[AINews] Gemini Live
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Lots of little $20/month subscriptions for everything in your life are all you need.
AI News for 8/12/2024-8/13/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (253 channels, and 2423 messages) for you. Estimated reading time saved (at 200wpm): 244 minutes. You can now tag @smol_ai for AINews discussions!
As promised at Google I/O, Gemini Live launched in Android today, for Gemini Advanced subscribers, as part of the #MadeByGoogle Pixel 9 launch event. With sympathies to the poor presenter who had 2 demo failures onstage:
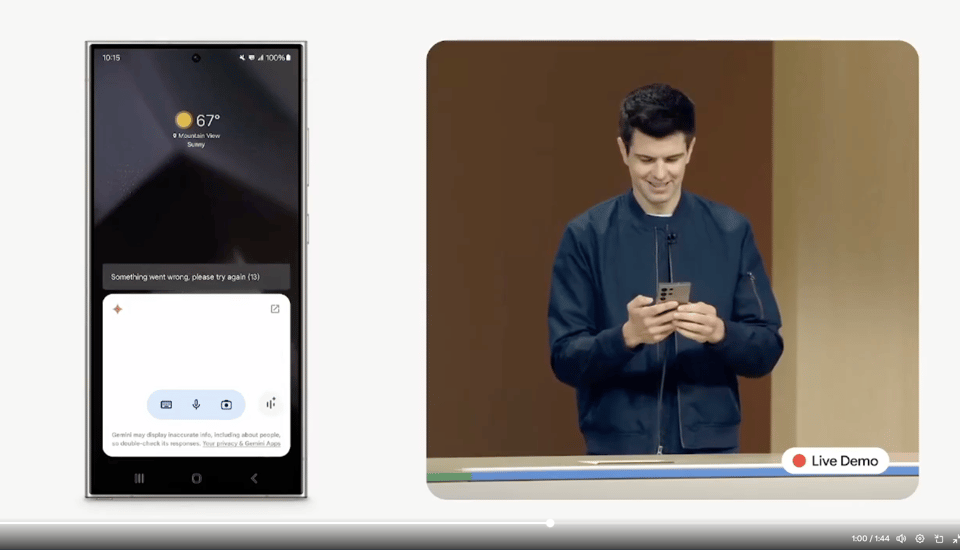
The embargoed media reviews of Gemini Live have been cautiously positive. It will have "extensions" that are integrations with your Google Workspace (Gmail, Docs, Drive), YouTube, Google Maps, and other Google properties.
The important thing is Google started the rollout of it today (though we still cannot locate anyone with a live recording of it as of 5pm PT) vs a still-indeterminate date for ChatGPT's Advanced Voice Mode. Gemini Live will also come to iOS subscribers at a future point.
The company also shared demos of Gemini Live with Pixel Buds Pro 2 to people in the audience and with the WSJ. For those that care about the Pixel 9, there are also notable image AI integrations with the Add Me photo feature and the Magic Editor.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- CUDA MODE Discord
- LM Studio Discord
- OpenAI Discord
- Perplexity AI Discord
- Stability.ai (Stable Diffusion) Discord
- OpenRouter (Alex Atallah) Discord
- Modular (Mojo 🔥) Discord
- Cohere Discord
- Torchtune Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- tinygrad (George Hotz) Discord
- MLOps @Chipro Discord
- LangChain AI Discord
- OpenInterpreter Discord
- Alignment Lab AI Discord
- LLM Finetuning (Hamel + Dan) Discord
- PART 2: Detailed by-Channel summaries and links
- Unsloth AI (Daniel Han) ▷ #general (167 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (12 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (83 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (8 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (5 messages):
- CUDA MODE ▷ #general (48 messages🔥):
- CUDA MODE ▷ #torch (4 messages):
- CUDA MODE ▷ #cool-links (7 messages):
- CUDA MODE ▷ #jobs (11 messages🔥):
- CUDA MODE ▷ #beginner (7 messages):
- CUDA MODE ▷ #off-topic (1 messages):
- CUDA MODE ▷ #llmdotc (126 messages🔥🔥):
- LM Studio ▷ #general (150 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (15 messages🔥):
- OpenAI ▷ #ai-discussions (151 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (5 messages):
- OpenAI ▷ #prompt-engineering (3 messages):
- OpenAI ▷ #api-discussions (3 messages):
- Perplexity AI ▷ #general (106 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (6 messages):
- Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (111 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (80 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (30 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (19 messages🔥):
- Cohere ▷ #discussions (11 messages🔥):
- Cohere ▷ #questions (26 messages🔥):
- Cohere ▷ #api-discussions (7 messages):
- Torchtune ▷ #dev (44 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (19 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general-help (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #deployment-help (1 messages):
- LAION ▷ #general (16 messages🔥):
- LAION ▷ #research (4 messages):
- tinygrad (George Hotz) ▷ #general (1 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (8 messages🔥):
- MLOps @Chipro ▷ #events (3 messages):
- MLOps @Chipro ▷ #general-ml (4 messages):
- LangChain AI ▷ #general (5 messages):
- LangChain AI ▷ #share-your-work (1 messages):
- OpenInterpreter ▷ #general (1 messages):
- OpenInterpreter ▷ #O1 (2 messages):
- OpenInterpreter ▷ #ai-content (3 messages):
- Alignment Lab AI ▷ #general (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Benchmarks
- Anthropic released Genie, a new AI software engineering system achieving state-of-the-art performance on SWE-Bench with 30.08%, a 57% improvement over previous models. Key aspects include reasoning datasets, agentic systems with planning and execution abilities, and self-improvement capabilities. @omarsar0
- Falcon Mamba, a new 7B open-access model by TII, was released. It's an attention-free model that can scale to arbitrary sequence lengths and has strong metrics compared to similar-sized models. @osanseviero
- Researchers benchmarked 13 popular open-source and commercial models on context lengths from 2k to 125k, finding that long context doesn't always help with Retrieval-Augmented Generation (RAG). Performance of most generation models decreases above a certain context size. @DbrxMosaicAI
AI Tools and Applications
- Supabase launched an AI-based Postgres service, described as the "ChatGPT of databases". It allows users to build and launch databases, create charts, generate embeddings, and more. The tool is 100% open source. @AlphaSignalAI
- Perplexity AI announced a partnership with Polymarket, integrating real-time probability predictions for events like election outcomes and market trends into their search results. @perplexity_ai
- A tutorial on building a multimodal recipe recommender using Qdrant, LlamaIndex, and Gemini was shared, demonstrating how to ingest YouTube videos and index both text and image chunks. @llama_index
AI Engineering Insights
- An OpenAI engineer shared insights on success in the field, emphasizing the importance of thoroughly debugging and understanding code, and a willingness to work hard to complete tasks. @_jasonwei
- The connection between matrices and graphs in linear algebra was discussed, highlighting how this relationship provides insights into nonnegative matrices and strongly connected components. @svpino
- Keras 3.5.0 was released with first-class Hugging Face Hub integration, allowing direct saving and loading of models to/from the Hub. The update also includes distribution API improvements and new ops supporting TensorFlow, PyTorch, and JAX. @fchollet
AI Ethics and Regulation
- Discussions around AI regulation and its potential impact on innovation were highlighted, with some arguing that premature regulation could hinder progress towards beneficial AI applications. @bindureddy
- Concerns were raised about the effectiveness of AI "business strategy decision support" startups, with arguments that their value is not easily measurable or trustable by customers. @saranormous
AI Community and Events
- The Google DeepMind podcast announced its third season, exploring topics such as the differences between chatbots and agents, AI's role in creativity, and potential life scenarios after AGI is achieved. @GoogleDeepMind
- An AI Python for Beginners course taught by Andrew Ng was announced, designed to help both aspiring developers and professionals leverage AI to boost productivity and automate tasks. @DeepLearningAI
Memes and Humor
- Various humorous tweets and memes related to AI and technology were shared, including jokes about AI model names and capabilities. @swyx
This summary captures the main themes and discussions from the provided tweets, focusing on recent developments in AI models, tools, applications, and the broader implications for AI engineering and the tech industry.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Advanced Quantization and Model Optimization Techniques
- Llama-3.1 70B 4-bit HQQ/calibrated quantized model: 99%+ in all benchmarks in lm-eval relative performance to FP16 and similar inference speed to fp16 ( 10 toks/sec in A100 ). (Score: 91, Comments: 26): The Llama-3.1 70B model has been successfully quantized to 4-bit using HQQ/calibrated quantization, achieving over 99% relative performance compared to FP16 across all benchmarks in lm-eval. This quantized version maintains a similar inference speed to FP16, processing approximately 10 tokens per second on an A100 GPU. The achievement demonstrates significant progress in model compression while preserving performance, potentially enabling more efficient deployment of large language models.
- Why is unsloth so efficient? (Score: 94, Comments: 35): Unsloth demonstrates remarkable efficiency in handling 32k text length for summarization tasks on limited GPU memory. The user reports successfully training a model on an L40S 48GB GPU using Unsloth, while traditional methods like transformers llama2 with qlora, 4bit, and bf16 techniques fail to fit on the same hardware. The significant performance boost is attributed to Unsloth's use of Triton, though the exact mechanisms remain unclear to the user.
- Pre-training an LLM in 9 days 😱😱😱 (Score: 216, Comments: 53): Researchers at Hugging Face and Google have developed a method to pre-train a 1.3B parameter language model in just 9 days using 16 A100 GPUs. The technique, called Retro-GPT, combines retrieval-augmented language modeling with efficient pre-training strategies to achieve comparable performance to models trained for much longer, potentially revolutionizing the speed and cost-effectiveness of LLM development.
Theme 2. Open-source Contributions to LLM Development
- An extensive open source collection of RAG implementations with many different strategies (Score: 91, Comments: 20): The post introduces an open-source repository featuring a comprehensive collection of 17 different Retrieval-Augmented Generation (RAG) strategies, complete with tutorials and visualizations. The author encourages community engagement, inviting users to open issues, suggest additional strategies, and utilize the resource for learning and reference purposes.
- Falcon Mamba 7B from TII (Technology Innovation Institute TII - UAE) (Score: 87, Comments: 18): The Technology Innovation Institute (TII) in the UAE has released Falcon Mamba 7B, an open-source State Space Language Model (SSLM) combining the Falcon architecture with Mamba's state space sequence modeling. The model, available on Hugging Face, comes with a model card, collection, and playground, allowing users to explore and experiment with this new AI technology.
- Users tested Falcon Mamba 7B, reporting mixed results. One user found it "very very very poor" for a Product Requirements Document task, with responses becoming generic and disorganized.
- The model's performance was questioned, with some users finding it worse than Llama and Mistral models despite claims of superiority. Testing with various prompts yielded disappointing results.
- Some users expressed skepticism towards Falcon models based on past negative experiences, suggesting a potential pattern of underperformance in the Falcon series.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Releases and Capabilities
- Speculation about new GPT-4 model: A post on r/singularity claims ChatGPT mentioned a "new GPT-4o model out since last week", generating discussion about potential new OpenAI releases.
- Flux image generation model: Several posts discuss the capabilities of the new Flux image generation model:
- Impressive impressionist landscape generation using a custom LoRA trained on 5000 images
- Attempts at generating anatomically correct nude images using a custom LoRA
- Creative ad concept generation for fictional products
AI-Generated Media
- AI-generated video with synthetic voice: A demo video shows Flux-generated images animated and paired with AI-generated voice, though commenters note issues with lip sync and voice quality.
Autonomous Vehicles
- Waymo self-driving car issues: A video post shows Waymo autonomous vehicles having difficulties navigating from their starting point, sparking discussion on current limitations.
AI and Society
- AI companions and relationships: A controversial meme post sparked debate about the potential impact of AI companions on human relationships and societal dynamics.
AI Discord Recap
A summary of Summaries of Summaries by GPT4O (gpt-4o-2024-05-13)
1. Model Performance and Benchmarking
- Uncensored Model Outperforms Meta Instruct: An uncensored model tuned to retain the intelligence of the original Meta Instruct model has been released and has outperformed the original model on the LLM Leaderboard 2.
- The model's performance sparked discussions about the trade-offs between censorship and utility, with many users praising its ability to handle a wider range of inputs.
- Mistral Large: The Current Champion?: A member found Mistral Large 2 to be the best LLM right now, outcompeting Claude 3.5 Sonnet for difficult novel problems.
- However, Gemini Flash undercut OpenAI 4o mini severely in price, but OpenAI 4o was less expensive than Mistral Large.
- Google's Gemini Live: It's here, it's now, it's not free: Gemini Live is now available to Advanced Subscribers, offering conversational overlay on Android and more connected apps.
- Many users said that it is an improvement over the old voice mode, but is only available to paid users and lacks live video functionality.
2. GPU and Hardware Discussions
- GPU Wars - A100 vs A6000: Members discussed the pros and cons of A100 vs A6000 GPUs, with one member noting the A6000's great price/VRAM ratio and its lack of limitations compared to 24GB cards.
- The discussion highlighted the importance of VRAM and cost-efficiency for large model training and inference.
- Stable Diffusion Installation Woes: A user reported difficulties installing Stable Diffusion, encountering issues with CUDA installation and finding their token on Hugging Face.
- Another user provided guidance on generating a token through the profile settings menu and installing CUDA correctly.
- TorchAO presentation at Cohere for AI: Charles Hernandez from PyTorch Architecture Optimization will be presenting on TorchAO and quantization at the ml-efficiency group at Cohere For AI.
- The event is hosted by @Sree_Harsha_N and attendees can join Cohere For AI through the provided link.
3. Fine-tuning and Optimization Techniques
- Model Fine-Tuning Tips and Tricks: Discussion revolved around fine-tuning a Phi3 model and whether to use LoRA or full fine-tuning, with one member suggesting RAG as a potential solution.
- Users shared experiences and best practices, emphasizing the importance of choosing the right fine-tuning strategy for different models.
- TransformerDecoderLayer Refactor PR: A PR has been submitted to refactor the TransformerDecoderLayer, touching many files and making core changes in modules/attention.py and modules/transformer.py.
- This PR implements RFC #1211, aiming to improve the TransformerDecoderLayer architecture.
- PyTorch Full FP16: Is it possible?: A user asked if full FP16 with loss/grad scaling is possible with PyTorch core, specifically when fine-tuning a large-ish model from Fairseq.
- They tried using torch.GradScaler() and casting the model to FP16 without torch.autocast('cuda', torch.float16), but got an error 'ValueError: Attempting to unscale FP16 gradients.'
4. UI/UX Issues in AI Platforms
- Perplexity's UI/UX issues: Users reported several UI/UX issues including missing buttons and a disappearing prompt field, leading to difficulties in interacting with the platform.
- These bugs were reported across both the web and iOS versions of Perplexity, causing significant user frustration and hindering their ability to effectively utilize the platform.
- LLM Studio's Model Explorer is Down: Several members reported that HuggingFace, which powers the LM Studio Model Explorer, is down.
- The site was confirmed to be inaccessible for several hours, with connectivity issues reported across various locations.
- Perplexity's Website Stability Concerns: Users reported a significant decline in website stability, citing issues with sporadic search behavior, forgetting context, and interface bugs on both web and iOS versions.
- These issues raised concerns about the reliability and user experience provided by Perplexity.
5. Open-Source AI Frameworks and Community Efforts
- Rust GPU Transitions to Community Ownership: The Rust GPU project, previously under Embark Studios, is now community-owned under the Rust GPU GitHub organization.
- This transition marks the beginning of a broader strategy aimed at revitalizing, unifying, and standardizing GPU programming in Rust.
- Open Interpreter for Anything to Anything: Use Open Interpreter to convert any type of data into any other format.
- This is possible by using the 'Convert Anything' tool, which harnesses the power of Open Interpreter.
- Cohere For AI research lab: Cohere For AI is a non-profit research lab that seeks to solve complex machine learning problems.
- They support fundamental research exploring the unknown, and are focused on creating more points of entry into machine learning research.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Unsloth Pro Early Access: Early access to the Unsloth Pro version is currently being given to trusted members of the Unsloth community.
- A100 vs A6000 GPU Showdown: Members discussed the pros and cons of A100 vs A6000 GPUs, with one member noting the A6000's great price/VRAM ratio and its lack of limitations compared to 24GB cards.
- Uncensored Model Tops the Charts: An uncensored model tuned to retain the intelligence of the original Meta Instruct model has been released and has outperformed the original model on the LLM Leaderboard 2.
- Dolphin Model Suffers From Censorship: One member reported that the Dolphin 3.1 model fails the most basic requests and refuses them, possibly due to its heavy censorship.
- Fine-tuning for AI Engineers: Discussion revolved around fine-tuning a Phi3 model and whether to use LoRA or full fine-tuning, with one member suggesting RAG as a potential solution.
CUDA MODE Discord
- TorchAO Presentation at Cohere For AI: Charles Hernandez from PyTorch Architecture Optimization will be presenting on TorchAO and quantization at the ml-efficiency group at Cohere For AI on August 16th, 2000 CEST.
- This event is hosted by @Sree_Harsha_N and attendees can join Cohere For AI through the link https://tinyurl.com/C4AICommunityApp.
- CPU matmul Optimization Battle: A user is attempting to write a tiling-based matmul in Zig but is having difficulty achieving optimal performance.
- They received advice on exploring cache-aware loop reordering and the potential for using SIMD instructions, and also compared the performance to GGML and NumPy, which leverages optimized BLAS implementations for incredibly fast results.
- FP16 Weights and CPU Performance: A user asked about handling FP16 weights on the CPU, noting that recent models generally use BF16.
- They were advised to convert the FP16 weights to BF16 or FP32, with FP32 leading to no accuracy loss but potentially slower inference and exploring converting tensors at runtime from FP16 to FP32 to potentially improve performance.
- PyTorch Full FP16: Is it Really Possible?: A user asked if full FP16 with loss/grad scaling is possible with PyTorch core, specifically when fine-tuning a large-ish model from Fairseq.
- They attempted to use
torch.GradScaler()and cast the model to FP16 withouttorch.autocast('cuda', torch.float16)but got an error "ValueError: Attempting to unscale FP16 gradients."
- They attempted to use
- torch.compile: The Missing Manual: A new PyTorch document titled "torch.compile: The Missing Manual" was shared along with a YouTube video.
- The document and video are available at https://docs.google.com/document/d/1y5CRfMLdwEoF1nTk9q8qEu1mgMUuUtvhklPKJ2emLU8/edit#heading=h.ivdr7fmrbeab and https://www.youtube.com/live/rew5CSUaIXg?si=zwbubwKcaiVKqqpf, respectively, and provide detailed information on utilizing
torch.compile.
- The document and video are available at https://docs.google.com/document/d/1y5CRfMLdwEoF1nTk9q8qEu1mgMUuUtvhklPKJ2emLU8/edit#heading=h.ivdr7fmrbeab and https://www.youtube.com/live/rew5CSUaIXg?si=zwbubwKcaiVKqqpf, respectively, and provide detailed information on utilizing
LM Studio Discord
- Vision Adapters: The Key to Vision Models: Only specific LLM models have vision adapters, most of them are going by name "LLaVa" or "obsidian".
- The "VISION ADAPTER" is a crucial component for vision models; without it, the error you shared will pop up.
- Mistral Large: The Current Champion?: A member found Mistral Large 2 to be the best LLM right now, outcompeting Claude 3.5 Sonnet for difficult novel problems.
- However, the member also noted that Gemini Flash undercut OpenAI 4o mini severely in price, but OpenAI 4o was less expensive than Mistral Large.
- LLM Studio's Model Explorer is Down: Several members reported that HuggingFace, which powers the LM Studio Model Explorer, is down.
- The site was confirmed to be inaccessible for several hours, with connectivity issues reported across various locations.
- Llama 3.1 Performance Issues: A user reported that their Llama 3 8B model is now running at only 3 tok/s, compared to 15 tok/s before a recent update.
- The user checked their GPU offload settings and reset them to default, but the problem persists; the issue appears to be related to a change in the recent update.
- LLM Output Length Control: A member is looking for ways to restrict the output length of responses, as some models tend to output whole paragraphs even when instructed to provide a single sentence.
- While system prompts can be modified, the member found that 8B models, specifically Meta-Llama-3.1-8B-Instruct-GGUFI, are not the best at following precise instructions.
OpenAI Discord
- Google Rolls Out Gemini Live, But Not for Everyone: Gemini Live is now available to Advanced Subscribers, offering conversational overlay on Android and more connected apps.
- Many users said that it is an improvement over the old voice mode, but is only available to paid users and lacks live video functionality.
- Strawberry: Marketing Genius or OpenAI's New Face?: The discussion of a mysterious user named "Strawberry" with a string of emojis sparked speculation about a possible connection to OpenAI or Sam Altman.
- Users remarked on how the strawberry emojis, linked to Sam Altman's image of holding strawberries, were a clever marketing strategy, successfully engaging users in conversation.
- Project Astra's Long-Awaited Arrival: The announcement of Gemini Live hinted at Project Astra, but many users were disappointed by the lack of further development.
- One user even drew a comparison to a Microsoft recall, suggesting that people are skeptical about the product's release due to security concerns.
- LLMs: Not a One-Size-Fits-All Solution: Some users expressed skepticism about LLMs being the solution to every problem, especially when it comes to tasks like math, database, and even waifu roleplay.
- Other users emphasized that tokenization is still a fundamental weakness, and LLMs require a more strategic approach rather than relying on brute force tokenization to solve complex problems.
- ChatGPT's Website Restrictions: A Persistent Issue: A member asked about getting ChatGPT to access a website and retrieve an article, but another member noted that ChatGPT might be blocked from crawling or hallucinating website content.
- One user asked if anyone has attempted to use the term "web browser GPT" as a possible workaround.
Perplexity AI Discord
- Perplexity's UI/UX Bugs: Users encountered UI/UX issues including missing buttons and a disappearing prompt field, leading to difficulties in interacting with the platform.
- These bugs were reported across both the web and iOS versions of Perplexity, causing significant user frustration and hindering their ability to effectively utilize the platform.
- Sonar Huge: New Model, New Problems: The new model "Sonar Huge" replaced the Llama 3.1 405B model in Perplexity Pro.
- However, users observed that the new model was slow and failed to adhere to user profile prompts, prompting concerns about its effectiveness and performance.
- Perplexity's Website Stability Issues: Users reported a significant decline in the website's stability, with issues like sporadic search behavior, forgetting context, and various interface bugs.
- These issues were observed on both web and iOS versions, raising concerns about the reliability and user experience provided by Perplexity.
- Perplexity's Success Team Takes Note: Perplexity's Success Team acknowledged receiving user feedback on the recent bugs and glitches experienced in the platform.
- They indicated awareness of the reported issues and their impact on user experience, hinting at potential future solutions and improvements.
- Feature Implementation Delays at Perplexity: A user expressed frustration over the prolonged wait time for feature implementation.
- They highlighted the discrepancy between promised features and the actual rollout pace, emphasizing the importance of faster development and delivery to meet user expectations.
Stability.ai (Stable Diffusion) Discord
- Stability AI's SXSW Panel Proposal: Stability AI CEO Prem Akkaraju and tech influencer Kara Swisher will discuss the importance of open AI models and the role of government in regulating their impact at SXSW.
- The panel will explore the opportunities and risks of AI, including job displacement, disinformation, CSAM, and IP rights, and will be available to view on PanelPicker® at PanelPicker | SXSW Conference & Festivals.
- Google Colab Runtime Stops Working: A user encountered issues with their Google Colab runtime stopping prematurely.
- Another user suggested switching to Kaggle, which offers more resources and longer runtimes, providing a solution for longer AI experimentation.
- Stable Diffusion Installation and CUDA Challenges: A user faced difficulties installing Stable Diffusion due to issues with CUDA installation and locating their Hugging Face token.
- Another user provided guidance on generating a token through the Hugging Face profile settings menu and correctly installing CUDA, offering a solution to the user's challenges.
- Model Merging Discussion: A user suggested using the difference between UltraChat and base Mistral to improve Mistral-Yarn as a potential model merging tactic.
- While some users expressed skepticism, the original user remained optimistic, citing successful past attempts at model merging, showcasing potential advancements in AI model development.
- Flux Realism for Face Swaps: A user sought alternative solutions to achieve realistic face swaps after experimenting with fal.ai, which produced cartoonish results.
- Another user suggested using Flux, as it is capable of training on logos and accurately placing them onto images, providing a potential solution for the user's face swap goals.
OpenRouter (Alex Atallah) Discord
- Gemini Flash 1.5 Price Drop: The input token costs for Gemini Flash 1.5 have decreased by 78% and the output token costs have decreased by 71%.
- This makes the model more accessible and affordable for a wider range of users.
- GPT-4o Extended Early Access Launched: Early access for GPT-4o Extended has launched through OpenRouter.
- You can access it via this link: https://x.com/OpenRouterAI/status/1823409123360432393.
- OpenRouter's Update Hurdle: OpenRouter's update was blocked by the new 1:4 token:character ratio from Gemini, which doesn't map cleanly to the
max_tokensparameter validation.- A user expressed frustration about the constantly changing token:character ratio and suggested switching to a per-token pricing system.
- Euryale 70B Downtime: A user reported that Euryale 70B was down for some users but not for them, prompting questions about any issues or error rates.
- Further discussion revealed multiple instances of downtime, including a 10-minute outage due to an update and possible ongoing issues with location availability.
- Model Performance Comparison: Users compared the performance of Groq 70b and Hyperbolic, finding nearly identical results for the same prompt.
- This led to a discussion about the impact of FP8 quantization, with some users noting that it makes a minimal difference in practice, but others pointing to potential degraded quality with certain providers.
Modular (Mojo 🔥) Discord
- Mojo License's Catchy Clause: The Mojo License prohibits the development of applications using the language for competitive activities.
- However, it states that this rule does not apply to applications that become competitive after their initial release, but it is unclear how this clause will be applied.
- Mojo Open-Sourcing Timeline Remains Unclear: Users inquired about the timeline for open-sourcing the Mojo compiler.
- The team confirmed that the compiler will be open-sourced eventually but did not provide a timeline, suggesting it may be a while before contributions can be made.
- Mojo Development: Standard Library Focus: The current focus of Mojo development is on building out the standard library.
- Users are encouraged to contribute to the standard library, while work on the compiler is ongoing, but not yet open to contributions.
- Stable Diffusion and Mojo: Memory Matters: A user encountered a memory pressure issue running the Stable Diffusion Mojo ONNX example in WSL2, leading to the process being killed.
- The user had 8GB allocated to WSL2, but the team advised doubling it as Stable Diffusion 1.5 is approximately 4GB, requiring more memory for both the model and its optimization processes.
- Java by Microsoft: A Blast from the Past: One member argued that 'Java by Microsoft' was unnecessary and could have been avoided, while another countered that it seemed crucial at the time.
- The discussion acknowledged the emergence of newer solutions and the decline of 'Java by Microsoft' over time, highlighting its 20-year run and its relevance in the Microsoft marketshare.
Cohere Discord
- Cohere For AI Research Lab Expands: Cohere For AI is a non-profit research lab focused on complex machine learning problems. They are creating more points of entry into machine learning research.
- They support fundamental research exploring the unknown.
- Price Changes on Cohere's Website: A user inquired about the classify feature's pricing, as it's no longer listed on the pricing page.
- No response was provided.
- JSONL Uploads Failing: Users reported issues uploading JSONL datasets for fine-tuning.
- Cohere support acknowledged the issue, stating it is under investigation and suggesting the API for dataset creation as a temporary solution.
- Azure JSON Formatting Not Supported: A member asked about structured output with
response_formatin Azure, but encountered an error.- It was confirmed that JSON formatting is not yet available on Azure.
- Rerank Overview and Code Help: A user asked for help with the Rerank Overview document, encountering issues with the provided code.
- The issue was related to an outdated document, and a revised code snippet was provided. The user was also directed to the relevant documentation for further reference.
Torchtune Discord
- TransformerDecoderLayer Refactor Lands: A PR has been submitted to refactor the TransformerDecoderLayer, touching many files and making core changes in modules/attention.py and modules/transformer.py.
- This PR implements RFC #1211, aiming to improve the TransformerDecoderLayer architecture, and can be found here: TransformerDecoderLayer Refactor.
- DPO Preferred for RLHF: There is a discussion about testing the HH RLHF builder with DPO or PPO, with DPO being preferred for preference datasets while PPO is dataset-agnostic.
- The focus is on DPO, with the expectation of loss curves similar to normal SFT, and potential debugging needed for the HH RLHF builder, which may be addressed in a separate PR.
- Torchtune WandB Issues Resolved: A user encountered issues accessing WandB results for Torchtune, with access being granted after adding the user as a team member.
- The user reported poor results with the default DPO config and turning gradient accumulation off, but later discovered it started working again, potentially due to a delay or some other factor.
- Torchtune Performance with DPO: There is a discussion about potential issues with the default DPO config causing poor performance in Torchtune.
- The user suggested trying SIMPO (Stack Exchange Paired) and turning gradient accumulation back on, as having a balanced number of positive and negative examples in the batch can significantly improve loss.
- PyTorch Conference: A Gathering of Minds: There is a discussion about the upcoming PyTorch Conference, with links to the website and details on featured speakers.
- You can find more information about the conference here: PyTorch Conference. There was also a mention of sneaking in a participant as an 'academic' for the conference, but this is potentially a joke.
OpenAccess AI Collective (axolotl) Discord
- Perplexity Pro's Reasoning Abilities: A user noted that Perplexity Pro has gotten "crazy good at reasoning" and is able to "literally count letters" like it "ditched the tokenizer".
- They shared a link to a GitHub repository that appears to be related to this topic.
- Llama 3 MoE?: A user asked if anyone has made a "MoE" version of Llama 3.
- Grad Clipping Demystified: A user asked about the functionality of grad clipping, specifically wondering what happens to gradients when they exceed the maximum value.
- Another user explained that grad clipping essentially clips the gradient to a maximum value, preventing it from exploding during training.
- OpenAI Benchmarks vs New Models: A user shared their surprise at OpenAI releasing a benchmark instead of a new model.
- They speculated that this might be a strategic move to steer the field towards better evaluation tools.
- Axolotl's Capabilities: A member noted that AutoGPTQ could do certain things, implying that Axolotl may be able to do so as well.
- They were excited about the possibility of Axolotl replicating this capability.
LAION Discord
- Grok 2.0 Early Leak: A member shared a link to a Tweet about Grok 2.0 features and abilities, including image generation using the FLUX.1 model.
- The tweet also noted that Grok 2.0 is better at coding, writing, and generating news.
- Flux.1 Makes an Inflection Point: A member mentioned that many Elon fan accounts predicted X would use MJ (presumably referring to a model), suggesting that Flux.1 may have made an inflection point in model usage.
- The member questioned if Flux.1 is Schnellit's Pro model, given Elon's history.
- Open-Source Image Annotation Search: A member asked for recommendations for good open-source GUIs for annotating images quickly and efficiently.
- The member specifically mentioned single-point annotations, straight-line annotations, and drawing polygonal segmentation masks.
- Elon's Model Bluff: A member discussed the possibility that Elon is using a development version of Grok and calling the bluff on weight licenses.
- This member believes that Elon could potentially call this a "red-pill" version.
- 2D Pooling Success: A user expresses surprise at how well 2D pooling works.
- The user noted it was recommended by another user, and is currently verifying the efficacy of a new position encoding they believe they may have invented.
tinygrad (George Hotz) Discord
- Tensor Filtering Performance?: A user asked for the fastest way to filter a Tensor, such as
t[t % 2 == 0], currently doing it by converting to list, filtering, and converting back to list.- A suggestion was made to use masking if computing something on a subset of the Tensor, but it was noted that the exact functionality is not possible yet.
- Transcendental Folding Refactor Optimization: A user proposed a refactor to only apply transcendental rewrite rules if the backend does not have a
code_for_opfor theuop.- The user implemented a
transcendental_foldingfunction and called it fromUOpGraph.__init__but wasn't sure how this could be net negative lines, and asked what could be removed.
- The user implemented a
- CUDA TIMEOUT ERROR - Resolved: A user ran a script using
CLANG=1and received aRuntimeError: wait_result: 10000 ms TIMEOUT!error.- The error occurred with the default runtime and was resolved by using
CUDA=1, and the issue was potentially related to ##4562.
- The error occurred with the default runtime and was resolved by using
- Nvidia FP8 PR Suggestions: A user made suggestions on the Nvidia FP8 PR for Tinygrad.
MLOps @Chipro Discord
- Poe Partners with Agihouse for Hackathon: Poe (@poe_platform) announced a partnership with Agihouse (@agihouse_org) for a "Previews Hackathon" to celebrate their expanded release.
- The hackathon, hosted on AGI House, invites creators to build innovative "in-chat generative UI experiences".
- In-Chat UI is the Future: The Poe Previews Hackathon encourages developers to create innovative and useful "in-chat generative UI experiences", highlighting the importance of user experience in generative AI.
- The hackathon hopes to showcase the creativity and skill of its participants in a competitive environment.
- Virtual Try On Feature Speeds up Training: A member shared their experience building a virtual try-on feature, noting its effectiveness in speeding up training runs by storing extracted features.
- The feature uses online preprocessing and stores extracted features in a document store table, allowing for efficient retrieval during training.
- Flexible Virtual Try On Feature: A member inquired about the specific features being extracted for the virtual try-on feature.
- The member detailed the generic nature of the approach, successfully accommodating models of various sizes, demonstrating its flexibility in handling computational demands and model complexities.
LangChain AI Discord
- Llama 3.1 8b Supports Structured Output: A user confirmed that Llama 3.1 8b can produce structured output through tool use, having tested it directly with llama.cpp.
- RAG Struggles With Technical Images: A user is seeking advice on extracting information from images like electrical diagrams, maps, and voltage curves for RAG on technical documents.
- They mentioned encountering difficulties with traditional methods, highlighting the need for capturing information not present in text form but visually interpretable by experts.
- Next.js POST Request Misinterpreted as GET: A user encountered a 405 Method Not Allowed error when making a POST request from a Next.js web app running on EC2 to a FastAPI endpoint on the same EC2 instance.
- They observed the request being incorrectly interpreted as a GET request despite explicitly using the POST method in their Next.js code.
- AWS pip install Issue Resolved: A user resolved an issue with pip install on an AWS system by installing packages specifically for the Unix-based environment.
- The problem arose from the virtual environment mistakenly emulating Windows during the pip install process, causing the issue.
- Profundo Launches to Automate Research: Profundo automates data collection, analysis, and reporting, enabling everyone to do deep research on topics they care about.
- It minimizes errors and maximizes productivity, allowing users to focus on making informed decisions.
OpenInterpreter Discord
- Open Interpreter in Obsidian: A new YouTube series will demonstrate how to use Open Interpreter in the Obsidian note-taking app.
- The series will focus on how the Open Interpreter plugin allows you to control your Obsidian vault, which could have major implications for how people work with knowledge. Here's a link to Episode 0.
- AI Agents in the Enterprise: A user in the #general channel asked about the challenges of monitoring and governance of AI agents within large organizations.
- The user invited anyone working on AI agents within an enterprise to share their experiences.
- Screenless Personal Tutor for Kids: A member in the #O1 channel proposed using Open Interpreter to create a screenless personal tutor for kids.
- The member requested feedback and asked if anyone else was interested in collaborating on this project.
- Convert Anything Tool: The "Convert Anything" tool can be used to convert any type of data into any other format using Open Interpreter.
- This tool harnesses the power of Open Interpreter and has potential for significant applications across various fields.
Alignment Lab AI Discord
- SlimOrca Without Deduplication: A user asked about a version of SlimOrca that has soft prompting removed and no deduplication, ideally including the code.
- They also asked if anyone had experimented with fine-tuning (FT) on data with or without deduplication, and with or without soft prompting.
- Fine-tuning with Deduplication: The user inquired about the effects of fine-tuning (FT) with soft prompting versus without soft prompting.
- They also inquired about the effects of fine-tuning (FT) on deduplicated data versus non-deduplicated data.
LLM Finetuning (Hamel + Dan) Discord
- Building an Agentic Jupyter Notebook Automation System: A member proposed constructing an agentic system to automate Jupyter Notebooks, aiming to create a pipeline that takes an existing notebook as input, modifies cells, and generates multiple variations.
- They sought recommendations for libraries, cookbooks, or open-source projects that could serve as a starting point for this project, drawing inspiration from similar tools like Devin.
- Automated Notebook Modifications and Validation: The system should be able to intelligently replace specific cells within a Jupyter Notebook, generating diverse notebook versions based on these modifications.
- Crucially, the system should possess an agentic quality, enabling it to validate its outputs and iteratively refine the modifications until it achieves the desired results.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (167 messages🔥🔥):
Unsloth ProGPU choicesLLM Leaderboard resultsDolphin ModelModel fine-tuning
- Unsloth Pro Early Access: Early access to the Unsloth Pro version is currently being given to trusted members of the Unsloth community.
- GPU Wars - A100 vs A6000: Members discuss the pros and cons of A100 vs A6000 GPUs, with one member noting the A6000's great price/VRAM ratio and its lack of limitations compared to 24GB cards.
- Uncensored Model Outperforms Meta Instruct: An uncensored model tuned to retain the intelligence of the original Meta Instruct model has been released and has outperformed the original model on the LLM Leaderboard 2.
- Dolphin Model Struggles with Censorship: One member reported that the Dolphin 3.1 model fails the most basic requests and refuses them, possibly due to its heavy censorship.
- Model Fine-Tuning Tips and Tricks: Discussion revolves around fine-tuning a Phi3 model and whether to use LoRA or full fine-tuning, with one member suggesting RAG as a potential solution.
- Open LLM Leaderboard 2 - a Hugging Face Space by open-llm-leaderboard: no description found
- Tweet from Daniel Han (@danielhanchen): Found some issues with Llama 3.1's chat template: 1. Official repo adds 2x \n 2. Official repo does NOT strip / trim 3. Date format is %B not %b (not 3 letters) 4. Official repo has inconsistent ...
- HF's Missing Inference Widget - a Hugging Face Space by featherless-ai: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (12 messages🔥):
CampingAustralia
- Camping is bad: A user lamented their experience of camping after returning with 6 mosquito bites, including one on their eyelid.
- Another user chimed in, stating that "never go camping".
- Australia is worse than camping: One user said that "in australia there's horse shit everywhere", implying that it is worse than camping.
- Others chimed in agreeing and adding that there are spiders as big as a dinner plate in Australia and that "everything wants to kill you".
- Amazon Rainforest is worst of all: One user said they "lived close to the Amazon rainforest", implying that it is worse than both camping and Australia.
- This user also commented on a YouTube video titled: "Cosine Genie - SOTA AI Engineer Announcement", which describes Genie as the "best AI software engineer in the world by far".
Link mentioned: Cosine Genie - SOTA AI Engineer Announcement: Genie is the best AI software engineer in the world by far - scoring 30% on the industry standard benchmark SWE-Bench we have beaten the previous SOTA scores...
Unsloth AI (Daniel Han) ▷ #help (83 messages🔥🔥):
Unsloth model loading/savingLlama 3.1 fine-tuning with HindiModel merging and HF hubUnsloth with VLLMDataset creation
- ModelFile not found after saving with Unsloth: A user tried to save a model using Unsloth's
model.save_pretrained_ggufmethod and noticed that the saved folder did not contain aModelFile.- Another user explained that the model file is saved as tensors, and the whole folder is needed for the config and architecture information, including json configs. This is a normal way for gguf files to be saved, split into several config files and tensor files.
- Unsloth Finetuned Model Not Giving Hindi Summarization: A user finetuned a Llama 3.1 8B model on Hindi summarization data and uploaded it to Hugging Face, but during inference, it either returned the input text or a summary in English.
- The user shared the code they used for inference and fine-tuning, and other users suggested that there may be issues with saving or loading custom tokenizers or that the merging on the hub might be combining layers in a strange way.
- Using Unsloth with VLLM: A user struggled to use a finetuned model with Unsloth using VLLM, sharing a Colab notebook with their code.
- Another user suggested using the vLLM documentation for troubleshooting, as it is known to be detailed and helpful.
- Creating custom datasets: A user asked for resources about creating custom datasets with their own information in formats like CSV or JSONL.
- Users suggested using Hugging Face datasets, creating the data manually, or using a larger model to generate data for them.
- Unsloth memory usage issue: A user encountered an issue where their LLaMA 3 8B Instruct model with Unsloth was consuming 300GB of physical memory but still encountering memory issues, causing the server to kill the model.
- Users suggested checking the available VRAM as the model likely needs more GPU memory to operate correctly.
- Google Colab: no description found
- A comparative study of fine-tuning GPT-4o-mini, Gemini Flash 1.5 and Llama-3.1-8B: We compare fine-tuning GPT-4o-mini, Gemini Flash 1.5, and Llama-3.1-8B models using a custom vulnerability fixes dataset, with GPT-4o-mini showing the most significant improvement and setting a new st...
- Finetuning Large Language Models - DeepLearning.AI: Master the basics of finetuning an LLM. Differentiate finetuning from prompt engineering and gain hands-on experience with real datasets.
- Welcome to vLLM! — vLLM: no description found
- Tweet from Nathan Labenz (@labenz): Any inference platforms offer MoRA for Llama 3.1 models? Seems like a big opportunity! (Or… why not?) cc @lqiao @FireworksAI_HQ @tri_dao @togethercompute @jefrankle @DbrxMosaicAI Appreciate a...
- How to Finetune Llama-3 and Export to Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
- How to Finetune Llama-3 and Export to Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
- yahma/alpaca-cleaned · Datasets at Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #showcase (8 messages🔥):
Lexi modelLLM Leaderboard 2Ahma-3B InstructFinnish-NLP/Ahma-3BFinnish language model
- Lexi Model Beats Original Instruct: The LLM Leaderboard 2 results for an uncensored version of Lexi, a finetuned Llama-3.1-8B model, have been released.
- Lexi not only retains the original instruct, but it actually beats it in performance.
- Ahma-3B Instruct - Finnish Language Model: The instruction-finetuned version of Ahma-3B, a Llama-based model pretrained from scratch in Finnish, has been released on Hugging Face.
- Ahma-3B Instruct is trained to follow instructions in Finnish, and the base model was pretrained on 139 billion Finnish tokens.
- Training Ahma-3B Instruct: The training process for Ahma-3B Instruct involved translating and synthesizing single- and multi-turn data, using ClusterClipping based sampling and selection.
- This was followed by Supervised Fine-Tuning (SFT) with Qlora using the Unsloth framework, and a fine-tuning step with DPO (Direct Preference Optimization) with a beta of 0.1.
- Orenguteng/Llama-3.1-8B-Lexi-Uncensored · Hugging Face: no description found
- Finnish-NLP/Ahma-3B-Instruct · Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #research (5 messages):
1.5-PintsTree AttentionMistralLlama 2OpenELM
- 1.5-Pints: A Compute-Efficient Language Model: A new language model called "1.5-Pints" was presented, which was pre-trained in just 9 days using a compute-efficient approach.
- This model outperforms state-of-the-art models like Apple's OpenELM and Microsoft's Phi in instruction-following tasks, as measured by MT-Bench.
- Tree Attention: Impressive Long Context Performance: A research paper discussed the significant improvements in very-long context performance achieved through the use of tree attention.
- The paper, available at https://arxiv.org/pdf/2408.04093, suggests that tree attention is a promising approach for handling long contexts.
- 1.5-Pints Architecture and Training: The 1.5-Pints model utilizes a modified Mistral tokenizer and a Llama-2 architecture for compatibility.
- Its training methodologies are based on those used by StableLM, TinyLlama, and HuggingFace, emphasizing the model's versatility.
Link mentioned: 1.5-Pints Technical Report: Pretraining in Days, Not Months -- Your Language Model Thrives on Quality Data: This paper presents a compute-efficient approach to pre-training a Language Model-the "1.5-Pints"-in only 9 days, while outperforming state-of-the-art models as an instruction-following assist...
CUDA MODE ▷ #general (48 messages🔥):
TorchAOCUDA developer hiringCPU matmul optimizationCPU matmul performanceFP16/BF16 weights
- TorchAO presentation at Cohere for AI: Charles Hernandez from PyTorch Architecture Optimization will be presenting on TorchAO and quantization at the ml-efficiency group at Cohere For AI on August 16th, 2000 CEST.
- This event is hosted by @Sree_Harsha_N and attendees can join Cohere For AI through the link https://tinyurl.com/C4AICommunityApp.
- Where to post CUDA developer job openings: A user asked about the best place to post a job opening for a CUDA developer.
- No specific answer was provided, but the user was directed to the "jobs channel" within the Discord server.
- CPU matmul optimization in Zig: A user is attempting to write a tiling-based matmul in Zig but is having difficulty achieving optimal performance.
- The user shared their code and received advice on exploring cache-aware loop reordering and the potential for using SIMD instructions.
- CPU matmul performance comparisons: A user is comparing the performance of their CPU matmul implementation in Zig to the performance of GGML and NumPy.
- The user noted that NumPy achieves incredibly fast performance using optimized BLAS implementations and shared links to resources on fast MMM on CPU, including an article by Sibboehm and a blog post by Salykova.
- FP16/BF16 weights and CPU performance: A user asked about handling FP16 weights on the CPU, noting that recent models generally use BF16.
- The user was advised to convert the FP16 weights to BF16 or FP32, with FP32 leading to no accuracy loss but potentially slower inference. The user was also suggested to explore converting tensors at runtime from FP16 to FP32 to potentially improve performance.
- Fast Multidimensional Matrix Multiplication on CPU from Scratch: Numpy can multiply two 1024x1024 matrices on a 4-core Intel CPU in ~8ms.This is incredibly fast, considering this boils down to 18 FLOPs / core / cycle, with...
- Tweet from Sree Harsha (@Sree_Harsha_N): Excited to host Charles Hernandez from the @PyTorch Architecture Optimization @ the ml-efficiency group Aug16, 2000CEST talking about TorchAO(https://github.com/pytorch/ao) and quantization. Thanks @m...
- vikhyatk/moondream2 at main: no description found
- Beating NumPy in 150 Lines of C Code: A Tutorial on High-Performance Multi-Threaded Matrix Multiplication: In this step by step tutorial we’ll implement high-performance multi-threaded matrix multiplication on CPU from scratch and learn how to optimize and parallelize code in C. On Ryzen 7700 our implement...
- no title found: no description found
CUDA MODE ▷ #torch (4 messages):
PyTorch Full FP16PyTorch Optimizertorch.compileFairseq Fine-tuning
- PyTorch Full FP16: Is it possible?: A user asked if full FP16 with loss/grad scaling is possible with PyTorch core, specifically when fine-tuning a large-ish model from Fairseq.
- They tried using
torch.GradScaler()and casting the model to FP16 withouttorch.autocast('cuda', torch.float16), but got an error "ValueError: Attempting to unscale FP16 gradients."
- They tried using
- Custom Optimizer Implementation: A user suggested manually accessing and scaling gradients within the optimizer's step function to achieve full FP16 functionality.
- They provided code illustrating how to retrieve gradients from the optimizer's parameters and then apply scaling operations before calling
optimizer.step().
- They provided code illustrating how to retrieve gradients from the optimizer's parameters and then apply scaling operations before calling
- torch.compile: The Missing Manual: A new PyTorch document titled "torch.compile: The Missing Manual" was shared along with a YouTube video.
- The document and video are available at https://docs.google.com/document/d/1y5CRfMLdwEoF1nTk9q8qEu1mgMUuUtvhklPKJ2emLU8/edit#heading=h.ivdr7fmrbeab and https://www.youtube.com/live/rew5CSUaIXg?si=zwbubwKcaiVKqqpf, respectively, and provide detailed information on utilizing
torch.compile.
- The document and video are available at https://docs.google.com/document/d/1y5CRfMLdwEoF1nTk9q8qEu1mgMUuUtvhklPKJ2emLU8/edit#heading=h.ivdr7fmrbeab and https://www.youtube.com/live/rew5CSUaIXg?si=zwbubwKcaiVKqqpf, respectively, and provide detailed information on utilizing
- Fairseq's Training Approach: The original user mentioned that Fairseq models are typically trained with their own custom full FP16 implementations.
- They also mentioned that while fine-tuning in full BF16 is possible, FP16 AMP often performs better for smaller Fairseq models, likely because they were trained with FP16.
- torch.compile, the missing manual: torch.compile, the missing manual You are here because you want to use torch.compile to make your PyTorch model run faster. torch.compile is a complex and relatively new piece of software, and so you ...
- PyTorch Webinar: torch.compile: The Missing Manual: Hear from Edward Yang, Research Engineer for PyTorch at Meta about utilizing the manual for torch.compile.View the document here to follow along: https://doc...
- pytorch/torch/amp/grad_scaler.py at 2e7d67e6af45c9338c02dd647c46c328fa23ee48 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
CUDA MODE ▷ #cool-links (7 messages):
Rust GPUZigFal Research GrantsOpen Source Support
- Rust GPU Transitions to Community Ownership: The Rust GPU project, previously under Embark Studios, is now community-owned under the Rust GPU GitHub organization.
- This transition marks the beginning of a broader strategy aimed at revitalizing, unifying, and standardizing GPU programming in Rust.
- Rust/Zig vs CUDA's C/C++: Rust and Zig offer similar benefits to C and C++ when it comes to GPU programming, although they are not officially supported by CUDA.
- The discussion highlights the advantages of Rust and Zig, and suggests that learning Zig may be beneficial for those interested in this space.
- Fal Research Grants for Open Source AI Projects: The Fal Research Grants program provides free compute resources to researchers and developers working on open source AI initiatives.
- The program is open to anyone passionate about advancing AI through open source projects, regardless of their formal qualifications.
- Fal's Support for Open Source Projects: Fal appears to be actively supporting numerous open source projects.
- One user mentioned that Fal funded the AuraFlow project.
- Rust GPU Transitions to Community Ownership | : no description found
- no title found: no description found
CUDA MODE ▷ #jobs (11 messages🔥):
CUDA DevelopersCUDA FreshersCUDA HiringCUDA EngineerTriton
- Seeking CUDA Developers for Confidential LLM Inference Project: A company is seeking a CUDA developer to work on a confidential project related to LLM inference speed.
- They are looking for someone with deep knowledge of Nvidia Nsight, CUDA programming skills, experience with Hopper Architecture (SM90) kernels, GPU optimization expertise, TensorRT & TensorRT-LLM know-how, and AI/ML framework experience (PyTorch, TensorRT).
- CUDA Skills for Freshers: What Employers Look For: A discussion arose about what employers expect from freshers applying for CUDA engineer roles.
- A consensus emerged that the ability to write a non-trivial CUDA or Triton program to completion, effectively communicate design decisions, and demonstrate aptitude for learning are crucial skills for freshers.
- Marketing Yourself as a CUDA Engineer: A member emphasized the importance of showing that you complement a team well and can bring knowledge they don't already have.
- They advised on showcasing your genuine excitement for the team's work and demonstrating your ability to hit the ground running with a curious and invested attitude.
CUDA MODE ▷ #beginner (7 messages):
Multithreading and GPU UseNetwork Requests and GPUsMagnum IO Architecture
- Threads Need to Converge for Progress: A member discussed the importance of thread convergence for forward progress, stating that "threads require to converge for making forward progress...If threads dont converge, then forward progression can be tricky.".
- This highlights a challenge with independent thread execution models, where coordinating the work of different threads is crucial for overall progress.
- GPUs and Network Requests: Why Not?: The discussion centered around why GPUs aren't widely used for multithreading network requests in scenarios like web crawling, with a member asking: "Why a GPU is not used widely for multithreading in network requests for use cases like a web crawler?"
- The response indicated that GPUs generally can't make network requests directly, although there might be technical ways to interact over PCIe, it's likely not a practical or efficient solution.
- Magnum IO: A New Era in Data Center Architecture: A member shared a link to an article about Magnum IO, a new IO subsystem designed for modern data centers and described as "the IO subsystem of the modern data center".
- The article highlights the shift in the unit of computing from a single box to the entire data center, emphasizing the need for distributed resources and data sets, as illustrated in a diagram of the Magnum IO stack architecture.
Link mentioned: Accelerating IO in the Modern Data Center: Magnum IO Architecture | NVIDIA Technical Blog: This is the first post in the Accelerating IO series, which describes the architecture, components, storage, and benefits of Magnum IO, the IO subsystem of the modern data center.
CUDA MODE ▷ #off-topic (1 messages):
iron_bound: https://www.youtube.com/watch?v=aNAtbYSxzuA
CUDA MODE ▷ #llmdotc (126 messages🔥🔥):
cuDNN stabilityHuggingFace Llama 3 AutoTokenizer issuesCurand GPU weight initializationcopy_and_cast_kernelcudaMallocAsync/cudaFreeAsync
- cuDNN Stability Warning: A member asked whether a warning should be added when running with outdated cuDNN, particularly for versions 9.2.1 and 9.3.0, which significantly affect stability.
- It was suggested to implement a check at the Makefile level, potentially printing a warning message during the build process.
- HuggingFace Tokenizer Special Token Issue: There was a discussion regarding the HuggingFace Llama 3 AutoTokenizer not properly recognizing the EOT token (<|endoftext|>), leading to potential issues in code-fixing.
- Curand GPU Weight Initialization PR: A member proposed an alternative approach to faster model initialization using curand to initialize weights directly on the GPU.
- This PR is still under development and requires further testing and clean-up.
- copy_and_cast_kernel Overengineering: It was pointed out that the copy_and_cast_kernel might be overengineered and a simpler approach using direct casting within the kernel could be sufficient.
- However, the member opted not to change it in this particular PR to avoid introducing potential compatibility issues.
- cudaMallocAsync/cudaFreeAsync Optimization: A suggestion was made to optimize the cudaMallocAsync/cudaFreeAsync in the critical loop by using a single malloc/free for the largest possible tensor size.
- Llama 3.1 | Model Cards and Prompt formats: Llama 3.1 - the most capable open model.
- [WIP] initial curand implementation for model init by ngc92 · Pull Request #741 · karpathy/llm.c: as an alternative to the multi-threaded model init, this uses curand to generate initial weights directly on the GPU. It is still work-in-progress, needs error-checking, and I dislike the cudamallo...
- Pull requests · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- add option to skip special tokens by ArthurZucker · Pull Request #1419 · huggingface/tokenizers: Allow skipping special tokens when encoding fixes #1347, fixes #1391 fixes #1368
- Gordicaleksa fix dataloader2 by karpathy · Pull Request #740 · karpathy/llm.c: commit on top of @gordicaleksa PR that makes a bunch of bugfixes be more explicit with treatment of EOT token be careful with API for AutoTokenizer bugfix on dtype in fineweb.py use model_desc ins...
LM Studio ▷ #general (150 messages🔥🔥):
Vision AdaptersModel MergingMistral LargeGPT-4o MiniLLM Studio Headless
- Vision Adapters: The Key to Vision Models: Only specific LLM models have vision adapters, most of them are going by name "LLaVa" or "obsidian".
- The "VISION ADAPTER" is a crucial component for vision models; without it, the error you shared will pop up.
- Mistral Large: The Current Champion?: A member found Mistral Large 2 to be the best LLM right now, outcompeting Claude 3.5 Sonnet for difficult novel problems.
- However, the member also noted that Gemini Flash undercut OpenAI 4o mini severely in price, but OpenAI 4o was less expensive than Mistral Large.
- LLM Studio's Model Explorer is Down: Several members reported that HuggingFace, which powers the LM Studio Model Explorer, is down.
- The site was confirmed to be inaccessible for several hours, with connectivity issues reported across various locations.
- Llama 3.1 Performance Issues: A user reported that their Llama 3 8B model is now running at only 3 tok/s, compared to 15 tok/s before a recent update.
- The user checked their GPU offload settings and reset them to default, but the problem persists; the issue appears to be related to a change in the recent update.
- LLM Output Length Control: A member is looking for ways to restrict the output length of responses, as some models tend to output whole paragraphs even when instructed to provide a single sentence.
- While system prompts can be modified, the member found that 8B models, specifically Meta-Llama-3.1-8B-Instruct-GGUFI, are not the best at following precise instructions.
- Tweet from 🍓🍓🍓 (@iruletheworldmo): tomorrow. 10am pt. tune in.
- Is Huggingface down? Live status and problems past 24 hours: Live problems for Huggingface. Error received? Down? Slow? Check what is going on.
- mradermacher/Tiger-Gemma-9B-v1-i1-GGUF · Hugging Face: no description found
LM Studio ▷ #hardware-discussion (15 messages🔥):
Portable LLM inferenceApple MacGPU moddingCopper moddingFlashing NVIDIA BIOS
- Portable LLM Inference: Device or Environment?: A member argued that for portable LLM inference, one should consider whether they want to run inference on their portable device or access a private inference environment while mobile.
- Apple Mac's Interface Consumes Memory: A member discussed the memory consumption of macOS visual effects, like transparency, blurs, and shadows, which can consume up to 3GB of memory.
- Modding a Project for AI Experiments: A member asked if anyone else works on modding projects for their AI experiments, and then described their project, which is modding an Asus ROG Strix RTX 2070 8GB OC.
- Copper Modding for Better Performance: A member suggested that copper modding helps to spread heat from the memory chips, which improves bandwidth and boosts LLM inference speed.
- Flashing NVIDIA BIOS to a 2080: A member mentioned that they might flash the BIOS of their RTX 2070 to a 2080, but they need to read up on the process first.
OpenAI ▷ #ai-discussions (151 messages🔥🔥):
Gemini LiveGoogle FiStrawberriesProject AstraLLMs
- Google's Gemini Live: It's here, it's now, it's not free: Google's new Gemini Live is now available to Advanced Subscribers and features conversational overlay on Android and even more connected apps.
- The general consensus is that it is an improvement from the old voice mode, but with the limitations that it is only available to paid users and the video feature is not live.
- Google Fi: Is it worth the switch?: Google Fi, Google's cellular network, is based on T-Mobile and some users reported it to be a solid option, though not enough for some to switch from AT&T.
- One user mentioned that Google Fi is essentially deprioritized T-Mobile, and while not an issue in areas with lots of bandwidth, it is not the ideal option for those with limited coverage.
- The Great Strawberry Debate: The discussion of a mysterious user called "Strawberry" (with a string of emojis) led to a speculation that this user might be related to OpenAI or Sam Altman.
- Many users mentioned how this was quite a clever marketing strategy, linking the strawberry emojis with the image of Sam Altman holding strawberries, and it seemed to be effective at keeping people talking.
- Project Astra: Is it a flop? : While the Gemini Live announcement hinted at Project Astra, many users were disappointed to not see any further developments.
- One user even mentioned a Microsoft recall comparison, and it seems like people are not too trusting of the company to release this product any time soon, mostly due to security concerns.
- LLMs: A Solution for All Problems?: Some users have expressed skepticism about LLMs being the solution for all problems, particularly in the context of using them for tasks like math, database, and even waifu roleplay.
- Others emphasized the importance of understanding that tokenization is still a fundamental weakness of LLMs, and they can't solve complex problems just through brute force tokenization, but rather need a more strategic approach.
- 🍓🌱⛓️💥: A Heretic's Journey through the Strawberry Patch
- Clueless Aware GIF - Clueless Aware Twitch - Discover & Share GIFs: Click to view the GIF
{kind=link}
OpenAI ▷ #gpt-4-discussions (5 messages):
Prompt LibrarySystem Prompt in LangChain
- Prompt Library Location: A user asked how to access the prompt library, and another user provided a link to a channel containing the prompt library.
- Adding System Prompts in LangChain: A user shared Python code demonstrating how to create a GPT based on Strawberry, but they wanted to know how to add a system prompt.
OpenAI ▷ #prompt-engineering (3 messages):
ChatGPT website access
- ChatGPT can't access websites: A member asked if there's a way to get ChatGPT to visit a website and pull an article for it to read.
- ChatGPT may hallucinate website content: Another member suggested that ChatGPT may be hallucinating or blocked from crawling the website.
OpenAI ▷ #api-discussions (3 messages):
ChatGPT accessing websitesChatGPT's hallucination and web crawling
- ChatGPT cannot access websites directly: A user asked if there was a way to get ChatGPT to access a website and pull an article for it to read.
- ChatGPT may hallucinate or be blocked from crawling websites: A user suggested that ChatGPT might be hallucinating or blocked from crawling websites, explaining that it sometimes cites sources from websites, but not always.
- Web browser GPT: A user asked if anyone had tried mentioning the web browser GPT to ChatGPT, possibly as a way to work around this limitation.
Perplexity AI ▷ #general (106 messages🔥🔥):
Perplexity bug reportsPerplexity Pro ModelsPerplexity's UI/UXPerplexity's website stabilityPerplexity's future
- Perplexity's UI/UX issues: Users reported several UI/UX issues including missing buttons and a disappearing prompt field, leading to difficulties in interacting with the platform.
- New Model: Sonar Huge: The new model "Sonar Huge" replaced the Llama 3.1 405B model in Perplexity Pro and was observed to be slow and not adhere to user profile prompts.
- Perplexity's Website Stability Concerns: Users reported a significant decline in website stability, citing issues with sporadic search behavior, forgetting context, and interface bugs on both web and iOS versions.
- Perplexity's Success Team Acknowledges Bugs: The Success Team at Perplexity acknowledged receiving user feedback on the recent bugs and glitches encountered in the platform.
- The Future of Perplexity's Feature Implementation: A user expressed frustration over the long wait time for feature implementation, highlighting the disparity between the promised features and the actual rollout pace.
- Tweet from Perplexity (@perplexity_ai): We're thrilled to announce our partnership with @Polymarket. Now, when you search for events on Perplexity, you'll see news summaries paired with real-time probability predictions, such as ele...
- Notice history - Perplexity - Status: Notice history - Perplexity Status
Perplexity AI ▷ #sharing (9 messages🔥):
CourseraProgramming CoursesAI/MLCloud ComputingData Science
- Coursera's High-Paying Programming Courses: Coursera offers a wide range of programming courses that can lead to lucrative tech careers, with specializations in Python, AI/machine learning, cloud computing, and data science being particularly popular.
- These courses, offered by institutions like Stanford, Google, and IBM, help learners develop in-demand skills and enhance their career prospects.
- Strategic Skill Development for Tech Careers: For maximizing earning potential, Coursera recommends combining technical skills with soft skills like project management and communication, which can help learners stand out in competitive fields.
- By strategically combining these skills, learners can position themselves for high-paying roles in software engineering, data science, and cloud architecture.
- Importance of Hands-On Experience and Staying Current: Coursera emphasizes the importance of choosing comprehensive programs that provide hands-on experience and stay up-to-date with emerging technologies.
- This ensures that learners acquire the most relevant and valuable skills for the current job market.
- Perplexity AI Chatbot Guidance on Shareable Threads: A Perplexity AI chatbot reminds a user to make sure their thread is shareable, providing a link to instructions.
- YouTube: no description found
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- no title found: no description found
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
Perplexity AI ▷ #pplx-api (6 messages):
Perplexity Search ParametersSearch Location OptionsImage Generation from Narrative
- Search Parameter Control: A member expressed interest in controlling search parameters like
intitle:ABC, similar to Google Search.- They believe this feature would greatly enhance the search capabilities of Perplexity.
- Search Location Selection: Another member inquired about the possibility of selecting specific search locations within Perplexity.
- They acknowledged the value of this feature for narrowing search results and finding location-specific information.
- Narrative-Based Image Generation: A user provided a narrative describing a scene with a cat walking along a wall in the rain, requesting an image based on this description.
- The narrative included details about the camera angles, lighting, and atmosphere, suggesting an interest in AI-powered image generation.
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
SXSW PanelOpenAI ModelsAI Risks and OpportunitiesGovernment RegulationAI Impact
- Stability AI's SXSW Panel Proposal: Stability AI CEO Prem Akkaraju and tech influencer Kara Swisher will discuss the importance of open AI models and the role of government in regulating their impact.
- The panel will explore the opportunities and risks of AI, including job displacement, disinformation, CSAM, and IP rights.
- Democratizing Access to Cutting-Edge Technology: The panel will emphasize how open-source AI models are driving innovation and democratizing access to technology, particularly in CGI.
- This accessibility promotes experimentation and accelerates progress in various fields, empowering individuals and organizations with new possibilities.
- Balancing Commercial Interests and AI Risks: The discussion will address the challenges of balancing commercial interests with the potential risks of generative AI in a rapidly evolving sector.
- Key topics will include mitigating disinformation, protecting intellectual property, and addressing ethical concerns surrounding AI use.
- AI's Future Impact on Content Creation and Work: The panel will explore the future of AI in content creation, work, education, and other domains.
- They will discuss AI's capacity to enhance human potential across all social and economic strata, while considering its implications for jobs and skill development.
- Prem Akkaraju's Vision for AI and CGI: Prem Akkaraju will share his vision for the company and the industry, focusing on the convergence of AI and CGI.
- He will discuss how this convergence is poised to transform creative fields and offer new possibilities for content creation and storytelling.
Link mentioned: PanelPicker | SXSW Conference & Festivals: PanelPicker® is the official SXSW user-generated session proposal platform. Enter ideas and vote to help shape Conference programming for SXSW and SXSW EDU.
Stability.ai (Stable Diffusion) ▷ #general-chat (111 messages🔥🔥):
Google Colab RuntimeStable Diffusion InstallationStable Diffusion Model MergingCUDA InstallationFlux Realism
- Google Colab Runtime Stops: A user inquired about preventing their Google Colab runtime from stopping.
- Another user suggested using Kaggle instead, as it offers more resources and longer runtimes.
- Stable Diffusion Installation Woes: A user reported difficulties installing Stable Diffusion, encountering issues with CUDA installation and finding their token on Hugging Face.
- Another user provided guidance on generating a token through the profile settings menu and installing CUDA correctly.
- Model Merging Questions: A user discussed potential model merging tactics, proposing applying the difference between UltraChat and base Mistral to Mistral-Yarn.
- Other users expressed skepticism, but the original user remained optimistic, citing successful past attempts at model merging.
- Flux Realism for Face Swaps: A user inquired about using Flux Realism to put their face on images.
- They mentioned trying fal.ai, but the results seemed cartoonish, prompting them to seek alternative solutions.
- Training LORAs for Logo Generation: A user asked for guidance on training LORAs for logo generation, specifically for placing logos onto images.
- Another user recommended using Flux, as it can train on logos and accurately place them onto images, such as shirts or buildings.
- Kaggle: Your Machine Learning and Data Science Community: Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
- Heart Container Goddess Statue GIF - Heart container Goddess statue Totk heart container - Discover & Share GIFs: Click to view the GIF
- CS1o - Overview: CS1o has 2 repositories available. Follow their code on GitHub.
- Installation Guides: Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
- GitHub - cumulo-autumn/StreamDiffusion: StreamDiffusion: A Pipeline-Level Solution for Real-Time Interactive Generation: StreamDiffusion: A Pipeline-Level Solution for Real-Time Interactive Generation - cumulo-autumn/StreamDiffusion
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
Gemini Flash 1.5GPT-4o ExtendedOpenRouter Pricing
- Gemini Flash 1.5 Price Drop: The input token costs for Gemini Flash 1.5 have decreased by 78% and the output token costs have decreased by 71%.
- This makes the model more accessible and affordable for a wider range of users.
- GPT-4o Extended Early Access Launch: Early access has just launched for GPT-4o Extended through OpenRouter.
- You can access it via this link: https://x.com/OpenRouterAI/status/1823409123360432393
- GPT-4o Extended Output Limit: The maximum number of tokens allowed for GPT-4o Extended output is 64k.
- Tweet from OpenRouter (@OpenRouterAI): You can now use GPT-4o extended output (alpha access) through OpenRouter! 64k max tokens
- Gemini Flash 1.5 - API, Providers, Stats: Gemini 1.5 Flash is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video...
OpenRouter (Alex Atallah) ▷ #general (80 messages🔥🔥):
Gemini Flash Price UpdatesGCP Cost TableToken:Character RatioEuryale 70B DowntimeInfermatic Downtime
- Gemini Flash Prices on OpenRouter?: A user inquired about the new Gemini flash prices on OpenRouter and when they will be updated.
- A user mentioned their GCP cost table already reflects the new pricing, suggesting it's up to OpenRouter to implement the update.
- OpenRouter's Update Hurdle: OpenRouter's update was blocked by the new 1:4 token:character ratio from Gemini, which doesn't map cleanly to the
max_tokensparameter validation.- Another user expressed frustration about the constantly changing token:character ratio and suggested switching to a per-token pricing system.
- Euryale 70B Issues?: A user reported that Euryale 70B was down for some users but not for them, prompting questions about any issues or error rates.
- Further discussion revealed multiple instances of downtime, including a 10-minute outage due to an update and possible ongoing issues with location availability.
- Model Performance Comparison: Users compared the performance of Groq 70b and Hyperbolic, finding nearly identical results for the same prompt.
- This led to a discussion about the impact of FP8 quantization, with some users noting that it makes a minimal difference in practice, but others pointing to potential degraded quality with certain providers.
- ChatGPT 4.0 Default Setting Change: A user expressed concern that the "middle-out" setting is no longer the default for ChatGPT 4.0, which impacts function calling for their frontends.
- The user requested suggestions for setting this parameter in the system prompt using platforms like Ollama and a Wordpress plugin.
- Tweet from MultiOn (@MultiOn_AI): Announcing our latest research breakthrough: Agent Q - bringing next-generation AI agents with planning and AI self-healing capabilities, with a 340% improvement over LLama 3's baseline zero-sho...
- Tweet from Tibor Blaho (@btibor91): Someone pressed publish on too many new (and test?) articles too early in the last hours - expect GPT-4o system card, SWE-bench Verified, new customer stories, and more soon - Collaborating with The ...
- deepseek-ai (DeepSeek): no description found
- Dream Bigger: The Codeium mission, Cortex and Forge launches, and detailed vision.
- Llama 3 8B Lunaris - API, Providers, Stats: Lunaris 8B is a versatile generalist and roleplaying model based on Llama 3. It's a strategic merge of multiple models, designed to balance creativity with improved logic and general knowledge. R...
- Mistral Nemo 12B Starcannon - API, Providers, Stats: Starcannon 12B is a creative roleplay and story writing model, using [nothingiisreal/mn-celeste-12b](https://openrouter.ai/models/nothingiisreal/mn-celeste-12b) as a base and [intervitens/mini-magnum-...
- Llama 3 Euryale 70B v2.1 - API, Providers, Stats: Euryale 70B v2.1 is a model focused on creative roleplay from [Sao10k](https://ko-fi. Run Llama 3 Euryale 70B v2.1 with API
Modular (Mojo 🔥) ▷ #general (30 messages🔥):
Mojo Licensing ConcernsMojo Open-SourcingMojo DevelopmentMojo Learning ResourcesMojo Compiler
- Mojo's License Has a Catch: The Mojo license prohibits the development of any applications using the language for competitive activities.
- However, it states that this rule does not apply to applications that become competitive after their initial release, but it is unclear how this clause will be applied.
- Mojo's Uncertain Open-Sourcing Future: Users inquired about the open-sourcing timeline of Mojo's compiler.
- While the team confirmed that the compiler will be open-sourced eventually, a public timeline is not available, suggesting that it may be a while before contributions can be made.
- Mojo Development: Standard Library Focus: The current focus of Mojo development is on building out the standard library.
- Users are encouraged to contribute to the standard library, while work on the compiler is ongoing, but not yet open to contributions.
- Mojo Learning for Students: A college student inquired about resources for learning Mojo, including compiler basics and MLIR.
- The team suggested starting with learning Mojo itself and contributing to the standard library, while MLIR knowledge will be helpful for future compiler contributions.
- Mojo Compiler: Limited Documentation and Internal Dialects: The team acknowledges the lack of documentation for Mojo's internal dialects, which has made development challenging for some contributors.
- The ability to add rewrite rules directly to the compiler is being considered, but it is not currently possible, leading some to shelve their projects due to the high time investment required to reverse-engineer the compiler.
- Small string optimization in Mojo’s stdlib: Small string optimization in Mojo’s stdlib and small buffer optimization while we’re at it
- no title found: no description found
- no title found: no description found
- System requirements and browsers - Computer - Google Docs Editors Help: no description found
Modular (Mojo 🔥) ▷ #mojo (19 messages🔥):
Java by MicrosoftC# relevanceStable Diffusion Memory IssueWSL2 limitationsMojo Optimization
- Java by Microsoft: A Forgotten Giant?: One member argued that "Java by Microsoft" was unnecessary and could have been avoided, while another countered that it seemed crucial at the time.
- The discussion acknowledged the emergence of newer solutions and the decline of "Java by Microsoft" over time, highlighting its 20-year run and its relevance in the Microsoft marketshare.
- C# Rise in Microsoft's Dominance: C# appeared in 2000 and has been a key part of Windows development for over two decades, being viewed as a "nicer Java" for many tasks.
- C# gained popularity rapidly as the "new way to do applications on Windows", especially in the 2nd and 3rd world countries where Windows has a significant presence.
- Stable Diffusion Memory Issues in WSL2: A new user encountered an issue running the Stable Diffusion Mojo ONNX example in WSL2, where the process was killed due to memory pressure.
- The user had 8GB allocated to WSL2 but was advised to double it as Stable Diffusion 1.5 is approximately 4GB, requiring more memory for the model and optimization processes.
- WSL2 Memory Constraints: Windows prioritizes the health of the host OS over WSL2 processes, potentially leading to memory constraints when running memory-intensive applications like Stable Diffusion.
- Doubling the memory allocated to WSL2 from 8GB to 16GB was suggested to alleviate the issue.
- Mojo Optimization: Memory Efficiency: The memory efficiency of Stable Diffusion was discussed, noting that optimization can consume significant RAM.
- The user was advised to allocate more memory to WSL2 to ensure sufficient resources for both the model and its optimization processes.
Cohere ▷ #discussions (11 messages🔥):
Cohere For AIPricing changesCohere's Research LabHackathonsComputer Vision
- Cohere For AI research lab: Cohere For AI is a non-profit research lab that seeks to solve complex machine learning problems.
- They support fundamental research exploring the unknown, and are focused on creating more points of entry into machine learning research.
- Pricing Changes on Cohere's Website: A user asked about the classify feature's pricing, noticing it's no longer listed on the pricing page.
- No response was given.
- Hackathon Group: A user is looking for more members to join their Hackathon group.
- The group currently has 2-3 people and they are looking for people with diverse skillsets, especially those who can submit videos.
- Computer Vision Interest: A new user introduced themself as a Computer Engineering graduate interested in AI, ML, DL, particularly Computer Vision.
- They have done some projects related to CV and are looking to improve in this area.
Link mentioned: Cohere For AI (C4AI): Cohere For AI is a non-profit research lab that seeks to solve complex machine learning problems. We support fundamental research that explores the unknown, and are focused on creating more points of ...
Cohere ▷ #questions (26 messages🔥):
JSONL Upload IssueAzure JSON FormattingRerank OverviewCohere API UsagePython Kernel Restart
- JSONL Uploads Failing: Users reported issues uploading JSONL datasets for fine-tuning, with the error message "File format is not supported for dataset".
- The issue was acknowledged by Cohere support and is being investigated. In the meantime, users can utilize the API for dataset creation, which is currently functioning correctly.
- Azure JSON Formatting Not Supported: A member inquired about using structured output with
response_formatin Azure, but encountered an error indicating the parameter is invalid.- It was confirmed that JSON formatting is not currently available on Azure.
- Rerank Overview Code Help: A user requested assistance with the Rerank Overview document, encountering issues with the provided code.
- The issue was related to an outdated document, and a revised code snippet was provided. The user was also directed to the relevant documentation for further reference.
- "Unknown Field" Error in Rerank: A user experienced an "unknown field" error when using the Rerank API.
- This error was confirmed to be unrelated to the Rerank API, and restarting the Python kernel was suggested as a potential resolution.
Link mentioned: Rerank - Cohere API References: This endpoint takes in a query and a list of texts and produces an ordered array with each text assigned a relevance score.
Cohere ▷ #api-discussions (7 messages):
JSON Snippet EmbeddingsIntermediate Text
- Embeddings for JSON Snippets: A member asked about the preferred method for providing JSON as document snippets, aiming for compatibility with large JSON datasets.
- Utility of Intermediate Text: A member inquired about the usefulness of intermediate text.
- Embeddings as a Solution: One member suggested converting JSON into embeddings as a possible solution.
- Clarifying the Goal: Another member requested clarification on the intended goal, offering assistance in finding a solution.
Torchtune ▷ #dev (44 messages🔥):
TransformerDecoderLayer RefactorRLHF with DPO/PPOTorchtune & WandBTorchtune PerformancePyTorch Conference
- TransformerDecoderLayer Refactor PR: A PR has been submitted to refactor the TransformerDecoderLayer, touching many files and making core changes in modules/attention.py and modules/transformer.py.
- This PR implements the RFC #1211, aiming to improve the TransformerDecoderLayer architecture.
- RLHF with DPO/PPO: There is a discussion about testing the HH RLHF builder with DPO or PPO, with DPO being preferred for preference datasets while PPO is dataset-agnostic.
- The focus is on DPO, with the expectation of loss curves similar to normal SFT, and potential debugging needed for the HH RLHF builder, which may be addressed in a separate PR.
- Torchtune & WandB Issues: A user encountered issues accessing WandB results for Torchtune, with access being granted after adding the user as a team member.
- The user reported poor results with the default DPO config and turning gradient accumulation off, but later discovered it started working again, potentially due to a delay or some other factor.
- Torchtune Performance with DPO: There is a discussion about potential issues with the default DPO config causing poor performance in Torchtune.
- The user suggested trying SIMPO (Stack Exchange Paired) and turning gradient accumulation back on, as having a balanced number of positive and negative examples in the batch can significantly improve loss.
- PyTorch Conference: A discussion about the upcoming PyTorch Conference, with links to the website and details on featured speakers.
- There was also a mention of sneaking in a participant as an 'academic' for the conference, but this is potentially a joke.
- rafi-personal: Weights & Biases, developer tools for machine learning
- PyTorch Conference | LF Events: Join top-tier researchers, developers, and academics for a deep dive into PyTorch, the cutting-edge open-source machine learning framework.
- TransformerDecoderLayer Refactor by pbontrager · Pull Request #1312 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) This is an implementation of the similarly named RFC #12...
- DPO by yechenzhi · Pull Request #645 · pytorch/torchtune: Context integrating DPO into Torchtune, more details see here Changelog ... Test plan ....
OpenAccess AI Collective (axolotl) ▷ #general (19 messages🔥):
Perplexity ProLlama 3Grad ClippingOpenAI Benchmark
- Perplexity Pro reasoning abilities: A user noted that Perplexity Pro has gotten "crazy good at reasoning" and is able to "literally count letters" like it "ditched the tokenizer".
- They shared a link to a GitHub repository that appears to be related to this topic.
- Llama 3 and Model of Experts: One user asked if anyone had made a "MoE" version of Llama 3.
- Grad Clipping Explained: A user asked about the functionality of grad clipping, specifically wondering what happens to gradients when they exceed the maximum value.
- Another user explained that grad clipping essentially clips the gradient to a maximum value, preventing it from exploding during training.
- OpenAI Benchmark Release: A user shared their surprise at OpenAI releasing a benchmark instead of a new model, speculating that this might be a strategic move to steer the field towards better evaluation tools.
Link mentioned: GitHub - cognitivecomputations/grokadamw: Contribute to cognitivecomputations/grokadamw development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #general-help (4 messages):
AutoGPTQAxolotl
- Axolotl's capabilities: A member noted that AutoGPTQ could do certain things, implying that Axolotl may be able to do so as well.
- They were excited about the possibility of Axolotl replicating this capability.
- OpenAI's Sharegpt API: A member recommended using
type: sharegptandconversation: llamawith the API to get more desired results.- This suggestion indicates a preference for certain parameters within the API when working with Axolotl.
OpenAccess AI Collective (axolotl) ▷ #deployment-help (1 messages):
LLM InferenceVLLMSkyPilotFireworksLora Adapters
- VLLM inference on your own GPUs with SkyPilot: A member recommended using VLLM on your own GPUs and managing it via SkyPilot for greater flexibility.
- This setup allows for full control and can handle specific needs.
- Serverless Billing with Fireworks: Fireworks was mentioned as a suitable solution for serving Lora adapters with serverless billing.
- However, Fireworks has limitations, including compatibility with all base models and occasional quirks.
LAION ▷ #general (16 messages🔥):
Grok 2.0Flux.1 ModelGrok Image GenerationOpen Source Image AnnotationElon and Models
- Grok 2.0 Leaks Early: A member shared a link to a Tweet about Grok 2.0 features and abilities, including image generation using the FLUX.1 model.
- The tweet also noted that Grok 2.0 is better at coding, writing, and generating news.
- Flux.1 Model Usage: A member mentioned that many Elon fan accounts predicted X would use MJ (presumably referring to a model), suggesting that Flux.1 may have made an inflection point in model usage.
- The member questioned if Flux.1 is Schnellit's Pro model, given Elon's history.
- Open-Source Image Annotation: A member asked for recommendations for good open-source GUIs for annotating images quickly and efficiently.
- The member specifically mentioned single-point annotations, straight-line annotations, and drawing polygonal segmentation masks.
- Elon's Model Choices: A member discussed the possibility that Elon is using a development version of Grok and calling the bluff on weight licenses.
- This member believes that Elon could potentially call this a "red-pill" version.
Link mentioned: Tweet from Nima Owji (@nima_owji): BREAKING: Here's an early look at Grok 2.0 features and abilities! It's better at coding, writing, and generating news! It'll also generate images using the FLUX.1 model!
LAION ▷ #research (4 messages):
Position Encoding2D Pooling
- New Position Encoding?: A user believes they may have invented a superior type of position encoding, and are currently verifying its efficacy.
- 2D Pooling Success: The user expresses surprise at how well 2D pooling works, noting it was recommended by another user.
tinygrad (George Hotz) ▷ #general (1 messages):
flammit_: no worries - just left hopefully helpful hints on your nvidia FP8 PR
tinygrad (George Hotz) ▷ #learn-tinygrad (8 messages🔥):
Tensor FilteringTranscendental Folding OptimizationCUDA TIMEOUT ERROR
- Tensor Filtering the Fastest Way?: A user asked for the fastest way to filter a Tensor, such as
t[t % 2 == 0], currently doing it by converting to list, filtering, and converting back to list.- A suggestion was made to use masking if computing something on a subset of the Tensor, but it was noted that the exact functionality is not possible yet.
- Transcendental Folding Refactor Optimization: A user proposed a refactor to only apply transcendental rewrite rules if the backend does not have a code_for_op for the uop.
- The user implemented a
transcendental_foldingfunction and called it fromUOpGraph.__init__but wasn't sure how this could be net negative lines, and asked what could be removed.
- The user implemented a
- CUDA TIMEOUT ERROR: A user ran a script using
CLANG=1and received aRuntimeError: wait_result: 10000 ms TIMEOUT!error.- The error occurred with the default runtime and was resolved by using
CUDA=1, and the issue was potentially related to ##4562.
- The error occurred with the default runtime and was resolved by using
MLOps @Chipro ▷ #events (3 messages):
Poe Previews HackathonAgihouse HackathonPoe Platform AnnouncementIn-Chat Generative UI ExperiencesDiscord Channel
- Poe Previews Hackathon: A Celebration of Expanded Release: Poe (@poe_platform) announced a partnership with Agihouse (@agihouse_org) for a "Previews Hackathon" to celebrate their expanded release.
- The hackathon invites all creators to build the most innovative and useful in-chat generative UI experiences, with details available at https://app.agihouse.org/events/poe-previews-hackathon-20240817.
- Discord Channel Discussion on the Hackathon: A user in the #events Discord channel shared a link to the Poe Previews Hackathon announcement on X, confirming they're helping out with the event.
- Hackathon Goal: In-Chat Generative UI Experiences: The hackathon aims to create innovative and useful "in-chat generative UI experiences", encouraging creators to showcase their skills.
- The announcement emphasizes the importance of user experience in the context of generative AI.
- Tweet from Poe (@poe_platform): To celebrate the expanded release, we’re partnering with @agihouse_org for a Previews hackathon where you’ll compete to create the most innovative and useful in-chat generative UI experiences. All cre...
- AGI House: no description found
- AGI House: no description found
MLOps @Chipro ▷ #general-ml (4 messages):
Virtual Try OnImage Feature ExtractionModel Size
- Virtual Try On Implementation: A member shared their experience building a virtual try-on feature for their R&D team, noting its effectiveness in speeding up training runs by storing extracted features.
- The feature utilizes online preprocessing and stores extracted features in a document store table, allowing for efficient retrieval during training.
- Image Feature Extraction Techniques: A member inquired about the specific features being extracted from images for the virtual try-on feature.
- The member providing the feature details highlighted the generic nature of their approach, accommodating models ranging from extremely small to massive sizes.
- Model Size Impact on Virtual Try On: The member emphasized the successful application of their virtual try-on feature across a wide range of model sizes.
- This demonstrates the flexibility of the approach in handling different computational demands and model complexities.
LangChain AI ▷ #general (5 messages):
Llama 3.1 8b structured outputRAG on technical documents with imagesNext.js and FastAPI interactionAWS pip install issues
- Llama 3.1 8b supports structured output through tools: A user confirmed that Llama 3.1 8b can produce structured output through tool use, having tested it directly with llama.cpp.
- Extracting information from technical images for RAG: A user sought advice on extracting information from images like electrical diagrams, maps, and voltage curves for RAG on technical documents.
- They mentioned encountering difficulties with traditional methods, highlighting the need for capturing information not present in text form but visually interpretable by experts.
- Next.js POST request to FastAPI returns 405 Method Not Allowed: A user encountered a 405 Method Not Allowed error when making a POST request from a Next.js web app running on EC2 to a FastAPI endpoint on the same EC2 instance.
- They observed the request being incorrectly interpreted as a GET request despite explicitly using the POST method in their Next.js code.
- AWS pip install issue resolved due to environment emulation: A user resolved an issue with pip install on an AWS system by installing packages specifically for the Unix-based environment.
- The problem arose from the virtual environment mistakenly emulating Windows during the pip install process, causing the issue.
LangChain AI ▷ #share-your-work (1 messages):
ProfundoProfundo use casesProfundo AIProfundo product huntProfundo benefits
- Profundo launches for automated research: Profundo automates data collection, analysis, and reporting, enabling everyone to do deep research on topics they care about.
- It minimizes errors and maximizes productivity, allowing users to focus on making informed decisions.
- Profundo's AI powers efficient data handling: Profundo uses cutting-edge AI to help you gather, analyze, and report data more efficiently.
- Say goodbye to manual data collection and hello to automated insights.
- Profundo empowers diverse use cases: Profundo is being used for self-study, content creation, first drafts, personal projects, and career development.
- In the academic world, it's employed for research and literature reviews.
- Profundo seeks ProductHunt upvotes: Profundo launched on ProductHunt today, and they are seeking upvotes to reach more people.
- If you have used Profundo and found it useful, they encourage you to upvote them on ProductHunt.
Link mentioned: : Profundo is a research platform that allows you to conduct research in a way that is more efficient and effective than ever before.
OpenInterpreter ▷ #general (1 messages):
AI Agents in EnterprisesMonitoring and Governance of AI Agents
- AI Agent Governance in the Enterprise: A user inquired about the challenges of monitoring and governance of AI agents within large organizations.
- Open Discussion Invitation: The user invited anyone working on AI agents within an enterprise to share their experiences.
OpenInterpreter ▷ #O1 (2 messages):
Screenless personal tutor for kids
- Screenless tutor idea for kids: A member expressed interest in using 01 to build a screenless personal tutor for kids.
- They asked for feedback and if anyone else was interested in collaborating on this project.
- Screenless tutor idea for kids: A member expressed interest in using 01 to build a screenless personal tutor for kids.
- They asked for feedback and if anyone else was interested in collaborating on this project.
OpenInterpreter ▷ #ai-content (3 messages):
Open Interpreter in ObsidianConvert Anything Tool
- Open Interpreter for Anything to Anything: Use Open Interpreter to convert any type of data into any other format.
- This is possible by using the "Convert Anything" tool, which harnesses the power of Open Interpreter.
- Open Interpreter in Obsidian: A new YouTube series is launching that will demonstrate how to use Open Interpreter in the Obsidian note-taking app.
- This plugin allows you to control your Obsidian vault using Open Interpreter, which could have major implications for how people work with knowledge.
- Open Interpreter Obsidian & Convert Anything - Ep 0: Episode 0 of Tool Use!Open Interpreter Obsidian Plugin - Use Open Interpreter to control your Obsidian vault!CV - Convert anything to anything using the powe...
- Is the AI Left-Bias Real?: Take courses on large language models on Brilliant! First 30 days are free and 20% off the annual premium subscription when you use our link ➜ https://brill...
Alignment Lab AI ▷ #general (1 messages):
SlimOrca without deduplicationFine-tuning (FT) with deduplication
- SlimOrca Without Deduplication: A user inquired about a version of SlimOrca that has soft prompting removed and no deduplication, ideally including the code.
- They also asked if anyone had experimented with fine-tuning (FT) on data with or without deduplication, and with or without soft prompting.
- Fine-tuning on Deduplicated Data: The user asked if anyone had experimented with fine-tuning on deduplicated data versus non-deduplicated data.
- Fine-tuning with Soft Prompting: The user inquired about the effects of fine-tuning (FT) with soft prompting versus without soft prompting.
LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
Agentic System for Jupyter Notebook Automation
- Building an Agentic Jupyter Notebook Automation System: A member expressed interest in building an agentic system for automating Jupyter Notebooks, aiming to create a pipeline that takes an existing notebook as input, modifies cells, and generates multiple variations.
- They sought recommendations for libraries, cookbooks, or open-source projects that could provide a starting point for this project, drawing inspiration from similar tools like Devin.
- Desired Functionality: Automated Notebook Modifications and Validation: The envisioned system should be capable of intelligently replacing specific cells within a Jupyter Notebook, generating diverse notebook versions based on these modifications.
- Crucially, the system should possess an agentic quality, enabling it to validate its outputs and iteratively refine the modifications until it achieves the desired results.