[AINews] DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
GPRO+ is all you need.
AI News for 4/7/2025-4/8/2025. We checked 7 subreddits, 433 Twitters and 30 Discords (229 channels, and 7279 messages) for you. Estimated reading time saved (at 200wpm): 692 minutes. You can now tag @smol_ai for AINews discussions!
After the DeepSeek R1 launch (our coverage here), a raft of "R1 but more open" clone attempts emerged, of which it seems only HuggingFace's OpenR1 is still posting active updates, if you discount the distillation work. However, today Together and the Agentica Project (previously of the DeepScaleR work) have come out with a 14B code-focused reasoning model that scores at O3-mini level:
Usually these projects are easy to game and therefore unremarkable, but this project distinguishes it self by being fully open source - dataset, code, recipe and all, meaning the educational value is high, particularly given the prior work of its collaborators.
Specifically for RL training, they note the sampler bottleneck:
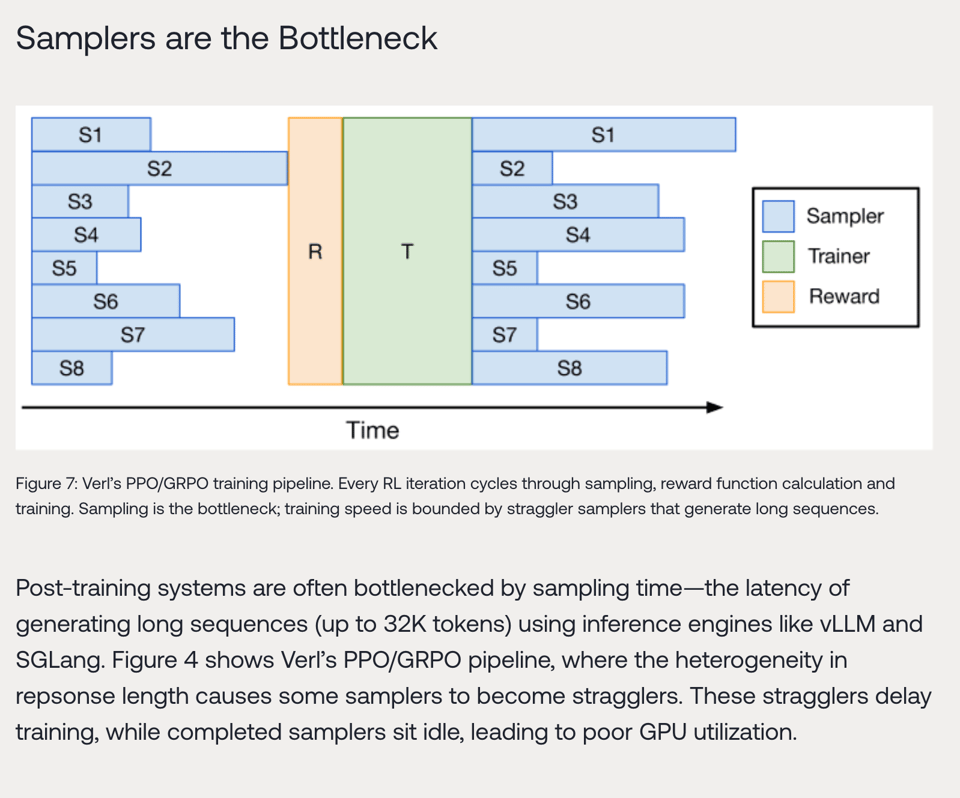
so they have very good thoughts on pipelining:
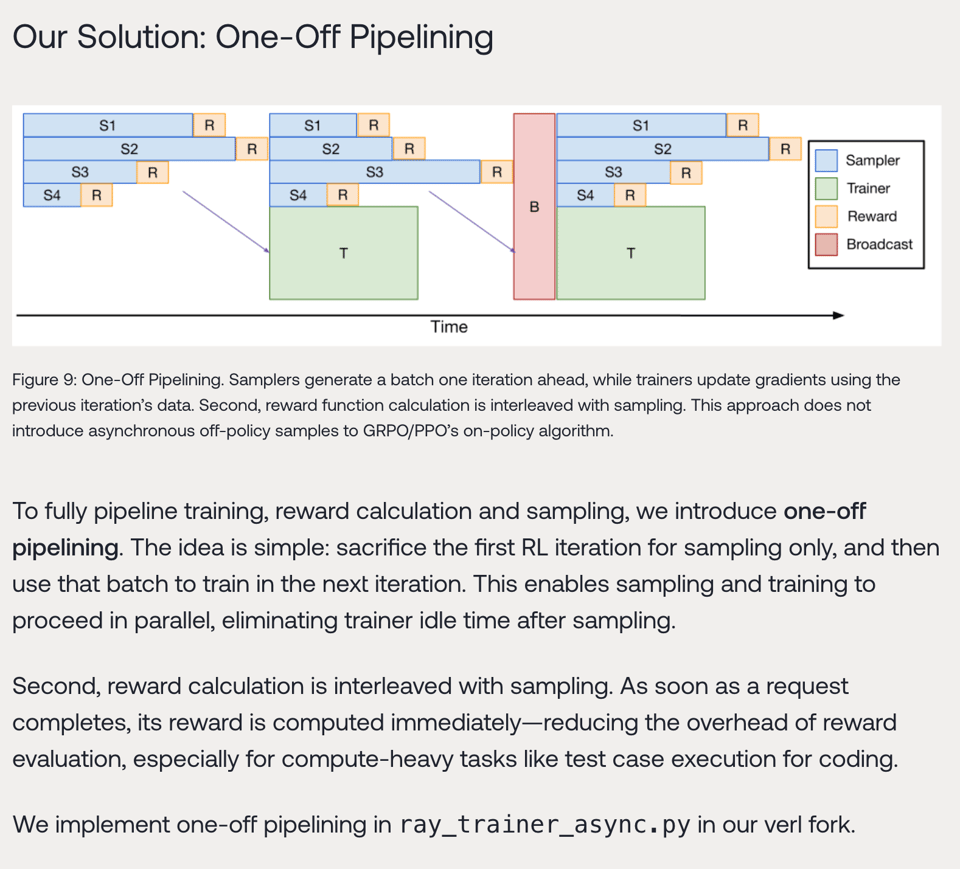
and they also propose an update to DeepSeek's GRPO:
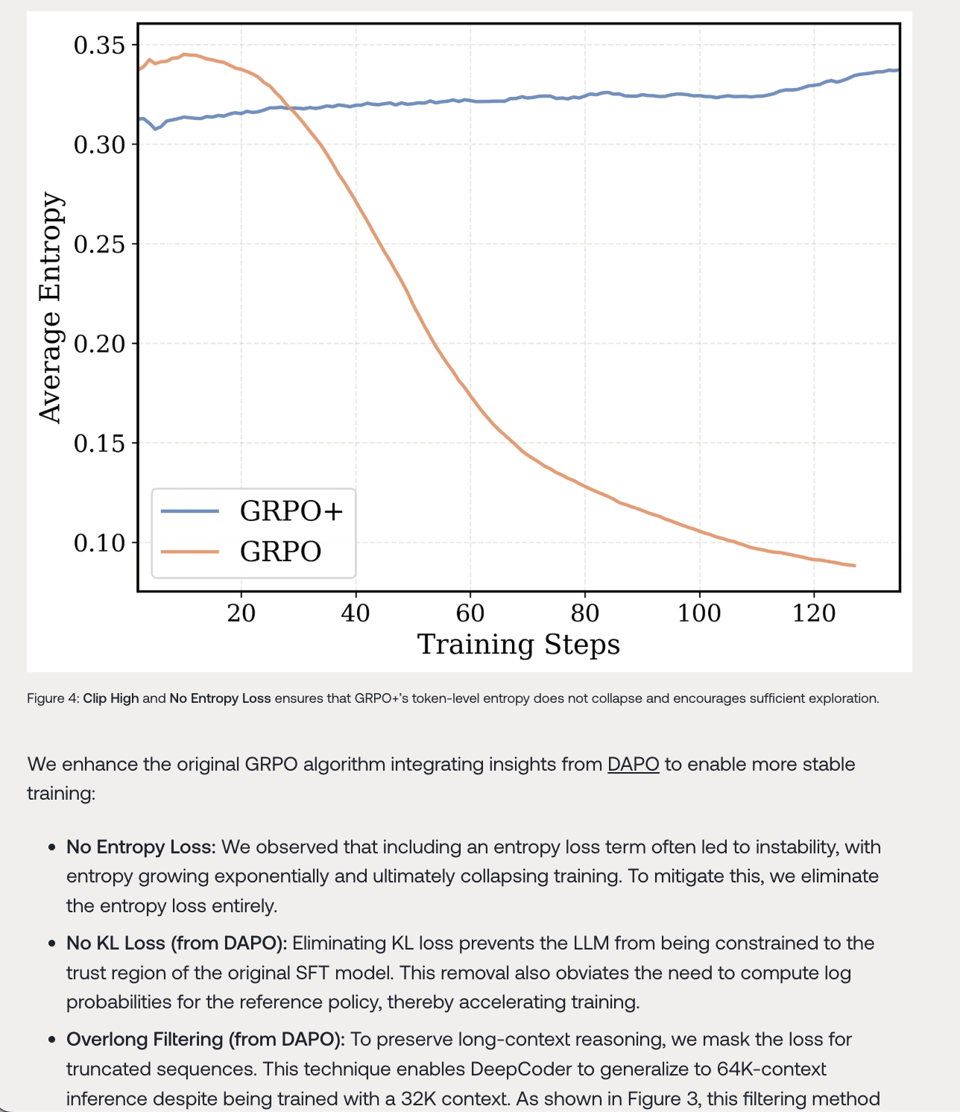
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- LMArena Discord
- Unsloth AI (Daniel Han) Discord
- OpenRouter (Alex Atallah) Discord
- Cursor Community Discord
- LM Studio Discord
- Perplexity AI Discord
- Manus.im Discord Discord
- aider (Paul Gauthier) Discord
- Notebook LM Discord
- Interconnects (Nathan Lambert) Discord
- Eleuther Discord
- Nous Research AI Discord
- GPU MODE Discord
- HuggingFace Discord
- MCP (Glama) Discord
- Latent Space Discord
- Yannick Kilcher Discord
- Nomic.ai (GPT4All) Discord
- Modular (Mojo 🔥) Discord
- tinygrad (George Hotz) Discord
- LlamaIndex Discord
- Cohere Discord
- Torchtune Discord
- DSPy Discord
- LLM Agents (Berkeley MOOC) Discord
- MLOps @Chipro Discord
- Codeium (Windsurf) Discord
- PART 2: Detailed by-Channel summaries and links
- LMArena ▷ #general (1134 messages🔥🔥🔥):
- LMArena ▷ #announcements (1 messages):
- Unsloth AI (Daniel Han) ▷ #general (586 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (21 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (175 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
- Unsloth AI (Daniel Han) ▷ #research (36 messages🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (5 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (758 messages🔥🔥🔥):
- Cursor Community ▷ #general (762 messages🔥🔥🔥):
- LM Studio ▷ #general (158 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (398 messages🔥🔥):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (453 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (1 messages):
- Perplexity AI ▷ #pplx-api (29 messages🔥):
- Manus.im Discord ▷ #general (463 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #general (237 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (8 messages🔥):
- aider (Paul Gauthier) ▷ #links (8 messages🔥):
- Notebook LM ▷ #use-cases (10 messages🔥):
- Notebook LM ▷ #general (204 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (92 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (30 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (5 messages):
- Interconnects (Nathan Lambert) ▷ #rl (24 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (3 messages):
- Interconnects (Nathan Lambert) ▷ #posts (1 messages):
- Eleuther ▷ #general (106 messages🔥🔥):
- Eleuther ▷ #research (35 messages🔥):
- Eleuther ▷ #interpretability-general (9 messages🔥):
- Eleuther ▷ #lm-thunderdome (1 messages):
- Nous Research AI ▷ #general (127 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (4 messages):
- Nous Research AI ▷ #interesting-links (18 messages🔥):
- GPU MODE ▷ #general (10 messages🔥):
- GPU MODE ▷ #triton (14 messages🔥):
- GPU MODE ▷ #cuda (4 messages):
- GPU MODE ▷ #torch (9 messages🔥):
- GPU MODE ▷ #cool-links (5 messages):
- GPU MODE ▷ #jobs (2 messages):
- GPU MODE ▷ #beginner (15 messages🔥):
- GPU MODE ▷ #torchao (1 messages):
- GPU MODE ▷ #off-topic (1 messages):
- GPU MODE ▷ #self-promotion (9 messages🔥):
- GPU MODE ▷ #🍿 (1 messages):
- GPU MODE ▷ #reasoning-gym (6 messages):
- GPU MODE ▷ #gpu模式 (3 messages):
- GPU MODE ▷ #general (11 messages🔥):
- GPU MODE ▷ #submissions (17 messages🔥):
- GPU MODE ▷ #feature-requests-and-bugs (5 messages):
- GPU MODE ▷ #hardware (3 messages):
- HuggingFace ▷ #general (52 messages🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #cool-finds (1 messages):
- HuggingFace ▷ #i-made-this (3 messages):
- HuggingFace ▷ #computer-vision (3 messages):
- HuggingFace ▷ #smol-course (4 messages):
- HuggingFace ▷ #agents-course (26 messages🔥):
- HuggingFace ▷ #open-r1 (13 messages🔥):
- MCP (Glama) ▷ #general (75 messages🔥🔥):
- MCP (Glama) ▷ #showcase (15 messages🔥):
- Latent Space ▷ #ai-general-chat (62 messages🔥🔥):
- Yannick Kilcher ▷ #general (14 messages🔥):
- Yannick Kilcher ▷ #paper-discussion (12 messages🔥):
- Yannick Kilcher ▷ #agents (1 messages):
- Yannick Kilcher ▷ #ml-news (9 messages🔥):
- Nomic.ai (GPT4All) ▷ #general (28 messages🔥):
- Modular (Mojo 🔥) ▷ #general (4 messages):
- Modular (Mojo 🔥) ▷ #mojo (16 messages🔥):
- tinygrad (George Hotz) ▷ #general (5 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (12 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (13 messages🔥):
- Cohere ▷ #「💬」general (8 messages🔥):
- Cohere ▷ #「🔌」api-discussions (1 messages):
- Cohere ▷ #「🤖」bot-cmd (1 messages):
- Cohere ▷ #「🤝」introductions (2 messages):
- Cohere ▷ #【🟢】status-updates (1 messages):
- Torchtune ▷ #general (1 messages):
- Torchtune ▷ #dev (6 messages):
- DSPy ▷ #show-and-tell (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- MLOps @Chipro ▷ #events (1 messages):
- Codeium (Windsurf) ▷ #announcements (1 messages):
AI Twitter Recap
Model Releases and Updates
- Gemini 2.5 Pro, including its "Flash" experimental versions, are now available for subscribers, according to @Google and @_philschmid. It can be accessed within the Deep Research feature of the Gemini app, as noted by @GoogleDeepMind. @lepikhin mentioned the team worked hard to serve all the traffic.
- Moonshot AI has released Kimi-VL-A3B, a multimodal LM with 128K context under the MIT license, outperforming GPT4o on vision + math benchmarks according to @reach_vb, with models available on Hugging Face and integrated with Transformers. @_akhaliq also noted the release.
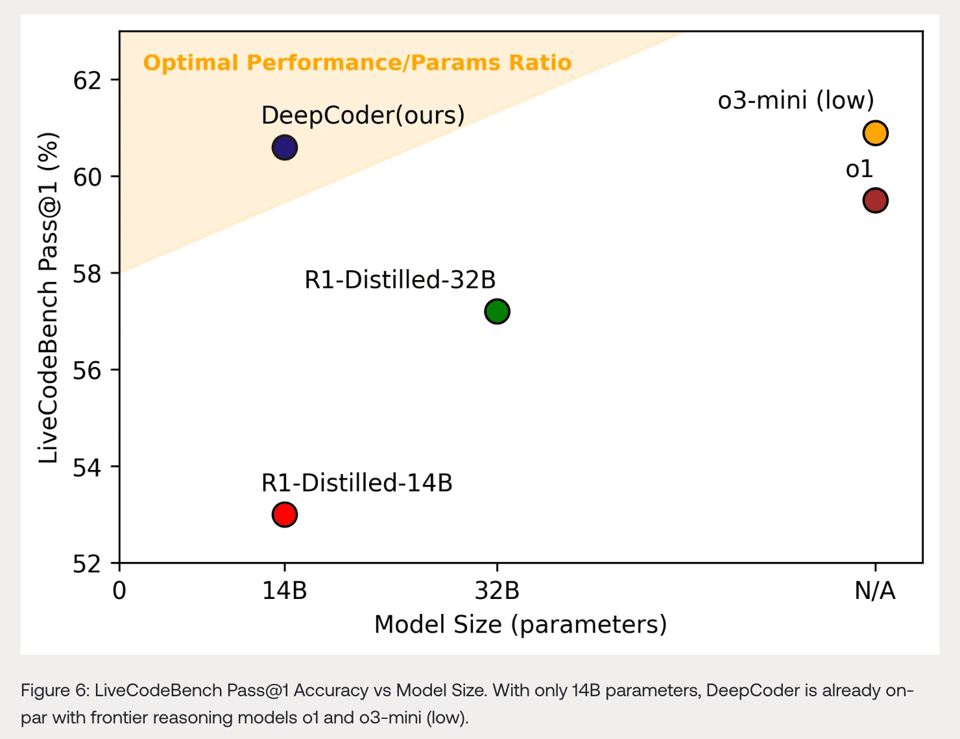
- Together AI and Agentica have collaborated to release DeepCoder-14B, an open-source coding model that rivals OpenAI's o3-mini and o1 on coding tasks, costing approximately $26,880 to train, according to @Yuchenj_UW. The model, training code, dataset, and a detailed blog are available, noted by @togethercompute. It achieves a 60.6% score on LiveCodeBench and 1936 on CodeForces, performing on par with o3-mini (low) and o1 on competition-level coding tasks, as per @togethercompute. It was trained using an open-source RL framework from ByteDance, as noted by @Yuchenj_UW.
- Meta AI has released Llama 4 Scout and Maverick, with a larger version called Behemoth in training, as mentioned by @EpochAIResearch. Maverick mixes MoE layers & dense, while Scout uses L2 Norm on QK, according to @danielhanchen.
- Runway has released Gen-4 Turbo, which offers 10x better results than Gen-3 at the same price point, according to @c_valenzuelab.
- Google has announced Imagen 3, their highest quality text-to-image model, now in Vertex AI, which allows for easier removal of unwanted objects, as per @GoogleDeepMind.
- Google has announced Veo 2 which allows users to refine and enhance existing footage and direct shot composition in Vertex AI, according to @GoogleDeepMind.
Evaluations and Benchmarks
- OpenAI has released a new Evals API for programmatically defining tests, automating evaluation runs, and iterating on prompts, integrating them into any workflow, as stated by @OpenAIDevs. @OpenAIDevs notes that good evals help improve the quality of model responses systematically.
- Epoch AI Research evaluated Llama 4, finding that Maverick and Scout scored 67% and 52% on GPQA Diamond, respectively, similar to Meta’s reported scores, according to @EpochAIResearch.
- ZeroBench tests reveal that current vision-language models fail, with GPT-4V and Gemini scoring 0% pass@1 and 0% 5/5 reliability on 100 hard visual reasoning questions, according to @LiorOnAI.
Agentic Systems and Tooling
- Auth0's Auth for GenAI now has native LlamaIndex support, making it easier to build authentication into agent workflows, as announced by @llama_index.
- MongoDB has released a repository with 100+ step-by-step notebooks on AI Agents and RAG, covering chatbot construction to Airbnb agents, according to @LiorOnAI.
Industry Analysis
- Swyx believes the twittersphere is well-calibrated on individual developer tooling but not on how AI is improving every aspect of the SDLC, which may be more impactful, making Sourcegraph well-positioned as an AI dev tooling company, according to @swyx.
- Nearcyan believes that consumers will not be prompting their own full apps because most good apps require data and there is no real data portability for consumers, according to @nearcyan.
- Svpino argues it is essential to learn how to apply AI in one's craft, as Shopify understands, and those who know what's up are asking people to learn and study, according to @svpino.
Humor/Memes
- Vikhyatk joked about lunch in downtown Seattle costing 16-20 H100-hours, with caloric consumption dropping by 10x since converting $ to H100-hours, according to @vikhyatk.
- Scaling01 joked that Gemini 3.0 will be too cheap to meter, according to @scaling01.
- Andrew Carr noted Gemini's run on Pokemon, citing Gemini "I can't believe it took six tries, and now the game is asking if I want to humiliate myself further by giving this thing a nickname. No way. I don't want to name this symbol of my failure. I'll press B to decline", according to @andrew_n_carr.
AI Reddit Recap
Our pipelines had an outage yesterday. Sorry!
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.5 Pro Exp
Theme 1: Model Mania: Gemini Reigns, Llama 4 Stumbles, New Contenders Emerge
- Gemini 2.5 Pro Crowned King, But Lacks Reasoning Transparency: Across multiple Discords (LMArena, OpenRouter, Perplexity AI, Nous Research AI, aider), Gemini 2.5 Pro earns high praise for general capabilities, creative writing, and even generating functional code from complex prompts, often cited as superior to competitors like GPT-4.5 and Claude 3.5 Sonnet. However, users note its reasoning tokens aren't exposed via the Perplexity API, hindering its use as a reasoning model there, and it can still hallucinate even with deep research capabilities unless specifically grounded in AI Studio.
- Llama 4 Launch Leaves Users Lamenting: The release of Llama 4 (Scout, Maverick) met widespread disappointment (LM Studio, Manus.im, Yannick Kilcher, Nomic.ai), with users calling it terrible, overhyped, and potentially a step backward despite some decent Japanese language performance. Concerns center on sloppy post-training, questionable benchmark validity possibly due to overfitting or gaming, and higher VRAM requirements than expected for its performance level, leading many to wait for an overhaul or stick with alternatives like Qwen's 14B.
- Cogito & Nvidia Models Challenge the Status Quo: New models are making waves, including DeepCogito's v1 Preview models (3B-70B), trained via Iterated Distillation and Amplification (IDA), claiming to outperform Llama, DeepSeek, and Qwen equivalents and even Llama 4 109B MoE, offering both direct answering and self-reflection modes (DeepCogito Research). Nvidia also quietly released a SOTA-level reasoning model, Llama-3.1-Nemotron-Ultra-253B-v1, featuring a toggle to turn reasoning capabilities on or off (Nvidia Blog Post).
Theme 2: Training & Fine-Tuning Frontiers
- Unsloth Fine-Tuning Fixes and FP4 Finds: Unsloth AI tackled DDP training issues on 3+ GPUs, recommending specific CUDA device visibility settings, while advocating for bitsandbytes (bnb) over GGUF for QLoRA training due to data efficiency. Users explored fine-tuning quantized models using FP4 via tools like Unsloth for faster training, clarifying that while direct fine-tuning of quantized models isn't feasible, LoRA offers a viable path.
- Distributed Training Debates: DeepSpeed vs. FSDP & Untrusted Compute: In Torchtune, the merits of integrating DeepSpeed were debated, with maintainers favoring native PyTorch FSDP for better composability, though offering support for community DeepSpeed recipes. Meanwhile, the Panthalia platform (X.com Waitlist), inspired by the Nous DeMo paper, aims to verify untrusted, low-cost compute for Distributed Data Parallel (DDP) training using gradient compression (Algorithm Docs).
- Novel Techniques and Research Directions Discussed: Researchers discussed the Hierarchical Perceiver patent by Google DeepMind, potentially related to long context in Gemini, and debated QKNorm advancements (Paper 1, Paper 2). Other discussions included the MIPRO algorithm for automated prompt engineering scaling across complex tasks (TensorZero Blog), and OLMo powering DAPO research for better RLHF answers (DAPO Paper, OLMo Paper).
Theme 3: Tools & Platforms: Updates, Bugs, and Battles
- Platform Updates: New UIs, Rate Limits, and Rebrands: LMArena launched its Alpha UI for testing, while OpenRouter debuted a slick new frontend but tightened free model rate limits to 50 RPD (unless users have $10+ credits), sparking user frustration. Codeium officially rebranded to Windsurf (Rebrand Announcement) following the success of its editor, launching a new SubReddit.
- Tool Troubles: Bugs Plague Cursor, Aider, and APIs: Cursor users reported issues with the C/C++ extension requiring rollbacks (Forum Thread), the auto-select feature choosing poor models, and potential bans for bypassing the trial. Aider users faced /architect mode edits being cut off and sought ways to disable auto-committing (Aider Config Docs), while Perplexity API users noted discrepancies compared to the web UI and issues with Sonar prompts focusing on the system prompt (Prompt Guide).
- Framework Frustrations and Fixes: Mojo, MAX, Granite: Mojo developers discussed its borrowing paradigm (Mojo vs Rust Blog),
__moveinit__vs__copyinit__(Example Code), and managingSpanlifetimes. Users compared MLX and MAX, noting MAX's current inability to target Apple Silicon GPUs, while Unsloth AI users found a quick fix for a GraniteModel bug in Colab involving editingconfig.json.
Theme 4: The AI Ecosystem: Research, Rumors, and Real-World Use
- Research Ripples: Patents, Audits, and Unlearning: Google DeepMind's attempt to patent the Hierarchical Perceiver (Patent Link, Paper Link) sparked discussion about defensive patenting and long-context Gemini. Researchers sought AI professionals for an ethics-based auditing survey (Survey Link), and ICML announced a machine unlearning workshop (Workshop Website).
- Industry Insights & Intrigue: Google's Payroll, Tariffs, and Cybercrime: A TechCrunch article alleged Google pays some departing AI staff for a year to prevent them joining competitors, raising questions about legality and impact. Concerns surfaced that potential tariffs on NVDA GPUs could slow AI progress, while others noted AI adoption by cybercriminals seems slower than expected, though a future "shock" remains possible.
- Applications & Integrations: MCP, Math, Auth, and Agents: The Model Context Protocol (MCP) saw use cases discussed, including integrating with Neo4j graph databases for RAG using clients like mcpomni-connect, and Semgrep rewrote its MCP server using SSE (Cursor Demo). AI4Math discussions highlighted using LLMs with formal systems like Lean for theorem proving (Kaiyu Yang Lecture), while Auth0's Auth for GenAI integrated native LlamaIndex support (Tweet). Mozilla AI released
any-agentto simplify agent framework evaluation (GitHub Repo).
Theme 5: GPU & Hardware Hustle
- Hardware Headaches: ROCm Woes and METAL Sync Glitches: Users continued to struggle getting ROCm via WSL working on AMD 7800XT GPUs due to lack of official support (AMD Docs) and WSL passthrough issues. In tinygrad, a user debugging a METAL sync issue bounty found that sharding problems in LLaMA might stem from COPY operations executing before XFER commands finished, causing incorrect data reads.
- Performance Puzzles & Optimizations: Tinygrad users reported significant speedups on AMD hardware using BEAM=2, surpassing Torch performance. In GPU MODE, discussions centered on Triton's
tl.make_block_ptrwithboundary_checkfor handling out-of-bounds memory safely (at a slight performance cost) and TorchTitan's unique pre-compile strategy potentially avoidingtorch.compilebugs (TorchTitan Code), though numerical issues withtorch.compileand FSDP persist. - New Releases & Resources for GPU Gurus: Nvidia's PhysX CUDA physics simulation kernels are now open source, inviting community ports (like ROCm). TorchAO v0.10.0 was released (Release Notes), adding MXFP8 training support for Nvidia B200 and a module swap quantization API. For learning, the geohotarchive YouTube channel and the Programming Massively Parallel Processors (PMPP) book (4th ed) were recommended.
PART 1: High level Discord summaries
LMArena Discord
- Gemini 2.5 Pro Declared A.I. Supreme: Members are calling Gemini 2.5 Pro the first true A.I., highlighting its superiority in creative writing and consistency over previous models.
- While Gemini 2.5 Pro excels in general tasks, it has been noted that the unreleased Nightwhisper model is superior in coding capabilities.
- OpenAI's Deep Research Gets Skeptical Eye: Doubts emerge regarding OpenAI's Deep Research project, despite claims of it being the best agent for web searching, with some stating 2.5 with tools is just on another level.
- The prevailing sentiment suggests that Deep Research is merely a rebranded version of OpenAI's existing o3 model.
- DeepCoder-14B Debuts with Muted Applause: Together AI and Agentica launched DeepCoder-14B-Preview, a code reasoning model, finetuned from Deepseek-R1-Distilled-Qwen-14B via distributed RL.
- However, this release was met with criticism, with one user deriding the marketing as the dumbest most shameful marketing ever, saying the gains aren't impressive considering this is just o3-mini.
- NightWhisper's Coding Skills Tease: Enthusiasm builds around the potential release of NightWhisper, celebrated for its coding capabilities demonstrated on the arena, despite its short webdev and lmarena availability.
- There's speculation that NightWhisper might align with the upcoming Google Ultra model.
- Alpha UI Opens for Crowd Testing: The Alpha UI is now available for testing here without a password.
- Users are prompted to provide feedback and bug reports through the provided Google Forms and Airtable links, as frequent updates are expected for both Desktop & Mobile.
Unsloth AI (Daniel Han) Discord
- Unsloth Patches DDP Training: Users reported issues with HF Trainer and DDP not working with 3 or more GPUs, and it was recommended ensuring CUDA visible devices are set to a specific GPU, but Unsloth supports DDP.
- After testing, it threw a ValueError, so members recommended ensuring CUDA visible devices are set to a specific GPU.
- bnb Is the Way for LoRA Training: It was advised to use bnb (bitsandbytes) for QLoRA training instead of GGUF, as it saves downloading 4x the data, and you can save and merge the adapter with the bnb model for later export to GGUF.
- Users were considering between training a LoRA on bnb 4-bit or GGUF for a tiny model, and the consensus leaned towards the former.
- Llama 4 Models Earn a Sloppy Reputation: Members testing Llama 4 (Scout and Maverick) found it to perform well in Japanese and to be capable base models despite sloppy post-training.
- The general sentiment is to await a forthcoming post-training overhaul.
- DeepCogito v1 Claims Lead in LLM Performance: DeepCogito's claims their v1 Preview models outperform the best available open models of the same size, including counterparts from LLaMA, DeepSeek, and Qwen.
- These models offer the ability to answer directly (standard LLM), or self-reflect before answering (like reasoning models).
- GraniteModel Bug Affects Colab: Users encountered a bug in the Colab notebook using GraniteModel, and suggested a quick fix that involves editing
granite_based/config.jsonto replace GraniteModel with GraniteForCausalLM and rerun the cell.- The recommended method for editing the file on Colab is to download, edit locally, and then upload the modified version back to Colab.
OpenRouter (Alex Atallah) Discord
- Free Model Limits Squeezed on OpenRouter: OpenRouter reduced the token limit for free models to 50, triggering negative reactions as users expressed frustration over the lowered limit, with some feeling that it's like a paywall.
- Accounts with at least $10 in credits will have their daily requests per day (RPD) boosted to 1000, while those with less than $10 will see a decrease from 200 RPD to 50 RPD.
- Quasar Credit-Dependent Rate Limit Coming: The update notes that Quasar will soon have a rate limit that is dependent on credits and there is no hourly rate limit, but the rate limit is 20 requests per minute.
- Members opened a feedback thread for users to post their thoughts on the changes.
- OpenRouter Debuts Slick New Frontend: OpenRouter has a new frontend that looks sick with big ups to clinemay!
- One user joked that it looked like gpt-3.5 made this website in about 4 minutes.
- Gemini Crowned King of the Models: Gemini 2.5 Pro is on a whole other level compared to the other models, making it the most powerful model up to day.
- One user noted it was rated as 1. gemini 2.5 pro ... 10. everyone else.
- Nvidia Stealthily Unleashes Reasoning Model: Nvidia silently dropped a SOTA-level reasoning model.
- The new model is casually showing it's better than Behemoth.
Cursor Community Discord
- Daniel Mac Graphs Code with GraphDB: A member shared Daniel Mac's tweet about using a graph database for code querying.
- This sparked a discussion on the potential benefits of using graph databases for code analysis and understanding complex relationships within codebases.
- Manus.im Devours Credits: A user reported that Manus.im failed to answer a question correctly and consumed 984 of their 1000 free credits on a single prompt.
- Alternatives like Smithery.ai and Awesome MCP Servers were suggested as potential solutions.
- C/C++ Extension Error Strikes: A user reported encountering an error related to the C/C++ extension after using Cursor since March 2023, noting that the extension may be limited to Microsoft products.
- A workaround involving rolling back to a previous version was suggested, with users sharing other forum threads discussing the issue.
- Auto-Select Model Labeled as Scam: Users are reporting that the auto-select model option is choosing low quality models, with one user claiming it fucked up my codebase.
- Another user suggested that this behavior might be intentional, raising concerns about the reliability of the auto-select feature.
- Cursor's Ban-Hammer Swings at Free Tier Bypassers: A member reported that bypassing the trial version of Cursor could lead to a complete ban from using the tool, with a warning that you won’t be able to use it at all soon.
- This sparked a debate about the fairness of Cursor's trial version restrictions and the consequences of attempting to circumvent them.
LM Studio Discord
- Llama 4 Disappoints Users: Users expressed disappointment with Llama 4's performance, some describing it as a step backwards, questioning benchmark validity.
- While Llama 4 provides speed/cost similar to 17B models with similar results to 24-27B, it requires more VRAM, making it pointless for simple users, while Qwen's 14B models are praised.
- ROCm on WSL Still Doesn't Work on 7800XT: A user reported that ROCm via WSL doesn't work with a 7800XT due to lack of official support (AMD documentation).
- Another user suggested it might work since both cards are RDNA3, while the first user confirmed that it was impossible to get working due to WSL passthrough issues.
- Fix Cogito Jinja Errors Quickly: Users reported errors with Jinja templates when using cogito-v1-preview-llama-3b, and were advised to use ChatGPT to quickly fix the template.
- The community model maintainer was notified about the wonky template and is expected to update the model soon.
- Docker Gets Bashed: After one member expressed wanting to be 'best friends' with anyone who says bad things about Docker, another member jokingly asked 'Did Docker take out your family or something?'
- The first member humorously replied, *'My therapist said I shouldn't talk about it.'
- Debating an Affordable Supercomputer Build: One user proposed building a 16-node supercomputer with either RTX 4090 D GPUs or a less powerful option, aiming for a 2T model with 1M context.
- Skeptics questioned the feasibility, highlighting the need for RDMA, fast interconnects, and skilled engineers.
Perplexity AI Discord
- Startups Snag Savings via Perplexity: Perplexity AI introduces a startup program offering $5000 in Perplexity API credits and 6 months of Perplexity Enterprise Pro for eligible startups.
- Eligibility requires less than $20M in funding, being less than 5 years old, and association with a Startup Partner.
- Gemini 2.5 Reasoning Ruckus Reported: Members noted that Gemini 2.5 Pro doesn't expose its reasoning tokens via the API, and therefore can't be included as a reasoning model on Perplexity, though it is a high latency thinking model.
- Consequently, the reasoning isn't displayed via the API, unlike in AI Studio.
- Deep Research High Hype but Hindered: Users await the rollout of Deep Research High, which aims to use 150-200 sources on average, yet one user reports Perplexity's deep research got 23 sources, the free gemini deep research got over 500.
- Some members are frustrated by the lack of communication on the release timeline and the current version's summary output, instead of a truly deep research; check out the DeepSeek Subreddit.
- Llama 4 faces Benchmark Faking Flak: Concerns were raised regarding a Perplexity AI search result questioning if Llama 4 is faking benchmarks.
- This is part of a broader discussion regarding model benchmarking transparency and the methodologies used to evaluate Llama 4.
- Perplexity API: Prompting Problems Persist: A user reported that Sonar responses focus on the system prompt, rather than user queries, while a team member clarified that the system prompt isn't used during the search phase, advising the user to optimize the user prompt instead using Prompt Guide.
- Also, some members discussed discrepancies between the Perplexity API and the web UI when summarizing web pages, with the API sandbox even giving way better results than the actual API when using sonar-reasoning-pro.
Manus.im Discord Discord
- Local Manus is on the Horizon: Members speculated that a local version of Manus will be possible in the future, similar to other AI models.
- This would allow users to run Manus on their own hardware, addressing concerns about credit usage and data privacy.
- MCP Servers Deployed on Claude: As of November 25, 2024, MCP servers are available on Claude and can be used with Claude code, as one member reported.
- This integration enables users to leverage MCP servers within the Claude environment for enhanced functionality.
- Llama 4 Hype Train Derails: After testing on Openrouter.AI, users report that Llama 4 is overhyped due to subpar responses.
- Criticism extends to Zucks, who is accused of gaming the benchmarks, leading to inflated performance expectations.
- Octopus Web Scraper Steals the Show: A member reported that the free website scraper Octopus works effectively on Zillow and Realtor, offering a cost-effective alternative to Bardeen, which is priced at $130/month.
- The high cost of Bardeen prompted suggestions to use Manus for building a custom scraper as a more economical solution.
- Manus Credit Crunch Angers Users: Users express dissatisfaction with the high cost of Manus credits, reporting that even simple tasks consume substantial credits, with one user exhausting 1000 free credits on a single Standard Complexity task.
- To mitigate credit consumption, users suggest breaking tasks into smaller dialogue windows and considering Proxy as a cheaper alternative, pending updates to Manus's pricing and credit plans.
aider (Paul Gauthier) Discord
- Gemini 2.5 vs Sonnet Prompting Power: Users found Gemini 2.5's logic strong but instruction following poor, contrasting it with Sonnet's feature-rich coding that needs more prompting.
- One user reported needing only 1 prompt with Gemini 2.5 compared to 3 prompts for Sonnet, even with Sonnet's advanced features like multiple file input methods and batch processing.
- Aider's Auto-Commit Causing Havoc?: A user seeks to disable Aider's auto-committing due to committing untested code, referencing the Aider configuration options.
- Another user suggested providing a model and key or Aider will guess based on available keys.
- OpenRouter's Missing Sonar Pro Citations: A user questioned missing citation links when using Perplexity Sonar Pro via OpenRouter, providing a visual reference here.
- The discussion implies potential issues with citation link reliability when using certain models through OpenRouter.
- Software Engineer Gap Year a Career Killer?: An article argues that taking a gap year/holiday would be a poor decision for software engineers, citing insights about the current tech landscape, see this article.
- The author suggests the fast-evolving nature of tech makes extended breaks detrimental for maintaining relevance.
- Architect Mode Edits Getting Interrupted: Users report /architect mode edits in Aider being cut off when adding new files, leading to potential loss of the editor state.
- Avoiding the addition of new files during editing appears to allow the process to continue without interruption.
Notebook LM Discord
- AgentSpace unlocks NotebookLM for Enterprise: Google's AgentSpace documentation reveals that NotebookLM Enterprise can now be set up with Customer-Managed Encryption Keys (CMEK) for better data encryption control.
- A user inquired about commercial-scale NotebookLM, and another member pointed out this new offering.
- NotebookLM's Privacy Assurances Confirmed: Both the Enterprise and Plus versions of NotebookLM ensure user data remains private and never enters the public domain, according to a member.
- This clarification addresses misunderstandings about Google's privacy policy and terms, noting built-in mechanisms to prevent prompt injection.
- User Correction Improves NotebookLM's Summary: A user reported that NotebookLM initially misread a scholarly article, but corrected itself after a quotation and explanation were provided.
- Repeating the same prompt in different Google accounts from the beginning yielded correct results, raising questions about training and privacy.
- Discovery Mode Rollout Still in Progress: Users are still awaiting the new Discovery Mode feature in NotebookLM, with the rollout expected to take up to two weeks from the release date.
- A user humorously demanded special treatment as a Google fanboy to get early access.
- Gemini Still Hallucinates with Deep Research: Users report that Gemini hallucinates with deep research, even with internet access.
- A member clarified that Gemini can connect to Google Search, but it requires specific grounding instructions in AI Studio.
Interconnects (Nathan Lambert) Discord
- DeepSeek R2 Primed for LlamaCon Release: Members are urging DeepSeek to release R2 on the same day as LlamaCon to capitalize on the hype, noting that training data for MoE differs from base models, citing this paper.
- The release could challenge other models and draw significant attention during the event.
- Together AI Gets into the Training Game: Together AI is entering the model training business, as evidenced by this case study showcasing the Cogito-v1-preview-llama-70B model.
- This move marks a shift towards providing comprehensive AI solutions, including training infrastructure and services.
- Google Rumored to Pay AI Staff for Idleness: According to this TechCrunch article, Google is allegedly paying some AI staff to do nothing for a year rather than allowing them to join competitors.
- A member critiqued this as a basic management idea with horrifically bad second-order effects, with another noting it could create legal perils by restricting what they do or build while under contract.
- Tariffs Threaten NVDA GPU Availability: Members speculated that if tariffs remain, the AI field may slow down due to the increased cost of NVDA GPUs.
- This could impact development and research, as access to necessary hardware becomes financially constrained.
- OLMo Powers DAPO Research: Members discussed a DAPO paper as offering 'Extreme value', referencing another paper built on OLMo.
- The researchers noted a novel compute method that results in better answers for RLHF tasks.
Eleuther Discord
- DeepMind's Hierarchical Patent Pursuit: Google DeepMind is trying to patent the Hierarchical Perceiver, drawing comparisons between the patent diagrams and those in the original research paper.
- Speculation suggests this patent might be related to DeepMind's work on ultra-long context lengths in Gemini, possibly as a defensive measure.
- Survey Seeks AI Auditing Experts: A researcher seeks participation from AI professionals for a survey on ethics-based auditing of generative AI systems.
- The survey aims to gather insights on auditing or evaluating AI systems, especially generative models.
- Debate Dawns Over Dubious Developments in QKNorm: Members debated that the QKNorm developments are not the right way to go, referencing this paper.
- A member suggested a better/earlier paper.
- ICML Invites Investigation Into Unlearning: A member shared that ICML will have a machine unlearning workshop.
- The workshop's website can be found here.
- LM Harness Hand-holding Heeded: A member inquired about a LM harness implementation for HotpotQA to evaluate Llama and GPT models.
- Guidance was requested on running evaluations against HotpotQA.
Nous Research AI Discord
- Llama-4-Scout-17B Ready for llama.cpp: Llama-4-Scout-17B text-to-text support has been added to llama.cpp, and members are converting and quantizing the model.
- This pre-release has generated excitement among users, eager to test its capabilities.
- Gemini 2.5 Pro Generates functional Code Snippets: Gemini 2.5 Pro is praised for generating functional code snippets from complex prompts, see the prompts and responses in this message.
- A user reports using aider-chat combined with Gemini 2.5 Pro to edit or create 15 files from a 300k token context, including their frontend, API, and microservices.
- HiDream-I1 Generates High-Quality Images: HiDream-I1 is a new open-source image generative foundation model with 17B parameters using Llama 3.1 8B as a text encoder, released under the MIT license.
- It produces exceptional results across multiple styles including photorealistic, cartoon, artistic, and more, achieving state-of-the-art HPS v2.1 score, which aligns with human preferences.
- Cogito Models use Iterated Distillation: A new suite of Cogito models (3B-70B) outperform models like Llama, DeepSeek, and Qwen, trained using Iterated Distillation and Amplification (IDA), which iteratively improves a model's capabilities.
- Notably, the 70B model allegedly surpasses the newly released Llama 4 109B MoE model, as outlined in this research.
- Panthalia Platform Aims to Verify Low-Cost Compute with DDP: Inspired by the Nous DeMo paper, a platform has been developed to verify untrusted, low-cost compute for training models over the internet using distributed data parallel (DDP), with a waitlist available via X.com.
GPU MODE Discord
- GPUMODE's dataset requires PyTorch 2.5: The GPUMODE "triton" dataset, used for Inductor Created Data, was created using PyTorch 2.5, and the creator promised to update the readme.
- Users may experience issues running the dataset on PyTorch 2.6+.
- Triton Gets Boundary Checks: A member suggested using
tl.make_block_ptrwithboundary_checkandpadding_option="zero"to create pointers that can fill with zeros for out-of-bounds memory accesses.- It was clarified that omitting
boundary_checkincreases speed, but risks errors like "device-side assert triggered" due to potential buffer overruns.
- It was clarified that omitting
- TorchTitan Compiles Before Ops: TorchTitan does a unique per-block compile before operations, potentially to circumvent some torch compile bugs; see torchtitan/parallelize_llama.py#L313.
- Numerical issues may still exist when using
torch.compileand FSDP together.
- Numerical issues may still exist when using
- PhysX now Open Source: NVIDIA's CUDA physics simulation kernels are now open source, and some are already working on a ROCm version.
- The Triton-Distributed learning note details fusing Triton with NVSHMEM/ROC-SHMEM to enable multi-GPU execution.
- LiveDocs Documents Legit Logistics: The creator of LiveDocs invites users to document your code with their upgraded service, now with more features available via signup at www.asvatthi.com.
- Included was an image of the interface, showing off various code documentation pages.
HuggingFace Discord
- FP4 Fine-Tuning Fuels Faster Finishes: Users are exploring fine-tuning quantized models using FP4 with tools like Unsloth, which allows loading lower precision models for training and quantization.
- While fine-tuning a quantized model is possible via LoRA, directly fine-tuning the quantized model itself is not.
- Parasail Provides Premier Performance: Parasail, a new inference provider, is looking to partner with Hugging Face after recently coming out of stealth, already serving 3B tokens a day on Open Router and 5B+ a day for private companies, as reported by The Next Platform.
- The Next Platform reported that Parasail brokers between AI compute demand and supply.
- Llama.cpp Leaps to Llama 4: The backend Llama.cpp has been updated to support Llama 4, according to the GitHub releases.
- This update allows for enhanced compatibility and performance with the latest Llama models.
- AI Runner Desktop GUI Takes Flight: A member released AI Runner, a desktop GUI for running AI models locally using HuggingFace libraries as described in this YouTube video.
- The tool enables users to create and manage chatbots with custom voices, personalities, and moods, and the bots are agents built with llama-index using ReAct tools to generate images with Stable Diffusion and real-time voice conversations (espeak, speecht5, or openvoice).
- any-agent Library Simplifies Agent Framework Evaluation: The Mozilla AI team released
any-agent, a library designed to simplify trying different agent frameworks, with a GitHub repository available for users to try and contribute.- The library supports frameworks like smolagents, OpenAI, Langchain, and Llama Index.
MCP (Glama) Discord
- Semgrep MCP Server Gets Docker Boost: A member reports running the Semgrep MCP server for over a month, hosted via Docker and AWS EC2.
- This setup is a practical demonstration of deploying MCP in a cloud environment, with potential for wider adoption given its ease of use.
- CORS Error Fixed in Semgrep MCP Server: A reported CORS error when connecting with the Cloudflare Playground was quickly resolved.
- The tool was being tested with Cursor, suggesting real-world application and integration needs.
- HTTP Request-Response Support in MCP for Enterprises: Discussion emerged regarding the need for HTTP request-response support in MCP for enterprise customers, highlighted in this pull request.
- The demand for this feature underscores MCP's growing adoption among enterprise organizations.
- MCP Integrates with Graph DB for RAG: A member inquired about using MCP in a RAG use case with a Neo4j graph database, focusing on vector search and custom CQL search.
- Another member confirmed this is a good use case, linking to mcpomni-connect as a viable MCP client, showcasing MCP's versatility.
- Semgrep Rewrites MCP Server with SSE: A member rewrote Semgrep's MCP server and shared demo videos using SSE in Cursor and Claude.
- The server is using SSE because the Python SDK doesn't support HTTP streaming yet.
Latent Space Discord
- Shopify's AI Quest Gains Momentum: Shopify's AI mandate is gaining attention, as highlighted in this tweet.
- The company is pushing towards AI integration across its platform, with internal discussions focusing on practical applications and strategic implications.
- Anthropic API Credits Have Expiration Dates: Anthropic API credits expire after one year, potentially for accounting simplification and to account for the rapidly evolving AI landscape.
- Members suggest that this policy helps manage projections in a quickly changing field, providing a framework for resource allocation and future planning.
- NVIDIA Reasoning Model Features On/Off Toggle: NVIDIA has released a new model with the ability to turn reasoning on or off, detailed in this blog post and available on Hugging Face.
- This feature allows developers to experiment with different reasoning approaches and fine-tune their AI applications for specific tasks.
- Cybercrime's AI Adoption Slower Than Expected: Despite basic AI applications like FraudGPT, mass adoption of AI by cybercriminals is surprisingly slow, with speculation that a "cybercrime AI shock" may occur when they adopt it more broadly.
- One member noted that LLMs may have only recently become good enough for use in cybercrime, indicating that the technology is still maturing in this context.
- Gemini Streams Pokemon Gameplay: The Gemini AI is now playing Pokémon, garnering attention as shown in this tweet.
- This showcases the potential of AI in gaming and interactive entertainment, demonstrating its ability to engage in complex tasks within virtual environments.
Yannick Kilcher Discord
- Llama 4 Benchmarking Shortcomings Exposed: A member asserted that Llama 4 flops on nongamed nonoverfitted benchmarks, sparking interest in the paper arxiv.org/abs/2408.04220 and a related YouTube talk.
- Concerns arose that Meta should have clarified that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference, according to this fxtwitter link.
- Decoding Bayesian Structural EM's Secrets: A member highlighted that Bayesian inference has been combining weights and architecture for around a century, citing Bayesian Structural EM as an example.
- DNA of a Model: Procedural Model Representation: A member introduced procedural model representation, where a small seed generates a large model (architecture + weights), envisioning downloading a 10MB model to generate a 100TB model.
- The member described downloading DNA to generate a human, by swapping seeds to generate different models.
- Cogito 14b Adopts Efficient Tool Template: The 14b model unexpectedly began utilizing a more efficient tool calling template than what was initially provided in the instructions, see the Cogito model.
- This suggests the model may have autonomously optimized its tool use, offering a potential area for further investigation.
- DeepCogito Improves Iteratively: A member shared a link from Hacker News about an iterative improvement strategy using test time compute for fine-tuning, from DeepCogito.
- Another member pointed to this paper and shared an Awesome talk about adapting pre-training text.
Nomic.ai (GPT4All) Discord
- Granite 8B Impresses with RAG-ability: Members reported that IBM Granite 8B is effective with RAG tasks, especially regarding providing references.
- Other members concurred, having also found Granite to be effective.
- Docling Does OCR Delicately: A member recommended docling for image OCR, especially for non-text PDFs like scans, for running embeddings.
- They highlighted its continuous operation for embeddings and integration into a database with indexed documents, enabling RAG through intersections.
- Semantic Chunking Chunks Context: A member shared a semantic chunking server, demonstrating its use with clipboard examples.
- They noted its compatibility with audio and image processing, suggesting ComfyUI for combining all modalities.
- Llama 4th Gen Bashed Badly: A member trashed the Llama 4th gen model for being terrible compared to smaller models.
- Others agreed, noting Reddit comments speculated that it may have overfit on smaller "high quality" datasets, despite some benchmarks showing promise.
- GPT4All: Run Locally!: A member advised using GPT4All primarily for local operations to ensure privacy and avoid sending private information to remote APIs.
- They detailed how to run embedding models locally and index files by chunking and embedding, referencing a shell script example.
Modular (Mojo 🔥) Discord
- MAX struggles with Apple Silicon Deployment: A member compared MLX and MAX, noting MAX currently cannot target Apple Silicon GPUs, unlike MLX, which poses challenges for direct comparison and deployment.
- They suggested that while MLX is convenient for initial experiments, the practical limitations of deploying Apple's ecosystem in server settings necessitates rewriting to frameworks like MAX, JAX, or PyTorch.
- Mojo Borrowing Paradigm Receives Praise: A newcomer shared a blog post comparing Mojo and Rust, observing that Mojo's borrow by default felt more intuitive, and wondered about how Mojo handles returning values from functions.
- Discussion ensued on how Mojo handles returning values from functions.
- Moveinit vs Copyinit deep dive: A member clarified that when returning objects in Mojo, the presence of
__moveinit__dictates whether the object is moved, otherwise__copyinit__is used, and provided an example on Github.- The member also pointed to the official Mojo documentation for a complete picture.
- Span Lifetimes got you down? Rebind!: A member inquired how to specify in Mojo that "the lifetime of the return value is at least the lifetime of self", specifically for a
Span.- Another member suggested using
rebind[Span[UInt8, __origin_of(self)]](Span(self.seq))or making the trait generic over origin, but noted that trait parameters are not yet supported.
- Another member suggested using
- Self-Promotion Rules Trigger Moderator!: A member flagged a post in the Discord channel as a violation of self-promotion rules.
- A moderator agreed, confirming the post indeed violated the community's self-promotion guidelines.
tinygrad (George Hotz) Discord
- Seeking Elegant Tensor Naming: A member is seeking a more elegant way to name tensors for easier tracking when printing model parameters, instead of manually adding a name attribute in the Tensor class.
- The member is seeking techniques to streamline tensor naming conventions for enhanced code readability.
- GPU Programming and Compiler Dev Resources: A member expressed interest in getting into GPU programming and compiler development for projects like tinygrad and requested learning resources or blog posts.
- The member is planning to read tinygrad-notes and asked for book or blog post recommendations on compiler development for GPUs, with another member recommending the geohotarchive YouTube channel as a resource for learning about tinygrad, and PMPP (4th ed) for GPU programming.
- METAL Sync Glitch Shards LLaMA: A member found unexpected behavior in sharding while reproducing a minimal example of a METAL sync issue from the bounty, suspecting that the COPY from METAL:1 to CPU was executing before the XFER from METAL to METAL:1 ended.
- The user suggests this caused the CPU to read zeros instead of the correct shard during LLaMA inference.
- AMD BEAM=2 Turbocharges Tinygrad: A user reported impressive speed improvements using AMD with BEAM=2, achieving 64 it/s, outperforming their previous best with Torch at 55+ it/s.
- Members noted that BEAM=2 often beats torch.
- LLaMA Sharding Loses Device Info: A user encountered an AssertionError while running llama.py with
--shard 4, indicating that the device info was lost after sampling.- A potential fix was proposed to move the tensor, as seen on GitHub.
LlamaIndex Discord
- Llama 4 Powers New RAG Workflow: A quickstart tutorial demonstrates building a RAG workflow from scratch using Llama 4, showcasing how to set up core steps around ingestion, retrieval, and generation using LlamaIndex workflows, as shown in this tweet.
- The tutorial focuses on core steps around ingestion, retrieval, and generation.
- Auth0 and LlamaIndex Join Forces on Auth for GenAI: Auth0's Auth for GenAI now ships with native LlamaIndex support, making it easier to build auth into agent workflows, as announced in this tweet.
- This integration simplifies incorporating authentication into agent-based applications.
- Gemini 2.5 Pro Shuttered, Points to Unified SDK: Members discovered that Gemini 2.5 Pro is deprecated and to use Google's latest unified SDK instead, as noted in the LlamaIndex Documentation.
- It was brought up that the Google SDK doesn't validate model names, but assumes provided name is valid, so it may be important to double check.
- StructuredPlannerAgent Gets the Axe: The documentation for
StructuredPlannerAgentwas removed because it is no longer maintained due to a cleanup of the agent docs, with a backlink provided for historical reference: StructuredPlannerAgent.- Instead of
StructuredPlannerAgent, it was suggested to use an agent with a planning tool that does some Chain of Thought (CoT) reasoning, or using the LLM itself to create a plan before using agent(s).
- Instead of
Cohere Discord
- Members Inquire on Event Recordings: A member inquired about the availability of event recordings for those unable to attend live, but no response was given.
- The member expressed interest, so in the future, posting event recordings would benefit absent members.
- Newbies Seek Structured Output Guidance: A new member requested examples of how to get structured output (e.g., a list of books) using Cohere, and were directed to the Cohere documentation.
- The user admitted to being inexperienced with Cohere, and more examples of structured output may be warranted in the official documentation.
- Pydantic Schemas Integrated via cURL: A member sought ways to use Pydantic schemas directly in
response_formatwith Cohere and avoid using the Cohere Python package.- They received a link to the Cohere Chat API reference and a cURL example for requests to
https://api.cohere.com/v2/chat, mirroring the approach in the OpenAI SDK.
- They received a link to the Cohere Chat API reference and a cURL example for requests to
- Cohere Side-Steps Vector DB Recommendations: Explicit recommendations for vector DBs have historically been avoided because Cohere's models are designed to function effectively with all vector DBs.
- This approach ensures broad compatibility and a neutral stance towards the vector database ecosystem, meaning no special optimizations are needed for any particular vector DB.
- Aditya Enters the Cohere Community: Aditya, with a background in machine vision and control, introduced themself while taking a sabbatical to explore web/AI with the openchain.earth project.
- Aditya is using VS Code, Github Co-Pilot, Flutter, MongoDB, JS, and Python (Evaluating), looking to learn more about integrating Cohere's AI into their projects.
Torchtune Discord
- Contributor Tag Sought After: A member requested a Contributor tag on Discord, sharing their GitHub username.
- The user lightheartedly mentioned their Discord profile picture featuring the character Gus from Psych.
- DeepSpeed Integration Debated for TorchTune: A member inquired about integrating DeepSpeed as a backend into TorchTune and created an issue to discuss the possibility.
- A maintainer asked for more context, noting that FSDP supports all the sharding options from DeepSpeed.
- TorchTune Favors FSDP Over DeepSpeed: TorchTune leans towards FSDP due to its better composition with other PyTorch distributed features, with the belief that supporting both versions well is not feasible.
- Users who migrated to TorchTune to avoid the complexities of composing DeepSpeed, PyTorch, and Megatron prefer sticking to native PyTorch.
- Recipe for DeepSpeed with TorchTune?: A maintainer suggested creating a community recipe that imports TorchTune and hosts a DeepSpeed recipe, offering to feature it if a repo is made.
- This allows users interested in DeepSpeed to leverage it with TorchTune while keeping the core framework focused on native PyTorch.
- Tweaking FSDPModule for zero1-2 Training: Since TorchTune defaults to the equivalent of zero3, documentation or more recipes on how to tweak recipes using the FSDPModule methods for zero1-2 training are appreciated.
- It's believed that zero 1-3 are all possible with very minor tweaks to the collectives.
DSPy Discord
- MIPRO Algorithm Scaled on Complex Tasks: An article tested the MIPRO automated prompt engineering algorithm across tasks of varied complexity, from named entity recognition to text-based game navigation.
- The study leveraged tasks like CoNLL++, HoVer, BabyAI, and τ-bench (customer support with agentic tool use).
- Larger Models Leverage MIPRO More: The study found that larger models benefit more from MIPRO optimization in complex settings, potentially because they handle longer multi-turn demonstrations more effectively.
- The quality of feedback significantly impacts the MIPRO optimization process, with meaningful improvements seen even from noisy AI-generated feedback.
LLM Agents (Berkeley MOOC) Discord
- Kaiyu Yang Explores Formal Math Reasoning: Guest speaker Kaiyu Yang presented on "Language models for autoformalization and theorem proving" on a livestream, available at this link.
- The lecture covered using LLMs for formal mathematical reasoning, including theorem proving and autoformalization.
- AI4Math Becomes Crucial for AI Systems: AI for Mathematics (AI4Math) is crucial for AI-driven system design and verification, mirroring NLP techniques, especially training LLMs on curated math datasets.
- A complementary approach involves formal mathematical reasoning grounded in systems like Lean, which verify reasoning correctness and provide feedback.
- Dr. Yang Enhances AI in Math: Dr. Kaiyu Yang, a Research Scientist at Meta FAIR, focuses on enhancing AI's mathematical reasoning by integrating formal systems like Lean.
- His work explores using LLMs for tasks like theorem proving (generating formal proofs) and autoformalization (translating informal to formal).
MLOps @Chipro Discord
- Manifold Research Deep Dive: The Manifold Research Group is hosting their Community Research Call #4 this Saturday (4/12 @ 9 AM PST), offering a look into their latest projects.
- Discussions will include Multimodal AI, self-assembling space robotics, and robotic metacognition, inviting collaboration in frontier science.
- Swarm Space Robotics Takes Flight: A PhD student at Manifold Research Group, who specializes in robotic swarms in space, extended an invitation to the research call.
- The research call seeks to encourage collaboration and probe frontier science in the field of space robotics.
Codeium (Windsurf) Discord
- Codeium Rebrands to Windsurf After Editor Success: Codeium rebranded to Windsurf after the successful launch of the Windsurf Editor in November 2024, explained in their rebrand announcement.
- The new name represents a blend of human and machine capabilities to create powerful experiences.
- Windsurf Floats a New SubReddit: Windsurf launched a new SubReddit to build a community, coinciding with changes to their Discord server.
- These changes included refreshed pages and channel renaming to reflect the new Windsurf branding.
- Codeium Extensions Get a New Plugin: With the rebrand, Codeium Extensions are now officially Windsurf Plugins and more innovation is promised.
- The company reiterated their dedication to enhancing the Windsurf Editor continually.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
LMArena ▷ #general (1134 messages🔥🔥🔥):
Gemini 2.5 Pro, OpenAI's Deep Research, Google's AI Strategy, DeepCoder-14B Preview Model, NightWhisper Model
- Gemini 2.5 Pro Hailed as Superior Model: Members are calling Gemini 2.5 Pro the first true A.I., noting its superiority in creative writing and consistency over other models.
- Some users have observed that while Gemini 2.5 Pro excels in general tasks, Nightwhisper is superior in coding.
- OpenAI's Deep Research Under Scrutiny: Users are questioning OpenAI's Deep Research, noting its potential as the best agent for web searching, with one stating that 2.5 with tools is just on another level.
- However, the general consensus is that Deep Research is just OpenAI's existing o3 model.
- Together AI Launches DeepCoder-14B Preview Model: Together AI and Agentica jointly released DeepCoder-14B-Preview, a code reasoning model, finetuned from Deepseek-R1-Distilled-Qwen-14B via distributed RL.
- A user pointed out the dumbest most shameful marketing ever used, saying the gains aren't impressive considering this is just o3-mini.
- NightWhisper Model's coding prowess praised: Users are eagerly awaiting the potential release of NightWhisper, highlighting its demonstrated coding capabilities on the arena, despite its brief availability on webdev and lmarena.
- Some speculate it's the same as the upcoming Google Ultra model.
- O3 model variations get mixed reviews: Members are comparing OpenAI's O3 Mini and O3 models, with one noting that O1 is more adept in deciding how long to think than O3 mini.
- One user with access to O3 medium described it as better at language-related problems than O1, but still weaker than Gemini 2.5 Pro for code.
LMArena ▷ #announcements (1 messages):
Alpha UI, Desktop & Mobile, Bugs, Leaderboard
- Alpha UI Open for Testing: The Alpha UI is now open for testing without a password at https://alpha.lmarena.ai/.
- Users are encouraged to submit feedback and bug reports via the provided Google Forms and Airtable links.
- Updates Coming Fast for Alpha UI: The announcement mentions that the Alpha UI is an early version with limited features, but updates are coming quickly for Desktop & Mobile.
- For the latest models and leaderboard data, users should refer to the main site, suggesting that the alpha version may not be fully up-to-date.
Unsloth AI (Daniel Han) ▷ #general (586 messages🔥🔥🔥):
Unsloth DDP Support, GGUF vs bnb LoRA training, Llama 4 Analysis, cogito-v1 preview LLMs
- Unsloth Addresses DDP Training Issues: A user reported issues with HF Trainer and DDP not working with 3 or more GPUs, but working fine with 2, but Unsloth supports DDP
- After testing, it threw a ValueError, and a member recommended ensuring CUDA visible devices are set to a specific GPU.
- bnb Is the Way to Go: A user inquired about whether to train a LoRA on bnb 4-bit or GGUF for a tiny model, to which it was advised to use bnb (bitsandbytes) for QLoRA training, as it saves downloading 4x the data.
- Once the adapter is trained, it can be saved and merged with the bnb model, then exported to GGUF.
- Llama 4 Models Get a Sloppy Reputation: A member tested Llama 4 (Scout and Maverick) and mentioned that it performs well in Japanese and seems to be capable base models with sloppily-put-together post-training.
- Another member commented that they will be waiting for the post-training overhaul.
- DeepCogito's v1 Preview LLMs Boast Strong Claims: A user shared DeepCogito's v1 Preview models, claiming their models outperform the best available open models of the same size, including counterparts from LLaMA, DeepSeek, and Qwen.
- They claim each model can answer directly (standard LLM), or self-reflect before answering (like reasoning models).
Unsloth AI (Daniel Han) ▷ #off-topic (21 messages🔥):
iMatrix Dynamic Uploads, Apple BFloat, Model Pruning, Online DPO
- iMatrix Dynamic Uploads Land on HF: Members uploaded iMatrix dynamic versions for Llama-4-Scout-17B-16E-Instruct-GGUF to HuggingFace.
- B in BFloat stands for Brain: The "B" in bfloat means "brain" and the dataype was developed at Google Brain, according to Apple's documentation.
- Schizo Theory: A member shared his "schizo theory is that companies like openai / claude / gemini use user inputs to prune their models".
- He believes the "Which one of these do you prefer"-like responses are for collecting user preference data for training their models.
- Online DPO learns you too well: One member noted that online DPO starts to understand you better than you understand yourself.
Unsloth AI (Daniel Han) ▷ #help (175 messages🔥🔥):
GraniteModel bug, Unsloth on MacOS, Multi-GPU Support, Gemma 3 12b issues, GRPO training
- *GraniteModel Bug Bites Colab Users!: Users encountered a bug in the Colab notebook using GraniteModel, but a quick fix involves editing
granite_based/config.jsonto replace GraniteModel with GraniteForCausalLM* and rerun the cell.- The recommended method for editing the file on Colab is to download, edit locally, and then upload the modified version back to Colab.
- *MacOS Misses Out on Unsloth's GPU Goodness: Unsloth currently only supports GPUs*, leading to an
NotImplementedErrorfor MacOS users without NVIDIA GPUs.- However, there's a potential solution via this pull request that aims to address MacOS compatibility.
- *Multi-GPU Support Coming Soon!*: Users are eagerly awaiting multi-GPU support for fine-tuning in Unsloth.
- The response from the team is that it's "soon (tm)".
- *Gemma 3 12b Faces Loading Fails*: Users reported that
push_to_hub_mergedisn't uploading all the necessary files to HF, so they cannot useAutoModelForCausalLM.from_pretrained("modelname/here")and get an errorOSError: modelname/here does not appear to have a file named pytorch_model.bin.- One member suggested that if you're using > 1B gemma it's a vision language model technically, so some things are slightly different. Users are suggested to try
FastModelvsFastLanguageModelfor gemma3.
- One member suggested that if you're using > 1B gemma it's a vision language model technically, so some things are slightly different. Users are suggested to try
- *GRPO Training Tips Sought for Massive Models: A user sought advice on training a 24B model with a 16k* context length using GRPO, managing only a batch size of 1 on an H200 with 141GB VRAM and asked about Unsloth pro plan multi GPU support.
- Suggestions included increasing gradient accumulation, with the possibility of multi-GRPO support via other frameworks, and discussions around distributed GRPO concepts for sampling efficiency.
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Location clarification
- Location not France: A member asked another member if they were from France.
- The member responded clarifying that they are from Dutch/Holland.
- Location Confirmed: The member confirmed they are from Dutch/Holland.
- This clarifies their origin in response to the initial question.
Unsloth AI (Daniel Han) ▷ #research (36 messages🔥):
LLMs knowledge storage alternatives, RAG for memory offloading, Vector DBs and privacy, Retrieval augmented training, DeepSeek-V3
- LLMs Mull Knowledge Storage Alternatives: Members discussed the potential of LLMs offloading knowledge retrieval to RAG pipelines to reduce the size and increase the speed of the models, and training the attention heads to learn in conjunction with a vector database.
- It was suggested that OpenAI could provide generalized vector DB knowledge lookup over private datasets that open LLM kernels could plug into for added context.
- RAG Reimagined: Retrieval Portion Evolved: Discussions revolved around splitting LLMs into a knowledge model and a chat model, where the chat model focuses on intelligence and reasoning and tool calls to the knowledge model.
- While likened to RAG, the focus is on a kernel that works with experts or specialized vector DBs built on the same embeddings, effectively increasing vocab size in some sense.
- Vector DB Ventures: Privacy Benefits Beckon: A member noted that OpenAI could potentially benefit from giving away an open kernel for free: *"Look at your benchmarks before our attention vector lookups. Now look at your benchmarks after our attention vector lookups."
- This could also lead to a privacy benefit by only offloading static knowledge memory lookup.
- Rewarding Retraining: Forget What's Efficiently Remembered: A participant suggested "retrieval augmented training", rewarding the model to forget what it can efficiently remember via vector search.
- This approach could lead to more efficient models by leveraging external knowledge sources during training.
- DeepCoder Optimization Detailed: A member shared a link to a Together AI blog post about DeepCoder optimization, highlighting its potential for optimizing the vLLM pipeline.
- The optimization minimizes the wait for sampling by doing an initial sample and training, while simultaneously sampling again.
OpenRouter (Alex Atallah) ▷ #announcements (5 messages):
Rate Limits, Credits, Quasar Rate Limit, Feedback on Rate Limiting
- OpenRouter adjusts Free Model Rate Limits: Accounts with at least $10 in credits will have their daily requests per day (RPD) boosted to 1000, while those with less than $10 will see a decrease from 200 RPD to 50 RPD.
- Quasar to get Credit-Dependent Rate Limit: The update also notes that Quasar will soon have a rate limit that is dependent on credits.
- Feedback on Free Model Rate Limits: A member opened a feedback thread for users to post their thoughts on the changes.
- Hourly rate limits not available: There is no hourly rate limit, but the rate limit is 20 requests per minute.
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
Olympia.chat, Shopify, SaaS Marketing, Turnkey Operation
- Olympia.chat Seeks New Leadership: The founder of Olympia.chat has taken a role as Principal Engineer at Shopify, and the company is seeking an experienced site operator to take over technical maintenance and SaaS marketing.
- The profitable site generates over $3k USD per month, and the founders are flexible about terms for a potential takeover, offering a turnkey operation with all IP included.
- Olympia.chat's Financial Performance: Despite peaking at nearly $8k last year, Olympia.chat currently generates over $3k USD per month consistently.
- Lack of funding led to a halt in marketing efforts, impacting customer churn.
OpenRouter (Alex Atallah) ▷ #general (758 messages🔥🔥🔥):
OpenRouter Frontend, Quasar Open Sourced, Free Model Rate Limits, API Keys Please, Gemini
- OpenRouter Drops Sick New Frontend: OpenRouter has a new frontend that looks sick, big ups clinemay!
- One user joked that it looked like gpt-3.5 made this website in about 4 minutes.
- Gemini models are top tier: Gemini 2.5 Pro is on a whole other level compared to the other models, making it the most powerful model up to day.
- One user noted it was rated as 1. gemini 2.5 pro ... 10. everyone else.
- Free Model Limits Tightened, Community Reacts: OpenRouter reduced the token limit for free models to 50, triggering mixed reactions from users, with some expressing frustration over the lowered limit.
- Some users feel that it's like a paywall.
- API Keys Made Easier: Users can now easily get an API key once they make an account, add credits then in the top right dropdown go to keys and create one there.
- A community member said: I was asking about the app so i could try to help you put the key in the right spot but not sure how Godot works iwth that.
- Nvidia Silently Drops SOTA-Level Reasoning Model Llama 3.1: Nvidia silently dropped a SOTA-level reasoning model.
- The new model casually showing it's better than Behemoth.
Cursor Community ▷ #general (762 messages🔥🔥🔥):
Augment, Vector DB vs graph DB, Manus.im, Cursor C/C++ extension error, Model selection
- Daniel Mac goes Graph DB for Code: A member shared a link to Daniel Mac's tweet about using a graph database for code querying.
- Manus.im burns through credits: A user reported that Manus.im failed to answer a question correctly and burned through 984 of 1000 free credits on a single prompt.
- Another member suggested exploring alternatives like Smithery.ai or Awesome MCP Servers.
- C/C++ Extension Error: A user reported receiving an error related to the C/C++ extension after using Cursor since its launch in March 2023, with the extension possibly limited to use with Microsoft products.
- A workaround involved rolling back to a previous version and users shared other forum threads discussing the issue.
- Auto-Select is a scam: Users are reporting that the auto-select model option is selecting trash models.
- One user claimed it fucked up my codebase, while another suggested that it's intentionally designed this way.
- Cursor's Free Tier Gets Heat: A member reported that bypassing the trial version of Cursor could result in getting the user completely banned from using Cursor.
- One user noted: Gonna ban you now, but just so you know, I hope you didn’t like using Cursor because you won’t be able to use it at all soon.
LM Studio ▷ #general (158 messages🔥🔥):
Llama 4 Disappointment, GPU requirements and model sizes, LM Studio and Ollama, Jinja templates
- Llama 4 performance leaves users disappointed: Users express disappointment with Llama 4's performance, describing it as bad and 10 steps backwards, questioning the validity of benchmarks.
- Others suggest that larger models may have quality control issues due to random data, too many connections, or poisoned datasets, while Qwen's 14B models are praised.
- LLM size and hardware implications: A discussion arose regarding the relationship between VRAM consumption and model dilution, with some noting that models consuming less VRAM often appear more distilled or diluted to reduce size.
- A user clarified that Llama 4 gives similar results to 24-27B models, but has speed and cost of 17B model, but requires more vram making it pointless for simple users.
- LM Studio's remote GPU compatibility is debated: Users discussed connecting LM Studio to remote instances of Ollama, but it was confirmed that LM Studio is not compatible with Ollama.
- Furthermore, the potential for connecting LM Studio with a remote GPU cluster was raised, alongside a discussion regarding the use of Snapdragon X Series NPUs and their (lack of) support with LM Studio and llama.cpp.
- Cogito models' Jinja errors fixed with ChatGPT: Users reported errors with Jinja templates when using cogito-v1-preview-llama-3b, and were advised to use ChatGPT to quickly fix the template.
- The community model maintainer was notified about the wonky template and is expected to update the model.
- Decoding MOE models for dummies: A user asked, what is an MoE model?
- A helpful member explained that Mixture of Experts (MoE) models can be faster than dense models, as only parts of the model are active per token, although the whole model must be in VRAM.
LM Studio ▷ #hardware-discussion (398 messages🔥🔥):
Docker Bad, AMD ROCm WSL Woes, Memory Limits and Motherboards, Umbrella Rack SuperComputer, Fast Reading Skills
- Docker Gets Roasted: After one member expressed wanting to be "best friends" with anyone who says bad things about Docker, another member jokingly asked "Did Docker take out your family or something?".
- The first member humorously replied, *"My therapist said I shouldn't talk about it."
- ROCm on WSL still problematic for 7800XT: A user reported that ROCm via WSL doesn't work with a 7800XT due to the lack of official support as seen in the AMD documentation.
- Despite this, another user suggested it might work since both cards are RDNA3 architecture, while the first user confirmed that it was impossible to get working half a year ago due to WSL passthrough issues.
- Memory Limits Debated: In a discussion about RAM limits, a user stated that a Ryzen 7000 has a weak memory controller and that the BIOS limit is 192GB on consumer hardware, while mainboards can fit 256GB.
- Another user pointed out that AMD's website states a 128GB limit, to which the first user responded that people have been running 192GB for years, and they attributed the discrepancy to server hardware having different quality targets.
- Assembling an NND Umbrella Rack SuperComputer: One user proposed building a 16-node supercomputer with either RTX 4090 D GPUs (totaling 3TB VRAM) or a less powerful option (1.5TB VRAM), aiming for a 2T model with 1M context within a budget cheaper than an Nvidia DGX B300.
- Skeptics questioned the feasibility, with one user bluntly stating, "this isn't how you do any of this....", highlighting the need for RDMA, fast interconnects, and skilled engineers, emphasizing that the user's goal was not possible on their current hardware.
- Language Model fine-tuning educational project: One member asked about a fun and educational project involving beefy hardware (2 RTX ADA 6000s, 512GB of RAM) and asked if it's a good idea to learn to fine-tune a small instance of something like phi4.
- Another member suggested pretraining an LLM from scratch or fine-tuning an LLM and pointed to a coding dataset from Nvidia (huggingface.co) and suggested that fine-tuning base models, not instruct ones would be better.
Perplexity AI ▷ #announcements (1 messages):
Perplexity for Startups program, API Credits, Enterprise Pro
- Perplexity Launches Startup Program: Perplexity AI is launching a startup program offering resources to help startups reduce research time and focus on building.
- The program provides $5000 in Perplexity API credits and 6 months of Perplexity Enterprise Pro for the entire team; eligibility requires less than $20M in funding, being less than 5 years old, and association with a Startup Partner.
- Startup Program Details: The Perplexity for Startups program aims to provide eligible startups with the resources they need to accelerate their development.
- Eligible startups can receive $5000 in API credits and a 6-month subscription to Perplexity Enterprise Pro, enabling access to advanced AI capabilities for their entire team.
Perplexity AI ▷ #general (453 messages🔥🔥🔥):
Gemini 2.5 Pro performance, Deep Research High rollout, Perplexity Discover tab, Manus Invites are still needed, AI image generation on Android
- Gemini 2.5 Pro's Reasoning Outputs Missing: Members discussed that Gemini 2.5 Pro doesn't expose its reasoning tokens, and therefore can't be included as a reasoning model on Perplexity, though it is a high latency thinking model.
- Because Gemini 2.5 Pro reasoning tokens aren’t sent, Perplexity via the API doesn't show the reasoning like you would via AI Studio, but is still a high latency thinking model.
- Deep Research High Rolling Out Slowly: Members are eagerly awaiting the rollout of Deep Research High, which is expected to use 150-200 sources on average, however, one user reports Perplexity's deep research got 23 sources, the free gemini deep research got over 500.
- Some members voiced frustration over the lack of communication regarding the release timeline, and the fact that the current version outputs a summary rather than conducting truly deep research. Check out the DeepSeek Subreddit.
- Gemini 2.5 Pro gives great performance on Perplexity: Users noted the addition of Gemini 2.5 Pro in Perplexity, with one user finding that Gemini 2.5 Pro's single story beat the other 3 stories by GPT 4.5, and another stating that it's now powering deep research, delivering detailed reports like this one.
- However, one user noted that answers are often truncated at 500-800 tokens, despite the model generating 16,098 tokens of detailed report.
- Users report Perplexity auto-enabling Pro mode: Several users have reported that Perplexity is auto-enabling Pro mode on free users to waste their daily limits.
- One user said the non-pro model seems to be balls.
- Reported issues when Uploading PDF files: Pro user tried uploading 8 .pdf files and after 5 minutes of loading it either uploads one or two that instantly disappear with an error pop up saying file upload failed.
- Files sizes ranges from 114kb to 9,502kb
Perplexity AI ▷ #sharing (1 messages):
Llama 4, Benchmark Faking
- Benchmark Faking Allegations against Llama 4: A user shared a Perplexity AI search result questioning whether Llama 4 is faking benchmarks.
- The shared link provides a discussion and potential evidence related to the alleged benchmark manipulation by Llama 4.
- Ongoing Debate on Model Benchmarking: The conversation highlights the broader issue of transparency and reliability in AI model benchmarking, a recurring theme in the AI community.
- Concerns were raised about the methodologies used to evaluate Llama 4 and the potential for misleading results.
Perplexity AI ▷ #pplx-api (29 messages🔥):
Perplexity API News Fetching, Perplexity API Sonar Prompting, Perplexity API Search Discrepancies, Perplexity API Citations, Perplexity API Sandbox
- *Perplexity API* News Fetching: A user requested a news API feature to fetch news based on queries or topics, similar to particle.news, and the team responded that they already have partnerships to surface news via their API.
- A team member suggested building a news API feature using Sonar's existing functionalities and adding it to the API cookbook.
- *Perplexity API* Sonar Prompting: A user reported issues with Sonar, where responses were focused around the system prompt rather than dynamically handling user queries.
- A team member clarified that the system prompt isn't used during the search phase, advising the user to optimize the user prompt instead, referencing the Prompt Guide.
- *Perplexity API* Search Discrepancies: A user reported discrepancies between the Perplexity API and the web UI when summarizing web pages, with some links not being retrieved by the API and the results being less structured.
- The user is seeking assistance to resolve the issues, as the Sonar-pro model yields different results between the API and the web UI.
- *Perplexity API* Sandbox superiority?: A user reported that the API sandbox is giving way better results than the actual API when using sonar-reasoning-pro.
- The user is seeking advice on how to make the API give the same results as the sandbox.
Manus.im Discord ▷ #general (463 messages🔥🔥🔥):
High Effort Mode, Manus Local Version, Genspark vs Manus, Llama 4 hype, Manus Credit Usage
- Local Manus Coming Soon: Members discussed that a local version of Manus will be possible in the future, like most other AI models.
- MCP Servers Available: Members noted that MCP servers are available on Claude since Nov 25/2024, and can be used with Claude code.
- Some members expressed skepticism, citing successful past attempts at what they termed cursed model merging.
- Llama 4 is Overhyped: Users share that Llama 4 is overhyped after testing it on Openrouter.AI and receiving subpar responses.
- Others claim Zucks is receiving criticism because he supposedly gamed the benchmarks.
- Octopus Web Scraper Works: A member reported that Octopus, a free website scraper, works pretty well on Zillow and Realtor, while Bardeen costs $130/month.
- Another member said $130/month seems expensive when you could use Manus to build your own.
- Manus credits are too expensive: Several users complain that Manus credits are too expensive, with one user reporting that a single Standard Complexity task used up all 1000 free credits and wishing the pricing and credit plans get updated.
- Some users shared it is better to break it into smaller tasks with new dialogue windows, and also recommend Proxy as a cheaper alternative.
aider (Paul Gauthier) ▷ #general (237 messages🔥🔥):
Gemini 2.5 vs Sonnet Thinking, Aider's auto-testing, Gemini 2.5 Pro vs exp, OpenRouter citation links, AI resume builder
- Gemini 2.5 and Sonnet Faceoff: Members discuss Gemini 2.5's strong logic but poor instruction following versus Sonnet's feature-rich but less accurate coding, ultimately requiring fewer prompts for a working program.
- One user reported that Gemini 2.5 only needed 1 prompt, while Sonnet needed 3 prompts, despite Sonnet including multiple file input methods, optional drag and drop, batch processing, file queue management, explicit conversion start, explicit cancellation, resizable window, etc.
- Aider's Auto-Testing Troubles: A user is looking to enable Aider's auto-testing and potentially disable auto-committing due to issues with committing untested code, with a pointer to the Aider configuration options.
- Another user suggests to provide a model and key or Aider will guess what you want based on whatever of your keys it can find.
- Gemini 2.5 Pro exp Rate Limits: Users compare Gemini 2.5 Pro exp to Gemini 2.5 Pro preview, noting different rate limits, and one reports getting charged for the seemingly free
pro-expmodel.- Despite one user feeling like exp is weaker, another user had cancelled Sonnet within an hour of using it, while another user got rate limit issues on both, especially through openrouter.
- OpenRouter Missing Citation Links: A user asks if missing citation links are normal when using services like Perplexity Sonar Pro through OpenRouter, attaching an image.
- DIY AI Resume Builder Idea: A user is seeking an LLM-powered tool to analyze resumes against job listings, suggesting wording modifications, and another user suggests building one's own tool.
- A user suggests if they had some programming experience that this could be built, and they could also use it to test out Gemini 2.5 pro.
aider (Paul Gauthier) ▷ #questions-and-tips (8 messages🔥):
Architect mode interruptions, Aider Response Time, Aider Cursor Rules
- Architect Mode Edits Getting Cut Off?: Users are reporting /architect mode edits getting interrupted when asked to add new files, potentially losing the editor.
- Saying no to adding new files appears to allow the edit to continue.
- Aider Response Time Questioned: Users are reporting that Aider v0.81.1 with
openrouter/deepseek/deepseek-r1andopenrouter/anthropic/claude-3.5-sonnetis as slow as ChatGPT.- One user waited "5 freaking minutes" for a schema file to be created, only to receive a
litellm.APIErrordue to a connection issue.
- One user waited "5 freaking minutes" for a schema file to be created, only to receive a
- Comparing Aider Conventions to Cursor Rules: Users are asking if Aider conventions are similar to Cursor rules.
- A member clarified that aider "conventions" isn't really a thing, but just added context sent to the LLM. They are added manually or with
--read CONVENTIONS.md.
- A member clarified that aider "conventions" isn't really a thing, but just added context sent to the LLM. They are added manually or with
aider (Paul Gauthier) ▷ #links (8 messages🔥):
Software Engineer Gap Year, LLMs as AI Coworkers, Programming LLMs for Successful Outcomes
- Gap Year Not a Good Idea for Software Engineers?: An article suggests that taking a gap year/holiday would be an incredibly bad decision/time for software engineers, pointing to insights about the current tech landscape, see this article.
- LLMs as 1000 AI Coworkers: Anni Betts from Anthropic suggests that software engineers should think beyond having "an AI coworker" and instead consider having "1000 AI coworkers that went ham on your entire issue backlog at once".
- According to the author this can be done by programming the LLMs and building a "stdlib" that manufactures successful LLM outcomes.
Notebook LM ▷ #use-cases (10 messages🔥):
NotebookLM Commercial Options, NotebookLM privacy assurances, NotebookLM Misreading Scholarly Articles
- Google's AgentSpace unlocks NotebookLM for Enterprise: A user inquired about a commercial-scale version of NotebookLM with data privacy and specific programming capabilities, and another member linked to Google's AgentSpace NotebookLM Enterprise documentation that enables CMEK.
- The documentation outlines how to set up NotebookLM with Customer-Managed Encryption Keys (CMEK), offering greater control over data encryption.
- Privacy Assurances Provided by NotebookLM: A member explained that both the Enterprise and Plus versions of NotebookLM offer privacy assurances, emphasizing that user data is never in the public domain, regardless of the version used.
- They clarified this point to address a fundamental misunderstanding of Google's privacy policy and terms of service, and further suggested that the platform has mechanisms to prevent prompt injection attempts.
- NotebookLM's improved Summary after user correction: A user noticed that NotebookLM initially misread a critical point in a scholarly article's summary but corrected itself after the user provided a quotation and explanation.
- Repeating the same prompt with the same article in different Google accounts yielded the correct summary from the beginning, raising questions about whether the model uses previous queries for training and whether the privacy statement is accurate, according to the user.
Notebook LM ▷ #general (204 messages🔥🔥):
Discovery Mode rollout, Google Cloud Next and Google I/O, NotebookLM Legal Use cases, New Gemini features with deep research, Podcast Audio Overviews
- Discovery Mode Still Rolling Out Slowly: Users report waiting for the new Discovery Mode feature, with the rollout expected to take up to two weeks from release date.
- One user jokingly demanded special treatment as a Google fanboy, requesting to be an alpha tester.
- Google Cloud Next and Google I/O Promise Surprises: The upcoming Google Cloud Next and Google I/O events are anticipated to reveal new features, though details remain tightly guarded.
- One user humorously compared Cloud Next to Christmas, with Google acting as Santa.
- NLM for Legal Use Cases and Printing Concerns: A user sought advice on using NotebookLM for extracting specific information from legal documents, aiming to get article numbers and relevant text, seeking assistance on printing the entire answer with all the links included.
- Another member suggested breaking content into 10-20 notebooks, each with its own specific content, to ask the same question immediately in each notebook.
- Gemini Still Hallucinates with Deep Research: Some users report experiencing hallucinations with Gemini's deep research, despite it having access to the internet.
- One member clarified that Gemini can connect to Google Search, but it doesn't do it if you don't specify you wanna ground it and recommends testing this in AI Studio.
- Podcast Audio Overviews Coming to NotebookLM: It was reported that the new 2.5 Pro deep research version will have the capability to make audio overviews, but it is not working for all users.
- A Google employee clarified that complex topics with several different angles covered in the sources around a central topic result in longer podcasts.
Interconnects (Nathan Lambert) ▷ #news (92 messages🔥🔥):
DeepSeek R2 Release, LlamaCon, Llama-4-Maverick, Style Control Ranking, HF version of Llama-4-Maverick
- DeepSeek R2 must release for LlamaCon: Members are encouraging those with connections at DeepSeek to release R2 on the same day as LlamaCon to leverage the hype, citing that the training data needed for MoE is different than base models according to research from arxiv.org.
- LM Arena policy updates: Early analysis shows style and model response tone was an important factor (demonstrated in style control ranking), and the HF version of Llama-4-Maverick is being added to Arena, but Meta should have made it clearer that Llama-4-Maverick-03-26-Experimental was a customized model to optimize for human preference, so leaderboard policies are being updated to reinforce commitment to fair, reproducible evaluations.
- Members reacted saying it was a yapping emoji slopfest.
- Cogito models released under open license: Strong LLMs of sizes 3B, 8B, 14B, 32B and 70B are being released under open license, with each model outperforming the best available open models of the same size from LLaMA, DeepSeek, and Qwen, across most standard benchmarks and the 70B model outperforming the newly released Llama 4 109B MoE model.
- These LLMs are trained using Iterated Distillation and Amplification (IDA), an scalable and efficient alignment strategy for superintelligence using iterative self-improvement from DeepCogito.
- Together AI moves into Training: Together AI is getting into the training business, as showcased by this case study.
- Google Gemini 2.5 Pro Deep Research Announced: Google Gemini 2.5 Pro Deep Research was announced according to 9to5Google with a member reporting that Gemini 2.5 deep research is roughly on par with OpenAI Plus with an audio overview podcast option thing.
Interconnects (Nathan Lambert) ▷ #ml-questions (30 messages🔥):
OpenAI Image Gen Capabilities, Logprob Reward, Arxiv Publishing, Arxiv Moderation, Phi-CTNL
- OpenAI's New Image Gen Capabilities: A member inquired about write-ups describing how OpenAI unlocked new image generation capabilities, suggesting it wasn't a new model but latent capabilities.
- Another member suggested it was achieved using an objective similar to this one and incorporating a logprob reward as seen in this paper.
- Arxiv Posting Process Revealed: Members discussed the process for posting on Arxiv, noting that a small vouch is needed, which differs from the old physics days of just dumping content.
- They added that a small random chance of moderation exists, where even nonsense papers can get rejected, but people mostly just post whatever anyway.
- Champion Phi-CTNL Paper has 20 Citations: A member shared a link to this paper describing a champion model that has 20 citations, exclaiming Godlike.
- Another member noted the brutal model name phi-CTNL, speculating on the reaction if Meta cites it in a future Llama 4 paper.
Interconnects (Nathan Lambert) ▷ #ml-drama (15 messages🔥):
Google AI Staff, AI Sabbatical, NVDA Tariffs, ASI, Google's management vibes
- Google allegedly pays AI staff to do nothing: A TechCrunch article discusses how Google is allegedly paying some AI staff to do nothing for a year rather than join rivals.
- A member described it as the most basic idea from management where all the second order effects are horrifically bad.
- AI Engineer eyes Sabbatical to look at trees: One member expressed that after AI settles down in a year or two, they'd happily take a sabbatical and write a book.
- Another member said that from the corporate side (McKinsey etc.) they give their researchers very long time off to make sure they stay engaged otherwise they found you just lose everyone over time.
- Tariffs May Accelerate AI Slowdown: A member suggested that if tariffs stay, the AI field will settle down in a month because people can't afford NVDA GPUs.
- They stated if tariffs stay it'll settle down in a month as you can't afford NVDA GPUs.
- Google Paying Quitters Creates Legal Peril: A member clarified that Google is paying people who have quit for another year but forcing them not to work.
- In theory, anything they do in that year belongs to Google, so they can't start working on their startup or something without legal peril.
Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
Google Cloud Next, Qwen 3 Launch, GPT 4.5 preferences, Claude Code Credits, Tim Apple
- *Google Cloud Next* to Drop New Models: A member shared that Google will drop new models on Cloud Next, which starts Wednesday, according to this X post.
- This may mean the launch of Qwen 3.
- *GPT 4.5* Preferences Underway: A member alluded to GPT 4.5 preferences being collected by OpenAI, linking to this X post.
- They were looking for the High Taste Tester LMarena to weigh in.
- *Anthropic* offers Claude Code Credits*: A member shared a link to *Anthropic offering $50 in Claude Code credits to 1,000 people for trying Claude Code.
- According to the post, that may be enough credit to change one var name.
Interconnects (Nathan Lambert) ▷ #memes (5 messages):
Jiankui He's X ad revenue
- *Jiankui He's* AdSense fortune: A user joked about Jiankui He making money from the X creator ad share.
- Another user joked that he makes $20 from that, or $20K if Elon Musk wants to "fuck him."
- AdSense Revenue Speculation: Speculation arose regarding the potential ad revenue earned by Jiankui He on X.
- Estimates ranged from a modest $20 to a more substantial $20,000, contingent on Elon Musk's intervention.
Interconnects (Nathan Lambert) ▷ #rl (24 messages🔥):
DAPO papers, OLMo, Tulu 3, BoN Sampling
- DAPO papers offer "Extreme value": Members in the channel discussed a DAPO paper as offering "Extreme value".
- They also referenced another paper built on OLMo.
- Tulu 3's work makes it into another paper: A paper using Tulu 3's work was mentioned and linked: https://arxiv.org/abs/2504.03790.
- Alpha in research = talk to other researchers: A member stated that "biggest alpha in research is just talking to other researchers" and shared some insights from a paper, noting it "uses a very different method of inference time compute".
- They also stated that it "shows that BoN sampling is effectively just changing the beta factor in RLHF (lowering the KL penalty)", and that "you can design the inference time compute differently, so that you aren't hacking RL (in this case using an RM as guidance) and get far better answers".
- BoN sampling to sub in future work?: A member asked whether BoN sampling could substitute in future work.
- Another member responded that "it’s more complicated to implement but sure why not if it’s flop equivalent".
- Ash Vaswani Tweet on Undergrad Technical Report: A user shared a tweet from Ash Vaswani and stating that a linked paper "didn't give very good vibes though".
- The member stated that the paper "felt very undergrad technical report", but declined to tweet negatively about it.
Interconnects (Nathan Lambert) ▷ #reads (3 messages):
Karan Dalal Post, Yuxi Liu Essay
- Karan Dalal's Post Goes Viral: A member shared a link to Karan Dalal's post on fxtwitter, generating excited discussion.
- The original poster reacted with simply, "WTF".
- Yuxi Liu's Essay Gains Attention: A member posted a link to Yuxi Liu's essay prompting immediate discussion.
- No specific details about the essay were mentioned.
Interconnects (Nathan Lambert) ▷ #posts (1 messages):
natolambert: My post looks generous next to Marcus’s, oh my
Eleuther ▷ #general (106 messages🔥🔥):
Adam second-moment estimate buffers, Google DeepMind Patents, Hierarchical Perceiver, AI Auditing Survey, GFlowNets
- Adam Buffers Reconstruction Discussions Emerge: Members discussed the utility of Adam second-moment estimate buffers and how to efficiently reconstruct them for open-source models, balancing accuracy with computational cost, for potential method improvements.
- It was noted that setting beta2 to a high value (e.g., 0.999999) and the learning rate to zero could improve accuracy, though the final epoch of pretraining presents challenges.
- DeepMind Patents Hierarchical Perceiver: Members noted that Google DeepMind is trying to patent the Hierarchical Perceiver, drawing comparisons between the patent diagrams and those in the original research paper.
- Some speculated this patent could be related to DeepMind's work on ultra-long context lengths in Gemini, with discussions on whether it's a defensive measure or indicative of current usage after its original lack of uptake.
- Licensing Faceoff: Apache 2.0 Prevails over MIT: The conversation mentioned a preference for the Apache 2.0 license over MIT, citing its defenses against patent-based lawfare in machine learning.
- It was highlighted that institutional inertia and GitHub org settings favored Apache 2.0, with the sentiment that outside of GPLv2 weirdness or wanting to engage in lawfare shenanigans, there's no reason to argue for MIT over Apache 2.0.
- DeepMind Rumored to Sandbag Model Releases: Members discussed a rumor, per a Reddit thread, that DeepMind may be delaying the release of research to maintain a competitive edge.
- One participant clarified that sandbagging refers to holding back in ability, not releasing purposely bad versions of models to mislead others.
- Survey seeks AI Auditing Experts: A researcher from the University of Turku, Finland, is conducting a survey on ethics-based auditing of generative AI systems and is seeking participation from professionals with practical experience in AI auditing, model evaluation, risk/compliance, or ethical alignment of AI principles.
- The survey aims to gather insights on auditing or evaluating AI systems, especially generative models.
Eleuther ▷ #research (35 messages🔥):
QKNorm, Soft RL, Llama 4 Memorization, Critical Batch Size, Reward, Value, Q-value letters
- *QKNorm* Developments Deemed Dubious: A member suggested a better/earlier paper and stated that the QKNorm developments are not the right way to go, referencing this paper.
- *Soft RL* Goal Gleaned: A member summarized that the goal of Soft RL is to learn a policy that not only knows a good response to every query, but ideally knows all good responses to every query.
- They linked to test-time-training.github.io/video-dit/ and this tweet while mentioning thread block clusters.
- *Llama 4* Lacks on MATH-Perturb: In a discussion about measuring memorization of test sets in the Llama 4 models, a member stated that it performs pretty badly on the MATH-Perturb dataset and linked to this tweet.
- *Critical Batch Size* Critiqued: Regarding the statement that very large batch sizes are not good for convergence, a member cited the standard McCandlish paper on critical batch sizes to back up the statement and linked to this paper.
- *R* stands for Return, Remarks a Redditor: A member joked that one day llm researchers will use the correct letters out of R, V, and Q to represent reward, state-value, and state-action values respectively but not today while linking to this paper.
- Another member responded Trick question, R stands for Return alongside a link to this paper.
Eleuther ▷ #interpretability-general (9 messages🔥):
Baranuik and Balestriero's works, ReLU networks, Boris Hanin's ReLU networks paper, ICML machine unlearning workshop
- Hyperplane Happy Neural Nets Hedge Overfitting: It was noted that because ReLU neural nets work by carving the input space along hyperplanes, they have an implicit bias against overfitting that gets better in high dimension.
- It takes at least d+1 hyperplanes to enclose a bounded set, so a perfectly overfitted model enclosing each datapoint in a separate bounded set would need at least n(d+1) neurons.
- Hanin's Hyperplane Handling Helpful Hints: A member shared a link to Boris Hanin's paper which demonstrates some mathematical properties of ReLU networks, specifically studying the geometry of their constant regions.
- Another member expressed their love for a specific figure in the paper.
- ICML Invites Insightful Investigation Into Unlearning: A member shared that ICML will have a machine unlearning workshop.
- The workshop's website can be found here.
Eleuther ▷ #lm-thunderdome (1 messages):
LM Harness, HotpotQA, Llama Eval, GPT Models
- Guidance Needed: LM Harness for HotpotQA: A member inquired about a LM harness implementation for HotpotQA to evaluate Llama and GPT models.
- They requested guidance on running evaluations against HotpotQA.
- Llama and GPT models under eval: Members are evaluating Llama and GPT models.
- They require a LM harness implementation for HotpotQA to do so.
Nous Research AI ▷ #general (127 messages🔥🔥):
Llama-4-Scout-17B, Gemini 2.5 Pro Code Generation, aider-chat & Gemini 2.5 Pro, HiDream-I1 Image Model, DeepCogito LLMs & IDA
- Llama-4-Scout-17B Gets Ready for llama.cpp: Llama-4-Scout-17B text-to-text support has been added to llama.cpp, with members working on converting and quantizing the model.
- This pre-release is generating excitement among users eager to test its capabilities.
- Gemini 2.5 Pro Generates Solid Code Snippets: Gemini 2.5 Pro is being lauded for its ability to generate functional code snippets from complex prompts. See the prompt and responses in this message.
- aider-chat plus Gemini 2.5 Pro Creates AGI Prototype: A user reported using aider-chat combined with Gemini 2.5 Pro to edit or create 15 files from a 300k token context, including their frontend, API, and microservices.
- The user feels like they now have all the files to deploy a production AGI prototype.
- HiDream-I1 Image Model Generates High-Quality Images: HiDream-I1 is a new open-source image generative foundation model with 17B parameters using Llama 3.1 8B as a text encoder, released under the MIT license that achieves state-of-the-art image generation quality within seconds.
- It produces exceptional results across multiple styles including photorealistic, cartoon, artistic, and more, achieving state-of-the-art HPS v2.1 score, which aligns with human preferences.
- DeepCogito Models use Iterated Distillation and Amplification: A new suite of Cogito models (3B-70B) claim to outperform same-size models like Llama, DeepSeek, and Qwen, and are trained using Iterated Distillation and Amplification (IDA), which iteratively improves a model's capabilities through cycles of amplification and distillation as outlined in this research.
- Notably, the 70B model allegedly surpasses the newly released Llama 4 109B MoE model.
Nous Research AI ▷ #ask-about-llms (4 messages):
LayerNorm Implementation, Llama4 Context Window, H100 Usage
- LayerNorm Stats Calculated Per Sample: A member implemented LayerNorm, noting the key difference from BatchNorm is computing statistics per sample (axis=1) instead of per batch, with keepdims=True to avoid operand issues.
- They also removed running averages since mean and variance depend on the number of features, not batch size, and attached an image showcasing it.
- Llama4 needs H100?: A member inquired about testing Llama4 with a 10M context window on a single H100.
Nous Research AI ▷ #interesting-links (18 messages🔥):
Distributed data parallel training, Untrusted low-cost compute, Nous DeMo paper, Gradient compression algorithm, P2P interruptible compute
- Panthalia Platform Verifies Low-Cost Compute with DDP: A platform has been developed to verify untrusted, low-cost compute for training models over the internet using distributed data parallel (DDP), inspired by the Nous DeMo paper for compression, with a waitlist available via X.com.
- Panthalia Aims to Resell H100 Compute at $0.60/hr: In its early stages, Panthalia aims to resell low-cost provider compute at interruptible prices, such as $0.60/hr for an H100 and $0.13/hr for a 4090, leveraging DDP and DeMo-style compression.
- The weights are stored on reliable servers, enabling scaling for initial users, and long-term plans include building a supply of P2P interruptible compute.
- Panthalia Enables User-Defined Training and Plugins: The platform supports model sizes limited only by device capacity, using DeMo compression to achieve significant reduction in size, with a plugin system allowing users to define their own models, training methods (QLoRA), and distributed training algorithms (DeMo vs. DiLoCo).
- Users can download weights, and compute units can be standardized within subnets to ensure validation, with Stripe (credit card) for payments and crypto for payouts.
GPU MODE ▷ #general (10 messages🔥):
GPUMODE triton dataset, PyTorch version for triton kernels, GPUMODE website improvements, GPUMODE Job Portal
- *GPUMODE Triton Dataset:* Genesis on PyTorch 2.5: The GPUMODE "triton" dataset, used for Inductor Created Data, was created using PyTorch 2.5.
- The creator promised to update the readme to reflect this crucial detail, since users may have issues running it on PyTorch 2.6+.
- *GPUMODE Website*: New Tab Navigations Suggested: A user suggested that the "Lectures" and "Resources" tabs on the GPUMODE website should open in a new tab, since they are hyperlinks to YouTube/GitHub.
- This would prevent users from navigating away from the GPUMODE website in the same tab, thus improving user experience.
- *GPUMODE*: Job Portal Idea Scraped: A member proposed adding a job portal to the GPUMODE website, which would scrape postings from a specific channel, to create new postings.
- They also suggested a static template (JSON or YAML) for job posters to ensure consistent formatting and simplify entry creation, and the GPUMODE staff have acknowledged the suggestion.
GPU MODE ▷ #triton (14 messages🔥):
block_ptr usage, tl.load and boundary_check, Boundary checks and performance
- Block Pointers to fill out-of-bounds: A member suggests using
tl.make_block_ptrto create pointers that can fill with zeros for out-of-bounds memory accesses, specifically highlighting usage withboundary_checkandpadding_option="zero".- The usage example provided utilizes
tl.make_block_ptrwith parameters likeshape,strides,offsets,block_shape, andorderto create the pointer, and then loads data usingtl.loadwith boundary checks.
- The usage example provided utilizes
tl.make_block_ptrdeep dive: A member inquired abouttl.make_block_ptr, asking if it could be spammed in a loop, how to use the offset parameter, and the meaning of the order parameter.- Another member clarified that
tl.advanceshould be called to increment the pointer for loading data in a loop, the offset represents the start element index, and the order parameter defines the memory layout (e.g., col-major matrix).
- Another member clarified that
boundary_checkorder is irrelevant, but required for correctness: A member asked about the meaning and behavior ofboundary_checkintl.load, specifically its order and the consequences of omitting it.- It was explained that the order of
boundary_checkdoesn't matter, and omitting it increases speed, but risks errors like "device-side assert triggered" due to potential buffer overruns, especially when array dimension is not a multiple of the block size.
- It was explained that the order of
- Can you fill with another value than zero or nan?: A member asked if it was possible to fill with a value other than zero or NaN when using block pointers.
- Another member answered that it is difficult to do, but you can replace NaN with another value by using
tl.where(x == x, x, another)becausenan != nan.
- Another member answered that it is difficult to do, but you can replace NaN with another value by using
GPU MODE ▷ #cuda (4 messages):
Deepseek communication library, NVSHMEM and Unified Virtual Addressing (UVA), LDSM (Local Data Share Memory), Optimized smem load
- Deepseek Lib Built off NVDA's NVSHMEM: The deepseek communication library is built off NVSHMEM library from NVDA.
- NVSHMEM Explored for UVA Intra-Node Comm: A member inquired whether NVSHMEM uses Unified Virtual Addressing (UVA) for intra-node communication, enabling peer-to-peer loads/stores to remote GPUs via NVlink.
- LDSM Copying Discussed: A user asked for the code for defining
make_tilded_copy, and stated that the current image does not look like one from atiled_mma, instead it looks like an LDSM copy.- One explained that with LDSM, 32 threads in a warp coordinate to copy data from smem to rmem, and if the smem is row-major, T0 loads from 0-7 from smem, and stores 0,1,8,9,128,129,136,137 into its own registers memory.
- Optimized smem load: A member shared a code snippet,
tCsA = thr_mma.partition_A(sA); tCrA = thr_mma.make_fragment_A(tCsA); copy(tCsA, tCrA);, for partitioningsAaccording to thetiled_mma.- They added that for optimized smem load we should use LDSM though.
GPU MODE ▷ #torch (9 messages🔥):
TorchTitan's Compile Strategy, FSDP Numerical Issues, FSDP2 Model Extraction
- TorchTitan's Pre-Compile Strategy: The standard practice is usually to compile after operations, but TorchTitan does a unique per-block compile before, potentially to circumvent some torch compile bugs; see torchtitan/parallelize_llama.py#L313.
- The block-wrapping approach aims to leverage Dynamo's caching to skip Triton's LLVM compilation, which is slow, however, numerical issues may still exist when using
torch.compileand FSDP together.
- The block-wrapping approach aims to leverage Dynamo's caching to skip Triton's LLVM compilation, which is slow, however, numerical issues may still exist when using
- FSDP and torch compile cause Numerical Issues: A research lab experienced numerical issues using FSDP with
torch.compile, leading to training instability, where the reward would suddenly plummet.- They discovered that disabling
torch.compileresolved the issues, and cautioned to be careful with torch compile, highlighting that these problems were observed with HF qwen2.5 and a custom GRPO+entropy loss.
- They discovered that disabling
- The wrapped model extraction from FSDP2 remains challenging: A member asked how to get the original model from an FSDP2 wrapped model because the modifications are done in place and
copy.deepcopyisn't implemented in FSDPModule.- Another member suggested that FSDP modifies the model in place by wrapping modules, recommending keeping the original model around before applying FSDP.
GPU MODE ▷ #cool-links (5 messages):
CUDA physics simulation kernels go open source, Triton-Distributed, SMERF 3D
- PhysX Goes Public!: NVIDIA's CUDA physics simulation kernels are now open source; some are already working on a ROCm version.
- Triton Gets Distributed Superpowers!: A learning note details Triton-Distributed, fusing Triton with NVSHMEM/ROC-SHMEM to enable multi-GPU execution, add IR for distributed tasks, and support compute-communication overlap (link).
- SMERF's Berlin Demo is Still Cool: The SMERF (Scalable Modelling of Explicit Radiance Fields) project's Berlin demo remains impressive for its 3D scene reconstruction capabilities; the project page is here.
GPU MODE ▷ #jobs (2 messages):
Krea hiring, ML engineers, GPU cluster, diffusion models, interns
- *Krea* Seeks ML Engineers for GPU Brilliance!: Krea is hiring ML engineers to optimize the training/inference pipeline for their GPU cluster, seeking individuals passionate about accelerating image generation models.
- *Krea* needs Researchers for diffusion models: Krea is also seeking researchers interested in enhancing the controllability and aesthetics of diffusion models.
- Inquiries Emerge for Internship Spots: A member inquired about potential internship openings at Krea.
GPU MODE ▷ #beginner (15 messages🔥):
Graph Neural Networks (GNNs), Graph Attention Networks (GATs), CUDA compilation of C code, NVIDIA Streaming Multiprocessors, Thread cooperation in CUDA
- GNN Computations are Radically Parallel: Members discussed the parallel nature of Graph Neural Networks (GNNs), noting that updates for each node in a graph can often be computed in parallel.
- One member mentioned that Graph Attention Networks (GATs) architecture is one such example that comes to mind.
- C++ Compilers may fail on valid C code: Members discussed the claim that C++ compilers can compile all C code, referencing the server's FAQ.
- One member pointed out that it's possible to write C code that does not compile with a C++ compiler, citing a Wikipedia article.
- CUDA Glossary Updated: A member suggested including a screenshot from Hennesy & Patterson that breaks down terminology into a common ground (Ex: NVIDIA Streaming Multiprocessors = Cores).
- Another member suggested adding it as a suggestion in the glossary, or post it in the channel.
GPU MODE ▷ #torchao (1 messages):
torchao 0.10.0 release, MXFP8 training, PARQ, Module Swap Quantization API, Low Bit Kernels
- TorchAO Drops New Release: v0.10.0: The 0.10.0 release of torchao introduces end-to-end training support for mxfp8 on Nvidia B200, along with PARQ for quantization-aware training.
- This release also includes a module swap quantization API for research and updates for low-bit kernels, with details available in the release notes.
- Nvidia B200 can use MXFP8 training: MXFP8 is now supported for end to end training on Nvidia B200 due to the updates from the torchao 0.10.0 release.
- These training capabilities will allow for better and faster quantization aware training and new research.
- TorchAO releases Module Swap Quantization API for Research: The new Module Swap Quantization API will enable researchers to effectively apply quantization to custom modules in models.
- The torchao 0.10.0 release enables researchers to experiment with quantization strategies more flexibly, by swapping standard modules with quantized versions.
GPU MODE ▷ #off-topic (1 messages):
twzy: met yann lecun today and he seemed pissed
GPU MODE ▷ #self-promotion (9 messages🔥):
Tom and Jerry Diffusion Transformers, Nvidia Hopper Distributed Shared Memory, Verifying Untrusted Low-Cost Compute, LiveDocs Code Documentation
- Toon Time: Team Triumphs with Tom & Jerry Transformer: A team completed a project creating 1 minute long Tom and Jerry cartoons by finetuning a diffusion transformer, and their work was accepted to CVPR 2025 and released their finetuning code on Github.
- They also released a sample video of the unedited output, fully generated by the diffusion transformer.
- Hopper's Hidden Hardware Helps High-Performance RNNs: A member mentioned that on Nvidia Hopper architecture, there is a really interesting feature where you can have distributed shared memory to transfer data directly between SRAM of SMs.
- They used this feature to run tensor parallelism across SMs of their RNN's hidden states on a single GPU to remove the need of writing back to HBM.
- Panthalia Platform Provides Proof of Trustworthy Parallelism: A member has been working on a platform that verifies untrusted low-cost compute to train models over the internet with distributed data parallel as described here.
- They use a compression algorithm heavily inspired by the DeMo paper (docs).
- LiveDocs Launches Legit Lookin' Logistics: The creator of LiveDocs invites users to document your code with their upgraded service, now with more features available via signup at www.asvatthi.com.
- Included was an image of the interface, showing off various code documentation pages.
GPU MODE ▷ #🍿 (1 messages):
AlphaGeometry, KernelBench, GPU kernel generation
- KernelBench Boasts Bootstrapping GPU Kernels: A member mentioned prior work on using verifiers to bootstrap GPU kernel generation capabilities through test-time compute scaling, referencing experiments in KernelBench.
- The approach isn't quite AlphaGeometry-style but involves a small set of actions to apply angle chasing solvers.
- Geometry and Verifiers Discussed: Discussion involved methods related to alpha-geometry style techniques and verifiers.
- Mentioned a method inherently involves a pretty small set of possible actions to apply angle chasing solvers.
GPU MODE ▷ #reasoning-gym (6 messages):
Quasar Alpha, Reasoning Gym Levels, Curricula Tasks
- Quasar Alpha: Open Router Test Model: A user shared the performance of Quasar Alpha, the open router test model, with an attached image.
- Another user asked for the raw outputs to potentially add in a PR to reasoning-gym-eval.
- Reasoning Gym Task Levels Need Definition: A user mentioned they are defining the levels for 15 tasks in reasoning-gym that currently lack a defined level, planning to finish by the evening.
- The user inquired about submitting a PR to make these definitions available on the main branch and it was approved.
- Reasoning Gym Curricula Task PRs: A user asked if adding curricula to tasks without them was appropriate for a PR to reasoning-gym-eval.
- It was encouraged to create a PR for this purpose.
GPU MODE ▷ #gpu模式 (3 messages):
DeepSeek Communication Library, NVSHMEM and UVA, Intra-node communication
- DeepSeek Leverages NVSHMEM: A member inquired whether the DeepSeek communication library is built off NVSHMEM library from NVDA.
- NVSHMEM's use of UVA Questioned: A member questioned whether NVSHMEM uses Unified Virtual Addressing (UVA) for intra-node communication.
- Peer-to-Peer Loads/Stores via NVLink: The member added that using UVA, one can perform peer-to-peer loads/stores to data stored in a remote GPU (connected by something like NVLink).
GPU MODE ▷ #general (11 messages🔥):
Submitting .py files with inline CUDA, CUDA Kernels, Grayscale CUDA Example, torch::extension
- Inline CUDA Submission Trouble: A user reported trouble submitting .py files with inline CUDA, questioning the validity of the reference script.
- Admins acknowledged the issue and requested a link to the failing job to assist with debugging. Another user suggested the sample submission might be incorrect and that other inline CUDA implementations may work.
- CUDA Inline Script Solution: A user requested a sample script for inline CUDA submissions, and another user provided a code template using C++ and CUDA.
- The code template included CUDA sources (a
grayscale_kernelfunction), C++ sources (including<torch/extension.h>), and a Python module loaded viaload_inline.
- The code template included CUDA sources (a
GPU MODE ▷ #submissions (17 messages🔥):
vectoradd benchmarks, grayscale benchmarks, Modal runners
- VectorAdd Benchmarks Galore: Multiple benchmark submissions for vectoradd on L4 GPUs using Modal runners have succeeded with IDs ranging from 3500 to 3532.
- Grayscale Leaderboard Gains Traction: Leaderboard submissions for grayscale on L4, T4, A100, and H100 GPUs using Modal runners were successful, including IDs 3503, 3536, 3539, and 3540.
- Modal Runners Deliver Results: Submissions to the vectoradd leaderboard on T4 and A100 GPUs, IDs 3537 and 3538 respectively, succeeded using Modal runners.
GPU MODE ▷ #feature-requests-and-bugs (5 messages):
Leaderboard discrepancy, CUDA submission failure
- Leaderboard Time Units Cause Confusion: A user noticed a discrepancy in time units between the web (https://gpu-mode.github.io/discord-cluster-manager/) and Discord leaderboards, with the former displaying nanos and the latter millis.
- A new leaderboard website is being prepared, with time units converted for clarity.
- CUDA Submission Stumbles: A user reported that the sample CUDA submission from (https://github.com/gpu-mode/reference-kernels/blob/main/problems/pmpp/vectoradd_py/solutions/correct/submission_cuda_inline.py) failed to run as a test.
- This was deemed unexpected, and the user was asked to provide the specific error message.
GPU MODE ▷ #hardware (3 messages):
A100 vs L40, FP8 support, 4bit weights, Open source w4a8 kernels, GPU Fryer tool
- A100 Dominates L40 in Bandwidth and Tensor Ops: The A100 is reportedly nearly twice as fast as the L40 in both DRAM bandwidth and tensor operations.
- Despite the L40 having FP8 support and a larger L2 cache, vLLM doesn't include optimized kernels for Lovelace in its normal distribution.
- Limited Benefits of 8-bit Floating Point with 4-bit Weights: With 4-bit weights, the benefits of 8-bit floating point support in Hopper/Lovelace are limited.
- There are currently no open-source w4a8 kernels available.
- GPU Fryer Tool for Problem Hunting: Running the GPU Fryer tool can help in identifying problems.
- This tool, maintained by Hugging Face, is useful for stress-testing and debugging GPU configurations.
HuggingFace ▷ #general (52 messages🔥):
FP4 Fine-tuning, Parasail Inference Provider, Llama.cpp Llama 4 Support, Mobile SQL Generation Models, Multi-Agent AI Deployment
- FP4 Fine-Tuning Frenzy Fuels Faster Finishes: Users are exploring fine-tuning quantized models using FP4 with tools like Unsloth, which allows loading lower precision models for training and quantization.
- While fine-tuning a quantized model is possible via LoRA, directly fine-tuning the quantized model itself is not.
- Parasail aims to Provide Premier Performance: Parasail, a new inference provider, is looking to partner with Hugging Face after recently coming out of stealth, already serving 3B tokens a day on Open Router and 5B+ a day for private companies, as reported by The Next Platform.
- Llama.cpp Leaps to Llama 4: The backend Llama.cpp has been updated to support Llama 4, according to the GitHub releases.
- Tiny Transformers Touted for Telephones: For generating SQL queries from data descriptions on mobile devices, Qwen 2.5 0.5B and models from the SmollM2 Intermediate Checkpoints collection and the TinyLlama collection are recommended.
- Converting models to TensorRT format via ONNX is suggested for leveraging older architectures.
- Orchestration Options Open Opportunities: Oblix (https://oblix.ai/), a new tool for orchestrating AI between edge and cloud, integrates with Ollama on the edge and supports OpenAI and ClaudeAI in the cloud, aiming to create low-latency, privacy-conscious workflows.
HuggingFace ▷ #today-im-learning (3 messages):
Ollama local deployment, NLP in HuggingFace
- Newbie Uses Ollama for Local Deployment: A member is starting to learn using Ollama for local deployment with Python and OpenAI.
- They are using Ollama local deployment to avoid paying for OpenAI's API keys.
- Newbie learning NLP in HuggingFace: A member mentioned they are learning about NLP in the HuggingFace page.
- They are hoping to finish the course by the deadline.
HuggingFace ▷ #cool-finds (1 messages):
Daily Papers Podcast, Takara TLDR
- *Takara TLDR* inspires a Daily Papers Podcast!: A user took the Takara TLDR concept and created a daily papers podcast.
- The podcast seems to be hosted on the HuggingFace platform.
- Daily AI paper summaries, now in Podcast form: A user has remixed the Takara TLDR concept into a daily papers podcast.
- This could be a valuable resource for staying up-to-date with the latest AI research.
HuggingFace ▷ #i-made-this (3 messages):
AI Runner, GAPRS
- *AI Runner* desktop GUI takes Flight!: A member released AI Runner, a desktop GUI for running AI models locally using HuggingFace libraries as described in this YouTube video.
- The tool enables users to create and manage chatbots with custom voices, personalities, and moods, and the bots are agents built with llama-index using ReAct tools to generate images with Stable Diffusion and real-time voice conversations (espeak, speecht5, or openvoice).
- GAPRS 3.0 sets Sail!: A member launched the 3rd iteration of their master's thesis project, a web application called GAPRS (graph-based academic recommender system) at lqhvwseh.manus.space.
- The goal of GAPRS is to help students know where to start when writing their theses, streamline the academic research process, and revolutionize monetization of academic papers; more details are available in the member's master's thesis.
HuggingFace ▷ #computer-vision (3 messages):
Monocular Depth Models, Segmentation Problem, Tools Recognition Task
- Monocular Depth Models Explored: A member inquired if another member had found a solution to a problem, noting they had already tried monocular depth models.
- Segmentation Solution Proposed: A member suggested a solution to a segmentation problem involving vertical poles, proposing to check the overlap of the x-coordinates of the bounding boxes of different segments with the same label.
- The user said to take the min(x_lefts)->max(x_rights); they also suggested trimming thick boxes by using (x_mid +/- 0.5*width_pole).
- Tools Recognition Task: A member asked for suggestions on the best model/algorithm for a tool recognition task, specifying that the model should identify tools by providing a reference picture.
- The member asked if the model should be enhanced for better feature extraction.
HuggingFace ▷ #smol-course (4 messages):
Dataset forms, Unit 1 Quiz failing to load, Agents Build Errors, Chat templating exercises
- Dataset forms cause confusion: A member pointed out that someone was doing the same thing to both datasets, but they start in different forms.
- Another member requested more details, asking what do you mean by forms?
- Unit 1 Quiz fails to load, redirects too many times: A member reported the Unit 1 quiz fails to load and gets stuck in a redirect loop: agents-course-unit-1-quiz.hf.space redirected you too many times.
- They mentioned they're new to coding and unsure how to resolve the issue, seeking support.
- Agents Get Build Error: A member reported experiencing a Build error when trying to fetch the error logs, getting stuck in a loop.
- Initially, they couldn't get any response when chatting with the agent, and they were having issues even with copying and pasting the name of the tool.
- Someone Needs Chat Template Exercise Buddy: A member is seeking someone to discuss the chat templating exercises with them.
- No other details were provided, they were just looking for a study buddy.
HuggingFace ▷ #agents-course (26 messages🔥):
Code Agents Ch. 2 Notebook Issues, Gemini Models as Alternatives, Course FAQ Request, any-agent library release, RAG with smart glasses challenge
- Code Agents Ch. 2 Notebook Requires Payment: A member reported needing to pay to run the Chapter 2 notebook for Code Agents, receiving errors about invalid credentials and payment requirements for the recommended model.
- They sought advice on logging in correctly or using alternative tokens to run the supposedly free course examples.
- Gemini Models Recommended to bypass paywalls: A member suggested using Gemini models as a free alternative in many countries, linking to course notes with instructions.
- Other members highlighted resources like Ollama and other providers (OpenAI, Grok) offering generous free tokens, in order to bypass the Hugging Face paywalls.
- FAQ Section Needed in Agent Course: Multiple members requested an FAQ section within the Agent Course itself, as many users face the same initial issues and find the Discord navigation difficult.
- The discussion clarified that while there isn't an official FAQ page, the Discord channel contains numerous frequently asked questions that can be searched.
any-agentLibrary Simplifies Agent Framework Evaluation: The Mozilla AI team releasedany-agent, a library designed to simplify trying different agent frameworks.- The library supports frameworks like smolagents, OpenAI, Langchain, and Llama Index, with a GitHub repository available for users to try and contribute.
- Meta CRAG Multi-Modal Challenge Release: The community shared an interesting challenge from Meta: the CRAG Multi-Modal Challenge 2025 related to RAG with smart glasses.
- This is recommended as a knowledge exercise to solidify what was learned in the course.
HuggingFace ▷ #open-r1 (13 messages🔥):
Deepseek R1, Active AI Discord Chats
- Deepseek R1 Chatroom Gossip Starts: A member asked which Deepseek versions another member had been working with.
- That other member quipped back that they aren't working at all, but assume this room is Deepseek R1 related, and so the AI is working for them.
- Chatter Seeks Active AI Communities: A member inquired about active chats on AI in Discord, or even better, active voice chats.
MCP (Glama) ▷ #general (75 messages🔥🔥):
Semgrep MCP server, MCP HTTP Streaming, MCP and CORS errors, MCP Github server issues, MCP for Graph API application
- Semgrep's MCP Server Makes Waves: A member has been running mcp.semgrep.ai/sse for over a month, hosted via Docker and AWS EC2.
- CORS Error Squashed in Semgrep MCP Server: A member reported a CORS error when connecting with the Cloudflare Playground, which was quickly fixed.
- The reporter noted the tool was testing with Cursor and will need to fix CORS there as well.
- MCP HTTP Request-Response Support Arrives: A discussion emerged regarding the need for HTTP request-response support in MCP for enterprise customers, as highlighted in this pull request.
- Members pointed out that many enterprise organizations are using MCP, and this feature is expected to further increase its adoption.
- MCP Powers Up RAG with Graph DB: A member inquired about using MCP in a RAG use case with a Neo4j graph database, focusing on vector search and custom CQL search.
- Another member confirmed this is a good usecase, linking to mcpomni-connect as a viable MCP client.
- Cloudflare Provides Remote MCP Server Tutorial: For those seeking an easier tutorial to get started with remote MCP servers, a member recommends the Cloudflare Agents guide.
MCP (Glama) ▷ #showcase (15 messages🔥):
Semgrep rewrites MCP, C# MCP SDK, ASGI style in process fastmcp sessions
- Semgrep Rewrites MCP Server: A member rewrote Semgrep's MCP server and shared demo videos in Cursor and Claude.
- The hosted server uses SSE, not HTTP streaming, because the Python SDK doesn't support it yet.
- MCP SDK Leverages Sqlite for LLM Memories: A member played with the C# MCP SDK to leverage sqlite for LLM memories.
- A new version is available that gives memories an importance ranking to help with search results, and is intended to scale to larger memory graphs.
- ASGI Style Fastmcp Sessions Finalized: A member bumped versions on easymcp to 0.4.0, with notable changes including ASGI style in process fastmcp sessions.
- Other updates included a finalized native docker transport, refactored protocol implementation, a new mkdocs, and a full proper pytest setup.
- Terminal Chat with MCP Servers: A member created a terminal chat with MCP servers.
Latent Space ▷ #ai-general-chat (62 messages🔥🔥):
Shopify AI Mandate, Anthropic API Credits, API Latency Benchmarking, Cybercriminals and AI, LLM Automated Exploitation
- Shopify's AI Quest Gets Noticed: Shopify's AI mandate is gaining traction, as highlighted in this tweet.
- Anthropic's API Credits have Expiration Dates: Anthropic API credits expire after one year, potentially for accounting simplification and to account for the rapidly evolving AI landscape.
- As one member suggested, this policy helps manage projections in a quickly changing field.
- NVIDIA's Reasoning Model has On/Off Switch: NVIDIA has released a new model with the ability to turn reasoning on or off, detailed in this blog post and available on Hugging Face.
- Cybercrime's AI Shock May Be Delayed: Despite basic AI applications like FraudGPT, mass adoption of AI by cybercriminals is surprisingly slow, with speculation that a "cybercrime AI shock" may occur when they adopt it more broadly.
- One member noted that LLMs may have only recently become good enough for use in cybercrime.
- Gemini Plays Pokemon and Streams the Madness: The Gemini AI is now playing Pokémon, garnering attention as shown in this tweet.
Yannick Kilcher ▷ #general (14 messages🔥):
Llama 4 flops on benchmarks, Bayesian Structural EM, Procedural model representation DNA, Meta should have clarified, Disrupt Science Hackathon Details
- Llama 4 flops on Nongamed Benchmarks: A member claimed that Llama 4 flops hard on nongamed nonoverfitted benchmarks.
- The Daily Paper Discussion room will be discussing this paper, and a recent talk by the main author (YouTube link) discusses this paper.
- Meta should clarify Llama 4: It was stated that Meta should have made it clearer that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference.
- This discussion was based on this fxtwitter link.
- Bayesian Inference Insights: A member pointed out that Bayesian inference has been combining weights and architecture for about 100 years, and cited Bayesian Structural EM as an advanced example.
- Procedural Model Representation: DNA of a Model: A member introduced the concept of procedural model representation, where a small seed can generate a large model (architecture + weights).
- They envisioned downloading a 10MB model that generates a 100TB model, or swapping seeds to generate different models, akin to downloading DNA to generate a human.
- Disrupt Science Hackathon Details Posted: Details for the Disrupt Science Hackathon have been posted.
- The details can be found in this discord link.
Yannick Kilcher ▷ #paper-discussion (12 messages🔥):
Fast.ai Diffusion Methods, F_A_E_S_I_k=2 Discussion, Open Source beautiful.ai Alternatives
- Fast.ai Explores Diffusion Methods: A member shared a link to Fast.ai's diffusion methods course.
- Another member inquired about the timing of the second part of the course.
- Decoding F_A_E_S_I_k=2 Revelations: A member joked about having
F_A_E_S_I_k=2, leading to getting 40 hours of video, in relation to a paper discussion on arxiv.org/abs/2408.04220.- They speculated it might by construction have built this in, but probably not good at needles in a haystack, especially when the needles have dependencies on one another.
- Quest for Beautiful.ai Open Source Twins: A member asked about open-source alternatives to Beautiful.ai.
Yannick Kilcher ▷ #agents (1 messages):
Efficient Tool Calling Templates, Cogito 14b
- Cogito 14b's Efficient Tool Template: The 14b model suddenly started using a more efficient tool calling template than was initially provided in the instructions.
- It's recommended to check out the Cogito model for examples and inspiration.
- New Efficient Tool Calling Template Implementation: A user reported that a 14b model unexpectedly adopted a more efficient tool calling template.
- This suggests the model may have autonomously optimized its tool use, offering a potential area for further investigation.
Yannick Kilcher ▷ #ml-news (9 messages🔥):
Adapting Pre-training Text, Diffusion Modeling to Control LLMs, Llama 4 Release Issues, Iterative Improvement Strategy
- Pre-Training Adaptation Talk: A member shared an Awesome talk about adapting pre-training text to include database lookups for relevant facts, to train the LLM to look things up during generation.
- Diffusion Models Guide LLMs: A member mentioned using diffusion modeling to control LLMs and pointed to this paper as a relevant resource.
- Llama 4's Flop Explained: The poor release of Llama 4 was attributed to bad implementations.
- DeepCogito Iterative Improvement Strategy Preview: A member shared a link from Hacker News about an iterative improvement strategy using test time compute for fine-tuning, from DeepCogito.
Nomic.ai (GPT4All) ▷ #general (28 messages🔥):
IBM Granite 8B, RAG references, docling OCR, semantic chunking server, ComfyUI image generation
- Granite 8B Shines for RAG tasks: A member reported that IBM Granite 8B works well with RAG, especially concerning providing references by LLM.
- Another member concurred, having also found Granite to be effective.
- Docling for Non-Text PDF OCR: A member recommended docling for excellent image OCR, especially for non-text PDFs like scans.
- They highlighted its continuous operation for embeddings and integration into a database with indexed documents, enabling RAG through intersections.
- Semantic Chunking for Contextual Text: A member shared a semantic chunking server, demonstrating its use with clipboard examples.
- They noted its compatibility with audio and image processing, suggesting ComfyUI for combining all modalities.
- Llama 4 Gets Trashed for Being Terrible: A member trashed the Llama 4th gen model for being terrible compared to smaller models.
- Others agreed, noting Reddit comments speculated that it may have overfit on smaller "high quality" datasets, despite some benchmarks showing promise.
- GPT4All: Keep it Local to Be Safe: A member advised using GPT4All primarily for local operations to ensure privacy and avoid sending private information to remote APIs.
- They detailed how to run embedding models locally and index files by chunking and embedding, referencing a shell script example.
Modular (Mojo 🔥) ▷ #general (4 messages):
MLX vs MAX, Apple Silicon GPU limitations, MAX capabilities
- MLX vs MAX: A Comparative Dive: A member compared MLX (an array programming framework akin to JAX) and MAX, noting that while MLX is tailored for Apple Silicon GPUs, MAX currently cannot target them, which poses challenges for direct comparison.
- The member highlighted that MAX for AMD GPUs will eventually mirror MLX's shared memory benefits on MI300A and AMD's consumer CPUs, suggesting a future convergence in capabilities.
- Apple Silicon's Deployment Drawbacks: The member cautioned against relying solely on MLX for extensive projects, citing the difficulty of deploying Apple Silicon in server environments, necessitating potential rewrites to frameworks like MAX, JAX, or PyTorch for deployment.
- They emphasized that while MLX might offer convenience for initial experimentation, the practical limitations of Apple's ecosystem in server settings should be a key consideration.
- MAX's Manual Vectorization and Multi-Device Support: The member detailed that MAX, despite its lower-level API, offers capabilities comparable to NumPy and leverages Mojo for both automatic and manual vectorization, making it programmer-friendly.
- They admitted MAX's limitations in autodiff but highlighted its multi-device support, exemplified by the Llama pipeline, and its avoidance of tensor shape issues, positioning it as a robust alternative despite certain challenges.
- Discord Self-Promotion Rules Violated: A member pointed out that a specific post seemed inappropriate for the Discord channel, suggesting it might be a violation of self-promotion rules.
- A moderator agreed, confirming that the post indeed violated the community's self-promotion guidelines.
Modular (Mojo 🔥) ▷ #mojo (16 messages🔥):
Mojo vs Rust, __moveinit__ and __copyinit__ in Mojo, Returning values in Mojo, Span lifetime in Mojo
- Mojo's Borrowing vs. Rust's: A Fresh Look: A newcomer to Mojo shared a blog post comparing Mojo and Rust, noting that Mojo's "borrow by default" felt more intuitive.
- The member then wondered about how Mojo handles returning values from functions.
- Moveinit vs Copyinit: Deep Dive into Mojo Object Returns: A member clarified that when returning objects in Mojo, the presence of
__moveinit__dictates whether the object is moved, otherwise__copyinit__is used, and provided an example on Github.- The member also pointed to the official Mojo documentation for a complete picture.
- Unlock Span Lifetimes in Mojo with rebinding!: A member inquired how to specify in Mojo that "the lifetime of the return value is at least the lifetime of self", specifically for a
Span.- Another member suggested using
rebind[Span[UInt8, __origin_of(self)]](Span(self.seq))or making the trait generic over origin, but noted that trait parameters are not yet supported.
- Another member suggested using
tinygrad (George Hotz) ▷ #general (5 messages):
Tensor Naming, GPU Programming, Compiler Development, Tinygrad Contribution Resources, PMPP 4th ed
- Elegant Tensor Naming Tricks Sought: A member inquired about a more elegant way to name a tensor for easier tracking when printing model parameters, noting they currently add a name attribute in the Tensor class manually.
- GPU Programming and Compiler Dev Resources Requested: A member expressed interest in getting into GPU programming and compiler development for projects like tinygrad and requested learning resources or blog posts.
- They are planning to read tinygrad-notes and asked for book or blog post recommendations on compiler development for GPUs.
- geohotarchive YouTube Channel recommended: A member suggested the geohotarchive YouTube channel as a resource for learning about tinygrad.
- "PMPP" 4th Edition Recommended for GPU Programming: A member recommended PMPP (4th ed) for GPU programming, suggesting to share any excellent compiler resources if found.
tinygrad (George Hotz) ▷ #learn-tinygrad (12 messages🔥):
METAL sync issue, AMD performance with BEAM=2, ContextVar type, LLaMA sharding issue, Device info loss after sampling
- METAL Sync Glitch Causes Sharding Shenanigans: A member found unexpected behavior in sharding while reproducing a minimal example of a METAL sync issue from the bounty.
- The user suspected that the COPY from METAL:1 to CPU was executing before the XFER from METAL to METAL:1 ended, causing the CPU to read zeros instead of the correct shard.
- AMD BEAM=2 Turbocharges Tinygrad: One user reported impressive speed improvements using AMD with BEAM=2, achieving 64 it/s, outperforming their previous best with Torch at 55+ it/s.
- Members noted that BEAM=2 often beats torch.
- LLaMA Sharding Snafu: Device Info Lost in Translation: A user encountered an AssertionError while running llama.py with
--shard 4, indicating that the device info was lost after sampling.- A potential fix was proposed to move the tensor, as seen on GitHub, but it's not directly related to METAL or sync issues.
LlamaIndex ▷ #blog (2 messages):
RAG workflow tutorial, Auth0 Auth for GenAI with LlamaIndex
- RAG workflows using Llama 4: A quickstart tutorial demonstrates building a RAG workflow from scratch using Llama 4, showcasing how to set up core steps around ingestion, retrieval, and generation using LlamaIndex workflows, as shown in this tweet.
- Auth0 Auth for GenAI ships with LlamaIndex support: Auth0's Auth for GenAI now ships with native LlamaIndex support, making it easier to build auth into agent workflows, as announced in this tweet.
LlamaIndex ▷ #general (13 messages🔥):
Gemini 2.5 Pro, Google's latest unified SDK, StructuredPlannerAgent Docs, Agent Planning Tool
- Gemini 2.5 Pro Not Available: A member inquired if Gemini 2.5 Pro was available, but discovered a deprecation message suggesting to use Google's latest unified SDK instead of Gemini 2.5 pro, as noted in the LlamaIndex Documentation.
- Google SDK model names aren't validated: A member noted that the Google SDK doesn't validate model names, but assumes the provided name is valid, and also suggests manually setting the
context_windowvalue since Gemini 2.5's context window is quite large. StructuredPlannerAgentDocs Removed: The documentation forStructuredPlannerAgentwas removed because it is no longer maintained due to a cleanup of the agent docs, due to duplicate implementations.- A backlink to the old documentation was provided: StructuredPlannerAgent.
- Agent Planning Tool recommended: Instead of
StructuredPlannerAgent, it was suggested to use an agent with a planning tool that does some Chain of Thought (CoT) reasoning, or using the LLM itself to create a plan before using agent(s).
Cohere ▷ #「💬」general (8 messages🔥):
Events Recording Availability, Structured Output Examples, Pydantic Schema Integration, API Requests without Cohere Package, Model Recommendation for Company List Generation
- Events Recordings: Are They Available?: A member inquired whether recordings of events are available for those unable to attend in real-time, as some events sounded interesting.
- No response was given.
- Members Seek Structured Output Examples: A new member asked for examples on how to get structured output (e.g., a list of books) using Cohere, expressing their lack of experience in the field.
- The member was directed to the Cohere documentation as a starting point.
- Pydantic Schema with Cohere: A member sought ways to use Pydantic schemas directly in
response_formatwith Cohere and on how to send requests without the Cohere Python package, aiming to avoid introducing a dependency.- They were provided with a link to the Cohere Chat API reference and shown how to use cURL for requests to
https://api.cohere.com/v2/chat.
- They were provided with a link to the Cohere Chat API reference and shown how to use cURL for requests to
- OpenAI SDK example with Response Format: A member found the cURL example useful and noted its presence in the OpenAI SDK example with the
response_formatparameter.- The member then asked for a recommendation on the most suitable model for generating a list of companies on a specific topic.
Cohere ▷ #「🔌」api-discussions (1 messages):
Vector Databases, Model Compatibility, Explicit Recommendations
- Vector DB Recommendations Historically Avoided: Historically, explicit recommendations for vector DBs have been avoided, because our models work well with all of them.
- This is because the models are designed to function effectively with all vector DBs without specific optimizations for any particular one.
- Model Compatibility Across Vector DBs: The models are designed for broad compatibility, ensuring they perform well with various vector database solutions.
- This approach avoids favoring specific vector DBs and maintains a neutral stance towards the ecosystem.
Cohere ▷ #「🤖」bot-cmd (1 messages):
competent: Currently not working!
Cohere ▷ #「🤝」introductions (2 messages):
Introduction to Aditya, Machine vision and control, Innovation accelerator, Openchain.earth project, Tools used by Aditya
- Aditya Joins Cohere's Community: Aditya introduced themself as having a background in machine vision and control for manufacturing equipment (Semi/Electronics).
- Currently, they are taking a sabbatical from an innovation accelerator/matchmaking/assessment role to explore web/AI, with a project on openchain.earth.
- Aditya's Tech Stack Revealed: Aditya uses VS Code, Github Co-Pilot, Flutter, MongoDB, JS, and Python (Evaluating) in their projects.
- They are here to find out more on Cohere's AI and how it can be used in their project.
Cohere ▷ #【🟢】status-updates (1 messages):
competent: Should work!
Torchtune ▷ #general (1 messages):
Contributor Tag Request, Discord Roles
- Contributor Tag Incoming: A member requested a Contributor tag on Discord, sharing their GitHub username.
- They also made a lighthearted mention of their Discord profile picture featuring the character Gus from Psych.
- Requesting Discord Roles: A user is seeking a role elevation within the Discord server, specifically the Contributor tag.
- They linked their GitHub profile for verification and joked about their profile picture.
Torchtune ▷ #dev (6 messages):
DeepSpeed Integration, FSDP vs DeepSpeed, FSDP Sharding, zero1-3 training
- DeepSpeed Integration Debated for TorchTune: A member inquired about integrating DeepSpeed as a backend into TorchTune and created an issue to discuss the possibility.
- A maintainer asked for more context, noting that FSDP supports all the sharding options from DeepSpeed; potential reasons for DeepSpeed integration include fallback in lieu of FSDP bugs, diverging hardware/accelerator support, and speed.
- FSDP Favored Over DeepSpeed in TorchTune: TorchTune leans towards FSDP due to its better composition with other PyTorch distributed features, with the belief that supporting both versions well is not feasible.
- Users who migrated to TorchTune to avoid the complexities of composing DeepSpeed, PyTorch, and Megatron prefer sticking to native PyTorch, so there is no need to over-index on integrating and supporting other frameworks.
- Community Recipe Idea: DeepSpeed with TorchTune: A maintainer suggested creating a community recipe that imports TorchTune and hosts a DeepSpeed recipe, offering to feature it if a repo is made.
- This allows users interested in DeepSpeed to leverage it with TorchTune while keeping the core framework focused on native PyTorch.
- Tweaking FSDPModule for zero1-2 Training: Since TorchTune defaults to the equivalent of zero3, documentation or more recipes on how to tweak recipes using the FSDPModule methods for zero1-2 training are appreciated.
- It's believed that zero 1-3 are all possible with very minor tweaks to the collectives.
DSPy ▷ #show-and-tell (1 messages):
MIPRO, Automated Prompt Engineering, Task Complexity Scaling
- MIPRO Algorithm Tested on Scaling Complex Tasks: An article tested the MIPRO automated prompt engineering algorithm across tasks of varied complexity, from named entity recognition to text-based game navigation.
- The study leveraged tasks like CoNLL++, HoVer, BabyAI, and τ-bench (customer support with agentic tool use).
- Model Size Matters for MIPRO Optimization: The study found that larger models benefit more from MIPRO optimization in complex settings, potentially because they handle longer multi-turn demonstrations more effectively.
- The quality of feedback significantly impacts the MIPRO optimization process, with meaningful improvements seen even from noisy AI-generated feedback.
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Kaiyu Yang, AI4Math, Theorem Proving, Autoformalization
- *Kaiyu Yang* Lectures on Formal Math Reasoning: Guest speaker Kaiyu Yang presented on "Language models for autoformalization and theorem proving" on a livestream today; link here.
- His lecture covered using LLMs for formal mathematical reasoning, including theorem proving and autoformalization.
- AI4Math Crucial for AI-Driven Systems: AI for Mathematics (AI4Math) is crucial for AI-driven system design and verification, and techniques mirror NLP, especially training LLMs on curated math datasets.
- A complementary approach involves formal mathematical reasoning grounded in systems like Lean, which verify reasoning correctness and provide feedback.
- Meta's Dr. Yang Enhances AI in Math: Dr. Kaiyu Yang, a Research Scientist at Meta FAIR, focuses on enhancing AI's mathematical reasoning by integrating formal systems like Lean.
- His work explores using LLMs for tasks like theorem proving (generating formal proofs) and autoformalization (translating informal to formal).
MLOps @Chipro ▷ #events (1 messages):
Manifold Research Group, Multimodal AI, self-assembling space robotics, robotic metacognition, Community Research Call #4
- Manifold Research Group hosts Research Call #4: Manifold Research Group is hosting Community Research Call #4 this Saturday (4/12 @ 9 AM PST).
- The call will cover their latest work in Multimodal AI, self-assembling space robotics, and robotic metacognition.
- Space Robotics Research Taking Off: A PhD student from Manifold Research Group, specializing in robotic swarms in space, extended an invitation to a research call.
- The call aims to foster collaboration and explore frontier science in space robotics.
Codeium (Windsurf) ▷ #announcements (1 messages):
Codeium rename, Windsurf Reddit, Windsurf Plugins
- Codeium Rebrands as Windsurf: Codeium has officially rebranded to Windsurf, following the launch and incredible adoption of the Windsurf Editor in November 2024.
- The new name better reflects their vision of combining human and machine to create effortlessly powerful experiences, according to their rebrand announcement.
- Windsurf Launches New SubReddit: The company has launched a new SubReddit for the community.
- The announcement was made alongside changes to the Discord server, including refreshed pages and renaming of channels.
- Codeium Extensions are now Windsurf Plugins: With the rebrand, Codeium Extensions are now officially Windsurf Plugins.
- The company promised to continue improving the Windsurf Editor, wave by wave, with the same commitment to innovation.