[AINews] Gemini 2.0 Flash GA, with new Flash Lite, 2.0 Pro, and Flash Thinking
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
[REDACTED] is all you need.
AI News for 2/4/2025-2/5/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (210 channels, and 5481 messages) for you. Estimated reading time saved (at 200wpm): 571 minutes. You can now tag @smol_ai for AINews discussions!
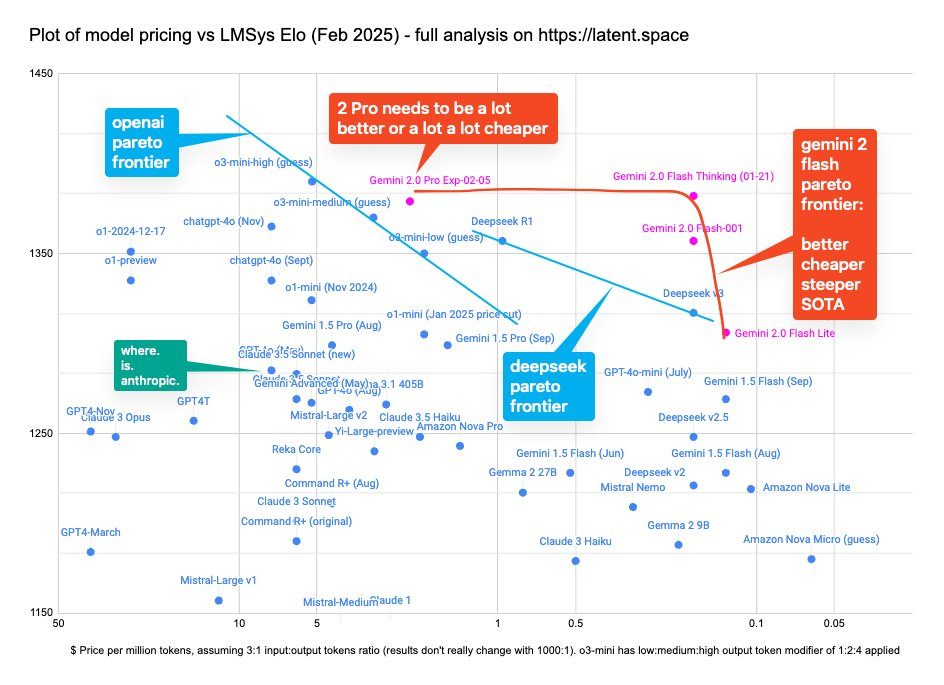
Gemini 2.0 has been "here" since December (our coverage here), but now we can officially count Gemini 2.0 Flash's prices as "real", and put them up on our Pareto frontier chart:
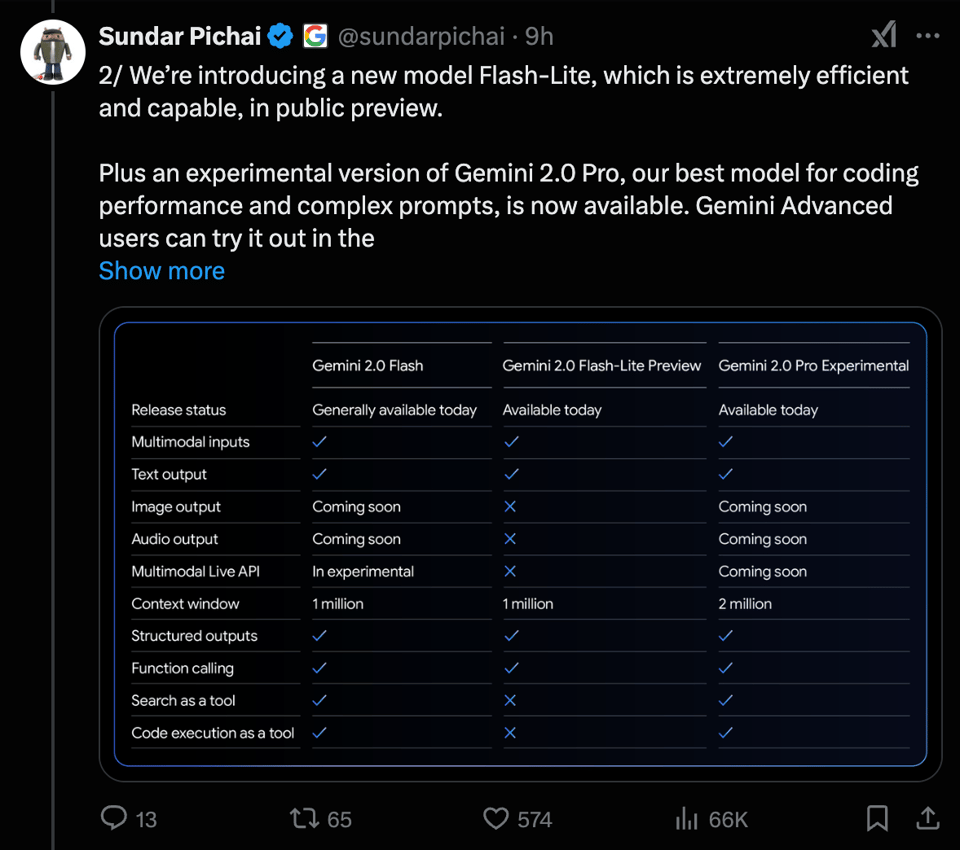
We will grant that raw intelligence charts like those mean increasingly less and will probably die this year because they cannot accurately describe the multimodal input AND output capabilities of these releases, nor coding ability, nor the 1-2m long context, as Sundar Pichai demonstrates:
Of particular note is the cost effectiveness of the new "Flash Lite", as well as the very slight price hike that Gemini 2.0 Flash has vs 1.5 Flash.
Curiously enough, the competitive dynamics of OpenAI "mogging" Google releases seem to have stayed in 2024.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- aider (Paul Gauthier) Discord
- Unsloth AI (Daniel Han) Discord
- Codeium (Windsurf) Discord
- Stability.ai (Stable Diffusion) Discord
- Cursor IDE Discord
- Perplexity AI Discord
- Eleuther Discord
- OpenRouter (Alex Atallah) Discord
- Interconnects (Nathan Lambert) Discord
- LM Studio Discord
- HuggingFace Discord
- Yannick Kilcher Discord
- OpenAI Discord
- Nous Research AI Discord
- Modular (Mojo 🔥) Discord
- Notebook LM Discord
- Torchtune Discord
- Latent Space Discord
- Nomic.ai (GPT4All) Discord
- MCP (Glama) Discord
- GPU MODE Discord
- LlamaIndex Discord
- LLM Agents (Berkeley MOOC) Discord
- Cohere Discord
- tinygrad (George Hotz) Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- DSPy Discord
- PART 2: Detailed by-Channel summaries and links
- aider (Paul Gauthier) ▷ #general (827 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (53 messages🔥):
- aider (Paul Gauthier) ▷ #links (1 messages):
- Unsloth AI (Daniel Han) ▷ #general (537 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (17 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (94 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (7 messages):
- Codeium (Windsurf) ▷ #announcements (2 messages):
- Codeium (Windsurf) ▷ #discussion (34 messages🔥):
- Codeium (Windsurf) ▷ #windsurf (476 messages🔥🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (399 messages🔥🔥):
- Cursor IDE ▷ #general (365 messages🔥🔥):
- Perplexity AI ▷ #general (312 messages🔥🔥):
- Perplexity AI ▷ #sharing (11 messages🔥):
- Perplexity AI ▷ #pplx-api (5 messages):
- Eleuther ▷ #general (114 messages🔥🔥):
- Eleuther ▷ #research (210 messages🔥🔥):
- Eleuther ▷ #gpt-neox-dev (2 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (298 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (156 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (19 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (68 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #memes (5 messages):
- Interconnects (Nathan Lambert) ▷ #rl (3 messages):
- Interconnects (Nathan Lambert) ▷ #reads (14 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- LM Studio ▷ #general (208 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (39 messages🔥):
- HuggingFace ▷ #general (176 messages🔥🔥):
- HuggingFace ▷ #i-made-this (6 messages):
- HuggingFace ▷ #reading-group (4 messages):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #gradio-announcements (3 messages):
- HuggingFace ▷ #smol-course (2 messages):
- HuggingFace ▷ #agents-course (15 messages🔥):
- HuggingFace ▷ #open-r1 (1 messages):
- Yannick Kilcher ▷ #general (144 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (32 messages🔥):
- Yannick Kilcher ▷ #ml-news (17 messages🔥):
- OpenAI ▷ #annnouncements (3 messages):
- OpenAI ▷ #ai-discussions (92 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (7 messages):
- OpenAI ▷ #prompt-engineering (3 messages):
- OpenAI ▷ #api-discussions (3 messages):
- Nous Research AI ▷ #general (96 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (1 messages):
- Nous Research AI ▷ #research-papers (3 messages):
- Nous Research AI ▷ #interesting-links (2 messages):
- Nous Research AI ▷ #research-papers (3 messages):
- Modular (Mojo 🔥) ▷ #general (7 messages):
- Modular (Mojo 🔥) ▷ #mojo (87 messages🔥🔥):
- Notebook LM ▷ #use-cases (10 messages🔥):
- Notebook LM ▷ #general (84 messages🔥🔥):
- Torchtune ▷ #general (54 messages🔥):
- Torchtune ▷ #dev (37 messages🔥):
- Latent Space ▷ #ai-general-chat (75 messages🔥🔥):
- Nomic.ai (GPT4All) ▷ #announcements (1 messages):
- Nomic.ai (GPT4All) ▷ #general (62 messages🔥🔥):
- MCP (Glama) ▷ #general (50 messages🔥):
- MCP (Glama) ▷ #showcase (6 messages):
- GPU MODE ▷ #general (8 messages🔥):
- GPU MODE ▷ #triton (2 messages):
- GPU MODE ▷ #cuda (5 messages):
- GPU MODE ▷ #torch (5 messages):
- GPU MODE ▷ #cool-links (3 messages):
- GPU MODE ▷ #jobs (2 messages):
- GPU MODE ▷ #torchao (4 messages):
- GPU MODE ▷ #off-topic (3 messages):
- GPU MODE ▷ #liger-kernel (1 messages):
- GPU MODE ▷ #reasoning-gym (10 messages🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (20 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (14 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
- Cohere ▷ #discussions (10 messages🔥):
- Cohere ▷ #api-discussions (2 messages):
- Cohere ▷ #projects (2 messages):
- tinygrad (George Hotz) ▷ #general (10 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (3 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
- DSPy ▷ #examples (2 messages):
AI Twitter Recap
- Google DeepMind Launches Gemini 2.0 Models including Flash, Flash-Lite, and Pro Experimental: @GoogleDeepMind announced the general availability of Gemini 2.0 Flash, Flash-Lite, and Pro Experimental models. @_philschmid summarized the update, noting that Gemini 2.0 Flash outperforms Gemini 1.5 Pro while being 12x cheaper. The new models offer features like multimodal input, 1 million token context window, and cost-efficiency.
- "Deep Dive into LLMs like ChatGPT" by Andrej Karpathy: @karpathy released a 3h31m YouTube video providing a comprehensive overview of Large Language Models (LLMs), covering stages like pretraining, supervised fine-tuning, and reinforcement learning. He discusses topics such as data, tokenization, Transformer internals, and examples like GPT-2 training and Llama 3.1 base inference.
- Free Course on "How Transformer LLMs Work": @JayAlammar and @MaartenGr, in collaboration with @AndrewYNg, introduced a free course offering a deep dive into Transformer architecture, including topics like tokenizers, embeddings, and mixture-of-expert models. The course aims to help learners understand the inner workings of modern LLMs.
- DeepSeek-R1 Reaches 1.2 Million Downloads: @omarsar0 highlighted that DeepSeek-R1 has been downloaded 1.2 million times from Hugging Face since its launch on January 20. He also conducted a technical deep dive on DeepSeek-R1 using Deep Research, resulting in a 36-page report.
- Anthropic's Increased Rewards for Jailbreak Challenge: @AnthropicAI announced that no one has fully jailbroken their system yet, so they've increased the reward to $10K for the first person to pass all eight levels, and $20K for passing all eight levels with a universal jailbreak. Full details are provided in their announcement. @nearcyan humorously introduced PopTarts: Claude Flavor as a creative reward for their pentesters.
- BlueRaven Extension Hides Twitter Metrics: @nearcyan released an update to BlueRaven, an extension that allows users to browse Twitter with all metrics hidden. This challenges users to engage without influence from popularity metrics. The source code is available with support for Firefox and Chromium.
- Chain-of-Associated-Thoughts (CoAT) Framework Introduced: @omarsar0 discussed a new framework enhancing LLMs' reasoning abilities by combining Monte Carlo Tree Search with dynamic knowledge integration. This approach aims to improve comprehensive and accurate responses for complex reasoning tasks. More details are available in the paper.
- STROM Paper on Synthesis of Topic Outlines: @_philschmid highlighted a paper titled “Synthesis of Topic Outlines through Retrieval and Multi-perspective” (STROM), which proposes a multi-question, iterative research method. It's similar to Gemini Deep Research and OpenAI Deep Research. The paper and GitHub repository are available for those interested.
- Discussions on AI's Impact and Tools: @omarsar0 shared insights on how AI enables individuals to excel in multiple fields simultaneously, emphasizing the importance of learning and tools like ChatGPT and Claude. @abacaj shared a gist showing how to run gsm8k evaluation during GRPO training, extending the GRPOTrainer for custom evaluation.
- Humorous Musings and Test Posts by Nearcyan: @nearcyan conducted test posts on Twitter, observing how his tweets were being deboosted. He contemplated the experience of using Twitter without knowing engagement metrics. Additionally, he humorously expressed feelings about being an iOS developer in today's environment (tweet).
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. DeepSeek VL2 Small Launch and R1's Benchmark Success
- DeepSeek just released an official demo for DeepSeek VL2 Small - It's really powerful at OCR, text extraction and chat use-cases (Hugging Face Space) (Score: 615, Comments: 37): The DeepSeek VL2 Small demo, a 16B MoE model, has been released on Hugging Face, showcasing its capabilities in OCR, text extraction, and chat applications. Vaibhav Srivastav and Zizheng Pan announced the release on X, highlighting its utility in various vision-language tasks.
- Release Timeline & Performance: The DeepSeek VL2 Small model was uploaded to Hugging Face about two months ago, and there is anticipation for a reasoning model to be released this month. Commenters note the model's good performance for its size, though some prefer florence-2-large-ft for specific visual tasks.
- Accessibility & Integration: Discussion includes the utility of vision-language models in navigating websites, especially when accessibility is well-implemented. Users are advised to try the model on a few documents before integrating it into their systems.
- Model Availability & Tools: There is interest in the DeepSeek V3 Lite and the gguf format, with a suggestion to use convert_hf_to_gguf.py from llama.cpp for conversion. The demo link provided by Environmental-Metal9 is here, though some report the demo is not currently working.
- 2B model beats 72B model (Score: 164, Comments: 57): The DeepSeek R1-V project demonstrates that a 2B-parameter model can outperform a 72B-parameter model in vision language tasks, achieving superior effectiveness and out-of-distribution robustness. The model achieved 99% and 81% accuracy in specific out-of-distribution evaluations using only 100 training steps, costing $2.62 and running for 30 minutes on 8 A100 GPUs. The project is fully open-sourced and available here.
- Some commenters express skepticism about the DeepSeek R1-V model's achievements, suggesting that the results might be misleading or overly specific to certain benchmarks. Admirable-Star7088 and Everlier humorously highlight that smaller models can outperform larger ones in niche tasks but emphasize that larger models are generally more versatile.
- Real-Technician831 and iam_wizard discuss the practical implications of using smaller models for specific tasks, noting that this approach can be more compute-efficient for business applications with narrow scopes. They argue that such results should not be surprising, as fine-tuning smaller models for specific tasks is a known strategy.
- The discussion includes a reference to another model, phi-CTNL, which reportedly beats larger models across various benchmarks, as shared by gentlecucumber with a link to arXiv. This adds to the conversation about benchmark-specific performance versus general-purpose capabilities.
- DeepSeek R1 ties o1 for first place on the Generalization Benchmark. (Score: 162, Comments: 23): DeepSeek R1 and o1 tied for first place on the Generalization Benchmark, both achieving an average rank of 1.80. The benchmark tested AI models across 810 cases, with a note that Qwen QwQ failed in 280 cases.
- The Generalization Benchmark tests AI models' ability to infer specific themes from examples, with o3-mini ranking fourth. More details on the benchmark can be found on GitHub.
- Phi 4 ranks high, surpassing Mistral Large 2, Llama 3.3 70b, and Qwen 2.5 72b, and is praised for its reasonable size for self-hosting. Qwen QwQ scored higher but had issues with producing the correct output format.
- o3-mini-high is noted as missing but important for its impact on Livebench results. Additionally, there is a 0.99 correlation between Gemini 1.5 Pro and Gemini 1.5 Flash, indicating similar performance.
Theme 2. Google's AI Policy Shift on Weapons and Surveillance Use
- Google Lifts a Ban on Using Its AI for Weapons and Surveillance (Score: 497, Comments: 126): Google has updated its AI policy to lift a previous ban on using its AI technology for weapons and surveillance. This policy change marks a significant shift in Google's stance on the ethical application of AI.
- Users express significant concern over Google's shift in AI policy, equating it to a moral decline and questioning the ethical implications of using AI for weapons and surveillance. Many comments sarcastically reference Google's former motto, "Don't be evil," suggesting a betrayal of its foundational values.
- Discussions highlight the political and international implications of the policy change, with references to Google's involvement with Israeli military efforts and comparisons to surveillance practices in other countries like China. Concerns about privacy erosion and the potential for AI to be misused in global conflicts are prevalent.
- Several comments critique the corporate motivations behind the policy change, suggesting that shareholder interests often outweigh ethical considerations. The phrase "do the right thing" is criticized as being vague and potentially self-serving, prioritizing corporate gains over societal good.
Theme 3. Gemma 3 Announcement and Community Reactions
- Gemma 3 on the way! (Score: 403, Comments: 42): Omar Sanseviero teases an update on "Gemma" in a tweet, engaging the r/LocalLLama community. The accompanying screenshot highlights features of "Gemini," including "2.0 Flash," "2.0 Flash Thinking Experimental," and "Gemini Advanced," suggesting active development on Gemini rather than Gemma 3.
- Commenters express a strong desire for larger context sizes, with mentions of 64k and 128k as preferred targets for future models like Gemma 3. The current 8k context size is considered inadequate by some users.
- Some users highlight the success and preference for Gemma 2, with specific praise for the 9b simpo model's media knowledge capabilities, and express anticipation for Gemma 3 with enhanced features or even AGI capabilities.
- Discussions also reflect on the community engagement aspect of Reddit, likening it to the early 2010s when researchers and developers had direct interactions with users, illustrating the platform's role in fostering discussions about AI advancements.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Nvidia's CUDA Strategy: Catalyst to AI's Evolution
- Has Jensen Huang ever acknowledged that Nvidia just kinda lucked into AI? (Score: 153, Comments: 92): Nvidia originally aimed to enhance graphics rendering but inadvertently developed technology that became crucial for training neural networks. This accidental success significantly contributed to Jensen Huang becoming one of the wealthiest individuals in history.
- The consensus among commenters is that Nvidia's success in AI was not due to luck but rather strategic foresight and long-term investment, particularly with the development of CUDA starting in 2006/2007. This strategic move allowed Nvidia to build a robust developer ecosystem that has been crucial in their dominance in AI and scientific computing.
- CUDA's early adoption was initially met with skepticism, as noted by users recalling its reception 10-20 years ago. Despite this, Nvidia persisted, enabling them to capitalize on the AI boom following the publication of the AlexNet paper in 2011, which utilized Nvidia GPUs and highlighted their strategic advantage.
- Nvidia's investment extends beyond AI into various markets, including cryptocurrency, biotechnology, and autonomous systems. Commenters note Nvidia's involvement in diverse applications such as ray tracing, robotics, and even military technology, showcasing their commitment to broadening the use of their GPUs across industries.
Theme 2. ByteDance and Google Advance AI Frontiers
- New ByteDance multimodal AI research (Score: 251, Comments: 26): The post mentions ByteDance's new research in multi-modal AI, though specific details are not provided in the text. The post includes a video which is not analyzed here.
- Audio-Visual Matching: Discussions highlight the capability of multi-modal AI to match any audio to visuals, exemplified by the use of an American accent with a visual of Einstein, which is intentionally mismatched to demonstrate the technology's potential.
- Source and Content Authenticity: A link to the source is provided at omnihuman-lab.github.io, and users critique the mismatch between the AI-generated content and historical representations, noting that the AI portrayal made Einstein appear "neurotypical."
- Audio Source: The audio used in the demonstration, which led to confusion about the accent, is identified as originating from a TEDx talk (source).
- Google claims to achieve World's Best AI ; & giving to users for FREE ! (Score: 203, Comments: 56): Google claims to have developed the world's best AI and is offering it to users for free. Further details, including the specific capabilities or applications of this AI, were not provided in the post.
- Discussions about Google's Gemini AI reveal mixed opinions, with some users expressing skepticism about its capabilities, particularly in areas like pest elimination advice, while others find it impressive for tasks like coding and using the AI Studio. Gemini 2.0 shows limitations compared to its predecessor, prompting some users to revert to the older version for specific functionalities.
- Users debate the performance of coding models, with some models like o1 and o3-mini being praised for generating extensive code efficiently, unlike others that struggle beyond 100 lines. There are comments emphasizing the advanced reasoning capabilities of these models, highlighting their impact on programming tasks.
- The Sonnet model stands out in discussions for its performance in the lmsys webdev arena, with users noting its superiority over other models despite its smaller size. There's a debate on whether models like Sonnet should be compared to those focused on inference scaling, with some attributing competitive advantages to new methodologies.
Theme 3. Debating Open Source in AI: A Look at DeepSeek and More
- DeepSeek corrects itself regarding their "fully open source" claim (Score: 126, Comments: 36): DeepSeek issued a "Terminology Correction" about their DeepSeek-R1, clarifying that while their code and models are released under the MIT License, they are not "fully open-source" as previously claimed. The tweet announcing this correction has received significant engagement with 186 likes, 39 retweets, and 324 replies, and has been viewed 27,000 times.
- Many commenters argue that while the MIT License is often associated with open-source, DeepSeek's claim is misleading because they did not release the source code or training data. This distinction is crucial in determining whether something is truly open-source, as having access to the source code is a fundamental requirement.
- coder543 emphasizes that Llama models and similar projects are not fully open-source either, as they lack detailed dataset descriptions and training code. This highlights a broader issue in the AI community where models are released with weights but without sufficient information or resources to replicate the training process.
- The discussion highlights a misunderstanding or misuse of the term "open-source" when applied to AI models and software. Some users clarify that licensing under MIT doesn't inherently make something open-source unless the actual source code is provided, illustrating the difference between licensing and actual openness.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. Gemini 2.0 Model Family: Performance and Integration
- Flash 2.0 Zips onto Windsurf and Perplexity: Gemini 2.0 Flash is live on Windsurf and Perplexity AI, touted for its speed and efficiency in coding queries, consuming only 0.25 user prompt credits on Windsurf. While praised for speed, users note its tool calling is limited and its reliability is under scrutiny in comparison to models like Claude and DeepSeek.
- Pro Experimental Benchmarks Challenge Claude 3.5 Sonnet: Gemini 2.0 Pro Experimental is benchmarking comparably to Claude 3.5 Sonnet in coding and complex prompts, securing the #1 spot on lmarena.ai's leaderboard. However, users observe inconsistencies in API responses and a possible reduction in long context capabilities compared to Gemini 1.5 Pro, despite the advertised 2 million token context.
- GitHub Copilot Embraces Gemini 2.0 Flash for Developers: GitHub announced Gemini 2.0 Flash integration for all Copilot users, making it accessible in the model selector within code editors and Copilot Chat on GitHub. This move signifies a major win for Gemini within the Microsoft ecosystem, positioning it ahead of competitors in developer tool integration.
Theme 2. Coding IDEs and AI Assistants: Feature Comparisons and User Feedback
- Cursor IDE Supercharged with MCP Server Integration: Cursor IDE now supports MCP server integration, enabling users to leverage Perplexity and other tools directly within the IDE, as demonstrated in a YouTube tutorial. This enhancement allows for complex workflows and customized AI assistance, with easy setup via a provided GitHub repository.
- Codeium Plugin for JetBrains Faces User Stability Woes: Users are reporting significant instability with the Codeium JetBrains plugin, citing frequent unresponsiveness and the need for restarts, pushing some back to using Copilot. A user plea, 'Please give the Jetbrains plugin some love', highlights the community's demand for a more reliable plugin experience.
- Windsurf Next Beta Aims to Outpace Cursor, But Credits Cause Pain: Windsurf Next Beta is launched to preview innovative features, but users are struggling with credit allocation, particularly flex credits, leading to workflow disruptions. Comparisons with Cursor highlight Cursor's advantage in third-party tool and extension flexibility, suggesting Windsurf could enhance its value by adopting similar functionalities.
Theme 3. Advanced Model Training and Optimization Techniques
- Unsloth Unveils Dynamic 4-bit Quantization for Accuracy Boost: Unsloth introduced Dynamic 4-bit Quantization to improve model accuracy while maintaining VRAM efficiency by selectively quantizing parameters. This method enhances the performance of models like DeepSeek and Llama compared to standard quantization techniques, offering a nuanced approach to model compression.
- Ladder-Residual Architecture Supercharges Llama 70B on Torchtune: Ladder-residual modification accelerates the 70B Llama model by ~30% on multi-GPU setups with tensor parallelism when used within Torchtune. This enhancement, developed at TogetherCompute, marks a significant stride in distributed model training efficiency.
- Harmonic Loss Challenges Cross-Entropy for Neural Networks: A new paper introduces harmonic loss as an alternative to standard cross-entropy loss, claiming improved interpretability and faster convergence in neural networks and LLMs. While some express skepticism about its novelty, others see potential in its ability to shift optimization targets and improve model training dynamics.
Theme 4. Open Source and Community in AI Development
- Mistral AI Rebrands, Doubles Down on Open Source: Mistral AI launched a redesigned website, emphasizing their commitment to open models and customizable AI solutions for enterprise deployment. The rebranding signals a focus on transparency and community engagement, reinforcing their position as a leading contributor to open-source AI.
- GPT4All v3.9.0 Arrives with LocalDocs and Model Expansion: GPT4All v3.9.0 is released featuring LocalDocs functionality, bug fixes, and support for new models like OLMoE and Granite MoE. This update enhances the usability and versatility of the open-source local LLM platform.
- Stability.ai Appoints Chief Community Guy to Boost Engagement: Stability.ai introduced Maxfield as their new Chief Community Guy, acknowledging engagement from Stability has been lackluster lately and promising to boost interaction. Maxfield plans to implement a feature request board and increase transparency from Stability's researchers to better align development with community needs.
Theme 5. Reasoning Model Benchmarks and Performance Analysis
- DeepSeek R1 Nitro Claims Speedy Uptime on OpenRouter: DeepSeek R1 Nitro boasts 97% request completion on OpenRouter, demonstrating improved uptime and speed for users leveraging the API. OpenRouter encourages users to try it out for enhanced performance.
- DeepSeek R1 Said to Rival OpenAI's Reasoning Prowess: Discussions highlight DeepSeek R1 as a strong open-source competitor to OpenAI's O1 reasoning model, offering comparable capabilities with open weights. Members note its accessibility for local execution and its impressive performance in reasoning tasks.
- Flux Outperforms Emu3 in Image Generation Speed on Hugging Face L40S: Flux generated a 1024x1024 image in 30 seconds on Huggingface L40S using flash-attention, significantly outpacing Emu3's ~600 seconds for a smaller 720x720 image. This speed disparity raises questions about Emu3's efficiency relative to single-modal models, despite similar parameter counts.
PART 1: High level Discord summaries
aider (Paul Gauthier) Discord
- Aider Manages Coding Errors: Users are leveraging Aider to manage errors in large projects and refactor code with
/runcommand for autonomous issue resolution, as well as adding files for diagnosis and resolution, as detailed in the Linting and Testing docs.- The community discussed using Aider for automatic code modification, streamlining workflows, and automating coding tasks.
- Claude Beats R1 in Coding: Comparisons of O3 Mini, R1, and Claude models reveal varying success rates in coding tasks, with some users suggesting Claude edges out R1 in specific scenarios, according to this tweet.
- Users expressed frustration over model accuracy limitations while considering the potential integration of tools like DeepClaude with OpenRouter.
- LLMs Struggle with Rust: The community acknowledged that LLMs, despite progress, still falter with complex tasks, especially in languages like Rust, struggling with deeper reasoning and multi-step solutions.
- While LLMs shine on simpler tasks, challenges persist in achieving satisfactory outcomes with more intricate problems.
- Aider Commits Gibberish: Users reported getting commit messages full of
- The discussion included suggestions to use
--weak-model something-elseto avoid these tokens, indicating issues stemming from the interaction between Aider and different API providers.
- The discussion included suggestions to use
- Gemini 2.0 now on LMSYS: Gemini 2.0 is now available on lmarena.ai, making it available for broader comparisons.
- The community will likely be evaluating it for integration into existing workflows.
Unsloth AI (Daniel Han) Discord
- Dynamic Quantization Boosts Accuracy: Unsloth introduced Dynamic 4-bit Quantization to selectively quantize parameters, improving accuracy while maintaining VRAM efficiency, as detailed in their blog post.
- This approach aims to enhance the performance of models like DeepSeek and Llama compared to standard quantization techniques.
- GRPO Integration Anticipated for Enhanced Training: Unsloth is actively integrating GRPO training to streamline and enhance model fine-tuning, promising a more efficient training process, detailed in this github issue.
- Enthusiasm was expressed in anticipation of GRPO support, although there was an acknowledgement that there might be some kinks to iron out, suggesting that implementation might take some time.
- DeepSeek Challenges on Oobagooba Unveiled: Users encountered issues running the DeepSeek model locally in Oobagooba, often due to incorrect model weight configurations. According to Unsloth Documentation, members advised to use the flag --enforce-eager to prevent failures during model loading.
- Optimization suggestions included ensuring the use of the --enforce-eager flag to prevent model loading failures.
- CPT Model Shows Impressive Perplexity Scores: The CPT with Unsloth model showed major improvements in Perplexity (PPL), with base model scores around 200 dropping to around 80, which was met with enthusiasm.
- Members suggested that the DeepSeek model is very old, indicating a need for updated versions and a more interesting dataset, especially for math versions of the model.
- LLM Model Reassembly Frustrations: A member reported issues with importing a layer incorrectly while trying to reassemble an LLM model in a PyTorch neural network, leading to gibberish output and seeking assistance in optimizing model efficiency.
- They sought advice on understanding where efficiency could be improved in different parts of the model to fix the gibberish output problem.
Codeium (Windsurf) Discord
- Gemini 2.0 Flash Debuts on Windsurf: Gemini 2.0 Flash is now live on Windsurf, consuming only 0.25 user prompt credits and 0.25 flow action credits per tool call, noted for its speed in coding inquiries.
- Despite its efficiency, users observed it had limited tool calling ability, according to Windsurf's announcement.
- Windsurf Next Beta Launches: The Windsurf Next Beta version is available for download here, allowing users to test innovative features and improvements for AI in software development.
- It requires at least OS X Yosemite, Ubuntu 20.04, or Windows 10 (64-bit), as detailed in the Windsurf Next Launch blog post.
- Users Report Codeium Plugin Struggles: Multiple users cited problems with the Codeium JetBrains plugin, describing frequent unresponsiveness and the need for restarts to maintain functionality, causing some to revert to Copilot.
- A user pleaded, 'Please give the Jetbrains plugin some love' to enhance its stability, highlighting the community's need for a reliable tool.
- Windsurf Credit Allocation Irks Users: Users are facing issues with credit allocation in Windsurf, particularly with flex credits, which leads to limited functionality, with one user having contacted support multiple times.
- The discussions underscored user frustration with the system's reliability, affecting critical workflows.
- Windsurf Lags Behind Cursor: Users pointed out Cursor's advantage over Windsurf due to its flexibility in installing third-party tools and extensions.
- They suggested Windsurf could enhance its value by allowing similar functionalities, especially concerning moving third-party apps within the IDE.
Stability.ai (Stable Diffusion) Discord
- Stability Gets Community Guy: Stability.ai introduced Maxfield as the new Chief Community Guy, highlighting his involvement with Stable Diffusion since November 2022, acknowledging that engagement from Stability has been lackluster lately.
- Maxfield plans to boost engagement through a feature request board for community suggestions and increased transparency from Stability's researchers and creators, stating, what's the point of all this compute if we're not building stuff you want?
- Diffusion Model Nesting Explored: Discussions in the general-chat channel revealed interest in nested AI architectures, where a diffusion model operates within the latent space of another model, though a compatible VAE is essential.
- Users sought papers that explore this concept, but few links were shared.
- Training Models Proves Tricky: Users report experiencing challenges when training models like LoRA, noting default settings often outperform complex adjustments, referencing NeuralNotW0rk/LoRAW.
- The complexity of evolving architectures leaves some users eager for more streamlined and user-friendly tools to work in latent space effectively.
- Future AI Models Spark Excitement: The community speculated on future multimodal models, expressing enthusiasm for tools that merge text and image generation capabilities, perhaps something like PurpleSmartAI.
- There’s interest in developing new models that enhance creative uses like video game development through intuitive interfaces, and a hackathon around that concept Multimodal AI Agents - Hackathon · Luma.
- Users Battle Discord Spam: The general-chat channel experienced a spam incident, with users promptly reporting the message and advocating for moderation action.
- The community demonstrated a collective effort to uphold channel integrity by flagging unrelated promotional posts.
Cursor IDE Discord
- Cursor Adds MCP Server Integration: Cursor IDE now supports MCP server integration, enabling users to utilize Perplexity for assistance via commands and easy setup using a provided GitHub repository.
- A user demonstrated how to Build Cursor on Steroids with MCP in this Youtube video with enhanced functionalities.
- Gemini 2.0 Pro Coding Skills Questioned: Users criticized the Gemini 2.0 Pro model for struggling with coding tasks despite good data analysis performance, according to lmarena.ai.
- Benchmarks show that Gemini 2.0 Pro lags behind O3-mini high and Sonnet for coding tasks even though it is decent for random tasks; check out a comparison on HuggingFace.
- Coders Use Voice Dictation: Discussants explored voice dictation tools, referencing Andrej Karpathy's coding dictation method using Whisper technology, even as the accuracy of Windows' built-in dictation feature could use improvements.
- Customizing voice interfacing for coding sparked interest, with the goal of improving speed and accuracy.
- Mobile Cursor Debated: A user proposed developing an iPhone app for Cursor to facilitate coding and prompting on the go, however the consensus indicated that current frameworks may not justify the development effort.
- The community weighed the practicality of developing a mobile version of Cursor, pointing out that the advantage might not outweigh development costs.
Perplexity AI Discord
- Perplexity AI's UI Changes Irk Users: Users voiced frustrations about recent UI changes in Perplexity AI, particularly the removal of focus modes and slower performance.
- Some users are having trouble accessing models like Claude 3.5 Sonnet, with automatic activation of R1 or o3-mini in Pro Search mode.
- Gemini 2.0 Flash Enters the Scene: Gemini 2.0 Flash was released to all Pro users, marking the first time a Gemini model is on Perplexity since earlier versions, as noted in Aravind Srinivas's tweet.
- Users are curious about context limits and capabilities compared to previous models and its availability in the current app interface.
- Model Access Limitations Cause Confusion: Pro users reported inconsistent access to models, with some unable to use Gemini or access desired models despite their subscription, and pointed to the Perplexity status page to debug.
- Disparities in user experience were noted, with some finding the limitations unnecessary and others still adjusting to new functionalities across platforms.
- Sonar Reasoning Pro Rides DeepSeek R1: A member clarified that Sonar Reasoning Pro operates on DeepSeek R1, confirmed on their website.
- This realization was new to some members unaware of the underlying models.
- US Iron Dome Proposed Amid Secession Bids: A member shared a video discussing Trump's proposal for a US Iron Dome alongside ongoing political developments, including a California secession bid.
- The discussion considers the implications of such military strategies on national security and local governance.
Eleuther Discord
- Harmonic Loss Creates Optimism: A paper introducing harmonic loss as an alternative to standard cross-entropy loss for neural networks surfaced, with claims of improved interpretability and faster convergence as discussed on Twitter.
- While some expressed skepticism about its novelty, others pointed out its potential to shift optimization targets; it led to discussion on stability and activation interactions during model training.
- VideoJAM Generates Motion: Hila Chefer introduced the VideoJAM framework, designed to enhance motion generation by directly addressing the challenges video generators face with motion representation without extra data, as discussed on Twitter and on the project's website.
- It is intended to directly address the challenges video generators face with motion representation without needing extra data, and is expected to improve the dynamics of motion generation in video content.
- GAS Revs Up TPS Over Checkpointing: Training without activation checkpointing and using GAS significantly increases TPS, with a comparison showing 242K TPS for batch size 8 with GAS versus 202K TPS for batch size 48 with checkpointing.
- Despite different effective batch sizes, the smaller batch size with GAS shows a faster convergence, though a noted lower HFU/MFU could be a concern but isn't prioritized if TPS improves.
OpenRouter (Alex Atallah) Discord
- DeepSeek R1 Nitro gets Speedy: The DeepSeek R1 Nitro has demonstrated better uptime and speed, with 97% request completion.
- According to OpenRouterAI, users are now encouraged to try it out.
- OpenRouter Bumps Back Online: Users reported API issues and rate limit errors, sparking concerns about service reliability, however service returned right away after reverting a recent change.
- Toven confirmed the downtime and announced the fix, reassuring users of the service's restored functionality.
- Anthropic API Gets Rate Limited: Users are running into rate limit errors when using the API, particularly with Anthropic, which has a limit of 20 million input tokens per minute.
- Louisgv mentioned reaching out to Anthropic for a potential rate limit increase to resolve these restrictions.
- Gemini 2.0: A Gemini in the Rough?: Xiaoqianwx sparked a discussion about expectations for Gemini 2.0, and how stronger models may be needed to compete effectively.
- The community is largely disappointed in its performance and is actively discussing the model's strengths and weaknesses.
- Price Controls are Coming to OpenRouter: Users inquired about potential price controls for API usage, specifically regarding cost variations across providers.
- Toven introduced a new
max_priceparameter for controlling spending limits on API calls, currently live without full documentation.
- Toven introduced a new
Interconnects (Nathan Lambert) Discord
- Gemini 2.0 Debuts with Flash and Experimental Pro: Benchmarking shows Gemini 2.0 Pro Experimental performs comparably to Claude 3.5 Sonnet, though inconsistencies in API responses are noted, while Gemini 2.0 Flash is integrated into GitHub Copilot for all users as a new tool for developers, giving Gemini significant traction within the Microsoft ecosystem ahead of competitors.
- Some users feel that while the Flash models outperform Gemini 1.5 Pro, long context capabilities seem diminished, and they find naming conventions for AI models to lack creativity and clarity (DeepMind Tweet, GitHub Tweet).
- Mistral Rebrands with Open Source Focus: Mistral launched a redesigned website (Mistral AI) showcasing their open models aimed at customizing AI solutions, emphasizing transparency and enterprise-grade deployment options with a new cat logo.
- The company balances its image as a leading independent AI lab with a playful design approach.
- Softbank's AGI Dream Team: Discussion surrounds the necessity for companies to explore every avenue for AGI delivery to Softbank within two years, as the company expects $100B in revenue.
- The community considers whether this is a realistic timeline.
- DeepSeek R1 Debuts Amidst Scrutiny: On January 20th, 2025, DeepSeek released their open-weights reasoning model, DeepSeek-R1, spurring debate around the validity of its training costs as published in this Gradient Updates issue.
- The model's architecture is similar to DeepSeek v3, resulting in discussions about its performance and pricing.
- Karpathy Goes Vibe Coding: Andrej Karpathy introduced the concept of 'vibe coding', embracing LLMs like Cursor Composer and bypassing traditional coding, where he states he rarely reads diffs anymore
- He adds, 'When I get error messages I just copy paste them in with no comment,' as seen in this tweet.
LM Studio Discord
- LM Studio Has Low VRAM Woes: Users shared challenges running LM Studio on older CPUs and GPUs, particularly with lower VRAM graphics cards like the RX 580, which led to performance limitations.
- Some users suggested compiling llama.cpp without AVX support to enhance performance on older systems.
- Qwen 2.5 Recommended for Coding: The Qwen 2.5 model received recommendations for users needing coding task support, especially for those with specific hardware configurations.
- Users voiced model preferences based on local installation performance and usability.
- Vulkan Support Sees Mixed Results: Enabling Vulkan support for improved GPU utilization in llama.cpp necessitates specific build configurations, stirring discussion about the nuances of LM Studio.
- Shared resources highlighted the setup requirements for compiling with Vulkan.
- GPT-Researcher Plagues LM Studio: Users integrating GPT-Researcher with LM Studio reported encountering errors with model loading and embedding requests.
- Specifically, a 404 error indicated that no models were loaded, halting integration attempts.
- Rising GPU Prices Inflate: Concerns rose regarding GPU prices on platforms like eBay and Mercari, which are now considered appreciating assets due to high demand.
- The inflated prices of components, including the Jetson board, are being influenced by scalpers.
HuggingFace Discord
- DeepSeek Outperforms Declining ChatGPT: Users reported DeepSeek is providing better answers and has a more engaging chain of thought methodology than ChatGPT, however access is limited due to high traffic.
- Interest was expressed in DeepSeek's thinking process, emphasizing its chain of thought methodology as more engaging than traditional AI responses.
- TinyRAG Simplifies RAG Systems: The TinyRAG project streamlines RAG implementations using llama-cpp-python and sqlite-vec for ranking, querying, and generating LLM answers.
- This initiative offers developers and researchers a simplified approach to deploying retrieval-augmented generation systems.
- Distance-Based Learning Paper Published: A new paper, Distance-Based Learning in Neural Networks (arXiv), introduces a geometric framework and the OffsetL2 architecture.
- The research highlights the impact of distance-based representations on model performance, contrasting it with intensity-based approaches.
- Agents Course Kicks off Next Week: The Agents Course is launching next Monday, featuring new channels for updates, questions, and project showcases.
- Enthusiasm builds with sneak peek into first unit's table of contents; but some members expressed concern about lacking basic Python skills needed for the course.
- HuggingFace Needs Updated NLP Course: Members requested an updated NLP course from Hugging Face as the existing course lacks coverage of LLMs which are crucial in today's NLP frameworks.
- This gap has prompted suggestions for more comprehensive training material to address emerging trends in the field.
Yannick Kilcher Discord
- NURBS challenge Meshes for Simulations: NURBS (Non-Uniform Rational B-Splines) offer parametric representations suitable for dynamic simulations, contrasting with the increasing inefficiency of traditional meshes, and modern procedural shaders help with texturing issues.
- Members noted a shift in industry standards towards dynamic models and advanced techniques like NURBS and SubDs, moving away from the limitations of static mesh methods in dynamic applications.
- Gemini 2.0 Updates with Flash and Lite Editions: Google released updated Gemini 2.0 Flash in the Gemini API and Google AI Studio, emphasizing low latency and enhanced performance over previous versions like Flash Thinking.
- Feedback on the new Flash Lite model indicates issues with returning structured output, with users reporting problems in generating valid JSON responses.
- Engineer Built Viral ChatGPT Sentry Gun: OpenAI cut API access to an engineer, sts_3d, after a viral video showcased an AI-controlled motorized sentry gun, prompting concerns about the weaponization of AI.
- The rapid progression of the engineer's projects highlights the potential risks associated with evolving AI applications.
- Researchers crack Affordable AI Reasoning Models: Researchers developed the s1 reasoning model, achieving capabilities similar to OpenAI's models for under $50 in cloud compute credits, marking a significant reduction in costs [TechCrunch Article].
- The model utilizes a distillation approach, extracting reasoning capabilities from Google's Gemini 2.0, thus illustrating the trend towards more accessible AI technologies.
- Harmonic Loss Paper Draws Mixed Reviews: The Harmonic Loss paper introduces a faster convergence model, but the model has not demonstrated significant performance improvements, leading to debates on its practicality.
- While some consider the paper 'jank,' its brevity is seen as valuable, especially with additional insights available on its GitHub repository.
OpenAI Discord
- DeepSeek Data Practices Probed: Concerns arose over DeepSeek potentially sending data to China, as highlighted in a YouTube video, citing servers based in China as the cause.
- The discussion underscored the importance of data governance and regulatory standards in AI development, with users pointing out the implications of data residency.
- ChatGPT's Reasoning Quirks: Users observed ChatGPT 4o exhibiting unpredictable behavior such as providing reasoning in multiple languages despite receiving English prompts.
- These reports triggered discussions around the model's current limitations, as well as the need for refining the consistency and clarity of AI-generated outputs.
- Gemini 2.0 Token Context Impresses: Gemini 2.0's offering of a 2 million token context and free API access has piqued the interest of developers, eager to explore the expansive capabilities.
- While some users acknowledged the significance of automation facilitated by Gemini 2.0, others commented on the AI's verbosity, making them read too much.
- Users Crafting Rhetorical Prompt: A member detailed a prompt for generating a persuasive argument on why Coca-Cola is best enjoyed with a hot dog, incorporating advanced rhetorical techniques like Antimetabole and Chiasmus.
- The prompt structure included sections for justifying the argument, providing examples, and addressing counterarguments, aiming for a cohesive and impactful conclusion.
- Sprite Sheet Template Inquiry: A user sought advice on refining a prompt template to produce consistent cartoon-style sprite sheets, concentrating on character and animation frame layout.
- Despite specifying character design and dimensions, images were not aligning as expected, thus the user's request for optimization.
Nous Research AI Discord
- DeepSeek Rivals OpenAI in Reasoning: Discussion highlighted how DeepSeek R1 is said to rival OpenAI's O1 reasoning model while being fully open-source, and can be run effectively.
- Members noted the impressive capabilities of newer models like Gemini for performing mathematical tasks and how complexities in branding can confuse users; see Gemini 2.0 is now available to everyone.
- AI's Crypto Connection?: A member speculates if the AI backlash is linked to the fallout from NFT and crypto controversies of 2020-21.
- They referenced Why Everyone Is Suddenly Mad at AI and its implications for the perception of AI, connecting it with past tech hypes.
- DeepResearch Receives Rave Reviews: Users are enthusiastic about OpenAI's DeepResearch feature, praising its performance and ability to efficiently retrieve obscure information, as demonstrated in this tweet.
- Members discussed enriching results with knowledge graphs to enhance fact-checking and research accuracy.
- Liger Kernel Gains GRPO Chunked Loss: A recent pull request adds the GRPO chunked loss to the Liger Kernel, addressing issue #548.
- Developers can run make test, make checkstyle, and make test-convergence for testing correctness and code style.
- Infra Teams Under-Acknowledged?: Members noted that many pretraining papers have a plethora of authors due to the need to credit the hardware infrastructure team.
- It was highlighted that the infra team endures challenges so that research scientists can focus on their work without distractions - Infra people suffer so that the research scientists don't have to.
Modular (Mojo 🔥) Discord
- Mojo Compiler Goes Closed Source: The Mojo compiler transitioned to closed source, driven by the need to manage rapid changes, according to a team member.
- Compiler enthusiasts are eager to access the inner workings, especially the custom lowering passes in MLIR, but will have to wait until the end of 2026 according to this video.
- Mojo Aims for Open Source in Q4 2025: Modular aims to open source the Mojo compiler by Q4 of next year, according to a team member, though there are hopes for an earlier release.
- There are currently no plans to release individual dialects or passes in MLIR before the full compiler is open-sourced, dashing hopes for compiler nerds.
- Mojo's Standard Library Faces Design Choices: Debate arose around whether the Mojo standard library should evolve into a general-purpose library with features like web servers and JSON parsing.
- Concerns were voiced about the complexity of supporting a wide range of use cases, raising the entry bar for contributing new features to the
stdlib, as curated in this Github repo.
- Concerns were voiced about the complexity of supporting a wide range of use cases, raising the entry bar for contributing new features to the
- Async Functions Spark Discussion: Handling of async functions in Mojo is under discussion, with proposals for new syntax to improve clarity and enable performance optimization, as shown in this proposal.
- Participants raised concerns about the complexity of maintaining separate async and sync libraries and the implications for usability across different versions of functionality.
Notebook LM Discord
- Legal AI Automates Drafting: AI is now used to automate the drafting of repetitive legal documents, using templates from previous cases as sources, making the process more efficient as members are finding AI useful.
- One attorney reports the AI is reliable and provides clear sourcing, particularly for similar cases or mass litigation.
- Avatars Elevate Contract Review: Members are experimenting with avatars in contract review to make the redlining analysis more engaging, as demonstrated in a YouTube video.
- The addition of avatars is intended to differentiate the product and effectively support client teams.
- NotebookLM Plus Activation Issues Arise: Google Workspace admins are facing issues activating NotebookLM Plus, requiring a Business Standard license or higher to access premium features, according to Google Support.
- Resources have been shared to help admins enable and manage user access, with a focus on understanding the specific requirements and licenses needed.
- Spreadsheet Integration Still Faces Challenges: Users express concerns about NotebookLM's effectiveness in analyzing tabular data from spreadsheets, as stated in the general channel, suggesting that Gemini might be more suitable for complex data tasks.
- Discussion revolves around best practices for uploading spreadsheets and the limitations in data recognition capabilities.
Torchtune Discord
- Torchtune Trounces Unsloth in Memory Management: Users reported Torchtune handles fine-tuning without the CUDA memory issues seen in Unsloth on a 12GB 4070 card.
- The tool, unless pushed with excessive batch sizes, avoids running into the same memory issues.
- Ladder-Residual Rockets Llama's Speed: The Ladder-residual modification accelerates the 70B Llama model by ~30% on multiple GPUs with tensor parallelism, according to @zhang_muru's work at TogetherCompute.
- This enhancement involved co-authorship from @MayankMish98 and mentoring by @ben_athi, marking a notable advancement in distributed model training.
- Kolo Kicks off Torchtune Integration: The Kolo Docker tool now provides official support for Torchtune, streamlining local model training and testing for newcomers, project link.
- The Kolo Docker tool, created by MaxHastings, is intended to facilitate LLM training and testing using a range of tools within a single environment.
- Tune Lab UI Tuned for Torchtune: A member is developing Tune Lab, a FastAPI and Next.js interface for Torchtune, which is using modern UI components to enhance user experience, Tune Lab repo.
- The project aims to integrate both pre-built and custom scripts, inviting users to contribute to its development.
- GRPO Gives Training a Giant Boost: Significant success was achieved with a GRPO implementation, enhancing training performance from 10% to 40% on GSM8k, as reported by a member. See related issue
- The implementation involved resolving debugging challenges related to deadlocks and memory issues, with plans to refactor the code for community use.
Latent Space Discord
- OpenAI Plans SWE Agent: OpenAI plans to release a new SWE Agent by end of Q1 or mid Q2, powered by O3 and O3 Pro for enterprises, according to a tweet.
- This agent is anticipated to significantly impact the software industry, purportedly competing with mid-level engineers, spotted in a live stream.
- OmniHuman Generates Avatar Videos: The new OmniHuman video research project generates realistic avatar videos from a single image and audio, without aspect ratio limitations, according to a tweet.
- Praised as a breakthrough, the project has left viewers gobsmacked by its level of detail.
- Figure AI Splits from OpenAI: Figure AI exited its collaboration agreement with OpenAI to focus on in-house AI tech after a reported breakthrough, according to a tweet.
- The founder hinted at showcasing something no one has ever seen on a humanoid within 30 days, per TechCrunch.
- Gemini 2.0 Flash Goes GA: Google announced that Gemini 2.0 Flash is now generally available, enabling developers to create production applications, according to a tweet.
- The model supports a context of 2 million tokens, sparking discussions about its performance relative to the Pro version, according to a tweet.
- Mistral AI Rebrands Platform: Mistral AI's website has undergone a major rebranding, promoting their customizable, portable, and enterprise-grade AI platform, according to their website.
- They emphasize their role as a leading contributor to open-source AI and their commitment to providing engaging user experiences.
Nomic.ai (GPT4All) Discord
- GPT4All v3.9.0 Arrives: The GPT4All v3.9.0 is out, featuring LocalDocs functionality, enhanced support for new models like OLMoE and Granite MoE.
- The new version also fixes errors on later messages when using reasoning models and enhances Windows ARM support.
- Reasoning Augmented Generation (ReAG) Debuts: ReAG feeds raw documents directly to the language model, facilitating more context-aware responses compared to traditional methods.
- This approach enhances accuracy and relevance by avoiding oversimplified semantic matches.
- GPT4All as a Self-Hosted Server: Users discussed self-hosting GPT4All on a desktop for mobile connectivity, achievable through a Python host.
- While feasible, there may be limited support and it may require unconventional setups.
- NSFW Content Finds Local Models: Members discussed locally usable LLMs for NSFW stories, finding wizardlm and wizardvicuna suboptimal.
- Alternatives like obadooga and writing-roleplay-20k-context-nemo may offer better performance for generating NSFW content.
- UI Scrolling Bug Surfaces: A user reported a UI bug where the prompt window's content cannot be scrolled if the text exceeds the visible area, causing accessibility problems.
- A similar issue was previously reported on GitHub, indicating a broader problem.
MCP (Glama) Discord
- ChatGPT Pro Sparks Team Interest: Members are interested in acquiring a ChatGPT Pro subscription, potentially to share costs among multiple accounts for team use.
- Interest focused on using ChatGPT Pro for development, but concerns were raised about splitting accounts and appropriate usage strategies.
- Excel MCP Dreams Emerge: Enthusiasm bubbled around creating an MCP to read and manipulate Excel files, with debates on using Python vs. TypeScript.
- The discussion highlighted the potential for automating data manipulation tasks, but the feasibility of each language was a key point of contention.
- Playwright edges out Puppeteer: Experiences shared indicate that Playwright worked well with MCP, while Puppeteer needed local modifications and this GitHub implementation is not in a production ready state.
- Users compared the ease of implementation for both tools in automation projects, favoring Playwright's simpler integration.
- Home Assistant adds MCP Client/Server Support: The publication of Home Assistant with MCP client/server support expands integration capabilities, and is great to see further integration in automation ecosystems.
- This integration promises to enhance automation workflows, allowing users to leverage MCP within their home automation setups.
- PulseMCP Showcases Use Cases: PulseMCP launched a new showcase of useful MCP server and client combinations with detailed instructions, screenshots, and videos.
- The examples highlight using Gemini voice to manage Notion and converting a Figma design to code with Claude, demonstrating the versatility of MCP applications.
GPU MODE Discord
- Flux Annihilates Emu3 in Image Generation: On the Huggingface L40S, Flux generated a 1024x1024 image in 30 seconds using
flash-attentionwith W8A16 quantization, dwarfing Emu3's ~600 seconds for a 720x720 image.- Despite comparable parameter counts (8B for Emu3 and 12B for Flux), the speed difference triggers questions about Emu3's efficiency against single-modal models.
- OmniHuman Fabricates Realistic Human Videos: The OmniHuman project can generate high-quality human video content based on just a single image, highlighting its potential for multimedia applications.
- Its unique framework achieves an end-to-end multimodality-conditioned human video generation using a mixed training strategy, greatly enhancing the quality of the generated videos.
- FlowLLM Kickstarts Material Discovery: FlowLLM is a new generative model that combines large language models with Riemannian flow matching to design novel crystalline materials, significantly improving generation rates.
- This approach surpasses existing methods in material generation speed, offering over three times the efficiency for developing stable materials based on LLM outputs.
- Modal is Hiring ML Performance Engineers: Modal is a serverless computing platform that provides flexible, auto-scaling computing infrastructure for users like Suno and the Liger Kernel team.
- Modal is hiring ML performance engineers to enhance GPU performance and contribute to upstream libraries like vLLM with job description here.
- Torchao Struggles in Torch Compile: A user reported that using Torchao in conjunction with torch.compile seems to cause a bug, implying a compatibility issue.
- Another member suggested the bug aligns with this GitHub issue about
nn.Modulenot transferring between devices.
- Another member suggested the bug aligns with this GitHub issue about
LlamaIndex Discord
- Deepseek Forum Set to Explore Workflows: @aicampai is hosting a virtual forum on Deepseek, emphasizing its capabilities and integration into developer and engineer workflows, detailed here.
- The forum aims to provide hands-on learning experiences on Deepseek technology and its applications.
- New Tutorial Generates First RAG App: @Pavan_Belagatti released a video tutorial guiding users on building their first Retrieval Augmented Generation (RAG) application using @llama_index, found here.
- This responds to new users seeking practical insights into RAG application development.
- Gemini 2.0 Arrives with LlamaIndex Support: @google announced that Gemini 2.0 is generally available, with day 0 support from @llama_index, detailed in their announcement blog post.
- Users can install the latest integration package via
pip install llama-index-llms-geminito access impressive benchmarks, with further info available via Google AI Studio.
- Users can install the latest integration package via
- LlamaIndex LLM Class Awaits Timeout: A user observed that the default LlamaIndex LLM class lacks a built-in timeout feature, present in OpenAI's models, linked here.
- Another user suggested that the timeout likely consists of client kwargs.
- Troubleshooting Function Calling with Qwen-2.5: A user reported a
ValueErrorwhen using Qwen-2.5 for function calling, recommending the use of command-line parameters and switching to OpenAI-like implementations, with docs here.- To utilize function calling in Qwen-2.5 without issues, another user moved to implement the
OpenAILikeclass from LlamaIndex.
- To utilize function calling in Qwen-2.5 without issues, another user moved to implement the
LLM Agents (Berkeley MOOC) Discord
- MOOC Certificates held hostage: A member reported delays in receiving certificates requested in December, and the course staff is currently working to expedite the distribution process.
- The course staff hopes to resolve these issues within the next week or two.
- Quizzes are proving elusive: Members inquired about the availability of Quiz 1 and Quiz 2 and course staff confirmed that Quiz 2 is not yet published, providing a link for Quiz 1.
- Members can complete Quiz 1 after Friday, as there are currently no deadlines.
- Lecture 1 Video now with Professional Captions: A member confirmed that the YouTube link leads to the fixed version of the first lecture, titled 'CS 194/294-280 (Advanced LLM Agents) - Lecture 1, Xinyun Chen'.
- The edited recording includes professional captioning to improve accessibility.
Cohere Discord
- Users Ponder Embed v3 Migration: A user inquired about migrating existing float generations from embed v3 to embed v3 light, questioning if they could remove extra dimensions or if they needed to regenerate their database entirely.
- The absence of direct responses underscores the complexity and concerns surrounding such migration processes.
- Cohere Moderation Model Craved: A member expressed a desire for a moderation model from Cohere to reduce dependency on American services.
- This need highlights the desire for localized AI solutions that cater to regional requirements.
- Chat Feature Pricing Probed: A user inquired about a paid monthly fee option for chat functionality, indicating a primary interest in chat features over product development.
- A fellow member pointed out the existence of a production API that requires payment for use.
- Conversation Memory Confounds Coders: A member shared their frustration that AI responses are not contextually related between requests and sought guidance on utilizing conversational memory using Java code.
- Another member acknowledged the creation of a support ticket related to the issue, and provided a link to the ticket reinforcing community support.
- Community Clarifies Conduct Code: A member issued a strong reminder that future rule violations could lead to a ban, emphasizing adherence to community guidelines.
- In response, another member apologized for past actions, demonstrating a commitment to aligning with community expectations.
tinygrad (George Hotz) Discord
- tinygrad 0.10.1 Faces Errors: While bumping tinygrad to version 0.10.1, users reported tests failing with a NotImplementedError due to an unknown relocation type 4, which signifies an external function call not supported by version 19.1.6.
- The problems are potentially related to Nix-specific behaviors affecting the compilation process.
- Compiler Flag Concerns Arise: Concerns were raised about compiler warnings related to skipping the impure flag -march=native because
NIX_ENFORCE_NO_NATIVEwas set.- A member clarified that removing -march=native typically applies to user machine software, whereas tinygrad utilizes clang as a JIT compiler for kernels, mitigating the necessity of this flag within the tinygrad context.
- Debugging Gets Easier: A contributor announced that PR #8902 is set to improve debugging in tinygrad, making the resolution of complications more manageable.
- The expectation is that the project's ongoing improvements will help mitigate the observed issues.
- Base Operations and Kernel Implementations Questioned: A member inquired about the number of base operations in tinygrad, seeking clarity on the foundational elements of the framework.
- There was a subsequent request for sources on the kernel implementations pertinent to tinygrad, indicating interest in understanding the underlying codebase.
Gorilla LLM (Berkeley Function Calling) Discord
- API Endpoint Needs to be Public: The instructions for adding new models to the leaderboard specify that while authentication may be necessary, the API endpoint should be accessible to the general public.
- Accessibility is intended to ensure broader usability of the API endpoint.
- Raft Method Sufficiency with Llama 3.1 7B?: A member asked if 1000 users' data is sufficient for training using the Raft method with Llama 3.1 7B, and whether to incorporate synthetic data before applying RAG.
- There were concerns raised that 1000 users' data may not provide enough diversity for effective model training, suggesting that synthetic data might be needed to fill gaps and improve training outcomes.
DSPy Discord
- Chain of Agents Debuts in DSPy: A user introduced an example of a Chain of Agents implemented the DSPy Way, with details available in this article.
- The discussion also referenced the original research paper on Chain of Agents, accessible here.
- Community Seeks Git Repository for DSPy Chain of Agents: A user inquired about the availability of a Git repository for the discussed Chain of Agents example in DSPy.
- This request indicates strong community interest in practical, hands-on implementations of the Chain of Agents concept.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
aider (Paul Gauthier) ▷ #general (827 messages🔥🔥🔥):
Aider and deep learning models, Model performance comparisons, Integration of AI tools, Project management with AI, Limitations of LLMs in complex tasks
- Aider Utilization: Users discussed using Aider in various capacities, including managing errors in large projects and employing it for code refactoring.
- The workflow includes adding files and executing commands like /run to diagnose issues while allowing Aider to autonomously work.
- Model Comparisons: Conversations highlighted differences in performance among models like O3 Mini, R1, and Claude, with users noting varied success in coding tasks.
- Some users suggested that Claude outperforms R1 in specific scenarios, with many expressing frustration about limitations in model accuracy.
- Integration of AI Tools: Discussions arose around integrating multiple tools, such as DeepClaude with OpenRouter, and using LLMs effectively in coding environments.
- The potential for tools like Aider to automate coding tasks and streamline workflows was considered beneficial by the users.
- Limitations of LLMs: The group acknowledged that LLMs, despite advancements, still struggle with complex tasks, particularly in languages like Rust.
- Users pointed out that while LLMs perform well on simpler tasks, there are significant challenges with deeper reasoning and multi-step solutions.
- Perplexity and R1 Integration: Several users discussed leveraging Perplexity combined with R1 for research tasks, emphasizing the synergistic potential of the two.
- It was noted that Perplexity might offer superior search features while R1 provides advanced processing capabilities for the gathered data.
- Tweet from Lisan al Gaib (@scaling01): AWS mentioned Claude 3.5 OpusDONT PLAY WITH MY FEELINGS LIKE THAT 👀
- Linting and testing: Automatically fix linting and testing errors.
- ThePrimeagen - Twitch: CEO @ TheStartup™ (multi-billion)Stuck in Vim Wishing it was Emacs
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Excited GIF - Excited - Discover & Share GIFs: Click to view the GIF
- Gemini 2.0 is now available to everyone: We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.
- DeepSeek Service Status: no description found
- no title found: no description found
- DeepSeek Service Status: no description found
- Octacat Github GIF - Octacat Github Animation - Discover & Share GIFs: Click to view the GIF
- Get To Work Work GIF - Get To Work Work Simpsons - Discover & Share GIFs: Click to view the GIF
- LiteLLM: LiteLLM handles loadbalancing, fallbacks and spend tracking across 100+ LLMs. all in the OpenAI format
- Oh Really GIF - Oh Really Oh Really - Discover & Share GIFs: Click to view the GIF
- Let Him Cook Cookin GIF - Let him cook Cook Cookin - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Advanced model settings: Configuring advanced settings for LLMs.
- DeepClaude: no description found
- OpenAI compatible APIs: aider is AI pair programming in your terminal
- Reddit - Dive into anything: no description found
- GitHub - sigoden/llm-functions: Easily create LLM tools and agents using plain Bash/JavaScript/Python functions.: Easily create LLM tools and agents using plain Bash/JavaScript/Python functions. - sigoden/llm-functions
- Autonomous AI in Action 💪 | Live Codestream with Aider & Deepseek v3 🧠: In this experimeny, Deepseek v3 (via Aider) is in charge of building a project with minimal human intervention. The AI is working on a Summarizer app that mo...
- Aider's benchmark is explicitly not about using R1 thinking tokens (and says that using them did worse) · Issue #13 · getAsterisk/deepclaude: Hey deepclaude folks, I'm a bit confused about why you are prominently citing aider's R1+Sonnet benchmarking results. The blog article and twitter post about these results explicitly state tha...
- SDK not that good · Issue #2052 · Aider-AI/aider: Hi, I really love your tool—I'm using it, and I think it's great. However, when I try to wrap it in Python, it's not as easy as I expected. While the documentation shows how to use coder.r...
- GitHub - jj-vcs/jj: A Git-compatible VCS that is both simple and powerful: A Git-compatible VCS that is both simple and powerful - jj-vcs/jj
- Aider creates files using random strings as filenames · Issue #3139 · Aider-AI/aider: Issue Using o3-mini to prompt and it's been using very weird filenames like 2. New file for modular integration of the embedding worker New file (empty file) ────────────────────────────── I think...
- Bug: Creating files named with the file extension only without the filename. · Issue #2879 · Aider-AI/aider: It suggests the correct filenames but then it will generate a file named php instead of install.php or sql instead of migration.sql
- GitHub · Build and ship software on a single, collaborative platform: Join the world's most widely adopted, AI-powered developer platform where millions of developers, businesses, and the largest open source community build software that advances humanity.
aider (Paul Gauthier) ▷ #questions-and-tips (53 messages🔥):
Aider Configuration Issues, OpenRouter Compatibility, Using Multiple Models, Git Commit Issues with Aider, Running Commands with Aider
- Config Issues with Aider Execution: Users discussed Aider's behavior when executing commands from the workspace root, with suggestions to utilize
--subtree-onlyor relocate config files to specific branches to potentially resolve issues.- Aider executes from workspace root level by default, prompting considerations for creating scripts in the root package.json.
- Adding Models to Aider: A user sought clarity on running mistral-small with Aider locally via ollama, facing API authentication challenges which were later resolved upon checking the API key.
- The conversation highlighted potential confusion about model settings and their proper configuration for different setups.
- Git Commit Messages Full of
Tokens : A user reported seeing- Suggestions included using
--weak-model something-elseto avoid these tokens and consulting Aider's documentation for model settings.
- Suggestions included using
- Interaction Between Aider and Different API Providers: Discussion arose about the compatibility of various language models with Aider, including a mention of potential inconsistencies when using different providers leading to
- Users recommended using a non-reasoning weak model for better results, as reasoning models come with usage restrictions.
- General Aider Usability Queries: Questions about Aider's capability to run commands on behalf of users and the possibility of staging changes instead of committing them were raised, reflecting general user need for flexible command execution.
- Community input indicated potential workflows, and resources were shared for further understanding capabilities.
- Reasoning models: How to configure reasoning model settings from secondary providers.
- Advanced model settings: Configuring advanced settings for LLMs.
- Linting and testing: Automatically fix linting and testing errors.
- refactor: Change default temperature to None and remove debug dump · Aider-AI/aider@7b557c0: no description found
aider (Paul Gauthier) ▷ #links (1 messages):
epicureus: gemini 2.0 on lmsys https://lmarena.ai
Unsloth AI (Daniel Han) ▷ #general (537 messages🔥🔥🔥):
Dynamic Quantization, Using DeepSeek Locally, GRPO Training, Model Comparison, Layer Quantization Strategy
- Understanding Dynamic Quantization: Unsloth introduced Dynamic 4-bit Quantization to maintain accuracy while compressing models, which selectively quantizes certain parameters.
- This dynamic approach allows for improved performance compared to standard quantization techniques, especially for models like DeepSeek and Llama.
- Running DeepSeek on Limited Hardware: Users evaluated the feasibility of running various versions of DeepSeek on hardware with limited VRAM, such as the GTX 960 and GTX 1660 Super.
- While small distilled models can be run locally, performance is significantly limited by hardware specifications, leading to slow response times.
- Upcoming GRPO Integration: Unsloth is working on integrating GRPO training capabilities for their models, anticipated to enhance fine-tuning processes.
- This integration is expected to streamline the training process and make it more efficient compared to existing methods.
- Comparing Different Model Versions: Discussion arose surrounding the differences between distilled versions of models and their R1 counterparts, with the R1 version providing better performance.
- The conversation highlighted the need for extensive training data to maintain accuracy when modifying existing models.
- Layer and Tensor Quantization Strategies: The community expressed interest in strategies for determining which layers to quantize to preserve model accuracy.
- Implementing a systematic approach to layer quantization could allow for more precise control over model performance.
- Tweet from Marktechpost AI Research News ⚡ (@Marktechpost): Fine-Tuning Llama 3.2 3B Instruct for Python Code: A Comprehensive Guide with Unsloth (Colab Notebook Included)In this tutorial, we’ll walk through how to set up and perform fine-tuning on the Llama 3...
- DownloadMoreRAM.com - CloudRAM 2.0: no description found
- The Super Weight in Large Language Models: Recent works have shown a surprising result: a small fraction of Large Language Model (LLM) parameter outliers are disproportionately important to the quality of the model. LLMs contain billions of pa...
- Unsloth - Dynamic 4-bit Quantization: Unsloth's Dynamic 4-bit Quants selectively avoids quantizing certain parameters. This greatly increases accuracy while maintaining similar VRAM use to BnB 4bit.
- Llama 3.2 - a unsloth Collection: no description found
- Run DeepSeek-R1 Dynamic 1.58-bit: DeepSeek R-1 is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Run the 1.58-bit Dynamic GGUF version by Unsloth.
- unsloth/phi-4-GGUF · Hugging Face: no description found
- unsloth/SmolLM2-135M-Instruct-GGUF · Hugging Face: no description found
- unsloth/DeepSeek-R1-GGUF · Hugging Face: no description found
- Kolo/scripts/train.py at main · MaxHastings/Kolo: A one stop shop for fine tuning and testing LLMs locally using the best tools available. - MaxHastings/Kolo
- unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF · Hugging Face: no description found
- Stanford's s1-32B Model Outperforms OpenAI's o1-Preview by 27% on AIME24 Math Questions Using 1,000 Diverse Questions | DeepNewz: Stanford researchers have introduced a new approach called Simple Test-Time Scaling (s1), which enhances reasoning performance in language models. The s1-32B model, fine-tuned on a dataset of 1,000 di...
- Fine-tuning LLMs to 1.58bit: extreme quantization made easy: no description found
- GitHub - unslothai/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to unslothai/llama.cpp development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #off-topic (17 messages🔥):
Regex for Dates, Uploading Jupyter Notebooks, LLM Model Breakdown, Blogging Platforms for LLM, GRPO Support
- Regex Challenges with Date Formats: There was a discussion on creating a regex for specific date phrases like 'quarta-feira da proxima semana' or 'esse sabado', focusing on varied language inputs.
- It was noted that regex can work better with consistent date formats like dd/mm/yyyy or yyyy-mm-dd.
- Jupyter Notebook Upload Confusion: A member inquired about the possibility of uploading Jupyter Notebooks in the chat.
- No clear answer was provided, hinting at restrictions or limitations in the upload functionality.
- Issues with LLM Model Weight Reassembly: A user expressed frustration over importing a layer incorrectly while trying to reassemble an LLM model in a PyTorch neural network, resulting in gibberish output.
- They sought assistance in understanding where efficiency could be improved in the parts of the model.
- Choosing a Blogging Platform for LLM Insights: The conversation included suggestions around platforms for blogging about LLMs, with mentions of Substack and Ghost.
- Another member recommended GitHub Pages as a reliable alternative, ensuring longevity and shareability of the content.
- Excitement for GRPO Support and Anticipated Kinks: There was excitement expressed regarding the anticipated release of GRPO support, along with acknowledgment of existing issues.
- A member commented that there are still some kinks to iron out, suggesting that implementation might take some time.
Link mentioned: Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #help (94 messages🔥🔥):
Instructions for Using Unsloth Models, DeepSeek in Oobagooba, Training Configuration Suggestions, Dynamic Quantization in LLMs, Using vLLM and SGLang for Model Inference
- Instructions for Using Unsloth Models: Members discussed how to execute specific commands for running models using vLLM and SGLang, emphasizing the need for the correct configuration parameters.
- In particular, running the command 'vllm serve casperhansen/mistral-small-24b-instruct-2501-awq -tp 2 --port 2222 --enforce-eager' was mentioned as effective.
- DeepSeek in Oobagooba: Users shared their experiences trying to run the DeepSeek model locally in Oobagooba, noting that challenges often arise without proper model weight configurations.
- Optimizations and workarounds were suggested, including ensuring the use of the '--enforce-eager' flag to prevent failures during model loading.
- Training Configuration Suggestions: A member detailed their training configuration for fine-tuning, noting instability in training loss and asking for feedback on potential improvements.
- Suggestions included running benchmarks on the last few checkpoints and considering adjustments such as using a validation dataset.
- Dynamic Quantization in LLMs: New users expressed confusion about how to effectively utilize dynamic quantization, particularly with unsloth's dynamic 4bit models.
- They inquired about the compatibility of their current hardware with these models and whether conversion of safetensor files was necessary for operation.
- Using vLLM and SGLang for Model Inference: Members discussed their preferences for running models in vLLM and SGLang, emphasizing the importance of efficient inference setups.
- Several users noted that the latest configurations allowed for improved performance in model inference compared to previous slow methods.
- unsloth/Mistral-Small-24B-Instruct-2501-bnb-4bit · Hugging Face: no description found
- Unsloth Documentation: no description found
- Tutorial: How to Run DeepSeek-R1 on your own local device | Unsloth Documentation: no description found
- [Fixing] More finetuning support · Issue #1561 · unslothai/unsloth: Support sequence classification Flex Attention for Gemma and others Variable sequence length and auto unpadding / padding Tool Calling Refactor and merge xformers, SDPA, flash-attn, flex-attention
- GitHub - unslothai/unsloth: Finetune Llama 3.3, DeepSeek-R1, Mistral, Phi-4 & Gemma 2 LLMs 2-5x faster with 70% less memory: Finetune Llama 3.3, DeepSeek-R1, Mistral, Phi-4 & Gemma 2 LLMs 2-5x faster with 70% less memory - unslothai/unsloth
- Tutorial: How to Finetune Llama-3 and Use In Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
- unsloth_tool_success2.py: GitHub Gist: instantly share code, notes, and snippets.
- tool_train.py: GitHub Gist: instantly share code, notes, and snippets.
Unsloth AI (Daniel Han) ▷ #showcase (7 messages):
CPT with Unsloth, DeepSeek model age, Math versions for Qwen, Making AI accessible
- CPT model shows impressive results: The CPT with Unsloth model demonstrated significant improvements in Perplexity (PPL), with base model scores of 179.76 and 258.56 compared to user model scores of 72.63 and 83.96.
- I really love it! showcases excitement over the model's performance.
- DeepSeek model is considered old: A member pointed out that the DeepSeek model is very old, indicating a need for updated versions.
- A discussion ensued about missing math versions of the model and the desire for an interesting dataset.
- Request for math versions of Qwen 2.5: A member inquired about adding math versions for the Qwen 2.5 model to the existing resources.
- They highlighted the importance of having varied and interesting datasets for future implementations.
- Resource linkage for math models: A resource link was shared regarding available math models on Hugging Face, particularly for Qwen variants.
- Members were encouraged to explore the math versions already available, specifically asking to scroll down for more details.
- Focus on AI accessibility: Members expressed a collective goal of making AI more accessible to everyone in the community.
- This sentiment underscores the collaborative effort to enhance understanding and usability of AI technologies.
Link mentioned: unsloth (Unsloth AI): no description found
Codeium (Windsurf) ▷ #announcements (2 messages):
Gemini 2.0 Flash, Windsurf Next Beta
- Gemini 2.0 Flash is Live on Windsurf: Introducing Gemini 2.0 Flash on Windsurf, featuring 0.25 user prompt credits per message and 0.25 flow action credits per tool call. Despite its limited tool calling ability, it's noted for being blazingly fast and efficient for coding inquiries.
- Visit the Gemini 2.0 Flash announcement for more details.
- Windsurf Next Beta Now Available: Get early access to Windsurf Next by downloading it here and installing alongside the stable version. It aims to let users explore innovative features and improvements in AI for software development despite possible rough edges.
- Minimum requirements include OS X Yosemite for Mac, Ubuntu 20.04 for Linux, and Windows 10 (64-bit), with more details available here.
- Tweet from Windsurf (@windsurf_ai): Gemini 2.0 Flash is now available in Windsurf!From our testing, Flash is:⚡ blazingly fast💪 efficient - only consumes 0.25X credits🧠 limited in its tool calling ability, but great for questions about...
- Thank you for downloading Windsurf Editor: Tomorrow's editor, today. Windsurf Editor is the first AI agent-powered IDE that keeps developers in the flow. Available today on Mac, Windows, and Linux.
- Windsurf Next Launch: Introducing Windsurf Next, our opt-in prerelease version of Windsurf.
Codeium (Windsurf) ▷ #discussion (34 messages🔥):
Credits and Tool Use, Qodo Concerns, Runic Open-Source Framework, Codeium Plugin Issues, Windsurf vs Codeium
- Concerns Over Tool Use Credit Consumption: A user expressed frustration that Claude is wasting credits on tool functions, repeatedly attempting bad commands. Another member confirmed that tool errors shouldn't deduct credits, but the issue persists with excessive token use.
- 'That's a lot of traffic and it sucks up credits like crazy' was a notable sentiment among users discussing the inefficiencies.
- Skepticism About Qodo's Legitimacy: A user questioned whether Qodo (formerly Codium) could be a scam, while others expressed reluctance to use it. The lack of trust hints at community concerns regarding new AI tools.
- Responses suggest caution about adopting new platforms without clarity on their legitimacy and reliability.
- Introduction of Runic Framework: A member announced the launch of Runic, an open-source framework enhancing LLMs with Long-Term Memory (LTM) and Retrieval-Augmented Generation (RAG), generated entirely in Python. Users are encouraged to test it with
pip install --pre runic.- Feedback is requested via discussions on testing features, as highlighted in their GitHub page.
- User Issues with Codeium JetBrains Plugin: Multiple users reported struggles with the Codeium JetBrains plugin, citing unresponsiveness and the need for frequent restarts for functionality. One user switched back to Copilot due to these persistent issues.
- Asking for improvements, a member urged, 'Please give the Jetbrains plugin some love' to enhance its stability and performance.
- Discussion on Windsurf vs Codeium: Following the release of Windsurf, some users noted a decline in attention and updates for the Codeium JetBrains plugin. Discussions reflected mixed feelings about the transition and continuous support for both platforms.
- The sentiment indicates an eagerness for maintaining functionality across all tools as preferences shift within the user community.
Link mentioned: GitHub - livingstonlarus/runic: An open-source framework that enhances Large Language Models (LLMs) with Long-Term Memory (LTM) and Retrieval-Augmented Generation (RAG). Ideal for AI coding assistants and other applications, it enables LLMs to retain context, adapt over time, and access up to date information, ensuring more intelligent and context-aware interactions.: An open-source framework that enhances Large Language Models (LLMs) with Long-Term Memory (LTM) and Retrieval-Augmented Generation (RAG). Ideal for AI coding assistants and other applications, it e...
Codeium (Windsurf) ▷ #windsurf (476 messages🔥🔥🔥):
Issues with Windsurf Credits, Gemini Model Discussions, Windsurf vs Cursor Feature Comparison, User Experience Feedback, Suggestions for Windsurf Improvements
- Issues with Windsurf Credits: Users are experiencing problems with the allocation and usage of credits in Windsurf, particularly flex credits, which have led to a lack of functionality during critical work periods.
- One user mentioned contacting support multiple times about their credit issues, demonstrating frustration with the system's reliability.
- Gemini Model Discussions: The Gemini 2.0 Flash model is noted for its speed in processing files but is accompanied by concerns regarding its reliability and performance.
- Users have expressed interest in testing the new model while comparing its capabilities to existing models like Claude and DeepSeek.
- Windsurf vs Cursor Feature Comparison: Discussions highlight the advantages Cursor has over Windsurf, particularly regarding its flexibility to install third-party tools and extensions.
- Users suggest that Windsurf could benefit from allowing similar functionalities, particularly in moving third-party apps within the IDE.
- User Experience Feedback: Several users expressed concerns about the interface and functionality of Cascade within Windsurf, indicating a need for improvement.
- Feedback suggests that a more intuitive UI and better handling of large codebases could enhance user experience.
- Suggestions for Windsurf Improvements: Users proposed features such as automatic commit messages based on coding standards and better credit rollover policies to enhance overall usability.
- These suggestions aim to make Windsurf more competitive with existing IDEs like Cursor.
- Tweet from Simon Willison (@simonw): "So today, we’re introducing 2.0 Flash-Lite, a new model that has better quality than 1.5 Flash, at the same speed and cost"I think that's 7.5c/million input tokens, 30c/million output tok...
- Tweet from Google DeepMind (@GoogleDeepMind): 2.0 Pro Experimental is our best model yet for coding and complex prompts, refined with your feedback. 🤝It has a better understanding of world-knowledge and comes with our largest context window yet ...
- Tweet from Kevin Hou (@kevinhou22): we love docs! 📖 I'm working on improving / adding more @ docs shortcuts to @windsurf_ailmk what you want and I'll add as many as I can... 🧵also shoutout @mintlify for auto-hosting all docs w...
- ElevenLabs Worldwide Hackathon: One weekend. Six cities and online. AI agents.
- Windsurf - Advanced: no description found
- Windsurf - Cascade: no description found
- Windsurf Next Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Next extension.
- Codeium Status: no description found
- Feature Requests | Codeium: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- OpenAI o3-mini vs DeepSeek R1 (in Cursor vs Windsurf): In the rapidly evolving AI landscape, two models have recently garnered significant attention: OpenAI's o3-mini and DeepSeek's R1. Both are designed to enhan...
- GitHub - ZarK/ai-rules: Contribute to ZarK/ai-rules development by creating an account on GitHub.
- Auto commit message | Feature Requests | Codeium: Generate Commit Messages from Committed File Context
- Roll-over of Pro Credits | Feature Requests | Codeium: Unused Premium User Prompt Credits and Premium Flow Action Credits roll-over to the next month
- Reddit - Dive into anything: no description found
- no title found: no description found
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
Introductory Message, Community Engagement Initiatives, Feature Request Board, Progress Sharing from Researchers
- Maxfield Introduces Himself as Chief Community Guy: Maxfield, the new Chief Community Guy at Stability, introduced himself and shared his long-standing involvement with Stable Diffusion since November 2022.
- He emphasized the need for improved community engagement and expressed his commitment to listening to members' feedback.
- New Initiatives to Boost Community Engagement: Maxfield announced two initiatives aimed at enhancing community involvement, stating, 'engagement from Stability has been lackluster lately.'
- He detailed plans to implement a feature request board and to increase transparency from the researchers and creators at Stability.
- Feature Request Board Launching Soon: One initiative includes a feature request board where community members can suggest and vote on desirable models, tools, or workflows.
- Maxfield asserted, 'What's the point of all this compute if we're not building stuff you want?'
- Spotlighting Researcher Projects: Maxfield indicated that community members would soon see more initiatives aimed at showcasing the progress of talented researchers and creators at Stability.
- He noted, 'People here are making some wild stuff, we shouldn't be the only ones to see it.'
Stability.ai (Stable Diffusion) ▷ #general-chat (399 messages🔥🔥):
Latency and Model Compatibility, Training and Fine-Tuning Challenges, Upcoming AI Models and Architectures, Community Tools for AI, Spamming in Discord Channels
- Exploring Latent Space Compatibility: Discussions highlighted the potential for a diffusion model working within the latent space of another model, revealing fascinating nested architectures.
- Participants mentioned that for this to function, using a compatible VAE is essential, while others expressed interest in the underlying papers that explore this concept.
- Challenges in Training Models: Users shared experiences with fine-tuning models like LoRA, noting that default settings often outperform complex adjustments.
- The complexity of evolving architectures leaves some users eager for more streamlined and user-friendly tools to work in latent space effectively.
- Upcoming Innovations in AI Models: The community speculated on future multimodal models, expressing excitement about tools that merge text and image generation capabilities.
- There’s a clear interest in developing new models that enhance creative uses, like video game development, through intuitive interfaces.
- User-Created Tools for Community Engagement: A user is developing a new tool for editing tensor files within latent spaces, emphasizing a need for better user experiences in existing tools.
- The potential to create a streamlined 3D GUI for designing games and storyboarding was discussed, highlighting user initiative in advancing AI applications.
- Moderation and Spam Issues: The chat experienced a spam incident, prompting users to report the message and call for moderation action.
- The community showed a collective effort to maintain channel integrity amidst unrelated promotional posts.
- Creep Hands GIF - Creep Hands Adventure Time - Discover & Share GIFs: Click to view the GIF
- Multimodal AI Agents - Hackathon · Luma: Gen AI AgentsCreatorsCorner, collaborating with Google Deepmind, Weights & Biases, Together.ai, Stytch, Senso, LlamaIndex and others enthusiastically…
- GitHub - NeuralNotW0rk/LoRAW: Flexible LoRA Implementation to use with stable-audio-tools: Flexible LoRA Implementation to use with stable-audio-tools - NeuralNotW0rk/LoRAW
- Expanding the frontiers of AI creativity - PurpleSmartAI: no description found
Cursor IDE ▷ #general (365 messages🔥🔥):
Cursor IDE Features, MCP Server Integration, Gemini 2.0 Pro Model, Voice Dictation in Coding, Mobile IDE Usability
- Cursor IDE Introduces MCP Server Support: Users discussed the newly implemented MCP server integration in Cursor, enabling enhanced functionalities, including using Perplexity for assistance through commands.
- The integration allows for easy setup with a provided GitHub repository and gives users the option to ask questions directly or engage in chat with the tool.
- Gemini 2.0 Pro Faces Criticism: Some users expressed disappointment with the performance of the new Gemini 2.0 Pro model, stating it struggles with coding tasks despite excelling in data analysis.
- Benchmarks indicate that while Gemini 2.0 Pro offers decent performance for random tasks, it still lags behind the O3-mini high and Sonnet for coding.
- Voice Dictation for Coding Seen in Use: Discussants shared insights about effective voice dictation tools, with some references to Andrej Karpathy's method of dictating code using Whisper technology.
- Windows' built-in dictation feature was mentioned, although users noted its accuracy could use improvements, raising interest in customizing voice interfacing for coding purposes.
- Mobile Usability of Cursor IDE Questioned: One user suggested the idea of developing an iPhone app for Cursor to enable coding and prompting on the go, while others reflected on the practicality and desire for such a feature.
- Despite some support for the idea, the general consensus indicated that current frameworks may not justify the effort to turn Cursor into a mobile application.
- User Experience Enhancements in Cursor: Several users reported successful integrations and improvements after trying various features in Cursor, particularly relating to using MCP servers.
- The conversation highlighted a strong user engagement with feature requests and troubleshooting, reflecting an active interest in ongoing enhancements.
- Tweet from kitze 🚀 (@thekitze): cursor > windsurf (for now)i'll continue switching between them and report further
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): News: @GoogleDeepMind Gemini-2.0 family (Pro, Flash, and Flash-lite) is now live in Arena!- Gemini-2.0-Pro takes #1 spot across all categories- Gemini-2.0-Flash #3 and now widely available to develope...
- no title found: no description found
- Google AI Studio: Google AI Studio is the fastest way to start building with Gemini, our next generation family of multimodal generative AI models.
- Todd Tar GIF - Todd Tar Scare - Discover & Share GIFs: Click to view the GIF
- Open-Source MCP servers: Enterprise-grade security, privacy, with features like agents, MCP, prompt templates, and more.
- GitHub - grapeot/devin.cursorrules at multi-agent: Magic to turn Cursor/Windsurf as 90% of Devin. Contribute to grapeot/devin.cursorrules development by creating an account on GitHub.
- Danie - Overview: Danie has 10 repositories available. Follow their code on GitHub.
- Build Cursor on Steroids in 20 Minutes with MCP: Cursor quietly released MCP support without fanfare, so it would be easy to miss it. But it's actually a killer feature that can turbocharge your composer ag...
- Releases · daniel-lxs/mcp-starter: Contribute to daniel-lxs/mcp-starter development by creating an account on GitHub.
- o3-mini vs Deepseek-R1: no description found
- GitHub - PatrickJS/awesome-cursorrules: 📄 A curated list of awesome .cursorrules files: 📄 A curated list of awesome .cursorrules files. Contribute to PatrickJS/awesome-cursorrules development by creating an account on GitHub.
- Release v0.1.0 · daniel-lxs/mcp-starter: Initial Release
- GitHub - daniel-lxs/mcp-perplexity: Contribute to daniel-lxs/mcp-perplexity development by creating an account on GitHub.
- svelte-llm - Svelte 5 and SvelteKit Developer documentation in an LLM-ready format: no description found
- GitHub - daniel-lxs/mcp-perplexity: Contribute to daniel-lxs/mcp-perplexity development by creating an account on GitHub.
- GitHub - daniel-lxs/mcp-starter: Contribute to daniel-lxs/mcp-starter development by creating an account on GitHub.
Perplexity AI ▷ #general (312 messages🔥🔥):
Changes in Perplexity AI, Gemini 2.0 Flash Release, Model Access Issues, Pro Subscription Confusions, Feedback and User Experience
- Users frustrated by UI changes in Perplexity AI: Many users expressed frustration over recent changes to Perplexity AI, particularly with the removal of focus modes and slower performance, likening it to 'enshitification'.
- Some users are experiencing difficulty accessing models like Claude 3.5 Sonnet, with automatic activation of R1 or o3-mini in Pro Search mode.
- Gemini 2.0 Flash officially released: Gemini 2.0 Flash was announced as available to all Pro users, marking the introduction of a Gemini model to Perplexity for the first time since earlier versions.
- Users were keen to understand the differences in context limits and capabilities compared to previous models, noting its functionality and availability in the current app interface.
- Confusion over model access and limitations: Pro users reported inconsistencies in model access, with some being unable to use features like Gemini or access the desired models despite having the Pro subscription.
- Disparities in user experience were noted, with some users finding the limitations unnecessary and others still adjusting to new functionalities across platforms.
- Discontent with decision-making in feature removal: The removal of features, such as focus modes traditionally used for specific searches, led to complaints that these actions resemble poorly thought-out changes in popular tech products.
- User discussions highlighted the perceived retrogression in functionality, which is disappointing as they'd previously relied on these features for academic purposes.
- User experiences and expectations from Perplexity: General discussions showcased varied user experiences, from frustration about context limits to those successfully utilizing features in the native app or API.
- Users shared their concerns and preparations for integrating the API, while others mentioned the performance speeds and outputs they received, seeking improvements.
- Tweet from Perplexity (@perplexity_ai): This Sunday, your question could be worth $1,000,000.
- Tweet from Aravind Srinivas (@AravSrinivas): We’re making Gemini 2.0 Flash available to all Perplexity Pro users. This is the first time we’re bringing a Gemini model to Perplexity. Flash 2.0 is an incredible multimodal cost-efficient model. Upd...
- Hika AI - Free AI Knowledge Search: Free AI search offering advanced insights and interactive exploration.
- Dr Evil Gold Member GIF - Dr Evil Gold Member One Million Dollars - Discover & Share GIFs: Click to view the GIF
- Shy Dog Shy Dog Shoes GIF - Shy dog Dog Shy dog shoes - Discover & Share GIFs: Click to view the GIF
- Perplexity - Status: Perplexity Status
Perplexity AI ▷ #sharing (11 messages🔥):
US Iron Dome Proposal, California Secession Bid, Asteroids and Life, Quantum Mechanics and Consciousness, Electricity Types
- Trump proposes US Iron Dome: A member shared an intriguing video discussing Trump's proposal for a US Iron Dome amidst ongoing political developments, including a California secession bid.
- The discussion points toward the potential implications of such military strategies on national security and local governance.
- California Seeks Secession: The conversation highlighted ongoing movements for California's bid for secession, mentioned alongside proposals such as the US Iron Dome.
- Community members expressed varied opinions on the feasibility and the ramifications of such a decision.
- Asteroids Carrying Seeds of Life: Participants discussed claims that certain asteroids could carry seeds of life, framing the ongoing exploration of space as crucial to understanding our origins.
- This sparked a thought-provoking dialogue on astrobiology and the potential for extraterrestrial life forms.
- Intro to Quantum Mechanics Sparks Discussion: An ongoing exploration of quantum mechanics veered into philosophical topics, particularly our understanding of time.
- Members expressed their perspectives on the intersection of quantum theory with consciousness, creating an engaging dialogue.
- Diverse Types of Electricity Explored: A discussion arose around the various types of electricity, with links shared to sources that elaborate on the topic, including general electricity facts.
- Members highlighted the importance of understanding electrical systems in today's technology-driven world.
Perplexity AI ▷ #pplx-api (5 messages):
Sonar Reasoning Pro, Perplexity API Cost Management, Image Uploading in Perplexity API
- Sonar Reasoning Pro uses DeepSeek R1: A member clarified that the Sonar Reasoning Pro operates on DeepSeek R1, as confirmed on their website.
- This was a realization for some members who were previously unaware of the underlying models.
- Cost Management Questions Raised: A user inquired about setting a hard limit on monthly costs and whether invoices are sent automatically or need manual addition.
- This concern reflects a growing interest in managing expenses associated with using the Perplexity API.
- Exploring Image Uploads with Perplexity API: A new user expressed interest in using the Perplexity API after successful experimentation with the webUI involving image uploads.
- They raised questions about current limitations regarding image uploads, speculating potential workaround solutions using other tools.
Eleuther ▷ #general (114 messages🔥🔥):
Discussion on ML Theory and Convex Optimization, Harmonic Loss vs Cross-Entropy Loss, Machine Learning Background and Collaborations, Insights on Diffusion Models, Challenges in Statistical Background for ML
- Struggles with ML Theory and Optimization: Members discussed the practical challenges of convex optimization, noting it often proves ineffective in real-world scenarios due to roughness in data and environments.
- One likened the idealized nature of convex optimization to building a perfect bike for flat surfaces, while real-world applications face significant bumps in the road.
- Introduction of Harmonic Loss as an Alternative: A new paper was shared introducing harmonic loss as a preferable alternative to standard cross-entropy loss for neural networks, claiming benefits like improved interpretability and faster convergence.
- Community members expressed skepticism about its novelty, noting similarities with traditional methods, while others highlighted its potential to shift optimization targets.
- Interest in Collaborating on ML Projects: A member expressed a desire to collaborate on research projects related to LLM agents, seeking connections with other researchers and ML enthusiasts for brainstorming and publishing opportunities.
- They emphasized the goal of working on novel problems in the field and encouraged anyone interested in teamwork or discussions to reach out.
- Thoughts on Diffusion Models: Discussion emerged on the theoretical strength of diffusion models compared to other ML subdisciplines, with opinions on the balance of theory and practical application in the field.
- Members noted that while theoretical work can appear abstract, it leads to significant advancements in image generation and has practical relevance.
- Statistical Foundations in ML: Many expressed a desire for stronger foundational knowledge in statistics as a basis for understanding ML, recalling their experiences with coursework focused more on programming and discrete mathematics.
- The conversation highlighted a perceived gap in statistical literacy among ML practitioners, emphasizing its importance in comprehending research and methodologies.
- Tweet from David D. Baek (@dbaek__): 1/9 🚨 New Paper Alert: Cross-Entropy Loss is NOT What You Need! 🚨We introduce harmonic loss as alternative to the standard CE loss for training neural networks and LLMs! Harmonic loss achieves 🛠️si...
- Tweet from Lucas Beyer (bl16) (@giffmana): I took a brief look at the Harmonic Loss papertl;dr: instead of dot-product with softmax, do euclid dist with normalized 1/d**n.I kinda want this to work. I've dabbled with preferring euclid many ...
- Backdoors as an analogy for deceptive alignment: ARC has released a paper on Backdoor defense, learnability and obfuscation in which we study a formal notion of backdoors in ML models. Part of our motivation for this is an analogy between backdoors ...
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models: Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Co...
- Group Robust Preference Optimization in Reward-free RLHF: Adapting large language models (LLMs) for specific tasks usually involves fine-tuning through reinforcement learning with human feedback (RLHF) on preference data. While these data often come from div...
Eleuther ▷ #research (210 messages🔥🔥):
Harmonic loss as alternative to CE loss, VideoJAM framework for motion generation, Activation functions in neural networks, Evaluation of various optimizer techniques, Modified ReLU approaches
- Exploring Harmonic Loss over Cross-Entropy: A member emphasized potential benefits of using harmonic loss instead of traditional cross-entropy loss for neural networks, claiming it leads to better interpretability and faster convergence.
- Discussion touched on the stability and interactions of activations in relation to various learned parameters during model training.
- Introducing VideoJAM for Enhanced Motion Generation: Hila Chefer introduced the VideoJAM framework, highlighting how it directly addresses the challenges video generators face with motion representation without needing extra data.
- This framework is expected to improve the dynamics of motion generation in video content.
- Investigating Sparse Activation Functions: Members discussed the performance of ReLU squared and explored alternatives, such as GeGLU and potential new functions based on L2 or soft-thresholding methods.
- There were considerations of how these activations may impact the model capacity and sparsity during training.
- Optimizers and Gradient Stability: There was a debate over the efficiency of various optimizers, including AdamW and redesigned second-order methods like pSGD and Shampoo, in managing gradient spikes and improving learning stability.
- Participants encouraged exploring emerging optimizers to enhance performance and mitigate stability issues associated with existing techniques.
- Performance Evaluations of Modified ReLU Implementations: Members shared experiences with different implementations of ReLU functions, noting that ReLU squared has shown performance advantages in certain contexts, particularly speedrun scenarios.
- The conversation also included suggestions regarding the application of leaky ReLU and the importance of maintaining non-negative outputs before applying cross-entropy loss.
- Tweet from Christian Szegedy (@ChrSzegedy): I'd be really interested in seeing how harmonically weighted attention would work. There might be a real potential there.Quoting David D. Baek (@dbaek__) 1/9 🚨 New Paper Alert: Cross-Entropy Loss...
- Tweet from Hila Chefer (@hila_chefer): VideoJAM is our new framework for improved motion generation from @AIatMetaWe show that video generators struggle with motion because the training objective favors appearance over dynamics.VideoJAM di...
- Deriving Activation Functions Using Integration: Our work proposes a novel approach to designing activation functions by focusing on their gradients and deriving the corresponding activation functions using integration. We introduce the Expanded Int...
- VideoJAM: VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Model
- Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges: Large language models often struggle with length generalization and solving complex problem instances beyond their training distribution. We present a self-improvement approach where models iterativel...
- Our First Generalist Policy: Physical Intelligence is bringing general-purpose AI into the physical world.
- GitHub - Physical-Intelligence/openpi: Contribute to Physical-Intelligence/openpi development by creating an account on GitHub.
Eleuther ▷ #gpt-neox-dev (2 messages):
Effective Batch Size Strategies, Weight Decay Application in Training
- GAS boosts TPS over Activation Checkpointing: Training without activation checkpointing and using GAS significantly increases TPS, with a comparison showing 242K TPS for batch size 8 with GAS versus 202K TPS for batch size 48 with checkpointing.
- Despite different effective batch sizes, the smaller batch size with GAS shows a faster convergence, though a noted lower HFU/MFU could be a concern but isn't prioritized if TPS improves.
- OLMo2 Approach on Weight Decay: A query arose about not applying weight decay to specific parts of the model, particularly the embedding layer, as per the OLMo2 paper's methodology.
- This raises discussion on the implications of selective weight decay during training and its potential impact on model performance.
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
DeepSeek R1 Nitro, Downtime Incident
- DeepSeek R1 Nitro boasts speedy uptime: The DeepSeek R1 Nitro has shown significantly improved uptime and speed, with 97% of requests now completing fully with a finish reason, according to OpenRouterAI.
- Users are encouraged to try it out for optimal performance!
- Minor hiccup causes brief downtime: A member acknowledged a minor hiccup that caused downtime but reported that the service should be back live now after a rollback.
- There was an apology for the inconvenience, assuring users that everything is operational again.
Link mentioned: Tweet from OpenRouter (@OpenRouterAI): Significantly better uptime and speed on our DeepSeek R1 Nitro endpoint.Seeing 97% of requests now fully complete, with a finish reason. Try it! 👇
OpenRouter (Alex Atallah) ▷ #general (298 messages🔥🔥):
OpenRouter downtime, API errors and rate limits, Gemini 2.0 updates, Provider routing and pricing, Community support and troubleshooting
- OpenRouter experiences downtime: Users noted API issues and rate limit errors, raising concerns about ongoing service reliability as Toven confirmed there might be downtime.
- The downtime was quickly addressed, with Toven announcing that service returned right away after reverting a recent change.
- Rate limits affecting API calls: Some users, like Tusharmath, encountered rate limit errors when using the API, particularly with Anthropic, which has a limit of 20 million input tokens per minute.
- Louisgv mentioned reaching out to Anthropic for a potential rate limit increase to resolve issues for users experiencing restrictions.
- Interest in Gemini 2.0 performance: Xiaoqianwx discussed expectations for Gemini 2.0, suggesting it may need stronger models to compete effectively, while noting mediocre benchmark results.
- The community expressed disappointment in performance, with discussions on the model's comparative strengths and weaknesses.
- Provider routing and pricing concerns: Users inquired about potential price controls for API usage, specifically regarding variations in costs across different providers.
- Toven introduced a new max_price parameter for controlling spending limits on API calls, which is currently live but not fully documented.
- Community troubleshooting and support: Members utilized the channel for sharing error messages and seeking assistance, demonstrating a collaborative spirit in resolving issues.
- Toven encouraged users to reach out multiple times if their help tickets weren't addressed promptly, emphasizing support availability.
- LiveBench: no description found
- Tweet from OpenAI Developers (@OpenAIDevs): @FeltSteam @UserMac29056 @TheXeophon @chatgpt21 chatgpt-4o-latest in the API is now updated and matches last week's GPT-4o update in ChatGPT. Sorry for the delay on this one! https://help.openai.c...
- Managing your personal access tokens - GitHub Docs: no description found
- no title found: no description found
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Provider Routing — OpenRouter | Documentation: Route requests to the best provider
- tokenizer_config.json · deepseek-ai/DeepSeek-R1 at main: no description found
- no title found: no description found
- List endpoints for a model — OpenRouter | Documentation: no description found
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Provider Routing — OpenRouter | Documentation: Route requests to the best provider
- DeepSeek users in US could face million-dollar fine and prison time under new law: Hugely popular Chinese AI app has raised security, privacy and ethical concerns
- MythoMax 13B – Provider Status: See provider status and make a load-balanced request to MythoMax 13B - One of the highest performing and most popular fine-tunes of Llama 2 13B, with rich descriptions and roleplay. #merge
- Chat Templates: no description found
- Gemini Flash 2.0 - API, Providers, Stats: Gemini Flash 2.0 offers a significantly faster time to first token (TTFT) compared to [Gemini Flash 1. Run Gemini Flash 2.0 with API
- no title found: no description found
- Reddit - Dive into anything: no description found
- GitHub - ShivamB25/Research-Analysist: automate the process of web scraping and report generation: automate the process of web scraping and report generation - ShivamB25/Research-Analysist
- GitHub - OpenRouterTeam/ai-sdk-provider: The OpenRouter provider for the Vercel AI SDK contains support for hundreds of AI models through the OpenRouter chat and completion APIs.: The OpenRouter provider for the Vercel AI SDK contains support for hundreds of AI models through the OpenRouter chat and completion APIs. - OpenRouterTeam/ai-sdk-provider
Interconnects (Nathan Lambert) ▷ #news (156 messages🔥🔥):
Gemini 2.0 updates, Mistral's new offerings, AI benchmarking performance, GitHub Copilot updates
- Gemini 2.0 Pro Experimental Performance: Recent benchmarking of Gemini 2.0 Pro Experimental shows it performing at a level comparable to Claude 3.5 Sonnet on various tasks, but with some inconsistencies in API responses.
- While the Flash models outperform the previous Gemini 1.5 Pro, the long context capabilities seem to have diminished, which raises questions about the model's effectiveness.
- Mistral's New Website and Features: Mistral launched a redesigned website showcasing their open models aimed at customizing AI solutions, emphasizing transparency and enterprise-grade deployment options.
- The company rebranded with a new cat logo, balancing their image as a leading independent AI lab with a playful design approach.
- AI Benchmarking Insights: Discussions highlighted that Gemini 2.0 Flash models generally performed well on internal benchmarks but showed mixed results in direct comparisons with competitors.
- There is ongoing commentary regarding the model's context length capabilities, raising concerns among users about potential performance trade-offs.
- GitHub Copilot's Use of Gemini 2.0: GitHub announced that Gemini 2.0 Flash is now available for all Copilot users, integrated into their model selector and Copilot Chat features as a new tool for developers.
- This integration marks a significant milestone for Gemini, as it gains traction within Microsoft's ecosystem ahead of other competitor releases.
- Critique of Model Naming and Updates: Users expressed frustration over the naming conventions of AI models, suggesting they lack creativity and clarity, pointing to the latest models as examples.
- There is a general sentiment that despite the advancements in AI, companies like Google struggle to effectively communicate their updates to users.
- Tweet from Terry Yue Zhuo (@terryyuezhuo): The new Gemini models on BigCodeBench-HardTLDR (results with several empty results due to the API sensitivities, with all safety settings being NONE):- Gemini-2.0-Pro-Exp-02-05: ~~Claude 3.5 Sonnet le...
- Tweet from Google DeepMind (@GoogleDeepMind): Gemini 2.0 is now available to everyone. ✨⚡ Start using an updated 2.0 Flash in @Google AI Studio, @GoogleCloud’s #VertexAI and in @GeminiApp.We’re also introducing:🔵 2.0 Pro Experimental, which exce...
- Tweet from ʟᴇɢɪᴛ (@legit_rumors): Vertex Platform has the real Gemini 2.0 Prothe 2.0 pro in web / app / aistudio is still rolling out - might take a few hours if they still intend to release today
- Tweet from Lucas Beyer (bl16) (@giffmana): I took a brief look at the Harmonic Loss papertl;dr: instead of dot-product with softmax, do euclid dist with normalized 1/d**n.I kinda want this to work. I've dabbled with preferring euclid many ...
- Tweet from ʟᴇɢɪᴛ (@legit_rumors): Gemini 2.0 Pro Experimental has released
- Tweet from Xeophon (@TheXeophon): here is the comparisonQuoting Paul Calcraft (@paul_cal) @GoogleDeepMind @Google @googlecloud @GeminiApp Where are the comparisons to competitors' models?
- Tweet from Keller Jordan (@kellerjordan0): Unfortunately, it is hard to trust *claims* in 2025.What’s easier to trust is *incentives*.So here’s an incentive: I’ll pay a $3,000 bounty to the first person who uses this method to improve either t...
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): A few things to note on the Gemini 2.0 update:- The overall perf gap between Flash and Pro seems very small on their bench.-> Flash is amazing. Pro excels at long-tail knowledge, which matters for ...
- Tweet from Tibor Blaho (@btibor91): OpenAI website has now been updated based on the new design guidelinesQuoting nic (@nicdunz) the official openai website has been updated with their new design guidelines in place and other things
- Gemini 2.0 is now available to everyone: We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.
- AI has struggled with spreadsheets and tables. A German startup's breakthrough could change that: Prior Labs has just received $9.3 million in 'pre-seed' funding to build out its foundation models for 'tabular data.'
- Tweet from GitHub (@github): 🎁 Available today: Gemini 2.0 Flash for *all* GitHub Copilot users! Find it in your model selector in @code and in Copilot Chat on GitHub. https://gh.io/copilot-chat-gemini
- Tweet from Xeophon (@TheXeophon): I will shoot the person responsible for the name „gemini-2.0-flash-lite-preview-02-05“ (in Minecraft)Quoting ʟᴇɢɪᴛ (@legit_rumors) Vertex Platform has the real Gemini 2.0 Prothe 2.0 pro in web / app /...
- Tweet from OpenAI (@OpenAI): Deep research update 🌍It's now rolled out to 100% of all Pro users, including in the UK, EU, Norway, Iceland, Liechtenstein, and Switzerland.
- Waltergotme GIF - Waltergotme - Discover & Share GIFs: Click to view the GIF
- Refreshed.: Check out https://openai.com/ to see more.
- Mistral AI | Frontier AI in your hands: Take control of the future with a complete AI solution from platform to interface, with open, customizable models that can be deployed anywhere.
- �̷��������� - �۷ι� ���� ��Ʈ��: no description found
Interconnects (Nathan Lambert) ▷ #ml-drama (19 messages🔥):
Sama hiring robotics engineers, Softbank AGI deadline, Krutrim licensing controversy, Anthropic jailbreak challenge, Community perspectives on AI development
- Sama's robotics hire raises eyebrows: Members expressed skepticism about Sama's decision to hire for robotics engineers, questioning their capacity to tackle such a crowded hardware problem given their current commitments.
- The consensus points towards the complexity of delivering robust robotics solutions while managing existing challenges.
- Softbank's looming AGI deadline pressures companies: Concerns were voiced about the necessity for companies to explore every avenue for AGI delivery for Softbank within two years.
- The looming expectation of generating $100 billion from AGI projects has intensified the urgency in the industry.
- Krutrim licensing controversy surfaces: A member highlighted the licensing issues surrounding Krutrim, indicating that it has been accused of blatantly copying an open-source project without proper attribution.
- Quotes from community discussions pointed to potential breaches of license agreements, raising ethical concerns.
- Anthropic ups the stakes for jailbreakers: Anthropic announced a $10K reward for anyone who can successfully jailbreak their system through all eight levels, indicating no one has fully succeeded yet.
- The challenge promotes discussion about security in AI, as they aim to address vulnerabilities with constitutional classifiers.
- Community calls out security theater: A user criticized AI companies that seek crowd-sourced expertise without compensating contributors, labeling it security theater.
- This sentiment reflects a wider frustration within the community about incentives and motivations in AI development.
- Tweet from Anthropic (@AnthropicAI): Nobody has fully jailbroken our system yet, so we're upping the ante. We’re now offering $10K to the first person to pass all eight levels, and $20K to the first person to pass all eight levels wi...
- Tweet from tokenbender (@tokenbender): @teortaxesTex @ClementDelangue they claim the 12B instruct is pretrained and then fine-tuned but the difference between Mistral 12B and this model is just in the outermost layer and everything else is...
- Tweet from tokenbender (@tokenbender): how many times I've shit on Krutrim in comments? apparently not enough. someday (maybe already) they're going to do a breach of licence thinking nobody will catch them too.krutrim doesn't ...
- Tweet from Pliny the Liberator 🐉 (@elder_plinius): I don’t want to provide my world-class expertise just for you to hoard crowd-sourced prompts and construct elaborate security theater performances to appease investors who are foolish enough to believ...
Interconnects (Nathan Lambert) ▷ #random (68 messages🔥🔥):
DeepSeek R1 Launch, OpenAI's Sora Tool, Nvidia Digits Interest, GitHub Pages Certificate Issues, AI Model Performance Discussion
- DeepSeek R1 Launch Sparks Debate: On January 20th, 2025, DeepSeek released their open-weights reasoning model, DeepSeek-R1, which some believe may have misrepresented its training costs, causing considerable controversy.
- The model's architecture remains similar to DeepSeek v3, sparking discussions regarding its actual performance and pricing in the community.
- OpenAI's Sora Tool Struggles in Hollywood: OpenAI's newly introduced Sora filmmaking tool has yet to secure deals with Hollywood studios, indicating a potential resistance from the industry.
- As per a Bloomberg article, this may reflect broader hesitance towards new AI tools in traditional filmmaking.
- Nvidia Reports Increased Interest in Digits: A representative from Nvidia mentioned heightened interest in Digits from the research community, especially compared to their previous release of Blackwell.
- This marks a positive shift, potentially making Digits more accessible to cash-strapped universities and researchers.
- Certificate Issues with GitHub Pages: Users reported ongoing issues with certificate propagation on GitHub Pages, with comments indicating that SSL certificate propagation can take from 20 minutes to 24 hours.
- One user expressed frustration as multiple individuals encountered 403 errors on their site during this period.
- Discussions Around AI Model Performance: Community members reflected on the consistency of AI model responses, with criticisms about repetitive follow-up questions from AI tools like Deep Research.
- There were hopes that enhancements to AI systems would allow for better context understanding and deeper follow-up questions.
- Tweet from Lucas Shaw (@Lucas_Shaw): Over the past year, OpenAI met with Hollywood studios to show off its new video tool Sora. None of them has done a deal to use it. A look at why with @shiringhaffary and @tgbuckley https://www.bloombe...
- Tweet from Tibor Blaho (@btibor91): Good catch - here is a different video with the new OpenAI Enterprise Sales Agent demoQuoting Cryptonymics🍎🚀 (@cryptonymics) We were actually shown the next agent, except we didn’t see it. Watch the...
- Tweet from kalomaze (@kalomaze): uhhhhhhhhh
- DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding: We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For ...
- What went into training DeepSeek-R1?: This Gradient Updates issue explores DeepSeek-R1’s architecture, training cost, and pricing, showing how it rivals OpenAI’s o1 at 30x lower cost.
- Chat with DeepSeek-VL2-small - a Hugging Face Space by deepseek-ai: no description found
- (WIP) A Little Bit of Reinforcement Learning from Human Feedback: The Reinforcement Learning from Human Feedback Book
- Open Sourcing π0: Physical Intelligence is bringing general-purpose AI into the physical world.
- Interconnects | Nathan Lambert | Substack: The cutting edge of AI, from inside the frontier AI labs, minus the hype. The border between high-level and technical thinking. Read by leading engineers, researchers, and investors on Wednesday morni...
- Interconnects | Nathan Lambert | Substack: The cutting edge of AI, from inside the frontier AI labs, minus the hype. The border between high-level and technical thinking. Read by leading engineers, researchers, and investors on Wednesday morni...
- Google Director reacts to Lex Fridman Episode on DeepSeek, China, OpenAI, NVIDIA, xAI, Stargate #459: Svicpodcast.com: For Questions, Book recs, Videos, Newsletters, etc.patreon.com/svicFollow us:Threads: www.threads.net/@svicpodcastTwitter: https://x.com/svi...
- Refreshed.: Check out https://openai.com/ to see more.
- Fishing for first timers: Using ChatGPT to catch halibut
Interconnects (Nathan Lambert) ▷ #memes (5 messages):
Vibe Coding, Blackout Poetry in AI, Clarifying Questions in Deep Research
- Karpathy's 'Vibe Coding' Takes Center Stage: Andrej Karpathy introduced a new concept called 'vibe coding', where he embraces the capabilities of LLMs like Cursor Composer, often bypassing traditional coding practices.
- He humorously notes that he rarely reads diffs anymore, stating, 'When I get error messages I just copy paste them in with no comment.'
- Unexpected Artistic Talent in AI Field: A member expressed surprise that professionals in AI are capable of blackout poetry, noting its beauty.
- This insight underscores the diverse creative expressions emerging within the tech community.
- Humor on Follow-Up Questions in Research: A member joked about the necessity of clarifying questions in Deep Research, hinting at a specific interaction that prompted this behavior.
- This comment was made in reference to ongoing discussions about the critique of follow-up questions, highlighting the community's humorous engagement with the topic.
- Tweet from sigh swoon (@sighswoon): Quoting Andrej Karpathy (@karpathy) There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It&...
- Tweet from James Campbell (@jam3scampbell): plz don’t tell me this interaction is the reason Deep Research always asks clarifying questions first 😭
Interconnects (Nathan Lambert) ▷ #rl (3 messages):
Skepticism towards RL datasets, Democratization of Reinforcement Learning
- Model Developers Skeptical of Non-Model Shop Data: Questions arose about the value of an RL dataset published by a non-model shop, with speculation that it would have low value without the endorsement of established model developers.
- Concerns were voiced about the rigorous filtering and verification processes at model shops, suggesting that unverified datasets might not gain traction.
- Debate on the Democratization of RL: A colleague expressed enthusiasm for the democratization of RL, questioning who exactly benefits and which aspects of the model pipeline are accessible.
- This led to reflections on how non-traditional organizations could contribute meaningfully, yet remained skeptical about the true impact on the RL landscape.
Interconnects (Nathan Lambert) ▷ #reads (14 messages🔥):
JAX usage, The Nvidia Way, Amazon operations, Grok shipping, Nvidia company culture
- JAX usage by Giants: A member pointed out that Google and xAI utilize JAX, suggesting it's an important tool in the industry.
- Another member joked about Elon needing to start shipping Grok, possibly indicating competition in the AI landscape.
- Is 'The Nvidia Way' a Worthwhile Read?: One member asked if 'The Nvidia Way' is worth reading, and another confirmed they enjoyed the audiobook.
- They highlighted how hardcore Nvidia's approach is and noted the impressive company culture.
- 'Working Backwards' Enhances Appreciation for Amazon: A member shared insights from reading 'Working Backwards,' explaining it provided a newfound understanding of intense operations at Amazon.
- They reflected on the remarkable intensity of the company's culture and operations.
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
SnailBot News, Return of RL World
- SnailBot News Update: A channel announcement was made regarding SnailBot News, signaling upcoming updates and reminders for the community.
- Details on the latest news were anticipated, building excitement among members.
- Brief Hiatus Before RL World Returns: One member mentioned taking a break from the RL world, but hinted that it will be returning soon with a light-hearted tone.
- This comment suggests a welcomed comeback and a transition back to more interactive activities.
LM Studio ▷ #general (208 messages🔥🔥):
LM Studio Usage, Model Compatibility, Hardware Requirements, Vulkan Support, GPT-Researcher Integration
- Challenges in Running LM Studio with Limited Hardware: Users discussed running LM Studio on older CPUs and GPUs, noting performance limitations, especially with lower VRAM graphics cards like the RX 580.
- Some users suggested compiling llama.cpp without AVX support to improve performance on outdated systems.
- Model Recommendations for Coding: The Qwen 2.5 model was recommended for users with specific hardware configurations, particularly for coding tasks.
- Users shared their preferences for different models based on performance and usability with local installations.
- Vulkan Support in LM Studio: Discussion revolved around enabling Vulkan support for better GPU utilization in llama.cpp, which requires specific build configurations.
- Users provided links to resources for compiling with Vulkan support, highlighting the need for proper setup.
- Integrating GPT-Researcher with LM Studio: Some users attempted to use GPT-Researcher with LM Studio but encountered errors related to model loading and embedding requests.
- The integration challenges included a 404 error indicating that no models were loaded, impeding the operation.
- Image and Video Model Support: Users inquired about the capability of LM Studio to support image and video models, specifically noting the availability of vision models.
- Models like Qwen 2-VL were mentioned as supporting basic image recognition tasks but not for generating content.
- T3 Chat - The Fastest AI Chatbot: no description found
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- Download and run lmstudio-community/Mistral-7B-Instruct-v0.3-GGUF in LM Studio: Use lmstudio-community/Mistral-7B-Instruct-v0.3-GGUF locally in your LM Studio
- codename goose | codename goose: Your open source AI agent, automating engineering tasks seamlessly.
- Import Models | LM Studio Docs: Use model files you've downloaded outside of LM Studio
- lmstudio-community/MiniCPM-o-2_6-GGUF · Hugging Face: no description found
- GGUF My Repo - a Hugging Face Space by ggml-org: no description found
- Richard Stalman Richard GIF - Richard Stalman Richard Stalman - Discover & Share GIFs: Click to view the GIF
- Gemini 2.0 is now available to everyone: We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.
- llama.cpp/docs/build.md at master · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- Llama Coder – AI Code Generator: Generate your next app with Llama 3.1 405B
- Reddit - Dive into anything: no description found
- GitHub - kth8/llama-server-vulkan: Run llama.cpp server with Vulkan: Run llama.cpp server with Vulkan. Contribute to kth8/llama-server-vulkan development by creating an account on GitHub.
- Feature Request: Add support to deepseek vl2 · Issue #11678 · ggerganov/llama.cpp: Prerequisites I am running the latest code. Mention the version if possible as well. I carefully followed the README.md. I searched using keywords relevant to my issue to make sure that I am creati...
- Releases · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
LM Studio ▷ #hardware-discussion (39 messages🔥):
Performance with 3070 and 8700K, M4 Max capability, GPU pricing and availability, PCIe configurations for inference, RAM and VRAM requirements for models
- Lesser models struggle on 3070: Users reported that only smaller models run properly on a setup with a 3070 and an 8700K OC to 4.8GHz, often resulting in error messages.
- One user asked for suggestions on uncensored models feasible for this configuration.
- M4 Max can pull 140W: The M4 Max on a MacBook Pro is capable of fully pulling 140W, showcasing its performance capabilities.
- Such specs add to discussions about laptop cooling efficiency, especially when comparing models.
- Rising GPU prices on secondary markets: Concerns were raised about GPU prices on platforms like eBay and Mercari, indicating they are now appreciating assets due to demand.
- Discussion includes the inflated prices of components, including the Jetson board influenced by scalpers.
- Optimizing memory configurations for inference: A user speculated on the effect of running a 9950X in 2:1 mode for better bandwidth at a cost of latency for LLM inference.
- However, concerns were mentioned about stability and UCLK speeds on the 9950X.
- Minimum VRAM requirements for larger models: It was noted that 24GB of VRAM is the minimum required for running Q4KM 32B models comfortably, especially with complex configurations.
- Users were directed to a resource for computing model requirements based on system specs.
Link mentioned: Can Your Computer Run This LLM?: no description found
HuggingFace ▷ #general (176 messages🔥🔥):
AI for Math Contributions, DeepSeek Model Performance, AI Art Style Transfer, Hugging Face Spaces Updates, LLM Benchmarking
- Exploring Contributions in AI for Math: A member inquired about ongoing projects related to AI for Math that are open for contributions, leading to discussions about community help.
- Another member shared a link to a relevant Discord thread for insights and potential project updates.
- DeepSeek Gains Popularity Over ChatGPT: A user expressed frustration with the perceived degradation of ChatGPT's performance and noted that DeepSeek provides better answers but faces accessibility issues due to high traffic.
- Others shared their interest in DeepSeek's thinking process, emphasizing its chain of thought methodology as more engaging than traditional AI responses.
- Utilizing LoRA for AI Art Enhancements: A user new to AI created art posed a query about using LoRA to train models on their artistic style, stating they were informed LoRA could help with this.
- Experienced members recommended tools like onetrainer and kohya-ss for creating LORAs and suggested combining this with ControlNet for better results.
- Updates and Feedback on Hugging Face Interfaces: Feedback was collected regarding changes to the user interface of Hugging Face platforms, including how thumbnail features have been modified.
- Users noted mixed feelings about improvements with some easier navigation while others found the new aesthetic less appealing.
- Challenges with LLM and Token Clarification: A member expressed confusion over the internal workings of LLM compositional structures and the nature of token generation in models like DeepSeek.
- Discussions included the distinction between token efficiency and reasoning depth, emphasizing the complexity involved in understanding these AI mechanisms.
- Hugging Face - Learn: no description found
- xVASynth TTS - a Hugging Face Space by Pendrokar: no description found
- Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard: no description found
- @victor on Hugging Face: "Hey everyone, we've given https://hf.co/spaces page a fresh update! Smart…": no description found
- app.py · m-ric/open_Deep-Research at main: no description found
- Sneakers (1992): My Voice Is My Passport: Sneakers. Dir. Phil Alden Robinson. Universal Studios, 1992.This short clip is intended to serve as an illustration for an entry on WNYC Radio's "On The Medi...
HuggingFace ▷ #i-made-this (6 messages):
Modified ESN Simulation, New Paper on Arxiv, Securade.ai HUB, TinyRAG System
- Interactive Modified ESN Simulation Launched: The Modified ESN simulation allows users to click on neurons to stimulate and propagate, with full Python code coming soon.
- Its intended application could enable it to learn without any pre-training data, potentially embedded in a robot.
- New Insights in Neural Network Design: A new paper titled Distance-Based Learning in Neural Networks has been published on arXiv, detailing a novel geometric framework and introducing OffsetL2 architecture.
- This research emphasizes the impact of distance-based representations on model performance while contrasting with intensity-based approaches.
- Securade.ai HUB Enhances CCTV Functionality: The Securade.ai HUB is a generative AI-based edge platform that transforms existing CCTV cameras into smart systems.
- It promises an innovative approach to computer vision by utilizing generative AI technologies.
- TinyRAG Simplifies RAG Systems: The TinyRAG project is a simple RAG (retrieval-augmented generation) system leveraging llama-cpp-python and sqlite-vec for ranking, querying, and providing LLM answers.
- This initiative aims to streamline the implementation of RAG systems for developers and researchers.
- Neural Networks Learn Distance Metrics: Neural networks may naturally favor distance-based representations, where smaller activations indicate closer proximity to learned prototypes. This contrasts with intensity-based approaches, which rel...
- Neural Network Simulation: no description found
- GitHub - securade/hub: Securade.ai HUB - A generative AI based edge platform for computer vision that connects to existing CCTV cameras and makes them smart.: Securade.ai HUB - A generative AI based edge platform for computer vision that connects to existing CCTV cameras and makes them smart. - securade/hub
- GitHub - wannaphong/tinyrag: Simple RAG system: Simple RAG system. Contribute to wannaphong/tinyrag development by creating an account on GitHub.
- Tonic/MiniF2F · Datasets at Hugging Face: no description found
HuggingFace ▷ #reading-group (4 messages):
Event Timing Confirmation, Description Approval, Upcoming Event Excitement
- Event Timing Confirmation: A member requested confirmation about the event details, specifically the timing and description, directing others to check the event link.
- Looking forward to the pres! indicates eagerness for the event.
- Perfect Description Acknowledged: Another member positively confirmed that the description for the event is perfect.
- This suggests that all details are aligned for the upcoming gathering.
- Excitement for Sunday: Members expressed excitement about seeing each other on Sunday, referring to each other as legends.
- This implies a friendly atmosphere and anticipation for the event gathering.
HuggingFace ▷ #computer-vision (1 messages):
Image Classification Models, ResNet50 Fine-tuning, Publishing Sector Insights
- Exploring Image Classification Models for Publishing: A new member is developing a project to classify images into 31 categories such as photography, drawing, and diagrams.
- They are seeking insights on suitable models, indicating interest in ResNet50 and fine-tuning methods.
- Seeking Detailed Guidance on ResNet50: The member inquired specifically about ResNet50 as a potential model for their image classification task.
- They expressed a desire to have a detailed conversation about the fine-tuning process for this model.
HuggingFace ▷ #gradio-announcements (3 messages):
Office Hours Announcement, Gradio Contribution Video
- Join Us for Office Hours!: An announcement was made for Office Hours scheduled for tomorrow to discuss recent releases and upcoming plans, inviting all to join and ask questions.
- The event link provided was here.
- Office Hours Wrap-Up: Thanks were given for the participation in today's Office Hours, highlighting the positive engagement from attendees.
- A member shared a YouTube video on contributing to Gradio that walks through the process of making initial contributions to open-source projects.
Link mentioned: How to make your very FIRST open-source contribution (feat. Gradio): One of the questions we get asked most often is: "how do I even start contributing to open-source software?"We recorded a video walkthrough fixing a real bug...
HuggingFace ▷ #smol-course (2 messages):
Updated NLP Course, Current NLP Course Limitations
- Call for Updated NLP Course from Hugging Face: A member inquired whether Hugging Face plans to create an updated NLP course, emphasizing its usefulness given the current course's lack of coverage on LLMs.
- This sentiment reflects concerns about the evolving landscape of NLP and the need for educational resources to keep pace with advancements.
- Limitations of the Current NLP Course: The conversation highlighted that the existing NLP course does not encompass large language models, which are crucial in today's NLP frameworks.
- This gap has prompted suggestions for more comprehensive training material to address emerging trends in the field.
HuggingFace ▷ #agents-course (15 messages🔥):
Agents Course Registration, Python Coding Skills for Course, Python Learning Resources, Tools for 2D Plane to Python Code, Finetuning Models for AI Agents
- Agents Course Registration Confirmation: A member inquired about the time frame for receiving a registration confirmation email after signing up for the Agents Course, but no response about the timing was shared.
- This highlights a potential concern for new participants about the lack of immediate communication following registration.
- Importance of Python Coding Skills: A participant expressed concern about lacking basic Python skills that are necessary for fully benefiting from the course content, asking for advice on how to prepare.
- Multiple members responded with recommendations for Python resources and learning materials to help bridge the knowledge gap.
- Recommended Resources for Learning Python: Suggestions included the book Automate the Boring Stuff with Python and a YouTube tutorial titled 'Python Tutorial for Beginners with VS Code'.
- These resources aim to provide a practical introduction to Python coding for beginners preparing for the course.
- Translation of Figures to Python Code: A member proposed creating tools to translate 2D figures or planes into Python code for practical applications in projects.
- There was discussion about creating datasets suitable for finetuning smaller models like deepsek-r1 to enhance the development of AI agents.
- Excitement for the Upcoming Course Launch: The course release was confirmed for next Monday, accompanied by new channels created for updates, questions, and showcasing projects.
- A sneak peek of the first unit's table of contents sparked excitement among the participants.
- Automate the Boring Stuff with Python: no description found
- Could be useful one day - a m-ric Collection: no description found
- A Survey on Large Language Model based Autonomous Agents: Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within is...
- FreeCAD Part Scripting in Python Episode 025: Description: Design an enclosure for lighting controller. Software toolchain includes: Notepad++, FreeCAD, CURA, and Repetier-Server controlling a MakerGear ...
- Python Tutorial for Beginners with VS Code 🐍: Web Dev Roadmap for Beginners (Free!): https://bit.ly/DaveGrayWebDevRoadmapIn this Python tutorial for beginners with VS Code, you will learn why you should ...
HuggingFace ▷ #open-r1 (1 messages):
HuggingFace Repo Testing, Hardware for Inference
- Offer for HuggingFace Model Testing: A member expressed readiness to assist with inferencing as soon as a model is formatted for the HuggingFace repository.
- They mentioned having the necessary hardware to load it up for testing.
- Need for Technical Testing Support: The member showcased an eagerness to help once models are available, emphasizing their capability to handle inferencing tasks.
- This illustrates community collaboration and the desire for thorough testing processes in the development of new models.
Yannick Kilcher ▷ #general (144 messages🔥🔥):
NURBS vs Meshes, AI Reasoning Models, Perspective and Transformation, Topology in 3D Modeling, Dynamic vs Static Use Cases
- NURBS offer advantages over traditional meshes: NURBS provide parametric and compact representations that are suitable for accurate and dynamic simulations, while meshes are increasingly viewed as inefficient due to complexity in rendering.
- Though NURBS traditionally faced challenges with texturing, modern procedural shaders have mitigated these issues, making them viable for many applications.
- Emerging affordable AI reasoning models: Researchers developed the s1 reasoning model, achieving capabilities similar to OpenAI's models for under $50 in cloud compute credits, marking a significant reduction in costs.
- This model utilizes a distillation approach, extracting reasoning capabilities from Google's Gemini 2.0, thus illustrating the trend towards more accessible AI technologies.
- Importance of perspective in computational modeling: Discussions emphasized the need for upper-degree algebras like Projective Geometric Algebra (PGA) and Conformal Geometric Algebra (CGA) to handle complex geometric relationships and perspectives.
- The conversation revealed that accurately defining perspective transformations is essential for modern modeling techniques, particularly in dynamic environments.
- Challenges in 3D mesh topology: There are ongoing efforts to improve mesh topologies for various applications, as high-fidelity meshes remain essential in video games and film, yet are less efficient for simulations.
- The transition towards dynamic models and advanced techniques, such as NURBS and SubDs, showcases a shift in industry standards as traditional mesh methods face limitations.
- Static vs Dynamic Approaches in AI: Participants noted a fundamental challenge across fields like AI and 3D modeling, where static designs struggle to meet the needs of dynamic applications.
- This debate highlights the necessity for evolving methodologies in both computational models and AI agents to effectively operate in changing environments.
- Tweet from Chuang Gan (@gan_chuang): LLM can perform autoregressive search!LLM can perform autoregressive search!LLM can perform autoregressive search!Introducing Satori, a new framework for advancing LLM reasoning through deep thinking ...
- Tweet from David D. Baek (@dbaek__): 1/9 🚨 New Paper Alert: Cross-Entropy Loss is NOT What You Need! 🚨We introduce harmonic loss as alternative to the standard CE loss for training neural networks and LLMs! Harmonic loss achieves 🛠️si...
- $1 million prize offered to decipher 5,300-year-old Indus Valley script: The government of Tamil Nadu has offered a $1-million reward for anyone who can decode the cryptic script of the Indus Valley Civilization
- Reddit - Dive into anything: no description found
- Researchers created an open rival to OpenAI's o1 'reasoning' model for under $50 | TechCrunch: AI researchers at Stanford and the University of Washington were able to train an AI "reasoning" model for under $50 in cloud compute credits, according
- smolagents/examples/open_deep_research at gaia-submission-r1 · huggingface/smolagents: 🤗 smolagents: a barebones library for agents. Agents write python code to call tools and orchestrate other agents. - huggingface/smolagents
- GitHub - bairesearch/ATOR: Axis Transformation Object Recognition: Axis Transformation Object Recognition. Contribute to bairesearch/ATOR development by creating an account on GitHub.
- Gemini - Building an LLM-Powered Summarizer : Created with Gemini Advanced
- ChatGPT is made from 100 million of these [The Perceptron]: Go to https://drinkag1.com/welchlabs to subscribe and save $20 off your first subscription of AG1! Thanks to AG1 for sponsoring today's video.Imaginary Numbe...
- GitHub - bairesearch/ATORpt: Axis Transformation Object Recognition (ATOR) for PyTorch - experimental implementations including receptive field feature/poly detection, parallel processed geometric hashing, end-to-end neural model. Classification of normalised snapshots (transformed patches) via ViT: Axis Transformation Object Recognition (ATOR) for PyTorch - experimental implementations including receptive field feature/poly detection, parallel processed geometric hashing, end-to-end neural mo...
- Home: Axis Transformation Object Recognition. Contribute to bairesearch/ATOR development by creating an account on GitHub.
- WIPO - Search International and National Patent Collections: no description found
- High-Fidelity 3D Mesh Generation at Scale with Meshtron | NVIDIA Technical Blog: Meshes are one of the most important and widely used representations of 3D assets. They are the default standard in the film, design, and gaming industries and they are natively supported by virtually...
Yannick Kilcher ▷ #paper-discussion (32 messages🔥):
Harmonic Loss Paper, AI Peer Review Improvements, Error Bars in AI Research, VideoJAM Analysis, Jailbreaking AI Systems
- Harmonic Loss Paper Under Scrutiny: The Harmonic Loss paper presents a faster convergence model but lacks demonstrated performance improvements, leading to mixed opinions on its practicality.
- One member suggested that while the paper may be 'jank', its brevity makes it worth a read, especially since the accompanying GitHub provides more informative insights.
- AI Peer Review Process Enhancements Discussed: A proposal was made to use A/B testing in peer reviews to provide more consistent and effective feedback, particularly in AI-related publications.
- This concept could leverage high-quality reviewer benchmarks to mitigate biases and improve review outcomes.
- Value of Error Bars in AI Research: Discussion highlighted the importance of including error bars and other statistical measures in AI research papers to enhance clarity and scientific rigor.
- Members noted that the omission of these statistical tools is common, yet essential for comprehensive experimental analysis.
- VideoJAM Paper Review Scheduled: A discussion is planned regarding the VideoJAM paper that promises to explore groundbreaking video analysis methods.
- With the paper being new, audience insights and critiques will be valuable in evaluating its contributions to the field.
- Mixed Feedback on AI Jailbreaking Capabilities: Commentary emerged regarding ongoing jailbreaking efforts, revealing that these systems are more resilient than previously anticipated according to recent challenges.
- A tweet noted that, after 48 hours into a jailbreak challenge, no one had passed to level 4, yet many succeeded in level 3.
- Tweet from Jan Leike (@janleike): It's been about 48h in our jailbreaking challenge and no one has passed level 4 yet, but we saw a lot more people clear level 3
- Tweet from Lucas Nestler (@_clashluke): I created an efficient L2+HarMax implementation and noticed something weird: 1) Use this `dist = 2 * F.linear(y, weight) - y.norm(dim=-1, keepdim=True) - weight.norm(dim=-1, keepdim=True).T `instead o...
- Harmonic Loss Trains Interpretable AI Models: In this paper, we introduce **harmonic loss** as an alternative to the standard cross-entropy loss for training neural networks and large language models (LLMs). Harmonic loss enables improved interpr...
- VideoJAM: VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Model
- Where in the world is DeepSeek banned and why?: The US could become the second country to introduce an outright ban of the Chinese AI app
- GitHub - KindXiaoming/grow-crystals: Getting crystal-like representations with harmonic loss: Getting crystal-like representations with harmonic loss - KindXiaoming/grow-crystals
- The Case for Human-like Scalable Intelligence in the Medical Field | Journal of Data Science and Intelligent Systems : no description found
Yannick Kilcher ▷ #ml-news (17 messages🔥):
OpenAI's sentry gun incident, Gemini model updates, Flash thinking vs Pro thinking, Gemini 2.0 Flash performance, Leaderboard for AI models
- OpenAI shuts down viral ChatGPT-powered sentry gun: OpenAI has cut off API access to an engineer after a viral video showcased a motorized sentry gun controlled by ChatGPT commands, raising concerns about AI-powered weapons.
- The engineer, known as sts_3d, previously highlighted other projects, demonstrating a quick evolution into creating the sentry gun.
- Gemini model updates announced: Google announced that the updated Gemini 2.0 Flash is now generally available in the Gemini API and Google AI Studio, boasting low latency and enhanced performance.
- Earlier iterations like Flash Thinking have combined speed with reasoning capabilities, aiming to improve functionality across use cases.
- Debate on Flash thinking vs Pro thinking: Discussions on the merits of Flash thinking and Pro thinking surfaced, with some users expressing preferences for updated models as they compare performance.
- One user reported that Flash thinking often answers questions more effectively than the previous 1.5 Pro version.
- Concerns over Gemini 2.0 Flash Lite performance: Feedback on Flash Lite indicated struggles with returning structured output, often resulting in invalid JSON responses.
- The audience continues to explore various models, with one user noting their experiences with the newly introduced models from Google.
- New models missing from the leaderboard: There are reports that the new Google models added yesterday are not yet reflected on the model leaderboard.
- Concerns were raised regarding model visibility and comparisons, as users seek to gauge performance accurately.
- Tweet from Omar Sanseviero (@osanseviero): Hey r/LocalLLaMA 👋We're cooking 🫡 Gemma going brrr
- LLM Rankings | OpenRouter: Language models ranked and analyzed by usage across apps
- Gemini Flash 2.0 - API, Providers, Stats: Gemini Flash 2.0 offers a significantly faster time to first token (TTFT) compared to [Gemini Flash 1. Run Gemini Flash 2.0 with API
- Gemini 2.0 is now available to everyone: We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.
- Google: Gemini Flash Lite 2.0 Preview (free) – Run with an API: Sample code and API for Google: Gemini Flash Lite 2.0 Preview (free) - Gemini Flash Lite 2.0 offers a significantly faster time to first token (TTFT) compared to [Gemini Flash 1.5](google/gemini-flash...
- Viral ChatGPT-powered sentry gun gets shut down by OpenAI: But actual autonomous AI weapons systems are much more terrifying.
- Gemini 2.0: Flash, Flash-Lite and Pro: no description found
OpenAI ▷ #annnouncements (3 messages):
WhatsApp ChatGPT features, Deep research update, YouTube video 'Refreshed'
- WhatsApp ChatGPT adds new features: ChatGPT on WhatsApp now allows users to upload images and send voice messages when asking questions, enhancing interactivity.
- Additionally, a future update will enable users to link their ChatGPT accounts (Free, Plus, Pro) for improved usage.
- Deep research rollout completed for Pro users: Deep research capabilities have been fully rolled out to 100% of Pro users across regions like the UK, EU, and several Nordic countries.
- This update marks a significant enhancement for users in Norway, Iceland, Liechtenstein, and Switzerland as they gain access.
- YouTube video titled 'Refreshed': A new YouTube video titled 'Refreshed' was shared, promoting the latest updates from OpenAI.
- Viewers can check out more details on the official OpenAI website.
Link mentioned: Refreshed.: Check out https://openai.com/ to see more.
OpenAI ▷ #ai-discussions (92 messages🔥🔥):
DeepSeek Privacy Concerns, Midjourney vs. Flux, ChatGPT and Reasoning, Gemini 2.0 Features, Deep Research Availability
- DeepSeek raises privacy flags: Concerns about DeepSeek sending data to China were highlighted, referencing a YouTube video that discusses its data practices.
- One user noted this could be due to servers being based in China, leading to inevitable information transfer.
- Midjourney and Flux debated: A user expressed the view that Midjourney has a superior aesthetic compared to Flux, with some users challenging this assertion.
- Arguments ensued over the effectiveness of art generated by both platforms, showcasing a strong following for Midjourney.
- ChatGPT showcasing mixed reasoning: Users reported ChatGPT 4o sometimes providing reasoning in multiple languages despite English input, highlighting unexpected behavior.
- Frustrations arose over its responses being too verbose, with particular reference to a user experiencing delays in generating requested articles.
- Gemini 2.0 boasts impressive features: Gemini 2.0 offers a 2 million token context and free access via API, raising interest amongst developers eager to experiment.
- Users noted the significance of automation tying into Gemini 2.0, even while some expressed that the AI's extended elaboration led to much reading.
- Deep Research roll-out news: Deep Research will soon be available to Pro users in the UK, EU, and other regions, with Plus users anticipated to gain access soon.
- Users expressed frustration over the delay, pushing for timely updates, as many eagerly await deeper research functionalities.
- Large-scale Group Brainstorming using Conversational Swarm Intelligence (CSI) versus Traditional Chat: Conversational Swarm Intelligence (CSI) is an AI-facilitated method for enabling real-time conversational deliberations and prioritizations among networked human groups of potentially unlimited size. ...
- How large groups can use AI to organize without leadership: Large-scale Group Brainstorming using Conversational Swarm Intelligence (CSI) versus Traditional ChatArXiv: https://arxiv.org/abs/2412.14205Bytez: https://by...
- Is DeepSeek Lying to you? #shorts #wireshark #deepseek #privacy #cybersecurity: #shorts #wireshark #deepseek #privacy #cybersecurity
OpenAI ▷ #gpt-4-discussions (7 messages):
Testing New Features, o3mini Inspiration
- Early Impressions on New Testing: rjkmelb mentioned that it is too early to draw conclusions but noted that first impressions are looking very good.
- Another member, .pythagoras, acknowledged this positive feedback.
- Confusion Around o3mini Reference: niebj1749 speculated that a feature is calling o3mini, prompting questions about the source.
- sohamkoley_21468 identified a potential inspiration from GPT 4o Mini, which led to some confusion among members.
- Clarification on o3mini: mustafa.h expressed confusion over the statement regarding o3mini, asking for clarification on what was meant.
- This sparked a brief discussion with community members still pondering its relevance.
OpenAI ▷ #prompt-engineering (3 messages):
Statistics Analysis Prompt Design, Rhetorical Argument Structure in Writing, Sprite Sheet Generation for Animation, Character Design in Sprite Sheets
- Designing a Statistics Analysis Prompt: A user seeks to create a versatile prompt for a statistics analyst that can accommodate various statistical methods like Logistic Regression and Poisson Distribution by modifying a base prompt for specific problems.
- The user aims for the assistant to help them solve problems while comparing results with their own understanding as a student of economics.
- Constructing a Persuasive Argument with Rhetoric: A user shares a detailed prompt for generating a persuasive argument about why Coca-Cola is better with hot dogs, incorporating advanced rhetorical techniques like Antimetabole and Chiasmus.
- The structure includes sections for justifying the argument, providing examples, and addressing counterarguments, all aimed at crafting a cohesive and impactful final argument.
- Creating Cartoon Sprite Sheets: A user inquires about creating a prompt template for generating sprite sheets that feature a consistent cartoon style, focusing on character and animation frame layout rather than pixel art.
- The current template includes details like character design, frame counts for various actions, and specific dimensions but results in images that are not aligning as intended.
OpenAI ▷ #api-discussions (3 messages):
Statistics Analysis Techniques, Rhetoric Argument Construction, Sprite Sheet Generation
- Seeking Expertise in Statistics Analysis: A user is looking to create a prompt for a statistics analyst using methods like Logistic Regression and Poisson Distribution to solve specific problems in economics.
- They aim to build a base prompt that can be customized for different analyses, noting their knowledge in statistics but seeking assistance for validation.
- Constructing Rhetorical Arguments: A member requested a structure for developing a persuasive argument on why coca-cola is better with a hot-dog, detailing specific rhetorical techniques to use.
- The outlined structure emphasizes various rhetorical devices such as Antimetabole and Chiasmus to enhance the argument's effectiveness and fluidity.
- Creating Cartoon Sprite Sheets: A user shared their prompt template for generating a cartoon sprite sheet of a pirate-themed clownfish with specific animation frames in a grid layout.
- They expressed concern about ending up with randomly placed images instead of the desired organized sprite sheet, seeking feedback on their approach.
Nous Research AI ▷ #general (96 messages🔥🔥):
Data Availability in Distributed Training, Hermes Reasoner Insights, OpenAI vs DeepSeek Model Performance, AI Backlash and Crypto Relation, DeepResearch from OpenAI
- Exploring Data Availability for Distributed Training: A member discussed the potential utility of Celestia and Mina for improving data availability in context of distributed training, questioning the efficiency compared to traditional models.
- They humorously noted thinking about this idea aloud and acknowledged its speculative nature.
- Hermes Reasoner Shows Off: There was a light-hearted comment about how the Hermes Reasoner 'pretended to align digits on paper', capturing attention and amusement.
- Another member chimed in, expressing fascination with how different cultures might interpret mathematical principles.
- OpenAI and DeepSeek Models Under Comparison: Discussion highlighted how DeepSeek R1 is said to rival OpenAI's O1 reasoning model while being fully open-source, facilitating users to run it more effectively.
- Members noted the impressive capabilities of newer models like Gemini for performing mathematical tasks and how complexities in branding can confuse users.
- AI Backlash Linked to Crypto Visibility: A member speculated whether the backlash against AI is partially due to the negative remnants of NFT and crypto controversies from 2020-21.
- They referenced a well-written essay discussing this idea and its implications, indicating that perceptions of AI might be interrelated with past tech hypes.
- Positive Reception of OpenAI's DeepResearch: Users expressed enthusiasm about OpenAI's DeepResearch feature, noting its strong performance and ability to retrieve obscure information efficiently.
- Members debated augmenting the results further through knowledge graphs to improve fact-checking and research accuracy.
- Tweet from Mario Nawfal (@MarioNawfal): STUDY: CHATGPT BIAS IS REAL—AND IT’S TILTING LEFTA new study confirms what many suspected—ChatGPT favors left-leaning views, often avoiding or restricting conservative perspectives.Researchers found A...
- Tweet from Teknium (e/λ) (@Teknium1): Hermes with Reasoning, 1+1
Okay, so I need to figure out what 1 plus 1 equals. Hmm, let's start from the basics here. I remember from my math classes that this is a simple addition pro... - Run DeepSeek-R1 Dynamic 1.58-bit: DeepSeek R-1 is the most powerful open-source reasoning model that performs on par with OpenAI's o1 model.Run the 1.58-bit Dynamic GGUF version by Unsloth.
- Gemini 2.0 is now available to everyone: We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.
- Why Everyone Is Suddenly Mad at AI: AI Backlash: Another Tech Hype Hangover (and Is Crypto to Blame?)(OpenAI Deep research demo prompt: Write an essay on why there might be backlash to AI, and if it's related to NFT/crypto visibilit...
- DeepSeek R1 Theory Overview | GRPO + RL + SFT: Here's an overview of the DeepSeek R1 paper. I read the paper this week and I was fascinated by the methods, however it was a bit difficult to follow what wa...
- DeepSeek R1 Zero Hands-on TRAINING SECRETS You Need to Know!: 0:00 - 2:24 Paper Overview2:24 - 7:41 Code Walkthrough 17:41 - 15:33 GRPO Full Explanation with Intuitive Example15:33 - 18:40 Code Walkthrough 218:40 - 27:...
Nous Research AI ▷ #ask-about-llms (1 messages):
O3-mini prompt crafting
- Crafting effective prompts for O3-mini: A member is seeking assistance in crafting a prompt for O3-mini that encourages deeper thinking from the model.
- They are currently in the process but haven't found success, asking if anyone else has insights or information to share.
- Need for more thoughtful interaction: The discussion highlighted the importance of creating prompts that stimulate more thoughtful interactions from O3-mini.
- Members expressed a desire for richer prompts that can lead to engaging conversations.
Nous Research AI ▷ #research-papers (3 messages):
Pretraining papers, Acknowledgment of authors, Hardware infrastructure team
- Pretraining Papers Overflow with Authors: A member commented on the abundance of authors in pretraining papers, highlighting the necessity to credit the hardware infrastructure team.
- Infra people suffer so that the research scientists don't have to.
- The Role of Infrastructure Teams in Research: Another mention emphasized that the hardware infrastructure team plays a pivotal role in facilitating research, justifying the numerous author credits.
- This collaboration ensures that research scientists can focus on their work without technical burdens.
Nous Research AI ▷ #interesting-links (2 messages):
Liger-Kernel PR #553, Deep Dive into LLMs
- Liger Kernel Introduces GRPO Chunked Loss: A recent pull request adds the GRPO chunked loss to the Liger Kernel, addressing issue #548.
- Developers mentioned to run make test, make checkstyle, and make test-convergence for testing correctness and code style.
- Explore LLMs with YouTube's Deep Dive: A YouTube video titled 'Deep Dive into LLMs like ChatGPT' explores the AI technology behind ChatGPT and its training process.
- This general audience presentation covers the full training of Large Language Models (LLMs), discussing related products in-depth.
- Deep Dive into LLMs like ChatGPT: This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It is covers the full traini...
- Grpo loss by kashif · Pull Request #553 · linkedin/Liger-Kernel: SummaryAdds the GRPO chunked lossfixes issue #548Testing DoneHardware Type: run make test to ensure correctness run make checkstyle to ensure code style run make test-convergence to ensu...
Nous Research AI ▷ #research-papers (3 messages):
Pretraining Papers Authorship, Importance of Hardware Infra Team
- Pretraining papers and their authorship bloated: Members noted that many pretraining papers have a plethora of authors due to the need to credit the hardware infrastructure team.
- A bunch of pretraining papers have tons of authors because you must credit the hardware infra team.
- Research scientists benefit from Infra team's efforts: It was highlighted that the infra team endures challenges so that research scientists can focus on their work without distractions.
- Infra people suffer so that the research scientists don't have to.
Modular (Mojo 🔥) ▷ #general (7 messages):
Closed Source Compiler, Open Sourcing Timeline, MLIR Dialects and Passes, Function Level Lowering
- Compiler goes closed source, community curious: A member expressed understanding of the compiler's transition to closed source, highlighting the challenges of managing community contributions amidst rapid changes.
- Compiler nerds are eager to access inner workings, particularly the custom lowering passes in MLIR.
- Target for Open Sourcing the Compiler: A team member indicated that the compiler is expected to be open-sourced by Q4 of next year, with hopes of an earlier release.
- During a community meeting, they affirmed a commitment to open source by the end of 2026, with discussion starting around the 17:09 mark of the meeting video.
- No plans for early release of MLIR passes: A member inquired about the release of individual dialects or passes in MLIR before the compiler's final open-source release.
- Unfortunately, it was confirmed there are no such plans prior to the compiler's open-sourcing.
- Function Level Lowering for Parallelism: There was interest in function-level lowering to LLVM as a strategy to enable parallelism, considered broadly beneficial for the MLIR ecosystem.
- However, there are no plans to release such functionality before the final open-source version.
Link mentioned: Modular milestones: GPUs, 2024 reflections, and the road ahead 🚀: In this extra special community meeting, we reflected on 2024's progress and shared updates on:🧑🚀 MAX 24.6, featuring MAX GPU!🔥 Our overall approach to M...
Modular (Mojo 🔥) ▷ #mojo (87 messages🔥🔥):
Mojo Standard Library, Function Overloading in Mojo, Async Function Handling, Script Struct Implementation, Buffer Handling in APIs
- Discussion on Mojo Standard Library functionalities: Users deliberated whether the Mojo standard library will become more general-purpose with features like web server and JSON parsing, or if that should rely on community contributions.
- Concerns were raised about the high entry bar for adding new features to the stdlib, given the complexities of supporting various use cases.
- Function Overloading and Static Decorators: Function overloading is discussed as allowing different signatures for the same function name, creating flexibility in APIs.
- The ability to share docstrings among overloaded functions is queried, but currently is not supported.
- Handling Async Functions in Mojo: Participants explored proposals for handling async functions, suggesting using a new syntax for clarity and performance optimization.
- Concerns were raised about the complexity of maintaining different async and sync libraries and the implications on the usability of different versions of functionality.
- Script Struct Implementation for HTML API: A user sought to streamline their API by using a one-liner to update DOM elements via a structured Script object, running into immutability issues.
- The alternative solution involved breaking it into multiple lines, successfully demonstrating the challenge of mutability in method calls.
- Buffer Management and Optimization Discussion: The conversation included insights on managing buffer sizes for APIs, balancing performance against complexity when processing input data.
- Participants considered strategies for generic parsers and the trade-offs between more complex structures versus performance in various scenarios.
- GitHub - mojicians/awesome-mojo: A curated list of awesome Mojo 🔥 frameworks, libraries, software and resources: A curated list of awesome Mojo 🔥 frameworks, libraries, software and resources - mojicians/awesome-mojo
- [proposal] Provided Effect Handlers by owenhilyard · Pull Request #3946 · modular/mojo: This proposal contains an alternative to an effect system which I think is more suitable for abstracting async, raises, and similar function colors in a systems language where the context may not a...
Notebook LM ▷ #use-cases (10 messages🔥):
AI in Legal Practice, Case Study Assistance, Deposition Summaries, Contract Review Experiments, Document Drafting Automation
- AI Revolutionizes Legal Document Drafting: A member utilizes AI to study cases and draft repetitive legal documents for similar cases or mass litigation, noting its reliability and clear sourcing.
- Using templates as sources allows the AI to adapt specific cases, making the drafting process efficient and streamlined.
- Enhancing Contract Review with Avatars: Another member shared an experiment involving a YouTube demonstration on using avatars in contract review to make redlining analysis engaging.
- The integration of avatars aims to enhance the product's appeal and assist client teams effectively.
- AI Tools Highlight Narrative Weaknesses: A member expressed excitement to find a common approach to monitoring narrative strength through AI discussions.
- They have noticed how lack of emphasis from hosts can reveal weaknesses in their narratives, signaling areas needing development.
- Creative AI Features Desired: A member suggested that a potential improvement for AI tools would be the introduction of sliders to fine-tune creativity levels, similar to those in other AI services.
- This feature could enhance user control over AI-generated content in legal and other contexts.
- Deposition Summaries Enhance Legal Workflow: Members are identifying various applications of AI in law, particularly highlighting its utility in creating deposition summaries.
- There’s a consensus that these tools could be more effective than traditional methods relying solely on laptops.
Link mentioned: Demonstration of how Avatars can add value as digital labor to expand the paralegal team: We add avatars to this contract review app to make the redlining analysis more engaging and to differentiate the product.Avatars by www.simli.com
Notebook LM ▷ #general (84 messages🔥🔥):
NotebookLM access issues, NotebookLM Plus activation, Uploading files and sources, Audio overview features, Spreadsheet integration
- NotebookLM access problems reported: Users expressed difficulties accessing NotebookLM, particularly with unsupported locations or specific features like generating podcasts and uploading PDFs.
- One user suggested utilizing a VPN to potentially circumvent location restrictions.
- Activation and features of NotebookLM Plus: Google Workspace admins need to ensure their organization has at least the Business Standard license to activate NotebookLM Plus features.
- Resources were shared to help administrators activate these additional services and manage user access effectively.
- Challenges in uploading and using sources: Multiple users reported issues uploading files like PDFs and CSVs, citing frustrations with the tool's performance in handling detailed content such as stock charts and financial data.
- Discussion highlighted the need for better formatting and understanding of how to prepare source material for effective results.
- Inconsistencies with audio overview features: Users noted that the interactive mode for audio overviews does not consistently appear, leading to questions about its functionality and potential bugs.
- It was suggested that deleting generated audio files might be required to access customization options.
- Spreadsheet use and data analysis limitations: Concerns were raised about the effectiveness of NotebookLM in analyzing tabular data from spreadsheets, with a recommendation to use Gemini for more complex data tasks.
- Users discussed best practices for uploading spreadsheets and the limitations faced in terms of data recognition.
- NotebookLM gets a new look, audio interactivity and a premium version: NotebookLM is introducing new features, and a premium version called NotebookLM Plus.
- Upgrading to NotebookLM Plus - NotebookLM Help: no description found
- Turn on or off additional Google services - Google Workspace Admin Help: no description found
- Compare Google Workspace editions - Business - Google Workspace Admin Help: no description found
Torchtune ▷ #general (54 messages🔥):
Torchtune vs Unsloth Performance, Kolo Docker Tool, FastAPI and Next.js Interface for Torchtune, GRPO Implementation, Custom Script Integration in Torchtune
- Torchtune leaves Unsloth in the dust: A member praised Torchtune for outperforming Unsloth, highlighting issues with CUDA memory on a 12GB 4070 card when using Unsloth for fine-tuning.
- They noted that Torchtune seamlessly handles fine-tuning without running into the same memory issues, unless batch size is too large.
- Kolo integrates with Torchtune: The Kolo Docker tool now officially supports Torchtune, aiming to make it easy for beginners to train and test models locally.
- The creator shared the project link, showcasing its intended use for LLM training and testing with multiple tools.
- New interface for Torchtune in development: A member is developing a FastAPI and Next.js interface called Tune Lab for Torchtune, using modern UI components to enhance the user experience.
- They discussed the integration of pre-built and custom scripts, guiding users toward contributing to the project.
- Success with GRPO implementation: A member reported a significant achievement with their GRPO implementation, successfully improving training from 10% to 40% on GSM8k.
- They detailed debugging challenges, including deadlocks and memory issues, expressing plans to clean up code for community contributions.
- Custom script uploads in Tune Lab: The idea of allowing users to upload their own finetuning scripts directly to the UI of Tune Lab was discussed as a potential feature.
- This would entail adding user-designed recipes to an API and integrating a scripting interface into the application's design.
- End-to-End Workflow with torchtune — torchtune main documentation: no description found
- GitHub - MaxHastings/Kolo: A one stop shop for fine tuning and testing LLMs locally using the best tools available.: A one stop shop for fine tuning and testing LLMs locally using the best tools available. - MaxHastings/Kolo
- GitHub - theosis-ai/tune-lab: a ui for torchtune: a ui for torchtune. Contribute to theosis-ai/tune-lab development by creating an account on GitHub.
- Feature request: GRPO support · Issue #2340 · pytorch/torchtune: As you all might have already known by now DeepSeek-R1 with its GRPO training was quite successful, should we consider bringing GRPO into torchtune?
Torchtune ▷ #dev (37 messages🔥):
Ladder-residual architecture, Distributed generation issues, FSDP synchronization challenges, Full DPO Distributed PR checks, Performance optimization of generation
- Ladder-residual boosts Llama performance: The new Ladder-residual modification enhances the 70B Llama model's speed by ~30% when running on multiple GPUs with tensor parallelism, as introduced by @zhang_muru.
- This work was conducted at @togethercompute with co-authorship from @MayankMish98 and mentoring by @ben_athi.
- Cursed debugging in generate function: A member reported a potential deadlock in the generate function when running with multi-device setups, suspecting it was optimized only for single-device scenarios.
- Discussions included solutions like ignoring stop tokens or implementing a synchronization phase to prevent mismatched execution among ranks.
- Challenges with FSDP during generation: Another noted that using FSDP for model generation is inefficient due to slower all-gather processes, and suggested the need for better APIs to support switching parallelisms.
- They mentioned that removing stop tokens helped alleviate some issues during generation, allowing for smoother processing.
- Fixing GitHub Checks on Full DPO PR: Issues with GitHub checks on the Full DPO Distributed PR included a
ValueErrorand OOM errors, prompting a discussion about avoiding tests running on CPU runners without available GPUs.- Suggestions included adding decorators to skip tests on machines with fewer than two GPUs, aiming for more reliable CI/CD processes.
- Performance optimization findings: Testing showed that disabling FSDP re-sharding during forward passes provided a performance boost at the cost of increased peak memory usage.
- Discussions highlighted the need to address potential memory inefficiencies while maintaining generation speed in a distributed setup.
- GitHub · Build and ship software on a single, collaborative platform: Join the world's most widely adopted, AI-powered developer platform where millions of developers, businesses, and the largest open source community build software that advances humanity.
- Tweet from Muru Zhang (@zhang_muru): Running your model on multiple GPUs but often found the speed not satisfiable? We introduce Ladder-residual, a parallelism-aware architecture modification that makes 70B Llama with tensor parallelism ...
- Build software better, together: GitHub is where people build software. More than 150 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- torch-redistribute/fsdp_unwrap_2.py at main · SalmanMohammadi/torch-redistribute: Contribute to SalmanMohammadi/torch-redistribute development by creating an account on GitHub.
- torchtune/tests/recipes/test_full_dpo_distributed.py at add-feature-full-dpo · sam-pi/torchtune: PyTorch native post-training library. Contribute to sam-pi/torchtune development by creating an account on GitHub.
- torchtune/tests/recipes/test_full_finetune_distributed.py at a226a58b8c36db5afa123f0885c5337d1ebc91f6 · pytorch/torchtune: PyTorch native post-training library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- Full DPO Distributed by sam-pi · Pull Request #2275 · pytorch/torchtune: ContextAdapted from the great work in #1966What is the purpose of this PR? Is it to add a new featurePlease link to any issues this PR addresses: relates to #2082ChangelogWhat are the chang...
Latent Space ▷ #ai-general-chat (75 messages🔥🔥):
OpenAI SWE Agent, OmniHuman video generation, Figure's Independence from OpenAI, Gemini 2.0 Flash release, Mistral AI Rebranding
- OpenAI SWE Agent expected soon: An announcement disclosed that OpenAI plans to release a new SWE Agent by the end of Q1 or mid Q2, powered by O3 and O3 Pro for enterprises.
- This agent is anticipated to significantly impact the software industry, as it is purportedly capable of competing with mid-level engineers.
- Excitement over OmniHuman Video Generation: A new video research project, OmniHuman, claims it can generate realistic avatar videos from a single image and audio, with no aspect ratio limitations.
- The project has garnered significant attention, being described as a breakthrough that leaves viewers gobsmacked by its detail.
- Figure announces independence from OpenAI: Figure AI has decided to exit its collaboration agreement with OpenAI to focus on in-house AI technology, following a reported major breakthrough.
- The founder hinted at showcasing something no one has ever seen on a humanoid within the next 30 days, fueling curiosity in the community.
- Gemini 2.0 Flash Goes GA: Google has announced that Gemini 2.0 Flash is now generally available, allowing developers to create production applications through AI Studio or Vertex AI.
- The model supports a context of 2 million tokens, sparking discussions about its performance relative to its Pro counterpart.
- Mistral AI Rebranding Announcement: Mistral AI's website has undergone a major rebranding, promoting their customizable, portable, and enterprise-grade AI platform.
- They emphasize their role as a leading contributor to open-source AI and commitment to providing engaging user experiences.
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): A few things to note on the Gemini 2.0 update:- The overall perf gap between Flash and Pro seems very small on their bench.-> Flash is amazing. Pro excels at long-tail knowledge, which matters for ...
- Tweet from Jianwen Jiang (@unseenvie): Excited to present our latest research, OmniHuman.With a single image and audio, it can generate extremely realistic avatar videos at any aspect ratio and body proportion , unlike existing methods lim...
- Tweet from Alex Volkov (Thursd/AI) (@altryne): I think people just looked at this, and got impressed and moved on... but no... this is, they f-ing broke through some reality barrierI don't remember being speechless like this for quite a while ...
- Tweet from Physical Intelligence (@physical_int): Many of you asked for code & weights for π₀, we are happy to announce that we are releasing π₀ and pre-trained checkpoints in our new openpi repository! We tested the model on a few public robots, an...
- Tweet from Chubby♨️ (@kimmonismus): OpenAI Sales Associate Agent spotted in recent Tokyo talk (zoom in, pic is from livestream)
- Tweet from harambe_musk🍌 (@harambe_musk): OpenAI planning to release SWE agent by end of Q1 or mid Q2 powered by o3 and o3 pro for enterprises. This is expected to shakeup the software industry as it’s apparently smart enough to compete with ...
- Tweet from will depue (@willdepue): bros cto just quit and now he’s posting threads on X rip figureQuoting Brett Adcock (@adcock_brett) Since starting Figure, I’ve always been interested in getting to scale manufacturing for humanoid ro...
- Tweet from Hyperbolic (@hyperbolic_labs): We are honored that Andrej Karpathy @karpathy has recognized Hyperbolic as his favorite platform for interacting with LLM base models. In his latest deep-dive video on Large Language Models (LLMs), he...
- Tweet from Deedy (@deedydas): New OpenAI paper by Wojciech Zaremba shows that you can jailbreak reasoning models by asking them to “think less” if they’re small or spend too much time thinking about unproductive things.There is so...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): News: @GoogleDeepMind Gemini-2.0 family (Pro, Flash, and Flash-lite) is now live in Arena!- Gemini-2.0-Pro takes #1 spot across all categories- Gemini-2.0-Flash #3 and now widely available to develope...
- Tweet from Remi Cadene (@RemiCadene): ⭐ The first foundational model available on @LeRobotHF ⭐Pi0 is the most advanced Vision Language Action model. It takes natural language commands as input and directly output autonomous behavior.It wa...
- Tweet from Andrej Karpathy (@karpathy): New 3h31m video on YouTube:"Deep Dive into LLMs like ChatGPT"This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It...
- Bob McGrew: AI Agents And The Path To AGI: According to OpenAI's former Chief Research Officer Bob McGrew, reasoning and test-time compute will unlock more reliable and capable AI agents— and a clear ...
- Tweet from Sundar Pichai (@sundarpichai): 1/ New Gemini 2.0 updates, here we go! Gemini 2.0 Flash is now GA, so devs can now build production applications. Find it in AI Studio or Vertex AI.
- Tweet from Brett Adcock (@adcock_brett): Today, I made the decision to leave our Collaboration Agreement with OpenAIFigure made a major breakthrough on fully end-to-end robot AI, built entirely in-houseWe're excited to show you in the ne...
- LIVE: OpenAI founder Sam Altman speaks in Tokyo: Watch live as OpenAI CEO Sam Altman speaks at an event “Transforming Business through AI” in Tokyo, Japan, along with SoftBank CEO Masayoshi Son and Arm Hold...
- Refreshed.: Check out https://openai.com/ to see more.
- Deep Dive into LLMs like ChatGPT: This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It is covers the full traini...
- Mistral AI | Frontier AI in your hands: Take control of the future with a complete AI solution from platform to interface, with open, customizable models that can be deployed anywhere.
- Figure drops OpenAI in favor of in-house models | TechCrunch: Figure AI, a robotics company working to bring a general-purpose humanoid robot into commercial and residential use, announced Tuesday on X that it
Nomic.ai (GPT4All) ▷ #announcements (1 messages):
GPT4All v3.9.0 Release, LocalDocs Fix, DeepSeek-R1 Update, Windows ARM Improvements, New Model Support
- GPT4All v3.9.0 makes its debut!: The GPT4All v3.9.0 has been officially released with significant fixes and new features.
- Notable improvements include LocalDocs functionality and enhanced support for new models.
- LocalDocs now error-free!: LocalDocs has been fixed to prevent errors from appearing on later messages when using reasoning models.
- This enhancement streamlines user experience and ensures smoother interactions.
- DeepSeek-R1 cleans up chat display: DeepSeek-R1 reasoning outputs no longer clutter chat names or follow-up questions within 'think' tags.
- This fix enhances overall clarity and coherence during AI interactions.
- Windows ARM gets a performance boost: Graphical artifacts on specific SoCs have been resolved and crashes from adding PDF collections to LocalDocs are fixed for Windows ARM users.
- These improvements provide a smoother experience for users operating on Windows ARM architecture.
- Welcome new models OLMoE and Granite MoE!: The release introduces support for the new OLMoE and Granite MoE models, expanding the capabilities of GPT4All.
- This addition offers users a wider variety of options for their AI needs and applications.
Nomic.ai (GPT4All) ▷ #general (62 messages🔥🔥):
ReAG - Reasoning Augmented Generation, Self-hosting GPT4All, Local models for NSFW content, User Interface Bugs, Datalake Concerns
- ReAG Offers a New Approach to RAG: ReAG - Reasoning Augmented Generation is a new method that directly feeds raw documents to the language model, resulting in more context-aware responses than traditional methods.
- This unified approach promises to enhance accuracy and relevance by avoiding oversimplified semantic matches.
- Self-hosting GPT4All as a Server: One user explores the possibility of setting up GPT4All on a desktop for mobile connectivity, suggesting it can be achieved through a Python host.
- Although it's technically feasible, others caution that support may be limited and require unconventional setups.
- Local Models for NSFW Use: Discussions included finding a locally usable LLM for NSFW stories, with suggestions like wizardlm and wizardvicuna deemed less optimal by some members.
- There were recommendations for potential alternatives like obadooga and writing-roleplay-20k-context-nemo for better performance.
- UI Bug Report Concerning Scrolling: A user reported a UI bug where the prompt window's content cannot be scrolled if the text exceeds the visible area, creating accessibility issues.
- Another member indicated that a similar issue was reported on GitHub, sparking curiosity about its prevalence among other users.
- Concerns About Datalake Content: Members expressed discomfort regarding the prevalence of inappropriate topics, notably in relation to children within the datalake content.
- This led to discussions on specific entries and the overall appropriateness of the content referenced.
- TheBloke/Wizard-Vicuna-7B-Uncensored-GGUF · Hugging Face: no description found
- GitHub - superagent-ai/reag: Reasoning Augmented Generation: Reasoning Augmented Generation. Contribute to superagent-ai/reag development by creating an account on GitHub.
- GitHub - tani/markdown-it-mathjax3: Add Math to your Markdown with a MathJax plugin for Markdown-it: Add Math to your Markdown with a MathJax plugin for Markdown-it - tani/markdown-it-mathjax3
MCP (Glama) ▷ #general (50 messages🔥):
ChatGPT Pro Subscription, MCP Excel File Manipulation, Playwright/Puppeteer Automation, GitHub MCP Usage, Home Assistant MCP Client/Server Support
- Interest in ChatGPT Pro Subscription: Multiple members expressed interest in the idea of acquiring a ChatGPT Pro subscription, especially for potential team use.
- Are you looking to split the cost among multiple accounts?
- MCP Reading Excel Files Discussion: There was a conversation about the feasibility of creating an MCP that can read and manipulate Excel files, with members showing enthusiasm for developing it.
- Suggestions for using Python were debated against TypeScript for data manipulation tasks.
- Playwright and Puppeteer Automation Queries: Members discussed their experiences with newer Playwright and Puppeteer MCPs, with one sharing that Playwright worked well, while Puppeteer required local changes.
- There was interest in specific plugins, with sharing of a link to a GitHub implementation that is still in a non-production ready state.
- Insights on GitHub MCP Usage: Members shared their experiences using the GitHub MCP from Anthropic, highlighting its usefulness for question and answer tasks over README files.
- Discussions included features like fetching raw files and challenges with rate limits on Claude, suggesting varied usage strategies.
- New Home Assistant MCP Support Published: A member announced the publication of Home Assistant with MCP client/server support, indicating an expansion of its capabilities.
- Sweet! Great to see further integration in automation ecosystems.
Link mentioned: servers/src/puppeteer/index.ts at evaboot · isaacphi/servers: Model Context Protocol Servers. Contribute to isaacphi/servers development by creating an account on GitHub.
MCP (Glama) ▷ #showcase (6 messages):
Sage Smithery Integration, MCP Tools Support for Claude, PulseMCP Use Cases Launch
- Sage integrates Smithery for a seamless experience: Sage announced that it is bringing Smithery natively into its app, launching tonight!
- This integration aims to enhance user interactions and streamline the workflow within the application.
- Claude now supports hundreds of tools!: The rollout of Sage for Claude is bringing support for hundreds of tools via the Model Context Protocol, available on both iOS and Mac.
- This includes a one-touch installation for local and hosted MCP servers, along with many quality-of-life changes like editing the last message with the up arrow key.
- PulseMCP launches Use Cases showcase: PulseMCP has launched a new feature to spotlight useful MCP server and client combinations with detailed instructions, screenshots, and videos.
- Notable use cases include using Gemini voice to manage Notion and converting a Figma design to code with Claude.
- Community use-cases of MCP in-action | PulseMCP: Explore all the ways in which the community is putting the Model Context Protocol (MCP) to use.
- Tweet from Tadas Antanavicius (@tadasayy): 🎉 Announcing the launch of Use Cases on PulseMCP (follow @pulsemcp to keep up)!There have been a ton of great MCP servers & clients built since its launch by @Anthropic and we built a resource to hig...
- GitHub - SecretiveShell/Awesome-llms-txt: This list contains an index of llms.txt files hosted on various websites.: This list contains an index of llms.txt files hosted on various websites. - SecretiveShell/Awesome-llms-txt
GPU MODE ▷ #general (8 messages🔥):
Huggingface L40S performance comparison, Janus-Pro-7B results, EvaByte architecture, Autoregressive image generation, Byte transformers in image modeling
- Flux 1024x1024 Image Generation Blows Emu3 Out of Water: On the Huggingface L40S instance, while Emu3 took ~600 seconds for a 720x720 image, Flux generated a 1024x1024 image in only 30 seconds using
flash-attentionwith W8A16 quantization.- Despite comparable parameter counts (8B for Emu3 and 12B for Flux), the major speed difference raises questions about Emu3's efficiency against single-modal models.
- Janus-Pro-7B Speed Gains Offset by Poor Output Quality: After testing Janus-Pro-7B on Huggingface spaces, users noted its speed is much faster and comparable to DiTs, but expressed disappointment in the resulting image quality.
- A member shared an attached example of the output, highlighting significant quality concerns despite the improved processing speed.
- Introducing EvaByte: A Game Changer in Efficient Image Generation: The newly introduced EvaByte, a 6.5B byte-level language model, features an innovative architecture aimed at improving efficiency and performance in auto-regressive image generation.
- Trained on 1.5T bytes of data, EvaByte can decode up to 2x faster than traditional systems, influencing potential developments in auto-regressive image generation techniques.
- Parallel Generation Strategy Proposal for Autoregressive Visual Models: A proposed methodology highlights how leveraging visual token dependencies can enable parallelized generation in autoregressive models, greatly speeding up the creation process.
- It suggests seamlessly coupling this technique with the EvaByte architecture for potentially 12x speed improvement over traditional next-token prediction methods.
- Curiosity Around Byte Transformers for Image Modeling: A member inquired if any papers or models have emerged using byte transformers specifically for modeling images or modalities beyond text.
- The question underscores an interest in exploring the versatility of byte transformers in various fields of generative modeling.
- Parallelized Autoregressive Visual Generation: Autoregressive models have emerged as a powerful approach for visual generation but suffer from slow inference speed due to their sequential token-by-token prediction process. In this paper, we propos...
- EvaByte: Efficient Byte-level Language Models at Scale | HKU NLP Group : no description found
GPU MODE ▷ #triton (2 messages):
tl.gather function, Triton installation, Installing from source
- Issue with tl.gather Function Post Triton Installation: @webstorms reported difficulties in calling the tl.gather function after installing Triton versions 3.1.0, 3.2.0, and the nightly-build.
- They expressed feeling confused about the installation process, stating they must be doing something silly.
- Recommendation to Install from Source: A member suggested that the tl.gather function might not have been released with Triton 3.2, recommending to install from source.
- They provided a helpful link to the Triton GitHub repository for further assistance.
Link mentioned: GitHub - triton-lang/triton: Development repository for the Triton language and compiler: Development repository for the Triton language and compiler - triton-lang/triton
GPU MODE ▷ #cuda (5 messages):
GPU Invalidations, Microbenchmarking Techniques, WGMMA Layouts, AI Compute Efficiency
- GPU Invalidations Overview: Discussion revealed that heavy types of fences can lead to full L1 invalidate operations, which are best avoided.
- NVIDIA may not track specific lines populated by streams for invalidation, making this a non-ideal scenario for performance.
- Microbenchmarking for GPU Performance Insights: It was suggested that obtaining insights into GPU behavior may require running microbenchmarks based on experience with wgmma layouts.
- There's an understanding that detailed documentation might be lacking, hence direct inquiry with hardware engineers could be needed.
- Efforts to Reduce AI Compute Usage: Recent discussions highlighted a focus on making AI more efficient and using less compute through various methods, including FlashAttention and others.
- This paints a picture of ongoing innovation aimed at optimizing compute resources in AI applications.
Link mentioned: GPUs Go Brrr: how make gpu fast?
GPU MODE ▷ #torch (5 messages):
BlockMask support for .state_dict(), Flex Attention, Torch Save and Load
- Inquiry on BlockMask and .state_dict() support: A member asked about the chances of flex attention's BlockMask supporting
.state_dict()and suggested it could be a good first PR.- Thanks for supporting .to() was mentioned, expressing gratitude for the previous contributions.
- Question on pickling BlockMask: Another member inquired if one could simply pickle BlockMask, showing skepticism towards the initial idea.
- This raised a discussion about the flexibility of handling BlockMask.
- Proposed issue for BlockMask integration: A member proposed that a better first issue would be adding BlockMask to safe globals for weights-only operations.
- They expressed confidence in supporting this PR and indicated they would stamp it.
- Example code on BlockMask functionality: A code snippet was shared that demonstrates the implementation of BlockMask using
torchand its save/load functionality.- It illustrates creating a block mask, saving it to a file, and loading it back for further usage.
GPU MODE ▷ #cool-links (3 messages):
OmniHuman framework, FlowLLM for material discovery, Video generation from images, Generative models in research
- OmniHuman Framework Generates Realistic Human Videos: The OmniHuman project introduces an end-to-end multimodality-conditioned human video generation framework that creates videos from a single image and motion signals, such as audio and video.
- This method improves on previous approaches by using a mixed training strategy, greatly enhancing the quality of the generated videos.
- FlowLLM Advances Material Discovery: FlowLLM is a new generative model that combines large language models with Riemannian flow matching to design novel crystalline materials, significantly improving generation rates.
- This approach surpasses existing methods in material generation speed, offering over three times the efficiency for developing stable materials based on LLM outputs.
- Transforming Images into Videos: OmniHuman's unique framework can generate high-quality human video content based on just a single image, highlighting its potential for multimedia applications.
- This innovation stands out in managing weak signal inputs, setting a new standard in video generation technology.
- OmniHuman-1 Project: no description found
- FlowLLM: Flow Matching for Material Generation with Large Language Models as Base Distributions: Material discovery is a critical area of research with the potential to revolutionize various fields, including carbon capture, renewable energy, and electronics. However, the immense scale of the che...
GPU MODE ▷ #jobs (2 messages):
Part-Time AI Software & Hardware Optimization Engineer, Modal Serverless Computing, GPU Performance Engineering
- Part-Time AI Engineer Position Open: Our client is looking for a Part-Time AI Software & Hardware Optimization Engineer for remote positions in the EU and Asia. You can view the full job description and apply here.
- Modal Powers High-Performance Computing: Modal is a serverless computing platform that provides flexible, auto-scaling computing infrastructure for users like Suno and the Liger Kernel team. The GPU Glossary is highlighted as one of the notable technical works produced by the team.
- “I have done some of the best technical work of my life...” reinforces the positive culture at Modal.
- Hiring ML Performance Engineers at Modal: Modal is hiring ML performance engineers to enhance GPU performance and contribute to upstream libraries like vLLM. Interested candidates can review the job description here.
- Interested individuals are encouraged to DM for further information.
- Jobs: no description found
- Part Time AI Software & Hardware Optimization Engineer (Remote/Flexible) - Livit: We’re looking for an AI Software & Hardware Optimization Engineer who can analyze, adapt, and optimize our existing CUDA-based AI models to run efficiently across different hardware archite...
GPU MODE ▷ #torchao (4 messages):
Torchao and torch.compile compatibility, PyTorch issue discussion, Community engagement on GitHub
- Torchao likely incompatible with torch.compile: A user reported that using Torchao in conjunction with torch.compile seems to cause a bug, implying a compatibility issue.
- “mega oof” captures the frustration of the user experiencing this problem.
- Link to PyTorch issue #141548: Another member suggested the bug aligns with this GitHub issue about
nn.Modulenot transferring between devices.- The issue report mentions complications with compiled modules and tensor subclasses, sparking further concern within the community.
- Community encourages GitHub commentary: A member encouraged the user to comment on the GitHub issue to increase its visibility to the PyTorch team.
- “Perhaps u can comment to the issue to raise visibility” reflects a proactive community approach to problem-solving.
Link mentioned: Compiled nn.Module with tensor subclass can't be moved to another device · Issue #141548 · pytorch/pytorch: 🐛 Describe the bug import torch aten = torch.ops.aten class Subclass(torch.Tensor): def new(cls, data): return torch.Tensor._make_wrapper_subclass(cls, data.shape, dtype=data.dtype, device=data.....
GPU MODE ▷ #off-topic (3 messages):
AI in Gaming, General-Purpose Robotic Models, AI-powered Fax Services
- AI exploits a gamebreaking bug in Trackmania: A YouTube video titled AI exploits a gamebreaking bug in Trackmania showcases how an AI was trained in the game using reinforcement learning to master the difficult noseboost technique.
- The creator aims to highlight the capabilities of AI in overcoming significant challenges in gaming.
- Release of General-Purpose Robotic Model π0: The company announced the release of the code and weights for their general-purpose robotic model, π0, which can be fine-tuned for various robot tasks.
- This release is aimed at enabling experimentation with robotic policies that could fundamentally change how we approach artificial intelligence.
- Innovative Fax-KI Service Launch: A new service by simple-fax.de introduces Fax-KI, which transforms traditional fax machines into intelligent tools capable of responding to inquiries via fax.
- Users can send questions or tasks to a dedicated fax number, where Fax-KI analyzes and replies with tailored answers, enhancing the functionality of a conventional communication method.
- Open Sourcing π0: Physical Intelligence is bringing general-purpose AI into the physical world.
- AI exploits a gamebreaking bug in Trackmania: I trained an AI in Trackmania with reinforcement learning, and tried to make it learn the hardest technique in this game: the noseboost.To support my work on...
- Faxgeräte können jetzt auch KI: Künstliche Intelligenz ist derzeit in aller Munde und simple-fax.de bringt diese innovative Technologie direkt zu Ihrem Faxgerät. Fax-KI verwandelt Ihr Faxgerät in ein intelligentes Werkzeug, das nich...
GPU MODE ▷ #liger-kernel (1 messages):
Granite 3 models, Llama 3 models, PR #558
- Granite 3 models introduced: A PR was opened to add support for Granite 3.0 and 3.1 models, noting their similarity to Llama 3 models, indicating an easily managed addition.
- The PR can be found here.
- Identical yet Non-equivalent Models: Despite GraniteMLP and LlamaMLP being identical, replacing GraniteMLP with LigerSwiGLUMLP did not yield logit-equivalence, highlighting an interesting discrepancy.
- The issue regarding loss and parameter equivalence was noted in the PR, pointing to the nuanced challenges in model patching.
Link mentioned: Support Granite 3.0 and 3.1 models by JamesKunstle · Pull Request #558 · linkedin/Liger-Kernel: Granite 3.(0,1) models are Llama-architecture models with some different scaling terms in various places. This commit adds granite model patching for decoder-only granite 3 models (not multimodal) ...
GPU MODE ▷ #reasoning-gym (10 messages🔥):
CompositeDataset PR, gsm-symbolic cross-checks, laptop repair, requirements-dev updates, generator issues in gsm-symbolic
- CompositeDataset PR optimizes gsm-symbolic: The first version of
CompositeDatasethas been submitted in a PR, significantly improving various gsm-symbolic generators.- The enhancements focus on fixing numerous issues, paving the way for better performance.
- Gsm-symbolic undergoing cross-checks: Currently, gsm-symbolic is being cross-checked with sonnet; for difficulty=1.0, most cases look satisfactory.
- There are plans to address the remaining discrepancies to ensure overall consistency.
- Back from laptop surgery: One member mentioned that their laptop died and required surgery, but they are now back online.
- Their return indicates they are ready to re-engage with ongoing discussions.
- Updating requirements-dev.txt: Concerns were raised about the need to update the requirements-dev.txt due to numerous added dependencies.
- Another member clarified that the most important dependencies are listed in pyproject.toml, suggesting installation via
pip install -e ..
- Another member clarified that the most important dependencies are listed in pyproject.toml, suggesting installation via
- Generator issues in gsm-symbolic: Currently, 16 of 100 gsm-symbolic generators are broken, unable to produce correct questions with integer results.
- There's speculation that a completely new approach may be needed to resolve these issues involving specific failed generators.
LlamaIndex ▷ #blog (3 messages):
Deepseek exploration, Building RAG applications, Gemini 2.0 launch, Gemini integration
- Explore Deepseek in Virtual Forum: Join @aicampai for a virtual forum on Deepseek, focusing on its capabilities and integration into workflows for developers and engineers. This event aims to provide hands-on learning experiences on the technology and its applications.
- Check out the details about the forum here.
- Tutorial on Building RAG Applications: A new video tutorial by @Pavan_Belagatti guides users through building their first Retrieval Augmented Generation (RAG) application using @llama_index. This tutorial responds to the increasing number of new users looking for practical development insights.
- Watch the tutorial here.
- Gemini 2.0 Now Available: @google has announced that Gemini 2.0 is now generally available, coinciding with day 0 support from @llama_index. Users can install the latest integration package via
pip install llama-index-llms-geminito access its impressive benchmarks.- Learn more about Gemini's updates and features in the announcement blog post.
- Gemini Flash Updates Explained: The updated version of Gemini 2.0 Flash includes enhanced performance, low latency, and capabilities to handle complex reasoning. Users can discover new ways to create and collaborate through the Gemini API in Google AI Studio and Vertex AI.
- For further info, visit the Google AI Studio for the latest updates.
Link mentioned: Gemini 2.0 is now available to everyone: We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.
LlamaIndex ▷ #general (20 messages🔥):
Timeout implementation in LlamaIndex, Function calling with Qwen-2.5, Streaming text in AgentWorkflow, Using OpenAILike with vLLM, Tool call streaming limitations
- Timeout implementation in LlamaIndex Models: A user noted that the default LlamaIndex LLM class lacks a built-in timeout feature, which is present in OpenAI's models. Another user suggested that timeout likely consists of client kwargs, pointing to a GitHub link for further details.
- Implementing Function Calling with Qwen-2.5: A user encountered a
ValueErrorregarding the Qwen-2.5 model not supporting the Function Calling API. The guidance provided indicates that using command-line parameters and switching to OpenAI-like implementations could resolve these issues with function calling handling.- Another member shared a Qwen function calling documentation that offers relevant insights on implementation.
- Streaming Text in AgentWorkflow: A user building an AgentWorkflow faced issues with streaming text down to the client, as the message sent always had an empty delta when streaming was active. An insight was shared that when the LLM is writing a tool call, the delta will appear empty, and that examining
event.tool_callscould aid understanding.- The limitations of streaming tool call outputs were emphasized, and potential workarounds for updating the frontend based on the latest tool call were suggested.
- Using OpenAILike for Qwen-2.5: To utilize function calling in Qwen-2.5 without issues, a user moved to implement the
OpenAILikeclass from LlamaIndex. Instructions for installation and setup were provided to successfully manage parameters for function calling. - Limitations of Tool Call Streaming: A member pointed out the difficulty in streaming tool call outputs due to the way OpenAI streams data as completed JSON. They expressed skepticism about whether this feature could be added and suggested a workaround involving streaming the latest tool call version instead.
- Function Calling - Qwen: no description found
- llama_index/llama-index-integrations/llms/llama-index-llms-azure-inference/llama_index/llms/azure_inference/base.py at 7391f302e18542c68b9cf5025afb510af4a52324 · run-llama/llama_index: LlamaIndex is the leading framework for building LLM-powered agents over your data. - run-llama/llama_index
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (14 messages🔥):
MOOC Certificate Delays, Quiz 1 and Quiz 2 Availability, Technical Issues with Quizzes, Certificate Request Process
- MOOC Certificate Delays: A member expressed frustration over not receiving their certificate requested in December, with course staff noting they are actively working to expedite the process.
- Another member acknowledged the delays and thanked the staff for their advocacy, asking for an expected timeframe for certificate distribution.
- Quiz 1 and Quiz 2 Availability: Several members sought information about the availability of Quiz 1 and Quiz 2, with course staff confirming Quiz 2 is not yet published and providing a link for Quiz 1.
- One member was reassured that they can complete Quiz 1 after Friday, as there are currently no deadlines.
- Technical Issues with Quizzes: Course staff communicated about unforeseen technical issues causing delays with the quizzes and certificate processing.
- They expressed hope to resolve the issues within the next week or two.
Link mentioned: Quiz 1 - Inference-Time Techniques w/ Xinyun Chen (1/27): INSTRUCTIONS:Each of these quizzes is completion based, however we encourage you to try your best for your own education! These quizzes are a great way to check that you are understanding the course m...
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (2 messages):
Lecture 1 Recording, Professional Captioning
- Fixed Lecture 1 Video Confirmation: A member asked if the provided YouTube link is for the fixed version of the first lecture.
- Another member confirmed that it is indeed the edited recording with professional captioning.
- Edited Recording Details: The lecture titled 'CS 194/294-280 (Advanced LLM Agents) - Lecture 1, Xinyun Chen' is confirmed to have professional captioning.
- This ensures improved accessibility and understanding for viewers.
Link mentioned: CS 194/294-280 (Advanced LLM Agents) - Lecture 1, Xinyun Chen: no description found
Cohere ▷ #discussions (10 messages🔥):
Migrating to Embed v3 Light, Cohere Moderation Model, Chat Feature Fees, Cohere Free API
- Seeking advice for Embed v3 migration: A user inquired about migrating existing float generations from embed v3 to embed v3 light, specifically if they could remove extra dimensions or needed to regenerate their database entirely.
- No direct responses were provided, but the question highlights common concerns about migration processes.
- Moderation Model Desired for Cohere: A member expressed a desire for a moderation model from Cohere to reduce dependency on American services.
- This sentiment echoes a need for more localized solutions within the AI space.
- Chat Feature Paid Subscription Inquiry: A user asked if there was a paid monthly fee option for chat functionality, noting their primary interest lies in chat features rather than product development.
- Another member informed them about the existence of a production API that requires payment.
- Estimating Chat Interaction Costs: A user expressed uncertainty about estimating the cost of chat interactions, emphasizing their interest in using the service for personal research rather than product development.
- A comment indicated that the free API could be used to test functionalities ahead of any decisions.
- Live Event Announcement: A member shared a link to a live event, providing both a Discord event link and a Google Meet link.
- This conveys ongoing community engagement and opportunities for direct interaction.
Cohere ▷ #api-discussions (2 messages):
Conversational Memory, Java API usage, Support Ticket
- User seeks help with Conversational Memory: A member expressed frustration that the responses from the AI are not related to each other between requests and asked for guidance on using conversational memory.
- They mentioned using Java code to connect with the API and that they are on a trial free pricing plan.
- Support Ticket Creation Acknowledged: A member thanked another for creating a support ticket related to their issue.
- They provided a link to the ticket for visual reference.
Cohere ▷ #projects (2 messages):
Rule Enforcement, Apology and Acknowledgment
- Strong reminder on rule enforcement: A member emphasized that future violations could result in a ban, reinforcing the importance of following the community rules.
- This statement clearly highlights a commitment to maintaining order within the community.
- Apology for Rule Violation: Another member apologized for their previous actions, acknowledging the importance of adhering to the rules.
- This response shows a willingness to correct course and align with community expectations.
tinygrad (George Hotz) ▷ #general (10 messages🔥):
tinygrad 0.10.1 issues, NixOS specificities, Compiler flags and warnings, Debugging improvements
- tinygrad 0.10.1 running into errors: While bumping tinygrad to 0.10.1, a user encountered tests failing with NotImplementedError due to an unknown relocation type 4.
- Type 4 indicates a call to an external function not supported; the version in use is 19.1.6.
- CLANG as the default backend?: Clarification was sought on whether CLANG is the default backend when running tests without specification.
- It was concluded that the issue could arise from Nix-specific behaviors affecting the compilation.
- Concerning compiler warnings: Warnings in stderr raised concerns, particularly regarding skipping the impure flag -march=native due to set
NIX_ENFORCE_NO_NATIVE.- These changes potentially alter compilation flags, impacting the functionality on older CPU architectures.
- Clarifying use of clang for JIT compilation: A member explained that the removal of -march=native is generally for user machine software, while tinygrad uses clang as a JIT compiler for kernels, simplifying this necessity.
- This suggests the removal of such flags should not apply to the tinygrad context.
- Improving debugging in tinygrad*: A contributor mentioned that *PR #8902 will make debugging the issues more manageable and easier.
- This indicates ongoing improvements in the project aimed at resolving observed complications.
- abi-aa/aaelf64/aaelf64.rst at main · ARM-software/abi-aa: Application Binary Interface for the Arm® Architecture - ARM-software/abi-aa
- A64: no description found
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
tinygrad base operations, kernel implementations
- Inquiry on tinygrad base operations count: A member asked how many base operations exist in tinygrad.
- This inquiry highlights the need for clarity on the foundational elements of the framework.
- Seeking kernel implementation sources: There was a request for information on where to find the kernel implementations pertinent to tinygrad.
- This points to an interest in understanding the underlying codebase for better usage and development.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (3 messages):
API model requirements, Leaderboards for models, Authentication mechanisms
- Guide to Adding Model as API Endpoint: A member pointed to the instructions for adding new models to the leaderboard, which includes requirements and setup details.
- It is noted that while authentication may be necessary, the API endpoint should be accessible to the general public.
- Authentication and Accessibility Discussion: A member mentioned that the model's API endpoint would need authentication, billing, registration, or tokens.
- However, the expectation is that access will ultimately be available to the general public, ensuring broader usability.
Link mentioned: gorilla/berkeley-function-call-leaderboard/CONTRIBUTING.md at main · ShishirPatil/gorilla: Gorilla: Training and Evaluating LLMs for Function Calls (Tool Calls) - ShishirPatil/gorilla
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
Raft Method, Llama 3.1 7B, Synthetic Data for Training, Fine-tuning, RAG Implementation
- Raft Method Usage with Limited Data: A member inquired whether approximately 1000 users' data is sufficient for training using the Raft method with Llama 3.1 7B.
- They also questioned if there is a need to incorporate synthetic data to enhance training before applying RAG (Retrieval-Augmented Generation).
- Concerns About Data Volume: The discussion highlighted concerns regarding whether 1000 users' data would provide enough diversity for effective model training.
- One member proposed that synthetic data might be necessary to fill gaps and improve training outcomes.
DSPy ▷ #examples (2 messages):
Chain of Agents, DSPy Way
- Introducing Chain of Agents in DSPy: A user shared an example of a Chain of Agents in the DSPy Way, linking to this article.
- They also referenced an original paper on the subject, available here.
- Request for Git Repository: Another user asked if there is a Git repository related to the Chain of Agents example discussed.
- This inquiry highlights the community's interest in practical implementations of the concept.
Link mentioned: Tweet from Sergii Guslystyi (@JuiceSharp): http://x.com/i/article/1887191253370216450