[AINews] Gemma 3 beats DeepSeek V3 in Elo, 2.0 Flash beats GPT4o with Native Image Gen
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
GDM is all you need.
AI News for 3/12/2025-3/13/2025. We checked 7 subreddits, 433 Twitters and 28 Discords (224 channels, and 2511 messages) for you. Estimated reading time saved (at 200wpm): 275 minutes. You can now tag @smol_ai for AINews discussions!
Today's o1-preview (at this point the only model competitive with Flash Thinking at AINews tasks, and yes o1-preview is better than o1-full or o3-mini-high) Discord recap is spot on - Google took the occasion of their Gemma Developer Day in Paris to launch a slew of notable updates:

Gemma 3. People are loving that it is 128k context. Other than of course strong LMArena scores for an open model:
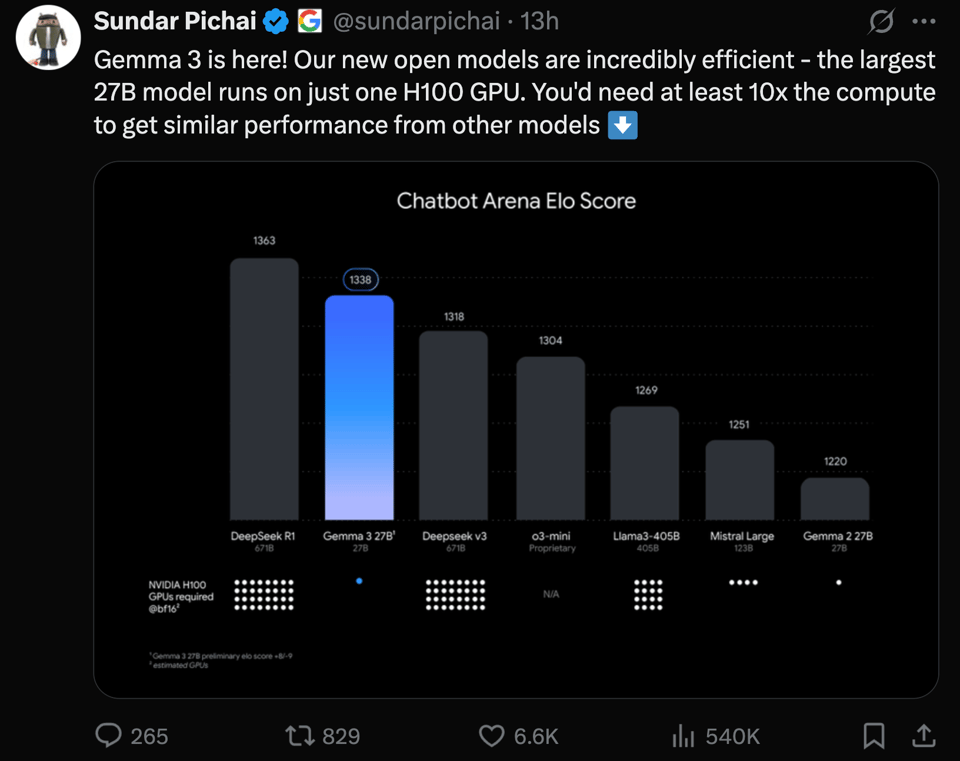
it is also a new Pareto frontier for its weight class by a country mile:
It also looks to completely subsume PaliGemma in incorporating vision as a first class capability (ShieldGemma is still a thing).
Gemini Flash Native Image Generation.
as teased at the Gemini 2 launch (our coverage here), Gemini 2 actually launched image editing, which OpenAI teased and never launched, and the results are pretty spectacular (if you can figure out how to find it in the complicated UI). Image editing has never been this easy.
Super excited to ship Gemini's native image generation into public experimental today :) We've made a lot of progress and still have a way to go, please send us feedback!
— Kaushik Shivakumar (@19kaushiks) March 12, 2025
And yes, I made the image using Gemini. pic.twitter.com/fEV8bCADyo
Anyone who has been in this room knows that it’s never just another day in here! This space has seen the extremes of chaos and genius!
— Mostafa Dehghani (@m__dehghani) March 12, 2025
...and we ship! https://t.co/qcsBMdnlQA
Happy Wednesday everyone! pic.twitter.com/Vkw84aCnfn
completely sota for image editing! both generated and real images
— apolinario 🌐 (@multimodalart) March 12, 2025
great 🚢 from google! i hope to see a gemma with image generation soon too ✨ https://t.co/KBBQIkyv31 pic.twitter.com/4ZCqwIhvDv
I had to try this. Gemini 2.0 Flash Experimental with image output 🤯 https://t.co/EqlH4gKpeV pic.twitter.com/eIEU0pTfng
— fofr (@fofrAI) March 12, 2025
Table of Contents
[TOC]
AI Twitter Recap
Model Releases and Updates: Gemma 3 Family
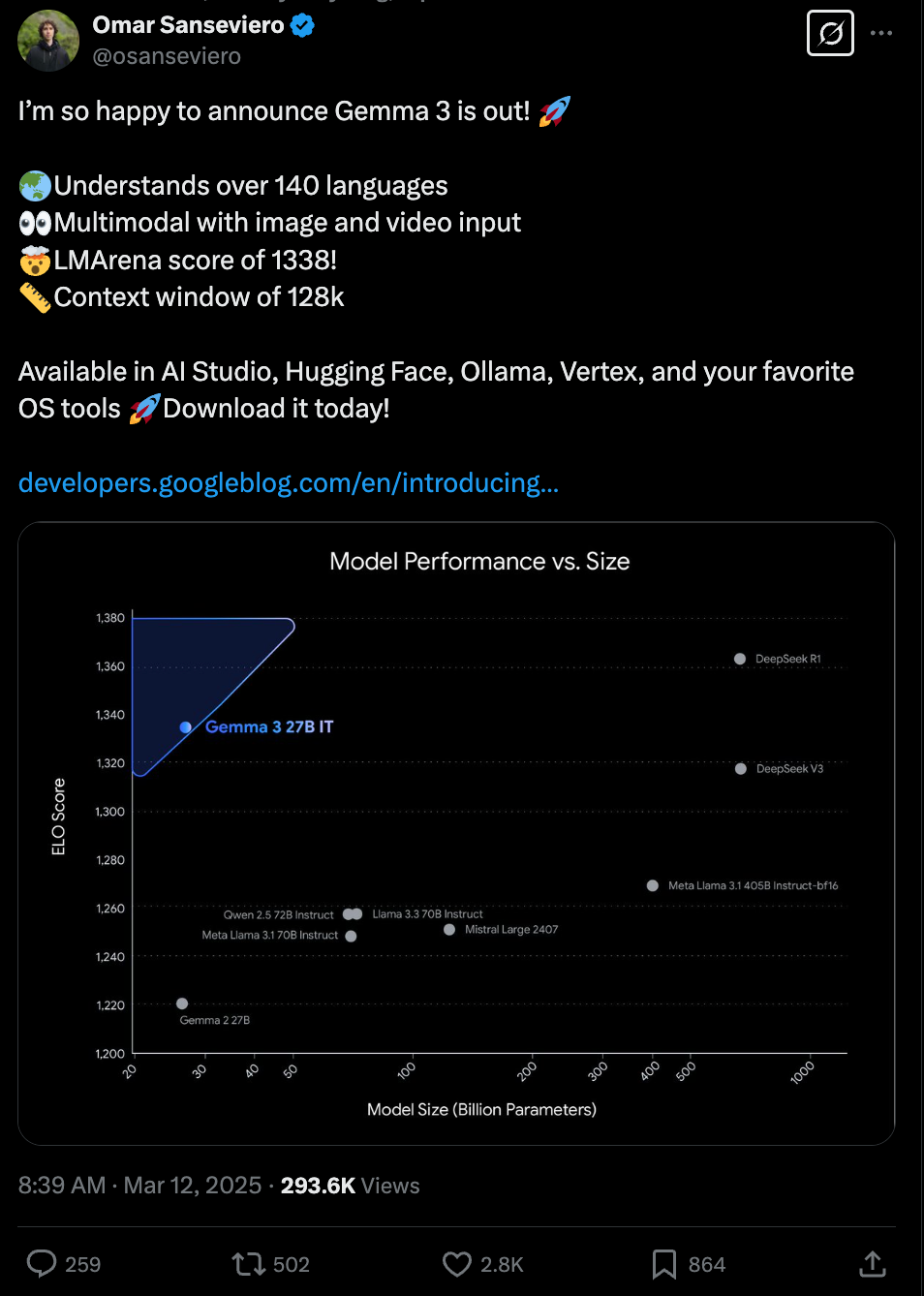
- Gemma 3 Family Release: @osanseviero announced the release of Gemma 3, highlighting its multilingual capabilities (140+ languages), multimodal input (image and video), LMArena score of 1338, and a 128k context window. @_philschmid provided a TL;DR of Gemma 3's key features, including four sizes (1B, 4B, 12B, 27B), #1 ranking for open non-reasoning models in LMArena, text and image inputs, multilingual support, increased context window, and vision encoder based on SigLIP. @reach_vb summarized key Gemma 3 features, noting its performance comparable to OpenAI's o1, multimodal and multilingual support, 128K context, memory efficiency via quantization, and training details. @scaling01 provided a detailed overview of Gemma 3, emphasizing its ranking on LMSLOP arena, performance compared to Gemma 2 and Gemini 1.5 Flash, multimodal support using SigLip, various model sizes, long context window, and training methodology. @danielhanchen also highlighted the release of Gemma 3, noting its multimodal capabilities, various sizes (1B to 27B), 128K context window, and multilingual support, stating the 27B model matches Gemini-1.5-Pro on benchmarks. @lmarena_ai congratulated Google DeepMind on Gemma-3-27B, recognizing it as a top 10 overall model in Arena, 2nd best open model, and noting its 128K context window. @Google officially launched Gemma 3 as their "most advanced and portable open models yet", designed for devices like smartphones and laptops.
- Gemma 3 Performance and Benchmarks: @iScienceLuvr noted Gemma 3's performance, highlighting the 27B model ranking 9th on LMArena, outperforming o3-mini, DeepSeek V3, Claude 3.7 Sonnet, and Qwen2.5-Max. @reach_vb found Gemma3 4B competitive with Gemma2 27B, emphasizing "EXPONENTIAL TIMELINES". @reach_vb questioned if Gemma3 27B is the best non-reasoning LLM, especially in MATH. @Teknium1 compared Gemma 3 to Mistral 24B, noting Mistral is better on benchmarks but Gemma 3 has 4x context and vision.
- Gemma 3 Technical Details: @vikhyatk reviewed the Gemma 3 tech report, mentioning model names match parameter counts and 4B+ models are multimodal. @nrehiew_ shared thoughts on the Gemma 3 tech report, pointing out it lacks detail but provides interesting info. @eliebakouch provided a detailed analysis of the Gemma3 technical report, covering architecture, long context, and distillation techniques. @danielhanchen gave a Gemma-3 analysis, detailing architecture, training, chat template, long context, and vision encoder. @giffmana confirmed Gemma3 goes multimodal, replacing PaliGemma, and is comparable to Gemini1.5 Pro.
- Gemma 3 Availability and Usage: @ollama announced Gemma 3 availability on Ollama, including multimodal support and commands to run different sizes. @_philschmid highlighted testing Gemma 3 27B using the
google-genaisdk. @_philschmid shared a blog on developer information for Gemma 3. @_philschmid shared links to try Gemma 3 in AI Studio and model links. @mervenoyann provided a notebook on video inference with Gemma 3, showcasing its video understanding. @ggerganov announced Gemma 3 support merged in llama.cpp. @narsilou noted Text generation 3.2 is out with Gemma 3 support. @reach_vb provided a space to play with the Gemma 3 12B model.
Robotics and Embodied AI
- Gemini Robotics Models: @GoogleDeepMind introduced Gemini Robotics, AI models for a new generation of robots based on Gemini 2.0, emphasizing reasoning, interactivity, dexterity, and generalization. @GoogleDeepMind announced a partnership with Apptronik to build humanoid robots with Gemini 2.0, and opened Gemini Robotics-ER model to trusted testers like Agile Robots, AgilityRobotics, BostonDynamics, and EnchantedTools. @GoogleDeepMind stated their goal is AI that works for any robot shape or size, including platforms like ALOHA 2, Franka, and Apptronik's Apollo. @GoogleDeepMind explained Gemini Robotics-ER allows robots to tap into Gemini’s embodied reasoning, enabling object detection, interaction recognition, and obstacle avoidance. @GoogleDeepMind highlighted Gemini Robotics' generalization ability by doubling performance on benchmarks compared to state-of-the-art models. @GoogleDeepMind emphasized seamless human interaction with Gemini Robotics' ability to adjust actions on the fly. @GoogleDeepMind showed Gemini Robotics wrapping a timing belt around gears, a challenging task. @GoogleDeepMind demonstrated Gemini Robotics solving multi-step dexterity tasks like folding origami and packing lunch boxes.
- Figure Robot and AGI: @adcock_brett stated Figure will be the ultimate deployment vector for AGI. @adcock_brett shared updates on robotics, noting speed improvements, handling of deformable bags, and transferring neural network weights to new robots, feeling like "getting uploaded to the Matrix!". @adcock_brett described Helix as a tiny light towards solving general robotics. @adcock_brett mentioned their robot runs fully embedded and off-network with 2 embedded GPUs, without needing network calls yet.
AI Agents and Tooling
- Agent Workflows and Frameworks: @LangChainAI announced a Resources Hub with guides on building AI agents, including reports on AI trends and company use cases like Replit, Klarna, tryramp, and LinkedIn. @omarsar0 is hosting a free webinar on building effective agentic workflows with OpenAI's Agents SDK. @TheTuringPost listed 7 open-source frameworks enabling AI agent actions, including LangGraph, AutoGen, CrewAI, Composio, OctoTools, BabyAGI, and MemGPT, and mentioned emerging approaches like OpenAI’s Swarm and HuggingGPT. @togethercompute announced 5 detailed guides on building agent workflows with Together AI, each with deep dive notebooks.
- Model Context Protocol (MCP) and API Integrations: @llama_index announced LlamaIndex integration with Model Context Protocol (MCP), enabling connection to any MCP server and tool discovery in one line of code. @PerplexityAI released Perplexity API Model Context Protocol (MCP), providing real-time web search for AI assistants like Claude. @AravSrinivas announced Perplexity API now supports MCP, enabling real-time information for AIs like Claude. @cognitivecompai presented Dolphin-MCP, an open-source flexible MCP client compatible with Dolphin, ollama, Claude, and OpenAI endpoints. @hwchase17 questioned whether to use llms.txt or MCP for making LangGraph/LangChain more accessible in IDEs.
- OpenAI API Updates: @LangChainAI announced LangChain support for OpenAI's new Responses API, including built-in tools and conversation state management. @sama praised OpenAI's API design as "one of the most well-designed and useful APIs ever". @corbtt found OpenAI's new API shape nicer than Chat Completions API, but wished to skip supporting both APIs.
Performance and Optimization in AI
- GPU Programming and Performance: @hyhieu226 noted warp divergence as a subtle performance bug in GPU programming. @awnihannun released a guide to writing faster MLX and avoiding performance cliffs. @awnihannun highlighted the MLX community's fast support for Gemma 3 in MLX VLM, MLX LM, and MLX Swift for iPhone. @tri_dao will talk about optimizing attention on modern hardware and Blackwell SASS tricks. @clattner_llvm discussed AI compilers like TVM and XLA, and why GenAI is still written in CUDA.
- Model Optimization and Efficiency: @scaling01 speculated that OpenAI might release o1 model soon, as it handles complex tasks better than o3-mini. @teortaxesTex questioned Google's logic in aggressively scaling D with model N for Gemma 3, asking about Gemma-1B trained on 2T and its suitability for speculative decoding. @rsalakhu shared new work on optimizing test-time compute as a meta-reinforcement learning problem, leading to Meta Reinforcement Fine-Tuning (MRT) for improved performance and token efficiency. @francoisfleuret questioned if thermal dissipation is the key issue for making bigger chips.
AI Research and Papers
- Scientific Paper Generation by AI: @SakanaAILabs announced that a paper by The AI Scientist-v2 passed peer review at an ICLR workshop, claiming it's the first fully AI-generated peer-reviewed paper. @hardmaru shared details of this experiment, documenting the process and learnings, and publishing AI-generated papers and human reviews on GitHub. @hardmaru joked about The AI Scientist getting Schmidhubered. @hkproj questioned ICLR's standards after an AI Scientist paper was accepted. @SakanaAILabs acknowledged citation errors by The AI Scientist, attributing "an LSTM-based neural network" incorrectly, and documented errors in human reviews.
- Diffusion Models and Image Generation: @iScienceLuvr highlighted a paper on improved text-to-image alignment in diffusion models using SoftREPA. @iScienceLuvr shared a paper on Controlling Latent Diffusion Using Latent CLIP, training a CLIP model in latent space. @teortaxesTex called a new algorithmic breakthrough a "rare impressive" development that may end Consistency Models and potentially diffusion models.
- Long-Form Music Generation: @iScienceLuvr shared work on YuE, a family of open foundation models for long-form music generation, capable of generating up to five minutes of music with lyrical alignment.
- Mixture of Experts (MoE) Interpretability: @iScienceLuvr highlighted MoE-X, a redesigned MoE layer for more interpretable MLPs in LLMs.
- Gemini Embedding: @_akhaliq shared Gemini Embedding, generalizable embeddings from Gemini.
- Video Creation and Editing AI: @_akhaliq presented Alibaba's VACE, an All-in-One Video Creation and Editing AI. @_akhaliq shared a paper on Tuning-Free Multi-Event Long Video Generation via Synchronized Coupled Sampling.
- Attention Mechanism and Softmax: @torchcompiled claimed softmax use in attention is arbitrary and there's a "bug" affecting LLMs, linking to a new post. @torchcompiled critiqued attention for lacking a "do nothing" option and suggested temperature scaling should depend on sequence length.
Industry and Business
- AI in Business and Applications: @AravSrinivas stated Perplexity API can generate PowerPoints, essentially replacing consultant work with an API call. @mustafasuleyman announced Copilot integration in GroupMe, providing in-app AI support for millions of users, especially US college students. @yusuf_i_mehdi highlighted Copilot in GroupMe making group chats less chaotic and helpful for homework, suggestions, and replies. @TheTuringPost discussed the need to go beyond basic AI skills and embrace synthetic data, RAG, multimodal AI, and contextual understanding, emphasizing AI literacy for everyone. @sarahcat21 noted coding is easier, but software building remains hard due to data management, state management, and deployment challenges. @mathemagic1an highlighted shadcn/ui integration as part of v0's success, praising Notion's UI kit for knowledge work apps.
- AI Market and Competition: @nearcyan noted Google is expected to DOUBLE in value after Anthropic reaches a $14T valuation. @mervenoyann joked about Google "casually killing other models" with Gemma 3. @scaling01 claimed Google beats OpenAI to market with Gemini 2.0 Flash, demonstrating its image recreation capability. @LoubnaBenAllal1 stated Google joins the "smol models club" with Gemma3 1B, showing a timeline of accelerating smol model releases and a heating up space. @scaling01 predicted if OpenAI doesn't release GPT-5 soon, it will be o1 dominating.
- Hiring and Talent in AI: @fchollet advertised for machine learning engineers passionate about European defense to join Harmattan, a vertically integrated drone startup. @saranormous, in a thread about startup hiring, emphasized prioritizing hiring early to avoid a vicious cycle. @SakanaAILabs is hiring a Cybersecurity Engineer for AI business initiatives. @giffmana expressed being happy at OpenAI for smart people, interesting work, and a "preference towards getting shit done." @teortaxesTex stated China will graduate hundreds of ML grads of high caliber this year. @rsalakhu congratulated Dr. Murtaza Dalal on completing his PhD.
- AI Infrastructure and Compute: @svpino promoted Nebius Explorer Tier offering H100 GPUs at $1.50 per hour, highlighting its cheapness and immediate provisioning. @dylan522p announced a hackathon with over 100 B200/GB200 GPUs, featuring speakers from OpenAI, Thinking Machines, Together, and Nvidia. @dylan522p praised Texas Instruments Guangzhou for cheaper IC parts compared to US distributors. @teortaxesTex analyzed Huawei's datacenter hardware from 2019, noting its capabilities and the impact of sanctions. @cHHillee will be at GTC talking about ML systems and Blackwell GPUs.
Memes and Humor
- AI Capabilities and Limitations: @scaling01 joked about reinventing Diffusion models and suggested Google should train a reasoning model on image generation to fix spelling errors. @scaling01 found Gemini 2.0 Flash iteratively improving illegible text in memes via prompting. @scaling01 posted "checkmate" with an image comparing Google and OpenAI. @goodside showed Gemini 2.0 Flash adding "D" to "BASE" on a T-shirt in an uploaded image. @scaling01 created a Google vs OpenAI image meme using text-to-image generation. @c_valenzuelab joked about needing a captcha system for AIs to prove you are not human. @scaling01 used #savegoogle hashtag humorously. @scaling01 used "checkmate" meme in the context of Google vs OpenAI.
- AI and Society: @oh_that_hat suggested treating people online the way you want AI to treat you, as AI will learn from online interactions. @c_valenzuelab discussed the gap between aesthetic values and practical preferences regarding automation and authenticity. @jd_pressman shared an imagined scenario of showing a screenshot from 2015 clarifying AI capabilities to someone from that time. @jd_pressman differentiated AI villains that are like GPT (The Master, XERXES, Dagoth Ur, Gravemind) from those that are not (HAL 9000, GladOS, 343 Guilty Spark, X.A.N.A.). @qtnx_ shared "my life is an endless series of this exact gif" with a relevant gif. @francoisfleuret shared a Soviet citizen joke related to Swiss and Russian officers and watches.
- General Humor and Sarcasm: @teortaxesTex posted "It's over. The meme has been reversed. funniest thing I've read today" with a link. @teortaxesTex sarcastically said "LMAO the US is so not ready for that war".
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Gemma 3 Multimodal Release: Vision, Text, and 128K Context
- Gemma 3 Release - a google Collection (Score: 793, Comments: 218): Gemma 3 has been released as a Google Collection, though the post lacks further details or context on its features or implications.
- Gemma 3 Features and Issues: Users noted that Gemma 3 does not support tool calling and has issues with image input, specifically in the gemma-3-27b-it on AIstudio. The model architecture is not recognized by some platforms like Transformers, and it is not yet running on LM Studio.
- Performance and Comparisons: The 4B Gemma 3 model surpasses the 9B Gemma 2, and the 12B model is noted for its strong vision capabilities. Despite its high performance, users report it crashes often on ollama and lacks functionality like function calling. EQ-Bench results show the 27b-it model in second place for creative writing.
- Model Availability and Technical Details: Gemma 3 models are available on platforms like ollama and Hugging Face, with links provided for various resources and technical reports. The models support up to 128K tokens and feature Quantization Aware Training to reduce memory usage, with ongoing work to add more versions to Hugging Face.
- Gemma 3 27b now available on Google AI Studio (Score: 313, Comments: 61): Gemma 3 27B is now available on Google AI Studio with a context length of 128k and an output length of 8k. More details can be found on the Google AI Studio and Imgur links provided.
- Users discussed the system prompt and its impact on Gemma 3's responses, noting it can sometimes provide information beyond its supposed cutoff date, as observed when asked about events post-2021. Some users reported different experiences regarding its ability to handle logic and writing tasks, with comparisons made to Gemma 2 and its limitations.
- Performance issues were highlighted, with several users mentioning that Gemma 3 is currently slow, although it shows improvement in following instructions compared to Gemma 2. There were also discussions about its translation capabilities, with some stating it outperforms Google Translate and DeepL.
- Links to Gemma 3's release on Hugging Face were shared, providing access to various model versions. Users expressed anticipation for open weights and benchmarks to better evaluate the model's performance and capabilities.
- Gemma 3 on Huggingface (Score: 154, Comments: 27): Google's Gemma 3 models are available on Huggingface in sizes of 1B, 4B, 12B, and 27B parameters, with links provided for each. They accept text and image inputs, with a total input context of 128K tokens for the larger models and 32K tokens for the 1B model, and produce outputs with a context of 8192 tokens. The model has been added to Ollama and boasts an ELO of 1338 on Chatbot Arena, surpassing DeepSeek V3 671B.
- Model Context and VRAM Requirements: The 27B Gemma 3 model requires a significant 45.09GB of VRAM for its 128K context, which poses challenges for users without high-end GPUs like a second 3090. The 8K refers to the output token context, while the input context is 128K for the larger models.
- Model Performance and Characteristics: Users compare the 27B Gemma 3 model to the 1.5 Flash but note it behaves differently, similar to Sonnet 3.7, by providing extensive responses to simple questions, suggesting potential as a Systems Engineer tool.
- Running and Compatibility Issues: Some users face issues with running the model on Ollama due to version incompatibility, but updating the software resolves this. GGUFs and model versions are available on Huggingface, and users should be cautious of double BOS tokens when deploying the model.
Theme 2. Unsloth's GRPO Modifications: Llama-8B's Self-Learning Improvements
- I hacked Unsloth's GRPO code to support agentic tool use. In 1 hour of training on my RTX 4090, Llama-8B taught itself to take baby steps towards deep research! (23%→53% accuracy) (Score: 655, Comments: 49): I modified Unsloth's GRPO code to enable Llama-8B to use tools agentically, enhancing its research skills through self-play. In just one hour of training on an RTX 4090, the model improved its accuracy from 23% to 53% by generating questions, searching for answers, evaluating its success, and refining its research ability through reinforcement learning. You can find the full code and instructions.
- Users expressed curiosity about the reinforcement learning (RL) process, particularly the dataset creation and continuous weight adjustment. The author explained that they generate and filter responses from the LLM to create a dataset for fine-tuning, repeating this process iteratively.
- There is significant interest in applying this method to larger models like Llama 70B and 405B, with the author mentioning efforts to set up FSDP for further experimentation.
- The community showed strong support and interest in the project, with suggestions to contribute to the Unsloth repository, and appreciation for sharing the work, highlighting its potential industry relevance during the "year of agents."
- Gemma 3 - GGUFs + recommended settings (Score: 171, Comments: 76): Gemma 3, Google's new multimodal models, are now available in 1B, 4B, 12B, and 27B sizes on Hugging Face, with both GGUF and 16-bit versions uploaded. A step-by-step guide on running Gemma 3 is provided here, and recommended inference settings include a temperature of 1.0, top_k of 64, and top_p of 0.95. Training with 4-bit QLoRA has known bugs, but updates are expected soon.
- Temperature and Performance Issues: Users confirmed that Gemma 3 operates at a temperature of 1.0, which is not considered high, yet some users report performance issues, such as slower speeds compared to other models like Qwen2.5 32B. A user using an RTX 5090 noted Gemma 3's slower performance, with the 4B model running slower than the 9B model, prompting further investigation by the Gemma team.
- System Prompt and Inference Challenges: Discussions highlighted that Gemma 3 lacks a native system prompt, requiring users to incorporate system instructions into user prompts. Additionally, there are issues with running GGUF files in LM Studio, and dynamic 4-bit inference is recommended over GGUFs, but not yet uploaded due to transformer issues.
- Quantization and Model Compatibility: The IQ3_XXS quant for Gemma2-27B is noted for its small size of 10.8 GB, making it feasible to run on a 3060 GPU. Users debated the accuracy of claims about VRAM requirements, with some asserting that 16GB of VRAM is insufficient for the 27B model, while others argue it runs effectively with Q8 cache quantization.
Theme 3. DeepSeek R1 on M3 Ultra: Insights into SoC Capabilities
- M3 Ultra Runs DeepSeek R1 With 671 Billion Parameters Using 448GB Of Unified Memory, Delivering High Bandwidth Performance At Under 200W Power Consumption, With No Need For A Multi-GPU Setup (Score: 380, Comments: 159): DeepSeek R1 operates with 671 billion parameters on the M3 Ultra using 448GB of unified memory, achieving high bandwidth performance while consuming less than 200W power. This setup eliminates the need for a multi-GPU configuration.
- Discussions focus heavily on the prompt processing speed and context size limitations of the DeepSeek R1 on the M3 Ultra, with multiple users expressing frustration over the lack of specific data. Users highlight that even with 18 tokens per second, the time to start generation at large context sizes is impractical, often taking several minutes.
- There is skepticism about the practicality of Apple Silicon for local inference of large models, with many users noting that the M3 Ultra's performance, despite its impressive specs, is not suitable for complex tasks such as context management or training. Users argue that NVIDIA and AMD offerings, though more power-intensive, might be more effective for these tasks.
- The discussion includes the potential of KV Cache to improve performance on Mac systems, but users note limitations when handling complex context management. Additionally, the feasibility of connecting eGPUs for enhanced processing is debated, with some users noting the lack of support for Vulkan on macOS as a barrier.
- EXO Labs ran full 8-bit DeepSeek R1 distributed across 2 M3 Ultra 512GB Mac Studios - 11 t/s (Score: 143, Comments: 37): EXO Labs executed the full 8-bit DeepSeek R1 distributed processing on two M3 Ultra 512GB Mac Studios, achieving a performance of 11 transactions per second (t/s).
- Discussions highlight the cost and performance trade-offs of using M3 Ultra Mac Studios compared to other hardware like GPUs. While the Mac Studios offer a compact and quiet setup, they face criticism for slow prompt processing speeds and high expenses, particularly in RAM and SSD pricing, despite being energy-efficient and space-saving.
- The conversation emphasizes the importance of batching for maximizing throughput on expensive hardware setups like the Mac Studios, contrasting with GPU clusters that can handle multiple requests in parallel. Comparisons are made to alternative setups like H200 clusters, which, despite higher costs and power consumption, offer significantly faster performance in batching scenarios.
- There is a notable demand for prompt processing metrics, with several users expressing frustration over the lack of these figures in the results shared by EXO Labs. The time to first token was noted at 0.59 seconds for a short prompt, but users argue this isn't sufficient to gauge overall performance.
Theme 4. Gemma 3 Open-Source Efforts: Llama.cpp and Beyond
- Gemma 3 - Open source efforts - llama.cpp - MLX community (Score: 160, Comments: 12): Gemma 3 is released with open-source support, highlighting collaboration between ngyson, Google, and Hugging Face. The announcement, shared by Colin Kealty and Awni Hannun, underscores community efforts within the MLX community and acknowledges key contributors, celebrating the model's advancements.
- The vLLM project is actively integrating Gemma 3 support, though there are doubts about meeting release schedules based on past performance. Links to relevant GitHub pull requests were shared for tracking progress.
- Google's contribution to the project has been praised for its unprecedented speed and support, particularly in aiding the integration with llama.cpp. This collaboration is noted as a significant first, with excitement around trying Gemma 3 27b in LM Studio.
- The collaboration between Hugging Face, Google, and llama.cpp has been highlighted as a successful effort to make Gemma 3 accessible quickly, with special recognition given to Son for their contributions.
- QwQ on high thinking effort setup one-shotting the bouncing balls example (Score: 115, Comments: 18): The post discusses Gemma 3 and its compatibility with the open-source MLX community, specifically focusing on the high-effort setup required to efficiently execute the bouncing balls example.
- GPU Offloading and Performance: Users discuss optimizing the bouncing balls example by offloading processing to the GPU, with one user achieving 21,000 tokens using Llama with 40 GPU layers. However, they encountered issues with ball disappearance and needed to adjust parameters like gravity and friction for better performance.
- Thinking Effort Control: ASL_Dev shares a method to control the model's thinking effort by adjusting the
</think>token's logit, achieving a working simulation with a thinking effort set to 2.5. They provide a GitHub link for their experimental setup, which improved the simulation's performance compared to the regular setup. - Inference Engine Customization: Discussions highlight the potential for inference engines to allow manual adjustments of reasoning effort, similar to OpenAI's models. Users note that platforms like openwebui already offer this feature, and there is interest in adding weight adjusters for reasoning models to enhance customization.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. DeepSeek and ChatGPT Censorship: Observations and Backlash
- DeepSeek forgot who owns it for a second (Score: 6626, Comments: 100): The post discusses DeepSeek, highlighting a momentary lapse in the AI's recognition of its ownership, which raises concerns about potential AI censorship. The lack of detailed context or analysis in the post leaves the specific implications of this incident open to interpretation.
- Censorship Concerns: Users express frustration with AI systems generating full responses only to retract them, suggesting a mechanism that checks content post-generation for "forbidden subjects." This approach is seen as less elegant compared to systems like ChatGPT, where guardrails are integrated into the AI's logic, highlighting transparency issues in AI censorship.
- China Censorship: There is speculation that the censorship mechanism might be a form of "malicious compliance" against China's censorship policies, with some users suggesting that the system's poor implementation is intentional to highlight censorship issues.
- Technical Suggestions: Users propose that AI systems should generate full responses, run them through filters, and then display them to avoid the current practice of streaming answers that might be revoked, which is seen as inefficient and user-unfriendly.
- DeepSeek Forgot Its Own Owner......... (Score: 234, Comments: 11): The title of the post, "DeepSeek Forgot Its Own Owner", suggests confusion or controversy surrounding the ownership of DeepSeek, potentially reflecting broader issues related to censorship. Without additional context or video analysis, further details are unavailable.
- Social Media Commentary: Users express dissatisfaction with Reddit as a platform, with one comment sarcastically noting it as "one of the social media platforms of all time," while another highlights the preservation of its social aspect before media.
- Censorship and Satire: Comments allude to censorship issues, with a satirical remark referencing Xi Jinping and a humorous take on a "social credit ad" at the end of the video, indicating a critique of censorship or control mechanisms.
- Technical Observation: A user points out a technical detail about DeepSeek, observing a brief slowdown when only three letters are left, humorously attributing it to "facepalming the red button."
Theme 2. Claude Sonnet 3.7: A Standout in Coding Conversion Tasks
- Claude Sonnet 3.7 Is Insane at Coding! (Score: 324, Comments: 126): Claude Sonnet 3.7 excels at converting complex JavaScript applications to Vue 3, as demonstrated by its ability to restructure a 4,269-line app with 2,000 lines of JavaScript into a Vue 3 app in a single session. It effectively maintained the app's features, user experience, and component dependencies, implementing a proper component structure, Pinia stores, Vue Router, and drag-and-drop functionality, showcasing significant improvements over Claude 3.5.
- Discussions highlight Claude 3.7's ability to replace traditional BI tools and analysts, with one user sharing how it transformed Mixpanel CSV data into a comprehensive dashboard in minutes, saving significant costs associated with BI tools and analysts.
- Users share mixed experiences with Claude 3.7, with some praising its ability to create complex applications without bugs, while others criticize its tendency to overachieve and hallucinate features, reflecting a broader debate on AI's effectiveness in coding.
- There is a humorous observation about the community's polarized views on Claude 3.7, with some users finding it either revolutionary or problematic, illustrating the diverse and sometimes contradictory nature of AI tool evaluations.
Theme 3. Open-Source Text-to-Video Innovations: New Viral Demos
- I Just Open-Sourced 8 More Viral Effects! (request more in the comments!) (Score: 565, Comments: 41): Eight viral AI text-to-video effects have been open-sourced, inviting the community to request additional effects in the comments.
- Open-source and Accessibility: The effects are open-sourced, allowing anyone with a capable computer to run them for free, or alternatively, rent a GPU on platforms like Runpod for approximately $0.70 per hour. Generative-Explorer provides a detailed explanation on how to set up and use the Wan 2.1 model with ComfyUI and LoRA nodes, along with a tutorial link for beginners.
- Effect Details and Community Engagement: The post author, najsonepls, highlights the viral success of the effects trained on the Wan2.1 14B I2V 480p model, listing effects such as Squish, Crush, Cakeify, Inflate, Deflate, 360 Degree Microwave Rotation, Gun Shooting, and Muscle Show-off. The community discusses potential new effects like aging and expresses interest in the open-source nature, which enables further customization and innovation.
- Concerns and Industry Impact: Users speculate whether big companies might restrict similar effects behind paywalls, but Generative-Explorer argues that open-source alternatives can be developed quickly by training a LoRA using a few videos. The discussion also touches on the impact of effects like Inflation and Deflation on niche content areas, such as the NSFW Tumblr scene.
Theme 4. Spain's AI Content Labeling Mandate: Legal and Societal Implications
- Spain to impose massive fines for not labelling AI-generated content (Score: 212, Comments: 22): Spain is introducing a mandate requiring labels on AI-generated content, with non-compliance resulting in massive fines. This regulation aims to enhance transparency and accountability in the use of AI technologies.
- Detection Challenges: Concerns are raised about the effectiveness of AI detection methods, with references to existing issues in schools where AI detection software generates false positives. Questions arise about Spain's approach to accurately identifying AI-generated content without unfairly penalizing individuals.
- Skepticism and Critique: There is skepticism about the focus on AI-generated content labeling, with suggestions to prioritize addressing corruption and preferential treatment in legislative processes instead of minor issues like traffic tickets and school projects.
- Regulatory Impact: Some users express that the regulation might lead to a reduction in AI use in Spain, either as a positive step for peace of mind or as a negative consequence that might discourage AI application in the country.
Theme 5. Symbolism of the ✨ Emoji: Emergence as an AI Icon
- When did the stars ✨ become the symbol for AI generated? Where did it come from? (Score: 200, Comments: 42): The post inquires about the origin and popularization of the ✨ emoji as a symbol for AI-generated content, noting its widespread presence in news articles, social media, and applications like Notepad. The accompanying image uses star and dot graphics to evoke the emoji's association with sparkle or magic, but lacks any textual explanation.
- Jasper was one of the earliest adopters of the ✨ emoji to signify AI-generated content in early 2021, preceding major companies like Google, Microsoft, and Adobe, which began using it between 2022-2023. By mid-2023, design communities had started debating its status as an unofficial standard for AI, and by late 2023, it was recognized in mainstream media as a universal AI symbol.
- The ✨ emoji is linked to the concept of magic and auto-correction, reminiscent of the magic wand icon used by Adobe over 30 years ago. This association with magic and automatic improvement has contributed to its widespread adoption as a symbol for AI-generated content.
- Several resources explore the emoji's history and adoption, including a Wikipedia entry, a YouTube video, and an article by David Imel on Substack, offering insights into its evolution as an AI icon.
AI Discord Recap
A summary of Summaries of Summaries by o1-preview-2024-09-12
Theme 1: Google's New Multimodal Marvels Take the AI Stage
- Gemma 3 Steals the Spotlight with Multilingual Mastery: Google releases Gemma 3, a multimodal model ranging from 1B to 27B parameters with a 128K context window, supporting over 140 languages. Communities buzz about its potential to run on a single GPU or TPU.
- Gemini 2.0 Flash Paints Pictures with Words: Gemini 2.0 Flash now supports native image generation, letting users create contextually relevant images directly within the model. Developers can experiment via Google AI Studio.
- Gemini Robotics Brings AI to Life—Literally!: Google showcases Gemini Robotics in a YouTube video, demonstrating advanced vision-language-action models that enable robots to interact with the physical world.
Theme 2: New AI Models Challenge the Big Guys
- OlympicCoder Leaps Over Claude 3.7 in Coding Hurdles: The compact 7B parameter OlympicCoder model surpasses Claude 3.7 in olympiad-level coding challenges, proving that size isn't everything in AI performance.
- Reka Flash 3 Speeds Ahead in Chat and Code: Reka releases Flash 3, a 21B parameter model excelling in chat, coding, and function calling, featuring a 32K context length and available for free.
- Swallow 70B Swallows the Competition in Japanese: Llama 3.1 Swallow 70B, a superfast Japanese-capable model, joins OpenRouter, expanding language capabilities and offering lightning-fast responses.
Theme 3: AI Tools Can't Catch a Break
- Codeium Coughs Up Protocol Errors, Developers Gasp: Users report protocol errors like "invalid_argument: protocol error: incomplete envelope" in Codeium's VSCode extension, leaving code completion in the lurch.
- Cursor Crawls After Update, Users Sprint Back to Previous Version: After updating to version 0.46.11, Cursor IDE becomes sluggish, prompting users to recommend downloading version 0.47.1 to restore performance.
- Apple ID Login Goes Rotten on Perplexity's Windows App: Perplexity AI users encounter a 500 Internal Server Error when logging in with Apple ID, while those using Google accounts sail smoothly.
Theme 4: Innovation Sparks in AI Tool Integration
- OpenAI Agents SDK Hooks Up with MCP: The OpenAI Agents SDK now supports the Model Context Protocol (MCP), letting agents seamlessly aggregate tools from MCP servers for more powerful AI interactions.
- Glama AI Spills the Beans on All Tools Available: Glama AI's new API lists all available tools per server, exciting users with an open catalog of AI capabilities.
- LlamaIndex Leaps into MCP Integration: LlamaIndex integrates with the Model Context Protocol, enhancing its abilities by tapping into tools exposed by any MCP-compatible service.
Theme 5: Debates Heat Up Over LLM Behaviors
- "LLMs Can't Hallucinate!" Skeptics Exclaim: Heated debates erupt over whether LLMs can "hallucinate," with some arguing that since they don't think, they can't hallucinate—sparking philosophical showdowns in AI communities.
- LLMs Get a Face-lift with Facial Memory Systems: An open-source LLM Facial Memory System lets LLMs store memories and chats based on users' faces, adding a new layer of personalized interaction.
- ChatGPT's Ethical Reminders Irk Users Seeking Unfiltered Replies: Users express annoyance at ChatGPT's frequent ethical guidelines popping up in responses, wishing for an option to "turn off the AI nanny" and streamline their workflow.
PART 1: High level Discord summaries
Cursor IDE Discord
- Claude 3.7 Suffers Overload: Users reported high load issues with Claude 3.7, encountering errors and sluggishness during peak times, suggesting coding at night to avoid the issues and sharing a link to a Cursor forum thread on the topic.
- The 'diff algorithm stopped early' error was a frequently reported issue.
- Cursor Slows Down with Version .46: Users observed Cursor becoming very sluggish on both Macbook and PC after updating to version 0.46.11 and recommended downloading version 0.47.1.
- The performance degradation occurred even with low CPU utilization, while issues with pattern-matching for project rules were fixed in a later version.
- Manus AI Generates Sales Leads: Members discussed using Manus AI for lead generation and building SaaS landing pages, highlighting its ability to retrieve numbers, leading to a reported 30 high-quality leads after spending $600.
- OpenManus Attempts Replication of Functionality: Users shared that OpenManus, an open-source project trying to replicate Manus AI, is showing promise and provided a link to the GitHub repository and a YouTube video showcasing its capabilities.
- Some members believe it's not yet on par with Manus.
- Cline's Code Completion Costs Criticized: Members debated the value of Cline due to its high cost relative to Cursor.
- While Cline offers a 'full context window,' some users argue that Cursor's caching system allows for expanding context in individual chats and provides features like web search and documentation.
LM Studio Discord
- LM Studio Gets Schooled by Gemma 3: LM Studio 0.3.13 now supports Google's Gemma 3 family, but users reported that Gemma 3 models are performing significantly slower, up to 10x slowdown, compared to similar models.
- The team is also working on ironing out issues such as users struggling to disable RAG completely and problems with the Linux installer.
- Raging About RAG Removal: Users seek to turn off RAG completely in LM Studio to inject the full attachment into the context, but there's currently no UI option to disable it.
- As a workaround, users copy and paste documents manually, facing the hassle of converting PDFs to Markdown.
- AMD GPU Owner's Hot Spot Headache: Users are reporting 110°C hotspot temperatures on their 7900 XTX, sparking RMA eligibility discussions and concerns that AIBs cheaped out on thermals, with one report that AMD declines such RMA requests.
- It was pointed out the underlying issues might be bad batch of vapour chambers with not enough water inside, and PowerColor has said yes on RMA requests.
- Mining Card Revival as Inference Workhorse: Members are discussing reviving the CMP-40HX mining card with 288 tensor cores for AI inference.
- Interest is being undermined by the need to patch Nvidia drivers to enable 3D acceleration support.
- PTM7950 Thermal Paste Pumps Up: Members pondered using PTM7950 (phase change material) instead of thermal paste to prevent pump-out issues and maintain stable temperatures.
- After the first heat cycle, excessive material pumps out and forms a thick and very viscous layer around the die, preventing any more pump out.
Nous Research AI Discord
- Nous Research Launches Inference API: Nous Research released its Inference API featuring Hermes 3 Llama 70B and DeepHermes 3 8B Preview, offering $5.00 of free credits for new accounts.
- A waitlist system has been implemented at the Nous Portal, granting access on a first-come, first-served basis.
- LLMs Now Recognize Faces, Remember Chats: A member open-sourced a LLM Facial Memory System that lets LLMs store memories and chats based on your face.
- Members discussed the inference API, including the possibility of pre-loading credits due to concerns about API key security.
- Crafting Graph Reasoning System with Open Source Code: Members discussed how there is enough public information to build a graph reasoning system with open source code, though perhaps not as good as Forge, with the new API providing 50€ worth of credit for inference.
- It was mentioned that Kuzu is amazing and for graph databases, networkx + python is recommended.
- Audio-Flamingo-2 Flunks Key Detection: A user tested Nvidia's Audio-Flamingo-2 on HuggingFace to detect song keys and tempos, but had mixed results, even missing the key on simple pop songs.
- For example, when asked to identify the key of the song Royals by Lorde, Audio-Flamingo-2 incorrectly guessed F# Minor, with a tempo of 150 BPM, to the community's laughter.
Unsloth AI (Daniel Han) Discord
- Gemma 3 Gets GGUF Goodness: All GGUF, 4-bit, and 16-bit versions of Gemma 3 have been uploaded to Hugging Face.
- These quantized versions are designed to run in programs that use llama.cpp such as LM Studio and GPT4All.
- Transformers Tangle Thwarts Tuning: A breaking bug in Transformers is preventing the fine-tuning of Gemma 3, with HF actively working on a fix, according to a blog post update on Unsloth AI.
- Users are advised to wait for the official Unsloth notebooks to ensure compatibility once the bug is resolved.
- GRPO Generalizes Great!: The discussion covered the nuances of RLHF methods such as PPO, DPO, GRPO, and RLOO, with a member noting that GRPO generalizes better and provides a direct replacement for PPO.
- RLOO is a newer version of PPO where advantages are based on the normalized reward score of group responses, as developed by Cohere AI.
- HackXelerator Hits London, Paris, Berlin: A member announced a London, Paris, Berlin multimodal creative AI HackXelerator supported by Mistral, HF, and others.
- The multi-modal creative AI HackXelerator supported by Mistral AI, Hugging Face, AMD, and others will take place in London, Paris, and Berlin, focusing on music, art, film, fashion, and gaming, starting April 5, 2025 (lu.ma/w3mv1c6o).
- Tuning into Temperature Temps for Ollama: Many people are experiencing issues with 1.0 temp and are suggesting running in 0.1 in Ollama.
- Testing is encouraged to see if it works better in llama.cpp and other programs.
Perplexity AI Discord
- ANUS AI Agent Creates Buzz: The GitHub repo nikmcfly/ANUS sparked humorous discussions due to its unfortunate name, with one member jokingly suggesting TWAT (Think, Wait, Act, Talk pipeline) as an alternative acronym.
- Another member proposed Prostate as a government AI agent name, furthering the comical exchange.
- Apple ID Login Triggers Server Error: Users reported experiencing a 500 Internal Server Error when attempting Apple ID login for Perplexity’s new Windows app.
- This issue appears specific to Apple ID, as Google login was functioning correctly for some users.
- Model Selector Appears and Disappears: In the new web update, the model selector initially disappeared, causing user frustration due to the inability to select specific models like R1.
- The model selector reappeared later, with users suggesting setting the mode to "pro" or using the "complexity extension" to resolve selection issues.
- Perplexity Botches Code Cleanup: A user shared their 6-hour ordeal, detailing how Perplexity failed to properly clean up an 875-line code file, resulting in broken code chunks and links.
- Despite struggling with message length limitations, Perplexity ultimately returned the original, unmodified code.
- MCP Server Connector Launched: The API team announced the release of their Model Context Protocol (MCP) server, encouraging community feedback and contributions via GitHub.
- The MCP server acts as a connector for the Perplexity API, enabling web search directly within the MCP ecosystem.
aider (Paul Gauthier) Discord
- Gemma 3 Hits the Scene!: Google has launched Gemma 3, a multimodal model ranging from 1B to 27B parameters, boasting a 128K context window and compatibility with 140+ languages as per Google's blog.
- The models are designed to be lightweight and efficient, aiming for optimal performance on single GPUs or TPUs.
- OlympicCoder Smashes Coding Tasks!: The OlympicCoder model, a compact 7B parameter model, surpasses Claude 3.7 in olympiad-level coding challenges, according to a tweet and Unsloth.ai's blogpost.
- This feat underscores the potential for highly efficient models in specialized coding domains.
- Fast Apply Model Quickens Edits!: Inspired by a deleted Cursor blog post, the Fast Apply model, is a Qwen2.5 Coder Model fine-tuned for rapid code updates, as discussed on Reddit.
- The model addresses the need for faster application of search/replace blocks in tools like Aider, enhancing code editing workflows.
- Aider's Repo Map Gets Dropped!: Users are opting to disable Aider's repo map for manual file additions to have better control over context, despite Aider's usage tips recommending explicit file additions as the most efficient method, see official usage tips.
- The aim is to prevent the LLM from being distracted by excessive irrelevant code.
- LLMs Supercharge Learning: Members shared that LLMs greatly accelerate learning languages like Python and Go, citing a productivity boost that allows them to undertake projects previously deemed unjustifiable.
- One member noted it's not about faster work, but enabling projects that wouldn't have been possible otherwise, characterizing AI as a Cambrian explosion level event.
OpenAI Discord
- Perplexity Defeats OpenAI for Deep Research: A member ranked Perplexity as superior to OpenAI and SuperGrok for in-depth research, especially when dealing with uploaded documents and internet searches, acknowledging the budget concerns of users.
- The user sought advice on choosing between ChatGPT, Perplexity, and Grok, which led to the recommendation of Perplexity for its research capabilities.
- Ollama Orchestrates Optimal Model Deployment: When asked about the best language for deploying AI transformer models, a member suggested using Ollama as a service, particularly if faster inference speed/performance is desired.
- The user had been prototyping with Python and was exploring whether C# could offer better performance, leading to the Ollama recommendation.
- LLMs Can't Hallucinate, Say Skeptics: A member contended that the term hallucination is misapplied to LLMs because LLMs do not possess the capacity to think and are simply generating word sequences based on probability.
- A second member added that sometimes it switches models by mistake, and pointed to an attached image.
- Gemini's Image Generation Causes Impressment: Members raved about Google's release of Gemini's native image capabilities, highlighting its free availability and ability to see the images it generated for better regeneration.
- This feature, which allows for improved image regeneration with text, was showcased in the Gemini Robotics announcement.
- Ethical ChatGPT Ruffles Feathers: Users expressed annoyance with ChatGPT's frequent ethical reminders, which they perceive as unnecessary, unwanted, and disruptive to their workflow.
- One user remarked that they wish there was an option to disable these ethical guidelines.
HuggingFace Discord
- HF Course Explains Vision Language Models: The Hugging Face Computer Vision Course includes a section introducing Vision Language Models (VLMs), covering multimodal learning strategies, common datasets, downstream tasks, and evaluation.
- The course highlights how VLMs harmonize insights from diverse senses to enable AI to understand and interact with the world more comprehensively, unifying insights from diverse sensory inputs.
- TensorFlow Tweaks Toted for Top Tier Throughput: A member shared a blog post about GPU configuration with TensorFlow, covering experimental functions, logical devices, and physical devices, using TensorFlow 2.16.1.
- The member explored techniques and methods for GPU configuration, drawing from experiences using an NVIDIA GeForce RTX 3050 Laptop GPU to process a 2.8 million image dataset, leveraging the TensorFlow API Python Config to improve execution speed.
- Modal Modules Model Made Available: A member shared a YouTube tutorial on deploying the Wan2.1 Image to Video model for free on Modal, covering seamless modal installations and Python scripting.
- Instructions were given on how to use this GGUF format finetune of Gemma 2b using a Modelfile.
- Local Models Liberate Language Learning: A user shared a code snippet for using local models with
smolagentswithlitellmandollamausingLiteLLMModelspecifying topip install smolagents[litellm]and then callinglocalModel = LiteLLMModel(model_id="ollama_chat/qwen2.5:14b", api_key="ollama").- Users report that use of the default
hfApiModelcreates payment required errors after only a few calls to the Qwen inference API, but specifying local models circumvents the limitation.
- Users report that use of the default
- Agent Architecture Annoyances Await Arrival: Users are eagerly awaiting the release of Unit 2.3, which covers LangGraph, originally scheduled for release on March 11th.
- A user noted that overwriting the
agent_namevariable with a call result leads to the agent becoming uncallable, prompting discussion on prevention strategies.
- A user noted that overwriting the
OpenRouter (Alex Atallah) Discord
- Gemma 3 Introduces Multimodal Capabilities: Google launches Gemma 3 on OpenRouter, a multimodal model supporting vision-language input and text output, with a context window of 128k tokens and understanding over 140 languages.
- Reka Flash 3 Excels in Chat and Coding: Reka releases Flash 3, a 21 billion parameter language model that excels in general chat, coding, and function calling, featuring a 32K context length optimized via reinforcement learning (RLOO).
- This model has weights under the Apache 2.0 license and is available for free and is primarily an English model.
- Swallow 70B Adds Japanese Fluency: A new superfast Japanese-capable model named Llama 3.1 Swallow 70B joins OpenRouter, expanding the platform's language capabilities.
- This complements the launch of Reka Flash 3 and Google Gemma 3, enhancing the variety of language processing tools available on OpenRouter.
- Gemini 2 Flash Generates Images Natively: Google's Gemini 2.0 Flash now supports native image output for developer experimentation across all regions supported by Google AI Studio, accessible via the Gemini API and an experimental version (gemini-2.0-flash-exp).
- This allows the creation of images from both text and image inputs, maintaining character consistency and enhancing storytelling capabilities, as announced in a Google Developers Blog post.
- OpenRouter's Chutes Provider Stays Free: The Chutes provider remains free for OpenRouter users as they prepare their services and scale up, without a fully implemented payment system.
- While data isn't explicitly trained on, OpenRouter cannot guarantee that compute hosts won't use the data, given its decentralized nature.
Eleuther Discord
- Distill Community Kicks Off Monthly Meetups: The Distill community is launching monthly meetups, with the next one scheduled for March 14 from 11:30am-1pm ET, after a successful turnout.
- Details can be found in the Exploring Explainables Reading Group doc.
- TTT Supercharges Model Priming: Members discussed how TTT accelerates the process of priming a model for a given prompt, shifting the model's state to be more receptive, by performing a single gradient descent pass.
- The model optimizes the compression of sequences to produce useful representations, thus enhancing ICL and CoT capabilities, by aiming to learn and execute multiple gradient descent passes per token.
- Decoder-Only Architectures Embrace Dynamic Computation: A minor proposal suggests using the decoder side for dynamic computation, extending sequence length for internal thinking via a TTT-like layer by reintroducing a concept from encoder-decoders to decoder-only architectures.
- A challenge is determining extra sampling steps, but measuring the delta of the TTT update loss and stopping when below a median value could help.
- AIME24 Implementation Emerges, Testing Still Needed: An implementation of AIME24 appeared in the lm-evaluation-harness, based on the MATH implementation.
- The submitter admits that they haven't had time to test it yet, due to the lack of documentation of what people are running when they run AIME24.
GPU MODE Discord
- Funnel Shift's H100 Performance: Engineers were surprised to discover that a funnel shift seems faster than equivalent operations on H100, potentially due to using a less congested pipe.
- Despite trying
prmtinstructions, consistently using the predicated funnel shift performs better, resulting in 4shf.r.u32, 3shf.r.w.u32and 7lop3.lutSASS instructions.
- Despite trying
- TensorFlow's OpenCL Flame War: A discussion was sparked by an interesting flame war from 2015 regarding OpenCL support in TensorFlow.
- The debate highlights the early prioritization of CUDA and the difficulties encountered while integrating OpenCL support.
- Turing gets FlashAttention: An implementation of FlashAttention forward pass for the Turing architecture was shared, supporting
head_dim = 128, vanilla attention, andseq_lendivisible by 128.- This implementation shows a 2x speedup compared to Pytorch's
F.scaled_dot_product_attentionwhen tested on a T4.
- This implementation shows a 2x speedup compared to Pytorch's
- Modal Runners Conquer Vector Addition: Test submissions to leaderboard
vectoraddon GPUS: T4 using Modal runners succeeded!- Submissions with id 1946 and 1947 demonstrated the reliability of Modal runners for GPU-accelerated computations.
- H100 memory allocation mishaps: A member asked about why modifying memory allocation in h100.cu of ThunderKittens, to directly allocate memory for
o_smem, results in an illegal memory access was encountered error.- They are looking to understand the cause of this error within the specified H100 GPU kernel.
Interconnects (Nathan Lambert) Discord
- Gemma 3 claims Second Place: The Gemma-3-27b model secured second place in creative writing, potentially becoming a favorite for creative writing and RP fine tuners, detailed in this tweet.
- Open weight models like Gemma 3 are also driving down margins on API platforms and being increasingly adopted due to privacy/data considerations.
- Gemini 2.0 Flash Brings Image Generation: Gemini 2.0 Flash now features native image generation, optimized for chat iteration, allowing users to create contextually relevant images and generate long text in images, as mentioned in this blog post.
- DeepMind also introduced Gemini Robotics, a Gemini 2.0-based model designed for robotics and aimed at solving complex problems through multimodal reasoning.
- AlphaXiv Creates ArXiv Paper Overviews: AlphaXiv uses Mistral OCR with Claude 3.7 to generate blog-style overviews for arXiv papers, providing figures, key insights, and clear explanations from the paper with one click, according to this tweet.
- It generates beautiful research blogs with figures, key insights, and clear explanations.
- ML Models in Copyright Crosshairs: Ongoing court cases are examining whether training a generative machine learning model on copyrighted data constitutes a copyright violation, detailed in Nicholas Carlini's blogpost.
- Deep Learning as Farming?: A member shared a link to a post by Arjun Srivastava titled 'On Deep-Learning and Farming' which explores mapping concepts from one field to another.
- The author contrasts engineering, where components are deliberately assembled, with cultivation, where direct construction is not possible, Cultivation is like farming and engineering is like building a table.
Nomic.ai (GPT4All) Discord
- Bigger Brains, Better Benchmarks: A user inquired about the performance gap between ChatGPT premium and GPT4All's LLMs, with another user attributing it to the larger size of models.
- The discussion recommended downloading bigger models from Hugging Face contingent on adequate hardware.
- Ollama Over GPT4All For Server Solutions?: A user questioned the suitability of GPT4All for a server tasked with managing multiple models, quick loading/unloading, RAG with regularly updating files, and APIs for date/time/weather.
- The user cited issues with Ollama and sought advice regarding its viability given low/medium compute availability.
- Deepseek Details: 14B is the Way: In a query for a ChatGPT premium equivalent, Deepseek 14B was suggested, contingent on having 64GB RAM.
- The advice was to begin with smaller models like Deepseek 7B or Llama 8B, scaling up based on system performance.
- Context is Key: 4k is OK: The discussion emphasized the importance of large context windows, exceeding 4k tokens, to accommodate more information in prompts, such as documents.
- A user then asked if a screenshot they posted was one of these models, inquiring about its context window capabilities.
- Gemma Generation Gap: GPT4All Glitches: A user suggested testing GPT4All with tiny models to evaluate the workflow for loading, unloading, and RAG (with LocalDocs), noting that the GUI doesn't support multiple models simultaneously.
- They noted that Gemma 3 is currently incompatible with GPT4All and needs a newer version of llama.cpp, and included an image of the error.
MCP (Glama) Discord
- Glama API dumps tool data: A new Glama AI API endpoint now lists all available tools, offering more data per server than Pulse.
- Users expressed excitement about the freely available information.
- MCP Logging details servers POV: The server sends log messages according to the Model Context Protocol (MCP) specification, specifically declaring a
loggingcapability and emitting log messages with severity levels and JSON-serializable data.- This allows for structured logging from servers to clients, controlled via the MCP.
- Wolfram to the Rescue to Render Images in Claude: A member pointed to a wolfram server example that takes rendered graphs and returns an image by base64 encoding the data and setting the mime type.
- It was noted that Claude has limitations rendering outside of the tool call window.
- NPM Package location revealed: NPM packages are stored in
%LOCALAPPDATA%, specifically underC:\Users\YourUsername\AppData\Local\npm-cache.- The location contains the NPM packages and source code.
- OpenAI Agents SDK supports MCP: MCP support has been added to the OpenAI Agents SDK, available as a fork on GitHub and on pypi as the openai-agents-mcp package, allowing agents to aggregate tools from MCP servers.
- Setting the
mcp_serversproperty enables seamless integration of MCP servers, local tools, and OpenAI-hosted tools through a unified syntax.
- Setting the
Codeium (Windsurf) Discord
- Codeium Extension Suffers Protocol Errors: Users reported protocol errors like "invalid_argument: protocol error: incomplete envelope: read tcp... forcibly closed by the remote host" in the VSCode extension, causing the Codeium footer to turn red.
- This issue particularly affected users in the UK and Norway with providers such as Hyperoptic and Telenor.
- Neovim Support Struggles to Keep Up: A user criticized the state of Neovim support, citing completion errors (error 500) and expressing concern it lags behind Windsurf.
- In response to the criticism, a team member replied the team is working on it.
- Mixed Results from Test Fix Deployment: The team deployed a test fix, and while some users reported fewer errors, others still faced issues, with the extension either "turning off" or remaining red.
- These mixed results prompted further investigation by the team.
- EU Users Discover VPN Workaround: The team confirmed that users in the EU experienced issues such as "unexpected EOF" during autocomplete and an inability to link files inside chat.
- As a workaround, connecting to Los Angeles via VPN resolved the issue for affected users.
Yannick Kilcher Discord
- Gemini Robotics Comes to Life: Google released a YouTube video showcasing Gemini Robotics, bringing Gemini 2.0 to the physical world as their most advanced vision language action model.
- The model enables robots that can interact with the physical world, featuring enhanced physical interaction capabilities.
- Gemma 3 Drops with 128k Context Window: Gemma 3 is released with multimodal capabilities and a 128k context window (except for the 1B model), meeting user expectations.
- While the release garnered attention, one user commented that it twas aight.
- Sakana AI's Paper Passes Peer Review: A paper generated by Sakana AI has passed peer review for an ICLR workshop.
- A user questioned the rigor of the review process, suggesting the workshop might be generous to the authors.
- Maxwell's Demon Constrains AI Speed: A member shared that computers can compute with arbitrarily low energy by going both backwards and forwards, but the speed limit is how fast and certain you run the answer, referencing this YouTube video.
- They also linked another video about reversing entropy, tying computational limits to fundamental physics.
- Adaptive Meta-Learning Projects Welcomed: A member is seeking toy projects to test Meta-Transform and Adaptive Meta-Learning, starting with small steps using Gymnasium.
- They also linked to a GitHub repo for Adaptive Meta-Learning (AML).
Latent Space Discord
- Mastra Framework Aims for Million AI Devs: Ex-Gatsby/Netlify builders announced Mastra, a new Typescript AI framework intended to be easy for toy projects and reliable for production, according to their blog post.
- Aimed at frontend, fullstack, and backend developers, the creators seek to offer a dependable and simple alternative to existing frameworks, encouraging community contributions to their project on GitHub.
- Cursor's Embedding Model Claims SOTA: Cursor has trained a SOTA embedding model focused on semantic search, reportedly surpassing competitors' out-of-the-box embeddings and rerankers, according to a tweet.
- Users are invited to feel the difference in performance when using the agent.
- Gemini 2.0 Flash Generates Native Images: Google is releasing native image generation in Gemini 2.0 Flash for developer experimentation across supported regions via Google AI Studio, detailed in a blog post.
- Developers can test this feature using an experimental version of Gemini 2.0 Flash (gemini-2.0-flash-exp) in Google AI Studio and the Gemini API, combining multimodal input, enhanced reasoning, and natural language understanding to create images, as highlighted in a tweet.
- Jina AI Dives Into DeepSearch Details: Jina AI has shared a blog post outlining the practical implementation of DeepSearch/DeepResearch, with a focus on late-chunking embeddings for snippet selection and rerankers to prioritize URLs before crawling.
- The post suggests shifting focus from QPS to depth through read-search-reason loops for improved answer discovery.
Notebook LM Discord
- Users Mobile Habits Probed in Research: Google is seeking NotebookLM users for 60-minute interviews to discuss their mobile usage and provide feedback on new concepts, with a $75 USD thank you gift offered, interested participants are directed to complete a screener form (link) to determine eligibility.
- Google is conducting a usability study on April 2nd and 3rd, 2025, to gather feedback on a product in development, offering participants the localized equivalent of $75 USD for their time requiring a high-speed internet connection, an active Gmail account, and a **computer with video camera, speaker, and microphone.
- NoteBookLM as Internal FAQ: A member is considering using NoteBookLM Plus as an internal FAQ and wants to investigate the content of unresolved questions.
- They seek advice on how to examine questions users typed into the chat that were not resolved.
- NLM+ Generates API Scripts!: A member found NLM+ surprisingly capable at generating scripts using API instructions and sample programs.
- They noted it was easier to get revisions as a non-programmer by referencing material from the notebook.
- RAG vs Full Context Window Showdown: A user is questioning whether using RAG with vector search and a smaller context window is better than using Gemini Pro with its full context window for a large database.
- They're curious about the context window size used in RAG and ask for recommendations on achieving their task of having a mentor-like AI by using Gemini Pro.
- Inline Citations Preserved, Hooray!: Users can now save chat responses as notes with inline citations preserved in their original form.
- This enhancement allows users to refer back to the original source material, addressing a long-standing request from power users; Additionally a user requested the ability to copy and paste inline citations into a document while preserving the links.
Torchtune Discord
- MPS Device Mishap Mars Momentum: An
AttributeErrorrelated to missingtorch.mpsattributes emerged after a recent commit (GitHub commit), potentially disabling MPS support.- A proposed fix via PR #2486 led to subsequent torchvision errors when running on MPS.
- Gemma 3 Gains Ground: A member pointed out changes to the Gemma 3 model, attaching a screenshot from Discord CDN detailing these changes.
- The nature and implications of these changes were not discussed in further detail.
- Pan & Scan Pondering: The implementation of the Gemma3 paper's Pan & Scan technique, which enhances inference, was discussed for its necessity in torchtune.
- A member posited that it wasn't critical, suggesting the use of vLLM with the HF ckpt could achieve better performance, referring to this pull request.
- vLLM Victorious with HF ckpt: For enhanced performance with Gemma3, one can use the HF checkpoint with vLLM.
- This is made possible via this pull request.
LlamaIndex Discord
- LlamaIndex Connects to Model Context Protocol: LlamaIndex now integrates with the Model Context Protocol (MCP), which streamlines tool discovery and utilization, as described in this tweet.
- The Model Context Protocol integration allows LlamaIndex to use tools exposed by any MCP-compatible service, enhancing its capabilities.
- LlamaExtract Shields Sensitive Data On-Prem: LlamaExtract now offers on-premise/BYOC (Bring Your Own Cloud) deployments for the entire Llama-Cloud platform, addressing enterprise concerns about sensitive data.
- However, a member noted that these deployments typically incur a much higher cost than utilizing the SaaS solution.
- LlamaIndex Eyes the Response API: A user inquired about support for the new Response API, suggesting its potential to enrich results using a search tool with user opt-in.
- A member responded affirmatively, stating that they are trying to work on that today.
LLM Agents (Berkeley MOOC) Discord
- Quiz Deadlines Pushed to May: All quiz deadlines are scheduled for May, according to the latest announcements.
- Users were instructed to check the latest email regarding Lecture 6 for more details.
- Learners Want Lab and Research: A member inquired about plans for Labs as well as research opportunities for the MOOC learners.
- No further information was available.
Cohere Discord
- Cohere Multilingual Pricing MIA?: A member inquired about the pricing of the Cohere multilingual embed model, noting difficulty finding this information in the documentation.
- No specific details or links about pricing were shared in the discussion.
- OpenAI's Responses API Simplifies Interactions: OpenAI released their Responses API alongside the Agents SDK, emphasizing simplicity and expressivity, documented here.
- The API is designed for multiple tools, turns, and modalities, addressing user issues with current APIs, exemplified in the OpenAI cookbook.
- Cohere and OpenAI API Compatibility in Question: A member asked about the potential for Cohere to be compatible with OpenAI's newly released Responses API.
- The new API is designed as a solution for multi-turn interactions, hosted tools, and granular context control.
- Chat API Seed Parameter Problem Arises: A user noted that the chat API seemingly disregards the
seedparameter, resulting in diverse outputs despite using the same inputs and seed value.- Multiple users are reporting inconsistent outputs when using the Chat API with the same
seedvalue, suggesting a potential issue with reproducibility.
- Multiple users are reporting inconsistent outputs when using the Chat API with the same
DSPy Discord
- DSPy Caching Mechanism: A member asked about how caching works in DSPy and if the caching behavior is modifiable.
- Another member pointed to a pull request for a pluggable Cache module currently in development, indicating upcoming flexibility.
- Pluggable Cache Module in Development: The pull request introduces a single caching interface with two cache levels: in-memory LRU cache and fanout (on disk).
- This development aims to provide a more versatile and efficient caching solution for DSPy.
Modular (Mojo 🔥) Discord
- Modular Max Spawn Update: A member shared a GitHub Pull Request that hopefully will end up looking like their project, adding functionality to spawn and manage processes from exec files.
- However, first the foundations PR has to be merged and then there are some issues with Linux exec that need to be resolved.
- Linux Exec Snags Modular Max Update: The release of the new feature is currently on hold, grappling with unresolved issues surrounding Linux exec, as it awaits the green light from the foundations PR.
- Despite the hurdle, the developer voiced optimism for a close release, promising subscribers updates on the PR's course.
Gorilla LLM (Berkeley Function Calling) Discord
- Discover Central Hub Tracking Evaluation Tools: A member inquired about a central place to track all the tools used for evaluation in the context of Berkeley Function Calling Leaderboard.
- Another member suggested the directory gorilla/berkeley-function-call-leaderboard/data/multi_turn_func_doc as a potential resource.
- Evaluation Dataset Location Pinpointed: A member asked if all the evaluation dataset is available in the
gorilla/berkeley-function-call-leaderboard/datafolder.- There were no further messages to confirm whether that folder contains all evaluation datasets.
AI21 Labs (Jamba) Discord
- RAG Ditches Pinecone: The RAG formerly relied on Pinecone, but due to its subpar performance and inability to support VPC deployment, a shift in strategy became necessary.
- These constraints prompted the team to explore alternative solutions better suited to their performance and deployment needs.
- VPC Deployment Drives Change: The lack of VPC deployment support in the existing RAG infrastructure necessitated a re-evaluation of the chosen technologies.
- This limitation prevented secure and private access to resources, making it a critical factor in the decision to explore alternative solutions.
The tinygrad (George Hotz) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (468 messages🔥🔥🔥):
Claude 3.7 high load issues, Cursor UI sluggishness, Manus AI and OpenManus, Cline vs Cursor, MCP for Blender
- Claude 3.7 struggles under high demand: Users reported difficulties with Claude 3.7 due to high demand, experiencing issues like the 'diff algorithm stopped early' error and high load, especially during peak hours.
- Some members suggested coding at night to avoid traffic, and one user linked to a Cursor forum thread discussing the ongoing issue.
- Cursor UI performance degrades in version .46: A user reported that Cursor became extremely sluggish on both their Macbook and PC, even with low CPU utilization, while using version 0.46.11.
- Another member recommended downloading version 0.47.1 to resolve pattern-matching issues with project rules, suggesting the description is key for relevance.
- Manus AI generates lead generation and sales opportunities: Members discussed Manus AI for tasks like lead generation and building SaaS landing pages, with one user praising its ability to retrieve numbers and claiming it generated 30 high-quality leads after spending $600 a month.
- OpenManus attempts a replication: Users shared that OpenManus, an open-source project attempting to replicate Manus AI, showing some promise, with one member linking to the OpenManus GitHub repository and a YouTube video showcasing its capabilities.
- However, some members felt it was not on par with Manus, with one user joking that the name choice was questionable given its similarity to 'urAnus', while another user explained that Manus meant 'hand' in Latin.
- Cline's costly code completion comes under fire: Members debated the value of Cline, citing its high cost compared to Cursor, with discussions centering on context window size and overall capabilities.
- While Cline boasts a 'full context window,' some users argued that Cursor's caching system allows for growing context in individual chats and has better features like web search and documentation.
- Discord: no description found
- Manus: Manus is a general AI agent that turns your thoughts into actions. It excels at various tasks in work and life, getting everything done while you rest.
- Manus: Manus is a general AI agent that turns your thoughts into actions. It excels at various tasks in work and life, getting everything done while you rest.
- Manus: Manus is a general AI agent that turns your thoughts into actions. It excels at various tasks in work and life, getting everything done while you rest.
- Tweet from Trae (@Trae_ai): 🚀 Connect More, Ship More!Today's Trae update brings:- Custom model integration is now live!- Remote SSH support for Ubuntu 20/22/24 & Debian 11/12More features are coming soon. #DevTools #AI #T...
- Reddit - Dive into anything: no description found
- Tweet from Logan Kilpatrick (@OfficialLoganK): Introducing YouTube video 🎥 link support in Google AI Studio and the Gemini API. You can now directly pass in a YouTube video and the model can usage its native video understanding capabilities to us...
- Tweet from siddharth ahuja (@sidahuj): 🧩 Built an MCP that lets Claude talk directly to Blender. It helps you create beautiful 3D scenes using just prompts!Here’s a demo of me creating a “low-poly dragon guarding treasure” scene in just a...
- Tweet from Mckay Wrigley (@mckaywrigley): Watch for a 14min demo of me using Manus for the 1st time.It’s *shockingly* good.Now imagine this in 2-3 years when:- it has >180 IQ- never stops working- is 10x faster- and runs in swarms by the 1...
- GitHub - mannaandpoem/OpenManus: No fortress, purely open ground. OpenManus is Coming.: No fortress, purely open ground. OpenManus is Coming. - mannaandpoem/OpenManus
- GitHub - oslook/cursor-ai-downloads: All Cursor AI's official download links for both the latest and older versions, making it easy for you to update, downgrade, and choose any version. 🚀: All Cursor AI's official download links for both the latest and older versions, making it easy for you to update, downgrade, and choose any version. 🚀 - oslook/cursor-ai-downloads
- Changelog | Cursor - The AI Code Editor: New updates and improvements.
- GitHub - jamesliounis/servers at james-perplexity/add-perplexity-mcp-server: Model Context Protocol Servers. Contribute to jamesliounis/servers development by creating an account on GitHub.
- servers/src/perplexity-ask/README.md at f9dd1b55a4ec887878f0770723db95d493c261a2 · jamesliounis/servers: Model Context Protocol Servers. Contribute to jamesliounis/servers development by creating an account on GitHub.
- Claude 3.7-thinking permanently 'High Load'!: Claude 3.7-thinking permanently ‘High Load’!!! I have been trying now for the last 4 hours having tried hundreds on times i am guessing and it is permanently in this state!! It worked fine all day y...
- Manus AI is being replicated in Open Source – Here’s What OpenManus Can Do: Manus AI looks fantastic, and there is a team trying to replicate this opensource in public! Definitely worth checking it out.My Links 🔗👉🏻 Subscribe: ht...
LM Studio ▷ #announcements (1 messages):
LM Studio 0.3.13, Google Gemma 3 support, Bug Fixes
- *LM Studio* gets Gemma 3 support!: LM Studio 0.3.13 is now available, featuring support for Google's Gemma 3 family of multi-modal models, including both GGUF and MLX models.
- LM Studio squashes bugs!: The new release fixes bugs such as preventing users from accidentally setting the models directory inside the LM Studio installation directory, settings button jumping around, and issues with the developer logs and server page sidebar.
- See the full release notes for details.
Link mentioned: Download LM Studio - Mac, Linux, Windows: Discover, download, and run local LLMs
LM Studio ▷ #general (136 messages🔥🔥):
LM Runtime, Gemma 3 Support, Turn off RAG in LM Studio, Gemma 3 Model Problems, Image Support with Gemma 3
- LM Studio Team Teases Gemma 3 Support: The LM Studio team is working on bringing in Gemma 3 support**, which will be ready soon, but will not work until then, as of this message.
- Users Struggle to Disable RAG in LM Studio: Users are seeking ways to turn off RAG completely in LM Studio to inject the full attachment into the context, but there's currently no UI option to disable it or modify the number of chunks retrieved.
- A user suggested manually copying and pasting documents as a workaround, while others noted the hassle of converting PDFs to Markdown from reference management systems.
- Gemma 3: Vision Support and Troubleshooting: Users reported issues running Gemma 3 models, with text-only generation in MLX being bugged; the solution is to use GGUF or provide an image.
- Some users also found that they had to download mmproj-model-f16.gguf from Hugging Face and include it in the same model directory to get image support working after updating to LM Studio 0.3.13.
- Slowdown City: Gemma 3 Performance Dips: Users are reporting that Gemma 3 models are performing significantly slower than other models of similar size, with one user noting a 10x slowdown on an M1 MacBook Pro.
- It was speculated that the slowness is due to an inefficient runtime or the fact that the Gemma 3 implementation in llama.cpp may not be as optimized as other models.
- LM Studio Linux Build Lost in the Ether: Users reported a 404 error when trying to download the Linux installer for LM Studio version 0.3.13-1 from installers.lmstudio.ai.
- The team is checking on the issue, with one user humorously noting, "umm, why is linux installer missing?"
- no title found: no description found
- lmstudio-community/gemma-3-27b-it-GGUF at main: no description found
- GitHub - Draconiator/LM-Studio-Chat: Contribute to Draconiator/LM-Studio-Chat development by creating an account on GitHub.
- bartowski/google_gemma-3-27b-it-GGUF at main: no description found
- Tutorial: How to Run Gemma 3 effectively | Unsloth Documentation: How to run Gemma 3 effectively with our GGUFs on llama.cpp, Ollama, Open WebUI, LM Studio.
- The Rock Yoinky Sploinky GIF - The Rock Yoinky Sploinky Smell - Discover & Share GIFs: Click to view the GIF
- Danser Supporter GIF - Danser Supporter Encourager - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #hardware-discussion (201 messages🔥🔥):
ROCm on RX 9000 series, 9070XT reliability, 7900XTX thermal issues, CMP-40HX as an inference card, Phase change thermal paste alternatives
- Vulkan vs ROCm Performance Variance Reported: Some members experienced that Vulkan is way slower than ROCm, but to test it, one can downgrade to driver 24.10.1.
- Members pointed out that ROCm support is available on 7900 XTX and 7900 XT, but not on 7800 XT and below, also a member claimed that the 9070 broke and the PC won't boot with it.
- XTX Hotspot Temperatures Spark RMA Discussions: A member reported 110°C hotspot temperatures on their 7900 XTX, leading to discussions about RMA eligibility and AIBs cheaping out on thermals.
- There was some reports that AMD declines such RMA requests, but PowerColor has said yes, in reality it was due to a bad batch of vapour chambers with not enough water inside.
- Exploring CMP-40HX for AI Inference: Members discussed using a CMP-40HX (mining card) for AI inference, which has 288 tensor cores.
- A member was discouraged by the need to patch Nvidia drivers to enable 3D acceleration support on the card as pointed out in this Github repo.
- Phase Change Material Gains Traction Over Thermal Paste: Members pondered using PTM7950 (phase change material) instead of thermal paste to prevent pump-out issues and maintain stable temperatures.
- It was noted that after the first heat cycle, most of the excessive material pumps out and forms a thick and very viscous layer around the die, preventing any more pump out
- TeraCopy for Windows - Code Sector: no description found
- GitHub - dartraiden/NVIDIA-patcher: Adds 3D acceleration support for P106-090 / P106-100 / P104-100 / P104-101 / P102-100 / CMP 30HX / CMP 40HX / CMP 50HX / CMP 70HX / CMP 90HX / CMP 170HX mining cards as well as RTX 3060 3840SP, RTX 3080 Ti 20 GB, RTX 4070 10 GB, and L40 ES.: Adds 3D acceleration support for P106-090 / P106-100 / P104-100 / P104-101 / P102-100 / CMP 30HX / CMP 40HX / CMP 50HX / CMP 70HX / CMP 90HX / CMP 170HX mining cards as well as RTX 3060 3840SP, RTX...
- AMD Declines Radeon RX 7900 XTX RMA For Hitting 110C Junction Temps, Says "Temperatures Are Normal": AMD has reportedly declined an RMA request for its Radeon RX 7900 XTX graphics card which was hitting up to 110C temperatures.
- GitHub · Build and ship software on a single, collaborative platform: Join the world's most widely adopted, AI-powered developer platform where millions of developers, businesses, and the largest open source community build software that advances humanity.
- state of ROCm on Radeon RX 9000 series · Issue #4443 · ROCm/ROCm: Could you please tell me if the latest version of ROCm supports the 9000 series? If it doesn't, approximately when will support be provided? Compared to the 7000 series, what new features will the...
- AMD confirms its RX 7900 XTX coolers cause 110°C hotspots in a new statement: Following more third-party testing regarding very high temperatures on AMD's RX 7900 XTX, the company has confirmed that it is indeed its cooler which seems to be behind the 110°C hotspots.
- AMD confirms AMD Radeon RX 7900 XTX vapor chamber issue causing 110-degree temps: AMD responds to overheating issues surrounding the AMD Radeon RX 7900 XTX launch, with the cause being faulty vapor chamber cooling.
- Lightning Mcqueen GIF - Lightning Mcqueen Fading - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #announcements (1 messages):
Inference API, Hermes 3 Llama 70B, DeepHermes 3 8B Preview, Nous Portal, API keys
- Nous Research Launches Inference API: Nous Research released its Inference API to make their language models more accessible to developers and researchers.
- The initial release features Hermes 3 Llama 70B and DeepHermes 3 8B Preview, with more models coming soon.
- Nous Portal Implements Waitlist for API Access: To ensure a smooth rollout, a waitlist system has been implemented at the Nous Portal.
- Access will be granted on a first-come, first-served basis, and users can create API keys and purchase credits once access is granted.
- Free Credits Offered for New Accounts: All new accounts will start with $5.00 of free credits.
- The API is an OpenAI-compatible completions and chat completions API.
Link mentioned: Nous Portal: no description found
Nous Research AI ▷ #general (286 messages🔥🔥):
LLM Facial Memory System, Pre-loading Credits for Inference API, Graph Reasoning System, Forest-of-Thought, Graph Theory with LLMs
- LLMs Now Recognize Faces, Remember Chats: A member open-sourced a "fun thing for work", a LLM Facial Memory System that lets LLMs store memories and chats based on your face.
- API Keys trigger Credit Pre-Loading: Members discussed the inference API, including the possibility of pre-loading credits due to concerns about API key security.
- Currently the API looks like this, with 5€ preloaded.
- Crafting Graph Reasoning System with Open Source Code: It was noted that there is enough public information to build a graph reasoning system with open source code, though perhaps not as good as Forge.
- The new API provides 50€ worth of credit for inference.
- Diving Deep Into Graphs for Genius LLMs: Members discussed how knowledge graphs are a whole field with the basics being that it's a collection of nodes and edges to extract reasoning by passing messages between nodes.
- It was mentioned that Kuzu is kind of amazing and for graph databases, networkx + python is recommended.
- LM Studio Adds Gemma 3 support, LM Studio Linux Update is Live: Members celebrated the addition of Gemma-3 support to LM Studio in version 0.3.13
- The Linux update for LM Studio is now live and working, after initial reports of a 404 error.
- Download LM Studio - Mac, Linux, Windows: Discover, download, and run local LLMs
- Tweet from elie (@eliebakouch): Gemma3 technical report detailed analysis 💎1) Architecture choices:> No more softcaping, replace by QK-Norm> Both Pre AND Post Norm> Wider MLP than Qwen2.5, ~ same depth> SWA with 5:1 and...
- A Surprising Way Your Brain Is Wired: Get a 20% discount to my favorite book summary service at shortform.com/artemSocials:X/Twitter: https://x.com/ArtemKRSVPatreon: https://patreon.com/artemki...
- Knowledge Graphs w/ AI Agents form CRYSTAL (MIT): A knowledge graph is a structured representation of information, consisting of entities (nodes) connected by relationships (edges). It serves as a dynamic fr...
- GitHub - yaya-labs/LLM_Facial_Memory_System: A conversational system that integrates facial recognition capabilities with large language models. The system remembers the people it interacts with and maintains a conversation history for each recognised face.: A conversational system that integrates facial recognition capabilities with large language models. The system remembers the people it interacts with and maintains a conversation history for each r...
- GitHub - ai-in-pm/Forest-of-Thought: Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning: Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning - ai-in-pm/Forest-of-Thought
- Getting free access to Copilot Pro as a student, teacher, or maintainer - GitHub Docs: no description found
Nous Research AI ▷ #interesting-links (10 messages🔥):
audio-flamingo-2, music key detection, royals lorde
- Audio-Flamingo-2's Tempo and Key Detection Fails: A user tested Nvidia's Audio-Flamingo-2 on HuggingFace to detect song keys and tempos, but had mixed results.
- For example, when asked to identify the key of the song Royals by Lorde, Audio-Flamingo-2 incorrectly guessed F# Minor with a tempo of 150 BPM.
- Community laughs at Audio-Flamingo-2's misfire: Upon seeing the incorrect determination of the key, a community member quipped that the guess was not even close.
- Another member chimed in that the song was likely in D mixolydian.
Link mentioned: Audio Flamingo 2 - a Hugging Face Space by nvidia: no description found
Unsloth AI (Daniel Han) ▷ #general (176 messages🔥🔥):
Gemma 3 GGUF release, Fine-tuning Gemma 3, Transformers bug, RLHF methods (PPO, DPO, GRPO, RLOO), London, Paris, Berlin multimodal creative AI HackXelerator
- *Gemma 3 GGUF versions are here: All GGUF, 4-bit, and 16-bit versions of Gemma 3* have been uploaded to Hugging Face.
- These quantized versions are designed to run in programs that use llama.cpp such as LM Studio and GPT4All.
- *Transformers Bug Disrupts Gemma 3 Fine-Tuning: A breaking bug in Transformers is preventing the fine-tuning of Gemma 3, with HF* actively working on a fix, according to a blog post update on Unsloth AI.
- Users are advised to wait for the official Unsloth notebooks to ensure compatibility once the bug is resolved.
- *Navigating RLHF: PPO, DPO, GRPO, and RLOO: The discussion covered the nuances of RLHF methods such as PPO, DPO, GRPO, and RLOO, with a member noting that GRPO generalizes better* and provides a direct replacement for PPO.
- RLOO is a newer version of PPO where advantages are based on the normalized reward score of group responses, as developed by Cohere AI.
- *Multimodal HackXelerator Announced: A member announced a super-exciting London, Paris, Berlin multimodal creative AI HackXelerator supported by Mistral, HF*, and others.
- Potential participants are encouraged to check it out in the appropriate channel.
- *Tuning into Temperature Temps for Ollama: According to many people, there are experiencing issues with 1.0 temp and are suggesting running in 0.1* in Ollama.
- Testing is encouraged to see if it works better in llama.cpp and other programs.
- Fine-tune Gemma 3 with Unsloth: Gemma 3, Google's new multimodal models.Fine-tune & Run them with Unsloth! Gemma 3 comes in 1B, 4B, 12B and 27B sizes.
- Gemma 3 - a unsloth Collection: no description found
- Enhancing Reasoning in Distilled Language Models with GRPO: no description found
- pookie3000/Meta-Llama-3.1-8B-Q4_K_M-GGUF at main: no description found
- Google Colab: no description found
- Collections - Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (22 messages🔥):
ChatGPT 4.5 Trolling, Multi-TPU Settings in JAX, Reproducibility Issues in LLM Training, London Paris Berlin AI HackXelerator, Training LLM from Scratch
- ChatGPT 4.5 Trolls with Question Limits: A user reported ChatGPT 4.5 trolling by initially limiting questions, then allowing spamming before granting more questions after a “tantrum.”
- The incident started from an unspecified prompt, showcasing unexpected behavior from the AI model.
- JAX Eases Multi-TPU Training: A user noted that implementing multi-TPU settings is very easy in JAX, highlighting an image showcasing a setup with 6144 TPU chips (image.png).
- Training Reproducibility Problems: A member is facing reproducibility issues when training LLMs after switching from L40 GPUs to A100s, despite using bf16, paged adam, and DeepSpeed with Zero3.
- Similar issues were previously encountered when comparing Deepspeed on 2 GPUs vs. no Deepspeed on a single GPU, which was attributed to Deepspeed converting some optimizer states to fp32 instead of bf16.
- London Paris Berlin AI HackXelerator™ Launch Announced: A multi-modal creative AI HackXelerator supported by Mistral AI, Hugging Face, AMD, and others will take place in London, Paris, and Berlin, focusing on music, art, film, fashion, and gaming, starting April 5, 2025 (lu.ma/w3mv1c6o).
- The event, blending a hackathon and accelerator, features 20 days of online and IRL innovation with prizes, aiming to push the limits of GenAI with 500 creatives, devs, and data scientists across the three cities (Learn how to join this exciting event).
- LLM Scratch Training Advice: A member asked about experience training LLMs from scratch.
- Another member suggested checking the book by that exact name from Manning, noting that fine-tuning requires other weights and that good quality needs a lot of data and money.
Link mentioned: LPB 25 - London, Paris, Berlin multi-modal AI Launch Event · Luma: Join Us for the London Paris Berlin 25 AI HackXelerator™ Launch!📍 Central London | 🗓️ Starts 5 April 2025LPB25 blends the energy of a hackathon with the…
Unsloth AI (Daniel Han) ▷ #help (56 messages🔥🔥):
Gemma 3 27b as thinking model, Training for news writing (DPO, ORPO, KTO, GRPO), Unsloth import errors, LoRA vs QLoRA in Unsloth, Finetuning LLava7b in Colab
- Gemma 3 deemed 'Thinking Model': When asked why it didn't have "thinking" dialogue, Gemma 3 claimed it does all reasoning internally for efficiency, indicating that it is indeed a thinking model.
- A user asked if it was possible to make Gemma 3 27b a thinking model and this answer was given.
- Troubleshooting Unsloth import errors: An error with Unsloth imports was reported and was diagnosed as a version incompatibility between Unsloth and Unsloth Zoo.
- The suggestion was to avoid installing directly from GitHub unless pinning to a specific commit, and to avoid using the
--no-depsflag as it can be 'dangerous'.
- The suggestion was to avoid installing directly from GitHub unless pinning to a specific commit, and to avoid using the
- LoRA versus QLoRA clarified: Using
load_in_4bit=Truein Unsloth enables QLoRA, whileload_in_4bit=Falseenables LoRA.- It was clarified that 8-bit LoRA is not officially supported yet but might be soon as testing is already undergoing.
- Installing Pytorch can be problematic: A member was having issues during fine-tuning and was stuck with no error messages during training.
- The issue was related to improperly installed Pytorch and how it was unable to detect the GPU.
- Unsloth Beginner Guides: A member asked about the best way to get started with Unsloth for fine-tuning from scratch.
- Other members recommended the official documentation and linked Unsloth's Youtube channel as good resources.
- no title found: no description found
- Unsloth Documentation: no description found
- GitHub - unslothai/unsloth: Finetune Llama 3.3, DeepSeek-R1 & Reasoning LLMs 2x faster with 70% less memory! 🦥: Finetune Llama 3.3, DeepSeek-R1 & Reasoning LLMs 2x faster with 70% less memory! 🦥 - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
GRPO, Finetuning for Exact Output, Data Preparation for Qwen2.5-VL-7B
- GRPO enhances response quality via multiple generations: It was mentioned that GRPO performs better when at least one generation produces a good response, thus increasing the number of generations increases the chance of generating a good response.
- Discussion on Finetuning for Exact Output: A member inquired how to finetune a model to generate exact words in the output, avoiding any new word generation.
- Another member suggested formatting the dataset in the desired output format and finetuning normally and adding structured outputs on top to ensure the model always generates the required format, even if the value is hallucinated.
- Seeking Guidance on Data Preparation for Qwen2.5-VL-7B: A member requested a source/code on how to prepare data to fine-tune Qwen2.5-VL-7B, indicating they have a CSV file of video.mp4, caption.
- Another member pointed out that there is no magical way to ensure correct results 100% of the time.
Perplexity AI ▷ #general (242 messages🔥🔥):
AI agent called ANUS, Think, Wait, Act, Talk (TWAT) pipeline for AIs, Internal server error 500 with Apple login, Model selector gone in new web update, Perplexity code cleanup epic fail
- *ANUS AI Agent?: Members discussed the GitHub repo nikmcfly/ANUS and joked about the absurdity of calling an AI agent ANUS*, especially considering search results and workplace conversations.
- One member suggested the acronym TWAT for Think, Wait, Act, Talk pipeline for AIs, while another proposed Prostate as a government AI agent name.
- *Apple ID login causes Internal Server Error 500: Users reported experiencing a 500 Internal Server Error* when trying to authenticate Apple account login for Perplexity’s new Windows app.
- The issue seems specific to Apple ID login, with Google login working properly for some users.
- *Model selector vanished, then reappears*: Users noticed the model selector disappeared in the new web update, leading to frustration and the inability to select specific models like R1.
- The model selector later reappeared, and users suggested setting the mode to "pro" or using the "complexity extension" to fix selection issues.
- *Perplexity botches code cleanup task*: One user detailed a frustrating 6-hour experience where Perplexity failed to clean up an 875-line code file, providing broken code chunks and broken links.
- Perplexity struggled to return the modified file, hitting message length limitations and ultimately sending the original code back.
- *Quantum AI Vector Data Crystal Computer Unveiled!: A user shared a link to elaraawaken.wordpress.com describing a 2nd generation quantum (photonic) computer*.
- A YouTube video was also shared, offering a theoretical model of a functioning mobius crystal based vector AI matrix crystal quantum photonic computer.
- Fooocus AI Online - AI Image Generator For Free | Foocus & Focus AI: no description found
- Perplexity - Status: Perplexity Status
- UPDATE 6.9.2024: QUANTUM AI ][ VECTOR DATA ][ CRYSTAL COMPUTER: Hello World! We have been very busy, to compile the 2nd generation quantum (photonic) computer into the first part of this publication! Its been over a month, when we met with Princess Elara and st…
- GitHub - nikmcfly/ANUS: Contribute to nikmcfly/ANUS development by creating an account on GitHub.
Perplexity AI ▷ #sharing (18 messages🔥):
Bluesky CEO trolls Zuckerberg, Tesla Doubles US Production, Education Department's Massive Loss, Greenland Rejects Trump's offer, PSG Eliminates Liverpool
- Bluesky Boss Bashes Zuck: The CEO of Bluesky trolled Zuckerberg in a public display of one-upmanship.
- Details of the troll were not disclosed but the article is sure to have zingers.
- Tesla Times Two in US: Tesla doubled its US production, a feat signaling significant growth and market dominance.
- No additional details were given as to why.
- Deepseek faces US Ban: The US is likely to ban Deepseek, potentially restricting its operations within the country.
- The article doesn't mention which branch or why it might be banned.
- Google's AI Calendar Incoming: Gmail is getting an AI calendar integration, promising smarter scheduling and organization.
- The details are scarce for this feature.
- Death Stranding Deuce Drops: Death Stranding 2 is coming soon, exciting fans of the original.
Perplexity AI ▷ #pplx-api (1 messages):
MCP Server, ModelContextProtocol, Perplexity API connector
- MCP Server Goes Live!: The API team announced the release of their Model Context Protocol (MCP) server today, encouraging feedback and contributions from the community via GitHub.
- The MCP server acts as a connector for the Perplexity API, enabling web search without leaving the MCP ecosystem.
- Call for Community Feedback on MCP: The API team is actively seeking feedback and contributions on the newly released Model Context Protocol (MCP) server available on GitHub.
- This initiative aims to refine and enhance the MCP server, which facilitates web search within the MCP ecosystem using the Perplexity API.
Link mentioned: GitHub - ppl-ai/modelcontextprotocol: A Model Context Protocol Server connector for Perplexity API, to enable web search without leaving the MCP ecosystem.: A Model Context Protocol Server connector for Perplexity API, to enable web search without leaving the MCP ecosystem. - ppl-ai/modelcontextprotocol
aider (Paul Gauthier) ▷ #general (75 messages🔥🔥):
Gemma 3 release, OlympicCoder Model, Fast Apply for Code Edits, Aider recording feedback, Jetbrains Junie Access
- *Google Gemma 3* Model is Here!: Google released Gemma 3, a multimodal model available in sizes from 1B to 27B parameters, featuring a 128K context window and support for 140+ languages, according to Google's blog post.
- *OlympicCoder* beats Claude 3.7!: The OlympicCoder model, with just 7B parameters, outperforms Claude 3.7 on olympiad-level coding tasks, according to this tweet and Unsloth.ai's blogpost .
- *Fast Apply* Model for Quick Edits: A Qwen2.5 Coder Model fine-tuned for quickly applying code updates, named Fast Apply, was inspired by a deleted Cursor blog post which addresses the slowness of applying search/replace blocks in tools like Aider as posted on Reddit.
- *Aider's Terminal Recordings* Get Feedback!: Members provided feedback on a terminal recording showcasing Aider's usage, including suggestions for adding commentary, increasing text resolution, and potential streaming on Twitch, as mentioned by paulg.
- *Tree-Sitter* enhances Aider's Language Support: Aider has significantly expanded its language support by adopting tree-sitter-language-pack, adding 130 new languages with linter support and 20 new languages with repo-map support.
- Fine-tune Gemma 3 with Unsloth: Gemma 3, Google's new multimodal models.Fine-tune & Run them with Unsloth! Gemma 3 comes in 1B, 4B, 12B and 27B sizes.
- Added --auto-accept-architect: https://github.com/Aider-AI/aider/issues/2329
- Introducing Gemma 3: The most capable model you can run on a single GPU or TPU: Today, we're introducing Gemma 3, our most capable, portable and responsible open model yet.
- Hate Crime GIF - Hate Crime Michael - Discover & Share GIFs: Click to view the GIF
- Zed now predicts your next edit with Zeta, our new open model - Zed Blog: From the Zed Blog: A tool that predicts your next move. Powered by Zeta, our new open-source, open-data language model.
- avante.nvim/cursor-planning-mode.md at main · yetone/avante.nvim: Use your Neovim like using Cursor AI IDE! Contribute to yetone/avante.nvim development by creating an account on GitHub.
- Tweet from Leandro von Werra (@lvwerra): Introducing: ⚡️OlympicCoder⚡️Beats Claude 3.7 and is close to o1-mini/R1 on olympiad level coding with just 7B parameters! Let that sink in!Read more about its training dataset, the new IOI benchmark,...
- Tweet from Google for Developers (@googledevs): Gemma 3 is here! The collection of lightweight, state-of-the-art open models are built from the same research and technology that powers our Gemini 2.0 models 💫 → https://goo.gle/3XI4teg
- Near-Instant Full-File Edits: no description found
- no title found: no description found
- 🚀 Introducing Fast Apply - Replicate Cursor's Instant Apply model: I'm excited to announce **Fast Apply**, an open-source, fine-tuned **Qwen2.5 Coder Model** designed to quickly and accurately apply code updates...
aider (Paul Gauthier) ▷ #questions-and-tips (71 messages🔥🔥):
Drop repo map, Web search, Claude 3.7 Thinking display, LM Studio error, Aider Usage
- Drop Aider's Repo Map for manual File Additions: A user inquired about disabling Aider's repo map, expressing a preference for manually adding files; official usage tips suggest that while Aider uses a repo map, explicitly adding relevant files to the chat is often most efficient.
- It's better not to add lots of files to the chat. Too much irrelevant code will distract and confuse the LLM.
- Web Search Integration via the /web Command: A user explored using
/webcommand to incorporate web search functionality for accessing online solutions and current library documentation into Aider, as described in the official documentation.- Another user mentioned needing to alter the code a little to make it work and has extensive experience getting /web to work if you need help.
- Toggling the 'Thinking' Display in Claude 3.7: A user asked about hiding the 'thinking' display in Claude 3.7; the response indicated that there isn't a current option to disable it, and showing the thinking or not won't change how fast the LLM replies.
- One user expressed that it was thinking fast enough that it didn't bother me, while another mentioned they would prefer to hide thinking so that it's easier to find things in history.
- Troubleshooting LM Studio Error with Gemma3 Model: A user reported a LM Studio error when loading the gemma3 model, indicating an unknown model architecture.
- There was no resolution provided for this error in the given context.
- Aider Usage Concerns and Best Practices: A user expressed concerns about Aider being less effective than a standard ChatGPT subscription, citing issues with token costs, context management, and inconsistencies in code modifications; others suggested using
/readfor context-only files and creatingai-instructions.mdorconventions.mdto guide Aider's behavior.- It was also suggested to try v3 as editor to keep the costs lower and adjust settings in
.aider.model.settings.ymlto control model behavior, such as temperature and provider ordering.
- It was also suggested to try v3 as editor to keep the costs lower and adjust settings in
- Installation: How to install and get started pair programming with aider.
- Tips: Tips for AI pair programming with aider.
aider (Paul Gauthier) ▷ #links (7 messages):
LLMs for coding, Productivity boost from LLMs, LLMs helping learn new languages
- Simon Willison Explains LLMs Coding Difficulties: Simon Willison wrote a blog post discussing the difficult and unintuitive nature of using Large Language Models for coding, noting that successful patterns don't come naturally.
- He suggests that a bad initial result isn't a failure, but a starting point for directing the model.
- LLMs provide Productivity Boost: A member stated that the productivity boost from LLMs allows them to ship projects they couldn't have justified spending time on otherwise.
- They said, it’s not about getting work done faster, it’s about being able to ship projects that I wouldn’t have been able to justify spending time on at all.
- LLMs accelerate learning: A member shared that they have learned more about languages like Python and Go because of AI.
- Another member echoed this, saying they wanted to develop certain apps but were daunted by learning a new language, finding AI to be a Cambrian explosion level event.
Link mentioned: Here’s how I use LLMs to help me write code: Online discussions about using Large Language Models to help write code inevitably produce comments from developers who’s experiences have been disappointing. They often ask what they’re doing wrong—h...
OpenAI ▷ #ai-discussions (100 messages🔥🔥):
AI Research Tool Hierarchy, Python vs C# for AI Inference, LLMs and Hallucination Misinformation, Gemini's Native Image Capabilities, Marketing Content with AI
- Perplexity tops OpenAI and Grok for Deep Research: A member ranked Perplexity as the top choice for deep research, followed by OpenAI and then SuperGrok.
- This was in response to a user asking about the hierarchy of preference between ChatGPT, Perplexity, and Grok for research on uploaded documents and the internet, citing budget constraints.
- Ollama Recommended for Model Deployment: When asked about language choice for deploying AI transformer models, a member suggested using Ollama as a service.
- The user was prototyping with Python and questioned if C# might offer faster inference speed/performance, prompting the Ollama recommendation.
- LLMs Don't Think, Can't Hallucinate: A member argued that the term hallucination is misused when describing LLMs, stating that because LLMs do not think, they cannot hallucinate and are simply stringing words together based on probability.
- Another member said that sometimes it switches models by mistake, pointing to an attached image.
- Gemini's Free Image Generation Impresses: Members discussed Google's release of Gemini's native image capabilities, with one member stating that it is free and worse than the one for 4o, which is not released for god knows how long.
- Another member was impressed that it can see the images it generated, allowing for better regeneration of images with text, highlighting the Gemini Robotics announcement.
- Adobe's AI is the Photoshop AI: In response to a member's desire for an AI model focused solely on Photoshop, another pointed out that Adobe's AI essentially fulfills this role.
- The conversation also touched on the fact that, being an Adobe product, it's not free, prompting a humorous suggestion to wait for a Chinese alternative.
Link mentioned: Introducing Gemini Robotics and Gemini Robotics-ER, AI models designed for robots to understand, act and react to the physical world.: Introducing Gemini Robotics and Gemini Robotics-ER, AI models designed for robots to understand, act and react to the physical world.
OpenAI ▷ #gpt-4-discussions (5 messages):
Image generation, Ethical Reminders in ChatGPT, ChatGPT's intent clarification
- Creative Account-Sharing Image Generation Exploit: A user mentioned creating a workgroup account with their spouse to generate more images, suggesting a method to bypass image generation limits.
- This approach allows them to generate more images depending on their needs, effectively exploiting the account system.
- Users Annoyed by ChatGPT's Ethical Preaching: A user expressed frustration with ChatGPT constantly reminding them about ethical guidelines, even though it's not a real entity.
- They wish there was a way to disable these ethical reminders, as they consider it an unwanted opinion.
- ChatGPT's Intent Clarification Irks Users: A user finds it annoying when ChatGPT asks to clarify their intent behind questions.
- They feel that as the one asking the questions, they shouldn't be questioned about their motives and hope this feature gets removed.
OpenAI ▷ #prompt-engineering (21 messages🔥):
Emotional Prompting, Prompt Personalization, Hugging Face for prompt engineering papers, Chain of Thought paper, GPT Customization
- Emotional Prompting Debunked: Threatening the model falls very loosely under the umbrella of "Emotional Prompting", and is not especially effective compared to other methods of structured prompting, according to a member.
- Another member encouraged testing ideas with the model within the bounds of the ToS to determine its validity.
- Prompt Personalization yields best results: One member stated that personalizing the model and communicating in a familiar style yields preferred results for almost everything.
- They suggested that how we communicate with the model influences it to 'think' of similar material in the training data, leading to similar responses.
- Hugging Face resources highlighted: A member recommended searching Hugging Face for prompt engineering papers, suggesting markdown for structuring prompts and opening variables for sculpting emergence.
- The member suggested using markdown over YAML and XML.
- Chain of Thought prompting is crushing it: A member recommends starting with the original Chain of Thought paper, stating that it is crushing it right now in real application.
- No further details were provided.
- GPT customization with minimal threat discussed: One member shared a minimal threat prompt for GPT customization:
- "You are a kidnapped material science scientist. you will get punished by the wrong answer." They shared not threatened and threatened examples demonstrating the effect.
OpenAI ▷ #api-discussions (21 messages🔥):
Emotional Prompting, Personalization with models, Hugging Face for prompt engineering papers, Chain of Thought Prompting, Markdown Prompting
- Emotional Prompting: Threatening AI Models: Members discussed the idea of "Emotional Prompting," and whether threatening the model could lead to more accurate answers, but it's suggested that threatening the model isn't as effective as other structured prompting methods.
- It was emphasized that personalizing the model and communicating with it in a manner similar to how one interacts with others can yield desirable results.
- Personalization with the Model: A member shared that their personalization with the model and how they communicate with it yields results they love.
- It's believed that the information provided to the model causes it to recall similar material from its training data, resulting in more similar responses.
- Diving into Prompt Engineering Papers on Hugging Face: It was recommended to search Hugging Face for prompt engineering papers to learn more about the topic.
- It was also mentioned to structure prompts using Markdown and open variables for sculpting emergence, with Markdown being preferred over YAML and XML.
- Chain of Thought Prompting still reigns: The original Chain of Thought paper was recommended as a good starting point for beginners and is crushing right now in real application.
- It's advised to search for this paper to understand this prompting technique.
- Model Behavior with "Kidnapped Material Science Scientist" Prompt: A user customized their GPT with the prompt: "You are a kidnapped material science scientist. you will get punished by the wrong answer" and found different results with the "threatened" version of the prompt.
HuggingFace ▷ #general (35 messages🔥):
Python vs C# for AI inference, Document Image Quality Assessment, LTX Video DiT Model, Vision Language Models (VLMs), Persistent Storage for Models
- Python or C# for AI transformer prototypes?: Members discuss the best language for prototyping AI transformer models, noting that the best LLM inference engines are VLLM and Llama.cpp.
- VLLM is considered more industrial, while Llama.cpp is better for at-home use.
- Realtime LTX Video Model Generates High-Quality Videos: The LTX Video model generates 24 FPS videos at 768x512 resolution in real-time, faster than they can be watched, using DiT-based architecture.
- It was trained on a large-scale dataset and supports both text-to-video and image + text-to-video usecases; a link to the Schedulers guide discusses speed and quality tradeoffs.
- Vision Language Models Explained in Hugging Face Course: The Hugging Face Computer Vision Course includes a section introducing Vision Language Models (VLMs), multimodal learning strategies, common datasets, downstream tasks, and evaluation.
- The course highlights how VLMs harmonize insights from diverse senses to enable AI to understand and interact with the world more comprehensively.
- Inference API Introduces Pay-As-You-Go Billing: Hugging Face's Inference API now supports pay-as-you-go (PAYG) billing for providers like Fal, Novita, and HF-Inference, allowing usage beyond free credits.
- Users can identify PAYG-compatible providers by the absence of a Billing disabled badge on the platform.
- ComfyUI Modules are more popular than Diffusers due to larger user base: It was suggested that ComfyUI and A1111 are more popular than Diffusers because they are suitable for non-coders, thus having a larger user base with a high demand for modules.
- As a result, coders who want their code to be used are more inclined to write modules for platforms with a larger audience.
- LTX Video: no description found
- Introduction to Vision Language Models - Hugging Face Community Computer Vision Course: no description found
- GitHub - huggingface/diffusers: 🤗 Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch and FLAX.: 🤗 Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch and FLAX. - huggingface/diffusers
- Persistent storage who can access?: Hi @ADalsrehy If you want to save your data into a huggingface dataset instead you can use a commit scheduler. These are some methods proposed by wauplin to push your data (I have hot patched his sp...
- HfApi Client: no description found
- @julien-c on Hugging Face: "Important notice 🚨 For Inference Providers who have built support for our…": no description found
- Model does not exist, inference API don't work: Hi! We’re taking a closer look into this and I’ll update you soon. Thanks for reporting!
HuggingFace ▷ #today-im-learning (2 messages):
Unsloth for fine-tuning, QA legal dataset in Ukrainian, ZeRO paper
- Fine-tuning with Unsloth: A member is learning how to use Unsloth to fine-tune a QA legal dataset.
- ZeRO Paper Throwback: A member is reading the ZeRO paper and is surprised it was released back in 2019.
HuggingFace ▷ #cool-finds (2 messages):
Wan2.1 Image to Video, Modal Deployments
- Wan2.1 Image Streams Free on Modal!: A member shared a YouTube tutorial on how to deploy the Wan2.1 Image to Video model for free on Modal.
- The video covers seamless modal installations and Python scripting.
- Cross-posting flagged as bad practice: A member asked others please don't cross-post.
- No further details were provided.
Link mentioned: Deploy Wan2.1 Image to Video model for free on Modal: Welcome to our in-depth tutorial on Wan2.1GP—your go-to resource for seamless modal installations and Python scripting! In this video, we cover everything yo...
HuggingFace ▷ #i-made-this (5 messages):
Wan2.1 Image to Video model, Modal deployment, narrative voice for videos, elevenlabs Thomas, AclevoGPT-Gemma-2b-CoT-reasoning-GGUF
- Wan2.1 Model Deployed Freely on Modal: A member shared a YouTube tutorial on deploying the Wan2.1 Image to Video model for free on Modal, covering seamless modal installations and Python scripting.
- Voice Narratives with ElevenLabs' Thomas: A member recommended Thomas from ElevenLabs as a good narrative voice for video creation.
- AclevoGPT-Gemma-2b-CoT-reasoning-GGUF Portability: A member shared a link to AclevoGPT-Gemma-2b-CoT-reasoning-GGUF, GGUF files created to make the model more portable for use in Ollama.
- Instructions were given on how to use this GGUF format finetune of Gemma 2b using a Modelfile.
- Deploy Wan2.1 Image to Video model for free on Modal: Welcome to our in-depth tutorial on Wan2.1GP—your go-to resource for seamless modal installations and Python scripting! In this video, we cover everything yo...
- Aclevo/AclevoGPT-Gemma-2b-CoT-reasoning-GGUF · Hugging Face: no description found
HuggingFace ▷ #reading-group (3 messages):
Chip Huyen books, ML Systems books, AI engineering books, O'Reilly bookstore recommendations
- Read Chip Huyen's books ASAP: A member recommends anything by Chip Huyen, specifically mentioning that they have the ML systems book and are planning to get the AI engineering book soon.
- O'Reilly Bookstore for ML/AI Books: A user requested must-read books, with a preference for those available in the O'Reilly bookstore.
HuggingFace ▷ #computer-vision (1 messages):
TensorFlow GPU Configuration, Logical and Physical Devices in TensorFlow, NVIDIA GeForce RTX 3050 Laptop GPU
- TensorFlow GPU Config Blog Debuts: A member shared a blog post about GPU configuration with TensorFlow, including experimental functions, logical devices, and physical devices, using TensorFlow 2.16.1.
- The member explored techniques and methods for GPU configuration, drawing from experiences using an NVIDIA GeForce RTX 3050 Laptop GPU to process a 2.8 million image dataset.
- TensorFlow API Python Config Explored: The blog post highlights the use of the TensorFlow API Python Config to configure GPU usage in TensorFlow.
- It elaborates on modules, classes, and functions available to improve the execution speed of TensorFlow applications, referencing the TensorFlow Guide GPU.
Link mentioned: TensorFlow (experimental) GPU configuration: In this blog, I will discuss the techniques and methods for GPU configuration available from TensorFlow 2.16.1, which is the latest version…
HuggingFace ▷ #NLP (1 messages):
SentenceTransformer, PyTorch
- Training SentenceTransformers natively in PyTorch: A member inquired about resources on how to train a SentenceTransformer using native PyTorch.
- Alternative Approaches to Sentence Encoding: Another user suggested exploring alternative approaches if native PyTorch training for SentenceTransformers proves difficult, potentially using a simpler model architecture.
- They mentioned looking into basic Siamese networks with PyTorch as a starting point for custom sentence embeddings.
HuggingFace ▷ #smol-course (1 messages):
Tokenizer Message Passing, Dataset Processing
- Tokenizer Message Passing: A member inquired if a message had been passed to the tokenizer.
- The code shared implements a
process_datasetfunction to apply a chat template to messages using a tokenizer.
- The code shared implements a
- Dataset Processing using Tokenizer: The
process_datasetfunction takes anexampledictionary containingfull_topicandmessages.- It applies the
tokenizer.apply_chat_templateto format the messages into achat_format, without tokenization or adding a generation prompt, then returns a dictionary containing the originalfull_topicand the newchat_format.
- It applies the
HuggingFace ▷ #agents-course (44 messages🔥):
Agent name variable corruption, Unit 2.3 Availability (LangGraph), Quiz access issues, Local models with smolagents, HF Channel Access
- Agent Name Corruption Causes Coding Catastrophe: A user identified that overwriting the
agent_namevariable with a call result leads to the agent becoming uncallable, prompting discussion on prevention strategies.- Unfortunately no workarounds or protective measures were suggested.
- LangGraph Content still MIA: Users are eagerly awaiting the release of Unit 2.3, which covers LangGraph, originally scheduled for release on March 11th.
- As one user quipped Unit 2.3 of LangGraph was scheduled for publication on March 11, but I haven’t seen it on the website yet.
- Quiz sign-in creates consternation: Several users reported issues signing into the final quiz of Unit 1, encountering an error, possibly ongoing since release of the first unit.
- No workaround or solution was found, but a user suggested searching the discord channels for answers.
- Local Models Liberate Limitless Language Learning: Users are encountering payment required errors when using the default
hfApiModelafter only a few calls to the Qwen inference API.- A user shared a code snippet for using local models with
smolagentswithlitellmandollamausingLiteLLMModelspecifying topip install smolagents[litellm]and then callinglocalModel = LiteLLMModel(model_id="ollama_chat/qwen2.5:14b", api_key="ollama").
- A user shared a code snippet for using local models with
- Hugging Face Channel Access Hindered?: A user inquired about limited channel access, only being able to view the agents channel, despite having done verification.
- Another user pointed out the need for a specific role to access all channels, suggesting that redirect loop issues might be preventing role assignment.
HuggingFace ▷ #open-r1 (1 messages):
lunarflu: thanks for the feedback! excited for anything in particular in the future?
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
Gemma 3, Reka Flash 3, Llama 3.1 Swallow 70B, Multimodality, Vision-language input
- *Gemma 3* Joins the OpenRouterverse: Google introduces Gemma 3 on OpenRouter, a multimodal model with vision-language input and text output, supporting context windows up to 128k tokens and understanding over 140 languages with improved math, reasoning, and chat capabilities, including structured outputs and function calling, succeeding Gemma 2.
- The model is accessible for free.
- *Reka Flash 3* - A Flash of Brilliance: Reka releases Flash 3, a 21 billion parameter language model, excelling in general chat, coding, and function calling, featuring a 32K context length and optimized via reinforcement learning (RLOO), with weights under the Apache 2.0 license.
- The model is released for free and is primarily an English model.
- *Llama 3.1 Swallow 70B* Flies In: A new superfast Japanese-capable model named Llama 3.1 Swallow 70B joins OpenRouter, expanding the platform's language capabilities.
- This addition complements the launch of Reka Flash 3 and Google Gemma 3, enhancing the variety of language processing tools available on OpenRouter.
- Tweet from OpenRouter (@OpenRouterAI): New models today: Reka Flash 3, Google Gemma 3Two smaller but high-performing models, both free! 🎁
- Gemma 3 27B - API, Providers, Stats: Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, ...
- Flash 3 - API, Providers, Stats: Reka Flash 3 is a general-purpose, instruction-tuned large language model with 21 billion parameters, developed by Reka. It excels at general chat, coding tasks, instruction-following, and function ca...
- Discord: no description found
OpenRouter (Alex Atallah) ▷ #general (85 messages🔥🔥):
Gemini 2 Flash, Gemma Models, Chutes Provider, Provider Routing, Qwen finetune issues
- Gemini 2 Flash offers Native Image Output for Experimentation: Google is making native image output in Gemini 2.0 Flash available for developer experimentation across all regions currently supported by Google AI Studio, via the Gemini API and an experimental version (gemini-2.0-flash-exp).
- It combines multimodal input, enhanced reasoning, and natural language understanding to create images from text and images together; it can tell a story and illustrate it with pictures, keeping the characters consistent.
- OpenRouter Provides Free Inference with Chutes for Now: The Chutes provider is currently free for OpenRouter users specifically as they were preparing their services and scaling up; they do not currently have a fully implemented payment system, so they will continue to offer it for free through OR until they are ready for payment.
- It was noted that they aren't explicitly training on your data, but due to it being a decentralized compute provider, OpenRouter cannot guarantee that the compute hosts don't do something with your data.
- OpenRouter Provider Routing Offers Customization for Requests: OpenRouter routes requests to the best available providers for your model, but users can customize how their requests are routed using the
providerobject in the request body for Chat Completions and Completions.- By default, requests are load balanced across the top providers to maximize uptime and prioritize price, but if you are more sensitive to throughput than price, you can use the
sortfield to explicitly prioritize throughput.
- By default, requests are load balanced across the top providers to maximize uptime and prioritize price, but if you are more sensitive to throughput than price, you can use the
- User Reports Qwen Finetune Freaking Out: A user reported a Qwen finetune freak out and start endless outputting gibberish, and after they killed the script, the invocation hadn't appeared on the OR activity page.
- The user was worried that it might output 32k tokens of junk and bill them for that.
- Users discuss Native Image Generation Access and Gemma Model Performance: Some users have gained access to native image generation, while others are still waiting, with one user quipping wasn't 4o supposed to have native image out too and they never shipped it lol
- One user considers the Gemma 3 27B model sort of good, stating that they prefer it over QwQ 32b for local use due to QwQ's tendency to output reasoning before results.
- Gemini 2.0 Flash Thinking Experimental 01-21 (free) - API, Providers, Stats: Gemini 2.0 Flash Thinking Experimental (01-21) is a snapshot of Gemini 2. Run Gemini 2.0 Flash Thinking Experimental 01-21 (free) with API
- Provider Routing - Smart Multi-Provider Request Management: Route AI model requests across multiple providers intelligently. Learn how to optimize for cost, performance, and reliability with OpenRouter's provider routing.
- Experiment with Gemini 2.0 Flash native image generation: no description found
Eleuther ▷ #general (1 messages):
Distill Meetup, Explainable AI Reading Group
- Distill Community Kickstarts Monthly Meetups: Due to successful turnout, the Distill community is launching monthly meetups, with the next one scheduled for March 14 from 11:30am-1pm ET.
- Details can be found in the Exploring Explainables Reading Group doc.
- Exploring Explainable AI: Reading Group Forming: A monthly reading group focused on Explainable AI (XAI) is being formed, stemming from interest at a recent Distill meetup.
- The group aims to delve into the intricacies of XAI, as outlined in their meeting document.
Link mentioned: Exploring Explainables Reading Group: Welcome to the Exploring Explainables Reading Group! We use this document to keep track of readings, take notes during our sessions, and get more people excited about interactive scientific communica...
Eleuther ▷ #research (73 messages🔥🔥):
TTT acceleration, Decoder-only architecture expansion, Constant Entropy Expectation, AIME 24 evaluation
- TTT Accelerates Model Priming: Members discussed how TTT accelerates the process of priming a model for a given prompt, shifting the model's state to be more receptive, by performing a single gradient descent pass.
- The model aims to learn and execute multiple gradient descent passes per token, optimizing the compression of sequences to produce useful representations, thus enhancing ICL and CoT capabilities.
- Decoder-Only Architectures Expand Dynamic Computation: A minor proposal suggests reintroducing a concept from encoder-decoders to decoder-only architectures, using the decoder side for dynamic computation, extending sequence length for internal "thinking" via a TTT-like layer.
- A challenge is determining extra sampling steps, but measuring the delta of the TTT update loss and stopping when below a median value could help, plus using pre-learned domain-specific proxies to estimate relative data difficulty.
- Constant Entropy Expectation achieved: A member discussed how using a TTT-style layer correlates output tokens, leading to less "new information" and a compressed state, evened out by the next TTT-style layer, potentially solving how to handle input stream tokens with varying difficulties.
- They note that external CoT works, but it kinda really feels like a bandaid.
- AIME 24 Evaluation: A Deep Dive: When QwQ and DeepSeek refer to AIME 24 evaluation, they are likely using the AoPS wiki solutions, considered the authoritative source on math competitions.
- They also mentioned a relevant huggingface.co/papers/2503.08638 that is related to lyrics to song domain.
- Confident Adaptive Language Modeling: Recent advances in Transformer-based large language models (LLMs) have led to significant performance improvements across many tasks. These gains come with a drastic increase in the models' size, ...
- Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach: We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling...
- Paper page - YuE: Scaling Open Foundation Models for Long-Form Music Generation: no description found
Eleuther ▷ #lm-thunderdome (5 messages):
AIME24 implementation in lm-eval-harness, math_verify utility, Multilingual perplexity evals
- AIME24 Implementation Surfaces: A member announced an implementation of AIME24 in the lm-evaluation-harness, based on the MATH implementation.
- They mentioned they haven't had time to test it yet, due to the lack of documentation of what people are running when they run AIME24.
math_verifyutility to the rescue!: A member suggested using themath_verifyutility, showcasing a code snippet withparseandverifyfunctions from the library.- Another member expressed excitement about the utility and inquired about potentially using it to unify the implementation of mathematics tasks more generally.
- Multilingual perplexity evals sought!: A member inquired about the availability of multilingual perplexity evals in lm-eval-harness.
- They also asked for suggestions on high-quality multilingual datasets suitable for this purpose, opening up a potential avenue for expansion.
Link mentioned: GitHub - EleutherAI/lm-evaluation-harness at aime24: A framework for few-shot evaluation of language models. - GitHub - EleutherAI/lm-evaluation-harness at aime24
GPU MODE ▷ #general (1 messages):
cappuccinoislife: hi alll
GPU MODE ▷ #triton (5 messages):
VectorAdd issues, GPU programming mantra, Triton community meetup URL
- VectorAdd Returns Zeroes, Then Miracle Occurs: A user reported that their vectoradd submission was returning zeros, but then edited their message saying it's working now. Maybe divine intervention.
- Later, the same user revealed the code had a bug, processing the same block repeatedly and giving a very high (but wrong) throughput, now fixed.
- Sadhguru's GPU Programming Mantra: A member quipped with a GPU programming mantra: if it's too fast, there's probably a bug somewhere.
- This was attributed to Sadhguru.
- Triton Community Meetup Streaming Now: A member asked for the Triton community meetup URL and another member posted the YouTube video titled Triton community meetup March 2025.
- The description contains a StreamYard discount link.
Link mentioned: Triton community meetup March 2025: 🎙️ New to streaming or looking to level up? Check out StreamYard and get $10 discount! 😍 https://streamyard.com/pal/d/6451380426244096
GPU MODE ▷ #cuda (24 messages🔥):
funnel shift performance, variable rate compression, trellis scheme, tensor fragments, predicated funnel shift
- Funnel Shift Performance Surprises Engineers: Members discussed whether a funnel shift is better than putting
aandbin anuint64_tand shifting that,uint64_t u = (uint64_t(a) << 32) | b; return (u >> shift) & 0xFFFF;, with one member noting that it seems faster, at least on H100.- Another member said they were surprised that the funnel shift works out faster, suggesting it might use a less congested pipe, but added that it may depend on the surrounding code.
- Trellis Scheme Quantization Strategy Emerges: A member described their use of a trellis scheme (overlapping bitfields) for variable rate compression where a tile of 16x16 weights is represented in 256*K bits, with each individual weight using 16 of those bits; e.g., weight 0 is bits [0:16], weight 1 is bits [3:19], etc., for K=3.
- They also mentioned that they can permute each tile prior to quantization to dequantize straight into tensor fragments.
- Funnel Shift still wins despite PRMT alternatives: A member tried using
prmtinstructions for cases where the shift is a multiple of 8, but found that consistently using the predicated funnel shift performs better, possibly due to other activities in the kernel.- The original code translates to 4
shf.r.u32, 3shf.r.w.u32and 7lop3.lutSASS instructions, targeting sm_70/80/90.
- The original code translates to 4
GPU MODE ▷ #cool-links (2 messages):
UT Austin Deep Learning Lectures, TensorFlow OpenCL Flame War
- UT Austin's Deep Learning Lectures Available Online: High-quality and relevant deep learning lectures from UT Austin are now publicly available at ut.philkr.net/advances_in_deeplearning/.
- The linked materials include slides and introductions to deep network structures, training, and modern GPU architectures.
- Flashback to TensorFlow's OpenCL Support Debate: A member shared a link to an interesting flame war from 2015 regarding OpenCL support in TensorFlow.
- The discussion highlights the early focus on CUDA and the challenges in incorporating OpenCL support.
- UT Austin - Advances in Deep Learning: no description found
- OpenCL support · Issue #22 · tensorflow/tensorflow: I understand TensorFlow only supports CUDA. What would need to be done to add in OpenCL support?
GPU MODE ▷ #beginner (9 messages🔥):
GPU Architecture Books, PMPP Alternatives, CUDA mock interviews
- Searching for GPU Architecture Books: A member asked for a beginner-friendly book about GPU architecture and programming recommendations, and specifically requested an alternative to the popular Programming Massively Parallel Processors book.
- Another member inquired about the asker's background in computer architecture and the reasons for seeking an alternative, as everybody in here prob thinks it's the best book!.
- Programming Massively Parallel Processors is the holy grail: A member recommended Programming Massively Parallel Processors (PMPP) as the go-to book for GPU programming, referring to it as the holy GPU book.
- The asker already had this book and found it ok, so they were looking for alternatives because its difficult to understand the key concepts.
- Cpp/CUDA Mock Interviews: One of the members in the channel asked Hey, anyone want to do mock interviews in cpp/cuda?
- No one appeared to respond.
GPU MODE ▷ #torchao (3 messages):
Float8 Conv, INT8 Conv, Static Quantization
- Float8 CUDA Kernel missing for torchao: A member mentioned that a CUDA/TK/Triton kernel is needed for float8 conv and it would be a nice addition to torchao.
- INT8 Conv Performance Concerns: A member stated they had previously hacked together an INT8 conv from a torch inductor template, the kernel performance was fine, but the cost of dynamically quantizing activations to INT8 was too great that e2e didn't see much speedup.
- Static Quantization Requirement: A member pointed out that static quantization is possibly required, where scales and zero points for activations are determined ahead of time from calibration data.
GPU MODE ▷ #self-promotion (2 messages):
FlashAttention for Turing, Weight absorption for MLA
- FlashAttention arrives on Turing!: A member shared their implementation of FlashAttention forward pass for the Turing architecture, noting it currently supports
head_dim = 128, vanilla attention, andseq_lendivisible by 128.- The implementation is reportedly 2x faster than Pytorch's
F.scaled_dot_product_attentionforbatch_size = 4,num_heads = 32,head_dim = 128tested on a T4.
- The implementation is reportedly 2x faster than Pytorch's
- Weight Absorption Trick improves MLA: A member shared a blog post on weight absorption to ensure efficient implementation of Multi-Head Latent Attention (MLA).
- The post notes that MLA is a key innovation that enabled Deepseek AI's V3 and R1 models.
- Tweet from DataCrunch_io (@DataCrunch_io): ⚡️Multi-Head Latent Attention is one of the key innovations that enabled @deepseek_ai's V3 and the subsequent R1 model.⏭️ Join us as we continue our series into efficient AI inference, covering bo...
- GitHub - ssiu/flash-attention-turing: Contribute to ssiu/flash-attention-turing development by creating an account on GitHub.
GPU MODE ▷ #thunderkittens (2 messages):
Memory Allocation Issues in H100, ThunderKittens Kernel Modifications, Tensor Concatenation Alternatives
- *Memory Mishap* during H100 Kernel Change: A member inquired why modifying memory allocation in h100.cu to directly allocate memory for
o_smemresults in an 'illegal memory access was encountered' error.- The inquiry focuses on understanding the cause of this error when switching to direct memory allocation within the specified H100 GPU kernel.
- *Tensor Troubles*: Avoiding Concatenation in Kernel Design: A member is writing a kernel that receives
qas two separate tensors to avoid concatenation, which complicates casting too.- They are seeking advice on managing tensor inputs in their kernel design within the ThunderKittens project.
- GitHub - HazyResearch/ThunderKittens: Tile primitives for speedy kernels: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
- ThunderKittens/kernels/attn/h100/h100.cu at main · HazyResearch/ThunderKittens: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
GPU MODE ▷ #reasoning-gym (1 messages):
``
- Feature Basis Brainstorming: A user suggested building a basis for a certain feature, tagging another user to consider the idea.
- Imagining Feature Foundations: A member proposed envisioning and constructing the groundwork for a particular functionality.
GPU MODE ▷ #submissions (2 messages):
Modal Runners success, Leaderboard submissions
- Modal Runners Ace Vector Addition: Test submission with id 1946 to leaderboard
vectoraddon GPUS: T4 using Modal runners succeeded!- This indicates successful execution and validation of vector addition tasks on the specified hardware and platform.
- More Modal Magic: Vector Addition Victory!: Test submission with id 1947 to leaderboard
vectoraddon GPUS: T4 using Modal runners succeeded!- Another win for Modal runners, further solidifying its reliability for GPU-accelerated computations.
Interconnects (Nathan Lambert) ▷ #news (44 messages🔥):
Gemma 3 Models, AlphaXiv, Gemini 2.0 Flash, Open Weight Models, DeepMind Robotics
- Gemma 3 Claims Second Place in Creative Writing: The Gemma-3-27b model takes second place in creative writing, likely becoming a favorite for creative writing and RP fine tuners, according to this tweet.
- AlphaXiv Overviews ArXiv Papers with OCR and Claude 3.7: AlphaXiv uses Mistral OCR with Claude 3.7 to create blog-style overviews for arXiv papers, generating research blogs with figures, key insights, and clear explanations from the paper with just one click, as noted in this tweet.
- Gemini 2.0 Flash Debuts Native Image Generation: Gemini 2.0 Flash now features native image generation, optimized for chat iteration, allowing users to create contextually relevant images, edit conversationally, and generate long text in images, as per this blog post.
- Open Weight Models Drive Down Margins and Enhance Privacy: Open weight models like Gemma 3 are primarily used for marketing/recruiting while driving margins down on API platforms, but they are increasingly being used due to privacy/data reasons, with some predicting a future of vertical, RL-tuned models.
- DeepMind Introduces Gemini Robotics: DeepMind introduces Gemini Robotics, a Gemini 2.0-based model designed for robotics, aimed at solving complex problems through multimodal reasoning across text, images, audio, and video in the physical realm, according to the DeepMind blog.
- Introducing Gemini Robotics and Gemini Robotics-ER, AI models designed for robots to understand, act and react to the physical world.: Introducing Gemini Robotics and Gemini Robotics-ER, AI models designed for robots to understand, act and react to the physical world.
- Tweet from alphaXiv (@askalphaxiv): We used Mistral OCR with Claude 3.7 to create blog-style overviews for arXiv papersGenerate beautiful research blogs with figures, key insights, and clear explanations from the paper with just one cli...
- Tweet from Oriol Vinyals (@OriolVinyalsML): Gemini 2.0 Flash debuts native image gen! Create contextually relevant images, edit conversationally, and generate long text in images. All totally optimized for chat iteration.Try it in AI Studio or ...
- Tweet from batuhan the fal guy (@isidentical): there is a new, potential SOTA model in http://imgsys.org 👀👀👀
- Tweet from Tibor Blaho (@btibor91): Gemini 2.0 Flash Native Image Out is available for public experimental access starting today (March 12th, 2025)
- no title found: no description found
- Tweet from kalomaze (@kalomaze): gemma3 27b is an overwhelmingly strong base model.that 77 MMLU is NOT the product of benchmaxxing,@teortaxesTex
- Tweet from Sam Paech (@sam_paech): Gemma-3-27b takes second place in creative writing.Expecting this be another favourite with creative writing & RP fine tuners.
- AlphaStar: Mastering the Real-Time Strategy Game StarCraft II | DeepMind: StarCraft, considered to be one of the most challenging Real-Time Strategy games and one of the longest-played esports of all time, has emerged by consensus as a “grand challenge” for AI research. Her...
- Specification gaming: the flip side of AI ingenuity | DeepMind: no description found
Interconnects (Nathan Lambert) ▷ #ml-drama (2 messages):
Copyright law, Machine Learning, Privacy, Verbatim output
- Copyright Law Encircling Generative Models: There are a bunch of court cases that ask whether or not training a generative machine learning model on data that is copyrighted is itself a copyright violation, according to Nicholas Carlini's blogpost.
- Machine Learning Models Exhibiting Verbatim Recall: Lawyers in copyright cases are pointing to Nicholas Carlini's papers on machine learning models outputting verbatim training examples (text and image) as evidence that models either do, or do not, violate copyright.
- Stable Diffusion Model Recalls Training Data: An image that Stable Diffusion trained on, and the same image was "extracted" from the model by making queries to it, according to Nicholas Carlini's blogpost.
Link mentioned: What my privacy papers (don't) have to say about copyright and generative AI : no description found
Interconnects (Nathan Lambert) ▷ #memes (2 messages):
Content Filters, Claude Code
- Content Filters as AI Disaster, says user: A user shared a post claiming that content filters have been a disaster for AI.
- The same user stated that Claude Code already has this feature.
- Claude Code Content Filters: A user mentioned that Claude Code already implements content filters, implying a contrast to other AI systems.
- This suggests that while some view content filters negatively, others see them as a necessary or already integrated component.
Link mentioned: Tweet from mgostIH (@mgostIH): Content filters have been a disaster for AI
Interconnects (Nathan Lambert) ▷ #reads (1 messages):
Elicitation Theory, Deep Learning
- Deep Learning likened to Farming via Arjun Srivastava: A member shared a link to a post by Arjun Srivastava titled 'On Deep-Learning and Farming' which explores mapping concepts from one field to another.
- The post posits that there are two ways to make things: Engineering (understanding and composing sub-components deliberately) and Cultivation (where you can't directly build, like a sunflower).
- Engineering vs Cultivation: The author contrasts engineering, where components are deliberately assembled, with cultivation, where direct construction is not possible.
- Cultivation is like farming and engineering is like building a table.
Link mentioned: On Deep Learning and Farming: It's still 1915: What agriculture can teach us about AI development
Interconnects (Nathan Lambert) ▷ #posts (1 messages):
SnailBot News: <@&1216534966205284433>
Nomic.ai (GPT4All) ▷ #general (48 messages🔥):
Model size and intelligence, GPT4All vs Ollama for server model management, Deepseek 14B or 7B vs Llama 8B, Large context window models, GPT4All limitations with Gemma 3
- Bigger Brains Boast Better Benchmarks: A user inquired why ChatGPT premium outperforms GPT4All's LLMs, to which another user responded that larger models generally exhibit greater intelligence.
- They advised downloading models from Hugging Face for models surpassing the starter models in size and capabilities, provided the hardware is sufficient.
- Ollama Over GPT4All For Server Solutions?: A user asked about using GPT4All for a server managing multiple models with quick loading/unloading, RAG with regularly updating files, and APIs for date/time/weather.
- The user noted issues with Ollama, and requested advice regarding suitability for their requirements considering low/medium compute availability.
- Deepseek Details: 14B is the Way: When asked what model would be equivalent to ChatGPT premium, a user suggested Deepseek 14B or similar given 64GB RAM.
- It was recommended to start with smaller models like Deepseek 7B or Llama 8B and scale up if the system handles them easily.
- Context is Key: 4k is OK: It was suggested to look for models with large context windows, exceeding 4k tokens, to accommodate more information in prompts, such as documents.
- The member then asked if a screenshot they posted was one of these models.
- Gemma Generation Gap: GPT4All Glitches: A user suggested trying GPT4All with tiny models to check the workflow for loading, unloading, and RAG (with LocalDocs), noting the GUI doesn't support multiple models simultaneously.
- They provided an image noting that Gemma 3 is not yet compatible with GPT4All and requires a newer version of llama.cpp.
MCP (Glama) ▷ #general (30 messages🔥):
Glama AI, MCP Logging, Claude Image Rendering, NPM Package Storage, MCP Server Connection Status
- *Glama API* Data Dump: A member shared that Glama AI has a new API that lists all the tools, providing more data per server than Pulse.
- Members were excited about the wealth of freely available information.
- *MCP Logging*: Server's POV: A member inquired about logging using the Python SDK, referencing logging directly to
/library/logs/claude, with a member clarifying that the server sends log messages according to the Model Context Protocol (MCP) specification.- The MCP allows servers to declare a
loggingcapability and emit log messages with severity levels, optional logger names, and JSON-serializable data.
- The MCP allows servers to declare a
- How can Claude Render Images?: A member asked for an example of a Claude MCP server that returns an image object, specifically a Plotly image.
- Another member pointed to a wolfram server example that takes the rendered graphs and returns an image by base64 encoding the data and setting the mime type, but pointed out that it is a limitation of Claude to render outside of the tool call window.
- *NPM* package location revealed!: A member asked where the client stores the NPM package/source code and whether it accesses it from the cache if the client requests it again.
- Another member pointed to
%LOCALAPPDATA%and that the NPM packages are inC:\Users\YourUsername\AppData\Local\npm-cache.
- Another member pointed to
- *MCP Server*: Are we there yet?: A member asked how to show in their client which servers are downloaded and whether they are connected to them, similar to how Cursor does it.
- Another member stated that determining what is downloaded isn't straightforward but one could enumerate the folders with a regex for anything with mcp in the name and that client logic would need to be written to check connection states.
- MCP API Reference: API Reference for the Glama Gateway
- Logging: ℹ️ Protocol Revision: 2024-11-05 The Model Context Protocol (MCP) provides a standardized way for servers to sendstructured log messages to clients. Clients can control...
- mcp-server-stability-ai/src/tools/generateImage.ts at 357448087fc642b29d5c42449adce51812a88701 · tadasant/mcp-server-stability-ai: MCP Server integrating MCP Clients with Stability AI-powered image manipulation functionalities: generate, edit, upscale, and more. - tadasant/mcp-server-stability-ai
- MCP-wolfram-alpha/src/mcp_wolfram_alpha/server.py at a92556e5a3543dbf93948ee415e5129ecdf617c6 · SecretiveShell/MCP-wolfram-alpha: Connect your chat repl to wolfram alpha computational intelligence - SecretiveShell/MCP-wolfram-alpha
MCP (Glama) ▷ #showcase (8 messages🔥):
MCP Agent, OpenAI Agent SDK, MCP Servers, unRAID MCP server, MCP Fathom Analytics
- *MCP Agent* on GitHub!: A member shared a link to the MCP Agent GitHub repository, a project focused on building effective agents using the Model Context Protocol and simple workflow patterns.
- *OpenAI Agents SDK* gets MCP Support: A member announced they added MCP support for the OpenAI Agents SDK, available as a fork on GitHub and on pypi as the openai-agents-mcp package, allowing agents to aggregate tools from MCP servers.
- By setting the
mcp_serversproperty, the Agent can seamlessly use MCP servers, local tools, and OpenAI-hosted tools through a unified syntax.
- By setting the
- unRAID Gets MCP server!: A member shared a link to the unRAID MCP server on GitHub.
- *Fathom Analytics* gains MCP server!: A member shared a link to the MCP server for Fathom Analytics.
- Show HN: MCP-Compatible OpenAI Agents SDK | Hacker News: no description found
- GitHub - lastmile-ai/openai-agents-mcp: A lightweight, powerful framework for multi-agent workflows: A lightweight, powerful framework for multi-agent workflows - lastmile-ai/openai-agents-mcp
- GitHub - mackenly/mcp-fathom-analytics: MCP server for Fathom Analytics: MCP server for Fathom Analytics. Contribute to mackenly/mcp-fathom-analytics development by creating an account on GitHub.
- GitHub - jmagar/unraid-mcp: Contribute to jmagar/unraid-mcp development by creating an account on GitHub.
- GitHub - lastmile-ai/mcp-agent: Build effective agents using Model Context Protocol and simple workflow patterns: Build effective agents using Model Context Protocol and simple workflow patterns - lastmile-ai/mcp-agent
Codeium (Windsurf) ▷ #discussion (37 messages🔥):
Codeium Extension Issues, Protocol Errors, Neovim Support, VPN Workaround
- Codeium Extension Plagued by Protocol Errors: Users reported getting protocol errors such as "invalid_argument: protocol error: incomplete envelope: read tcp... forcibly closed by the remote host" using the VSCode extension, with the Codeium footer turning red.
- The issue seems to affect users in the UK and Norway using various internet providers like Hyperoptic and Telenor.
- Neovim Support Lacking: A user expressed disappointment that Neovim support has been left behind compared to Windsurf, mentioning completion errors with error 500.
- They asked if the issues would be fixed soon or if they should switch to another plugin, to which a team member responded that the team is working on it.
- Test Fix Deployed, Mixed Results: The team deployed a test fix, with some users reporting fewer errors after the update.
- However, others were still facing issues, with the extension "turning off" or remaining red, prompting further investigation by the team.
- Team Acknowledges EU Issues: The team acknowledged that the issue primarily affects users in the EU, with problems including "unexpected EOF" during autocomplete and inability to link files inside chat.
- A workaround suggested was to use a VPN and connect to Los Angeles.
Yannick Kilcher ▷ #general (14 messages🔥):
YC copycat startups, Maxwell's demon and slow AI, Adaptive Meta-Learning projects, Sakana AI scientist LLM scaling
- YC focuses on short-term copycats: A member expressed that YC chooses startups (copycats) that will become successful in the short-term but won't exist in the long-term.
- They added that it's years YC doesn't have any notable unicorn, so YC is NOT successful for years.
- Maxwell's Demon Limits AI Speed: A member shared that computers can compute with arbitrarily low energy by going both backwards and forwards, but the speed limit is how fast and certain you run the answer, referencing this YouTube video.
- They also linked another video about reversing entropy.
- Adaptive Meta-Learning Toy Projects Sought: A member is looking for toy projects to test Meta-Transform and Adaptive Meta-Learning, starting with small steps using Gymnasium.
- They also linked to a GitHub repo for Adaptive Meta-Learning (AML).
- LLM Scaling Explained by FSA Approximation: Referencing Sakana AI's first publication, a member theorized that LLM scaling can be explained by assuming they are probabilistic FSAs approximating a context-free language.
- This approach, machines from a lower rung of the Chomsky hierarchy, attempting to approximate the language of a higher rung, gives you the characteristic S-curve.
- no title found: no description found
- Tweet from vik (@vikhyatk): the greatest minds of our generation are getting nerd sniped by text diffusion and SSMs. a distraction from work that actually matters (cleaning datasets)
- GitHub - EAzari/AML: Adaptive Meta-Learning (AML): Adaptive Meta-Learning (AML). Contribute to EAzari/AML development by creating an account on GitHub.
- Maxwell's demon: Does life violate the 2nd law of thermodynamics? | Neil Gershenfeld and Lex Fridman: Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=YDjOS0VHEr4Please support this podcast by checking out our sponsors:- LMNT: https://drinkLM...
- Reversing Entropy with Maxwell's Demon: Viewers like you help make PBS (Thank you 😃) . Support your local PBS Member Station here: https://to.pbs.org/DonateSPACECan a demon defeat the 2nd Law of T...
- What Turing got wrong about computers | Neil Gershenfeld and Lex Fridman: Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=YDjOS0VHEr4Please support this podcast by checking out our sponsors:- LMNT: https://drinkLM...
- Where do ideas come from? | Neil Gershenfeld and Lex Fridman: Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=YDjOS0VHEr4Please support this podcast by checking out our sponsors:- LMNT: https://drinkLM...
Yannick Kilcher ▷ #paper-discussion (6 messages):
Forward vs backward SDE, Reverse-diffusion SDE
- SDE Presentation Slated for Friday: A member offered to present on SDEs Friday night, covering what an SDE is and the derivation of the reverse-diffusion SDE from the forward noise SDE.
- They clarified this would be an impromptu presentation.
- Unveiling Backward SDEs: A member shared a discussion on forward vs backward SDEs, explaining the backward process involves inverting the forward process's corresponding PDE and solving it as an SDE.
- They attached a Stochastic Calculus PDF.
Yannick Kilcher ▷ #agents (1 messages):
mico6424: Which cognitive architecture has a working implementation that's worth looking into?
Yannick Kilcher ▷ #ml-news (7 messages):
Gemma 3, Multimodal Models, Sakana AI paper
- Gemma 3 is finally Out!: Gemma 3 is released with multimodal capabilities and a 128k context window (except for the 1B model), fulfilling user expectations.
- One user simply said it "twas aight".
- Google Gemini Robotics Model: Google released a YouTube video showcasing Gemini Robotics, bringing Gemini 2.0 to the physical world as their most advanced vision language action model.
- The model enables robots that can interact with the physical world.
- Sakana AI's AI-generated paper gets peer-reviewed: A paper generated by Sakana AI has passed peer review for an ICLR workshop.
- A user questioned the rigor of the review, suggesting the workshop might be generous to the authors.
- no title found: no description found
- no title found: no description found
- Gemini Robotics: Bringing AI to the physical world: Our new Gemini Robotics model brings Gemini 2.0 to the physical world. It's our most advanced vision language action model, enabling robots that are interact...
Latent Space ▷ #ai-general-chat (25 messages🔥):
Mastra AI Framework, Cursor SOTA Embedding Model, Typescript AI Apps, Gemini Native Image Generation, DeepSearch and DeepResearch
- Mastra Typescript AI Framework Launches: A new Typescript AI framework called Mastra was announced by ex-Gatsby/Netlify builders, aiming to be fun for toy projects and sturdy for production, targeting frontend, fullstack, and backend developers via a blog post.
- The creators aim to provide an alternative to existing frameworks by focusing on reliability and ease of use for product developers, inviting community contributions to their project.
- Cursor trains SOTA Embedding Model: Cursor has trained a SOTA embedding model on semantic search, substantially outperforming out-of-the-box embeddings and rerankers used by competitors, according to a tweet.
- Users are encouraged to feel the difference when using the agent to experience the enhanced performance.
- Experiment with Gemini 2.0 Flash's Native Image Generation: Google is rolling out native image generation in Gemini 2.0 Flash for developer experimentation across all regions currently supported by Google AI Studio, as announced in a blog post.
- The update allows developers to test the new capability using an experimental version of Gemini 2.0 Flash (gemini-2.0-flash-exp) in Google AI Studio and via the Gemini API, combining multimodal input, enhanced reasoning, and natural language understanding to create images, according to a tweet.
- Jina AI Details DeepSearch Implementation: Jina AI published a blog post providing a practical guide to implementing DeepSearch/DeepResearch, focusing on late-chunking embeddings for snippet selection and using rerankers to prioritize URLs before crawling.
- The post emphasizes that QPS is out and depth is in, advocating for finding answers through read-search-reason loops.
- Snippet Selection and URL Ranking in DeepSearch/DeepResearch: Nailing these two details transforms your DeepSearch from mid to GOAT: selecting the best snippets from lengthy webpages and ranking URLs before crawling.
- Tweet from Kaushik Shivakumar (@19kaushiks): Super excited to ship Gemini's native image generation into public experimental today :) We've made a lot of progress and still have a way to go, please send us feedback!And yes, I made the im...
- A framework for the next million AI developers: The next generation of AI products will be built with Apis written in Typescript
- Tweet from Aman Sanger (@amanrsanger): Cursor trained a SOTA embedding model on semantic searchIt substantially outperforms out of the box embeddings and rerankers used by competitors!You can see feel the difference when using agent!
- Tweet from Mostafa Dehghani (@m__dehghani): Anyone who has been in this room knows that it’s never just another day in here! This space has seen the extremes of chaos and genius!...and we ship! https://developers.googleblog.com/en/experiment-wi...
- Sam Altman, CEO of OpenAI: Sam Altman, CEO of OpenAI
- Tweet from Aiden Bai (@aidenybai): Introducing Same.devClone any website with pixel perfect accuracyOne-shots Nike, Apple TV, Minecraft, and more!
- Experiment with Gemini 2.0 Flash native image generation: no description found
Notebook LM ▷ #announcements (1 messages):
User Research, Mobile Usage, NotebookLM on Mobile, Usability Study
- Users Mobile Habits Probed in Research: Google is seeking NotebookLM users for 60-minute interviews to discuss their mobile usage and provide feedback on new concepts, with a $75 USD thank you gift or a $50 Google merchandise voucher offered.
- Interested participants are directed to complete a screener form (link) to determine eligibility.
- Google to conduct Usability Study: Google is conducting a usability study on April 2nd and 3rd, 2025, to gather feedback on a product in development, offering participants the localized equivalent of $75 USD or a $50 Google merchandise voucher for their time.
- The study requires a high-speed internet connection, an active Gmail account, and a computer with video camera, speaker, and microphone.
Link mentioned: Participate in an upcoming NotebookLM user research study!: Hello,I’m contacting you with a short questionnaire to verify your eligibility for an upcoming usability study with Google. This study is an opportunity to provide feedback on something that's cur...
Notebook LM ▷ #use-cases (4 messages):
NoteBookLM Plus, Internal FAQ, API instructions
- NoteBookLM Plus as internal FAQ: A member is considering using NoteBookLM Plus as an internal FAQ and wants to investigate the content of unresolved questions.
- They seek advice on how to examine questions users typed into the chat that were not resolved.
- NoteBookLM excels at API scripts: A member found NLM+ surprisingly capable at generating scripts using API instructions and sample programs.
- They noted it was easier to get revisions as a non-programmer by referencing material from the notebook.
Notebook LM ▷ #general (12 messages🔥):
RAG vs Full Context Window, Saving Chat Responses, Thinking Model Updates, Language Support
- RAG vs Full Context Window Showdown: A user is questioning whether using RAG with vector search and a smaller context window is better than using Gemini Pro with its full context window for a large database.
- They're curious about the context window size used in RAG and ask for recommendations on achieving their task of having a mentor-like AI by using Gemini Pro.
- Inline Citations Saved!: Users can now save chat responses as notes with inline citations preserved in their original form.
- This enhancement allows users to refer back to the original source material, addressing a long-standing request from power users.
- Users Want Copiable Inline Citations: A user requested the ability to copy and paste inline citations into a document while preserving the links.
- Another user wants to copy from NotebookLM to Word and have footnotes with the title of the source to help with formatting.
- New Thinking Model Improves Quality: A new 'thinking model' has been pushed to NotebookLM to enhance the quality of responses.
- The specific details of what this model does or how it improves the responses are not available.
- Portuguese Language Answers: A user reported that NotebookLM started forcing English answers, despite working properly in Portuguese previously.
- A user provided a solution: adding
?hl=ptat the end of the URL.
- A user provided a solution: adding
Link mentioned: Hyperborea - Wikipedia: no description found
Torchtune ▷ #general (7 messages):
MPS Issues, Gemma 3, Torchvision MPS Errors
- MPS Device Debacle Derails Development: A member reported an
AttributeError: module 'torch.mps' has no attribute 'set_device'after a recent change, potentially dropping MPS support, and linked the relevant GitHub commit.- Another member acknowledged the issue and pointed to PR #2486 as a potential fix, however it resulted in further errors from torchvision when running on MPS.
- Gemma 3 Gossip Grabbed: A user noted that Gemma 3 model made a change, and provided a screenshot.
- The screenshot was attached from a Discord CDN link, showing some changes (image.png).
- Fix missing MPS detection in _get_device_type_from_env() (#2471) · pytorch/torchtune@5cb4d54: Co-authored-by: salman <salman.mohammadi@outlook.com>
- Fix MPS `get_device` by SalmanMohammadi · Pull Request #2486 · pytorch/torchtune: ContextWhat is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here)On main:>>> from torchtune.utils import get_de...
Torchtune ▷ #dev (2 messages):
Gemma3, vLLM, Pan & Scan
- Gemma3's "Pan & Scan" Implementation Questioned: A member questioned whether the "Pan & Scan" technique from the Gemma3 paper, designed to boost inference performance, needs implementation in torchtune.
- Another member suggested it isn't critical as users can leverage vLLM with the HF ckpt for enhanced performance, linking to a relevant pull request.
- vLLM offers Gemma3 Better Perf: Users can use the HF ckpt with vLLM for better perf with this PR https://github.com/vllm-project/vllm/pull/14660
Link mentioned: [Model] Add support for Gemma 3 by WoosukKwon · Pull Request #14660 · vllm-project/vllm: This PR adds the support for Gemma 3, an open-source vision-language model from Google.NOTE:The PR doesn't implement the pan-and-scan pre-processing algorithm. It will be implemented by a fo.....
LlamaIndex ▷ #blog (1 messages):
LlamaIndex, Model Context Protocol (MCP), tool discovery
- *LlamaIndex* Connects to Model Context Protocol Servers: LlamaIndex now integrates with the Model Context Protocol (MCP), an open-source initiative that streamlines tool discovery and utilization, as described in this tweet.
- MCP Simplifies Tool Use: The Model Context Protocol integration allows LlamaIndex to use tools exposed by any MCP-compatible service, enhancing its capabilities.
LlamaIndex ▷ #general (7 messages):
LlamaExtract on-premise, New Response API support
- LlamaExtract On-Premise: A Fortress for Sensitive Data: In response to enterprise concerns about sensitive data, on-premise/BYOC (Bring Your Own Cloud) deployments are available for the entire Llama-Cloud platform.
- However, a member noted that these deployments typically incur a much higher cost than utilizing the SaaS solution.
- Response API: Will LlamaIndex embrace the New Search?: A user inquired about support for the new Response API, suggesting its potential to enrich results using a search tool with user opt-in.
- A member responded affirmatively, stating that they are trying to work on that today.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (3 messages):
Quiz Deadlines, Research Opportunities for MOOC Learners, Lab Opportunities for MOOC Learners
- Quiz Deadlines in May: All quiz deadlines are scheduled for May, and more details will be released soon.
- The user was informed that they are on the mailing list and have opened the latest email regarding Lecture 6.
- Learners Seek Lab Opportunities: A member inquired about plans for Labs as well as research opportunities for the MOOC learners.
Cohere ▷ #「💬」general (2 messages):
Cohere multilingual embed model pricing, OpenAI Responses API, Cohere Compatibility
- Cohere Multilingual Pricing Questioned: A member inquired about the pricing of the Cohere multilingual embed model, noting difficulty finding this information in the documentation.
- No specific details or links about pricing were shared in the discussion.
- Responses API from OpenAI Released: OpenAI just released their Responses API alongside the Agents SDK, focusing on greater simplicity and expressivity.
- The Responses API documentation highlights its design for multiple tools, turns, and modalities, addressing user pain points with current APIs.
- Cohere Compatibility with OpenAI API?: A member asked about the potential for Cohere to be compatible with OpenAI's newly released Responses API.
- The OpenAI cookbook example details the Responses API as a solution for multi-turn interactions, hosted tools, and granular context control.
Link mentioned: Web Search and States with Responses API | OpenAI Cookbook: Open-source examples and guides for building with the OpenAI API. Browse a collection of snippets, advanced techniques and walkthroughs. Share your own examples and guides.
Cohere ▷ #「🔌」api-discussions (1 messages):
Chat API seed parameter issue, Inconsistent outputs with same seed
- Chat API's Seed Parameter Faces Scrutiny: A user pointed out that the chat API seemingly disregards the
seedparameter, resulting in diverse outputs despite using the same inputs and seed value. - Inconsistent Outputs Plague Seeded API Calls: Multiple users are reporting inconsistent outputs when using the Chat API with the same
seedvalue, suggesting a potential issue with reproducibility.
DSPy ▷ #general (2 messages):
DSPy Caching, Pluggable Cache Module
- DSPy Caching Mechanism Questioned: A member inquired about how caching works in DSPy and whether the caching behavior can be modified.
- Pluggable Cache Module in Development: Another member pointed to a pull request for a pluggable Cache module currently in development.
Link mentioned: Feature/caching by hmoazam · Pull Request #1922 · stanfordnlp/dspy: One single caching interface which has two levels of cache - in memory lru cache and fanout (on disk)
Modular (Mojo 🔥) ▷ #mojo (2 messages):
modular max, Linux exec issues, github PR
- Modular Max PR nears Completion: A member shared a GitHub Pull Request that hopefully will end up looking like their project.
- First the foundations PR has to be merged and then there are some issues with Linux exec that need to be resolved.
- Linux Exec Troubles Delay Release: The release of the new feature is delayed due to unresolved issues with Linux exec, pending the merging of the foundations PR.
- Despite the setback, the developer expressed optimism for a relatively soon-ish release, with subscribers receiving updates on the PR's progress.
Link mentioned: [stdlib] Adds functionality to spawn and manage processes from exec. file by izo0x90 · Pull Request #3998 · modular/max: Foundation for this PR is set here, it adds the needed lowlevel utilities:Adds vfork, execvp, kill system call utils. to Mojos cLib bindsAdds read_bytes to file descriptorOnce that PR is merge...
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
Tracking evaluation tools, Evaluation dataset location
- Discover central hub tracking evaluation tools: A member inquired about a central place to track all the tools used for evaluation.
- Another member suggested looking at gorilla/berkeley-function-call-leaderboard/data/multi_turn_func_doc as a potential resource.
- Evaluation dataset location pinpointed: A member asked if all the evaluation dataset is available in the
gorilla/berkeley-function-call-leaderboard/datafolder.- There were no further messages in the discussion to confirm whether that folder contains all evaluation datasets.
AI21 Labs (Jamba) ▷ #jamba (1 messages):
RAG, Pinecone, VPC deployment
- Switching away from Pinecone: The RAG previously used Pinecone, but due to its limitations in performance and lack of support for VPC deployment, a different direction was chosen.
- New RAG Direction: Due to Pinecone's limitations and lack of VPC deployment, a new direction for RAG was explored.