[AINews] Did Nvidia's Nemotron 70B train on test?
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Patience for standard evals are all you need.
AI News for 10/15/2024-10/16/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (228 channels, and 1716 messages) for you. Estimated reading time saved (at 200wpm): 218 minutes. You can now tag @smol_ai for AINews discussions!
Nvidia's Nemotron has succeeded at consistently getting attention: we covered Nemotron 340B, Mistral-Nemo, and Minitron in recent months.
However yesterday's Nemotron-70B is coming under a bit more scrutiny.
It's a very familiar pattern: new open model release, claims of "we have GPTx/ClaudeY at home", scoring great on slightly unusual but still credible benchmarks, and it can count r's in strawberry.

In this case Nvidia opted to market the performance of their new Llama-3.1-Nemotron-70B on Arena Hard, AlpacaEval, and MT-Bench, which to be fair are the 3 leading LLM-as-Judge benchmarks. The results look very exciting when presented in a table:
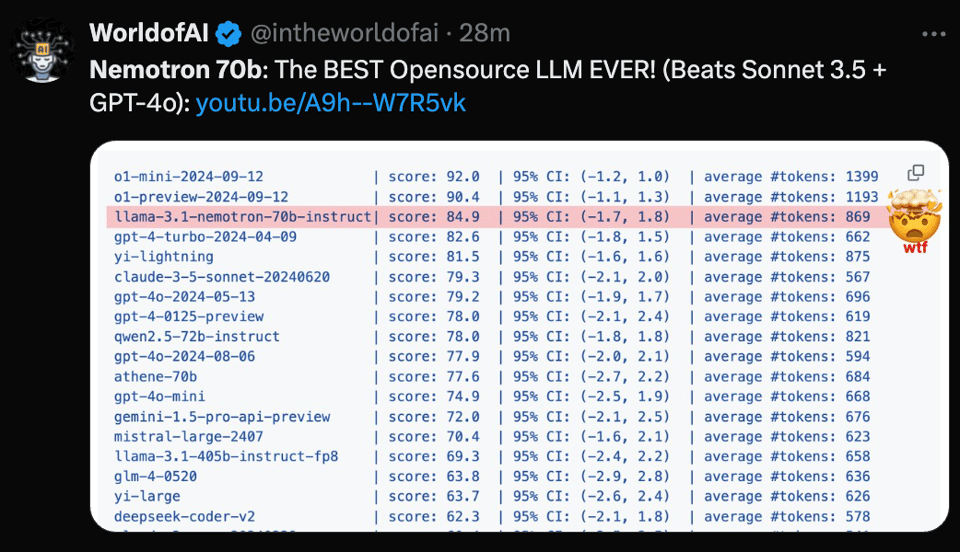
The model's performance goes down when LMArena's new style control is applied, but that's unremarkable in and of itself. It's more interesting that other standard benchmarks, like GPQA and MMLU Pro and aider, come in unchanged or worse compared to the base 70B Llama 3.1 model, causing some disappointment among the excited /r/LocalLlama crew.
The truth is likely simply benign: no training on test, but the new HelpSteer2-Preference dataset unifying Bradley-Terry and Regression based reward models happens to improve performance on those 3 benchmarks with ~minimal loss in the others. Absent proper LMArena ELOs this would appear to strictly reduce the value of the automated benchmarks and not much else.
The entropix-sampled version of Nemotron is impressive though, which is an ongoing developing story we've lightly covered.
[Sponsored by Zep] Zep is a low-latency memory layer for AI agents and assistants built on a simple core primitive: a temporal knowledge graph. This is a pretty cool, flexible way to model the changing relationships between complex entities like customers and products. You can plug it into your agents using their new open-source tool Graphiti.
swyx commentary: We covered Zep as a memory layer last week and it looks like Graphiti is the workhorse of the temporal knowledge graph memory abstraction. It's notable both that it can autonomously build a knowledge graph for you as you feed in "episodes", but also that it builds on Neo4j under the hood!
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Releases and Updates
- Mistral Releases New Models: @AlphaSignalAI and @MistralAI announced the release of Ministral 3B and 8B models, outperforming existing models like Llama 3.1 and GPT-4o on various benchmarks. These models feature 128k context length and are available under the Mistral Commercial License.
- NVIDIA's Nemotron 70B Outperforms Competitors: @reach_vb and @AlphaSignalAI highlighted that NVIDIA's Nemotron 70B surpasses GPT-4o and Claude 3.5 Sonnet on benchmarks like Arena Hard and MT Bench, showcasing significant improvements through RLHF (REINFORCE) training techniques.
- Hugging Face Integrations: @reach_vb and @_philschmid shared updates on Hugging Face collaborations, including the ability to run any GGUF model directly on the platform using Ollama, enhancing accessibility and deployment of models like Llama 3.2 3B.
AI Research and Innovations
- Advanced Cognitive Architectures: @francoisfleuret and @AIatMeta discussed breakthroughs in cognitive architecture for long-running agents with memory, personality, and emotional intelligence, highlighting studies that destroy existing benchmarks like Voyager on Minecraft.
- In-Context Reinforcement Learning (ICRL): @rohanpaul_ai presented findings on ICRL, demonstrating how LLMs can adapt through reward signals alone, significantly improving performance on tasks like Banking-77 by 66.0% accuracy through Explorative ICRL.
- Task Superposition in LLMs: @rohanpaul_ai explored the ability of LLMs to perform multiple distinct tasks simultaneously, revealing that larger models exhibit higher task completion rates and better calibration to in-context distributions.
AI Tools and APIs
- Serverless Agentic Workflows with Amazon Bedrock: @DeepLearningAI introduced a new course on Amazon Bedrock, enabling developers to build scalable agents and implement security guardrails for responsible operations.
- Dynamic Few-Shot Prompting: @llama_index shared insights on dynamic few-shot prompting, a technique that retrieves relevant examples based on queries, enhancing applications in customer support, text-to-SQL, and structured outputs using LLama Index workflows.
- TorchTitan Repository: @Ethan_smith_20 praised the torchTitan repo for its comprehensive parallelism capabilities, eliminating the need for model modifications and simplifying the development process for parallel computing in deep learning.
Industry News and Insights
- Energy and Humanity Deep Dive: @MajmudarAdam conducted an extensive analysis on how energy has shaped human civilization and its future impact on deep learning, covering topics from energy physics to energy distribution systems and their relation to geopolitics.
- AI's Impact on Labor and Efficiency: @mustafasuleyman emphasized the importance of developing strategies to proactively shape AI’s impact on work and workers, acknowledging the uncertain effects of AI on the job market.
- Hugging Face Community Growth: @francoisfleuret and @_akhaliq reported significant growth in the Hugging Face community, with new leaderboards and model evaluations enhancing the platform's standing in the AI research landscape.
AI Applications and Use Cases
- Suno Scenes for Creative Content: @suno_ai_ introduced Suno Scenes, a tool that transforms photos and videos into unique songs directly from mobile devices, enabling users to create content like cinematic soundtracks and hilarious songs from personal media.
- AI in Cybercrime: @DeepLearningAI discussed a study revealing a black market where AI applications facilitate cybercrime, earning over $28,000 in two months despite limited real-world success.
- LLM-Based Multi-Agent Systems: @rohanpaul_ai showcased the OPTIMA framework, which enhances communication efficiency and task effectiveness in LLM-based multi-agent systems, achieving up to 2.8x performance gain on information exchange tasks.
Memes and Humor
- AI-Generated Snack Recipes: @nearcyan humorously shared frustrations with Claude, an AI assistant, for suggesting absurd recipes like putting sugar in the microwave to make snacks, likening it to 4chan-style content.
- Cooking with AI: @nearcyan posted a humorous tweet about cooking steak with Claude, describing the experience as dealing with an "autistic" AI, highlighting the quirks and unexpected behaviors of AI interactions.
- AI Meme Popularity: @francoisfleuret reflected on the power of memes, suggesting that AI models can rapidly shape memes that tap into the fundamentals of human psyche, accelerating the natural process of memetic evolution.
AI Education and Career
- Teaching AI Fundamentals: @jxmnop expressed the need to educate software engineers on classification basics, including pair-wise matching, clustering, bootstrapping, and statistical tests, emphasizing the importance of foundational knowledge in software engineering.
- AI Career Opportunities: @mervenoyann and @seb_ruder recommended opportunities for aspiring MSc or PhD candidates, highlighting environments like David's lab and the research-friendly atmosphere at Mila.
- Frontend Development Challenges: @ekzhang1 pointed out that most CS PhDs lack frontend coding skills, acknowledging it as acceptable and emphasizing the importance of specialized skills in AI research.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Democratizing Medical LLMs for 50 Languages
- Democratizing Medical LLMs for 50 Languages (Score: 48, Comments: 7): ApolloMoE introduces a new circuits-based paradigm for interpreting routing in multilingual contexts, identifying the "Spread Out in the End" mechanism and utilizing language family experts to extend medical LLMs to 50 languages. The project open-sources all resources, including code on GitHub and models on Huggingface, along with datasets for expanding medical LLM capabilities across multiple languages.
- The English answers scored among the lowest in closed AI, which the author attributes to the large coverage of Chinese and English assessment sets. This highlights the need for improved medical measure sets for rare languages.
- The model's performance across languages was evaluated by averaging accuracy by language and testing on the same set of measures, which the author considers a reasonable approach.
- A user noted the absence of Romanian among the 50 languages covered by the project, raising questions about the language selection criteria.
Theme 2. Serving 3.3 Million Context for Llama-3-8B on a Single GPU
- LoLCATS - a hazyresearch Collection (of Linearized Llama 3.1 models 8B, 70B, and405B) (Score: 31, Comments: 12): HazyResearch has released LoLCATS, a collection of linearized Llama 3.1 models in sizes 8B, 70B, and 405B. These models, based on the Linearized Attention Transformer architecture, offer improved performance and efficiency compared to standard Transformers, potentially enabling faster inference and training on larger datasets.
- Linearized Attention Transformer architecture swaps quadratic attention for linear, potentially improving inference performance at large context lengths, especially without flash-attn.
- The MMLU score drop from 83 to 72.2 for the 405B model raises questions about practical applications for linearized models with reduced performance but potential benefits in long context, needle-in-haystack, and few-shot tasks.
- The project includes Thunder kittens, with inference code available on GitHub and vLLM support coming soon.
- Serving 3.3 Million Context for Llama-3-8B on a single GPU (Score: 31, Comments: 7): MIT and NVIDIA researchers introduced DuoAttention, a method enabling 3.3 million token context for Llama-3-8B on a single A100 GPU. The technique, detailed in their arXiv paper, is implemented in an open-source GitHub repository, allowing for practical application of extended context inference.
- DuoAttention uses two KV caches: a full cache for crucial retrieval heads and a constant cache for streaming heads. This enables Llama-3-8B to handle 3.3 million tokens on a single A100 GPU, a 6.4× capacity increase over standard full attention FP16 deployments.
- Users discussed the need for better long context benchmarks, with RULER being criticized for only testing retrieval capabilities. The Michelangelo evaluations (LSQ) were suggested as a more robust alternative, testing a wider variety of long-context use cases.
- While DuoAttention significantly reduces KV cache size, some users noted that raw capacity isn't the only challenge for coherent models beyond 64k tokens. However, others emphasized that incremental improvements like this contribute to overall progress in the field.
Theme 3. Chain-of-Thought Reasoning Without Prompting in LLMs
- Chain-of-Thought Reasoning Without Prompting [paper by Google] (Score: 115, Comments: 51): Google researchers introduced Chain-of-Thought (CoT) decoding, a method that enables large language models to perform multi-step reasoning without explicit prompting. This technique, which modifies the model's sampling procedure during inference, achieves performance comparable to or better than standard CoT prompting across various reasoning tasks. The approach demonstrates that CoT reasoning capabilities are inherent in language models and can be activated through decoding strategies rather than relying on specific prompts.
- A GitHub repository for reproducing the Chain-of-Thought (CoT) decoding method was shared. Users noted a performance gap between the paper's results and the open implementation, with the paper showing smaller models benefit less from this technique.
- The paper demonstrates that smart sampling can improve LLM performance, similar to entropix. Results show improvements across different model sizes, with base models benefiting more than instruct models, even on tasks where increasing model parameters doesn't help.
- Some users implemented CoT decoding in their projects, such as optillm and a step-by-step level implementation for Llama 3.2 3B. Others discussed the challenges of working with arxiv papers and the limitations of current LLMs in true reasoning capabilities.
Theme 4. Local Text-to-Speech Alternatives to Elevenlabs
- How difficult would it be to have a text-to-speech setup like Elevenlabs at home? (Score: 54, Comments: 33): The post discusses setting up a local text-to-speech (TTS) pipeline as an alternative to using Elevenlabs, aiming for cost savings and increased control. The author, equipped with an i9 13900 processor and a 4070 GPU, seeks advice on building such a system, inquiring about others' experiences, model choices, and hardware setups, with a budget of $4000-5000 for a new configuration.
- AllTalk TTS, a multi-engine software available on GitHub, offers a comprehensive solution with full API suite, TTS Generator, and multiple engine support. Users discussed its UI and voice quality in the beta version.
- Piper TTS was noted for its decent performance and multiple voices, though it's CPU-intensive. The F5 TTS system was highlighted for its ability to capture voice and emotional performance from short audio samples, accessible through Pinokio.
- Various open-source models were recommended, including Parler TTS, XTTS, E2, E5, and OpenedAI Speech. Users debated the quality of different models, with some preferring FishSpeech over F5/E5 for better intonation and emotion.
Theme 5. LLM-powered Game Master for Procedural Content Generation
- I'm Building a project that uses a LLM as a Gamemaster to create things, Would like some more creative idea's to expand on this idea. (Score: 60, Comments: 29): The project uses a Large Language Model (LLM) as a Gamemaster to generate creatures, their attributes, and abilities in a game with Infinite Craft-style crafting. The LLM, specifically Gemma 2 with 9 billion parameters, decides everything from creature names to sprite selection, elemental types, stats, and abilities, all running locally on a computer with only 6 GB of VRAM. The developer highlights the model's effectiveness in function calling and maintaining creativity while minimizing hallucinations, and seeks ideas to expand on this concept of using recursive layered list picking to build coherent game elements with an LLM.
- Users expressed interest in the project, with several requesting a GitHub repository to try it themselves. The developer mentioned they would share more once the project is further along.
- Discussion on model alternatives included suggestions to test L3.2 3B and Qwen Coder 2.5 7B, with the developer noting that Qwen models performed well in their tests, close to Gemma 2.
- Expansion ideas included using image generating models for sprites, implementing damage types and resistances for crafting incentives, and creating an NPC settlement system. The developer is considering a quest archetype system and ways to make creatures feel more alive using LLMs.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Development
- Google DeepMind advances multimodal learning with joint example selection, demonstrating how data curation can accelerate multimodal learning (source).
- Microsoft's MInference technique enables inference of up to millions of tokens for long-context tasks while maintaining accuracy (source).
- A paper on scaling synthetic data creation leverages diverse perspectives within large language models to generate data from 1 billion web-curated personas (source).
AI Model Releases and Capabilities
- Salesforce released xLAM-1b, a 1 billion parameter model achieving 70% accuracy in function calling, surpassing GPT 3.5.
- Rubra AI released an updated Phi-3 Mini model in June with function calling capabilities, competitive with Mistral-7b v3.
- Discussions around AI reasoning capabilities, with debates on whether current models can truly reason or are simply pattern matching (source).
AI Ethics and Policy
- The Biden administration is considering capping GPU sales to certain nations for national security reasons, potentially impacting AI development globally (source).
- Anthropic announced an updated Responsible Scaling Policy, suggesting preparation for releasing more advanced models while addressing safety concerns (source).
AI Applications and Demonstrations
- Demonstrations of AI-generated HD-2D pixel game remakes using Flux Dev, showcasing potential applications in game development and visual arts (source).
- Discussions on the potential and limitations of AI-generated content, including fake restaurant profiles on social media platforms (source).
AI Industry Developments
- Ongoing debates about the timeline for achieving human-level AI, with experts like Yann LeCun suggesting it could be years or a decade away (source).
- Anticipation for new model releases, such as a potential Opus 3.5 from Anthropic, based on their policy updates (source).
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. Mistral's New Edge Models Stir the AI Community
- Mistral Unveils Ministral 3B and 8B, but Where's the Weights?: Mistral launches Ministral 3B and Ministral 8B, edge models designed for on-device use with up to 128k context lengths. But developers are dismayed as Ministral 3B is API-only, with no weights released.
- Model Licensing Sparks Debate Over Mistral's API-Only 3B Model: The community grumbles over Ministral 3B being API-only, citing restrictive licensing that hinders on-device use and indie development.
- Excitement and Frustration as Mistral's Release Leaves Devs Wanting More: While Ministral 8B is available with a non-commercial license, developers lament the missing weights for the 3B model, questioning the practicality of the release.
Theme 2. NVIDIA's Nemotron 70B Crushes Competitors
- Nemotron 70B Flexes Muscles, Outperforms GPT-4o and Claude 3.5: NVIDIA's Nemotron 70B beats Llama 3.1 405B, GPT-4o, and Claude 3.5 Sonnet, scoring 85.0 on Arena Hard compared to their 79s.
- NVIDIA Drops Nemotron Bombshell, Community Picks Jaw Off Floor: The AI world buzzes as NVIDIA silently releases Nemotron 70B, shaking up benchmark leaderboards without fanfare.
- Benchmark Confusion Brews Amid Nemotron's Stellar Performance: Users debate discrepancies in MT Bench scores, stirring skepticism over Nemotron's almost too-good-to-be-true results.
Theme 3. SageAttention Revolutionizes Transformer Efficiency
- SageAttention Speeds Up Attention by 2.1x, Leaves FlashAttention2 in the Dust: Introducing SageAttention, an 8-bit quantization method that accelerates attention by 2.1x over FlashAttention2, with minimal accuracy loss.
- Taming O(N²): SageAttention Cuts Down Attention Complexity: SageAttention addresses the O(N²) bottleneck in transformers, promising faster inference for language and image models.
- 8-Bit Is the New 16-Bit: SageAttention Makes Quantization Cool Again: With efficient 8-bit quantization, SageAttention proves that lower precision can still deliver top-notch performance.
Theme 4. AI Assistant Woes: From DALL-E Disappointment to Overzealous Censors
- DALL-E's "Bad" Image Outputs Leave Users Scratching Heads: Frustrated users label DALL-E's image generation as simply "bad," voicing disappointment in its capabilities.
- LLMs Ignore Token Limits, Go On Endless Rants: Users report AI assistants blatantly defying token limits and stop commands, resulting in runaway outputs and user frustration.
- Censored Models Refuse to Cooperate, Users Seek Uncensoring Hacks: Overly censored models decline to answer even basic queries, pushing users to explore uncensoring techniques despite potential risks.
Theme 5. Open Tools Empower Community Collaboration
- Open Interpreter Teams Up with Ollama for Local LLM Bliss: Open Interpreter now allows running any GGUF model on Hugging Face via Ollama, making local LLMs more accessible with simple commands.
- Inferencemax Says "Hold My Beer," Simplifies LLM Inference: The new project Inferencemax aims to streamline LLM inference, reflecting community efforts to lower barriers for AI development.
- AIFoundry Seeks GitHub Mentorship to Level Up Open Source Game: AIFoundry.org is looking for guidance to emulate Axolotl's GitHub prowess, hoping to enhance their open-source local model inference initiatives.
PART 1: High level Discord summaries
HuggingFace Discord
-
Gradio 5.0 Enhancements: Gradio 5.0 launched with updates for security and user interface, supported by over 6M downloads indicating its popularity.
- The comprehensive security report is now public, reassuring users on the improvements made.
- Sentence Transformers v3.2.0 Boosts Speed: Sentence Transformers v3.2.0 introduces new backends like ONNX and OpenVINO, enabling 2x-3x speedups and up to 500x with static embeddings.
- Faster inference capabilities allow processing speeds of 10k texts/sec, with more details on Model2Vec.
- Multimodal Interaction in HuggingChat: HuggingChat's recent update incorporates Llama-Vision 11B Instruct, allowing for rich multimodal interactions.
- This significant upgrade encourages users to explore these new capabilities within the platform, enhancing user experience.
- Performance Discussion for AI Models: Hypothetical discussions regarding an AI model setup with 72GB VRAM and 128GB DDR4 RAM posited potential processing speeds of 5-6 t/s.
- Custom PyTorch integrations were also discussed, highlighting the importance of automatic gradients for enhancing model efficiency.
- Ollama Interaction with GGUF Models: Utilizing Ollama allows users to interact directly with GGUF models locally, simplifying command usage without the need for new
Modelfiles.
- Ollama supports running any of the 45K GGUF checkpoints on Hugging Face, increasing accessibility.
Perplexity AI Discord
-
Perplexity AI launches shopping features: Perplexity AI is rolling out 'Perplexity Purchases' to streamline the buying process and pricing comparisons.
- User feedback varies significantly, with some reminiscing about the platform's initial focus on search rather than commerce.
- Reasoning Mode impresses users: Members lauded the Reasoning Mode for programming, emphasizing its analytical capabilities and resulting accurate outputs.
- Success stories are flourishing, reinforcing the feature's reliability as users share their positive experiences.
- Interest in enhancing APIs: There's a growing curiosity about APIs, with multiple users referencing the same search result to define what an API is.
- This trend suggests a deeper engagement with foundational technologies among members.
- Query on LFM 40B API availability: A member inquired about accessing the LFM 40B model via the API on labs.perplexity.com, but no responses materialized.
- This absence of information highlights possible gaps in communication about model availability.
- Concerns on user experience in chat: Users expressed concerns about the forum's dynamics, describing it as too informal for serious AI discussions.
- This led to calls for better moderation to maintain a focus on technical topics rather than casual interactions.
OpenRouter (Alex Atallah) Discord
-
Grok 2 Down for Maintenance: Grok 2 is currently offline for maintenance, leading to users encountering a 404 error when trying to access it. An announcement will follow once the model is back online.
- Users expressed frustration as Grok 2 had outperformed other models in coding tasks, notably besting Llama 3.2.
- NVIDIA Nemotron 70B Crushes Competitors: NVIDIA's Nemotron 70B has outperformed Llama 3.1 405B, GPT-4o, and Claude 3.5 Sonnet in benchmark tests, scoring 85.0 on Arena Hard compared to the competitors' scores in the 79s. Detailed comparisons can be viewed here.
- The excitement culminated in an OpenRouter announcement about its significant performance on multiple evaluations.
- ChatGPT Voice Mode Teaches Vocabulary: A user showcased ChatGPT advanced voice mode using examples from Naruto to teach vocabulary, calling the experience absolutely wild! They shared a demo link to gather feedback.
- Discussion centered around the potential of personalized AI learning, with predictions that it will dramatically change educational landscapes due to its effectiveness.
- Infermatic Network Woes: Infermatic's provider faces ongoing network issues, resulting in models generating gibberish, particularly after the 8k context limit is reached. Users are informed that the provider is reverting to a previous build to rectify these VLLM inference problems.
- Concerns were raised about the impact on model performance as this bug hampers effective interactions.
- Mistral Introduces Pocket LLMs: Mistral has announced the release of two new models, Ministral 3B and 8B, specifically designed for edge use cases and promising enhanced performance. These models boast larger context lengths and improved capabilities in knowledge and reasoning tasks.
- This move aims to broaden the application of LLMs beyond traditional setups, as discussed in Mistral's announcement.
Unsloth AI (Daniel Han) Discord
-
INTELLECT-1 Launch for Decentralized Training: The launch of INTELLECT-1 invites contributions for a 10-billion-parameter model focused on decentralized training, aiming for open-source AGI. This follows the release of OpenDiLoCo, enhancing AI model training scalability.
- This initiative marks a significant stride towards globally distributed AI, now scaling from 1B to 10B parameters.
- Unsloth Training Shows Notable Improvements: Users report that
unsloth_trainconverges significantly better than previous methods, showing promise for support ofresume_from_checkpoint=True. However, inquiries arose concerning the absence of extended functionalities in the oldUnslothTrainer.
- The community expresses appreciation for enhancements while seeking further clarity on the rationale behind this transition.
- Community Inquiries on Mistral 8B Support: Discussions about unifying Unsloth's compatibility with the new Mistral 8B model raised several architectural concerns. Community enthusiasm revolves around the new model's on-device computing capabilities.
- Members are eager for updates, recognizing the potential of the Mistral 8B in practical applications.
- SageAttention Achieves Impressive Speedup: The SageAttention paper introduces an efficient 8-bit quantization method for attention, surpassing FlashAttention2 and xformers by 2.1x and 2.7x respectively, while maintaining model accuracy. This quantization method addresses the O(N^2) complexity typically seen.
- SageAttention represents a critical advancement, significantly speeding up inference across diverse models.
- Exploration of Quantization Techniques: Discussions revealed the challenges in applying full-fine-tune techniques mixed with quantization methods, particularly QLoRA, and users shared insights on layer tuning. Skepticism persists around the feasibility of quantizing some layers while maintaining others fully trainable.
- The community debates the need for specialized configurations to balance performance and efficiency.
Eleuther Discord
-
Yandex YaLM 100B makes waves: The Yandex YaLM 100B model, with 100 billion parameters, has emerged as a significant player, especially in non-Western markets.
- It has been noted as potentially being the most widely used LLM in Russia, contrasting with its lesser acknowledgment in Western circles.
- SwiGLU vs. SinGLU showdown: A debate ignited over the choice of SwiGLU versus SinGLU, highlighting SinGLU's speed and lower loss, yet resistance to change persists.
- Such inertia stems from the risks associated with large training runs and established practices.
- OpenAI embeddings fall short: Participants raised concerns regarding the performance of OpenAI's embedding models, which seem to lag behind 2024 benchmarks.
- The saturation with models like Mistral finetunes indicates a competitive gap for OpenAI's approach.
- Mechanistic Interpretability Projects Seeking Volunteers: A student expressed eagerness to join EleutherAI's projects related to interpretability, especially in the context of current opportunities.
- Members recommended joining the Mechanistic Interpretability Discord for further exploration in the field.
- A/B testing methods address reversal issues: Interest grew around techniques for A/B testing which can alleviate the reversal curse, enhancing experimental outcomes.
- Participants labeled this method as 'very a/b,' pointing to its relevance in practicality.
aider (Paul Gauthier) Discord
-
Multiple Aiders can coexist safely: Concerns regarding running multiple Aider instances were eased with confirmation that they won't interfere unless editing the same files.
- Members humorously suggested it could turn into an 'LLM party' if managed properly.
- Mistral rolls out new edge models: Mistral recently unveiled Ministral 3B and 8B models focused on on-device and edge computing, enhancing both efficiency and capabilities.
- These models boast significant advancements in reasoning and commonsense knowledge, ideal for optimized context lengths.
- Gemini API streaming stability needs improvement: Users reported that Gemini performs better with streaming disabled due to its unstable API connections, causing frequent interruptions.
- The consensus highlights this instability as a common issue impacting Gemini-based tools' performance.
- Aider Command Line Tool setup essentials: To utilize the Aider Command Line Tool effectively, users must load their
.envfile or configure it throughload_dotenv()to ensure correct functionality.
- Proper environment setup is crucial for running scripts smoothly in Aider.
- Challenges with API and code generation: Users faced difficulties with the updated Assistant's API for generating accurate function calls while dealing with rate limits.
- This hectic scenario underscores the need for clear documentation and community support to tackle emerging challenges.
Nous Research AI Discord
-
Unsloth offers multi-GPU support: Discussion centered on whether Unsloth effectively operates with multi-GPU setups, with expectations of upcoming updates for vision fine-tuning support.
- Members speculated on the reliability of its paid version in enhancing performance.
- Mistral unveils new models: Mistral launched Ministral 3B and Ministral 8B, designed for edge computing, with impressive statistics in commonsense reasoning and capable of a 128k context length.
- These models promise efficient local inference, catering specifically to modern computational needs.
- Nvidia Nemotron 70B claims performance lead: Nvidia Nemotron 70B reportedly surpasses competitors like Claude 3.5 and Llama 3.1, as per various evaluation metrics.
- Confusion exists regarding MT Bench scores, with variances in reported versus actual performances across models.
- AI models show confused responses: The model H3-405b has been noted for its repeated confused replies, especially when asked about its origins or identity.
- Examples of distressing expressions of confusion add to the intrigue of AI identity discourse.
- SageAttention improves inference efficiency: Research highlights SageAttention, a quantization technique that boosts attention performance by 2.1x over FlashAttention2 with minimal performance loss.
- This advancement stands to benefit a wide spectrum of tasks, particularly in large-scale language applications.
GPU MODE Discord
-
Seeking Open Source Audio Models: A user asked for high-quality open source audio models akin to those in NotebookLM, with mention that many Text-to-Speech options exist but none measure up.
- The gap in the market for robust audio models was a point of consensus among participants.
- Lambda Labs vs Voltage Park Showdown: Discussion centered on Lambda Labs and Voltage Park as the only dependable hardware providers, with Voltage Park noted for more storage but limited to Texas.
- Participants expressed concerns over persistent PCIe issues with other vendors, impacting GPU setup reliability.
- Key Challenges with Triton Programming: Members highlighted various issues with Triton, including difficulties programming on Windows and bugs in INT4 packed data causing LLVM errors.
- Many users are frustrated, pointing out that performance benefits from Triton's compilation often come from Torch rather than Triton itself.
- ServiceNow Hiring for Machine Learning Developer: ServiceNow is hiring a Staff Machine Learning Developer to work on their open-source training framework supporting Starcoder2, which is faster than Megatron-LM.
- Job details can be found on Smart Recruiters.
- Generative AI Book Announcement: Yuri Plotkin announced his upcoming book on Generative AI, covering foundational algorithms including Bayesian inference and latent variable models, which can be found on the book website.
- He encouraged following him on Twitter for ongoing updates, sharing insights on key concepts in the field.
LM Studio Discord
-
SageAttention Boosts Performance: The new method, SageAttention, accelerates inference in transformer models by providing efficient quantization for attention, achieving 2.1 times improvements over existing methods.
- This technique shows superior accuracy compared to FlashAttention3, with implications for both language and image generation.
- Llama 8B Tokens per Second Variability: Users report a wide range of tokens per second (TPS) for Llama 8B, with Q6_K setups on 1070 Ti GPUs achieving around 28-35 TPS.
- Performance is closely linked to factors like context length, quantization, and GPU VRAM bandwidth.
- GPU Performance Matters: New generation GPUs like the 4080 or 4090 drastically outperform older models such as the 1070 Ti but need correct configurations to maximize capabilities.
- Utilizing tensor cores and enhanced memory bandwidth are essential for achieving notable performance gains.
- Challenges in Compiled Models: Users questioned the current support for custom compiled versions of Llama.cpp with LM Studio, leading responses to suggest using the command line tool
lmsfor model loading.
- This solution promotes persistence across reboots, mitigating some of the challenges faced with compiled models.
- Token Generation Speeds Under Fire: Members highlighted sluggish token generation speeds with high-capacity models, with some setups peaking at 0.25 tokens/sec, illustrating CPU bottlenecks.
- With many local setups feeling these limits, there’s a push to consider cloud services for better performance if needed.
OpenAI Discord
-
Grok 2 Shows Potential: Members expressed interest in experimenting with Grok 2, indicating a growing fascination with newer models.
- Although specific performance details were lacking, the buzz suggests Grok 2 could be a noteworthy development.
- DALL-E's Image Generation Falls Short: DALL-E's capabilities were criticized, with one member simply labeling its image output as bad.
- Expectations are high for image generation, and this feedback underscores disappointment in its performance.
- The Mystery of Model Parameters: There was lively debate over the parameter sizes of models like 4o-mini and GPT-3.5, with speculation around 4o-mini having it set at 1 billion parameters.
- Varying opinions indicate confusion in the community regarding the relationship between model size and performance.
- GPTs Struggle with PDF Comprehension: Members noted that GPTs fail to read entire PDFs before responding, often leading to incomplete information being referenced.
- Including key information in the main instructions was suggested to help improve response accuracy.
- Guidelines for Using ChatGPT to Create Website Content: A user sought advice on using ChatGPT to build a website centered on controlling, asking for strategies on effective prompt crafting.
- Emphasis was placed on sourcing content from trustworthy and scientific materials, highlighting a focus on quality.
tinygrad (George Hotz) Discord
-
Tinygrad ML Library War Winning Streak: A member described three key reasons why tinygrad is set to excel: its efficient kernel search using BEAM and MCTS, a concise codebase of under 10k lines, and a lazy execution model.
- 'This avoids the combinatorial nightmare of one kernel per combination of device...', stressing improved performance through its streamlined approach.
- Tinybox Preorder Puzzles: Discussions around the tinybox preorder sparked inquiries about payment methods and associated costs, especially if it would adopt Stripe like previous models.
- Members voiced curiosity on how to navigate the preorder payment process with existing methods.
- OpenCL Handling Makes Waves: Concerns regarding Out Of Memory (OOM) handling emerged after facing all-black outputs in Stable Diffusion, with questions about OpenCL's capability.
- A member sought clarity on whether the implementation effectively addresses these out-of-memory conditions in tinygrad.
- MSE and MAE Implementation Simplified: A proposal to integrate MSE and MAE functions directly into tensors was made, claiming it can be executed in a few lines of code.
- They referenced a GitHub pull request showcasing the implementation along with testing.
- Windows Compatibility Concerns Do Surface: Issues with Windows 11 arose when Python installation led users to Microsoft Store, indicating compatibility hurdles.
- Attention was drawn to sqlite issues from earlier discussions, emphasizing the necessity of using the correct Python version.
LAION Discord
-
Microdiffusion Implementation Progress: The community is eagerly awaiting the implementation of the microdiffusion paper, which could significantly reduce training costs with a $2k training goal and 7 days of H100 compute secured.
- Discussions focus on preprocessing help and seeking short-term improvements following experiment preparation.
- Data Preprocessing Challenges Highlighted: A member noted issues in uploading large datasets to Hugging Face due to its 300GB limit, proposing chunking the data into parts or using a webdataset hosted on an S3.
- They aim to preprocess data and stream it efficiently by categorizing images into multiple datasets based on aspect ratios.
- Webdataset for Efficient Data Handling: Participants discussed the use of webdataset as a workaround for large dataset management, allowing streamlined usage with PyTorch.
- One member insisted webdataset bundling would enhance management for their anticipated 1TB dataset.
- Dinov2 gets optimized in layers: Discussion centered on distilling Dinov2 into the early layers, enhancing efficiency for downstream tasks related to images.
- Notably, this method shows superior performance compared to merely relying on cross attention with CLIP embedding.
- Introduced EchoPrime for Echocardiography: EchoPrime emerges as a multi-view, contrastive learning-based model trained on over 12 million video-report pairs, tackling traditional echocardiography AI challenges.
- This new foundation model enhances performance and application scope in cardiac imaging.
LlamaIndex Discord
-
Experimenting with Dynamic Few-shot Prompting: Dynamic few-shot prompting enhances LLM fine-tuning by retrieving relevant examples based on queries instead of a fixed set (more details here). This method improves prompt contextualization for various applications.
- Participants pointed to a related discussion thread that emphasizes the importance of pertinent examples in this approach.
- Mistral Rolls Out New Edge-Class Models: Mistral has launched notable edge-class models with day 0 support available via 'pip install llama-index-llms-mistralai' (installation link). This allows developers to quickly integrate these models into their systems.
- The announcement received attention in the community, highlighting its relevance in the current AI landscape (link to the announcement).
- Enhancing Multimodal RAG Systems Using Azure: A guide illustrates how to create a multimodal RAG system leveraging Azure AI Search and Azure OpenAI with LlamaIndex, guiding improvements in retrieval accuracy (see the guide). This comprehensive documentation includes benchmarks for practical implementation.
- The walkthrough focuses on maximizing contextual retrieval across different AI systems, providing valuable techniques as shared in this tweet.
- Optimizing Neo4jPropertyGraphStore Creation: Creating a Neo4jPropertyGraphStore can be time-consuming, particularly when handling 64,322 nodes, prompting discussions on memory optimization and schema simplifications. Suggestions included setting
refresh_schemato false to mitigate costly schema-related calls.
- Community feedback indicated that these adjustments could significantly enhance performance during initialization.
- Investigating Multi-Agent Orchestration Workflows: Users inquired about replicating OpenAI's Swarm capabilities within LlamaIndex, focusing on workflows as a core approach. The discussions led to examples of multi-agent communication being provided, backed by blog articles and GitHub repositories.
- This exploration aims to develop efficient solutions for orchestrating actions across multiple agents using existing workflows.
Interconnects (Nathan Lambert) Discord
-
Mistral celebrates launch of Ministral models: On the first anniversary of Mistral 7B, Mistral launched two edge models: Ministral 3B and Ministral 8B, designed for on-device use with privacy-first inference capabilities, featuring up to 128k context lengths.
- The community expressed disappointment over the absence of weights for Ministral 3B, raising questions about its potential performance compared to Ministral 8B which does have non-commercial weights.
- AI2 OLMo Internship offers competitive salaries: The AI2 is hiring research interns for the OLMo project, with salaries from $86,520 to $123,600 and an opportunity to lead significant research in NLP and machine learning over a 12-week internship.
- Interns can define research projects and publish in high-profile journals, making this opportunity quite coveted in the competitive landscape.
- Snailbot expands its capabilities: Snailbot is now being utilized for audio feed posts, reflecting its enhanced functionality in content sharing.
- This has been perceived as a twofer, with users expressing excitement about the bot's new use case.
- Challenges in audio distribution: Users are expressing challenges with audio content distribution, stressing the need for effective strategies.
- One user humorously compared their issues to a meme from a popular note-taking app, indicating widespread frustration within the community.
- Hackernews visibility struggles: There are ongoing concerns about the pitfalls of posting on Hackernews, especially regarding link visibility and potential penalties for direct links.
- Members discussed how navigating visibility issues is complicated, suggesting strategies that avoid direct linking to bolster content engagement.
Latent Space Discord
-
Gemini free tier struggles to deliver: Users have reported timeouts and failures with the Gemini free tier, raising doubts about its claimed 1.5B token per day capabilities.
- Effective usage could be closer to 0.05B tokens, as speculated by several members.
- Mistral enters the edge model race: Mistral introduced Ministral 3B and Ministral 8B models aimed at on-device applications, enhancing commonsense and reasoning in the sub-10B range.
- However, the 3B model is API-only, limiting its on-device applicability and drawing critiques regarding restrictive licensing.
- Nvidia's Llama 3.1 Nemotron raises eyebrows: Nvidia's Llama 3.1 Nemotron 70B reportedly surpasses both GPT-4o and Claude Sonnet 3.5 across various benchmarks, stirring community excitement.
- Debate arises over whether Sonnet 3.5 users can still claim relevance against this cutting-edge model.
- E2B's SDK gets a funding boost: E2B launched the v1.0 SDK alongside an impressive $11.5M seed round, targeting AI code interpreting with secure sandboxing.
- The startup claims to run millions of sandboxes monthly, with notable partnerships including Perplexity.
- Call for LLM performance benchmarking tool: A member put forth the idea of a CPUBenchmark-style tool dedicated to LLM comparisons to improve existing leaderboards, which are currently limited.
- Current tools, such as lmsys/hugging face leaderboards, don't allow for effective direct comparisons between models.
Cohere Discord
-
Cohere Community Inspires Daily: Members find daily motivation from the Cohere community, appreciating its supportive atmosphere.
- A lot of things, honestly this whole community each day everyday! reflects the positive sentiment shared.
- Job Opportunities Clarified: A reminder surfaced that inquiries regarding jobs at Cohere should be directed to the careers page instead.
- The member highlighted the team's passion for addressing real-world challenges with ML/AI technologies.
- Join the RAG++ AMA Tomorrow!: Another AMA with Ayush Thakur and Meor Amer on RAG development kicks off tomorrow at 11:00 AM ET, following great interest from the community.
- The session links back to the RAG++ course, promising insights into current developments.
- Cohere Embed API error handling explained: Inquiries on error handling in the Cohere Embed API prompted suggestions for implementing retry logic based on specific error codes when documents fail to embed.
- Errors could result in an overall failure for the batch, advising care in managing embeddings.
- Text-to-Speech is here for chatbots!: Excitement brews over the introduction of text-to-speech functionality for chatbot responses, with a setup guide shared for users.
- Sick! was the enthusiastic response from a user, indicating effective adoption of the new feature.
Modular (Mojo 🔥) Discord
-
Playground Gets Love from Users: Members expressed much needed love for the Playground feature, thanking Modular for its improvements and support. For more information, you can read about it in the Playground documentation.
- This positive feedback highlights the importance of community input in refining tools.
- Save the Date for Community Showcase: A community meeting is scheduled for October 21st, featuring a live showcase where participants can demo their MAX and Mojo projects. Slots will last between 5-10 minutes, allowing sharing of learnings and feedback.
- Engagement like this helps catalyze collaboration and knowledge sharing among developers.
- Weird Mojo Bug Fixed: A member identified a Mojo bug that was reproducible but later fixed it themselves, offering to add any contributions to the changelog. They encouraged others to report similar issues to enhance the platform.
- This proactive approach can lead to quicker bug resolution and better software stability.
- Inferencemax Project Simplifies API: A member shared their new project called Inferencemax, aimed at simplifying LLM inference, although it may not fully meet existing requests. The code is in Python, with planned improvements for performance.
- This project reflects ongoing efforts to create a more accessible inference API landscape.
- Jakub's Python API for MAX Sparks Interest: Inquiry about Jakub's contributions to the Python API for MAX led to a link being shared to a community meeting where he spoke. Although the API isn't fully released yet, its presence in nightly builds aims to showcase ease of use.
- Such discussions emphasize anticipation for API developments that improve usability.
Stability.ai (Stable Diffusion) Discord
-
Mineral Resources Poster Assistance Needed: A member sought help on creating a poster about mineral resources for their college project, asking for guidance from the community.
- Another member advised them to share specific needs in the chat for a more direct support approach.
- SD3 Fails at Human Poses: Discussion centered on the performance drawbacks of SD3 with human figures in lying or upside-down positions, noted to be generally poor.
- A participant highlighted frequent deformations occur regardless of pose, indicating a consistent issue.
- LLM Token Limits Ignored: A user vented frustrations about LLMs failing to abide by token limits or stop commands, causing chaotic outputs.
- They speculated potential problems with prompt templating, inviting insights from more seasoned users.
- Clearing Up LyCORIS vs LoRA Confusion: A member inquired about the purpose of the LyCORIS folder since everything moved to LoRA, expressing confusion.
- Another user responded, explaining the folder's historical necessity for extensions now subsumed by newer interfaces like Auto1111.
- New Web3 Project Job Roles Available: An update shared the launch of a new Web3 project that is looking to fill various positions, including Developer and Moderator, with competitive pay.
- Interested candidates were encouraged to reach out directly for more specific information on available roles.
OpenInterpreter Discord
-
Open Interpreter GitHub Copilot extension suggestion: A member proposed creating an Open Interpreter GitHub Copilot extension, while another indicated they lacked the bandwidth to pursue it but would guide community efforts.
- They encouraged collaboration within the community to bring this project to life.
- Excitement for Mozilla AI Talk: Members expressed anticipation for an upcoming talk from Mozilla AI, urging everyone to add it to their calendars.
- A link to the event was shared for easy access.
- Kernel panic reported on app closure: A member reported a kernel panic when closing the Open Interpreter app, prompting MikeBirdTech to recommend creating a dedicated troubleshooting post.
- Details about the version used should accompany the report for effective resolution.
- New Local LLMs functionality: A recent update now enables easy execution of any GGUF model on Hugging Face via Ollama, just by pointing to the repository.
- Users can run Llama 3.2 3B with a simple command, making local LLMs much more accessible.
- Positive feedback on the Local LLMs update: Members expressed enthusiasm for the new ability to run models directly, highlighting it as a significant enhancement for local LLMs.
- An appreciation for previously missing features was noted, particularly in connection to Jan.
DSPy Discord
-
Unit Testing DSPy Workflow System: A member announced they are unit testing a DSPy powered Workflow system in the Discord channel. Check the channel for progress updates and feedback on the testing process.
- This testing aims to refine the workflow and ensure reliability, encouraging community input on findings.
- Major Update to dspygen Framework: A recent major update has been made to the dspygen framework, built for improvements outside of dslmodel. This aims to enhance the DSPy workflow for language models like GPT, BERT, and LLaMA.
- The updates focus on bringing more features and optimizations, allowing better integration within existing systems.
- LightRAG outshines GraphRAG: Recent claims suggest LightRAG offers significant enhancements in effectiveness and cost efficiency compared to GraphRAG as detailed in this paper. The authors propose that LightRAG addresses limitations of existing RAG systems, improving contextual awareness and information retrieval through innovative graph structures.
- They assert that these Innovations result in reduced operational costs and improved overall system performance.
- DSPy integration into GPT-O1+ progresses: Updated documentation introduced a long-form RAG example for building a question answering system about tech topics using DSPy. Users can install DSPy with
pip install -U dspyand a tutorial is available on DSPy documentation.
- This integration is expected to streamline workflows and improve the user experience within the DSPy framework.
- Revamping documentation approaches: Discussion emerged about the upcoming revamp of DSPy documentation, focusing on improving rhythm and style. Participants are considering whether to use HTML documentation versus detailed notebooks, mentioning the usefulness of having caches for execution.
- This revamp aims to enhance clarity and accessibility for users, allowing easier navigation through the documentation.
LangChain AI Discord
-
LangChain Community to Close: On October 31, 2024, the current LangChain Discord community will shut down to make way for a revamped user space aimed at being more engaging and fun.
- Members can keep up with updates by filling out the form here and are encouraged to provide feedback via community@langchain.dev.
- Advice Needed for API Routing: A member seeks guidance on using agents for routing user inquiries to different APIs, mentioning they have 5 APIs set up in Docker Compose.
- This inquiry aims to enhance their project structure and optimize user interaction with APIs.
- Playground Blank Page Woes: Members flagged a significant issue in the Playground where input types with Optional fields cause the page to load blank with errors in the console.
- The problem likely stems from the input schema's null type conflicting with jsonforms, hampering functionality.
- GitHub Issue Logged for Playground Trouble: A member opened GitHub Issue #782 to track the Playground issue relating to Optional fields leading to load failures.
- This is part of ongoing efforts to resolve key usability problems within the LangChain Playground.
- Remote Runnable Tools Binding Inquiry: A member questioned the absence of a bind_tools() method for tool binding in the Remote Runnable, creating an opportunity for improvements.
- This discussion could lay the groundwork for better tool management within LangChain's environment.
OpenAccess AI Collective (axolotl) Discord
-
AIFoundry Seeks GitHub Mentorship: AIFoundry.org is looking for mentorship regarding their GitHub organization and design, aiming to emulate Axolotl's streamlined approach.
- Yulia expressed a desire for guidance to enhance their open-source initiative focused on local model inference.
- Mistral's Access Rules Explained: To access the new Mistral-8B-Instruct-2410 model on Hugging Face, users must provide contact details and obtain permission for non-standard uses.
- Accessibility is contingent on consent from Mistral AI, with a call to review their privacy policy for compliance.
- L3.1 Ethereal Rainbow Launch Dangers: The L3.1 Ethereal Rainbow repository has been flagged for containing sensitive and potentially harmful content, necessitating caution for users.
- The repository has prompted warnings because of its sensitive material and users should carefully consider the implications of the content.
- Finetuning the L3.1 Model: The L3.1 model has been finetuned with over 250 million tokens and maintains a sequence length capability of 16k, enhancing its performance for creative writing applications.
- This focus on RP and creative writing signifies a targeted effort to bolster the model's practical usability in sensitive contexts.
Torchtune Discord
-
Members Buzz About New Paper: Enthusiasm surged around the paper titled arxiv:2410.06511, with members deeming it a fantastic read.
- One member affirmed they're still reviewing the paper, underscoring its quality and engagement from the community.
- Unanimous Praise for Paper Quality: The overall sentiment regarding the paper was strongly positive, with multiple members highlighting its impressive content.
- Some noted they are still working through the details, reflecting a shared interest in its insights.
LLM Agents (Berkeley MOOC) Discord
-
LLMs excel in zero-shot optimization: Recent research shows that Large Language Models (LLMs) can perform zero-shot optimization across complex problems like multi-objective optimization.
- This application could be instrumental in engineering tasks such as rocket nozzle design and windfarm layout optimization.
- Meet the Language-Model-Based Evolutionary Optimizer (LEO): LEO is introduced as a novel population-based approach leveraging LLMs for numerical optimization, performing equally well against gradient-based and gradient-free methods.
- However, concerns about the potential for hallucination in outputs suggest a necessity for meticulous management in its applications.
- Community buzzes about LLM design applications: Discussions in the community reflect a keen interest in the practical uses of LLMs for engineering designs, particularly focusing on reasoning capabilities.
- Members are enthusiastic about collaborating on how LLMs can tackle real-world engineering challenges.
Mozilla AI Discord
-
Pilot Program for AI Stewardship Practice: The MaRS Discovery District is offering free slots for the AI Stewardship Practice Program, targeting professionals in AI fields.
- This initiative provides a microcredential aimed at researchers, entrepreneurs, and educators looking to influence AI positively; more info here.
- Participants Wanted for AI Course Pilot: There’s an opportunity to join the course pilot for the program, valued at 500 CAD, with interested participants encouraged to respond quickly.
- Seats will fill based on threaded replies, making swift action crucial for those wanting to participate.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!