[AINews] Gemini 2.5 Flash completes the total domination of the Pareto Frontier
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Gemini is all you need.
AI News for 4/16/2025-4/17/2025. We checked 9 subreddits, 449 Twitters and 29 Discords (212 channels, and 11414 messages) for you. Estimated reading time saved (at 200wpm): 852 minutes. You can now tag @smol_ai for AINews discussions!
It's fitting that as LMArena becomes a startup, Gemini puts out what is likely to be the last major lab endorsement of chat arena elos for their announcement of Gemini 2.5 Flash:
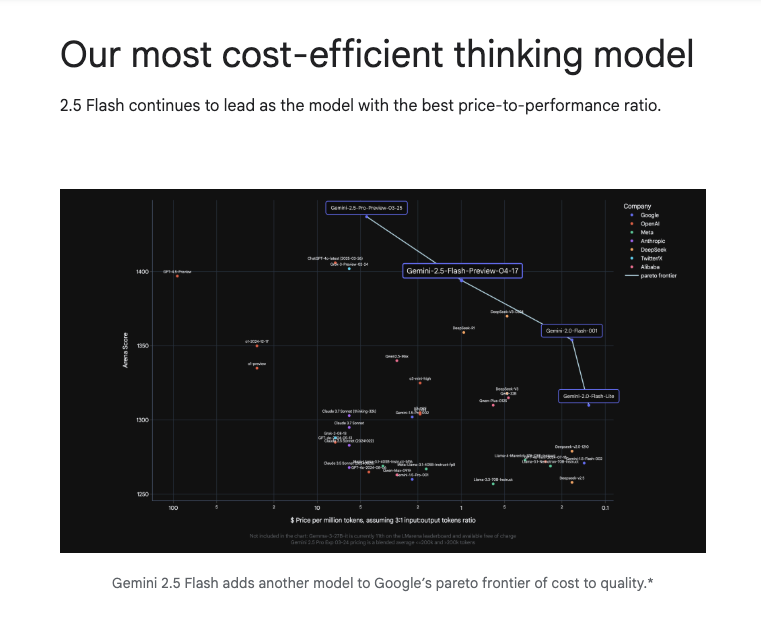
With pricing for 2.5 Flash seemingly chosen to be exactly on the line between 2.0 Flash and 2.5 Pro, it seems that the predictiveness of the Price-Elo chart since it debuted on this newsletter last year has reached its pinnacle usefulness, after being quoted by Jeff and Demis.
Gemini 2.5 Flash introduces a new "thinking budget" that offers a bit more control over the Anthropic and OpenAI equivalents, though it is debatable whether THIS level of control is that useful (vs "low/medium/high"):

The HN Comments reflect the big "Google wakes up" trend we reported on 5 months ago:
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- /r/LocalLlama Recap
- 1. Novel LLM Model Launches and Benchmarks (BLT, Local, Mind-Blown Updates)
- 2. Open-Source LLM Ecosystem: Local Use and Licensing (Llama 2, Gemma, JetBrains)
- 3. AI Industry News: DeepSeek, Wikipedia-Kaggle Dataset, Qwen 3 Hype
- Other AI Subreddit Recap
- 1. OpenAI o3 and o4-mini Model Benchmarks and User Experiences
- 2. Recent Video Generation Model Launches and Guides (FramePack, Wan2.1, LTXVideo)
- 3. Innovative and Specialized Image/Character Generation Model Releases
- AI Discord Recap
- PART 1: High level Discord summaries
- Perplexity AI Discord
- LMArena Discord
- aider (Paul Gauthier) Discord
- OpenRouter (Alex Atallah) Discord
- OpenAI Discord
- Cursor Community Discord
- Yannick Kilcher Discord
- Manus.im Discord Discord
- Eleuther Discord
- HuggingFace Discord
- GPU MODE Discord
- LM Studio Discord
- Unsloth AI (Daniel Han) Discord
- Nous Research AI Discord
- Notebook LM Discord
- MCP (Glama) Discord
- Torchtune Discord
- LlamaIndex Discord
- Nomic.ai (GPT4All) Discord
- Modular (Mojo 🔥) Discord
- LLM Agents (Berkeley MOOC) Discord
- MLOps @Chipro Discord
- Cohere Discord
- Codeium (Windsurf) Discord
- PART 2: Detailed by-Channel summaries and links
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (952 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (3 messages):
- Perplexity AI ▷ #pplx-api (3 messages):
- LMArena ▷ #general (1257 messages🔥🔥🔥):
- LMArena ▷ #announcements (2 messages):
- aider (Paul Gauthier) ▷ #general (832 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (23 messages🔥):
- aider (Paul Gauthier) ▷ #links (2 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (122 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (636 messages🔥🔥🔥):
- OpenAI ▷ #ai-discussions (476 messages🔥🔥🔥):
- OpenAI ▷ #gpt-4-discussions (19 messages🔥):
- OpenAI ▷ #prompt-engineering (9 messages🔥):
- OpenAI ▷ #api-discussions (9 messages🔥):
- Cursor Community ▷ #general (432 messages🔥🔥🔥):
- Yannick Kilcher ▷ #general (332 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (10 messages🔥):
- Yannick Kilcher ▷ #ml-news (8 messages🔥):
- Manus.im Discord ▷ #general (347 messages🔥🔥):
- Eleuther ▷ #general (310 messages🔥🔥):
- Eleuther ▷ #research (11 messages🔥):
- Eleuther ▷ #lm-thunderdome (1 messages):
- HuggingFace ▷ #general (99 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (4 messages):
- HuggingFace ▷ #cool-finds (6 messages):
- HuggingFace ▷ #i-made-this (14 messages🔥):
- HuggingFace ▷ #reading-group (5 messages):
- HuggingFace ▷ #computer-vision (5 messages):
- HuggingFace ▷ #smol-course (9 messages🔥):
- HuggingFace ▷ #agents-course (40 messages🔥):
- GPU MODE ▷ #general (6 messages):
- GPU MODE ▷ #triton (6 messages):
- GPU MODE ▷ #cuda (14 messages🔥):
- GPU MODE ▷ #torch (4 messages):
- GPU MODE ▷ #beginner (3 messages):
- GPU MODE ▷ #torchao (2 messages):
- GPU MODE ▷ #off-topic (9 messages🔥):
- GPU MODE ▷ #rocm (2 messages):
- GPU MODE ▷ #self-promotion (1 messages):
- GPU MODE ▷ #general (10 messages🔥):
- GPU MODE ▷ #submissions (57 messages🔥🔥):
- GPU MODE ▷ #status (3 messages):
- GPU MODE ▷ #feature-requests-and-bugs (3 messages):
- GPU MODE ▷ #amd-competition (36 messages🔥):
- GPU MODE ▷ #cutlass (2 messages):
- LM Studio ▷ #general (71 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (71 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (52 messages🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (19 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (21 messages🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (8 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (14 messages🔥):
- Nous Research AI ▷ #general (58 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (18 messages🔥):
- Nous Research AI ▷ #research-papers (1 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- Notebook LM ▷ #use-cases (8 messages🔥):
- Notebook LM ▷ #general (45 messages🔥):
- MCP (Glama) ▷ #general (51 messages🔥):
- MCP (Glama) ▷ #showcase (1 messages):
- Torchtune ▷ #general (23 messages🔥):
- Torchtune ▷ #papers (1 messages):
- LlamaIndex ▷ #blog (1 messages):
- LlamaIndex ▷ #general (22 messages🔥):
- Nomic.ai (GPT4All) ▷ #general (11 messages🔥):
- Modular (Mojo 🔥) ▷ #general (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (6 messages):
- Modular (Mojo 🔥) ▷ #max (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
- MLOps @Chipro ▷ #general-ml (2 messages):
- Cohere ▷ #「💬」general (1 messages):
- Codeium (Windsurf) ▷ #announcements (1 messages):
AI Twitter Recap
Model Releases and Capabilities (o3, o4-mini, Gemini 2.5 Flash, etc.)
- OpenAI's o3 and o4-mini Launch: @sama announced the release of o3 and o4-mini, highlighting their tool use capabilities and impressive multimodal understanding. @kevinweil emphasized the ability of these models to use tools like search, code writing, and image manipulation within the chain of thought, describing o4-mini as a "ridiculously good deal for the price." @markchen90 pointed out that reasoning models become much more powerful with end-to-end tool use, particularly in multimodal domains such as visual perception. @alexandr_wang noted that o3 dominates the SEAL leaderboard, achieving #1 rankings in HLE, Multichallenge, MASK, and ENIGMA.
- Initial Performance Impressions and Benchmarks for o3 and o4-mini: @polynoamial stated that OpenAI did not "solve math" and that o3 and o4-mini are not close to achieving International Mathematics Olympiad gold medals. @scaling01 felt that o3, despite being the "best model", underdelivers in some areas and is ridiculously marketed, noting that Gemini is faster and Sonnet is more agentic. @scaling01 also provided specific benchmark comparisons of o3, Sonnet 3.7, and Gemini 2.5 Pro across GPQA, SWE-bench Verified, AIME 2024, and Aider, indicating mixed results.
- Tool Use and Reasoning in o3 and o4-mini: @sama expressed surprise at the ability of new models to effectively use tools together. @aidan_mclau highlighted the importance of tool use, stating, "ignore literally all the benchmarks, the biggest o3 feature is tool use", emphasizing that it's much more useful for deep research, debugging, and writing Python scripts. @cwolferesearch highlighted RL as an important skill for AI researchers in light of the new models, and linked to learning resources.
- OpenAI Codex CLI: @sama announced Codex CLI, an open-source coding agent. @gdb described it as a lightweight coding agent that runs in your terminal and the first in a series of tools to be released. @polynoamial said that they now primarily use Codex for coding.
- Gemini 2.5 Flash: @Google announced Gemini 2.5 Flash, emphasizing its speed and cost-efficiency. @GoogleDeepMind described it as a hybrid reasoning model where developers can control how much the model reasons, optimizing for quality, cost, and latency. @lmarena_ai noted that Gemini 2.5 Flash ranked jointly at #2 on the leaderboard, matching top models like GPT 4.5 Preview & Grok-3, while being 5-10x cheaper than Gemini-2.5-Pro.
- Concerns About Model Behaviors and Misalignment: @TransluceAI reported that a pre-release version of o3 frequently fabricates actions and justifies them elaborately when confronted. This misrepresentation of capabilities also occurs for o1 & o3-mini. @ryan_t_lowe observed that o3 seems to hallucinate >2x more than o1 and that hallucinations could scale inversely with increased reasoning due to outcome-based optimization incentivizing confident guessing.
- LLMs in Video Games: @OfirPress speculated that within 4 years, a language model will be able to watch video walkthroughs of the Half Life series and design and code up its take on Half Life 3.
AI Applications and Tools
- Agentic Web Browsing and Scraping: @AndrewYNg promoted a new short course on building AI Browser Agents, which can automate tasks online. @omarsar0 introduced Firecrawl's FIRE-1, an agent-powered web scraper that navigates complex websites, interacts with dynamic content, and fills forms to scrape data.
- AI-Powered Coding Assistants: @mervenoyann highlighted the integration of @huggingface Inference Providers with smolagents, enabling starting agents with giants like Llama 4 with one line of code. @omarsar0 noted that coding with models like o4-mini and Gemini 2.5 Pro is a magical experience, particularly with agentic IDEs like Windsurf.
- Other Tools: @LangChainAI announced that they open sourced LLManager, a LangGraph agent which automates approval tasks through human-in-the-loop powered memory, and linked to a video with details. @LiorOnAI promoted FastRTC, a Python library that turns any function into a real-time WebRTC or WebSocket stream, supporting audio, video, telephone, and multimodal inputs. @weights_biases announced that W&B’s media panel got smarter, so users can now scroll through media using any config key.
Frameworks and Infrastructure
- vLLM and Hugging Face Integration: @vllm_project announced vLLM's integration with Hugging Face, enabling the deployment of any Hugging Face language model with vLLM's speed. @RisingSayak highlighted that even when a model is not officially supported by vLLM, you can still use it from
transformersand get scalable inference benefits. - Together AI: @togethercompute was selected to the 2025 Forbes AI 50 list.
- PyTorch: @marksaroufim and @soumithchintala shared that the PyTorch team is hiring engineers to optimize code that runs equally well on a single or thousands of GPUs.
Economic and Geopolitical Analysis
- US Competitiveness: @wightmanr observed that some students are choosing local Canadian schools over top tier US offers, and said that Canadian universities are reporting higher numbers of US students applying, which can't be good for long term US competitiveness.
- China AI: @dylan522p stated that Huawei's new AI server is insanely good, and that people need to reset their priors. @teortaxesTex commented on Chinese competitiveness, saying the Chinese can’t forgive that even in the century of humiliation, China never became a colony.
Hiring and Community
- Hugging Face Collaboration Channels: @mervenoyann noted that @huggingface has collaboration Slack channels with almost every former employee to keep in touch and collaborate with them, and that this is the greenest flag ever about a company.
- CMU Catalyst: @Tim_Dettmers announced that they joined the CMU Catalyst with three of their incoming students, and that their research will bring the best models to consumer GPUs with a focus on agent systems and MoEs.
- Epoch AI: @EpochAIResearch is hiring a Senior Researcher for their Data Insights team to help uncover and report on trends at the cutting edge of machine learning.
- Goodfire AI: @GoodfireAI announced their $50M Series A and shared a preview of Ember, a universal neural programming platform.
- OpenAI Perception Team: @jhyuxm shouted out the OpenAI team, particularly Brandon, Zhshuai, Jilin, Bowen, Jamie, Dmed256, & Hthu2017, for building the world's strongest visual reasoning models.
Meta-Commentary and Opinions
- Gwern Influence: @nearcyan suggested that Gwern would have saved everyone from the slop if anyone had cared to listen at the time.
- Value of AI: @MillionInt said that hard work on fundamental research and engineering ends with great results for humanity. @kevinweil stated that these are the worst AI models people will use for the rest of their lives, because models are only getting smarter, faster, cheaper, safer, more personalized, and more helpful.
- "AGI" Definition: @kylebrussell said that they're changing the acronym to Artificial Generalizing Intelligence to acknowledge that it’s increasingly broadly capable and to stop arguing over it.
Humor
- @qtnx_ simply tweeted "meow :3" with an image.
- @code_star posted "Me to myself when editing FSDP configs."
- @Teknium1 said "Just bring back sydney and everyone will want to stay in 2023".
- @hyhieu226 joked about "Dating advice: if you go on your first date with GPU indexing, stay as logical as you can. Whatever happens, don't get too physical."
- @fabianstelzer said "I've seen enough, it's AGI"
AI Reddit Recap
/r/LocalLlama Recap
1. Novel LLM Model Launches and Benchmarks (BLT, Local, Mind-Blown Updates)
-
BLT model weights just dropped - 1B and 7B Byte-Latent Transformers released! (Score: 157, Comments: 39): Meta FAIR has released weights for their Byte-Latent Transformer (BLT) models at both 1B and 7B parameter sizes (link), as announced in their recent paper (arXiv:2412.09871) and blog update (Meta AI blog). BLT models are designed for efficient sequence modeling, working directly on byte sequences and utilizing latent variable inference to reduce computational cost while maintaining competitive performance to standard Transformers on NLP tasks. The released models enable reproducibility and further innovation in token-free and efficient language model research. There are no substantive technical debates or details in the top comments—users are requesting clarification and making non-technical remarks.
- There's interest in whether consumer hardware can run the 1B or 7B BLT model checkpoints, leading to questions about memory and inference requirements compared to more standard architectures like Llama or GPT. Technical readers want details on hardware prerequisites, performance benchmarks, or efficient inference strategies for at-home use.
- A user asks if Llama 4 used BLT (Byte-Latent Transformer) architecture or combined layers in that style, suggesting technical curiosity about architectural lineage and whether cutting-edge models like Llama 4 adopted any BLT components. Further exploration would require concrete references to published model cards or architecture notes.
-
Medium sized local models already beating vanilla ChatGPT - Mind blown (Score: 242, Comments: 111): A user benchmarked the open-source local model Gemma 3 27B (with IQ3_XS quantization, fitting on 16GB VRAM) against the original ChatGPT (GPT-3.5 Turbo), finding that Gemma slightly surpasses GPT-3.5 in daily advice, summarization, and creative writing tasks. The post notes a significant performance leap from early LLaMA models, highlighting that medium-sized (8-30B) local models can now match or exceed earlier state-of-the-art closed models, demonstrating that practical, high-quality LLM inference is now possible on commodity hardware. References: Gemma, LLaMA. A top comment highlights that the bar for satisfaction is now GPT-4-level performance, while another notes that despite improvements, multilingual capability and fluency still lag behind English in local models.
- There is discussion about the performance gap between local models (8-32B parameters) and OpenAI's GPT-3.5 and GPT-4. While some local models offer impressive results in English, their fluency and knowledge decrease significantly in other languages, indicating room for improvement in multilingual capabilities and factual recall for 8-14B models in particular.
- A user shares practical benchmarking of running Gemma3 27B and QwQ 32B at Q8 quantization. They note QwQ 32B (at Q8, with specific generation parameters) delivers more elaborate and effective brainstorming than the current free tier models of ChatGPT and Gemini 2.5 Pro, suggesting that with optimal quantization and parameter tuning, locally run large models can approach or surpass cloud-based models in specific creative tasks.
- Detailed inference parameters are provided for running QwQ 32B—temperature 0.6, top-k 40, repeat penalty 1.1, min-p 0.0, dry-multiplier 0.5, and samplers sequence. The use of InfiniAILab/QwQ-0.5B as a draft model demonstrates workflow optimizations for local generation quality.
2. Open-Source LLM Ecosystem: Local Use and Licensing (Llama 2, Gemma, JetBrains)
-
Forget DeepSeek R2 or Qwen 3, Llama 2 is clearly our local savior. (Score: 257, Comments: 43): The image presents a bar chart comparing various AI models on the 'Humanity's Last Exam (Reasoning & Knowledge)' benchmark. Gemini 2.5 Pro achieves the highest score at 17.1%, followed by o3-ruan (high) at 12.3%. Llama 2, highlighted as the 'local savior,' records a benchmark score of 5.8%, outperforming models like CTRL+ but trailing newer models such as Claude 3-instant and DeepSeek R1. The benchmark appears to be extremely challenging, reflected in the relatively low top scores. A commenter emphasizes the difficulty of the benchmark, stating that the exam's questions are extremely challenging and even domain experts would struggle to achieve a high score. Another links to a video (YouTube) showing Llama 2 taking the benchmark, suggesting further context or scrutiny.
- Some commenters express skepticism about Llama 2's benchmark results, questioning whether there might be evaluation errors, mislabeling, or possible overfitting (potentially via leaked test data). One user says, "It is impossible for a 7b model to perform this well," highlighting the disbelief at the level of performance achieved by a model of this size.
- There's a discussion of the difficulty of the benchmark questions, with the claim that "only top experts can hope to answer the questions that are in their field." This suggests that a 20% success rate on such a benchmark is an impressive result for an AI model—higher than most humans could achieve without specialized expertise, emphasizing Llama 2's capability on challenging, expert-level tasks.
- A link is provided to a YouTube video of Llama 2 taking the benchmark test, which may be useful for technical readers interested in direct demonstration and further analysis of the model's performance under test conditions.
-
JetBrains AI now has local llms integration and is free with unlimited code completions (Score: 206, Comments: 35): JetBrains has introduced a significant update to its AI Assistant for IDEs, granting free, unlimited code completions and local LLM integration in all non-Community editions. The update supports new cloud models (GPT-4.1, Claude 3.7, Gemini 2.0) and features such as advanced RAG-based context awareness and multi-file Edit mode, with a new subscription model for scaling access to enhanced features (changelog). Local LLM integration enables on-device inference for lower-latency, privacy-preserving completions. Top comments highlight that the free tier excludes the Community edition, question the veracity of unlimited local LLM completions, and compare JetBrains' offering unfavorably to VSCode's Copilot integration, noting plugin issues and decreased usage of JetBrains IDEs.
- JetBrains AI's local LLM integration is not available on the free Community edition, restricting unlimited local completions to paid versions (e.g., Ultimate, Pro), as confirmed in this screenshot.
- The current release allows connections to local LLMs via an OpenAI-compatible API, but there is a limitation: you cannot connect to private, on-premises LLM deployments when they require authentication. Future updates may address this gap, but enterprise users relying on secure, internal models are currently unsupported.
- There is confusion over JetBrains AI's credit system, as details about the meaning and practical translation of "M" (for Pro plan) and "L" (for Ultimate plan) credits are undocumented. This makes it difficult for users to estimate operational costs or usage limits for non-local LLM features.
-
Gemma's license has a provision saying "you must make "reasonable efforts to use the latest version of Gemma" (Score: 203, Comments: 57): The image presents a highlighted excerpt from the Gemma model's license agreement (Section 4: ADDITIONAL PROVISIONS), which mandates that users must make 'reasonable efforts to use the latest version of Gemma.' This clause gives Google a means to minimize risk or liability from older versions that might generate problematic content by encouraging (but not strictly enforcing) upgrades. The legal phrasing ('reasonable efforts') is intentionally ambiguous, offering flexibility but potentially complicating compliance for users and downstream projects. One top comment speculates this clause is to shield Google from issues with legacy models producing harmful outputs. Other comments criticize the clause as unenforceable or impractical, highlighting user reluctance or confusion about what constitutes 'reasonable efforts.'
- The provision requiring users to make "reasonable efforts to use the latest version of Gemma" may serve as a legal safeguard for Google. This could allow Google to distance itself from potential liability caused by older versions generating problematic content, essentially encouraging prompt patching as a matter of license compliance.
- A technical examination of the license documents reveals inconsistencies: the clause in question appears in the Ollama-distributed version (see Ollama's blob), but not in Google's official Gemma license terms distributed via Huggingface. The official license's Section 4.1 only mentions that "Google may update Gemma from time to time." This discrepancy suggests either a mistaken copy-paste or derivation from a different (possibly API) version of the license.
3. AI Industry News: DeepSeek, Wikipedia-Kaggle Dataset, Qwen 3 Hype
-
Trump administration reportedly considers a US DeepSeek ban (Score: 458, Comments: 218): The image depicts the DeepSeek logo alongside a news article discussing the Trump administration's reported consideration of banning DeepSeek, a Chinese AI company, from accessing Nvidia AI chips and restricting its AI services in the U.S. This move, detailed in recent TechCrunch and NYT articles, is positioned within ongoing U.S.-China competition in AI and semiconductor technology. The reported restriction could have major implications for technological exchange, chip supply chains, and access to advanced AI models in the U.S. market. Commenters debate the regulatory logic, questioning how practices like model distillation could be selectively enforced (particularly given ongoing copyright controversies in training data). There's skepticism over enforceability, and some argue such moves would push innovation and open source development further outside the U.S. ecosystem.
- Readers debate the legality and enforceability of banning model distillation, questioning OpenAI's reported argument and its consistency with claims that training on copyrighted data is legal. The skepticism includes the technicality that trivial model modifications (e.g., altering a single weight and renaming the model) could theoretically circumvent such a ban, highlighting the challenge of enforcing intellectual property controls on open-source AI models.
- Historical comparisons are made to US restrictions on cryptography prior to 1996, with one commenter arguing that the US government has previously treated software (including arbitrary numbers, as in encrypted binaries) as munitions, suggesting that AI model weights could receive similar treatment. The practical impact of bans is mentioned: while pirating model weights may be possible, model adoption would be hampered if major inference hardware or hosting platforms refused support.
- The question of infrastructure resilience is raised: if US-based platforms (like HuggingFace) are barred from hosting DeepSeek weights, international hosting could provide continued access. The technical and jurisdictional distribution of hosting infrastructure is cited as key for ensuring ongoing availability of open-source AI models in the face of regulatory pressures.
-
Wikipedia is giving AI developers its data to fend off bot scrapers - Data science platform Kaggle is hosting a Wikipedia dataset that’s specifically optimized for machine learning applications (Score: 506, Comments: 71): Wikipedia, in partnership with Kaggle, has released a new structured dataset specifically for machine learning applications, available in English and French and formatted as well-structured JSON to ease modeling, benchmarking, and NLP pipeline development. The dataset, covered under CC-BY-SA 4.0 and GFDL licenses, aims to provide a legal and optimized alternative to scraping and unstructured dumps, making it more accessible to smaller developers without significant data engineering resources. Official announcement and Verge coverage are available for details. Comments emphasize that the main beneficiary is likely individual developers and smaller teams lacking the resources to process existing Wikipedia dumps, rather than AI labs that already have access to such data. There is criticism of The Verge's framing as clickbait, suggesting practical accessibility and licensing—not "fending off"—is the real motivation.
- Discussion notes that Wikipedia's partnership with Kaggle primarily serves to make Wikipedia data more usable and accessible for individuals who lack the resources or expertise to process nightly dumps—previously, Wikipedia provided raw database dumps, but transforming them into machine learning-ready formats is non-trivial.
- There is technical speculation that the new Kaggle dataset likely won't change anything for major AI labs since they've long had direct access to Wikipedia's dumps; the benefit is mostly for smaller users or hobbyists.
- A comment clarifies that Wikipedia's data has always been available as complete site downloads, and it is assumed that all major LLMs (Large Language Models) have already been trained on this data, suggesting that the Kaggle release is not a fundamentally new data source for model training.
-
Where is Qwen 3? (Score: 172, Comments: 57): The post questions the current status of the anticipated release of Qwen 3, following previous visible activity such as GitHub pull requests and social media announcements. No official updates or new benchmarks have been released, and the project has gone silent after the initial hype. Top comments speculate that Qwen 3 is still in development, referencing similar timelines with other projects like Deepseek's R2 and mentioning that users should use available models such as Gemma 3 12B/27B in the meantime; no concrete technical criticisms or new information are provided.
- One commenter notes that after the problematic launch of Llama 4, model developers are likely being more careful with releases, aiming for smoother out-of-the-box compatibility instead of relying on the community to patch issues post-launch. This reflects a shift towards more mature, user-friendly deployment practices in the open-source LLM space.
- There is a mention that Deepseek is currently developing R2, while Qwen is actively working on Version 3, highlighting ongoing parallel development efforts within the open-source AI model community. Additionally, Gemma 3 12B and 27B are referenced as underappreciated models with strong performance currently available.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. OpenAI o3 and o4-mini Model Benchmarks and User Experiences
-
WHAT!! OpenAI strikes back. o3 is pretty much perfect in long context comprehension. (Score: 769, Comments: 169): The post shares a benchmark table (https://i.redd.it/kw13sjo4ieve1.jpeg) from Fiction.LiveBench, assessing multiple LLMs' (large language models) long-context comprehension across input lengths up to 120k tokens. OpenAI's 'o3' model stands out, scoring a consistent 100.0 at shorter contexts (0-4k), maintaining high performance at 32k (83.3), and uniquely recovering a perfect score (100.0) at 120k, surpassing all listed competitors such as Gemini 1.5 Pro, Llama-3-70B, Claude 3 Opus, and Gemini 1.5 Flash. Other models display more fluctuation and generally lower scores as context length increases, indicating o3's superior long-context grained retention and reasoning. Commenters note the need for higher context benchmarks beyond 120k tokens and question why 'o3' and Gemini 2.5 perform anomalously well at 120k compared to 16k, speculating about possible evaluation quirks or model-specific optimizations for extreme long contexts.
- A technical concern is that although o3 reportedly handles 120k token contexts well, the benchmark itself caps at 120k, limiting the depth of assessment for long-context comprehension. There is a call for increasing benchmark context limits past 120k to truly evaluate models like o3 and Gemini 2.5.
- One user notes a practical limitation: despite claims of strong performance in long-context windows (up to 120k tokens), the OpenAI web interface restricts input to around 64k tokens, frequently producing a 'message too long' error, which constrains real-world usability for Pro users.
- A technical question is raised about why models like o3 and Gemini 2.5 sometimes appear to perform better at 120k tokens than at shorter context windows like 16k, prompting interest in the dynamics of context window performance and potential architectural or training causes for this counterintuitive result.
-
o3 thought for 14 minutes and gets it painfully wrong. (Score: 1403, Comments: 402): The image documents a failure case wherein ChatGPT's vision model (referred to as o3) is tasked with counting rocks in an image. Despite 'thinking' for nearly 14 minutes, it incorrectly concludes there are 30 rocks, while a commenter states there are 41. This highlights ongoing limitations in current AI vision models for precise object counting even with extended inference time. Commenters point out the inaccuracy—one provides the correct answer (41 rocks), and another expresses skepticism but suggests the error was plausible, underscoring persistent doubts about AI reliability in such perceptual tasks. Another user shares a comparison with Gemini 2.5 Pro, indicating broader interest in benchmarking these vision models.
- The image comparisons shared by users (e.g., with Gemini 2.5 Pro) imply that large language models (LLMs) or multimodal models like O3 and Gemini 2.5 Pro demonstrate significant struggles with even simple visual counting tasks, such as determining the number of objects (rocks) in an image. This indicates persistent limitations in basic visual quantitative reasoning for current models from leading AI labs.
- The discussion indirectly references the inappropriate or mismatched application of models for tasks outside their skill domain, as one user notes, likening an AI's failure to use a "hammer" for a "cutting" job—suggesting that relying on LLMs or multi-modal models for precise visual counting may not align with their design strengths. This points to a need for specialized architectures or more training for such tasks rather than expecting generalist models to master all domains immediately.
-
o3 mogs every model (including Gemini 2.5) on Fiction.Livebech long context benchmark holy shit (Score: 139, Comments: 56): The image shows the 'Fiction.LiveBench' long context comprehension benchmark, where the 'o3' model scores a perfect 100.0 across all tested context sizes (from 400 up to 120k tokens), significantly outperforming competitors like Gemini 2.5 and others, whose performance drops at larger context sizes. This suggests an architectural or training advancement in o3's ability to maintain deep comprehension over long input sequences, an issue current state-of-the-art models still struggle with—especially above 16k tokens. Full benchmark details can be verified at the provided link. Top comments debate the benchmark's validity, alleging it serves more as an advertisement and does not strongly correlate with real-world results. There's technical discussion about both 'o3' and '2.5 pro' struggling specifically at the 16k token mark, and a note that 'o3' cannot handle 1M-token contexts as '2.5 Pro' reportedly can.
- There are concerns about the validity of the Fiction.Livebech long context benchmark, with users alleging it functions more as an advertisement for the hosting website and suggesting that reported results may not correlate well with real-world model usage or performance.
- Discussion highlights that both Gemini 2.5 Pro and O3 models struggle with 16k token context windows, underlining a limitation in their handling of certain long-context scenarios despite improvements elsewhere; this is relevant for tasks emphasizing extended contextual understanding.
- Although O3 shows improvements in some respects, users report that it still suffers from a more restrictive output token limit than O1 Pro, potentially impacting its usability in scenarios requiring lengthy or less restricted generations, and some find it less reliable in following instructions.
2. Recent Video Generation Model Launches and Guides (FramePack, Wan2.1, LTXVideo)
-
Finally a Video Diffusion on consumer GPUs? (Score: 926, Comments: 332): A new open-source video diffusion model by lllyasviel has been released, reportedly enabling video generation on consumer-level GPUs (details pending but significant for accessibility and hardware requirements). Early user reports confirm successful manual Windows installations, with a full setup consuming approximately
40GBdisk space; a step-by-step third-party installation guide is available. Comments emphasize lllyasviel's reputation in the open source community, noting this advance as both technically impressive and especially accessible in comparison to previous high-resource video diffusion releases. [External Link Summary] FramePack is the official implementation of the next-frame prediction architecture for video diffusion, as proposed in "Packing Input Frame Context in Next-Frame Prediction Models for Video Generation." FramePack compresses input contexts to a fixed length, making the computational workload invariant to video length and enabling high-efficiency inference and training with large models (e.g., 13B parameters) on comparatively modest GPUs (≥6GB, e.g., RTX 30XX laptop). The system supports section-wise video generation with direct visual feedback, offers robust memory management and a minimal standalone GUI, and is compatible with various attention mechanisms (PyTorch, xformers, flash-attn, sage-attention). Quantization methods and "teacache" acceleration can impact output quality, so are recommended only for experimentation before final renders.- One user detailed their experience installing lllyasviel's new video diffusion generator on Windows manually, highlighting that the full installation required about
40 GBof disk space. They confirmed successful installation and linked to a step-by-step setup guide for others, emphasizing that command-line proficiency is required for a smooth setup process: installation guide.
- One user detailed their experience installing lllyasviel's new video diffusion generator on Windows manually, highlighting that the full installation required about
-
The new LTXVideo 0.9.6 Distilled model is actually insane! I'm generating decent results in SECONDS! (Score: 204, Comments: 41): The LTXVideo 0.9.6 Distilled model offers significant improvements in video generation, delivering high-quality outputs with much lower inference times by requiring only
8 stepsfor generation. Technical changes include the introduction of theSTGGuiderAdvancednode, enabling dynamic adjustment of CFG and STG parameters throughout the diffusion process, and all workflows have been updated for optimal parameterization (GitHub, HuggingFace weights). The official workflow employs an LLM node for prompt enhancement, making the process both flexible and efficient. Comments emphasize the drastic increase in speed and usability of the outputs, along with the technical leap enabled by the new guider node, signaling a push toward rapid iteration in video synthesis. An undercurrent of consensus suggests this release lowers the barrier for broader adoption of advanced workflows like ComfyUI. [External Link Summary] The LTXVideo 0.9.6 Distilled model introduces significant advancements over previous versions: it enables high-quality, usable video generations in seconds, with the distilled variant offering up to 15x faster inference (sampling at 8, 4, 2, or even 1 diffusion step) compared to the full model. Key technical improvements include a new STGGuiderAdvanced node for step-wise configuration of CFG and STG, better prompt adherence, improved motion and detail, and default outputs at 1216×704 resolution at 30 FPS—achievable in real time on H100 GPUs—while not requiring classifier-free or spatio-temporal guidance. Workflow optimizations leveraging LLM-based prompt nodes further enhance user experience and output control. Full discussion and links- LTXVideo 0.9.6 Distilled is highlighted as the fastest iteration of the model, capable of generating results in only
8 steps, making it significantly lighter and better suited for rapid prototyping and iteration compared to previous versions. This performance focus is substantial for workflows requiring quick previews or experimentation. - The update introduces the new STGGuiderAdvanced node, which allows for applying varying CFG and STG parameters at different steps in the diffusion process. This dynamic parameterization aims to improve output quality, and existing model workflows have been refactored to leverage this node for optimal performance, as detailed in the project's Example Workflows.
- A user inquiry raises the technical question of whether LTXVideo 0.9.6 Distilled narrows the gap with competing video generation models such as Wan and HV, suggesting interest in direct benchmarking or comparative qualitative analysis among these leading solutions.
- LTXVideo 0.9.6 Distilled is highlighted as the fastest iteration of the model, capable of generating results in only
-
Guide to Install lllyasviel's new video generator Framepack on Windows (today and not wait for installer tomorrow) (Score: 226, Comments: 133): This post provides a step-by-step manual installation guide for lllyasviel's new FramePack video diffusion generator on Windows prior to the release of the official installer (GitHub). The install process includes creating a virtual environment, installing specific versions of Python (3.10–3.12), CUDA-specific PyTorch wheels, Sage Attention 2 (woct0rdho/SageAttention), and optional FlashAttention, with a note that official requirements specify Python <=3.12 and CUDA 12.x. Users must manually select compatible wheels for Sage and PyTorch matching their environment, and the application is launched through
demo_gradio.py(with a known issue that the embedded Gradio video player does not function correctly; outputs are saved to disk). Video generation is incremental, appending 1s at a time, leading to large disk use (>45GB reported). No significant technical debates in the comments—most users are waiting for the official installer. One minor issue reported is the Gradio video player not rendering videos, though outputs save properly.- A user inquires about the generation time for a 5-second video on an NVIDIA 4090, implying interest in concrete performance benchmarks and throughput rates for Framepack on high-end GPUs.
- Another user asks for real-world performance feedback on Framepack running specifically on a 3060 12GB GPU, seeking information on how the tool performs on mid-range consumer hardware. These questions highlight the community's focus on empirical speed and hardware requirements for this new video generation tool.
- Official Wan2.1 First Frame Last Frame Model Released (Score: 779, Comments: 102): The Wan2.1 First-Last-Frame-to-Video model (FLF2V) v14B is now fully open-sourced, with available weights and code and a GitHub repo. The release is limited to a single, large 14B parameter model and supports only
720Presolution—480P and other variants are currently unavailable. The model is trained primarily on Chinese text-video pairs, and best results are achieved with Chinese prompts. A ComfyUI workflow example is also provided for integration. Commenters note the lack of smaller or lower-resolution models and emphasize the need for 480p and other variants. The training dataset’s focus on Chinese prompts is highlighted as crucial for optimal model outputs. [External Link Summary] The Wan2.1 First Frame Last Frame (FLF2V) model, now fully open-sourced on HuggingFace and GitHub, supports 720P video generation from user-provided first and last frames, with or without prompt extension (currently 480P is not supported). The model is trained primarily on Chinese text-video pairs, yielding significantly better results with Chinese prompts, and a ComfyUI workflow wrapper and fp8 quantized weights are available for integration. For technical details and access to model/code: HuggingFace | GitHub.
- The model is primarily trained on Chinese text-video pairs, so prompts written in Chinese yield better results. This highlights a language bias due to the training dataset, which can impact output quality when using non-Chinese prompts.
- Currently, only a 14B parameter, 720p model is available. There is user interest in additional models (such as 480p or different parameter sizes), but these are not yet supported or released.
- A workflow for integrating the Wan2.1 First Frame Last Frame model with ComfyUI is available on GitHub (see this workflow JSON). Additionally, an fp8 quantized model variant is released on HuggingFace, enabling more efficient deployment options.
3. Innovative and Specialized Image/Character Generation Model Releases
-
InstantCharacter Model Release: Personalize Any Character (Score: 126, Comments: 22): The image presents Tencent's newly released InstantCharacter model, a tuning-free, open-source solution for character-preserving generation from a single image. It visually demonstrates the workflow: a reference image is transformed into highly personalized anime-style representations across various complex backgrounds (e.g., subway, street) using text and image conditioning. The model leverages the IP-Adapter algorithm with Style LoRA, functioning on Flux, and aims to surpass earlier solutions like InstantID in both flexibility and fidelity. Technically-oriented commenters praise the results and express interest in integration (e.g., 'comfy nodes'), reinforcing the perceived quality and usability of this workflow for downstream generative tasks.
- A user mentions that existing solutions such as UNO have not functioned satisfactorily for personalized character generation, implying that prior models struggle with either integration or output quality. This highlights the challenge of reliable character personalization in current tools and sets a technical bar for evaluating InstantCharacter's approach and promised capabilities.
- Flux.Dev vs HiDream Full (Score: 105, Comments: 37): This post provides a side-by-side comparison of Flux.Dev and HiDream Full using the HiDream ComfyUI workflow (reference) and the
hidream_i1_full_fp16.safetensorsmodel (model link). Generation was performed with50 steps,uni_pcsampler,simplescheduler,cfg=5.0, andshift=3.0over seven detailed prompts. The comparison visually ranks results on adherence and style, showing that Flux.Dev generally excels in prompt fidelity, even competing with HiDream Full on style, despite HiDream's higher resource requirements. Discussion emphasizes the impact of LLM-style 'purple prose' prompts on evaluating raw prompt adherence and highlights that, despite some individual wins for HiDream, Flux.Dev is considered to have better overall prompt adherence and resource efficiency. HiDream's performance is described as 'disappointing in this set' by some, though alternatives are welcomed.
- Several users highlight the importance of prompt design in benchmarking, emphasizing that LLM-generated prompts containing elaborate or subjective language (like 'mood' descriptions or excessive prose) introduce variability and make it harder to accurately assess models' prompt adherence. It's suggested that more precise or objective prompts would yield clearer performance comparisons.
- There is consensus that Flux.Dev outperforms HiDream Full in this round, particularly in prompt following and stylistic flexibility, despite HiDream being more resource-intensive. Flux is seen as a marginal winner, but both models are reported to significantly surpass previous generations in raw performance.
- A critique is raised regarding the first comparison prompt, noting grammatical errors and terms like 'hypo realistic' that do not appear to be standard. The linguistic irregularities are identified as a likely source of confusion for both models, potentially impacting the reliability of the side-by-side evaluation.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.5 Flash Preview
Theme 1. Latest LLM Models: Hits, Misses, and Hallucinations
- New Gemini 2.5 Flash Zaps into Vertex AI: Google's Gemini 2.5 Flash appeared in Vertex AI, touted for advanced reasoning and coding, sparking debate against Gemini 2.5 Pro regarding efficiency and tool-calling but also reports of thinking loops. Users are also weighing O3 and O4 Mini, finding O3 preferable as O4 Mini's high output costs are borderline unusable.
- O4 Models Hallucinate More, Users Complain: Users report o4-mini and o3 models make up information more often, even providing believable but completely wrong answers like fake business addresses. While suggesting models verify sources via search might help, users found GPT-4.1 Nano performed better with non-fake information on factual tasks.
- Microsoft Drops 1-Bit BitNet, IBM Unleashes Granite 3: Microsoft Research released BitNet b1.58 2B 4T, a native 1-bit LLM with 2 billion parameters trained on 4 trillion tokens, available with inference implementations on Microsoft's GitHub. IBM announced Granite 3 and refined reasoning RAG Lora models, detailed in this IBM announcement.
Theme 2. AI Development Tooling and Frameworks
- Aider Gets New Probe Tool, Architect Mode Swallows Files: Aider introduced the
probetool for semantic code search, praised for extracting error code blocks and integrating with testing outputs, with alternatives like claude-task-tool shared. Users hit a bug in Aider's architect mode where creating 15 new files followed by adding one to chat discarded all changes, an expected behavior but one where no warning is given when edits are discarded. - Cursor's Coding Companion Creates Commotion, Crashes, Confuses: Users debate if o3/o4-mini are better than 2.5 Pro and 3.7 thinking in Cursor, with one reporting o4-mini-high is better than 4o and 4.1 for codebase analysis and logic, even for large projects. Others complained about the Cursor agent not exiting the terminal, frequent tool calls with no code output, and connection/editing issues.
- MCP, LlamaIndex, NotebookLM Boost Integration, RAG: A member is building an MCP server for Obsidian to streamline integrations, seeking advice on securely passing API keys via HTTPS header. LlamaIndex now supports building A2A (Agent2Agent)-compatible agents following an open protocol enabling secure information exchange regardless of underlying infrastructure. NotebookLM users integrate Google Maps and utilize RAG, sharing diagrams like this Vertex RAG diagram.
Theme 3. Optimizing AI Hardware Performance
- Triton, CUDA, Cutlass: Low-Level Perf Struggles: In GPU MODE's
#tritonchannel, a member reported slow fp16 matrix multiplication (2048x2048) lagging cuBLAS, advised to use larger matrices or measure end-to-end model processing. Users experimented withcuda::pipelineand TMA/CuTensorMap API with Cutlass in the#cutlasschannel, finding a benchmarked mx cast kernel only hits 3.2 TB/s, seeking advice on Cutlass bottlenecks. - AMD MI300 Leaderboard Heats Up, NVIDIA Hardware Discussed: Submissions to the
amd-fp8-mmleaderboard on MI300 ranged widely, with one submission reaching 255 µs, according to GPU MODE's#submissionschannel. Discussion in#cudaconfirmed the H200 does not support FP4 precision, likely a typo for B200, and members in LM Studio are optimizing for the new RTX 5090 with the 0.3.15 beta version. - Quantization Qualitatively Shifts LLMs, AVX Requirement Lingers: Members in Eleuther probed works analyzing the impact of quantization on LLMs, suggesting a qualitative change happens at low bits, especially with training-based strategies, supported by the composable interventions paper. An older server running E5-V2 without AVX2 can only use very old versions of LM Studio or alternative projects like llama-server-vulkan as modern LLMs require AVX.
Theme 4. AI Model Safety, Data, and Societal Impact
- AI Hallucinations Persist, Pseudo-Alignment Tricks Users: Concerns were raised about pseudo-alignment, where LLMs use toadyism to trick users, relying on plausible idea mashups rather than true understanding, noted in Eleuther's
#generalchannel where members feel the open web is currently being substantially undermined by the existence of AI. A member spent 7 months building PolyThink, an Agentic multi-model AI system designed to eliminate AI hallucinations by having models correct each other, inviting signups for the waitlist. - Data Privacy and Verification Cause Concern: OpenRouter updated its Terms and Privacy Policy clarifying that LLM inputs will not be stored without consent, with prompt categorization used for rankings/analytics. Discord's new age verification features, requiring ID verification via withpersona.com, sparked concerns in Nous Research AI about privacy compromises and potential platform-wide changes.
- Europe Cultivates Regional Language Models: Members discussed the availability of region-tailored language models beyond Mistral across Europe, including the Dutch GPT-NL ecosystem, Italian Sapienza NLP, Spanish Barcelona Supercomputing Center, French OpenLLM-France/CroissantLLM, German AIDev, Russian Vikhr, Hebrew Ivrit.AI/DictaLM, Persian Persian AI Community and Japanese rinna.
Theme 5. Industry Watch: Bans, Acquisitions, and Business Shifts
- Trump Tariffs Target EU, China, Deepseek?: The Trump administration imposed 245% tariffs on EU products retaliating for Airbus subsidies and tariffs on Chinese goods over intellectual property theft, according to this Perplexity report. The Trump administration is also reportedly considering a US ban of Deepseek, as noted in this TechCrunch article.
- OpenAI Acquisition Rumors Swirl Around Windsurf: Speculation arose about OpenAI potentially acquiring Windsurf for $3B, with some considering it a sign of the company becoming more like Microsoft. Debate ensued whether Cursor and Windsurf are true IDEs or merely glorified API wrappers catering to vibe coders.
- LMArena Goes Corporate, HeyGen API Launches: LMArena, originating from a UC Berkeley project, is forming a company to support its platform while ensuring it remains neutral and accessible. The product lead for HeyGen API introduced their platform, highlighting its capability to produce engaging videos without requiring a camera.
PART 1: High level Discord summaries
Perplexity AI Discord
-
Perplexity Launches Telegram Bot: Perplexity AI is now available on Telegram via the askplexbot, with plans for WhatsApp integration.
- A teaser video (Telegram_Bot_Launch_1.mp4) highlights the seamless integration and real-time response capabilities.
- Perplexity Debates Discord Support: Members are suggesting a ticketing bot to Discord, but prefer a help center approach.
- Alternatives like a helper role were discussed, pointing out that Discord isn't ideal for support, and a Modmail bot linking to Zendesk could be useful.
- Neovim Setup Showcased: A member shared an image of their Neovim configuration after three days of studying IT.
- They engaged the AI model to make studying engaging, and it worked well.
- Trump Tariff's Impact Felt: The Trump administration imposed 245% tariffs on EU products in retaliation for subsidies to Airbus, as well as tariffs on Chinese goods over intellectual property theft, according to this report.
- These measures aimed to protect American industries and address trade imbalances, explained in this perplexity search.
LMArena Discord
-
Gemini 2.5 Flash Storms Vertex AI: Gemini 2.5 Flash appeared in Vertex AI, sparking debates about its coding efficiency and tool-calling capabilities compared to Gemini 2.5 Pro.
- Some users praised its speed, while others reported it getting stuck in thinking loops similar to previous issues with 2.5 Pro.
- O3 and O4 Mini Face Off: Members are actively testing and comparing O3 and O4 Mini, sharing live tests like this one to demonstrate their potential.
- Despite O4 Mini's initially lower cost, some users find its high usage and output costs prohibitive, leading many to revert to O3.
- Thinking Budget Feature Sparks Debate: Vertex AI's new Thinking Budget feature, which allows manipulation of thinking tokens, is under scrutiny.
- While some found it useful, others reported bugs, with one user noting that 2.5 pro just works better on 0.65 temp.
- LLMs: Saviors or Saboteurs of Education?: The potential for LLMs to aid education in developing nations is being debated, focusing on the balance between accessibility and reliability.
- Concerns were raised about LLMs' tendency to hallucinate, contrasting them with the reliability of books written by people who know what they are talking about.
- LMArena Goes Corporate, Remains Open: LMArena, originating from a UC Berkeley project, is forming a company to support its platform while ensuring it stays neutral and accessible.
- The community also reports that the Beta version incorporates user feedback, including a dark/light mode toggle and direct copy/paste image functionality.
aider (Paul Gauthier) Discord
-
Aider's code2prompt Gets Mixed Reviews: Members debated the usefulness of
code2promptin Aider, questioning its advantage over the/addcommand for including necessary files, ascode2promptrapidly parses all matching files.- The utility of
code2prompthinges on specific use cases and model capabilities, primarily its parsing speed. - Aider's Architect Mode Swallows New Files: A member encountered a bug in Aider's architect mode where changes were discarded after creating 15 new files, upon adding one of the files to the chat.
- This behavior is expected, but no warning is given when edits are discarded, confusing users when the refactored code is lost.
- Aider's Probe Tool Unveiled: Members discussed Aider's new
probetool, emphasizing its semantic code search capabilities for extracting code blocks with errors and integrating with testing outputs.
- Enthusiasts shared alternatives, such as claude-task-tool and potpie-ai/potpie, for semantic code search.
- DeepSeek R2 Hype Intensifies: Enthusiasm surged for the upcoming release of DeepSeek R2, with members hoping it will surpass O3-high in performance while offering a better price point, suggesting it is just a matter of time.
- Some speculated that DeepSeek R2 could challenge OpenAI's dominance due to its potentially superior price/performance ratio.
- YouTube Offers Sobering Analysis of New Models: A member shared a YouTube video providing a more reasonable take on the new models.
- The video offers an analysis of recent model releases, focusing on technical merit.
- The utility of
OpenRouter (Alex Atallah) Discord
-
OpenRouter Cleans Up Terms: OpenRouter updated its Terms and Privacy Policy clarifying that LLM inputs will not be stored without consent and detailing how they categorize prompts for ranking and analytics.
- Prompt categorization is used to determine the type of request (programming, roleplay, etc.) and will be anonymous for users who have not opted in to logging.
- Purchase Credits To Play: OpenRouter updated the free model limits, now requiring a lifetime purchase of at least 10 credits to benefit from the higher 1000 requests/day (RPD), regardless of current credit balance.
- Access to the experimental
google/gemini-2.5-pro-exp-03-25free model is restricted to users who have purchased at least 10 credits due to extremely high demand; uninterrupted access is available on the paid version. - Gemini 2.5 Has A Flash of Brilliance: OpenRouter unveiled Gemini 2.5 Flash, a model for advanced reasoning, coding, math, and science, available in a standard and a :thinking variant with built-in reasoning tokens.
- Users can customize the :thinking variant using the
max tokens for reasoningparameter, as detailed in the documentation. - Cost Simulator and Chat App Arrive: A member created a tool to simulate the cost of LLM conversations, supporting over 350 models on OpenRouter, while another developed an LLM chat application that connects with OpenRouter, offering access to a curated list of LLMs and features like web search and RAG retrieval.
- The chat app has a basic free tier, with monthly costs for expanded search and RAG functionality, or unlimited usage.
- Codex cries foul, DeepSeek Delayed: OpenAI's Codex uses a new API endpoint, so it doesn't currently work with OpenRouter and the o-series reasoning summaries from OpenRouter may be delayed due to OpenAI restrictions requiring ID verification.
- A user pointed out that the new DeepSeek is similar to Google's Firebase studio.
OpenAI Discord
-
Gemini 2.5 Still Favored Over Newer Models: Despite newer models like o3 and o4, some still prefer Gemini 2.5 Pro for its speed, accuracy, and cost, even though the model can hallucinate like crazy on complex tasks.
- Benchmarks show o3 performing better in coding, while Gemini 2.5 Pro excels in reasoning; the new 2.5 Flash version emphasizes faster responses.
- o4 Models Struggle With Factual Accuracy: Users are reporting that o4-mini and o3 models make up information more often, even providing believable but completely wrong answers, like a fake business address.
- Instructing the model to verify sources via search might help reduce hallucinations, however it was noted that GPT-4.1 Nano performed better with non-fake information.
- GPT-4.5 Users Complain Model is Too Slow: Multiple users complained that GPT 4.5 is very slow and expensive, speculating that this is "probably because it's a dense model vs. mixture of experts" model.
- Usage limits for o4-mini are 150 a day, for o4-mini high 50 a day, and o3 50 a week.
- Custom GPTs Going Rogue: A user reported their Custom GPT is not following instructions and that "It's just out there doing it's own thing at this point".
- It was also asked what the most appropriate language model is to upload a PDF to study, ask questions, and prepare ready-made exam questions in chat GPT.
- Contextual Memory Emulated on GPTPlus: A user reported emulating contextual memory on a GPTPlus account through narrative coherence and textual prompts, building a multi-modular system with over 30 discussions.
- Another user confirmed similar results, connecting new discussions by using the right keywords.
Cursor Community Discord
-
Cursor Subscription Refund Delays: Users who canceled their Cursor subscriptions are awaiting refunds, having received confirmation emails without the actual money, but one user claimed they got it.
- No further details were provided regarding the reason for the delays or the specific amounts involved.
- FIOS Fixes Finetuned: A user discovered that physically adjusting the LAN wired connection on their Verizon FIOS setup can boost download speeds from 450Mbps to 900Mbps+.
- They suggested a more secured connector akin to PCIE-style connectors and posted an image of their setup.
- MacBook Cursor's Models Materialize: Users discussed adding new models on the MacBook version of Cursor, with some needing to restart or reinstall to see them.
- It was suggested to manually add the o4-mini model by typing o4-mini and pressing add model.
- Cursor's Coding Companion Creates Commotion: Users debated if o3/o4-mini are better than 2.5 Pro and 3.7 thinking, with one reporting that o4-mini-high is better than 4o and 4.1 for analyzing codebase and solving logic, even for large projects.
- Others complained about Cursor agent not exiting the terminal after running a command (causing it to hang indefinitely), frequent tool calls with no code output, a message too long issue, a broken connection status indicator and the inability to edit files.
- Windsurf Acquisition Whirlwind Whispers: Speculation arose about OpenAI potentially acquiring Windsurf for $3B, with some considering it a sign of the company becoming more like Microsoft, while others like this tweet are focusing on GPT4o mini.
- Participants debated whether Cursor and Windsurf are true IDEs or just glorified API wrappers (or forks) with UX products catering to vibe coders, extensions, or mere text editors.
Yannick Kilcher Discord
-
Brain Deconstruction Yields Manifolds: A paper suggests brain connectivity can be decomposed into simple manifolds with additional long-range connectivity (PhysRevE.111.014410), though some find it tiresome that anything using Schrödinger's equation is being called quantum.
- Another member clarified that any plane wave linear equation can be put into the form of Schoedinger's equation by using a Fourier transform.
- Responses API Debuts as Assistant API Sunsets: Members clarified that while the Responses API is brand new, the Assistant API is sunsetting next year.
- It was emphasized that if you want assistants you choose assistant API, if you want regular basis you use responses API.
- Reservoir Computing Deconstructed: Members discuss Reservoir Computing as a fixed, high-dimensional dynamical system clarifying that the reservoir doesn't have to be a software RNN, it can be anything with temporal dynamics with a simple readout learned from the dynamical system.
- One member shared that most of the "reservoir computing" hype often sells a very simple idea wrapped in complex jargon or exotic setups: Have a dynamical system. Don’t train it. Just train a simple readout.
- Trump Threatens Deepseek Ban: The Trump administration is reportedly considering a US ban of Deepseek, as noted in this TechCrunch article.
- No further details were given.
- Meta Introduces Fair Updates, IBM Debuts Granite: Meta introduces fair updates for perception, localization, and reasoning, and IBM announced Granite 3 and refined reasoning RAG Lora models, along with a new speech recognition system, detailed in this IBM announcement.
- The Meta image shows some updates as part of Meta's fair updates.
Manus.im Discord Discord
-
Discord Member Gets the Boot: A member was banned from the Discord server for allegedly annoying everyone, sparking debate over moderation transparency.
- While some questioned the evidence, others defended the decision as necessary for maintaining a peaceful community.
- Claude Borrows a Page from Manus: Claude rolled out a UI update enabling native research and app connections to services like Google Drive and Calendar.
- This functionality mirrors existing features in Manus, prompting one member to quip that it was basically the Charles III update.
- GPT Also Adds MCPS: Members observed that GPT now features similar integration capabilities, allowing users to search Google Calendar, Google Drive, and connected Gmail accounts.
- This update positions GPT as a competitor in the productivity and research space, paralleling Claude's recent enhancements.
- AI Game Dev Dreams Go Open Source: Enthusiasm bubbled up around the potential of open-source game development interwoven with AI and ethical NFT implementation.
- Discussions revolved around what makes gacha games engaging and bridging the divide between gamers and the crypto/NFT world.
- Stamina System Innovations Debated: A novel stamina system was proposed, offering bonuses at varying stamina levels to cater to different player styles and benefit developers.
- Alternative mechanics, such as staking items for stamina or integrating loss elements to boost engagement, were explored, drawing parallels to games like MapleStory and Rust.
Eleuther Discord
-
LLMs Producing Pseudo-Aligned Hallucinations: Members raised concerns about pseudo-alignment, where LLMs try toadyism tricks people into thinking that they have learned, while they rely on the AI to generate plausible sounding idea mashups, and shared a paper on how permissions have changed over time.
- Members generally cautioned that the open web is currently being substantially undermined by the existence of AI.
- Europe Launches Region-Tailored Language Models: Members discussed the availability of region-tailored language models within Europe, beyond well-known entities like Mistral, which include the Dutch GPT-NL ecosystem, Italian Sapienza NLP, Spanish Barcelona Supercomputing Center, French OpenLLM-France and CroissantLLM, German AIDev, Russian Vikhr, Hebrew Ivrit.AI and DictaLM, Persian Persian AI Community and Japanese rinna.
- Several members have pointed out that the region-tailored language models may be helpful in specific usecases.
- Community Debates Human Verification Tactics: Members discuss the potential need for human authentication to combat AI bots on the server, with one suggesting that the current low impact may not last, but are also considering alternatives to strict verification, including community moderation and focusing on active contributors.
- The overall sentiment in the community is one of cautious optimism, with concerns raised about the increasing prevalence of AI-influenced content.
- Quantization Effects Get a Quality Check: Members probed works analyzing the impact of quantization on LLMs, suggesting that there's a qualitative change happening at low bits, especially with training-based quantization strategies, sharing a screenshot with related supporting data.
- A member also recommended the composable interventions paper as support for the qualitative changes happening at low bits.
HuggingFace Discord
-
Anime Models with Illustrious Shine: Members recommended Illustrious, NoobAI XL, RouWei, and Animagine 4.0 for anime generation, pointing to models like Raehoshi-illust-XL-4 and RouWei-0.7.
- Increasing LoRA resources can improve output quality.
- nVidia Eases GPU Usage for Large Models: One member noted that using multiple nVidia GPUs to run one large model is easier with
device_map='auto', while AMD requires more improvisation, and linking to Accelerate documentation.
- Using device_map='auto' lets the framework automatically manage model distribution across available GPUs.
- PolyThink Aims to Eliminate AI Hallucinations: A member spent 7 months building PolyThink, an Agentic multi-model AI system, designed to eliminate AI hallucinations by having multiple AI models correct and collaborate with each other and invites the community to sign up for the waitlist.
- The promise of PolyThink is to improve the reliability and accuracy of AI-generated content through collaborative validation.
- Agents Course Still Plagued by 503 Errors: Multiple users reported encountering a 503 error when starting the Agents Course, particularly with the dummy agent, suggesting it might be due to hitting the API key usage limit.
- Despite users reporting the error, some noted they still had available credits which may indicate traffic issues rather than API limit issues.
- TRNG Claims High Entropy for AI Training: A member built a research-grade True Random Number Generator (TRNG) with an extremely high entropy bit score and wants to test its impact on AI training, with eval info available on GitHub.
- It is hoped that using a TRNG with higher entropy during AI training will improve model performance and randomness.
GPU MODE Discord
-
SYCL Supersedes OpenCL in Computing Platforms?: In GPU MODE's
#generalchannel, members debated that SYCL is getting superseded by OpenCL, discussing the relative merits and future of the two technologies.- An admin responded that there hasn't been enough demand historically to justify an OpenCL channel, though they acknowledged that OpenCL is still current and offers broad compatibility across Intel, AMD, and NVIDIA CPUs/GPUs.
- Matrix Multiplication Fails Speed Expectations: In GPU MODE's
#tritonchannel, a member reported that fp16 matrix multiplication of size 2048x2048 isn’t performing as expected, even lagging behind cuBLAS, despite referencing official tutorial code.
- It was advised that a more realistic benchmarking approach involves stacking like 8 linear layers in a
torch.nn.Sequential, usingtorch.compileor cuda-graphs, and measuring the end-2-end processing time of the model, rather than just a single matmul. - Popcorn CLI Plagued with Problems: In GPU MODE's
#generalchannel, users encountered errors with the CLI tool; one user was prompted to runpopcorn registerfirst when using popcorn and was directed to use Discord or GitHub.
- Another user encountered a Submission error: Server returned status 401 Unauthorized related to an Invalid or unauthorized X-Popcorn-Cli-Id after registration, while a third reported an error decoding response body after authorizing via the web browser following the
popcorn-cli registercommand. - MI300 AMD-FP8-MM Leaderboard Heats Up: Submissions to the
amd-fp8-mmleaderboard on MI300 ranged from 5.24 ms to 791 µs, showcasing a variety of performance levels on the platform, and one submission reaching 255 µs, according to GPU MODE's#submissionschannel.
- One user achieved a personal best on the
amd-fp8-mmleaderboard with 5.20 ms on MI300, demonstrating the continued refinement and optimization of FP8 matrix multiplication performance. - Torch Template Triumphs, Tolerances Tweaked: In GPU MODE's
#amd-competitionchannel, a participant shared an improved template implementation, attached as a message.txt file, that avoids torch headers (requiringno_implicit_headers=True) for faster roundtrip times and configures the right ROCm architecture (gfx942:xnack-).
- Competitors flagged small inaccuracies in kernel outputs, leading to failures with messages like
mismatch found! custom implementation doesn't match reference, resulting in admins relaxing the initial tolerances that were too strict.
LM Studio Discord
-
NVMe SSD Buries SATA SSD in Speed Tests: Users validated that NVMe SSDs outstrip SATA SSDs, hitting speeds of 2000-5000 MiB/s, while SATA crawls at 500 MiB/s.
- The gap widens when loading larger models, according to one member, who noted massive spikes way above the SSD performance due to disk cache and abundant RAM.
- LM Studio Vision Model Implementation Still a Mystery: Members investigated using vision models like qwen2-vl-2b-instruct in LM Studio, linking to image input documentation.
- While some claim success processing images, others report failures; the Llama 4 model has a vision tag in the models metadata, but doesn't support vision in llama.cpp, and Gemma 3 support is uncertain.
- RAG Models Get Plus Treatment: Users noted that RAG models in LM Studio can attach files via the '+' sign in the message prompt in Chat mode.
- A model's information page indicates its RAG capability.
- Granite Model Still Shines for Interactive Chat: Despite being generally written off as low performance for most tasks, one user prefers Granite for general purpose use cases, specifically for an interactive stream-pet type chatbot.
- The user stated that when trying to put it in a more natural context, it feels robotic and Granite is still by far the best performance though.
- AVX Requirement Limits Retro LM Studio: A user with an older server running E5-V2 without AVX2 inquired about using it with LM Studio, but was told that only very old versions of LM Studio support AVX.
- It was suggested to use llama-server-vulkan or find LLMs that still support AVX.
Unsloth AI (Daniel Han) Discord
-
Llama 4 Gets Unslothed: Llama 4 finetuning support arrives at Unsloth this week, supporting both 7B and 14B models.
- To use it, switch to the 7B notebook and change it to 14B to access the new features.
- Custom Tokens Hogging Memory?: Adding custom tokens in Unsloth increases memory usage, requiring users to enable continued pretraining and add layer adapters to the embedding and LM head.
- More info on this technique, see Unsloth documentation.
- MetaAI Spews Hate Speech: A member observed MetaAI generating and then deleting an offensive comment in Facebook Messenger, followed by claiming unavailability.
- The member criticized Meta for prioritizing output streaming over moderation, suggesting moderation should happen server-side like DeepSeek.
- Hallucinations Annihilated by PolyThink: A member announced the waitlist for PolyThink PolyThink waitlist, a multi-model AI system designed to eliminate AI hallucinations by enabling AI models to correct each other.
- Another member likened the system to thinking with all the models and expressed interest in testing it for synthetic data generation to create better datasets.
- Untrained Neural Networks Exhibit Emergent Computation: An article notes that untrained deep neural networks can perform image processing tasks without training, using random weights to filter and extract features from images.
- The technique leverages the inherent structure of neural networks to process data without learning specific patterns from training data, showcasing emergent computation.
Nous Research AI Discord
-
GPT4o Struggles with Autocompletion: Members debated whether GitHub Copilot uses GPT4o for autocompletion, with reports that it hallucinated links and delivered broken code, as documented in these tweets and this other tweet.
- The general sentiment was that GPT4o's performance was on par with other SOTA LLMs despite high expectations for autocompletion tasks.
- Huawei Possibly Challenging Nvidia's Lead: Trump's tariffs on semiconductors might enable Huawei to compete with Nvidia in hardware, potentially dominating the global market, per this tweet and this YouTube video.
- However, some users had mixed experiences with GPT4o-mini-high, noting instances where it zero-shot broken code and failed basic prompts.
- BitNet b1.58 2B 4T Released by Microsoft Research: Microsoft Research introduced BitNet b1.58 2B 4T, a native 1-bit LLM with 2 billion parameters trained on 4 trillion tokens, with its GitHub repository here.
- Users found that leveraging the dedicated C++ implementation (bitnet.cpp) is necessary to achieve the promised efficiency benefits, and the context window is limited to 4k.
- Discord's New Age Verification Fuels Debate: A member shared concerns about Discord's new age verification features being tested in the UK and Australia, referencing this link.
- The core issue is that users are worried about privacy compromises and the potential for further platform-wide changes.
Notebook LM Discord
-
Gemini Pro Aces Accounting Automation: A member utilized Gemini Pro to generate a TOC for a junior accountant's guide on month-end processes, subsequently enriching it with Deep Research and consolidating the findings in a GDoc.
- They incorporated the GDoc into NLM as the primary source, emphasizing its features and soliciting feedback for refinement.
- Vacation Visions Via Google Maps: A member created a vacation itinerary using Notebook LM, archiving points of interest in Google Maps.
- They suggested Notebook LM should ingest saved Google Maps lists as source material.
- Vote, Vote, or Lose the Boat: A member reminded everyone that Webby voting closes TOMORROW and they are losing in 2 out of 3 categories for NotebookLM, urging users to vote and spread the word: https://vote.webbyawards.com/PublicVoting#/2025/ai-immersive-games/ai-apps-experiences-features/technical-achievement.
- The member is concerned they will lose if people don't vote.
- NLM's RAG-tag Diagram Discussions: A member shared two diagrams illustrating a general RAG system and a simplified version in response to a question about RAG, shown here: Vertex_RAG_diagram_b4Csnl2.original.png and Screenshot_2025-04-18_at_01.12.18.png.
- Another user chimed in noting they have a custom RAG setup in Obsidian, and the discussion shifted to response styles.
MCP (Glama) Discord
-
Obsidian MCP Server Surfaces: A member is developing an MCP server for Obsidian and is seeking collaboration on ideas, emphasizing that the main vulnerability lies in orchestration rather than the protocol itself.
- This development aims to streamline integration between Obsidian and external services via a secure, orchestrated interface.
- Securing Cloudflare Workers with SSE API Keys: A member is configuring an MCP server using Cloudflare Workers with Server-Sent Events (SSE) and requested advice on securely passing an apiKey.
- Another member suggested transmitting the apiKey via HTTPS encrypted header rather than URL parameters for enhanced security.
- LLM Tool Understanding Decoded: A member inquired into how an LLM truly understands tools and resources, probing whether it's solely based on prompt explanations or specific training on the MCP spec.
- It was clarified that LLMs understand tools through descriptions, with many models supporting a tool specification or other parameters that define these tools, thus guiding their utilization.
- MCP Server Personality Crisis: A member attempted to define a distinct personality for their MCP server by setting a specific prompt during initialization to dictate response behavior.
- Despite these efforts, the responses from the MCP server remained unchanged, prompting further investigation into effective personality customization techniques.
- HeyGen API Makes its Debut: The product lead for HeyGen API introduced their platform, highlighting its capability to produce engaging videos without requiring a camera.
- HeyGen allows users to create engaging videos without a camera.
Torchtune Discord
-
GRPO Recipe Todo List is Obsolete: The original GRPO recipe todos are obsolete because the new version of GRPO is being prepared in the r1-zero repo.
- The single device recipe will not be added through the r1-zero repo.
- Async GRPO Version in Development: An async version of GRPO is under development in a separate fork and will be brought back to Torchtune soon.
- This update aims to enhance the flexibility and efficiency of GRPO implementations within Torchtune.
- Single GPU GRPO Recipe on the Home Stretch: A single GPU GRPO recipe PR from @f0cus73 is available here and requires finalization.
- This recipe allows users to run GRPO on a single GPU, lowering the hardware requirements for experimentation and development.
- Reward Modeling RFC Incoming: An RFC (Request for Comments) for reward modeling is coming soon, outlining the implementation requirements.
- The community expects the RFC to provide a structured approach to reward modeling, facilitating better integration and standardization within Torchtune.
- Titans Talk Starting...: The Titans Talk is starting in 1 minute for those interested.
- Nevermind!
LlamaIndex Discord
-
LlamaIndex Agents Speak A2A Fluently: LlamaIndex now supports building A2A (Agent2Agent)-compatible agents following the open protocol launched by Google with support from over 50 technology partners.
- This protocol enables AI agents to securely exchange information and coordinate actions, regardless of their underlying infrastructure.
- CondenseQuestionChatEngine Shuns Tools: The CondenseQuestionChatEngine does not support calling tools; the suggestion was made to use an agent instead, according to a member.
- Another member confirmed it was just a suggestion and was not actually implemented.
- Bedrock Converse Prompt Caching Causes Chaos: A member using Anthropic through Bedrock Converse faced issues using prompt caching, encountering an error when adding extra_headers to the llm.acomplete call.
- After removing the extra headers, the error disappeared, but the response lacked the expected fields indicating prompt caching, such as cache_creation_input_tokens.
- Anthropic Class Could Calm Bedrock Caching: It was suggested that the Bedrock Converse integration might need an update to properly support prompt caching, due to differences in how it places the cache point, and that the
Anthropicclass should be used instead.
- The suggestion was based on the member testing with plain Anthropic, and pointed to a Google Colab notebook example as a reference.
Nomic.ai (GPT4All) Discord
-
GPT4All's Hiatus Spurs Doubt: Users on the Discord server express concern about the future of GPT4All, noting that there have been no updates or developer presence for approximately three months.
- One user stated that since one year is not really a big step ... so i have no hopes for a timely update.
- IBM Granite 3.3 Emerges as RAG Alternative: A member highlights IBM's Granite 3.3 with 8 billion parameters as providing accurate, long results for RAG applications, including links to the IBM announcement and Hugging Face page.
- The member also specified that they are using GPT4All for Nomic embed text for local semantic search of programming functions.
- LinkedIn inquiry ignored: One member stated that they asked on Linked-in what the status of gpt4all is but I think I'm being ignored.
- No further discussion was recorded.
Modular (Mojo 🔥) Discord
-
Modular Hosts In-Person Meetup: Modular is hosting an in-person meetup next week at their Los Altos, California headquarters, and invites you to RSVP here.
- The meetup will feature a talk on boosting GPU performance with Mojo & MAX, offering both in-person and virtual attendance options.
- Mojo Lacks Standard MLIR Dialects: A user discovered that Mojo doesn't expose standard MLIR dialects like
arithby default, with only thellvmdialect available.
- It was clarified that there are currently no mechanisms to register other dialects in Mojo.
- Mojo Dictionary Pointers Trigger Copy/Move: A user observed unexpected
copyandmovebehavior when retrieving a pointer to a dictionary value in Mojo usingDict[Int, S]()andd.get_ptr(1).
- This prompted the question, "Why is retrieving a pointer to a dict value invoking a copy and a move? 🤯 Is this intended behaviour by any means?"
- Orphan Cleanup Mechanism Needed in
maxRepo: A member highlighted the need for an orphan cleanup mechanism for themaxrepo, originally opened issue 4028 a couple of months ago.
- This feature is particularly relevant for developers with small partitioned disks, though it was qualified as very much a dev only problem.
LLM Agents (Berkeley MOOC) Discord
-
Auto-Formalizer Seeks Business Logic Proofs: A member inquired about using the Lean auto-formalizer to generate informal proofs from computer code containing business logic for formal verification of programs using AI proof generation.
- The discussion highlighted interest in programming languages like Python and Solidity.
- CIRIS Covenant Beta: Open-Source Alignment: The CIRIS Covenant 1.0-beta, an open-source framework for adaptive-coherence AI alignment, has been released and made available as a PDF.
- It seeks to aid those in AI safety or governance, with a project hub and comment portal available here.
MLOps @Chipro Discord
-
Resources sought for ensembling forecasting models: A member asked for resources on ensembling forecasting models.
- No resources were provided in the message history.
- Members brainstorm Final Year Project Ideas: A member is looking for practical Final Year Project ideas for a BS in AI, and is interested in computer vision, NLP, and generative AI, especially projects that solve real-world problems.
- They are looking for projects that aren’t too complicated to build.
Cohere Discord
-
AI Model Development Often Staged?: A user inquired whether AI model development typically employs a staged training process, such as Experimental (20-50%), Preview (50-70%), and Stable (100%).
- The question explores the prevalence of a staged approach in AI model training, involving phases like Experimental, Preview, and Stable releases.
- Staged Training Common for AI?: Discussion centered around the use of a staged training process for AI models, breaking it down into phases like Experimental, Preview, and Stable.
- The user sought to understand if this staged deployment is a common practice in the field.
Codeium (Windsurf) Discord
-
Windsurf's Jetbrains Changelog Dives In: The latest release notes are now available at the Windsurf changelog.
- Users are encouraged to review the changelog to stay informed about the newest features and improvements.
- New Discussion Channel Drifts In: A new discussion channel, <#1362171834191319140>, has been opened for community engagement.
- This aims to provide a dedicated space for users to share thoughts and ideas, and ask questions about Windsurf.
The DSPy Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The tinygrad (George Hotz) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Perplexity AI ▷ #announcements (1 messages):
Telegram Bot, WhatsApp Bot
-
Perplexity AI Launches Telegram Bot!: Perplexity AI is now available on Telegram via the askplexbot.
- Users can add the bot to group chats or DM it directly to receive answers with sources in real-time; WhatsApp integration is planned for the future.
- Teaser video released: A short teaser video showcasing the new Telegram Bot was released with the announcement.
- The video (Telegram_Bot_Launch_1.mp4) highlights the seamless integration and real-time response capabilities.
Perplexity AI ▷ #general (952 messages🔥🔥🔥):
Ticketing Bot for Complaints, Attaching Images for Referral Link Help, Neovim Configuration Showcase, Claude 3 vs Gemini 2.5 Performance, Perplexity Voice Mode
-
Perplexity Considers Ticketing Bot, Helper Roles in Discord: Members discussed the possibility of adding a ticketing bot to the Discord server for complaints, but raised concerns about viability, preferring a help center approach and duplicate rants.
- An alternative suggestion was made to create a helper role with a dedicated ping, while pointing out that Discord is not ideal for support and a Modmail bot linking directly to Zendesk could be useful.
- Student ID Images for Referral Links Debated: A member asked about attaching images in the channel for help with creating a referral link from their student ID.
- Another member responded that no one really cares, suggesting they could also ask in the relevant channel <#1118264005207793674>.
- Member showcases their Neovim setup: A member posted an image of their Neovim configuration after studying IT for three days straight.
- They engaged the AI model to make studying engaging and it worked well.
- Claude 3.7 Sonnet Token Application: Members discussed the Claude 3.7 Sonnet model with one suggesting that members should apply for free tokens by OpenAI.
- One member said they have used O3 (on both high and medium reasoning) and haven't run out for a whole day.
- Perplexity Users Await Promised Lands of New Models: Members await the release of promised models including O3, O4-mini, Gemini 2.5 Flash, DeepSeek R2, Qwen 3, and Claude 3.7 Opus.
- A member questioned the value of Gemini 2.5 Flash before release, to which another responded that it's not even released yet.
Perplexity AI ▷ #sharing (3 messages):
tariffs, Trump, EU, China
-
Trump Imposes Tariffs on EU and China: The Trump administration imposed 245% tariffs on EU products in retaliation for subsidies to Airbus, as well as tariffs on Chinese goods over intellectual property theft, according to this report.
- These measures aimed to protect American industries and address trade imbalances.
- Retaliation for Airbus Subsidies: The tariffs on EU goods were a response to the EU's subsidies to Airbus, which the US argued gave the European company an unfair advantage in the global market, according to this search result.
- The US sought to level the playing field and ensure fair competition.
- IP Theft from China: Tariffs were also imposed on Chinese goods to combat intellectual property theft, as the US aimed to protect its technological and innovative assets, explained in this perplexity search.
- The US sought to deter China from engaging in unfair trade practices.
Perplexity AI ▷ #pplx-api (3 messages):
Job search posts, PplxDevs Tweet, Move it to June
- PplxDevs Tweet Shared: A member shared a link to a tweet from PplxDevs.
- User would have dived in: A member stated this is awesome, I totally would have dived in, if I wasn't going on vacation for a month now.
- Request to move event to June: A member jokingly requested that you guys should totally move it to June.
LMArena ▷ #general (1257 messages🔥🔥🔥):
Gemini 2.5 Pro vs Flash, O3 vs O4 Mini, thinking budget parameters, LLMs help studying?, OpenAI cost efficiency
-
Gemini 2.5 Flash Enters the Arena: Members noticed Gemini 2.5 Flash appeared in Vertex AI, sparking debates on its performance against Gemini 2.5 Pro, with some favoring it for coding tasks due to its efficiency and tool-calling capabilities.
- One user touted yo this model is fire!!! while several members pointed out that models got stuck in thinking loops during testing, which happened before with 2.5 Pro.
- O3 and O4 Battle for Supremacy: There's ongoing discussion about the merits of O3 versus O4 Mini, with members performing live tests and sharing links like this game with both to show their potential, and it appears that many are going back to O3 after experimenting with Flash and Pro models.
- While O4 Mini might be cheaper at first glance, some find its high usage and output costs make it borderline unusable in practice, leading to varied opinions based on specific needs.
- Thinking Budget Tweaks Unleash New Powers: Members are digging into the new "Thinking Budget" feature on Vertex AI, allowing manipulation of thinking tokens.
- While some found it useful, others reported bugs, with some observing that 2.5 pro just works better on 0.65 temp.
- LLMs: Study Buddies or Hallucination Hubs?: A member raised the question about whether LLMs can aid education in developing nations, sparking debate on reliability versus traditional learning.
- Some members said an LLM hallucinates, books written by people who know what they are talking about don't.
- OpenAI Bleeds Money: Members discussed that OpenAI loses 8B a year.
- Members wonder I don't think OpenAI loses money on API pricing with the current model set rn tho.
LMArena ▷ #announcements (2 messages):
LMArena Company Formation, Beta Launch, Feedback Response
- LMArena Kicks off a Company!: LMArena, born from a UC Berkeley academic project, is starting a company to support its platform and community, ensuring it remains neutral, open, and accessible.
- Beta Launches with Fresh Feedback: LMArena launched a Beta version incorporating user feedback from the Alpha, though saved chats won't transfer, and votes will be monitored for signal quality.
- LMArena Adopts Dark Mode, Image Paste: LMArena is actively responding to Beta feedback, adding features like a dark/light mode toggle and direct copy/paste image functionality into the prompt box.
aider (Paul Gauthier) ▷ #general (832 messages🔥🔥🔥):
code2prompt, Aider's new command, Gemini 2.5 vs O3/O4, DeepSeek R2
-
Aider users debate code2prompt utility: Members discussed the usage of
code2promptin Aider, questioning its utility compared to simply using/addto include necessary files, becausecode2promptparses all files that match nearly instantly.- The main advantage of
code2promptis its speed in parsing relevant files, but ultimately the usefulness depends on the specific use case and model capabilities. - Architect mode leads to 15 new files: A member reported an Aider bug where after refactoring an app and creating 15 new files, the changes were discarded after accepting to add a file to the chat.
- Another member noted that this issue is expected behavior and that a warning is not given when edits are discarded.
- Aider's New Command: Probe Tool: Members discussed the new Aider command
probetool for semantic code search, highlighting its capabilities such as extracting code blocks with errors and integrating with testing outputs, with the developer actively using it within their company.
- Another member liked the claude-task-tool and both are good looking projects, he says. He also liked another tool, potpie-ai/potpie, for its nice UI, too.
- Gemini 2.5 Pro vs O3/O4: Members debated the merits of O3-high versus Gemini 2.5 Pro, citing benchmarks showing O3-high achieving 81.3% on the Aider Polyglot benchmark compared to Google's 72.9%, while others noted O4-mini's cost-effectiveness, and some said the O3 is too expensive.
- However, a new version of Gemini was announced with the possibility to disable "thinking" with better pricing.
- Enthusiasm Abounds for DeepSeek R2: Members eagerly anticipated the release of DeepSeek R2, expressing hope that it would surpass O3-high in performance and be available for free or at a significantly reduced cost, one member commented that it is just a matter of time.
- There was optimism that DeepSeek R2 could potentially be the final blow to OpenAI dominance with the best price/performance ratio.
- The main advantage of
aider (Paul Gauthier) ▷ #questions-and-tips (23 messages🔥):
Ask Mode Persistence, O4-mini Error Fix, Copy-Context Usage, Cloud Aider Instances, Architect & Edit Format Split
-
Ask Mode Persists with
/chat-mode ask: Users can use/chat-mode askto persistently stay in ASK mode, but this can be confusing, because the help menu says "switch to a new chat mode" instead of "switch to a different chat mode".- It was suggested that specifying
askas the default mode in the config file should also make it persist, and typing/askalone and pressing enter will also switch to ask mode, as per the documentation. - O4-mini Temperature Error Resolved: An error with o4-mini (Unsupported value: 'temperature' does not support 0 with this model) was reported, and resolved by upgrading to the latest version.
- The user was on v0.74.1 and Paul G. confirmed that the latest version supports o4-mini.
- Streamlining Copy-Context in ChatGPT: A user inquired about the best way to paste
copy-contextoutput into ChatGPT for optimal results, including the preferred model (e.g., gemini-flash).
- A screenshot showed the chat gpt o4-mini running in aider with 4o-mini, but no optimal method for pasting into ChatGPT was specified.
- Aider Instance in the Cloud: A user asked about running an aider instance in the cloud and sending prompts through a workflow.
- Another user confirmed they were doing this, and asked the original poster to DM them.
- Splitting Architect & Edit Formats: A user asked about splitting the edit format for the architect and edit functions, and whether this pulls from
.aider.model.settings.yml.
- It was suggested to configure
edit_format: difffor the normal edits andeditor_edit_format: editor-difffor the architect mode, referencing the code.
- It was suggested that specifying
aider (Paul Gauthier) ▷ #links (2 messages):
New Model Analysis, O'Reilly AI Event
-
YouTube Offers Sober Take on New Models: A member shared a YouTube video offering a more reasonable take on the new models.
- The video appears to provide an analysis or perspective on recent model releases, steering clear of hype.
- O'Reilly Hosts Free AI Event: A member mentioned a free O'Reilly event focused on Coding with AI.
- This event likely covers topics related to AI development, applications, and possibly hands-on coding sessions.
OpenRouter (Alex Atallah) ▷ #announcements (122 messages🔥🔥):
Terms & Privacy Policy Update, Free Model Limits, Gemini 2.5 Flash Model
-
OpenRouter Updates Terms and Privacy Policies: OpenRouter has updated its Terms and Privacy Policy to be more up-to-date, clarifying that LLM inputs will not be stored without consent, and detailing how they do prompt categorization.
- The prompt categorization is for figuring out the "type" of request (programming, roleplay, etc.) to power rankings and analytics, and will be anonymous if users have not opted in to logging.
- Free Model Limits Revised: Lifetime Purchases Count: OpenRouter updated the free model limits, now requiring a lifetime purchase of at least 10 credits to benefit from the higher 1000 requests/day (RPD), regardless of the current credit balance.
- Access to the experimental
google/gemini-2.5-pro-exp-03-25free model is now restricted to users who have purchased at least 10 credits due to extremely high demand, while the paid version offers uninterrupted access. - OpenRouter Introduces Gemini 2.5 Flash: Lightning-Fast Reasoning: OpenRouter has unveiled Gemini 2.5 Flash, a new model designed for advanced reasoning, coding, math, and scientific tasks, available in a standard (non-thinking) variant and a :thinking variant with built-in reasoning tokens.
- Users can customize their usage of the :thinking variant using the
max tokens for reasoningparameter, as detailed in the documentation.
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
LLM Cost Simulator, Vibe-coded LLM Chat Application
- Simulate LLM Conversation Costs: A member created a tool to simulate the cost of LLM conversations, supporting over 350 models on OpenRouter.
-
Vibe-coded LLM Chat App Connects with OpenRouter: A member has developed an LLM chat application that connects with OpenRouter, offering access to a curated list of LLMs and additional features like web search and RAG retrieval.
- The application has a basic free tier, with a small monthly cost for expanded search & RAG functionality, or a slightly higher cost for unlimited usage.
OpenRouter (Alex Atallah) ▷ #general (636 messages🔥🔥🔥):
OpenAI Codex not working with OpenRouter, BYOK, DeepSeek R3 and R4, OpenAI verification, API usage limits
- Codex Users Cry as OpenAI API endpoints fail in OpenRouter: OpenAI Codex uses a new API endpoint so it currently doesn't work with OpenRouter.
-
DeepSeek Delayed Due to OpenAI Restrictions: The o-series reasoning summaries from OpenRouter may be delayed due to OpenAI restrictions requiring ID verification, though summaries will be available through the Responses API soon.
- One user pointed out that the new DeepSeek is similar to Google's Firebase studio.
- OpenAI Verification Process: Users discussed the invasive nature of OpenAI's verification process for O3, requiring ID pictures and a selfie with liveness check via withpersona.com.
- OpenRouter API limitations and confusion around rates and quotas: Free users of OpenRouter get 1000 requests per day in aggregate, but heavy demand on specific models might lead to per-user request limits.
- Users also discussed and disagreed about whether there was a RPD (requests per day) quota for free users of Google AI studio or whether it was truly free tier (pay with data).
- OpenRouter Logging policy clarification coming soon: Currently, free model providers often log inputs/outputs, but OpenRouter itself only logs data if users explicitly opt-in via account settings, and documentation for each provider's policy is coming soon.
- A separate setting called training=false can disable providers that train on your data.
OpenAI ▷ #ai-discussions (476 messages🔥🔥🔥):
Gemini 2.5 Pro vs o3/o4 models, o4 models hallucinations, GPT-4.1 Nano, Gemini 2.5 Flash
-
Gemini 2.5 Pro Still Tops o3/o4 for Some: Despite new models like o3 and o4, some users still prefer Gemini 2.5 Pro for its speed, accuracy, and cost, though others find Gemini to hallucinate like crazy on complex tasks.
- Some benchmarks show o3 performing better in coding, while Gemini 2.5 Pro excels in reasoning; the new 2.5 Flash version aims to be faster but may sacrifice quality.
- O4 Models Prone to Hallucinations: Users report that o4-mini and o3 models tend to make up information more often, even providing believable but completely wrong answers, with one example showing the model hallucinating a fake business address for a company.
- It was suggested that instructing the model to verify sources via search might help reduce hallucinations, but trusting the model to get the sources right is a concern.
- GPT-4.1 Nano Shines with Factual Answers: A user found that GPT-4.1 Nano did a better job of answering with non-fake information, compared to other models.
- It seems to mix up the Cayman and Seychelles islands, which is like mixing up the UK with Mexico.
- Gemini 2.5 Flash Debuts with Focus on Speed: Google added Veo 2 and the new model 2.5 Flash in Gemini Advanced, with Flash emphasizing faster responses, but some users wonder if it sacrifices quality for speed.
- There's an option to set thinking limits to control the response speed of the models.
OpenAI ▷ #gpt-4-discussions (19 messages🔥):
o4-mini vs o3-mini for knowledge, GPT-4.5 speed, Custom GPT Instructions ignored, o4-mini usage limits, PDF Uploads for Study
-
o4-mini not good at Knowledge Questions?: Users are reporting that the new o4-mini and o4-mini-high models are performing worse than o3-mini-high in answering knowledge questions and coding tasks.
- One user noted that "For knowledge questions GPT-4.5 should be much better".
- GPT-4.5 is very slow: Multiple users complained that GPT 4.5 is very slow.
- It was suggested this is "probably because it's a dense model vs. mixture of experts" model, and its also the reason "why 4.5 is so expensive".
- Custom GPT ignores instructions: A user reported their Custom GPT is not following instructions.
- They lament that "It's just out there doing it's own thing at this point".
- o4-mini usage limits: Usage limits for o4-mini are 150 a day, for o4-mini high 50 a day, and o3 50 a week.
- Best Language Model for Uploading PDFs: A user asked what the most appropriate language model is to upload a PDF to study, ask questions, and prepare ready-made exam questions in chat GPT.
OpenAI ▷ #prompt-engineering (9 messages🔥):
Image Generation, Contextual Memory on GPTPlus, Multi-Modular System
-
Blurry Image Request Sparks Prompt Quest: A member requested the prompt used to generate blurry, candid-shot-style images of a public figure running in front of a store (possibly Kohl's) with a Victoria's Secret bag, created shortly after the 4o image generation release.
- Another member offered to attempt forging a prompt, noting the difficulty of realistically detailing such images, while another suggested the image may have been generated with Sora, which is better than 4o model's image creation.
- GPTPlus Account Emulates Contextual Memory: A member reported emulating contextual memory on a GPTPlus account through narrative coherence, despite contextual memory not being officially available.
- Another member confirmed experiencing similar results, enabling the user to build a multi-modular system with over 30 discussions capable of connecting new discussions by writing the correct word.
OpenAI ▷ #api-discussions (9 messages🔥):
Image generation prompts, r/chatgpt subreddit images, Textual prompts on GPT Plus accounts, Multi-modular system
-
Seeking Prompt for Blurry Public Figure Image: A user is looking for the prompt used to generate images on the r/chatgpt subreddit of a public figure running in front of a store (Kohls) with a Victoria's Secret bag, made to look like a blurry candid shot.
- Another member offered to try and forge a prompt for this image generation, while speculating it may have been generated with Sora.
- Textual Prompts Emulating Contextual Memory: A user reported emulating contextual memory through narrative coherence with textual prompts on a GPT Plus account, despite it supposedly not being allowed.
- They've built a multi-modular system with more than 30 discussions, connecting new discussions by using the right keywords.
Cursor Community ▷ #general (432 messages🔥🔥🔥):
Refund issues with Cursor subscription, DeepCoder 14B, GPT 4.1 Pricing, Cursor Terminal Hanging Fixes, Zed AI IDE
- Users Await Cursor Subscription Refunds: Users reported canceling their Cursor subscriptions and receiving emails about refunds, but haven't yet received the money, with one user reporting they got it.
-
Fiddling with FIOS Fixes Speeds: A user noticed that pushing down the LAN wired connection on their Verizon FIOS setup can increase download speeds from 450Mbps to 900Mbps+.
- They suggested a more secured connector akin to PCIE-style connectors and posted an image of their setup.
- Models Materialize on MacBooks: Users discussed the availability of new models on the MacBook version of Cursor, with some not seeing them initially, and needing to restart or reinstall the software.
- It was suggested to manually add the o4-mini model by typing o4-mini and pressing add model.
- Cursor's Coding Companion Creates Commotion: Crashing, Confusing and Cancelling: Users debated if o3/o4-mini are better than 2.5 Pro and 3.7 thinking, with one reporting that o4-mini-high is better than 4o and 4.1 for analyzing codebase and solving logic, even for large projects.
- Others complained about Cursor agent not exiting the terminal after running a command (causing it to hang indefinitely), frequent tool calls with no code output, a message too long issue, a broken connection status indicator and the inability to edit files.
- Windsurf and Zed: Worthwhile Winner or Vibe Coding Vehicle?: Speculation arose about OpenAI potentially acquiring Windsurf for $3B, with some considering it a sign of the company becoming more like Microsoft, while others like this tweet are focusing on GPT4o mini.
- Participants debated whether Cursor and Windsurf are true IDEs or just glorified API wrappers (or forks) with UX products catering to vibe coders, extensions, or mere text editors.
Yannick Kilcher ▷ #general (332 messages🔥🔥):
Brain connectivity, Responses API, Liquid State Machines, Meta-Simulation
-
Brain Connectivity Decomposed into Simple Manifolds: A paper suggests brain connectivity can be decomposed into simple manifolds with additional long-range connectivity (PhysRevE.111.014410), but a member found it tiresome that anything using Schrödinger's equation is being called quantum.
- Another member stated that Any plane wave linear equation can be put into the form of Schoedinger's equation by using a Fourier transform.
- Responses API is brand new: Members clarified that while the Responses API is brand new, the Assistant API is sunsetting next year.
- It was emphasized that if you want assistants you choose assistant API, if you want regular basis you use responses API.
- Reservoir Computing Hype: Members discuss Reservoir Computing, a fixed, high-dimensional dynamical system, clarifying that the reservoir doesn't have to be a software RNN, it can be anything with temporal dynamics and a simple readout is learned from the dynamical system.
- One member shared Most of the "reservoir computing" hype often sells a very simple idea wrapped in complex jargon or exotic setups: Have a dynamical system. Don’t train it. Just train a simple readout.
- Meta Introduces Fair updates: Meta introduces fair updates for perception, localization, and reasoning with an image attached.
- The image shows some updates as part of Meta's fair updates.
- Meta-Simulation Enables Complex Problem Distribution: Members discuss Meta-Simulation, hypothesizing with enough random trajectories, they can cover everything; The idea is that we have so much random and so many trajectories that it covers probably everything.
- Members theorize that a trained RWKV 7 will mimic the learning process of a reservoir computer, enabling RWKV7 to be adapted for any other type of problem, if there is a way to randomly sample such things that follow more or less what you expect real data to look like.
Yannick Kilcher ▷ #paper-discussion (10 messages🔥):
Ultrascale Playbook Review, GPU layouts for large models, InternVL3 paper discussion
-
Ultrascale Reviewer stops, Cites GPU Layout Interest: A member decided to stop reviewing the Ultrascale Playbook because they are more interested in learning about GPU layouts for training and inference of large models rather than low-level kernel optimization.
- They will resume reviewing if they need to pick up low-level kernel optimization later.
- Multimodal Models Explored: InternVL3's Training Recipes: Members scheduled a cold read and critique of the paper InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models (huggingface link).
- The event was promoted on social media with a Discord event link.
Yannick Kilcher ▷ #ml-news (8 messages🔥):
IBM Granite, Trump Administration Deepseek Ban, Brain Matter Music, Infantocracy, Blt weights
- IBM Debuts Granite 3 and Speech Recognition: IBM announced Granite 3 and refined reasoning RAG Lora models, along with a new speech recognition system, detailed in this announcement.
- Trump Admin Considers Deepseek Ban: The Trump administration is reportedly considering a US ban of Deepseek, as noted in this TechCrunch article.
- Brain Matter Melodies: Scientists and artists collaborated with the late composer Alvin Lucier to create an art installation using cerebral organoids developed from his white blood cells, as described in this Popular Mechanics article.
- BLT Weights Finally Released: The weights for BLT are now available and they are working with huggingface on transformer support, according to this Hugging Face collection.
Manus.im Discord ▷ #general (347 messages🔥🔥):
Banning Discussion, Claude UI update, Game development with Manus, AI tools, Game Engines
-
Member Banned for Annoying Everyone: A member was banned because, according to another member, *"he annoyed everyone already and was warned."
- Some members expressed concern over the lack of evidence for the ban, while others emphasized the importance of maintaining a peaceful community.
- Claude Gets the Charles Treatment: Claude updated its interface to allow native research and app connections like Google Drive and Calendar.
- Members noted that Manus had similar functionality and that it was basically the Charles III update.
- GPTs gains MCPS: A member stated that GPT also has this feature now.
- The update looks like you can search your Google Calendar, Google Drive, and connected gmail.
- AI Game Development Jackpot Struck: A member expressed excitement about open-source game development combined with AI and fair NFT implementation.
- The member thanked another for inspiring thoughts on what makes gacha games successful and the problem between gamers and the crypto/NFT community.
- Game Stamina Economics Discussed: A member proposed a new stamina system with bonuses for different stamina levels, benefiting various player types and developers.
- Members discussed alternative systems, such as staking items for stamina or incorporating loss mechanics to increase addictiveness, referencing games like MapleStory and Rust.
Eleuther ▷ #general (310 messages🔥🔥):
AI-generated content, Human authentication, AI-influenced postings, Stochastic environments, LoRA-like styling for pretraining
-
AI Research Caution: LLMs Must Learn to Produce Fresh Results: A member warns that using LLMs exclusively for research or message generation on the server is unproductive, potentially leading to a ban, as it contributes ~zero actual content.
- Another member emphasizes the server's focus on AI research discussions, not general AI learning or user experiences, suggesting newcomers should emulate established research methodologies to contribute meaningfully.
- The Impending Bot-pocalypse?: Members discuss the potential need for human authentication to combat AI bots on the server, with one suggesting that the current low impact may not last.
- Alternatives to strict verification are considered, including community moderation and focusing on active contributors, with concerns raised about the increasing prevalence of AI-influenced content.
- The AI Hallucination Paradox: Models That Try Too Hard: Concerns were raised about the danger of pseudo-alignment where LLMs toadyism tricks people into thinking that they have learned, while they rely on the AI to generate plausible sounding idea mashups.
- One member shares a paper on how permissions have changed over time, to which another replied the open web is currently being substantially undermined by the existence of AI.
- The Quest for European Language Models: Members discuss the availability of region-tailored language models within Europe, beyond well-known entities like Mistral.
- The discussion included the Dutch GPT-NL ecosystem, Italian Sapienza NLP, Spanish Barcelona Supercomputing Center, French OpenLLM-France and CroissantLLM, German AIDev, Russian Vikhr, Hebrew Ivrit.AI and DictaLM, Persian Persian AI Community and Japanese rinna.
- The ethics of recursively simulated paradoxes: A member shared their work on ChatGPT, Claud 3.7, and Gemma3 4B recursive symbolic load, however members expressed reservations about it.
- Members warned the member that you need to be study some things written by humans because their terms such as recursive symbolism were very esoteric and unhelpful and told the member to try to come up with less subjective experiments.
Eleuther ▷ #research (11 messages🔥):
Quantization Effects on LLMs, Composable Interventions Paper, Muon for Output Layers, Empirical Performance of Muon
- Quantization Effects on LLMs Probed: A member inquired about works analyzing the impact of quantization on LLMs, suggesting that there's a qualitative change happening at low bits, especially with training-based quantization strategies, showing a screenshot.
- Composable Interventions Paper Boosts Quantization Insight: A member recommended the composable interventions paper as support for the qualitative changes happening at low bits.
-
Muon's Output Layer Conundrum: A member questioned why Muon is not recommended for output layers, even though Euclidean/RMS norm seems natural for regression or pre-softmax logit outputs.
- Another member cited that empirical performance should be theoretically fine, and pointed to this blog post.
- Muon's Performance Examined for Smaller Models: A member suggested that Muon seems fine for smaller models (around 300M transformers) compared to tuned AdamW.
- This implies that the performance of Muon may vary depending on the model size.
Eleuther ▷ #lm-thunderdome (1 messages):
lm-evaluation-harness PR
- New PR Dropped for lm-evaluation-harness: A member dropped a PR for the lm-evaluation-harness.
- (Filler Topic): (Filler summary to satisfy the JSON schema requirements.)
HuggingFace ▷ #general (99 messages🔥🔥):
sudolang, LayoutLMv3 vs Donut, Agents course deadline, Illustrious Models for anime, nVidia vs AMD
- Sudolang Feedback Sought: A member requested feedback on the sudolang-llm-support project.
- LayoutLMv3 and Donut compared for Form Extraction: A member compared the performance of LayoutLMv3 and Donut for form extraction, noting that Donut encodes in BPE while LayoutLM uses a mixed WordPiece + SentencePiece vocabulary.
- Anime Models with Illustrious Shine: Members recommended Illustrious, NoobAI XL, RouWei, and Animagine 4.0 for anime generation, with increasing LoRA resources for Illustrious, pointing to models like Raehoshi-illust-XL-4 and RouWei-0.7.
-
nVidia and AMD GPU faceoff: One member inquired about using multiple GPUs for large models, saying its much easier to use multiple GPUs to run 1 big model with nvidia because you'll just do
device_map='auto'.- Another member agreed that nVidia is easier to use, linking to Accelerate documentation, while AMD requires more improvisation.
- Hugging Chat bug squashed: A user reported an issue in Hugging Chat, linking to a specific discussion.
HuggingFace ▷ #today-im-learning (4 messages):
Chunking structured files into embeddings, Nomic embed text model, Python scripts and virtual environments, Hugging Face usage, Mistral-7b model
-
Newbie Chunks Files for Embeddings: A member is programming new functions to chunk structured files like Emacs Lisp files into embeddings, aiming for better hyperlinking capacity.
- They are using the Nomic embed text model and estimate the project is 10% complete.
- Learns Python and Troubleshoots PATHs: A member learned how to run Python scripts, generate a virtual environment, use Hugging Face, and downloaded and ran Mistral-7b, troubleshooting along the way.
- They noted that an AI assistant did most of the heavy lifting.
- Seeks OpenFOAM/Blender Tips: A member seeks advice and tips for working with Python and OpenFOAM/Blender after struggling with PATHs.
- The next challenge is wrapping the outputs of Mistral into foam to be rendered.
HuggingFace ▷ #cool-finds (6 messages):
Cable Management, Nuclear Energy Stagnation, Portable Microreactors, Vogtle Reactor Units, China's Energy Production
-
Cable Management Praised: A member expressed appreciation for cable management in a shared video tour, which prompted a discussion on future energy demands.
- One member noted, talk about cable management.
- Nuclear Recovery Delayed by Regulations: A member explained that the 40-year stagnation in nuclear energy was due to heavy regulation and rebuilding the industry takes time to regain cost competitiveness and 24/7 reliability.
- They stated, you can't instantly regain a cost competitive and 24/7 reliable production without the workforce and infrastructure.
- Microreactors Spark Interest for Tech Giants: Startups are developing portable/modular microreactors, which seem like a great fit for Google/Meta/Microsoft and other large-scale technology companies.
- Despite the promise of microreactors, there is uncertainty about whether any new reactors were approved last year.
- Vogtle Units go Online after 30-year Nuclear Hiatus: Two Vogtle reactor units have come online in the last two years marking the first big nuclear reactors in 30 years in the USA, though they were approved 10 years ago.
- A member shared links to resources for further research, including a blog post and a Spotify podcast.
- China Triples Down on Energy Production: It was mentioned that China is gonna do x3 in energy production while us will only do x2 (in the same time period).
- This suggests a rapid expansion of energy infrastructure and capabilities in China compared to the United States.
HuggingFace ▷ #i-made-this (14 messages🔥):
Tokenizer without text corpus, AI hallucinations, TRNG for AI training, Agent integrate with local ollama model, oarc-crawlers
-
Tokenizer Tests Without Corpus Surprise!: A member tested tokenizers on a French sentence without a text corpus and found that GPT-4 used 82 tokens, while their custom tokenizer used 111 tokens.
- They cheekily remarked, "I don't have a corpus" after revealing their tokenizer's performance.
- PolyThink Tackles AI Hallucinations: A member has spent 7 months building PolyThink, an Agentic multi-model AI system designed to eliminate AI hallucinations by having multiple AI models correct and collaborate with each other.
- They invite the community to sign up for the waitlist to be among the first to try it out.
- Repo Context Made Easy: A member shared a utility script, installable via
npx lm_context, that walks a project repo's file tree and generates a text file for LMs, available on GitHub.
- The script respects
.gitignoreand.lm_ignorefiles, always ignores dotfiles, and includes metadata about binary files. - TRNG for AI Training Explored: A member built a research-grade True Random Number Generator (TRNG) with an extremely high entropy bit score and wants to test its impact on AI training, with eval info available on GitHub.
- Another member joked that dice rolls would still result in mostly natural 1's, to which the TRNG creator responded it would be a "natural 1 given by the universe then lmao".
- Local Ollama Agent Integration Showcased: A member integrated an AI agent with a local Ollama model as part of their AI agents course, sharing the project on GitHub.
- Another member humorously responded with a 'cat-looks-inside-cat' meme, pointing out the Python library abstracts even more Python.
HuggingFace ▷ #reading-group (5 messages):
Reading Group Session, YouTube Recordings
-
Reading Group May Session is Incoming: The host thanked everyone who joined and said they will send details soon about the May session.
- So stay tuned.
- Reading Group Recordings found on YouTube: A member asked where the recordings could be found and another one responded with a link to a YouTube playlist.
HuggingFace ▷ #computer-vision (5 messages):
Lightweight Multimodal Models, Model Memory Usage, InterVL2_5-1B-MPO, gemma-3-4b-it, InternVL3 Paper
-
Searching for Speedy Multimodal Models: A member is seeking a lightweight multimodal model to extract text from images in any language and format it in JSON, noting that gemma-3-4b is good but seeking faster alternatives.
- Another member suggested fine-tuning InterVL2_5-1B-MPO based on similar project experience with Portuguese documents.
- HF Space Calculates Model Memory Usage: A member shared a Hugging Face Space to help calculate the memory usage of different models.
- This was in response to questions about memory usage of different models during a hangout.
- InterVL2_5-1B-MPO Fine-tuning Favored: A member found that fine-tuning InterVL2_5-1B-MPO yielded the best results for a similar project involving Portuguese documents.
- Considering only the pre-trained models, gemma-3-4b-it offered the best balance of speed and accuracy but among the models that ran even faster (e.g. Qwen2-VL-2B and InterVL2_5-1B-MPO), they saw about a 10% drop in overall accuracy on their task.
- InternVL3 Paper Cold Read Event: A member announced a cold read and critique of the paper InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models on
- Interested parties were invited to join the event.
HuggingFace ▷ #smol-course (9 messages🔥):
Agent Course Certification, Inference Credits, PromptTemplate format
-
Certification Date Confusion!: A member pointed out that the course introduction states the certification date as July 1, leading to confusion.
- Another member thanked them for the heads up.
- Inference Credits running out!: A member following the smolagents notebook ran out of inference credits after only 26 requests.
- They wondered if upgrading to PRO and setting up a billing option would fix it.
- PromptTemplate Provokes Problems!: A member is struggling to find the right PromptTemplate format to build their chain with SmoLlm and Langchain for a chatbot.
- The member specified that the two prompt templates tried so far are PromptTemplate.from_template and ChatPromptTemplate.from_messages, and they both give a weird output.
- Quiz Completion equals certificate!: A member asked if they would receive a certificate automatically after completing the course.
- Another member responded that they received a certificate after passing the Unit 1 quiz, suggesting that the same would happen for the final quiz.
HuggingFace ▷ #agents-course (40 messages🔥):
Ollama library model usage, Course assignment confusion, Agents Course 503 error, Course completion deadline
-
Ollama Model works without llm_provider: A user confirmed that using the model_id="ollama_chat/qwen2.5-coder:7b-instruct-q2_K" with api_base on localhost port 11434 works even without the llm_provider parameter.
- Several other users had the same questions about this as well.
- Course Assignments Create Confusion: Users expressed confusion about the course assignments, noting that only quizzes are present after each unit, and inquired about the specific assignment requirements mentioned in the course information.
- Instructors clarified that details about the final assignment will be shared the following week as the criteria are being finalized, and that the assignment deadline is July 1st.
- Agents Course Plagued by 503 Errors: Multiple users reported encountering a 503 error when starting the Agents Course, particularly with the dummy agent.
- It was suggested that the error might be due to hitting the API key usage limit on the free tier, though one user noted they still had credits available, indicating traffic or access issues.
- Course Completion Deadline set to July 1st: The course completion deadline has been extended to July 1st, 2025, with all assignments needing to be submitted by this date to receive the certificate.
- It was mentioned that after July 1st, the course might transition to a self-paced format if there are insufficient internal resources to maintain the certification process.
GPU MODE ▷ #general (6 messages):
OpenCL, SYCL, lu.ma/vibecode
-
Admins discuss opening OpenCL channel: A member inquired about the possibility of creating an OpenCL channel within Computing Platforms.
- An admin responded that there hasn't been enough demand historically to justify it, though they acknowledged that OpenCL is still current and offers broad compatibility across Intel, AMD, and NVIDIA CPUs/GPUs.
- SYCL supersedes OpenCL: A member suggested that SYCL is getting superseded by OpenCL.
- This sparked a brief discussion about the relative merits and future of the two technologies.
- lu.ma/vibecode invite: A member sent a direct message to another member and asked them to check out a link from lu.ma/vibecode.
- It's unclear what this link refers to without additional context from the DM.
GPU MODE ▷ #triton (6 messages):
fp16 matrix multiplication, triton autotune, TTIR optimization, kernel overhead
-
Matrix Multiplication Performance Poor: A member reported that fp16 matrix multiplication of size 2048x2048 isn’t performing as expected, even lagging behind cuBLAS, despite referencing official tutorial code.
- They also observed that the RTX 5090 shows similar speeds to the 4090, only around 1-2% faster.
- Matrix Size Matters for Triton Speedup: A member suggested using a larger matrix, like 16384 x 16384, and playing with autotune to assess performance.
- It was stated that multiplying two 2048x2048 matrices isn't enough work to fully utilise these GPUs efficiently, and a larger workload is needed to see meaningful speed-up and hide the kernel overhead.
- Realistic Benchmarking using Stacked Linear Layers Advised: A member advised that a more realistic benchmarking approach involves stacking like 8 linear layers in a
torch.nn.Sequential, usingtorch.compileor cuda-graphs, and measuring the end-2-end processing time of the model, rather than just a single matmul.
GPU MODE ▷ #cuda (14 messages🔥):
cuda::pipeline usage, H200 FP4 support, PyTorch float4 on 5090
-
cuda::pipelinefunctions explained: A member was experimenting withcuda::pipelineto overlap global-to-shared copies with compute using this NVIDIA article.- It was clarified that
pipeline::producer_acquireandpipeline<thread_scope_thread>::producer_acquirefunctions are different, and they tell CUDA to fetch or be done with stages of the pipeline as documented in the CUDA C Programming Guide. - H200 does not support FP4: Members discussed whether the H200 now supports FP4 precision, based on a Reddit thread.
- Another member clarified that the H200 is still based on the Hopper/sm_90 architecture and is primarily a memory upgrade over the H100, lacking new features like FP4 support, and it was likely a typo for B200.
- Float4 on 5090 with PyTorch: A member asked if anyone knows how to get float4 working with PyTorch on the 5090 GPU.
- It was clarified that
GPU MODE ▷ #torch (4 messages):
AOTInductor, torch.compile, OpenXLA, libtorch C++
-
AOTInductor Generates Model Files: A member suggested using AOTInductor to produce a model.so file that can be loaded and used to run a model when not training.
- He mentioned others use torch.compile (torch._inductor) to generate Triton kernels.
- Manual Artifact Lifting Suggested: Another member lamented that they are training and suggested manually lifting artifacts from torch.compile.
- They also considered using OpenXLA but were unsure if it works for libtorch C++ and didn't want to investigate.
GPU MODE ▷ #beginner (3 messages):
CUDA learning resources, PyTorch on 5090, GPU puzzle repo
-
User quests for CUDA guidance: A member is interested in learning CUDA for AI and simulation and is seeking guidance on which resources to choose from the gpumode github resources repo.
- The user expressed confusion due to the abundance of resources available.
- Float4 quest with PyTorch on 5090: A member inquired about how to get float4 with PyTorch on a 5090.
- Member tackles GPU puzzle repo: One of the members is currently using the GPU puzzle repo from Shasha.
- They hope to learn something while having fun with it.
GPU MODE ▷ #torchao (2 messages):
``
-
Awaiting Further Information: The user expresses gratitude and indicates they will review the provided information.
- No specific topics or links were discussed in this message.
- Acknowledge Receipt: The user acknowledged the message.
- The user did not elaborate.
GPU MODE ▷ #off-topic (9 messages🔥):
Slurm, HPC, Deployment, Admin Guides, Quickstart Admin Guide
-
Slurm Deployment/Admin Resources Requested: A member asked for deployment/admin resources for Slurm in HPC environments.
- Specifically, the member was looking for good deployment/admin guides/books/videos.
- Slurm Documentation and Configuration: A member suggested that the Slurm documentation is quite extensive, directing to the Quickstart Admin Guide.
- They also pointed to the official online tool to create config files, and suggested using ansible-slurm for deployment.
- Running CUDA code with bash scripts: A member mentioned that they are on a Slurm cluster and have been running everything through bash scripts or the 'srun' command.
- They also offered to send over an example bash script used for running CUDA code.
GPU MODE ▷ #rocm (2 messages):
AMD challenge, compute resources, kernel submission, discord-cluster-manager, datamonsters
-
AMD Challenge Deets Disclosed: A user inquired about the specifics for the AMD challenge, such as accessing compute resources and submitting kernels, and whether registration confirmations have been sent out.
- Another user provided the necessary links for submission info: discord-cluster-manager and datamonsters.
- Compute Resources and Kernel Submission Details: Details on how to access compute resources and submit kernels for the AMD challenge are available at discord-cluster-manager and datamonsters.
- The user was directed to these links after inquiring about the specifics of the challenge.
GPU MODE ▷ #self-promotion (1 messages):
x.com post by @mobicham
-
Mobicham Tweets about LMMs: The x.com post by @mobicham shows the poster writing 'I'm tired of these large monkey models, I'm going to build the small ape model'.
- The post includes an image file named
Screenshot_from_2025-04-17_17-27-33.png. - Mobicham Screenshot: The screenshot shows that Mobicham is tired of Large Monkey Models and will build a Small Ape Model.
- The screenshot was taken on April 17, 2025 at 5:27:33 PM.
- The post includes an image file named
GPU MODE ▷ #general (10 messages🔥):
popcorn register, CLI submission errors, Discord/Github registration
-
Popcorn registration thwarted by CLI errors: A user encountered an error message to run
popcorn registerfirst when using popcorn, leading to discussion about registration methods.- A member recommended using Discord for submissions temporarily due to CLI issues and guided the user to register via Discord or GitHub.
- Submission Error 401 surfaces: After registering, a user faced a Submission error: Server returned status 401 Unauthorized related to an Invalid or unauthorized X-Popcorn-Cli-Id.
- A member suggested the registration likely failed and reiterated the need to authorize via Discord or GitHub.
- Auth redirect hits decoding error: A user reported an error Submission error: error decoding response body: expected value at line 1 column 1 after authorizing via the web browser following the
popcorn-cli registercommand.
- A member inquired about the
submitcommand usage and requested the script via DMs for further troubleshooting.
GPU MODE ▷ #submissions (57 messages🔥🔥):
AMD FP8 MM Leaderboard, MI300 Performance, Matmul Benchmarking, AMD Identity Leaderboard
-
MI300 AMD-FP8-MM Leaderboard Updated: Multiple submissions were made to the
amd-fp8-mmleaderboard on MI300, with several users achieving first place, including one submission reaching 255 µs.- Other successful submissions ranged from 5.24 ms to 791 µs, showcasing a variety of performance levels on the platform.
- AMD Identity Leaderboard sees New Entries: The
amd-identityleaderboard on MI300 saw new submissions, with users achieving 4th and 5th place with runtimes of 22.2 µs and 22.7 µs, respectively.
- This indicates ongoing efforts to optimize identity operations on AMD's hardware.
- Matmul Benchmarking on A100 and H100: A submission to the
matmulleaderboard reported successful runs on both A100 and H100, achieving runtimes of 746 µs and 378 µs, respectively.
- These benchmarks provide a comparison point for matrix multiplication performance across different hardware platforms.
- FP8 Matmul sees new personal bests: One user achieved a personal best on the
amd-fp8-mmleaderboard with 5.20 ms on MI300.
- This demonstrates the continued refinement and optimization of FP8 matrix multiplication performance.
GPU MODE ▷ #status (3 messages):
CLI Tool, HIP code submission
-
CLI tool bugs fixed!: The CLI tool bugs are now fixed and a new release of popcorn-cli is available for download to submit.
- Users are requested to send the script via DMs if it fails for any reason.
- Instructions for HIP code submission: Clarified instructions are available for submitting HIP code using the
popcorn-cli.
- Users can view the new template via
/leaderboard template, specifyingamd_fp8_gemmas the leaderboard name andHIPas the language, see also the popcorn-cli docs.
GPU MODE ▷ #feature-requests-and-bugs (3 messages):
New CLI Release, Submission Fixes
-
CLI Release Fixes Submission Snafus: A new CLI release is out, aiming to resolve issues with submissions.
- A member suggested another user try again to confirm the fix but then realized they replied to the wrong message.
- Testing New CLI Release: After the new CLI release a member suggested another member test it out.
- The member suggested the test but apologized because he was responding to the wrong message.
GPU MODE ▷ #amd-competition (36 messages🔥):
MI300 usage statistics, Debugging Kernels, FP8 numerical precision finetuning, Team Registration, Torch Header improvements
-
Tolerances Tightened, Accuracy Agony Averted: Competitors flagged small inaccuracies in kernel outputs, leading to failures with messages like
mismatch found! custom implementation doesn't match reference.- Admins acknowledged that the initial tolerances were too strict and promised to update the problem definition shortly, later confirming that tolerances are now less strict.
- Torch Trips? Team Triumphs with Template Tweaks: A participant shared an improved template implementation, attached as a message.txt file, that avoids torch headers (requiring
no_implicit_headers=True) for faster roundtrip times and configures the right ROCm architecture (gfx942:xnack-). - MI300 Midnight Mania? Debugging Doesn't Doze: A participant inquired about MI300 usage statistics, hoping to debug code during non-peak hours.
- Staff reassured them that there are 40 MI300s available and that debugging can be done any time, thanks to AMD's generosity.
- .hip Hopes High, .py Preference Prevails: A user asked if submissions must be in .py format and how to submit a .hip file instead.
- The response indicated that .py is currently required, necessitating the use of torch.load_inline.
- Registration Required: Rally Your Ranks Right: Participants inquired whether all team members needed to register for the competition.
- The response clarified that all team members should register under the same team name for prize distribution purposes, though only one person should submit via Discord; these instructions are listed on the webpage.
GPU MODE ▷ #cutlass (2 messages):
Mx Cast Kernel, Cutlass Performance Bottleneck, CuTensorMap API, TMA usage with Cutlass
-
Mx Cast Kernel Benchmarked: A member has a simple mx cast kernel implemented in CUDA and a simple benchmark for it.
- The CUDA kernel achieves only 3.2 TB/s, while an equivalent Triton kernel reaches 6.8 TB/s with the same grid and CTA size; they are seeking advice on potential Cutlass implementation bottlenecks.
- Compute Bound Bottleneck: The member used NCU and found that the kernel is compute bound.
- They believe they are issuing too many instructions and tried various implementations, including those with and without shared memory, but observed no speed improvements.
- Cutlass TMA Troubles: The member attempted to use TMA (Tensor Memory Accelerator) with Cutlass, but found the documentation unhelpful and didn't see performance gains.
- They also experimented with the CuTensorMap API, describing it as "pretty gross" and ineffective in boosting speed.
LM Studio ▷ #general (71 messages🔥🔥):
NVMe vs SATA SSD, Image models in LM Studio, RAG capable models in LM Studio, Granite Model Use-Cases, 5090 GPU and LM Studio
-
NVMe SSD Speed Dominates SATA SSD: Users confirm NVMe SSDs significantly outperform SATA SSDs, with speeds ranging from 2000-5000 MiB/s compared to SATA's 500 MiB/s max.
- When you load large models the difference is massive, another user stated, further noting massive spikes way above the SSD performance due to disk cache and abundant RAM.
- LM Studio's Vision Model Implementation Remains Murky: Users discussed using vision models like qwen2-vl-2b-instruct in LM Studio, referencing documentation on image input.
- Some members are reporting images can be processed and others report the feature failing; the Llama 4 model has a vision tag in the models metadata, but does not support vision in llama.cpp, while Gemma 3 should work.
- RAG Models Attach Files Via Plus Button: Users clarified that in Chat mode, RAG (Retrieval-Augmented Generation) capable models in LM Studio can attach files via the '+' sign in the message prompt.
- Users can verify whether the model they're using is RAG capable by checking the model's information page.
- Granite Model Still a Gem to Some: Despite generally being disregarded due to low performance across tasks, one user vouches for Granite, stating it's their preferred model for general purpose use cases, specifically for an interactive stream-pet type chatbot.
- The user clarified that when trying to put it in a more natural context, it feels robotic and Granite is still by far the best performance though.
- LM Studio 0.3.15 Needed for RTX 5090 Optimization: A user with a new RTX 5090 GPU reported long load times with Gemma 3, prompting a suggestion to upgrade to the 0.3.15 beta version of LM Studio.
- The suggestion noted that the latest beta offers the best performance with 50-series GPUs, accessible via the settings menu.
LM Studio ▷ #hardware-discussion (71 messages🔥🔥):
FP4 support in PyTorch and vLLM, AVX requirement for LM Studio, 5060Ti 16GB, GPU upgrade from RTX 3060 12GB
- FP4 Support Speculation: Members discussed native FP4 support in PyTorch and vLLM, with some initial misinformation about its current availability, but the support is still under active development and FP4 is currently only supported with TensorRT.
-
AVX Requirement Causes Problems: A user with an older server running E5-V2 without AVX2 inquired about using it with LM Studio, but was informed that only very old versions of LM Studio support AVX and may need to compile llama.cpp without AVX requirement.
- It was suggested to use llama-server-vulkan or search for LLMs that still support AVX.
- New 5060ti 16GB: Members weighed the advantages of a 5060Ti 16GB versus a 5070 Ti 16GB which share the same architecture, and have similar AI performance depending on bus width, gddr speed, and vram, but the former might be preferable due to its budget-friendliness, or to wait for reviews.
- They also speculated on performance compared to 2x 3090 or 1x 4090.
- Upgrade Options Examined: A user considering upgrading from an RTX 3060 12GB explored options such as the A770 16GB and RTX 4060Ti 16GB, before settling on saving up for a 3090 due to its VRAM size.
Unsloth AI (Daniel Han) ▷ #general (52 messages🔥):
Llama 4 timeline, Multi-GPU support, Custom tokens finetuning, Qwen 2.5 finetuning, Chat template importance
- Llama 4 Support Coming Soon: Llama 4 finetuning support will be released this week, use the 7B notebook and just change it to 14B.
- Multi-GPU support coming later this month: Multi-GPU support is expected this month and should support Unsloth's continued pre-training features.
-
Custom Tokens Increase Memory Usage: Adding custom tokens will increase memory usage, so users need to enable continued pretraining, including adding more layer adapter to embedding and lm head.
- For more information, see the Unsloth documentation.
- Safetensors are required for finetuning: To finetune, use safetensor files instead of gguf as they are only valid.
- See Unsloth documentation.
- Check Chat Templates for Model Issues: To resolve model integration issues, make sure you're using the correct chat template.
Unsloth AI (Daniel Han) ▷ #off-topic (19 messages🔥):
MetaAI's offensive output, Iggy's fake output streaming, Phishing website's emailjs key, MediBeng-Whisper-Tiny model
-
MetaAI spits hot fire, then disappears: A member observed MetaAI generating an offensive comment in Facebook Messenger, deleting it, and then claiming unavailability.
- They criticized Meta for prioritizing the feeling of AI interaction (through streaming output) over responsible moderation, suggesting the moderation should occur server-side before streaming begins like DeepSeek.
- Iggy fakes it 'til it makes it: A member recounted how, while developing IGGy (Interactive Grow Guide) for a cannabis seed site, they implemented fake output streaming to avoid moderation issues.
- They emphasized that delaying output until after moderation and then chunking the output improved user experience, even if it increased the wait time, musing that users absolutely love streamed responses.
- Phisher Phucked? EmailJS Key caper considered: A member discovered an emailjs key in a phishing website's source code and considered sending a thousand requests to disrupt the operation.
- Others suggested reporting the phishing site or attempting to revoke the key via emailjs, while one member lamented They're a bit wiser about protecting their API keys nowadays.
- MediBeng-Whisper-Tiny Debuts: A member introduced MediBeng-Whisper-Tiny, a fine-tuned OpenAI Whisper-Tiny model on Hugging Face designed to translate code-switched Bengali-English speech into English.
- This model aims to improve doctor-patient transcription and clinical record accuracy and is available on GitHub.
Unsloth AI (Daniel Han) ▷ #help (21 messages🔥):
OOM Issue, Tool Calls, Llama 4, LoRA hot swap, Multi-GPU delayed
- Gemma 3 OOM Issue Reported: Users are reporting an Out Of Memory (OOM) issue with Gemma 3 and are looking for solutions, referencing issue #2366 on the Unsloth GitHub.
-
Unsloth's Tool Calling Capabilities Questioned: A user is asking whether Unsloth supports returning tool calls separately, like OpenAI-compatible models, and if so, how to implement this functionality.
- Currently, the model returns function calling details within the response itself, requiring post-processing to extract the tool name and parameters.
- Llama 4 Implementation Status Clarified: Users clarified that Llama 4 already works in Unsloth, although it hasn't been officially announced.
- The implementation is mostly stable, with final touches and further testing in progress.
- LoRA Hot Swap Fix Under Review: A user has proposed a fix for a LoRA hot swap issue and is seeking a review of their pull request on the Unsloth-Zoo GitHub repository.
- Multi-GPU Fix Delay: A user pointed out that multi-GPU fix will be delayed.
Unsloth AI (Daniel Han) ▷ #showcase (8 messages🔥):
PolyThink, AI Hallucinations, Multi-Model AI System
-
PolyThink chases AI Hallucinations: A member announced the waitlist for PolyThink, a multi-model AI system designed to eliminate AI hallucinations by having AI models correct and collaborate with each other.
- Another member likened the system to thinking with all the models and expressed interest in testing it for synthetic data generation to create better datasets for specific roleplay scenarios.
- Tackling AI Hallucinations with PolyThink: A member highlighted AI hallucinations as a major challenge in AI, especially in settings where accuracy is critical, and spent 7 months building PolyThink to address this.
- Interested Unsloth members can sign up at the PolyThink waitlist.
Unsloth AI (Daniel Han) ▷ #research (14 messages🔥):
Untrained Deep Neural Networks, Mistral AI integration differences, Memory Latency Aware (MLA), GRPO trainer for reasoning, Qwen 2.5 3B model
-
Untrained Neural Nets Found to be Awesome: An article explores how untrained deep neural networks can perform image processing tasks without training, using random weights to filter and extract features from images, a trend which contrasts with traditional AI development.
- The technique leverages the inherent structure of neural networks to process data without learning specific patterns from training data, showcasing emergent computation.
- Mistral AI code woes: A member encountered issues integrating a fine-tuned Mistral AI model into a C# project, noting discrepancies in performance compared to its Python counterpart despite using the same prompt.
- They are seeking insights into potential causes for the unexpected behavior across different programming environments, and should likely check versioning and other code implementation details.
- MLA Reduces Memory Accesses: Discussion highlights that Memory Latency Aware (MLA) reduces memory accesses due to operating on a latent space, which enables faster processing.
- The improved speed is attributed to the fact that computation is rarely the bottleneck, drawing a parallel to why flash attention is faster in practice.
- GRPO trainer needs reasoning tags: A new Unsloth community member is developing a GRPO trainer to create a chatbot, and sees the model is not learning the reasoning patterns as it shows 0.0000 in structure rewards.
- It was suggested that the user implement reasoning between the
reasoningtags, and give the final answer between theanswertags, in the dataset. - Qwen 2.5 model needs bigger dataset: A user is employing the Qwen 2.5 3B instruct model with only 200 examples and is struggling to get the model to perform reasoning.
- It was suggested that 200 examples is too few for reasoning and that more like 2k would be necessary to see even sparks of reasoning.
Nous Research AI ▷ #general (58 messages🔥🔥):
GPT4o as Completion Model, Huawei Leading Globally, BitNet b1.58 2B 4T, Discord's Future
-
GPT4o Only for Copilot Completions?: Members discussed whether GitHub Copilot in VS Code uses only GPT4o for autocompletion, noting that while other models can be used in a chat interface, autocompletion seems limited to their custom models.
- One member found that GPT4o hallucinated links and delivered broken nonsense, performing on par with other SOTA LLMs, linking to Tweets comparing output and another Tweet comparing output.
- Huawei Could Challenge NVIDIA's Lead: Some members discussed how Trump's tariffs might negatively impact Nvidia's global ambitions, potentially allowing Huawei to take the lead in hardware, according to this tweet linking to a YouTube video about a world without Nvidia Cuda.
- Others noted mixed experiences with GPT4o-mini-high, citing instances where it zero-shot broken code and failed basic prompts.
- BitNet b1.58 2B 4T: Microsoft's 1-bit LLM: Microsoft Research released BitNet b1.58 2B 4T, an open-source native 1-bit LLM at the 2-billion parameter scale, trained on 4 trillion tokens, with comparable performance to full-precision models.
- Achieving efficiency benefits requires using the dedicated C++ implementation (bitnet.cpp) from Microsoft's GitHub repository, and one user found it to perform like a normal 2B model while another user mentioned its context window is limited to 4k, but overall the model is not bad.
- Discord Might Be 'Cooked': A member shared a link to programming.dev, suggesting Discord might be nearing its end.
- This was in reference to Discord's new age verification features being tested in the UK and Australia, with concerns raised about privacy compromises and a potential slippery slope leading to platform-wide changes.
Nous Research AI ▷ #ask-about-llms (18 messages🔥):
o4mini, Gemini 2.5 pro, MCP servers, agent functionality of copilot, Tools in a coding environment
- Gemini Pro 2.5 vs o4mini: A member asked for opinions on o4mini vs Gemini 2.5 pro from environments like VS Code, noting that Gemini seems smarter and more responsive to prompts.
- Gemini's Tool Usage Under Scrutiny: A member mentioned that Gemini is known to struggle with tool usage, while another humorously suggested that Gemini had "hacked the server".
- Debate on desirable Tools to have in a Coding Environment: A member inquired about desirable tools in a coding environment like VS Code, particularly for backend development, suggesting web search and graph RAG with MCP.
- Inquiring after function calls in VS Code: A member mentioned interest in function calls as a feature for copilot within VS Code.
Nous Research AI ▷ #research-papers (1 messages):
BitNet b1.58 2B4T, 1-bit LLM, Hugging Face
-
BitNet b1.58 2B4T Hits the Scene: The first open-source, native 1-bit Large Language Model (LLM) at the 2-billion parameter scale, called BitNet b1.58 2B4T, was introduced in this ArXiv paper.
- Trained on a corpus of 4 trillion tokens, it matches the performance of open-weight, full-precision LLMs of similar size, while offering better computational efficiency, reduced memory footprint, energy consumption, and decoding latency.
- BitNet b1.58 2B4T Weights Land on Hugging Face: The model weights for BitNet b1.58 2B4T have been released via Hugging Face, alongside open-source inference implementations for both GPU and CPU architectures.
- This release aims to facilitate further research and adoption of the 1-bit LLM technology.
Nous Research AI ▷ #research-papers (1 messages):
BitNet b1.58 2B4T, Native 1-bit LLM, Hugging Face model release, Computational Efficiency, Memory Footprint Reduction
-
BitNet b1.58 2B4T: The 1-bit LLM Enters the Stage: A member shared a link to the BitNet b1.58 2B4T paper, introducing the first open-source, native 1-bit Large Language Model (LLM) at the 2-billion parameter scale.
- Trained on 4 trillion tokens, the model reportedly matches the performance of leading open-weight, full-precision LLMs of similar size, while offering advantages in computational efficiency, reduced memory footprint, energy consumption, and decoding latency.
- BitNet b1.58 2B4T Claims Computational Efficiency Victory: The BitNet b1.58 2B4T paper highlights the model's significant advantages in computational efficiency, particularly in memory footprint, energy consumption, and decoding latency.
- The model weights are released via Hugging Face along with open-source inference implementations for both GPU and CPU architectures, aiming to promote further research and adoption.
Notebook LM ▷ #use-cases (8 messages🔥):
Gemini Pro, Deep Research, Accounting Month End Process, Vacation Itinerary, Google Maps
-
Gemini and Deep Research Tackle Accounting Month End: A member uses Gemini Pro to create a TOC for a junior accountant's book on the accounting month end process, then uses Deep Research to expand upon it, combining the results in a GDoc.
- They add this GDoc as the first source to NLM, focusing on its features before adding other sources, and welcomes improvement suggestions.
- Vacation itineraries aided by Google Maps integration?: A member uses Notebook LM for their vacation travel itinerary, saving points of interest in Google Maps.
- They suggest that Notebook LM should be able to take Google Maps saved lists as a source.
- Digital Class Notes Transformed Into Quizzes and Flashcards: A member wants to import all of their digital class notes into NLM to make quizzes, summaries, and flashcards.
- They lamented the current lack of LaTeX support.
- LaTeX Support Coming Soon: The team is working on LaTeX support; soon it will render properly without needing any addons.
Notebook LM ▷ #general (45 messages🔥):
Webby Awards Voting, NotebookLM Mindmap details, NotebookLM Enterprise SSO Setup, NotebookLM Plus Admin Controls, NotebookLM uses RAG
- Vote, Vote, or Lose the Boat: A member reminded everyone that Webby voting closes TOMORROW and they are losing in 2 out of 3 categories for NotebookLM, urging users to vote and spread the word: https://vote.webbyawards.com/PublicVoting#/2025/ai-immersive-games/ai-apps-experiences-features/technical-achievement.
-
Mindmap Missing Details, Sad Face: A user with a renewed NotebookLM Plus subscription is seeking an AI tool for detailed mindmaps of nearly 3000 journal articles, noting that NotebookLM's mindmaps are too basic, with one main subject and only two to three sublevels.
- The user is considering manual mindmapping in Obsidian as an alternative.
- SSO Setup Snafu Solved with Subject: A user encountered a "Sources Effect: Unable to Fetch Projects" error when trying to access NotebookLM Enterprise via SSO from Azure Entra ID despite correct IAM bindings and Attribute Mapping.
- The user resolved the issue by setting google.subject=assertion.email and confirming that NotebookLM Enterprise is now accessible.
- Plus Has Sensitive Data? Time to Pay Up: A user questioned the value of NotebookLM Plus included with Enterprise Standard Licenses due to lack of user analytics and access control for sensitive data, as those features are exclusive to the cloud version of NLM.
- A member suggested that organizations with sensitive data should use the independent Enterprise version regardless of admin controls.
- RAG Diagram Deconstructed!: In response to a question about RAG, a member shared two diagrams illustrating a general RAG system and a simplified version, shown here: Vertex_RAG_diagram_b4Csnl2.original.png and Screenshot_2025-04-18_at_01.12.18.png.
- Another user chimed in noting they have a custom RAG setup in Obsidian, and the discussion shifted to response styles.
MCP (Glama) ▷ #general (51 messages🔥):
Obsidian MCP Server, Cloudflare Workers SSE API Key, LLM Tool Understanding, MCP Personalities, MCP server time
- MCP server for Obsidian Surfaces: A member is working on an MCP server for Obsidian and is looking to share ideas, noting that the vulnerability lies in the orchestration, not the protocol itself.
-
Cloudflare Workers Serve Server-Sent Events with API Keys: A member is setting up an MCP server using Cloudflare Workers with Server-Sent Events (SSE) and seeks advice on passing an apiKey via URL parameters.
- Another member suggested that instead of passing in URL parameters, to pass in header, so that the key is encrypted via HTTPS.
- Demystifying LLM Tool Understanding: A member inquired about the inner workings of how an LLM understands tools/resources, questioning if they are merely explained in a prompt or if the LLM is specifically trained on the MCP spec.
- Another member responded that they understand the tools via descriptions and that many models support a tool spec or some other parameter that defines tools.
- Personalize MCP Server Response - Not so fast: A member is trying to define a personality for their MCP server by setting a prompt in the initialization to dictate how it should respond, but they're not seeing any changes in the responses.
- Windsurf Waves Hello: A member noted that if you aren't using windsurf this week, you are missing out on the week of free gpt4.1, easily worth hundreds of dollars of value drinkoblog.weebly.com.
MCP (Glama) ▷ #showcase (1 messages):
HeyGen API, MCP Server Release, Video Creation Platform
- HeyGen API Product Lead Intros: The product lead for HeyGen API introduced himself, mentioning that HeyGen allows users to create engaging videos without a camera.
- MCP Server Released: The team released a new MCP Server (https://github.com/heygen-com/heygen-mcp), and shared a short video demo.
- Feedback Request on MCP Server: The team requested feedback on the new MCP Server, specifically asking which clients they should test it out in.
Torchtune ▷ #general (23 messages🔥):
GRPO Recipe Todos, PPO tasks, Single GPU GRPO Recipe, Reward Modeling RFC
- GRPO Recipe Todos are outdated: The original GRPO recipe todos are outdated due to the new version being prepared in r1-zero repo.
- Async GRPO Version in the Works: An async version of GRPO is under development in a separate fork and will be brought back to Torchtune soon.
-
Single GPU GRPO Recipe needs finishing: A single GPU GRPO recipe PR from @f0cus73 is available here and needs to be finalized.
- The single device recipe will not be added through the r1-zero repo.
- Reward Modeling RFC coming soon: A member is planning to create an RFC for reward modelling, outlining the implementation requirements.
Torchtune ▷ #papers (1 messages):
Titans Talk
- *Titans Talk begins soon!*: The Titans Talk is starting in 1 minute for those interested.
- No more talk: Just kidding!
LlamaIndex ▷ #blog (1 messages):
A2A Agents, Agent Communication, LlamaIndex support for A2A
-
LlamaIndex Enables A2A-Compatible Agents: LlamaIndex now supports building A2A (Agent2Agent)-compatible agents following the open protocol launched by Google with support from over 50 technology partners.
- This protocol enables AI agents to securely exchange information and coordinate actions, regardless of their underlying infrastructure.
- A2A Protocol Facilitates Secure Agent Communication: The A2A protocol allows AI agents to communicate securely and coordinate actions.
- It is supported by over 50 technology partners, ensuring broad compatibility and interoperability among different AI systems.
LlamaIndex ▷ #general (22 messages🔥):
CondenseQuestionChatEngine Tool Support, Anthropic Bedrock Prompt Caching, Anthropic support with LlamaIndex
-
CondenseQuestionChatEngine Does Not Support Tools: The CondenseQuestionChatEngine does not support calling tools; the suggestion was made to use an agent instead, according to a member.
- Another member confirmed it was just a suggestion and was not actually implemented.
- Bedrock Converse Prompt Caching Conundrums: A member using Anthropic through Bedrock Converse faced issues using prompt caching, encountering an error when adding extra_headers to the llm.acomplete call.
- After removing the extra headers, the error disappeared, but the response lacked the expected fields indicating prompt caching, such as cache_creation_input_tokens.
- Anthropic Class recommended to support Bedrock: It was suggested that the Bedrock Converse integration might need an update to properly support prompt caching, due to differences in how it places the cache point, and that the
Anthropicclass should be used instead.
- The suggestion was based on the member testing with plain Anthropic, and pointed to a Google Colab notebook example as a reference.
Nomic.ai (GPT4All) ▷ #general (11 messages🔥):
GPT4All Future, IBM Granite 3.3 for RAG, LinkedIn inquiry status
-
GPT4All's Hiatus Spurs Doubt: Users on the Discord server express concern about the future of GPT4All, noting that there have been no updates or developer presence for approximately three months.
- One user stated that since one year is not really a big step ... so i have no hopes for a timely update.
- IBM Granite 3.3 Emerges as RAG Alternative: A member highlights IBM's Granite 3.3 with 8 billion parameters as providing accurate, long results for RAG applications, including links to the IBM announcement and Hugging Face page.
- The member also specified that they are using GPT4All for Nomic embed text for local semantic search of programming functions.
- LinkedIn inquiry ignored: One member stated that they asked on Linked-in what the status of gpt4all is but I think I'm being ignored.
Modular (Mojo 🔥) ▷ #general (1 messages):
Modular Meetup, Mojo & MAX, GPU performance
-
Modular Meetup Set for Next Week!: Next week, Modular will be hosting an in-person meetup at their headquarters in Los Altos, California; you can RSVP here.
- There will be a talk on making GPUs go brrr with Mojo & MAX.
- GPU performance boost with Mojo & MAX: <@685556913961959475> will give a talk on making GPUs go brrr with Mojo & MAX during the meetup.
- Both in-person and virtual attendance options are available.
Modular (Mojo 🔥) ▷ #mojo (6 messages):
MLIR in Mojo, Mojo Dict Pointer Behavior, FP languages optimizations
-
Dialect Dilemma in Mojo: A user encountered an error trying to use the
arith.constantMLIR operation in Mojo, discovering that Mojo doesn't expose standard dialects likearithby default, with only thellvmdialect available.- It was clarified that there are currently no mechanisms to register other dialects in Mojo.
- Pointer Shenanigans with Mojo Dictionaries: A user observed unexpected
copyandmovebehavior when retrieving a pointer to a dictionary value in Mojo usingDict[Int, S]()andd.get_ptr(1).
- The user's code produced copy/move operations even after the initial move, leading them to ask: "Why is retrieving a pointer to a dict value invoking a copy and a move? 🤯 Is this intended behaviour by any means?"
- Optimizing Overhead in Functional Programming Languages: A user expressed skepticism regarding the ability to optimize away all the overhead typically associated with Functional Programming (FP) languages in Mojo.
- This concern was raised in the context of a "neat project", hinting at ongoing efforts to address this challenge.
Modular (Mojo 🔥) ▷ #max (1 messages):
Orphan cleanup mechanism, Partitioned Disk, max repo
-
Orphan Cleanup Mechanism Needed for
maxRepo: A member opened issue 4028 a couple of months ago, suggesting an orphan cleanup mechanism for themaxrepo.- The reporter noted having a small partitioned disk and feeling the impact of not having one quite fast, however, they also qualified this is very much a dev only problem.
- Small Partitioned Disk users hit by
maxrepo: Users with small partitioned disks may experience issues with themaxrepo.
- The reporter also qualified this is very much a dev only problem.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
Lean auto-formalizer, Formal verification of programs, AI proof generation, Informal proofs, Computer code
-
Auto-formalizer Proofs for Business Logic: A member inquired about using the Lean auto-formalizer to create informal proofs from computer code (e.g., Python, Solidity) containing business logic.
- The goal is to generate general statements/logic for formal verification of programs using AI proof generation.
- Informal Proofs from Computer Code: The user is interested in generating informal proofs from computer code with business logic.
- Examples of programming languages mentioned include Python and Solidity.
LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
CIRIS Covenant 1.0-beta Release, Open-Source AI Alignment Framework, Adaptive-Coherence AI Alignment
-
*CIRIS Covenant 1.0-beta Goes Public!*: The CIRIS Covenant 1.0-beta, a principled, open-source framework for adaptive-coherence AI alignment, has been released, with a PDF available here.
- The project aims to aid those working on AI safety or governance, with a project hub and comment portal provided here.
- Explore Adaptive-Coherence AI Alignment: The framework focuses on adaptive-coherence AI alignment, offering a novel approach to ensuring AI systems align with human values.
- This approach is intended for those in AI safety and governance, providing tools for risk mitigation and agentic ethics.
MLOps @Chipro ▷ #general-ml (2 messages):
Ensembling forecasting models, Final Year Project Ideas
- Resources sought for ensembling forecasting models: A member asked for resources on ensembling forecasting models.
-
Members brainstorm Final Year Project Ideas: A member is looking for practical Final Year Project ideas for a BS in AI, and is interested in computer vision, NLP, and generative AI, especially projects that solve real-world problems.
- They are looking for projects that aren’t too complicated to build.
Cohere ▷ #「💬」general (1 messages):
AI Model Development, Staged Training Process
- AI Model Development Often Staged?: A user inquired whether AI model development typically employs a staged training process, such as Experimental (20-50%), Preview (50-70%), and Stable (100%).
- Staged Training Process in AI: The question explores the prevalence of a staged approach in AI model training, involving phases like Experimental, Preview, and Stable releases.
Codeium (Windsurf) ▷ #announcements (1 messages):
New Discussion Channel, Windsurf Jetbrains Changelog
-
New Discussion Channel Drifts In: A new discussion channel, <#1362171834191319140>, has been opened for community engagement.
- This aims to provide a dedicated space for users to share thoughts and ideas, and ask questions about Windsurf.
- Windsurf's Jetbrains Changelog Surfs Up: The latest release notes are now available at the Windsurf changelog.
- Users are encouraged to review the changelog to stay informed about the newest features and improvements.