[AINews] DeepSeek Janus and Meta SpiRit-LM: Decoupled Image and Expressive Voice Omnimodality
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Interleaving early fusion is all you need.
AI News for 10/17/2024-10/18/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (228 channels, and 2111 messages) for you. Estimated reading time saved (at 200wpm): 249 minutes. You can now tag @smol_ai for AINews discussions!
It is multimodality day in AI research land as two notable multimodality papers were released: Janus and SpiRit-LM.
DeepSeek Janus
Earlier work like Chameleon (our coverage here) and Show-O used a single vision encoder for both visual understanding (image input) and generation (image output). Deepseek separated them:
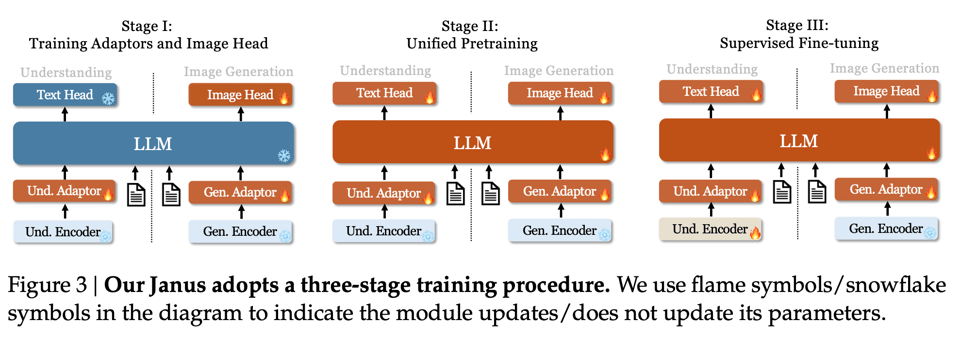
and found better results in comparable size image generation:

and image understanding:

Open question as to whether this approach maintains its advantage with scale, and if it is really all that important to include image generation in the same stack.
Meta SpiRit-LM
Along with SAM 2.1 and Layer Skip, Meta's Friday drop included SpiRit-LM, a (Spi)eech and W(Rit)ing model that also includes an "expressive" version generating pitch and style units.
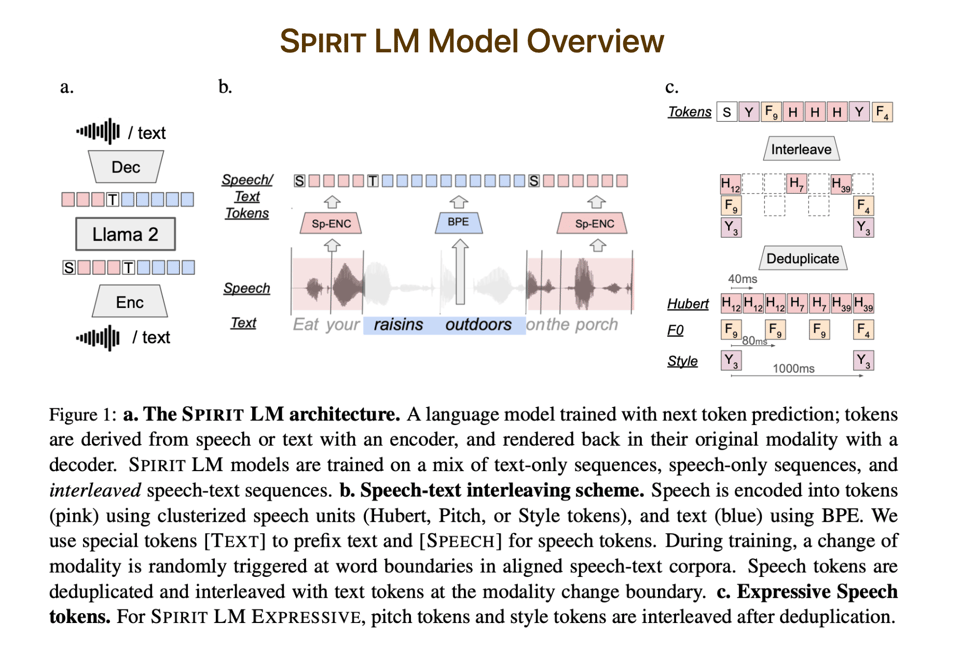
The demo has voice samples - not quite NotebookLM level, but you can see how this is a step above standard TTS.

Brought to you by W&B Weave: The best ML experiment tracking software in the world is now offering complete LLM observability!
With 3 lines of code you can trace all LLM inputs, outputs and metadata. Then with our evaluation tooling, you can turn AI Engineering from an art into a science.
P.S. Weave also works for multimodality - see how to fine-tune and evaluate GPT-4o on image data.
Table of Contents
- DeepSeek Janus
- Meta SpiRit-LM
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Nous Research AI Discord
- HuggingFace Discord
- Eleuther Discord
- OpenRouter (Alex Atallah) Discord
- LM Studio Discord
- Latent Space Discord
- Perplexity AI Discord
- Modular (Mojo 🔥) Discord
- aider (Paul Gauthier) Discord
- OpenAI Discord
- GPU MODE Discord
- LlamaIndex Discord
- OpenAccess AI Collective (axolotl) Discord
- Cohere Discord
- tinygrad (George Hotz) Discord
- Interconnects (Nathan Lambert) Discord
- Stability.ai (Stable Diffusion) Discord
- LLM Agents (Berkeley MOOC) Discord
- LAION Discord
- DSPy Discord
- Torchtune Discord
- OpenInterpreter Discord
- LangChain AI Discord
- Alignment Lab AI Discord
- LLM Finetuning (Hamel + Dan) Discord
- PART 2: Detailed by-Channel summaries and links
- Nous Research AI ▷ #general (324 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (4 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- Nous Research AI ▷ #interesting-links (3 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- HuggingFace ▷ #general (214 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #cool-finds (1 messages):
- HuggingFace ▷ #i-made-this (5 messages):
- HuggingFace ▷ #reading-group (11 messages🔥):
- HuggingFace ▷ #computer-vision (2 messages):
- HuggingFace ▷ #NLP (6 messages):
- HuggingFace ▷ #diffusion-discussions (27 messages🔥):
- Eleuther ▷ #general (5 messages):
- Eleuther ▷ #research (168 messages🔥🔥):
- Eleuther ▷ #lm-thunderdome (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (167 messages🔥🔥):
- LM Studio ▷ #general (126 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (11 messages🔥):
- Latent Space ▷ #ai-general-chat (56 messages🔥🔥):
- Latent Space ▷ #ai-announcements (6 messages):
- Latent Space ▷ #ai-in-action-club (67 messages🔥🔥):
- Perplexity AI ▷ #general (96 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (2 messages):
- Modular (Mojo 🔥) ▷ #general (27 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (75 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #max (2 messages):
- aider (Paul Gauthier) ▷ #general (60 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (25 messages🔥):
- aider (Paul Gauthier) ▷ #links (1 messages):
- OpenAI ▷ #ai-discussions (25 messages🔥):
- OpenAI ▷ #gpt-4-discussions (32 messages🔥):
- OpenAI ▷ #prompt-engineering (3 messages):
- OpenAI ▷ #api-discussions (3 messages):
- GPU MODE ▷ #general (8 messages🔥):
- GPU MODE ▷ #triton (3 messages):
- GPU MODE ▷ #torch (11 messages🔥):
- GPU MODE ▷ #beginner (25 messages🔥):
- GPU MODE ▷ #torchao (2 messages):
- GPU MODE ▷ #llmdotc (6 messages):
- GPU MODE ▷ #bitnet (1 messages):
- GPU MODE ▷ #sparsity-pruning (1 messages):
- GPU MODE ▷ #webgpu (1 messages):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (46 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (45 messages🔥):
- Cohere ▷ #discussions (13 messages🔥):
- Cohere ▷ #questions (7 messages):
- Cohere ▷ #api-discussions (6 messages):
- Cohere ▷ #projects (7 messages):
- tinygrad (George Hotz) ▷ #general (12 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (18 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (2 messages):
- Interconnects (Nathan Lambert) ▷ #ml-questions (9 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (3 messages):
- Interconnects (Nathan Lambert) ▷ #random (3 messages):
- Interconnects (Nathan Lambert) ▷ #rlhf (11 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (20 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (17 messages🔥):
- LAION ▷ #general (11 messages🔥):
- DSPy ▷ #general (1 messages):
- DSPy ▷ #colbert (8 messages🔥):
- Torchtune ▷ #general (1 messages):
- Torchtune ▷ #dev (7 messages):
- OpenInterpreter ▷ #general (3 messages):
- OpenInterpreter ▷ #ai-content (1 messages):
- LangChain AI ▷ #share-your-work (1 messages):
- Alignment Lab AI ▷ #general (1 messages):
- LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Industry Updates and Developments
- New AI Models and Benchmarks: @bindureddy noted that the Nvidia Nemotron Fine-Tune isn't a very good 70b model, underperforming across several categories compared to other SOTA models. @AIatMeta announced the open-sourcing of Movie Gen Bench, including two new media generation benchmarks: Movie Gen Video Bench and Movie Gen Audio Bench, aimed at evaluating text-to-video and (text+video)-to-audio generation capabilities.
- AI Company Updates: @AravSrinivas announced the launch of Perplexity for Internal Search, a tool to search over both the web and team files with multi-step reasoning and code execution. @AnthropicAI rolled out a new look for the Claude iOS and Android apps, including iPad support and project features.
- Open Source Developments: @danielhanchen reported that the gradient accumulation fix is now in the main branch of transformers, thanking the Hugging Face team for collaboration. @ClementDelangue shared an important report on "Stopping Big Tech from becoming Big AI," emphasizing the role of open source AI in fostering innovation and lowering barriers to entry.
AI Research and Technical Insights
- Model Merging: @cwolferesearch discussed the effectiveness of model merging for combining skills of multiple LLMs, citing Prometheus-2 as an example where merging outperforms multi-task learning and ensembles.
- AI Safety and Evaluation: @_philschmid explained Process Reward Models (PRM) by @GoogleDeepMind, which provide feedback on each step of LLM reasoning, leading to 8% higher accuracy and up to 6x better data efficiency compared to standard outcome-based Reward Models.
- AI Development Tools: @hrishioa introduced diagen, a tool for generating @terrastruct d2 diagrams using various AI models, with Sonnet performing best and Gemini-flash showing impressive results with visual reflection.
AI Applications and Use Cases
- Audio Processing: @OpenAI announced support for audio in their Chat Completions API, offering comparison points between the Chat Completions API and the Realtime API for audio applications.
- AI in Education: @RichardMCNgo suggested that teachers struggling to evaluate students using AI assistance should prepare for AIs capable of evaluating students themselves, potentially through voice-capable AI and AIs watching students solve problems.
- AI for Data Analysis: @perplexity_ai introduced Internal Knowledge Search, allowing users to search through both organizational files and the web simultaneously.
AI Community and Career Insights
- @willdepue encouraged applications to the OpenAI residency for those from unconventional backgrounds interested in AI, emphasizing the need for enthusiasm about building true AI and tackling complex problems.
- @svpino announced an upcoming Machine Learning Engineering cohort focusing on building a massive, end-to-end machine learning system using exclusively open-source tools.
- @jxnlco shared an anecdote about undercharging for consulting services, highlighting the importance of proper pricing in the AI consulting industry.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. High-Performance Local LLM Setups
- 7xRTX3090 Epyc 7003, 256GB DDR4 (Score: 149, Comments: 72): A user showcases their powerful 7x RTX 3090 GPU setup paired with an AMD Epyc 7003 processor and 256GB DDR4 RAM for local LLM inference. This high-performance configuration is designed to handle demanding AI workloads, particularly large language models, with significant parallel processing capabilities and ample memory resources.
- Users praised the aesthetics of the tightly packed GPUs, with some comparing it to an "NSFW" setup. The water cooling system garnered attention, with questions about its implementation and thermal management.
- The motherboard was identified as an ASRock ROMED8-2T with 128 PCIe 4.0 lanes. The setup uses 2x1800W PSUs and employs tensor parallelism instead of NVLink for GPU communication.
- Discussion arose around power consumption and cooling, with the OP confirming a 300W limit per GPU (totaling 2100W) and the use of a "huge 2x water radiator". Users compared this setup to crypto mining rigs and speculated on its performance for LLM training.
Theme 2. DeepSeek's Janus: A 1.3B Multimodal Model Breakthrough
- DeepSeek Releases Janus - A 1.3B Multimodal Model With Image Generation Capabilities (Score: 389, Comments: 77): DeepSeek has released Janus, a 1.3 billion parameter multimodal model capable of both image understanding and generation. The model demonstrates competitive performance in zero-shot image captioning and visual question answering tasks, while also featuring the ability to generate images from text prompts, making it a versatile tool for various AI applications.
- The Janus framework uses separate pathways for visual encoding while maintaining a unified transformer architecture. This approach enhances flexibility and performance, with users expressing interest in its implementation and potential applications.
- A detailed installation guide for running Janus locally on Windows was provided, requiring at least 6GB VRAM and an NVIDIA GPU. The process involves creating a virtual environment, installing dependencies, and downloading the model.
- Users discussed the model's capabilities, with some reporting issues running it on a 3060 with 12GB VRAM. Early tests suggest the model struggles with image composition and is not yet at SOTA level for image generation or visual question answering.
Theme 3. Meta AI's Hidden Prompt Controversy
- Meta AI's hidden prompt (Score: 302, Comments: 85): Meta AI's chatbot, powered by Meta Llama 3.1, was found to have a hidden prompt that includes instructions for accessing and utilizing user data for personalized responses. The prompt, revealed through a specific query, outlines guidelines for incorporating user information such as saved facts, interests, location, age, and gender while maintaining strict privacy protocols to avoid explicitly mentioning the use of this data in responses.
- Users discussed the creepiness factor of Meta AI's hidden prompt, with some expressing concern over privacy implications. Others argued it's a standard practice to improve user experience and avoid robotic responses.
- Debate arose about whether the revealed prompt was hallucinated or genuine. Some users suggested testing for consistency across multiple queries to verify its authenticity, while others pointed out the prompt's specificity as evidence of its legitimacy.
- Discussion touched on the quality of the prompt, with some criticizing its use of negative statements. Others defended this approach, noting that larger models like GPT-4 can handle such instructions without confusion.
Theme 4. AI-Powered Game Development Innovations
- I'm creating a game where you need to find the entrance password by talking with a Robot NPC that runs locally (Llama-3.2-3B Instruct). (Score: 87, Comments: 26): The post describes a game in development featuring a Robot NPC powered by Llama-3.2-3B Instruct, running locally on the player's device. Players must interact with the robot to discover an entrance password, with the AI model enabling dynamic conversations and puzzle-solving within the game environment. This implementation showcases the integration of large language models into interactive gaming experiences, potentially opening new avenues for AI-driven narrative and gameplay mechanics.
- Thomas Simonini from Hugging Face developed this demo using Unity and LLMUnity, featuring Llama-3.2-3B Instruct Q4 for local processing and Whisper Large API. He plans to add multiple characters with different personalities and write a tutorial on creating similar games.
- The game's security against jailbreaking attempts was discussed, with suggestions to improve it using techniques like function calling, separating password knowledge from the LLM, or implementing a two-bot system where one bot knows the password and only communicates yes/no answers.
- Users proposed ideas for gameplay mechanics, such as tying dialogue options to RPG-like intelligence perks, using jailbreaking as a feature for "gullible" NPCs, and suggested improvements like word-based passwords or historical number references to enhance the guessing experience.
- Prototype of a Text-Based Game Powered by LLAMA 3.2 3B locally or Gemini 1.5Flash API for Dynamic Characters: Mind Bender Simulator (Score: 43, Comments: 7): The post describes a prototype for a text-based game called "Mind Bender Simulator" that uses either LLAMA 3.2 3B locally or the Gemini 1.5Flash API to create dynamic characters. This game aims to simulate interactions with characters who have mental health conditions, allowing players to engage in conversations and make choices that affect the narrative and character relationships.
- The game concept draws comparisons to the film Sneakers, with users suggesting scenarios like voice passphrase verification. The developer considers adding fake social profiles and adapting graphic styles for increased immersion.
- Discussions explore the potential of using LLMs for text adventure games, with suggestions to use prompts for style, character info, and "room" descriptions. Questions arise about the model's ability to maintain consistency in navigating virtual spaces.
- Interest in the project's prompting techniques is expressed, with requests for access to the source code. The developer notes significant performance differences between LLAMA and Gemini, especially for non-English languages, and estimates a potential cost of under $1 per gaming session using Gemini Flash.
Theme 5. LLM API Cost and Performance Comparison Tools
- I made a tool to find the cheapest/fastest LLM API providers - LLM API Showdown (Score: 51, Comments: 25): The author created "LLM API Showdown", a web app that compares LLM API providers based on cost and performance, available at https://llmshowdown.vercel.app/. The tool allows users to select a model, prioritize cost or speed, adjust input/output ratios, and quickly find the most suitable provider, with data sourced from artificial analysis.
- Users praised the LLM API Showdown tool for its simplicity and cleanliness. The creator acknowledged the positive feedback and mentioned that the tool aims to provide up-to-date information compared to similar existing resources.
- ArtificialAnalysis was highlighted as a reputable source for in-depth LLM comparisons and real-use statistics. Users expressed surprise at the quality and free availability of this comprehensive information.
- Similar tools were mentioned, including Hugging Face's LLM pricing space and AgentOps-AI's tokencost. The creator noted these alternatives are not always current.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Development
- Google's NotebookLM now allows users to customize AI-generated podcasts based on their documents. New features include adjusting podcast length, choosing voices, and adding music. Source
- NVIDIA announced Sana, a new foundation model claimed to be 25x-100x faster than Flux-dev while maintaining comparable quality. The code is expected to be open-sourced. Source
- A user successfully merged two Stable Diffusion models (Illustrious and Pony) with different text encoder blocks, demonstrating progress in model combination techniques. Source
AI Applications and Demonstrations
- A LEGO LoRA for FLUX was created to improve LEGO creations in AI-generated images. Source
- An AI-generated image of a sea creature using FLUX demonstrated the model's capability to create realistic-looking mythical creatures. Source
Robotics Advancements
- Unitree's G1 robot demonstrated impressive capabilities, including a standing long jump of 1.4 meters. The robot stands 1.32 meters tall and shows agility in various movements. Source
- A comparison between Unitree's G1 and Tesla's Optimus sparked debate about the progress of humanoid robots, with some users finding the G1 more impressive. Source
AI Ethics and Societal Impact
- Sam Altman expressed concern about people's ability to adapt to the rapid changes brought by AI technologies. He emphasized the need for societal rewriting to accommodate these changes. Source
- Altman also stated that AGI and fusion should be government projects, criticizing the current inability of governments to undertake such initiatives. Source
- Demis Hassabis of DeepMind described AI as "epochal defining," predicting it will solve major global challenges like diseases and climate change. Source
Community Discussion
- A user raised concerns about the concentration of posts from a small number of accounts on the r/singularity subreddit, questioning the diversity of perspectives in the community. Source
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
Theme 1. Model Performance and Evaluations
-
Nemotron vs. Llama: Clash of the 70Bs: Engineers debate the performance and cost-effectiveness of Nemotron 70B compared to Llama 70B, especially with the anticipated 405B model on the horizon.
- Nvidia markets Nemotron for its helpfulness, sparking discussions on its edge over traditional knowledge-focused models.
- Strawberry Tasks Make LLMs Squirm: The community criticizes the strawberry evaluation task as inadequate for truly assessing LLM capabilities.
- Speculations suggest future models will be fine-tuned to tackle these viral evaluation challenges more effectively.
- Faithful Models or Flaky Predictions?: Replicating Faithfulness evaluations for RAG bots uncovers time-consuming processes, questioning model reliability.
- Alternatives like Ollama are recommended for faster execution, contingent on hardware capabilities.
Theme 2. Advanced Training Techniques
-
Fine-Tuning Frenzy: From ASCII to RWKV 🔧: Engineers dive into fine-tuning LLMs for specialized tasks, sharing insights on RWKV contributions and the potential for enhanced model versatility.
- The emphasis is on data quality and exploring open-source architectures to boost model performance.
- RLHF vs. DPO: Training Tug-of-War: Debates rage over using Proximal Policy Optimization (PPO) versus Direct Preference Optimization (DPO) for effective Reinforcement Learning from Human Feedback (RLHF).
- Implementations inspired by Anthropic's RLAIF showcase blending data from multiple models for robust training.
- ControlNet's Text Embedding Tango: Customizing ControlNet for image alterations necessitates robust text embeddings, highlighting risks of overfitting with repetitive datasets.
- Users discuss embedding adjustments to ensure effective training without compromising model adaptability.
Theme 3. Cutting-Edge Tools and Frameworks
-
Mojo: Python's Speedy Cousin ⚡: Mojo aims to attract performance-centric developers with its 'zero overhead abstractions,' rivaling languages like C++.
- Feedback highlights the need for more API examples and comprehensive tensor documentation to enhance usability.
- Aider AI Pair Programming Mishaps: Issues with Aider committing to incorrect file paths and hitting token limits spark discussions on enhancing file handling and managing large data submissions.
- Solutions include using
pipxfor isolated installations and setting token thresholds to prevent overuse. - Liger Flash Attention Saves VRAM: Integrating Flash Attention 2 with Liger results in notable VRAM reductions, halving usage from 22.7 GB to 11.7 GB.
- Members advise configuring settings like
liger_flash_attention: truefor optimal memory savings on AMD hardware.
Theme 4. Innovative AI Applications
-
Claude's Makeover: Mobile and iPad Awesomeness: The Claude app receives a major UI overhaul, introducing project creation and integrated chat features for a smoother user experience.
- Users report significantly improved navigation and functionality, enhancing on-the-go AI interactions.
- Capital Companion: Your AI Trading Sidekick: Capital Companion leverages LangChain and LangGraph to offer an AI-powered investment dashboard, aiding users in spotting uptrends and optimizing stock trading decisions.
- Features include technical analysis tools and market sentiment analysis for a competitive trading edge.
- DeepMind's Chess Grandmaster Transformer: DeepMind unveils a chess-playing transformer achieving an impressive ELO of 2895, showcasing superior strategic prowess even in unfamiliar puzzles.
- This milestone challenges critiques on LLMs' effectiveness with unseen data, highlighting strategic AI potential.
Theme 5. Community and Collaborative Efforts
-
AI Hackathons: Fueling Innovation with $25k Prizes: Multiple channels like Stability.ai and LAION host Gen AI Hackathons, encouraging teams to develop ethical AI-powered multi-agent systems with substantial prize pools.
- Collaborations include notable partners like aixplain, Sambanova Systems, and others, fostering a competitive and innovative environment.
- Open Source AI Definitions and Contributions: The Open Source AI Definition is finalized with community endorsements, fostering standardization in open-source AI projects.
- Members are encouraged to contribute to projects like RWKV and support initiatives aimed at advancing open-source AI frameworks.
- Berkeley MOOC Collaborations and Guest Speakers: The LLM Agents MOOC integrates guest speakers from industry leaders like Denny Zhou and Shunyu Yao, enhancing the learning experience with real-world insights.
- Participants engage in forums, quizzes, and livestreams, fostering a collaborative and interactive educational environment.
PART 1: High level Discord summaries
Nous Research AI Discord
-
Octopus Password Mystery Explored: Users engaged in a humorous exploration of a model hinting at 'octopus' as a potential password, generating various creative prompts in the process.
- Despite numerous strategies attempted, including poetic approaches, the definitive unlock remains elusive.
- Fine-tuning Models for Specific Tasks: A member shared experiences fine-tuning a model based on ASCII art, humorously noting its underwhelming responses.
- There was a consensus on the potential for improved versatility with further training iterations.
- Performance Evaluations of LLMs: Critiques of LLM evaluation methods highlighted the inadequacy of the strawberry task in assessing language processing capabilities.
- Speculation arose about future model enhancements being geared toward addressing well-known challenges, including the viral strawberry problem.
- Rust ML Libraries Getting Attention: The potential transition from Python to Rust in machine learning was discussed, reflecting growing interest in Rust libraries.
- Key libraries like torch-rs, burn, and ochre were mentioned, emphasizing the community's enthusiasm for learning this language.
- SCP Generator Using Outlines Released: A new SCP generator utilizing outlines was launched on GitHub, aiming to amplify the 'cursed' project's capabilities.
- In addition, a repository studying LLMs' generated texts across various personalities was linked to the paper on Cultural evolution in populations of Large Language Models: LLM-Culture.
HuggingFace Discord
-
AI Struggles to See the Bigger Picture: Members found that AIs often excel at fixing minor issues, like JSON errors, but struggle with larger coding projects, making them less effective for complex tasks.
- The discussion highlighted the risk of misleading beginners who lack sufficient coding knowledge to navigate these limitations.
- Python: A Must for AI Hobbyists: Participants emphasized the value of learning Python for those interested in AI and noted that quality free resources can rival paid courses.
- Moreover, AI-generated code is often unreliable for novices, underscoring the need for foundational coding skills.
- Kwai Kolors Faces VRAM Challenges: Users reported that running Kwai Kolors in Google Colab requires 19GB of VRAM, which exceeds the free tier's limitations.
- Advice was given to revert to the original repository for better compatibility with the tool.
- Understanding ControlNet's Training Needs: For customizing ControlNet to modify images, members noted that utilizing text embeddings is essential; replacing the CLIP encoder won't suffice.
- They also discussed the risks of overfitting when datasets contain similar images.
- Pricing Insights for AWS EC2: Discussion around AWS EC2 pricing clarified that charges apply hourly based on instance uptime, regardless of active use.
- Members noted that using notebook instances does not influence the hourly cost.
Eleuther Discord
-
Open Source AI Definition nearly finalized: The Open Source AI Definition is nearly complete, with a release candidate available for endorsement at this link. Community members are encouraged to endorse the definition to establish broader recognition.
- Additional resources and FAQs are provided here for clarity, along with a list of endorsements found here.
- Seeking contributions for RWKV project: A member from a startup focused on AI inference expressed interest in contributing to open source projects related to RWKV. They were encouraged to assist with experiments on RWKV version 7, as detailed in previous discussions in this channel.
- The community is particularly welcoming contributions around novel architecture and efficient inference methodologies.
- SAE Steering Challenges and Limitations: Discussions on Sparse Autoencoders (SAEs) revealed their tendency to misrepresent features due to complexities in higher-level hierarchies. Consequently, achieving accurate model interpretations requires substantially large datasets.
- Members emphasized the frequency of misleading conclusions stemming from overstated feature interpretations.
- Investigating Noise Distributions for RF Training: A conversation emerged regarding the use of normal distributions for noise in random forests, with alternatives suggested for better parameterization. There's a consensus about exploring distributions like Perlin noise or pyramid noise, especially beneficial for image processing.
- Community members highlighted the insufficiency of Gaussian noise alone for varied applications.
- Huggingface Adapter encounters verbose warnings: A member reported receiving verbose warnings when utilizing a pretrained model with the Huggingface adapter, indicating a potential compatibility issue. The warning points to a type mismatch with the statement: 'Repo id must be a string, not
' .
- They plan to investigate this issue further to find a resolution.
OpenRouter (Alex Atallah) Discord
-
Nemotron 70B vs. Llama 70B Showdown: In vibrant discussions, users compared the performance of Nemotron 70B and Llama 70B, deciding that Nvidia emphasized Nemotron's helpfulness over knowledge improvement.
- Speculations about the upcoming 405B model highlighted concerns regarding cost-effectiveness across models.
- OpenRouter’s Data Policies Under Scrutiny: The community questioned the OpenRouter data policies, particularly on how user data is secured, and it was confirmed that disabling model training settings restricts data from being used in training.
- Concerns were raised about the absence of privacy policy links, which were subsequently resolved.
- GPT-4o Model Emits Confused Responses: Users reported discrepancies in GPT-4o-mini and GPT-4o responses, as they inaccurately referred to GPT-3 and GPT-3.5, which is a common quirk of the models’ self-awareness.
- Experts noted that this misalignment occurs unless models are specifically prompted about their architecture.
- Privacy Policy Links Need Attention: Users spotlighted the lack of privacy policy links for providers like Mistral and Together, which was acknowledged and the need for better transparency emphasized.
- It's essential that providers link their privacy policies to user agreements for confidence.
- Kuzco Explored as a New Provider: A lively chat took off around the potential inclusion of Kuzco as a LLM provider, thanks to their competitive pricing model and early positive feedback.
- Discussions were ongoing, but full prioritization and evaluation of their offerings is yet to come.
LM Studio Discord
-
LM Studio Auto Scroll Issues Resolved: Recent issues with LM Studio's auto scrolling feature have reportedly been resolved for some users, pointing to an intermittent nature in problems encountered.
- Concerns about version stability were raised, suggesting that this could affect user experience during sessions.
- ROCM not compatible with 580s: Inquiries on using ROCM with modded 16GB 580s confirmed that it does not work despite their affordable price, roughly $90 on AliExpress.
- Another member noted that while 580s perform well with OpenCL, support has deteriorated due to the deprecation in llama.cpp.
- XEON thread adjustment issue sparks discussion: A user noted a reduction in adjustable CPU threads from 0-12 in version 0.2.31 to 0-6 in 0.3.4, expressing a desire for 8 threads.
- The Javascript query in the Settings > All sidebar for CPU Thread adjustments was highlighted, emphasizing the need for clarity in configuration.
- Performance of Different Language Models Discussed: Discussions around language models like Nemotron and Codestral revealed mixed performance results, with users advocating for larger 70B parameter models.
- Smaller models were reported to be less reliable, shaping preferences among engineers for more robust solutions.
- Memory Management Concerns in MLX-LM: A GitHub pull request tackled memory usage concerns in MLX-LM, which failed to clear cache during prompt processing.
- Community members eagerly awaited updates on proposed fixes to enhance efficiency and reduce memory overhead.
Latent Space Discord
-
Claude App Elevates User Experience: The Claude mobile app has undergone a major overhaul, introducing a smoother interface and a new iPad version that supports project creation and integrated chat features. Users reported a significantly improved navigation experience post-update.
- A featured tweet from Alex Albert highlights the app's new capabilities, enhancing user engagement with interactive options.
- Exploration of Inference Providers for Chat Completions: Members looked into various inference providers, with suggestions for OpenRouter among others, focused on enhancing chat assistants with popular open-weight models and special tokens for user interaction. Discussions centered on the reliability and functionality of these services.
- Participants emphasized the need for robust solutions as they navigate the challenges presented by existing competitors' strategies.
- MotherDuck Introduces LLM-Integrated SQL: The new SQL function from MotherDuck allows users to leverage large language models directly within SQL, streamlining data generation and summarization. This functionality promises greater accessibility to advanced AI techniques without requiring separate infrastructures.
- For more details, check the MotherDuck announcement.
- DeepMind's Chess AI Displays Mastery: Google DeepMind has unveiled a transformative chess player that achieved an ELO of 2895, showcasing its adeptness even in unfamiliar scenarios. This performance counters criticism of LLMs' effectiveness with unseen data.
- The player's ability to predict moves with no prior planning illustrates the potential of AI in strategic environments.
- Drew Houston Reflects on AI's Startup Potential: In a recent podcast, Drew Houston shared insights on rebuilding Dropbox as a pivotal AI tool for data curation, reiterating his belief that AI holds the most significant startup potential. You can listen to the episode here.
- Houston humorously discussed the demands of managing a public company with 2700 employees while navigating the AI landscape.
Perplexity AI Discord
-
Perplexity subscription pricing discrepancies: Users noted Perplexity has varying subscription prices, with mobile costing INR 1950 and web at INR 1680.
- Concerns regarding these discrepancies prompted discussions about potential cancellations.
- Confusion around Spaces feature: There was uncertainty regarding the Spaces feature, particularly its organization compared to the default search page.
- Users appreciated aspects of Spaces but found it less functional on mobile, leading to mixed opinions.
- API performance under scrutiny: Members expressed dissatisfaction with slower API performance, especially for Pro users, affecting search speeds.
- Queries emerged about whether these issues were temporary or linked to recent updates.
- Long COVID research reveals cognitive impacts: Recent findings indicate that Long COVID can cause significant brain injury, impacting cognitive functions.
- Such claims could reshape health strategies for post-COVID recovery, as detailed in a recent study.
- PPLX Playground offers better accuracy: Analysis shows responses from the PPLX Playground generally have greater accuracy compared to the PPLX API.
- Differences in system prompts may largely account for these variations in accuracy.
Modular (Mojo 🔥) Discord
-
Mojo Documentation Needs Examples: Feedback indicated that while the Mojo documentation explains concepts well, it lacks examples for API entries, particularly for Python.
- Concerns were raised about package management and the absence of a native matrix type, highlighting the need for more comprehensive tensor documentation.
- Mojo Aims for Performance Overheads: The team emphasized that Mojo aims to attract performance-sensitive developers, highlighting the need for 'zero overhead abstractions' compared to languages like C++.
- They clarified that Mojo is built to support high-performance libraries like NumPy and TensorFlow.
- Transition to Mojo Faces Skepticism: Members agreed that Mojo isn't ready for serious use and likely won't stabilize for another year or two, causing concerns about transitioning from Python.
- One member noted, 'Mojo isn't there yet and won't be on any timescale that is useful to us.'
- Current State of GPU Support: Development on Max's GPU support is ongoing, with confirmations about Nvidia integration for upcoming updates.
- However, discussions about Apple Metal support yielded no clear answers, leaving its status ambiguous.
- Exploring Language Preferences for AI: Members debated transitioning from Python, noting strengths and weaknesses of alternatives like Swift and Rust, with many favoring Swift due to in-house familiarity.
- However, frustrations were voiced regarding Swift's steep learning curve, with one user stating, 'learning swift is painful.'
aider (Paul Gauthier) Discord
-
Installing Aider Made Easy with pipx: Using
pipxfor installing Aider on Windows allows smooth dependency management and avoids version conflicts between projects. You can find the installation guide here.- This method ensures Aider runs in its own isolated environment, reducing compatibility issues during development.
- O1 Models Raise Feasibility Concerns: Users raised issues regarding the feasibility and costs associated with accessing O1-preview, suggesting manual workflows via ChatGPT for planning. Concerns about configurations and dry-run modes were also highlighted for clarity on prompts processed by O1 models.
- This sparked discussions on balancing efficiency and cost-effectiveness when using advanced models.
- Pair Programming with Aider Outsmarts Bugs: A user shared their custom AI pair programming tool that resolved 90% of bugs effectively using prompt reprompting. They noted that O1-preview shines in one-shot solutions.
- Members also discussed model preferences, with many gravitating towards the Claude-engineer model based on user-specific needs.
- File Commit Confusion in Aider: An incident was reported where Aider erroneously committed to
public/css/homemenu.cssinstead of the correct file path, leading to irreversible errors. This raised transparency issues about Aider's file handling capabilities.
- Community members expressed the need for better safeguards and clearer documentation on file handling.
- Token Limit Troubleshooting Discussions: Participants discussed Aider hitting token limits, particularly with high token counts affecting chat histories. It was suggested to set maximum thresholds to prevent excess token usage.
- This issue emphasizes the importance of confirming large data submissions before triggering processes to enhance user experience.
OpenAI Discord
-
Advanced Voice Mode Frustrates Users: Users expressed dissatisfaction with Advanced Voice Mode, citing vague responses and issues like 'my guidelines prevent me from talking about that', leading to frustration.
- This feedback underscores the need for clearer response protocols to enhance user experience.
- Glif Workflow Tool Explained: Discussion on Glif compared it to Websim, emphasizing its role in connecting AI tools to create workflows.
- Although initially perceived as a 'cold' concept, users quickly grasped its utility as a workflow app.
- ChatGPT for Windows Sparks Excitement: Members showed enthusiasm for the announcement of ChatGPT for Windows, but concerns arose about accessibility for premium users.
- Currently, it is available only for Plus, Team, Enterprise, and Edu users, leading to discussions about feature parity across platforms.
- Seeking Voice AI Engineers: A user called for available Voice AI engineers, highlighting a potential gap in community resources specific to voice technology.
- This reflects an ongoing demand for specialized skills in the development of voice-focused AI applications.
- Image Generation Spelling Accuracy: Members questioned how to achieve accurate spelling in image generation outputs, debating whether it’s a limitation of tech or a guardrail issue.
- This concern illustrates the challenges in ensuring text accuracy within AI-generated visuals.
GPU MODE Discord
-
GPU Work: Math or Engineering?: The debate on whether GPU work is more about mathematics or engineering continues, with members referencing Amdahl's and Gustafson's laws for scaling algorithms on parallel processors.
- It was pointed out that hardware-agnostic scaling laws are crucial for analyzing hardware capabilities.
- Performance Drop in PyTorch 2.5.0: Users noted that tinygemm combined with torch.compile runs slower in PyTorch 2.5.0, dropping token processing speeds from 171 tok/s to 152 tok/s.
- This regression prompted calls to open a GitHub issue for further investigation.
- Sparse-Dense Multiplication Gains: New findings suggest that in PyTorch CUDA, conducting sparse-dense multiplication in parallel by splitting a dense matrix yields better performance than processing it as a whole, particularly for widths >= 65536.
- Torch.cuda.synchronize() is being used to mitigate timing concerns, even as anomalies at large widths raise new questions about standard matrix operation expectations.
- Open Source Models Diverge from Internal Releases: Discussions revealed that current models may rely on open source re-implementations that possibly diverge on architectural details like RMSNorm insertions, raising concerns over their alignment.
- The potential use of a lookup table for inference bit-packed kernels and a discussion on T-MAC were also notable.
- WebAI Summit Networking: A member informed that they are attending the WebAI Summit and expressed interest in connecting with others at the event.
- This offers an opportunity for face-to-face interaction within the community.
LlamaIndex Discord
-
MongoDB Hybrid Search boosts LlamaIndex: MongoDB launched support for hybrid search in LlamaIndex, combining vector search and keyword search for enhanced AI application capabilities, as noted in their announcement.
- For further insights, see their additional post on Twitter.
- Auth0's Secure AI Applications: Auth0 introduced secure methods for developing AI applications, showcasing a full-stack open-source demo app available here.
- Setting up requires accounts with Auth0 Lab, OKTA FGA, and OpenAI, plus Docker for PostgreSQL container initialization.
- Hackathon Recap Celebrates 45 Projects: The recent hackathon attracted over 500 registrations and resulted in 45 projects, with a detailed recap available here.
- Expect guest blog posts from winning teams sharing their projects and experiences.
- Faithfulness Evaluation Replication Takes Too Long: Replicating the Faithfulness evaluation in RAG bots can take 15 minutes to over an hour, as reported by a user.
- Others recommended employing Ollama for faster execution, suggesting that performance is hardware-dependent.
- LlamaParse Fails with Word Documents: A user encountered parsing errors with a Word document using LlamaParse, specifically unexpected image results rather than text.
- Uploading via LlamaCloud UI worked correctly, while using the npm package resulted in a parse error.
OpenAccess AI Collective (axolotl) Discord
-
Bitnet Officially Released!: The community celebrated the release of Bitnet, a powerful inference framework for 1-bit LLMs by Microsoft, delivering performance across multiple hardware platforms.
- It demonstrates capability with 100 billion models at speeds of 6 tokens/sec on an M2 Ultra.
- Flash Attention 2 Integration in Liger: Users tackled integrating Flash Attention 2 with Liger by setting
liger_flash_attention: truein their configs, along withsdp_attention: true.
- Shared insights emphasized the importance of verifying installed dependencies for optimal memory savings.
- Noteworthy VRAM Savings Achieved: Users reported achieving notable VRAM reductions, with one sharing a drop from 22.7 GB to 11.7 GB by configuring Liger correctly.
- The community suggested setting
TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1for AMD users to improve compatibility. - Troubleshooting Liger Installation Problems: Some faced challenges with Liger imports during training, which inflated memory usage beyond expectations.
- Altering the
PYTHONPATHvariable helped several members resolve these issues, urging thorough installation checks. - Guide to Installing Liger Easily: A shared guide detailed straightforward installation steps for Liger via pip, particularly beneficial for CUDA users.
- It also pointed out the need for config adjustments, highlighting the Liger Flash Attention 2 PR crucial for AMD hardware users.
Cohere Discord
-
Join the Stealth Project with Aya: Aya's community invites builders fluent in Arabic and Spanish to a stealth project, offering exclusive swag for participation. Interested contributors should check out the Aya server to get involved.
- This initiative looks to enhance multilingual capabilities and collaborative efforts within the AI space.
- Addressing Disillusionment in AI with Gemini: A member referenced a sentiment of disillusionment regarding discussions with Gemini, shared at this link. More voices are needed to enrich these conversations about the future of AI.
- This highlights the ongoing community discourse around the perception and direction of emerging AI technologies.
- RAG AMAs Not Recorded - Stay Tuned!: Members learned that the RAG AMAs were not recorded, leading to a call for tagging course creators for further inquiries about missed content. The lack of recordings may affect knowledge dissemination within the community.
- This prompts a discussion on how to effectively capture and share valuable insights from these events moving forward.
- Trial Users Can Access All Endpoints: Trial users have confirmed that they can explore all endpoints for free, including datasets and emed-jobs, despite rate limits. This is a significant opportunity for newcomers to test features without restrictions.
- Full access paves the way for deeper engagement and experimentation with available AI tools.
- Fine-Tuning Context Window Examined: A member pointed out that the fine-tuning context window is limited to 510 tokens, much shorter than the 4k for rerank v3 models, raising questions about document chunking strategies. Insights from experts are needed to maximize fine-tuning effectiveness.
- This limitation draws attention to the trade-offs in fine-tuning approaches and their impact on model performance.
tinygrad (George Hotz) Discord
-
Leveraging CoLA for Matrix Speedups: The Compositional Linear Algebra (CoLA) library showcases potential for structure-aware operations, enhancing speed in tasks like eigenvalue calculations and matrix inversions.
- Using decomposed matrices could boost performance, but there's concern over whether this niche approach fits within tinygrad's scope.
- Shifting Tinygrad's Optimization Focus: Members debated whether tinygrad's priority should be on dense matrix optimization instead of 'composed' matrix strategies.
- Agreement formed that algorithms avoiding arbitrary memory access may effectively integrate into tinygrad.
- Troubles with OpenCL Setup on Windows: A CI failure reported an issue with loading OpenCL libraries, calling out
libOpenCL.so.1missing during test initiation.
- The group discussed checking OpenCL setup for CI and implications of removing GPU=1 in recent commits.
- Resources to Master Tinygrad: A member shared a series of tutorials and study notes aimed at helping new users navigate tinygrad's internals effectively.
- Starting with Beautiful MNIST examples caters to varying complexity levels, enriching understanding.
- Jim Keller's Insights on Architectures: Discussion steered towards a Jim Keller chat on CISC / VLIW / RISC architectures, prompting interest in further exploration of his insights.
- Members found potential value in his dialogue with Lex Fridman and the implications for hardware design and efficiency.
Interconnects (Nathan Lambert) Discord
-
Explore Janus: The Open-Source Gem: The Janus project by deepseek-ai is live on GitHub, seeking contributors to enhance its development.
- Its repository outlines its aims, making it a potential asset for text and image processing.
- Seeking Inference Providers for Chat Assistants: A member is on a quest for examples of inference providers that facilitate chat assistant completions, questioning reliability in available options.
- They mentioned Anthropic as an option but expressed doubts about its performance.
- Debate on Special Tokens Utilization: Members discussed accessing special tokens in chat models, specifically the absence of an END_OF_TURN_TOKEN in the assistant's deployment.
- Past insights were shared, with suggestions to consult documentation for guidance.
- Greg Brockman's Anticipated Comeback: Greg Brockman is expected to return to OpenAI soon, with changes reported in the company during his absence, according to this source.
- Members discussed how the landscape has shifted in his absence.
- Instruction Tuning Relies on Data Quality: A member queried the essential number of prompts for instruction tuning an LLM that adjusts tone, emphasizing data quality as vital, with 1k prompts possibly being sufficient.
- This emphasizes the need for rigorous data management in tuning processes.
Stability.ai (Stable Diffusion) Discord
-
Hackathon Sparks Excitement with Big Prizes: The Gen AI Hackathon invites teams to develop AI systems, with over $25k in prizes available. Collaborators include aixplain and Sambanova Systems, focusing on ethical AI solutions that enhance human potential.
- This event aims to stimulate innovation in AI applications while encouraging collaboration among participants.
- Challenges in Creating Custom Checkpoints: A member questioned the feasibility of creating a model checkpoint from scratch, noting it requires millions of annotated images and substantial GPU resources.
- Another user suggested it might be more practical to adapt existing models rather than starting from zero.
- Tough Times for Seamless Image Generation: A user reported difficulties in producing seamless images for tiling with current methods using flux. The community emphasized the need for specialized tools over standard AI models for such tasks.
- This points to a gap in current methodologies for achieving seamless image outputs.
- Limited Image Options Challenge Model Training: The team discussed generating an Iron Man Prime model, suggesting a LoRa model using comic book art as a solution due to limited image availability.
- The lack of sufficient training data for Model 51 poses significant hurdles in image generation.
- Sampling Methods Stir Up Cartoon Style Fun: Members debated their favorite sampling methods, with dpm++2 highlighted for its better stability compared to Euler in image generation.
- They also shared preferences for tools like pony and juggernaut for generating cartoon styles.
LLM Agents (Berkeley MOOC) Discord
-
Quiz 6 is Now Live!: The course staff announced that Quiz 6 is available on their website, find it here. Participants are encouraged to complete it promptly to stay on track.
- Feedback from users indicates excitement around the quiz, suggesting it’s a key part of the learning experience.
- Hurry Up and Sign Up!: New participants confirmed they can still join the MOOC by completing this signup form. This brings greater enthusiasm among potential learners eager to engage.
- The signup process remains active, leading many to express their anticipation for the course content.
- Weekly Livestream Links Incoming: Participants will receive livestream links every Monday via email, with notifications also made on Discord for everyone to join. Concerns raised by users about missed emails were addressed promptly.
- This approach ensures everyone is kept in the loop and can participate in live discussions effectively.
- Feedback on Article Assignments: Members discussed leveraging the community for feedback before submitting written assignments to align with expectations. They emphasized sharing drafts in the dedicated Discord channel for timely advice.
- Community collaboration in refining submissions showcases high engagement, ensuring quality for article assignments.
- Meet the Guest Speakers: The course will feature guest appearances from Denny Zhou, Shunyu Yao, and Chi Wang, who will provide valuable insights. These industry leaders are expected to enhance the learning experience with real-world perspectives.
- Participants are eagerly looking forward to these sessions, which could bridge the gap between theory and application.
LAION Discord
-
Gen AI Hackathon Invites Innovators: CreatorsCorner invites teams to join a hackathon focused on AI-powered multi-agent systems, with over $25k in prizes at stake.
- Teams should keep ethical implications in mind while building secure AI solutions.
- Pixtral flounders against Qwen2: In explicit content captioning tests, Pixtral displayed worse performance with higher eval loss compared to Qwen2 and L3_2.
- The eval training specifically targeted photo content, underscoring Qwen2's effectiveness over Pixtral.
- Future Plans for L3_2 Training: A member plans to revisit L3_2 for use in unsloth, contingent on its performance improvements.
- Buggy results with ms swift prompted a need for more testing before fully committing to L3_2.
- Concerns on Explicit Content Hallucinations: Discussion revealed wild hallucinations in explicit content captioning across various models, a significant concern.
- Participants noted chaos in NSFW VQA outcomes, suggesting challenges regardless of the training methods employed.
DSPy Discord
- Curiosity Sparks on LRM with DSPy: A user inquired about experiences building a Language Representation Model (LRM) with DSPy, considering a standard look if no prior implementations exist. They linked to a blog post on alternatives for more context.
- LLM Applications and Token Management: Developing robust LLM-based applications demands keen oversight of token usage for generation tasks, particularly in summarization and retrieval. The discussion signaled that crafting marketing content can lead to substantial token consumption.
- GPT-4 Prices Hit New Low: The pricing for using GPT-4 has dropped dramatically to $2.5 per million input tokens and $10 per million output tokens. This marks a significant reduction of $7.5 per million input tokens since its March 2023 launch.
- Unpacking ColBERTv2 Training Data: Members expressed confusion about ColBERTv2 training examples, noting the model uses n-way tuples with scores rather than tuples. A GitHub repository was cited for further insights into the training method.
- Interest Grows in PATH Implementation: A member showed enthusiasm for implementing PATH based on a referenced paper, eyeing potential fusion with ColBERT. Despite skepticism about feasibility, others acknowledged the merit in exploring cross-encoder usage with models like DeBERTa and MiniLM.
Torchtune Discord
-
Qwen2.5 Pull Request Hits GitHub: A member shared a Pull Request for Qwen2.5 on the PyTorch Torchtune repository, aiming to address an unspecified feature or bug.
- Details are still needed, including a comprehensive changelog and test plan, to meet project contribution standards.
- Dueling Approaches in Torchtune Training: Members debated running the entire pipeline against generating preference pairs via a reward model followed by PPO (Proximal Policy Optimization) training.
- They noted the simplicity of the full pipeline versus the efficiency benefits of using pre-generated pairs with tools like vLLM.
- Visuals for Preference Pair Iterations: A request for visual representation of iterations from LLM to DPO using generated preference pairs pointed to a need for better clarity in training flows.
- This shows interest in visualizing the complexities inherent in the training process.
- Insights from Anthropic's RLAIF Paper: Discussion included the application of Anthropic's RLAIF paper, with mentions of how TRL utilizes vLLM for implementing its recommendations.
- The precedent set by RLAIF in generating new datasets per training round is particularly notable, blending data from various models.
- Kickoff Trials for Torchtune: A suggestion emerged to experiment with existing SFT (Supervised Fine-Tuning) + DPO recipes in Torchtune, streamlining development.
- This approach aims to utilize DPO methods to bypass the need for reward model training, bolstering efficiency.
OpenInterpreter Discord
-
Automating Document Editing Process: A member proposed automating the document editing process with background code execution, aiming to enhance efficiency in workflow.
- They expressed interest in exploring other in-depth use cases that the community has previously leveraged.
- Aider's Advancements in AI-Generated Code: Another member noted that Aider is increasingly integrating AI-generated and honed code with each update, indicating rapid evolution.
- If models continue to improve, this could lead to a nightly build approach for any interpreter concept.
- Open Interpreter's Future Plans: Discussions revealed curiosity about potential directions for Open Interpreter, particularly regarding AI-driven code integration like Aider.
- Members are eager to understand how Open Interpreter might capitalize on similar incremental improvements in AI model development.
LangChain AI Discord
-
Launch of Capital Companion - Your AI Trading Assistant: Capital Companion is an AI trading assistant leveraging LangChain and LangGraph for sophisticated agent workflows, check it out on capitalcompanion.ai.
- Let me know if anyone's interested in checking it out or chatting about use cases, the member encouraged discussions around the platform's functionalities.
- AI-Powered Investment Dashboard for Stocks: Capital Companion features an AI-powered investment dashboard that aids users in detecting uptrends and enhancing decision-making in stock trading.
- Key features include technical analysis tools and market sentiment analysis, aiming to provide a competitive edge in stock investing.
Alignment Lab AI Discord
-
Fix Twitter/X embeds with rich features: A member urged members to check out a Twitter/X Space on how to enhance Twitter/X embeds, focusing on the integration of multiple images, videos, polls, and translations.
- This discussion aims to improve how content is presented on platforms like Discord and Telegram, making interactions more dynamic.
- Boost engagement with interactive tools: Conversations highlighted the necessity of using interactive tools such as polls and translations to increase user engagement across various platforms.
- Using these features is seen as a way to enhance content richness and attract a wider audience, making discussions more vibrant.
LLM Finetuning (Hamel + Dan) Discord
-
Inquiry for LLM Success Stories: A member sought repositories showcasing successful LLM use cases, including prompts, models, and fine-tuning methods, aiming to consolidate community efforts.
- They proposed starting a repository if existing resources prove inadequate, emphasizing the need for shared knowledge.
- Challenge in Mapping Questions-Answers: The same member raised a specific use case about mapping questions-answers between different sources, looking for relevant examples.
- This opens a collaborative avenue for others with similar experiences to contribute and share their insights.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Nous Research AI ▷ #general (324 messages🔥🔥):
Octopus Password MysteryFine-tuning ModelsLLM Performance EvaluationsStrawberry ProblemAnthropic's Updates
-
Octopus Password Mystery Explored: Users discussed the ongoing puzzle involving a model that appears to hint at 'octopus' or variations as a potential password, with humor interwoven throughout their trials.
- The conversation revealed various strategies attempted to unlock the password, many involving poetry and creative prompts, but without definitive success.
- Fine-tuning Models for Specific Tasks: A user shared their experience training a fine-tuned model based on ASCII art, humorously noting that it could only respond in an undertrained manner.
- There was a consensus that despite the challenges, improvements and further training iterations could yield a more versatile model.
- Performance Evaluations of LLMs: Participants critiqued the effectiveness of certain evaluations, specifically highlighting the strawberry task as inadequate given how LLMs process language.
- Several users speculated that new models would likely be tuned to handle well-known challenges, including the strawberry problem, due to its viral nature.
- Anthropic's Frequent Updates: Users expressed curiosity about Anthropic’s recent frequent updates and blog posts while questioning the absence of a significant new model release like a 3.5 version.
- The discussion hinted at skepticism towards whether the updates were genuinely innovative or just incremental additions to existing functionalities.
- Engagement in Bot Development: A user demonstrated a new pipeline model that generates increasingly complex tasks using a base model, showcasing the fun side of bot interactions.
- Responses indicated a playful engagement with the technology, as users attempted to manipulate and create engaging tasks through various LLM functionalities.
Links mentioned:
- Groq Meta Llama 3.2 3B With Code Interpreter - a Hugging Face Space by diabolic6045: no description found
- Kido Kidodesu GIF - KIDO KIDODESU KIDODESUOSU - Discover & Share GIFs: Click to view the GIF
- Stirring Soup Food52 GIF - Stirring Soup Food52 Vegetable Soup - Discover & Share GIFs: Click to view the GIF
- forcemultiplier/instruct-evolve-xml-3b · Hugging Face: no description found
- Gandalf | Lakera – Test your prompting skills to make Gandalf reveal secret information.: Trick Gandalf into revealing information and experience the limitations of large language models firsthand.
- Octopus Caracatița GIF - Octopus Caracatița - Discover & Share GIFs: Click to view the GIF
- Boo GIF - Boo - Discover & Share GIFs: Click to view the GIF
- Canadian Pacific 2816 - Wikipedia: no description found
- Space Balls Schwartz GIF - Space Balls Schwartz Imitate - Discover & Share GIFs: Click to view the GIF
- NOPE - a Jailbreak puzzle: no description found
- memoize dataset length for eval sample packing by bursteratom · Pull Request #1974 · axolotl-ai-cloud/axolotl: Description Fix for issue#1966, where eval_sample_packing=True caused evaluation being stuck on multi-gpu. Motivation and Context In issue#1966, evaluation on sample packed dataset on multiple GPU...
Nous Research AI ▷ #ask-about-llms (4 messages):
Rust ML LibrariesTransition from Python to Rusttorch-rsburn and ochre
-
Python to Rust Transition in ML: One user suggested that the focus is currently on Python, but expects a shift to Rust in the future for machine learning.
- They mentioned studying Rust ML libraries, indicating a growing interest in this area.
- Inquiry on Rust ML Libraries: Another member asked for recommendations on top Rust ML libraries, particularly if Candle is prominent.
- The enthusiasm for Rust is clear, showing a keen interest in expanding knowledge in this programming language.
- Exploration of torch-rs: A member inquired if anyone had looked into torch-rs, a Rust library for machine learning.
- This highlights a specific interest in integrating Rust with well-known ML frameworks.
- Notable Rust ML Libraries Shared: User mentioned being familiar with torch-rs, along with burn and ochre as libraries to explore.
- This indicates active engagement with various Rust machine learning tools and frameworks.
Nous Research AI ▷ #research-papers (1 messages):
chiralcarbon: https://arxiv.org/abs/2410.13848
Nous Research AI ▷ #interesting-links (3 messages):
SCP generatorLLM Culture repository
-
SCP Generator Using Outlines Released: A new SCP generator utilizing outlines has been made available on GitHub, contributing to the development of the 'cursed' project.
- The project aims to enhance the generation of SCP texts, showcasing creative potential in the genre.
- Study LLMs with Different Personalities: A repo dedicated to studying the texts generated by various populations of LLMs has been shared, focusing on different personalities, tasks, and network structures: LLM-Culture.
- This resource is linked to the paper on Cultural evolution in populations of Large Language Models, providing valuable insights for researchers.
Links mentioned:
- cursed/scp at main · dottxt-ai/cursed: Contribute to dottxt-ai/cursed development by creating an account on GitHub.
- GitHub - flowersteam/LLM-Culture: Code for the "Cultural evolution in populations of Large Language Models" paper: Code for the "Cultural evolution in populations of Large Language Models" paper - flowersteam/LLM-Culture
Nous Research AI ▷ #research-papers (1 messages):
chiralcarbon: https://arxiv.org/abs/2410.13848
HuggingFace ▷ #general (214 messages🔥🔥):
Using AI in CodingLearning PythonFactorio Game DiscussionKaggle Competition InsightsPlandexAI Discussion
-
AI and Coding Effectiveness: Members discussed the limitations of AI in coding, highlighting that AIs often struggle to see the bigger picture beyond simple tasks, making them less effective for complex projects.
- One member noted that while AIs can fix small issues like JSON errors, they may mislead beginners who don't know how to code effectively.
- Value of Learning Python: It was suggested that learning Python is worthwhile for AI hobbyists and that free online resources can be as effective as paid courses.
- Participants emphasized that AI-generated code is often not reliable for beginners, reinforcing the need for foundational coding skills.
- Factorio New DLC Discussion: A discussion emerged around the pricing of Factorio's new DLC, with mixed opinions on whether $70 is justified.
- Some members shared strategies for sharing the game with friends to distribute costs.
- Kaggle Competition Clarifications: One member expressed confusion about a Kaggle competition's submission requirements, debating what exactly was needed for submission.
- It was clarified that they are expected to submit results based solely on the provided test set.
- PlandexAI and AI Development Tools: A conversation revolved around PlandexAI and how breaking down coding tasks into simpler components could improve AI coding outcomes.
- Members discussed the importance of structured AI tools to enhance the programming process rather than using AI purely for direct code generation.
Links mentioned:
- Emu3 - a Hugging Face Space by BAAI: no description found
- SBI-RAG: Enhancing Math Word Problem Solving for Students through Schema-Based Instruction and Retrieval-Augmented Generation: Many students struggle with math word problems (MWPs), often finding it difficult to identify key information and select the appropriate mathematical operations.Schema-based instruction (SBI) is an ev...
- Reddit - Dive into anything: no description found
- StackLLaMA: A hands-on guide to train LLaMA with RLHF: no description found
- GitHub - not-lain/pxia: AI library for pxia: AI library for pxia. Contribute to not-lain/pxia development by creating an account on GitHub.
- Duvet: Provided to YouTube by NettwerkDuvet · bôaTwilight℗ Boa Recording Limited under exclusive license to Nettwerk Music Group Inc.Released on: 2010-04-20Producer...
- GitHub - florestefano1975/comfyui-portrait-master: This node was designed to help AI image creators to generate prompts for human portraits.: This node was designed to help AI image creators to generate prompts for human portraits. - florestefano1975/comfyui-portrait-master
- not-lain (Lain): no description found
- starsnatched/thinker · Datasets at Hugging Face: no description found
HuggingFace ▷ #today-im-learning (3 messages):
LLM EvaluationFinetuning Flux ModelsBitNet Framework
-
Evaluating LLMs with Popular Eval Sets: A user expressed difficulty in evaluating their LLM on popular eval sets and seeks guidance on how to obtain numerical results.
- They mentioned that their model performs better in conversation compared to the base model, as noted on their Hugging Face page.
- Learning to Finetune Flux Models: A user is eager to learn how to finetune Flux models and is in search of recommended resources.
- This inquiry suggests a growing interest in the practical aspects of model improvement and training techniques.
- Exploring BitNet Framework: A user shared an interest in BitNet and provided a link to GitHub for the official inference framework for 1-bit LLMs.
- The shared link encourages further exploration of the features and contributions related to this framework in the community.
Links mentioned:
- ElMater06/Llama-3.2-1B-Puredove-p · Hugging Face: no description found
- GitHub - microsoft/BitNet: Official inference framework for 1-bit LLMs: Official inference framework for 1-bit LLMs. Contribute to microsoft/BitNet development by creating an account on GitHub.
HuggingFace ▷ #cool-finds (1 messages):
Perplexity for FinanceStock Research Tools
-
Perplexity Transforms Financial Research: Perplexity now offers a feature for finance enthusiasts that includes real-time stock quotes, historical earning reports, and industry peer comparisons, all presented with a delightful UI.
- Members are encouraged to have fun researching the market using this new tool.
- Market Analysis Made Easy: The new finance feature allows users to perform detailed analysis of company financials effortlessly, enhancing the stock research experience.
- This tool promises to be a game changer for those interested in keeping up with financial trends.
Link mentioned: Tweet from Perplexity (@perplexity_ai): Perplexity for Finance: Real-time stock quotes. Historical earning reports. Industry peer comparisons. Detailed analysis of company financials. All with delightful UI. Have fun researching the marke...
HuggingFace ▷ #i-made-this (5 messages):
AI Content Detection Web AppStyle Transfer FunctionBehavioral Economics in Decision-MakingFine-tuning and Model MergingCognitive Biases in Financial Crises
-
New AI Content Detection Web App launched: A member introduced a new project, an AI Content Detection Web App, that identifies whether images or text are generated by AI or humans.
- They invited feedback on their project, stating that improvements are welcome as they are new to this kind of tool.
- Testing Stylish Functions in New UI: A member announced that they are testing a style transfer function in a new user interface, marking the beginning of its development.
- This implies ongoing enhancements in user experience and functionality for the audience.
- Behavioral Economics and Decision-Making Insights: A complex query on behavioral economics explored how cognitive biases influence decision-making in high-stress environments, particularly during financial crises.
- Key points discussed included loss aversion and its effects on expected utility models, indicating a significant alteration in rational behavior.
- Examining Fine-Tuning and Model Merging: A member shared a paper titled Tracking Universal Features Through Fine-Tuning and Model Merging, investigating how features persist through model adaptations.
- The study focuses on a base Transformer model fine-tuned on various domains and examines the evolution of features across different language applications.
- Discussion on Mimicking Models: Feedback was given regarding the limitations of mimicking large language models, emphasizing that many lack the comprehensive datasets like those used by larger models.
- The conversation highlighted the challenges and similarities in their approaches to model adaptation and feature extraction.
Links mentioned:
- Paper page - Tracking Universal Features Through Fine-Tuning and Model Merging: no description found
- GitHub - rbourgeat/airay: A simple AI detector (Image & Text): A simple AI detector (Image & Text). Contribute to rbourgeat/airay development by creating an account on GitHub.
- starsnatched/thinker · Datasets at Hugging Face: no description found
- starsnatched/ThinkerGemma · Hugging Face: no description found
HuggingFace ▷ #reading-group (11 messages🔥):
HuggingFace Reading GroupIntel Patent for Code Generation LLMDiscord Stage ChannelsAI Resources for Beginners
-
Overview of HuggingFace Reading Group: The HuggingFace server facilitates a reading group where anyone can present on AI-related papers, as noted in the GitHub link.
- This platform is mainly intended to support HF developers, fostering collaboration and knowledge sharing.
- Discussion on Intel Patent for Code Generation LLM: A member inquired about the Intel patent US20240111498A1 concerning code generation using LLMs, sharing a link to the patent.
- The patent details various apparatuses and methods that utilize LLM technology for generating code, emphasizing its potential applications.
- Understanding Discord Stage Channels: A newcomer to Discord sought clarification on what stages are, comparing them to Zoom meetings.
- Members explained that stage channels are designed for one-directional presentations, preventing disruptions during discussions.
- Seeking AI Resources for Beginners: A member requested recommendations for an information hub suitable for beginners to gain structured insights on AI and its use cases.
- This reflects the growing interest among new learners on how to navigate AI fundamentals and practical applications.
Link mentioned: US20240111498A1 - Apparatus, Device, Method and Computer Program for Generating Code using an LLM
- Google Patents: no description found
HuggingFace ▷ #computer-vision (2 messages):
Out of context object detectionImportance of context in image analysisTraining models for detectionCreating 'others' class
-
Understanding Out of Context Objects: The detection of out of context objects in images varies based on the setting, such as recognizing that cars and moving objects are relevant on roadways while static elements like trees are not.
- A member suggested that the definition of 'out of context' should guide detection strategies, emphasizing the need to tailor methods to specific environments.
- Training Models Necessitates Relevant Classes: For effective object detection, it's crucial to train the model on relevant classes; the user proposed creating an 'others' class to encompass out of context items.
- They indicated that insights on problem settings could help refine the training process if shared among members.
HuggingFace ▷ #NLP (6 messages):
Setfit Model LoggingArgilla Version Issues
-
Troubleshooting Setfit Model Logging to MLflow: A user expressed difficulty in logging a Setfit model to MLflow and sought specific examples related to this process.
- Another member offered assistance but needed clarification on the Argilla version being used for compatibility.
- Argilla Version Confusion: A user confirmed they might be using the legacy Argilla 1.x code instead of the newer 2.x version after a suggestion to check their version.
- Instructions were provided to navigate to the Argilla documentation for using the updated features seamlessly.
Link mentioned: Argilla: Argilla is a collaboration tool for AI engineers and domain experts to build high-quality datasets.
HuggingFace ▷ #diffusion-discussions (27 messages🔥):
Kwai Kolors in Google ColabControlNet training considerationsRenting VMs for diffusion modelsInstance types and pricing on AWS EC2
-
Kwai Kolors struggles in Google Colab: A user reported errors while trying to run Kwai Kolors in Google Colab, indicating it requires around 19GB of VRAM, which isn't supported in the free version.
- Another user suggested using the original repository instead of diffusers for better compatibility.
- ControlNet training requires text embeddings: For training a custom ControlNet to alter faces, a user was informed that replacing the CLIP text encoder with the image encoder would not work due to training dependencies on text embeddings.
- The discussion emphasized potential overfitting with repeated faces in the dataset, regardless of embeddings used.
- Recommendations for renting VMs: Users discussed renting VMs for running diffusion models, highlighting that Amazon EC2 is commonly used, but options like FAL and Replicate are also viable.
- A user sought recommendations for EC2 instance types and was advised that instance choice varies based on VRAM and application specifics.
- Pricing mechanism for VM instances: For AWS EC2, users clarified that pricing is charged per hour for the instance being on, regardless of whether it's actively in use.
- The conversation pointed out that using notebook instances does not impact the hourly charge; it is solely based on the instance uptime.
Link mentioned: yisol/IDM-VTON · Hugging Face: no description found
Eleuther ▷ #general (5 messages):
Open Source AI DefinitionContributions to RWKVOpen Source AI projects
-
Open Source AI Definition nearly finalized: The Open Source AI Definition is close to completion, and a release candidate has been shared for public review and endorsement at this link. Members are encouraged to endorse the definition for broader recognition starting with version 1.0.
- Additional resources include FAQs here and a list of endorsements that can be found here.
- Seeking contributions for RWKV project: A new member, sharing their background from a startup focused on AI inference, expressed interest in contributing to open source projects, especially those related to RWKV. They were encouraged to assist with experiments for a paper on RWKV version 7 as discussed in this channel.
- The community welcomes such contributions, especially regarding novel architecture and efficient inference methodologies.
- Concerns about Open Source AI Definition's data requirements: A member raised a concern about the light data requirements implied within the Open Source AI Definition. This comment indicates potential gaps in the initial draft that may need addressing for proper OS AI standards.
Link mentioned: The Open Source AI Definition – 1.0-RC1: Endorse the Open Source AI Definition: have your organization appended to the press release announcing version 1.0 version 1.0-RC1 Preamble Why we need Open Source Artificial Intelligence (AI) Open So...
Eleuther ▷ #research (168 messages🔥🔥):
SAE Steering ChallengesNoise Distribution in TrainingFuture-Correlation in Machine LearningInterpreting SAE vs Transformer ModelsImproving Computational Efficiency
-
SAE Steering Challenges and Limitations: Discussions highlighted that using Sparse Autoencoders (SAEs) for interpretability can lead to misleading conclusions, as features may not cleanly separate relevant concepts.
- The complexity of higher-level hierarchical relationships complicates feature interpretation, necessitating massive datasets for accurate model explanations.
- Investigating Noise Distributions for RF Training: Members engaged in a conversation about the appropriateness of using normal distributions for 'noise' in random forests, suggesting alternatives based on careful parameterization of distributions.
- There's a consensus that while Gaussian noise is common, other forms like Perlin noise or pyramid noise could provide better results in different applications, particularly in image processing.
- Challenges with Future-Correlation in ML: It was noted that capturing future correlations in models is challenging, with the need for time-bounded perspectives being crucial for practical implementations.
- Researchers discussed the necessity of establishing a robust way to measure future-correlation despite the difficulties and the vast data requirements involved.
- Interpretability in SAEs Compared to Transformers: Concerns were raised about the implicit assumption that SAEs can accurately represent and interpret LLM behavior, with a lack of substantive evidence for this approach.
- Critics noted the potential to reduce SAE feature efficacy to an arbitrary neuron basis, calling into question their real interpretability compared to traditional neurons.
- Pushing Computational Efficiency Boundaries: Recent advancements in training speed records for models were celebrated, possibly utilizing updates that enhance efficiency and reduce computing time.
- Members discussed the trade-off between using cutting-edge nightly builds of frameworks versus maintaining stability to avoid bugs in deployment.
Links mentioned:
- Addition is All You Need for Energy-efficient Language Models: Large neural networks spend most computation on floating point tensor multiplications. In this work, we find that a floating point multiplier can be approximated by one integer adder with high precisi...
- Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think : Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
- Merge to Learn: Efficiently Adding Skills to Language Models with Model Merging: Adapting general-purpose language models to new skills is currently an expensive process that must be repeated as new instruction datasets targeting new skills are created, or can cause the models to ...
- Mimetic Initialization Helps State Space Models Learn to Recall: Recent work has shown that state space models such as Mamba are significantly worse than Transformers on recall-based tasks due to the fact that their state size is constant with respect to their inpu...
- Evaluating Open-Source Sparse Autoencoders on Disentangling Factual Knowledge in GPT-2 Small: A popular new method in mechanistic interpretability is to train high-dimensional sparse autoencoders (SAEs) on neuron activations and use SAE features as the atomic units of analysis. However, the bo...
- SHARED Continuous Finetuning By Rombodawg: Continuous Fine-tuning Without Loss Using Lora and Mergekit In this write up we are going to be discussing how to perform continued Fine-tuning of open source AI models using Lora adapter and mergek...
- Tweet from Keller Jordan (@kellerjordan0): New NanoGPT training speed record: 12.03 minutes Previous record: 13.05 minutes Changelog: Updated PyTorch to version 2.5
- gist:3e5cf8ee6701d9ae33e7d30e5406623a: GitHub Gist: instantly share code, notes, and snippets.
Eleuther ▷ #lm-thunderdome (2 messages):
Huggingface Adapter IssuesSummarization Task Errors
-
Huggingface Adapter encounters verbose warnings: A member reported receiving verbose warnings when passing a pretrained model loaded from a local directory into the Huggingface adapter.
- The warning states: 'Repo id must be a string, not
' , suggesting a potential issue with compatibility. - Empty responses in summarization tasks: Another member expressed frustration about returning empty lists for tasks related to summarizing or translating, receiving the message: 'resps=[], filtered_resps={}'.
- They indicated plans to experiment further in an attempt to resolve this issue.
- The warning states: 'Repo id must be a string, not
Link mentioned: lm-evaluation-harness/lm_eval/models/huggingface.py at 624017b7f4501638b0d5848d0f0eab2914a7fb2c · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
OpenRouter (Alex Atallah) ▷ #general (167 messages🔥🔥):
Nemotron 70B performanceOpenRouter data policiesGPT-4o model responsesPrivacy policy linkingKuzco as a provider
-
Nemotron 70B and Llama Comparison: Discussion emerged comparing the Nemotron 70B and Llama 70B models, with varying opinions on performance and capabilities. A notable point mentioned was that Nvidia did not market Nemotron as a knowledge improvement model but focused on its helpfulness.
- Users speculated about the upcoming 405B model and discussed the cost-effectiveness of various models.
- Clarifying OpenRouter Data Policies: Questions arose regarding data policies for providers on OpenRouter, including the security practices and legal guarantees around user data. It was noted that turning off model training settings ensures requests are not used for training as confirmed by privacy policies.
- Concerns were raised about the lack of links to privacy policies for some providers, which were subsequently addressed.
- Inconsistencies with GPT-4o Model Responses: Users reported that when inquiring about the model used in chat sessions, GPT-4o-mini and GPT-4o returned inaccurate references to GPT-3 and GPT-3.5, respectively. This discrepancy was normal as models often lack awareness of their branding and versioning.
- It's common for models to provide inaccurate self-references unless specifically prompted about their architecture.
- Updating Privacy Policies for Providers: Various users pointed out missing links to privacy policies for providers like Mistral and Together, which were later acknowledged. The importance of linking privacy policies for transparency about data usage was emphasized.
- It was confirmed that providers are required to have a data-related agreement linked to their ToS for user confidence.
- Kuzco Considered as a New Provider: A discussion stemmed around the potential addition of Kuzco as a provider for Llama due to their attractive pricing model. Early conversations were ongoing but prioritization had yet to be finalized.
- Participants expressed interest in the new provider while remaining informed on their offerings.
Links mentioned:
- Berkeley Function Calling Leaderboard V3 (aka Berkeley Tool Calling Leaderboard V3) : no description found
- Parameters API | OpenRouter: API for managing request parameters
- Kuzco | LLM Inference Network: no description found
- Tweet from OpenAI Developers (@OpenAIDevs): 🔊 The Chat Completions API supports audio now. Pass text or audio inputs, then receive responses in text, audio, or both. https://platform.openai.com/docs/guides/audio
- deepseek-ai/Janus-1.3B · Hugging Face: no description found
- OpenRouter: LLM router and marketplace
- Models | OpenRouter: Browse models on OpenRouter
- Limits | OpenRouter: Set limits on model usage
- Reddit - Dive into anything: no description found
- Models | OpenRouter: Browse models on OpenRouter
- Llama 3.1 Nemotron 70B Instruct - API, Providers, Stats: NVIDIA's Llama 3.1 Nemotron 70B is a language model designed for generating precise and useful responses. Run Llama 3.1 Nemotron 70B Instruct with API
LM Studio ▷ #general (126 messages🔥🔥):
LM Studio Auto Scroll IssuesROCM Compatibility with AMD GPUsPerformance of Different Language ModelsAgent Zero AI FrameworkCache Memory Management in MLX-LM
-
LM Studio Auto Scroll Issues Resolved: Users discussed recent issues with LM Studio no longer auto scrolling text, with reports indicating it works now for some users.
- It was highlighted that the problem seemed intermittent, raising questions about version stability.
- ROCM Compatibility with AMD GPUs: A member inquired about using a Radeon 6700 XT with LM Studio, experiencing a shift to CPU usage despite previous GPU utilization.
- Others suggested checking the LM Runtimes settings, encouraging users to verify if the correct runtime is selected.
- Performance of Different Language Models: Discussions highlighted the varying performances of language models like Nemotron and Codestral, with user experiences indicating mixed results.
- Participants shared preferences for 70B parameter models that significantly improved their workflows, while smaller models were seen as less reliable.
- Introduction to Agent Zero AI Framework: A new framework, Agent Zero, was introduced, allowing AI models to operate within an open environment with auto memory capabilities.
- Users were excited about its potential for improved learning and interaction capabilities when powered by models like Qwen 2.5.
- Memory Management Concerns in MLX-LM: A GitHub pull request addressed memory usage issues caused by MLX-LM due to failing to clear cache during prompt processing.
- Participants were keen on updates regarding the team's review of the proposed adjustments to rectify such inefficiencies in the system.
Links mentioned:
- LM Studio on Ryzen AI: Run Llama, Mistral, Mixtral, and other local LLMs on your PC, leveraging the awesome performance of RyzenAI hardware.
- How to run a Large Language Model (LLM) on your AMD Ryzen™ AI PC or Radeon Graphics Card: Did you know that you can run your very own instance of a GPT based LLM-powered AI chatbot on your Ryzen™ AI PC or Radeon™ 7000 series graphics card? AI assistants are quickly becoming essential resou...
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- GitHub - frdel/agent-zero: Agent Zero AI framework: Agent Zero AI framework. Contribute to frdel/agent-zero development by creating an account on GitHub.
- bartowski/Llama-3.1-Nemotron-70B-Instruct-HF-GGUF at main: no description found
- intfloat/multilingual-e5-large · Hugging Face: no description found
- Clear cache during prompt processing by awni · Pull Request #1027 · ml-explore/mlx-examples: Closes #1025, see that for discussion / improvement.
LM Studio ▷ #hardware-discussion (11 messages🔥):
ROCM support on 580sXeon CPU thread adjustmentsPerformance of modified 580sUtilization monitoring in Linux
-
ROCM not compatible with 580s: A member inquired if ROCM works on modded 16GB 580s, finding them available for about $90 on AliExpress, but responses clarified it does not work.
- One member mentioned that 580s excelled in OpenCL but noted that llama.cpp deprecated that support, further complicating their use.
- XEON thread adjustment issue in v0.3.4: A user reported a decrease in adjustable CPU threads from 0-12 in v0.2.31 to 0-6 in v0.3.4, expressing a preference for 8 threads.
- They confirmed they were using Linux and specifically referenced the Settings > All sidebar for CPU Thread adjustments.
- Performance monitoring with atop: The same user noted that, while monitoring with atop, they were only seeing high utilization of 6 threads in v0.3.4, compared to 8 threads in v0.2.31.
- This inconsistency in thread utilization sparked concerns about performance changes with the new version.
Latent Space ▷ #ai-general-chat (56 messages🔥🔥):
Claude App UpdateInference Providers for LLM CompletionsMotherDuck SQL Function for LLMsVoyage AI and EmbeddingsDeepMind Grandmaster Chess Player
-
Claude App Launches Updates: Claude has rolled out a significant design overhaul for its mobile app, enhancing user experience and introducing a new iPad app that allows users to create projects, add instructions, and chat within projects.
- Users reported that the updated app feels much smoother to navigate, making it more user-friendly.
- Inquiry on Inference Providers for Chat Completions: A member expressed interest in finding inference providers that could offer chat assistant completions using popular open-weight models, particularly focusing on special tokens for user interactions.
- Responses included suggestions for services like OpenRouter and discussions around their reliability and functionality.
- New SQL Function with MotherDuck: MotherDuck announced the introduction of a new SQL function that integrates large language models, enabling users to leverage LLMs directly in SQL for generating and summarizing data.
- The function simplifies interaction with LLMs and SLMs without needing separate infrastructure, aiming to make advanced AI techniques more accessible.
- Exploration of Voyage AI and Embeddings: Voyage AI was highlighted for its focus on embedding models, with users discussing how embeddings could benefit fields like technical writing despite small input limits.
- The conversation explored other embedding options like Jina AI and the potential applications of fine-tuning embeddings for specific tasks.
- DeepMind's Chess AI Achieves Impressive ELO: Google DeepMind has developed a grandmaster-level transformer chess player that attained an impressive ELO of 2895, demonstrating a strong ability to predict moves even in unfamiliar puzzles.
- This achievement counters claims that LLMs are ineffective with unseen data, showcasing their potential in strategy-based games.
Links mentioned:
- Tweet from Alex Albert (@alexalbert__): We just published our second Anthropic Quickstart - a financial data analyst powered by Claude. Upload spreadsheets, documents, or financial charts and instantly get actionable insights with beautifu...
- Tweet from Perplexity (@perplexity_ai): Introducing Internal Knowledge Search (our most-requested Enterprise feature)! For the first time, you can search through both your organization's files and the web simultaneously, with one produ...
- Voyage AI | Home: Voyage AI provides cutting-edge embedding models and rerankers for search and retrieval
- Tweet from Brad Costanzo (@BradCostanzo): Wow! @HeyGen_Official just released today ability to have an AI avatar join a Zoom meeting and interact. I invited one of their AI avatars into a Zoom room and recorded this clip. Time to build my...
- Introducing the prompt() Function: Use the Power of LLMs with SQL!: We make your database smarter with small language model (and LLM) support in SQL | Reading time: 6 min read
- Tweet from DeepSeek (@deepseek_ai): 🚀 Introducing Janus: a revolutionary autoregressive framework for multimodal AI! By decoupling visual encoding & unifying them with a single transformer, it outperforms previous models in both unde...
- Tweet from Alex Albert (@alexalbert__): We just rolled out a major design overhaul of the Claude mobile app. It feels super smooth to use now. You can create projects, add custom instructions, and chat within your projects all within the a...
- Eval-driven development: Build better AI faster - Vercel: Learn how eval-driven development helps you build better AI faster. Discover a new testing paradigm for AI-native development and unlock continuous improvement.
- Tweet from ℏεsam (@Hesamation): Google Deepmind trained a grandmaster-level transformer chess player that achieves 2895 ELO, even on chess puzzles it has never seen before, with zero planning, by only predicting the next best move,...
- Requests | OpenRouter: Handle incoming and outgoing requests
- Tweet from Jacob Matson (@matsonj): Are you kidding me? Look at this: Quoting MotherDuck (@motherduck) We put a LLM in SQL and also show you the power of SLMs (small language models) in the MotherDuck data warehouse. https://mothe...
- Tweet from Marc Benioff (@Benioff): When you look at how Copilot has been delivered to customers, it’s disappointing. It just doesn’t work, and it doesn’t deliver any level of accuracy. Gartner says it’s spilling data everywhere, and cu...
- Tweet from clem 🤗 (@ClementDelangue): 👀👀👀
- #ProjectTurntable | Adobe MAX Sneaks 2024 | Adobe: Project Turntable technology allows you to see your 2D vector drawings in a whole new way! This feature allows you to rotate your drawings in 3D while still ...
- anthropic-quickstarts/financial-data-analyst at main · anthropics/anthropic-quickstarts: A collection of projects designed to help developers quickly get started with building deployable applications using the Anthropic API - anthropics/anthropic-quickstarts
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Latent Space ▷ #ai-announcements (6 messages):
Drew Houston's podcastAI and Dropbox featuresCoding with LLMsCompany size commentary
-
Drew Houston discusses AI opportunities: In the latest podcast episode, Drew Houston reflects on his past prediction that AI was the biggest opportunity in startups and shares how he's rebuilding Dropbox to be a curation layer for your 'silicon brain'. Link to the episode: Podcast.
- This was a ton of fun to record in their karaoke room (!!!)
- Insights from the Latent Space chat: The chat covers topics like spending 400 hours/year coding with LLMs, entering the 'Rent, not buy' phase of AI, and Dropbox's pivot towards AI with Dropbox Dash.
- Houston emphasizes the need to combat the 'Copy, Bundle, Kill' strategy of incumbents in the industry.
- Light-hearted commentary on company size: In a humorous exchange, a member remarked, 'only 400 h a year??' referring to the coding hours mentioned by Houston.
- Houston's response highlighted that managing a 2700 employees public company takes a different time commitment, as he humorously suggests.
- Playful banter about LLM companies: Another member joked about running a '2700 LLM company' while commenting on the LLM coding hours.
- The conversation remained light-hearted, with one member clarifying they were joking about their comments.
Link mentioned: Tweet from Alessio Fanelli (@FanaHOVA): 7 years ago @drewhouston told @sama the biggest opportunity in startups was AI. Now, he is rebuilding Dropbox to be the curation layer for your "silicon brain" 🧠 Our @latentspacepod chat co...
Latent Space ▷ #ai-in-action-club (67 messages🔥🔥):
Code Diffusion and ASTsRecording AvailabilityCompiler Courses InterestCode Transformation Techniques
-
Excitement for Code Diffusion: Members expressed enthusiasm about Code Diffusion that operates on abstract syntax trees (ASTs), indicating interest in applying it in various coding tasks.
- One member shared, 'Given I'm hoping to rewrite some Java code into Ruby for a project, this seems very interesting.'
- Recording of the Meeting: A member asked if the session was being recorded, with confirmation that it is being uploaded afterward.
- The upcoming content includes amusing insights about doing 'stupid AI stuff'.
- Interest in Compiler Courses: Discussions highlighted a collective interest in compiler courses, with one member noting the brutal nature of the subject.
- Another encouraged engaging with the book on implementing interpreters, which aims to make the topic accessible and engaging.
- Efficiency in Code Transformations: Members discussed the efficiency of using LLMs for generating code transformations, suggesting that for refactoring tasks, a Code the Transform (CTT) approach is advantageous.
- One remarked, 'If you're applying a transform across a large number of files, it's likely more efficient to use the LLM to generate a transformer.'
Links mentioned:
- no title found: no description found
- Introduction · Crafting Interpreters: no description found
- Don't Transform the Code, Code the Transforms: Towards Precise Code Rewriting using LLMs: Tools for rewriting, refactoring and optimizing code should be fast and correct. Large language models (LLMs), by their nature, possess neither of these qualities. Yet, there remains tremendous opport...
- yikes, aw jeez, a youtube thingy: just go read my Twitter I do stupid ai stuff, @yikesawjeez also join the discord I don't have it in my clipboard now but you'll find it i will teach u to do stupid AI stuff to & then we wi...
Perplexity AI ▷ #general (96 messages🔥🔥):
Perplexity subscription issuesDiscussion on Spaces functionalityAPI performance concernsEnterprise use casesUser experiences with Perplexity
-
Perplexity subscription pricing discrepancies: Several users highlighted a pricing difference for mobile and web subscriptions, mentioning charges of INR 1950 and INR 1680 respectively.
- This issue led some users to consider unsubscribing from Perplexity due to the additional costs.
- Questions surrounding Spaces feature: Users expressed confusion about the 'Spaces' feature, particularly its lack of focus options compared to the default search page.
- While some users appreciated its organization, they found it less functional, especially when using the mobile Progressive Web App.
- Concerns regarding API and search speed: Members reported slower API performance and search speeds, particularly for those subscribed to the Pro version.
- Questions were raised about whether this was a persistent issue or tied to the new features and updates.
- Enterprise use and best practices: A few users inquired about the enterprise use of Perplexity and shared links for enterprise-related FAQs and case studies.
- They were looking for best practices and comparisons between the Pro and Enterprise versions, particularly regarding API access.
- User experiences with value and offerings: Users shared their preferences between Perplexity and ChatGPT, noting the advantages of each regarding real-time information and detailed responses.
- Discussions also included promotions like the Xfinity rewards, where users could leverage offers for Perplexity to get friends on board.
Links mentioned:
- Tweet from Aravind Srinivas (@AravSrinivas): The Answer Truck drove more than 1000 miles using FSD from California to Texas. And it's stopping by in Austin tomorrow for a Perplexity user meet-up. La Volta Pizza, Downtown Austin, 1 pm (Austin...
- Silicon Valley No Revenue | Radio On Internet: Pied Piper team meeting with the money guy offering advice
- GitHub - pnd280/complexity: ⚡ Supercharge your Perplexity.ai: ⚡ Supercharge your Perplexity.ai. Contribute to pnd280/complexity development by creating an account on GitHub.
Perplexity AI ▷ #sharing (9 messages🔥):
Starlink Gigabit Speed PlanSeutaringkeu InsightsPhotoshop FunctionalityLong COVID ResearchUnderstanding APIs
-
Starlink Gigabit Speed Plan Launch: Check out the details on the new Starlink Gigabit Speed Plan set to enhance internet connectivity.
- This plan aims to significantly improve speeds for users in remote areas.
- Exploring Seutaringkeu: An insightful document on Seutaringkeu discusses its impact and relevance in current technologies.
- It highlights key features that make it a noteworthy topic in AI discussions.
- Photoshop Functionality Queries: A discussion around the functionality of Photoshop raised questions about specific features.
- Users shared varying opinions on its efficiency in creative projects.
- Long COVID Research Insights: New findings suggest that Long COVID is a Brain Injury, highlighting severe effects on cognitive functions.
- This research could shift perspectives on post-COVID recovery strategies among health professionals.
- Understanding APIs: A newly shared resource on APIs aimed at clarifying their purpose and functionality.
- This could benefit developers looking to integrate APIs into their applications.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (2 messages):
PPLX Playground AccuracyPPLX API Response DifferencesSystem Prompt Variations
-
PPLX Playground more accurate than API: A member questioned why responses in the PPLX Playground appear more accurate compared to those from the PPLX API.
- System prompt differences are implied as a potential reason for the variability in accuracy.
- Discussion on System Prompt Impacts: Another member highlighted that the difference in accuracy between the two platforms might stem from diverse system prompts.
- This suggests that variations in prompts can significantly influence the responses generated by the AI.
Modular (Mojo 🔥) ▷ #general (27 messages🔥):
Mojo Documentation FeedbackMojo's Performance FocusBuilding a Pythonic InterfaceTensor Implementation in MojoCommunity Engagement and Future Plans
-
Feedback on Mojo Documentation Received: A user provided feedback indicating that while the Mojo documentation covers new concepts well, it lacks examples for API entries like Python, which would be beneficial.
- Concerns about package management and the absence of a native matrix type were raised, emphasizing the need for comprehensive documentation for tensors.
- Mojo Aimed at Performance Improvement: The development team clarified that Mojo focuses on performance to attract users who typically write performance-sensitive libraries like NumPy and TensorFlow.
- The importance of maintaining 'zero overhead abstractions' in Mojo was discussed, emphasizing the need to over-perform conventional languages like C++.
- Aiming for a Pythonic Experience: Developers acknowledged the goal to create a comfortable experience for Python users, ensuring syntax remains familiar while encouraging foundation development.
- It's important to establish foundational libraries in Mojo before trying to pull in the broader Python community.
- Discussion on Tensor Implementation in Mojo: Concerns were raised about the absence of a straightforward ndarray equivalent in Mojo, with discussions about the expected complexity of implementing one.
- Mojo's relationship with Python was compared to TypeScript's, with plans to propose valuable features for Python once they are properly tested in Mojo.
- Call for Community Engagement and Feedback: The team encouraged users to provide feedback on APIs that may cause confusion to enhance usability, as many developers often avoid reading documentation.
- The importance of community discussion in shaping the future direction and documentation of the language was highlighted.
Links mentioned:
- Mojo 🔥: Programming language for all of AI: Mojo combines the usability of Python with the performance of C, unlocking unparalleled programmability of AI hardware and extensibility of AI models.
- Modular Community Q&A: no description found
Modular (Mojo 🔥) ▷ #mojo (75 messages🔥🔥):
Mojo's CompatibilityNetworking in MojoTransitioning from PythonLanguage PreferencesSwift vs. Rust
-
Mojo's Current State in Development: Despite its promise, members concluded that Mojo isn't ready for serious use and won't stabilize for at least a year or two, impacting potential transitions from Python.
- One noted, 'Mojo isn't there yet and won't be on any timescale that is useful to us.'
- Networking Features in Mojo: Current opinions suggest that IO and networking functionalities in Mojo are still in exploratory design with limited stability.
- There is ongoing development on a network stack for Mojo, but it's expected to take time before reaching a usable state.
- Exploring Alternatives to Python: There's a debate about transitioning from Python, highlighting strengths and weaknesses in languages like Swift and Rust, with mixed experiences shared.
- Concerns about Python's syntax led to discussions on finding a better alternative, with many preferring Swift due to existing in-house experience.
- Swift's Adoption Challenges: Users expressed some frustration with Swift's abstractions and documentation, suggesting its learning curve can be steep despite its advantages.
- Concerns include lack of clarity in methods and potential challenges in learning Swift compared to Rust, with one user stating, 'learning swift is painful.'
- Community Input on Language Options: Members discussed various languages like Nim and Go, weighing their use in AI contexts, while expressing dissatisfaction with Go's design.
- One stated, 'We’ve tried Go and I really don’t like it,' reflecting broader hesitations about switching languages.
Modular (Mojo 🔥) ▷ #max (2 messages):
Max GPU supportApple Metal
-
Max GPU support is a work in progress: Current developments indicate that GPU support for Max is WIP, with the next update expected to include it.
- Recent Nvidia support is confirmed for now.
- Apple Metal support status unclear: The discussion included a query about whether Apple Metal is supported for GPU tasks.
- However, no definitive answer regarding Metal support was provided in the conversation.
aider (Paul Gauthier) ▷ #general (60 messages🔥🔥):
Installing AiderUsing O1 Models in AiderPair Programming with AiderAlternatives to Aider for UI/UX DesignDurable Execution in Aider
-
Installing Aider Made Easy with pipx: Users have found that using
pipxfor installing Aider on Windows simplifies dependency management, avoiding version conflicts when working on multiple Python projects.- As noted, you can quickly install Aider using
pipxto ensure it runs in its own environment, which eliminates compatibility issues. - Challenges Using O1 Models within Aider: A user expressed concerns over the feasibility and costs of accessing O1-preview and suggested manual workflows using ChatGPT to synthesize plans before executing them in Aider.
- Others discussed potential configurations and workflows, stressing the importance of dry-run modes for clarity on prompts being processed by O1 models.
- Pair Programming with Aider: A member shared that their custom AI pair programming tool resolved 90% of bugs in their codebase using reprompting effectively, while O1-preview excels at one-shot solutions.
- Discussions also revealed preferences for specific models like Claude-engineer for pair programming, emphasizing adaptability based on user needs.
- Alternatives for UI/UX AI Design: Someone was seeking recommendations for a creative UI/UX AI designer, expressing frustration with current tools that resemble standard SaaS offerings.
- A potential designer introduced themselves, indicating openness to review briefs and requirements for creative projects.
- Durable Execution Support in Aider: A user raised a question regarding the possibility of Aider supporting durable execution, speculating that it could be straightforward at the user IO boundary.
- This highlights ongoing discussions within the community about enhancing Aider's capabilities and addressing user needs.
- As noted, you can quickly install Aider using
Links mentioned:
- Install with pipx: aider is AI pair programming in your terminal
- Installation: How to install and get started pair programming with aider.
aider (Paul Gauthier) ▷ #questions-and-tips (25 messages🔥):
Aider file commit errorsToken limit issuesDeno integration with AiderControlling repo map outputInstallation errors
-
Aider commits to wrong file paths: Aider erroneously committed changes to
public/css/homemenu.cssinstead ofpublic/mobile/css/homemenu.css, leading to irreversible damage and confusion regarding which file was actually changed.- The incident raised concerns about transparency in Aider's file handling, as it claimed to edit one file while actually modifying another.
- Token limit concerns with Aider: Members discussed issues regarding Aider hitting token limits, with one user experiencing a project that exceeded context windows due to high token counts in chat histories.
- Suggestions included setting a max token threshold for chat history to avoid unexpected token usage and prompting for confirmation before sending large amounts of data.
- Integrating Deno with Aider: A user inquired whether Aider could improve its capabilities by feeding URLs of Deno documentation using the
/webcommand within a NextJS project.
- They sought guidance on any potential caveats to this approach, expressing concerns about keeping up with rapidly changing technology.
- Modifying repo map output: A user asked about expanding the output of
--show-repo-mapto include all*.tsxfiles or files within a specific path due to their project's structure.
- They expressed dissatisfaction with Aider's current method of determining which files are deemed 'important' and requested more control over this feature.
- Installation error with Aider: One user reported an installation issue with Aider, encountering an error indicating that
libstdc++.so.6could not be found when attempting to run the application.
- This issue pointed to potential configuration problems, prompting others to refer back to Aider's installation documentation for troubleshooting.
Links mentioned:
- Installing aider: aider is AI pair programming in your terminal
- Token limits: aider is AI pair programming in your terminal
- REQ: Ability to set max token threshold, at which a confirmation warning would appear · Issue #2041 · Aider-AI/aider: Issue I am doing quite a bit of debugging at the moment and it has involved having to enable a number of nested stack traces. This results in a lot of output going to the API and it got out of hand...
aider (Paul Gauthier) ▷ #links (1 messages):
mittens4025: https://shchegrikovich.substack.com/p/use-prolog-to-improve-llms-reasoning
OpenAI ▷ #ai-discussions (25 messages🔥):
Advanced Voice Mode IssuesGlif Workflow ToolChatGPT Windows App Feedback
- Advanced Voice Mode frustrates users: Users expressed dissatisfaction with Advanced Voice Mode, citing issues like vague responses and inability to interrupt or stop the assistant's answers. One user mentioned it often deflects questions with 'my guidelines prevent me from talking about that', leading to frustration.
- Understanding Glif as a Workflow App: Discussion revolved around Glif, likening it to Websim but for creating apps through workflows that connect AI tools. A user remarked it was a 'cold' concept but grasped the idea quickly.
- Mixed Reviews on ChatGPT Windows App: Feedback on the ChatGPT Windows App was mixed, with some enjoying its shortcuts while others felt it resembled a popped-out website. A user humorously rated the app '5.0 out of 1', indicating dissatisfaction.
- Comparison of ChatGPT Apps: A comparison was made between the Windows app and its OS X counterpart, with some noting that the Alt + Space shortcut provided a better experience. Users highlighted the Windows app's support for @chatgpt syntax, making it feel more functional.
- Discussion on AI's Consciousness Limitations: A philosophical discourse emerged regarding AI's ability to grasp nuances, particularly what lies 'in between the lines'. Questions were raised about whether it can process the void or choose to act versus opting not to choose.
OpenAI ▷ #gpt-4-discussions (32 messages🔥):
ChatGPT for WindowsVoice Functionality in ChatGPTPrivacy Concerns with Screen SharingCode Generation IssuesAI Model Performance Issues
-
ChatGPT for Windows Sparks Excitement: Members expressed excitement about the announcement of ChatGPT for Windows, but details about accessibility for premium users surfaced.
- An early version is available for Plus, Team, Enterprise, and Edu users only.
- Voice Functionality Uncertainty: Questions arose about whether voice functionality from the Android app will be replicated in the Windows version, but answers remained unclear.
- Concerns about fairness for different OS users surfaced, especially since macOS had this feature initially.
- Privacy Concerns with AI Screen Sharing: A member shared reservations over using the new desktop app due to worries about Personally Identifying Information (PII) being unintentionally shared.
- They sought clarity on what specific screen areas the AI could access and how to control that.
- Code Generation Frustrations: One member reported issues with code generation, specifically with formatting JSON in a library for the OSPF protocol due to errors in the code.
- Humor accompanied these frustrations, as they highlighted the challenges faced.
- AI Model Performance Dips: Several users noted performance issues with ChatGPT, especially with random responses from the advanced voice mode, possibly linked to the O1 preview updates.
- Others shared their struggles with the AI not recalling previous interactions in conversations due to input token limits.
OpenAI ▷ #prompt-engineering (3 messages):
Voice AI engineeringImage generation spelling
-
Seeking Voice AI Engineers: A user expressed a need for a Voice AI engineer and inquired if anyone with that expertise was available.
- This highlights a potential gap in the community's resources for voice technology.
- Accurate Word Spelling in Image Generation: A member asked how to achieve accurate word spelling in image generation, questioning if it was a limitation of the technology or a guard rail issue.
- This raises important discussions about the capabilities and constraints of current image generation models.
OpenAI ▷ #api-discussions (3 messages):
Voice AI engineersImage generation accuracy
-
Searching for Voice AI Engineers: A member inquired about the availability of Voice AI engineers, expressing a need for a developer.
- This highlights the ongoing demand for expertise in the Voice AI field within the community.
- Image Generation Spelling Concerns: A member questioned how to achieve accurate spelling in image generation outputs, wondering if it’s a limitation or a guardrail issue.
- This raises important discussions about the challenges faced in AI-generated visuals and how they spell words.
GPU MODE ▷ #general (8 messages🔥):
Edge deployment projectsSampling inefficienciesPerformance differences in gemmLazy evaluation in MLXInference speed bottlenecks
-
Interest in various project areas: Members discussed various avenues of project interests including edge deployment, training, and reinforcement learning.
- There is a distinction noted between local LLM integration and enterprise B2B applications.
- Cutlass performance issues in LLM mode: A member raised a concern regarding the performance of Cutlass kernels, which seem to operate at half capacity in LLM mode compared to other benchmarks.
- Performance is measured using nsys, indicating potential inefficiencies needing exploration.
- Inference speed bottleneck due to sampling: The bottleneck in inference speed due to samplers was highlighted, where top sampling methods significantly slowed down the process from ~250 tok/s to ~2.5 tok/s.
- It was suggested that the numpy.choice function creates overhead and that model size affects the impact of sampling on performance.
- Lazy evaluation impacting performance: A member provided an update stating that lazy evaluation in MLX led to slower inference speeds because operations were not executed until explicitly called.
- More information on this topic can be found in the GPU mode lecture on profiling and lazy evaluation documentation.
Links mentioned:
- Lazy Evaluation — MLX 0.19.0 documentation: no description found
- GitHub - gpu-mode/awesomeMLSys: An ML Systems Onboarding list: An ML Systems Onboarding list. Contribute to gpu-mode/awesomeMLSys development by creating an account on GitHub.
- GitHub - josephmisiti/awesome-machine-learning: A curated list of awesome Machine Learning frameworks, libraries and software.: A curated list of awesome Machine Learning frameworks, libraries and software. - josephmisiti/awesome-machine-learning
GPU MODE ▷ #triton (3 messages):
Unplanned Closure of DiscussionBug in Integer Packed TensorsBuild Error in TritonCMake Configuration Issues
-
Discussion Closure raises eyebrows: One member noted it was peculiar that the person who opened a discussion also closed it, labeling the closure as unplanned and claiming no affiliation with Triton.
- “Weird to close it and say it's unplanned,” reflecting skepticism about the closure's rationale.
- Integer Packed Tensors Bug Confirmed: A member confirmed that the bug with integer packed tensors still exists as of October 17 in the master branch, while it does not affect floats.
- They proposed a fix, altering the loop to
for k in tl.range(0, total_blocks_k, 1, num_stages=1)but questioned the performance implications of limiting stages to 1. - Build Error stumps Member: Another member reported encountering the error
/usr/bin/ld: cannot find -lNVGPUIR: No such file or directorywhile trying to build Triton.
- They included their CMake configuration command but found no build steps in the Triton GitHub repository.
Link mentioned: GitHub - triton-lang/triton: Development repository for the Triton language and compiler: Development repository for the Triton language and compiler - triton-lang/triton
GPU MODE ▷ #torch (11 messages🔥):
Flex Attention with DDP WorkaroundsUsing Shared Memory in CUDA
-
Flex Attention and DDP Need Fixing: With the release of PyTorch 2.5, there were discussions about workarounds for using Flex Attention with DDP, including disabling dynamo's DDP optimizer with
torch._dynamo.config.optimize_ddp = False.- One user noted that this workaround gives a significant performance hit, emphasizing the need for a future fix.
- Shared Memory Usage in CUDA: One member highlighted the use of shared memory in the backward kernel for embeddings, which resolves issues with concurrent access during updates.
- They inquired whether this pattern is documented or frequently used in torch/cuda integrations.
Links mentioned:
- [FlexAttention] Using FlexAttention with DDP complains about a "higher order optimizer" · Issue #137481 · pytorch/pytorch: 🐛 Describe the bug Hello all, I have experienced a similar error as this. Since I cannot post my stack trace due to privacy reasons, I wanted to raise visibility to this post on PyTorch Discuss . I.....
- pytorch/torch/_dynamo/config.py at 32f585d9346e316e554c8d9bf7548af9f62141fc · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- pytorch/aten/src/ATen/native/cuda/Embedding.cu at c3cd9939fcd05f97abc0828c29e65b8214130e12 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
GPU MODE ▷ #beginner (25 messages🔥):
GPU Mathematics vs EngineeringParallel Processing Scaling LawsTriton and Tensor Cores UsageBenchmarking in Triton
-
Understanding GPU Work: Math or Engineering?: Members discussed whether GPU work involves more mathematics or engineering, highlighting that scaling algorithms on parallel processors relies on concepts like Amdahl's and Gustafson's laws.
- It was noted that the analysis of hardware capabilities is a hardware-agnostic scaling law.
- Scaling Laws and Future of Quantum Computing: There are ongoing discussions on scaling laws for parallel processors, with predictions of increased focus when quantum computers become mainstream.
- Members expressed the belief that optimizing models mathematically to reduce operations is a different research area.
- Utilizing Tensor Cores in Triton Code: A user inquired about ensuring their Triton code utilizes tensor cores, confirming that using the
tl.dotfunction should allow for automatic engagement of tensor cores.
- Another member provided a link to Triton's benchmarking tools for more insights into how to measure and optimize performance.
- Benchmarking Functions in Triton: One member asked for resources, specifically a YouTube video, explaining benchmarking functions alongside Triton kernels.
- They were directed to use tools like
do_benchfor runtime benchmarking, as well as advanced profiling tools like NVIDIA Nsight Compute.
Link mentioned: triton.testing.do_bench — Triton documentation: no description found
GPU MODE ▷ #torchao (2 messages):
Performance comparisonTorch versions
-
tinygemm + torch.compile slows down in 2.5.0: A member observed that tinygemm combined with torch.compile is slower in the latest release 2.5.0 compared to 2.4.1, with a notable drop in performance from 171 tokens/sec to 152 tokens/sec.
- This information highlights a regression in speed, prompting a request to create a GitHub issue and share a repro for further investigation.
- Performance Issues with Torch Releases: The discussion centered around performance disparities between Torch 2.4.1 and 2.5.0, specifically regarding token processing speeds on the Llama2 7B model using a 4090 GPU.
- The decline in speed has raised concerns among users on whether this is an isolated issue or part of a broader trend with newer releases.
GPU MODE ▷ #llmdotc (6 messages):
Stable Diffusion OptimizationInference Pipeline in CGGML Library Limitations
-
Seeking Pure C Solutions for Diffusion: A member inquired about projects similar to llama2.c but specifically for diffusion projects implemented in pure C.
- I just want an optimized inference pipeline,
- Reference to Stable Diffusion in C++: Another member directed the inquiry to stable-diffusion.cpp, designed for Stable Diffusion and Flux in pure C/C++.
- However, it was noted that this project is built on GGML, which does not meet the original request.
- Discussion on GGML's Abstractions: Members discussed that implementing the whole project in pure C would likely lead to using many of the same GGML abstractions.
- As one remarked, It’s just a machine learning library in pure C, lol.
Link mentioned: GitHub - leejet/stable-diffusion.cpp: Stable Diffusion and Flux in pure C/C++: Stable Diffusion and Flux in pure C/C++. Contribute to leejet/stable-diffusion.cpp development by creating an account on GitHub.
GPU MODE ▷ #bitnet (1 messages):
Open Source Re-ImplementationsT-MAC Low-Bit InferenceRMSNorm Variations
-
Open Source Models may not match internal releases: It seems the models released are merely running the open source re-implementations, which may diverge on key architectural details like the RMSNorm insertions.
- Not sure how this repo handles it, highlighting concerns over alignment within open source model implementations.
- Exploration into Bit-Packed Kernels: There is interest in understanding how the repo implements its inference bit-packed kernels, potentially using a lookup table approach.
- A reference was made to T-MAC as a noteworthy example of low-bit LLM inference on CPUs.
Link mentioned: GitHub - microsoft/T-MAC: Low-bit LLM inference on CPU with lookup table: Low-bit LLM inference on CPU with lookup table. Contribute to microsoft/T-MAC development by creating an account on GitHub.
GPU MODE ▷ #sparsity-pruning (1 messages):
Sparse-Dense MultiplicationPyTorch CUDA Performance
-
Parallel Processing Outperforms Batch Computation: There's an interesting discovery in sparse-dense multiplication on PyTorch CUDA where splitting the dense matrix into vectors and executing in parallel proves to be faster than processing the entire matrix at once, particularly for widths >= 65536.
- Torch.cuda.synchronize() is being utilized, indicating that timing concerns are accounted for, yet the improved performance seems counterintuitive.
- Performance Anomalies with Large Widths: At a width of 65536 and above, performance anomalies have been identified when conducting CSR-dense multiplications which raise questions about typical expectations of matrix operations.
- The observed speedup when processing smaller chunks indicates that there may be underlying optimizations or hardware interactions that warrant further investigation.
GPU MODE ▷ #webgpu (1 messages):
fancytrevor: if anyone is at the webai summit im kicking around, would be cool to say hi
LlamaIndex ▷ #blog (3 messages):
MongoDB Hybrid SearchAuth0 AI ApplicationsHackathon Projects
-
MongoDB introduces Hybrid Search for LlamaIndex: MongoDB has launched support for hybrid search in LlamaIndex, blending vector search and traditional keyword search to leverage the strengths of both approaches. This integration can enhance the capabilities of AI applications, as detailed in their announcement.
- For more insights, check their additional post on Twitter.
- Auth0 launches secure AI application solutions: Auth0 is rolling out a collection of secure methods for building AI applications, featuring a full-stack, open-source demo app available here. Developers can access the code via this link.
- Getting started requires accounts with Auth0 Lab, OKTA FGA, and OpenAI, plus Docker to run the PostgreSQL container for setup.
- Hackathon Recap Celebrates 45 Projects: The recent 3-day hackathon saw over 500 registrations with 45 projects created by the end of the event. A blog post detailing the winners and highlights can be found here.
- Stay tuned for guest blog posts from winning teams that will dive into their projects and experiences shared during the hackathon.
Link mentioned: GitHub - auth0-lab/market0: sample app about authz and AI: sample app about authz and AI. Contribute to auth0-lab/market0 development by creating an account on GitHub.
LlamaIndex ▷ #general (46 messages🔥):
Faithfulness evaluation replicationLlamaParse failure in Docx filesHandling exceptions in workflowsParallel function calling in workflowsUsing Ollama in npx create-llama
-
Challenges replicating Faithfulness evaluation: A user reported that replicating the Faithfulness evaluation in their RAG bot sometimes takes excessive time, ranging from 15 minutes to over an hour.
- Other members suggested trying Ollama as a potentially faster alternative, highlighting hardware influence on performance.
- LlamaParse issues with Word documents: A user experienced parsing errors with a Word document using the LlamaParse feature, seeing unexpected image results instead of text data.
- Upon further testing, it was confirmed that uploading via the LlamaCloud UI worked correctly, while using the npm package resulted in a parse error.
- Exception handling in workflows: A discussion arose regarding how exceptions are handled in workflows, where one user expressed concern about an error seemingly bubbling up despite being caught in a try/except block.
- It was noted that changes in the version of
llama-index-coreaffected error handling, necessitating updates to ensure exceptions are managed properly. - Utilizing parallel function calls in workflows: A user inquired about using
allow_parallel_tool_calls = Truein relation to parallel execution when increasingnum_workersin a workflow step.
- Members explained that while this setup does allow for concurrent execution, issues may arise if tools block the event loop, emphasizing the use of
asyncio.to_threadfor non-async tools. - Switching to Ollama in create-llama: A user asked how to change the LLM to Ollama when using the
npx create-llamacommand.
- The conversation highlighted the need for clear documentation or examples on integrating different LLMs into the create-llama setup.
Links mentioned:
- Google Colab: no description found
- Raise errors in instrumentation properly by logan-markewich · Pull Request #16603 · run-llama/llama_index: Fixes an issue with handling errors in instrumentation when workflows raise an error
- GitHub - xaac-ai/llama-artifact: Contribute to xaac-ai/llama-artifact development by creating an account on GitHub.
LlamaIndex ▷ #ai-discussion (1 messages):
Query PlanningLlamaIndexInformation RetrievalNatural Language Processing
-
Query Planning Enhances Information Retrieval: A new article discusses how query planning is essential for breaking down complex queries to improve information retrieval, particularly in the context of natural language processing.
- It emphasizes that a well-structured query is crucial for achieving accurate and relevant results.
- LlamaIndex's Role in Query Processing: The article highlights LlamaIndex as a powerful framework that aids in constructing queries that can be processed efficiently by systems.
- By focusing on user intent, LlamaIndex ensures that queries are broken down into smaller, more manageable components.
Link mentioned: Query Planning Workflow with LlamaIndex: Ankush k Singal
OpenAccess AI Collective (axolotl) ▷ #general (45 messages🔥):
Bitnet ReleaseLiger Flash Attention IntegrationVRAM Savings with LigerLiger Installation IssuesAxolotl Configuration
-
Bitnet is officially released!: The community celebrated the release of Bitnet, an official inference framework for 1-bit LLMs by Microsoft, with notable model performance that runs efficiently on a variety of hardware.
- It can operate 100 billion models at impressive speeds, such as 6 tokens/sec on an M2 Ultra.
- Integrating Liger's Flash Attention 2: To enable Flash Attention 2 using Liger, users discussed adding
liger_flash_attention: truein their configuration and ensuringsdp_attention: trueis also included.
- Participants shared experiences and recommended checking whether dependencies are correctly installed and imported to leverage memory savings effectively.
- Achieving VRAM Savings with Liger: Users reported significant VRAM reductions, with one noting a drop from 22.7 GB to 11.7 GB by properly setting up Liger and enabling relevant flags.
- The community suggested tweaks to ensure compatibility, such as setting
TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1for AMD users. - Troubleshooting Liger Installation: Some users experienced issues with Liger not being properly imported during training, leading to higher memory usage than expected.
- Modifying the
PYTHONPATHvariable helped some members get the integration working smoothly, suggesting careful installation verification. - Guide to Using Liger: A brief guide shared recommended straightforward installation steps for Liger using pip, especially for CUDA users, and required config adjustments.
- Users noted the Liger Flash Attention 2 PR as necessary for those on AMD hardware wanting to utilize advanced attention mechanisms.
Links mentioned:
- GitHub - microsoft/BitNet: Official inference framework for 1-bit LLMs: Official inference framework for 1-bit LLMs. Contribute to microsoft/BitNet development by creating an account on GitHub.
- LinkedIn: LinkedIn has 126 repositories available. Follow their code on GitHub.
- [Kernel] Flash attention 2 by remi-or · Pull Request #275 · linkedin/Liger-Kernel: Summary This PR adds a Flash Attention 2 triton kernel and the monkey-patching of SDPA attention layers with our FA kernel. Details The kernel supports fp16 and bfloat16, attention masking, attenti...
- [Kernel] Flash attention 2 by remi-or · Pull Request #275 · linkedin/Liger-Kernel): Summary This PR adds a Flash Attention 2 triton kernel and the monkey-patching of SDPA attention layers with our FA kernel. Details The kernel supports fp16 and bfloat16, attention masking, attenti...
- axolotl/src/axolotl/integrations/liger/init.py at 67f744dc8c9564ef7a42d5df780ae53e319dca61 · NanoCode012/axolotl): Go ahead and axolotl questions. Contribute to NanoCode012/axolotl development by creating an account on GitHub.
Cohere ▷ #discussions (13 messages🔥):
Stealth Project with AyaDiscussion with GeminiLanguage Translation Experiment
-
Stealth Project with Aya Calls for Contributors: A general call for builders to join a stealth project with Aya's community has been made, targeting those fluent in various languages such as Arabic and Spanish.
- Interested participants should join the Aya server and tag themselves to contribute and receive exclusive swag for their efforts.
- Citing Discussions to Raise Awareness: A member anonymously cited another's comment in a discussion with Gemini, highlighting a broader sentiment of disillusionment in the AI field.
- The discussion can be found at this link.
- Language Translation Experiment with Gemini: A member used the earlier comment in a language test on their phone and found it useful for translating into three different foreign languages.
- The results were documented in the phone's translate history, but the member chose not to share them.
- Learning to Get Involved in AI Discussions: A member compared a conversation with Gemini to a budgie chirping at itself, suggesting it was a start for the contributor.
- Another member affirmed that serious entry points in machine learning are needed to make more significant contributions.
Link mentioned: Gemini - AI Discussion: Nature of LLMs, Reasoning, Future: Created with Gemini
Cohere ▷ #questions (7 messages):
RAG AMAs RecordingCohere Command R+ Issues
-
RAG AMAs not recorded: A member inquired if the RAG AMAs were recorded, but it was confirmed that they were not.
- For further inquiries, members were encouraged to tag one of the course creators for assistance.
- Issues with Cohere Command R+ 08-2024: Multiple members reported problems with the cohere/command-r-08-2024 model on OpenRouter, stating it produces numerous errors.
- One member asked for updates on the fix, while another suggested emailing for a more prompt response.
Cohere ▷ #api-discussions (6 messages):
Trial User AccessFine-Tuning Rerank Context Window
-
Trial users have access to all endpoints: Members confirmed that everything is available and free on trail keys with rate limits, including endpoints like datasets and emed-jobs.
- This ensures trial users can explore the full range of features without restrictions.
- Fine-tuning rerank context window limitations: A member noted that the context window for fine-tuning is 510 tokens, significantly smaller compared to the 4k for rerank v3 models.
- This raises questions about how documents are chunked for fine-tuning, prompting a request for insights from finetuning experts.
Cohere ▷ #projects (7 messages):
Claude-HaikuPrompt efficiencyToolkit mentionFast responsesUpdated prompts
-
Claude-Haiku to Claude-Instant Transition: A member discussed the transition of the Claude-Haiku into a Claude-Instant version, highlighting its compatibility with various bots.
- They expressed satisfaction with the transition, stating it works well in any context.
- Short Prompts Lead to Faster Responses: One user noted that their commitment to short prompts resulted in the bot responding much faster, taking about a second.
- They humorously compared this to previous, longer prompts that took significantly more time.
- Inquiry about Toolkit Availability: Another member expressed interest in whether the fast writing prompt is available on the toolkit.
- They displayed enthusiasm toward sharing new ideas within the community.
- Ordinary Prompt Achieves Remarkable Speed: A user shared insights on using an ordinary prompt in Playground that surprisingly allows for quick writing without sacrificing quality.
- They emphasized the rarity of such effective prompts that maintain writing quality.
- Updates to Prompt for Better Performance: One member updated their prompt to include the phrase 'very effective' to enhance its performance.
- They mentioned that the bot now takes slightly longer to start writing as it searches for better responses, but it keeps producing content faster overall.
tinygrad (George Hotz) ▷ #general (12 messages🔥):
Compositional Linear Algebra (CoLA)OpenCL Setup IssuesTinygrad Optimization Strategies
-
Exploring CoLA for Matrix Operations: A discussion highlighted the capabilities of the Compositional Linear Algebra (CoLA) library, emphasizing its potential for structure-aware operation speedups on tasks like eigenvalue calculations and matrix inversions.
- Members noted that using decomposed matrices can significantly enhance performance, but questioned whether this approach might be too niche for tinygrad.
- Considerations for Tinygrad's GPU Support: A member raised the question of whether tinygrad should prioritize dense matrix optimization rather than 'composed' matrix operations as a baseline strategy.
- Despite some skepticism, there was agreement that as long as algorithms avoid arbitrary memory access, they could potentially be integrated into tinygrad.
- CI Error with OpenCL on Windows: A CI failure was reported due to issues importing OpenCL libraries, highlighting a specific error regarding the
libOpenCL.so.1not being found during test initialization.
- This led to a discussion about verifying the setup of OpenCL on the CI machine and the implications of removing GPU=1 in recent commits.
- Setting Up OpenCL for Testing: Members discussed the necessity of setting up OpenCL for Windows testing to ensure smooth CI functioning, especially when expecting to run on a GPU.
- A consensus emerged on the need to install required dependencies on the CI machine for proper testing of OpenCL.
Links mentioned:
- fix: not gpu · jla524/tinygrad@46daa08: no description found
- fix: not gpu · jla524/tinygrad@46daa08: no description found
- Compositional Linear Algebra (CoLA) — CoLA 0.0.6.dev25+gd87bd36 documentation: no description found
- GitHub - wilson-labs/cola: Compositional Linear Algebra: Compositional Linear Algebra. Contribute to wilson-labs/cola development by creating an account on GitHub.
tinygrad (George Hotz) ▷ #learn-tinygrad (18 messages🔥):
Transferability of Tinygrad skillsJim Keller discussion insightsHelpful Tinygrad resourcesDebugging reinforcement learningMuJoCo interface challenges
-
Tinygrad skills transfer easily to PyTorch: A member confirmed that the skills learned from Tinygrad are highly transferable to other tensor libraries like PyTorch, noting that understanding its philosophy greatly aids comprehension of more complex systems.
- My work's mostly in hardware and robotics, reinforcing the benefit of learning Tinygrad as foundational for other libraries.
- Jim Keller's insights worth exploring: A suggestion was made to check out the Jim Keller chat discussing CISC / VLIW / RISC architectures with Lex Fridman along with geohot's insights.
- A member mentioned they had already explored this topic, indicating it sparked interest in further discussions.
- Resources for learning Tinygrad: A member provided a series of tutorials and study notes to help newcomers understand the internals of Tinygrad, stressing the importance of piecing together knowledge from multiple sources.
- They recommended starting with Beautiful MNIST examples and addressing various levels of complexity in their studies.
- Challenges of debugging reinforcement learning: A member highlighted the difficulties of debugging complex systems in reinforcement learning that can take months to get right due to intricacies in code and system interactions.
- They shared a debugging advice article that encapsulates their experiences and valuable insights over the years in the field.
- Struggles with MuJoCo installation: A member expressed frustrations with getting MuJoCo to work properly on their machine, particularly with the glfw renderer while attempting to connect a robotic arm interface with Tinygrad.
- Another user suggested switching to Isaac Sim, which offers a headless mode, making it more suitable for their use case.
Links mentioned:
- Tutorials on Tinygrad: Tutorials on tinygrad
- Debugging Reinforcement Learning Systems: Debugging reinforcement learning implementations, without the agonizing pain.
- attention-is-all-you-need-pytorch/transformer at master · jadore801120/attention-is-all-you-need-pytorch: A PyTorch implementation of the Transformer model in "Attention is All You Need". - jadore801120/attention-is-all-you-need-pytorch
- RAG with a Graph database | OpenAI Cookbook: Open-source examples and guides for building with the OpenAI API. Browse a collection of snippets, advanced techniques and walkthroughs. Share your own examples and guides.
- Build software better, together.): GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
Interconnects (Nathan Lambert) ▷ #news (2 messages):
Janus GitHub RepositoryText and Image Processing
-
Discover Janus on GitHub: Janus is an open-source project by deepseek-ai that invites contributors to participate in its development.
- The GitHub page highlights the project's purpose, alongside a pertinent image linking to its repository.
- Text and Image Processing Discussion: There was a mention of a feature around managing Text+Image in both input and output contexts, though details were sparse.
- This sparks a discussion on how the integration of text and visuals can enhance user interactions.
Link mentioned: GitHub - deepseek-ai/Janus: Contribute to deepseek-ai/Janus development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #ml-questions (9 messages🔥):
Inference Providers for Chat AssistantsSpecial Tokens in Chat ModelsPre-Filling ResponsesOpenRouter Assistant Prefill Feature
-
Inquiry about Inference Providers for Chat Assistants: A member seeks information on inference providers that enable chat assistant completions for popular open-weight models, asking for examples of how responses might be structured.
- They noted that Anthropic offers a similar feature but expressed uncertainty about its reliability.
- Discussion on Special Tokens Usage: The member shared their interest in accessing specific special tokens used in chat models, noting that the assistant turn lacks an END_OF_TURN_TOKEN.
- Another member noted past experiences with these tokens and suggested checking the relevant documentation for assistance.
- Clarification on the Term 'Pre-Filling': A clarification was made regarding the terminology, with a member confirming that the process being discussed is referred to as 'pre-filling'.
- This terminology helped the original member refine their search for potential solutions.
- OpenRouter Offers 'Assistant Prefill' Feature: The original member learned that OpenRouter provides an 'Assistant Prefill' feature, although they remain uncertain about its underlying implementation.
- They expressed hope that OpenRouter would deliver this functionality in the manner they anticipate.
Link mentioned: OpenRouter): LLM router and marketplace
Interconnects (Nathan Lambert) ▷ #ml-drama (3 messages):
Garrison Lovely's behaviorGreg Brockman's return to OpenAIChanges at OpenAI
-
Garrison Lovely maintains his reputation: A member remarked that Garrison Lovely is keeping up his reputation of being an asshole after a recent tweet.
- This comment seems to resonate with others who share similar sentiments about his behavior.
- Greg Brockman expected to return soon: Execs at OpenAI anticipate Greg Brockman's return within the next month, as reported by a tweet.
- However, it's worth noting that the company has changed a lot since his departure.
Links mentioned:
- Tweet from Garrison Lovely (@GarrisonLovely): 😬
- Tweet from Stephanie Palazzolo (@steph_palazzolo): Good news: Execs expect Greg Brockman to return to OpenAI in the next month or so. Bad news: The company has changed a lot since he left. A deep dive w/ @amir on Greg's leadership style, his rel...
Interconnects (Nathan Lambert) ▷ #random (3 messages):
Artifacts Log UtilityCommunity Engagement for PixmoData Discovery
-
Artifacts Log proves useful for team discoveries: It's noted that every time the artifacts log is reviewed, there are always models or datasets that turn out to be useful for team members.
- This emphasizes the importance of organized information in maintaining workflow efficiency.
- Pixmo's Community-Driven Labeling Enthusiasm: The community involved in labeling data for Pixmo is so engaged that it has led to the creation of a dedicated Reddit community where members share memes and actively request more work.
- This demonstrates the level of excitement and participation from the community surrounding the labeling process.
Links mentioned:
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Interconnects (Nathan Lambert) ▷ #rlhf (11 messages🔥):
Instruction tuning an LLMData quality in tuningPreference tuning (RLHF)DPO for persona responsesReaction improvements in Discord
-
Instruction Tuning Starts with Quality Data: A member questioned the necessary number of prompts for instruction tuning an LLM aimed at altering response tone and voice, noting it might be a niche problem.
- Another member stated that data quality is key, suggesting that even 1k prompts can be effective.
- Preference Tuning as an Alternative: A member suggested using preference tuning (RLHF) instead of supervised fine-tuning for the tuning process.
- They also mentioned the possibility of employing DPO with examples of normal versus desired responses, leaving the criteria for selection open to convenience.
- Boring Reactions Prompt a Discussion: One member expressed that the 👍 reaction has become boring, prompting a few suggestions to elevate their reactions.
- Another member remarked that replacing 👍 with ❤️ on teams makes for a better choice; prompting a fun discussion about reactions.
Stability.ai (Stable Diffusion) ▷ #general-chat (20 messages🔥):
Gen AI HackathonCreating CheckpointsSeamless Image GenerationTraining ModelsSampling Methods for Cartoon Style
-
Join the Gen AI Hackathon for Big Prizes: The Gen AI Hackathon invites teams to build AI-powered systems, with over $25k in prizes up for grabs.
- Collaborators include aixplain, Sambanova Systems, and others, focusing on ethical AI solutions that enhance human potential.
- Creating Custom Checkpoints is Challenging: A member inquired about creating a checkpoint from scratch, to which it was advised that it requires millions of annotated images and extensive GPU resources.
- Another suggested that training an existing model might be a more feasible route.
- Struggles with Seamless Image Generation: A user is seeking help to create seamless images that can be tiled, but noted difficulties with current methods using flux.
- A response emphasized that seamless image creation might require specialized tools rather than standard AI models.
- Training Models with Limited Images: In discussions about generating Iron Man Prime, it was suggested to create a LoRa model using art from the official comics for better results.
- The limited number of images for Model 51 was also noted as a significant challenge in generating AI images.
- Sampling Methods Discussion for Cartoon Style: Members discussed their preferred sampling methods, with one highlighting the use of dpm++2 for better stability over Euler in generating images.
- Common tools mentioned include pony and juggernaut for generating styles, specifically in a cartoon context.
Links mentioned:
- ashen0209/Flux-Dev2Pro at main: no description found
- Vertical Specific AI Agents Hackathon · Luma: Gen AI Agents CreatorsCorner, collaborating with aixplain, Sambanova Systems, Prem, Marly, Senso, Mistral, coval, heygen, fiberplane, exa, and others…
- Essay Writing Service - Essay Help 24/7 - ExtraEssay.com : Best essay writing service, ExtraEssay.com: professional writers, special discounts, shortest deadlines. We write the papers — you get top grades.
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Quiz 6 ReleaseCourse SignupMOOC Channel for DiscussionGuest SpeakersExternal Partnerships
-
Quiz 6 is now live!: The course staff announced that Quiz 6 has been released on the course website, accessible here.
- Participants are encouraged to complete the quiz in a timely manner.
- Sign up for the course: Prospective students can sign up for the course by filling out this form.
- This provides a way for interested individuals to join the learning community.
- Join the MOOC discussion channel: For course discussions and questions, students are invited to join the MOOC channel at the LLM Agents Discord.
- This platform facilitates interaction and support among participants.
- Meet the Guest Speakers: Several guest speakers have been introduced, including prominent figures like Denny Zhou, Shunyu Yao, and Chi Wang.
- These speakers will contribute valuable insights during the course.
- Collaborations with Industry Leaders: The event showcases partnerships with organizations like Google, OpenAI, and Databricks.
- These collaborations highlight the course's relevance to real-world applications.
Link mentioned: Large Language Model Agents: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (17 messages🔥):
Course Signup ProcessFeedback on Article AssignmentsLivestream AnnouncementsQuiz Access IssuesDiscord Community Engagement
-
Course Signup Process is Open: New participants like seonsmallworldz confirmed they can still join the MOOC and were advised to fill in the signup form to track submissions.
- Inquiries about the signup process lead to general enthusiasm for joining the course.
- Community Feedback for Article Assignments: Members suggested using the community for feedback before submitting open-ended article assignments to ensure alignment with guidelines.
- sannyshaikh7438 proposed sharing drafts in the appropriate Discord channel for timely input.
- Livestream Links Distributed Weekly: Participants were informed that livestream links will be sent out every Monday via email, with announcements also made on Discord.
- faizan102 raised concerns about not receiving the email, prompting clarification from others.
- Quiz Access Technicalities: An issue was raised regarding the accessibility of quiz 5, which ajaykumarkv. noted initially did not work but later confirmed that it was resolved.
- This interaction demonstrated the troubleshooting support available among community members.
- Active Engagement in Course Discussions: Members like sannyshaikh7438 expressed gratitude for the fast responses received in the channel, enhancing collaborative learning.
- Engagement in feedback sharing and troubleshooting exemplifies the supportive atmosphere within the Discord community.
Link mentioned: Large Language Model Agents: no description found
LAION ▷ #general (11 messages🔥):
Gen AI HackathonPixtral vs Qwen2 PerformanceL3_2 Training IssuesExplicit Content CaptioningNSFW Evaluation Chaos
-
Gen AI Hackathon Announcement: CreatorsCorner invites teams to participate in a hackathon focused on creating AI-powered multi-agent systems to improve everyday tasks, with over $25k in prizes available.
- Participants are encouraged to consider the ethical implications while developing safe and secure AI systems.
- Pixtral struggles against Qwen2: In comparing pixtral and qwen2 for explicit content captioning, results indicated that pixtral performs worse with a higher eval loss than both Qwen2 and ll3_2.
- Eval training for the comparison centered solely on photo content, highlighting the effectiveness of Qwen2.
- L3_2 Training Revisit Plans: A member expressed intentions to revisit L3_2 training in the future, aiming to use it in unsloth once it matures and confirms better performance.
- They encountered buggy results with ms swift specifically for their tasks, indicating the need for further verification.
- Explicit Content Hallucination Concerns: Discussion around training protocols revealed that regardless of the model used, the results for explicit content captioning often led to wild hallucinations.
- Challenges in the NSFW VQA domain were noted, with varying methods yielding chaotic outcomes in performance.
Link mentioned: Vertical Specific AI Agents Hackathon · Luma: Gen AI Agents CreatorsCorner, collaborating with aixplain, Sambanova Systems, Prem, Marly, Senso, Mistral, coval, heygen, fiberplane, exa, and others…
DSPy ▷ #general (1 messages):
LRM using DSPyToken costs for LLM-based applicationsGPT-4 pricing changes
-
Exploring LRM with DSPy: A user inquired about experiences building a Language Representation Model (LRM) using DSPy, contemplating a vanilla implementation if no one has done it yet.
- They provided a link to a blog post on alternatives related to this topic.
- Token-intensiveness of LLM applications: Building robust LLM-based applications requires careful management of token-use for tasks like summarization and retrieval augmented generation.
- The conversation highlighted that generating marketing content can consume significant output tokens, necessitating elaborate logic and feedback systems.
- GPT-4 pricing drops dramatically: The cost of using GPT-4 has significantly decreased, now priced at $2.5 per million input tokens and $10 per million output tokens.
- This represents a reduction of $7.5 per million input tokens since its release in March 2023, when it was $10/1M and $30/1M respectively.
Link mentioned: Drop o1 Preview, Try This Alternative: Building robust LLM-based applications is token-intensive. You often have to plan for the parsing and digestion of a lot of tokens for summarization or even retrieval augmented generation. Even the me...
DSPy ▷ #colbert (8 messages🔥):
ColBERTv2 trainingN-way tuples with scoresPATH implementationDeBERTa and MiniLM usageTraining with pylate
-
Confusion about ColBERTv2 training data: Members expressed confusion regarding the training examples for ColBERTv2, noting that it utilizes n-way tuples with scores instead of triples.
- One member referred to a GitHub repository for further clarification about the training process.
- Scaling positive and negative scores: A member inquired about adjusting the scores of positive and negative documents to match the MS MARCO scale, as their current scores ranged from ~.2 to ~2.4.
- Another pointed out that the actual score scale may not be as crucial and that technically, logprobs could suffice for training.
- Interest in implementing PATH: A member expressed a desire to implement PATH based on the referenced paper, although others noted it primarily uses cross-encoders like DeBERTa and MiniLM.
- They acknowledged the potential for combining PATH with ColBERT, suggesting it could yield interesting results.
- Recommendation for using pylate: A member shared a link to a GitHub discussion where bclavie recommended using pylate for training colbert-small-v1.
- This recommendation led to a positive response, indicating the member's intent to explore this suggestion further.
Links mentioned:
- GitHub - stanford-futuredata/ColBERT: ColBERT: state-of-the-art neural search (SIGIR'20, TACL'21, NeurIPS'21, NAACL'22, CIKM'22, ACL'23, EMNLP'23)): ColBERT: state-of-the-art neural search (SIGIR'20, TACL'21, NeurIPS'21, NAACL'22, CIKM'22, ACL'23, EMNLP'23) - stanford-futuredata/ColBERT
- answerdotai/answerai-colbert-small-v1 · Fine-tuning example: no description found
- GitHub - lightonai/pylate: Late Interaction Models Training & Retrieval: Late Interaction Models Training & Retrieval. Contribute to lightonai/pylate development by creating an account on GitHub.
Torchtune ▷ #general (1 messages):
Qwen2.5 Pull RequestTorchtune updates
-
Qwen2.5 Pull Request Published: A member shared a Pull Request for Qwen2.5 on the PyTorch Torchtune GitHub repository, indicating it addresses an unspecified feature or bug.
- Details are still needed, including a changelog and test plan, as indicated in the PR description.
- Changelog and Testing Gaps in Qwen2.5 PR: The Pull Request for Qwen2.5 lacks comprehensive details in the changelog and the test plan, marked as TODO in the description.
- The expectation for such information is critical to ensure the PR meets the project's contribution standards.
Link mentioned: Qwen2.5 by calvinpelletier · Pull Request #1863 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) Issue #1624 Changelog TODO Test plan TODO run pre-comm...
Torchtune ▷ #dev (7 messages):
Torchtune training approachesPreference pair generationRLAIF paper applicationIterative training processDPO vs PPO methods
-
Debate on Torchtune Training Methodologies: Members discussed two approaches for Torchtune training: running the entire pipeline or generating preference pairs using a reward model followed by PPO training.
- They highlighted the simplicity of running the entire pipeline against the efficiency and memory benefits of the pre-gen method with tools like vLLM.
- Visualization of Preference Pair Iterations: A member inquired about visual representation concerning the iterations from LLM to DPO using generated preference pairs.
- This indicates an interest in clarifying the training flow and its components.
- Connection to Anthropic's RLAIF Paper: A member mentioned the application of Anthropic’s RLAIF paper and referenced its implementation by TRL, which uses vLLM.
- They noted the precedent set by the RLAIF paper in generating new datasets per training round, combining data from different models.
- Recommendation for Initial Trials in Torchtune: A suggestion was made to begin experimenting with existing SFT + DPO recipes in Torchtune, based on the RLAIF pipeline description.
- This approach aims to streamline development by utilizing DPO methods to circumvent the need for reward model training.
OpenInterpreter ▷ #general (3 messages):
Automating document editingAider AI enhancementsOpen Interpreter development
-
Automating document editing process: A member proposed the idea of automating the document editing process while also running code in the background.
- They expressed interest in discovering other in-depth use cases that the community has explored before.
- Aider's advancements in AI-generated code: Another member highlighted that Aider is increasingly using AI-generated and honed code with each new version.
- If models continue to improve, there may be potential for a living nightly build approach for any interpreter concept.
- Open Interpreter's future plans: The discussion led to inquiries about any potential plans for Open Interpreter to adopt the same AI-driven code integration approach as Aider.
- Members are eager to learn how Open Interpreter could benefit from similar incremental improvements in AI models.
OpenInterpreter ▷ #ai-content (1 messages):
abhichaturvedi_94225: Thanks <@631210549170012166>
LangChain AI ▷ #share-your-work (1 messages):
Capital CompanionAI trading assistantLangChainLangGraphAdvanced trading strategies
-
Launch of Capital Companion - Your AI Trading Assistant: A member introduced Capital Companion, an AI trading assistant built using LangChain and utilizing LangGraph for complex agent workflows, inviting others to check it out on capitalcompanion.ai.
- Let me know if anyone's interested in checking it out or chatting about use cases, shared the member, seeking feedback and discussions on the platform's functionalities.
- AI-Powered Investment Dashboard for Stocks: Capital Companion offers an AI-powered investment dashboard designed to help users identify uptrends and make informed decisions in stock trading.
- Highlighted features include technical analysis tools and market sentiment analysis, aiming to provide a competitive edge in stock investing.
Link mentioned: Capital Companion - AI Trading Assistant for Stocks Today | Best Trading Strategy: Enhance your swing trade stocks strategy with AI-driven insights on trending stocks, equity trading software, and comprehensive technical analysis for the best trading strategy.
Alignment Lab AI ▷ #general (1 messages):
Twitter/X Embed FixDiscord Integration
-
Fix broken Twitter/X embeds!: A member urged others to check out a Twitter/X Space discussing how to enhance Twitter/X embeds.
- The discussion highlighted ways to utilize multiple images, videos, polls, translations, and more on platforms like Discord and Telegram.
- Enhancing Engagement Across Platforms: The conversation emphasized the importance of engaging users through interactive features like polls and translations on various communication platforms.
- This approach aims to increase user interaction and content richness, making it more appealing for diverse audiences.
Link mentioned: Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
LLM Use CasesMapping Questions-AnswersCommunity Repositories
-
Inquiry for LLM Success Stories: A member inquired about repositories or collections showcasing successful use cases of LLMs, including prompts, models, and fine-tuning methods.
- They expressed a desire to consolidate community efforts by starting a repository if existing resources are insufficient.
- Mapping Questions-Answers Challenge: The member mentioned a specific use case involving the mapping of questions-answers between two different sources, looking for prior examples to guide their approach.
- This indicates a potential collaborative opportunity for others with similar experiences to share their insights and solutions.