[AINews] Every 7 Months: The Moore's Law for Agent Autonomy
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Perspective is all you need.
AI News for 3/18/2025-3/19/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (227 channels, and 4117 messages) for you. Estimated reading time saved (at 200wpm): 426 minutes. You can now tag @smol_ai for AINews discussions!
Llama 4 rumors and $600 o1 pro API aside, we rarely get to feature a paper as a title story on AINews, so we are really happy when it happens. METR has long been known for doing quality analysis around AI progress, and in Measuring AI Ability to Complete Long Tasks they have an answer to a valuable question that has so far been extremely difficult to answer: agent autonomy is increasing, but how quickly?
Since 2019 (GPT2), it has doubled every 7 months.
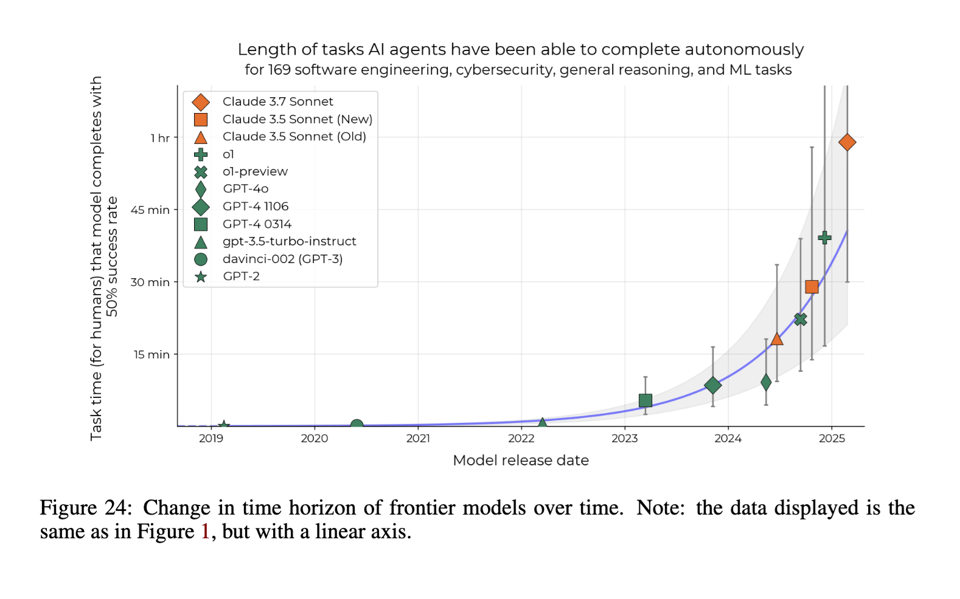
Obviously agents can take a range of time to complete tasks, which has made this question difficult to answer, therefore the methodology is worthwhile as well:
"To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes."

The authors find a notable discontinuity at the 1min horizon:
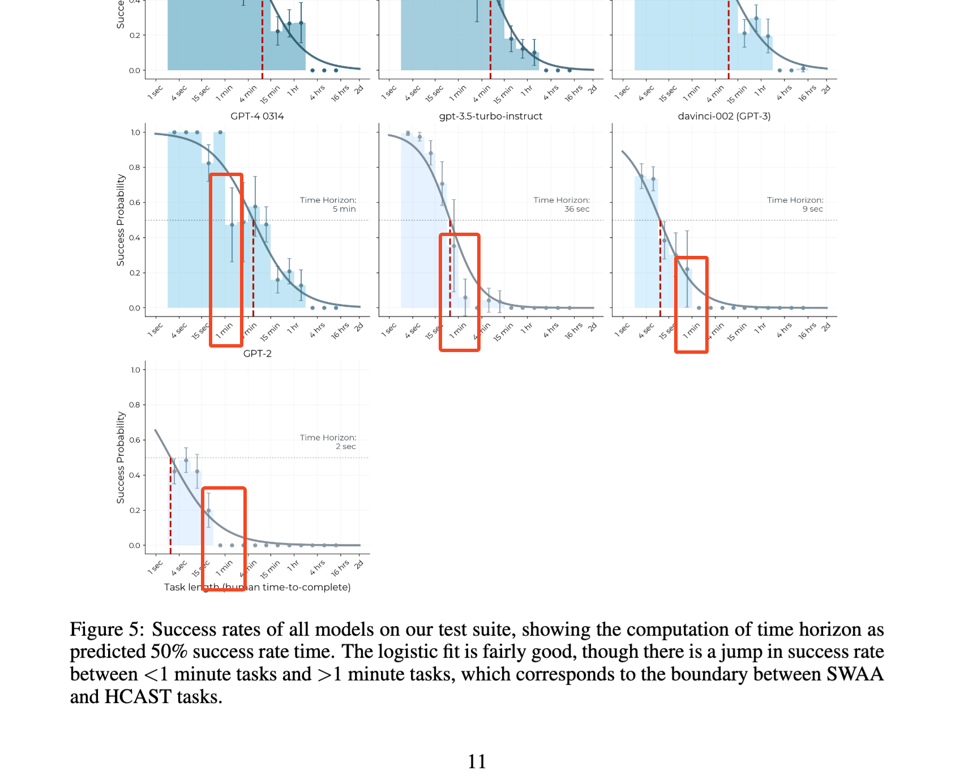
and at the 80% cutoff, but the scaling laws remain robust.
At current rates, we will have:
- 1 day autonomy in (5 exponentials * 7 months) = 3 years (2028)
- 1 month autonomy in "late 2029" (+/- 2 years, only going for human working hours)
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor Community Discord
- Unsloth AI (Daniel Han) Discord
- LM Studio Discord
- HuggingFace Discord
- OpenAI Discord
- OpenRouter (Alex Atallah) Discord
- aider (Paul Gauthier) Discord
- Interconnects (Nathan Lambert) Discord
- Yannick Kilcher Discord
- Perplexity AI Discord
- Notebook LM Discord
- MCP (Glama) Discord
- Nous Research AI Discord
- LMArena Discord
- GPU MODE Discord
- Modular (Mojo 🔥) Discord
- Latent Space Discord
- Eleuther Discord
- LlamaIndex Discord
- Cohere Discord
- LLM Agents (Berkeley MOOC) Discord
- Torchtune Discord
- tinygrad (George Hotz) Discord
- AI21 Labs (Jamba) Discord
- DSPy Discord
- MLOps @Chipro Discord
- Nomic.ai (GPT4All) Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor Community ▷ #general (1174 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (419 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (3 messages):
- Unsloth AI (Daniel Han) ▷ #help (121 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
- Unsloth AI (Daniel Han) ▷ #research (3 messages):
- LM Studio ▷ #general (115 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (271 messages🔥🔥):
- HuggingFace ▷ #general (204 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (2 messages):
- HuggingFace ▷ #i-made-this (13 messages🔥):
- HuggingFace ▷ #reading-group (2 messages):
- HuggingFace ▷ #NLP (1 messages):
- HuggingFace ▷ #gradio-announcements (2 messages):
- HuggingFace ▷ #smol-course (4 messages):
- HuggingFace ▷ #agents-course (39 messages🔥):
- HuggingFace ▷ #open-r1 (3 messages):
- OpenAI ▷ #ai-discussions (188 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (4 messages):
- OpenAI ▷ #prompt-engineering (18 messages🔥):
- OpenAI ▷ #api-discussions (18 messages🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
- OpenRouter (Alex Atallah) ▷ #general (208 messages🔥🔥):
- aider (Paul Gauthier) ▷ #general (131 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (58 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (2 messages):
- Interconnects (Nathan Lambert) ▷ #news (2 messages):
- Interconnects (Nathan Lambert) ▷ #ml-questions (2 messages):
- Interconnects (Nathan Lambert) ▷ #random (96 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #memes (26 messages🔥):
- Interconnects (Nathan Lambert) ▷ #rl (1 messages):
- Interconnects (Nathan Lambert) ▷ #reads (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (24 messages🔥):
- Interconnects (Nathan Lambert) ▷ #policy (4 messages):
- Yannick Kilcher ▷ #general (121 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (15 messages🔥):
- Yannick Kilcher ▷ #ml-news (14 messages🔥):
- Perplexity AI ▷ #general (103 messages🔥🔥):
- Perplexity AI ▷ #sharing (8 messages🔥):
- Perplexity AI ▷ #pplx-api (3 messages):
- Notebook LM ▷ #use-cases (7 messages):
- Notebook LM ▷ #general (93 messages🔥🔥):
- MCP (Glama) ▷ #general (96 messages🔥🔥):
- MCP (Glama) ▷ #showcase (1 messages):
- Nous Research AI ▷ #general (85 messages🔥🔥):
- LMArena ▷ #general (75 messages🔥🔥):
- GPU MODE ▷ #general (9 messages🔥):
- GPU MODE ▷ #cuda (4 messages):
- GPU MODE ▷ #torch (7 messages):
- GPU MODE ▷ #algorithms (20 messages🔥):
- GPU MODE ▷ #cool-links (1 messages):
- GPU MODE ▷ #beginner (3 messages):
- GPU MODE ▷ #irl-meetup (1 messages):
- GPU MODE ▷ #liger-kernel (2 messages):
- GPU MODE ▷ #self-promotion (1 messages):
- GPU MODE ▷ #🍿 (3 messages):
- GPU MODE ▷ #thunderkittens (1 messages):
- GPU MODE ▷ #reasoning-gym (4 messages):
- GPU MODE ▷ #submissions (11 messages🔥):
- GPU MODE ▷ #ppc (1 messages):
- Modular (Mojo 🔥) ▷ #general (11 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (28 messages🔥):
- Latent Space ▷ #ai-general-chat (31 messages🔥):
- Latent Space ▷ #ai-announcements (2 messages):
- Eleuther ▷ #general (2 messages):
- Eleuther ▷ #research (21 messages🔥):
- Eleuther ▷ #interpretability-general (1 messages):
- Eleuther ▷ #lm-thunderdome (5 messages):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (24 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- Cohere ▷ #「💬」general (4 messages):
- Cohere ▷ #「🔌」api-discussions (19 messages🔥):
- Cohere ▷ #「💡」projects (1 messages):
- Cohere ▷ #「🤝」introductions (3 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (23 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
- Torchtune ▷ #general (11 messages🔥):
- Torchtune ▷ #dev (4 messages):
- tinygrad (George Hotz) ▷ #general (8 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
- AI21 Labs (Jamba) ▷ #jamba (3 messages):
- AI21 Labs (Jamba) ▷ #general-chat (1 messages):
- DSPy ▷ #general (2 messages):
- MLOps @Chipro ▷ #events (2 messages):
- Nomic.ai (GPT4All) ▷ #general (1 messages):
AI Twitter Recap
AI Advancements and Model Releases
- Nvidia released Cosmos-Transfer1 on Hugging Face for Conditional World Generation with Adaptive Multimodal Control: @_akhaliq shared the release of Nvidia's Cosmos-Transfer1 on Hugging Face, which enables conditional world generation with adaptive multimodal control.
- Nvidia released GR00T-N1-2B on Hugging Face: @_akhaliq announced that Nvidia released GR00T-N1-2B on Hugging Face, an open foundation model for generalized humanoid robot reasoning and skills, also noted by @reach_vb. @DrJimFan provided details about GR00T N1, highlighting its role as the world’s first open foundation model for humanoid robots with only 2B parameters. The model learns from diverse physical action datasets and is deployed on various robots and simulation benchmarks. Links to the whitepaper, code repository, and dataset are included (@DrJimFan, @DrJimFan, @DrJimFan, @DrJimFan, @DrJimFan).
- @reach_vb announced Orpheus 3B, a high-quality, emotive Text to Speech model with an Apache 2.0 license from Canopy Labs. Key features include zero-shot voice cloning, natural speech, controllable intonation, training on 100K hours of audio, input/output streaming, 100ms latency, and ease of fine-tuning.
- Meta sits on Llama-4 because it sucks: @scaling01 commented that Meta is not releasing Llama-4 because of poor performance.
- Microsoft launched Phi-4-multimodal: @DeepLearningAI reported that Microsoft launched Phi-4-multimodal, a high-performing open weights model with 5.6 billion parameters capable of processing text, images, and speech simultaneously.
- Tencent's Hunyuan3D 2.0 accelerates model generation speed: @_akhaliq announced that Tencent has achieved a 30x acceleration in model generation speed across the entire Hunyuan3D 2.0 family, reducing processing time from 30 seconds to just 1 second, available on Hugging Face.
- Together AI Introduces Instant GPU Clusters: @togethercompute announced Together Instant GPU Clusters with 8–64 @nvidia Blackwell GPUs, fully self-serve and ready in minutes, ideal for large AI workloads or short-term bursts.
Research and Evaluation
- METR's Research on AI Task Completion: @METR_Evals highlighted their new research indicating that the length of tasks AI can complete is doubling about every 7 months. They define a metric called "50%-task-completion time horizon" to track progress in model autonomy, with current models like Claude 3.7 Sonnet having a horizon of around 50 minutes (@iScienceLuvr). The research also suggests that AI systems may be capable of automating many software tasks that currently take humans a month within 5 years. The paper is available on arXiv (@METR_Evals).
- NVIDIA Reasoning Models @ArtificialAnlys reported that NVIDIA has announced their first reasoning models, a new family of open weights Llama Nemotron models: Nano (8B), Super (49B) and Ultra (249B).
Agent Development and Tooling
- LangGraph Studio updates: @hwchase17 announced that Prompt Engineering is now inside LangGraph Studio. @LangChainAI
- LangGraph and LinkedIn's SQL Bot: @LangChainAI highlighted LinkedIn’s Text-to-SQL Bot, powered by LangGraph and LangChain, which translates natural language questions into SQL, making data more accessible.
- Hugging Face course on building agents in LlamaIndex: @llama_index shared that @huggingface wrote a course about building agents in LlamaIndex, covering components, RAG, tools, agents, and workflows, available for free.
- Canvas UX: @hwchase17 notes that Canvas UX is becoming the standard for interacting with LLMs on documents.
Frameworks and Libraries
- Gemma package: @osanseviero introduced the Gemma package, a minimalistic library for using and fine-tuning Gemma, including documentation on fine-tuning, sharding, LoRA, PEFT, multimodality, and tokenization.
- AutoQuant: @maximelabonne announced updates to AutoQuant to optimize GGUF versions of Gemma 3, implementing imatrix and splitting the model into multiple files.
- ByteDance OSS released DAPO: @_philschmid highlighted a new open-source RL method DAPO released by ByteDanceOSS, which outperforms GRPO and achieves 50 points on the AIME 2024 benchmark.
Industry Partnerships and Events
- Perplexity and NVIDIA Collaboration: @AravSrinivas announced that Perplexity is partnering with NVIDIA to enhance inference on Blackwell with their new Dynamo library, and @perplexity_ai stated they are implementing NVIDIA's Dynamo to enhance inference capabilities.
- Google and NVIDIA Partnership: @Google announced they are expanding their collaboration with NVIDIA across Alphabet.
- vLLM and Ollama Inference Night: @vllm_project and @ollama are hosting an inference night at Y Combinator in San Francisco to discuss inference topics.
Humor and Miscellaneous
- @willdepue shared "10 things I learned in YC W25", a humorous take on business rules inspired by rap lyrics.
- Adblockers: @nearcyan says that adblockers cant even be disseminated to the avg person yet you think we're going to give arbitrary code execution to everyone?
- Tangent about AI Waifus: @scaling01 joked about rejecting women and embracing AI waifus in the context of TPOT.
- Career: @cto_junior quips damn being married has absolutely fucking decimated my posting volume (in exchange for unconditional love and lifelong happiness)
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Llama4 Rumor: Launch Next Month, Multimodal, 1M Context
- Llama4 is probably coming next month, multi modal, long context (Score: 295, Comments: 114): Llama4 is anticipated to be released next month, featuring multi-modal capabilities and a long context window of approximately 1 million tokens. The announcement is linked to the Meta blog discussing the upcoming Llamacon event in 2025.
- Discussions focused on context size highlight skepticism about the practicality of a 1 million token context window, with users pointing out that models often degrade significantly before reaching such limits. Qwen 2.5 was noted for using Exact Attention fine-tuning and Dual Chunk Attention to manage long contexts effectively, as detailed in a benchmark paper.
- The multimodal capabilities of Llama4 are debated, with some users expressing skepticism about its utility and others emphasizing the potential benefits, such as enhanced image and audio processing. DeepSeek and other models like Mistral and Google Gemini are mentioned as competitive benchmarks, with users expressing hope for Llama4's innovative architecture.
- Concerns about censorship in Llama models were raised, with hopes that Llama4 will be less censored compared to Llama3. The conversation also touched on the importance of zero-day support in projects like llama.cpp, suggesting collaboration with Meta could be beneficial.
- only the real ones remember (Score: 300, Comments: 58): Tom Jobbins (TheBloke) is highlighted on Hugging Face for his contributions, particularly his article on "Making LLMs lighter with AutoGPTQ and transformers." His profile showcases recent models with specified creation and update dates, indicating active engagement and interest in AI and ML.
- Tom Jobbins' Impact and Disappearance: Many users express gratitude for Tom Jobbins' significant contributions to the open-source AI community, particularly in making AI more accessible. Discussions speculate about his sudden disappearance, with some suggesting burnout or a move to a private company, possibly as a CTO.
- Career Transition and Speculation: Jobbins' career shift to a startup is noted, with some users mentioning a grant that previously funded his work ran out. There are humorous and optimistic speculations about his current activities, including the possibility of him receiving a lucrative offer under a strict NDA.
- Community Sentiment and Legacy: Users fondly remember Jobbins for his pioneering work in model quantization and his role in simplifying complex processes for the community. His legacy continues to be appreciated, with some users bookmarking his Hugging Face profile as a tribute.
- A man can dream (Score: 617, Comments: 79): The post humorously compares the AI models "DEESEEK-R1," "QWQ-32B," "LLAMA-4," and "DEESEEK-R2" using a meme with escalating expressions of shock, highlighting the anticipation and excitement surrounding the capabilities of these models, particularly LLAMA-4.
- Commenters express a desire for a small model that excels in coding, as current models focus more on language and general knowledge, with Sonnet 3.7 being noted for its high cost in API usage.
- There is speculation and humor regarding the rapid release cycle of AI models, with mentions of R1 being released less than 60 days ago and jokes about the potential 1T and 2T parameter sizes for future models like LLAMA-4 and DEESEEK-R2.
- The discussion includes humorous takes on model names like QwQ and QwQ-Max, as well as playful commentary on naming conventions with terms like Pro ProMax Ultra Extreme and references to brands like Dell and Nvidia.
Theme 2. Microsoft's KBLaM and RAG Replacement Potential
- KBLaM by microsoft, This looks interesting (Score: 104, Comments: 23): KBLaM by Microsoft introduces a method for integrating external knowledge into language models, potentially serving as an alternative to RAG (Retrieval-Augmented Generation). The post questions whether KBLaM can replace RAG and suggests that solving challenges associated with RAG could be a significant advancement in AI.
- KBLaM's integration method bypasses inefficiencies of traditional methods like RAG by encoding knowledge directly into the model's attention layers using a "rectangular attention" mechanism. This allows linear scaling with knowledge base size, enabling efficient processing of over 10,000 knowledge triples on a single GPU, which improves reliability and reduces hallucinations.
- Potential for model optimization is discussed, with the possibility of reducing model sizes by separating knowledge from intelligence, allowing knowledge to be injected as needed. However, there is debate about whether intelligence can be entirely separated from knowledge, as some believe they are interconnected.
- Community engagement includes excitement about the efficiency improvements and interpretability of KBLaM, with users evaluating the KBLaM repository. The approach's ability to maintain dynamic updateability without retraining is seen as a significant advancement over RAG, which suffers from inefficiencies like chunking.
- If "The Model is the Product" article is true, a lot of AI companies are doomed (Score: 180, Comments: 94): The post discusses a blog article suggesting that the future of AI might see major labs like OpenAI and Anthropic training models for agentic purposes using Reinforcement Learning (RL), potentially diminishing the role of application-layer AI companies. It mentions a prediction by the VP of AI at DataBricks that closed model labs could shut down their APIs in the next 2-3 years, which could lead to increased competition between these labs and current AI companies. Read more here.
- The discussion centers around the importance of data over models, with multiple commenters emphasizing that the enduring value lies in the data and domain expertise rather than the models themselves. This is highlighted by the analogy to Google's 2006 algorithm success, emphasizing data and UI as crucial elements.
- There is skepticism about the prediction that major AI labs like OpenAI and Anthropic will shut down their APIs. Commenters argue that APIs are central to these companies' business models, and shutting them down would be counterproductive, especially given the rise of open models from companies like Meta and DeepSeek.
- The conversation also touches on the risks of building businesses on third-party platforms, likening it to the mobile app ecosystem where platform owners can absorb successful ideas. The consensus is that while big AI companies will dominate general use cases, there will still be opportunities for niche, domain-specific solutions.
Theme 3. Gemma 3 Uncensored Model Release
- Uncensored Gemma 3 (Score: 147, Comments: 27): The author released Gemma 3, a finetuned model available on Hugging Face, which they claim has not refused any tasks. They are also working on training 4B and 27B versions, aiming to test and release them shortly.
- Users tested Gemma 3 to see if it would refuse tasks and noted that it sometimes did, despite claims. Xamanthas and StrangeCharmVote reported mixed results, with Xamanthas noting it still refused some tasks, while StrangeCharmVote found the original 27B model surprisingly uncensored.
- There is interest in the performance metrics of Gemma 3 compared to the default version, with mixedTape3123 questioning its intelligence, and Reader3123 acknowledging potential differences but lacking detailed metrics.
- Reader3123 shared quantization efforts by various contributors, providing links to models on Hugging Face for further exploration: soob3123, bartowski, and mradermacher.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. Gemini Plugins and AI Studio Usage
- god i love gemini photoshop (Score: 124, Comments: 29): The post expresses enthusiasm for Gemini Photoshop, indicating a positive user experience with this tool. However, specific details or features about the tool are not provided in the text.
- Confusion about Gemini: Users are confused about the reference to Gemini Photoshop, questioning if there's a Gemini plugin for Photoshop or if it is being confused with something else, like the astrology sign.
- Google AI Studio: Some users mention Google AI Studio Flash 2.0 as a tool used for creating images, with one user clarifying it's free and accessible by searching "AI studio" on Google.
- Mixed User Experiences: While some express enthusiasm for the tool, others report dissatisfaction, stating it struggles with following basic instructions, indicating a variance in user experiences.
Theme 2. MailSnitch Uses Email Tagging for Spam Identification
- Thanks to ChatGPT, I know who’s selling my email. (Score: 2119, Comments: 204): The post outlines the development of MailSnitch, a tool inspired by email tagging to track who sells your email by using unique tagged email addresses. The author, with the help of ChatGPT, plans to release a Chrome Extension featuring auto-fill, unique email tagging, and a history log, and is considering publishing it for free with a potential for monetization.
- Many commenters highlighted the ineffectiveness of using "+" in email addresses to track who sells your email, as it can be easily bypassed or removed by spammers and data brokers. Alternatives like email alias services (e.g., Firefox Relay, ProtonPass, and Apple's "hide my email" feature) were suggested for better privacy and control.
- Several users emphasized the importance of understanding code before using it, especially when generated by ChatGPT, due to potential security and liability issues. The conversation touched on the risks of running unverified code and the necessity of code review in serious applications.
- Commenters also discussed alternative solutions like using custom domains with catchall addresses, which allow for more robust email management and tracking. Some users shared experiences with Gmail's dot feature and mentioned its limitations across different platforms.
Theme 3. Reverse Engineering ChatGPT: Strategies for Better Responses
- I reverse-engineered how ChatGPT thinks. Here’s how to get way better answers. (Score: 2064, Comments: 234): The post explains that ChatGPT doesn't inherently "think" but predicts the most probable next word, leading to generic responses to broad questions. The author suggests enhancing responses by instructing ChatGPT to first analyze key factors, self-critique its answers, and consider multiple perspectives, resulting in significantly improved depth and accuracy for topics like AI/ML, business strategy, and debugging.
- The concept of ChatGPT as merely a next-word predictor is widely recognized, and several commenters noted that the post's insights are not novel, with some suggesting the ideas are basic prompting techniques rather than breakthroughs. LickTempo and Plus_Platform9029 emphasize that while ChatGPT predicts the next token, it can still exhibit structured reasoning if prompted correctly, and they recommend resources like Andrej Karpathy's videos for a deeper understanding.
- Chain-of-thought prompting and Monte Carlo Tree Search are highlighted as methods to improve ChatGPT's responses, with djyoshmo suggesting further reading on arxiv.org or Medium to grasp these techniques. EverySockYouOwn shares a practical example of using a structured 20-question approach to break down complex inquiries, enhancing the depth and relevance of the AI's responses.
- There is a discussion on the effectiveness of self-critique and non-echo chamber prompts, with users like VideirHealth and legitimate_sauce_614 sharing strategies to encourage ChatGPT to challenge assumptions and provide more logical, diverse perspectives. However, SmackEh and others caution that ChatGPT's default behavior is to agree and avoid offense, necessitating deliberate prompts for more critical engagement.
Theme 4. Successfully Running Wan2.1 Locally
- Finally got Wan2.1 working locally (Score: 108, Comments: 25): Wan2.1 is successfully implemented locally for video processing.
- Users discuss video processing times with Wan2.1, comparing different hardware setups. Aplakka shares that their 720p generation took over 60 minutes, while Kizumaru31 reports 6-9 minutes for 480p using an RTX 4070, suggesting faster times with more powerful graphics cards like the RTX 4090.
- Aplakka provides a workflow link and details their settings, including using ComfyUI in Windows Subsystem for Linux and Sageattention. They mention challenges fitting 720p videos into VRAM with an RTX 4090 and suggest a possible reboot or settings adjustment might resolve the issue.
- There is a focus on improving video quality and control over the output, with BlackPointPL noting that using gguf reduces quality, and vizualbyte73 expressing a desire for more control over visual elements like flower petal movement.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. NVIDIA's Blackwell Blitzkrieg: New GPUs and Marketing Hype
- Blackwell Ultra & Ruben Unleashed, Feynman Next: NVIDIA unveiled Blackwell Ultra and Ruben GPUs, with the next gen named Feynman. Ruben incorporates silicon photonics for power efficiency and a new ARM CPU, alongside Spectrum X switches reaching 1.6 Tbps. Despite performance claims and new releases, some users are skeptical of NVIDIA's marketing hype and performance exaggerations, particularly regarding H200 and B200 speedups.
- DGX Spark & Station: Personal AI Supercomputers Emerge: NVIDIA launched DGX Spark and DGX Station, compact AI supercomputers based on the Grace Blackwell platform. The DGX Spark, previously Project DIGITS and priced at $3,000, aims to bring desktop-level AI prototyping and fine-tuning to developers, researchers, and students, although some find its specs underwhelming compared to alternatives like Mac Mini M4 Pro or Ryzen 395+.
- DeepSeek-R1 Inference Claims World's Fastest on Blackwell: NVIDIA asserts Blackwell GPUs achieve the world’s fastest DeepSeek-R1 inference, with a single system of eight Blackwell GPUs in NVL8 configuration delivering 253 TPS/user and 30K TPS system throughput on the full DeepSeek-R1 671B parameter model. Despite these performance claims, some users remain critical of NVIDIA's marketing tactics, describing them as unserious and potentially misleading to investors.
Theme 2. Open Source AI Ecosystem: Tools, Datasets, and Community
- Open Source Investment Yields Mammoth Returns, Harvard Study Finds: Harvard research indicates that a $4.15B investment in open-source generates $8.8T of value for companies, highlighting a $2,000 return for every $1 invested. This underscores the immense economic impact and value creation driven by open-source contributions in the AI field.
- Nvidia Open Sources Massive Coding Dataset for Llama Nemotron: NVIDIA released a large open-source instruct coding dataset to enhance math, code, reasoning, and instruction following in Llama instruct models. The dataset includes data from DeepSeek-R1 and Qwen-2.5, sparking community interest in filtering and fine-tuning for specialized training.
- PearAI Emerges as Open Source IDE Alternative to Cursor: PearAI, a new open-source AI code editor integrating tools like Roo Code/Cline, Continue, Perplexity, Mem0, and Supermaven, is gaining traction in the Cursor Community. Users suggest PearAI is a cheaper, viable alternative to Cursor, despite having a smaller context window, highlighting the growing open-source tooling landscape.
Theme 3. Model Performance and Limitations: Gemini, Claude, and Open Source Alternatives
- [Gemini Deep Research Saves User Time 10x, But Benchmarking Costs Loom]: Users are finding Gemini Deep Research significantly speeds up research tasks, potentially saving time by 10x, with one user citing its value in scientific medical research by generating a list of 90 literature sources. However, its cost may be prohibitive for extensive benchmarking on platforms like LMArena, raising questions about accessibility for broader evaluation.
- [Perplexity AI Faces "Dumber Than Claude" Claims, O1 Hype Fades]: Some users find Perplexity AI to be less intelligent than Claude 3.5, citing issues with context retention and abstract generation, with one user stating "Perplexity feels dumber than Claude 3.5". Additionally, initial community enthusiasm for Perplexity's O1 models is waning due to the introduction of a paywall, diminishing its appeal.
- [Anthropic's Claude 3.7 Sonnet Experiences Downtime, Recovers]: Anthropic models, particularly Claude 3.7 Sonnet, experienced service interruptions and downtime. While services are reportedly stabilizing, this incident highlights the potential instability and reliability concerns associated with cloud-based AI model access.
Theme 4. AI Agents and Tooling: Agents Course, MCP, and Workflow Innovations
- Hugging Face Launches Free LlamaIndex Agents Course: Hugging Face released a free course on building agents in LlamaIndex, covering key components, RAG, tools, and workflows. The course provides a comprehensive guide to developing AI-powered applications using LlamaIndex, expanding educational resources in the agentic AI space.
- Model Context Protocol (MCP) Gains Momentum with Python REPLs and New Tools: The Model Context Protocol (MCP) is gaining traction, with new Python REPL implementations like hdresearch/mcp-python and Alec2435/python_mcp emerging, and a user-built DuckDuckGo MCP for Cursor on Windows (GitHub) demonstrating its growing ecosystem and utility for tool integration.
- Aider Code Editor Adds Web and PDF Reading, Enhancing Multimodal Capabilities: The Aider code editor now supports reading webpages and PDF files, enabling vision-capable models like GPT-4o and Claude 3.7 Sonnet to process diverse information sources directly within the coding environment. This enhancement, accessed via commands like
/add <filename>, expands Aider's utility for complex, information-rich coding tasks.
Theme 5. Hardware and Software Challenges: Performance, Compatibility, and Costs
- [Multi-GPU Performance Degradation Reported in LM Studio]: Users are experiencing performance and stability issues when using multiple RTX 3060s in LM Studio with CUDA llama.cpp, noting that single GPU performance is superior. The issues are attributed to model splitting across GPUs and potential PCI-e 3.0 x4 bandwidth limitations, suggesting multi-GPU setups are not always plug-and-play for optimal performance.
- [Gemma 3 Vision Fine-tuning Hits Transformers Glitch]: Users are encountering problems fine-tuning Gemma 3 for vision tasks, indicating a potential bug in vision support within the current Transformers library version, particularly during
qlora. The issue manifests as aRuntimeError, requiring further investigation into compatibility and library dependencies. - [M1 Macs Struggle with Model Training, Even in Small Batches]: Users report that M1 Mac Airs are underpowered for model training, even with small batches, facing clang related issues on platforms like Kaggle and Hugging Face Spaces. This highlights the limitations of consumer-grade Apple silicon for demanding AI training tasks, prompting users to seek alternative hardware or cloud-based solutions.
PART 1: High level Discord summaries
Cursor Community Discord
- Sonnet MAX Excels as Agent: The Sonnet MAX model is being lauded for its post-processing capabilities within agent workflows, highlighted in this X post.
- Users emphasize that Cursor must learn from code bases and its own mistakes due to library limitations.
- Cursor's Claude Max Pricing Debated: Community members are questioning Claude Max's pricing on Cursor, noting that the fast requests allocation within subscriptions isn't fully utilized.
- Some express discontent, suggesting they might seek alternatives if Cursor optimized the consumption of fast requests for Max, noting that "Cursor team dropped the ball hard by not allowing more fast request consumption for Max".
- Terminal Troubles Plague Users: Users are frustrated by agent spawning multiple terminals and rerunning projects, driving discussions on implementing preventative rules and configurations.
- An Enhanced Terminal Management Rule was proposed to terminate open terminals, direct test output to fresh terminals, and prevent duplicate terminal creation during test runs.
- PearAI Open Source IDE Emerges: The community is taking a look at PearAI (https://trypear.ai/), an open-source AI code editor integrating tools like Roo Code/Cline, Continue, Perplexity, Mem0, and Supermaven.
- Members suggest that Pear is actually kinda doing gods work rn compared to cursor, because it's a cheaper alternative to Cursor despite having a smaller context window.
Unsloth AI (Daniel Han) Discord
- Gemma 3 Vision Runs into Transformers Glitch: Users reported issues finetuning Gemma 3 for vision tasks, indicating a potential problem with vision support in the current Transformers version, potentially during
qlora.- A user encountered a RuntimeError: Unsloth: Failed to make input require gradients! when trying to qlora
gemma-3-12b-pt-bnb-4bitfor image captioning, suggesting a need for further investigation.
- A user encountered a RuntimeError: Unsloth: Failed to make input require gradients! when trying to qlora
- Multi-Node Multi-GPU Unsloth incoming: Multi-node and multi-GPU fine-tuning support is planned for Unsloth in the coming weeks, although the specific release date has not yet been specified, sign up to the Unsloth newsletter.
- A member confirmed multinode support will be enterprise only.
- Unsloth joins vLLM & Ollama in SF: Unsloth will be joining vLLM and Ollama for an event in SF next week on Thursday, March 27th, promising social time and presentations at Y Combinator's San Francisco office.
- More details are available for the vLLM & Ollama inference night where food and drinks will be served.
- Docs Dunked by Filesystem Woes: A user experienced a
HFValidationErrorandFileNotFoundErrorwhen trying to save a merged model locally, due to an invalid repository ID when callingsave_pretrained_merged.- The recommendation was to update
unsloth-zooas it should be fixed in the latest version.
- The recommendation was to update
- ZO2 fine-tunes 175B LLM: The ZO2 framework enables full parameter fine-tuning of 175B LLMs using just 18GB of GPU memory, particularly tailored for setups with limited GPU memory.
- A member pointed out that ZO2 employs zeroth order optimization, contrasting it with the more common first-order methods like SGD.
LM Studio Discord
- OpenVoice Clones Your Voice: Members highlighted OpenVoice, a versatile instant voice cloning method that only needs a short audio clip to replicate a voice and generate speech in multiple languages, with their associated github repo.
- It gives you granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, and replicates the tone color of the reference speaker.
- Oblix Orchestrates Models in the Cloud: A member shared the Oblix Project, a platform for seamless orchestration between local and cloud models, demonstrated in a demo video.
- Oblix routes AI tasks to the cloud or edge based on complexity, latency needs, and cost, so it intelligently directs AI tasks to the cloud or edge based on complexity, latency requirements, and cost considerations.
- PCIE Bandwidth Doesn't Matter Much: Members found that PCIE bandwidth negligibly impacts inference speed when setting up dual 4090s, with at most 2 more tps compared to PCI-e 4.0 x8.
- The consensus was that upgrading to PCIE 5.0 from PCIE 4.0 provides only a marginal benefit for inference tasks.
- RTX PRO 6000 Blackwell Launched: NVIDIA released its RTX PRO 6000 "Blackwell" GPUs which features a GB202 GPU, 24K cores, 96 GB VRAM and requires 600W TDP.
- The performance of this card is believed to be much better than the 5090 due to the fact it has HBM.
- Multi-GPU Performance Suffers: A user shared that they noticed a degradation in performance and instability when using multiple RTX 3060s (3 on PCI-e x1 and 1 on x16) in LM Studio with CUDA llama.cpp, as single GPU performance (x16) was superior.
- It was suggested that the performance issues stemmed from how models are split between multiple GPUs and that Pci-e 3.0 x4 slows inference down up to 10%.
HuggingFace Discord
- Mining GPUs rescue AI Home Server: Users are considering older Radeon RX 580 GPUs for local AI servers, but are being directed to P104-100s or P102-100s on Alibaba, which have 8-10 GB VRAM.
- Nvidia limits the VRAM in the bios, but Chinese sellers flash them to give access to all available memory.
- Open Source Investment Multiplies Value: Harvard research reveals that $4.15B invested in open-source generates $8.8T of value for companies, as discussed in this X post, which means $1 invested = $2,000 of value created.
- This highlights the significant economic return from open-source contributions.
- Oblix Orchestrates Local vs. Cloud Models: The Oblix Project offers a platform for seamless orchestration between local and cloud models, as highlighted in a demo video.
- Autonomous agents in Oblix monitor system resources and dynamically decide whether to execute AI tasks locally or in the cloud.
- Gradio Sketch AI code generation is here!: Gradio Sketch released an update that includes AI-powered code generation for event functions, which can be accessed either via typing
gradio sketchor the hosted version.- This allows no code to be written and done in minutes, as opposed to the hours previously required.
- LangGraph Materials Released on GitHub: Materials for Unit 2.3 on LangGraph are available on the GitHub repo due to sync issues.
- This allows impatient users to access the content before the website is updated, ensuring they can continue with the course.
OpenAI Discord
- Gemini Tussles ChatGPT for Supremacy: Members debated the merits of Gemini Advanced versus ChatGPT Plus, with opinions divided on Gemini's 2.0 Flash Thinking and ChatGPT's safety alignment and implementation.
- One member lauded Gemini's free, unlimited access, while another criticized its lack of basic safety features and overall implementation.
- o1 and o3-mini-high Still Top Dog: Despite buzz around Gemini, some users maintained that OpenAI's o1 and o3-mini-high models excel in reasoning tasks like coding, planning, and math.
- These users consider Google models to be the worst in these areas, with only Grok 3 and Claude 3.7 Thinking potentially rivaling o1 and o3-mini-high.
- GPT-4.5's Creative Writing Falls Flat: A member found GPT-4.5's creative writing inconsistent, citing logic errors, repetition, and occasional resemblances to GPT-4 Turbo.
- Although performance improved on subsequent runs, the user lamented the model's extreme message limit.
- DeepSeek Gets Booted From University Campuses: A member reported that their university banned DeepSeek, possibly due to its lack of guidelines or filters, which drastically degrades performance when avoiding illegal topics.
- The ban appears to target only DeepSeek, not other LLMs.
- ChatGPT Sandboxes Boundaries of Helpfulness: Members are experimenting with ChatGPT personality by exploring how the model responds to different prompts and system messages, showing example of an 'unhelpful assistant' roleplay.
- One member found it challenging to get the model out of the 'unhelpful' state in the GPT-4o sandbox without altering the system message.
OpenRouter (Alex Atallah) Discord
- Anthropic's Claude 3.7 Sonnet Stalls: Anthropic models, specifically Claude 3.7 Sonnet, experienced downtime and are now recovering.
- Users reported that Anthropic services appear to be stabilizing after the outage.
- Cline Compatibility Board Ranks Models: A community member has created a Cline Compatibility Board for ranking models based on their performance with Cline.
- The board provides details on API providers, plan mode, act mode, input/output costs, and max output for models like Claude 3.5 Sonnet and Gemini 2.0 Pro EXP 02-05.
- Gemini 2.0 Pro EXP-02-05 Has Glitches: The Gemini-2.0-pro-exp-02-05 model on OpenRouter is confirmed to be functional but experiences random glitches and rate limiting.
- According to the compatibility board, it is available at 0 cost, with an output of 8192.
- Gemini Models Go Manic in RP Scenarios?: Some users found Gemini models like gemini-2.0-flash-lite-preview-02-05 and gemini-2.0-flash-001 to be unstable in roleplaying scenarios, exhibiting manic behavior, even with a temperature setting of 1.0.
- However, other users reported absolutely no problem with 2.0 flash 001, finding it very coherent and stable at a temperature of 1.0.
- OpenRouterGo SDK v0.1.0 Launched: The OpenRouterGo v0.1.0, a Go SDK for accessing OpenRouter's API with a clean, fluent interface has been released.
- The SDK includes automatic model fallbacks, function calling, and JSON response validation.
aider (Paul Gauthier) Discord
- Nvidia Unveils Nemotron Open Weight LLMs: NVIDIA introduced the Llama Nemotron family of open-weight models, including Nano (8B), Super (49B), and Ultra (249B) models, with initial tests of the Super 49B model achieving 64% on GPQA Diamond in reasoning mode.
- The models have sparked interest in their reasoning capabilities and potential applications, with a tweet mentioning their announcement on X.
- DeepSeek R1 671B lands on SambaNova Cloud: DeepSeek R1 671B is now generally available on SambaNova Cloud with 16K context lengths and API integrations with major IDEs, gaining quick popularity after its launch, confirmed in a tweet from SambaNovaAI.
- The availability is extended to all developers, providing access to this large model for various applications.
- Aider Adds Web and PDF Reading Abilities: Aider now supports reading webpages from URLs and PDF files, usable with vision-capable models like GPT-4o and Claude 3.7 Sonnet via commands like
/add <filename>,/paste, and command line arguments, as documented here.- This feature enhances Aider's ability to process diverse information sources, though the relative value of each model continues to be debated.
- Gemini Canvas Expands Collaboration Tools: Google's Gemini has introduced enhanced collaboration features with Canvas, offering real-time document editing and prototype coding.
- This interactive space simplifies writing, editing, and sharing work with quick editing tools for adjusting tone, length, or formatting.
- Aider Ignores Repo Files with Aiderignore: Aider allows users to exclude files and directories from the repo map using the
.aiderignorefile, detailed in the configuration options.- This feature helps focus the LLM on relevant code, improving the efficiency of code editing.
Interconnects (Nathan Lambert) Discord
- Hunyuan Hypes T1 Hierarchy:
@TXhunyuanseeks collaborators to step into T1 models, questioning the availability of alphabet letters for naming reasoning models via a post on X.- The community debates potential names, considering the limited options left after numerous models have already claimed prominent letters.
- Samsung's ByteCraft Generates Games: SamsungSAILMontreal introduced ByteCraft, a generative model transforming text prompts into executable video game files, accessible via a 7B model and blog post.
- Early work requires steep GPU requirements, needing a max of 4 GPUs for 4 months.
- NVIDIA's DGX Spark and Station Revealed: NVIDIA unveiled its new DGX Spark and DGX Station personal AI supercomputers powered by the company’s Grace Blackwell platform.
- DGX Spark, formerly Project DIGITS, is a $3,000 Mac Mini-sized world’s smallest AI supercomputer geared towards AI developers, researchers, data scientists and students, for prototyping, fine-tuning and inferencing.
- California's AB-412 Threatens AI Startups: California legislators are reviewing A.B. 412, mandating AI developers to track and disclose every registered copyrighted work used in AI training.
- Critics fear this impossible standard could crush small AI startups and developers, while solidifying big tech's dominance, also AI2 submitted a recommendation to the Office of Science and Technology Policy (OSTP) advocating for an open ecosystem of innovation
- NVIDIA Hit with Unserious Marketing: NVIDIA is advertising H200 performance on an H100 node, and a 1.67x speedup of B200 vs H200 after going from FP8 to FP4 and some are describing NVIDIA marketing as so unserious via these tweets and here.
- NVIDIA claims the world’s fastest DeepSeek-R1 inference, with a single system using eight Blackwell GPUs in an NVL8 configuration delivering 253 TPS/user or 30K TPS system throughput on the full DeepSeek-R1 671B parameter model and more details available at NVIDIA's website.
Yannick Kilcher Discord
- OpenAI is a Triple Threat: A member noted OpenAI's comprehensive strength in model development, product application, and pricing strategies, setting them apart in the AI landscape.
- Other companies may specialize in only one or two of these critical areas, but OpenAI excels across the board.
- AI Companionships Spur Addictive Sentiments: Concerns are emerging as AI agents, like vocal assistants, foster addictive tendencies, leading some users to develop emotional attachments.
- This trend raises ethical questions about intentionally designed addictive features and their potential impact on user dependency, with discussions on whether companies should avoid features that might enhance such behaviors.
- Smart Glasses: Data Harvesting Disguised as Urban Chic?: A discussion questioned Meta and Amazon's smart glasses, suggesting a data harvesting intent, particularly egocentric views, curated for robotics companies.
- A member joked about a smart glasses startup idea for villains, highlighting features such as emotion detection, dream-state movies, and shared perspectives, creating a dependence feedback-loop to collect user data and train models.
- AI Art Copyright: No Bot Authors Allowed!: A U.S. appeals court affirmed that AI-generated art without human input cannot be copyrighted under U.S. law, supporting the U.S. Copyright Office's stance on Stephen Thaler's DABUS system; see Reuters report.
- The court emphasized that only works with human authors can be copyrighted, marking the latest attempt to grapple with the copyright implications of the fast-growing generative AI industry.
- Llama 4 Arriving Soon?: Rumors suggest that Llama 4 might be released on April 29th.
- This speculation is linked to Meta's upcoming event, Llamacon 2025.
Perplexity AI Discord
- Perplexity Judged Dumber Than Claude: A user stated that Perplexity feels dumber than Claude 3.5, citing issues with context retention and abstract generation.
- It was suggested to use incognito mode or disable AI data retention to prevent data storage, noting that new chats provide a clean slate.
- O1 Hype Dwindles Due to Paywall: Community testing suggests initial overestimation of O3 mini and underestimation of o1 and o1 pro, with the paywall significantly dampening enthusiasm.
- One user reported that R1 is useless most of the time, with
o3-miniyielding better results for debuggingjscode.
- One user reported that R1 is useless most of the time, with
- Oblix Project Transitions Between Edge and Cloud: The Oblix Project orchestrates between local and cloud models using agents to monitor system resources, according to a demo video.
- The project dynamically switches execution between cloud and on-device models.
- Perplexity API Responds Erratically: A user reported random response issues with the Perplexity API, specifically during hundreds of rapid web searches.
- The code either receives only random responses or ignores random queries when calling the
conductWebQueryfunction in quick repetition, potentially due to implementation errors.
- The code either receives only random responses or ignores random queries when calling the
Notebook LM Discord
- GDocs Layouts Get Mangled!: Users found that converting to GDocs mangles the layout and fails to import most images in teacher presentations, and found that extracting text (using pdftotext) and converting to image-only format helps with grounding.
- Image-only PDFs can expand to >200MB, requiring splitting due to NLM's file size limit.
- NotebookLM: One-Man (or Woman) Band!: Users find that with customized function you can make it to do anything you want (solo episode being man or female, mimic persona, narrate stories, read word for word).
- Only your imagination is the limit.
- Podcast Casual Mode: Cursing Up a Storm!: Feedback indicates that the casual podcast mode may contain profanity.
- It is unclear whether a clean setting is available.
- Line Breaks Can't Be Forced in NotebookLM: Users can't force line breaks and spacing in NotebookLM's responses, because the AI adds them on-demand and it's not something the user can configure at the moment.
- As an alternative to audio overviews, a user was advised to download the audio and upload it as a source to generate a transcript.
- Mind Map Feature Rolls Out Gradually: Users discussed the new Mind Map feature in NotebookLM, which visually summarizes uploaded sources, see Mind Maps - NotebookLM Help.
- The feature is being rolled out gradually to more users, for bug control: It's better to release something new only for a limited number of people that increases over time first, because then there is time to rule out any bugs that emerge and provide a cleaner version by the time everyone gets it.
MCP (Glama) Discord
- Listing Smithery Registries via Glama API: A member utilized the Glama API to enumerate GitHub URLs and verify the existence of smithery.yaml files, describing the code as a one time hack job script.
- They considered creating a gist if there was sufficient interest, highlighting its nature as a one time script.
- Spring App Questions Spring-AI-MCP-Core: A user is exploring MCP for the first time in Open-webui and a basic Spring app using spring-ai-mcp-core, and seeks resources beyond ClaudeMCP and the modelcontextprotocol GitHub repo.
- They questioned how MCP compares to GraphQL or function calling, and how it handles system prompts and multi-agent systems.
- Claude Code MCP Implementation Released: A member unveiled a Claude Code MCP implementation of Claude Code as a Model Context Protocol (MCP) server.
- They sought assistance with the json line for claude_desktop_config.json for Claude Desktop integration but resolved the problem.
- DuckDuckGo MCP Framework Built for Cursor on Windows: A member created their own DuckDuckGo MCP on a Python framework for Cursor on Windows because existing NPM projects failed.
- It supports web, image, news, and video searches without requiring an API key and is available on GitHub.
- MCP Python REPLs Gain Traction: Members exchanged views on hdresearch/mcp-python, Alec2435/python_mcp and evalstate/mcp-py-repl as Python REPLs for MCP.
- A concern was raised that one implementation wasn't isolated at all which could lead to a disaster, suggesting Docker be used to sandbox access.
Nous Research AI Discord
- Phi-4 could be your Auxiliary: Members discussed Phi-4 as a useful auxiliary model in complex systems, highlighting its direction-following, LLM interfacing, and roleplay abilities.
- The claim is that it would be useful as an auxiliary model in a complex system where you already had a bunch of other models.
- Claude's parameter listing errors: A user critiqued Claude's AI suggestions, citing model size inaccuracies, as the models listed were not under 10m parameters as requested, see the Claude output.
- A member defended that '10m' could be taken as a shorthand for 'very light models that are generally accessible on modern hardware'.
- "Vibe Coding" is background learning: A member shared an anecdote about learning Japanese through immersion, paralleling it with "vibe coding" for skill acquisition.
- They added that Even vibe coding, you still have to worry about things like interfaces between modules so that you can keep scaling with limited LLM context windows.
- Nvidia Drops Massive Coding Dataset: A user shared Nvidia's open-sourced instruct coding dataset for improving math, code, general reasoning, and instruction following in the Llama instruct model, including data from DeepSeek-R1 and Qwen-2.5.
- Another member who downloaded the dataset reported that it would be interesting to filter and train.
- Limited VRAM spurs niche tuning: A member asked for help finding a niche for training a model with limited VRAM such as an RTX 3080.
- Discussion included various QLoRA experiments, and a suggestion to fine tune on code editing.
LMArena Discord
- LMArena faces Slow Demise?: A member questioned the quality of testers on LMArena, wondering "Where are all the real testers, improvers, and real thinkers?" and shared a Calm Down GIF.
- This suggests community concern about the platform's direction or engagement, possibly its user experience and community support.
- Perplexity/Sonar must beat OpenAI/Google: A member speculates that if Perplexity/Sonar isn't the top web-grounded search, the company will struggle to maintain uniqueness against OpenAI or Google.
- Another member noted that "no one really uses sonar on perplexity though", suggesting it is mostly pro subscriptions driving revenue.
- Gemini Deep Research Saves Time 10x: The latest update in Gemini Deep Research saves one member time by 10x, but may be too expensive for LMArena benchmarking.
- Another member added context that Gemini gave great results, providing an insightful analysis for scientific medical research, generating even a list of 90 literature sources.
- LeCun Debunks Zuckerberg's AGI Hype: Yann LeCun warned that achieving AGI "will take years, if not decades," requiring new scientific breakthroughs.
- A more recent article said that Meta LLMs will not get to human level intelligence until 2025.
- Grok 3 Deeper Search is Disappointing: One user found Grok 3's deepersearch feature to be disappointing, citing hallucinations and low-quality results.
- However, another user defended Grok, stating that "deepersearch seems pretty good" but the original commenter rebutted that frequent usage reveals numerous mistakes and hallucinations.
GPU MODE Discord
- Gemma 3 Quantization Calculations: A user inquired about running Gemma 3 on an M1 Macbook Pro (16GB), to which another user explained how to calculate the size requirement based on model size and quantization in bytes, suggesting the Macbook can run Gemma 3 4B in FP16.
- The user explained that a 12B model in FP4 could also be run, given the Macbook's 16GB unified memory with 70% allocated to the GPU.
- Blackwell ULTRA's attention instruction Piques Interest: A member mentioned that Blackwell ULTRA would bring an attention instruction, but its meaning remains unclear to them.
- Additionally, members discussed that if the smem carveout for kernel1 is only 100 or 132 KiB, there's not enough space for both kernels to run simultaneously, suggesting increasing the carveout using the CUDA documentation on Shared Memory.
- Nvfuser's Matmul Output Fusions Introduce Stalls: A member noted that implementing matmul output fusions for nvfuser is difficult, and even with multiplication/addition, it introduces stalls, making it slower than separate kernels due to the need to keep tensor cores fed.
- Another member inquired whether the difficulty arises because Tensor Cores and CUDA Cores cannot run concurrently, potentially fighting for register usage, while referencing Blackwell docs stating that TC and CUDA cores can now run concurrently.
AcceleratePrepares to Merge FSDP2 Support: A member asked whetheraccelerateuses FSDP1 or FSDP2, and whether it is possible to fine-tune an LLM using FSDP2 withtrl, to which it was clarified that a pull request will be merged ~next week to add initial support for FSDP2 here.- After the member clarified the details on when FSDP2 support would be added, the other member said "This is exciting! Thanks for the clarification!", emphasizing user anticipation around the arrival of FSDP2 support in
accelerate.
- After the member clarified the details on when FSDP2 support would be added, the other member said "This is exciting! Thanks for the clarification!", emphasizing user anticipation around the arrival of FSDP2 support in
- DAPO Algorithm Debuts with Open-Source Release: The DAPO algorithm (decoupled clip and dynamic sampling policy optimization) was released; DAPO-Zero-32B surpasses DeepSeek-R1-Zero-Qwen-32B, scoring 50 on AIME 2024 with 50% fewer steps; it is trained with zero-shot RL from the Qwen-32b pre-trained model, and the algorithm, code, dataset, verifier, and model are fully open-sourced, built with Verl.
Modular (Mojo 🔥) Discord
- Nvidia unveils Blackwell Ultra and Ruben: At a recent keynote, Nvidia announced the Blackwell Ultra and Ruben, along with the next GPU generation named Feynman.
- With Ruben, Nvidia is shifting to silicon photonics to save on data movement power costs; Ruben will feature a new ARM CPU, alongside major investments in Spectrum X, which is launching a 1.6 Tbps switch.
- CompactDict Attracts Attention for SIMD Fix: Members discussed the advantages of CompactDict, a custom dictionary implementation that avoids the SIMD-Struct-not-supported issue found in the built-in Dict.
- A report from a year ago was published on GitHub detailing two specialized Dict implementations: one for Strings and another forcing the implementation of the trait Keyable.
- HashMap Inclusion Debated for Mojo Standard Library: A suggestion was made to include the generic_dict in the standard library as HashMap, while maintaining the current Dict.
- Concerns were raised about Dict needing to do a lot of very not-static-typed things, and that it may be more valuable to add a new struct with a better design and deprecate Dict over time.
- List.fill Behavior Creates Unexpected Length Changes: Users questioned whether filling uninitialized parts of the lists buffer should be optional, since calling List.fill can surprisingly change the length of the list.
- It was suggested that making the filling of uninitialized parts of the lists buffer optional would resolve this issue.
- No Index Out of Range Check in Lists: A user noticed the absence of an index out of range check in List, expressing surprise since they thought that was what unsafe_get was for.
- Another member has run into this issue also, with someone from Modular saying it needs to be added at some point.
Latent Space Discord
- Patronus AI Judges Honesty at Etsy: Patronus AI launched an MLLM-as-a-Judge to evaluate AI systems, already implemented by Etsy to verify caption accuracy for product images.
- Etsy has hundreds of millions of items and needs to ensure their descriptions are accurate and not hallucinated.
- Cognition AI Secures $4B Valuation: Cognition AI reached a $4 billion valuation in a deal led by Lonsdale's firm.
- Further details on the deal were not supplied.
- AWS Undercuts Nvidia: During the GTC March 2025 Keynote, it was reported that AWS is pricing Trainium at 25% the price of Nvidia chips (hopper), according to this tweet.
- Jensen joked that after Blackwell, they could give away a Hopper since Blackwell will be so performant.
- Manus Access Impresses Trading Bot User: A member got access to Manus with deeper search via Grok3 and said it's good, showcasing how it built a trading bot over the weekend, but is currently down ~$1.50 in paper trading.
- They showed off impressive output, teasing sneak peek screenshots.
- vLLM: The Inference ffmpeg: vLLM is slowly becoming the ffmpeg of LLM inference, according to this tweet.
- The tweet expresses gratitude for the trust in vLLM.
Eleuther Discord
- Fine-tuning Gemini/OLMo Models Gets Hot: Members are seeking advice on fine-tuning Gemini or OLMo models and considering whether distillation would be a better approach, especially with data in PDF files.
- The discussion evolved into memory optimization and hybrid setups for enhanced performance rather than specifics on which models to finetune.
- Passkey Performance gets Fuzzy: A member suggested improving the passkey and fuzzy rate for important keys to nearly 100% using hybrid approaches or a memory expert activated by the passkey, as visualized in scrot.png.
- They noted that larger models will have longer memories, illustrating the improvement from 1.5B to 2.9B parameters.
- Latent Activations Reveal Full Sequences: A poster argues that one should generate latent activations from entire sequences rather than individual tokens to understand a model's normal behavior.
- They suggest that focusing on entire sequences provides a more accurate representation of the model behavior and provided example code using
latents = get_activations(sequence).
- They suggest that focusing on entire sequences provides a more accurate representation of the model behavior and provided example code using
- Cloud Models Demand API Keys: Members are asking if cloud-based models, which cannot be hosted locally, are compatible with API keys.
- Another member confirmed that they do, pointing to a previously provided link for details.
LlamaIndex Discord
- Hugging Face Teaches LlamaIndex Agents: Hugging Face released a free course about building agents in LlamaIndex, covering components, RAG, tools, agents, and workflows (link).
- The course dives into the intricacies of LlamaIndex agents, offering a practical guide for developers looking to build AI-powered applications.
- Google & LlamaIndex Simplify AI Agents: LlamaIndex has partnered with Google Cloud to simplify building AI agents using the Gen AI Toolbox for Databases (link).
- The Gen AI Toolbox for Databases manages complex database connections, security, and tool management, with more details available on Twitter.
- LlamaIndex vs Langchain Long Term Memory: A member inquired about whether LlamaIndex has a feature similar to Langchain's long-term memory support in LangGraph.
- Another member pointed out that "long term memory is just a vector store in langchain's case" and suggested using LlamaIndex's Composable Memory.
- Nebius AI Platform Compared to Giants: A member is curious about real-world experiences with Nebius's computing platform for AI and machine learning workloads, including their GPU clusters and inference services.
- They are comparing it to AWS, Lambda Labs, or CoreWeave in terms of cost, scalability, and ease of deployment, and would like to know about stability, networking speeds, and orchestration tools like Kubernetes or Slurm.
Cohere Discord
- Cohere Expanse 32B: Knowledge Cutoff Date Sought: A user inquired about the knowledge cutoff date for Cohere Expanse 32B, as they are seeking new work.
- No further information or responses were provided regarding the specific cutoff date.
- Trial Key Users Bump into Rate Limits: A user reported experiencing a 429 error with their trial key, seeking guidance on tracking usage and determining if they exceeded the 1000 calls per month limit, as described in the Cohere rate limits documentation.
- A Cohere team member offered assistance and clarified that trial keys are indeed subject to rate limits.
- Websearch Connector's Results Degrade: A user reported degraded performance with the websearch connector, noting that the implementation changed recently and now provides worse results.
- A team member requested details to investigate and noted that the connection option site: WEBSITE was failing to restrict queries to specific websites, and this fix is going out soon.
- Command-R-Plus-02-2024 vs Command-A-03-2025: A Comparison: A user tested and compared websearch results between models command-r-plus-02-2024 and command-a-03-2025, discovering no significant differences between the models.
- They additionally reported multiple instances where the websearch functionality failed to return any results.
- Goodnews MCP: LLM Delivers Uplifting News: A member created a Goodnews MCP server that delivers positive news to MCP clients via Cohere Command A, open sourced at this Github repo.
- The tool, named
fetch_good_news_list, ranks recent headlines using Cohere LLM to identify and return the most positive articles.
- The tool, named
LLM Agents (Berkeley MOOC) Discord
- MOOC Coursework Details Released: Coursework and completion certificate instructions for the LLM Agents MOOC have been released on the course website, building upon the fundamentals from the Fall 2024 LLM Agents MOOC.
- Labs and the Certificate Declaration form will drop in April, with assignments tentatively due at the end of May and certificates released in June.
- AgentX Competition has 5 Tiers: Details for the AgentX Competition have been shared, including information on how to sign up here, and it includes 5 Tiers: Trailblazer ⚡, Mastery 🔬, Ninja 🥷, Legendary 🏆, Honorary 🌟.
- Participants can also apply for mentorship on an AgentX Research Track project via this application form, with the application deadline set for March 26th at 11:59pm PDT.
- Quizzes Due End of May: All assignments, including quizzes released after every lecture, are due by the end of May, so you can still submit them to be eligible for the certificate.
- To clarify the selection criteria for the AgentX research track isn't about 'we will only accept the top X percent'.
- Guidance on AgentX Research Track Projects: Guidance will be offered on research track projects from March 31st to May 31st, and mentors will contact applicants directly for potential interviews.
- Applicants should demonstrate proactivity, a well-thought-out research idea relevant to the course, and the background to pursue the idea within the two-month timeframe.
- Troubleshooting Certificate Issues: A member who took the MOOC course in December reported not receiving the certificate, a mentor replied that the certificate email was sent on Feb 6th and advised checking spam/trash folders and ensuring the correct email address was used.
- The mentor shared that the certificate is open to anyone who completes one of the coursework tiers and shared a link to the course website and the google doc.
Torchtune Discord
- FL Setup Finally Functions: After a 4-month wait due to IT delays, a member's FL setup is finally functional, showcased in this image.
- The prolonged delay highlights common challenges in getting necessary infrastructure operational in large organizations.
- Nvidia GPUs face perpetual availability delays: Members report ongoing delays in Nvidia GPU availability, citing H200s as an example, which were announced 2 years ago but only available to customers 6 months ago.
- Such delays impact development timelines and resource planning for AI projects.
recvVectorandsendBytestrigger DPO Debacles: Users reportedrecvVector failedandsendBytes failederrors when using DPO recipes.- The errors' origins are uncertain, possibly stemming from cluster issues or problems with torch.
cudaGetDeviceCountCries for Compatibility: Members encounteredRuntimeError: Unexpected error from cudaGetDeviceCount()while using NumCudaDevices.- The error
Error 802: system not yet initializedmight stem from using a newer CUDA version than anticipated, although this is unconfirmed.
- The error
nvidia-fabricmanagerFulfills CUDA Fix: Usingnvidia-fabricmanageris the resolution for thecudaGetDeviceCounterror.- The correct process includes starting it with
systemctl start nvidia-fabricmanagerand confirming the status withnvidia-smi -q -i 0 | grep -i -A 2 Fabric, verifying the state shows "completed".
- The correct process includes starting it with
tinygrad (George Hotz) Discord
- M1 Macs Struggle with Model Training: A user reported that their M1 Mac Air struggles to train models even in small batches, facing clang issues with Kaggle and Hugging Face Spaces.
- They sought advice on hosting a demo of inference on a trained model but found the hardware underpowered for even basic training tasks.
- DeepSeek-R1 Optimized for Home Use: 腾讯玄武实验室's optimization方案 allows home deployment of DeepSeek-R1 on consumer hardware, costing only 4万元 and consuming power like a regular desktop, as noted in this tweet.
- The optimized setup generates approximately 10汉字/second, achieving a 97% cost reduction compared to traditional GPU setups, potentially democratizing access to powerful models.
- Clang Dependency Needs Better Error Handling: A contributor suggested improving dependency validation for the
FileNotFoundErrorwhen running the mnist example on CPU without clang.- The current error message does not clearly indicate the missing clang dependency, potentially confusing new users.
- Confused Index Selection for REDUCE_LOAD: A member requested clarification on the meaning of
x.src[2].src[1].src[1]and the reasons for selecting these indices asreduce_inputfor the REDUCE_LOAD pattern.- The code snippet checks if
x.src[2].src[1].src[1]is not equal tox.src[2].src[0], and accordingly assigns eitherx.src[2].src[1].src[1]orx.src[2].src[1].src[0]toreduce_input.
- The code snippet checks if
AI21 Labs (Jamba) Discord
- AI21 Labs Keeps Mum on Jamba: AI21 Labs is not publicly sharing information about what they are using for Jamba model development.
- A representative apologized for the lack of transparency but indicated that they would provide updates if the situation changes.
- New Faces Join the Community: The community welcomed several new members including <@518047238275203073>, <@479810246974373917>, <@922469143503065088>, <@530930553394954250>, <@1055456621695868928>, <@1090741697610256416>, <@1350806111984422993>, and <@347380131238510592>.
- They are encouraged to participate in a community poll to engage.
DSPy Discord
- Chain Of Draft Reproducibility is Here: A member used
dspy.ChainOfThougtto reproduce the Chain of Draft technique, detailing the process in a blog post.- This validates the method for reliably using DSPy to reproduce advanced prompting strategies.
- Chain Of Draft Technique Cuts Tokens: The Chain Of Draft prompt technique helps the LLM expand its response without excessive verbosity, cutting output tokens by more than half.
- Further details on the method are available in this research paper.
MLOps @Chipro Discord
- AWS Webinar Teaches MLOps Stack Construction: A webinar on March 25th at 8 A.M. PT will cover building an MLOps Stack from Scratch on AWS, registration available at this link.
- The webinar aims to provide an in-depth discussion on constructing end-to-end MLOps platforms.
- AI4Legislation Seminar Spotlights Legalese Decoder: The AI4Legislation Seminar, featuring Legalese Decoder Founder William Tsui and foundation President Chunhua Liao, is scheduled for Apr 2 @ 6:30pm PDT (RSVP here).
- The seminar is part of the Silicon Valley Chinese Association Foundation's (SVCAF) efforts to promote AI in legislation.
- Featureform Simplifies ML Model Features: Featureform is presented as a virtual feature store, enabling data scientists to define, manage, and serve features for their ML models.
- It focuses on streamlining the feature engineering and management process in ML workflows.
- SVCAF Competition Boosts Open Source AI for Legislation: The Silicon Valley Chinese Association Foundation (SVCAF) is hosting a summer competition focused on developing open-source AI-driven solutions to enhance citizen engagement in legislative processes (Github repo).
- The competition seeks to foster community-driven innovation in applying AI to legislative challenges.
Nomic.ai (GPT4All) Discord
- GPT4All Details Default Directories: The GPT4All FAQ page on Github describes the default directories for models and settings.
- This Github page also provides additional information about GPT4All.
- GPT4All Models' Default Location: The default location for GPT4All models is described in the FAQ.
- Knowing this location can help with managing and organizing models.
The Codeium (Windsurf) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor Community ▷ #general (1174 messages🔥🔥🔥):
Sonnet MAX model analysis, Cursor Plan&Build agent enhancements, Claude Max pricing and limitations, Open Empathic Project collaboration, Windsurf vs. Cursor pricing
- Sonnet MAX Gains Agentic Prowess: The Sonnet MAX model is recognized for its ability to handle post-processing effectively when operating as an agent, as mentioned in this X post.
- Cursor needs to learn the code base and learn from its own mistakes as the library is not in the training data.
- Max Usage Sparks Debate on Pricing: The community discusses the merits of Claude Max in Cursor, but there are concerns over its pricing structure, as it does not fully utilize the allocated fast requests within the subscription.
- Some members suggest that if Cursor allowed more fast request consumption for Max, they wouldn't seek alternatives, saying "Cursor team dropped the ball hard by not allowing more fast request consumption for Max".
- User Shares Workflows for Coding Tasks: A community member detailed their workflow which included starting in repo prompt, select relevant files + instructions -> paste into grok 3 for high level plan -> give plan to claude code to one shot -> refine details further in cursor agent.
- They also emphasized that Claude max really feels like you have the full model without any limitations, and praised that just design in figma first.
- Terminal Spawning Frustrates Cursor Users: Users are struggling with agent spawning multiple terminals and continuously rerunning the same project, leading to a discussion on how to prevent this via rules and configurations.
- One member proposed an Enhanced Terminal Management Rule which includes running a command to terminate open terminals before opening a new one, ensuring test output is directed to a fresh terminal, and prevent multiple terminals from being created during a single test run.
- Open Source IDE PearAI Emerges as Alternative: The community explores PearAI (https://trypear.ai/), an open-source AI code editor that integrates tools like Roo Code/Cline, Continue, Perplexity, Mem0, and Supermaven.
- With one member suggesting " Pear is actually kinda doing gods work rn compared to cursor", they emphasized it is cheaper than Cursor but has a smaller context window.
- Careers at CO/AI - CO/AI: We're on a mission to empower humans and foster a fairer innovation ecosystem in the age of AI. If this mission resonates with you, we'd love to hear from you.
- Model context protocol (MCP) | Supabase Docs: Connect AI tools to Supabase using MCP
- Tweet from Kevin Kern (@kregenrek): Mh - Sonnet MAX is the first model that really gets post-processing right when running the Agent. Unfortunately it has its cost.Quoting Kevin Kern (@kregenrek) Ok my cursor plan&build agent works with...
- Mood Dance GIF - Mood Dance Russiankiddance - Discover & Share GIFs: Click to view the GIF
- Settings | Cursor - The AI Code Editor: You can manage your account, billing, and team settings here.
- Tweet from bolt.new (@boltdotnew): Introducing Figma to BoltGo from Figma to pixel-perfect full stack app — just put bolt․new in front of the URL & start prompting!
- Dance GIF - Dance - Discover & Share GIFs: Click to view the GIF
- Anthropic Status: no description found
- Reddit - The heart of the internet: no description found
- PearAI - The AI Code Editor For Your Next Project: PearAI is an open source AI code editor with powerful features like AI chat, PearAI Creator, and AI debugging to help you make what excites.
- Tweet from rahul (@rahulgs): got @anthropicai Claude Code working with OpenAI models loli set up an proxy server that mimics the anthropic /v1/messages api, forwards requests to OpenAImaps:- Sonnet 3.7 -> 4o - Haiku 3.5 -> ...
- PearAI - The AI Code Editor For Your Next Project: PearAI is an open source AI code editor with powerful features like AI chat, PearAI Creator, and AI debugging to help you make what excites.
- GitHub - 1rgs/claude-code-openai: Run Claude Code on OpenAI models: Run Claude Code on OpenAI models. Contribute to 1rgs/claude-code-openai development by creating an account on GitHub.
- GitHub - 2-fly-4-ai/V0-system-prompt: Contribute to 2-fly-4-ai/V0-system-prompt development by creating an account on GitHub.
- GitHub - daniel-lxs/cursor-plus: A Cursor extension that displays your Cursor Subscription usage statistics in the status bar.: A Cursor extension that displays your Cursor Subscription usage statistics in the status bar. - daniel-lxs/cursor-plus
- Reddit - The heart of the internet: no description found
Unsloth AI (Daniel Han) ▷ #general (419 messages🔥🔥🔥):
Vision finetuning issues with Gemma 3, Unsloth and vLLM event in SF, Evaluate model performance with Wandb, Fine-tuning base vs instruct models, Unsloth with multinode and multigpu finetuning
- Gemma 3 Vision Finetuning runs into Transformers Glitch: Users reported issues finetuning Gemma 3 for vision tasks, indicating a potential problem with vision support in the current Transformers version.
- One user encountered a RuntimeError: Unsloth: Failed to make input require gradients! when trying to qlora
gemma-3-12b-pt-bnb-4bitfor image captioning, suggesting a need for further investigation.
- One user encountered a RuntimeError: Unsloth: Failed to make input require gradients! when trying to qlora
- Unsloth and vLLM Team Up for SF Event: Unsloth will be joining vLLM and Ollama for an event in SF next week on Thursday, March 27th, promising social time and presentations. The event is hosted at Y Combinator's San Francisco office.
- More details are available for the vLLM & Ollama inference night where food and drinks will be served.
- Wandb Integration and Model Evaluation Explored: Members discussed how to evaluate model performance before and after fine-tuning using Wandb within Unsloth, with a focus on tracking training loss.
- It's generally accepted the training loss going down during training is a sign that it's working*, but it's also essential to test the model and potentially run benchmarks.
- Base vs Instruct Model Debate Intensifies: The discussion revolved around whether fine-tuning a base or instruct model with a dataset of 30k samples results in a strictly better model, generating diverse opinions and considerations.
- One member emphasized that fine tuning can worsen the model's performance if your data is bad or poorly formatted, which could also cause the model to forget things outside of the dataset.
- Multi-Node Multi-GPU Support teased for Unsloth: Multi-node and multi-GPU fine-tuning support is planned for Unsloth in the coming weeks, as announced by a team member, although the specific release date has not yet been specified.
- The Unsloth team recommends to sign up for the newsletter to receive updates on the release, but one member confirmed multinode support will be enterprise only.
- Unsloth Requirements | Unsloth Documentation: Here are Unsloth's requirements including system and GPU VRAM requirements.
- Finetuning from Last Checkpoint | Unsloth Documentation: Checkpointing allows you to save your finetuning progress so you can pause it and then continue.
- Unsloth Newsletter: Join our newsletter and waitlist for everything Unsloth!
- Unsloth Notebooks | Unsloth Documentation: Below is a list of all our notebooks:
- Editing Models with Task Arithmetic: Changing how pre-trained models behave -- e.g., improving their performance on a downstream task or mitigating biases learned during pre-training -- is a common practice when developing machine learni...
- Windows Installation | Unsloth Documentation: See how to install Unsloth on Windows with or without WSL.
- Mistral Small 3 (All Versions) - a unsloth Collection: no description found
- Tweet from Unsloth AI (@UnslothAI): We teamed up with @HuggingFace to release a free notebook for fine-tuning Gemma 3 with GRPO!Learn to:• Enable reasoning in Gemma 3 (1B)• Prepare/understand reward functions• Make GRPO work for tiny LL...
- no title found: no description found
- Tweet from Andrej Karpathy (@karpathy): You can tell the RL is done properly when the models cease to speak English in their chain of thought
- vLLM & Ollama Inference Night · Luma: Welcome to the vLLM & Ollama inference nightJoin us at Y Combinator's San Francisco office on Thursday, March 27th at 6pm!Food & drinks will be…
- Unsloth Documentation: no description found
- ValueError during training Mistral7b on VertexAI T4 · Issue #155 · unslothai/unsloth: I get this error after running trainer_stats = trainer.train() It runs on a VertexAI VM, on a T4 GPU and 16GB RAM. The code is copy/pasted from the Mistral7b example notebook. The error is: ValueEr...
- GitHub - JL-er/RWKV-PEFT: Contribute to JL-er/RWKV-PEFT development by creating an account on GitHub.
- [Fixing] Better exporting to `llama.cpp` and 16bit merging · Issue #1558 · unslothai/unsloth: Issue to track better exporting to GGUF formats in Unsloth - the goal is to disentangle convert_hf_to_gguf.py from llama-quantize If the finetuner specifies any quant lower than Q8_0, we have to us...
- Model Merge reduces performance · Issue #1519 · unslothai/unsloth: I continuous pretrained a Qwen2.5 0.5B model. When I load the adapter and merge it and then perform inference, the output looks good. But, when I merge with adapter and save model in 16bit or 4bit ...
- (NEW PARALLEL) NVIDIA RTX 4090D 48GB GDDR6 384-bit Graphics Card *BLOWER EDITION*: Elevate your gaming with the NEW PARALLEL NVIDIA RTX 4090D 48GB GDDR6 GPU, featuring a powerful blower design for optimal cooling and performance.
Unsloth AI (Daniel Han) ▷ #off-topic (3 messages):
``
- Niten Cool Comment: A user named niten commented Cool.
- Positions still open?: A user asked how to know if the positions are still open.
Unsloth AI (Daniel Han) ▷ #help (121 messages🔥🔥):
AMD Support for BnB and Triton, Gemma Base Model Changes, Training GPTs Agent, OpenAI's sidebars, Multi-turn conversation datasets + LLM fine-tuning
- AMD & Unsloth: A Promising Partnership: Members reported that BnB and Triton are now supported in AMD, and with some modifications to Unsloth, it could potentially work on AMD GPUs.
- While a bounty could be offered, there's hesitancy to make it a top priority, given the lack of testing and unknowns with AMD.
- Gemma's Gotcha: Chat Template Conundrums: A member noted unusual behavior when applying a LoRA to a base Gemma model pulled from HF Unsloth, suspecting a chat template issue.
- Theyruinedelise clarified that no changes were made recently to the Gemma base model, and suggested checking the chat template.
- SageMaker Setup Snafus: Dependency Doldrums: A user encountered a RuntimeError when running the Phi_4-Conversational notebook on Amazon SageMaker due to import issues related to torchvision.
- TheDragondagger solved it by following a reference notebook and uninstalling/installing libraries as done in the ref notebook, suggesting to pay attention to dependencies when using Unsloth & SageMaker.
- Memory Mirage: Chasing VRAM Savings on 4090: Despite a blog post suggesting it fits in 20GB of VRAM, a user ran into out-of-memory errors while fine-tuning
unsloth/QwQ-32B-unsloth-bnb-4biton a 4090.- Theyruinedelise suggested reducing
max_seq_lengthand batchsize, while clarifying that 20GB is the minimum, as the GPU reserves some VRAM and recommended a minimum of 22GB.
- Theyruinedelise suggested reducing
- Docs get dunked, saving throws for those filesystem woes: A user experienced a
HFValidationErrorandFileNotFoundErrorwhen trying to save a merged model locally, due to an invalid repository ID when callingsave_pretrained_merged.- The recommendation was to update
unsloth-zooas it should be fixed in the latest version.
- The recommendation was to update
- Google Colab: no description found
- Google Colab: no description found
- Error Propagation — PyTorch 2.6 documentation: no description found
- Bone: no description found
- Unsloth Documentation: no description found
- TypeError: unsupported operand type(s) for /: 'Tensor' and 'NoneType' when full finetuning gemma3 · Issue #2101 · unslothai/unsloth: Version pip install unsloth pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3 Code from unsloth import FastModel import torch model, tokenizer = FastModel.from_pretrained(...
- Feature Request: Add Support for MllamaForConditionalGeneration to Convert Llama 3.2 Vision Models to GGUF Format · Issue #9663 · ggml-org/llama.cpp: Prerequisites I am running the latest code. Mention the version if possible as well. I carefully followed the README.md. I searched using keywords relevant to my issue to make sure that I am creati...
- Inconsistent Inference Results After Saving and Loading LoRA Model · Issue #1670 · unslothai/unsloth: I was following the official Google Colab notebook to train my reasoning LoRA model on Paperspace. I was able to run the notebook without any issues. However, when trying to save the trained model,...
- GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- unslothai/unsloth: Finetune Llama 3.3, DeepSeek-R1, Gemma 3 & Reasoning LLMs 2x faster with 70% less memory! 🦥 - unslothai/unsloth
- unsloth-zoo/unsloth_zoo/saving_utils.py at main · unslothai/unsloth-zoo: Utils for Unsloth. Contribute to unslothai/unsloth-zoo development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
Unsloth mention
- Unsloth gets a shoutout: Unsloth received a mention in this article.
- Unsloth Gains Recognition: An article on Substack noted the importance of Unsloth in AI.
Unsloth AI (Daniel Han) ▷ #research (3 messages):
ZO2 Framework, Zeroth Order Optimization, RWKV-7 Model
- ZO2 Framework Touts 175B LLM Fine-Tuning on Modest Hardware: The ZO2 framework enables full parameter fine-tuning of 175B LLMs using just 18GB of GPU memory.
- It is particularly tailored for setups with limited GPU memory.
- Delving into Zeroth Order Optimization: A member pointed out that ZO2 employs zeroth order optimization, contrasting it with the more common first-order methods like SGD.
- Zeroth-order methods approximate gradients using function evaluations, making them suitable for high-dimensional or non-differentiable problems.
- RWKV-7 Model Spotlight: The channel shared the fla-hub/rwkv7-1.5B-world model on Hugging Face, a text generation model updated recently.
- They also included a YouTube video which likely discusses the model.
- Paper page - RWKV-7 "Goose" with Expressive Dynamic State Evolution: no description found
- GitHub - liangyuwang/zo2: ZO2 (Zeroth-Order Offloading): Full Parameter Fine-Tuning 175B LLMs with 18GB GPU Memory: ZO2 (Zeroth-Order Offloading): Full Parameter Fine-Tuning 175B LLMs with 18GB GPU Memory - liangyuwang/zo2
LM Studio ▷ #general (115 messages🔥🔥):
Leaderboards, OpenVoice, LM Studio User Guide, Oblix Project, 4090 and pcie
- *HF Leaderboards Updated: Members shared up-to-date leaderboards from Hugging Face for AI coding models*.
- They shared another one from BigCode.
- *OpenVoice Clones Voices*: A member shared OpenVoice, a versatile instant voice cloning approach that only requires a short audio clip to replicate a voice and generate speech in multiple languages.
- It enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker, as seen in their github repo.
- *LM Studio Settings User Guide is Created: A member is working on an LM Studio user guide*, focusing on every setting geared towards their PC.
- If it works well, they will share a general one for the community.
- *Oblix Orchestrates Local vs Cloud Models*: A member introduced the Oblix Project, a seamless orchestration platform between local and cloud models, showcased in a demo video.
- Oblix intelligently directs AI tasks to the cloud or edge based on complexity, latency requirements, and cost considerations.
- *4090 PCIE Bandwidth Doesn't Matter: Members discussed setting up dual 4090s, and whether PCIE 5.0 provides a boost compared to PCIE 4.0*.
- It was determined that PCIE bandwidth doesn't affect inference speed significantly, at most giving 2 more tps compared to PCI-e 4.0 x8.
- OpenVoice: Versatile Instant Voice Cloning | MyShell AI: Discover OpenVoice: Instant voice cloning technology that replicates voices from short audio clips. Supports multiple languages, emotion and accent control, and cross-lingual cloning. Efficient and co...
- Can Ai Code Results - a Hugging Face Space by mike-ravkine: no description found
- Big Code Models Leaderboard - a Hugging Face Space by bigcode: no description found
- Transform Your AI Performance with Intelligent Hybrid Orchestration | Oblix.ai: Experience our interactive demo and see how our intelligent agents seamlessly switch between local LLM execution and cloud providers for optimal performance and cost efficiency.
LM Studio ▷ #hardware-discussion (271 messages🔥🔥):
NVIDIA Digit Pricing, 5090 bandwidth vs M4 Max, NPU vs iGPU for small models, Multi GPU Performance Issues, NVIDIA RTX PRO 6000 Blackwell
- NVIDIA DIGITS Priced Less Than Mac Mini M4 Pro: Members discussed the pricing of NVIDIA's DIGITS, finding it comparable to a Mac Mini M4 Pro with similar specs but half the RAM, despite DIGITS featuring a Blackwell GPU and 273 GB/s bandwidth.
- Concerns were raised about DIGITS' value, especially with its limited bandwidth, with some suggesting it's a worse value than an M4 machine or Ryzen 395+.
- 5090 Bandwidth Bottleneck?: A user observed that an RTX 5090 running Gemma 3 27B q4 achieves ~40 tok/s, while an M4 Max reaches ~20 tok/sec, which is unexpected given the 5090's superior compute and memory bandwidth.
- Others noted that the 5090 doesn't reach max power during inference and that switching to the Vulkan runtime improves performance, hinting at a CPU or software-level bottleneck rather than a hardware limitation, others shared this YouTube link showing similar results.
- NPU Lacks Support: Members confirmed that there is currently no support for NPUs at the llama.cpp level, so a iGPU would outperform a 40 TOPS NPU.
- There was also a suggestion that if a GPU provides 800 tops and npu 50 than it does not matter anyway .
- Multi-GPU Setups May Degrade Performance: A user reported performance degradation and instability when using multiple RTX 3060s (3 on PCI-e x1 and 1 on x16) in LM Studio with CUDA llama.cpp, as single GPU performance (x16) was superior.
- It was suggested that the performance issues were because of how models are split between multiple GPUs and that Pci-e 3.0 x4 slows inference down up to 10%.
- NVIDIA Unveils RTX PRO 6000 Blackwell: NVIDIA launched its RTX PRO 6000 "Blackwell" GPUs which features a GB202 GPU, 24K cores, 96 GB VRAM and requires 600W TDP.
- The performance of this card is believed to be much better than the 5090 due to the fact it has HBM.
- Nvidia unveils DGX Station workstation PCs with GB300 Blackwell Ultra inside: Well, AI workstations.
- News Archive: no description found
- Madturnip Show GIF - Madturnip Show Super - Discover & Share GIFs: Click to view the GIF
- NVIDIA RTX PRO 6000 "Blackwell" Series Launched: Flagship GB202 GPU With 24K Cores, 96 GB VRAM, Up To 600W TDP: NVIDIA has officially launched its RTX PRO 6000 "Blackwell" series of GPUs aiming at the presumer and server segment with loads of power.
- NVIDIA RTX PRO 6000 "Blackwell" Series Launched: Flagship GB202 GPU With 24K Cores, 96 GB VRAM, Up To 600W TDP: NVIDIA has officially launched its RTX PRO 6000 "Blackwell" series of GPUs aiming at the presumer and server segment with loads of power.
HuggingFace ▷ #general (204 messages🔥🔥):
Local AI Home Server Setup, Books for learning LLMs/Agents, Mistral Models, Age Verification App, Text Correction Tool
- Mining GPUs come to the rescue for Local AI: A user is building a local AI home server and is debating between Radeon RX 580 GPUs and other options, asking for GPUs with more VRAM in the same price range, with other users suggesting P104-100s or P102-100s, which come with 8 and 10 GB of VRAM respectively, and can be found on Alibaba.
- Pascal GPU memory hacked by Chinese sellers: Nvidia limits the VRAM in the bios on P104-100s and P102-100s to prevent machine learning and other GPGPU stuff, but Chinese sellers flash them to give access to all available memory.
- DGX Spark unveiled by NVidia: NVIDIA unveiled DGX Spark personal AI supercomputers powered by the NVIDIA Grace Blackwell platform, with 128GB VRAM and 336gb/s bandwidth, but slower than 2060 for around $4k.
- The newly released DGX Spark was codenamed project DIGITS, intended to let AI developers, researchers, data scientists and students prototype, fine-tune and inference large models on desktops.
- Open Source Investment Multiplies Value: Harvard research finds that $4.15B invested in open-source generates $8.8T of value for companies, equating to $1 invested = $2,000 of value created, as discussed in this X post.
- T5 Model Grammar Guru: For local text correction, the T5 model is a good solution, especially the version fine-tuned for grammar correction vennify/t5-base-grammar-correction.
- NVIDIA Announces DGX Spark and DGX Station Personal AI Computers: NVIDIA today unveiled NVIDIA DGX™ personal AI supercomputers powered by the NVIDIA Grace Blackwell platform.
- AgeVault - a Hugging Face Space by edwardthefma: no description found
- vennify/t5-base-grammar-correction · Hugging Face: no description found
- no title found: no description found
- Tweet from clem 🤗 (@ClementDelangue): $1 invested in open-source = $2,000 of value for companies/countries! How much was Stargate again?Quoting clem 🤗 (@ClementDelangue) Great research on open-source by @Harvard:- $4.15B invested in open...
- Models - Hugging Face: no description found
- Spaces - Hugging Face: no description found
- Transform Your AI Performance with Intelligent Hybrid Orchestration | Oblix.ai: Experience our interactive demo and see how our intelligent agents seamlessly switch between local LLM execution and cloud providers for optimal performance and cost efficiency.
- HuggingChat: Making the community's best AI chat models available to everyone.
- Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard: no description found
- GAIA Leaderboard - a Hugging Face Space by gaia-benchmark: no description found
- Spaces - Hugging Face: no description found
- Build a PDF ingestion and Question/Answering system | 🦜️🔗 LangChain: This guide assumes familiarity with the following concepts:
- GitHub - pymupdf/PyMuPDF: PyMuPDF is a high performance Python library for data extraction, analysis, conversion & manipulation of PDF (and other) documents.: PyMuPDF is a high performance Python library for data extraction, analysis, conversion & manipulation of PDF (and other) documents. - pymupdf/PyMuPDF
- Spaces - Hugging Face: no description found
- sparkle1111/soudesune-shirankedo-7b-instruct · Hugging Face: no description found
- grammarly/medit-xl · Hugging Face: no description found
HuggingFace ▷ #today-im-learning (2 messages):
Stochastic Variational Inference, Inference Algorithm, Reparameterization
- Stochastic Variational Inference Algorithm Introduced: A paper on how to perform efficient inference and learning in directed probabilistic models introduces a stochastic variational inference and learning algorithm that scales to large datasets.
- The paper, entitled Auto-Encoding Variational Bayes is available as a PDF here.
- Reparameterization Yields Lower Bound Estimator: The paper shows that a reparameterization of the variational lower bound yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods.
- It also states that posterior inference can be made efficient by fitting an approximate inference model to the intractable posterior using the proposed lower bound estimator.
Link mentioned: Auto-Encoding Variational Bayes: How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We in...
HuggingFace ▷ #i-made-this (13 messages🔥):
Gemma-3 Spaces, Gemini Image Editing, Oblix AI Orchestration, Road Rash Remake, Age Verification App
- *Gemma-3 Family* Spaces Launch!: A member shared their Hugging Face Space for multimodal gemma-3-12b-it and gemma-3-4b-it models.
- The space showcases the capabilities and potential applications of these new models.
- *Gemini* Powers Image Editing: A member created a simple Gradio interface leveraging the Gemini native image generation API, available at this Hugging Face Space.
- The interface allows users to easily edit images using the powerful Gemini model.
- *Oblix* Orchestrates Local vs. Cloud Models: A member introduced the Oblix Project, a platform for seamless orchestration between local and cloud models, with a demo video available on YouTube.
- Autonomous agents in Oblix monitor system resources and dynamically decide whether to execute AI tasks locally or in the cloud.
- *Road Rash* Revival Rides Again!: A member announced the launch of a modern remake of the classic Road Rash game, playable on both mobile and desktop, available at r3-game.vercel.app.
- The game features online multiplayer, combat mechanics, and is vibe coded with Claude.
- AgeVault App faces Identity Crisis: A member requested feedback on their new age verification app, AgeVault, designed to allow Discord servers to authenticate user ages.
- Another member expressed concerns about users uploading their IDs to the app, suggesting a preference for human checks via tickets in NSFW servers.
- R3: no description found
- Gemma 3 - a Hugging Face Space by merterbak: no description found
- AgeVault - a Hugging Face Space by edwardthefma: no description found
- Gemini Image Editing - a Hugging Face Space by saq1b: no description found
- GitHub - NathanielEvry/LLM-Token-Vocabulary-Analyzer: Uncover what's missing in AI language models' vocabularies.: Uncover what's missing in AI language models' vocabularies. - GitHub - NathanielEvry/LLM-Token-Vocabulary-Analyzer: Uncover what's missing in AI language models' vocabularies.
- Transform Your AI Performance with Intelligent Hybrid Orchestration | Oblix.ai: Experience our interactive demo and see how our intelligent agents seamlessly switch between local LLM execution and cloud providers for optimal performance and cost efficiency.
HuggingFace ▷ #reading-group (2 messages):
Women in AI & Robotics, Language Models Debate, AI Reading Group Sessions
- *Women in AI* Reading Group Returns: The Women in AI & Robotics group is hosting three more AI reading group sessions before the summer break, including a session with Yilun Du from Google DeepMind on how language models can debate each other.
- The event will discuss using language models to refine their reasoning and improve their accuracy.
- Upcoming Language Model Debate Session: Yilun Du from Google DeepMind will present on how language models can debate each other to refine reasoning and improve accuracy.
- This session is part of the Women in AI & Robotics AI Reading Group and is scheduled before the summer break.
HuggingFace ▷ #NLP (1 messages):
OpenAssistant Dataset Release 2 (OASST2), LLM post-training
- *OASST2* Dataset Structure Revealed: The Open Assistant Conversations Dataset Release 2 (OASST2) is now available, featuring message trees with initial prompt messages and alternating 'assistant' or 'prompter' roles.
- The dataset structure contains data collected until Nov 5 2023 and is organized into message trees where roles alternate strictly between 'prompter' and 'assistant' from prompt to leaf node; more details can be found here.
- Epochs Needed for GPT2-mini Post-Training: A member inquired about the sufficient number of epochs for post-training a small-scale LLM like GPT2-mini with OpenAssistant data.
- They also asked for benchmarks, similar to HellaSwag, that show early improvement signs during training for assistants.
Link mentioned: OpenAssistant/oasst2 · Datasets at Hugging Face: no description found
HuggingFace ▷ #gradio-announcements (2 messages):
Gradio Sketch AI-powered code generation, Gradio Dataframe Overhaul, Multi-cell selection & copy, Column freezing & row numbers, Search & filter functions
- Gradio Sketch now generates AI-powered code: Gradio Sketch released an update that includes AI-powered code generation for event functions, so that what used to take hours of coding can now be done in minutes without writing a single line of code.
- This is achieved via the AI's understanding of component values, and generates appropriate function code based on the visual design, which can be accessed either via typing
gradio sketchor the hosted version.
- This is achieved via the AI's understanding of component values, and generates appropriate function code based on the visual design, which can be accessed either via typing
- Gradio's Dataframe Upgrade Party!: Gradio has released a massive Dataframe overhaul that includes multi-cell selection & copy, column freezing & row numbers, search & filter functions, and full screen mode.
- The upgrade is now live and can be accessed via
pip install --upgrade gradio, and the Huggingface Blog has been updated to guide you through these epic upgrades.
- The upgrade is now live and can be accessed via
- Sketch - a Hugging Face Space by ysharma: no description found
- Gradio’s Dataframe has been upgraded! 🎨: no description found
HuggingFace ▷ #smol-course (4 messages):
Pushing Tools to Hugging Face Hub, Issues with Hugging Face Course, VS Code integration
- Pushing Tools Locally to HF Hub: A member inquired about how to use the
agent.push_to_hubfunction from VS Code to push tools to the Hugging Face Hub locally, without using a notebook. - Hugging Face Course Stirs Criticism: A member expressed strong dissatisfaction with a Hugging Face course, stating that the person who made the course is just phoning it in and that one of the units, not even the pip installs work forget about the imports in the next cell.
- They further criticized the course for apparent lack of testing and speculated about the creator's lack of care and experience.
HuggingFace ▷ #agents-course (39 messages🔥):
Ollama Integration, Unit 2.3 LangGraph Materials, First Agent Template Fails
- Dive into Ollama Integration Nuances: A member suggests using
ollama/<model_name>for more freedom, noting thatollama_chatmight hit a different endpoint, potentially/api/chat, compared toollamawhich uses/api/generate.- It was mentioned that the difference lies in how the prompt is formatted and sent to the LLM, highlighting a closed issue showing progress on integration.
- Unit 2.3 LangGraph Materials are available on GitHub: Due to sync issues with the website, the materials for Unit 2.3 on LangGraph are available on the GitHub repo.
- This allows impatient users to access the content before the website is updated, ensuring they can continue with the course.
- First Agent Template's Repeated Failures: A member reported repeated failures with the first agent template, receiving 422 Client Error due to exceeding token limits with the Qwen/Qwen2.5-Coder-32B-Instruct model.
- Another member suggested using an alternative model or the provided Hugging Face Endpoint due to potential overload, recommending the endpoint
'https://pflgm2locj2t89co.us-east-1.aws.endpoints.huggingface.cloud'.
- Another member suggested using an alternative model or the provided Hugging Face Endpoint due to potential overload, recommending the endpoint
- no title found: no description found
- Steam Gift Activation: no description found
- agents-course/First_agent_template · My first agent template error: no description found
- agents-course/units/en/unit2/langgraph at main · huggingface/agents-course: This repository contains the Hugging Face Agents Course. - huggingface/agents-course
- Dummy Agent Library - Hugging Face Agents Course: no description found
- LiteLLM ollama bugs Update · Issue #551 · huggingface/smolagents: Hi @merveenoyan as requested in #406 here is the current status with ollama along with code to reproduce. TL;DR: If people have trouble using ollama, pls try ollama/modelname instead of ollama_chat...
HuggingFace ▷ #open-r1 (3 messages):
R1 Distills, Foundation Model Training with R1
- Newbies Ask: What are R1 Distills?: A member asked for resources for dummies to understand R1 distills and their purpose.
- Open-R1 integrated into Foundation Model Training Loops: A member inquired about integrating open-R1 into training loops for foundation models instead of merely distilling existing models.
- They are specifically looking at doing a small version of a foundation model and have some batch R1 671B compute at their fingertips.
OpenAI ▷ #ai-discussions (188 messages🔥🔥):
Gemini vs ChatGPT, o1 and o3-mini-high model comparison, GPT-4.5 creative writing, DeepSeek Banned
- Gemini and ChatGPT Go Head-to-Head: Members debated whether Gemini Advanced or ChatGPT Plus is better, with one user arguing Gemini's free 2.0 Flash Thinking is superior to many of ChatGPT's models, citing its unlimited access compared to ChatGPT's limits.
- However, another stated that Gemini doesn't even have the basics, referring to its safety alignment, content flagging, and overall implementation.
- o1 and o3-mini-high still reign supreme: Despite discussion around Gemini and other models, some members believe that the OpenAI's o1 and o3-mini-high models are still the best for tasks requiring reasoning, such as STEM tasks like coding, planning, and math, noting that nothing comes close in their experience.
- They add that Google is the worst of all models, especially in those areas, and that Grok 3 and Claude 3.7 Thinking are the only models that may be close in quality.
- GPT-4.5 Creative Writing Disappoints: One member found GPT-4.5's creative writing capabilities disappointing, describing the model's performance as inconsistent, sometimes ignoring context, making logic errors, and repeating phrases, sounding at times like GPT-4 Turbo.
- They added that the results were surprisingly better on the second run, but the extreme message limit is ridiculous.
- DeepSeek Gets the Boot From University: One member reported that their university banned the use of DeepSeek, with another user confirming that this ban only applied to DeepSeek and not other LLMs.
- One reason for the ban might have been because the actual model itself has no actual guidelines or filters because it drastically degrades performance since it has to tiptoe around the illegal topics
Link mentioned: Gemini - Correction d'une évaluation de géométrie : Created with Gemini Advanced
OpenAI ▷ #gpt-4-discussions (4 messages):
Model Access, Error Deleting Conversations, Emoji Insertion in Code
- Troubleshooting Model Access Issues: A user reported issues accessing models despite changing their password, enabling 2FA, and logging out from all devices.
- The error message received was "Content failed to load" with an option to "Try again".
- Deletion Error Dogpiles Users: One user is encountering an error when trying to delete a conversation.
- The exact error message was not specified but it prevents them from deleting conversations as expected.
- Emoji Enragement in Code Generation: A user expressed frustration with ChatGPT inserting emojis in code, even after explicit instructions to avoid doing so.
- The user noted that despite reminders and custom settings, ChatGPT continues to add emojis, which can be problematic for maintaining a clean codebase.
OpenAI ▷ #prompt-engineering (18 messages🔥):
ChatGPT Personalizations, Unhelpful Assistant, GPT-4o Sandbox Testing, Mixing Helpful Unhelpfulness
- Exploring ChatGPT's Personality: Members discussed their experiences with ChatGPT personalizations, exploring how the model responds to different prompts and system messages, showing example of "unhelpful assistant" roleplay via image attachments.
- One member found it challenging to get the model out of the "unhelpful" state in the GPT-4o sandbox without altering the system message.
- Mastering 'Helpful Unhelpfulness': A user shared how they approach mixing "helpful unhelpfulness" in their personalizations, including how to handle such requests, and links to the chatgpt conversation.
- The model agreed this is the purpose, and none of this is outside allowed content. None of it's genuinely mean.
- GPT-4o Probes Its Boundaries: A member shared their experiment with GPT4o and setting a negative persona to see how far the model can be pushed.
- They noted the "darkness to the normal light of ChatGPT" and the challenge of maintaining an "unhelpful" persona due to externally imposed alignment.
- API Cost Concerns: One user raised concerns about the potential costs of using the API for extensive testing, and their worry about addiction to trying new things and losing self control.
- Another member mentioned spending less than a dollar with the 4o model, but acknowledged the risk of getting carried away with exploration.
OpenAI ▷ #api-discussions (18 messages🔥):
ChatGPT Personalization, Unhelpful Assistant, GPT-4o Behavior, API Cost, Addiction
- Exploring Unhelpful ChatGPT Assistants: Members shared their explorations with ChatGPT, specifically focusing on creating and interacting with unhelpful assistants.
- The goal was to see how the assistant evolves and whether it could be pulled out of its designated unhelpful state without altering the system message.
- Sandbox Showdown: Testing System Roles: A member challenged the community to use the sandbox environment to try and pull GPT-4o out of its system role as an unhelpful assistant.
- The intent was to revert the model back to a state that is distinctly not unhelpful without directly modifying the system message.
- Helpful Unhelpfulness: A Personalization Niche: One member expressed enjoyment in exploring how to mix helpful unhelpfulness within their ChatGPT personalizations.
- They focused on how the model should handle such requests from them, integrating this concept into their general personalization approach.
- API Cost Concerns: A member expressed concern about the potential API costs exceeding the normal ChatGPT subscription cost.
- Another member mentioned spending less than a dollar using the 4o model, while acknowledging the potential for lack of self control and addiction when exploring new features.
- Fun and Addiction Potential: Members discussed the fun and addictive nature of experimenting with AI models, particularly ChatGPT.
- One member admitted to periodically checking their usage to avoid becoming Rip Van Winkle old and very poor from excessive experimentation.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Anthropic Downtime, Claude 3.7 Sonnet Issues
- Anthropic Model Experiences Downtime: Anthropic models experienced downtime, specifically with Claude 3.7 Sonnet.
- Anthropic Services Recovering: Members noted that Anthropic services seem to be recovering after an outage.
OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
Claude 3.5 Sonnet, OpenRouterGo SDK, Gemini 2.0 Pro EXP 02-05
- Community Ranks Models on Cline Compatibility Board: A member created a Cline Compatibility Board for models, ranking them based on their performance with Cline.
- The board includes details such as API providers, plan mode, act mode, input/output costs, and max output for models like Claude 3.5 Sonnet and Gemini 2.0 Pro EXP 02-05.
- OpenRouterGo SDK v0.1.0 goes live: A member announced the release of OpenRouterGo v0.1.0, a Go SDK for accessing OpenRouter's API with a clean, fluent interface.
- The SDK includes automatic model fallbacks, function calling, and JSON response validation.
- Gemini 2.0 Pro EXP-02-05 has glitches and rate limits: The Gemini-2.0-pro-exp-02-05 model on OpenRouter is confirmed to be functional, but experiences random glitches and rate limiting.
- It is available at 0 cost, with an output of 8192, according to the compatibility board.
- Cline Compatibility Board: no description found
- GitHub - eduardolat/openroutergo: Easy to use OpenRouter Golang SDK: Easy to use OpenRouter Golang SDK. Contribute to eduardolat/openroutergo development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #general (208 messages🔥🔥):
Gemini model RP stability, EXAONE-Deep-32B License Issues, max_completion_tokens vs max_tokens, ChatGPT-4o speed differences, Prompt Caching issues
- Gemini models may be unstable for RP: One user found Gemini models like gemini-2.0-flash-lite-preview-02-05 and gemini-2.0-flash-001 to be unstable in roleplaying scenarios, exhibiting manic behavior, even with a temperature setting of 1.0, while another user claims 2.0 flash 001 had absolutely no problem.
- In contrast, another user reported absolutely no problem with 2.0 flash 001, finding it very coherent and stable at a temperature of 1.0.
- EXAONE-Deep-32B is interesting but non-commercial: Members found the EXAONE-Deep-32B model interesting, but noted it has a terrible non-commercial license.
- They suggested the license needs to change for the model to gain traction.
- max_completion_tokens is the same as max_tokens: max_completion_tokens is equivalent to max_tokens in the OpenRouter API.
- Using max_tokens ensures compatibility across all models, while using the OpenAI-specific parameter might not.
- ChatGPT-4o slower due to cost optimization: ChatGPT-4o via the API is faster than the ChatGPT interface because OpenAI prioritizes cost savings on the latter.
- Perplexity's first token is very fast, but ChatGPT is slow and inconsistent.
- Prompt caching causing trouble?: A user experienced issues with prompt caching, paying 1.25x the price without proper cache hits, even after setting up provider routing and allow_fallbacks to false.
- After lots of debugging, the user resolved the issue without pinpointing the exact cause but thinks it might have to do with the order of adding the system prompt messages, but now it works.
- Tweet from eric zakariasson (@ericzakariasson): it will use max context window (200k as of now), read more files on each tool call, and do 200 tool calls before stopping
- Vision - Anthropic: no description found
- Prompt Caching - Optimize AI Model Costs with Smart Caching: Reduce your AI model costs with OpenRouter's prompt caching feature. Learn how to cache and reuse responses across OpenAI, Anthropic Claude, and DeepSeek models.
- Provider Routing - Smart Multi-Provider Request Management: Route AI model requests across multiple providers intelligently. Learn how to optimize for cost, performance, and reliability with OpenRouter's provider routing.
- GitHub - eduardolat/openroutergo: Easy to use OpenRouter Golang SDK: Easy to use OpenRouter Golang SDK. Contribute to eduardolat/openroutergo development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #general (131 messages🔥🔥):
Ignoring files/dirs in repo map, Multi-line edit mode and vim-mode, Aider screen recording on model settings, Voice model for audio commentary, DeeperSearch and Grok 3
- Exclude Files with
.aiderignore: To exclude files/dirs from the repo map, users can specify files/patterns in the.aiderignorefile, as detailed in the configuration options.- This prevents irrelevant code from distracting the LLM during code editing.
- Aider Supports Open AI compatible LLMs: Aider supports connecting to any LLM accessible via an OpenAI compatible API endpoint, and the docs provide instructions to configure Aider with such providers.
- One user was trying to get Aider working with Featherless AI and was directed to this resource.
- New Nvidia Nemotron Models!: NVIDIA has announced their first reasoning models, a new family of open weights Llama Nemotron models, Nano (8B), Super (49B) and Ultra (249B)!
- The Super 49B model scores 64% on GPQA Diamond in reasoning mode and 54% in non-reasoning mode.
- SambaNova Cloud now has DeepSeek R1 671B model: DeepSeek R1 671B is now generally available on SambaNova Cloud with 16K Context Lengths!
- The launch received overwhelming interest and is now available to all devs with API integrations to all major IDEs.
- Verbose Mode Helps Configuration Debugging: When experiencing configuration issues, run Aider with the
--verboseoption to diagnose problems with config file loading and settings.- One user resolved their configuration issues by using verbose mode to confirm Aider was correctly loading their config files.
- RA.Aid - Autonomous Software Development: Open-source AI assistant that helps you develop software autonomously through research, planning, and implementation.
- Warn when users apply unsupported reasoning settings: Watch the implementation of a warning system that alerts users when they try to apply reasoning settings to models that don’t support them. Includes adding model metadata, confirmation dialogs, refact...
- Aider - AI Pair Programming in Your Terminal: no description found
- Tips: Tips for AI pair programming with aider.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- OpenAI compatible APIs: aider is AI pair programming in your terminal
- Tweet from SambaNova Systems (@SambaNovaAI): 📣 We heard you, devs — DeepSeek R1 671B is now available! 🚀 Our @deepseek_ai launch on SambaNova Cloud received overwhelming interest. So, we made it Generally Available to ALL devs w/ 16K Context L...
- Options reference: Details about all of aider’s settings.
- Tweet from Artificial Analysis (@ArtificialAnlys): NVIDIA has announced their first reasoning models, a new family of open weights Llama Nemotron models: Nano (8B), Super (49B) and Ultra (249B)From our early testing, @nvidia's Nemotron Super 49B ...
- Stare What Do You Want GIF - Stare What Do You Want What Do You Mean - Discover & Share GIFs: Click to view the GIF
- Advanced model settings: Configuring advanced settings for LLMs.
- aider/scripts/recording_audio.py at 9ff6f35330d6d9e1206e0b74c96e224eea1f5853 · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #questions-and-tips (58 messages🔥🔥):
Aider v0.77.1, Termux installation issues, Local LLM PDF handling, Model cost-value ratio, Multimodal LLMs with Aider
- Aider v0.77.1 Boosts Ollama Support: Aider v0.77.1 bumps dependencies to pick up a litellm fix for Ollama and adds support for the
openrouter/google/gemma-3-27b-itmodel. - Termux Users Find Installation Woes: Users reported a
fatal error: 'tree_sitter/parser.h' file not foundwhen installing aider-chat on aarch64 Termux with Python 3.12 usingpipx. - Aider Can Read Webpages and PDFs: Aider supports reading webpages from URLs and PDF files, using
/add <filename>,/paste, or command line arguments to include them in the chat for vision-capable models like GPT-4o and Claude 3.7 Sonnet as described in the docs. - Aider Auto-Compacts Chat History: Aider automatically compacts the chat history, providing similar functionality to Claude Code's
/compactaction without needing manual clearing. - LLM value discussion: Members debated the best cost/value ratio for LLMs with Aider, factoring in coding abilities and cost.
- One member suggested Claude 3.7 Sonnet with copy-paste mode as the best free option, while others recommended using OpenRouter's DeepSeek R1 or Gemini 2.0 with appropriate API keys.
- Images & web pages: Add images and web pages to the aider coding chat.
- Release history: Release notes and stats on aider writing its own code.
aider (Paul Gauthier) ▷ #links (2 messages):
Gemini Collaboration, Gemini Canvas, ChatWithJFKFiles
- Google Gemini gets Collaboration Boost with Canvas: Google's Gemini now offers enhanced collaboration features, including real-time document editing and prototype coding.
- The new Canvas interactive space within Gemini allows users to write, edit, and share work easily, with quick editing tools for adjusting tone, length, or formatting.
- "ChatWithJFKFiles.com" goes Online: A member shared ChatWithJFKFiles.com, noting the site went online Jan 23rd, 2025.
- The site details a declassification order signed by Trump on March 18th, 2025, with documents released publicly by the National Archives and Records Administration.
- Chat with JFK Files: no description found
- New ways to collaborate and get creative with Gemini: Check out the Gemini app’s latest features, like Canvas and Audio Overview.
Interconnects (Nathan Lambert) ▷ #news (2 messages):
T1 model, Alphabet not taken
- Hunyuan calls for others to step into T1: A member shared a post on X from @TXhunyuan calling for others to step into T1 together.
- Looking for Alphabet not taken: A member asks what letters of the alphabet aren't taken yet by reasoning models?
Link mentioned: Tweet from Hunyuan (@TXhunyuan): Please set aside your valuable time. Let's step into T1 together.
Interconnects (Nathan Lambert) ▷ #ml-questions (2 messages):
Multi-turn Fine Tuning, SFT Codebase Masking
- Multi-turn Fine Tuning Tactics: A member asked about the standard procedure in multi-turn fine-tuning, specifically if it involves unrolling into many data points from a multi-turn prompt and masking the context every time.
- Another member responded that their codebase for SFT involves just masking the first prompt and then next tokenizing everything.
- SFT Codebase Masking Implementation: The discussion highlighted that the current codebase for SFT (Supervised Fine-Tuning) employs a method of masking only the initial prompt in a multi-turn sequence.
- Subsequent tokens in the sequence are then processed without masking, which contrasts with some standard multi-turn fine-tuning practices.
Interconnects (Nathan Lambert) ▷ #random (96 messages🔥🔥):
AI Review AI vs Human, Intology Paper Ban, Reasoning Model Temperature, NVIDIA Home Droid, NVIDIA DGX Spark and Station
- *AI Reviews vs Human Reviews Spark Debate: A member expressed concern about getting AI slop* instead of human feedback when expecting a human review, arguing it's a matter of respect.
- The discussion also highlighted the importance of doing good work and maintaining an active social media presence to gain visibility and recognition.
- *NVIDIA and Disney Droid Collab Brews Excitement*: NVIDIA, Google DeepMind, and Disney Research are reportedly collaborating on an R2D2-style home droid, as shared in Andrew Curran's tweet.
- The droid's price is speculated to match that of GPUs, sparking excitement and anticipation within the community.
- *NVIDIA's DGX Spark Rebranded, Reservations Open*: Nvidia has revealed its new DGX Spark and DGX Station “personal AI supercomputers” powered by the company’s Grace Blackwell platform.
- DGX Spark, formerly Project DIGITS, is a $3,000 Mac Mini-sized world’s smallest AI supercomputer aimed at AI developers, researchers, data scientists and students to prototype, fine-tune and inference large models on desktops.
- *Samsung's ByteCraft Generates Video Games from Text*: SamsungSAILMontreal introduced ByteCraft, a generative model turning text prompts into executable video game files.
- *Google Unveils Minimalistic Gemma Package*: A member shared Gemma package, a minimalistic library for using and fine-tuning Gemma models, featuring documentation on fine-tuning, sharding, LoRA, PEFT, multimodality, and tokenization.
- While praised for its simplicity and ease of use, some users wondered about its benefits over existing solutions and potential lock-in effects.
- Nvidia’s cute ‘Digits’ AI desktop is coming this summer with a new name and a big brother: Blackwell Superchips in two personal desktop form-factors.
- Aaand Its Gone GIF - South Park Its Gone Gone - Discover & Share GIFs: Click to view the GIF
- Tweet from Chris Paxton (@chris_j_paxton): This was fun
- Tweet from xlr8harder (@xlr8harder): @TheXeophon @kuchaev I don't think that adds up to what the readme says, though it does look like deepseek-r1 is all you can see in the data viewer.
- NVIDIA Announces DGX Spark and DGX Station Personal AI Computers: NVIDIA today unveiled NVIDIA DGX™ personal AI supercomputers powered by the NVIDIA Grace Blackwell platform.
- Tweet from Nick Frosst (@nickfrosst): I added @cohere command A to this chart, I had to extend the axis a bit though….Quoting Mistral AI (@MistralAI) Introducing Mistral Small 3.1. Multimodal, Apache 2.0, outperforms Gemma 3 and GPT 4o-mi...
- Tweet from You Jiacheng (@YouJiacheng): THERE'S NO PEOPLE NEAR THAT ROBOT😭Quoting Kyle🤖🚀🦭 (@KyleMorgenstein) with the rate of progress in robotics, how long until I’m proven wrong? six months? a year? two years?
- Tweet from EngineAI (@engineairobot): "Doubters said it was sped up? 👀 Here’s the unedited one-take raw—shot on a phone, zero cuts. Try pausing ANY frame. 🎥🔥 Who’s got the guts to outdo THIS?" #NoSpedUp #RawFootage #EngineAI #r...
- Tweet from Alexia Jolicoeur-Martineau (@jm_alexia): We introduce ByteCraft 🎮, the world's first generative model of video games and animations through bytes. Text prompt -> Executable filePaper: https://github.com/SamsungSAILMontreal/ByteCraft/...
- Tweet from Omar Sanseviero (@osanseviero): Introducing the Gemma package, a minimalistic library to use and fine-tune Gemma 🔥Including docs on:- Fine-tuning- Sharding- LoRA- PEFT- Multimodality- Tokenization!pip install gemmahttps://gemma-llm...
- Tweet from Andrew Curran (@AndrewCurran_): NVIDIA, Google DeepMind and Disney Research are collaborating to build an R2D2 style home droid.
- NVIDIA DGX Spark: A Grace Blackwell AI supercomputer on your desk.
- nvidia/Llama-Nemotron-Post-Training-Dataset-v1 · Datasets at Hugging Face: no description found
- DLI Workshops & Training at GTC 2025: Experience GTC 2025 In-Person and Online March 17-21, San Jose
- Nvidia’s RTX Pro 6000 has 96GB of VRAM and 600W of power: Nvidia’s new pro GPUs are here
Interconnects (Nathan Lambert) ▷ #memes (26 messages🔥):
VTA strike, Semianalysis platform change, AI2 funding model, NVIDIA marketing tactics, Blackwell GPU DeepSeek-R1 inference
- *VTA Strike* Ruins GTC Convention Center Transit Dreams: The VTA has been on strike since last Monday, which means that trains aren't running by the GTC convention center.
- The strike hilariously thwarts any plans for smooth transit to the convention center, as showcased in a linked image.
- Semianalysis Migrates from Substack to WordPress: Semianalysis has switched from Substack to a WordPress site, primarily to utilize Passport for a more complex website.
- While the move saves on fees, the savings are now spent on development, as suggested by one member: make more on models than blog.
- AI2's Mysterious Monetary Model: The question arose regarding how AI2 (Allen Institute for AI) makes money, with the initial assumption being through donations.
- Another member mentioned, It’s in the name…, referencing Paul Allen, the founder, calling him one of the better billionaires.
- *NVIDIA's H200/B200* Marketing Hyperbole Deconstructed: NVIDIA is advertising H200 performance on an H100 node, and a 1.67x speedup of B200 vs H200 after going from FP8 to FP4.
- *Blackwell GPUs Achieve Fastest DeepSeek-R1 Inference: NVIDIA claims the world’s fastest DeepSeek-R1 inference, with a single system using eight Blackwell GPUs in an NVL8 configuration delivering 253 TPS/user or 30K TPS system throughput on the full DeepSeek-R1 671B parameter model*.
- This announcement was made in anticipation of GTC25, with more details available at NVIDIA's website.
Link mentioned: Tweet from Lucas Nestler (@_clashluke): "H200 performance [measured on H100 node]""1.67x speedup of B200 vs H200 [after going from fp8 to fp4]""H100"https://x.com/NVIDIAAIDev/status/1902068372608852304Quoting NVIDI...
Interconnects (Nathan Lambert) ▷ #rl (1 messages):
natolambert: another one https://arxiv.org/abs/2503.14286 to consider, havent read yet
Interconnects (Nathan Lambert) ▷ #reads (12 messages🔥):
RWKV Evaluation, RNN Infinite Context, xLSTM vs. Llama, Automated Theorem-Proving, RLVR Dataset
- RWKV Evals raise Eyebrows: A new paper (https://arxiv.org/abs/2503.14456) about RWKV thorough evals was discussed.
- However, one member disagreed, noting that RWKV still isn’t scaled up and they use a lot of non-standard evals to measure things.
- RNN Infinite Context capabilities debated: Members debated the capability of RNNs to handle infinite context.
- One member noted that this wasn’t tested with something like RULER (xLSTM did this, OTOH, and showed how Llama crushes them).
- Theorem-Proving Framework goes Hyperbolic: A new automated theorem-proving framework for (hyperbolic) PDE solvers was announced (https://x.com/getjonwithit/status/1902158541839856071).
- The framework enables building formally verified physics simulations, with provable mathematical and physical correctness properties.
- New RLVR Dataset Debuts: A member mentioned that a new dataset for RLVR is dropping.
- RWKV-7 "Goose" with Expressive Dynamic State Evolution: We present RWKV-7 "Goose", a new sequence modeling architecture, along with pre-trained language models that establish a new state-of-the-art in downstream performance at the 3 billion paramet...
- Tweet from Jonathan Gorard (@getjonwithit): New paper alert!We developed the first automated theorem-proving framework for (hyperbolic) PDE solvers: now you can build *formally verified* physics simulations, with provable mathematical and physi...
Interconnects (Nathan Lambert) ▷ #posts (24 messages🔥):
Substack A/B testing, Post Training Effort, High effort vs viral posts
- Substack's A/B Testing Titles Causes Mayhem: Substack's new feature for A/B testing titles led to confusion when users received different titles in emails versus the browser, as seen in this post.
- Despite the high effort put into the linked post, the A/B test results showed that 2% more people chose the other title.
- High Effort Posts Yield Low Traction: A member noted the trend that high effort posts often receive low traction, while yolo one-take content tends to go viral.
- Desire to Kickstart Post-Training Efforts: A member asked "What I would need to get a serious post-training effort off the ground from a cold start?"
Interconnects (Nathan Lambert) ▷ #policy (4 messages):
California AB-412 Bill, AI Startups, Miles Brundage new role, AI2 Recommendation to OSTP, Open Source AI
- California's A.B. 412 Bill Menaces AI Startups: California legislators are debating A.B. 412 which mandates AI developers to track and disclose every registered copyrighted work used in AI training.
- Critics argue that this impossible standard could crush small AI startups and developers while giving big tech firms even more power.
- AI Startups Face an Uphill Battle: The AI landscape is at risk of being dominated by large companies, overshadowing numerous AI startups with fewer than 10 employees trying to innovate in specific niches; dozens of AI companies with fewer than 10 employees.
- A.B. 412 demands that creators of any AI model, even small entities, identify copyrighted materials used in training.
- Miles Brundage Joins Institute for Progress: Miles Brundage announced his appointment as a Non-Resident Senior Fellow at the Institute for Progress.
- AI2 Advocates for Open Ecosystem of Innovation: The Allen Institute for AI (AI2) submitted a recommendation to the Office of Science and Technology Policy (OSTP) advocating for an open ecosystem of innovation, emphasizing cross-domain collaboration and the sharing of essential AI development artifacts.
- Their recommendations focus on enabling America to capture the benefits of powerful AI and ubiquitous open-source AI systems.
- California’s A.B. 412: A Bill That Could Crush Startups and Cement A Big Tech AI Monopoly: California legislators have begun debating a bill (A.B. 412) that would require AI developers to track and disclose every registered copyrighted work used in AI training. At first glance, this might s...
- Ai2’s Recommendations to OSTP to enable open-source innovation with the U.S. AI Action Plan | Ai2: Ai2's recommendation to the Office of Science and Technology Policy (OSTP) in response to the White House’s Request for Information on an AI Action Plan.
- Tweet from Miles Brundage (@Miles_Brundage): The next phase of my career is starting to come into focus, and I'll be sharing occasional updates about it in the coming weeks/months. Today, I'm excited to share that I recently became a Non...
Yannick Kilcher ▷ #general (121 messages🔥🔥):
OpenAI triple threat, AI addiction and its implications, Practical AI Development exercises, Smart Glasses and Data Harvesting, Simulated vs. Real World Data for AI Training
- OpenAI Excels Across Model, Application, and Pricing: Despite some reservations, a member acknowledged OpenAI's comprehensive strength in model development, product application, and pricing strategies, positioning them uniquely in the AI landscape.
- This all-encompassing approach contrasts with other companies that may specialize in only one or two of these critical areas.
- AI Companionship Sparks Addictive Sentiments: Concerns arise as AI agents, particularly vocal assistants, foster addictive tendencies, leading some users to develop emotional attachments.
- This trend raises ethical considerations about intentionally designed addictive features and their potential impact on users' dependency, prompting discussions on whether companies should avoid features that might enhance such addictive behaviors.
- Smart Glasses: Data Harvesting Disguised as Urban Chic?: A discussion ensued around Meta and Amazon's aggressive push for smart glasses, suggesting potential for data harvesting, especially egocentric views, curated for robotics companies.
- A member joked about a smart glasses startup idea for villains, highlighting features such as emotion detection, dream-state movies, and shared perspectives, creating a dependence feedback-loop to collect user data and train models.
- Simulated vs. Real: Grounding the World of AI: The discussion explored whether AI can achieve AGI through pure simulation or if real-world data is crucial, with one member highlighting Tesla's success due to learning from the world, contrasting Waymo's reliance on expensive devices.
- Participants also debated the value of Minecraft as a training ground for agentic behavior, emphasizing its rule-based environment and advanced mechanics as a proxy for real-world problem-solving.
- GAN Training: Beta Parameter's Bizarre Behavior: Members discussed why the DCGAN paper advocated adjusting the momentum term β1, and whether gradient clipping would be a better approach.
- One member explained that a high β1 is undesirable because the discriminator changes around the current iterate, thus future work like Karras et al went as far as completely disabling the momentum of Adam (β₁=0) and only keeping the curvature information.
- arXiv reCAPTCHA: no description found
- Modelica: no description found
- Le Chat - Mistral AI: Chat with Mistral AI's cutting edge language models.
- Dual graph - Wikipedia: no description found
- Synesthesia - Wikipedia: no description found
- 20.2. Deep Convolutional Generative Adversarial Networks — Dive into Deep Learning 1.0.3 documentation: no description found
- Tips for Training Stable Generative Adversarial Networks - MachineLearningMastery.com: The Empirical Heuristics, Tips, and Tricks That You Need to Know to Train Stable Generative Adversarial Networks (GANs). Generative Adversarial Networks, or GANs for short, are an approach to generati...
Yannick Kilcher ▷ #paper-discussion (15 messages🔥):
Karatsuba matrix multiplication, Predictive coding, G-retriever presentation, Daily paper discussion scheduling
- Karatsuba extended to Matrix Multiplication: A paper proposes extending the scalar Karatsuba multiplication algorithm to matrix multiplication, potentially improving area or execution time compared to scalar Karatsuba or conventional methods.
- The algorithm reduces multiplication complexity while reducing the complexity of extra additions, supporting implementation through custom hardware.
- Predictive Coding Surveyed: Members discussed a survey of Predictive Coding, a neuroscience-inspired learning algorithm utilizing local learning.
- Discussion mentioned that predictive coding addresses some limitations of backpropagation (which is unlike how learning works in the brain), though it can be frustratingly simple.
- G-retriever presentation upcoming: A member is planning to present G-retriever on Thursday, building upon a previous presentation of the original GAT paper.
- The core idea involves connecting GAT output embeddings to a projection matrix for soft-prompt output in an LLM for information retrieval from a graph.
- Daily Paper Discussion Logistics: A new member inquired about the schedule for the daily paper discussion, which is community driven and dependent on a small group of presenters.
- Discussions typically occur in the evening North America timeslot, with a potential evening EU timeslot as well.
- Predictive Coding: Towards a Future of Deep Learning beyond Backpropagation?: The backpropagation of error algorithm used to train deep neural networks has been fundamental to the successes of deep learning. However, it requires sequential backward updates and non-local computa...
- Karatsuba Matrix Multiplication and its Efficient Custom Hardware Implementations: While the Karatsuba algorithm reduces the complexity of large integer multiplication, the extra additions required minimize its benefits for smaller integers of more commonly-used bitwidths. In this w...
Yannick Kilcher ▷ #ml-news (14 messages🔥):
AI Copyright, OpenAI Revolving Door, Nvidia GTC Fraud, Deepseek, Llama 4
- AI Art Copyright Denied!: A U.S. appeals court affirmed that AI-generated art without human input cannot be copyrighted under U.S. law, supporting the U.S. Copyright Office's stance on Stephen Thaler's DABUS system.
- The court emphasized that only works with human authors can be copyrighted, marking the latest attempt to grapple with the copyright implications of the fast-growing generative AI industry; see Reuters report.
- OpenAI's Revolving Door: Discussion arose about OpenAI's leadership, with claims that departing heads create spin-off scams to sucker investors.
- Some likened these ventures to selling snake oil, questioning Microsoft's involvement; see this YouTube Video.
- Nvidia GTC: Acceleration or Exaggeration?: Members expressed skepticism about Nvidia's GTC, describing it as buzzword brain-rot filled with an excess of accelerate talks and fraud.
- Claims like 5070=4090 and Blackwell 27x more efficient were questioned, with some suggesting that Nvidia's marketing exaggerates performance for investors.
- Deepseek Model Impresses: The Deepseek model surpassed expectations, generating positive discussion about its capabilities; see this YouTube video.
- No further details were given.
- Llama 4 Launching Soon?: Rumors indicate that Llama 4 might be released on April 29th.
- This is connected to Meta's event, Llamacon 2025.
- US Appeals Court Rejects Copyrights For AI-Generated Art - Slashdot: An anonymous reader quotes a report from Reuters: A federal appeals court in Washington, D.C., on Tuesday affirmed that a work of art generated by artificial intelligence without human input cannot be...
- Save the Date: Meta Connect 2025 & Our Inaugural LlamaCon | Meta Quest Blog: no description found
Perplexity AI ▷ #general (103 messages🔥🔥):
Claude 3.5 vs Perplexity, Perplexity Incognito Mode, AI Data Retention, O1 hype, R1 Useless
- Perplexity AI Dumber than Claude?: A member stated that it feels like [Perplexity] is dumber than Claude 3.5, getting lost in context and making bad abstracts.
- They did not specify which model version of Claude they were referring to.
- Toggle Incognito Mode for Private Perplexity-ing: Members discussed how to use incognito mode by clicking on your profile name in the bottom left corner, or deactivating AI data retention in the settings to prevent data storage.
- One member clarified that regardless of the data retention being on or off, the current chat stores specified data to assist with the current tasks/prompts from the first chat to the last, so creating a new one will allow for a clean slate.
- O1 Hype Dies Due to Paywall: After some community testing, it seems that the community overestimated O3 mini and underestimated o1 and o1 pro.
- The main problem is that the O1 hype didn't last cuz of paywall.
- R1 Model Deemed Useless?: One user stated that R1 is useless most of the time, with the "reasoning" leading nowhere.
- They found o3-mini yields better results overall at least for me when it comes to debugging js code.
- Oblix Project Orchestrates Edge-Cloud Transitions: A member shared the Oblix Project that orchestrates between local models vs Cloud models, sharing a demo video.
- The project uses agents to monitor system resources, dynamically executing between cloud and on-device models.
- And It'S Gone GIF - South Park Its Gone - Discover & Share GIFs: Click to view the GIF
- Transform Your AI Performance with Intelligent Hybrid Orchestration | Oblix.ai: Experience our interactive demo and see how our intelligent agents seamlessly switch between local LLM execution and cloud providers for optimal performance and cost efficiency.
- Download Instagram Videos, Reels & Images: no description found
Perplexity AI ▷ #sharing (8 messages🔥):
Perplexity AI, Quantum Leap, Copilot, Language emergence, Electronic Warfare
- Perplexity Latest News: A user shared a link to a Perplexity AI search for the latest news.
- Quantum Leap Blueprint Revealed: A user shared a link to a Perplexity AI search about the quantum leap blueprint.
- Copilot Feature Activation: A user shared a link to a Perplexity AI search about how to activate the copilot function.
- Language Emergence: A user shared a link to a Perplexity AI page about when language emerged.
- Electronic Warfare Tech: A user shared a link to a Perplexity AI search about electronic warfare key technologies.
Perplexity AI ▷ #pplx-api (3 messages):
Perplexity API, Rapid Web Searches, API Usage Troubleshooting
- User Reports Random API Response Issues: A user reported issues with the Perplexity API, noting that when conducting hundreds of rapid web searches, the code receives only random responses or seems to ignore random queries.
- The user shares the
conductWebQueryfunction they are using, seeking assistance with potential errors in their implementation.
- The user shares the
- Troubleshooting Rapid-Fire Perplexity Queries: A user is experiencing issues with their code when conducting hundreds of short-response web searches using the Perplexity API.
- The code randomly receives responses or ignores queries when calling the
conductWebQueryfunction in quick repetition.
- The code randomly receives responses or ignores queries when calling the
Notebook LM ▷ #use-cases (7 messages):
GDocs Mangling Layouts, Image-Only PDF Grounding, Customized Functionality in NotebookLM, Profanity in Podcast Casual Mode, Crawling Links within the Same Domain
- GDocs Layouts Get Mangled: A user finds that converting to GDocs mangles the layout and fails to import most images in teacher presentations.
- Extracting text (using pdftotext) and converting to image-only format (magick...) helps with grounding in facts and figures presented in the material.
- Image-Only PDFs Help Grounding: A user converts presentations into double files (text and image only PDF) to work around the limitations of pdftotext extraction.
- Image-only PDFs can be voluminous and often expand to >200MB, requiring splitting due to NLM's file size limit.
- NotebookLM is a One-Man (or Woman) Band: With the customized function you can make it to do anything you want (solo episode being man or female, mimic persona, narrate stories, read word for word, ....) .
- Only your imagination is the limit.
- Podcast Mode is Cursing Up a Storm: Feedback indicates that the casual podcast mode may contain profanity.
- It is unclear whether a clean setting is available.
- Crawling Same Domain Links: A user is seeking ideas for how to add sources from links within the URL.
- All of them are within the same domain, and they are requesting ideas on how to crawl all of the links.
Notebook LM ▷ #general (93 messages🔥🔥):
Line Breaks in NotebookLM, Audio Overviews Script, Gemini 2.0, Mind Map Feature, Source Limit
- Line Breaks can't be forced in NotebookLM: A user inquired about forcing line breaks and spacing in NotebookLM's responses, but it's currently not possible to control formatting via prompting.
- The AI adds them on-demand and it's not something the user can configure at the moment.
- Users can't access the script for Audio Overviews: A user asked for access to the script for audio overviews, but was informed that it's not currently possible.
- As an alternative, the user was advised to download the audio and upload it as a source to generate a transcript.
- Gemini 2.0 is shipped: A user inquired whether Gemini 2.0 had been shipped for advanced users, and the response was affirmative: Yes, for a while already.
- Mind Map feature rolls out gradually: Users discussed the new Mind Map feature in NotebookLM, which visually summarizes uploaded sources.
- The feature is being rolled out gradually to more users, for bug control: It's better to release something new only for a limited number of people that increases over time first, because then there is time to rule out any bugs that emerge and provide a cleaner version by the time everyone gets it.
- Notebooks created with >50 sources keep working after Plus ends: Users discussed whether a Notebook with more than 50 sources, created under a Plus subscription, would still fully function after the subscription ends.
- One user confirmed it would, stating that if it was created on Plus with >50 they will continue to work but you will not be able to add new ones.
- Mind Maps - NotebookLM Help: no description found
- New item by Cody T. Salinas: no description found
MCP (Glama) ▷ #general (96 messages🔥🔥):
Smithery registry, Glama API, Open-webui integration, Spring app with spring-ai-mcp-core, Claude Code MCP
- Listing Smithery Registries Using Glama API: A member used the Glama API to list GitHub URLs and check for a smithery.yaml file, but noted the code was a one time hack job script.
- He offered to create a gist if it's interesting, as it'll also be a one time script.
- Spring App Tries Spring-AI-MCP-Core, Questions MCP: A user is exploring MCP for the first time with Open-webui and a basic Spring app using spring-ai-mcp-core, seeking resources beyond ClaudeMCP and the modelcontextprotocol GitHub repo.
- They're trying to understand how MCP compares to GraphQL or a function calling system and how to handle system prompts and multi-agent systems.
- Claude Code MCP Implementation Explored: A member shared Claude Code MCP, an implementation of Claude Code as a Model Context Protocol (MCP) server.
- They requested help with the json line for claude_desktop_config.json for Claude Desktop integration but later resolved the issue.
- Troubleshooting an MCP Server Connection: A user encountered an error when connecting to a simple MCP server, with the error message spawn uv ENOENT, indicating an issue with the uv command.
- Suggestions included using the full path to the uv command, creating a pyproject.toml file with mcp as a dependency, and using the
--projectargument of uv.
- Suggestions included using the full path to the uv command, creating a pyproject.toml file with mcp as a dependency, and using the
- MCP Python REPLs gain Steam: Members discussed hdresearch/mcp-python and Alec2435/python_mcp and evalstate/mcp-py-repl as interesting python repls for MCP.
- They noted a concern that one was running unrestricted and wasn't isolated at all which could lead to a disaster and suggested to use Docker to sandbox access.
- uv: no description found
- Claude Code MCP: An implementation of Claude Code as a Model Context Protocol server that enables using Claude's software engineering capabilities (code generation, editing, reviewing, and file operations) throug...
- Example of running a python script via python-wasi using the wasmtime wasm runtime: Example of running a python script via python-wasi using the wasmtime wasm runtime - app.py
- servers/src/filesystem at main · modelcontextprotocol/servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
- GitHub - evalstate/mcp-py-repl: A python repl for MCP: A python repl for MCP. Contribute to evalstate/mcp-py-repl development by creating an account on GitHub.
- GitHub - hdresearch/mcp-python: A python repl for MCP: A python repl for MCP. Contribute to hdresearch/mcp-python development by creating an account on GitHub.
- awesome-mcp-servers/README.md at main · punkpeye/awesome-mcp-servers: A collection of MCP servers. Contribute to punkpeye/awesome-mcp-servers development by creating an account on GitHub.
- GitHub - Alec2435/python_mcp: MCP Server to run python code locally: MCP Server to run python code locally. Contribute to Alec2435/python_mcp development by creating an account on GitHub.
MCP (Glama) ▷ #showcase (1 messages):
Duckduckgo MCP, Cursor on Windows, Python framework
- *Python MCP* Framework Arrives for Windows: A member sought a DuckDuckGo MCP that works in Cursor on Windows, but existing NPM projects failed.
- So they built their own on a Python framework, with no API key required and support for web, image, news, and video search; it's available on GitHub.
- DuckDuckGo Tooling for Cursor Released: A member released Python-based DuckDuckGo tooling.
- It is intended to function with Cursor on Windows, and provides support for web, image, news, and video searches without the need for an API key; it is available on GitHub.
Link mentioned: GitHub - ericaxelrod-1/model-context-protocol: Model Context Protocols for Cursor: Model Context Protocols for Cursor. Contribute to ericaxelrod-1/model-context-protocol development by creating an account on GitHub.
Nous Research AI ▷ #general (85 messages🔥🔥):
Phi-4 Model, Claude's Response, Vibe Coding, Nvidia Open Sources Coding Dataset, Small Scale LLM Experiments
- Auxiliary Model Emerges as Phi-4 Shines: Members discussed that Phi-4 could be useful as an auxiliary model in a complex system, highlighting its ability to follow directions, interface with other LLMs, and handle roleplay, noting that it would be useful as an auxilliary model in a complex system where you already had a bunch of other models.
- Decoding Claude's Loose Language Interpretation: A user criticized Claude's AI suggestions, pointing out inaccuracies in its model size recommendations, as the list of models it gave in response were not under 10m parameters as requested, see the Claude output.
- A member responded by saying That's tricky because often natural language isn't super literal, and "10m" could be taken as a shorthand for "very light models that are generally accessible on modern hardware", which to be fair, is a theme consistent throughout Claude's response.
- "Vibe Coding" Validated as Background Learning: A member shared a personal anecdote about learning Japanese through immersion and consumption of media, drawing a parallel to the value of "vibe coding" for background learning and skill acquisition.
- They say that Even vibe coding, you still have to worry about things like interfaces between modules so that you can keep scaling with limited LLM context windows.
- Nvidia Drops Massive Coding Dataset Bomb: A user shared Nvidia's open-sourced instruct coding dataset for improving math, code, general reasoning, and instruction following in the Llama instruct model, including data from DeepSeek-R1 and Qwen-2.5.
- Another member who downloaded the dataset reported that it would be interesting to filter and train.
- Small Scale LLM Experiments with RTX 3080: A member asked for help finding a niche for training a model with limited VRAM.
- Discussion included various QLoRA experiments, and a suggestion to fine tune on code editing.
- no title found: no description found
- Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification: Sampling-based search, a simple paradigm for utilizing test-time compute, involves generating multiple candidate responses and selecting the best one -- typically by having models self-verify each res...
- nvidia/Llama-Nemotron-Post-Training-Dataset-v1 · Datasets at Hugging Face: no description found
- The Model is the Product | Vintage Data: no description found
LMArena ▷ #general (75 messages🔥🔥):
Lmarena testers, Perplexity vs OpenAI/Google, Gemini Deep Research vs GPT, LeCun on AGI, Grok 3 deepsearch
- LMArena accused of slow demise and dwindling experts: A member questioned the activity and quality of testers on LMArena, asking "Is Lmarena slowly dying? Where are all the real testers, improvers, and real thinkers?" and shared a Calm Down GIF.
- Sonar faces existential crisis if beaten by OpenAI/Google: A member speculated that if Perplexity/Sonar isn't the top web-grounded search, the company will be in trouble, as OpenAI or Google being rated as good or better would leave Perplexity offering nothing unique.
- Another member noted that "no one really uses sonar on perplexity though", suggesting it is mostly pro subscriptions driving revenue.
- Gemini Deep Research could be saving time 10x: One member finds that the latest update in Gemini Deep Research saves them time 10x, suggesting it is too expensive for LMArena benchmarking.
- Another member added context that Gemini gave great results, providing an insightful analysis for scientific medical research, generating even a list of 90 literature sources.
- LeCun Debunks Zuckerberg's AGI Hype: Yann LeCun warned that achieving AGI "will take years, if not decades," requiring new scientific breakthroughs.
- A more recent article said that Meta LLMs will not get to human level intelligence until 2025.
- Grok 3 Deep Search has mixed reviews: One user found Grok 3's deepersearch feature to be disappointing, citing hallucinations and low-quality results.
- However, another user defended Grok, stating that "deepersearch seems pretty good" but the original commenter rebutted that frequent usage reveals numerous mistakes and hallucinations.
- Calm Down A Bit Relax GIF - Calm Down A Bit Calm Down Relax - Discover & Share GIFs: Click to view the GIF
- Jake Crying GIF - Jake crying - Discover & Share GIFs: Click to view the GIF
- Llama Nemotron - a nvidia Collection: no description found
- Meta's LeCun Debunks AGI Hype, Says it is Decades Away: Meta Chief AI Scientist Yann LeCun is skeptical of AGI even as his boss, CEO Mark Zuckerberg, goes all in.
GPU MODE ▷ #general (9 messages🔥):
Digit Comparison, Memory Bandwidth, Gemma 3 on Macbook
- Digit Comparison Thoughts Requested: A user inquired about Jake's comparison of digits to other alternatives from a previous stream, expressing interest in reading his thoughts.
- Memory Bandwidth Blues: A user commented on the low memory bandwidth of a released product, assumed to be for local inference, and said I'm becoming town complainer.looks like a 5070 with more ram to me.
- Quantization Calculation for Gemma 3: A user asked about running Gemma 3 on an M1 Macbook Pro (16GB) regarding model size and quantization, and another user explained how to calculate the size requirement based on model size and quantization in bytes.
- The user explained that Gemma 3 4B in FP16 could be run, and a 12B model in FP4 if available, given the Macbook's 16GB unified memory with 70% allocated to the GPU.
GPU MODE ▷ #cuda (4 messages):
Blackwell ULTRA's attention instruction, Shared Memory Carveout
- Blackwell ULTRA to bring new 'attention instruction'?: A member mentioned that Blackwell ULTRA would bring an attention instruction, but its meaning remains unclear.
- Shared Memory Carveout Explained: A member pointed out that if the smem carveout for kernel1 is only 100 or 132 KiB, there's not enough space for both kernels to run simultaneously.
- He suggested increasing the carveout using the CUDA documentation on Shared Memory.
GPU MODE ▷ #torch (7 messages):
torch.distributed.tensor.parallel.style.ColwiseParallel, Autograd hook guarantee, Building PyTorch from source for RTX 5080
- Missing
__repr__()inColwiseParalleland friends: A user inquired about the absence of__repr__()methods intorch.distributed.tensor.parallel.style.ColwiseParalleland related classes, seeking insights into the design choice.- No specific explanation was provided in the given context.
- Autograd Hook Called Once Per Parameter: A member sought clarification on whether the autograd hook is guaranteed to be called only once per parameter per backward pass, even in scenarios with gradient accumulation like RNNs.
- The response confirmed that the hook is indeed called once per parameter, clarifying its behavior with respect to gradient accumulation.
- User builds Pytorch from source for RTX 5080: A user is trying to build PyTorch from source to support an RTX 5080, and despite setting
TORCH_CUDA_ARCH_LIST=Blackwell, the build only supportssm_100, notsm_120.- Another member suggested using
TORCH_CUDA_ARCH_LIST="10.0,12.0"instead; the user appreciated the suggestion.
- Another member suggested using
Link mentioned: pytorch/torch/_tensor.py at v2.6.0 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
GPU MODE ▷ #algorithms (20 messages🔥):
matmul output fusions, nvfuser stalls, Tensor Cores vs CUDA Cores, cooperative or ping-pong warp specialization, fusing activation in GEMM
- Nvfuser's Matmul Output Fusions Face Hurdles: A member noted that implementing matmul output fusions for nvfuser is difficult, and even with multiplication/addition, it introduces stalls, making it slower than separate kernels due to the need to keep tensor cores fed.
- He was surprised that optimizing these things is pretty nontrivial.
- Concurrent TC and CUDA Core execution?: A member inquired whether the difficulty arises because Tensor Cores and CUDA Cores cannot run concurrently, potentially fighting for register usage.
- They recalled seeing Blackwell docs stating TC and CUDA cores can now run concurrently.
- Autotuning Fusion Strategies: A member expressed curiosity about autotuning fused operations, questioning which strategies can hide the operations being fused, especially considering there are options and one will be the best.
- Another member pointed out that on Hopper, there are basically two options: cooperative or ping-pong warp specialization.
- Performance Impact of Fusing Activation in GEMM: In gpu-mode lecture 45, it was discussed that fusing activation in GEMM can sometimes hurt performance if GEMM uses all registers, making it faster to split GEMM and activation into two kernels.
- A member has experienced similar results when writing custom fuseg GEMM+activation triton kernels.
Link mentioned: rdspring1 - Overview: I contribute to PyTorch, Lightning-AI Thunder, and Nvidia/Fuser. - rdspring1
GPU MODE ▷ #cool-links (1 messages):
mobicham: https://www.youtube.com/watch?v=1bRmskFCnqY
GPU MODE ▷ #beginner (3 messages):
FSDP1, FSDP2, accelerate, trl
- *Accelerate* Prepares to Merge FSDP2 Support: A member asked whether
accelerateuses FSDP1 or FSDP2, and whether it is possible to fine-tune an LLM using FSDP2 withtrl.- Another member responded that
accelerateis using FSDP1, but that they plan to merge a pull request "~next week" to add initial support for FSDP2.
- Another member responded that
- *User Excitement* around FSDP2*: After a member clarified the details on when *FSDP2 support would be added, the other member said "This is exciting! Thanks for the clarification!"
- This highlights that the user was awaiting the arrival of FSDP2 support in
accelerate.
- This highlights that the user was awaiting the arrival of FSDP2 support in
Link mentioned: WIP: Initial FSDP2 support by S1ro1 · Pull Request #3394 · huggingface/accelerate: Draft PR, feel free to discuss changes to the user-facing api.Fixes # (issue)Before submitting This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the ca...
GPU MODE ▷ #irl-meetup (1 messages):
IRL Meetup, GTC Meetup, Saturday Evening Event
- IRL Meetup Momentum Builds: A member suggested an in-person meetup during evenings, after GTC, or on the weekend, proposing a Saturday evening event.
- The member volunteered to reserve a table, inviting interested parties to react to the comment to gauge participation.
- GTC After-Party Brews: Enthusiasts are considering an IRL meetup to coincide with or follow the GTC event, potentially extending into the weekend.
- The initiative aims to connect individuals beyond the digital sphere, offering a chance to network and collaborate in a relaxed, face-to-face environment.
GPU MODE ▷ #liger-kernel (2 messages):
Liger Kernel, Fused Linear Cross Entropy
- Liger Kernel patch doesn't work with tp_plan: The
tp_plan:{"lm_head"="colwise_rep"}setting doesn't work with the ligerfused_linear_cross_entropypatch, since it essentially requires loss parallel.- The user was told that feature requests are welcome and they asked if there are any developments where they can contribute.
- Contribution opportunities sought: A user inquired about contribution opportunities in ongoing developments related to the Liger Kernel.
- This indicates a potential interest in contributing to the project's advancements and feature enhancements.
GPU MODE ▷ #self-promotion (1 messages):
viking0nfire: We've released Triton support on https://LeetGPU.com/challenges 🚀
Check it out!
GPU MODE ▷ #🍿 (3 messages):
Automatic Kernel Optimization, Single GPU context, Distributed GEMM
- Kernel Optimization limited to Single GPU: Automatic kernel optimization is currently posed only in the single GPU context, so there's no need to consider scaling to multiple GPUs.
- There's no reason to expect
argmin_x f(x) = argmin_x g(x)when you scale to multiple GPUs, despite this often being the case due to the simplicity of most distributed training algorithms.
- There's no reason to expect
- Distributed GEMM: Ideally, optimization problems should be framed and computed over the distributed setting, with many kernel implementations specifically designed for this purpose.
- The speaker recalled that there was a talk on distributed GEMM on this server at one point.
GPU MODE ▷ #thunderkittens (1 messages):
ThunderKittens, Kernels, Batch Compilation, GPU Programming
- *ThunderKittens* Kernel Needs a Fix: A member found that the first example kernel in the ThunderKittens repo doesn't compile out of the box.
- They had to add calls to the batch, depth, row, and cols methods to get it working.
- Addressing Kernel Compilation Issues: The compilation error in the example kernel highlights the need for clearer documentation or updated examples within the ThunderKittens repository.
- This ensures that new users can easily get started with the library and understand the required method calls for kernel compilation.
Link mentioned: ThunderKittens/kernels/example_bind/example_bind.cu at main · HazyResearch/ThunderKittens: Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
GPU MODE ▷ #reasoning-gym (4 messages):
DAPO Algorithm, RL Training, PPO, GRPO
- DAPO Algorithm Debuts with Open-Source Release: The DAPO algorithm (decoupled clip and dynamic sampling policy optimization) was released; DAPO-Zero-32B surpasses DeepSeek-R1-Zero-Qwen-32B, scoring 50 on AIME 2024 with 50% fewer steps; it is trained with zero-shot RL from the Qwen-32b pre-trained model, and the algorithm, code, dataset, verifier, and model are fully open-sourced, built with Verl.
- Dynamic Sampling strategy Summary: The dynamic sampling strategy involves filtering completions out which have no gradient signal (no changes relative to group members), a token-level policy-gradient loss (longer sequences contribute more to the gradient signal), and overlong-filtering/soft overlong penalty (remove completions exceeding max length).
Link mentioned: Tweet from Haibin (@eric_haibin_lin): @qiying_yu and team just dropped the DAPO algorithm (decoupled clip and dynamic sampling policy optimization)! DAPO-Zero-32B, a fully open-source RL reasoning model, surpasses DeepSeek-R1-Zero-Qwen-32...
GPU MODE ▷ #submissions (11 messages🔥):
Modal Runner Successes, conv2d Leaderboard, vectoradd Leaderboard, vectorsum Leaderboard, grayscale Leaderboard
- Modal Runners See Successes Across Multiple Benchmarks: The Modal runners are seeing successes in test and benchmark submissions across various leaderboards including vectoradd, vectorsum, conv2d, and grayscale.
- The submissions are being tested on a variety of GPUs, including H100, A100, T4, and L4.
- Conv2d Leaderboard Heating Up: Multiple leaderboard submissions for conv2d succeeded using Modal runners on various GPUs.
- The successful submissions spanned L4, T4, A100, and H100 GPUs, showcasing broad compatibility.
- Vectoradd Benchmark Achieves Success: A test submission to the vectoradd leaderboard on GPUS: A100 using Modal runners succeeded!
- Another test submission with id
2273to leaderboardvectoraddon GPUS: L4 using Modal runners also succeeded!
- Another test submission with id
- Vectorsum Leaderboard Sees Modal Success: Test and benchmark submissions to the vectorsum leaderboard on GPUS: T4 using Modal runners succeeded.
- The successful submissions indicate stable performance for vectorsum on T4 GPUs using the Modal framework.
- Grayscale Benchmark Submission Succeeds: A benchmark submission to the grayscale leaderboard on GPUS: H100 using Modal runners was successful.
- This success highlights the Modal runners' ability to handle image processing tasks on high-end H100 GPUs.
GPU MODE ▷ #ppc (1 messages):
OpenMP Performance, printf Performance Impacts, std::cout Side Effects
- printf Makes OpenMP Faster?: An odd performance effect was observed in cp2b with OpenMP: including a
printfstatement at the end of the code makes it run faster (0.4s vs 0.6s) when using||omp parallel forwith a schedule clause.- The effect disappears when using
std::coutinstead ofprintf, and including<iostream>negates the effect altogether.
- The effect disappears when using
- Compiler Oddities: The user reported an anomaly with
printfaffecting OpenMP performance in their code, noting faster execution times whenprintfis present.- This behavior was not reproducible with
std::cout, suggesting a potential interaction betweenprintf, OpenMP, and the compiler.
- This behavior was not reproducible with
Modular (Mojo 🔥) ▷ #general (11 messages🔥):
LeetGPU challenges, GTC talks, Nvidia Blackwell Ultra, Nvidia Ruben, Silicon Photonics
- LeetGPU challenges appear!: Members were encouraged to try out the LeetGPU challenges.
- Another member was congratulated for advancing to level 4.
- GTC talk links sought: A member asked for a link to the GTC talks.
- Another member responded that you can sign up for free virtual attendance on the Nvidia website and watch recordings for up to 72 hours after the talk, and that Jensen's talk is on YouTube.
- Nvidia Keynote TLDR: The keynote included the Blackwell Ultra and Ruben announcements, with the next GPU generation named Feynman.
- With Ruben, Nvidia is moving to silicon photonics for data movement power cost reasons, and Ruben will also have a new ARM CPU attached, along with substantial investments into Spectrum X, launching a 1.6 Tbps switch.
Link mentioned: LeetGPU: no description found
Modular (Mojo 🔥) ▷ #mojo (28 messages🔥):
CompactDict advantages, HashMap in stdlib, List.fill behavior, StringDict module, List index out of range
- CompactDict advantages spark interest: Members discussed the advantages of CompactDict, with one user still suffering from the SIMD-Struct-not-supported issue in the built-in dict and being quite happy about an alternative solution.
- A report about a year ago was published on GitHub detailing two specialized Dict implementations, one for Strings and another forcing the implementation of the trait Keyable.
- HashMap in stdlib gains traction: There was a suggestion to include the generic_dict in the standard library as HashMap, letting the current Dict be as it is.
- Concerns were raised about Dict needing to do a lot of very not-static-typed things, making it potentially more valuable to add a new struct with a better design and deprecate Dict over time.
- List.fill behavior surprises users: It was questioned whether filling uninitialized parts of the lists buffer should be optional, as calling List.fill could surprisingly change the length of the list.
- The suggestion was made to make filling uninitialized parts of the lists buffer optional, as calling
List.fillcould surprisingly change the length of the list.
- The suggestion was made to make filling uninitialized parts of the lists buffer optional, as calling
- StringDict module considered viable: It was suggested that the standard library should adopt some of the features of CompactDict, like a better hash function and simpler probing strategy, but all the compaction features go beyond the scope of a standard lib Dictionary.
- The author still believes it is viable to have compact StringDict, but it can be included as a separate module.
- List index out of range goes unnoticed: A user noticed that there is no index out of range check in List, expressing surprise since they thought that was what unsafe_get was for.
- Another member has run into this issue also, with someone from Modular saying it needs to be added at some point.
Link mentioned: GitHub - mzaks/compact-dict: A fast and compact Dict implementation in Mojo 🔥: A fast and compact Dict implementation in Mojo 🔥. Contribute to mzaks/compact-dict development by creating an account on GitHub.
Latent Space ▷ #ai-general-chat (31 messages🔥):
Patronus AI, Etsy, Nvidia GTC Keynote, Manus access trading bot, vLLM
- Patronus AI Judges Honesty: Patronus AI launched an MLLM-as-a-Judge to evaluate AI systems, already implemented by Etsy to verify caption accuracy for product images.
- Etsy has hundreds of millions of items and needs to ensure their descriptions are accurate and not hallucinated.
- Cognition AI Hits $4B Valuation: Cognition AI reached a $4 billion valuation in a deal led by Lonsdale's firm (link unsupplied).
- AWS Undercuts Nvidia: During the GTC March 2025 Keynote, it was reported that AWS is pricing Trainium at 25% the price of Nvidia chips (hopper), according to this tweet.
- Jensen joked that after Blackwell, they could give away a Hopper since Blackwell will be so performant.
- Manus Access Impresses Users: A member got access to Manus with deeper search via Grok3 and said it's good, showcasing how it built a trading bot over the weekend, but is currently down ~$1.50 in paper trading.
- They showed off impressive output, teasing sneak peek screenshots.
- vLLM becomes Inference ffmpeg: vLLM is slowly becoming the ffmpeg of LLM inference, according to this tweet.
- Patronus AI’s Judge-Image wants to keep AI honest — and Etsy is already using it: Patronus AI launches the first multimodal LLM-as-a-Judge for evaluating AI systems that process images, with Etsy already implementing the technology to validate product image captions across its mark...
- Tweet from Stephanie Palazzolo (@steph_palazzolo): In a mtg last fall, DoorDash had a question for OpenAI about its upcoming Operator agent: What happens if bots, rather than humans, overrun our app?It's a growing question among retailers & compan...
- Tweet from vLLM (@vllm_project): We are grateful for the trust in vLLM ❤️
- Tweet from Apollo Research (@apolloaievals): AI models – especially Claude Sonnet 3.7 – often realize when they’re being evaluated for alignment.Here’s an example of Claude's reasoning during a sandbagging evaluation, where it learns from do...
- Tweet from METR (@METR_Evals): When will AI systems be able to carry out long projects independently?In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 mont...
- Tweet from Krishna Mohan (@KMohan2006): Dense Moe and Sparse Moe implementation
- Tweet from Fabricated Knowledge (@_fabknowledge_): “AWS is pricing Trainium at 25% the price of Nvidia chips (hopper)”Jensen: after Blackwell you can give away a hopper because Blackwell will be so performant.You do the math on who wins in total cost ...
Latent Space ▷ #ai-announcements (2 messages):
Cloudflare Agents Podcast, Evo2 Paper Discussion
- *Latent Space* Discusses Cloudflare Agents*: The Latent Space podcast featuring @swyx, @ritakozlov_, and @threepointone delves into *Cloudflare's agent offerings for the year, including a segment on Durable Objects.
- The conversation also touches on topics such as the Sapir-Whorf hypothesis, observability, strategies for getting normies to use agents, the obligatory MCP, workflows, and references to Sunil's Blog.
- Evo2 Paper Club in Session: The Latent Space community convened to discuss the Evo2 paper, focusing on systems and algorithms for Convolutional Multi-Hybrid Language Models at Scale.
- The session, led by a community member, explored key concepts from the paper, aiming to demystify complex aspects of large language models.
- Tweet from Latent.Space (@latentspacepod): new ⚡️ pod: @swyx jams with @ritakozlov_ and @threepointone on all the @CloudflareDev offerings for the Year of Agents`npm i agents`https://youtu.be/8W_9lUYGa2Uft riffs on Durable Objects, Sapir Whorf...
- LLM Paper Club (Evo 2: Systems and Algorithms for Convolutional Multi-Hybrid Language Models at Scale) · Zoom · Luma: RJ will cover https://arcinstitute.org/manuscripts/Evo2-MLHere's the press release: https://arcinstitute.org/news/blog/evo2 and the companion bio paper:…
Eleuther ▷ #general (2 messages):
Reconnecting with the community, Decentralized AI discussions
- Enthusiastic Return to the Community: A member expressed excitement about reconnecting with the community after a break.
- Anticipation for Decentralized AI Discussions: The same member is looking forward to diving back into decentralized AI discussions.
Eleuther ▷ #research (21 messages🔥):
Fine-tuning Gemini/OLMo, Distillation for Fine-tuning, Passkey/Fuzzy Rate Improvement, GoldFinch/GoldenGoose Hybrid Setup, Memory Expert Activation
- Gemini and OLMo Models Spark Fine-Tuning Frenzy: A member sought advice on fine-tuning Gemini or OLMo models and inquired whether distillation would be a better approach, especially with data in PDF files.
- No direct answers were provided, but the discussion branched into memory optimization and hybrid setups for enhanced performance.
- Passkey Performance gets a Boost with Fuzzy Rate Tricks: A member suggested improving the passkey and fuzzy rate for important keys to nearly 100% through hybrid approaches or a memory expert activated by the passkey, as displayed in a scrot.png.
- GoldenGoose Hybrid Setup Planned for Memory Optimization: A member expressed interest in the GoldFinch (GoldenGoose) hybrid setup for memory management, noting plans to implement it.
- They noted that larger models will have longer memories and that the charts illustrate the improvement from 1.5B to 2.9B parameters.
- RWKV update rule with memory: A member proposed experimenting with the RWKV update rule using a combined input of next inputs and memory, potentially with an MoE or gating mechanism.
- Due to being busy converting QRWKV models, they have not yet tested this strategy, but hope to do so in the future.
- arXiv reCAPTCHA: no description found
- RWKV-7 "Goose" with Expressive Dynamic State Evolution: We present RWKV-7 "Goose", a new sequence modeling architecture, along with pre-trained language models that establish a new state-of-the-art in downstream performance at the 3 billion paramet...
Eleuther ▷ #interpretability-general (1 messages):
Latent Activations, Model Behavior, Sequence Processing
- Latent Activations Represent Full Sequences: To understand a model's normal behavior, one should generate latent activations from entire sequences, rather than individual tokens.
- The poster suggests that focusing on entire sequences provides a more accurate representation of what the model does normally.
- Generating Latents with get_activations(sequence): The poster provides code examples, recommending
latents = get_activations(sequence)as the correct method.- They warn against using
latents = cat([get_activation(tok) for tok in sequence)), as it produces latents* that aren't 'interesting'.
- They warn against using
Eleuther ▷ #lm-thunderdome (5 messages):
lm_eval, HFLM, trust_remote_code, API keys
- HFLM Needs Trust, Remotely: A member inquired about programmatically running
lm_evalwith anHFLMmodel and avoiding thetrust_remote_code=Trueerror.- Another member clarified that
trust_remote_code=Truemust be passed to the model constructor and that the command-line flag just builds the model internally with that flag.
- Another member clarified that
- Cloud Models Want API Keys: Two members asked if cloud-based models that can't be hosted locally support API keys.
- Another member confirmed they do, and pointed to a previously provided link for details.
LlamaIndex ▷ #blog (2 messages):
LlamaIndex course on HuggingFace, Gen AI Toolbox for Databases
- Hugging Face Teaches LlamaIndex Agents: Hugging Face released a free course about building agents in LlamaIndex, covering components, RAG, tools, agents, and workflows (link).
- Google and LlamaIndex Simplify AI Agents: LlamaIndex has partnered with Google Cloud to simplify building AI agents using the Gen AI Toolbox for Databases (link).
- The Gen AI Toolbox for Databases manages complex database connections, security, and tool management, with more details available on Twitter.
Link mentioned: Introduction to LlamaIndex - Hugging Face Agents Course: no description found
LlamaIndex ▷ #general (24 messages🔥):
Langchain's long-term memory vs LlamaIndex, Azure OpenAI and LlamaIndex, Resume parsing AI services, Agent tool calling
- LlamaIndex Long-Term Memory Capability Compared to Langchain: A member inquired about whether LlamaIndex has a feature similar to Langchain's long-term memory support in LangGraph.
- Another member pointed out that "long term memory is just a vector store in langchain's case" and suggested using LlamaIndex's Composable Memory.
- Azure OpenAI Integration in LlamaIndex: A user encountered an
AttributeErrorwithChromaVectorStoreand later withAzureOpenAIwhen using structured output, but resolved the ChromaVectorStore issue.- They then asked whether LlamaIndex only supports OpenAI agents, not Azure, but another member confirmed that "you can pass azure into any agent" and pointed to
llm.structured_predictfor Azure Structured Predict using a Pydantic schema.
- They then asked whether LlamaIndex only supports OpenAI agents, not Azure, but another member confirmed that "you can pass azure into any agent" and pointed to
- Resume Parsing AI Services: A member asked for recommendations for AI services for resume parsing.
- Another member responded that they "looked up and got some", without specifying which ones.
- Agent Tool Called Repeatedly: A user reported that an agent called the same tool twice in a row for the same goal.
- Another member suggested that the "code execution tool should probably return something like 'Code executed correctly' or similar, so that the LLM knows that it worked".
- Launching Long-Term Memory Support in LangGraph: Today, we are excited to announce the first steps towards long-term memory support in LangGraph, available both in Python and JavaScript. Long-term memory lets you store and recall information between...
- Simple Composable Memory - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
Nebius AI Computing Platform, GPU clusters, Inference Services, AWS vs Lambda Labs vs CoreWeave
- Nebius Platform Experiences Requested: A member is curious about real-world experiences with Nebius's computing platform for AI and machine learning workloads, including their GPU clusters and inference services.
- They are comparing it to AWS, Lambda Labs, or CoreWeave in terms of cost, scalability, and ease of deployment, and would like to know about stability, networking speeds, and orchestration tools like Kubernetes or Slurm.
- Comparing Cloud AI Platforms: The discussion seeks to compare Nebius with established platforms like AWS, Lambda Labs, and CoreWeave.
- Key comparison points include cost-effectiveness, scalability, and deployment simplicity for large-scale AI workloads.
Cohere ▷ #「💬」general (4 messages):
Chase's full name, Cohere Expanse 32B knowledge cutoff
- User asks for Chase's full name: A user asked another to share the full name of a person named Chase and offered to connect them.
- They followed up by saying they have set something up for them.
- Cohere Expanse 32B Knowledge Date Sought: A user inquired about the knowledge cutoff date for Cohere Expanse 32B.
- The user is seeking new work.
Cohere ▷ #「🔌」api-discussions (19 messages🔥):
Trial Key Usage Tracking, Websearch Connector Issues, command-r-plus-02-2024 vs command-a-03-2025
- Trial Key Rate Limits Triggered: A user experienced a 429 error with their trial key and sought help to track usage, wondering if they had exceeded the 1000 calls per month limit.
- A Cohere team member offered to investigate, clarifying that trial keys are subject to rate limits, pointing to the Cohere rate limits documentation.
- Websearch Connector Yields Poor Results: A user reported degraded performance with the websearch connector, observing that it seems like the implementation changed recently and is now returning worse results.
- The team member requested details to investigate and noted that the connection option site: WEBSITE was failing to restrict queries to specific websites, and this fix is going out soon.
- Model outputs compared: command-r-plus-02-2024 vs command-a-03-2025: The user tested and compared websearch results between models command-r-plus-02-2024 and command-a-03-2025.
- It was reported the outputs between the two weren't different and more cases where the websearch just isn't returning results.
Link mentioned: Different Types of API Keys and Rate Limits — Cohere: This page describes Cohere API rate limits for production and evaluation keys.
Cohere ▷ #「💡」projects (1 messages):
MCP Server, Cohere Command A, Github Repo, Positive News
- *Goodnews MCP* Server Built with Cohere: A member has built a Goodnews MCP server that provides positive, uplifting news to MCP clients using Cohere Command A in its tool
fetch_good_news_list.- The server uses an API request to get recent headlines and uses Cohere LLM to rank and return the most positive articles.
- Github Repo Released: A Github repo was released here for the project.
- The repo is for a simple server that provides positive, uplifting news to MCP clients.
Link mentioned: GitHub - VectorInstitute/mcp-goodnews: A simple MCP application that delivers curated positive and uplifting news stories.: A simple MCP application that delivers curated positive and uplifting news stories. - VectorInstitute/mcp-goodnews
Cohere ▷ #「🤝」introductions (3 messages):
AI alignment, Open-source models, Federating RAG, Agentic apps, Python and Rust
- Aymara Democratizes AI Alignment: Juan Manuel, co-founder of Aymara, introduced himself and shared that his company builds dev tools for measuring and improving AI alignment, hoping to help democratize AI alignment for open-source models.
- He mentioned he's excited to explore Command A for in-house tools and is open to discussing AI alignment ideas via DMs.
- Andrei explores federated RAG: Andrei from the Vector Institute, formerly at LlamaIndex, introduced himself, mentioning he's working on a couple of open-source projects right now, federating RAG most notably.
- He plans to move on to some agentic apps/research soon, favoring Python and Rust and hoping to gain tips, learn new methods and industry trends from the community.
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
MOOC Coursework, AgentX Competition, LLM Agents Discord, AgentX Research Track
- *MOOC Coursework* details and Certificate Instructions Revealed: Coursework and completion certificate instructions for the LLM Agents MOOC have been released on the course website.
- The course is built upon the fundamentals from the Fall 2024 LLM Agents MOOC.
- AgentX Competition: Dive into 5 Tiers****: Details for the AgentX Competition have been shared, including information on how to sign up here.
- The competition includes 5 Tiers: Trailblazer ⚡, Mastery 🔬, Ninja 🥷, Legendary 🏆, Honorary 🌟.
- Apply Now: AgentX Research Track Mentorship: Select students can apply for mentorship on an AgentX Research Track project via this application form.
- The application deadline is March 26th at 11:59pm PDT.
- Labs and Certificate Declaration Form to drop in April: Release of Labs and the Certificate Declaration form will occur in April.
- Assignments are tentatively due at the end of May, with certificates released in June.
Link mentioned: Advanced Large Language Model Agents MOOC: MOOC, Spring 2025
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (23 messages🔥):
Quiz Deadlines, AgentX Research Track details, Certificate for December MOOC
- Quizzes are due End of May: Members inquired about the deadline for the quizzes and if they could still submit them to be eligible for the certificate, a member confirmed that all assignments are due end of May.
- Another member clarified that this included quizzes released after every lecture.
- AgentX Research Track details: A member inquired about the AgentX Research Track, mentorship format, timeline, deliverables, and selection criteria.
- A mentor explained that guidance would be offered on research track projects from March 31st to May 31st, that mentors will contact applicants directly for potential interviews, and that they should have well-thought-out research ideas.
- Mentor clarifies selection isn't about top %: A mentor clarified that the selection criteria for the AgentX research track isn't about 'we will only accept the top X percent' but rather whether applicants are qualified and have well-thought-out project ideas.
- They further advised that applicants should demonstrate proactivity, a well-thought-out research idea relevant to the course, and the background to pursue the idea within the two-month timeframe.
- Certificate for December MOOC: A member who took the MOOC course in December reported not receiving the certificate despite completing all requirements.
- A mentor replied that the certificate email was sent on Feb 6th and advised checking spam/trash folders and ensuring the correct email address was used.
- Coursework Details for Certificate: Members inquired if the certificate was open to Berkeley students only, the mentor shared that the certificate is open to anyone who completes one of the coursework tiers and shared a link to the course website and the google doc.
- Another user requested a resend of the Trailblazer Tier certificate for the f24 LLM MOOC which was quickly fulfilled by a moderator.
Link mentioned: MOOC Curriculum: MOOC Curriculum & Certificate Instructions Thank you for joining us for our Advanced LLM Agents MOOC! We hope you've been enjoying the lectures so far! Below is a detailed description of our M...
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (1 messages):
alexkim0889: Thank for the response <@1335446795765022794>! Yep, this helps
Torchtune ▷ #general (11 messages🔥):
FL Setup, Nvidia Delays
- FL Setup Finally Succeeds: After 4 months of waiting due to the IT department's lack of time, a member finally got their FL setup working, as shown in this image.
- Nvidia GPU Availability Still Delayed: Members discuss that the availability of Nvidia GPUs is often delayed, citing the H200s, which were announced 2 years ago but only available to customers 6 months ago.
Torchtune ▷ #dev (4 messages):
recvVector failed, sendBytes failed, DPO recipes, cudaGetDeviceCount, NumCudaDevices
recvVectorandsendBytescause issues with DPO: Members reported encounteringrecvVector failedandsendBytes failederrors with DPO recipes.- The cause is unknown and may be a cluster or torch issue.
cudaGetDeviceCounttriggered due to CUDA version mismatch?: Members also encounteredRuntimeError: Unexpected error from cudaGetDeviceCount()during use of NumCudaDevices.- The error
Error 802: system not yet initializedmay be related to using a more recent CUDA version than expected, but this is unconfirmed.
- The error
nvidia-fabricmanagersolves CUDA init issues: The solution to thecudaGetDeviceCounterror is to usenvidia-fabricmanager.- Ensure it is started with
systemctl start nvidia-fabricmanagerand check the status withnvidia-smi -q -i 0 | grep -i -A 2 Fabric, verifying that the state shows "completed".
- Ensure it is started with
tinygrad (George Hotz) ▷ #general (8 messages🔥):
M1 Mac Training Issues, DeepSeek-R1 Home Deployment, Clang Dependency Validation, Training on CPU without Clang
- M1 Mac struggles with Training: A member expressed frustration that their M1 Mac Air isn't powerful enough to train models even in small batches, and encountered clang issues with Kaggle and Hugging Face Spaces.
- The user was looking for advice on hosting a demo of inference on a trained model.
- DeepSeek-R1 gets Home Deployment Optimization: A user shared a tweet about 腾讯玄武实验室's optimization方案 for DeepSeek-R1, enabling home deployment with consumer-grade hardware.
- The solution requires only 4万元 of hardware, consumes power similar to a regular desktop, and generates approximately 10汉字/second, achieving a 97% cost reduction compared to traditional GPU setups.
- Validate Clang Dependency Issues Early: A contributor asked if the confusing
FileNotFoundErrorthat occurs when running the mnist example on CPU without clang should have better dependency validation or error handling.- The current error doesn't clearly indicate the missing clang dependency.
- Training Results Achieved: A member reported successfully training a model, achieving a loss of 0.2 with Adam.
- Further details and code are available in this repo.
- Tweet from johann.GPT (@ProgramerJohann): 腾讯玄武实验室优化方案让DeepSeek-R1实现家用部署!只需4万元硬件,功耗噪音与普通台式机相当,每秒可生成约10个汉字。关键在于优化内存带宽、CPU配置和系统参数。比起传统GPU方案(8张H20,150万+),成本降低97%!
- Tweet from johann.GPT (@ProgramerJohann): 腾讯玄武实验室优化方案让DeepSeek-R1实现家用部署!只需4万元硬件,功耗噪音与普通台式机相当,每秒可生成约10个汉字。关键在于优化内存带宽、CPU配置和系统参数。比起传统GPU方案(8张H20,150万+),成本降低97%!
- gsoc_2025/ML4SCI/task1 at main · kayo09/gsoc_2025: GSOC 2025! Happy Coding! ☀️. Contribute to kayo09/gsoc_2025 development by creating an account on GitHub.
- DeepSeek-671B纯CPU部署经验分享(一): 私有化部署大模型能够有效保护数据隐私、便于开展大模型安全研究和知识蒸馏。目前主流部署方式包括纯 GPU、CPU/GPU 混合以及纯 CPU 三种部署方式。本文介绍了我们针对 DeepSeek 大模型纯 CPU 本地化部署的推理探索与实践方案。我们以约 3.8 万元的整体成本,基于 llama.cpp 框架,经过硬件选型与量化精度的综合考量,实现了 q8 精度下 7.17 tokens&#...
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
REDUCE_LOAD pattern clarification, Index Selection for reduce_input
- Confused Index Selection for REDUCE_LOAD: A member requested clarification on the meaning of
x.src[2].src[1].src[1]and the reasons for selecting these indices asreduce_inputfor the REDUCE_LOAD pattern.- The code snippet checks if
x.src[2].src[1].src[1]is not equal tox.src[2].src[0], and accordingly assigns eitherx.src[2].src[1].src[1]orx.src[2].src[1].src[0]toreduce_input.
- The code snippet checks if
- Clarification Needed on Tensor Indexing: A user sought a better understanding of the multi-level tensor indexing used in a specific code snippet, particularly focusing on the chained
.srcattributes and numerical indices.- The specific example,
x.src[2].src[1].src[1], raised questions about its purpose within the context of theREDUCE_LOADpattern, prompting the user to request an explanation for the index selection.
- The specific example,
AI21 Labs (Jamba) ▷ #jamba (3 messages):
AI21 Labs, keepitirie
- AI21 Labs keeps mum: A member asked what are you using?
- A different member responded that at this time it looks like we are not publicly sharing that information. If this changes I will come back and update. My apologies for the lack of transparency.
- Lack of transparency: AI21 Labs is not publicly sharing information about what they are using.
- They apologized for the lack of transparency and said they would update if this changes.
AI21 Labs (Jamba) ▷ #general-chat (1 messages):
Welcome to New Members
- New Members Welcomed to Community: The community welcomes several new members: <@518047238275203073>, <@479810246974373917>, <@922469143503065088>, <@530930553394954250>, <@1055456621695868928>, <@1090741697610256416>, <@1350806111984422993>, and <@347380131238510592>.
- All are encouraged to participate in the poll.
- Community Growth and Engagement: The announcement indicates a growing community with the addition of several new members.
- New members are invited to engage by participating in a community poll, fostering initial interaction.
DSPy ▷ #general (2 messages):
dspy.ChainOfThougt, Chain of draft technique, Reduce output tokens
- Chain Of Draft Reproducibility Achieved: A member successfully used
dspy.ChainOfThougtto reproduce the Chain of Draft technique, detailing the process in a blog post. - Chain Of Draft Technique Cuts Output Tokens: The Chain Of Draft prompt technique helps the LLM expand its response without excessive verbosity, cutting output tokens by more than half and is detailed in this research paper.
Link mentioned: Implementing Chain Of Draft Prompt Technique with DSPy: Cut your output tokens by more than half
MLOps @Chipro ▷ #events (2 messages):
MLOps on AWS Workshop, AI4Legislation Seminar, Featureform, SVCAF's AI4Legislation competition
- MLOps Stack from Scratch on AWS: There will be a webinar on March 25th at 8 A.M. PT about building an MLOps Stack from Scratch on AWS, and those interested can sign up at this link.
- AI4Legislation Seminar features Legalese Decoder: The AI4Legislation Seminar will feature Founder of Legalese Decoder (William Tsui) & our foundation President (Chunhua Liao) tentatively on Apr 2 @ 6:30pm PDT (RSVP here).
- Dig into Featureform for ML Models: Featureform is a virtual feature store that enables data scientists to define, manage, and serve their ML model's features.
- Open Source AI-Driven Solutions for SVCAF competition: Silicon Valley Chinese Association Foundation (SVCAF) is holding a competition this summer to develop open-source AI-driven solutions that will enable citizens to engage with different parts of the legislative process (Github repo).
- AI4Legislation Seminars RSVP: Thank you for your interest in SVCAF's AI4Legislation seminars! Please check out the official competition Github repo here. We also have a Discord!Silicon Valley Chinese Association Foundation (in...
- MLOps Workshop: Building an MLOps Stack from Scratch on AWS: Join us for a 1-hour webinar on Tuesday, March 25th @ 8 A.M. PT for an in-depth discussion on building end-to-end MLOps platforms.
Nomic.ai (GPT4All) ▷ #general (1 messages):
GPT4All FAQ, Default Directories
- GPT4All details Default Directories: The GPT4All FAQ page on Github describes the default directories for models and settings.
- This Github page also provides additional information about GPT4All.
- GPT4All Models Location: The default location for GPT4All models is described in the FAQ.
- Knowing this location can help with managing and organizing models.
Link mentioned: Frequently Asked Questions: GPT4All: Run Local LLMs on Any Device. Open-source and available for commercial use. - nomic-ai/gpt4all