[AINews] DeepSeek #1 on US App Store, Nvidia stock tanks -17%
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
DeepSeek is all you need.
AI News for 1/24/2025-1/27/2025. We checked 7 subreddits, 433 Twitters and 34 Discords (225 channels, and 11316 messages) for you. Estimated reading time saved (at 200wpm): 1229 minutes. You can now tag @smol_ai for AINews discussions!
We really try to keep news reporting technical here, but on rare occasions, mainstream/nontechnical news is so significant that it gets through.
This is one of those days.
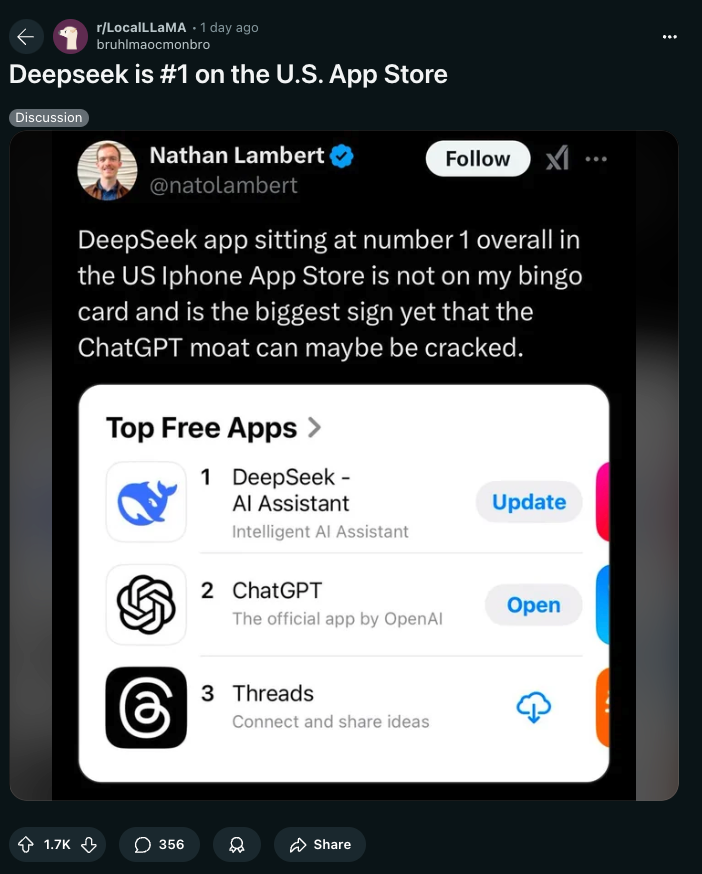
and sama:
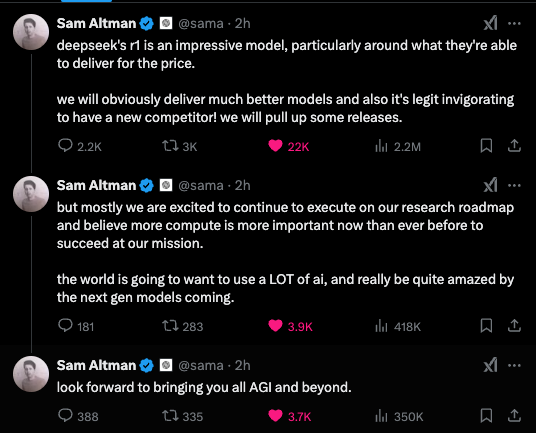
Ultimately much of the discussion is very unhelpful that looks like some version of this

and we are reporting mostly on the cultural moment of DeepSeek hitting mainstream news which was not ever on our bingo card for 2025.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Releases and Enhancements
- DeepSeek-R1 and V3 Efficiency: @teortaxesTex discussed how V3 demonstrates the ability to train a 236B model 42% faster than their previous 67B model, utilizing fp8 precision to maintain speed for larger models. @nptacek highlighted that DeepSeek-R1 requires substantial GPUs, emphasizing its MoE architecture with 671B parameters. @carpeetti praised DeepSeek-R1 for its chain-of-thought (CoT) capabilities, rivaling OpenAI's o1 at a fraction of the cost.
- Qwen2.5 Models: @mervenoyann announced the release of Qwen2.5-VL, a multimodal model capable of handling images and videos, with versions including 3B, 7B, and 72B parameters. @omarasar0 detailed the strong vision capabilities and agentic features of Qwen2.5, supporting long video understanding and structured data outputs.
- LangChain and LangGraph Integration: @LangChainAI shared tutorials on building AI chatbots using LangGraph, enabling memory and tool integration. They also showcased applications like the DeFi Agent, automating Aave protocol operations.
Compute and Hardware
- NVIDIA Impact: @teortaxesTex expressed concerns about training on a 32K Ascend 910C cluster, suggesting potential shorting of NVIDIA stocks. @samyj19 and @ykylee discussed DeepSeek-R1's inference speed optimizations, leveraging NVIDIA H800 GPUs for enhanced performance.
- Compute Demand: @finbarrtimbers argued that compute demand will increase due to inference scaling, despite DeepSeek's efficiency. @cwolferesearch analyzed DeepSeek-v3's Mixture-of-Experts (MoE) design, highlighting its efficiency and performance improvements.
AI Competition and Market Reactions
- Stock Market Reactions: @MiddleOpenAI reported a significant drop in NVIDIA's stock following DeepSeek's advancements, citing a -17% decline due to market fears. @arthurrapier echoed concerns about NVIDIA's bearish signals, while others like @DanHendrycks emphasized the strategic vulnerabilities due to chip supply chain dependencies.
- Competitive Landscape: @scaling01 criticized the market's reaction to DeepSeek, arguing that DeepSeek's efficiencies challenge the assumptions behind high-profit models. @janusflow noted that DeepSeek's releases are disruptive to the tech ecosystem, causing market volatility.
AI Applications and Use Cases
- Agentic Capabilities: @teortaxesTex introduced Grace, Kane, and Flows, AI agents capable of executing commands on computers and smartphones, demonstrating real-time interactions and multi-step reasoning.
- Historical Research and Drug Discovery: @omarsar0 explored the application of LLMs in historical research, such as transcribing early modern Italian and generating historical interpretations. Additionally, integration with drug discovery through hallucination features was discussed.
- Video and Image Processing: @mervenoyann showcased DeepSeek's Janus-Pro for multimodal image generation, surpassing models like DALL-E. @chethaan saggeev highlighted NVIDIA’s Cosmos Tokenizer for physical AI training, enhancing image and video tokenization.
Technical Discussions and Innovations
- Reinforcement Learning and Training Efficiency: @teortaxesTex emphasized the importance of reinforcement learning (RL) in DeepSeek's models, highlighting the independent concurrent work in DeepSeek Zero paradigm. @lateinteraction discussed the absence of a secret revolutionary technique, attributing success to engineering precision.
- Quantization Techniques: @danielhanchen detailed the quantization of DeepSeek R1 to 1.58bit, achieving an 80% size reduction while maintaining usability through dynamic quantization. This innovation allows models to run on more accessible hardware.
- Mixture-of-Experts (MoE) Models: @cwolferesearch explained DeepSeek-v3's MoE architecture with shared experts and multi-token prediction, enhancing both training efficiency and model performance.
AI Business and Market Reactions
- Open-Source vs. Proprietary Models: @ClementDelangue advocated for open-source AI, stating, "AI is not a zero-sum game. Open-source AI is the tide that lifts all boats!" This sentiment was echoed by @cwolferesearch, who praised the transparency and cost-effectiveness of DeepSeek's open-source models.
- Investment Strategies: @swyx advised against shorting NVIDIA, arguing that DeepSeek's advancements drive compute demand rather than reduce it. Conversely, @scaling01 suggested shorting strategies based on DeepSeek's impact on AI compute economics.
- Hiring and Talent Acquisition: @AlexAlbert__ and others mentioned hiring opportunities within AI companies like Anthropic, emphasizing the need for diverse technical backgrounds to drive future AI innovations.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. DeepSeek is #1 on U.S. App Store: Market Implications
- Deepseek is #1 on the U.S. App Store (Score: 1618, Comments: 341): Deepseek has achieved the top position in the U.S. App Store's "Top Free Apps" section, surpassing notable applications like ChatGPT and Threads. This ranking highlights its competitive edge as an Intelligent AI Assistant, with implications for its market position against established AI tools.
- There is skepticism about Deepseek's competitive advantage and concerns about it facing a similar fate as TikTok due to potential national security risks. Some users express frustration with the app's server downtime due to high traffic, while others question its unique offerings to the average user compared to other AI models like ChatGPT and Perplexity.
- The discussion highlights the open-source nature of Deepseek, with users noting that its model weights and training methods could potentially be released, making it more accessible. Some users discuss the feasibility of running Deepseek locally, with references to distilled models that can operate on consumer-grade hardware, though the full model requires significant resources.
- Comments reflect a broader conversation about global competition in AI development, with some users criticizing the notion of a "moat" and emphasizing that multiple countries can create competitive software. There is also debate over the perception of American approaches to technology competition and the implications of Deepseek's open-source approach on international dynamics.
- OpenAI employee’s reaction to Deepseek (Score: 1239, Comments: 256): An OpenAI employee, Steven Heidel, criticized data privacy concerns related to DeepSeek, suggesting that Americans are trading their data to the CCP for free services. The discussion highlights that DeepSeek can operate locally without an internet connection, unlike OpenAI's models.
- Open Source and Local Operation: Many commenters highlight that DeepSeek is open source and can be run on local or cloud hardware, which addresses concerns about data privacy and reliance on foreign entities. TogetherAI is mentioned as a service that hosts the model without using data for training, providing an alternative to running it locally.
- Censorship and Model Transparency: There is skepticism about the transparency of AI models, with some users noting that DeepSeek exhibits censorship tendencies by aligning with CCP narratives, which underscores the need for truly open models like those being developed by HuggingFace.
- Hardware and Accessibility: Discussions around the hardware requirements for running large models like DeepSeek emphasize that while individuals may lack the resources, well-funded startups could potentially afford the necessary infrastructure. Some users mention specific hardware setups, such as using 30 3090/4090s or 9 large 80 GB GPUs, to manage the model's demands.
- 1.58bit DeepSeek R1 - 131GB Dynamic GGUF (Score: 552, Comments: 125): The post discusses the dynamic quantization of the DeepSeek R1 671B MoE model to 1.58bits in GGUF format, effectively reducing the disk size to 131GB by quantizing only the MoE layers to 1.5bit while keeping attention and other layers at 4 or 6bit. This method prevents issues like producing gibberish and infinite repetitions, achieving a processing speed of 140 tokens/s on 2x H100 80GB GPUs, and successfully generating a Flappy Bird game under specific conditions. Additional resources and details are available on Hugging Face and Unsloth's blog.
- Quantization Strategy: The key to the successful quantization of the DeepSeek R1 671B MoE model was only quantizing the MoE layers to 1.5bit while maintaining other layers in higher precision (4 or 6 bits), aligning with principles from the BitNet paper that suggests retaining high precision for certain layers to optimize performance. This approach prevents issues like excessive computational costs and maintains the model's ability to perform complex tasks, such as generating a Flappy Bird game.
- Compatibility and Implementation Concerns: Users discussed challenges and sought guidance on running the model with different setups, such as Ollama, LM studio, and llama.cpp, highlighting the importance of understanding specific implementations and compatibility issues. There were inquiries about hardware requirements, with one user noting that a 24GB GPU like RTX 4090 should handle 1 to 3 tokens/s.
- Community Feedback and Performance Expectations: There was significant positive feedback on the model's performance, with users expressing amazement at its capabilities, especially the ability to generate a bug-free Flappy Bird game. Users also discussed potential performance metrics, such as inference speed on different hardware configurations, and expressed interest in benchmarks and comparisons with other models like Q2KS.
Theme 2. How Deepseek Reduces Costs by 95-97%
- How exactly is Deepseek so cheap? (Score: 386, Comments: 334): Deepseek achieves a 95-97% reduction in costs by employing strategies like avoiding RLHF (Reinforcement Learning from Human Feedback), utilizing quantization, and implementing semantic input HTTP caching. However, there is confusion about whether R1 is quantized, leading to questions about potential subsidies or if OpenAI/Anthropic are overcharging.
- Discussions highlight the cost-saving strategies of Deepseek, emphasizing MoE (Mixture of Experts), FP8 precision, and multi-token prediction (MTP) as key factors. These technological choices, alongside cheap electricity and lower R&D costs, contribute to their significant cost reductions compared to OpenAI/Anthropic. Some users suspect government subsidies or operating at a loss to capture market share.
- There is skepticism regarding the true costs and efficiency of Deepseek's operations, with some commenters questioning the financial transparency and sustainability of their pricing model. Concerns are raised about whether they are using cheaper Nvidia H800 chips and if OpenAI/Anthropic are overcharging due to potentially unsustainable business models.
- The open-source nature of Deepseek's models, available on platforms like Huggingface, is seen as a competitive advantage, allowing for widespread adoption and flexibility in hosting. However, there are doubts about the operational quality and performance of these models, with some users reporting issues in translation capabilities and questioning the credibility of Deepseek's claims.
Theme 3. New Tool for Local LLM Compatibility: 'Can You Run It?'
- Someone needs to create a "Can You Run It?" tool for open-source LLMs (Score: 298, Comments: 64): A non-techie user expresses the need for a tool similar to System Requirements Lab for open-source LLMs like Deepseek, LLaMA, and Mistral, to determine if these models can run on their hardware. They propose a system where users can input their computer specs to receive a straightforward performance verdict and suggestions for optimizations, such as using quantized versions for better compatibility with lower-end systems.
- Several tools and resources are mentioned for determining if LLMs can run on specific hardware, including Vokturz's can-it-run-llm and NyxKrage's LLM-Model-VRAM-Calculator. These tools help users calculate VRAM requirements and assess model compatibility with their systems.
- Community members share rules of thumb for estimating hardware needs, such as 1GB per 1B parameter count and 1GB per 1K context, with recommendations like llama 3.2 or Qwen 2.5 for optimal performance on lower-end systems. They also discuss the impact of quantization and context length on performance and memory usage.
- There is a demand for a user-friendly, open-source tool that offers privacy and keeps up-to-date with model requirements, as expressed by users like Solid_Owl and Shark_Tooth1, who express concerns about privacy and seek a reliable performance expectation tool for local LLM use.
- I created a "Can you run it" tool for open source LLMs (Score: 261, Comments: 50): I created a "Can you run it" tool for open source LLMs that provides a tk/s estimate and instructions for running models with options like 80% layer offload and KV offload on GPU. The tool has been tested on Linux with a single Nvidia GPU, and feedback from other systems, including multi-GPU setups, is requested to identify potential issues. GitHub link.
- Mac Compatibility: Environmental-Metal9 adjusted calculations for macOS, reporting discrepancies in performance estimates on an M1 Max. They offered to contribute a patch for Mac support via a pull request or pastebin.
- User Interface Suggestions: Users, including Catch_022 and MixtureOfAmateurs, suggested simplifying the tool's usability by creating a portable executable with a GUI or hosting it as a website to eliminate the need for Python installation.
- Web Interface and Monetization: Whole-Mastodon6063 developed a web app interface for the tool, and mxforest suggested hosting it online with ads for potential revenue, with Ok-Protection-6612 and femio supporting the idea of monetization through sponsorships.
Theme 4. Qwen 3.0 MOE: Emerging Reasoning Model
- Qwen3.0 MOE? New Reasoning Model? (Score: 239, Comments: 34): Qwen3.0 MOE and a potential New Reasoning Model are hinted at in a tweet by Binyuan Hui, suggesting upcoming announcements or events. The tweet implies significant developments in AI, though specific details are not provided.
- Qwen2.5-VL is confirmed to be part of the upcoming releases, with a collection already created on Hugging Face. This suggests imminent updates beyond just vision models, possibly including Qwen MoE and Qwen 3.0.
- DeepSeek is mentioned as a partner to handle the significant compute needs, with some users hoping for new reasoning models under Apache/MIT licenses. There is anticipation for various model sizes and capabilities, including audio and large-scale models like Qwen 2.5 100B+.
- The timing of the announcements is questioned due to the proximity to the Chinese New Year holiday, with skepticism about the hype surrounding the release.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Nvidia Stock Volatility: Impact of DeepSeek's Efficient Model
- Nvidia Bubble Bursting (Score: 627, Comments: 245): Nvidia's stock has experienced a significant decline, with a drop of $17.66 (12.68%) over five days, from a peak of $142.02 on January 24, 2023, to $121.56 by January 27. The company's market cap is reported at $2.97 trillion, with a P/E ratio of 48.07, and a 52-week range between $60.70 and $153.13.
- Many commenters view the stock decline as a buying opportunity, with several expressing confidence that Nvidia will rebound. itsreallyreallytrue and AGIwhen suggest that the demand for Nvidia's GPUs remains strong due to their critical role in AI infrastructure, despite DeepSeek's claims of reduced GPU requirements.
- Discussions highlight skepticism towards DeepSeek's claims and their impact on Nvidia's stock, with TheorySudden5996 and Agreeable_Service407 noting that despite potential efficiency gains, the need for GPUs remains significant. DerpDerper909 argues that even with efficiency improvements, Nvidia will benefit from the lowered entry barriers for smaller companies developing AI models.
- Cramer4President and others criticize the notion of a "bubble bursting" based on short-term stock performance, advocating for a broader perspective over a longer timeframe. OptionsDonkey and Legitimate-Arm9438 emphasize that Nvidia's long-term value remains strong, suggesting that the current dip is a temporary fluctuation rather than a fundamental issue.
- Was this about DeepSeek? Do you think he is really worried about it? (Score: 540, Comments: 203): Sam Altman highlights the challenge of creating innovative and risky projects compared to copying existing successful ideas, emphasizing the importance of recognizing individual researchers for their groundbreaking work. He concludes by stating that these efforts represent the "coolest thing in the world."
- Criticism of Sam Altman's Statement: Many commenters criticized Sam Altman's emphasis on individual researchers, arguing that breakthroughs are often the result of collaborative efforts. Neofelis213 highlighted the myth of the lone researcher and pointed out that figures like Sam Altman and Elon Musk often overshadow the actual contributors to technological advancements.
- Historical Context and Contributions: Discussions focused on the origins of transformer architecture and LLMs, with users noting that Google published the foundational paper, "Attention Is All You Need," which OpenAI built upon. coloradical5280 and others emphasized the collaborative nature of these developments and the role of key figures like Ilya Sutskever in evolving the technology.
- Ethics and Copyright Concerns: Several comments addressed the ethical implications of using copyrighted material in training AI models, with Riegel_Haribo mentioning the large-scale copyright infringement involved in AI training. This sparked debates over the legality and fairness of using public data, referencing historical cases like Aaron Swartz's prosecution.
- "Every model has censorship" is an ignorant argument (Score: 179, Comments: 146): The post criticizes Western perceptions of DeepSeek and ChatGPT censorship, arguing that while both have censorship, the CCP's is far more harmful as it suppresses criticism of authoritarian power. The author emphasizes that Chinese AI models are universally government-censored, unlike Western alternatives, and highlights the exploitation of Chinese citizens under the CCP, with many earning less than $4,000 annually and lacking free healthcare. The post condemns Westerners for overlooking these issues in favor of cheap Chinese products.
- Several commenters argue that censorship and authoritarianism are not unique to China, as the US also engages in similar practices, including censorship in AI models like Gemini and ChatGPT, and reliance on undocumented labor. They argue that Western AI models are also censored to protect political interests and that the US has its own issues with wealth inequality and exploitation.
- Discussions highlight the exploitative nature of AI technology, noting that datasets are often compiled using unpaid intellectual property and that the labor involved in creating and maintaining these technologies is undervalued. Commenters criticize the hypocrisy in condemning China's practices while ignoring similar issues in Western countries, such as the role of companies like Lockheed Martin in government spending and the role of billionaires like Larry Ellison in AI surveillance.
- Some commenters express skepticism about the impact of censorship on AI development, suggesting that open-source projects like those on HuggingFace can bypass censorship. They note that the rapid progress in AI, with models like R1 being reverse-engineered, diminishes the power of censorship, as more models are developed locally and with fewer restrictions.
Theme 2. DeepSeek R1's Coding Efficiency vs OpenAI O3
- DeepSeek R1 is 25x cheaper than o1 and better in coding benchmarks than the "unreleased" o3 at the same* cost. DeepSeek is giving OpenAI a run for their money. (Score: 355, Comments: 111): DeepSeek R1 is positioned as being 25x cheaper than OpenAI's o1 model and demonstrates superior coding performance compared to the "unreleased" o3 at a similar cost. Graphical data highlights DeepSeek R1's favorable 15.8% performance score in coding benchmarks, underscoring its cost-effectiveness and competitive edge against other models.
- Several commenters question the credibility of DeepSeek R1's performance claims, highlighting the presence of a question mark in the data and the need for third-party validation. Concerns are raised about the paper's methodology and the lack of verifiable information regarding the training hardware.
- There is skepticism about the frequency and nature of DeepSeek promotions, with suggestions of a possible deliberate campaign or "astroturfing." Commenters compare this to the promotion of other models like Claude and Gemini, noting a similar pattern of aggressive marketing.
- Some users express support for increased competition in the AI space, hoping for more entrants like Meta and Claude. However, others are frustrated with the overwhelming number of promotional posts about DeepSeek, questioning its actual utility and performance compared to established models like OpenAI and Claude.
Theme 3. Debates on DeepSeek vs ChatGPT: A Censorship Perspective
- Octopus-inspired logarithmic spiral manipulator can manipulate a wide variety of objects (Score: 537, Comments: 41): The post title suggests a discussion on a logarithmic spiral manipulator inspired by an octopus, capable of handling diverse objects. The ethical implications of AI in political censorship are not directly addressed, indicating a possible mix-up between the topic and the title.
- Technological Origin: The logarithmic spiral manipulator technology was developed by the University of Science and Technology of China, with testing also conducted in China. This clarifies any confusion about the origin, as some comments mistakenly attributed it to Japan.
- Design and Construction: The manipulator appears to be constructed from 3D printed pieces and operates using two threads on opposite sides, emphasizing the significant role of software in its functionality. There is interest in the possibility of the software being open source, which could make it more accessible for use.
- Public Reaction and Humor: The discussion includes humorous and dystopian reactions, with references to robot tentacles and their potential use in both war and entertainment scenarios. This highlights the mixed feelings and imaginative speculation surrounding advanced robotics.
AI Discord Recap
A summary of Summaries of Summaries by o1-preview-2024-09-12
Theme 1. DeepSeek R1 Models Upending the AI Landscape
- DeepSeek R1 Shrinks to 1.58-Bit, Packs a Punch!: Community marvels at DeepSeek R1 running at 1.58-bit quant, reducing size from 720GB to 131GB, yet retaining full reasoning capabilities.
- DeepSeek R1 Challenges OpenAI O1 Head-On: Users compare DeepSeek-R1 to OpenAI's O1, noting that R1 matches or surpasses O1 in performance on benchmarks like aider's polyglot.
- DeepSeek's Debut Rattles Tech Market: Reports claim DeepSeek's R1 caused a $600 billion drop in US tech stocks, fueling discussions about China's rising AI prowess; see the frenzy in this Bloomberg clip.
Theme 2. Qwen2.5 Models Breaking Context Barriers
- Qwen2.5 Unveils 1 Million Token Context—Is Bigger Better?: Alibaba releases Qwen2.5 models with a whopping 1 million token context length, sparking debates on the practicality of such large contexts.
- Qwen2.5-VL Excels at OCR—Handwriting No Problem!: The new Qwen2.5-VL-72B-Instruct impresses users with its advanced OCR capabilities, including handwriting analysis and robust visual content parsing.
- Qwen2.5-VL vs DALL-E 3: The Battle of Vision-Language Models: Users compare Qwen2.5-VL's visual understanding to models like DALL-E 3, highlighting its ability to handle structured data outputs in finance and commerce tasks.
Theme 3. AI Tools Advance, Integrating Into Developer Workflows
- RAG Tactics Spark Dev Conversations: Developers delve into retrieval-augmented generation methods, discussing vector stores and embeddings like voyage-code-3.
- Codebase Indexing: A Bare-Bones Approach?: Some users criticize codebase indexing tools for not fully leveraging project files, referencing Cursor's documentation, while others find them useful with proper configuration.
- AI Pair Programming Takes Off with Aider and CodeGate: CodeGate integration allows developers to pair program directly in the terminal, enhancing coding workflows with AI assistance.
Theme 4. OpenRouter Expands with New Models and Providers
- Liquid AI Makes a Splash on OpenRouter: Liquid AI brings multilingual models LFM 40B, 7B, and 3B to OpenRouter, claiming top performance in major languages.
- DeepSeek Nitro: Fast but Not Furious Enough?: The Nitro variant for DeepSeek R1 promises faster responses, but users report it doesn't outperform the standard R1 in real-world scenarios.
- OpenRouter Users Bring Their Own Keys (BYOK): Discussions emphasize using personal API keys with OpenRouter to mitigate rate limits and control expenses, with a 5% fee applied on usage.
Theme 5. Global AI Policies and Investments Heating Up the Competition
- China's 1 Trillion Yuan Bet on AI Ignites Global Race: China announces a 1 trillion yuan ($137B) investment in AI, as reported here, raising questions about the US's ability to keep pace.
- US Debates AI Policy Amid Great Power Competition: Discussions highlight the US considering funding AI under the banner of great power competition, drawing parallels to historical industrial policies like the CHIPS Act.
- DeepSeek's Rise Raises Geopolitical Eyebrows: The success of DeepSeek's models fuels concerns over China's growing influence in AI, prompting analysis of AI's role in national competitiveness.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- DeepSeek R1 Levels Up: Community members showcased DeepSeek R1 running at 1.58-bit quant with fully functional reasoning, citing this tweet and highlighting a size reduction from 720GB to 131GB.
- They compared DeepSeek-R1 to OpenAI’s O1 model, noting growing interest in local usage and open-source collaboration for advanced reasoning tasks.
- Qwen2.5’s Million-Token Release: Chat focused on Qwen2.5 from Alibaba, revealing 1 million token context length in the Qwen tweet and mentioning 14B parameter instruct versions.
- Members debated whether the expanded context size justified the hype, expressing optimism about large-scale local inference supported by abundant VRAM.
- SmoLlm Fine-Tuning Gains Traction: Multiple users tested SmoLlm fine-tuning with Unsloth and successfully deployed it using ollama with default temperature
0.8, clarified in a discussion thread.- They emphasized smooth integration into personal workflows, stating “It just works without explicit temperature settings” and confirming readiness for local code review tasks.
- Nuances in Dataset Formatting: Users exchanged tips about structuring training data with 'instruction', 'input', and 'output' fields, referencing examples from Wikimedia dataset and personal forum collections.
- They pinpointed how mismatched field names caused Unsloth errors during fine-tuning, reinforcing the need for consistent question-answer formats to ensure correct model behavior.
Cursor IDE Discord
- Speed Struggles or Speed Gains? Cursor IDE in Focus: Users reported slow request times and some friction with Claude on Cursor, with a partial fix during off-peak hours as described in Fast and Slow Requests – Cursor.
- They also praised DeepSeek R1 for certain tasks and mentioned the possibility of using Spark Engine as a complement to reduce request times and costs.
- Claude vs DeepSeek: Battle for Code Insights: DeepSeek R1 excelled at planning tasks, while Claude produced more advanced responses, as shown in DeepSeek R1 - API Docs.
- Community discussions noted that using DeepSeek for simpler tasks saves money, but users still relied on Claude for heavier code generation and debugging.
- Codebase Indexing: A Bare-Bones Approach?: Some users felt Cursor’s codebase indexing wasn't leveraging all project files, as shown in Context / Codebase Indexing – Cursor.
- Others defended it, arguing that indexing can improve code suggestions and recommended adjusting settings for better results.
- RAG Tactics Spark Dev Conversations: Talk of retrieval-augmented generation methods included vector stores and embedding approaches like voyage-code-3 described in this blog post.
- Participants stressed that well-structured embedding and retrieval can minimize mistakes and boost output quality for code-heavy projects.
- Stepping Away from Claude: Alternatives Abound: Some users weighed swapping out Claude for DeepSeek in simpler scenarios, while also exploring GitHub Copilot and Spark Engine.
- Opinions varied, but the conversation pointed to blending each platform’s strengths for a balanced workflow.
Codeium (Windsurf) Discord
- Windsurf 1.2.2 Debuts with Smoother Cascade: The team launched Windsurf 1.2.2 featuring enhanced Cascade memory and fixes for laggy conversations, as noted in Windsurf Editor Changelogs. Cascade now supports web queries or direct URL inputs, making prompt interactions more dynamic.
- Despite these fixes, some users still encounter internal error spikes that disrupt daily coding tasks, prompting calls for further stability updates.
- Performance Takes a Hit & Free Credits Slashed: Frequent errors and latency across channels have led to frustration and lost credits, weakening trust in Windsurf. The free plan now offers only 5 premium model credits (down from 50), as indicated in Pricing.
- Community feedback highlights concerns that these changes limit new-user onboarding and hamper debugging sessions.
- DeepSeek's Debut Remains Uncertain: Conversations suggest that a DeepSeek integration into Codeium is not arriving anytime soon, raising worries about missing out on its budget-friendly operation. Some users openly discuss ditching Windsurf if no timeline is announced soon.
- They also question DeepSeek’s reliability for tool calls, expressing hope for Codeium to address these doubts quickly.
- Git to the Rescue: Members recommend version control with Git to guard against unexpected errors triggered by Cascade and Windsurf updates. They cited resources such as Learn Git Branching to keep code stable and maintain progress.
- Best practices like tagging milestones and reverting to previous commits help prevent major setbacks when AI-driven changes fail.
Perplexity AI Discord
- Perplexity’s R1 Rollout Raises Ruckus: R1 replaced older favorites like O1 and Grok on Perplexity Pro, limiting daily queries to 10 and sparking user outcry.
- Some threatened to switch to DeepSeek or ChatGPT, citing subpar performance and unclear usage terms, while others demanded refunds via this reference.
- DeepSeek’s Data Dilemma Divides Opinions: DeepSeek triggers privacy concerns due to Chinese ownership, with users worrying about US-to-China data routing practices.
- Community feedback mixes caution and curiosity, as some see potential in DeepSeek’s R1 model but question data sovereignty for sensitive queries.
- Billion-Dollar Brainchild: The $500B AI Shift: A rumored $500 billion deal could reshape AI according to this source, fueling speculation about future directions in automation and machine learning.
- Contributors view this possibility as a major pivot point for advanced research funding, seeing parallels with past booms that propelled new AI frameworks.
- Startup’s $200M Path and S&P Soars: A member showcased how to bootstrap a $200 million startup exit in the Wingify approach, focusing on resourceful scaling and investor relations.
- They also noted the S&P 500 hit a record closing high, which they believe adds momentum for ambitious founders eager to replicate this success.
Nous Research AI Discord
- Nous Psyche Nudges Collaboration: Nous introduced Nous Psyche on Solana, a cooperative training network for open-source generative AI using heterogeneous compute, with code shared via GitHub.
- They plan a testnet event on the 30th in partnership with the Solana Foundation, referencing mythic inspiration on their blog to unify developers.
- DeepSeek R1 Distillation Gains Ground: Researchers referenced the Distilling System 2 into System 1 paper (arXiv), proposing new improvements for R1 distillation models.
- They also pointed to potential synergy with Bespoke-Stratos-17k to refine dataset coverage and handling.
- LLM Live2D Desktop Assistant Debuts: The new LLM Live2D Desktop Assistant supports Windows and Mac, featuring voice triggers and full computer control with screen sensing.
- Its approach merges system clipboard retrieval and interactive commands, giving users a lively character interface for daily tasks.
- Qwen2.5-VL Breaks OCR Barriers: The new Qwen2.5-VL-72B-Instruct model shows advanced OCR, including handwriting analysis and robust visual content parsing.
- Community members praised its strong text recognition capabilities across images, signaling a big leap for multi-modal tasks.
- Human-Like LLM Paper Sparks Ethical Debate: The paper Enhancing Human-Like Responses in Large Language Models explores refined techniques for natural language understanding and emotional intelligence in AI.
- It highlights gains in user engagement while raising concerns about biases, urging a closer look at the human-AI dynamic.
OpenAI Discord
- Canvas Connects with O1: OpenAI introduced a new update enabling ChatGPT Canvas to work with OpenAI o1 and render HTML and React code on macOS desktop apps for all tiers.
- They teased upcoming releases for Enterprise and Edu users, signaling extended features for professional settings.
- DeepSeek Rattles Tech Market: DeepSeek R1 went head-to-head with O1 and GPT-4o, garnering praise for code-generation accuracy and cost advantages.
- Its debut allegedly wiped out nearly $600 billion from major US tech stocks, fueling speculation about bigger disruptions in the AI race.
- O3 Mini Teeters on Release: Community buzz indicates O3 Mini may launch soon, though some fear it might be just a slight upgrade over O1 Mini without true multimodal features.
- A tweet from Sam Altman promised 100 daily queries for Plus tier, hinting at extended operator access on the horizon.
- Token Troubles with Tiktoken: Users reported uncertainties around Tiktoken splitting tokens into single characters, causing confusion in certain inputs.
- It sparked discussions about special token limits, pointing to research that might explain Tiktoken's irregular merging rules.
- LangChain’s ChatPrompt & Vector Stores: Members explored feeding vector store documents into LangChain’s ChatPromptTemplate, noting limited official guidance.
- They considered the standard prompt route as a fallback, awaiting any success stories for more robust configurations.
aider (Paul Gauthier) Discord
- DeepSeek Derailed by Attacks: Malicious attacks hammered the DeepSeek API, causing intermittent outages and slower response times, as confirmed by DeepSeek Service Status and user reports.
- Some noted surging demand for R1-based offerings, while others speculated on the severity of these attacks, exploring OpenRouter alternatives.
- LLM Inference Providers: Profit or Pitfall?: Inference provider profitability hinged on high utilization to offset fixed costs, as members weighed different pricing models among various services.
- Some agreed low usage yields slim margins, spurring discussion on synergy with high-traffic releases like DeepSeek-R1-Nitro.
- R1 vs O1 Rivalry Ramps Up: A fresh benchmark hinted DeepSeek's R1 with Sonnet might outperform O1 in certain scenarios, backed by data from R1+Sonnet set SOTA on aider’s polyglot benchmark.
- Skeptics insisted O1 Pro excels at coding tasks, while some pinned hopes on R1’s 1.58-bit format referenced in Tweet from Unsloth AI.
- Qwen2.5 & Janus-Pro Storm the Scene: Alibaba Qwen2.5-1M and Janus-Pro captured attention for their 1 million token contexts, highlighted in Qwen's tweet and Janus-Pro mentions.
- Commenters regarded them as formidable contenders against O1, citing parallels with DeepSeek-R1 on DeepInfra.
- Aider Allies with CodeGate (and Rust): CodeGate integration authorized Aider users to pair program directly in the terminal, toggling between OpenAI and Ollama via API keys.
- Others tested new Rust crates within Aider for boosted context, noting that architect mode hides editor model responses, leading them to request bug fixes on GitHub.
LM Studio Discord
- DeepSeek Distill Delights: Participants tested DeepSeek R1 Distill across Q3 and Q4 quants, praising its strong knowledge retention and performance on LLM Explorer directories.
- They observed that higher parameter models can boost coding tasks but require careful concurrency and VRAM planning for smooth inference.
- Chatter UI Confusion: Members reported issues when hooking Chatter UI to LM Studio, tracing faults to incorrect URLs and port conflicts in the ChatterUI GitHub repo.
- They urged verifying local host addresses and aligning LM Studio’s recognized endpoints to stabilize requests.
- Apple M3 Max Token Tempo: A few users estimated DeepSeek-R1 hitting 16–17 tokens per second on an Apple M3 Max with 48GB RAM, underlining hardware constraints.
- Discussions centered on the chip architecture’s efficiency limits, with some considering load balancing methods in llama.cpp for added speed.
- MoE Maneuvers: Enthusiasts examined Mixture of Experts (MoE) solutions for specialized tasks, noting potential performance gains in code generation workflows.
- They emphasized memory considerations and pointed to MoE resources for practical insights and deployment strategies.
OpenRouter (Alex Atallah) Discord
- Liquid AI Floats into OpenRouter: Liquid AI introduced new models LFM 40B, LFM 3B, and LFM 7B via OpenRouter as they expanded multilingual coverage.
- They cited LFM-7B as their top pick for enterprise chat, highlighting a strong performance-to-size ratio across major languages.
- DeepSeek Nitro: Speedy Shortcut or Letdown?: The Nitro variant for DeepSeek R1 launched with claims of faster responses, as seen in the announcement.
- Some users reported that it failed to surpass standard R1 in real-world performance, while feedback hinted at heavy user demand causing system strain.
- Amazon Nova's Abrupt Crash: The Amazon Nova models are down because Amazon Bedrock flagged a surge in usage as a key leak, causing a misleading 400 status code.
- Teams are rushing to resolve this upstream issue, with official updates expected once the service stabilizes.
- DeepSeek's Overloaded Ordeals: Frequent 503 errors and slow response times plagued DeepSeek R1, pointing to high traffic as well as potential malicious activity.
- DeepSeek limited new registrations and faced reliability concerns, highlighting the challenge of accommodating intense user loads.
- BYOK Gains Steam: OpenRouter discussions emphasized feeding BYOK to mitigate rate limits and control expenses, with a 5% fee on usage.
- Community members agreed that plugging in personal keys can help dodge bottlenecks, though some worried about cost management complexities.
Yannick Kilcher Discord
- Janus Jumps Ahead: DeepSeek introduced Janus Pro model, boasting advanced reasoning performance without high-end GPU requirements, fueling speculation about new frontiers beyond US-based benchmarks.
- Participants praised Janus Pro’s improved multimodal understanding, referencing the whitepaper titled Janus-Series: Unified Multimodal Understanding and Generation Models, and debated its potential to shift tech market sentiment.
- Qwen2.5-VL’s Visionary Venture: Alibaba Qwen revealed Qwen2.5-VL-72B-Instruct celebrating the Chinese New Year, emphasizing long video comprehension and advanced visual recognition.
- Discussion highlighted its capacity to handle structured data outputs for finance and commerce tasks, while a blog post details its context length reaching 1M tokens for broader enterprise use cases.
- GPRO Gains Ground in PPO: A robust conversation centered on GPRO’s elimination of the Value Function and Generalised Advantage Estimation (GAE), with claims it might address stuck loss and early convergence issues in PPO.
- Users noted GAE’s reliance on a discounted sum hinders scaling in certain scenarios, whereas GPRO’s globally normalized rewards keep training stable, prompting curiosity about integration with open-source RL libraries.
- DSL Dreams & PydanticAI Pronto: A member explored PydanticAI for structured output in production-grade generative apps, suggesting it could integrate with LlamaIndex+LangChain.
- They also discussed building a workout logging app that converts natural language to DSL, referencing the Microsoft ODSL paper for partial solutions and emphasizing the challenge of voice-to-DSL pipelines.
Interconnects (Nathan Lambert) Discord
- DeepSeek’s Double Punch: R1 & Janus Pro: DeepSeek’s new R1 model generated major buzz for its open-weight approach, matching or surpassing some established LLMs in reasoning and performance benchmarks with minimal training cost. Industry chatter points to the release of Janus Pro (7B) on Hugging Face, emphasizing transparency and advanced capabilities for both text and images.
- Skeptics questioned R1’s generalization and reasoning limits, while others praised its impressive leaps in math and coding tasks. As a result, big players like Meta have set up "war rooms" to analyze DeepSeek’s training recipes and cost efficiency.
- Qwen2.5-VL Lights Up Vision-Language Fusion: Alibaba’s Qwen2.5-VL debuted with powerful multimodal capacity, supporting long video comprehension and precise localization. Observers compared it to past major releases, noting potential shifts in perception and competition for vision-language models.
- Developers highlighted the dramatic performance gains on curated tasks, prompting speculation about real-world use cases. Official demos and commits (e.g. Qwen2.5-VL GitHub) show a convergence of advanced image-to-text synergy and lengthy context handling.
- Nous Psyche Hack & Solana Setup: Nous Research launched Nous Psyche, a Solana-based cooperative training network aimed at open superintelligence initiatives. Though the concept fueled excitement, news of a hack rattled trust in its security measures.
- Discussions also touched on broader questions around open labs vs. well-funded closed labs in advancing sophisticated generative models. The hack underscored the importance of rigorous safeguards when merging blockchain ecosystems with AI training.
- Tulu 3 vs Tulu 4 & Preference Tuning Woes: Enthusiasts revisited Tulu3, noting the use of off-policy data in preference tuning despite the common stance favoring on-policy approaches. This signaled ongoing complexities in perfecting preference-based training pipelines.
- Anticipation grows for Tulu4, with users hoping it addresses the hills faced by Tulu3. Discussions highlight the unresolved challenges in scaling preference tuning to broader applications.
- China’s Multi-Billion AI Policy & Global Ripples: China’s announcement of a 1 trillion yuan ($137B) investment in AI led to intense speculation about rapidly expanding R&D. Participants noted parallels to US industrial policies like the CHIPS Act but questioned America’s readiness to match large-scale AI funding.
- Defense-related angles emerged as Republicans might fund AI under great power competition ideals. For engineers, these policies might grant more cutting-edge hardware and incentives, intensifying the global AI race.
Latent Space Discord
- DeepSeek R1 Sparks Debate: Members noted a $5M training cost (referencing DeepSeek V3) in its project report, also mentioning an image attachment as confirmation. DeepSeek R1 claims to rival older closed models like o1 at a fraction of the cost, raising questions on open-source competitiveness.
- Community chatter highlighted a new SOTA claim on aider’s polyglot benchmark from R1+Sonnet, and tweets suggesting strong results leave many curious about deeper reasoning capabilities.
- Qwen2.5-VL vs DALL-E 3 Face-Off: Alibaba launched Qwen2.5-VL, a multimodal model aiming to surpass DALL-E 3 on visual understanding and localization, as seen in their official announcement. The model also competes with Stable Diffusion on specific benchmarks, emphasizing advanced image generation features in their Qwen collection.
- Users compared metrics on GenEval and DPG-Bench, noting Janus-Pro-7B from DeepSeek also contends in the multimodal space, fueling a broader conversation on cost-effectiveness and real-world applicability of these newer models.
- Operator & Reasoning Models Make Waves: Participants praised Operator for generating initial codebases quickly, but raised concerns on handling complex sites and video sampling rates, shown in this video demo. In parallel, discussions on reasoning models like R1 suggested advanced agentic capabilities for coding tasks and beyond.
- Some credited function calling benchmarks for pointing out multi-step constraints, adding perspective on how DeepSeek R1 and others handle intricate workflows when integrated into development pipelines.
- Model Context Protocol (MCP) Gathers Momentum: Members showed enthusiasm for MCP as a unifying approach to integrate AI features across tools, referencing servers built in Go, Rust, and even assembly, per MCP server repos. They compared how it interlinks with Obsidian for transcription and documentation through plugins like mcp-obsidian.
- Plans for an MCP party encourage community feedback and synergy, with a call to review the latest specs and tutorials, highlighting a strong interest in consistent cross-application protocols.
- Latent Space Launches a New Pod: A brief mention announced a fresh episode on the Latent Space podcast, shared here.
- The community welcomed the update, anticipating discussions that might delve further into these emerging AI technologies and collaborative initiatives.
Eleuther Discord
- Layer Convergence & Tokenization Tactics: In an ICLR 2023 paper, members observed how Layer Convergence Bias makes shallower layers learn faster than deeper ones.
- Another group applauded the new Causally Regularized Tokenization from Armen Aghajanyan's paper, noting improved efficiency in LlamaGen-3B.
- DeepSeek R1 & GRPO Gaps: Participants questioned DeepSeek's cheaper-chip claims for R1, referencing approximate training costs of $1.6M and a shortage of open-source details.
- AlphaZero Evolution & Curiosity-Driven AI: Adopters recognized AlphaZero's streamlined design but noted that practical setups rarely jump straight to its techniques.
- Some pointed to empowerment concepts (Wikipedia entry) and curiosity-driven methods as flexible approaches for future large-scale training.
- Scaling Laws & The 20-Token Trick: A Chinchilla library analysis suggested the 20-tokens-per-parameter rule nearly matches fully-optimized Chinchilla setups.
- Community members linked this to flat minima in tokens-per-parameter ratios, indicating minor deviations may not hurt performance drastically.
- Interpretability & Multi-turn Benchmarks: Some users highlighted verified reasoning in training as a new priority for interpretability, focusing on how LLMs reason rather than just outputs.
- Meanwhile, frameworks like scbench, zeroSCROLLS, and longbench are being integrated, though their multi-turn nature may require distinct implementation strategies.
Stackblitz (Bolt.new) Discord
- System Prompt Panache: You can now set up a system prompt on a project or global level in Bolt, letting you inject your preferred libraries and methods from the start.
- Community members are trading tips on the best ways to shape Bolt's behavior, with calls to share advanced usage tricks for smoother development.
- Structuring & Splitting Strategies: Members debated the impact of too-rigid planning on creativity, referencing cycles of restarts and the need for flexible approaches when dividing complex components.
- One user recommended a systematic approach with a NEXTSTEPS.md outline, noting how structured migrations help maintain clarity without stifling new ideas.
- Guidelines as a Safety Net: Adhering to GUIDELINES.md improved stability, ensuring each component was built in sequence and integrated with a properly managed context window.
- Participants credited these guardrails for avoiding chaotic merges, with stable documentation practices paving the way for consistent progress.
- Bolt's Billing & Error Bruises: Some folks complained about massive token usage and frequent rate limits, mentioning issues with refunds and cost discrepancies.
- Error messages and network failures left them searching for professional help, as Bolt sometimes consumed large amounts of tokens without delivering results.
- Supabase Roles Earn a Win: A user overcame complicated Supabase policies to build multiple login roles, including super admin and admin, tackling recursion pitfalls.
- Integrations with Netlify and GitHub were also explored, though private repos remain off-limits for now, prompting further modifications to Bolt's core features.
MCP (Glama) Discord
- MCP Client Complaints & Voice Chat Groans: Developers wrestled with the inability to dynamically update MCP client tools without restarts, calling for clearer voice integration docs in multimodal-mcp-client.
- Much attention went toward server config improvements and minimizing proprietary API reliance, especially for Kubernetes deployments.
- Variance Log Tool Catches Oddities: The MCP Variance Log solution collects low-probability conversation events in a SQLite database for user data analysis.
- Adopters pointed to the Titans Surprise mechanism as inspiration for an approach that can bolster long-term memory across agentic workflows.
- KoboldCPP & Claude Make New Connections: A fresh KoboldCPP-MCP Server fosters AI collaboration among Claude and other MCP apps as shown on GitHub.
- Community members noted it paves the way for more synchronized tasks and deeper AI-to-AI interactions.
- Inception Server Runs Parallel LLM Missions: The MCP Inception server allows concurrent queries with various parameters, detailed in its repo.
- Developers plan to extend functionality for cryptocurrencies via scraping, hinting at expanded use cases.
- Shopify Merchants Chat With Claude: An MCP server for Shopify uses Claude for store analytics, as shown in this repo.
- Current endpoints focus on products and orders, giving merchants a path to direct AI-driven data insights.
Notebook LM Discord Discord
- HeyGen Scenes & ElevenLabs Tones: One user showcased a workflow with HeyGen and RunWayML’s Act-One to produce lifelike avatar videos that appear to be listening, linking to UnrealMysteries.com.
- They also revealed an ElevenLabs voice named "Thomas," evoking a HAL vibe for extra flair.
- NotebookLM for Podcast Summaries: A user employed NotebookLM to condense weekly news into a podcast format, praising its quick summarization.
- Others hope for stronger prompts to improve audio content creation and push the tool's capabilities.
- Mixing HeyGen & MiniMax: Members experimented with hybrid content, combining HeyGen stills and insights from MiniMax for extended videos.
- They observed more engaging narratives than using either technology alone, sparking further creative attempts.
- NotebookLM Constraints & Confusion: Members encountered missing linked sources in NotebookLM after UI changes, prompting concerns about lost references.
- Another user discovered a 1000-note limit, urging clearer documentation for advanced usage.
- Language Twists & PDF Page Disputes: Some folks wrestle with default language settings, toggling URLs like notebooklm.google/?hl=es for better control.
- Others notice partial PDF pages failing to produce insights, pointing to inconsistent page references in NotebookLM.
Stability.ai (Stable Diffusion) Discord
- Hunyuan-Video Triumphs on 12GB VRAM: The hunyuan-video model runs effectively on as little as 12GB VRAM, delivering local image-to-video processing that appeals to many developers.
- Community members praised its usability for casual experimentation, referencing Webui Installation Guides for advanced tweaks.
- Kling AI Lacks Image-to-Video Features: Users noted that Kling AI stands close to hunyuan in image quality, but it doesn't support video conversion yet.
- They found the missing function disappointing for a complete pipeline, with some hoping updates will address this gap soon.
- Forge vs Swarm for New Image Creators: Forge and Swarm emerged as popular picks for newcomers seeking simpler local AI image generation tools.
- Advanced users recommended ComfyUI for more flexibility, but they cautioned beginners about its extra complexity.
- Stable Diffusion Prefers 32GB RAM or More: A well-equipped system with 32GB RAM is best for Stable Diffusion, and 64GB ensures a smoother experience.
- Members running RTX 4090 or AMD 7900XTX reported fewer hardware conflicts once they upgraded their memory.
- Deepseek Requires Massive 1.3TB VRAM: The Deepseek lines, including V3 and R1, need more than 1.3TB of VRAM at full precision, which surpasses consumer-level gear.
- People with multi-GPU clusters like A100 or H100 cards can handle these models, forcing everyone else to look for smaller alternatives.
GPU MODE Discord
- DeepSeek Doubles with TinyZero & Open R1: The TinyZero project replicates DeepSeek R1 Zero in a clean, accessible way, offering images and details for contributors. Meanwhile, Open R1 by Hugging Face provides a fully open take on DeepSeek-R1, encouraging collaborative development.
- Both repos invite community involvement, showcasing a strong push toward reproducible research in HPC contexts.
- Taming NCCL Timeouts for HPC: Multiple members reported NCCL timeouts during multi-node training and asked for best practices in debugging. They profiled GPU jobs and considered advanced strategies to handle timeouts in large-scale setups.
- The community documented common pitfalls including mismatch of CUDA versions, emphasizing the need for robust HPC debugging tools.
- Adam Paszke’s Mosaic GPU DSL Magic: Renowned Adam Paszke discussed his Mosaic GPU DSL in a live YouTube session, emphasizing low-level GPU programming. Community members can find supplementary materials on GitHub and join Discord for active learning.
- The talk promises deeper exploration of layout systems and tiling for GPU optimization.
- JAX Runs FP8 on Legacy GPUs: A GitHub discussion revealed JAX can use fp8 on Nvidia GPUs with sm<89, defying typical hardware constraints. PyTorch users reported failures on older GPUs, sparking intrigue about JAX’s workaround.
- This gap piqued interest in how exactly JAX bypasses standard limitations, prompting further exploration of library internals.
- Arc-AGI Expands with Maze & FSDP: The Arc-AGI environment gained polynomial equations, maze tasks, and more examples in reasoning-gym, referencing algorithms from CLRS. Meanwhile, Tiny-GRPO introduced FSDP support, slashing VRAM usage and boosting efficiency.
- Members also floated ideas on family relationship data and GSM8K templates, planning to push to the HF hub for user-friendly downloads.
Modular (Mojo 🔥) Discord
- Mojo Docs Vanish, Then Reappear: The Mojo documentation abruptly went offline due to Cloudflare hosting troubles, sparking user frustration.
- The dev team apologized and confirmed the docs were back online with updated references from the Mojo GitHub changelog.
- New GPU Package API Hits Nightly: Users confirmed that the GPU package API docs landed in the nightly release, offering advanced GPU functionality in Mojo.
- They welcomed this addition as a significant improvement, pointing to the changelog for recent updates.
- CSS Struct Fluent API Sparks Warnings: A developer built a
structto generate CSS using a fluent API style but encountered unused value warnings in Zed Preview.- They tried
_ =to suppress the warnings yet wanted a cleaner solution to maintain code clarity.
- They tried
- List and Representable Trait Tangle: A user wrestled with
List[Int]passing into a function, discovering Int wasn't recognized as Representable by the compiler.- They highlighted possible conditional conformance issues in int.mojo and the List module.
- Unsafe Pointers & Function Pointer FFI Bumps: Working with UnsafePointer revealed shifting object identity in value structs, causing confusion as pointers moved independently.
- They also noted that function pointer FFI remains unreliable in Mojo, with partial C ABI compliance and limited documentation.
LlamaIndex Discord
- Presenter Pizzazz & Multi-Agent Magic: LlamaIndex introduced Presenter, a multi-agent workflow that creates visually rich slides with Mermaid diagrams, script generation, and report generation all in one pipeline.
- Community members praised Presenter’s accessible structure, showcasing how these references could evolve into advanced presentation-building agents that orchestrate complex steps.
- Doc Driller & Google-Style Gains: MarcusSchiesser released a fully open-source template for multi-step document research agents, inspired by Google's deep research approach.
- Users mentioned the template’s capacity to handle complex research workflows, noting it addresses a common demand for integrated analysis and referencing in advanced projects.
- Scaleport’s Swift Claim Crunch: Scaleport AI formed a partnership with a travel insurer to automate claim estimation from medical reports using LlamaIndex, featuring OCR for data extraction.
- Community members highlighted significant time savings, emphasizing how these methods showcase AI-driven risk analysis for more efficient insurance processes.
- DeepSeek’s Deft LlamaIndex Integration: LlamaIndex now integrates with the DeepSeek-R1 API, supporting deepseek-chat and deepseek-reasoner for advanced calls in a unified environment.
- Developers affirmed the boosted synergy, referencing the DeepSeek docs to enable API-key onboarding and seamless model usage.
Cohere Discord
- Japan Regulation Freedoms: Cohere Remains Unscathed: Cohere discovered that new Japanese AI regulations focusing on advanced computing are unlikely to affect them until May 2025, since their language models fall outside key restrictions.
- The rules specifically target powerful chips and expansions, leaving Cohere untouched for now, while their legal team keeps a close watch in case of amendments.
- Dashboard Dilemmas: UI Overhaul on Cohere's Horizon: Community feedback flagged confusing interface elements on the Cohere dashboard, highlighting mirrored button layouts.
- Suggested fixes included bigger calls to action for Discord and email support, with users pushing for a more streamlined design approach.
- Bare-Bones Audio: No TTS or STT on Cohere: Cohere officially confirmed a pure focus on large language models, offering no built-in text-to-speech or speech-to-text features.
- This clarity ended speculation about audio capabilities, reaffirming that LLM support is the platform's primary strength.
- ChatCohere Code Chronicles: Step-by-Step LLM Setup: Developers showcased how to define ChatCohere, bind tools with
bind_tools, then invoke the LLM with structured messages for advanced tasks.- Some mentioned reverse planning as a final-step check, emphasizing that Cohere sticks to text-based solutions rather than TTS or STT integrations.
- Tool Tiers: Cohere's Multi-Step Approach: Cohere's documentation details a staged multi-step flow, from user prompt retrieval to final text generation.
- Community members praised the systematic breakdown, underscoring how sequential reasoning refines complex outputs and ensures relevant data is pulled at each stage.
Nomic.ai (GPT4All) Discord
- Open Source Image Analysis Gains Traction: People sought an open-source model to handle image prompts, turning to frameworks like Taggui for tagging. They struggled to find a definitive option that excels at both tagging and response generation.
- Some advocated for easier setups that don't demand advanced configuration. Others noted the market lacks a clear front-runner, prompting more experimentation.
- DeepSeek's R1 Model Trips Early: Multiple users reported incomplete reasoning and chat template errors with DeepSeek R1. They mentioned difficulty running it locally without a patch for stable performance.
- Benchmarks hinted at results comparable to LLAMA, though no one confirmed fully reliable output. Some called for further testing before trusting the model in real scenarios.
- Local Document Analysis Piques Curiosity: Enthusiasts want to keep data private by exploring tools like PDFGear for local text indexing. They aim to query personal documents without relying on cloud services or uploads.
- Opinions varied on how to handle complex PDFs and large volumes of text. People requested detailed examples and simpler pipelines to streamline these processes.
- GPT4All Waits for DeepSeek R1 Support: Community members asked when DeepSeek R1 would reach GPT4All in an official, easy-to-install manner. Contributors indicated integration is still in progress, but gave no exact release window.
- They want a one-click setup that doesn't require extensive manual tweaking. Some suggested a fix is close, yet no official statement has been released.
LLM Agents (Berkeley MOOC) Discord
- MOOC Monday Mayhem: The Advanced LLM Agents MOOC starts on January 27th at 4:00PM PST and continues until April 28th, providing weekly livestreams and resources via the course site.
- Attendees can sign up here and watch replays on YouTube, with no immediate deadlines or in-person attendance available for non-Berkeley students.
- Certificates & Confusions Collide: Members reported Fall'24 MOOC certificates still pending, with staff announcing upcoming news and encouraging patience.
- Some also mentioned missing confirmation emails after enrolling, echoing In the same boat..., while staff promised official updates soon.
- Hackathons & No Hangouts: Enthusiasts asked about hackathon opportunities, and staff noted strong interest but no final plan for the semester.
- Others sought in-person access but learned only official Berkeley students are allowed on site, so everyone else relies on the virtual platform.
- Substack Enigma Surfaces: A curious Substack link emerged in #mooc-readings-discussion, offered with scant context.
- The community left it hanging, waiting for any follow-up to clarify the resource shared.
tinygrad (George Hotz) Discord
- Gradient Guidance Gains Ground: Confusion on
Tensor.gradientusage erupted as the doc states 'Compute the gradient of the targets with respect to self' though context suggests it means 'Compute the gradient of self with respect to the targets', sparking discussion.- Participants proposed a doc revision for accuracy, noting that tensor.py may require further clarifications for future references.
- STRIDE vs FLIP Fling: A rebranding from STRIDE to FLIP was recommended to avoid generic naming, aiming for sharper clarity in the codebase.
- Contributors supported the shift, citing that lingering references can complicate updates and slow down feature integration.
- Monday Madness: Meeting #55: Scheduled for 6am Monday San Diego time, Meeting #55 plans to discuss recent multi gradient designs, company updates, and projects like resnet and bert.
- Attendees expect to address new project bounties, intending to refine upcoming tasks and deadlines.
- BobNet Branding Baffled: Questions surrounded BobNet after a GitHub reference implied bounding box usage, yet the code is ordinary feed-forward.
- Members emphasized naming clarity, noting mismatches between title and functionality can mislead new adopters.
- Formatting Fracas in Tinygrad: Users debated official formatting tools, with some citing Black while others pointed to Ruff in the pre-commit config.
- Consensus emerged that Ruff standardizes formatting effectively, urging contributors to follow the recommended approach.
Torchtune Discord
- Federated Frenzy in Torchtune: Contributors proposed creating N splits per node for Torchtune federated learning, merging weights with the saved optimizer state after each chunk is trained.
- Some questioned how to streamline training 'without excessive interruptions' while others discussed the potential synergy with torch distributed and raylib approaches.
- Partial Parameter Pandemonium: Community members debated the performance gains of applying opt-in backward hooks so certain parameters get updated as soon as their gradients are ready.
- They also weighed a strategy to only optimize the output projection with a separate updater, with concerns over the complexity of running multiple optimizers in parallel.
- EBNF Edges Out Regex: A shift away from regex emerged after a member claimed it 'looks like a misformatted tokenizer,' prompting interest in EBNF grammars for better readability.
- Some found EBNF more verbose yet easier to follow, with direct quotes praising it as 'human readable while still robust.'
- Deepseek's Dashing Janus Series: A user critiqued Deepseek for updating too often, referencing this report on Janus-Series: Unified Multimodal Understanding and Generation Models.
- Others bantered over the potential reach of these multimodal features, with one quipping 'They need to chill' amid ongoing comparisons to outdated models.
OpenInterpreter Discord
- OpenInterpreter 1.0 keeps Python interpreter: The OpenInterpreter project had a commit yesterday, is planning a 1.0 release with Python interpreter integration, and is keeping the site in a minimal state until a major launch, as confirmed in their GitHub repository.
- They promise a bigger refresh once the main launch happens, with community feedback focusing on user interaction expansions.
- DeepSeek R1 triggers 400 errors: A user reported a 400 error with the Deepseek_r1 model, configured via
api_basepointing to https://api.deepseek.com, yielding a BadRequestError due to the model’s absence.- The conversation indicated an invalid_request_error under OpenAIException, causing confusion for those attempting to run
$ interpreter -y --profile deepseek.yamlin a workflow.
- The conversation indicated an invalid_request_error under OpenAIException, causing confusion for those attempting to run
- DeepSeek matches OpenAI-o1 in tests: Community members noted DeepSeek-R1 and smaller Distill-Qwen-1.5B models achieving performance on par with OpenAI-o1 across math and code tasks, referencing deepseek-r1 library info.
- They also highlighted DeepSeek’s tool-calling requirements in OS mode and possible issues integrating a vision model, aiming to refine usage for advanced scenarios.
- Local usage with Ollama and Llamafile: Efforts to run Open Interpreter fully on local resources were demonstrated using Ollama and Llamafile, echoing the command
interpreter --localfrom the official running-locally guide.- The chat centered on whether enabling a vision model in a multi-model setup is necessary, prompting calls for clarity on usage in combined frameworks.
- DSH - AI Terminal invites contributors: A project named DSH - Ai terminal is seeking improvements to its open-source app, referencing their GitHub repo.
- Developers were encouraged to star the project and share user feedback to enhance its features going forward.
LAION Discord
- DeepSeek R1 Under Scrutiny: Preliminary benchmarks indicate DeepSeek R1 matches o1-mini and Claude 3.5 Sonnet, contradicting claims it rivals o1 on challenging LLM benchmarks, as seen here.
- Participants questioned its efficacy on olympiad-level AIW problems, referencing this paper to gauge its true capabilities.
- Pipeline Gains Audio Upgrades: A suggestion emerged for audio widgets to compare augmentation effects, integrating distortions from libraries like DeepSeq or O1.
- Contributors emphasized the convenience of interactive features for examining and refining audio changes, targeting pipeline improvements.
- Testing Pipeline Rolls Out: A user shared a development-phase pipeline revealing initial progress after a busy travel day.
- They invited feedback on the pipeline’s features and functionality, focusing on how best to explore audio augmentation capabilities.
DSPy Discord
- GitHub Guff Grows: A member pointed out random spam issues flooding the GitHub repository, overwhelming valuable reports on project bugs and features.
- This sparked frustration as others discussed possible filters and more vigilant triaging to curb the clutter.
- Language Lines: Natural vs Code: A user asked about a dependable way to detect whether text is natural language or structured code such as HTML or Python.
- They floated the idea of specialized classifiers to cleanly categorize textual formats.
- Dspy + Deepseek Dilemma: A participant tried optimizing dspy + deepseek for 70B COT examples but couldn't clarify the exact steps to streamline the process.
- Others chimed in with questions about runtime and memory constraints, highlighting complexities in large-scale optimization.
- BSR’s Six-Hour Standstill: A user ran a BSR example for six hours without convergence, raising eyebrows about the approach’s practicality.
- This prompted a debate on alternative tactics or whether the massive run time was even worth the outcomes.
- PyPI Pressure for FastAPI: A developer needed an updated RC on PyPI to match modern FastAPI dependencies since outdated packages caused broken installs.
- They pointed to a fix on the main branch from three weeks ago, urging maintainers to publish a fresh release.
Axolotl AI Discord
- Deepseek Debut & GRPO Guess: Members asked about the deepseek algorithm and whether anyone is reproducing it, referencing a possible link to grpo in trl.
- One participant suggested it may refer to grpo, indicating renewed interest in advanced RL methods, though no official confirmation was provided.
- H200 vs 5090 GPU Gamble: A user weighed purchasing 2x 5090s or 1x H200, noting that the H200 has more RAM but uncertain performance benefits.
- They cited cost and speed concerns, hoping for real-world feedback on which setup best supports heavy AI workloads.
- Stalled RL Framework Support: A member noted the lack of trl’s online RL trainers, expressing a desire for broader RL library integration.
- Another response, however, insisted it was most likely not going to happen, amplifying doubts about extended RL support.
Gorilla LLM (Berkeley Function Calling) Discord
- Gorilla Gains Prompt Peek: A user asked about system prompts for models not supporting function calls on the Berkeley Function Call Leaderboard, leading to a reference to the Gorilla GitHub code (lines 3-18).
- This repository focuses on training and evaluating LLMs for function calls, offering the needed system messages for non-function versions.
- Gorilla's Leaderboard Resource Emerges: The Gorilla function call leaderboard's code was shared as the seat of relevant system prompts.
- It contains definitions for function-inspired prompts and can guide users seeking references for non-function usage.
MLOps @Chipro Discord
- 2025 Crystal Ball & Real-Time Rendezvous: On January 28, an event titled 2025 Crystal Ball: Real-Time Data & AI will feature Rayees Pasha (RisingWave Labs), Sijie Guo (StreamNative), and Chang She (LanceDB), highlighting how real-time data boosts AI, as seen in this Meetup link.
- They stress that AI’s potential stays underused without low-latency data pipelines, pointing to Apache Iceberg as a key approach for powering emerging analytics across industries.
- Industry Leaders Forecast 2025 Innovations: Panelists predict that real-time data streaming will shape new workflows for AI by 2025, granting significant advantages in operational efficiency and swift decision-making.
- They plan to tackle evolving data infrastructure hurdles, from consumer applications to enterprise use cases, underscoring the synergy between streaming technologies and AI’s growing demands.
Mozilla AI Discord
- Paper Reading Club Meets Again: The Paper Reading Club returns this week with a scheduled session, as shared in the Discord event link. Attendees can expect an in-depth look at AI research, centering on advanced papers that resonate with an engineering audience.
- Organizers encourage participants to join and share their thoughts for a lively exploration of cutting-edge discussion in a communal setting.
- Discord Events Spark Community Involvement: Beyond the Paper Reading Club, various Discord events are highlighted to keep members engaged with new activities this week. Users are invited to join the ongoing conversations, giving them a chance to exchange technical insights.
- Leaders remind everyone to check the announcements channel for real-time updates, emphasizing the importance of active participation in these collaborative gatherings.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!