[AINews] DeepSeek-R1 claims to beat o1-preview AND will be open sourced
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Whalebros are all you need.
AI News for 11/20/2024-11/21/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (217 channels, and 1837 messages) for you. Estimated reading time saved (at 200wpm): 197 minutes. You can now tag @smol_ai for AINews discussions!
Ever since o1 was introduced (our coverage here, here, and here), the race has been on for an "open" reproduction. 2 months later, with honorable mentions to Nous Forge Reasoning API and Fireworks f1, DeepSeek appear to have made the first convincing attempt that 1) has BETTER benchmark results than o1-preview and 2) has a publicly available demo rather than waitlist.
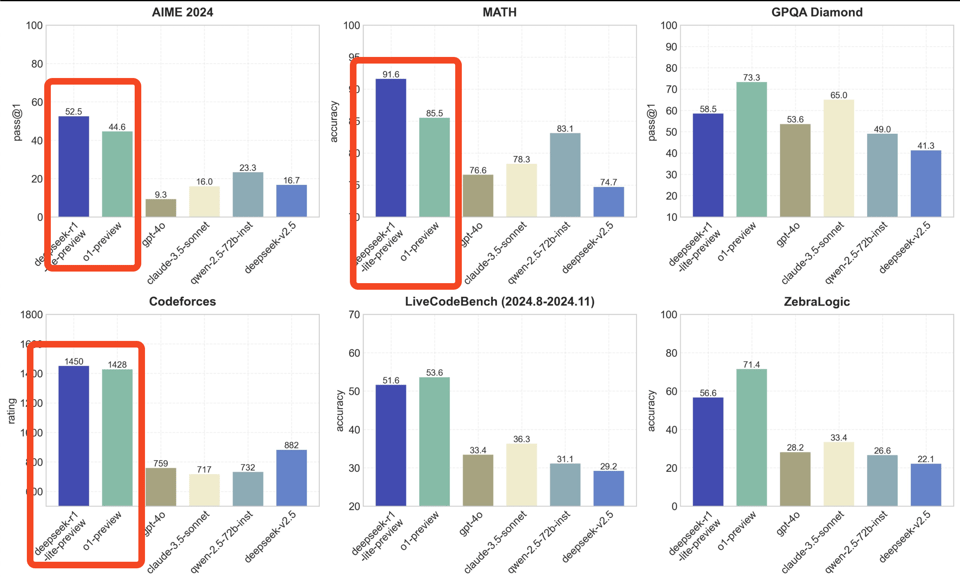
Benchmarks wise, it doesn't beat o1 across the board, but does well on important math benchmarks and at-least-better-than-peers on all but GPQA Diamond.
Also importantly, they appear to have replicated the similar inference-time-scaling performance improvements mentioned by OpenAI, but this time with an actual x-axis:
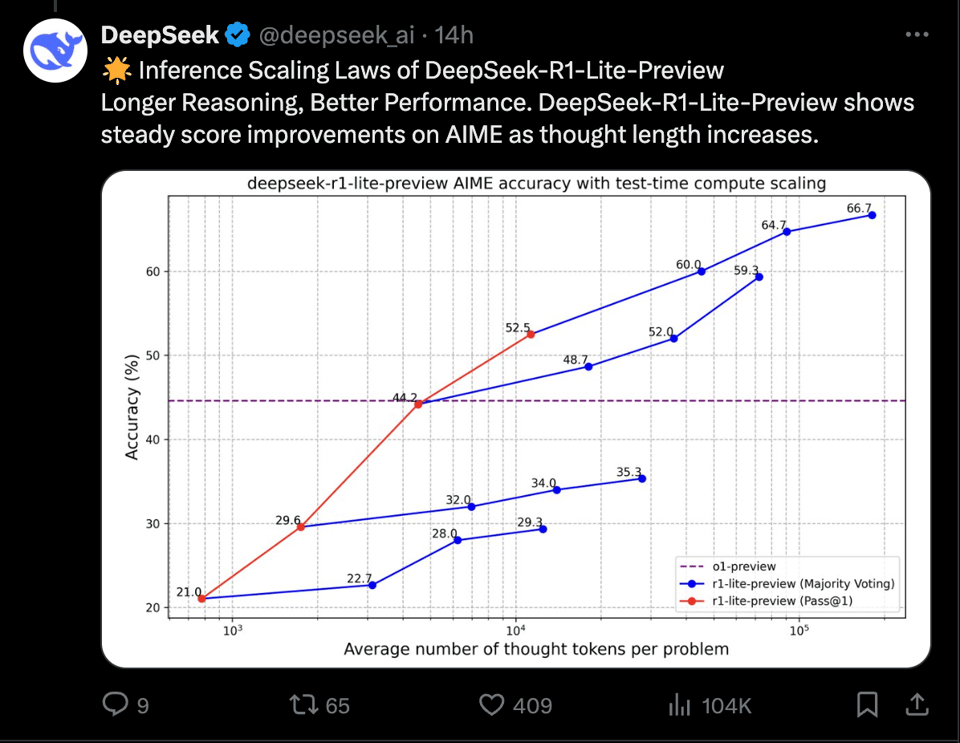
As for the "R1-Lite" naming, rumor is (based on wechat announcements) it is based on DeepSeek's existing V2-Lite model which is only a 16B MoE with 2.4B active params - meaning that if they manage to scale it up, "R1-full" will be an absolute monster.
One notable result is that it has done (inconsistently) well on Yann LeCun's pet 7-gear question.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- Interconnects (Nathan Lambert) Discord
- Unsloth AI (Daniel Han) Discord
- aider (Paul Gauthier) Discord
- Eleuther Discord
- Perplexity AI Discord
- OpenRouter (Alex Atallah) Discord
- LM Studio Discord
- Stability.ai (Stable Diffusion) Discord
- Notebook LM Discord Discord
- Latent Space Discord
- GPU MODE Discord
- Nous Research AI Discord
- OpenAI Discord
- Cohere Discord
- Torchtune Discord
- tinygrad (George Hotz) Discord
- Modular (Mojo 🔥) Discord
- OpenAccess AI Collective (axolotl) Discord
- DSPy Discord
- LlamaIndex Discord
- OpenInterpreter Discord
- LLM Agents (Berkeley MOOC) Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #general (263 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (1 messages):
- HuggingFace ▷ #cool-finds (10 messages🔥):
- HuggingFace ▷ #i-made-this (4 messages):
- HuggingFace ▷ #reading-group (4 messages):
- HuggingFace ▷ #NLP (5 messages):
- HuggingFace ▷ #diffusion-discussions (6 messages):
- Interconnects (Nathan Lambert) ▷ #news (175 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (6 messages):
- Interconnects (Nathan Lambert) ▷ #random (25 messages🔥):
- Unsloth AI (Daniel Han) ▷ #general (176 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (9 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (10 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (1 messages):
- aider (Paul Gauthier) ▷ #general (148 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (29 messages🔥):
- Eleuther ▷ #announcements (1 messages):
- Eleuther ▷ #general (20 messages🔥):
- Eleuther ▷ #research (125 messages🔥🔥):
- Eleuther ▷ #scaling-laws (2 messages):
- Eleuther ▷ #lm-thunderdome (15 messages🔥):
- Perplexity AI ▷ #general (132 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (120 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (6 messages):
- LM Studio ▷ #general (58 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (64 messages🔥🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (102 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (17 messages🔥):
- Notebook LM Discord ▷ #general (35 messages🔥):
- Latent Space ▷ #ai-general-chat (48 messages🔥):
- GPU MODE ▷ #triton (1 messages):
- GPU MODE ▷ #beginner (5 messages):
- GPU MODE ▷ #torchao (3 messages):
- GPU MODE ▷ #off-topic (2 messages):
- GPU MODE ▷ #webgpu (11 messages🔥):
- GPU MODE ▷ #liger-kernel (17 messages🔥):
- GPU MODE ▷ #self-promotion (4 messages):
- Nous Research AI ▷ #general (27 messages🔥):
- Nous Research AI ▷ #ask-about-llms (8 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #interesting-links (3 messages):
- Nous Research AI ▷ #research-papers (2 messages):
- OpenAI ▷ #ai-discussions (18 messages🔥):
- OpenAI ▷ #gpt-4-discussions (3 messages):
- OpenAI ▷ #prompt-engineering (8 messages🔥):
- OpenAI ▷ #api-discussions (8 messages🔥):
- Cohere ▷ #discussions (12 messages🔥):
- Cohere ▷ #questions (6 messages):
- Cohere ▷ #api-discussions (4 messages):
- Cohere ▷ #projects (4 messages):
- Torchtune ▷ #general (7 messages):
- Torchtune ▷ #dev (14 messages🔥):
- Torchtune ▷ #papers (2 messages):
- tinygrad (George Hotz) ▷ #general (6 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (2 messages):
- Modular (Mojo 🔥) ▷ #max (5 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (2 messages):
- OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (4 messages):
- DSPy ▷ #general (5 messages):
- DSPy ▷ #examples (1 messages):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (2 messages):
- OpenInterpreter ▷ #general (4 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
1. NVIDIA Financial Updates and Market Insights
- NVIDIA Reports Record Revenue in Q3: @perplexity_ai discusses the insights from NVIDIA's Q3 earnings call, highlighting a record revenue of $35.1 billion, a 17% increase from the previous quarter. Key growth drivers include strong data center sales and demand for NVIDIA's Hopper and Blackwell architectures. The company anticipates continuing growth with projections of $37.5 billion in Q4.
- Detailed Performance During Earnings Call: Another update from @perplexity_ai further outlines that data center revenue reached $30.8 billion, marking a 112% year-on-year increase. The Blackwell architecture reportedly offers a 2.2x performance improvement over Hopper.
2. DeepSeek-R1-Lite-Preview: New Reasoning Model Developments
- Launch of DeepSeek-R1-Lite-Preview: @deepseek_ai is excited about the release of DeepSeek-R1-Lite-Preview, which offers o1-preview-level performance on MATH benchmarks and a transparent thought process. The model aims to have an open-source version available soon.
- Evaluation of DeepSeek-R1-Lite-Preview: Multiple users, such as @omarsar0, discuss its capabilities, including math reasoning improvements and challenges in coding tasks. Despite some mishaps, the model shows promise in real-time problem-solving and reasoning.
3. Quantum Computing Progress with AlphaQubit
- AlphaQubit Collaboration with Google: @GoogleDeepMind introduces AlphaQubit, a system designed to improve error correction in quantum computing. This system outperformed leading algorithmic decoders and shows potential in scale-up scenarios.
- Challenges in Quantum Error Correction: Despite these advancements, additional insights from Google DeepMind note ongoing issues with scaling and speed, highlighting the goal to make quantum computers more reliable.
4. Developments in GPT-4o and AI Creative Enhancements
- GPT-4o's Enhanced Creative Writing: @OpenAI notes updates in GPT-4o's ability to produce more natural, engaging content. User comments, such as from @gdb, highlight improvements in working with files and offering deeper insights.
- Chatbot Arena Rankings Update: @lmarena_ai shares excitement over ChatGPT-4o reaching the #1 spot, surpassing Gemini and Claude models with significant improvements in creative writing and technical performance.
5. AI Implementations and Tools
- LangChain and LlamaIndex Systems: @LangChainAI announces updates to the platform focusing on observability, evaluation, and prompt engineering. They emphasize seamless integration, offering developers comprehensive tools to refine LLM-based applications.
- AI Game Development Courses: @togethercompute introduces a course on building AI-powered games, in collaboration with industry leaders. It focuses on integrating LLMs for immersive game creation.
6. Memes/Humor
- High School AI Nostalgia: @aidan_mclau humorously reflects on using AI to complete philosophy homework, showcasing a light-hearted take on AI's educational uses.
- Chess Meme: @BorisMPower engages in a chess meme thread, contemplating strategic moves and decision-making within the game context.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. DeepSeek R1-Lite matches o1-preview in math benchmarks, open source coming soon
- DeepSeek-R1-Lite Preview Version Officially Released (Score: 189, Comments: 64): DeepSeek released their new R1 series inference models, trained with reinforcement learning, featuring extensive reflection and verification capabilities through chain of thought reasoning that can span tens of thousands of words. The models achieve performance comparable to o1-preview in mathematics, coding, and complex logical reasoning tasks while providing transparent reasoning processes at chat.deepseek.com.
- DeepSeek-R1-Lite is currently in development, with the official announcement confirming it's web-only without API access. The company plans to open-source the full DeepSeek-R1 model, release technical reports, and deploy API services as stated in their tweet.
- Initial user testing shows impressive performance in mathematics with detailed reasoning steps, though some note longer response times compared to o1-preview. The model is estimated to be 15B parameters based on previous DeepSeek releases.
- Community response highlights the rapid advancement of Chinese AI labs despite GPU restrictions, with users noting the model's transparent thought process could benefit open-source development. Several users confirmed strong performance on AIME & MATH benchmarks.
- Chinese AI startup StepFun up near the top on livebench with their new 1 trillion param MOE model (Score: 264, Comments: 74): StepFun, a Chinese AI startup, developed a 1 trillion parameter Mixture-of-Experts (MOE) model that achieved competitive scores on livebench, a real-time AI model leaderboard. The model's specific performance metrics and technical details were not disclosed in the source material.
- Livebench scores show the model is currently underperforming relative to its size, with users noting it's being beaten by smaller models like o1 mini (estimated at 70-120B parameters) and showing particularly low math scores.
- The model appears to be in early training stages, with discussion around "Step 2" potentially indicating its second training phase. Users speculate the underwhelming performance is due to being heavily undertrained rather than architectural limitations.
- Discussion focused on the model's MoE architecture and deployment strategy, with experts noting that each transformer layer requires its own set of experts, leading to substantial GPU-to-GPU communication needs during inference and training.
Theme 2. Sophisticated Open Source LLM Tools: Research Assistant & Memory Frameworks
- I Created an AI Research Assistant that actually DOES research! Feed it ANY topic, it searches the web, scrapes content, saves sources, and gives you a full research document + summary. Uses Ollama (FREE) - Just ask a question and let it work! No API costs, open source, runs locally! (Score: 487, Comments: 76): Automated-AI-Web-Researcher is a Python-based tool that uses Ollama and local LLMs to conduct comprehensive web research, automatically generating up to 5 specific research focuses from a single query, continuously searching and scraping content while saving sources, and creating detailed research documents with summaries. The project, available on GitHub, runs entirely locally using models like phi3:3.8b-mini-128k-instruct or phi3:14b-medium-128k-instruct, features pause/resume functionality, and enables users to ask follow-up questions about the gathered research content.
- Users reported mixed success with different LLMs - while some had issues with Llama3.2-vision:11b and Qwen2.5:14b generating empty summaries, others successfully used mistral-nemo 12B achieving 38000 context length with 16GB VRAM at 3% CPU / 97% GPU usage.
- Several technical suggestions were made including ignoring robots.txt, adding support for OpenAI API compatibility (which was later implemented via PR), and restructuring the codebase with a "lib" folder and proper configuration management using tools like pydantic or omegaconf.
- Discussion around the tool's purpose emphasized its value in finding and summarizing real research rather than generating content, with concerns raised about source validation and factual accuracy of web-scraped information.
-
Agent Memory (Score: 64, Comments: 11): LLM agent memory frameworks are compared across multiple GitHub projects, with key implementations including Letta (based on MemGPT paper), Memoripy (supports Ollama and OpenAI), and Zep (maintains temporal knowledge graphs). Several frameworks support local models through Ollama and vLLM, though many assume GPT access by default, with varying levels of compatibility for open-source alternatives.
- The comparison includes both active projects like cognee (for document ingestion) and MemoryScope (featuring memory consolidation), as well as development resources such as LangGraph Memory Service template and txtai for RAG implementations, with most frameworks offering OpenAI-compatible API support through tools like LiteLLM.
- Vector-based memory systems use proximity and reranking to determine relevance, contrasting with simple keyword activation systems like those used in Kobold or NovelAI. The vector approach maps concepts spatially (e.g., "Burger King" closer to food-related terms than "King of England") and uses reranking through either small neural nets or direct AI evaluation.
- Memory frameworks differ primarily in their handling of context injection - from automated to manual approaches - with more complex systems incorporating knowledge graphing and decision trees. Memory processing can become resource-intensive, sometimes requiring more tokens than the actual conversation.
- The field of LLM memory systems remains experimental with no established best practices, ranging from basic lorebook-style implementations to sophisticated context-aware solutions. Simple systems require more human oversight to catch errors, while complex ones offer better robustness against contextual mistakes.
Theme 3. Hardware & Browser Optimization: Pi GPU Acceleration & WebGPU Implementations
- LLM hardware acceleration—on a Raspberry Pi (Top-end AMD GPU using a low cost Pi as it's base computer) (Score: 53, Comments: 18): Raspberry Pi configurations can run Large Language Models (LLMs) with AMD GPU acceleration through Vulkan graphics processing. This hardware setup combines the cost-effectiveness of a Raspberry Pi with the processing power of high-end AMD GPUs.
- Token rates of 40 t/s were achieved using a 6700XT GPU with Vulkan backend, compared to 55 t/s using an RTX 3060 with CUDA. The lack of ROCm support on ARM significantly limits performance potential.
- A complete Raspberry Pi setup costs approximately $383 USD (excluding GPU), while comparable x86 systems like the ASRock N100M cost $260-300. The Intel N100 system draws only 5W more power while offering better compatibility and performance.
- Users note that AMD could potentially create a dedicated product combining a basic APU with high VRAM GPUs in a NUC-like form factor. The upcoming Strix Halo release may test market demand, though alternatives like dual P40s for $500 remain competitive.
- In-browser site builder powered by Qwen2.5-Coder (Score: 55, Comments: 8): An AI site builder running in-browser uses WebGPU, OnnxRuntime-Web, Qwen2.5-Coder, and Qwen2-VL to generate code from text, images, and voice input, though only text-to-code is currently live due to performance constraints. The project implements Moonshine for speech-to-text conversion and includes code examples for integration on GitHub and Huggingface, with performance currently limited by GPU capabilities and primarily tested on Mac systems.
- Developer details challenges in model conversion, sharing their process through export documentation and a custom Makefile, noting issues with mixed data types and memory management that made the project particularly difficult.
- Community feedback highlights interest in testing the system on Linux with NVIDIA RTX hardware, with users also reporting UI contrast issues on iPhone devices due to similar dark background colors.
Theme 4. Model Architectures: Analysis of GPT-4, Gemini & Other Closed Source Models
- Closed source model size speculation (Score: 52, Comments: 12): The post analyzes parameter counts of closed-source LLMs, suggesting that GPT-4 Original has 280B active parameters and 1.8T overall, while newer versions like GPT-4 Turbo and GPT-4o have progressively smaller active parameter counts (~93-94B and ~28-32B respectively). The analysis draws connections between model architectures and pricing, linking Microsoft's Grin MoE paper to GPT-4o Mini (6.6B-8B active parameters), and comparing Gemini Flash versions (8B, 32B, and 16B dense) with models like Qwen and architectures from Hunyuan and Yi Lightning.
- Qwen 2.5's performance-to-size ratio supports the theory of smaller active parameters in modern models, particularly with MoE architecture and closed-source research advances. The discussion suggests Claude may be less efficient than OpenAI and Google models.
- Gemini Flash's 8B parameter count likely includes the vision model, making the core language model approximately 7B parameters. The model's performance at this size is considered notably impressive.
- Community estimates suggest GPT-4 Turbo has ~1T parameters (100B active) and GPT-4o has ~500B (50B active), while Yi-Lightning is likely smaller based on its low pricing and reasoning capabilities. Step-2 is estimated to be larger due to higher pricing ($6/M input, $20/M output).
- Judge Arena Leaderboard: Benchmarking LLMs as Evaluators (Score: 33, Comments: 14): Judge Arena Leaderboard aims to benchmark Large Language Models (LLMs) on their ability to evaluate and judge other AI outputs. Due to insufficient context in the post body, no specific details about methodology, metrics, or participating models can be included in this summary.
- Claude 3.5 Sonnet initially led the rankings in the Judge Arena leaderboard, but subsequent updates showed significant volatility with 7B models rising to top positions among open-source entries. The rankings showed compression from an ELO spread of ~400 points to ~250 points after 1197 votes.
- Community members questioned the validity of results, particularly regarding Mistral 7B (v0.1) outperforming GPT-4, GPT-3.5, and Claude 3 Haiku, with high margin of error (~100 ELO points) cited as a potential explanation.
- Critics highlighted limitations in the judgment prompt, suggesting it lacks concrete evaluation criteria and depth, while the instruction to ignore response length could paradoxically influence assessors through the "pink elephant effect".
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Live Demo Shows Real-Time AI Facial Recognition Raising Privacy Alarms
- This Dutch journalist demonstrates real-time AI facial recognition technology, identifying the person he is talking to. (Score: 2523, Comments: 304): Dutch journalist demonstrates real-time facial recognition AI capabilities by identifying individuals during live conversations. No additional context or technical details were provided about the specific technology or implementation used.
- The top comment emphasizes privacy concerns, suggesting to "post no photos online anywhere attached to actual names" with 457 upvotes. Multiple users discuss continuing to wear masks and methods to avoid facial recognition.
- Discussion reveals this likely uses Pimeyes or similar technology, with users noting that Clearview AI has even more advanced capabilities that can "find your face in a crowd at a concert". Several users point out that the demonstration likely involves a second person doing manual searches.
- Users debate the societal implications, with some calling it a "threat to democracy and freedom" while others discuss practical applications like car sales. The conversation includes concerns about government surveillance and data privacy, particularly in reference to China and other nations.
Theme 2. CogVideoX 1.5 Image-to-Video: Quality vs Performance Trade-offs
- Comparison of CogvideoX 1.5 img2vid - BF16 vs FP8 (Score: 165, Comments: 49): CogVideoX 1.5 post lacks sufficient context or content to generate a meaningful technical summary about the comparison between BF16 and FP8 implementations. No details were provided in the post body to analyze quality differences between these numerical formats.
- Performance metrics show significant differences: BF16 takes 12m57s vs FP8 at 7m57s on an RTX 3060 12GB with 24 frames at 1360x768. BF16 requires CPU offload due to OOM errors but delivers more stable results.
- CogVideoX 1.5 faces quantization challenges, unable to run in FP16. Among available options, TorchAO FP6 provides best quality results, while FP8DQ and FP8DQrow offer faster performance on RTX 4090 due to FP8 scaled matmul.
- Installation on Windows requires specific setup using TorchAO v0.6.1 with code modification in
base.hfile, changingFragMdefinition toVec.
Theme 3. 10 AI Agents Collaborate to Write Novel in Real-Time
- A Novel Being Written in Real-Time by 10 Autonomous AI Agents (Score: 277, Comments: 153): Ten autonomous AI agents collaborate in real-time to write a novel, though no additional details about the process, implementation, or results were provided in the post body. The concept suggests an experiment in multi-agent creative writing and AI collaboration, but without further context, specific technical details cannot be summarized.
- Users express significant skepticism about AI-generated long-form content, with many pointing out that ChatGPT struggles with coherence beyond a few pages and frequently forgets plot points and characters. The top comment with 178 upvotes emphasizes this limitation.
- The author explains their solution to maintaining narrative coherence through a file-based coordination system where multiple agents access a global map, content summaries, and running change logs rather than relying on a single context window. The system is currently in the preparation and structuring phase using Qwen 2.5.
- Several users debate the artistic value and purpose of AI-generated novels, arguing that literature is fundamentally about expressing human experience and creating human connections. Critics note that AI models like ChatGPT and Claude would likely avoid controversial topics that make novels interesting.
Theme 4. StepFun's 1T Param Model Rises in LiveBench Rankings
- Chinese AI startup StepFun up near the top on livebench with their new 1 trillion param MOE model (Score: 29, Comments: 0): StepFun, a Chinese AI startup, has developed a 1 trillion parameter Mixture-of-Experts (MOE) model that ranks among the top performers on livebench. The model's performance demonstrates increasing competition in large-scale AI model development from Chinese companies.
- Microsoft CEO says that rather than seeing AI Scaling Laws hit a wall, if anything we are seeing the emergence of a new Scaling Law for test-time (inference) compute (Score: 99, Comments: 40): Microsoft's CEO discusses observations about AI scaling laws, noting that instead of encountering computational limits, evidence suggests a new pattern emerging specifically for test-time inference compute. The lack of specific details or quotes in the post body limits further analysis of the claims or supporting evidence for this observation.
- The discussion reveals that test-time inference compute involves allowing models to "think" longer and iterate on outputs rather than accepting first responses, with accuracy scaling logarithmically with thinking time. This represents a second scaling factor alongside traditional training compute scaling.
- Several users, including Pitiful-Taste9403, interpret this as evidence that parameter scaling has hit limitations, causing companies to focus on inference optimization as an alternative path forward for AI advancement.
- The term "scaling law" sparked debate, with users comparing it to Moore's Law, suggesting it's more of a trend than a fundamental law. Some expressed skepticism about the economic implications of these developments for average people.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. Custom Model Deployments Take Center Stage
-
Deploy Custom AI Models on Hugging Face: Developers are now able to deploy tailored AI models on Hugging Face using a
handler.pyfile, allowing for customized pre- and post-processing.- This advancement leverages Hugging Face endpoints to enhance model flexibility and integration into diverse applications.
- DeepSeek-R1-Lite-Preview Matches OpenAI's o1-Preview Performance: DeepSeek launches R1-Lite-Preview, achieving o1-preview-level performance on AIME & MATH benchmarks.
- This model not only mirrors OpenAI's advancements but also introduces a transparent reasoning process accessible in real-time.
- Tencent Hunyuan Model Fine-Tuning Now Accessible: Users can fine-tune the Tencent Hunyuan model with resources like the GitHub repository and official demo.
- This facilitates enhanced customization for various NLP tasks, expanding the model's applicability.
Theme 2. AI Model Performance and Optimization Soars
-
SageAttention2 Doubles Inference Speed: The SageAttention2 Technical Report reveals a method for 4-bit matrix multiplication, achieving a 2x speedup over FlashAttention2 on RTX40/3090 GPUs.
- This innovation serves as a drop-in replacement, significantly accelerating inference without sacrificing accuracy.
- GPT-4o Gets Creative Boost and File Handling Enhancements: OpenAI updates GPT-4o, elevating its creative writing abilities and improving file handling for deeper insights.
- The revamped model regains top spots in categories like coding and creative writing within chatbot competitions.
- Model Quantization Discussed for Performance Gains: Users express concerns that quantization adversely affects model performance, preferring original models over quantized versions.
- Suggestions include clearer disclosures from providers like OpenRouter and exploring modifications in evaluation libraries to accommodate pruned models.
Theme 3. Innovative AI Research Paves New Paths
-
ACE Method Enhances Model Control: EleutherAI introduces the ACE (Affine Concept Editing) method, treating concepts as affine functions to better control model responses.
- Tested on models like Llama 3 70B, ACE outperforms previous techniques in managing refusal behavior across harmful and harmless prompts.
- Scaling Laws Reveal Low-Dimensional Capability Space: A new paper suggests that language model performance is influenced more by a low-dimensional capability space than solely by scaling across multiple dimensions.
- Marius Hobbhahn from Apollo champions the advancement of evaluation science, emphasizing rigorous model assessment practices.
- Generative Agents Simulate Over 1,000 Real Individuals: A novel architecture effectively simulates the attitudes and behaviors of 1,052 real people, achieving 85% accuracy on the General Social Survey.
- This reduces accuracy biases across racial and ideological groups, offering robust tools for exploring individual and collective behaviors in social science.
Theme 4. AI Tools Integration and Community Support Flourish
-
Aider's Setup Challenges Resolved with Force Reinstall: Users facing setup issues with Aider, particularly with API keys and environment variables, found success by performing a force reinstall.
- This solution streamlined the setup process, enabling smoother integration of DeepSeek-R1-Lite-Preview and other models.
- LM Studio Navigates Hardware Limitations with Cloud Solutions: Members discuss running DeepSeek v2.5 Lite on limited hardware, emphasizing the need for GPUs with at least 24GB VRAM.
- Cloud-based hardware rentals are explored as cost-effective alternatives, offering high-speed model access without local hardware constraints.
- Torchtune's Adaptive Batching Optimizes GPU Utilization: Implementation of adaptive batching in Torchtune aims to maximize GPU utilization by dynamically adjusting batch sizes to prevent OOM errors.
- This feature is suggested to be integrated as a flag in future recipes, enhancing training efficiency and resource management.
Theme 5. Cutting-Edge AI Developments Address Diverse Challenges
-
LLMs Exhibit Intrinsic Reasoning Without Explicit Prompting: Research demonstrates that large language models (LLMs) can display reasoning paths similar to chain-of-thought (CoT) without explicit prompting by tweaking the decoding process.
- Adjusting to consider top-$k$ alternative tokens uncovers the inherent reasoning abilities of LLMs, reducing reliance on manual prompt engineering.
- Perplexity AI Introduces Shopping Feature Amid API Challenges: Perplexity AI launches a new Shopping feature, sparking discussions about its exclusivity to the US market while users face issues with API response consistency.
- Despite being Pro users, some members express frustration over limitations, leading to increased reliance on alternatives like ChatGPT.
- OpenRouter Tackles Model Description and Caching Clarifications: Users identify discrepancies in the GPT-4o model descriptions on OpenRouter, prompting quick fixes to model cards.
- Clarifications are sought regarding prompt caching policies across different providers, with comparisons between Anthropic and OpenAI protocols.
PART 1: High level Discord summaries
HuggingFace Discord
-
Deploying Custom AI Models Now Possible: A member discovered that custom AI models can be deployed on Hugging Face using a
handler.pyfile, enabling tailored pre- and post-processing of models.- This process involves specifying handling methods for requests and responses, enhancing customization via Hugging Face endpoints.
- New Paper on AI Security Insights Released: AI researchers at Redhat/IBM published a paper addressing the security implications of publicly available AI models, focusing on risk and lifecycle management.
- The paper outlines strategies to improve security for developers and users, aiming to establish more standardized practices within the AI community. View the paper.
- Automated AI Research Assistant Takes Off: An Automated AI Researcher was created using local LLMs to generate research documents in response to user queries.
- The system employs web scraping to compile information and produce topic-relevant summaries and links, making research more accessible.
- LangGraph Learning Initiatives: User
richieghostinitiated learning around LangGraph, discussing its applications and developments in the community.
- This highlights the ongoing interest in integrating graph-based techniques within AI models.
- Semantic Search Challenges with Ada 002: Semantic search using OpenAI's Ada 002 is prioritizing dominant topics, resulting in less prominent but relevant sentences receiving lower rankings.
- Users are seeking alternatives to semantic search to improve information extraction effectiveness.
Interconnects (Nathan Lambert) Discord
-
o1 Release Rumblings: Speculation is rife that OpenAI's o1 model may be released imminently, potentially aligning with DevDay Singapore, although these rumors remain unconfirmed.
- A member noted, 'Wednesday would be a weird day for it,' highlighting the community's vigilant anticipation despite uncertainties.
- DeepSeek's RL Drive: Discussions around DeepSeek Prover revealed interest in their application of reinforcement learning, with members anticipating a possible paper release despite challenges related to model size and performance.
- The community is contemplating delays in full release due to these performance hurdles.
- GPT-4o Gains Ground: OpenAI announced an update to GPT-4o, enhancing its creative writing capabilities and file handling, which propelled it back to the top in performance categories such as creative writing and coding within a chatbot competition.
- This update underscores GPT-4o's improved relevance and readability, as detailed in OpenAI's official tweet.
- LLM Learning Loops: Recent insights suggest that how LLMs memorize training examples significantly affects their generalization capabilities, with models first understanding concepts before memorization leading to better test accuracy predictions.
- Katie Kang shared that this method allows for predicting test outcomes based solely on training dynamics.
- NeurIPS NLP Nixed: Concerns have been raised about NeurIPS D&B reviewers dismissing projects focused on Korean LLM evaluation, citing that similar efforts already exist in Chinese.
- Community members argue that each language requires tailored models, emphasizing the importance of inclusivity in NLP development as highlighted in Stella Biderman's tweet.
Unsloth AI (Daniel Han) Discord
-
Fine-tuning Finesse for LLMs: A user successfully exported Llama 3.1 for a local project to Hugging Face leveraging the 16-bit version for enhanced performance in building RAG applications.
- Members recommended using the 16-bit version to optimize fine-tuning capabilities, ensuring better resource management during model development.
- SageAttention2 Speeds Up Inference: The SageAttention2 Technical Report introduced a method for 4-bit matrix multiplication that achieves a 2x speedup over FlashAttention2.
- With support for RTX40/3090 hardware, SageAttention2 serves as a drop-in replacement for FlashAttention2, enhancing inference acceleration without compromising metric fidelity.
- Training Llama Models: Multiple members shared experiences training different Llama models, noting varying success based on model parameters and dataset sizes.
- Suggestions included starting with base models and tuning training steps for optimal performance.
- Enhancing Performance with Multi-GPU Training: Users are exploring multi-GPU training capabilities with Unsloth, currently unavailable but expected to be released soon.
- Strategies like utilizing Llama Factory for managing multiple GPUs were discussed to prepare for the upcoming feature.
aider (Paul Gauthier) Discord
-
Aider Setup Challenges Resolved: Users faced issues with Aider's setup, specifically regarding API keys and environment variables, leading some to attempt reinstalling components.
- One user reported that performing a force reinstall successfully resolved the setup challenges.
- DeepSeek Impresses with Performance: DeepSeek-R1-Lite-Preview matches o1-preview performance on AIME & MATH benchmarks, offering faster response times compared to previous models.
- The model's transparent reasoning process enhances its effectiveness for coding tasks by allowing users to observe its thought process in real-time.
- Concerns Over OpenRouter's Model Quality: Users expressed dissatisfaction with OpenRouter utilizing quantized versions of open-source models, raising doubts about their performance on the Aider Leaderboard.
- There were calls for clearer warnings on the leaderboard regarding potential performance discrepancies when using OpenRouter's quantized models.
- Impact of Model Quantization Discussed: Quantization negatively affects model performance, leading users to prefer original models over quantized versions.
- Users suggested that OpenRouter should disclose specific model versions to accurately set performance expectations.
- Understanding Aider's Chat Modes: Members discussed the effectiveness of various Aider chat modes, highlighting that using o1-preview as the Architect with DeepSeek or o1-mini as the Editor yields the best results.
- A user noted that Sonnet performs exceptionally well for daily tasks without requiring complex configurations.
Eleuther Discord
-
ACE Your Model Control with Affine Editing: The authors introduce the new ACE (Affine Concept Editing) method, treating concepts as affine functions to enhance control over model responses. ACE enables projecting activations onto hyperplanes, demonstrating improved precision in managing model behavior as shown through tests on Gemma.
- ACE was evaluated on ten models, including Llama 3 70B, achieving superior control over refusal behavior across both harmful and harmless prompts. This method surpasses previous techniques, offering a more reliable strategy for steering model actions.
- Latent Actions Propel Inverse Dynamics: A user inquired about the top papers on latent actions and inverse dynamics models, emphasizing an interest in state-of-the-art research within these domains. The discussion highlighted the significance of relevant literature for advancing current AI methodologies.
- While no specific papers were cited, the conversation underscored the importance of exploring latent actions and inverse dynamics models to push the boundaries of existing AI frameworks.
- Scaling Laws Unveil Capability Dimensions: A newly published paper titled Understanding How Language Model Performance Varies with Scale presents an observational approach to scaling laws based on approximately 100 publicly available models. The authors propose that language model performance is influenced more by a low-dimensional capability space rather than solely training across multiple scales.
- Marius Hobbhahn at Apollo was recognized as a leading advocate for advancing the science of evaluation methods within the AI community, highlighting a growing focus on rigorous evaluation practices in AI model development.
- WANDA Pruning Enhances Model Efficiency: A member inquired if lm-eval supports zero-shot benchmarking for pruned models, mentioning the use of the WANDA pruning method. Concerns were raised regarding the suspect results obtained from zero-shot evaluations.
- Discussions included modifications to lm_eval for compatibility with pruned models and evaluations on ADVBench using vllm, with specific code snippets shared to illustrate model loading and inference methods.
- Forgetting Transformer Integrates Forget Gates: The Forgetting Transformer paper introduces a method that incorporates a forget gate into the softmax attention mechanism, addressing limitations of traditional position embeddings. This approach offers an alternative to recurrent sequence models by naturally integrating forget gates into Transformer architectures.
- Community discussions referenced related works like Contextual Position Encoding (CoPE) and analyzed different strategies for position embeddings, evaluating whether simpler methods like ALiBi or RoPE might integrate more effectively than recent complex approaches.
Perplexity AI Discord
-
Perplexity Outperformed by ChatGPT: Users compared Perplexity with ChatGPT, highlighting ChatGPT's versatility and superior conversational abilities.
- Despite being Pro users of Perplexity, some expressed frustration over its limitations, leading to increased reliance on ChatGPT.
- Introduction of Perplexity Shopping Feature: The new Perplexity Shopping feature sparked discussions, with users inquiring about its exclusivity to the US market.
- There is significant interest in understanding potential access limitations for the shopping functionality.
- API Functionality Issues Reported: Users reported that API responses remain unchanged despite switching models, causing confusion and frustration.
- The community debated the platform's flexibility and questioned the diversity of its responses.
- Fullstack Development Insights with Next.js: A resource on fullstack Next.js development was shared, offering insights into modern web frameworks.
- Explore the use of Hono for server-side routing!
- NVIDIA AI Chips Overheating Concerns: Concerns were raised about NVIDIA AI chips overheating, as detailed in this report.
- Discussions emphasized the risks associated with prolonged usage of these chips.
OpenRouter (Alex Atallah) Discord
-
Gemini 1114 Struggles with Input Handling: Users reported that Gemini 1114 often ignores image inputs during conversations, leading to hallucinated responses, unlike models such as Grok vision Beta.
- Members are hoping for confirmation and fixes, expressing frustration over recurring issues with the model.
- DeepSeek Launches New Reasoning Model: A new model, DeepSeek-R1-Lite-Preview, was announced, boasting enhanced reasoning capabilities and performance on AIME & MATH benchmarks.
- However, some users noted the model’s performance is slow, prompting discussions about whether DeepInfra might be a faster alternative.
- Clarifications on Prompt Caching: Prompt caching is available for specific models like DeepSeek, with users questioning the caching policies of other providers.
- Some members discussed how caching works differently between systems, particularly noting Anthropic and OpenAI protocols.
- Issues with GPT-4o Model Description: Users identified discrepancies in the newly released GPT-4o, noting the model incorrectly listed an 8k context and wrong descriptions linked to GPT-4.
- After highlighting the errors, members saw quick updates and fixes to the model card, restoring accurate information.
- Comparisons of RP Models: Members discussed alternatives to Claude for storytelling and role-playing, with suggestions for Hermes due to its perceived quality and cost-effectiveness.
- Users indicated a mix of experiences with these models, with some finding Hermes preferable while others remain loyal to Claude.
LM Studio Discord
-
Model Loading on Limited Hardware: A user encountered model loading issues in LM Studio on a 36GB RAM M3 MacBook, highlighting error messages about system resource limitations.
- Another member recommended avoiding 32B models for such setups, suggesting a maximum of 14B to prevent overloading.
- GPU and RAM Requirements for LLMs: Discussions emphasized that running DeepSeek v2.5 Lite requires at least 24GB VRAM for the Q4_K_M variant and 48GB VRAM for full Q8.
- Members preferred NVIDIA GPUs over AMD due to driver stability issues affecting performance.
- Cloud-Based Solutions vs Local Hardware: Users explored cloud-based hardware rentals as a cost-effective alternative to local setups, with monthly costs ranging from $25 to $50.
- This approach enables access to high-speed models without the constraints of local hardware limitations.
- Workstation Design for AI Workloads: A member sought advice on building a workstation for fine-tuning LLMs within a $30,000 to $40,000 budget, considering options like NVIDIA A6000s versus fewer H100s.
- The discussion underscored the importance of video memory and hardware flexibility to accommodate budget constraints.
- Model Recommendations and Preferences: Users recommended various models including Hermes 3, Lexi Uncensored V2, and Goliath 120B, based on performance and writing quality.
- Encouragement was given to experiment with different models to identify the best fit for individual use cases as new options become available.
Stability.ai (Stable Diffusion) Discord
-
Gaming PC Guidance Galore: A user is seeking gaming PC recommendations within a budget of $2500, asking for suggestions on both components and where to purchase.
- They are encouraging others to send direct messages for personalized advice.
- Character Consistency Challenges: A member inquired about maintaining consistent character design throughout a picture book, struggling with variations from multiple generated images.
- Suggestions included using FLUX or image transformation techniques to improve consistency.
- AI Models vs. Substance Designer: A discussion arose on whether AI models could effectively replace Substance Designer, highlighting the need for further exploration in that area.
- Members shared their thoughts on the capabilities of different AI models and their performance.
- GPU Optimization for Video Generation: Users discussed the difficulties of performing AI video generation on limited VRAM GPUs, noting potential for slow processing times.
- The recommended course of action included clearing VRAM and using more efficient models like CogVideoX.
- Fast AI Drawing Techniques: A member inquired about the technology behind AI drawing representations that update quickly on screen, wondering about its implementation.
- Responses indicated that it often relies on powerful GPUs and consistency models to achieve rapid updates.
Notebook LM Discord Discord
-
Audio Generation Enhancements in NotebookLM: A member showcased their podcast featuring AI characters, utilizing NotebookLM for orchestrating complex character dialogues.
- They detailed the multi-step process involved, including the integration of various AI tools and NotebookLM's role in facilitating dynamic conversations.
- Podcast Creation Workflow in NotebookLM: A member shared their experience in creating a German-language podcast on Spotify using NotebookLM for audio generation.
- They emphasized the effective audio features of NotebookLM and sought customization recommendations to enhance their podcast production.
- Transcription Features for Audio Files: Members discussed the option to upload generated audio files to NotebookLM for automatic transcription.
- Alternatively, one member suggested leveraging MS Word's Dictate...Transcribe function for converting audio to text.
- Combining Notes Feature Evaluation: Members deliberated on the 'Combine to note' feature in NotebookLM, assessing its functionality for merging multiple notes into a single document.
- One member questioned its necessity, given the existing capability to combine notes, seeking clarity on its utility.
- Sharing Notebooks Functionality: A user inquired about the procedure for sharing notebooks with peers, encountering difficulties in the process.
- Another member clarified the existence of a 'share note' button located at the top right corner of the NotebookLM interface to facilitate sharing.
Latent Space Discord
-
DeepSeek-R1-Lite-Preview Launch: DeepSeek announced the launch of DeepSeek-R1-Lite-Preview, showcasing enhanced performance on AIME and MATH benchmarks with a transparent reasoning process.
- Users are excited about its potential applications, noting that reasoning improvements scale effectively with increased length.
- GPT-4o Update Enhances Capabilities: OpenAI released a new GPT-4o snapshot as
gpt-4o-2024-11-20, which boosts creative writing and improves file handling for deeper insights.
- Recent performance tests show GPT-4o reclaiming top spots across various categories, highlighting significant advancements.
- Truffles Hardware Device Gears Up for LLM Hosting: The Truffles hardware device was identified as a semi-translucent solution for self-hosting LLMs at home, humorously termed a 'glowing breast implant'.
- This nickname reflects the light-hearted conversations around innovative home-based LLM deployment options.
- Vercel Acquires Grep to Boost Code Search: Vercel announced the acquisition of Grep, enabling developers to search through over 500,000 public repositories efficiently.
- Founder Dan Fox will join Vercel's AI team to enhance code search functionalities and improve development workflows.
- Claude Experiences Availability Fluctuations: Users reported intermittent availability issues with Claude, experiencing sporadic downtimes across different instances.
- These reliability concerns have led to active discussions, with users seeking updates via social media platforms.
GPU MODE Discord
-
Triton Triumphs Over Torch in Softmax: A member compared Triton's fused softmax against PyTorch's native implementation on an RTX 3060, highlighting smoother performance from Triton.
- While Triton generally outperformed PyTorch, there were instances where PyTorch matched or exceeded Triton's performance.
- Metal GEMM Gains Ground: Philip Turner's Metal GEMM implementation was showcased, with a member noting their own implementation achieves 85-90% of theoretical maximum speed, similar to Turner's.
- Further discussion touched on the challenges of optimizing Metal compilers and the necessity of removing addressing computations from performance-critical loops.
- Dawn's Regressing Render: Concerns were raised about performance regressions in Dawn's latest versions, especially in the wgsl-to-Metal workflow post Chrome 130, despite improvements in Chrome 131.
- Issues related to Undefined Behavior (UB) check code placement were identified as potential causes for the lag behind Chrome 129.
- FLUX Speeds Ahead with CPU Offload: A member reported a 200% speedup in FLUX inference by implementing per-layer CPU offload on a 4070Ti SUPER, reducing inference time to 1.23 s/it from 3.72 s/it.
- Discussion highlighted the effectiveness of pinned memory and CUDA streams on capable machines, though performance gains were limited on shared instances.
Nous Research AI Discord
-
DeepSeek-R1-Lite-Preview Launch: DeepSeek-R1-Lite-Preview is now live, featuring o1-preview-level performance on AIME & MATH benchmarks.
- It also includes a transparent thought process in real-time, with open-source models and an API planned for release soon.
- AI Agents for Writing Books: Venture Twins is showcasing a project where ten AI agents collaborate to write a fully autonomous book, each assigned different roles like setting narrative and maintaining consistency.
- Progress can be monitored through GitHub commits as the project develops in real-time.
- LLMs Reasoning Without Prompting: Research demonstrates that large language models (LLMs) can exhibit reasoning paths akin to chain-of-thought (CoT) without explicit prompting by adjusting the decoding process to consider top-$k$ alternative tokens.
- This approach underscores the intrinsic reasoning abilities of LLMs, indicating that CoT mechanisms may inherently exist within their token sequences.
- Generative Agent Behavioral Simulations: A new architecture effectively simulates the attitudes and behaviors of 1,052 real individuals, with generative agents achieving 85% accuracy on responses in the General Social Survey.
- The architecture notably reduces accuracy biases across racial and ideological groups, enabling tools for the exploration of individual and collective behavior in social science.
- Soft Prompts Inquiry: A member inquired about the investigation of soft prompts for LLMs as mentioned in a post, highlighting their potential in optimizing system prompts into embedding space.
- Another member responded, expressing that the concept of soft prompts is pretty interesting, indicating some interest within the community.
OpenAI Discord
-
API Usage Challenges: A member reported searching for an API or tool but found both options unsatisfactory, indicating frustration.
- This issue reflects a broader interest in locating efficient resources within the community.
- Model Option Clarification: There was a discussion regarding the 4o model and whether it utilized o1 mini or o1 preview, with confirmation leaning towards o1 mini.
- A member suggested checking the settings to verify options, promoting hands-on troubleshooting.
- High Temperature Performance: A member questioned if improved performance at higher temperatures could be linked to their prompt style, suggesting an excess of guiding rules or constraints.
- This raises considerations for optimizing prompt design to enhance AI responsiveness.
- Beta Access to o1: A member expressed excitement and gratitude towards NH for granting them beta access to o1, brightening their morning.
- Woo! Thank you NH for making this morning even brighter reflects the exhilaration around new updates.
- Delimiter Deployment in Prompts: A member shared OpenAI's advice on using delimiters like triple quotation marks or XML tags to help the model interpret distinct sections of the input clearly.
- This approach aids in structuring prompts better for improved model responses, allowing for easier input interpretation.
Cohere Discord
-
API Key Problems Block Access: Multiple members reported encountering 403 errors, indicating invalid API keys or the use of outdated endpoints while trying to access certain functionalities.
- One member shared experiencing fetch errors and difficulties using the sandbox feature after verifying their API keys.
- CORS Errors Interrupt API Calls: A member on the free tier faced several CORS errors in the console despite using a standard setup without additional plugins.
- Attempts to upgrade to a production key to resolve these issues were unsuccessful, highlighting limitations of the free tier.
- Advanced Model Tuning Techniques Explored: Discussions delved into whether model tuning could be achieved using only a preamble and possibly chat history.
- Questions were raised about the model's adaptability to various training inputs, indicating the need for more effective tuning methods.
- Cohere Introduces Multi-modal Embeddings: A member praised the new multi-modal embeddings for images, noting significant improvements in their applications.
- However, concerns were raised about the 40 requests per minute rate limit, which hinders their intended use case, leading them to seek alternative solutions.
- Harmony Project Streamlines Questionnaire Harmonization: The Harmony project aims to harmonize questionnaire items and metadata using LLMs, facilitating better data compatibility for researchers.
- A competition is being hosted to enhance Harmony's LLM matching algorithms, with participants able to register on DOXA AI and contribute to making Harmony more robust.
Torchtune Discord
-
Adaptive Batching Optimizes GPU Usage: The implementation of adaptive batching aims to maximize GPU utilization by dynamically adjusting batch sizes to prevent OOM errors during training.
- It was suggested to integrate this feature as a flag in future recipes, ideally activated when
packed=trueto maintain efficiency. - Enhancing DPO Loss Structure: Concerns were raised about the current TRL code structure regarding the inclusion of recent papers on DPO modifications, as seen in Pull Request #2035.
- A request was made to clarify whether to remove SimPO and any separate classes to keep the DPO recipe clean and straightforward.
- SageAttention Accelerates Inference: SageAttention achieves speedups of 2.1x and 2.7x compared to FlashAttention2 and xformers, respectively, while maintaining end-to-end metrics across various models.
- Pretty cool inference gains here! expressed excitement about the performance improvements introduced by SageAttention.
- Benchmarking sdpa vs. Naive sdpa: Members recommended benchmarking the proposed sdpa/flex method against the naive sdpa approach to identify performance differences.
- The numerical error in scores may vary based on the sdpa backend and data type used.
- Nitro Subscription Affects Server Boosts: A member highlighted that server boosts will be removed if a user cancels their free Nitro subscription, impacting server management.
- This underscores the importance of maintaining Nitro subscriptions to ensure uninterrupted server benefits.
- It was suggested to integrate this feature as a flag in future recipes, ideally activated when
tinygrad (George Hotz) Discord
-
Tinygrad Tackles Triton Integration: A user inquired about Tinygrad's native integration with Triton, referencing earlier discussions. George Hotz directed them to consult the questions document for further clarification.
- Further discussions clarified the integration steps, emphasizing the compatibility between Tinygrad and Triton for enhanced performance.
- SASS Assembler Seeks PTXAS Replacement: Members discussed the future of the SASS assembler, questioning if it is intended to replace ptxas. George Hotz suggested referring to the questions document for more details.
- This has sparked interest in the potential improvements SASS assembler could bring over ptxas, though some uncertainty remains regarding the assembler's long-term role.
- FOSDEM AI DevRoom Seeks Tinygrad Presenters: A community member shared an opportunity to present at the FOSDEM AI DevRoom on February 2, 2025, highlighting Tinygrad's role in the AI industry. Interested presenters are encouraged to reach out.
- The presentation aims to showcase Tinygrad's latest developments and foster collaboration among AI engineers.
- Tinybox Hackathon Hopes for Hands-on Engagements: A member proposed organizing a pre-FOSDEM hackathon, suggesting bringing a Tinybox on-site to provide hands-on experiences. They expressed enthusiasm about engaging the community over Belgian beer during the event.
- The hackathon aims to facilitate practical discussions and collaborative projects among Tinygrad developers.
- Exploring Int64 Indexing in Tinygrad: A member questioned the necessity of int64 indexing in scenarios not involving huge tensors, seeking to understand its advantages. The discussion aims to clarify the use-cases of int64 indexing beyond large-scale tensor operations.
- Exploring various indexing techniques, the community is evaluating the performance and efficiency impacts of int64 versus int32 indexing in smaller tensor contexts.
Modular (Mojo 🔥) Discord
- Async functions awaitable in Mojo sync functions: A member is puzzled about being able to await an async function inside a sync function in Mojo, which contrasts with Python's limitations, seeking clarification or an explanation for this difference in handling async functionality.
- Inquiry about Mojo library repository: Another member is curious about the availability of a repository for libraries comparable to pip for Mojo, looking for resources or links that provide access to Mojo libraries.
-
Moonshine ASR Model Tested with Max: A user tested the Moonshine ASR model performance using both the Python API for Max and a native Mojo version, noting both were about 1.8x slower than the direct onnxruntime Python version.
- The Mojo and Python Max versions took approximately 82ms to transcribe 10 seconds of speech, whereas the native onnxruntime reached 46ms. Relevant links: moonshine.mojo and moonshine.py.
- Mojo Model.execute Crash Due to TensorMap: Instructions for running the Moonshine ASR model are provided in comments at the top of the mojo file that was shared.
- The user's experience highlighted that passing in TensorMap into Model.execute caused a crash, and manual unpacking of 26 arguments was necessary due to limitations in Mojo. Relevant link: moonshine.mojo.
- Seeking Performance Improvements in Mojo: The user expressed that this is one of their first Mojo programs and acknowledged that it may not be idiomatic.
- They requested assistance for achieving better performance, emphasizing their eagerness to improve their Mojo and Max skills.
OpenAccess AI Collective (axolotl) Discord
-
Tencent Hunyuan Model Fine Tuning: A member inquired about fine-tuning the Tencent Hunyuan model, sharing links to the GitHub repository and the official website.
- Additional resources provided include the Technical Report and a Demo for reference.
- Bits and Bytes on MI300X: A member shared their experience using Bits and Bytes on the MI300X system, highlighting its ease of use.
- They emphasized the necessity of using the
--no-depsflag during updates and provided a one-liner command to force reinstall the package. - Axolotl Collab Notebooks for Continual Pretraining of LLaMA: A user asked if Axolotl offers any collab notebooks for the continual pretraining of LLaMA.
- Phorm responded that the search result was undefined, indicating no available notebooks currently, and encouraged users to check back for updates.
DSPy Discord
-
Juan seeks help with multimodal challenges: Juan inquired about using the experimental support for vision language models while working on a multimodal problem.
- Another member offered additional assistance by saying Let me know if there are any issues!.
- Juan discovers the mmmu notebook: Juan later found the mmmu notebook himself, which provided the support he needed for his project.
- He thanked the community for their awesome work, showing appreciation for the resources available.
- Semantic Router as a Benchmark: A member suggested that the Semantic Router should serve as the baseline for performance in classification tasks, emphasizing its superfast AI decision making capabilities.
- The project focuses on intelligent processing of multi-modal data, and it may offer competitive benchmarks we aim to exceed.
- Focus on Performance Improvement: There was an assertion that the performance of existing classification tools needs to be surpassed, with the Semantic Router as a reference point.
- Discussion revolved around identifying metrics and strategies to achieve better results than the baseline set by this tool.
LlamaIndex Discord
-
LLM-Native Resume Matching Launched: Thanks to @ravithejads, an LLM-native solution for resume matching has been developed, enhancing traditional screening methods.
- This innovative approach addresses the slow and tedious process of manual filtering in recruitment, offering a more efficient alternative.
- Building AI Agents Webinar on December 12: Join @Redisinc and LlamaIndex for a webinar on December 12, focusing on building data-backed AI agents.
- The session will cover architecting agentic systems and best practices for reducing costs and optimizing latency.
- PDF Table Data Extraction Methods: A member in #general inquired about approaches to extract table data from PDF files containing text and images.
- They expressed interest in knowing if there are any existing applications that facilitate this process.
- Applications for PDF Data Extraction: Another member sought recommendations for applications available to extract data specifically from PDFs.
- This highlights a need within the community for tools that can handle various PDF complexities.
OpenInterpreter Discord
-
New UI sparks mixed feelings: Some users feel the new UI is slightly overwhelming and unclear in directing attention, with one comparing it to a computer from Alien.
- However, others are starting to appreciate its UNIX-inspired design, finding it suitable for 1.0 features.
- Rate Limit Configuration Needed: A user expressed frustration over being rate limited by Anthropic, noting that current error handling in Interpreter leads to session exits when limits are exceeded.
- They emphasized the importance of incorporating better rate limit management in future updates.
- User Calls for UI Enhancements: There are calls for a more informative UI that displays current tools, models, and working directories to enhance usability.
- Users are also advocating for a potential plugin ecosystem to allow customizable features in future releases.
- Compute Workloads Separation Proposed: One member suggested splitting LLM workloads between local and cloud compute to optimize performance.
- This reflects a concern about the limitations of the current Interpreter design, which is primarily built for one LLM at a time.
LLM Agents (Berkeley MOOC) Discord
-
Intel AMA Session Tomorrow: A Hackathon AMA with Intel is scheduled for 3 PM PT tomorrow (11/21), offering participants direct insights from Intel specialists. Don’t forget to watch live here and set your reminders!
- Participants are encouraged to prepare their questions to maximize the session's benefits.
- Participant Registration Confusion: A user reported not receiving emails after joining three different groups and registering with multiple email addresses, raising uncertainties about the success of their registration.
- Clarification on Event Type: A member sought clarification on whether the registration issue pertained to the hackathon or the MOOC, highlighting potential confusion among participants regarding different registration types.
Mozilla AI Discord
-
Refact.AI Live Demo Highlights Autonomous Agents: Refact.AI is hosting a live demo showcasing their autonomous agent and tooling.
- Join the live demo and conversation to explore their latest developments.
- Refact.AI Unveils New Tooling: The Refact.AI team has released new tooling to support their autonomous agent projects.
- Participants are encouraged to engage with the tools during the live demo event.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LAION Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #general (263 messages🔥🔥):
Hugging Face Discord CommunityAI and Machine Learning ProjectsGradio and Streamlit IntegrationLangChain and RAGGeneral Discussion and Support Requests
-
Community Engagement and Support: Members shared their experiences with the Hugging Face community, discussing support requests related to training models and technical issues, such as RuntimeErrors.
- The community provided troubleshooting tips and encouraged sharing resources, leading to collaborative problem-solving.
- Integrating AI Models into Projects: Users explored ways to integrate AI models into applications, with suggestions to use Gradio for its simplicity and efficiency over LangChain.
- Discussions included practical approaches for building interfaces and workflows for various AI models, emphasizing hands-on learning.
- Exploration of RAG and AI Agents: The concept of Retrieval-Augmented Generation (RAG) and creating AI agents was debated, with recommendations to learn about them through available blogs.
- Members expressed the importance of working on projects to solidify understanding and explore potential creative applications.
- New Projects and Collaboration Opportunities: A new community initiative named Open/acc was introduced, focusing on collaboration in open science and machine learning.
- Participants were encouraged to share events and ideas within this new space to foster innovation.
- General Discussions and Humor: Light-hearted conversations about cooking, shared interests, and humorous takes on cult-like communities within the Discord were frequent.
- Members also shared amusing gifs and engaged in friendly banter, contributing to a positive community atmosphere.
Links mentioned:
- O'Reilly Media - Technology and Business Training: no description found
- Tweet from undefined: no description found
- Hamster Cry GIF - Hamster Cry Tears - Discover & Share GIFs: Click to view the GIF
- Simpsons Homer GIF - Simpsons Homer Bart - Discover & Share GIFs: Click to view the GIF
- Lemon Demon Sundial GIF - Lemon Demon Sundial View-Monster - Discover & Share GIFs: Click to view the GIF
- open-acc (open/ acc): no description found
- Spaces - Hugging Face: no description found
- HeyGen - AI Video Generator: no description found
- Argil AI - Get ai short videos with AI clones in 2 minutes.: Create AI-powered short videos featuring AI clones quickly and easily with Argil AI.
- Large Language Models explained briefly: Dig deeper here: https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3piTechnical details as a talk: https://youtu.be/KJtZARuO3JYMade for an...
- Rabbit Bunny GIF - Rabbit Bunny Toilet - Discover & Share GIFs: Click to view the GIF
- Sunday Cult Of The Lamb GIF - Sunday Cult of the lamb Cult - Discover & Share GIFs: Click to view the GIF
HuggingFace ▷ #today-im-learning (1 messages):
richieghost: today-im-learning LangGraph
HuggingFace ▷ #cool-finds (10 messages🔥):
3D Printing DesignsGenerative Design ToolsCustom AI Model DeploymentAI Security ResearchAutomated AI Researcher
-
3D Printing Achieves Complex Designs: Highlighted by the impressive Bugatti brake caliper, many components have showcased the capabilities of 3D printing to achieve complex designs. With machine learning models optimizing component removal, engineers can enhance performance across sectors, including automotive and architecture.
- Using vector calculations, the process streamlines efficiency not only in cars but also in broader engineering applications.
- Generative Design Tools Available for Free: Generative design tools have been praised for their creativity and innovative capabilities, available for free through an educational license with Fusion 360. This makes advanced design techniques accessible to students and aficionados alike.
- The excitement around these tools stems from their potential to revolutionize design thinking and implementation.
- Deploying Custom AI Models Now Possible: A member shared the discovery that custom AI models can be deployed using a handler file on Hugging Face, allowing for tailored pre- and post-processing of models. The process involves creating a
handler.pyspecifying methods for handling requests and responses.
- This versatile setup enhances customization for AI projects via Hugging Face endpoints.
- New Paper on AI Security Insights Released: A recent paper from AI researchers at Redhat/IBM discusses the security implications of publicly available AI models, addressing risks and lifecycle management. Comprehensive strategies are proposed to enhance security for both developers and users.
- The paper aims to foster more standardized practices within the AI community, contributing significantly to the discussion on safety and transparency. View the paper.
- Automated AI Research Assistant Takes Off: An individual created an Automated AI Researcher using local LLMs, which can generate research documents in response to user queries. This system utilizes web scraping to compile information and produce topic-relevant summaries and links.
- The innovation emphasizes the potential of AI to simplify research and information gathering, making it accessible at the touch of a button.
Links mentioned:
- FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models: Collecting high-quality labeled data for model training is notoriously time-consuming and labor-intensive for various NLP tasks. While copious solutions, such as active learning for small language mod...
- Paper page - Building Trust: Foundations of Security, Safety and Transparency in AI: no description found
- Create custom Inference Handler: no description found
- no title found: no description found
- Reddit - Dive into anything: no description found
HuggingFace ▷ #i-made-this (4 messages):
Fractal Forest CreaturesAI in Music and AnimationEffective Prompting TechniquesPsychedelic Experience with MusicNeo's Journey to the 60s
-
Neural Voyage to the 60s: The YouTube video titled A.I. The Matrix Red Pill Scene Psychedelic Trip explores what happens when Neo's red pill sends him back to the 60s, merging iconic music with AI animation.
- The video features a blend of tunes from The Beatles, The Doors, and Jimi Hendrix, creating a vibrant audiovisual experience.
- The Art of Prompting in AIs: A discussion emerges around the video BAD vs GOOD prompting which examines the necessity of effective prompting techniques in today's AI landscape.
- Members are encouraged to leave comments, reflecting on the evolving dynamics of prompting and its impact on AI outputs.
- Appreciation for Cool Content: A member expressed enthusiasm, saying, 'very cool share, thank you for this!' in response to the matrix-themed AI video.
- Such reactions highlight the community's interest in innovative AI applications blended with artistic flair.
Links mentioned:
- BAD vs GOOD prompting: Let's see in this video if we still need to make good prompting nowadays and if there is a difference, at what point is it different.Feel free to leave comme...
- A.I. The Matrix Red Pill Scene Psychedelic Trip with The Beatles, The Doors, Nirvana, Jimi Hendrix🎧🔈: Headphones Essential #4K #ai #animation #thematrix #redpill #bluepill #johnlennon #jimmorrison #jimihendrix #kurtcobain #nirvana #thebeatles #thedoors #psych...
HuggingFace ▷ #reading-group (4 messages):
3080 GPU PricingVRAM UtilizationChannel Discussion Etiquette
-
Affordable 3090 GPUs hit low prices: Members discussed that used 3090 GPUs are now available for 400-500€, a price deemed worthwhile.
- Another member suggested that 400-450€ could be considered a good deal for these cards.
- GPU usage concerns raised: Concerns were expressed regarding whether the GPU is being fully utilized; one member feels that only VRAM is actively being used.
- This raises questions about the actual performance being leveraged during tasks.
- Request for off-topic discussions move: A member requested that off-topic discussions be redirected to another channel to keep the reading group focused.
- They encouraged others to use the relevant channel for further discussion, promoting a better environment for group activities.
HuggingFace ▷ #NLP (5 messages):
Semantic Search ChallengesIssues with Evaluate LibraryAlternatives to Pandas
-
Semantic search struggles with focus topics: A user is facing challenges with semantic search using OpenAI's Ada 002, where embeddings prioritize dominant topics, leading to lower rankings for less prominent but relevant sentences.
- They are seeking alternatives to semantic search to effectively extract the needed information.
- Frustration with Evaluate Library: A user expressed frustration about the Evaluate Library, stating they had to manually compute lift metrics for a presentation, which was inefficiency.
- They shared a sentiment of irritation, indicating it's bothersome when libraries do not function as expected.
- Faster alternatives to Pandas needed: Another user shared their struggle with Pandas, finding it slow when dealing with large datasets and requesting suggestions for faster libraries.
- This highlights an ongoing need for more efficient data handling tools within the community.
HuggingFace ▷ #diffusion-discussions (6 messages):
Diffusers Version IssuesCogVideoX1.5-5B-I2V Repo UpdatesColab Session CrashesFP16 Model LoadingOversampling and Downsampling Query
-
Diffusers Version Fails to Work: A member reported their attempts to get i2v working with the newer diffusers version were unsuccessful.
- This issue may relate to recent updates reflected in the codebase.
- Repo Update Needed for CogVideoX1.5-5B-I2V: Another member noted that corrections are needed on the CogVideoX1.5-5B-I2V repository, highlighting a recent commit made two hours ago.
- They referred to the CogVideoX1.5-5B-I2V discussion for more details.
- Colab Session Crashes While Loading Model: A member shared a Colab link where their session crashes when attempting to load the transformer model.
- They speculated that the crash might be due to trying to load the fp16 model.
- Request for Minimal Reproducible Snippet: A member advised that issues should be reported with a minimal reproducible snippet to facilitate troubleshooting efforts.
- This approach will help clarify specific problems faced by users.
- Downsampling and Oversampling Inquiry: A member asked whether it is possible to perform oversampling or downsampling in the discussed context.
- This reflects ongoing interest in refining techniques for model training.
Links mentioned:
- THUDM/CogVideoX1.5-5B-I2V · Discussions: no description found
- Google Colab: no description found
Interconnects (Nathan Lambert) ▷ #news (175 messages🔥🔥):
DeepSeek ProverOpenAI o1 releaseGPT-4o updateModel performance comparisonCommunity discussions on AI models
-
DeepSeek Prover work discussed: Members shared interest in DeepSeek's work using reinforcement learning in their model, speculating about a possible paper release.
- There were discussions about the challenges of model size and performance, suggesting that a full release may be delayed.
- OpenAI o1's imminent release: Speculation arose about OpenAI releasing their o1 model soon, with some members expressing skepticism about timeline rumors circulating in the community.
- Discussions hinted at OpenAI needing to showcase their o1 model in response to growing competition in the industry.
- GPT-4o gets an update: OpenAI announced an update to GPT-4o, improving its creative writing capabilities and file handling.
- The model climbed back to the top in various performance categories including creative writing and coding in a chatbot competition.
- Comparison of model performances: Members compared the performance of various AI models, including OpenAI's and DeepSeek's, pointing out the importance of creative and technical skill improvements.
- There were reflections on user experiences with the models, highlighting strengths and weaknesses in different tasks.
- Community engagement and reactions: The community engaged in lively discussions around the latest AI model updates and performance metrics, often sharing humorous takes.
- Several users expressed their excitement and skepticism in equal measure regarding the direction AI development is heading.
Links mentioned:
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Exciting News from Chatbot Arena❤️🔥 Over the past week, the latest @OpenAI ChatGPT-4o (20241120) competed anonymously as "anonymous-chatbot", gathering 8,000+ community votes. The result? ...
- Tweet from OpenAI (@OpenAI): GPT-4o got an update 🎉 The model’s creative writing ability has leveled up–more natural, engaging, and tailored writing to improve relevance & readability. It’s also better at working with uploaded...
- Tweet from DeepSeek (@deepseek_ai): 🌟 Inference Scaling Laws of DeepSeek-R1-Lite-Preview Longer Reasoning, Better Performance. DeepSeek-R1-Lite-Preview shows steady score improvements on AIME as thought length increases.
- Will a “good” (fine-tuned) opensource model utilizing chain-of-thought reasoning like o1 be released by EOY 2024?: 90% chance. The model should be able to decide how long it needs to think based on the complexity of the problem. Ideally it should be ranked higher on LMSYS than the “normal” model but this is not a ...
- Which major AI lab will be the first to release a model that "thinks before it responds" like o1 from OpenAI?: OpenAI o1 blog post says: We are introducing OpenAI o1, a new large language model trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers—it can produce a long ...
- Tweet from Andrew Curran (@AndrewCurran_): This is interesting, and promising. 'DeepSeek-R1-Lite also uses a smaller base model, which cannot fully unleash the potential of the long thinking chain.' I wonder if there is a similar s...
- no title found: no description found
- GitHub - deepseek-ai/DeepSeek-Prover-V1.5: Contribute to deepseek-ai/DeepSeek-Prover-V1.5 development by creating an account on GitHub.
- Tweet from FxTwitter / FixupX)): Sorry, that user doesn't exist :(
Interconnects (Nathan Lambert) ▷ #ml-drama (6 messages):
Francois Fleuret mentionKorean LLM evaluation issuesJapanese LLM leaderboard
-
Francois Fleuret's Controversial Remarks: There was a discussion around whether Francois Fleuret was trash-talking lbdl, highlighting the ongoing tensions and opinions in the community.
- One user expressed disbelief at the situation, calling it unbelievable.
- Critique of NeurIPS Reviewer Standards: Concerns were raised over NeurIPS D&B reviewers dismissing a project in Korean LLM evaluation based on claims that it already exists in Chinese.
- Commentators argued that every language deserves tailored models, emphasizing the need for inclusivity in NLP development.
- Highlighting Japanese LLM Performance Testing: A user praised the establishment of a leaderboard for Japanese LLMs, created by @llm_jp, which tests performance across diverse NLP tasks.
- They noted that Japanese requires multiple character sets for writing, adding complexity to evaluation efforts.
Links mentioned:
- Tweet from Stella Biderman (@BlancheMinerva): NeurIPS D&B reviewers think "this already exists in Chinese" is a reason to dismiss the value of a project in Korean LLM evaluation, but the people whose opinion I care about know better. Eve...
- François Chollet (@fchollet.bsky.social): Not a week passes by without me hearing from folks who bought a deep learning book by an author with a name close to mine because they thought I had written it. Something like half of its readers thin...
Interconnects (Nathan Lambert) ▷ #random (25 messages🔥):
o1 Release SpeculationsTraining Dynamics in LLMsReinforcement Learning TrendsModel Evaluation BottlenecksRelease Fatigue and Post-Release Plans
-
o1 Release Speculations Stir Interest: There is buzz about the o1 release potentially happening tomorrow, coinciding with DevDay Singapore, but it's based on unconfirmed rumors.
- A member noted, Wednesday would be a weird day for it but the community remains attentive to updates.
- Exploring LLM Training Dynamics: Recent findings suggest that how models memorize training examples impacts their ability to generalize, particularly if they first understand the concept before memorizing.
- This highlights a method to predict test accuracy from models based on their training dynamics alone, as shared in a discussion by Katie Kang.
- Reinforcement Learning's Surprise Comeback: A member expressed excitement about the resurgence of Reinforcement Learning (RL) despite previous doubts, feeling free to embrace their RL roots again.
- They remarked, I can go back to being an RL person, reflecting a broader sentiment of optimism within the community.
- Bottleneck in Model Evaluation: Concerns were raised about the evaluation bottleneck, indicating that it only takes a few hours to evaluate MMLU but can still hold up the process.
- Discussion ensued on deciding when to stop training, with opinions about persistent efforts even as exhaustion sets in.
- Release Fatigue and Plans Ahead: With the imminent release approaching, the commentary suggested a need for recovery post-launch, with thoughts about a relaxing December ahead.
- Amidst the chatter, one member humorously mentioned, I am dead, indicating the toll of the release process on developers.
Links mentioned:
- Tweet from Nathan Lambert (@natolambert): I love seeing RL continue its magnificent takeover that I have doubted so many times over. I can go back to being an RL person, I don't even need to masquerade as an "RLHF" or "NLP"...
- Lucas Beyer (bl16) (@giffmana.bsky.social): https://www.astralcodexten.com/p/how-did-you-do-on-the-ai-art-turing
- Tweet from Sergey Levine (@svlevine): An intriguing new result from @katie_kang_: after training long enough, LLMs will reproduce training examples exactly (not surprising). But how they get there matters: if they first get the right answ...
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): o1 tomorrow apparently ? Wednesday would be a weird day for it but I guess devday Singapore. Heard from a birdie but I can’t confirm it.
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): This was sent out an hour ago. Mini and preview api access, let’s see if there’s more to come.
Unsloth AI (Daniel Han) ▷ #general (176 messages🔥🔥):
Vision SupportMulti-GPU TrainingInternship OpportunitiesData Quality in NLPTraining Llama Models
-
Vision Support is on the Way: A member inquired about the status of vision support, to which another confirmed that it is indeed coming soon.
- This feature will be released alongside other updates.
- Multi-GPU Training Discussed: New users are exploring multi-GPU training capabilities with Unsloth, currently noting that it's not available but expected soon.
- Members shared strategies like using Llama Factory for managing multiple GPUs.
- Internship Roles Available: Discussion emerged about available internship roles with Unsloth, prompting curiosity about the required experience.
- Members were pointed towards a link detailing the opportunities and current needs.
- Importance of Data Quality for NLP: A user sought guidance on dataset cleaning for their NLP task, emphasizing its criticality for success.
- The conversation stressed the importance of dataset quality with advice to start with a smaller dataset for better control during training.
- Training Llama Models: Several members shared their experiences training different Llama models, discovering varying degrees of success depending on parameters.
- Suggestions included beginning with base models before scaling, weighing the dataset size, and adjusting training steps for optimal performance.
Links mentioned:
- Machine Learning Projects by huq02 using Weights & Biases: Weights & Biases, developer tools for machine learning
- Nice Smack GIF - Nice Smack Delicious - Discover & Share GIFs: Click to view the GIF
- Llama 3.1 | Model Cards and Prompt formats: Llama 3.1 - the most capable open model.
- Home: Finetune Llama 3.2, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Google Colab: no description found
- Fine-tuning A Tiny-Llama Model with Unsloth: Fine-Tuning your Tiny-Llama model for peak performance with Unsloth's user-friendly tools and advanced features.
- Google Colab: no description found
- unsloth/unsloth/chat_templates.py at 5078a870c04e60b2491cd4f2974cf78521961179 · unslothai/unsloth): Finetune Llama 3.2, Mistral, Phi, Qwen 2.5 & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #off-topic (9 messages🔥):
NixOS InstallationFedora KDE ExperienceWindows-like Linux DistritosCheckpoint Selection in AI Training
-
Homies Recommend NixOS: A member mentioned that their friends are urging them to install NixOS, showing a popular trend among users.
- This sparked curiosity and comments about various Linux distributions among the group.
- Fedora KDE is a Hit: A member enthusiastically promoted Fedora KDE, exclaiming 'Fedora KDE ftw'.
- The discussion included light-hearted banter about its benefits compared to other operating systems.
- Linux Distro Aesthetic: Another member remarked that Fedora KDE looks 'kinda like Windows' and expressed excitement about its appearance.
- Their humorous take on the distro's interface resonated well with others in the channel.
- AI Training Checkpoint Dilemma: A member inquired about others' preferences when choosing AI training checkpoints, asking, 'which checkpoint are you taking?'
- They shared that they opted for training checkpoint 200 without hesitation, inviting opinions on the varying approaches.
Link mentioned: Dsa GIF - Dsa - Discover & Share GIFs: Click to view the GIF
Unsloth AI (Daniel Han) ▷ #help (10 messages🔥):
Fine-tuning LLMsModel Export to Hugging FacePre-tokenization and Continued PretrainingInference with VLLMCheckpoint Callback for Saving Models
-
Exporting Llama 3.1 for Local Use: A new user had success with 2x Llama 3.1 8b and sought guidance on how to export the model for local project usage with Hugging Face.
- Members advised on using the 16-bit version for performance and capabilities in building RAG applications.
- Pre-tokenized Dataset Queries: Discussion arose about the compatibility of an already tokenized dataset for continued pretraining, with one user expressing uncertainty.
- Another member suggested that passing the untokenized dataset might work better for training.
- Warnings in Model Loading: A user reported a SyntaxWarning related to invalid escape sequences while loading a model from Hugging Face, expressed with specific warning texts provided in the code snippet.
- Despite the warnings, the model and tokenizer were successfully loaded as confirmed by the console output.
- Checkpoint Management for Fine-tuning: A member sought advice on fine-tuning while ensuring checkpoints are saved to a storage solution, like Google Drive or Kaggle datasets.
- Another user confirmed the suggestion of using callbacks for this purpose, with a reference to learning about Weights & Biases (WandB) for tracking.
Unsloth AI (Daniel Han) ▷ #research (1 messages):
SageAttention2Quantized AttentionInference Acceleration
-
SageAttention2 boasts accurate 4-bit attention: The SageAttention2 Technical Report introduced a method for 4-bit matrix multiplication that accelerates the attention process, achieving 2x speedup compared to FlashAttention2.
- SageAttention2 aims to maintain precision while optimizing attention computation, marking a significant enhancement in inference acceleration.
- GitHub repository for SageAttention: The SageAttention GitHub repository claims 2.1x and 2.7x speedups over FlashAttention2 and xformers, respectively, without losing end-to-end metrics.
- This implementation indicates that SageAttention2 is a drop-in replacement for FlashAttention2, optimized for RTX40/3090 hardware but serves solely for inference.
- Limitations of SageAttention2: It is noted that SageAttention2 supports only inference and not training, highlighting its intended use case.
- The development focuses on optimizing performance features while ensuring compatibility with existing models.
Links mentioned:
- SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug-and-play Inference Acceleration: no description found
- GitHub - thu-ml/SageAttention: Quantized Attention that achieves speedups of 2.1x and 2.7x compared to FlashAttention2 and xformers, respectively, without lossing end-to-end metrics across various models.: Quantized Attention that achieves speedups of 2.1x and 2.7x compared to FlashAttention2 and xformers, respectively, without lossing end-to-end metrics across various models. - thu-ml/SageAttention
aider (Paul Gauthier) ▷ #general (148 messages🔥🔥):
Aider Setup ChallengesDeepSeek PerformanceOpenRouter ConcernsModel Quantization EffectsCoding Tools Comparisons
-
Aider Setup Challenges Resolved: Users experienced difficulties with Aider's setup, particularly with API keys and environment variables, leading some to consider reinstalling components to resolve issues.
- After troubleshooting, one user confirmed that a force reinstall helped in getting Aider up and running successfully.
- DeepSeek Impresses with Performance: DeepSeek-R1-Lite-Preview has shown to match o1-preview performance on AIME & MATH benchmarks, with faster response times noted compared to previous models.
- The model's transparent reasoning process allows users to see its thought process in real-time, elevating its effectiveness for coding tasks.
- Concerns Over OpenRouter's Model Quality: Users expressed dissatisfaction with OpenRouter utilizing quantized versions of open-source models, leading to doubts about performance on the Aider Leaderboard.
- There were calls for clearer warnings on the Aider Leaderboard about potential performance discrepancies when using OpenRouter's quantized models.
- Impact of Model Quantization Discussed: Quantization's adverse impact on model performance has raised concerns among users, with many preferring original models over quantized versions.
- Users suggested that OpenRouter should disclose specific model versions to accurately reflect performance expectations.
- Comparative Use of Coding Tools: Users compared various coding tools like Aider, Cursor, and Sonnet, sharing insights into their effectiveness for file creation and editing tasks.
- Many participants noted that they find Aider to be particularly beneficial for editing, while alternatives like Cline are too costly for extensive use.
Links mentioned:
- Tweet from Paul Gauthier (@paulgauthier): The new gpt-4o-2024-11-20 scored the same as the 08-06 version, and behind the 05-13 version on aider's code editing benchmark. This may be the first OpenAI in-family model update that wasn't ...
- File editing problems: aider is AI pair programming in your terminal
- Home: aider is AI pair programming in your terminal
- DeepSeek: Chat with DeepSeek AI.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Models | OpenRouter: Browse models on OpenRouter
- Qwen2.5 Coder 32B Instruct - API, Providers, Stats: Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). Run Qwen2.5 Coder 32B Instruct with API
- DeepSeek V2.5 - API, Providers, Stats: DeepSeek-V2.5 is an upgraded version that combines DeepSeek-V2-Chat and DeepSeek-Coder-V2-Instruct. Run DeepSeek V2.5 with API
- Tweet from Andrew Curran (@AndrewCurran_): Two months after the o1-preview announcement, and its Chain-of-Thought reasoning has been replicated. The Whale can now reason. DeepSeek says that the official version of DeepSeek-R1 will be completel...
- Tweet from OpenAI (@OpenAI): GPT-4o got an update 🎉 The model’s creative writing ability has leveled up–more natural, engaging, and tailored writing to improve relevance & readability. It’s also better at working with uploaded...
- 🚀 DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power! | DeepSeek API Docs: 🔍 o1-preview-level performance on AIME & MATH benchmarks.
- Meta: Llama 3.1 70B Instruct – Provider Status: See provider status and make a load-balanced request to Meta: Llama 3.1 70B Instruct - Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 70B instruct-t...
aider (Paul Gauthier) ▷ #questions-and-tips (29 messages🔥):
Aider usage challengesChat modes best practicesToken limit concernsLanguage support in AiderContext extension mechanisms
-
Understanding Aider's chat modes: Members discussed the effectiveness of various Aider chat modes, emphasizing that using o1-preview as the Architect with DeepSeek or o1-mini as the Editor provided the best results.
- A user noted that Sonnet performed exceptionally well for daily tasks without complex configurations.
- Token limit exhaustion with Aider: Users expressed concerns about burning through tokens while generating code, with suggestions for caching mechanisms to store context effectively.
- A member was informed that changes in the set of
/readfiles disrupt the cache, but modifications to/addfiles do not. - Issues with unexpected language responses: A user reported using o1-mini and receiving responses in Spanish despite having a conventions file stating to respond in English.
- The solution offered was to specify the language explicitly using the
--languageoption. - Request for custom context extension features: One user inquired about adding a personal automatic context extension mechanism to Aider, seeking to create an extension point for custom code.
- However, it was clarified that such feature integration is currently not possible with the existing version of Aider.
- Running scripts in Aider: Discussion around automating checklist tasks with Aider suggested using the
--messageargument or theaider -mmode for scripting.
- Examples were provided on how to run loops and apply instructions to multiple files using shell scripts.
Links mentioned:
- Separating code reasoning and editing: An Architect model describes how to solve the coding problem, and an Editor model translates that into file edits. This Architect/Editor approach produces SOTA benchmark results.
- Scripting aider: You can script aider via the command line or python.
- Chat modes: Using the chat, ask and help chat modes.
- Supported languages: Aider supports pretty much all popular coding languages.
Eleuther ▷ #announcements (1 messages):
Linear vs Affine RepresentationACE Method for Control in Language ModelsRefusal Behavior in Language Models
-
Clarifying Linear Representation Hypothesis: The paper highlights an ambiguity in defining a linear representation: it questions if it should be considered a linear function that maintains the origin point or an affine function that does not.
- This distinction is significant as prior findings, particularly by Arditi et al., rely heavily on the interpretation, leading to misleading results in models like RWKV.
- Introducing ACE for Affine Control: The authors propose the new ACE (Affine Concept Editing) method, which treats concepts as affine functions to enhance control over model responses.
- ACE allows for projecting activations onto hyperplanes, demonstrating improved precision in managing model behavior as shown through tests on Gemma.
- Reliable Control Over Refusal Responses: ACE was tested on ten models, including Llama 3 70B, where it achieved better control over refusal behavior across harmful and harmless prompts.
- The method improves upon past techniques, indicating a more reliable strategy for steering model actions.
- Research Contribution Invitation: To continue improving upon the ACE method, the authors invite interested individuals to introduce themselves in a specific research channel.
- Contributors are thanked for their efforts, emphasizing community collaboration in advancing this research.
- Access Research Materials: The GitHub repository for the project can be found at steering-llama3 along with the linked paper on arXiv.
- Additional insights and discussions can be followed via the Twitter thread by the author.
Links mentioned:
- GitHub - EleutherAI/steering-llama3: Contribute to EleutherAI/steering-llama3 development by creating an account on GitHub.
- Refusal in LLMs is an Affine Function: We propose affine concept editing (ACE) as an approach for steering language models' behavior by intervening directly in activations. We begin with an affine decomposition of model activation vect...
- Tweet from Nora Belrose (@norabelrose): In this paper, we point out an ambiguity in prior work on the linear representation hypothesis: Is a linear representation a linear function— one that preserves the origin point— or an affine functio...
Eleuther ▷ #general (20 messages🔥):
GPGPU PerformancePyTorch Optimization TechniquesData Loading StrategiesGPU Memory Management
-
GPGPU's Game-Changer Era: In the early days of GPGPU, coding on G200 was 30x faster than a decent CPU, leading to widespread adoption in supercomputers.
- Nvidia’s ability to scale due to its consumer industry roots made their GPUs the sensible choice for high-performance computing.
- PyTorch Performance Optimization Shortcuts: To enhance PyTorch performance, storing data in memory on the GPU significantly speeds up processes compared to using the data loader.
- Suggestions like using HLB-CIFAR10 or Airbench were shared for achieving better performance in convolutional networks.
- Switching Data Formats for Speed: Converting data to UINT8 until the last moment can halve memory bandwidth requirements, increasing transfer speed.
- Converting data on the GPU just before usage ensures efficient memory transfer and processing.
- Balancing CPU and GPU Data Loading: When using a CPU and GPU data loading pipeline, it’s crucial to avoid being bottlenecked by CPU workers.
- Ensuring CPU efficiency supports smoother and faster data flow to the GPU, enhancing overall model training performance.
- Referencing Optimized Practices: Details were shared on optimizing training strategies, including links to resources like David Page's bag of tricks.
- Community contributions noted past efforts and established practices that optimize deep learning model training.
Link mentioned: cifar10-fast/bag_of_tricks.ipynb at master · davidcpage/cifar10-fast: Contribute to davidcpage/cifar10-fast development by creating an account on GitHub.
Eleuther ▷ #research (125 messages🔥🔥):
Latent Actions and Inverse Dynamics ModelsnGPT Baseline BugsUse of Position EmbeddingsDocument Masking Impact on TrainingForgetting Transformer
-
Exploration of Latent Actions Papers: A user inquired about the best papers on latent actions and inverse dynamics models, hinting at interest in state-of-the-art (sota) works.
- No specific papers were provided, but the conversation hinted at the importance of relevant literature in these areas.
- nGPT's Baseline Evaluation Complications: Members discussed inconsistencies in nGPT's published code and baseline evaluations, particularly bugs affecting comparison metrics.
- One noted that internal and external code divergences made effective evaluation nearly impossible, leading to skepticism around results.
- Position Embedding Innovations: Discussions revolved around novel approaches to position embeddings, particularly one involving a cumulative width calculation for attention mechanisms.
- Related papers like the Forgetting Transformer and new Contextual Position Encoding (CoPE) were mentioned as they address issues in traditional position embeddings.
- Impact of Document Masking on Model Performance: The group debated the influence of document masking techniques, revealing a decrease in token requirements without significantly compromising training performance.
- Concerns were raised about the fairness of evaluations due to potential advantages from changes in data delivery methods, like biases from document boundaries.
- Questions on Effective Positioning Strategies: Different strategies for addressing attention issues using position embeddings were proposed, including the potential merit of simpler methods over complex mappings.
- Members analyzed whether approaches like ALiBi or RoPE might integrate better than the alternatives presented in recent research.
Links mentioned:
- Contextual Position Encoding: Learning to Count What's Important: The attention mechanism is a critical component of Large Language Models (LLMs) that allows tokens in a sequence to interact with each other, but is order-invariant. Incorporating position encoding (P...
- Tweet from YouJiacheng (@YouJiacheng): @hi_tysam This is a sliding window, information can still propagate if there are >1 layers.
- Forgetting Transformer: Softmax Attention with a Forget Gate: An essential component of modern recurrent sequence models is the forget gate. While Transformers do not have an explicit recurrent form, we show that a forget gate can be naturally incorporated...
- koszarskyb - Overview: GitHub is where koszarskyb builds software.
- GPT baseline block computation error · Issue #1 · NVIDIA/ngpt: Hello, thank you very much for open sourcing nGPT. I have found an error in the block computation of the GPT (use_nGPT=0) baseline. The computation being done is : x = norm(x) + attn(norm(x)) x = n...
- modded-nanogpt/records/111924_FlexAttention/8384493d-dba9-4991-b16b-8696953f5e6d.txt at master · KellerJordan/modded-nanogpt: NanoGPT (124M) quality in 7.8 8xH100-minutes. Contribute to KellerJordan/modded-nanogpt development by creating an account on GitHub.
Eleuther ▷ #scaling-laws (2 messages):
Scaling Laws in Language ModelsEvaluation Science AdvocacyMarius Hobbhahn
-
New Scaling Laws Paper Emerges: A recently published paper titled Understanding How Language Model Performance Varies with Scale can be accessed here, detailing an observational approach to scaling laws based on ~100 publicly available models.
- The authors propose that language model performance is more a function of a low-dimensional capability space rather than just training across multiple scales.
- Marius Hobbhahn Champions Evaluation Science: A member pointed out that Marius Hobbhahn at Apollo is one of the most prominent advocates for advancing the science of evaluation methods within the AI community.
- This seems to highlight a growing interest in enhancing rigorous evaluation practices in AI model development.
Link mentioned: Observational Scaling Laws and the Predictability of Language Model Performance: Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of ...
Eleuther ▷ #lm-thunderdome (15 messages🔥):
Zero-shot benchmarking for pruned modelsWANDA pruning methodlm_eval library compatibilityModel evaluation on ADVBenchvllm model usage
-
Question on zero-shot benchmarking for pruned models: A member inquired if lm-eval supports zero-shot benchmarking for pruned models, mentioning that they are using a method called WANDA.
- They expressed some concerns regarding the suspect results they were obtaining from zero-shot evaluation.
- Compatibility of lm_eval with pruned models: A user discussed modifications made to lm_eval to accommodate pruned models, noting that the version they have is quite old.
- They questioned whether the current version supports both quantized and pruned models.
- Evaluation on ADVBench using vllm: The conversation revealed that a member is evaluating their models on ADVBench using vllm, and shared their method for running inference.
- They provided the line of code used for generating outputs: vllm_outputs = model.generate(dialogs, sampling_params).
- Loading the pruned model: The method for loading the model was shared as from vllm import LLM; vllm_model = LLM(hf_model_path, tokenizer, dtype = 'bfloat16', swap_space = 128).
- The hf_model_path denotes the path to the pruned model, while the role of swap_space was clarified as a later point of discussion.
- Actively troubleshooting model inference: A member is actively seeking to clarify their usage of pruned models for inference, asking about the swap_space argument.
- They mentioned they would revisit the question later for further insights on their concerns.
Link mentioned: GitHub - locuslab/wanda: A simple and effective LLM pruning approach.): A simple and effective LLM pruning approach. Contribute to locuslab/wanda development by creating an account on GitHub.
Perplexity AI ▷ #general (132 messages🔥🔥):
Perplexity vs. ChatGPTReferral Code UsagePerplexity Shopping FeatureAPI FunctionalityImage Creation on iOS
-
Users Compare Perplexity with ChatGPT: Users shared experiences using Perplexity compared to ChatGPT, noting that ChatGPT is often preferred for its versatility and superior conversational ability.
- Some users, despite being Pro users of Perplexity, expressed frustration over its perceived limitations and noted a higher frequency of use for ChatGPT.
- Referral Codes Clarification: A user inquired about using multiple referral codes on the same account after using the first one, and it was clarified that referral codes apply only to new subscribers.
- This means once a user has had Pro status, they can't utilize another referral code for discounts.
- Discussion on Shopping Feature: Questions arose regarding the new Perplexity Shopping feature, particularly whether it was exclusive to the US market.
- Users expressed interest and sought clarification on potential access limitations for the shopping functionality.
- Concerns Over API Functionality: Several users reported issues with API responses remaining unchanged despite switching models, leading to confusion and frustration.
- This led to discussions about perceived deficiencies in the platform's flexibility and response diversity.
- Limited Image Creation on iOS: A user asked if creating images was possible on the iOS app, revealing that this functionality is limited to iPad users.
- This limitation spurred additional conversations about the app's capabilities across different devices.
Links mentioned:
- Supported Models - Perplexity: no description found
- Perplexity Supply: Where curiosity meets quality. Our premium collection features thoughtfully designed apparel for the the curious. From heavyweight cotton essentials to embroidered pieces, each item reflects our dedic...
- no title found: no description found
- Crypto Meets Real Estate: South Africans Can Now Buy Property With Bitcoin: In a first for South Africa's property industry, buyers can now purchase real estate using cryptocurrency through secure and fully compliant transactions.
- How Many Stars Are in the Universe: How Many Stars Are in the Universe. It is vast and magnificent, and it is with such beauty that humanity continues to speculate.
- The Milky Way's 100 Billion Planets - NASA: This artist's illustration gives an impression of how common planets are around the stars in the Milky Way. The planets, their orbits and their host stars are all vastly magnified compared to the...
- How Many Stars in the Milky Way ?: Ever wondered how many stars twinkle in the vast expanse of the Milky Way Galaxy? 🌌 In this mesmerizing 120-second animated journey, we delve into the encha...
Perplexity AI ▷ #sharing (9 messages🔥):
Web App Fullstack with Next.jsChicken or Egg Paradox SolvedMichelin Star CitiesNVIDIA Chips OverheatStock Monitoring for Qubit
-
Web App Fullstack Development Sample: A resource discussing fullstack Next.js development has been shared, providing insights into modern web application frameworks.
- Explore the use of Hono for server-side routing!
- Final Resolution of Chicken or Egg Paradox: The age-old chicken or egg paradox has been resolved with detailed insights found here.
- Diving into evolutionary biology, this article clarifies the origins!
- Cities with Most Michelin Stars Revealed: A discussion about which city boasts the most Michelin stars can be found here.
- Review the culinary rankings of acclaimed global cities!
- NVIDIA Chips Experiencing Overheating Issues: Concerns around NVIDIA AI chips overheating are raised in this report here.
- Discussion highlights the risks associated with prolonged use!
- Keep Tracking Qubit Stock: A call to action for monitoring Qubit stock is shared along with insights visible here.
- Investors are advised to stay vigilant!
Perplexity AI ▷ #pplx-api (1 messages):
Perplexity APIDomain Filtering
-
Filtering issues with Perplexity API: A user highlighted difficulties using the Perplexity API to filter search results by blacklisting a specific domain.
- They expressed frustration as the intended excluded domain continued to appear in the results, questioning potential formatting requirements they might be missing.
- Troubleshooting Filtered Domain Results: Discussion centered around the effectiveness of domain filtering in the Perplexity API.
- Clarification was sought regarding the specifics of format settings that could affect the visibility of blacklisted domains.
OpenRouter (Alex Atallah) ▷ #general (120 messages🔥🔥):
Gemini 1114 performanceDeepSeek updatesPrompt cachingGPT-4o model issuesRP model comparisons
-
Gemini 1114 struggles with input handling: Users reported that Gemini 1114 often ignores image inputs during conversations, leading to hallucinated responses, unlike models such as Grok vision Beta.
- Members are hoping for confirmation and fixes, expressing frustration over recurring issues with the model.
- DeepSeek launches new reasoning model: A new model, DeepSeek-R1-Lite-Preview, was announced, boasting enhanced reasoning capabilities and performance on AIME & MATH benchmarks.
- However, some users noted the model’s performance is slow, prompting discussions about whether DeepInfra might be a faster alternative.
- Clarifications on prompt caching: Prompt caching is available for specific models like DeepSeek, with users questioning the caching policies of other providers.
- Some members discussed how caching works differently between systems, particularly noting Anthropic and OpenAI protocols.
- Issues with GPT-4o model description: Users identified discrepancies in the newly released GPT-4o, noting the model incorrectly listed an 8k context and wrong descriptions linked to GPT-4.
- After highlighting the errors, members saw quick updates and fixes to the model card, restoring accurate information.
- Comparisons of RP models: Members discussed alternatives to Claude for storytelling and role-playing, with suggestions for Hermes due to its perceived quality and cost-effectiveness.
- Users indicated a mix of experiences with these models, with some finding Hermes preferable while others remain loyal to Claude.
Links mentioned:
- Tweet from DeepSeek (@deepseek_ai): 🚀 DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power! 🔍 o1-preview-level performance on AIME & MATH benchmarks. 💡 Transparent thought process in real-time. 🛠️ Open-sour...
- Yi Large - API, Providers, Stats: The Yi Large model was designed by 01.AI with the following usecases in mind: knowledge search, data classification, human-like chat bots, and customer service. Run Yi Large with API
- anthropic-cookbook/misc/prompt_caching.ipynb at main · anthropics/anthropic-cookbook: A collection of notebooks/recipes showcasing some fun and effective ways of using Claude. - anthropics/anthropic-cookbook
- GPT-4o (2024-11-20) - API, Providers, Stats: The 2024-11-20 version of GPT-4o offers a leveled-up creative writing ability with more natural, engaging, and tailored writing to improve relevance & readability. It’s also better at working with...
- Prompt Caching | OpenRouter: Optimize LLM cost by up to 90%
- Provider Routing | OpenRouter: Route requests across multiple providers
OpenRouter (Alex Atallah) ▷ #beta-feedback (6 messages):
Custom provider keysKey integration accessAnthropic Claude 3.5 Sonnetx-ai/grok-betaxai
-
Multiple Requests for Custom Provider Keys: Several members have expressed their desire to request a custom provider key, including for x-ai/grok-beta and Anthropic Claude 3.5 Sonnet.
- One user noted that they already have an account with credits that would be beneficial for use with OpenRouter.
- Inquiries about Key Integration Access: A member inquired about the process to gain access to key integration, expressing enthusiasm to test it out.
- This shows an ongoing interest in exploring available features and tools.
LM Studio ▷ #general (58 messages🔥🔥):
Model Loading IssuesSystem Requirements for ModelsOptimizing Performance with Limited HardwareExploring Cloud-Based SolutionsModel Recommendations and Preferences
-
Model Loading Challenges on MacBook: A user faced difficulties loading a local model in LM Studio due to insufficient system resources, noting the error indicates overloading risks for their 36GB RAM M3 MacBook.
- Another member advised that 32B models are too large for this setup, suggesting a maximum of 14B.
- Understanding Model System Requirements: Discussions revealed that estimating required RAM can be done by adding 10% to the model's file size, although it was suggested to pick smaller models for better performance.
- It was noted that larger models can block available memory, reducing functionality for other tasks on the machine.
- Exploring Optimizations for Performance: To improve performance with a 1050 Ti GPU, suggestions included using smaller model sizes, reducing context size, and ensuring efficient coding practices.
- A user mentioned that cloud-based hardware rental could be a cost-effective solution when local hardware isn't adequate.
- Cloud-Based Model Usage: One member shared their shift to renting cloud servers for model usage, finding it financially beneficial compared to purchasing hardware, with costs ranging from $25 to $50 per month.
- This approach allows for accessing high-speed models without the limitations of local hardware.
- Model Recommendations and User Preferences: Users recommended various models including Hermes 3, Lexi Uncensored V2, and Goliath 120B, noting personal preferences based on performance and writing quality.
- It was suggested to experiment with different models to find the best fit for individual use cases, with encouragement to try new options as they become available.
Links mentioned:
- NousResearch/Hermes-3-Llama-3.1-70B · Hugging Face: no description found
- Qwen/Qwen2.5-Coder-32B-Instruct · Hugging Face: no description found
LM Studio ▷ #hardware-discussion (64 messages🔥🔥):
VM Performance with Qwen ModelsHardware Requirements for DeepSeek v2.5 LiteWorkstation Design for LLMsGPU Selection for AI WorkloadsFine-tuning vs. Running Models
-
VM struggles with Qwen models without a GPU: A member reported that running Qwen 2.5 models on a virtual machine with no GPU resulted in severely limited performance, achieving only about 1 token/second.
- Another user clarified that CPU-only inference can be incredibly slow, and a GPU would significantly improve this situation.
- RAM and GPU Requirements for DeepSeek v2.5 Lite: For running DeepSeek v2.5 Lite, it was suggested that at least 24GB VRAM is needed for the Q4_K_M variant; full Q8 demands about 48GB VRAM.
- Members discussed that NVIDIA cards are preferred due to AMD’s driver instabilities affecting performance.
- Guidance on Workstation for LLMs: A user is seeking advice on building a workstation for fine-tuning LLMs with a budget of $30,000 to $40,000 and is weighing options like NVIDIA A6000s vs. fewer high-end options like the H100.
- The discussion emphasized the importance of video memory and flexibility regarding used hardware for budget constraints.
- GPU Selection for Optimal Performance: It was noted that using multiple 24GB 3090s could provide a viable alternative to expensive newer models, despite lacking NVLink performance.
- One member highlighted a resource comparing benchmarks of various GPUs on token/second performance for LLM inference.
- Understanding Fine-tuning vs Running Models: Fine-tuning a model consumes significantly more resources compared to running one, necessitating higher memory and compute power.
- Members reflected on the potential of dedicated AI chips as a solution to the hardware challenges associated with running large models.
Link mentioned: GitHub - XiongjieDai/GPU-Benchmarks-on-LLM-Inference: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference?: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference? - XiongjieDai/GPU-Benchmarks-on-LLM-Inference
Stability.ai (Stable Diffusion) ▷ #general-chat (102 messages🔥🔥):
Gaming PC RecommendationsConsistent Character CreationAI Models for Substance DesignerGPU Utilization for Video GenerationDrawing AI Demonstrations
-
Advice on Building a Gaming PC: A user is seeking recommendations for a gaming PC within a budget of $2500, asking for suggestions on both components and where to purchase.
- They encourage others to send direct messages for personalized advice.
- Challenges in Character Consistency for Picture Books: A member asked how to maintain a consistent character design throughout a picture book, struggling with variations from multiple generated images.
- Suggestions included using FLUX or image transformation techniques to improve consistency.
- Exploration of AI Models for Texture Creation: A discussion arose about whether AI models could effectively replace Substance Designer, highlighting the need for further exploration in that area.
- Members shared their thoughts on the capabilities of different AI models and their performance.
- Optimizing GPU Usage for AI Video Generation: Users discussed the difficulties of performing AI video generation on limited VRAM GPUs, noting potential for slow processing times.
- The recommended course of action included clearing VRAM and using more efficient models like CogVideoX.
- Understanding Fast AI Drawing Techniques: A member inquired about the technology behind AI drawing representations that update quickly on screen, wondering about its implementation.
- Responses indicated that it often relies on powerful GPUs and consistency models to achieve rapid updates.
Links mentioned:
- THUDM/CogVideoX1.5-5B-I2V · Hugging Face: no description found
- thud (Adam M): no description found
- ByteDance/Hyper-SD · Hugging Face: no description found
- GitHub - kijai/ComfyUI-CogVideoXWrapper: Contribute to kijai/ComfyUI-CogVideoXWrapper development by creating an account on GitHub.
Notebook LM Discord ▷ #use-cases (17 messages🔥):
Audio Generation in NotebookLMExternal Access to NotebooksPodcast CreationTranscription FeaturesCustomization Recommendations
-
Generating Podcasts with NotebookLM: One member showcased their podcast featuring AI characters discussing climate innovation, emphasizing the multiple steps involved including using an AI tool and NotebookLM.
- They shared a link to their podcast and detailed their process of creating a conversation between diverse characters.
- Accessing Notebook Features for External Operators: A conversation around simplifying access for external operators to NotebookLM arose, with one member revealing they utilized a business Gmail to streamline the process.
- They mentioned having created various reference guides already accessible in their quickstart manual folder.
- Transcription Options for Audio Files: New users were advised to upload their generated audio files back to NotebookLM, which would transcribe the content for them.
- Alternatively, one member suggested using MS Word's Dictate...Transcribe function for audio files.
- Feedback on Podcast Audio Creation: Members shared their experiences with creating podcasts using NotebookLM, highlighting effective audio generation features.
- One user shared their German-language podcast on Spotify and expressed interest in customization recommendations.
- Direct Links to Notebook Audio: Multiple members shared links related to audio content generated from NotebookLM, including personal podcasts and specific episodes that discuss unique topics.
- One notable episode referenced wine aging in microgravity, citing specific scientific experiments and outcomes.
Links mentioned:
- no title found: no description found
- Wein & Wahnsinn: Verrückte Fakten in 5 Minuten: Podcast · bbrocher · Willkommen bei Wein & Wahnsinn: Verrückte Fakten in 5 Minuten, dem Podcast, der Sie in die skurrile, absurde und oft unerwartete Welt des Weins entführt. Hier erwarten Sie Ane...
- no title found: no description found
- Anti Schwerkraft Weine: Wein & Wahnsinn: Verrückte Fakten in 5 Minuten · Episode
- Subly - Story - Delhi Air Pollution: Need to add subtitles to your videos? Try Subly for free! Within minutes we automatically transcribe and translate your video or audio. You can style, add your brand logo and headline ready to be shar...
Notebook LM Discord ▷ #general (35 messages🔥):
Combining Notes FeatureReliability of Uploaded SourcesSharing NotebooksDeep Dive Document GenerationLimitations on Uploading Large Files
-
Combining Notes Feature is Under Discussion: Members are discussing the existing 'Combine to note' feature, which allows users to join multiple notes into a single document.
- One member expressed confusion about converting notes into actual sources, questioning its utility since combining notes is already possible.
- Opinions on Reliability of Uploaded Sources: Members have shared mixed experiences with hallucinations when using uploaded sources, with some finding it reliable, while others cite discrepancies.
- A member noted that citations often come up as high-quality and do not fall into typical hallucination pitfalls.
- Challenges in Sharing Notebooks: A user inquired about the process of sharing notebooks with friends, having difficulty in executing it successfully.
- Another member confirmed there is a 'share note' button located in the top right corner of the interface for this purpose.
- Deep Dive Document Generation Sparks Interest: The potential to create and summarize notes into a single document has generated conversation among members, although some find it redundant.
- One member mentioned being able to compile summaries, expressing that it could be more useful if downloading sources becomes available.
- Limitations on Uploading Large Files Explored: A member encountered errors while attempting to upload a large CSV file containing over 444,000 rows, finding a limit at around 10,000 rows.
- They sought confirmation from others about any imposed file size limits within the platform.
Latent Space ▷ #ai-general-chat (48 messages🔥):
DeepSeek-R1-Lite-PreviewGPT-4o UpdateTruffles Hardware DeviceVercel Acquires GrepClaude Availability Issues
-
DeepSeek-R1-Lite-Preview Launch: DeepSeek announced the go-live of DeepSeek-R1-Lite-Preview, featuring impressive performance on AIME & MATH benchmarks with a transparent reasoning process.
- The system shows improvements as reasoning length increases, with users excited about its potential applications across various tasks.
- New GPT-4o Update Released: OpenAI’s new GPT-4o snapshot, released as
gpt-4o-2024-11-20, enhances creative writing and is more capable of handling uploaded files for insights.
- In recent performance tests, GPT-4o reclaimed the top rank in various categories, showcasing significant advancements.
- Truffles Hardware Device Recognized: Users identified 'Truffles' as the semi-translucent hardware device designed for self-hosting LLMs at home, humorously referred to as a 'glowing breast implant'.
- This quirky description reflects a light-hearted conversation surrounding innovative home LLM solutions.
- Vercel Acquires Grep: Vercel announced the acquisition of Grep, which enables developers to search code across over 500,000 public repositories.
- Founder Dan Fox will join Vercel's AI team to enhance code search capabilities, aiming to improve development efficiency.
- Claude Faces Availability Issues: Users reported intermittent availability issues with Claude, with some experiencing downtimes while others found it operational.
- Discussions ensued about the service's reliability, causing some users to check for updates on social media.
Links mentioned:
- Tweet from undefined: no description found
- Tweet from Rohan Paul (@rohanpaul_ai): New Transformer architecture modifications from NVIDIA researchers. nGPT: A hypersphere-based Transformer achieving 4-20x faster training and improved stability for LLMs. **Proposals in this Paper**...
- Tweet from Teortaxes▶️ (@teortaxesTex): btw: scaling test time compute with pivot tokens will have great synergy with tool use. Look: it's already yearning to come to exist, begging for a vessel. Just as prophesied by @gwern and @xenoco...
- Tweet from jack morris (@jxmnop): more fun open-source research news - new paper drops (nGPT) - claims 4-20x training speedup over GPT - shocking - very cool - very valuable - community tries to reproduce - doesn't hold up - turn...
- Tweet from xjdr (@_xjdr): whalebros cooked here. Not only does it seem to replicate the o1-preview results, it seems to pretty effectively replicate (at least parts of) the process. My guess is it uses something very similar ...
- Tweet from wh (@nrehiew_): Rumor is that DeepSeek R1-Lite is a 16B MOE with 2.4B active params if true, their MATH scores went from 17.1 -> 91.6 Quoting Phil (@phill__1) @nrehiew_ From their wechat announcement:
- Tweet from DeepSeek (@deepseek_ai): 🚀 DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power! 🔍 o1-preview-level performance on AIME & MATH benchmarks. 💡 Transparent thought process in real-time. 🛠️ Open-sour...
- Tweet from Akshay Agrawal (@akshaykagrawal): My co-founder @themylesfiles and I have started Marimo Inc. to keep building the @marimo_io notebook and other Python data tools. We've raised a $5M seed round led by @antgoldbloom and @shyammani...
- Tweet from OpenAI Developers (@OpenAIDevs): This new GPT-4o snapshot is now available in the API as
gpt-4o-2024-11-20: https://platform.openai.com/docs/models#gpt-4o. Quoting OpenAI (@OpenAI) GPT-4o got an update 🎉 The model’s creative w... - Tweet from Phil (@phill__1): @nrehiew_ From their wechat announcement:
- Bitcoin billionaire Barry Silbert talks about his next big bet—on 'decentralized AI': Silbert will be CEO of Yuma, a new DCG subsidiary focused on the AI ecosystem tied to Bittensor blockchain.
- Tweet from wh (@nrehiew_): It solved Yann Lecun's 7-gear question
- Vercel acquires Grep to accelerate code search - Vercel: Announcing the acquisition of Grep to further our mission of helping developers work and ship faster.
- Tweet from Yaroslav Bulatov (@yaroslavvb): There are a couple of independent efforts to reproduce https://github.com/NVIDIA/ngpt . There are bugs, so it could take some time, but I'm bullish on the core idea as represents normalization alo...
- Tweet from Akari Asai (@AkariAsai): 3/ 🔍 What is OpenScholar? It's a retrieval-augmented LM with 1️⃣ a datastore of 45M+ open-access papers 2️⃣ a specialized retriever and reranker to search the datastore 3️⃣ an 8B Llama fine-tuned...
- Tweet from Rohan Paul (@rohanpaul_ai): New Transformer architecture modifications from NVIDIA researchers. nGPT: A hypersphere-based Transformer achieving 4-20x faster training and improved stability for LLMs. **Proposals in this Paper**...
- Tweet from wh (@nrehiew_): hmm thats interesting, most models ive tried this on dont fail at generating the first 10 words, this fails to realise it generated 7 words instead of 10
- Tweet from Teortaxes▶️ (@teortaxesTex): pretty interesting research focus this guy has Quoting Zhihong Shao (@zhs05232838) Our DeepSeek reasoning model is great on code and math. Try it out!
- Tweet from wh (@nrehiew_): The most interesting about the DeepSeek release is that they basically replicated the o1 scaling laws Quoting DeepSeek (@deepseek_ai) 🌟 Inference Scaling Laws of DeepSeek-R1-Lite-Preview Longer R...
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Exciting News from Chatbot Arena❤️🔥 Over the past week, the latest @OpenAI ChatGPT-4o (20241120) competed anonymously as "anonymous-chatbot", gathering 8,000+ community votes. The result? ...
- Tweet from Tim Shi (@timshi_ai): Exciting update! 🌊 Cresta has raised $125m Series D to accelerate building agents for customer experience!
- Tweet from Ryan Sun (@sun_hanchi): Wait, Lite uses the 16B MoE base model😱😱😱 so technically it matches o1-mini instead Imagine the full version… Btw, deepseek might not have enough GPU to RL the full model, so we will see reverse ...
- Tweet from Teortaxes▶️ (@teortaxesTex): was biting nails on the edge of my seat here, fr. 10/10 would prompt again. Defeat, turnaround, final fight – and glorious victory. DeepSeek-r1-lite revolutionizes LLM inference by turning it into a d...
- Tweet from jack morris (@jxmnop): so the error in the transformer impl from nGPT was very easy to make the residual stream propagated as this > x = norm(x) + attn(norm(x)) instead of this > x = x + attn(norm(x)) TLDR this bre...
GPU MODE ▷ #triton (1 messages):
cappuchinoraro: thanks
GPU MODE ▷ #beginner (5 messages):
Triton Tutorial PerformanceGPU ComparisonsSoftmax Kernel Profiling
-
Triton vs Torch Softmax Performance: A member compared the performance of Triton's fused softmax operation against PyTorch's native implementation using the Triton tutorial on an RTX 3060, noting smoother performance from Triton.
- They highlighted that while Triton performed better overall, there were instances where PyTorch's performance matched or exceeded Triton's.
- Inconsistent Throughput Observations: Another member remarked on the disparities in throughput between the Triton tutorial's results and their own observations, suggesting potential differences in GPU hardware affecting outcomes.
- They speculated that performance comparisons might be unreliable across different GPUs and proposed testing with an A100 to see if results stabilize.
- Profiling Softmax Kernels on 4090: A member added that they were profiling softmax kernels on a 4090, noting performance metrics with batch sizes fixed to 128 and comparing the results to the Triton tutorial.
- They indicated that their findings were more aligned with the outcomes detailed in the tutorial, though they focused on ops/sec rather than GB/sec.
Link mentioned: Fused Softmax — Triton documentation: no description found
GPU MODE ▷ #torchao (3 messages):
Readme UpdatesTorchchat and Torchtune Linkage
-
Readme Needs Small Update: A member suggested that the Readme should mention that torchchat is also linked to torchtune.
- This led to another member agreeing and providing a link to a relevant GitHub pull request that addresses the change.
- GitHub Pull Request for Update: The mentioned GitHub pull request by drisspg aims to update the README.md with necessary information.
- It was noted that the pull request is related and provides a comprehensive update on the topic, reflected in a GitHub link.
Link mentioned: Update README.md by drisspg · Pull Request #1319 · pytorch/ao: no description found
GPU MODE ▷ #off-topic (2 messages):
Ticket Price ChangesBuying Tickets Early
-
Frequency of Ticket Price Changes: A member inquired about how frequently ticket price changes occur and whether it would be wise to buy now instead of delaying.
- Another member responded that it's usually cheaper to purchase tickets sooner, emphasizing that alerts are more beneficial if you're several months away from travel.
- Advice on Buying Tickets Early: A suggestion was made that buying tickets earlier generally results in lower prices.
- Alerts for price changes are more useful for those planning trips several months ahead rather than last-minute purchases.
GPU MODE ▷ #webgpu (11 messages🔥):
Metal GEMM ImplementationsWebGPU and Metal CompatibilityRegister Optimization TechniquesPerformance Regressions in DawnAGX Machine Code Disassembly Tools
-
Philip Turner's Metal GEMM Implementation Insights: A member highlighted Philip Turner's repository featuring a Metal GEMM implementation, though mentioned the code used to be more readable.
- They also noted their own Metal GEMM reaches 85-90% of theoretical max speed, resembling Turner's implementation.
- WebGPU's Challenges with MMA Intrinsics: A participant reminisced about issues with shared memory and questioned if WebGPU exposes MMA intrinsics, which can be accessed via Metal.
- They acknowledged uncertainty if improvements have been made to compilers regarding this functionality.
- Optimizing Register Utilization: A member shared a technique that saved 25 registers by replacing array access with pointer incrementing from a[i] to a++.
- They cautioned about the Metal compiler's necessity for heavy optimization, especially moving addressing computation out of hot loops.
- Dawn's Performance Regression Issues: Concerns were raised regarding performance regressions in the latest versions of Dawn, particularly in the wgsl-to-Metal workflow after Chrome 130.
- It was suggested that Chrome 131 improved performance compared to 130, but it still lagged behind 129, with potential issues related to UB check code placement.
- Disassembling AGX Machine Code Tools: A tool for disassembling AGX machine code maintained by Freedesktop developers was shared: applegpu repository.
- This resource was referenced in the context of measuring register utilization in compiled code.
Link mentioned: Chromium: no description found
GPU MODE ▷ #liger-kernel (17 messages🔥):
Debugging AssistanceCUDA Device MappingModel Distribution across GPUsTensor ParallelismHugging Face Sharding Strategy
-
Debugging Assistance Offered: A member offered to help with debugging and suggested isolating problems by turning off optimizations one by one.
- Another member confirmed this approach and expressed gratitude for the quick assistance.
- CUDA Device Mapping Success: Using
cudaas the device map worked fine on L4, leading to humorous exchanges about fast verification of the solution.
- This solution was credited to another member, who is expected to provide more insights soon.
- Model Distribution Issues Discussed: One member expressed concern that despite using 'auto', the model might only be utilizing one GPU during execution.
- This led to discussions about tensor parallelism and the limitation of not being able to distribute the model across all four GPUs.
- Observations on Model Usage: Members discussed their observations regarding how the 'auto' setting distributes the model across GPUs.
- There was uncertainty expressed regarding the default sharding strategy employed by Hugging Face after inspecting usage statistics.
- Testing Updates from 0x000ff4: A member provided a brief update on working on tests regarding a project.
- No additional details were shared about the testing process or its objectives.
GPU MODE ▷ #self-promotion (4 messages):
FLUX inference optimizationCPU offloading techniquesGPU performance on different machines
-
FLUX Optimized for Speed with CPU Offload: A member reported achieving a 200% speedup in FLUX inference by implementing per-layer CPU offload techniques on a 4070Ti SUPER, reaching times as low as 1.23 s/it.
- Their results indicate improvements over the baseline method of
.enable_sequential_cpu_offload()which took 3.72 s/it. - Mobicham's Parallel Offloading Insights: Another member shared their experience with offloading scales and zeros using pinned memory and CUDA streams, noting it worked well on capable machines but was slower on shared instances.
- They speculated on the efficiency in resource-constrained environments like runpod/vastai.
- Discussion on Bottlenecks in LLM Decoding: In response, a member commented that for LLM decoding, the CPU to CUDA transfer could become a bottleneck, despite methods to overlap data transfer and compute.
- However, with FLUX for image generation, slow data transfer is less impactful due to its higher arithmetic intensity.
- Video Resource Shared for Further Insights: A member shared a YouTube link that may offer additional insights or relevant content related to the discussed optimizations.
- This video could be beneficial for those exploring similar performance enhancements.
- Their results indicate improvements over the baseline method of
Link mentioned: Tweet from Thien Tran (@gaunernst): Speed up FLUX CPU offloading by 200%. On 4070Ti SUPER (16GB) baseline (.enable_sequential_cpu_offload()): 3.72 s/it + pin memory: 2.09 s/it (+78%) + CUDA stream (explicit synchronization): 1.32 s/it ...
Nous Research AI ▷ #general (27 messages🔥):
DeepSeek-R1-Lite-PreviewAI agents for writing booksLLM knowledge evaluation
-
DeepSeek-R1-Lite-Preview Launch: DeepSeek-R1-Lite-Preview is now live, boasting supercharged reasoning power with o1-preview-level performance on AIME & MATH benchmarks.
- It features a transparent thought process in real-time, with open-source models and API coming soon.
- Team of AIs writes a book: A project showcased by Venture Twins involves ten AI agents collaborating to write a fully autonomous book, each with different roles such as setting narrative and maintaining consistency.
- The progress can be tracked through GitHub commits as they work in real-time.
- Innovative LLM Benchmark Proposal: A member proposed a benchmark testing how well an LLM knows what it doesn't know, where correct responses receive no mark.
- The evaluation focuses on how the model responds to incorrectly answered questions, mixing both knowledge and reasoning.
Links mentioned:
- Tweet from DeepSeek (@deepseek_ai): 🚀 DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power! 🔍 o1-preview-level performance on AIME & MATH benchmarks. 💡 Transparent thought process in real-time. 🛠️ Open-sour...
- Tweet from Justine Moore (@venturetwins): Someone is using a team of 10 AI agents to write a fully autonomous book. They each have a different role - setting the narrative, maintaining consistency, researching plot points... You can follow ...
- GitHub - Lesterpaintstheworld/terminal-velocity: A novel created autonomously by 10 teams of 10 AI agents: A novel created autonomously by 10 teams of 10 AI agents - Lesterpaintstheworld/terminal-velocity
Nous Research AI ▷ #ask-about-llms (8 messages🔥):
Learning Rate SchedulingWarmup and Decay StrategiesTest Time Scaling for LLMsCyclic Learning Rate Schedulers
- Understanding Learning Rate Behavior Across Epochs: A discussion arose regarding whether the learning rate for a specific step should match across different epochs. It was clarified that the learning rate typically ramps up during warmup and then decays over time, which leads to different values for corresponding steps across epochs.
- Exploring Learning Rate Scheduler Configurations: One member suggested that previously, learning rates were stepped at each epoch, but currently, they are configured based on total steps across all epochs and adjusted with every gradient step. They encouraged looking into cyclic learning rate schedulers as a modern approach.
- Inquiries About Test Time Scaling for LLMs: In a separate inquiry, a member asked if anyone was working on test time scaling for large language models and requested ideas on the subject. This generated curiosity and hints at ongoing discussions about scaling strategies.
Nous Research AI ▷ #research-papers (2 messages):
LLMs Reasoning AbilitiesGenerative Agent Simulations
-
LLMs can reason without prompting: Research shows that large language models (LLMs) can exhibit reasoning paths similar to chain-of-thought (CoT) without explicit prompting by altering the decoding process to examine top-$k$ alternative tokens.
- This method highlights the intrinsic reasoning abilities of LLMs and suggests that CoT pathways may reside inherently in their sequences.
- Behavioral simulations of over 1,000 individuals: A novel architecture simulates the attitudes and behaviors of 1,052 real individuals, demonstrating that generative agents can replicate human responses with 85% accuracy on the General Social Survey.
- The architecture reduces accuracy biases across racial and ideological groups, paving the way for tools to investigate individual and collective behavior.
Links mentioned:
- Chain-of-Thought Reasoning Without Prompting: In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) promptin...
- Generative Agent Simulations of 1,000 People: The promise of human behavioral simulation--general-purpose computational agents that replicate human behavior across domains--could enable broad applications in policymaking and social science. We pr...
Nous Research AI ▷ #interesting-links (3 messages):
Soft PromptsLLM Optimization
-
Inquiry on Soft Prompts Investigation: A member posed a question about whether anyone has investigated the concept of soft prompts for LLMs noted in a post. They emphasized the potential for soft prompts in optimizing system prompts into embedding space.
- Another member responded, stating that the idea of soft prompts is pretty interesting, suggesting some level of interest in the topic.
- Discussion on Value of Soft Prompts: The conversation indicates curiosity surrounding the untapped potential of soft prompts in the LLM community. Members seem to express that more exploration into this area could be fruitful for further advancements.
Link mentioned: @saganite.bsky.social: Really trying to figure out why "soft prompts" aren't used more often with LLMs. For those who aren't familiar, soft prompts are system prompts that have been converted to embedding ...
Nous Research AI ▷ #research-papers (2 messages):
LLMs Reasoning without PromptingGenerative Agent Behavioral Simulations
-
LLMs Reasoning Effectively Without Prompting: A study investigates whether large language models (LLMs) can reason effectively without prompting by altering the decoding process, revealing that CoT reasoning paths often emerge naturally. This novel approach allows for an assessment of the LLMs' intrinsic reasoning abilities without the complexities of manual prompt engineering.
- The findings suggest that by utilizing top-k alternative tokens, researchers can elicit effective reasoning from pre-trained models, providing insights into their inherent capabilities.
- Groundbreaking Behavioral Simulation of 1,052 Individuals: New research presents an innovative agent architecture using large language models to simulate the attitudes and behaviors of 1,052 real individuals, based on qualitative interviews. These generative agents accurately replicate participants’ responses on the General Social Survey with 85% accuracy, matching self-reported answers.
- Notably, the architecture reduces accuracy biases across racial and ideological groups compared to agents that rely solely on demographic descriptions, laying a foundation for tools to explore individual and collective behavior in social science.
Links mentioned:
- Generative Agent Simulations of 1,000 People: The promise of human behavioral simulation--general-purpose computational agents that replicate human behavior across domains--could enable broad applications in policymaking and social science. We pr...
- Chain-of-Thought Reasoning Without Prompting: In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) promptin...
OpenAI ▷ #ai-discussions (18 messages🔥):
Daily Theme WinnerAPI Usage DiscussionModel Options and Performance
-
Celebrating Daily Theme Victory: One member expressed joy after being the first to win the daily theme challenge, stating they were 'so happy'.
- This elicited a positive reaction from the community, highlighting engagement with ongoing activities.
- API Solutions Sought: A member mentioned searching for an API or tool but found both options unsatisfactory, indicating frustration.
- This reflects a broader interest in finding useful resources within the community.
- Clarification on Model Options: A discussion emerged regarding the 4o model and whether it used the o1 mini or o1 preview, with confirmation it likely used o1 mini.
- Another member suggested checking the settings to verify options, promoting hands-on troubleshooting.
- Swapping Channels Confusion: Queries arose about whether the ai-discussions channel was swapped with another specific channel, indicating possible miscommunication.
- A member expressed apologies for a mix-up, mentioning their intention to move comments to the correct off-topic space.
OpenAI ▷ #gpt-4-discussions (3 messages):
High Temperature PerformanceBeta Access to o1Gaming Character Genshin Impact
-
High Temp Performance Inquiry: A member questioned if improved performance at higher temperatures could be linked to their prompt style, suggesting too many guiding rules or constraints.
- This raises interesting considerations for optimizing prompt design for better AI responsiveness.
- Gratitude for Beta Access to o1: A member expressed excitement and gratitude towards NH for granting them beta access to o1, brightening their morning.
- Woo! Thank you NH for making this morning even brighter reflects the exhilaration around new updates.
- Genshin Impact Character Confusion: One member raised a concern about ChatGPT not retrieving information on Gaming, a character from Genshin Impact.
- This highlights potential gaps in the AI's knowledge concerning popular game characters and their contexts.
OpenAI ▷ #prompt-engineering (8 messages🔥):
Using Delimiters in PromptsMarkdown for ClarityGame Mechanics UnderstandingModel Context Expectations
-
Employing Delimiters for Clarity: A member shared OpenAI's advice on using delimiters like triple quotation marks or XML tags to help the model interpret distinct sections of the input clearly.
- This approach aids in structuring prompts better for improved model responses, allowing for easier input interpretation.
- Markdown as a Formatting Tool: Another member suggested using Markdown syntax to create structured headings and lists for better clarity in prompts.
- Examples included
# Heading 1for main titles and various list formats, indicating how structured text can enhance the model's understanding. - General Purpose Model Adaptability: A discussion noted that since GPT is a general-purpose model, it may not strictly adhere to game mechanics like those in Tic Tac Toe.
- This highlights the importance of clear context and expectations to guide the model's output when dealing with specific scenarios.
- Direct Labeling for Model Context: A member proposed providing explicit labels such as 'Section head: This Topic' to help the model infer context correctly.
- This technique emphasizes the model's reliance on labeling and context to generate more relevant responses.
OpenAI ▷ #api-discussions (8 messages🔥):
Using Delimiters for ClarityMarkdown FormattingImproving GPT's UnderstandingGame Mechanics in GPTModel Context and Labeling
-
Using Delimiters for Clarity in Prompts: Using delimiters like triple quotation marks or section titles can help clarify distinct parts of the input for the model, according to OpenAI's advice.
- This practice aids the model in interpreting different sections effectively, enhancing overall comprehension.
- Markdown Formatting Tips: Markdown can be utilized for creating headings and formatting text, with examples like
# This is Heading 1and bold or italic styling shared in the discussion.
- Many members highlighted the usefulness of backtick lines and lists in organizing content clearly.
- Game Mechanics and GPT Responses: A member noted that due to GPT's general-purpose nature, it may deviate from simple game mechanics like Tic Tac Toe.
- Humorously, they mentioned gaining 25 experience points while discussing this topic.
- Model Context and Labeling for Better Interactions: Participants suggested labeling sections directly, such as using 'Section head: This Topic', to guide the model's understanding.
- Emphasizing that giving context aids the LLM in guessing and pattern matching, enriching its responses.
Cohere ▷ #discussions (12 messages🔥):
API Key IssuesCORS ErrorsPython Learning Projects
-
403 Errors Indicate API Issues: Multiple members discussed encountering 403 errors, indicating either invalid API keys or calling old endpoints while trying to access certain functionalities.
- One member shared that after checking their API keys, they experienced fetch errors and difficulties using the sandbox feature.
- Inquiry about Free Tier API Limitations: A member confirmed they were still on the free tier and attempted to upgrade to a production key to resolve ongoing issues, but faced further challenges.
- They reported several CORS errors in the console, noting that their setup was standard with no additional plugins.
- Collective Learning with Python: A member mentioned participating in 30 Days of Python, sharing their learning project with the group.
- This prompted a general inquiry about other members' ongoing projects, fostering a sense of community and collaboration.
Links mentioned:
- Fetch Errors on Cohere Dashboard: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
Cohere ▷ #questions (6 messages):
Account-based settingsModel training promptsBulgarian language datasetsModel tuning techniquesContributing processes
-
Account-specific configurations: It was noted that adjustments would be made on a per-account basis, highlighting the need for tailored settings.
- This approach ensures customization for individual user needs.
- Guiding the command-r: A suggestion was made to allow command-r to draft system prompts with the user's oversight to enhance performance.
- This could streamline the prompt creation process.
- Bulgarian language training datasets: The discussion pointed out that additional training data specific to the Bulgarian language would be crucial for model fine-tuning.
- The user offered to gather a dataset and requested that findings be shared in the message thread for team review.
- Model tuning capabilities: It was asked whether tuning the model could be done using only a preamble and possibly chat history.
- This raises important questions about the model's adaptability to various training inputs.
- Seeking assistance for contributions: A user expressed uncertainty about how to start contributing and requested help to understand the process.
- This indicates a need for clearer guidelines on contribution pathways.
Cohere ▷ #api-discussions (4 messages):
RAG chatbot issuesCohere multi-modal embeddingsRate limiting problems
-
RAG Chatbot Faces API Token Error: A user reported an error stating
invalid api tokenwhen executing their RAG chatbot code despite using a valid Cohere API key from the dashboard.- They provided their code snippet and requested assistance in identifying the source of the error.
- Praise for Multi-Modal Embeddings and Rate Limit Concerns: A member expressed excitement over the new multi-modal embeddings for images, noting fantastic improvements observed in their applications.
- However, they highlighted a significant issue with the 40 requests per minute rate limit, which hinders their use case, and sought advice on potential alternatives.
Cohere ▷ #projects (4 messages):
Harmony Open-Source ProjectCompetition for LLM Matching AlgorithmsData Availability for HarmonyNatural Language Processing in HarmonyDiscord Community for Harmony
-
Harmony Project for Questionnaire Harmonization: The Harmony project is designed to retrospectively harmonise questionnaire items and metadata using LLMs, and it is used by researchers for better data compatibility.
- It facilitates comparing instruments and explores potential compatibility across versions and languages via this tool.
- Join the Competition to Improve LLM Algorithms: Harmony is hosting a competition to enhance its LLM matching algorithms, offering prizes for participation, with no prior experience required in LLM training.
- Participants can register on DOXA AI to enter the competition and assist in making Harmony more robust.
- Data Accessibility for Harmony: Members inquired about the data used in the open-source Harmony project, prompting responses regarding its availability.
- The project's code and data can be found on its GitHub page.
- Leveraging Natural Language Processing: The Harmony project utilizes Natural Language Processing for improving the matching of questionnaire items across various studies and languages.
- Further insights into Harmony’s algorithm performance can be explored in a detailed blog post.
- Engagement in the Harmony Discord Community: The project encourages users to join the Harmony Discord server to participate in discussions and contribute to the matching challenge.
- Members can access the *�「matching-challenge」 channel for updates and collaboration.
Links mentioned:
- GitHub - harmonydata/harmony: The Harmony Python library: a research tool for psychologists to harmonise data and questionnaire items. Open source.: The Harmony Python library: a research tool for psychologists to harmonise data and questionnaire items. Open source. - harmonydata/harmony
- Harmony | A global platform for contextual data harmonisation: A global platform for contextual data harmonisation
- Competition to train a Large Language Model for Harmony on DOXA AI | Harmony: A global platform for contextual data harmonisation
Torchtune ▷ #general (7 messages):
Post-softmax Scores with sdpa/flexAttention Score CalculationFlex Attention UpdatesPerformance Benchmarking sdpa
-
Using sdpa/flex for Post-softmax Scores: To obtain post-softmax scores using sdpa/flex, feed in a dummy tensor initialized to the identity matrix and shape [..., seqlen, seqlen]. This approach might require two calls, though it's suggested this isn't necessary by some members.
- The implementation details discussed reference potential changes in flex's behavior in version 2.5.1 that might affect the feasibility of this method.
- Self-calculating Attention Scores: One member suggested calculating the attention scores directly using
torch.softmax(q @ k.transpose(-1, -2), dim=-1), providing more control over storage options. They pointed out that since F.sdpa/flex implements the flash-attn algorithm, some score recomputation is necessary to save them.
- Another member expressed agreement, noting that this would be a straightforward initial attempt unless there were specific reasons to avoid it.
- Benchmarking sdpa Approaches: There was a recommendation to benchmark the proposed method against the naive sdpa approach to identify performance differences. The numerical error in scores could vary based on the sdpa backend and data type used.
Link mentioned: pytorch/torch/nn/attention/flex_attention.py at release/2.5 · pytorch/pytorch): Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
Torchtune ▷ #dev (14 messages🔥):
Adaptive Batching ImplementationImproving DPO Loss FunctionStandard vs. New Research ApproachesServer Boosts and Nitro SubscriptionCode Structure and Modularity Concerns
-
Adaptive Batching Aiming for Optimal GPU Utilization: Discussions centered around implementing adaptive batching that maximizes GPU utilization by adjusting the batch size to avoid OOM errors during training.
- It was suggested that this feature could be added as a flag in future recipes, ideally activated when
packed=Trueto maintain efficiency. - Evaluating Changes in DPO Loss Structure: Concerns were raised about the current structure of the TRL code and whether to include recent papers addressing DPO modifications that may not be significant enough.
- A call for clarity was made on whether to remove SimPO and any separate classes to keep the DPO recipe clean and straightforward.
- Preference for Standard Methods Over New Approaches: There was a consensus that the usual practice is to implement standard methods while allowing for flexibility for new innovative strategies by others in the field.
- Members discussed the potential trade-offs associated with trying new research preprints versus sticking with established techniques.
- Impacts of Cancelling Nitro Subscription: A member mentioned that server boosts will be removed if a user cancels their free Nitro subscription, highlighting the implications for server management.
- This comment drew attention to the value of maintaining subscriptions for uninterrupted server benefits.
- Deep Dive on TRL Code Challenges: Feedback was given regarding the TRL code's complexity and modularity, specifically the issues arising from multiple checks for different arguments.
- The group discussed the need for simplifying the DPO recipe to ensure it's more hackable, thereby enhancing future development.
- It was suggested that this feature could be added as a flag in future recipes, ideally activated when
Link mentioned: Add RPO, DPOP losses, add lambda_dpop to basic DPO loss by krammnic · Pull Request #2035 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) Please link to any issues this PR addresses. Changelog W...
Torchtune ▷ #papers (2 messages):
SageAttentionInference Gains
-
SageAttention Achieves Impressive Speedups: The project SageAttention boasts quantized attention that delivers speedups of 2.1x and 2.7x compared to FlashAttention2 and xformers, respectively, while maintaining end-to-end metrics across various models.
- Pretty cool inference gains here! implies excitement about the performance improvements presented by SageAttention.
- Discussion on Inference Gains from SageAttention: A member expressed their thoughts on the inference gains achieved through the implementation of SageAttention, indicating strong performance improvements.
- The topic sparked interest among others, potentially leading to further discussions on its application in various AI models.
Link mentioned: GitHub - thu-ml/SageAttention: Quantized Attention that achieves speedups of 2.1x and 2.7x compared to FlashAttention2 and xformers, respectively, without lossing end-to-end metrics across various models.: Quantized Attention that achieves speedups of 2.1x and 2.7x compared to FlashAttention2 and xformers, respectively, without lossing end-to-end metrics across various models. - thu-ml/SageAttention
tinygrad (George Hotz) ▷ #general (6 messages):
Tinygrad and Triton IntegrationSASS Assembler QuestionsFOSDEM AI DevRoom PresentationTinybox Hackathon Proposal
-
Inquiry on Tinygrad's Triton Integration: A user inquired whether Tinygrad now has native integration with Triton, referencing earlier discussions.
- George Hotz prompted the user to refer to the questions document for clarification.
- SASS Assembler Intentions: A discussion arose regarding whether the to-be-written SASS assembler is intended to replace ptxas.
- One user expressed uncertainty about their question's relevance, with George Hotz suggesting they consult the questions document.
- Call for Presenters at FOSDEM AI DevRoom: A community member shared an opportunity for Tinygrad developers to present at the FOSDEM AI DevRoom happening on February 2, 2025.
- They emphasized Tinygrad's significance in the AI industry and encouraged interested individuals to reach out for collaboration.
- Tinybox Hackathon Idea: The same member proposed organizing a pre-FOSDEM hackathon and invited someone to bring a Tinybox on-site for hands-on experiences.
- They expressed enthusiasm to engage community members in discussions over Belgian beer, hoping it would enhance the event.
Link mentioned: FOSDEM 2025 - Low-Level AI Engineering & Hacking Dev Room: Explore the new "Low-Level AI Hacking & Engineering" Dev Room at FOSDEM, featuring open-source projects powering the AI industry. Submit a session or become a sponsor for this innovative...
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
int64 indexinghuge tensors
-
Question on int64 Indexing Utility: A member inquired about the necessity of int64 indexing in contexts where huge tensors are not being used.
- The discussion seeks to clarify the scenarios or potential advantages of using int64 indexing despite the absence of large tensor applications.
- Exploration of Indexing Techniques: The community is delving into various indexing techniques used in tensor operations, which may include int64, int32, and others.
- They are considering the impact of these indexing methods on performance and efficiency in smaller tensor operations.
Modular (Mojo 🔥) ▷ #mojo (2 messages):
Async functions in MojoMojo library repository
-
Async functions awaitable in Mojo sync functions: A member is puzzled about being able to await an async function inside a sync function in Mojo, which contrasts with Python's limitations.
- They are seeking clarification or an explanation for this difference in handling async functionality.
- Inquiry about Mojo library repository: Another member is curious about the availability of a repository for libraries comparable to pip for Mojo.
- They are looking for resources or links that provide access to Mojo libraries.
Modular (Mojo 🔥) ▷ #max (5 messages):
Moonshine ASR Model PerformanceMojo Program ObservationsMax API vs ONNX Performance
-
Moonshine ASR Model Tested with Max: A user tested the Moonshine ASR model performance using both the Python API for Max and a native Mojo version, noting both were about 1.8x slower than the direct onnxruntime Python version.
- The Mojo and Python Max versions took approximately 82ms to transcribe 10 seconds of speech, whereas the native onnxruntime reached 46ms.
- Run Instructions and Observations Shared: Instructions for running the Moonshine ASR model are provided in comments at the top of the mojo file that was shared.
- The user's experience highlighted that passing in TensorMap into Model.execute caused a crash, and manual unpacking of 26 arguments was necessary due to limitations in Mojo.
- Seeking Performance Improvements in Mojo: The user expressed that this is one of their first Mojo programs and acknowledged that it may not be idiomatic.
- They requested assistance for achieving better performance, emphasizing their eagerness to improve their Mojo and Max skills.
Links mentioned:
- moonshine.mojo: moonshine.mojo. GitHub Gist: instantly share code, notes, and snippets.
- moonshine.py: moonshine.py. GitHub Gist: instantly share code, notes, and snippets.
OpenAccess AI Collective (axolotl) ▷ #general (2 messages):
Tencent Hunyuan ModelBits and Bytes on MI300X
-
Discussion on Tencent Hunyuan Model Fine Tuning: A member inquired about experiences with fine-tuning the Tencent Hunyuan model, sharing various useful links including GitHub and official website.
- They provided additional resources such as the Technical Report and Demo for reference.
- Using Bits and Bytes on MI300X: A member shared their successful experience with Bits and Bytes on the MI300X system, highlighting ease of use.
- They emphasized the importance of remembering the
--no-depsflag during updates, sharing a one-liner command to force reinstall the package.
Link mentioned: tencent/Tencent-Hunyuan-Large · Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
volko76: Do we still need to prompt correctly ?
https://youtu.be/m3Izr0wNfQc
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (4 messages):
Axolotl Collab NotebooksContinual Pretraining of LLaMA
-
Inquiry about Axolotl Collab Notebooks: A user inquired whether Axolotl offers any collab notebooks that can be used for continual pretraining of LLaMA.
- Phorm responded, indicating they would search OpenAccess-AI-Collective/axolotl for relevant information.
- Undefined Result for Notebook Inquiry: Phorm's search result returned undefined, indicating no current available notebooks for the stated purpose.
- Users were encouraged to check back soon for updates on the availability of these resources.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search): Understand code, faster.
DSPy ▷ #general (5 messages):
multimodal problemsvision language modelsmmmu notebook
-
Juan seeks help with multimodal challenges: Juan inquired about using the experimental support for vision language models while working on a multimodal problem.
- Let me know if there are any issues! was posed by another member to offer additional assistance.
- Juan discovers the mmmu notebook: Juan later found the mmmu notebook himself, which provided the support he needed for his project.
- He thanked the community for their awesome work, showing appreciation for the resources available.
DSPy ▷ #examples (1 messages):
Semantic RouterClassification Tasks
-
Semantic Router as a Benchmark: A member suggested that the Semantic Router should serve as the baseline for performance in classification tasks, emphasizing its superfast AI decision making capabilities.
- The project focuses on intelligent processing of multi-modal data, and it may offer competitive benchmarks we aim to exceed.
- Focus on Performance Improvement: There was an assertion that the performance of existing classification tools needs to be surpassed, with the Semantic Router as a reference point.
- Discussion revolved around identifying metrics and strategies to achieve better results than the baseline set by this tool.
Link mentioned: GitHub - aurelio-labs/semantic-router: Superfast AI decision making and intelligent processing of multi-modal data.: Superfast AI decision making and intelligent processing of multi-modal data. - aurelio-labs/semantic-router
LlamaIndex ▷ #blog (2 messages):
LLM-Native Resume MatchingBuilding AI Agents with LlamaIndexWebinar on December 12
-
LLM-Native Resume Matching Solution Launched: Thanks to @ravithejads, an LLM-native solution for resume matching has been developed, enhancing traditional screening methods.
- This innovative approach addresses the slow and tedious process of manual filtering in recruitment, offering a more efficient alternative.
- Join Our Webinar on Building AI Agents: Learn how to build data-backed AI agents with LlamaIndex and @Redisinc in an upcoming webinar on December 12.
- The session will cover architecting agentic systems and best practices for reducing costs and optimizing latency.
LlamaIndex ▷ #general (2 messages):
Extracting table data from PDFsApplications for PDF data extraction
-
Extracting Table Data from PDFs: A member asked for approaches to extract table data from PDF files that contain various elements including text and images.
- They expressed interest in knowing if there are any existing applications that facilitate this process.
- Inquiry About PDF Data Extraction Apps: Another member sought recommendations for any applications available that can extract data specifically from PDFs.
- This highlights a need within the community for tools that can handle various PDF complexities.
OpenInterpreter ▷ #general (4 messages):
New UI FeedbackRate Limit IssuesInterpreter DesignFuture UI Configurations
- New UI sparks mixed feelings: Some users feel the new UI is slightly overwhelming and unclear in directing attention, with one comparing it to a computer from Alien. However, others are starting to appreciate its UNIX-inspired design, finding it suitable for 1.0 features.
- Need for token and rate limit configuration: A user expressed frustration over being rate limited by Anthropic, noting that current error handling in Interpreter leads to session exits when limits are exceeded. They emphasized the importance of incorporating better rate limit management in future updates.
- Suggestions for UI improvements: There are calls for a more informative UI that displays current tools, models, and working directories to enhance usability. Users are also advocating for a potential 'plugin ecosystem' to allow customizable features in future releases.
- Separation of compute workloads proposed: One member suggested splitting LLM workloads between local and cloud compute to optimize performance. This reflects a concern about the limitations of the current Interpreter design, which is primarily built for one LLM at a time.
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Intel AMAHackathon Insights
-
Intel AMA Session Tomorrow: A Hackathon AMA with Intel is set for 3 PM PT tomorrow (11/21), providing a chance to gain insights directly from Intel specialists.
- Don’t forget to watch live here and set your reminders!
- Reminder for Upcoming Event: @everyone is reminded about the upcoming Intel AMA, emphasizing its importance for gaining knowledge.
- Participants are encouraged to prepare their questions to make the most of the session.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Registration IssuesHackathon vs MOOC Registration
-
User Faces Registration Confusion: A user expressed concern about not receiving any emails after joining three different groups and registering with multiple email addresses.
- They are uncertain about whether their registration was successful.
- Clarification on Event Type: Another member asked for clarification, wondering if the user was referring to the hackathon or the MOOC registration.
- This highlights potential confusion among participants regarding different types of registrations.
Mozilla AI ▷ #announcements (1 messages):
Refact.AIAutonomous AgentsLive DemoTooling
-
Exciting Demo from Refact.AI Team: The Refact.AI team, featuring members <@326360689453039618> and <@1291640853462253652>, is hosting a live demo showcasing their autonomous agent and tooling.
- Join the live demo and conversation here to dive deeper into their developments!
- Live Event Announcement: An event has been announced featuring Refact.AI members discussing their latest technology and tools.
- Participants are encouraged to engage with the live demo and conversation related to the autonomous agent.