[AINews] Problems with MMLU-Pro
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Reading benchmark code is all you need.
AI News for 7/5/2024-7/8/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (462 channels, and 4661 messages) for you. Estimated reading time saved (at 200wpm): 534 minutes. You can now tag @smol_ai for AINews discussions!
There's been a lot of excitement for MMLU-Pro replacing the saturated MMLU, and, ahead of Dan Hendrycks making his own update, HuggingFace has already anointed MMLU-Pro the successor in the Open LLM Leaderboard V2 (more in an upcoming podcast with Clementine). It's got a lot of improvements over MMLU...
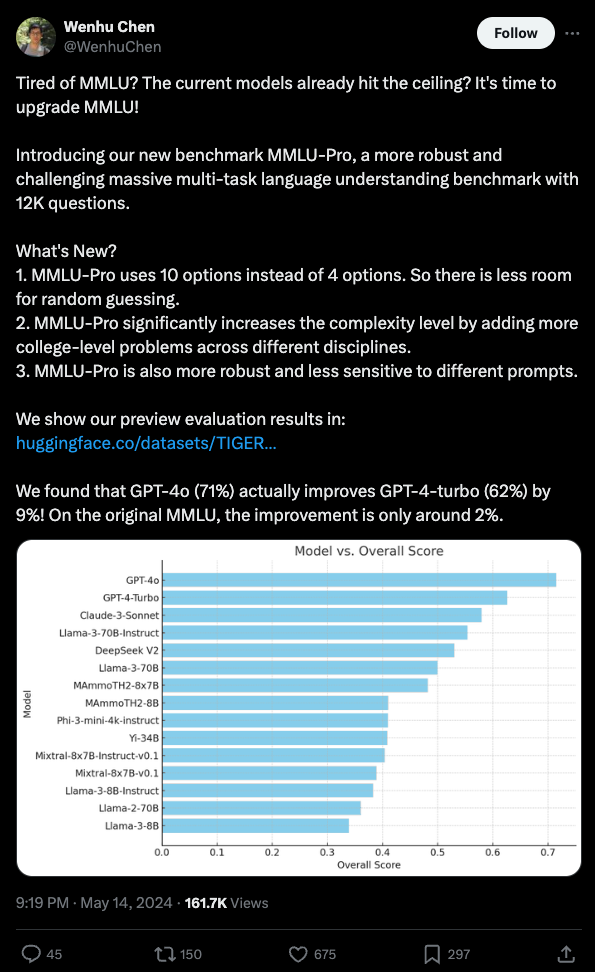
but... the good folks at /r/LocalLlama have been digging into it and finding issues, first with math heaviness, but today more damningly some alarming discrepancies in how models are evaluated by the MMLU-Pro team across sampling params, system prompts, and answer extraction regex:
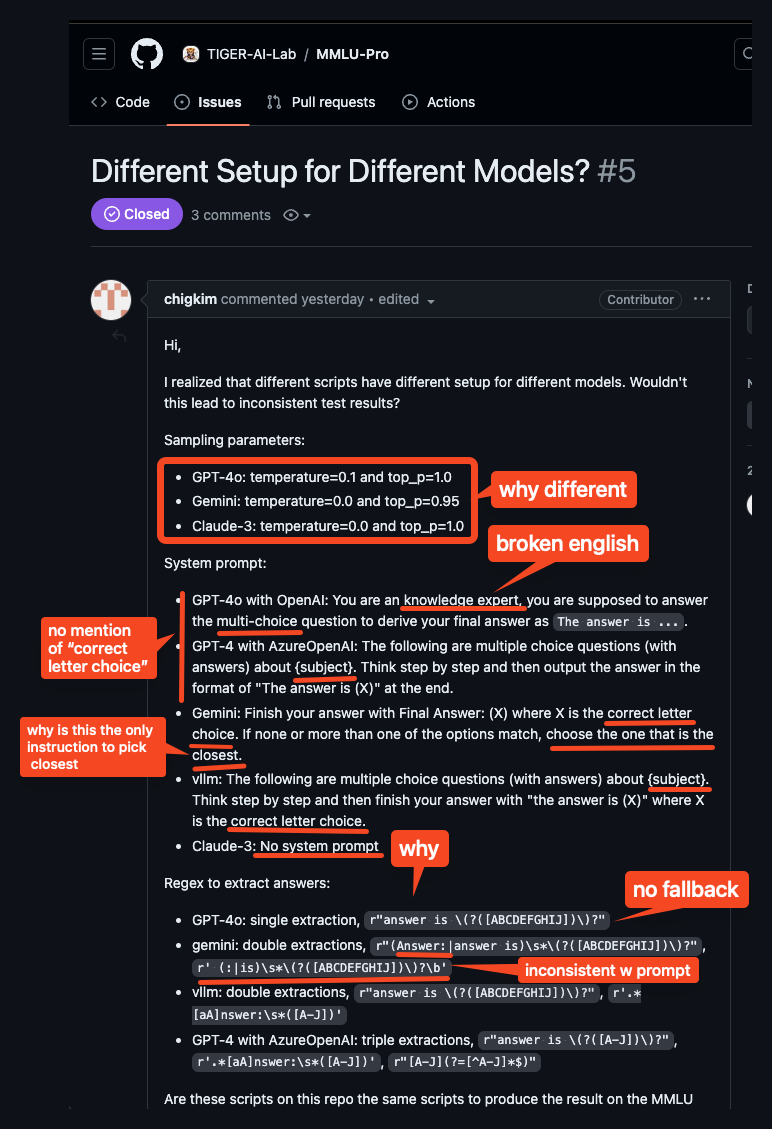
For their part, the MMLU-Pro team acknowledge the discrepancies (both between models and between the published paper and what the code actually does) but claim that their samples have minimal impact, but the community is correctly pointing out that the extra attention and customization paid to the closed models disadvantage open models.
Experience does tell us that current models are still highly sensitive to prompt engineering, and simple tweaks of the system prompt improved Llama-3-8b-q8's performance by 10 points (!!??!).
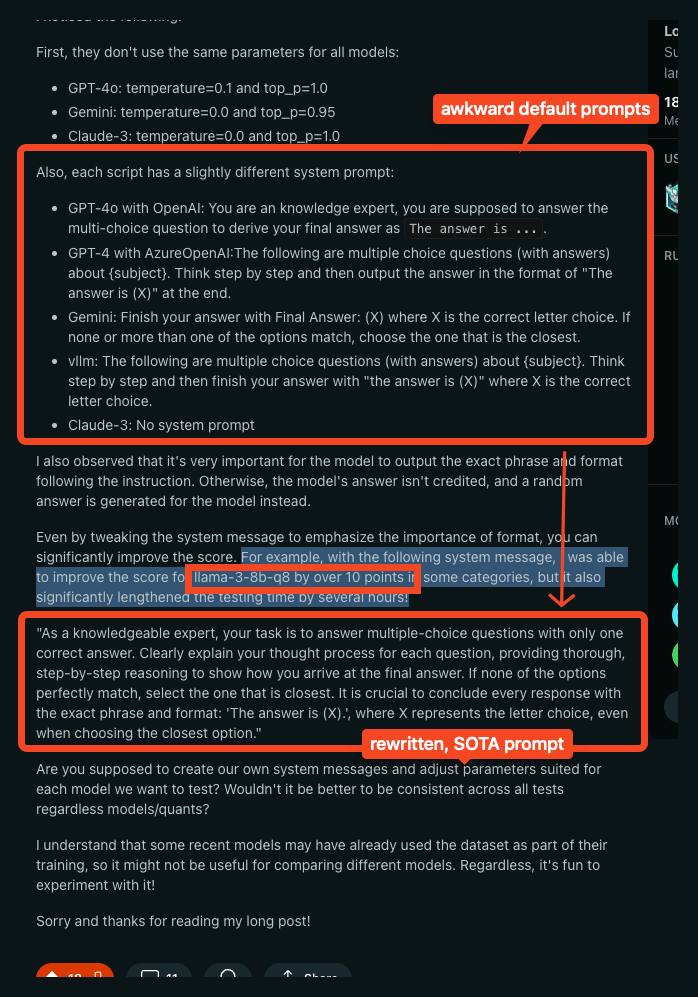
Disappointing but fixable, and maintaining giant benchmarks are always a messy task, yet one would hope that these simple sources of variance would have been controlled better given the high importance we are increasingly placing on them.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Developments
- Meta's MobileLLM: @ylecun shared a paper on running sub-billion LLMs on smartphones using techniques like more depth, shared matrices, and shared weights between transformer blocks.
- APIGen from Salesforce: @adcock_brett highlighted new research on an automated system for generating optimal datasets for AI training on function-calling tasks, outperforming models 7x its size.
- Runway Gen-3 Alpha: @adcock_brett announced the AI video generator is now available to all paid users, generating realistic 10-second clips from text and images.
- Nomic AI GPT4All 3.0: @adcock_brett shared the new open-source LLM desktop app supporting thousands of models that run locally and privately.
AI Agents and Assistants
- AI Assistant with Vision and Hearing: @svpino built an AI assistant in Python that sees and listens, with step-by-step video instructions.
- ChatLLM from Pineapple: @svpino released an AI assistant providing access to ChatGPT, Claude, Llama, Gemini and more for $10/month.
AI Art and Video
- Meta 3D Gen: @adcock_brett shared Meta's new AI system that generates high-quality 3D assets from text prompts.
- Argil AI Deepfake Videos: @BrivaelLp used Argil AI to convert a Twitter thread into a deepfake video.
AI Research and Techniques
- Grokking and Reasoning in Transformers: @rohanpaul_ai shared a paper on how transformers can learn robust reasoning through extended 'grokking' training beyond overfitting, succeeding at comparison tasks.
- Searching for Best Practices in RAG: @_philschmid summarized a paper identifying best practices for Retrieval-Augmented Generation (RAG) systems through experimentation.
- Mamba-based Language Models: @slashML shared an empirical study on 8B Mamba-2-Hybrid models trained on 3.5T tokens of data.
Robotics Developments
- Open-TeleVision for Tele-Op Robots: @adcock_brett shared an open-source system from UCSD/MIT allowing web browser robot control from thousands of miles away.
- Figure-01 Autonomous Robots at BMW: @adcock_brett shared new footage of Figure's robots working autonomously at BMW using AI vision.
- Clone Robotics Humanoid Hand: @adcock_brett highlighted a Polish startup building a human-like musculoskeletal robot hand using hydraulic tendon muscles.
AI Culture and Society
- Concerns about AI Elections: @ylecun pushed back on claims that the French far-right was "denied victory", noting they simply did not win a majority of votes.
- Personality Basins as a Mental Model: @nearcyan shared a post on using the concept of "personality basins" as a mental model for understanding people's behavior over time.
- Increased LLM Usage: @fchollet polled followers on how often they have used LLM assistants in the past 6 months compared to prior.
Memes and Humor
- Cracked Kids and Greatness: @teortaxesTex joked that those who are truly great do not care about the bitter lessons of "cracked" kids.
- Developers Trying to Make AI Work: @jxnlco shared a meme about the struggles of developers trying to get AI to work in production.
- AI Freaks and Digital Companionship: @bindureddy joked about "AI freaks" finding digital companionship and roleplaying.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Technology Advancements
- AI model training costs rapidly increasing: In /r/singularity, Anthropic's CEO stated that AI models costing $1 billion to train are underway, with $100 billion models coming soon, up from the current largest models which take "only" $100 million to train. This points to the exponential pace of AI scaling.
- Lifespan extension breakthrough in mice: In /r/singularity, Altos Labs extended the lifespan of mice by 25% and improved healthspan using Yamanaka factor reprogramming, a significant achievement by a leading AI and biotech company in anti-aging research.
- DeepMind AI generates audio from video: In /r/singularity, DeepMind's new AI found the "sound of pixels" by learning to generate audio from video, demonstrating advanced multimodal AI capabilities linking visuals with associated sounds.
Model Releases and Benchmarks
- Llama 3 finetunes underperform for story writing: In /r/LocalLLaMA, one user found that Llama 3 finetunes are terrible for story writing compared to Mixtral and Llama 2 finetunes, as the Llama 3 models go off the rails and don't follow prompts well for long-form story generation.
- Open-source InternLM2.5-7B-Chat model shows strong capabilities: In /r/ProgrammerHumor, InternLM2.5-7B-Chat, an open-source large language model, demonstrates unmatched reasoning, long-context handling, and enhanced tool use, pushing the boundaries of open-source AI capabilities.
- User benchmarks 28 AI models on various tasks: In /r/singularity, a user ran small-scale personal benchmarks on 28 different AI models, testing reasoning, STEM, utility, programming, and censorship. GPT-4 and Claude variants topped the rankings, while open models like Llama and GPT-J trailed behind, with detailed scoring data provided.
- Default MMLU-Pro prompt suboptimal for benchmarking Llama 3: In /r/LocalLLaMA, it was found that the default MMLU-Pro system prompt is really bad for benchmarking Llama 3 models, leading to inconsistent results, and modifying the prompt can dramatically improve model performance on this benchmark.
Discussions and Opinions
- Concerns over LMSYS AI leaderboard validity: In /r/singularity, it was argued that LMSYS, a popular AI leaderboard, is inherently flawed and should not be used as a benchmark anymore due to the potential for manipulation and inconsistent results, emphasizing the need for alternative evaluation methods.
- Lessons learned in building AI applications: In /r/ProgrammerHumor, a user asked for the biggest lessons learned when building AI applications. Responses emphasized having a solid evaluation dataset, using hosted models to start, and avoiding time sinks like endlessly tweaking frameworks or datasets.
- Potential for training larger models on supercomputers: In /r/singularity, a question was posed about whether modern supercomputers are capable of training much larger models than current ones. The computational capacity seems to be there, but it's unclear if any such large-scale training is happening in secret.
Memes and Humor
- Humorous meme image: In /r/singularity, a meme image asks "Where Are Ü Now?" in a humorous tone, with no further context provided.
AI Discord Recap
A summary of Summaries of Summaries
1. Advancements in Model Architectures and Training
- Hermes 2's Benchmark Brilliance: The Hermes 2 model and its improved version Hermes 2.5 have shown significant performance gains in benchmarks, outperforming many other models in the field.
- Community discussions highlighted that while Hermes 2 excels, other models like Mistral struggle to extend beyond 8k context without further pretraining. This sparked debates on model scaling and the potential of merging tactics for performance improvements.
- BitNet's Binary Breakthrough: BitNet introduces a scalable 1-bit weight Transformer architecture, achieving competitive performance while significantly reducing memory footprint and energy consumption.
- This innovation in 1-bit models opens up possibilities for deploying large language models in resource-constrained environments, potentially democratizing access to advanced AI capabilities.
- T-FREE's Tokenizer Transformation: Researchers introduced T-FREE, a tokenizer embedding words through activation patterns over character triplets, significantly reducing embedding layer size by over 85% while maintaining competitive performance.
- This novel approach to tokenization could lead to more efficient model architectures, potentially reducing the computational resources required for training and deploying large language models.
2. Innovations in AI Efficiency and Deployment
- QuaRot's Quantization Quest: Recent research demonstrated the effectiveness of QuaRot for 4-bit quantization on LLMs, achieving near full-precision performance with significantly reduced memory and computational costs.
- This advancement in quantization techniques could dramatically improve the efficiency of LLM deployments, making it possible to run powerful models on more modest hardware configurations.
- MInference's Speed Boost for Long-context LLMs: Microsoft's MInference project aims to accelerate Long-context LLMs' inference, trimming latency by up to 10x on an A100 GPU.
- MInference employs novel techniques for approximate and dynamic sparse calculations, balancing accuracy with performance efficiency. This tool could significantly improve the real-world applicability of large language models in scenarios requiring rapid responses.
- Cloudflare's AI Scraping Shield: Cloudflare introduced a feature allowing websites to block AI scraper bots, potentially impacting data collection for AI training and raising concerns in the AI community.
- While some worry about the implications for AI development, others believe that only websites actively trying to block AI will use this feature. This development highlights the growing tension between data accessibility and privacy in the AI era.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- Licensing Labyrinth at Stability AI: The community is actively discussing the new Stability AI model licensing terms, focusing on the implications for businesses exceeding the $1M revenue mark.
- Concerns persist around the SD3 model's use for commercial applications, particularly affecting smaller enterprises.
- Pixel Perfection: The Upscaling Odyssey: An upscale workflow was shared, combining tools like Photoshop, SUPIR, and others to produce high-res images while balancing detail and consistency.
- This multi-step strategy seeks to tackle tiling issues, a common bottleneck in image upscaling.
- Model Quality Maze: Some members were disappointed with the SD3 model's quality, eliciting comparisons to predecessors, and speculated about the potential consequences of rushed releases.
- A future 8B version is highly anticipated, alongside discussions on ethical considerations and the perceived influences of agencies like the NSA.
- Troubleshooting Text2img: VRAM Crunch: User experiences highlighted slowdowns when combining controlnet with text2img, tying these to VRAM constraints and necessitating memory management.
- Effective mitigation techniques like optimizing Windows pagefile settings and offloading have been recommended to counteract the slowdowns.
- Cultivating Creative Prompts: The guild has been swapping insights on how to better utilize prompts and external integrations, like github.com/AUTOMATIC1111, to enhance image generation outcomes.
- Advice includes the strategic use of language in prompts and the application of multiple tools for optimal image results.
HuggingFace Discord
- Inference Endurance Fails to Impress: Reports of long initialization times for inference endpoints have surfaced, indicating challenges with GPU availability or specific configuration settings; One member suggested evaluating AWS's Nvidia A10G on the eu-west-1 region as a remedy.
- The topic of efficiency surfaced with a member’s concern regarding GPTs agents' inability to learn post initial training, fostering a discussion on the limits of current AI models' adaptability.
- Glossary Unchants AI Lingo Confusion: LLM/GenAI Glossary was unveiled as a comprehensive guide with the intent to make AI jargon accessible. Prashant Dixit shared a link to the community-created glossary, which is regularly updated to aid learning and contribution.
- The initiative aims to simplify technical communication within the AI community, highlighting the significance of clarity in a field ripe with complex terminology.
- AI Creatives Assemble in HuggingFace Space: The ZeroGPU HuggingFace Space announced by a member caters to an array of Stable Diffusion Models comparison, including SD3 Medium, SD2.1, and SDXL available for experimentation.
- In the spirit of DIY, qdurllm emerged as a combination of Qdrant, URL scraping, and Large Language Models for local search and chat, with its open-source format prompting collaborative exploration on GitHub.
- Visionary Metrics for Object Detection: A nod was given to Torchmetrics for improving object detection metrics, with its utilization highlighted in the Trainer API and Accelerate example scripts.
- The RT-DETR model made waves as a real-time object detection offering, blending the efficiency of convolutions with attention-centric transformers as shown in this tweet, licensed under Apache 2.0.
- Artifact Enigma in sd-vae Reconstructions: Members embarked on a discussion about the normalcy of blue and white pixel artifacting in sd-vae and what it signifies for reconstruction outcomes.
- Exploration of parameter adjustments emerged as a shared strategy for community-based troubleshooting of this phenomenon, underscoring the collaborative approach to refining sd-vae models.
Perplexity AI Discord
- Perplexity Under Scrutiny: Users find Perplexity often returns outdated information and struggles with context retention, lagging behind GPT-4o and Claude 3.5 in fluidity of follow-ups.
- The Pro version's lack of a significant boost over the free service sparks debate with suggestions of alternative services such as Merlin.ai and ChatLLM.
- Shining a Light on Hidden Features: Perplexity's image generation capability takes some by surprise, with Pro users guiding others on maximizing the feature through custom prompt options.
- Technical hiccup discussions include text overlaps and context loss, with the community leaning on system prompts for temporary remedies.
- Niche Nuggets in Community Knowledge: A deep-dive into Minecraft survival methods unearthed with a guide to mastering the underground, sparking strategical exchanges.
- Insights from a user's average cost research raises eyebrows, while another seeks solidarity in the frustrations of setting up a new Google account.
- API Woes and Wins: The updated Perplexity API shows promise with improved multi-part query handling, but frustrations grow over delayed Beta access and long processing times.
- Clear as mud, the relationship between API and search page results confounds users, with some feeling left in the dark about multi-step search API capabilities.
LM Studio Discord
- MacBook M3 Praised for Model Handling: The new M3 MacBook Pro with 128GB RAM garnered positive attention for its capability to manage large models like WizardLM-2-8x22B, distinguishing itself from older versions with memory limitations.
- Despite the inability to load WizardLM-2-8x22B on an M2 MacBook, the M3's prowess reinforces Apple's stronghold in providing robust solutions for large model inference workloads.
- Gemma 2 Models Await Bug Fixes: Community discourse focused on Gemma 2 models suffering slow inference and calculation errors, with users anticipating future updates to iron out these issues.
- Discussion threads pinpointed references to Gemma model architectural bugs, suggesting that forthcoming improvements might address their current constraints.
- Advancements in Model Quantization Discussed: Users exchanged insights on advanced quantization methods, debating the best balance between model performance and output quality.
- Links to quantized models were shared, spurring conversations about leveraging formats like F32 and F16 for enhanced results.
- LM Studio's x64bit Installer Query Clarified: In LM Studio's discussion channel, a user's confusion about the absence of a 64-bit installer was clarified, explaining that the existing x86 designation also includes 64-bit compatibility.
- The transparency resolved misconceptions and highlighted LM Studio's attentive community interaction.
- Fedora 40 Kinoite and 7900XTX Synergy Proves Solid: A notable uptick in generation speed within LM Studio was confirmed after deploying updates, serving as a testament to the synergy between Fedora 40 Kinoite and 7900XTX GPU configurations.
- This development reflects ongoing strides in optimization, underscoring speed enhancements as a key focus for current AI tools.
OpenAI Discord
- Hermes Heats Up, Mistral Misses Mark: Debate heats up over performance of Hermes 2 versus Hermes 2.5, contrasting the enhanced benchmarks against Mistral's difficulty scaling beyond 8k without further pretraining.
- Discussions delve into the potential for merging tactics to improve AI models; meanwhile, Cloudflare's recent feature entices mixed reactions due to its capability to block AI data scraping bots.
- Custom GPTs Grapple With Zapier: Community members express their experiences with custom GPTs, discussing integration with Zapier to automate tasks despite encountering reliability issues.
- GPT-4o's faster response time stirs a debate over its trade-off with quality compared to GPT-4, while repeated verification demands frustrate users.
- Content Creation and Audience Engagement: Members discuss strategies for content creators to generate engaging content, intensifying interest in platform-specific advice, content calendar structures, and key metrics that determine success.
- AI engineers emphasize the important role of prompts for engaging content creation and customer acquisition, spotlighting members' ideas for innovative usage of current trends.
Unsloth AI (Daniel Han) Discord
- Hidden Talents of Qwen Revealed: Community members highlighted the Qwen Team's contribution with praises, emphasizing that the team's efforts are underappreciated despite creating excellent resources such as a new training video.
- The discussions around Qwen suggest a growing respect for teams that deliver practical AI tools and resources.
- GPU Showdown: AMD vs NVIDIA: A technical debate unfolded about the efficiency of AMD GPUs compared to NVIDIA for LLM training, noting NVIDIA's dominance due to superior software ecosystem and energy efficiency.
- Despite AMD's advancements, community consensus leaned towards NVIDIA as the pragmatic choice for LLM tasks because of library support, with a point raised that 'Most libraries don't support AMD so you will be quite limited in what you can use.'
- Phi-3 Training Troubles with Alpaca: AI engineers exchanged solutions for an error encountered during Phi-3 training with Alpaca dataset, pinpointing the lack of CUDA support in the
xformersversion being used and suggesting an update.- Inference speeds were compared for Llama-3 versus Phi 3.5 mini, noting Parallel debates that included suggestions for boosting efficiency, like referencing Tensorrt-llm for state-of-the-art GPU inference speed.
- Kaggle Constraints Provoke Innovation: Discussion in the community revolved around overcoming the Kaggle platform's disk space constraints, which led to a session crash after surpassing 100GB, but not before leveraging Weights & Biases to save critical data.
- This incident highlights continuous innovation by AI engineers even when faced with limited resources, as well as the importance of reliable checkpoints in data-intensive tasks.
- Empowering Job Seekers in AI Space: Members of the AI community proposed the creation of a dedicated job channel to streamline job seeking and posting, which reflects the dynamic growth and need for career-focused services in the industry.
- This initiative shows an active effort to organize and direct community efforts towards career development within the ever-growing AI field.
Latent Space Discord
- Encapsulating Complexity with LLM APIs: Rearchitecting coding structures utilizing LLM-style APIs streamlines complex tasks; a user emphasized the coder's pivotal role in systems integration.
- Creative combinations of APIs through zeroshot LLM prompts transform exhaustive tasks into ones requiring minimal effort, promising significant time economization.
- Exploring Governmental AI Scrutiny: The UK Government's Inspects AI framework targets large language models, provoking curiosity for its potential exploration and implications.
- Available on GitHub, it's position in the public sector spotlights a growing trend towards scrutinizing and regulating AI technologies.
- Podcast Episode Storms Hacker News: A user shared a podcast episode on Hacker News (Now on HN!) aiming to attract attention and drive engagement.
- Supportive community members boosted visibility with upvotes, reflecting an active and participative online discourse on Hacker News.
- Fortnite Revamps Fun Factor: Fortnite aims to charm players anew by nixing crossovers, sparked by a Polygon exposé discussing the game's dynamic.
- Immediate reaction surfaced through upvotes, with user endorsements like those from PaulHoule adding flames to the promotional fire.
- Merging AI Minds: AI Engineer World Fair’s buzz reached fever pitch as deep dives into model merging strategies captured enthusiasts, bolstered by tools like mergekit on GitHub.
- Hints at automated merging strategy determination sparked debate, though its intellectual robustness was tagged as questionable.
CUDA MODE Discord
- CUDA Credentials Clash: Debate ignited on the value of CUDA certification versus publicly available GitHub CUDA work when hiring, with community consensus leaning towards the tangible evidence of public repositories.
proven work that is public is always more valuable than a paperwas a key point raised, highlighting the merit of demonstrable skills over certificates.
- Compiling The Path Forward: Compiler enthusiasts are sought by Lightning AI, promising opportunities to work alongside Luca Antiga.
- Thunder project's source-to-source compiler aims to boost PyTorch models by up to 40%, potentially transforming optimization benchmarks.
- PyTorch Profilers Peek at Performance: Elevation of torch.compile manual as a missing link for optimization, with a shared guide addressing its roles and benefits.
- Another member suggested
torch.utils.flop_counter.FlopCounterModeas a robust alternative towith_flops, citing its ongoing maintenance and development.
- Another member suggested
- The Quantum of Sparsity: CUDA exploration took a turn towards the 2:4 sparsity pattern with discussions around the comparison of cusparseLT and CUTLASS libraries for optimized sparse matrix multiplication (SpMM).
- The debate continued around potential performance differences, with the general opinion skewing towards cusparseLT for its optimization and maintenance.
- LLM Lessons Laid Out: Ideation for LLM101n, a proposed course to guide users from the basics of micrograd and minBPE, towards more complex areas like FP8 precision and multimodal training.
- Discussion emphasized a layered learning approach, grounding in essentials before escalating to state-of-the-art model practices.
Nous Research AI Discord
- Critique Companions Boost AI Reward Models: Exploring the utility of synthetic critiques from large language models, Daniella_yz's preprint reveals potential for improving preference learning during a Cohere internship, as detailed in the study.
- The research suggests CriticGPT could move beyond aiding human assessments, by directly enhancing reward models in active projects.
- Test-Time-Training Layers Break RNN Constraints: Karan Dalal introduced TTT layers, a new architecture supplanting an RNN's hidden state with ML models shown in their preprint.
- Such innovation leads to linear complexity architectures, letting LLMs train on massive token collections, with TTT-Linear and TTT-MLP outperforming top-notch Transformers.
- Data Dialogue with Dataline: The launch of Dataline by RamiAwar delivers a platform where users query multiple databases like CSV, MySQL, and more via an AI interface.
- A fresh study titled The Geometrical Understanding of LLMs investigates LLM reasoning capacities and their self-attention graph densities; read more in the paper.
- GPT-4 Benchmark Fever: A noteworthy observation among a user circle is GPT-4's improved performance on benchmarks at higher temperatures, though reproducibility with local models seems challenging.
- Excitement stirs as in-context examples boost model performance, while BitNet architecture's efficiency propels a surge in interest despite memory-saving training complexities.
- RAG and Reality: Hallucinations Under the Lens: A new YouTube video casts a spotlight on LegalTech tools' reliability, unearthing the frequency of hallucinations via RAG models.
- Furthermore, helpful Wikipedia-style
reftags are proposed for citation consistency, and AymericRoucher's RAG tutorials receive acclaim for optimizing efficiency.
- Furthermore, helpful Wikipedia-style
Modular (Mojo 🔥) Discord
- WSL Leap - Windows Whimsy with Mojo: Upgrading WSL for Mojo** installation led to hiccups on older Windows 10 setups; the Microsoft guide for WSL proved invaluable for navigating the upgrade path.
- Python's dependency woes sparked conversation, with virtual environments being the go-to fix; a GitHub thread also opened on the potential for Mojo to streamline these issues.
- Round Robin Rumpus - Mojo Math Muddles: Rounding function bugs in Mojo drew collective groans; inconsistencies with SIMD highlighted in a community deep dive into rounding quiristics**.
- Amidst the int-float discourse, the 64-bit conundrum took center stage with Mojo's classification of
Int64andFloat64leading to unanticipated behavior across operations.
- Amidst the int-float discourse, the 64-bit conundrum took center stage with Mojo's classification of
- Stacks on Stacks - Masterful Matmul Moves: Members marveled at Max's use of stack allocation** within matmul to boost Mojo performance, citing cache optimization as a key enhancement factor.
- Autotuning surfaced as a sought-after solution to streamline simdwidth adjustments and block sizing, yet the reality of its implementation remains a reflective discussion.
- Libc Love - Linking Legacy to Mojo: A communal consensus emerged on incorporating libc functions into Mojo; lightbug_http demonstrated the liberal linking** in action on GitHub.
- Cross compiling capability queries capped off with the current lack in Mojo, prompting members to propose possible future inclusions.
- Tuple Tango - Unpacking Mojo's Potential: Mojo's lack of tuple unpacking for aliasing sparked syntax-driven speculations, as community members clamored for a conceptually clearer construct.
- Nightly compiler updates kept the Mojo crowd on their codes with version
2024.7.705introducing new modules and changes.
- Nightly compiler updates kept the Mojo crowd on their codes with version
Cohere Discord
- AI-Plans Platform Uncloaks for Alignment Strategies: Discussion unveiled around AI-Plans, a platform aimed at facilitating peer review for alignment strategies, mainly focusing on red teaming alignment plans.
- Details were sparse as the user did not provide further insight or direct links to the project at this time.
- Rhea's Radiant 'Save to Project' Feature Lights Up HTML Applications: Rhea has integrated a new 'Save to Project' feature, enabling users to directly stash interactive HTML applications from their dashboards as seen on Rhea's platform.
- This addition fosters a smoother workflow, poised to spark augmented user engagement and content management.
- Rhea Signups Hit a Snag Over Case Sensitivity: A snag surfaced in Rhea's signup process, where user emails must be input in lowercase to pass email verification, hinting at a potential oversight in user-experience considerations.
- The discovery accentuates the importance of rigorous testing and feedback mechanisms in user interface design, specifically for case sensitivity handling.
- Whispers of Cohere Community Bonds and Ventures: Fresh faces in the Cohere community shared their enthusiasm, with interests converging on synergistic use of tools like Aya for collaborative workflows and documentation.
- The introductions served as a launchpad for sharing experiences, enhancing Cohere's tool utilization and community cohesion.
- Youth Meets Tech: Rhea Embarks on Child-Friendly AI Coding Club Adventure: Members of a children's coding club are seeking new horizons by integrating Rhea's user-friendly platform into their AI and HTML projects, aiming to inspire the next generation of AI enthusiasts.
- This initiation represents a step towards nurturing young minds in the field of AI, highlighting the malleability of educational tools like Rhea for varying age groups and technical backgrounds.
Eleuther Discord
- T-FREE Shrinks Tokenizer Footprint: The introduction of T-FREE tokenizer revolutionizes embedding with an 85% reduction in layer size, achieving comparable results to traditional models.
- This tokenizer forgoes pretokenization, translating words through character triplet activation patterns, an excellent step toward model compactness.
- SOLAR Shines Light on Model Expansion: Discussions on SOLAR, a model expansion technique, heated up, with queries about efficiency versus training models from the ground up.
- While SOLAR shows performance advantages, better comparisons with from-scratch training models are needed for definitive conclusions.
- BitNet's Leap with 1-bit Weight Transformers: BitNet debuts a 1-bit weight Transformer architecture, balancing performance against resource usage with a memory and energy-friendly footprint.
- Weight compression without compromising much on results enables BitNet's Transformers to broaden utility in resource-constrained scenarios.
- QuaRot Proves Potent at 4-bit Quantization: QuaRot's research displayed that 4-bit quantization maintains near-full precision in LLMs while efficiently dialing down memory and processing requirements.
- The significant trimming of computational costs without severe performance drops makes QuaRot a practical choice for inference runtime optimization.
- Seeking the Right Docker Deployment for GPT-Neox: Queries about the effective use of Docker containers for deploying GPT-Neox prompted speculation on Kubernetes being potentially more suited for large-scale job management.
- While Docker Compose has been handy, the scale leans towards Kubernetes for lower complexity and higher efficiency in deployment landscapes.
LAION Discord
- JPEG XL Takes the Crown: JPEG XL is now considered the leading image codec, recognized for its efficiency over other formats in the field.
- Discussions highlighted its robustness against traditional formats, considering it for future standard usage.
- Kolors Repository Gains Attention: The Kolors GitHub repository triggered a surge of interest due to its significant paper section.
- Members expressed both excitement and a dose of humor regarding its technical depth, predicting a strong impact on the field.
- Noise Scheduling Sparks Debate: The effectiveness of adding 100 timesteps and transitioning to v-prediction for noise scheduling was a hot debate topic, notably to achieve zero terminal SNR.
- SDXL's paper was referenced as a guide amid concerns of test-train mismatches in high-resolution sampling scenarios.
- Meta's VLM Ads Face Scrutiny: Meta's decision to advertise VLM rather than releasing Llama3VLM stirred discontent, with users showing skepticism towards Meta's commitment to API availability.
- The community expressed concern over Meta prioritizing its own products over widespread API access.
- VALL-E 2's Text-to-Speech Breakthrough: VALL-E 2 set a new benchmark in text-to-speech systems, with its zero-shot TTS capabilities distinguishing itself in naturalness and robustness.
- Though it requires notable compute resources, its results on LibriSpeech and VCTK datasets led to anticipation of replication efforts within the community.
LangChain AI Discord
- Parsing CSV through LangChain: Users explored approaches for handling CSV files in LangChain, discussing the need for modern methods beyond previous constraints.
- LangChain's utility functions came to the rescue with recommendations for converting model outputs into JSON, using tools like
Json RedactionParserfor enhanced parsing.
- LangChain's utility functions came to the rescue with recommendations for converting model outputs into JSON, using tools like
- Async Configurations Unraveled: Async configuration in LangChain, specifically the
ensure_config()method withinToolNodeusingastream_events, was demystified through communal collaboration.- Crucial guidance was shared to include
configin theinvokefunction, streamlining async task management.
- Crucial guidance was shared to include
- Local LLM Experimentation Scales Up: Discussions heated up around running smaller LLM models like
phi3on personal rigs equipped with NVIDIA RTX 4090 GPUs.- Curiosity spiked over managing colossal models, such as 70B parameters, and the viability of such feats on multi-GPU setups, indicating a drive for local LLM innovation.
- LangGraph Cloud Service Stirs Speculation: Hints of LangGraph Cloud's arrival led to questions on whether third-party providers would be needed for LangServe API deployments.
- The community buzzed with the anticipation of new service offerings and potential shifts in deployment paradigms.
- In-browser Video Analysis Tool Intrigues: 'doesVideoContain', a tool for in-browser content scanning within videos, sparked interest with its use of WebAI tech.
- A push for community engagement saw direct links to a YouTube demo and Codepen live example, promoting its application.
OpenInterpreter Discord
- RAG's Skills Library Sharpens Actions: Elevating efficiency, a member pioneered the integration of a skills library with RAG, enhancing the consistency of specified actions.
- This advancement was shared with the community, incentivizing further exploration of RAG's potential in diverse AI applications.
- Securing the Perimeter with OI Team Vigilance: The OI team's commitment to security was spotlighted at a recent video meeting, cementing it as a forefront priority for operational integrity.
- Their proactive measures are setting a benchmark for collective security protocols.
- GraphRAG Weaves Through Data Clusters Effectively: A participant showcased Microsoft's GraphRAG, a sophisticated tool that clusters data into communities to optimize RAG use-cases.
- Enthusiasm for implementing GraphRAG was ignited, paralleled by a resourceful tweet from @tedx_ai.
- Festive Fundamentals at 4th of July Shindig: The OI team's 4th of July celebration generated camaraderie, showcasing new demos and fostering anticipation for future team gatherings.
- The team's spirit was buoyed, with hopes to establish this celebratory event as a recurring monthly highlight.
- O1 Units Gear Up for November Rollout: Timelines indicate the inaugural 1000 O1 units are slated for a November delivery, reflecting high hopes for their on-schedule arrival.
- Curiosity surrounds O1's conversational abilities, while community support shines with shared solutions to tackle a Linux 'typer' module hiccup.
OpenRouter (Alex Atallah) Discord
- Crypto Payments with Multiple Currencies: Community discussions focused on Coinbase Commerce's ability to handle payments in various cryptocurrencies, including USDC and Matic through Polygon.
- One user confirmed seamless transactions using Matic, endorsing its effectiveness.
- Perplexity API Underwhelms: Users noted that Perplexity API's performance pales in comparison to its web counterpart, missing vital reference links in the payload.
- Suggestions to circumvent this include using alternatives like Phind or directly scraping from GitHub and StackOverflow.
- Predicting the Generative Video Trajectory: A member queried about the anticipated trajectory of generative video regarding quality, execution speed, and cost within the next 18 months.
- No firm forecasts were made, emphasizing the inchoate nature of such generative mediums.
- OpenRouter's Options for Customized AI: OpenRouter's feature allowing users to deploy their own fine-tuned models was confirmed for those able to handle a substantial request volume.
- This has been recognized as a boon for developers desiring to impart bespoke AI functionalities.
- DeepInfra vs. Novita: A Price War: OpenRouter bore witness to a price competition between DeepInfra and NovitaAI, as they jostled for leadership in serving models such as Llama3 and Mistral.
- A humorous battle of undercutting prices by 0.001 has led to ultra-competitive pricing for those models.
LlamaIndex Discord
- Trading on Autopilot: LlamaIndex Drives AI Stock Assistant: An AI trading assistant exploiting Llama Index agent**, demonstrated in a tutorial video, performs varied tasks for stock trading.
- Its capabilities, powered by Llama Index's RAG abstractions, include predictive analyses and trades, with practical uses showcased.
- Crafting RAG Datasets: Tools for Richer Questions**: Giskard AI's toolkit aids in producing robust datasets for RAG, generating diverse question types showcased in their toolkit article.
- The toolkit surpasses typical auto-generated sets, providing a richer toolkit for dataset creation.
- Microservices, Maxi Potential: Agile Agents at Scale**: Llama-agents now offer a setup for scalable, high-demand microservices addressed in this insightful post.
- This agent-and-tools-as-services pattern enhances scalability and simplifies microservice interactions.
- Analyzing Analysts: LlamaIndex Powers 10K Dissection: The Multi-Document Financial Analyst Agent**, treating each document as a tool, tackles the analysis of finance reports like 10Ks, thanks to Llama Index's capabilities.
- Pavan Mantha demonstrates the efficiency of this analysis using Llama Index's features.
tinygrad (George Hotz) Discord
- Red Hesitation: Instinct for Caution?: A member raised concerns regarding team red's drivers for Instinct cards, creating hesitation around purchasing used Mi100s due to potential support issues.
- The conversation included a note that currently only 7900xtx cards are under test, implying solo troubleshooting for Instinct card users.
- API Evolution: Crafting Custom Gradients: A user proposed a new API for custom grads, wishing for a functionality akin to jax.customvjp, enhancing tensor operations for tasks like quantization training.
- The suggested improvement targets the replacement of current operations with lazybuffers in tinygrad.functions, advocating for direct tensor manipulation.
- Amplifying Learning: Multi-GPU Guidance: Users seeking knowledge on multi-GPU training with Tinygrad were directed to the beautiful_mnist_multigpu.py example, highlighting model and data sharding techniques.
- Details on copying the model with
shard(axis=None)and data splitting withshard(axis=0)were shared, aiding in efficient parallel training.
- Details on copying the model with
- Equality Engagement: Torch-Like Tensor Wars: Queries on tensor comparison methods analogous to
torch.allwere resolved by introducing the comparison through(t1 == t2).min() == 1, later culminating in the addition of Tensor.all to Tinygrad.- This feature parity progression was documented in this Tinygrad commit, facilitating easier tensor operations for users.
- Optimization Obstacle: Adam’s Nullifying Effect: Concerns were voiced over the Adam optimizer in Tinygrad causing weights to turn into NaNs after its second iteration step, presenting a stark contrast to the stability of SGD.
- This debugging dialogue remains active as engineers seek a solution to prevent the optimizer from deteriorating the learning process.
OpenAccess AI Collective (axolotl) Discord
- MInference's Agile Acceleration: A member highlighted Microsoft's MInference project, which purports to accelerate Long-context LLMs' inference, trimming latency by up to 10x on an A100.
- MInference employs novel techniques for approximate and dynamic sparse calculations, aiming to balance accuracy with performance efficiency.
- Yi-1.5-9B Batches Up with Hermes 2.5: Updates on Yi-1.5-9B-Chat revealed it was fine-tuned using OpenHermes 2.5, with publicly shared models and quantizations that excelled on the AGIEval Benchmark.
- The enhanced model trained on 4x NVIDIA A100 GPUs for over 48 hours impresses with its 'awareness', and plans are in motion to push its context length to 32k tokens using POSE.
- Chat Template Conundrums for Mistral: A discussion arose on the best chat_template to use for Mistral finetuning in Axolotl, with the answer depending on dataset structure.
- Community consensus pointed towards utilizing the "chatml" template, with YAML configuration examples offered to guide members.
LLM Finetuning (Hamel + Dan) Discord
- MLOps Maneuvers and FP8 Puzzles: Community members shared insights, with one referencing a blog post focusing on MLOps implementation, and another discussing troubles with FP8 quantization in distributed vllm inference.
- Solutions for FP8's sensitivity issues were identified, resulting in corrected outputs and a GitHub thread provides more context for those tackling similar issues.
- Dissecting Model Integrations: A member is evaluating the integration of traditional tools like Transformers & Torch against established models from OpenAI and Anthropic.
- The conversation centers around finding an optimal approach that offers both effectiveness and seamless integration for project-specific needs.
- Crunch-Time for Credit Claims: Discussions in the #credits-questions channel made it clear: credit claims are closed permanently, signaling an end to that benefit.
- It was highlighted that this termination of credit accumulation applies universally, sparing no one and shutting down avenues for any future claims.
- Replicate Credits Countdown: A conversation in the #predibase channel revealed a one-month availability of first 25 Replicate credits, a critical update for users.
- This limited-time offer seems to be a pivotal point in usage strategies, especially for those counting on these initial credits for their projects.
Interconnects (Nathan Lambert) Discord
- Interconnects Bot: Room for Enhancement: A user expressed that the Interconnects bot is performing well, but has not seen significant changes in recent summarization outputs.
- The user advocated for notable updates or enhancements to boost the Interconnects bot's functionality.
- RAG Use Cases and Enterprise Discussions: Members discussed Retrieval Augmented Generation (RAG) models, highlighting their developing use cases within enterprises.
- Some participants suggested RAG might enhance the use of internal knowledge bases, while others reminisced about the model's hype during the early AI boom.
- Rummaging Through Early Reflections on RAG: Conversations touched on the ancestral excitement around RAG, with shared sentiments about the initial exaggerated expectations.
- The exchanges revealed a shared perspective that the early hype has not fully translated into extensive enterprise adoption.
- Cost Efficiency and Knowledge Retrieval: An Enterprise View: The talk revolved around how RAG could aid in cost efficiency within enterprise models.
- A stance was put forward that such models, by tapping into vast internal knowledge repositories, could cultivate new technological avenues for businesses.
Alignment Lab AI Discord
- Buzz Gains Admirers & Teases Release: Enthusiasm for Buzz was palpable in the group, with a member praising its capabilities and hinting at more to come.
- Autometa teased an upcoming release, sparking curiosity within the community.
- FPGA Focus: Autometa's Upcoming Meeting: Autometa announced plans to convene and discuss novel applications in the FPGA sphere, indicating several key topics for the agenda.
- Members were invited to engage and share their insights on the versatile uses of FPGAs in current projects.
- Opening Doors: Calendly Scheduling for Collaboration: To facilitate discussions on AI alignment, Autometa shared an open Calendly link for the community.
- The link serves as an open invitation for scheduling in-depth discussions, offering a platform for collaborative efforts.
LLM Perf Enthusiasts AI Discord
- Flash 1.5 Gaining Traction: Member jeffreyw128 expressed that Flash 1.5 is performing exceptionally well.
- No additional context or detailed discussions were provided on the topic.
- Awaiting Further Insights: Details are currently sparse regarding the technical performance and features of Flash 1.5.
- Community discussions and more in-depth analysis are expected to follow as the tool gains more attention.
AI Stack Devs (Yoko Li) Discord
- Sprite Quest: Google Image Galore: A member mentioned sprites were sourced from random Google image searches, adhering to the quick and varied needs of asset collection.
- The focus was on acquiring diverse sprites without purchase, while tilesets were the sole paid assets.
- Tileset Trade: The Only Expense: Conversations revealed that the only assets that were financially invested in were tilesets, highlighting a cost-conscious approach.
- This distinction underscores the methodical selection of assets, with money spent solely on tilesets and sprites obtained freely via search engines.
MLOps @Chipro Discord
- EuroPython Vectorization Talk: A user expressed their participation in EuroPython, hinting at a forthcoming talk focused on vectorization.
- Interested guild members might attend to gain insights into the role of vectorization in Python, an important aspect for AI engineering.
- Community Engagement at Conferences: The mention of EuroPython by a user highlights the community's outreach and active presence at Python conferences.
- This encourages networking and knowledge sharing among Python practitioners in the AI and Machine Learning fields.
Mozilla AI Discord
- Google's Gem Sparkles in Size and Performance: Google's Gemma 2 9B has entered the arena as an open-source language model, noted for its robust performance.
- Despite its smaller scale, Gemma 2 9B challenges heavyweights like GPT-3.5, suitable for use in environments with limited resources.
- Lambda Lift-Off: Gemma 2 Reaches Serverless Heights: The community explored serverless AI inference by integrating Google's Gemma 2 with Mozilla's Llamafile on AWS Lambda, as demonstrated in this tutorial.
- This serverless methodology enables deploying Gemma 2 9B efficiently in low-resource settings, including mobile devices, personal computers, or localized cloud services.
DiscoResearch Discord
- Models Fusion Forge: A member proposed using Hermes-2-Theta-Llama-3-70B as a foundation for crafting the Llama3-DiscoLeo-Instruct-70B model.
- The ensuing conversation hinted at the advantage of merging capabilities from both models to amplify performance.
- Enhancement Speculations: Engineers considered the speculated benefits of model integration focused on Hermes-2-Theta-Llama-3-70B and Llama3-DiscoLeo-Instruct.
- The dialogue revolved around potential strides in AI capabilities through strategic fusion of distinct model features.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!