[AINews] Gemini (Experimental-1114) retakes #1 LLM rank with 1344 Elo
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Race dynamics is all you need.
AI News for 11/13/2024-11/14/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (217 channels, and 2424 messages) for you. Estimated reading time saved (at 200wpm): 272 minutes. You can now tag @smol_ai for AINews discussions!
Special note from the team: Thanks Andrej! Hi to the >3k of you who joined us! As a brief intro, hi, we are AI News, a side project started over the 2023 holiday break to solve AI Discord overwhelm almost 1 year ago. We currently save ~15 human years of reading per day.
- The main thing to understand is this is a recursively summarized tool for AI Engineers. You are not meant to read the whole thing! Skim, then cmd+f or search archives for more on the thing you want.
- If you'd like a personalized version pointed at different data sources/with different priorities, you can now try Smol Talk for Twitter and Reddit which we just launched today!
- We are also experimenting with smol text ads to fund development, email us only if you have something relevant for AI Engineers!
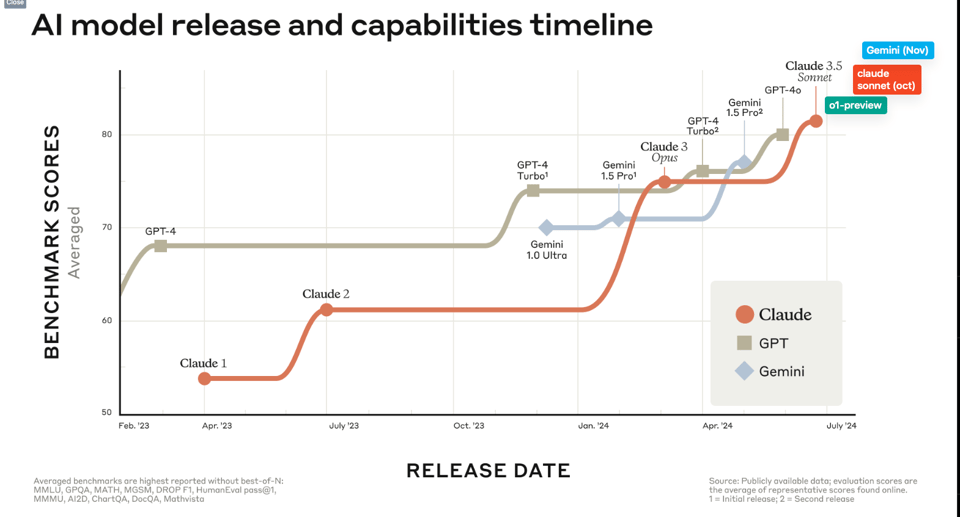
When Anthropic announced 3.5 Sonnet in June, they also published an oddly descriptive chart demonstrating what Dario terms a "race to the top" - the world's top 3 AI labs (ex Meta/X.ai/01.ai) running up benchmarks in tight lockstep. With the latest Nov 14 edition of Gemini, we can now update this chart with the fall editions of all 3 frontier models:
LMArena (formerly LMsys) explains the rank updates best:
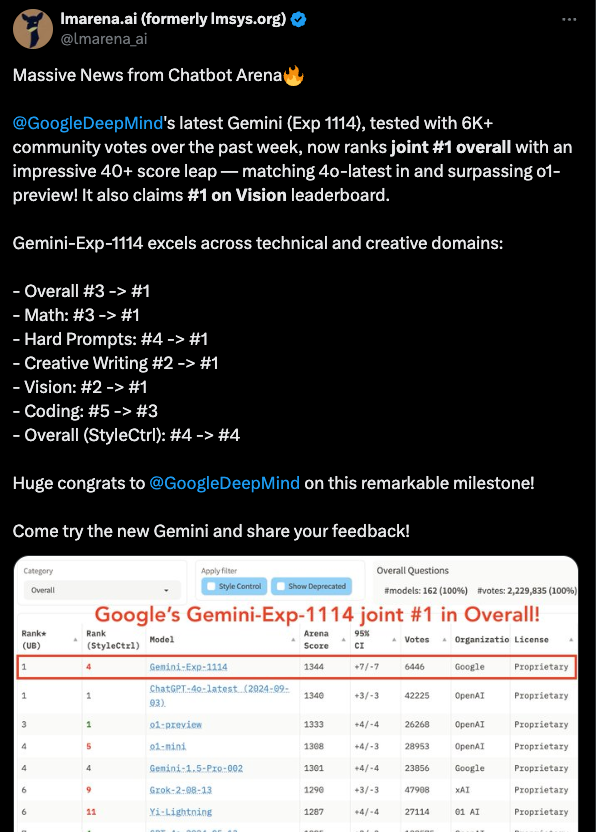
There is no paper accompanying this update, nor is it yet available in the API, so there's unfortunately not much else to discuss here - normally a disqualifier for feature story, but when we have a new #1 LLM, we have to report on it.
This update comes at a convenient time for Gemini just as it deals with some very bizarre and alarming alignment issues.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- LM Studio Discord
- Unsloth AI (Daniel Han) Discord
- OpenRouter (Alex Atallah) Discord
- Eleuther Discord
- aider (Paul Gauthier) Discord
- Nous Research AI Discord
- Modular (Mojo 🔥) Discord
- Perplexity AI Discord
- Interconnects (Nathan Lambert) Discord
- GPU MODE Discord
- Notebook LM Discord Discord
- Latent Space Discord
- OpenAI Discord
- OpenInterpreter Discord
- Cohere Discord
- LlamaIndex Discord
- tinygrad (George Hotz) Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- DSPy Discord
- LLM Agents (Berkeley MOOC) Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- AI21 Labs (Jamba) Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #general (392 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (2 messages):
- HuggingFace ▷ #cool-finds (5 messages):
- HuggingFace ▷ #i-made-this (51 messages🔥):
- HuggingFace ▷ #reading-group (51 messages🔥):
- HuggingFace ▷ #computer-vision (3 messages):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- LM Studio ▷ #general (54 messages🔥):
- LM Studio ▷ #hardware-discussion (246 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (217 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (11 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (31 messages🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (2 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (5 messages):
- OpenRouter (Alex Atallah) ▷ #general (201 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (7 messages):
- Eleuther ▷ #general (43 messages🔥):
- Eleuther ▷ #research (123 messages🔥🔥):
- Eleuther ▷ #interpretability-general (4 messages):
- Eleuther ▷ #lm-thunderdome (7 messages):
- aider (Paul Gauthier) ▷ #announcements (1 messages):
- aider (Paul Gauthier) ▷ #general (123 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (29 messages🔥):
- aider (Paul Gauthier) ▷ #links (2 messages):
- Nous Research AI ▷ #general (142 messages🔥🔥):
- Nous Research AI ▷ #interesting-links (6 messages):
- Modular (Mojo 🔥) ▷ #general (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (120 messages🔥🔥):
- Perplexity AI ▷ #general (72 messages🔥🔥):
- Perplexity AI ▷ #sharing (8 messages🔥):
- Perplexity AI ▷ #pplx-api (7 messages):
- Interconnects (Nathan Lambert) ▷ #news (22 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
- Interconnects (Nathan Lambert) ▷ #random (18 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (26 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (9 messages🔥):
- GPU MODE ▷ #general (2 messages):
- GPU MODE ▷ #triton (4 messages):
- GPU MODE ▷ #torch (2 messages):
- GPU MODE ▷ #beginner (4 messages):
- GPU MODE ▷ #off-topic (1 messages):
- GPU MODE ▷ #rocm (1 messages):
- GPU MODE ▷ #self-promotion (3 messages):
- GPU MODE ▷ #🍿 (1 messages):
- GPU MODE ▷ #thunderkittens (34 messages🔥):
- GPU MODE ▷ #edge (5 messages):
- Notebook LM Discord ▷ #use-cases (16 messages🔥):
- Notebook LM Discord ▷ #general (40 messages🔥):
- Latent Space ▷ #ai-general-chat (53 messages🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- OpenAI ▷ #ai-discussions (31 messages🔥):
- OpenAI ▷ #gpt-4-discussions (11 messages🔥):
- OpenAI ▷ #prompt-engineering (5 messages):
- OpenAI ▷ #api-discussions (5 messages):
- OpenInterpreter ▷ #general (34 messages🔥):
- OpenInterpreter ▷ #ai-content (7 messages):
- Cohere ▷ #discussions (15 messages🔥):
- Cohere ▷ #announcements (1 messages):
- Cohere ▷ #questions (2 messages):
- Cohere ▷ #api-discussions (13 messages🔥):
- Cohere ▷ #projects (1 messages):
- LlamaIndex ▷ #blog (1 messages):
- LlamaIndex ▷ #general (26 messages🔥):
- tinygrad (George Hotz) ▷ #general (16 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (15 messages🔥):
- LAION ▷ #general (5 messages):
- LAION ▷ #research (5 messages):
- DSPy ▷ #show-and-tell (1 messages):
- DSPy ▷ #general (7 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (2 messages):
- AI21 Labs (Jamba) ▷ #general-chat (2 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Tools
- Model Releases and Enhancements: @jerryjliu0 introduced a new RAG technique for contiguous chunk retrieval, enhancing @OpenAI's GPT-4 capabilities. Additionally, @AnthropicAI announced the release of their benchmark for jailbreak robustness, emphasizing adaptive defenses against new attack classes. @LangChainAI launched Promptim, an experimental library for prompt optimization, aimed at systematically improving AI system prompts.
- Tool Integrations and Services: @Philschmid highlighted the decoupling of hf(.co)/playground into a standalone open-source project, fostering community collaboration. @AIatMeta unveiled NeuralFeels with neural fields, enhancing visuotactile perception for in-hand manipulation.
AI Governance and Ethics
- Resignations and Governance Insights: @RichardMCNgo announced his resignation from OpenAI, urging stakeholders to read his thoughtful message on AI governance and theoretical alignment. @teortaxesTex discussed the importance of truthful public information in AI governance to prevent misinformation and ensure ethical alignment.
- Ethical Deployment and Guardrails: @AndrewYNg and @ShreyaR promoted a new course on AI guardrails, focusing on reliable LLM applications. @AnthropicAI emphasized the significance of jailbreak rapid response in making LLMs safer through adaptive techniques.
Scaling AI and Evaluation Challenges
- Scaling Limits and Evaluation Saturation: @swxy addressed the notion that scaling has hit a wall, citing evaluation saturation as a primary factor. @synchroz echoed concerns about scaling limitations, highlighting the economic challenges in further scaling AI models.
- Compute and Optimization: @bindureddy argued that the perceived AI slowdown is misleading, attributing it to the saturation of benchmarks. @sarahookr discussed the diminishing returns of scaling pre-training and the need to explore architecture optimization beyond current paradigms.
Software Tools, Libraries, and Development Platforms
- Development Tools and Libraries: @tom_doerr shared multiple releases, including a zero-config tool for development certificates and the Spin framework for serverless applications powered by WebAssembly. @wightmanr enhanced timm.optim, making optimizer factories more accessible for developers.
- Integration and Workflow Automation: @LangChainAI demonstrated how AI Assistants can leverage custom knowledge sources for improved threat detection. @swyx emphasized the importance of focusing on AI product development rather than research for non-researchers.
AI Research and Papers
- Published Research and Papers: @SchmidhuberAI presented a new paper on narrative essence for story formation with potential military applications. @wsmerk shared insights from the paper titled "On the diminishing returns of scaling", discussing compute thresholds and the limitations of current scaling laws.
- Conference Highlights: @sarahookr showcased their main-track work at #EMNLP2024, highlighting Aya Expanse breakthroughs. @finbarrtimbers announced an upcoming event related to reinforcement learning and the exploration of exploitation/exploration boundaries.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Nvidia RTX 5090 enters production with 32GB VRAM
- Nvidia RTX 5090 with 32GB of RAM rumored to be entering production (Score: 271, Comments: 139): Nvidia is reportedly shifting its production focus to the RTX 50 series, with the RTX 5090 rumored to feature 32GB of RAM. Concerns are rising about potential scalper activity affecting the availability and pricing of these new GPUs, as highlighted in multiple sources including VideoCardz and PCGamesN.
- There is skepticism about the 32GB RAM rumor for the RTX 5090, with some users questioning the validity of the sources and suggesting that Nvidia might change specifications last minute, referencing past incidents like the 4080/4070 fiasco. The rumor of 32GB VRAM has been circulating widely, but it remains unconfirmed by official sources.
- Users express concerns over scalper activity and high pricing, with predictions of prices reaching $3000 or more due to scalpers and market demand. Some comments discuss the potential impact of Nvidia's production shifts and legal restrictions, like the inability to sell in China, on the availability and pricing in other regions such as the European Union.
- Discussions highlight the use cases of RTX 5090 beyond gaming, focusing on professional and hobbyist applications like running local models and AI tasks. Users compare the potential performance and VRAM requirements of the 5090 with current models like the RTX 3090 and emphasize the importance of VRAM in handling tasks like AI video generation and large language models.
Theme 2. MMLU-Pro scores: Qwen and Claude Sonnet models
- MMLU-Pro score vs inference costs (Score: 215, Comments: 31): MMLU-Pro score and inference costs are likely the focus of analysis, examining the relationship between model performance metrics and the financial implications of running inference tasks. This discussion is relevant for engineers optimizing AI models for cost-efficiency while maintaining high performance.
- Claude Sonnet 3.5 is praised for its versatility and accuracy in handling complex tasks, though it requires specific prompting for novel solutions. It is considered a highly efficient tool for programmers due to its ability to understand and solve errors quickly.
- The Tencent Hunyuan model is noted for its high MMLU score and its architecture as a mixture of experts with 52 billion active parameters. This model is suggested as potentially outperforming existing models like Sonnet 3.5.
- Discussions highlight the Qwen models as cost-effective, with Qwen 2.5 prominently defining the Pareto curve for performance and cost efficiency. The Haiku model is criticized for being overpriced, and the analysis of inference costs shows Claude 3.5 Sonnet has significantly higher costs compared to 70B models.
Theme 3. Qwen2.5 RPMax v1.3: Creative Writing Model
- Write-up on repetition and creativity of LLM models and New Qwen2.5 32B based ArliAI RPMax v1.3 Model! (Score: 103, Comments: 60): The post discusses the Qwen2.5 32B based ArliAI RPMax v1.3 Model, focusing on its repetition and creativity in the context of LLM (Large Language Model) performance. The absence of a detailed post body limits specific insights into the model's training methods or performance metrics.
- Model Versions and Training Improvements: The discussion highlights the evolution of the RPMax model from v1.0 to v1.3, with improvements in training parameters and dataset curation. Notably, v1.3 uses rsLoRA+ for better learning and lower loss, and the model is praised for its creativity and reduced repetition in writing tasks.
- Dataset and Fine-Tuning Strategy: The model's success is attributed to a curated dataset that avoids repetition and focuses on quality over quantity. The training involves only a single epoch with a higher learning rate, aiming for creative output rather than exact replication of training data, which differs from traditional fine-tuning methods.
- Community Feedback and Model Performance: Users report that the model achieves its goal of being a creative writing/RP model, with some describing interactions as feeling almost like engaging with a real person. The model's performance in creative writing is discussed, with comparisons to other models like EVA-Qwen2.5-32B for context handling and writing quality.
Theme 4. Qwen 32B vs 72B-Ins on Leetcode Comparison
- Qwen 32B Coder-Ins vs 72B-Ins on the latest Leetcode problems (Score: 79, Comments: 23): The post evaluates the performance of Qwen 32B Coder versus 72B non-coder variant and GPT-4o on recent Leetcode problems, highlighting the models' strengths in reasoning over pure coding. Tests were conducted using vLLM with models quantized to FP8 and a 32,768-token context length, running on H100 GPUs. The author notes that this benchmark is 70% reasoning and 30% coding, emphasizing that hard Leetcode problems were mostly excluded due to their complexity and the models' generally poor performance on them.
- The author confirms that all test results are based on pass@1, which is a common metric for evaluating model performance on coding tasks. A user suggests expanding the tests to include 14B and 7B coders for broader comparison, and the author expresses openness to this if there is enough interest, potentially leading to an open-source project.
- One commenter suggests that the skill required to solve Leetcode problems has become more accessible due to advancements in AI, equating the skillset to the size of a PS4 game. Another user counters that this raises the skill floor, implying that while AI can handle simpler tasks, more complex problem-solving skills are still necessary.
- There is interest in comparing different quantization methods, specifically FP8 versus Q4_K_M, to determine which is better for inference. This highlights ongoing curiosity about the efficiency and performance trade-offs in model quantization techniques.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Gemini 1.5 Pro Released - Claims Top Spot on LMSys Leaderboard
- Gemini-1.5-Pro, the BEST vision model ever, WITHOUT EXCEPTION, based on my personal testing (Score: 48, Comments: 28): Gemini-1.5-Pro appears to be a multimodal vision model, but without any post content or testing details provided, no substantive claims about its performance can be verified. The title makes subjective claims about the model's superiority but lacks supporting evidence or comparative analysis.
- Users noted varying performance across different tasks, with one reporting that for graph analysis, their testing showed Claude Sonnet 3.5 > GPT-4 > Gemini-1.5-Pro, though others cautioned against drawing conclusions from limited testing samples.
- Discussion of multimodal capabilities highlighted both strengths and limitations, with users noting that while Gemini and Imagen are underrated for multimodal input and image generation, the technology isn't yet advanced enough for real-time webcam interaction.
- Specific image analysis comparisons showed mixed accuracy, with Flash correctly identifying certain details (pigtails) while Pro provided more comprehensive descriptions, though both had some inaccuracies in their observations.
- New Gemini model #1 on lmsys leaderboard above o1 models ? Anthropic release 3.5 opus soon (Score: 163, Comments: 57): Google's Gemini has reached the #1 position on the LMSys leaderboard, surpassing OpenAI's models in performance rankings. Anthropic plans to release their new Claude 3.5 Opus model in the near future.
- LMSYS leaderboard is criticized for lacking quality control and being based solely on user votes about formatting rather than actual performance. Multiple users point to LiveBench as a more reliable benchmark for model evaluation.
- Users debate the performance of Claude 3.5 Sonnet (also referred to as 3.6), with some highlighting its 32k input context and slower but more thorough "thinking" approach. Several alternative benchmarking resources were shared, including Scale.com and LiveBench.ai.
- Anthropic's CEO Dario acknowledged in a Lex interview that naming both versions "3.5" was confusing and suggested they should have called the new version "3.6" instead. The company has recently removed the "new" label from their UI for the model.
Theme 2. Undetectable ML Model Backdoors Using Digital Signatures - New Research
- [R] Undetectable Backdoors in ML Models: Novel Techniques Using Digital Signatures and Random Features, with Implications for Adversarial Robustness (Score: 27, Comments: 5): The research demonstrates how to construct undetectable backdoors in ML models using two frameworks: digital signature scheme-based backdoors and Random Fourier Features/Random ReLU based backdoors, which remain undetectable even under white-box analysis and with full access to model architecture, parameters, and training data. The findings reveal critical implications for ML security and outsourced training, showing that backdoored models maintain identical generalization error as clean models while allowing arbitrary output manipulation through subtle input perturbations, as detailed in their paper "Planting Undetectable Backdoors in Machine Learning Models".
Theme 3. New CogVideoX-5B Open Source Text-to-Video Model Released
- CogvideoX + DimensionX (Comfy Lora Orbit Left) + Super Mario Bros. [NES] (Score: 52, Comments: 4): A post referencing CogVideoX 5B and DimensionX models used with Super Mario Bros NES content, though no specific details or examples were provided in the post body. The combination suggests video generation capabilities using these AI models with retro gaming content.
- CogVideoX-5b multiresolution finetuning on 4090 (Score: 21, Comments: 0): CogVideoX-5b model can be fine-tuned using LoRA on an NVIDIA RTX 4090 GPU using the cogvideox-factory repository. The post includes a video demonstration of the fine-tuning process.
Theme 4. StackOverflow Traffic Plummets as AI Tools Rise
- RIP Stackoverflow (Score: 703, Comments: 125): Stack Overflow experienced a significant traffic decline after the rise of AI coding tools, leading to discussions about the future viability of traditional programming Q&A platforms. The lack of post body content prevents a more detailed analysis of specific metrics or causes of this decline.
- Users overwhelmingly criticize Stack Overflow's toxic culture, with a 40-year software engineering veteran receiving 552 upvotes for condemning the platform's arrogant attitude, and multiple users citing frustration with the "duplicate question" responses and dismissive treatment of newcomers.
- Concerns about model collapse and AI training data were raised, as the decline in Stack Overflow traffic could lead to outdated information sources for future AI models, with users noting that AI tools still rely on human-annotated data for training.
- Multiple developers express preference for ChatGPT's friendlier approach to answering questions, with users highlighting that AI tools provide immediate responses without the gatekeeping and hostility experienced on Stack Overflow, particularly noting that GPT was released in late 2022.
- ChatGPT doesn’t have a shitty attitude when you ask a relevant question either. (Score: 221, Comments: 25): ChatGPT provides a more welcoming environment for asking technical questions compared to Stack Overflow's known hostile community responses. The post implies that ChatGPT delivers answers without the negative attitudes sometimes encountered on Stack Overflow when users ask legitimate questions.
- Users strongly criticize Stack Overflow's toxic culture, with multiple examples of questions being marked as duplicates linking to 14-year-old obsolete answers. The community's elitist behavior includes dismissive responses and hostile treatment of new users.
- ChatGPT learned from a broad range of internet content including public GitHub repositories and pastebin scripts, not just Stack Overflow. The AI provides a more approachable platform for asking repeated or basic questions without fear of negative feedback.
- The post references a traffic bump in July 2023 coinciding with the launch of OverflowAI. Users note that Stack Exchange forums beyond programming, such as physics and electrical engineering, suffer from similar toxicity issues.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. AI Models Take the Spotlight: Gemini Soars and New Releases Impress
- Gemini AI Takes the Throne in Chatbot Arena: Google's Gemini (Exp 1114) skyrockets to the top rank in Chatbot Arena, outperforming competitors with a 40+ point increase based on 6K+ community votes. Users praise its enhanced performance in creative writing and mathematics.
- UnslopNemo 12B and Friends Join the Adventure Club: UnslopNemo 12B v4 launches for adventure writing and role-play, joined by SorcererLM and Inferor 12B, models optimized for storytelling and role-play scenarios.
- Tinygrad Flexes Muscles at MLPerf Training 4.1: Tinygrad participates in MLPerf Training 4.1, successfully training BERT and aiming for a 3x performance boost in the next cycle, marking the first inclusion of AMD in their training process.
Theme 2. AI Gets Cozy with Developers: Tools Integrate into Coding Environments
- ChatGPT Moves into VS Code's Spare Room: ChatGPT for macOS now integrates with desktop applications like VS Code and Terminal, offering context-aware coding assistance for Plus and Team users in beta.
- Code Editors Break the Token Ceiling: Tools like Cursor and Aider defy limits by generating code edits exceeding 4096 tokens, prompting developers to wonder about their token management magic.
- LM Studio Users Sideload Llama.cpp for Extra Power: Frustrated LM Studio users discuss sideloading features from llama.cpp, eager to overcome current limitations and enhance their AI models' capabilities.
Theme 3. Data Privacy Panic: GPT-4 and LAION Face Scrutiny
- GPT-4 Spills the Beans with Data Leaks: Users report potential data leaks in GPT-4, noting unexpected Instagram usernames in outputs, sparking concerns over training data integrity.
- LAION Tangled in EU Copyright Web: Debates ignite over LAION's dataset allowing downloads of 5 billion images, with critics claiming violations of EU copyright laws due to circumventing licensing terms.
Theme 4. Robots Meet AI: Benchmarking Vision Language Action Models
- AI Models Put Through Their Paces on 20 Real-World Tasks: A collaborative paper titled "Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks" evaluates how VLA models control robots across 20 tasks, aiming to establish new benchmarks.
- Researchers Unite: Georgia Tech, MIT, and More Dive into Robotics: Institutions like Georgia Tech, MIT, and Metarch AI collaborate to assess VLA models, sharing resources and code on GitHub for community engagement.
Theme 5. Ads Crash the AI Party: Users Frown at Sponsored Questions
- Perplexity's Ads Perplex Users (Even the Paying Ones): Perplexity introduces ads as "sponsored follow-up questions", frustrating Pro subscribers who expected an ad-free experience.
- Ad Rage: Subscription Value Questioned: Users across platforms express dissatisfaction over ads appearing despite paid subscriptions, sparking debates on the viability of current subscription models.
PART 1: High level Discord summaries
HuggingFace Discord
-
GPT-4 Data Leak Raises Data Integrity Concerns: Users reported potential data leaks in the GPT-4 series, specifically noting the inclusion of Instagram usernames in the model's outputs.
- This issue raises questions about the integrity of training data and the completeness of leak assessments.
- Benchmarking Vision Language Action Models Released: A new paper titled Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks profiles VLA models and evaluates their performance on 20 real-world tasks.
- The study, a collaboration between Georgia Tech, MIT, and Manifold, aims to establish benchmarks for multimodal action models.
- Kokoro TTS Model Gains Community Feedback: The Kokoro TTS model with approximately 80M parameters was shared for feedback, with users noting improvements in English output quality.
- Despite its compact size, the model's speed and stability impressed users, accompanied by a roadmap for enhanced emotional speech capabilities.
- Open3D-ML Enhances 3D Machine Learning: Open3D-ML was highlighted as a promising extension of Open3D tailored for 3D Machine Learning tasks.
- Its integration is attracting interest for its potential to improve various 3D applications, expanding the utility of the framework.
- Stable Diffusion 1.5 Optimized for CPU Performance: A user opted for Stable Diffusion 1.5 as the lightest version available to ensure efficient CPU performance.
- This choice underscores the community's focus on optimizing model operations for more accessible hardware configurations.
LM Studio Discord
-
Boosting LM Studio with llama.cpp Sideloading: A user requested a method to seamlessly sideload features from llama.cpp into LM Studio, highlighting frustrations with the existing limitations.
- The discussion emphasized ongoing development efforts to incorporate this functionality in upcoming updates, with the community eagerly anticipating a more flexible integration.
- GPU Struggles Running Nemotron 70b Models: Users reported varying performance metrics when running Nemotron 70b on different GPU setups, achieving throughput rates between 1.97 to 14.0 tok/s.
- It was identified that memory availability and CPU bottlenecks are primary factors affecting model performance, prompting considerations for GPU upgrades.
- CPUs Lag Behind GPUs for LLM Workloads: The consensus among members is that CPUs are often unable to match the performance of GPUs for modern LLM tasks, as evidenced by lower tok/s rates.
- Insights were shared on how memory bandwidth and effective GPU offloading are critical for optimizing overall model performance.
- M4 Max's Potential with 128GB RAM: With the M4 Max equipped with 128GB of RAM, users are keen to test its capabilities against dedicated GPU configurations for LLM performance.
- There is a strong interest in conducting and sharing benchmarks to guide purchasing decisions, addressing the community's need for AI-specific performance evaluations.
- Integrating AI into SaaS Platforms: A member outlined plans to embed AI functionalities into a SaaS application, leveraging LM Studio's API to enhance development processes.
- The conversation explored various AI tools that could be utilized to improve software features, indicating a robust interest in practical AI integrations.
Unsloth AI (Daniel Han) Discord
-
Unsloth AI Training Efficiency: Members discussed the memory efficiency of the Unsloth platform, with theyruinedelise affirming that it is the most memory-efficient training service available.
- Unsloth is set to implement a CPO trainer, further enhancing its training efficiency.
- LoRA Parameters in Fine-Tuning: It was indicated that using smaller values for rank and adaptation can help improve training on datasets without distorting model quality.
- Users were advised to understand rank (r) and adaptation (a) factors, emphasizing that a quality dataset is crucial for effective training.
- Harmony Project Collaboration: A member introduced the Harmony project, an initiative developing an AI LLM-based tool for data harmonization, and provided a Discord server for contributions.
- Currently based at UCL, Harmony is seeking volunteers and is hosting a competition to enhance their LLM matching algorithms, with details available on their competition page.
- Editing Code with AI Tools: anubis7645 is building a utility for editing large React files, considering how tools like Cursor generate edits seamlessly despite model token limits.
- lee0099 explained the concept of speculative edits, allowing for fast application and relating it to coding practices.
- Using LoftQ without Loading Unquantized Models: A query was raised about using LoftQ directly without loading an unquantized model in VRAM-constrained environments like T4.
- It was suggested to adjust target modules for LoRA to include only linear and embedding layers to enhance patch efficacy during fine-tuning.
OpenRouter (Alex Atallah) Discord
-
Launch of UnslopNemo 12B v4 for Adventure Writing: The latest model, UnslopNemo 12B, is now available, optimized for adventure writing and role-play scenarios.
- A free variant can be accessed for 24 hours via UnslopNemo 12B Free.
- SorcererLM Enhances Storytelling: SorcererLM is fine-tuned on WizardLM-2-8x22B, offering improved storytelling capabilities.
- Users can request access or seek further information through the Discord channel.
- Inferor 12B: The Ultimate Roleplay Model: Inferor 12B integrates top roleplay models, though users are advised to set output limits to prevent excessive text.
- Access to this model is available upon request through Discord.
- AI Studio Introduces generateSpeech API: A new
generateSpeechAPI endpoint has been launched in AI Studio, enabling speech generation from input transcripts.
- This feature aims to enhance model capabilities in converting text to audio output.
- Companion Bot Enhances Discord Security: Companion is introduced as an AI-powered Discord bot that personalizes personas while automating moderation.
- Features include impersonation detection, age exploit detection, and dynamic message rate adjustments to boost server engagement.
Eleuther Discord
-
Benchmarking Vision Language Action Models: A collaboration between Manifold, Georgia Tech, MIT, and Metarch AI released the paper 'Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks', evaluating models like GPT4o across 20 real-world tasks.
- Related resources include Twitter highlights and the GitHub repository, providing detailed insights into the experimental setups and results.
- Transformer Architecture Evolves with Decoder-Only Models: Transformers continue to dominate with advancements like decoder-only architectures and mixtures of experts, though their compatibility with current hardware remains under scrutiny.
- Members debated the necessity for evolving hardware to support these architectures, acknowledging the ongoing trade-offs in performance and efficiency.
- Shampoo and Muon Optimize Learning: Discussions on Shampoo and Muon algorithms highlighted their roles in optimizing the Fisher Information Matrix for better Hessian estimation, referencing the paper 'Old Optimizer, New Norm: An Anthology'.
- Participants questioned the underlying assumptions of these algorithms, comparing them to methods like KFAC and debating their practical effectiveness in diverse training scenarios.
- Hardware Advances Boost AI Training Efficiency: Blackwell's latest hardware advancements have significantly improved transformer inference efficiency, surpassing previous benchmarks set by Hopper.
- Conversations emphasized the critical importance of memory bandwidth and VRAM in implementing large-scale AI models effectively.
- Enhancing Pythia with Mixture of Experts: A query about integrating a mixture-of-expert (MoE) version of the Pythia model suite sparked interest in modernizing hyperparameters using techniques like SwiGLU.
- The discussion focused on determining specific research questions that MoE could address within the Pythia framework, considering the existing training setup and potential benefits.
aider (Paul Gauthier) Discord
-
Aider v0.63.0 Now Available: The new release of Aider v0.63.0 integrates support for Qwen 2.5 Coder 32B and includes enhancements like Web Command improvements and Prompting Enhancements.
- Aider's contribution comprises 55% of the code in this update, boosting performance and reliability.
- Qwen 2.5 Coder Gains Ground in Aider v0.63.0: The Qwen 2.5 Coder 32B model is now supported in Aider v0.63.0, demonstrating improved performance in benchmarks compared to previous versions.
- Users are experimenting with the model through OpenRouter, though some report underwhelming results against established benchmarks.
- Gemini Experimental Models Introduced: New Gemini experimental models have been released, aiming to tackle complex prompts and enhance usability within the Aider ecosystem.
- However, accessing these models has been challenging due to permission restrictions on Google Cloud, limiting user experimentation.
- CLI Scripting Enhancements with Aider: Members are leveraging CLI scripting with Aider to automate repetitive tasks, indicating a growing demand for programmable interactions.
- The Aider scripting documentation highlights capabilities like applying edits to multiple files programmatically, showcasing the tool’s adaptability.
- Aider Ecosystem Documentation Improvements: Users are advocating for enhanced documentation within the Aider ecosystem, considering platforms like Ravel for improved searchability.
- These discussions underscore the necessity for clearer guides as Aider’s functionalities expand rapidly.
Nous Research AI Discord
-
Joining Forge API Beta Made Easier: Multiple members experienced issues joining the Forge API Beta, with teknium confirming additions based on requests.
- Some users were confused about email links directing them to the general channel instead.
- Insights into Hermes Programming: Members discussed their initial programming languages, with shunoia pivoting to Python thanks to Hermes, while oleegg offered sympathy for the decision.
- jkimergodic_72500 elaborated on Perl as a flexible language, providing context for the current dialogue on programming experiences.
- Concerns Over TEE Wallet Collation: mrpampa69 raised concerns regarding the inconsistency of wallets for TEE, arguing that it undermines the bot's perceived sovereignty.
- Responses indicated a need for robust decision-making before collation to maintain operational autonomy and prevent misuse.
- Advanced Translation Tool Launched: A new AI-driven translation tool focuses on cultural nuance and adaptability, making translations more human-like.
- It tailors the output by considering dialects, formality, tone, and gender, making it a flexible choice for diverse needs.
Modular (Mojo 🔥) Discord
-
Mojo's Low-Level Syntax Performance: Members discussed how Mojo's low-level syntax may not maintain the Pythonic essence while providing better performance compared to high-level syntax.
- One pointed out that high-level syntax lacks the performance of C, but tools like NumPy can still achieve close results under certain conditions.
- Struggles with Recursive Vectorization: The conversation shifted to Recursive Vectorization and its impact on performance in Mojo, highlighting concerns over the lack of optimizations in recursive code compared to Rust or C++.
- Participants agreed that missing features in the type system currently impede the development of the standard library, making it hard to write efficient code.
- Tail Call Optimization in MLIR: A sentiment emerged around implementing Tail Call Optimization (TCO) in MLIR to enable compiler optimizations for recursive code and better performance.
- Members expressed uncertainty over the need for preserving control flow graphs in LLVM IR, debating its importance for debugging.
- Lang Features Priority Discussion: There was a consensus on prioritizing basic type system features over more advanced optimizations to ensure language readiness as more users are onboarded.
- Participants warned against overwhelming the development with additional issues while the foundational features are still pending.
- LLVM Offload and Coroutine Implementation: Interest was shown in LLVM's offload capabilities and how coroutine implementations are being facilitated in Mojo.
- Discussion highlighted that coroutines are conceptually similar to tail-recursive functions, leading to considerations of whether transparent boxing is necessary.
Perplexity AI Discord
-
Perplexity Expands Campus Strategist Program to Canada: Responding to high demand, Perplexity is extending their Campus Strategist Program to Canada, allowing interested applicants to apply for the 2024 cohort.
- The program offers hands-on experience and mentorship for university students, enhancing their skills and providing valuable industry exposure.
- Google Gemini Dominates Chatbot Arena: Google's Gemini (Exp 1114) has achieved the top rank in the Chatbot Arena, outperforming competitors with a 40+ score increase based on 6K+ community votes over the past week, as highlighted by lmarena.ai.
- This advancement underscores Gemini's enhanced performance and solidifies its position as a leading model in AI chatbot competitions.
- Ads Challenge Pro Subscription Value: Users are expressing frustration over the introduction of ads for all users, including Pro subscribers, questioning the value of their subscriptions.
- Concerns center around the expectation of an ad-free experience for paying users, leading to discussions about the subscription model's viability.
- API Dashboard Reports Inaccurate Token Usage: Several users have reported that the API dashboard is not updating token usage accurately, causing confusion and potential billing issues.
- This malfunction affects multiple members, prompting suggestions to report the issue for a timely resolution.
- Reddit Citations Failing via API: Users are encountering issues with Reddit citations not functioning correctly through the API, despite previous reliability.
- Instances of random URL injections without valid sources are leading to inaccurate results, raising concerns about the API's citation integrity.
Interconnects (Nathan Lambert) Discord
-
Operator AI Agent Set to Automate Tasks: OpenAI's new AI agent tool, Operator, is scheduled for a January launch, aiming to automate browser-based tasks such as writing code and booking travel, as detailed in this tweet.
- This tool represents a significant advancement in AI utility, enhancing user efficiency in managing routine operations.
- Gemini-Exp-1114 Dominates Chatbot Arena: @GoogleDeepMind's Gemini-Exp-1114 achieved a top ranking in the Chatbot Arena, outperforming competing models with substantial score improvements across various categories.
- It now leads the Vision leaderboard and excels in creative writing and mathematical tasks, demonstrating its superior capabilities.
- Qwen Outperforms Llama in Division Tasks: In comparative tests, Qwen 2.5 outperformed Llama-3.1 405B when handling basic division problems with prompts like
A / B.
- Funnily enough, Qwen switches to CoT mode with large numbers using LaTeX or Python, whereas Llama's output remains unchanged.
- Open-source AI Urged Before Competitors Involve: Community members emphasized the urgent need to engage in open-source AI discussions with Dwarkesh to prevent another prominent firm from taking the lead.
- Collaboration was proposed to address current concerns over financial powers influencing technology dialogues.
GPU MODE Discord
-
Triton Performance Tuning: Discussions highlighted challenges in kernel design, particularly in determining if the first dimension is a vector with sizes varying between 1 and 16, considering padding to a minimum size of 16 as a potential solution.
- Members suggested utilizing
BLOCK_SIZE_Mastl.constexprfor conditional statements in kernels and employingearly_config_prunefor autotuning based on batch size, recommending a gemv implementation for batch size of 1 to enhance GPU performance. - torch.compile() Integration with Distributed Training: Concerns were raised about using torch.compile() in conjunction with Distributed Data Parallel (DDP), specifically whether to wrap torch.compile() around the DDP wrapper or place it inside.
- Similar inquiries were made regarding the integration of torch.compile() with Fully Sharded Data Parallel (FSDP), questioning if analogous considerations apply as with DDP.
- Shared Memory Constraints in CUDA Kernels: A user encountered kernel crashes when requesting 49,160 bytes of shared memory, which is below the
MAX_SHARED_MEMORYlimit, attributing the issue to static shared memory constraints on certain architectures.
- The discussion included the necessity of using dynamic shared memory for allocations exceeding 48KB, referencing the StackOverflow discussion for potential solutions involving
cudaFuncSetAttribute(). - GPU Profiling Tools Insights: A member sought recommendations on GPU profiling tools, expressing difficulties in interpreting reports generated by ncu.
- Another member advised acclimating to NCU, asserting it as the premier profiler that provides valuable optimization insights despite its learning curve.
- React Native LLM Library Launch: Software Mansion unveiled a new library for integrating LLMs within React Native, leveraging ExecuTorch to enhance performance.
- The library streamlines usage through installation commands that involve cloning the GitHub repository and running it on the iOS simulator, facilitating easier adoption and contribution.
- Members suggested utilizing
Notebook LM Discord Discord
-
Magic Book Podcast Experiment: A member created a magical PDF that reveals different interpretations based on who views it, shared in a podcast format.
- Listeners were encouraged to share their thoughts on this innovative podcast approach.
- NotebookLM Data Security Clarification: According to Google's support page, users' data is secure and not used to train NotebookLM models, regardless of account type.
- The privacy notice reiterated that human reviewers may only access information for troubleshooting.
- Feature Requests for Response Language: A user requested the ability to set response languages per notebook due to issues receiving answers in English instead of Greek.
- Implementing this feature could enhance user satisfaction in multilingual contexts.
- Pronunciation Challenges in NotebookLM: NotebookLM struggles with correctly pronouncing certain words, such as treating 'presents' as a gift rather than as an action.
- A suggested workaround involved using pasted text to instruct on pronunciation directly.
- Interest in API Updates: Members showed curiosity about potential updates regarding an API for NotebookLM, but were informed that no roadmap for features is currently published.
- The community relies on the announcement channel for any updates and new features.
Latent Space Discord
-
Perplexity's Ads Experimentation: Perplexity is initiating ads as 'sponsored follow-up questions' in the U.S., partnering with brands like Indeed and Whole Foods. TechCrunch Article details the launch.
- They stated that revenue from ads would help support publishers, as subscriptions alone aren’t enough for sustainable revenue generation.
- Gemini AI Ascends to #1: @GoogleDeepMind's Gemini (Exp 1114) has risen to joint #1 in the Chatbot Arena after a substantial performance boost in areas like math and creative writing. Google AI Studio is currently offering testing access.
- API access for Gemini is forthcoming, expanding its availability for developers and engineers.
- ChatGPT Desktop Gains Integrations: The ChatGPT desktop app for macOS now integrates with local applications such as VS Code and Terminal, available to Plus and Team users in a beta version.
- Some users have reported missing features and slow performance, raising questions about its current integration capabilities.
- AI Amplifies Tech Debt Costs: A blog post titled AI Makes Tech Debt More Expensive discussed how AI could increase the costs associated with tech debt, suggesting that companies with older codebases will struggle more than those with high-quality code.
- The post emphasized how generative AI widens the performance gap between these two groups.
- LLM Strategies for Excel Parsing: Users explored effective methods for handling Excel files with LLMs, particularly focusing on parsing financial data into JSON or markdown tables.
- Suggestions included exporting data as CSV for easier programming language integration.
OpenAI Discord
-
AI UI Control with ChatGPT: A member shared their system where ChatGPT can indirectly control a computer's UI using a tech stack that includes Computer Vision and Python's PyAutoGUI, and hinted at a video demonstration.
- Others raised questions about the code's availability and compared it to existing solutions like OpenInterpreter.
- GPT Lorebook Development: A user created a lorebook for GPT that loads entries based on keywords, featuring import/export capabilities and preventing spammed entries, set to be shared on GreasyFork after debugging.
- Discussions clarified that this lorebook is implemented as a script for Tampermonkey or Violentmonkey.
- Mac App Interface Optimizations: Members expressed gratitude for the optimization in the Mac App's model chooser interface, noting it enhances user experience significantly.
- One member remarked that the entire community is indebted to the team who implemented this change, echoing appreciation for usability improvements.
- LLM Mastery Techniques: Members discussed that while anyone can use LLMs, effectively prompting them requires skill and practice, much like carpentry tools.
- Knowing what to include to improve the chance of getting desired output can significantly enhance the interaction experience.
- 9 Pillars Solutions Exploration: A member encouraged pushing the limits of ChatGPT to discover the potential of the 9 Pillars Solutions, hinting at transformative outcomes.
- They claimed that significant insights could be achieved through this approach, sparking interest among other members.
OpenInterpreter Discord
-
Docker Open Interpreter: Streamlining Worker Management: A member proposed a fully supported Docker image for Open Interpreter, optimized for running as workers or warm spares, enhancing their current workaround-based workflow.
- They emphasized the necessity for additional configuration features, such as maximum iterations and settings for ephemeral instances, pointing to significant backend improvements.
- VividNode v1.7.1 Amplifies LiteLLM Integration: The new release of VividNode v1.7.1 introduces comprehensive support for LiteLLM API Keys, encompassing 60+ providers and 100+ models as detailed on GitHub.
- Enhancements feature improved usability with QLineEdit for model input and address bugs related to text input and LlamaIndex functionality, ensuring a smoother user experience.
- Voice Lab Unleashed: Open-Sourcing LLM Agent Evaluation: A member announced the open sourcing of Voice Lab, a framework designed for evaluating LLM-powered agents across various models and prompts, available on GitHub.
- Voice Lab aims to refine prompts and enhance agent performance, actively inviting community contributions and discussions to drive improvements.
- ChatGPT Desktop Dive: macOS Apps Integration: ChatGPT has been integrated with desktop applications on macOS, enabling enhanced responses in coding environments for Plus and Team users in its beta version.
- This update marks a significant shift in how ChatGPT interacts with coding tools on user desktops, offering a more cohesive development experience.
- Probabilistic Prowess: 100Mx GPU Efficiency Leap: A YouTube video highlighted a breakthrough in probabilistic computing that reportedly achieves 100 million times better energy efficiency compared to leading NVIDIA GPUs, available here.
- The video delves into advancements in probabilistic algorithms, suggesting potential revolutionary impacts on computational efficiency.
Cohere Discord
-
Cohere’s Token Tuning: Optimal Embedding Count: A member inquired about the optimal number of tokens for Cohere embedding models, especially for multi-modal inputs, clarifying based on current limits.
- Another member explained that the max context is currently 512 tokens, recommending experimentation within this boundary to achieve optimal performance.
- Beta Program Blitz: Research Prototype Sign-ups: Reminders were sent that the research prototype beta program sign-ups close before Tuesday, urging interested participants to register via the sign-up form.
- The program aims to explore the new Cohere tool for enhancing research and writing tasks, with participants providing valuable feedback.
- Podcast Purging: Scrubbing Content for LLMs: A member sought advice on how to scrub hours of podcast content, aiming to extract information for use with large language models.
- Another member queried if the goal was to transcribe the podcast content, emphasizing the importance of accurate transcriptions for effective LLM integration.
- VLA Models Unveiled: New Robotics Benchmarks: A new paper titled Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks was released, showcasing collaborations among Manifold, Georgia Tech, MIT, and Metarch AI.
- The research evaluates how Vision Language Action models control robots across 20 different real-world tasks, marking a significant advancement in benchmarking robotics.
- Azure AI V2 API Status: Coming Soon: Users inquired about the availability of the Azure AI V2 API, which is currently not operational as per the documentation.
- It was noted that existing offerings support the Cohere v1 API, with the V2 API expected to be available soon, according to the latest updates.
LlamaIndex Discord
-
RAGformation automates cloud setup: RAGformation allows users to automatically generate cloud configurations by describing their use case in natural language, producing a tailored cloud architecture.
- It also provides dynamically generated flow diagrams for visualizing the setup.
- Mem0 memory system integration: Mem0 was recently added to LlamaIndex, introducing an intelligent memory layer that personalizes AI assistant interactions over time. Detailed information is available in the Mem0 Memory documentation.
- Users can access this system via a managed platform or an open source solution.
- ChromaDB ingestion issues: A user reported unexpected vector counts when ingesting a PDF into ChromaDB, resulting in two vectors instead of the expected one. Members suggested this might be due to the default behavior of the PDF loader splitting documents by page.
- Additionally, the SentenceWindowNodeParser may increase vector counts because it generates a node for each sentence.
- Using SentenceSplitter with SentenceWindowNodeParser: A user inquired about combining SentenceSplitter and SentenceWindowNodeParser in an ingestion pipeline, noting concerns over the resulting vector count.
- Community feedback confirmed that improper combination can lead to excessive node creation, complicating outcomes.
tinygrad (George Hotz) Discord
-
Tinygrad Shines in MLPerf Training 4.1: Tinygrad showcased its capabilities by having both tinybox red and green participate in MLPerf Training 4.1, successfully training BERT.
- The team aims for a 3x performance improvement in the next MLPerf cycle and is the first to integrate AMD in their training process.
- New Buffer Transfer Function Introduced: A contributor submitted a pull request for a buffer transfer function in tinygrad, enabling seamless data movement between CLOUD devices.
- The implementation focuses on maintaining consistency with existing features, deeming size checks as non-essential.
- Evaluating PCIe Bandwidth Enhancements: Members discussed the potential of ConnectX-6 adapters to achieve up to 200Gb/s with InfiniBand, relating it to OCP3.0 bandwidth.
- Theoretical assessments suggest the possibility of 400 GbE bidirectional connectivity by bypassing the CPU.
- Optimizing Bitwise Operations in Tinygrad: A proposal was made to modify the minimum fix using bitwise_not, targeting improvements in the argmin and minimum functions.
- This enhancement is expected to significantly boost the efficiency of these operations.
- Investigating CLANG Backend Bug: A bug was identified in the CLANG backend affecting maximum value calculations in tensor operations, leading to inconsistent outputs from
.max().numpy()and.realize().max().numpy().
- The issue highlights potential flaws in handling tensor operations, especially with negative values.
OpenAccess AI Collective (axolotl) Discord
-
Nanobitz recommends alternative Docker images: Nanobitz advised using the axolotlai/axolotl images even if they lag a day behind the winglian versions.
- Hub.docker.com reflects that the latest tags are from 20241110.
- Discussion on Optimal Dataset Size for Fine-Tuning Llama: Arcadefira inquired about the ideal dataset size for fine-tuning a Llama 8B model, especially given its low-resourced language.
- Nanobitz responded with questions about tokenizer overlaps and suggested that if overlaps are sufficient, a dataset of 5k may be adequate.
- Llama Event at Meta HQ: Le_mess asked if anyone is attending the Llama event at Meta HQ on December 3-4.
- Neodymiumyag expressed interest, requesting a link to more information about the event.
- Liger kernel sees improvements: Xzuyn mentioned that the Liger project has an improved orpo kernel, detailing this through a GitHub pull request.
- They also noted it behaves like a flat line with an increase in batch size.
- Social Media Insight shared: Kearm shared a post from Nottlespike on X.com, indicating a humorous perspective on their day.
- The shared link leads to a post detailing Nottlespike's experiences.
LAION Discord
-
EPOCH 58 COCK model updates: The EPOCH 58 COCK model now has 60M parameters and utilizes f16, showing progress as its legs and cockscomb become more defined.
- This advancement indicates improvements in the model's structural detail and parameter efficiency.
- LAION copyright debate intensifies: A debate emerged around LAION's dataset, which allows downloading of 5 Billion images, with claims it may violate EU copyright laws.
- Critics argue this approach circumvents licensing terms and paywalls, unlike standard browser caching.
- New paper benchmarks VLA models on 20 robotics tasks: A collaborative paper titled Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks was released by Manifold, Georgia Tech, MIT, and Metarch AI, evaluating VLA models' performance on 20 real-world robotics tasks.
- Highlights are available in the Thread w/ Highlights, and the full analysis can be accessed via the Arxiv paper.
- Watermark Anything implementation launched on GitHub: The project Watermark Anything with Localized Messages is now available on GitHub, providing an official implementation of the research paper.
- This tool enables dynamic watermarking, potentially enhancing various AI workflows.
- 12M Public Domain Images dataset released: A 12M image set in the public domain has been released, offering valuable resources for machine learning projects.
- Interested developers can access the dataset here.
DSPy Discord
-
ChatGPT for macOS Integrates with Desktop Apps: ChatGPT for macOS now integrates with desktop applications such as VS Code, Xcode, Terminal, and iTerm2, enhancing coding assistance capabilities for users. This feature is currently in beta for Plus and Team users.
- The integration allows ChatGPT to interact directly with development environments, improving workflow productivity. Details were shared in a tweet from OpenAI Developers.
- Code Editing Tools Surpass 4096 Tokens: Tools like Cursor and Aider are successfully generating code edits that exceed 4096 tokens, showcasing advancements in handling large token outputs. Developers are seeking clarity on the token management strategies employed by these tools.
- The discussion emphasizes the need for effective token handling mechanisms to maintain performance in large-scale code generation tasks.
- Clarifying LM Assertions Deprecation: Members have raised concerns about the potential deprecation of LM assertions, noting the absence of
dspy.Suggestordspy.Assertin the latest documentation.
- It was clarified that while direct references are missing, these functions can still be accessed via the search bar, indicating ongoing updates to the documentation.
- Expanding Multi-Infraction LLM Applications: A member is developing an LLM application that currently generates defensive documents for specific infractions, such as alcohol ingestion. They aim to extend its capabilities to cover additional infractions without the need for separate optimized prompts.
- This initiative seeks to create a unified approach for handling various infractions, enhancing the application's versatility and efficiency.
LLM Agents (Berkeley MOOC) Discord
-
Quiz Eligibility and Deadlines: A new member inquired about completing quizzes to remain eligible for Trailblazer and above trails. Another member confirmed eligibility but stressed the importance of catching up quickly, with all quizzes and assignments due by December 12th.
- Members emphasized that quizzes are directly related to the course content, highlighting the necessity to stay up to date for full participation.
- Upcoming Event Announcement:
sheilabelannounced an event happening today: Event Link.
- No further details were provided about the event.
Gorilla LLM (Berkeley Function Calling) Discord
-
Writer Handler and Palmyra X 004 Model Added: A member announced the submission of a PR to incorporate a Writer handler and the Palmyra X 004 model into the leaderboard.
- This addition enhances the leaderboard's functionality, awaiting feedback and integration from the development team.
- Commitment to Review PR: Another member expressed intent to review the submitted PR, stating, 'Will take a look. Thank you!'
- This response underscores the collaborative effort and active participation within the project's review process.
AI21 Labs (Jamba) Discord
-
Legacy Models Cause Disruption: A member expressed frustration over the deprecation of legacy models, stating that the impact has been hugely disruptive due to the new models not being 1:1 in terms of output.
- We would like to continue using legacy models as the transition has not been smooth.
- Transition to Open Source Solutions: A member is working on converting to an open source solution but has been paying for the old models for almost 2 years.
- They raised concerns about future deprecations, asking, How can we be sure AI21 won't deprecate the new models in the future too?
Mozilla AI Discord
-
Local LLMs Workshop Kicks Off Tuesday: Join the Local LLMs Workshop on Tuesday, featuring Building your own local LLM's: Train, Tune, Eval, RAG all in your Local Env., to develop local language models.
- Participants will engage in hands-on training and gain insights on constructing effective local LLM systems.
- SQLite-Vec Enhances Metadata Filtering: Attend the SQLite-Vec Metadata Filtering event on Wednesday at SQLite-Vec now supports metadata filtering! to explore the new metadata filtering feature.
- This update allows users to efficiently filter metadata, improving data management capabilities.
- Autonomous AI Sessions with Refact.AI: Explore autonomous agents at the Explore Autonomous AI with Refact.AI session on Thursday, detailed in Autonomous AI Agents with Refact.AI.
- Learn about innovative strategies and applications for AI technologies through this engaging presentation.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Stability.ai (Stable Diffusion) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #general (392 messages🔥🔥):
GPT-4 Data LeakHugging Face AI ModelsLLM Integration HypotheticalsSample Size and Model TrainingCoffee Preferences
-
Concerns over GPT-4 Data Leak: Some users expressed concerns about potential leaks from the GPT-4 series, specifically the presence of Instagram usernames in outputs, raising questions about the integrity of the training data.
- The discussion highlighted the difficulty in assessing the seriousness of such leaks and what critical information might still be undisclosed.
- Hugging Face AI Models' Performance: Users discussed odd behaviors in AI models on Hugging Chat, particularly the generation of nonsensical responses, attributing issues to the sampling parameters that may require tuning.
- It was mentioned that such anomalies are common and can affect all models in the platform.
- Theoretical LLM Supermodel Scenario: In a hypothetical question about merging all LLMs into one 'super' model, participants debated the implications of having an all-knowing AI and the consequences of its eventual decline in capability.
- This led to considerations about potential long-term impacts and a comparison of a one-time powerful model against slow but steady improvements in existing AI technologies.
- Challenges in Model Training: A user shared their experience with a slow training process on multiple GPUs due to memory constraints and large input dimensions, questioning if they could achieve faster training by adjusting parameters.
- It was advised to perform a warmup run, tweak hyperparameters, and possibly reduce input dimensions to better manage training efficiency.
- Inquiry About Hugging Face Email Validity: One user questioned the legitimacy of an invitation email from 'website@huggingface.co' regarding joining an organization, suspecting potential phishing.
- The community confirmed the email's validity and suggested checking notifications directly on Hugging Face or manually joining the organization for security.
Links mentioned:
- DownloadMoreRAM.com - CloudRAM 2.0: no description found
- ArliAI/Qwen2.5-32B-ArliAI-RPMax-v1.3 · Hugging Face: no description found
- 🆕🖧 Distributed Inference: This functionality enables LocalAI to distribute inference requests across multiple worker nodes, improving efficiency and performance. Nodes are automatically discovered and connect via p2p by using ...
- PEFT: no description found
- Mark Cuban Shark Tank GIF - Mark Cuban Shark Tank Notes - Discover & Share GIFs: Click to view the GIF
- Burgess Merdith The Penguin GIF - Burgess Merdith The Penguin El Pinguino - Discover & Share GIFs: Click to view the GIF
- Hail Zorp Parks And Rec GIF - Hail Zorp Parks And Rec April - Discover & Share GIFs: Click to view the GIF
- Learn R, Python & Data Science Online: Learn Data Science & AI from the comfort of your browser, at your own pace with DataCamp's video tutorials & coding challenges on R, Python, Statistics & more.
- You Have Heard Of Me GIF - Pirates Of The Carribean Jack Sparrow Johnny Depp - Discover & Share GIFs: Click to view the GIF
- Alien Talking GIF - Alien Talking Alien talking - Discover & Share GIFs: Click to view the GIF
- Writing Markdown in LaTeX Documents - Overleaf, Online LaTeX Editor: An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
- Aigis Persona 3 GIF - Aigis Persona 3 Jumpscare - Discover & Share GIFs: Click to view the GIF
- Monty Python GIF - Monty Python Knights Who Say Ni - Discover & Share GIFs: Click to view the GIF
- Kittensleep Cute GIF - Kittensleep Cute Catsleep - Discover & Share GIFs: Click to view the GIF
- Friends don’t let friends train small diffusion models – Non_Interactive – Software & ML: no description found
- no title found: no description found
- Monty Python Life Of Brian GIF - Monty Python Life Of Brian Speak Up - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- Monty Python Teacakes GIF - Monty Python Teacakes Ayrshireshoppers - Discover & Share GIFs: Click to view the GIF
- Stoning Stone GIF - Stoning Stone Monty Python - Discover & Share GIFs: Click to view the GIF
- Home: no description found
- Monty Python Life Of Brian GIF - Monty python LIFE OF BRIAN STAN AKA LORETTA - Discover & Share GIFs: Click to view the GIF
- http://info.cern.ch: no description found
- A Man Of Culture Meme GIF - A Man Of Culture Meme Мем - Discover & Share GIFs: Click to view the GIF
- TeXstudio - A LaTeX editor: no description found
- GeForce 40 series - Wikipedia: no description found
- GeForce 30 series - Wikipedia: no description found
- Home - UserBenchmark: no description found
HuggingFace ▷ #today-im-learning (2 messages):
AI image generationGame developmentBone animation in UnityProject journey resources
-
Curiosity about Project Journeys: A member inquired about how to start a project journey, asking for recommendations on resources that could aid in the process.
- This highlights the community's interest in learning from each other's experiences in project initiation.
- Experimentation with AI in Game Dev: A member shared their experiments with AI image generation and bone animation in Unity for game development, demonstrating innovative approaches.
- They provided a link to their LinkedIn post showcasing their work.
HuggingFace ▷ #cool-finds (5 messages):
Platform AffiliationUser Trust Concerns
-
Affiliation Clarity Needed: A member expressed concern over someone posting about the platform without clearly stating their affiliation, suggesting it felt disingenuous.
- They urged that in future posts, affiliations should be made clear to avoid confusion.
- Perception of Scam: Another member commented that the discussion surrounding the platform felt like a scam due to the lack of transparency.
- This raised questions about trust within the community regarding posts and affiliations.
HuggingFace ▷ #i-made-this (51 messages🔥):
Benchmarking Vision Language Action ModelsKokoro TTS Model UpdatesIDEFICS3_ROCO Medical Imaging ProjectVividNode v1.7.1 ReleaseData Mixing Script
-
Benchmarking Vision Language Action Models released: A new research paper titled Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks was announced, profiling VLA models and evaluating their performance on 20 different real-world tasks.
- This study is a collaboration among several institutions including Georgia Tech, MIT, and Manifold, aiming to establish benchmarks for multimodal action models.
- Kokoro TTS Model Gains Attention: The Kokoro TTS model, equipped with approximately 80M parameters, has been shared for feedback with improvements in English output quality noted by users.
- Despite its small size, users are impressed by its speed and stability, alongside a roadmap for enhancing emotional speech capabilities.
- IDEFICS3_ROCO Medical Imaging Project Development: An ongoing discussion focused on the IDEFICS3_ROCO project, which includes efforts to improve datasets and model evaluation for medical imaging tasks.
- Participants have noted the importance of clear labeling in datasets and offered support to enhance the project's GPU accessibility.
- VividNode v1.7.1 Is Here!: The latest version of VividNode, an open-source desktop app designed for AI interactions, has been released with expanded support for LiteLLM API Keys and various bug fixes.
- Improvements include enhanced usability and a streamlined interface for better interactions with 60+ providers and 100+ models.
- Data Mixing Script Shared: A user shared a script on GitHub for mixing datasets from Hugging Face, allowing users to build new datasets by combining existing sets by weight.
- This tool aims to streamline dataset creation for AI training and experimentation, promoting research and development within the community.
Links mentioned:
- Update app.py · hexgrad/IDEFICS3_ROCO_ZeroGPU at d96f8ab: no description found
- eltorio/IDEFICS3_ROCO · Discussions: no description found
- IDEFICS3 ROCO - a Hugging Face Space by hexgrad: no description found
- IDEFICS3 ROCO - a Hugging Face Space by eltorio: no description found
- GitHub - theprint/DataMix: Python script for building new data sets by combining existing sets from huggingface by weight.: Python script for building new data sets by combining existing sets from huggingface by weight. - theprint/DataMix
- UMLS Metathesaurus Browser.): no description found
- Tweet from harsh (@HarshSikka)): Excited to share our new paper "Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks" We evaluate how well VLM & VLA models can control robots across 20 different real-wor...
- Kokoro - a Hugging Face Space by hexgrad: no description found
- app.py · hexgrad/kokoro at c8ab947245742e5e652255ceecec8e0199b7c244): no description found
HuggingFace ▷ #reading-group (51 messages🔥):
AI Reading Group IntroductionQuestions on MitigationPublic Domain DatasetsTechnical Feasibility of Hardware Setup
-
AI Reading Group Hosted by Women in AI & Robotics: The AI Reading Group meeting began with a reminder that the live discussion was about a chosen paper, with questions encouraged during the presentation.
- A recording of the session will be released for those who missed it, along with announcements for the next meeting on December 5.
- Questions Raised on Mitigation: Participants expressed concerns regarding the future of data availability, noting that the closure of many open web resources impacts both commercial and non-commercial AI.
- Questions arose about the authors' thoughts on the topic of mitigation, particularly in the context of crawling restrictions affecting datasets like C4.
- Discussion on Public Domain Datasets: One member inquired about free-to-use public domain text datasets, highlighting known sources like Project Gutenberg and Wikipedia, while seeking alternatives outside of restricted datasets.
- Another member indicated that many accessible datasets require extensive human effort to curate and are often found behind paywalls, limiting availability.
- Technical Feasibility of Hardware Setup: A member asked whether it is technically feasible to run 2 Instinct MI60 GPUs on an MSI Godlike X570 motherboard with a Ryzen 9 3950X without considering software or other factors.
- They also inquired about adding an RX 6800 for display output, focusing solely on the hardware compatibility.
HuggingFace ▷ #computer-vision (3 messages):
Open3D-MLO3D and Its Historical Context3D Object ClassificationLiDAR ApplicationsPoint Cloud Library Usage
-
Open3D-ML Shows Promise: A member mentioned Open3D-ML as a promising extension of Open3D aimed at 3D Machine Learning tasks.
- This new integration has garnered interest for its potential in enhancing 3D applications.
- O3D's Legacy in 3D Frameworks: Another member shared their surprise at the longevity of O3D, recalling its launch around the same time as AlexNet.
- They reflected that despite its robust design, Open3D did not gain the same traction as WebGL.
- Innovative Approach to 3D Object Classification: A suggestion was made to use a Python script in Blender to generate images of 3D objects from multiple angles for classification purposes.
- This method could help in creating a model that interprets and validates classification across different perspectives.
- LiDAR Applications with Open3D: One member discovered Open3D while researching a company utilizing LiDAR for forest analysis.
- Their previous experience mostly involved using the Point Cloud Library for 3D objects.
Links mentioned:
- GitHub - isl-org/Open3D-ML: An extension of Open3D to address 3D Machine Learning tasks: An extension of Open3D to address 3D Machine Learning tasks - isl-org/Open3D-ML
- The o3d Bible by Kara Rawson: This document provides a summary of the Google O3D API library. It includes an introduction, installation instructions, system requirements, supported graphics hardware, and an overview of the program...
HuggingFace ▷ #diffusion-discussions (1 messages):
Stable Diffusion 1.5CPU performance optimization
-
Choosing Stable Diffusion 1.5 for CPU Optimization: A user noted their intention to use Stable Diffusion 1.5, citing it as the lightest version available for efficient performance.
- They emphasized the need for the model to work quickly on CPU, indicating potential resource optimization preferences.
- Efficiency Considerations on CPU: The necessity to ensure that the model can operate quickly on CPU was highlighted, as users seek optimized solutions for their setups.
- This reflects a broader trend of adapting models to run efficiently on more accessible hardware configurations.
LM Studio ▷ #general (54 messages🔥):
In-line LaTeX rendering in LM StudioSideloading llama.cppRunning large models on limited RAMAutogen and API issuesNexus team performance
-
In-line LaTeX rendering in LM Studio: Users discussed challenges with LaTeX rendering, particularly with the Qwen2.5-Math-72B-Instruct model, which produces unexpected results when wrapped in dollar signs.
- One user recommended creating a system prompt with clear instructions to improve consistency in LaTeX interpretation.
- Sideloading llama.cpp features: A user requested a way to easily sideload features from llama.cpp into LM Studio, expressing frustration with the limitations of the current setup.
- The conversation highlighted ongoing efforts to enable this capability in future updates, with users eager for a more accessible solution.
- Running large models on limited RAM: Individuals speculated whether it was feasible to run models larger than available RAM using virtual memory or disk-based solutions, although performance was likely to suffer.
- One user dismissed the idea of using a slow storage medium, reinforcing that RAM is crucial for model performance.
- Autogen and API issues: A user faced issues running the LM Studio local server and was advised to look into tutorials or provide detailed error reports for better assistance.
- After updates and changes to the configuration, the user solved the initial problem but expressed the need for shared experiences on similar issues.
- Nexus team performance: A user expressed admiration for the Nexus team's capabilities, suggesting that their work has significantly impacted the community.
- The enthusiasm for the Nexus team's contributions reflects broader support and appreciation from users engaged in the discussion.
LM Studio ▷ #hardware-discussion (246 messages🔥🔥):
GPU performance with large modelsCPUs vs GPUs for LLM workloadsM4 Max benchmark comparisonModel offloading to different hardwareIntegrating AI in SaaS applications
-
GPU performance struggles with large models: Users noted that running large models like Nemotron 70b on a mix of GPU setups yielded varying performance, with results ranging from 1.97 to 14.0 tok/s. Testing with different configurations revealed that memory availability and CPU bottlenecks significantly impact throughput.
- Despite high expectations, benchmarks indicated that using only the CPU resulted in low tok/s rates, leading some users to consider upgrading GPU configurations.
- Challenges of CPU vs GPU in LLM operations: The consensus is that CPUs are often unable to keep pace with modern LLMs, even with high memory capacity, as demonstrated by lower tok/s rates compared to GPU acceleration. Several members shared insights on how memory bandwidth and GPU offloading impact overall model performance.
- Users expressed the need for better handling of resources, emphasizing that CPU usage tends to be low when using larger models, with a call for more efficient adjustments.
- M4 Max performance potential discussed: With the M4 Max featuring 128GB of RAM, users are eager to test its performance with LLMs, considering how it compares to dedicated GPU setups. Discussions revealed a willingness to experiment with benchmarks, especially as many are new to LLMs and exploring self-hosting options.
- Members expressed interest in sharing results and benchmarks to inform purchasing decisions, revealing a gap in AI-specific performance evaluations in the community.
- Offloading layers for improved performance: The potential for offloading model layers to the Neural Engine (NE) on Apple devices was discussed, noting current limitations with most runtimes solely using the GPU/CPU. There was speculation on how enabling direct NE usage could amplify performance for heavy LLM tasks.
- Concerns were raised about how current implementations rarely tap into the full capabilities of NE despite its powerful theoretical performance.
- Integrating AI into SaaS applications: A member shared plans to integrate AI capabilities into a SaaS application, showcasing enthusiasm about leveraging LM Studio's API for this purpose. The potential for AI assistance in development was highlighted, indicating an ongoing exploration in the application domain.
- Participants discussed the possibilities of utilizing various AI tools to enhance software features, reflecting an eagerness to adopt AI technologies in practical settings.
Unsloth AI (Daniel Han) ▷ #general (217 messages🔥🔥):
Unsloth AI Training EfficiencyUnderstanding LLMs and MathEditing Code with AI ToolsGPU Programming and TritonEducational Chatbot Data Chunking
-
Unsloth AI Training Efficiency: Members discussed the memory efficiency of the Unsloth platform, with theyruinedelise affirming that it is the most memory efficient training service available.
- There was also mention of Unsloth's upcoming implementation of a CPO trainer, further improving its efficiency.
- Understanding LLMs and Math: Participants emphasized the importance of understanding linear algebra and calculus for grasping LLM concepts, with _niten stating these fundamentally express LLM mechanics.
- Many suggested reviewing courses and resources that cover the essential mathematics needed for machine learning, such as chain rule and matrix properties.
- Editing Code with AI Tools: anubis7645 shared that they are building a utility for editing large React files while considering how tools like Cursor generate edits seamlessly despite model token limits.
- lee0099 explained the concept of speculative edits that allow for fast application, hinting at how it relates to coding practices.
- GPU Programming and Triton: The discussion touched on the relevance of learning Triton and CUDA for GPU programming, with eduuu stating that they offer future engineering opportunities amidst evolving models.
- tenderrizedd inquired about Triton's application for inference, underscoring ongoing interests in improving model efficiency.
- Educational Chatbot Data Chunking: arena1040 sought advice on chunking datasets for an education-focused chatbot, specifically dealing with Persian text and embedded MathType formulas.
- mollel. suggested using RAG methods while generating datasets directly from OpenAI API for more pedagogical material.
Links mentioned:
- Welcome | Unsloth Documentation: New to Unsloth? Start here!
- How Cursor built Fast Apply using the Speculative Decoding API : Cursor, an AI-native IDE, leveraged Fireworks inference stack to enhance its features like Instant Apply, Smart Rewrites, and Cursor Prediction. The blog post introduces the Speculative Decoding API, ...
Unsloth AI (Daniel Han) ▷ #off-topic (11 messages🔥):
Brunch ChoicesDiet AdjustmentsAnimal-derived ProductsNuts and Seeds Discussion
-
Brunch Menu Highlights: One member shared their brunch consisting of chicken, salad (no dressing), egg, milk, and half avocado.
- They expressed satisfaction with their meal, stating it 'feels good so far'.
- Body Adjustments to Diet: A discussion arose about the body's adjustment period when cutting carbs, with one member noting it may take about a week.
- Concerns were raised about fatigue associated with carbs, prompting dietary changes.
- Animal-derived Products Under Scrutiny: Another participant remarked on the high quantity of animal-derived products in the brunch, like chicken, egg, and milk.
- This prompted a light-hearted inquiry about the absence of nuts and seeds in the meal.
- Nuts and Seeds Preferences: In response to the conversation about nuts and seeds, one member humorously stated, 'I eat nothing'.
- Another member jokingly referred to themselves as 'an animal,' indicating they do not consume nuts or seeds.
Unsloth AI (Daniel Han) ▷ #help (31 messages🔥):
Train on responses only functionLoRA parameters in fine-tuningDataset quality concernsFrench chatbot model selectionUsing LoftQ without unquantized models
-
Clarifying Train on Responses Only Function: Discussion on the
train_on_responses_onlyfunction revealed it masks user inputs while predicting assistant responses sequentially, raising questions about the model's training efficiency.- Concerns were voiced about the practice of splitting longer chat histories into samples, with suggestions to focus on the last assistant message for training.
- LoRA Parameters in Fine-Tuning: It was indicated that using smaller values for rank and adaptation can help improve training on datasets without distorting model quality, especially under certain conditions.
- Users were advised to learn more about rank (r) and adaptation (a) factors, noting that a quality dataset is crucial for effective training.
- Optimizing Dataset Quality: Members discussed the impact of dataset quality on model performance, emphasizing that a lackluster dataset may hinder the reduction of loss during training.
- Suggestions were made to reduce the dataset size or enhance its quality to achieve better training outcomes.
- Selecting a Base Model for French Chatbots: For creating a French chatbot, the Mistral model was recommended as a suitable foundation, with emphasis on the importance of selecting appropriate training parameters.
- It was noted that low rank and alpha values in training can assist in maintaining the base model's quality during fine-tuning.
- Using LoftQ Without Loading Unquantized Models: A query was raised regarding the possibility of using LoftQ directly without loading an unquantized model, especially in VRAM-constrained environments like T4.
- A suggestion was made to adjust the target modules for LoRA to include only linear and embedding layers to enhance patch efficacy during fine-tuning.
Links mentioned:
- Google Colab: no description found
- Unsloth Documentation: no description found
Unsloth AI (Daniel Han) ▷ #community-collaboration (2 messages):
Harmony projectOpen-source questionnaire harmonizationLLM matching competitionNatural Language Processing enhancements
-
Harmony project seeks collaboration: A member announced the Harmony project, a joint initiative between multiple institutions working on an AI LLM-based tool for data harmonization. They provided a link to their Discord server for those interested in contributing.
- Currently based at UCL, they are actively looking for volunteers to assist with the project.
- Explore Harmonise questionnaire items: The Harmony tool facilitates retrospective harmonization of questionnaire items and metadata, beneficial for comparing items across studies. Details on its capabilities can be found on their website.
- The tool addresses issues such as compatibility of different questionnaire versions and translations, making it versatile for various research contexts.
- Competition to enhance LLM algorithms: Harmony is hosting a competition to improve their LLM matching algorithms, offering prizes to participants. Interested individuals can find more information about the competition on their competition page.
- The goal is to refine Harmony's ability to accurately assess sentence similarity, correcting current misalignments with human evaluators as highlighted in their blog post.
Links mentioned:
- Harmony | A global platform for contextual data harmonisation: A global platform for contextual data harmonisation
- Competition to train a Large Language Model for Harmony on DOXA AI | Harmony: A global platform for contextual data harmonisation
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
UnslopNemo 12B v4SorcererLMInferor 12BModel Status UpdatesUI Improvements
-
Introducing UnslopNemo 12B v4 for Adventure Writing: The latest model, UnslopNemo 12B, designed for adventure writing and role-play scenarios, has been launched.
- Access a free variant for 24 hours with this link: UnslopNemo 12B Free.
- Advanced Roleplay with SorcererLM: The new SorcererLM is fine-tuned on WizardLM-2-8x22B for enhanced storytelling experiences.
- Join our Discord to request access or for further inquiries.
- Inferor 12B is the Ultimate Roleplay Model: Inferor 12B combines top roleplay models, although users should set reasonable output limits to avoid excessive text.
- Request this model through our Discord for access.
- Service Downtime Briefly Disrupts Operations: A brief downtime of about 1.5 minutes occurred due to an environment syncing issue but has since been resolved.
- Further updates and status can always be found at OpenRouter Status.
- User Experience Enhanced with UI Improvements: Recent updates include visibility of max context length on model pages and the introduction of a document search functionality using cmd + K.
- A new table list view also allows for better model visualization, making it easier to find information.
Links mentioned:
- OpenRouter Status: OpenRouter Incident History
- OpenRouter): LLM router and marketplace
- OpenRouter): LLM router and marketplace
- OpenRouter): LLM router and marketplace
- OpenRouter): LLM router and marketplace
OpenRouter (Alex Atallah) ▷ #app-showcase (5 messages):
GitHub open source project policiesWordPress Chatbot Plugin LaunchCompanion Discord Bot Features
-
Inquiry on GitHub Open Source Posting Rules: A user inquired about the rules and policies for posting GitHub open source projects.
- Another member responded that the guidelines are very lax, stating that if you use OpenRouter in any way, it should be acceptable.
- Launch of WordPress Chatbot Plugin: A user announced their WordPress chatbot plugin is live with features for custom shortcodes and dynamic tags.
- They noted that the chatbot can serve multiple roles such as a support bot or sales bot, and confirmed support for OpenRouter.
- Companion: Enhancing Discord Security and Interaction: A member introduced Companion, a program aimed at personalizing Discord personas while enhancing safety through automated moderation.
- It features impersonation detection, age exploit detection, and allows for dynamic message rate adjustments to improve server engagement.
Links mentioned:
- no title found: no description found
- Home: An AI-powered Discord bot blending playful conversation with smart moderation tools, adding charm and order to your server. - rapmd73/Companion
OpenRouter (Alex Atallah) ▷ #general (201 messages🔥🔥):
Unslopnemo 12bDeepSeek context limitationsGemini API updatesOpenRouter API IssuesAI Studio generateSpeech API
-
Unslopnemo 12b searchability issue: Unslopnemo 12b is searchable but does not appear in the newest models sort feature on the models page.
- This discrepancy prompted a brief discussion about whether sorting mechanics are functioning properly.
- DeepSeek's context error: Users reported that despite documentation claiming a 128k context capacity, DeepSeek's API fails with inputs exceeding 47k tokens.
- After further investigation, it was determined that the actual maximum context length is 65k tokens.
- Gemini API and model availability: It was discussed that while Gemini has experimental models available, they are not yet accessible via the OpenRouter API.
- Users noted that a particular model,
gemini-exp-1114, is currently limited to AI Studio. - OpenRouter API stability: There was a brief downtime reported for OpenRouter services, causing some users to experience issues with various models.
- The situation was clarified, confirming the services returned to normal and models like Claude were functioning.
- New AI Studio features: AI Studio is launching a new
generateSpeechAPI endpoint designed to create speech from specified models based on input transcripts.
- This feature aims to enhance the capabilities of existing models in generating audio output from text.
Links mentioned:
- Quick Start | OpenRouter: Start building with OpenRouter
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Elevated errors on the API: no description found
- Models | OpenRouter: Browse models on OpenRouter
- no title found: no description found
- 2024-11-14-214227 hosted at ImgBB: Image 2024-11-14-214227 hosted in ImgBB
- OpenRouter: LLM router and marketplace
- Anthropic Status: no description found
- Models | OpenRouter: Browse models on OpenRouter
- OpenRouter: LLM router and marketplace
- Provider Routing | OpenRouter: Route requests across multiple providers
- OpenRouter Status: OpenRouter Incident History
OpenRouter (Alex Atallah) ▷ #beta-feedback (7 messages):
Custom Provider KeysCustomer Integration Access
-
Multiple Requests for Custom Provider Keys: Several members requested access to Custom Provider Keys, citing their interest and need for the feature.
- One member explicitly stated, 'I would like to request Custom Provider Keys please.'
- Inquiry about Customer Integration Access: One member sought clarification on how to obtain access for customer integration.
- They asked, 'How do we get access for customer integration?' indicating interest in utilizing related features.
Eleuther ▷ #general (43 messages🔥):
Job Transitioning ChallengesDownloading The Pile DatasetIBM's Granite and Open SourceTransformer Architecture EvolutionHardware Developments for AI
-
Job Transitioning Challenges in Tech: A member expressed frustration about being stuck in a product-focused ML role due to a 12-month tenure requirement to switch roles, while exploring opportunities at PyTorch.
- They noted that discussing potential moves involves navigating both internal processes and pay cut considerations.
- The Pile Dataset Availability: Inquiry was made about downloading The Pile for legacy reasons, leading to a suggestion of using an uncopyrighted version available on Hugging Face.
- The dataset has been cleared of copyrighted content, allowing it to be used in training LLMs while respecting copyright law.
- Skepticism around IBM's Granite as Open Source AI: Discussion arose around IBM's Granite, questioning its classification as 'Open Source AI' given its lack of shared code or dataset details involved in training.
- Members debated whether the documentation allows for recreation of Granite outside of what has been disclosed.
- Evolving Transformer Architecture: The conversation highlighted the endurance of transformers, noting advancements like decoder-only architectures and mixtures of experts while still questioning their hardware suitability.
- Members argued the need for evolving hardware to match these architectures, recognizing the trade-offs currently being made.
- Hardware Developments for AI Training: Insights were shared about new hardware advancements improving transformer inference efficiency, particularly highlighting the improvements made by Blackwell compared to Hopper.
- Discussions pointed to the critical role of memory bandwidth and VRAM for effective implementations of large-scale AI models.
Links mentioned:
- Efficiently Scaling Transformer Inference: We study the problem of efficient generative inference for Transformer models, in one of its most challenging settings: large deep models, with tight latency targets and long sequence lengths. Better ...
- monology/pile-uncopyrighted · Datasets at Hugging Face: no description found
- granite-3.0-language-models/paper.pdf at main · ibm-granite/granite-3.0-language-models: Contribute to ibm-granite/granite-3.0-language-models development by creating an account on GitHub.
Eleuther ▷ #research (123 messages🔥🔥):
Benchmarking Vision Language Action modelsDiscussion on Scaling LawsShampoo and Muon Algorithms in OptimizationImpact of Int8 TrainingUsefulness of Synthetic Tasks
-
New Research on Vision Language Action Models: A collaboration between Manifold, Georgia Tech, MIT, and Metarch AI released a paper titled 'Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks', evaluating VLMs like GPT4o across 20 real-world tasks.
- Related links were shared to Twitter highlights and the GitHub repository for more detailed information.
- Controversy Surrounding Scaling Laws: Rumors suggest that recent scaling efforts in LLMs may not yield new capabilities, leading to discussions around the reliability of scaling laws.
- Participants noted that diminishing returns are evident; however, the claim remains largely based on speculation rather than empirical evidence from rigorous studies.
- Insights into Shampoo and Muon Optimization Techniques: Questions were raised regarding the effectiveness of various optimization algorithms, including Shampoo and Muon, particularly in the context of estimating the Hessian using the Fisher Information Matrix.
- Discussion revolved around whether the assumptions regarding these algorithms hold true, with references to related papers such as KFAC highlights in contrast to Shampoo.
- Challenges in Int8 Training: In a tangent on performance, participants explored the implications of using int8 versus uint8 training, expressing curiosity about how scaling and optimization techniques handle the low dynamic range.
- The consensus highlighted that adopting a comprehensive design approach is critical when transitioning to these lower precision formats.
- Relevance of Synthetic Tasks: A debate sparked concerning the usefulness of synthetic tasks in evaluating transformer models, with some claiming they do not mirror real-world performance capabilities.
- Participants expressed skepticism toward synthetic task results, suggesting many papers showcasing transformer limitations have questionable applicability to effective AI deployment.
Links mentioned:
- Old Optimizer, New Norm: An Anthology: Deep learning optimizers are often motivated through a mix of convex and approximate second-order theory. We select three such methods -- Adam, Shampoo and Prodigy -- and argue that each method can in...
- How to represent part-whole hierarchies in a neural network: This paper does not describe a working system. Instead, it presents a single idea about representation which allows advances made by several different groups to be combined into an imaginary system ca...
- Tweet from BlinkDL (@BlinkDL_AI): New RWKV CoT demo: 4M params to solve 15-puzzle 🔥 https://github.com/Jellyfish042/RWKV-15Puzzle #RWKV #RNN Quoting BlinkDL (@BlinkDL_AI) RWKV-Sudoku extreme CoT code & model: https://github.com/J...
- Modular Duality in Deep Learning: An old idea in optimization theory says that since the gradient is a dual vector it may not be subtracted from the weights without first being mapped to the primal space where the weights reside. We t...
- ZipNN: Lossless Compression for AI Models: With the growth of model sizes and the scale of their deployment, their sheer size burdens the infrastructure requiring more network and more storage to accommodate these. While there is a vast model ...
- Tweet from harsh (@HarshSikka)): Excited to share our new paper "Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks" We evaluate how well VLM & VLA models can control robots across 20 different real-wor...
- Euclidean plane isometry - Wikipedia: no description found
- GitHub - NVIDIA/ngpt: Normalized Transformer (nGPT): Normalized Transformer (nGPT). Contribute to NVIDIA/ngpt development by creating an account on GitHub.
- RWKV-15Puzzle/puzzle15_vocab.txt at main · Jellyfish042/RWKV-15Puzzle: Contribute to Jellyfish042/RWKV-15Puzzle development by creating an account on GitHub.
- RWKV-15Puzzle/generate_data.py at main · Jellyfish042/RWKV-15Puzzle: Contribute to Jellyfish042/RWKV-15Puzzle development by creating an account on GitHub.
Eleuther ▷ #interpretability-general (4 messages):
Pythia model suiteMixture of Experts (MoE)OLMo and OLMOE comparisonInterpolation-focused trainingHyperparameter modernization
-
Debate on Pythia with MoE: A member inquired about the potential for a mixture-of-expert version of the Pythia model suite, questioning whether to replicate the existing training setup or modernize the hyperparameters, like using SwiGLU.
- This effort aims to determine which specific questions could be addressed by implementing MoE in this context.
- OLMo and OLMOE's fit with Pythia: One member proposed that OLMo and OLMOE already align with the goals discussed, citing their modern architecture choices despite differing model sizes from Pythia.
- They noted that the main distinction is the absence of multiple sizes found in Pythia, but the contemporary design is similar.
- MoE training vs. Pythia's focus: Discussion highlighted that while OLMo explored the MoE search space, it lacked the extensive interpolation-focused training that Pythia employed, except for domain specialization experiments.
- The consistency across model scales and the specific training data order in Pythia were underscored as significant factors.
- Factors affecting MoE performance: A member acknowledged differences in data order and continued training strategies adopted in the newer OLMo releases, impacting performance comparisons.
- These elements contribute to understanding why OLMo may not match Pythia's interpolation-focused objectives.
Link mentioned: Tweet from Nora Belrose (@norabelrose): If there were a mixture-of-expert version of the Pythia model suite, what sorts of questions would you want to answer with it? Should we try to exactly replicate the Pythia training setup, but with M...
Eleuther ▷ #lm-thunderdome (7 messages):
Eval prompt modificationsOfficial parser modificationsMmlu standardizationMMMU evaluation details
-
Modifying Eval Prompts: Not Heinous, But Caution Required: A member asked if it's acceptable to add phrases like 'Final answer:' to an official eval prompt to aid in parsing.
- Another member noted it's not necessarily heinous, but best practice is to stick with the same prompt for fair comparisons unless justified.
- Task-Dependent Parser Modifications Discussed: The same member inquired about the acceptability of modifying the official parser, citing differences between the lmms-eval and MMMU parsers.
- Another member responded that it's very task-dependent, mentioning some tasks have standardized implementations, but multimodal tasks are less consistent.
- Lack of Details in MMMU Evaluations: One member pointed out the lack of detailed evaluations from most model releases related to the MMMU.
- This highlights a gap in transparency for multimodal tasks, which may affect the understanding of evaluation setups used.
Links mentioned:
- lmms-eval/lmms_eval/tasks/mmmu/utils.py at bcbdc493d729e830f4775d1a1af4c1d7d8e449f2 · EvolvingLMMs-Lab/lmms-eval: Accelerating the development of large multimodal models (LMMs) with lmms-eval - EvolvingLMMs-Lab/lmms-eval
- MMMU/eval/eval_utils.py at 51ce7f3e829c16bb44bc5445782686b4c3508794 · MMMU-Benchmark/MMMU: This repo contains evaluation code for the paper "MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI" - MMMU-Benchmark/MMMU
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.63.0Qwen 2.5 Coder 32B SupportWeb Command ImprovementPrompting EnhancementsBug Fixes
-
Aider v0.63.0 Now Available!: The new release of Aider v0.63.0 includes support for Qwen 2.5 Coder 32B and introduces various performance improvements.
- Additionally, Aider contributed 55% of the code for this update.
- Web Command Gets a Fresh Update: The
/webcommand now simply adds the page to the chat, not triggering an LLM response as before.
- This change accelerates user interactions by streamlining web page integrations.
- Improved Language Preference Handling: Users can now enjoy enhanced prompting for selecting their preferred chat language, making interactions more personalized.
- This update aims to increase user engagement by facilitating smoother conversations.
- LiteLLM Exception Handling Upgraded: Handling of LiteLLM exceptions has improved significantly, reducing disruption in user experience.
- This fix contributes to smoother operations throughout the bot’s functionalities.
- Bugs Be Gone: Multiple Fixes Implemented: Several bug fixes have been rolled out, including addressing double-counting tokens in cache stats and issues with the LLM creating new files.
- These minor fixes bolster the overall reliability and performance of Aider.
aider (Paul Gauthier) ▷ #general (123 messages🔥🔥):
Aider enhancementsQwen 2.5 Coder performanceGemini experimental modelsOpenRouter compatibilityCLI scripting with Aider
-
Aider Ecosystem and Documentation Efforts: Users are looking to improve documentation for the Aider ecosystem, expressing interest in using platforms like Ravel to make details more searchable and coherent.
- Discussions highlight the need for clearer guides as Aider's capabilities grow rapidly, often outpacing the existing documentation.
- Experiences with Qwen 2.5 Coder: Opinions vary on the performance of Qwen 2.5 Coder when using it through OpenRouter, with some users reporting it as underwhelming compared to benchmark statistics.
- The model
aider --model openrouter/qwen/qwen-2.5-coder-32b-instructis proposed as a viable option, although mixed results are shared. - Emerging Gemini Experimental Models: New Gemini experimental models have been introduced, prompting curiosity about their effectiveness on challenging prompts and general usability.
- Some users report trying the models, but face access issues, suggesting that permissions on Google Cloud might restrict availability.
- Interest in CLI Scripting with Aider: Members are exploring scripting capabilities in Aider to automate repetitive tasks, highlighting the potential of using command line options to streamline workflows.
- The documentation link provided emphasizes the ability to apply edits to multiple files programmatically, showcasing Aider's versatility.
- Combination of Qwen with Different Editors: Users discuss the compatibility of Qwen 2.5 Coder with various editors, noting that while it works well, its performance can suffer with certain combinations like Haiku as an editor.
- General consensus indicates varying experiences, with some combinations yielding effective results while others fall short.
Links mentioned:
- Scripting aider: You can script aider via the command line or python.
- OpenRouter: LLM router and marketplace
- Qwen/Qwen2.5-Coder-32B-Instruct - Demo - DeepInfra: Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). It has significant improvements in code generation, code reasoning and code fixing. A more ...
- xingyaoww/Qwen2.5-Coder-32B-Instruct-AWQ-128k · Hugging Face: no description found
- no title found: no description found
- unsloth/Qwen2.5-Coder-7B-Instruct-128K-GGUF · Hugging Face: no description found
- Ravel: no description found
- GitHub - nekowasabi/aider.vim: Helper aider with neovim: Helper aider with neovim. Contribute to nekowasabi/aider.vim development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #questions-and-tips (29 messages🔥):
Installing Aider in TermuxTriggering Rust Analyzer in VSCodeUsing Aider with git diffAider modes comparisonAider usage tips
-
Installing Aider in Termux: A member asked if anyone has tried installing Aider in Termux or another mobile terminal, noting the IDE agnosticism of Aider as long as it can run in a Python environment.
- Another member confirmed the flexibility of Aider, emphasizing interaction with CLI and git.
- Triggering Rust Analyzer in VSCode: A user inquired about the simplest way to trigger the Rust analyzer in VSCode after Aider finishes running, contemplating filesystem watching as a solution.
- A member suggested running
cargo check, with or without thecdcommand as necessary, which often does the trick efficiently. - Using Aider with git diff: One member wanted to know if Aider can read file edits (diff) and plan changes based on those, prompting a sharing of necessary commands.
- Another member recommended using
/run git diff ..., which offers an option to add the output to the chat for further planning. - Aider modes comparison: A new user expressed confusion regarding switching between architect mode and other modes in Aider, highlighting potential high token usage.
- A more experienced user suggested starting without architect mode and opting for gpt-4o or Sonnet instead to ease usage.
- Aider usage tips: A user offered tips for getting started with Aider, advising against adding too many files to the chat to keep it efficient and reduce distractions.
- One member expressed their intent to review documentation before diving deeper into using Aider, seeking further clarification as needed.
Links mentioned:
- Tips: Tips for AI pair programming with aider.
- FAQ: Frequently asked questions about aider.
- Linting and testing: Automatically fix linting and testing errors.
aider (Paul Gauthier) ▷ #links (2 messages):
Organizing Code for AIAider Discord GuidelinesServer Rule Changes
-
Organizing Code Base for AI: A member noted that organizing a code base for AI is similar to organizing it for humans, emphasizing the need to break things into logical modules and add comments.
- They highlighted the importance of clean organization to enhance understandability and maintenance.
- Aider Discord Imposes New Rules: A user mentioned that their original tweet with links to windsurf was deleted, possibly due to new server rules.
- They referenced a set of guidelines stating that the Aider Discord is specifically for discussing Aider, prohibiting spam and unsolicited promotions.
Nous Research AI ▷ #general (142 messages🔥🔥):
Joining Forge API Beta3D Printer RecommendationsHermes Programming InsightsResearch Project ParticipationTEE Wallet Collation Concerns
-
Joining #forge-api-beta made easier: Multiple members expressed issues with joining the #forge-api-beta, with teknium confirming additions based on requests.
- Some users were confused about email links directing them to the general channel instead.
- 3D Printer Recommendations Fly Around: Discussions arose regarding 3D printers, with bliponnobodysradar considering an Ender 3 S1, while oleegg suggested Bambu Lab for ease of use.
- Members shared insights about their experiences and preferences, leading to strong recommendations against Ultimaker during the chat.
- Hermes Programming as a Learning Tool: Members discussed their initial programming languages, with shunoia pivoting to Python thanks to Hermes, while oleegg offered sympathy for the decision.
- jkimergodic_72500 explained Perl as a flexible language, providing a backdrop for the current dialogue on programming experiences.
- How to Get Involved in Research Projects: Members inquired about joining research projects, with teknium suggesting several public projects as opportunities for contributions.
- The group showed interest in how to engage more effectively, indicating a community eager to contribute to ongoing research.
- Concerns Over TEE Wallet Collation: mrpampa69 raised concerns regarding the inconsistency of wallets for TEE, arguing that it undermines the bot's perceived sovereignty.
- Responses indicated a need for robust decision-making before collation, as operational autonomy remains a priority to prevent misuse.
Links mentioned:
- Tweet from JX (@JingxiangMo): Introducing Zeroth-01 Bot: the world's smallest open-source end-to-end humanoid robot starting at $350! Fully open-source, including hardware, SDK, sim environments & more. Zeroth-01 is the most ...
- Your Life Story: no description found
- Bambu Lab X1C 3D Printer: Introducing our 3D Printer, Bambu Lab X1 Carbon. With faster and smarter printing, you are free from waiting to just enjoy the creation. Experience and enjoy the 3D printing in precision and detail wi...
Nous Research AI ▷ #interesting-links (6 messages):
RizzlerSlang TranslatorTranslation ToolResume to Website Tool
-
Rizzler Wins the Day: Check out Rizzler, a platform promising engaging interactions and smooth connections.
- This site is specifically crafted for users looking to enhance their social dynamics online.
- Slang Translator Features: The Slang Translator offers an easy way to decode and understand various slang terms.
- By navigating the platform, users can quickly bridge communication gaps in regional dialects.
- Advanced Translation Tool Shines: A new AI-driven translation tool focuses on cultural nuance and adaptability, making translations more human-like.
- It tailors the output by considering dialects, formality, tone, and gender, making it a flexible choice for diverse needs.
- Transform Your Resume into a Website: The Resume to Website Tool quickly converts resumes into a professional Bootstrap site.
- Users can upload resumes and get a responsive site in just minutes, enhancing their job application presentations.
Links mentioned:
- Resume to Website Generator: no description found
- Advanced Translation Tool - Accurate and Culturally Nuanced Translations: Translate text between languages with cultural nuance, context, formality, tone, and gender considerations.
Modular (Mojo 🔥) ▷ #general (1 messages):
aka_afnan: Hi beautiful community i just finished basic tutorials on mojo lang.
Modular (Mojo 🔥) ▷ #mojo (120 messages🔥🔥):
Mojo Low-Level SyntaxPerformance of High-Level Syntax vs CRecursive Vectorization & Tail Call OptimizationLLVM and MLIR in MojoImportance of Language Features
-
Mojo's Low-Level Syntax Performance: Members discussed how Mojo's low-level syntax may not maintain the Pythonic essence while providing better performance compared to high-level syntax.
- One pointed out that high-level syntax lacks the performance of C, but tools like NumPy can still achieve close results under certain conditions.
- Struggles with Recursive Vectorization: The conversation shifted to Recursive Vectorization and its impact on performance in Mojo, highlighting concerns over the lack of optimizations in recursive code compared to Rust or C++.
- Participants agreed that missing features in the type system currently impede the development of the standard library, making it hard to write efficient code.
- Tail Call Optimization (TCO) in MLIR: A sentiment emerged around implementing TCO in MLIR to enable compiler optimizations for recursive code and better performance.
- Members expressed uncertainty over the need for preserving control flow graphs in LLVM IR, debating its importance for debugging.
- Lang Features Priority Discussion: There was a consensus on prioritizing basic type system features over more advanced optimizations to ensure language readiness as more users are onboarded.
- Participants warned against overwhelming the development with additional issues while the foundational features are still pending.
- LLVM Offload and Coroutine Implementation: Interest was shown in LLVM's offload capabilities and how coroutine implementations are being facilitated in Mojo.
- Discussion highlighted that coroutines are conceptually similar to tail-recursive functions, leading to considerations of whether transparent boxing is necessary.
Links mentioned:
- No Stop GIF - No Stop Pleading - Discover & Share GIFs: Click to view the GIF
- Write Haskell as fast as C: exploiting strictness, laziness and recursion: In a recent mailing list thread Andrew Coppin complained of poor performance with “nice, declarative” code for computing the mean of a very large list of double precision floating point…
- fixpt · All About Strictness Analysis (part 1): no description found
Perplexity AI ▷ #general (72 messages🔥🔥):
Perplexity's Campus Strategist ProgramAds and subscription model concernsUpdates on model availabilityGemini performance in Chatbot ArenaAPI dashboard issues
-
Perplexity expands Campus Strategist Program to Canada: By popular demand, Perplexity is expanding their Campus Strategist Program to Canada, inviting interested applicants to reach out for more information.
- Applications are currently open for the 2024 program, which offers hands-on experience and mentorship for university students in the US.
- Concerns about ads for Pro users: There are mixed responses regarding the implementation of ads for all users, including Pro subscribers, with many expressing frustrations over this change.
- Users are particularly concerned about the perceived value of paying a subscription while still encountering advertisements.
- Updates on AI models' availability: Claude Opus 3 was removed from Perplexity to ensure the best models are available, now featuring Claude 3.5 Sonnet and Haiku.
- Users noted that Gemini (Exp 1114) recently achieved top rankings in various categories in the Chatbot Arena, with positive first impressions on its performance.
- Issues with the API dashboard: Some users reported that the API dashboard is not updating accurately, leading to confusion about token usage.
- One user confirmed that this issue is affecting multiple members and may warrant reporting for a resolution.
- ChatGPT search engine inquiry: A user inquired about which search engine ChatGPT uses, questioning if it uses Bing similarly to Perplexity.
- This discussion highlights ongoing curiosity about the search functionalities and underlying engines of competing AI platforms.
Links mentioned:
- Tweet from Phi Hoang (@apostraphi): naturally
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Massive News from Chatbot Arena🔥 @GoogleDeepMind's latest Gemini (Exp 1114), tested with 6K+ community votes over the past week, now ranks joint #1 overall with an impressive 40+ score leap — ma...
- Tweet from Greg Feingold (@GregFeingold): By popular demand, we’re expanding our campus strategist program to Canada 🇨🇦 If you’re interested in applying, or know someone who would be a good fit, please reach out! Quoting Perplexity (@per...
Perplexity AI ▷ #sharing (8 messages🔥):
Perplexity AI featuresBest mouse for workGoogle Gemini launchSharing thread settings
-
Perplexity AI declared a sports machine: A user enthusiastically described Perplexity as an INSANE sports machine in a post, highlighting its impressive capabilities.
- They shared a link for further insights: link.
- Discussion on mouse recommendations: A user posted a link discussing the best mouse for work, indicating a growing interest in optimized productivity tools.
- This link was shared multiple times, emphasizing its relevance within the community: link.
- Google launches Gemini app: A couple of users shared links about the Google Gemini app, showcasing excitement about new tech announcements.
- Relevant articles include TechCrunch's announcement and a page on Gemini's features: Gemini app.
- Thread shareability notice: Moderators reminded a user to ensure their thread is marked as Shareable, pointing to an attachment for reference.
- This notice was accompanied by a structured message link: link.
Perplexity AI ▷ #pplx-api (7 messages):
Vercel AI SDK usageReddit citation issuesSearch domain filter problem
-
Vercel AI SDK with Perplexity: A user inquired about how to use the Vercel AI SDK with Perplexity while including citations.
- No responses were provided, leaving details about implementation or potential documentation unclear.
- Reddit citations failing via API: Multiple users reported issues with pulling Reddit as a source in citations over the past week, indicating it was previously working well.
- One user mentioned that random URLs might be injected if a confident source isn't found, resulting in inaccurate results.
- Search domain filter not functioning: A user expressed frustration with the search_domain_filter, stating it is not working despite following the correct formatting guidelines.
- Another user confirmed similar issues, raising questions about potential bugs in the filtering feature.
Interconnects (Nathan Lambert) ▷ #news (22 messages🔥):
AI Agent Tool Operator LaunchFrancois Chollet Leaves GoogleGemini-Exp-1114 PerformanceChatGPT for macOS UpdatesScaling Laws Theory Concerns
-
AI Agent Tool 'Operator' Set to Launch: OpenAI's upcoming AI agent tool, codenamed 'Operator', is expected to automate tasks via a browser and will launch in January, according to staff updates from an all-hands meeting.
- This tool will assist users with actions like writing code and booking travel, marking a significant step in AI utility.
- Francois Chollet Announces Departure from Google: Francois Chollet, the creator of Keras, is leaving Google to start a new company while remaining engaged with the Keras project externally, led by Jeff Carpenter.
- Chollet emphasized his gratitude for his decade at Google and the growth of Keras to a widely used framework among developers.
- Gemini-Exp-1114 Dominates Chatbot Arena: @GoogleDeepMind's Gemini-Exp-1114 has achieved a top ranking in the Chatbot Arena, surpassing competing models with significant score improvements across various categories.
- It now leads the Vision leaderboard and excels in creative writing and math, demonstrating its advanced capabilities.
- ChatGPT for macOS Enhances Coding Support: The beta version of ChatGPT for macOS now allows users to read content from coding apps like VS Code and Xcode, providing context-aware responses for Plus and Team users.
- This functionality aims to enhance coding efficiency and streamline workflows for developers.
- Skepticism on AI Scaling Laws: Concerns were raised regarding the validity of 'scaling laws' in AI development, questioning whether increased computational resources and larger models will necessarily lead to advancements.
- Discussions highlighted that decreasing cross-entropy loss alone might not be enough to improve AI capabilities, reflecting industry skepticism.
Links mentioned:
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Massive News from Chatbot Arena🔥 @GoogleDeepMind's latest Gemini (Exp 1114), tested with 6K+ community votes over the past week, now ranks joint #1 overall with an impressive 40+ score leap — ma...
- Tweet from Shirin Ghaffary (@shiringhaffary): NEW: OpenAI is preparing to launch a new computer using AI agent tool codenamed “Operator” that take actions on a person’s behalf thru a browser, such as writing code or booking travel. Staff told in...
- Tweet from François Chollet (@fchollet): Consulting my heart... Ok, looks like you haven't. But whenever you have a SotA (or close) solution built on top of the OpenAI API we're more than happy to verify it and add it to the public A...
- Tweet from Casper Hansen (@casper_hansen_): What a great way to find out OpenAI will release o1 within 24 hours Quoting Logan Kilpatrick (@OfficialLoganK) Yeah, Gemini-exp-1114 is pretty good :)
- Tweet from Logan Kilpatrick (@OfficialLoganK): gemini-exp-1114…. available in Google AI Studio right now, enjoy : ) https://aistudio.google.com
- Farewell and thank you for the continued partnership, Francois Chollet!: no description found
- Tweet from François Chollet (@fchollet): Some personal news -- I'm leaving Google to go start a new company with a friend. More to be announced soon! I will stay deeply involved with the Keras project from the outside -- you'll stil...
- Tweet from Tibor Blaho (@btibor91): ChatGPT for macOS can now read content from coding apps like VS Code, Xcode, TextEdit and Terminal to provide context-aware answers, available in beta for Plus and Team users
Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
420gunna: https://x.com/richardmcngo/status/1856843040427839804?s=46
Interconnects (Nathan Lambert) ▷ #random (18 messages🔥):
Qwen vs Llama performanceCognitive revolution podcastSimple division problems with QwenSynthetic data in model training
-
Qwen surpasses Llama in simple division: In tests comparing Qwen 2.5 and Llama-3.1 405B, Qwen outperformed Llama when processing basic division problems with a prompt of
A / B.- Funnily enough, Qwen switches to CoT mode with large numbers, utilizing either LaTeX or Python, while Llama's output remains unchanged.
- Post-training insights on cognitive revolution: A member recorded a 90+ minute podcast discussing the cognitive revolution, highlighting its solid foundation.
- They noted that it's more about the process involving the model, data, evals, and code working together.
- Synthetic data contributes to Qwen's training: There's speculation that a significant portion of the 20T tokens used for training Qwen consists of synthetic data.
- Differences in results between rounding and truncating numbers suggest that models may not be perfectly aligned.
- Expectations for new model: There are high expectations for the upcoming model, anticipated to meet a very high bar for those interested in its technical performance.
- It's clarified that the model should not be seen as a direct counterpart to GPT-5.
Interconnects (Nathan Lambert) ▷ #memes (26 messages🔥):
Leadership StrategiesOpen-source AI DiscussionScaling Laws in LabsDiscord Shop Characters
-
Controversial Leadership Strategy: A member expressed skepticism about a leadership strategy that seems to encourage employees to believe recklessly, stating it's not a good strategy but can be motivating.
- This discussion was tied to a quote that indicated a lack of guidance, with commentary on its implications.
- Urgent Need for Open-source AI Discussion: Members urged a conversation with Dwarkesh about the value of open-source AI before another prominent firm jumps in, highlighting the urgency of the topic.
- Collaboration was proposed to ensure that the conversation leans into current concerns over financial powers influencing tech discussions.
- Scaling Laws and Google Sheets: A remark was made regarding the ongoing validity of scaling laws, attributing misunderstandings to labs using Google Sheets which cannot adequately plot data, specifically sigmoids.
- This prompted laughter over financial experts being able to plot the curves without understanding their implications, emphasizing disconnects in data representation.
- Squidward, Patrick, and SpongeBob Confusion: Amidst lighthearted banter, a member mistakenly referred to a character as Squidward when it was actually Patrick, leading to a humorous exchange.
- The conversation highlighted the availability of SpongeBob-themed decorations in the Discord shop, showcasing the community's playful spirit.
Links mentioned:
- Tweet from Dylan Patel (@dylan522p): Scaling laws are still true because all the labs use Google Sheets and can't fit a sigmoid in that, just straight lines on log log plots. All the finance Excel bros freaking out because they can p...
- Tweet from Sam Altman (@sama): there is no wall
- Tweet from Timothy O'Hear (@timohear): @francoisfleuret Seen on the François Chollet AMA https://news.ycombinator.com/item?id=42130881 ☺️
- Tweet from morgan — (@morqon): how to reply to requests for comment
Interconnects (Nathan Lambert) ▷ #posts (9 messages🔥):
Andrew Carr InterviewGemini 1.5 UltraClaude 3.5 OpusPersonas in AIScaling Realities
-
Andrew Carr discusses Tencent's Persona Method: In a recent interview, Andrew Carr mentioned, 'Oh, we're using Tencent's persona method a lot right now,' while elaborating on text-to-motion AI models.
- Another participant recalled reading about this paper during their exploration of synthetic data, expressing curiosity about its practical usefulness.
- Waiting for New AI Models: Gemini 1.5 Ultra and Claude 3.5 Opus seem to be highly anticipated, as noted by a member who commented, 'We’re still waiting for them,' emphasizing the ongoing interest in advancements.
- There seems to be a community eagerness for upcoming indexing updates as well.
- Positive Feedback on Scaling Realities: A member expressed appreciation for the shorter version on scaling realities, stating it's really good and felt it was more impactful compared to the longer version.
- They acknowledged the longer version's technical merits but preferred the concise delivery.
- Discussion on Personas in AI: The sentiment around personas was reiterated by a member who enthusiastically dropped applause emojis, suggesting its importance in AI discussions.
- Another participant affirmed that utilizing personas is straightforward and enhances prompts effectively.
- Synthetic SFT and DPO Improvements: There was mention of how the persona method has significantly aided their synthetic SFT and DPO efforts, indicating a beneficial impact on model performance.
- The conversation hinted at further discussions to come in the following week regarding the benefits of diversity in these models.
Link mentioned: Andrew Carr on Pushing the Boundaries of Generative AI (Beyond Text),): Andrew Carr is co-founder and chief scientist at Cartwheel, where he is building text-to-motion AI models and products for gaming, film, and other creative e...
GPU MODE ▷ #general (2 messages):
rapids cudf
-
Inquiry about rapids cudf knowledge: A member asked if anyone is familiar with rapids cudf, indicating a desire for information or assistance on the matter.
- Just go ahead and ask your question, suggested another member, encouraging open dialogue.
- Encouragement for Questions: A member prompted the conversation by suggesting that the original poster simply ask their question about rapids cudf directly.
GPU MODE ▷ #triton (4 messages):
Kernel Design ChallengesTriton and Performance TuningIssues with torch.compile
-
Kernel Design Faces Dimension Dilemmas: A member discussed challenges in kernel design, noting difficulty in determining if the first dimension is a vector, as sizes can vary between 1 and 16.
- They questioned if padding to a minimum size of 16 is the only viable solution.
- Efficient Configuration for BLOCK_SIZE_M: Another member suggested utilizing
BLOCK_SIZE_Mastl.constexprfor an if statement in the kernel, along with usingearly_config_prunefor autotuning based on batch size.
- For batch size of 1, they recommended implementing a gemv for improved GPU performance, despite potential kernel crashes.
- Encountering Crashes with Triton Implementation: After trying the suggested adjustments, a member reported ongoing crashes, linking to a GitHub issue that details problems with
torch.compilewhen using Triton built from source.
- They noted that the issue arises when compiling a model containing Triton modules, specifically referencing the errors encountered.
Link mentioned: torch.compile breaks with Triton built from source · Issue #140423 · pytorch/pytorch: 🐛 Describe the bug torch.compile breaks with Triton built from source (as of Nov 12): How to reproduce: Build Triton from the master branch Run torch.compile with a model containing Triton modules,.....
GPU MODE ▷ #torch (2 messages):
Direct Access to GPUTorch.compile() with DDPTorch.compile() with FSDP
-
Inquiry on Direct GPU Access: A member asked about methods to achieve direct access to GPU for improved performance.
- No specific methods were shared in the discussion.
- Torch.compile() Usage with DDP: A follow-up question was raised about using torch.compile() in combination with Distributed Data Parallel (DDP).
- Members inquired whether torch.compile() should be wrapped around the DDP wrapper or placed inside it, highlighting potential issues.
- Torch.compile() with FSDP Considerations: The conversation also touched on the use of torch.compile() with Fully Sharded Data Parallel (FSDP).
- Participants were curious if similar considerations apply as with DDP when integrating with FSDP.
GPU MODE ▷ #beginner (4 messages):
GPU profiling toolsThread creation on GPUsRGB to greyscale conversion performance
-
Users explore GPU profiling tools: A member asked about the profiling tools used by others, expressing difficulties in understanding the reports generated by ncu.
- You'll want to get used to NCU, another member suggested, stating it's the best profiler out there that offers valuable optimization insights.
- Understanding thread creation on GPUs: One member clarified that on a GPU, there is no overhead for creating threads, as they all run from the start of the kernel.
- While it’s ideal for threads to perform more work, the challenge lies in balancing computation against the data loaded.
- Converting RGB to greyscale poses bandwidth challenges: Discussion arose around the efficiency of spawning threads for tasks like converting an RGB image to greyscale, questioning if too many threads could introduce overhead.
- It was noted that the conversion process is typically bandwidth limited, involving loading three values for a simple computation to produce one value.
GPU MODE ▷ #off-topic (1 messages):
Feijoa dessertGrilled beef pattiesIvan tea
-
Feijoa dessert blends flavors: A delicious dessert was prepared by mixing feijoa puree with tvorog, sour cream, and stevia.
- This unique combination showcased the ability to blend sweet and creamy elements effectively.
- Grilled beef patties take center stage: The main dish featured grilled beef patties served alongside potatoes and ketchup.
- This hearty meal balanced savory flavors with a classic condiment for enhancement.
- Refreshing Ivan tea for a perfect finish: To complement the meal, Ivan tea (fireweed tea) was enjoyed with milk, providing a soothing end to the day's menu.
- This beverage added a unique, herbal touch to the dining experience.
- Colorful salad adds crunch: A refreshing salad comprised of cucumber, daikon radish, Napa cabbage, and more was featured, tossed with mayonnaise.
- The mix brought a crunch and freshness that complemented the richer elements of the meal.
GPU MODE ▷ #rocm (1 messages):
leiwang1999_53585: did you use ck profiler?
GPU MODE ▷ #self-promotion (3 messages):
Video Length DiscussionsInterest in Triton Content
-
7.5-Hour Video Sparks Mixed Responses: A member mentioned that they skimmed through the 7.5-hour video because it felt like too much to handle, but they enjoyed the parts they watched.
- Another member humorously remarked about the video's length, stating, 'You can only watch the parts you are interested in,' and highlighted the chapters included in the description.
- Demand for More Triton Videos: A member expressed appreciation for the creator's videos and specifically requested more Triton content in the near future.
- This request reflects a growing interest in Triton-related discussions among viewers.
GPU MODE ▷ #🍿 (1 messages):
apaz: <@325883680419610631>
https://github.com/gpu-mode/discord-cluster-manager/issues/23
GPU MODE ▷ #thunderkittens (34 messages🔥):
Kernel Shared MemoryMatrix Multiplication OptimizationDynamic Shared Memory IssuesCUDA Function Attributes
-
Kernel Shared Memory Crashes at High Usage: A user encountered a kernel crash when requesting 49160 bytes or more of shared memory, which is supposed to be smaller than
MAX_SHARED_MEMORY.- This issue was related to the use of static shared memory, which has a limit on certain architectures.
- Synchronous Matrix Multiplications Explained: A discussion revealed that a 16x64 * 64x16 matmul cannot use async WGMMAs, while sync instructions allow use on tensor cores but may lead to performance bottlenecks.
- A user was advised that increasing batch size can optimize performance, targeting 64 dimensions preferred by the H100 architecture.
- Issues with Dynamic Shared Memory: It was noted that CUDA has a limitation where static shared memory cannot exceed 50KB, requiring the use of dynamic shared memory instead.
- To allocate more than 48KB, the cudaFuncSetAttribute() function must be used, introducing a caveat for specific architectures.
- Dynamic Shared Memory Behavior Confirmed: A user verified that increasing the dynamic shared memory allocation to 40,000 bytes worked, while 50,000 bytes caused failure.
- They pondered whether using a different API for kernel launches would resolve the issue, as indicated in a referenced StackOverflow post.
- Successful Resolution Achieved: After exchanging advice and references, the initially problematic kernel configuration was eventually made to work.
- One member expressed gratitude for the assistance received in resolving the issues faced.
Link mentioned: Using maximum shared memory in Cuda: I am unable to use more than 48K of shared memory (on V100, Cuda 10.2) I call cudaFuncSetAttribute(my_kernel, cudaFuncAttributePreferredSharedMemoryCarveout, ...
GPU MODE ▷ #edge (5 messages):
React Native LLM LibraryLLM Inference on AndroidTransformer Memory BoundBitnet 1.58 A4GGUF Q8 Performance
-
Software Mansion's React Native LLM Library Launch: Software Mansion released a new library for using LLMs within React Native, utilizing ExecuTorch for performance. It simplifies usage with installation commands that include cloning the repository and running on the iOS simulator.
- Here’s the GitHub repository for more information and to contribute.
- Memory Constraints on LLM Inference in Android: Members discussed whether LLM inference on newer Android smartphones is memory bound. The consensus is that it depends on application context, with low context generally being memory bound and high context being compute bound.
- One user pointed out that modern processors usually offer more compute than memory bandwidth, suggesting that newer hardware might still face memory limitations.
- Bitnet 1.58 A4 for Optimized Inference: For fast inference, Bitnet 1.58 A4 with Microsoft's T-MAC operations is recommended, boasting a performance of 10 token/s on a 7B model. It can run on a desktop CPU, making it accessible even for those with limited GPU resources.
- Training doesn't need to start from scratch since Hugging Face offers guidance on converting models to Bitnet, though it may be complex.
- GGUF Q8 Offers Near Free Performance: When discussing alternatives, GGUF Q8 is noted to have minimal performance impact, especially for 7B-13B models. The user has not yet tested it on models smaller than that but suggests it could be beneficial for resource-constrained devices.
- This implies that GGUF Q8 is a viable option for those operating on lower-end hardware without demanding significant performance trade-offs.
Link mentioned: GitHub - software-mansion/react-native-executorch: Contribute to software-mansion/react-native-executorch development by creating an account on GitHub.
Notebook LM Discord ▷ #use-cases (16 messages🔥):
Magic Book Podcast ExperimentFunctionality Concerns with Podcast ToolsMobile Version Usability IssuesSummarizing 'The Body Keeps Score'Connecting Old Theories with Current Events
-
Magic Book Podcast Experiment Captivates: A member created a magical PDF that reveals different interpretations based on who views it, shared in a podcast format.
- Listeners were encouraged to share their thoughts on this innovative podcast approach.
- Need for Granular Control in Podcast Tools: There's acknowledgment that users seek enhanced functionalities for podcast development, but current tools may lack the granular control needed.
- A member offered assistance for any serious product development needs that arise.
- Mobile Version of Notebook Critiqued: Concerns were raised about the mobile version of Notebook being almost useless, particularly regarding basic functionalities like copying notes and scrolling.
- Members agreed on these issues and expressed hopes for a dedicated app in the near future.
- The Body Keeps Score Gets Summarized Well: A member praised the AI's ability to summarize 'The Body Keeps Score', capturing the serious topics within the book effectively.
- The conversation highlighted the value of microlearning in a busy world, contrasting it with mindless scrolling.
- Linking Journalism Theories to Modern Events: A member reflected on the spiral of silence theory and its relevance to current media dynamics, specifically mentioning the Guardian's exit from Twitter.
- This use case emphasizes married old theories with contemporary events for sociological insights.
Link mentioned: Top Shelf: Podcast · Four By One Technologies · "Top Shelf" is your go-to podcast for quick, insightful takes on today’s best-selling books. In just 15 minutes, get the gist, the gold, and a fresh pers...
Notebook LM Discord ▷ #general (40 messages🔥):
Privacy and Data Security on NotebookLMFeature Requests for NotebookLMPronunciation Issues in NotebookLMUser Experience Feedback
-
NotebookLM Data Security Clarification: A discussion highlighted that, according to Google's support page, users' data is secure and not used to train NotebookLM models, regardless of account type.
- This was reiterated by the privacy notice, stating that human reviewers may only access information for troubleshooting.
- Feature Requests for Response Language: A user expressed a request for the ability to set response languages per notebook, as they experienced issues with receiving answers in English instead of Greek.
- This feature could enhance user satisfaction in multilingual contexts.
- Pronunciation Challenges in NotebookLM: Users reported that NotebookLM struggles with correctly pronouncing certain words, such as treating 'presents' as a gift rather than as an action.
- A workaround suggested involved using pasted text to instruct on pronunciation directly.
- User Experience Issues with File Uploads: A user raised concerns about challenges faced while uploading files to NotebookLM, indicating these issues are being addressed by the team.
- Another user mentioned hitting the max notebook limit, leading to cutdowns of information.
- Interest in API Updates: Members showed curiosity about potential updates regarding an API for NotebookLM, yet were informed that no roadmap for features is currently published.
- The community relies on the announcement channel for any updates and new features.
Link mentioned: Privacy - Help: no description found
Latent Space ▷ #ai-general-chat (53 messages🔥):
Perplexity Ads IntroductionAI Agent Performance UpdateChatGPT Desktop App EnhancementsGemini AI FeedbackTech Debt and AI Impact
-
Perplexity Unveils Ads Experimentation: Perplexity announced it will begin experimenting with ads formatted as ‘sponsored follow-up questions’ in the U.S., with brands like Indeed and Whole Foods participating.
- They stated that revenue from ads would help support publishers, as subscriptions alone aren’t enough for sustainable revenue generation.
- Gemini AI Performance Surges: @GoogleDeepMind's Gemini (Exp 1114) has jumped to joint #1 in the Chatbot Arena after a substantial performance boost across various domains including math and creative writing.
- It is now available for testing in Google AI Studio, though API access is upcoming.
- New Features in ChatGPT Desktop App: The ChatGPT desktop app for macOS can now integrate with local applications like VS Code and Terminal, available to Plus and Team users in a beta version.
- However, some users reported missing features and slow performance, raising questions about its current integration capabilities.
- Concerns About AI and Tech Debt: A blog discussed how AI may actually increase the costs associated with tech debt, suggesting that companies with older codebases will struggle more than those with high-quality code.
- The post emphasized how generative AI widens the performance gap between these two groups.
- Discussion on Parsing Excel Files: Users discussed the best methods for handling Excel files with LLMs, particularly for parsing financial data into JSON or markdown tables.
- Suggestions included exporting data as CSV for easier programming language integration.
Links mentioned:
- Tweet from Logan Kilpatrick (@OfficialLoganK): gemini-exp-1114…. available in Google AI Studio right now, enjoy : ) https://aistudio.google.com
- AI Makes Tech Debt More Expensive: AI increases the penalty for low quality code
- Bloomberg - Are you a robot?: no description found
- Bloomberg - Are you a robot?: no description found
- Prompt Injecting Your Way To Shell: OpenAI's Containerized ChatGPT Environment: Dive into OpenAI’s containerized ChatGPT environment, demonstrating how users can interact with its underlying structure through controlled prompt injections and file management techniques. By explori...
- Perplexity brings ads to its platform | TechCrunch: AI-powered search engine Perplexity says it'll begin experimenting with ads on its platform starting this week.
- Introduction to Playbooks - Devin Docs: no description found
- Tweet from Kevin Weil 🇺🇸 (@kevinweil): Launching today: two big updates that make @ChatGPTapp more useful on PC and Mac desktops 🖥 💻 First, the ChatGPT desktop app for Windows is now available to all users. Since launching the early ver...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Massive News from Chatbot Arena🔥 @GoogleDeepMind's latest Gemini (Exp 1114), tested with 6K+ community votes over the past week, now ranks joint #1 overall with an impressive 40+ score leap — ma...
- Tweet from Andrej Karpathy (@karpathy): I'm not sure that enough people subscribe to the @Smol_AI newsletter. It's 1 very comprehensive email per day summarizing AI/LLM chatter across X, Reddit, Discord. There's probably others ...
- Tweet from Lucas Beyer (bl16) (@giffmana): Quoting yobibyte (@y0b1byte) https://www.lakera.ai/blog/visual-prompt-injections
- Bloomberg - Are you a robot?: no description found
- ChatGPT desktop paired with Xcode VERSUS Alter [COMPARISON] #chatgpt #chatgptupdate #apple: A quick comparison of ChatGPT desktop paired with Xcode.Findings:1. Doesn't see everything in Xcode, only code panes2. Code too long is truncated3. A probabl...
- Tweet from Kol Tregaskes (@koltregaskes): Google Gemini tells a user to die!!! 😲 The chat is legit, and you can read and continue it here: https://g.co/gemini/share/6d141b742a13
- Reddit - Dive into anything: no description found
- GitHub - google-deepmind/alphafold3: AlphaFold 3 inference pipeline.: AlphaFold 3 inference pipeline. Contribute to google-deepmind/alphafold3 development by creating an account on GitHub.
- Tessl raises $125M at $500M+ valuation to build AI that writes and maintains code | TechCrunch: Many startups and larger tech companies have taken a crack at building artificial intelligence to code software. Now another new player is coming out of
Latent Space ▷ #ai-announcements (1 messages):
swyxio: posted on hn!
OpenAI ▷ #ai-discussions (31 messages🔥):
AI-Driven Computer ControlLorebook for GPTChanges in Mac App InterfaceFuture of AI AdvancementsImage Tools in Copilot
-
AI controls computer UI with ChatGPT: A member shared their system where ChatGPT can indirectly control a computer's UI using a tech stack that includes Computer Vision and Python's PyAutoGUI. The member invites feedback and is eager to connect with others on enhancing AI-driven automation, hinting at a video demonstration.
- Others raised questions about the code's availability and compared it to existing solutions like OpenInterpreter.
- Lorebook for GPT enhances context: A user created a lorebook for GPT that loads entries based on keywords, featuring import/export capabilities and preventing spammed entries. They plan to share it on GreasyFork once debugging is complete and welcomed suggestions for new features.
- Discussions also clarified that this lorebook is implemented as a script for Tampermonkey or Violentmonkey.
- Mac App interface changes praised: Members expressed gratitude for the optimization in the Mac App's model chooser interface, noting it enhances user experience significantly. One member remarked that the entire community is indebted to the team who implemented this change.
- This comment echoes a sentiment of appreciation for updates that improve tool usability.
- Predictions on AI's future impact: There was a discussion about the transformative potential of AI, comparing it to the internet's evolution during the dot-com bubble. Participants expressed optimism that AI could lead to unprecedented changes in society, comparing it to a 'total consciousness shift.'
- Members reflected on past predictions about technology advancements, suggesting that those recognizing AI's potential early could gain significant influence.
- Curiosity about new image tools: A member speculated whether the new images on the Copilot homepage were created with a new image tool. This sparked further inquiries, prompting discussions about the underlying technology used for image generation.
- The speculation indicates ongoing interest in AI-generated content and its integration into existing products.
OpenAI ▷ #gpt-4-discussions (11 messages🔥):
Using LLMs EffectivelyContent Flags ConcernsCustom GPTs UsageRoleplay Character CreationModel Performance in Writing
-
Mastering LLMs is a Learned Skill: Members discussed that while anyone can use LLMs, effectively prompting them requires skill and practice, much like carpentry tools.
- Knowing what to include to improve the chance of getting desired output can significantly enhance the interaction experience.
- Navigating Content Flags without Fear: Concerns were raised about receiving content flags during interactions with the model, particularly for sensitive topics.
- However, some members noted that as long as users operate within legal bounds and avoid harmful content, they are likely safe from account consequences.
- Positive Experiences with Custom GPTs: Discussions highlighted the effectiveness of custom GPTs for specialized tasks, with one member mentioning the benefits of using Wolfram for math.
- The customization has proven valuable in enhancing productivity and utility for community members.
- Challenges in Roleplay Character Development: A user expressed frustrations about content flags hindering their attempts to create a complex roleplay character with a narrative tied to sensitive historical events.
- They noted that repetitive flagging leads to concerns about account risks, especially when pushing the model's boundaries.
- Reflections on GPT Performance in Creative Writing: One member shared their positive experience in using the model to help refine themes and descriptions in their fictional war stories.
- While the model struggles with dialogue, it can assist in organizing thoughts and providing useful suggestions in storytelling.
OpenAI ▷ #prompt-engineering (5 messages):
ChatGPT capabilitiesRetrieving information from ancient textsNostalgia for old prompting techniquesModel improvements in games
-
Exploring ChatGPT's Limits with 9 Pillars Solutions: A member encouraged others to push the boundaries of ChatGPT by experimenting with the formation of 9 pillars solutions.
- They claimed that significant insights could be achieved through this approach.
- Quest for Ancient Texts in Tech Engineering: Inquiries arose about refining searches for ancient texts within the context of advanced tech and engineering development platforms.
- Members were curious about how to reset the platform's search program for better results.
- Reminiscing Old Prompting Techniques: A member expressed nostalgia for earlier days spent trying to get the model to calculate the height of an owl using prompts.
- Another chimed in, suggesting that similar explorations may still be possible and fun.
- ChatGPT 3.5 Shows Progress in Games: A user excitedly shared that they got GPT-3.5 to successfully play the game of 24, even winning sometimes.
- This raised discussions around improvements in performance and reliability of the model in games.
OpenAI ▷ #api-discussions (5 messages):
9 Pillars SolutionsInformation Retrieval from Ancient TextsAdvancements in TechnologyModel Performance in Games
-
Exploring 9 Pillars Solutions: A member encouraged pushing the limits of ChatGPT to discover the potential of the 9 Pillars Solutions.
- They hinted at the transformative outcomes this exploration might bring.
- Challenges in Retrieving Ancient Text Information: A member inquired about refining searches for ancient texts using advanced tech on the development platform and resetting search parameters.
- They sought assistance on how to effectively utilize the platform for their information retrieval needs.
- Nostalgia for Model Problem Solving: A member reminisced about past experiences attempting to prompt models to determine the height of an owl from images.
- They expressed a desire to revisit those experiments with the model today.
- Model 3.5 shows impressive game performance: Another member shared success with model 3.5, reporting it could regularly win while playing the game of 24.
- They highlighted that the model rarely lied during gameplay, showcasing its capabilities.
- Looking Back at Past Experiments: A member acknowledged the nostalgia expressed and suggested revisiting the owl problem-solving challenge.
- They believed there were still opportunities to explore similar prompts with current models.
OpenInterpreter ▷ #general (34 messages🔥):
Dockerized Open InterpreterOpen Interpreter as a Shell Pass-ThroughBeta App PerformanceWorker Pool ConfigurationMemory Store Concept
-
Feedback on Dockerized Open Interpreter: A member suggested that a fully supported Docker image with optimizations for running as workers or warm spares would greatly improve their workflow with OI, which they currently manage through a workaround.
- They highlighted the need for more configuration features for max iterations and settings for ephemeral instances, indicating significant backend potential.
- Open Interpreter as a Shell Pass-Through Idea: There was a discussion about using Open Interpreter primarily as a pass-through to the shell to execute commands seamlessly, akin to how Vim operates in different modes.
- The feasibility of having a long-running process for easier integration with the interpreter was explored, highlighting the need for context management.
- Performance of Beta Desktop App: A member inquired whether the beta app performs significantly better than the console integration, and responses indicated that it likely does.
- It was confirmed that the desktop app promises the best Interpreter experience due to enhanced infrastructure compared to the open source repo.
- Worker Pool Configuration Concepts: A member raised questions about the ideal form of communication with containers, seeking input into setup for worker pools and expressing excitement about upcoming improvements in the development branch.
- They discussed specific command structures to enhance usability when running processing jobs or scripts.
- Concept of Memory Store for Context Management: The idea of implementing a memory store to retain command history instead of outputs was proposed to manage context efficiently without overspending on tokens.
- The potential for using a new pipe signature to specify which outputs to keep for the LLM was also discussed as a way to streamline context management.
OpenInterpreter ▷ #ai-content (7 messages):
VividNode v1.7.1 releaseVoice Lab frameworkChatGPT for macOSProbabilistic computing breakthroughs
-
VividNode v1.7.1 brings exciting features: The new release of VividNode v1.7.1 adds full support for LiteLLM API Keys, covering 60+ providers and 100+ models at this link.
- Enhancements include improved usability with QLineEdit for model input, and bug fixes related to text input and LlamaIndex functionality.
- Voice Lab Framework Open-Sourced: A member announced the open sourcing of Voice Lab, a framework for evaluating LLM-powered agents across different models and prompts at GitHub.
- Voice Lab aims to refine prompts and improve agent performance, inviting community contributions and discussions.
- ChatGPT integrates with desktop apps: ChatGPT is now compatible with desktop applications on macOS, allowing enhanced responses related to coding apps in its beta for Plus and Team users, shared by OpenAIDevs here.
- This update signifies a pivotal shift in how ChatGPT interacts with coding environments on user desktops.
- New Breakthrough in Probabilistic Computing: A YouTube video highlights a new computing breakthrough that reportedly achieves 100 million times better energy efficiency than leading NVIDIA GPUs; watch it here.
- The video discusses advancements in probabilistic computing, potentially revolutionizing the field of computational efficiency.
- VividNode and Custom URL Support: A member inquired about VividNode's compatibility with custom URLs for LLM inference and OpenAI integration.
- The developer confirmed compatibility with multiple providers and is actively working on custom URL support.
Links mentioned:
- Tweet from OpenAI Developers (@OpenAIDevs): ChatGPT 🤝 VS Code, Xcode, Terminal, iTerm2 ChatGPT for macOS can now work with apps on your desktop. In this early beta for Plus and Team users, you can let ChatGPT look at coding apps to provide be...
- New Computing Breakthrough achieves 100 MILLION Times GPU Performance!: In this video I discuss probabilistic computing that reportedly allows for 100 million times better energy efficiency compared to the best NVIDIA GPUs.Check ...
- GitHub - saharmor/voice-lab: Testing and evaluation framework for voice agents: Testing and evaluation framework for voice agents - GitHub - saharmor/voice-lab: Testing and evaluation framework for voice agents
Cohere ▷ #discussions (15 messages🔥):
Cohere embedding modelsDiscord access issuesFostering young talent in AI and roboticsPodcast content analysisUpcoming events
-
Optimal Token Count for Cohere Embedding: A member inquired about the optimal amount of characters/tokens for Cohere embedding models, particularly for multi-modal inputs.
- Another member clarified that the max context is currently 512 tokens and suggested experimenting within that limit.
- Discord Access Issues for Members: A member expressed frustration about being unable to access Discord due to a ban, sharing that it affected their online participation.
- Another member offered support, stating that they were glad their friend was back online and engaging with the community.
- Event Highlight: Ageing, Progress, and Decline Workshop: An event titled 'Ageing, Progress, and Decline' was shared, scheduled for Dec 6, 2024, and it will be livestreamed on the Hugging Face Discord server.
- A link to register was provided, inviting members to join both virtually and in-person.
- Advice Needed for Podcast Content Analysis: One member asked for advice on how to scrub hours of podcast content for information and how to utilize the data afterwards.
- Another member engaged by asking if the goal was to transcribe podcast content for use with large language models.
Link mentioned: Consent in Crisis: The Rapid Decline of the AI Data Commons: AI Reading Group session with one of the authors of "Consent in Crisis: The Rapid Decline of the AI Data Commons".
Cohere ▷ #announcements (1 messages):
Research Prototype Beta ProgramText-based DeliverablesUser Feedback for Tool Development
-
Last Call for Research Prototype Sign-ups: A reminder was issued that the sign-ups for the research prototype beta program are closing soon, specifically before Tuesday. Interested participants are encouraged to sign up via the provided link.
- This program offers a chance to explore a new Cohere tool aimed at enhancing research and writing tasks, providing valuable insights and feedback.
- Opportunity for Frequent Text Creators: The program targets those who regularly work on text-based deliverables like reports and blog posts, facilitating the use of the new tool before its public release. Participants will help shape the tool’s features catering to their workflows.
- The beta testers will be involved in the iterative development process, with the aim of creating an effective assistant for tackling complex tasks.
- Invitation for Constructive Feedback: Participants in the beta testing group are expected to provide detailed, constructive feedback as they engage with the experimental tool. The goal is to ensure the tool effectively assists users in their research and writing endeavors.
- By influencing its development, users can help refine the prototype to better meet the needs of real-world applications.
Link mentioned: Research Prototype - Early Beta Sign Up Form: Thank you for your interest in participating in the beta testing phase of our research prototype — a tool designed to help users tackle research and writing tasks such as: creating complex reports, do...
Cohere ▷ #questions (2 messages):
Bug reporting process
-
Benny seeks bug reporting guidance: @benny0917 inquired about the process for reporting a bug, referencing a specific message link on Discord.
- The response from sssandra confirmed awareness of the situation, indicating that the bug has been flagged.
- sssandra acknowledges the issue: sssandra apologized for keeping @benny0917 waiting while flagging the potential bug.
- This indicates prompt action in response to the inquiry about reporting a bug.
Cohere ▷ #api-discussions (13 messages🔥):
HTTP Request DetailsNetwork Error AnalysisAzure AI V2 API Status
-
Sharing HTTP Request for Reranking: A user shared their HTTP request payload for reranking using the model 'rerank-english-v3.0'. This highlights how others are troubleshooting issues related to this specific functionality.
- Another user provided a code snippet related to finding segments but clarified that it doesn't use the 'return_documents' parameter.
- Identifying Network Errors in API Calls: A user reported encountering a network/OpenSSL error with a specific error message indicating connection issues. They noted that this seems to occur occasionally rather than as a complete API connection problem.
- The user plans to update libraries and implement a retry mechanism, suggesting further checks on network or SSL setups might be beneficial.
- Azure AI V2 API Unavailable Status: A user inquired about the availability of the API V2 from Azure AI endpoints, which is not operational yet as indicated in the documentation. The current offerings include various models but only support the Cohere v1 API.
- Users pointed out the models currently available on Azure AI Studio and noted that the v2 API is 'coming soon', according to the documentation link provided.
Link mentioned: Cohere on Azure — Cohere: This page describes how to work with Cohere models on Microsoft Azure.
Cohere ▷ #projects (1 messages):
Vision Language Action ModelsBenchmarking Robotic Learning TasksSoTA VLMs like GPT4oMultimodal Action ModelsCollaborative Research Release
-
Launch of New Research on VLA Models: Today, a new paper titled Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks has been released, detailing collaborations among Manifold, Georgia Tech, MIT, and Metarch AI.
- The paper evaluates how well Vision Language and Vision Language Action models can control robots across 20 different real-world tasks, making it a significant step towards a broader benchmark.
- Exciting insights and model evaluations: The research highlights the emerging class of VLA models and includes evaluations of some State-of-the-Art VLMs like GPT4o.
- The authors are eager for feedback, sharing links to their work for community discussion, including a Twitter thread with highlights.
- Access to experimental details and resources: The researchers provided various resources, including the project website, code repository, and the Arxiv paper.
- These resources include experimental details, model descriptions, and further insights into their innovative work.
Link mentioned: Tweet from harsh (@HarshSikka)): Excited to share our new paper "Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks" We evaluate how well VLM & VLA models can control robots across 20 different real-wor...
LlamaIndex ▷ #blog (1 messages):
RAGformationCloud architecture automationDynamic flow diagramsPricing estimates for architecture
-
RAGformation automates cloud setup: RAGformation allows users to automatically generate cloud configurations by describing their use case in natural language, producing a tailored cloud architecture.
- Users can also visualize their setup through dynamically generated flow diagrams.
- Get pricing estimates instantly: The platform provides pricing estimates for the generated architecture, enabling users to budget their projects effectively.
- Refinement options are available, allowing users to adjust the configurations as needed.
LlamaIndex ▷ #general (26 messages🔥):
Memory for AI agentsGo version of LlamaIndexChromaDB ingestion issueUsing SentenceSplitter and SentenceWindowNodeParserLlamaParse contact assistance
-
Mem0 memory system enhances AI interactions: Recently, Mem0 was added to LlamaIndex, introducing an intelligent memory layer that personalizes AI assistant interactions over time. For more details, check Mem0 Memory.
- This system can be accessed via a managed platform or an open source solution.
- No plans for a Go version of LlamaIndex: There are currently no plans for releasing a Go version of LlamaIndex, as building one would require wrapping Python functions. Existing members discussed the necessary libraries for Go, emphasizing that API calls could be utilized without them.
- No one* is pursuing a native Go version right now, given that many models can be accessed via direct API calls without needing local libraries.
- Unexpected vector creation in ChromaDB ingestion: A user reported unexpected vector counts when ingesting a PDF into ChromaDB with an expected output of one vector but receiving two. Other members suggested it could be due to the default behavior of the PDF loader splitting documents by page.
- The SentenceWindowNodeParser was also discussed as potentially increasing vector counts due to its design, which generates a node for each sentence.
- Querying about using SentenceSplitter with SentenceWindowNodeParser: One user inquired about using SentenceSplitter and SentenceWindowNodeParser together in an ingestion pipeline, expressing concern over the resulting vector count. Community feedback confirmed that combining them improperly can lead to excessive node creation, complicating the outcomes.
- The default PDF loader splitting behavior could also contribute to the increased count observed, regardless of chosen configurations.
- Seeking assistance for LlamaParse integration: A member raised a request for support regarding LlamaParse and contact methods beyond the website's form. The community promptly referred them to another member who could assist further with their inquiry.
- Direct messages were initiated for personalized support regarding the integration with their enterprise RAG pipeline.
Link mentioned: Mem0 - LlamaIndex: no description found
tinygrad (George Hotz) ▷ #general (16 messages🔥):
GPU resource sharing between tinyboxesMLPerf Training 4.1 resultsBuffer transfer function in tinygradNetwork interactions and bottlenecksPCIe bandwidth capabilities
-
Cloud Sharding vs Machine Sharding: A member expressed the need to understand if they are machine sharded or cloud sharded, highlighting potential charges during slow syncs on the cloud layer.
- They noted that if performance drops due to cloud configurations, it would be a negative experience.
- Exciting News on MLPerf 4.1: Tinygrad achieved a notable milestone as both tinybox red and green participated in MLPerf Training 4.1, showcasing training of BERT.
- The team aims for 3x faster performance in the next MLPerf round, and is the first to include AMD in their training.
- Introduced Buffer Transfer Function: A contributor shared a pull request for a function enabling buffer transfer between CLOUD devices in tinygrad, ensuring a smooth out-of-buffer copy process.
- While size checks might not be essential, maintaining congruence with existing functionalities was emphasized.
- Exploring Network Protocols: Conversations included the capabilities of hybrid virtual cloud setups facilitating networked interactions, suggesting even a node configuration with GPUs for better performance.
- However, members expressed concerns over potential bottlenecks through CPU and PCIe connections.
- Assessing PCIe Bandwidth Metrics: Members discussed the potential of ConnectX-6 adapters for achieving up to 200Gb/s with InfiniBand and their relation to OCP3.0 bandwidth.
- Theoretical evaluations suggested achieving 400 GbE bidirectional connectivity bypassing the CPU.
Links mentioned:
- Tweet from the tiny corp (@tinygrad): MLPerf Training 4.1 is out, and both tinybox red and green on on there training BERT using tinygrad. (ResNet-50 was discontinued) These times are pace setter times. We are targeting 3x faster next ML...
- Buffer transfer on CLOUD devices by mdaiter · Pull Request #7705 · tinygrad/tinygrad: Title says it all - read out buffer from one device, put it into another on a different device. You don't really need the assert or the sz param in there, but I wanted to keep this congruent w...
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
Bitwise Operations in TinygradCLANG Backend Bug InvestigationTensor Gather Functionality
-
Enhancing Minimum Fix with Bitwise Operations: A member suggested changing the minimum fix to use bitwise_not, proposing it as a good first issue to apply the same on argmin and minimum functions.
- This change aims to improve the efficiency of these operations significantly.
- Bug in CLANG Backend Raises Questions: Another member investigated a bug in the CLANG backend related to maximum value calculations with a tensor operation, resulting in unexpected outputs from
.max().numpy()and.realize().max().numpy().
- This discrepancy highlights potential issues with handling tensor operations, particularly with negative values.
- Fusing Gather Operations in kv_pass Function: A member inquired about the possibility of fusing the
Tensor.gathercalls in the kv_pass function and whether the resultant tensors k_seqs and v_seqs would be materialized.
- They seek guidance on how to efficiently check for this fusion, emphasizing its impact on performance.
OpenAccess AI Collective (axolotl) ▷ #general (15 messages🔥):
Nanobitz RecommendationsLlama Event at Meta HQTokenization StrategiesOptimal Dataset Size for Fine-Tuning LlamaLiger Kernel Improvements
-
Nanobitz recommends alternative Docker images: Nanobitz advised using the axolotlai/axolotl images even if they lag a day behind the winglian versions.
- Hub.docker.com reflects that the latest tags are from 20241110.
- Discussion on Optimal Dataset Size for Fine-Tuning Llama: Arcadefira inquired about the ideal dataset size for fine-tuning a Llama 8B model, especially given its low-resourced language.
- Nanobitz responded with questions about tokenizer overlaps and suggested that if overlaps are sufficient, a dataset of 5k may be adequate.
- Llama Event at Meta HQ: Le_mess asked if anyone is attending the Llama event at Meta HQ on December 3-4.
- Neodymiumyag expressed interest, requesting a link to more information about the event.
- Liger kernel sees improvements: Xzuyn mentioned that the Liger project has an improved orpo kernel, detailing this through a GitHub pull request.
- They also noted it behaves like a flat line with an increase in batch size.
- Social Media Insight shared: Kearm shared a post from Nottlespike on X.com, indicating a humorous perspective on their day.
- The shared link leads to a post detailing Nottlespike's experiences.
Links mentioned:
- Tweet from Kearm (@Nottlespike): So this is how my day has been going
- no title found: no description found
- no title found: no description found
LAION ▷ #general (5 messages):
EPOCH 58 COCKLAION copyright discussionPublic indexing and copyright
-
EPOCH 58 COCK gets its legs: The EPOCH 58 COCK model, now at 60M params and using f16, is showing progress as the legs come in and the cockscomb becomes more defined.
- This model appears to be advancing in both detail and structure.
- LAION's copyright issues debated: A discussion arose about LAION datasets enabling users to download 5 Billion images, with claims it constitutes a copyright violation under EU law.
- Critics argue that this circumvents paywalls and licensing terms, differing from regular browser caching.
- Debate over copyright law knowledge: Trevityger was called out for allegedly spewing pseudolegal nonsense regarding copyright law issues in LAION's actions.
- Members expressed frustration over false equivalences drawn between LAION's downloading practices and typical web browser behavior.
- Public indexing and copyright legality: One member argued there's no world where a public index of public links constitutes a copyright infringement.
- This perspective suggests that access to public links should not interfere with copyright laws.
Link mentioned: Re: LAION. Downloading 5Billion images 220TB of data permanently on external hard drives is not "Browser caching": Most on this sub are not erudite enough to have opinions about complex copyright law and yet some try to make false equivalence arguments to the...
LAION ▷ #research (5 messages):
Benchmarking Vision Language Action ModelsWatermark AnythingAI Generators12M Public Domain Images
-
Collaborative Benchmarking of VLA Models: A new paper titled Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks was released by a collaboration of Manifold, Georgia Tech, MIT, and Metarch AI, focusing on VLA models' performance on 20 real-world robotics tasks.
- You can find highlights in this Thread w/ Highlights and access the Arxiv paper for more in-depth analysis.
- Watermark Anything Implementation Released: The project Watermark Anything with Localized Messages is now available on GitHub, showcasing an official implementation of the research paper.
- This implementation allows for dynamic watermarking, which might prove useful in various AI applications.
- Fast Model with 1M Parameters: A member noted that the model discussed has only 1M parameters, suggesting it could be fast enough for integration into various AI generators.
- This efficiency could enhance the accessibility of watermarking technologies across the field.
- Public Domain Image Set Released: A 12M image set is now in the public domain, which can be valuable for various machine learning tasks and projects.
- The set can be accessed here for those interested in utilizing open-source resources.
Links mentioned:
- Tweet from harsh (@HarshSikka)): Excited to share our new paper "Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks" We evaluate how well VLM & VLA models can control robots across 20 different real-wor...
- GitHub - facebookresearch/watermark-anything: Official implementation of the paper "Watermark Anything with Localized Messages": Official implementation of the paper "Watermark Anything with Localized Messages" - facebookresearch/watermark-anything
DSPy ▷ #show-and-tell (1 messages):
ChatGPT for macOSIntegration with desktop appsdspy workflowsCoding assistance
-
ChatGPT for macOS integrates with desktop apps: Exciting news! ChatGPT for macOS can now integrate with desktop apps like VS Code, Xcode, Terminal, and iTerm2, providing improved coding assistance for users.
- This feature, currently in beta for Plus and Team users, allows ChatGPT to interact directly with development environments, enhancing productivity.
- Potential for dspy workflows enhancement: A member expressed hope that this functionality could extend to dspy GPTs, enhancing workflows even further.
- They highlighted the potential impact on projects, suggesting it could be a game-changer for their work.
Link mentioned: Tweet from OpenAI Developers (@OpenAIDevs): ChatGPT 🤝 VS Code, Xcode, Terminal, iTerm2 ChatGPT for macOS can now work with apps on your desktop. In this early beta for Plus and Team users, you can let ChatGPT look at coding apps to provide be...
DSPy ▷ #general (7 messages):
Long-code generation with large tokensDeprecation of LM assertionsDeveloping a multi-infraction LLM application
-
Tools generating code edits over 4096 tokens: A member inquired about how tools like Cursor and Aider manage to generate edits in code exceeding 4096 tokens.
- This suggests a need for clarity on token management in these tools as developers seek effective solutions.
- LM assertions causing confusion: A member questioned whether LM assertions were being deprecated, noting a lack of references to
dspy.Suggestordspy.Assertin the current documentation.
- Another responded that while the references are absent, these can still be located via the search bar, indicating ongoing updates to the material.
- Assistance with Value and Key Errors: In the discussion about LM assertions, one member mentioned ongoing issues with Value and Key Errors, asking for resources or help with their code.
- This highlights a shared concern in seeking technical support while navigating documentation changes.
- Creating a versatile LLM application: A member described developing a LLM application that currently generates defensive documents for specific infractions, namely related to alcohol ingestion.
- They seek to extend its capabilities for other infractions without needing separate optimized prompts, calling into question the potential for a unified approach.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Quiz EligibilityCourse Content Timeline
-
New Member Queries Quiz Eligibility: A new member inquired about the possibility of completing quizzes and still being eligible for the Trailblazer and above trails.
- Another member confirmed eligibility but emphasized the importance of catching up quickly as each quiz is directly related to the course content, with everything due by December 12th.
- Emphasis on Course Content Relevance: Members discussed the importance of staying up to date with course content in relation to quiz completion.
- The reminder was made that all quizzes and assignments must be submitted by December 12th to ensure full participation.
LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
sheilabel: Happening today! https://www.eventbrite.ca/e/1039740199927?aff=oddtdtcreator
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (2 messages):
Palmyra X 004 modelWriter handler implementationPull Request Review
-
New Writer Handler and Palmyra X 004 Model Submitted: A member announced the submission of a PR to add a Writer handler and the Palmyra X 004 model to the leaderboard.
- This contribution has been acknowledged and is open for review, with thanks extended to the reviewers.
- Quick Acknowledgment for PR Review: Another member expressed intent to review the submitted PR, stating, 'Will take a look. Thank you!'
- This reflects ongoing collaboration and support in the project's development activities.
Link mentioned: [BFCL] Add support for Writer models and Palmyra X 004 by samjulien · Pull Request #755 · ShishirPatil/gorilla: This PR adds support for Writer models and our latest Palmyra X 004 to BFCL. Thank you!
AI21 Labs (Jamba) ▷ #general-chat (2 messages):
Legacy Model DeprecationTransition to Open Source Solutions
-
Legacy Models Cause Disruption: A member expressed frustration over the deprecation of legacy models, stating that the impact has been hugely disruptive due to the new models not being 1:1 in terms of output.
- We would like to continue using legacy models as they feel the transition has not been smooth.
- Conversion to Open Source Still Ongoing: The same member noted that they are working on converting to an open source solution but have been paying for the old models for almost 2 years.
- They raised concerns about future deprecations, asking, How can we be sure AI21 won't deprecate the new models in the future too?
Mozilla AI ▷ #announcements (1 messages):
Local LLMs WorkshopSQLite-Vec Metadata FilteringRefact.AI Autonomous Agents
-
Build Your Own Local LLMs Workshop: Join the upcoming event on Tuesday titled Building your own local LLM's: Train, Tune, Eval, RAG all in your Local Env. to learn how to develop local language models.
- Participants can expect hands-on training and insights on building effective local LLM systems.
- SQLite-Vec Now Supports Metadata Filtering: On Wednesday, there's an event about the new feature in SQLite-Vec: SQLite-Vec now supports metadata filtering!.
- This will enable users to efficiently filter metadata, enhancing data management capabilities.
- Explore Autonomous AI with Refact.AI: This Thursday, attend the session on Autonomous AI Agents with Refact.AI to dive into the world of autonomous agents.
- Learn about innovative strategies and applications for AI technologies through this engaging presentation.