[AINews] Gemini Nano: 50-90% of Gemini Pro, <100ms inference, on device, in Chrome Canary
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
window.ai.createTextSession() is all you need
AI News for 6/21/2024-6/24/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (415 channels, and 5896 messages) for you. Estimated reading time saved (at 200wpm): 660 minutes. You can now tag @smol_ai for AINews discussions!
The latest Chrome Canary now has Gemini Nano in a feature flag:
- Prompt API for Gemini Nano chrome://flags/#prompt-api-for-gemini-nano
- Optimization guide on device chrome://flags/#optimization-guide-on-device-model
- Navigate to chrome://components/ and look for Optimization Guide On Device Model; Check for update to start the download
You'll now have access to the model via the console: http://window.ai.createTextSession()
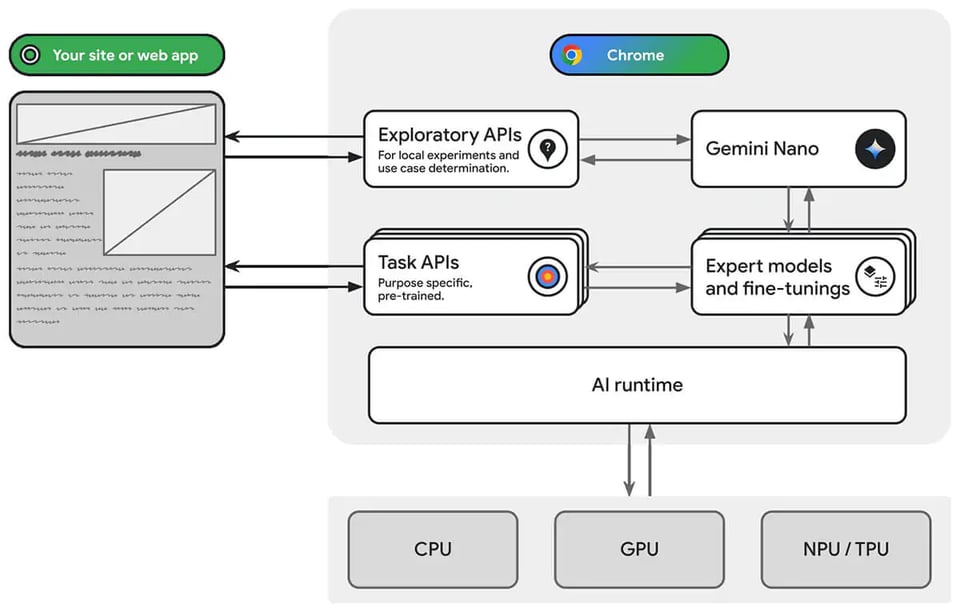
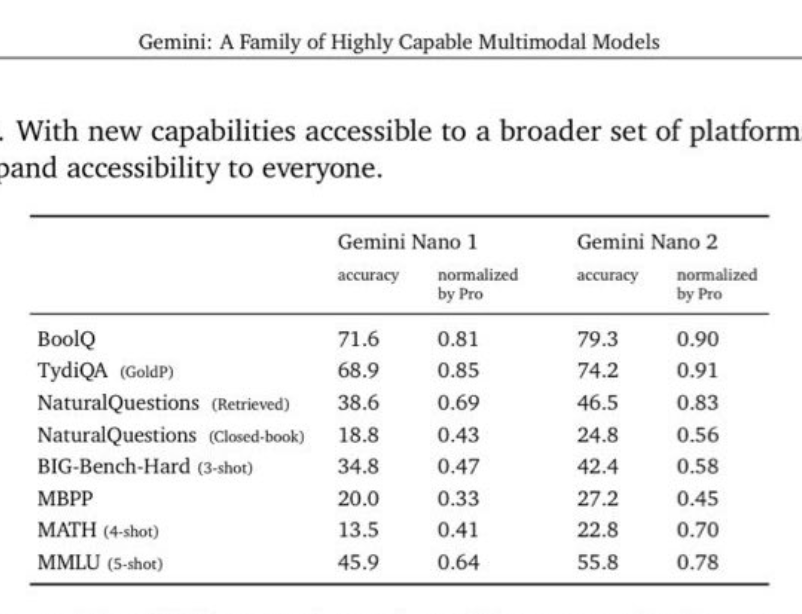
Nano 1 and 2, at a 4bit quantized 1.8B and 3.25B parameters has decent performance relative to Gemini Pro:
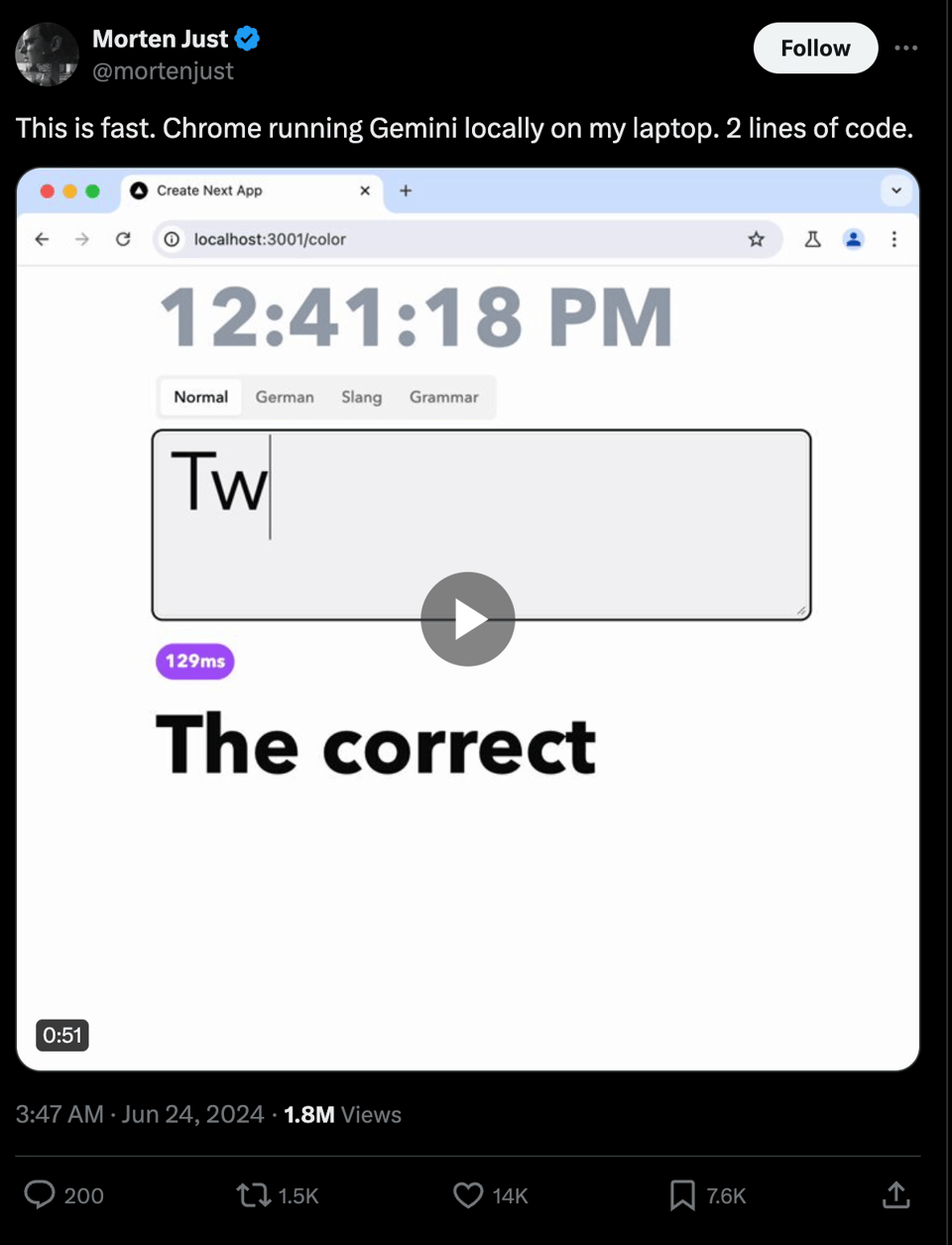
and you should see this live demo of how fast it runs
Lastly, the base model and instruct-tuned model weights have already been extracted and posted to HuggingFace.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Model Releases and Benchmarks
- Anthropic Claude 3.5 Sonnet: @adcock_brett noted Anthropic launched Claude 3.5 Sonnet, an upgraded model that bests GPT-4o across some benchmarks. For devs, it's 2x the speed of Opus, while pricing comes in at 1/5 the cost of Anthropic's previous top model. For consumers, it's completely free to try. @lmsysorg reported Claude 3.5 Sonnet has climbed to #4 in Coding Arena, nearing GPT-4-Turbo levels. It's now the top open model for coding. It also ranks #11 in Hard Prompts and #20 in Overall generic questions.
- DeepSeek-Coder-V2: @dair_ai noted DeepSeek-Coder-V2 competes with closed-sourced models on code and math generation tasks. It achieves 90.2% on HumanEval and 75.7% on MATH, higher than GPT-4-Turbo-0409 performance according to their report. Includes a 16B and 236B parameter model with 128K context length.
- GLM-0520: @lmsysorg reported GLM-0520 from Zhipu AI/Tsinghua impresses at #9 in Coding and #11 Overall. Chinese LLMs are getting more competitive than ever!
- Nemotron 340B: @dl_weekly reported NVIDIA announced Nemotron-4 340B, a family of open models that developers can use to generate synthetic data for training large language models.
AI Research Papers
- TextGrad: @dair_ai noted TextGrad is a new framework for automatic differentiation through backpropagation on textual feedback provided by an LLM. This improves individual components and the natural language helps to optimize the computation graph.
- PlanRAG: @dair_ai reported PlanRAG enhances decision making with a new RAG technique called iterative plan-then-RAG. It involves two steps: 1) an LLM generates the plan for decision making by examining data schema and questions and 2) the retriever generates the queries for data analysis. The final step checks if a new plan for further analysis is needed and iterates on previous steps or makes a decision on the data.
- Mitigating Memorization in LLMs: @dair_ai noted this paper presents a modification of the next-token prediction objective called goldfish loss to help mitigate the verbatim generation of memorized training data.
- Tree Search for Language Model Agents: @dair_ai reported this paper proposes an inference-time tree search algorithm for LM agents to perform exploration and enable multi-step reasoning. It's tested on interactive web environments and applied to GPT-4o to significantly improve performance.
AI Applications and Demos
- Wayve PRISM-1: @adcock_brett reported Wayve AI introduced PRISM-1, a scene reconstruction model of 4D scenes (3D in space + time) from video data. Breakthroughs like this will be crucial in the development of autonomous driving.
- Runway Gen-3 Alpha: @adcock_brett noted Runway demoed Gen-3 Alpha, a new AI model that can generate 10-second videos from text prompts and images. These human characters are 100% AI-generated.
- Hedra Character-1: @adcock_brett reported Hedra launched Character-1, a new foundation model that can turn images into singing portrait videos. The public preview web app can generate up to 30 seconds of expressive talking, singing, or rapping characters.
- ElevenLabs Text/Video-to-Sound: @adcock_brett noted ElevenLabs launched a new open-source text and video-to-sound effects app and API. Devs can now build apps that generate sound effects based on text prompts or add sound to silent videos.
Memes and Humor
- Gilded Frogs: @c_valenzuelab defined "Gilded Frogs" as frogs that have amassed great wealth and adorn themselves with luxurious jewelry, including gold chains, gem-encrusted bracelets, and rings, covering their skins with diamonds, rubies, and sapphires.
- Llama.ttf: @osanseviero noted Llama.ttf is a font which is also an LLM. TinyStories (15M) as a font 🤯 The font engine runs inference of the LLM. Local LLMs taken to an extreme.
- VCs Funding GPT Wrapper Startups: @abacaj posted a meme image joking about VCs funding GPT wrapper startups.
- Philosophers vs ML Researchers: @AmandaAskell posted a meme image comparing the number of papers published by philosophers vs ML researchers.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Stable Diffusion / AI Image Generation
- Pony Diffusion model impresses users: In /r/StableDiffusion, users are discovering the capabilities and creative potential of the Pony Diffusion model, finding it fun and refreshing to use. Some admit to underestimating Pony's responsibility and prompt adherence. There are requests for in-depth Pony tutorials to help produce desired family-friendly anime/manga style images while avoiding unintended NSFW generations.
- New techniques and model updates: Users are sharing background replacement, re-lighting and compositing workflows in ComfyUI and demonstrating the use of the [SEP] token for multiple prompts in adetailer models. The SD.Next release announcement highlights 10+ improvements like quantized T5 encoder support, PixArt-Sigma variants, HunyuanDiT 1.1, and efficiency upgrades for low VRAM GPUs. sd-scripts now supports training Stable Diffusion 3 models.
- Creative applications and model comparisons: An exhibition at the Nikola Tesla Museum features 118 AI-assisted artworks created with Stable Diffusion, highlighting adoption outside the AI community. New LoRA models like Aether Illustration for Nordic-style portraits and a black-and-white illustration style for SDXL are being released. A comparison of various models on a "woman lying on grass" prompt sparks discussion on their relative performance.
- Licensing discussions: Users discovered the initial Stable Cascade weights were released under an MIT license for about 4 days before changing to a more restrictive one, suggesting potential for commercial use of the MIT-licensed version. This has led to people downloading that specific version.
ChatGPT / AI Assistants
- AI-generated games impress users: In /r/ChatGPT, Claude, an AI assistant, created a playable 3D first-person shooter game within the chat interface. The game, which involves shooting happy emojis at sad monsters, was Claude's own idea. This is seen as a groundbreaking moment, with AI now competing with beginner human game developers. Users appreciate Claude's cute and hopeful approach.
- Model performance and benchmarks: Claude 3.5 Sonnet outperforms other models on various benchmarks like MMLU-Pro, according to recently released results.
- Improving chatbots with knowledge integration: In /r/singularity, a user is surprised large AI companies haven't connected their chatbots to knowledge bases like Wikipedia or tools like WolframAlpha for improved accuracy on facts, math, physics, etc. They believe the underlying technology exists but needs integration, though language models may still face fundamental limitations.
AI Discord Recap
SPECIAL NOTE: As we do for fresh frontier model launches, we are displaying the differences in output from running the same prompts across Claude 3.5 and 3 and GPT4o.
Claude 3 Sonnet
1. LLM Performance Benchmarking and Advancements
- Meta's Llama 3 model has rapidly risen to the top of leaderboards like ChatbotArena, outperforming models like GPT-4-Turbo and Claude 3 Opus as mentioned in this discussion.
- New models like IBM's Granite-8B-Code-Instruct and DeepSeek's DeepSeek-V2 236B model were discussed, with the latter outperforming GPT-4 in some benchmarks.
- However, there was skepticism around certain benchmarks and calls for credible sources to set realistic evaluation standards.
2. Techniques for Efficient LLM Training and Inference
- DeepSpeed's ZeRO++ was mentioned as promising 4x reduced communication overhead for large model training on GPUs.
- The vAttention system was discussed for dynamically managing KV-cache for efficient inference without PagedAttention.
- QServe's W4A8KV4 quantization was highlighted as a technique to boost cloud LLM serving performance on GPUs.
- Techniques like Consistency LLMs were mentioned for exploring parallel token decoding to reduce inference latency.
3. Open-Source AI Frameworks and Community Efforts
- The Axolotl project was discussed for supporting diverse dataset formats for instruction tuning and LLM pre-training.
- LlamaIndex was mentioned as powering a new course on building agentic RAG systems with Andrew Ng.
- The open-source RefuelLLM-2 model was introduced, claiming to be the best for "unsexy data tasks".
- Discussions around Modular's Mojo highlighted its potential for Python integration and AI extensions like bfloat16 as mentioned here.
4. Multimodal AI and Generative Modeling
- The Idefics2 8B Chatty and CodeGemma 1.1 7B models were mentioned for their focus on chat interactions and coding abilities respectively, as discussed here.
- The Phi 3 model was highlighted for bringing powerful AI chatbots to browsers via WebGPU, according to this Reddit link.
- Combining Pixart Sigma, SDXL and PAG was mentioned as aiming to achieve DALLE-3 level outputs, with potential for further refinement through fine-tuning, as per this discussion.
- The open-source IC-Light project focused on improving image relighting techniques was also brought up in this conversation.
Claude 3.5 Sonnet
-
LLM Performance and Benchmarking Debates:
- New models like DeepSeek-V2 and Hermes 2 Theta Llama-3 70B are generating buzz for their performance. However, there's growing skepticism across communities about AI benchmarks and leaderboards, with calls for more credible evaluation methods.
- Discussions in multiple discords touched on the challenges of comparing models like GPT-4, Claude, and newer open-source alternatives, highlighting the complexity of real-world performance versus benchmark scores.
-
Optimizing LLM Training and Inference:
- Communities are sharing techniques for improving LLM efficiency, such as quantization methods and optimizing for specific hardware like AMD GPUs.
- There's significant interest in reducing computational costs, with discussions ranging from VRAM optimization to novel architectures for more efficient inference.
-
Open-Source AI Development and Collaboration:
- Projects like Axolotl and LlamaIndex are fostering community-driven development of AI tools and frameworks.
- There's a trend towards open-sourcing models and tools, as seen with RefuelLLM-2 and Llamafile, encouraging wider participation in AI development.
-
Multimodal AI and Creative Applications:
- Discussions across discords highlight the growing interest in multimodal models that can handle text, image, and potentially video, with projects like Stable Artisan bringing these capabilities to wider audiences.
- There's ongoing experimentation with combining different models and techniques to achieve DALL-E 3-level outputs, showing a community-driven approach to advancing generative AI capabilities.
-
AI Integration and Practical Applications:
- Multiple communities are exploring ways to integrate AI into everyday tools, from browser-based models to Discord bots for media creation.
- There's a growing focus on making AI more accessible and useful for specific tasks, as seen in discussions about code generation, data analysis, and creative applications across various discord channels.
Claude 3 Opus
-
LLM Performance and Benchmarking:
- Discussions on the performance of models like Llama 3, DeepSeek-V2, and Claude 3.5 Sonnet across various benchmarks and leaderboards.
- Skepticism surrounding certain benchmarks, such as AlpacaEval, with calls for more credible assessment standards.
-
Optimizing LLM Training and Inference:
- Techniques for efficient training, such as ZeRO++ and Consistency LLMs, and optimized inference with vAttention and QServe.
- Discussions on quantization methods, like W4A8KV4, and their impact on model performance and resource requirements.
-
Open-Source AI Frameworks and Collaborations:
- Updates and collaborations involving open-source frameworks like Axolotl, LlamaIndex, and Modular.
- Introducing new open-source models, such as RefuelLLM-2 and Granite-8B-Code-Instruct.
-
Multimodal AI and Generative Models:
- Advancements in multimodal AI with models like Idefics2 8B Chatty and CodeGemma 1.1 7B.
- Innovations in generative modeling, such as Phi 3 for browser-based chatbots and combining techniques to achieve DALLE-3-level outputs.
- Open-source efforts in image relighting with projects like IC-Light.
-
AI Ethics, Legality, and Accountability:
- Discussions on the ethical implications of AI-generated content, as seen with Perplexity AI's alleged plagiarism.
- Concerns about the legal risks associated with AI models making inaccurate or defamatory statements, as highlighted in the Perplexity AI case.
- Debates on the accountability of tech companies using open datasets and the practice of "AI data laundering".
GPT4T (gpt-4-turbo-2024-04-09)
**1. AI Hardware Evolves but Costs Spiral:
- VRAM requirements for AI models like Command R (34b) Q4_K_S lead to discussions about switching to EXL2, a more VRAM-efficient format. The NVIDIA DGX GH200 remains out of reach due to high costs.
**2. Optimization Takes Center Stage in AI Tools:
- Quantization techniques are leveraged to optimize model performance, with ROCm's versions of xformers and flash-attention mentioned for efficiency. Implementation of PyTorch enhancements in the Llama-2 model results in significant performance boosts.
**3. AI Breaks New Ground in Multifaceted Applications:
- AI-powered reading aid Pebble, developed with OpenRouter, Pebble, illustrates novel uses of AI in enhancing reading comprehension. Cohere's APIs enable multi-step tool uses, significantly broadening functional reach, aided by detailed documentation on multi-step tool use.
**4. AI-centric Education and Jobs Expanding:
- MJCET launches the first AWS Cloud Club in Telangana to educate students on AWS technologies, celebrating with an event featuring AWS Community Hero Mr. Faizal Khan. RSVP through event link. Also, AI-inspired educational content is proffered through Hamel Dan's LLM101n course, teaching LLM building from scratch.
**5. Miscellaneous AI Developments Reflect Wide Impact:
- Intel retracts from AWS, puzzling the AI community on resource allocations. Claude Sonnet 3.5's prowess in coding tasks garners praise, showcasing AI's advancement in technical applications. In bizarre turns, Mozilla's Llamafile ventures into Android territory promising innovative mobile solutions.
GPT4O (gpt-4o-2024-05-13)
Model Optimization and LLM Innovations
- DeepSeek and Sonnet 3.5 Dominate Benchmarks: The DeepSeek model impressed the community with its quick performance and coding abilities, surpassing GPT-4 in some cases (DeepSeek announcement). Similarly, Claude 3.5 Sonnet outperformed GPT-4o in coding tasks, validated through LMSYS leaderboard positions and hands-on usage (Claude thread).
- ZeRO++ and PyTorch Accelerate LLM Training: ZeRO++ reduces communication overhead in large model training by 4x, while new PyTorch techniques accelerate Llama-2 inference by 10x, encapsulated in the GPTFast package, optimizing its use on A100 or H100 GPUs (ZeRO++ tutorial).
Open-Source Developments and Community Efforts
- Axolotl and Modular Encourage Community Contributions: Axolotl announced the integration of ROCm fork versions of xformers for AMD GPU support, and Modular users discussed contributing to learning materials for LLVM and CUTLASS (related guide).
- Featherless.ai and LlamaIndex Expand Capabilities: Featherless.ai, a new platform to run public models serverlessly, was launched to wide curiosity (Featherless). LlamaIndex now supports image generation via StabilityAI, enhancing its toolkit for AI developers (LlamaIndex-StabilityAI).
AI in Production and Real-World Applications
- MJCET's AWS Cloud Club Takes Off: The inauguration of the AWS Cloud Club at MJCET promoted hands-on AWS training and career-building initiatives (AWS event).
- Use of OpenRouter in Practical Applications: JojoAI was highlighted for its proactive assistant capabilities, using integrations like DigiCord to outshine competitive models like ChatGPT and Claude (JojoAI site).
Operational Challenges and Support Queries
- Installation and Compatibility Issues Plague Users: Difficulties in setting up libraries like xformers on Windows raised compatibility discussions, with suggestions converging on Linux for more stable operations (Unsloth troubleshooting).
- Credit and Support Issues: Numerous members of the Hugging Face and Predibase communities faced issues with missing service credits and billing inquiries, showcasing the need for improved customer support systems (Predibase).
Upcoming Technologies and Future Directions
- Announcing New AI Models and Clusters: AI21's Jamba-Instruct with a 256K context window and NVIDIA's Nemotron 4 highlighted breakthroughs in handling large-scale enterprise documents (Jamba-Instruct, Nemotron-4).
- Multi Fusion and Quantization Techniques: Discussions on the merits of early versus later fusion in multimodal models and advancements in quantization highlighted ongoing research in reducing AI model inference cost and boosting efficiency (Multi Fusion).
PART 1: High level Discord summaries
HuggingFace Discord
Juggernaut or SD3 Turbo for Virtual Realities?: While Juggernaut Lightning is favored for its realism in non-coding creative scenarios, SD3 Turbo wasn't discussed as favorably, suggesting that choices between models are influenced by specific context and goals.
Quantum Leap for PyTorch Users: Investments in libraries like PyTorch and HuggingFace are recommended over dated ones like sklearn, and use of bitsandbytes and precision modifications such as 4-bit quantization can assist with model loading on constrained hardware.
Meta-Model Mergers and Empathic Evolutions: The Open Empathic project is expanding with contributed movie scene categories via YouTube, while merging tactics for UltraChat and Mistral-Yarn elicited debate, with references to mergekit and frankenMoE finetuning as noteworthy techniques for improving AI models.
Souped-Up Software and Services: A suite of contributions surfaced, including Mistroll 7B v2.2's release, simple finetuning utilities for Stable Diffusion, a media-to-text conversion GUI using PyQt and Whisper, and the new AI platform Featherless.ai for serverless model usage.
In Pursuit of AI Reasoning Revelations: Plans to unravel recent works on reasoning with LLMs are brewing, with Understanding the Current State of Reasoning with LLMs (arXiv link) and repositories like Awesome-LLM-Reasoning and its namesake alternative repository link earmarked for examination.
Unsloth AI (Daniel Han) Discord
- Unsloth AI Previews Generate Buzz: A member's anticipation for Unsloth AI's release led to the sharing of a temporary recording, as theywaited for early access after a video filming announcement. Thumbnail updates, such as changing "csv -> unsloth + ollama" to "csv -> unsloth -> ollama", were suggested for clarity, alongside adding explainer text for newcomers.
- Big VRAM Brings Bigger Conversations: A YouTube video showcased the PCIe-NVMe card by Phison as an astonishing 1Tb VRAM solution, sparking discussions about its impact on performance. Meanwhile, Fimbulvntr's success in extending Llama-3-70b to a 64k context and the debate on VRAM expansion highlighted the ongoing exploration of large model capacities.
- Upgrades and Emotions in LLMs: Monday or Tuesday earmarked the Ollama update, promising CSV file support, while Sebastien's emotional llama model, fostering a better understanding of emotions in AI, became available on Ollama and YouTube.
- Solving Setups & Compatibility: From struggles to install xformers on Windows with Unsloth via conda to ensuring correct execution of initial setup cells in Google Colab notebooks, members swapped tips for overcoming software challenges. GPU Cloud (NGC) container setup discussions, as well as CUDA and PyTorch version constraints, featured solutions like using different containers and sharing Dockerfile configurations.
- Pondering on Partnerships & AI Integration: A blog titled "Apple and Meta Partnership: The Future of Generative AI in iPhones" stirred the guild's interest, with discussions focused on the strategic implications and potential integration challenges of generative AI in mobile devices.
Stability.ai (Stable Diffusion) Discord
- Bot Beware: A Discord bot was shared for integrating Gemini and StabilityAI services, but members raised safety and context concerns regarding the link.
- Civitai Pulls SD3 Amidst License Concerns: The removal of SD3 resources by Civitai sparked intense discussions, suggesting the step was taken to preempt legal issues.
- Running Stable with Less: Techniques for operating Stable Diffusion on lower specification GPUs, like utilizing automatic1111, were debated, weighing the efficiency of older GPUs against newer models like the RTX 4080.
- Training Troubles and Tips: Community members sought advice for training models and overcoming errors such as VRAM limits and problematic metadata, with some suggesting specialized tools like ComfyUI and OneTrainer for enhanced management.
- Model Compatibility Confusion: Discussions highlighted the necessity for alignment between models like SD 1.5 and SDXL with add-ons such as ControlNet; mismatched types can lead to performance degradation and errors.
CUDA MODE Discord
- CUTLASS and CUDA Collaboration Call: Users expressed interest in forming a CUTLASS working group, encouraged by a shared YouTube talk on Tensor Cores. Additionally, insights on the CPU cache were amplified with a shared primer on cache functionality, highlighting its significance for programmers.
- Floating Points and Precision Perils: Precision loss in FP8 conversion drew attention, prompting a shared resource for understanding rounding per IEEE convention and the use of tensor scaling to counteract loss. For those exploring quantization, a compilation of papers and educational content was recommended, including Quantization explained and Advanced Quantization.
- Enthusiasts of INT4 and QLoRA Weigh In: In a discussion contrasting INT4 LoRA fine-tuning versus QLoRA, it was noted that QLoRA's inclusion of a CUDA dequant kernel (axis=0) sustains both quality and pace, especially compared to solutions using tinnygemm for large sequences.
- Networks Need Nurturing: The integration of Bitnet tensors with AffineQuantizedTensor sparked debate, considering special layouts for specifying packed dimensions. For assistance with debugging Bitnet tensor issues, CoffeeVampire3's GitHub and the PyTorch ao library tutorials were spotlighted as go-to resources.
- Strategies to Scale System Stability: Strategies for multi-node setup optimizations and integrating FP8 matmuls were at the forefront of conversations, addressing performance challenges and training stability, especially on H100 GPUs which showed issues compared to A100. Upcoming large language model training on a Lambda cluster was also prepped for, with an eye on efficiency and stability.
LM Studio Discord
VRAM Crunch and Hefty Price Tags: Engineers highlighted the VRAM bottleneck when handling colossal models like Command R (34b) Q4_K_S, suggesting EXL2 as a more VRAM-efficient format. For heavy-duty AI work, the NVIDIA DGX GH200, touted for its mammoth memory, remains out of reach financially for most, hinting at thousands of dollars in investment.
Quantum Leaps in LLM Reasoning: Users were impressed with the Hermes 2 Theta Llama-3 70B model, known for its significant token context limit and creative strengths. Conversations around LLMs lack temporal awareness spurred mention of the Hathor Fractionate-L3-8B for its performance when output tensors and embeddings remain unquantized.
Cool Rigs and Hot Chips: On the hardware battlefield, using P40 GPUs with Codestral demonstrated a surge in power utilization to 12 tokens/second. Meanwhile, the iPad Pro’s 16GB RAM was debated for its ability to handle AI models, and the dream of using DX or Vulkan for multi-GPU support in AI was floated in response to the absence of NVlink in 4000 series GPUs.
Patchwork and Plugins: The LLaMa library vexed users with errors stemming from a model's expected tensor count mismatch, whereas deepseekV2 faced loading woes, potentially fixable by updating to V0.2.25. Enthusiasm bubbled for a hypothetical all-in-one model runner that could handle a gamut of Huggingface models including text-to-speech and text-to-image.
Model Engineering and Enigmas: The quaintly named Llama 3 CursedStock V1.8-8B model piqued curiosity for its unique performance, especially in creative content generation. There was chatter about a Multi-model sequence map allowing data flow among several models, and the latest quantized Qwen2 500M model made waves for its ability to operate on less capable rigs, even a Raspberry Pi.
OpenAI Discord
- Siri and ChatGPT's Odd Couple: There's confusion among users about Siri's integration with ChatGPT, with the consensus being that ChatGPT acts as an enhancement to Siri rather than a core integration. Elon Musk's critical comments fueled further discussion on the topic.
- Claude's Coding Coup Over GPT-4o: The Claude 3.5 Sonnet is praised for its superior performance in coding tasks compared to GPT-4o, with users highlighting Claude's success in areas where GPT-4o stumbled. Effectiveness is gauged by both practical usage and positions on the LMSYS leaderboard rather than just benchmark scores.
- Persistent LLM Personal Assistant Dreaming: Enthusiasm is noted regarding the possibility of tailoring and maintaining language models, like Sonnet 3.5 or Gemini 1.5 Pro, to serve as personalized work-bots trained on an individual's documents, prompting discussions about long-term and specialized applications of LLMs.
- GPT-4o’s Context Window Woes: Users struggle with limitations in GPT-4o's ability to adhere to complex prompt instructions and handle lengthy documents. Alternatives such as Gemini and Claude are suggested for better performance with larger token windows.
- DALL-E Vs. Midjourney Artistic Showdown: A debate is unfolding on the server over DALL-E 3 and Midjourney’s capacities for generating AI images, particularly in the realm of paint-like artworks, with some showing a preference for the former's distinct artistic styles.
Perplexity AI Discord
- Perplexity AI Caught in Plagiarism Uproar: Wired reported Perplexity AI's alleged policy violations by scraping websites, with its chatbot misattributing a crime to a police officer and a debate emerging on the legal implications of inaccurate AI summaries.
- Mixed Reactions to Claude 3.5 Sonnet: The release of Claude 3.5 Sonnet was met with both applause for its capabilities and frustration for seeming overcautious, as reported by Forbes, while users experienced inconsistencies with Pro search results leading to dissatisfaction with Perplexity's service.
- Exclusives on Apple and Boeing's Struggles: Apple's AI faced limitations in Europe while Boeing's Starliner confronted significant challenges, information disseminated on Perplexity with direct links to articles on these issues (Apple Intelligence Isn't, Boeing’s Starliner Stuck).
- Perplexity API Quandaries: The Perplexity API community discussed issues like potential moderation triggers or technical errors with LLama-3-70B when handling long token sequences, and queries about restricting link summarization and time filtration in citations via the API were raised as documented in the API reference.
- Community Convergence for Better Engagement: An OpenAI community message highlighted the need for shareable threads to foster greater collaboration, while a Perplexity AI-authored YouTube video previews diverse topics like Starliner dilemmas and OpenAI's latest moves for educational consumption.
Nous Research AI Discord
Boost in Dataset Deduplication: Rensa outperforms datasketch with a 2.5-3x speed boost, leveraging Rust's FxHash, LSH index, and on-the-fly permutations for dataset deduplication.
Model Jailbreak Exposed: A Financial Times article highlights hackers "jailbreaking" AI models to reveal flaws, while contributors on GitHub share a "smol q* implementation" and innovative projects like llama.ttf, an LLM inference engine disguised as a font file.
Lively Debate on Model Parameters: In the ask-about-llms, discussions ranged from the surprisingly capable story generation of TinyStories-656K to assertions that general-purpose performance soars with 70B+ parameter models.
Dataset Synthesis and Classification Enhanced: Members share a Google Sheet for collaborative dataset tracking, explore improvements using the Hermes RAG format, and delve into datasets like SciRIFF and ft-instruction-synthesizer-collection for scientific and instructional purposes.
AI Safety Models Scrutiny and Coursework: #general sees a mix, from Gemini and OpenAI's redaction-capable safety models to the launch of Karpathy's LLM101n course, encouraging engineers to build a storytelling LLM.
Eleuther Discord
- SLURM Hiccups with Jupyter: Engineers are facing issues with SLURM-managed nodes when connecting via Jupyter Notebook, citing errors potentially due to SLURM restrictions. A user experienced a 'kill' message on console before training even with correct GPU specifications.
- PyTorch Boosts Llama-2 Performance: PyTorch's team has implemented techniques to accelerate the Llama-2 inference speed by up to a factor of ten; the enhancements are encapsulated in the GPTFast package, which requires A100 or H100 GPUs.
- Ethics and Sharing of AI Models: A serious conversation about the ethical and practical considerations of distributing proprietary AI models such as Mistral outside official sources highlighted concerns for legalities and the importance of transparency.
- Understanding AI Model Variants: Users debate methods to determine if an AI model is GPT-4 or a different variant, including examining knowledge cutoffs, latency disparities, and network traffic analysis.
- LingOly Challenge Introduces: A new LingOly benchmark is addressing the evaluation of LLMs in advanced reasoning involving linguistic puzzles. With over a thousand problems presented, top models are achieving below 50% accuracy, indicating a robust challenge for current architectures.
- Text-to-Speech Innovation with ARDiT: A podcast episode explores the usage of SAEs for model editing, inspired by the approach detailed in the MEMIT paper and its source code, suggesting wide applications for this technology.
- Pondering the Optimality of Multimodal Architectures: Dialogue surfaced about whether an early fusion model, like Chameleon, stands superior to later fusion approaches for multimodal tasks. The trade-off between generalizability and visual acuity loss in the image tokenization process of early fusion was a focus.
- Intel Retreats from AWS Instance: Intel is discontinuing their AWS instance leveraged by the gpt-neox development team, prompting discussions on cost-effective or alternative manual solutions for computational resources.
- Execution Error: NCCL Backend: Engineers report persistent NCCL backend challenges while attempting to train models with gpt-neox on A100 GPUs, a problem consistent across various NCCL and CUDA versions, with Docker use or without.
Latent Space Discord
- Character.AI Cracks Inference at Scale: Noam Shazeer of Character.AI illuminates the pursuit of AGI through optimization of inference processes, emphasizing their capability to handle upwards of 20,000 inference queries every second.
- Acquisition News: OpenAI Welcomes Rockset: OpenAI has acquired Rockset, a company skilled in hybrid search architecture with solutions like vector (FAISS) and keyword search, strengthening OpenAI's RAG suite.
- AI Education boost by Karpathy: Andrej Karpathy plants the seeds of an ambitious new course, "LLM101n," which will deep dive into constructing ChatGPT-like models from ground up, following the legacy of the legendary CS231n.
- LangChain Clears the Air on Funds: Harrison Chase addresses scrutiny regarding LangChain's expenditure of venture capital on product development instead of promotions, with a response detailed in a tweet.
- Murati Teases GPT's Next Leap: Mira Murati of OpenAI teases enthusiasts with a timeline hinting at a possible release of the next GPT model in about 1.5 years, while discussing the sweeping changes AI is bringing into creative and productive industries, available in a YouTube video.
- Latent Space Scholarship on Hiring AI Pros: A new "Latent Space Podcast" episode breaks down the art and science of hiring AI engineers, guiding listeners through hiring processes and defensive AI engineering strategies, with insights from @james_elicit and @adamwiggins available on this page and gathering buzz on Hacker News.
- Embarking on new YAML Frontiers: Conversations illustrate developing a YAML-based DSL for Twitter management to enhance post analytics, with a nod to Zoho Social's comprehensive features; for similar ventures, Anthropics suggests employing XML tags, and a GitHub repo showcases the successful design of a YAML templating language with LLMs in Go.
Modular (Mojo 🔥) Discord
- LLVM's Price Tag: An article estimating the cost of the LLVM project was shared, detailing that 1.2k developers produced a codebase of 6.9M lines with an estimated cost of $530 million. Cloning and checking out LLVM is part of understanding its development costs.
- Installation Troubles and Request for Help: Issues with Mojo installation on 22.04 were highlighted, citing failures in all devrel-extras tests; a problematic situation that led to a pause for troubleshooting. Separately, frustration over segmentation faults during Mojo development prompted a user to offer a $10 OpenAI API key for help with their critical issue.
- Discussions on Caching and Prefetching Performance: Deep dives into caching and prefetching, with emphasis on correct application and pitfalls, were a significant conversation topic. Insights shared included the potential for adverse effects on performance if prefetching is incorrectly utilized, and recommendations to utilize profiling tools such as
vtunefor Intel caches, even though Mojo does not support compile-time cache size retrieval. - Improvement Proposals and Nightly Mojo Builds: Suggested improvements for Mojo's documentation and a proposal for controlled implicit conversion in Mojo were noted. Updates on new nightly Mojo compiler releases as well as MAX repo updates sparked discussions on developmental workflow and productivity.
- Data Labeling and Integration Insights: A new data labeling platform initiative received feedback about common pain points and successes in automation with tools like Haystack. The potential for ERP integration (prompted by manual data entry challenges and PDF processing) was also a focal point, indicating a push towards streamlining workflows in data management.
LAION Discord
- New Gates Open at Weta & Stability AI: A wave of discussions followed news of leadership changes at Weta Digital and Stability AI, focusing on the implications of these shake-ups and questioning the motives behind the appointments. Some talks pointed to Sean Parker and shared articles on the subject, linking a Reuters article Reuters article on Stability AI.
- Llama 3 on the Prowl: There was palpable excitement about the Llama 3 hardware specifications suggesting impressive performance, potentially outclassing rival models like GPT-4O and Claude 3. Participants shared projected throughputs of "1 to 2 tokens per second" on advanced setups.
- The Protection Paradox with Glaze & Nightshade: A sobering conversation unfolded over the limited ability of programs like Glaze and Nightshade to protect artists' rights. Skeptics noted that second movers often find ways around such protections, thus providing artists with potentially false hope.
- Multimodal Models – A Repetitive Breakthrough?: The guild examined a new paper on multimodal models, raising the question of whether the purported advancements were meaningful. The paper promotes training on a variety of modalities to enhance versatility, yet participants critiqued the repeated 'breakthrough' narrative with little substantial novelty.
- Testing Limits: Promises and Limitations of Diffusion Models: A deeper dive into diffusion models was encapsulated in a GitHub repository shared by lucidrains, discussing the EMA (Exponential Moving Average) model updates (Diffusion Models on GitHub) and their use in image restoration, despite evidence pointing to the consistent bypassing of protections like Glaze.
Cohere Discord
- Welcome Wagon for Newcomers: New members joined the Cohere-focused Discord, guided by shared insights and tool use documentation that helps connect Cohere models to external applications.
- Skepticism Surrounding BitNet Practicality: Amidst debates on BitNet's future, it's noted to require training from scratch and is not optimized for existing hardware, leading Mr. Dragonfox to express concerns about its commercial impracticality.
- Cohere Capacities and Contributions: Following the integration of a Cohere client in Microsoft's AutoGen framework, there was a call within the community for further support from the Cohere team in the project's advancement.
- AI Enthusiasts Eager for Multilingual Expansions: Cohere's model's ability to understand and respond in multiple languages, including Chinese, was confirmed, directing interested parties to documentation and a GitHub notebook example to learn more.
- Developer Office Hours and Multi-Step Innovations: Cohere announced upcoming developer office hours emphasizing the Command R family's tool use capabilities, providing resources on multi-step tool use for leveraging models to execute complex sequences of tasks.
LangChain AI Discord
- Confusion Over Context and Tokens: Users reported confusion regarding the integration of max tokens and context windows in agents, specifically with LangChain not adhering to Pydantic models' validations. It was noted that context window or max token counts should include both the input and generated tokens.
- LangChain Learning and Implementation Queries: There was a spirited discussion about the learning curve with LangChain, with members sharing resources like Grecil's personal journey that includes tutorials and documentation. Meanwhile, debate about ChatOpenAI versus Huggingface models highlighted performance differences and adaptation in various scenarios.
- Enhancing PDF Interrogation with LangChain: A detailed guide was shared for generating Q&A pairs from PDFs using LangChain, referring to issues like #17008 on GitHub for further guidance. Adjustments for using Llama2 as the LLM were also discussed, emphasizing customizing the
QAGenerationChain. - From Zero to RAG Hero: Members showcased their experience building no-code RAG workflows for financial documents, an article detailing the process was shared. A discussion also centered around a custom Corrective RAG app and Edimate, an AI-driven video creation, demoed here, which signs a future for e-learning.
- AI Framework Evaluation Video: For engineers evaluating AI frameworks for app integration including models like GPT-4o, a YouTube video was shared, urging developers to consider critical questions regarding the necessity and choice of the AI framework for specific applications.
OpenRouter (Alex Atallah) Discord
- Jamba Instruct Boasts Big Context Window: AI21's Jamba-Instruct model has been introduced, showcasing a gigantic 256K context window, ideal for handling extensive documents in enterprise settings.
- Nemotron 4 Makes Waves with Synthetic Data Generation: NVIDIA's release of Nemotron-4-340B-Instruct focuses on synthetic data generation for English-language applications with its new chat model.
- JojoAI Levels Up to Proactive Assistant: JojoAI differentiates itself by becoming a proactive assistant that can set reminders, employing DigiCord integrations, positioning it apart from competitors like ChatGPT or Claude. Experience it on the JojoAI site.
- Pebble's Pioneering Reading Aid Tool: The unveiling of the Pebble tool, powered by OpenRouter with Mistral 8x7b and Gemini, provides a resource for enhancing reading comprehension and retention for web content. Kudos to the OpenRouter team for their support as acknowledged at Pebble.
- Tech Community Tackles Environmental and Technical Issues: Discussions pointed to concerns about the environmental footprint of using models like Nemotron 340b, with smaller models being recommended for efficiency and eco-friendliness. The community also dealt with practical affairs, such as resolving the disappearance of Claude self-moderated endpoints, praising Sonnet 3.5 for coding capabilities, addressing OpenRouter rate limits, and advising on best practices for handling exposed API keys.
OpenInterpreter Discord
- Local LLMs Enter OS Mode: The OpenInterpreter community has been discussing the use of local LLMs in OS mode with the command
interpreter --local --os, but there are concerns regarding their performance levels. - Desktop Delights and GitHub Glory: The OpenInterpreter team is promoting a forthcoming desktop app with a unique experience compared to the GitHub version, encouraging users to join the waitlist. Meanwhile, the project has celebrated 50,000 GitHub stars, hinting at a major upcoming announcement.
- Model Benchmarking Banter: The Codestral and Deepseek models have sparked attention with Codestral surpassing internal benchmarks and Deepseek impressing users with its quick performance. There's buzz about a future optimized
interpreter --deepseekcommand. - Cross-Platform Poetry Performance: The use of Poetry for dependency management over
requirements.txthas been a contentious topic, with some engineers pointing to its shortcomings on various operating systems and advocating for alternatives like conda. - Community Kudos and Concerns: While there's enthusiasm and appreciation for the community's support, particularly for beginners, there's also frustration regarding shipping delays for the 01 device, highlighting the balance between community sentiment and product delivery expectations.
LLM Finetuning (Hamel + Dan) Discord
Instruction Synthesizing for the Win: A newly shared Hugging Face repository highlights the potential of Instruction Pre-Training, providing 200M synthesized pairs across 40+ tasks, likely offering a robust approach to multi-task learning for AI practitioners looking to push the envelope in supervised multitask pre-training.
Bringing DeBERTa and Flash Together?: Curiosity is brewing over the possibility of combining DeBERTa with Flash Attention 2, posing the question of potential implementations that leverage both technologies to AI engineers interested in novel model architecture synergies.
Fixes and Workarounds: From a Maven course platform blank page issue solved using mobile devices to the resolution of permission errors after a kernel restart within braintrust, practical troubleshooting remains a staple of community discourse.
Credits Saga Continues: Persistent reports of missing service credits on platforms like Huggingface and Predibase sparked member-to-member support and referrals to respective billing supports. This included a tip that Predibase credits expire after 30 days, suggesting that engineers keep a keen eye on expiry dates to maximize credit use.
Training Errors and Overfitting Queries: Errors in running Axolotl's training command (Modal FTJ) and concerns about LORA overfitting ('significantly lower training loss compared to validation loss') were significant pain points, showcasing the need for vigilant model monitoring practices among AI engineers.
LlamaIndex Discord
- LightningAI and LlamaIndex Join Forces: LightningAI's RAG template offers an easy setup for multi-document agentic RAGs, promoting efficiency in AI development. Additionally, LlamaIndex's integration with StabilityAI now allows for image generation, broadening AI developer capabilities.
- Customizing Complexity with LlamaIndex: Those developing with LlamaIndex can customize text-to-SQL pipelines using Directed Acyclic Graphs (DAGs), as explained in this feature overview. Meanwhile, for better financial analysis, the CRAG technique can be leveraged using Hanane Dupouy's tutorial slides for improved retrieval quality.
- Fine-Tuning RAGs with Mlflow: To enhance answer accuracy in RAGs, integrating LlamaIndex with Mlflow provides a systematic way to manage critical parameters and evaluation methods.
- In-Depth Query Formatting and Parallel Execution in LlamaIndex: Members discussed LlamaIndex's query response modes like Refine and Accumulate, and the utilization of OLLAMA_NUM_PARALLEL for concurrent model execution; document parsing and embedding mismatches were also topics of technical advice.
- Streamlining ML Workflows with MLflow and LLMs: A Medium article by Ankush K Singal highlights the practical integration of MLflow and LLMs through LlamaIndex to streamline ML workflows.
Interconnects (Nathan Lambert) Discord
- Gemini vs. LLAMA Parameter Showdown: A source from Meta indicated that Gemini 1.5 Pro has fewer parameters than LLAMA 3 70B, inciting discussions about the impact of MoE architectures on parameter count during inference.
- GPT-4's Secret Sauce or Distilled Power: The community debated whether GPT-4T/o are early fusion models or distilled versions of larger predecessors, showing divergence in understanding of their fundamental architectures.
- Multimodal Training Dilemmas: Members highlighted the difficulties in post-training multimodal models, citing the challenges of transferring knowledge across different data modalities. The struggles suggest a general consensus on the complexity of enhancing native multimodal systems.
- Nosing Into Nous and Sony's Stir: A tongue-in-cheek enquiry by a Nous Research member to @sonymusic sparked a blend of confusion and interest, touching upon AI's role in legal and innovation spaces.
- Sketchy Metrics on AI Leaderboards: The legitimacy of the AlpacaEval leaderboard came under fire with engineers questioning biased metrics after a model claimed to have beaten GPT-4 while being more cost-effective. This led to discussions on the reliability of performance leaderboards in the field.
OpenAccess AI Collective (axolotl) Discord
- ROCm Forks Entering the Fray: To utilize certain functionalities, engineers are advised to use the ROCm fork versions of xformers and flash-attention, with a note on hardware support specifically for MI200 & MI300 GPUs and requirement of ROCm 5.4+ and PyTorch 1.12.1+.
- Reward Models Dubbed Subpar for Data Gen: The consensus is that the reward model isn't efficient for generating data, as it is designed mainly for classifying the quality of data, not producing it.
- Synthesizing Standardized Test Questions: An idea was shared to improve AGI evaluations for smaller models by synthesizing SAT, GRE, and MCAT questions, with an additional proposal to include LSAT questions.
- Enigmatic Epoch Saving Quirks: Training epochs are saving at seemingly random intervals, a behavior recognized as unusual but familiar to the community. This may be linked to the steps counter during the training process.
- Dataset Formatting 101 and MinHash Acceleration: A member sought advice on dataset formatting for llama2-13b, while another discussed formatting for the Alpaca dataset using JSONL. Moreover, a fast MinHash implementation named Rensa is shared for dataset deduplication, boasting a 2.5-3x speed increase over similar libraries, with its GitHub repository available for community inputs (Rensa on GitHub).
- Prompt Structures Dissected and Mirrored: Clarification on
prompt_stylein the Axolotl codebase unveiled different prompt formatting strategies with INSTRUCT, CHAT, and CHATML highlighted for contrasting interactive uses. The use ofReflectAlpacaPrompterto automate prompt structuring using the designated style was exemplified (More on Phorm AI Code Search).
Mozilla AI Discord
- Llamafile Leveled Up: Llamafile v0.8.7 has been released, boasting faster quant operations and bug fixes, with whispers of an upcoming Android adaptation.
- Globetrotting AI Events on the Horizon: SF gears up for the World's Fair of AI and the AI Quality Conference with community leaders in attendance, while the Mozilla Nightly Blog hints at potential llamafile integration offering AI services.
- Mozilla Nightly Blog Talks Llamafile: The Nightly blog details experimentation with local AI chat services powered by llamafile, signaling potential for wider adoption and user accessibility.
- Llamafile Execution on Colab Achieved: Successful execution of a llamafile on Google Colab demonstrated, providing a template for others to follow.
- Memory Manager Facelift Connects Cosmos with Android: A significant GitHub commit for the Cosmopolitan project revamps the memory manager, enabling support for Android and stirring interest in running llamafile through Termux.
Torchtune Discord
- ORPO's Missing Piece: The ORPO training option for Torchtune is not supported, though DPO can use a documented recipe for training, as noted by guild members citing a mix dataset for ORPO/DPO.
- Epochs Stuck on Single Setting: Training on multiple datasets with Torchtune does not currently allow for different epoch settings for each—users should utilize ConcatDataset for combining datasets, but the same number of epochs applies to all.
- To ChatML or Not to ChatML: Engineers debated the efficacy of utilizing ChatML templates with the Llama3 model, contrasting approaches using instruct tokenizer and special tokens against base models without these elements, referencing models like Mahou-1.2-llama3-8B and Olethros-8B.
- Tuning Phi-3 Takes Tweaks: The task of fine-tuning Phi-3 models (like Phi-3-Medium-4K-Instruct) was addressed, with suggestions to modify the tokenizer and add a custom build function within Torchtune to enable compatibility.
- System Prompts: Hack It With Phi-3: Despite Phi-3 not being optimized for system prompts, users can work around this by prepending system prompts to user messages and adjusting the tokenizer configuration with a specific flag discussed to facilitate fine-tuning.
tinygrad (George Hotz) Discord
- Conditional Coding Conundrum: In discussions about tinygrad, the use of a conditional operation like
condition * a + !condition * bas a simplification for the WHERE function was met with caution due to potential issues with NaNs. - Intel Adventures in Tinygrad: Queries about Intel support in tinygrad revealed that while opencl is an available option, the framework has not integrated XMX support to date.
- Monday Meeting Must-Knows: The 0.9.1 release of tinygrad is on the agenda for the upcoming Monday meeting, focusing on tinybox updates, a new profiler, runtime improvements,
Tensor._tri, llama cast speedup, and bounties for uop matcher speed and unet3d improvements. - Buffer View Toggle Added to Tinygrad: A commit in tinygrad introduced a new flag to toggle the buffer view, a change that was substantiated with a GitHub Actions run.
- Lazy.py Logic in the Limelight: An engineer seeks clarification after their edits to
lazy.pywithin tinygrad resulted in a mix of both positive and negative process replay outcomes, suggesting a need for further investigation or peer review.
LLM Perf Enthusiasts AI Discord
- Claude Sonnet 3.5 Stuns with Performance: An engineer shared their experience using Claude Sonnet 3.5 in Websim, praising its speed, creativity, and intelligence. They were particularly taken with the "generate in new tab" feature and experimented with sensory engagement by toying with color schemes from iconic fashion brands, as shown in a shared tweet.
MLOps @Chipro Discord
- AWS Cloud Club Lifts Off at MJCET: MJCET has launched the first AWS Cloud Club in Telangana, a community aimed at providing students with resources and experience in Amazon Web Services to prepare for tech industry careers.
- Cloud Mastery Event with an AWS Expert: An inaugural event will celebrate the AWS Cloud Club's launch on June 28th, 2024, featuring AWS Community Hero Mr. Faizal Khan. Interested parties can RSVP via an event link.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Datasette - LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
>:iscord.com/channels/1104757954588196865/1104757955204743201/1253827044463083582)** (33 messages🔥): - **Use ROCm Fork Versions**: Members discussed needing to use the ROCm fork versions of [xformers](https://github.com/ROCm/xformers) and [flash-attention](https://github.com/ROCm/flash-attention) for certain functionalities. One user confirmed that flash-attention support requires ROCm 5.4+, PyTorch 1.12.1+, and MI200 & MI300 GPUs. - **Reward Model Not Effective for Data Generation**: A brief exchange concluded that the reward model isn't worthwhile for generating data, as it primarily classifies data quality. - **Boosting AGI Eval**: One user mentioned plans to synthesize SAT, GRE, and MCAT questions to potentially boost AGI evaluations for smaller models, with suggestions to include LSAT questions as well. - **Epoch Saving Issues**: A user reported issues with epoch saving during training, where it saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter. - **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- Why Perplexity’s Cynical Theft Represents Everything That Could Go Wrong With AInd [flash-attention](https://github.com/ROCm/flash-attention) for certain functionalities. One user confirmed that flash-attention support requires ROCm 5.4+, PyTorch 1.12.1+, and MI200 & MI300 GPUs.
- **Reward Model Not Effective for Data Generation**: A brief exchange concluded that the reward model isn't worthwhile for generating data, as it primarily classifies data quality.
- **Boosting AGI Eval**: One user mentioned plans to synthesize SAT, GRE, and MCAT questions to potentially boost AGI evaluations for smaller models, with suggestions to include LSAT questions as well.
- **Epoch Saving Issues**: A user reported issues with epoch saving during training, where it saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter.
- **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process.
**Links mentioned**:
- [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub.
- [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers
---
### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages):
lore0012: I am no longer hitting the issue.
---
### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages):
- **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards.
- **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS.
- **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script.
**Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER...
---
### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages):
- **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?"
- **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left."
- **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions.
**Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa
---
### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages):
- **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types.
- **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style.
**Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster.
---
### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages):
- **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned.
- **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided.
- **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239).
- **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member.
- **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438).
---
### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥):
- **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat.
- **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g).
- **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes.
- **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux.
- **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users.
**Links mentioned**:
- [no title found](http://localhost:8080`): no description found
- [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range...
- [Mozilla Builders](https://future.mozilla.org/builders/): no description found
- [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on...
- [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g....
- [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub.
- [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found
- [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response
---
### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥):
- **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning.
- **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported.
- **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate.
- **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired.
- **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage.
**Links mentioned**:
- [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found
- [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found
- [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found
- [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found
- [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found
- [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found
- [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found
- [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found
---
### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥):
- **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue.
- **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet.
- **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*.
- **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.*
---
### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages):
- **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided.
- **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications.
**Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002
---
### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages):
- **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413).
**Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t...
---
### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages):
- **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career.
- **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance.
**Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world
---
---
---
---
---
{% else %}
>: It’s the perfect case study for this critical moment: AI is only as good as the people overseeing it.ed that flash-attention support requires ROCm 5.4+, PyTorch 1.12.1+, and MI200 & MI300 GPUs.
- **Reward Model Not Effective for Data Generation**: A brief exchange concluded that the reward model isn't worthwhile for generating data, as it primarily classifies data quality.
- **Boosting AGI Eval**: One user mentioned plans to synthesize SAT, GRE, and MCAT questions to potentially boost AGI evaluations for smaller models, with suggestions to include LSAT questions as well.
- **Epoch Saving Issues**: A user reported issues with epoch saving during training, where it saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter.
- **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process.
**Links mentioned**:
- [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub.
- [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers
---
### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages):
lore0012: I am no longer hitting the issue.
---
### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages):
- **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards.
- **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS.
- **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script.
**Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER...
---
### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages):
- **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?"
- **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left."
- **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions.
**Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa
---
### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages):
- **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types.
- **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style.
**Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster.
---
### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages):
- **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned.
- **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided.
- **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239).
- **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member.
- **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438).
---
### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥):
- **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat.
- **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g).
- **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes.
- **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux.
- **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users.
**Links mentioned**:
- [no title found](http://localhost:8080`): no description found
- [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range...
- [Mozilla Builders](https://future.mozilla.org/builders/): no description found
- [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on...
- [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g....
- [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub.
- [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found
- [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response
---
### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥):
- **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning.
- **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported.
- **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate.
- **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired.
- **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage.
**Links mentioned**:
- [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found
- [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found
- [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found
- [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found
- [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found
- [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found
- [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found
- [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found
---
### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥):
- **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue.
- **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet.
- **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*.
- **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.*
---
### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages):
- **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided.
- **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications.
**Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002
---
### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages):
- **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413).
**Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t...
---
### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages):
- **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career.
- **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance.
**Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world
---
---
---
---
---
{% else %}
>
- Perplexity Plagiarized Our Story About How Perplexity Is a Bullshit Machine't worthwhile for generating data, as it primarily classifies data quality. - **Boosting AGI Eval**: One user mentioned plans to synthesize SAT, GRE, and MCAT questions to potentially boost AGI evaluations for smaller models, with suggestions to include LSAT questions as well. - **Epoch Saving Issues**: A user reported issues with epoch saving during training, where it saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter. - **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: Experts aren’t unanimous about whether the AI-powered search startup’s practices could expose it to legal claims ranging from infringement to defamation—but some say plaintiffs would have strong cases... smaller models, with suggestions to include LSAT questions as well. - **Epoch Saving Issues**: A user reported issues with epoch saving during training, where it saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter. - **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- no title foundng during training, where it saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter. - **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: no description foundit saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter. - **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- I installed Android on Rabbit R1 & Made it Useful known but peculiar behavior, possibly related to the steps counter. - **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: I managed to install Android 13 onto the Rabbit R1 and it made the device a lot more useful! Letting me download apps, send messages, and a lot more. Here's ...indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- Tweet from Cubicle e/acc (@roramora0)s. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: @dwarkesh_sp Dwarkesh, if you're in touch with Anthropic please notify them that their recaptcha-en.js file has a security loophole that allows mouse action simulation using js code. this allowed ...Cm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- Reddit - Dive into anythingposable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: no description foundps://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- Just When I Thought I Was Out They Pull Me Back In GIF - Just When I Thought I Was Out They Pull Me Back In Michael Corleone - Discover & Share GIFs: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: Click to view the GIFe issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- Robot Mimics Human Sense of Touch to Better Sort Through Litter - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: The authors explain that human touch has many layers of sensory perception, including changes in how different temperatures feel.ng header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- Perplexity - AI Companion occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: Ask anything while you browseckpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- Robot Mimics Human Sense of Touch to Better Sort Through Litterepository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: The authors explain that human touch has many layers of sensory perception, including changes in how different temperatures feel. folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
- Perplexity Plagiarized Our Story About How Perplexity Is a Bullshit M…g a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: no description foundatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >o work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >
Perplexity AI ▷ #sharing (12 messages🔥):
- Discover Apple AI Delayed in Europe: Members shared a page discussing Apple's AI capabilities and their limitations in the European region. For more details, check out Apple Intelligence Isn't.
- Perplexity Search and Learning: Multiple members shared their unique searches on Perplexity AI, indicating its diverse usage for learning and information-gathering. Notable searches included topics like AI improvements and language exploration.
- Boeing's Starliner Issues: Two members highlighted an article on Perplexity AI about Boeing's Starliner facing challenges. Read more via Boeing’s Starliner Stuck.
- OpenAI Community Message: A community message advised members to ensure their threads are shareable for better community engagement. Read the full advisory here.
- YouTube Educational Content: Perplexity AI shared an upcoming YouTube video, hinting at important topics like Starliner issues, Apple AI in Europe, OpenAI's acquisition, and more. Watch the preview here.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (12 messages🔥):
- Looking for project ideas: A user is seeking interesting projects to build using the API and resources to understand what is being done and what is possible.
- LLama-3-70B API context length confusion: A user noted a connection error when total tokens exceed around 1642, while another user reported success with a nearly 3000-token request. Possible moderation trigger or technical issue is suspected.
- Perplexity summarization navigates hyperlinks: When asking Perplexity to summarize a webpage via a link, it navigates through hyperlinks from the provided link. The user is looking for a way to restrict summarization to the initial URL.
- Inquiry on citations time filter in API: A user asked if there is a time filter for citations for online models via API, noting the presence of some undocumented request parameters. The user does not have beta access but has requested it.
Link mentioned: Chat Completions: no description found
Nous Research AI ▷ #off-topic (20 messages🔥):
- Rensa boosts dataset deduplication: A member introduced Rensa, a high-performance MinHash implementation in Rust with Python bindings, showcasing features like FxHash, LSH index, and on-the-fly permutations. They claimed it is 2.5-3x faster than datasketch and shared it on GitHub.
- Claude's odd reaction to The Cyberiad: Members discussed the AI Claude producing a sonnet break when asked about The Cyberiad. One participant shared a prompt that caused this and suggested that "
"ew member experimenting with fine-tuning llama2-13b using axolotl* inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - Formatting example for 'Alpaca' dataset: Another member shared a dataset case using JSONL for fine-tuning Alpaca. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left."
- Introducing Rensa for high-performance MinHash: A member excitedly introduced their side project, Rensa, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like
datasketchfor tasks like dataset deduplication and shared its GitHub link for community feedback and contributions.
Link mentioned: GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (5 messages):
- Prompt Style Explained in Axolotl Codebase: The inquiry about
prompt_styleled to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such asINSTRUCT,CHAT, andCHATMLwere detailed to illustrate different prompt structuring strategies for various interaction types. - Example of ReflectAlpacaPrompter Usage: The
ReflectAlpacaPrompterclass example highlights how differentprompt_stylevalues like "instruct" and "chat" dictate the structure of generated prompts. Thematch_prompt_stylemethod is used to set up the prompt template according to the selected style.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search): Understand code, faster.
Mozilla AI ▷ #announcements (1 messages):
- Llamafile v0.8.7 releases with upgrades: Llamafile v0.8.7 released with faster quant operations and bug fixes. An Android version hint was also mentioned.
- San Francisco hosts major AI events: World's Fair of AI and AI Quality Conference will feature prominent community members. Links to World's Fair of AI and AI Quality Conference are provided.
- Firefox Nightly AI services experiment: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the Nightly blog.
- Latest ML Paper Picks available: The latest ML Paper Picks have been shared by a community member.
- RSVP for upcoming July AI events: Events include Jan AI, AI Foundry Podcast Roadshow, and AutoFIx by Sentry.io.
Mozilla AI ▷ #llamafile (31 messages🔥):
- Llamafile Help Command Issue: A user reported that running
llamafile.exe --helpreturns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - Running Llamafile on Google Colab: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a link to their example.
- Llamafile Repackaging Concerns: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes.
- New Memory Manager for Cosmopolitan: A commit on GitHub discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux.
- Mozilla Nightly Blog Mentions Llamafile: The Nightly blog mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users.
Links mentioned:
- no title found: no description found
- Tweet from Dylan Freedman (@dylfreed): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range...
- Mozilla Builders: no description found
- Release llamafile v0.8.7 · Mozilla-Ocho/llamafile: This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on...
- Rewrite memory manager · jart/cosmopolitan@6ffed14: Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g....
- ggerganov - Overview: I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub.
- Google Colab: no description found
- Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp: Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response
Torchtune ▷ #general (24 messages🔥):
- DPO Training Options Available; ORPO Not Yet Supported: When asked about the options for DPO and ORPO training with Torchtune, a member shared a dataset for ORPO/DPO and mentioned that ORPO is not yet supported while DPO has a recipe available. This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning.
- Training on Multiple Datasets and Epochs Limitation: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use ConcatDataset. It was highlighted that setting different epochs per dataset is not supported.
- Debate on ChatML Template Use with Llama3: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring Mahou-1.2-llama3-8B and Olethros-8B. Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate.
- Phi-3 Model Fine-Tuning Feasibility: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired.
- Instruction on Using System Prompts with Phi-3: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration was mentioned for allowing system prompt usage.
Links mentioned:
- lodrick-the-lafted/Olethros-8B · Hugging Face: no description found
- flammenai/Mahou-1.2-llama3-8B · Hugging Face: no description found
- microsoft/Phi-3-mini-4k-instruct · Hugging Face: no description found
- torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face: no description found
- torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone): no description found
- microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions: no description found
- microsoft/Phi-3-medium-4k-instruct · Hugging Face: no description found
- config.json · microsoft/Phi-3-medium-4k-instruct at main: no description found
tinygrad (George Hotz) ▷ #general (8 messages🔥):
- WHERE Function Clarification: A member asked if the WHERE function could be simplified with conditional operations like
condition * a + !condition * band was pointed out that NaNs could be an issue. - Intel Support Inquiry: Someone inquired about Intel support in tinygrad. Another member responded that opencl can be used, but there is no XMX support yet.
- Monday Meeting Overview: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on tinybox, new profiler, runtime enhancements, and plans for the 0.9.1 release. Specific agenda items cover enhancements like
Tensor._tri, llama cast speedup, and mentions of bounties such as improvements in uop matcher speed and unet3d. - Future of Linear Algebra Functions: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. No specific response was given in the extracted messages.
tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
- Buffer view option flagged in tinygrad: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, "make buffer view optional with a flag" and the associated GitHub Actions run was provided.
- Change in lazy.py raises concerns: A member questioned if they were doing something wrong as their changes to
lazy.pyresulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications.
Link mentioned: make buffer view optional with a flag · tinygrad/tinygrad@bdda002: You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002
LLM Perf Enthusiasts AI ▷ #claude (1 messages):
- Claude Sonnet 3.5 impresses in Websim: A member was testing Claude Sonnet 3.5 in Websim and was highly impressed by the model's "speed, creativity, and intelligence". They highlighted features such as "generate in new tab" and shared their experience of trying to "hypnotize" themselves with the color schemes of different iconic fashion brands. Twitter link.
Link mentioned: Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t...
MLOps @Chipro ▷ #events (1 messages):
- MJCET launches AWS Cloud Club: We are delighted to share that MJCET has launched the FIRST AWS Cloud Club in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career.
- Exclusive inaugural event with AWS Hero: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring Mr. Faizal Khan, AWS Community Hero. RSVP via this meetup link to confirm your attendance.
Link mentioned: Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup: Join Us for the Grand Inauguration of AWS Cloud Club MJCET! We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world
{% else %}
- could be a glitch token.
- Glitch token research shared: During the discussion on Claude's behavior, a member shared arXiv articles on glitch tokens for further reading: article 1 and article 2.
- Sonnet's reluctance on tech topics: A member observed that the AI model was frequently refusing requests related to tech news and machine merging. Another member humorously remarked that the sensitivity to AI-related questions seems heightened.
- Critical view on ChatGPT paper: A link to a critique of the "ChatGPT is bullshit" paper was shared, arguing against the paper's point that LLMs produce deceptive and truth-indifferent outputs. The critique is available on Substack.
Links mentioned:
- Nothing is an absolute reality, all is permitted: What is truth in the age of machine learning?
- GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa
Nous Research AI ▷ #interesting-links (9 messages🔥):
- Hackers jailbreak AI models: Shared a tweet about hackers "jailbreaking" powerful AI models to highlight their flaws. The detailed article can be found here.
- GitHub's smol q* implementation: Mention of a GitHub repository ganymede, which is a "smol implementation of q*". It's a resource for those interested in a hacky q* star implementation with qwen 0.5b.
- Game made from "Claude thingy": A member shared a link to a game they made, available on Replit.
- LLM inference in a font: Described llama.ttf, a font file that's also a large language model and an inference engine. Explanation involves using HarfBuzz's Wasm shaper for font shaping, allowing for complex LLM functionalities within a font.
- Tweet link by mautonomy: Shared a Twitter link without additional context. The tweet can be found here.
Links mentioned:
- llama.ttf: no description found
- Tweet from Financial Times (@FT): Hackers ‘jailbreak’ powerful AI models in global effort to highlight flaws https://on.ft.com/45ByjEj
- SkeletalExpensiveEmbeds: Run Python code live in your browser. Write and run code in 50+ languages online with Replit, a powerful IDE, compiler, & interpreter.
- GitHub - EveryOneIsGross/ganymede: smol implementation of q*: smol implementation of q*. Contribute to EveryOneIsGross/ganymede development by creating an account on GitHub.
Nous Research AI ▷ #general (278 messages🔥🔥):
- Link for the bloke server shared: A user asked for a link to the bloke server, and another member responded with the Discord invite link.
- Safety models in AI responses: A discussion highlighted that safety models in Gemini and possibly OpenAI check responses and can redact or reject them. One user noted, "Even though you could jailbreak it, you will not see the message if it cannot escape the safety filtering."
- Karpathy's new course: A user pointed out a new course by Karpathy, LLM101n: Let's build a Storyteller, mistaking it initially for the micrograd repo.
- Hermes 2 Pro 70b format issues: Users reported issues with Hermes-2-Theta-Llama-3-70B model responses starting with "<|end_header_id|>" and were advised to use the llama3 instruct format instead.
- Release of Replete-Coder: A new model, Replete-Coder-Qwen2-1.5b, was announced, scoring a 35 on HumanEval across 100 coding languages. More details were shared in a tweet.
Links mentioned:
- PromptIde: no description found
- Dołącz do serwera TheBloke AI na Discordzie!: For discussion of and support for AI Large Language Models, and AI in general. | 23728 członków
- BigCodeBench Leaderboard - a Hugging Face Space by bigcode: no description found
- Xiaojie Xiaocat GIF - Xiaojie Xiaocat - Discover & Share GIFs: Click to view the GIF
- Skeleton Skeletons GIF - Skeleton Skeletons Skull - Discover & Share GIFs: Click to view the GIF
- Tweet from RomboDawg (@dudeman6790): Announcing Replete-Coder-Qwen2-1.5b An uncensored, 1.5b model with good coding performance across over 100 coding languages, open source data, weights, training code, and fully usable on mobile platfo...
- Cool Beans GIF - Cool Beans Thumbsup - Discover & Share GIFs: Click to view the GIF
- GitHub - karpathy/LLM101n: LLM101n: Let's build a Storyteller: LLM101n: Let's build a Storyteller. Contribute to karpathy/LLM101n development by creating an account on GitHub.
- Tweet from Andrew Curran (@AndrewCurran_): This morning the RIAA, on behalf of Universal, Warner and Sony, filed a copyright infringement lawsuit against Suno and Udio.
- Tweet from Keyon Vafa (@keyonV): New paper: How can you tell if a transformer has the right world model? We trained a transformer to predict directions for NYC taxi rides. The model was good. It could find shortest paths between new...
- Announcing PromptIDE: no description found
Nous Research AI ▷ #ask-about-llms (15 messages🔥):
- Tiny Stories Model Impresses with Compact Size: Discussion centered around the smallest LLMs, with a notable highlight being the TinyStories-656K model, which has only 600k parameters. This lightweight model is capable of generating coherent stories utilizing a llama architecture.
- Larger Models Show Superior Performance: Members discussed the effectiveness of larger models, noting that good general-purpose performance starts at around 3B parameters with significant improvements seen in 7B-8B models. For top-tier performance, models with 70B+ parameters are considered the benchmark.
- Autonomous Agents: There was a debate on the potential of text predictors like Claude performing tasks comparable to a sentient human, with some asserting that autonomous, self-improving agents are within reach.
- Fun with AI: A humorous greentext story created by Claude emphasized its capability for creative text generation, illustrating advanced text prediction abilities and entertaining the users.
Link mentioned: raincandy-u/TinyStories-656K · Hugging Face: no description found
Nous Research AI ▷ #rag-dataset (12 messages🔥):
- Track dataset generation in Google Sheets: A member shared a Google Sheet for tracking dataset generation domains, encouraging participation by indicating interest, potential document sources, and target sizes. This aims to streamline the dataset creation process.
- Huggingface chat template simplifies document input: Members discussed enhancing the Huggingface chat template with document input fields, promoting the Hermes RAG format for standard metadata. This modification makes integrating documents into the model input heaps easier by using tools like jinja templates and XML for formatting.
- AllenAI citation classification prompt: An interesting citation classification prompt by AllenAI was shared, potentially useful for the
academic paperscategory. This YAML-based prompt helps classify citations into categories like "Background," "Extends," "Uses," "Motivation," "CompareOrContrast," and "FutureWork." - SciRIFF dataset: The group discussed the SciRIFF dataset, which includes 137K instruction-following demonstrations for understanding scientific literature across five domains. The dataset comes with various configurations and a corresponding GitHub repo for code, model training, and evaluation.
- Instruction-pretrain dataset: A member highlighted the ft-instruction-synthesizer-collection, noting it's fully RAG formatted and suggesting it might be interesting despite it being primarily multi-choice instead of free-form. The possibility of augmentation was considered to adapt the dataset for varied uses.
Links mentioned:
- instruction-pretrain/ft-instruction-synthesizer-collection at main: no description found
- allenai/SciRIFF · Datasets at Hugging Face: no description found
- RAG Data Synthesis: Sheet1 Domain,Curriculum file,Source/links,HF repo,Size (rows),Status,Who's working,Reviewer,Review Notes Websearch Wikipedia Codebase Academic Papers Books Finance ,SEC filings etc.,1000,Agent s...
Nous Research AI ▷ #world-sim (1 messages):
teknium: https://twitter.com/hamish_kerr/status/1804352352511836403
Eleuther ▷ #general (114 messages🔥🔥):
- SLURM Node Issues: A user reported connecting to a SLURM-managed node through Jupyter Notebook, encountering errors at the training stage potentially due to SLURM restrictions. They mentioned testing on the console and receiving a 'kill' message before starting training, despite specifying GPU usage correctly.
- PyTorch Accelerates Llama-2: The PyTorch team released techniques for increasing Llama-2 inference speed by 10x, shared in a blog post. A user developed a pip package GPTFast that applies these techniques to all HF models, asking for access to A100 or H100 GPU clusters.
- Open-Source AI Model Issues: Discussions arose around the ethics and practicality of sharing proprietary AI models like Mistral outside official channels. Users stressed the legal and moral implications of such actions, emphasizing the need for accountability and transparency in AI development.
- Model Latency Profiling: Users discussed methods for determining if an AI model is GPT-4 or another variant, with suggestions including checking knowledge cutoffs and profiling latency differences. Sniffing network traffic to identify the model used in API calls was also proposed.
- LingOly Benchmark Discussion: A new benchmark called LingOly, evaluating large language models (LLMs) on advanced reasoning with linguistic puzzles from low-resource languages, was discussed. The benchmark presents 1,133 problems and top models achieving below 50% accuracy, noted for its challenging nature and potential memorization concerns.
Links mentioned:
- LINGOLY: A Benchmark of Olympiad-Level Linguistic Reasoning Puzzles in Low-Resource and Extinct Languages: In this paper, we present the LingOly benchmark, a novel benchmark for advanced reasoning abilities in large language models. Using challenging Linguistic Olympiad puzzles, we evaluate (i) capabilitie...
- Virus Computer GIF - Virus Computer Hello Your Computer Has Virus - Discover & Share GIFs: Click to view the GIF
- examples/examples/benchmarks/bert at main · mosaicml/examples: Fast and flexible reference benchmarks. Contribute to mosaicml/examples development by creating an account on GitHub.
- Accelerating Generative AI with PyTorch II: GPT, Fast: This post is the second part of a multi-series blog focused on how to accelerate generative AI models with pure, native PyTorch. We are excited to share a breadth of newly released PyTorch performance...
- GitHub - AnswerDotAI/bert24: Contribute to AnswerDotAI/bert24 development by creating an account on GitHub.
Eleuther ▷ #research (155 messages🔥🔥):
- TTS Paper Introduces ARDiT: Discussion around a new TTS paper highlighting the potential of ARDiT in zero-shot text-to-speech. A member remarked, "there's a bunch of ideas that could be used elsewhere."
- Exploring Multi-Objective Loss: Intense debate on enforcing Pareto improvements in neural network training, focusing on multidimensional objectives. One member shared insights on multi-objective optimization and another concluded, "probably you'd have to pick a small subset of the weights (say, the norm weights and biases) that vary between the different Pareto versions and share the rest."
- Quadratic Voting in Optimization: Reference to quadratic voting as a method to balance competing human values and integrate it into multi-objective optimization. The conversation weaved around the feasibility and implications of using quadratic voting in machine learning models.
- Controversy in Multi-Task Learning: A member recommends a paper revealing no significant benefits from specialized multi-task optimization methods over traditional approaches (read here). Another member highlights a follow-up study discussing optimization dynamics in data-imbalanced task collections.
- Latent Space Regularization in AEs: A thread discussed how to incorporate noise in autoencoder embeddings, suggesting adding Gaussian noise directly to the encoded output. Members debated on the necessity of regularization and batch normalization to prevent embeddings from scaling uncontrollably.
Links mentioned:
- Towards an Improved Understanding and Utilization of Maximum Manifold Capacity Representations: Maximum Manifold Capacity Representations (MMCR) is a recent multi-view self-supervised learning (MVSSL) method that matches or surpasses other leading MVSSL methods. MMCR is intriguing because it doe...
- HyperZ$\cdot$Z$\cdot$W Operator Connects Slow-Fast Networks for Full Context Interaction: The self-attention mechanism utilizes large implicit weight matrices, programmed through dot product-based activations with very few trainable parameters, to enable long sequence modeling. In this pap...
- Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data: One way to address safety risks from large language models (LLMs) is to censor dangerous knowledge from their training data. While this removes the explicit information, implicit information can remai...
- Quadratic voting - Wikipedia: no description found
- 4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities: Current multimodal and multitask foundation models like 4M or UnifiedIO show promising results, but in practice their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are li...
- Gradient Surgery for Multi-Task Learning: While deep learning and deep reinforcement learning (RL) systems have demonstrated impressive results in domains such as image classification, game playing, and robotic control, data efficiency remain...
- Multi-objective optimization - Wikipedia: no description found
- VisualRWKV: Exploring Recurrent Neural Networks for Visual Language Models: Visual Language Models (VLMs) have rapidly progressed with the recent success of large language models. However, there have been few attempts to incorporate efficient linear Recurrent Neural Networks ...
- Transformers Can Do Arithmetic with the Right Embeddings: The poor performance of transformers on arithmetic tasks seems to stem in large part from their inability to keep track of the exact position of each digit inside of a large span of digits. We mend th...
- Gradient Vaccine: Investigating and Improving Multi-task Optimization in Massively Multilingual Models: Massively multilingual models subsuming tens or even hundreds of languages pose great challenges to multi-task optimization. While it is a common practice to apply a language-agnostic procedure optimi...
- Toward Infinite-Long Prefix in Transformer: Prompting and contextual-based fine-tuning methods, which we call Prefix Learning, have been proposed to enhance the performance of language models on various downstream tasks that can match full para...
- Order Matters in the Presence of Dataset Imbalance for Multilingual Learning: In this paper, we empirically study the optimization dynamics of multi-task learning, particularly focusing on those that govern a collection of tasks with significant data imbalance. We present a sim...
- Tweet from François Fleuret (@francoisfleuret): A little report!
- Do Current Multi-Task Optimization Methods in Deep Learning Even Help?: Recent research has proposed a series of specialized optimization algorithms for deep multi-task models. It is often claimed that these multi-task optimization (MTO) methods yield solutions that are s...
- Autoregressive Diffusion Transformer for Text-to-Speech Synthesis: Audio language models have recently emerged as a promising approach for various audio generation tasks, relying on audio tokenizers to encode waveforms into sequences of discrete symbols. Audio tokeni...
- Grokking of Hierarchical Structure in Vanilla Transformers: For humans, language production and comprehension is sensitive to the hierarchical structure of sentences. In natural language processing, past work has questioned how effectively neural sequence mode...
- Why Momentum Really Works: We often think of optimization with momentum as a ball rolling down a hill. This isn't wrong, but there is much more to the story.
- no title found: no description found
Eleuther ▷ #scaling-laws (10 messages🔥):
- Epoch revisits compute trade-offs in machine learning: Members discussed Epoch AI's blog post about balancing compute during training and inference. One stated, "It's possible to increase inference compute by 1-2 orders of magnitude, saving ~1 OOM in training compute."
- Paper on Neural Redshifts sparks interest: Members shared a paper on Neural Redshifts, noting that initializations may be more significant than researchers often acknowledge. One remarked, "Initializations are a lot more interesting than researchers give them credit for being."
- AI Koans elicit laughs and enlightenment: A humorous exchange about AI koans was shared, linking to a collection of hacker jokes. The illustration included an anecdote about a novice and an experienced hacker, showing how “turning it off and on” can fix problems unexpectedly.
Links mentioned:
- Trading Off Compute in Training and Inference: We explore several techniques that induce a tradeoff between spending more resources on training or on inference and characterize the properties of this tradeoff. We outline some implications for AI g...
- Some AI Koans: no description found
Eleuther ▷ #interpretability-general (3 messages):
- Model editing using SAEs explored in podcast: A member referenced a podcast episode discussing the potential for using SAEs for model editing, specifically evaluating effectiveness using a non-cherrypicked list of edits from the MEMIT paper. They linked to the MEMIT paper and its source code for further exploration.
- Interest in empirical evaluation for dictionary learning: A member inquired if there are any recommended papers that empirically evaluate model behavior when influenced by features found via dictionary learning. This suggests a focus on empirical methods to understand model steering through structured feature manipulation.
Links mentioned:
- Ep 14 - Interp, latent robustness, RLHF limitations w/ Stephen Casper (PhD AI researcher, MIT): We speak with Stephen Casper, or "Cas" as his friends call him. Cas is a PhD student at MIT in the Computer Science (EECS) department, in the Algorithmic Ali...
- Mass Editing Memory in a Transformer: Updating thousands of memories in GPT by directly calculating parameter changes.
Eleuther ▷ #lm-thunderdome (6 messages):
- Local Model Registration Simplified: A user inquired about the possibility of registering a model locally without altering
lm_eval/models/__init__.py. Another user explained the usage ofregister_modeland provided a code snippet showcasing how to achieve this with a wrapper module. - Breaking Change in Commit Highlighted: A commit that added
tokenizer logs infoinadvertently broke the main branch. The user highlighted the issue with incorrect importing paths and requested a hotfix. - Hotfix Requested and Applied: Another user directed attention to a proposed hotfix, asking someone to test it. After confirmation, they acknowledged the fix resolved the issue.
Link mentioned: add tokenizer logs info (#1731) · EleutherAI/lm-evaluation-harness@536691d: * add tokenizer logs info
- add no tokenizer case
- Update lm_eval/logging_utils.py
Co-authored-by: Hailey Schoelkopf <65563625+haileyschoelkopf@users.noreply.github.com>
- U...
Eleuther ▷ #multimodal-general (2 messages):
- Debate over best multimodal LLM architecture: A member questioned whether early fusion models like Chameleon are superior to using a vision encoder before feeding the image into the LLM context. They expressed concern that each approach might not be definitively better for all tasks but could be task-dependent.
- Visual acuity trade-offs in early fusion: They noted that early fusion might be better for generality; however, they heard the model struggles with visual acuity. This is due to the image tokenization process that compresses image information, losing clarity compared to patch embedding with a vision encoder.
Eleuther ▷ #gpt-neox-dev (3 messages):
- Intel pulling AWS instance, considers alternatives: “Intel is pulling our AWS instance so I'm thinking we either pay a little for these, or switch to manually-triggered free github runners.” No definitive decision mentioned.
- NCCL backend issues on A100 GPUs: Attempts to train a model with gpt-neox on in-house A100 GPUs are facing NCCL backend issues. The issue persists across various versions of NCCL and Cuda, even with and without Docker.
Latent Space ▷ #ai-general-chat (133 messages🔥🔥):
- Noam Shazeer talks optimizing inference at Character.AI: A new blog post from Noam Shazeer discusses how Character.AI is working towards AGI by optimizing inference processes. The post highlights their efforts to handle over 20,000 inference queries per second.
- OpenAI acquires Rockset: OpenAI has acquired Rockset to bolster their Retrieval-Augmented Generation (RAG) capabilities. Founded in 2016, Rockset's team has deep expertise in building hybrid search solutions like vector (FAISS) and keyword search.
- Karpathy announces a new course: Karpathy is planning an ambitious "LLM101n" course on building ChatGPT-like models from scratch, similar to his famous CS231n course.
- LangChain funding controversy addressed: LangChain's Harrison Chase clarifies that their funding is focused solely on product development, not on sponsoring events or ads, in response to criticisms about their use of venture capital funds.
- Mira Murati hints at GPTnext: Mira Murati implied that the next major GPT model might release in 1.5 years, discussing the monumental shifts AI tools bring to creativity and efficiency in various fields.
Links mentioned:
- llama.ttf: no description found
- llama.ttf: no description found
- Optimizing AI Inference at Character.AI: At Character.AI, we're building toward AGI. In that future state, large language models (LLMs) will enhance daily life, providing business productivity and entertainment and helping people with e...
- Multi Blog – Multi is joining OpenAI : Recently, we’ve been increasingly asking ourselves how we should work with computers. Not on or using computers, but truly with computers. With AI. We think it’s one of the most importan...
- Olympia | Better Than ChatGPT: Grow your business with affordable AI-powered consultants that are experts in business strategy, content development, marketing, programming, legal strategy and more.
- Tweet from Hamel Husain (@HamelHusain): In most cases i’ve encountered in the wild, the title “AI Engineer” is harmful. I explain why in the below video Quoting Hugo Bowne-Anderson (@hugobowne) The AI Engineer Data Literacy Divide 🎙...
- AI Everywhere: Transforming Our World, Empowering Humanity: Dartmouth Engineering hosted an exclusive conversation with alum and OpenAI Chief Technology Officer Mira Murati Th'12. She discussed the artificial intellig...
- Tweet from Sully (@SullyOmarr): Introducing Otto - a new way to interact and work with AI Agents - using tables! Now you can have hundreds of agents working for you at the same time
- Tweet from Harrison Chase (@hwchase17): @levelsio all of our funding is going to our core team to help build out LangChain, LangSmith, and other related things we literally have a policy where we don't sponsor events with $$$, let alon...
- Tweet from Alex Albert (@alexalbert__): Artifacts pro tip: If you are running into unsupported library errors with NPM modules, just ask Claude to use the cdnjs link instead and it should work just fine.
- Tweet from nano (@nanulled): 100x checked data training and... It fking works and actually reasons over patterns. I can't fking believe that.
- Tweet from Morten Just (@mortenjust): This is fast. Chrome running Gemini locally on my laptop. 2 lines of code.
- Tweet from Andrew Curran (@AndrewCurran_): This morning the RIAA, on behalf of Universal, Warner and Sony, filed a copyright infringement lawsuit against Suno and Udio.
- Tweet from Ammaar Reshi (@ammaar): Claude Sonnet 3.5 with Artifacts can also play sound! Using the @elevenlabs API it created a functional AI sound effects generator app, all I did was paste in the API documentation. I'm mind bl...
- no title found: no description found
- Tweet from Andrew Curran (@AndrewCurran_): This morning the RIAA, on behalf of Universal, Warner and Sony, filed a copyright infringement lawsuit against Suno and Udio.
- Tweet from Morten Just (@mortenjust): This is fast. Chrome running Gemini locally on my laptop. 2 lines of code.
- Tweet from TestingCatalog News 🗞 (@testingcatalog): It is coming 🔥
- Tweet from Vaibhav (VB) Srivastav (@reach_vb): Wait WHAT? Someone already extracted Gemini Nano weights from Chrome and shared them on the Hub ⚡ > Looks like 4-bit running on tf-lite (?) > base + instruction tuned adapter Obligatory disclo...
- Tweet from Deedy (@deedydas): OpenAI just acquired Rockset to power RAG. Rockset was founded in 2016 by an ex-Facebook team that built RocksDB, a fork of Google's LevelDB, an embeddable NoSQL DB written by Jeff Dean himself. ...
- Tweet from Bilawal Sidhu (@bilawalsidhu): Wow. Stability AI's new CEO is Prem Akkaraju, Ex-CEO of the legendary VFX studio Weta Digital. SVD could've been competitive with Runway/Luma, but they dropped the ball. In fact, Luma AI go...
- Tweet from Bilawal Sidhu (@bilawalsidhu): Wow. Stability AI's new CEO is Prem Akkaraju, Ex-CEO of the legendary VFX studio Weta Digital. SVD could've been competitive with Runway/Luma, but they dropped the ball. In fact, Luma AI go...
- Tweet from miru (@miru_why): looks like @karpathy is now planning out a full cs231n-like course ‘LLM101n’ covering how to build a ChatGPT-like model from scratch https://github.com/karpathy/LLM101n. very ambitious!
- Tweet from Robert Graham 𝕏 (@ErrataRob): nVidia is in the same position as Sun Microsystems was in the early days of the dot-com bubble. Sun had the leading edge web servers, the smartest engineers, the most respect in the industry. If you ...
- Tweet from jason liu (@jxnlco): This seems made up. If you’ve built mle systems. I’m not convinced chaining and agents isn’t just a pipeline. Mle has never build a fault tolerance system?
- Tweet from Mira Murati (@miramurati): At OpenAI, we’re working to advance scientific understanding to help improve human well-being. The AI tools we are building, like Sora, GPT-4o, DALL·E and ChatGPT, are impressive from a technical stan...
- Tweet from Andrej Karpathy (@karpathy): The @aiDotEngineer World's Fair in SF this week 🔥 https://www.ai.engineer/worldsfair Reminded of slide #1 from my most recent talk: "Just in case you were wondering… No, this is not a norma...
- GitHub - admineral/Reactor: Early Alpha: Chat with React Code-Editor and Live-preview using Sandpack by Codesandbox. Vercel ai SDK RSC GenUI: Early Alpha: Chat with React Code-Editor and Live-preview using Sandpack by Codesandbox. Vercel ai SDK RSC GenUI - admineral/Reactor
- Reddit - Dive into anything: no description found
- GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa
Latent Space ▷ #ai-announcements (3 messages):
- New podcast on hiring AI engineers drops!: A new episode of the Latent Space Podcast titled "How to Hire AI Engineers" has been released, featuring guest posts and a bonus pod from @james_elicit and @adamwiggins. The episode covers a range of topics including "Defining the Hiring Process," "Defensive AI Engineering," and "Tech Choices for Defensive AI Engineering" full details here.
- Podcast also featured on Hacker News: In addition to the direct link, it was mentioned that the podcast is also being discussed on Hacker News. No further details were provided.
Link mentioned: Tweet from Latent Space Podcast (@latentspacepod): 🆕How to Hire AI Engineers a rare guest post (and bonus pod) from @james_elicit and @adamwiggins! Covering: - Defining the Hiring Process - Defensive AI Engineering as a chaotic medium - Tech Choi...
Latent Space ▷ #ai-in-action-club (72 messages🔥🔥):
- Recording Permissions Pending World's Fair: One member asked another if they could record the session and promised to hold off on uploads until after the World's Fair. Permission was granted with a thumbs up emoticon.
- Developing a Twitter Management Application: One member discussed creating a YAML-based DSL for a Twitter management app using the Twitter API, aiming to generate better analytics on social posts. They sought feedback on the importance of adding more features and shared detailed YAML code segments.
- Zoho Social for Inspiration: A member suggested referencing features from Zoho Social to build the Twitter analytics app. They provided a Zoho Social link detailing various features like scheduling, monitoring, and analyzing social media posts.
- Anthropic's XML Tags Suggestion: It was mentioned that Anthropics recommends using XML tags for certain functionalities, linking to a related document.
- LLM-generated YAML Project Success: A discussion followed about the usefulness of LLMs in generating YAML-based projects, with one member sharing their experience of using an LLM to create a YAML templating language implementation in Go, pointing to their GitHub repository.
Links mentioned:
- ai-workshop.md: GitHub Gist: instantly share code, notes, and snippets.
- Zoho Social - Features: Zoho Social's features tell you what makes it the best social media marketing software your money can buy today.
- GitHub - go-go-golems/go-emrichen: YAML templating language emrichen implementation in go: YAML templating language emrichen implementation in go - go-go-golems/go-emrichen
Modular (Mojo 🔥) ▷ #general (62 messages🔥🔥):
- Estimating the Cost of LLVM: Curiosity.fan shared an article estimating the cost of LLVM which concluded that 1.2k developers produced a 6.9M line codebase with an estimated cost of $530 million. The discussion included cloning and checking out the LLVM project to understand its development costs.
- Issues with Mojo Installation: Darinsimmons shared his frustrations with a fresh install of 22.04 and nightly builds of Mojo, stating none of the devrel-extras tests, including blog 2406, passed. He plans to take a break from the computer to resolve the issue.
- Interactive Discussion on LLVM and Mojo: Interest in LLVM and Mojo was enhanced by videos like the EuroLLVM 2024 talks, with users expressing their enthusiasm and plans to delve deeper into MLIR and LLDB extensions.
- Documentation Navigation Confusion: Users discussed the confusion stemming from the lack of clear differentiation between nightly and stable documentation in Mojo. Suggestions were made to maintain separate documentation sets for stable and nightly versions to aid clarity.
- Curiosity about Mojo Stencil Operations: Benny.n showed interest in exploring the
stencilfunction in Mojo's algorithm library, speculating its use in reducing dimensions. He also expressed plans to reimplement autotune functionality, making hyperparameter evaluations more efficient at compile time.
Links mentioned:
- 2024 EuroLLVM - How Slow is MLIR: 2024 European LLVM Developers' Meetinghttps://llvm.org/devmtg/2024-04/------How Slow is MLIRSpeaker: Mehdi Amini, Jeff Niu------Slides: https://llvm.org/devm...
- stencil | Modular Docs: stencilrank Int, stencilaxis Int, type fn(StaticIntTuple[$1]) capturing -> Tuple[StaticIntTuple[$1], StaticIntTuple[$1]], mapstrides Int) capturing -> Int, loadfn fn[Int capturing -> SIMD$4, ...
- 2024 EuroLLVM - Mojo debugging: extending MLIR and LLDB: 2024 European LLVM Developers' Meetinghttps://llvm.org/devmtg/2024-04/------Mojo debugging: extending MLIR and LLDBSpeaker: Walter Erquinigo, Billy Zhu------...
- 2024 EuroLLVM - Efficient Data-Flow Analysis on Region-Based Control Flow in MLIR: 2024 European LLVM Developers' Meetinghttps://llvm.org/devmtg/2024-04/------Efficient Data-Flow Analysis on Region-Based Control Flow in MLIRSpeaker: Weiwei ...
- Estimating the Dollar Cost of LLVM: Full time geek and research student with a passion for developing great software, often late at night.
- mojo/examples/reduce.mojo at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojo/docs/changelog.md at 1b79ef249f52163b0bafbd10c1925bfc81ea1cb3 · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #📺︱youtube (1 messages):
- Modular posts new video: Modular just announced a new YouTube video titled " - YouTube." The description of the video is currently undefined.
Link mentioned: - YouTube: no description found
Modular (Mojo 🔥) ▷ #ai (5 messages):
- Building a new data labeling platform: A member asked for feedback on building a different kind of data labeling platform, inquiring about the most common types of data labeled, methods used, pain points, human intervention, and potential cost of an automated solution.
- Product image labeling pain points: A member discussed labeling product images and metadata, emphasizing pain points like ambiguity and the extent of manual effort required. They expressed willingness to use an automated product if it's cost-effective and reliable.
- Manual labeling for PDFs: Another member shared their experience with manual data labeling for PDFs and mentioned trying to fine-tune models for automation. They highlighted Haystack as a tool they've explored and underlined the importance of accuracy in pdf data extraction and labeling, especially for ERP integration.
- Interest in ERP integration: The original poster appreciated the feedback and noted the possibility of integrating their labeling platform with ERP systems, prompted by the insights shared about quickbooks and manual data entry.
Link mentioned: Haystack | Haystack: Haystack, the composable open-source AI framework
Modular (Mojo 🔥) ▷ #🔥mojo (51 messages🔥):
- CONTRIBUTING.md lacks testing instructions: A user noticed that the
CONTRIBUTING.mdfile in the Mojo repo doesn't specify how to run all tests before submitting a PR. They recommended adding these instructions and linked the relevant document here. - Error with Mojo's control-flow.ipynb: A user reported a SIGSEGV error when running a code snippet in
control-flow.ipynb. Another user couldn't reproduce the issue and suggested updating to the latest nightly version and changing the type as a possible fix. - Issue with Mojo's staticmethod.ipynb: An error was reported involving the destruction of a field out of a value in
staticmethod.ipynb. Despite updating, the issue persisted, leading the user to consider filing a GitHub issue for further assistance. - OpenAI API key offer for help: A user experiencing a critical issue offered an OpenAI API key worth $10 as an incentive for someone to help solve their problem, highlighting the community spirit and urgency of the issue. They emphasized the blocking nature of the problem and provided the GitHub issue link.
- Development and Docker support for Mojo: Discussions included setups for running Mojo in dev containers, with links to example projects like benz0li/mojo-dev-container and an official modular Docker container example here. Users shared their preferences and experiences with these environments.
Links mentioned:
- YouTube: no description found
- 2024 EuroLLVM - Mojo debugging: extending MLIR and LLDB: 2024 European LLVM Developers' Meetinghttps://llvm.org/devmtg/2024-04/------Mojo debugging: extending MLIR and LLDBSpeaker: Walter Erquinigo, Billy Zhu------...
- thatstoasty - Overview: thatstoasty has 19 repositories available. Follow their code on GitHub.
- mojo/stdlib/docs/development.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojo/examples/docker at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [BUG] LSP & Mojo crashes when using Python.evaluate in a certain way · Issue #3102 · modularml/mojo: Bug description LSP and mojo crashes when using Python.evaluate in a certain way. i expected it to show me what the issue with the code was instead of crashing. Steps to reproduce Include relevant ...
- GitHub - benz0li/mojo-dev-container: Multi-arch (linux/amd64, linux/arm64/v8) Mojo dev container: Multi-arch (linux/amd64, linux/arm64/v8) Mojo dev container - benz0li/mojo-dev-container
- Modular Inc: Modular is an integrated, composable suite of tools that simplifies your AI infrastructure so your team can develop, deploy, and innovate faster. - Modular Inc
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (58 messages🔥🔥):
- Help with
prefetchandPrefetchOptions: One member asked for guidance onprefetchandPrefetchOptions, noting an unexpected speedup when usingPrefetchOptions().for_write().low_locality().to_instruction_cache()for reading data immediately after. Another member confirmed prefetching is usually beneficial only for largeN, as smallerNcan be counterproductive. - Cache Performance and Prefetching: Members discussed the importance of understanding cache activities via a profiler, as misuse of manual prefetching can degrade performance. They emphasized reading relevant manuals like the Intel HPC tuning manual for further insights on prefetching mechanics.
- Instruction vs Data Cache: Clarification was given that fetching to the instruction cache (
icache) also affects theL2cache shared between instructions and data. This can result in unexpected speedups due to structural cache management differences. - Function Inlining in Vectorized/Parallelized Calls: It was discussed that inlining functions often leads to performance improvements in vectorized/parallelized operations since outlined functions are rarely vectorized automatically.
- Tools for Optimization: For cache size optimizations and other performance reasons, tools like
vtunefor Intel orAMD uProffor AMD are recommended. Mojo currently lacks compile-time cache size retrieval, which is necessary to avoid issues like false sharing.
Links mentioned:
- Prefetching - Algorithmica: no description found
- PREFETCHW — Prefetch Data Into Caches in Anticipation of a Write: no description found
- PREFETCHh — Prefetch Data Into Caches: no description found
Modular (Mojo 🔥) ▷ #nightly (21 messages🔥):
- Nightly MAX repo lags behind Mojo: A member noticed the nightly/max repo hadn't been updated for almost a week. Another member explained that there's been an issue with the CI that publishes nightly builds of MAX, and a fix is in progress.
- New Mojo Nightly Builds Released: Announcements were made for new nightly Mojo compiler releases. Users can update to
2024.6.2205and2024.6.2305with details provided in the raw diffs and changelog. - Controlled implicit conversion proposal: A discussion revealed that the proposal to make implicit conversion opt-in is coming from Modular. The plan is to use a decorator to enable it only where it makes sense.
- Troubleshooting segmentation faults in input() function: A user sought help for a segmentation fault issue when resizing buffers in their
input()function. Another user suggested it might be related to an existing bug about unsigned integer casting. - External emojis are functional: A member celebrated that external emojis now work in the Discord. They expressed excitement at the new capability.
Links mentioned:
- gojo/input.mojo at input · thatstoasty/gojo: Experiments in porting over Golang stdlib into Mojo. - thatstoasty/gojo
- mojo/stdlib/docs/development.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [BUG] Unsigned integer casting overflowing as if signed when using
int()orUInt32()· Issue #3065 · modularml/mojo: Bug description Migrating this here after a bit of discussion in Discord. It seems like casting to unsigned integers actually just casts to signed integers, but has different behaviour in different...
LAION ▷ #general (102 messages🔥🔥):
- Weta Digital leadership changes spark reactions: Discussions emerged about Weta Digital and their new CEO, with mentions of Sean Parker and speculation about the decision being more of a sale. "Prem Akkaraju from Weta Digital huh", referenced along with frustrations over potential harassment faced by the company.
- New CEO at Stability AI and industry intrigue: A Reuters article about Stability AI appointing a new CEO was shared, with skepticism over the motives behind the leadership change. One member highlighted "for those who don't want to pay these clowns for a $400 subscription" and shared a Reuters link.
- Llama 3 hardware recommendations draw interest: Specifications for running Q6 llama 400 on a 12-channel AMD server were shared, along with cost approximations, eliciting excitement over potential performance. Expectations set for "1 to 2 tokens per second with this setup" prompted predictions on how it would compare to GPT-4O and Claude 3.
- Debate on Meta model speculation: Users debated the projected capabilities of Meta's 405B models and their potential training overhauls. Comments included hopes for updated weights from models like the 8B and 70B, along with observations such as, "Meta didn't release a paper for Llama 3."
- Exploring advancements in EMA and model distillations: Users discussed the implementation of EMA model updates in diffusers, shared by lucidrains on GitHub, and their applicability to specific projects. The value of multiple captions in training datasets and the nuances of text embeddings were also analyzed, considering their impact on model training and performance.
Links mentioned:
- Connecting Living Neurons to a Computer: Use code thoughtemporium at the link below to get an exclusive 60% off anannual Incogni plan: https://incogni.com/thoughtemporium____...
- Call to Build Open Multi-Modal Models for Personal Assistants | LAION:
Technologies like the recently introduced GPT-4-OMNI from OpenAI show again the potential which strong multi-modal models might have to positively transfo...
- ema: offload to cpu, update every n steps by bghira · Pull Request #517 · bghira/SimpleTuner: no description found
- Neuroplatform - FinalSpark: no description found
LAION ▷ #research (27 messages🔥):
- Glaze team remarks on new attack paper: The Glaze team responded to the new paper on adversarial perturbations, acknowledging the paper's findings and discussing their own tests with the authors' code. They highlighted the "noisy upscaling" method and its reliance on diffusion models, similar to DiffPure, to remove artifacts from images.
- Skepticism on Glaze/Nightshade's efficacy: Members expressed skepticism and sadness over artists who believe Glaze or Nightshade will protect their art. They stressed the inevitable advantage of second movers in circumventing these protections and the resultant false hopes for artists.
- New paper on multimodal models: A new paper on multimodal models was discussed, noting its efforts to train on a wide range of modalities and tasks, improving model versatility. However, members felt like such papers repetitively declare breakthroughs without substantial new results.
- Discussion on diffusion models for image restoration: A detailed inquiry into image restoration tools was made, with Robert Hoenig discussing their experimental use of super-resolution adversarial defense and training on specific image resolutions. The tests revealed that Glaze protections were consistently bypassed.
Links mentioned:
- Tweet from François Fleuret (@francoisfleuret): A little report!
- 4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities: Current multimodal and multitask foundation models like 4M or UnifiedIO show promising results, but in practice their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are li...
- KalMamba: Towards Efficient Probabilistic State Space Models for RL under Uncertainty: Probabilistic State Space Models (SSMs) are essential for Reinforcement Learning (RL) from high-dimensional, partial information as they provide concise representations for control. Yet, they lack the...
- DataComp-LM: In search of the next generation of training sets for language models: We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tok...
- Glaze - v2.1 Update: no description found
Cohere ▷ #general (117 messages🔥🔥):
- New Members Navigate Discord and Cohere Channels: Several new members joined the Discord, including one invited by Varun. Advice was given on navigating the platform, utilizing specific channels, and a tool use documentation link was shared to assist in understanding how to connect Cohere models to external tools.
- Discussion on BitNet and Model Quantization: Members debated the feasibility and future use of BitNet, noting that BitNet is not optimized for current hardware and requires training from scratch. Mr. Dragonfox elaborated on why BitNet is currently impractical for commercial use, mentioning its lack of hardware support and inefficient training demands.
- Interest in New AI Models and Rumors: A member expressed interest in Cohere releasing new models, similar to recent updates from Meta, OpenAI, and Anthropic. There was also speculation on Anthropic's latest model, Claude-3.5-Sonnet, and discussions were held on scaling monosemanticity in models, linking to a paper on the topic.
- Discussion on Cohere's Multilingual Capabilities: A user inquired whether Cohere can respond in other languages such as Chinese. Nick_Frosst confirmed this ability and directed users to documentation and a notebook example for implementing tool use with Cohere models.
Links mentioned:
- abideen/Bitnet-Llama-70M · Hugging Face: no description found
- Bonjour Bonjour Mon Amor GIF - Bonjour Bonjour mon amor Bonjour mon cher - Discover & Share GIFs: Click to view the GIF
- Tool Use with Cohere's Models - Cohere Docs: no description found
- Login | Cohere: Cohere provides access to advanced Large Language Models and NLP tools through one easy-to-use API. Get started for free.
- Add support for BitnetForCausalLM (new model / new datatype) by Eddie-Wang1120 · Pull Request #7931 · ggerganov/llama.cpp: Self Reported Review Complexity: Review Complexity : Low Review Complexity : Medium Review Complexity : High I have read the contributing guidelines PR Intro This PR is to support BitnetFor...
Cohere ▷ #project-sharing (10 messages🔥):
- Microsoft AutoGen adds Cohere Client: A contributor shared a GitHub pull request for adding the Cohere client in AutoGen. Users expressed excitement, saying "siiick, thx for adding the client support!"
- Call for Cohere team involvement: A member clarified that the contribution was not theirs and called out to community contributors. Another member requested the Cohere team's assistance for further implementation, "we would like the cohere team to help us with the CohereClient implementation."
Link mentioned: Cohere Client by Hk669 · Pull Request #3004 · microsoft/autogen: Why are these changes needed? To enhance the support of non-OpenAI models with AutoGen. The Command family of models includes Command, Command R, and Command R+. Together, they are the text-generat...
Cohere ▷ #announcements (1 messages):
- Cohere Developer Office Hours Announcement: "Join us tomorrow for our upcoming Cohere Developer Office Hours!" A Senior Product Manager at Cohere will co-host the session to discuss the Command R family tool use capabilities, with a specific focus on multi-step tool use in the Cohere API.
- Detailed Multi-step Tool Use Overview: Cohere shared an overview of multi-step tool use, which "allows Cohere's models to invoke external tools: search engines, APIs, functions, databases, and so on." For more information, refer to the Cohere documentation and blog posts (multi-step tool use, Command R+).
Links mentioned:
- Join the Cohere Community Discord Server!: Cohere community server. Come chat about Cohere API, LLMs, Generative AI, and everything in between. | 17232 members
- Automating Complex Business Workflows with Cohere: Multi-Step Tool Use in Action: Enterprises are increasingly adopting AI to enhance business workflows. AI models, equipped with external tools, have the potential to streamline business operations. At Cohere, we’re excited to shar...
- Multi-step Tool Use (Agents): no description found
LangChain AI ▷ #general (100 messages🔥🔥):
- Max Tokens and Pydantic Validations Confuse Users: Users discussed confusion around max tokens for agents and context windows, and issues with LLM not following Pydantic validation. "The context window or max token always includes the complete input token plus generated token."
- LangChain Tutorials and Resources: Several users expressed difficulty learning LangChain, particularly in building chatbots and handling conversational digressions. Grecil shared a personal journey into LangChain and provided links to tutorials and documentation.
- Using Multiple Chat Models and APIs: Users debated performance issues and the application in different scenarios of ChatOpenAI vs. open-source models from Huggingface. One user asked about handling RAG on Excel files, implying versatility concerns with LangChain support for various data formats.
- Handling Message History and Metadata in Chains: Users sought help with implementing and troubleshooting RunnableWithMessageHistory and incorporating metadata in document retrievers. "How to add the metadata that contains the documents/chunks retrieved in this chain."
- Streamlit App Hosting Discussions: Issues of resource management and concurrency in Streamlit apps were discussed, including embedding API keys and handling multiple users simultaneously. "Yeah, Streamlit takes care of that. As soon as you close the tab, your instance and the files you uploaded are erased."
Links mentioned:
- simplememory: The framework for agent memory
- Reflexion - LangGraph: no description found
- NVIDIA NIMs | 🦜️🔗 LangChain.): The langchain-nvidia-ai-endpoints package contains LangChain integrations building applications with models on
- Build a Chatbot | 🦜️🔗 Langchain:): Overview
- Build a Chatbot | 🦜️🔗 LangChain): This guide assumes familiarity with the following concepts:
- Build a Chatbot | 🦜️🔗 LangChain): This guide assumes familiarity with the following concepts:
- TiDB Vector | 🦜️🔗 LangChain): TiDB Cloud, is a comprehensive Database-as-a-Service (DBaaS) solution, that provides dedicated and serverless options. TiDB Serverless is now integrating a built-in vector search into the MySQL landsc...
- Introduction - LangGraph: no description found
- no title found: no description found
LangChain AI ▷ #langchain-templates (21 messages🔥):
- Generate QA pairs from PDF using LangChain: A user requested the code to generate questions and answers from a PDF using LangChain. The Python code involves loading the PDF with
PyPDFLoader, splitting it into chunks, creating embeddings withOpenAIEmbeddings, and setting up aRetrievalQAchain. - Linking issues from GitHub: The code provided references several GitHub issues, such as this one for guidance on generating question-answer pairs from PDFs.
- Using Llama2 as LLM: Another user requested modifications to the code to use Llama2 as the LLM. The updated instructions suggested initializing
LlamaCppand setting upQAGenerationChainwith theprompt_template. - Iterating through text for QA pairs: Lastly, instructions were given on how to iterate through text chunks from the PDF to generate question-answer pairs using the
QAGenerationChain. This approach ensures multiple pairs are generated from the document.
Links mentioned:
- Issues · langchain-ai/langchain.): 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain): 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain.): 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain): 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain.): 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #share-your-work (5 messages):
- No Code RAG Workflows for Financial Documents: A member shared an article on designing a Retrieval-Augmented Generation (RAG) application using Flowise for financial document analysis. Key features include embedding cache using Redis and Qdrant for semantic search.
- Linear Regression from Scratch: Another member posted an article detailing how to implement linear regression from scratch in Python. The tutorial avoids using machine learning packages like scikit-learn, focusing instead on core concepts.
- Corrective RAG App: A member provided a link to their Corrective RAG app on Streamlit.
- Edimate: AI-driven Educational Videos: A member introduced Edimate, a tool that generates educational videos in about three minutes. They shared a demo showing its potential to transform e-learning by creating captivating, animated videos.
- Regression Testing for LLMs: An informative post linked to a code tutorial on regression testing for LLMs using open-source tools. The tutorial covers creating golden datasets, assessing response changes, and using the Evidently Python library to evaluate LLM outputs.
Links mentioned:
- Tweet from Harshit Tyagi (@dswharshit): How can you re-define E-learning with AI? This was the question I had as I have spent close to a decade in Edtech. The answer turned out to be generate videos/courses to explain any topic, on demand...
- A tutorial on regression testing for LLMs: In this tutorial, you will learn how to systematically check the quality of LLM outputs. You will work with issues like changes in answer content, length, or tone, and see which methods can detect the...
- Linear Regression From Scratch In Python: Learn the implementation of linear regression from scratch in pure Python. Cost function, gradient descent algorithm, training the model…
- Effortless No Code RAG Workflows for Financial Documents: Implementing Embedding Cache and Chat…: In the rapidly evolving landscape of financial data analysis, harnessing the power of advanced technologies without the need for extensive…
- no title found: no description found
LangChain AI ▷ #tutorials (1 messages):
- Deciding on an AI Framework? Ask Critical Questions First: A member shared a YouTube video on AI framework considerations. The video discusses essential questions developers should ask before integrating AI tools like GPT-4o into their apps.
Link mentioned: Do you even need an AI Framework or GPT-4o for your app?: So, you want to integrate AI into your product, right? Whoa there, not so fast!With models like GPT-4o, Gemini, Claude, Mistral, and others and frameworks li...
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- AI21 introduces Jamba-Instruct: Jamba-Instruct, an instruction-tuned variant by AI21, is tailored for enterprise use with an impressive 256K context window to handle large documents. Check out more details here.
- NVIDIA releases Nemotron 4 340B Instruct: Nemotron-4-340B-Instruct is a chat model focused on synthetic data generation for English-language applications. Find out more here.
Links mentioned:
- AI21: Jamba Instruct by ai21: The Jamba-Instruct model, introduced by AI21 Labs, is an instruction-tuned variant of their hybrid SSM-Transformer Jamba model, specifically optimized for enterprise applications. - 256K Context Wind...
- NVIDIA Nemotron-4 340B Instruct by nvidia: Nemotron-4-340B-Instruct is an English-language chat model optimized for synthetic data generation. This large language model (LLM) is a fine-tuned version of Nemotron-4-340B-Base, designed for single...
OpenRouter (Alex Atallah) ▷ #app-showcase (7 messages):
- JojoAI transforms into a proactive assistant: A member has transformed JojoAI into a proactive assistant capable of functions like setting reminders. They highlight that, unlike ChatGPT or Claude, JojoAI uses DigiCord integrations to remind users at specific times JojoAI site.
- Pebble: AI reading comprehension tool: An AI-powered reading comprehension tool called Pebble was launched to help users remember information on the web. The developer used OpenRouter with Mistral 8x7b and Gemini and shared gratitude for the support of the OpenRouter team Pebble.
- MoA project modified with OpenRouter: A contributor modified the MoA project to use OpenRouter and added a server with an API endpoint, creating a GUI for usage. The project is available on GitHub.
Links mentioned:
- Pebble: no description found
- DigiCord: The most powerful AI-powered Discord Bot ever!
- MoA-Openrouter/gui.ipynb at main · timothelaborie/MoA-Openrouter: together MoA but with Openrouter. Contribute to timothelaborie/MoA-Openrouter development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #general (106 messages🔥🔥):
- Nemotron 340b's environmental impact questioned: "Nemotron 340b is definitely one of the most environmentally unfriendly models u could ever use." Discussion continued with comparisons suggesting Gemini Flash and other smaller, cheaper models as better alternatives for synthetic data generation.
- Claude self-moderated endpoints issue fixed: "Looks like the Claude self-moderated endpoints are gone?" After flagging a 404 error, a fix was implemented quickly, and the issue was resolved.
- Sonnet 3.5 praised for coding: A user shared positive experiences using Sonnet 3.5 for coding, calling it impressive and pointing to a real-world demo with Retrieval Augmented Generation (RAG).
- OpenRouter rate limits and credits explained: "How do you increase the rate limits for a particular LLM?" Documentation on rate limits and credits was shared, explaining how to check the balance and usage via API requests.
- Handling exposed API keys: "Hey, I like an idiot, showed a newly made api key on a stream and someone used it." Recommendations were given to disable rather than delete compromised keys to trace any improper usage better.
Links mentioned:
- Transforms | OpenRouter: Transform data for model consumption
- Limits | OpenRouter: Set limits on model usage
- Building search-based RAG using Claude, Datasette and Val Town: Retrieval Augmented Generation (RAG) is a technique for adding extra “knowledge” to systems built on LLMs, allowing them to answer questions against custom information not included in their training d...
OpenInterpreter ▷ #general (85 messages🔥🔥):
- Local LLMs on OS mode?: A member asked whether local LLMs can be used in OS mode. Another member confirmed "Yes! But performance of these models aren't very good..." and provided the command
interpreter --local --os. - Desktop App Premium Experience: A member inquired about differences between the desktop app and the GitHub version. Mikebirdtech emphasized that "The desktop app is going to be a very cool way to experience Open Interpreter" and recommended joining the waitlist for the desktop app.
- Hitting GitHub Star Milestone: Killianlucas excitedly announced the project has hit 50,000 stars on GitHub, describing it as a huge accomplishment for the community. He mentioned a big server announcement coming soon.
- Codestral and Deepseek Model Hype: Several members discussed the recently released Deepseek and Codestral models, with Killianlucas noting that "codestral... beat all our internal benchmarks..." and favored Deepseek for its speed, mentioning an upcoming update with an optimized
interpreter --deepseekcommand. - Ollama Connection Issues: Arsaboo had issues connecting to Ollama hosted on a different computer using the OI interface. Multiple members suggested various fixes and troubleshooting steps, including changing API base URLs and using proxies, but none resolved the issue conclusively.
Links mentioned:
- no title found: no description found
- Open Interpreter v0.3 Part 2: 0:00 - Setting up6:10 - Debugging
interpeter --os8:01 - Using cursor to help debug19:38 - chat22:24 - Sonnet gives better answer than 4o29:00 - Fixing bash... - open-interpreter/interpreter/terminal_interface/profiles/defaults/codestral.py at main · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
- Update vision model to gpt-4o by MikeBirdTech · Pull Request #1318 · OpenInterpreter/open-interpreter: Describe the changes you have made: gpt-4-vision-preview was deprecated and should be updated to gpt-4o https://platform.openai.com/docs/deprecations/2024-06-06-gpt-4-32k-and-vision-preview-models ...
- Using open interpreter with Ollama on a different machine · Issue #1157 · OpenInterpreter/open-interpreter: Describe the bug I am trying to use OI with Ollama running on a different computer. I am using the command: interpreter -y --context_window 1000 --api_base http://192.168.2.162:11434/api/generate -...
- Open Interpreter - Desktop App: Apply for early access to the Open Interpreter Desktop App.
- Google Colab): no description found
OpenInterpreter ▷ #O1 (17 messages🔥):
- Poetry vs requirements.txt sparks debate: Members discussed the advantages and disadvantages of using Poetry over a traditional
requirements.txtfile. One member highlighted Poetry's deterministic builds and ease of management, while another pointed out that it can be difficult to manage across platforms, suggesting conda as an alternative. - 01 Installation Documentation Shared: A member shared a setup link for installing 01 on different operating systems. Another member expressed frustration, stating that it "doesn't work yet" on some platforms.
- Windows Installation Challenges: Discussions highlighted difficulties in managing dependencies on Windows with tools like Poetry and venv compared to conda. Despite one user's assertion that Poetry and venv work fine on Windows, another noted frequent failures for non-01 packages.
- Community Sentiments: A member expressed strong positive sentiments, calling this discord community their favorite. Others discussed the beginner-friendliness of the 01 light, with developers noting current versions require technical knowledge but future releases aim to be more accessible.
- Shipping Timeline Frustrations: Members expressed concerns over the shipping timelines of the 01 device. One user mentioned repeated delays, while another defended the timelines against perceived misinformation.
Links mentioned:
- Poetry - Python dependency management and packaging made easy: no description found
- Setup - 01: no description found
OpenInterpreter ▷ #ai-content (5 messages):
- Funny Thumbnail from Techfren’s Community: A member shared a YouTube live video and noted the amusing thumbnail made by Flashwebby from the techfrens community. Another member commented on loving the thumbnail, which prompted the original member to share their lighthearted contribution to the video.
- Amoner Remixes "The Wheels on the Bus" with AI: A member presented a YouTube video highlighting a remix of "The Wheels on the Bus" using Suno and Luma technologies. The video description emphasizes the innovative use of GenAI technology for creating next-gen music and visuals.
Link mentioned: AI Remix: The Wheels on the Bus | Next-Gen Music & Visuals by Suno & LumaLabs: Experience 'The Wheels on the Bus' like never before with this innovative AI-generated remix! Using the latest in GenAI technology, we've collaborated with S...
LLM Finetuning (Hamel + Dan) ▷ #general (33 messages🔥):
- Explore Instruction Pre-Training for multi-task learning: A member shared a Hugging Face repository on Instruction Pre-Training, which augments raw corpora with instruction-response pairs for supervised multitask pre-training. This method has effectively synthesized 200M pairs across 40+ task categories.
- DeBERTa with Flash Attention 2: A user inquired if anyone knew of any DeBERTa implementations using Flash Attention 2, indicating interest in combining these two technologies.
- Blank Page Issue on Maven Course Platform: Multiple users experienced a blank page when trying to access a course on Maven, prompting discussion about troubleshooting and attempts to contact Maven support. A temporary workaround involved accessing the course on mobile devices.
- Running AI Applications Workshop: Attendees discussed an upcoming event in San Francisco, AI Engineer World’s Fair, which includes workshops on quickly deploying AI applications with templates. Several members expressed interest in meeting up at the event.
- Why companies prefer fine-tuning over RAG: There was a discussion on why job ads often seek fine-tuning expertise rather than Retrieval-Augmented Generation (RAG). It was suggested that companies aim to reduce LLM costs, making fine-tuning a valuable skill.
Links mentioned:
- AI Mathematical Olympiad - Progress Prize 1 | Kaggle: no description found
- Welcome to Outlines! - Outlines 〰️: Structured text generation with LLMs
- instruction-pretrain/instruction-synthesizer · Hugging Face: no description found
- Instruction Pre-Training: Language Models are Supervised Multitask Learners: Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling ...
- no title found: no description found
- GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa
- AI Engineer World's Fair: Join 2,000 software engineers enhanced by and building with AI. June 25 - 27, 2024, San Francisco.
LLM Finetuning (Hamel + Dan) ▷ #learning-resources (1 messages):
christopher_39608: Interesting post:
https://x.com/rasbt/status/1805217026161401984
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (6 messages):
- Missing Credits and Troubleshooting: A user reported, "I haven't received the credits yet," and was advised to contact billing if they had filled out the form correctly. They were informed to email billing with proof of sign-up date, HF username, and email.
- Prompt Customer Service Response: Another individual faced the same issue and mentioned their HF username and email directly in the channel. They received a quick response advising them to contact billing for further assistance and acknowledged sending the receipt to the provided email.
LLM Finetuning (Hamel + Dan) ▷ #replicate (3 messages):
- Broken template reported for Mixtral 8x22: A user inquired about the broken template issue for Mixtral 8x22 and tagged two members, seeking help to address it.
- Replicate credits usage with VScode extension: It was shared that Replicate credits can be utilized with a VScode extension named continue.dev. This extension functions similar to Github Copilot, using Replicate APIs, and also offers a @docs feature to interact with Replicate documentation locally.
LLM Finetuning (Hamel + Dan) ▷ #langsmith (1 messages):
- Missing Credits Frustrate User: A user reported not seeing their credits after logging in and adding a credit card for billing. They shared their organization ID, be7114fc-9d79-475a-a258-ddbda1553c9a, to seek assistance.
LLM Finetuning (Hamel + Dan) ▷ #jason_improving_rag (1 messages):
jxnlco: nah
LLM Finetuning (Hamel + Dan) ▷ #axolotl (3 messages):
- Subprocess.CalledProcessError plagues training: A user reported an error, subprocess.CalledProcessError: Command '['/usr/bin/python3', '-m', 'axolotl.cli.train', '/content/qlora.yml']' returned non-zero exit status 1, indicating issues with running Axolotl's training command.
- LORA overfitting concerns: Another user queried whether significantly lower training loss compared to validation loss signals overfitting, even when using LORA. The question implies common concerns among users about overfitting in fine-tuning models.
LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (1 messages):
- Help requested for error in .yml and dataset: A member asked for assistance with an error they encountered. They attached the .yml and dataset to provide context and mentioned using Modal for this FTJ, appreciating any support offered.
LLM Finetuning (Hamel + Dan) ▷ #simon_cli_llms (1 messages):
mgrcic: Also available at https://www.youtube.com/watch?v=QUXQNi6jQ30
LLM Finetuning (Hamel + Dan) ▷ #credits-questions (3 messages):
- Dan clarifies credit issues: A user sought help figuring out credits as they hadn't received any yet. Dan asked if the user signed up and responded to the forms by the deadline, and offered to check what data was sent to the platforms if provided with the email address.
LLM Finetuning (Hamel + Dan) ▷ #fireworks (2 messages):
- User tags and codes dominate the chat: With user tags like
<@466291653154439169>and codes such astyagi-dushyant1991-e4d1a8andwilliambarberjr-b3d836, it appears members are sharing unique identifiers or codes. No further context on the usage or purpose of these tags was provided.
LLM Finetuning (Hamel + Dan) ▷ #braintrust (25 messages🔥):
- Some users are missing their credits: Several members, including xyz444139, nima01258, and claudio_08887, reported not receiving their credits despite following procedures. ankrgyl addressed these issues by checking email records, confirming permissions, and applying credits where appropriate.
- Permission issues resolved after kernel restart: claudio_08887 encountered a "User does not have permissions to create a project within this org" error while running an evaluation example. The problem was resolved after restarting the kernel, indicating it might have been a transient issue.
- braintrust lacks direct fine-tuning capabilities: When asked about tutorials for fine-tuning Huggingface models with braintrust, ankrgyl clarified that braintrust can assist in evaluating fine-tuned models but does not have built-in fine-tuning capabilities.
- Customer feedback is appreciated and encouraged: lapuerta91 expressed admiration for the product, to which ankrgyl responded with appreciation and invited further feedback on potential improvements.
LLM Finetuning (Hamel + Dan) ▷ #predibase (13 messages🔥):
- Predibase credits expire in 30 days: A user queried if Predibase credits expire at the end of the month. Confirmation was provided that credits expire 30 days after they are issued with a reference link.
- New user assistance with credits: A new user noted only seeing $25 in available credits. Predibase support suggested directly messaging or emailing support@predibase.com for assistance.
- Enterprise tier features: There was a discussion about the enterprise tier of Predibase, stating it offers features for production-scale applications. Users interested in this tier were advised to contact support.
LlamaIndex ▷ #blog (5 messages):
- LightningAI's RAG template simplifies AI development: LightningAI provides tools for developing and sharing both traditional ML and genAI apps, as shown in Jay Shah's template for setting up a multi-document agentic RAG. This template allows for an out-of-the-box setup to streamline the development process.
- Customizable Text-to-SQL with DAGs: Existing text-to-SQL modules often need custom orchestration and prompt adjustments for production use. An underrated feature of llama_index is its ability to support these advanced LLM customizations.
- Corrective RAG for better financial analysis: The CRAG technique, as described by Yan et al., assesses retrieval quality and uses web search for backup context when the knowledge base is insufficient. Hanane Dupouy's tutorial slides offer detailed guidance on implementing this advanced RAG technique.
- RAG parameter tuning with Mlflow: Managing RAG's numerous parameters, from chunking to indexing, is crucial for answer accuracy, and it’s essential to have a systematic tracking and evaluation method. Integrating llama_index with Mlflow helps achieve this by defining proper eval metrics and datasets.
- LlamaIndex integrates image generation via StabilityAI: The new feature in create-llama now supports image generation using StabilityAI. This integration expands the capabilities of LlamaIndex for AI developers.
LlamaIndex ▷ #general (70 messages🔥🔥):
- LlamaIndex's Query Response Modes Explained: Members discussed various query response modes in LlamaIndex, such as Refine, Compact, Tree Summarize, and Accumulate. Each mode uses different strategies to generate and refine responses incrementally or through tree summarization (source).
- Using OLLAMA_NUM_PARALLEL with LlamaIndex: A member inquired about the use of OLLAMA_NUM_PARALLEL to run multiple models concurrently in LlamaIndex. It was noted that this seems to only require setting an environment variable and no changes in LlamaIndex are needed yet.
- Document Parsing Issues: Issues were raised about some documentation pages not rendering correctly on LlamaIndex's site. Links ending in .md were pointed out as the cause, leading to a plan to update those pages (example link).
- Discussion on Custom Similarity Scores in Vector Databases: A member asked about defining custom similarity scores using Weaviate or Elasticsearch in LlamaIndex. It was recommended to implement this at the level of the vector database, as LlamaIndex wraps around their libraries and doesn't directly support custom retrievers.
- Embedding Dimensions Mismatch in PGVectorStore: A member faced issues with embedding dimension mismatches when using bge-small embedding model with PGVectorStore, which required 384-dimension embeddings instead of the default 1536. Adjustments in the
embed_dimparameter and ensuring the correct embedding model was advised.
Links mentioned:
- Retrieval-Augmented Generation for Large Language Models: A Survey: Large Language Models (LLMs) showcase impressive capabilities but encounter challenges like hallucination, outdated knowledge, and non-transparent, untraceable reasoning processes. Retrieval-Augmented...
- Anthropic | LlamaIndex.TS: Usage
- Full Stack Projects - LlamaIndex: no description found
- Full-Stack Web Application - LlamaIndex: no description found
- Query Engine with Pydantic Outputs - LlamaIndex): no description found
- Index - LlamaIndex): no description found
LlamaIndex ▷ #ai-discussion (1 messages):
- Guide to MLflow and LLMs with LlamaIndex: A link to a Medium article about integrating MLflow and LLMs using LlamaIndex was shared. The article aims to "unlock efficiency in machine learning", authored by Ankush K Singal.
Link mentioned: Unlocking Efficiency in Machine Learning: A Guide to MLflow and LLMs with LlamaIndex Integration: Ankush k Singal
Interconnects (Nathan Lambert) ▷ #news (17 messages🔥):
- Gemini 1.5 Pro has fewer parameters than LLAMA 3 70B: A member with a "reputable source at Meta" claimed "Gemini 1.5 Pro has fewer parameters than LLAMA 3 70B." This led to discussions on the architecture differences, esp. MoE (Mixture of Experts), influencing the active parameter count during inference.
- Early fusion technique in GPT-4: There's a debate whether GPT-4T/o are distilled models or utilize an early fusion technique. One member suggested "GPT4 o is just early fusion GPT4" while another believed it involved larger models like "GPT4-omni" distilled down.
- Difficulty in post-training multimodal models: A discussion emerged on post-training multimodal models like Gemini Ultra and GPT4-o, highlighting challenges in modality transfer. One pointed out that "post-training for native multimodal models are really hard, and the transfer across modalities seem small."
- Multi joins OpenAI, sunsets app: Multi, once aiming to reimagine desktop computing as inherently multiplayer, is joining OpenAI according to a blog post. Multi will stop service by July 24, 2024, a member remarked "OpenAI is on a shopping spree".
Link mentioned: Multi Blog – Multi is joining OpenAI : Recently, we’ve been increasingly asking ourselves how we should work with computers. Not on or using computers, but truly with computers. With AI. We think it’s one of the most importan...
Interconnects (Nathan Lambert) ▷ #ml-questions (20 messages🔥):
- The Value of Faulty Code: Members debated the importance of including faulty code during training. One stated, "code with errors so that it understands how to fix errors" is necessary, while another emphasized that "bad data needs to be situated in some context that makes it obvious that it's bad."
- Risk Aversion in AI Datasets: There was a discussion on the high stakes of using open datasets. A member pointed out, "the stakes are too high now... people filter down CommonCrawl the millionth time" largely due to concerns over legality and backlash.
- Ethical and License Issues: The conversation covered the inconsistency of license terms. One member humorously remarked, "you just can't upload and train on your own lolol" pointing to practical evasions of restrictive licenses.
- High-Risk Data Types: Natolambert noted that video and image datasets carry a higher risk compared to other types of data. They also expressed a need for faster improvements in synthetic data options, implying current limitations.
- Link To Relevant Article: Discussion included a 2022 article on AI data laundering that highlighted the shielding of tech companies from accountability, shared by dn123456789. This sparked remarks on the sad state of dataset ethics in current AI practices.
Links mentioned:
- AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability - Waxy.org: Tech companies working with AI are outsourcing data collection and training to academic/nonprofit research groups, shielding them from potential accountability and legal liability.
- AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability - Waxy.org: Tech companies working with AI are outsourcing data collection and training to academic/nonprofit research groups, shielding them from potential accountability and legal liability.
Interconnects (Nathan Lambert) ▷ #ml-drama (13 messages🔥):
- Sony Music vs Nous Research: A Nous Research member tagged @sonymusic on X, questioning, “who exactly is nouse research?". This sparked curiosity and seemed to mix up the conversation about AI innovation and potential legal entanglements.
- Pre-emptive Cease and Desist Joke: One member joked about unlocking the "ultra-rare 'Pre-emptive cease and desist' achievement" despite never having trained audio models, adding humor to the legal concerns.
- Claude 3.5 Conspiracy Theory: There was a humorous conspiracy theory shared that "Claude 3.5 isn’t real but just Claude 3 with the 'I’m very smart' vector cranked up," demonstrating skepticism towards model improvements.
- OpenAI's Vague Apology: Mira Murati’s post on X addressed OpenAI’s mission, tools like Sora and GPT-4o, and the balance between creating innovative AI while managing its impact. Despite her detailed explanation, a member commented that the apology was "clearly not pleasing anybody."
- Hugging Face Access Drama: An announcement on a Hugging Face model page states they are suspending new download access requests due to conflicts, citing a perceived “repeated misuse of the 'Contributor Covenant Code of Conduct'" by Hugging Face, and prioritization of commercialization over community well-being.
Links mentioned:
- CausalLM/14B-DPO-alpha · Hugging Face: no description found
- Tweet from Nous Research (@NousResearch): uhh hey @sonymusic who exactly is nouse research
- Tweet from Tsarathustra (@tsarnick): Mira Murati: GPT-3 was toddler-level, GPT-4 was a smart high schooler and the next gen, to be released in a year and a half, will be PhD-level
- Tweet from emozilla (@theemozilla): I unlocked the ultra-rare "Pre-emptive cease and desist" achievement (p.s. I've never trained any audio models) Quoting Nous Research (@NousResearch) uhh hey @sonymusic who exactly is ...
- Tweet from Mira Murati (@miramurati): At OpenAI, we’re working to advance scientific understanding to help improve human well-being. The AI tools we are building, like Sora, GPT-4o, DALL·E and ChatGPT, are impressive from a technical stan...
Interconnects (Nathan Lambert) ▷ #random (9 messages🔥):
- Internet Traffic and Content Quality: A member suggested that if the content is really good, people will click and explore it. However, they noted that if the content is mediocre, it doesn’t deserve much traffic anyway.
- Farmer and Sheep Problem Joke: A shared a humorous tweet that extends the "one farmer and one sheep problem," suggesting that "sheep can row the boat as well." The full tweet can be viewed here.
- Gemini 1.5 Bragging Rights: There was a mention of an updated Gemini model that reportedly didn't make it into the I/O presentation. The tweet about this can be found here.
- Anthropic's AI Videos: Anthropic has been sharing videos on YouTube about topics like AI personality and interpretability. Noteworthy videos are "What should an AI's personality be?" and "Scaling interpretability".
- Mixed Reception to AI Content: Some members felt that certain parts of AI-related content were boring or not as interesting as hoped. Despite these critiques, there is a desire for continued production of such content.
Links mentioned:
- Tweet from rohan anil (@_arohan_): Sorry I had to share this one. Sheep can row the boat as well you know!
- Tweet from Stephen Malina (@an1lam): Can't believe this didn't make it into the I/O presentation! Updated Gemini passing.
- What should an AI's personality be?: How do you imbue character in an AI assistant? What does that even mean? And why would you do it in the first place? In this conversation, Stuart Ritchie (Re...
- Scaling interpretability: Science and engineering are inseparable. Our researchers reflect on the close relationship between scientific and engineering progress, and discuss the techn...
Interconnects (Nathan Lambert) ▷ #memes (3 messages):
- Eat up piggies: A user shared the message "eat up piggies". It remains unclear in context without further explanation.
- Model hubs on the way: Another message stated simply "model hubs soon 🤗". This hints at upcoming developments or releases related to model hubs.
- Expressing confusion: Nathan Lambert shared the sentiment "This makes no sense in so lost". This suggests some confusion or misunderstanding regarding the previous messages.
Interconnects (Nathan Lambert) ▷ #reads (4 messages):
- Mixture of Agents model raises eyebrows: A member shared a tweet about the Mixture of Agents model being the strongest on the AlpacaEval leaderboard, claiming it beats GPT-4 by being 25 times cheaper. Another member deemed it dumb, questioning the legitimacy of the leaderboard which allegedly incorporates biased metrics.
- Alpaca Eval skepticism: Several members expressed skepticism about the Alpaca Eval leaderboard, indicating that it might include biased or inflated performance metrics. One member bluntly stated, "They add all sorts of slop to their leaderboard" and labeled themselves as an "alpaca eval hater".
Link mentioned: Tweet from Kyle Corbitt (@corbtt): Thrilled to be officially recognized as the strongest model on the AlpacaEval leaderboard. 🙂 https://tatsu-lab.github.io/alpaca_eval/ Quoting Kyle Corbitt (@corbtt) Super excited to announce our ...
OpenAccess AI Collective (axolotl) ▷ #general (33 messages🔥):
- Use ROCm Fork Versions: Members discussed needing to use the ROCm fork versions of xformers and flash-attention for certain functionalities. One user confirmed that flash-attention support requires ROCm 5.4+, PyTorch 1.12.1+, and MI200 & MI300 GPUs.
- Reward Model Not Effective for Data Generation: A brief exchange concluded that the reward model isn't worthwhile for generating data, as it primarily classifies data quality.
- Boosting AGI Eval: One user mentioned plans to synthesize SAT, GRE, and MCAT questions to potentially boost AGI evaluations for smaller models, with suggestions to include LSAT questions as well.
- Epoch Saving Issues: A user reported issues with epoch saving during training, where it saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter.
- Finetuning on AMD: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process.
Links mentioned:
- GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention: Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub.
- GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.: Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
lore0012: I am no longer hitting the issue.
OpenAccess AI Collective (axolotl) ▷ #general-help (4 messages):
- HeaderTooLarge error in fine-tuning Qwen2 7b: A member encountered a
safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLargewhile runningCUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml. This error occurs when attempting to load checkpoint shards. - Local directory issues with Qwen2 7b model: The fine-tuning configuration works when setting
base_modelto a Hugging Face repository but fails when pointing to a local directory (/large_models/base_models/llm/Qwen2-7B). The failure persists even though the folder is a mounted NFS. - Frustration with NVIDIA Megatron-LM bugs: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in GitHub Issue #866, which discusses a problem with a parser argument in the
convert.pyscript.
Link mentioned: [BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM: Describe the bug https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115 It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER...
OpenAccess AI Collective (axolotl) ▷ #datasets (5 messages):
- Newbie asks about dataset suitability: A new member experimenting with fine-tuning llama2-13b using axolotl inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?"
- Formatting example for 'Alpaca' dataset: Another member shared a dataset case using JSONL for fine-tuning Alpaca. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left."
- Introducing Rensa for high-performance MinHash: A member excitedly introduced their side project, Rensa, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like
datasketchfor tasks like dataset deduplication and shared its GitHub link for community feedback and contributions.
Link mentioned: GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (5 messages):
- Prompt Style Explained in Axolotl Codebase: The inquiry about
prompt_styleled to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such asINSTRUCT,CHAT, andCHATMLwere detailed to illustrate different prompt structuring strategies for various interaction types. - Example of ReflectAlpacaPrompter Usage: The
ReflectAlpacaPrompterclass example highlights how differentprompt_stylevalues like "instruct" and "chat" dictate the structure of generated prompts. Thematch_prompt_stylemethod is used to set up the prompt template according to the selected style.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search): Understand code, faster.
Mozilla AI ▷ #announcements (1 messages):
- Llamafile v0.8.7 releases with upgrades: Llamafile v0.8.7 released with faster quant operations and bug fixes. An Android version hint was also mentioned.
- San Francisco hosts major AI events: World's Fair of AI and AI Quality Conference will feature prominent community members. Links to World's Fair of AI and AI Quality Conference are provided.
- Firefox Nightly AI services experiment: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the Nightly blog.
- Latest ML Paper Picks available: The latest ML Paper Picks have been shared by a community member.
- RSVP for upcoming July AI events: Events include Jan AI, AI Foundry Podcast Roadshow, and AutoFIx by Sentry.io.
Mozilla AI ▷ #llamafile (31 messages🔥):
- Llamafile Help Command Issue: A user reported that running
llamafile.exe --helpreturns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - Running Llamafile on Google Colab: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a link to their example.
- Llamafile Repackaging Concerns: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes.
- New Memory Manager for Cosmopolitan: A commit on GitHub discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux.
- Mozilla Nightly Blog Mentions Llamafile: The Nightly blog mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users.
Links mentioned:
- no title found: no description found
- Tweet from Dylan Freedman (@dylfreed): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range...
- Mozilla Builders: no description found
- Release llamafile v0.8.7 · Mozilla-Ocho/llamafile: This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on...
- Rewrite memory manager · jart/cosmopolitan@6ffed14: Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g....
- ggerganov - Overview: I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub.
- Google Colab: no description found
- Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp: Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response
Torchtune ▷ #general (24 messages🔥):
- DPO Training Options Available; ORPO Not Yet Supported: When asked about the options for DPO and ORPO training with Torchtune, a member shared a dataset for ORPO/DPO and mentioned that ORPO is not yet supported while DPO has a recipe available. This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning.
- Training on Multiple Datasets and Epochs Limitation: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use ConcatDataset. It was highlighted that setting different epochs per dataset is not supported.
- Debate on ChatML Template Use with Llama3: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring Mahou-1.2-llama3-8B and Olethros-8B. Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate.
- Phi-3 Model Fine-Tuning Feasibility: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired.
- Instruction on Using System Prompts with Phi-3: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration was mentioned for allowing system prompt usage.
Links mentioned:
- lodrick-the-lafted/Olethros-8B · Hugging Face: no description found
- flammenai/Mahou-1.2-llama3-8B · Hugging Face: no description found
- microsoft/Phi-3-mini-4k-instruct · Hugging Face: no description found
- torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face: no description found
- torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone): no description found
- microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions: no description found
- microsoft/Phi-3-medium-4k-instruct · Hugging Face: no description found
- config.json · microsoft/Phi-3-medium-4k-instruct at main: no description found
tinygrad (George Hotz) ▷ #general (8 messages🔥):
- WHERE Function Clarification: A member asked if the WHERE function could be simplified with conditional operations like
condition * a + !condition * band was pointed out that NaNs could be an issue. - Intel Support Inquiry: Someone inquired about Intel support in tinygrad. Another member responded that opencl can be used, but there is no XMX support yet.
- Monday Meeting Overview: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on tinybox, new profiler, runtime enhancements, and plans for the 0.9.1 release. Specific agenda items cover enhancements like
Tensor._tri, llama cast speedup, and mentions of bounties such as improvements in uop matcher speed and unet3d. - Future of Linear Algebra Functions: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. No specific response was given in the extracted messages.
tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
- Buffer view option flagged in tinygrad: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, "make buffer view optional with a flag" and the associated GitHub Actions run was provided.
- Change in lazy.py raises concerns: A member questioned if they were doing something wrong as their changes to
lazy.pyresulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications.
Link mentioned: make buffer view optional with a flag · tinygrad/tinygrad@bdda002: You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002
LLM Perf Enthusiasts AI ▷ #claude (1 messages):
- Claude Sonnet 3.5 impresses in Websim: A member was testing Claude Sonnet 3.5 in Websim and was highly impressed by the model's "speed, creativity, and intelligence". They highlighted features such as "generate in new tab" and shared their experience of trying to "hypnotize" themselves with the color schemes of different iconic fashion brands. Twitter link.
Link mentioned: Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t...
MLOps @Chipro ▷ #events (1 messages):
- MJCET launches AWS Cloud Club: We are delighted to share that MJCET has launched the FIRST AWS Cloud Club in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career.
- Exclusive inaugural event with AWS Hero: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring Mr. Faizal Khan, AWS Community Hero. RSVP via this meetup link to confirm your attendance.
Link mentioned: Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup: Join Us for the Grand Inauguration of AWS Cloud Club MJCET! We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!
- Perplexity Plagiarized Our Story About How Perplexity Is a Bullshit Machine't worthwhile for generating data, as it primarily classifies data quality. - **Boosting AGI Eval**: One user mentioned plans to synthesize SAT, GRE, and MCAT questions to potentially boost AGI evaluations for smaller models, with suggestions to include LSAT questions as well. - **Epoch Saving Issues**: A user reported issues with epoch saving during training, where it saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter. - **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >: Experts aren’t unanimous about whether the AI-powered search startup’s practices could expose it to legal claims ranging from infringement to defamation—but some say plaintiffs would have strong cases... smaller models, with suggestions to include LSAT questions as well. - **Epoch Saving Issues**: A user reported issues with epoch saving during training, where it saves at seemingly inconsistent points like 1.05 epochs and then returns to 0.99 epochs. This was recognized as a known but peculiar behavior, possibly related to the steps counter. - **Finetuning on AMD**: Questions were raised about finetuning on AMD hardware, with a response indicating that Eric has experience with this, though it wasn't confirmed if it is a straightforward process. **Links mentioned**: - [GitHub - ROCm/flash-attention: Fast and memory-efficient exact attention](https://github.com/ROCm/flash-attention): Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub. - [GitHub - ROCm/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.](https://github.com/ROCm/xformers): Hackable and optimized Transformers building blocks, supporting a composable construction. - ROCm/xformers --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/)** (1 messages): lore0012: I am no longer hitting the issue. --- ### **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1253830860449382578)** (4 messages): - **HeaderTooLarge error in fine-tuning Qwen2 7b**: A member encountered a `safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge` while running `CUDA_VISIBLE_DEVICES="" python -m axolotl.cli.preprocess axolotl/ben_configs/qwen2_first.yaml`. This error occurs when attempting to load checkpoint shards. - **Local directory issues with Qwen2 7b model**: The fine-tuning configuration works when setting `base_model` to a Hugging Face repository but fails when pointing to a local directory (`/large_models/base_models/llm/Qwen2-7B`). The failure persists even though the folder is a mounted NFS. - **Frustration with NVIDIA Megatron-LM bugs**: A user expressed frustration after spending a week trying to get megatron-lm to work, encountering numerous errors. An example of the issues faced can be seen in [GitHub Issue #866](https://github.com/NVIDIA/Megatron-LM/issues/866), which discusses a problem with a parser argument in the `convert.py` script. **Link mentioned**: [[BUG] the argument of parser.add_argument is wrong in tools/checkpoint/convert.py · Issue #866 · NVIDIA/Megatron-LM](https://github.com/NVIDIA/Megatron-LM/issues/866): Describe the bug [https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115](https://github.com/NVIDIA/Megatron-LM/blob/main/tools/checkpoint/convert.py#L115) It must be 'choices=['GPT', 'BERT'],' not 'choice=['GPT', 'BER... --- ### **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1254518443789648024)** (5 messages): - **Newbie asks about dataset suitability**: A new member experimenting with fine-tuning **llama2-13b** using **axolotl** inquired about dataset formatting and content. They asked, "Would this be an appropriate place to ask about dataset formatting and content?" - **Formatting example for 'Alpaca' dataset**: Another member shared a dataset case using **JSONL** for fine-tuning **Alpaca**. They provided detailed examples, including instructions, input patterns, and expected outputs, and questioned if the LLM could generalize commands like "move to the left" and "move a little to the left." - **Introducing Rensa for high-performance MinHash**: A member excitedly introduced their side project, **Rensa**, a high-performance MinHash implementation in Rust with Python bindings. They claimed it is 2.5-3x faster than existing libraries like `datasketch` for tasks like dataset deduplication and shared its [GitHub link](https://github.com/beowolx/rensa) for community feedback and contributions. **Link mentioned**: [GitHub - beowolx/rensa: High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets](https://github.com/beowolx/rensa): High-performance MinHash implementation in Rust with Python bindings for efficient similarity estimation and deduplication of large datasets - beowolx/rensa --- ### **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1254711001174245438)** (5 messages): - **Prompt Style Explained in Axolotl Codebase**: The inquiry about `prompt_style` led to an explanation that it specifies how prompts are formatted for interacting with language models, impacting the performance and relevance of responses. Examples such as `INSTRUCT`, `CHAT`, and `CHATML` were detailed to illustrate different prompt structuring strategies for various interaction types. - **Example of ReflectAlpacaPrompter Usage**: The `ReflectAlpacaPrompter` class example highlights how different `prompt_style` values like "instruct" and "chat" dictate the structure of generated prompts. The `match_prompt_style` method is used to set up the prompt template according to the selected style. **Link mentioned**: [OpenAccess-AI-Collective/axolotl | Phorm AI Code Search](https://phorm.ai/query?projectId=1e8ce0ca-5f45-4b83-a0f4-9da45ce8e78b&threadId=4809da1a-b260-413e-bdbe-8b82397846e6)): Understand code, faster. --- ### **Mozilla AI ▷ #[announcements](https://discord.com/channels/1089876418936180786/1089876419926032396/1254906057256468573)** (1 messages): - **Llamafile v0.8.7 releases with upgrades**: [Llamafile v0.8.7](https://discord.com/channels/1089876418936180786/1182689832057716778/1254823644320763987) released with **faster quant operations** and **bug fixes**. An Android version hint was also mentioned. - **San Francisco hosts major AI events**: **World's Fair of AI** and **AI Quality Conference** will feature prominent community members. Links to [World's Fair of AI](https://www.ai.engineer/worldsfair) and [AI Quality Conference](https://www.aiqualityconference.com/) are provided. - **Firefox Nightly AI services experiment**: Firefox Nightly consumers can access optional AI services through an ongoing experiment. Details can be explored in the [Nightly blog](https://discord.com/channels/1089876418936180786/1254858795998384239). - **Latest ML Paper Picks available**: The [latest ML Paper Picks](https://discord.com/channels/1089876418936180786/1253145681338830888) have been shared by a community member. - **RSVP for upcoming July AI events**: Events include [Jan AI](https://discord.com/events/1089876418936180786/1251002752239407134), [AI Foundry Podcast Roadshow](https://discord.com/events/1089876418936180786/1253834248574468249), and [AutoFIx by Sentry.io](https://discord.com/events/1089876418936180786/1245836053458190438). --- ### **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1253796478535860266)** (31 messages🔥): - **Llamafile Help Command Issue**: A user reported that running `llamafile.exe --help` returns empty output and inquired if this is a known issue. There was no further discussion or solutions provided in the chat. - **Running Llamafile on Google Colab**: A user, after some initial confusion, successfully ran a llamafile on Google Colab and shared a [link to their example](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g). - **Llamafile Repackaging Concerns**: A user expressed concerns about the disk space requirements when repackaging llamafiles, suggesting the ability to specify different locations for extraction and repackaging. This sparked a discussion on the potential need for specified locations via environment variables or flags due to large llamafile sizes. - **New Memory Manager for Cosmopolitan**: A [commit on GitHub](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca) discussing a rewrite of the memory manager to support Android was shared and sparked interest in potentially running llamafile on Android via Termux. - **Mozilla Nightly Blog Mentions Llamafile**: The [Nightly blog](https://blog.nightly.mozilla.org/2024/06/24/experimenting-with-ai-services-in-nightly/) mentioned llamafile, offering guidance on toggling Firefox configurations to enable local AI chat. This excited the community, with suggestions to provide clearer instructions for new users. **Links mentioned**: - [no title found](http://localhost:8080`): no description found - [Tweet from Dylan Freedman (@dylfreed)](https://x.com/dylfreed/status/1803502158672761113): New open source OCR model just dropped! This one by Microsoft features the best text recognition I've seen in any open model and performs admirably on handwriting. It also handles a diverse range... - [Mozilla Builders](https://future.mozilla.org/builders/): no description found - [Release llamafile v0.8.7 · Mozilla-Ocho/llamafile](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.8.7): This release includes important performance enhancements for quants. 293a528 Performance improvements on Arm for legacy and k-quants (#453) c38feb4 Optimized matrix multiplications for i-quants on... - [Rewrite memory manager · jart/cosmopolitan@6ffed14](https://github.com/jart/cosmopolitan/commit/6ffed14b9cc68b79d530b23876f522f906173cca): Actually Portable Executable now supports Android. Cosmo's old mmap code required a 47 bit address space. The new implementation is very agnostic and supports both smaller address spaces (e.g.... - [ggerganov - Overview](https://github.com/ggerganov/): I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub. - [Google Colab](https://colab.research.google.com/drive/1jWKKwVCQneCTB5VNQNWO0Wxqg1vG_E1T#scrollTo=13ISLtY9_v7g): no description found - [Feature Request: Support for Florence-2 Vision Models · Issue #8012 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/issues/8012): Feature Description Support for Florence-2 Family of Vision Models needed Motivation A 400M model beating a 15-16B parameter model in benchmarks? Possible Implementation No response --- ### **Torchtune ▷ #[general](https://discord.com/channels/1216353675241590815/1216353675744641096/1253791496432517293)** (24 messages🔥): - **DPO Training Options Available; ORPO Not Yet Supported**: When asked about the options for DPO and ORPO training with Torchtune, a member shared a [dataset for ORPO/DPO](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) and mentioned that ORPO is not yet supported while DPO has a [recipe available](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9). This was confirmed by another member who added that ORPO would need to be implemented separately from supervised fine-tuning. - **Training on Multiple Datasets and Epochs Limitation**: A member inquired about training on multiple datasets and setting different epochs per dataset, and was directed to use *ConcatDataset*. It was highlighted that setting different epochs per dataset is not supported. - **Debate on ChatML Template Use with Llama3**: There was an ongoing discussion about the use of ChatML templates with Llama3, featuring [Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B) and [Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B). Participants debated whether using an instruct tokenizer and the base model without special tokens versus with ChatML was appropriate. - **Phi-3 Model Fine-Tuning Feasibility**: Queries about the feasibility of fine-tuning the Phi-3-Medium-4K-Instruct model using torchtune were addressed. It was suggested to update the tokenizer and add a custom build function in torchtune for compatibility, and include system prompts by prepending them to user messages if desired. - **Instruction on Using System Prompts with Phi-3**: It was noted that Phi-3 models might not have been optimized for system prompts, but users can still prepend system prompts to user messages for fine-tuning on Phi-3 as usual. A specific flag in the tokenizer configuration [was mentioned](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128) for allowing system prompt usage. **Links mentioned**: - [lodrick-the-lafted/Olethros-8B · Hugging Face](https://huggingface.co/lodrick-the-lafted/Olethros-8B): no description found - [flammenai/Mahou-1.2-llama3-8B · Hugging Face](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B): no description found - [microsoft/Phi-3-mini-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct): no description found - [torchtune/torchtune/models/phi3/_sentencepiece.py at main · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/main/torchtune/models/phi3/_sentencepiece.py#L128.): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [mlabonne/orpo-dpo-mix-40k · Datasets at Hugging Face](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k): no description found - [torchtune/recipes/configs/llama2/7B_lora_dpo.yaml at f200da58c8f5007b61266504204c61a171f6b3dd · pytorch/torchtune](https://github.com/pytorch/torchtune/blob/f200da58c8f5007b61266504204c61a171f6b3dd/recipes/configs/llama2/7B_lora_dpo.yaml#L9): A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub. - [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/html/2404.14219v1#S2)): no description found - [microsoft/Phi-3-mini-4k-instruct · System prompts ignored in chat completions](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/discussions/51#665f24e07a329f831b1e3e4e.): no description found - [microsoft/Phi-3-medium-4k-instruct · Hugging Face](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct): no description found - [config.json · microsoft/Phi-3-medium-4k-instruct at main](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/config.json): no description found --- ### **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1253788818042126418)** (8 messages🔥): - **WHERE Function Clarification**: A member asked if the WHERE function could be simplified with conditional operations like `condition * a + !condition * b` and was pointed out that *NaNs* could be an issue. - **Intel Support Inquiry**: Someone inquired about **Intel support** in tinygrad. Another member responded that **opencl** can be used, but there is no XMX support yet. - **Monday Meeting Overview**: Key topics for the upcoming Monday meeting at 9:40 a.m. PT include updates on *tinybox*, new profiler, runtime enhancements, and plans for the **0.9.1 release**. Specific agenda items cover enhancements like `Tensor._tri`, llama cast speedup, and mentions of bounties such as improvements in *uop matcher speed* and *unet3d*. - **Future of Linear Algebra Functions**: A user asked about plans for implementing general linear algebra functions like determinant calculations or matrix decompositions in tinygrad. *No specific response was given in the extracted messages.* --- ### **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1254621018971050006)** (2 messages): - **Buffer view option flagged in tinygrad**: A commit was shared that introduces a flag to make the buffer view optional in tinygrad. The commit message reads, *"make buffer view optional with a flag"* and the associated [GitHub Actions run](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120) was provided. - **Change in lazy.py raises concerns**: A member questioned if they were doing something wrong as their changes to `lazy.py` resulted in positive (good) and negative (bad) process replay outputs. They were seeking clarity on this unexpected behavior, implying potential issues with their modifications. **Link mentioned**: [make buffer view optional with a flag · tinygrad/tinygrad@bdda002](https://github.com/tinygrad/tinygrad/actions/runs/9638260193/job/26578693946?pr=5120): You like pytorch? You like micrograd? You love tinygrad! ❤️ - make buffer view optional with a flag · tinygrad/tinygrad@bdda002 --- ### **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1254510317266796731)** (1 messages): - **Claude Sonnet 3.5 impresses in Websim**: A member was testing **Claude Sonnet 3.5** in Websim and was highly impressed by the model's *"speed, creativity, and intelligence"*. They highlighted features such as "generate in new tab" and shared their experience of trying to *"hypnotize" themselves with the color schemes of different iconic fashion brands*. [Twitter link](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413). **Link mentioned**: [Tweet from Rob Haisfield (robhaisfield.com) (@RobertHaisfield)](https://fxtwitter.com/RobertHaisfield/status/1804945938936668413): I was "testing" Sonnet 3.5 @websim_ai + new features (mainly "generate in new tab"). I'm FLOORED by this model's speed, creativity, intelligence 🫨😂 Highlights from the lab t... --- ### **MLOps @Chipro ▷ #[events](https://discord.com/channels/814557108065534033/869270934773727272/1254828730174406738)** (1 messages): - **MJCET launches AWS Cloud Club**: We are delighted to share that MJCET has launched the FIRST **AWS Cloud Club** in Telangana! This vibrant community provides resources, training, and hands-on experience with Amazon Web Services (AWS), equipping members with essential skills for a tech industry career. - **Exclusive inaugural event with AWS Hero**: Join the grand inauguration of AWS Cloud Club MJCET on June 28th, 2024, from 10am to 12pm at Block 4 Seminar Hall, featuring **Mr. Faizal Khan**, AWS Community Hero. RSVP via this [meetup link](https://meetu.ps/e/NgmgX/14DgQ2/i) to confirm your attendance. **Link mentioned**: [Inauguration of AWS Cloud Clubs MJCET, Fri, Jun 28, 2024, 10:00 AM | Meetup](https://meetu.ps/e/NgmgX/14DgQ2/i): **Join Us for the Grand Inauguration of AWS Cloud Club MJCET!** We are delighted to announce the launching event of our AWS Cloud Club at MJCET! Come and explore the world --- --- --- --- --- {% else %} >