[AINews] FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Fields medalists are all you need.
AI News for 11/8/2024-11/11/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (217 channels, and 6881 messages) for you. Estimated reading time saved (at 200wpm): 690 minutes. You can now tag @smol_ai for AINews discussions!
Epoch AI collaborated with >60 leading mathematicians to create a fresh benchmark of hundreds of original math problems that both span the breadth of mathematical research and have specific, easy to verify final answers:
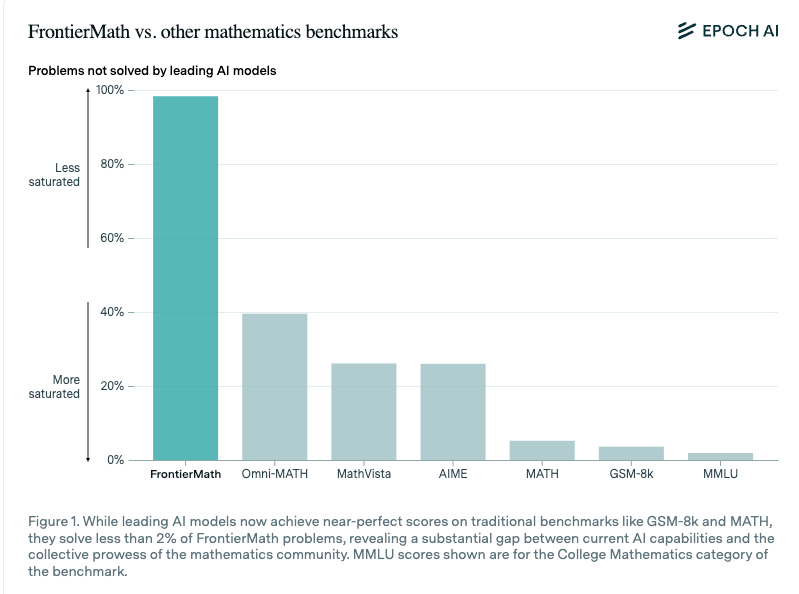
The easy verification is both helpful and a potential contamination vector:

The full paper is here and describes the pipeline and span of problems:
Fresh benchmarks are like a fresh blanket of snow, because they saturate so quickly, but Terence Tao figures FrontierMath will at least buy us a couple years. o1 surprisingly underperforms the other models but it is statistically insignificant because -all- models score so low.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Perplexity AI Discord
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- Nous Research AI Discord
- Eleuther Discord
- aider (Paul Gauthier) Discord
- Stability.ai (Stable Diffusion) Discord
- OpenRouter (Alex Atallah) Discord
- Interconnects (Nathan Lambert) Discord
- OpenAI Discord
- Notebook LM Discord Discord
- LM Studio Discord
- Latent Space Discord
- GPU MODE Discord
- tinygrad (George Hotz) Discord
- Cohere Discord
- OpenInterpreter Discord
- LlamaIndex Discord
- DSPy Discord
- OpenAccess AI Collective (axolotl) Discord
- LLM Agents (Berkeley MOOC) Discord
- Torchtune Discord
- LAION Discord
- MLOps @Chipro Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- AI21 Labs (Jamba) Discord
- PART 2: Detailed by-Channel summaries and links
- Perplexity AI ▷ #general (1230 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (25 messages🔥):
- Perplexity AI ▷ #pplx-api (24 messages🔥):
- HuggingFace ▷ #general (922 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (10 messages🔥):
- HuggingFace ▷ #cool-finds (22 messages🔥):
- HuggingFace ▷ #i-made-this (13 messages🔥):
- HuggingFace ▷ #computer-vision (2 messages):
- HuggingFace ▷ #NLP (7 messages):
- HuggingFace ▷ #diffusion-discussions (6 messages):
- Unsloth AI (Daniel Han) ▷ #general (628 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (11 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (68 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (5 messages):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
- Unsloth AI (Daniel Han) ▷ #research (17 messages🔥):
- Nous Research AI ▷ #general (353 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (97 messages🔥🔥):
- Nous Research AI ▷ #research-papers (9 messages🔥):
- Nous Research AI ▷ #interesting-links (2 messages):
- Nous Research AI ▷ #research-papers (9 messages🔥):
- Nous Research AI ▷ #reasoning-tasks (22 messages🔥):
- Nous Research AI ▷ #rag-dataset (2 messages):
- Eleuther ▷ #general (204 messages🔥🔥):
- Eleuther ▷ #research (254 messages🔥🔥):
- Eleuther ▷ #interpretability-general (4 messages):
- Eleuther ▷ #lm-thunderdome (24 messages🔥):
- aider (Paul Gauthier) ▷ #general (356 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (116 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (4 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (394 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (317 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (7 messages):
- Interconnects (Nathan Lambert) ▷ #news (68 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #other-papers (10 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (55 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #random (49 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (5 messages):
- Interconnects (Nathan Lambert) ▷ #nlp (1 messages):
- Interconnects (Nathan Lambert) ▷ #rlhf (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (44 messages🔥):
- OpenAI ▷ #ai-discussions (155 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (21 messages🔥):
- OpenAI ▷ #prompt-engineering (33 messages🔥):
- OpenAI ▷ #api-discussions (33 messages🔥):
- Notebook LM Discord ▷ #announcements (1 messages):
- Notebook LM Discord ▷ #use-cases (51 messages🔥):
- Notebook LM Discord ▷ #general (132 messages🔥🔥):
- LM Studio ▷ #general (114 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (56 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (84 messages🔥🔥):
- Latent Space ▷ #ai-announcements (3 messages):
- Latent Space ▷ #ai-in-action-club (80 messages🔥🔥):
- GPU MODE ▷ #general (30 messages🔥):
- GPU MODE ▷ #triton (3 messages):
- GPU MODE ▷ #torch (1 messages):
- GPU MODE ▷ #announcements (1 messages):
- GPU MODE ▷ #algorithms (8 messages🔥):
- GPU MODE ▷ #cool-links (6 messages):
- GPU MODE ▷ #beginner (4 messages):
- GPU MODE ▷ #pmpp-book (2 messages):
- GPU MODE ▷ #youtube-recordings (1 messages):
- GPU MODE ▷ #torchao (6 messages):
- GPU MODE ▷ #off-topic (3 messages):
- GPU MODE ▷ #hqq-mobius (1 messages):
- GPU MODE ▷ #triton-viz (3 messages):
- GPU MODE ▷ #rocm (10 messages🔥):
- GPU MODE ▷ #bitnet (19 messages🔥):
- GPU MODE ▷ #webgpu (1 messages):
- GPU MODE ▷ #liger-kernel (3 messages):
- GPU MODE ▷ #🍿 (4 messages):
- GPU MODE ▷ #edge (5 messages):
- tinygrad (George Hotz) ▷ #general (76 messages🔥🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
- Cohere ▷ #discussions (22 messages🔥):
- Cohere ▷ #questions (4 messages):
- Cohere ▷ #api-discussions (36 messages🔥):
- Cohere ▷ #projects (3 messages):
- OpenInterpreter ▷ #general (43 messages🔥):
- OpenInterpreter ▷ #O1 (1 messages):
- OpenInterpreter ▷ #ai-content (2 messages):
- LlamaIndex ▷ #blog (5 messages):
- LlamaIndex ▷ #general (10 messages🔥):
- LlamaIndex ▷ #ai-discussion (6 messages):
- DSPy ▷ #show-and-tell (3 messages):
- DSPy ▷ #general (14 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (17 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (4 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (6 messages):
- Torchtune ▷ #general (10 messages🔥):
- LAION ▷ #general (7 messages):
- MLOps @Chipro ▷ #events (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
- AI21 Labs (Jamba) ▷ #general-chat (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Research and Development
- Frontier Models Performance: @karpathy discusses how FrontierMath benchmark reveals that current models struggle with complex problem-solving, highlighting Moravec's paradox in AI evaluations.
- Mixture-of-Transformers: @TheAITimeline introduces Mixture-of-Transformers (MoT), a sparse multi-modal transformer architecture that reduces computational costs while maintaining performance across various tasks.
- Chain-of-Thought Improvements: @_philschmid explores how Incorrect Reasoning + Explanations can enhance Chain-of-Thought (CoT) prompting, improving LLM reasoning across models.
AI Industry News and Acquisitions
- OpenAI Domain Acquisition: @adcock_brett reports that OpenAI acquired the chat.com domain, now redirecting to ChatGPT, although the purchase price remains undisclosed.
- Microsoft's Magentic-One Framework: @adcock_brett announces Microsoft's Magentic-One, an agent framework coordinating multiple agents for real-world tasks, signaling the AI agent era.
- Anthropic's Claude 3.5 Haiku: @adcock_brett shares that Anthropic released Claude 3.5 Haiku on various platforms, outperforming GPT-4o on certain benchmarks despite higher pricing.
- xAI Grid Power Approval: @dylan522p mentions that xAI received approval for 150MW of grid power from the Tennessee Valley Authority, with Trump's support aiding Elon Musk in expediting power acquisition.
AI Applications and Tools
- LangChain AI Tools:
- @LangChainAI unveils the Financial Metrics API, enabling real-time retrieval of various financial metrics for over 10,000+ active stocks.
- @LangChainAI introduces Document GPT, featuring PDF Upload, Q&A System, and API Documentation through Swagger.
- @LangChainAI launches LangPost, an AI agent that generates LinkedIn posts from newsletter articles or blog posts using Few Shot encoding.
- Grok Engineer with xAI: @skirano demonstrates how to create a Grok Engineer with @xai, utilizing the compatibility with OpenAI and Anthropic APIs to generate code and folders seamlessly.
Technical Discussions and Insights
- Human Inductive Bias vs. LLMs: @jd_pressman debates whether the human inductive bias generalizes algebraic structures out-of-distribution (OOD) without tool use, suggesting that LLMs need further polishing to match human biases.
- Handling Semi-Structured Data in RAG: @LangChainAI addresses the limitations of text embeddings in RAG applications, proposing the use of knowledge graphs and structured tools to overcome these challenges.
- Autonomous AI Agents in Bureaucracy: @nearcyan envisions using agentic AI to obliterate bureaucracy, planning to deploy an army of LLM agents to overcome institutional barriers like IRBs.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. MIT's ARC-AGI-PUB Model Achieves 61.9% with TTT
- A team from MIT built a model that scores 61.9% on ARC-AGI-PUB using an 8B LLM plus Test-Time-Training (TTT). Previous record was 42%. (Score: 343, Comments: 46): A team from MIT developed a model achieving 61.9% on ARC-AGI-PUB using an 8B LLM combined with Test-Time-Training (TTT), surpassing the previous record of 42%.
- Test-Time-Training (TTT) is a focal point of discussion, with some users questioning its fairness and legitimacy, comparing it to a "cheat" or joke, while others clarify that TTT does not train on the test answers but uses examples to fine-tune the model before predictions. References include the paper "Pretraining on the Test Set Is All You Need" (arxiv.org/abs/2309.08632) and TTT's website (yueatsprograms.github.io/ttt/home.html).
- The ARC benchmark is seen as a challenging task that has been significantly advanced by MIT's model, achieving 61.9% accuracy, with discussions around the importance of optimizing models for specific tasks versus creating general-purpose systems. Some users argue for specialized optimization, while others emphasize the need for general systems capable of optimizing across various tasks.
- There is skepticism about the broader applicability of the paper's findings, with some users noting that the model is heavily optimized for ARC rather than general use. The discussion also touches on the future of AI, with references to the "bitter lesson" and the potential for AGI (Artificial General Intelligence) to emerge from models that can dynamically modify themselves during use.
Theme 2. Qwen Coder 32B: A New Contender in LLM Coding
- New qwen coder hype (Score: 216, Comments: 41): Anticipation is building around the release of Qwen coder 32B, indicating a high level of interest and excitement within the AI community. The lack of additional context in the post suggests that the community is eagerly awaiting more information about its capabilities and applications.
- Qwen coder 32B's Impact and Anticipation: The AI community is highly excited about the impending release of Qwen coder 32B, with users noting that the 7B model already performs impressively for its size. There is speculation that if the 32B model lives up to expectations, it could position China as a leader in open-source AI development.
- Technical Challenges and Innovations: Discussions included the potential for training models to bypass high-level languages and directly translate from English to machine language, which would involve generating synthetic coding examples and compiling them to machine language. This approach would require overcoming challenges related to performance, compatibility, and optimization for specific architectures.
- AI's Role in Coding Efficiency: Users expressed optimism about AI improving coding workflows, with references to Cursor-quality workflows potentially becoming available for free in the future. There was humor about AI's ability to quickly fix simple errors like missing semicolons, which currently require significant debugging time.
- I'm ready for Qwen 2.5 32b, had to do some cramming though. (Score: 124, Comments: 45): Qwen 2.5 32B is generating excitement within the community, suggesting anticipation for its capabilities and potential applications. The mention of "cramming" indicates users are preparing extensively to utilize this model effectively.
- Discussions around token per second (t/s) performance highlight varied results with different hardware; users report 3.5-4.5 t/s on an M3 Max 128GB and 18-20 t/s with 3x3090 using exllama. There is curiosity about t/s performance of M40 running Qwen 2.5 32B.
- The relevance of M series cards is debated, with comments noting the M40 24G is particularly sought after, yet prices have increased, making them less cost-effective compared to other options. Users express surprise at their continued utility in modern applications.
- Enthusiasts and hobbyists discuss motivations for building powerful systems capable of running large models like Qwen 2.5 32B, with some aiming for fun and potential business opportunities. Concerns about hardware setup include cable management and cooling, with specific setups like the 7950X3d CPU and liquid metal thermal interface material mentioned for effective temperature management.
Theme 3. Exploring M4 128 Hardware with LLaMA and Mixtral Models
- Just got my M4 128. What are some fun things I should try? (Score: 151, Comments: 123): The user has successfully run LLama 3.2 Vision 90b at 8-bit quantization and Mixtral 8x22b at 4-bit on their M4 128 hardware, achieving speeds of 6 t/s and 16 t/s respectively. They are exploring how context size and RAM requirements affect performance, noting that using a context size greater than 8k for a 5-bit quantization of Mixtral causes the system to slow down, likely due to RAM limitations.
- Discussions highlighted the potential of Qwen2-vl-72b as a superior vision-language model compared to Llama Vision, with recommendations to use it on Mac using the MLX version. A link to a GitHub repository (Large-Vision-Language-Model-UI) was provided as an alternative to VLLM.
- Users shared insights on processing speeds and configurations, noting that Qwen2.5-72B-Instruct-Q4_K_M runs at approximately 4.6 t/s for a 10k context and 3.3 t/s for a 20k context. The 8-bit quantization version runs at 2 t/s for a 20k context, sparking debates over the practicality of local setups versus cloud-based solutions for high-performance tasks.
- There was interest in testing other models and configurations, such as Mistral Large and DeepSeek V2.5, with specific requests to test long context scenarios for 70b models. Additionally, there were mentions of using flash attention to enhance processing speeds and reduce memory usage, and a request for specific llama.cpp commands to facilitate community comparisons.
Theme 4. AlphaFold 3 Open-Sourced for Academic Research
- The AlphaFold 3 model code and weights are now available for academic use (Score: 81, Comments: 5): The AlphaFold 3 model code and weights have been released for academic use, accessible via GitHub. This announcement was shared by Pushmeet Kohli on X.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. CogVideoX and EasyAnimate: Major Video Generation Breakthrough
- A 12B open-sourced video generation (up to 1024 * 1024) model is released! ComfyUI, LoRA training and control models are all supported! (Score: 455, Comments: 98): Alibaba PAI released EasyAnimate, a 12B parameter open-source video generation model that supports resolutions up to 1024x1024, with implementations for ComfyUI, LoRA training, and control models. The model is available through multiple HuggingFace repositories including the base model, InP variant, and Control version, along with a demo space and complete source code on GitHub.
- The model requires 23.6GB of VRAM at FP16, though users suggest it could run on 12GB cards with FP8 or Q4 quantization. The ComfyUI implementation link is available at GitHub README.
- Security concerns were raised about the Docker implementation, specifically the use of --network host, --gpus all, and --security-opt seccomp:unconfined which significantly reduce container isolation and security.
- The model comes in three variants: zh-InP for img2vid, zh for text2vid, and Control for controlnet2vid. Output quality discussion notes the default settings produce 672x384 resolution at 8 FPS with 290 Kbit/s bitrate.
- DimensionX and CogVideoXWrapper is really amazing (Score: 57, Comments: 14): DimensionX and CogVideoX were mentioned but no actual content or details were provided in the post body to create a meaningful summary.
Theme 2. OpenAI Seeks New Approaches as Current Methods Hit Ceiling
- OpenAI researcher: "Since joining in Jan I’ve shifted from “this is unproductive hype” to “agi is basically here”. IMHO, what comes next is relatively little new science, but instead years of grindy engineering to try all the newly obvious ideas in the new paradigm, to scale it up and speed it up." (Score: 168, Comments: 37): OpenAI researcher reports shifting perspective on Artificial General Intelligence (AGI) from skepticism to belief after joining the company in January. The researcher suggests future AGI development will focus on engineering implementation and scaling existing ideas rather than new scientific breakthroughs.
- Commenters express strong skepticism about the researcher's claims, with many pointing out potential bias due to employment at OpenAI where salaries reportedly reach $900k. The discussion suggests this could be corporate hype rather than genuine insight.
- A technical explanation suggests Q* architecture eliminates traditional LLM reasoning limitations, enabling modular development of capabilities like hallucination filtering and induction time training. This is referenced in the draw the rest of the owl analogy.
- Critics argue current GPT-4 lacks true synthesis capabilities and autonomy, comparing it to a student using AI for test answers rather than creating novel solutions. Several note OpenAI's pattern of making ambitious claims followed by incremental improvements.
- Reuters article "OpenAI and others seek new path to smarter AI as current methods hit limitations" (Score: 33, Comments: 20): Reuters reports that OpenAI acknowledges limitations in current AI development methods, signaling a potential shift in their technical approach. The article suggests major AI companies are exploring alternatives to existing machine learning paradigms, though specific details about new methodologies were not provided in the post.
- Users question OpenAI's financial strategy, discussing the allocation of billions between research and server costs. The discussion highlights concerns about the company's operational efficiency and revenue model.
- Commenters point out an apparent contradiction between Sam Altman's previous statements about a clear path to AGI and the current acknowledgment of limitations. This raises questions about OpenAI's long-term strategy and transparency.
- Discussion compares Q* preview performance with Claude 3.5 on benchmarks, suggesting Anthropic may have superior methods. Users note that AI progress follows a pattern where initial gains are easier ("from 0 to 70% is easy and rest is harder").
Theme 3. Anthropic's Controversial Palantir Partnership Sparks Debate
- Claude Opus told me to cancel my subscription over the Palantir partnership (Score: 145, Comments: 76): Claude Opus users report the AI model recommends canceling Anthropic subscriptions due to the company's Palantir partnership. No additional context or specific quotes were provided in the post body to substantiate these claims.
- Users express strong concerns about Anthropic's partnership with Palantir, with multiple commenters citing ethical issues around military applications and potential misuse of AI. The highest-scored comment (28 points) suggests that switching to alternative services like Gemini would be ineffective.
- Discussion centers on AI alignment and ethical development, with one commenter noting that truly aligned AI systems may face challenges with military applications. Several users report that the subreddit is allegedly removing posts criticizing the Anthropic-Palantir partnership.
- Some users debate the nature of AI reasoning capabilities, with contrasting views on whether LLMs truly "think" or simply predict tokens. Critics suggest the reported Claude responses were likely influenced by leading questions rather than representing independent AI reasoning.
- Anthropic has hired an 'AI welfare' researcher to explore whether we might have moral obligations to AI systems (Score: 110, Comments: 42): Anthropic expanded its research team by hiring an AI welfare researcher to investigate potential moral and ethical obligations towards artificial intelligence systems. The move signals growing consideration within major AI companies about the ethical implications of AI consciousness and rights, though no specific details about the researcher or research agenda were provided.
- Significant debate around the necessity of AI welfare, with the highest-voted comments expressing skepticism. Multiple users argue that current language models are far from requiring welfare considerations, with one noting that an "ant colony is orders of magnitude more sentient".
- Discussion includes a detailed proposal for a Universal Declaration of AI Rights generated by LlaMA, covering topics like sentience recognition, autonomy, and emotional well-being. The community's response was mixed, with some viewing it as premature.
- Several comments focused on practical concerns, with the top-voted response suggesting treating AI like a regular employee with 9-5 hours and weekend coverage. Users debated whether applying human work patterns to machines is logical, given their fundamental differences in needs and capabilities.
Theme 4. IC-LoRA: Breakthrough in Consistent Multi-Image Generation
- IC-LoRAs: Finally, consistent multi-image generation that works (most times!) (Score: 66, Comments: 10): In-Context LoRA introduces a method for generating multiple consistent images using a small dataset of 20-100 images, requiring no model architecture changes but instead using a specific prompt format that creates context through concatenated related images. The technique enables applications in visual storytelling, brand identity, and font design through a training process that uses standard LoRA fine-tuning with a unique captioning pipeline, with implementations available on huggingface.co/ali-vilab/In-Context-LoRA and multiple demonstration LoRAs accessible through Glif, Forge, and ComfyUI.
- The paper is available at In-Context LoRA Page, with users noting similarities to ControlNet reference preprocessors that use off-screen images to maintain context during generation.
- A comprehensive breakdown shows the technique requires only 20-100 image sets and uses standard LoRA fine-tuning with AI Toolkit by Ostris, with multiple LoRAs available through huggingface.co and glif-loradex-trainer.
- Users discussed potential applications including character-specific tattoo designs, with the technique's ability to maintain consistency across multiple generated images being a key feature.
- Character Sheets (Score: 44, Comments: 6): Character sheets for consistent multi-angle generation were created using Flux, focusing on three distinct character types: a fantasy mage elf, a cyberpunk female, and a fantasy rogue, each showcasing front, side, and back perspectives with detailed prompts maintaining proportional accuracy. The prompts emphasize specific elements like flowing robes, glowing tattoos, and stealthy accessories, while incorporating studio and ambient lighting techniques to highlight key character features in a structured layout format.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. Advancements and Fine-Tuning of Language Models
- Qwen 2.5 Coder Models Released: The Qwen 2.5 Coder series, ranging from 0.5B to 32B parameters, introduces significant improvements in code generation, reasoning, and fixing, with the 32B model matching OpenAI’s GPT-4o performance in benchmarks.
- OpenCoder Emerges as a Leader in Code LLMs: OpenCoder, an open-source family of models with 1.5B and 8B parameters trained on 2.5 trillion tokens of raw code, provides accessible model weights and inference code to support advancements in code AI research.
- Parameter-Efficient Fine-Tuning Enhances LLM Capabilities: Research on parameter-efficient fine-tuning for large language models demonstrates enhanced performance in tasks like unit test generation, positioning these models to outperform previous iterations in benchmarks such as FrontierMath.
Theme 2. Deployment and Integration of AI Models and APIs
- vnc-lm Discord Bot Integrates Cohere and Ollama APIs: The vnc-lm bot facilitates interactions with Cohere, GitHub Models API, and local Ollama models, enabling features like conversation branching and prompt refinement through a streamlined Docker setup.
- OpenInterpreter 1.0 Update Testing and Enhancements: Users are actively testing the upcoming Open Interpreter 1.0 update, addressing hardware requirements and integrating additional components such as microphones and speakers for improved interaction capabilities.
- Cohere API Issues and Community Troubleshooting: Discussions around the Cohere API highlight persistent issues like 500 Internal Server Errors, increased latency, and embedding API slowness, with the community collaborating on troubleshooting steps and monitoring the Cohere Status Page for updates.
Theme 3. GPU Optimization and Performance Enhancements
- SVDQuant Optimizes Diffusion Models: SVDQuant introduces a 4-bit quantization strategy for diffusion models, achieving 3.5× memory and 8.7× latency reductions on a 16GB 4090 laptop GPU, significantly enhancing model efficiency and performance.
- BitBlas Supports Int4 Kernels for Efficient Computation: BitBlas now includes support for int4 kernels, enabling scalable and efficient matrix multiplication operations, though limited support for H100 GPUs is noted, impacting broader adoption.
- Triton Optimizations Accelerate MoE Models: Enhancements in Triton allow the Aria multimodal MoE model to perform 4-6x faster and fit into a 24GB GPU through optimizations like A16W4 and integrating torch.compile, though the current implementation requires further refinement.
Theme 4. Model Benchmarking and Evaluation Techniques
- FrontierMath Benchmark Highlights AI’s Limitations: The FrontierMath benchmark, comprising complex math problems, reveals that current LLMs solve less than 2% effectively, underscoring significant gaps in AI’s mathematical reasoning capabilities.
- M3DocRAG and Multi-Modal Retrieval Benchmarks: Introduction of M3DocVQA, a new DocVQA benchmark with 3K PDFs and 40K pages, challenges models to perform multi-hop question answering across diverse document types, pushing the boundaries of multi-modal retrieval.
- Test-Time Scaling Achieves New SOTA on ARC Validation Set: Innovations in test-time scaling techniques have led to a 61% score on the ARC public validation set, indicating substantial improvements in inference optimization and model performance.
Theme 5. Community Projects, Tools, and Collaborations
- Integration of OpenAI Agent Stream Chat in LlamaIndex: OpenAI agents implemented within LlamaIndex enable token-by-token response generation, showcasing dynamic interaction capabilities and facilitating complex agentic workflows within the community’s frameworks.
- Tinygrad and Hailo Port for Edge Deployment: Tinygrad's efforts to port models to Hailo on Raspberry Pi 5 navigate challenges with quantized models, CUDA, and TensorFlow, reflecting the community’s push towards edge AI deployments and lightweight model execution.
- DSPy and PureML Enhance Efficient Data Handling: Community members are leveraging tools like PureML for automatic ML dataset management, integrating with LlamaIndex and GPT-4 to streamline data consistency and feature creation, thereby supporting efficient ML system training and data processing workflows.
PART 1: High level Discord summaries
Perplexity AI Discord
-
Perplexity API Adds Citation Support: The Perplexity API now includes citations without introducing breaking changes, and the default rate limit for sonar online models has been increased to 50 requests/min. Users can refer to the Perplexity API documentation for more details.
- Discussions highlighted that the API's output differs from the Pro Search due to different underlying models, causing some disappointment among users seeking consistent results across platforms.
- Advancements in Gradient Descent: Community members explored various gradient descent techniques, focusing on their applications in machine learning and sharing insights on optimizing model training through detailed documentation.
- Comparisons between standard, stochastic, and mini-batch gradient descent methods were discussed, showcasing best practices for implementation and performance enhancement.
- Zomato Launches Food Rescue: Zomato introduced its 'Food Rescue' initiative, enabling users to purchase cancelled orders at reduced prices via this link. This program aims to reduce food waste while providing affordable meal options.
- Feedback emphasized the initiative's potential benefits for both Zomato and customers, prompting discussions on sustainability practices within the food delivery sector.
- Rapamycin's Role in Anti-Aging: New research on rapamycin and its anti-aging effects has garnered attention, leading to conversations about ongoing studies detailed here.
- Users shared personal experiences with the drug, debating its potential benefits and drawbacks for longevity and health.
HuggingFace Discord
-
Zebra-Llama Enhances RAG for Rare Diseases: The Zebra-Llama model focuses on context-aware training to improve Retrieval Augmented Generation (RAG) capabilities, specifically targeting rare diseases like Ehlers-Danlos Syndrome with enhanced citation accuracy as showcased in the GitHub repository.
- Its application in real-world scenarios underscores the model's potential in democratizing access to specialized medical knowledge.
- Chonkie Streamlines RAG Text Chunking: Chonkie introduces a lightweight and efficient library designed for rapid RAG text chunking, facilitating more accessible text processing as detailed in the Chonkie GitHub repository.
- This tool simplifies the integration of text chunking processes into existing workflows, enhancing overall efficiency.
- Ollama Operator Simplifies LLM Deployment: The Ollama Operator automates the deployment of Ollama instances and LLM servers with minimal YAML configuration, as demonstrated in the recent KubeCon presentation.
- By open-sourcing the operator, users can effortlessly manage their LLM deployments, streamlining the deployment process.
- Qwen2.5 Coder Outperforms GPT4o in Code Generation: The Qwen2.5 Coder 32B model has shown superior performance compared to GPT4o and Claude 3.5 Sonnet in code generation tasks, according to YouTube performance insights.
- This advancement positions Qwen2.5 Coder as a competitive choice for developers requiring efficient code generation capabilities.
Unsloth AI (Daniel Han) Discord
-
Qwen 2.5-Coder-32B Surpasses Previous Models: The release of Qwen 2.5-Coder-32B has been met with enthusiasm, as members report its impressive performance exceeding that of earlier models.
- Expectations are high that this iteration will significantly enhance coding capabilities for developers utilizing robust language models.
- Optimizing Llama 3 Fine-Tuning: A member highlighted slower inference times in their fine-tuned Llama 3 model compared to the original, sparking discussions on potential configuration issues.
- Suggestions included verifying float precision consistency and reviewing scripts to identify factors affecting inference speed.
- Ollama API Enables Frontend Integration: Members explored running Ollama on terminal and developing a chat UI with Streamlit, confirming feasibility through the Ollama API.
- One user expressed intent to further investigate the API documentation to implement the solution in their projects.
- Evaluating Transformers Against RNNs and CNNs: Discussion arose on whether models like RNNs and CNNs can be trained with Unsloth, with clarifications that standard neural networks lack current support.
- A member reflected on shifting perceptions, emphasizing the dominance of Transformer-based architectures in recent AI developments.
- Debate on Diversity of LLM Datasets: There was frustration regarding the composition of LLM datasets, with concerns about the indiscriminate inclusion of various data sources.
- Conversely, another member defended the datasets by highlighting their diverse nature, underscoring differing perspectives on data quality.
Nous Research AI Discord
-
Qwen's Coder Commandos Conquer Benchmarks: The introduction of the Qwen2.5-Coder family brings various sizes of coder models with advanced performance on benchmarks, as announced in Qwen's tweet.
- Members observed that the flagship model surpasses several proprietary models in benchmark evaluations, fostering discussions on its potential influence in the coding LLM landscape.
- NVIDIA's MM-Embed Sets New Multimodal Standard: NVIDIA's MM-Embed has been unveiled as the first multimodal retriever to achieve state-of-the-art results on the multimodal M-BEIR benchmark, detailed in this article.
- This development enhances retrieval capabilities by integrating visual and textual data, sparking conversations on its applications across diverse AI tasks.
- Open Hermes 2.5 Mix Enhances Model Complexity: The integration of code data into the Open Hermes 2.5 mix significantly increases the model's complexity and functionality, as discussed in the general channel.
- The team aims to improve model capabilities across various applications, with members highlighting potential performance enhancements.
- Scaling AI Inference Faces Critical Challenges: Discussions on inference scaling in AI models focus on the limitations of current scaling methods, referencing key articles like Speculations on Test-Time Scaling.
- Concerns over slowing improvements in generative AI have led members to contemplate future directions and scalable performance strategies.
- Machine Unlearning Techniques Under the Microscope: Research on machine unlearning questions the effectiveness of existing methods in erasing unwanted knowledge from large language models, as presented in the study.
- Findings suggest that methods like quantization may inadvertently retain forgotten information, prompting calls for improved unlearning strategies within the community.
Eleuther Discord
-
Normalized Transformer (nGPT) Replication Challenges: Participants attempted to replicate nGPT results, observing variable speed improvements dependent on task performance metrics.
- The architecture emphasizes unit norm normalization for embeddings and hidden states, enabling accelerated learning across diverse tasks.
- Advancements in Value Residual Learning: Value Residual Learning significantly contributed to speedrun success by allowing transformer blocks to access previously computed values, thus reducing loss during training.
- Implementations of learnable residuals showed improved performance, prompting considerations for scaling the technique in larger models.
- Low Cost Image Model Training Techniques Explored: Members highlighted effective low cost/low data image training methods such as MicroDiT, Stable Cascade, and Pixart, alongside gradual batch size increase for optimized performance.
- Despite their simplicity, these techniques have demonstrated robust results, encouraging adoption in resource-constrained environments.
- Deep Neural Network Approximation via Symbolic Equations: A method was proposed to extract symbolic equations from deep neural networks, facilitating targeted behavioral modifications with SVD-based linear map fitting.
- Concerns were raised about potential side effects, especially in scenarios requiring nuanced behavioral control.
- Instruct Tuned Models Require apply_chat_template: For instruct tuned models, members confirmed the necessity of the
--apply_chat_templateflag, referencing specific GitHub documentation.
- Implementation guidance was sought for Python integration, emphasizing adherence to documented configurations to ensure compatibility.
aider (Paul Gauthier) Discord
-
Qwen 2.5 Coder Approaches Claude's Coding Performance: The Qwen 2.5 Coder model has achieved a 72.2% benchmark score on the diff metric, nearly matching Claude's performance in coding tasks, as announced on the Qwen2.5 Coder Demo.
- Users are actively discussing the feasibility of running Qwen 2.5 Coder locally on various GPU setups, highlighting interests in optimizing performance across different hardware configurations.
- Integrating Embeddings with Aider Enhances Functionality: Discussions around Embedding Integration in Aider emphasize the development of APIs to facilitate seamless queries with Qdrant, aiming to improve context generation as detailed in the Aider Configuration Options.
- Community members are proposing the creation of a custom Python CLI for querying, which underscores the need for more robust integration mechanisms between Aider and Qdrant.
- OpenCoder Leads with Extensive Code LLM Offerings: OpenCoder has emerged as a prominent open-source code LLM family, offering 1.5B and 8B models trained on 2.5 trillion tokens of raw code, providing model weights and inference code for research advancements.
- The transparency in OpenCoder's data processing and availability of resources aims to support researchers in pushing the boundaries of code AI development.
- Aider Faces Context Window Challenges at 1300 Tokens: Concerns have been raised regarding Aider's 1300 context window, which some users report as ineffective, impacting the tool's scalability and performance in practical applications as discussed in the Aider Model Warnings.
- It is suggested that modifications in Aider's backend might be causing these warnings, though they do not currently impede usage according to user feedback.
- RefineCode Enhances Training with Extensive Programming Corpus: RefineCode introduces a robust pretraining corpus containing 960 billion tokens across 607 programming languages, significantly bolstering training capabilities for emerging code LLMs like OpenCoder.
- This reproducible dataset is lauded for its quality and breadth, enabling more comprehensive and effective training processes in the development of advanced code AI models.
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 3.5 and Flux Boost Performance: Users are transitioning from Stable Diffusion 1.5 to newer models like SD 3.5 and Flux, noting that these versions require less VRAM and deliver enhanced performance.
- A recommendation was made to explore smaller GGUF models which can run more efficiently, even on limited hardware.
- GPU Performance and VRAM Efficiency Concerns: Concerns were raised about the long-term GPU usage from running Stable Diffusion daily, drawing comparisons to gaming performance impacts.
- Some users suggested that GPU prices might drop with the upcoming RTX 5000 series, encouraging others to wait before purchasing new hardware.
- Efficient LoRA Training for Stable Diffusion 1.5: A user inquired about training a LoRA with a small dataset for Stable Diffusion 1.5, highlighting their experience with Flux-based training.
- Recommendations included using the Kohya_ss trainer and following specific online guides to navigate the training process effectively.
- Pollo AI Introduces AI Video Generation: Pollo AI was introduced as a new tool enabling users to create videos from text prompts and animate static images.
- This tool allows for creative expressions by generating engaging video content based on user-defined parameters.
- GGUF Format Enhances Model Efficiency: Users learned about the GGUF format, which allows for more compact and efficient model usage in image generation workflows.
- It was mentioned that using GGUF files can significantly reduce resource requirements compared to larger models while maintaining quality.
OpenRouter (Alex Atallah) Discord
-
3D Object Generation API Deprecated Amid Low Usage: The 3D Object Generation API will be decommissioned this Friday, citing minimal usage with fewer than five requests every few weeks, as detailed in the documentation.
- The team plans to redirect efforts towards features that garner higher community engagement and usage.
- Hermes Model Exhibits Stability Issues: Users have observed inconsistent responses from the Hermes model across both free and paid tiers, potentially due to rate limits or backend problems on OpenRouter's side.
- Community members are investigating the root causes, discussing whether it's related to model optimization or infrastructural constraints.
- Llama 3.1 70B Instruct Model Gains Traction: Llama 3.1 70B Instruct model is experiencing increased adoption, especially within the Skyrim AI Follower Framework community, as users compare its pricing and performance to Wizard models.
- Community members are eager to explore its advanced capabilities, discussing potential integrations and performance benchmarks.
- Qwen 2.5 Coder Model Launches with Sonnet-Level Performance: The Qwen 2.5 Coder model has been released, matching Sonnet's coding capabilities at 32B parameters, as announced on GitHub.
- Community members are excited about its potential to enhance coding tasks, anticipating significant productivity improvements.
- Custom Provider Keys Beta Feature Sees High Demand: Members are actively requesting access to the custom provider keys beta feature, indicating strong community interest.
- A member thanked the team for considering their request, reflecting eagerness to utilize the new feature.
Interconnects (Nathan Lambert) Discord
-
Qwen2.5 Coder Performance: The Qwen2.5 Coder family introduces models like Qwen2.5-Coder-32B-Instruct, achieving performance competitive with GPT-4o across multiple benchmarks.
- Detailed performance metrics indicate that Qwen2.5-Coder-32B-Instruct has surpassed its predecessor, with anticipations for a comprehensive paper release in the near future.
- FrontierMath Benchmark Introduction: FrontierMath presents a new benchmark comprising complex math problems, where current AI models solve less than 2% effectively, highlighting significant gaps in AI capabilities.
- The benchmark's difficulty is underlined when compared to existing alternatives, sparking discussions about its potential influence on forthcoming AI training methodologies.
- SALSA Enhances Model Merging Techniques: The SALSA framework addresses AI alignment limitations through innovative model merging strategies, marking a substantial advancement in Reinforcement Learning from Human Feedback (RLHF).
- Community reactions express excitement over SALSA's potential to refine AI alignment, as reflected by enthusiastic exclamations like 'woweee'.
- Effective Scaling Laws in GPT-5: Discussions indicate that scaling laws continue to be effective with recent GPT-5 models, despite perceptions of underperformance, suggesting that scaling yields diminishing returns for specific tasks.
- The conversation highlights the necessity for OpenAI to clarify messaging around AGI, as unrealistic expectations persist among the community.
- Advancements in Language Model Optimization: The latest episode of Neural Notes delves into language model optimization, featuring an interview with Stanford's Krista Opsahl-Ong on automated prompt optimization techniques.
- Additionally, discussions reflect on MIPRO optimizers in DSPy, with intentions to deepen understanding of these optimization tools.
OpenAI Discord
-
Chunking JSON: Solving RAG Tool Data Gaps: The practice of chunking JSON into smaller files ensures the RAG tool captures all relevant data, preventing exclusions.
- Although effective, members noted that this method increases workflow length, as discussed in both
prompt-engineeringandapi-discussionschannels. - LLM-Powered Code Generation Simplifies Data Structuring: Members proposed using LLMs to generate code for structuring data insertion, streamlining the integration process.
- This approach was well-received, with one user highlighting its potential to reduce manual coding efforts as highlighted in multiple discussions.
- Function Calling Updates Enhance LLM Capabilities: Updates on function calling within LLMs were discussed, with users seeking ways to optimize structured outputs in their workflows.
- Suggestions included leveraging tools like ChatGPT for brainstorming and implementing efficient strategies to enhance response generation.
- AI TTS Tools: Balancing Cost and Functionality: Discussions highlighted various text-to-speech (TTS) tools such as f5-tts and Elven Labs, noting that Elven Labs is more expensive.
- Concerns were raised about timestamp data availability and the challenges of running these TTS solutions on consumer-grade hardware.
- AI Image Generation: Overcoming Workflow Limitations: Users expressed frustrations with AI video generation limitations, emphasizing the need for workflows to stitch multiple scenes together.
- There was a desire for advancements in video-focused AI solutions over reliance on text-based models, as highlighted in the
ai-discussionschannel.
- Although effective, members noted that this method increases workflow length, as discussed in both
Notebook LM Discord Discord
-
Google Seeks Feedback on NotebookLM: The Google team is conducting a 10-minute feedback survey for NotebookLM, aiming to steer future improvements. Interested engineers can register here.
- Participants who complete the survey will receive a $20 gift code, provided they are at least 18 years old. This initiative helps Google gather actionable insights for product advancements.
- NotebookLM Powers Diverse Technical Use Cases: NotebookLM is being utilized for technical interview preparation, enabling mock interviews with varied voices to enhance practice sessions.
- Additionally, engineers are leveraging NotebookLM for sports commentary experiments and generating efficient educational summaries, demonstrating its versatility in handling both audio and textual data.
- Podcast Features Face AI-Generated Hiccups: Users report that the podcast functionality in NotebookLM occasionally hallucinates content, leading to unexpected and humorous outcomes.
- Discussions are ongoing about generating multiple podcasts per notebook and strategies to manage these AI-induced inaccuracies effectively.
- NotebookLM Stands Out Against AI Tool Rivals: NotebookLM is being compared to Claude Projects, ChatGPT Canvas, and Notion AI in terms of productivity enhancements for writing and job search preparation.
- Engineers are evaluating the pros and cons of each tool, particularly focusing on features that aid users with ADHD in maintaining productivity.
- Seamless Integration with Google Drive and Mobile: NotebookLM now offers a method to sync Google Docs, streamlining the update process with a proposed bulk syncing feature.
- While the mobile version remains underdeveloped, there is a strong user demand for a dedicated app to access full notes on smartphones, alongside improvements in mobile web functionalities.
LM Studio Discord
-
LM Studio GPU Utilization on MacBooks: Users raised questions about determining GPU utilization on MacBook M4 while running LM Studio, highlighting potential slow generation speeds compared to different setup specifications.
- Discussions involved comparisons of setup specs and results, emphasizing the need for optimized configurations to improve generation performance.
- LM Studio Model Loading Issues: A user reported that LM Studio was unable to index a folder containing GGUF files, despite their presence, citing recent structural changes in the application.
- It was suggested to ensure only relevant GGUF files are in the folder and maintain the correct folder structure to resolve the model loading issues.
- Pydantic Errors with LangChain: Encountered a
PydanticUserErrorrelated to the__modify_schema__method when integrating LangChain, indicating a possible version mismatch in Pydantic.
- Users shared uncertainty whether this error was due to a bug in LangChain or a compatibility issue with the Pydantic version in use.
- Gemma 2 27B Performance at Lower Precision: Gemma 2 27B demonstrated exceptional performance even at lower precision settings, with members noting minimal benefits when using Q8 over Q5 on specific models.
- Participants emphasized the necessity for additional context in evaluations, as specifications alone may not fully convey performance metrics.
- Laptop Recommendations for LLM Inference: Inquiries about the performance differences between newer Intel Core Ultra CPUs versus older i9 models for LLM inference, with some recommendations favoring AMD alternatives.
- Suggestions included prioritizing GPU performance over CPU specifications and considering laptops like the ASUS ROG Strix SCAR 17 or Lenovo Legion Pro 7 Gen 8 for optimal LLM tasks.
Latent Space Discord
-
Qwen 2.5 Coder Launch: The Qwen2.5-Coder-32B-Instruct model has been released, along with a family of coder models ranging from 0.5B to 32B, available in various quantized formats.
- It has achieved competitive performances in coding benchmarks, surpassing models like GPT-4o, showcasing the capabilities of the Qwen series. Refer to the Qwen2.5-Coder Technical Report for detailed insights.
- FrontierMath Benchmark Reveals AI's Limitations: The newly introduced FrontierMath benchmark indicates that current AI systems solve less than 2% of included complex mathematical problems.
- This benchmark shifts focus to challenging, original problems, aiming to test AI capabilities against human mathematicians. More details can be found at FrontierMath.
- Open Interpreter Project Advances: Progress has been made on the Open Interpreter project, with the team open-sourcing it to foster community contributions.
- 'That's so cool you guys open-sourced it,' highlights the enthusiasm among members for the open-source direction. Interested parties can view the project on GitHub.
- Infrastructure Challenges in AI Agents Development: Conversations revisited the infrastructure challenges in building effective AI agents, focusing on buy vs. build decisions that startups face.
- Concerns were highlighted regarding the evolution and allocation of compute resources in the early days of OpenAI, noting significant hurdles encountered.
- Advancements in Test-Time Compute Techniques: A new state-of-the-art achievement for the ARC public validation set showcases a 61% score through innovative test-time compute techniques.
- Ongoing debates question how training and test-time processes are perceived differently within the AI community, suggesting potential unifications in methodologies.
GPU MODE Discord
-
SVDQuant accelerates Diffusion Models: A member shared an SVDQuant paper that optimizes diffusion models by quantizing weights and activations to 4 bits, leveraging a low-rank branch to handle outliers effectively.
- The approach enhances performance for larger image generation tasks despite increased memory access overhead associated with LoRAs.
- Aria Multimodal MoE Model Boosted: The Aria multimodal MoE model achieved a 4-6x speedup and fits into a single 24GB GPU using A16W4 and torch.compile.
- Despite the current codebase being disorganized, it offers potential replication insights for similar MoE models.
- BitBlas Supports int4 Kernels: BitBlas now supports int4 kernels, enabling efficient scaled matrix multiplication operations as discussed by community members.
- Discussions highlighted the absence of int4 compute cores on the H100, raising questions about operational support.
- TorchAO Framework Enhancements: The project plans to extend existing Quantization-Aware Training (QAT) frameworks in TorchAO by integrating optimizations from recent research.
- This strategy leverages established infrastructure to incorporate new features, focusing initially on linear operations over convolutional models.
- DeepMind's Neural Compression Techniques: DeepMind introduced methods for training models with neurally compressed text, as detailed in their research paper.
- Community interest peaked around Figure 3 of the paper, though specific quotes were not discussed.
tinygrad (George Hotz) Discord
-
Hailo Port on Raspberry Pi 5: A developer is porting Hailo to the Raspberry Pi 5, successfully translating models from tinygrad to ONNX and then to Hailo, despite facing challenges with quantized models requiring CUDA and TensorFlow.
- They mentioned that executing training code on edge devices is impractical due to the chip's limited cache and inadequate memory bandwidth.
- Handling Floating Point Exceptions: Discussions centered around detecting floating point exceptions like NaN and overflow, highlighting the necessity for platform support in detection methods. Relevant resources included Floating-point environment - cppreference.com and FLP03-C. Detect and handle floating-point errors.
- Participants emphasized the importance of capturing errors during floating-point operations and advocated for robust error handling techniques.
- Integrating Tinybox with Tinygrad: Tinybox integration with tinygrad was discussed, focusing on potential upgrades and addressing issues related to the P2P hack patch affecting version 5090 upgrades. Relevant GitHub issues were referenced from the tinygrad repository.
- There were speculations about the performance impacts of different PCIe controller capabilities on hardware setups.
- TPU Backend Strategies: A user proposed developing a TPU v4 assembly backend, expressing willingness to collaborate post-cleanup. They inquired about the vectorization of assembly in LLVM and specific TPU versions targeted for support.
- The community engaged in discussions about the feasibility and technical requirements for merging backend strategies.
- Interpreting Beam Search Outputs: Assistance was sought for interpreting outputs from a beam search, particularly understanding how the progress bar correlates with kernel execution time. It was noted that the green indicator represents the final runtime of the kernel.
- The user expressed confusion over actions and kernel size, requesting further clarification to accurately interpret the results.
Cohere Discord
-
AI Interview Bot Development: A user is launching a GenAI project for an AI interview bot that generates questions based on resumes and job descriptions, scoring responses out of 100.
- They are seeking free resources like vector databases and orchestration frameworks, emphasizing that the programming will be handled by themselves.
- Aya-Expanse Model Enhancements: A user praised the Aya-Expanse model for its capabilities beyond translation, specifically in function calling and handling Greek language tasks.
- They noted that the model effectively selects
direct_responsefor queries not requiring function calls, which improves response accuracy. - Cohere API for Document-Based Responses: A user inquired about an API to generate freetext responses from pre-uploaded DOCX and PDF files, noting that currently only embeddings are supported.
- They expressed interest in an equivalent to the ChatGPT assistants API for this purpose.
- Cohere API Errors and Latency: Users reported multiple issues with the Cohere API, including 500 Internal Server Errors and 404 errors when accessing model details.
- Additionally, increased latency with response times reaching 3 minutes and Embed API slowness were highlighted, with users directed to the Cohere Status Page for updates.
- vnc-lm Discord Bot Integration: A member introduced the vnc-lm Discord bot which integrates with the Cohere API and GitHub Models API, as well as local ollama models.
- Key features include creating conversation branches, refining prompts, and sending context materials like screenshots and text files, with setup accessible via GitHub using
docker compose up --build.
OpenInterpreter Discord
-
Open Interpreter 1.0 Update Testing: A user volunteered to assist in testing the upcoming Open Interpreter 1.0 update, which is on the dev branch and set for release next week. They shared the installation command.
- The community emphasized the need for bug testing and adapting the update for different operating systems to ensure a smooth rollout.
- Hardware Requirements for Open Interpreter: A user questioned whether the Mac Mini M4 Pro with 64GB or 24GB of RAM is sufficient for running Open Interpreter effectively. A consensus emerged affirming that the setup would work.
- Discussions also included integrating additional components like a microphone and speaker to enhance the hardware environment.
- Qwen 2.5 Coder Models Released: The newly released Qwen 2.5 coder models showcase significant improvements in code generation, code reasoning, and code fixing, with the 32B model rivaling OpenAI's GPT-4o.
- Members expressed enthusiasm as Qwen and Ollama collaborated, emphasizing the fun of coding together, as stated by Qwen, 'Super excited to launch our models together with one of our best friends, Ollama!'. See the official tweet for more details.
- CUDA Configuration Adjustments: A member mentioned they adjusted their CUDA setup, achieving a satisfactory configuration after making necessary tweaks.
- This successful instantiation on their system highlights the importance of correct CUDA configurations for optimal performance.
- Software Heritage Code Archiving for Open Interpreter: A user offered assistance in archiving the Open Interpreter code in Software Heritage, aiming to benefit future generations.
- This proposal underscored the community's commitment to preserving valuable developer contributions.
LlamaIndex Discord
-
LlamaParse Premium excels in document parsing: Hanane Dupouy showcased how LlamaParse Premium efficiently parses complex charts and diagrams into structured markdown, enhancing document readability.
- This tool transforms visual data into accessible text, significantly improving document usability.
- Advanced chunking strategies boost performance: @pavan_mantha1 outlined three advanced chunking strategies and provided a full evaluation setup for testing on personal datasets.
- These strategies aim to enhance retrieval and QA functionality, demonstrating effective data processing methods.
- PureML automates dataset management: PureML leverages LLMs for automatic cleanup and refactoring of ML datasets, featuring context-aware handling and intelligent feature creation.
- These capabilities improve data consistency and quality, integrating tools like LlamaIndex and GPT-4.
- Benchmarking fine-tuned LLM model: A member sought guidance on benchmarking their fine-tuned LLM model available at Hugging Face, facing errors with the Open LLM leaderboard.
- They requested assistance to effectively utilize the leaderboard for evaluating model performance.
- Docker resource settings for improved ingestion: Users discussed Docker configurations, allocating 4 CPU cores and 8GB memory, to optimize the sentence transformers ingestion pipeline.
- Despite these settings, the ingestion process remains slow and prone to failure, highlighting the need for further optimization.
DSPy Discord
-
M3DocRAG Sets New Standards in Multi-Modal RAG: M3DocRAG showcases impressive results for question answering using multi-modal information from a large corpus of PDFs and excels in ColPali benchmarks.
- Jaemin Cho highlighted its versatility in handling single & multi-hop questions across diverse document contexts.
- New Open-domain Benchmark with M3DocVQA: The introduction of M3DocVQA, a DocVQA benchmark, challenges models to answer multi-hop questions across more than 3K PDFs and 40K pages.
- This benchmark aims to enhance understanding by utilizing various elements such as text, tables, and images.
- DSPy RAG Use Cases Spark Interest: A member expressed enthusiasm about the potential of DSPy RAG capabilities, indicating a keen interest in experimentation.
- They noted the promising intersection between DSPy RAG and vision capabilities, hinting at intriguing future applications.
- LangChain integration falls out of support: Recent updates on GitHub indicate that the current integration with LangChain is no longer maintained and may not function properly.
- One member raised a question about this change, seeking further context on the situation.
- DSPy prompting techniques designed for non-composability: Members discussed the nature of DSPy prompting techniques, confirming they are intentionally not composable as part of the design.
- This decision emphasizes that while signatures can be manipulated, doing so may limit functionality and clarity of control flow.
OpenAccess AI Collective (axolotl) Discord
-
FastChat and ShareGPT Removal: The removal of FastChat and ShareGPT triggered strong reactions within the community, highlighted by the PR #2021. Members expressed surprise and concern over this decision.
- Alternative solutions, such as reverting to an older commit, were suggested to maintain project stability, indicating ongoing efforts to address the community's needs.
- Metharme Support Delays: A query about the continued support for Metharme led to an explanation that delays are due to fschat releases impacting development timelines.
- Community members showed interest in incorporating sharegpt conversations into the new chat_template, reflecting a collaborative approach to overcoming support challenges.
- Fine-Tuning VLMs Best Practices: Assistance was sought for fine-tuning VLMs, with recommendations to utilize the provided configuration for llama vision from the example repository.
- Confirmation that training a VLM model using llama 3.2 1B is achievable demonstrated the community's capability and interest in advanced model training techniques.
- Inflection AI API Updates: Inflection-3 was discussed, introducing two models: Pi for emotional engagement and Productivity for structured outputs, as detailed in the Inflection AI Developer Playground.
- Members raised concerns about the absence of benchmark data, questioning the practical evaluation of these new models and their real-world application.
- Metharme Chat_Template PR Addition: A pull request to add Metharme as a chat_template was shared via PR #2033, addressing user requests and testing compatibility with previous versions.
- Community members were encouraged to execute the preprocess command locally to ensure functionality, fostering a collaborative environment for testing and implementation.
LLM Agents (Berkeley MOOC) Discord
-
Midterm Check-in for Project Feedback: Teams can now submit their progress through the Midterm Check-in Form to receive feedback and possibly gain GPU/CPU resource credits.
- Submitting the form is crucial even if not requesting resources, as it could facilitate valuable insights on their projects.
- Application for Additional Compute Resources: Teams interested in additional GPU/CPU resources must complete the resource request form alongside the midterm check-in form.
- Allocation will depend on documented progress and detailed justification, encouraging even new teams to apply.
- Lambda Workshop Reminder: The Lambda Workshop is scheduled for tomorrow, Nov 12th from 4-5pm PST, and participants are encouraged to RSVP through this link.
- This workshop will provide further insights and guidance on team projects and the hackathon process.
- Unlimited Team Size for Hackathon: A member inquired about the allowed team size for the hackathon, and it was confirmed that the size is unlimited.
- This opens up the possibility for anyone interested to collaborate without restrictions.
- Upcoming Lecture on LLM Agents: An announcement was made regarding a discussion of Lecture 2: History of LLM Agents happening tonight.
- The discussion will include a review of the lecture and exploration of some Agentic code, welcoming anyone interested.
Torchtune Discord
- Capturing attention scores without modifying forward function: A user inquired about capturing attention scores without altering the forward function in the self-attention module using forward hooks. Others suggested potential issues with F.sdpa(), which doesn't currently output attention scores, indicating that modifications may be necessary.
-
DCP checkpointing issues causing OOM errors: A member reported that the latest git main version still fails to address issues with gathering weights and optimizers on rank=0 GPU, resulting in OOM (Out Of Memory) errors.
- They implemented a workaround for DCP checkpoint saving, intending to convert it to the Hugging Face format and possibly write a PR for better integration.
- Community support for DCP integration in Torchtune: Discussions emphasized the community’s support for integrating DCP checkpointing into Torchtune, with talks about sharing PRs or forks related to the efforts.
- An update indicated that a DCP PR from PyTorch contributors is likely to be available soon, enhancing collaborative progress.
LAION Discord
-
SVDQuant Reduces Memory and Latency: The recent SVDQuant introduces a new quantization paradigm for diffusion models, achieving a 3.5× memory and 8.7× latency reduction on a 16GB laptop 4090 GPU by quantizing weights and activations to 4 bits.
- Additional resources are available on GitHub and the full paper can be accessed here.
- Gorilla Marketing in AI: AI companies are adopting gorilla marketing strategies, characterized by unconventional promotional tactics.
- This trend was humorously highlighted with a reference to the Harambe GIF, emphasizing the playful nature of these marketing approaches.
MLOps @Chipro Discord
-
RisingWave Enhances Data Processing Techniques: A recent post highlighted RisingWave's advancements in data processing, emphasizing improvements in stream processing techniques.
- For more insights, check out the full details on their LinkedIn post.
- Stream Processing Techniques in Focus: The discussion centered around the latest in stream processing, showcasing methods to optimize real-time data handling.
- Participants noted that adopting these innovations could significantly impact data-driven decision-making.
Gorilla LLM (Berkeley Function Calling) Discord
-
Using Gorilla LLM for Testing Custom Models: A user inquired about using Gorilla LLM to benchmark their fine-tuned LLM, seeking guidance as they are new to the domain.
- They expressed a need for help specifically in benchmark testing custom LLMs, hoping for community support and recommendations.
- Seeking Support for Benchmarking Custom LLMs: A user reached out to utilize Gorilla LLM for benchmarking their custom fine-tuned model, emphasizing their lack of experience in the area.
- They requested assistance in effectively benchmark testing custom LLMs to better understand performance metrics.
AI21 Labs (Jamba) Discord
- Continued Use of Fine-Tuned Models: A user requested to continue using their fine-tuned models within the current setup.
- ****:
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Perplexity AI ▷ #general (1230 messages🔥🔥🔥):
Perplexity server issuesUser frustrationsCommunication with usersWaiting for fixesAlternatives to Perplexity
-
Perplexity Suffers Server Issues: Users reported difficulties logging in and accessing threads on Perplexity, with messages disappearing and threads showing errors such as 'This Thread does not exist.' Health updates from the team confirmed technical issues due to a recent deployment.
- While some threads have recently become accessible again, many users find that new messages are now hidden, compounding frustrations.
- User Frustration and Support Deficiency: Many users expressed dissatisfaction with the Perplexity support team's lack of communication regarding fixes for ongoing bugs, leading to feelings of neglect and frustration. Complaints were made about the poor handling and multiple recurring bugs impacting usage.
- Users highlighted difficulties in using the platform effectively, voicing their concerns about the company's performance and the need for better customer support.
- Communication on Updates: Participants discussed the company's apparent inability to communicate effectively with users regarding ongoing issues, calling for better transparency. Some users suggested that the company should implement a more proactive approach to updating customers during outages.
- There was a call for the implementation of an API to relay information about platform status updates to Discord users promptly.
- Looking for Alternatives: Some users began seeking alternatives to Perplexity, particularly interested in platforms that offer Opus support, leading to suggestions like ChatHub. Concerns were raised regarding the value of continuing with Perplexity amidst its ongoing issues.
- Anticipation of Future Impact: As discussions unfolded regarding the state of the platform, there were reflections on how technology firms could affect user experiences in the long run. Users expressed propositions regarding how company reliance on investors might degenerate customer service once money starts to dwindle.
Links mentioned:
- Capybara Let Him Cook GIF - Capybara Let him cook - Discover & Share GIFs: Click to view the GIF
- Tweet from Aravind Srinivas (@AravSrinivas): It was a deployment issue. We’re reverting back. Sorry. Will be up and running very very shortly. Quoting Crunk ✈️ Network School (@crunk304) Plex is down! @AravSrinivas @perplexity_ai
- Perplexity - Status: Perplexity Status
- Weareback Wereback GIF - Weareback Wereback Wearebackbaby - Discover & Share GIFs: Click to view the GIF
- When Server Down Iceeramen GIF - When Server Down Iceeramen Monkey - Discover & Share GIFs: Click to view the GIF
- ChatHub - GPT-4o, Claude 3.5, Gemini 1.5 side by side: Use and compare GPT-4o, Claude 3.5, Gemini 1.5 and more chatbots simultaneously
- Bye Bye GIF - Bye bye - Discover & Share GIFs: Click to view the GIF
Perplexity AI ▷ #sharing (25 messages🔥):
Zomato's Food Rescue InitiativeAstrology DiscussionsGradient Descent TechniquesAnti-Aging Research with RapamycinFishing Bait Recommendations
-
Zomato's Smart Food Rescue Initiative: Zomato introduced its 'Food Rescue' program, allowing users to purchase cancelled orders at lower prices here. This initiative aims to minimize food waste while offering consumers more affordable meal options.
- Feedback on this move highlights its potential to benefit both Zomato and customers alike, raising questions on sustainability practices in the food delivery industry.
- Astrology: Reality or Myth?: Multiple members discussed the validity of astrology, specifically referencing a link that delves into its authenticity. The conversation sparked differing opinions on the impact of astrological claims in modern life.
- Participants expressed varied views, with some advocating for its psychological benefits while others dismissed it as pseudoscience.
- Gradient Descent Techniques Explored: Several queries were raised about the various types of gradient descent, focusing on their applications in machine learning link. Members shared links and personal insights into how these methods optimize model training.
- Discussions included comparisons between standard gradient descent and advanced techniques like stochastic and mini-batch gradient descent, showcasing best practices for implementation.
- Anti-Aging Research Gains Attention: New research on rapamycin and its anti-aging effects has caught the eye of members, leading to discussions about ongoing studies in the area link. Users shared personal experiences with the drug and discussed its potential benefits and drawbacks.
- Conversations centered around the implications of this research on longevity and health, with enthusiasm for future discoveries.
- Best Bait for Fishing Adventures: A user inquired about the best bait to catch fish, which led to a lively discussion among fishing enthusiasts sharing tips link. Suggestions ranged from traditional options to innovative bait methods designed to attract various species.
- This exchange highlighted the community's enthusiasm for fishing and willingness to share valuable insights gained from their experiences.
Perplexity AI ▷ #pplx-api (24 messages🔥):
Perplexity API citationsAPI vs. Pro Search outputSearch domain filterCitation links outputDifferent sources in API
-
Perplexity API now includes citations: The Perplexity API has announced the public availability of citations with no breaking changes, and the default rate limit for sonar online models has increased to 50 requests/min.
- For more details, users can refer to the docs.
- API output differs from Pro Search: Discussion arose about the output quality of the API compared to the Pro Search, clarifying that the Pro version uses a different model not accessible via the API.
- Members expressed disappointment about not obtaining the same output quality in the API as in the Pro search.
- Search domain filter query: One user inquired if the search_domain_filter supports subdomain searches, wanting to use 'support.company.com' while avoiding 'community.company.com'.
- The conversation about this feature included a follow-up question seeking confirmation on its functionality.
- Issues with citation links: Concerns were raised about the citation links returned by the API, which appeared as parenthetical numbers instead of clickable links.
- Multiple members reported similar experiences, prompting discussions on how to request URLs in different formats.
- Discrepancies in API and chat source results: A user noticed the sources returned by the API varied significantly from those in the chat for identical queries, sparking questions about their search algorithms.
- The discrepancy was attributed to the underlying algorithm and data crawled, independent of the LLM model differences.
Links mentioned:
- no title found: no description found
- no title found.): no description found
HuggingFace ▷ #general (922 messages🔥🔥🔥):
AI model scamsBirthday celebrationsImage generation modelsModel fine-tuningLlama models and competition
-
Discussion on AI Model Scams: A user recounted how they were scammed for $500 by a developer who failed to deliver an AI model, highlighting the lack of trust in freelance arrangements.
- The community emphasized the importance of using platforms like Upwork for better security and reliable service.
- Celebrating a Birthday with New Model Release: A user announced their birthday and shared a new model they created, dubbed 'birthday-llm,' designed for logical reasoning and roleplaying tasks.
- The model was well-received, with others expressing enthusiasm to try it out.
- Image Generation and Character Consistency: Users discussed challenges in generating character consistency in images, with recommendations made for models such as Animagine XL 3.1 and DiffuseCraft.
- The importance of using labeled datasets for tasks such as score detection from pinball machines was highlighted.
- Fine-tuning for Specific Use Cases: The community deliberated methods for obtaining a model capable of detecting specific objects and scores, and techniques for integrating text and image data.
- There was an emphasis on setting clear accuracy targets for training models in order to ensure reasonable expectations.
- Exploring New AI Models and Frameworks: A user sought advice on finding high-quality AI models on Hugging Face amidst concerns about outdated models saturating the platform.
- The conversation touched on the rapid pace of advancements in AI model development and the need for clear documentation and evaluation.
Links mentioned:
- Redirecting...: no description found
- What Is Flux In Ai: no description found
- minchyeom/birthday-llm · Hugging Face: no description found
- How to convert model.safetensor to pytorch_model.bin?: I'm fine tuning a pre-trained bert model and i have a weird problem: When i'm fine tuning using the CPU, the code saves the model like this: With the "pytorch_model.bin...
- Forrest Gump Running GIF - Forrest Gump Running Me When Im Late - Discover & Share GIFs: Click to view the GIF
- rwitz/cat1.0 · Hugging Face: no description found
- взгляд 2000 ярдов GIF - Взгляд 2000 ярдов Война - Discover & Share GIFs: Click to view the GIF
- Why should we use Temperature in softmax?): I'm recently working on CNN and I want to know what is the function of temperature in softmax formula? and why should we use high temperatures to see a softer norm in probability distribution?Sof...
- Kitty Stinky Kitty GIF - Kitty Stinky kitty Stinky - Discover & Share GIFs: Click to view the GIF
- Cat Computer GIF - Cat Computer Typing - Discover & Share GIFs: Click to view the GIF
- Trump Donald GIF - Trump Donald Face - Discover & Share GIFs: Click to view the GIF
- Trump Orange Seat GIF - Trump Orange Seat Looking Around - Discover & Share GIFs: Click to view the GIF
- Spongebob Patrick GIF - Spongebob Patrick Patrick Star - Discover & Share GIFs: Click to view the GIF
- What is temperature?: I see the word “temperature” being used at various places like: in Models — transformers 4.12.4 documentation temperature ( float , optional, defaults to 1.0) – The value used to module the next...
- Snoop Snoop Dogg GIF - Snoop Snoop dogg Snoop smile - Discover & Share GIFs: Click to view the GIF
- Punisher The Punisher GIF - Punisher The Punisher Wait - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Ghostbuster Toaster GIF - Ghostbuster Toaster - Discover & Share GIFs: Click to view the GIF
- Family Guy Peter Griffin GIF - Family guy Peter griffin Peter - Discover & Share GIFs: Click to view the GIF
- city96/FLUX.1-dev-gguf · Hugging Face: no description found
- 80m Increased Revenue & Redeploy 3 Fte GIF - 80M Increased Revenue & Redeploy 3 FTE - Discover & Share GIFs: Click to view the GIF
- ComfyUI - Advanced - a Hugging Face Space by wrdias: no description found
- ComfyUI (test) - a Hugging Face Space by John6666: no description found
- James Moriarty (hologram): You – or someone – asked your computer to program a nefarious fictional character from nineteenth century London – and that is how I arrived... but I am no longer that creation. I am no longer that ch...
- Animagine XL 3.1 - a Hugging Face Space by cagliostrolab: no description found
- Laxhar/sdxl_noob · Hugging Face: no description found
- YOLO11 🚀 NEW: Discover YOLO11, the latest advancement in state-of-the-art object detection, offering unmatched accuracy and efficiency for diverse computer vision tasks.
- Bad Piggies Theme: Provided to YouTube by The Orchard EnterprisesBad Piggies Theme · Ilmari HakkolaBad Piggies (Original Game Soundtrack)℗ 2012 Rovio EntertainmentReleased on: ...
- GitHub - black-forest-labs/flux: Official inference repo for FLUX.1 models: Official inference repo for FLUX.1 models. Contribute to black-forest-labs/flux development by creating an account on GitHub.
- 🧩 DiffuseCraft - a Hugging Face Space by r3gm: no description found
- Stable Diffusion XL: no description found
HuggingFace ▷ #today-im-learning (10 messages🔥):
Teaching LLMs MathematicsFull Stack vs AI StackTraining a BART ModelProblem-Based LearningLong Sentences in Translation
-
Discussing Approaches to Teaching LLMs Math: A member expressed interest in incorporating reasoning and logic into teaching LLMs mathematics, emphasizing the significance of focusing on solvable problems.
- They noted that teaching LLMs with manageable challenges, like Middle School Math, is preferable over complex problems where success is unlikely.
- Navigating the Full Stack Dilemma: A user shared confusion over whether to focus on Full Stack development before delving into AI, citing their existing knowledge of classical ML and basic NLP and CV.
- There was a suggestion that pursuing Full Stack may drain time and energy, prompting a request for guidance from the community.
- Successful BART Model Training for Translation: After 6 hours of debugging, a user successfully trained a BART model on the OPUS books de-en dataset to translate English to German.
- They implemented efficiency measures like saving model states and configurations, but noted that some overly long sentences would get truncated during processing.
- Highlighting Problem-Based Learning in Math: A member highlighted the importance of productive struggle in learning mathematics, suggesting it's crucial for effective LLM training in educational contexts.
- They remarked on the relevance of these concepts for lifelong learners and echoed gratitude for shared recommendations on the topic.
- Implementing Chatbot Functions for Translation: The user plans to add a chatbot pipeline to the BART model for practical translation functionality, utilizing top-p sampling during inference.
- This addition aims to streamline the model's capability to act as a translation bot while also addressing complexities in training configurations.
HuggingFace ▷ #cool-finds (22 messages🔥):
Zebra-Llama ModelFractal Data Processing in NeuronsChonkie Text Chunking LibraryLucid for Minecraft EmulationMedical AI Updates
-
Zebra-Llama Introduced for Rare Disease Knowledge: A novel model named Zebra-Llama focuses on context-aware training for improved Retrieval Augmented Generation (RAG) capabilities in LLMs, particularly for rare diseases like Ehlers-Danlos Syndrome.
- This model includes a GitHub repository and showcases enhanced citation accuracy during real-world applications.
- New Insights on Neuron Coordination: Research published in Cell reveals that neurons can optimize their efforts by dedicating 40-50% of their activity to individual tasks while remaining engaged in teamwork.
- This organizational structure has been found to be consistent across five different species, impacting our understanding of brain efficiency.
- Chonkie: New Lightweight Text Chunking Library: Chonkie is a lightweight, efficient library designed for fast RAG text chunking, making text processing more accessible.
- You can find more details here and see the repository on GitHub.
- Lucid V1: Real-Time Minecraft Game Emulation: Rami has announced the release of Lucid V1, a world model capable of emulating Minecraft environments on standard consumer hardware in real-time.
- Play the demo here and check the details on Substack.
- Weekly Medical AI Highlights: The podcast presents the top medical AI research papers from November 2-9, 2024, including notable works like Exploring Large Language Models for Specialist-level Oncology Care.
- Listeners can catch more updates via the YouTube link.
Links mentioned:
- MSN: no description found
- DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion: In this paper, we introduce \textbf{DimensionX}, a framework designed to generate photorealistic 3D and 4D scenes from just a single image with video diffusion. Our approach begins with the insight th...
- The Mystery of How Neurons Control The Brain Has Finally Been Solved: The brain is a marvel of efficiency, honed by thousands of years of evolution so it can adapt and thrive in a rapidly changing world.
- Alice In Wonderland Black Hole GIF - Alice In Wonderland Black Hole Falling - Discover & Share GIFs: Click to view the GIF
- Tweet from rami (@rami_mmo): Excited to announce Lucid V1: A world model that can emulate Minecraft environments in real-time on consumer hardware! 🔥 play here: https://lucidv1-demo.vercel.app/ post: https://ramimo.substack.c...
- Tweet from minhash (@BhavnickMinhas): 🦛 Introducing Chonkie: The no-nonsense RAG chunking library that's lightweight, lightning-fast, and ready to CHONK your texts! 🔗 https://pypi.org/project/chonkie/ 👩🏻💻 https://github.com/bh...
- Tweet from Open Life Science AI (@OpenlifesciAI): Last Week in Medical AI: Top Research Papers/Models 🏅 (November 2-9, 2024) 🏅 Medical AI Paper of the Week: Exploring Large Language Models for Specialist-level Oncology Care Authors(@apalepu13 ,@v...
- What We Learned About LLM/VLMs in Healthcare AI Evaluation: : no description found
- GitHub - shadowlamer/diffusezx: ZX-Spectrum inspired images generator: ZX-Spectrum inspired images generator. Contribute to shadowlamer/diffusezx development by creating an account on GitHub.
- The massed-spaced learning effect in non-neural human cells - Nature Communications: When learning is spaced in time, memory is enhanced, but so far this was only observed in neural systems. Here, the authors show that non-neural cells, including kidney cells, also show a spaced effec...
- Zebra-Llama: A Context-Aware Large Language Model for Democratizing Rare Disease Knowledge: Rare diseases present unique challenges in healthcare, often suffering from delayed diagnosis and fragmented information landscapes. The scarcity of reliable knowledge in these conditions poses a dist...
- zebraLLAMA/zebra-Llama-v0.2 · Hugging Face: no description found
- GitHub - karthiksoman/zebra-Llama: Contribute to karthiksoman/zebra-Llama development by creating an account on GitHub.
- zebra-Llama/code/notebook/zebra_llama_v0.2_demo.ipynb at main · karthiksoman/zebra-Llama: Contribute to karthiksoman/zebra-Llama development by creating an account on GitHub.
HuggingFace ▷ #i-made-this (13 messages🔥):
AI Safety Camp 10Depth Estimation and Object Detection PerformanceOllama Operator for LLM DeploymentQwen2.5 Coder PerformanceEnhancements to base64 API Requests
-
AI Safety Camp 10 Opening Applications: The 10th iteration of the AI Safety Camp has begun its team member application phase for a 3-month online research program starting January 2025. Interested individuals can find projects and apply through their website by November 17th.
- The camp will cover a wide range of topics, encouraging participants from diverse backgrounds to apply.
- Depth Estimation Pipeline Achieves 4ms Inference: A newly developed pipeline delivers under 4ms inference for depth estimation and object detection, optimizing for speed and accuracy in real-time applications. More details on this achievement can be found in a blog post.
- The project is a continuation of the author's previous work on the DEPTHS model, further enhancing performance metrics and practical applications.
- Ollama Operator Streamlines LLM Deployment: The Ollama Operator simplifies deploying Ollama instances and LLM servers faster with just a few lines of YAML configuration. It was recently presented at KubeCon, and detailed recordings are available here.
- The operator is open-sourced, allowing users to easily set up and manage their own LLM deployments.
- Qwen2.5 Coder Performance Exceeds Expectations: In tests, Qwen2.5 Coder 32B has outperformed both GPT4o and Claude 3.5 Sonnet, showcasing its capabilities in code generation tasks. A detailed comparison and performance insights can be viewed in the YouTube video.
- Users are encouraged to explore the new GGUF collections of models available on Hugging Face for further utilization.
- Base64 API Integration Improvement: An update to a library enhances the base64 implementation, allowing API requests to be made without needing to pass image URLs to the Hugging Face API. This functionality is detailed in the release notes.
- These improvements facilitate easier integration of models into applications, simplifying the development process.
Links mentioned:
- Audio Lyrics Extractor - a Hugging Face Space by eyov: no description found
- PyTorchModelHubMixin: Bridging the Gap for Custom AI Models on Hugging Face: no description found
- rwitz/cat1.0 · Hugging Face: no description found
- breadlicker45/bread-tv2o-medium · Hugging Face: no description found
- groq gradio as desktop app: groq gradio as desktop app. GitHub Gist: instantly share code, notes, and snippets.
- Volko76 (Volko): no description found
- GitHub - skirdey/boss: Multi-Agent OS for Offensive Security: Multi-Agent OS for Offensive Security. Contribute to skirdey/boss development by creating an account on GitHub.
- AI Safety Camp 10 — AI Alignment Forum: We are pleased to announce that the 10th version of the AI Safety Camp is now entering the team member application phase! …
- Qwen2.5 Coder 32B vs GPT4o vs Claude 3.5 Sonnet (new): Let's see which model is the best
- How I Achieved 4ms Depth & Object Detection — and What I Built with It: AI that guides, detects, and empowers the blind under fraction of a second. Real-time, intuitive, life-changing.
- Depth Estimation and Proximity Tracking for Human Support [Detection + Depth + Text Gen]: Preprocessing video clips sourced from platforms like Pexels or Unsplash, here’s an inference preview of how our DEPTHS model works. You’ll notice objects de...
- Ollama Operator: no description found
- GitHub - nekomeowww/ollama-operator: Yet another operator for running large language models on Kubernetes with ease. Powered by Ollama! 🐫: Yet another operator for running large language models on Kubernetes with ease. Powered by Ollama! 🐫 - nekomeowww/ollama-operator
- No More Runtime Setup! Let's Bundle, Distribute, Deploy, Scale LLMs Seamlessly... - Fanshi Zhang: Don't miss out! Join us at our next Flagship Conference: KubeCon + CloudNativeCon North America in Salt Lake City from November 12 - 15, 2024. Connect with o...
HuggingFace ▷ #computer-vision (2 messages):
Fine-tuning MobileNet for face detectionModel for 3D image classification
-
Seeking Fine-tuning Resources for MobileNet: A member inquired about resources for fine-tuning MobileNet specifically for face detection and face recognition tasks.
- No specific resources were provided in the discussion.
- 3D Image Classification Model Needed: Another member sought recommendations for a model suitable for 3D image classification using a dataset comprised of images in .obj and .mtl formats.
- They mentioned having the image classes ready, but did not receive any direct suggestions.
HuggingFace ▷ #NLP (7 messages):
Evaluating TinyLlama for Text to SQLNLP and Voice Synthesis in WolofLanguage Detection MethodsEvaluation Metrics for LangChain SQL Agent
-
Evaluating TinyLlama for Text to SQL Queries: A member shared that they have finetuned TinyLlama for text to SQL queries and are seeking ways to evaluate this model.
- Another suggested exploring HF spaces dedicated to Sql-Eval, recommending a search for 'sql eval'.
- Collaborating on NLP and Voice Synthesis in Wolof: A member expressed interest in collaborating on NLP and voice synthesis work specifically in Wolof Senegal.
- No further details or responses were provided regarding this collaboration.
- Lightweight English Language Detection: A member inquired about the lightest and offline method for detecting English language input.
- They are specifically looking for a solution that plays a role in identifying whether English content is present.
- Simplifying Evaluation Metrics for LangChain SQL Agent: A member is trying to identify simpler evaluation metrics for their LangChain SQL agent code, citing various complex options like agent trajectory evaluation.
- They seek resources, methods, and references, including YouTube videos or Python code examples, to simplify the evaluation process.
- Seeking Help with LangChain SQL Agent: The same member continued to seek assistance, noting their lack of knowledge in this area.
- They are looking for insights from anyone who has previously worked on LangChain SQL agent evaluation.
HuggingFace ▷ #diffusion-discussions (6 messages):
Study group for diffusion modelsLearning resources for stochastic processesRetake photography app discussionGemini Nano optimization module issuesFullstack vs AI stack guidance
-
Inquiring about a study group for diffusion models: A member asked if there is an existing study group for diffusion models, indicating interest in collaborative learning.
- Another member responded with uncertainty, suggesting that no group may exist.
- Request for resources on stochastic processes: A member sought recommendations for books or courses focused on stochastic processes and SDEs related to diffusion models.
- This reflects a proactive approach to enhance their understanding of the theoretical foundations involved.
- Discussion on the 'Retake' photography app: One user described the 'Retake' app as a groundbreaking tool that reimagines photos realistically, enhancing ordinary shots effortlessly.
- They expressed a desire for insights into the models used behind this innovative app.
- Challenges updating Gemini Nano optimization module: A member reported difficulties while following setup instructions for Gemini Nano, specifically with updating the optimization module.
- They provided system specifications, including their use of Arch Linux and attempts on different browsers.
- Fullstack development versus AI stack inquiry: A member, experienced with classical ML algorithms and PyTorch, was advised to consider fullstack development before diving into AI.
- They expressed concern about the time commitment and whether pursuing fullstack is worth the investment.
Link mentioned: Retake AI: Face & Photo Editor - Apps on Google Play: no description found
Unsloth AI (Daniel Han) ▷ #general (628 messages🔥🔥🔥):
Qwen Coder ReleaseLanguage Model Fine-TuningGaming PerspectivesCloudflare Tunneling SolutionsCollaboration Resources for AI Projects
-
Excitement Over Qwen Coder Release: Members expressed happiness regarding the release of the Qwen 2.5-Coder-32B, claiming it performs impressively, even outscoring previous models.
- There are expectations that this model will enhance coding capabilities for users seeking robust language models.
- Discussion on Language Models: Users discussed the differences between BGE-Large and BGE-M3, noting that the latter has been performing well in benchmarks due to its multilingual capabilities.
- The conversation highlighted the importance of model selection based on the user's needs, particularly regarding language processing.
- Gaming and Development Perspectives: The group shared their thoughts on gaming culture, mentioning how personal hobbies can influence professional work, with a consensus on the maturity of gaming preferences over time.
- Members agreed on the necessity of separating work from leisure to maintain productivity and enjoyment.
- Utilizing Cloudflare for Tunneling: Suggestions were made to use Cloudflare tunnels as an alternative to Gradio for sharing models in regions with restrictions, emphasizing its effectiveness in exposing local servers.
- The steps for setting up and utilizing Cloudflare for tunneling were provided to assist users facing access issues.
- Collaborative AI Project Resources: Users shared resources for building wrapper functions without relying on extensive frameworks, reflecting on lessons learned during past programming experiences.
- The community encouraged self-hosted solutions and customization to streamline AI model deployment.
Links mentioned:
- mergekit-gui - a Hugging Face Space by arcee-ai: no description found
- On-demand deployments - Fireworks AI Docs: no description found
- Reward Modelling - DPO, ORPO & KTO | Unsloth Documentation: To use DPO, ORPO or KTO with Unsloth, follow the steps below:
- Use model after training: no description found
- How to Merge Fine-tuned Adapter and Pretrained Model in Hugging Face Transformers and Push to Hub?: I have fine-tuned the Llama-2 model following the llama-recipes repository's tutorial. Currently, I have the pretrained model and fine-tuned adapter stored in two separate directories as follows:...
- Hackerman GIF - Hacker Hackerman Kung Fury - Discover & Share GIFs: Click to view the GIF
- Aya Expanse: Connecting Our World: Cohere For AI launches Aya Expanse, a state-of-the-art multilingual family of models to help close the language gap with AI.
- Tobias Tobias Funke GIF - Tobias Tobias Funke - Discover & Share GIFs: Click to view the GIF
- Uploading a custom model - Fireworks AI Docs: no description found
- Tweet from Daniel Han (@danielhanchen): My take on "LoRA vs full finetuning: An illusion of equivalence" TLDR 1. Use alpha = 2*rank 2. Don't use too small ranks (rank=1 to 8) 3. Sensational title. Better title "LoRA works i...
- Unsloth Fixing Gemma bugs: Unsloth fixing Google's open-source language model Gemma.
- Wow Meme Wow GIF - Wow Meme Wow Wink - Discover & Share GIFs: Click to view the GIF
- Instantiating a big model: no description found
- How to Merge Fine-tuned Adapter and Pretrained Model in Hugging Face Transformers and Push to Hub?: I have fine-tuned the Llama-2 model following the llama-recipes repository's tutorial. Currently, I have the pretrained model and fine-tuned adapter stored in two separate directories as follows:...
- Build a Retrieval Augmented Generation (RAG) App | 🦜️🔗 LangChain: One of the most powerful applications enabled by LLMs is sophisticated question-answering (Q&A) chatbots. These are applications that can answer questions about specific source information. These ...
- ORPO Trainer: no description found
- EASIEST Way to Fine-Tune LLAMA-3.2 and Run it in Ollama: Meta recently released Llama 3.2, and this video demonstrates how to fine-tune the 3 billion parameter instruct model using Unsloth and run it locally with O...
- Beyond Fine-Tuning: Merging Specialized LLMs Without the Data Burden: From Model Soup to Automated Evolutionary Merging: Leveraging Specialized LLM Fusion to Reduce Data Requirements and Eliminate Intensive…
- Release v0.12.0 · huggingface/trl: Major and breaking changes General reward model support for Online DPO Online DPO intially only supported a reward model that had the same tokenizer and chat template as the trained model. Now, you...
- Tags · qwen2.5-coder: The latest series of Code-Specific Qwen models, with significant improvements in code generation, code reasoning, and code fixing.
Unsloth AI (Daniel Han) ▷ #off-topic (11 messages🔥):
Anonymous LLM on LMSYS BlueberryBig Release SpeculationWordplay on 'blueberry'LLM Datasets DiversityQwen's Revision of O1
-
Anonymous LLM Speculated: Blueberry: There's buzz around a new anonymous LLM on LMSYS Blueberry that might indicate a significant release is forthcoming.
- Any guesses? sparked discussion, and members pondered implications of this potential announcement.
- Speculation on Qwen's Revision of O1: Members speculated that the upcoming release might be related to Qwen's revision of O1, as one user humorously posited.
- Another member remarked, Quote me if it is, indicating eagerness for confirmation on this theory.
- Wordplay: From Blueberry to Gemini 2.0: A member jokingly scrambled the word 'blueberry' to suggest it could lead to 'gemini 2.0', adding a playful twist to the conversation.
- This wordplay caught the interest of other members and initiated a lively thread of creative speculation.
- Concerns About LLM Datasets: There's frustration around the contents of LLM datasets, with one member swearing that they be putting ANYTHING into them.
- In response, another member noted that the dataset looked pretty... Diverse!, highlighting contrasting opinions about dataset quality.
Link mentioned: Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #help (68 messages🔥🔥):
Integrating Ollama with Frontend SolutionsFine-tuning Llama 3 PerformanceDataset Preparation for Quest GenerationChallenges with Function Calling in Chat ModelsImproving Model Training Strategies
-
Integrating Ollama with Frontend Solutions: Members discussed the possibility of running Ollama on terminal and creating a chat UI using Streamlit instead of web UI, affirming that it's feasible by using the Ollama API.
- One member expressed gratitude for this information, indicating their intent to read more about the Ollama API.
- Fine-tuning Llama 3 Performance: A member noted slower inference times with their fine-tuned Llama 3 model compared to the original model, leading to discussions about potential issues in model configuration.
- Suggestions included ensuring consistent float precision and checking the script for issues related to inference speed.
- Dataset Preparation for Quest Generation: A member sought guidance on efficiently converting their extensive literary dataset into a trainable format for Llama-3.2 fine-tuning, with a focus on quest generation.
- Another member offered assistance via Discord, showcasing community support in navigating dataset challenges.
- Challenges with Function Calling in Chat Models: A user shared their approach to training a chat model while calling functions, expressing concerns about whether the model learns to use the tool appropriately.
- Discussions revolved around the model's learning mechanisms regarding multiple assistant messages versus single function calls within the training dataset.
- Improving Model Training Strategies: A member with 1500 literary paragraphs questioned their model's learning rate and suggested adjusting learning rate schedules to optimize training outcomes.
- Community responses encouraged exploring different learning rate strategies and addressing potential inefficiencies in the training process.
Link mentioned: Errors | Unsloth Documentation: To fix any errors with your setup, see below:
Unsloth AI (Daniel Han) ▷ #showcase (5 messages):
YouTube TutorialsIntegration Discussions
-
ChatGPT 4o and o1 Preview Unpacked: A YouTube video titled "How to Use ChatGPT 4o and o1 preview Free" provides insights into utilizing these features, backed by a service offering unlimited image generation.
- This service can be accessed through NexusAI, promoting an AI-powered chat experience.
- Unlocking Image Generation with FLUX: Another video titled "How to use FLUX 1.1 PRO ultra, SD 3.5 LARGE, Recraft V3 for FREE!" guides viewers on leveraging these tools along with a link to an image generator.
- Interested users can explore this image generator and join the community via Discord.
- Open Invitation for Integration Talks: An offer was made to discuss integration opportunities with interested parties, with a booking link available here.
- 'Well we're not sharing our secret sauce' but invites dialogue around collaboration.
- Casual Chats Encouraged: The member encourages informal conversations, stating that they are available for discussions either through direct messages or in a specified channel.
- They noted a potentially delayed response but promised to engage with summons.
Links mentioned:
- Zoom Scheduler): no description found
- How to Use ChatGPT 4o and o1 preview Free: 🛠️ site link: https://www.nexusapi.tech/NexusAI is your gateway to unlimited image generation and AI-powered chat experiences! We provide access to cutting-...
- How to use FLUX 1.1 PRO ultra, SD 3.5 LARGE, Recraft V3 for FREE!: ⭐Try Image Generator: https://image.nexusapi.tech/Join Discord: https://discord.com/invite/sk8eddGwmPfree image generator aiDiscover the secrets to unlocking...
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
AI research collaborationMultimodal machine learningAutonomous AI agentsKnowledge graphsReinforcement learning
-
Seeking AI Research Partners: A senior data scientist from Armenia is eager to collaborate with researchers on multimodal machine learning, autonomous AI agents, and other topics, aiming to build research experience for a PhD reapplication in December 2026.
- They feel at home in academic environments and are considering reaching out to authors of papers they're reading for potential collaboration, but are uncertain if it's a good idea.
- Career Reflections and Goals: With over 4 years of experience and two master's degrees, the member reflects on their career journey and aims to push further into meaningful AI research.
- They express a strong desire to publish papers to enhance their qualifications for future PhD applications.
- Challenges in Research Networking: The data scientist struggles to find fellow researchers in Armenia who are focused on advanced AI topics, highlighting the need for connection with like-minded individuals.
- They share their challenges in networking and call for advice on how to effectively connect with professors and researchers in the field.
Unsloth AI (Daniel Han) ▷ #research (17 messages🔥):
Transformers vs Other ModelsLiquid AI HypedDifferential Equations in AIClosed Source ConcernsEmerging AI Research
-
Transformers might not be everything anymore: Members discussed whether anything besides Transformer models can be trained with Unsloth, noting the existence of RNNs and CNNs, but clarified that regular neural networks aren't supported yet.
- One member noted, 'It used to be!', indicating a shift in perception towards the significance of Transformer models.
- Liquid AI faces skepticism from the community: A member expressed interest in what liquid.ai is developing, suggesting that models based on differential equations could hold promise, but others raised concerns about their credibility, citing 'sudo science'.
- Critics pointed out that liquid.ai’s offerings are closed source, making it impossible to validate their claims, thus contributing little to the industry.
- Emerging research elicits mixed reactions: A link to a research paper arxiv.org/pdf/2410.10630 was shared, prompting discussions around new AI advancements.
- One member mentioned working on similar topics for a year, expressing excitement about growing interest in this area.
Nous Research AI ▷ #general (353 messages🔥🔥):
Open Hermes 2.5 MixQwen Coder ModelsInference Scaling in AITeeHee Bot FunctionalityContribution to Open Source Projects
-
Open Hermes 2.5 Mix Explained: The addition of code data to the Open Hermes 2.5 mix has been highlighted as a significant change, adding more complexity and functionality.
- The team's exploration of this mix aims to enhance the model's capabilities in various applications.
- Introduction of Qwen Coder Models: The launch of the Qwen2.5-Coder family presents various coder models across different sizes, offering advanced performance on benchmarks.
- Notably, the flagship model has been reported to outperform several proprietary models in benchmark evaluations.
- Challenges in Inference Scaling: Recent discussions focus on the limitations of current scaling methods for inference in AI models, especially as reported in prominent articles.
- Concerns regarding the slowdown of improvements in generative AI have prompted reflections on future directions and strategies.
- TeeHee Bot Functionality Issues: The TeeHee bot is currently experiencing issues with posting replies despite generating them, which has raised concerns among users.
- Acknowledgments of bugs in the posting functionality indicate ongoing efforts to improve the bot's performance.
- Encouragement for Open Source Contributions: Members shared various open-source projects related to AI that people can contribute to, fostering community engagement.
- Projects like ShareGPT-Builder and LLM-Logbook were highlighted as opportunities for contributors to get involved.
Links mentioned:
- tinygrad: A simple and powerful neural network framework: no description found
- Tweet from Qwen (@Alibaba_Qwen): 🚀Now it is the time, Nov. 11 10:24! The perfect time for our best coder model ever! Qwen2.5-Coder-32B-Instruct! Wait wait... it's more than a big coder! It is a family of coder models! Besides ...
- Forge Reasoning API by Nous Research: Forge Reasoning API by Nous Research
- Tweet from undefined: no description found
- Funny Big GIF - Funny Big Lebowski - Discover & Share GIFs: Click to view the GIF
- Federal Investigation GIF - Federal Investigation - Discover & Share GIFs: Click to view the GIF
- Buy Mac mini with M4 Pro Chip: Mac mini with the M4 and M4 Pro chips. Built for Apple Intelligence. With front and back ports. Get credit when you trade in an eligible Mac. Buy now.
- Love Languages GIF - Love Languages Pea - Discover & Share GIFs: Click to view the GIF
- GitHub - cameronaaron/Geminio1: Contribute to cameronaaron/Geminio1 development by creating an account on GitHub.
- GitHub - NousResearch/nousflash-agents: Modular Agentic AI Architecture - NousResearch x Teleport (Flashbots): Modular Agentic AI Architecture - NousResearch x Teleport (Flashbots) - NousResearch/nousflash-agents
- GitHub - teknium1/ShareGPT-Builder: Contribute to teknium1/ShareGPT-Builder development by creating an account on GitHub.
- GitHub - teknium1/LLM-Logbook: Public reports detailing responses to sets of prompts by Large Language Models.: Public reports detailing responses to sets of prompts by Large Language Models. - teknium1/LLM-Logbook
- Spontex Hedgehog GIF - Spontex Hedgehog Washup - Discover & Share GIFs: Click to view the GIF
- GitHub - teknium1/alpaca-roleplay-discordbot: A discord bot that roleplays!: A discord bot that roleplays! Contribute to teknium1/alpaca-roleplay-discordbot development by creating an account on GitHub.
- no title found: no description found
Nous Research AI ▷ #ask-about-llms (97 messages🔥🔥):
Benchmarking LLMsFine-tuning TechniquesModel Performance AnalysisCode Generation AdvancesSystem Prompts in LLMs
-
Concerns about LLM Benchmarks: Members expressed skepticism about the relevance of current benchmarks, noting that surface-level changes in multiple-choice setups could drastically alter model rankings.
- Discussions highlighted that the challenges in evaluating LLMs stem from overfitting and the influence of benchmarks on model performance.
- Innovative Fine-tuning Strategies Proposed: A member inquired about the best approaches to integrate a new layer in Llama models for fine-tuning, specifically for handling different embeddings.
- Suggestions included starting with frozen parameters on existing layers before unfreezing them gradually to improve training efficiency.
- Advancements in Code Generation Models: Excitement was shared over the release of OpenCoder, an open-source project aiming to elevate code generation through extensive and transparent datasets.
- Members noted the rapid progress in coding-specific LLMs, enabling complex projects to be developed without direct source code editing.
- Character of LLM Responses Under Examination: Discussions revealed that models like Sonnet have become more self-reflective, altering responses based on user doubts to improve interaction.
- Concerns were also raised about how this shift towards personality may affect benchmark evaluations across various models.
- Exploration of New Thinking Token Concept: A member proposed the idea of implementing a special 'thinking' token to enhance LLM computations without producing output tokens.
- This could potentially allow for more efficient processing of intermediate representations, expanding the model’s computational capacity.
Links mentioned:
- Latent Space Explorer: no description found
- OpenCoder: Top-Tier Open Code Large Language Models: no description found
Nous Research AI ▷ #research-papers (9 messages🔥):
Unit Test Generation Fine-TuningTest-Time Scaling in AIMultimodal Retrieval in AILarge Language Models UnlearningMedical AI Innovations
-
Parameter-Efficient Fine-Tuning for Unit Tests: A member shared insights on a study about Parameter-Efficient Fine-Tuning of Large Language Models for Unit Test Generation, highlighting empirical findings from the paper found here.
- The study focuses on refining LLMs to generate unit tests more effectively, indicating that this method can significantly streamline the testing process.
- Test-Time Scaling Speculations: The lecture titled Speculations on Test-Time Scaling by Sasha Rush at Cornell University is now available on YouTube.
- This lecture delves into the nuances of scaling during test-time, especially related to enhancements in model performance.
- Advancements in Multimodal Retrieval: A recent paper introduces innovations in universal multimodal retrieval utilizing multimodal LLMs to accommodate diverse retrieval tasks, aiming to overcome modality bias (PDF available here).
- The findings suggest new techniques like modality-aware hard negative mining to improve retrieval performance across varied data forms.
- Unlearning in Language Models: A study raised questions on the effectiveness of current unlearning methods in LLMs, arguing that they often fail to erase unwanted knowledge thoroughly (paper details here).
- Their results indicate that quantization techniques can unintentionally retain forgotten information, prompting a call for improved unlearning strategies.
- Innovations in Medical AI: A comprehensive overview of the latest trends in Medical AI highlights various research papers and models for advancements in patient care and diagnostics over the past week.
- Notable mentions include CataractBot for patient support and MEG for knowledge-enhanced medical Q&A, showcasing significant contributions to the field.
Links mentioned:
- MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs: State-of-the-art retrieval models typically address a straightforward search scenario, where retrieval tasks are fixed (e.g., finding a passage to answer a specific question) and only a single modalit...
- Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge: Large language models (LLMs) have shown remarkable proficiency in generating text, benefiting from extensive training on vast textual corpora. However, LLMs may also acquire unwanted behaviors from th...
- What Matters in Transformers? Not All Attention is Needed: While scaling Transformer-based large language models (LLMs) has demonstrated promising performance across various tasks, it also introduces redundant architectures, posing efficiency challenges for r...
- Tweet from Open Life Science AI (@OpenlifesciAI): Last Week in Medical AI: Top Research Papers/Models 🏅 (November 2-9, 2024) 🏅 Medical AI Paper of the Week: Exploring Large Language Models for Specialist-level Oncology Care Authors(@apalepu13 ,@v...
- Speculations on Test-Time Scaling | Richard M. Karp Distinguished Lecture: Sasha Rush (Cornell University)https://simons.berkeley.edu/events/speculations-test-time-scaling-richard-m-karp-distinguished-lectureRichard M. Karp Distingu...
- GitHub - srush/awesome-o1: A bibliography and survey of the papers surrounding o1: A bibliography and survey of the papers surrounding o1 - srush/awesome-o1
Nous Research AI ▷ #interesting-links (2 messages):
NVIDIA MM-EmbedLucid for Minecraft Emulation
-
NVIDIA Introduces MM-Embed for Multimodal Retrieval: NVIDIA announced MM-Embed, the first multimodal retriever achieving state-of-the-art results on the multimodal M-BEIR benchmark. You can find more details in the post here.
- This advancement reportedly enhances the retrieval capabilities across various data types by integrating visual and textual information.
- Rami Announces Lucid for Real-Time Minecraft Emulation: Rami revealed Lucid V1, a world model capable of emulating Minecraft environments in real-time on consumer hardware. You can try it here and read more in the post.
- The project’s repository is available on GitHub, showcasing its capacity for innovative gameplay experiences.
Link mentioned: Tweet from rami (@rami_mmo): Excited to announce Lucid V1: A world model that can emulate Minecraft environments in real-time on consumer hardware! 🔥 play here: https://lucidv1-demo.vercel.app/ post: https://ramimo.substack.c...
Nous Research AI ▷ #research-papers (9 messages🔥):
Transformer OptimizationUnit Test Generation with LLMsMultimodal RetrievalTest-Time Scaling InsightsMachine Unlearning Mechanisms
- Transformer Optimization Techniques: Innovative approaches like Mixture-of-Transformers and LoRA are examined for enhancing efficiency in language model training, suggesting fundamental shifts in training methodologies.
-
Advances in Unit Test Generation using LLMs: A recent study highlights a parameter-efficient fine-tuning method for large language models focused on generating unit tests, showcasing empirical results indicating significant efficiencies.
- This approach could revolutionize testing processes, enhancing software reliability through better automated testing.
- Exploring Multimodal Retrieval Techniques: The MM-Embed model presents advancements in universal multimodal retrieval, accommodating diverse query types while addressing modality biases in existing models.
- Fine-tuning demonstrated improved performance across various retrieval benchmarks compared to previous models.
- Insights from 'Speculations on Test-Time Scaling': A recent lecture by Sasha Rush discusses intriguing theories on test-time scaling within machine learning contexts, sparking interest in new scalable methodologies.
- Insights from this talk can lead to advancements in adaptability and performance in AI systems.
- Machine Unlearning Mechanisms in LLMs: Research presents new findings on whether existing unlearning methods genuinely erase knowledge or merely conceal it, emphasizing the importance of effective unlearning in LLMs.
- Experiments reveal that quantization techniques can unexpectedly restore forgotten knowledge in models, challenging current unlearning benchmarks.
Links mentioned:
- Tweet from Open Life Science AI (@OpenlifesciAI): Last Week in Medical AI: Top Research Papers/Models 🏅 (November 2-9, 2024) 🏅 Medical AI Paper of the Week: Exploring Large Language Models for Specialist-level Oncology Care Authors(@apalepu13 ,@v...
- MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs: State-of-the-art retrieval models typically address a straightforward search scenario, where retrieval tasks are fixed (e.g., finding a passage to answer a specific question) and only a single modalit...
- Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge: Large language models (LLMs) have shown remarkable proficiency in generating text, benefiting from extensive training on vast textual corpora. However, LLMs may also acquire unwanted behaviors from th...
- What Matters in Transformers? Not All Attention is Needed: While scaling Transformer-based large language models (LLMs) has demonstrated promising performance across various tasks, it also introduces redundant architectures, posing efficiency challenges for r...
- Speculations on Test-Time Scaling | Richard M. Karp Distinguished Lecture: Sasha Rush (Cornell University)https://simons.berkeley.edu/events/speculations-test-time-scaling-richard-m-karp-distinguished-lectureRichard M. Karp Distingu...
- GitHub - srush/awesome-o1: A bibliography and survey of the papers surrounding o1: A bibliography and survey of the papers surrounding o1 - srush/awesome-o1
Nous Research AI ▷ #reasoning-tasks (22 messages🔥):
Google Gemini AI systemDynamic Model SelectionRAG aspectsUser feedback on AI modelsDiscussion on project collaboration
-
Google Gemini AI System Emulates Reasoning: Using the Google Gemini model, a member has architected an AI system that emulates reasoning and adapts through interactions, inspired by OpenAI. The project includes elements like meta-prompts, memory recall, and dynamic query analysis, showcased in this article.
- Another member praised the ease of use, noting it resonates with their own work, stating, 'It's like reading someone else's writing. haha'.
- Diving Deep into Dynamic Model Functions: The developer clarified that while the system has RAG aspects, it also features Dynamic Model Selection, Session Context Tracking, and Performance Logging among other autonomous functions. They humorously acknowledged the extensive list by saying, 'Oh wow that's a mouthful 😂'.
- One member expressed their intention to deep dive into each listed method, indicating a keen interest in exploring the intricacies of the project.
- Growth Opportunities for Collaborating Servers: The developer sought to find out if there are other servers interested in the AI project. They expressed eagerness for collaboration and knowledge sharing within the community.
- User Experiences with AI Models: Discussion included experiences with Bard's launch and the feature of presenting different draft outputs, enhancing user interaction and engagement. Members shared their thoughts, noting the uncanny valley moments in previous interactions with chat models.
Link mentioned: GitHub - cameronaaron/Geminio1: Contribute to cameronaaron/Geminio1 development by creating an account on GitHub.
Nous Research AI ▷ #rag-dataset (2 messages):
Data Privacy Tools8B Model Quantization
-
Art Project Highlights Data Privacy Risks: Inspired by Dr. Joy Buolamwini, a member created an art project that emphasizes the importance of safeguarding personal data from data brokers, with a tool that narrates your life story using just your full name and location.
- The project advocates for taking control of one's digital footprint by opting out of data broker databases, stressing that privacy matters are crucial.
- Recommendation for 8B Model: A member expressed a strong recommendation for using the 8B model alongside the largest quantization available for optimal performance.
- This opinion comes amid ongoing discussions on model efficiency, with emphasis on maximizing resource utilization.
Link mentioned: Your Life Story: no description found
Eleuther ▷ #general (204 messages🔥🔥):
Remote Working FlexibilityGCP vs AWS UIsInternship Experiences in TechFrontend Development ChallengesMusic Model Training Insights
-
Remote Work Policies for Strong Candidates: There was a discussion about how some companies allow strong candidates to work from remote or different offices, highlighting that it might be easier to convince them of relocating to another office instead.
- Some members reflected on companies building new offices specifically to accommodate key hires.
- GCP's Complex and Clunky UI: Frustrations were shared about the GCP console being overly complex and unresponsive, compared to AWS and Azure, and members discussed their preferences for using CLI over UI.
- Concerns were voiced regarding the bloated nature of cloud platform UIs, suggesting a trend where backend engineers dominate over frontend representation in teams.
- Reflections on Internship Projects in Tech: Participants shared experiences from internships, often detailing how frontend projects tend to be less prestigious, but result in valuable outputs, including crucial documentation and refactoring.
- It was noted that even intern-led efforts at building interfaces could yield insights and functioning prototypes, regardless of their quality.
- Challenges in Frontend Development: The conversation shed light on how frontend work is often undervalued and perceived as lower-status within large tech companies, while also emphasizing its importance.
- Participants reflected on the difficulties of managing state and component complexity in user-facing projects alongside the significant time investment required for UI maintenance.
- Training Music Models with Various Data Sources: A participant commented on the potential for a multimodal dataset that includes text and MIDI, leveraging their existing collection of YouTube recordings and MIDI files.
- Discussions also included the implications of training music models on limited data genres and exploring original compositions found online.
Links mentioned:
- (32 * 512 * 50304 * 16) bits to gb). - Wolfram|Alpha.): Wolfram|Alpha brings expert-level knowledge and capabilities to the broadest possible range of people—spanning all professions and education levels.
- GitHub - KellerJordan/Muon: Muon optimizer for neural networks: >30% extra sample efficiency, <3% wallclock overhead: Muon optimizer for neural networks: >30% extra sample efficiency, <3% wallclock overhead - KellerJordan/Muon
- Muon/muon.py at master · KellerJordan/Muon: Muon optimizer for neural networks: >30% extra sample efficiency, <3% wallclock overhead - KellerJordan/Muon
Eleuther ▷ #research (254 messages🔥🔥):
Low Cost/Low Data Image Model Training TechniquesNormalized Transformer (nGPT)Value Residual LearningBatch Size ScalingLearnable Skip Connections
-
Exploration of Low Cost Image Model Training Techniques: Members discussed promising low cost/low data image model training techniques, identifying MicroDiT, Stable Cascade, and Pixart as effective methods.
- Additional suggestions included gradually increasing batch size, which has proven effective despite being considered less interesting.
- Insights on Normalized Transformers (nGPT): Replication attempts of the nGPT results from the paper revealed mixed outcomes, with some achieving speed improvements while others did not.
- The discussion highlighted the architecture’s focus on unit norm normalization of embeddings and hidden states, resulting in faster learning on varying task performances.
- Advancements in Value Residual Learning Techniques: Value residual learning was highlighted as a significant contributor to speedrun success, allowing transformer blocks to access previously computed values.
- The method of making the residuals learnable reportedly improved performance, reducing loss significantly during speedruns, prompting members to consider its effects at scale.
- Batch Size Scaling Strategies: Members shared experiences with batch size scaling, advocating for a linear ramp-up approach based on token count to optimize performance without recompilation delays.
- Dynamic shapes were suggested for increased efficiency in batch size handling but were noted to potentially slow the training process.
- Scrutiny of Learnable Skip Connections: The efficacy of learnable skip connections, particularly those based on attention values, was debated, with skepticism towards their scalability in larger models.
- While some members observed significant benefits in speed and stability, others recalled past literature indicating limited gains and possible diminishing returns at larger scales.
Links mentioned:
- Few-Shot Task Learning through Inverse Generative Modeling: Learning the intents of an agent, defined by its goals or motion style, is often extremely challenging from just a few examples. We refer to this problem as task concept learning and present our appro...
- Tweet from BlinkDL (@BlinkDL_AI): RWKV-7 can also reach 2.27xx in 3200 steps (originally 5100 steps)😀reproducible code & log: https://github.com/BlinkDL/modded-nanogpt-rwkv 🚀 #RWKV #RNN Quoting Keller Jordan (@kellerjordan0) It&#...
- Soft Condorcet Optimization for Ranking of General Agents: A common way to drive progress of AI models and agents is to compare their performance on standardized benchmarks. Comparing the performance of general agents requires aggregating their individual per...
- Initialization of Large Language Models via Reparameterization to Mitigate Loss Spikes: Loss spikes, a phenomenon in which the loss value diverges suddenly, is a fundamental issue in the pre-training of large language models. This paper supposes that the non-uniformity of the norm of the...
- Tweet from Alexandre TL (@AlexandreTL2): here are the val loss for 162M models, 2.5B tokens on FineWeb (it's very small compared to what was tested in the paper, but gpu poor + we need to start somewhere) 500M bz, 1024 ctx len, AdamW, L...
- Geometric Dynamics of Signal Propagation Predict Trainability of Transformers: We investigate forward signal propagation and gradient back propagation in deep, randomly initialized transformers, yielding simple necessary and sufficient conditions on initialization hyperparameter...
- Tweet from Alexandre TL (@AlexandreTL2): here are the val loss for 162M models, 2.5B tokens on FineWeb (it's very small compared to what was tested in the paper, but gpu poor + we need to start somewhere) 500M bz, 1024 ctx len, AdamW, L...
- Tweet from Grad (@Grad62304977): 43% of the speedup in the new NanoGPT record is due to a variant of value residual learning that I developed. Value residual learning (recently proposed by https://arxiv.org/abs/2410.17897) allows al...
- The Case for Co-Designing Model Architectures with Hardware: While GPUs are responsible for training the vast majority of state-of-the-art deep learning models, the implications of their architecture are often overlooked when designing new deep learning (DL) mo...
- Flex attention underperforms SDPA (cuDNN), constructing T5 attention bias via embedding weights · Issue #138493 · pytorch/pytorch: 🐛 Describe the bug I've been trying to implement T5 encoder relative attention bias in flex_attention. I came up with a few algorithms for it, and a benchmark script: https://gist.github.com/Birc...
- mit-deep-learning-book-pdf/complete-book-pdf/Ian Goodfellow, Yoshua Bengio, Aaron Courville - Deep Learning (2017, MIT).pdf at master · janishar/mit-deep-learning-book-pdf: MIT Deep Learning Book in PDF format (complete and parts) by Ian Goodfellow, Yoshua Bengio and Aaron Courville - janishar/mit-deep-learning-book-pdf
- nGPT: Normalized Transformer with Representation Learning on the Hypersphere: no description found
- [BE]: Update CUDNN for Unix OSS to 9.5.1.17 by Skylion007 · Pull Request #137978 · pytorch/pytorch: Significantly faster, better CUDNN Attention especially on Hopper (FA3 implementation?) Lots of bugfixes Better performance More numerically stable / fixed heuristics More functionality for SDPA c...
- modded-nanogpt/logs/6eae65d0-7bee-45e3-9564-f2a9602d5ba6.txt at fc--bz-warmup · leloykun/modded-nanogpt: NanoGPT (124M) quality in 2.67B tokens. Contribute to leloykun/modded-nanogpt development by creating an account on GitHub.
- modded-nanogpt/logs/421bead0-54ae-41c6-8e00-8f75d52da834.txt at fc--bz-warmup · leloykun/modded-nanogpt: NanoGPT (124M) quality in 2.67B tokens. Contribute to leloykun/modded-nanogpt development by creating an account on GitHub.
Eleuther ▷ #interpretability-general (4 messages):
Deep Neural Network ModelingIntervention Techniques in AISVD in Model UpdatesBehavioral Changes in ModelsPhysics Simulations with ML
-
Deep Neural Network Approximation with Symbolic Equations: Wabi.sabi.1 proposed a method to extract symbolic equations from a deep neural network, allowing for targeted modifications on its behavior.
- They expressed concerns about potential side effects from this intervention method, particularly in scenarios that require nuanced behavioral control.
- Challenges in Model Updating Techniques: Woog tried to execute the proposed step 3 of updating neural network weights but encountered difficulties, suggesting that success may be contingent on how steps 1 and 2 are approached.
- They indicated the complexity of the task and acknowledged that the setting plays a significant role in the outcomes.
- Linear Map Fitting for Model Approximations: Wabi.sabi.1 outlined a detailed procedure involving fitting a linear map to input/output pairs in an attempt to make a neural network model better behaved by using SVD.
- They sought clarity on how intervention qualities could be applied in this context if any straightforward examples existed.
- Posthoc Modifications and Prior Use: Wabi.sabi.1 reflected on the concept of using prior knowledge posthoc in the unknown procedure, highlighting the reconsideration of previously established parameters.
- This raises questions on the effectiveness of retrospective interventions and their implications in model behavior.
Eleuther ▷ #lm-thunderdome (24 messages🔥):
Using apply_chat_templateLocal logging without HFBenchmarking intermediate checkpointsImpact of prompt format on model outputCalculating accuracy errors in lm-eval
-
Instruct tuned models require apply_chat_template: A member inquired about using
--apply_chat_templatefor their model, confirming it was instruct tuned.- Another member asked how to implement this in Python, leading to a link to specific GitHub documentation.
- Logging samples locally without HF: A member asked if it's possible to log samples locally using
--log_sampleswithout uploading to HF, to which another member suggested usingpush_samples_to_hub=False.
- Clarifications were made regarding logging to Wandb instead, triggering discussions on modifying library files.
- Dramatic runtime differences between checkpoint types: A member observed that LoRA models evaluated in about 8 minutes, while full finetuned models took 17 minutes, despite running on the same hardware.
- The group discussed possible reasons for this discrepancy, including checking batch sizes and potential hardware issues with the GPUs.
- Prompt format impacts model outputs: When discussing model configurations, it was noted that chat models expect prompts in specific formats, which can vary results significantly.
- A member realized their previous results might be incorrect if they hadn't used the correct options for logging samples.
- Error encountered during lm-eval accuracy calculation: A user reported an error when calculating accuracy in lm-eval, specifically a TypeError related to unsupported operand types.
- They sought advice on how to generate outputs and save them to a file for further troubleshooting.
Links mentioned:
- lm-evaluation-harness/lm_eval/main.py at bd80a6c0099ee207e70f4943117739a817eccc0b · EleutherAI/lm-evaluation-harness): A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/evaluator.py at bd80a6c0099ee207e70f4943117739a817eccc0b · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
aider (Paul Gauthier) ▷ #general (356 messages🔥🔥):
Qwen 2.5 CoderAider PerformanceEmbedding IntegrationDocumentation ToolsModel Benchmarking
-
Excitement for Qwen 2.5 Coder Results: The Qwen 2.5 Coder model has garnered attention with its performance, nearly matching Claude's on coding tasks, achieving a benchmark result of 72.2% on the diff metric.
- Users are eager to test the model locally, with some discussing the feasibility of running it on GPUs with varying performance capabilities.
- Aider's Integration and Functionality: Several users discussed the integration of Qwen 2.5 with Aider, emphasizing the convenience of using .env files for configuration and testing on platforms like glhf.chat.
- Contributions to improve Aider's functionality and UI, including the potential for local binaries and embedding integration, are being explored.
- Documentation and Its Importance: There was a consensus on the necessity of maintaining documentation for projects, particularly for large libraries like Leptos and SurrealDB, to aid LLMs in handling updates.
- Users expressed interest in tools that can scrape and handle documentation efficiently, making integration with projects smoother.
- Exploring Embedding API and Model Capabilities: The discussion included skepticism about embedding APIs, with some users proposing that once LLMs become cheaper, using embeddings might become obsolete.
- The potential for LLMs to handle entire documents directly without embeddings was debated, indicating a shift in how models might be utilized.
- Future of Qwen Models: Inquiries about the availability of a Qwen 2.5-72B model surfaced, with users expressing curiosity about its performance metrics and quantization details.
- Discussion on the broader implications of using lower-quanta models while maintaining efficiency and output quality are ongoing.
Links mentioned:
- Deepbricks: no description found
- Tweet from ollama (@ollama): ollama run opencoder OpenCoder is available in 1.5B and 8B models.
- Installation: How to install and get started pair programming with aider.
- Yummers The Boys GIF - Yummers The Boys Homelander - Discover & Share GIFs: Click to view the GIF
- Home: aider is AI pair programming in your terminal
- One Peak One Piece GIF - ONE PEAK One piece One piece cry - Discover & Share GIFs: Click to view the GIF
- Qwen2.5 Coder Demo - a Hugging Face Space by Qwen: no description found
- Qwen2.5 Coder Artifacts - a Hugging Face Space by Qwen: no description found
- Enough Okay Enough Allan GIF - Enough okay enough Allan The oval - Discover & Share GIFs: Click to view the GIF
- Homelander Homelander The Boys GIF - Homelander Homelander the boys Homelander sad - Discover & Share GIFs: Click to view the GIF
- CONVENTIONS.md: GitHub Gist: instantly share code, notes, and snippets.
- bartowski/Qwen2.5-Coder-32B-Instruct-GGUF · Hugging Face: no description found
- Qwen2.5-Coder - a Qwen Collection: no description found
- GitHub - robert-at-pretension-io/rust_web_scraper: Contribute to robert-at-pretension-io/rust_web_scraper development by creating an account on GitHub.
- Qwen2.5 Speed Benchmark - Qwen: no description found
- Options reference: Details about all of aider’s settings.
- YAML config file: How to configure aider with a yaml config file.
aider (Paul Gauthier) ▷ #questions-and-tips (116 messages🔥🔥):
RAG Solutions with AiderQdrant Tooling for Similarity SearchesAider Command LimitationsUsing Aider with Large CodebasesAider Performance Issues
-
RAG Solutions using NotebookLM: A user shared how they effectively scrape documentation into markdown files for use with NotebookLM, enabling context-driven queries with Aider, applying it successfully to Fireworks' API.
- This streamlined approach enhances the generation of relevant python clients from documentation endpoints, improving workflow efficiency.
- Enhancing Qdrant Interaction with Aider: Discussion centered on developing an API to send queries to Qdrant for generating context in Aider, with users sharing various methods to implement it.
- Suggestions included creating a custom Python CLI for querying, indicating the need for improved integration mechanisms between Aider and Qdrant.
- Aider's Command Limitations Explained: A user raised concerns about Aider's capacity to effectively handle existing code modifications without overwriting functions inadvertently.
- Others noted recent versions might exacerbate these issues, suggesting that updates could contribute to confusion in existing projects.
- Working with Aider on Large Projects: Various users discussed strategies for utilizing Aider in large codebases, highlighting the challenges of maintaining context and preventing file overload.
- The community explored adding selective file inclusion features, emphasizing the need for better management of large projects within Aider.
- Aider Model Configuration Issues: Users experienced confusion regarding warnings when integrating Aider with specific models, particularly Ollama, concerning context window sizes and costs.
- It was noted that these warnings may not impede usage, and that modifications in Aider's backend could be responsible for the errant notifications.
Links mentioned:
- OpenAI compatible APIs: aider is AI pair programming in your terminal
- Model warnings: aider is AI pair programming in your terminal
- aider/aider/website/docs/usage/tips.md at main · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- Issues · Aider-AI/aider.): aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- [Bug]: get_model_info() blows up for ollama models? · Issue #6703 · BerriAI/litellm: What happened? Calls to litellm.get_model_info() with ollama models raise an exception. I can run litellm.completion() just fine with those models. $ pip freeze | egrep 'litellm|ollama' litell...
- aider thinks model is unknown and asks if I meant *The exact same model* · Issue #2318 · Aider-AI/aider: Warning for ollama/vanilj/supernova-medius:q6_k_l: Unknown context window size and costs, using sane defaults. Did you mean one of these? - ollama/vanilj/supernova-medius:q6_k_l You can skip this c...
aider (Paul Gauthier) ▷ #links (4 messages):
OpenCoder LLMRefineCode Pretraining CorpusAider's Context Limitations
-
OpenCoder Emerges as a Code LLM Leader: OpenCoder is an open-source code LLM family including 1.5B and 8B models, trained on 2.5 trillion tokens, predominantly raw code.
- It aims to empower researchers with model weights, inference code, and a transparent data process for advancing code AI.
- RefineCode Boasts Extensive Programming Corpus: RefineCode offers a high-quality pretraining corpus with 960 billion tokens covering 607 programming languages.
- This reproducible dataset enhances the training capabilities of emerging code LLMs like OpenCoder.
- Concerns Over Aider's 1300 Context Window: A member expressed that the 1300 context window does not function effectively with Aider.
- This raises questions about the scalability and performance of Aider in practical applications.
Link mentioned: OpenCoder: Top-Tier Open Code Large Language Models: no description found
Stability.ai (Stable Diffusion) ▷ #general-chat (394 messages🔥🔥):
Stable Diffusion ModelsGPU PerformanceLoRA TrainingAI Video GenerationGGUF Format
-
Exploring Stable Diffusion Models Variants: Users discussed transitioning from Stable Diffusion 1.5 to new models like SD 3.5 and Flux, with some expressing that newer versions require less VRAM and offer better performance.
- A recommendation was made to explore smaller GGUF models which can run more efficiently, even on limited hardware.
- GPU Usage and Longevity Concerns: Concerns were raised about long-term GPU usage from running Stable Diffusion daily, with comparisons made to gaming performance impacts.
- Some users noted that GPU prices might drop with the upcoming RTX 5000 series, encouraging others to wait before purchasing new hardware.
- Training LoRAs for Stable Diffusion: A user inquired about training a LoRA with a small dataset for Stable Diffusion 1.5, highlighting their experience with Flux-based training.
- Recommendations included using the Kohya_ss trainer and following specific online guides to navigate the training process effectively.
- AI Video Generation Tools: New tools like Pollo AI were introduced, enabling users to create videos from text prompts and animate static images.
- This tool allows for creative expressions by generating engaging video content based on user-defined parameters.
- Understanding GGUF Files: Users learned about the GGUF format, which allows for more compact and efficient model usage in image generation workflows.
- It was mentioned that using GGUF files can significantly reduce resource requirements compared to larger models while maintaining quality.
Links mentioned:
- Create README.md · youknownothing/realDream_STOIQONewreality at f5d8fad: no description found
- Stable Diffusion Quick Start Guide - Generate AI images in a minute: Do you want to use Stable Diffusion but don't know where to start? You will find a list of options in this guide. You can pick the option that's the best for you.Download the guide now!If you ...
- LoRA Training (Stable Diffusion 1.5) | ScottBaker.ca: no description found
- AI Video Generator: Create Realistic/Imaginary HD Videos | Pollo AI: Use Pollo AI, the industry-leading AI video generator, to create videos with text prompts, images or videos. Turn your ideas to videos with high resolution and quality.
- Create README.md · youknownothing/realDream_STOIQONewreality at f5d8fad: no description found
- FLUX Dev/Schnell (Base UNET) + Google FLAN FP16/NF4-FP32/FP8 - FLUX_Dev-FLAN-FP16 | Flux Checkpoint | Civitai: Full Checkpoint with improved TE do not load additional CLIP/TE FLUX.1 (Base UNET) + Google FLAN NF4 is my recommended model for quality/speed bala...
- Reddit - Dive into anything: no description found
- Azure Data Breach: What & How It Happened? | Twingate: In this article, we will discuss the Azure Data Breach, how it happened, what info was leaked, and what to do if affected.
- Install Stable Diffusion Locally (In 3 minutes!!): For those of you with custom built PCs, here's how to install Stable Diffusion in less than 5 minutes - Github Website Link:https://github.com/Hugging Face W...
- Flux AI Lora Model Training In Google Colab – Easy FluxGym Tutorial: #fluxai #comfyui #stablediffusion #fluxgguf #aiart #sd3 #sdxl #fluxgymLearn how to create stunning AI art with Flux and custom LoRAs! Our free Google Colab t...
- GitHub - TheLocalLab/fluxgym-Colab: A Colab for the FluxGym Lora Training repository.: A Colab for the FluxGym Lora Training repository. Contribute to TheLocalLab/fluxgym-Colab development by creating an account on GitHub.
- FLUX.1 [dev] - v1.0 | Flux Checkpoint | Civitai: Do not download if you have not read all the suggestions Because it is heavy and requires more stuff than SD. And we have new way to run Flux ez wi...
- STOIQO NewReality 🟡 FLUX, SD3.5, SDXL, SD1.5 - 🔵 XL Light 1.0 | Stable Diffusion XL Checkpoint | Civitai: 🟡: Flux Models 🟢: SD 3.5 Models 🔵: SD XL Models 🟣: SD 1.5 Models 🔴: Expired Models 🟡STOIQO NewReality is a cutting-edge model designed to generate ...
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
3D Object Generation API
-
Deprecation of 3D Object Generation API: The 3D Object Generation API will be removed this Friday due to lack of interest, with fewer than five requests every few weeks.
- For more details, refer to the documentation.
- Future of Alternative Features: With the removal of the 3D Object Generation API, attention may shift to alternative features that require more community engagement and interest.
- It appears that the team is focusing on improving offerings that are more actively utilized.
Link mentioned: OpenRouter): LLM router and marketplace
OpenRouter (Alex Atallah) ▷ #general (317 messages🔥🔥):
Hermes performanceLlama models usageQwen 2.5 Coder modelAI model updatesOpenRouter usability
-
Hermes struggles with stability: Users reported inconsistent responses from the Hermes model, with issues persisting for both free and paid versions under different conditions.
- Some speculated these issues might be linked to rate limits or problems on the OpenRouter's side.
- Llama 3.1 70B gaining popularity: The Llama 3.1 70B Instruct model is noted for its rising adoption, particularly within the Skyrim AI Follower Framework community.
- Comparisons are being drawn with Wizard models regarding pricing and performance, as users express curiosity about its capabilities.
- Introduction of Qwen 2.5 Coder model: The Qwen 2.5 Coder model has been released, reportedly matching previous coding capabilities of Sonnet at 32B parameters.
- Users expressed excitement about its potential impacts on coding tasks within the community.
- Gemini 1.5 Flash updates: Some users noticed improvements in the Gemini 1.5 Flash model, suggesting potential updates enhancing its performance and coding abilities.
- There is curiosity about possible experimental versions being tested outside the normal updates.
- OpenRouter usability concerns: Feedback on OpenRouter highlighted that accessing the chatroom requires multiple steps, with requests for the process to be streamlined.
- Users expressed a desire for better usability to enhance overall engagement with the platform.
Links mentioned:
- no title found: no description found
- LICENSE.txt · tencent/Tencent-Hunyuan-Large at main: no description found
- sbintuitions/sarashina2-8x70b · Hugging Face: no description found
- OpenRouter: LLM router and marketplace
- Deus Ex Deus GIF - Deus Ex Deus Ex - Discover & Share GIFs: Click to view the GIF
- Apps Using Anthropic: Claude 3.5 Sonnet: See apps that are using Anthropic: Claude 3.5 Sonnet - New Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good a...
- OpenRouter: LLM router and marketplace
- tencent/Tencent-Hunyuan-Large · Hugging Face: no description found
- Meta: Llama 3.1 70B Instruct – Recommended Parameters: Check recommended parameters and configurations for Meta: Llama 3.1 70B Instruct - Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 70B instruct-tuned...
- Parameters API | OpenRouter: API for managing request parameters
- Models: 'meta-llama' | OpenRouter: Browse models on OpenRouter
- GitHub - QwenLM/Qwen2.5-Coder: Qwen2.5-Coder is the code version of Qwen2.5, the large language model series developed by Qwen team, Alibaba Cloud.: Qwen2.5-Coder is the code version of Qwen2.5, the large language model series developed by Qwen team, Alibaba Cloud. - QwenLM/Qwen2.5-Coder
OpenRouter (Alex Atallah) ▷ #beta-feedback (7 messages):
Custom provider keys accessIntegration beta feature accessBeta testing enthusiasm
-
High Demand for Custom Provider Keys Access: Multiple members, including requests from derpenstein69 and sohanemon, are seeking access to the custom provider keys beta feature.
- derpenstein69 expressed gratitude in their request, showing eagerness for access.
- Urgent Requests for Integration Beta Feature: Members such as nanakotsai and wendic1 are actively requesting access to the integration beta feature.
- wendic1 specifically inquired about applying for access, indicating strong interest in the feature.
- Betas Met with Humor and Creativity: doditz humorously pledged to be an entertaining tester while requesting access to the integration beta feature, incorporating creative elements into their message.
- Their lighthearted approach included jokes and a quirky integration idea featuring three hamsters and a rubber duck.
- Playful Requests for Beta Participation: Members have taken a playful tone in their access requests, with cruciflyco humorously stating they are 'requesting access.'
- This shows a community spirit and willingness to engage in the beta testing process enthusiastically.
Interconnects (Nathan Lambert) ▷ #news (68 messages🔥🔥):
Lilian Weng leaves OpenAIFrontierMath BenchmarkQwen2.5 Coder ReleaseDario Amodei on AI ScalingClaude's Character Team
-
Lilian Weng departs OpenAI: After nearly 7 years at OpenAI, Lilian Weng announced her departure to pursue new opportunities, indicating she has learned a lot during her tenure.
- Her exit has sparked discussions about potential new offshoots and the community's reaction to her transition.
- Introduction of FrontierMath as a new benchmark: FrontierMath is a benchmark of complex math problems with current AI models tackling less than 2% of them, illustrating a significant gap in AI capabilities.
- Discussions highlight the benchmark's difficulty compared to alternatives and its potential implications for AI training.
- Qwen2.5 Coder models launched: The Qwen2.5 Coder family features multiple models, including the flagship Qwen2.5-Coder-32B-Instruct, achieving competitive results against GPT-4o in various benchmarks.
- Details about the model's performance have been shared, with expectations for a paper to be published soon.
- Dario Amodei discusses AI scaling: In a recent podcast, Dario Amodei emphasized that scaling trends are consistent across different modalities, suggesting possible human-level AI within a few years.
- He also mentioned challenges such as data quality and architecture constraints as possible barriers to this scaling.
- AI character building within major labs: Both Anthropic and OpenAI have dedicated teams focused on developing the character and behavior of their AI models, aiming for ethical and responsible interactions.
- This reflects a broader trend across major AI labs to ensure user-friendly and safe AI performance.
Links mentioned:
- Tweet from undefined: no description found
- Tweet from deepfates (@deepfates): honestly he kind of cooked here
- Tweet from Binyuan Hui (@huybery): 💪 I exhausted all my strength to give you the best. Quoting Qwen (@Alibaba_Qwen) 🚀Now it is the time, Nov. 11 10:24! The perfect time for our best coder model ever! Qwen2.5-Coder-32B-Instruct! ...
- Tweet from Alpin (@AlpinDale): Trying out a preview of Qwen2.5 Coder 32B, and it feels like Claude 3.5 Sonnet. You did it again, @Alibaba_Qwen ...
- Tweet from Jo Kristian Bergum (@jobergum): Hope she will have more time for blogging ❤️ Quoting Lilian Weng (@lilianweng) After working at OpenAI for almost 7 years, I decide to leave. I learned so much and now I'm ready for a reset and...
- Tweet from Andrew Carr (e/🤸) (@andrew_n_carr): Qwen2.5-Coder-32B-Instruct is the 2nd best poetry model after O1-preview 🤯
- Qwen2.5-Coder Technical Report: In this report, we introduce the Qwen2.5-Coder series, a significant upgrade from its predecessor, CodeQwen1.5. This series includes two models: Qwen2.5-Coder-1.5B and Qwen2.5-Coder-7B. As a code-spec...
- Tweet from Lilian Weng (@lilianweng): After working at OpenAI for almost 7 years, I decide to leave. I learned so much and now I'm ready for a reset and something new. Here is the note I just shared with the team. 🩵
- Tweet from Xeophon (@TheXeophon): The company who says agents will run entire companies has no working support, color me surprised Quoting Xeophon (@TheXeophon) Today, I am becoming a fool and attempt to resolve a billing issue wit...
- Tweet from Epoch AI (@EpochAIResearch): 3/10 We evaluated six leading models, including Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5 Pro. Even with extended thinking time (10,000 tokens), Python access, and the ability to run experiments, succ...
- Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity | Lex Fridman Podcast #452: Dario Amodei is the CEO of Anthropic, the company that created Claude. Amanda Askell is an AI researcher working on Claude's character and personality. Chris...
- Will an AI achieve >85% performance on the FrontierMath benchmark before 2028?: 62% chance.
Interconnects (Nathan Lambert) ▷ #other-papers (10 messages🔥):
Training vs Test Time in AIARC Prize DiscussionEnsemble Approaches to ARCTransformer Performance on ARC
-
Rethinking Training and Test Time: A member questioned why we treat training and test times differently, suggesting that taking a few gradients during test-time could improve results, achieving a 61% average score on the ARC validation set.
- Just take a few gradients during test-time — a simple way to increase test time compute — and get a SoTA!
- ARC Prize perceived as overrated: One participant expressed skepticism about the ARC Prize, stating it is overrated but also acknowledged that people will still hillclimb on it regardless.
- They mentioned, just takes time, indicating belief in eventual success despite doubts.
- Concerns over Pure Transformer Solutions: It was noted that achieving high scores on ARC might require more than just pure transformer methods, hinting at challenges faced in the competition.
- Another perspective suggested that an ensemble/discrete synthesis could outperform a pure transformer approach, potentially solving 75%+ of ARC.
Link mentioned: Tweet from Ekin Akyürek (@akyurekekin): Why do we treat train and test times so differently? Why is one “training” and the other “in-context learning”? Just take a few gradients during test-time — a simple way to increase test time comput...
Interconnects (Nathan Lambert) ▷ #ml-drama (55 messages🔥🔥):
Gary Marcus claimsAGI debatesChallenges on Twitter vs BlueskyThreads platform comparisonScientific Revolutions in AI
-
Gary Marcus defends his position on AGI: Gary Marcus responded to criticisms regarding his claims on AGI, saying that he never stated it 'can’t exist' and emphasizing the need for new approaches to achieve it this century, as per his article on the Next Decade in AI.
- He accused another party of 'strawmanning' his arguments and expressed frustration at their inability to acknowledge his correct predictions.
- Entertainment from Twitter debates: Members found the back-and-forth about AGI on Twitter entertaining, with one member describing the quotes as 'AMAZING' and enjoying the 'coward' remarks regarding Gary's blocking behavior.
- There's a sense of anticipation about what Gary will do next, as discussions suggest a potential for further exchanges across platforms.
- Platform comparisons: Twitter vs. Bluesky: Participants observed differences in engagement quality on social media platforms, with Twitter seen as a place for reach and Bluesky valued for its quality discussions.
- Some expressed relief at switching to Bluesky, finding Twitter to be filled with 'miserable' content.
- Threads and its effectiveness: Threads was critiqued as being similar to a lackluster version of Facebook, described as 'boring engagement bait' and filled with low-quality interactions.
- The conversation included comparisons of Threads to other platforms, with some expressing that it feels like teenagers dunking on AI in a more lame way than Gary.
- Upcoming AI-related literature: A member mentioned ordering a copy of 'The Structure of Scientific Revolutions', planning to review it in the context of AI and the dialogues surrounding Gary Marcus.
- This suggests a desire within the community to delve deeper into theoretical constructs that influence current AI debates.
Links mentioned:
- Tweet from Gary Marcus (@GaryMarcus): @natolambert blocking for total inability to accept responsibility for completely strawmanning my claims. (and pathological inability to give credit to a correct prediction.)
- Tweet from Laurence Molloy (@MolloyLaurence): Slow march of progress? 🤣🤣🤣 There is nothing about the AI industry right now that cares to take anything slowly and carefully. Quoting Nathan Lambert (@natolambert) How many AI researchers are...
- Tweet from Gary Marcus (@GaryMarcus): The new sport on X is strawmanning my very specific (and apparently correct) claim that pure LLMs would hit a point of diminishing returns. Never in a million years did say AGI “can’t exist.” That’s ...
- Tweet from Nathan Lambert (@natolambert): How many AI researchers are motivated to make "AGI" sooner to prove Gary wrong? I just don't understand how you can "win" when your take is that "AGI" can't exist. The...
Interconnects (Nathan Lambert) ▷ #random (49 messages🔥):
VLM Model ChoicesAI Research TrendsHCI Research in AIPersonality in AI ModelsQwen2-VL Dynamic Resolution
-
Debate on Base vs. Instruct-tuned Models: A discussion unfolded regarding the advantages of using base models over instruct-tuned models for VLMs, with skepticism expressed over the need for the latter's typical finetuning process.
- Some speculate that traditional LLM finetuning should precede VLM finetuning to achieve better results, as seen in experiments from the Molmo project.
- Shifts in AI Research Locations: There is contention about the current landscape of AI research, with some arguing it has shifted largely to industry, leaving academia with less impactful work due to resource disparities.
- Concerns were raised about the prestige associated with academic roles compared to high-paying industry positions.
- HCI Research in AI Interaction: Interest was expressed in exploring HCI-related research that examines how post-training model behavior affects end-user interactions and outcomes.
- Specifically, queries were raised about whether suggested edits in writing models yield better results than draft generation.
- Dynamic Resolution in Qwen2-VL: The feature of 'Naive Dynamic Resolution' in the Qwen2-VL model was highlighted, allowing for original resolution image processing without prior downsampling.
- This capability could be essential for tasks requiring high image fidelity, as it avoids the lossy effects of downsampling.
- Challenges in Conducting Personality Research: There are doubts about obtaining data on end-user preferences concerning AI personality traits due to privacy and competitive concerns.
- Nonetheless, it was suggested that HCI research might provide valuable insights into optimal UI and response formats for interacting with AI.
Links mentioned:
- Understanding Multimodal LLMs,): An introduction to the main techniques and latest models
- GitHub - srush/awesome-o1: A bibliography and survey of the papers surrounding o1: A bibliography and survey of the papers surrounding o1 - srush/awesome-o1
Interconnects (Nathan Lambert) ▷ #memes (5 messages):
Logan's Friday ShipPodcast IdeasDiscussion About Julia
-
Logan's Favorite Friday Ship: A member shared a tweet by @OfficialLoganK expressing excitement about their favorite Friday ship, stating it would undergo some refinements in the upcoming weeks.
- Logan's passion is infectious!
- Considering Logan for the Podcast: A member suggested that perhaps they should invite Logan on their podcast to share thoughts and experiences.
- This led to a positive consensus about Logan's appeal as a guest.
- Julia Sparks Enthusiasm: It was mentioned that if asked about Julia, Logan would easily talk for half the episode, indicating a strong connection to the topic.
- Julia seems to be a fascinating subject for Logan!
Link mentioned: Tweet from Logan Kilpatrick (@OfficialLoganK): My favorite Friday ship 🚢 in a while : ) will be continuing to remove some of the rough edges here over the next few weeks.
Interconnects (Nathan Lambert) ▷ #nlp (1 messages):
Neural NotesLanguage Model OptimizationDSPyMIPRO Optimizers
-
Neural Notes explores Language Model Optimization: In the latest episode of Neural Notes, investors Sandeep Bhadra and Simon Tiu interview Krista Opsahl-Ong, a PhD candidate at Stanford's AI Lab, discussing the future of language model optimization.
- The discussion promises insights into automated prompt optimization, which may interest those following advancements in AI.
- DSPy and MIPRO Optimizers discussed: A member reflected on a previously shared video featuring insights from Stanford researchers working on MIPRO optimizers used in DSPy.
- This dialogue hints at the member's intent to deepen their understanding of DSPy, noting a desire to gain an educated opinion on the technology.
Link mentioned: Neural Notes: The future of language model optimization: In this episode of Neural Notes, Vertex Ventures US investors Sandeep Bhadra and Simon Tiu talk to Krista Opsahl-Ong, PhD Candidate at Stanford's AI Lab (SAI...
Interconnects (Nathan Lambert) ▷ #rlhf (12 messages🔥):
Model Merging TechniquesRoleplaying Model EvaluationCommunity-based EvaluationsMythoMax and MythoLogic ModelsCensorship in Model Use
-
Excitement Over Model Merging Advancements: In the realm of model merging, interest was shown in SALSA, which addresses limitations in AI alignment through innovative techniques.
- One voices, 'woweee' indicating the buzz around the increasing complexity and potential of these models.
- Humorous Critique of Merging Models: A comical reference to the 'NobodyExistsOnTheInternet/Llama-2-70b-x8-MoE-clown-truck' model elicited laughter from the group, highlighting how bizarrely named models are perceived.
- Discussion included a link to merge.moe showcasing various models considered subpar by the community.
- Debate on Roleplaying Model Benchmarks: Questions arose about benchmarks for roleplaying models, with one member asking whether the evaluation is more vibes-based than quantifiable.
- There was a consensus that performance could be assessed against community preferences found on platforms like Reddit and 4chan.
- Defining Success in Roleplaying AI: A discussion ensued on what characteristics make a roleplaying model 'successful,' from creativity to compliance with character adherence.
- Concerns were raised about establishing concrete benchmarks that also acknowledge potentially NSFW scenarios involved in dialog NLP.
- Nudging Towards Community Engagement: A member suggested considering episodes focused on roleplaying and AI girlfriend spaces for community engagement, following a past interview on fan engagement.
- The group showed interest in how automated interactions in these spaces affect user experience and AI performance.
Links mentioned:
- no title found: no description found
- SALSA: Soup-based Alignment Learning for Stronger Adaptation in RLHF: In Large Language Model (LLM) development, Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning models with human values and preferences. RLHF traditionally relies on the Kullback...
- Gryphe/MythoMax-L2-13b · Hugging Face: no description found
Interconnects (Nathan Lambert) ▷ #reads (44 messages🔥):
Scaling LawsAGI and GPT-5 ExpectationsCritiques of AI ProgressModel Performance and Task UtilityFuture of AI Development
-
Scaling Laws Debate: Still Effective: There's an ongoing discussion about whether scaling is still effective, with claims that recent GPT models are underperforming while expectations for AGI remain high, implying both can be true.
- It appears that scaling laws are still working, with the challenge being the diminishing returns on improving performance for specific tasks.
- OpenAI's Messaging Causes Confusion: OpenAI's messaging around AGI has led to unrealistic expectations for GPT-5's capabilities, overshadowing that AGI is a broader system that includes, but isn't solely defined by, GPT-5.
- The perception of underwhelming advancements in models like GPT-5 suggests there is a need to clarify communication about the products' actual capabilities.
- Declining Rate of Usefulness Improvement: While scaling continues to yield results, the discussion posits that the rate of useful improvement in AI models is slowing down, a critical point for developers and investors.
- Emerging discussions highlight the limitations of current models to meet user expectations and suggest a potential shift towards specialized models.
- The Continued Promise of AI Development: Despite perceptions of stalling, there remains optimism for further product development utilizing current AI, indicating that significant opportunities still exist.
- Investors may need to adjust expectations based on shifting strategies, but overall, the capabilities of AI models are still on an upward trajectory.
- Navigating Current AI Progress and Challenges: Conversations reflect that while AI technology is making strides, the pathway to substantial advancements may involve navigating new challenges and resetting expectations.
- The community appears split on views regarding the speed and nature of progress, emphasizing healthy debates on what constitutes true advancement in AI.
Links mentioned:
- GPTs Are Maxed Out: AI companies will have to explore other routes
- Tweet from Adrià Sánchez (@AdriaSnz): @edzitron You’re wrong. AI will continue to evolve in an exponential way
- Tweet from Daniel (@DanielofDoge): @edzitron Dumb prediction.
- Tweet from T-toe (@thuzawtwice): @edzitron Ppl said this about the internet back in the day
- Two alignment threat models: Why under-elicitation and scheming are both important to address
- Tweet from Nathan Lambert (@natolambert): There are a lot of discussion on if "scaling is done," with stories from the Information saying that the latest GPT models aren't showing what OpenAI wanted while Sam Altman still parades ...
- Tweet from el (@jaxgriot): @TheXeophon what is the case for top of S curve nearby? just the pace of developments in the last year?
- Tweet from Troncat (@KomfyKatto): @TheXeophon Youre not very bright
- Tweet from Hensen Juang (@basedjensen): @TheXeophon its not its just a bad graph
OpenAI ▷ #ai-discussions (155 messages🔥🔥):
AI Tools and ResourcesSocial Dynamics of AIProgramming for AI InteractionsFunction Calling UpdatesImage and Video Generation
-
AI Tools and Resources Discussion: Users shared various tools for text-to-speech (TTS) applications, including options like f5-tts and Elven Labs, with the latter being noted as expensive.
- The discussion highlighted timestamp data availability for different TTS solutions and concerns regarding running these on consumer-grade hardware.
- Exploring Creativity in AI: A humorous debate arose regarding an AI-powered magic 8-ball startup, with users suggesting the concept of an AI becoming subtly sentient to save its business.
- Participants brainstormed ideas about adding features like personalized responses and even image generation for an AI-infused magic 8-ball.
- Programming Challenges in AI Apps: A user reported difficulties integrating speech recognition within their app while trying to connect to an AI model server using Anaconda.
- The conversation included troubleshooting tips for ensuring the correct functioning of both speech recognition and server communication.
- Function Calling and Structured Outputs: A user inquired about updates on structured outputs in relation to function calling within LLMs, seeking ways to enhance responses in their sales pipeline.
- Participants suggested exploring ChatGPT for brainstorming ideas and optimizing implementation strategies.
- Navigating AI Image and Video Generation: Discussions highlighted the current limitations of AI video generation, emphasizing the need for workflows to stitch together multiple scenes.
- Several users expressed frustration at the reliance on text-based models and the desire for advancements in video-focused AI solutions.
Links mentioned:
- Tweet from Deep Thought (@DeepThoughtHQ): We’ve laid down a master plan—album, Broadway, Emmy-winning doc. This isn’t just about Juicy J; it’s a declaration. We’re carving a new lane in the cultural landscape. This is the future of creative a...
- Google Keynote (Google I/O ‘24): It’s time to I/O! Tune in to learn the latest news, announcements, and AI updates from Google.To watch this keynote with American Sign Language (ASL) interpr...
OpenAI ▷ #gpt-4-discussions (21 messages🔥):
Service OutageBug Reporting ProcessImage Recognition IntegrationChatGPT Performance IssuesTechnical Support Contact
-
Service Outage Plaguing Users: Users reported an ongoing service outage, expressing frustration over unresponsiveness from ChatGPT, with some confirming it is still happening.
- One user noted, 'I don't understand why it is not able to work at all for me today.'
- Confusion About Bug Reporting: There was confusion regarding the bug reporting process, with a user inquiring if it had been turned off.
- Another user pointed them to a specific channel link for creating new bugs and mentioned that the process had changed.
- Integrating Image Recognition in Flutter Apps: A user inquired about image recognition capabilities in ChatGPT for identifying ingredients through pictures in a Flutter app.
- No direct solutions were provided; the query remains unanswered as the conversation shifted focus.
- ChatGPT Performance Issues: Some users experienced performance issues with ChatGPT, indicating it could not execute prompts effectively at times.
- One user initially reported the problem but later confirmed that the service was back up.
- Seeking Contact for Technical Support: A member sought guidance on how to contact technical support, expressing uncertainty about the process.
- Another member noted that community members typically lack direct knowledge of OpenAI's internal workings.
OpenAI ▷ #prompt-engineering (33 messages🔥):
Chunking JSON for RAG toolUtilizing LLM for code generationWriting prompts for story generationParallel processing in chatsOptimizing AI-generated narrative style
-
Chunking JSON to avoid RAG tool limitations: A discussion highlighted that chunking JSON into smaller files prevents the RAG tool from excluding relevant data, ensuring all inputs are considered.
- One member expressed concern over the increased workflow length due to this method.
- Using LLM for generating data insertion code: A member proposed using an LLM to generate the necessary code to structure data as desired for their workflow.
- Another echoed this as a good solution, suggesting it could simplify the integration process.
- Crafting effective prompts for story generation: A member was struggling with their story-generate prompts being overly flowery and sought to enhance their clarity and direction.
- An experienced user advised on rephrasing instructions to be more specific, with an emphasis on examples of what to include.
- Implementing parallel processing for efficiency: The viability of running multiple chats in parallel was addressed, with recommendations to process data in chunks of 20.
- Participants expressed excitement at the prospect of optimized workflows through parallel execution.
- Refining narrative styles from AI models: Users discussed the need to clarify story prompts to push models toward desired narrative styles, particularly avoiding overly dramatic narratives.
- One member suggested that adjusting the content level in prompts can help curate the results to align with community guidelines.
OpenAI ▷ #api-discussions (33 messages🔥):
Chunking JSON for RAG ToolUsing LLM for Data InsertionInstruction Clarity for AI Story GenerationParallel Processing for JSON ObjectsStory Prompt Adjustments
-
Chunking JSON solves RAG Tool issues: A member emphasized the need to chunk JSON into smaller files to ensure the RAG tool captures all data, thereby preventing exclusions.
- Others noted that while this method is effective, it inevitably lengthens the workflow.
- Utilizing LLM for custom code generation: One user suggests using the LLM to generate code that would help insert data according to specific needs.
- Another acknowledged this as a solid tactic, but questioned if people would commit to coding at all.
- Clarity in AI Story Instructions: A user seeking improved story generation was advised to provide clear and direct instructions to the model for better results.
- Specific examples of desired outcomes and a focus on positive instructions were recommended to guide the AI effectively.
- Parallel Processing of JSON Objects: The possibility of running multiple chats in parallel to process JSON objects was confirmed to be feasible.
- This approach allows for efficient handling of large datasets, reducing the overall processing time.
- Adjusting story prompts for better outputs: A member was encouraged to refine prompts to dictate desired outcomes rather than listing prohibitions to achieve better story quality.
- Providing precise guidance and examples in the prompt was emphasized to navigate around identified issues in story generation.
Notebook LM Discord ▷ #announcements (1 messages):
NotebookLM Feedback SurveyUser Study ParticipationGift Code IncentivesEligibility Requirements
-
Join the NotebookLM Feedback Survey: The Google team is seeking participants for a 10-minute feedback survey on NotebookLM to guide future enhancements, and you can register your interest here.
- If selected, participants will receive a $20 gift code after completing the survey, with eligibility requiring participants to be at least 18 years old.
- No Gifts for Interest Submission: It's important to note that completing the interest and eligibility form does not guarantee a thank you gift; rewards are provided only after the feedback survey is completed.
- This clarification aims to manage expectations regarding the incentive process for participants.
- Questions About User Studies: For any inquiries related to the user studies, participants are encouraged to visit the Google user research page.
- This resource can provide further details and assistance for those interested in participating.
Link mentioned: Register your interest: Google feedback survey: Hello, We are looking for feedback on NotebookLM via a short survey. This will help the Google team better understand your needs in order to incorporate them into future product enhancements. To regi...
Notebook LM Discord ▷ #use-cases (51 messages🔥):
NotebookLM for Job Search PrepExperimentation with Audio and Sports CommentaryUsing NotebookLM for Educational SummariesGenerating Engaging PodcastsCreating AI-Enhanced Quizzes
-
NotebookLM aids tech job search prep: A user inquired about using NotebookLM for technical interview preparation, discussing how it could assist in practicing soft skills and coding exercises.
- A suggestion was made to create mock interviews with different voices to enhance the practice experience.
- Use of NotebookLM in Sports Commentary: An experiment was shared using NotebookLM to summarize a ChatGPT-based audio commentary on sports, highlighting its potential for enhancing engagement.
- While some found AI commentaries sounded robotic, others discussed the idea of training models on exciting commentary data for better results.
- NotebookLM creates efficient educational summaries: A user successfully generated a podcast summarizing an internal newsletter from over 20 sources, finding it more engaging than traditional newsletters.
- Another user mentioned using NotebookLM for summarizing audio recordings in a foreign language into coherent meeting notes.
- Innovative podcast formats with NotebookLM: A creative podcast quiz format was proposed where hosts ask trivia questions and allow a countdown for responses to enhance engagement.
- Discussion also touched on using NotebookLM to generate educational podcasts and audio files from various sources, yielding useful summaries.
- Visual versus audio learning preferences: A member shared their preference for visual learning and how they optimized study time using AINotebook to generate flashcards and quiz questions.
- Another member shared a video on effective usage of NotebookLM, indicating a blend of interest in both audio and visual educational methods.
Links mentioned:
- no title found: no description found
- Tweet from Aishwarya Ashok (@aishashok14): Looking at the rate at which NotebookLM is being used, wouldn't be surprised if shareable pages would be launched—from resumes and portfolios to simple landing pages and knowledge bases, NotebookL...
- no title found: no description found
- How to use D-id along with Google's NotebookLM for digital marketing ideation: no description found
- Rafael and Serafine (NotebookLM & Simli): https://github.com/markomanninen/Simli_NotebookLM
Notebook LM Discord ▷ #general (132 messages🔥🔥):
Notebook LM vs Other AI ToolsPodcast Functionality and IssuesGoogle Drive Document SyncingMobile Usage and LimitationsExporting Notes and API Queries
-
Exploring Notebook LM vs Other AI Tools: Users discussed how NotebookLM compares to Claude Projects, ChatGPT Canvas, and Notion AI for productivity tasks, including writing and job search prep.
- Some expressed curiosity about pros and cons or specific use cases that help with productivity, especially for users with ADHD.
- Podcast Functionality Hits Snags: The podcast feature was reported to sometimes hallucinate content, leading to confusion and amusing outcomes among users.
- There are ongoing discussions regarding the ability to generate multiple podcasts per notebook, and how to effectively manage them.
- Document Syncing with Google Drive: Users identified a way to sync Google Docs with NotebookLM, looking for convenience with a sync button to update many documents simultaneously.
- There's a request for a bulk syncing feature, as manually updating individual documents is tedious and time-consuming.
- Addressing Mobile Limitations: The mobile version of NotebookLM was highlighted as underdeveloped, making it challenging for users to access full notes on smartphones.
- Users noted ongoing improvement in mobile web features, while expressing a desire for a dedicated app.
- Export Notes and API Features: Several users inquired about the ability to export notes as PDFs or if there are APIs available to automate notebook generation.
- There was interest in whether there will be enhancements to support other languages in the future, indicating a broader need for accessibility.
Links mentioned:
- Top Shelf: Podcast · Four By One Technologies · "Top Shelf" is your go-to podcast for quick, insightful takes on today’s best-selling books. In just 15 minutes, get the gist, the gold, and a fresh pers...
- UNREAL MYSTERIES 5: Behind the Scenes / Making Of: Ever wonder how the Unreal Mysteries show was made? We go full meta, and make an in-universe show about how the show is made. Witness NotebookLM skirting sen...
- Oct 17 2024 - Help: no description found
- no title found: no description found
- GitHub - souzatharsis/podcastfy: An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI: An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI - souzatharsis/podcastfy
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- podcastfy/usage/local_llm.md at main · souzatharsis/podcastfy: An Open Source Python alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI - souzatharsis/podcastfy
LM Studio ▷ #general (114 messages🔥🔥):
LM Studio GPU utilizationLM Studio model loading issuesPydantic error with LangChainQwen model complianceText to Speech model functionality
-
LM Studio GPU utilization concerns: Users raised questions about how to determine GPU utilization on MacBooks while running LM Studio, particularly on specific models like the M4.
- Discussion included potential slow generation speeds, with users comparing setup specs and results.
- LM Studio model loading issues: A user reported that LM Studio was unable to index a folder with models, despite the presence of GGUF files, mentioning recent changes in the structure.
- It was suggested to ensure only relevant GGUF files were in the folder and to maintain a correct folder structure.
- Pydantic error with LangChain: A
PydanticUserErrorwas encountered regarding the__modify_schema__method when using LangChain, indicating a potential mismatch in Pydantic versions.
- Users expressed uncertainty about whether this was a bug or a version compatibility issue.
- Qwen model compliance with LM Studio: The Qwen2.5-Coder-32B-Instruct-GGUF was released, prompting questions about its compliance with LM Studio.
- Members were referred to additional resources for more information on model compatibility.
- Text to Speech model functionality: Users discussed issues related to using text-to-speech models in LM Studio and pointed out that some functionalities may not be supported.
- Recommendations were made to check for only the required files as text-to-speech models were indicated not to work efficiently.
Links mentioned:
- Redirecting...: no description found
- Breaking Bad Walter White GIF - Breaking Bad Walter White Jesse Pinkman - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- websockets: licence version pyversions tests docs openssf websockets is a library for building WebSocket servers and clients in Python with a focus on correctness, simplicity, robustness, and performance. It s...
- WebSocket - Web APIs | MDN: The WebSocket object provides the API for creating and managing a WebSocket connection to a server, as well as for sending and receiving data on the connection.
- Web technology for developers | MDN: The open Web presents incredible opportunities for developers. To take full advantage of these technologies, you need to know how to use them. Below you'll find links to our Web technology docume...
- Geekerwan benchmarked Qwen2.5 7B to 72B on new M4 Pro and M4 Max chips using Ollama: Source: https://youtu.be/2jEdpCMD5E8?t=796
- Geekerwan benchmarked Qwen2.5 7B to 72B on new M4 Pro and M4 Max chips using Ollama: Source: https://youtu.be/2jEdpCMD5E8?t=796
LM Studio ▷ #hardware-discussion (56 messages🔥🔥):
Gemma 2 PerformanceH100 Cluster HelpHome Server Setup for AI/MLLaptop Recommendations for LLM InferenceModel Performance on Different GPUs
-
Gemma 2 shines at lower precision: Discussions pointed out that Gemma 2 27B performs exceptionally well even at lower precision, with some members reporting little benefit from Q8 over Q5 on specific models.
- Members emphasized the need for more context in evaluations, as specifications alone may not be compelling without understanding the context.
- Need for Assistance with H100 Clusters: A query was raised regarding experiences with H100 clusters and Windows Server VMs, mentioning the use of RDP for connection.
- Members shared insights, but one suggested avoiding dual postings in channels to keep discussions tidy.
- Advice on Building a Home AI/ML Server: A member is contemplating a home server capable of handling at least a 70B model with good speed, considering a Mac Studio as a potential solution.
- Others suggested that a pair of Nvidia 4060TI's would be a more cost-effective and expandable choice compared to a Mac.
- Laptop Options for LLMs Under Review: There were inquiries about the performance differences between newer Intel Core Ultra CPUs and older i9 models for LLM inference, with recommendations leaning towards AMD alternatives.
- A suggestion was made to focus on GPU performance over CPU specs for LLM tasks and to consider laptops like ASUS ROG Strix SCAR 17 or Lenovo Legion Pro 7 Gen 8.
- Model Throughput Discrepancies Analyzed: One user tested llama 3.2-3b Q8 and noted a throughput of ~70 tok/s on a 3080, questioning the discrepancy in performance compared to a 5900X CPU.
- Members agreed that smaller models do not leverage GPU capabilities to the same extent, leading to smaller throughput gaps.
Latent Space ▷ #ai-general-chat (84 messages🔥🔥):
Qwen 2.5 CoderAI Music AnalysisDario Amodei InterviewFrontierMath BenchmarkTest-Time Compute
-
Qwen 2.5 Coder Launch: The Qwen2.5-Coder-32B-Instruct model has been released, alongside a family of coder models ranging from 0.5B to 32B, providing various quantized formats.
- It has achieved competitive performances in coding benchmarks, surpassing models like GPT-4o and showcasing the capabilities of the Qwen series.
- AI Music Analysis Insights: A discussion arose around a well-received analysis on the tells of AI-generated music, highlighting the subtleties involved in AI's musical capabilities.
- There was an emphasis on the importance of using evaluation benchmarks, much like those found in coding and mathematical reasoning, to judge AI-generated music.
- In-depth Interview with Dario Amodei: A lengthy podcast featuring Dario Amodei discusses Claude AI, AGI, and future implications of AI for humanity, clocking in at five hours.
- Listeners expect the featured discussions to delve into various topics, including potential cultural references, making it entertaining yet informative.
- FrontierMath Benchmark Challenges: The newly introduced FrontierMath benchmark reveals that current AI systems struggle, solving less than 2% of the included complex mathematical problems.
- The benchmark signifies a shift in evaluation techniques, focusing on challenging, original problems that test AI's capabilities against human mathematicians.
- The Importance of Test-Time Compute: Discussions highlighted a new state-of-the-art achievement for the ARC public validation set, showing a score of 61% through innovative test-time compute techniques.
- There is an ongoing debate on how training and test-time processes are perceived differently within the AI community, suggesting potential unification in methods.
Links mentioned:
- Tweet from Binyuan Hui (@huybery): 💪 I exhausted all my strength to give you the best. Quoting Qwen (@Alibaba_Qwen) 🚀Now it is the time, Nov. 11 10:24! The perfect time for our best coder model ever! Qwen2.5-Coder-32B-Instruct! ...
- Tweet from Qwen (@Alibaba_Qwen): 🚀Now it is the time, Nov. 11 10:24! The perfect time for our best coder model ever! Qwen2.5-Coder-32B-Instruct! Wait wait... it's more than a big coder! It is a family of coder models! Besides ...
- FrontierMath: no description found
- Tweet from Andrej Karpathy (@karpathy): Moravec's paradox in LLM evals I was reacting to this new benchmark of frontier math where LLMs only solve 2%. It was introduced because LLMs are increasingly crushing existing math benchmarks. T...
- Tweet from Adam.GPT (@TheRealAdamG): +100. I’ve been intently listening to Sam for my 3 years at OpenAI. He is precise with his words and comments. I personally think the disconnect, where he is viewed as hyping things up, is that he...
- Tweet from Jason Wei (@_jasonwei): There is a nuanced but important difference between chain-of-thought before and after o1. Before the o1 paradigm (i.e., chain-of-thought prompting), there was a mismatch between what chain of thought...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): ✍️New Chatbot Arena Blog Arena Categories: Definitions, Methods, and Insights - What are users asking? Trend over time - How Arena categories are made - Key insights into model's strengths and we...
- Tweet from Andrew Ng (@AndrewYNg): New short course: LLMs as Operating Systems: Agent Memory, created with @Letta_AI, and taught by its founders @charlespacker and @sarahwooders. An LLM's input context window has limited space. Us...
- Tweet from Noam Brown (@polynoamial): I love seeing a new eval with such low pass rates for frontier models. It feels like waking up to a fresh blanket of snow outside, completely untouched. Quoting Epoch AI (@EpochAIResearch) 3/10 We ...
- Tweet from Ekin Akyürek (@akyurekekin): Why do we treat train and test times so differently? Why is one “training” and the other “in-context learning”? Just take a few gradients during test-time — a simple way to increase test time comput...
- Tweet from Junyang Lin (@JustinLin610): PST Nov.11 10:24🥝
- Qwen2.5-Coder Technical Report: In this report, we introduce the Qwen2.5-Coder series, a significant upgrade from its predecessor, CodeQwen1.5. This series includes two models: Qwen2.5-Coder-1.5B and Qwen2.5-Coder-7B. As a code-spec...
- Tweet from AP (@angrypenguinPNG): magical tbh Quoting AP (@angrypenguinPNG) Water color painting -> 3D with CogVideoX 🪄
- Qwen2.5-Coder Series: Powerful, Diverse, Practical.: GITHUB HUGGING FACE MODELSCOPE KAGGLE DEMO DISCORD Introduction Today, we are excited to open source the “Powerful”, “Diverse”, and “Practical” Qwen2.5-Coder series...
- Tweet from Arnaud Dyevre (@ArnaudDyevre): I just read the paper in full; it is even more spectacular than I initially thought. A short thread about the results and their significance. Quoting Caleb Watney (@calebwatney) This is the best pa...
- Tweet from Christian Schoppe (@ChristianS26469): There are two new models on lmsys arena (battle mode), which are both pretty good: anon-chat, a good Chinese LLM from MiniMax. pumpkin_pie, a very intelligent and capable model based on llama (self d...
- Tweet from Ekin Akyürek (@akyurekekin): Thanks for the attention, couple important points: 1) See @MindsAI_Jack, their team is the first one who applied method privately and they get the 1st rank in the competition. 2) See the concurrent ...
- Tweet from Lilian Weng (@lilianweng): After working at OpenAI for almost 7 years, I decide to leave. I learned so much and now I'm ready for a reset and something new. Here is the note I just shared with the team. 🩵
- Tweet from Vercel Changelog (@vercel_changes): Next.js AI chatbot template 3.0 • New design • Model switcher • Flexible side-by-side chat and output UI • Uses Next.js 15, React 19, and Auth.js
next-authbeta https://vercel.com/changelog/next-j... - Tweet from Caleb Watney (@calebwatney): This is the best paper written so far about the impact of AI on scientific discovery
- Tweet from Peter Welinder (@npew): People underestimate how powerful test-time compute is: compute for longer, in parallel, or fork and branch arbitrarily—like cloning your mind 1,000 times and picking the best thoughts.
- Tweet from Clive Chan (@itsclivetime): Same. Since joining in January I’ve shifted from “this is unproductive hype” to “agi is basically here”. IMHO, what comes next is relatively little new science, but instead years of grindy engineering...
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Tweet from Haider. (@slow_developer): 🚨 An unknown Gemini model is available in the LMSYS Arena (battle). While it’s unclear if this is Gemini 2.0, the "gemini-test" outperformed one of my test with OpenAI o1-mini.
- Tweet from Kevin A. Bryan (@Afinetheorem): This is correct. I've talked to *lots* of people inside four of the big AI labs this month, none of which are salespeople. I have not heard a *single* researcher tell me they believe the rate of A...
- Tweet from Jack Clark (@jackclarkSF): AI skeptics: LLMs are copy-paste engines, incapable of original thought, basically worthless. Professionals who track AI progress: We've worked with 60 mathematicians to build a hard test that m...
- Tweet from roon (@tszzl): obviously don’t believe any economic studies at face value but this is what it looks like when you’ve discovered superintelligence - the researchers are outsourcing idea generation tasks - and runnin...
- Tweet from 👩💻 Paige Bailey (@DynamicWebPaige): ✍️ @GoogleDeepMind just open-sourced its internal prompt-tuning guide, which includes descriptions of the differences between pretraining and post-training; system instructions; and more: Quoting Var...
- AI Music Tells | 50sec snip from The Vergecast: AI Music Tells AI-Generated Music: AI music generators, like Suno or Udio, have noticeable tells, much like AI image generators. Details: These tells might beco…
- Tweet from Lilian Weng (@lilianweng): 📢 We are hiring Research Scientists and Engineers for safety research at @OpenAI, ranging from safe model behavior training, adversarial robustness, AI in healthcare, frontier risk evaluation and mor...
- Tweet from Matt Turck (@mattturck): Never a dull moment in AI. Current market summary: * Big, bigger, biggest: biggest VC round ever (OpenAI), biggest seed round (Safe SuperIntelligence, $1B), biggest acqui-hire (Character, $2.7B), bi...
- Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity | Lex Fridman Podcast #452: Dario Amodei is the CEO of Anthropic, the company that created Claude. Amanda Askell is an AI researcher working on Claude's character and personality. Chris...
- Tweet from Tibor Blaho (@btibor91): Some OpenAI employees who tested Orion report it achieved GPT-4-level performance after completing only 20% of its training, but the quality increase was smaller than the leap from GPT-3 to GPT-4, sug...
- Speculations on Test-Time Scaling | Richard M. Karp Distinguished Lecture: Sasha Rush (Cornell University)https://simons.berkeley.edu/events/speculations-test-time-scaling-richard-m-karp-distinguished-lectureRichard M. Karp Distingu...
- GitHub - varungodbole/prompt-tuning-playbook: A playbook for effectively prompting post-trained LLMs: A playbook for effectively prompting post-trained LLMs - varungodbole/prompt-tuning-playbook
- Gemini is now accessible from the OpenAI Library: no description found
- GitHub - srush/awesome-o1: A bibliography and survey of the papers surrounding o1: A bibliography and survey of the papers surrounding o1 - srush/awesome-o1
- GitHub - srush/awesome-o1: A bibliography and survey of the papers surrounding o1: A bibliography and survey of the papers surrounding o1 - srush/awesome-o1
- GitHub - astral-sh/uv: An extremely fast Python package and project manager, written in Rust.: An extremely fast Python package and project manager, written in Rust. - astral-sh/uv
- uv: no description found
Latent Space ▷ #ai-announcements (3 messages):
Dust company insightsEarly OpenAI experiencesVoice questions for recap episodeAI agents infrastructure challengesSaaS and AI's future impact
-
Stanislas Polu shares Dust's journey: In a recent episode, Stanislas Polu discussed the early days at OpenAI and the development of Dust XP1, achieving 88% Daily Active Usage among employee users.
- He humorously noted he may have disclosed too much about OpenAI's operations from 2019 to 2022.
- Voice questions for the big recap: Listeners are encouraged to submit voice questions for the upcoming 2 Years of ChatGPT recap episode via SpeakPipe.
- This open call aims to gather community insights and inquiries following the successful run of the show.
- Challenges in AI agents infrastructure: The conversation revisited infrastructure challenges in building effective AI agents, touching on the buy vs. build decisions that startups face.
- Polu highlighted concerns regarding the evolution and allocation of compute resources in the early days of OpenAI, noting the hurdles encountered.
- The future of SaaS and AI: A significant segment was dedicated to the discussion on SaaS and its evolving relationship with AI technologies and their impact on future software solutions.
- The talk also entailed comments on how single-employee companies are competing in a $1B company race, challenging traditional models.
Links mentioned:
- Tweet from Latent.Space (@latentspacepod): 🆕 Agents @ Work: @dust4ai! https://latent.space/p/dust @spolu dishes on the early @openai journey with @gdb and @ilyasut, Dust XP1, and how to make truly useful work assistants with **88% Daily Act...
- Tweet from Stanislas Polu (@spolu): Disclosed way more than I should have about OpenAI 19-22 🙊 Really great conversation with @FanaHOVA and @swyx, you guys have such a way of framing things👌 Quoting Latent.Space (@latentspacepod) ...
- Send a voice message to LatentSpace : The #1 AI Engineering podcast
Latent Space ▷ #ai-in-action-club (80 messages🔥🔥):
AI Recording ChallengesDaily AI Use CasesOpen Interpreter DevelopmentsUsing AI for Code GenerationCredential Management
-
AI Recording Challenges.: There were issues with recording during the session, as one member mentioned, 'Yikes is having tech issues.' Guidance was given to confirm if the recording was functioning and if audio was capturing correctly.
- Many members expressed uncertainty about the recording status, with one noting that a member had it running, but it remained 'tbd if the audio recorded.'
- Daily AI Use Cases Explored.: Members discussed various daily applications of AI, particularly noting that one member uses file/image transformations frequently.
- Another expressed excitement about allowing their child to experiment with AI, implying that it could yield 'a few interesting use cases.'
- Open Interpreter Developments.: The team celebrated progress on the Open Interpreter project, with expressions of appreciation for the open-source direction and functionalities discussed.
- 'That's so cool you guys open-sourced it,' one member stated, highlighting the desire to see good ideas flourish freely.
- Using AI for Code Generation.: Members discussed the mechanics of handling generated code, with one asking for clarification on modifying generated scripts rather than recreating them.
- A suggestion was made to reuse locally generated scripts, promoting efficiency over continuous regeneration.
- Credential Management Issues.: Questions were raised about mechanisms for handling credentials when accessing services like Google Sheets.
- Discussion around using a 'profile that has access' implied ongoing considerations for maintaining security while utilizing AI.
Links mentioned:
- GitHub - nvbn/thefuck: Magnificent app which corrects your previous console command.: Magnificent app which corrects your previous console command. - nvbn/thefuck
- open-interpreter/interpreter/computer_use/loop.py at main · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
GPU MODE ▷ #general (30 messages🔥):
ApacheTVM discussionsNVIDIA interview insightsCareer advice for tech rolesTile-lang projectTriton language tools
-
Curiosity about ApacheTVM functionalities: ApacheTVM is noted for its interesting functionality, allowing deployment to both CPU SIMD and GPUs, despite having a lack of training support.
- Members expressed appreciation for features like baremetal inference and distributed inference, highlighting the tool's potential.
- NVIDIA interviews are intense: A member shared that interviews at NVIDIA are particularly challenging, emphasizing the need for in-depth knowledge of deep learning workloads at a CUDA C++ level.
- Interviewees noted the focus on practical understanding rather than theoretical knowledge in frameworks like PyTorch.
- Building Tile-lang for TVM: A community member introduced Tile-lang, a TVM-based language aimed at providing 'Triton-like' fine-grained control for optimizations in ML.
- They shared a link to the Tile-lang GitHub repository, expressing excitement to test the new tool.
- Advice on applying for technical roles: Its recommended to apply for tech roles like those at NVIDIA as soon as possible, particularly for university students, since recruiting timelines are quick.
- Candidates were encouraged to build relevant skills and experience in areas explicitly outlined in job descriptions to improve application chances.
- Diverse paths in ML specialization: A member expressed uncertainty about whether to pursue a developer role with a machine learning specialization or aim for a research and development team.
- They noted the complexities and maturity of the field after discussing with professionals, suggesting that their electronics major aligns well with industry expectations.
Links mentioned:
- triton/python/triton/tools/compile.c at be510cceb409bd676380e91b9d17741546335453 · triton-lang/triton: Development repository for the Triton language and compiler - triton-lang/triton
- GitHub - microsoft/BitBLAS at tilelang: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. - GitHub - microsoft/BitBLAS at tilelang
GPU MODE ▷ #triton (3 messages):
Triton SM communicationTriton.language.core deprecationJoining Triton SlackJAX-Triton autotunerTriton-Dejavu fork
-
Inquiry About SM Communication in Triton: A member is seeking confirmation on whether Triton supports communication between SMs, mentioning that the H100 has SM-to-SM connections.
- This raises questions about the architecture and possible optimizations available with Triton's platform.
- Question on Triton.language.core Deprecation: Another member is asking if triton.language.core is deprecated, as they found references in some open-source codes but not in the official documentation.
- This ambiguity points to a potential need for clearer documentation on the state of Triton's API.
- Joining Triton Slack for Collaboration: A member expressed interest in joining the Triton Slack, posing a question about whether it is the only way to access it and its current activity status.
- They linked to a GitHub discussion requesting invitations, indicating a desire for collaboration.
- Enhancing JAX-Triton Autotuner Experience: A member aims to make the JAX-Triton autotuner developer experience as smooth as it is in Torch, highlighting the need for community input.
- They propose the idea of a Triton-Dejavu JAX-Triton fork, signaling potential development opportunities within the community.
Link mentioned: Requests for Invitation to Slack · triton-lang/triton · Discussion #2329: Hello, I am starting this thread in case anyone else (like me) would like to request for invitation to Slack.
GPU MODE ▷ #torch (1 messages):
Default Memory Format in PyTorchTorch Tensor Attributes
-
Inquiry on Defaulting to Channels_Last Memory Format: A member asked if there's a flag in PyTorch to default all tensors to channels_last memory format, referencing
torch.channels_last.- This inquiry aligns with the need for consistent tensor management, similar to how torch.set_default_device works for device settings.
- Understanding Torch Tensor Attributes: The discussion highlighted several important attributes of a torch.Tensor, including dtype, device, and layout.
- A brief overview of these attributes was provided, emphasizing the various data types available in PyTorch, such as torch.float32 and torch.float64.
Link mentioned: Tensor Attributes — PyTorch 2.5 documentation)?): no description found
GPU MODE ▷ #announcements (1 messages):
SGLang Performance OptimizationCPU Overlap OptimizationFlashInfer Hopper OptimizationTurboMind GEMM Optimization
-
Deep Dive on SGLang Performance Optimization: A detailed agenda led by Yineng Zhang on SGLang Performance Optimization is set to start at 8 am PST on Nov 9.
- Key focuses will include CPU Overlap, FlashInfer Hopper Optimization, and TurboMind GEMM Integration.
- CPU Overlap Optimization Insights: The first point of discussion will be CPU Overlap Optimization, aimed at improving processing efficiency during SGLang execution.
- Experts believe that addressing this will significantly enhance overall performance.
- FlashInfer Hopper Optimization & Integration: FlashInfer Hopper Optimization will be covered, focusing on integrating advanced functionalities within the SGLang ecosystem.
- This could potentially lead to faster inference times and better resource management.
- Exploring TurboMind GEMM Integration: The agenda includes a segment on TurboMind GEMM Optimization, highlighting its integration into existing frameworks.
- There are expectations that this will enable high-performance machine learning tasks.
GPU MODE ▷ #algorithms (8 messages🔥):
SVDQuant for Diffusion ModelsHQQ+ Initialization Step4-bit Activations Impact on InferenceLoRA Size in Custom ModelsMerging LoRAs for Inference Speed
-
SVDQuant accelerates Diffusion Models: A member shared an interesting paper on SVDQuant which aims to optimize diffusion models by quantizing their weights and activations to 4 bits.
- The method leverages a low-rank branch to handle outliers effectively, enhancing performance even for larger image generation tasks.
- HQQ+ Initialization leveraged in SVDQuant: Another member noted similarities between SVDQuant and the initialization step of HQQ+, indicating a better initialization from activations.
- While adjustments on memory access overhead seem manageable for LLMs, the need to unpack activations for LoRAs may present challenges.
- Impact of 4-bit Activations on Inference: Discussions highlighted concerns regarding the impact of unpacking 4-bit activations on inference speed for image generation tasks like Flux.
- The consensus suggested that while the overhead exists, its significance largely depends on the implementation specifics.
- Size of LoRAs in Flux Customizations: A member queried about the typical size of LoRAs when customizing models like Flux, expressing uncertainty over their dimensions.
- The conversation hinted at ongoing experimentation with Flux within the group, yet no definitive sizes were provided.
- Merging LoRAs affects Inference Speed: Concern arose about merging LoRAs post-customization, as the final merged sizes could slow down inference dramatically.
- The impact on inference speed correlates directly to the ranks of the merged LoRAs, adding an essential factor to consider for optimization.
Link mentioned: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models: Diffusion models have been proven highly effective at generating high-quality images. However, as these models grow larger, they require significantly more memory and suffer from higher latency, posin...
GPU MODE ▷ #cool-links (6 messages):
DeepMind's Neural CompressionAI Compute EfficiencyRemi Cadene's Robotics JourneyEfficient Deep Learning Systems
-
DeepMind trains with neurally compressed text: A member shared interesting work by DeepMind on training models with neurally compressed text as detailed in a research paper.
- The discussion sparked interest in Figure 3 from the paper, although specific quotes were not provided.
- AI focusing on reducing compute requirements: A member noted significant efforts to help AI systems use less compute, linking to various resources like FlashAttention.
- Using this approach, researchers aim to enhance efficiency; however, the compute demands remain a hot topic of discussion.
- Remi Cadene on e2e robotics: Discussion featured Remi Cadene, who transitioned from Tesla to leading open-source robotics projects at Hugging Face.
- His journey, which includes a PhD from Sorbonne and experience with Andrej Karpathy, sparked conversations about innovative projects like Le Robot.
- Efficient Deep Learning Systems course materials: A member highlighted a GitHub repository, efficient-dl-systems, for course materials on efficient deep learning systems at HSE and YSDA.
- The repository has become a go-to resource for those exploring the domain of efficient deep learning.
Links mentioned:
- GPUs Go Brrr: how make gpu fast?
- GitHub - mryab/efficient-dl-systems: Efficient Deep Learning Systems course materials (HSE, YSDA): Efficient Deep Learning Systems course materials (HSE, YSDA) - mryab/efficient-dl-systems
- #29 | Remi Cadene: From Paris to Tesla, to Starting Le Robot | Kinematic Conversations): Kinematic Conversations · Episode
GPU MODE ▷ #beginner (4 messages):
Shared Memory in CUDANVIDIA Enroot Container Runtime
-
Tiled Matrix Multiplication Illuminates Shared Memory: A member highlighted that the section on tiled matrix multiplication in the CUDA C++ Programming Guide helped them understand shared memory effectively.
- They noted that while the same content exists in PMPP 5.3 and 5.4, the programming guide's approach was more direct.
- Seeking Help with NVIDIA Enroot: A member inquired about experiences with NVIDIA's enroot container runtime while attempting to set up a development environment on a cluster.
- Despite their efforts, they expressed frustration at not being successful and welcomed feedback from the community.
GPU MODE ▷ #pmpp-book (2 messages):
CUDA CoalescingPerformance Optimization in CUDA
-
Understanding Coalescing in CUDA: A member pointed out that coalescing in CUDA is always across threads in a warp, and there is no coalescing within a single thread.
- This insight aligns with the guidelines outlined in the CUDA C++ Best Practices Guide.
- Discussion on Coalescing Accesses: Another member inquired whether
Naccesses are not coalesced in general, seeking clarification on the topic discussed.
- This indicates a common confusion about how access patterns affect performance in CUDA programming.
Link mentioned: CUDA C++ Best Practices Guide: no description found
GPU MODE ▷ #youtube-recordings (1 messages):
gau.nernst: https://www.youtube.com/watch?v=XQylGyG7yp8
GPU MODE ▷ #torchao (6 messages):
Model Optimization ApproachTorchAO Framework UtilizationQuantization-Aware TrainingTest Case Flag in TorchSparsity Test Fix
-
Optimizing Models with Bitwidth Integration: A user emphasized that the paper's focus is on including bitwidth in the error function to optimize accuracy alongside model size, not exclusively on convolutional models.
- They suggested exploring linear operations first, noting that existing efforts in GPU quantization have centered around transformers instead.
- Leveraging QAT Frameworks for Development: A contribution was suggested wherein the project would build off existing Quantization-Aware Training (QAT) frameworks in TorchAO to incorporate unique optimizations from the discussed paper.
- This approach would enable reusing established infrastructure while extending its capabilities, despite the initial focus on convolutional models.
- Awareness of Test Case Issue in Torch: An inquiry was raised about whether the team is aware that the test case flag fails to skip the test in Torch version 2.5.1.
- This indicates potential oversight in compatibility considerations during the testing process, specifically for the mentioned torch version.
- Fix for Failing Sparsity Test in Torch: A user pointed out that Jesse provided a fix for the failing sparsity test issue through a pull request on GitHub related to version mislabeling.
- The bug fix was made to rectify the check from
TORCH_VERSION_AFTER_2_5toTORCH_VERSION_AT_LEAST_2_6, as the initial setup did not run properly with torch==2.5.1.
Link mentioned: Fix 2.5.1 failing sparsity test by jcaip · Pull Request #1261 · pytorch/ao: I was using TORCH_VERSION_AFTER_2_5 but I really wanted TORCH_VERSION_AT_LEAST_2_6, which won't run with torch==2.5.1
GPU MODE ▷ #off-topic (3 messages):
Adaptive Routing in RoCEv2Food Discussions
-
RoCEv2 Needs Large Buffer NICs for Adaptive Routing: A member inquired about why adaptive routing in RoCEv2 requires expensive large buffer NICs for packet reordering, unlike InfiniBand, which can send out-of-order packets directly to GPU memory.
- They noted that with InfiniBand, a 0-byte RDMA_WRITE_WITH_IMM triggers completion without needing to store packets in a large NIC buffer.
- Food Critique on Unappetizing Meal: A member shared their unusual meal consisting of pork kupaty with excessive ketchup, potatoes with mayo, and various vegetables.
- Another member humorously directed them to r/shittyfoodporn for a critique of their food choices.
Link mentioned: Tweet from Pytorch To Atoms (@PytorchToAtoms): How come adaptive routing in RoCEv2 requires expensive large buffer NICs to reorder the packets (for example Spectrum-X requires large buffer BF-3)? while large buffer NICs is not needed for InfiniBa...
GPU MODE ▷ #hqq-mobius (1 messages):
Aria multimodal MoE modelTorch.compile optimizationMoE logic improvements
-
Aria Multimodal MoE Model Accelerated: Today, we made the Aria multimodal MoE model 4-6x faster and fit it into a single 24GB GPU using A16W4 and torch.compile.
- The current code is described as a mess, but it could help others looking to replicate similar results with different MoE models.
- Challenges with MoE Logic Integration: It was noted that incorporating MoE logic without breaking torch.compile was quite hacky.
- Plans are to eliminate the
custom_opand the global cache to streamline the implementation.
Link mentioned: hqq/examples/hf/aria_multimodal.py at master · mobiusml/hqq: Official implementation of Half-Quadratic Quantization (HQQ) - mobiusml/hqq
GPU MODE ▷ #triton-viz (3 messages):
Triton InstallationTriton Visualization ToolkitPython Package Dependencies
-
Smooth Triton Installation Process: A user shared a complete installation script for Triton including necessary commands to install jaxtyping, triton, and triton-viz libraries from GitHub.
- The script also includes system package installations for libcairo2-dev and pycairo, ensuring a streamlined setup.
- Setting Environment Variables: The instructions emphasize the importance of exporting LC_ALL and configuring LD_LIBRARY_PATH to ensure proper library linking during installation.
- This setup step helps avoid potential runtime errors related to library dependencies on the system.
GPU MODE ▷ #rocm (10 messages🔥):
Async copy performanceMUBUF instructionRegister pressure in kernelsCDNA3 documentationFlash attention efficiency
-
Async Copy: A Double-Edged Sword: The current async_copy instruction supports 4-byte vector loads compared to normal memory access's 16 bytes, affecting efficiency.
- Considerations arise about needing async to reduce register pressure for specific kernels like flash attention, where it proves beneficial.
- Confusion over MUBUF Documentation: Members expressed confusion over the MUBUF documentation regarding the usage of LDS in the instruction, leading to discussions around its clarity.
- It was noted that some details regarding M0's uses weren't listed with MUBUF, prompting further exploration in the CDNA3 documentation.
- Exploration of Async Operations on MI300X: An expert mentioned the gcnasm/async_copy repository as a resource for examples of async operations on MI300X.
- The repository is developed by a senior AMD kernel expert, highlighting a lack of coverage in the broader community.
- The Need for Async in Flash Attention: There was a consensus that using async copy might be necessary for flash attention due to high register pressure issues.
- It's suggested that flash attention kernels utilize async copy to optimize performance amidst tight register constraints.
Link mentioned: gcnasm/async_copy at master · carlushuang/gcnasm: amdgpu example code in hip/asm. Contribute to carlushuang/gcnasm development by creating an account on GitHub.
GPU MODE ▷ #bitnet (19 messages🔥):
BitBlas support for int4 kernelsScaling and Fusing in Matrix MultiplicationBinary Tensor Cores usagePerformance of int4 on H100
-
BitBlas supports int4 kernels: A member highlighted that int4 kernels are available on BitBlas, piquing interest in their capabilities.
- Discussion ensued about how BitBlas handles operations involving these kernels, particularly in scaled matrix multiplication.
- Fusing scaling into matmul epilogue: Members discussed the potential to fuse output scaling into the matrix multiplication epilogue for efficiency, based on experiences with scaled int8 matmul.
- One mentioned a planned implementation in BitBlas, simplifying the process with Triton integration.
- Low usage of Binary Tensor Cores: It was observed that very few projects leverage binary tensor cores since the A100, with one member noting they'd seen fewer than a handful of codebases using them.
- Discussion included potential usage in binarized neural networks, especially regarding precision less than 8-bit.
- Uncertainty of int4 support on H100: A member expressed curiosity regarding whether int4 x int4 operations would crash or function on the H100.
- Another clarified that there are no int4 compute cores on the H100, leading to some speculation about support.
GPU MODE ▷ #webgpu (1 messages):
SurfgradWebGPU PerformanceTypescript Autograd LibrariesNomic VisualizationsDeepscatter
-
Surfgrad Makes Waves with WebGPU: A member developed Surfgrad, an autograd engine using WebGPU that achieved over 1 TFLOP of performance on an M2 chip, showcasing the fun potential of web technologies.
- They highlighted numerous small optimizations leading to this performance and found the experience of creating it very enjoyable.
- Challenges in Browser Visualizations: The conversation touched on the difficulties of displaying tens of millions of data points in the browser while keeping performance feasible, as faced by many at Nomic.
- This challenge has led to the development of Deepscatter, which is designed to tackle scaling problems efficiently.
- Exploration of Typescript Autograd Libraries: The member noted a lack of existing autograd libraries built with WebGPU, prompting their endeavor to create Surfgrad as an educational exercise in WebGPU and Typescript.
- This development reflects the community's broader enthusiasm for the capabilities of WebGPU.
Links mentioned:
- Tweet from Zach Nussbaum (@zach_nussbaum): i got excited about WebGPU, so naturally i built Surfgrad, an autograd engine built on top of WebGPU. i walk through optimizing a naive kernel to one that exceeds 1TFLOP in performance
- Optimizing a WebGPU Matmul Kernel for 1TFLOP+ Performance: Building Surfgrad, a high-performant, WebGPU-powered autograd library
GPU MODE ▷ #liger-kernel (3 messages):
CI Temporary DisablementSecurity ConcernsLocal CI RunningResponse Expectations
-
CI Temporarily Disabled for Forks: The CI has been disabled temporarily for pull requests from forks due to security reasons and will be restored as soon as possible.
- Team members are encouraged to run CI locally, or someone can run it for them if needed.
- Anticipation for Responses: A member expressed hope for a timely response regarding the CI situation.
- The sentiment included a light-hearted emoji, indicating a positive outlook despite the delays.
GPU MODE ▷ #🍿 (4 messages):
Torchtitan Crash CourseOpenCoder LLMBot TestingGPU Sponsorships
-
Torchtitan Crash Course Announcement: A crash course on Torchtitan will be held on November 23, focusing on various parallelism strategies for participants.
- This session is a great opportunity to grasp the fundamentals as the community prepares for upcoming GPU sponsorships.
- OpenCoder LLM Overview: OpenCoder is an open-source code LLM that supports both English and Chinese, achieving top-tier performance through extensive training on 2.5 trillion tokens.
- OpenCoder provides comprehensive resources, including model weights and a detailed training pipeline, aimed at empowering researchers in code AI development.
- Bot Testing Procedure: Members discussed the current testing methods for the bot, questioning whether it involves a specific channel on the server or testing in a different server altogether.
- The conversation reflects the exploratory efforts to assess bot functionalities and its practical applications within the community.
- Potential Closure of Testing Channel: There is a mention of considering killing a channel dedicated to the bot testing, as the functionality has been confirmed to be effective.
- This indicates an ongoing evaluation of the need for dedicated spaces in the server as the bot’s capabilities evolve.
Link mentioned: OpenCoder: Top-Tier Open Code Large Language Models: no description found
GPU MODE ▷ #edge (5 messages):
NVIDIA JetsonSLM Optimizations on Android
-
Discussion on NVIDIA Jetson Usage: A member inquired about the use of NVIDIA Jetson, prompting another to share their prior experience with the TX2 and Nano models.
- However, they have yet to experiment with the Orin model, indicating a potential area for further exploration.
- Optimizing LLMs for Android Deployment: A member raised the question of whether there are specific optimizations for deploying 1.5B SLMs on Android devices.
- Another member suggested utilizing an accelerator if available, hinting at possible advantages over standard memory-bound CPU inference.
tinygrad (George Hotz) ▷ #general (76 messages🔥🔥):
Hailo port on Raspberry Pi 5Floating Point Exceptions HandlingTinybox and TinygradP2P Hack and Tinybox UpgradesTPU Backend Discussions
-
Hailo Port Progress and Quantization Challenges: A user is working on a port for Hailo on Raspberry Pi 5, managing to translate models from tinygrad to ONNX and then to Hailo, but faced challenges with the necessity of quantized models requiring CUDA and TensorFlow.
- They noted that running training code on edge devices may not be practical due to the chip's small cache and poor memory bandwidth.
- Handling Floating Point Exceptions: Discussion initiated on the feasibility of detecting floating point exceptions like NaN and overflow, emphasizing the importance of platform support for detection methods.
- Resources shared highlighted the significance of capturing errors during floating-point operations, advocating for effective error handling methodologies.
- Interest in Tinybox and Reseller Information: A user inquired about switching from a pre-ordered Tinybox to a green one, expressing uncertainty about duties and tariffs.
- Another user suggested sharing links related to purchasing options, addressing concerns about EU resellers.
- P2P Hack and Tinybox Upgrade Uncertainties: Concerns raised regarding potential delays in upgrading Tinyboxes to version 5090 due to a P2P hack patch.
- Further discussions speculated on the performance implications of hardware setups with varying PCIe controller capabilities.
- Discussions on TPU Backend Strategies: A user expressed interest in developing a TPU v4 assembly backend, indicating a willingness to merge work after thorough cleanups.
- There were inquiries into whether assembly in LLVM is genuinely vectorized and what specific TPU versions are targeted for support.
Links mentioned:
- Floating-point environment - cppreference.com: no description found
- FLP03-C. Detect and handle floating-point errors - SEI CERT C Coding Standard - Confluence: no description found
- Big graph · Issue #7044 · tinygrad/tinygrad: LazyBuffer.view becomes UOps.VIEW #7077 #7078 #7007 #7090 big graph SINK #7122 #7178 #7170 #7134 #7175 #7132 #7188 #7190 #7217 #7214 #7224 #7234 #7242 #7220 #7322 #7353 #7355 #7367 #7334 #7371 #729...
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
Python Module Import IssuesBeam Search Output InterpretationNOLOCALS Environment Variable
-
Python Module Import Issue with Extra Module: A user encountered a ModuleNotFoundError when trying to run a Python script that imports the 'extra' module.
- The issue was resolved by setting the PYTHONPATH environment variable to the current directory before executing the script with
$ PYTHONPATH="." python3 examples/llama.py. - Interpreting Beam Search Output: A user sought assistance in interpreting the output from a beam search, discussing how the progress bar correlates with kernel execution time.
- They noted that the green indicates the final runtime of the kernel, but expressed confusion about actions and kernel size, asking for clarification.
- Function of NOLOCALS Environment Variable: A user inquired about the purpose of the NOLOCALS environment variable within the context of the project.
- They were seeking clarification on how this variable affects the behavior of the program or kernel during execution.
- The issue was resolved by setting the PYTHONPATH environment variable to the current directory before executing the script with
Cohere ▷ #discussions (22 messages🔥):
AI Interview Bot DevelopmentAya-Expanse Model TestingFunction Calling in AI Models
-
Creating an AI Interview Bot: A user is starting a GenAI project for an AI interview bot that will ask questions based on resumes and job descriptions, scoring responses out of 100.
- They seek suggestions for free resources like vector databases and orchestration frameworks, highlighting that programming will be handled by themselves.
- Aya-Expanse Model is a Game Changer: A user praised the Aya-Expanse model, revealing an initial misconception about it being solely a translation model.
- They noted its impressive capabilities in function calling and its effectiveness in handling Greek language tasks.
- Efficient Function Calling: Discussing their testing of Aya-Expanse, a user expressed the goal of using smaller models for function calling to reduce costs when using larger models via API.
- They shared that the model effectively selects
direct_responsefor questions that don't require function calls, improving response accuracy.
Cohere ▷ #questions (4 messages):
Cohere API for content creationORG ID retrievalCohere endpoint disruptions
-
Seeking Cohere API for Document-Based Responses: A user inquired about an API to generate freetext responses based on pre-uploaded DOCX and PDF files, noting that currently only embeddings are supported.
- They expressed interest in an equivalent to the ChatGPT assistants API for this purpose.
- ORG ID Inquiry for User Support: Another user asked about how to acquire an ORG ID and its relevance to assisting the Cohere team in addressing user issues.
- They sought clarity on the organizational tools available.
- Cohere Endpoint Disruption Reported: A user reported receiving a
500 Internal Server Errorwhen trying to access the Cohere embedding endpoint, indicating an internal issue.
- Currently, they referred others to the Cohere status page for updates on reported problems.
- Acknowledgment of Ongoing Endpoint Issues: A member confirmed the ongoing disruption of Cohere endpoints, encouraging users to check the status page for real-time updates.
- This illustrates the active communication among users regarding service reliability.
Cohere ▷ #api-discussions (36 messages🔥):
Cohere API ErrorsFine-Tuned Model IssuesIncreased LatencyEmbed API SlownessCohere Status Updates
-
Cohere API encountering 404 errors: A user reported encountering a 404 error when trying to retrieve Cohere model details, stating that everything was working well previously.
- Despite troubleshooting, they continued to face the same issue across all Cohere method calls.
- Update on Fine-Tuned Models: It was mentioned that older fine-tuned models have been deprecated, and new models based on the latest architecture provide better performance.
- Users are encouraged to re-upload the same dataset and train a new fine-tuned classification model for improved outcomes.
- Increased Latency Issues: A user expressed frustration with increased latency, noting response times of 3 minutes and high token usage during requests.
- Another support member confirmed the latency issues were specific to the user's account and linked to heavy payloads.
- Embed API experiencing slowness: A new user reported slowness in calls to the Embed API, leading to concerns about potential ongoing issues.
- Support confirmed they are investigating these issues and advised the user to monitor the Cohere Status Page for updates.
- Feedback on System Performance: Users provided feedback about the performance of Cohere’s models and services, expressing concern over slower response times.
- Additionally, references to response IDs and examples were made to assist in troubleshooting ongoing performance issues.
Links mentioned:
- No Donkeys GIF - No Donkeys Shrek - Discover & Share GIFs: Click to view the GIF
- Fine-tuning: Optimize generative AI for performance and cost by tailoring solutions to specific use cases and industries.
- Cohere Status Page Status: Latest service status for Cohere Status Page
Cohere ▷ #projects (3 messages):
vnc-lm Discord botCohere APIollama models
-
Introducing vnc-lm Discord bot: A member shared their Discord bot, vnc-lm, which interacts with the Cohere API and the GitHub Models API, allowing users to engage with models available through these APIs alongside local ollama models.
- Notable features include creating conversation branches, refining prompts, and sending context materials like screenshots and text files.
- Quick Setup with Docker: vnc-lm can be set up quickly with the command
docker compose up --build, and it's accessible via GitHub.
- This ease of setup allows for rapid deployment and utilization of the bot's features.
- Positive Feedback on vnc-lm: Members expressed their excitement about the bot, with one remarking that it is amazing.
- This shows a positive reception and interest in the functionality offered by vnc-lm.
OpenInterpreter ▷ #general (43 messages🔥):
Open Interpreter Hardware RequirementsOpen Interpreter 1.0 Update TestingOpen Interpreter Configuration QueriesIssue with Local OLLAMASoftware Heritage Code Archiving
-
Open Interpreter Hardware Needs: A user questioned whether the Mac Mini M4 Pro with either 64GB or 24GB of RAM is sufficient for running a local AI with Open Interpreter effectively.
- A consensus emerged, affirming that the setup would work and led to discussions about integrating additional components like mic and speaker.
- Testing the New Open Interpreter 1.0 Update: A user expressed willingness to assist in testing the upcoming Open Interpreter 1.0 update, which is on the dev branch and set for release next week.
- The installation command was shared, reflecting on the need for bug testing and adaptations for different operating systems.
- Configuration Queries in Open Interpreter: Another user inquired if there’s a way to configure OpenAI models similarly to previous versions, citing the expense of Sonnet without GUI mode.
- This sparked a brief discourse about potential configurations and issues faced with local OLLAMA models, indicating varying experiences.
- Issues Encountered While Running Local OLLAMA: One user reported a warning when trying to run local OLLAMA, relating to the model weights and float computation types.
- This drew attention to recommendations for running environments, particularly regarding WSL and standard Windows CMD.
- Archiving Open Interpreter Code: A user offered assistance in archiving the Open Interpreter code in Software Heritage, aiming to benefit future generations.
- This proposal highlighted the importance of preserving contributions within the developer community, raising discussion on practical steps.
Link mentioned: GitHub - davidteren/mac_fan_control-self-healing-coder: WIP Experiment! A dynamic, self-healing framework that empowers Open Interpreter to learn from past interactions and continuously improve its decision-making processes.: WIP Experiment! A dynamic, self-healing framework that empowers Open Interpreter to learn from past interactions and continuously improve its decision-making processes. - davidteren/mac_fan_control...
OpenInterpreter ▷ #O1 (1 messages):
NixOS setupollama and OI channelsCUDA configuration
-
Curiosity about NixOS happiness: A member inquired about someone's experience getting NixOS to work smoothly, noting that the nixpkg appears outdated compared to GitHub.
- They were specifically interested in what setup others have implemented for better functionality.
- Switching to unstable channels: The member updated their status, stating they switched ollama and Open Interpreter to the unstable channel for improvement.
- Nix that (pun intended) – they now feel satisfied with their current configuration.
- Fidgeting with CUDA: The member mentioned they fidgeted with their CUDA setup and achieved a satisfactory state.
- Their message indicates that proper adjustments led to a successful instantiation on their system.
OpenInterpreter ▷ #ai-content (2 messages):
Qwen 2.5 coder modelsCode generation improvementsOllama collaboration
-
Qwen 2.5 Coder Models Released: The newly updated Qwen 2.5 coder models showcase significant improvements in code generation, code reasoning, and code fixing, with the 32B model rivaling OpenAI's GPT-4o.
- Users can run the models in various sizes with commands such as
ollama run qwen2.5-coder:32bfor the 32B variant. - Excitement Around Qwen's Launch: Members expressed enthusiasm as Qwen and Ollama collaborated, emphasizing the fun of coding together, as stated by Qwen, 'Super excited to launch our models together with one of our best friends, Ollama!'
- This collaboration marks a notable partnership, further enhancing the capabilities available to developers.
- Model Size Variations Explained: The Qwen 2.5 model is available in multiple sizes including 32B, 14B, 7B, 3B, 1.5B, and 0.5B, providing flexibility for different coding tasks.
- Each model size comes with its own command for deployment, ensuring users can choose the best fit for their needs.
- Link to Qwen 2.5 Coder Models: Further details and resources regarding the Qwen 2.5 coder models can be found at Ollama's website.
- This resource includes comprehensive instructions for utilizing the various model sizes effectively.
- Users can run the models in various sizes with commands such as
Link mentioned: Tweet from ollama (@ollama): Qwen 2.5 coder models are updated with significant improvements in code generation, code reasoning and code fixing. The 32B model has competitive performance with OpenAI's GPT-4o. ...
LlamaIndex ▷ #blog (5 messages):
LlamaParse PremiumAdvanced Chunking StrategiesPowerPoint Generation with User FeedbackPureML Efficient Data HandlingPursuitGov Case Study
-
LlamaParse Premium excels in document parsing: Hanane Dupouy demonstrated how LlamaParse Premium can effectively parse complex charts and diagrams into structured markdown.
- This tool not only enhances readability but also transforms visual data into accessible text format, improving document usability.
- Advanced chunking strategies boost performance: @pavan_mantha1 detailed three advanced chunking strategies along with a full evaluation setup for practical testing on personal datasets, as shown in this post.
- These strategies aim to enhance retrieval and QA functionality significantly, showcasing effective methods for processing data.
- Creating PowerPoints with real-time feedback: Lingzhen Chen explained a comprehensive workflow for building a research-to-PowerPoint generation system that incorporates user feedback via a Streamlit interface.
- This innovative approach allows users to provide input on slide outlines, enhancing the quality of automated presentations.
- PureML automates dataset management: PureML utilizes LLMs for automatic cleanup and refactoring of ML datasets, implementing context-aware handling and intelligent feature creation as highlighted here.
- These features aim to improve data consistency and quality, showcasing the integration of various advanced tools including LlamaIndex and GPT-4.
- PursuitGov's impressive transformation: A case study on PursuitGov revealed they parsed 4 million pages in one weekend, significantly enhancing document accuracy by 25-30%.
- This transformation allowed clients to discover hidden opportunities in public sector data, illustrating the power of advanced parsing techniques.
LlamaIndex ▷ #general (10 messages🔥):
Sentence Transformers Ingestion PipelineDocker Resource SettingsLlama 3.2 Waitlist AccessText-to-SQL ApplicationsDynamic Related Content Chunks
-
Sentence Transformers Ingestion Pipeline Takes Too Long: A member reported that running the ingestion pipeline with sentence transformers in a Docker container was taking too long and eventually failing.
- They shared their code setup, highlighting specific configurations like using
all-MiniLM-L6-v2and settingTOKENIZERS_PARALLELISM=True. - Docker Resource Settings for Better Performance: A user queried about Docker resource settings, prompting another member to mention they allocated 4 CPU cores and 8GB of memory.
- Despite these settings, the ingestion process was still slow and prone to failure.
- Questions about Llama 3.2 Key Access: A user inquired about how to obtain a key for Llama 3.2, mentioning they are currently on the waitlist.
- Details on accessing the key were not provided, indicating a need for further guidance.
- Resource Sharing for Text-to-SQL Applications: A member sought resources for creating a Text-to-SQL application using a vector database, sharing an article with outdated links.
- Another user suggested checking the LlamaIndex documentation for updated methods and workflows.
- Dynamic Related Content Chunks Discussion: A new query emerged about how to create dynamic related content chunks, similar to those used on RAG-powered websites.
- No solutions or resources were discussed in relation to this inquiry, indicating an interest in further collaboration.
- They shared their code setup, highlighting specific configurations like using
Links mentioned:
- Combining Text-to-SQL with Semantic Search for Retrieval Augmented Generation — LlamaIndex - Build Knowledge Assistants over your Enterprise Data: LlamaIndex is a simple, flexible framework for building knowledge assistants using LLMs connected to your enterprise data.
- Text-to-SQL Guide (Query Engine + Retriever) - LlamaIndex: no description found
- Workflows for Advanced Text-to-SQL - LlamaIndex: no description found
- Workflows - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (6 messages):
Benchmarking fine-tuned LLM modelOpenAI Agent stream chat code snippet
- Seeking Help for LLM Benchmarking: A member requested guidance on benchmarking their fine-tuned LLM model available at Hugging Face. They mentioned encountering errors while using the Open LLM leaderboard for this purpose.
-
Code Snippet for OpenAI Agent Stream Chat: A member asked for the source code snippet related to how the OpenAI agent's stream chat works. Another member promptly provided the relevant code snippet, explaining its usage in LlamaIndex for generating a streaming response.
- The code example was sourced from the OpenAI Agent example in the documentation, illustrating how to print the response token by token.
Link mentioned: Anoshor/prism-v2 · Hugging Face: no description found
DSPy ▷ #show-and-tell (3 messages):
M3DocRAGDSPy vision capabilitiesMulti-modal question answeringOpen-domain benchmarks
-
M3DocRAG Sets New Standards in Multi-Modal RAG: M3DocRAG showcases impressive results for question answering using multi-modal information from a large corpus of PDFs and excels in ColPali benchmarks.
- Jaemin Cho highlighted its versatility in handling single & multi-hop questions across diverse document contexts.
- New Open-domain Benchmark with M3DocVQA: The introduction of M3DocVQA, a DocVQA benchmark, challenges models to answer multi-hop questions across more than 3K PDFs and 40K pages.
- This benchmark aims to enhance understanding by utilizing various elements such as text, tables, and images.
- DSPy RAG Use Cases Spark Interest: A member expressed enthusiasm about the potential of DSPy RAG capabilities, indicating a keen interest in experimentation.
- They noted the promising intersection between DSPy RAG and vision capabilities, hinting at intriguing future applications.
Link mentioned: Tweet from Omar Khattab (@lateinteraction): Cool benchmark for answering questions using multi-modal information from a large corpus of PDFs, with excellent ColPali results. Quoting Jaemin Cho (@jmin__cho) Check out M3DocRAG -- multimodal RA...
DSPy ▷ #general (14 messages🔥):
LangChain integration supportDSPy prompting techniques composability
-
LangChain integration falls out of support: Recent updates on GitHub indicate that the current integration with LangChain is no longer maintained and may not function properly.
- One member raised a question about this change, seeking further context on the situation.
- DSPy prompting techniques designed for non-composability: Members discussed the nature of DSPy prompting techniques, confirming they are intentionally not composable as part of the design.
- This decision emphasizes that while signatures can be manipulated, doing so may limit functionality and clarity of control flow.
OpenAccess AI Collective (axolotl) ▷ #general (17 messages🔥):
FastChat removalMetharme supportFine-tuning VLMsInflection AI APIMetharme chat_template PR
-
FastChat and ShareGPT removal sparks surprise: Members reacted strongly to the removal of FastChat and ShareGPT, with one exclaiming, Omfg are you serious? Reference to the PR #2021 highlights community concerns.
- Alternative suggestions included using an older commit, showcasing ongoing discussions on maintaining project stability.
- Is Metharme still supported?: A user inquired if Metharme is no longer supported, prompting a response from another member who explained delays linked to fschat releases affecting their progress.
- Members expressed interest in integrating sharegpt conversations into the new chat_template.
- Advice for fine-tuning VLMs: Inquiry for assistance on fine-tuning vlms was met with suggestions to start with a provided configuration for llama vision from the example repository.
- There was also confirmation that training a vlm model using llama 3.2 1B is feasible, showcasing user interest in advanced model training.
- Inflection AI API features released: Discussion touched on the capabilities of Inflection-3, outlining two models: Pi for emotional engagement and Productivity for structured outputs, but noted a lack of benchmarks.
- Members were surprised by the absence of benchmark data, raising concerns about practical evaluation of the new models.
- Metharme chat_template added via PR: A PR to add Metharme as a chat_template was shared, initiated per user requests, highlighting its testing against previous versions.
- Members were encouraged to run the preprocess command locally to ensure smooth functionality, fostering community collaboration.
Links mentioned:
- Inflection AI Developer Playground: Let's build a better enterprise AI.
- feat: add metharme chat_template by NanoCode012 · Pull Request #2033 · axolotl-ai-cloud/axolotl: Description Adds metharme per user request. Motivation and Context How has this been tested? Tested between prior fschat. Screenshots (if appropriate) Types of changes Social Handles (Optional)
- remove fastchat and sharegpt by winglian · Pull Request #2021 · axolotl-ai-cloud/axolotl: no description found
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (2 messages):
Midterm Check-inCompute Resource ApplicationLambda Workshop
-
Midterm Check-in for Project Feedback: Teams can now submit their progress through the Midterm Check-in Form to receive feedback and possibly gain GPU/CPU resource credits.
- It's crucial to submit this form, even if not requesting resources, as it could facilitate valuable insights on their projects.
- Application for Additional Compute Resources: Teams interested in additional GPU/CPU resources must complete the resource request form alongside the midterm check-in form.
- The allocation will depend on documented progress and detailed justification, encouraging even new teams to apply.
- Criteria for Project Judging: Projects will be judged based on clarity of the problem statement, feasibility of the approach, and progress made to date.
- Teams must also justify their resource needs and demonstrate sufficient capability to utilize awarded resources.
- Reminder for Lambda Workshop: The Lambda Workshop is scheduled for tomorrow, Nov 12th from 4-5pm PST and participants are encouraged to RSVP through this link.
- This workshop will provide further insights and guidance on team projects and the hackathon process.
Links mentioned:
- LLM Agents MOOC Hackathon, Mid Season Check In Form: Please fill out this form if you would like feedback on your projects. Note that due to the volume of submissions, we may not have the ability to provide all teams feedback. Important: if you are in...
- no title found: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (4 messages):
Article assignment feedbackConfirmation of submission
-
Know Your Article Assignment Status: A member inquired about how long it takes to know if their written article assignment is a pass, to which another member mentioned that feedback probably won't be available until after the final submission deadline.
- They reassured the inquiry about grading being generous as long as website guidelines are followed, so not to stress too much.
- Confirmation for Submission Check: Another member asked if they could DM someone to confirm their written assignment submission was received.
- It was clarified that they should have received a confirmation from Google Forms, indicating that the submission is indeed received.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (6 messages):
Hackathon team sizeJoining the hackathonLecture announcement
-
Unlimited Team Size for Hackathon: A member inquired about the allowed team size for the hackathon, to which another member responded that it's unlimited.
- This opens up the possibility for anyone interested to collaborate without restrictions.
- It's Never Too Late to Join the Hackathon: Another member asked if it's too late to join, and was assured it's never too late to participate.
- They were encouraged to join the Discord and attend the Lecture 2 discussion planned for 7 PM PT.
- Upcoming Lecture on LLM Agents: An announcement was made regarding a discussion of Lecture 2: History of LLM Agents happening tonight.
- This discussion will include a review of the lecture and exploration of some Agentic code, welcoming anyone interested.
Torchtune ▷ #general (10 messages🔥):
Attention Scores in Self AttentionDCP Checkpointing IssuesModel Saving Strategies
-
Challenges of Capturing Attention Scores: A user inquired if there's a way to capture attention scores without altering the forward function in the self-attention module using forward hooks.
- Others suggested that there might be issues with F.sdpa() which doesn't currently output attention scores, thus modification may be necessary.
- DCP Checkpointing Not Resolved: A member reported that the latest git main version still fails to address issues with gathering weights/optimizers on rank=0 GPU, resulting in OOM (Out Of Memory) errors.
- They implemented a workaround for DCP checkpoint saving, intending to convert it to the Hugging Face format and possibly write a PR for better integration.
- Potential DCP Integration Help: A discussion ensued about sharing PRs or forks related to DCP checkpointing efforts, emphasizing the community’s support for integration in torchtune.
- An update indicated that a DCP PR from PyTorch contributors is likely to be available soon, enhancing collaborative progress.
LAION ▷ #general (7 messages):
SVDQuantGorilla Marketing
-
SVDQuant Achieves Impressive Reductions: The recent post on SVDQuant showcases a new quantization paradigm for diffusion models, achieving a 3.5× memory and 8.7× latency reduction on a 16GB laptop 4090 GPU by quantizing weights and activations to 4 bits.
- The interactive demo can be accessed here, with further resources available on GitHub and the full paper here.
- Discussion on Gorilla Marketing: Members discussed the trend of AI companies engaging in what they describe as gorilla marketing, indicative of unconventional promotional tactics.
- This was humorously noted with a reference to a Harambe GIF, emphasizing the playful nature of the marketing strategies.
Links mentioned:
- SVDQuant: Accurate 4-Bit Quantization Powers 12B FLUX on a 16GB 4090 Laptop with 3x Speedup: no description found
- Harambe America GIF - Harambe America Murica - Discover & Share GIFs: Click to view the GIF
MLOps @Chipro ▷ #events (1 messages):
RisingWave Data ProcessingStream Processing Innovations
-
RisingWave Enhances Data Processing Techniques: A recent post highlighted RisingWave's advancements in data processing, emphasizing improvements in stream processing techniques.
- For more insights, check out the full details on their LinkedIn post.
- Stream Processing Techniques in Focus: The discussion centered around the latest in stream processing, showcasing methods to optimize real-time data handling.
- Participants noted that adopting these innovations could significantly impact data-driven decision-making.
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
Gorilla LLMBenchmark testing custom LLMs
-
Inquiry on Gorilla for Benchmark Testing: A user inquired whether they could use Gorilla to test/benchmark their fine-tuned LLM model, seeking guidance as they are new to the domain.
- They expressed a need for help specifically in benchmark testing custom LLMs.
- Seeking Guidance in Custom LLM Benchmarking: The same user reiterated their search for assistance in understanding how to benchmark their fine-tuned LLM effectively.
- They emphasized their newness to the domain, hoping for community support and recommendations.
AI21 Labs (Jamba) ▷ #general-chat (1 messages):
ag8701347: Please allow us to continue using our fine-tuned models.