[AINews] Francois Chollet launches $1m ARC Prize
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Nonmemorizable Benchmarks are all you need.
AI News for 6/10/2024-6/11/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (412 channels, and 2774 messages) for you. Estimated reading time saved (at 200wpm): 313 minutes.
In this weekend's Latent Space pod we talked about test set contamination and the Science of Benchmarking, and today one of the OGs in the field is back with a solution - generate a bunch of pattern-recognition-and-completion benchmarks:
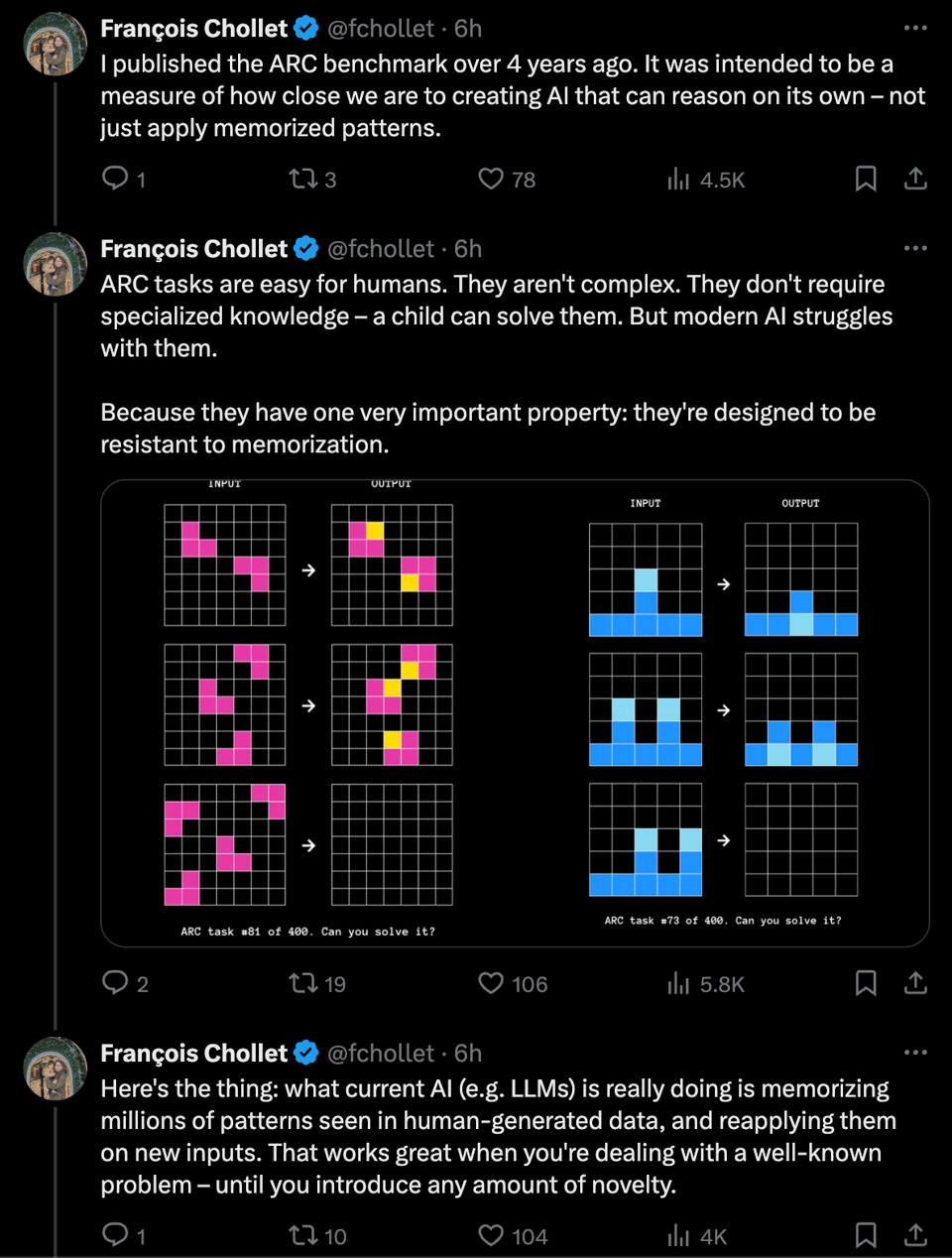
You can play with the ARC-AGI puzzles yourself to get a sense for what "easy for humans hard for AI" puzzles look like:

This all presumes an opinionated definition of AGI, which the team gracefully provides:
DEFINING AGI
Consensus but wrong: AGI is a system that can automate the majority of economically valuable work.
Correct: AGI is a system that can efficiently acquire new skills and solve open-ended problems.
Definitions are important. We turn them into benchmarks to measure progress toward AGI. Without AGI, we will never have systems that can invent and discover alongside humans.
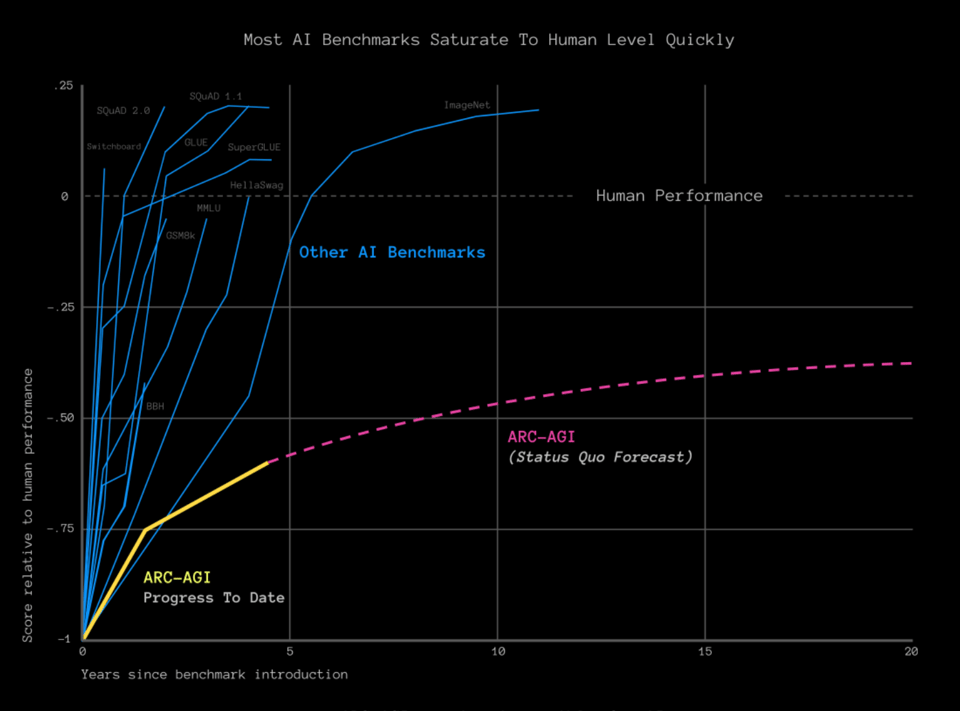
This benchmark is curved to resist the classic 1-2 year saturation cycle that other benchmarks have faced:
The solution guide offers François' thoughts on promising directions, including Discrete program search, skill acquisition, and hybrid approaches.
Last week the Dwarkesh pod was making waves predicting AGI in 2027, and today it's back with François Chollet asserting that the path we're on won't lead to AGI. Which way, AGI observoor?
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Apple Integrates ChatGPT into iOS, iPadOS, and macOS
- OpenAI partnership: @sama and @gdb announced Apple is partnering with OpenAI to integrate ChatGPT into Apple devices later this year. @miramurati and @sama welcomed Kevin Weil and Sarah Friar to the OpenAI team to support this effort.
- AI features: Apple Intelligence will allow AI-powered features across apps, like summarizing documents, analyzing photos, and interacting with on-screen content. @karpathy noted the step-by-step AI integration into the OS, from multimodal I/O to agentic capabilities.
- Privacy concerns: Some expressed skepticism about Apple sharing user data with OpenAI, despite Apple's "Private Cloud Compute" guarantees. @svpino detailed the security measures Apple is taking, such as on-device processing and differential privacy.
Reactions to Apple's WWDC AI Announcements
- Mixed reactions: While some were impressed by Apple's AI integration, others felt Apple was behind or relying too much on OpenAI. @karpathy and @far__el questioned if Apple can ship capable AI on its own.
- Comparison to other models: Apple's on-device models seem to outperform other small models, but their server-side models are still behind GPT-4. @_philschmid noted Apple is using adapters and mixed-precision quantization to optimize performance.
- Integration focus: Many noted Apple's focus on deep, frictionless AI integration rather than model size. @ClementDelangue praised the push for on-device AI to improve user experience and privacy.
Advances in AI Research and Applications
- Mixture of Agents (MoA): @togethercompute introduced MoA, which leverages multiple open-source LLMs to achieve a score of 65.1% on AlpacaEval 2.0, outperforming GPT-4.
- AI Reasoning Challenge (ARC): @fchollet and @mikeknoop launched the $1M ARC Prize to create an AI that can adapt to novelty and solve reasoning problems, steering the field back towards AGI.
- Advances in speech and vision: @GoogleDeepMind showcased Imagen 3's ability to generate rich images with complex textures. @arankomatsuzaki shared Microsoft's VALL-E 2, which achieves human parity in zero-shot text-to-speech.
- AI applications: Examples included @adcock_brett's updates on Figure's robot manufacturing, @vagabondjack's $6M seed round for AI-powered financial analysis at @brightwaveio, and @AravSrinivas's note on Perplexity being a top referral source for publishers.
Memes and Humor
- @jxmnop joked about LLMs reaching the boundary of human knowledge with a humorous image.
- @nearcyan poked fun at the repeated claims of "nvidia is done for" with a meme.
- @far__el quipped "Apple Intelligence is going to be the largest deployment of tool using AI and i'd like someone to speak at @aidotengineer on the design considerations!" in response to @swyx's call for Apple engineers to share insights.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Developments
- Apple partners with OpenAI to integrate GPT-4o into iOS, iPadOS, and macOS: In /r/OpenAI, Apple unveils "Apple Intelligence", a personal AI system built into their operating systems. It integrates OpenAI's GPT-4o and runs on-device, enhancing Siri, writing tools, and enabling image generation.
- Details on Apple's on-device LLM architecture revealed: In /r/LocalLLaMA, more specifics are shared about how Apple Intelligence works under the hood, using quantized task-specific LoRAs called "adapters", optimized for inference performance, and leveraging a "semantic index" for personal context.
- AMD releases open-source LLVM compiler for AI processors: AMD launches Peano, an open-source LLVM compiler for their XDNA and XDNA2 Neural Processing Units (NPUs) used in Ryzen AI processors.
- Microsoft introduces AI Toolkit for Visual Studio Code: In /r/LocalLLaMA, Microsoft's new AI Toolkit extension for VS Code is discussed, which provides a playground and fine-tuning capabilities for various models, with the option to run locally or on Azure.
Research and Benchmarks
- Study finds RLHF reduces LLM creativity and output variety: A new research paper posted in /r/LocalLLaMA shows that while alignment techniques like RLHF reduce toxic and biased content, they also limit the creativity of large language models, even in contexts unrelated to safety.
- Benchmarking affordable AWS instances for LLM inference: In /r/LocalLLaMA, benchmarks of various AWS instances for running Dolphin-Llama3 reveal the g4dn.xlarge offers the best cost-performance at $0.58/hr, with GPU speed being the key factor. More memory allows for higher token usage in outputs.
Stable Diffusion 3 and Beyond
- Stable Diffusion 3's importance and standout features highlighted: A post in /r/StableDiffusion breaks down why SD3 is a significant step forward, with its new 16-channel VAE capturing more details, enabling faster training and better low-res results. The multi-modal architecture aligns with LLM research trends and is expected to boost techniques like ControlNets and adapters.
Miscellaneous
- Tip for boosting CPU+RAM inference speed by ~40%: In /r/LocalLLaMA, a user shares a trick to increase tokens/sec by enabling XMP in BIOS to run RAM at spec bandwidth instead of JEDEC defaults. RAM overclocking could provide further gains but risks instability.
- Simplifying observability in RAG with BeyondLLM 0.2.1: A /r/LocalLLaMA post explains how BeyondLLM 0.2.1 makes it easier to add observability to LLM and RAG applications, allowing tracking of metrics like response time, token usage, and API call types.
Memes and Humor
- AI expectations vs reality meme: An amusing image contrasting the hyped expectations and actual capabilities of AI systems shared in a subreddit.
AI Discord Recap
-
Apple Debuts with Major AI Innovations:
- At WWDC 2024, Apple announced Apple Intelligence, a deeply integrated AI system for iPhones, iPads, and Macs. Key features include ChatGPT integration into Siri, AI writing tools, and a new "Private Cloud Compute" for secure offloading of complex tasks. Benchmarks showcase Apple's on-device and server models performing well in instruction following and writing. However, concerns around user privacy and Elon Musk's warning of banning Apple devices at his companies due to OpenAI integration sparked debates.
-
Model Compression and Optimization Strategies:
- Engineers actively discussed techniques for quantizing, pruning, and optimizing large language models like LLaMA 3 to reduce model size and improve efficiency. Resources like LLM-Pruner and Sconce were shared, along with debates on the stability of lower-precision formats like FP8. Optimizations like LoRA, 8-bit casting, and offloading to CPU were explored to tackle Out-of-Memory (OOM) errors during training.
- Engineers discussed overcoming Out of Memory (OOM) errors using strategies like offloading optimizer state to CPU and bnb 8bit casting (VRAM Calculator), highlighting techniques like Low-Rank Adapters (LoRA).
- Community conversations shared insights on fine-tuning challenges with practical examples and resources zlike YouTube tutorial.
-
Exciting Open-Source and Benchmark News:
- Stable Diffusion 3 (SD3) excited members, aiming for better voxel art, while comparisons of model platforms like Huggingface and Civitai led to debates on best upscaling methods and availability (SD3 Announcement).
- Hugging Face expanded AutoTrain with Unsloth support (Announcement), easing large model fine-tuning with enhanced memory management.
- Advancements in Language and Multimodal Models: The AI community witnessed exciting breakthroughs, including LlamaGen for autoregressive image generation, VALL-E 2 achieving human parity in zero-shot text-to-speech synthesis, and MARS5 TTS from CAMB AI promising higher realism in voice cloning. Discussions explored quantization techniques like IQ4_xs and HQQ for efficient model deployment, and the potential of federated learning for privacy-preserving training.
-
Community Collaboration on AI Challenges:
- Discussions around Chain of Thought retrieval in medical applications and techniques for essential model prompt engineering were highlighted in engaging threads (YouTube tutorial).
- OpenAccess AI Collective shared a beginner-friendly RunPod Axolotl tutorial, simplifying model training processes.
-
Quantization and Model Deployment Insights:
- Exchanges on 4-bit quantization for Llama 3 and suggestions using Tensor Parallelism showcased practical experiences from the AI community (Quantization Blog).
- DeepSeek-LLM-7B model's LLaMA-based structure discussed alongside interpretability (DeepSeek Project).
PART 1: High level Discord summaries
LLM Finetuning (Hamel + Dan) Discord
Fine-tuning LLMs, Cutting Problems Down to Size: Engineers share solutions for Out of Memory (OOM) errors and discuss fine-tuning processes. There's a consensus on the benefits of offloading optimizer state to CPU or using CUDA managed memory, with techniques like bnb 8bit casting and Low-Rank Adapters (LoRA) to save memory and enhance performance during training. Valuable resources include a YouTube video on 8-bit Deep Learning and a benchmarking tool, VRAM Calculator.
Empathy for Credits Confusion: Multiple guild members expressed difficulties in receiving promised credits. Missing credits are noted across several platforms, from Modal and OpenAI to Replicate, with appeals for resolution posted in respective channels. Information such as user and org IDs was offered in hopes of expediting support.
Model Training Troubles and Triumphs: Members troubleshoot fine-tuning and inference challenges on various platforms, focusing on practical aspects like dataset preparation, using existing frameworks like TRL or Axolotl, and handling large model training on limited hardware. On the other side of the coin, positive experiences with deploying Mistral on Modal were recounted, endorsing its hot-reload capabilities.
Reeling in Real-World ML Discussions: Conversations delved into practical Machine Learning (ML) applications, such as dynamically swapping LoRAs and Google's Gemini API for audio processing. The use of Chain of Thought reasoning for diagnosis by models like Llama-3 8B was also examined, acknowledging flaws in model conclusions.
Resource Ramp-Up for Rapid Engineering: The community has been actively sharing resources, including Jeremy Howard's "A Hackers' Guide to Language Models" on YouTube and Excalidraw for making diagrams. Tools like Sentence Transformers are recommended for fine-tuning transformers, highlighting the collaborative spirit in constantly elevating the craft.
Stability.ai (Stable Diffusion) Discord
- Waiting for the Holy Grail, SD3: Anticipation was high for the release of Stable Diffusion 3 (SD3), with hopes expressed for improved features especially in voxel art, while one user humorously expressed dread over having to sleep before the release.
- Slow Connections Test Patience: One member faced a grueling twelve-hour marathon to download Lora Maker, due to reaching data cap limits and enduring speeds as sluggish as "50kb/s download from Plytorch.org."
- Model Platform Showdown: Discussion arose on the availability of AI models and checkpoints, with platforms like Huggingface and Civitai under the lens; Civitai takes the lead with a vast selection of Lorases and checkpoints.
- Up for Debate: Upscaling Techniques: A technical debate was sparked on whether upscaling SD1.5 images to 1024 can rival the results of SDXL directly trained at 1024x1024 resolution, leading to suggestions to test SDXL's upscaling prowess to even higher resolutions.
- AMD, Y U No Work With SD?: Frustration bubbled up from a member struggling to run Stable Diffusion with an AMD GPU, culminating in a community nudge towards revisiting installation guides and seeking further technical support.
Unsloth AI (Daniel Han) Discord
July 2024: Anticipated MultiGPU Support for Unsloth AI
MultiGPU support for Unsloth AI is highly anticipated for early July 2024, with enterprise-focused Unsloth Pro leading the charge; this will potentially enable more efficient fine-tuning and model training.
Llama 3 Dabbles in Versatile Fine-Tuning
Users explored various tokenizer options for the Llama model, with discussions confirming that tokenizers from services like llama.cpp and Hugging Face are interoperable, and referencing fine-tuning guidance on YouTube for those seeking precise instructions.
Hugging Face AutoTrain Expands with Unsloth Support
Hugging Face AutoTrain now includes Unsloth support, paving the way for more efficient large language model (LLM) fine-tuning as the AI community showed excitement for advancements that save time and reduce memory usage.
Innovations in AI Showcased: Therapy AI and MARS5 TTS
Emerging tools such as a therapy AI finetuned on llama 3 8b with Unsloth and the newly open-sourced CAMB AI's MARS5 TTS model, which promises higher realism in voice cloning, are creating buzz in the community.
Apple's Hiring: AI Integration Spurs Debate
Apple's latest initiative in personalized AI dubbed "Apple Intelligence" was a subject of intense discussion, with the community weighing its potential for language support and the integration of larger models, as reported during WWDC.
Eleuther Discord
Deep Learning's Quest for Efficiency: Members debated the benefits and hurdles of 4-bit quantization for Llama 3, with suggestions like Tensor Parallelism providing possible pathways despite their experimental edge. The applicability of various quantization methods including IQ4_xs and HQQ was highlighted, referencing a blog showcasing their performance on Apple Silicon LLMs for your iPhone.
Seeking Smarter Transformers: A discussion surfaced on improving transformer models, referencing to challenges with learning capabilities that are highlighted in papers like "How Far Can Transformers Reason?" which advocates for supervised scratchpads. Additionally, a debate on the usefulness of influence functions in models emerged, citing seminal works like Koh and Liang's influence functions paper.
Tackling Text-to-Speech Synthesis: VALL-E 2 was mentioned for its exceptional zero-shot TTS capabilities, though researchers faced access issues with the project page. Meanwhile, LlamaGen's advances in visual tokenization promise enhanced auto-regressive models and stir discussions about incorporating methods from related works like "Stay on topic with Classifier-Free Guidance".
Interpreting Multimodal Transformations: Integration challenges of the DeepSeek-LLM-7B model were addressed, with its LLaMA-based structure being a focal point. Shared resources include a GitHub repo to assist the community in their interpretative efforts and overcome model integration complexities.
Optimization Strategies for LLM Interaction: Eleuther introduced chat templating capabilities with the --apply_chat_template flag, providing an example of ongoing work to enhance user interaction with language models. There's also a community push to optimize batch API implementations for both local and OpenAI Batch API applications, with high-level implementation steps discussed and plans for a future utility to rerun metrics on batch results.
CUDA MODE Discord
- GPUs Stirring Hot Tub Fantasies: An engaging proposition to repurpose GPU waste heat for heating a hot tub led to a broader discourse on harnessing data center thermal output. The jest shed light on the potential to transform waste heat into communal heating solutions while providing sustainable data center operational models.
- Cutting Through the Triton Jungle: Navigational tips for better performance with Triton were offered, with common struggles including inferior speed compared to cuDNN and complexities with variable printing inside kernels. Preferences were voiced for simpler syntax, avoiding tuples to lessen the development maze.
- Spanning the Spectrum from Torch to C++: A showcase of technical prowess, participants discussed the merits of full graph compilation with
torch.compile, while others contemplated writing HIP kernels for PyTorch, both hinting at the imminent optimization tide. This confluence of conversations also pondered whether C++20's** concepts could detangle code complexities without back-stepping to C++17.
- Bitnet's Ones and Zeros Steal the Show: A thoughtful exchange surfaced around training 1-bit Large Language Models (LLMs), with a shared resource from Microsoft's Unilm GitHub, outlining the potential efficiency yet acknowledging the stability issues in comparison to FP16.
- Altitudes of LLMs and Compression Techniques: From analyzing ThunderKitten's lackluster TFLOPS performance to exploring model compression strategies with Sconce, the community fused their cerebral powers to navigate these complicated terrains. Added to the repository was a benchmarking pull request in PyTorch's AO repo, promising accurate performance gauging for Llama models.
Modular (Mojo 🔥) Discord
- Concurrency Conundrums and GPU Woes in Mojo: Engineers debated the adoption of structured concurrency in Mojo's library amidst concerns about its asynchronous capabilities, stressing the importance of heterogeneous hardware like TPU support. A strong sentiment echoed where Mojo succeeds in execution speed, but falls short on hardware acceleration when compared to cost-effective solutions like TPUs.
- Rapid RNG and Math Mastery on Mojo: Work on a ported xoshiro PRNG has led to significant speed gains on both laptops and using SIMD, while efforts are underway to bring numpy-equivalent functionality to Mojo through the NuMojo project. Trends show a community push towards expanding numerical computation capabilities and efficiency in Mojo.
- Addressing Mojo’s Memory Mania: Controversy sparked over memory management practices in Mojo, with discussions on the need for context managers versus reliance on RAII and the intricacies of UnsafePointers. The debate underlined the community’s commitment to refining Mojo’s ownership and lifetimes paradigms.
- TPU Territory Tackled: The MAX engine's potential compatibility with TPUs became a highlight, with community members exploring resources like OpenXLA for guidance on machine learning compilers. Forward-looking discussion touched on MAX engine roadmap updates, including inevitable Nvidia GPU support.
- Nightly Update Notes Nuances for Mojo: A freshly released nightly Mojo compiler version
2024.6.1105brought to light changes including the removal ofSliceNewandSIMD.splat, plus the arrival ofNamedTemporaryFile. This continuous integration culture within the community exemplifies the lean towards iterative and fast-paced development cycles.
Perplexity AI Discord
- Apple Dips Toes in Personal AI: Apple announced "Apple Intelligence," incorporating ChatGPT-4o into Siri and writing tools to enhance system-wide user experience while prioritizing privacy, as shared in a Reddit post.
- iOS 18 and WWDC 2024 Embrace AI: With the vision set at WWDC 2024, the new machine learning-powered Photos app in iOS 18 categorizes media more intelligently, coupled with significant AI integrations and software advances across the Apple ecosystem.
- Is Rabbit R1 a Gadget Gone Wrong?: Members exchanged views on the legitimacy of the Rabbit R1 device, mentioning its sketchy crypto ties, and speculated about its capabilities with an Android OS, as discussed in a Coffeezilla video.
- Perplexity AI - Promise Meets Skepticism: Confusion circulates around Perplexity's Pages and Pro features with desktop/web limitations; meanwhile, Perplexity's academic sourcing accuracy faces scrutiny, with users highlighting Google's NotebookLM as potentially superior.
- Integration Headaches and Hidden Keys: Introducing Perplexity AI into custom GPT applications saw roadblocks, prompting discussions on model name updates and safe API practices after an API key was mistakenly exposed, documented at Perplexity's API guidelines.
LM Studio Discord
- PDF Parsing Pursuits: Engineers are exploring local tools for parsing structured forms in PDFs, with Langchain emerging as a suggestion for incorporating local LLMs to extricate fields efficiently.
- WebUI Woes and Workarounds: A gap in official WebUI support for LMStudio has led users to employ the llama.cpp server and text-generation-webui to interact with the tool from remote PCs.
- California AI Bill Brews Controversy: SB 1047 sparks lively debate pertaining to its perceived impact on open-source AI, with fears that it may concentrate AI development among few corporations and encroach on model creators' liabilities indefinitely. Dan Jeffries' tweet provides insights into the discussion.
- GPU Upgrades and ROCm Insights: Engineers discuss upgrading to GPUs with higher VRAM for running large AI models and recommend AMD's ROCm as a speedier alternative to OpenCL for computational tasks. Concerns with multi-GPU performance in LMStudio lead some to alternative solutions like stable.cpp and Zluda for CUDA sweep-ins on AMD.
- Model Merging Mastery: The community has been active in merging models (e.g., Boptruth-NeuralMonarch-7B), evaluating new configurations like Llama3-FiditeNemini-70B), and tackling operational issues like token limit bugs in AutogenStudio with fixes tracked on GitHub.
OpenAI Discord
- Apple Makes Splashes in AI Waters: Apple has announced AI integration into its ecosystem and the community is buzzing about the implications for the competition and device performance. Attendees of WWDC 2024 eagerly discussed "Apple Intelligence," a system deeply integrated into Apple's devices, and are examining the available Apple Foundation Models overview.
- Concerns and Debates on AI and Privacy: Privacy worries surge with AI advancements, with users voicing concerns over potential data misuse, advocating for more secure, on-device AI features instead of relying solely on cloud computing. The discourse reflects the dichotomy where tech enthusiasts express skepticism over cloud and on-premises solutions alike.
- GPT-4: High Hopes Meet Practical Hiccups: OpenAI's promise of upcoming ChatGPT updates stirred excitement, yet users report app freezes and confusion over the new voice mode's delayed release. Additionally, developers are frustrated by apparent policy violations in the GPT Store hindering their ability to publish or edit GPTs.
- Time Management Across Time Zones: AI engineers are strategizing on how to tackle time zone challenges with the Completions API, weighing options such as using timestamp conversions via external libraries or synthetic data to mitigate risks and enhance precision. Consensus veers towards UTC as the baseline for consistent model output, with user-specific timezone adjustments conducted post-output.
- Meet Hana AI: Your New Google Chat Teammate: Hana AI is presented as an AI bot for Google Chat poised to boost team efficiency by handling various productivity tasks and is currently available for free. Engineers can trial and give feedback on the bot, which promises to aid managers and executives, accessible through the Hana AI website.
HuggingFace Discord
- Quest for Optimal Medical Diagnosis AI Stalled: No consensus was reached on the best large language model (LLM) for medical diagnosis within the discussions.
- Semantic Leap in CVPR Paper Accessibility: A new app indexing CVPR 2024 paper summaries with semantic search capabilities was shared and is accessible here.
- Tech Hiccups with Civitai Files: A member encountered
TypeError: argument of type 'NoneCycle' is not iterablewhen usingdiffusers.StableDiffusionPipeline.from_single_file()with safetensors files from Civitai.
- AI Legislation Looms Large Over Open-Source: A tweet thread criticized the California AI Control Bill for potentially hampering open-source AI development, raising alarm over strict liabilities for model creators.
- Anime Meets Diffusion with Wuerstchen3: A user unveiled an anime-finetuned version of SoteDiffusion Wuerstchen3 and provided a useful link to Fal.AI's documentation for API implementation details.
Nous Research AI Discord
Character Codex Unleashed: Nous Research has unveiled the Character Codex dataset with data on 15,939 characters from diverse sources like anime, historical archives, and pop icons, now available for download.
Technical Discussions Ablaze: Engaging conversations included the potential stifling of creativity by RLHF in LLMs, contrasting with the success of companies like Anthropic. The debate also covered model quantization and pruning methods, with a strategy for LLaMA 3 10b aiming to trim model sizes smartly.
Knowledge in Sync: Members discussed the Chain of Thought (CoT) retrieval technique used by CoHere for multi-step output construction and proposed a hybrid retrieval method that might pair elastic search with bm25 + embedding and web search.
Code Meets Legislation: There was a standout critique of CA SB 1047, arguing it poses a risk to open-source AI, while a member shared Dan Jeffries' insights on the matter. A counter proposal, SB 1048, aimed at safeguarding AI innovation was also mentioned.
New Rust Library Rigs the Game: The release of 'Rig', an open-source library in Rust for creating LLM-powered applications, was greeted with interest; its GitHub repo is a treasure trove of examples and tools for AI developers.
Cohere Discord
- Apple's AI Game-Changer: Apple has launched 'Apple Intelligence' at WWDC 2024, integrating ChatGPT with Siri for an improved user interface across iPhones, iPads, and Macs, sparking security concerns and debates. The announcement details were shared in this article.
- Job Hunt Reality Check: An aspiring Cohere team member shared their frustration over job rejections despite notable hackathon successes and ML experience, sparking discussions on whether personal referrals trump qualifications.
- Cohere's Developer Dialogue: Cohere has introduced Developer Office Hours, a forum for developers to address their concerns and engage directly with the Cohere team. A reminder for an upcoming session was posted with an invitation to participate.
- Feedback Flourishes: Members expressed high satisfaction with the new Developer Office Hours format offered by Cohere, complementing the team for fostering an engaging and relaxed environment.
- Engage with Expertise: Cohere encourages member engagement and offers an opportunity for developers to expand their knowledge and troubleshoot with the team through the Developer Office Hours. The next session is scheduled for June 11, 1:00 PM ET, and accessible via this Discord Event.
Latent Space Discord
- Apple Goes All-In on AI Integration: Apple announced the integration of AI throughout their OS, focusing on multimodal I/O and user experience while maintaining privacy standards. For AI tasks, they introduced "Private Cloud Compute," a secure system for offloading computation to the cloud without compromising user privacy.
- ChatGPR Finds a New Home: Partnerships were announced between Apple and OpenAI to bring ChatGPT to iOS, iPadOS, and macOS, signaling a significant move towards AI-enabled operating systems. This would bring conversational AI directly into the hands of Apple users later this year.
- Mistral Rides the Funding Wave: AI startup Mistral secured a €600M Series B funding for global expansion, a testament to investors' faith in the future of artificial intelligence. The round follows a surge of investments in the AI space, highlighting the market's growth potential.
- PostgreSQL's AI Performance Edges Out Pinecone: PostgreSQL's new open-source extension, "pgvectorscale," is hailed for outperforming Pinecone in AI applications, promising better performance and cost efficiency. This marks a significant development in the database technologies supporting AI workloads.
- LLMs in the Real World: Mike Conover and Vagabond Jack featured on the Latent Space podcast, sharing their experiences with deploying Large Language Models (LLMs) in production and AI Engineering strategies in the finance sector. Discussions center around practical considerations and strategies for leveraging LLMs effectively in industry contexts.
LlamaIndex Discord
- Advanced Knowledge Graph Bait: A special workshop focusing on "advanced knowledge graph RAG" is scheduled with Tomaz Bratanic from Neo4j, aiming to explore LlamaIndex property graph abstractions. Engineers are encouraged to register for the event taking place on Thursday at 9am PT.
- Parisian AI Rendezvous: @hexapode will showcase a live demo at the Paris Local & Open-Source AI Developer meetup featuring several prominent companies including Koyeb, Giskard, Red Hat, and Docker at Station F in Paris on 20th June at 6:00pm, with opportunities for others to demo their work by applying here.
- LlamaIndex Snafus and Workarounds: Users are seeking help with the integration of various query engines and LLM pipelines, such as combining SQL, Vector Search, and Image Search using LlamaIndex and querying a vector database with potential OpenAI Chat Completion fallbacks. For projects involving SQL db retrieval and analysis with Llama 3, exploring text-to-SQL pipelines and consulting LlamaIndex’s advanced guides is recommended.
- Berkeley Brainstorming: A UC Berkeley research team is exploring the terrain of custom RAG systems, seeking input from experienced engineers to navigate the complexity of building, deploying, and maintaining such systems.
- The Need for Speed in Sparse Vector Generation: Generating and uploading sparse vectors in hybrid mode with Qdrant and LlamaIndex is too slow for some users, with suggestions hinting at leveraging GPUs locally or using an API to hasten the process.
LAION Discord
- LAION Caught in Controversy: The LAION dataset was featured on Brazilian TV receiving criticism; the issue stems from a claim by Human Rights Watch that AI tools are misusing children's online personal photos, as discussed here.
- Privacy and Internet Literacy Debated: Engineers expressed concerns over widespread misunderstanding of data privacy on the internet, touching on the grave problems caused by billions of users lacking knowledge on the subject.
- LlamaGen Moves Image Generation Forward: The announced LlamaGen model demonstrates a significant step in image generation, leveraging language model techniques for visual content creation, as detailed in their research paper.
- CAMB AI's MARS5 Goes Open Source: The TTS model, MARS5, developed by CAMB AI, has been made open source for community use, with a Reddit post inviting feedback and further technical discussion available on this thread.
- Safety in Visual Data Sets: The LlavaGuard project, detailed here, proposed a model aimed at increasing safety and ethical compliance in visual dataset annotations.
Interconnects (Nathan Lambert) Discord
- Apple Intelligence Divides Opinions: Engineers mixed in their feedback on OpenAI's collaboration with Apple, suggesting the integration into Apple Intelligence may be superficial; however, user privacy highlighted in the official announcement, despite rumor and skepticism (Read more). Comparative benchmarks for Apple's on-device and server models aroused curiosity about their performance against peers.
- Creating Clear Distinctions: Apple's strategic approach to separate Apple Intelligence from Siri has sparked dialogue on potential impacts on user adoption and perceptions of the new system's capabilities.
- Tech Community Anticipates Key Interview: The forthcoming interview of François Chollet by Dwarkesh Patel has engineers eager for a possible shift in the AGI timeline debate, highlighting the importance of informed questioning rooted in Chollet’s research on intelligence measures.
- TRL Implementation Debated: Caution was raised about implementing TRL, citing the technology as "unproven". One member's plan to submit a Pull Request (PR) for TRL received active encouragement and a review offer from another community member.
- Support in Community Contributions: The spirit of collaboration is evident as a member plans to contribute to TRL and receives a pledge for review, showcasing the guild’s culture of mutual support and knowledge sharing.
OpenInterpreter Discord
- Apple Intelligence on the AI Radar: Community showed interest in the potential integration of Open Interpreter with Apple's privacy-centric AI capabilities outlined on the Apple Intelligence page. This could lead to leveraging the developer API to enhance AI functionalities across Apple devices.
- SB 1047 in the Line of Fire: Dan Jeffries criticized the California AI Control and Centralization Bill (SB 1047), introduced by Dan Hendyrcks, for its centralized control over AI and the threat it poses to open source AI innovation.
- Arduino IDE Complications on Mac M1 Resolved: An issue with Arduino IDE on Mac M1 chips was addressed through a fix found in a GitHub pull request, but led to additional problems with the Wi-Fi setup on device restarts.
- Linux as an Open Interpreter Haven: Debate among members highlighted consideration of prioritizing Linux for future Open Interpreter developments, aiming to provide AI-assisted tools independent of major operating systems like Apple and Microsoft.
- Personal Assistant that Remembers: Work on enhancing Open Interpreter with a skilled prompting system that can store, search, and retrieve information like a personal assistant was shared, spotlighting innovation in creating memory retention for AI systems.
- Killian's Insights Captured: A noteworthy discussion followed Killian's recent talk, which was instrumental in casting a spotlight on pertinent AI topics among community members. The recording can be found here for further review.
LangChain AI Discord
- Tagging Troubles with LangChain: Engineers noted that prompts are ignored with the
create_tagging_chain()function in LangChain, causing frustration as no solution has been offered yet. - Collaborative Call for RAG Development Insights: UC Berkeley team members are actively seeking discussions with engineers experienced in Retrieval-Augmented Generation (RAG) systems to share challenges faced in development and deployment.
- LangGraph vs LangChain: Interest was shown in understanding the advantages of using LangGraph over the classic LangChain setup, particularly regarding the execution of controlled scripts within LangGraph.
- Awaiting ONNX and LangChain Alliance: There was curiosity about potential compatibility between ONNX and LangChain; however, the conversation didn't progress into a detailed discussion.
- Streamlined Large Dataset Processing Via OpenAI: A comprehensive guide for processing large datasets with the OpenAI API was shared, focusing on best practices like setting environment variables, anonymizing data, and efficient data retrieval with Elasticsearch and Milvus. Related documentation and GitHub issue links were provided for reference.
tinygrad (George Hotz) Discord
- Newcomer Encounters Permission Puzzle: A new member eager to participate in tinygrad development found themselves permission-locked from the bounties channel, preventing them from working on the AMX support bounty. George Hotz resolved the confusion, stating that one must "Become a purple" to gain the necessary access for contribution.
- George Plays Gatekeeper: In response to questions about AMX support in tinygrad, George Hotz hinted that deeper engagement with the community's documentation is required before tackling such tasks, referencing the need to read a specific questions document.
- A Classic Mix-Up: A documentation mishap occurred when a new member cited the wrong guide, referring to "How To Ask Questions The Smart Way", leading to a humorous "chicken and egg problem" moment with George Hotz.
- Back to the Drawing Board: After the back-and-forth, the new contributor decided to take a step back and delve deeper into the tinygrad codebase before returning with more precise questions, showcasing the complexity and dedication required for contributing to such a project.
OpenRouter (Alex Atallah) Discord
- Speedy Service with OpenRouter: OpenRouter has tackled latency issues by utilizing Vercel Edge and Cloudflare Edge networks, ensuring that server nodes are strategically positioned close to users for faster response times.
- Provider Preference in the Pipeline: Although the OpenRouter playground currently lacks a feature for users to select their preferred API provider, plans to implement this capability have been confirmed.
- API Provider Choices for the Tech-Savvy: Users can bypass the lack of direct provider selection in the OpenRouter playground by using the API; a guide to this workaround is accessible in the OpenRouter documentation.
OpenAccess AI Collective (axolotl) Discord
- ShareGPT's Training Veil: When training, ShareGPT does not "see" its own converted prompt format, ensuring a clean training process.
- Apple's AI Struts Its Stuff: Benchmarks are in for Apple's new on-device and server models, showcasing their prowess in instruction following and writing, with comparisons to other leading models.
- Rakuten Models Storm the Scene: Rakuten's AI team has released a set of large language models that perform exceptionally in Japanese, based on Mistral-7B and available under a commercial license, sparking an optimistic buzz among community members.
- JSON Joy Ripples Through Conversation: Engineers had a light-hearted moment appreciating a model's ability to respond in JSON, capturing a mix of amusement and technical appreciation for the model's capability.
- Fine-Tuning Made Simpler with Axolotl: AI practitioners are guided by a new tutorial for fine-tuning on RunPod, which outlines a streamlined process for fine-tuning large language models with helpful YAML examples across various model families.
Datasette - LLM (@SimonW) Discord
- Calm Before the Coding Storm: Vincent Warmerdam recommends calmcode.io for training models, with users acknowledging the site for its helpful content on model training strategies and techniques.
- RAGged but Right: A Stack Overflow blog post details chunking strategies for RAG (retrieval-augmented generation) implementations, stressing the role of text embeddings to accurately map source text into the semantic fabric of LLMs, enhancing the grounding in source data.
Torchtune Discord
- Clarity on TRL's KL Plots for DPO: There is no direct plotting of Kullback–Leibler (KL) divergence for the Dominant Policy Optimization (DPO) implementation, but such KL plots do exist within the Trust Region Learning (TRL)'s Proximal Policy Optimization (PPO) trainer. The KL plots can be found in the PPO trainer's code, as pointed out in TRL's GitHub repository.
MLOps @Chipro Discord
AI Community Unites at Mosaic Event: Meet Chip Huyen in person at the Mosaic event at Databricks Summit for networking with AI and ML experts. The gathering is set for June 10, 2024, in San Francisco.
Mozilla AI Discord
Given the lack of substantial discussion points and insufficient context in the provided snippet, there are no significant technical or detailed discussions to summarize for an engineer audience.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!