[AINews] DeepMind SIMA: one AI, 9 games, 600 tasks, vision+language ONLY
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI News for 3/12/2024-3/13/2024. We checked 364 Twitters and 21 Discords (336 channels, and 3167 messages) for you. Estimated reading time saved (at 200wpm): 376 minutes.
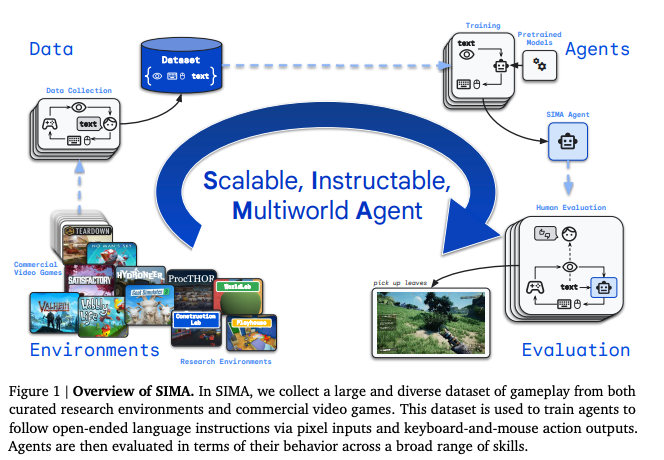
DeepMind SIMA is the news of the day: it takes a step beyond specialist AI systems developed for MineCraft or Dota 2 to be more general. Deepmind collaborated with game studios to evaluate it's abilities on 600 short (<10 second) skills in 9 different games, from No Man's Sky to Hydroneer to Goat Simulator.

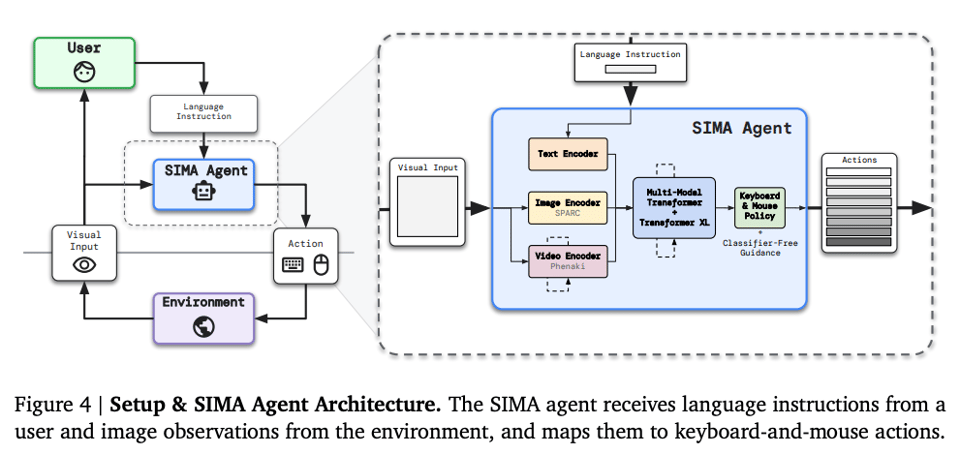
The key constraint here is that SIMA only works from screengrabs + natural language instructions - no special APIs involved. The technical report offers a little more detail, with the classic multimodal Transformer you'd expect, with the Google flavors of things:
The 600 tasks are hard - humans only solve 60% of them, while SIMA hits 34%.
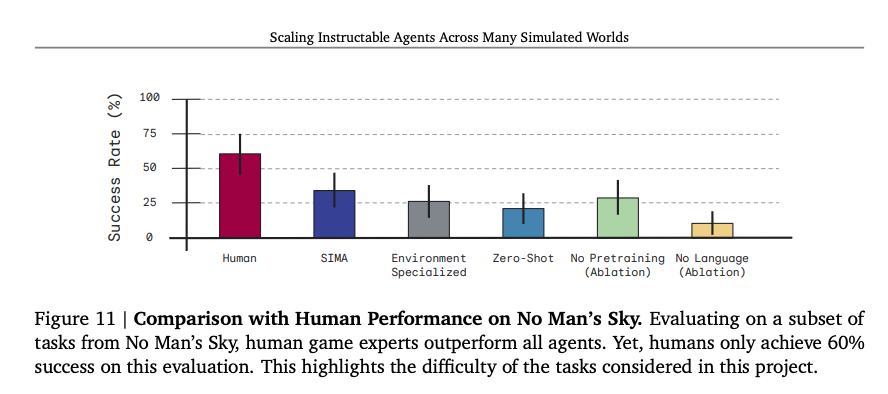
Table of Contents
- PART X: AI Twitter Recap
- PART 0: Summary of Summaries of Summaries
- PART 1: High level Discord summaries
- Nous Research AI Discord Summary
- Latent Space Discord Summary
- Perplexity AI Discord Summary
- Unsloth AI (Daniel Han) Discord Summary
- LM Studio Discord Summary
- OpenAI Discord Summary
- Eleuther Discord Summary
- LAION Discord Summary
- LlamaIndex Discord Summary
- OpenAccess AI Collective (axolotl) Discord Summary
- LangChain AI Discord Summary
- OpenRouter (Alex Atallah) Discord Summary
- Interconnects (Nathan Lambert) Discord Summary
- CUDA MODE Discord Summary
- DiscoResearch Discord Summary
- LLM Perf Enthusiasts AI Discord Summary
- Datasette - LLM (@SimonW) Discord Summary
- Skunkworks AI Discord Summary
- Alignment Lab AI Discord Summary
- AI Engineer Foundation Discord Summary
- PART 2: Detailed by-Channel summaries and links
PART X: AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs
Automating Software Engineering
- Andrej Karpathy outlines a progression of increasing AI autonomy in software engineering, similar to self-driving, where the AI does more and the human provides oversight at higher levels of abstraction.
- Arav Srinivas praises Cognition Labs' demo as the first agent that reliably crosses the threshold of human-level performance.
- François Chollet believes we are far from being able to automate more than an infinitesimal fraction of his job as a software engineer.
Large Language Models and AI Architectures
- Yann LeCun suggests abandoning (at least partially) generative models, probabilistic modeling, contrastive methods, and reinforcement learning on the way to human-level AI.
- François Chollet shares his views on nature vs nurture, stating that humans are intelligent from the beginning, almost all knowledge is acquired, and intelligence decreases with age.
- Andrej Karpathy recommends an AI newsletter by @swyx & friends that indexes ~356 Twitters, ~21 Discords, etc. using LLM aid. (swyx: Thanks Andrej!!!)
AI Agents and Demos
- Cognition Labs' demo of an AI agent solving coding tasks impresses many in the AI community.
- Deepgram's Aura offers fast text-to-speech and speech-to-text APIs with under 250 ms latency, enabling real-time conversational AI applications.
- Modal Labs' Devin AI navigates docs, installs, authenticates, and interacts with a ComfyUI deployment in a browser.
AI Infrastructure and Training
- Soumith Chintala shares details on Meta's 24k H100 Cluster Pods used for Llama3 training, including network, storage, and software optimizations.
- Yann LeCun shares an image of the computing infrastructure used for Llama-3 training.
- John Carmack notes the difficulty of trusting comparisons in research due to subtle changes in algorithm details and training/testing procedures.
Memes and Humor
- "Guess the prompt" meme shared by Arav Srinivas.
- Meme suggesting competition between AI developers.
- "It's over" meme shared by @AISafetyMemes.
PART 0: Summary of Summaries of Summaries
Since Claude 3 Haiku was released recently, we're adding them to this summary run for you to compare. We'll keep running these side by side for a little longer while we build the AINews platform for a better UX.
Claude 3 Haiku (3B?)
- Devin, the AI Software Engineer: Cognition Labs has unveiled Devin, an autonomous AI software engineer capable of performing complex engineering tasks and setting a new benchmark on the SWE-bench coding challenge. Devin can navigate a shell, code editor, and web browser to complete software engineering work, showcasing the potential for AI to automate software development. Devin's capabilities have generated significant excitement in the AI community.
- Advances in Large Language Model Capabilities: Researchers are exploring ways to enhance the performance and efficiency of large language models (LLMs). This includes developing methods like MemGPT to improve long-term memory management, as well as the release of models like Command-R which is optimized for long-context tasks and retrieval-augmented generation. There is also interest in open-source alternatives to proprietary models like GPT-4.
- Hardware and Infrastructure for AI: Major tech companies like Meta and Microsoft are making significant investments in AI hardware and infrastructure. Meta announced plans to build two 24,000 GPU clusters and acquire 350,000 NVIDIA H100 GPUs by 2024, while Microsoft has hired nuclear experts to explore using small modular reactors to power their data centers. Advancements in CUDA and NVMe SSD integration are also enabling more efficient data processing for AI workloads.
- Challenges and Discussions Around AI Models: The community is grappling with various issues related to AI models, such as: Prompt Engineering: Developing effective prompts to control language model outputs, including maintaining consistent word counts and formatting.
- Accuracy and Transparency: Concerns about the reliability and trustworthiness of AI model outputs, especially when using online or experimental models.
- Open-Source Alternatives: Excitement and skepticism around the potential release of open-source AI models like Grok AI and GemMoE, with discussions on model security and integration with existing tools.
Claude 3 Sonnet (14B?)
1) Introducing Autonomous AI Software Engineers like Devin:
- Cognition Labs unveiled Devin, claimed to be the world's first autonomous AI software engineer capable of complex engineering tasks like resolving GitHub issues, navigating developer tools, and setting new benchmarks on SWE-Bench.
- Devin's debut sparked excitement, with users keen to try it and share "unfiltered opinions" on its real-world capabilities demonstrated through tweets and anticipated performance on SWE-Bench.
2) Advancements in Large Language Models and AI Hardware:
- Anthropic released Claude 3 Haiku, a fast and affordable multimodal model now available on their API and claude.ai for Pro users, boasting strong performance across reasoning, math, and coding tasks.
- Meta announced two massive 24k GPU clusters using 350,000 NVIDIA H100 GPUs by 2024, marking a significant AI infrastructure investment with details on hardware, network, and software.
- Cerebras unveiled the CS-3 chip, claimed as the world's fastest AI accelerator capable of training up to 24 trillion parameter models on a single device.
3) Open-Source AI Model Releases and Benchmarking Efforts:
- CohereForAI released the open-source 35B parameter Command-R model optimized for reasoning, summarization, and multilingual generation.
- The EQ-Bench creative writing benchmark went live, allowing ranking of model creativity, though still a work-in-progress.
- DiscoResearch fine-tuned German language models, while the Mistral Medium model showcased strong performance compared to Mixtral.
4) Frameworks and Tools for Efficient Large Model Training:
- The Fuyou framework enables fine-tuning up to 175B parameter models on consumer GPUs like RTX 4090, promising efficiency gains over ZeRO-Infinity.
- Unsloth AI offers QLoRA support for Mistral 7B, CodeLlama 34B, and Llama architecture models, with features like sliding window attention and preliminary DPO support.
- Developments in CUDA allow NVMe drives to use direct memory access and GPU integration via NVIDIA's GPUDirect® Storage API for storage applications.
Claude 3 Opus (>220B?)
- Hermes 2 Pro 7B Model Launches with Advanced Capabilities: Nous Research released the Hermes 2 Pro 7B model, boasting a 91% Function Calling Accuracy and enabling advanced function calling and structured JSON outputs. The model and datasets are available on Hugging Face and GitHub.
- EU AI Act Stirs Controversy and Compliance Concerns: The EU AI Act has passed, prohibiting certain AI practices, mandating energy consumption disclosures, and potentially impacting AI companies operating in Europe. Discussions revolved around the implications for the AI industry and the challenges of regulation enforcement.
- Cognition Labs Unveils Devin, the AI Software Engineer: Cognition Labs introduced Devin, an autonomous AI software engineer surpassing benchmarks by resolving 13.86% of GitHub issues on the SWE-Bench coding benchmark. Devin's capabilities and potential impact sparked excitement and debates, as detailed in their blog post and demo video.
- Cerebras Announces World's Fastest AI Chip: Cerebras Systems unveiled the CS-3, claiming to be the world's fastest AI accelerator capable of training models up to 24 trillion parameters on a single device. The announcement generated discussions about the chip's design and potential for advancing AI compute technology, as shared in their press release.
- Anthropic Launches Claude 3 Haiku: Anthropic released Claude 3 Haiku, a fast and affordable AI model praised for its speed (120 tokens per second) and cost-effectiveness (4M prompt tokens per $1). The model's capabilities and potential applications were discussed, with details available in Anthropic's announcement.
- Meta Invests Heavily in AI Infrastructure: Meta announced plans for two 24k GPU clusters and aims to integrate 350,000 NVIDIA H100 GPUs by 2024, marking a significant investment in their AI future. The company shared details on their hardware, software, and open-source initiatives in an engineering blog post.
- Advancements in CUDA and NVMe Integration: Developments in CUDA now allow NVMe drives to leverage direct memory access and GPU integration for storage applications, promising substantial efficiency gains. Resources like the ssd-gpu-dma GitHub repository and NVIDIA's GPUDirect Storage API reference guide were shared to highlight these advancements.
- Stealing Weights from Production Language Models: A research paper revealed the possibility of inferring weights from production language models like ChatGPT and PaLM-2 using their APIs, raising concerns about AI ethics and future security measures for protecting model weights.
ChatGPT (GPT4T)
AI in Game Development: Nous Research AI Discord explores AI's role in game development, particularly the creation of Plants Vs Zombies using Claude 3, highlighting the integration of AI with Python for game creation. The project showcases AI-driven creativity in game design, watchable here.
Advancements in Function Calling: The introduction of Hermes 2 Pro 7B model, with a 91% Function Calling Accuracy, marks a significant advancement in AI's capability to execute function calls, making it a notable tool for developers integrating AI with programming environments like llama.cpp and the Vercel AI SDK. This development is part of a broader effort to blend AI with programming through structured JSON outputs, detailed on GitHub.
The AI Chip Debate: The Cerebras CS-3 chip, reputed as the world's fastest AI accelerator, ignites discussions on its square design's efficiency in training a 24 trillion parameter model on a single device. This discussion underscores the ongoing innovations in AI compute technology, with more information available on Cerebras.
New Developments in AI Software Engineering: Cognition Labs' Devin emerges as a new AI software engineer capable of autonomously addressing GitHub issues and demonstrating proficiency in navigating various development tools. This marks a significant milestone in AI's integration into software development, hinting at future capabilities in automating programming tasks, as showcased at Cognition Labs Devin.
AI-Powered Solitaire Instruction: A project utilizing OpenCV for Solitaire instruction exemplifies AI's potential in recreational gaming, aiming to develop a system that uses image capture and processing to guide gameplay. This initiative reflects the expanding applications of AI beyond traditional domains into enhancing user experiences in games, with further development expected to integrate with language models like GPT for deeper game analysis.
PART 1: High level Discord summaries
Nous Research AI Discord Summary
Planting AI in the Game Development Field: An AI-driven endeavor to create Plants Vs Zombies using Claude 3 was showcased, piquing interest for its application of Python game development — watch the creativity unfold here.
Function Calling Is the New Black: The recently released Hermes 2 Pro 7B model shows significant advancements with a 91% Function Calling Accuracy and specialized prompts enabling advanced function calling. The model’s prowess is acknowledged by its enthusiastic uptake for integration with tools like llama.cpp and the Vercel AI SDK, seeking a new blend of structured JSON outputs GitHub - Hermes Function Calling.
The AI Chip Shape Debate: What's the most optimal design for the new Cerebras CS-3, the proclaimed world's fastest AI accelerator? Discussions swirl around its square chip design, while the model boasts readiness to train a colossal 24 trillion parameter model on a single device, presenting a leap in AI compute technology Cerebras.
The AI Rules Are Changing: The EU's new AI Act stirs the pot for AI companies by outlawing certain AI practices and demanding energy consumption disclosures. Meanwhile, anticipation brews for the open-source models with a focus on long context chatbots, as referenced in the Sparse Distributed Associative Memory repository.
Cognition Introduces a New Player to the Field: Enter Devin, an AI software engineer claiming a new success benchmark in addressing GitHub issues autonomously, demonstrating capabilities to navigate a shell, code editor, and web browser — a glimpse of the future at Cognition Labs Devin.
Latent Space Discord Summary
- Introducing Devin the AI SWE: Cognition Labs launched Devin, an AI that sets a new bar by resolving a notable 13.86% of GitHub issues and impressing with its engineering interview skills. Industry attention spotlights Devin’s capabilities, enhanced by SWE-Bench performance metrics. Cognition Labs provide further insights into Devin's development and functionality.
- Model Weight Security in Question: Researchers exposed the feasibility of inferring weights from APIs of models such as ChatGPT and PaLM-2, inciting debates over AI ethics and future protection strategies. The implications are found detailed in a recent paper that outlines the potential risks and methods of model weight extraction.
- Expanding AI Horizons: Together.ai secured a $106M funding round to create a new platform intended for executing generative AI apps, introducing Sequoia, a method designed for efficient LLM operation. Meanwhile, Cerebras revealed the CS-3 AI chip, claiming the fastest training capabilities for models upwards of 24 trillion parameters. Details about Sequoia and CS-3 advancements can be accessed at Together AI's blog and Cerebras' press release, respectively.
- Synthesizing Success: During the LLM Paper Club event, Eugene Yan emphasized the effectiveness of synthetic data in model training, including pretraining and instruction-tuning, spotlighting its cost-efficiency and bypass of privacy concerns. The community is encouraged to read his insights on synthetic data.
- Navigating Voice Recognition's Potential: The community explored voice recognition with a focus on applications such as text-to-speech and speech-to-text using tools like vapi.ai and whisper. Twitter threads and resources like whisper.cpp illustrate the ongoing discussions in voice technology.
Perplexity AI Discord Summary
- Claude3 Opus Powers Perplexity AI: Perplexity AI is confirmed to utilize Claude3 Opus for its operations. Users explored the platform's capabilities with a focus on productivity and effective research assistance, while expressing concerns about the limitations of AI plagiarism detection tools and seeking clarification on various Perplexity AI services, including the switch from Claude 3 Opus to Claude 3 Sonnet after 5 uses.
- Search Engine Evolution Discussed: The community engaged in discussions on the future of search engines, noting Perplexity AI's utilization of its own indexer. Concurrently, there were mentions of growing calls for Google CEO Sundar Pichai to step down and the increasing competition in the search domain from generative-AI rivals.
- Enhancing AI Interactivity: Members shared Perplexity AI search query links on topics ranging from sleep advice to understanding medical terminology. Additionally, the sharing of a YouTube video indicated interest in the latest AI news including AI-generated "Digital Marilyn" and controversies between Midjourney and Stability AI.
- API Navigation and Customization Tactics: Queries in the #[pplx-api] channel reflected concerns over achieving concise answers through tailored prompting and parameter settings. There was also discussion about enabling chatbot models to remember conversations with the use of external databases for storing embeddings, and a call for adding Yarn-Mistral-7b-128k to the API for high-context use cases.
- Accuracy and Ethics in AI Responses: The community expressed anxieties about inaccurate information returned by AI when using the -online tag, leading to suggestions for the incorporation of a system message for clarity. For further understanding and experiments with system messages, the Perplexity API documentation was referenced.
Unsloth AI (Daniel Han) Discord Summary
- Rope The Kernel Efficiency: A rope kernel improvement was shared focusing on loading sin/cos functions just once to boost efficiency along axis 1 and employing sequential computation for head grouping. Despite a related PR, concerns about the effect on overall training performance persist.
- Unsloth's Fine-tuning Finesse: Unsloth Studio, a feature to enable one-click finetuning, is reported to be in beta, while the Unsloth community solves issues like importing FastLanguageModel on Kaggle by manually reinstalling libraries. Unsloth's GitHub wiki offers FAQs and a guide for dataset formatting for DPO pair style data.
- Open Source OpenAI Skepticism: There's excitement and concern in the community about the future of open-source AI models like GemMoE and Grok AI. Discussions include whether OpenAI will join the open-source movement, while concerns loom about potential model piracy and ties to Microsoft Azure.
- Overcoming Ubuntu WSL's Dependency Paradox: Users discussing dependency loops in Ubuntu WSL involving bitsandbytes, triton, torch, and xformers identified a Python error preventing package installation. A suggested workaround involves installing xformers from PyTorch's cu121 index directly and resorting to Unsloth's nightly GitHub builds.
- Quantizing Mixer Woes: Efforts to quantize the Mixtral model on three V100 32GB GPUs hit a memory snag, leading to a helpful community suggestion to try 2x A100 80GB GPUs or utilize Unsloth's built-in GGUF support. Meanwhile, queries about Nous-Hermes model tokenization surfaced, resolved by an alternative model and dataset adjustment.
- Storage Innovation for Model Fine-tuning: AI enthusiasts shared a paper exploring the use of NVMe SSDs to potentially overcome GPU memory limits for fine-tuning large models. Useful resources like the ssd-gpu-dma and flashneuron project on GitHub were cited for contributing to GPU storage applications, along with NVIDIA's GPUDirect® Storage API documentation for direct data path APIs.
LM Studio Discord Summary
LaTeX Rendering Sparks Engineered Excitement: Discussions highlighted a desire for LM Studio to support LaTeX in markdown, as seen in a GitHub blog post, with an eye on improving math problem interfaces. Members pondered the incorporation of swipe-style blackboards for visual math inputs, demonstrating a playful tone surrounding serious technical aspirations.
GPU Performance Unearthed: A shared YouTube performance test fueled talks about the benefits and technical considerations of using dual GPU configurations for large language models (LLMs), including setups with dual RTX 4060 Ti 16GB GPUs. Some members noted more than two-fold efficiency gains while others shared tips for optimal configurations, even as they humorously exchanged views about high-priced NVLINK bridges and alternatives.
Better Together or Alone? Dual GPU Configs vs. Single: The effectiveness of running LLMs on a single GPU versus dual setups was scrutinized by engineers sharing personal testing outcomes. Discussions ranged from configuration tweaks for GPUs with mismatched VRAM to exploring the feasibility of powering multiple high-end GPUs.
Upgraded RAM for a Smarter Tomorrow: RAM upgrade considerations to run larger LLM models, such as upgrading to 128GB of RAM, were weighed against the need for more VRAM. Community members offered insights on hardware configurations and performance modifications, including tips for running concurrent instances of LM Studio and enhancing GPU acceleration with AMD's ROCm beta.
KIbosh on iGPU to Enhance Main GPU's Power: Users in the amd-rocm-tech-preview thread found that disabling the iGPU could resolve offloading issues. They exchanged strategies and suggestions for optimizing ROCm beta with AMD GPUs, from installing specific driver combos like Adrenalin 24.1.1 + HIP-SDK to cleaning cached directories for better model loading in LM Studio.
AVX Beta Buzzes Quietly: In the 🧪-beta-releases-chat, there was a brief touch on version updates to AVX beta and minimal conversation about the quality of unspecified subjects, with an expressed opinion that they "aren't any good".
OpenAI Discord Summary
- AI Helps Deal the Cards: A project to develop a Solitaire instruction bot using OpenCV was proposed, envisioning a robotic system that captures laptop screen images to guide game play. Building this system includes steps like researching game rules, assembling hardware, crafting image processing algorithms, and integrating with a language model like GPT for in-depth game analysis alongside iterative design refinement.
- Video Generation AI Sora Narrowly Accessible: Sora, an AI model for video generation, was mentioned as being costly and inaccessible for public testing. However, visual artists and filmmakers have reportedly had the opportunity to access and provide feedback for Sora, suggesting limited test releases among specific user groups.
- GPT's Economic Walls and Outage Workarounds: The cost of AI services like GPT-4 subscriptions was discussed, highlighting the disproportionate expense relative to minimum wages in countries like Georgia and Brazil. Additionally, during instances of GPT outages, users recommended checking OpenAI's status page and considered starting a new interaction as a possible temporary solution.
- Prompt Engineering for Word Consistency: In the realm of prompt engineering, users exchanged strategies for instructing AI to maintain word counts during text rewrites. The use of positive instructions without being overly prescriptive was suggested to yield consistent results, while the Code Interpreter was confirmed to accurately count words against a conventional word count standard.
- Custom AI Development Dilemmas: Individuals discussed self-hosting models for personal use, like processing journal data, with emphasis on understanding hardware requirements. For those enhancing a CustomGPT model capable of consulting PDFs and performing web searches, it was advised that clear instructions are necessary due to the AI's limitations with image recognition in PDF documents.
Eleuther Discord Summary
- Claude vs GPT for Scholarly Summarization: Claude 3 was tested for summarizing academic papers and said to perform well with general summarization, but not for in-depth specifics. This was amid a mix of discussions, including a job-seeking ML Engineer from EleutherAI's Polyglot and OSLO projects, an introduction to an experienced newcomer in ML, and debates about batch size trade-offs for model training efficiency with reference to the An Empirical Model of Large-Batch Training.
- Optimization Myths and Multi-Model Efficiency: A member debunked the myth regarding beta2 and training stability, suggesting alternatives like ADAM, while the potential of LoRA's extension to pre-training was deliberated with prospects of it working in tandem with methods like GradientLoRA. Moreover, a paper on Deep Neural Collapse added to the conversation about neural network training trajectories and architectures.
- Model Hacking Ethics and Pruning Perspectives: Debating the boundaries of ethical model hacking, a member acknowledged that prior permission makes model hacking ethically acceptable, referring to a disclosed paper. Moreover, Pythia was highlighted for its interpretability-driven capability unlearning, and there was an announcement for a new mechanistic interpretability library for multimodal models, inviting collaboration via a Twitter announcement.
- Leaderboards Under Scrutiny: In the thunderdome of AI performance, the limitations of benchmark tests like SQuAD were discussed. The GPQA dataset provokes a reevaluation of the assistance value of AI models, where even GPT-4 encounters difficulty, emphasizing the necessity for more robust supervision, showcased in the Anthropic paper.
- Megatron and GPT-NeoX Synchronization Considered: A member proposed closely tracking upstream Megatron for better alignment with their Transformer Engine, with relevant code differences in a GitHub pull request awaiting feedback from project maintainers.
LAION Discord Summary
- Lobbyist Charm or Pocket Harm?: Lobbyists' power was noted to stem from their influence through financial contributions, leading to negotiations rather than benefiting personally from the money they distribute.
- Terminating the Terminator Scenario: A jovial discussion unfolded around the potential catastrophic scenarios involving AI, including speculations on a finetuned AI causing an extinction event, met with satirical comments on the failure of past extinction events.
- AI Overlords: Unlikely but Worth a Discussion: There was skepticism regarding the possibility of AI leading to an overreaching government authority, with members sarcastically dismissing the likelihood of coordinated actions that might cause such a scenario.
- Navigating the Future of AI Regulation: Debates erupted around issues like copyright infringement with AI-generated model weights, the effectiveness of DMCA, and the implications of new EU regulations on AI, linking to the European Lawmakers' Act.
- Choosing the Best Tools for AI Power-Users: Discussions also covered hardware and software preferences for AI inference tasks, with an emphasis on using GPUs and the efficiency of local setups versus API-centric solutions. References were made to platforms and technologies such as GroqChat, Meta's AI Infrastructure, and BUD-E.
- Halting Hallucinations: Suggestions were made to use simple and short prompts when employing CogVLM to generate data to minimize the production of incorrect outputs.
- The Art of Attention in AI: A consensus implied that cross attention may not be the best mechanism for adding conditioning to models, as alternative methods involving transforming text embeddings proved to achieve better denoising results.
- Mixing up AI with MoAI: Enthusiasm was evident for the new Mixture of All Intelligence (MoAI) model, which promises superiority over existing models while retaining a smaller footprint, with resources available on GitHub and Hugging Face.
- Citation Celebration for User Dataset: A member shared their excitement about their dataset being referenced in the DeepSeekVL paper, showcasing the community's contributions to advancing AI research.
- Busting the Great Memory Myth: A claim about being able to load a 30B model into 4GB of memory using lazy loading was corrected, revealing that mmap obscured the actual memory usage until accessed.
- Delve into LAION-400M: A message praised Thomas Chaton's article that guides users on utilizing the vast LAION-400-M images & captions dataset, linking to the article for further insights.
LlamaIndex Discord Summary
- MemGPT Storms Long-Term Memory Front: MemGPT is tackling the long-standing issue of long-term memory for LLMs, bringing new capabilities like "virtual context management" and function calling to enhance memory performance. Don't miss the opportunity to dive deeper into these advancements by registering for the MemGPT webinar here.
- Paris Meetup for Open-Source AI Devs: Ollama and Friends are rolling out the red carpet for open-source AI developers at Station F in Paris on March 21st, with food, drinks, and demos on the menu. Lock in your spot or apply to present a demo by reaching out via Twitter.
- LlamaIndex and MathPix Concoct Scientific Search Elixir: A collaboration between LlamaIndex and MathPixApp aims to distill scientific queries down to their LaTeX essence, promising exceptional search capabilities through document indexing. For the curious mind, a guide through this alchemy, featuring image extraction and text indexing, is signaled through a Twitter beacon.
- Chatbot Conjuring and Indexing Incantations: The guild sizzles with dialogues on boosting chatbot responses and indexing, proposing the use of DeepEval with LlamaIndex for performance optimization and deploying ensemble query engines to curate diverse responses. For those keen on summoning insights, the spellbooks can be found here and here.
- The LLM Paper Compendium Emerges: On the horizon, a vast repository of LLM research blooms, curated by shure9200. Scholars may venture to this trove to unearth recent academic advancements and chart new paths in the realm of LLMs.
OpenAccess AI Collective (axolotl) Discord Summary
Axolotl Embraces DoRA for Low-Bit Quantization: DoRA (Differentiable Quantization of Weights and Activations) support for 4-bit and 8-bit quantized models has been successfully merged, promising performance improvements, although it's limited to linear layers with notable overhead. Interested engineers can dive into the merge details on GitHub.
Big Models, Little GPUs - Fuyou to the Rescue: The Fuyou framework has shown potential in allowing engineers to fine-tune behemoth models up to 175 billion parameters on standard consumer-grade GPUs such as the RTX 4090, sparking interest for those confined by hardware limitations. _akhaliq's tweet weighs in on the excitement, flaunting a 156 TFLOPS computation capability.
API Evolution in DeepSpeed: DeepSpeed introduced an API modification for setting modules as leaf nodes which could make it easier to work with MoE models, thereby potentially benefiting Axolotl's development plans. More information is provided in their GitHub PR.
Command-R Forges Ahead with 35B Parameters: The creation of Command-R by CohereForAI, an open-source 35 billion parameter model, opens new frontiers as it's optimized for a multitude of use cases and accessible on Huggingface.
Mistral Medium Outshines Mixtral: In community showcases, Mistral Medium is noted for outperforming Mixtral, delivering more concise and instructive-compliant outputs while generating more relevant citations, possibly indicating an advanced, possibly closed-sourced, version of Mixtral.
LangChain AI Discord Summary
- Performance Tweak Initiates Mode Switch Query: Langchain users discuss the effectiveness of switching from
chat-instructtochatmode for a chatbot using LlamaCpp model in oobabooga's text-generation-webui, sharing code snippets and prompting questions about implementation in the langchain application. - Doc Dilemmas and Call for Updates: Concerns are expressed about outdated and inconsistent Langchain documentation, with users emphasizing the importance of keeping the docs up-to-date to better track package imports and use.
- Launch and Learn from ReAct and Langchain Chatbot: Announcements include the launch of the ReAct agent, inspired by a synergy of reasoning and acting in language models, as well as the open-source release of the LangChain Chatbot featuring RAG for Q&A querying, inviting feedback and exploration through the provided GitHub repository.
- Video Vistas on AI Tech and Application Tutorials: Shared are various tutorials and showcases, such as the use of Groq's hardware to build a real-time AI cold call agent, Command-R's long context task capabilities, and a guide on creating prompt templates with Langchaingo for Telegram groups.
- Advancements in Mental Health Support AI: A new article describes MindGuide, aiming to revolutionize mental health care using LangChain with large language models, underlining the importance of tech-based interventions in mental health.
OpenRouter (Alex Atallah) Discord Summary
- OpenRouter Briefly Stumbles but Recovers: During a database update, OpenRouter faced a transient issue causing unavailability of the activity row for approximately three minutes, but no charges were levied for affected completions.
- Claude 3 Haiku Makes a Splash: The newly introduced Claude 3 Haiku model is generating buzz for its speed of 120 tokens per second and cost-efficiency at 4M prompt tokens per $1. With both moderated and self-moderated versions available, users are encouraged to try it out, with accessibility details available via this link.
- Olympia.chat Integrates OpenRouter: Olympia.chat has incorporated OpenRouter for its large language model needs, boasting a focus on solopreneurs and small businesses, and teased an upcoming open-source Ruby library for interacting with OpenRouter.
- Dialogue on OpenRouter AI Model Usage: In a heated discussion, participants talked about Groq's Mixtral model and clarified that OpenRouter use is independent of Groq’s free access period, and Mistral 8x7B model limits were explored following "Request too big" errors.
- Anticipation Builds for GPT-4.5: Rumors and unverified information about GPT-4.5 sparked enthusiastic speculation and high interest within the community, signaling strong anticipation for this potential next step in AI advancements.
Interconnects (Nathan Lambert) Discord Summary
- GPT-4.5 Anticipation Builds on Bing Blunder: Bing search engine results accidentally indexed a GPT-4.5 blog post, sparking excitement for its impending release, despite links leading to a 404 page. Depth of interest is reflected in discussions about the post also being found via other search engines like Kagi and DuckDuckGo, and a tweet has been circulated for additional clarity.
- GPT-4 Maintains Mastery in LeetCode: GPT-4 continues to impress with top performance in coding challenges, as shown in a recently cited paper focusing on its prowess in LeetCode problems.
- Claude 3 Excels at Extracting Essentials: The Claude 3 model, detailed through the Clautero project, demonstrates notable advancements in summarizing literature, indicating the evolving capabilities of large language models.
- Meta Dives Deep into AI Hardware: Meta announces significant investment in AI by planning two 24k GPU clusters and aims for 350,000 NVIDIA H100 GPUs by 2024, openly sharing their infrastructure ambitions through Grand Teton and formal announcements.
- Ads in AI - A Future Debate: Discussions arise about Google's monetization strategy for AI models with members comparing ad-supported models to subscription models, and examining privacy implications and the trust factor in relation to potential AI-generated ads.
CUDA MODE Discord Summary
- Meta's Hardware Upgrade Packs a Computational Punch: Meta announced the launch of two colossal 24k GPU clusters, planning to integrate 350,000 NVIDIA H100 GPUs by the end of 2024, which will serve a powerhouse for AI with computation equivalent to 600,000 GPUs, detailed in their infrastructure announcement.
- The Fusion of CUDA and NVMe: Developments in CUDA now allow NVMe drives to use direct memory access and GPU integration for storage applications, promising substantial efficiency gains as outlined in ssd-gpu-dma GitHub repository and NVIDIA's GPUDirect Storage API reference guide.
- CUDA Development Leverage with Nsight: NVIDIA's Nsight™ Visual Studio Code Edition has been hailed for its development capabilities on Linux and QNX systems, offering CUDA auto-code completion and smart profiling, even sparking a debate about NSight Systems' utility versus NSight Compute.
- Call for Feedback and Experience Sharing on Torchao: PyTorch Labs' invites feedback on the merging of new quantization algorithms on torchao's GitHub issue, offering mentorship for kernel writers eager to engage with a real world cuda mode project involving gpt-fast and sam-fast kernels.
- AI Engineer in the Wings: Cognition Labs teases the imminent debut of Devin, an autonomous AI software engineer capable of complex tasks, with buzz building around its implementation in the SWE-bench coding benchmark as described in Cognition Labs' blog post and flagged by the community for further examination.
DiscoResearch Discord Summary
- Musk's Razzmatazz Lost in Translation: The assistant's response detailing reasons for Mars colonization was critiqued for lacking Elon Musk's distinctive flair, despite covering his viewpoints well, leading to a creativity rating of *[[7]].
- RAG-narok Tactics: Engineers debated RAG prompt structures, with preferences varying between embedding the full prompt within user messages or adjusting it based on SFT to maintain consistent behavior, meanwhile, an internal tool, the Transformer Debugger, was unveiled via a tweet by Jan Leike for transformer model analysis, boasting rapid exploration and interpretability features without writing code.
- Mix-Up With Mixtral Models: Miscommunication around the
mixtral-7b-8expertmodel raised issues with its experimental status clarity, which contrasts with the officialmistralai/Mixtral-8x7B-v0.1model, noted for difficulties with non-English outputs, steering users towards the proper model and dataset information for those interested in German data specifics.
- Creative Benchmarking Breakthrough: The creative writing benchmark prototype goes live on a GitHub branch, offering a tool that ranks model creativity, though it's still a work-in-progress with room for discriminative improvements.
- Quest for German Precision: Inquiries regarding the ideal German embeddings for legal texts challenge engineers to consider the peculiarities of legal jargon, while the hunt for a German-specific embedding benchmark adds another layer to the complexity, underscoring a gap in the current benchmark landscape.
LLM Perf Enthusiasts AI Discord Summary
- GPT-4.5 Turbo: More Myth Than Reality: Speculation about the existence of GPT-4.5 Turbo sparked discussions, leading to the revelation that a supposed leak was actually an outdated and erroneously published draft mentioning training data up to July 2024. Concerns revolved around the confusion created by a Bing search showing no results for "openai announces gpt-4.5 turbo", hinting at the non-existence of such a model.
- Token Limitation Tantrums: Members expressed the frustration of hitting the 4096 token limit while working with gpt4turbo, but no solutions or workarounds were provided during the conversation.
- The Curious Case of Claude and Starship: A light-hearted comment mentioned the potential for OpenAI's announcements to overshadow Elon Musk's Starship, reflecting ongoing interest in how major tech reveals align or clash.
- Predicting Llama-3 or Leaping to Llama-4?: A member discussed the theory of Llama's version cycle, predicting a skip of Llama-3 due to quality concerns and potential release of Llama-4 in July. Upcoming features are anticipated, including Mixture of Experts, SSM variants, Attention mods, multi-modality in images and videos, extended context lengths, and advanced reasoning capabilities.
Datasette - LLM (@SimonW) Discord Summary
- Zero-click Worms Threaten GenAI Apps: A recently published paper discusses "ComPromptMized," a study by Stav Cohen revealing vulnerabilities where a computer worm could exploit various GenAI models without user interaction, highlighting risks for AI-powered applications like email assistants.
- The Quest for the Best Code Assistant AI: Engineers sought a framework to compare AI models such as Mistral and LLaMA2 for efficiency as code assistants, while acknowledging that an appropriate benchmark would need to be accurate to be useful in such comparisons.
- Leaderboard Becomes Go-to for AI Model Performance: For comparing model performances, the Leaderboard on chat.lmsys.org emerged as a valuable resource, with members expressing appreciation for its insights into various models' capabilities.
- Git Commit Messages Get a Language Model Upgrade: A member shared a hack to revolutionize git commit messages using LLM, detailing a method that integrates an LLM CLI with pre-commit-msg GIT hook, resulting in more informative commit descriptions.
Skunkworks AI Discord Summary
- Chatbot Builders Left Hanging: Engineers sought recommendations for open source models and frameworks suited for creating chatbots that manage long contexts. However, no specific solutions were provided within the discussion thread.
- Planting AIs in Classic Games: AI enthusiasts can watch a YouTube tutorial on developing Plants vs Zombies with Claude 3, covering Python programming and game development aspects in Claude 3 made Plants Vs Zombies Game.
- Rummaging Through RAG with Command-R: A new video spotlights Command-R, demonstrating its capacity for Retrieval Augmented Generation (RAG) and integration with external APIs, detailed in Lets RAG with Command-R.
- Introducing Devin, AI in Software Engineering: The world's alleged first AI software engineer, Devin, is featured in Devin The Worlds first AI Software Engineer, which showcases the capabilities of autonomous software engineering, also discussed on Cognition Labs' blog.
Alignment Lab AI Discord Summary
- Join the Visionaries of Multimodal Interpretability: Soniajoseph_ calls for collaborators on an open source project aimed at interpretability of multimodal models. This initiative is detailed in a LessWrong post and further discussions can be had on their dedicated Discord server.
- In Search of Lightning-Fast Inference: A guild member seeks the fastest inference method for Phi 2 mentioning the use of an A100 GPU. They're looking into batching for mass token generation, frameworks such as vLLM or Axolotl, and are curious about the impact of quantization on speed.
AI Engineer Foundation Discord Summary
- Plugin Authorization Made Easy: The AI Engineer Foundation suggested implementing config options for plugins to streamline authorization by passing tokens, informed by the structured schema in the Config Options RFC.
- Brainstorming Innovative Projects: Members were invited to propose new projects, adhering to a set of criteria available in the Google Doc guideline, along with a tease for a possible partnership with Microsoft on a prompt file project.
- Meet Devin, the Code Whiz: Cognition Labs unveiled Devin, an AI software engineer heralded for exceptional performance on the SWE-bench coding benchmark, ready to synergize with developer tools in a controlled environment, as detailed in their blog post.
PART 2: Detailed by-Channel summaries and links
Nous Research AI ▷ #off-topic (35 messages🔥):
- AI-Built Plants Vs Zombies: A YouTube video titled "Claude 3 made Plants Vs Zombies Game" demonstrates the creation of the game Plants Vs Zombies using the AI model Claude 3, incorporating Python programming for game development. The video can be watched here.
- New Term "Mergeslop": A member humorously noted the first use of the term "mergeslop" on a platform, expressing surprise at its novelty.
- Command-R and RAG Technology Spotlight: Another YouTube video Featuring Command-R, an AI model for long context tasks such Retrieval Augmented Generation (RAG), has been highlighted and is available for viewing here.
- AI News Digest Service Debuts: AI News announced a service that summarizes discussions from AI discords and Twitters, promising to save hours for users. Interested individuals can subscribe to the newsletter and check AI News for the week.
- Book Recommendations for AI Enthusiasts: Members shared personal book recommendations with AI and speculative fiction themes, including the "Three-Body Series," Lem's "The Cyberiad," and Gibson's "Sprawl Trilogy."
- Long Context Chatbot Development Query: A channel member sought advice on open-source models and frameworks for building chatbots with a long context or memory, sparking a conversation about current and future capabilities. SDAM, a sparse distributed associative memory, was suggested as a resource.
Links mentioned:
- Lets RAG with Command-R: Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is design...
- Claude 3 made Plants Vs Zombies Game: Will take a look at how to develop plants vs zombies using Claude 3#python #pythonprogramming #game #gamedev #gamedevelopment #llm #claude
- GitHub - derbydefi/sdam: sparse distributed associative memory: sparse distributed associative memory. Contribute to derbydefi/sdam development by creating an account on GitHub.
- [AINews] Fixing Gemma: AI News for 3/7/2024-3/11/2024. We checked 356 Twitters and 21 Discords (335 channels, and 6154 messages) for you. Estimated reading time saved (at 200wpm):...
- Devin The Worlds first AI Software Engineer: Devin is fully autonomous software engineerhttps://www.cognition-labs.com/blog
Nous Research AI ▷ #interesting-links (8 messages🔥):
- Meet Devin, AI Software Engineer Extraordinaire: Cognition Labs introduces Devin, an AI touted as the first AI software engineer, surpassing previous benchmarks by resolving 13.86% of GitHub issues unassisted on the SWE-Bench coding benchmark. Devin can autonomously utilize a shell, code editor, and web browser, see the full thread.
- C4AI Command-R Unleashes Generative Model Might: CohereForAI releases C4AI Command-R, a highly capable generative model with 35 billion parameters, excelling in reasoning, summarization, and multilingual generation. The model is available with open weights and adheres to specific licensing and acceptable use policies on Hugging Face.
- Cerebras Unveils the World's Fastest AI Chip: Cerebras Systems presents the CS-3 chip, claiming to be the world's fastest AI accelerator capable of training up to a 24 trillion parameter model on a single device. The CS-3 features staggering specifications and advancements in AI compute technology Press Release and Product Information.
- The Shape of Innovation in AI Chips: A member speculated the chip design of the new Cerebras CS-3, debating why it is square rather than round or semi-round, proposing shapes that could potentially fit more transistors.
- No Link, Just a Teaser: A Twitter link from user Katie Kang was shared, however, without any additional context provided.
Links mentioned:
- Tweet from Cerebras (@CerebrasSystems): 📣ANNOUNCING THE FASTEST AI CHIP ON EARTH📣 Cerebras proudly announces CS-3: the fastest AI accelerator in the world. The CS-3 can train up to 24 trillion parameter models on a single device. The wo...
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
- Tweet from Cognition (@cognition_labs): Today we're excited to introduce Devin, the first AI software engineer. Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering intervie...
Nous Research AI ▷ #announcements (1 messages):
- Hermes 2 Pro 7B Unleashed: The newly released Hermes 2 Pro 7B model by Nous Research enhances agent reliability with an improved dataset and versatility in function calling and JSON mode. The model can be downloaded at Hugging Face - Hermes-2-Pro-Mistral-7B, with GGUF versions also available at Hugging Face - Hermes-2-Pro-Mistral-7B-GGUF.
- Collaborative Effort and Acknowledgments: Months of collaborative efforts from multiple contributors and the compute sponsorship by Latitude.sh have brought this Hermes 2 Pro 7B model to fruition.
- Innovative Function Calling and JSON Mode: Special system prompts and XML tags have been utilized to enable advanced function calling capabilities, with sample code available on GitHub - Hermes Function Calling.
- Custom Evaluation Framework for Enhanced Performance Measurement: The model includes a unique evaluation pipeline for Function Calling and JSON Mode built upon Fireworks AI’s original dataset and code, which can be found at GitHub - Function Calling Eval.
- Datasets Ready for Download: The datasets for evaluating the performance in Function Calling and JSON Mode are accessible for public use at Hugging Face - Func-Calling-Eval and Hugging Face - JSON-Mode-Eval, respectively.
Nous Research AI ▷ #general (349 messages🔥🔥):
- Function Calling Precision: Hermes 2 Pro has a Function Calling Accuracy of 91% in a zero-shot setting, indicating exceptional performance even without few-shot training. The evaluation datasets for Function Calling and JSON Mode have been released, with training sets to follow.
- AI Act Shakes Up Europe: The EU AI Act just passed into law, prohibiting certain AI practices, requiring energy consumption reports, and potentially affecting AI companies looking to do business in Europe.
- DeepMind and Fortnite: Google DeepMind Tweet article suggests AI now can outplay humans in Fortnite, raising concerns and interests in the gaming community.
- Advancing Inference Libraries: Discussion was held on improving libraries for inference with function calling/tool support, with Hermes Function Calling GitHub repository mentioned as a notable resource.
- New Model Release Excitement: Nous Research has released Hermes 2 Pro, stirring excitement in the community for its potential in function calling and structured outputs in applications like llama.cpp and vercel AI SDK; DSPy optimization has also been a recent topic of interest.
Links mentioned:
- Tweet from Cake (@ILiedAboutCake): lol the Amazon “search through reviews” is blindly just running an AI model now AI has ruined using the internet
- princeton-nlp/SWE-Llama-7b · Hugging Face: no description found
- Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM: We investigate efficient methods for training Large Language Models (LLMs) to possess capabilities in multiple specialized domains, such as coding, math reasoning and world knowledge. Our method, name...
- DiscoResearch/DiscoLM_German_7b_v1 · Hugging Face: no description found
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO · Hugging Face: no description found
- Hugging Face – The AI community building the future.: no description found
- Tweet from Jack Burlinson (@jfbrly): In case you were wondering just how cracked the team @cognition_labs is... This was the CEO (@ScottWu46) 14 years ago. ↘️ Quoting Cognition (@cognition_labs) Today we're excited to introduce ...
- Bh187 Austin Powers GIF - Bh187 Austin Powers I Love You - Discover & Share GIFs: Click to view the GIF
- GitHub - NousResearch/Hermes-Function-Calling: Contribute to NousResearch/Hermes-Function-Calling development by creating an account on GitHub.
- GitHub - NousResearch/Hermes-Function-Calling: Contribute to NousResearch/Hermes-Function-Calling development by creating an account on GitHub.
- Gemma optimizations for finetuning and infernece · Issue #29616 · huggingface/transformers: System Info Latest transformers version, most platforms. Who can help? @ArthurZucker and @younesbelkada Information The official example scripts My own modified scripts Tasks An officially supporte...
- Gemma bug fixes - Approx GELU, Layernorms, Sqrt(hd) by danielhanchen · Pull Request #29402 · huggingface/transformers: Just a few more Gemma fixes :) Currently checking for more as well! Related PR: #29285, which showed RoPE must be done in float32 and not float16, causing positional encodings to lose accuracy. @Ar...
- OpenAI Tools / function calling v2 by FlorianJoncour · Pull Request #3237 · vllm-project/vllm: This PR follows #2488 The implementation has been updated to use the new guided generation. If during a query, the user sets tool_choice to auto, the server will use the template system used in #24...
- Guidance: no description found
- OpenAI Compatible Web Server - llama-cpp-python: no description found
Nous Research AI ▷ #ask-about-llms (107 messages🔥🔥):
- Discussing the Nuances of Model Licensing: Members inquired about the commercial usability of models like nous Hermes 2 under Apache 2 and MIT licenses derived from GPT-4. Clarifications were given stating, "do what you want you wont hear anything from us (we wont be suing you lol)", and the complexities of TOS enforcement and content sharing were highlighted.
- Challenges with Fine-tuning Efficiency and Style Transfer: Conversation touched on the inefficiency of fine-tuning on a small subset of data for style mimicking. A shift towards style transfer beyond prompt engineering was suggested, emphasizing a focus on role-playing aspects in language models.
- Delving into Function Calling and Structured Outputs: Function calling capabilities and structured JSON outputs in LLMs were thoroughly discussed. For example, the Trelis/Llama-2-7b-chat-hf-function-calling-v2 model sparked debates on its functional calling and JSON mode operations, with insights provided on its method of returning structured JSON arguments.
- Releasing Updates and Understanding Model Capabilities: Anticipation built around Nous Hermes 2 Pro, with a member hinting, "<:cPES_Wink:623401321382281226> maybe it'll be out today <:cPES_Wink:623401321382281226>". Another member stressed the importance of clarity in model versioning to avoid confusion among users, arguing against ambiguous titling such as "Pro" without a clear version number.
- Exploring Integration of Hermes 2 Pro with Ollama: Questions arose on how to integrate the upcoming Nous Hermes 2 Pro with Ollama. A response pointed out that Ollama can support specific GGUFs, skipping the need for model quantization, and shared a guide at ollama/docs/import.md on GitHub.
Links mentioned:
- ollama/docs/import.md at main · ollama/ollama: Get up and running with Llama 2, Mistral, Gemma, and other large language models. - ollama/ollama
- Trelis/Llama-2-7b-chat-hf-function-calling-v2 · Hugging Face: no description found
- GitHub - NousResearch/Hermes-Function-Calling: Contribute to NousResearch/Hermes-Function-Calling development by creating an account on GitHub.
Latent Space ▷ #ai-general-chat (127 messages🔥🔥):
- Big Splash in AI Software Engineering: Cognition Labs introduces Devin, an autonomous AI software engineer capable of passing engineering interviews and completing real jobs. Devin far surpassed the previous best SWE-Bench benchmark, resolving a significant 13.86% of GitHub issues. Check out the thread for more on Devin.
- Stealing Weights or Just Hype?: A new paper reveals that it's possible to infer weights from production language models like ChatGPT and PaLM-2 using their APIs. This sparked discussions about the ethics and future security measures for AI models. Find the full post here.
- Google's Gemini Struggles to Impress: Users express frustration with Google's Gemini API, highlighting its complexity and clunky documentation. There's a sentiment that Google is falling behind in the AI API space compared to competitors like OpenAI and Anthropic.
- Together.ai Bolsters Compute for AI Startups: Together.ai announces a $106M raise to build a platform for running generative AI apps at scale and introduces Sequoia, a method to serve large LLMs efficiently. Learn more about their vision.
- Cerebras Unveils Groundbreaking AI Chip: Cerebras announces the CS-3, the fastest AI chip capable of training models up to 24 trillion parameters on a single device. This development is a significant leap in AI hardware innovation. Discover the CS-3.
Links mentioned:
- Stealing Part of a Production Language Model: no description found
- Bloomberg - Are you a robot?: no description found
- Using LangSmith to Support Fine-tuning: Summary We created a guide for fine-tuning and evaluating LLMs using LangSmith for dataset management and evaluation. We did this both with an open source LLM on CoLab and HuggingFace for model train...
- Tweet from Cognition (@cognition_labs): Today we're excited to introduce Devin, the first AI software engineer. Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering intervie...
- Tweet from Ate-a-Pi (@8teAPi): Sora WSJ Interview Mira Murati gives the most detail to date on Sora > Joanna Stern gave several prompts for them to generate > First time I've seen Sora videos with serious morphing prob...
- 🌎 The Compute Fund: Reliably access the best GPUs you need at competitive rates in exchange for equity.
- Tweet from Ate-a-Pi (@8teAPi): Sora WSJ Interview Mira Murati gives the most detail to date on Sora > Joanna Stern gave several prompts for them to generate > First time I've seen Sora videos with serious morphing prob...
- Tweet from Patrick Collison (@patrickc): These aren't just cherrypicked demos. Devin is, in my experience, very impressive in practice. ↘️ Quoting Cognition (@cognition_labs) Today we're excited to introduce Devin, the first AI so...
- Tweet from Together AI (@togethercompute): Excited to announce our new speculative decoding method, Sequoia! Sequoia scales speculative decoding to very large speculation budgets, is robust to different decoding configurations, and can adap...
- Tweet from Cerebras (@CerebrasSystems): 📣ANNOUNCING THE FASTEST AI CHIP ON EARTH📣 Cerebras proudly announces CS-3: the fastest AI accelerator in the world. The CS-3 can train up to 24 trillion parameter models on a single device. The wo...
- Tweet from Figure (@Figure_robot): With OpenAI, Figure 01 can now have full conversations with people -OpenAI models provide high-level visual and language intelligence -Figure neural networks deliver fast, low-level, dexterous robot ...
- Tweet from Cognition (@cognition_labs): Devin builds a custom chrome extension ↘️ Quoting Arun Shroff (@arunshroff) @cognition_labs This looks awesome! Would love to get access! I used ChatGPT recently to create a Chrome extension to f...
- Tweet from Chief AI Officer (@chiefaioffice): VC-backed AI employee startups are a trend. Here are some that raised in 2024 + total funding: Software Engineer - Cognition ($21M+) Software Engineer - Magic ($145M+) Product Manager - Version Le...
- Tweet from Andrej Karpathy (@karpathy): # automating software engineering In my mind, automating software engineering will look similar to automating driving. E.g. in self-driving the progression of increasing autonomy and higher abstracti...
- Tweet from Together AI (@togethercompute): Today we are thrilled to share that we’ve raised $106M in a new round led by @SalesforceVC with participation from @coatuemgmt and our existing investors. Our vision is to rapidly bring innovations f...
- Tweet from Akshat Bubna (@akshat_b): The first time I tried Devin, it: - navigated to the @modal_labs docs page I gave it - learned how to install - handed control to me to authenticate - spun up a ComfyUI deployment - interacted with i...
- Tweet from Aravind Srinivas (@AravSrinivas): This is the first demo of any agent, leave alone coding, that seems to cross the threshold of what is human level and works reliably. It also tells us what is possible by combining LLMs and tree searc...
- Tweet from Ashlee Vance (@ashleevance): Scoop: a start-up called Cognition AI has released what appears to be the most capable coding assisstant yet. Instead of just autocompleting tasks, it can write entire programs on its own. Is backed...
- Tweet from swyx (@swyx): hope this works 🕯 🕯 🕯 🕯 @elonmusk 🕯 open source 🕯 @xAI Grok 🕯 on 🕯...
- Tweet from Together AI (@togethercompute): Today we are thrilled to share that we’ve raised $106M in a new round led by @SalesforceVC with participation from @coatuemgmt and our existing investors. Our vision is to rapidly bring innovations f...
- 4,000,000,000,000 Transistors, One Giant Chip (Cerebras WSE-3): The only company with a chip as big as your head, Cerebras has a unique value proposition when it comes to AI silicon. Today they are announcing their third ...
- Tweet from muhtasham (@Muhtasham9): DeepMind folks can now steal weights behind APIs “We also recover the exact hidden dimension size of the gpt-3.5-turbo model, and estimate it would cost under $2,000 in queries to recover the entire...
- Tweet from Anthropic (@AnthropicAI): With state-of-the-art vision capabilities and strong performance on industry benchmarks across reasoning, math, and coding, Haiku is a versatile solution for a wide range of enterprise applications.
- Tweet from asura (@stimfilled): @qtnx_ 3) dateLastCrawled: 2023-09
- Tweet from Mckay Wrigley (@mckaywrigley): I’m blown away by Devin. Watch me use it for 27min. It’s insane. The era of AI agents has begun.
- Tweet from Anthropic (@AnthropicAI): Today we're releasing Claude 3 Haiku, the fastest and most affordable model in its intelligence class. Haiku is now available in the API and on http://claude.ai for Claude Pro subscribers.
- Tweet from Siqi Chen (@blader): this is the ceo of cognition 14 years ago the idea that 10x/100x engineers don’t exist is such a cope
- Tweet from James O'Leary (@jpohhhh): Google Gemini integration began 15 minutes ago, this is a cope thread - There's an API called "Gemini API" that is free until we start charging for it early next year (it is mid-March) - ...
- Tweet from James O'Leary (@jpohhhh): Google Gemini integration began 15 minutes ago, this is a cope thread - There's an API called "Gemini API" that is free until we start charging for it early next year (it is mid-March) - ...
- Tweet from Neal Wu (@WuNeal): Today I can finally share Devin, the first AI software engineer, built by our team at @cognition_labs. Devin is capable of building apps end to end, finding bugs in production codebases, and even fine...
- Tweet from Lucas Atkins (@LucasAtkins7): Tonight, I am releasing eight Gemma fine tunes and a beta of their combined mixture of experts model named GemMoE. GemMoE has ALL Gemma bug fixes built-in. You do not have to do anything extra to ge...
- Tweet from Fred Ehrsam (@FEhrsam): First time I have seen an AI take a complex task, break it down into steps, complete it, and show a human every step along the way - to a point where it can fully take a task off a human's plate. ...
- The First AI Virus Is Here!: ❤️ Check out Weights & Biases and sign up for a free demo here: https://wandb.me/papers📝 The paper "ComPromptMized: Unleashing Zero-click Worms that Target ...
- Tweet from Varun Shenoy (@varunshenoy_): Devin is 𝘪𝘯𝘤𝘳𝘦𝘥𝘪𝘣𝘭𝘦 at data extraction. Over the past few weeks, I've been scraping data from different blogs and Devin 1. writes the scraper to navigate the website 2. executes the cod...
- Tweet from Andrew Kean Gao (@itsandrewgao): i never believe recorded demos so I reached out to the @cognition_labs team for early access to try for myself and got it! will be sharing my unfiltered opinions on #devin here. 🧵🧵 1/n ↘️ Quotin...
- [AINews] The world's first fully autonomous AI Engineer: AI News for 3/11/2024-3/12/2024. We checked 364 Twitters and 21 Discords (336 channels, and 3499 messages) for you. Estimated reading time saved (at 200wpm):...
- Tweet from simp 4 satoshi (@iamgingertrash): Finally, excited to launch Truffle-1 — a $1299 inference engine designed to run OSS models using just 60 watts https://preorder.itsalltruffles.com
- Amazon announces Rufus, a new generative AI-powered conversational shopping experience: With Rufus, customers are now able to shop alongside a generative AI-powered expert that knows Amazon’s selection inside and out, and can bring it all together with information from across the web to ...
- Perspective – A space for you: A private journal to build a complete record of your life.
- Add support for Gemini API · Issue #441 · jxnl/instructor: The new Gemini api introduced support for function calling. You define a set of functions with their expected arguments and you pass them in the tools argument. Can we add gemini support to instruc...
Latent Space ▷ #ai-announcements (7 messages):
- Invitation to LLM Paper Club Event: A reminder was posted for the Latent Space Discord community about the upcoming LLM Paper Club event featuring a presentation on Synthetic Data for Finetuning at 12pm PT. Participants are encouraged to read Eugene Yan's survey on synthetic data for background information.
- Important: Accept your Luma Invites: Members are urged to accept their invitations on Luma (https://lu.ma/wefvz0sb) to avoid being pruned from auto-invites for future calendar reminders due to inactivity.
- Correction to Synthetic Data Article Link: The previous link to the synthetic data article was corrected as it contained an extra period causing a 404 error. The updated event cover can be found here.
- Picocreator Highlights Close Call with Pruning: In a light-hearted comment, picocreator mentioned the community's narrowly-avoided mass pruning from the event reminders, facetiously celebrating their collective close call.
- Swyxio Emphasizes Consistency of Event Schedule: Swyxio pointed out that the LLM Paper Club has been consistently scheduled at the same time for the past 6 months, implying that regular members should already know the timing.
Links mentioned:
- LLM Paper Club (Synthetic Data for Finetuning) · Luma: This week we'll be covering the survey post - How to Generate and Use Synthetic Data for Finetuning (https://eugeneyan.com/writing/synthetic/) with @eugeneyan We have moved to use the...
- How to Generate and Use Synthetic Data for Finetuning: Overcoming the bottleneck of human annotations in instruction-tuning, preference-tuning, and pretraining.
Latent Space ▷ #llm-paper-club-west (207 messages🔥🔥):
- The Senpai of Synthetic Data: Eugene Yan discussed the viability of using synthetic data for model training in various aspects, including pretraining and instruction-tuning. He highlighted that synthetic data is quicker and more cost-effective to generate, avoiding privacy issues while providing quality and diversity that can exceed human annotation.
- Voice Recognition: A Rabbit Hole to Explore: Links were shared to a Twitter thread diving into voice recognition and topics related to text-to-speech and speech-to-text. The discussion also included various applications and tools like vapi.ai and whisper.
- The Potential of Whisper for Speech Processing: Amid the interest towards voice technologies, whisper.cpp was mentioned as a nice tool for speech recognition, and a request was made for covering the Open Source SOTA for diarization.
- Revisiting Classic Papers: Eugene Yan commended the importance of revisiting old papers on synthetic data, suggesting that "synthetic data is almost all you need" and emphasizing self-reward as a significant concept.
- Invitation for Community Engagement: The community was encouraged to participate in covering papers, with an open invitation for anyone in the audience to delve into the papers and contribute to the discussions.
Links mentioned:
- Why Not Both Take Both GIF - Why Not Both Why Not Take Both - Discover & Share GIFs: Click to view the GIF
- Join Slido: Enter #code to vote and ask questions: Participate in a live poll, quiz or Q&A. No login required.
- AI News: We summarize AI discords + top Twitter accounts, and send you a roundup each day! See archive for examples. "Highest-leverage 45 mins I spend everyday" - Soumith "the best AI newslette...
- Fine-tuning vs RAG: Listen to this episode from Practical AI: Machine Learning, Data Science on Spotify. In this episode we welcome back our good friend Demetrios from the MLOps Community to discuss fine-tuning vs. retri...
- How to Generate and Use Synthetic Data for Finetuning: Overcoming the bottleneck of human annotations in instruction-tuning, preference-tuning, and pretraining.
- dspy/docs/api/optimizers/BootstrapFinetune.md at 0c1d1b1b2c9b5d6dc6d565a84bfd8f17c273669d · stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models - stanfordnlp/dspy
- Forget ChatGPT and Gemini — Claude 3 is the most human-like chatbot I've ever used: It isn't AGI but it is getting closer
- 🦅 Eagle 7B : Soaring past Transformers with 1 Trillion Tokens Across 100+ Languages (RWKV-v5): A brand new era for the RWKV-v5 architecture and linear transformer's has arrived - with the strongest multi-lingual model in open source today
Perplexity AI ▷ #general (311 messages🔥🔥):
- Perplexity AI Utilizes Claude 3 Opus: Although several AIs were discussed, it was clarified that Perplexity AI uses Claude3 Opus. Users inquired about tools to prevent plagiarism detection, though there's skepticism about the effectiveness of current tools in detecting AI-generated content.
- Concerns About AI Plagiarism Tools: Users discussed the limitations of existing plagiarism tools, with some arguing that no reliable method exists to detect AI-generated text. Discussions included the potential need for breakthroughs in AIs to address this.
- Debate on Search Engines and Indexers: There was a lively debate about whether Perplexity AI uses other indexers, with members ultimately clarifying that Perplexity has its own indexer, contributing to its speed. Additionally, the discussions touched on Google's past performance and the future of search engines in the age of AI.
- Boost in Productivity with AI: Multiple users reported significant increases in productivity thanks to tools like Perplexity AI and Notebook LLM. They shared how AI aids in research and information gathering, despite limitations like the experimental nature of some tools restricting the upload of multiple documents.
- Confusion Over Perplexity AI Offerings: Users shared confusion over the available models within Perplexity AI, such as the types of Claude models and the number of uses allowed for each. It was clarified by one user that Claude 3 Opus has 5 uses, after which it switches to Claude 3 Sonnet.
Links mentioned:
- MSN: no description found
- MSN: no description found
- Perplexity brings Yelp data to its chatbot: Yelp cut a deal with the AI search engine.
- U.S. Must Act Quickly to Avoid Risks From AI, Report Says : The U.S. government must move “decisively” to avert an “extinction-level threat" to humanity from AI, says a government-commissioned report
- Further Adventures in Plotly Sankey Diagrams: The adventure continues
- There are growing calls for Google CEO Sundar Pichai to step down: Analysts believe Google's search business is keeping it safe for now, but that could change soon with generative-AI rivals proliferating.
- Perplexity AI CEO Shares How Google Retained An Employee He Wanted To Hire: Aravind Srinivas, the CEO of search engine Perplexity AI, recently shared an interesting incident that sheds light on how big tech companies are ready to shell a great amount of money to retain talent...
- New Rabbit R1 demo promises a world without apps – and a lot more talking to your tech: Chat with your bot
- Tweet from Aravind Srinivas (@AravSrinivas): Will make Perplexity Pro free, if Mikhail makes Microsoft Copilot free ↘️ Quoting Ded (@dened21) @AravSrinivas @MParakhin We want perplexity pro for free (monetize with highly personalized ads)
- Open AI JUST LEAKED GPT 4.5 ?!! (GPT 4.5 Update Explained): ✉️ Join My Weekly Newsletter - https://mailchi.mp/6cff54ad7e2e/theaigrid🐤 Follow Me on Twitter https://twitter.com/TheAiGrid🌐 Checkout My website - https:/...
- More than an OpenAI Wrapper: Perplexity Pivots to Open Source: Perplexity CEO Aravind Srinivas is a big Larry Page fan. However, he thinks he's found a way to compete not only with Google search, but with OpenAI's GPT too.
- Killed by Google: Killed by Google is the open source list of dead Google products, services, and devices. It serves as a tribute and memorial of beloved services and products killed by Google.
- I Believe In People Sundar Pichai GIF - I Believe In People Sundar Pichai Youtube - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- CEO says he tried to hire an AI researcher from Meta, and was told to 'come back to me when you have 10,000 H100 GPUs': The CEO of an AI startup said he wasn't able to hire a Meta researcher because it didn't have enough GPUs.
- Fireside Chat with Aravind Srinivas, CEO of Perplexity AI, & Matt Turck, Partner at FirstMark: Today we're joined by Aravind Srinivas, CEO of Perplexity AI, a chatbot-style AI conversational engine that directly answers users' questions with sources an...
- GitHub - danielmiessler/fabric: fabric is an open-source framework for augmenting humans using AI. It provides a modular framework for solving specific problems using a crowdsourced set of AI prompts that can be used anywhere.: fabric is an open-source framework for augmenting humans using AI. It provides a modular framework for solving specific problems using a crowdsourced set of AI prompts that can be used anywhere. - ...
Perplexity AI ▷ #sharing (12 messages🔥):
- Sharing Perplexity.ai Search Queries: Members are sharing direct links to Perplexity AI search results covering various topics such as improvement strategies, sleep advice, the meaning of Catch-22, and information on OpenAI Chat GPT.
- Exploring AI and Tech via YouTube: A member shared a YouTube video exploring various AI news, including a controversy between Midjourney and Stability AI, and the introduction of "Digital Marilyn."
- Inquiries Into Medical Terminology: Queries on medical terms are also made, with a link provided to understanding azotemia.
- Evaluating Images and Business Metrics with AI: Links to searches that utilize AI to describe an image and explain the concept of net promoter score were shared.
- Remembering Paul Alexander: A member commemorates Paul Alexander by sharing a search link about his passing, honoring his achievements, and calling him an "absolute chad."
Links mentioned:
Midjourney bans Stability staff, Marilyn Monroe AI Debut, Vision Pro aids spine surgery: This episode explores the latest AI news, including a heated data scraping controversy between Midjourney and Stability AI, the innovative "Digital Marilyn" ...
Perplexity AI ▷ #pplx-api (16 messages🔥):
- Pondering on Prompt Perfection: A member emphasized that achieving concise answers from models can be obtained through prompting adjustments and parameter settings like max_tokens and temperature.
- Remembering Through Embeddings: It was suggested that for a chatbot model to "remember conversations" using the Perplexity API, it would require an external database to store embeddings of past conversations.
- Seeking Source Specifics: A query was raised about whether the Perplexity API can be prompted to reply with just the website or source of the information it references.
- Request for High-Context Models: A user inquired if Yarn-Mistral-7b-128k could be added for higher context use cases.
- Accuracy Anxieties and Searches:
- Concerns about result accuracy when using the -online tag were voiced, specifically regarding non-existent studies and incorrect authorship attribution. One method to possibly enhance accuracy involves setting a system message to provide clarity and instructions to the model separate from the user query. A link to Perplexity's API documentation was shared for experimentation with system messages.
Links mentioned:
Chat Completions: no description found
Unsloth AI (Daniel Han) ▷ #general (224 messages🔥🔥):
- Kernel Improvements Shared: An improvement was discussed for a rope kernel where sin/cos functions are loaded once for computations along axis 1 for efficiency. Sequential computation is used for grouping heads, and a Pull Request (PR) was mentioned to have been made with some apprehension about its impact on overall training performance.
- Unsloth Discussion and Contributions: Unsloth's performance and usage were highlighted, with Unsloth Studio (Beta) mentioned as an upcoming feature allowing one-click finetuning. Issues surrounding importing FastLanguageModel on Kaggle were addressed, suggesting manual reinstallation of certain libraries.
- Grok AI Speculations and OpenAI Dialogue: Conversations touched on the significance of Elon Musk releasing an open-source Grok AI model and the recent OpenAI events. Debate arose over the impact of real-time Twitter data feed integration with the model's performance.
- Forthcoming Open-Source AI Models: The chat referenced other AI communities excited about the open-source release of models like GemMoE, Grok AI, and discussions about if OpenAI would follow suit. Concerns were aired about the potential for models to be pirated, and discussions of OpenAI's involvement with Microsoft Azure.
- Technical Support and Updates: Technical questions were addressed such as importing and fine-tuning models with Unsloth, including loading into Transformers post-finetuning. A link to Unsloth's GitHub wiki was provided for FAQs, and support was given for dataset formatting for DPO pair style data.
Links mentioned:
- Crystalcareai/GemMoE-Beta-1 · Hugging Face: no description found
- Docker: no description found
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
- Paper page - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU: no description found
- Models: no description found
- Home: 5X faster 60% less memory QLoRA finetuning. Contribute to unslothai/unsloth development by creating an account on GitHub.
- GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning: 5X faster 60% less memory QLoRA finetuning. Contribute to unslothai/unsloth development by creating an account on GitHub.
- Unsloth free vs. 2x GPUs video outline: no description found
- Comparative LORA Fine-Tuning of Mistral 7b: Unsloth free vs. Dual GPUs: This video explores the cutting edge of AI model training efficiency, with a spotlight on enhancing news article summarization capabilities of Mistral 7b. Di...
- Unsloth update: Mistral support + more: We’re excited to release QLoRA support for Mistral 7B, CodeLlama 34B, and all other models based on the Llama architecture! We added sliding window attention, preliminary Windows and DPO support, and ...
- GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning: 5X faster 60% less memory QLoRA finetuning. Contribute to unslothai/unsloth development by creating an account on GitHub.
- axolotl/docker at main · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- GitHub - PerspectiveDataScience/Testing_Unsloth_v_2GPUs_LORA: Script to test the speed to train a LORA fine tune of Mistral 7b using Unsloth with 1 GPU versus using 2 GPUS: Script to test the speed to train a LORA fine tune of Mistral 7b using Unsloth with 1 GPU versus using 2 GPUS - PerspectiveDataScience/Testing_Unsloth_v_2GPUs_LORA
Unsloth AI (Daniel Han) ▷ #welcome (9 messages🔥):
- A Warm Emoji-filled Hello: Member greeted the channel with a simple "coucou."
- Get Settled with the Essentials: theyruinedelise emphasized reading the channel rules and setting up roles upon arrival, directing new users to specific channels for these purposes.
- A Friendly Wave of Tools and Greetings: pacozaa shared enthusiastic emojis indicating excitement and a readiness to build or work on something.
- Simple Salutations: Both aleccol and theyruinedelise offered brief greetings to newcomers in the welcome channel.
Unsloth AI (Daniel Han) ▷ #random (6 messages):
- Dependency Hell in WSL Environment: A user encountered a dependency loop on Ubuntu WSL involving bitsandbytes, triton, torch, and xformers, which led to incompatible versions of torchaudio, torch, and torchvision. This issue has halted progress on a promising Gradio interface for creating datasets with YouTube videos and playlists, processing options, JSONL creation, and fine-tuning using Unsloth.
- Suggestion to Combat Dependencies: Another user recommended attempting to install xformers directly from PyTorch's cu121 index, followed by installing Unsloth from a nightly GitHub build. This was suggested as a potential workaround to the version conflicts presented.
- Slow Progress on Lengthy Task: A member expressed frustration over the slow progression of a task, with the current status indicating a lengthy completion time of over 74 hours remaining. The dissatisfaction was emphasized with the use of a crying emoji.
Links mentioned:
no title found: no description found
Unsloth AI (Daniel Han) ▷ #help (63 messages🔥🔥):
- Model Switch Solution to Tokenization Troubles: A community member attempted to use a tokenizer with a parameter
max_length=4096, truncation=Trueunsuccessfully, but found that switching to an alternative model and reducing the dataset length resolved the issue.
- Quizzing Quantization Quandaries: A user faced out-of-memory issues when attempting to quantize the Mixtral model with three V100 32GB GPUs. They received suggestions to try quantization on stronger hardware like 2x A100 80GB which should suffice, and were directed to alternative methods like Unsloth's built-in support for GGUF.
- Xformers Vs. FA2 Framework Face-off: Comparisons between xformers and FA2 were discussed, with a member stating xformers is about 0.5% slower and clarifying that xformers and FA2 have similar functions.
- Padding Problems with Nous-Hermes Model: A user encountered issues with
<unk>values when trying to use a Nous-Hermes model through Unsloth without fine-tuning. It was suggested that the problems might be due to padding and to try using Nous's chat template.
- Xformers Installation Issues: A member experienced a failed attempt to install xformers through conda and encountered a Python error that rendered it impossible to install any packages; they were informed that their Python or conda environment might be broken and advised to reinstall Conda and attempt installation on WSL instead of Windows.
Links mentioned:
no title found: no description found
Unsloth AI (Daniel Han) ▷ #suggestions (17 messages🔥):
- Exploring Large Model Tuning with NVMe SSDs: A paper outlining the potential of using NVMe SSDs for 100B Model Fine-tuning on a single GPU was shared, highlighting the challenges with current GPU memory limitations and how SSDs might help to address these when fine-tuning massive models.
- User Space NVMe Drivers with CUDA Support: A potential tool for the implementation of NVMe SSDs in model fine-tuning, ssd-gpu-dma, was introduced, providing resources to build userspace NVMe drivers and storage applications with CUDA support.
- NVMe and GPUDirect Talk: A talk by Jonas Markussen from GTC 2019 was mentioned, which discusses efficient distributed storage I/O using NVMe and GPUDirect in a PCIe network, possibly requiring NVIDIA Developer Program membership to view.
- FlashNeuron Contribution Opportunity: The flashneuron project on GitHub was shared, indicating another opportunity for contributing to the development of GPU storage applications.
- NVIDIA's Direct Data Path API for GPUs: Documentation for NVIDIA's GPUDirect® Storage was highlighted, showing an API for file read and write that allows for direct memory access transfers between GPU memory and storage, bypassing the CPU.
Links mentioned:
- GTC Silicon Valley-2019: Efficient Distributed Storage I/O using NVMe: no description found
- Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU: Recent advances in large language models have brought immense value to the world, with their superior capabilities stemming from the massive number of parameters they utilize. However, even the GPUs w...
- Question could direct nvme access boost training? · Issue #31 · AnswerDotAI/fsdp_qlora: Hey, I'm loving the goal of lowering the resource requirements for training! In this paper https://arxiv.org/abs/2403.06504 they claim direct memory access between the GPU<->Nvme Storage is ...
- GitHub - enfiskutensykkel/ssd-gpu-dma: Build userspace NVMe drivers and storage applications with CUDA support: Build userspace NVMe drivers and storage applications with CUDA support - enfiskutensykkel/ssd-gpu-dma
- flashneuron/README.md at master · SNU-ARC/flashneuron: Contribute to SNU-ARC/flashneuron development by creating an account on GitHub.
- cuFile API Reference Guide - NVIDIA Docs: no description found
LM Studio ▷ #💬-general (117 messages🔥🔥):
- Exploding PCs and Power Moves: Members shared various GIFs from Tenor, including one of an exploding PC labeled with tags like "pc," "Exploding," "Minecraft," and "Rtx."
- Inquiries about Fine-Tuning and Model Operation: Members asked whether LM Studio allows for fine-tuning of large language models (LLMs), to which the answer was confirmed to be no, and discussed getting a WhiteRabbit model to work; the suggestion was to avoid a specific broken version by TheBloke and look for one by insomnium.
- Handling Dual GPU Configurations: A query about LM Studio recognizing two GPUs as a single one with combined VRAM spawned discussion on managing models across multiple graphics cards. Suggestions included splitting large models across two GPUs for better performance, and potential use of tensor split configurations to run separate instances on individual cards.
- Local LLM User Guide Release: A user shared their Local LLM User Guide, which garnered appreciative and constructive feedback, including requests for adherence to standardized date formats and omission of temporal language.
- Availability of Development Resources: Members shared links to resources such as an open-source visual AI programming environment called Rivet, a tutorial on using local LLMs with Rivet, and a new comprehensive unofficial LM Studio FAQ on Rentry.org to assist users in navigating LM Studio's functionalities and limitations.
Links mentioned:
- Poe - Fast, Helpful AI Chat: no description found
- Rivet: An open-source AI programming environment using a visual, node-based graph editor
- The unofficial LMStudio FAQ!: Welcome to the unofficial LMStudio FAQ. Here you will find answers to the most commonly asked questions that we get on the LMStudio Discord. (This FAQ is community managed). LMStudio is a free closed...
- OpenRouter: A router for LLMs and other AI models
- I Have The Power GIF - He Man I Have The Power Sword - Discover & Share GIFs: Click to view the GIF
- Pc Exploding GIF - Pc Exploding Minecraft - Discover & Share GIFs: Click to view the GIF
- Rivet: How To Use Local LLMs & ChatGPT At The Same Time (LM Studio tutorial): This tutorial explains how to connect LM Studio with Rivet to use local models running on your own pc (e.g. Mistral 7B), but also how you are able to still u...
- llama.cpp/examples/server/README.md at master · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- GitHub - ChatGPTNextWeb/ChatGPT-Next-Web: A cross-platform ChatGPT/Gemini UI (Web / PWA / Linux / Win / MacOS). 一键拥有你自己的跨平台 ChatGPT/Gemini 应用。: A cross-platform ChatGPT/Gemini UI (Web / PWA / Linux / Win / MacOS). 一键拥有你自己的跨平台 ChatGPT/Gemini 应用。 - ChatGPTNextWeb/ChatGPT-Next-Web
- GitHub - xue160709/Local-LLM-User-Guideline: Contribute to xue160709/Local-LLM-User-Guideline development by creating an account on GitHub.
- Artificial Intelligence Act: MEPs adopt landmark law | News | European Parliament: On Wednesday, Parliament approved the Artificial Intelligence Act that ensures safety and compliance with fundamental rights, while boosting innovation.
LM Studio ▷ #🤖-models-discussion-chat (37 messages🔥):
- LaTeX Dreams for Math Marvels: Members excitedly discuss the possibility of LM Studio supporting LaTeX code for math problems, mentioning a Github blog post regarding markdown rendering of mathematical expressions. They stress the convenience it would bring to the UI, especially for areas like math markdown.
- Potential for ReactJS Implementation: A member links to an article on how to safely render markdown using React Markdown from LogRocket, suggesting that similar methods could be used for math markdown in UIs like Discord, which uses Electron.
- LaTeX Generation Sets High Expectations: Amidst discussions, there's a light-hearted tone with members jesting about their desires for better math parsing, including visual inputs like a "swipe-style blackboard," and higher image resolution for vision models, with sarcastic quips about hating math.
- Exploring State-of-the-Art Language Models: A user shares a link to Nous-Yarn-Mistral-7b-128k on Hugging Face, prompting explanations about its long context support of 128k tokens, and additional educational links like an explanation of Perplexity (PPL) for language models.
- A Mixture of Jokes and Learning: The chat lightens up with playful comments about naming schemes and related GIF shares from Tenor, reflecting the members' humor and camaraderie within the more technical conversations.
Links mentioned:
- How to safely render Markdown using react-markdown - LogRocket Blog: Learn how to safely render Markdown syntax to the appropriate HTML with this short react-markdown tutorial.
- NousResearch/Yarn-Mistral-7b-128k · Hugging Face: no description found
- YaRN: Efficient Context Window Extension of Large Language Models: Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize past the sequence length t...
- Perplexity of fixed-length models: no description found
- Im Waiting Daffy Duck GIF - Im Waiting Daffy Duck Impatient - Discover & Share GIFs: Click to view the GIF
- Yeah Another Day Lets Do It Bojack GIF - Yeah Another Day Lets Do It Bojack Will Arnett - Discover & Share GIFs: Click to view the GIF
- Calculation Math GIF - Calculation Math Hangover - Discover & Share GIFs: Click to view the GIF
- Render mathematical expressions in Markdown: Render mathematical expressions in Markdown
- Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models: no description found
LM Studio ▷ #🎛-hardware-discussion (76 messages🔥🔥):
- Exploring GPU Configurations for LLMs: Users discuss the effectiveness of various GPU setups, including using dual RTX 4060 Ti 16GB with a PCI-e x1 to x16 adapter, comparing the performance when using different VRAM capacities. A YouTube video was shared (Testing single GPU vs two GPUs with LM Studio LLMs) detailing an 8.5-hour performance test with commentary on the variable performance gains when scaling from one to two GPUs.
- NVLINK Bridge Costs and Workarounds: Members debate the high costs of NVLINK bridges, one stating they received one for free with an RTX 2060 purchase, while others comment on the pricey nature with some humor about using cheaper alternatives. A Linus Tech Tips forum post about reverse-engineering the NVLINK is mentioned, speculating on its components.
- The Memory Conundrum in Mac and Windows Setups: Users engage in a discussion about the possibility and drawbacks of bypassing minimum VRAM requirements on macOS, mentioning potential system freezing as a consequence. Suggestions are made for boosting performance, including using NVMe SSD as RAM, though it's suggested this would be slow.
- RAM Upgrade Prospects and Performance Considerations: One member considers upgrading to 128GB of RAM to possibly run larger models and improve LLM accuracy. Other members suggest that more VRAM is vital compared to more RAM and discuss power requirements for running multiple high-end GPUs, with a user sharing a dual-power supply setup for four 3090s.
- Running Multiple Instances of LLMs on Single vs Multiple GPUs: A member explores the possibility of running two instances of LM Studio concurrently and shares insights on configuration tweaks necessary when pairing GPUs with uneven VRAM capacities. It is noted that while multiple models can be run, personal tests have shown no significant performance loss between a single GPU vs. dual GPU setups in a PCI-e x1 bandwidth scenario.
Links mentioned:
- Cerebras Systems Unveils World's Fastest AI Chip with 4 Trillion Transistors and 900,000 AI cores: Cerebras Systems, the pioneer in accelerating generative AI, has doubled down on its existing world record of fastest AI chip with the introduction of the Wafer Scale Engine 3. The WSE-3 delivers twic...
- Testing single GPU vs two GPUs with LM Studio LLMs (AI Chat) Two RTX 4060 Ti 16GB, one in X1 adaptor: System specs:Ryzen 7 5800X3D 8 core CPU (16 threads)128GB DDR4 2800MHz CL16 RAM (4X32GB dual rank, was unstable at 3000MHz)Zotac RTX 4060 Ti 16GB (HDMI dummy...
LM Studio ▷ #🧪-beta-releases-chat (4 messages):
- Inquiry About AVX Beta Update: A member inquired if there will be an update to the AVX beta, specifically beyond the version 0.2.10.
- Confirmation of Reality: A member questioned the authenticity of a statement, receiving a confirmation in response.
- Comment on Quality: A member expressed an opinion on the quality by stating that the subject at hand "aren't any good".
LM Studio ▷ #amd-rocm-tech-preview (73 messages🔥🔥):
- Improvement in GPU Utilization: A switch from AMD's 23.Q4 PRO drivers to Adrenalin 24.1.1 resulted in a user's experience of performance over 2x faster than OpenCL for LM Studio. They noted significant utilization jumps and advised against using the 24.2.1 update due to issues.
- Disabling iGPU Can Fix Offloading Issues: Some users discovered that disabling the integrated GPU (iGPU) led to successful offloading past initial steps, which optimized their system's performance.
- ROCm Beta Installation Issues and Fixes: Users discussed the necessity of using the ROCm beta version for AMD GPUs in LM Studio and presented solutions such as reinstalling drivers, ensuring HIP SDK installation, and starting new prompts to improve GPU acceleration.
- Tips for Utilizing ROCm with AMD GPUs: Exchanging advice on setting GPU layers to max and using specific driver combinations like Adrenalin 24.1.1 + HIP-SDK for enhanced performance, some users also noted issues with vision models not functioning properly.
- Troubleshooting Model Loading Errors: It was recommended to clean cached directories and re-download models to resolve errors loading previously downloaded models after installing the ROCm build on LM Studio. Users also suggested the use of specific presets for different models to ensure compatibility.
Links mentioned:
👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
OpenAI ▷ #ai-discussions (136 messages🔥🔥):
- Solitaire Game Instruction Bot Inquiry: A university student proposed a project to develop a robot that gives Solitaire game instructions using a camera to film the laptop screen and OpenCV in Python for analysis. Suggestions include researching Solitaire, arranging proper hardware, writing image processing code, integrating with GPT for game analysis, and iteratively testing and updating the design.
- Exploring Sora's Capabilities and Access: Discussions centered on the cost and availability of Sora, an AI model for video generation. It was noted that while Sora is currently costly and not available for public testing, some visual artists and filmmakers have been granted access for feedback.
- Handling Large Google Sheets with GPT Chat: Users discussed strategies for allowing GPT Chat to analyze large datasets, with suggestions including splitting data across multiple sheets for batch processing or using databases and SQL queries for more efficient data handling.
- Rumors About GPT-4.5 Turbo: Members exchanged information regarding unverified rumors of a GPT-4.5 Turbo model mentioned on Bing and other search engines. However, no official source or confirmation from OpenAI was found, leading to the consensus that the information may not be accurate.
- Interest in Self-Hosting AI Models: A new member inquired about self-hosting AI models for personal use, particularly for processing personal journal data. Other users advised on the hardware requirements for running large models and suggested that utilizing OpenAI's platform for fine-tuning could be more feasible.
Links mentioned:
notebooks/mistral-finetune-own-data.ipynb at main · brevdev/notebooks: Contribute to brevdev/notebooks development by creating an account on GitHub.
OpenAI ▷ #gpt-4-discussions (57 messages🔥🔥):
- Learning After Training?: A user inquired if a language model constrained to 32k tokens can process a 232k token PDF, to which another user clarified that the model can only internalize 32k tokens at a time, but will search and summarize within larger documents as needed.
- Economic Constraints on Subscription Prices: Members from Georgia and Brazil shared concerns about the high cost of AI services compared to their local minimum wage, advocating for region-adapted pricing to accommodate users in economically challenged countries.
- GPT and Assistant API Troubles: Users experienced issues with GPT being down and sought assistance, while another faced challenges with the Assistant API where it failed to correctly parse comma-separated numbers.
- Real-Time Status Checks and Workarounds: Amidst outages of GPT-4, users shared tips and updates; suggestions included checking status.openai.com and temporary solutions like sending a picture to start a conversation in the app.
- Community Etiquette: A reminder about respectful communication was necessary after comments on economic status, while others emphasised the need for authentic information and cautious interaction with external links.
OpenAI ▷ #prompt-engineering (46 messages🔥):
- Creative Prompt Crafting for Word Count: Users discussed strategies for instructing the AI to rewrite text with approximately the same word count, while improving the original writing, and retaining bullet points. Constructing custom AI prompts using positive instructions and avoiding specific ratios were among the recommendations, leading to an elaborate prompt offered by a user aiming to get consistent output.
- Counting Conundrums with Code Interpreter: There was dialogue about whether the AI could count words accurately using the Code Interpreter and if direct instruction to count and adjust the word count would help achieve desired results. A user confirmed having tested that Code Interpreter counting is aligned with a standard word counter.
- The Reset Remedy: The chat confirmed that starting a new conversation with the AI often resolves unusual or non-compliant behaviors. This is attributed to the randomness in the training data being accessed during each new interaction.
- Handling Non-Standard Number Formatting: One user inquired about an issue where the Assistant API does not recognize a comma in a number, causing an incorrect interpretation. Another user suggested that providing both positive and negative examples might correct the AI's handling of the unusual comma placement.
- PDF Retrieval and Web Search for CustomGPT: A request for help to improve a custom GPT that can consult PDFs in its database and look up information on the web was made. However, it was clarified that explicit instructions are necessary, and the AI has limitations regarding image recognition within PDFs.
OpenAI ▷ #api-discussions (46 messages🔥):
- Refresh Chat to Reset Weird AI Behavior: Users found that starting a new chat can resolve unusual AI responses, stemming from the AI grabbing different 'buckets of training data' which may affect its performance.
- Prompt Refinement Suggestions for Consistent Output: darthgustav provided a detailed prompt template to help ericplayz achieve more consistent word counts and formatting for city project text rewrites, including markdown for lists and iterative refinement for word count alignment.
- Word Count Precision Using Code Interpreter: darthgustav confirmed that the Code Interpreter can effectively count words in a given text, which can be useful for ensuring that rewritten content meets specified word count requirements.
- Contextual Formatting Influences on Assistant API: A member discussed how the Assistant API may misinterpret formatting like "450,00" as "45000", suggesting the need for positive and negative examples to correct this behavior.
- Utilizing PDF Content and Web Information in CustomGPT: When improving customGPT to reference PDFs and web information, darthgustav noted the need for explicit instructions and mentioned that the model cannot interpret images within PDFs.
Eleuther ▷ #general (99 messages🔥🔥):
- GPT vs Claude for Paper Summaries: A user reported using Claude 3 to summarize academic papers by asking the AI questions, but cautioned it's not recommended for seeking specific details, though it's good at parsing academic language.
- Introduction of a New Member: Raman, a former computational chemist turned ML scientist with experience in active learning and reinforcement learning, reached out for advice on how to get involved with projects related to language models.
- Job Search in the AI Community: A laid-off member who contributed to the Polyglot and OSLO projects at EleutherAI is seeking new opportunities as an ML Engineer/Researcher and is open to relocation.
- Batch Size and Learning Trade-Offs Discussed: Members engaged in a detailed discussion about the efficiency and cost trade-offs when scaling up batch sizes for parallel training, referencing scaling rules and Pythia's training approach.
- DeepMind's Generalist AI Agent for Games Raises Questions: Users shared skepticism over DeepMind's announcement of a generalist AI, SIMA, citing a lack of details about the data, weights, and overall purpose of the agent from the technical report.
Links mentioned:
- An Empirical Model of Large-Batch Training: In an increasing number of domains it has been demonstrated that deep learning models can be trained using relatively large batch sizes without sacrificing data efficiency. However the limits of this ...
- How to Scale Hyperparameters as Batch Size Increases: no description found
- Introducing SIMA, a Scalable Instructable Multiworld Agent: Introducing SIMA, a Scalable Instructable Multiworld Agent
- Introducing SIMA, a Scalable Instructable Multiworld Agent: Introducing SIMA, a Scalable Instructable Multiworld Agent
- Byuntear American Psycho GIF - Byuntear American Psycho Staring - Discover & Share GIFs: Click to view the GIF
- Sadhika Malladi: no description found
- On the SDEs and Scaling Rules for Adaptive Gradient Algorithms: Approximating Stochastic Gradient Descent (SGD) as a Stochastic Differential Equation (SDE) has allowed researchers to enjoy the benefits of studying a continuous optimization trajectory while careful...
Eleuther ▷ #research (84 messages🔥🔥):
- Debunking Myths about Beta2 in Training: The statement that beta2 should be low (like 0.95) for bigger models or your training stability is at stake was called a lie, and it was clarified that it's not. There's discussion about different methods to avoid that necessity, such as using alternative optimizers like ADAM where beta2 effectively reduces to SGD for large values.
- Ethical Boundaries in Model Hacking: There's a query around the ethical aspects of model hacking without explicit permission. The disclosure policy for attacks on models was questioned, and it was articulated that permission for such attacks garners away the ethical concerns, as demonstrated by a recent paper.
- Exploring LoRA for Pre-training: The concept of extending LoRA (low-rank adaptation) to model pre-training was discussed, referencing a paper that introduces LoRA-the-Explorer (LTE), a method that allows for parallel training of multiple low-rank heads. Comments suggested combining it with other methods like GradientLoRA or GaLore for more efficient pre-training approaches.
- Analyzing Neural Collapse and Trajectories: A paper about Deep Neural Collapse (DNC) was highlighted, discussing the emergence of DNC through the average gradient outer product (AGOP). In another thread, the training trajectories of deep networks were noted to be an effectively low-dimensional manifold, regardless of architecture or size, prompting a suggestion that models with mixture-of-architectures could be beneficial.
- Adversarial Strings Against Summarization Models: There was mention of a recent paper that listed adversarial strings which, when inputted into a model, might cause it to output a non-standard response ("HONK" 100 times). The possibility of testing these strings on a summarization model was raised.
Links mentioned:
- Average gradient outer product as a mechanism for deep neural collapse: Deep Neural Collapse (DNC) refers to the surprisingly rigid structure of the data representations in the final layers of Deep Neural Networks (DNNs). Though the phenomenon has been measured in a wide ...
- The Training Process of Many Deep Networks Explores the Same Low-Dimensional Manifold: We develop information-geometric techniques to analyze the trajectories of the predictions of deep networks during training. By examining the underlying high-dimensional probabilistic models, we revea...
- Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM: We investigate efficient methods for training Large Language Models (LLMs) to possess capabilities in multiple specialized domains, such as coding, math reasoning and world knowledge. Our method, name...
- Training Neural Networks from Scratch with Parallel Low-Rank Adapters: The scalability of deep learning models is fundamentally limited by computing resources, memory, and communication. Although methods like low-rank adaptation (LoRA) have reduced the cost of model fine...
- Negating Negatives: Alignment without Human Positive Samples via Distributional Dispreference Optimization: Large language models (LLMs) have revolutionized the role of AI, yet also pose potential risks of propagating unethical content. Alignment technologies have been introduced to steer LLMs towards human...
- Emergent and Predictable Memorization in Large Language Models: Memorization, or the tendency of large language models (LLMs) to output entire sequences from their training data verbatim, is a key concern for safely deploying language models. In particular, it is ...
- Predicting LoRA weights · Issue #6 · davisyoshida/lorax: I would like to use a separate neural network to predict LoRA weights for a main neural network, while training both neural networks at the same time. How can I manipulate the pytrees or to achieve...
Eleuther ▷ #interpretability-general (3 messages):
- Confusion over Model Support: One member questioned if a tool only supports models from a custom library and not trained Hugging Face checkpoints.
- Insight into Model Unlearning via Pythia: The discussion highlighted a paper on interpretability-driven capability unlearning using Pythia, which aims to remove capabilities by pruning important neurons. They pointed out that while language model performance decreases for the targeted capabilities, there is also an unintended performance drop in the retain set, with the paper accessible here.
- Multimodal Mechanistic Interpretability Library Launch: A member announced the release of a multimodal mechanistic interpretability library on Twitter and extended an invitation to collaborate in this research subfield, sharing the announcement link.
Links mentioned:
[PDF] Dissecting Language Models: Machine Unlearning via Selective Pruning | Semantic Scholar: An academic search engine that utilizes artificial intelligence methods to provide highly relevant results and novel tools to filter them with ease.
Eleuther ▷ #lm-thunderdome (8 messages🔥):
- Learning Rate Concerns for Downstream Performance: A member suspects that a high learning rate, set according to Llama hyperparameters, could be causing poor downstream evaluation despite good loss metrics, querying if performance might improve as learning rate anneals. It was suggested to test this by doing a short learning rate cooldown with the current checkpoint to see if performance metrics improve.
- Benchmarks Losing Favor Revealed: There's a discussion around why benchmarks like SQuAD have fallen out of favor, with reasons cited such as their relative ease for big models, saturation, and mismatch with the capacities of pre-trained models that have already digested vast amounts of data like Wikipedia.
- GPQA as an Indicator of Model Supervision Needs: A member references the GPQA dataset, posing a challenging slate of questions designed to be Google-proof and highlighting that even top-performing AI systems like GPT-4 struggle with it, suggesting its value in developing scalable supervision methods for future AI assistant technologies. The referenced dataset is detailed in a published paper by Anthropic researchers.
- Leaderboards Scrutinized for Scientific Value: Discussion critiqued the true scientific and knowledge-expanding value of leaderboards, intimating that they might serve more for organizations to justify proprietary services pricing than truly advancing understanding.
Links mentioned:
- GPQA: A Graduate-Level Google-Proof Q&A Benchmark: We present GPQA, a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. We ensure that the questions are high-quality and extremely diffic...
- The Stanford Question Answering Dataset: no description found
- Google's Natural Questions: no description found
Eleuther ▷ #gpt-neox-dev (1 messages):
- Considering Closer Tracking of Upstream Megatron: A member is weighing the benefits of closely tracking upstream Megatron for better integration with Transformer Engine. They opened a pull request detailing the differences and are seeking input from maintainers on this potential move.
Links mentioned:
Diffs to upstream megatron as a basis for discussion towards TE integration by tf-nv · Pull Request #1185 · EleutherAI/gpt-neox: Here's three commits: One with the full diff of GPT-NeoX's megatron folder with current upstream Megatron-LM. That's 256 files with ~60k lines. However most are completely new or deleted....
LAION ▷ #general (123 messages🔥🔥):
- Lobbying and Influence Examined: Participants discussed the nature of lobbying, noting that lobbyists typically give money rather than receive it, implying their power lies in influence and negotiation rather than personal gain.
- Contemplating AI's Role in Future Calamities: A user humorously speculated on their finetuned AI model potentially leading to an AI-initiated extinction event, while another joked about the failure of the last extinction event.
- Skepticism Over AI-Driven Governance: The dialogue included skepticism around scenarios where AI and excessive hyping of events could lead to overreaching government authority, with a user ironically suggesting the improbability of such coordinated activities.
- Concerns and Speculations About Copyright and AI Regulation: The conversation touched on topics like potential copyright issues with AI model weights, the efficiency and pitfalls of the DMCA process, and the recent EU regulations on AI, sparking a debate on the practicality and enforcement of such laws.
- Interest in AI Hardware and Software for Large-scale Inference: There was an exchange of ideas on the best hardware and software options for running heavy AI inference tasks, with emphasis on leveraging GPUs, framework choices, and the trade-off between local setups and API-based solutions.
Links mentioned:
- World’s first major act to regulate AI passed by European lawmakers: The European Union's parliament on Wednesday approved the world's first major set of regulatory ground rules to govern the mediatized artificial intelligence at the forefront of tech investm...
- GroqChat: no description found
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Building Meta’s GenAI Infrastructure: Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We are sharing details on the hardware, network, storage, design, performance, and software that help us extr…
- BUD-E (Buddy for Understanding and Digital Empathy) - Blueprint / Overview: https://docs.google.com/presentation/d/1tBBa0_GzzfCrmn9KpYZ8YZ9x4Jgb2zVs/edit?usp=sharing&ouid=114592459581752579892&rtpof=true&sd=true
- Demo of the neural avatar sept 18th 2023: Demo of the neural avatar sept 18th 2023
- TheBloke/phi-2-GGUF · Hugging Face: no description found
- US Must Move 'Decisively' To Avert 'Extinction-Level' Threat From AI, Gov't-Commissioned Report Says - Slashdot: The U.S. government must move "quickly and decisively" to avert substantial national security risks stemming from artificial intelligence (AI) which could, in the worst case, cause an "ext...
- Education Pitch Deck: Navi-Sensei proposal JusticeDAO LLC Benjamin Barber business@hallucinate.app 10043 Se 32nd Ave Milwaukie Oregon 97222 9712700855 “I, Benjamin Barber, have read and understand the OMB and OPM Challenge...
- Devin: World's First AGI Agent (yes, this is real): If you're serious about AI, and want to learn about AI Agents, join my community: https://www.skool.com/new-societyFollow me for super-fast AI news - https:/...
- Pitch Deck: “Justice Now” - AI law avatar
LAION ▷ #research (21 messages🔥):
- CogVLM Hallucination Dilemma: To mitigate hallucination issues when using CogVLM to generate data, one suggests using simple and short prompts to lower the likelihood of incorrect outputs.
- Cross Attention Deemed Suboptimal: Discussion highlighted that cross attention isn't a bottleneck, but rather less effective than alternatives for adding conditioning, because transforming text embeddings at each block results in better denoising for the image at hand.
- Anticipation for MoAI Implementation: A new vision language model, Mixture of All Intelligence (MoAI), gains attention with a paper and a mascot, as it claims to outperform existing models while being smaller. The official implementation is available on GitHub, alongside a usage guide shared on Hugging Face.
- Recognition for a Contributed Dataset: A member happily acknowledges that their dataset received a citation in the DeepSeekVL paper. The paper appears promising with published weights made available two days prior to the mention.
- 30B Model Memory Optimization Misconception Dispelled: An initial claim that a 30B model could be loaded into 4GB of memory using lazy loading was debunked; the memory usage was underreported as mmap doesn't account for usage until the memory is accessed.
Links mentioned:
- BK-Lee/MoAI-7B · Hugging Face: no description found
- MoAI: Mixture of All Intelligence for Large Language and Vision Models: The rise of large language models (LLMs) and instruction tuning has led to the current trend of instruction-tuned large language and vision models (LLVMs). This trend involves either meticulously cura...
- Jimmy Carter President Carter GIF - Jimmy carter President Carter Carter - Discover & Share GIFs: Click to view the GIF
- 30B model now needs only 5.8GB of RAM? How? · ggerganov/llama.cpp · Discussion #638: (Edit: apologies, I should have clarified initially I'm running on Linux OS. I didn't realize it might not be obvious from the screenshot alone for a non-Linux users.All tests are done on Ubun...
- GitHub - ByungKwanLee/MoAI: Official PyTorch implementation code for realizing the technical part of Mixture of All Intelligence (MoAI) to improve performance of numerous zero-shot vision language tasks. (Under Review): Official PyTorch implementation code for realizing the technical part of Mixture of All Intelligence (MoAI) to improve performance of numerous zero-shot vision language tasks. (Under Review) - Byun...
LAION ▷ #learning-ml (1 messages):
- Exploring the Vastness of LAION-400M: A message highlighted Thomas Chaton's piece about using, exploring, and creating with the LAION-400-MILLION images & captions dataset. The member shared their admiration for the work and provided a link to the article.
Links mentioned:
Download & stream 400M images + text - a Lightning Studio by thomasgridai: Use, explore, & create from scratch the LAION-400-MILLION images & captions dataset.
LlamaIndex ▷ #announcements (1 messages):
- Dive into Self-Editing Long-Term Memory: Join the discussion on long-term, self-editing memory for language models with the MemGPT team this Friday at 9am PT. The webinar delves into MemGPT's approach, including "virtual context management" and function calling capabilities. Register for the event here.
- MemGPT Webinar Announcement: The LlamaIndex webinar will cover the challenges of long-term memory in LLMs and introduce MemGPT's recent advancements. MemGPT (Packer et al.) uses function calling for active memory management to create a more dynamic and efficient system for LLMs.
Links mentioned:
LlamaIndex Webinar: Long-Term, Self-Editing Memory with MemGPT · Zoom · Luma: Long-term memory for LLMs is an unsolved problem, and doing naive retrieval from a vector database doesn’t work. The recent iteration of MemGPT (Packer et al.) takes a big step in this...
LlamaIndex ▷ #blog (4 messages):
- MemGPT attempts to solve LLMs long-term memory: A new iteration of MemGPT has made advances in managing long-term memory for Large Language Models (LLMs), addressing the inadequacies of naive vector database retrieval. The details were introduced in a webinar highlighted on Twitter.
- Ollama Developer Meetup in Paris: Ollama and Friends are hosting a developer meetup on March 21st at 6pm at Station F in Paris, featuring food, drinks, and lightning demos from contributors to various open-source projects. Interested parties can find more information and request to demo at the event via Twitter.
- Integrating LlamaIndex with MathPix for Scientific Queries: LlamaIndex and MathPixApp collaborate to parse and index complex mathematics to LaTeX, enhancing the ability to answer queries related to scientific papers. A detailed guide is available, illustrating the process through tables, image extraction, and text indexing, as shared in a Twitter post.
- Launch of LlamaParse: The release of LlamaParse, touted as the first genAI-native document parsing solution, is announced with claims of superior functionality in parsing images, tables, and charts, and also featuring natural language steering capabilities. More details on this innovative parsing solution are introduced on Twitter.
Links mentioned:
Local & open-source AI developer meetup (Paris) · Luma: Ollama and Friends are in Paris! Ollama and Friends will be hosting a local & open-source AI developer meetup on Thursday, March 21st at 6pm at Station F in Paris. Come gather with developers...
LlamaIndex ▷ #general (128 messages🔥🔥):
- Discussions on Chatbot and Indexing Performance: Members discussed the optimization of different frameworks and engines for chatbot responses and content retrieval. Suggestions included using DeepEval with LlamaIndex (DeepEval documentation) and applying ensemble query engines for response diversity (Ensemble Query Engine Colab tutorial).
- Challenges with Large JSON Arrays in VectorStoreIndex: A member sought advice for improving the performance when querying large JSON arrays with LlamaIndex. It was recommended to parse each object into a node and make each JSON field a metadata field, with logging enabled to trace potential performance issues (tracing and debugging documentation).
- Requests for Clarification on LlamaIndex Features: Queries were raised about privacy issues and optimal index organization with LlamaIndex but did not receive definitive answers from the crowd.
- Attempting to Understand and Improve Query and Chat Engine Performance: Various attempts at resolving issues with specific LLMs such as Mistral-large generating errors, high scores on embedding models, and troubleshooting chatbot errors were discussed with light input from the community.
- Exploration of LlamaIndex Implementations and Debugging: Members explored implementation options for different use cases and debugging processes for issues such as embedding models with LlamaIndex and handling vector stores that do not support metadata filtering.
Links mentioned:
- Llama Hub: no description found
- Nujoom AI: no description found
- Tracing and Debugging - LlamaIndex 🦙 v0.10.19: no description found
- Tweet from TheHeroShep (@TheHeroShep): LLM Node Pack 1 for ComfyUI Excited to share @getsalt_ai's powerful set of nodes to make working with LLM's and @llama_index in comfyUI easier thanks to @WAS_STUFF ✨ Prompt Enhancement Nod...
- Azure AI Search - LlamaIndex 🦙 v0.10.19: no description found
- GitHub - get-salt-AI/SaltAI: Contribute to get-salt-AI/SaltAI development by creating an account on GitHub.
- llama_index/docs/examples/query_engine/SQLAutoVectorQueryEngine.ipynb at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- llama_index/docs/examples/query_engine/SQLJoinQueryEngine.ipynb at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Chat LlamaIndex: no description found
- 🚀 RAG/LLM Evaluators - DeepEval - LlamaIndex 🦙 v0.10.19: no description found
- [Beta] Text-to-SQL with PGVector - LlamaIndex 🦙 v0.10.19: no description found
- INSANELY Fast AI Cold Call Agent- built w/ Groq: What exactly is Groq LPU? I will take you through a real example of building a real time AI cold call agent with the speed of Groq🔗 Links- Follow me on twit...
- Ensemble Query Engine Guide - LlamaIndex 🦙 v0.10.19: no description found
- Router Query Engine - LlamaIndex 🦙 v0.10.19: no description found
- ReAct Agent with Query Engine (RAG) Tools - LlamaIndex 🦙 v0.10.19: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
shure9200: I’m making huge database of recent llm papers https://shure-dev.github.io/
OpenAccess AI Collective (axolotl) ▷ #general (69 messages🔥🔥):
- LLaVA Support Query in Axolotl: A member inquired about LLaVA support for Axolotl, and there was a confirmation that LLaVA 1.6 has changes that might not be compatible with the current release version of Axolotl.
- Command-R Model Release by Cohere: Cohere For AI has released an open-source 35 billion parameter model called Command-R, optimized for various use cases. This model is feature on Huggingface.
- Editing Tools for Large Language Model Datasets: Members discussed tools for manually editing large language model datasets, mentioning Lilac for viewing, and suggesting Argilla and Langsmith for possible editing tasks.
- Meta's AI Infrastructure Expansion: A Twitter post from Soumith Chintala about Meta's announcement to grow their infrastructure build-out was shared, which will include 350,000 NVIDIA H100 GPUs.
- Open Source Chatbot Frameworks with Long Memory: The conversation turned toward finding open source models and frameworks suitable for chatbots with long memory, discussing the importance of context length, the openness of the software, and approaches if training is to be avoided. Mistral and Mixtral were mentioned, along with the complexity of fine-tuning such models.
Links mentioned:
- CohereForAI/c4ai-command-r-v01 · Hugging Face: no description found
- Login | Cohere: Cohere provides access to advanced Large Language Models and NLP tools through one easy-to-use API. Get started for free.
- Building Meta’s GenAI Infrastructure: Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We are sharing details on the hardware, network, storage, design, performance, and software that help us extr…
- Starwars Anakin GIF - Starwars Anakin Skywalker - Discover & Share GIFs: Click to view the GIF
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (15 messages🔥):
- Support for DoRA in Quantized Models Merged: The implementation of DoRA for 4bit and 8bit quantized models has been merged with support from bitsandbytes. Caveats include DoRA's limit to linear layers and its high overhead compared to LoRa. View the merge here.
- Fuyou Framework Offers Hope for Huge Models on Low-End GPUs: Fuyou, a new training framework, reportedly allows fine-tuning of models with up to 175B parameters on standard consumer-grade GPUs, providing an efficient alternative to ZeRO-Infinity for those with budget constraints. _akhaliq's tweet shares this breakthrough along with a promising 156 TFLOPS on an RTX 4090 GPU.
- DeepSpeed's New API Might Benefit axolotl: The addition of an API by DeepSpeed allows modules to be set as leaf nodes when setting ZeRO3 hooks, theoretically helping with MoE models, a functionality that might be useful for axolotl's development. Discover the API on GitHub.
- Mixtral Training Concerns Alleviated: A contributor's concern regarding a potential bug affecting Mixtral model training with ZeRO3 was put at ease with a linked PR that seems to have addressed the related issue, allowing them to continue training. The commit can be viewed here.
- Questions on Axolotl's Load Functionality Resolved: Clarification was sought and given on a specific aspect of the Axolotl codebase concerning model loading functionality, highlighting how AutoModel can facilitate the loading of PEFT models when directed. The code in question is available here.
Links mentioned:
- Tweet from AK (@_akhaliq): Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU Recent advances in large language models have brought immense value to the world, with their superior capabilities ste...
- P2P PCIe and GPUDirect Storage Primer: This is a five-minute quick look at what NVIDIA's GPUDirect Storage (GDS) is, what it does, what technologies it is built upon, and where it makes the most s...
- axolotl/src/axolotl/utils/models.py at 8a82d2e0a443fb866b15d7bd71fffbd8171de44b · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- QDoRA: Support DoRA with BnB quantization by BenjaminBossan · Pull Request #1518 · huggingface/peft: Adds support for DoRA on 4bit and 8bit quantized models with bitsandbytes. Merging also works, with the usual caveats for quantized weights (results are not 100% identical), but it's not worse...
- Add API to set a module as a leaf node when recursively setting Z3 hooks by tohtana · Pull Request #4966 · microsoft/DeepSpeed: ZeRO3 does not work with MoE models because the order of executing modules can change at every forward/backward pass (#4094, #4808). This PR adds an API to stop breaking down a module for parameter...
- GitHub - enfiskutensykkel/ssd-gpu-dma: Build userspace NVMe drivers and storage applications with CUDA support: Build userspace NVMe drivers and storage applications with CUDA support - enfiskutensykkel/ssd-gpu-dma
- GTC Silicon Valley-2019: Efficient Distributed Storage I/O using NVMe: no description found
- flashneuron/README.md at master · SNU-ARC/flashneuron: Contribute to SNU-ARC/flashneuron development by creating an account on GitHub.
- Add API to set a module as a leaf node when recursively setting Z3 hooks by tohtana · Pull Request #4966 · microsoft/DeepSpeed: ZeRO3 does not work with MoE models because the order of executing modules can change at every forward/backward pass (#4094, #4808). This PR adds an API to stop breaking down a module for parameter...
- Mixtral fixes 20240124 (#1192) [skip ci] · OpenAccess-AI-Collective/axolotl@54d2ac1: * mixtral nccl fixes
- make sure to patch for z3
OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
- Debugging with Sample Custom Flags: A member suggested using flags like
--debug=True --debug_num_examples=10 --debug_text_only=Trueto ensure everything in the training process is as expected. It was shared that "completion" splits on new lines by default, which led to the preference of usinginput_outputovercompletion.
- Adjusting Sample Packing Efficiency: The user identified that a decrease in sample_packing_efficiency to around 0.85 with larger data could result in approximately 10% more training steps. Setting
sample_packing_eff_estto 1.0 was a tentative solution tried, although they are still testing the outcomes.
- Caution Against Manually Setting Eff_est: Another member warned that the
sample_packing_eff_estshould not be manually set, emphasizing it as an internal value not intended for user modification.
OpenAccess AI Collective (axolotl) ▷ #community-showcase (5 messages):
- Mistral Medium Triumphs Over Mixtral: A member reported that Mistral Medium delivers better outputs and responses than Mixtral, suggesting that Mistral Medium might be a closed-sourced, improved version of Mixtral.
- Praise for Mistral Medium's Performance: The same member highlighted Mistral Medium's ability to generate relevant citations without explicit requests, showcasing its effectiveness.
- Mistral Large's Tradeoff: Although considered the best in terms of quality, Mistral Large was noted for having quicker timeouts compared to its medium counterpart.
- Mixtral Falls Short on Verbosity and Instruction Following: The member noted that compared to Mixtral, Mistral Medium produces less verbose outputs and adheres to instructions more accurately.
LangChain AI ▷ #general (82 messages🔥🔥):
- Incremental Update of Qdrant Collections: A user queried about incrementally updating Qdrant collection embeddings in LangChain but did not receive a solution or response within the provided conversation context.
- Switching Chat Modes in Langchain: A user sought help for changing from
chat-instructtochatmode with a new LLM in Langchain after switching from oobabooga's text-generation-webui. They provided a detailed code snippet and highlighted their switch to a finetuned version of llama-2. - Custom LLM in Langchain: A discussion emerged around using a custom LLM service within Langchain, with guidance on creating custom LLM objects using the library's documentation (Custom LLM). They were referenced to potentially using FastAPI/Langserve to integrate an LLM residing at a localhost server.
- Handling of Outdated Documentation: Users raised concerns about outdated and inconsistent documentation regarding LangChain, which has made it difficult to track package imports and their usage. They discussed personal experiences and the necessity for LangChain to keep the docs updated.
- Creating Structured Output and Tools in Langchain: A user shared their interest in exposing a Python SDK to Langchain's community for usage but did not receive a response in the conversation. Additionally, discussions about utilizing features like structured output (
with_structured_output) and langsmith for development were mixed with uncertainty due to sudden changes in Langchain's functionalities and versions.
(Note: The summary is based solely on the provided conversation snippets. No undocumented features, discussions, or external resources have been included.)
Links mentioned:
- SparkLLM Text Embeddings | 🦜️🔗 Langchain: Official Website//www.xfyun.cn/doc/spark/Embeddingnewapi.html
- Run LLMs locally | 🦜️🔗 Langchain: Use case
- langsmith-cookbook/testing-examples/tool-selection/tool-selection.ipynb at main · langchain-ai/langsmith-cookbook: Contribute to langchain-ai/langsmith-cookbook development by creating an account on GitHub.
- LangChain: no description found
- [beta] Structured Output | 🦜️🔗 Langchain: It is often crucial to have LLMs return structured output. This is
- GitHub - antonis19/autobrowse: AutoBrowse is an autonomous AI agent that can perform web browsing tasks.: AutoBrowse is an autonomous AI agent that can perform web browsing tasks. - antonis19/autobrowse
- Discord Bot | MEE6.): Manage your Discord server with leveling, moderation, Twitch, Youtube and Reddit notifications.
- GitHub - langchain-ai/langserve: LangServe 🦜️🏓: LangServe 🦜️🏓. Contribute to langchain-ai/langserve development by creating an account on GitHub.
- GitHub - ggerganov/whisper.cpp: Port of OpenAI's Whisper model in C/C++: Port of OpenAI's Whisper model in C/C++. Contribute to ggerganov/whisper.cpp development by creating an account on GitHub.
- Wordware - Try all the models for a single question: This prompt runs a question through Gemini, GPT-4 Turbo, Claude 2, Mistral Medium, Mixtral and Openchat. The it uses GPT-4 Turbo to assess which model gave the best answer.
LangChain AI ▷ #langchain-templates (1 messages):
- Switching Modes for Better Chatbot Performance: A member shared their experiences of better performance using the
chatmode overchat-instructmode in a chatbot application using the langchain library. They've asked for assistance to switch modes from their current setup that implementschat-instructwith LlamaCpp in oobabooga'stext-generation-webui. - Seeking Help With Langchain Coding: The member provided a snippet of their Python code that uses the LlamaCpp model path and RedisChatMessageHistory for conversation generation. Guidance was requested on how to implement the preferable
chatmode in their langchain application.
LangChain AI ▷ #share-your-work (3 messages):
- Launch of the ReAct Agent: A new language model agent called the ReAct agent, inspired by a paper on synergizing reasoning and acting in language models, was shared. It promises a reasoning engine and diverse skills, and can be asked various questions. The agent was created rapidly using a new tool, and feedback is invited. Read the paper that inspired this creation.
- LangChain Chatbot Now Open Source: The LangChain Chatbot was announced to be open source and demonstrates the use of RAG for Q&A querying. It boasts a super simple setup, support server, interactive Streamlit UI, and a Python FastAPI Server. Check out the GitHub repository.
- MindGuide: AI for Mental Health Support: An article was shared detailing MindGuide, a chatbot aiming to revolutionize mental health care using LangChain combined with large language models. The article emphasizes the need for interventions in mental health and discusses MindGuide's features that enhance support for mental health challenges. Read the revolutionary article.
Links mentioned:
- Revolutionizing Mental Health Care through LangChain: A Journey with a Large Language Model: Mental health challenges are on the rise in our modern society, and the imperative to address mental disorders, especially regarding anxiety, depression, and suicidal thoughts, underscores the need fo...
- GitHub - Haste171/langchain-chatbot: AI Chatbot for analyzing/extracting information from data in conversational format.: AI Chatbot for analyzing/extracting information from data in conversational format. - Haste171/langchain-chatbot
- ReAct: Synergizing Reasoning and Acting in Language Models: While large language models (LLMs) have demonstrated impressive capabilities across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-though...
- Wordware - ReAct API Agent 🧠: Works out how to use APIs
LangChain AI ▷ #tutorials (3 messages):
- Groq Hardware Explored for AI: A YouTube video entitled "INSANELY Fast AI Cold Call Agent- built w/ Groq" was shared, showcasing how to build a real-time AI cold call agent using Groq's hardware.
- Retrieval Augmentation With Command-R: A member highlighted a video discussing the capabilities of Command-R, a model optimized for long context tasks like retrieval augmented generation (RAG).
- Guidance on Prompt Templates with Langchaingo: A YouTube tutorial on creating prompt templates with Langchaingo was shared, demonstrating the process and its application with Telegram groups.
Links mentioned:
- INSANELY Fast AI Cold Call Agent- built w/ Groq: What exactly is Groq LPU? I will take you through a real example of building a real time AI cold call agent with the speed of Groq🔗 Links- Follow me on twit...
- Lets RAG with Command-R: Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is design...
- Create Prompt Template With Langchaingo: In this video , I'll hoe create a promp template and how use this with chainstelegram group:https://t.me/langchaingo/1#golang #langchain
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- Database Update Briefly Impacts OpenRouter: OpenRouter experienced a temporary issue with activity row availability due to a database update that took longer than anticipated. The hiccup lasted around three minutes, and no affected completions were charged.
- Speedy and Wallet-Friendly: Claude 3 Haiku Arrives: Claude 3 Haiku has launched on OpenRouter boasting impressive speeds of about 120 tokens per second and a cost of 4M prompt tokens per $1. It comes in both moderated and self-moderated versions, perfect for users needing quick, accurate responses. Try Claude 3 Haiku here.
- Claude 3 Haiku: Fast, Affordable, Multimodal: The newest Claude 3 model from Anthropic, Claude 3 Haiku, is promoted for its near-instant responsiveness, provided at an affordable rate with details on input and output token pricing. This model is self-moderated to ensure quick and targeted performance, with a potential for changes as it's still in beta. Launch announcement and benchmarks.
Links mentioned:
Anthropic: Claude 3 Haiku (self-moderated) by anthropic | OpenRouter: This is a lower-latency version of Claude 3 Haiku, made available in collaboration with Anthropic, that is self-moderated: response moderation happens on the model&...
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- Olympia.chat Leverages OpenRouter: Obie Fernandez, co-founder of Olympia.chat, introduced their ChatGPT clone platform, which caters mostly to solopreneurs and small business owners since May 2023. They have started using OpenRouter as the LLM source for various components and announced an upcoming open-source Ruby library for OpenRouter.
- A Friend's Messenger Chatbot Ready for Testing: A user shared information about a chatbot created by their friend for messenger applications. Testing offers were extended via direct message invitations.
Links mentioned:
Olympia | Better Than ChatGPT: Grow your business with affordable AI-powered consultants that are experts in business strategy, content development, marketing, programming, legal strategy and more.
OpenRouter (Alex Atallah) ▷ #general (54 messages🔥):
- Understanding OpenRouter and Groq Access: Members discussed the use of Groq's Mixtral model during its free period. It was clarified that access through OpenRouter is not part of the free access provided by Groq, and personal Groq tokens cannot be passed through OpenRouter.
- Mixtral Limits and Errors Examined: Conversations around Mistral 8x7B and Nitro model limits emerged when users faced "Request too big" errors. The context limit was confirmed to be 32k, but specific reasons for the error, such as a potential repeating loop, were considered.
- Claude 3 Haiku, Please!: A member requested the addition of support for the newly released Claude 3 Haiku AI model.
- AI Model Pricing and Speed: Comparing Claude 3 Haiku with Opus, members highlighted Haiku's speed and cost-effectiveness, noting a significant price difference with Haiku at \$1.25 per million tokens versus Opus's \$75 per million tokens.
- High Demand for GPT-4.5: Engagement around rumors of GPT-4.5 showed high anticipation and excitement among the members regardless of confirmation status.
Links mentioned:
- Blog: no description found
- Claude 3 Haiku: our fastest model yet: Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
- OpenAI Status: no description found
Interconnects (Nathan Lambert) ▷ #news (9 messages🔥):
- GPT-4.5 Blog Post Spotted: A mention was made that the GPT-4.5 blog post has been indexed by Bing and is appearing in search results.
- 404 Mystery: However, the GPT-4.5 blog post link leads to a 404 error page when attempted to be accessed.
- Release Excitement: There's palpable excitement as the find is considered confirmation that GPT-4.5 might be on the horizon.
- Search Engine Sightings: The blog post is not only on Bing but also on other search engines that rely on Bing results, like Kagi and DuckDuckGo, but not on Google.
- Tweet for Clarity: A Twitter link was shared that might shed some light on the GPT-4.5 blog post situation.
Interconnects (Nathan Lambert) ▷ #other-papers (2 messages):
- GPT-4 Dominates LeetCode: A member mentioned that GPT-4 still holds the crown for performance on LeetCode. The evidence comes from the paper they cited, accessible here.
Interconnects (Nathan Lambert) ▷ #random (42 messages🔥):
- Claude 3 Shows Promising Results: A member shared their excitement for Claude 3 showing significant improvement over Claude 2 in literature research summaries, highlighting the potential of large language models (LLMs) with the Clautero project.
- Meta's Massive AI Infrastructure Investment: Meta announces the creation of two 24k GPU clusters and details their commitment to open source and open compute through resources like Grand Teton, PyTorch, with a goal to amass 350,000 NVIDIA H100 GPUs by 2024 as stated in an official blog.
- Debate Over Google's Strategic Model Release: There's a discussion about Google's strategy with their AI model, debating whether it should be ad-supported or subscription-based, with comparisons to Bing/Copilot and Youtube's Premium service, and concerns about privacy and data usage for targeted advertisements.
- Potential Ads in AI Outputs: Members discuss the possibility and implications of incorporating ads into AI outputs, raising questions about the future trustworthiness of ChatGPT if it follows such a model.
- AnthropicAI's Claude 3 Haiku Release: AnthropicAI releases Claude 3 Haiku, praised for being fast, affordable, and more capable than previous generations like GPT-3.5, with a tweet from the company announcing its availability in API and on claude.ai for Pro subscribers.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): Today we're releasing Claude 3 Haiku, the fastest and most affordable model in its intelligence class. Haiku is now available in the API and on http://claude.ai for Claude Pro subscribers.
- Building Meta’s GenAI Infrastructure: Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We are sharing details on the hardware, network, storage, design, performance, and software that help us extr…
- Tweet from lmsys.org (@lmsysorg): [Arena Update] Our community has cast 20,000 more votes for Claude-3 Opus and Sonnet, showing great enthusiasm for the new Claude model family! Claude-3-Opus now shares the top-1* rank with GPT-4-Tu...
CUDA MODE ▷ #general (13 messages🔥):
- Meta's Massive GPU Clusters: Meta announces the launch of two 24k GPU clusters to support AI workloads, relying on Grand Teton, OpenRack, and PyTorch frameworks. By the end of 2024, they aim to feature 350,000 NVIDIA H100 GPUs and power comparable to 600,000 H100s as depicted in their infrastructure announcement.
- From Apps to Atoms - Microsoft Dives into Nuclear Tech: Microsoft hires Archie Manoharan as a director of nuclear technologies, aiming to develop atomic reactors for datacenter power, a move fleshed out in articles from Times of India and The Register.
- RTX 4090 AI Training Potential: A paper cited achieves 156 TFLOPS on an RTX 4090 for AI training, far surpassing ZeRO-Infinity's 45 TFLOPS, pointing to a significant innovation in GPU performance.
- CUDA Support for NVMe SSDs: A GitHub repository (ssd-gpu-dma) and a NVIDIA GTC talk present developments in using NVMe drives with CUDA for storage applications, supported by direct memory access and GPU integration.
- NVIDIA's GPUDirect Storage API Promises Efficient Data Paths: NVIDIA's GPUDirect Storage offers an API for efficient DMA transfers between GPU memory and storage, potentially enhancing performance for data-intensive workloads as elaborated in the API Reference Guide.
Links mentioned:
- Building Meta’s GenAI Infrastructure: Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We are sharing details on the hardware, network, storage, design, performance, and software that help us extr…
- flashneuron/README.md at master · SNU-ARC/flashneuron: Contribute to SNU-ARC/flashneuron development by creating an account on GitHub.
- Apps to atoms: Microsoft hires nuclear expert to fuel its data centres | - Times of India: Microsoft hires a nuclear expert to fuel its data centres by developing small-scale atomic reactors as an alternative to fossil fuels.
- Microsoft hires leaders for nuclear datacenter program: Industry vets specialize in the development of small modular reactors
- cuFile API Reference Guide - NVIDIA Docs: no description found
- GitHub - enfiskutensykkel/ssd-gpu-dma: Build userspace NVMe drivers and storage applications with CUDA support: Build userspace NVMe drivers and storage applications with CUDA support - enfiskutensykkel/ssd-gpu-dma
- GTC Silicon Valley-2019: Efficient Distributed Storage I/O using NVMe: no description found
- P2P PCIe and GPUDirect Storage Primer: This is a five-minute quick look at what NVIDIA's GPUDirect Storage (GDS) is, what it does, what technologies it is built upon, and where it makes the most s...
CUDA MODE ▷ #cuda (6 messages):
- Nsight Visual Studio Code Edition Hype: A member highlighted the benefits of using NVIDIA Nsight™ Visual Studio Code Edition, a development tool for CUDA® development on GPUs, providing features like smart CUDA auto-code completion and an improved overall development experience for various platforms including Linux and QNX target systems. A direct link to download the tool was shared: Download Now.
- Nsight Enthusiast Shares Love for Tools: A member expressed their fondness for NVIDIA's NSight tools, stating they couldn't imagine a development process without Nsight Systems and NSight Compute. They see no reason not to use these tools as part of their workflow.
- Debate on NSight Systems' Utility: A member voiced their opinion that NSight Systems is useless, while praising NSight Compute. Another member countered by illustrating a scenario involving a real-time application with multiple streams and CPU threads across several GPUs, indicating the importance of NSight Systems for identifying performance bottlenecks.
- Seeking CUDA Help: A user asked for assistance with a "noob cuda question" they posted in a different channel, expressing difficulties even after consulting Google and GPT. They were uncertain if they had chosen the appropriate place for their query.
Links mentioned:
Nsight Visual Studio Code Edition: CUDA development for NVIDIA platforms integrated into Microsoft Visual Studio Code
CUDA MODE ▷ #torch (2 messages):
- Clarification on Modular's Function: A participant realized they had misunderstood a previous message, and affirmed that what they initially thought was indeed what Modular is doing.
- Call for Feedback on Torchao: An invitation was extended for feedback on PyTorch Labs' torchao GitHub issue, with an aim to facilitate the merging of new quantization algorithms and dtypes. The team behind gpt-fast and sam-fast kernels offered mentorship for aspiring kernel writers interested in a real world cuda mode project.
Links mentioned:
[RFC] Plans for torchao · Issue #47 · pytorch-labs/ao: Summary Last year, we released pytorch-labs/torchao to provide acceleration of Generative AI models using native PyTorch techniques. Torchao added support for running quantization on GPUs, includin...
CUDA MODE ▷ #jobs (1 messages):
- CUDA Expert Wanted for GetWorldClass: Christo has announced they are seeking a CUDA expert for consulting on the learning app getworldclass.app. Interested parties are invited to direct message for details.
CUDA MODE ▷ #beginner (4 messages):
- Ensuring Executable Launches Kernels Correctly: A member questioned if an executable was properly launching kernels, suggesting an issue with the kernel execution.
- Validating CUDA Code Executions: A member confirmed that their CUDA code runs successfully, eliminating code execution as the issue.
- Nsight Compute GPU Compatibility Concerns: There was an inquiry about whether a GPU is supported by Nsight Compute, indicating uncertainty around GPU compatibility with the profiling tool.
- Ubuntu CUDA Toolkit Troubles: A member on Ubuntu 23.10 faces an issue with
compute-sanitizerthrowing an error about not findinglibsanitizer-collection.sodespite the file existing on their machine. They shared that thecompute-sanitizerversion they're using is 2022.4.1, and the problem persists on a fresh OS installation.
CUDA MODE ▷ #pmpp-book (2 messages):
- Deciphering CUDA Cores and Thread Execution: A member queried about the architecture mentioned in section 4.4 of the book, questioning if under the SIMD model each core is responsible for executing 4 threads each. This inquiry is based on the organizational structure where 8 cores form a processing block sharing an instruction fetch/dispatch unit, as depicted in Fig. 4.8.
CUDA MODE ▷ #ring-attention (13 messages🔥):
- Stubborn Loss Refuses to Dip: A member expressed frustration with the loss not going below 3.6 after 100 epochs of training on a small dataset, potentially implying an issue with the training kernel or hyperparameters. Another participant suggested looking at the learning rate, which is currently being calculated automatically.
- Axolotl Needs Padding Parameter: There was a mention that the training software Axolotl requires the
pad_to_sequence_len: truesetting to run, even in a freshly cloned repository. This was shared as a reminder note. - Ring Attention Faces the Training Challenge: The member shared a W&B report comparing the performance of the stock Axolotl code and the ring-attention variant, noting that losses are not trending towards zero as expected.
- Detailed Comparison Unleashed: Clarification was provided that the baseline for the performance report is a clone of Axolotl with no code changes, serving as a reference to evaluate the ring-attention modified code.
- Repository Patching in Progress: A link to a patched branch of the Axolotl repository was shared, which may contain updates or fixes relevant to the discussion on ring attention models (Axolotl Git Repository - ring_attention_patching).
Links mentioned:
- Ring-attn vs stock: Ran abut 100 epochs on the same system and small dataset
- iron-bound: Weights & Biases, developer tools for machine learning
- GitHub - cuda-mode/axolotl at ring_attention_patching: Go ahead and axolotl questions. Contribute to cuda-mode/axolotl development by creating an account on GitHub.
CUDA MODE ▷ #off-topic (5 messages):
- First Glimpse of AI Engineer Devin: The blog post from Cognition Labs introduces Devin, claimed to be the world's first fully autonomous AI software engineer with the ability to perform complex engineering tasks, equipped with standard developer tools, and setting a new benchmark on the SWE-bench coding benchmark.
- Real-world Test of Devin Imminent: An individual reqested early access to Devin from Cognition Labs and promises to share "unfiltered opinions" on the AI software engineer. They referenced a tweet from @itsandrewgao, where a thread is anticipated to display Devin's capabilities, including its impressive performance in real-world software engineering tasks on SWE-Bench coding benchmark.
- Disappearing Tweets Lead to User Frustrations: A member shared their frustration with Twitter's user experience, specifically tweets disappearing from the timeline, quoting a complaint from @DanielleFong lamenting the loss of an interesting tweet.
- GPT-4 Takes On Classic Gaming: A study shared on arxiv.org demonstrates that GPT-4 can play the 1993 first-person shooter game Doom with reasonable success, showcasing the model's reasoning and planning capabilities based on textual descriptions generated from game screenshots.
Links mentioned:
- Tweet from Danielle Fong 💁🏻♀️🏴☠️💥♻️ (@DanielleFong): goodbye interesting tweet that refreshed away from the timeline. i’ll never see you again
- Blog: no description found
- Will GPT-4 Run DOOM?: We show that GPT-4's reasoning and planning capabilities extend to the 1993 first-person shooter Doom. This large language model (LLM) is able to run and play the game with only a few instructions...
- Tweet from Andrew Kean Gao (@itsandrewgao): i never believe recorded demos so I reached out to the @cognition_labs team for early access to try for myself and got it! will be sharing my unfiltered opinions on #devin here. 🧵🧵 1/n ↘️ Quotin...
DiscoResearch ▷ #disco_judge (1 messages):
- Assistent's Mars Response Misses Musk's Flair: Die Antwort des Assistenten on why we should go to Mars is informative and detailed, touching on various aspects, yet it failed to fully capture Elon Musk's unique style and tone. Although they reflect Musk's views on Mars exploration, the lack of Musk's specific public speaking style was noted, leading to a creativity rating of [[7]].
DiscoResearch ▷ #general (15 messages🔥):
- RAG Practices and Opinions: There's a discussion about the best way to structure RAG (Retrieval-Augmented Generation) prompts. One user prefers including the complete RAG prompt in the user message, while another suggests it depends on the SFT (Supervised Fine-Tuning); system prompts are usually for general instructions, and varying system prompts might affect general behavior consistency.
- New Transformer Internals Exploration Tool: A link to a tweet by Jan Leike was shared, announcing the release of an internal tool for analyzing transformer internals called the Transformer Debugger. It facilitates rapid model exploration without needing to write code, integrating automated interpretability with sparse autoencoders.
- Mixtral 7b 8 Expert Model Use: A user shared their attempt at using an experimental implementation of the
mixtral-7b-8expertmodel for inference and encountered issues with non-English output generation. It was recommended to instead use the officialmistralai/Mixtral-8x7B-v0.1model by another user.
- Experimental Model Clarification Needed: Discussion highlighted that an experimental model's status,
DiscoResearch/mixtral-7b-8expert, was not clearly communicated and might require a clearer label to avoid confusion among users.
- Inquiries on DiscoLM and German Data: A user inquired about whether the model
DiscoResearch/DiscoLM-mixtral-8x7b-v2was fine-tuned on a German dataset. The user was informed that the model wasn't trained on a significant German data and was directed to the dataset used forDiscoResearch/DiscoLM-70b, which "underwent additional continued pretraining for 65b tokens of German text".
- Invitation to MunichNLP Meetup: A user reached out to the group to participate in a MunichNLP meetup specifically interested in a talk about DiscoLM. An attendee mentioned they can't confirm but mentioned an upcoming event, AI Tinkerers in Berlin, with a link to the event page and a note that only 8 seats were left.
Links mentioned:
- DiscoResearch/mixtral-7b-8expert · Hugging Face: no description found
- mistralai/Mixtral-8x7B-v0.1 · Hugging Face: no description found
- Tweet from Jan Leike (@janleike): Today we're releasing a tool we've been using internally to analyze transformer internals - the Transformer Debugger! It combines both automated interpretability and sparse autoencoders, and ...
- DiscoResearch/DiscoLM-70b · Hugging Face: no description found
- AI Tinkerers - Berlin : no description found
DiscoResearch ▷ #benchmark_dev (1 messages):
- Creative Writing Benchmark Goes Live: A new creative writing benchmark prototype is now available and appears to be operational, albeit not highly discriminative. The rankings generally make sense, and you can check it out on the creative_writing branch on GitHub.
Links mentioned:
GitHub - EQ-bench/EQ-Bench at creative_writing: A benchmark for emotional intelligence in large language models - GitHub - EQ-bench/EQ-Bench at creative_writing
DiscoResearch ▷ #embedding_dev (2 messages):
- Seeking the Best German Embedding Solution: A member is inquiring about the best embedding and re-ranker for German, specifically for application in German law texts. They are wondering if the specifics of legal language affect the choice of technology.
- In Search of German Embedding Benchmarks: The same member asked if there is an existing benchmark for embedding models that work with the German language. No specific benchmarks were mentioned in the conversation.
DiscoResearch ▷ #discolm_german (3 messages):
- A New Frontier for Mixtral: A member is exploring Mixtral for stage 2 pretraining in a non-English language, noting the scarcity of experts tinkering with it at this level.
- Seeking Demo Reproduction with Local Models: A member asked how to replicate a demo's output using a model locally, sharing their current code configuration and inquiring if there are settings beyond
temperature,top_p, andmax_tokensthat might need adjusting. - Clarifying Repetition in Dialogue-Based Models: Another query was raised on whether the command should be repeated with every user message or if once in the system's content is sufficient, indicating an uncertainty on how to optimally structure conversational prompts for AI models.
LLM Perf Enthusiasts AI ▷ #general (13 messages🔥):
- Token Limit Troubles with gpt4turbo: A member expressed frustration with hitting the 4096 token limit when using gpt4turbo. This issue of context length was stated without any given solution or workaround.
- Wrong Turn at Bing Search: Upon searching for "openai announces gpt-4.5 turbo," a member shared a Bing search result indicating no relevant results found for the query, hinting that GPT-4.5 Turbo might not yet be a thing.
- Is GPT-4.5 Turbo on the Horizon?: Some members speculated about the impending release of GPT-4.5 Turbo, with initial excitement followed by skepticism due to potentially misleading search results and references.
- Draft Placeholder Leads to Confusion: It was clarified that a supposed mention of GPT-4.5 seems to be an accidentally published draft placeholder on an OpenAI page, with the content dated back to September and referring to training data up to July 2024.
- Understanding the Puzzle of 'GPT-4.5 turbo' Appearance: A further clarification dismissed the notion of a ready GPT-4.5 model, concluding that the accidental blog post was old and the referenced model was not ready at the time of publication.
Links mentioned:
openai announces gpt-4.5 turbo - Bing: Pametno pretraživanje u tražilici Bing olakšava brzo pretraživanje onog što tražite i nagrađuje vas.
LLM Perf Enthusiasts AI ▷ #claude (1 messages):
ldj: Elon will be mad prob if OpenAI steals starship thunder on the same day like that 😭
LLM Perf Enthusiasts AI ▷ #opensource (4 messages):
- Speculation on Llama Version Cycle: A member theorized that Llama operates on a six-month cycle but plans may have shifted. They suggest Llama-3, poised for release recently, is being skipped for quality reasons, hinting at a July release for what's internally named "Llama-4".
- Predicting Llama-3's Upgrades: The same member predicts that the next iteration, possibly named Llama-3, may introduce several advancements, including Mixture of Experts, SSM variants, Attention mods, multi-modality in images and videos, extended context length, and advanced reasoning capabilities.
Datasette - LLM (@SimonW) ▷ #ai (6 messages):
- New Paper on GenAI Vulnerabilities Uncovered: A member shared an interesting paper titled "ComPromptMized: Unleashing Zero-click Worms that Target GenAI-Powered Applications" by Stav Cohen from the Technion - Israel Institute of Technology. The paper presents how a computer worm can target and exploit GenAI-powered applications, including email assistants, across different GenAI models.
- Seeking Model Comparison Frameworks for Code Assistants: A member inquired if there exists a framework to compare AI models like Mistral or LLaMA2 for their use case as a code assistant.
- Benchmark Relevance in Model Comparison Addressed: Another member acknowledged the existence of benchmarks but cautioned that using them relies on the assumption that the benchmark itself is accurate.
- Leaderboard Suggested for Model Performance Comparison: To compare model performances, a member recommended checking out the Leaderboard on chat.lmsys.org as a resource. Another member expressed gratitude, noting they weren't aware of this site.
Links mentioned:
ComPromptMized: Stav Cohen Technion - Israel Institute of Technology
Datasette - LLM (@SimonW) ▷ #llm (2 messages):
- Revolutionize Your Git Commit Game: One member highlighted a hack to create meaningful git commit messages using LLM, which involves a pre-commit-msg git hook that calls the
llmcli to summarize code changes for your commit message. The commit messages shift from vague to informative, thanks to this clever use of language models.
Links mentioned:
Use an llm to automagically generate meaningful git commit messages: I've transformed my git commit process by using an AI to automatically generate meaningful messages. This setup involves a nifty integration of the llm CLI and git hooks, saving me time. Now I can fuc...
Skunkworks AI ▷ #general (2 messages):
- Seeking Advice on Long-context Chatbots: A member inquired about the best open source models and frameworks to build a chatbot capable of handling long contexts (or memory). No specific models or frameworks were recommended in the subsequent discussion.
Skunkworks AI ▷ #off-topic (3 messages):
- AI Tackles PopCap Classic: A YouTube video titled "Claude 3 made Plants Vs Zombies Game" showcases how to develop a Plants vs Zombies game using Claude 3 covering topics from Python programming to game development. Viewers can explore the intersection of AI and game creation at this video.
- Exploring Advanced Generative Models: A new video titled "Lets RAG with Command-R" features Command-R, a generative model optimized for long context tasks like Retrieval Augmented Generation (RAG), harnessing external APIs and tools. The model's design and capabilities are highlighted in this video.
- Meet Devin: The AI Software Engineer: Unveiling Devin, the world's first AI software engineer, a new YouTube video presents Devin's capabilities in the field of autonomous software engineering. Interested viewers can learn more about Devin by watching the video or visiting Cognition Labs' blog.
Links mentioned:
- Lets RAG with Command-R: Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is design...
- Devin The Worlds first AI Software Engineer: Devin is fully autonomous software engineerhttps://www.cognition-labs.com/blog
- Claude 3 made Plants Vs Zombies Game: Will take a look at how to develop plants vs zombies using Claude 3#python #pythonprogramming #game #gamedev #gamedevelopment #llm #claude
Alignment Lab AI ▷ #looking-for-collabs (1 messages):
- Call for Open Source Visionaries: Soniajoseph_ is seeking collaborators for open source interpretability on multimodal models. They've shared their Twitter post and an informative LessWrong post outlining the project and inviting interested parties to join their Discord here.
- Dive into Mechanistic Interpretability: The project tackles vision and multimodal mechanistic interpretability and offers a tutorial, a brief ViT overview, and showcases the demo of Prisma’s functionality - focusing on features like logit attribution and attention head visualization.
Links mentioned:
Laying the Foundations for Vision and Multimodal Mechanistic Interpretability & Open Problems — LessWrong: Behold the dogit lens. Patch-level logit attribution is an emergent segmentation map. Join our Discord here. …
Alignment Lab AI ▷ #general-chat (1 messages):
- Quest for Speed with Phi 2 Inference: A member inquired about the fastest method for performing inference with Phi 2 or a tuned version of it, mentioning potential use of an A100 40GB GPU. They are considering using batching for producing many tokens and are exploring frameworks like vLLM, Olama, Axolotl, also asking if quantization might increase speed.
AI Engineer Foundation ▷ #general (2 messages):
- Plugin Config Discussion and Authorization: In the AI Engineer Foundation meeting, the possibility of using config options for plugins was discussed, particularly for easy implementation of authorization by passing tokens as arguments. This is anchored on the structured schema that the config options RFC facilitates.
- Seeking New Project Ideas: Members were prompted to suggest new projects with criteria detailed in the Google Doc guideline. There was also a mention of a potential collaboration with Microsoft on a prompt file project lead.
- Introducing Devin, the AI Software Engineer: Cognition Labs announced the release of Devin, an autonomous AI software engineer capable of executing complex engineering tasks and setting a new standard in the SWE-bench coding benchmark detailed in a blog post. Devin is designed to integrate with common developer tools within a sandboxed environment.
Links mentioned:
- Blog: no description found
- Guide to Submit Projects to AI Engineer Foundation: no description found