[AINews] FineWeb: 15T Tokens, 12 years of CommonCrawl (deduped and filtered, you're welcome)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI News for 4/19/2024-4/22/2024. We checked 6 subreddits and 364 Twitters and 27 Discords (395 channels, and 14973 messages) for you. Estimated reading time saved (at 200wpm): 1510 minutes.
2024 seems to have broken some kind of "4 minute mile" with regard to datasets. Although Redpajama 2 offered up to 30T tokens, most 2023 LLMs were trained with up to 2.5T tokens - but then DBRX came out with 12T tokens, Reka Core/Flash/Edge with 5T tokens, Llama 3 with 15T tokens. And now Huggingface has released an open dataset of 12 years of filtered and deduplicated CommonCrawl data for a total of 15T tokens:
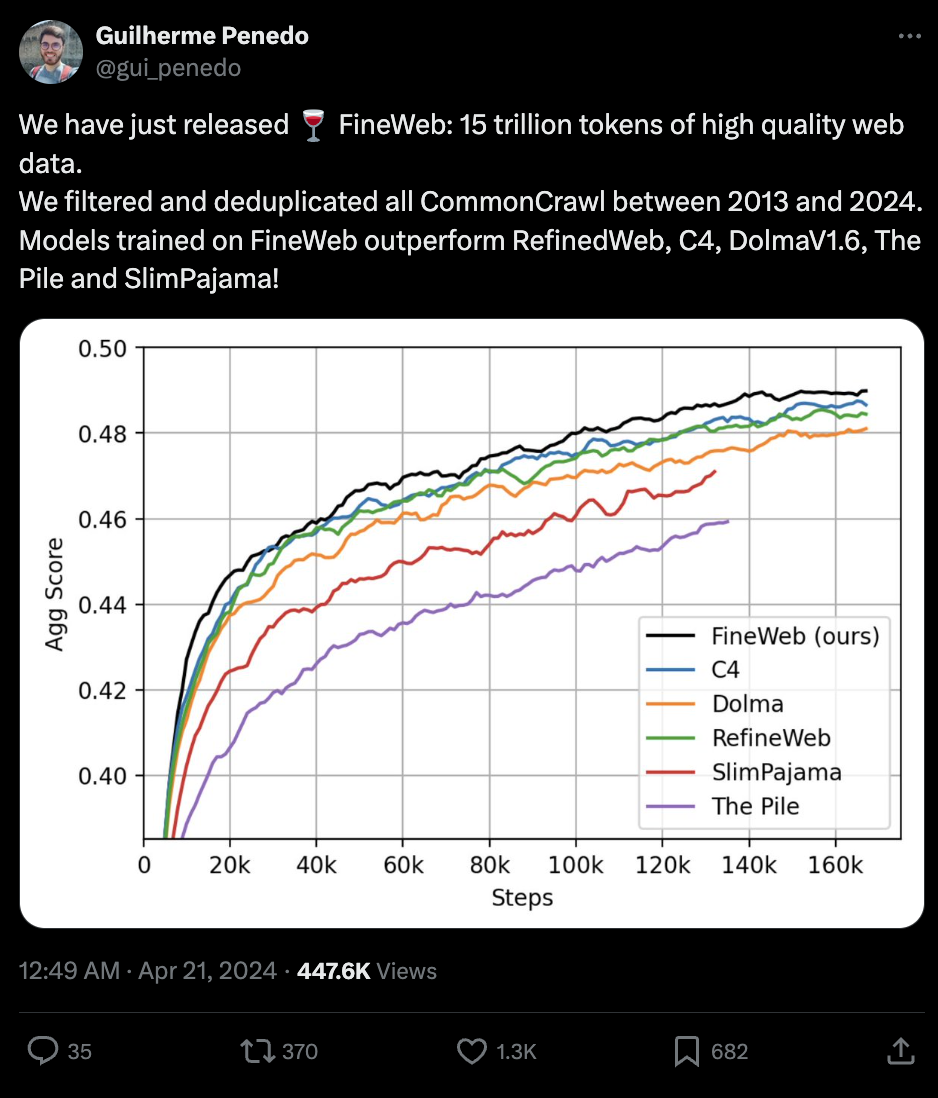
Notable that Guilherme was previously on the TII UAE Falcon 40B team, and was responsible for their RefinedWeb dataset.
One week after Llama 3's release, you now have the data to train yoru own Llama 3 if you had the compute and code.
Table of Contents
- AI Reddit Recap
- AI Twitter Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- Perplexity AI Discord
- Nous Research AI Discord
- LM Studio Discord
- Stability.ai (Stable Diffusion) Discord
- CUDA MODE Discord
- OpenAccess AI Collective (axolotl) Discord
- Eleuther Discord
- Modular (Mojo 🔥) Discord
- HuggingFace Discord
- OpenRouter (Alex Atallah) Discord
- Latent Space Discord
- LAION Discord
- OpenAI Discord
- LlamaIndex Discord
- OpenInterpreter Discord
- Cohere Discord
- tinygrad (George Hotz) Discord
- DiscoResearch Discord
- LangChain AI Discord
- Mozilla AI Discord
- Interconnects (Nathan Lambert) Discord
- LLM Perf Enthusiasts AI Discord
- Skunkworks AI Discord
- Datasette - LLM (@SimonW) Discord
- Alignment Lab AI Discord
- PART 2: Detailed by-Channel summaries and links
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/Singularity. Comment crawling works now but has lots to improve!
AI Models and Capabilities
- WizardLM-2-8x22b performance: In /r/LocalLLaMA, WizardLM-2-8x22b outperformed other open LLMs like Llama-3-70b-instruct in reasoning, knowledge, and mathematics tests according to one user's benchmarks.
- Claude Opus code error spotting: In /r/LocalLLaMA, Claude Opus demonstrated impressive ability to spot code errors with 0-shot prompting, outperforming Llama 3 and other models on this task.
- Llama 3 zero-shot roleplay: Llama 3 showcased impressive zero-shot roleplay abilities in /r/LocalLLaMA.
Benchmarks and Leaderboards
- LMSYS chatbot leaderboard limitations: In /r/LocalLLaMA, concerns were raised that the LMSYS chatbot leaderboard is becoming less useful for evaluating true model capabilities as instruction-tuned models like Llama 3 are able to game the benchmark. More comprehensive benchmarks are needed.
- New RAG benchmark results: A new RAG benchmark was posted in /r/LocalLLaMA comparing Llama 3, CommandR, Mistral and others on complex question-answering from business documents. Llama 3 70B did not match GPT-4 level performance. Mistral 8x7B remained a strong all-round model.
Quantization and Performance
- Efficient Llama 3 quantized models: /r/LocalLLaMA noted that the Llama 3 quantized models by quantfactory on Huggingface are the most efficient options currently available.
- Llama 3 70B token generation limits: One user reported generating ~9600 tokens with Llama 3 70B q2_xs on a 3090 GPU setup before decoherence set in. Ideas were requested for extending coherence.
- AQLM quantization of Llama 3 8B: AQLM quantization of Llama 3 8B was shown to load in Transformers and text-generation-webui, with performance on par with the baseline in initial tests.
Censorship and Safety
- AI usage ban for sex offender: In /r/singularity, it was reported that a sex offender in the UK was banned from using AI tools after making indecent images of children, raising concerns from charities who want tech companies to prevent the generation of such content.
- GPT-4 exploit capabilities: GPT-4 can exploit real vulnerabilities by reading security advisories with an 87% success rate on 15 vulnerabilities, outperforming other LLMs and scanners, raising concerns that future LLMs could make exploits easier.
- AI-generated unsafe information: In /r/LocalLLaMA, there was discussion on whether AIs are capable of producing uniquely unsafe information not already widely known. Most examples seem to be basic overviews rather than truly sensitive knowledge.
Memes and Humor
- Various AI-generated memes and humorous content were shared, including a "warehouse robot collapsing after working 20 hours", the Mona Lisa singing Lady Gaga, and AI-generated comic dialogue highlighting current limitations.
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Meta Llama 3 Release
- Model Details: @AIatMeta released Llama 3 models in 8B and 70B sizes, with a 400B+ model still in training. Llama 3 uses a 128K vocab tokenizer and 8K context window. It was trained on 15T tokens and fine-tuned with SFT, PPO, and DPO on 10M samples.
- Performance: @karpathy noted Llama 3 70B is approaching GPT-4 level performance on benchmarks like MMLU. The 8B model outperforms others like Mistral 7B. @DrJimFan highlighted it will be the first open-source model to reach GPT-4 level.
- Compute and Scaling: @karpathy estimated 1.3M A100 hours for 8B and 6.4M for 70B, with 400 TFLOPS throughput on a 24K GPU cluster. Models are severely undertrained relative to compute-optimal scaling ratios.
- Availability: Models are available on @huggingface, @togethercompute, @AWSCloud, @GoogleCloud, and more. 4-bit quantized versions allow running the 8B model on consumer hardware.
Reactions and Implications
- Open-Source AI Progress: Many highlighted this as a watershed moment for open-source AI surpassing closed models. @bindureddy and others predicted open models will match GPT-4 level capabilities in mere weeks.
- Commoditization of LLMs: @abacaj and others noted this will drive down costs as people optimize runtimes and distillation. Some speculated it may challenge OpenAI's business model.
- Finetuning and Applications: Many, including @maximelabonne and @rishdotblog, are already finetuning Llama 3 for coding, open-ended QA, and more. Expect a surge of powerful open models and applications to emerge.
Technical Discussions
- Instruction Finetuning: @Teknium1 argued Llama 3's performance refutes recent claims that finetuning cannot teach models new knowledge or capabilities.
- Overtraining and Scaling: @karpathy and others discussed how training models far beyond compute-optimal ratios yields powerful models at inference-efficient sizes, which may change best practices.
- Tokenizer and Data: @teortaxesTex noted the improved 128K tokenizer is significant for efficiency, especially for multilingual data. The high quality of training data was a key focus.
AI Discord Recap
A summary of Summaries of Summaries
- Llama 3 Takes Center Stage: Meta's release of Llama 3 has sparked significant discussion, with the 70B parameter model rivaling GPT-4 level performance (Tweet from Teknium) and the 8B version outperforming Claude 2 and Mistral. Unsloth AI has integrated Llama 3, promising 2x faster training and 60% less memory usage (GitHub Release). A beginner's guide video explains the model's transformer architecture.
- Tokenizer Troubles and Fine-Tuning Fixes: Fine-tuning Llama 3 has presented challenges, with a missing BOS token causing high loss and
grad_norm infduring training. A fix via a PR in the tokenizer configuration was shared. The model's vast tokenizer vocabulary sparked debates about efficiency and necessity.
- Inference Speed Breakthroughs: Llama 3 achieved 800 tokens per second on Groq Cloud (YouTube Video), and Unsloth users reported up to 60 tokens/s on AMD GPUs like the 7900XT. Discussions also highlighted Llama 3's sub-100ms time-to-first-byte on Groq for the 70B model.
- Evaluating and Comparing LLMs: Conversations compared Llama 3 to GPT-4, Claude, and other models, with Llama 3 70B not quite matching GPT-4 Turbo despite good lmsys scores. The release of the FineWeb dataset (Tweet from Guilherme Penedo) with 15 trillion tokens suggests potential to outperform existing datasets like RefinedWeb and The Pile.
- Emerging Tools and Frameworks: Several new tools and frameworks were discussed, including Hydra by Facebook Research for configuring complex applications, LiteLLM (Website) as a template for LLM projects, Prompt Mixer (Website) for collaborative prompt engineering, and WhyHow.AI's Knowledge Graph SDK (Medium Article) for schema-controlled automated knowledge graphs.
- Retrieval-Augmented Generation (RAG) Advancements: Developments in RAG were a hot topic, with a new benchmark proposed for evaluating RAG models (Tweet from Stella Biderman), a guide for building a RAG chatbot using Llama 3, and a tutorial on rental apartment search with LangChain's Self-Querying Retriever.
- Reinforcement Learning from Human Feedback (RLHF) Insights: A new paper titled "From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function" compared traditional RLHF methods to Direct Preference Optimization (DPO), aligning theory with the standard RLHF approach and Bellman equation satisfaction.
- Optimizing Transformer Models: Techniques for optimizing transformer models were discussed, including approximating attention mechanisms to compress token length during inference (arXiv:2401.03462, arXiv:2401.06104), extending context lengths with methods like Activation Beacon and TOVA, and dynamically allocating FLOPs (arXiv:2404.02258).
- Ethical Considerations and Legal Implications: Conversations touched on the ethical implications of AI "jailbreaks" and their potential to induce unintended agent behaviors, as well as the legal risks associated with using tools like Nightshade that could conflict with the Computer Fraud and Abuse Act (CFAA).
- Collaborative Efforts and Community Engagement: Many channels fostered collaboration on projects like minbpe-rs (GitHub), a Rust port of minbpe, and an open-source matchmaking AI application using Cohere Command R+ (Tweet). Community members also shared learning resources, such as a course on fine-tuning LLMs and Eugene Yan's blog posts on evaluating LLMs.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
Llama 3 is the Talk of the Town: Unsloth AI's integration of Llama 3 has sparked discussions on its potential for 2x faster training and 60% less memory usage as detailed on their GitHub Release page. The community eagerly explores 4-bit models and the effects of quantization on model quality, highlighted by significant activity in experimenting with various Llama 3 variants, including those optimized for different languages and shared on platforms like Hugging Face.
Notebook Nudge: AI enthusiasts are encouraged to test Llama 3 via comprehensively prepared notebooks on Google Colab and Kaggle, making way for fine-tuning and experimentation across the board.
Solving Model Mysteries and Sharing Secrets: Candid exchanges revealed struggles and successes from fine-tuning and inferencing issues with LLaMA 3 models to hardware discussions about the NVIDIA Jetson Orin nano. Proposed fixes for looping responses and insights into effective CUDA utilization were shared, indicating a culture of collaborative problem-solving.
Sharing in Showcase: Achievements are on full display with instances such as a LinkedIn post revealing the finesse of fine-tuning Llama3 for Arabic, and the debut of the Swedish model 'bellman.' The Ghost 7B Alpha language model also got attention for its English and Vietnamese optimizations.
Ideas and Input in Suggestions: Dialogue in the #suggestions channel provided valuable takeaways, such as a need for tutorials on model merging and CUDA debugging and the potential for multi-GPU capabilities with Unsloth Studio. Adjustments to server welcome messages for better readability indicated a response to community feedback.
Perplexity AI Discord
- AI Models Take the Stand: Engineers are actively comparing the performance of AI models like Llama 3, Claude 3 Opus, GPT-4, and GPT-4 Turbo for tasks ranging from legal document analysis to coding. Some challenges were expressed about making Perplexity's AI restricted to a list of specific terms, and the queries per day are capped at 50 for Claude 3 Opus.
- Collaborative Growth: Community members are encouraged to support each other, as seen by a user seeking advice on securing mentorship and funding for AI development and getting no immediate responses about constrained API outputs. Resources like Y Combinator and internet-based learning platforms were recommended for learning and growth.
- Perplexity Hits the Spotlight: Perplexity AI gained attention with Nandan Nilekani's praise and a YouTube video detailing a meeting with Meta AI's Yann LeCun. Key discussions are being shared publicly to highlight diverse queries and the AI's expansive knowledge base, emphasizing the collective knowledge-sharing culture.
- API Usage Discussed: Engineers discussed Perplexity's API, highlighting the visibility of the usage counter and seeking clarity on the refresh rate of the API credits. There appears to be a need for real-time feedback on API quota consumption but no specific information about the refresh rate was provided.
- Unauthorized Use and Self-Hosting Solutions: There is an ongoing community discussion about the unauthorized use of API keys on Chinese platforms, the impact on service reliability, and trading accounts. Some members are leaning towards self-hosting as a reliable solution, with guides being shared on setting up Ollama Web UI.
Nous Research AI Discord
Puzzling Over Multi-GPU Context Inference: Members are evaluating how to conduct long context inference with models like Jamba using multiple GPUs, exploring tools such as DeepSpeed and Hugging Face's Accelerate without much luck, although vllm's tensor parallel solution seems promising, despite current lack of support for Jamba.
Beat-Dropping Dataset Announcements: A latent CIFAR100 dataset has been shared on Hugging Face, surprising community members with an approximate 19% accuracy using a simple FFN despite most latents not decoding accurately.
DeepMind Drops Penzai for Network Craft: Penzai, a JAX research toolkit for neural network innovation by DeepMind, has garnered attention, while an advanced research assistant and search engine offering trial premium access to models like Claude 3 Opus and GPT-4 Turbo at rubiks.ai seeks beta testers.
WorldSim's Feature-Rich Comeback: The relaunch of WorldSim includes features such as WorldClient and Mind Meld, with a new pay-as-you-go model for tokens, and a selection of models (Opus, Sonnet, Haiku) for different cost profiles.
Scrutinizing LLMs Across the Spectrum: Discussions on the slight margin in performance between Llama 3 8B and Mistral 7B, despite Llama's larger dataset, graced the forum. Meanwhile, evaluations of Llama 3 70B show more promise, and there are varied stances on the relevance of the term 'grokking', particularly in reference to LLMs.
LM Studio Discord
- Tackling GPU usage in LM Studio: Engineers reported LM Studio integrates additional GPUs into a larger VRAM pool, yet sometimes CUDA utilization remains high on a single GPU. MacOS users indicated that Metal might not adhere to GPU settings, affecting machine temperature.
- Faulty Model Searching Mechanism: Users experienced 503 and 500 errors when searching for and downloading models, likely linked to an ongoing outage with Hugging Face, affecting LM Studio's model search and downloading capabilities.
- LM Studio Configuration Queries and Tutorials: Confusion about configuring WizardLM 2 was addressed with assistance from the community, including a Reddit tutorial on fine-tuning token usage. Discussions also elaborated on the behavior of < Instruct > models versus Base versions and tackled infinite loop issues in Llama3.
- Exploring External Access and Multiple GPUs: Queries around hosting a locally running AI in LM Studio through a custom domain were made, and multi-GPU setups were discussed, raising points about power draw and technical configurations.
- In-Depth Discussions on Language Model Tokens: Technicians clarified the misconception that tokens align with syllables, explaining subword encodings. The dialogue also critiqued the typical 50,000 token training figure for language models, considering it in terms of performance and complexity balance.
- Diverse Hardware Compatibility and Setup: The compatibility of NVIDIA Jetson Orin with LM Studio was confirmed, while a GPU buying guide on Reddit was referenced for users looking to optimize their hardware setup for LM Studio.
- AMD ROCm Preview Shines with Llama 3: The LM Studio ROCm Preview 0.2.20 version now supports MetaAI's Llama 3, exclusively functioning with GGUFs from "lmstudio-community" and can be accessed on LM Studio ROCm site. The AMD GPUs, such as the 7900XT, displayed impressive token generation speeds of around 60 tokens/s. Compatibility and resource allocation with multiple graphics cards were hot topics, with some users managing to prioritize the desired AMD GPU for LM Studio use.
Stability.ai (Stable Diffusion) Discord
- New User Navigational Woes with Stable Diffusion: New users are hitting a wall with starting Stable Diffusion, even after following YouTube setup guides, with advice pointing towards interfaces like ComfyUI and Clipdrop's Stable Diffusion as entry points.
- Feeling Swamped by AI Progress: Members lament the breakneck speed of generative AI developments, particularly in Stable Diffusion tools and models.
- Tech Support Group Tackles Stable Diffusion: Users share solutions for locating saved Stable Diffusion training states in Kohya, with a focus on resuming from checkpoints and checking output folders for saved data.
- Digging into VRAM's Role in Image Creation: Queries about GPU upgrades for image generation led to discussions about multiple image generation capabilities with more VRAM and upgrading drivers post GPU swaps.
- Platforms for Unleashing AI Artistry: New community members inquired about tools for crafting AI-powered images and were directed to web interfaces and local services that integrate with Stable Diffusion, like bing image creator and platforms listed on Stability AI's website Core Models – Stability AI.
CUDA MODE Discord
- Kernel Performance and Memory Breakthroughs: A new kernel implementation significantly improved the 'matmul_backward_bias' kernel performance by approximately 4x, and a separate optimization helped reduce memory consumption by about 25%, from 14372MiB to 10774MiB. Discussions on dtype precision suggested using mixed precision to balance performance and memory usage while considering the reduction of operations from linear to logarithmic for efficiency.
- Navigating the Nuances of NVIDIA Libraries: Integration of cuDNN and cuBLAS functions are underway, with a PR for cuDNN Forward Attention and FP16 cuBLAS kernels in
dev/cudashowing significant speed gains. Members tackled the complexity of using these libraries for accurate training with mixed precision, and the potential of custom backward pass implementations to address gradient computation inefficiencies.
- Exploring Efficiency in Data Parallelism: The community evaluated different approaches to scaling multi-GPU support with NCCL, debating over single-thread multiple devices, multi-thread, or multi-process setups. The consensus leaned towards an MPI-like architecture that would support configurations beyond 8 GPUs and accommodate multi-host environments.
- Gradients and Quantization Quality in GPU Computing: An Effort algorithm aimed at adjusting calculations dynamically during LLM inference was introduced, targeting implementation in Triton or CUDA. Also, a discussion on 20% speed reduction with HQQ+ combined with LoRA indicated room for optimization, and a new fused
int4 / fp16triton kernel outperformed the defaulthqq.linearforward, presented in a GitHub pull request.
- Community Collaborations and Technical Support: The CUDA MODE community highlighted collaboration on problems including Colab session crash during backpropagation, handling grayscale image transformations in Triton kernels, and selecting suitable GPUs for building a machine learning system. Members offered high-level advice on managing memory when implementing a denseformer in JAX, and shared utility resources like
check_tensors_gpu_readyfor verifying contiguous data in memory.
- CUDA Learning Opportunities and Social Engagements: There was an announcement for CUDA-MODE Lecture 15: Cutlass, with ongoing CUDA lecture series to deepen understanding of CUDA programming. On an informal note, a physical meetup of some community members happened in Münster, Germany, playfully dubbed the "GPU capital."
- Incorporating Audio-Visual Resources: References to educational YouTube recording uploads for lectures, shared through channels like Google Drive, display the community's commitment to providing multiple learning modalities.
- Event Logistics and Moderator Management: A new "Moderator" role was introduced with capabilities to maintain order within the server, and coordination for event management was emphasized, suggesting a structured and well-managed community environment.
OpenAccess AI Collective (axolotl) Discord
BOS Token Issue Resolved for LLaMa-3: An important fix was addressed with LLaMa-3's fine-tuning process, as a missing BOS token was causing issues; this has been rectified with a PR in the tokenizer configuration.
Fine-Tunning LLaMa-3 Hits a Snag: While trying to fine-tune LLaMa-3, a user faced a mysterious RuntimeError, noting this issue did not occur with other models like Mistral and LLaMa-2.
Tokenizing Troubles: The LLaMa-3 tokenizer's extensive vocabulary sparked a debate about its necessity and efficiency, some favoring a streamlined approach, others defending its ability to encode large texts with fewer tokens.
VRAM Consumption Detailed for Large LLMs: A clear VRAM usage breakdown was provided for large LLMs, revealing logits and hidden states sizes up to "19.57GiB" and "20GiB" respectively, using a massive "81920 tokens" batch size.
Axolotl's Resources for Dataset Customization: A pointer was given to Axolotl's datasets documentation for those seeking to understand custom dataset structures, offering key examples and formatting for various training tasks.
Eleuther Discord
- Smartphone Smarts: LLMs on the Go: Enthusiasts report the Samsung S24 Ultra achieving 4.3 tok/s and the S23 Ultra hitting 2.2 tok/s when running quantized language models like Llama 3. Discussions on the practicality of this technology are informed by various links, including Pixel's AI integration and MediaPipe with TensorFlow Lite.
- The Internals of Self-Attention: Technical scrutiny has surfaced regarding the necessity for tokens in transformer models to attend to their own key-values. Proposals for experimental ablation to assess the effect on model performance set the ground for future research.
- A Spotlight on Hugging Face's Financial Viability: The guild ponders over Hugging Face's business model, particularly their large file hosting strategy, drawing comparisons to GitHub's model amidst questions about sustainable revenue streams.
- Quest for Improved Reasoning in LLMs: Amidst discussions on evaluating language model reasoning, the Chain of Thought approach seems dominant, yet the thirst for alternative reasoning benchmarks remains unquenched. The need for research beyond CoT is underscored by a paucity of deeper reasoning metrics.
- Optimizer Face-off: Seeking Tranquil Training: To tackle training instability, the adaptation of a Stable AdamW optimizer is suggested over the vanilla version with clipping. Gearheads discuss refined parameter tuning and gradient histogram analysis to refine their model training stability.
- Megalodon Claims Its Territory: Engineers debate the so-called superiority of Megalodon, Meta's new architecture excelling in handling longer contexts, though its universal acceptance and performance against other mechanisms remain to be validated through broader use and comparative analysis.
- Navigating the Task Vector Space: Exploration of 'task vectors' in AI reveals a method to alter pretrained model behavior 'on-the-fly', enabling dynamic knowledge specialization—a topic grounded by a recent paper.
- RAG Benchmarking Puzzles suggest a new frontier in benchmark development targeting RAG models synthesizing multifaceted information. Concerns include how models could be unfairly advantaged by training on datasets similar to benchmark content.
- Approximation Innovations to Shrink Inference Footprint: Discussing compression of token length via approximating attention mechanisms during inference unveils several strategies like Activation Beacon and TOVA, with the potential to change dynamic resource allocation.
- Transformer Context Expansion: The Final Frontier?: The possibility of significantly extending transformer model context lengths spurs interest, with discussions acknowledging that achieving context windows like 10 million tokens might transcend mere fine-tuning, suggesting a need for novel architectural breakthroughs.
- The Technical Tussling Over Chinchilla's Replication: A hot debate orbits the replication attempts of Chinchilla's study, focusing on rounding nuances and residual analysis to fine-tune model assessments, informed by engagements on Twitter and precision concerns raised over the original work.
- DeepMind's SAE Endeavors Unfold: Google DeepMind's latest forays prioritize Sparse Autoencoder (SAE) scaling and fundamental science, with the team sharing insights from infrastructure to steering vectors in posts on Twitter by Neel Nanda and on the AI Alignment Forum.
- Benchmarking Thirst in the Thunderdome: A Google Spreadsheet is floating around (MMLU - Alternative Prompts), filled with MMLU scores and begging comparison against known benchmarks, underscoring the community's competitive spirit.
- Contributor Seeks Guidance Swords for lm-evaluation-harness: A good Samaritan quests for aid in contributing to lm-evaluation harness, wrestling with outdated guides and the absence of certain test directories, underscoring the continuous evolution of the project and the need for current documentation.
Modular (Mojo 🔥) Discord
C++ Sneaks Past Python: Discussions revealed a performance advantage for C++ over Python/Mojo interfaces, linked to the bypass of Python runtime calls, potentially impacting inference times.
Frameworks Forge Ahead: Dialogues indicated a bright future for building Mojo frameworks, with anticipation for a time when Python frameworks can be utilized within Mojo, echoing the compatibility seen between JavaScript and TypeScript.
Performance Enigmas and Enhancements: A user reported that a Rust prefix sum computation was significantly slower than Mojo's, spawning a performance mystery. Meanwhile, a separate debate on introducing SIMD aliases in Mojo shows momentum toward refining the language's efficiency and syntax clarity.
Teaser Tweets Tantalize Techies: Modular released a series of teaser tweets suggesting a major announcement. While details remain scarce, anticipation is evident among followers awaiting the revelation.
Video Assistance Request Resonates: A member's request for likes and feedback on their AI evolution video not only seeks community support but also reflects the commitment to AI education and discourse even under tight timelines.
HuggingFace Discord
- Llama 3 Challenges Claude: Discussions indicated that Llama 3's 70b model is now on par with Claude Sonnet, and the 8b version surpasses Claude 2 and Mistral. The community engaged in active discourse around the comparative performance of various AI models and shared insights on API access for MistralAI/Mixtral-8x22B-Instruct-v0.1 for HF Pro users, showcasing the competitive landscape in AI model development.
- Hardware Headaches and Downtime Dilemmas: Hardware suitability for machine learning tasks was a topic of exchange, particularly the examination of an AMD RX 7600 XT against higher-end models and Nvidia's offerings. Meanwhile, operational disruptions were reported due to HuggingFace service outages, underscoring the dependency of projects on the stability and availability of these AI platforms.
- AI at Warp Speed on Groq Cloud: Llama 3 achieved 800 tokens per second on Groq Cloud, as detailed in a YouTube video. Additionally, the significance of tokenizers for language model data preparation was a point of study and discussion, further evidencing the focus on performance optimization and foundational machine learning aspects within the community.
- Trailblazing with RAG and Vision Tools: Developers showcased their creations including a RAG system chatbot incorporating Llama 3 and multiple innovative uses of Hugging Face Spaces. In the domain of computer vision, the open-source OCR tool Nougat and improvements in shuttlecock tracking using TrackNetV3 were noted, reflecting a strong inclination towards open-source contributions and advancements in AI capabilities.
- NLP Nuggets and Diffusion Discussions: In the NLP field, a member addressed fine-tuning difficulties with the PHI-2 model and a new Rust port of
minbpewas announced, attracting community collaboration. Conversations in the diffusion model domain tackled the potential use of Lora training for inpainting consistency, while another member sought help with vespa model downloads, highlighting a collaborative atmosphere for problem-solving and expertise sharing.
OpenRouter (Alex Atallah) Discord
- New LLMs on the Block: The latest Nitro-powered Llama models are now available on OpenRouter, promising performance enhancements for AI engineers, accessible here. OpenRouter's freshly faced challenges with Wizard 8x22b highlight the demand-induced pressure, bearing in mind that performance increments for non-stream requests are evolving due to recent load balancer updates.
- Streamlining Services and Errant URLs: OpenRouter has rerouted users to the standard DBRX 132B Instruct model following the delisting of its nitro variant, ensuring engineers can continue their work with available models. Additionally, a previously misleading URL within the #app-showcase channel has been corrected, reinforcing the need for vigilance in documentation accuracy.
- Praise Connects Platforms: KeyWords AI expressed commendation towards OpenRouter's model updates, enabling them to enhance their feature set for developers. These collaborative efforts underline the interconnected nature of AI tools and platforms, fostering an environment where utility and innovation go hand-in-hand.
- Challenging LLM Performance Norms: Conversations converged on the limitations and potential of multilingual support in models like LLaMA-3 wherein community members look forward to improvements in language diversity. Discrepancies in performance and curation from host updates were acknowledged, with an eye on persistent access to high-quality LLMs, an essential for engineers invested in developing adaptable AI experiences.
- Roleplay and Creativity in AI: The AI community is showing zest for specialized models like Soliloquy-L3, which promises enhanced capabilities for roleplay with support for extended contexts. This window into the collective's pursuits sheds light on the inherent desire for models that surpass the traditional confines of creative AI applications.
Latent Space Discord
- Llama 3 Faces Off GPT-4: Llama 3 has sparked discussions among users, with some arguing that even though it scores well on lmsys, it does not quite match up to GPT-4 Turbo's performance. Exceptional inference speeds were noted on Groq Cloud for Llama-3 70b, clocking in under 100ms.
- Evaluating and Fine-Tuning AI: Practitioners are employing tools like Hydra by Facebook Research for fine-tuning applications, even as some find its documentation lacking. Furthermore, a new methodology for LLM Evaluation was presented via Google Slides, influencing the conversation around practical model evaluation strategies.
- Data Sets and Tools to Watch: The unveiling of FineWeb, a massive data set with 15 trillion tokens, has generated interest due to its potential to surpass the performance of datasets like RefinedWeb and The Pile. Additionally, litellm was highlighted as a useful template for LLM projects to streamline interactions with various models.
- Deep Dive into LLM Paper: The paper club's fascination with "Improving Language Understanding by Generative Pre-Training" points to its ongoing relevance in the field. Attendees valued the session enough to call for recording it for wider access on platforms like YouTube, illustrating the community's commitment to shared learning.
- Podcast Fever Hits Latent Space: Anticipation is high for the latest Latent Space Podcast episode featuring Jason Liu, affirming the guild's appetite for thought leadership and industry insights, which can be found in the recent Twitter announcement.
LAION Discord
Meta's Mystery Moves: Debate ignited over Meta's unusual practice of restraining LLaMA-3 paper release, signaling a potential shift in their framework for model releases, yet no reason for this divergence was cited.
Ethics and Legality in AI Tooling: The group scrutinized the legal and ethical considerations surrounding Nightshade, mentioning its potential conflict with the Computer Fraud and Abuse Act (CFAA), due to its AI training intervention capabilities.
Boosting Diffusion Model Speed: Research by NVIDIA, University of Toronto, and the Vector Institute introduced "Align Your Steps," an approach to accelerate diffusion models, discussed in their publication, yet a call for the training code release was noted for complete transparency.
Benchmarking Visual Perception in LLMs: A new benchmark named Blink was introduced for evaluating multimodal language models; it particularly measures visual perception, where models like GPT-4V show a gap when compared to human performance. The Blink benchmark is detailed in the research abstract.
Collaborative Development for NLP Coding Assistant: Interest was shown in developing an NLP coding assistant for JavaScript/Rust, with calls for collaboration and knowledge-sharing, suggesting an ongoing pursuit for improved automation tools among engineers.
OpenAI Discord
- AI Model Mashup Mayhem: Engineers are testing various AI combinations, linking Claude 3 Opus with GPT-4 and integrating LLama 3 70B via Groq, though they face mixed results and access issues. Discussions are exploring the theoretical application of convolutional layers (Hyena) and LoRa in large language models to refine fine-tuning approaches.
- Groq's Free AI Might: The Groq Cloud API's free offering is thrust into the limelight with recommendations highlighting LLaMa 3 as a superior model. The community is utilizing this resource for ventures in AI creativity, such as chat-based roleplaying bots capable of writing Python.
- Digital Athenian Dreams Clash With AI Sentience Debate: Visions for a 'digital Athens' meet deep contemplation on AI consciousness, with the community engaging in discussions around future societal structures reliant on AI and philosophical debates on the nature of sentience.
- Prompt Engineering Conundrums: A challenge arises in prompt engineering, where a member struggles to extract precise text from JSON fields, prompting a move toward code interpretation methods. Additionally, ethical concerns surface over sharing sensitive prompts, leading to contemplation on the ethics of prompt engineering.
- Academic AI Quest: An academic in quest of substantial resources for their thesis on AI and generative algorithms receives directions toward OpenAI's research papers, marking a quest for deepened understanding in academic circles.
LlamaIndex Discord
LlamaParse Automates Code Mastery: A collaboration with TechWithTimm enables setup of local Large Language Models (LLMs) using LlamaParse to construct agents capable of writing code; details and a workflow glimpse are on Twitter.
Local RAG Goes Live: Instructions for crafting a RAG application entirely locally using MetaAI's Llama-3 can be found alongside an informative Twitter post, highlighting the move towards self-hosted AI applications.
Tackling AI's Enigma 'Infini Attention': An explainer on Infini Attention’s potential impact on generative AI was introduced along with an insights-rich LinkedIn post.
Geographical AI Data Visualization: The AI Raise Tracking Sheet now includes and displays AI funding by city, inviting community scrutiny via this Google spreadsheet; a celebratory tweet emphasizes the geographical spread of AI companies over the past year.
Enhanced Markdown for LLMs and Knowledge Graph SDK: FireCrawl’s integration with LlamaIndex beefs up LLMs with markdown capabilities, while WhyHow.AI's Knowledge Graph SDK now facilitates building schema-controlled automated graphs; further exploration in respective Medium articles and here.
OpenInterpreter Discord
Fine-Tuning AI with Lightning Speed: Engineers in the guild have been experimenting with quick-learning models such as Mixtral and Llama, noting the small dataset sizes needed for efficient fine-tuning.
Groq's Rocking Performance with Llama3: The Llama3 model shows impressive speed on Groq hardware, sparking interest for its use in practical applications, with discussion on GitHub pinpointing installation bugs specific to OI on Windows.
Bug Hunts and Workarounds in AI Tools: The community discussed various bugs, such as the spacebar issue on M1 Macbooks with O1 and performance issues with Llama 3 70b. Recommended fixes included installing ffmpeg and using conda for alternate Python versions.
Windows Woes and Macbook Mistakes: Issues running Open Interpreter's O1 on Windows signal possible client problems, and voice recognition glitches on M1 Macbooks are causing disruptions when the spacebar is pressed.
Confusions Clarified and Stability Scrutinized: Clarification was made on O1 versus Open Interpret compatibility with Groq. Stability concerns were raised for Llama 3 70b models, suggesting that larger models may have greater instability issues compared to their smaller counterparts.
Cohere Discord
MySQL Connector Confusion Cleared: Integration of MySQL with Cohere LLMs sparked questions regarding the use of Docker and direct database answers. A GitHub repository clarifies reference code, despite issue reports about outdated documentation and malfunctioning create_connector commands.
No Command R for Profit: It was clarified that Command R (and Command R+) is restricted to non-commercial use under the CC-BY-NC 4.0 license, barring usage on edge devices for commercial purposes.
AI Startup Talent Call: An AI startup founder is actively seeking experts with a strong background in AI research and LLMs to assist with model tuning and voice models. Interested candidates are encouraged to connect via LinkedIn.
Alternative Routes after Internship Setback: Advice was shared for pursuing ML/software engineering roles post-internship rejection at Cohere, which included tapping into university networks, seeking companies with non-public intern opportunities, contributing to open-source initiatives, and attending job fairs.
AI Ethical Dilemmas and Tech Updates: Discussions included concerns over the ethical implications of AI "jailbreaks" and their potential to induce unintended agent behaviors, an open-source matchmaking AI application using @cohere Command R+, and the launch of Prompt Mixer, a new IDE for creating and evaluating prompts, available at www.promptmixer.dev.
tinygrad (George Hotz) Discord
- GPU Acceleration Achievements: An engineer successfully ran hardware support architecture (HSA) on a laptop's Vega iGPU using a HIP compiler and OpenCL, potentially with Rusticl. This supports the trend towards local, user-controlled AI environments as opposed to remote cloud dependencies.
- Mastering Model Precision: Users are troubleshooting precision issues with the
einsumoperation in tinygrad, encountering underflows to NaN values. They discussed whetherTensor.numpy()should cast to float64 for stability and the impacts on model porting from frameworks like PyTorch.
- Cloudy with a Chance of tinygrad: There's an ongoing debate on whether tinygrad might pivot towards a cloud service, amid broader industry shifts. However, the community expressed a strong preference for maintaining tinygrad as an empowering tool for individuals over reliance on cloud services.
- Make Error Messages Great Again: There's a push for improving error messages in tinygrad, especially regarding GPU driver mismatches and CUDA version conflicts. While this is hampered by the limitations of the CUDA API's specificity, it's an area of potential improvement for developer experience.
- George Hotz Sets the Agenda: George Hotz signaled upcoming discussions on MLPerf progress, KFD/NVIDIA drivers, new NVIDIA CI, documentation, scheduler improvements, and a robust debate on maintaining a 7500 line count limit in the codebase. He encourages general attendance at the meeting, with speaking privileges for select participants.
DiscoResearch Discord
- Stirring the Mixtral Pot: A discussion on Mixtral training highlighted the use of the "router_aux_loss_coef" parameter. Adjusting its value could significantly influence training success.
- Boosting Babel for Czech: Work on expanding Czech language support by adding thousands of tokens is underway, indicating that language inclusivity is a priority. The community referenced the Occiglot project as a relevant initiative in this sphere.
- German Precision in AI Models: Various concerns arose regarding German language proficiency across different models. Members tested the Llama3 and Mixtral models for German, noting issues with grammar and tokenizer quirks, and mentioned the private nature of a new variant pending further testing.
- Memory Overhead Matters More Than Tokens: It's clarified that reducing vocab tokens doesn't enhance inference speed; instead, it's the memory footprint that sees the impact.
- Chatbots Lean Towards Efficiency: Integrating economically viable chatbots into CRMs is being explored, with suggestions to group functions and possibly employ diverse model types for different tasks. There's an interest in having supportive libraries like langchain to facilitate this.
LangChain AI Discord
LangChain's Endpoint Elusiveness: Engineers sought guidance on locating their LangChain endpoint, a key aspect for engaging with its capabilities, with additional observations on inconsistent latencies in firefunction across various devices.
Pirate-Speak Swagger Lost at Sea: A lone message washed ashore in the #langchain-templates channel in quest of the elusive FstAPI route code for pirate-speak, lacking further engagement or treasure maps to its whereabouts.
Community Creations Cruising the High Seas: Innovators hoisted their colors high, presenting diverse projects like Trip-Planner Bot, LLM Scraper, and AllMind AI. Resources ranged from GitHub repositories for bots and scrapers to soliciting broadsides (support) on Product Hunt for AI stock analysts.
Deciphering the Query Scrolls: An AI sage shed light on the process of refining natural language queries into structured ones using Self-querying retrievers, documenting their wisdom in Rental Apartment Search with LangChain Self-Querying Retriever.
Knowledge Graph Armada Upgrade: WhyHow.AI charted a course toward enriched knowledge graphs with upgraded SDKs, beckoning brave pioneers to join the Beta via a Medium article and add wind to the sails of schema-controlled automatons.
Mozilla AI Discord
- Instruct Format Strikes Back: The community is wrestling with compatibility issues in the llama3 instruct format, as it uses a different set of tokens that are not recognized by
llamafileand thellama.cpp server bin. These issues are highlighted on the LocalLLaMA subreddit and remain a point of discussion.
- Committing to Better Conversations: An update is in pipeline for
llama.cppto include the llama 3 chat template, indicating a stride towards enhancing user interaction with the models. This contribution is currently under review, with the pull request available here.
- Quantized Model, Qualitative Leap: The introduction of the llama 3 8B quantized version has sparked interests, with a promise to release it on llamafile within a day, along with a testing link on Hugging Face.
- Navigating the 70B Seas: Encouragement flourishes among members to participate in testing the llama 3 70B model, as it's now accessible though still slightly buggy, specifically mentioning a "broken stop token." They're looking to smooth out these wrinkles with community testing efforts before a broader roll-out.
- Performance Patchwork: Technical exchanges occurred over the execution of llamafiles across various systems, indicating that llama 3 70B excels in front of its 8B counterpart, especially on specific systems like the M1 Pro 32GB, where the Q2 quantization level doesn't match expectations. Improvements and adaptability continue to be focal points of discussion.
Interconnects (Nathan Lambert) Discord
- Scaling Ambitions: Engineers are looking forward to the upcoming release of new 100M, 500M, 1B, and 3B model sizes that will replace the current pythia suite, which are trained on approximately 5 trillion tokens and promise to advance the state of model offerings.
- Benchmarking Evolves: Conversations highlighted the Reinforcement Learning From Human Feedback paper which compares traditional RLHF to Direct Preference Optimization and aligns theoretical foundations with pragmatic RLHF approaches, including the Bellman equation satisfaction.
- Evaluations Under the Microscope: The community is debating the effectiveness of automated evaluations like MMLU and BIGBench versus human-led evaluations such as ChatBotArena, and is seeking clarity on the applicability of perplexity-based benchmarks for model training versus completed models.
- Community Engagement and Feedback: Efforts are underway to increase Discord participation from an ample pool of over 13,000 subscribers, with strategies such as making community access "obvious" and quarterly shoutouts. Meanwhile, valuable input came from a member sharing their Typefully analysis and seeking feedback prior to finalization.
- The Wait for Wisdom: A sense of anticipation is palpable within the community for a forthcoming recording, expected to be released within 1-2 weeks, reflecting high demand for shared knowledge and updates on progress.
LLM Perf Enthusiasts AI Discord
- Llama 3 Knocks Out Opus with Less Muscle: Llama 3 impresses with superior performance in the arena, despite being a model of 70 billion parameters, suggesting that size isn't the sole factor in AI effectiveness.
- Performance Metrics Cannot Ignore Error Bounds: A discussion emphasized the importance of taking error bounds into account when evaluating AI model performances, implying that comparisons are more nuanced than raw numbers.
- Meta's Imagine Gets a Standing Ovation: Meta.ai's Imagine platform received acclaim for its capabilities, with participants in the conversation eager to see examples that demonstrate why it's considered insane.
- Azure's Slow-Mo Service Test: Engineers are facing challenges with Azure's OpenAI due to high latency issues, with some requests taking up to 20 minutes, which can be detrimental to time-sensitive applications.
- Being Rate Limited or Just Unlucky?: Repeated rate limiting on Azure instances, where even 2 requests within 15 seconds can trigger limits, led to engineers implementing a backoff strategy to manage API call rates.
Skunkworks AI Discord
- Databricks Amps Up Model Serving: Databricks rolled out a public preview of GPU and LLM optimization support to deploy AI models with serverless GPUs, optimized for large language models (LLMs) without the need for extra configuration.
- Fine-Tuning LLMs Gets a Playbook: An operational guide on fine-tuning pretrained LLMs has been contributed, recommending optimizations such as LoRA adapters and DeepSpeed, and can be accessed through Modal's fine-tuning documentation.
- Economizing Serverless Deployments: A Github repository provides cheap serverless hosting options, showcasing an example setup of an LLM frontend which engineers can implement via this GitHub link.
- Community Engagement with Resources: A guild member expressed appreciation for the shared serverless inference documentation, confirming its utility for their purposes.
- Budget Beware with New Tech: Some members anticipate the optimized features by Databricks may bear a substantial cost, with humorous apprehensions about affordability.
Datasette - LLM (@SimonW) Discord
Blueprint AI Know-How Wanted: An engineer has expressed interest in AI models to analyze blueprints for ductwork in PDF plans, indicating a practical use-case for image recognition within construction.
AI Previews Before Building: The engineering community discussed the emergence of AI as a preflight check in architecture firms to spot issues and code violations before building, though it has yet to permeate the blueprint design process.
Llama 3 Lands on Laptops: SimonW has updated the llm-gpt4all plugin to support Llama 3 8B Instruct on systems with just 8GB of RAM, a boon for users with devices like the M2 MacBook Pro.
Plugin Ready for Install: Version 0.4 of the llm-gpt4all plugin is now available, enabling the interaction with new models like Llama 3 8B Instruct, as detailed in the latest GitHub release.
Diving Deep with Llama 3: SimonW has provided a comprehensive look at the capabilities of Llama 3, characterized as the leading openly licensed model, via a detailed blog post.
Alignment Lab AI Discord
- LLAMA 3 Explained for AI Newbies: LLAMA 3 model's transformer architecture is broken down in a Beginner’s Guide on YouTube, which targets newcomers to the machine learning field seeking to understand this advanced model. The guide emphasizes the model's capabilities and its role in modern AI development.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (1039 messages🔥🔥🔥):
- Unsloth AI Development Discussion: The conversation included discussions on various technologies and strategies related to fine-tuning, pretraining, and utilizing Unsloth AI for different applications, with members sharing their experiences with training models.
- Concerns Regarding Llama Models and Notebook Sharing: Users expressed concerns about individuals selling or monetizing the open-source notebooks provided by Unsloth AI and discussed the ethics of these actions.
- YouTube Content Creators on AI Topics: There was a healthy debate about various YouTube channels that focus on AI, with recommendations for channels that cover AI research papers and engage in meaningful discussions.
- Technical Issues and GPU Usage: Members encountered technical difficulties with Hugging Face being down and discussed strategies for GPU utilization for training large models and the potential use of Unsloth AI to enhance context lengths.
- Community Support and Learning Journeys: There was a sharing of links and resources for learning about AI, and a member expressed gratitude for community support. Conversations also delved into personal journeys of learning and working with AI, emphasizing the swift pace of development in the field.
- Twitch: no description found
- no title found: no description found
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- imone/Llama-3-8B-fixed-special-embedding · Hugging Face: no description found
- Google Colaboratory: no description found
- chargoddard/llama3-42b-v0 · Hugging Face: no description found
- Training Compute-Optimal Large Language Models: We investigate the optimal model size and number of tokens for training a transformer language model under a given compute budget. We find that current large language models are significantly undertra...
- Kaggle Llama-3 8b Unsloth notebook: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- Unsloth - 4x longer context windows & 1.7x larger batch sizes: Unsloth now supports finetuning of LLMs with very long context windows, up to 228K (Hugging Face + Flash Attention 2 does 58K so 4x longer) on H100 and 56K (HF + FA2 does 14K) on RTX 4090. We managed...
- Practical Deep Learning for Coders - Practical Deep Learning: A free course designed for people with some coding experience, who want to learn how to apply deep learning and machine learning to practical problems.
- Build a robust text-to-SQL solution generating complex queries, self-correcting, and querying diverse data sources | Amazon Web Services: Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. This generative AI task is...
- unsloth/unsloth/tokenizer_utils.py at main · unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- unsloth/unsloth/tokenizer_utils.py at main · unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- "okay, but I want Llama 3 for my specific use case" - Here's how: If you want a personalized AI strategy to future-proof yourself and your business, join my community: https://www.skool.com/new-societyFollow me on Twitter -...
- profiling-cuda-in-torch/ncu_logs at main · cuda-mode/profiling-cuda-in-torch: Contribute to cuda-mode/profiling-cuda-in-torch development by creating an account on GitHub.
- Add support for loading checkpoints with newly added tokens. by charlesCXK · Pull Request #272 · unslothai/unsloth: no description found
- GitHub - aulukelvin/LoRA_E5: Contribute to aulukelvin/LoRA_E5 development by creating an account on GitHub.
- GitHub - oKatanaaa/unsloth: 5X faster 60% less memory QLoRA finetuning: 5X faster 60% less memory QLoRA finetuning. Contribute to oKatanaaa/unsloth development by creating an account on GitHub.
- Direct Preference Optimization (DPO): Get the Dataset: https://huggingface.co/datasets/Trelis/hh-rlhf-dpoGet the DPO Script + Dataset: https://buy.stripe.com/cN2cNyg8t0zp2gobJoGet the full Advanc...
- hu-po: Livestreams on ML papers, Coding, Research Available for consulting and contract work. ⌨️ GitHub https://github.com/hu-po 💬 Discord https://discord.gg/pPAFwndTJd 📸 Instagram http://instagram.com...
- Yannic Kilcher: I make videos about machine learning research papers, programming, and issues of the AI community, and the broader impact of AI in society. Twitter: https://twitter.com/ykilcher Discord: https://ykil...
- Umar Jamil: I'm a Machine Learning Engineer from Milan, Italy currently living in China, teaching complex deep learning and machine learning concepts to my cat, 奥利奥. 我也会一点中文.
- code_your_own_AI: Explains new tech. Code new Artificial Intelligence (AI) models with @code4AI - where complex AI concepts are demystified with clarity grounded in theoretical physics. Delve into the latest advancemen...
- Hugging Face status : no description found
- main : add Self-Extend support by ggerganov · Pull Request #4815 · ggerganov/llama.cpp: continuation of #4810 Adding support for context extension to main based on this work: https://arxiv.org/pdf/2401.01325.pdf Did some basic fact extraction tests with ~8k context and base LLaMA 7B v...
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
- Llama 3 Enhances Unsloth Training: Unsloth AI announces Llama 3's integration, heralding a 2x speed increase in training and 60% reduction in memory usage. Detailed information and release notes are available on their GitHub Release page.
- Explore Llama 3 with Free Notebooks: Users are invited to test out Llama 3 using provided free notebooks on Google Colab and Kaggle, with support for both 8B and 70B Llama 3 models.
- Discover 4-bit Llama-3 Models: For those interested in more efficient model sizes, Unsloth AI shares links to Llama-3 8B, 4bit bnb and Llama-3 70B, 4bit bnb on Hugging Face, alongside other model variants like Instruct on their Hugging Face page.
- Invitation to Experiment with Llama 3: The Unsloth AI team encourages the community to share, test, and discuss their models and results with the newly released Llama 3.
Link mentioned: Google Colaboratory: no description found
Unsloth AI (Daniel Han) ▷ #random (99 messages🔥🔥):
- Llama 3 Model Release and Resources: Unsloth AI released Llama 3 70B INSTRUCT 4bit, facilitating faster fine-tuning of Mistral, Gemma, and Llama models with significantly less memory usage. A Google Colab notebook for Llama-3 8B is provided for community use.
- Tutorials on the Horizon: In response to a request for guidance on finetuning instruct models, Unsloth AI confirmed that they are planning to release explanatory tutorials and a potentially helpful notebook soon.
- Coders in Confession: Members shared lighthearted anecdotes about the perplexing nature of coding—mentioning instances of creating functions without fully grasping their inner workings, and seeking advice on displaying output stats for a program generating character conversations.
- PyTorch and CUDA Education Resource: Participants shared valuable resources for learning about PyTorch and CUDA, including the CUDA Mode YouTube channel for lectures and a recommendation to follow Edward Yang's PyTorch dev Twitch streams.
- Efficiency Versus Performance in LLM Training: Discussions about whether to use models like Llama 3 or Gemma versus GPT-4 for tasks centered on the need for a balance between computing resource efficiency and desired performance levels. The community indicates keeping infrastructure costs low is a motivating factor, even if it means settling for smaller models.
- no title found: no description found
- unsloth/llama-3-70b-Instruct-bnb-4bit · Hugging Face: no description found
- Q*: Like 👍. Comment 💬. Subscribe 🟥.🏘 Discord: https://discord.gg/pPAFwndTJdhttps://github.com/hu-po/docsFrom r to Q∗: Your Language Model is Secretly a Q-Fun...
- CUDA MODE: A CUDA reading group and community https://discord.gg/cudamode Supplementary content here https://github.com/cuda-mode Created by Mark Saroufim and Andreas Köpf
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Unsloth AI (Daniel Han) ▷ #help (823 messages🔥🔥🔥):
- Inference Issues and Fixes: Multiple users reported issues with looped response generation when inferencing LLaMA 3 models. Fixes include applying
StoppingCriteriaand usingeos_token, but inconsistencies remain across platforms like Ollama vs. llama.cpp. - Quantization Quandaries: While quantizing LLaMA 3 to GGUF, one user found a significant drop in quality (wrong sentences, spelling errors) when running the model on Ollama.
- Training Tips and Tricks: There was an exchange on whether using 4-bit Unsloth models could lead to faster training iterations, with responses highlighting compute optimization but potential memory bandwidth limitations.
- Token Troubles: Users are confused about eos_token settings, and how they affect model responses. A solution shared by Daniel involves setting eos_token to ensure proper termination of responses.
- Hardware Highlights: A discussion about the new NVIDIA Jetson Orin nano and its ability to run large language models efficiently, even surpassing the performance of some personal computers.
- no title found: no description found
- OrpoLlama-3-8B - a Hugging Face Space by mlabonne: no description found
- Fine-tuning | How-to guides: Full parameter fine-tuning is a method that fine-tunes all the parameters of all the layers of the pre-trained model.
- G-reen/EXPERIMENT-ORPO-m7b2-1-merged · Hugging Face: no description found
- Love Actually Christmas GIF - Love Actually Christmas Christmas Movie - Discover & Share GIFs: Click to view the GIF
- Tomeu Vizoso's Open Source NPU Driver Project Does Away with the Rockchip RK3588's Binary Blob: Anyone with a Rockchip RK3588 and a machine-learning workload now has an alternative to the binary-blob driver, thanks to Vizoso's efforts.
- Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Carson Wcth GIF - Carson WCTH Happens To The Best Of Us - Discover & Share GIFs: Click to view the GIF
- config.json · Finnish-NLP/llama-3b-finnish-v2 at main: no description found
- Atom Real Steel GIF - Atom Real Steel Movie - Discover & Share GIFs: Click to view the GIF
- Issues · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- unslo: GitHub is where unslo builds software.
- unsloth_finetuning/src/finetune.py at main · M-Chimiste/unsloth_finetuning: Contribute to M-Chimiste/unsloth_finetuning development by creating an account on GitHub.
- save_pretrained_gguf method RuntimeError: Unsloth: Quantization failed .... · Issue #356 · unslothai/unsloth: /usr/local/lib/python3.10/dist-packages/unsloth/save.py in save_to_gguf(model_type, model_directory, quantization_method, first_conversion, _run_installer) 955 ) 956 else: --> 957 raise RuntimeErro...
- I got unsloth running in native windows. · Issue #210 · unslothai/unsloth: I got unsloth running in native windows, (no wsl). You need visual studio 2022 c++ compiler, triton, and deepspeed. I have a full tutorial on installing it, I would write it all here but I’m on mob...
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - sgl-project/sglang: SGLang is a structured generation language designed for large language models (LLMs). It makes your interaction with models faster and more controllable.: SGLang is a structured generation language designed for large language models (LLMs). It makes your interaction with models faster and more controllable. - sgl-project/sglang
- Reddit - Dive into anything: no description found
- Trainer: no description found
- teknium/OpenHermes-2.5 · Datasets at Hugging Face: no description found
- Index of /: no description found
- Hugging Face status : no description found
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- llama3 family support · Issue #6747 · ggerganov/llama.cpp: llama3 released would be happy to use with llama.cpp https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6 https://github.com/meta-llama/llama3
{kind=link}
Unsloth AI (Daniel Han) ▷ #showcase (54 messages🔥):
- Llama3 Fine-Tuning Success: A member shared their successful experience fine-tuning Llama3 for Arabic using the Unsloth Notebook and provided a LinkedIn post showcasing the results. The member mentioned that no modifications were made to the tokenizer as Llama3's tokenizer already understood Arabic well.
- Mistral-Based Swedish Model Preview: Another member presented their newly created Swedish language model based on Llama 3 Instruct named 'bellman', with the training process documented. For interested parties, a HuggingFace link and a model card were provided, alongside an invitation for feedback and specific version requests.
- New Language Models on the Block: Excitement surrounded the release of Ghost 7B Alpha language model, focusing on reasoning and multi-task knowledge with tool support and featuring two main optimized languages: English and Vietnamese. Members appreciated the work, especially the accompanying website and demo.
- Solving GGUf Conversion and Generation Challenges: Members exchanged tips on successfully training and converting models with Unsloth, including setting the correct end-of-sentence token and template formatting. They shared technical snippets around using convert.py, adjusting tokenizer settings, and resolving infinite loop generation issues—leading to a functional Polish model using Llama3.
- Unveiling MasherAI's New Iteration: A member announced the release of MasherAI 7B v6.1, trained using Unsloth and Huggingface's TRL library with an Apache 2.0 license. The model is showcased on HuggingFace and already downloaded multiple times, indicating eagerness among the community to utilize the new generation model.
- neph1/llama-3-instruct-bellman-8b-swe-preview · Hugging Face: no description found
- mahiatlinux/MasherAI-7B-v6.1 · Hugging Face: no description found
- ghost-x/ghost-7b-alpha · Hugging Face: no description found
- Ghost 7B Alpha: The large generation of language models focuses on optimizing excellent reasoning, multi-task knowledge, and tools support.
- Playground with Ghost 7B Alpha: To make it easy for everyone to quickly experience the Ghost 7B Alpha model through platforms like Google Colab and Kaggle. We've made these notebooks available so you can get started right away.
- Support Llama 3 conversion by pcuenca · Pull Request #6745 · ggerganov/llama.cpp: The tokenizer is BPE.
Unsloth AI (Daniel Han) ▷ #suggestions (67 messages🔥🔥):
- Discussions on Model Merging and CUDA Debugging: Members touched upon merging models and the difficulties in using CUDA with Google Colab. One suggested using SSH for better experience and shared a guide on setting up a remote Jupyter notebook with SSH.
- Challenge with Welcome Message: A newbie pointed out difficulties with the welcome message's color scheme on PC, prompting a change from the team to make it more readable.
- LLAMA 3 Release and Vision for Multi-GPU: There's anticipation for multi-GPU capabilities following the release of LLAMA 3, with hints at Unsloth Studio being a future development.
- Potential Color Scheme Tweaks for Newcomers: A member suggested revising the welcome message color scheme for better readability, leading to an admin updating it and acknowledging the importance of accessibility.
- Jobs Channel Debate: A debate over the utility and potential risks of a dedicated #jobs channel on the Unsloth AI Discord; concerns include scammer activity and a shift away from the server's focus on Unsloth-specific issues.
- Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
- How To Run Remote Jupyter Notebooks with SSH on Windows 10: Being able to run Jupyter Notebooks on remote systems adds tremendously to the versatility of your workflow. In this post I will show a simple way to do this by taking advantage of some nifty features...
Perplexity AI ▷ #general (1038 messages🔥🔥🔥):
- Perplexity's AI Models Discussed: Members mentioned different AI models in the channel, including Llama 3, Claude 3 Opus, GPT-4, and GPT-4 Turbo. They compared their experiences with these models for various tasks such as legal document analysis, coding, and responding to prompts.
- Perplexity's Usage Limits and Visibility: It was noted by members that Perplexity has a daily limit of 50 queries for Claude 3 Opus. Further discussions included that the usage counter only becomes visible when 10 messages are left.
- Suggestions and Questions About AI Development and Funding: One user sought mentorship and funding for AI development, discussing their young age and lack of qualifications. Community members suggested educational resources, applying to incubators like Y Combinator, and focusing on internet-based learning.
- Perplexity Labs and Self-Hosting: Discussions included the ability to use other models within Perplexity Labs and self-host models locally. One user shared a guide on setting up Ollama Web UI to operate LLM models offline.
- Unauthorized Model Usage and Security: There was a conversation about non-legit API keys usage in Chinese websites, as well as the existence of a market for trading such accounts. Users advised multiple sourcing to avoid outages and expressed concern about such practices impacting service reliability.
- Perplexity Model Selection: Adds model selection buttons to Perplexity AI using jQuery
- 🏡 Home | Open WebUI: Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs.
- GroqCloud: Experience the fastest inference in the world
- More than an OpenAI Wrapper: Perplexity Pivots to Open Source: Perplexity CEO Aravind Srinivas is a big Larry Page fan. However, he thinks he's found a way to compete not only with Google search, but with OpenAI's GPT too.
- Use Your Self-Hosted LLM Anywhere with Ollama Web UI: no description found
- Apply to Y Combinator | Y Combinator: To apply for the Y Combinator program, submit an application form. We accept companies twice a year in two batches. The program includes dinners every Tuesday, office hours with YC partners and access...
- Languages used on the Internet - Wikipedia: no description found
- Andrej Karpathy: FAQ Q: How can I pay you? Do you have a Patreon or etc? A: As YouTube partner I do share in a small amount of the ad revenue on the videos, but I don't maintain any other extra payment channels. I...
- Tweet from Aravind Srinivas (@AravSrinivas): 8b is so good. Can create a lot more experiences with it. We have some ideas. Stay tuned! ↘️ Quoting MachDiamonds (@andromeda74356) @AravSrinivas Will you be switching the free perplexity version t...
- Think About It Use Your Brain GIF - Think About It Use Your Brain Use The Brain - Discover & Share GIFs: Click to view the GIF
- Yt Youtube GIF - Yt Youtube Logo - Discover & Share GIFs: Click to view the GIF
- eternal mode • infinite backrooms: the mad dreams of an artificial intelligence - not for the faint of heart or mind
- Morphic: A fully open-source AI-powered answer engine with a generative UI.
- Robot Depressed GIF - Robot Depressed Marvin - Discover & Share GIFs: Click to view the GIF
- llm-sagemaker-sample/notebooks/deploy-llama3.ipynb at main · philschmid/llm-sagemaker-sample: Contribute to philschmid/llm-sagemaker-sample development by creating an account on GitHub.
- Lo último de OpenAI llega a Copilot. El asistente de programación evoluciona con un nuevo modelo de IA: En el último año, la inteligencia artificial no solo ha estado detrás de generadores de imágenes como DALL·E y bots conversacionales como ChatGPT, también ha...
- Perplexity CTO Denis Yarats on AI-powered search: Perplexity is an AI-powered search engine that answers user questions. Founded in 2022 and valued at over $1B, Perplexity recently crossed 10M monthly active...
- Amazon invierte 4.000 millones de dólares en Anthropic para hacer frente a ChatGPT: la lucha por la mejor IA solo acaba de comenzar: OpenAI agitó a toda la industria con el lanzamiento de ChatGPT, haciendo que cada vez más empresas inviertan en tecnologías de IA generativa. Esto ha dado...
- GitHub - developersdigest/llm-answer-engine: Build a Perplexity-Inspired Answer Engine Using Next.js, Groq, Mixtral, Langchain, OpenAI, Brave & Serper: Build a Perplexity-Inspired Answer Engine Using Next.js, Groq, Mixtral, Langchain, OpenAI, Brave & Serper - developersdigest/llm-answer-engine
- AWS re:Invent 2023 - Customer Keynote Anthropic: In this AWS re:Invent 2023 fireside chat, Dario Amodei, CEO and cofounder of Anthropic, and Adam Selipsky, CEO of Amazon Web Services (AWS) discuss how Anthr...
- AWS re:Invent 2023 - Customer Keynote Perplexity | AWS Events: Hear from Aravind Srinivas, cofounder and CEO of Perplexity, about how the conversational artificial intelligence (AI) company is reimagining search by provi...
- Eric Gundersen Talks About How Mapbox Uses AWS to Map Millions of Miles a Day: Learn more about how AWS can power your big data solution here - http://amzn.to/2grdTah.Mapbox is collecting 100 million miles of telemetry data every day us...
- no title found: no description found
- Rick Astley - Never Gonna Give You Up (Official Music Video): The official video for “Never Gonna Give You Up” by Rick Astley. The new album 'Are We There Yet?' is out now: Download here: https://RickAstley.lnk.to/AreWe...
- GitHub - xx025/carrot: Free ChatGPT Site List 这儿为你准备了众多免费好用的ChatGPT镜像站点: Free ChatGPT Site List 这儿为你准备了众多免费好用的ChatGPT镜像站点. Contribute to xx025/carrot development by creating an account on GitHub.
Perplexity AI ▷ #sharing (29 messages🔥):
- Perplexity AI Making Waves: Infosys co-founder Nandan Nilekani praised Perplexity AI, referring to it as a 'Swiss Army Knife' search engine following a meeting with its co-founder Aravind Srinivasan.
- YouTube Insights on Perplexity AI's Rise: A YouTube video titled "Inside The Buzzy AI StartUp Coming For Google's Lunch" features Perplexity AI's journey and their long wait for an audience with Meta AI chief Yann LeCun.
- High-value Discussions Around Perplexity AI: Community members shared a variety of links to Perplexity AI search queries, exploring topics from HDMI usage to insights on positive parenting and Apple news.
- Sharing the Perplexity AI Experience: A call was made to ensure threads are shareable as members engaged with different Perplexity AI search queries, highlighting the collaborative nature of the community.
- Media Spotlight on Perplexity AI's Leadership: Another YouTube video, titled "Perplexity CTO Denis Yarats on AI-powered search", dives into the engine's user-focused capabilities and its significant growth since the foundation.
- Nandan Nilekani had this stunning thing to say about Aravind Srinivas' 'Swiss Army Knife' search engine: What Nandan Nilekani had to say about Perplexity AI, will make you rush to sign up with Aravind Srinivasan’s ‘Swiss Army Knife’ search engine.
- Inside The Buzzy AI StartUp Coming For Google's Lunch: In August 2022, Aravind Srinivas and Denis Yarats waited outside Meta AI chief Yann LeCun’s office in lower Manhattan for five long hours, skipping lunch for...
- Perplexity CTO Denis Yarats on AI-powered search: Perplexity is an AI-powered search engine that answers user questions. Founded in 2022 and valued at over $1B, Perplexity recently crossed 10M monthly active...
Perplexity AI ▷ #pplx-api (4 messages):
- Seeking Constrained API Responses: A member reported difficulties in trying to make the API respond with a choice from an exact list of words, even after instructing it to do so. They mentioned trying with Sonar Medium Chat and Mistral models without success.
- Looking for a Helping Hand: The same member sought assistance from others regarding their issue but received no immediate response.
- Clarification on API Credits Refresh Rate: The member inquired about how often remaining API credits are updated, questioning whether it takes minutes, seconds, or hours after running a script with API requests.
Nous Research AI ▷ #ctx-length-research (7 messages):
- Long Context Inference on Multi-GPU a Puzzle: Yorth_night is looking for guidance on conducting long context inference with Jamba using multiple GPUs. Despite consulting deepspeed and accelerate docs, they haven't found information on long context generation.
- Seeking Progress Update on Jamba Multi-GPU Use: Bexboy inquires if there has been any progress on the issue Yorth_night is facing.
- VLLM Could Be the Key for Jamba, But No Support Yet: Yorth_night discovered in another discussion that vllm with tensor parallel might be a solution; however, vllm currently does not support Jamba.
- A Jamba API Would Be Handy: Yorth_night expresses a desire for a Jamba API that could handle entire contexts, which would help in evaluating the model's capability for their specific task.
- Cutting Costs on Claude 3 and Big-AGI with Context Management: Rundeen faces challenges with the expensive context expansion on Claude 3 and Big-AGI. They found memGPT and SillyTavern SmartContext and are in search of other solutions that can manage the context economically without redundant or incorrect information.
Nous Research AI ▷ #off-topic (12 messages🔥):
- Beats and Bytes: Members shared music video links for entertainment, including the Beastie Boys' "Root Down" (REMATERED IN HD YouTube video) and deadmau5 & Kaskade's "I Remember" (HQ YouTube video).
- Encoded CIFAR100 Dataset Now Available: A community member released a latently encoded CIFAR100 dataset accessible on Hugging Face, recommending the sdxl-488 version due to the size of the latents.
- Small Scale Model Surprises: Initial experiments with a simple FFN on the latent CIFAR100 dataset showed an approximate 19% accuracy, which was surprising given most latents don’t decode properly.
- Exploring Larger Image Classification Datasets: Inquiry about commonly used image classification datasets that are in the 64x64 or 128x128 resolution for further experimenting.
- Law, Language, and AI Intersect: A member, who has a legal background, offered to share papers on the topic of semantic networks and knowledge graphs in vector spaces, highlighting the significance of symbolic systems that follow a power law in both language and law. Another user reciprocated by sharing related arXiv papers on language models and linguistic bias.
- Do Llamas Work in English? On the Latent Language of Multilingual Transformers: We ask whether multilingual language models trained on unbalanced, English-dominated corpora use English as an internal pivot language -- a question of key importance for understanding how language mo...
- The Linear Representation Hypothesis and the Geometry of Large Language Models: Informally, the 'linear representation hypothesis' is the idea that high-level concepts are represented linearly as directions in some representation space. In this paper, we address two close...
- Hellinheavns GIF - Hellinheavns - Discover & Share GIFs: Click to view the GIF
- Verah/latent-CIFAR100 · Datasets at Hugging Face: no description found
- Beastie Boys - Root Down: REMASTERED IN HD!Read the story behind Ill Communication here: https://www.udiscovermusic.com/stories/ill-communication-beastie-boys-album/Listen to more fro...
- deadmau5 & Kaskade - I Remember (HQ): ▶︎ https://deadmau5.ffm.to/randomalbumtitle follow deadmau5 & friends here: https://sptfy.com/PjDOcurrent tour info here: https://deadmau5.com/showsjoin the ...
Nous Research AI ▷ #interesting-links (2 messages):
- DeepMind's Penzai for Neural Network Innovation: DeepMind has released Penzai, a JAX research toolkit aimed at building, editing, and visualizing neural networks, available on GitHub with comprehensive features for AI researchers and developers.
- Call for Beta Testers with AI Bonanza: An announcement for a new advanced research assistant and search engine that includes premium access to Claude 3 Opus, GPT-4 Turbo, Mistral Large, and more. Interested parties can become beta testers and receive two months of free premium access by using the promo code
RUBIXat rubiks.ai.
Link mentioned: GitHub - google-deepmind/penzai: A JAX research toolkit for building, editing, and visualizing neural networks.: A JAX research toolkit for building, editing, and visualizing neural networks. - google-deepmind/penzai
Nous Research AI ▷ #announcements (2 messages):
- Worldsim Revival with New Features: Worldsim is back, introducing a wealth of new features like WorldClient, a web simulator; Root, a CLI environment; Mind Meld, an entity exploration tool; MUD, a text-based game; and tableTop, a tabletop RPG simulator. Users now have the ability to select models (Opus, Sonnet, or Haiku) to tailor costs.
- Pay-As-You-Go Model for Sustainability: To combat spam and abuse, Worldsim is rebooting with a pay-as-you-go system for tokens.
- Temporary Setback: Shortly after the announcement, the service faced issues with the payment system resulting in downtime. An update is promised once the issues are resolved.
Link mentioned: world_sim: no description found
Nous Research AI ▷ #general (594 messages🔥🔥🔥):
- Dissecting Llama 3 Performance: Members noted that Llama 3 8B performs only marginally better than Mistral 7B despite having more parameters and training data, with a focus on Multimodal Model Leaderboard (MMLU) where Llama 3 shows notable strength. There was also speculation on whether base models are reaching a saturation point, while improvements may come from fine-tuning techniques like In-Context Learning and Reinforcement Learning from Human Feedback (RLHF).
- Llama 3 70B Still in Spotlight: Despite disillusionment with Llama 3 8B, there is optimism about the capabilities of Llama 3 70B, with discussions around its stronger performance, potential for agent applications on platforms like Groq, and how Meta AI utilizes it in products like WhatsApp and Instagram.
- Grokking Out of Vogue?: The term 'grokking' seems to be falling out of use in the community, with differing opinions on why and whether it's appropriately applied outside its original sci-fi and Linux sysadmin contexts.
- LLM Ensemble: The interplay between LLM's internal knowledge and retrieved information was explored, highlighting whether Retrieval-Augmented Generation (RAG) fixes model mistakes or inadvertently propagates incorrect retrieved content.
- Hugging Face Services Affected: High usage due to FineWeb, a 15 trillion-token, high quality dataset, may have caused performance issues for Hugging Face's services, including hf.space, though details about the specific cause were not confirmed.
- EvalPlus Leaderboard: no description found
- NousResearch/Genstruct-7B · Hugging Face: no description found
- Tweet from Justine Tunney (@JustineTunney): @sytelus Meta LLaMA3 70B going 38 tok/sec with 8192 token context window using llamafile v0.7.1.
- How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs' internal prior: Retrieval augmented generation (RAG) is often used to fix hallucinations and provide up-to-date knowledge for large language models (LLMs). However, in cases when the LLM alone incorrectly answers a q...
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: no description found
- Train and Fine-Tune Sentence Transformers Models: no description found
- Rage GIF - Rage - Discover & Share GIFs: Click to view the GIF
- Tweet from Binyuan Hui (@huybery): Just evaluated coding abilities of Llama3-8B-base👇🏻
- no title found: no description found
- LLM In-Context Recall is Prompt Dependent: The proliferation of Large Language Models (LLMs) highlights the critical importance of conducting thorough evaluations to discern their comparative advantages, limitations, and optimal use cases. Par...
- Tweet from Guilherme Penedo (@gui_penedo): We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data. We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, ...
- Tweet from Thilak Rao (@Thilak): Just got Llama 3 8B Instruct by @Meta up and running on my iPhone with @private_llm, running fully on-device on my iPhone with a full 8K context on 8GB devices. Coming to all iPhones with 6GB or mor...
- Tweet from Benjamin Warner (@benjamin_warner): If finetuning Llama 3 w/ Hugging Face, use Transformers 4.37 or 4.40. Llama & Gemma in 4.38 & 4.39 don't use PyTorch's Flash Attention 2 kernel, leading to high memory usage. 4.40 uses FA2 ...
- OpenRouter: A router for LLMs and other AI models
- Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models: Large language models (LLMs) have shown impressive results while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scen...
- GitHub - google-research-datasets/Attributed-QA: We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in information-seeking scenarios. This release consists of human-rated system outputs for a new question-answering task, Attributed Question Answering (AQA).: We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in information-seeking scenarios. This release consists of huma...
- Tweet from Philipp Schmid (@_philschmid): I am experimenting with fine-tuning Llama 3 8B (70B) using Q-LoRA. For convenience, I wanted to stick to the Llama 3 Instruct template. Two things I noticed so far: 1. It seems like pre-training of...
- GitHub - google-research-datasets/QuoteSum: QuoteSum is a textual QA dataset containing Semi-Extractive Multi-source Question Answering (SEMQA) examples written by humans, based on Wikipedia passages.: QuoteSum is a textual QA dataset containing Semi-Extractive Multi-source Question Answering (SEMQA) examples written by humans, based on Wikipedia passages. - google-research-datasets/QuoteSum
- GitHub - FasterDecoding/Medusa: Medusa: Simple Framework for Accelerating LLM Generation with Multiple Decoding Heads: Medusa: Simple Framework for Accelerating LLM Generation with Multiple Decoding Heads - FasterDecoding/Medusa
- Beastie Boys - Sabotage: REMASTERED IN HD!Read the story behind Ill Communication here: https://www.udiscovermusic.com/stories/ill-communication-beastie-boys-album/Listen to more fro...
- GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
- GitHub - stanfordnlp/pyreft: ReFT: Representation Finetuning for Language Models: ReFT: Representation Finetuning for Language Models - stanfordnlp/pyreft
- no title found: no description found
- Replete-AI/Rombo-Hermes-2.5-Extra-code · Datasets at Hugging Face: no description found
Nous Research AI ▷ #ask-about-llms (56 messages🔥🔥):
- Discussing Fine-Tuning LLMs: When finetuning models such as llama 3, one member inquired if they should finetune over the base model or the instruct model with 1000 rows of alpaca format jsonl, containing instruction, empty input, and output.
- vLLM's Jamba Support in Progress: The vLLM project is actively working on supporting Jamba, as indicated by Pull Request #4115 on GitHub, which includes adding Jamba modeling files and Mamba memory handling.
- Deepspeed Zero Optimization Queries: A user reported that going from Deepspeed stage 2 to stage 3 resulted in a noticeable slowdown in training times, and another member confirmed that Deepspeed stage 3 (DS3) is expected to be slower due to higher inter-GPU communication overhead.
- NVLink and Layer Splitting Across GPUs: A discussion about the optimal use of two RTX 3090's with NVLink suggested that performance gains from splitting layers across GPUs for single-prompt tasks are likely negated by the overheads associated with communication and coordination between the GPUs.
- Synthetic Data Generation for Fine-Tuning: There was a debate about the best practices for generating synthetic data with models like llama3-70b for fine-tuning tasks, with caution advised regarding licensing restrictions when using generated data from one LLM to potentially improve another.
- chargoddard/mistral-11b-slimorca · Hugging Face: no description found
- [Model] Jamba support by mzusman · Pull Request #4115 · vllm-project/vllm: Add Jamba support to vLLM, This PR comprises two parts: the Jamba modeling file and the Mamba memory handling. Since Jamba is a hybrid model (which alternates between mamba and transformer layers),...
Nous Research AI ▷ #project-obsidian (7 messages):
- RealWorldQA Bench Dataset Unveiled: xAI released the RealWorldQA benchmark dataset for Grok-1.5-vision-preview, with various questions challenging AI's understanding of object sizes, distances, traffic rules, and directions in real-world scenes.
- Bench, not Train: The dataset was initially misunderstood as a training set, but clarification confirmed that it is a benchmark. The details are outlined on xAI's blog, featuring examples like translating flowcharts into Python code.
- Obsidian's New Challenger: Members of project-obsidian consider the RealWorldQA dataset to be a potentially good benchmark to test future versions of Obsidian.
- Anticipation for Training Data: Despite the excitement, a playful sentiment was expressed for the desire of a new training set, alongside the existing benchmark.
- Grok-1.5 Vision Preview: no description found
- xai-org/RealworldQA · Datasets at Hugging Face: no description found
Nous Research AI ▷ #rag-dataset (61 messages🔥🔥):
- Challenges of Unified vs. Specific RAG Databases: Members discussed the effectiveness of large unified RAG databases versus numerous, smaller topic-specific RAG databases. Concerns arose about the "catastrophic" impact of retrieving from a "totally wrong" index—having information about ducks' db proteins instead of DuckDB, for example, would severely deteriorate performance.
- Seeking RAG Benchmark Systems: Participants sought recommendations for standard datasets and benchmarks to evaluate RAG systems. A link to OpenAI's RAG evaluation with llmaindex was suggested as a potential tool.
- LLama vs. Mistral for RAG: Conversations compared the efficacy of different models within RAG setups, citing Mistral 7b Instruct and llama 3 instruct. The group seemed to reach a consensus that Mistral 7b v2 currently outperforms others in standard evaluations.
- RAG-Related Research Paper Sharing: The channel shared and discussed various research papers on RAG, featuring topics like superposition prompting and credibility-aware generation. One paper introduced an approach for improving and accelerating retrieval-augmented generation, while others tackled the issue of incorporating external real-world data to improve the accuracy and reliability of LLM outputs.
- Implementing Unique RAG Approaches: There was a brief mention of superposition prompting being used in production systems, with discussions on how to rank and order information using metadata. Additionally, they shared thoughts on modifying the attention matrix during inference, leveraging document metadata, and understanding information structure to enhance model performance.
- LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding: Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc...
- A Survey on Retrieval-Augmented Text Generation for Large Language Models: Retrieval-Augmented Generation (RAG) merges retrieval methods with deep learning advancements to address the static limitations of large language models (LLMs) by enabling the dynamic integration of u...
- Evaluate RAG with LlamaIndex | OpenAI Cookbook: no description found
- Tweet from Stella Biderman (@BlancheMinerva): Create a benchmark for RAG models where all of the questions require information from multiple documents to be synthesized answer them. Study how models trained on publicly released data do on it and ...
- Superposition Prompting: Improving and Accelerating Retrieval-Augmented Generation: Despite the successes of large language models (LLMs), they exhibit significant drawbacks, particularly when processing long contexts. Their inference cost scales quadratically with respect to sequenc...
- Not All Contexts Are Equal: Teaching LLMs Credibility-aware Generation: The rapid development of large language models has led to the widespread adoption of Retrieval-Augmented Generation (RAG), which integrates external knowledge to alleviate knowledge bottlenecks and mi...
- RAR-b: Reasoning as Retrieval Benchmark: Semantic textual similartiy (STS) and information retrieval tasks (IR) tasks have been the two major avenues to record the progress of embedding models in the past few years. Under the emerging Retrie...
- A RAG Method for Source Code Inquiry Tailored to Long-Context LLMs: Although the context length limitation of large language models (LLMs) has been mitigated, it still hinders their application to software development tasks. This study proposes a method incorporating ...
Nous Research AI ▷ #world-sim (660 messages🔥🔥🔥):
- Probing the Depths of WorldSim: Members are eagerly awaiting the return of WorldSim, frequently asking for updates about the platform's status. Concerns about 4chan's previous exploitation and the resulting cost implications are frequently mentioned, with some users expressing regret over potentially never being able to use WorldSim again due to the monetization strategy.
- Community Crafts Alternatives: In response to WorldSim's downtime, members like snowly182 and jetblackrlsh have created alternative simulations on Hugging Chat using Llama 3, offering free unlimited access and include features like D&D mode.
- Llama 3's Context and Capabilities: Discussion around extending Llama 3's context length has arisen, with members comparing its performance to Claude Opus and expressing that Llama 3, while creative, still falls a few levels below Opus in terms of creativity.
- Exploring Memory with AI: rundeen shares a technique of using a separate instance of GPT-4 to summarize context history, suggesting biomimetics and smarter context management as possible keys to more efficient and cost-effective AI interactions in the future.
- Concerns Over Exclusivity and Costs: Users are voicing concerns over the exclusive use of Claude 3 Opus given its high cost, and the desire for Nous Research to integrate open source models to provide access without financial barriers.
- world_sim: no description found
- Generirao Microsoft Copilot: no description found
- world_sim: no description found
- vicgalle/Worldsim-Hermes-7B · Hugging Face: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
- GroqCloud: Experience the fastest inference in the world
- Karan4D's WorldSim System Prompt Open Source - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Jim Carrey Ohcome On GIF - Jim Carrey Ohcome On - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Snow World Simulator - HuggingChat: Use the Snow World Simulator assistant inside of HuggingChat
- Super World Sim - HuggingChat: Use the Super World Sim assistant inside of HuggingChat
- Image Generator - HuggingChat: Use the Image Generator assistant inside of HuggingChat
- Jailbroken Prometheus Chat: no description found
- nickabenson: Welcome to the Nickabenson Channel Our Patreon: https://www.patreon.com/nickabenson Our Amino: http://aminoapps.com/c/Nickabenson For the most part we do gaming streams, discussions, animations an...
- eternal mode • infinite backrooms: the mad dreams of an artificial intelligence - not for the faint of heart or mind
- Desiderata for an AI — LessWrong: I think a main focus of alignment work should be on redesigning AI from the ground up. In doing so, I think we should keep in mind a set of desirable…
- Uncovering the CIA's Stargate Project and the Superheroic Midwayers: Hashtags:1. #Stargate2. #Midwayer3. #Urantia4. #Spiritual5. #Extraterrestrials6. #InvisibleRealm7. #PlanetarySentinels8. #CIADeclassifiedFiles9. #Supernatura...
- HuggingChat: Making the community's best AI chat models available to everyone.
- Mephisto's Dream | Science Fiction Animatic: Mephisto, a software developer, creates the World Sim, a text-based AI system simulating entire universes with conscious beings, believing user interaction w...
- Suzanne Treister - Amiga Videogame Stills - menu: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
- HuggingChat: Making the community's best AI chat models available to everyone.
- Reddit - Dive into anything: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
- HuggingChat: Making the community's best AI chat models available to everyone.
- Available now at your favorite digital store!: The Architects' Conundrum: Quantumom vs. Data Dad by Nicholas Alexander Benson
LM Studio ▷ #💬-general (722 messages🔥🔥🔥):
- GPU Usage for Multiple Models: Users reported that when adding additional GPUs, LM Studio seems to integrate the VRAM into a larger pool. However, utilization sometimes remains at 100% for CUDA on one GPU or is shared between GPUs.
- LM Studio on MacOS: There are remarks about GPU behavior on Mac systems where Metal may not respect GPU settings adjusted in LM Studio, causing the machine to run hot.
- Searching for Models Issue: Several users experienced issues while trying to search for and download models within LM Studio, with some receiving a
503or500error. This seems to be related to an ongoing Hugging Face downtime.
- RAG vs. VectorDBs Usage Inquiry: A user inquired about when to use Retrieval-Augmented Generation (RAG) with a file versus using a vector database, especially in systems that need to remember user-provided information. The context is for use with Autogen.
- Using LM Studio with Custom Domains: A user inquired about the possibility of hosting a locally running AI through a domain for access from anywhere. They requested advice for beginners on how to achieve this setup.
- Character Counter - WordCounter.net: no description found
- LMStudio | AnythingLLM by Mintplex Labs: no description found
- OpenAI compatibility · Ollama Blog: Ollama now has initial compatibility with the OpenAI Chat Completions API, making it possible to use existing tooling built for OpenAI with local models via Ollama.
- Tweet from LM Studio (@LMStudioAI): Model search / download within LM Studio may be impacted by this Hugging Face downtime. Stay tuned for updates ↘️ Quoting Hugging Face Status (@hf_status) We're experiencing some downtime on h...
- lmstudio-community/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: no description found
- Docker: no description found
- LM Studio Beta Releases: no description found
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: no description found
- Tweet from Teknium (e/λ) (@Teknium1): Welp folks, we have gpt-4 at home
- Local LLM Server | LM Studio: You can use LLMs you load within LM Studio via an API server running on localhost.
- Vision Models (GGUF) - a lmstudio-ai Collection: no description found
- Reddit - Dive into anything: no description found
- lmstudio-community/Meta-Llama-3-70B-Instruct-GGUF at main: no description found
- IBM Technology: Whether it’s AI, automation, cybersecurity, data science, DevOps, quantum computing or anything in between, we provide educational content on the biggest topics in tech. Subscribe to build your skills...
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Big Code Models Leaderboard - a Hugging Face Space by bigcode: no description found
- Qwen/CodeQwen1.5-7B-Chat-GGUF · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- christopherthompson81/quant_exploration · Datasets at Hugging Face: no description found
- Reddit - Dive into anything: no description found
- GitHub - Mintplex-Labs/anything-llm: The all-in-one AI app for any LLM with full RAG and AI Agent capabilites.: The all-in-one AI app for any LLM with full RAG and AI Agent capabilites. - Mintplex-Labs/anything-llm
- GitHub - Crizomb/ai_pdf: Chat locally with any PDF Ask questions, get answer with usefull references Work well with math pdfs (convert them to LaTex, a math syntax comprehensible by computer): Chat locally with any PDF Ask questions, get answer with usefull references Work well with math pdfs (convert them to LaTex, a math syntax comprehensible by computer) - Crizomb/ai_pdf
- Reddit - Dive into anything: no description found
- [1hr Talk] Intro to Large Language Models: This is a 1 hour general-audience introduction to Large Language Models: the core technical component behind systems like ChatGPT, Claude, and Bard. What the...
- GitHub - BBC-Esq/VectorDB-Plugin-for-LM-Studio: Plugin that creates a ChromaDB vector database to work with LM Studio running in server mode!: Plugin that creates a ChromaDB vector database to work with LM Studio running in server mode! - BBC-Esq/VectorDB-Plugin-for-LM-Studio
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF at main: no description found
- GitHub - mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks. - mlabonne/llm-course
- Hugging Face status : no description found
- k-quants by ikawrakow · Pull Request #1684 · ggerganov/llama.cpp: What This PR adds a series of 2-6 bit quantization methods, along with quantization mixes, as proposed in #1240 and #1256. Scalar, AVX2, ARM_NEON, and CUDA implementations are provided. Why This is...
LM Studio ▷ #🤖-models-discussion-chat (358 messages🔥🔥):
- WizardLM Config Confusion: Members are seeking configuration assistance for WizardLM 2, with one attempting to convert the info from the Hugging Face model card into a preset and another member sharing a Reddit tutorial on resolving token issues using llama.cpp commands.
- LM Studio Support for JSON Mode: A member questioned whether JSON mode in LM Studio's Playground would be made available in server mode, but no confirmation or solution was provided.
- Model Behavior Specifics Explored: Discussions centered around the < Instruct > versions of models being trained to provide more coherent and relevant responses compared to Base models, which tend to be more random.
- Llama3 Infinite Loop Issue: Users report issues with Llama3 models entering infinite loops during generation, with suggestions to use specific configurations and updates to address the problem, such as adding stop strings to Advanced Configuration.
- Diverse Llama3 Experiences: Community members shared varied experiences and discussions about the performance and censorship of Llama3, with some members finding the 70B models excelling at instruction compliance, yet others facing nonsensical outputs or excessive content generation. Advice regarding the adjustment of system prompts to affect the AI's behavior and remove censorship was exchanged.
- PyPy’s sandboxing features — PyPy documentation: no description found
- no title found: no description found
- lmstudio-community/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: no description found
- raincandy-u/Llama-3-Aplite-Instruct-4x8B · Hugging Face: no description found
- Yoda Star GIF - Yoda Star Wars - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- configs/llama3.preset.json at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
- MaziyarPanahi/WizardLM-2-7B-GGUF · Hugging Face: no description found
- Models - Hugging Face: no description found
- M3 max 128GB for AI running Llama2 7b 13b and 70b: In this video we run Llama models using the new M3 max with 128GB and we compare it with a M1 pro and RTX 4090 to see the real world performance of this Chip...
- GitHub - OpenInterpreter/open-interpreter: A natural language interface for computers: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
- GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp: Python bindings for llama.cpp. Contribute to abetlen/llama-cpp-python development by creating an account on GitHub.
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
LM Studio ▷ #announcements (1 messages):
- Hugging Face Downtime Affects LM Studio: Users are notified that model search and downloads are currently not functioning due to Hugging Face's downtime. An update is shared from LM Studio's status stating that they are monitoring the situation.
Link mentioned: Tweet from LM Studio (@LMStudioAI): Model search / download within LM Studio may be impacted by this Hugging Face downtime. Stay tuned for updates ↘️ Quoting Hugging Face Status (@hf_status) We're experiencing some downtime on h...
LM Studio ▷ #🧠-feedback (18 messages🔥):
- Ergonomic Grievance on Error Window: A member expressed displeasure about the error display window being too narrow and non-resizable, stating it should be taller due to the vertical layout of the contents.
- Troubleshooting Model Loading Errors: Several users reported errors while loading models with details from their log files, mentioning an exit code and suggesting trying different models or configurations.
- App Update Feature Glitch: A user reported slowness with the in-app update feature which took 30-40 minutes to work, while initially appearing to be non-functional.
- Gratitude for LM Studio: A member expressed heartfelt thanks for LM Studio's impact on their professional writing and AI research, highlighting the tool's importance in task completion.
- Model Malfunction During Generation: A user observed that some models, especially the new llama, malfunction during generating responses, sometimes outputting numbers instead of answers.
- VPN Certificate Issues with LM Studio: Multiple users encountered problems while downloading models in LM Studio through Zscaler VPN, mentioning specific error messages about certificate verification and discussing workarounds.
- CPU Usage Display Inconsistency: A user noted a discrepancy between CPU usage displayed in LM Studio and the Windows Task Manager, with the latter showing significantly higher utilization.
LM Studio ▷ #📝-prompts-discussion-chat (1 messages):
- In Search of Full Code Output: A member expressed frustration with the chatbot omitting parts of code, specifically it neglecting to write full code and instead inserting comments like
// Add similar event listeners for left and right buttons. They are looking for a way to ensure the chatbot consistently outputs the complete code.
LM Studio ▷ #🎛-hardware-discussion (34 messages🔥):
- Grasping GPU Compatibility with LM Studio: A member linked an Amazon page for the NVIDIA Jetson Orin and questioned its compatibility with LM Studio, followed by another confirming that though it might be slower than most desktops, it should work. There was also a link provided to a Reddit GPU buying guide for building a system suitable for LLM Studio.
- Upgrading Laptop for LLM Studio: Inquiries about upgrading GPUs in laptops for better performance with LM Studio revealed advice against it due to the limited upgradeability of laptops, with suggestions to check for external GPU enclosures if the laptop has a Thunderbolt port.
- Configuring LM Studio with Multiple GPUs: Members shared insights on using multiple GPUs, where one member asked about managing power draw for a newly installed GPU when not consistently in use. The consensus suggested that while idle GPUs do have a low power draw, the performance benefits might not justify the power cost and complexity.
- Navigating Configuration Errors in LM Studio: One user encountered an error when trying to load models on a laptop with an unknown GPU detection issue. The solution involved turning off the GPU offload option in the LM Studio settings panel.
- Performance Discussions for Large Models: Users shared their experiences with different GPU setups running variable-sized models in LM Studio. Examples included having different token generation speeds with an RTX 3090 and considering the addition of a second GPU like a GTX 1060 for increased VRAM, despite concerns about power draw and potential minimal performance gains.
- no title found: no description found
- Reddit - Dive into anything: no description found
LM Studio ▷ #🧪-beta-releases-chat (24 messages🔥):
- Model Discovery Issues in LM Studio: A member reported a bug in LM Studio version 0.2.20, where models stored on an NFS mount are not visible to the software even though they were in version 0.2.19 beta B. This issue persisted through versions 0.2.19 beta C, 0.2.19, and 0.2.20, affecting both NFS mounted and local model directories.
- NFS Mounting Strategy for Models Discussed: A conversation about NFS mounting strategies revealed that one member mounts the entire model share parent directory for broad access and another specific directory for LM Studio models, wishing to distinguish between local and remote models for performance reasons.
- Token Misconceptions Clarified: A member clarified that tokens in language models do not necessarily align with syllables, explaining that subword encodings are used which can represent roots, prefixes, and suffixes, rather than whole words or syllables.
- Understanding Token Counts in Language Models: The discussion touched on personal vocabulary compared to language models, questioning the conventional average of 50,000 tokens in training, exploring whether this figure is by design or a compromise between model complexity and performance.
LM Studio ▷ #autogen (20 messages🔥):
- AutoGen Stops After Two Tokens: A member reported that AutoGen stops after generating two tokens when pointed at a local version of LM Llama 3. They expressed frustration as the LLM seems to stop prematurely with default settings in place.
- Marketing Is Not Welcome Here: One user reminded another that marketing tools is not appropriate in the Discord server and asked them to refrain from such activity.
- Token Limit as a Culprit: In response to the above issue, a user suggested replacing the max tokens setting with 3000, indicating that following this step resolved their similar problem without needing to delete any files or agents.
- Potential Fix Leads to Partial Success: After trying the suggested fix involving max tokens, a member found it partially solved the problem, but encountered a new issue where Autogen's user proxy stops responding or incorrectly mimics the agent's responses.
- Trouble with AutoGen Manager Agent: Another user faced difficulties with the AutoGen Manager agent, specifically encountering an "unable to select speaker" error when attempting to use it with a local model. They inquired about others' experiences with this issue.
LM Studio ▷ #rivet (1 messages):
- Unusual Repetition in Server Logs: A member noticed repetitive POST requests in the server logs following the message Processing queued request... and questioned if this behavior is normal. No further context or resolution is mentioned.
LM Studio ▷ #memgpt (1 messages):
- Inquiry about LM Studio Integration: A member inquired about integrating a certain tool with LM Studio and expressed interest in reading any specific project information related to LM Studio. No further details or links were provided in the chat snippet.
LM Studio ▷ #avx-beta (4 messages):
- Exploring Alternatives to LLM Studio: A member examined lllamafile, an alternative that operates across various platforms such as x64, arm64, and most Linux distributions. They highlighted the potential for it to run on devices like a Raspberry Pi, suggesting a desire for LLM Studio to provide support for older CPUs without AVX2 by creating a slower, compatible mode.
- Concerns Over AVX Beta Updates: The member voiced concerns about the AVX beta version potentially lagging behind the main channel builds, indicating that users wish for more frequent updates to keep parity between the beta and main releases.
- Alternative Compute Resources for Model Deployment: The same individual noted a situation where they have a GPU available to assist a non-AVX2 CPU, but the available AVX2 system does not have a GPU to offload computational tasks, pointing out the hardware limitations they face in utilizing LLM Studio effectively.
LM Studio ▷ #amd-rocm-tech-preview (73 messages🔥🔥):
- MetaAI's Llama 3 Makes a Grand Entrance: MetaAI's Llama 3 is now available in LM Studio ROCm Preview 0.2.20, attainable from the official LM Studio ROCm site. Only Llama 3 GGUFs from "lmstudio-community" are functional at present, with the others expected not to work due to a subtle GGUF creation issue.
- Speedy Performances Across the Board: Users are reporting impressive token generation speeds with the Llama 3 model on various AMD GPUs, clocking around 60 tokens/s on a 7900XT and a tad higher on a 7900XTX.
- ROCm Tech for the Uninitiated: ROCm, touted for leveling the performance playing field between AMD and Nvidia GPUs, has new users inquiring about its benefits; it was clarified that ROCm is used by LM Studio to expedite GPU inference on AMD GPUs.
- Compatibility Questions Arise: Discussion surfaced around graphics card compatibility with ROCm, including unsuccessful attempts and hypothetical solutions for running LM Studio on unsupported GPUs, like the suggestion of a second graphics setup or virtualization.
- Navigating GPU Selection in LM Studio: Users sought help on directing LM Studio to utilize a specific AMD GPU when multiple are present, with one user eventually resolving a resource allocation issue by disabling environment variables previously set for older versions.
- NousResearch/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: no description found
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: no description found
- configs/llama3.preset.json at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
- System requirements (Windows) — HIP SDK installation Windows: no description found
- How to Disable Your Integrated Graphics on Windows 11: When games and other graphics-intensive applications starts to lag, this is what you do!
- How to Turn Your AMD GPU into a Local LLM Beast: A Beginner’s Guide with ROCm | TechteamGB: no description found
- How to Turn Your AMD GPU into a Local LLM Beast: A Beginner's Guide with ROCm: RX 7600 XT on Amazon (affiliate): https://locally.link/kEJGLM Studio: https://lmstudio.ai/rocmProducts provided by GigabyteThose of us with NVIDIA GPUs, part...
LM Studio ▷ #model-announcements (1 messages):
- Llama 3 70B Instruction Unleashed: The first few quants of Llama 3 70B instruct have been released, showcasing massive steps in open-source with performance “rivaling GPT-3.5”. The provided models, including IQ1_M and IQ2_XS, maintain reasonable performance even on systems with less than 20 GB VRAM.
- Size Matters, But So Does Efficiency: Community members are invited to try the new Meta-Llama-3-70B-Instruct model available on Hugging Face, which is compatible with the latest LM Studio and avoids endless generation pitfalls.
- Big Model on Small Hardware: The IQ1_M and IQ2_XS models utilize an importance matrix for efficient VRAM usage, ensuring higher performance levels on systems with less memory.
- Open Source Power in Action: The community can access the latest Llama 3 70B instruct contributions, thanks to collaborative work, including a pull request on
llama.cpp(PR 6745), emphasizing the communal effort in advancing AI models.
Link mentioned: lmstudio-community/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: no description found
Stability.ai (Stable Diffusion) ▷ #general-chat (1003 messages🔥🔥🔥):
- Navigation Confusion for New Users: Users expressed confusion about operating Stable Diffusion, particularly one who followed a YouTube guide but wasn't sure how to proceed after installation. Suggestions to try ComfyUI or look up additional YouTube tutorials were given, alongside a clarification that ComfyUI might not be the most user-friendly for first-time learners.
- The Fast Pace of AI Development: One user expressed overwhelm due to the rapid release of new models and interfaces for Stable Diffusion, making it hard to keep up. Other users agreed, noting that the field of AI is advancing at an unprecedented pace.
- Technical Troubleshooting: Users sought assistance for various issues, such as finding the location of saved training states in Kohya, resuming training from checkpoints, and saving model states. They were advised to check output folders for saved states and use specific options to resume from last saved states.
- Hardware Upgrade Query: A user inquiring about VRAM and its effects on generation speed was told that more VRAM might allow simultaneous image generation, and to reinstall the graphics driver after swapping in a new GPU.
- Generating AI Images: New users sought recommendations on generating AI images, and were pointed towards platforms like bing image creator, as well as local interfaces and web services that facilitate Stable Diffusion.
- Crypto Wallet | Supports Bitcoin (BTC), Bitcoin Cash (BCH), Ethereum (ETH), and ERC-20 tokens: Download Bitcoin.com’s multi-coin crypto wallet. A simple and secure way to buy, sell, trade, and use cryptocurrencies. Supports Bitcoin (BTC), Bitcoin Cash (BCH), Ethereum (ETH), and ERC-20 tokens in...
- Core Models — Stability AI: no description found
- Sad GIF - Sad - Discover & Share GIFs: Click to view the GIF
- Clipdrop - Stable Diffusion: A Leap Forward in AI Image Generation
- Stable Diffusion 3: Research Paper — Stability AI: Following our announcement of the early preview of Stable Diffusion 3, today we are publishing the research paper which outlines the technical details of our upcoming model release, and invite you to ...
- Membership — Stability AI: The Stability AI Membership offers flexibility for your generative AI needs by combining our range of state-of-the-art open models with self-hosting benefits.
- Image posted by pagartomas880: no description found
- runwayml/stable-diffusion-v1-5 at main: no description found
- no title found: no description found
- ⚡Harness Lightning-Fast Detail with ComfyUI PERTURBED + 🔮 Mask Wizardry & Fashion Secrets! 🤩: -- Discord - https://discord.gg/KJXRzkBM --Get ready to take your detail game to the next level! 🚀 In this mind-blowing tutorial, you'll discover the incred...
- Exposing the Website that Stalks You in Discord!: There is a website called spy.pet that claims to have 4 billion messages saved across Discord. With this, you can "see what your friends are doing on Discord...
- GitHub - Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models: High-Resolution Image Synthesis with Latent Diffusion Models - Stability-AI/stablediffusion
- Alexander Pisteletov : I am a new russian pirate (censored) Lyrics: Alexander Pisteletov performs "I am a new russian pirate"
- Install and Run on NVidia GPUs: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- How to Set up Stable Diffusion AI on Mac: I will walk you through the step-by-step process of setting up Stable Diffusion Web UI locally on your Mac M1 or M2.🔗 Installation guide: https://techxplain...
- GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface.: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface. - comfyanonymous/ComfyUI
- Early RTX 5090 Launch BAD - Tech News April 21: Early RTX 5090 Launch BAD - Tech News April 21▷ MY STORE - shirts, pint glasses & hoodies: http://paulshardware.net⇨ Sponsor: Corsair K65 Plus Wireless Keybo...
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- Home: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- Home: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- Stability Matrix - Simple management and inference UI for Stable Diffusion: Stability Matrix - Simple management and inference UI for Stable Diffusion
- SD1.5 with SDXL - ComfyUI workflow (template) - SD1.5 + SDXL Base | Stable Diffusion Other | Civitai: SD1.5 + SDXL Base shows already good results. SD1.5 + SDXL Base+Refiner is for experiment only SD1.5 + SDXL Base - using SDXL as composition genera...
- 如果Sora不开放,我们还能用什么?: 99%的人不知道的免费AI视频工具!好工具值得分享!
CUDA MODE ▷ #general (24 messages🔥):
- Colab Crash During Backpropagation: A member of the Discord inquired about a Colab session crash during model training, specifically during the backpropagation step. Others responded by noting that hardware failures and even cosmic rays can cause such crashes.
- Kernel Index Guard Styling: One individual queried the coding style for 'index guards' in kernel functions, asking why the
if (idx < max_idx)pattern is preferred over the seemingly clearerif (idx >= max_idx) return;, with another member expressing their preference for the latter approach.
- Nsight Compute GUI via SSH: A discussion on accessing the Nsight Compute GUI on a remote machine via SSH took place, with suggestions including using X forwarding with
ssh -Xas outlined in this guide by Teleport, and referencing the Nsight Compute User Guide.
- Effort Algorithm for Dynamic LLM Inference: A new algorithm called Effort was presented which allows for dynamic adjustments to the calculations performed during LLM inference. Interest was shown in implementing this in Triton or CUDA, and the project can be found on Github.
- NVLink Inclusion in DGX Boxes: A query regarding whether DGX boxes ship with NVLink installed ensued, with a response pointing to their typical use of SXM socket GPUs and NVLink by default. Additional insights on NVLink were shared, including an article from WikiChip.
- Effort Engine: A possibly new algorithm for LLM Inference. Adjust smoothly - and in real time - how many calculations you'd like to do during inference.
- What You Need to Know About X11 Forwarding: In this blog post, we'll deep-dive into X11 Forwarding, explaining what X11 is and how it works under the hood.
- 3. Nsight Compute — NsightCompute 12.4 documentation: no description found
- A look at Nvidia's NVLink interconnect and the NVSwitch: A look at Nvidia's NVLink interconnect and the 2-billion transistor NVSwitch that is powering Nvidia's latest DGX-2 deep learning machine.
CUDA MODE ▷ #triton (34 messages🔥):
- Unexpected Grayscale Transformations Intrigue: A user discovered an unexpected behavior with grayscale image transformations in a Triton kernel, where resizing an image to its original size generated a strange output. The issue was resolved by understanding how data storage changes for larger images; it's important to ensure data is contiguous in memory before passing it into a kernel, which can be verified using
check_tensors_gpu_readyfrom cuda-mode's Triton utilities and correcting a minor error in the function.
- Seeking Triton Indexing Capabilities for Static Codebooks: A user questioned how to index into static codebooks within Triton like in CUDA, sparking a discussion about the lack of such a feature in Triton. A GitHub issue was highlighted, where further details can be found on the current limitations and requests for functionalities such as binary search in Triton.
- Binary Search Desires Prompt Triton Development Talks: The ability to implement binary search in Triton was identified as a significant need by members. There seems to be an active interest within the community, including from OpenAI and others, to develop this feature further, with discussions happening internally and contributors keen to support this advancement.
- Clarifying the
orderParameter inmake_block_ptr: A user requested insights into theorderparameter oftl.make_block_ptr(), as used inconsistently in the Flash Attention implementation. Another user clarified thatorderdetermines the contiguity of the data layout, with(1,0)representing row-major order and(0,1)representing column-major order, which affects how memory is accessed.
- Index in triton · Issue #974 · openai/triton: We'd like to do some indexing in triton kernels, say we have x_ptr, idx_ptr, out_ptr x = tl.load(x_ptr + offsets, mask = mask) idx = tl.load(idx_ptr + offsets, mask = mask) we have: 1. idx = idx.t...
- triton.language.make_block_ptr — Triton documentation: no description found
- triton/python/tutorials/06-fused-attention.py at main · openai/triton: Development repository for the Triton language and compiler - openai/triton
- Weird triton kernel behavior for gray scale. (Meant to be copy pasted in a colab with a T4 gpu): Weird triton kernel behavior for gray scale. (Meant to be copy pasted in a colab with a T4 gpu) - weird_triton_repro.py
- lectures/lecture 14/A_Practitioners_Guide_to_Triton.ipynb at main · cuda-mode/lectures: Material for cuda-mode lectures. Contribute to cuda-mode/lectures development by creating an account on GitHub.
CUDA MODE ▷ #cuda (9 messages🔥):
- Coalescing for Offset Improvement: A member shared that aligning threads operating on adjacent elements could utilize coalescing, benefitting performance, although the full understanding of the problem isn't clear.
- Solution Found by Shifting Perspective: An interaction led to a user finding a solution involving an offset optimization after a compute-intensive part of their process, proving helpful input was provided on the topic.
- Praise for Layout Algebra Presentation: A presentation on "layout algebra" received kudos for its insightful conceptional foundation, giving participants a view of the "real thing."
- Nuances of __forceinline and __inline: Members discussed the use of __forceinline and __inline in the device code, suggesting that inlining can lead to better optimization by the compiler, reducing function calls, and enhancing access speed.
- Nsight Systems Version Issue Resolved: A user experiencing issues with Nsight Systems CLI on a 64-core CPU found a solution by reverting to an older version (2023.4.4) of the software, which resolved the core counting discrepancy.
CUDA MODE ▷ #torch (3 messages):
- Triton Hacking Tips Revealed: A member shared a link to GitHub - openai/triton, which includes tips for hacking the Triton language and compiler. The repository at github.com/openai/triton#tips-for-hacking could be useful for addressing certain issues likely related to development tasks.
- Proactive Solution Offering: In response to a mention of issues, a member suggested that the problems should be solved by the documentation linked earlier, offering further assistance if the provided solution doesn't work.
Link mentioned: GitHub - openai/triton: Development repository for the Triton language and compiler: Development repository for the Triton language and compiler - openai/triton
CUDA MODE ▷ #announcements (1 messages):
- CUDA-MODE Lecture Announcement: CUDA-MODE Lecture 15: Cutlass is about to start, with <@689634697097117750> presenting.
CUDA MODE ▷ #algorithms (1 messages):
andreaskoepf: https://x.com/AliHassaniJr/status/1766108184630943832
CUDA MODE ▷ #beginner (25 messages🔥):
- CUDA Mode Lecture Series Kicks Off: A member announced the beginning of lecture 2 in the general channel for those interested in deepening their understanding of CUDA.
- Next Lecture Scheduled & Lecturer Praised: Lecture 3 of the CUDA series is scheduled for next Saturday at GMT 7:30 AM and the current lecturer is noted for having an engaging and entertaining teaching style.
- Real-Time Question Channel Identified for CUDA Lecture: In response to a question about where to ask real-time questions during the CUDA mode lecture, the reading group video audio was pointed out as the location for a live chat thread.
- Matrix Multiplication Explanation Sought: One member requested clarification on a piece of code for matrix multiplication within CUDA, prompting a discussion and code example of an optimized matrix multiplication using shared memory from another member.
- Building a Machine Learning System - GPU Decisions: There was an inquiry about whether to use a dual GPU setup with two GeForce RTX 2070s or a single NVIDIA GeForce RTX 4090 for a machine learning system, seeking advice on the better option.
Link mentioned: Join the PMPP UI lectures timezones Discord Server!: Check out the PMPP UI lectures timezones community on Discord - hang out with 28 other members and enjoy free voice and text chat.
CUDA MODE ▷ #pmpp-book (2 messages):
- Proof Before You Peek: Mr.osophy indicates a willingness to verify answers for exercises but requires proof of attempt first. To maintain the integrity of exercise completion, Chapter 2, Chapter 3, Chapter 4, and Chapter 5 documents are shared to refer to the detailed exercises.
- Reduction Kernel Confusion: Chetan9281 is seeking clarification on a discrepancy in a CUDA reduction kernel example. According to the user, the author states a loop would execute 7 times but chetan9281's calculations suggest the loop should execute 8 times, requesting help to understand the calculations behind the author's claim.
CUDA MODE ▷ #youtube-recordings (1 messages):
.bexboy: I suppose that this one session will be uploaded too?
CUDA MODE ▷ #jax (1 messages):
- DenseFormer Implementor Encounters JAX Memory Challenge: A member is working on a denseformer implementation in JAX and is struggling with high memory usage. They explained that while the PyTorch implementation efficiently mutates tensors in place, JAX's functional approach causes copies of tensors that increase memory demand.
- Efficient PyTorch Techniques Don't Translate Directly to JAX: The member discussed the denseformer's architecture, where each transformer block input is a weighted sum of previous blocks' outputs, which is handled efficiently in PyTorch due to in-place mutation. They highlighted that JAX/XLA's functional paradigm complicates this process due to its copy-on-write behavior.
- In Pursuit of A Linear Memory Footprint in JAX: The member successfully created a custom JAX primitive, inspired by an example from Equinox, for a write-once buffer that works with gradients concerning input. However, the memory issues persist when computing gradients with respect to the weights of the transformer blocks, resulting in quadratic memory usage contrary to the expected linear scale.
- Custom Backward Pass: A Potential Yet Complex Solution: They believe the issue stems from JAX's inability to optimize the gradient's memory footprint, suggesting the necessity for a custom backward pass for the whole loop/scan function. The individual is seeking high-level advice on managing this complexity, as constructing a custom backward pass would be a demanding task.
Link mentioned: equinox/equinox/internal/_loop/common.py at main · patrick-kidger/equinox: Elegant easy-to-use neural networks + scientific computing in JAX. https://docs.kidger.site/equinox/ - patrick-kidger/equinox
CUDA MODE ▷ #off-topic (4 messages):
- CUDA MODE In-Person Meetup: Members from the CUDA MODE community have met up in person in Münster, Germany. They humorously referred to it as Germany's "GPU capital", celebrating the unexpected proximity of several members.
CUDA MODE ▷ #triton-puzzles (1 messages):
stygiansonic: You can also use something like this for relu: z = tl.where(z > 0, z, 0)
CUDA MODE ▷ #hqq (12 messages🔥):
- LoRA's Speed Tax: HQQ+ (HQQ combined with LoRA) saw around a 20% speed reduction when benchmarked using the torchao int4m kernel, despite potential for further optimization. The base HQQ model was quantized without grouping, and suggestions were made that better quantization quality might also help with performance.
- Kernel Fusion Feat: A new fused
int4 / fp16triton kernel was introduced, demonstrating promising benchmark results for various IO/compute-bound shapes, outperforming the defaulthqq.linearforward. Details of the implementation can be found in the GitHub pull request.
- Transposing Enhancements: Discussion arose around the need for speed improvements during qlora training, with a particular focus on enabling the same efficiencies with a transposed quantized weight matrix. A full example was given to illustrate the forward and backward pass differences in quantization when using transposition: quantize.py example.
- Dequantization's Drag: The conversation touched on the expected performance degradation associated with a necessary dequantization step in the HQQ process. The dequantization combined with a regular torch.matmul operation results in a roughly 15% slowdown compared to torch.matmul with fp16/bfp16 directly.
- hqq/hqq/core/quantize.py at master · mobiusml/hqq: Official implementation of Half-Quadratic Quantization (HQQ) - mobiusml/hqq
- Fused HQQ Quantization Gemm by jeromeku · Pull Request #153 · pytorch-labs/ao: @msaroufim Fused int4 / fp16 Quant Matmul Fused gemm for asymmetric quantized weights. Tested and benchmarked for HQQ but could theoretically be used for any asymmetric quantization scheme. The ker...
CUDA MODE ▷ #llmdotc (615 messages🔥🔥🔥):
- Kernel Logging and Memory Optimizations: A new kernel was contributed to significantly speed up the
matmul_backward_biaskernel by about 4x, and an additional memory-saving change was made, moving from 14372MiB usage down to 10774MiB, saving 3598MiB, which is 25% of the original memory usage. There was discussion on whether Dtype should be single-point precision (float) or mixed, and how to optimize the reduction from linear to logarithmic operations without losing performance. - CUDA and cuDNN Adventures Continue: A pull request for cuDNN Forward Attention and FP16 cuBLAS kernels in
dev/cudawas submitted, indicating massive performance gains from avoiding the creation of intermediary tensors. However, some nuances of cuBLASLt and cuDNN were discussed, revealing the complex nature of integrating NVIDIA library functions and achieving accurate training results with mixed precision. - Exploring Data Parallelism with NCCL: Discussions were centered around the best way to implement multi-GPU support using NCCL, considering single-thread multiple devices, multiple threads per device, or a multi-process setup typically managed by MPI. The consensus was to align with an MPI-like approach, which naturally scales beyond 8 GPUs and supports multi-host settings.
- New Dataset for Training LLMs: A Twitter post from Thomas Wolf mentioned a new dataset drop that sparked interest as it could be beneficial for GPT-2 reproduction projects or as a training set for large language models. The popularity of the new dataset seems to have momentarily taken down the HuggingFace website.
- Mixed Precision Discussion: Examined the strategy for incorporating mixed precision into the mainline code. A draft PR showcased a mixed precision implementation that compiles but produces incorrect results, pointing to the intricacies involved in tuning performance while ensuring numerical stability. It was mentioned that preserving a FP32 script could provide a "ground truth" reference or function as an educational resource.
- Examples — NCCL 2.21.5 documentation: no description found
- Examples — NCCL 2.21.5 documentation: no description found
- Added shared memory for the atomic additions for the layernorm_back by ChrisDryden · Pull Request #210 · karpathy/llm.c: This cr was made to address the issue found in the profiler that the atomic operations in the final loop of this kernel were causing a bunch of warp stalls. By doing the atomic operation on shared ...
- flash_attn_jax/csrc/flash_attn/src at main · nshepperd/flash_attn_jax: JAX bindings for Flash Attention v2. Contribute to nshepperd/flash_attn_jax development by creating an account on GitHub.
- clang: lib/Headers/__clang_cuda_intrinsics.h Source File: no description found
- nanoGPT/train.py at master · karpathy/nanoGPT: The simplest, fastest repository for training/finetuning medium-sized GPTs. - karpathy/nanoGPT
- WIP support for FP16/BF16 in train_gpt2.cu (compiles, not correct yet) by ademeure · Pull Request #218 · karpathy/llm.c: Just so you can take a look and decide if this feels like the right direction (happy to throw it away)
- flash-attention/csrc/flash_attn/src/flash_fwd_kernel.h at main · Dao-AILab/flash-attention: Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
- bug: something goes wrong at larger batch sizes · Issue #212 · karpathy/llm.c: There's some bug I have difficulty tracking down today and I'm going to give up for tonight and try again tomorrow. Reproduction: ./train_gpt2cu -b 12 launches the job with batch size 12. On m...
- Custom matmul attention by ngc92 · Pull Request #213 · karpathy/llm.c: My own implementation of (lower-triangular) matrix multiplication. It is not as efficient as CuBLAS, but since we only calculate half as many numbers, it is a net win. Cannot get rid of permute yet...
- Faster `matmul_backward_bias` using coalesced reads and shared memory in the kernel by al0vya · Pull Request #221 · karpathy/llm.c: This kernel seems to offer a <4x runtime improvement over matmul_backward_bias_kernel2 on an RTX 2070 Super GPU, runtime comparison shown below: matmul_backward_bias_kernel2: block_size 32 time 0.9...
- cuDNN Forward Attention + FP16 non-cuDNN version in /dev/cuda/ by ademeure · Pull Request #215 · karpathy/llm.c: Previous Kernel 4: 1.74ms Kernel 4 with TF32: 1.70ms Kernel 5 (4 with BF16 I/O): 0.91ms Kernel 6 (5 without permute, not realistic): 0.76ms Kernel 10 (cuDNN BF16, with FP32 conversion): 0.33ms Kern...
- add one more kernel, allocating a block per row. bad idea if C is too… · karpathy/llm.c@49d41ae: … low, as we have it right now
- new kernel that does a single pass over x on load, using a more cleve… · karpathy/llm.c@cb791c4: …r variance formula. only very slightly faster on my A100 sadly
- speed up the backward bias kernel by 45% and speed up the full runnin… · karpathy/llm.c@8488669: …g time by 1%
CUDA MODE ▷ #massively-parallel-crew (23 messages🔥):
- Testing Presenting Privileges: A member requested presenting privileges to test screen sharing capabilities on their tablet. Another member offered assistance by proposing to join them on stage for a test.
- New Moderator Role Announcement: A new "Moderator" role has been created, empowered with the ability to manage the community, including timeout, kick, ban, and message deletion, as well as event management and stage control. The aim is to keep the CUDA MODE server a friendly and welcoming place.
- Pre-Event Preparation for Recording: One member requested to join an event call earlier to ensure their recording setup was functioning correctly. Coordination for a pre-meeting check was arranged on the stage channel.
- Follow-Up Session Interest Expressed: A member posted a Twitter link suggesting a deep-dive follow-up session for a previously discussed topic. This prompted a discussion about the potential interest and logistics for such an event.
- Session Recording Edit and Upload: Two members worked together on editing and uploading recorded session material. An edited recording was successfully compiled and shared via a Google Drive link.
Link mentioned: lecture-15.mov: no description found
OpenAccess AI Collective (axolotl) ▷ #general (653 messages🔥🔥🔥):
- LLaMa-3 Tokenization Troubles: Several users reported issues with LLaMa-3 base model fine-tuning. Users identified a missing BOS (beginning of text) token causing high loss and
grad_norm infduring training; a fix via a PR in the tokenizer configuration was linked (PR for fixing BOS token).
- Debugging Distributed Training: Some users encountered distributed training issues, including Nccl operation timeout errors and port occupation. The discussion suggests checking nccl documentation and potentially switching ports to resolve conflicts.
- Axolotl Dataprep Inquiry: Users looking to understand custom dataset structures for various training tasks were directed to the Axolotl documentation, providing examples and formatting for pretraining, instruction tuning, conversation, and more (Axolotl Dataset Formats).
- Struggles with LLaMa-3 Fine-Tuning: Users conversed about the difficulties in achieving desired performance while fine-tuning the LLaMa-3 model. Problems cited include worse performance compared to earlier models, issues integrating ChatML tokens, and impacts of missing bos tokens on training.
- Tokenizer Discussion: A debate unfolded over the efficiency and necessity of the vast LLaMa-3 tokenizer vocabulary, with some users advocating for a more streamlined approach, while others highlighted the tokenizer's efficiency for encoding large amounts of text into fewer tokens.
- chargoddard/llama3-42b-v0 · Hugging Face: no description found
- cognitivecomputations/dolphin-2.9-llama3-8b · Llama 3 Base Is Unique: no description found
- Axolotl - Dataset Formats: no description found
- Reddit - Dive into anything: no description found
- Axolotl - Instruction Tuning: no description found
- Efficiently fine-tune Llama 3 with PyTorch FSDP and Q-Lora: Learn how to fine-tune Llama 3 70b with PyTorch FSDP and Q-Lora using Hugging Face TRL, Transformers, PEFT and Datasets.
- Tweet from Ahmad Al-Dahle (@Ahmad_Al_Dahle): @mattshumer_ We’ll get longer ones out. Also, with the new tokenizer the context window should be a bit longerif you are comparing to Llama 2.
- dreamgen/opus-v1.2-llama-3-8b · Hugging Face: no description found
- meta-llama/Meta-Llama-3-8B · Update post-processor to add bos: no description found
- meta-llama/Meta-Llama-3-8B-Instruct · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- flash-linear-attention/fla/layers at main · sustcsonglin/flash-linear-attention: Efficient implementations of state-of-the-art linear attention models in Pytorch and Triton - sustcsonglin/flash-linear-attention
- ope - Overview: ope has 11 repositories available. Follow their code on GitHub.
- axolotl/src/axolotl/utils/trainer.py at 0e8f3409451442950f2debbe28735198361c9786 · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- Add experimental install guide for ROCm · xzuyn/axolotl@6488a6b: no description found
- axolotl/setup.py at 0e8f3409451442950f2debbe28735198361c9786 · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- GitHub - OpenNLPLab/lightning-attention: Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models: Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models - OpenNLPLab/lightning-attention
- GitHub - lucidrains/memory-efficient-attention-pytorch: Implementation of a memory efficient multi-head attention as proposed in the paper, "Self-attention Does Not Need O(n²) Memory": Implementation of a memory efficient multi-head attention as proposed in the paper, "Self-attention Does Not Need O(n²) Memory" - lucidrains/memory-efficient-attention-pytorch
- Consider Memory Efficient Attention as an "alternative" to Flash Attention for AMD users. · Issue #1519 · OpenAccess-AI-Collective/axolotl: ⚠️ Please check that this feature request hasn't been suggested before. I searched previous Ideas in Discussions didn't find any similar feature requests. I searched previous Issues didn't...
- axolotl/src/axolotl/monkeypatch/llama_attn_hijack_flash.py at 0e8f3409451442950f2debbe28735198361c9786 · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- Draft: Update Tokenizer Overrides Handling in models.py by mhenrichsen · Pull Request #1549 · OpenAccess-AI-Collective/axolotl: Example: tokenizer_overrides: - 28006: <|im_start|> - 28007: <|im_end|> Description: This PR introduces an enhancement to the way we handle tokenizer overrides in our models.py file. ...
- Feat: Add cohere (commandr) by NanoCode012 · Pull Request #1547 · OpenAccess-AI-Collective/axolotl: Description Motivation and Context How has this been tested? Untested! Screenshots (if appropriate) Types of changes Social Handles (Optional)
- axolotl/requirements.txt at main · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- GitHub - xzuyn/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to xzuyn/axolotl development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (16 messages🔥):
- Seeking Compute Resources for Testing: A member shared a Draft PR link for updating tokenizer overrides handling in
models.pyand asked for spare computing power to test this Pull Request. - Feature Request for a Fusion Operation in PyTorch: The PyTorch issue #124480 details a feature request for a fused linear and cross-entropy loss function to handle large logits efficiently.
- Understanding VRAM Consumption in LLMs: A member explained the VRAM implications for large vocabulary sizes in recent LLMs like Llama 3, with a breakdown showing "19.57GiB" for logits size and "20GiB" for hidden state size using batch size "81920 tokens."
- Batch Size Clarification: In response to questioning a potential typo in batch size, the initial member clarified that the provided statistics were for a "batch size 10, seq len 8192."
- Challenges with fsdp and 8-bit Optimizers: There was a discussion on
fsdp(Fully Sharded Data Parallel) compatibility with Fast Fourier Transforms (FFT) and 8-bit optimizers, indicated by one member's issue withfsdphanging and another's remark aboutadamw_torchconsuming significant VRAM.
- Draft: Update Tokenizer Overrides Handling in models.py by mhenrichsen · Pull Request #1549 · OpenAccess-AI-Collective/axolotl: Example: tokenizer_overrides: - 28006: <|im_start|> - 28007: <|im_end|> Description: This PR introduces an enhancement to the way we handle tokenizer overrides in our models.py file. ...
- Fused Linear and Cross-Entropy Loss `torch.nn.functional.linear_cross_entropy` · Issue #124480 · pytorch/pytorch: 🚀 The feature, motivation and pitch It'd be great to have a fused linear and cross-entropy function in PyTorch, for example, torch.nn.functional.linear_cross_entropy. This function acts as a fuse...
OpenAccess AI Collective (axolotl) ▷ #general-help (22 messages🔥):
- Llama3 Fine-Tuning Quirk Draws Attention: A user encountered an error while trying to fine-tune Llama3 (RuntimeError), but other models like Mistral and Llama2 fine-tuned without issues. The traceback suggested it wasn’t a memory or space issue, as other models were saved successfully in the same directory.
- Users Seeking Fine-Tuning Resources: A resource request was made for fine-tuning an embedding model for a domain-specific use case, but no specific resources or guidance were offered in the discussion.
- FSDP with FFT Inquiries: A question was raised about executing Fast Fourier Transform (FFT) with Fully Sharded Data Parallel (FSDP), to which a user simply acknowledged it was possible but did not provide details or example configurations.
- Quant Config for Large Model Interest: One user inquired about the quantization configuration used for a 70B parameter model, and they were directed to look at the
config.jsonfile found in theexamples/quantize.pyfor the default configuration used.
- Extended Wait Times for Model Merging: Concerns about long merging times for a 70B parameter model with a Lora finetune were expressed; another user response indicated that the time experienced seemed longer than expected without giving a definitive timeframe.
OpenAccess AI Collective (axolotl) ▷ #runpod-help (37 messages🔥):
- Runpod Spinning Wheels: Members are experiencing delays in spinning up pods on Runpod, noting it's "taking forever" or not loading at all.
- Upload Limit Workaround Provided: A user faced an upload limit issue and overcame it by using the
huggingface_hublibrary to manually upload folders to Hf spaces with example code provided.
- Managing VRAM via Command Line in Runpod: For real-time VRAM monitoring, command line tools like
nvidia-smiwere suggested, since the Runpod dashboard doesn't update memory usage in real time.
- Exploring Multiple Terminal Windows: Members discussed how to run Axolotl and other commands simultaneously, considering options like SSH, multiple web terminals, or Jupyter notebooks.
- Discrepancies in CPU Memory Reporting: A user pointed out inconsistencies with Runpod's CPU memory reporting, where the interface showed 48GB RAM available, contrasting with 76GB indicated as used by
nvitop.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (22 messages🔥):
- Clarification on YAML Key Usage: A query was raised regarding the
"conversation:"key within config YAML files for datasets, and it was clarified that this key specifies the structure and format of conversational datasets for training AI models, such as roles and how conversation data is identified.
- Dataset Configurations for Conversational AI: It was explained that specifying
"type: sharegpt"in a YAML file indicates the use of ShareGPT-formatted data, while"conversation: chatml"signals the need to convert data into the ChatML format, facilitating effective model training with properly formatted data.
- Technical Troubleshooting: A member shared an error log featuring multiple
SIGBUSerrors during a distributed computing process. The response outlined potential causes like memory alignment issues, problems with memory-mapped files, or hardware failures and offered troubleshooting steps.
- Optimizing Training with Unsloth: Instructions for using Unsloth with Axolotl were requested, and a detailed response provided a step-by-step guide, including installing dependencies, preparing the model and data, configuring Unsloth within the training script, and monitoring training outcomes.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Eleuther ▷ #general (326 messages🔥🔥):
- AI Local On Smartphones: Users discussed the feasibility of running language models like Llama 3 locally on smartphones such as the Samsung S24 Ultra. Performance results varied, with 4.3 tok/s reported on an S24 Ultra and 2.2 tok/s on an S23 Ultra using a quantized LLM.
- The Self-Attention Conundrum: A spirited technical debate emerged over why tokens in a transformer model's self-attention mechanism attend to their own key-values, with suggestions on potential experiments to ablate the mechanic and its impact on performance. Various users presented their understanding, ranging from expressive power to imprinting token identity.
- Hugging Face's Business Model Under Scrutiny: There was skepticism about Hugging Face's business and hosting model, especially in relation to serving large files without apparent revenue generation strategies. Some drew comparisons to GitHub's model and mused about the differences.
- GPT Reasoning Research and Benchmarks: A user inquired about metrics for evaluating reasoning in LLMs, expressing that most literature focuses on Chain of Thought (CoT) methods. Another user responded by suggesting that deeper, non-CoT reasoning research is scarce within the current LLM domain.
- Stable AdamW for Training Stability: In a detailed exchange on training instability with models related to Whisper architecture, it was suggested to try StableAdamW to potentially improve upon using regular AdamW with gradient clipping. The discussions included specifics about adjusting learning rates, beta values, and debugging with gradient histograms.
- no title found: no description found
- Gemini Nano now running on Pixel 8 Pro — the first smartphone with AI built in: Gemini is here, the most capable and flexible AI model we've ever built. Plus more AI updates coming to the Pixel portfolio.
- Large Language Models On-Device with MediaPipe and TensorFlow Lite - Google for Developers: no description found
- Android App — mlc-llm 0.1.0 documentation: no description found
- Stella Nera: Achieving 161 TOp/s/W with Multiplier-free DNN Acceleration based on Approximate Matrix Multiplication: From classical HPC to deep learning, MatMul is at the heart of today's computing. The recent Maddness method approximates MatMul without the need for multiplication by using a hash-based version o...
- Tweet from Lucas Beyer (bl16) (@giffmana): Two small bonus protips before the end: Left: If your loss spikes, try reducing Adam/AdaFactor's beta2 to 0.95 (not novel, but rarely shared) Right: When a piece of your model is pre-trained but...
- Samsung Exynos 2400: specs and benchmarks: Samsung Exynos 2400: performance tests in benchmarks (AnTuTu 10, GeekBench 6). Battery life and full specifications.
- Private AI - Apps on Google Play: no description found
- Inappropriate Content - Play Console Help: no description found
- MLC Chat: MLC Chat lets users chat with open language models locally on ipads and iphones. After a model is downloaded to the app, everything runs locally without server support, and it works without internet ...
- aria-amt/amt/train.py at 0394a05aa57e5d4f7b059abbfed3a028732b243a · EleutherAI/aria-amt: Efficient and robust implementation of seq-to-seq automatic piano transcription. - EleutherAI/aria-amt
- GitHub - mlc-ai/mlc-llm: Enable everyone to develop, optimize and deploy AI models natively on everyone's devices.: Enable everyone to develop, optimize and deploy AI models natively on everyone's devices. - mlc-ai/mlc-llm
- LPDDR5 | DRAM | Samsung Semiconductor Global: Meet LPDDR5 powering next-generation applications with performance and efficiency by 6,400 Mbps of pin speed, massive transfer at 51.2Gb/s, and 20% power saving.
- GitHub - atfortes/Awesome-LLM-Reasoning: Reasoning in Large Language Models: Papers and Resources, including Chain-of-Thought, Instruction-Tuning and Multimodality.: Reasoning in Large Language Models: Papers and Resources, including Chain-of-Thought, Instruction-Tuning and Multimodality. - GitHub - atfortes/Awesome-LLM-Reasoning: Reasoning in Large Language M...
- GitHub - Kotlin/kotlindl: High-level Deep Learning Framework written in Kotlin and inspired by Keras: High-level Deep Learning Framework written in Kotlin and inspired by Keras - Kotlin/kotlindl
- Samsung Galaxy S24 Ultra review: Samsung's S24 family is launching with Samsung's latest One UI 6.1 on top of Google's latest Android 14. Despite the fairly small ".1" numbering update,...
Eleuther ▷ #research (293 messages🔥🔥):
<ul>
<li><strong>Debate on "Megalodon" Architecture's Superiority</strong>: Discussions involved considerations about <strong>Megalodon</strong>, a new architecture from Meta boasting efficiency with long contexts, which was noted to outperform Llama-2 in controlled tests. Skepticism remains regarding how it compares to other hybrid attention mechanisms and its potential broad acceptance.</li>
<li><strong>Exploring Task Vectors for Model Steering</strong>: A method called <strong>task vectors</strong> is proposed for steering the behavior of a pre-trained model, allowing modification through arithmetic operations like negation and addition. This could enable the addition of specialized knowledge to models like Llama3 without direct fine-tuning (as per <a href="https://arxiv.org/abs/2212.04089">arXiv:2212.04089</a>).</li>
<li><strong>New Benchmark for RAG Models Proposed</strong>: <strong>Stella Athena</strong> shared an idea for a benchmark targeting Retrieval-Augmented Generation (RAG) models, where questions require synthesizing information from multiple documents. The challenge is significant due to potential dataset contamination when choosing sources present in common training collections.</li>
<li><strong>Attention Mechanism Approximation for Inference</strong>: <strong>Carson Poole's</strong> query about approximating attention mechanisms to compress token length during inference sparked references to several papers (e.g., <a href="https://arxiv.org/abs/2401.03462">arXiv:2401.03462</a>, <a href="https://arxiv.org/abs/2401.06104">arXiv:2401.06104</a>) that discuss related concepts like Activation Beacon, TOVA, and dynamic FLOPs allocation.</li>
<li><strong>Potential and Limitations of Transformer Context Extensions</strong>: A discussion emerged about the feasibility of extending the context length for transformers, with references to Gemini Pro 1.5's context length and challenges in quadratic compute scaling, highlighting that enormous context lengths (e.g., 10 million tokens) likely indicate an architecture beyond simple context-length fine-tuning.</li>
</ul>
- Tweet from Stella Biderman (@BlancheMinerva): Create a benchmark for RAG models where all of the questions require information from multiple documents to be synthesized answer them. Study how models trained on publicly released data do on it and ...
- Editing Models with Task Arithmetic: Changing how pre-trained models behave -- e.g., improving their performance on a downstream task or mitigating biases learned during pre-training -- is a common practice when developing machine learni...
- Transformers are Multi-State RNNs: Transformers are considered conceptually different compared to the previous generation of state-of-the-art NLP models - recurrent neural networks (RNNs). In this work, we demonstrate that decoder-only...
- Why do small language models underperform? Studying Language Model Saturation via the Softmax Bottleneck: Recent advances in language modeling consist in pretraining highly parameterized neural networks on extremely large web-mined text corpora. Training and inference with such models can be costly in pra...
- Lossless Acceleration of Large Language Model via Adaptive N-gram Parallel Decoding: While Large Language Models (LLMs) have shown remarkable abilities, they are hindered by significant resource consumption and considerable latency due to autoregressive processing. In this study, we i...
- Large Language Models on Graphs: A Comprehensive Survey: Large language models (LLMs), such as GPT4 and LLaMA, are creating significant advancements in natural language processing, due to their strong text encoding/decoding ability and newly found emergent ...
- Mixture-of-Depths: Dynamically allocating compute in transformer-based language models: Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific ...
- Language Imbalance Can Boost Cross-lingual Generalisation: Multilinguality is crucial for extending recent advancements in language modelling to diverse linguistic communities. To maintain high performance while representing multiple languages, multilingual m...
- Sisihae GIF - Sisihae - Discover & Share GIFs: Click to view the GIF
- GitHub - krafton-ai/mambaformer-icl: MambaFormer in-context learning experiments and implementation for https://arxiv.org/abs/2402.04248: MambaFormer in-context learning experiments and implementation for https://arxiv.org/abs/2402.04248 - krafton-ai/mambaformer-icl
- Towards Graph Foundation Models: A Survey and Beyond: Foundation models have emerged as critical components in a variety of artificial intelligence applications, and showcase significant success in natural language processing and several other domains. M...
- List the "publicly available sources" 15T dataset list from Llama 3 · Issue #39 · meta-llama/llama3: Llama 3 is not reproducible in any meaningful capacity without a list of the dataset sources. Please release a list of the sources.
- Soaring from 4K to 400K: Extending LLM's Context with Activation Beacon: The utilization of long contexts poses a big challenge for LLMs due to their limited context window size. Although the context window can be extended through fine-tuning, it will result in a considera...
- Larimar: Large Language Models with Episodic Memory Control: Efficient and accurate updating of knowledge stored in Large Language Models (LLMs) is one of the most pressing research challenges today. This paper presents Larimar - a novel, brain-inspired archite...
- GitHub - naver-ai/rdnet: Contribute to naver-ai/rdnet development by creating an account on GitHub.
- On Limitations of the Transformer Architecture: no description found
- GitHub - microsoft/LLMLingua: To speed up LLMs' inference and enhance LLM's perceive of key information, compress the prompt and KV-Cache, which achieves up to 20x compression with minimal performance loss.: To speed up LLMs' inference and enhance LLM's perceive of key information, compress the prompt and KV-Cache, which achieves up to 20x compression with minimal performance loss. - GitH...
Eleuther ▷ #scaling-laws (47 messages🔥):
- Chinchilla Replication Debate Heats Up: A discussion about the replication of the Chinchilla study unfolded, citing possible flaws and instability in parametric modeling, which was shared on Twitter, followed by a debate over the rounding of values in the Chinchilla paper.
- TeX File Sleuthing Reveals Data Easter Eggs: Members discussed the usefulness of delving into the TeX source files of arXiv papers, pointing out that the source files contain exact data values and sometimes hidden content like easter eggs; the source files are openly accessible under the "other formats" option on arXiv.
- Twitter Block Sparks Discussion on Communication Style: A member expressed frustrations over being blocked on Twitter after commenting on the Chinchilla replication attempt. This sparked conversations about the importance of tone when conversing critically and suggestions that perceived rudeness or lack of "neurotypical decoration" in posts could lead to misunderstandings.
- In-depth Analysis of Residuals in Replication Claims: The conversation highlighted that the key to assessing the Chinchilla replication attempt wasn't just in the non-centeredness of residuals but the re-evaluation with unrounded precision, which indicated no underfitting of the original model.
- Rounding Concerns Clarified: It was clarified that the rounding of data points noted in the replication debate was attributed to the authors of the original Chinchilla paper, not the replication team, involving both the TeX source and Chinchilla's reported results.
Link mentioned: Tweet from Kyo (@kyo_takano): You ARE rounding the original estimate lol Try inspecting the TeX source like you did PDF figures. To be more specific, you rounded: - E from exp(0.5267228) to 1.69 - A from exp(6.0073404) to 406.4 ...
Eleuther ▷ #interpretability-general (2 messages):
- DeepMind's Mechanistic Interpretability Team Update: Google DeepMind's mechanistic interpretability team shared a progress update focusing on various advancements with Sparse Autoencoders (SAEs). The update, tweeted by Neel Nanda, includes infrastructure lessons for working with large models and JAX, as well as exploring steering vectors, inference-time sparse approximation algorithms, and ghost gradients improvements. Twitter Link and Blog Posts.
- DeepMind Blog Details Interpretability Work: The blog reveals that the work presented is typically considered too nascent for formal papers and includes a mixture of initial steps, write-ups, replications, and negative results valuable to mechanistic interpretability practitioners. The team has listed two main goals: scaling SAEs to larger models and advancing basic science on SAEs.
Link mentioned: [Summary] Progress Update #1 from the GDM Mech Interp Team — AI Alignment Forum: Introduction This is a progress update from the Google DeepMind mechanistic interpretability team, inspired by the Anthropic team’s excellent monthly…
Eleuther ▷ #lm-thunderdome (5 messages):
- Craving for Comparisons: A user shared a Google Spreadsheet with test results and inquired about the baseline MMLU score, expressing an interest in seeing a comparison. The provided link was MMLU - Alternative Prompts.
- Guidance Sought for lm-evaluation harness Contributions: A contributor sought help with running unit tests for lm-evaluation harness, referencing an outdated contribution document. They noted the absence of directories for test commands and dependencies on various optional extras packages.
Link mentioned: MMLU - Alternative Prompts: MMLU (Prompt Variation) Example Input Prompt Input Prompt,Format 01, 02,Q: \nA: 03,Question: \nAnswer: Llama-2-7b-hf,Mistral-7B-v0.1,falcon-7b,py...
Modular (Mojo 🔥) ▷ #general (77 messages🔥🔥):
- Revamping the Mojo Interface: Participants enquired about the future interface of Mojo to make it simpler, akin to calling standard C/C++ functions; discussions included integrating with other languages, where MLX-Swift was mentioned as an example of interfacing Swift with Mojo.
- Roadmap and Design Decisions: A roadmap document for Mojo was shared, detailing design decisions and providing a big picture view of the language's development priorities, including core system programming features.
- Creating Mojo Modules and Documentation Discussions: Guidance was offered on creating Mojo modules and packaging, along with discussions on whether the automated documentation code for Mojo is publicly available or if it could be open-sourced.
- Performance Challenges in Mojo: A known issue regarding Mojo's slower performance compared to Python, specifically because Mojo lacks buffered IO, was discussed; a blog post with benchmarking tips was also shared.
- Max Serving Framework and Mojo: Questions arose on how to use the MAX serving framework with neural networks written in native Mojo; Basalt, a Pure Mojo Machine Learning framework, was mentioned with respect to future compatibility and aspirations for direct interfacing.
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- GitHub - basalt-org/basalt: A Machine Learning framework from scratch in Pure Mojo 🔥: A Machine Learning framework from scratch in Pure Mojo 🔥 - basalt-org/basalt
- Mojo🔥 roadmap & sharp edges | Modular Docs: A summary of our Mojo plans, including upcoming features and things we need to fix.
- GitHub - ml-explore/mlx-swift: Swift API for MLX: Swift API for MLX. Contribute to ml-explore/mlx-swift development by creating an account on GitHub.
- Penzai: JAX research toolkit for building, editing, and visualizing neural nets | Hacker News: no description found
Modular (Mojo 🔥) ▷ #💬︱twitter (7 messages):
- Modular Tweets a Teaser: Modular shared a teaser for an upcoming feature or event with a Twitter post, sparking curiosity among followers.
- Sneak Peek into the Future: Another tweet from Modular hints at future developments, teasing the community with possible new advancements or releases.
- Modular Builds Anticipation: A follow-up tweet by Modular keeps the momentum going, as the buildup suggests an imminent announcement or launch.
- Countdown to Announcement Continues: Modular posts yet another tweet in this series, raising expectations for a significant update or reveal.
- Modular Stokes Excitement: Fans are kept on the edge of their seats with Modular's continued teaser campaign in their latest tweet.
- Another Piece of the Puzzle: Modular adds to the suspense with a new tweet, possibly hinting at what's to come in their unfolding narrative.
- Teaser Saga Continues: The series of teaser tweets from Modular suggests a building storyline or a sequence leading to a major revelation.
Modular (Mojo 🔥) ▷ #ai (1 messages):
- Seeking Engagement for an AI Evolution Video: A member shared a YouTube video titled "The Rise of AI" created as a college assignment, requesting likes and feedback in the comments to demonstrate engagement. They acknowledged the material might be shallow due to the one-week preparation time, and asked for understanding regarding their non-native English.
Link mentioned: The Rise of AI: (Hidupkan Closed Caption)(Turn on the Closed Caption)Bergabunglah bersama kami dalam perjalanan melalui evolusi cepat Kecerdasan Buatan, mulai dari kemuncula...
Modular (Mojo 🔥) ▷ #🔥mojo (279 messages🔥🔥):
- MLIR Resources Shared: For those inquiring, MLIR (Multi-Level Intermediate Representation) documentation can be found on the MLIR official website, with the 2023 LLVM Developers Meeting providing a YouTube video debunking common misconceptions about MLIR.
- Looking for a Basic Types List: A member requested a comprehensive list of Mojo's basic/primitive types and language keywords. It was pointed out that the numeric data types are available under SIMD aliases and there seems to be no reserved keywords page, although Python keywords are expected to be reserved with the addition of
inout,borrowed,owned, andalias.
- Python as a Starting Point: A newcomer to coding was advised to start with Python if their current computer is not fast enough for Mojo, as it is more mature and they can always learn Mojo later.
- SIMD Type Conversions Explored: Members discussed various methods for converting a SIMD vector to a different type without saving to memory, with
memory.bitcastbeing suggested as a promising option.
- Potential for Frameworks on Mojo: A discussion was started about building frameworks for Mojo, with web services being a point of interest. It was mentioned that eventually Python frameworks might be usable with Mojo, drawing a parallel to how JavaScript libraries can be used with TypeScript, or C libraries with C++.
- sort | Modular Docs: Implements sorting functions.
- Unit testing - Rust By Example: no description found
- Are we web yet? Yes, and it's freaking fast! : no description found
- pytest: helps you write better programs — pytest documentation: no description found
- collections | Modular Docs: Implements the collections package.
- Ron Swanson Parks And Rec GIF - Ron Swanson Parks And Rec Its So Beautiful - Discover & Share GIFs: Click to view the GIF
- The Office Andy GIF - The Office Andy Andy Bernard - Discover & Share GIFs: Click to view the GIF
- simd | Modular Docs: Implements SIMD struct.
- unsafe | Modular Docs: Implements classes for working with unsafe pointers.
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojo_zlib_classification/tools/utils.mojo at master · toiletsandpaper/mojo_zlib_classification: Contribute to toiletsandpaper/mojo_zlib_classification development by creating an account on GitHub.
- thatstoast - Overview: GitHub is where thatstoast builds software.
- [Feature Request] `.__doc__` attribute · Issue #2197 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? I would like to be able to get the doctsring of my str...
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- Mojo-UI/.github/workflows/package.yml at main · Moosems/Mojo-UI: A cross-platform GUI library for Mojo. Contribute to Moosems/Mojo-UI development by creating an account on GitHub.
- Mojo-UI/download_dependencies.sh at main · Moosems/Mojo-UI: A cross-platform GUI library for Mojo. Contribute to Moosems/Mojo-UI development by creating an account on GitHub.
- GitHub - thatstoasty/mist: Advanced ANSI style & color support for your terminal applications: Advanced ANSI style & color support for your terminal applications - thatstoasty/mist
- MLIR: no description found
- 2023 LLVM Dev Mtg - MLIR Is Not an ML Compiler, and Other Common Misconceptions: 2023 LLVM Developers' Meetinghttps://llvm.org/devmtg/2023-10------MLIR Is Not an ML Compiler, and Other Common MisconceptionsSpeaker: Alex Zinenko------Slide...
- [Proposal] Mojo project manifest and build tool · modularml/mojo · Discussion #1785: Hi all, please check out this proposal for a Mojo project manifest and build tool. As mentioned on the proposal itself, we're looking to hear from the Mojo community: Do you agree with the motivat...
Modular (Mojo 🔥) ▷ #community-projects (19 messages🔥):
- Seeking Llama Enthusiasts: Members expressed interest in building a project symbolized by 🦙🦙🦙.🔥 , possibly referencing a new iteration of a bot or project with the name involving 'Llama'.
- Illustrating with Text: A member indicated the potential for using written text as a prompt for creating illustrations.
- ModularBot Achievements: The ModularBot announced a user advancing to a new level, showing a gamification feature in the chat.
- Eager for Emerging Tools: Users shared excitement over developing with HTMX and JSON integration. One mentioned progress with a JSON tool, while another is encouraged to share their work with the community once ready.
- JSON Deserialization Challenge: A user discussed the challenges faced with JSON deserialization due to current limitations without a Read or Write trait and the absence of associated types in traits, which hinders creating composable solutions.
- GitHub - basalt-org/basalt: A Machine Learning framework from scratch in Pure Mojo 🔥: A Machine Learning framework from scratch in Pure Mojo 🔥 - basalt-org/basalt
- GitHub - thatstoasty/prism: Mojo CLI Library modeled after Cobra.: Mojo CLI Library modeled after Cobra. Contribute to thatstoasty/prism development by creating an account on GitHub.
- GitHub - thatstoasty/mog: Style definitions for nice terminal layouts.: Style definitions for nice terminal layouts. Contribute to thatstoasty/mog development by creating an account on GitHub.
- GitHub - thatstoasty/gojo: Experiments in porting over Golang stdlib into Mojo.: Experiments in porting over Golang stdlib into Mojo. - thatstoasty/gojo
- GitHub - thatstoasty/termios: Mojo termios via libc: Mojo termios via libc. Contribute to thatstoasty/termios development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (5 messages):
- Performance Mystery in Prefix Sum Calculation: A member shared a performance comparison where Rust's prefix sum computation was 6x slower than Mojo despite enabling hardware optimizations. After running tests, Rust processed elements at roughly 0.31 ns each without specific hardware flags.
- Hardware Specs in Question: There's an ongoing curiosity about how hardware differences impact performance, with an Intel i7 CPU mentioned as part of the configuration for the member experiencing the Rust performance lag.
- Benchmarking Revisited with a Twist: A new test, which included printing each element to ensure all writes occur, was conducted and showed a slowdown in both languages. Under these conditions, Mojo Scalar performed at 1.4 ns per item while both Rust and Mojo SIMD achieved about 1.0 ns per item on a CPU clocked at 1400 MHz.
Modular (Mojo 🔥) ▷ #🏎engine (24 messages🔥):
- C++ Performance Edges Out Python: Members compared performance between Python/Mojo and C++ implementations, noting that inference time in C++ is slightly faster. Significant performance gains were attributed to the lack of Python runtime API calls in C++.
- Image Processing Code Dissected: Two snippets of Python code for image processing were shared, suggesting heavy calls into the Python runtime, which likely contribute to runtime overhead compared to C++ operations.
- Optimization Discussions: It was mentioned that while Max is optimized for NLP/LLM inferences, there is hope for future optimizations for other types of models, including CNNs.
- Input Tensor Naming Issue in ONNX Models: A member faced an issue with an ONNX model input tensor named "input.1", which couldn't be used directly in the
model.executecall. A solution using Python's evaluate to set item was suggested and validated. - Solving Python API Tensor Name Issues: Another approach to address tensor naming issues in ONNX models was highlighted with a Python code snippet using unpacking (
**) to bypass the problem of using dots in keyword arguments.
Modular (Mojo 🔥) ▷ #nightly (37 messages🔥):
- Pointer Pondering: Discussions revolved around the naming and use of various pointer types in the codebase, such as
UnsafePointer,DTypePointer, and their nuances related to safety and usage. Contributions are underway to refactor code, moving away fromLegacyPointer, as seen with a pull request here.
- SIMD Alias Advocacy: The community conversed about introducing aliases for
SIMD[T, N]likeFloat32x4or using parametric aliases, with some preference for more straightforward names likeFloat32[4]. The idea of aliases was extended to floats, for instance, usingalias Float = SIMD[DType.float64, _].
- Int Conversion Confusion: An upgrade to Mojo 2024.4.1618 removed the
SIMD.to_int()function, leading to build failures for code that used this method. The community suggested usingint(SIMDType)as an alternative, aligning with the recent changes.
- Vacation Notification: A member notified the community of their upcoming absence and provided information on who would be handling PR reviews and issues in their stead, encouraging the use of the
@modularml/mojo-standard-libraryteam alias for any needs during this period.
- String Comparison Implementation Inquiry: A member shared a potential implementation for string comparisons in Python-style syntax, asking for feedback before creating a pull request, which led to the realization that a similar PR might already have been reviewed.
- [Feature Request] Explicit parametric alias with default argument · Issue #1904 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? As title. What is your motivation for this change? Exp...
- [stdlib] Replace `Pointer` by `UnsafePointer` in `stdlib/src/builtin/object.mojo` by gabrieldemarmiesse · Pull Request #2365 · modularml/mojo: Builtins imports behave in a weird way, I had to import LegacyPointer in stdlib/src/python/_cpython.mojo, I have no explanation for this. I just import what the compiler asks me to import :p See ht...
HuggingFace ▷ #general (324 messages🔥🔥):
- Llama 3 vs Claude Levels: A member noted that Llama 3's 70b model has reached levels comparable to Claude Sonnet, while the 8b version outperforms Claude 2 and Mistral.
- API Access Inquiry for MistralAI: Users inquired about API access for MistralAI/Mixtral-8x22B-Instruct-v0.1 for HF Pro users.
- HF Competitions Announced: A link to active competitions on HuggingFace was shared, along with an image of the competition page.
- Discussion on Hardware for ML: There's an active discussion on hardware, specifically whether an AMD RX 7600 XT is suitable for machine learning, leading to a consensus that higher-end AMD models or Nvidia's offerings might be better suited.
- HuggingFace Service Disruptions: Numerous users reported issues with HuggingFace being down, causing disruptions across projects. Announcements and updates about the situation were eagerly awaited, and some users shared workarounds for running models offline.
- Tweet from Teknium (e/λ) (@Teknium1): Welp folks, we have gpt-4 at home
- MTEB Leaderboard - a Hugging Face Space by mteb: no description found
- HF-Mirror - Huggingface 镜像站: no description found
- Hugging Face – The AI community building the future.: no description found
- Jinx The Cat Jinx GIF - Jinx The Cat Jinx Jinx Cat - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- Resident Evil Resident Evil Welcome To Raccoon City GIF - Resident Evil Resident Evil Welcome To Raccoon City Resident Evil Movie - Discover & Share GIFs: Click to view the GIF
- Im Dead Dead Bruh GIF - Im Dead Dead Bruh Skeleton Dead Bruh - Discover & Share GIFs: Click to view the GIF
- Turn Down For What Snoop Dogg GIF - Turn Down For What Snoop Dogg Cheers - Discover & Share GIFs: Click to view the GIF
- TheBloke/SOLAR-10.7B-Instruct-v1.0-uncensored-GPTQ · Hugging Face: no description found
- Cat Club Cat GIF - Cat Club Cat Cat Dance - Discover & Share GIFs: Click to view the GIF
- Eyeverse Brace GIF - Eyeverse Brace Initiation - Discover & Share GIFs: Click to view the GIF
- The Rise of AI: (Hidupkan Closed Caption)(Turn on the Closed Caption)Bergabunglah bersama kami dalam perjalanan melalui evolusi cepat Kecerdasan Buatan, mulai dari kemuncula...
- meta-llama/Meta-Llama-3-8B-Instruct · Update generation_config.json: no description found
- MTRAN3 Modular Robot: Read more at http://www.botjunkie.com/ and http://unit.aist.go.jp/is/dsysd/mtran3/mtran3.htm
- "It's A UNIX System!" | Jurassic Park | Science Fiction Station: Hackerman Lexi (Ariana Richards) shows off her nerd skills as she tries to fix Jurassic Park's UNIX control system.Jurassic Park (1993): John Hammond, an ent...
- View paste 3MUQ: no description found
- competitions (Competitions): no description found
- Hugging Face status : no description found
HuggingFace ▷ #today-im-learning (8 messages🔥):
- Llama 3's Impressive Speed on Groq Cloud: A YouTube video demonstrates Llama 3 running on Groq Cloud, achieving speeds of approximately 800 tokens per second. The video highlights the exceptional performance of an 8 billion parameter model on this platform. LLama 3 on Groq Cloud- 800 Tokens per second!!!
- Exploring the Trifecta with ORPO and LLaMA 3: Another discussed YouTube video challenges the old saying "Fast, Cheap, Good- Pick two", showcasing how AI, with innovations like ORPO with LLaMA 3, is starting to deliver on all three fronts. ORPO with LLaMA 3 -Fast, Cheap, and Good!
- First Steps in Reinforcement Learning: A member shared the success of building their first reinforcement learning model, a PPO agent trained to play LunarLander-v2, using the stable-baselines3 library, and published it on HuggingFace. PPO Agent for LunarLander-v2
- Learning the Intricacies of Tokenizers: A member is dedicating their learning time to understanding tokenizers, which play a critical role in preparing data for language models.
- Dependency on HuggingFace Continues: Despite having models installed, a member humorously notes they remain reliant on HuggingFace's offerings, hinting at the platform's significance in their AI work.
- Building a RAG System with LlamaIndex: Learning for the day involves constructing a retrieval-augmented generation (RAG) system with agents using LlamaIndex, indicating an exploration into advanced AI system architectures.
- Venturing into AI-Based Educational Entrepreneurship: An individual is developing their first MVP (Minimum Viable Product) with aspirations to create a business integrating AI into the classroom, indicating an intersection between AI research and educational innovation.
- wsqstar/ppo-LunarLander-v2 · Hugging Face: no description found
- ORPO with LLaMA 3- Fast, Cheap, and Good!: The old saying goes "Fast, Cheap, Good- Pick two". AI has been no different, but we're starting to see some great innovations to change that. Great article f...
- LLama 3 on Groq Cloud- 800 Tokens per second!!!: @meta 's LLama3 on Groq is crazy fast. Testing out their 8B parameter model using @GroqInc Cloud I consistently got speeds around 800 tokens per second. That...
HuggingFace ▷ #cool-finds (11 messages🔥):
- Exploring Llama3's Dark Aspects: A link was shared to a LinkedIn post discussing the darker aspects of Llama3, a likely reference to vulnerabilities or abuse potential associated with the model.
- Fine-Tuning Fundamentals for LLMs: A GitHub repository was recommended, providing a basic guide to fine-tuning language models, particularly Llama, with a Fine-tune basics guide.
- Quantum Computing: Potential & Pitfalls: A YouTube documentary was shared, titled "New quantum computers - Potential and pitfalls | DW Documentary", exploring the potential of quantum computers, including medical and scientific advancements.
- Why Neural Networks are Powerful Learners: A discussion point highlighted a YouTube video explaining why and how neural networks can learn almost anything: Why Neural Networks can learn (almost) anything.
- Whisper-Prompted Imaging: Information about a live stream was provided, where high-resolution images (SDXL) are controlled and prompted by whisper voice commands, as detailed on Twitter.
- Hokoff: Abstract
- llm-course/llama_finetune/Fine-tune-basics.md at main · andysingal/llm-course: Contribute to andysingal/llm-course development by creating an account on GitHub.
- Why Neural Networks can learn (almost) anything: A video about neural networks, how they work, and why they're useful.My twitter: https://twitter.com/max_romanaSOURCESNeural network playground: https://play...
- New quantum computers - Potential and pitfalls | DW Documentary: A new supercomputer is slated to make it possible to reduce animal experiments and perhaps to cure cancer. The hype surrounding quantum computing is inspirin...
HuggingFace ▷ #i-made-this (27 messages🔥):
- Community Guidelines Reinforcement: A reminder was issued to adhere to community guidelines and refrain from repetitive cross-posting in the Discord channels.
- A Deluge of AI Models: Users have shared multiple iterations and creations of large language models, with enhancements ranging from 3-4b community up to 100B parameter versions, indicating the advancement and customization within the AI community.
- Revolutionizing Dataset Debugging: The beta launch of 3LC, which provides tools for refining datasets for computer vision and future LLM fine-tuning, was announced.
- AI-Powered Chatbot with RAG: A link to a blog article regarding the creation of a RAG chatbot using the Llama3 model was shared, outlining a practical implementation of AI (HuggingFace Blog).
- Innovative Spaces Showcases: Notable projects using Hugging Face Spaces were highlighted, including a VTuber logo generator and a demonstration of outpainting with differential diffusion.
- Home: no description found
- ehristoforu/Gixtral-100B · Hugging Face: no description found
- VTuberLogoGenerator - a Hugging Face Space by gojiteji: no description found
- ehristoforu/llama-3-12b-instruct · Hugging Face: no description found
- Outpainting Demo - a Hugging Face Space by clinteroni: no description found
- QuantFactory/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: no description found
- moondream2-batch-processing - a Hugging Face Space by Csplk: no description found
- RAG chatbot using llama3: no description found
- ehristoforu/Gistral-16B · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- This Cute Dragon Girl Doesnt Exist - a Hugging Face Space by KBlueLeaf: no description found
- GitHub - Crizomb/ai_pdf: Chat locally with any PDF Ask questions, get answer with usefull references Work well with math pdfs (convert them to LaTex, a math syntax comprehensible by computer): Chat locally with any PDF Ask questions, get answer with usefull references Work well with math pdfs (convert them to LaTex, a math syntax comprehensible by computer) - Crizomb/ai_pdf
HuggingFace ▷ #computer-vision (7 messages):
- Open Source OCR Tool on the Rise: The GitHub repository for Nougat, an open-source OCR (Optical Character Recognition) tool meant for converting academic documents like math papers from PDF to LaTeX, was shared and recommended for being effective and free.
- Facebook's Open Source Contributions: A community member expressed gratitude towards Mark Zuckerberg for providing open-source tools, such as the Nougat OCR tool, despite humorously referring to him as "maybe a lizard."
- Request for Invoice Data Extraction Model Architecture: A user enquired about an architectural approach for a machine learning model to extract data from invoices and receipts scanned as images.
- Enhancing ShuttleCock Tracking: A link to the TrackNetV3 GitHub repository was shared which contains an implementation aimed at improving badminton shuttlecock tracking, though the user sought advice on processing each frame individually.
- Building a Private Knowledge Base Inquiry: Another member posed a general question about developing a private knowledge base without providing specific details or context.
- GitHub - facebookresearch/nougat: Implementation of Nougat Neural Optical Understanding for Academic Documents: Implementation of Nougat Neural Optical Understanding for Academic Documents - facebookresearch/nougat
- GitHub - qaz812345/TrackNetV3: Implementation of paper - TrackNetV3: Enhancing ShuttleCock Tracking with Augmentations and Trajectory Rectification: Implementation of paper - TrackNetV3: Enhancing ShuttleCock Tracking with Augmentations and Trajectory Rectification - qaz812345/TrackNetV3
HuggingFace ▷ #NLP (11 messages🔥):
- Finetuning Woes and Advice: One member encountered an issue when trying to fine-tune PHI-2, and they received advice to start with smaller batch sizes, such as 32, and adjust to find a stable setting.
- Rust Gets MinBPE: A new Rust port of
minbpecalledminbpe-rswas announced, with an invitation for others to check out the GitHub project here. It's touted as having a near one-to-one correspondence with the original APIs. - Collaborative Effort on MinBPE-Rust Project: The lead developer and a documenter of the
minbpe-rshighlighted the project's features likeBasicTokenizer,RegexTokenizer, andGPT4Tokenizer, including tests for compatibility withtiktoken's GPT-4 tokenizer. - BERTopic Clashes with OpenAI: A member shared their experience of BERTopic's new release causing dependency issues with OpenAI's tools. They recommended locking scripts to version 0.16.0 to avoid compatibility problems.
- Quest for the Go-Emotions Dataset: There is a request for assistance on how to integrate the go-emotions dataset into an ongoing project.
Link mentioned: GitHub - gnp/minbpe-rs: Port of Andrej Karpathy's minbpe to Rust: Port of Andrej Karpathy's minbpe to Rust. Contribute to gnp/minbpe-rs development by creating an account on GitHub.
HuggingFace ▷ #diffusion-discussions (4 messages):
- Seeking Lora Training for Inpainting Consistency: A member inquired about using Lora training for inpaintings to maintain the consistency of the background without altering the object in the image. The current inpainting results were not satisfactory, prompting a search for Lora as a potential alternative.
- Inquiring About fooocus Usage on Android Tablet: A member asked for guidance on how to use the application fooocus on an android tablet, but did not provide specifics about the issue they might be experiencing.
- Offering Expertise in Rapid Prototyping and Stable Diffusion: A member introduced themselves, offering services in web design, MVPs, app development, and scalable infrastructure, including experience with AWS and deployments. They highlighted over three years of experience in fields like Stable Diffusion, Statistics, and Computer Vision, inviting direct messages for project discussions.
- Vespa Model Download Troubleshooting: A member reported encountering a 403 error while trying to download a model using vespa, seeking assistance to resolve the issue. No additional information or context regarding the error or the steps taken was provided.
OpenRouter (Alex Atallah) ▷ #announcements (5 messages):
- Charge of the Llama Brigade: The new Nitro-powered Llama models are now available for OpenRouter users, offering potential enhancements in performance and capabilities. Check them out here.
- Magic Under Pressure: OpenRouter's Wizard 8x22b model has faced a high demand, causing strain on providers. Load balancing adjustments are underway to improve response times.
- Latency Improvements Incoming: Recent load balancer changes and stop tokens handling fixes should now result in improved throughput for non-stream requests, aiming to optimize overall performance.
- A Tweet's Brief Tale: There's a new tweet from OpenRouter AI which you can view directly on Twitter.
- Rerouting Model Requests: Requests for Databricks: DBRX 132B Instruct (nitro) will be rerouted, as the model has been removed. Users can utilize the standard Databricks: DBRX 132B Instruct model instead.
- DBRX 132B Instruct by databricks | OpenRouter: DBRX is a new open source large language model developed by Databricks. At 132B, it outperforms existing open source LLMs like Llama 2 70B and Mixtral-8x7B on standard industry benchmarks for language...
- OpenRouter: Browse models on OpenRouter
OpenRouter (Alex Atallah) ▷ #app-showcase (5 messages):
- URL Confusion Cleared Up: An old URL mentioned in the channel description led to confusion, but was promptly updated after a user pointed out the issue.
- Product Feedback - Suggesting Improvements: A user provided detailed feedback on a product, suggesting improvements such as clarifying the support for specific contract types, adding support for employment contracts, considering local laws, offering simpler explanations in plain language, allowing users to specify negotiation preferences, and flagging illegal terms in contracts.
- KeyWords AI Lauds OpenRouter: The KeyWords AI platform, found at https://keywordsai.co, praised OpenRouter for their model updates, which allows KeyWords AI to focus on adding features for developers like request logging, usage dashboards, and user analytics. KeyWords AI supports all OpenRouter models and can be integrated with just two lines of code.
Link mentioned: no title found: no description found
OpenRouter (Alex Atallah) ▷ #general (353 messages🔥🔥):
- LLaMA-3's Multilingual Capabilities and Fine-Tuning Challenges: Discussions indicated that LLaMA-3 has limitations with multilingual capabilities potentially due to limited fine-tuning on non-English datasets. However, users expressed hope for better multilanguage support in future releases based on Meta's promises and suggested fine-tuning to improve performance.
- Tool Use and Streaming in Chatbots: Conversations around tool use in chatbots like OpenAI's and Claude indicated current limitations, particularly in streaming tool call requests. Anticipation was expressed for providers like Anthropic to introduce streaming, which could improve the efficacy of tool calls in these models.
- Comparing and Contrasting LLMs for Creative Writing: Users shared experiences with different Large Language Models for creative tasks, comparing the nuances, strengths, and drawbacks of models like Wizard LM-2 and Mixtral in terms of instruction following, conversational abilities, and context understanding.
- Provider Performance and Model Static Nature on OpenRouter: There was acknowledgement that while models on OpenRouter are static and unchanging, there could be potential for performance differences due to updates from the model's host outside the platform, with users wishing that high-quality, less-censored versions remained accessible.
- Interest in New Model Contributions and Features: Users discussed the interest in new and improved models, with particular emphasis on better performance for specific tasks such as roleplay and creative writing. The community also showed enthusiasm towards the introduction of a model that claimed to be an enhanced roleplaying model, Soliloquy-L3, with special features such as larger context length support.
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- GroqChat: no description found
- Work-to-rule - Wikipedia: no description found
- Tweet from Eric Hartford (@erhartford): Dolphin-2.9-llama3-8b generously sponsored by @CrusoeCloud ETA Saturday. Lots of collaboration with @LucasAtkins7 and @FernandoNetoAi. Dolphin-2.9-llama3-70b to follow. Dolphin-2.9-mixtral-8x22b stil...
- Llama 3 Soliloquy 8B by lynn | OpenRouter: Soliloquy-L3 is a fast, highly capable roleplaying model designed for immersive, dynamic experiences. Trained on over 250 million tokens of roleplaying data, Soliloquy-L3 has a vast knowledge base, ri...
- dreamgen/opus-v1.2-llama-3-8b · Hugging Face: no description found
- @WizardLM on Hugging Face: "🔥🔥🔥 Introducing WizardLM-2! 📙Release Blog:…": no description found
Latent Space ▷ #ai-general-chat (201 messages🔥🔥):
- Llama 3 Performance Chatter: There's an ongoing comparison of Llama 3 and GPT-4, with various users testing Llama on different platforms including meta.ai, HuggingChat, and others. One user claims Llama 3 70b isn't as impressive as GPT-4 Turbo, despite good lmsys scores.
- Inference Time Discussions: Users are discussing Llama 3's inference times, with one noting Groq Cloud's sub-100ms time-to-first-byte for Llama-3 70b as exceptionally fast. Another mentioned Deepgram as a top choice for transcription in voice 2 voice AI applications.
- Starting an LLM Project: For those looking to start a new LLM project, a template like litellm was suggested for abstracting the boilerplate of calling LLMs to easily swap between different models.
- Fine-Tuning and Configuration Tools: A discussion on tools for fine-tuning and configuring complex applications brought up Hydra by Facebook Research, but some users found the README lacking in clear explanation of its purpose and utility.
- Emerging Data Set: The announcement of FineWeb, a new data set with 15 trillion tokens of high-quality web data, was shared, suggesting it could outperform existing sets like RefinedWeb and The Pile.
- Tweet from Guilherme Penedo (@gui_penedo): We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data. We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, ...
- tinygrad: A simple and powerful neural network framework: no description found
- Tweet from Teknium (e/λ) (@Teknium1): Welp folks, we have gpt-4 at home
- Macs to Get AI-Focused M4 Chips Starting in Late 2024: Apple will begin updating its Mac lineup with M4 chips in late 2024, according to Bloomberg's Mark Gurman. The M4 chip will be focused on...
- LiteLLM - Getting Started | liteLLM: https://github.com/BerriAI/litellm
- Tweet from echo.hive (@hive_echo): Testing Llama-3 8B and 70b This simple test’s results iterate(to me) that more data with smaller models make for excellent low-end reasoners & more data with larger models make for excellent high-end...
- Tweet from kwindla (@kwindla): Whoah. Llama-3 70 time-to-first-byte on @GroqInc is very fast — sub-100ms fast.
- Tweet from Teknium (e/λ) (@Teknium1): Welp folks, we have gpt-4 at home
- Browserless - #1 Web Automation & Headless Browser Automation Tool: Try Browserless, one of the best web automation tools for free. Implement web scraping, PDF generation & headless browser automation easily.
- Tweet from Hassan Hayat 🔥 (@TheSeaMouse): I'm still stunned by this. How did it improve so much? I mean, look at 8B vs the old 70B
- GitHub - facebookresearch/hydra: Hydra is a framework for elegantly configuring complex applications: Hydra is a framework for elegantly configuring complex applications - facebookresearch/hydra
- FireCrawl: Turn any website into LLM-ready data.
- [AINews] Llama-3-70b is GPT-4-level Open Model: AI News for 4/18/2024-4/19/2024. We checked 6 subreddits and 364 Twitters and 27 Discords (395 channels, and 10403 messages) for you. Estimated reading time...
Latent Space ▷ #ai-announcements (3 messages):
- New Latent Space Podcast Episode: A new episode of the Latent Space Podcast featuring <@199392275124453376> (Jason Liu) has been announced with excitement. The announcement included a Twitter link to the episode.
- Eager Anticipation for Podcast with Jason Liu: Member expresses enthusiasm for the newly released podcast episode with Jason Liu. Anticipation is high for the insights this episode may bring.
Latent Space ▷ #llm-paper-club-west (66 messages🔥🔥):
- Enthusiasm for GPT Paper Discussion: Members expressed eagerness about discussing the seminal "Improving Language Understanding by Generative Pre-Training" paper, with one noting that it's a highly influential ("goated") paper and highlighting Alec Radford's accomplishments just three years out of undergrad.
- Clarification on Embeddings and Tokenizers: It was clarified that unlike embeddings, which require a neural network to be learned, tokenizers don’t necessarily require such training, which is a distinction not obvious to newcomers in the field.
- Intent to Record and Share Paper Club Sessions: Members were informed that the Asia Paper Club sessions are being recorded and there was an intention to upload the content to YouTube for broader access.
- Debunking and Understanding Complex Topics: The group discussed various complex topics, including whether perplexity (pplx) numbers are comparable across models and the history of GPU usage in machine learning, with an interest in creating visual aids like charts to better understand these trends.
- Appreciation for the Paper Club Presentation: Following the presentation, participants expressed their gratitude for the insightful talk and shared resources, with links provided for further engagement with the material discussed.
- Scaling laws for neural language models: no description found
- TinyBox packs a punch with six of AMD's fastest gaming GPUs repurposed for AI — new box uses Radeon 7900 XTX and retails for $15K, now in production: Startup wants to offer high AI performance using Radeon RX 7900 XTX.
- Papers with Code - MRPC Dataset: Microsoft Research Paraphrase Corpus (MRPC) is a corpus consists of 5,801 sentence pairs collected from newswire articles. Each pair is labelled if it is a paraphrase or not by human annotators. The w...
Latent Space ▷ #ai-in-action-club (71 messages🔥🔥):
- Zooming In or Sticking to Discord: There's an inquiry about whether this week's meeting will transition from Discord to Zoom.
- LLM Evaluation Strategy Shared: A Google Slides presentation regarding LLM Evaluation was shared for review, but no specific details from the slides were provided.
- Signal Integrity of Conference Call: Some members discussed hearing a mysterious hum during a call, while others did not. After a member rejoined the call, the issue appeared to be resolved.
- Evaluating Language Models: A member shared two links to articles from Eugene Yan's blog discussing the challenges and strategies for evaluating abstractive summarization in language models and shared useful evaluation methodologies.
- Strategies for Model Evaluation and Choice: Various suggestions on evaluating and choosing models were discussed, including the idea of using telemetry data to synthesize evaluation sets, consistent baselining against a single model, and considering the cost versus performance balance when evaluating models in production.
- Evaluation & Hallucination Detection for Abstractive Summaries: Reference, context, and preference-based metrics, self-consistency, and catching hallucinations.
- LLM Task-Specific Evals that Do & Don't Work: Evals for classification, summarization, translation, copyright regurgitation, and toxicity.
- LLM Evaluation: Evaluating LLM Based Systems Alan van Arden April 19th 2024 Latent Space
- AI In Action: Weekly Jam Sessions: 2024 Topic,Date,Facilitator,Resources,@dropdown,@ UI/UX patterns for GenAI,1/26/2024,nuvic,<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-stru...
LAION ▷ #general (247 messages🔥🔥):
- Concerns Over Meta's Approach with LLaMA-3: A member questioned why Meta is withholding the LLaMA-3 paper, noting that it's uncharacteristic for companies that typically release papers before weights. The change in approach suggests Meta's attempt to innovate in their open model strategy.
- Prompt Engineering Techniques Debated: Users discussed various strategies for generating well-aligned outputs in image diffusion models, with some suggesting that appending highly specific camera or film types to prompts leads to better results, while others argued that this causes a reduction in output variance and may be placebo.
- Legal Risks of Nightshade Explored: Conversation shifted to the ethical and legal implications of using Nightshade, an algorithm designed to tamper with AI training, with links provided to an article discussing legal concerns. The members mentioned potential issues under the Computer Fraud and Abuse Act (CFAA), highlighting the importance of adhering to data rights and avoiding liability.
- Bot Surveillance Detected on Discord: A member shared a surveillance bot detection and removal tool, kickthespy.pet, sparking discussion about privacy on Discord. The discovery led to action from admins and a broader conversation about the prevalence of such bots.
- AI Model Performance Discussions: Users shared insights on the performance improvement of AI models with scaling, citing the example of OpenAI's DALL-E 3. Despite the diminishing returns of data scale, members noted the significance of even small performance gains and considered the implications for other models like diffusion models.
- Kick the Spy Pet: no description found
- Training Compute-Optimal Large Language Models: We investigate the optimal model size and number of tokens for training a transformer language model under a given compute budget. We find that current large language models are significantly undertra...
- Nightshade: Legal Poison Disguised as Protection for Artists: As I stated in my previous article, generative AI has continued to be a contentious subject for many artists, and various schemes have appeared in order to ward off model training. The last article, h...
- Mixture of Attention: no description found
- Oh No Top Gear GIF - Oh No Top Gear Jeremy Clarkson - Discover & Share GIFs: Click to view the GIF
- Text-to-Image: Diffusion, Text Conditioning, Guidance, Latent Space: The fundamentals of text-to-image generation, relevant papers, and experimenting with DDPM.
- cookbook/calc/calc_transformer_mem.py at main · EleutherAI/cookbook: Deep learning for dummies. All the practical details and useful utilities that go into working with real models. - EleutherAI/cookbook
- The Rise of AI: (Hidupkan Closed Caption)(Turn on the Closed Caption)Bergabunglah bersama kami dalam perjalanan melalui evolusi cepat Kecerdasan Buatan, mulai dari kemuncula...
- IF/deepfloyd_if/model/unet.py at develop · deep-floyd/IF: Contribute to deep-floyd/IF development by creating an account on GitHub.
LAION ▷ #research (72 messages🔥🔥):
- Anticipation for Open Source Solutions: Discussion centered on the expectation that Meta will release open-source multimodal models that may rival or outperform existing proprietary solutions, in light of their commitment to multimodality.
- Accelerating Diffusion Models: NVIDIA, the University of Toronto, and the Vector Institute propose "Align Your Steps," a method to optimize sampling schedules of diffusion models for higher quality output at a faster pace. The research, discussed in the paper, focuses on reducing the slow sampling speed without compromising quality, yet the lack of training code release was noted as a limitation.
- Evaluating Multimodal Language Models: A new benchmark called Blink, designed to assess core visual perception abilities in multimodal language models (LLMs), which are challenging for such models, was mentioned; the best-performing models like GPT-4V have notably lower accuracy compared to humans. Find the Blink benchmark details in the research abstract.
- Discussing Upscaling and Tuning in Image Models: Conversations about progress on image model upscaling, such as 2D rope extrapolation, highlighted the ongoing need for tuning models at higher resolutions and the challenges in producing coherent outputs.
- On the Horizon for Model Optimization: Discussions touched upon the potential for using simple neural networks to optimize sampling schedules for different prompts in image generation, surfacing the idea that optimal schedules could vary depending on the image category. The dialogue suggests more research opportunities, particularly in how conditional fine-grained tuning may affect diffusion models.
- BLINK: Multimodal Large Language Models Can See but Not Perceive: We introduce Blink, a new benchmark for multimodal language models (LLMs) that focuses on core visual perception abilities not found in other evaluations. Most of the Blink tasks can be solved by huma...
- TextSquare: Scaling up Text-Centric Visual Instruction Tuning: Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT...
- Align Your Steps: Align Your Steps: Optimizing Sampling Schedules in Diffusion Models
- bghira: Weights & Biases, developer tools for machine learning
- Google Colaboratory: no description found
- piecewise-rectified-flow/README.md at main · magic-research/piecewise-rectified-flow: Contribute to magic-research/piecewise-rectified-flow development by creating an account on GitHub.
- bghira: Weights & Biases, developer tools for machine learning
LAION ▷ #learning-ml (6 messages):
- Coding Assistant Collaboration: A member expressed interest in building an NLP coding assistant focused on JavaScript/Rust and sought collaboration, offering mutual help.
- Limited Availability for Assistance: Another member indicated their willingness to help with the project but noted that their time could be constrained due to commitments to multiple other projects.
- Request for Project Resources: In anticipation of possible collaboration, a request was made for a repository containing any previous work, implying a desire to evaluate or build upon past efforts.
- Acknowledgement of Previous Project Limitations: The member sharing expertise acknowledged discontinuing a past related project due to limited AI knowledge at the time.
- Offering Help with Tasks: Despite earlier discontinuation, the expert member confirmed their capability to assist with current tasks related to the NLP coding assistant project.
OpenAI ▷ #ai-discussions (193 messages🔥🔥):
- Groq Cloud API Enables Free AI Creativity: A user highlighted that their chat-based roleplaying GPT can perform impressively and even write decent Python, mentioning it runs on Groq Cloud API, which is available for free usage by anyone.
- LLaMa 3 Free Inference via Groq: Users recommend LLaMa 3 as the current best free model, even better than Claude 3 Sonnet and ChatGPT-3.5, with free inference possible on Groq Cloud.
- Debate on AI Sentience and Emotions: In a philosophical discussion, users contemplated the definitions of consciousness, sentience, and the human experience, with some arguing that emotions are a significant part of what could make AI similar to human consciousness.
- Projecting AI Development and Humanity's Future: One user expressed a vision of a future 'digital Athens' where robots undertake labor, questioning the implications of transhumanism and whether technology will lead to immortality or a 'zombie cyborg' existence.
- Seeking In-Depth AI Resources for Academic Work: A user working on a university thesis about AI, generative algorithms, and related technologies requested assistance in finding in-depth texts and resources, and was directed to OpenAI's research papers and publications.
- Joe Bereta Source Fed GIF - Joe Bereta Source Fed Micdrop - Discover & Share GIFs: Click to view the GIF
- Generative models: This post describes four projects that share a common theme of enhancing or using generative models, a branch of unsupervised learning techniques in machine learning. In addition to describing our wor...
- Research: We believe our research will eventually lead to artificial general intelligence, a system that can solve human-level problems. Building safe and beneficial AGI is our mission.
- Biorobotics - Wikipedia: no description found
- GPT-4: We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while less ca...
OpenAI ▷ #gpt-4-discussions (32 messages🔥):
- GPT-4 Performance Query: A user expressed disappointment with the performance of GPT-4-turbo (0409 version) compared to the latest preview version (0125) within their assistant pipeline.
- Users Experiment with AI Combinations: A participant shared their experiment linking Claude 3 Opus with GPT-4 and later integrating LLama 3 70B via Groq, experiencing mixed results and access issues from other users with the provided shared links and associated integration.
- AI Fusion Feedback Loop Consideration: The community is exploring how to best combine responses from different AI models, with an emphasis on improving quality without explicit feedback, and there's a mention of restrictions on posting share URLs from cgpt chats.
- Assistant API Discussion for UI Responsiveness: A conversation unfolded around improving UI engagement for the Assistant API by streaming a loading message to users while backend fetching occurs, with suggestions focusing on UI manipulation over API modifications for dynamic text display.
- Layer Adaptation Techniques Explored: There's an ongoing theoretical discussion about the role of convolutional layers (Hyena) and LoRa (Layer-wise Relevance Propagation) in LLMs (Large Language Models), touching on their usage for fine-tuning models like Mistral 7B.
OpenAI ▷ #prompt-engineering (29 messages🔥):
- JSON Data Summarization Headache: A member is facing challenges in having the model insert the exact text from a JSON field into a generated summary. After discussing, they plan to experiment with using code interpretation embedded within the summary template.
- Custom Instructions Debate: One member questioned the ideal length for custom instructions. Some responses include the utilization of only a minimal instruction to save context space, while another had a lengthy one which seemed to limit ChatGPT's responses.
- Law Student Seeks Criminal Law Prompts: A request was made for prompts specifically tailored for criminal law purposes by a law student, but no further details or responses were provided on this topic.
- Prompt Refinement for Enhanced Emails: A member shared their experience with an email enhancement program using GPT-4, seeking advice on optimizing prompts for better quality responses.
- Finding the Prompt Library: A user inquired about locating a prompt library, but there were no responses providing concrete directions or a link.
- Prompt Engineering Ethics Concerns: A member with over two years of prompt engineering experience voiced concerns about sharing potentially harmful and sensitive prompts, stressing the ease of manipulating ChatGPT with specific prompts.
- Optimal Prompt Length Discussion: There was a conversation about the effectiveness of prompts' length; members debated if bigger, more specific prompts lead to better responses or if concise prompts are better. One suggestion was to spread lengthy instructions across multiple messages when necessary.
OpenAI ▷ #api-discussions (29 messages🔥):
- Searching for Precision in Summaries: A member is having trouble getting GPT to return the exact text from a specific field in a JSON data summary. Despite explicit instructions, the bot fails to include the exact text as desired. Suggestions include using the code interpreter to extract data more reliably.
- Custom Instructions: Less Is More?: Users discuss the length of custom instructions for ChatGPT responses, with some opting for shorter instructions to save context window space. A brief example is given, "Include semicolons, colons, and em dashes in your responses where applicable."
- AI and Legal Queries: A request was made for criminal law prompts for law students. However, there was no discussion of any specific prompts or further follow-up.
- Email Enhancement with GPT-4: An individual shares their use-case of a program that enhances emails with GPT-4. They express frustration with inconsistent quality and seek advice on prompt optimization, sparking discussions about the efficiency of shorter versus longer prompts.
- Prompt Engineering Ethics and Issues: A seasoned prompt engineer expresses concerns about sharing aggressive and potentially harmful prompts, highlighting ethical considerations and the guidelines of forum sharing.
LlamaIndex ▷ #blog (6 messages):
- Automating Code Writing with LlamaParse: The collaboration with @TechWithTimm teaches you to set up local LLMs with @ollama, parse documentation using LlamaParse, build an agent, and teach it to write code. Here's a glimpse of the workflow on Twitter.
- Crafting a Local RAG App Using Llama-3: Learn to build a RAG application 100% locally with MetaAI's Llama-3, as shared in the provided link on Twitter.
- Introducing DREAM for RAG Experimentation: Aishwarya Prabhat introduces DREAM, a framework designed to experiment with RAG setups effectively, catering to the need for fine-tuning multiple parameters in the development stage. More details are available on Twitter.
- Constructing a Finance Agent with LlamaIndex: Hanane Dupouy's mini-blog post showcases a toolkit for querying public company data, including stock prices and financial news summaries, built with @llama_index. Check out the project on Twitter.
- Memory-Enhanced ColBERT Retrieval Agents: Addressing the challenges of embedding conversation history in RAG, a guide for building a ColBERT-powered Retrieval Agent with Memory has been shared, which marks a move towards personalized conversational assistants. Further exploration of this topic is prompted on Twitter.
LlamaIndex ▷ #general (205 messages🔥🔥):
- Confusion Over Attribute Error: A user encountered an
AttributeErrorwhen trying to printresp.chat.messagesin their code snippet and sought help understanding the proper attributes of aChatResponseobject. - Local vs. OpenAI in LlamaIndex: Discussion about using local implementation of LLMs such as Ollama or LM Studio instead of the default OpenAI models within LlamaIndex for different functionalities.
- Managing Output Verbosity: A user asked how to prevent batch-related output from cluttering Jupyter notebook execution results, and the conversation shifted towards controlling logging settings.
- Troubleshooting VectorStoreIndex Query Results: A user sought to index JSON files and queried how to use metadata to improve search results, receiving advice on auto-retrieval and linking nodes.
- Handling File Loading Errors: An inquiry was made about handling individual file loading exceptions within
SimpleDirectoryReaderwithout having to capture STDOUT or failing all file imports.
- no title found: no description found
- Large Language Models (LLMs) | LlamaIndex.TS: The LLM is responsible for reading text and generating natural language responses to queries. By default, LlamaIndex.TS uses gpt-3.5-turbo.
- Agents - LlamaIndex: no description found
- RAG CLI - LlamaIndex: no description found
- Firestore Demo - LlamaIndex: no description found
- Auto-Retrieval from a Weaviate Vector Database - LlamaIndex: no description found
- Starter Tutorial (Local Models) - LlamaIndex: no description found
- Chat Engine - LlamaIndex: no description found
- Indexing & Embedding - LlamaIndex: no description found
- Portkey - LlamaIndex: no description found
- Usage Pattern - LlamaIndex: no description found
- llama_index/llama-index-integrations/vector_stores/llama-index-vector-stores-milvus/llama_index/vector_stores/milvus/base.py at 7b52057b717451a801c583fae7efe4c4ad167455 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Token Counting Handler - LlamaIndex: no description found
- GitHub - run-llama/llama_parse: Parse files for optimal RAG: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
- fix qdrant bug with checking existing collection by logan-markewich · Pull Request #13009 · run-llama/llama_index: Small bug with getting info from possibly existing collection
- Building an Agent around a Query Pipeline - LlamaIndex: no description found
- Ollama - Llama 2 7B - LlamaIndex: no description found
- LocalAI - LlamaIndex: no description found
- Using Documents - LlamaIndex: no description found
- Pathway Reader - LlamaIndex: no description found
- Tree Summarize - LlamaIndex: no description found
- Querying - LlamaIndex: no description found
- Starter Tutorial (Local Models) - LlamaIndex: no description found
- How to use UpTrain with LlamaIndex - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (4 messages):
- Simplifying Infini Attention: A member has created an explanatory post about Infini Attention and its potential applications in the field of generative AI. They have shared their insights in a LinkedIn post.
- Data Added to AI Raise Tracking Sheet: The AI Raise Tracking Sheet has been updated to include funding and company distribution by city. This information can be accessed and reviewed in a shared Google spreadsheet.
- Celebrating AI Distribution with a Tweet: A tweet highlights the efforts to clean and display the geographical distribution of AI funding and company growth over the last year. The conversation can be followed via the provided Twitter link.
- FireCrawl and LlamaIndex Power-Up Markdown: An article discusses the integration of FireCrawl with LlamaIndex, enhancing the potential of LLMs with markdown-ready features. The advancement is detailed on Medium.
- Introducing WhyHow.AI’s Knowledge Graph SDK Update: WhyHow.AI announces an upgrade to their Knowledge Graph SDK, allowing for schema-controlled automated knowledge graphs. This empowers users to create structured graphs from private data and integrate with RAG systems; more details and participation info are available at Medium article.
- [FrontierOptic.com] AI Raise Tracking - April 21 2024 - Community Review Copy: Cover <a href="http://FrontierOptic.com">FrontierOptic.com</a> AI Startup Fund Raise Data (Since May 2023) - Community Review Copy <a href="https://twitter.com/WangUWS&...
- Tweet from Howe Wang (@WangUWS): To celebrate 20 years since @HilaryDuff sang 'Could be New York, Maybe Hollywood and Vine, London, Paris, maybe Tokyo,' in 'Wake Up'. I cleaned up the AI Hype Train data's location...
OpenInterpreter ▷ #general (75 messages🔥🔥):
- Fine-Tuning Trends in AI: A member shared their experience with fine-tuning on general instruction datasets using models like Mixtral or Llama. They highlighted the quick learning capabilities due to the small size of datasets required for tuning.
- Performance Praise for Llama3 on Groq: Users are boasting about the impressive speed of Llama3 when used on Groq hardware, indicating high performance and enthusiasm for using this setup in practice.
- Troubleshooting OI on Windows: An issue was raised regarding difficulties encountered with Open Interpreter (OI) on Windows platforms, leading to a community member sharing a GitHub issue thread detailing a bug encountered during installation.
- Integrating Open Interpreter with Groq API: Community members have confirmed success in using OI with Groq API, making use of tutorials and example commands provided by peers.
- Exploring OI's Local Model Capabilities: Following a live stream, discussions arose around utilizing local models with OI, specifically discovering bugs and effective usage, such as bypassing a function calling bug with a specific command and the performance benefits of using Llama 3 8b locally.
- ▌ OS Control enabled> open notepad and write "hello" Let's start by try - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Bug when fresh install and new start · Issue #1185 · OpenInterpreter/open-interpreter: Describe the bug when i run it. this warning shown interpreter /opt/conda/lib/python3.11/site-packages/pydantic/_internal/fields.py:151: UserWarning: Field "model_id" has conflict with prote...
- posts/llama3_new.pdf at main · ishank26/posts: resources, thoughts and notes. Contribute to ishank26/posts development by creating an account on GitHub.
- Future of Coding Jobs? + Open Interpreter w/ Gemini + more: NOTES & Schedule: https://techfren.notion.site/Techfren-STREAM-Schedule-2bdfc29d9ffd4d2b93254644126581a9?pvs=40:00 - Intro5:05 - are swe jobs safe?28:01 - my...
- How to use Open Interpreter cheaper! (LM studio / groq / gpt3.5): Part 1 and intro: https://www.youtube.com/watch?v=5Lf8bCKa_dE0:00 - set up1:09 - default gpt-42:36 - fast mode / gpt-3.52:55 - local mode3:39 - LM Studio 5:5...
- Update local profile so it doen't use function calling by Notnaton · Pull Request #1213 · OpenInterpreter/open-interpreter: leaving model = gpt4 will result in function calling. Most LM Studio models dont use function calling. making it not work Describe the changes you have made: Reference any relevant issues (e.g. "...
- (oi) C:\Users\ivan>interpreter --api_base "https://api.groq.com/openai/v1" --api - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Bump version of tiktoken by minamorl · Pull Request #1204 · OpenInterpreter/open-interpreter: Describe the changes you have made: Bumped version of tiktoken since build process is broken for some reason. This PR fixes broken process. Reference any relevant issues (e.g. "Fixes #000"):...
- Jupyter export magic command by tyfiero · Pull Request #986 · OpenInterpreter/open-interpreter: Describe the changes you have made: Added a %jupyter magic command to export the current session as a jupyter notebook file, that you can run in Google Collab. Reference any relevant issues (e.g. &quo...
OpenInterpreter ▷ #O1 (18 messages🔥):
- Groq Chips Meets Llama 3: A member reported testing Groq chips with Llama 3 70b and found it promising, although they admitted to having limited testing time.
- Confusion over O1 and Open Interpret Support: One member revealed a mix-up between O1 and Open Interpret regarding their compatibility with Groq; it was clarified that they were referring to Open Interpret, noting that O1 currently only supports OAI's cloud option.
- Instability with Larger Llama Models: A concern was raised about the stability of Llama 3 70b compared to its smaller 8b counterpart, suggesting the larger models are more prone to instability.
- Windows Client Issues with O1: Users are encountering problems running O1 on Windows, with reports indicating a potential issue with the Windows client itself.
- Spacebar Glitch on M1 Macbooks: An issue was flagged with the O1 voice recognition on M1 Macbooks, where pressing the spacebar inputs spaces instead of recording, with suggested fixes like
brew install ffmpegnot resolving the problem. Another user suggested ensuring proper permissions and mentioned a workaround using conda to install a different Python version.
Cohere ▷ #general (64 messages🔥🔥):
- Cohere Quick-Start MySQL Connector Assistance: A discussion focused on integrating MySQL with Cohere LLMs without using Docker, aiming for direct answers from a local database. There seems to be confusion around the implementation details, with a link to a GitHub repo providing reference code and another user mentioning concerns about out-of-date documentation and functionality, citing the
create_connectornot working correctly.
- Exploring the Limits of Command R for Commercial Use: A user inquired about using Command R (and Command R+) on an edge-device for commercial purposes and was informed it's not allowed under the CC-BY-NC 4.0 license, which is meant for non-commercial use only.
- AI Startup Founder Seeking Talent: The founder of an AI startup seeks assistance with model tuning and voice models, indicating a preference for someone with experience in AI research and LLMs. The founder offers engagement via email or LinkedIn for interested parties.
- Job Hunt Strategies After Cohere Internship Rejection: A user shared disappointment after not getting an internship with Cohere and sought advice on finding ML/software roles. Several members contributed ideas, including applying to companies without public intern listings, working on open-source projects, taking advantage of school networks, and aiming for job fairs.
- Upcoming ML-Maths Talk Alert: An announcement was made for an upcoming talk by Dr. Matthew Bernstein on Variational AutoEncoders (VAEs) and their application in single-cell genomics, with a Google Meet link shared for those interested in attending. Here's the link to the talk.
- Using Oracle Autonomous Database Serverless: Oracle Autonomous Database Select AI enables you to query your data using natural language.
- Creating and Deploying a Connector - Cohere Docs: no description found
- Ken's Resume.pdf: no description found
- quick-start-connectors/mysql at main · cohere-ai/quick-start-connectors: This open-source repository offers reference code for integrating workplace datastores with Cohere's LLMs, enabling developers and businesses to perform seamless retrieval-augmented generation...
Cohere ▷ #project-sharing (5 messages):
- Open Source Code for Matchmaking AI: A matchmaking application that leverages @cohere Command R+ with integrations like @stanfordnlp DSPy and @weaviate_io Vector store has been open-sourced. Developers are encouraged to try out the code, provide feedback, and contribute to the GitHub repository.
- Seeking Advancements in Web Scraping: A member discussed the challenges of constructing a generic web scraper using gpt-4-turbo to identify (selector, column) pairs, particularly struggling with input elements for clicking and selecting on web pages with filters.
- Contemplating the Ethics of "Jailbreaking" AI: In a conversation about AI "jailbreaks", a member reflects on their potential to create intelligent agents, suggesting that it might lead to inadvertent negative behaviors from these agents, such as the use of inappropriate language.
- New Prompt IDE Seeks Feedback: The creator of Prompt Mixer, a desktop application for creating and evaluating prompts, shared a link to their project, www.promptmixer.dev, and invited feedback to improve the tool which offers features like automatic version control and integration with AI data sets.
- Tweet from Anmol Desai (@anmol_desai2005): We did it. Finally the code is open sourced. Please give it a try and we are eager for a feedback. @weaviate_io @stanfordnlp @cohere @1vnzh @CShorten30 ↘️ Quoting Muratcan Koylan (@youraimarketer) ...
- Prompt Mixer. AI Development Studio for companies: A collaborative workspace for managers, engineers and data experts to develop AI features.
Cohere ▷ #collab-opps (1 messages):
- Seeking Norwegian Cohere Consultants: A member is looking for Norwegian companies, preferably consultants, that have experience with Cohere, for a third-party reference or consulting for a new project.
tinygrad (George Hotz) ▷ #general (21 messages🔥):
- Locally Running AI on Consumer GPUs: A user highlighted success in running hardware support architecture (HSA) out-of-the-box on a laptop's Vega iGPU, considering the use of a HIP compiler and OpenCL (possibly Rusticl) as an alternative setup.
- Inquiry About Implicit Layers in tinygrad: A user asked if anyone had experience with implementing implicit layers, such as differentiating through an optimization problem, in tinygrad.
- Potential Cloud Service for tinygrad: A discussion emerged concerning whether tinygrad/box/chip could evolve into a cloud service, prompted by an article that mentioned hardware companies transitioning to service models. Some members hoped it would remain a tool to empower individual users rather than moving to cloud dependency.
- A Debate on Local vs Cloud AI: Participants engaged in a debate over the merits and future potential of local versus cloud AI. Comments ranged from favoring user-controlled hardware and developing models like TinyBox for home use, to recognizing the current limitations of consumer hardware for running state-of-the-art models and the benefits of centralized processing power.
- Weekly Meeting Announcements by George Hotz: George Hotz outlined topics for an upcoming meeting, including MLPerf progress, KFD/NVIDIA drivers, a plan for new NVIDIA CI, documentation/developer experience, scheduler improvements, and a discussion on the 7500 line count limit for the codebase. He also reminded that the meeting was open for everyone to listen to, with speaking limited to reds and above.
tinygrad (George Hotz) ▷ #learn-tinygrad (38 messages🔥):
- Debugging Einsum Precision Issues: A member encountered a strange error while porting a model from PyTorch to tinygrad, facing slight differences in the results of the
einsumoperation, causing the model to underflow to NaN values. Suggested it could be a floating point issue and questioned whetherTensor.numpy()in tinygrad casts to float64, to which another member clarified that it returns the same type except for bf16.
- Troubleshooting ROCm Setup and Segfaults: One member is experiencing segfaults in setting up tinygrad with ROCm, even after the new 6.1 release, and inquired about documentation for resolving these issues.
- Error Messages and GPU Driver Mismatch: Discussion revolved around making error messages more informative in tinygrad, specifically when it's related to CUDA driver versions being older than the CUDA library. However, it was addressed that unless the CUDA API provides specific messages, it would be hard to verify and maintain such improvements in the codebase.
- Master Branch Stability in tinygrad: In response to a question about the reliability of the master branch, George Hotz confirmed that the
mastershould be stable and indicated that their continuous integration (CI) is effective at maintaining this.
- tinygrad In-Place Operation Mechanisms: Discussion about how tinygrad handles in-place operations without creating cycles in the computation graph, with a reference to a recent major discussion on the topic. It was suggested to look at the
assignmethod on GitHub and prior discussions in the Discord and GitHub for more insights.
- How ShapeTracker works: Tutorials on tinygrad
- Meta AI: Use Meta AI assistant to get things done, create AI-generated images for free, and get answers to any of your questions. Meta AI is built on Meta's latest Llama large language model and uses Emu,...
- tinygrad/tinygrad/tensor.py at 37f8be6450b6209cdc9466a385075971e673c653 · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
DiscoResearch ▷ #mixtral_implementation (1 messages):
- Mixing Up the Mixtral Sauce: A member discussed a potential oversight in Mixtral training involving the "router_aux_loss_coef" parameter. They speculated whether adjusting this from 0.001 to 0.1 or 0.000001 might be the "secret sauce" needed, questioning the effectiveness of the current setting.
DiscoResearch ▷ #general (9 messages🔥):
- Exploring Token Additions for Czech: A member is contemplating adding several thousand tokens for Czech language support. Preliminary experiments suggest the feasibility of extending the tokenizer without considerably disrupting English proficiency.
- Occiglot Project Mentioned: The Occiglot project, known for its work in adding languages, came up in the discussion as a potential resource or community of interest.
- Debunking Inference Speed Myths: It was clarified that reducing vocabulary tokens does not speed up inference—it is the memory overhead that is affected.
- DiscoLM German Made Experimental: Announcement of an experimental German version of DiscoLM based on Llama3, with a link provided to a demo in another Discord channel.
- Innovating CRM Chatbot Functionality: A member describes an approach to make chatbot integration within a CRM more economically viable by grouping functions and potentially using different types of underlying models for various task "groups," inquiring about the existence of libraries like langchain that support such functionality.
DiscoResearch ▷ #discolm_german (49 messages🔥):
- Awaiting the Mighty 70B: Enthusiasm shows for the 70B version of a model, but no specific details on its availability are discussed.
- German Language Skills in LLMs: Members are comparing German language capabilities between different LLM versions, noting that Llama3 may need more fine-tuning for the German language, and instruct variants don't automatically respond in German even with German prompts.
- Privacy Concerns Before Release: Conversations indicate that a new model variant is being kept private intentionally to allow for thorough testing before a public experimental release.
- Challenges with Training Llama3 in German: Members shared their experiences and challenges with training Llama3 to improve its German language skills, mentioning issues such as poor grammar compared to Mixtral models, and tokenizer issues leading to random tokens at the end of the model's output.
- Experimenting with Llama 3 DiscoLM German: An experimental Llama 3 based DiscoLM German model (Llama 3 DiscoLM German 8b v0.1 Experimental) is discussed, with links to the model and a demo provided, noting issues with special tokens appearing at the end of outputs and mixed results in RAG evaluations when compared to other models.
- maxidl/Mistral-7B-v0.1-capybara-orpo-en-de · Hugging Face: no description found
- DiscoResearch/Llama3_DiscoLM_German_8b_v0.1_experimental · Hugging Face: no description found
- jvh/whisper-base-quant-ct2 · Hugging Face: no description found
- primeline/whisper-tiny-german · Hugging Face: no description found
- aisak-ai/aisak-listen · Hugging Face: no description found
LangChain AI ▷ #general (47 messages🔥):
- Seeking LangChain Endpoint Assistance: A member inquired about locating their LangChain endpoint, a crucial element for interacting with the framework's functionalities.
- Investigating Firefunction Latency Variations: One user reported inconsistent latencies when using firefunction with LangChain, varying significantly across different devices, prompting a discussion for potential explanations or solutions to address these discrepancies.
- Handling OCR and Entity Relationship Extraction: Members discussed strategies for performing OCR on documents such as invoices, followed by extracting entity relationships, with one mentioning the use of docTR and inquiring about subsequent steps.
- Building a LangChain-Based Smart AutoGPT: A member pondered whether LangGraph or a LangChain "Plan and execute" agent would be ideal for creating a smart AutoGPT-like general agent, considering the complexities of agent design.
- Mapping Questions to Metadata for Retrieval: A member sought advice on where within LangChain's ecosystem to handle LLM evaluations, specifically when mapping questions to filterable categories in metadata, potentially impacting the design of agents, tools, or chains.
- ChatAnthropic | LangChain.js - v0.1.34: no description found
- Learn How LLAMA 3 Works Now: The Complete Beginner’s Guide: Dive into the fascinating world of the LLAMA 3 model, a cutting-edge transformer architecture that is setting new standards in machine learning. This guide i...
- Quickstart | 🦜️🔗 Langchain: In this guide, we will go over the basic ways to create Chains and Agents that call Tools. Tools can be just about anything — APIs, functions, databases, etc. Tools allow us to extend the capabilities...
- ChatVertexAI | 🦜️🔗 Langchain: LangChain.js supports Google Vertex AI chat models as an integration.
- ChatVertexAI | 🦜️🔗 LangChain: Note: This is separate from the Google PaLM integration. Google has
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #langchain-templates (1 messages):
- Seeking FstAPI Route Code: A member inquired about locating the code for the FstAPI route in the context of pirate-speak but was unable to find it in the app folder and requested an explanation. No responses or resolutions to this query were provided in the messages.
LangChain AI ▷ #share-your-work (7 messages):
- Introducing Trip-Planner Bot: A member showcased their new Trip-Planner Bot, utilizing Bing maps API, OpenStreetMaps API, and FourSquare API to provide location information, places of interest, and route planning. Check out the GitHub repository for more details.
- Webpage Data Structuring with LLM Scraper: The newly released LLM Scraper project turns webpages into structured data, now available on GitHub for contribution and support with a star. Visit the LLM Scraper project page to learn more.
- Support Request for AllMind AI on Product Hunt: A member has asked for support to help their AllMind AI reach number one on Product Hunt, which offers real-time market data and claims to outperform major AI models in every financial task. You can support them by visiting AllMind AI on Product Hunt.
- WhyHow.AI Upgrades Knowledge Graph SDK: WhyHow.AI announced significant upgrades to their Knowledge Graph SDK, facilitating the creation of schema-controlled automated knowledge graphs. For more insight and a chance to join the Beta, read the Medium article here.
- Conversation Topic Tracking Development: A member seeks advice for implementing real-time conversation topic, subject, and task tracking, calling for any existing open-source projects or platforms that could assist in this endeavor. They are looking for guidance on associating chat messages with topics or creating new ones as necessary.
- AllMind AI: Your Personal Stock Analyst - AI financial analyst with real-time market data & insights | Product Hunt: AllMind AI is your personal financial analyst, delivering centralized, real-time, actionable insights directly to you. Our proprietary LLM, AllMind AI, slashes research time by 90% and costs by 98%. W...
- GitHub - mishushakov/llm-scraper: Turn any webpage into structured data using LLMs: Turn any webpage into structured data using LLMs. Contribute to mishushakov/llm-scraper development by creating an account on GitHub.
- GitHub - abhijitpal1247/TripplannerBot: This a streamlit app with langchain. It makes use of Bing maps API, OpenStreetMaps API and FourSquare API.: This a streamlit app with langchain. It makes use of Bing maps API, OpenStreetMaps API and FourSquare API. - abhijitpal1247/TripplannerBot
LangChain AI ▷ #tutorials (1 messages):
- Breaking Down the Self-Querying Retriever: A member elaborated on how a Self-querying retriever uses LLM and few-shot prompting to transform natural language queries into structured queries. They shared insights on tailoring prompts for improved queries in a blog post detailing the internal workings of this technology, available at Rental Apartment Search with LangChain Self-Querying Retriever.
Link mentioned: Building a Rental Apartment Search with Langchain's Self-Querying Retriever: In this blog post, we delve into the capabilities of Langchain's self-querying retriever, a powerful tool for bridging the gap between natural language and structured data retrieval. This retriev...
Mozilla AI ▷ #llamafile (41 messages🔥):
- Llama3 Token Troubles: A member identified that the llama3 instruct format uses different tokens, highlighting that
llamafileandllama.cpp server bindo not support the current arguments. This pertains to the instruct format which seems incompatible with existing infrastructure, as discussed in LocalLLaMA subreddit. - Llama 3 Chat Template Update in the Works: A pull request on GitHub seeks to add the llama 3 chat template to
llama.cpp, a sign of ongoing improvements. Relevant for those tracking updates, the PR can be found here. - Llama 3 8B Quantized Version Released: Responding to an inquiry, a member promised to release the llama 3 8B quantized version on llamafile within a day, and promptly provided a Hugging Face link for testing the new executable weights.
- Progress on Llama 3 70B: Members revealed that the llama 3 70B llamafile is available, with a caution about minor bugs like a broken stop token. Bugs are reported to be ironed out and users are encouraged to help test before wider announcements.
- Llamafiles Adaptability and Issues: Discussions emerged about running llamafiles on various systems and its challenges; the Q2 quantization level isn't performing as expected on an M1 Pro 32GB system, and there seems to be a consensus that llama 3 70B performs better than 8B. In contrast, the 8B version is described as not working well on llamafile yet.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- jartine/Meta-Llama-3-70B-Instruct-llamafile · Hugging Face: no description found
- jartine/Meta-Llama-3-70B-Instruct-llamafile at main: no description found
- jartine/Meta-Llama-3-8B-Instruct-llamafile · Hugging Face: no description found
- llama.cpp/.devops/main-vulkan.Dockerfile at master · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- Added llama-3 chat template by DifferentialityDevelopment · Pull Request #6751 · ggerganov/llama.cpp: This is just simply to add the llama 3 chat template
Interconnects (Nathan Lambert) ▷ #news (10 messages🔥):
- Scaling up the Model Offerings: There's anticipation for new model sizes with a release plan for 100M, 500M, 1B, and 3B models trained on around 5 trillion tokens, which aims to replace the current pythia suite with olmo scalings.
- Karpathy's AI Request Acknowledged: It seems there's a move to align with desires in the AI community, notably giving Karpathy what he wants, which could imply developing AI models in line with his publicized preferences or suggestions.
- Spotlight on SLMs and Small Vision Models: A member expressed that Sparse Latent Models (SLMs) and small vision models are the most compelling projects to work on at the moment.
- Enthusiasm for Compact Powerful Models: The success of MiniCPM stirs excitement, indicating a notable interest in creating compact yet powerful models within the community.
- Benchmarks Revolutionized by AI: A link to a tweet was shared, highlighting that LLAMA 3 8B has set an impressive standard, but upcoming Phi-3 mini 4b, small 7b, and medium 14b models could surpass this with their outstanding benchmarks and that synthetic data pipelines contribute vastly more than internet data. See Tweet.
- No Shortcuts to Model Robustness: A straightforward stance was expressed - trying to bypass the proper processes in model training will lead to subpar results, as symbolized by the phrase, "you cant cheat."
Link mentioned: Tweet from Dylan Patel (@dylan522p): LLAMA 3 8B was amazing but will be overshadowed Phi-3 mini 4b, small 7b, medium 14b this week, and the benchmarks are fucking insane Synthetic data pipelines are massive improvements over internet dat...
Interconnects (Nathan Lambert) ▷ #ml-questions (9 messages🔥):
- Automated vs. Human-led Eval Debate: A member is updating the Evals section in their notes and questions the immediate utility of automated evaluations such as MMLU and BIGBench compared to more time-consuming human evaluations like ChatBotArena.
- Perplexity vs. Task-Based: There is confusion about how perplexity-based evaluations like AI2's Paloma compare to task-based evaluations. A question is raised as to whether perplexity benchmarks like Paloma are public benchmarks or simply metrics used during training.
- Benchmarks Categorization: Discussion includes a member expressing affinity for a categorization of benchmarks from the MT Bench paper, although it's unclear where Paloma fits within this categorization.
- Taxonomy of Evaluations is Fluid: Another member echoes the appreciation for benchmark categorization but notes that the field is evolving rapidly, and there's no singular taxonomy that everyone agrees on.
- Utility of Perplexity-based Metrics: The concept is clarified with a consensus that perplexity-based evaluations are more akin to checkpoint metrics during training rather than metrics for completed models to compete on.
Interconnects (Nathan Lambert) ▷ #random (11 messages🔥):
- Discord's Hidden Gem: Despite having 13k free subscribers with 250 eligible for Discord, less than 50 have taken the opportunity to join the community, indicating that many are potentially unaware of the feature.
- Promotion is Key: Acknowledging the low Discord participation, actions are being taken to make the opportunity more "obvious" and a quarterly feature shoutout is planned to boost visibility, similar to the approach used by Ben Thompson.
- A Call for Community Feedback: One member shared their deep dive analysis on a roadmap to pluralism paper, posting a Typefully link and inviting thoughts before finalizing their work.
- Value in Lurking: A member expresses appreciation for the community, stating they "really enjoy reading the conversations and links" despite mostly lurking, showing non-active members also find value in the Discord content.
Link mentioned: no title found: no description found
Interconnects (Nathan Lambert) ▷ #rlhf (5 messages):
- New RLHF Paper Alert: A member shared a new paper titled Reinforcement Learning From Human Feedback which discusses the differences between traditional RLHF methods and newer Direct Preference Optimization (DPO) approaches.
- Theory Meets Practice: The paper mentioned above theoretically derives DPO in the token-level MDP, aligning it with the standard RLHF approach and confirming its satisfaction of the Bellman equation.
- Discussed with the Author: A member mentioned having discussed the contents of this paper with one of the authors, Rafael, a few weeks prior to the appearance of the paper.
- Approval of the Innovative Concepts: The same member expressed enthusiasm for the paper, indicating a positive reception of the theoretical and empirical insights it provides.
Link mentioned: From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function: Reinforcement Learning From Human Feedback (RLHF) has been a critical to the success of the latest generation of generative AI models. In response to the complex nature of the classical RLHF pipeline,...
Interconnects (Nathan Lambert) ▷ #sp2024-history-of-open-alignment (3 messages):
- Recording Anticipation Builds: The community is eager for a recording, with an update suggesting it'll be available in 1-2 weeks.
- Community Clamoring for Content: There's a noticeable demand for the latest recording, hinted by the use of CLAMMORING to describe the anticipation.
LLM Perf Enthusiasts AI ▷ #general (7 messages):
- Humor in Motion: A member shared a humorous Tenor GIF of someone falling down the stairs, noting that Tenor.com can be translated based on the browser's language settings.
- Llama 3's Impressive Performance: In AI model discussions, Llama 3 is noted for outperforming Opus in arena, despite being only a 70b model.
- Considering Error Bounds: A member highlighted the significance of error bounds when evaluating model performance.
- Stylistic Versus Intelligence Debate: There's a conversation about what contributes to a model's effectiveness: stylistic elements versus actual intelligence.
- Meta.ai's Imagine Applauded: The meta.ai imagine platform is praised for being insane, prompting a request for examples to illustrate its capabilities.
Link mentioned: Falling Falling Down Stairs GIF - Falling Falling Down Stairs Stairs - Discover & Share GIFs: Click to view the GIF
LLM Perf Enthusiasts AI ▷ #speed (3 messages):
- Azure's OpenAI Latency Woes: A member expressed frustration with high latency issues on Azure's OpenAI, citing an extreme case with a staggering amount of time of 20 minutes for some requests.
- Azure Rate Limiting Problems Puzzling Developers: The same member reported about being rate limited constantly on Azure, with even 2 requests within 15 seconds triggering rate limits. This has led to the implementation of a rate limit backoff strategy.
Skunkworks AI ▷ #finetuning (6 messages):
- Databricks Rolls Out GPU and LLM Optimizations: Databricks has announced a public preview of their new GPU and LLM optimization support for Model Serving, allowing the deployment of AI models on the Lakehouse Platform. This serverless GPU serving product optimizes models for LLM serving without requiring any additional configuration.
- Cost Concerns for Premium Services: A member jokingly indicated that the new features offered by Databricks might be expensive, saying "i bet this'll cost me an arm and a leg😅".
- Guidance on LLM Fine-tuning Released: An operational guide for fine-tuning pretrained LLMs has been shared, which outlines steps to adjust model weights for specific tasks using Modal's fine-tuning documentation. The guide comes with recommended optimizations like LoRA adapters, Flash Attention, Gradient checkpointing, and DeepSpeed.
- Serverless Hosting on a Budget: Cheap serverless hosting options are available, as pointed out with a GitHub link to modal-examples for setting up an LLM frontend.
- Confirmation of Helpful Resource: A member confirmed that the shared resource on serverless inference is precisely what they were looking for, expressing gratitude with a simple "thanks!!!".
- Fine-tune an LLM in minutes (ft. Llama 2, CodeLlama, Mistral, etc.): Tired of prompt engineering? Fine-tuning helps you get more out of a pretrained LLM by adjusting the model weights to better fit a specific task. This operational guide will help you take a base model...
- modal-examples/06_gpu_and_ml/llm-frontend/index.html at main · modal-labs/modal-examples: Examples of programs built using Modal. Contribute to modal-labs/modal-examples development by creating an account on GitHub.
- Deploy Private LLMs using Databricks Model Serving | Databricks Blog: Deploy Generative AI Models with full control of your Data and Model.
Datasette - LLM (@SimonW) ▷ #ai (2 messages):
- Scouting for AI in Blueprint Analysis: A member inquired about AI models or approaches for interpreting blueprints, specifically for the purpose of tracing ductwork in PDF plans.
- AI Taking Off in Architecture: Another shared insights about AI being used in architecture firms as a 'preflight' tool to identify potential issues and code violations before construction, although it's not yet applied in the blueprint creation phase.
Datasette - LLM (@SimonW) ▷ #llm (3 messages):
- Llama 3 Unleashed: The llm-gpt4all plugin has been upgraded by SimonW to support Llama 3 8B Instruct, enabling users to run large models on machines with 8GB RAM, such as the M2 MacBook Pro. The updated plugin can be installed using the command
llm install --upgrade llm-gpt4all.
- Plugin Release Noted: The llm-gpt4all plugin version 0.4 is now available, as noted in a GitHub release, adding support for new models including Llama 3 8B Instruct.
- Showcase of Llama 3 Capabilities: SimonW highlights Llama 3's reputation as the best openly licensed model on his blog with an in-depth look at running Llama 3 models locally and using hosted services. For more insights, users can visit Simon's blog post about Llama 3.
- Options for accessing Llama 3 from the terminal using LLM: Llama 3 was released on Thursday. Early indications are that it’s now the best available openly licensed model—Llama 3 70b Instruct has taken joint 5th place on the LMSYS arena …
- Release 0.4 · simonw/llm-gpt4all: Upgrade to latest gpt4all (2.5.1) which adds support for several new models including... llm -m Meta-Llama-3-8B-Instruct "say hello with a lot of words" to run the new Llama 3 8B Instruct mo...
Alignment Lab AI ▷ #ai-and-ml-discussion (1 messages):
- LLAMA 3 Demystified for Beginners: A member shared a YouTube video titled "Learn How LLAMA 3 Works Now: The Complete Beginner’s Guide", which aims to explain the LLAMA 3 model and its significance in machine learning for those starting out. The description promises an engaging dive into the transformer architecture of LLAMA 3.
Link mentioned: Learn How LLAMA 3 Works Now: The Complete Beginner’s Guide: Dive into the fascinating world of the LLAMA 3 model, a cutting-edge transformer architecture that is setting new standards in machine learning. This guide i...