflows.
- CuTe layout algebra and mergeability: A discussion emerged questioning whether mergeability in TinyGrad is analogous to composition in CuTe's layout algebra, linking to resources for deeper understanding.
- Another member noted that proving certain properties in layout algebra, such as necessity and sufficiency, can be quite challenging.
- Injectivity in layout algebra is NP hard: A member expressed skepticism about proving the injectivity in layout algebra, suggesting it may be computationally complex.
- They reasoned that checking both necessity and sufficiency for injectivity could be categorized as NP hard.
Links mentioned:
- A note on the algebra of CuTe Layouts: The core abstraction of NVIDIA’s CUTLASS library for high-performance linear algebra is the CuTe Layout. In this technical note, we give a rigorous, mathematical treatment of the algebra of these l…
- Issues · tinygrad/tinygrad,): You like pytorch? You like micrograd? You love tinygrad! ❤️ - Issues · tinygrad/tinygrad
- cutlass/media/docs/cute/02_layout_algebra.md at main · NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines. Contribute to NVIDIA/cutlass development by creating an account on GitHub.
Torchtune ▷ #dev (25 messages🔥):
FSDP Adjustment, Bug Fix in TRL, Loss Scaling Discussion, Gradient Scaling, Optimizer in Backward Case
-
FSDP Adjustment Needed for Scaling: Members concur that if the FSDP reduce operation averages, scaling by
world_sizeis necessary to undo this effect in the gradient calculation.- This adjustment would involve only changing the call to
scale_gradsin the provided code example, simplifying the implementation. - Potential Bug in TRL: A member suggested that a bug related to scaling exists in the trl library that might be pervasive, implying it could affect other areas as well.
- The discussion hints at an opportunity for a bug fix report styled after Unsloth if the scaling error is confirmed to be widespread.
- Scaling Loss in Training Recipes: There was a consensus among members that scaling the loss directly in the training recipe is preferable for maintaining explicitness and clarity in code.
- Members discussed the implications of scaling strategies, indicating that additional comments should accompany the code modifications for better understanding.
- Gradient Scaling Consideration: The team explored whether adjusting the gradient scaling appropriately in different scenarios might require various solutions, especially in relation to no-sync cases.
- One member emphasized the preference for explicit scaling in the training loop rather than relying on hidden adjustments in hooks.
- Optimizer in Backward Case Fix: An update was made to include a scaling factor for the optimizer_in_bwd case in the ongoing PR, addressing concerns about loss normalization.
- The member noted a clearer approach is being taken to handle scaling directly in the recipe for improved code readability and maintainability.
- This adjustment would involve only changing the call to
Links mentioned:
- torchtune/recipes/full_finetune_distributed.py at 3518492f43a8a5a462cbd604be4101268ff5bd52 · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/torchtune/training/memory.py at main · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- transformers/src/transformers/trainer.py at 052e652d6d53c2b26ffde87e039b723949a53493 · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- Add DDP token averaging for equivalent non-parallel training similar to #34191 · Issue #34242 · huggingface/transformers: Feature request Token averaging in gradient accumulation was fixed in #34191 . But token averaging in DDP seems to have the same issue. Expected behaivor With all the tokens contributing to loss in...
- Fix gradient scaling to account for world_size normalization by mirceamironenco · Pull Request #2172 · pytorch/torchtune: ContextWhat is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here)Please link to any issues this PR addresses.ChangelogW...
- GitHub - pytorch/torchtune at 3518492f43a8a5a462cbd604be4101268ff5bd52: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
Torchtune ▷ #papers (2 messages):
Evolutionary Algorithms, Sakana Scaling, Gradient Techniques
-
Evolutionary Algorithms Spark Interest: Discussion highlighted the interesting use of evolutionary algorithms in current AI methodologies.
- Very interesting that it uses evolutionary algorithms sparked curiosity about its applications.
- Sakana Aims to Compete with Gradients: A member mentioned that Sakana is attempting to scale up evolution to match the performance of existing gradient techniques.
- This effort signals a push towards integrating evolutionary concepts into competitive AI strategies.
DSPy ▷ #show-and-tell (1 messages):
collabin: https://youtu.be/BrvVheleOqc
DSPy ▷ #papers (4 messages):
AI's impact on knowledge economy, Chain of Continuous Thought
-
AI reshapes the knowledge economy through autonomous agents: The paper discusses how autonomous AI agents tend to benefit the most knowledgeable individuals by enabling them to perform routine tasks more efficiently, while non-autonomous AI helps the least knowledgeable by providing access to expert problem-solving.
- As autonomous agents become more prevalent, the dynamic shifts, potentially increasing benefits for those with greater knowledge and skills.
- Coconut proposes unrestrictive reasoning for LLMs: A new approach called Coconut (Chain of Continuous Thought) challenges the idea that language space is always ideal for reasoning in large language models (LLMs), advocating for a latent space model instead.
- It suggests that reducing reliance on textual coherence can enhance the reasoning process, as some essential tokens necessitate complex planning.
Links mentioned:
- Artificial Intelligence in the Knowledge Economy: The rise of Artificial Intelligence (AI) has the potential to reshape the knowledge economy by enabling problem solving at scale. This paper introduces a framework to analyze this transformation, inco...
- Training Large Language Models to Reason in a Continuous Latent Space: no description found
DSPy ▷ #general (11 messages🔥):
TypedReAct Class, RouteLLM Maintenance, DSPy Evolution with Reasoning Models
-
Confusion over
TypedReActUsage: A member expressed uncertainty about sending a PR for their newTypedReActimplementation, stating it works fine but hasn't been fully stress tested.- Another member pointed out that using
TypedChainOfThoughtis unnecessary and suggested removing the 'Typed' from the name since it's deprecated in version 2.5 and removed in 2.6. - RouteLLM's Lack of Maintenance: A user noted that the project RouteLLM seems to be unmaintained and inquired about integrating similar functionality into DSPy.
- No direct response was given regarding the integration but it highlights a concern over project viability moving forward.
- Discussion on DSPy and Reasoning Models: A member questioned ongoing discussions about how DSPy will evolve with new reasoning models, suggesting that fine-tuning might shift towards the branching or process reward level.
- This indicates a potential pivot in focus from traditional prompting to enhancing reward structures within the system.
- Another member pointed out that using
Link mentioned: Agents - DSPy: The framework for programming—rather than prompting—language models.
Nomic.ai (GPT4All) ▷ #general (12 messages🔥):
Jinja template issues, GPT4All CLI usage, Localdocs support in GPT4All, Docker container version
-
Jinja Templates Bug Report: Multiple members discussed issues with Jinja templates, noting problems like spacing errors and unsupported functions such as 'none' and
[1:].- One member highlighted the importance of Jinja for model functionality, while another offered to assist in resolving template errors when posted.
- GPT4All CLI Limitations: A user reported using GPT4All-Cli to access models but faced issues with referencing local documents.
- Another member clarified that the older CLI is not officially supported but the server API can programmatically access local docs when enabled in the GUI.
- Inquiries About Docker Version: A member asked if there is a version of GPT4All that runs from a Docker container with a web UI.
- No responses were provided, leaving the inquiry open.
LlamaIndex ▷ #blog (2 messages):
Agentic AI SDR, Composio platform, Function calling in LlamaIndex, Agentic RAG, ReAct integration
-
Agentic AI SDR generates leads: Check out this agentic AI SDR that generates leads for you, built with LlamaIndex, showcasing its potential in lead generation.
- This SDR symbolizes the innovative applications of LlamaIndex in automating revenue generation tasks.
- Explore Composio for AI agents: The Quickstarters folder serves as a gateway to Composio, enabling users to build intelligent agents for platforms like GitHub and Gmail.
- By leveraging Composio, users can automate tasks and enhance productivity with natural language commands.
- Crash Course on Building Agents: Learn how to build agents from scratch with a crash course from @TRJ_0751 focused on function calling in LlamaIndex.
- Participants will explore three different approaches to handle real-time data queries and create agentic RAGs that route intelligently between tools.
- Creating ReAct with LlamaIndex: The course includes a segment on creating ReAct, showcasing the capabilities of LlamaIndex.
- This integration exemplifies innovative approaches to developing interactive AI agents.
Link mentioned: composio/python/examples/quickstarters at master · ComposioHQ/composio: Composio equip's your AI agents & LLMs with 100+ high-quality integrations via function calling - ComposioHQ/composio
LlamaIndex ▷ #general (4 messages):
OpenAIAgent concurrency, RAG evaluation, Async function execution
-
Exploring OpenAIAgent Concurrency: A member inquired whether
OpenAIAgentfunction executions can be concurrent in an asynchronous environment, distinguishing it from parallel function calling.- They referenced the OpenAI docs explaining the updated feature of parallel function calls in API v. 1.1.0+, while noting that the current implementation does not allow for true parallel computations.
- Async Function Tooling with OpenAIAgent: In response, a member suggested using async entry points with async tools to achieve concurrency in
OpenAIAgentexecutions.
- They provided code snippets illustrating an async function implementation with
FunctionToolandOpenAIAgentto facilitate concurrent behavior. - Interest in RAG Evaluation Discussion: Another member expressed interest in collaborating on RAG evaluation, inviting others to direct message them for a chat.
- This indicates a push for community interaction and knowledge sharing in the area of Retrieval-Augmented Generation.
Link mentioned: Single-Turn Multi-Function Calling OpenAI Agents - LlamaIndex: no description found
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (3 messages):
BFCL Leaderboard Issues, Gorilla Benchmark for Structured Outputs
-
BFCL Leaderboard demo facing issues: A member reported that the function call demo on the BFCL Leaderboard is stuck on 'Loading Model Response...'.
- Another member confirmed this is due to a certificate issue, causing the model endpoint to be down temporarily.
- Interest in Gorilla Benchmark for Evaluating Structured Outputs: A member expressed interest in using the Gorilla benchmark to evaluate how well the model generates text adhering to a provided JSON schema or Pydantic model.
- They inquired if there are any specific subtasks focused on this evaluation within the current framework.
Link mentioned:
Berkeley Function Calling Leaderboard V3 (aka Berkeley Tool Calling Leaderboard V3)
: no description found
LAION ▷ #general (1 messages):
GPT-O1 Reverse Engineering, Technical Reports, Twitter Updates on GPT-O1
-
Seeking GPT-O1 Reverse Engineering Insights: A member inquired if anyone has encountered any reverse engineering efforts related to GPT-O1 and requested sharing of relevant papers, technical reports, or Twitter updates.
- The discussion highlights an emerging interest in GPT-O1 and potential collaborative sharing of resources within the community.
- Call for Collaboration on GPT-O1: Members are encouraged to share any findings about GPT-O1, specifically any technical reports or discussions observed on social media.
- This effort aims to foster community engagement and gather pertinent information regarding the reverse engineering of GPT-O1.
LAION ▷ #research (1 messages):
GenAI Research Internship, Generative AI advancements, Monetization AI team
-
Meta's GenAI Research Internship Opportunity: My team at Meta is offering a research internship focused on generative AI, including areas like text-to-image models and vision-language models. Interested candidates can apply directly here for the position.
- The internship lasts 3–6 months and aims to drive fundamental advances in technology, providing interns the opportunity to make core algorithmic advances at scale.
- Contributions to Generative AI Field: Meta's Monetization Generative AI team seeks individuals passionate about deep learning, computer vision, and natural language processing. Interns will have the chance to impact how people connect and communicate globally.
- The team is dedicated to advancing generative AI research and applying innovative ideas within a fast-growing organization.
Link mentioned: Research Scientist Intern, Monetization AI (PhD): Meta's mission is to build the future of human connection and the technology that makes it possible.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (1 messages):
kallemickelborg: Thank you for that!
Axolotl AI ▷ #general (1 messages):
New engineer for RL, KTO assistance
-
New Engineer Joining for RL Support: A new engineer is set to join the team in January to assist with Reinforcement Learning (RL) initiatives.
- They will also provide support for the KTO project at that time.
- Additional Resource for KTO: The new engineer will contribute to enhancing the capabilities of the KTO system once onboard.
- This addition is expected to boost the overall productivity in RL related tasks.
Mozilla AI ▷ #announcements (1 messages):
Developer Hub Announcement, Blueprints Initiative
-
Developer Hub Launches Exciting Features: A big announcement was made regarding the Developer Hub and its latest features, highlighting the need for community feedback and engagement.
- You can check out the full announcement here for all the details.
- Blueprints Initiative for Open-Source AI Solutions: The Blueprints initiative aims to assist developers in creating open-source AI solutions, providing essential resources and guidance.
- More insights and discussions can be found in this thread here.